
正则
帝国CMS采集教程:帝国cms采集内容分页教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 412 次浏览 • 2020-07-22 08:01
相关文章:帝国cms采集功能:采集新浪各地新闻栏目内容
那么我们这一讲介绍帝国cms如何采集内容分页。不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:(1)全部列举式(2)上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以“中华网内容分页()”为例:
可以看见这条新闻总共有3条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:
可以看见这条新闻总共有20条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:
(2)第2页代码:
从这两幅图片可以见到她们有着相同的“分页区域开始代码”帝国cms采集分页教程,“分页链接”格式,“分页区域结束代码”,那么就可以确定“分页区域正则”,“分页链接正则”。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
5、为了便捷教程显示,newstext我采集了标题而不是采集内容,预览结果:
注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用“全部列出式”。在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时,老是采到第1页,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟帝国cms采集分页教程,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
好的,这一讲就到这儿,下一讲我们主要介绍帝国cms采集过滤和替换。 查看全部
相关文章:帝国cms采集功能:采集新浪各地新闻栏目内容
那么我们这一讲介绍帝国cms如何采集内容分页。不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:(1)全部列举式(2)上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以“中华网内容分页()”为例:

可以看见这条新闻总共有3条分页。
2、查看源代码:

这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
3、取得 分页区域正则([!--smallpageallzz--]):

4、取得 分页链接正则([!--pageallzz--]):

二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:

可以看见这条新闻总共有20条分页。
2、查看源代码:

这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:

(2)第2页代码:

从这两幅图片可以见到她们有着相同的“分页区域开始代码”帝国cms采集分页教程,“分页链接”格式,“分页区域结束代码”,那么就可以确定“分页区域正则”,“分页链接正则”。
3、取得 分页区域正则([!--smallpageallzz--]):

4、取得 分页链接正则([!--pageallzz--]):

5、为了便捷教程显示,newstext我采集了标题而不是采集内容,预览结果:

注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用“全部列出式”。在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时,老是采到第1页,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟帝国cms采集分页教程,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
好的,这一讲就到这儿,下一讲我们主要介绍帝国cms采集过滤和替换。
帝国cms网站采集内容分页教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 485 次浏览 • 2020-07-22 08:00
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以“中华网内容分页()”为例:
可以看见这条新闻总共有3条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:
可以看见这条新闻总共有20条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:
(2)第2页代码:
从这两幅图片可以见到她们有着相同的“分页区域开始代码”,“分页链接”格式,“分页区域结束代码”,那么就可以确定“分页区域正则”,“分页链接正则”。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
5、为了便捷教程显示,newstext我采集了标题而不是采集内容,预览结果:
注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用“全部列出式”。在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时帝国cms采集分页教程,老是采到第1页帝国cms采集分页教程,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。 查看全部

一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以“中华网内容分页()”为例:

可以看见这条新闻总共有3条分页。
2、查看源代码:

这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
3、取得 分页区域正则([!--smallpageallzz--]):

4、取得 分页链接正则([!--pageallzz--]):

二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:

可以看见这条新闻总共有20条分页。
2、查看源代码:

这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:

(2)第2页代码:

从这两幅图片可以见到她们有着相同的“分页区域开始代码”,“分页链接”格式,“分页区域结束代码”,那么就可以确定“分页区域正则”,“分页链接正则”。
3、取得 分页区域正则([!--smallpageallzz--]):

4、取得 分页链接正则([!--pageallzz--]):

5、为了便捷教程显示,newstext我采集了标题而不是采集内容,预览结果:

注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用“全部列出式”。在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时帝国cms采集分页教程,老是采到第1页帝国cms采集分页教程,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
帝国cms采集图文教程(中)
采集交流 • 优采云 发表了文章 • 0 个评论 • 415 次浏览 • 2020-07-21 08:03
1、 我们以“爱丽网内容分页()”为例: 可以看见这条新闻总共有 20 条分页。 2、 查看源代码: 这一页里不仅早已采集到的第 1 条分页外, 还包括了 第 2, 第 3, 第 4, 第 5, 第 6, 第 7,第 8, 第 20 条分页, 但是第 9 到第 19 条分页并没有列下来, 这时候我们拿用第 1 页和第 2页的代码来进行对比剖析, 来确定分页正则: (1) 第 1 页代码:(2) 第 2 页代码: 从这两幅图片可以见到她们有着相同的“分页区域开始代码”, “分页链接”格式, “分页区域结束代码”,那么就可以确定“分页区域正则”, “分页链接正则”。 3、 取得 分页区域正则([!--smallpageallzz--]): 4、 取得 分页链接正则([!--pageallzz--]):5、 为了便捷教程显示, newstext 我采集了标题而不是采集内容, 预览结果: 注意事项: 第一、 在第一页的页面 HTML 代码里, 内容分页链接全部列下来的情况下我们使用“全部列出式”。 在第一页的页面 HTML 代码里, 内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、 用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页帝国cms采集分页教程, 这时可以借助替换法把它过滤掉(下一讲我们再说)。 第三、 用上下页导航式时, 老是采到第 1 页, 其他页连个影子都没有见过, 这是因为分页区域正则([!--smallpagezz--])截取错误。 第四、 用上下页导航式时, 可以采集到前几页了 , 但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误, 截取范围过大, 导致重复截取前几个分页链接。 好的, 这一讲就到这儿, 下一讲我们主要介绍帝国 cms 采集过滤和替换。 本文由 国外网站大全 原创, 转载请标明出处, 谢谢! 查看全部
1、 我们以“爱丽网内容分页()”为例: 可以看见这条新闻总共有 20 条分页。 2、 查看源代码: 这一页里不仅早已采集到的第 1 条分页外, 还包括了 第 2, 第 3, 第 4, 第 5, 第 6, 第 7,第 8, 第 20 条分页, 但是第 9 到第 19 条分页并没有列下来, 这时候我们拿用第 1 页和第 2页的代码来进行对比剖析, 来确定分页正则: (1) 第 1 页代码:(2) 第 2 页代码: 从这两幅图片可以见到她们有着相同的“分页区域开始代码”, “分页链接”格式, “分页区域结束代码”,那么就可以确定“分页区域正则”, “分页链接正则”。 3、 取得 分页区域正则([!--smallpageallzz--]): 4、 取得 分页链接正则([!--pageallzz--]):5、 为了便捷教程显示, newstext 我采集了标题而不是采集内容, 预览结果: 注意事项: 第一、 在第一页的页面 HTML 代码里, 内容分页链接全部列下来的情况下我们使用“全部列出式”。 在第一页的页面 HTML 代码里, 内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、 用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页帝国cms采集分页教程, 这时可以借助替换法把它过滤掉(下一讲我们再说)。 第三、 用上下页导航式时, 老是采到第 1 页, 其他页连个影子都没有见过, 这是因为分页区域正则([!--smallpagezz--])截取错误。 第四、 用上下页导航式时, 可以采集到前几页了 , 但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误, 截取范围过大, 导致重复截取前几个分页链接。 好的, 这一讲就到这儿, 下一讲我们主要介绍帝国 cms 采集过滤和替换。 本文由 国外网站大全 原创, 转载请标明出处, 谢谢!
帝国cms采集教程二:如何采集内容分页
站长必读 • 优采云 发表了文章 • 0 个评论 • 498 次浏览 • 2020-07-20 08:05
上一讲我们介绍了帝国cms采集基本流程,那么我们这一讲介绍帝国cms如何采集内容分页。不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:(1)全部列举式(2)上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以“中华网内容分页()”为例:
可以看见这条新闻总共有3条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:
可以看见这条新闻总共有20条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来帝国cms采集分页教程,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:
(2)第2页代码:
从这两幅图片可以见到她们有着相同的“分页区域开始代码”,“分页链接”格式,“分页区域结束代码”,那么就可以确定“分页区域正则”,“分页链接正则”。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
5、为了便捷教程显示帝国cms采集分页教程,newstext我采集了标题而不是采集内容,预览结果:
注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用“全部列出式”。在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时,老是采到第1页,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
好的,这一讲就到这儿,下一讲我们主要介绍帝国cms采集过滤和替换。 查看全部

上一讲我们介绍了帝国cms采集基本流程,那么我们这一讲介绍帝国cms如何采集内容分页。不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:(1)全部列举式(2)上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以“中华网内容分页()”为例:

可以看见这条新闻总共有3条分页。
2、查看源代码:

这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
3、取得 分页区域正则([!--smallpageallzz--]):

4、取得 分页链接正则([!--pageallzz--]):

二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:

可以看见这条新闻总共有20条分页。
2、查看源代码:

这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来帝国cms采集分页教程,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:

(2)第2页代码:

从这两幅图片可以见到她们有着相同的“分页区域开始代码”,“分页链接”格式,“分页区域结束代码”,那么就可以确定“分页区域正则”,“分页链接正则”。
3、取得 分页区域正则([!--smallpageallzz--]):

4、取得 分页链接正则([!--pageallzz--]):

5、为了便捷教程显示帝国cms采集分页教程,newstext我采集了标题而不是采集内容,预览结果:

注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用“全部列出式”。在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时,老是采到第1页,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
好的,这一讲就到这儿,下一讲我们主要介绍帝国cms采集过滤和替换。
火车头网页正则提取电话 – 火车头正则采集电话
采集交流 • 优采云 发表了文章 • 0 个评论 • 711 次浏览 • 2020-05-25 08:01
分分钟搞定,咱们先熟悉一下火车头的规则。
(?<content>[\s\S]*?)
Content //代表内容
? //表示匹配0次或则1次
\s //匹配所有空白字符
\S //匹配所有非空白字符
* //修饰匹配次数为 0 次或任意次
火车头采集手机号的正则:(?<content>1[34578]{1}[0-9]{9})
火车头采集邮箱的正则:(?<content>[\w\-\.]+@[\w\-\.]+\.\w+)
--------------------下方是正则表达式说明。-----------------------
表1.常用的元字符代码说明
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或顿号或汉字
\s 匹配任意的空白符
\d 匹配数字
\b 匹配词组的开始或结束
^ 匹配字符串的开始$匹配字符串的结束
表2.常用的限定符代码/语法说明
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
表3.常用的反义代码代码/语法说明
\W 匹配任意不是字母,数字,下划线,汉字的字符
\S 匹配任意不是空白符的字符
\D 匹配任意非数字的字符
\B 匹配不是词组开头或结束的位置
[^x] 匹配不仅x以外的任意字符
[^aeiou] 匹配不仅aeiou这几个字母以外的任意字符
常用分组句型
表5.懒惰限定符代码/语法说明
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
表7.尚未详尽讨论的句型代码/语法说明
\a 报案字符(打印它的疗效是笔记本嘀一声)
\b 一般是词组分界位置,但若果在字符类里使用代表退格
\t 制表符火车采集器 手机正则表达式,Tab
\r 回车
\v 竖向制表符
\f 换页符
\n 换行符
\e Escape
\0nn ASCII代码中八进制代码为nn的字符
\xnn ASCII代码中十六进制代码为nn的字符
\unnnn Unicode代码中十六进制代码为nnnn的字符
\cN ASCII控制字符。比如\cC代表Ctrl+C
\A 字符串开头(类似^,但不受处理多行选项的影响)
\Z 字符串结尾或行尾(不受处理多行选项的影响)
\z 字符串结尾(类似$火车采集器 手机正则表达式,但不受处理多行选项的影响)
\G 当前搜索的开头
\p{name} Unicode中命名为name的字符类,例如\p{IsGreek}
(?>exp) 贪婪子表达式(?<x>-<y>exp)平衡组
(?im-nsx:exp) 在子表达式exp中改变处理选项
(?im-nsx) 为表达式旁边的部份改变处理选项
(?(exp)yes|no) 把exp当成零宽正向先行断定,如果在这个位置能匹配,使用yes作为此组的表达式;否则使用no(?(exp)yes)同上,只是使用空表达式作为no
(?(name)yes|no) 假如命名为name的组捕获到了内容,使用yes作为表达式;否则使用no
(?(name)yes) 同上,只是使用空表达式作为no 查看全部
话说好长时间不用火车头了。都有点蒙逼忘了。记得曾经用火车头采集论坛做垃圾文章网站,都多少年前的事情了,如今须要采集一些手机号,想想懒得写PHP,有现成的工具为何不用对吧,没毛病。
分分钟搞定,咱们先熟悉一下火车头的规则。
(?<content>[\s\S]*?)
Content //代表内容
? //表示匹配0次或则1次
\s //匹配所有空白字符
\S //匹配所有非空白字符
* //修饰匹配次数为 0 次或任意次
火车头采集手机号的正则:(?<content>1[34578]{1}[0-9]{9})
火车头采集邮箱的正则:(?<content>[\w\-\.]+@[\w\-\.]+\.\w+)
--------------------下方是正则表达式说明。-----------------------
表1.常用的元字符代码说明
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或顿号或汉字
\s 匹配任意的空白符
\d 匹配数字
\b 匹配词组的开始或结束
^ 匹配字符串的开始$匹配字符串的结束
表2.常用的限定符代码/语法说明
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
表3.常用的反义代码代码/语法说明
\W 匹配任意不是字母,数字,下划线,汉字的字符
\S 匹配任意不是空白符的字符
\D 匹配任意非数字的字符
\B 匹配不是词组开头或结束的位置
[^x] 匹配不仅x以外的任意字符
[^aeiou] 匹配不仅aeiou这几个字母以外的任意字符
常用分组句型
表5.懒惰限定符代码/语法说明
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
表7.尚未详尽讨论的句型代码/语法说明
\a 报案字符(打印它的疗效是笔记本嘀一声)
\b 一般是词组分界位置,但若果在字符类里使用代表退格
\t 制表符火车采集器 手机正则表达式,Tab
\r 回车
\v 竖向制表符
\f 换页符
\n 换行符
\e Escape
\0nn ASCII代码中八进制代码为nn的字符
\xnn ASCII代码中十六进制代码为nn的字符
\unnnn Unicode代码中十六进制代码为nnnn的字符
\cN ASCII控制字符。比如\cC代表Ctrl+C
\A 字符串开头(类似^,但不受处理多行选项的影响)
\Z 字符串结尾或行尾(不受处理多行选项的影响)
\z 字符串结尾(类似$火车采集器 手机正则表达式,但不受处理多行选项的影响)
\G 当前搜索的开头
\p{name} Unicode中命名为name的字符类,例如\p{IsGreek}
(?>exp) 贪婪子表达式(?<x>-<y>exp)平衡组
(?im-nsx:exp) 在子表达式exp中改变处理选项
(?im-nsx) 为表达式旁边的部份改变处理选项
(?(exp)yes|no) 把exp当成零宽正向先行断定,如果在这个位置能匹配,使用yes作为此组的表达式;否则使用no(?(exp)yes)同上,只是使用空表达式作为no
