
智能采集器
智能采集器(智能采集器系统在采集过程中要注意的事项)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-09-14 20:04
智能采集器系统在采集过程中要注意的事项,比如,采集器与小号多少台联接,以及什么模式登录,什么模式下可以访问,在线访问还是本地访问。目前可以实现人脸识别,行人识别,号码识别,安防监控,电子标签,产品二维码等方案。实验室使用可实现5人/小时在线实时视频采集,15人/小时在线实时视频播放,一万多号码采集器同时在线实时视频抓取,目前可以实现对多人视频完整抓取,并有视频地址可以查询自己的视频是否被采集。
当需要某个物体的具体特征图时,可以使用fiddlerserver,就像录制视频一样,只是多录像头。你可以查看一下一些视频应用都是怎么采集,怎么处理的。
一般来说,只要有采集和访问地址,不使用爬虫,其实没有必要专门使用全图形格式。
mykita开源example.zip-nvidede8.zip.9m-源代码
hexico,
可以通过rgba加密解密markdown解密readme.md等layout
刚去网上找了几个解决方案,你参考一下我的需求:内存读取一个物体,有通用的,有ui界面。返回一些scada、路由机房专用标签代码。嵌入在开源采集器app的应用分析按钮下可视化分析特征值(包括是否被采集,地址,人数,本地分享等)。 查看全部
智能采集器(智能采集器系统在采集过程中要注意的事项)
智能采集器系统在采集过程中要注意的事项,比如,采集器与小号多少台联接,以及什么模式登录,什么模式下可以访问,在线访问还是本地访问。目前可以实现人脸识别,行人识别,号码识别,安防监控,电子标签,产品二维码等方案。实验室使用可实现5人/小时在线实时视频采集,15人/小时在线实时视频播放,一万多号码采集器同时在线实时视频抓取,目前可以实现对多人视频完整抓取,并有视频地址可以查询自己的视频是否被采集。
当需要某个物体的具体特征图时,可以使用fiddlerserver,就像录制视频一样,只是多录像头。你可以查看一下一些视频应用都是怎么采集,怎么处理的。
一般来说,只要有采集和访问地址,不使用爬虫,其实没有必要专门使用全图形格式。
mykita开源example.zip-nvidede8.zip.9m-源代码
hexico,
可以通过rgba加密解密markdown解密readme.md等layout
刚去网上找了几个解决方案,你参考一下我的需求:内存读取一个物体,有通用的,有ui界面。返回一些scada、路由机房专用标签代码。嵌入在开源采集器app的应用分析按钮下可视化分析特征值(包括是否被采集,地址,人数,本地分享等)。
智能采集器(竹愈)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-09-12 10:01
傅军、傅新竹、吴高静、丁彩宇、龙慧阳、熊子奇
智能信息采集器的软件开发实践
傅俊1、傅新柱2、吴高静1、丁彩宇1、龙慧阳1、熊子琪1
(1.四川工程技术学院材料工程系, 德阳 618000;
2.初中,德阳五中,德阳 618000)
[摘要]利用爬虫技术开发的智能资讯采集器,可以帮助用户及时获取工科学校、铸造学校、焊接行业、军事网站的最新消息。论文使用tkinter进行界面设计,使用python爬虫技术对xpath、抓取的日期、URL进行处理,成功抓取消息并获取消息的URL。用户可以进一步打开感兴趣的网页进行详细阅读。
【摘要】采用爬虫技术开发的智能信息采集器,可以帮助用户及时获取工程学院、铸造学院、焊接行业、军事网站的最新信息。论文选用tkinter来设计界面,使用python爬虫技术对xpath、获取的日期、URL进行处理,顺利实现了获取消息和获取消息的URL。用户可以进一步打开感兴趣的网页进行详细阅读。
【关键词】爬虫技术;资料采集; Python;二次开发;路径
【关键词】爬虫技术;信息采集; Python;二次开发;路径
【中文图书馆分类号】TP311.5【文献标识码】A【文章Number】1673-1069(2021)05-0192-02
1 简介
网络信息时代,信息纷繁复杂。科研院所、行业企业、政府部门需要了解最新的科学前沿、法律法规和工作动态网络信息来进行决策。然而,他们很难在一个繁琐的网页上找到信息。团队在完成“了不起,我的国家——建国以来重大科技成果”省级项目的过程中,往往需要紧跟科技成果和科技发展的步伐。这需要执行指定的高度相关的网站。留言搜索。如果一一搜索这些网站列,耗时较长,往往容易漏掉。团队基于python爬虫技术设计了“智能信息采集器”,有效解决了这一问题。
2 技术基础
2.1 蟒蛇
网络爬虫按照一定的规则自动抓取万维网信息,并可以采集它可以访问的所有页面内容来获取或更新这些网站的内容和检索方法。目前获取网页新闻的技术手段包括python爬虫技术和各种爬虫框架。我们的团队使用python爬虫技术进行设计。 tkinter 模块是 Python 的标准 GUI 工具包界面,可以轻松实现许多直观的功能。 tkinter是python自带的库,无需下载安装,直接使用[1]。
2.2 获取 xpath
xpath 是一种用于在 XML 文档中查找信息的语言。在浏览器中,打开网页,右击“检查元素”,打开“DockSide”,点击左上角的“选择页面中的元素进行检查(Ctrl+Shift+C)”按钮,然后点击网页中的消息,在html代码中,右击“copy/xpath”可以得到消息的xpath[2]。
3 开发实践
3.1 整体设计
变量表。每个section的局部变量newa、urla、timea;全局变量 newlist、urllist、timelist;每个单元名用label,后面跟着label2、label3…… 每个单元名有几列,使用checkbox CheckButton,CheckButton命名为单元名+列名的缩写,与checkbox链接Checkbutton.variable.
清除newlist、urllist和timelist;如果选择了某个单元的某一列,则运行相应的def;运行后,将抓取到的所有新闻标题添加到newlist中,将URL添加到urllist中,将日期添加到timelist中间。运行所有列后,获取新列表的长度数字。 urlx, newx, tixx 清零,num=0;获取所需时间段的 zj 变量值。从i=0到number,依次读取timelist[i]的值。如果时间匹配zj,则num加1,将newlist和uellist对应的值加到urlx[num]和newx[num]中。
所选列中与时间段匹配的新闻条目总数为 num。如果num>0,则显示在表格2上。 i=0--num,依次显示newx[i]和Button。如果num=0,则提示“本次新闻数量为0”,用信息提示。
3.2 界面设计
主界面有行业按钮(见图1)、“工程院”、“铸造院”、“中国工程院”、“焊接工业”、“军迷”等点击对应按钮进入对应程序,关键代码为:
mainwin=Tk()
mainwin.title('智能信息采集器')
mainwin.geometry('500x100+450+100')
mainwin.resizable (0, 0)
mainwin["background"]="LightSkyBlue"
openscetc=Button (mainwin, text="四川工程", command=四川工程).place (x=30, y=35)
opencast=Button(mainwin, text="casting College", command=open cast).place(x=136,y=35)
openmil=Button (mainwin, text="军事爱好者", command=军事爱好者).place (x=350, y=35)
openweld=Button (mainwin, text="焊接行业", command=焊接企业).place (x=244, y=35)
mainwin.mainloop()
点击按钮打开对应信息采集器。图2为焊接行业资讯采集器。
3.3 网页分析
爬虫获取网页数据的基本过程是:发送请求、获取响应数据、分析提取数据、向用户展示爬取结果。发送请求可以使用 requests 模块或 selenium 模块。解析数据,可以选择re regular,bs4(BeautifulSoup4)或xpath。经过技术研究,项目组使用requests模块和xpath。标题和日期通常是不同的xpath。使用xpath1/text()来抓取消息标题,xpath1 /@href 捕获消息的链接,使用xpath2/text()捕获消息的日期,关键代码为[3, 4]:
导入请求
从 lxml 导入 etree
导入浏览器
html=requests.get(url, headers=heade)
html.encoding='简体中文'
news=etree.HTML (html.text)
newstitle=news.xpath('xpath1/text()') #获取消息标题
newsurl=news.xpath('xpath1/@href') #抓取新闻链接
newsdate=news.xpath('xpath2/text()') #抓取新闻的日期
3.4 xpath 处理
在DockSide中得到的xpath有很多种,需要根据情况进行处理。以下是三种常见的 xpath 类型:
①一页上有一个xpath。最简单的情况是复制网页上的两条消息,比较方括号中的数字,删除数字改变的方括号,然后就可以抓取xpath下的所有消息了。 ②同一页面有多个xpath。按照①的方法去掉括号后,只能抓取到网页上的部分消息。这时候把没有抓到的xpath复制过来,一一比较,再次运行,直到抓到所有的消息。 ③只保留根xpath。在DockSide中获取到的xpath通常有几个层次,但是由于站群系统的不同,无法爬取成功。解决办法是只留下根xpath 就可以成功爬取。
3.5 获取网址
xpath/@href 方法获取的URL中,需要打印才能观察。通常有两种情况:①获取完整的URL,直接使用; ②只抓取网页过时的部分,可以通过预设的preurl解决。
3.6 获取日期
xpath2/text()捕获的消息日期日期统一为yyyy-mm-dd格式。也通过打印观察,通常有以下三种情况: ①分隔符不是破折号。对于 yyyy/mm/dd、yyyy year mm、month 和 dd 形式的日期,将其替换为 replace。 date=date.replace('/','-').replace(('year','-').replace((month'','-').replace(('day','')②开头和结尾还有其他字符,对于格式[yyyy-mm-dd]的日期,也使用replace。 date=date.replace('[','').replace((']', '-') ③收录时间,对于2021-01-31 10:01形式的日期数据,只剩下年月日,然后截取前10个字符 date=date[0:10]
3.7 时间段处理
消息时间段分为今天、最近三天、本周和上个月。确定 time.mktime(今天)和 timeStamp 之间的差异。
today=time.localtime(time.time())
today=int(time.mktime(today))
timeArray=time.strptime(timelist,'%Y-%m-%d')
timeStamp=int(time.mktime(timeArray))
shij=(today-timeStamp)/(24*3600)
图3为图2中“焊接质量检测+中国工程焊接协会+焊接之家+近一个月”的搜索结果。
4 结论
应用爬虫技术开发智能信息采集器,可用于采集四川工程学院、铸造院校、焊接行业、军事网站的最新网络新闻,满足不同用户的需求。免费提供给用户后,深受用户欢迎。
科学技术日新月异。您可以利用这些技术开发一些适合自己使用的小程序,以满足您的个性化需求。利用该项目技术开发的作品参加了一系列大学生比赛,并多次获奖。
[参考文献]
[1] 戴元,郑传兴。基于Python的南京二手房数据抓取与分析[J].计算机时代,2021 (1): 37-40+45.
