
正则表达式
想入门爬虫?那你就必须学好正则!爬虫入门和正则表达式超全合辑
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-06-30 08:02
urllib.request.urlopen(url)官方文档返回一个 http.client.HTTPResponse 对象, 这个对象又用到的read()方法;返回数据;这个函数返回一个 http.client.HTTPResponse 对象, 这个对象又有各类方式, 比如我们用到的read()方法;如果你也是编程的学习者或则早已学会了的编程者!小编这儿有个群:103456743!大家可以加下,里面布满了全国各地的学习者!为你们提供一个交流平台,不管平常有遇到哪些BUG或则学习过程中卡壳,找不到人替你解决?那么就进来吧,里面热心的小伙伴还是十分多的,管理也是很好的,有哪些问题,他假如有时间都能给你们解决,我认为是一个特别不错的交流平台,没事也可以和你们扯扯公司的事中学发生的轶事,群文件早已上传了很多G的资料,PDF,视频 安装工具,安装教程都是有的,为了你们的学习能更进一步!也为了你们能愉快的交流,讨论学术问题!所以你还在等哪些呢?好了马上给你们带来正文!
data是一个字典, 然后通过urllib.parse.urlencode()来将data转换为 ‘word=one+peace’的字符串, 最后和url合并为full_url
python正则表达式介绍:
队列 介绍
在爬虫的程序中用到了广度优先级算法,该算法用到了数据结构,当然你用list也可以实现队列,但是效率不高。现在在此处介绍下:
在容器中有队列:collection.deque
集合介绍:
在爬虫程序中, 为了不重复爬这些早已爬过的网站, 我们须要把爬过的页面的url放进集合中, 在每一次要爬某一个url之前, 先瞧瞧集合上面是否早已存在. 如果早已存在, 我们就跳过这个url; 如果不存在, 我们先把url装入集合中, 然后再去爬这个页面.
Python 还 包 含 了 一 个 数 据 类 型—— set ( 集 合 ) 。 集 合 是 一 个 无 序 不 重 复 元素 的 集 。 基 本 功 能 包 括 关 系 测 试 和 消 除 重 复 元 素 。 集 合 对 象 还 支 持 union( 联
合),intersection(交),difference(差)和 sysmmetric difference(对称差集)等物理运算。
大括号或 set() 函数可以拿来创建集合。 注意:想要创建空集合,你必须使用set() 而不是 {} 。{}用于创建空字典;
集合的创建演示如下:
正则表达式
在爬虫时搜集回去的通常是字符流,我们要从中选购出url就要求有简单的字符串处理能力,而用正则表达式可以轻松的完成这一任务;
正则表达式的步骤:1,正则表达式的编译 2,正则表达式匹配字符串 3,结果的处理
下图列举了正则表达式的句型:
在pytho中使用正则表达式网络爬虫 正则表达式,需要引入re模块;下面介绍下该模块中的一些技巧;
pile和match
re模块中compile用于生成pattern的对象,再通过调用pattern实例的match方式处理文本最终获得match实例;通过使用match获得信息;
pattern:
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方式可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用pile()进行构造。
2.re.match(pattern, string, flags=0)
函数参数说明:
参数描述
pattern
匹配的正则表达式
string
要匹配的字符串。
flags
标志位,用于控制正则表达式的匹配方法,如:是否分辨大小写,多行匹配等等。
匹配成功re.match方式返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
匹配对象方式描述
group(num=0)
匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这些情况下它将返回一个包含这些组所对应值的元组。
groups()
返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
re.search方式
re.search 扫描整个字符串并返回第一个成功的匹配。
函数句型:
re.search(pattern, string, flags=0)
函数参数说明:
参数描述
pattern
匹配的正则表达式
string
要匹配的字符串。
flags
标志位,用于控制正则表达式的匹配方法,如:是否分辨大小写,多行匹配等等。
匹配成功re.search方式返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
匹配对象方式描述
group(num=0)
匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这些情况下它将返回一个包含这些组所对应值的元组。
groups()
返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
实例一:
search和match区别:
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串网络爬虫 正则表达式,直到找到一个匹配。
python爬虫小试牛刀
利用python抓取页面中所有的http合同的链接,并递归抓取子页面的链接。使用了集合和队列;此去爬的是我的网站,第一版好多bug;
代码如下:
那么你学会了吗? 查看全部

urllib.request.urlopen(url)官方文档返回一个 http.client.HTTPResponse 对象, 这个对象又用到的read()方法;返回数据;这个函数返回一个 http.client.HTTPResponse 对象, 这个对象又有各类方式, 比如我们用到的read()方法;如果你也是编程的学习者或则早已学会了的编程者!小编这儿有个群:103456743!大家可以加下,里面布满了全国各地的学习者!为你们提供一个交流平台,不管平常有遇到哪些BUG或则学习过程中卡壳,找不到人替你解决?那么就进来吧,里面热心的小伙伴还是十分多的,管理也是很好的,有哪些问题,他假如有时间都能给你们解决,我认为是一个特别不错的交流平台,没事也可以和你们扯扯公司的事中学发生的轶事,群文件早已上传了很多G的资料,PDF,视频 安装工具,安装教程都是有的,为了你们的学习能更进一步!也为了你们能愉快的交流,讨论学术问题!所以你还在等哪些呢?好了马上给你们带来正文!


data是一个字典, 然后通过urllib.parse.urlencode()来将data转换为 ‘word=one+peace’的字符串, 最后和url合并为full_url
python正则表达式介绍:
队列 介绍
在爬虫的程序中用到了广度优先级算法,该算法用到了数据结构,当然你用list也可以实现队列,但是效率不高。现在在此处介绍下:
在容器中有队列:collection.deque

集合介绍:
在爬虫程序中, 为了不重复爬这些早已爬过的网站, 我们须要把爬过的页面的url放进集合中, 在每一次要爬某一个url之前, 先瞧瞧集合上面是否早已存在. 如果早已存在, 我们就跳过这个url; 如果不存在, 我们先把url装入集合中, 然后再去爬这个页面.
Python 还 包 含 了 一 个 数 据 类 型—— set ( 集 合 ) 。 集 合 是 一 个 无 序 不 重 复 元素 的 集 。 基 本 功 能 包 括 关 系 测 试 和 消 除 重 复 元 素 。 集 合 对 象 还 支 持 union( 联
合),intersection(交),difference(差)和 sysmmetric difference(对称差集)等物理运算。
大括号或 set() 函数可以拿来创建集合。 注意:想要创建空集合,你必须使用set() 而不是 {} 。{}用于创建空字典;
集合的创建演示如下:

正则表达式
在爬虫时搜集回去的通常是字符流,我们要从中选购出url就要求有简单的字符串处理能力,而用正则表达式可以轻松的完成这一任务;
正则表达式的步骤:1,正则表达式的编译 2,正则表达式匹配字符串 3,结果的处理
下图列举了正则表达式的句型:

在pytho中使用正则表达式网络爬虫 正则表达式,需要引入re模块;下面介绍下该模块中的一些技巧;
pile和match
re模块中compile用于生成pattern的对象,再通过调用pattern实例的match方式处理文本最终获得match实例;通过使用match获得信息;



pattern:
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方式可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用pile()进行构造。

2.re.match(pattern, string, flags=0)
函数参数说明:
参数描述
pattern
匹配的正则表达式
string
要匹配的字符串。
flags
标志位,用于控制正则表达式的匹配方法,如:是否分辨大小写,多行匹配等等。
匹配成功re.match方式返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
匹配对象方式描述
group(num=0)
匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这些情况下它将返回一个包含这些组所对应值的元组。
groups()
返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。



re.search方式
re.search 扫描整个字符串并返回第一个成功的匹配。
函数句型:
re.search(pattern, string, flags=0)
函数参数说明:
参数描述
pattern
匹配的正则表达式
string
要匹配的字符串。
flags
标志位,用于控制正则表达式的匹配方法,如:是否分辨大小写,多行匹配等等。
匹配成功re.search方式返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
匹配对象方式描述
group(num=0)
匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这些情况下它将返回一个包含这些组所对应值的元组。
groups()
返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
实例一:


search和match区别:
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串网络爬虫 正则表达式,直到找到一个匹配。
python爬虫小试牛刀
利用python抓取页面中所有的http合同的链接,并递归抓取子页面的链接。使用了集合和队列;此去爬的是我的网站,第一版好多bug;
代码如下:



那么你学会了吗?
Ipidea丨网络爬虫正则表达式的使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 392 次浏览 • 2020-06-17 08:00
## 网络爬虫正则表达式的使用
---
我们在处理网页文本内容时有时会碰到一些特殊的情况网络爬虫 正则表达式,或者须要匹配某类字符串方式,通常都会用到正则表达式。许多程序语言都支持使用正则表达式,python中正则表达式可以实现字符串的匹配、检索和替换等功能,是一个比较强悍的工具。
### 1.正则表达式句型
Python中实现正则表达式功能一般使用re模块,可以实现对文本字符串的匹配,检索和替换,但不仅引入正则模块网络爬虫 正则表达式,还须要把握正则表达式字符和基本句型,才能正确使用python进行正则表达式提取。
部分常用的正则表达式:
| 字符 | 功能 |
| :--: | :--: |
| \ |转义字符,标记下一个字符为特殊字符|
| ^ |匹配输入字符串的开始位置|
| $ |匹配输入字符串的结束位置|
| * |匹配上面的子表达式零次或多次 |
| + |匹配上面的子表达式一次或多次 |
| ? |匹配上面的子表达式零次或一次 |
| . |匹配除“\n”之外的任何单个字符 |
| () | 匹配括弧里的表达式 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符 |
| \w |匹配包括顿号的任何词组字符|
| \W |匹配任何非词组字符|
|{n}|n是一个非负整数,匹配确定的n次|
|{n,m}|m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次|
|[x,y,z]| 匹配一组字符集 |
| \^[x,y,z] | 匹配不在[]中的字符 |
| a\|b | 匹配a或b | 查看全部