(?(name)yes|no) 假如命名为name的组捕获到了内容,使用yes作为表达式;否则使用no
(?(name)yes) 同上,只是使用空表达式作为no
火车采集器系列教程 之 使用正则采集链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 740 次浏览 • 2020-05-15 08:01
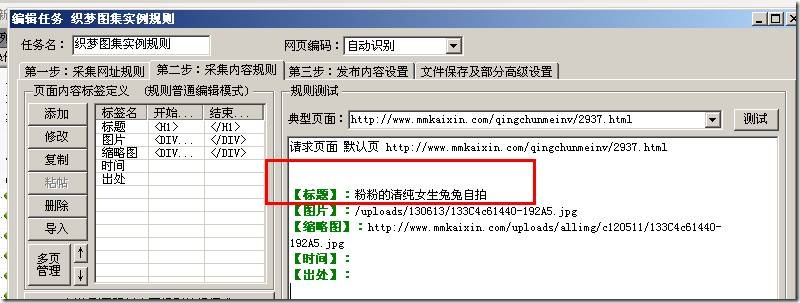
火车采集器系列教程 之 使用正则采集网址 图片版 先来瞧瞧这段加密后代码 <a href=";s=1&ct=201326592&cl=2&lm=-1&tn=baiduimage&word=&#34081;&#20381;&#26519;&z=4" target="_blank">蔡依林</a> 生成之后可以正常访问的联接是: ;s=1&ct=201326592&cl=2&lm=-1&tn=baiduimage&word=蔡依林&z=4 而我们能获取到却难以访问的链接是: ;s=1&ct=201326592&cl=2&lm=-1&tn=baiduimage&word=&#34081;&#20381;&#26519;&z=4 经过对比我们可以看出,两个链接只有 从 word=到&这之间的代码不一样,我们还可以看出,之间的代码恰好对应 蔡依林 这个链接的标题,我们可以想,如果我们可以把这之间的乱码用这段链接的标题来取代或则说替换,那不就完全一样了吗? 是的,我们完全可以借助正则来采集这样的网站地址! 列表地址: 在页面链接的采集方法这儿,我们有两个选择,一个是自动填写链接地址规则,一个是启动向导添加,进入正则提取!以下火车采集器 正则提取,我们两种方式都一并讲解! 列车采集器系列教程 之 使用正则采集链接 一 下面,启动我们的列车,建立一个站点,建立一个任务! 自动添加模式1,打开自动添加模式之后,我们先设置禁用系统手动辨识联接,启用自定义联接格式 火车采集器系列教程 之 使用正则采集网址 图片版 2,修改我们的正则规则如下: <a href="(*)" target="_blank">[参数]</a> 这里, <a href=" 的作用是取固定字符在确定联接所在区域,设定参数为我们想获取的目标内容。
实际联接设置为正确的可以访问的链接前部份 ;s=1&ct=201326592&cl=2&lm=-1&tn=baiduimage&word=[参数 1]&pic=1 这里的参数 1表示它就是获取的参数,如果你想在其它地方再使用,可以继续使用到参数 N,不过你要注意了,如果你要获取多个参数,这里复杂了,请注意下边这张图片: 假如你要获取多个参数火车采集器 正则提取,请注意她们出现的位次,在引用过程中,也要注意位次,不然会出现参数值传递错误!同时,你可以将[参数 N]修改为你想获取的参数。 在这里,如果有缩略图,我们也可以加上缩略图,也可以下载!将缩略图标签替换图片地址就可以了! 向导添加信正则提取模式 在源地址处添加我们要采集的列表地址 进一步设置正则参数,这里的参数就和我们刚才说过的就是一模一样的了,这两种模式方式一样,但也适用于采集不同地址的列表,就看你们的喜好了! 设置完成之后就可以提取地址并完了! 火车采集器系列教程 之 使用正则采集网址 图片版 以下展示一下我们采集到的地址: 好了,经过比较长时间的制做,这份文档加图片的教程就制做得差不多了,现在是早上两点,应该休息了! 剩下的视频部份,就等今天来完成吧!最后,感谢你们对火车头的支持,3Q and 88 本文没有来得急校对,如果出现错误的地方欢迎你们修正! 查看全部
火车采集器系列教程 之 使用正则采集网址 图片版 先来瞧瞧这段加密后代码 <a href=";s=1&ct=201326592&cl=2&lm=-1&tn=baiduimage&word=&#34081;&#20381;&#26519;&z=4" target="_blank">蔡依林</a> 生成之后可以正常访问的联接是: ;s=1&ct=201326592&cl=2&lm=-1&tn=baiduimage&word=蔡依林&z=4 而我们能获取到却难以访问的链接是: ;s=1&ct=201326592&cl=2&lm=-1&tn=baiduimage&word=&#34081;&#20381;&#26519;&z=4 经过对比我们可以看出,两个链接只有 从 word=到&这之间的代码不一样,我们还可以看出,之间的代码恰好对应 蔡依林 这个链接的标题,我们可以想,如果我们可以把这之间的乱码用这段链接的标题来取代或则说替换,那不就完全一样了吗? 是的,我们完全可以借助正则来采集这样的网站地址! 列表地址: 在页面链接的采集方法这儿,我们有两个选择,一个是自动填写链接地址规则,一个是启动向导添加,进入正则提取!以下火车采集器 正则提取,我们两种方式都一并讲解! 列车采集器系列教程 之 使用正则采集链接 一 下面,启动我们的列车,建立一个站点,建立一个任务! 自动添加模式1,打开自动添加模式之后,我们先设置禁用系统手动辨识联接,启用自定义联接格式 火车采集器系列教程 之 使用正则采集网址 图片版 2,修改我们的正则规则如下: <a href="(*)" target="_blank">[参数]</a> 这里, <a href=" 的作用是取固定字符在确定联接所在区域,设定参数为我们想获取的目标内容。
实际联接设置为正确的可以访问的链接前部份 ;s=1&ct=201326592&cl=2&lm=-1&tn=baiduimage&word=[参数 1]&pic=1 这里的参数 1表示它就是获取的参数,如果你想在其它地方再使用,可以继续使用到参数 N,不过你要注意了,如果你要获取多个参数,这里复杂了,请注意下边这张图片: 假如你要获取多个参数火车采集器 正则提取,请注意她们出现的位次,在引用过程中,也要注意位次,不然会出现参数值传递错误!同时,你可以将[参数 N]修改为你想获取的参数。 在这里,如果有缩略图,我们也可以加上缩略图,也可以下载!将缩略图标签替换图片地址就可以了! 向导添加信正则提取模式 在源地址处添加我们要采集的列表地址 进一步设置正则参数,这里的参数就和我们刚才说过的就是一模一样的了,这两种模式方式一样,但也适用于采集不同地址的列表,就看你们的喜好了! 设置完成之后就可以提取地址并完了! 火车采集器系列教程 之 使用正则采集网址 图片版 以下展示一下我们采集到的地址: 好了,经过比较长时间的制做,这份文档加图片的教程就制做得差不多了,现在是早上两点,应该休息了! 剩下的视频部份,就等今天来完成吧!最后,感谢你们对火车头的支持,3Q and 88 本文没有来得急校对,如果出现错误的地方欢迎你们修正!
帝国CMS采集教程:帝国cms采集内容分页教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 412 次浏览 • 2020-07-22 08:01
