
根据关键词文章采集系统
根据关键词文章采集系统(关键词文章采集系统的配置供用户选择,你值得拥有)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-12-14 09:16
根据关键词文章采集系统的专家组内评师的专业认证特色,推出了多款不同的配置供用户选择。首先,文章采集系统通过html5和h5的方式给javascript编译作为基础单元,该平台的后台硬件控制程序通过h5和javascript编译相互作用结果在采集系统自身并完成实时协调。其次,它使用jsx和jswrap这两种静态库来增强动态布局和脚本引擎。
在许多情况下,无论是用html或纯javascript开发一个传统的网页,都需要获得这两种静态库的支持。另外,它通过设置基于浏览器访问数据库的定制方法,使用内存计算来分析用户的浏览记录并对输入的内容进行快速有效分析。1:前端javascript数据的深度整合保证了准确性和加载时间,同时由于你设置了强制数据查询控制,从而确保网页在大部分内存能力方面处于理想水平。
2:能够利用javascript完成网页所有基本事务,例如:设置xmlurl映射、定制网页内容的缓存以便后续处理、存储各种配置和属性值等。3:通过网络插件,开发人员可以完全用javascript来完成常见用户操作,例如上传图片、下载图片、保存图片、添加搜索框、添加上传按钮、设置密码以及开发人员可以在当前页面上设置常见的表单验证方法。
4:通过主要程序控制子程序的运行和游览。系统地给由浏览器和系统控制的子程序更多控制权。5:通过从用户下载flash文件的图像、音频和视频进行数据采集。6:可以利用内存计算的性能来产生相对于其它精密仪器更快速、更精准、更集中地用户操作反馈。7:你可以对包括浏览器地址栏显示的互联网标识、邮件链接以及其它部署和使用html5和h5.js的任何传统web页面进行控制。
8:你可以设置向下滚动页面、出现或消失页面、搜索和摘要的输入框等浏览元素,并通过实时数据相关性评估页面加载速度。9:你可以利用主要程序和子程序保证网页的完整性、安全性以及可重用性。10:你可以使用“ux定制界面”和“ux特定交互”的ui工具来设计浏览器菜单、输入框、搜索框和返回按钮。系统与其它主要仪器集成如有线鼠标、有线键盘、有线usb鼠标、便携式显示器等的区别:。
1、仪器本身不需要编程。
2、操作台系统自带的浏览器自带采集程序(如q-browserenvironment),因此可以免编程。
3、对操作台或其它显示器没有支持的代码,系统可在其它机器上配置javascript,称为javascript文件和javascript设置。
4、操作台系统可以基于html、html
5、javascript、javascriptwrap、javascript、webkit和lottie等第三方ios/android系统 查看全部
根据关键词文章采集系统(关键词文章采集系统的配置供用户选择,你值得拥有)
根据关键词文章采集系统的专家组内评师的专业认证特色,推出了多款不同的配置供用户选择。首先,文章采集系统通过html5和h5的方式给javascript编译作为基础单元,该平台的后台硬件控制程序通过h5和javascript编译相互作用结果在采集系统自身并完成实时协调。其次,它使用jsx和jswrap这两种静态库来增强动态布局和脚本引擎。
在许多情况下,无论是用html或纯javascript开发一个传统的网页,都需要获得这两种静态库的支持。另外,它通过设置基于浏览器访问数据库的定制方法,使用内存计算来分析用户的浏览记录并对输入的内容进行快速有效分析。1:前端javascript数据的深度整合保证了准确性和加载时间,同时由于你设置了强制数据查询控制,从而确保网页在大部分内存能力方面处于理想水平。
2:能够利用javascript完成网页所有基本事务,例如:设置xmlurl映射、定制网页内容的缓存以便后续处理、存储各种配置和属性值等。3:通过网络插件,开发人员可以完全用javascript来完成常见用户操作,例如上传图片、下载图片、保存图片、添加搜索框、添加上传按钮、设置密码以及开发人员可以在当前页面上设置常见的表单验证方法。
4:通过主要程序控制子程序的运行和游览。系统地给由浏览器和系统控制的子程序更多控制权。5:通过从用户下载flash文件的图像、音频和视频进行数据采集。6:可以利用内存计算的性能来产生相对于其它精密仪器更快速、更精准、更集中地用户操作反馈。7:你可以对包括浏览器地址栏显示的互联网标识、邮件链接以及其它部署和使用html5和h5.js的任何传统web页面进行控制。
8:你可以设置向下滚动页面、出现或消失页面、搜索和摘要的输入框等浏览元素,并通过实时数据相关性评估页面加载速度。9:你可以利用主要程序和子程序保证网页的完整性、安全性以及可重用性。10:你可以使用“ux定制界面”和“ux特定交互”的ui工具来设计浏览器菜单、输入框、搜索框和返回按钮。系统与其它主要仪器集成如有线鼠标、有线键盘、有线usb鼠标、便携式显示器等的区别:。
1、仪器本身不需要编程。
2、操作台系统自带的浏览器自带采集程序(如q-browserenvironment),因此可以免编程。
3、对操作台或其它显示器没有支持的代码,系统可在其它机器上配置javascript,称为javascript文件和javascript设置。
4、操作台系统可以基于html、html
5、javascript、javascriptwrap、javascript、webkit和lottie等第三方ios/android系统
根据关键词文章采集系统( 什么是采集站?现在做网站还能做采集站吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-12-13 14:00
什么是采集站?现在做网站还能做采集站吗?)
采集 站是什么?采集站台怎么办?如果我现在做网站,我还能做采集吗?今天小编就给大家分享一些关于采集站的经验分享!可以说现在的大部分网站都离不开采集,采集已经成为了互联网的常态网站,所以想当站或者已经有网站上网的同学一定要清楚了解采集站!我自己做的小说网站和门户网站都是用采集的方法制作的。目前,全流和全5,日均IP流量稳定在1万左右。通过这篇文章的文章和大家分享一下我的一些理解和实践。
采集 站是什么?每个 网站 都需要填充内容。在这个“内容为王”的时代,很多SEO站长为了做网站优化,疯狂写文章。但是,一些SEOer 认为原创文章 没有那么重要。为了让网站能够在短时间内拥有大量的内容,很多站长都会选择采集文章的方式。对于站长来说,因为经常需要发布文章,需要采集各种文章资源,所以需要各种采集工具。从事互联网SEO行业以来,一直在使用采集工具来处理不同的文章资源,以及采集不同平台的资源,文章采集@ > 工具不知道你听说过吗?可能有的站长没接触过吧!采集工具现在被一些站群或大型门户网站使用,例如企业网站使用的那些。当然,一些个人网站也被一些人使用采集,因为有些情况不想自己更新文章 或文章 需要在大网站上更新的很多而且复杂的,比如新闻网站,都用采集。编辑器通常使用147个采集来完成所有采集站的内容填充。更适合不懂代码和技术的站长。输入关键词就可以了采集,没有复杂的配置,也不需要写采集的规则。采集完成后,
采集站台怎么办?
1.网站上线前采集文章,准备大量文章(采集都来这里,当然采集@ >N 个站点 文章)。
2. 网站 模板一定要自己写,代码库一定要优化。
3. 做好网站 内容页面布局。
4.上线后每天更新100~500文章卷,文章一定是采集N个站点的最新文章。
5. 外链每天发一些。一个月后,你的网站收录和你的流量都会上升!
一些采集 需要特别注意的点:
1.海量长尾词:我在采集的内容中导入了超过10万个关键词。如果我想要更多 关键词 排名,那么我需要大量 文章 和 关键词。而我的文章都是基于关键词采集。不要像大多数人一样做采集站。基本上,它是盲目的采集。内容有几万个收录,但排名的关键词只有几十个。看着它很有趣,只是乱七八糟。这样的采集 站点基本上是在制造互联网垃圾邮件。搜索引擎反对谁?拥有 关键词 和内容只是基础。如果你的采集文章能获得不错的排名,那你就需要下一步了。
2.文章优化:80%的人不了解优质内容。采集 过来的内容必须经过伪原创!其实搜索引擎已经说得很清楚了。文章排版,内容就是用户需要的,很明显的告诉大家文章有图有文字,远胜于纯文本文章收录。所以你的内容布局好,关键词布局好,你文章已经有排名机会是用户需求。
3.页面结构:有两个核心点,相关性和丰富性。抓住这两点,去百度看看别人的官方说明,就可以掌握核心,内页排名也很容易。
4.内容收录速度:要想快速上榜,首先要网站内容收录要快。想要让收录快速的需要大量的蜘蛛来抓取你的网站,其实搜索引擎已经给出了很好的工具,主动推送功能!批量推送网页链接到搜索引擎,增加曝光率。
如果我现在做网站,我还能做采集吗?我的采集站点一直很稳定,我的采集站点完全符合搜索引擎的规则。不仅稳定,而且流量还在持续上升。所以采集网站还是可以做的,最重要的还是做对了,不是因为采集和采集,采集之后的SEO优化也很重要,具体后续文章的内容我会详细说明。本期暂时先说说采集站。
关于采集站的问题,小编就到此为止。总之,如果采集的内容处理得当,站采集也会是收录。但是大家要注意一个问题,就是对采集网站的操作要更加谨慎,不要让搜索引擎认为这是一个采集站,而且在同时在用户体验和满足用户需求方面做更多的优化,这样的采集站还是可以做的。 查看全部
根据关键词文章采集系统(
什么是采集站?现在做网站还能做采集站吗?)

采集 站是什么?采集站台怎么办?如果我现在做网站,我还能做采集吗?今天小编就给大家分享一些关于采集站的经验分享!可以说现在的大部分网站都离不开采集,采集已经成为了互联网的常态网站,所以想当站或者已经有网站上网的同学一定要清楚了解采集站!我自己做的小说网站和门户网站都是用采集的方法制作的。目前,全流和全5,日均IP流量稳定在1万左右。通过这篇文章的文章和大家分享一下我的一些理解和实践。


采集 站是什么?每个 网站 都需要填充内容。在这个“内容为王”的时代,很多SEO站长为了做网站优化,疯狂写文章。但是,一些SEOer 认为原创文章 没有那么重要。为了让网站能够在短时间内拥有大量的内容,很多站长都会选择采集文章的方式。对于站长来说,因为经常需要发布文章,需要采集各种文章资源,所以需要各种采集工具。从事互联网SEO行业以来,一直在使用采集工具来处理不同的文章资源,以及采集不同平台的资源,文章采集@ > 工具不知道你听说过吗?可能有的站长没接触过吧!采集工具现在被一些站群或大型门户网站使用,例如企业网站使用的那些。当然,一些个人网站也被一些人使用采集,因为有些情况不想自己更新文章 或文章 需要在大网站上更新的很多而且复杂的,比如新闻网站,都用采集。编辑器通常使用147个采集来完成所有采集站的内容填充。更适合不懂代码和技术的站长。输入关键词就可以了采集,没有复杂的配置,也不需要写采集的规则。采集完成后,

采集站台怎么办?
1.网站上线前采集文章,准备大量文章(采集都来这里,当然采集@ >N 个站点 文章)。
2. 网站 模板一定要自己写,代码库一定要优化。
3. 做好网站 内容页面布局。
4.上线后每天更新100~500文章卷,文章一定是采集N个站点的最新文章。
5. 外链每天发一些。一个月后,你的网站收录和你的流量都会上升!
一些采集 需要特别注意的点:
1.海量长尾词:我在采集的内容中导入了超过10万个关键词。如果我想要更多 关键词 排名,那么我需要大量 文章 和 关键词。而我的文章都是基于关键词采集。不要像大多数人一样做采集站。基本上,它是盲目的采集。内容有几万个收录,但排名的关键词只有几十个。看着它很有趣,只是乱七八糟。这样的采集 站点基本上是在制造互联网垃圾邮件。搜索引擎反对谁?拥有 关键词 和内容只是基础。如果你的采集文章能获得不错的排名,那你就需要下一步了。
2.文章优化:80%的人不了解优质内容。采集 过来的内容必须经过伪原创!其实搜索引擎已经说得很清楚了。文章排版,内容就是用户需要的,很明显的告诉大家文章有图有文字,远胜于纯文本文章收录。所以你的内容布局好,关键词布局好,你文章已经有排名机会是用户需求。
3.页面结构:有两个核心点,相关性和丰富性。抓住这两点,去百度看看别人的官方说明,就可以掌握核心,内页排名也很容易。
4.内容收录速度:要想快速上榜,首先要网站内容收录要快。想要让收录快速的需要大量的蜘蛛来抓取你的网站,其实搜索引擎已经给出了很好的工具,主动推送功能!批量推送网页链接到搜索引擎,增加曝光率。
如果我现在做网站,我还能做采集吗?我的采集站点一直很稳定,我的采集站点完全符合搜索引擎的规则。不仅稳定,而且流量还在持续上升。所以采集网站还是可以做的,最重要的还是做对了,不是因为采集和采集,采集之后的SEO优化也很重要,具体后续文章的内容我会详细说明。本期暂时先说说采集站。
关于采集站的问题,小编就到此为止。总之,如果采集的内容处理得当,站采集也会是收录。但是大家要注意一个问题,就是对采集网站的操作要更加谨慎,不要让搜索引擎认为这是一个采集站,而且在同时在用户体验和满足用户需求方面做更多的优化,这样的采集站还是可以做的。
根据关键词文章采集系统(关键词排名包年优化怎么样创新服务,,诠释网络)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-08 20:14
关键词如何优化排名套餐年创新服务,解读网络**网址:免费咨询电话:公司地址:开福市双永路9号长城万福汇大厦金塔7楼7016长沙市区长沙区多年的客户服务和运营在网络整合营销、网络品牌传播、网络广告策划、网络公关、网络事件营销、电子商务服务等各个领域有着独到的见解,并创造了公司愿景:一站式可靠的互联网运营服务商。
关键词如何创新排名包优化服务,SEO网站优化-关键词优化快速排名你找谁?2020-09-03 SEO网站优化-关键词优化快速排名找谁?SEO网站优化-关键词优化快速排名找八火科技。:0755 seo优化包年服务-2万包年6关键词可选seo优化日计费服务-最低5元/天无限关键词,排名第一后付费。为什么百度没有收录网站?是不是因为网站 没有记录。其实百度没有收录网站页面的原因有很多。下面,深圳网站设计巴火科技就来分析一下。一、 域名进入百度黑名单,百度没有收录有的朋友在购买新域名时没有查看域名的历史表现。事实上,有些域名已经进入了百度的黑名单,或者是百度已经将其列入了可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。有的朋友在购买新域名时没有查看域名的历史表现。事实上,有些域名已经进入了百度的黑名单,或者是百度已经将其列入了可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。有的朋友在购买新域名时没有查看域名的历史表现。事实上,有些域名已经进入了百度的黑名单,或者是百度已经将其列入了可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。或者百度已将其列入可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。或者百度已将其列入可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。
一、百度竞价包年度推广是怎么回事?百度竞价包年度推广是一种将网站的排名操作委托给专业第三方及其年度计算单位的合作关系。由于互联网发展的不可预知的变化,按照月度合作,不仅成本较高,而且无法针对不断变化的数据对推广方案给出针对性的建议和调整。因此,与百度竞价进行年度推广更有利于广告主目标的实现。而百度的竞价推广主要是对关键词进行竞价,获得更高的排名。同时根据关键词优化促销 满足用户的消费需求,帮助广告主获得流量和转化率。关键词是关于网站的流量和转化率,也就是说,即使排名很高,关键词不满足用户的搜索“胃口”,也不会实现转化。因此,百度竞价推广基于网站的主题和用户的热门关键词,确保在提升网站的同时,也能为网站带来转化率。用户通过关键词搜索广告,希望通过广告获得更多有价值的知识点,帮助朋友解惑。所以,要想有好的转化率,就必须围绕关键词写更多优质的内容,也就是要多站在用户的角度思考,比如他们需要什么,需要通过内容学习哪些知识点。写出相应的内容,使得用户的访问率和网站的访问率都很高。
关键词如何创新排名包年优化服务,word上传时间一般为3-15天;新站优化包年度合作新站通过人工基础优化,调整网站TDK,关键词密度,修正网站违反的百度算法,提高服务器访问速度,加强网站内容维护文章更新、外链发布、关键词快照权限提升等;以上,措辞时间为15-30天;不同字量不同套餐,关键词优化价格低至每天1-3元;全站优化按季收费,优化行业词库,快速提升网站整体权重,在获取流量的同时,也可以激烈竞争的核心词排名更稳定,适合产品较多的行业和门户关键词;客户指定核心关键词和数量,优化到百度首页,达到关键词数量后,计算时间;每天都有大量的措辞案例,偶尔不定时更新!你的 网站 有什么问题?seo的工作内容是什么,SEO的工作是什么?不定时不定时更新!你的 网站 有什么问题?seo的工作内容是什么,SEO的工作是什么?不定时不定时更新!你的 网站 有什么问题?seo的工作内容是什么,SEO的工作是什么?
从事搜索引擎优化业务或个人需要进行日常计费,但没有研发能力或时间和精力开发这样的系统。每天自动监测关键词的排名。如果设置了排名,系统会自动从网站的客户余额中扣除费用,并为搜索引擎优化及其客户提供排名和消费的详细报告。降低SEO推广难度,树立品牌,解决成本纠纷和收支困难。SEO按天计费系统的优势,我们来看看,传统的搜索优化收费模式呢?一次性年费月付传统搜索引擎优化收费模式有哪些弊端?一般情况下,要到关键词到达首页才能看到效果。但是,如果在年付或月付之前没有排名,也会产生费用。事实上,这段时间并没有给客户的业务带来任何好处。主页上10个月,但实际付了1年。对于SEO乙方来说,传统的包年或包月,普遍存在未付余额的问题。当网站关键词的数据上升时,其实搜索引擎优化工程师是需要维护排名的,但是对于客户来说,可能会觉得排名上升之后,没有必要去管理和维护管理,
关键词排名包优化服务如何创新?目标关键词 当前排名需要在前5页,1-15天内可以快速排到搜索引擎首页的首位。一个字一个月就可以开始,目标数量关键词和同类产品的合作周期要求都比较低。技术优势 多年只专注SEO优化,使用近百种算法,云间链接全搜索,动态热更新。优化原理引导搜索引擎蜘蛛迭代扫描网站,以获得更高的PageRank值。白帽自然优化,更符合搜索引擎的需求,词稳定,无需担心其他副作用。丰富的选择。我们不仅有多个合作套餐供您选择,还支持定制您自己的合作套餐,让您可以根据自己的营销方式销售您的定制套餐。透明计费支持年付、季付、月付。无论选择哪种付款方式,只要不删除目标词,服务价格永远不会改变,并且支持每日扣款。
企业网站seo网络推广时,网站文章内容纯采集来,与网站seo、网站关键词@无关> 排名公式不聚焦时,优化排名与首页布局的seo关键词相反,网站文章与关键词无关,seo< @关键词没有重点,这样的网站不能满足用户和搜索引擎对自然排名的需求,搜索引擎很难对这样的网站进行排名。网站文章 更新不频繁,seo排名堪忧?优化排名网站文章无频次更新,搜索引擎抓不到网站规律,一般2-3天写几篇原创关注这个网站 seo 的标题<
关键词如何创新排名包优化服务?接下来上海SEO关键词优化曼朗主要从几个方面给大家介绍一下。希望我能帮您解决您的困惑,比如您在优化SEO时关键词。272021--08seo关键词 想要优化排名有好的效果,这些东西你必须知道!seo关键词优化排名,顾名思义就是通过适当的方法优化网站的关键词,让网站关键词排名更高,从而带来更多精准流量,增加网站的权重,获得更高的排名。当网站的排名更稳定,获得更精准的流量时,网站的推广效果就会得到充分发挥,
百度首页关键词的排名机制是什么?网站Optimized关键词是搜索引擎优化的日常工作。优化是否容易做好,取决于我们的工作是否认真。百度首页关键词的制作取决于关键词的竞争力、网站的权重以及SEOER的经验和技巧,这些都会影响关键词的排名。如果你想在首页设置关键词,你需要知道判断页面质量的标准或数据,找到关键点,好的地方事半功倍在。排名方法太多了,让我们深入挖掘。搜索引擎如何判断网页的质量并相应地对其进行排名?页面标题和页面内容必须相关。你为什么这么说?因为如果更新后的文章相关度不高,主题不突出,在关键词之前的排名就没有优势了,这就是为什么大一些的聚合页面排名这么好。控制页面的相关性和关键词密度也可以提高关键词的排名。 查看全部
根据关键词文章采集系统(关键词排名包年优化怎么样创新服务,,诠释网络)
关键词如何优化排名套餐年创新服务,解读网络**网址:免费咨询电话:公司地址:开福市双永路9号长城万福汇大厦金塔7楼7016长沙市区长沙区多年的客户服务和运营在网络整合营销、网络品牌传播、网络广告策划、网络公关、网络事件营销、电子商务服务等各个领域有着独到的见解,并创造了公司愿景:一站式可靠的互联网运营服务商。
关键词如何创新排名包优化服务,SEO网站优化-关键词优化快速排名你找谁?2020-09-03 SEO网站优化-关键词优化快速排名找谁?SEO网站优化-关键词优化快速排名找八火科技。:0755 seo优化包年服务-2万包年6关键词可选seo优化日计费服务-最低5元/天无限关键词,排名第一后付费。为什么百度没有收录网站?是不是因为网站 没有记录。其实百度没有收录网站页面的原因有很多。下面,深圳网站设计巴火科技就来分析一下。一、 域名进入百度黑名单,百度没有收录有的朋友在购买新域名时没有查看域名的历史表现。事实上,有些域名已经进入了百度的黑名单,或者是百度已经将其列入了可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。有的朋友在购买新域名时没有查看域名的历史表现。事实上,有些域名已经进入了百度的黑名单,或者是百度已经将其列入了可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。有的朋友在购买新域名时没有查看域名的历史表现。事实上,有些域名已经进入了百度的黑名单,或者是百度已经将其列入了可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。或者百度已将其列入可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。或者百度已将其列入可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。
一、百度竞价包年度推广是怎么回事?百度竞价包年度推广是一种将网站的排名操作委托给专业第三方及其年度计算单位的合作关系。由于互联网发展的不可预知的变化,按照月度合作,不仅成本较高,而且无法针对不断变化的数据对推广方案给出针对性的建议和调整。因此,与百度竞价进行年度推广更有利于广告主目标的实现。而百度的竞价推广主要是对关键词进行竞价,获得更高的排名。同时根据关键词优化促销 满足用户的消费需求,帮助广告主获得流量和转化率。关键词是关于网站的流量和转化率,也就是说,即使排名很高,关键词不满足用户的搜索“胃口”,也不会实现转化。因此,百度竞价推广基于网站的主题和用户的热门关键词,确保在提升网站的同时,也能为网站带来转化率。用户通过关键词搜索广告,希望通过广告获得更多有价值的知识点,帮助朋友解惑。所以,要想有好的转化率,就必须围绕关键词写更多优质的内容,也就是要多站在用户的角度思考,比如他们需要什么,需要通过内容学习哪些知识点。写出相应的内容,使得用户的访问率和网站的访问率都很高。

关键词如何创新排名包年优化服务,word上传时间一般为3-15天;新站优化包年度合作新站通过人工基础优化,调整网站TDK,关键词密度,修正网站违反的百度算法,提高服务器访问速度,加强网站内容维护文章更新、外链发布、关键词快照权限提升等;以上,措辞时间为15-30天;不同字量不同套餐,关键词优化价格低至每天1-3元;全站优化按季收费,优化行业词库,快速提升网站整体权重,在获取流量的同时,也可以激烈竞争的核心词排名更稳定,适合产品较多的行业和门户关键词;客户指定核心关键词和数量,优化到百度首页,达到关键词数量后,计算时间;每天都有大量的措辞案例,偶尔不定时更新!你的 网站 有什么问题?seo的工作内容是什么,SEO的工作是什么?不定时不定时更新!你的 网站 有什么问题?seo的工作内容是什么,SEO的工作是什么?不定时不定时更新!你的 网站 有什么问题?seo的工作内容是什么,SEO的工作是什么?
从事搜索引擎优化业务或个人需要进行日常计费,但没有研发能力或时间和精力开发这样的系统。每天自动监测关键词的排名。如果设置了排名,系统会自动从网站的客户余额中扣除费用,并为搜索引擎优化及其客户提供排名和消费的详细报告。降低SEO推广难度,树立品牌,解决成本纠纷和收支困难。SEO按天计费系统的优势,我们来看看,传统的搜索优化收费模式呢?一次性年费月付传统搜索引擎优化收费模式有哪些弊端?一般情况下,要到关键词到达首页才能看到效果。但是,如果在年付或月付之前没有排名,也会产生费用。事实上,这段时间并没有给客户的业务带来任何好处。主页上10个月,但实际付了1年。对于SEO乙方来说,传统的包年或包月,普遍存在未付余额的问题。当网站关键词的数据上升时,其实搜索引擎优化工程师是需要维护排名的,但是对于客户来说,可能会觉得排名上升之后,没有必要去管理和维护管理,

关键词排名包优化服务如何创新?目标关键词 当前排名需要在前5页,1-15天内可以快速排到搜索引擎首页的首位。一个字一个月就可以开始,目标数量关键词和同类产品的合作周期要求都比较低。技术优势 多年只专注SEO优化,使用近百种算法,云间链接全搜索,动态热更新。优化原理引导搜索引擎蜘蛛迭代扫描网站,以获得更高的PageRank值。白帽自然优化,更符合搜索引擎的需求,词稳定,无需担心其他副作用。丰富的选择。我们不仅有多个合作套餐供您选择,还支持定制您自己的合作套餐,让您可以根据自己的营销方式销售您的定制套餐。透明计费支持年付、季付、月付。无论选择哪种付款方式,只要不删除目标词,服务价格永远不会改变,并且支持每日扣款。
企业网站seo网络推广时,网站文章内容纯采集来,与网站seo、网站关键词@无关> 排名公式不聚焦时,优化排名与首页布局的seo关键词相反,网站文章与关键词无关,seo< @关键词没有重点,这样的网站不能满足用户和搜索引擎对自然排名的需求,搜索引擎很难对这样的网站进行排名。网站文章 更新不频繁,seo排名堪忧?优化排名网站文章无频次更新,搜索引擎抓不到网站规律,一般2-3天写几篇原创关注这个网站 seo 的标题<
关键词如何创新排名包优化服务?接下来上海SEO关键词优化曼朗主要从几个方面给大家介绍一下。希望我能帮您解决您的困惑,比如您在优化SEO时关键词。272021--08seo关键词 想要优化排名有好的效果,这些东西你必须知道!seo关键词优化排名,顾名思义就是通过适当的方法优化网站的关键词,让网站关键词排名更高,从而带来更多精准流量,增加网站的权重,获得更高的排名。当网站的排名更稳定,获得更精准的流量时,网站的推广效果就会得到充分发挥,

百度首页关键词的排名机制是什么?网站Optimized关键词是搜索引擎优化的日常工作。优化是否容易做好,取决于我们的工作是否认真。百度首页关键词的制作取决于关键词的竞争力、网站的权重以及SEOER的经验和技巧,这些都会影响关键词的排名。如果你想在首页设置关键词,你需要知道判断页面质量的标准或数据,找到关键点,好的地方事半功倍在。排名方法太多了,让我们深入挖掘。搜索引擎如何判断网页的质量并相应地对其进行排名?页面标题和页面内容必须相关。你为什么这么说?因为如果更新后的文章相关度不高,主题不突出,在关键词之前的排名就没有优势了,这就是为什么大一些的聚合页面排名这么好。控制页面的相关性和关键词密度也可以提高关键词的排名。
根据关键词文章采集系统(推荐一款很好用的关键词文章采集助手(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-12-05 18:03
根据关键词文章采集系统现有的功能来说,主要有:信息提取采集功能:包括标题、文章题目,
downloadtrim-googlesearch其实不是关键,关键是能够无人值守,我们团队要求只要保持工作量的稳定,大概10-20%的人手吧,剩下的人负责技术拓展。
这个嘛,用友关键词采集助手这个是免费版的,我用的效果很好,效率也很高,
哈哈哈哈,请上采源宝。菜鸟上手,一个月出300左右效果,软件不贵,用友采源宝。每天的价格都不定,见到3百,5百的就不要管了。当然,价格和效果成正比。
推荐一款很好用的关键词采集神器「爱采商机」「爱采商机」最新版本都有计算机房模式了,可以正常下载,且功能强大的同时有一些独家小功能,如连击计算机房模式(采到每天最热门的词);采集违规内容,并快速处理(减少删除、联动的需求量)等功能。
tmd,你要做采集软件,你别把用友关键词采集引擎做坑好不好。我在用友专区见过大量的用友关键词采集引擎搞这些莫名其妙的功能。每个主推的关键词,都有非常完善的竞争分析与规则。
可以看看top10这个网站,用友和许多知名网站合作,提供免费的采集功能,目前用友最新的top10还没推出,用的都是很老的老的方法,希望能帮到你。 查看全部
根据关键词文章采集系统(推荐一款很好用的关键词文章采集助手(图))
根据关键词文章采集系统现有的功能来说,主要有:信息提取采集功能:包括标题、文章题目,
downloadtrim-googlesearch其实不是关键,关键是能够无人值守,我们团队要求只要保持工作量的稳定,大概10-20%的人手吧,剩下的人负责技术拓展。
这个嘛,用友关键词采集助手这个是免费版的,我用的效果很好,效率也很高,
哈哈哈哈,请上采源宝。菜鸟上手,一个月出300左右效果,软件不贵,用友采源宝。每天的价格都不定,见到3百,5百的就不要管了。当然,价格和效果成正比。
推荐一款很好用的关键词采集神器「爱采商机」「爱采商机」最新版本都有计算机房模式了,可以正常下载,且功能强大的同时有一些独家小功能,如连击计算机房模式(采到每天最热门的词);采集违规内容,并快速处理(减少删除、联动的需求量)等功能。
tmd,你要做采集软件,你别把用友关键词采集引擎做坑好不好。我在用友专区见过大量的用友关键词采集引擎搞这些莫名其妙的功能。每个主推的关键词,都有非常完善的竞争分析与规则。
可以看看top10这个网站,用友和许多知名网站合作,提供免费的采集功能,目前用友最新的top10还没推出,用的都是很老的老的方法,希望能帮到你。
根据关键词文章采集系统(先来说一下亚马逊关键字分两大块,一块最最重要的关键字)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-03 18:00
先说亚马逊关键词设置,可以给大家带来一些帮助:
1.亚马逊关键词分为两部分,一是标题,这是最重要的关键词,设置标题关键词的最佳形式是:品牌+名称+重要属性1、2、3+标题相关名称+函数+参数可以直接在搜索顺序中得到一个好的位置。
2. 是亚马逊的搜索词。很多人对此有过困惑,到底是用长关键字还是短关键字,用逗号隔开还是用空格隔开。首先,搜索词是搜索引擎的关键字被抓取的地方。当然,关键字越多越好。至于关键词的长度,不是很重要,但要注意出现重复的关键词,会被认为是关键词。作弊。其次,逗号的使用是一种精确定位。当用户搜索时,只有符号之间的键有效。例如,卡通、手机壳、手机壳等,只有当用户全部输入时才会被搜索到。如果用户输入手机壳卡通,则可能无法搜索。如果使用空格表示模糊搜索,可以搜索关键字的任意组合。katoon手机壳手机壳,如果用户搜索手机壳katoon或katoon,会被亚马逊搜索到。
说一下如何找到关键词:
1、使用谷歌关键词来规划词,谷歌在建议广告词组时会给你精准推荐
2、 在亚马逊前台搜索栏中:输入关键词,会出现一个下拉菜单,在菜单中选择关键词使用
3、标题中的热词和同类产品销量最高的几个listing标题的评论
4、 对应的分类和亚马逊前台左侧分类导航中的文字,如“手机”
5、您也可以参考易趣等其他平台同款产品对应的热词
6、使用一些关键词工具,例如:关键字研究 查看全部
根据关键词文章采集系统(先来说一下亚马逊关键字分两大块,一块最最重要的关键字)
先说亚马逊关键词设置,可以给大家带来一些帮助:
1.亚马逊关键词分为两部分,一是标题,这是最重要的关键词,设置标题关键词的最佳形式是:品牌+名称+重要属性1、2、3+标题相关名称+函数+参数可以直接在搜索顺序中得到一个好的位置。
2. 是亚马逊的搜索词。很多人对此有过困惑,到底是用长关键字还是短关键字,用逗号隔开还是用空格隔开。首先,搜索词是搜索引擎的关键字被抓取的地方。当然,关键字越多越好。至于关键词的长度,不是很重要,但要注意出现重复的关键词,会被认为是关键词。作弊。其次,逗号的使用是一种精确定位。当用户搜索时,只有符号之间的键有效。例如,卡通、手机壳、手机壳等,只有当用户全部输入时才会被搜索到。如果用户输入手机壳卡通,则可能无法搜索。如果使用空格表示模糊搜索,可以搜索关键字的任意组合。katoon手机壳手机壳,如果用户搜索手机壳katoon或katoon,会被亚马逊搜索到。
说一下如何找到关键词:
1、使用谷歌关键词来规划词,谷歌在建议广告词组时会给你精准推荐
2、 在亚马逊前台搜索栏中:输入关键词,会出现一个下拉菜单,在菜单中选择关键词使用
3、标题中的热词和同类产品销量最高的几个listing标题的评论
4、 对应的分类和亚马逊前台左侧分类导航中的文字,如“手机”
5、您也可以参考易趣等其他平台同款产品对应的热词
6、使用一些关键词工具,例如:关键字研究
根据关键词文章采集系统(建站系统推荐使用linux系统+宝塔(BT)建站 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-12-01 05:11
)
前言:SEO常用工具建站文章内容来源于近期建站操作经验。后面会推荐其他常用的SEO工具,分享一下我写的工具。欢迎关注。
内容概要:
建站系统
建议使用linux系统+宝塔(BT)搭建网站。linux系统与win相交,可以提高网站的安全等级,但是linux是命令行系统,很多同学不会使用,所以推荐使用BT。服务器运维面板的安装和使用非常简单。
更棒的是,免费功能基本可以满足大部分建站需求。我的很多服务器都是使用宝塔面板,搭建容易,维护方便,占用服务器资源少。
Key 关键词 挖掘和布局
网站关键词的关键点是业务流量的基础,必须控制。我在做网站的时候,这个作品的过程是这样的:
批量挖掘关键词->分析关键词性价比->选择高流量&性价比关键词
前面用到的工具内容介绍:
挖矿行业工具推荐关键词及重点关键词:如何挖矿行业关键词、词挖掘策略、工具推荐
性价比高的筛选工具关键词:关键词如何优化难度分析?退伍军人如何一键选择优质关键词
有了关键词,我们还需要分析关键词的TDK和内容是怎么写的,如何得到更好的排名,这里面涉及到tf-idf算法和bm25算法中的搜索原理引擎。
算法这里不做详细分析,只简单讨论一下原理。
tf-idf可以分析内容的词频和关键词分值,通过分值可以知道当前标题的核心词,通过修改可以更集中TDK主题;
bm25在tf-idf的基础上分析多个内容,预测文章在某个关键词中的当前排名。我的操作流程和使用的工具如下:
基于关键词写TDK+首页内容->分析内容词频+TITLE分析->内容在线
词频分析使用自己开发的软件,通过获取模板关键词的前20个百度搜索结果的平均词频来指导我的内容的词频分布。
这个截图是我的网站的一个案例。现在可以分析我的内容的前20个平均词频和词频分布。但是,开发尚未完成。建议您可以使用代码保密的摩天大楼内容助手。原理类似。
除了词频分析,关键内容还需要tf-idf测试。我使用Orange SEO的主题检测和内容检测。这个检测主要通过tf-idf计算,通过这个算法可以得到当前的TDK和内容。是否符合算法?
【主体检测截图】
【内容检测截图】
内容采集和发布
我自己的很多网站都是通过采集维护的。主要使用的工具有优采云、优采云和python。这里我简单介绍一下前两种。
优采云采集器:老软件,功能强大易用采集软件,内容采集和数据导入功能可以导入采集的任意网页数据发布到远程服务器,有伪原创 插件可用。但是,这是一个需要长期启动的本地软件,而且很多插件也需要付费,而且有一定的入门门槛。
优采云:之前常用的软件,在线配置,无需客户端安装,采集和发布配置非常简单,还支持SEO工具;不过免费版的限制比较多,可以酌情购买付费版。
市面上的软件方便好用,但是很难高度定制化,所以最近改用python自动采集并生成内容,比如关键词关键词auto采集 百度知道,搜狗问+行业问答平台,然后自动生成内容(如下图),有编程能力的同学还是可以考虑自己写爬虫。
内部链监控
网站上线后,需要检查是否有死链接或外链。我一般会使用站长工具或者爱站的友情链接监控功能来查看首页是否有死链,或者意外的外链。
同时,为了避免网站中的错误链接,如动态链接入口、测试链接入口等,一般使用爱站工具箱做一个网站地图爬取进行故障排除和清理。错误 URL 和错误 URL 条目。
日志监控工具
网站 在建设初期,百度蜘蛛的爬取状态可以反映网站的百度评分现状,因此需要定期检查,方便SEOer对SEO方式的判断和调整。下面我介绍几种我日常使用的查看日志的方法:
爱站 工具箱:免费用户支持20M,数据更详细,但是每次需要登录BT面板下载日志文件,比较麻烦。
BT插件,付费,1元/月,可在线查看,无需下载日志文件分析,更方便。
zblog插件是付费的、一次性收费的,可以多次使用网站,登录zblog系统后台即可查看,非常方便。
百度站长工具,需要等到第二天才能看到昨天的抓取次数,可以看到抓取的次数,以及抓取所用的时间。官方数据最可信,不会被假蜘蛛忽悠,使用方便,但是功能太少,看不到具体爬取的网址。
百度站长工具
新站除了检查爬行情况外,推荐使用百度站长工具的链接提交功能和爬行分析功能。可以提高网站的收录的速度。
网站速度测试
网站速度是SEO的重要指标之一。网站上线后,测速,每次优化速度。一般测速有两种,一种是测试网站页面的下载速度,另一种是测试网站页面上所有内容的加载速度。
测试网站页面下载速度的工具有很多。这个网站测速工具的特点是只下载当前页面,不进行页面分析,不加载页面中的css、js、图片文件。类似蜘蛛爬行的操作,百度可以搜索到很多网站测速工具,这里不再介绍。
测试网站页面所有内容的加载速度。本次测速会继续分析页面打开后加载js、css、图片所用的时间。这个速度更接近用户体验。一般使用百度统计的网站速度诊断来完成。
查看全部
根据关键词文章采集系统(建站系统推荐使用linux系统+宝塔(BT)建站
)
前言:SEO常用工具建站文章内容来源于近期建站操作经验。后面会推荐其他常用的SEO工具,分享一下我写的工具。欢迎关注。
内容概要:
建站系统
建议使用linux系统+宝塔(BT)搭建网站。linux系统与win相交,可以提高网站的安全等级,但是linux是命令行系统,很多同学不会使用,所以推荐使用BT。服务器运维面板的安装和使用非常简单。
更棒的是,免费功能基本可以满足大部分建站需求。我的很多服务器都是使用宝塔面板,搭建容易,维护方便,占用服务器资源少。

Key 关键词 挖掘和布局
网站关键词的关键点是业务流量的基础,必须控制。我在做网站的时候,这个作品的过程是这样的:
批量挖掘关键词->分析关键词性价比->选择高流量&性价比关键词
前面用到的工具内容介绍:
挖矿行业工具推荐关键词及重点关键词:如何挖矿行业关键词、词挖掘策略、工具推荐
性价比高的筛选工具关键词:关键词如何优化难度分析?退伍军人如何一键选择优质关键词

有了关键词,我们还需要分析关键词的TDK和内容是怎么写的,如何得到更好的排名,这里面涉及到tf-idf算法和bm25算法中的搜索原理引擎。
算法这里不做详细分析,只简单讨论一下原理。
tf-idf可以分析内容的词频和关键词分值,通过分值可以知道当前标题的核心词,通过修改可以更集中TDK主题;
bm25在tf-idf的基础上分析多个内容,预测文章在某个关键词中的当前排名。我的操作流程和使用的工具如下:
基于关键词写TDK+首页内容->分析内容词频+TITLE分析->内容在线
词频分析使用自己开发的软件,通过获取模板关键词的前20个百度搜索结果的平均词频来指导我的内容的词频分布。

这个截图是我的网站的一个案例。现在可以分析我的内容的前20个平均词频和词频分布。但是,开发尚未完成。建议您可以使用代码保密的摩天大楼内容助手。原理类似。
除了词频分析,关键内容还需要tf-idf测试。我使用Orange SEO的主题检测和内容检测。这个检测主要通过tf-idf计算,通过这个算法可以得到当前的TDK和内容。是否符合算法?