[2] 李文华.网络爬虫技术原理解析[J].福建计算机, 2021, 37 (1):95-96.
[3] 许景贤,林金成,程雨萌。基于Selenium框架的反爬虫程序设计与实现[J].福建计算机, 2021, 37 (1):26-29.
[4] 傅军,郑定元,张俊宁,等。 Python爬虫技术在文献计量学中的应用与实践[J].计算机产品与流通, 2019 (7): 133. 查看全部
智能采集器(竹愈)
傅军、傅新竹、吴高静、丁彩宇、龙慧阳、熊子奇



智能信息采集器的软件开发实践
傅俊1、傅新柱2、吴高静1、丁彩宇1、龙慧阳1、熊子琪1
(1.四川工程技术学院材料工程系, 德阳 618000;
2.初中,德阳五中,德阳 618000)
[摘要]利用爬虫技术开发的智能资讯采集器,可以帮助用户及时获取工科学校、铸造学校、焊接行业、军事网站的最新消息。论文使用tkinter进行界面设计,使用python爬虫技术对xpath、抓取的日期、URL进行处理,成功抓取消息并获取消息的URL。用户可以进一步打开感兴趣的网页进行详细阅读。
【摘要】采用爬虫技术开发的智能信息采集器,可以帮助用户及时获取工程学院、铸造学院、焊接行业、军事网站的最新信息。论文选用tkinter来设计界面,使用python爬虫技术对xpath、获取的日期、URL进行处理,顺利实现了获取消息和获取消息的URL。用户可以进一步打开感兴趣的网页进行详细阅读。
【关键词】爬虫技术;资料采集; Python;二次开发;路径
【关键词】爬虫技术;信息采集; Python;二次开发;路径
【中文图书馆分类号】TP311.5【文献标识码】A【文章Number】1673-1069(2021)05-0192-02
1 简介
网络信息时代,信息纷繁复杂。科研院所、行业企业、政府部门需要了解最新的科学前沿、法律法规和工作动态网络信息来进行决策。然而,他们很难在一个繁琐的网页上找到信息。团队在完成“了不起,我的国家——建国以来重大科技成果”省级项目的过程中,往往需要紧跟科技成果和科技发展的步伐。这需要执行指定的高度相关的网站。留言搜索。如果一一搜索这些网站列,耗时较长,往往容易漏掉。团队基于python爬虫技术设计了“智能信息采集器”,有效解决了这一问题。
2 技术基础
2.1 蟒蛇
网络爬虫按照一定的规则自动抓取万维网信息,并可以采集它可以访问的所有页面内容来获取或更新这些网站的内容和检索方法。目前获取网页新闻的技术手段包括python爬虫技术和各种爬虫框架。我们的团队使用python爬虫技术进行设计。 tkinter 模块是 Python 的标准 GUI 工具包界面,可以轻松实现许多直观的功能。 tkinter是python自带的库,无需下载安装,直接使用[1]。
2.2 获取 xpath
xpath 是一种用于在 XML 文档中查找信息的语言。在浏览器中,打开网页,右击“检查元素”,打开“DockSide”,点击左上角的“选择页面中的元素进行检查(Ctrl+Shift+C)”按钮,然后点击网页中的消息,在html代码中,右击“copy/xpath”可以得到消息的xpath[2]。
3 开发实践
3.1 整体设计
变量表。每个section的局部变量newa、urla、timea;全局变量 newlist、urllist、timelist;每个单元名用label,后面跟着label2、label3…… 每个单元名有几列,使用checkbox CheckButton,CheckButton命名为单元名+列名的缩写,与checkbox链接Checkbutton.variable.
清除newlist、urllist和timelist;如果选择了某个单元的某一列,则运行相应的def;运行后,将抓取到的所有新闻标题添加到newlist中,将URL添加到urllist中,将日期添加到timelist中间。运行所有列后,获取新列表的长度数字。 urlx, newx, tixx 清零,num=0;获取所需时间段的 zj 变量值。从i=0到number,依次读取timelist[i]的值。如果时间匹配zj,则num加1,将newlist和uellist对应的值加到urlx[num]和newx[num]中。
所选列中与时间段匹配的新闻条目总数为 num。如果num>0,则显示在表格2上。 i=0--num,依次显示newx[i]和Button。如果num=0,则提示“本次新闻数量为0”,用信息提示。
3.2 界面设计
主界面有行业按钮(见图1)、“工程院”、“铸造院”、“中国工程院”、“焊接工业”、“军迷”等点击对应按钮进入对应程序,关键代码为:
mainwin=Tk()
mainwin.title('智能信息采集器')
mainwin.geometry('500x100+450+100')
mainwin.resizable (0, 0)
mainwin["background"]="LightSkyBlue"
openscetc=Button (mainwin, text="四川工程", command=四川工程).place (x=30, y=35)
opencast=Button(mainwin, text="casting College", command=open cast).place(x=136,y=35)
openmil=Button (mainwin, text="军事爱好者", command=军事爱好者).place (x=350, y=35)
openweld=Button (mainwin, text="焊接行业", command=焊接企业).place (x=244, y=35)
mainwin.mainloop()
点击按钮打开对应信息采集器。图2为焊接行业资讯采集器。
3.3 网页分析
爬虫获取网页数据的基本过程是:发送请求、获取响应数据、分析提取数据、向用户展示爬取结果。发送请求可以使用 requests 模块或 selenium 模块。解析数据,可以选择re regular,bs4(BeautifulSoup4)或xpath。经过技术研究,项目组使用requests模块和xpath。标题和日期通常是不同的xpath。使用xpath1/text()来抓取消息标题,xpath1 /@href 捕获消息的链接,使用xpath2/text()捕获消息的日期,关键代码为[3, 4]:
导入请求
从 lxml 导入 etree
导入浏览器
html=requests.get(url, headers=heade)
html.encoding='简体中文'
news=etree.HTML (html.text)
newstitle=news.xpath('xpath1/text()') #获取消息标题
newsurl=news.xpath('xpath1/@href') #抓取新闻链接
newsdate=news.xpath('xpath2/text()') #抓取新闻的日期
3.4 xpath 处理
在DockSide中得到的xpath有很多种,需要根据情况进行处理。以下是三种常见的 xpath 类型:
①一页上有一个xpath。最简单的情况是复制网页上的两条消息,比较方括号中的数字,删除数字改变的方括号,然后就可以抓取xpath下的所有消息了。 ②同一页面有多个xpath。按照①的方法去掉括号后,只能抓取到网页上的部分消息。这时候把没有抓到的xpath复制过来,一一比较,再次运行,直到抓到所有的消息。 ③只保留根xpath。在DockSide中获取到的xpath通常有几个层次,但是由于站群系统的不同,无法爬取成功。解决办法是只留下根xpath 就可以成功爬取。
3.5 获取网址
xpath/@href 方法获取的URL中,需要打印才能观察。通常有两种情况:①获取完整的URL,直接使用; ②只抓取网页过时的部分,可以通过预设的preurl解决。
3.6 获取日期
xpath2/text()捕获的消息日期日期统一为yyyy-mm-dd格式。也通过打印观察,通常有以下三种情况: ①分隔符不是破折号。对于 yyyy/mm/dd、yyyy year mm、month 和 dd 形式的日期,将其替换为 replace。 date=date.replace('/','-').replace(('year','-').replace((month'','-').replace(('day','')②开头和结尾还有其他字符,对于格式[yyyy-mm-dd]的日期,也使用replace。 date=date.replace('[','').replace((']', '-') ③收录时间,对于2021-01-31 10:01形式的日期数据,只剩下年月日,然后截取前10个字符 date=date[0:10]
3.7 时间段处理
消息时间段分为今天、最近三天、本周和上个月。确定 time.mktime(今天)和 timeStamp 之间的差异。
today=time.localtime(time.time())
today=int(time.mktime(today))
timeArray=time.strptime(timelist,'%Y-%m-%d')
timeStamp=int(time.mktime(timeArray))
shij=(today-timeStamp)/(24*3600)
图3为图2中“焊接质量检测+中国工程焊接协会+焊接之家+近一个月”的搜索结果。
4 结论
应用爬虫技术开发智能信息采集器,可用于采集四川工程学院、铸造院校、焊接行业、军事网站的最新网络新闻,满足不同用户的需求。免费提供给用户后,深受用户欢迎。
科学技术日新月异。您可以利用这些技术开发一些适合自己使用的小程序,以满足您的个性化需求。利用该项目技术开发的作品参加了一系列大学生比赛,并多次获奖。
[参考文献]
[1] 戴元,郑传兴。基于Python的南京二手房数据抓取与分析[J].计算机时代,2021 (1): 37-40+45.