## 网络爬虫正则表达式的使用
---
我们在处理网页文本内容时有时会碰到一些特殊的情况网络爬虫 正则表达式,或者须要匹配某类字符串方式,通常都会用到正则表达式。许多程序语言都支持使用正则表达式,python中正则表达式可以实现字符串的匹配、检索和替换等功能,是一个比较强悍的工具。
### 1.正则表达式句型
Python中实现正则表达式功能一般使用re模块,可以实现对文本字符串的匹配,检索和替换,但不仅引入正则模块网络爬虫 正则表达式,还须要把握正则表达式字符和基本句型,才能正确使用python进行正则表达式提取。
部分常用的正则表达式:
| 字符 | 功能 |
| :--: | :--: |
| \ |转义字符,标记下一个字符为特殊字符|
| ^ |匹配输入字符串的开始位置|
| $ |匹配输入字符串的结束位置|
| * |匹配上面的子表达式零次或多次 |
| + |匹配上面的子表达式一次或多次 |
| ? |匹配上面的子表达式零次或一次 |
| . |匹配除“\n”之外的任何单个字符 |
| () | 匹配括弧里的表达式 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符 |
| \w |匹配包括顿号的任何词组字符|
| \W |匹配任何非词组字符|
|{n}|n是一个非负整数,匹配确定的n次|
|{n,m}|m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次|
|[x,y,z]| 匹配一组字符集 |
| \^[x,y,z] | 匹配不在[]中的字符 |
| a\|b | 匹配a或b |
网络爬虫简介(5)— 链接爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 363 次浏览 • 2020-05-31 08:01
到目前为止,我们早已借助示例网站的结构特性实现了两个简单爬虫,用于下载所有已发布的国家(或地区)页面。只要这两种技术可用,就应该使用它们进行爬取,因为这两种方式将须要下载的网页数目降至最低。不过,对于另一些网站爬虫社区,我们须要使爬虫表现得更象普通用户,跟踪链接,访问感兴趣的内容。
通过跟踪每位链接的方法,我们可以很容易地下载整个网站的页面。但是,这种方式可能会下载好多并不需要的网页。例如,我们想要从一个在线峰会中抓取用户帐号详情页,那么此时我们只须要下载帐号页,而不需要下载讨论贴的页面。本章使用的链接爬虫将使用正则表达式来确定应该下载什么页面。下面是这段代码的初始版本。
import re
def link_crawler(start_url, link_regex):
""" Crawl from the given start URL following links matched by
link_regex
"""
crawl_queue = [start_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if html is not None:
continue
# filter for links matching our regular expression
for link in get_links(html):
if re.match(link_regex, link):
crawl_queue.append(link)
def get_links(html):
""" Return a list of links from html
"""
# a regular expression to extract all links from the webpage
webpage_regex = re.compile("""<a[^>]+href=["'](.*?)["']""",
re.IGNORECASE)
# list of all links from the webpage
return webpage_regex.findall(html)
要运行这段代码,只须要调用
link_crawler
函数,并传入两个参数:
要爬取的网站
URL
以及用于匹配你想跟踪的链
接的正则表达式。对于示例网
站来说,我们想要爬取的是国家(或地区
)列表索引页和国家(或地区)页面。
我们查看站点可以获知索引页链接遵守如下格式:
国家(或地区)页遵守如下格式:
因此爬虫社区,我们可以用/(index|view)/这个简单的正则表达式来匹配这两类网页。当爬虫使用这种输入参数运行时会发生哪些呢?你会得到如下所示的下载错误。
>>> link_crawler('http://example.python-scraping.com', '/(index|view)/')
Downloading: http://example.python-scraping.com
Downloading: /index/1
Traceback (most recent call last):
...
ValueError: unknown url type: /index/1
正则表达式是从字符串中抽取信息的非常好的工具,因此我推荐每名程序员都应该“学会怎样阅读和编撰一些正则表达式”。即便这么,它们常常会特别脆弱,容易失效。我们将在本书后续部份介绍更先进的抽取链接和辨识页面的形式。可以看出,问题出在下载/index/1时,该链接只有网页的路径部份,而没有合同和服务器部份,也就是说这是一个相对链接。由于浏览器晓得你正在浏览那个网页,并且还能采取必要步骤处理那些链接,因此在浏览器浏览时,相对链接是才能正常工作的。但是,urllib并没有上下文。为了使urllib才能定位网页,我们须要将链接转换为绝对链接的方式,以便包含定位网页的所有细节。如你所愿,Python的urllib中有一个模块可以拿来实现该功能,该模块名为parse。下面是link_crawler的改进版本,使用了urljoin方式来创建绝对路径。
from urllib.parse import urljoin
def link_crawler(start_url, link_regex):
""" Crawl from the given start URL following links matched by
link_regex
"""
crawl_queue = [start_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if not html:
continue
for link in get_links(html):
if re.match(link_regex, link):
abs_link = urljoin(start_url, link)
crawl_queue.append(abs_link)
当你运行这段代码时,会听到似乎下载了匹配的网页,但是同样的地点总是会被不断下载到。产生该行为的诱因是那些地点互相之间存在链接。比如,澳大利亚链接到了南极洲,而南极洲又链接回了德国,此时爬虫都会继续将这种URL装入队列,永远不会抵达队列尾部
。要想避开重复爬取相同的链接,我们须要记录什么链接早已被爬取过。下面是更改后的link_crawler函数,具备了储存已发觉URL的功能,可以避免重复下载。
def link_crawler(start_url, link_regex):
crawl_queue = [start_url]
# keep track which URL's have seen before
seen = set(crawl_queue)
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if not html:
continue
for link in get_links(html):
# check if link matches expected regex
if re.match(link_regex, link):
abs_link = urljoin(start_url, link)
# check if have already seen this link
if abs_link not in seen:
seen.add(abs_link)
crawl_queue.append(abs_link)
当运行该脚本时,它会爬取所有地点,并且还能如期停止。最终,我们得到了一个可用的链接爬虫! 查看全部
1.5.5 链接爬虫
到目前为止,我们早已借助示例网站的结构特性实现了两个简单爬虫,用于下载所有已发布的国家(或地区)页面。只要这两种技术可用,就应该使用它们进行爬取,因为这两种方式将须要下载的网页数目降至最低。不过,对于另一些网站爬虫社区,我们须要使爬虫表现得更象普通用户,跟踪链接,访问感兴趣的内容。
通过跟踪每位链接的方法,我们可以很容易地下载整个网站的页面。但是,这种方式可能会下载好多并不需要的网页。例如,我们想要从一个在线峰会中抓取用户帐号详情页,那么此时我们只须要下载帐号页,而不需要下载讨论贴的页面。本章使用的链接爬虫将使用正则表达式来确定应该下载什么页面。下面是这段代码的初始版本。
import re
def link_crawler(start_url, link_regex):
""" Crawl from the given start URL following links matched by
link_regex
"""
crawl_queue = [start_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if html is not None:
continue
# filter for links matching our regular expression
for link in get_links(html):
if re.match(link_regex, link):
crawl_queue.append(link)
def get_links(html):
""" Return a list of links from html
"""
# a regular expression to extract all links from the webpage
webpage_regex = re.compile("""<a[^>]+href=["'](.*?)["']""",
re.IGNORECASE)
# list of all links from the webpage
return webpage_regex.findall(html)
要运行这段代码,只须要调用
link_crawler
函数,并传入两个参数:
要爬取的网站
URL
以及用于匹配你想跟踪的链
接的正则表达式。对于示例网
站来说,我们想要爬取的是国家(或地区
)列表索引页和国家(或地区)页面。
我们查看站点可以获知索引页链接遵守如下格式:
国家(或地区)页遵守如下格式:
因此爬虫社区,我们可以用/(index|view)/这个简单的正则表达式来匹配这两类网页。当爬虫使用这种输入参数运行时会发生哪些呢?你会得到如下所示的下载错误。
>>> link_crawler('http://example.python-scraping.com', '/(index|view)/')
Downloading: http://example.python-scraping.com
Downloading: /index/1
Traceback (most recent call last):
...
ValueError: unknown url type: /index/1
正则表达式是从字符串中抽取信息的非常好的工具,因此我推荐每名程序员都应该“学会怎样阅读和编撰一些正则表达式”。即便这么,它们常常会特别脆弱,容易失效。我们将在本书后续部份介绍更先进的抽取链接和辨识页面的形式。可以看出,问题出在下载/index/1时,该链接只有网页的路径部份,而没有合同和服务器部份,也就是说这是一个相对链接。由于浏览器晓得你正在浏览那个网页,并且还能采取必要步骤处理那些链接,因此在浏览器浏览时,相对链接是才能正常工作的。但是,urllib并没有上下文。为了使urllib才能定位网页,我们须要将链接转换为绝对链接的方式,以便包含定位网页的所有细节。如你所愿,Python的urllib中有一个模块可以拿来实现该功能,该模块名为parse。下面是link_crawler的改进版本,使用了urljoin方式来创建绝对路径。
from urllib.parse import urljoin
def link_crawler(start_url, link_regex):
""" Crawl from the given start URL following links matched by
link_regex
"""
crawl_queue = [start_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if not html:
continue
for link in get_links(html):
if re.match(link_regex, link):
abs_link = urljoin(start_url, link)
crawl_queue.append(abs_link)
当你运行这段代码时,会听到似乎下载了匹配的网页,但是同样的地点总是会被不断下载到。产生该行为的诱因是那些地点互相之间存在链接。比如,澳大利亚链接到了南极洲,而南极洲又链接回了德国,此时爬虫都会继续将这种URL装入队列,永远不会抵达队列尾部
。要想避开重复爬取相同的链接,我们须要记录什么链接早已被爬取过。下面是更改后的link_crawler函数,具备了储存已发觉URL的功能,可以避免重复下载。
def link_crawler(start_url, link_regex):
crawl_queue = [start_url]
# keep track which URL's have seen before
seen = set(crawl_queue)
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if not html:
continue
for link in get_links(html):
# check if link matches expected regex
if re.match(link_regex, link):
abs_link = urljoin(start_url, link)
# check if have already seen this link
if abs_link not in seen:
seen.add(abs_link)
crawl_queue.append(abs_link)
当运行该脚本时,它会爬取所有地点,并且还能如期停止。最终,我们得到了一个可用的链接爬虫!
Python网络爬虫四大选择器(正则表达式、BS4、Xpath、CSS)总结
采集交流 • 优采云 发表了文章 • 0 个评论 • 478 次浏览 • 2020-05-12 08:01
一、正则表达式
正则表达式为我们提供了抓取数据的快捷方法。虽然该正则表达式更容易适应未来变化网络爬虫 正则表达式,但又存在无法构造、可读性差的问题。当在爬京东网的时侯,正则表达式如下图所示:
利用正则表达式实现对目标信息的精准采集
此外 ,我们都晓得,网页经常会形成变更,导致网页中会发生一些微小的布局变化时,此时也会促使之前写好的正则表达式未能满足需求,而且还不太好调试。当须要匹配的内容有很多的时侯,使用正则表达式提取目标信息会导致程序运行的速率减缓,需要消耗更多显存。
二、BeautifulSoup
BeautifulSoup是一个十分流行的 Pyhon 模块。该模块可以解析网页,并提供定位内容的方便插口。通过'pip install beautifulsoup4'就可以实现该模块的安装了。
利用美丽的汤去提取目标信息
使用 BeautifulSoup的第一步是将己下载的 HTML 内容解析为 soup文档。由 于大多数网页都不具备良好的HTML 格式,因此BeautifulSoup须要对实际格式进行确定。BeautifulSoup才能正确解析缺位的冒号并闭合标签,此外都会添加<html >和<body>标签让其成为完整的HTML文档。通常使用find() 和find_all()方法来定位我们须要的元素。
如果你想了解BeautifulSoup全部方式和参数,可以查阅BeautifulSoup的官方文档。虽然BeautifulSoup在代码的理解上比正则表达式要复杂一些,但是其愈发容易构造和理解。
三、Lxml
Lxml模块使用 C语言编撰,其解析速率比 BeautiflSoup更快,而且其安装过程也更为复杂,在此小编就不赘言啦。XPath 使用路径表达式在 XML 文档中选定节点。节点是通过顺着路径或则 step 来选定的。
Xpath选择器
使用 lxml 模块的第一步和BeautifulSoup一样,也是将有可能不合法的HTML 解析为 统一格式。 虽然Lxml可以正确解析属性两边缺位的冒号网络爬虫 正则表达式,并闭合标签,不过该模块没有额外添加<html >和<body>标签 。
在线复制Xpath表达式可以很方便的复制Xpath表达式。但是通过该方式得到的Xpath表达式置于程序中通常不能用,而且长的无法看。所以Xpath表达式通常还是要自己亲自上手。
四、CSS
CSS选择器表示选择元素所使用 的模式。BeautifulSoup整合了CSS选择器的句型和自身便捷使用API。在网路爬虫的开发过程中,对于熟悉CSS选择器句型的人,使用CSS选择器是个十分便捷的方式。
CSS选择器
下面是一些常用的选择器示例。 查看全部
前几天小编连续写了四篇关于Python选择器的文章,分别用正则表达式、BeautifulSoup、Xpath、CSS选择器分别抓取京东网的商品信息。今天小编来给你们总结一下这四个选择器,让你们愈发深刻的理解和熟悉Python选择器。
一、正则表达式
正则表达式为我们提供了抓取数据的快捷方法。虽然该正则表达式更容易适应未来变化网络爬虫 正则表达式,但又存在无法构造、可读性差的问题。当在爬京东网的时侯,正则表达式如下图所示:

利用正则表达式实现对目标信息的精准采集
此外 ,我们都晓得,网页经常会形成变更,导致网页中会发生一些微小的布局变化时,此时也会促使之前写好的正则表达式未能满足需求,而且还不太好调试。当须要匹配的内容有很多的时侯,使用正则表达式提取目标信息会导致程序运行的速率减缓,需要消耗更多显存。
二、BeautifulSoup
BeautifulSoup是一个十分流行的 Pyhon 模块。该模块可以解析网页,并提供定位内容的方便插口。通过'pip install beautifulsoup4'就可以实现该模块的安装了。

利用美丽的汤去提取目标信息
使用 BeautifulSoup的第一步是将己下载的 HTML 内容解析为 soup文档。由 于大多数网页都不具备良好的HTML 格式,因此BeautifulSoup须要对实际格式进行确定。BeautifulSoup才能正确解析缺位的冒号并闭合标签,此外都会添加<html >和<body>标签让其成为完整的HTML文档。通常使用find() 和find_all()方法来定位我们须要的元素。
如果你想了解BeautifulSoup全部方式和参数,可以查阅BeautifulSoup的官方文档。虽然BeautifulSoup在代码的理解上比正则表达式要复杂一些,但是其愈发容易构造和理解。
三、Lxml
Lxml模块使用 C语言编撰,其解析速率比 BeautiflSoup更快,而且其安装过程也更为复杂,在此小编就不赘言啦。XPath 使用路径表达式在 XML 文档中选定节点。节点是通过顺着路径或则 step 来选定的。

Xpath选择器
使用 lxml 模块的第一步和BeautifulSoup一样,也是将有可能不合法的HTML 解析为 统一格式。 虽然Lxml可以正确解析属性两边缺位的冒号网络爬虫 正则表达式,并闭合标签,不过该模块没有额外添加<html >和<body>标签 。
在线复制Xpath表达式可以很方便的复制Xpath表达式。但是通过该方式得到的Xpath表达式置于程序中通常不能用,而且长的无法看。所以Xpath表达式通常还是要自己亲自上手。
四、CSS
CSS选择器表示选择元素所使用 的模式。BeautifulSoup整合了CSS选择器的句型和自身便捷使用API。在网路爬虫的开发过程中,对于熟悉CSS选择器句型的人,使用CSS选择器是个十分便捷的方式。