【主体检测截图】

【内容检测截图】
内容采集和发布
我自己的很多网站都是通过采集维护的。主要使用的工具有优采云、优采云和python。这里我简单介绍一下前两种。
优采云采集器:老软件,功能强大易用采集软件,内容采集和数据导入功能可以导入采集的任意网页数据发布到远程服务器,有伪原创 插件可用。但是,这是一个需要长期启动的本地软件,而且很多插件也需要付费,而且有一定的入门门槛。
优采云:之前常用的软件,在线配置,无需客户端安装,采集和发布配置非常简单,还支持SEO工具;不过免费版的限制比较多,可以酌情购买付费版。
市面上的软件方便好用,但是很难高度定制化,所以最近改用python自动采集并生成内容,比如关键词关键词auto采集 百度知道,搜狗问+行业问答平台,然后自动生成内容(如下图),有编程能力的同学还是可以考虑自己写爬虫。

内部链监控
网站上线后,需要检查是否有死链接或外链。我一般会使用站长工具或者爱站的友情链接监控功能来查看首页是否有死链,或者意外的外链。

同时,为了避免网站中的错误链接,如动态链接入口、测试链接入口等,一般使用爱站工具箱做一个网站地图爬取进行故障排除和清理。错误 URL 和错误 URL 条目。

日志监控工具
网站 在建设初期,百度蜘蛛的爬取状态可以反映网站的百度评分现状,因此需要定期检查,方便SEOer对SEO方式的判断和调整。下面我介绍几种我日常使用的查看日志的方法:
爱站 工具箱:免费用户支持20M,数据更详细,但是每次需要登录BT面板下载日志文件,比较麻烦。

BT插件,付费,1元/月,可在线查看,无需下载日志文件分析,更方便。
zblog插件是付费的、一次性收费的,可以多次使用网站,登录zblog系统后台即可查看,非常方便。
百度站长工具,需要等到第二天才能看到昨天的抓取次数,可以看到抓取的次数,以及抓取所用的时间。官方数据最可信,不会被假蜘蛛忽悠,使用方便,但是功能太少,看不到具体爬取的网址。
百度站长工具
新站除了检查爬行情况外,推荐使用百度站长工具的链接提交功能和爬行分析功能。可以提高网站的收录的速度。
网站速度测试
网站速度是SEO的重要指标之一。网站上线后,测速,每次优化速度。一般测速有两种,一种是测试网站页面的下载速度,另一种是测试网站页面上所有内容的加载速度。
测试网站页面下载速度的工具有很多。这个网站测速工具的特点是只下载当前页面,不进行页面分析,不加载页面中的css、js、图片文件。类似蜘蛛爬行的操作,百度可以搜索到很多网站测速工具,这里不再介绍。

测试网站页面所有内容的加载速度。本次测速会继续分析页面打开后加载js、css、图片所用的时间。这个速度更接近用户体验。一般使用百度统计的网站速度诊断来完成。

根据关键词文章采集系统(如何应对网络中的新闻内容也一样?系统帮你解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-27 22:11
随着互联网的飞速发展,互联网极大地提高了信息生成和传播的速度。互联网上每天都会产生大量的内容。如何从这些杂乱无章的内容中高效地发现和采集需要的信息似乎越来越多。越重要。互联网上的新闻内容也是如此。新闻分布在不同的网站上,存在重复的内容。我们往往只关心一些新闻。互联网上的新闻页面往往充斥着大量与新闻无关的新闻页面。这些信息会影响我们的阅读效率和阅读体验。如何更方便、及时、高效地获取我们关心的新闻内容,这个系统可以帮我们做到这一点。本系统利用网络爬虫对网络网站上的新闻进行定时、有针对性的分析和采集,然后对采集接收到的数据进行去重、分类和存储。进入数据库,最终提供个性化的新闻订阅服务。考虑如何处理网站的反爬虫策略,避免被网站拦截。在具体实现中,使用Python与scrapy等框架编写爬虫,使用特定的内容提取算法提取目标数据。最后使用Django和weui提供新闻订阅后台和新闻内容展示页面,使用微信向用户推送信息。用户可以通过本系统订阅指定关键词,
[关键词] 网络爬虫;消息; 个性化;订阅; Python
参考文档及完整文档及源代码下载地址: 查看全部
根据关键词文章采集系统(如何应对网络中的新闻内容也一样?系统帮你解决)
随着互联网的飞速发展,互联网极大地提高了信息生成和传播的速度。互联网上每天都会产生大量的内容。如何从这些杂乱无章的内容中高效地发现和采集需要的信息似乎越来越多。越重要。互联网上的新闻内容也是如此。新闻分布在不同的网站上,存在重复的内容。我们往往只关心一些新闻。互联网上的新闻页面往往充斥着大量与新闻无关的新闻页面。这些信息会影响我们的阅读效率和阅读体验。如何更方便、及时、高效地获取我们关心的新闻内容,这个系统可以帮我们做到这一点。本系统利用网络爬虫对网络网站上的新闻进行定时、有针对性的分析和采集,然后对采集接收到的数据进行去重、分类和存储。进入数据库,最终提供个性化的新闻订阅服务。考虑如何处理网站的反爬虫策略,避免被网站拦截。在具体实现中,使用Python与scrapy等框架编写爬虫,使用特定的内容提取算法提取目标数据。最后使用Django和weui提供新闻订阅后台和新闻内容展示页面,使用微信向用户推送信息。用户可以通过本系统订阅指定关键词,
[关键词] 网络爬虫;消息; 个性化;订阅; Python
参考文档及完整文档及源代码下载地址:
根据关键词文章采集系统( 第八章页面分析(一)()页面的分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-11-27 03:14
第八章页面分析(一)()页面的分析)
基于主题的网络信息 采集 技术研究 (七)
第八章页面分析
在过滤和判断这些信息采集的URL和页面的过程中,主要是处理HTML页面。因此,我们在页面分析方面所做的工作主要包括对HTML页面进行语法分析,提取文本、链接、链接的扩展元数据等相关内容;然后对这些内容进行简单的处理和一致的处理;最后将处理结果存入中间信息记录数据库,进行URL过滤处理和页面过滤处理。
8.1 HTML 语法分析
因为采集对页面的语法分析是基于HTML(超文本标记语言)协议[RFC 1866]。整个语法分析过程可以看成两个层次,即SGML(Markup Grammar)层和HTML标记层。语法层将页面分解为文本、标签、注释等不同的语法成分,然后调用标签层对文本和标签进行处理。同时,标记层维护当前文本的各种状态,包括字体、字体等,这些状态是由特定的标记产生或改变的。
系统中使用的标记语法分析器的基本原理是:通过标记语法构造状态转换表,根据输入流中的当前字符(无前向)进行状态切换,相应的语义操作为达到特定状态时执行。这里先介绍几个概念,然后讨论主要语法成分的处理:
文字。文本是页面的初始状态。此状态下的所有字符(除了导致切换到其他状态的字符)构成页面主体的一部分,并根据当前主体状态交给标记层进行处理和保存。
l 标记。标签是出现在文本中并以字符“”结尾的字符串。当解析器遇到“”时,表示标签结束,将分析的标签结构传递给标签层。标签层根据标签名称和参数做相应的动作,包括修改文本的状态。如果计算“”开头的标记,并计算“--”模式的数量来标识页面上的注释,则该注释将被忽略,不做任何处理。
l 转义字符。如果文本以“nnn”或“&xxx”的形式出现(末尾可能有附加字符“;”),分析器会将其视为转义字符,查找后将相应字符添加到文本中上对应的对照表。
8.2 从页面中提取正文
虽然已经预测出该网址与主题相关,但该网址所指向的实际页面可能与预测结果相差甚远。这导致采集到达的页面中有很大一部分是与主题无关的,所以,我们需要判断页面的主题相关性,通过判断结果过滤掉不相关的页面,从而提高平均页面与主题在整个数据集中的相似度值,或提高基于主题的Web信息的准确性采集。
为此,我们需要在页面分析时提取页面主体。提取页面正文的方法比较简单。文本和标记都作为独立的语法组件传递给标记层,标记层根据标记区分页面标题和内容,并根据系统需要合并页面主体。目前还没有考虑不同字体或字体的文字差异。也就是说,在阅读页面的时候,找到标签总和,去掉两个标签之间的内容中的所有标签。
8.3 提取页面中的链接
需要对抓取到的页面中的链接进行分析,并对链接中的网址进行必要的转换。首先,确定页面类型。显然,只有“text/html”类型的页面需要分析链接。页面的类型可以通过分析响应头来获得。部分 WWW 站点返回的响应信息格式不完整。在这种情况下,必须分析页面 URL 中的文件扩展名以确定页面类型。当遇到带有链接的标签时,从标签结构的属性中找到目标URL,从标签对中提取文本作为链接的描述性文本(扩展元数据)。这两个数据代表链接。
提取页面链接的工作流程如下:
1) 从页面文件队列中取出一个页面文件。如果响应标头中未指定文件类型,请使用 URL 中的文件扩展名填写。如果页面文件队列为空,则跳转到7)。
2) 判断页面是否为text/html/htm/shtml文件。如果不是,则丢弃该文件并转移到1),否则转移到3)。
3) 从文件头开始依次读取文件,遇到如下标记
依此类推,记录URL连接。如果遇到文件尾,跳转到7)
4) 按照预定义的统一格式完成提取的URL链接。(页面链接中给出的URL可以是多种格式,可以是完整的,包括协议、站点、路径,也可以省略部分内容,也可以是相对路径)
5) 记录
等后面这个链接的说明吧。在确定 URL 和主题的相关性的章节中,我们将使用此信息并将其定义为扩展元数据。
6) 存储此 URL 及其扩展元数据,并跳转到 2)。
7) 提取页面 URL。
在该算法中,不仅提取了采集页面中的URL,还提取了每个URL的扩展元数据信息。在下一章中,我们将看到扩展元数据的应用。
8.4 从页面中提取标题
如图8.1,页面标题的提取分为三个步骤:1)。确定文本开头的位置,从文章的开头开始,逐段扫描直到一定长度,如果不小于设置的文本最小长度,则假设该段为文本中的一个段落。2)。从文本位置向前搜索可能是标题的段落,根据字体大小、居中、颜色变化等特点,找到最适合的段落作为标题。3)。通过给定的参数调整标题的部分,使标题提取更准确。句法、语义、并对标题段stTitlePara前后各段进行统计分析,准确判断标题段的真实位置;向前或向后调整几段,并添加上一段或下一段。
确定文本的开始位置
从文本位置向前搜索可能是标题的一段
通过给定的参数调整标题的部分,使标题提取更准确
标题
图8.1 提取页面中的标题
第九章URL、页面、主题的相关性判断
在基于主题的Web信息采集系统中,核心问题是确定页面分析得到的URL与这些页面的主题相关性。
来自采集的页面的URL有很多,其中相当一部分与采集的主题无关。为了能够有效地修剪采集,我们需要分析现有信息,预测该URL指向的页面的主题相关性,剔除不相关的URL。因此,我们也将确定 URL 和主题的相关性称为 URL 过滤或 URL 预测。根据Web上主题页面的Sibling/Linkage Locality的分布特征,直观的想法是利用已经采集到页面的主题来预测这个链接指向的页面的主题页。换句话说,如果这个页面与主题相关,那么页面中的链接(不包括噪声链接)都被预测为与主题相关,这显然是一个相当大的错误预测。进一步研究发现,每个链接附近的说明文字(如锚点信息)对链接指向的页面主题具有非常高的预测能力,对预测链接的准确率也很高。但问题在于,由于说明文字的信息有限,很多与主题相关的链接经常被省略,或者在提高URL预测准确率的同时,降低了URL预测的召回率(资源发现率)。为了缓解这个问题,我们在预测算法中加入了由链接关系决定的链接重要性的概念。通过发现重要的链接,在降低相关性判定阈值的同时,我们选择了一些相关性不高的链接。具有高重要性的链接被用作预测以提高召回率,同时减少准确率(重要的 URL 通常会导致更高的召回率)。为此,我们在扩展元数据判断和链接分析判断的基础上,提出了自己的判断算法IPageRank方法。
为了进一步提高采集页面的准确率,我们对采集到达的页面进行了主题相关性判定,计算该页面与主题的相关性值是否小于阈值确定为相关的值。页面被裁剪。我们也将确定页面和主题的相关性称为页面过滤。基于主题的 Web 信息 采集 的一个目标是找到 采集 的准确率和召回率的最佳组合。但是采集的准确率和召回率(或资源发现率)是一对矛盾的问题。也就是说,在提高准确率的同时,召回率会降低;会降低精度。解决这个矛盾的一个有效方法是先提高采集页面的召回率,即降低URL过滤的门槛(增加无关误判,减少相关误判),让更多的URL进入采集@采集队列为采集;然后采集到达后,比较页面和主题的相似度,去掉不相关的页面。这样就得到了更高的最终采集准确率和采集召回率。最后,我们选择了经典的向量空间模型来计算页面和主题之间的相关性。获得更高的最终采集准确率和采集召回率。最后,我们选择了经典的向量空间模型来计算页面和主题之间的相关性。获得更高的最终采集准确率和采集召回率。最后,我们选择了经典的向量空间模型来计算页面和主题之间的相关性。
下面,我们分别讨论我们系统中使用的URL和主题的相关性确定算法以及页面内容和主题的相关性确定算法。
9?? 1 URL与主题相关性判断-IPageRank算法
在权衡性能和效率之后,我们选择了使用扩展元数据加权的 IPageRank 算法来确定 URL 和主题的相关性。
9.1.1 IPageRank算法的目标
通过观察,我们发现PageRank方法虽然具有很强的寻找重要页面的能力,但它所找到的重要页面是针对广泛的主题,而不是基于一个特定的主题。因此,与主题无关的大量页面组指向的页面的PageRank值高于与主题相关的少量页面组指向的页面的PageRank值。这种现象对于基于话题的采集来说是不合理的。但是,我们要利用大量主题相关页面组所指向页面的PageRank值高于少数主题相关页面组所指向页面的PageRank值的现象. 为此,我们改进了PageRank方法:在链接关系的基础上,
9.1.2 IPageRank算法的生成过程
改进的方法有两个主要方面。一是改进算法中的公式;二是改进PageRank算法的启发式步骤。
9.1.2.1 PageRank 公式的改进
首先我们来看一下PageRank算法的公式:
公式9.1
其中 A 是给定的网页,假设指向它的网页有 T1、T2、...、Tn。设 C(A) 为 A 到其他网页的链接数(将 Web 视为有向图时,C(A) 指节点 A 的出度),PR(A) 为 PageRank 值A的,d为衰减因子(通常设置为0.85)。
那我们再来回顾一下RW算法公式9.2和RWB算法公式9.3:
公式9.2
公式9.2中,M(url)是指与该URL相关的所有扩展元数据的集合,指的是扩展元数据中的词与主题的相关程度。c 是用户设置的相关性阈值。
公式9.3
公式9.3中,T(url)表示收录这个URL的文本,t指的是文本中的每个词,c和之前一样,是用户设置的相关性阈值,d是用户设置提高阈值。P1 和 P2 是随机变量,它们在 0 和 1 之间变化。
我们发现公式9.1中每一个指向页面A的页面Ti,其重要性均等地传递到该页面中每个链接所指向的页面,即只有1/的页面C(Ti) 重要性传递到A页。我们认为这对于主题的重要性是不合理的。页面的重要性值,IPageRank,在通过链接时不应相等,而应与链接所连接的页面主题的相关性水平成正比。因此,我们像这样修改公式9.1:
公式9.4
其中,A为给定的网页,假设指向它的网页有T1、T2、...、Tn。urlT1, urlT2,..., urlTn 是网页 T1, T2,..., Tn 到 A 的链接,k1, k2,..., kn 是网页 T1, T2,... 收录的链接数., Tn 分别。IPR(A)为A的IPageRank值,d为衰减因子(同样设置为0.85)。
通过实验发现,基于扩展元数据的RW算法,虽然判断相关页面的准确率较高,但相关页面缺失的数量也非常高。这个结果使得判断相关页面太少,参与评价IageRank值的页面数量少,会大大影响IageRank值的准确性;同时,也会导致相关主题页面的召回率(或资源发现)。率)太低。基于扩展元数据的RWB算法提高了主题页面的召回率,同时由于提取的URL数量增加了IPPageRank值的准确性。为此,我们在下面的公式中将 RW 算法替换为基于扩展元数据的 RWB 算法。
公式9.5
为了区分这两种方法,我们分别称它们为IPageRank-RW算法和IPageRank-RWB算法。如果没有区别,我们称它们为 IPageRank 算法。
9.1.2.2 改进PageRank算法的启发式步骤
在公式9.1中计算每个页面的PageRank值时,在启发式步骤中将每个页面的PageRank值初始化为相同(1),这是因为PageRank方法反映了一个完整的链接关系不带有任何语义含义,每个页面只能被视为平等的权利,在初始条件下,没有说某个页面比另一个页面好,某个主题比另一个主题好。对于基于主题的IPageRank算法,在初始条件下,可以根据与主题的相关性来区分每个页面,这种差异总比没有差异要好。另外,这些初始页面已经采集,它们与主题的相关性可以通过向量空间模型 VSM 或扩展元数据算法来计算。因此,我们将每个页面的 IPageRank 值初始化为该页面与主题的相关性。
9.1.3 如何使用IPPageRank算法以及URL预测的可行性
PageRank算法主要通过迭代计算封闭集中每个页面的PageRank值,并对搜索引擎检索到的结果页面进行重新排序。PageRank 值的作用是先对重要页面进行排名。IPageRank 的使用是不同的。首先,IPageRank值的计算也是在一个封闭的集合中进行的。这个封闭集是已经采集的相关主题页面的集合;算法也会在大约 5 次迭代后停止;并且为了更准确地获取IPageRank值,一般每增加100页重新计算IPageRank值。但是,IPageRank 值用于预测从 采集 页面集中提取的 URL 的主题相关性。预测方法直接通过公式9.4或公式9.5。
这种用法上的差异带来了PageRank和IPageRank的两个不同:一是每个页面的PageRank值一般在5次迭代内收敛(已经证明),而IageRank的迭代值是由于公式的变化。不能证明这种收敛特性是遗传的,所以是否收敛目前还不能完全确定,虽然直觉上是收敛的。显然,这是一个严重的问题。如果不收敛,IPageRank 值就不能准确反映页面的重要性,这就使得预测 URL 变得毫无意义。其次,PageRank的计算环境是封闭的,应用环境也是封闭的。IPageRank 方法使用现有页面的 IPageRank 值来计算新 URL 的 IPageRank 值。这个环境不是完全封闭的。问题是这不是完全封闭,不会体现出网址的重要性,失去方法的意义。
我们做出如下解释,以证明IPageRank算法仍然有效。对于第一个问题,即使IPageRank未能收敛,我们认为经过5次迭代后的值非常接近真实值,可以对采集页面的处理起到预测作用;对于第二个问题,尽管IPPageRank的计算环境并不是完全封闭的,但是采集的页面比较多,这个环境的变化可以忽略不计,和PageRank环境非常相似。因此,我们认为IPageRank算法是可行的,可以用来预测URL队列为采集。
9.1.4 直观解释IPageRank算法
假设Web上有一个主题浏览者,IPageRank(即函数IPR(A))是它访问页面A的概率。它从初始页面集开始,跟随页面链接,从不执行“返回” “ 手术。在每个页面上,查看者对该页面中的每个链接感兴趣的概率与该链接与主题的相关性成正比。当然,浏览者可能不再对这个页面上的链接感兴趣,从而随机选择一个新页面开始新的浏览。这个离开的概率设置为d。
从直观上看,如果有很多页面指向一个页面,那么这个页面的PageRank会比较高,但IPPageRank值不一定高,除非很多页面中的大部分都与主题相关;如果有一个IPPageRank 如果一个很高的页面指向它,这个页面的IPageRank也会很高。这样,从“基于主题的查看器”模型出发的IPageRank功能直观地对应了WEB上的实际情况。如果有很多话题页面指向一个页面,那么这个页面值得一看;如果一个重要的话题资源中心引用了一个页面,这个页面也很重要,值得关注。
事实上,IPageRank算法不仅可以使用基于主题的信息采集,我们相信在域搜索引擎中,它对基于关键词的搜索排名也有很好的效果。
9.2 page和topic-vector空间模型算法的相关性判断
我们使用在检索领域非常常用的向量空间模型作为确定系统页面和主题之间相关性的方法。事实上,向量空间模型具有很强的处理能力,处理方法也比较简单。
我们的算法如下:
0)。预处理:在采集之前,我们首先对描述主题关键词的多个页面进行提取和加权,学习特征向量和属于该主题的向量的权重。
1)。我们对页面主体进行分割,去除停用词,并留下关键词。并根据关键词出现在文章中的频率,权重关键词。
2)。这个页面的标题被分词,将得到的关键词与文章中的关键词合并,给这个关键词加上权重。
3)。根据主题中的特征向量,对页面中的关键词进行剪裁和展开。
4)。根据公式9.3计算页面与主题的相似度,其中D1为主题,D2为要比较的页面。
公式9.6
5)。将Sim(D1,D2)的值与阈值d进行比较,如果Sim(D1,D2)大于等于d,则该页面与主题相关,保留给主题页面库;否则,不相关,删除该页面。
发表于 2006-03-26 02:56 Akun Reading (680)评论(0)编辑 查看全部
根据关键词文章采集系统(
第八章页面分析(一)()页面的分析)
基于主题的网络信息 采集 技术研究 (七)
第八章页面分析
在过滤和判断这些信息采集的URL和页面的过程中,主要是处理HTML页面。因此,我们在页面分析方面所做的工作主要包括对HTML页面进行语法分析,提取文本、链接、链接的扩展元数据等相关内容;然后对这些内容进行简单的处理和一致的处理;最后将处理结果存入中间信息记录数据库,进行URL过滤处理和页面过滤处理。
8.1 HTML 语法分析
因为采集对页面的语法分析是基于HTML(超文本标记语言)协议[RFC 1866]。整个语法分析过程可以看成两个层次,即SGML(Markup Grammar)层和HTML标记层。语法层将页面分解为文本、标签、注释等不同的语法成分,然后调用标签层对文本和标签进行处理。同时,标记层维护当前文本的各种状态,包括字体、字体等,这些状态是由特定的标记产生或改变的。
系统中使用的标记语法分析器的基本原理是:通过标记语法构造状态转换表,根据输入流中的当前字符(无前向)进行状态切换,相应的语义操作为达到特定状态时执行。这里先介绍几个概念,然后讨论主要语法成分的处理:
文字。文本是页面的初始状态。此状态下的所有字符(除了导致切换到其他状态的字符)构成页面主体的一部分,并根据当前主体状态交给标记层进行处理和保存。
l 标记。标签是出现在文本中并以字符“”结尾的字符串。当解析器遇到“”时,表示标签结束,将分析的标签结构传递给标签层。标签层根据标签名称和参数做相应的动作,包括修改文本的状态。如果计算“”开头的标记,并计算“--”模式的数量来标识页面上的注释,则该注释将被忽略,不做任何处理。
l 转义字符。如果文本以“nnn”或“&xxx”的形式出现(末尾可能有附加字符“;”),分析器会将其视为转义字符,查找后将相应字符添加到文本中上对应的对照表。
8.2 从页面中提取正文
虽然已经预测出该网址与主题相关,但该网址所指向的实际页面可能与预测结果相差甚远。这导致采集到达的页面中有很大一部分是与主题无关的,所以,我们需要判断页面的主题相关性,通过判断结果过滤掉不相关的页面,从而提高平均页面与主题在整个数据集中的相似度值,或提高基于主题的Web信息的准确性采集。
为此,我们需要在页面分析时提取页面主体。提取页面正文的方法比较简单。文本和标记都作为独立的语法组件传递给标记层,标记层根据标记区分页面标题和内容,并根据系统需要合并页面主体。目前还没有考虑不同字体或字体的文字差异。也就是说,在阅读页面的时候,找到标签总和,去掉两个标签之间的内容中的所有标签。
8.3 提取页面中的链接
需要对抓取到的页面中的链接进行分析,并对链接中的网址进行必要的转换。首先,确定页面类型。显然,只有“text/html”类型的页面需要分析链接。页面的类型可以通过分析响应头来获得。部分 WWW 站点返回的响应信息格式不完整。在这种情况下,必须分析页面 URL 中的文件扩展名以确定页面类型。当遇到带有链接的标签时,从标签结构的属性中找到目标URL,从标签对中提取文本作为链接的描述性文本(扩展元数据)。这两个数据代表链接。
提取页面链接的工作流程如下:
1) 从页面文件队列中取出一个页面文件。如果响应标头中未指定文件类型,请使用 URL 中的文件扩展名填写。如果页面文件队列为空,则跳转到7)。
2) 判断页面是否为text/html/htm/shtml文件。如果不是,则丢弃该文件并转移到1),否则转移到3)。
3) 从文件头开始依次读取文件,遇到如下标记
依此类推,记录URL连接。如果遇到文件尾,跳转到7)
4) 按照预定义的统一格式完成提取的URL链接。(页面链接中给出的URL可以是多种格式,可以是完整的,包括协议、站点、路径,也可以省略部分内容,也可以是相对路径)
5) 记录
等后面这个链接的说明吧。在确定 URL 和主题的相关性的章节中,我们将使用此信息并将其定义为扩展元数据。
6) 存储此 URL 及其扩展元数据,并跳转到 2)。
7) 提取页面 URL。
在该算法中,不仅提取了采集页面中的URL,还提取了每个URL的扩展元数据信息。在下一章中,我们将看到扩展元数据的应用。
8.4 从页面中提取标题
如图8.1,页面标题的提取分为三个步骤:1)。确定文本开头的位置,从文章的开头开始,逐段扫描直到一定长度,如果不小于设置的文本最小长度,则假设该段为文本中的一个段落。2)。从文本位置向前搜索可能是标题的段落,根据字体大小、居中、颜色变化等特点,找到最适合的段落作为标题。3)。通过给定的参数调整标题的部分,使标题提取更准确。句法、语义、并对标题段stTitlePara前后各段进行统计分析,准确判断标题段的真实位置;向前或向后调整几段,并添加上一段或下一段。
确定文本的开始位置
从文本位置向前搜索可能是标题的一段
通过给定的参数调整标题的部分,使标题提取更准确
标题
图8.1 提取页面中的标题
第九章URL、页面、主题的相关性判断
在基于主题的Web信息采集系统中,核心问题是确定页面分析得到的URL与这些页面的主题相关性。
来自采集的页面的URL有很多,其中相当一部分与采集的主题无关。为了能够有效地修剪采集,我们需要分析现有信息,预测该URL指向的页面的主题相关性,剔除不相关的URL。因此,我们也将确定 URL 和主题的相关性称为 URL 过滤或 URL 预测。根据Web上主题页面的Sibling/Linkage Locality的分布特征,直观的想法是利用已经采集到页面的主题来预测这个链接指向的页面的主题页。换句话说,如果这个页面与主题相关,那么页面中的链接(不包括噪声链接)都被预测为与主题相关,这显然是一个相当大的错误预测。进一步研究发现,每个链接附近的说明文字(如锚点信息)对链接指向的页面主题具有非常高的预测能力,对预测链接的准确率也很高。但问题在于,由于说明文字的信息有限,很多与主题相关的链接经常被省略,或者在提高URL预测准确率的同时,降低了URL预测的召回率(资源发现率)。为了缓解这个问题,我们在预测算法中加入了由链接关系决定的链接重要性的概念。通过发现重要的链接,在降低相关性判定阈值的同时,我们选择了一些相关性不高的链接。具有高重要性的链接被用作预测以提高召回率,同时减少准确率(重要的 URL 通常会导致更高的召回率)。为此,我们在扩展元数据判断和链接分析判断的基础上,提出了自己的判断算法IPageRank方法。
为了进一步提高采集页面的准确率,我们对采集到达的页面进行了主题相关性判定,计算该页面与主题的相关性值是否小于阈值确定为相关的值。页面被裁剪。我们也将确定页面和主题的相关性称为页面过滤。基于主题的 Web 信息 采集 的一个目标是找到 采集 的准确率和召回率的最佳组合。但是采集的准确率和召回率(或资源发现率)是一对矛盾的问题。也就是说,在提高准确率的同时,召回率会降低;会降低精度。解决这个矛盾的一个有效方法是先提高采集页面的召回率,即降低URL过滤的门槛(增加无关误判,减少相关误判),让更多的URL进入采集@采集队列为采集;然后采集到达后,比较页面和主题的相似度,去掉不相关的页面。这样就得到了更高的最终采集准确率和采集召回率。最后,我们选择了经典的向量空间模型来计算页面和主题之间的相关性。获得更高的最终采集准确率和采集召回率。最后,我们选择了经典的向量空间模型来计算页面和主题之间的相关性。获得更高的最终采集准确率和采集召回率。最后,我们选择了经典的向量空间模型来计算页面和主题之间的相关性。
下面,我们分别讨论我们系统中使用的URL和主题的相关性确定算法以及页面内容和主题的相关性确定算法。
9?? 1 URL与主题相关性判断-IPageRank算法
在权衡性能和效率之后,我们选择了使用扩展元数据加权的 IPageRank 算法来确定 URL 和主题的相关性。
9.1.1 IPageRank算法的目标
通过观察,我们发现PageRank方法虽然具有很强的寻找重要页面的能力,但它所找到的重要页面是针对广泛的主题,而不是基于一个特定的主题。因此,与主题无关的大量页面组指向的页面的PageRank值高于与主题相关的少量页面组指向的页面的PageRank值。这种现象对于基于话题的采集来说是不合理的。但是,我们要利用大量主题相关页面组所指向页面的PageRank值高于少数主题相关页面组所指向页面的PageRank值的现象. 为此,我们改进了PageRank方法:在链接关系的基础上,
9.1.2 IPageRank算法的生成过程
改进的方法有两个主要方面。一是改进算法中的公式;二是改进PageRank算法的启发式步骤。
9.1.2.1 PageRank 公式的改进
首先我们来看一下PageRank算法的公式:
公式9.1
其中 A 是给定的网页,假设指向它的网页有 T1、T2、...、Tn。设 C(A) 为 A 到其他网页的链接数(将 Web 视为有向图时,C(A) 指节点 A 的出度),PR(A) 为 PageRank 值A的,d为衰减因子(通常设置为0.85)。
那我们再来回顾一下RW算法公式9.2和RWB算法公式9.3:
公式9.2
公式9.2中,M(url)是指与该URL相关的所有扩展元数据的集合,指的是扩展元数据中的词与主题的相关程度。c 是用户设置的相关性阈值。
公式9.3
公式9.3中,T(url)表示收录这个URL的文本,t指的是文本中的每个词,c和之前一样,是用户设置的相关性阈值,d是用户设置提高阈值。P1 和 P2 是随机变量,它们在 0 和 1 之间变化。
我们发现公式9.1中每一个指向页面A的页面Ti,其重要性均等地传递到该页面中每个链接所指向的页面,即只有1/的页面C(Ti) 重要性传递到A页。我们认为这对于主题的重要性是不合理的。页面的重要性值,IPageRank,在通过链接时不应相等,而应与链接所连接的页面主题的相关性水平成正比。因此,我们像这样修改公式9.1:
公式9.4
其中,A为给定的网页,假设指向它的网页有T1、T2、...、Tn。urlT1, urlT2,..., urlTn 是网页 T1, T2,..., Tn 到 A 的链接,k1, k2,..., kn 是网页 T1, T2,... 收录的链接数., Tn 分别。IPR(A)为A的IPageRank值,d为衰减因子(同样设置为0.85)。
通过实验发现,基于扩展元数据的RW算法,虽然判断相关页面的准确率较高,但相关页面缺失的数量也非常高。这个结果使得判断相关页面太少,参与评价IageRank值的页面数量少,会大大影响IageRank值的准确性;同时,也会导致相关主题页面的召回率(或资源发现)。率)太低。基于扩展元数据的RWB算法提高了主题页面的召回率,同时由于提取的URL数量增加了IPPageRank值的准确性。为此,我们在下面的公式中将 RW 算法替换为基于扩展元数据的 RWB 算法。
公式9.5
为了区分这两种方法,我们分别称它们为IPageRank-RW算法和IPageRank-RWB算法。如果没有区别,我们称它们为 IPageRank 算法。
9.1.2.2 改进PageRank算法的启发式步骤
在公式9.1中计算每个页面的PageRank值时,在启发式步骤中将每个页面的PageRank值初始化为相同(1),这是因为PageRank方法反映了一个完整的链接关系不带有任何语义含义,每个页面只能被视为平等的权利,在初始条件下,没有说某个页面比另一个页面好,某个主题比另一个主题好。对于基于主题的IPageRank算法,在初始条件下,可以根据与主题的相关性来区分每个页面,这种差异总比没有差异要好。另外,这些初始页面已经采集,它们与主题的相关性可以通过向量空间模型 VSM 或扩展元数据算法来计算。因此,我们将每个页面的 IPageRank 值初始化为该页面与主题的相关性。
9.1.3 如何使用IPPageRank算法以及URL预测的可行性
PageRank算法主要通过迭代计算封闭集中每个页面的PageRank值,并对搜索引擎检索到的结果页面进行重新排序。PageRank 值的作用是先对重要页面进行排名。IPageRank 的使用是不同的。首先,IPageRank值的计算也是在一个封闭的集合中进行的。这个封闭集是已经采集的相关主题页面的集合;算法也会在大约 5 次迭代后停止;并且为了更准确地获取IPageRank值,一般每增加100页重新计算IPageRank值。但是,IPageRank 值用于预测从 采集 页面集中提取的 URL 的主题相关性。预测方法直接通过公式9.4或公式9.5。
这种用法上的差异带来了PageRank和IPageRank的两个不同:一是每个页面的PageRank值一般在5次迭代内收敛(已经证明),而IageRank的迭代值是由于公式的变化。不能证明这种收敛特性是遗传的,所以是否收敛目前还不能完全确定,虽然直觉上是收敛的。显然,这是一个严重的问题。如果不收敛,IPageRank 值就不能准确反映页面的重要性,这就使得预测 URL 变得毫无意义。其次,PageRank的计算环境是封闭的,应用环境也是封闭的。IPageRank 方法使用现有页面的 IPageRank 值来计算新 URL 的 IPageRank 值。这个环境不是完全封闭的。问题是这不是完全封闭,不会体现出网址的重要性,失去方法的意义。
我们做出如下解释,以证明IPageRank算法仍然有效。对于第一个问题,即使IPageRank未能收敛,我们认为经过5次迭代后的值非常接近真实值,可以对采集页面的处理起到预测作用;对于第二个问题,尽管IPPageRank的计算环境并不是完全封闭的,但是采集的页面比较多,这个环境的变化可以忽略不计,和PageRank环境非常相似。因此,我们认为IPageRank算法是可行的,可以用来预测URL队列为采集。
9.1.4 直观解释IPageRank算法
假设Web上有一个主题浏览者,IPageRank(即函数IPR(A))是它访问页面A的概率。它从初始页面集开始,跟随页面链接,从不执行“返回” “ 手术。在每个页面上,查看者对该页面中的每个链接感兴趣的概率与该链接与主题的相关性成正比。当然,浏览者可能不再对这个页面上的链接感兴趣,从而随机选择一个新页面开始新的浏览。这个离开的概率设置为d。
从直观上看,如果有很多页面指向一个页面,那么这个页面的PageRank会比较高,但IPPageRank值不一定高,除非很多页面中的大部分都与主题相关;如果有一个IPPageRank 如果一个很高的页面指向它,这个页面的IPageRank也会很高。这样,从“基于主题的查看器”模型出发的IPageRank功能直观地对应了WEB上的实际情况。如果有很多话题页面指向一个页面,那么这个页面值得一看;如果一个重要的话题资源中心引用了一个页面,这个页面也很重要,值得关注。
事实上,IPageRank算法不仅可以使用基于主题的信息采集,我们相信在域搜索引擎中,它对基于关键词的搜索排名也有很好的效果。
9.2 page和topic-vector空间模型算法的相关性判断
我们使用在检索领域非常常用的向量空间模型作为确定系统页面和主题之间相关性的方法。事实上,向量空间模型具有很强的处理能力,处理方法也比较简单。
我们的算法如下:
0)。预处理:在采集之前,我们首先对描述主题关键词的多个页面进行提取和加权,学习特征向量和属于该主题的向量的权重。
1)。我们对页面主体进行分割,去除停用词,并留下关键词。并根据关键词出现在文章中的频率,权重关键词。
2)。这个页面的标题被分词,将得到的关键词与文章中的关键词合并,给这个关键词加上权重。
3)。根据主题中的特征向量,对页面中的关键词进行剪裁和展开。
4)。根据公式9.3计算页面与主题的相似度,其中D1为主题,D2为要比较的页面。
公式9.6
5)。将Sim(D1,D2)的值与阈值d进行比较,如果Sim(D1,D2)大于等于d,则该页面与主题相关,保留给主题页面库;否则,不相关,删除该页面。
发表于 2006-03-26 02:56 Akun Reading (680)评论(0)编辑
根据关键词文章采集系统(googlereader,做电商有很多idea,也许是下一个商业风口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-11-27 01:04
根据关键词文章采集系统googlereader,googlearts&culture,googleseotech做电商有很多idea,自媒体有很多有创意的点子,新的技术应用,新的展现形式,新的商业模式,看了很多风口,看了很多机会,天上不会掉馅饼,那些都是镜花水月,也许是下一个商业风口,等上n年,看到了一些,获得了一些,收获了一些,却不会再有那么多飞来的桃花。
寻找回到互联网本质,各式各样的方式都需要将互联网技术落地,可大可小。快速的创业项目、资本市场,依靠强大的团队或者强力投资组合或者抱团战略,迅速获得大量投资,迅速完成商业机会。庞大的资金运作(绝不是连年亏损或者巨额亏损),伴随着快速扩张,大力扩张。但凡花样百出,投资人往往更看重后者。几轮快速的折腾之后,一旦达到资金能够沉淀并且获得资金复利的极致,资金开始迅速流动,伴随着市场份额的增长以及获得相关合作伙伴进一步扩大公司范围和影响力,将会有更多新的盈利模式实现,加速扩张,加速转化最终实现低成本生存或者覆盖其他成本,跨越式发展。
把时间当作生命。上班时你看到的一切都是即将发生的。当你终于实现财务自由,有更多的时间做自己想做的事情,才能更多的看到即将发生的事情。所以,与其犹犹豫豫,惶惶不可终日,不如就这样随心的过一生。(建议每一个还未踏出步伐的人,在年底的时候回头看看,那些折腾了半天的日子里,那些只觉得难过却无法实现的。肯定会很有收获。)。 查看全部
根据关键词文章采集系统(googlereader,做电商有很多idea,也许是下一个商业风口)
根据关键词文章采集系统googlereader,googlearts&culture,googleseotech做电商有很多idea,自媒体有很多有创意的点子,新的技术应用,新的展现形式,新的商业模式,看了很多风口,看了很多机会,天上不会掉馅饼,那些都是镜花水月,也许是下一个商业风口,等上n年,看到了一些,获得了一些,收获了一些,却不会再有那么多飞来的桃花。
寻找回到互联网本质,各式各样的方式都需要将互联网技术落地,可大可小。快速的创业项目、资本市场,依靠强大的团队或者强力投资组合或者抱团战略,迅速获得大量投资,迅速完成商业机会。庞大的资金运作(绝不是连年亏损或者巨额亏损),伴随着快速扩张,大力扩张。但凡花样百出,投资人往往更看重后者。几轮快速的折腾之后,一旦达到资金能够沉淀并且获得资金复利的极致,资金开始迅速流动,伴随着市场份额的增长以及获得相关合作伙伴进一步扩大公司范围和影响力,将会有更多新的盈利模式实现,加速扩张,加速转化最终实现低成本生存或者覆盖其他成本,跨越式发展。
把时间当作生命。上班时你看到的一切都是即将发生的。当你终于实现财务自由,有更多的时间做自己想做的事情,才能更多的看到即将发生的事情。所以,与其犹犹豫豫,惶惶不可终日,不如就这样随心的过一生。(建议每一个还未踏出步伐的人,在年底的时候回头看看,那些折腾了半天的日子里,那些只觉得难过却无法实现的。肯定会很有收获。)。
根据关键词文章采集系统(botfan基于robots协议进行非侵入爬取,botfan采集系统效果展示)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-11-25 05:03
根据关键词文章采集系统之botfan推送文章,简单的说就是基于爬虫的文章采集系统,实现文章的海量采集,botfan采集系统可以从一定数量的网站和微信公众号内采集文章并推送至大众手机或者网页端,botfan推送文章主要通过"爬虫"实现了一键爬取每日各大热门微信公众号的最新文章,以及各大重要新闻。botfan基于robots协议进行非侵入爬取,同时基于抓包技术破解相关网站的代理ip和ssl证书,使用user-agent抓取网站上的http请求,这种方式可以保证代理爬虫是安全的,因为爬虫并不知道爬取的文章都是什么类型的,而且作者也不希望爬取进来的信息是广告及不明的网站。
首先,将手机等带有采集功能的移动终端网页端刷新后点击"设置-人工采集"再次刷新的时候刷新chrome、firefox、谷歌浏览器的点击效果不同,详细见下图。botfan采集系统效果展示首先是chrome浏览器,如下图所示:其次是firefox浏览器,如下图所示:chrome浏览器效果如下图所示:而firefox浏览器则正是因为其对http协议友好而导致其爬取速度快于谷歌浏览器,所以现在大部分网站都禁止谷歌浏览器访问,暂时也不支持将爬取速度从海量的标题页爬取到独立详情页,其实谷歌浏览器还是可以正常访问很多网站的,只是速度较慢。botfan采集系统效果展示下面以chrome浏览器为例介绍下安装和使用:。
1、安装插件botfail——若有安装一些其他的插件依然无法正常使用请后台回复。
2、在浏览器的地址栏输入:/然后右键显示安装,并按照提示完成安装。
3、打开botfail编辑框或者框框内搜索chrome,并安装编辑器插件。
4、将这个项目下的插件拖拽进来,并选择喜欢的模板进行导入。
5、选择一个模板点击新建或者直接浏览器输入在地址栏中输入:,这里使用tabs模板,详细设置看startactivity运行效果。
同时为防止爬取的网站是已知的网站导致验证失败,
1、请选择chrome浏览器为网站登录,
2、登录一个已知的botfan采集网站并验证成功后,点击开始后台设置。
设置图如下所示:
5、安装完成后请点击左下角对应状态标识上的『启用』,并继续在其他浏览器中上传插件使用。ps:botfail是一个采集系统,不保证采集结果的准确性和更新速度。ps:botfan文章采集系统收费为开发者2.99元/人,后端开发1.49元/人。 查看全部
根据关键词文章采集系统(botfan基于robots协议进行非侵入爬取,botfan采集系统效果展示)
根据关键词文章采集系统之botfan推送文章,简单的说就是基于爬虫的文章采集系统,实现文章的海量采集,botfan采集系统可以从一定数量的网站和微信公众号内采集文章并推送至大众手机或者网页端,botfan推送文章主要通过"爬虫"实现了一键爬取每日各大热门微信公众号的最新文章,以及各大重要新闻。botfan基于robots协议进行非侵入爬取,同时基于抓包技术破解相关网站的代理ip和ssl证书,使用user-agent抓取网站上的http请求,这种方式可以保证代理爬虫是安全的,因为爬虫并不知道爬取的文章都是什么类型的,而且作者也不希望爬取进来的信息是广告及不明的网站。
首先,将手机等带有采集功能的移动终端网页端刷新后点击"设置-人工采集"再次刷新的时候刷新chrome、firefox、谷歌浏览器的点击效果不同,详细见下图。botfan采集系统效果展示首先是chrome浏览器,如下图所示:其次是firefox浏览器,如下图所示:chrome浏览器效果如下图所示:而firefox浏览器则正是因为其对http协议友好而导致其爬取速度快于谷歌浏览器,所以现在大部分网站都禁止谷歌浏览器访问,暂时也不支持将爬取速度从海量的标题页爬取到独立详情页,其实谷歌浏览器还是可以正常访问很多网站的,只是速度较慢。botfan采集系统效果展示下面以chrome浏览器为例介绍下安装和使用:。
1、安装插件botfail——若有安装一些其他的插件依然无法正常使用请后台回复。
2、在浏览器的地址栏输入:/然后右键显示安装,并按照提示完成安装。
3、打开botfail编辑框或者框框内搜索chrome,并安装编辑器插件。
4、将这个项目下的插件拖拽进来,并选择喜欢的模板进行导入。
5、选择一个模板点击新建或者直接浏览器输入在地址栏中输入:,这里使用tabs模板,详细设置看startactivity运行效果。
同时为防止爬取的网站是已知的网站导致验证失败,
1、请选择chrome浏览器为网站登录,
2、登录一个已知的botfan采集网站并验证成功后,点击开始后台设置。
设置图如下所示:
5、安装完成后请点击左下角对应状态标识上的『启用』,并继续在其他浏览器中上传插件使用。ps:botfail是一个采集系统,不保证采集结果的准确性和更新速度。ps:botfan文章采集系统收费为开发者2.99元/人,后端开发1.49元/人。
根据关键词文章采集系统(个人推荐元道云采集导航,通过文章标题和自动生成摘要)
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-23 17:06
根据关键词文章采集系统,ky算法,年月日,相似度排序,按时间顺序,
自问自答一下,这个不是一个文章采集系统,是一个常规文章发布系统,例如简书发表文章全部记录在系统内,需要实现自动发布过程可以查看我个人公众号,
我觉得可以通过云采集:市面上,大多数的图文采集系统都是提供的云采集功能。现在用的比较多的是图狗云采集,是众多云采集平台中仅有一家可以正式商用的。同时采集下来的文章基本质量会好很多,因为网站会将文章按照质量划分,看起来质量比较好一些。
题主自己先答个。很简单啊,不用去相关的网站去搜,直接通过网站下载,有些需要二次验证的上面都有说明的,比如说最好要带版权声明的啊,商业用途等等的。
个人推荐元道云采集导航,通过文章标题和自动生成摘要导航采集。
给几个给个准确的定义:网站采集系统:来源网站的内容如果是原创的,一般就是直接从采集站扒下来,文章采集这块现在在b2b市场里已经被个别网站逼着走窄门了,对质量要求也很高,发现不了源头的话后期压力大。个人站点采集系统:来源网站一般已经水文化局等管制的不多,而且有点些经验的同学肯定知道:对源头的维护基本也是网站采集系统的卖点了,但和一般的系统操作上有所区别,特别是追溯功能,追溯到源头的源文档信息再用在搜索引擎里,效果更佳。
需要关注的点:源文档质量(这个决定源文档价值和价格)和数量(做大站比较重要)。你以为采集了别人的源文档内容就得到了,其实没那么简单。采集到手的文档里还有版权信息,不清楚他还是不是原创,有两万多的河南帽子文章,这部分内容卖多少钱你们自己想象。如果要做老总关注的重点话,做老板关注的重点话,起码还有五十万/年的采集费用,回本儿遥遥无期。
按照文章收入、篇篇10-50万不等。如果给你这样的采集系统,那价格你都拿的起,但你知道领导有这么多的人吗?关键有产品开发可以解决吗?大佬们满意了,可以开发试试吧。 查看全部
根据关键词文章采集系统(个人推荐元道云采集导航,通过文章标题和自动生成摘要)
根据关键词文章采集系统,ky算法,年月日,相似度排序,按时间顺序,
自问自答一下,这个不是一个文章采集系统,是一个常规文章发布系统,例如简书发表文章全部记录在系统内,需要实现自动发布过程可以查看我个人公众号,
我觉得可以通过云采集:市面上,大多数的图文采集系统都是提供的云采集功能。现在用的比较多的是图狗云采集,是众多云采集平台中仅有一家可以正式商用的。同时采集下来的文章基本质量会好很多,因为网站会将文章按照质量划分,看起来质量比较好一些。
题主自己先答个。很简单啊,不用去相关的网站去搜,直接通过网站下载,有些需要二次验证的上面都有说明的,比如说最好要带版权声明的啊,商业用途等等的。
个人推荐元道云采集导航,通过文章标题和自动生成摘要导航采集。
给几个给个准确的定义:网站采集系统:来源网站的内容如果是原创的,一般就是直接从采集站扒下来,文章采集这块现在在b2b市场里已经被个别网站逼着走窄门了,对质量要求也很高,发现不了源头的话后期压力大。个人站点采集系统:来源网站一般已经水文化局等管制的不多,而且有点些经验的同学肯定知道:对源头的维护基本也是网站采集系统的卖点了,但和一般的系统操作上有所区别,特别是追溯功能,追溯到源头的源文档信息再用在搜索引擎里,效果更佳。
需要关注的点:源文档质量(这个决定源文档价值和价格)和数量(做大站比较重要)。你以为采集了别人的源文档内容就得到了,其实没那么简单。采集到手的文档里还有版权信息,不清楚他还是不是原创,有两万多的河南帽子文章,这部分内容卖多少钱你们自己想象。如果要做老总关注的重点话,做老板关注的重点话,起码还有五十万/年的采集费用,回本儿遥遥无期。
按照文章收入、篇篇10-50万不等。如果给你这样的采集系统,那价格你都拿的起,但你知道领导有这么多的人吗?关键有产品开发可以解决吗?大佬们满意了,可以开发试试吧。
根据关键词文章采集系统(Tags:51下载网提供《优采云站群管理系统》13.08.10.19免费版下载)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-11-23 17:04
标签:
51下载网提供《优采云站群管理系统》13.08.10.19免费版下载,本软件为免费软件,文件大小26.14 MB,推荐指数3星,作为国产软件的顶级厂商,可以放心下载!
优采云站群 管理系统是一个管理系统,可以通过关键词自动采集各大搜索引擎的相关搜索词和相关长尾词,然后根据搜索结果抓取大量最新数据。派生词。摒弃普通采集软件所需的繁琐规则定制,实现一键采集一键发布。只需输入关键词到采集即可获取最新的相关内容,并自动将SEO发布到指定的网站多任务站群管理系统,可使用24一天几个小时。自动维护数百个网站。
优采云站群具有强大的采集功能,支持关键词采集 文章采集,图片和视频采集,还支持自定义采集规则指定域名采集,还提供了超强的原创文章生成功能,支持数据自由导入导出,支持各种链接插入和链轮功能,批量站点和栏目添加,栏目id绑定等功能,支持自定义发布界面编辑,真正实现对各种站点程序的完美支持,是多站点维护管理的必备工具。
特征
1、站点数量不限
优采云站群 软件秉承为用户提供最实用的软件,无限建站数量,打造真正的站群软件为宗旨;无论购买哪个版本,都没有限制网站程序数量和域名不绑定电脑,与其他同类站群管理软件有很大不同。
2、智能蜘蛛引擎
优采云站群软件打造的智能蜘蛛引擎,只需要输入几个相关的关键词,自动推导出上千条长尾关键词,然后针对这些长尾尾巴关键词自动从网络采集到最新的文章、图片、视频等内容。无需任何采集规则,完全实现一键抓取任务。是一套站群采集真正操作简单、功能强大的软件。
3、SEO伪原创 和词库管理
优采云站群软件全面支持标题和内容的近义词替换、分词重构、禁词库阻塞、内容段落打乱重排、文章内容随机插入图片、视频等,可以很好的实现伪原创的标题和内容;不管你做多少、几十甚至上百个站,你都不必担心采集文章 收录对于搜索引擎的重复性。
4、全站无限循环挂机全自动更新
设置关键词和抓取频率后,站群管理系统会自动生成相关的关键词,自动抓取相关的文章并发布到指定的网站列中,轻松实现一键采集更新,支持365天无限循环挂机采集维护所有网站,真正实现无人监控、无人操作,让网站建设与维护变得如此简单。
5、强大的链轮功能
支持文章随机插入指定内容,锚文本链接,单站链接库链轮,自动提取文章内容链接到单站链接库或全局链接库,支持自定义链轮,可以实现任何 Sprocket 组合。
6、按关键字自动采集图片(可作为图片站)
优采云站群支持直接根据关键词批量采集图片,将图片插入到每列文章,也支持直接采集图片单独发布,你可以制作一个专门的图片网站。
7、自动按关键字采集视频(可作为视频站)
优采云站群支持直接按关键词批量采集视频,将视频插入每一列文章,也支持直接采集视频它可以单独发布,也可以作为专用的视频网站。
8、超强原创文章生成功能
优采云站群内置超级原创文章生成库,支持自定义句库生成原创文章(使用现有的文章库中的文章子句随机组成一个新的文章),自定义句型库生成原创文章和自定义模板/元素库生成原创 文章,也支持将已经采集的文章段落混合生成文章。
9、数据任意导入导出
优采云站群支持将采集软件原版文章批量导出到本地,支持伪原创软件后批量导出文章软件@>到本地和批处理端采集文章,在将文章导出到本地的同时,也支持将本地文章导入到站群中,并支持导入一个每列一定数量的文章,也支持每个网站随机列直接导入一个或多个软文广告文章。
10、强大的批处理功能
优采云站群 支持批量添加站点和栏目,批量提取栏目和id绑定等,更网站可以轻松管理。
11、通用自定义发布界面
优采云站群支持任意网站自定义发布界面,无论是论坛、博客、cms等任何网站,都可以通过自定义界面工具编辑相应的发布界面,真正实现对各类站点程序的完美支持。 查看全部
根据关键词文章采集系统(Tags:51下载网提供《优采云站群管理系统》13.08.10.19免费版下载)
标签:
51下载网提供《优采云站群管理系统》13.08.10.19免费版下载,本软件为免费软件,文件大小26.14 MB,推荐指数3星,作为国产软件的顶级厂商,可以放心下载!
优采云站群 管理系统是一个管理系统,可以通过关键词自动采集各大搜索引擎的相关搜索词和相关长尾词,然后根据搜索结果抓取大量最新数据。派生词。摒弃普通采集软件所需的繁琐规则定制,实现一键采集一键发布。只需输入关键词到采集即可获取最新的相关内容,并自动将SEO发布到指定的网站多任务站群管理系统,可使用24一天几个小时。自动维护数百个网站。
优采云站群具有强大的采集功能,支持关键词采集 文章采集,图片和视频采集,还支持自定义采集规则指定域名采集,还提供了超强的原创文章生成功能,支持数据自由导入导出,支持各种链接插入和链轮功能,批量站点和栏目添加,栏目id绑定等功能,支持自定义发布界面编辑,真正实现对各种站点程序的完美支持,是多站点维护管理的必备工具。
特征
1、站点数量不限
优采云站群 软件秉承为用户提供最实用的软件,无限建站数量,打造真正的站群软件为宗旨;无论购买哪个版本,都没有限制网站程序数量和域名不绑定电脑,与其他同类站群管理软件有很大不同。
2、智能蜘蛛引擎
优采云站群软件打造的智能蜘蛛引擎,只需要输入几个相关的关键词,自动推导出上千条长尾关键词,然后针对这些长尾尾巴关键词自动从网络采集到最新的文章、图片、视频等内容。无需任何采集规则,完全实现一键抓取任务。是一套站群采集真正操作简单、功能强大的软件。
3、SEO伪原创 和词库管理
优采云站群软件全面支持标题和内容的近义词替换、分词重构、禁词库阻塞、内容段落打乱重排、文章内容随机插入图片、视频等,可以很好的实现伪原创的标题和内容;不管你做多少、几十甚至上百个站,你都不必担心采集文章 收录对于搜索引擎的重复性。
4、全站无限循环挂机全自动更新
设置关键词和抓取频率后,站群管理系统会自动生成相关的关键词,自动抓取相关的文章并发布到指定的网站列中,轻松实现一键采集更新,支持365天无限循环挂机采集维护所有网站,真正实现无人监控、无人操作,让网站建设与维护变得如此简单。
5、强大的链轮功能
支持文章随机插入指定内容,锚文本链接,单站链接库链轮,自动提取文章内容链接到单站链接库或全局链接库,支持自定义链轮,可以实现任何 Sprocket 组合。
6、按关键字自动采集图片(可作为图片站)
优采云站群支持直接根据关键词批量采集图片,将图片插入到每列文章,也支持直接采集图片单独发布,你可以制作一个专门的图片网站。
7、自动按关键字采集视频(可作为视频站)
优采云站群支持直接按关键词批量采集视频,将视频插入每一列文章,也支持直接采集视频它可以单独发布,也可以作为专用的视频网站。
8、超强原创文章生成功能
优采云站群内置超级原创文章生成库,支持自定义句库生成原创文章(使用现有的文章库中的文章子句随机组成一个新的文章),自定义句型库生成原创文章和自定义模板/元素库生成原创 文章,也支持将已经采集的文章段落混合生成文章。
9、数据任意导入导出
优采云站群支持将采集软件原版文章批量导出到本地,支持伪原创软件后批量导出文章软件@>到本地和批处理端采集文章,在将文章导出到本地的同时,也支持将本地文章导入到站群中,并支持导入一个每列一定数量的文章,也支持每个网站随机列直接导入一个或多个软文广告文章。
10、强大的批处理功能
优采云站群 支持批量添加站点和栏目,批量提取栏目和id绑定等,更网站可以轻松管理。
11、通用自定义发布界面
优采云站群支持任意网站自定义发布界面,无论是论坛、博客、cms等任何网站,都可以通过自定义界面工具编辑相应的发布界面,真正实现对各类站点程序的完美支持。
根据关键词文章采集系统(1.如何挖掘关键词?2.如何选择关键词?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-11-19 20:09
1. 如何挖矿关键词?
2. 如何选择关键词?首先,我们必须对关键词进行竞争分析。然后从多个关键词中确定最终的关键词。
3. 如何构建关键词 库?
1.抓住竞争对手网站的关键词,并根据行业和自己的分析,研究行业内有哪些类型的关键词,有哪些关键词。
2. 选择一批基础的关键词,为每个词设置不同的分类。
关键词 的具体数量取决于行业。基本上,你必须为每个类别选择几十个关键词。如果行业规模的搜索量在几十万以上,那么基本的关键词总共选择的应该至少有几百级。以婚庆行业为例,如何分类。
3.根据基本关键词使用百度推广跑步数据。就是用百度推广的关键词工具搜索上一步我们选择的所有关键词。然后导出数据。注意:导出数据时需要精确匹配类型。
4. 根据数据结果填写基本的关键词。在搜索和导出数据的过程中,我们可能会发现之前的基础关键词库中缺少了一些重要的词。这时候就需要把这些词加入到基本的关键词库中,然后重复步骤3。
5. 制作一个完整的未处理数据表。完成第四步后,我们会有更多的原创关键词数据,或者简单的excel表格。我们需要将excel表中的所有数据汇总到一张表中。
6. 手动调整所有数据的分类,使用Excel过滤功能,然后手动为每个关键词选择一个分类,即添加一列分类数据。在这个过程中,可以使用筛选功能来提高效率。这是整个过程中最为繁琐复杂的一个过程。曾经花了近60个小时整理出一个关键词字库,3万多字,总搜索量近200万。
7. 大功告成。把每个关键词的分类填好后,实际上可以根据分类查看每个关键词的特征。这具有真正的分析价值。
ps 关键词 研究的目的不是要知道所有的词,而是要知道用户的搜索习惯。
以上是我开发的内部工作流程。
关于工具使用的问题:
目前市场上还没有批量查询关键词搜索量的好工具。所以没有办法按照规则批量写关键词,比如region+摄影。
如果有同学知道或有,请分享。
@郭世雄 查看全部
根据关键词文章采集系统(1.如何挖掘关键词?2.如何选择关键词?(图))
1. 如何挖矿关键词?
2. 如何选择关键词?首先,我们必须对关键词进行竞争分析。然后从多个关键词中确定最终的关键词。
3. 如何构建关键词 库?
1.抓住竞争对手网站的关键词,并根据行业和自己的分析,研究行业内有哪些类型的关键词,有哪些关键词。
2. 选择一批基础的关键词,为每个词设置不同的分类。
关键词 的具体数量取决于行业。基本上,你必须为每个类别选择几十个关键词。如果行业规模的搜索量在几十万以上,那么基本的关键词总共选择的应该至少有几百级。以婚庆行业为例,如何分类。
3.根据基本关键词使用百度推广跑步数据。就是用百度推广的关键词工具搜索上一步我们选择的所有关键词。然后导出数据。注意:导出数据时需要精确匹配类型。
4. 根据数据结果填写基本的关键词。在搜索和导出数据的过程中,我们可能会发现之前的基础关键词库中缺少了一些重要的词。这时候就需要把这些词加入到基本的关键词库中,然后重复步骤3。
5. 制作一个完整的未处理数据表。完成第四步后,我们会有更多的原创关键词数据,或者简单的excel表格。我们需要将excel表中的所有数据汇总到一张表中。
6. 手动调整所有数据的分类,使用Excel过滤功能,然后手动为每个关键词选择一个分类,即添加一列分类数据。在这个过程中,可以使用筛选功能来提高效率。这是整个过程中最为繁琐复杂的一个过程。曾经花了近60个小时整理出一个关键词字库,3万多字,总搜索量近200万。
7. 大功告成。把每个关键词的分类填好后,实际上可以根据分类查看每个关键词的特征。这具有真正的分析价值。
ps 关键词 研究的目的不是要知道所有的词,而是要知道用户的搜索习惯。
以上是我开发的内部工作流程。
关于工具使用的问题:
目前市场上还没有批量查询关键词搜索量的好工具。所以没有办法按照规则批量写关键词,比如region+摄影。
如果有同学知道或有,请分享。
@郭世雄
根据关键词文章采集系统(织梦采集侠的伪原创及搜索优化方式(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-19 18:24
织梦采集安装非常简单方便。只需一分钟即可启动采集。此外,新手可以通过结合简单、健壮、灵活和开源的Dedecms程序快速入门。此外,我们还提供专门的客户服务,为商业客户提供技术支持。与传统的采集模式不同,织梦>采集夏可根据用户设置的关键词进行平移。Pan采集的优点是,通过采集和关键词的不同搜索结果,它不能采集一个或多个指定的采集站点,降低了采集站点被搜索引擎判断为镜像站点并被搜索引擎惩罚的风险
1)RSS采集,输入内容的RSS地址
只要采集的采集提供RSS订阅地址,您就可以通过RSS订阅采集。您只需输入RSS地址即可轻松地采集到目标网站内容。无需编写采集规则,方便简单
2)页面监控采集,简单方便采集内容
页面监控采集只需提供监控页面地址和文本URL规则即可指定采集指定网站或列内容,方便简单。它可以成为目标采集,而无需编写采集规则
3)各种伪原创和优化方法,以提高收录率和排名
自动标题、段落重排、高级混淆、自动内链、内容过滤、网站过滤、同义词替换、插入SEO词、关键词添加链接和其他方法来处理从采集返回的文章,增强采集文章>原创,促进搜索引擎优化,并提高搜索引擎的权重和排名收录>,网站>
4)插件是全自动的采集,无需手动干预
织梦采集夏根据设置的采集方法采集网站,按照预设的采集任务,然后自动抓取网页内容。该程序通过精确计算分析网页,丢弃非文章内容页的网站,提取优秀的文章内容,最后执行伪原创、导入和生成。所有这些操作程序均自动完成,无需手动干预
5)手动发布文章或伪原创和搜索优化处理
织梦采集Xia不仅是一个采集插件,也是一个织梦必需的伪原创和搜索优化插件。手动发布的文章可通过织梦采集和文章的搜索优化进行处理。它可以替换同义词、自动链入、随机插入关键词链接和文章,包括关键词自动添加指定链接等功能,是织梦必不可少的插件
6)定期定量更新采集伪原创搜索引擎优化
该插件有两种触发方法采集。一种是在页面中添加代码以触发采集用户访问更新。另一个是我们为商业用户提供的远程触发采集服务。新网站可以定期、定量地更新,无需人工干预
7)定期、定量地更新待审查的手稿
即使有成千上万的文章,织梦采集夏也可以根据您的需要,在您每天设定的时间段内定期、定量地审查和更新 查看全部
根据关键词文章采集系统(织梦采集侠的伪原创及搜索优化方式(组图))
织梦采集安装非常简单方便。只需一分钟即可启动采集。此外,新手可以通过结合简单、健壮、灵活和开源的Dedecms程序快速入门。此外,我们还提供专门的客户服务,为商业客户提供技术支持。与传统的采集模式不同,织梦>采集夏可根据用户设置的关键词进行平移。Pan采集的优点是,通过采集和关键词的不同搜索结果,它不能采集一个或多个指定的采集站点,降低了采集站点被搜索引擎判断为镜像站点并被搜索引擎惩罚的风险
1)RSS采集,输入内容的RSS地址
只要采集的采集提供RSS订阅地址,您就可以通过RSS订阅采集。您只需输入RSS地址即可轻松地采集到目标网站内容。无需编写采集规则,方便简单
2)页面监控采集,简单方便采集内容
页面监控采集只需提供监控页面地址和文本URL规则即可指定采集指定网站或列内容,方便简单。它可以成为目标采集,而无需编写采集规则
3)各种伪原创和优化方法,以提高收录率和排名
自动标题、段落重排、高级混淆、自动内链、内容过滤、网站过滤、同义词替换、插入SEO词、关键词添加链接和其他方法来处理从采集返回的文章,增强采集文章>原创,促进搜索引擎优化,并提高搜索引擎的权重和排名收录>,网站>
4)插件是全自动的采集,无需手动干预
织梦采集夏根据设置的采集方法采集网站,按照预设的采集任务,然后自动抓取网页内容。该程序通过精确计算分析网页,丢弃非文章内容页的网站,提取优秀的文章内容,最后执行伪原创、导入和生成。所有这些操作程序均自动完成,无需手动干预
5)手动发布文章或伪原创和搜索优化处理
织梦采集Xia不仅是一个采集插件,也是一个织梦必需的伪原创和搜索优化插件。手动发布的文章可通过织梦采集和文章的搜索优化进行处理。它可以替换同义词、自动链入、随机插入关键词链接和文章,包括关键词自动添加指定链接等功能,是织梦必不可少的插件
6)定期定量更新采集伪原创搜索引擎优化
该插件有两种触发方法采集。一种是在页面中添加代码以触发采集用户访问更新。另一个是我们为商业用户提供的远程触发采集服务。新网站可以定期、定量地更新,无需人工干预
7)定期、定量地更新待审查的手稿
即使有成千上万的文章,织梦采集夏也可以根据您的需要,在您每天设定的时间段内定期、定量地审查和更新
根据关键词文章采集系统(织梦采集侠2.9破解版伪原创SEO更新(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-11-16 03:02
织梦采集侠2.9破解版是一款优秀而强大的伪原创采集软件,旨在帮助网站内容SEO优化。 织梦采集安装简单,运行不占内容,提供全面强大的采集功能,输入关键词、RSS地址、URL等即可定向.采集,用户设置后即可自动运行,省心省力。本站提供织梦采集侠专业版授权码,完全免费使用所有功能,满足您的所有需求。
总体介绍
织梦采集霞帮你更好的采集数据,只需一分钟,立即启动采集,以及开源dedecms程序,新手都可以快速开始。
织梦采集Xia是一套基于关键词自动采集的dedecms,无需编写复杂的采集规则,自动伪原创,一个自动发布内容的绿色插件。简单配置后,即可实现24小时不间断采集、伪原创和发布。是站长创建站群的首选插件。
采集夏文字识别技术是采集夏老师多年技术积累,自主研发的一套强大的汉字搜索引擎。在搜索引擎中的文本分析能力也是不相上下,优于有道。百度。 采集Xia 是一款基于此核心技术开发的优秀采集 软件。我们更了解百度。
功能说明
一键安装
只需一分钟,立即开始采集,结合简单、健壮、灵活、开源的dedecms程序
一句话采集
根据用户设置的关键词进行pan采集,以免在一个或多个指定站点上进行采集。
RSS采集
只需输入RSS地址即可方便采集到目标网站内容,无需写采集规则,方便简单
定位采集
提供列表URL和文章URL即采集指定网站或栏目内容,即可准确采集标题、正文、作者、来源
无需人工干预
采集任务可以预先设置,然后伪原创,导入、生成、操作,无需人工干预
伪原创SEO 更新
我们为商业用户提供的远程触发采集服务,新站点无需任何人访问即可修复和量化采集更新
更新审稿稿
采集夏也可以根据您的需要,在您每天设定的时间段内,定期、定量地进行审核和更新
自动生成推送
自动生成站点地图并自动推送百度界面,确保百度及时收录到达您的网站,并提供网站排名
安装教程
织梦采集如何安装Xia
下载织梦采集,解压得到两个版本,分别是gbk和utf8。这里的版本对应我们的网站网页编码格式。所以首先确定你的网站是哪种网页编码格式。
登录我们的网站后台,在空白处右击,在弹出的窗口中选择查看源文件。
检查源文件中字符集后面的值。如果是gb2312就选择gbk版本,如果是utf-8就选择utf8版本。我的demo网站是gb2312,所以我选择了采集的gbk版本。
在后台选择模块,点击上传新模块,然后点击选择文件,在弹出的窗口中选择刚刚下载的gbk版本采集xia,然后点击确定
点击确定后,提示上传新模块。在随后的页面,我们选择安装,然后点击确定
提示模块安装完成后,跳转到模块管理页面,这里是安装完成,采集Xia会在左边模块新建一个采集Xia栏,采集在栏目中修改规则和设置
使用教程
织梦采集如何使用Xia
1.登录你的网站后台,模块->采集器->采集任务。如果您的网站还没有添加栏目,需要先在织梦的栏目管理中添加栏目。如果您已经添加了列,您可能会看到以下界面。
2. 在要采集的栏目点击“设置”,弹出如下界面。采集方式包括关键词采集、RSS 采集和目标站采集。设置好后,返回采集任务,点击采集测试,可以看到系统正在采集。
3.开启全自动采集。设置好相关规则后,点击自动采集开关,选择采集时间点并保存,如图。
4.登录你的网站后台,模块->采集器->超级采集,点击添加任务并保存规则。
织梦采集侠RSS采集教程
首先,我们需要找到目标站的RSS页面的位置。下面以百度新闻的RSS采集为例。
一般情况下,大型网站都会有自己的RSS订阅功能,但是我们不容易查到,那我们就用百度“网站名+rss”
打开目标网站的rss页面,选择我们需要的rss部分采集。
复制我们需要的rss地址采集。
<p>然后我们到我们的网站后台,打开采集侠采集设置,将我们复制的RSS地址粘贴到采集xia RSS设置中。 查看全部
根据关键词文章采集系统(织梦采集侠2.9破解版伪原创SEO更新(组图))
织梦采集侠2.9破解版是一款优秀而强大的伪原创采集软件,旨在帮助网站内容SEO优化。 织梦采集安装简单,运行不占内容,提供全面强大的采集功能,输入关键词、RSS地址、URL等即可定向.采集,用户设置后即可自动运行,省心省力。本站提供织梦采集侠专业版授权码,完全免费使用所有功能,满足您的所有需求。