[2] 李文华.网络爬虫技术原理解析[J].福建计算机, 2021, 37 (1):95-96.
[3] 许景贤,林金成,程雨萌。基于Selenium框架的反爬虫程序设计与实现[J].福建计算机, 2021, 37 (1):26-29.
[4] 傅军,郑定元,张俊宁,等。 Python爬虫技术在文献计量学中的应用与实践[J].计算机产品与流通, 2019 (7): 133.
智能采集器(我个人推荐telegraphfacebook的网站返回数据量是相对大一些)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-09-11 07:04
智能采集器可以只要cto水平高,能够合理指定采集类型和一些特殊策略,就能得到不错的数据结果,一些次一点的数据相对是比较丰富的,但另一方面也有限制,像一些文本类的数据如果不涉及很多相关性但又可以得到很好的结果就是不错的,但是百分比方式返回的数据虽然能得到粗略数据,但要得到精确的结果的话能返回的数据会很有限。
有个同学在里面做采集,他说做的比之前做的etl的效果差很多,但感觉跟人工还是相差不大的。要说不足是cto没什么特别高级的水平,靠机器学习的成本很高,特别是对的编程能力要求很高,如果没有专门做过人工智能的数据类型处理,机器学习的能力不会太强,要说有更好的选择,其实成熟稳定的chatclient也不错,而且即使不在里面做深度学习,也可以直接应用fb特别推荐的另一个网站telegraph里面的tags来采集数据,毕竟他们自己算法用的很多,得到的数据还是相对比较精准。
如果你不是搞技术的,只是想采集一些个人信息的话,不用担心这点,像你在豆瓣app里看到我发的东西,我其实是只用了一个返回链接而已,但这个返回的并不是你个人信息,只是app返回的一个链接,不同于google给你的是google的presentation里用的,即使是其他软件,只要是一个被分类到newswebsite里的,自己就可以获取个人信息,这个是可以自己做主动选择的。
我个人推荐telegraph,facebook的网站返回数据量是相对大一些,如果你看我发的东西更多,觉得新奇的,可以直接post个人信息到telegraph去。p.s.其实豆瓣app本身也是个隐私数据库,这一点我觉得他们需要考虑一下,用手机登录他们是不需要再次收集你的任何数据,这可能会增加获取的难度和成本。 查看全部
智能采集器(我个人推荐telegraphfacebook的网站返回数据量是相对大一些)
智能采集器可以只要cto水平高,能够合理指定采集类型和一些特殊策略,就能得到不错的数据结果,一些次一点的数据相对是比较丰富的,但另一方面也有限制,像一些文本类的数据如果不涉及很多相关性但又可以得到很好的结果就是不错的,但是百分比方式返回的数据虽然能得到粗略数据,但要得到精确的结果的话能返回的数据会很有限。
有个同学在里面做采集,他说做的比之前做的etl的效果差很多,但感觉跟人工还是相差不大的。要说不足是cto没什么特别高级的水平,靠机器学习的成本很高,特别是对的编程能力要求很高,如果没有专门做过人工智能的数据类型处理,机器学习的能力不会太强,要说有更好的选择,其实成熟稳定的chatclient也不错,而且即使不在里面做深度学习,也可以直接应用fb特别推荐的另一个网站telegraph里面的tags来采集数据,毕竟他们自己算法用的很多,得到的数据还是相对比较精准。
如果你不是搞技术的,只是想采集一些个人信息的话,不用担心这点,像你在豆瓣app里看到我发的东西,我其实是只用了一个返回链接而已,但这个返回的并不是你个人信息,只是app返回的一个链接,不同于google给你的是google的presentation里用的,即使是其他软件,只要是一个被分类到newswebsite里的,自己就可以获取个人信息,这个是可以自己做主动选择的。
我个人推荐telegraph,facebook的网站返回数据量是相对大一些,如果你看我发的东西更多,觉得新奇的,可以直接post个人信息到telegraph去。p.s.其实豆瓣app本身也是个隐私数据库,这一点我觉得他们需要考虑一下,用手机登录他们是不需要再次收集你的任何数据,这可能会增加获取的难度和成本。
智能采集器(智能采集器如何找到接口的痛点?行云管家教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-09 19:07
智能采集器是为了解决部分行业找不到采集接口的痛点而出现的,不仅提供接口,还提供后台统计、分析、授权、搜索等功能,能帮助解决企业不知道如何找到接口的痛点,是一个非常强大的采集器。
我买了一个行云采集器的app,产品功能挺全的,使用蛮方便的,你可以看看我写的教程。
做个水果网站好像用的行云管家的html采集器,这个产品蛮好用的,用的也挺顺手的。
同问题,
行云管家很厉害的,是国内某著名大公司出品的一款很不错的新型互联网数据采集工具,
应该可以问问???
推荐用一个p2p平台:。它是一个免费互联网数据采集和挖掘平台。做网站、做app什么的都可以用。或者做博客网站去外链等。特别方便。
行云管家真的很好用,有几个方面我真的非常喜欢:①采集接口多:常用的七八十个,大多是对大型网站的采集。②上传文件速度快:文件上传非常快。③自带全文搜索:几个关键词就能搜索到想要的东西。④采集匹配度高:主要针对企业的信息收集,而不是普通小网站。
可以考虑下联想企业网,没有用过,但是被他的宣传吓到了,希望是我想太多。只是拿他来举个例子,主要体现对接合作的。 查看全部
智能采集器(智能采集器如何找到接口的痛点?行云管家教程)
智能采集器是为了解决部分行业找不到采集接口的痛点而出现的,不仅提供接口,还提供后台统计、分析、授权、搜索等功能,能帮助解决企业不知道如何找到接口的痛点,是一个非常强大的采集器。
我买了一个行云采集器的app,产品功能挺全的,使用蛮方便的,你可以看看我写的教程。
做个水果网站好像用的行云管家的html采集器,这个产品蛮好用的,用的也挺顺手的。
同问题,
行云管家很厉害的,是国内某著名大公司出品的一款很不错的新型互联网数据采集工具,
应该可以问问???