相关文章:帝国cms采集功能:采集新浪各地新闻栏目内容
那么我们这一讲介绍帝国cms如何采集内容分页。不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:(1)全部列举式(2)上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以“中华网内容分页()”为例:
可以看见这条新闻总共有3条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:
可以看见这条新闻总共有20条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:
(2)第2页代码:
从这两幅图片可以见到她们有着相同的“分页区域开始代码”帝国cms采集分页教程,“分页链接”格式,“分页区域结束代码”,那么就可以确定“分页区域正则”,“分页链接正则”。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
5、为了便捷教程显示,newstext我采集了标题而不是采集内容,预览结果:
注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用“全部列出式”。在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时,老是采到第1页,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟帝国cms采集分页教程,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
好的,这一讲就到这儿,下一讲我们主要介绍帝国cms采集过滤和替换。 查看全部
相关文章:帝国cms采集功能:采集新浪各地新闻栏目内容
那么我们这一讲介绍帝国cms如何采集内容分页。不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:(1)全部列举式(2)上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以“中华网内容分页()”为例:
可以看见这条新闻总共有3条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:
可以看见这条新闻总共有20条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:
(2)第2页代码:
从这两幅图片可以见到她们有着相同的“分页区域开始代码”帝国cms采集分页教程,“分页链接”格式,“分页区域结束代码”,那么就可以确定“分页区域正则”,“分页链接正则”。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
5、为了便捷教程显示,newstext我采集了标题而不是采集内容,预览结果:
注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用“全部列出式”。在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时,老是采到第1页,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟帝国cms采集分页教程,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
好的,这一讲就到这儿,下一讲我们主要介绍帝国cms采集过滤和替换。
帝国cms网站采集内容分页教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 485 次浏览 • 2020-07-22 08:00
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以“中华网内容分页()”为例:
可以看见这条新闻总共有3条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:
可以看见这条新闻总共有20条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:
(2)第2页代码:
从这两幅图片可以见到她们有着相同的“分页区域开始代码”,“分页链接”格式,“分页区域结束代码”,那么就可以确定“分页区域正则”,“分页链接正则”。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
5、为了便捷教程显示,newstext我采集了标题而不是采集内容,预览结果:
注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用“全部列出式”。在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时帝国cms采集分页教程,老是采到第1页帝国cms采集分页教程,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。 查看全部
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以“中华网内容分页()”为例:
可以看见这条新闻总共有3条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:
可以看见这条新闻总共有20条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:
(2)第2页代码:
从这两幅图片可以见到她们有着相同的“分页区域开始代码”,“分页链接”格式,“分页区域结束代码”,那么就可以确定“分页区域正则”,“分页链接正则”。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
5、为了便捷教程显示,newstext我采集了标题而不是采集内容,预览结果:
注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用“全部列出式”。在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时帝国cms采集分页教程,老是采到第1页帝国cms采集分页教程,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
帝国cms采集图文教程(中)
采集交流 • 优采云 发表了文章 • 0 个评论 • 415 次浏览 • 2020-07-21 08:03