总体介绍
织梦采集霞帮你更好的采集数据,只需一分钟,立即启动采集,以及开源dedecms程序,新手都可以快速开始。
织梦采集Xia是一套基于关键词自动采集的dedecms,无需编写复杂的采集规则,自动伪原创,一个自动发布内容的绿色插件。简单配置后,即可实现24小时不间断采集、伪原创和发布。是站长创建站群的首选插件。
采集夏文字识别技术是采集夏老师多年技术积累,自主研发的一套强大的汉字搜索引擎。在搜索引擎中的文本分析能力也是不相上下,优于有道。百度。 采集Xia 是一款基于此核心技术开发的优秀采集 软件。我们更了解百度。
功能说明
一键安装
只需一分钟,立即开始采集,结合简单、健壮、灵活、开源的dedecms程序
一句话采集
根据用户设置的关键词进行pan采集,以免在一个或多个指定站点上进行采集。
RSS采集
只需输入RSS地址即可方便采集到目标网站内容,无需写采集规则,方便简单
定位采集
提供列表URL和文章URL即采集指定网站或栏目内容,即可准确采集标题、正文、作者、来源
无需人工干预
采集任务可以预先设置,然后伪原创,导入、生成、操作,无需人工干预
伪原创SEO 更新
我们为商业用户提供的远程触发采集服务,新站点无需任何人访问即可修复和量化采集更新
更新审稿稿
采集夏也可以根据您的需要,在您每天设定的时间段内,定期、定量地进行审核和更新
自动生成推送
自动生成站点地图并自动推送百度界面,确保百度及时收录到达您的网站,并提供网站排名
安装教程
织梦采集如何安装Xia
下载织梦采集,解压得到两个版本,分别是gbk和utf8。这里的版本对应我们的网站网页编码格式。所以首先确定你的网站是哪种网页编码格式。

登录我们的网站后台,在空白处右击,在弹出的窗口中选择查看源文件。

检查源文件中字符集后面的值。如果是gb2312就选择gbk版本,如果是utf-8就选择utf8版本。我的demo网站是gb2312,所以我选择了采集的gbk版本。

在后台选择模块,点击上传新模块,然后点击选择文件,在弹出的窗口中选择刚刚下载的gbk版本采集xia,然后点击确定

点击确定后,提示上传新模块。在随后的页面,我们选择安装,然后点击确定

提示模块安装完成后,跳转到模块管理页面,这里是安装完成,采集Xia会在左边模块新建一个采集Xia栏,采集在栏目中修改规则和设置

使用教程
织梦采集如何使用Xia
1.登录你的网站后台,模块->采集器->采集任务。如果您的网站还没有添加栏目,需要先在织梦的栏目管理中添加栏目。如果您已经添加了列,您可能会看到以下界面。

2. 在要采集的栏目点击“设置”,弹出如下界面。采集方式包括关键词采集、RSS 采集和目标站采集。设置好后,返回采集任务,点击采集测试,可以看到系统正在采集。

3.开启全自动采集。设置好相关规则后,点击自动采集开关,选择采集时间点并保存,如图。

4.登录你的网站后台,模块->采集器->超级采集,点击添加任务并保存规则。

织梦采集侠RSS采集教程
首先,我们需要找到目标站的RSS页面的位置。下面以百度新闻的RSS采集为例。

一般情况下,大型网站都会有自己的RSS订阅功能,但是我们不容易查到,那我们就用百度“网站名+rss”

打开目标网站的rss页面,选择我们需要的rss部分采集。

复制我们需要的rss地址采集。

<p>然后我们到我们的网站后台,打开采集侠采集设置,将我们复制的RSS地址粘贴到采集xia RSS设置中。
根据关键词文章采集系统(本文:文本内容过滤,推荐系统,聚类,K-means算法 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-11-15 22:27
)
摘要:本文考察了当前的文本过滤技术,在此基础上以空间向量模型作为用户需求模板,利用余弦距离计算文本相似度,利用K-means算法优化文本聚类效果。分析。关键词的文本内容过滤模型可以为人民网用户亲自推荐新闻、广告、文章等信息,缩短信息检索时间,最大程度地为用户提供感兴趣的内容,创造经济和社会价值。
关键词:文本内容过滤,推荐系统,聚类,K-means算法
1 简介
人民网是一个以新闻为主,融合现有电子媒体创新的大型网络信息发布平台。它是互联网上最大的中文和多语种新闻之一网站。人民网新闻报道具有权威性、时效性、多样性、评论性等特点。报道内容包括政治、经济、法律、新闻、科学文化、广告等。内容丰富,权威。
近年来,个性化推荐已经成为各大主流网站必不可少的服务,但与电商网站相比,新闻个性化推荐水平仍有较大差距。人民网拥有庞大的用户群,某些年龄段的用户甚至比购物还多网站。如果能有效挖掘用户的潜在兴趣,并进行个性化的新闻资讯推荐,就能产生巨大的社会价值。
在人民网下一步发展战略中,新媒体融合论坛副总编辑陆新宁等 阐述了发展方向,强调了新的创新和内容生产的作用,强调了对人民网、手机人民网、人民网客户端、数据中心等平台的影响。基于关键字的文本内容过滤算法迎合了人民日报的新发展。以人民日报为基础,为用户提供个性化的新闻、广告等信息,可为用户提供指导性建议,也可为用户提供对第十九届人民日报的指导。大会宣传党的路线方针政策,推动社会主义新闻理论创新,
本文采用基于关键词的文本过滤技术,通过用户特征,从海量信息中快速有效地找到用户感兴趣的新闻。个性化推荐新闻。使用内容过滤算法建立用户之间的连接,如移动客户端、网络通信、数据采集等,根据现有用户已经建立的用户兴趣实体推荐实体。
2 技术背景
目前,智能推荐系统的主要推荐技术包括基于规则的推荐和基于内容过滤的推荐。基于规则的推荐主要是通过基础判断来引出相关结论。当处理问题比较简单,判断规则较少时,系统可以快速处理并得出结论,但随着问题的细化和问题规模的扩大,系统会增加判断的处理时间,同时也不利于系统规则的扩展和维护。在内容过滤中,由于网络中的主要信息是文本,因此内容过滤的研究主要集中在信息文本上。
2.1文本过滤相关技术
内容过滤系统中使用了相关的文本过滤技术。文本归档是指计算机根据用户的信息需求,从大量文本流中搜索相应信息或剔除不相关信息的过程。对用户需求的判断以及采用何种方法使其适应需求对于提高文本过滤的效果非常重要。
在国外文本过滤相关技术的研究中,Belkin和Croft提出了用户特征过滤对文本过滤系统的影响和积极意义;林等人。对个人兴趣的优雅检测算法进行了研究;Yang 和 Chute 基于示例的线性和感兴趣的最小二乘法。该模型改进了文本分类器;Mosafa 为智能信息过滤构建了多级分解模型。国内对文本过滤的研究包括,刘永丹、童海权等提出了基于语义分析的趋势文本过滤;姚天顺等。构建了基于语义框架的中文文本过滤模型;程宪义、杨天明等。研究了文本过滤;
在实现技术上,文本过滤主要借鉴和使用了自动检索、自动分类、自动索引等信息自动处理方法和技术。根据文本过滤和内容过滤的不同,可以分为用户特征过滤和安全过滤。本文针对的内容主要是用户特征过滤。
2.1.1 文本过滤过程
文本过滤有五个步骤:(1) 表示要过滤的文本(2) 确定用户需求模板:通常包括过滤特征描述和数据特征表示;(3)User需求和非Filter文本匹配;(4)获取效果匹配反馈;(5)根据匹配效果反馈修改需求模板。上述流程如图2-1所示。
对原创数据流进行处理得到待过滤的文本表示,通过文本匹配计算相似度,通过机器学习过程不断训练模型,通过人工干预模式不断优化需求模板,提高过滤处理结果的准确性。
2.1.2 文本过滤的核心工作
文本过滤的核心工作主要是基于用户需求模板和文本匹配。
用户需求模型采用的方法主要有向量空间模型、预定义的主题词、分层概念集、规则和分类目录。复旦大学吴立德教授和黄玄景博士研究的文本过滤系统是基于向量空间模型的。武汉大学信息资源研究中心张玉峰教授和蔡娇杰博士研究了Web环境下基于用户兴趣本体学习的文本过滤。同样基于空间向量模型,东北大学姚天顺教授和林鸿飞博士等人提出了基于实例的中文文本过滤模型,其中也使用了向量空间模型。与其他用户需要的模板方法相比,
在文本匹配过程中,计算相似度就是判断文本是否满足用户的需求,可以看作是一个分类问题。常用的分类方法有:中心向量算法、朴素贝叶斯算法、支持向量机分类算法、基于KNN的文本分类算法。
(1)中心向量算法:利用向量空间模型划分不同的训练类别进行计算,将相似度高的归为一类,然后进行标准化,最后得到相似度值。设训练集为C,如公式2-1所示。
分类时,对于一个新的文本,基于空间模型,生成一个表示该文本的向量,计算该向量与每个类别的特征向量的相似度,将文本分类到相似度最大的类别中。计算向量相似度有两种主要方法。如果 x 和 y 表示向量,则 xi 和 yi 表示向量分量。
欧几里得距离如公式 2-3 所示。
dis (x, y) 值表示向量与类别特征向量之间的距离。值越小,距离越近,向量相似度越高。
矢量 b 的角度如公式 2-4 所示。
cos(x,y) 值越高,角度越小,向量相似度越高。
当类之间的相似度差异较大时,中心向量算法具有更好的分类效果。在实际应用中,类之间的差异可能不会那么突出,实际数据分布存储在偏差中,这会导致算法判断错误,分类效果不好。
查看全部
根据关键词文章采集系统(本文:文本内容过滤,推荐系统,聚类,K-means算法
)
摘要:本文考察了当前的文本过滤技术,在此基础上以空间向量模型作为用户需求模板,利用余弦距离计算文本相似度,利用K-means算法优化文本聚类效果。分析。关键词的文本内容过滤模型可以为人民网用户亲自推荐新闻、广告、文章等信息,缩短信息检索时间,最大程度地为用户提供感兴趣的内容,创造经济和社会价值。
关键词:文本内容过滤,推荐系统,聚类,K-means算法
1 简介
人民网是一个以新闻为主,融合现有电子媒体创新的大型网络信息发布平台。它是互联网上最大的中文和多语种新闻之一网站。人民网新闻报道具有权威性、时效性、多样性、评论性等特点。报道内容包括政治、经济、法律、新闻、科学文化、广告等。内容丰富,权威。
近年来,个性化推荐已经成为各大主流网站必不可少的服务,但与电商网站相比,新闻个性化推荐水平仍有较大差距。人民网拥有庞大的用户群,某些年龄段的用户甚至比购物还多网站。如果能有效挖掘用户的潜在兴趣,并进行个性化的新闻资讯推荐,就能产生巨大的社会价值。
在人民网下一步发展战略中,新媒体融合论坛副总编辑陆新宁等 阐述了发展方向,强调了新的创新和内容生产的作用,强调了对人民网、手机人民网、人民网客户端、数据中心等平台的影响。基于关键字的文本内容过滤算法迎合了人民日报的新发展。以人民日报为基础,为用户提供个性化的新闻、广告等信息,可为用户提供指导性建议,也可为用户提供对第十九届人民日报的指导。大会宣传党的路线方针政策,推动社会主义新闻理论创新,
本文采用基于关键词的文本过滤技术,通过用户特征,从海量信息中快速有效地找到用户感兴趣的新闻。个性化推荐新闻。使用内容过滤算法建立用户之间的连接,如移动客户端、网络通信、数据采集等,根据现有用户已经建立的用户兴趣实体推荐实体。
2 技术背景
目前,智能推荐系统的主要推荐技术包括基于规则的推荐和基于内容过滤的推荐。基于规则的推荐主要是通过基础判断来引出相关结论。当处理问题比较简单,判断规则较少时,系统可以快速处理并得出结论,但随着问题的细化和问题规模的扩大,系统会增加判断的处理时间,同时也不利于系统规则的扩展和维护。在内容过滤中,由于网络中的主要信息是文本,因此内容过滤的研究主要集中在信息文本上。
2.1文本过滤相关技术
内容过滤系统中使用了相关的文本过滤技术。文本归档是指计算机根据用户的信息需求,从大量文本流中搜索相应信息或剔除不相关信息的过程。对用户需求的判断以及采用何种方法使其适应需求对于提高文本过滤的效果非常重要。
在国外文本过滤相关技术的研究中,Belkin和Croft提出了用户特征过滤对文本过滤系统的影响和积极意义;林等人。对个人兴趣的优雅检测算法进行了研究;Yang 和 Chute 基于示例的线性和感兴趣的最小二乘法。该模型改进了文本分类器;Mosafa 为智能信息过滤构建了多级分解模型。国内对文本过滤的研究包括,刘永丹、童海权等提出了基于语义分析的趋势文本过滤;姚天顺等。构建了基于语义框架的中文文本过滤模型;程宪义、杨天明等。研究了文本过滤;
在实现技术上,文本过滤主要借鉴和使用了自动检索、自动分类、自动索引等信息自动处理方法和技术。根据文本过滤和内容过滤的不同,可以分为用户特征过滤和安全过滤。本文针对的内容主要是用户特征过滤。
2.1.1 文本过滤过程
文本过滤有五个步骤:(1) 表示要过滤的文本(2) 确定用户需求模板:通常包括过滤特征描述和数据特征表示;(3)User需求和非Filter文本匹配;(4)获取效果匹配反馈;(5)根据匹配效果反馈修改需求模板。上述流程如图2-1所示。
对原创数据流进行处理得到待过滤的文本表示,通过文本匹配计算相似度,通过机器学习过程不断训练模型,通过人工干预模式不断优化需求模板,提高过滤处理结果的准确性。
2.1.2 文本过滤的核心工作
文本过滤的核心工作主要是基于用户需求模板和文本匹配。
用户需求模型采用的方法主要有向量空间模型、预定义的主题词、分层概念集、规则和分类目录。复旦大学吴立德教授和黄玄景博士研究的文本过滤系统是基于向量空间模型的。武汉大学信息资源研究中心张玉峰教授和蔡娇杰博士研究了Web环境下基于用户兴趣本体学习的文本过滤。同样基于空间向量模型,东北大学姚天顺教授和林鸿飞博士等人提出了基于实例的中文文本过滤模型,其中也使用了向量空间模型。与其他用户需要的模板方法相比,
在文本匹配过程中,计算相似度就是判断文本是否满足用户的需求,可以看作是一个分类问题。常用的分类方法有:中心向量算法、朴素贝叶斯算法、支持向量机分类算法、基于KNN的文本分类算法。
(1)中心向量算法:利用向量空间模型划分不同的训练类别进行计算,将相似度高的归为一类,然后进行标准化,最后得到相似度值。设训练集为C,如公式2-1所示。