推荐用一个p2p平台:。它是一个免费互联网数据采集和挖掘平台。做网站、做app什么的都可以用。或者做博客网站去外链等。特别方便。
行云管家真的很好用,有几个方面我真的非常喜欢:①采集接口多:常用的七八十个,大多是对大型网站的采集。②上传文件速度快:文件上传非常快。③自带全文搜索:几个关键词就能搜索到想要的东西。④采集匹配度高:主要针对企业的信息收集,而不是普通小网站。
可以考虑下联想企业网,没有用过,但是被他的宣传吓到了,希望是我想太多。只是拿他来举个例子,主要体现对接合作的。
智能采集器(百度影音自带的一键采集spider功能文件分类过多容易造成采集错误)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-09-08 09:07
智能采集器关键是通过控制采集端口速率为200mbps,实现全国范围内所有网站一键采集,采集效率比较高。
国内来说,是采集开发平台做快数的团队做的比较好些,如采数科技,
快数采集器一键采集神器!完美解决大文件、大图片、多账号采集。目前获得125万用户使用,粉丝数超过100万,开发团队有60人,为了给新用户更好的体验和服务,提供免费有效的技术支持。
为了采到更好的网站地址,百度搜了一圈,baiduspider能采到。
米采2.0基于spider+diy极客+http2,相对较新,安装也比较方便,而且支持跨区域spider爬取,如果文件较大的话可以提供单spider模式。
百度影音自带的一键采集spider功能
文件分类过多容易造成采集错误,智能采集最大程度上避免了问题,通过一个规则实现多个功能,
我们公司正在做这方面的探索,个人对一些集采集,云采集的公司比较推荐。有人说智能采集采集一些新闻内容(视频,音频等)效率不高,集采集,云采集更加高效。最近在研究m站的集采集(需要vps才能采集,发现上也有一些集采集服务商,模仿这个模式)。最后针对m站这块,综合各方面, 查看全部
智能采集器(百度影音自带的一键采集spider功能文件分类过多容易造成采集错误)
智能采集器关键是通过控制采集端口速率为200mbps,实现全国范围内所有网站一键采集,采集效率比较高。
国内来说,是采集开发平台做快数的团队做的比较好些,如采数科技,
快数采集器一键采集神器!完美解决大文件、大图片、多账号采集。目前获得125万用户使用,粉丝数超过100万,开发团队有60人,为了给新用户更好的体验和服务,提供免费有效的技术支持。
为了采到更好的网站地址,百度搜了一圈,baiduspider能采到。
米采2.0基于spider+diy极客+http2,相对较新,安装也比较方便,而且支持跨区域spider爬取,如果文件较大的话可以提供单spider模式。
百度影音自带的一键采集spider功能
文件分类过多容易造成采集错误,智能采集最大程度上避免了问题,通过一个规则实现多个功能,
我们公司正在做这方面的探索,个人对一些集采集,云采集的公司比较推荐。有人说智能采集采集一些新闻内容(视频,音频等)效率不高,集采集,云采集更加高效。最近在研究m站的集采集(需要vps才能采集,发现上也有一些集采集服务商,模仿这个模式)。最后针对m站这块,综合各方面,
智能采集器(智能采集器,电商企业需要做的开发,复制粘贴)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-09-03 16:36
智能采集器,就像机器人采集商品一样,可以任意浏览、扫码、识别、购买、推送信息,就像扫描码一样,更人性化。使用起来简单,易上手,一步实现全网商品的采集以及识别,还可以对识别到的商品进行编辑、推送、关联微信公众号,等操作。另外,还有一些现成的商品数据可以下载,电商企业需要做的开发,复制粘贴使用起来是很方便的。功能:。
1、采集全网海量自媒体平台
2、识别商品,
3、后台商品一键编辑、修改、查看
4、手机端多端打开,
5、手机端多端同步登录,
微信搜索“有货”小程序,选择“市场”,输入需要进行采集的商品,完成以后点击“确认”,商品信息就会全部采集到小程序里,前提是要扫描二维码进行登录。另外还有各种价格、佣金信息,甚至有图片、视频等等,可供商家选择。
我们商掌门采集大众点评、微信、京东上的商品信息已经很长时间了,采集技术之所以能够成功,不是看采集软件的采集速度。小程序尚未上线,我们还有很长的路要走。另外,大部分商家,小程序不适合需要非常专业的采集软件,我们的采集软件,需要各种各样的数据接口、分发接口,数据采集相关的传输技术等,不是我们这个方向要解决的问题。
等到小程序正式上线,我们将全力做好。好的采集软件,采集速度越快的,在其他方面不具备优势,更容易让人离开。不如当用户第一次购买我们产品时,先进去体验下。 查看全部
智能采集器(智能采集器,电商企业需要做的开发,复制粘贴)
智能采集器,就像机器人采集商品一样,可以任意浏览、扫码、识别、购买、推送信息,就像扫描码一样,更人性化。使用起来简单,易上手,一步实现全网商品的采集以及识别,还可以对识别到的商品进行编辑、推送、关联微信公众号,等操作。另外,还有一些现成的商品数据可以下载,电商企业需要做的开发,复制粘贴使用起来是很方便的。功能:。
1、采集全网海量自媒体平台
2、识别商品,
3、后台商品一键编辑、修改、查看
4、手机端多端打开,
5、手机端多端同步登录,
微信搜索“有货”小程序,选择“市场”,输入需要进行采集的商品,完成以后点击“确认”,商品信息就会全部采集到小程序里,前提是要扫描二维码进行登录。另外还有各种价格、佣金信息,甚至有图片、视频等等,可供商家选择。
我们商掌门采集大众点评、微信、京东上的商品信息已经很长时间了,采集技术之所以能够成功,不是看采集软件的采集速度。小程序尚未上线,我们还有很长的路要走。另外,大部分商家,小程序不适合需要非常专业的采集软件,我们的采集软件,需要各种各样的数据接口、分发接口,数据采集相关的传输技术等,不是我们这个方向要解决的问题。
等到小程序正式上线,我们将全力做好。好的采集软件,采集速度越快的,在其他方面不具备优势,更容易让人离开。不如当用户第一次购买我们产品时,先进去体验下。
智能采集器(熊猫智能采集软件是一款快速专业的采集工具,功能强大,操作简单)
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-08-29 15:11
熊猫智能采集软件是一款快速专业的采集工具,功能强大,操作简单,轻松帮助用户实现批量采集,下载、复制互联网资源,欢迎有需要的朋友下载使用!
Panda Smart采集软件介绍
优采云采集器软件是新一代采集软件,鼠标操作全过程可视化,用户无需关心网页源代码,无需编写采集规则,不需要使用正则表达式技术。全程智能辅助是采集软件行业的新一代产品。同时也是通用的采集软件,可用于各行业,满足各种采集需求。是采集复杂需求的必备,也是采集软件新手用户的首选。
熊猫智能采集器功能
操作简单,不懂技术也能轻松操作
只需输入列表页面 URL 或 关键词 即可启动 采集。您无需关心网页的源代码,鼠标操作就是整个过程。操作界面友好直观。全程智能协助。
全面强大的功能
该软件虽然操作简单,但功能强大且功能全面。可以实现各种复杂的采集需求。多功能采集软件,可应用于各种场合。是复杂采集需求的首选。
任何网页都可以采集
只要能在浏览器中看到内容,几乎都可以采集你需要的格式。支持JS输出内容的采集。
采集 速度快,数据完整性高
Panda 的采集 速度是采集 软件中最快的速度之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整。
熊猫智能采集Function
全方位的采集功能
采集的对象包括文字内容、图片、flash动画视频、下载文件等网络内容。 采集 同时支持混合图形和文本对象。支持复杂结构化的采集对象集合,支持复杂的多库表单,支持跨页面内容合并采集的能力。
采集速快
使用我们自己开发的解析引擎,实现网页源代码的类似浏览器的解析。分解网页的视觉内容元素,在此基础上进行机器学习和批量采集匹配。经过实际测试,比传统的正则匹配方式采集快2~5倍。比第三方内置浏览器采集快10-20倍。
结果数据的高度完整性
在实际采集过程中,由于目标页面具有丰富的内容页面格式,这时候就需要借助pandas独有的“多模板功能”来实现一个完整的采集。页面上采集的内容为100%采集。
多模板自动适配
很多网站“内容页”都会有多种不同类型的模板,所以优采云采集器软件允许每个采集项目同时设置多个内容页引用模板,在采集处运行时,系统会自动匹配找到最合适的参考模板来分析内容页面。
实时帮助窗口
在采集项目设置链接中,系统会在窗口右上角显示当前配置相关的实时帮助内容,为新手用户提供实时帮助。因此,优采云采集器 软件可以轻松使用。全程智能辅助,即使是第一次接触优采云采集器软件,配置采集项目也更加轻松。 查看全部
智能采集器(熊猫智能采集软件是一款快速专业的采集工具,功能强大,操作简单)
熊猫智能采集软件是一款快速专业的采集工具,功能强大,操作简单,轻松帮助用户实现批量采集,下载、复制互联网资源,欢迎有需要的朋友下载使用!