CSS选择器
下面是一些常用的选择器示例。
使用正则表达式实现网页爬虫的思路解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-05-06 08:04
思路:
1.为模拟网页爬虫,我们可以如今我们的tomcat服务器端布署一个1.html网页。(部署的步骤:在tomcat目录的webapps目录的ROOTS目录下新建一个1.html。使用notepad++进行编辑网络爬虫 正则表达式,编辑内容为:
)
2.使用URL与网页构建联系
3.获取输入流,用于读取网页中的内容
4.建立正则规则,因为这儿我们是爬去网页中的邮箱信息网络爬虫 正则表达式,所以构建匹配 邮箱的正则表达式:String regex="\w+@\w+(\.\w+)+";
5.将提取到的数据放在集合中。
代码:
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网页爬虫:就是一个程序用于在互联网中获取指定规则的数据
*
*
*/
public class RegexDemo {
public static void main(String args) throws Exception {
List<String> list=getMailByWeb();
for(String str:list){
System.out.println(str);
}
}
private static List<String> getMailByWeb() throws Exception {
//1.与网页建立联系。使用URL
String path="http://localhost:8080//1.html";//后面写双斜杠是用于转义
URL url=new URL(path);
//2.获取输入流
InputStream is=url.openStream();
//加缓冲
BufferedReader br=new BufferedReader(new InputStreamReader(is));
//3.提取符合邮箱的数据
String regex="\\w+@\\w+(\\.\\w+)+";
//进行匹配
//将正则规则封装成对象
Pattern p=Pattern.compile(regex);
//将提取到的数据放到一个集合中
List<String> list=new ArrayList<String>();
String line=null;
while((line=br.readLine())!=null){
//匹配器
Matcher m=p.matcher(line);
while(m.find()){
//3.将符合规则的数据存储到集合中
list.add(m.group());
}
}
return list;
}
}
注意:在执行前须要先开启tomcat服务器
运行结果:
总结
以上所述是小编给你们介绍的使用正则表达式实现网页爬虫的思路解读,希望对你们有所帮助,如果你们有任何疑惑请给我留言,小编会及时回复你们的。在此也特别谢谢你们对优采云的支持! 查看全部
思路:
1.为模拟网页爬虫,我们可以如今我们的tomcat服务器端布署一个1.html网页。(部署的步骤:在tomcat目录的webapps目录的ROOTS目录下新建一个1.html。使用notepad++进行编辑网络爬虫 正则表达式,编辑内容为:
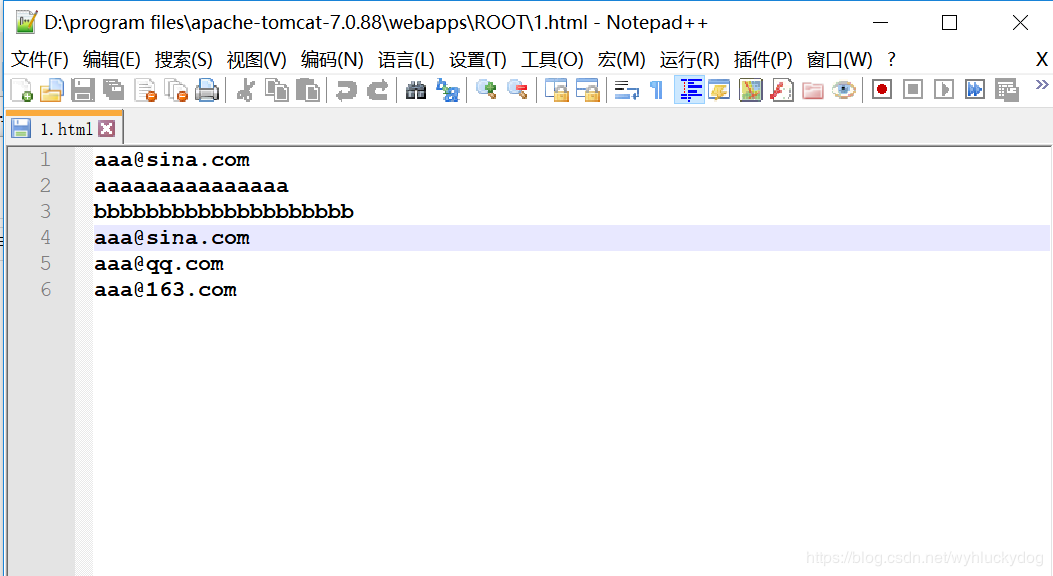
)
2.使用URL与网页构建联系
3.获取输入流,用于读取网页中的内容
4.建立正则规则,因为这儿我们是爬去网页中的邮箱信息网络爬虫 正则表达式,所以构建匹配 邮箱的正则表达式:String regex="\w+@\w+(\.\w+)+";
5.将提取到的数据放在集合中。
代码:
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网页爬虫:就是一个程序用于在互联网中获取指定规则的数据
*
*
*/
public class RegexDemo {
public static void main(String args) throws Exception {
List<String> list=getMailByWeb();
for(String str:list){
System.out.println(str);
}
}
private static List<String> getMailByWeb() throws Exception {
//1.与网页建立联系。使用URL
String path="http://localhost:8080//1.html";//后面写双斜杠是用于转义
URL url=new URL(path);
//2.获取输入流
InputStream is=url.openStream();
//加缓冲
BufferedReader br=new BufferedReader(new InputStreamReader(is));
//3.提取符合邮箱的数据
String regex="\\w+@\\w+(\\.\\w+)+";
//进行匹配
//将正则规则封装成对象
Pattern p=Pattern.compile(regex);
//将提取到的数据放到一个集合中
List<String> list=new ArrayList<String>();
String line=null;
while((line=br.readLine())!=null){
//匹配器
Matcher m=p.matcher(line);
while(m.find()){
//3.将符合规则的数据存储到集合中
list.add(m.group());
}
}
return list;
}
}
注意:在执行前须要先开启tomcat服务器
运行结果:
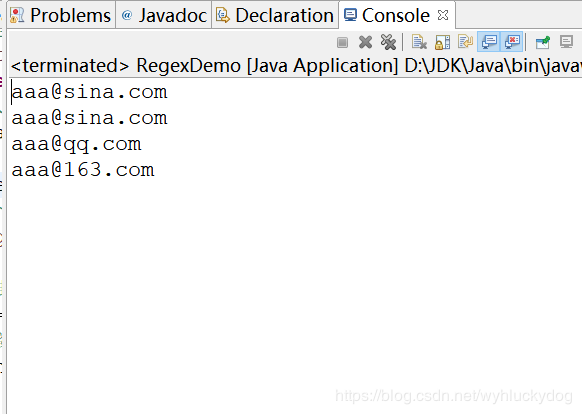
总结
以上所述是小编给你们介绍的使用正则表达式实现网页爬虫的思路解读,希望对你们有所帮助,如果你们有任何疑惑请给我留言,小编会及时回复你们的。在此也特别谢谢你们对优采云的支持!
phpcms跟dedecms比较
采集交流 • 优采云 发表了文章 • 0 个评论 • 452 次浏览 • 2020-04-26 11:01
首先从用户界面来看,也就是管理后台,首先是登陆,dedecms登录框下边的几个广告,着实叫人烦躁,看着不爽。当然了,毕竟人家靠这这点儿微薄的收入给俺开发出了如此强悍的cms系统。phpcms的登入界面就没有广告了,盛大也不缺这点儿钱。当步入后台主界面后,dedecms则变得有些狭小,界面也不是太华丽。在这一点上,phpcms做的很不错,大气,华丽。
从使用上来看,dedecms的操作去集中在了左侧,条例太清楚。phpcms则把一级导航放到了里面,二级导航放到了左侧,但是当选择完后,却没有相应的指示,往往使用户不知道自己处于那个导航之中,而且,phpcms在导航手动收起功能,感觉象是鸡肋,每次他收起时,我正在进行的操作还会被打乱,还不如没有这个功能来的好,也许是我的浏览器是宽屏的,即使不收起,依然觉得左侧的可编辑区域不小。
从模板开发上,dedecms面向的是中级站长,甚至不懂编程的计算机爱好者都可以,而且,dedecms的标签都不容许编程({dede:php}除外),完全都是模板标签操作,入门十分简单,当然了这也是以牺牲可定制性为代价的。phpcms的模板制做,也取样了dede同意的方法,标签式,但是这个要比dedecms宽松的多,你可以在上面嵌入php代码,可以在模板上面编程,虽然这是软件开发的三忌,但是模板的灵活性显著降低了,用户有了更多的权限和方法去实现自己想要的疗效。
SEO方面,做完网站了,如果他人都不来访问,或者根本找不到你的网站,那就很没面子了,而且也没收入了。在SEO方面,这两个cms做的都很不错,最通常的关键词和描述都有,而且是针对每位页面的。默认都可以设置页面生成的文件名称(补充一点,这两个cms都可以生成静态的html页面,这也对seo有很大帮助)。phpcms相对于dedecms的一些不足之处,网站的seo优化没有dedecms设计的好火车头采集教程,dedecms可以很简单的在后台控制url的生成方法,并且重命名,而phpcms貌似很复杂,最重要的是官方不给一点详尽的说明。
论坛活跃程度方面,如果使用dedecms遇到问题,可以去任何一个峰会发贴,很快有人回复,其峰会的活跃程度可不是通常的高。而phpcms呢,毕竟这个产品是盛大开发的,你问客服吧,不敢,我相信大部分人都和我一样,用的是免费的。所以只能老老实实的去峰会发贴,希望有人回答,但是峰会活跃程度远不如dedecms,而且phpcms还同时维护了两个版本,一个2008(听这名子,盛大也很懒了吧,4年不更新了),一个V9。
其他方面,很多人离开dedecms而转投phpcms,还有一个很重要的方面,那就是phpcms有一个dede所没有的功能――站群,当年我就是,从一个站长峰会上面看见了站群的概念,看了看仍然使用的dedecms很是沮丧,果断Google了一下支持站群的cms,然后转入了phpcms门下。
总结火车头采集教程,比较了这么多,两个cms都各有千秋,其实对于用户来说,还是使用习惯,当我们一旦习惯了一个工具的时侯,自然都会得心应手。 查看全部
现在做一个网站是越来越容易了,很多公司和个人站长开始使用内容管理系统,在CMS方面,尤其是PHP的CMS,更是百花齐放,当然了,质量也参差不齐。目前国外比较流行的有Dedecms和Phpcms,下面华来科技就这两个cms做一下简单的对比。
首先从用户界面来看,也就是管理后台,首先是登陆,dedecms登录框下边的几个广告,着实叫人烦躁,看着不爽。当然了,毕竟人家靠这这点儿微薄的收入给俺开发出了如此强悍的cms系统。phpcms的登入界面就没有广告了,盛大也不缺这点儿钱。当步入后台主界面后,dedecms则变得有些狭小,界面也不是太华丽。在这一点上,phpcms做的很不错,大气,华丽。
从使用上来看,dedecms的操作去集中在了左侧,条例太清楚。phpcms则把一级导航放到了里面,二级导航放到了左侧,但是当选择完后,却没有相应的指示,往往使用户不知道自己处于那个导航之中,而且,phpcms在导航手动收起功能,感觉象是鸡肋,每次他收起时,我正在进行的操作还会被打乱,还不如没有这个功能来的好,也许是我的浏览器是宽屏的,即使不收起,依然觉得左侧的可编辑区域不小。
从模板开发上,dedecms面向的是中级站长,甚至不懂编程的计算机爱好者都可以,而且,dedecms的标签都不容许编程({dede:php}除外),完全都是模板标签操作,入门十分简单,当然了这也是以牺牲可定制性为代价的。phpcms的模板制做,也取样了dede同意的方法,标签式,但是这个要比dedecms宽松的多,你可以在上面嵌入php代码,可以在模板上面编程,虽然这是软件开发的三忌,但是模板的灵活性显著降低了,用户有了更多的权限和方法去实现自己想要的疗效。
SEO方面,做完网站了,如果他人都不来访问,或者根本找不到你的网站,那就很没面子了,而且也没收入了。在SEO方面,这两个cms做的都很不错,最通常的关键词和描述都有,而且是针对每位页面的。默认都可以设置页面生成的文件名称(补充一点,这两个cms都可以生成静态的html页面,这也对seo有很大帮助)。phpcms相对于dedecms的一些不足之处,网站的seo优化没有dedecms设计的好火车头采集教程,dedecms可以很简单的在后台控制url的生成方法,并且重命名,而phpcms貌似很复杂,最重要的是官方不给一点详尽的说明。