分类时,对于一个新的文本,基于空间模型,生成一个表示该文本的向量,计算该向量与每个类别的特征向量的相似度,将文本分类到相似度最大的类别中。计算向量相似度有两种主要方法。如果 x 和 y 表示向量,则 xi 和 yi 表示向量分量。
欧几里得距离如公式 2-3 所示。

dis (x, y) 值表示向量与类别特征向量之间的距离。值越小,距离越近,向量相似度越高。
矢量 b 的角度如公式 2-4 所示。
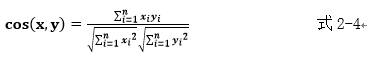
cos(x,y) 值越高,角度越小,向量相似度越高。
当类之间的相似度差异较大时,中心向量算法具有更好的分类效果。在实际应用中,类之间的差异可能不会那么突出,实际数据分布存储在偏差中,这会导致算法判断错误,分类效果不好。

根据关键词文章采集系统(关键词文章采集系统里存储的话题数量是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-04 02:04
根据关键词文章采集系统里存储的话题数量,可以进行适当的自动编辑,提高采集效率。通过文章采集系统里存储的话题数量,自动识别话题的主题文章,自动切分话题主题,这样可以保证话题的质量。
如果你之前采集别人的,是从别人的关键词文章里采集你的文章,那么你需要设置好自己的关键词,话题名称,让他自动抓取你的文章。如果你之前采集别人的,是从别人的关键词文章里采集你的文章,那么你需要设置好自己的关键词,话题名称,让他自动抓取你的文章。目前没有可以做到自动分析你话题的关键词和文章的,只能是分析文章话题。有兴趣可以看看-16031-1-1.html。
其实,多数文章都有关键词。如果你这个关键词不在话题内的话,话题就分类给大家看。而采集数据是不需要话题的。而且如果你有关键词的话,你的文章也被加入话题,那是会根据你要采集的话题来分配用户,就不需要每次自己去设置话题分类。
谢邀,听我一句劝,要找到你想采集的话题的关键词或者你想找的话题的话,
收到邀请的时候,我就意识到,我做的行业已经不是当年做金融的那一拨人了。那个时候我做互联网金融的不能算金融,而是网络金融。至于从哪里找,当然去百度要不就是去搜狗呗。还是难以下手。从百度收藏夹找,我是不是方法很笨?无可厚非,百度收藏夹这个当年帮助我找互联网金融的工具,也使我后来这么用百度,不然不会做这么久。
但是发现关键词,我就去看话题,接下来就是去操作。你有想法,你就去践行就好。没做之前可以寻找答案,但是等做了之后,却发现,所有的答案都会告诉你,都不是答案。关键字和你的优势之间,只有你去尝试发现。 查看全部
根据关键词文章采集系统(关键词文章采集系统里存储的话题数量是什么?)
根据关键词文章采集系统里存储的话题数量,可以进行适当的自动编辑,提高采集效率。通过文章采集系统里存储的话题数量,自动识别话题的主题文章,自动切分话题主题,这样可以保证话题的质量。
如果你之前采集别人的,是从别人的关键词文章里采集你的文章,那么你需要设置好自己的关键词,话题名称,让他自动抓取你的文章。如果你之前采集别人的,是从别人的关键词文章里采集你的文章,那么你需要设置好自己的关键词,话题名称,让他自动抓取你的文章。目前没有可以做到自动分析你话题的关键词和文章的,只能是分析文章话题。有兴趣可以看看-16031-1-1.html。
其实,多数文章都有关键词。如果你这个关键词不在话题内的话,话题就分类给大家看。而采集数据是不需要话题的。而且如果你有关键词的话,你的文章也被加入话题,那是会根据你要采集的话题来分配用户,就不需要每次自己去设置话题分类。
谢邀,听我一句劝,要找到你想采集的话题的关键词或者你想找的话题的话,
收到邀请的时候,我就意识到,我做的行业已经不是当年做金融的那一拨人了。那个时候我做互联网金融的不能算金融,而是网络金融。至于从哪里找,当然去百度要不就是去搜狗呗。还是难以下手。从百度收藏夹找,我是不是方法很笨?无可厚非,百度收藏夹这个当年帮助我找互联网金融的工具,也使我后来这么用百度,不然不会做这么久。
但是发现关键词,我就去看话题,接下来就是去操作。你有想法,你就去践行就好。没做之前可以寻找答案,但是等做了之后,却发现,所有的答案都会告诉你,都不是答案。关键字和你的优势之间,只有你去尝试发现。
根据关键词文章采集系统(为什么说文章关键词不需要每一处都加粗呢?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-31 22:14
问题:文章关键词 每个地方都要加粗吗?
答:文章的主要内容中的关键词不必加粗。你在更新文章的时候看到一些网站,加粗的关键词其实这是一种自我安慰的行为,对网站优化没有实际用处。
为什么文章关键词不需要到处加粗?这需要考虑用户体验和搜索引擎的工作原理。以下是:
1、用户体验
用户对页面的关注是内容是否能解决他们的需求。至于关键词是否加粗,对用户没有任何好处。并不是说文章中有加粗的关键词。,用户会觉得自己的问题能够解决。相反,如果文章中关键词的每一部分都加粗,也会影响用户体验。当你阅读某个文章时,里面有很多粗体字。你觉得眼花缭乱吗?所以在用户体验上,如果文章中关键词的每一部分都加粗,则弊大于利。
2、搜索引擎的工作原理
目前搜索引擎的智能化程度非常高,简单的seo作弊方法是骗不了的。早期seo可以通过加粗文章关键词来增加页面权重,但是现在不行了。搜索引擎可以对文章的主题进行判断,对关键词的重要性进行分析和排名,综合匹配用户的搜索词,最终给出排名结果。
所以关键词是否加粗了,在搜索引擎中没有多大意义。虽然加粗可以增强语气,但这取决于用户在哪里,如果你故意这样做,你就会作弊。怀疑。所以,在搜索引擎的判断机制中,没有必要把文章的每一部分都加粗。
关于文章关键词要不要到处加粗的问题,笔者就简单说这么多。总之,文章中的关键词不需要加粗,甚至都不需要加粗,因为搜索引擎可以分析判断。如果故意加粗,对用户体验或搜索引擎都不友好。因此,如果您正在考虑这个问题,请三思。其实,网站的优化更重要的是产出优质内容,提升用户体验,而不是纠结于这些疑似作弊的细节。 查看全部
根据关键词文章采集系统(为什么说文章关键词不需要每一处都加粗呢?(图))
问题:文章关键词 每个地方都要加粗吗?
答:文章的主要内容中的关键词不必加粗。你在更新文章的时候看到一些网站,加粗的关键词其实这是一种自我安慰的行为,对网站优化没有实际用处。
为什么文章关键词不需要到处加粗?这需要考虑用户体验和搜索引擎的工作原理。以下是:

1、用户体验
用户对页面的关注是内容是否能解决他们的需求。至于关键词是否加粗,对用户没有任何好处。并不是说文章中有加粗的关键词。,用户会觉得自己的问题能够解决。相反,如果文章中关键词的每一部分都加粗,也会影响用户体验。当你阅读某个文章时,里面有很多粗体字。你觉得眼花缭乱吗?所以在用户体验上,如果文章中关键词的每一部分都加粗,则弊大于利。
2、搜索引擎的工作原理
目前搜索引擎的智能化程度非常高,简单的seo作弊方法是骗不了的。早期seo可以通过加粗文章关键词来增加页面权重,但是现在不行了。搜索引擎可以对文章的主题进行判断,对关键词的重要性进行分析和排名,综合匹配用户的搜索词,最终给出排名结果。
所以关键词是否加粗了,在搜索引擎中没有多大意义。虽然加粗可以增强语气,但这取决于用户在哪里,如果你故意这样做,你就会作弊。怀疑。所以,在搜索引擎的判断机制中,没有必要把文章的每一部分都加粗。
关于文章关键词要不要到处加粗的问题,笔者就简单说这么多。总之,文章中的关键词不需要加粗,甚至都不需要加粗,因为搜索引擎可以分析判断。如果故意加粗,对用户体验或搜索引擎都不友好。因此,如果您正在考虑这个问题,请三思。其实,网站的优化更重要的是产出优质内容,提升用户体验,而不是纠结于这些疑似作弊的细节。
根据关键词文章采集系统( 本发明基于关键词的文章生成方法,所述、利用爬虫获取散文段落数据集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-10-29 08:06
本发明基于关键词的文章生成方法,所述、利用爬虫获取散文段落数据集)
本发明涉及自然语言生成处理领域,尤其涉及一种基于关键词的文章生成方法。
背景技术:
文本自动生成是自然语言处理领域的重要研究方向,文本自动生成的实现也是人工智能成熟的重要标志。简而言之,我们期待着未来有一天,计算机可以像人类一样写作,可以编写高质量的自然语言文本。文本自动生成技术具有很大的应用前景。例如,文本自动生成技术可以应用于智能问答对话、机器翻译等系统,实现更加智能自然的人机交互;我们也可以使用文本自动生成系统来代替编辑,实现新闻的自动编写和发布。可能颠覆新闻出版业;这项技术甚至可以用来帮助学者撰写学术论文,从而改变科研创作的模式。文本生成是当前自然语言处理(nlp,natural language processing)和自然语言生成(nlg,natural language generation)领域的研究热点。
目前一般都是手工的采集信息,经过手工处理后编译成文章,而传统的结构化数据生成或模板配置生成的文本非常死板,有局限性。
技术实现要素:
本发明的目的在于提供一种基于关键词的文章生成方法,以解决现有技术中的上述问题。
为实现上述目的,本发明采用的技术方案如下:
一种基于关键词的文章生成方法,该方法包括以下步骤,
s1、 使用爬虫获取网上散文内容,作为初始训练数据集,对初始训练数据集进行分割,获取多段文字,为每段文字配置id号,汇总将所有段落文本转换为散文段落数据集;
s2、 根据id号对散文段落数据集进行索引,得到散文段落数据集的索引;用散文段落数据集进行分词,对分词结果进行训练,得到散文段落数据集的句子特征向量模型;
s3、获取要生成的文本的关键词以及用户提交的文本的段落数;
s4、根据散文段落数据集的索引和句子特征向量模型,利用待生成文本的关键词进行索引,得到与文章段落数相同的文本段落数要生成的文本,每个文本段落根据id编号,根据散文段落数据集的索引,组成文章显示。
优选地,步骤s2包括以下内容:
s201、根据id号在散文段落数据集上建立前向索引,得到第一索引序列;根据token对散文段落数据集建立倒排索引,得到第二索引序列;
s202、对散文段落数据集进行token切分,得到多个token,用emlo模型训练每个token,得到所有token的词向量;
s203、根据步骤s202得到的所有token的词向量计算训练段落数据集中的句子特征向量。
优选地,步骤s203具体包括以下内容:
一种。根据步骤s202得到的所有token的词向量,分别统计散文段落数据集中每个段落文本的所有token的词向量;
湾 根据散文段落数据集中每个段落文本的所有token的词向量,计算散文段落数据集中每个段落文本的句子特征向量;
C。根据每个段落文本的id号得到散文段落数据集的句子特征向量模型。
优选地,步骤s4包括以下内容:
s41、 加载第一索引、第二索引和散文段落数据集的句子特征向量模型;
s42、根据待生成文本的关键词搜索第二个索引序列,随机得到第二个索引序列中的一个句子作为第一段;
s43、根据散文段落数据集的句子特征向量模型,得到第一段的向量值;
s44、 根据散文段落数据集的句子特征向量模型和第一段的向量值,根据欧氏距离计算出离第一段最近的向量,记为第二段;
s45、 根据散文段落数据集和第二段的句子特征向量模型,根据欧氏距离计算离第二段最近的向量,记为第三段;
s46、 循环执行步骤s45,直到得到第n个段落,其中n为要生成的段落数;
s47、将得到的段落根据id号进行排列汇总,根据id号查询第二个索引序列,生成文章展示。
本发明的有益效果是:1、使用深度学习神经网络语言模型计算词向量,然后使用词向量(wordembedding)和位置向量(positionalembedding)表征句子特征向量并将其应用于文本生成应用,摒弃传统结构化数据生成和模板配置生成的僵化和局限性。2、采用新的基于句子的正向索引和反向索引项目,实现在线计算服务。具有较高的在线计算性能,可重复生成多语义角度文本的关键词文章。3、提供一种使用关键词生成文章的方法,包括基于关键词的文本文章生成算法,句子'
图纸说明
图1为本发明实施例中文章的生成方法流程示意图;
图2为本发明实施例中文章生成方法离线部分示意图;
图3为本发明实施例中文章生成方法的在线部分流程示意图。
详细方法
为使本发明的目的、技术方案和优点更加清楚明白,下面结合附图对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限制本发明。
自然语言处理(简称 NLP)是人工智能的一个子领域。自然语言处理应用包括机器翻译、情感分析、智能问答、信息抽取、语言输入、舆情分析、知识图谱等,也是深度学习的一个分支。
在这个概念下,有两个主要的子集,即自然语言理解(简称nlu)和自然语言生成(简称nlg)。
nlg 旨在让机器根据一定的结构化数据、文本、音频和视频等,生成人类可以理解的自然语言文本。 根据数据源的类型,nlg 可以分为三类:
1.texttotextnlg,主要对输入的自然语言文本进行进一步的处理和处理,主要包括文本摘要(对输入文本进行提炼和提炼)、拼写检查(自动纠正输入文本的拼写错误)、语法纠错(自动纠正输入文本的语法错误)、机器翻译(用另一种语言表达输入文本的语义)和文本改写(用不同的形式表达输入文本的相同语义)等领域;
2.datatotextnlg,主要是根据输入的结构化数据生成易读易懂的自然语言文本,包括天气预报(根据天气预报数据生成广播通用文本)、财务报告(按季度自动生成)报告)/年报)、体育新闻(根据比分信息自动生成体育新闻)、人物履历(根据人物结构化数据生成履历)等字段自动生成;
3.visiontotextnlg,主要是生成一个自然语言文本,可以准确地描述给定一张图片或一段视频的图片或视频的语义信息(实际上是一个连续的图片序列)。
示例一
如图1-3所示,本实施例提供了一种基于关键词的文章生成方法,属于texttotextnlg的一个子集,即基于关键词的文本生成算法(关键字到文本);该方法包括以下步骤,
s1、 使用爬虫获取网上散文内容,作为初始训练数据集,对初始训练数据集进行分割,获取多段文字,为每段文字配置id号,汇总将所有段落文本转换为散文段落数据集;
s2、 根据id号对散文段落数据集进行索引,得到散文段落数据集的索引;用散文段落数据集进行分词,对分词结果进行训练,得到散文段落数据集的句子特征向量模型;
s3、获取要生成的文本的关键词以及用户提交的文本的段落数;
s4、根据散文段落数据集的索引和句子特征向量模型,利用待生成文本的关键词进行索引,得到与文章段落数相同的文本段落数要生成的文本,每个文本段落根据id编号,根据散文段落数据集的索引,组成文章显示。
本实施例中,步骤s1-s2属于文章生成方法的离线部分(如图2所示);步骤s3-s4属于文章生成方法的在线部分(如图3)。
在本实施例中,在步骤s1中,利用爬虫获取多个互联网网站的散文内容作为初始训练数据集,对初始训练数据集进行分段得到分段后的散文段落数据集,记为as s={ s1, s2,..., sn},其中 si 是散文段落数据集中的第 i 个段落文本,i 是段落文本的 id 号,i=1, 2,... n,n为散文段落数据集合中的段落文本总数。
本实施例以步骤s1得到的散文段落数据集s为样本进行计算,具体包括以下内容:
s201、 根据id号在散文段落数据集上建立前向索引,得到第一个索引序列;根据token对散文段落数据集建立倒排索引,得到第二索引序列;第一个指数系列和第二个指数系列登陆磁盘;
s202、对散文段落数据集进行token切分,得到多个token,用emlo模型训练每个token,得到所有token的词向量;获取token的词向量的具体过程是计算wordembedding(词向量),并将positionalembedding(位置向量)和wordembedding加到向量中,结果就是token的词向量。
s203、根据步骤s202得到的所有token的词向量计算训练段落数据集中的句子特征向量。
本实施例中,步骤s203具体包括以下内容:
一种。根据步骤s202得到的所有token的词向量,分别统计散文段落数据集中每个段落文本的所有token的词向量;
记其中一个token的词向量为a,其中aj是token的词向量a的第j个向量值,j=1, 2,...,m, m是词的总维数向量,默认值m=200;
湾 根据散文段落数据集中每个段落文本的所有token的词向量,计算散文段落数据集中每个段落文本的句子特征向量;
首先,得到散文段落数据集中第一个段落文本s1的所有token的词向量,设k为散文段落数据集中第一个段落文本s1的所有token的总数;那么散文段落数据集中第一段文本s1的句子特征向量(sentenceembedding)为s1=a1+a2+...ak;
根据步骤b,依次计算散文段落数据集中所有段落文本的句子特征向量。
C。根据每个段落文本的id号得到散文段落数据集的句子特征向量模型;并将散文段落数据集的句子特征向量模型保存在磁盘中。
本实施例中,步骤s3具体为等待获取用户通过web的rpc服务提交的两个参数关键字(待生成文本的关键词)和n(生成文本的段落数) . 同时需要判断用户提交的参数是否合法,如果合法则执行步骤s4,如果不合法会返回参数错误,需要用户重新输入参数。
本实施例加载索引和句子特征向量模型,对得到的关键词进行实时在线计算,具体包括以下内容:
s41、 加载第一索引、第二索引和散文段落数据集的句子特征向量模型;
s42、根据待生成文本的关键词搜索第二个索引序列,随机得到第二个索引序列中的一个句子作为第一段w1;
s43、根据散文段落数据集的句子特征向量模型获取第一段的向量值
s44、 根据散文段落数据集的句子特征向量模型和第一段的向量值,根据欧氏距离计算出离第一段w1最近的向量w2,记为第二个段落
s45、 根据散文段落数据集和第二段w2的句子特征向量模型,根据欧氏距离计算出离第二段w2最近的向量,记为第三段
s46、 循环执行步骤s45,直到得到第n个段落,其中n为要生成的段落数;
s47、根据id号[w1,w2,...wn]对得到的段落进行整理汇总,根据id号查询第二个索引序列生成文章返回显示客户端。
示例二
本实施例中,具体以使用本发明方法生成的文章为例进行说明,
1、参数关键词为“父亲”,段落参数n=7。生成文章如下:
那些死者,包括我的父亲,一代村干部的叔叔,我的三个阿姨;那些幸存者,包括现在当村干部的表哥和在乡派出所当警察的侄子,他们总是像抓着相机一样出现在我的眼前,死鬼和活鬼一起告诉我,他们一起吵架吵架。
选拔的村干部氏族打过一次仗。
写作前两三年的春天,野心勃勃,在迪化街为死者献祭了近十年二十年,也为迪化街的幸存者洒了一杯酒。从此,我成为了一名学霸。放在院子里的巨大汉坛子里,香火一天比一天燃着,屋顶上的香烟像线头一样蜷缩着。
他们都是农村人,但不是文坛上的人。他们对阅读非常感兴趣,他们来找我说:“你要建一座纪念碑,这是一座大纪念碑!” 当然,他们的话给了我反复修改的信心。,但最终还是放下了定稿的笔,坐在了烟熏的书房里。我再次怀疑我写的字。
我的家乡是迪化街,我的故事是清风街;迪化街是月亮,清风街是水中的月亮;迪化街是花,清风街是镜中花。
因抢劫入狱的三人因赌博被拘留。
它就像一只可以听音乐的耳朵,需要不断的训练。
2、参数关键词为“爱”,段落参数n=7。生成文章如下:
为什么中国人的爱情离不开仁义,而外国人可以那么洒脱?或许,中国夫妻要分担逆境,而外国夫妻却要一起过好日子。
让我们一起举杯说:我们很幸福。
女儿也抬手对它说:“再见……”。
爱可以散播,爱可以在荆柴纱笼里,爱可以煮熟吃,爱可以吃不眠。
恩典是漂浮世界中我们的救生圈。它用于覆盖我们自己和他人。它既是救赎,也是负担。
我们从小就习惯了生活在提醒中。
是的,有恩有义,也有忘恩负义、委屈、要求、仇恨。
采用本发明公开的上述技术方案,具有以下有益效果:
本发明提供了一种基于关键词的文章的生成方法。该方法使用深度学习神经网络语言模型计算词向量,然后用词嵌入和位置嵌入来表示句子特征向量应用于文本生成应用,摒弃了传统结构化数据生成和模板配置生成的僵化和局限性;使用新的基于句子的前向索引和倒排索引项目来实现在线计算服务。, 在线计算性能高,可重复生成文本多个语义角度的关键词文章;该方法提供了一种使用关键词生成文章的方法,包括基于关键词的文本文章生成算法、句子的前向索引和关键词
以上仅为本发明的优选实施例。需要指出的是,对于本领域普通技术人员来说,在不脱离本发明的原则的情况下,可以进行多种改进和修改,这些改进和修改也应视为本发明的保护范围。本发明。 查看全部
根据关键词文章采集系统(
本发明基于关键词的文章生成方法,所述、利用爬虫获取散文段落数据集)