Panda Smart采集软件介绍
优采云采集器软件是新一代采集软件,鼠标操作全过程可视化,用户无需关心网页源代码,无需编写采集规则,不需要使用正则表达式技术。全程智能辅助是采集软件行业的新一代产品。同时也是通用的采集软件,可用于各行业,满足各种采集需求。是采集复杂需求的必备,也是采集软件新手用户的首选。

熊猫智能采集器功能
操作简单,不懂技术也能轻松操作
只需输入列表页面 URL 或 关键词 即可启动 采集。您无需关心网页的源代码,鼠标操作就是整个过程。操作界面友好直观。全程智能协助。
全面强大的功能
该软件虽然操作简单,但功能强大且功能全面。可以实现各种复杂的采集需求。多功能采集软件,可应用于各种场合。是复杂采集需求的首选。
任何网页都可以采集
只要能在浏览器中看到内容,几乎都可以采集你需要的格式。支持JS输出内容的采集。
采集 速度快,数据完整性高
Panda 的采集 速度是采集 软件中最快的速度之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整。
熊猫智能采集Function
全方位的采集功能
采集的对象包括文字内容、图片、flash动画视频、下载文件等网络内容。 采集 同时支持混合图形和文本对象。支持复杂结构化的采集对象集合,支持复杂的多库表单,支持跨页面内容合并采集的能力。
采集速快
使用我们自己开发的解析引擎,实现网页源代码的类似浏览器的解析。分解网页的视觉内容元素,在此基础上进行机器学习和批量采集匹配。经过实际测试,比传统的正则匹配方式采集快2~5倍。比第三方内置浏览器采集快10-20倍。
结果数据的高度完整性
在实际采集过程中,由于目标页面具有丰富的内容页面格式,这时候就需要借助pandas独有的“多模板功能”来实现一个完整的采集。页面上采集的内容为100%采集。
多模板自动适配
很多网站“内容页”都会有多种不同类型的模板,所以优采云采集器软件允许每个采集项目同时设置多个内容页引用模板,在采集处运行时,系统会自动匹配找到最合适的参考模板来分析内容页面。
实时帮助窗口
在采集项目设置链接中,系统会在窗口右上角显示当前配置相关的实时帮助内容,为新手用户提供实时帮助。因此,优采云采集器 软件可以轻松使用。全程智能辅助,即使是第一次接触优采云采集器软件,配置采集项目也更加轻松。
智能采集器(优化啦·智能信息采集器软件特点:1.智能邮箱采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-08-28 00:16
优化。智讯采集器是基于爬取搜索引擎邮件资源开发的一款功能强大的采集软件。来自采集、QQ的邮箱地址具有很强的定向性,排除你与目标受众无关的Email,会让你得到的邮箱列表更有针对性,发送的效果自然会更好。优化。智能信息采集器提供强大的邮箱地址、导出、去重功能。是邮箱营销和QQ营销的必备软件!
优化·智能信息采集器软件特点:
1.智慧邮采集器是一款功能强大、易于使用且友好的专业邮件按钮搜索器。
2.通过页面多平台智能分析,深度挖掘所有页面的邮箱地址,扣号,准确率99%。
3. 根据设定的目标关键词,软件会自动从搜索引擎结果中采集 对应的邮箱地址。 采集发送的邮件地址非常准确,更符合精准邮件营销的理念。
4. 根据设定的目标关键词,软件自动从搜索引擎结果中检索出采集对应的所有扣号。 采集收到的扣号非常准确,更适合扣精准营销。想法。
客户信息采集器是一个强大的客户挖掘工具。使用本软件挖掘客户时,用户只需要输入关键词软件即可自动采集在线客户信息并过滤,最终过滤结果显示供客户参考。
优化·智能信息采集器使用提醒:
提醒:部分杀毒软件返回误报,加入白名单正常使用即可。 查看全部
智能采集器(优化啦·智能信息采集器软件特点:1.智能邮箱采集器)
优化。智讯采集器是基于爬取搜索引擎邮件资源开发的一款功能强大的采集软件。来自采集、QQ的邮箱地址具有很强的定向性,排除你与目标受众无关的Email,会让你得到的邮箱列表更有针对性,发送的效果自然会更好。优化。智能信息采集器提供强大的邮箱地址、导出、去重功能。是邮箱营销和QQ营销的必备软件!
优化·智能信息采集器软件特点:
1.智慧邮采集器是一款功能强大、易于使用且友好的专业邮件按钮搜索器。
2.通过页面多平台智能分析,深度挖掘所有页面的邮箱地址,扣号,准确率99%。
3. 根据设定的目标关键词,软件会自动从搜索引擎结果中采集 对应的邮箱地址。 采集发送的邮件地址非常准确,更符合精准邮件营销的理念。
4. 根据设定的目标关键词,软件自动从搜索引擎结果中检索出采集对应的所有扣号。 采集收到的扣号非常准确,更适合扣精准营销。想法。
客户信息采集器是一个强大的客户挖掘工具。使用本软件挖掘客户时,用户只需要输入关键词软件即可自动采集在线客户信息并过滤,最终过滤结果显示供客户参考。
优化·智能信息采集器使用提醒:
提醒:部分杀毒软件返回误报,加入白名单正常使用即可。
优采云软件开发智能文章采集系统介绍及功能介绍(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-08-26 02:05
优采云智能文章采集系统是优采云software开发的网站文章采集器系统。软件内置智能分块算法,可以直接将html代码和主要内容分开,只需要输入网站网址,软件就可以轻松准确地将采集网站中的所有文章 @。除了采集文章功能,软件还有强大的原创功能,可以将采集收到的内容处理两次,直接发布到你的网站,或者直接导出到txt格式本地化,功能非常强大,适合每一位站长下载使用。
软件功能
1、智能区块算法采集任何内容站点,真的傻瓜式采集
智能块算法自动提取网页正文内容,无需配置源码规则,真的傻瓜式采集;
自动去噪,可自动过滤标题内容中的图片\URL\电话\QQ\email等信息;
可以针对全球任何小语种,任意编码文章采集,无乱码;
多任务(多站点/列)多线程同步采集,支持代理采集,快速高效;
指定任何文章内容类网站采集,而不是文章源
2、Powerful 伪原创function
内置中文分词功能,强大的近义词和同义词数据库引擎,替换效率高;
自带英文分词词库和语料库,支持TBS模式批量原创,保持句子语义流畅;
标题和内容可以伪原创单独处理;
3、内置主流cmsrelease接口
可直接导出为TXT文件,可根据标题或序号生成文件名。
支持wordpress、zblog、dedecms、phpcms等国内外主流cms自动发布;
支持多线程、多任务同时发布;
功能介绍
1、Content 区块自动识别并自动提取任意页面内容
自动识别html代码并过滤正文内容,完整率95%以上,只要是基于内容的页面,都可以自动提取。
2、使用代理IP模拟真实蜘蛛头采集防止同一IP采集被过多限制
目前很多大规模网站对同一个IP的访问过于频繁会被限制。软件可以使用采集的代理IP绕过限制,同时模拟真实蜘蛛爬取采集页面,最大可能受到网站采集某个大频率的限制。
3、任何编码和小语种采集全球小语种采集,无乱码
一般网页采集乱码都是编码不正确造成的。本软件内置所有全球编码格式,可以选择不同的编码采集,确保任何语言和任意编码采集都不会出现乱码。
4、中英文伪原创处理多种原创模式,对搜索引擎收录有好处
中文采用内置同义词和同义词数据库替换模式,英文采用伪原创强大的TBS预测数据库,保证句子前后流畅。同一篇文章文章的内容每次原创之后都会改变。
5、多种导出/发布模式,灵活的内容导出和发布
可以根据序列号或标题为文件名直接以TXT格式导出到本地,也可以直接使用内置发布接口发布到当前主流的几个内容cms程序,目前支持dedecms、wordpress、zblog 等
常见问题
1、是否可以在任何网站上采集?
只要是本站主要内容,如论坛、博客、文章站等都可以采集、优采云智能文章采集系统会自动识别正文块并自动提取正文内容。
2、采集的文章乱七八糟?
优采云智能文章采集系统是针对指定的网站采集,得到的文章是原页面文章的正文内容,不是源码的文本字符网页,但干净的原创文章Content。 查看全部
优采云软件开发智能文章采集系统介绍及功能介绍(组图)
优采云智能文章采集系统是优采云software开发的网站文章采集器系统。软件内置智能分块算法,可以直接将html代码和主要内容分开,只需要输入网站网址,软件就可以轻松准确地将采集网站中的所有文章 @。除了采集文章功能,软件还有强大的原创功能,可以将采集收到的内容处理两次,直接发布到你的网站,或者直接导出到txt格式本地化,功能非常强大,适合每一位站长下载使用。

软件功能
1、智能区块算法采集任何内容站点,真的傻瓜式采集
智能块算法自动提取网页正文内容,无需配置源码规则,真的傻瓜式采集;
自动去噪,可自动过滤标题内容中的图片\URL\电话\QQ\email等信息;
可以针对全球任何小语种,任意编码文章采集,无乱码;
多任务(多站点/列)多线程同步采集,支持代理采集,快速高效;
指定任何文章内容类网站采集,而不是文章源

2、Powerful 伪原创function
内置中文分词功能,强大的近义词和同义词数据库引擎,替换效率高;
自带英文分词词库和语料库,支持TBS模式批量原创,保持句子语义流畅;
标题和内容可以伪原创单独处理;

3、内置主流cmsrelease接口
可直接导出为TXT文件,可根据标题或序号生成文件名。
支持wordpress、zblog、dedecms、phpcms等国内外主流cms自动发布;
支持多线程、多任务同时发布;

功能介绍
1、Content 区块自动识别并自动提取任意页面内容
自动识别html代码并过滤正文内容,完整率95%以上,只要是基于内容的页面,都可以自动提取。
2、使用代理IP模拟真实蜘蛛头采集防止同一IP采集被过多限制
目前很多大规模网站对同一个IP的访问过于频繁会被限制。软件可以使用采集的代理IP绕过限制,同时模拟真实蜘蛛爬取采集页面,最大可能受到网站采集某个大频率的限制。
3、任何编码和小语种采集全球小语种采集,无乱码
一般网页采集乱码都是编码不正确造成的。本软件内置所有全球编码格式,可以选择不同的编码采集,确保任何语言和任意编码采集都不会出现乱码。
4、中英文伪原创处理多种原创模式,对搜索引擎收录有好处
中文采用内置同义词和同义词数据库替换模式,英文采用伪原创强大的TBS预测数据库,保证句子前后流畅。同一篇文章文章的内容每次原创之后都会改变。
5、多种导出/发布模式,灵活的内容导出和发布
可以根据序列号或标题为文件名直接以TXT格式导出到本地,也可以直接使用内置发布接口发布到当前主流的几个内容cms程序,目前支持dedecms、wordpress、zblog 等
常见问题
1、是否可以在任何网站上采集?