论坛活跃程度方面,如果使用dedecms遇到问题,可以去任何一个峰会发贴,很快有人回复,其峰会的活跃程度可不是通常的高。而phpcms呢,毕竟这个产品是盛大开发的,你问客服吧,不敢,我相信大部分人都和我一样,用的是免费的。所以只能老老实实的去峰会发贴,希望有人回答,但是峰会活跃程度远不如dedecms,而且phpcms还同时维护了两个版本,一个2008(听这名子,盛大也很懒了吧,4年不更新了),一个V9。
其他方面,很多人离开dedecms而转投phpcms,还有一个很重要的方面,那就是phpcms有一个dede所没有的功能――站群,当年我就是,从一个站长峰会上面看见了站群的概念,看了看仍然使用的dedecms很是沮丧,果断Google了一下支持站群的cms,然后转入了phpcms门下。
总结火车头采集教程,比较了这么多,两个cms都各有千秋,其实对于用户来说,还是使用习惯,当我们一旦习惯了一个工具的时侯,自然都会得心应手。
想入门爬虫?那你就必须学好正则!爬虫入门和正则表达式超全合辑
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-06-30 08:02
urllib.request.urlopen(url)官方文档返回一个 http.client.HTTPResponse 对象, 这个对象又用到的read()方法;返回数据;这个函数返回一个 http.client.HTTPResponse 对象, 这个对象又有各类方式, 比如我们用到的read()方法;如果你也是编程的学习者或则早已学会了的编程者!小编这儿有个群:103456743!大家可以加下,里面布满了全国各地的学习者!为你们提供一个交流平台,不管平常有遇到哪些BUG或则学习过程中卡壳,找不到人替你解决?那么就进来吧,里面热心的小伙伴还是十分多的,管理也是很好的,有哪些问题,他假如有时间都能给你们解决,我认为是一个特别不错的交流平台,没事也可以和你们扯扯公司的事中学发生的轶事,群文件早已上传了很多G的资料,PDF,视频 安装工具,安装教程都是有的,为了你们的学习能更进一步!也为了你们能愉快的交流,讨论学术问题!所以你还在等哪些呢?好了马上给你们带来正文!
data是一个字典, 然后通过urllib.parse.urlencode()来将data转换为 ‘word=one+peace’的字符串, 最后和url合并为full_url
python正则表达式介绍:
队列 介绍
在爬虫的程序中用到了广度优先级算法,该算法用到了数据结构,当然你用list也可以实现队列,但是效率不高。现在在此处介绍下:
在容器中有队列:collection.deque
集合介绍:
在爬虫程序中, 为了不重复爬这些早已爬过的网站, 我们须要把爬过的页面的url放进集合中, 在每一次要爬某一个url之前, 先瞧瞧集合上面是否早已存在. 如果早已存在, 我们就跳过这个url; 如果不存在, 我们先把url装入集合中, 然后再去爬这个页面.
Python 还 包 含 了 一 个 数 据 类 型—— set ( 集 合 ) 。 集 合 是 一 个 无 序 不 重 复 元素 的 集 。 基 本 功 能 包 括 关 系 测 试 和 消 除 重 复 元 素 。 集 合 对 象 还 支 持 union( 联
合),intersection(交),difference(差)和 sysmmetric difference(对称差集)等物理运算。
大括号或 set() 函数可以拿来创建集合。 注意:想要创建空集合,你必须使用set() 而不是 {} 。{}用于创建空字典;
集合的创建演示如下:
正则表达式
在爬虫时搜集回去的通常是字符流,我们要从中选购出url就要求有简单的字符串处理能力,而用正则表达式可以轻松的完成这一任务;
正则表达式的步骤:1,正则表达式的编译 2,正则表达式匹配字符串 3,结果的处理
下图列举了正则表达式的句型:
在pytho中使用正则表达式网络爬虫 正则表达式,需要引入re模块;下面介绍下该模块中的一些技巧;
pile和match
re模块中compile用于生成pattern的对象,再通过调用pattern实例的match方式处理文本最终获得match实例;通过使用match获得信息;
pattern:
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方式可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用pile()进行构造。
2.re.match(pattern, string, flags=0)
函数参数说明:
参数描述
pattern
匹配的正则表达式
string
要匹配的字符串。
flags
标志位,用于控制正则表达式的匹配方法,如:是否分辨大小写,多行匹配等等。
匹配成功re.match方式返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
匹配对象方式描述
group(num=0)
匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这些情况下它将返回一个包含这些组所对应值的元组。
groups()
返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
re.search方式
re.search 扫描整个字符串并返回第一个成功的匹配。
函数句型:
re.search(pattern, string, flags=0)
函数参数说明:
参数描述
pattern
匹配的正则表达式
string
要匹配的字符串。
flags
标志位,用于控制正则表达式的匹配方法,如:是否分辨大小写,多行匹配等等。
匹配成功re.search方式返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
匹配对象方式描述
group(num=0)
匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这些情况下它将返回一个包含这些组所对应值的元组。
groups()
返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
实例一:
search和match区别:
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串网络爬虫 正则表达式,直到找到一个匹配。
python爬虫小试牛刀
利用python抓取页面中所有的http合同的链接,并递归抓取子页面的链接。使用了集合和队列;此去爬的是我的网站,第一版好多bug;
代码如下:
那么你学会了吗? 查看全部
urllib.request.urlopen(url)官方文档返回一个 http.client.HTTPResponse 对象, 这个对象又用到的read()方法;返回数据;这个函数返回一个 http.client.HTTPResponse 对象, 这个对象又有各类方式, 比如我们用到的read()方法;如果你也是编程的学习者或则早已学会了的编程者!小编这儿有个群:103456743!大家可以加下,里面布满了全国各地的学习者!为你们提供一个交流平台,不管平常有遇到哪些BUG或则学习过程中卡壳,找不到人替你解决?那么就进来吧,里面热心的小伙伴还是十分多的,管理也是很好的,有哪些问题,他假如有时间都能给你们解决,我认为是一个特别不错的交流平台,没事也可以和你们扯扯公司的事中学发生的轶事,群文件早已上传了很多G的资料,PDF,视频 安装工具,安装教程都是有的,为了你们的学习能更进一步!也为了你们能愉快的交流,讨论学术问题!所以你还在等哪些呢?好了马上给你们带来正文!
data是一个字典, 然后通过urllib.parse.urlencode()来将data转换为 ‘word=one+peace’的字符串, 最后和url合并为full_url
python正则表达式介绍:
队列 介绍
在爬虫的程序中用到了广度优先级算法,该算法用到了数据结构,当然你用list也可以实现队列,但是效率不高。现在在此处介绍下:
在容器中有队列:collection.deque
集合介绍:
在爬虫程序中, 为了不重复爬这些早已爬过的网站, 我们须要把爬过的页面的url放进集合中, 在每一次要爬某一个url之前, 先瞧瞧集合上面是否早已存在. 如果早已存在, 我们就跳过这个url; 如果不存在, 我们先把url装入集合中, 然后再去爬这个页面.
Python 还 包 含 了 一 个 数 据 类 型—— set ( 集 合 ) 。 集 合 是 一 个 无 序 不 重 复 元素 的 集 。 基 本 功 能 包 括 关 系 测 试 和 消 除 重 复 元 素 。 集 合 对 象 还 支 持 union( 联
合),intersection(交),difference(差)和 sysmmetric difference(对称差集)等物理运算。
大括号或 set() 函数可以拿来创建集合。 注意:想要创建空集合,你必须使用set() 而不是 {} 。{}用于创建空字典;
集合的创建演示如下:
正则表达式
在爬虫时搜集回去的通常是字符流,我们要从中选购出url就要求有简单的字符串处理能力,而用正则表达式可以轻松的完成这一任务;
正则表达式的步骤:1,正则表达式的编译 2,正则表达式匹配字符串 3,结果的处理
下图列举了正则表达式的句型:
在pytho中使用正则表达式网络爬虫 正则表达式,需要引入re模块;下面介绍下该模块中的一些技巧;
pile和match
re模块中compile用于生成pattern的对象,再通过调用pattern实例的match方式处理文本最终获得match实例;通过使用match获得信息;
pattern:
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方式可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用pile()进行构造。
2.re.match(pattern, string, flags=0)
函数参数说明:
参数描述
pattern
匹配的正则表达式
string
要匹配的字符串。
flags
标志位,用于控制正则表达式的匹配方法,如:是否分辨大小写,多行匹配等等。
匹配成功re.match方式返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
匹配对象方式描述
group(num=0)
匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这些情况下它将返回一个包含这些组所对应值的元组。
groups()
返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
re.search方式
re.search 扫描整个字符串并返回第一个成功的匹配。
函数句型:
re.search(pattern, string, flags=0)
函数参数说明:
参数描述
pattern
匹配的正则表达式
string
要匹配的字符串。
flags
标志位,用于控制正则表达式的匹配方法,如:是否分辨大小写,多行匹配等等。
匹配成功re.search方式返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
匹配对象方式描述
group(num=0)
匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这些情况下它将返回一个包含这些组所对应值的元组。
groups()
返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
实例一:
search和match区别:
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串网络爬虫 正则表达式,直到找到一个匹配。
python爬虫小试牛刀
利用python抓取页面中所有的http合同的链接,并递归抓取子页面的链接。使用了集合和队列;此去爬的是我的网站,第一版好多bug;
代码如下:
那么你学会了吗?
Ipidea丨网络爬虫正则表达式的使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 392 次浏览 • 2020-06-17 08:00
## 网络爬虫正则表达式的使用
---
我们在处理网页文本内容时有时会碰到一些特殊的情况网络爬虫 正则表达式,或者须要匹配某类字符串方式,通常都会用到正则表达式。许多程序语言都支持使用正则表达式,python中正则表达式可以实现字符串的匹配、检索和替换等功能,是一个比较强悍的工具。
### 1.正则表达式句型
Python中实现正则表达式功能一般使用re模块,可以实现对文本字符串的匹配,检索和替换,但不仅引入正则模块网络爬虫 正则表达式,还须要把握正则表达式字符和基本句型,才能正确使用python进行正则表达式提取。
部分常用的正则表达式:
| 字符 | 功能 |
| :--: | :--: |
| \ |转义字符,标记下一个字符为特殊字符|
| ^ |匹配输入字符串的开始位置|
| $ |匹配输入字符串的结束位置|
| * |匹配上面的子表达式零次或多次 |
| + |匹配上面的子表达式一次或多次 |
| ? |匹配上面的子表达式零次或一次 |
| . |匹配除“\n”之外的任何单个字符 |
| () | 匹配括弧里的表达式 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符 |
| \w |匹配包括顿号的任何词组字符|
| \W |匹配任何非词组字符|
|{n}|n是一个非负整数,匹配确定的n次|
|{n,m}|m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次|
|[x,y,z]| 匹配一组字符集 |
| \^[x,y,z] | 匹配不在[]中的字符 |
| a\|b | 匹配a或b | 查看全部
## 网络爬虫正则表达式的使用
---
我们在处理网页文本内容时有时会碰到一些特殊的情况网络爬虫 正则表达式,或者须要匹配某类字符串方式,通常都会用到正则表达式。许多程序语言都支持使用正则表达式,python中正则表达式可以实现字符串的匹配、检索和替换等功能,是一个比较强悍的工具。
### 1.正则表达式句型
Python中实现正则表达式功能一般使用re模块,可以实现对文本字符串的匹配,检索和替换,但不仅引入正则模块网络爬虫 正则表达式,还须要把握正则表达式字符和基本句型,才能正确使用python进行正则表达式提取。
部分常用的正则表达式:
| 字符 | 功能 |
| :--: | :--: |
| \ |转义字符,标记下一个字符为特殊字符|
| ^ |匹配输入字符串的开始位置|
| $ |匹配输入字符串的结束位置|
| * |匹配上面的子表达式零次或多次 |
| + |匹配上面的子表达式一次或多次 |
| ? |匹配上面的子表达式零次或一次 |
| . |匹配除“\n”之外的任何单个字符 |
| () | 匹配括弧里的表达式 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符 |
| \w |匹配包括顿号的任何词组字符|
| \W |匹配任何非词组字符|
|{n}|n是一个非负整数,匹配确定的n次|
|{n,m}|m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次|
|[x,y,z]| 匹配一组字符集 |
| \^[x,y,z] | 匹配不在[]中的字符 |
| a\|b | 匹配a或b |
网络爬虫简介(5)— 链接爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 363 次浏览 • 2020-05-31 08:01
到目前为止,我们早已借助示例网站的结构特性实现了两个简单爬虫,用于下载所有已发布的国家(或地区)页面。只要这两种技术可用,就应该使用它们进行爬取,因为这两种方式将须要下载的网页数目降至最低。不过,对于另一些网站爬虫社区,我们须要使爬虫表现得更象普通用户,跟踪链接,访问感兴趣的内容。
通过跟踪每位链接的方法,我们可以很容易地下载整个网站的页面。但是,这种方式可能会下载好多并不需要的网页。例如,我们想要从一个在线峰会中抓取用户帐号详情页,那么此时我们只须要下载帐号页,而不需要下载讨论贴的页面。本章使用的链接爬虫将使用正则表达式来确定应该下载什么页面。下面是这段代码的初始版本。
import re
def link_crawler(start_url, link_regex):
""" Crawl from the given start URL following links matched by
link_regex
"""
crawl_queue = [start_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if html is not None:
continue
# filter for links matching our regular expression
for link in get_links(html):
if re.match(link_regex, link):
crawl_queue.append(link)
def get_links(html):
""" Return a list of links from html
"""
# a regular expression to extract all links from the webpage
webpage_regex = re.compile("""<a[^>]+href=["'](.*?)["']""",
re.IGNORECASE)
# list of all links from the webpage
return webpage_regex.findall(html)
要运行这段代码,只须要调用
link_crawler
函数,并传入两个参数:
要爬取的网站
URL
以及用于匹配你想跟踪的链
接的正则表达式。对于示例网
站来说,我们想要爬取的是国家(或地区
)列表索引页和国家(或地区)页面。
我们查看站点可以获知索引页链接遵守如下格式:
国家(或地区)页遵守如下格式:
因此爬虫社区,我们可以用/(index|view)/这个简单的正则表达式来匹配这两类网页。当爬虫使用这种输入参数运行时会发生哪些呢?你会得到如下所示的下载错误。
>>> link_crawler('http://example.python-scraping.com', '/(index|view)/')
Downloading: http://example.python-scraping.com
Downloading: /index/1
Traceback (most recent call last):
...
ValueError: unknown url type: /index/1
正则表达式是从字符串中抽取信息的非常好的工具,因此我推荐每名程序员都应该“学会怎样阅读和编撰一些正则表达式”。即便这么,它们常常会特别脆弱,容易失效。我们将在本书后续部份介绍更先进的抽取链接和辨识页面的形式。可以看出,问题出在下载/index/1时,该链接只有网页的路径部份,而没有合同和服务器部份,也就是说这是一个相对链接。由于浏览器晓得你正在浏览那个网页,并且还能采取必要步骤处理那些链接,因此在浏览器浏览时,相对链接是才能正常工作的。但是,urllib并没有上下文。为了使urllib才能定位网页,我们须要将链接转换为绝对链接的方式,以便包含定位网页的所有细节。如你所愿,Python的urllib中有一个模块可以拿来实现该功能,该模块名为parse。下面是link_crawler的改进版本,使用了urljoin方式来创建绝对路径。
from urllib.parse import urljoin
def link_crawler(start_url, link_regex):
""" Crawl from the given start URL following links matched by
link_regex
"""
crawl_queue = [start_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if not html:
continue
for link in get_links(html):
if re.match(link_regex, link):
abs_link = urljoin(start_url, link)
crawl_queue.append(abs_link)
当你运行这段代码时,会听到似乎下载了匹配的网页,但是同样的地点总是会被不断下载到。产生该行为的诱因是那些地点互相之间存在链接。比如,澳大利亚链接到了南极洲,而南极洲又链接回了德国,此时爬虫都会继续将这种URL装入队列,永远不会抵达队列尾部
。要想避开重复爬取相同的链接,我们须要记录什么链接早已被爬取过。下面是更改后的link_crawler函数,具备了储存已发觉URL的功能,可以避免重复下载。
def link_crawler(start_url, link_regex):
crawl_queue = [start_url]
# keep track which URL's have seen before
seen = set(crawl_queue)
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if not html:
continue
for link in get_links(html):
# check if link matches expected regex
if re.match(link_regex, link):
abs_link = urljoin(start_url, link)
# check if have already seen this link
if abs_link not in seen:
seen.add(abs_link)
crawl_queue.append(abs_link)
当运行该脚本时,它会爬取所有地点,并且还能如期停止。最终,我们得到了一个可用的链接爬虫! 查看全部
1.5.5 链接爬虫
到目前为止,我们早已借助示例网站的结构特性实现了两个简单爬虫,用于下载所有已发布的国家(或地区)页面。只要这两种技术可用,就应该使用它们进行爬取,因为这两种方式将须要下载的网页数目降至最低。不过,对于另一些网站爬虫社区,我们须要使爬虫表现得更象普通用户,跟踪链接,访问感兴趣的内容。
通过跟踪每位链接的方法,我们可以很容易地下载整个网站的页面。但是,这种方式可能会下载好多并不需要的网页。例如,我们想要从一个在线峰会中抓取用户帐号详情页,那么此时我们只须要下载帐号页,而不需要下载讨论贴的页面。本章使用的链接爬虫将使用正则表达式来确定应该下载什么页面。下面是这段代码的初始版本。
import re
def link_crawler(start_url, link_regex):
""" Crawl from the given start URL following links matched by
link_regex
"""