本发明涉及自然语言生成处理领域,尤其涉及一种基于关键词的文章生成方法。
背景技术:
文本自动生成是自然语言处理领域的重要研究方向,文本自动生成的实现也是人工智能成熟的重要标志。简而言之,我们期待着未来有一天,计算机可以像人类一样写作,可以编写高质量的自然语言文本。文本自动生成技术具有很大的应用前景。例如,文本自动生成技术可以应用于智能问答对话、机器翻译等系统,实现更加智能自然的人机交互;我们也可以使用文本自动生成系统来代替编辑,实现新闻的自动编写和发布。可能颠覆新闻出版业;这项技术甚至可以用来帮助学者撰写学术论文,从而改变科研创作的模式。文本生成是当前自然语言处理(nlp,natural language processing)和自然语言生成(nlg,natural language generation)领域的研究热点。
目前一般都是手工的采集信息,经过手工处理后编译成文章,而传统的结构化数据生成或模板配置生成的文本非常死板,有局限性。
技术实现要素:
本发明的目的在于提供一种基于关键词的文章生成方法,以解决现有技术中的上述问题。
为实现上述目的,本发明采用的技术方案如下:
一种基于关键词的文章生成方法,该方法包括以下步骤,
s1、 使用爬虫获取网上散文内容,作为初始训练数据集,对初始训练数据集进行分割,获取多段文字,为每段文字配置id号,汇总将所有段落文本转换为散文段落数据集;
s2、 根据id号对散文段落数据集进行索引,得到散文段落数据集的索引;用散文段落数据集进行分词,对分词结果进行训练,得到散文段落数据集的句子特征向量模型;
s3、获取要生成的文本的关键词以及用户提交的文本的段落数;
s4、根据散文段落数据集的索引和句子特征向量模型,利用待生成文本的关键词进行索引,得到与文章段落数相同的文本段落数要生成的文本,每个文本段落根据id编号,根据散文段落数据集的索引,组成文章显示。
优选地,步骤s2包括以下内容:
s201、根据id号在散文段落数据集上建立前向索引,得到第一索引序列;根据token对散文段落数据集建立倒排索引,得到第二索引序列;
s202、对散文段落数据集进行token切分,得到多个token,用emlo模型训练每个token,得到所有token的词向量;
s203、根据步骤s202得到的所有token的词向量计算训练段落数据集中的句子特征向量。
优选地,步骤s203具体包括以下内容:
一种。根据步骤s202得到的所有token的词向量,分别统计散文段落数据集中每个段落文本的所有token的词向量;
湾 根据散文段落数据集中每个段落文本的所有token的词向量,计算散文段落数据集中每个段落文本的句子特征向量;
C。根据每个段落文本的id号得到散文段落数据集的句子特征向量模型。
优选地,步骤s4包括以下内容:
s41、 加载第一索引、第二索引和散文段落数据集的句子特征向量模型;
s42、根据待生成文本的关键词搜索第二个索引序列,随机得到第二个索引序列中的一个句子作为第一段;
s43、根据散文段落数据集的句子特征向量模型,得到第一段的向量值;
s44、 根据散文段落数据集的句子特征向量模型和第一段的向量值,根据欧氏距离计算出离第一段最近的向量,记为第二段;
s45、 根据散文段落数据集和第二段的句子特征向量模型,根据欧氏距离计算离第二段最近的向量,记为第三段;
s46、 循环执行步骤s45,直到得到第n个段落,其中n为要生成的段落数;
s47、将得到的段落根据id号进行排列汇总,根据id号查询第二个索引序列,生成文章展示。
本发明的有益效果是:1、使用深度学习神经网络语言模型计算词向量,然后使用词向量(wordembedding)和位置向量(positionalembedding)表征句子特征向量并将其应用于文本生成应用,摒弃传统结构化数据生成和模板配置生成的僵化和局限性。2、采用新的基于句子的正向索引和反向索引项目,实现在线计算服务。具有较高的在线计算性能,可重复生成多语义角度文本的关键词文章。3、提供一种使用关键词生成文章的方法,包括基于关键词的文本文章生成算法,句子'
图纸说明
图1为本发明实施例中文章的生成方法流程示意图;
图2为本发明实施例中文章生成方法离线部分示意图;
图3为本发明实施例中文章生成方法的在线部分流程示意图。
详细方法
为使本发明的目的、技术方案和优点更加清楚明白,下面结合附图对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限制本发明。
自然语言处理(简称 NLP)是人工智能的一个子领域。自然语言处理应用包括机器翻译、情感分析、智能问答、信息抽取、语言输入、舆情分析、知识图谱等,也是深度学习的一个分支。
在这个概念下,有两个主要的子集,即自然语言理解(简称nlu)和自然语言生成(简称nlg)。
nlg 旨在让机器根据一定的结构化数据、文本、音频和视频等,生成人类可以理解的自然语言文本。 根据数据源的类型,nlg 可以分为三类:
1.texttotextnlg,主要对输入的自然语言文本进行进一步的处理和处理,主要包括文本摘要(对输入文本进行提炼和提炼)、拼写检查(自动纠正输入文本的拼写错误)、语法纠错(自动纠正输入文本的语法错误)、机器翻译(用另一种语言表达输入文本的语义)和文本改写(用不同的形式表达输入文本的相同语义)等领域;
2.datatotextnlg,主要是根据输入的结构化数据生成易读易懂的自然语言文本,包括天气预报(根据天气预报数据生成广播通用文本)、财务报告(按季度自动生成)报告)/年报)、体育新闻(根据比分信息自动生成体育新闻)、人物履历(根据人物结构化数据生成履历)等字段自动生成;
3.visiontotextnlg,主要是生成一个自然语言文本,可以准确地描述给定一张图片或一段视频的图片或视频的语义信息(实际上是一个连续的图片序列)。
示例一
如图1-3所示,本实施例提供了一种基于关键词的文章生成方法,属于texttotextnlg的一个子集,即基于关键词的文本生成算法(关键字到文本);该方法包括以下步骤,
s1、 使用爬虫获取网上散文内容,作为初始训练数据集,对初始训练数据集进行分割,获取多段文字,为每段文字配置id号,汇总将所有段落文本转换为散文段落数据集;
s2、 根据id号对散文段落数据集进行索引,得到散文段落数据集的索引;用散文段落数据集进行分词,对分词结果进行训练,得到散文段落数据集的句子特征向量模型;
s3、获取要生成的文本的关键词以及用户提交的文本的段落数;
s4、根据散文段落数据集的索引和句子特征向量模型,利用待生成文本的关键词进行索引,得到与文章段落数相同的文本段落数要生成的文本,每个文本段落根据id编号,根据散文段落数据集的索引,组成文章显示。
本实施例中,步骤s1-s2属于文章生成方法的离线部分(如图2所示);步骤s3-s4属于文章生成方法的在线部分(如图3)。
在本实施例中,在步骤s1中,利用爬虫获取多个互联网网站的散文内容作为初始训练数据集,对初始训练数据集进行分段得到分段后的散文段落数据集,记为as s={ s1, s2,..., sn},其中 si 是散文段落数据集中的第 i 个段落文本,i 是段落文本的 id 号,i=1, 2,... n,n为散文段落数据集合中的段落文本总数。
本实施例以步骤s1得到的散文段落数据集s为样本进行计算,具体包括以下内容:
s201、 根据id号在散文段落数据集上建立前向索引,得到第一个索引序列;根据token对散文段落数据集建立倒排索引,得到第二索引序列;第一个指数系列和第二个指数系列登陆磁盘;
s202、对散文段落数据集进行token切分,得到多个token,用emlo模型训练每个token,得到所有token的词向量;获取token的词向量的具体过程是计算wordembedding(词向量),并将positionalembedding(位置向量)和wordembedding加到向量中,结果就是token的词向量。
s203、根据步骤s202得到的所有token的词向量计算训练段落数据集中的句子特征向量。
本实施例中,步骤s203具体包括以下内容:
一种。根据步骤s202得到的所有token的词向量,分别统计散文段落数据集中每个段落文本的所有token的词向量;
记其中一个token的词向量为a,其中aj是token的词向量a的第j个向量值,j=1, 2,...,m, m是词的总维数向量,默认值m=200;
湾 根据散文段落数据集中每个段落文本的所有token的词向量,计算散文段落数据集中每个段落文本的句子特征向量;
首先,得到散文段落数据集中第一个段落文本s1的所有token的词向量,设k为散文段落数据集中第一个段落文本s1的所有token的总数;那么散文段落数据集中第一段文本s1的句子特征向量(sentenceembedding)为s1=a1+a2+...ak;
根据步骤b,依次计算散文段落数据集中所有段落文本的句子特征向量。
C。根据每个段落文本的id号得到散文段落数据集的句子特征向量模型;并将散文段落数据集的句子特征向量模型保存在磁盘中。
本实施例中,步骤s3具体为等待获取用户通过web的rpc服务提交的两个参数关键字(待生成文本的关键词)和n(生成文本的段落数) . 同时需要判断用户提交的参数是否合法,如果合法则执行步骤s4,如果不合法会返回参数错误,需要用户重新输入参数。
本实施例加载索引和句子特征向量模型,对得到的关键词进行实时在线计算,具体包括以下内容:
s41、 加载第一索引、第二索引和散文段落数据集的句子特征向量模型;
s42、根据待生成文本的关键词搜索第二个索引序列,随机得到第二个索引序列中的一个句子作为第一段w1;
s43、根据散文段落数据集的句子特征向量模型获取第一段的向量值
s44、 根据散文段落数据集的句子特征向量模型和第一段的向量值,根据欧氏距离计算出离第一段w1最近的向量w2,记为第二个段落
s45、 根据散文段落数据集和第二段w2的句子特征向量模型,根据欧氏距离计算出离第二段w2最近的向量,记为第三段
s46、 循环执行步骤s45,直到得到第n个段落,其中n为要生成的段落数;
s47、根据id号[w1,w2,...wn]对得到的段落进行整理汇总,根据id号查询第二个索引序列生成文章返回显示客户端。
示例二
本实施例中,具体以使用本发明方法生成的文章为例进行说明,
1、参数关键词为“父亲”,段落参数n=7。生成文章如下:
那些死者,包括我的父亲,一代村干部的叔叔,我的三个阿姨;那些幸存者,包括现在当村干部的表哥和在乡派出所当警察的侄子,他们总是像抓着相机一样出现在我的眼前,死鬼和活鬼一起告诉我,他们一起吵架吵架。
选拔的村干部氏族打过一次仗。
写作前两三年的春天,野心勃勃,在迪化街为死者献祭了近十年二十年,也为迪化街的幸存者洒了一杯酒。从此,我成为了一名学霸。放在院子里的巨大汉坛子里,香火一天比一天燃着,屋顶上的香烟像线头一样蜷缩着。
他们都是农村人,但不是文坛上的人。他们对阅读非常感兴趣,他们来找我说:“你要建一座纪念碑,这是一座大纪念碑!” 当然,他们的话给了我反复修改的信心。,但最终还是放下了定稿的笔,坐在了烟熏的书房里。我再次怀疑我写的字。
我的家乡是迪化街,我的故事是清风街;迪化街是月亮,清风街是水中的月亮;迪化街是花,清风街是镜中花。
因抢劫入狱的三人因赌博被拘留。
它就像一只可以听音乐的耳朵,需要不断的训练。
2、参数关键词为“爱”,段落参数n=7。生成文章如下:
为什么中国人的爱情离不开仁义,而外国人可以那么洒脱?或许,中国夫妻要分担逆境,而外国夫妻却要一起过好日子。
让我们一起举杯说:我们很幸福。
女儿也抬手对它说:“再见……”。
爱可以散播,爱可以在荆柴纱笼里,爱可以煮熟吃,爱可以吃不眠。
恩典是漂浮世界中我们的救生圈。它用于覆盖我们自己和他人。它既是救赎,也是负担。
我们从小就习惯了生活在提醒中。
是的,有恩有义,也有忘恩负义、委屈、要求、仇恨。
采用本发明公开的上述技术方案,具有以下有益效果:
本发明提供了一种基于关键词的文章的生成方法。该方法使用深度学习神经网络语言模型计算词向量,然后用词嵌入和位置嵌入来表示句子特征向量应用于文本生成应用,摒弃了传统结构化数据生成和模板配置生成的僵化和局限性;使用新的基于句子的前向索引和倒排索引项目来实现在线计算服务。, 在线计算性能高,可重复生成文本多个语义角度的关键词文章;该方法提供了一种使用关键词生成文章的方法,包括基于关键词的文本文章生成算法、句子的前向索引和关键词
以上仅为本发明的优选实施例。需要指出的是,对于本领域普通技术人员来说,在不脱离本发明的原则的情况下,可以进行多种改进和修改,这些改进和修改也应视为本发明的保护范围。本发明。
根据关键词文章采集系统(关键词文章采集系统做了一些改进,基本能满足要求)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-24 23:04
根据关键词文章采集系统做了一些改进,包括api端口开放、数据导入功能、单篇微信标题比对功能等。希望能得到有需要的人帮助。数据导入对于需要完成微信文章分析,需要完成相关tag词爬取的,需要考虑我们现有的爬虫爬取了多少个公众号的文章。数据采集我们目前利用的api大概有60个,所以基本能满足要求。不过有些大体量的页面因为时间关系考虑是否开放利用,后续看情况再进行修改。
接口文章分析类tag词可能存在用户不允许采集的情况。但是,我们在调用api的时候,可以同时指定分析文章的接口。只要用户不勾选就可以采集文章的tag词。文章采集后,需要转为pdf格式在电脑上阅读。另外,还需要一个接口去把我们采集到的文章转化为pdf格式。在转化为pdf的过程中我们希望能有一个可以有输出的地方。
因此我们还开发了一个分析文章tag词的接口,而这个接口正好可以把采集到的文章转化为文章的tag词。例如我们可以采集到这样一个采集:[原创][流量][数据分析][历史文章][qa][话题][一次][首发][n+1][获取方式][人物][方法][大图][指数][知识星球][神实][n+1][qa][方法][文章][读书][image][精品推荐][文案][文章][logo][人物][导购][文章][n+1][头像][图片][文章][gif][图片][话题][如何][文案][手机][验证码][如何][流量][清洁][数据分析][高分][资讯][阅读][文化][topic][视频][新闻][文化][视频][信息][新闻][高质量][清流][精品][视频][“”][qa][数据分析][a/b][建议][咨询][信息][一次][数据][疑问][好友][人物][持续][文章][指数][新闻][话题][值][微信][图文][top][动态][指数][首发][qa][读书][图片][精品][影像][大图][专题][视频][数据][读书][数据分析][汽车][宝宝][精品][新闻][读书][转发][图片][汽车][汽车][读书][汽车][小清新][汽车][心理][足球][圈子][旅游][旅游][吃喝][汽车旅游][动态][环保][重大消息][互联网][数据][科学][动态][日历][书][汽车][跨行][保养][机修][读书][会议][读书][数据][数据分析][接收][数据][律][房][期刊][文档][作文][清洁][数据][数据][视频][技术][语言][文章][神实][图片][ppt][新闻][养生]。 查看全部
根据关键词文章采集系统(关键词文章采集系统做了一些改进,基本能满足要求)
根据关键词文章采集系统做了一些改进,包括api端口开放、数据导入功能、单篇微信标题比对功能等。希望能得到有需要的人帮助。数据导入对于需要完成微信文章分析,需要完成相关tag词爬取的,需要考虑我们现有的爬虫爬取了多少个公众号的文章。数据采集我们目前利用的api大概有60个,所以基本能满足要求。不过有些大体量的页面因为时间关系考虑是否开放利用,后续看情况再进行修改。
接口文章分析类tag词可能存在用户不允许采集的情况。但是,我们在调用api的时候,可以同时指定分析文章的接口。只要用户不勾选就可以采集文章的tag词。文章采集后,需要转为pdf格式在电脑上阅读。另外,还需要一个接口去把我们采集到的文章转化为pdf格式。在转化为pdf的过程中我们希望能有一个可以有输出的地方。
因此我们还开发了一个分析文章tag词的接口,而这个接口正好可以把采集到的文章转化为文章的tag词。例如我们可以采集到这样一个采集:[原创][流量][数据分析][历史文章][qa][话题][一次][首发][n+1][获取方式][人物][方法][大图][指数][知识星球][神实][n+1][qa][方法][文章][读书][image][精品推荐][文案][文章][logo][人物][导购][文章][n+1][头像][图片][文章][gif][图片][话题][如何][文案][手机][验证码][如何][流量][清洁][数据分析][高分][资讯][阅读][文化][topic][视频][新闻][文化][视频][信息][新闻][高质量][清流][精品][视频][“”][qa][数据分析][a/b][建议][咨询][信息][一次][数据][疑问][好友][人物][持续][文章][指数][新闻][话题][值][微信][图文][top][动态][指数][首发][qa][读书][图片][精品][影像][大图][专题][视频][数据][读书][数据分析][汽车][宝宝][精品][新闻][读书][转发][图片][汽车][汽车][读书][汽车][小清新][汽车][心理][足球][圈子][旅游][旅游][吃喝][汽车旅游][动态][环保][重大消息][互联网][数据][科学][动态][日历][书][汽车][跨行][保养][机修][读书][会议][读书][数据][数据分析][接收][数据][律][房][期刊][文档][作文][清洁][数据][数据][视频][技术][语言][文章][神实][图片][ppt][新闻][养生]。
根据关键词文章采集系统(关键词文章采集系统的配置供用户选择,你值得拥有)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-12-14 09:16
根据关键词文章采集系统的专家组内评师的专业认证特色,推出了多款不同的配置供用户选择。首先,文章采集系统通过html5和h5的方式给javascript编译作为基础单元,该平台的后台硬件控制程序通过h5和javascript编译相互作用结果在采集系统自身并完成实时协调。其次,它使用jsx和jswrap这两种静态库来增强动态布局和脚本引擎。
在许多情况下,无论是用html或纯javascript开发一个传统的网页,都需要获得这两种静态库的支持。另外,它通过设置基于浏览器访问数据库的定制方法,使用内存计算来分析用户的浏览记录并对输入的内容进行快速有效分析。1:前端javascript数据的深度整合保证了准确性和加载时间,同时由于你设置了强制数据查询控制,从而确保网页在大部分内存能力方面处于理想水平。
2:能够利用javascript完成网页所有基本事务,例如:设置xmlurl映射、定制网页内容的缓存以便后续处理、存储各种配置和属性值等。3:通过网络插件,开发人员可以完全用javascript来完成常见用户操作,例如上传图片、下载图片、保存图片、添加搜索框、添加上传按钮、设置密码以及开发人员可以在当前页面上设置常见的表单验证方法。
4:通过主要程序控制子程序的运行和游览。系统地给由浏览器和系统控制的子程序更多控制权。5:通过从用户下载flash文件的图像、音频和视频进行数据采集。6:可以利用内存计算的性能来产生相对于其它精密仪器更快速、更精准、更集中地用户操作反馈。7:你可以对包括浏览器地址栏显示的互联网标识、邮件链接以及其它部署和使用html5和h5.js的任何传统web页面进行控制。
8:你可以设置向下滚动页面、出现或消失页面、搜索和摘要的输入框等浏览元素,并通过实时数据相关性评估页面加载速度。9:你可以利用主要程序和子程序保证网页的完整性、安全性以及可重用性。10:你可以使用“ux定制界面”和“ux特定交互”的ui工具来设计浏览器菜单、输入框、搜索框和返回按钮。系统与其它主要仪器集成如有线鼠标、有线键盘、有线usb鼠标、便携式显示器等的区别:。
1、仪器本身不需要编程。
2、操作台系统自带的浏览器自带采集程序(如q-browserenvironment),因此可以免编程。
3、对操作台或其它显示器没有支持的代码,系统可在其它机器上配置javascript,称为javascript文件和javascript设置。
4、操作台系统可以基于html、html
5、javascript、javascriptwrap、javascript、webkit和lottie等第三方ios/android系统 查看全部
根据关键词文章采集系统(关键词文章采集系统的配置供用户选择,你值得拥有)
根据关键词文章采集系统的专家组内评师的专业认证特色,推出了多款不同的配置供用户选择。首先,文章采集系统通过html5和h5的方式给javascript编译作为基础单元,该平台的后台硬件控制程序通过h5和javascript编译相互作用结果在采集系统自身并完成实时协调。其次,它使用jsx和jswrap这两种静态库来增强动态布局和脚本引擎。
在许多情况下,无论是用html或纯javascript开发一个传统的网页,都需要获得这两种静态库的支持。另外,它通过设置基于浏览器访问数据库的定制方法,使用内存计算来分析用户的浏览记录并对输入的内容进行快速有效分析。1:前端javascript数据的深度整合保证了准确性和加载时间,同时由于你设置了强制数据查询控制,从而确保网页在大部分内存能力方面处于理想水平。
2:能够利用javascript完成网页所有基本事务,例如:设置xmlurl映射、定制网页内容的缓存以便后续处理、存储各种配置和属性值等。3:通过网络插件,开发人员可以完全用javascript来完成常见用户操作,例如上传图片、下载图片、保存图片、添加搜索框、添加上传按钮、设置密码以及开发人员可以在当前页面上设置常见的表单验证方法。
4:通过主要程序控制子程序的运行和游览。系统地给由浏览器和系统控制的子程序更多控制权。5:通过从用户下载flash文件的图像、音频和视频进行数据采集。6:可以利用内存计算的性能来产生相对于其它精密仪器更快速、更精准、更集中地用户操作反馈。7:你可以对包括浏览器地址栏显示的互联网标识、邮件链接以及其它部署和使用html5和h5.js的任何传统web页面进行控制。
8:你可以设置向下滚动页面、出现或消失页面、搜索和摘要的输入框等浏览元素,并通过实时数据相关性评估页面加载速度。9:你可以利用主要程序和子程序保证网页的完整性、安全性以及可重用性。10:你可以使用“ux定制界面”和“ux特定交互”的ui工具来设计浏览器菜单、输入框、搜索框和返回按钮。系统与其它主要仪器集成如有线鼠标、有线键盘、有线usb鼠标、便携式显示器等的区别:。
1、仪器本身不需要编程。
2、操作台系统自带的浏览器自带采集程序(如q-browserenvironment),因此可以免编程。
3、对操作台或其它显示器没有支持的代码,系统可在其它机器上配置javascript,称为javascript文件和javascript设置。
4、操作台系统可以基于html、html
5、javascript、javascriptwrap、javascript、webkit和lottie等第三方ios/android系统
根据关键词文章采集系统( 什么是采集站?现在做网站还能做采集站吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-12-13 14:00
什么是采集站?现在做网站还能做采集站吗?)
采集 站是什么?采集站台怎么办?如果我现在做网站,我还能做采集吗?今天小编就给大家分享一些关于采集站的经验分享!可以说现在的大部分网站都离不开采集,采集已经成为了互联网的常态网站,所以想当站或者已经有网站上网的同学一定要清楚了解采集站!我自己做的小说网站和门户网站都是用采集的方法制作的。目前,全流和全5,日均IP流量稳定在1万左右。通过这篇文章的文章和大家分享一下我的一些理解和实践。
采集 站是什么?每个 网站 都需要填充内容。在这个“内容为王”的时代,很多SEO站长为了做网站优化,疯狂写文章。但是,一些SEOer 认为原创文章 没有那么重要。为了让网站能够在短时间内拥有大量的内容,很多站长都会选择采集文章的方式。对于站长来说,因为经常需要发布文章,需要采集各种文章资源,所以需要各种采集工具。从事互联网SEO行业以来,一直在使用采集工具来处理不同的文章资源,以及采集不同平台的资源,文章采集@ > 工具不知道你听说过吗?可能有的站长没接触过吧!采集工具现在被一些站群或大型门户网站使用,例如企业网站使用的那些。当然,一些个人网站也被一些人使用采集,因为有些情况不想自己更新文章 或文章 需要在大网站上更新的很多而且复杂的,比如新闻网站,都用采集。编辑器通常使用147个采集来完成所有采集站的内容填充。更适合不懂代码和技术的站长。输入关键词就可以了采集,没有复杂的配置,也不需要写采集的规则。采集完成后,
采集站台怎么办?
1.网站上线前采集文章,准备大量文章(采集都来这里,当然采集@ >N 个站点 文章)。
2. 网站 模板一定要自己写,代码库一定要优化。
3. 做好网站 内容页面布局。
4.上线后每天更新100~500文章卷,文章一定是采集N个站点的最新文章。
5. 外链每天发一些。一个月后,你的网站收录和你的流量都会上升!
一些采集 需要特别注意的点:
1.海量长尾词:我在采集的内容中导入了超过10万个关键词。如果我想要更多 关键词 排名,那么我需要大量 文章 和 关键词。而我的文章都是基于关键词采集。不要像大多数人一样做采集站。基本上,它是盲目的采集。内容有几万个收录,但排名的关键词只有几十个。看着它很有趣,只是乱七八糟。这样的采集 站点基本上是在制造互联网垃圾邮件。搜索引擎反对谁?拥有 关键词 和内容只是基础。如果你的采集文章能获得不错的排名,那你就需要下一步了。
2.文章优化:80%的人不了解优质内容。采集 过来的内容必须经过伪原创!其实搜索引擎已经说得很清楚了。文章排版,内容就是用户需要的,很明显的告诉大家文章有图有文字,远胜于纯文本文章收录。所以你的内容布局好,关键词布局好,你文章已经有排名机会是用户需求。
3.页面结构:有两个核心点,相关性和丰富性。抓住这两点,去百度看看别人的官方说明,就可以掌握核心,内页排名也很容易。
4.内容收录速度:要想快速上榜,首先要网站内容收录要快。想要让收录快速的需要大量的蜘蛛来抓取你的网站,其实搜索引擎已经给出了很好的工具,主动推送功能!批量推送网页链接到搜索引擎,增加曝光率。
如果我现在做网站,我还能做采集吗?我的采集站点一直很稳定,我的采集站点完全符合搜索引擎的规则。不仅稳定,而且流量还在持续上升。所以采集网站还是可以做的,最重要的还是做对了,不是因为采集和采集,采集之后的SEO优化也很重要,具体后续文章的内容我会详细说明。本期暂时先说说采集站。
关于采集站的问题,小编就到此为止。总之,如果采集的内容处理得当,站采集也会是收录。但是大家要注意一个问题,就是对采集网站的操作要更加谨慎,不要让搜索引擎认为这是一个采集站,而且在同时在用户体验和满足用户需求方面做更多的优化,这样的采集站还是可以做的。 查看全部
根据关键词文章采集系统(
什么是采集站?现在做网站还能做采集站吗?)
采集 站是什么?采集站台怎么办?如果我现在做网站,我还能做采集吗?今天小编就给大家分享一些关于采集站的经验分享!可以说现在的大部分网站都离不开采集,采集已经成为了互联网的常态网站,所以想当站或者已经有网站上网的同学一定要清楚了解采集站!我自己做的小说网站和门户网站都是用采集的方法制作的。目前,全流和全5,日均IP流量稳定在1万左右。通过这篇文章的文章和大家分享一下我的一些理解和实践。
采集 站是什么?每个 网站 都需要填充内容。在这个“内容为王”的时代,很多SEO站长为了做网站优化,疯狂写文章。但是,一些SEOer 认为原创文章 没有那么重要。为了让网站能够在短时间内拥有大量的内容,很多站长都会选择采集文章的方式。对于站长来说,因为经常需要发布文章,需要采集各种文章资源,所以需要各种采集工具。从事互联网SEO行业以来,一直在使用采集工具来处理不同的文章资源,以及采集不同平台的资源,文章采集@ > 工具不知道你听说过吗?可能有的站长没接触过吧!采集工具现在被一些站群或大型门户网站使用,例如企业网站使用的那些。当然,一些个人网站也被一些人使用采集,因为有些情况不想自己更新文章 或文章 需要在大网站上更新的很多而且复杂的,比如新闻网站,都用采集。编辑器通常使用147个采集来完成所有采集站的内容填充。更适合不懂代码和技术的站长。输入关键词就可以了采集,没有复杂的配置,也不需要写采集的规则。采集完成后,
采集站台怎么办?
1.网站上线前采集文章,准备大量文章(采集都来这里,当然采集@ >N 个站点 文章)。
2. 网站 模板一定要自己写,代码库一定要优化。
3. 做好网站 内容页面布局。
4.上线后每天更新100~500文章卷,文章一定是采集N个站点的最新文章。
5. 外链每天发一些。一个月后,你的网站收录和你的流量都会上升!
一些采集 需要特别注意的点:
1.海量长尾词:我在采集的内容中导入了超过10万个关键词。如果我想要更多 关键词 排名,那么我需要大量 文章 和 关键词。而我的文章都是基于关键词采集。不要像大多数人一样做采集站。基本上,它是盲目的采集。内容有几万个收录,但排名的关键词只有几十个。看着它很有趣,只是乱七八糟。这样的采集 站点基本上是在制造互联网垃圾邮件。搜索引擎反对谁?拥有 关键词 和内容只是基础。如果你的采集文章能获得不错的排名,那你就需要下一步了。
2.文章优化:80%的人不了解优质内容。采集 过来的内容必须经过伪原创!其实搜索引擎已经说得很清楚了。文章排版,内容就是用户需要的,很明显的告诉大家文章有图有文字,远胜于纯文本文章收录。所以你的内容布局好,关键词布局好,你文章已经有排名机会是用户需求。
3.页面结构:有两个核心点,相关性和丰富性。抓住这两点,去百度看看别人的官方说明,就可以掌握核心,内页排名也很容易。
4.内容收录速度:要想快速上榜,首先要网站内容收录要快。想要让收录快速的需要大量的蜘蛛来抓取你的网站,其实搜索引擎已经给出了很好的工具,主动推送功能!批量推送网页链接到搜索引擎,增加曝光率。
如果我现在做网站,我还能做采集吗?我的采集站点一直很稳定,我的采集站点完全符合搜索引擎的规则。不仅稳定,而且流量还在持续上升。所以采集网站还是可以做的,最重要的还是做对了,不是因为采集和采集,采集之后的SEO优化也很重要,具体后续文章的内容我会详细说明。本期暂时先说说采集站。
关于采集站的问题,小编就到此为止。总之,如果采集的内容处理得当,站采集也会是收录。但是大家要注意一个问题,就是对采集网站的操作要更加谨慎,不要让搜索引擎认为这是一个采集站,而且在同时在用户体验和满足用户需求方面做更多的优化,这样的采集站还是可以做的。
根据关键词文章采集系统(关键词排名包年优化怎么样创新服务,,诠释网络)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-08 20:14
关键词如何优化排名套餐年创新服务,解读网络**网址:免费咨询电话:公司地址:开福市双永路9号长城万福汇大厦金塔7楼7016长沙市区长沙区多年的客户服务和运营在网络整合营销、网络品牌传播、网络广告策划、网络公关、网络事件营销、电子商务服务等各个领域有着独到的见解,并创造了公司愿景:一站式可靠的互联网运营服务商。
关键词如何创新排名包优化服务,SEO网站优化-关键词优化快速排名你找谁?2020-09-03 SEO网站优化-关键词优化快速排名找谁?SEO网站优化-关键词优化快速排名找八火科技。:0755 seo优化包年服务-2万包年6关键词可选seo优化日计费服务-最低5元/天无限关键词,排名第一后付费。为什么百度没有收录网站?是不是因为网站 没有记录。其实百度没有收录网站页面的原因有很多。下面,深圳网站设计巴火科技就来分析一下。一、 域名进入百度黑名单,百度没有收录有的朋友在购买新域名时没有查看域名的历史表现。事实上,有些域名已经进入了百度的黑名单,或者是百度已经将其列入了可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。有的朋友在购买新域名时没有查看域名的历史表现。事实上,有些域名已经进入了百度的黑名单,或者是百度已经将其列入了可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。有的朋友在购买新域名时没有查看域名的历史表现。事实上,有些域名已经进入了百度的黑名单,或者是百度已经将其列入了可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。或者百度已将其列入可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。或者百度已将其列入可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。
一、百度竞价包年度推广是怎么回事?百度竞价包年度推广是一种将网站的排名操作委托给专业第三方及其年度计算单位的合作关系。由于互联网发展的不可预知的变化,按照月度合作,不仅成本较高,而且无法针对不断变化的数据对推广方案给出针对性的建议和调整。因此,与百度竞价进行年度推广更有利于广告主目标的实现。而百度的竞价推广主要是对关键词进行竞价,获得更高的排名。同时根据关键词优化促销 满足用户的消费需求,帮助广告主获得流量和转化率。关键词是关于网站的流量和转化率,也就是说,即使排名很高,关键词不满足用户的搜索“胃口”,也不会实现转化。因此,百度竞价推广基于网站的主题和用户的热门关键词,确保在提升网站的同时,也能为网站带来转化率。用户通过关键词搜索广告,希望通过广告获得更多有价值的知识点,帮助朋友解惑。所以,要想有好的转化率,就必须围绕关键词写更多优质的内容,也就是要多站在用户的角度思考,比如他们需要什么,需要通过内容学习哪些知识点。写出相应的内容,使得用户的访问率和网站的访问率都很高。
关键词如何创新排名包年优化服务,word上传时间一般为3-15天;新站优化包年度合作新站通过人工基础优化,调整网站TDK,关键词密度,修正网站违反的百度算法,提高服务器访问速度,加强网站内容维护文章更新、外链发布、关键词快照权限提升等;以上,措辞时间为15-30天;不同字量不同套餐,关键词优化价格低至每天1-3元;全站优化按季收费,优化行业词库,快速提升网站整体权重,在获取流量的同时,也可以激烈竞争的核心词排名更稳定,适合产品较多的行业和门户关键词;客户指定核心关键词和数量,优化到百度首页,达到关键词数量后,计算时间;每天都有大量的措辞案例,偶尔不定时更新!你的 网站 有什么问题?seo的工作内容是什么,SEO的工作是什么?不定时不定时更新!你的 网站 有什么问题?seo的工作内容是什么,SEO的工作是什么?不定时不定时更新!你的 网站 有什么问题?seo的工作内容是什么,SEO的工作是什么?
从事搜索引擎优化业务或个人需要进行日常计费,但没有研发能力或时间和精力开发这样的系统。每天自动监测关键词的排名。如果设置了排名,系统会自动从网站的客户余额中扣除费用,并为搜索引擎优化及其客户提供排名和消费的详细报告。降低SEO推广难度,树立品牌,解决成本纠纷和收支困难。SEO按天计费系统的优势,我们来看看,传统的搜索优化收费模式呢?一次性年费月付传统搜索引擎优化收费模式有哪些弊端?一般情况下,要到关键词到达首页才能看到效果。但是,如果在年付或月付之前没有排名,也会产生费用。事实上,这段时间并没有给客户的业务带来任何好处。主页上10个月,但实际付了1年。对于SEO乙方来说,传统的包年或包月,普遍存在未付余额的问题。当网站关键词的数据上升时,其实搜索引擎优化工程师是需要维护排名的,但是对于客户来说,可能会觉得排名上升之后,没有必要去管理和维护管理,
关键词排名包优化服务如何创新?目标关键词 当前排名需要在前5页,1-15天内可以快速排到搜索引擎首页的首位。一个字一个月就可以开始,目标数量关键词和同类产品的合作周期要求都比较低。技术优势 多年只专注SEO优化,使用近百种算法,云间链接全搜索,动态热更新。优化原理引导搜索引擎蜘蛛迭代扫描网站,以获得更高的PageRank值。白帽自然优化,更符合搜索引擎的需求,词稳定,无需担心其他副作用。丰富的选择。我们不仅有多个合作套餐供您选择,还支持定制您自己的合作套餐,让您可以根据自己的营销方式销售您的定制套餐。透明计费支持年付、季付、月付。无论选择哪种付款方式,只要不删除目标词,服务价格永远不会改变,并且支持每日扣款。
企业网站seo网络推广时,网站文章内容纯采集来,与网站seo、网站关键词@无关> 排名公式不聚焦时,优化排名与首页布局的seo关键词相反,网站文章与关键词无关,seo< @关键词没有重点,这样的网站不能满足用户和搜索引擎对自然排名的需求,搜索引擎很难对这样的网站进行排名。网站文章 更新不频繁,seo排名堪忧?优化排名网站文章无频次更新,搜索引擎抓不到网站规律,一般2-3天写几篇原创关注这个网站 seo 的标题<
关键词如何创新排名包优化服务?接下来上海SEO关键词优化曼朗主要从几个方面给大家介绍一下。希望我能帮您解决您的困惑,比如您在优化SEO时关键词。272021--08seo关键词 想要优化排名有好的效果,这些东西你必须知道!seo关键词优化排名,顾名思义就是通过适当的方法优化网站的关键词,让网站关键词排名更高,从而带来更多精准流量,增加网站的权重,获得更高的排名。当网站的排名更稳定,获得更精准的流量时,网站的推广效果就会得到充分发挥,
百度首页关键词的排名机制是什么?网站Optimized关键词是搜索引擎优化的日常工作。优化是否容易做好,取决于我们的工作是否认真。百度首页关键词的制作取决于关键词的竞争力、网站的权重以及SEOER的经验和技巧,这些都会影响关键词的排名。如果你想在首页设置关键词,你需要知道判断页面质量的标准或数据,找到关键点,好的地方事半功倍在。排名方法太多了,让我们深入挖掘。搜索引擎如何判断网页的质量并相应地对其进行排名?页面标题和页面内容必须相关。你为什么这么说?因为如果更新后的文章相关度不高,主题不突出,在关键词之前的排名就没有优势了,这就是为什么大一些的聚合页面排名这么好。控制页面的相关性和关键词密度也可以提高关键词的排名。 查看全部
根据关键词文章采集系统(关键词排名包年优化怎么样创新服务,,诠释网络)
关键词如何优化排名套餐年创新服务,解读网络**网址:免费咨询电话:公司地址:开福市双永路9号长城万福汇大厦金塔7楼7016长沙市区长沙区多年的客户服务和运营在网络整合营销、网络品牌传播、网络广告策划、网络公关、网络事件营销、电子商务服务等各个领域有着独到的见解,并创造了公司愿景:一站式可靠的互联网运营服务商。
关键词如何创新排名包优化服务,SEO网站优化-关键词优化快速排名你找谁?2020-09-03 SEO网站优化-关键词优化快速排名找谁?SEO网站优化-关键词优化快速排名找八火科技。:0755 seo优化包年服务-2万包年6关键词可选seo优化日计费服务-最低5元/天无限关键词,排名第一后付费。为什么百度没有收录网站?是不是因为网站 没有记录。其实百度没有收录网站页面的原因有很多。下面,深圳网站设计巴火科技就来分析一下。一、 域名进入百度黑名单,百度没有收录有的朋友在购买新域名时没有查看域名的历史表现。事实上,有些域名已经进入了百度的黑名单,或者是百度已经将其列入了可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。有的朋友在购买新域名时没有查看域名的历史表现。事实上,有些域名已经进入了百度的黑名单,或者是百度已经将其列入了可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。有的朋友在购买新域名时没有查看域名的历史表现。事实上,有些域名已经进入了百度的黑名单,或者是百度已经将其列入了可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。或者百度已将其列入可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。或者百度已将其列入可疑名单。2021-10-22 对于SEO优化,网站打开响应速度也是优化的关键。如果开口很慢,蜘蛛恰好在爬行,对蜘蛛不友好。和你谈谈如何提高网站的打开速度。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。域名解析尽量使用国内运营商的域名解析,不要使用境外运营商。由于海外DNS解析可能会延迟或不稳定,无法打开网站。
一、百度竞价包年度推广是怎么回事?百度竞价包年度推广是一种将网站的排名操作委托给专业第三方及其年度计算单位的合作关系。由于互联网发展的不可预知的变化,按照月度合作,不仅成本较高,而且无法针对不断变化的数据对推广方案给出针对性的建议和调整。因此,与百度竞价进行年度推广更有利于广告主目标的实现。而百度的竞价推广主要是对关键词进行竞价,获得更高的排名。同时根据关键词优化促销 满足用户的消费需求,帮助广告主获得流量和转化率。关键词是关于网站的流量和转化率,也就是说,即使排名很高,关键词不满足用户的搜索“胃口”,也不会实现转化。因此,百度竞价推广基于网站的主题和用户的热门关键词,确保在提升网站的同时,也能为网站带来转化率。用户通过关键词搜索广告,希望通过广告获得更多有价值的知识点,帮助朋友解惑。所以,要想有好的转化率,就必须围绕关键词写更多优质的内容,也就是要多站在用户的角度思考,比如他们需要什么,需要通过内容学习哪些知识点。写出相应的内容,使得用户的访问率和网站的访问率都很高。
关键词如何创新排名包年优化服务,word上传时间一般为3-15天;新站优化包年度合作新站通过人工基础优化,调整网站TDK,关键词密度,修正网站违反的百度算法,提高服务器访问速度,加强网站内容维护文章更新、外链发布、关键词快照权限提升等;以上,措辞时间为15-30天;不同字量不同套餐,关键词优化价格低至每天1-3元;全站优化按季收费,优化行业词库,快速提升网站整体权重,在获取流量的同时,也可以激烈竞争的核心词排名更稳定,适合产品较多的行业和门户关键词;客户指定核心关键词和数量,优化到百度首页,达到关键词数量后,计算时间;每天都有大量的措辞案例,偶尔不定时更新!你的 网站 有什么问题?seo的工作内容是什么,SEO的工作是什么?不定时不定时更新!你的 网站 有什么问题?seo的工作内容是什么,SEO的工作是什么?不定时不定时更新!你的 网站 有什么问题?seo的工作内容是什么,SEO的工作是什么?
从事搜索引擎优化业务或个人需要进行日常计费,但没有研发能力或时间和精力开发这样的系统。每天自动监测关键词的排名。如果设置了排名,系统会自动从网站的客户余额中扣除费用,并为搜索引擎优化及其客户提供排名和消费的详细报告。降低SEO推广难度,树立品牌,解决成本纠纷和收支困难。SEO按天计费系统的优势,我们来看看,传统的搜索优化收费模式呢?一次性年费月付传统搜索引擎优化收费模式有哪些弊端?一般情况下,要到关键词到达首页才能看到效果。但是,如果在年付或月付之前没有排名,也会产生费用。事实上,这段时间并没有给客户的业务带来任何好处。主页上10个月,但实际付了1年。对于SEO乙方来说,传统的包年或包月,普遍存在未付余额的问题。当网站关键词的数据上升时,其实搜索引擎优化工程师是需要维护排名的,但是对于客户来说,可能会觉得排名上升之后,没有必要去管理和维护管理,
关键词排名包优化服务如何创新?目标关键词 当前排名需要在前5页,1-15天内可以快速排到搜索引擎首页的首位。一个字一个月就可以开始,目标数量关键词和同类产品的合作周期要求都比较低。技术优势 多年只专注SEO优化,使用近百种算法,云间链接全搜索,动态热更新。优化原理引导搜索引擎蜘蛛迭代扫描网站,以获得更高的PageRank值。白帽自然优化,更符合搜索引擎的需求,词稳定,无需担心其他副作用。丰富的选择。我们不仅有多个合作套餐供您选择,还支持定制您自己的合作套餐,让您可以根据自己的营销方式销售您的定制套餐。透明计费支持年付、季付、月付。无论选择哪种付款方式,只要不删除目标词,服务价格永远不会改变,并且支持每日扣款。
企业网站seo网络推广时,网站文章内容纯采集来,与网站seo、网站关键词@无关> 排名公式不聚焦时,优化排名与首页布局的seo关键词相反,网站文章与关键词无关,seo< @关键词没有重点,这样的网站不能满足用户和搜索引擎对自然排名的需求,搜索引擎很难对这样的网站进行排名。网站文章 更新不频繁,seo排名堪忧?优化排名网站文章无频次更新,搜索引擎抓不到网站规律,一般2-3天写几篇原创关注这个网站 seo 的标题<
关键词如何创新排名包优化服务?接下来上海SEO关键词优化曼朗主要从几个方面给大家介绍一下。希望我能帮您解决您的困惑,比如您在优化SEO时关键词。272021--08seo关键词 想要优化排名有好的效果,这些东西你必须知道!seo关键词优化排名,顾名思义就是通过适当的方法优化网站的关键词,让网站关键词排名更高,从而带来更多精准流量,增加网站的权重,获得更高的排名。当网站的排名更稳定,获得更精准的流量时,网站的推广效果就会得到充分发挥,