1、 我们以“爱丽网内容分页()”为例: 可以看见这条新闻总共有 20 条分页。 2、 查看源代码: 这一页里不仅早已采集到的第 1 条分页外, 还包括了 第 2, 第 3, 第 4, 第 5, 第 6, 第 7,第 8, 第 20 条分页, 但是第 9 到第 19 条分页并没有列下来, 这时候我们拿用第 1 页和第 2页的代码来进行对比剖析, 来确定分页正则: (1) 第 1 页代码:(2) 第 2 页代码: 从这两幅图片可以见到她们有着相同的“分页区域开始代码”, “分页链接”格式, “分页区域结束代码”,那么就可以确定“分页区域正则”, “分页链接正则”。 3、 取得 分页区域正则([!--smallpageallzz--]): 4、 取得 分页链接正则([!--pageallzz--]):5、 为了便捷教程显示, newstext 我采集了标题而不是采集内容, 预览结果: 注意事项: 第一、 在第一页的页面 HTML 代码里, 内容分页链接全部列下来的情况下我们使用“全部列出式”。 在第一页的页面 HTML 代码里, 内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、 用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页帝国cms采集分页教程, 这时可以借助替换法把它过滤掉(下一讲我们再说)。 第三、 用上下页导航式时, 老是采到第 1 页, 其他页连个影子都没有见过, 这是因为分页区域正则([!--smallpagezz--])截取错误。 第四、 用上下页导航式时, 可以采集到前几页了 , 但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误, 截取范围过大, 导致重复截取前几个分页链接。 好的, 这一讲就到这儿, 下一讲我们主要介绍帝国 cms 采集过滤和替换。 本文由 国外网站大全 原创, 转载请标明出处, 谢谢! 查看全部
1、 我们以“爱丽网内容分页()”为例: 可以看见这条新闻总共有 20 条分页。 2、 查看源代码: 这一页里不仅早已采集到的第 1 条分页外, 还包括了 第 2, 第 3, 第 4, 第 5, 第 6, 第 7,第 8, 第 20 条分页, 但是第 9 到第 19 条分页并没有列下来, 这时候我们拿用第 1 页和第 2页的代码来进行对比剖析, 来确定分页正则: (1) 第 1 页代码:(2) 第 2 页代码: 从这两幅图片可以见到她们有着相同的“分页区域开始代码”, “分页链接”格式, “分页区域结束代码”,那么就可以确定“分页区域正则”, “分页链接正则”。 3、 取得 分页区域正则([!--smallpageallzz--]): 4、 取得 分页链接正则([!--pageallzz--]):5、 为了便捷教程显示, newstext 我采集了标题而不是采集内容, 预览结果: 注意事项: 第一、 在第一页的页面 HTML 代码里, 内容分页链接全部列下来的情况下我们使用“全部列出式”。 在第一页的页面 HTML 代码里, 内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、 用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页帝国cms采集分页教程, 这时可以借助替换法把它过滤掉(下一讲我们再说)。 第三、 用上下页导航式时, 老是采到第 1 页, 其他页连个影子都没有见过, 这是因为分页区域正则([!--smallpagezz--])截取错误。 第四、 用上下页导航式时, 可以采集到前几页了 , 但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误, 截取范围过大, 导致重复截取前几个分页链接。 好的, 这一讲就到这儿, 下一讲我们主要介绍帝国 cms 采集过滤和替换。 本文由 国外网站大全 原创, 转载请标明出处, 谢谢!
帝国cms采集教程二:如何采集内容分页
站长必读 • 优采云 发表了文章 • 0 个评论 • 498 次浏览 • 2020-07-20 08:05
上一讲我们介绍了帝国cms采集基本流程,那么我们这一讲介绍帝国cms如何采集内容分页。不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:(1)全部列举式(2)上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以“中华网内容分页()”为例:
可以看见这条新闻总共有3条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:
可以看见这条新闻总共有20条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来帝国cms采集分页教程,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:
(2)第2页代码:
从这两幅图片可以见到她们有着相同的“分页区域开始代码”,“分页链接”格式,“分页区域结束代码”,那么就可以确定“分页区域正则”,“分页链接正则”。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
5、为了便捷教程显示帝国cms采集分页教程,newstext我采集了标题而不是采集内容,预览结果:
注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用“全部列出式”。在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时,老是采到第1页,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
好的,这一讲就到这儿,下一讲我们主要介绍帝国cms采集过滤和替换。 查看全部
上一讲我们介绍了帝国cms采集基本流程,那么我们这一讲介绍帝国cms如何采集内容分页。不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:(1)全部列举式(2)上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以“中华网内容分页()”为例:
可以看见这条新闻总共有3条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:
可以看见这条新闻总共有20条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来帝国cms采集分页教程,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:
(2)第2页代码:
从这两幅图片可以见到她们有着相同的“分页区域开始代码”,“分页链接”格式,“分页区域结束代码”,那么就可以确定“分页区域正则”,“分页链接正则”。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
5、为了便捷教程显示帝国cms采集分页教程,newstext我采集了标题而不是采集内容,预览结果:
注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用“全部列出式”。在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时,老是采到第1页,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
好的,这一讲就到这儿,下一讲我们主要介绍帝国cms采集过滤和替换。
火车头网页正则提取电话 – 火车头正则采集电话
采集交流 • 优采云 发表了文章 • 0 个评论 • 711 次浏览 • 2020-05-25 08:01
分分钟搞定,咱们先熟悉一下火车头的规则。
(?<content>[\s\S]*?)
Content //代表内容
? //表示匹配0次或则1次
\s //匹配所有空白字符
\S //匹配所有非空白字符
* //修饰匹配次数为 0 次或任意次
火车头采集手机号的正则:(?<content>1[34578]{1}[0-9]{9})
火车头采集邮箱的正则:(?<content>[\w\-\.]+@[\w\-\.]+\.\w+)
--------------------下方是正则表达式说明。-----------------------
表1.常用的元字符代码说明
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或顿号或汉字
\s 匹配任意的空白符
\d 匹配数字
\b 匹配词组的开始或结束
^ 匹配字符串的开始$匹配字符串的结束
表2.常用的限定符代码/语法说明
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
表3.常用的反义代码代码/语法说明
\W 匹配任意不是字母,数字,下划线,汉字的字符
\S 匹配任意不是空白符的字符
\D 匹配任意非数字的字符
\B 匹配不是词组开头或结束的位置
[^x] 匹配不仅x以外的任意字符
[^aeiou] 匹配不仅aeiou这几个字母以外的任意字符
常用分组句型
表5.懒惰限定符代码/语法说明
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
表7.尚未详尽讨论的句型代码/语法说明
\a 报案字符(打印它的疗效是笔记本嘀一声)
\b 一般是词组分界位置,但若果在字符类里使用代表退格
\t 制表符火车采集器 手机正则表达式,Tab
\r 回车
\v 竖向制表符
\f 换页符
\n 换行符
\e Escape
\0nn ASCII代码中八进制代码为nn的字符
\xnn ASCII代码中十六进制代码为nn的字符
\unnnn Unicode代码中十六进制代码为nnnn的字符
\cN ASCII控制字符。比如\cC代表Ctrl+C
\A 字符串开头(类似^,但不受处理多行选项的影响)
\Z 字符串结尾或行尾(不受处理多行选项的影响)
\z 字符串结尾(类似$火车采集器 手机正则表达式,但不受处理多行选项的影响)
\G 当前搜索的开头
\p{name} Unicode中命名为name的字符类,例如\p{IsGreek}
(?>exp) 贪婪子表达式(?<x>-<y>exp)平衡组
(?im-nsx:exp) 在子表达式exp中改变处理选项
(?im-nsx) 为表达式旁边的部份改变处理选项
(?(exp)yes|no) 把exp当成零宽正向先行断定,如果在这个位置能匹配,使用yes作为此组的表达式;否则使用no(?(exp)yes)同上,只是使用空表达式作为no
(?(name)yes|no) 假如命名为name的组捕获到了内容,使用yes作为表达式;否则使用no
(?(name)yes) 同上,只是使用空表达式作为no 查看全部
话说好长时间不用火车头了。都有点蒙逼忘了。记得曾经用火车头采集论坛做垃圾文章网站,都多少年前的事情了,如今须要采集一些手机号,想想懒得写PHP,有现成的工具为何不用对吧,没毛病。
分分钟搞定,咱们先熟悉一下火车头的规则。
(?<content>[\s\S]*?)
Content //代表内容
? //表示匹配0次或则1次
\s //匹配所有空白字符
\S //匹配所有非空白字符
* //修饰匹配次数为 0 次或任意次
火车头采集手机号的正则:(?<content>1[34578]{1}[0-9]{9})
火车头采集邮箱的正则:(?<content>[\w\-\.]+@[\w\-\.]+\.\w+)
--------------------下方是正则表达式说明。-----------------------
表1.常用的元字符代码说明
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或顿号或汉字
\s 匹配任意的空白符
\d 匹配数字
\b 匹配词组的开始或结束
^ 匹配字符串的开始$匹配字符串的结束
表2.常用的限定符代码/语法说明
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
表3.常用的反义代码代码/语法说明
\W 匹配任意不是字母,数字,下划线,汉字的字符
\S 匹配任意不是空白符的字符
\D 匹配任意非数字的字符
\B 匹配不是词组开头或结束的位置
[^x] 匹配不仅x以外的任意字符
[^aeiou] 匹配不仅aeiou这几个字母以外的任意字符
常用分组句型
表5.懒惰限定符代码/语法说明
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
表7.尚未详尽讨论的句型代码/语法说明
\a 报案字符(打印它的疗效是笔记本嘀一声)
\b 一般是词组分界位置,但若果在字符类里使用代表退格
\t 制表符火车采集器 手机正则表达式,Tab
\r 回车
\v 竖向制表符
\f 换页符
\n 换行符
\e Escape
\0nn ASCII代码中八进制代码为nn的字符
\xnn ASCII代码中十六进制代码为nn的字符
\unnnn Unicode代码中十六进制代码为nnnn的字符
\cN ASCII控制字符。比如\cC代表Ctrl+C
\A 字符串开头(类似^,但不受处理多行选项的影响)
\Z 字符串结尾或行尾(不受处理多行选项的影响)
\z 字符串结尾(类似$火车采集器 手机正则表达式,但不受处理多行选项的影响)
\G 当前搜索的开头
\p{name} Unicode中命名为name的字符类,例如\p{IsGreek}
(?>exp) 贪婪子表达式(?<x>-<y>exp)平衡组