只要是本站主要内容,如论坛、博客、文章站等都可以采集、优采云智能文章采集系统会自动识别正文块并自动提取正文内容。
2、采集的文章乱七八糟?
优采云智能文章采集系统是针对指定的网站采集,得到的文章是原页面文章的正文内容,不是源码的文本字符网页,但干净的原创文章Content。
智能采集器如何开发多种聚合搜索、采集方案?
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-08-25 01:06
智能采集器,可以进行聚合搜索、采集分析,针对不同的行业可以开发多种聚合采集方案,如网站采集、app采集、小程序采集、内容聚合等。打开智能采集器,以“采五颜六色”为例子,进行一次安装教程说明操作说明:进入pc端,点击上方“采五颜六色”里面的五种功能进行一个下载。打开我们的电脑,双击我们刚刚准备好的采集器,找到我们需要搜索的内容。
点击五颜六色中的“采集源地址”,点击保存,然后可以开始搜索了,或者点击文中的“采集源地址”,返回到智能采集器里,点击搜索源地址。在我们前面的操作页面,可以看到是我们的模拟浏览器在浏览网页。点击浏览器里面的“全部浏览器”,然后找到我们需要搜索的链接,或者百度地址。点击网址上方的“realpage”点击点击即可播放样式,点击我们准备好的搜索源地址即可开始搜索了。
智能采集器可以免费使用1个月,保存之后文件如何打包呢?答案很简单,我们直接把下载的文件上传到我们的百度云里就可以了。不会有一点点的乱码吧!搜索完之后,如果需要特别的效果,或者需要我们自己想要这样的效果的,直接购买。如果你没有购买的话,那我们要怎么找呢?要怎么样才能开通花呗呢?我们把有搜索词的样式拖到智能采集器,或者直接把文件拖到里面,就可以开通花呗了。
打开花呗还款智能采集器,扫码也可以开通花呗呀,或者说是扫码就开通花呗也可以,管理访客,也可以自己添加访客,不管是通过微信还是别的方式添加访客,添加方式都一样的。只要我们购买了花呗,在我们有花呗的界面会有一个“添加花呗”,我们可以在里面把自己的花呗添加进去,但是现在花呗是一分钱都可以购买的。想了解更多,那就来找我吧!喜欢记得点赞哦!。 查看全部
智能采集器如何开发多种聚合搜索、采集方案?
智能采集器,可以进行聚合搜索、采集分析,针对不同的行业可以开发多种聚合采集方案,如网站采集、app采集、小程序采集、内容聚合等。打开智能采集器,以“采五颜六色”为例子,进行一次安装教程说明操作说明:进入pc端,点击上方“采五颜六色”里面的五种功能进行一个下载。打开我们的电脑,双击我们刚刚准备好的采集器,找到我们需要搜索的内容。
点击五颜六色中的“采集源地址”,点击保存,然后可以开始搜索了,或者点击文中的“采集源地址”,返回到智能采集器里,点击搜索源地址。在我们前面的操作页面,可以看到是我们的模拟浏览器在浏览网页。点击浏览器里面的“全部浏览器”,然后找到我们需要搜索的链接,或者百度地址。点击网址上方的“realpage”点击点击即可播放样式,点击我们准备好的搜索源地址即可开始搜索了。
智能采集器可以免费使用1个月,保存之后文件如何打包呢?答案很简单,我们直接把下载的文件上传到我们的百度云里就可以了。不会有一点点的乱码吧!搜索完之后,如果需要特别的效果,或者需要我们自己想要这样的效果的,直接购买。如果你没有购买的话,那我们要怎么找呢?要怎么样才能开通花呗呢?我们把有搜索词的样式拖到智能采集器,或者直接把文件拖到里面,就可以开通花呗了。
打开花呗还款智能采集器,扫码也可以开通花呗呀,或者说是扫码就开通花呗也可以,管理访客,也可以自己添加访客,不管是通过微信还是别的方式添加访客,添加方式都一样的。只要我们购买了花呗,在我们有花呗的界面会有一个“添加花呗”,我们可以在里面把自己的花呗添加进去,但是现在花呗是一分钱都可以购买的。想了解更多,那就来找我吧!喜欢记得点赞哦!。
智能采集器 竹愈
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-08-18 06:02
傅军、傅新竹、吴高静、丁彩宇、龙慧阳、熊子奇
智能信息采集器的软件开发实践
傅俊1、傅新柱2、吴高静1、丁彩宇1、龙慧阳1、熊子琪1
(1.四川工程技术学院材料工程系, 德阳 618000;
2.初中,德阳五中,德阳 618000)
[摘要]利用爬虫技术开发的智能资讯采集器,可以帮助用户及时获取工科学校、铸造学校、焊接行业、军事网站的最新消息。论文使用tkinter进行界面设计,使用python爬虫技术对xpath、抓取的日期、URL进行处理,成功抓取消息并获取消息的URL。用户可以进一步打开感兴趣的网页进行详细阅读。
【摘要】采用爬虫技术开发的智能信息采集器,可以帮助用户及时获取工程学院、铸造学院、焊接行业、军事网站的最新信息。论文选用tkinter来设计界面,使用python爬虫技术对xpath、获取的日期、URL进行处理,顺利实现了获取消息和获取消息的URL。用户可以进一步打开感兴趣的网页进行详细阅读。
【关键词】爬虫技术;资料采集; Python;二次开发;路径
【关键词】爬虫技术;信息采集; Python;二次开发;路径
【中文图书馆分类号】TP311.5【文献标识码】A【文章Number】1673-1069(2021)05-0192-02
1 简介
网络信息时代,信息纷繁复杂。科研院所、行业企业和政府部门需要了解最新的科学前沿、法律法规和工作动态网络信息来进行决策。然而,他们很难在一个繁琐的网页上找到信息。团队在完成“了不起,我国——建国以来重大科技成果”省级项目的过程中,往往需要紧跟科技成果和科技发展的步伐。这需要执行指定的高度相关的网站。留言搜索。如果一一搜索这些网站列,耗时较长,往往容易漏掉。团队基于python爬虫技术设计了“智能信息采集器”,有效解决了这一问题。
2 技术基础
2.1 蟒蛇
网络爬虫按照一定的规则自动抓取万维网信息,并可以采集它可以访问的所有页面内容来获取或更新这些网站的内容和检索方法。目前获取网页新闻的技术手段包括python爬虫技术和各种爬虫框架。我们的团队使用python爬虫技术进行设计。 tkinter 模块是 Python 的标准 GUI 工具包界面,可以轻松实现许多直观的功能。 tkinter是python自带的库,无需下载安装,直接使用[1]。
2.2 获取 xpath
xpath 是一种用于在 XML 文档中查找信息的语言。在浏览器中,打开网页,右击“检查元素”,打开“DockSide”,点击左上角的“选择页面中的元素进行检查(Ctrl+Shift+C)”按钮,然后点击网页中的消息,在html代码中,右击“copy/xpath”可以得到消息的xpath[2]。
3 开发实践
3.1 整体设计
变量表。每个section的局部变量newa、urla、timea;全局变量 newlist、urllist、timelist;每个单元名用label,后面跟着label2、label3……每个单元名下面有几列,使用checkbox CheckButton,CheckButton命名为单元名+列名的缩写,链接复选框 Checkbutton.variable。
清除newlist、urllist和timelist;如果选择了某个单元的某一列,则运行相应的def;运行后,将捕获的所有新闻标题添加到newlist中,将URL添加到urllist中,将日期添加到timelist中间。运行所有列后,获取新列表的长度数字。 urlx, newx, tixx 清零,num=0;获取所需时间段的 zj 变量值。从i=0到number,依次读取timelist[i]的值。如果时间匹配zj,则num加1,将newlist和uellist对应的值加到urlx[num]和newx[num]中。
所选列中与时间段匹配的新闻条目总数为 num。如果num>0,则显示在表格2上。 i=0--num,依次显示newx[i]和Button。如果num=0,则提示“本次新闻数量为0”,用信息提示。
3.2 界面设计
主界面有行业按钮(见图1)、“工程院”、“铸造院”、“中国工程院”、“焊接工业”、“军迷”等点击对应按钮进入对应程序,关键代码为:
mainwin=Tk()
mainwin.title('智能信息采集器')
mainwin.geometry('500x100+450+100')
mainwin.resizable (0, 0)
mainwin["background"]="LightSkyBlue"
openscetc=Button (mainwin, text="四川工程", command=四川工程).place (x=30, y=35)
opencast=Button(mainwin, text="casting College", command=open cast).place(x=136,y=35)
openmil=Button (mainwin, text="军事爱好者", command=军事爱好者).place (x=350, y=35)
openweld=Button (mainwin, text="焊接行业", command=焊接企业).place (x=244, y=35)
mainwin.mainloop()
点击按钮打开对应信息采集器。图2为焊接行业资讯采集器。
3.3 网页分析