百度首页关键词的排名机制是什么?网站Optimized关键词是搜索引擎优化的日常工作。优化是否容易做好,取决于我们的工作是否认真。百度首页关键词的制作取决于关键词的竞争力、网站的权重以及SEOER的经验和技巧,这些都会影响关键词的排名。如果你想在首页设置关键词,你需要知道判断页面质量的标准或数据,找到关键点,好的地方事半功倍在。排名方法太多了,让我们深入挖掘。搜索引擎如何判断网页的质量并相应地对其进行排名?页面标题和页面内容必须相关。你为什么这么说?因为如果更新后的文章相关度不高,主题不突出,在关键词之前的排名就没有优势了,这就是为什么大一些的聚合页面排名这么好。控制页面的相关性和关键词密度也可以提高关键词的排名。
根据关键词文章采集系统(推荐一款很好用的关键词文章采集助手(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-12-05 18:03
根据关键词文章采集系统现有的功能来说,主要有:信息提取采集功能:包括标题、文章题目,
downloadtrim-googlesearch其实不是关键,关键是能够无人值守,我们团队要求只要保持工作量的稳定,大概10-20%的人手吧,剩下的人负责技术拓展。
这个嘛,用友关键词采集助手这个是免费版的,我用的效果很好,效率也很高,
哈哈哈哈,请上采源宝。菜鸟上手,一个月出300左右效果,软件不贵,用友采源宝。每天的价格都不定,见到3百,5百的就不要管了。当然,价格和效果成正比。
推荐一款很好用的关键词采集神器「爱采商机」「爱采商机」最新版本都有计算机房模式了,可以正常下载,且功能强大的同时有一些独家小功能,如连击计算机房模式(采到每天最热门的词);采集违规内容,并快速处理(减少删除、联动的需求量)等功能。
tmd,你要做采集软件,你别把用友关键词采集引擎做坑好不好。我在用友专区见过大量的用友关键词采集引擎搞这些莫名其妙的功能。每个主推的关键词,都有非常完善的竞争分析与规则。
可以看看top10这个网站,用友和许多知名网站合作,提供免费的采集功能,目前用友最新的top10还没推出,用的都是很老的老的方法,希望能帮到你。 查看全部
根据关键词文章采集系统(推荐一款很好用的关键词文章采集助手(图))
根据关键词文章采集系统现有的功能来说,主要有:信息提取采集功能:包括标题、文章题目,
downloadtrim-googlesearch其实不是关键,关键是能够无人值守,我们团队要求只要保持工作量的稳定,大概10-20%的人手吧,剩下的人负责技术拓展。
这个嘛,用友关键词采集助手这个是免费版的,我用的效果很好,效率也很高,
哈哈哈哈,请上采源宝。菜鸟上手,一个月出300左右效果,软件不贵,用友采源宝。每天的价格都不定,见到3百,5百的就不要管了。当然,价格和效果成正比。
推荐一款很好用的关键词采集神器「爱采商机」「爱采商机」最新版本都有计算机房模式了,可以正常下载,且功能强大的同时有一些独家小功能,如连击计算机房模式(采到每天最热门的词);采集违规内容,并快速处理(减少删除、联动的需求量)等功能。
tmd,你要做采集软件,你别把用友关键词采集引擎做坑好不好。我在用友专区见过大量的用友关键词采集引擎搞这些莫名其妙的功能。每个主推的关键词,都有非常完善的竞争分析与规则。
可以看看top10这个网站,用友和许多知名网站合作,提供免费的采集功能,目前用友最新的top10还没推出,用的都是很老的老的方法,希望能帮到你。
根据关键词文章采集系统(先来说一下亚马逊关键字分两大块,一块最最重要的关键字)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-03 18:00
先说亚马逊关键词设置,可以给大家带来一些帮助:
1.亚马逊关键词分为两部分,一是标题,这是最重要的关键词,设置标题关键词的最佳形式是:品牌+名称+重要属性1、2、3+标题相关名称+函数+参数可以直接在搜索顺序中得到一个好的位置。
2. 是亚马逊的搜索词。很多人对此有过困惑,到底是用长关键字还是短关键字,用逗号隔开还是用空格隔开。首先,搜索词是搜索引擎的关键字被抓取的地方。当然,关键字越多越好。至于关键词的长度,不是很重要,但要注意出现重复的关键词,会被认为是关键词。作弊。其次,逗号的使用是一种精确定位。当用户搜索时,只有符号之间的键有效。例如,卡通、手机壳、手机壳等,只有当用户全部输入时才会被搜索到。如果用户输入手机壳卡通,则可能无法搜索。如果使用空格表示模糊搜索,可以搜索关键字的任意组合。katoon手机壳手机壳,如果用户搜索手机壳katoon或katoon,会被亚马逊搜索到。
说一下如何找到关键词:
1、使用谷歌关键词来规划词,谷歌在建议广告词组时会给你精准推荐
2、 在亚马逊前台搜索栏中:输入关键词,会出现一个下拉菜单,在菜单中选择关键词使用
3、标题中的热词和同类产品销量最高的几个listing标题的评论
4、 对应的分类和亚马逊前台左侧分类导航中的文字,如“手机”
5、您也可以参考易趣等其他平台同款产品对应的热词
6、使用一些关键词工具,例如:关键字研究 查看全部
根据关键词文章采集系统(先来说一下亚马逊关键字分两大块,一块最最重要的关键字)
先说亚马逊关键词设置,可以给大家带来一些帮助:
1.亚马逊关键词分为两部分,一是标题,这是最重要的关键词,设置标题关键词的最佳形式是:品牌+名称+重要属性1、2、3+标题相关名称+函数+参数可以直接在搜索顺序中得到一个好的位置。
2. 是亚马逊的搜索词。很多人对此有过困惑,到底是用长关键字还是短关键字,用逗号隔开还是用空格隔开。首先,搜索词是搜索引擎的关键字被抓取的地方。当然,关键字越多越好。至于关键词的长度,不是很重要,但要注意出现重复的关键词,会被认为是关键词。作弊。其次,逗号的使用是一种精确定位。当用户搜索时,只有符号之间的键有效。例如,卡通、手机壳、手机壳等,只有当用户全部输入时才会被搜索到。如果用户输入手机壳卡通,则可能无法搜索。如果使用空格表示模糊搜索,可以搜索关键字的任意组合。katoon手机壳手机壳,如果用户搜索手机壳katoon或katoon,会被亚马逊搜索到。
说一下如何找到关键词:
1、使用谷歌关键词来规划词,谷歌在建议广告词组时会给你精准推荐
2、 在亚马逊前台搜索栏中:输入关键词,会出现一个下拉菜单,在菜单中选择关键词使用
3、标题中的热词和同类产品销量最高的几个listing标题的评论
4、 对应的分类和亚马逊前台左侧分类导航中的文字,如“手机”
5、您也可以参考易趣等其他平台同款产品对应的热词
6、使用一些关键词工具,例如:关键字研究
根据关键词文章采集系统(建站系统推荐使用linux系统+宝塔(BT)建站 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-12-01 05:11
)
前言:SEO常用工具建站文章内容来源于近期建站操作经验。后面会推荐其他常用的SEO工具,分享一下我写的工具。欢迎关注。
内容概要:
建站系统
建议使用linux系统+宝塔(BT)搭建网站。linux系统与win相交,可以提高网站的安全等级,但是linux是命令行系统,很多同学不会使用,所以推荐使用BT。服务器运维面板的安装和使用非常简单。
更棒的是,免费功能基本可以满足大部分建站需求。我的很多服务器都是使用宝塔面板,搭建容易,维护方便,占用服务器资源少。
Key 关键词 挖掘和布局
网站关键词的关键点是业务流量的基础,必须控制。我在做网站的时候,这个作品的过程是这样的:
批量挖掘关键词->分析关键词性价比->选择高流量&性价比关键词
前面用到的工具内容介绍:
挖矿行业工具推荐关键词及重点关键词:如何挖矿行业关键词、词挖掘策略、工具推荐
性价比高的筛选工具关键词:关键词如何优化难度分析?退伍军人如何一键选择优质关键词
有了关键词,我们还需要分析关键词的TDK和内容是怎么写的,如何得到更好的排名,这里面涉及到tf-idf算法和bm25算法中的搜索原理引擎。
算法这里不做详细分析,只简单讨论一下原理。
tf-idf可以分析内容的词频和关键词分值,通过分值可以知道当前标题的核心词,通过修改可以更集中TDK主题;
bm25在tf-idf的基础上分析多个内容,预测文章在某个关键词中的当前排名。我的操作流程和使用的工具如下:
基于关键词写TDK+首页内容->分析内容词频+TITLE分析->内容在线
词频分析使用自己开发的软件,通过获取模板关键词的前20个百度搜索结果的平均词频来指导我的内容的词频分布。
这个截图是我的网站的一个案例。现在可以分析我的内容的前20个平均词频和词频分布。但是,开发尚未完成。建议您可以使用代码保密的摩天大楼内容助手。原理类似。
除了词频分析,关键内容还需要tf-idf测试。我使用Orange SEO的主题检测和内容检测。这个检测主要通过tf-idf计算,通过这个算法可以得到当前的TDK和内容。是否符合算法?
【主体检测截图】
【内容检测截图】
内容采集和发布
我自己的很多网站都是通过采集维护的。主要使用的工具有优采云、优采云和python。这里我简单介绍一下前两种。
优采云采集器:老软件,功能强大易用采集软件,内容采集和数据导入功能可以导入采集的任意网页数据发布到远程服务器,有伪原创 插件可用。但是,这是一个需要长期启动的本地软件,而且很多插件也需要付费,而且有一定的入门门槛。
优采云:之前常用的软件,在线配置,无需客户端安装,采集和发布配置非常简单,还支持SEO工具;不过免费版的限制比较多,可以酌情购买付费版。
市面上的软件方便好用,但是很难高度定制化,所以最近改用python自动采集并生成内容,比如关键词关键词auto采集 百度知道,搜狗问+行业问答平台,然后自动生成内容(如下图),有编程能力的同学还是可以考虑自己写爬虫。
内部链监控
网站上线后,需要检查是否有死链接或外链。我一般会使用站长工具或者爱站的友情链接监控功能来查看首页是否有死链,或者意外的外链。
同时,为了避免网站中的错误链接,如动态链接入口、测试链接入口等,一般使用爱站工具箱做一个网站地图爬取进行故障排除和清理。错误 URL 和错误 URL 条目。
日志监控工具
网站 在建设初期,百度蜘蛛的爬取状态可以反映网站的百度评分现状,因此需要定期检查,方便SEOer对SEO方式的判断和调整。下面我介绍几种我日常使用的查看日志的方法:
爱站 工具箱:免费用户支持20M,数据更详细,但是每次需要登录BT面板下载日志文件,比较麻烦。
BT插件,付费,1元/月,可在线查看,无需下载日志文件分析,更方便。
zblog插件是付费的、一次性收费的,可以多次使用网站,登录zblog系统后台即可查看,非常方便。
百度站长工具,需要等到第二天才能看到昨天的抓取次数,可以看到抓取的次数,以及抓取所用的时间。官方数据最可信,不会被假蜘蛛忽悠,使用方便,但是功能太少,看不到具体爬取的网址。
百度站长工具
新站除了检查爬行情况外,推荐使用百度站长工具的链接提交功能和爬行分析功能。可以提高网站的收录的速度。
网站速度测试
网站速度是SEO的重要指标之一。网站上线后,测速,每次优化速度。一般测速有两种,一种是测试网站页面的下载速度,另一种是测试网站页面上所有内容的加载速度。
测试网站页面下载速度的工具有很多。这个网站测速工具的特点是只下载当前页面,不进行页面分析,不加载页面中的css、js、图片文件。类似蜘蛛爬行的操作,百度可以搜索到很多网站测速工具,这里不再介绍。
测试网站页面所有内容的加载速度。本次测速会继续分析页面打开后加载js、css、图片所用的时间。这个速度更接近用户体验。一般使用百度统计的网站速度诊断来完成。
查看全部
根据关键词文章采集系统(建站系统推荐使用linux系统+宝塔(BT)建站
)
前言:SEO常用工具建站文章内容来源于近期建站操作经验。后面会推荐其他常用的SEO工具,分享一下我写的工具。欢迎关注。
内容概要:
建站系统
建议使用linux系统+宝塔(BT)搭建网站。linux系统与win相交,可以提高网站的安全等级,但是linux是命令行系统,很多同学不会使用,所以推荐使用BT。服务器运维面板的安装和使用非常简单。
更棒的是,免费功能基本可以满足大部分建站需求。我的很多服务器都是使用宝塔面板,搭建容易,维护方便,占用服务器资源少。
Key 关键词 挖掘和布局
网站关键词的关键点是业务流量的基础,必须控制。我在做网站的时候,这个作品的过程是这样的:
批量挖掘关键词->分析关键词性价比->选择高流量&性价比关键词
前面用到的工具内容介绍:
挖矿行业工具推荐关键词及重点关键词:如何挖矿行业关键词、词挖掘策略、工具推荐
性价比高的筛选工具关键词:关键词如何优化难度分析?退伍军人如何一键选择优质关键词
有了关键词,我们还需要分析关键词的TDK和内容是怎么写的,如何得到更好的排名,这里面涉及到tf-idf算法和bm25算法中的搜索原理引擎。
算法这里不做详细分析,只简单讨论一下原理。
tf-idf可以分析内容的词频和关键词分值,通过分值可以知道当前标题的核心词,通过修改可以更集中TDK主题;
bm25在tf-idf的基础上分析多个内容,预测文章在某个关键词中的当前排名。我的操作流程和使用的工具如下:
基于关键词写TDK+首页内容->分析内容词频+TITLE分析->内容在线
词频分析使用自己开发的软件,通过获取模板关键词的前20个百度搜索结果的平均词频来指导我的内容的词频分布。
这个截图是我的网站的一个案例。现在可以分析我的内容的前20个平均词频和词频分布。但是,开发尚未完成。建议您可以使用代码保密的摩天大楼内容助手。原理类似。
除了词频分析,关键内容还需要tf-idf测试。我使用Orange SEO的主题检测和内容检测。这个检测主要通过tf-idf计算,通过这个算法可以得到当前的TDK和内容。是否符合算法?
【主体检测截图】
【内容检测截图】
内容采集和发布
我自己的很多网站都是通过采集维护的。主要使用的工具有优采云、优采云和python。这里我简单介绍一下前两种。
优采云采集器:老软件,功能强大易用采集软件,内容采集和数据导入功能可以导入采集的任意网页数据发布到远程服务器,有伪原创 插件可用。但是,这是一个需要长期启动的本地软件,而且很多插件也需要付费,而且有一定的入门门槛。
优采云:之前常用的软件,在线配置,无需客户端安装,采集和发布配置非常简单,还支持SEO工具;不过免费版的限制比较多,可以酌情购买付费版。
市面上的软件方便好用,但是很难高度定制化,所以最近改用python自动采集并生成内容,比如关键词关键词auto采集 百度知道,搜狗问+行业问答平台,然后自动生成内容(如下图),有编程能力的同学还是可以考虑自己写爬虫。
内部链监控
网站上线后,需要检查是否有死链接或外链。我一般会使用站长工具或者爱站的友情链接监控功能来查看首页是否有死链,或者意外的外链。
同时,为了避免网站中的错误链接,如动态链接入口、测试链接入口等,一般使用爱站工具箱做一个网站地图爬取进行故障排除和清理。错误 URL 和错误 URL 条目。
日志监控工具
网站 在建设初期,百度蜘蛛的爬取状态可以反映网站的百度评分现状,因此需要定期检查,方便SEOer对SEO方式的判断和调整。下面我介绍几种我日常使用的查看日志的方法:
爱站 工具箱:免费用户支持20M,数据更详细,但是每次需要登录BT面板下载日志文件,比较麻烦。
BT插件,付费,1元/月,可在线查看,无需下载日志文件分析,更方便。
zblog插件是付费的、一次性收费的,可以多次使用网站,登录zblog系统后台即可查看,非常方便。
百度站长工具,需要等到第二天才能看到昨天的抓取次数,可以看到抓取的次数,以及抓取所用的时间。官方数据最可信,不会被假蜘蛛忽悠,使用方便,但是功能太少,看不到具体爬取的网址。
百度站长工具
新站除了检查爬行情况外,推荐使用百度站长工具的链接提交功能和爬行分析功能。可以提高网站的收录的速度。
网站速度测试
网站速度是SEO的重要指标之一。网站上线后,测速,每次优化速度。一般测速有两种,一种是测试网站页面的下载速度,另一种是测试网站页面上所有内容的加载速度。
测试网站页面下载速度的工具有很多。这个网站测速工具的特点是只下载当前页面,不进行页面分析,不加载页面中的css、js、图片文件。类似蜘蛛爬行的操作,百度可以搜索到很多网站测速工具,这里不再介绍。
测试网站页面所有内容的加载速度。本次测速会继续分析页面打开后加载js、css、图片所用的时间。这个速度更接近用户体验。一般使用百度统计的网站速度诊断来完成。
根据关键词文章采集系统(如何应对网络中的新闻内容也一样?系统帮你解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-27 22:11
随着互联网的飞速发展,互联网极大地提高了信息生成和传播的速度。互联网上每天都会产生大量的内容。如何从这些杂乱无章的内容中高效地发现和采集需要的信息似乎越来越多。越重要。互联网上的新闻内容也是如此。新闻分布在不同的网站上,存在重复的内容。我们往往只关心一些新闻。互联网上的新闻页面往往充斥着大量与新闻无关的新闻页面。这些信息会影响我们的阅读效率和阅读体验。如何更方便、及时、高效地获取我们关心的新闻内容,这个系统可以帮我们做到这一点。本系统利用网络爬虫对网络网站上的新闻进行定时、有针对性的分析和采集,然后对采集接收到的数据进行去重、分类和存储。进入数据库,最终提供个性化的新闻订阅服务。考虑如何处理网站的反爬虫策略,避免被网站拦截。在具体实现中,使用Python与scrapy等框架编写爬虫,使用特定的内容提取算法提取目标数据。最后使用Django和weui提供新闻订阅后台和新闻内容展示页面,使用微信向用户推送信息。用户可以通过本系统订阅指定关键词,
[关键词] 网络爬虫;消息; 个性化;订阅; Python
参考文档及完整文档及源代码下载地址: 查看全部
根据关键词文章采集系统(如何应对网络中的新闻内容也一样?系统帮你解决)
随着互联网的飞速发展,互联网极大地提高了信息生成和传播的速度。互联网上每天都会产生大量的内容。如何从这些杂乱无章的内容中高效地发现和采集需要的信息似乎越来越多。越重要。互联网上的新闻内容也是如此。新闻分布在不同的网站上,存在重复的内容。我们往往只关心一些新闻。互联网上的新闻页面往往充斥着大量与新闻无关的新闻页面。这些信息会影响我们的阅读效率和阅读体验。如何更方便、及时、高效地获取我们关心的新闻内容,这个系统可以帮我们做到这一点。本系统利用网络爬虫对网络网站上的新闻进行定时、有针对性的分析和采集,然后对采集接收到的数据进行去重、分类和存储。进入数据库,最终提供个性化的新闻订阅服务。考虑如何处理网站的反爬虫策略,避免被网站拦截。在具体实现中,使用Python与scrapy等框架编写爬虫,使用特定的内容提取算法提取目标数据。最后使用Django和weui提供新闻订阅后台和新闻内容展示页面,使用微信向用户推送信息。用户可以通过本系统订阅指定关键词,
[关键词] 网络爬虫;消息; 个性化;订阅; Python
参考文档及完整文档及源代码下载地址:
根据关键词文章采集系统( 第八章页面分析(一)()页面的分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-11-27 03:14
第八章页面分析(一)()页面的分析)
基于主题的网络信息 采集 技术研究 (七)
第八章页面分析
在过滤和判断这些信息采集的URL和页面的过程中,主要是处理HTML页面。因此,我们在页面分析方面所做的工作主要包括对HTML页面进行语法分析,提取文本、链接、链接的扩展元数据等相关内容;然后对这些内容进行简单的处理和一致的处理;最后将处理结果存入中间信息记录数据库,进行URL过滤处理和页面过滤处理。
8.1 HTML 语法分析
因为采集对页面的语法分析是基于HTML(超文本标记语言)协议[RFC 1866]。整个语法分析过程可以看成两个层次,即SGML(Markup Grammar)层和HTML标记层。语法层将页面分解为文本、标签、注释等不同的语法成分,然后调用标签层对文本和标签进行处理。同时,标记层维护当前文本的各种状态,包括字体、字体等,这些状态是由特定的标记产生或改变的。
系统中使用的标记语法分析器的基本原理是:通过标记语法构造状态转换表,根据输入流中的当前字符(无前向)进行状态切换,相应的语义操作为达到特定状态时执行。这里先介绍几个概念,然后讨论主要语法成分的处理:
文字。文本是页面的初始状态。此状态下的所有字符(除了导致切换到其他状态的字符)构成页面主体的一部分,并根据当前主体状态交给标记层进行处理和保存。
l 标记。标签是出现在文本中并以字符“”结尾的字符串。当解析器遇到“”时,表示标签结束,将分析的标签结构传递给标签层。标签层根据标签名称和参数做相应的动作,包括修改文本的状态。如果计算“”开头的标记,并计算“--”模式的数量来标识页面上的注释,则该注释将被忽略,不做任何处理。
l 转义字符。如果文本以“nnn”或“&xxx”的形式出现(末尾可能有附加字符“;”),分析器会将其视为转义字符,查找后将相应字符添加到文本中上对应的对照表。
8.2 从页面中提取正文
虽然已经预测出该网址与主题相关,但该网址所指向的实际页面可能与预测结果相差甚远。这导致采集到达的页面中有很大一部分是与主题无关的,所以,我们需要判断页面的主题相关性,通过判断结果过滤掉不相关的页面,从而提高平均页面与主题在整个数据集中的相似度值,或提高基于主题的Web信息的准确性采集。
为此,我们需要在页面分析时提取页面主体。提取页面正文的方法比较简单。文本和标记都作为独立的语法组件传递给标记层,标记层根据标记区分页面标题和内容,并根据系统需要合并页面主体。目前还没有考虑不同字体或字体的文字差异。也就是说,在阅读页面的时候,找到标签总和,去掉两个标签之间的内容中的所有标签。
8.3 提取页面中的链接
需要对抓取到的页面中的链接进行分析,并对链接中的网址进行必要的转换。首先,确定页面类型。显然,只有“text/html”类型的页面需要分析链接。页面的类型可以通过分析响应头来获得。部分 WWW 站点返回的响应信息格式不完整。在这种情况下,必须分析页面 URL 中的文件扩展名以确定页面类型。当遇到带有链接的标签时,从标签结构的属性中找到目标URL,从标签对中提取文本作为链接的描述性文本(扩展元数据)。这两个数据代表链接。
提取页面链接的工作流程如下:
1) 从页面文件队列中取出一个页面文件。如果响应标头中未指定文件类型,请使用 URL 中的文件扩展名填写。如果页面文件队列为空,则跳转到7)。
2) 判断页面是否为text/html/htm/shtml文件。如果不是,则丢弃该文件并转移到1),否则转移到3)。
3) 从文件头开始依次读取文件,遇到如下标记
依此类推,记录URL连接。如果遇到文件尾,跳转到7)
4) 按照预定义的统一格式完成提取的URL链接。(页面链接中给出的URL可以是多种格式,可以是完整的,包括协议、站点、路径,也可以省略部分内容,也可以是相对路径)
5) 记录
等后面这个链接的说明吧。在确定 URL 和主题的相关性的章节中,我们将使用此信息并将其定义为扩展元数据。
6) 存储此 URL 及其扩展元数据,并跳转到 2)。
7) 提取页面 URL。
在该算法中,不仅提取了采集页面中的URL,还提取了每个URL的扩展元数据信息。在下一章中,我们将看到扩展元数据的应用。
8.4 从页面中提取标题
如图8.1,页面标题的提取分为三个步骤:1)。确定文本开头的位置,从文章的开头开始,逐段扫描直到一定长度,如果不小于设置的文本最小长度,则假设该段为文本中的一个段落。2)。从文本位置向前搜索可能是标题的段落,根据字体大小、居中、颜色变化等特点,找到最适合的段落作为标题。3)。通过给定的参数调整标题的部分,使标题提取更准确。句法、语义、并对标题段stTitlePara前后各段进行统计分析,准确判断标题段的真实位置;向前或向后调整几段,并添加上一段或下一段。
确定文本的开始位置
从文本位置向前搜索可能是标题的一段
通过给定的参数调整标题的部分,使标题提取更准确
标题
图8.1 提取页面中的标题
第九章URL、页面、主题的相关性判断
在基于主题的Web信息采集系统中,核心问题是确定页面分析得到的URL与这些页面的主题相关性。
来自采集的页面的URL有很多,其中相当一部分与采集的主题无关。为了能够有效地修剪采集,我们需要分析现有信息,预测该URL指向的页面的主题相关性,剔除不相关的URL。因此,我们也将确定 URL 和主题的相关性称为 URL 过滤或 URL 预测。根据Web上主题页面的Sibling/Linkage Locality的分布特征,直观的想法是利用已经采集到页面的主题来预测这个链接指向的页面的主题页。换句话说,如果这个页面与主题相关,那么页面中的链接(不包括噪声链接)都被预测为与主题相关,这显然是一个相当大的错误预测。进一步研究发现,每个链接附近的说明文字(如锚点信息)对链接指向的页面主题具有非常高的预测能力,对预测链接的准确率也很高。但问题在于,由于说明文字的信息有限,很多与主题相关的链接经常被省略,或者在提高URL预测准确率的同时,降低了URL预测的召回率(资源发现率)。为了缓解这个问题,我们在预测算法中加入了由链接关系决定的链接重要性的概念。通过发现重要的链接,在降低相关性判定阈值的同时,我们选择了一些相关性不高的链接。具有高重要性的链接被用作预测以提高召回率,同时减少准确率(重要的 URL 通常会导致更高的召回率)。为此,我们在扩展元数据判断和链接分析判断的基础上,提出了自己的判断算法IPageRank方法。
为了进一步提高采集页面的准确率,我们对采集到达的页面进行了主题相关性判定,计算该页面与主题的相关性值是否小于阈值确定为相关的值。页面被裁剪。我们也将确定页面和主题的相关性称为页面过滤。基于主题的 Web 信息 采集 的一个目标是找到 采集 的准确率和召回率的最佳组合。但是采集的准确率和召回率(或资源发现率)是一对矛盾的问题。也就是说,在提高准确率的同时,召回率会降低;会降低精度。解决这个矛盾的一个有效方法是先提高采集页面的召回率,即降低URL过滤的门槛(增加无关误判,减少相关误判),让更多的URL进入采集@采集队列为采集;然后采集到达后,比较页面和主题的相似度,去掉不相关的页面。这样就得到了更高的最终采集准确率和采集召回率。最后,我们选择了经典的向量空间模型来计算页面和主题之间的相关性。获得更高的最终采集准确率和采集召回率。最后,我们选择了经典的向量空间模型来计算页面和主题之间的相关性。获得更高的最终采集准确率和采集召回率。最后,我们选择了经典的向量空间模型来计算页面和主题之间的相关性。
下面,我们分别讨论我们系统中使用的URL和主题的相关性确定算法以及页面内容和主题的相关性确定算法。
9?? 1 URL与主题相关性判断-IPageRank算法
在权衡性能和效率之后,我们选择了使用扩展元数据加权的 IPageRank 算法来确定 URL 和主题的相关性。
9.1.1 IPageRank算法的目标
通过观察,我们发现PageRank方法虽然具有很强的寻找重要页面的能力,但它所找到的重要页面是针对广泛的主题,而不是基于一个特定的主题。因此,与主题无关的大量页面组指向的页面的PageRank值高于与主题相关的少量页面组指向的页面的PageRank值。这种现象对于基于话题的采集来说是不合理的。但是,我们要利用大量主题相关页面组所指向页面的PageRank值高于少数主题相关页面组所指向页面的PageRank值的现象. 为此,我们改进了PageRank方法:在链接关系的基础上,
9.1.2 IPageRank算法的生成过程
改进的方法有两个主要方面。一是改进算法中的公式;二是改进PageRank算法的启发式步骤。
9.1.2.1 PageRank 公式的改进
首先我们来看一下PageRank算法的公式:
公式9.1
其中 A 是给定的网页,假设指向它的网页有 T1、T2、...、Tn。设 C(A) 为 A 到其他网页的链接数(将 Web 视为有向图时,C(A) 指节点 A 的出度),PR(A) 为 PageRank 值A的,d为衰减因子(通常设置为0.85)。
那我们再来回顾一下RW算法公式9.2和RWB算法公式9.3:
公式9.2
公式9.2中,M(url)是指与该URL相关的所有扩展元数据的集合,指的是扩展元数据中的词与主题的相关程度。c 是用户设置的相关性阈值。
公式9.3
公式9.3中,T(url)表示收录这个URL的文本,t指的是文本中的每个词,c和之前一样,是用户设置的相关性阈值,d是用户设置提高阈值。P1 和 P2 是随机变量,它们在 0 和 1 之间变化。
我们发现公式9.1中每一个指向页面A的页面Ti,其重要性均等地传递到该页面中每个链接所指向的页面,即只有1/的页面C(Ti) 重要性传递到A页。我们认为这对于主题的重要性是不合理的。页面的重要性值,IPageRank,在通过链接时不应相等,而应与链接所连接的页面主题的相关性水平成正比。因此,我们像这样修改公式9.1:
公式9.4
其中,A为给定的网页,假设指向它的网页有T1、T2、...、Tn。urlT1, urlT2,..., urlTn 是网页 T1, T2,..., Tn 到 A 的链接,k1, k2,..., kn 是网页 T1, T2,... 收录的链接数., Tn 分别。IPR(A)为A的IPageRank值,d为衰减因子(同样设置为0.85)。
通过实验发现,基于扩展元数据的RW算法,虽然判断相关页面的准确率较高,但相关页面缺失的数量也非常高。这个结果使得判断相关页面太少,参与评价IageRank值的页面数量少,会大大影响IageRank值的准确性;同时,也会导致相关主题页面的召回率(或资源发现)。率)太低。基于扩展元数据的RWB算法提高了主题页面的召回率,同时由于提取的URL数量增加了IPPageRank值的准确性。为此,我们在下面的公式中将 RW 算法替换为基于扩展元数据的 RWB 算法。
公式9.5
为了区分这两种方法,我们分别称它们为IPageRank-RW算法和IPageRank-RWB算法。如果没有区别,我们称它们为 IPageRank 算法。
9.1.2.2 改进PageRank算法的启发式步骤
在公式9.1中计算每个页面的PageRank值时,在启发式步骤中将每个页面的PageRank值初始化为相同(1),这是因为PageRank方法反映了一个完整的链接关系不带有任何语义含义,每个页面只能被视为平等的权利,在初始条件下,没有说某个页面比另一个页面好,某个主题比另一个主题好。对于基于主题的IPageRank算法,在初始条件下,可以根据与主题的相关性来区分每个页面,这种差异总比没有差异要好。另外,这些初始页面已经采集,它们与主题的相关性可以通过向量空间模型 VSM 或扩展元数据算法来计算。因此,我们将每个页面的 IPageRank 值初始化为该页面与主题的相关性。
9.1.3 如何使用IPPageRank算法以及URL预测的可行性
PageRank算法主要通过迭代计算封闭集中每个页面的PageRank值,并对搜索引擎检索到的结果页面进行重新排序。PageRank 值的作用是先对重要页面进行排名。IPageRank 的使用是不同的。首先,IPageRank值的计算也是在一个封闭的集合中进行的。这个封闭集是已经采集的相关主题页面的集合;算法也会在大约 5 次迭代后停止;并且为了更准确地获取IPageRank值,一般每增加100页重新计算IPageRank值。但是,IPageRank 值用于预测从 采集 页面集中提取的 URL 的主题相关性。预测方法直接通过公式9.4或公式9.5。
这种用法上的差异带来了PageRank和IPageRank的两个不同:一是每个页面的PageRank值一般在5次迭代内收敛(已经证明),而IageRank的迭代值是由于公式的变化。不能证明这种收敛特性是遗传的,所以是否收敛目前还不能完全确定,虽然直觉上是收敛的。显然,这是一个严重的问题。如果不收敛,IPageRank 值就不能准确反映页面的重要性,这就使得预测 URL 变得毫无意义。其次,PageRank的计算环境是封闭的,应用环境也是封闭的。IPageRank 方法使用现有页面的 IPageRank 值来计算新 URL 的 IPageRank 值。这个环境不是完全封闭的。问题是这不是完全封闭,不会体现出网址的重要性,失去方法的意义。
我们做出如下解释,以证明IPageRank算法仍然有效。对于第一个问题,即使IPageRank未能收敛,我们认为经过5次迭代后的值非常接近真实值,可以对采集页面的处理起到预测作用;对于第二个问题,尽管IPPageRank的计算环境并不是完全封闭的,但是采集的页面比较多,这个环境的变化可以忽略不计,和PageRank环境非常相似。因此,我们认为IPageRank算法是可行的,可以用来预测URL队列为采集。
9.1.4 直观解释IPageRank算法
假设Web上有一个主题浏览者,IPageRank(即函数IPR(A))是它访问页面A的概率。它从初始页面集开始,跟随页面链接,从不执行“返回” “ 手术。在每个页面上,查看者对该页面中的每个链接感兴趣的概率与该链接与主题的相关性成正比。当然,浏览者可能不再对这个页面上的链接感兴趣,从而随机选择一个新页面开始新的浏览。这个离开的概率设置为d。
从直观上看,如果有很多页面指向一个页面,那么这个页面的PageRank会比较高,但IPPageRank值不一定高,除非很多页面中的大部分都与主题相关;如果有一个IPPageRank 如果一个很高的页面指向它,这个页面的IPageRank也会很高。这样,从“基于主题的查看器”模型出发的IPageRank功能直观地对应了WEB上的实际情况。如果有很多话题页面指向一个页面,那么这个页面值得一看;如果一个重要的话题资源中心引用了一个页面,这个页面也很重要,值得关注。
事实上,IPageRank算法不仅可以使用基于主题的信息采集,我们相信在域搜索引擎中,它对基于关键词的搜索排名也有很好的效果。
9.2 page和topic-vector空间模型算法的相关性判断
我们使用在检索领域非常常用的向量空间模型作为确定系统页面和主题之间相关性的方法。事实上,向量空间模型具有很强的处理能力,处理方法也比较简单。
我们的算法如下:
0)。预处理:在采集之前,我们首先对描述主题关键词的多个页面进行提取和加权,学习特征向量和属于该主题的向量的权重。
1)。我们对页面主体进行分割,去除停用词,并留下关键词。并根据关键词出现在文章中的频率,权重关键词。
2)。这个页面的标题被分词,将得到的关键词与文章中的关键词合并,给这个关键词加上权重。
3)。根据主题中的特征向量,对页面中的关键词进行剪裁和展开。
4)。根据公式9.3计算页面与主题的相似度,其中D1为主题,D2为要比较的页面。
公式9.6
5)。将Sim(D1,D2)的值与阈值d进行比较,如果Sim(D1,D2)大于等于d,则该页面与主题相关,保留给主题页面库;否则,不相关,删除该页面。
发表于 2006-03-26 02:56 Akun Reading (680)评论(0)编辑 查看全部
根据关键词文章采集系统(
第八章页面分析(一)()页面的分析)
基于主题的网络信息 采集 技术研究 (七)
第八章页面分析
在过滤和判断这些信息采集的URL和页面的过程中,主要是处理HTML页面。因此,我们在页面分析方面所做的工作主要包括对HTML页面进行语法分析,提取文本、链接、链接的扩展元数据等相关内容;然后对这些内容进行简单的处理和一致的处理;最后将处理结果存入中间信息记录数据库,进行URL过滤处理和页面过滤处理。
8.1 HTML 语法分析
因为采集对页面的语法分析是基于HTML(超文本标记语言)协议[RFC 1866]。整个语法分析过程可以看成两个层次,即SGML(Markup Grammar)层和HTML标记层。语法层将页面分解为文本、标签、注释等不同的语法成分,然后调用标签层对文本和标签进行处理。同时,标记层维护当前文本的各种状态,包括字体、字体等,这些状态是由特定的标记产生或改变的。
系统中使用的标记语法分析器的基本原理是:通过标记语法构造状态转换表,根据输入流中的当前字符(无前向)进行状态切换,相应的语义操作为达到特定状态时执行。这里先介绍几个概念,然后讨论主要语法成分的处理:
文字。文本是页面的初始状态。此状态下的所有字符(除了导致切换到其他状态的字符)构成页面主体的一部分,并根据当前主体状态交给标记层进行处理和保存。
l 标记。标签是出现在文本中并以字符“”结尾的字符串。当解析器遇到“”时,表示标签结束,将分析的标签结构传递给标签层。标签层根据标签名称和参数做相应的动作,包括修改文本的状态。如果计算“”开头的标记,并计算“--”模式的数量来标识页面上的注释,则该注释将被忽略,不做任何处理。
l 转义字符。如果文本以“nnn”或“&xxx”的形式出现(末尾可能有附加字符“;”),分析器会将其视为转义字符,查找后将相应字符添加到文本中上对应的对照表。
8.2 从页面中提取正文
虽然已经预测出该网址与主题相关,但该网址所指向的实际页面可能与预测结果相差甚远。这导致采集到达的页面中有很大一部分是与主题无关的,所以,我们需要判断页面的主题相关性,通过判断结果过滤掉不相关的页面,从而提高平均页面与主题在整个数据集中的相似度值,或提高基于主题的Web信息的准确性采集。
为此,我们需要在页面分析时提取页面主体。提取页面正文的方法比较简单。文本和标记都作为独立的语法组件传递给标记层,标记层根据标记区分页面标题和内容,并根据系统需要合并页面主体。目前还没有考虑不同字体或字体的文字差异。也就是说,在阅读页面的时候,找到标签总和,去掉两个标签之间的内容中的所有标签。
8.3 提取页面中的链接
需要对抓取到的页面中的链接进行分析,并对链接中的网址进行必要的转换。首先,确定页面类型。显然,只有“text/html”类型的页面需要分析链接。页面的类型可以通过分析响应头来获得。部分 WWW 站点返回的响应信息格式不完整。在这种情况下,必须分析页面 URL 中的文件扩展名以确定页面类型。当遇到带有链接的标签时,从标签结构的属性中找到目标URL,从标签对中提取文本作为链接的描述性文本(扩展元数据)。这两个数据代表链接。
提取页面链接的工作流程如下:
1) 从页面文件队列中取出一个页面文件。如果响应标头中未指定文件类型,请使用 URL 中的文件扩展名填写。如果页面文件队列为空,则跳转到7)。
2) 判断页面是否为text/html/htm/shtml文件。如果不是,则丢弃该文件并转移到1),否则转移到3)。
3) 从文件头开始依次读取文件,遇到如下标记
依此类推,记录URL连接。如果遇到文件尾,跳转到7)
4) 按照预定义的统一格式完成提取的URL链接。(页面链接中给出的URL可以是多种格式,可以是完整的,包括协议、站点、路径,也可以省略部分内容,也可以是相对路径)
5) 记录
等后面这个链接的说明吧。在确定 URL 和主题的相关性的章节中,我们将使用此信息并将其定义为扩展元数据。
6) 存储此 URL 及其扩展元数据,并跳转到 2)。
7) 提取页面 URL。
在该算法中,不仅提取了采集页面中的URL,还提取了每个URL的扩展元数据信息。在下一章中,我们将看到扩展元数据的应用。
8.4 从页面中提取标题
如图8.1,页面标题的提取分为三个步骤:1)。确定文本开头的位置,从文章的开头开始,逐段扫描直到一定长度,如果不小于设置的文本最小长度,则假设该段为文本中的一个段落。2)。从文本位置向前搜索可能是标题的段落,根据字体大小、居中、颜色变化等特点,找到最适合的段落作为标题。3)。通过给定的参数调整标题的部分,使标题提取更准确。句法、语义、并对标题段stTitlePara前后各段进行统计分析,准确判断标题段的真实位置;向前或向后调整几段,并添加上一段或下一段。
确定文本的开始位置
从文本位置向前搜索可能是标题的一段
通过给定的参数调整标题的部分,使标题提取更准确
标题
图8.1 提取页面中的标题
第九章URL、页面、主题的相关性判断
在基于主题的Web信息采集系统中,核心问题是确定页面分析得到的URL与这些页面的主题相关性。
来自采集的页面的URL有很多,其中相当一部分与采集的主题无关。为了能够有效地修剪采集,我们需要分析现有信息,预测该URL指向的页面的主题相关性,剔除不相关的URL。因此,我们也将确定 URL 和主题的相关性称为 URL 过滤或 URL 预测。根据Web上主题页面的Sibling/Linkage Locality的分布特征,直观的想法是利用已经采集到页面的主题来预测这个链接指向的页面的主题页。换句话说,如果这个页面与主题相关,那么页面中的链接(不包括噪声链接)都被预测为与主题相关,这显然是一个相当大的错误预测。进一步研究发现,每个链接附近的说明文字(如锚点信息)对链接指向的页面主题具有非常高的预测能力,对预测链接的准确率也很高。但问题在于,由于说明文字的信息有限,很多与主题相关的链接经常被省略,或者在提高URL预测准确率的同时,降低了URL预测的召回率(资源发现率)。为了缓解这个问题,我们在预测算法中加入了由链接关系决定的链接重要性的概念。通过发现重要的链接,在降低相关性判定阈值的同时,我们选择了一些相关性不高的链接。具有高重要性的链接被用作预测以提高召回率,同时减少准确率(重要的 URL 通常会导致更高的召回率)。为此,我们在扩展元数据判断和链接分析判断的基础上,提出了自己的判断算法IPageRank方法。
为了进一步提高采集页面的准确率,我们对采集到达的页面进行了主题相关性判定,计算该页面与主题的相关性值是否小于阈值确定为相关的值。页面被裁剪。我们也将确定页面和主题的相关性称为页面过滤。基于主题的 Web 信息 采集 的一个目标是找到 采集 的准确率和召回率的最佳组合。但是采集的准确率和召回率(或资源发现率)是一对矛盾的问题。也就是说,在提高准确率的同时,召回率会降低;会降低精度。解决这个矛盾的一个有效方法是先提高采集页面的召回率,即降低URL过滤的门槛(增加无关误判,减少相关误判),让更多的URL进入采集@采集队列为采集;然后采集到达后,比较页面和主题的相似度,去掉不相关的页面。这样就得到了更高的最终采集准确率和采集召回率。最后,我们选择了经典的向量空间模型来计算页面和主题之间的相关性。获得更高的最终采集准确率和采集召回率。最后,我们选择了经典的向量空间模型来计算页面和主题之间的相关性。获得更高的最终采集准确率和采集召回率。最后,我们选择了经典的向量空间模型来计算页面和主题之间的相关性。
下面,我们分别讨论我们系统中使用的URL和主题的相关性确定算法以及页面内容和主题的相关性确定算法。
9?? 1 URL与主题相关性判断-IPageRank算法
在权衡性能和效率之后,我们选择了使用扩展元数据加权的 IPageRank 算法来确定 URL 和主题的相关性。
9.1.1 IPageRank算法的目标
通过观察,我们发现PageRank方法虽然具有很强的寻找重要页面的能力,但它所找到的重要页面是针对广泛的主题,而不是基于一个特定的主题。因此,与主题无关的大量页面组指向的页面的PageRank值高于与主题相关的少量页面组指向的页面的PageRank值。这种现象对于基于话题的采集来说是不合理的。但是,我们要利用大量主题相关页面组所指向页面的PageRank值高于少数主题相关页面组所指向页面的PageRank值的现象. 为此,我们改进了PageRank方法:在链接关系的基础上,
9.1.2 IPageRank算法的生成过程
改进的方法有两个主要方面。一是改进算法中的公式;二是改进PageRank算法的启发式步骤。
9.1.2.1 PageRank 公式的改进
首先我们来看一下PageRank算法的公式:
公式9.1
其中 A 是给定的网页,假设指向它的网页有 T1、T2、...、Tn。设 C(A) 为 A 到其他网页的链接数(将 Web 视为有向图时,C(A) 指节点 A 的出度),PR(A) 为 PageRank 值A的,d为衰减因子(通常设置为0.85)。
那我们再来回顾一下RW算法公式9.2和RWB算法公式9.3:
公式9.2
公式9.2中,M(url)是指与该URL相关的所有扩展元数据的集合,指的是扩展元数据中的词与主题的相关程度。c 是用户设置的相关性阈值。
公式9.3
公式9.3中,T(url)表示收录这个URL的文本,t指的是文本中的每个词,c和之前一样,是用户设置的相关性阈值,d是用户设置提高阈值。P1 和 P2 是随机变量,它们在 0 和 1 之间变化。
我们发现公式9.1中每一个指向页面A的页面Ti,其重要性均等地传递到该页面中每个链接所指向的页面,即只有1/的页面C(Ti) 重要性传递到A页。我们认为这对于主题的重要性是不合理的。页面的重要性值,IPageRank,在通过链接时不应相等,而应与链接所连接的页面主题的相关性水平成正比。因此,我们像这样修改公式9.1:
公式9.4
其中,A为给定的网页,假设指向它的网页有T1、T2、...、Tn。urlT1, urlT2,..., urlTn 是网页 T1, T2,..., Tn 到 A 的链接,k1, k2,..., kn 是网页 T1, T2,... 收录的链接数., Tn 分别。IPR(A)为A的IPageRank值,d为衰减因子(同样设置为0.85)。