crawl_queue = [start_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if html is not None:
continue
# filter for links matching our regular expression
for link in get_links(html):
if re.match(link_regex, link):
crawl_queue.append(link)
def get_links(html):
""" Return a list of links from html
"""
# a regular expression to extract all links from the webpage
webpage_regex = re.compile("""<a[^>]+href=["'](.*?)["']""",
re.IGNORECASE)
# list of all links from the webpage
return webpage_regex.findall(html)
要运行这段代码,只须要调用
link_crawler
函数,并传入两个参数:
要爬取的网站
URL
以及用于匹配你想跟踪的链
接的正则表达式。对于示例网
站来说,我们想要爬取的是国家(或地区
)列表索引页和国家(或地区)页面。
我们查看站点可以获知索引页链接遵守如下格式:
国家(或地区)页遵守如下格式:
因此爬虫社区,我们可以用/(index|view)/这个简单的正则表达式来匹配这两类网页。当爬虫使用这种输入参数运行时会发生哪些呢?你会得到如下所示的下载错误。
>>> link_crawler('http://example.python-scraping.com', '/(index|view)/')
Downloading: http://example.python-scraping.com
Downloading: /index/1
Traceback (most recent call last):
...
ValueError: unknown url type: /index/1
正则表达式是从字符串中抽取信息的非常好的工具,因此我推荐每名程序员都应该“学会怎样阅读和编撰一些正则表达式”。即便这么,它们常常会特别脆弱,容易失效。我们将在本书后续部份介绍更先进的抽取链接和辨识页面的形式。可以看出,问题出在下载/index/1时,该链接只有网页的路径部份,而没有合同和服务器部份,也就是说这是一个相对链接。由于浏览器晓得你正在浏览那个网页,并且还能采取必要步骤处理那些链接,因此在浏览器浏览时,相对链接是才能正常工作的。但是,urllib并没有上下文。为了使urllib才能定位网页,我们须要将链接转换为绝对链接的方式,以便包含定位网页的所有细节。如你所愿,Python的urllib中有一个模块可以拿来实现该功能,该模块名为parse。下面是link_crawler的改进版本,使用了urljoin方式来创建绝对路径。
from urllib.parse import urljoin
def link_crawler(start_url, link_regex):
""" Crawl from the given start URL following links matched by
link_regex
"""
crawl_queue = [start_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if not html:
continue
for link in get_links(html):
if re.match(link_regex, link):
abs_link = urljoin(start_url, link)
crawl_queue.append(abs_link)
当你运行这段代码时,会听到似乎下载了匹配的网页,但是同样的地点总是会被不断下载到。产生该行为的诱因是那些地点互相之间存在链接。比如,澳大利亚链接到了南极洲,而南极洲又链接回了德国,此时爬虫都会继续将这种URL装入队列,永远不会抵达队列尾部
。要想避开重复爬取相同的链接,我们须要记录什么链接早已被爬取过。下面是更改后的link_crawler函数,具备了储存已发觉URL的功能,可以避免重复下载。
def link_crawler(start_url, link_regex):
crawl_queue = [start_url]
# keep track which URL's have seen before
seen = set(crawl_queue)
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if not html:
continue
for link in get_links(html):
# check if link matches expected regex
if re.match(link_regex, link):
abs_link = urljoin(start_url, link)
# check if have already seen this link
if abs_link not in seen:
seen.add(abs_link)
crawl_queue.append(abs_link)
当运行该脚本时,它会爬取所有地点,并且还能如期停止。最终,我们得到了一个可用的链接爬虫!
Python网络爬虫四大选择器(正则表达式、BS4、Xpath、CSS)总结
采集交流 • 优采云 发表了文章 • 0 个评论 • 478 次浏览 • 2020-05-12 08:01
一、正则表达式
正则表达式为我们提供了抓取数据的快捷方法。虽然该正则表达式更容易适应未来变化网络爬虫 正则表达式,但又存在无法构造、可读性差的问题。当在爬京东网的时侯,正则表达式如下图所示:
利用正则表达式实现对目标信息的精准采集
此外 ,我们都晓得,网页经常会形成变更,导致网页中会发生一些微小的布局变化时,此时也会促使之前写好的正则表达式未能满足需求,而且还不太好调试。当须要匹配的内容有很多的时侯,使用正则表达式提取目标信息会导致程序运行的速率减缓,需要消耗更多显存。
二、BeautifulSoup
BeautifulSoup是一个十分流行的 Pyhon 模块。该模块可以解析网页,并提供定位内容的方便插口。通过'pip install beautifulsoup4'就可以实现该模块的安装了。
利用美丽的汤去提取目标信息
使用 BeautifulSoup的第一步是将己下载的 HTML 内容解析为 soup文档。由 于大多数网页都不具备良好的HTML 格式,因此BeautifulSoup须要对实际格式进行确定。BeautifulSoup才能正确解析缺位的冒号并闭合标签,此外都会添加<html >和<body>标签让其成为完整的HTML文档。通常使用find() 和find_all()方法来定位我们须要的元素。
如果你想了解BeautifulSoup全部方式和参数,可以查阅BeautifulSoup的官方文档。虽然BeautifulSoup在代码的理解上比正则表达式要复杂一些,但是其愈发容易构造和理解。
三、Lxml
Lxml模块使用 C语言编撰,其解析速率比 BeautiflSoup更快,而且其安装过程也更为复杂,在此小编就不赘言啦。XPath 使用路径表达式在 XML 文档中选定节点。节点是通过顺着路径或则 step 来选定的。
Xpath选择器
使用 lxml 模块的第一步和BeautifulSoup一样,也是将有可能不合法的HTML 解析为 统一格式。 虽然Lxml可以正确解析属性两边缺位的冒号网络爬虫 正则表达式,并闭合标签,不过该模块没有额外添加<html >和<body>标签 。
在线复制Xpath表达式可以很方便的复制Xpath表达式。但是通过该方式得到的Xpath表达式置于程序中通常不能用,而且长的无法看。所以Xpath表达式通常还是要自己亲自上手。
四、CSS
CSS选择器表示选择元素所使用 的模式。BeautifulSoup整合了CSS选择器的句型和自身便捷使用API。在网路爬虫的开发过程中,对于熟悉CSS选择器句型的人,使用CSS选择器是个十分便捷的方式。
CSS选择器
下面是一些常用的选择器示例。 查看全部
前几天小编连续写了四篇关于Python选择器的文章,分别用正则表达式、BeautifulSoup、Xpath、CSS选择器分别抓取京东网的商品信息。今天小编来给你们总结一下这四个选择器,让你们愈发深刻的理解和熟悉Python选择器。
一、正则表达式
正则表达式为我们提供了抓取数据的快捷方法。虽然该正则表达式更容易适应未来变化网络爬虫 正则表达式,但又存在无法构造、可读性差的问题。当在爬京东网的时侯,正则表达式如下图所示:
利用正则表达式实现对目标信息的精准采集
此外 ,我们都晓得,网页经常会形成变更,导致网页中会发生一些微小的布局变化时,此时也会促使之前写好的正则表达式未能满足需求,而且还不太好调试。当须要匹配的内容有很多的时侯,使用正则表达式提取目标信息会导致程序运行的速率减缓,需要消耗更多显存。
二、BeautifulSoup
BeautifulSoup是一个十分流行的 Pyhon 模块。该模块可以解析网页,并提供定位内容的方便插口。通过'pip install beautifulsoup4'就可以实现该模块的安装了。
利用美丽的汤去提取目标信息
使用 BeautifulSoup的第一步是将己下载的 HTML 内容解析为 soup文档。由 于大多数网页都不具备良好的HTML 格式,因此BeautifulSoup须要对实际格式进行确定。BeautifulSoup才能正确解析缺位的冒号并闭合标签,此外都会添加<html >和<body>标签让其成为完整的HTML文档。通常使用find() 和find_all()方法来定位我们须要的元素。
如果你想了解BeautifulSoup全部方式和参数,可以查阅BeautifulSoup的官方文档。虽然BeautifulSoup在代码的理解上比正则表达式要复杂一些,但是其愈发容易构造和理解。
三、Lxml
Lxml模块使用 C语言编撰,其解析速率比 BeautiflSoup更快,而且其安装过程也更为复杂,在此小编就不赘言啦。XPath 使用路径表达式在 XML 文档中选定节点。节点是通过顺着路径或则 step 来选定的。
Xpath选择器
使用 lxml 模块的第一步和BeautifulSoup一样,也是将有可能不合法的HTML 解析为 统一格式。 虽然Lxml可以正确解析属性两边缺位的冒号网络爬虫 正则表达式,并闭合标签,不过该模块没有额外添加<html >和<body>标签 。
在线复制Xpath表达式可以很方便的复制Xpath表达式。但是通过该方式得到的Xpath表达式置于程序中通常不能用,而且长的无法看。所以Xpath表达式通常还是要自己亲自上手。
四、CSS
CSS选择器表示选择元素所使用 的模式。BeautifulSoup整合了CSS选择器的句型和自身便捷使用API。在网路爬虫的开发过程中,对于熟悉CSS选择器句型的人,使用CSS选择器是个十分便捷的方式。
CSS选择器
下面是一些常用的选择器示例。
使用正则表达式实现网页爬虫的思路解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-05-06 08:04
思路:
1.为模拟网页爬虫,我们可以如今我们的tomcat服务器端布署一个1.html网页。(部署的步骤:在tomcat目录的webapps目录的ROOTS目录下新建一个1.html。使用notepad++进行编辑网络爬虫 正则表达式,编辑内容为:
)
2.使用URL与网页构建联系
3.获取输入流,用于读取网页中的内容