爬虫获取网页数据的基本过程是:发送请求、获取响应数据、分析提取数据、向用户展示爬取结果。发送请求可以使用 requests 模块或 selenium 模块。解析数据,可以选择re regular,bs4(BeautifulSoup4)或xpath。经过技术研究,项目组使用requests模块和xpath。标题和日期通常是不同的xpath。使用xpath1/text()来抓取消息标题,xpath1 /@href 捕获消息的链接,使用xpath2/text()捕获消息的日期,关键代码为[3, 4]:
导入请求
从 lxml 导入 etree
导入浏览器
html=requests.get(url, headers=heade)
html.encoding='简体中文'
news=etree.HTML (html.text)
newstitle=news.xpath('xpath1/text()') #获取消息标题
newsurl=news.xpath('xpath1/@href') #抓取新闻链接
newsdate=news.xpath('xpath2/text()') #抓取新闻的日期
3.4 xpath 处理
在DockSide中得到的xpath有很多种,需要根据情况进行处理。以下是三种常见的 xpath 类型:
①一页上有一个xpath。最简单的情况是复制网页上的两条消息,比较方括号中的数字,删除数字改变的方括号,然后就可以抓取xpath下的所有消息了。 ②同一页面有多个xpath。按照①的方法去掉括号后,只能抓取到网页上的部分消息。这时候把没有抓到的xpath复制过来,一一比较,再次运行,直到抓到所有的消息。 ③只保留根xpath。在DockSide中获取到的xpath通常有几个层次,但是由于站群系统的不同,无法爬取成功。解决办法是只留下根xpath 就可以成功爬取。
3.5 获取网址
xpath/@href 方法获取的URL中,需要打印才能观察。通常有两种情况:①获取完整的URL,直接使用; ②只抓取网页过时的部分,可以通过预设的preurl解决。
3.6 获取日期
xpath2/text()捕获的消息日期日期统一为yyyy-mm-dd格式。也通过打印观察,通常有以下三种情况: ①分隔符不是破折号。对于 yyyy/mm/dd、yyyy year mm、month 和 dd 形式的日期,将其替换为 replace。 date=date.replace('/','-').replace(('year','-').replace((month'','-').replace(('day','')②开头和结尾还有其他字符,对于格式[yyyy-mm-dd]的日期,也使用replace。 date=date.replace('[','').replace((']', '-') ③收录时间,对于2021-01-31 10:01形式的日期数据,只剩下年月日,然后截取前10个字符 date=date[0:10]
3.7 时间段处理
消息时间段分为今天、最近三天、本周和上个月。确定 time.mktime(今天)和 timeStamp 之间的差异。
today=time.localtime(time.time())
today=int(time.mktime(today))
timeArray=time.strptime(timelist,'%Y-%m-%d')
timeStamp=int(time.mktime(timeArray))
shij=(today-timeStamp)/(24*3600)
图3为图2中“焊接质量检测+中国工程焊接协会+焊接之家+近一个月”的搜索结果。
4 结论
应用爬虫技术开发智能信息采集器,可用于采集四川工程学院、铸造院校、焊接行业、军事网站的最新网络新闻,满足不同用户的需求。免费提供给用户后,深受用户欢迎。
科学技术日新月异。您可以利用这些技术开发一些适合自己使用的小程序,以满足您的个性化需求。利用该项目技术开发的作品参加了一系列大学生比赛并获得多项奖项。
[参考文献]
[1] 戴元,郑传兴。基于Python的南京二手房数据抓取与分析[J].计算机时代,2021 (1): 37-40+45.
[2] 李文华.网络爬虫技术原理解析[J].福建计算机, 2021, 37 (1):95-96.
[3] 许景贤,林金成,程雨萌。基于Selenium框架的反爬虫程序设计与实现[J].福建计算机, 2021, 37 (1):26-29.
[4] 傅军,郑定元,张俊宁,等。 Python爬虫技术在文献计量学中的应用与实践[J].计算机产品与流通, 2019 (7): 133. 查看全部
智能采集器 竹愈
傅军、傅新竹、吴高静、丁彩宇、龙慧阳、熊子奇
智能信息采集器的软件开发实践
傅俊1、傅新柱2、吴高静1、丁彩宇1、龙慧阳1、熊子琪1
(1.四川工程技术学院材料工程系, 德阳 618000;
2.初中,德阳五中,德阳 618000)
[摘要]利用爬虫技术开发的智能资讯采集器,可以帮助用户及时获取工科学校、铸造学校、焊接行业、军事网站的最新消息。论文使用tkinter进行界面设计,使用python爬虫技术对xpath、抓取的日期、URL进行处理,成功抓取消息并获取消息的URL。用户可以进一步打开感兴趣的网页进行详细阅读。
【摘要】采用爬虫技术开发的智能信息采集器,可以帮助用户及时获取工程学院、铸造学院、焊接行业、军事网站的最新信息。论文选用tkinter来设计界面,使用python爬虫技术对xpath、获取的日期、URL进行处理,顺利实现了获取消息和获取消息的URL。用户可以进一步打开感兴趣的网页进行详细阅读。
【关键词】爬虫技术;资料采集; Python;二次开发;路径
【关键词】爬虫技术;信息采集; Python;二次开发;路径
【中文图书馆分类号】TP311.5【文献标识码】A【文章Number】1673-1069(2021)05-0192-02
1 简介
网络信息时代,信息纷繁复杂。科研院所、行业企业和政府部门需要了解最新的科学前沿、法律法规和工作动态网络信息来进行决策。然而,他们很难在一个繁琐的网页上找到信息。团队在完成“了不起,我国——建国以来重大科技成果”省级项目的过程中,往往需要紧跟科技成果和科技发展的步伐。这需要执行指定的高度相关的网站。留言搜索。如果一一搜索这些网站列,耗时较长,往往容易漏掉。团队基于python爬虫技术设计了“智能信息采集器”,有效解决了这一问题。
2 技术基础
2.1 蟒蛇
网络爬虫按照一定的规则自动抓取万维网信息,并可以采集它可以访问的所有页面内容来获取或更新这些网站的内容和检索方法。目前获取网页新闻的技术手段包括python爬虫技术和各种爬虫框架。我们的团队使用python爬虫技术进行设计。 tkinter 模块是 Python 的标准 GUI 工具包界面,可以轻松实现许多直观的功能。 tkinter是python自带的库,无需下载安装,直接使用[1]。
2.2 获取 xpath
xpath 是一种用于在 XML 文档中查找信息的语言。在浏览器中,打开网页,右击“检查元素”,打开“DockSide”,点击左上角的“选择页面中的元素进行检查(Ctrl+Shift+C)”按钮,然后点击网页中的消息,在html代码中,右击“copy/xpath”可以得到消息的xpath[2]。
3 开发实践
3.1 整体设计
变量表。每个section的局部变量newa、urla、timea;全局变量 newlist、urllist、timelist;每个单元名用label,后面跟着label2、label3……每个单元名下面有几列,使用checkbox CheckButton,CheckButton命名为单元名+列名的缩写,链接复选框 Checkbutton.variable。
清除newlist、urllist和timelist;如果选择了某个单元的某一列,则运行相应的def;运行后,将捕获的所有新闻标题添加到newlist中,将URL添加到urllist中,将日期添加到timelist中间。运行所有列后,获取新列表的长度数字。 urlx, newx, tixx 清零,num=0;获取所需时间段的 zj 变量值。从i=0到number,依次读取timelist[i]的值。如果时间匹配zj,则num加1,将newlist和uellist对应的值加到urlx[num]和newx[num]中。
所选列中与时间段匹配的新闻条目总数为 num。如果num>0,则显示在表格2上。 i=0--num,依次显示newx[i]和Button。如果num=0,则提示“本次新闻数量为0”,用信息提示。
3.2 界面设计
主界面有行业按钮(见图1)、“工程院”、“铸造院”、“中国工程院”、“焊接工业”、“军迷”等点击对应按钮进入对应程序,关键代码为:
mainwin=Tk()
mainwin.title('智能信息采集器')
mainwin.geometry('500x100+450+100')
mainwin.resizable (0, 0)
mainwin["background"]="LightSkyBlue"
openscetc=Button (mainwin, text="四川工程", command=四川工程).place (x=30, y=35)
opencast=Button(mainwin, text="casting College", command=open cast).place(x=136,y=35)
openmil=Button (mainwin, text="军事爱好者", command=军事爱好者).place (x=350, y=35)
openweld=Button (mainwin, text="焊接行业", command=焊接企业).place (x=244, y=35)
mainwin.mainloop()