通过实验发现,基于扩展元数据的RW算法,虽然判断相关页面的准确率较高,但相关页面缺失的数量也非常高。这个结果使得判断相关页面太少,参与评价IageRank值的页面数量少,会大大影响IageRank值的准确性;同时,也会导致相关主题页面的召回率(或资源发现)。率)太低。基于扩展元数据的RWB算法提高了主题页面的召回率,同时由于提取的URL数量增加了IPPageRank值的准确性。为此,我们在下面的公式中将 RW 算法替换为基于扩展元数据的 RWB 算法。
公式9.5
为了区分这两种方法,我们分别称它们为IPageRank-RW算法和IPageRank-RWB算法。如果没有区别,我们称它们为 IPageRank 算法。
9.1.2.2 改进PageRank算法的启发式步骤
在公式9.1中计算每个页面的PageRank值时,在启发式步骤中将每个页面的PageRank值初始化为相同(1),这是因为PageRank方法反映了一个完整的链接关系不带有任何语义含义,每个页面只能被视为平等的权利,在初始条件下,没有说某个页面比另一个页面好,某个主题比另一个主题好。对于基于主题的IPageRank算法,在初始条件下,可以根据与主题的相关性来区分每个页面,这种差异总比没有差异要好。另外,这些初始页面已经采集,它们与主题的相关性可以通过向量空间模型 VSM 或扩展元数据算法来计算。因此,我们将每个页面的 IPageRank 值初始化为该页面与主题的相关性。
9.1.3 如何使用IPPageRank算法以及URL预测的可行性
PageRank算法主要通过迭代计算封闭集中每个页面的PageRank值,并对搜索引擎检索到的结果页面进行重新排序。PageRank 值的作用是先对重要页面进行排名。IPageRank 的使用是不同的。首先,IPageRank值的计算也是在一个封闭的集合中进行的。这个封闭集是已经采集的相关主题页面的集合;算法也会在大约 5 次迭代后停止;并且为了更准确地获取IPageRank值,一般每增加100页重新计算IPageRank值。但是,IPageRank 值用于预测从 采集 页面集中提取的 URL 的主题相关性。预测方法直接通过公式9.4或公式9.5。
这种用法上的差异带来了PageRank和IPageRank的两个不同:一是每个页面的PageRank值一般在5次迭代内收敛(已经证明),而IageRank的迭代值是由于公式的变化。不能证明这种收敛特性是遗传的,所以是否收敛目前还不能完全确定,虽然直觉上是收敛的。显然,这是一个严重的问题。如果不收敛,IPageRank 值就不能准确反映页面的重要性,这就使得预测 URL 变得毫无意义。其次,PageRank的计算环境是封闭的,应用环境也是封闭的。IPageRank 方法使用现有页面的 IPageRank 值来计算新 URL 的 IPageRank 值。这个环境不是完全封闭的。问题是这不是完全封闭,不会体现出网址的重要性,失去方法的意义。
我们做出如下解释,以证明IPageRank算法仍然有效。对于第一个问题,即使IPageRank未能收敛,我们认为经过5次迭代后的值非常接近真实值,可以对采集页面的处理起到预测作用;对于第二个问题,尽管IPPageRank的计算环境并不是完全封闭的,但是采集的页面比较多,这个环境的变化可以忽略不计,和PageRank环境非常相似。因此,我们认为IPageRank算法是可行的,可以用来预测URL队列为采集。
9.1.4 直观解释IPageRank算法
假设Web上有一个主题浏览者,IPageRank(即函数IPR(A))是它访问页面A的概率。它从初始页面集开始,跟随页面链接,从不执行“返回” “ 手术。在每个页面上,查看者对该页面中的每个链接感兴趣的概率与该链接与主题的相关性成正比。当然,浏览者可能不再对这个页面上的链接感兴趣,从而随机选择一个新页面开始新的浏览。这个离开的概率设置为d。
从直观上看,如果有很多页面指向一个页面,那么这个页面的PageRank会比较高,但IPPageRank值不一定高,除非很多页面中的大部分都与主题相关;如果有一个IPPageRank 如果一个很高的页面指向它,这个页面的IPageRank也会很高。这样,从“基于主题的查看器”模型出发的IPageRank功能直观地对应了WEB上的实际情况。如果有很多话题页面指向一个页面,那么这个页面值得一看;如果一个重要的话题资源中心引用了一个页面,这个页面也很重要,值得关注。
事实上,IPageRank算法不仅可以使用基于主题的信息采集,我们相信在域搜索引擎中,它对基于关键词的搜索排名也有很好的效果。
9.2 page和topic-vector空间模型算法的相关性判断
我们使用在检索领域非常常用的向量空间模型作为确定系统页面和主题之间相关性的方法。事实上,向量空间模型具有很强的处理能力,处理方法也比较简单。
我们的算法如下:
0)。预处理:在采集之前,我们首先对描述主题关键词的多个页面进行提取和加权,学习特征向量和属于该主题的向量的权重。
1)。我们对页面主体进行分割,去除停用词,并留下关键词。并根据关键词出现在文章中的频率,权重关键词。
2)。这个页面的标题被分词,将得到的关键词与文章中的关键词合并,给这个关键词加上权重。
3)。根据主题中的特征向量,对页面中的关键词进行剪裁和展开。
4)。根据公式9.3计算页面与主题的相似度,其中D1为主题,D2为要比较的页面。
公式9.6
5)。将Sim(D1,D2)的值与阈值d进行比较,如果Sim(D1,D2)大于等于d,则该页面与主题相关,保留给主题页面库;否则,不相关,删除该页面。
发表于 2006-03-26 02:56 Akun Reading (680)评论(0)编辑
根据关键词文章采集系统(googlereader,做电商有很多idea,也许是下一个商业风口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-11-27 01:04
根据关键词文章采集系统googlereader,googlearts&culture,googleseotech做电商有很多idea,自媒体有很多有创意的点子,新的技术应用,新的展现形式,新的商业模式,看了很多风口,看了很多机会,天上不会掉馅饼,那些都是镜花水月,也许是下一个商业风口,等上n年,看到了一些,获得了一些,收获了一些,却不会再有那么多飞来的桃花。
寻找回到互联网本质,各式各样的方式都需要将互联网技术落地,可大可小。快速的创业项目、资本市场,依靠强大的团队或者强力投资组合或者抱团战略,迅速获得大量投资,迅速完成商业机会。庞大的资金运作(绝不是连年亏损或者巨额亏损),伴随着快速扩张,大力扩张。但凡花样百出,投资人往往更看重后者。几轮快速的折腾之后,一旦达到资金能够沉淀并且获得资金复利的极致,资金开始迅速流动,伴随着市场份额的增长以及获得相关合作伙伴进一步扩大公司范围和影响力,将会有更多新的盈利模式实现,加速扩张,加速转化最终实现低成本生存或者覆盖其他成本,跨越式发展。
把时间当作生命。上班时你看到的一切都是即将发生的。当你终于实现财务自由,有更多的时间做自己想做的事情,才能更多的看到即将发生的事情。所以,与其犹犹豫豫,惶惶不可终日,不如就这样随心的过一生。(建议每一个还未踏出步伐的人,在年底的时候回头看看,那些折腾了半天的日子里,那些只觉得难过却无法实现的。肯定会很有收获。)。 查看全部
根据关键词文章采集系统(googlereader,做电商有很多idea,也许是下一个商业风口)
根据关键词文章采集系统googlereader,googlearts&culture,googleseotech做电商有很多idea,自媒体有很多有创意的点子,新的技术应用,新的展现形式,新的商业模式,看了很多风口,看了很多机会,天上不会掉馅饼,那些都是镜花水月,也许是下一个商业风口,等上n年,看到了一些,获得了一些,收获了一些,却不会再有那么多飞来的桃花。
寻找回到互联网本质,各式各样的方式都需要将互联网技术落地,可大可小。快速的创业项目、资本市场,依靠强大的团队或者强力投资组合或者抱团战略,迅速获得大量投资,迅速完成商业机会。庞大的资金运作(绝不是连年亏损或者巨额亏损),伴随着快速扩张,大力扩张。但凡花样百出,投资人往往更看重后者。几轮快速的折腾之后,一旦达到资金能够沉淀并且获得资金复利的极致,资金开始迅速流动,伴随着市场份额的增长以及获得相关合作伙伴进一步扩大公司范围和影响力,将会有更多新的盈利模式实现,加速扩张,加速转化最终实现低成本生存或者覆盖其他成本,跨越式发展。
把时间当作生命。上班时你看到的一切都是即将发生的。当你终于实现财务自由,有更多的时间做自己想做的事情,才能更多的看到即将发生的事情。所以,与其犹犹豫豫,惶惶不可终日,不如就这样随心的过一生。(建议每一个还未踏出步伐的人,在年底的时候回头看看,那些折腾了半天的日子里,那些只觉得难过却无法实现的。肯定会很有收获。)。
根据关键词文章采集系统(botfan基于robots协议进行非侵入爬取,botfan采集系统效果展示)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-11-25 05:03
根据关键词文章采集系统之botfan推送文章,简单的说就是基于爬虫的文章采集系统,实现文章的海量采集,botfan采集系统可以从一定数量的网站和微信公众号内采集文章并推送至大众手机或者网页端,botfan推送文章主要通过"爬虫"实现了一键爬取每日各大热门微信公众号的最新文章,以及各大重要新闻。botfan基于robots协议进行非侵入爬取,同时基于抓包技术破解相关网站的代理ip和ssl证书,使用user-agent抓取网站上的http请求,这种方式可以保证代理爬虫是安全的,因为爬虫并不知道爬取的文章都是什么类型的,而且作者也不希望爬取进来的信息是广告及不明的网站。
首先,将手机等带有采集功能的移动终端网页端刷新后点击"设置-人工采集"再次刷新的时候刷新chrome、firefox、谷歌浏览器的点击效果不同,详细见下图。botfan采集系统效果展示首先是chrome浏览器,如下图所示:其次是firefox浏览器,如下图所示:chrome浏览器效果如下图所示:而firefox浏览器则正是因为其对http协议友好而导致其爬取速度快于谷歌浏览器,所以现在大部分网站都禁止谷歌浏览器访问,暂时也不支持将爬取速度从海量的标题页爬取到独立详情页,其实谷歌浏览器还是可以正常访问很多网站的,只是速度较慢。botfan采集系统效果展示下面以chrome浏览器为例介绍下安装和使用:。
1、安装插件botfail——若有安装一些其他的插件依然无法正常使用请后台回复。
2、在浏览器的地址栏输入:/然后右键显示安装,并按照提示完成安装。
3、打开botfail编辑框或者框框内搜索chrome,并安装编辑器插件。
4、将这个项目下的插件拖拽进来,并选择喜欢的模板进行导入。
5、选择一个模板点击新建或者直接浏览器输入在地址栏中输入:,这里使用tabs模板,详细设置看startactivity运行效果。
同时为防止爬取的网站是已知的网站导致验证失败,
1、请选择chrome浏览器为网站登录,
2、登录一个已知的botfan采集网站并验证成功后,点击开始后台设置。
设置图如下所示:
5、安装完成后请点击左下角对应状态标识上的『启用』,并继续在其他浏览器中上传插件使用。ps:botfail是一个采集系统,不保证采集结果的准确性和更新速度。ps:botfan文章采集系统收费为开发者2.99元/人,后端开发1.49元/人。 查看全部
根据关键词文章采集系统(botfan基于robots协议进行非侵入爬取,botfan采集系统效果展示)
根据关键词文章采集系统之botfan推送文章,简单的说就是基于爬虫的文章采集系统,实现文章的海量采集,botfan采集系统可以从一定数量的网站和微信公众号内采集文章并推送至大众手机或者网页端,botfan推送文章主要通过"爬虫"实现了一键爬取每日各大热门微信公众号的最新文章,以及各大重要新闻。botfan基于robots协议进行非侵入爬取,同时基于抓包技术破解相关网站的代理ip和ssl证书,使用user-agent抓取网站上的http请求,这种方式可以保证代理爬虫是安全的,因为爬虫并不知道爬取的文章都是什么类型的,而且作者也不希望爬取进来的信息是广告及不明的网站。
首先,将手机等带有采集功能的移动终端网页端刷新后点击"设置-人工采集"再次刷新的时候刷新chrome、firefox、谷歌浏览器的点击效果不同,详细见下图。botfan采集系统效果展示首先是chrome浏览器,如下图所示:其次是firefox浏览器,如下图所示:chrome浏览器效果如下图所示:而firefox浏览器则正是因为其对http协议友好而导致其爬取速度快于谷歌浏览器,所以现在大部分网站都禁止谷歌浏览器访问,暂时也不支持将爬取速度从海量的标题页爬取到独立详情页,其实谷歌浏览器还是可以正常访问很多网站的,只是速度较慢。botfan采集系统效果展示下面以chrome浏览器为例介绍下安装和使用:。
1、安装插件botfail——若有安装一些其他的插件依然无法正常使用请后台回复。
2、在浏览器的地址栏输入:/然后右键显示安装,并按照提示完成安装。
3、打开botfail编辑框或者框框内搜索chrome,并安装编辑器插件。
4、将这个项目下的插件拖拽进来,并选择喜欢的模板进行导入。
5、选择一个模板点击新建或者直接浏览器输入在地址栏中输入:,这里使用tabs模板,详细设置看startactivity运行效果。
同时为防止爬取的网站是已知的网站导致验证失败,
1、请选择chrome浏览器为网站登录,
2、登录一个已知的botfan采集网站并验证成功后,点击开始后台设置。
设置图如下所示:
5、安装完成后请点击左下角对应状态标识上的『启用』,并继续在其他浏览器中上传插件使用。ps:botfail是一个采集系统,不保证采集结果的准确性和更新速度。ps:botfan文章采集系统收费为开发者2.99元/人,后端开发1.49元/人。
根据关键词文章采集系统(个人推荐元道云采集导航,通过文章标题和自动生成摘要)
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-23 17:06
根据关键词文章采集系统,ky算法,年月日,相似度排序,按时间顺序,
自问自答一下,这个不是一个文章采集系统,是一个常规文章发布系统,例如简书发表文章全部记录在系统内,需要实现自动发布过程可以查看我个人公众号,
我觉得可以通过云采集:市面上,大多数的图文采集系统都是提供的云采集功能。现在用的比较多的是图狗云采集,是众多云采集平台中仅有一家可以正式商用的。同时采集下来的文章基本质量会好很多,因为网站会将文章按照质量划分,看起来质量比较好一些。
题主自己先答个。很简单啊,不用去相关的网站去搜,直接通过网站下载,有些需要二次验证的上面都有说明的,比如说最好要带版权声明的啊,商业用途等等的。
个人推荐元道云采集导航,通过文章标题和自动生成摘要导航采集。
给几个给个准确的定义:网站采集系统:来源网站的内容如果是原创的,一般就是直接从采集站扒下来,文章采集这块现在在b2b市场里已经被个别网站逼着走窄门了,对质量要求也很高,发现不了源头的话后期压力大。个人站点采集系统:来源网站一般已经水文化局等管制的不多,而且有点些经验的同学肯定知道:对源头的维护基本也是网站采集系统的卖点了,但和一般的系统操作上有所区别,特别是追溯功能,追溯到源头的源文档信息再用在搜索引擎里,效果更佳。
需要关注的点:源文档质量(这个决定源文档价值和价格)和数量(做大站比较重要)。你以为采集了别人的源文档内容就得到了,其实没那么简单。采集到手的文档里还有版权信息,不清楚他还是不是原创,有两万多的河南帽子文章,这部分内容卖多少钱你们自己想象。如果要做老总关注的重点话,做老板关注的重点话,起码还有五十万/年的采集费用,回本儿遥遥无期。
按照文章收入、篇篇10-50万不等。如果给你这样的采集系统,那价格你都拿的起,但你知道领导有这么多的人吗?关键有产品开发可以解决吗?大佬们满意了,可以开发试试吧。 查看全部
根据关键词文章采集系统(个人推荐元道云采集导航,通过文章标题和自动生成摘要)
根据关键词文章采集系统,ky算法,年月日,相似度排序,按时间顺序,
自问自答一下,这个不是一个文章采集系统,是一个常规文章发布系统,例如简书发表文章全部记录在系统内,需要实现自动发布过程可以查看我个人公众号,
我觉得可以通过云采集:市面上,大多数的图文采集系统都是提供的云采集功能。现在用的比较多的是图狗云采集,是众多云采集平台中仅有一家可以正式商用的。同时采集下来的文章基本质量会好很多,因为网站会将文章按照质量划分,看起来质量比较好一些。
题主自己先答个。很简单啊,不用去相关的网站去搜,直接通过网站下载,有些需要二次验证的上面都有说明的,比如说最好要带版权声明的啊,商业用途等等的。
个人推荐元道云采集导航,通过文章标题和自动生成摘要导航采集。
给几个给个准确的定义:网站采集系统:来源网站的内容如果是原创的,一般就是直接从采集站扒下来,文章采集这块现在在b2b市场里已经被个别网站逼着走窄门了,对质量要求也很高,发现不了源头的话后期压力大。个人站点采集系统:来源网站一般已经水文化局等管制的不多,而且有点些经验的同学肯定知道:对源头的维护基本也是网站采集系统的卖点了,但和一般的系统操作上有所区别,特别是追溯功能,追溯到源头的源文档信息再用在搜索引擎里,效果更佳。
需要关注的点:源文档质量(这个决定源文档价值和价格)和数量(做大站比较重要)。你以为采集了别人的源文档内容就得到了,其实没那么简单。采集到手的文档里还有版权信息,不清楚他还是不是原创,有两万多的河南帽子文章,这部分内容卖多少钱你们自己想象。如果要做老总关注的重点话,做老板关注的重点话,起码还有五十万/年的采集费用,回本儿遥遥无期。
按照文章收入、篇篇10-50万不等。如果给你这样的采集系统,那价格你都拿的起,但你知道领导有这么多的人吗?关键有产品开发可以解决吗?大佬们满意了,可以开发试试吧。
根据关键词文章采集系统(Tags:51下载网提供《优采云站群管理系统》13.08.10.19免费版下载)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-11-23 17:04
标签:
51下载网提供《优采云站群管理系统》13.08.10.19免费版下载,本软件为免费软件,文件大小26.14 MB,推荐指数3星,作为国产软件的顶级厂商,可以放心下载!
优采云站群 管理系统是一个管理系统,可以通过关键词自动采集各大搜索引擎的相关搜索词和相关长尾词,然后根据搜索结果抓取大量最新数据。派生词。摒弃普通采集软件所需的繁琐规则定制,实现一键采集一键发布。只需输入关键词到采集即可获取最新的相关内容,并自动将SEO发布到指定的网站多任务站群管理系统,可使用24一天几个小时。自动维护数百个网站。
优采云站群具有强大的采集功能,支持关键词采集 文章采集,图片和视频采集,还支持自定义采集规则指定域名采集,还提供了超强的原创文章生成功能,支持数据自由导入导出,支持各种链接插入和链轮功能,批量站点和栏目添加,栏目id绑定等功能,支持自定义发布界面编辑,真正实现对各种站点程序的完美支持,是多站点维护管理的必备工具。
特征
1、站点数量不限
优采云站群 软件秉承为用户提供最实用的软件,无限建站数量,打造真正的站群软件为宗旨;无论购买哪个版本,都没有限制网站程序数量和域名不绑定电脑,与其他同类站群管理软件有很大不同。
2、智能蜘蛛引擎
优采云站群软件打造的智能蜘蛛引擎,只需要输入几个相关的关键词,自动推导出上千条长尾关键词,然后针对这些长尾尾巴关键词自动从网络采集到最新的文章、图片、视频等内容。无需任何采集规则,完全实现一键抓取任务。是一套站群采集真正操作简单、功能强大的软件。
3、SEO伪原创 和词库管理
优采云站群软件全面支持标题和内容的近义词替换、分词重构、禁词库阻塞、内容段落打乱重排、文章内容随机插入图片、视频等,可以很好的实现伪原创的标题和内容;不管你做多少、几十甚至上百个站,你都不必担心采集文章 收录对于搜索引擎的重复性。
4、全站无限循环挂机全自动更新
设置关键词和抓取频率后,站群管理系统会自动生成相关的关键词,自动抓取相关的文章并发布到指定的网站列中,轻松实现一键采集更新,支持365天无限循环挂机采集维护所有网站,真正实现无人监控、无人操作,让网站建设与维护变得如此简单。
5、强大的链轮功能
支持文章随机插入指定内容,锚文本链接,单站链接库链轮,自动提取文章内容链接到单站链接库或全局链接库,支持自定义链轮,可以实现任何 Sprocket 组合。
6、按关键字自动采集图片(可作为图片站)
优采云站群支持直接根据关键词批量采集图片,将图片插入到每列文章,也支持直接采集图片单独发布,你可以制作一个专门的图片网站。
7、自动按关键字采集视频(可作为视频站)
优采云站群支持直接按关键词批量采集视频,将视频插入每一列文章,也支持直接采集视频它可以单独发布,也可以作为专用的视频网站。
8、超强原创文章生成功能
优采云站群内置超级原创文章生成库,支持自定义句库生成原创文章(使用现有的文章库中的文章子句随机组成一个新的文章),自定义句型库生成原创文章和自定义模板/元素库生成原创 文章,也支持将已经采集的文章段落混合生成文章。
9、数据任意导入导出
优采云站群支持将采集软件原版文章批量导出到本地,支持伪原创软件后批量导出文章软件@>到本地和批处理端采集文章,在将文章导出到本地的同时,也支持将本地文章导入到站群中,并支持导入一个每列一定数量的文章,也支持每个网站随机列直接导入一个或多个软文广告文章。
10、强大的批处理功能
优采云站群 支持批量添加站点和栏目,批量提取栏目和id绑定等,更网站可以轻松管理。
11、通用自定义发布界面
优采云站群支持任意网站自定义发布界面,无论是论坛、博客、cms等任何网站,都可以通过自定义界面工具编辑相应的发布界面,真正实现对各类站点程序的完美支持。 查看全部
根据关键词文章采集系统(Tags:51下载网提供《优采云站群管理系统》13.08.10.19免费版下载)
标签:
51下载网提供《优采云站群管理系统》13.08.10.19免费版下载,本软件为免费软件,文件大小26.14 MB,推荐指数3星,作为国产软件的顶级厂商,可以放心下载!
优采云站群 管理系统是一个管理系统,可以通过关键词自动采集各大搜索引擎的相关搜索词和相关长尾词,然后根据搜索结果抓取大量最新数据。派生词。摒弃普通采集软件所需的繁琐规则定制,实现一键采集一键发布。只需输入关键词到采集即可获取最新的相关内容,并自动将SEO发布到指定的网站多任务站群管理系统,可使用24一天几个小时。自动维护数百个网站。
优采云站群具有强大的采集功能,支持关键词采集 文章采集,图片和视频采集,还支持自定义采集规则指定域名采集,还提供了超强的原创文章生成功能,支持数据自由导入导出,支持各种链接插入和链轮功能,批量站点和栏目添加,栏目id绑定等功能,支持自定义发布界面编辑,真正实现对各种站点程序的完美支持,是多站点维护管理的必备工具。
特征
1、站点数量不限
优采云站群 软件秉承为用户提供最实用的软件,无限建站数量,打造真正的站群软件为宗旨;无论购买哪个版本,都没有限制网站程序数量和域名不绑定电脑,与其他同类站群管理软件有很大不同。
2、智能蜘蛛引擎
优采云站群软件打造的智能蜘蛛引擎,只需要输入几个相关的关键词,自动推导出上千条长尾关键词,然后针对这些长尾尾巴关键词自动从网络采集到最新的文章、图片、视频等内容。无需任何采集规则,完全实现一键抓取任务。是一套站群采集真正操作简单、功能强大的软件。
3、SEO伪原创 和词库管理
优采云站群软件全面支持标题和内容的近义词替换、分词重构、禁词库阻塞、内容段落打乱重排、文章内容随机插入图片、视频等,可以很好的实现伪原创的标题和内容;不管你做多少、几十甚至上百个站,你都不必担心采集文章 收录对于搜索引擎的重复性。
4、全站无限循环挂机全自动更新
设置关键词和抓取频率后,站群管理系统会自动生成相关的关键词,自动抓取相关的文章并发布到指定的网站列中,轻松实现一键采集更新,支持365天无限循环挂机采集维护所有网站,真正实现无人监控、无人操作,让网站建设与维护变得如此简单。
5、强大的链轮功能
支持文章随机插入指定内容,锚文本链接,单站链接库链轮,自动提取文章内容链接到单站链接库或全局链接库,支持自定义链轮,可以实现任何 Sprocket 组合。
6、按关键字自动采集图片(可作为图片站)
优采云站群支持直接根据关键词批量采集图片,将图片插入到每列文章,也支持直接采集图片单独发布,你可以制作一个专门的图片网站。
7、自动按关键字采集视频(可作为视频站)
优采云站群支持直接按关键词批量采集视频,将视频插入每一列文章,也支持直接采集视频它可以单独发布,也可以作为专用的视频网站。
8、超强原创文章生成功能
优采云站群内置超级原创文章生成库,支持自定义句库生成原创文章(使用现有的文章库中的文章子句随机组成一个新的文章),自定义句型库生成原创文章和自定义模板/元素库生成原创 文章,也支持将已经采集的文章段落混合生成文章。
9、数据任意导入导出
优采云站群支持将采集软件原版文章批量导出到本地,支持伪原创软件后批量导出文章软件@>到本地和批处理端采集文章,在将文章导出到本地的同时,也支持将本地文章导入到站群中,并支持导入一个每列一定数量的文章,也支持每个网站随机列直接导入一个或多个软文广告文章。
10、强大的批处理功能
优采云站群 支持批量添加站点和栏目,批量提取栏目和id绑定等,更网站可以轻松管理。
11、通用自定义发布界面
优采云站群支持任意网站自定义发布界面,无论是论坛、博客、cms等任何网站,都可以通过自定义界面工具编辑相应的发布界面,真正实现对各类站点程序的完美支持。
根据关键词文章采集系统(1.如何挖掘关键词?2.如何选择关键词?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-11-19 20:09
1. 如何挖矿关键词?
2. 如何选择关键词?首先,我们必须对关键词进行竞争分析。然后从多个关键词中确定最终的关键词。
3. 如何构建关键词 库?
1.抓住竞争对手网站的关键词,并根据行业和自己的分析,研究行业内有哪些类型的关键词,有哪些关键词。
2. 选择一批基础的关键词,为每个词设置不同的分类。
关键词 的具体数量取决于行业。基本上,你必须为每个类别选择几十个关键词。如果行业规模的搜索量在几十万以上,那么基本的关键词总共选择的应该至少有几百级。以婚庆行业为例,如何分类。
3.根据基本关键词使用百度推广跑步数据。就是用百度推广的关键词工具搜索上一步我们选择的所有关键词。然后导出数据。注意:导出数据时需要精确匹配类型。
4. 根据数据结果填写基本的关键词。在搜索和导出数据的过程中,我们可能会发现之前的基础关键词库中缺少了一些重要的词。这时候就需要把这些词加入到基本的关键词库中,然后重复步骤3。
5. 制作一个完整的未处理数据表。完成第四步后,我们会有更多的原创关键词数据,或者简单的excel表格。我们需要将excel表中的所有数据汇总到一张表中。
6. 手动调整所有数据的分类,使用Excel过滤功能,然后手动为每个关键词选择一个分类,即添加一列分类数据。在这个过程中,可以使用筛选功能来提高效率。这是整个过程中最为繁琐复杂的一个过程。曾经花了近60个小时整理出一个关键词字库,3万多字,总搜索量近200万。
7. 大功告成。把每个关键词的分类填好后,实际上可以根据分类查看每个关键词的特征。这具有真正的分析价值。
ps 关键词 研究的目的不是要知道所有的词,而是要知道用户的搜索习惯。
以上是我开发的内部工作流程。
关于工具使用的问题:
目前市场上还没有批量查询关键词搜索量的好工具。所以没有办法按照规则批量写关键词,比如region+摄影。
如果有同学知道或有,请分享。
@郭世雄 查看全部
根据关键词文章采集系统(1.如何挖掘关键词?2.如何选择关键词?(图))
1. 如何挖矿关键词?
2. 如何选择关键词?首先,我们必须对关键词进行竞争分析。然后从多个关键词中确定最终的关键词。
3. 如何构建关键词 库?
1.抓住竞争对手网站的关键词,并根据行业和自己的分析,研究行业内有哪些类型的关键词,有哪些关键词。
2. 选择一批基础的关键词,为每个词设置不同的分类。
关键词 的具体数量取决于行业。基本上,你必须为每个类别选择几十个关键词。如果行业规模的搜索量在几十万以上,那么基本的关键词总共选择的应该至少有几百级。以婚庆行业为例,如何分类。
3.根据基本关键词使用百度推广跑步数据。就是用百度推广的关键词工具搜索上一步我们选择的所有关键词。然后导出数据。注意:导出数据时需要精确匹配类型。
4. 根据数据结果填写基本的关键词。在搜索和导出数据的过程中,我们可能会发现之前的基础关键词库中缺少了一些重要的词。这时候就需要把这些词加入到基本的关键词库中,然后重复步骤3。
5. 制作一个完整的未处理数据表。完成第四步后,我们会有更多的原创关键词数据,或者简单的excel表格。我们需要将excel表中的所有数据汇总到一张表中。
6. 手动调整所有数据的分类,使用Excel过滤功能,然后手动为每个关键词选择一个分类,即添加一列分类数据。在这个过程中,可以使用筛选功能来提高效率。这是整个过程中最为繁琐复杂的一个过程。曾经花了近60个小时整理出一个关键词字库,3万多字,总搜索量近200万。
7. 大功告成。把每个关键词的分类填好后,实际上可以根据分类查看每个关键词的特征。这具有真正的分析价值。
ps 关键词 研究的目的不是要知道所有的词,而是要知道用户的搜索习惯。
以上是我开发的内部工作流程。
关于工具使用的问题:
目前市场上还没有批量查询关键词搜索量的好工具。所以没有办法按照规则批量写关键词,比如region+摄影。
如果有同学知道或有,请分享。
@郭世雄
根据关键词文章采集系统(织梦采集侠的伪原创及搜索优化方式(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-19 18:24
织梦采集安装非常简单方便。只需一分钟即可启动采集。此外,新手可以通过结合简单、健壮、灵活和开源的Dedecms程序快速入门。此外,我们还提供专门的客户服务,为商业客户提供技术支持。与传统的采集模式不同,织梦>采集夏可根据用户设置的关键词进行平移。Pan采集的优点是,通过采集和关键词的不同搜索结果,它不能采集一个或多个指定的采集站点,降低了采集站点被搜索引擎判断为镜像站点并被搜索引擎惩罚的风险
1)RSS采集,输入内容的RSS地址
只要采集的采集提供RSS订阅地址,您就可以通过RSS订阅采集。您只需输入RSS地址即可轻松地采集到目标网站内容。无需编写采集规则,方便简单
2)页面监控采集,简单方便采集内容
页面监控采集只需提供监控页面地址和文本URL规则即可指定采集指定网站或列内容,方便简单。它可以成为目标采集,而无需编写采集规则
3)各种伪原创和优化方法,以提高收录率和排名
自动标题、段落重排、高级混淆、自动内链、内容过滤、网站过滤、同义词替换、插入SEO词、关键词添加链接和其他方法来处理从采集返回的文章,增强采集文章>原创,促进搜索引擎优化,并提高搜索引擎的权重和排名收录>,网站>
4)插件是全自动的采集,无需手动干预
织梦采集夏根据设置的采集方法采集网站,按照预设的采集任务,然后自动抓取网页内容。该程序通过精确计算分析网页,丢弃非文章内容页的网站,提取优秀的文章内容,最后执行伪原创、导入和生成。所有这些操作程序均自动完成,无需手动干预
5)手动发布文章或伪原创和搜索优化处理
织梦采集Xia不仅是一个采集插件,也是一个织梦必需的伪原创和搜索优化插件。手动发布的文章可通过织梦采集和文章的搜索优化进行处理。它可以替换同义词、自动链入、随机插入关键词链接和文章,包括关键词自动添加指定链接等功能,是织梦必不可少的插件
6)定期定量更新采集伪原创搜索引擎优化
该插件有两种触发方法采集。一种是在页面中添加代码以触发采集用户访问更新。另一个是我们为商业用户提供的远程触发采集服务。新网站可以定期、定量地更新,无需人工干预
7)定期、定量地更新待审查的手稿
即使有成千上万的文章,织梦采集夏也可以根据您的需要,在您每天设定的时间段内定期、定量地审查和更新 查看全部
根据关键词文章采集系统(织梦采集侠的伪原创及搜索优化方式(组图))
织梦采集安装非常简单方便。只需一分钟即可启动采集。此外,新手可以通过结合简单、健壮、灵活和开源的Dedecms程序快速入门。此外,我们还提供专门的客户服务,为商业客户提供技术支持。与传统的采集模式不同,织梦>采集夏可根据用户设置的关键词进行平移。Pan采集的优点是,通过采集和关键词的不同搜索结果,它不能采集一个或多个指定的采集站点,降低了采集站点被搜索引擎判断为镜像站点并被搜索引擎惩罚的风险
1)RSS采集,输入内容的RSS地址
只要采集的采集提供RSS订阅地址,您就可以通过RSS订阅采集。您只需输入RSS地址即可轻松地采集到目标网站内容。无需编写采集规则,方便简单
2)页面监控采集,简单方便采集内容
页面监控采集只需提供监控页面地址和文本URL规则即可指定采集指定网站或列内容,方便简单。它可以成为目标采集,而无需编写采集规则
3)各种伪原创和优化方法,以提高收录率和排名
自动标题、段落重排、高级混淆、自动内链、内容过滤、网站过滤、同义词替换、插入SEO词、关键词添加链接和其他方法来处理从采集返回的文章,增强采集文章>原创,促进搜索引擎优化,并提高搜索引擎的权重和排名收录>,网站>
4)插件是全自动的采集,无需手动干预
织梦采集夏根据设置的采集方法采集网站,按照预设的采集任务,然后自动抓取网页内容。该程序通过精确计算分析网页,丢弃非文章内容页的网站,提取优秀的文章内容,最后执行伪原创、导入和生成。所有这些操作程序均自动完成,无需手动干预
5)手动发布文章或伪原创和搜索优化处理
织梦采集Xia不仅是一个采集插件,也是一个织梦必需的伪原创和搜索优化插件。手动发布的文章可通过织梦采集和文章的搜索优化进行处理。它可以替换同义词、自动链入、随机插入关键词链接和文章,包括关键词自动添加指定链接等功能,是织梦必不可少的插件
6)定期定量更新采集伪原创搜索引擎优化
该插件有两种触发方法采集。一种是在页面中添加代码以触发采集用户访问更新。另一个是我们为商业用户提供的远程触发采集服务。新网站可以定期、定量地更新,无需人工干预
7)定期、定量地更新待审查的手稿
即使有成千上万的文章,织梦采集夏也可以根据您的需要,在您每天设定的时间段内定期、定量地审查和更新
根据关键词文章采集系统(织梦采集侠2.9破解版伪原创SEO更新(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-11-16 03:02
织梦采集侠2.9破解版是一款优秀而强大的伪原创采集软件,旨在帮助网站内容SEO优化。 织梦采集安装简单,运行不占内容,提供全面强大的采集功能,输入关键词、RSS地址、URL等即可定向.采集,用户设置后即可自动运行,省心省力。本站提供织梦采集侠专业版授权码,完全免费使用所有功能,满足您的所有需求。
总体介绍
织梦采集霞帮你更好的采集数据,只需一分钟,立即启动采集,以及开源dedecms程序,新手都可以快速开始。
织梦采集Xia是一套基于关键词自动采集的dedecms,无需编写复杂的采集规则,自动伪原创,一个自动发布内容的绿色插件。简单配置后,即可实现24小时不间断采集、伪原创和发布。是站长创建站群的首选插件。
采集夏文字识别技术是采集夏老师多年技术积累,自主研发的一套强大的汉字搜索引擎。在搜索引擎中的文本分析能力也是不相上下,优于有道。百度。 采集Xia 是一款基于此核心技术开发的优秀采集 软件。我们更了解百度。
功能说明
一键安装
只需一分钟,立即开始采集,结合简单、健壮、灵活、开源的dedecms程序
一句话采集
根据用户设置的关键词进行pan采集,以免在一个或多个指定站点上进行采集。
RSS采集
只需输入RSS地址即可方便采集到目标网站内容,无需写采集规则,方便简单
定位采集
提供列表URL和文章URL即采集指定网站或栏目内容,即可准确采集标题、正文、作者、来源
无需人工干预
采集任务可以预先设置,然后伪原创,导入、生成、操作,无需人工干预
伪原创SEO 更新
我们为商业用户提供的远程触发采集服务,新站点无需任何人访问即可修复和量化采集更新
更新审稿稿
采集夏也可以根据您的需要,在您每天设定的时间段内,定期、定量地进行审核和更新
自动生成推送
自动生成站点地图并自动推送百度界面,确保百度及时收录到达您的网站,并提供网站排名
安装教程
织梦采集如何安装Xia
下载织梦采集,解压得到两个版本,分别是gbk和utf8。这里的版本对应我们的网站网页编码格式。所以首先确定你的网站是哪种网页编码格式。
登录我们的网站后台,在空白处右击,在弹出的窗口中选择查看源文件。
检查源文件中字符集后面的值。如果是gb2312就选择gbk版本,如果是utf-8就选择utf8版本。我的demo网站是gb2312,所以我选择了采集的gbk版本。
在后台选择模块,点击上传新模块,然后点击选择文件,在弹出的窗口中选择刚刚下载的gbk版本采集xia,然后点击确定
点击确定后,提示上传新模块。在随后的页面,我们选择安装,然后点击确定
提示模块安装完成后,跳转到模块管理页面,这里是安装完成,采集Xia会在左边模块新建一个采集Xia栏,采集在栏目中修改规则和设置
使用教程
织梦采集如何使用Xia
1.登录你的网站后台,模块->采集器->采集任务。如果您的网站还没有添加栏目,需要先在织梦的栏目管理中添加栏目。如果您已经添加了列,您可能会看到以下界面。
2. 在要采集的栏目点击“设置”,弹出如下界面。采集方式包括关键词采集、RSS 采集和目标站采集。设置好后,返回采集任务,点击采集测试,可以看到系统正在采集。
3.开启全自动采集。设置好相关规则后,点击自动采集开关,选择采集时间点并保存,如图。
4.登录你的网站后台,模块->采集器->超级采集,点击添加任务并保存规则。
织梦采集侠RSS采集教程
首先,我们需要找到目标站的RSS页面的位置。下面以百度新闻的RSS采集为例。
一般情况下,大型网站都会有自己的RSS订阅功能,但是我们不容易查到,那我们就用百度“网站名+rss”
打开目标网站的rss页面,选择我们需要的rss部分采集。
复制我们需要的rss地址采集。
<p>然后我们到我们的网站后台,打开采集侠采集设置,将我们复制的RSS地址粘贴到采集xia RSS设置中。 查看全部
根据关键词文章采集系统(织梦采集侠2.9破解版伪原创SEO更新(组图))
织梦采集侠2.9破解版是一款优秀而强大的伪原创采集软件,旨在帮助网站内容SEO优化。 织梦采集安装简单,运行不占内容,提供全面强大的采集功能,输入关键词、RSS地址、URL等即可定向.采集,用户设置后即可自动运行,省心省力。本站提供织梦采集侠专业版授权码,完全免费使用所有功能,满足您的所有需求。
总体介绍
织梦采集霞帮你更好的采集数据,只需一分钟,立即启动采集,以及开源dedecms程序,新手都可以快速开始。
织梦采集Xia是一套基于关键词自动采集的dedecms,无需编写复杂的采集规则,自动伪原创,一个自动发布内容的绿色插件。简单配置后,即可实现24小时不间断采集、伪原创和发布。是站长创建站群的首选插件。
采集夏文字识别技术是采集夏老师多年技术积累,自主研发的一套强大的汉字搜索引擎。在搜索引擎中的文本分析能力也是不相上下,优于有道。百度。 采集Xia 是一款基于此核心技术开发的优秀采集 软件。我们更了解百度。
功能说明
一键安装
只需一分钟,立即开始采集,结合简单、健壮、灵活、开源的dedecms程序
一句话采集
根据用户设置的关键词进行pan采集,以免在一个或多个指定站点上进行采集。
RSS采集
只需输入RSS地址即可方便采集到目标网站内容,无需写采集规则,方便简单
定位采集
提供列表URL和文章URL即采集指定网站或栏目内容,即可准确采集标题、正文、作者、来源
无需人工干预
采集任务可以预先设置,然后伪原创,导入、生成、操作,无需人工干预
伪原创SEO 更新
我们为商业用户提供的远程触发采集服务,新站点无需任何人访问即可修复和量化采集更新
更新审稿稿
采集夏也可以根据您的需要,在您每天设定的时间段内,定期、定量地进行审核和更新
自动生成推送
自动生成站点地图并自动推送百度界面,确保百度及时收录到达您的网站,并提供网站排名
安装教程
织梦采集如何安装Xia
下载织梦采集,解压得到两个版本,分别是gbk和utf8。这里的版本对应我们的网站网页编码格式。所以首先确定你的网站是哪种网页编码格式。
登录我们的网站后台,在空白处右击,在弹出的窗口中选择查看源文件。
检查源文件中字符集后面的值。如果是gb2312就选择gbk版本,如果是utf-8就选择utf8版本。我的demo网站是gb2312,所以我选择了采集的gbk版本。
在后台选择模块,点击上传新模块,然后点击选择文件,在弹出的窗口中选择刚刚下载的gbk版本采集xia,然后点击确定
点击确定后,提示上传新模块。在随后的页面,我们选择安装,然后点击确定
提示模块安装完成后,跳转到模块管理页面,这里是安装完成,采集Xia会在左边模块新建一个采集Xia栏,采集在栏目中修改规则和设置
使用教程
织梦采集如何使用Xia
1.登录你的网站后台,模块->采集器->采集任务。如果您的网站还没有添加栏目,需要先在织梦的栏目管理中添加栏目。如果您已经添加了列,您可能会看到以下界面。
2. 在要采集的栏目点击“设置”,弹出如下界面。采集方式包括关键词采集、RSS 采集和目标站采集。设置好后,返回采集任务,点击采集测试,可以看到系统正在采集。
3.开启全自动采集。设置好相关规则后,点击自动采集开关,选择采集时间点并保存,如图。
4.登录你的网站后台,模块->采集器->超级采集,点击添加任务并保存规则。
织梦采集侠RSS采集教程
首先,我们需要找到目标站的RSS页面的位置。下面以百度新闻的RSS采集为例。
一般情况下,大型网站都会有自己的RSS订阅功能,但是我们不容易查到,那我们就用百度“网站名+rss”
打开目标网站的rss页面,选择我们需要的rss部分采集。
复制我们需要的rss地址采集。
<p>然后我们到我们的网站后台,打开采集侠采集设置,将我们复制的RSS地址粘贴到采集xia RSS设置中。
根据关键词文章采集系统(本文:文本内容过滤,推荐系统,聚类,K-means算法 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-11-15 22:27
)
摘要:本文考察了当前的文本过滤技术,在此基础上以空间向量模型作为用户需求模板,利用余弦距离计算文本相似度,利用K-means算法优化文本聚类效果。分析。关键词的文本内容过滤模型可以为人民网用户亲自推荐新闻、广告、文章等信息,缩短信息检索时间,最大程度地为用户提供感兴趣的内容,创造经济和社会价值。
关键词:文本内容过滤,推荐系统,聚类,K-means算法
1 简介
人民网是一个以新闻为主,融合现有电子媒体创新的大型网络信息发布平台。它是互联网上最大的中文和多语种新闻之一网站。人民网新闻报道具有权威性、时效性、多样性、评论性等特点。报道内容包括政治、经济、法律、新闻、科学文化、广告等。内容丰富,权威。
近年来,个性化推荐已经成为各大主流网站必不可少的服务,但与电商网站相比,新闻个性化推荐水平仍有较大差距。人民网拥有庞大的用户群,某些年龄段的用户甚至比购物还多网站。如果能有效挖掘用户的潜在兴趣,并进行个性化的新闻资讯推荐,就能产生巨大的社会价值。
在人民网下一步发展战略中,新媒体融合论坛副总编辑陆新宁等 阐述了发展方向,强调了新的创新和内容生产的作用,强调了对人民网、手机人民网、人民网客户端、数据中心等平台的影响。基于关键字的文本内容过滤算法迎合了人民日报的新发展。以人民日报为基础,为用户提供个性化的新闻、广告等信息,可为用户提供指导性建议,也可为用户提供对第十九届人民日报的指导。大会宣传党的路线方针政策,推动社会主义新闻理论创新,
本文采用基于关键词的文本过滤技术,通过用户特征,从海量信息中快速有效地找到用户感兴趣的新闻。个性化推荐新闻。使用内容过滤算法建立用户之间的连接,如移动客户端、网络通信、数据采集等,根据现有用户已经建立的用户兴趣实体推荐实体。
2 技术背景
目前,智能推荐系统的主要推荐技术包括基于规则的推荐和基于内容过滤的推荐。基于规则的推荐主要是通过基础判断来引出相关结论。当处理问题比较简单,判断规则较少时,系统可以快速处理并得出结论,但随着问题的细化和问题规模的扩大,系统会增加判断的处理时间,同时也不利于系统规则的扩展和维护。在内容过滤中,由于网络中的主要信息是文本,因此内容过滤的研究主要集中在信息文本上。
2.1文本过滤相关技术
内容过滤系统中使用了相关的文本过滤技术。文本归档是指计算机根据用户的信息需求,从大量文本流中搜索相应信息或剔除不相关信息的过程。对用户需求的判断以及采用何种方法使其适应需求对于提高文本过滤的效果非常重要。
在国外文本过滤相关技术的研究中,Belkin和Croft提出了用户特征过滤对文本过滤系统的影响和积极意义;林等人。对个人兴趣的优雅检测算法进行了研究;Yang 和 Chute 基于示例的线性和感兴趣的最小二乘法。该模型改进了文本分类器;Mosafa 为智能信息过滤构建了多级分解模型。国内对文本过滤的研究包括,刘永丹、童海权等提出了基于语义分析的趋势文本过滤;姚天顺等。构建了基于语义框架的中文文本过滤模型;程宪义、杨天明等。研究了文本过滤;
在实现技术上,文本过滤主要借鉴和使用了自动检索、自动分类、自动索引等信息自动处理方法和技术。根据文本过滤和内容过滤的不同,可以分为用户特征过滤和安全过滤。本文针对的内容主要是用户特征过滤。