4.建立正则规则,因为这儿我们是爬去网页中的邮箱信息网络爬虫 正则表达式,所以构建匹配 邮箱的正则表达式:String regex="\w+@\w+(\.\w+)+";
5.将提取到的数据放在集合中。
代码:
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网页爬虫:就是一个程序用于在互联网中获取指定规则的数据
*
*
*/
public class RegexDemo {
public static void main(String args) throws Exception {
List<String> list=getMailByWeb();
for(String str:list){
System.out.println(str);
}
}
private static List<String> getMailByWeb() throws Exception {
//1.与网页建立联系。使用URL
String path="http://localhost:8080//1.html";//后面写双斜杠是用于转义
URL url=new URL(path);
//2.获取输入流
InputStream is=url.openStream();
//加缓冲
BufferedReader br=new BufferedReader(new InputStreamReader(is));
//3.提取符合邮箱的数据
String regex="\\w+@\\w+(\\.\\w+)+";
//进行匹配
//将正则规则封装成对象
Pattern p=Pattern.compile(regex);
//将提取到的数据放到一个集合中
List<String> list=new ArrayList<String>();
String line=null;
while((line=br.readLine())!=null){
//匹配器
Matcher m=p.matcher(line);
while(m.find()){
//3.将符合规则的数据存储到集合中
list.add(m.group());
}
}
return list;
}
}
注意:在执行前须要先开启tomcat服务器
运行结果:
总结
以上所述是小编给你们介绍的使用正则表达式实现网页爬虫的思路解读,希望对你们有所帮助,如果你们有任何疑惑请给我留言,小编会及时回复你们的。在此也特别谢谢你们对优采云的支持! 查看全部
思路:
1.为模拟网页爬虫,我们可以如今我们的tomcat服务器端布署一个1.html网页。(部署的步骤:在tomcat目录的webapps目录的ROOTS目录下新建一个1.html。使用notepad++进行编辑网络爬虫 正则表达式,编辑内容为:
)
2.使用URL与网页构建联系
3.获取输入流,用于读取网页中的内容
4.建立正则规则,因为这儿我们是爬去网页中的邮箱信息网络爬虫 正则表达式,所以构建匹配 邮箱的正则表达式:String regex="\w+@\w+(\.\w+)+";
5.将提取到的数据放在集合中。
代码:
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网页爬虫:就是一个程序用于在互联网中获取指定规则的数据
*
*
*/
public class RegexDemo {
public static void main(String args) throws Exception {
List<String> list=getMailByWeb();
for(String str:list){
System.out.println(str);
}
}
private static List<String> getMailByWeb() throws Exception {
//1.与网页建立联系。使用URL
String path="http://localhost:8080//1.html";//后面写双斜杠是用于转义
URL url=new URL(path);
//2.获取输入流
InputStream is=url.openStream();
//加缓冲
BufferedReader br=new BufferedReader(new InputStreamReader(is));
//3.提取符合邮箱的数据
String regex="\\w+@\\w+(\\.\\w+)+";
//进行匹配
//将正则规则封装成对象
Pattern p=Pattern.compile(regex);
//将提取到的数据放到一个集合中
List<String> list=new ArrayList<String>();
String line=null;
while((line=br.readLine())!=null){
//匹配器
Matcher m=p.matcher(line);
while(m.find()){
//3.将符合规则的数据存储到集合中
list.add(m.group());
}
}
return list;
}
}
注意:在执行前须要先开启tomcat服务器
运行结果:
总结
以上所述是小编给你们介绍的使用正则表达式实现网页爬虫的思路解读,希望对你们有所帮助,如果你们有任何疑惑请给我留言,小编会及时回复你们的。在此也特别谢谢你们对优采云的支持!
phpcms跟dedecms比较
采集交流 • 优采云 发表了文章 • 0 个评论 • 452 次浏览 • 2020-04-26 11:01
首先从用户界面来看,也就是管理后台,首先是登陆,dedecms登录框下边的几个广告,着实叫人烦躁,看着不爽。当然了,毕竟人家靠这这点儿微薄的收入给俺开发出了如此强悍的cms系统。phpcms的登入界面就没有广告了,盛大也不缺这点儿钱。当步入后台主界面后,dedecms则变得有些狭小,界面也不是太华丽。在这一点上,phpcms做的很不错,大气,华丽。
从使用上来看,dedecms的操作去集中在了左侧,条例太清楚。phpcms则把一级导航放到了里面,二级导航放到了左侧,但是当选择完后,却没有相应的指示,往往使用户不知道自己处于那个导航之中,而且,phpcms在导航手动收起功能,感觉象是鸡肋,每次他收起时,我正在进行的操作还会被打乱,还不如没有这个功能来的好,也许是我的浏览器是宽屏的,即使不收起,依然觉得左侧的可编辑区域不小。
从模板开发上,dedecms面向的是中级站长,甚至不懂编程的计算机爱好者都可以,而且,dedecms的标签都不容许编程({dede:php}除外),完全都是模板标签操作,入门十分简单,当然了这也是以牺牲可定制性为代价的。phpcms的模板制做,也取样了dede同意的方法,标签式,但是这个要比dedecms宽松的多,你可以在上面嵌入php代码,可以在模板上面编程,虽然这是软件开发的三忌,但是模板的灵活性显著降低了,用户有了更多的权限和方法去实现自己想要的疗效。
SEO方面,做完网站了,如果他人都不来访问,或者根本找不到你的网站,那就很没面子了,而且也没收入了。在SEO方面,这两个cms做的都很不错,最通常的关键词和描述都有,而且是针对每位页面的。默认都可以设置页面生成的文件名称(补充一点,这两个cms都可以生成静态的html页面,这也对seo有很大帮助)。phpcms相对于dedecms的一些不足之处,网站的seo优化没有dedecms设计的好火车头采集教程,dedecms可以很简单的在后台控制url的生成方法,并且重命名,而phpcms貌似很复杂,最重要的是官方不给一点详尽的说明。
论坛活跃程度方面,如果使用dedecms遇到问题,可以去任何一个峰会发贴,很快有人回复,其峰会的活跃程度可不是通常的高。而phpcms呢,毕竟这个产品是盛大开发的,你问客服吧,不敢,我相信大部分人都和我一样,用的是免费的。所以只能老老实实的去峰会发贴,希望有人回答,但是峰会活跃程度远不如dedecms,而且phpcms还同时维护了两个版本,一个2008(听这名子,盛大也很懒了吧,4年不更新了),一个V9。
其他方面,很多人离开dedecms而转投phpcms,还有一个很重要的方面,那就是phpcms有一个dede所没有的功能――站群,当年我就是,从一个站长峰会上面看见了站群的概念,看了看仍然使用的dedecms很是沮丧,果断Google了一下支持站群的cms,然后转入了phpcms门下。
总结火车头采集教程,比较了这么多,两个cms都各有千秋,其实对于用户来说,还是使用习惯,当我们一旦习惯了一个工具的时侯,自然都会得心应手。 查看全部
现在做一个网站是越来越容易了,很多公司和个人站长开始使用内容管理系统,在CMS方面,尤其是PHP的CMS,更是百花齐放,当然了,质量也参差不齐。目前国外比较流行的有Dedecms和Phpcms,下面华来科技就这两个cms做一下简单的对比。
首先从用户界面来看,也就是管理后台,首先是登陆,dedecms登录框下边的几个广告,着实叫人烦躁,看着不爽。当然了,毕竟人家靠这这点儿微薄的收入给俺开发出了如此强悍的cms系统。phpcms的登入界面就没有广告了,盛大也不缺这点儿钱。当步入后台主界面后,dedecms则变得有些狭小,界面也不是太华丽。在这一点上,phpcms做的很不错,大气,华丽。
从使用上来看,dedecms的操作去集中在了左侧,条例太清楚。phpcms则把一级导航放到了里面,二级导航放到了左侧,但是当选择完后,却没有相应的指示,往往使用户不知道自己处于那个导航之中,而且,phpcms在导航手动收起功能,感觉象是鸡肋,每次他收起时,我正在进行的操作还会被打乱,还不如没有这个功能来的好,也许是我的浏览器是宽屏的,即使不收起,依然觉得左侧的可编辑区域不小。
从模板开发上,dedecms面向的是中级站长,甚至不懂编程的计算机爱好者都可以,而且,dedecms的标签都不容许编程({dede:php}除外),完全都是模板标签操作,入门十分简单,当然了这也是以牺牲可定制性为代价的。phpcms的模板制做,也取样了dede同意的方法,标签式,但是这个要比dedecms宽松的多,你可以在上面嵌入php代码,可以在模板上面编程,虽然这是软件开发的三忌,但是模板的灵活性显著降低了,用户有了更多的权限和方法去实现自己想要的疗效。
SEO方面,做完网站了,如果他人都不来访问,或者根本找不到你的网站,那就很没面子了,而且也没收入了。在SEO方面,这两个cms做的都很不错,最通常的关键词和描述都有,而且是针对每位页面的。默认都可以设置页面生成的文件名称(补充一点,这两个cms都可以生成静态的html页面,这也对seo有很大帮助)。phpcms相对于dedecms的一些不足之处,网站的seo优化没有dedecms设计的好火车头采集教程,dedecms可以很简单的在后台控制url的生成方法,并且重命名,而phpcms貌似很复杂,最重要的是官方不给一点详尽的说明。
论坛活跃程度方面,如果使用dedecms遇到问题,可以去任何一个峰会发贴,很快有人回复,其峰会的活跃程度可不是通常的高。而phpcms呢,毕竟这个产品是盛大开发的,你问客服吧,不敢,我相信大部分人都和我一样,用的是免费的。所以只能老老实实的去峰会发贴,希望有人回答,但是峰会活跃程度远不如dedecms,而且phpcms还同时维护了两个版本,一个2008(听这名子,盛大也很懒了吧,4年不更新了),一个V9。
其他方面,很多人离开dedecms而转投phpcms,还有一个很重要的方面,那就是phpcms有一个dede所没有的功能――站群,当年我就是,从一个站长峰会上面看见了站群的概念,看了看仍然使用的dedecms很是沮丧,果断Google了一下支持站群的cms,然后转入了phpcms门下。
总结火车头采集教程,比较了这么多,两个cms都各有千秋,其实对于用户来说,还是使用习惯,当我们一旦习惯了一个工具的时侯,自然都会得心应手。