(?im-nsx:exp) 在子表达式exp中改变处理选项
(?im-nsx) 为表达式旁边的部份改变处理选项
(?(exp)yes|no) 把exp当成零宽正向先行断定,如果在这个位置能匹配,使用yes作为此组的表达式;否则使用no(?(exp)yes)同上,只是使用空表达式作为no
(?(name)yes|no) 假如命名为name的组捕获到了内容,使用yes作为表达式;否则使用no
(?(name)yes) 同上,只是使用空表达式作为no
火车采集器系列教程 之 使用正则采集链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 740 次浏览 • 2020-05-15 08:01
火车采集器系列教程 之 使用正则采集网址 图片版 先来瞧瞧这段加密后代码 <a href=";s=1&ct=201326592&cl=2&lm=-1&tn=baiduimage&word=&#34081;&#20381;&#26519;&z=4" target="_blank">蔡依林</a> 生成之后可以正常访问的联接是: ;s=1&ct=201326592&cl=2&lm=-1&tn=baiduimage&word=蔡依林&z=4 而我们能获取到却难以访问的链接是: ;s=1&ct=201326592&cl=2&lm=-1&tn=baiduimage&word=&#34081;&#20381;&#26519;&z=4 经过对比我们可以看出,两个链接只有 从 word=到&这之间的代码不一样,我们还可以看出,之间的代码恰好对应 蔡依林 这个链接的标题,我们可以想,如果我们可以把这之间的乱码用这段链接的标题来取代或则说替换,那不就完全一样了吗? 是的,我们完全可以借助正则来采集这样的网站地址! 列表地址: 在页面链接的采集方法这儿,我们有两个选择,一个是自动填写链接地址规则,一个是启动向导添加,进入正则提取!以下火车采集器 正则提取,我们两种方式都一并讲解! 列车采集器系列教程 之 使用正则采集链接 一 下面,启动我们的列车,建立一个站点,建立一个任务! 自动添加模式1,打开自动添加模式之后,我们先设置禁用系统手动辨识联接,启用自定义联接格式 火车采集器系列教程 之 使用正则采集网址 图片版 2,修改我们的正则规则如下: <a href="(*)" target="_blank">[参数]</a> 这里, <a href=" 的作用是取固定字符在确定联接所在区域,设定参数为我们想获取的目标内容。
实际联接设置为正确的可以访问的链接前部份 ;s=1&ct=201326592&cl=2&lm=-1&tn=baiduimage&word=[参数 1]&pic=1 这里的参数 1表示它就是获取的参数,如果你想在其它地方再使用,可以继续使用到参数 N,不过你要注意了,如果你要获取多个参数,这里复杂了,请注意下边这张图片: 假如你要获取多个参数火车采集器 正则提取,请注意她们出现的位次,在引用过程中,也要注意位次,不然会出现参数值传递错误!同时,你可以将[参数 N]修改为你想获取的参数。 在这里,如果有缩略图,我们也可以加上缩略图,也可以下载!将缩略图标签替换图片地址就可以了! 向导添加信正则提取模式 在源地址处添加我们要采集的列表地址 进一步设置正则参数,这里的参数就和我们刚才说过的就是一模一样的了,这两种模式方式一样,但也适用于采集不同地址的列表,就看你们的喜好了! 设置完成之后就可以提取地址并完了! 火车采集器系列教程 之 使用正则采集网址 图片版 以下展示一下我们采集到的地址: 好了,经过比较长时间的制做,这份文档加图片的教程就制做得差不多了,现在是早上两点,应该休息了! 剩下的视频部份,就等今天来完成吧!最后,感谢你们对火车头的支持,3Q and 88 本文没有来得急校对,如果出现错误的地方欢迎你们修正! 查看全部
火车采集器系列教程 之 使用正则采集网址 图片版 先来瞧瞧这段加密后代码 <a href=";s=1&ct=201326592&cl=2&lm=-1&tn=baiduimage&word=&#34081;&#20381;&#26519;&z=4" target="_blank">蔡依林</a> 生成之后可以正常访问的联接是: ;s=1&ct=201326592&cl=2&lm=-1&tn=baiduimage&word=蔡依林&z=4 而我们能获取到却难以访问的链接是: ;s=1&ct=201326592&cl=2&lm=-1&tn=baiduimage&word=&#34081;&#20381;&#26519;&z=4 经过对比我们可以看出,两个链接只有 从 word=到&这之间的代码不一样,我们还可以看出,之间的代码恰好对应 蔡依林 这个链接的标题,我们可以想,如果我们可以把这之间的乱码用这段链接的标题来取代或则说替换,那不就完全一样了吗? 是的,我们完全可以借助正则来采集这样的网站地址! 列表地址: 在页面链接的采集方法这儿,我们有两个选择,一个是自动填写链接地址规则,一个是启动向导添加,进入正则提取!以下火车采集器 正则提取,我们两种方式都一并讲解! 列车采集器系列教程 之 使用正则采集链接 一 下面,启动我们的列车,建立一个站点,建立一个任务! 自动添加模式1,打开自动添加模式之后,我们先设置禁用系统手动辨识联接,启用自定义联接格式 火车采集器系列教程 之 使用正则采集网址 图片版 2,修改我们的正则规则如下: <a href="(*)" target="_blank">[参数]</a> 这里, <a href=" 的作用是取固定字符在确定联接所在区域,设定参数为我们想获取的目标内容。
实际联接设置为正确的可以访问的链接前部份 ;s=1&ct=201326592&cl=2&lm=-1&tn=baiduimage&word=[参数 1]&pic=1 这里的参数 1表示它就是获取的参数,如果你想在其它地方再使用,可以继续使用到参数 N,不过你要注意了,如果你要获取多个参数,这里复杂了,请注意下边这张图片: 假如你要获取多个参数火车采集器 正则提取,请注意她们出现的位次,在引用过程中,也要注意位次,不然会出现参数值传递错误!同时,你可以将[参数 N]修改为你想获取的参数。 在这里,如果有缩略图,我们也可以加上缩略图,也可以下载!将缩略图标签替换图片地址就可以了! 向导添加信正则提取模式 在源地址处添加我们要采集的列表地址 进一步设置正则参数,这里的参数就和我们刚才说过的就是一模一样的了,这两种模式方式一样,但也适用于采集不同地址的列表,就看你们的喜好了! 设置完成之后就可以提取地址并完了! 火车采集器系列教程 之 使用正则采集网址 图片版 以下展示一下我们采集到的地址: 好了,经过比较长时间的制做,这份文档加图片的教程就制做得差不多了,现在是早上两点,应该休息了! 剩下的视频部份,就等今天来完成吧!最后,感谢你们对火车头的支持,3Q and 88 本文没有来得急校对,如果出现错误的地方欢迎你们修正!