2.1.1 文本过滤过程
文本过滤有五个步骤:(1) 表示要过滤的文本(2) 确定用户需求模板:通常包括过滤特征描述和数据特征表示;(3)User需求和非Filter文本匹配;(4)获取效果匹配反馈;(5)根据匹配效果反馈修改需求模板。上述流程如图2-1所示。
对原创数据流进行处理得到待过滤的文本表示,通过文本匹配计算相似度,通过机器学习过程不断训练模型,通过人工干预模式不断优化需求模板,提高过滤处理结果的准确性。
2.1.2 文本过滤的核心工作
文本过滤的核心工作主要是基于用户需求模板和文本匹配。
用户需求模型采用的方法主要有向量空间模型、预定义的主题词、分层概念集、规则和分类目录。复旦大学吴立德教授和黄玄景博士研究的文本过滤系统是基于向量空间模型的。武汉大学信息资源研究中心张玉峰教授和蔡娇杰博士研究了Web环境下基于用户兴趣本体学习的文本过滤。同样基于空间向量模型,东北大学姚天顺教授和林鸿飞博士等人提出了基于实例的中文文本过滤模型,其中也使用了向量空间模型。与其他用户需要的模板方法相比,
在文本匹配过程中,计算相似度就是判断文本是否满足用户的需求,可以看作是一个分类问题。常用的分类方法有:中心向量算法、朴素贝叶斯算法、支持向量机分类算法、基于KNN的文本分类算法。
(1)中心向量算法:利用向量空间模型划分不同的训练类别进行计算,将相似度高的归为一类,然后进行标准化,最后得到相似度值。设训练集为C,如公式2-1所示。
分类时,对于一个新的文本,基于空间模型,生成一个表示该文本的向量,计算该向量与每个类别的特征向量的相似度,将文本分类到相似度最大的类别中。计算向量相似度有两种主要方法。如果 x 和 y 表示向量,则 xi 和 yi 表示向量分量。
欧几里得距离如公式 2-3 所示。
dis (x, y) 值表示向量与类别特征向量之间的距离。值越小,距离越近,向量相似度越高。
矢量 b 的角度如公式 2-4 所示。
cos(x,y) 值越高,角度越小,向量相似度越高。
当类之间的相似度差异较大时,中心向量算法具有更好的分类效果。在实际应用中,类之间的差异可能不会那么突出,实际数据分布存储在偏差中,这会导致算法判断错误,分类效果不好。
查看全部
根据关键词文章采集系统(本文:文本内容过滤,推荐系统,聚类,K-means算法
)
摘要:本文考察了当前的文本过滤技术,在此基础上以空间向量模型作为用户需求模板,利用余弦距离计算文本相似度,利用K-means算法优化文本聚类效果。分析。关键词的文本内容过滤模型可以为人民网用户亲自推荐新闻、广告、文章等信息,缩短信息检索时间,最大程度地为用户提供感兴趣的内容,创造经济和社会价值。
关键词:文本内容过滤,推荐系统,聚类,K-means算法
1 简介
人民网是一个以新闻为主,融合现有电子媒体创新的大型网络信息发布平台。它是互联网上最大的中文和多语种新闻之一网站。人民网新闻报道具有权威性、时效性、多样性、评论性等特点。报道内容包括政治、经济、法律、新闻、科学文化、广告等。内容丰富,权威。
近年来,个性化推荐已经成为各大主流网站必不可少的服务,但与电商网站相比,新闻个性化推荐水平仍有较大差距。人民网拥有庞大的用户群,某些年龄段的用户甚至比购物还多网站。如果能有效挖掘用户的潜在兴趣,并进行个性化的新闻资讯推荐,就能产生巨大的社会价值。
在人民网下一步发展战略中,新媒体融合论坛副总编辑陆新宁等 阐述了发展方向,强调了新的创新和内容生产的作用,强调了对人民网、手机人民网、人民网客户端、数据中心等平台的影响。基于关键字的文本内容过滤算法迎合了人民日报的新发展。以人民日报为基础,为用户提供个性化的新闻、广告等信息,可为用户提供指导性建议,也可为用户提供对第十九届人民日报的指导。大会宣传党的路线方针政策,推动社会主义新闻理论创新,
本文采用基于关键词的文本过滤技术,通过用户特征,从海量信息中快速有效地找到用户感兴趣的新闻。个性化推荐新闻。使用内容过滤算法建立用户之间的连接,如移动客户端、网络通信、数据采集等,根据现有用户已经建立的用户兴趣实体推荐实体。
2 技术背景
目前,智能推荐系统的主要推荐技术包括基于规则的推荐和基于内容过滤的推荐。基于规则的推荐主要是通过基础判断来引出相关结论。当处理问题比较简单,判断规则较少时,系统可以快速处理并得出结论,但随着问题的细化和问题规模的扩大,系统会增加判断的处理时间,同时也不利于系统规则的扩展和维护。在内容过滤中,由于网络中的主要信息是文本,因此内容过滤的研究主要集中在信息文本上。
2.1文本过滤相关技术
内容过滤系统中使用了相关的文本过滤技术。文本归档是指计算机根据用户的信息需求,从大量文本流中搜索相应信息或剔除不相关信息的过程。对用户需求的判断以及采用何种方法使其适应需求对于提高文本过滤的效果非常重要。
在国外文本过滤相关技术的研究中,Belkin和Croft提出了用户特征过滤对文本过滤系统的影响和积极意义;林等人。对个人兴趣的优雅检测算法进行了研究;Yang 和 Chute 基于示例的线性和感兴趣的最小二乘法。该模型改进了文本分类器;Mosafa 为智能信息过滤构建了多级分解模型。国内对文本过滤的研究包括,刘永丹、童海权等提出了基于语义分析的趋势文本过滤;姚天顺等。构建了基于语义框架的中文文本过滤模型;程宪义、杨天明等。研究了文本过滤;
在实现技术上,文本过滤主要借鉴和使用了自动检索、自动分类、自动索引等信息自动处理方法和技术。根据文本过滤和内容过滤的不同,可以分为用户特征过滤和安全过滤。本文针对的内容主要是用户特征过滤。
2.1.1 文本过滤过程
文本过滤有五个步骤:(1) 表示要过滤的文本(2) 确定用户需求模板:通常包括过滤特征描述和数据特征表示;(3)User需求和非Filter文本匹配;(4)获取效果匹配反馈;(5)根据匹配效果反馈修改需求模板。上述流程如图2-1所示。
对原创数据流进行处理得到待过滤的文本表示,通过文本匹配计算相似度,通过机器学习过程不断训练模型,通过人工干预模式不断优化需求模板,提高过滤处理结果的准确性。
2.1.2 文本过滤的核心工作
文本过滤的核心工作主要是基于用户需求模板和文本匹配。
用户需求模型采用的方法主要有向量空间模型、预定义的主题词、分层概念集、规则和分类目录。复旦大学吴立德教授和黄玄景博士研究的文本过滤系统是基于向量空间模型的。武汉大学信息资源研究中心张玉峰教授和蔡娇杰博士研究了Web环境下基于用户兴趣本体学习的文本过滤。同样基于空间向量模型,东北大学姚天顺教授和林鸿飞博士等人提出了基于实例的中文文本过滤模型,其中也使用了向量空间模型。与其他用户需要的模板方法相比,
在文本匹配过程中,计算相似度就是判断文本是否满足用户的需求,可以看作是一个分类问题。常用的分类方法有:中心向量算法、朴素贝叶斯算法、支持向量机分类算法、基于KNN的文本分类算法。
(1)中心向量算法:利用向量空间模型划分不同的训练类别进行计算,将相似度高的归为一类,然后进行标准化,最后得到相似度值。设训练集为C,如公式2-1所示。
分类时,对于一个新的文本,基于空间模型,生成一个表示该文本的向量,计算该向量与每个类别的特征向量的相似度,将文本分类到相似度最大的类别中。计算向量相似度有两种主要方法。如果 x 和 y 表示向量,则 xi 和 yi 表示向量分量。
欧几里得距离如公式 2-3 所示。
dis (x, y) 值表示向量与类别特征向量之间的距离。值越小,距离越近,向量相似度越高。
矢量 b 的角度如公式 2-4 所示。
cos(x,y) 值越高,角度越小,向量相似度越高。
当类之间的相似度差异较大时,中心向量算法具有更好的分类效果。在实际应用中,类之间的差异可能不会那么突出,实际数据分布存储在偏差中,这会导致算法判断错误,分类效果不好。
根据关键词文章采集系统(关键词文章采集系统里存储的话题数量是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-04 02:04
根据关键词文章采集系统里存储的话题数量,可以进行适当的自动编辑,提高采集效率。通过文章采集系统里存储的话题数量,自动识别话题的主题文章,自动切分话题主题,这样可以保证话题的质量。
如果你之前采集别人的,是从别人的关键词文章里采集你的文章,那么你需要设置好自己的关键词,话题名称,让他自动抓取你的文章。如果你之前采集别人的,是从别人的关键词文章里采集你的文章,那么你需要设置好自己的关键词,话题名称,让他自动抓取你的文章。目前没有可以做到自动分析你话题的关键词和文章的,只能是分析文章话题。有兴趣可以看看-16031-1-1.html。
其实,多数文章都有关键词。如果你这个关键词不在话题内的话,话题就分类给大家看。而采集数据是不需要话题的。而且如果你有关键词的话,你的文章也被加入话题,那是会根据你要采集的话题来分配用户,就不需要每次自己去设置话题分类。
谢邀,听我一句劝,要找到你想采集的话题的关键词或者你想找的话题的话,
收到邀请的时候,我就意识到,我做的行业已经不是当年做金融的那一拨人了。那个时候我做互联网金融的不能算金融,而是网络金融。至于从哪里找,当然去百度要不就是去搜狗呗。还是难以下手。从百度收藏夹找,我是不是方法很笨?无可厚非,百度收藏夹这个当年帮助我找互联网金融的工具,也使我后来这么用百度,不然不会做这么久。
但是发现关键词,我就去看话题,接下来就是去操作。你有想法,你就去践行就好。没做之前可以寻找答案,但是等做了之后,却发现,所有的答案都会告诉你,都不是答案。关键字和你的优势之间,只有你去尝试发现。 查看全部
根据关键词文章采集系统(关键词文章采集系统里存储的话题数量是什么?)
根据关键词文章采集系统里存储的话题数量,可以进行适当的自动编辑,提高采集效率。通过文章采集系统里存储的话题数量,自动识别话题的主题文章,自动切分话题主题,这样可以保证话题的质量。
如果你之前采集别人的,是从别人的关键词文章里采集你的文章,那么你需要设置好自己的关键词,话题名称,让他自动抓取你的文章。如果你之前采集别人的,是从别人的关键词文章里采集你的文章,那么你需要设置好自己的关键词,话题名称,让他自动抓取你的文章。目前没有可以做到自动分析你话题的关键词和文章的,只能是分析文章话题。有兴趣可以看看-16031-1-1.html。
其实,多数文章都有关键词。如果你这个关键词不在话题内的话,话题就分类给大家看。而采集数据是不需要话题的。而且如果你有关键词的话,你的文章也被加入话题,那是会根据你要采集的话题来分配用户,就不需要每次自己去设置话题分类。
谢邀,听我一句劝,要找到你想采集的话题的关键词或者你想找的话题的话,
收到邀请的时候,我就意识到,我做的行业已经不是当年做金融的那一拨人了。那个时候我做互联网金融的不能算金融,而是网络金融。至于从哪里找,当然去百度要不就是去搜狗呗。还是难以下手。从百度收藏夹找,我是不是方法很笨?无可厚非,百度收藏夹这个当年帮助我找互联网金融的工具,也使我后来这么用百度,不然不会做这么久。
但是发现关键词,我就去看话题,接下来就是去操作。你有想法,你就去践行就好。没做之前可以寻找答案,但是等做了之后,却发现,所有的答案都会告诉你,都不是答案。关键字和你的优势之间,只有你去尝试发现。
根据关键词文章采集系统(为什么说文章关键词不需要每一处都加粗呢?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-31 22:14
问题:文章关键词 每个地方都要加粗吗?
答:文章的主要内容中的关键词不必加粗。你在更新文章的时候看到一些网站,加粗的关键词其实这是一种自我安慰的行为,对网站优化没有实际用处。
为什么文章关键词不需要到处加粗?这需要考虑用户体验和搜索引擎的工作原理。以下是:
1、用户体验
用户对页面的关注是内容是否能解决他们的需求。至于关键词是否加粗,对用户没有任何好处。并不是说文章中有加粗的关键词。,用户会觉得自己的问题能够解决。相反,如果文章中关键词的每一部分都加粗,也会影响用户体验。当你阅读某个文章时,里面有很多粗体字。你觉得眼花缭乱吗?所以在用户体验上,如果文章中关键词的每一部分都加粗,则弊大于利。
2、搜索引擎的工作原理
目前搜索引擎的智能化程度非常高,简单的seo作弊方法是骗不了的。早期seo可以通过加粗文章关键词来增加页面权重,但是现在不行了。搜索引擎可以对文章的主题进行判断,对关键词的重要性进行分析和排名,综合匹配用户的搜索词,最终给出排名结果。
所以关键词是否加粗了,在搜索引擎中没有多大意义。虽然加粗可以增强语气,但这取决于用户在哪里,如果你故意这样做,你就会作弊。怀疑。所以,在搜索引擎的判断机制中,没有必要把文章的每一部分都加粗。
关于文章关键词要不要到处加粗的问题,笔者就简单说这么多。总之,文章中的关键词不需要加粗,甚至都不需要加粗,因为搜索引擎可以分析判断。如果故意加粗,对用户体验或搜索引擎都不友好。因此,如果您正在考虑这个问题,请三思。其实,网站的优化更重要的是产出优质内容,提升用户体验,而不是纠结于这些疑似作弊的细节。 查看全部
根据关键词文章采集系统(为什么说文章关键词不需要每一处都加粗呢?(图))
问题:文章关键词 每个地方都要加粗吗?
答:文章的主要内容中的关键词不必加粗。你在更新文章的时候看到一些网站,加粗的关键词其实这是一种自我安慰的行为,对网站优化没有实际用处。
为什么文章关键词不需要到处加粗?这需要考虑用户体验和搜索引擎的工作原理。以下是:
1、用户体验
用户对页面的关注是内容是否能解决他们的需求。至于关键词是否加粗,对用户没有任何好处。并不是说文章中有加粗的关键词。,用户会觉得自己的问题能够解决。相反,如果文章中关键词的每一部分都加粗,也会影响用户体验。当你阅读某个文章时,里面有很多粗体字。你觉得眼花缭乱吗?所以在用户体验上,如果文章中关键词的每一部分都加粗,则弊大于利。
2、搜索引擎的工作原理
目前搜索引擎的智能化程度非常高,简单的seo作弊方法是骗不了的。早期seo可以通过加粗文章关键词来增加页面权重,但是现在不行了。搜索引擎可以对文章的主题进行判断,对关键词的重要性进行分析和排名,综合匹配用户的搜索词,最终给出排名结果。
所以关键词是否加粗了,在搜索引擎中没有多大意义。虽然加粗可以增强语气,但这取决于用户在哪里,如果你故意这样做,你就会作弊。怀疑。所以,在搜索引擎的判断机制中,没有必要把文章的每一部分都加粗。
关于文章关键词要不要到处加粗的问题,笔者就简单说这么多。总之,文章中的关键词不需要加粗,甚至都不需要加粗,因为搜索引擎可以分析判断。如果故意加粗,对用户体验或搜索引擎都不友好。因此,如果您正在考虑这个问题,请三思。其实,网站的优化更重要的是产出优质内容,提升用户体验,而不是纠结于这些疑似作弊的细节。
根据关键词文章采集系统( 本发明基于关键词的文章生成方法,所述、利用爬虫获取散文段落数据集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-10-29 08:06
本发明基于关键词的文章生成方法,所述、利用爬虫获取散文段落数据集)
本发明涉及自然语言生成处理领域,尤其涉及一种基于关键词的文章生成方法。
背景技术:
文本自动生成是自然语言处理领域的重要研究方向,文本自动生成的实现也是人工智能成熟的重要标志。简而言之,我们期待着未来有一天,计算机可以像人类一样写作,可以编写高质量的自然语言文本。文本自动生成技术具有很大的应用前景。例如,文本自动生成技术可以应用于智能问答对话、机器翻译等系统,实现更加智能自然的人机交互;我们也可以使用文本自动生成系统来代替编辑,实现新闻的自动编写和发布。可能颠覆新闻出版业;这项技术甚至可以用来帮助学者撰写学术论文,从而改变科研创作的模式。文本生成是当前自然语言处理(nlp,natural language processing)和自然语言生成(nlg,natural language generation)领域的研究热点。
目前一般都是手工的采集信息,经过手工处理后编译成文章,而传统的结构化数据生成或模板配置生成的文本非常死板,有局限性。
技术实现要素:
本发明的目的在于提供一种基于关键词的文章生成方法,以解决现有技术中的上述问题。
为实现上述目的,本发明采用的技术方案如下:
一种基于关键词的文章生成方法,该方法包括以下步骤,
s1、 使用爬虫获取网上散文内容,作为初始训练数据集,对初始训练数据集进行分割,获取多段文字,为每段文字配置id号,汇总将所有段落文本转换为散文段落数据集;
s2、 根据id号对散文段落数据集进行索引,得到散文段落数据集的索引;用散文段落数据集进行分词,对分词结果进行训练,得到散文段落数据集的句子特征向量模型;
s3、获取要生成的文本的关键词以及用户提交的文本的段落数;
s4、根据散文段落数据集的索引和句子特征向量模型,利用待生成文本的关键词进行索引,得到与文章段落数相同的文本段落数要生成的文本,每个文本段落根据id编号,根据散文段落数据集的索引,组成文章显示。
优选地,步骤s2包括以下内容:
s201、根据id号在散文段落数据集上建立前向索引,得到第一索引序列;根据token对散文段落数据集建立倒排索引,得到第二索引序列;
s202、对散文段落数据集进行token切分,得到多个token,用emlo模型训练每个token,得到所有token的词向量;
s203、根据步骤s202得到的所有token的词向量计算训练段落数据集中的句子特征向量。
优选地,步骤s203具体包括以下内容:
一种。根据步骤s202得到的所有token的词向量,分别统计散文段落数据集中每个段落文本的所有token的词向量;
湾 根据散文段落数据集中每个段落文本的所有token的词向量,计算散文段落数据集中每个段落文本的句子特征向量;
C。根据每个段落文本的id号得到散文段落数据集的句子特征向量模型。
优选地,步骤s4包括以下内容:
s41、 加载第一索引、第二索引和散文段落数据集的句子特征向量模型;
s42、根据待生成文本的关键词搜索第二个索引序列,随机得到第二个索引序列中的一个句子作为第一段;
s43、根据散文段落数据集的句子特征向量模型,得到第一段的向量值;
s44、 根据散文段落数据集的句子特征向量模型和第一段的向量值,根据欧氏距离计算出离第一段最近的向量,记为第二段;
s45、 根据散文段落数据集和第二段的句子特征向量模型,根据欧氏距离计算离第二段最近的向量,记为第三段;
s46、 循环执行步骤s45,直到得到第n个段落,其中n为要生成的段落数;
s47、将得到的段落根据id号进行排列汇总,根据id号查询第二个索引序列,生成文章展示。
本发明的有益效果是:1、使用深度学习神经网络语言模型计算词向量,然后使用词向量(wordembedding)和位置向量(positionalembedding)表征句子特征向量并将其应用于文本生成应用,摒弃传统结构化数据生成和模板配置生成的僵化和局限性。2、采用新的基于句子的正向索引和反向索引项目,实现在线计算服务。具有较高的在线计算性能,可重复生成多语义角度文本的关键词文章。3、提供一种使用关键词生成文章的方法,包括基于关键词的文本文章生成算法,句子'
图纸说明
图1为本发明实施例中文章的生成方法流程示意图;
图2为本发明实施例中文章生成方法离线部分示意图;
图3为本发明实施例中文章生成方法的在线部分流程示意图。
详细方法
为使本发明的目的、技术方案和优点更加清楚明白,下面结合附图对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限制本发明。
自然语言处理(简称 NLP)是人工智能的一个子领域。自然语言处理应用包括机器翻译、情感分析、智能问答、信息抽取、语言输入、舆情分析、知识图谱等,也是深度学习的一个分支。
在这个概念下,有两个主要的子集,即自然语言理解(简称nlu)和自然语言生成(简称nlg)。
nlg 旨在让机器根据一定的结构化数据、文本、音频和视频等,生成人类可以理解的自然语言文本。 根据数据源的类型,nlg 可以分为三类:
1.texttotextnlg,主要对输入的自然语言文本进行进一步的处理和处理,主要包括文本摘要(对输入文本进行提炼和提炼)、拼写检查(自动纠正输入文本的拼写错误)、语法纠错(自动纠正输入文本的语法错误)、机器翻译(用另一种语言表达输入文本的语义)和文本改写(用不同的形式表达输入文本的相同语义)等领域;
2.datatotextnlg,主要是根据输入的结构化数据生成易读易懂的自然语言文本,包括天气预报(根据天气预报数据生成广播通用文本)、财务报告(按季度自动生成)报告)/年报)、体育新闻(根据比分信息自动生成体育新闻)、人物履历(根据人物结构化数据生成履历)等字段自动生成;
3.visiontotextnlg,主要是生成一个自然语言文本,可以准确地描述给定一张图片或一段视频的图片或视频的语义信息(实际上是一个连续的图片序列)。
示例一
如图1-3所示,本实施例提供了一种基于关键词的文章生成方法,属于texttotextnlg的一个子集,即基于关键词的文本生成算法(关键字到文本);该方法包括以下步骤,
s1、 使用爬虫获取网上散文内容,作为初始训练数据集,对初始训练数据集进行分割,获取多段文字,为每段文字配置id号,汇总将所有段落文本转换为散文段落数据集;
s2、 根据id号对散文段落数据集进行索引,得到散文段落数据集的索引;用散文段落数据集进行分词,对分词结果进行训练,得到散文段落数据集的句子特征向量模型;
s3、获取要生成的文本的关键词以及用户提交的文本的段落数;
s4、根据散文段落数据集的索引和句子特征向量模型,利用待生成文本的关键词进行索引,得到与文章段落数相同的文本段落数要生成的文本,每个文本段落根据id编号,根据散文段落数据集的索引,组成文章显示。
本实施例中,步骤s1-s2属于文章生成方法的离线部分(如图2所示);步骤s3-s4属于文章生成方法的在线部分(如图3)。
在本实施例中,在步骤s1中,利用爬虫获取多个互联网网站的散文内容作为初始训练数据集,对初始训练数据集进行分段得到分段后的散文段落数据集,记为as s={ s1, s2,..., sn},其中 si 是散文段落数据集中的第 i 个段落文本,i 是段落文本的 id 号,i=1, 2,... n,n为散文段落数据集合中的段落文本总数。
本实施例以步骤s1得到的散文段落数据集s为样本进行计算,具体包括以下内容:
s201、 根据id号在散文段落数据集上建立前向索引,得到第一个索引序列;根据token对散文段落数据集建立倒排索引,得到第二索引序列;第一个指数系列和第二个指数系列登陆磁盘;
s202、对散文段落数据集进行token切分,得到多个token,用emlo模型训练每个token,得到所有token的词向量;获取token的词向量的具体过程是计算wordembedding(词向量),并将positionalembedding(位置向量)和wordembedding加到向量中,结果就是token的词向量。
s203、根据步骤s202得到的所有token的词向量计算训练段落数据集中的句子特征向量。
本实施例中,步骤s203具体包括以下内容:
一种。根据步骤s202得到的所有token的词向量,分别统计散文段落数据集中每个段落文本的所有token的词向量;
记其中一个token的词向量为a,其中aj是token的词向量a的第j个向量值,j=1, 2,...,m, m是词的总维数向量,默认值m=200;
湾 根据散文段落数据集中每个段落文本的所有token的词向量,计算散文段落数据集中每个段落文本的句子特征向量;
首先,得到散文段落数据集中第一个段落文本s1的所有token的词向量,设k为散文段落数据集中第一个段落文本s1的所有token的总数;那么散文段落数据集中第一段文本s1的句子特征向量(sentenceembedding)为s1=a1+a2+...ak;
根据步骤b,依次计算散文段落数据集中所有段落文本的句子特征向量。
C。根据每个段落文本的id号得到散文段落数据集的句子特征向量模型;并将散文段落数据集的句子特征向量模型保存在磁盘中。
本实施例中,步骤s3具体为等待获取用户通过web的rpc服务提交的两个参数关键字(待生成文本的关键词)和n(生成文本的段落数) . 同时需要判断用户提交的参数是否合法,如果合法则执行步骤s4,如果不合法会返回参数错误,需要用户重新输入参数。
本实施例加载索引和句子特征向量模型,对得到的关键词进行实时在线计算,具体包括以下内容:
s41、 加载第一索引、第二索引和散文段落数据集的句子特征向量模型;
s42、根据待生成文本的关键词搜索第二个索引序列,随机得到第二个索引序列中的一个句子作为第一段w1;
s43、根据散文段落数据集的句子特征向量模型获取第一段的向量值
s44、 根据散文段落数据集的句子特征向量模型和第一段的向量值,根据欧氏距离计算出离第一段w1最近的向量w2,记为第二个段落
s45、 根据散文段落数据集和第二段w2的句子特征向量模型,根据欧氏距离计算出离第二段w2最近的向量,记为第三段
s46、 循环执行步骤s45,直到得到第n个段落,其中n为要生成的段落数;
s47、根据id号[w1,w2,...wn]对得到的段落进行整理汇总,根据id号查询第二个索引序列生成文章返回显示客户端。
示例二
本实施例中,具体以使用本发明方法生成的文章为例进行说明,
1、参数关键词为“父亲”,段落参数n=7。生成文章如下:
那些死者,包括我的父亲,一代村干部的叔叔,我的三个阿姨;那些幸存者,包括现在当村干部的表哥和在乡派出所当警察的侄子,他们总是像抓着相机一样出现在我的眼前,死鬼和活鬼一起告诉我,他们一起吵架吵架。
选拔的村干部氏族打过一次仗。
写作前两三年的春天,野心勃勃,在迪化街为死者献祭了近十年二十年,也为迪化街的幸存者洒了一杯酒。从此,我成为了一名学霸。放在院子里的巨大汉坛子里,香火一天比一天燃着,屋顶上的香烟像线头一样蜷缩着。
他们都是农村人,但不是文坛上的人。他们对阅读非常感兴趣,他们来找我说:“你要建一座纪念碑,这是一座大纪念碑!” 当然,他们的话给了我反复修改的信心。,但最终还是放下了定稿的笔,坐在了烟熏的书房里。我再次怀疑我写的字。
我的家乡是迪化街,我的故事是清风街;迪化街是月亮,清风街是水中的月亮;迪化街是花,清风街是镜中花。
因抢劫入狱的三人因赌博被拘留。
它就像一只可以听音乐的耳朵,需要不断的训练。
2、参数关键词为“爱”,段落参数n=7。生成文章如下:
为什么中国人的爱情离不开仁义,而外国人可以那么洒脱?或许,中国夫妻要分担逆境,而外国夫妻却要一起过好日子。
让我们一起举杯说:我们很幸福。
女儿也抬手对它说:“再见……”。
爱可以散播,爱可以在荆柴纱笼里,爱可以煮熟吃,爱可以吃不眠。
恩典是漂浮世界中我们的救生圈。它用于覆盖我们自己和他人。它既是救赎,也是负担。
我们从小就习惯了生活在提醒中。
是的,有恩有义,也有忘恩负义、委屈、要求、仇恨。
采用本发明公开的上述技术方案,具有以下有益效果:
本发明提供了一种基于关键词的文章的生成方法。该方法使用深度学习神经网络语言模型计算词向量,然后用词嵌入和位置嵌入来表示句子特征向量应用于文本生成应用,摒弃了传统结构化数据生成和模板配置生成的僵化和局限性;使用新的基于句子的前向索引和倒排索引项目来实现在线计算服务。, 在线计算性能高,可重复生成文本多个语义角度的关键词文章;该方法提供了一种使用关键词生成文章的方法,包括基于关键词的文本文章生成算法、句子的前向索引和关键词
以上仅为本发明的优选实施例。需要指出的是,对于本领域普通技术人员来说,在不脱离本发明的原则的情况下,可以进行多种改进和修改,这些改进和修改也应视为本发明的保护范围。本发明。 查看全部
根据关键词文章采集系统(
本发明基于关键词的文章生成方法,所述、利用爬虫获取散文段落数据集)
本发明涉及自然语言生成处理领域,尤其涉及一种基于关键词的文章生成方法。
背景技术:
文本自动生成是自然语言处理领域的重要研究方向,文本自动生成的实现也是人工智能成熟的重要标志。简而言之,我们期待着未来有一天,计算机可以像人类一样写作,可以编写高质量的自然语言文本。文本自动生成技术具有很大的应用前景。例如,文本自动生成技术可以应用于智能问答对话、机器翻译等系统,实现更加智能自然的人机交互;我们也可以使用文本自动生成系统来代替编辑,实现新闻的自动编写和发布。可能颠覆新闻出版业;这项技术甚至可以用来帮助学者撰写学术论文,从而改变科研创作的模式。文本生成是当前自然语言处理(nlp,natural language processing)和自然语言生成(nlg,natural language generation)领域的研究热点。
目前一般都是手工的采集信息,经过手工处理后编译成文章,而传统的结构化数据生成或模板配置生成的文本非常死板,有局限性。
技术实现要素:
本发明的目的在于提供一种基于关键词的文章生成方法,以解决现有技术中的上述问题。
为实现上述目的,本发明采用的技术方案如下:
一种基于关键词的文章生成方法,该方法包括以下步骤,
s1、 使用爬虫获取网上散文内容,作为初始训练数据集,对初始训练数据集进行分割,获取多段文字,为每段文字配置id号,汇总将所有段落文本转换为散文段落数据集;
s2、 根据id号对散文段落数据集进行索引,得到散文段落数据集的索引;用散文段落数据集进行分词,对分词结果进行训练,得到散文段落数据集的句子特征向量模型;
s3、获取要生成的文本的关键词以及用户提交的文本的段落数;
s4、根据散文段落数据集的索引和句子特征向量模型,利用待生成文本的关键词进行索引,得到与文章段落数相同的文本段落数要生成的文本,每个文本段落根据id编号,根据散文段落数据集的索引,组成文章显示。
优选地,步骤s2包括以下内容:
s201、根据id号在散文段落数据集上建立前向索引,得到第一索引序列;根据token对散文段落数据集建立倒排索引,得到第二索引序列;
s202、对散文段落数据集进行token切分,得到多个token,用emlo模型训练每个token,得到所有token的词向量;
s203、根据步骤s202得到的所有token的词向量计算训练段落数据集中的句子特征向量。
优选地,步骤s203具体包括以下内容:
一种。根据步骤s202得到的所有token的词向量,分别统计散文段落数据集中每个段落文本的所有token的词向量;
湾 根据散文段落数据集中每个段落文本的所有token的词向量,计算散文段落数据集中每个段落文本的句子特征向量;
C。根据每个段落文本的id号得到散文段落数据集的句子特征向量模型。
优选地,步骤s4包括以下内容:
s41、 加载第一索引、第二索引和散文段落数据集的句子特征向量模型;
s42、根据待生成文本的关键词搜索第二个索引序列,随机得到第二个索引序列中的一个句子作为第一段;
s43、根据散文段落数据集的句子特征向量模型,得到第一段的向量值;
s44、 根据散文段落数据集的句子特征向量模型和第一段的向量值,根据欧氏距离计算出离第一段最近的向量,记为第二段;
s45、 根据散文段落数据集和第二段的句子特征向量模型,根据欧氏距离计算离第二段最近的向量,记为第三段;
s46、 循环执行步骤s45,直到得到第n个段落,其中n为要生成的段落数;
s47、将得到的段落根据id号进行排列汇总,根据id号查询第二个索引序列,生成文章展示。
本发明的有益效果是:1、使用深度学习神经网络语言模型计算词向量,然后使用词向量(wordembedding)和位置向量(positionalembedding)表征句子特征向量并将其应用于文本生成应用,摒弃传统结构化数据生成和模板配置生成的僵化和局限性。2、采用新的基于句子的正向索引和反向索引项目,实现在线计算服务。具有较高的在线计算性能,可重复生成多语义角度文本的关键词文章。3、提供一种使用关键词生成文章的方法,包括基于关键词的文本文章生成算法,句子'
图纸说明
图1为本发明实施例中文章的生成方法流程示意图;
图2为本发明实施例中文章生成方法离线部分示意图;
图3为本发明实施例中文章生成方法的在线部分流程示意图。
详细方法
为使本发明的目的、技术方案和优点更加清楚明白,下面结合附图对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限制本发明。
自然语言处理(简称 NLP)是人工智能的一个子领域。自然语言处理应用包括机器翻译、情感分析、智能问答、信息抽取、语言输入、舆情分析、知识图谱等,也是深度学习的一个分支。
在这个概念下,有两个主要的子集,即自然语言理解(简称nlu)和自然语言生成(简称nlg)。
nlg 旨在让机器根据一定的结构化数据、文本、音频和视频等,生成人类可以理解的自然语言文本。 根据数据源的类型,nlg 可以分为三类:
1.texttotextnlg,主要对输入的自然语言文本进行进一步的处理和处理,主要包括文本摘要(对输入文本进行提炼和提炼)、拼写检查(自动纠正输入文本的拼写错误)、语法纠错(自动纠正输入文本的语法错误)、机器翻译(用另一种语言表达输入文本的语义)和文本改写(用不同的形式表达输入文本的相同语义)等领域;
2.datatotextnlg,主要是根据输入的结构化数据生成易读易懂的自然语言文本,包括天气预报(根据天气预报数据生成广播通用文本)、财务报告(按季度自动生成)报告)/年报)、体育新闻(根据比分信息自动生成体育新闻)、人物履历(根据人物结构化数据生成履历)等字段自动生成;
3.visiontotextnlg,主要是生成一个自然语言文本,可以准确地描述给定一张图片或一段视频的图片或视频的语义信息(实际上是一个连续的图片序列)。
示例一
如图1-3所示,本实施例提供了一种基于关键词的文章生成方法,属于texttotextnlg的一个子集,即基于关键词的文本生成算法(关键字到文本);该方法包括以下步骤,
s1、 使用爬虫获取网上散文内容,作为初始训练数据集,对初始训练数据集进行分割,获取多段文字,为每段文字配置id号,汇总将所有段落文本转换为散文段落数据集;
s2、 根据id号对散文段落数据集进行索引,得到散文段落数据集的索引;用散文段落数据集进行分词,对分词结果进行训练,得到散文段落数据集的句子特征向量模型;
s3、获取要生成的文本的关键词以及用户提交的文本的段落数;
s4、根据散文段落数据集的索引和句子特征向量模型,利用待生成文本的关键词进行索引,得到与文章段落数相同的文本段落数要生成的文本,每个文本段落根据id编号,根据散文段落数据集的索引,组成文章显示。
本实施例中,步骤s1-s2属于文章生成方法的离线部分(如图2所示);步骤s3-s4属于文章生成方法的在线部分(如图3)。
在本实施例中,在步骤s1中,利用爬虫获取多个互联网网站的散文内容作为初始训练数据集,对初始训练数据集进行分段得到分段后的散文段落数据集,记为as s={ s1, s2,..., sn},其中 si 是散文段落数据集中的第 i 个段落文本,i 是段落文本的 id 号,i=1, 2,... n,n为散文段落数据集合中的段落文本总数。
本实施例以步骤s1得到的散文段落数据集s为样本进行计算,具体包括以下内容:
s201、 根据id号在散文段落数据集上建立前向索引,得到第一个索引序列;根据token对散文段落数据集建立倒排索引,得到第二索引序列;第一个指数系列和第二个指数系列登陆磁盘;
s202、对散文段落数据集进行token切分,得到多个token,用emlo模型训练每个token,得到所有token的词向量;获取token的词向量的具体过程是计算wordembedding(词向量),并将positionalembedding(位置向量)和wordembedding加到向量中,结果就是token的词向量。
s203、根据步骤s202得到的所有token的词向量计算训练段落数据集中的句子特征向量。
本实施例中,步骤s203具体包括以下内容:
一种。根据步骤s202得到的所有token的词向量,分别统计散文段落数据集中每个段落文本的所有token的词向量;
记其中一个token的词向量为a,其中aj是token的词向量a的第j个向量值,j=1, 2,...,m, m是词的总维数向量,默认值m=200;
湾 根据散文段落数据集中每个段落文本的所有token的词向量,计算散文段落数据集中每个段落文本的句子特征向量;
首先,得到散文段落数据集中第一个段落文本s1的所有token的词向量,设k为散文段落数据集中第一个段落文本s1的所有token的总数;那么散文段落数据集中第一段文本s1的句子特征向量(sentenceembedding)为s1=a1+a2+...ak;
根据步骤b,依次计算散文段落数据集中所有段落文本的句子特征向量。
C。根据每个段落文本的id号得到散文段落数据集的句子特征向量模型;并将散文段落数据集的句子特征向量模型保存在磁盘中。
本实施例中,步骤s3具体为等待获取用户通过web的rpc服务提交的两个参数关键字(待生成文本的关键词)和n(生成文本的段落数) . 同时需要判断用户提交的参数是否合法,如果合法则执行步骤s4,如果不合法会返回参数错误,需要用户重新输入参数。
本实施例加载索引和句子特征向量模型,对得到的关键词进行实时在线计算,具体包括以下内容:
s41、 加载第一索引、第二索引和散文段落数据集的句子特征向量模型;
s42、根据待生成文本的关键词搜索第二个索引序列,随机得到第二个索引序列中的一个句子作为第一段w1;
s43、根据散文段落数据集的句子特征向量模型获取第一段的向量值
s44、 根据散文段落数据集的句子特征向量模型和第一段的向量值,根据欧氏距离计算出离第一段w1最近的向量w2,记为第二个段落
s45、 根据散文段落数据集和第二段w2的句子特征向量模型,根据欧氏距离计算出离第二段w2最近的向量,记为第三段
s46、 循环执行步骤s45,直到得到第n个段落,其中n为要生成的段落数;
s47、根据id号[w1,w2,...wn]对得到的段落进行整理汇总,根据id号查询第二个索引序列生成文章返回显示客户端。
示例二
本实施例中,具体以使用本发明方法生成的文章为例进行说明,
1、参数关键词为“父亲”,段落参数n=7。生成文章如下:
那些死者,包括我的父亲,一代村干部的叔叔,我的三个阿姨;那些幸存者,包括现在当村干部的表哥和在乡派出所当警察的侄子,他们总是像抓着相机一样出现在我的眼前,死鬼和活鬼一起告诉我,他们一起吵架吵架。
选拔的村干部氏族打过一次仗。
写作前两三年的春天,野心勃勃,在迪化街为死者献祭了近十年二十年,也为迪化街的幸存者洒了一杯酒。从此,我成为了一名学霸。放在院子里的巨大汉坛子里,香火一天比一天燃着,屋顶上的香烟像线头一样蜷缩着。
他们都是农村人,但不是文坛上的人。他们对阅读非常感兴趣,他们来找我说:“你要建一座纪念碑,这是一座大纪念碑!” 当然,他们的话给了我反复修改的信心。,但最终还是放下了定稿的笔,坐在了烟熏的书房里。我再次怀疑我写的字。
我的家乡是迪化街,我的故事是清风街;迪化街是月亮,清风街是水中的月亮;迪化街是花,清风街是镜中花。
因抢劫入狱的三人因赌博被拘留。
它就像一只可以听音乐的耳朵,需要不断的训练。
2、参数关键词为“爱”,段落参数n=7。生成文章如下:
为什么中国人的爱情离不开仁义,而外国人可以那么洒脱?或许,中国夫妻要分担逆境,而外国夫妻却要一起过好日子。
让我们一起举杯说:我们很幸福。
女儿也抬手对它说:“再见……”。
爱可以散播,爱可以在荆柴纱笼里,爱可以煮熟吃,爱可以吃不眠。
恩典是漂浮世界中我们的救生圈。它用于覆盖我们自己和他人。它既是救赎,也是负担。
我们从小就习惯了生活在提醒中。
是的,有恩有义,也有忘恩负义、委屈、要求、仇恨。
采用本发明公开的上述技术方案,具有以下有益效果:
本发明提供了一种基于关键词的文章的生成方法。该方法使用深度学习神经网络语言模型计算词向量,然后用词嵌入和位置嵌入来表示句子特征向量应用于文本生成应用,摒弃了传统结构化数据生成和模板配置生成的僵化和局限性;使用新的基于句子的前向索引和倒排索引项目来实现在线计算服务。, 在线计算性能高,可重复生成文本多个语义角度的关键词文章;该方法提供了一种使用关键词生成文章的方法,包括基于关键词的文本文章生成算法、句子的前向索引和关键词
以上仅为本发明的优选实施例。需要指出的是,对于本领域普通技术人员来说,在不脱离本发明的原则的情况下,可以进行多种改进和修改,这些改进和修改也应视为本发明的保护范围。本发明。
根据关键词文章采集系统(关键词文章采集系统做了一些改进,基本能满足要求)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-24 23:04
根据关键词文章采集系统做了一些改进,包括api端口开放、数据导入功能、单篇微信标题比对功能等。希望能得到有需要的人帮助。数据导入对于需要完成微信文章分析,需要完成相关tag词爬取的,需要考虑我们现有的爬虫爬取了多少个公众号的文章。数据采集我们目前利用的api大概有60个,所以基本能满足要求。不过有些大体量的页面因为时间关系考虑是否开放利用,后续看情况再进行修改。
接口文章分析类tag词可能存在用户不允许采集的情况。但是,我们在调用api的时候,可以同时指定分析文章的接口。只要用户不勾选就可以采集文章的tag词。文章采集后,需要转为pdf格式在电脑上阅读。另外,还需要一个接口去把我们采集到的文章转化为pdf格式。在转化为pdf的过程中我们希望能有一个可以有输出的地方。
因此我们还开发了一个分析文章tag词的接口,而这个接口正好可以把采集到的文章转化为文章的tag词。例如我们可以采集到这样一个采集:[原创][流量][数据分析][历史文章][qa][话题][一次][首发][n+1][获取方式][人物][方法][大图][指数][知识星球][神实][n+1][qa][方法][文章][读书][image][精品推荐][文案][文章][logo][人物][导购][文章][n+1][头像][图片][文章][gif][图片][话题][如何][文案][手机][验证码][如何][流量][清洁][数据分析][高分][资讯][阅读][文化][topic][视频][新闻][文化][视频][信息][新闻][高质量][清流][精品][视频][“”][qa][数据分析][a/b][建议][咨询][信息][一次][数据][疑问][好友][人物][持续][文章][指数][新闻][话题][值][微信][图文][top][动态][指数][首发][qa][读书][图片][精品][影像][大图][专题][视频][数据][读书][数据分析][汽车][宝宝][精品][新闻][读书][转发][图片][汽车][汽车][读书][汽车][小清新][汽车][心理][足球][圈子][旅游][旅游][吃喝][汽车旅游][动态][环保][重大消息][互联网][数据][科学][动态][日历][书][汽车][跨行][保养][机修][读书][会议][读书][数据][数据分析][接收][数据][律][房][期刊][文档][作文][清洁][数据][数据][视频][技术][语言][文章][神实][图片][ppt][新闻][养生]。 查看全部
根据关键词文章采集系统(关键词文章采集系统做了一些改进,基本能满足要求)
根据关键词文章采集系统做了一些改进,包括api端口开放、数据导入功能、单篇微信标题比对功能等。希望能得到有需要的人帮助。数据导入对于需要完成微信文章分析,需要完成相关tag词爬取的,需要考虑我们现有的爬虫爬取了多少个公众号的文章。数据采集我们目前利用的api大概有60个,所以基本能满足要求。不过有些大体量的页面因为时间关系考虑是否开放利用,后续看情况再进行修改。
接口文章分析类tag词可能存在用户不允许采集的情况。但是,我们在调用api的时候,可以同时指定分析文章的接口。只要用户不勾选就可以采集文章的tag词。文章采集后,需要转为pdf格式在电脑上阅读。另外,还需要一个接口去把我们采集到的文章转化为pdf格式。在转化为pdf的过程中我们希望能有一个可以有输出的地方。
因此我们还开发了一个分析文章tag词的接口,而这个接口正好可以把采集到的文章转化为文章的tag词。例如我们可以采集到这样一个采集:[原创][流量][数据分析][历史文章][qa][话题][一次][首发][n+1][获取方式][人物][方法][大图][指数][知识星球][神实][n+1][qa][方法][文章][读书][image][精品推荐][文案][文章][logo][人物][导购][文章][n+1][头像][图片][文章][gif][图片][话题][如何][文案][手机][验证码][如何][流量][清洁][数据分析][高分][资讯][阅读][文化][topic][视频][新闻][文化][视频][信息][新闻][高质量][清流][精品][视频][“”][qa][数据分析][a/b][建议][咨询][信息][一次][数据][疑问][好友][人物][持续][文章][指数][新闻][话题][值][微信][图文][top][动态][指数][首发][qa][读书][图片][精品][影像][大图][专题][视频][数据][读书][数据分析][汽车][宝宝][精品][新闻][读书][转发][图片][汽车][汽车][读书][汽车][小清新][汽车][心理][足球][圈子][旅游][旅游][吃喝][汽车旅游][动态][环保][重大消息][互联网][数据][科学][动态][日历][书][汽车][跨行][保养][机修][读书][会议][读书][数据][数据分析][接收][数据][律][房][期刊][文档][作文][清洁][数据][数据][视频][技术][语言][文章][神实][图片][ppt][新闻][养生]。