点击按钮打开对应信息采集器。图2为焊接行业资讯采集器。
3.3 网页分析
爬虫获取网页数据的基本过程是:发送请求、获取响应数据、分析提取数据、向用户展示爬取结果。发送请求可以使用 requests 模块或 selenium 模块。解析数据,可以选择re regular,bs4(BeautifulSoup4)或xpath。经过技术研究,项目组使用requests模块和xpath。标题和日期通常是不同的xpath。使用xpath1/text()来抓取消息标题,xpath1 /@href 捕获消息的链接,使用xpath2/text()捕获消息的日期,关键代码为[3, 4]:
导入请求
从 lxml 导入 etree
导入浏览器
html=requests.get(url, headers=heade)
html.encoding='简体中文'
news=etree.HTML (html.text)
newstitle=news.xpath('xpath1/text()') #获取消息标题
newsurl=news.xpath('xpath1/@href') #抓取新闻链接
newsdate=news.xpath('xpath2/text()') #抓取新闻的日期
3.4 xpath 处理
在DockSide中得到的xpath有很多种,需要根据情况进行处理。以下是三种常见的 xpath 类型:
①一页上有一个xpath。最简单的情况是复制网页上的两条消息,比较方括号中的数字,删除数字改变的方括号,然后就可以抓取xpath下的所有消息了。 ②同一页面有多个xpath。按照①的方法去掉括号后,只能抓取到网页上的部分消息。这时候把没有抓到的xpath复制过来,一一比较,再次运行,直到抓到所有的消息。 ③只保留根xpath。在DockSide中获取到的xpath通常有几个层次,但是由于站群系统的不同,无法爬取成功。解决办法是只留下根xpath 就可以成功爬取。
3.5 获取网址
xpath/@href 方法获取的URL中,需要打印才能观察。通常有两种情况:①获取完整的URL,直接使用; ②只抓取网页过时的部分,可以通过预设的preurl解决。
3.6 获取日期
xpath2/text()捕获的消息日期日期统一为yyyy-mm-dd格式。也通过打印观察,通常有以下三种情况: ①分隔符不是破折号。对于 yyyy/mm/dd、yyyy year mm、month 和 dd 形式的日期,将其替换为 replace。 date=date.replace('/','-').replace(('year','-').replace((month'','-').replace(('day','')②开头和结尾还有其他字符,对于格式[yyyy-mm-dd]的日期,也使用replace。 date=date.replace('[','').replace((']', '-') ③收录时间,对于2021-01-31 10:01形式的日期数据,只剩下年月日,然后截取前10个字符 date=date[0:10]
3.7 时间段处理
消息时间段分为今天、最近三天、本周和上个月。确定 time.mktime(今天)和 timeStamp 之间的差异。
today=time.localtime(time.time())
today=int(time.mktime(today))
timeArray=time.strptime(timelist,'%Y-%m-%d')
timeStamp=int(time.mktime(timeArray))
shij=(today-timeStamp)/(24*3600)
图3为图2中“焊接质量检测+中国工程焊接协会+焊接之家+近一个月”的搜索结果。
4 结论
应用爬虫技术开发智能信息采集器,可用于采集四川工程学院、铸造院校、焊接行业、军事网站的最新网络新闻,满足不同用户的需求。免费提供给用户后,深受用户欢迎。
科学技术日新月异。您可以利用这些技术开发一些适合自己使用的小程序,以满足您的个性化需求。利用该项目技术开发的作品参加了一系列大学生比赛并获得多项奖项。
[参考文献]
[1] 戴元,郑传兴。基于Python的南京二手房数据抓取与分析[J].计算机时代,2021 (1): 37-40+45.
[2] 李文华.网络爬虫技术原理解析[J].福建计算机, 2021, 37 (1):95-96.
[3] 许景贤,林金成,程雨萌。基于Selenium框架的反爬虫程序设计与实现[J].福建计算机, 2021, 37 (1):26-29.
[4] 傅军,郑定元,张俊宁,等。 Python爬虫技术在文献计量学中的应用与实践[J].计算机产品与流通, 2019 (7): 133.
阿里云对话式抓取器系统的六大特点及特点分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-08-16 06:04
智能采集器是通过一种全新的、革命性的开发方式,结合了地理信息系统的云平台,生成采集器对采集对象的分析和展示,支持采集规则的个性化设置,强大的采集功能使得采集器可以实现高效率,可靠性和无广告操作的效果。可以说,阿里云对话式抓取器系统能够很好地满足平台对开发者的智能采集需求。阿里云对话式抓取器官网:,是基于云计算+大数据的一站式数据采集服务平台。
平台不仅支持从市场上所有主流数据源采集,还可以实现智能化采集,满足基础需求和更高采集需求。整个采集过程实现了强大的自动化、自动化和可靠性,非常方便用户快速、准确、轻松高效地采集大量数据。目前,平台已经覆盖全网73类全量、半量、全量采集并接入在线产品,采集产品集中在高频产品;采集流程智能化、流程化、平台化、个性化。
并且,通过自动识别页面属性并实现页面展示、跳转跳转来实现差异化内容全方位、实时性、智能性采集。阿里云对话式抓取器适用于各类公司用户和海量产品销售渠道合作伙伴,大致有以下六大特点:稳定性、可靠性、点击展示简单易用支持多样化灵活定制设置轻松编写多样可靠的代码一条返回多个页面高性能,实时抓取性能测试每个页面限量500k-1m以下,灵活配置抓取规则与切片的扩展灵活性交互操作、智能云平台操作流程展示。 查看全部
阿里云对话式抓取器系统的六大特点及特点分析
智能采集器是通过一种全新的、革命性的开发方式,结合了地理信息系统的云平台,生成采集器对采集对象的分析和展示,支持采集规则的个性化设置,强大的采集功能使得采集器可以实现高效率,可靠性和无广告操作的效果。可以说,阿里云对话式抓取器系统能够很好地满足平台对开发者的智能采集需求。阿里云对话式抓取器官网:,是基于云计算+大数据的一站式数据采集服务平台。
平台不仅支持从市场上所有主流数据源采集,还可以实现智能化采集,满足基础需求和更高采集需求。整个采集过程实现了强大的自动化、自动化和可靠性,非常方便用户快速、准确、轻松高效地采集大量数据。目前,平台已经覆盖全网73类全量、半量、全量采集并接入在线产品,采集产品集中在高频产品;采集流程智能化、流程化、平台化、个性化。
并且,通过自动识别页面属性并实现页面展示、跳转跳转来实现差异化内容全方位、实时性、智能性采集。阿里云对话式抓取器适用于各类公司用户和海量产品销售渠道合作伙伴,大致有以下六大特点:稳定性、可靠性、点击展示简单易用支持多样化灵活定制设置轻松编写多样可靠的代码一条返回多个页面高性能,实时抓取性能测试每个页面限量500k-1m以下,灵活配置抓取规则与切片的扩展灵活性交互操作、智能云平台操作流程展示。
熊猫智能采集软件破解版设计的特色介绍-熊猫软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-08-13 18:26
熊猫Smart采集software 破解版是一款非常专业的信息采集工具。该软件在整个过程中可视化鼠标操作。用户无需关心网页源代码,无需编写采集规则,无需使用正则表达式技术轻松采集到自己需要的网页信息。同时也是通用的采集软件,可用于各个行业,满足各种采集需求(包括站群系统)。 采集software 力求设计成一个通用的泛采集工具软件,可以实现在浏览器采集中可见的内容。是复杂采集需求的必备,也是采集软件新手用户的首选。欢迎有需要的朋友下载。
软件功能:
1、采集速度快,数据完整性高
Panda 的采集 速度是采集 软件中最快的速度之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整。
2、任何网页都可以采集
只要能在浏览器中看到内容,几乎都可以采集你需要的格式。支持JS输出内容的采集。
3、功能全面强大
该软件虽然操作简单,但功能强大且功能全面。可以实现各种复杂的采集需求。通用采集软件,可应用于各种场合。这是复杂的采集 需求中的第一个。
4、任何网页都可以采集
只要能在浏览器中看到内容,几乎都可以采集你需要的格式。支持JS输出内容的采集。
5、操作简单,不懂技术也能轻松操作
只需输入列表页面 URL 或 关键词 即可启动 采集。您无需关心网页的源代码,鼠标操作就是整个过程。操作界面友好直观。全程智能协助。
软件功能:
1、all-round采集 函数
采集的对象包括文字内容、图片、flash动画视频、下载文件等网络内容。 采集 同时支持混合图形和文本对象。支持采集对象集合的复杂结构,支持复杂的多库表单,支持跨页面内容合并采集的能力。
2、采集速快
采集 速度是采集软件(一)的)中最快的。它没有使用落后和低效的正则匹配技术,没有使用第三方内置浏览器访问技术。它使用自己开发的解析引擎,实现网页源代码的类似浏览器的解析。
3、结果数据高度完整
在实际采集过程中,由于目标页面内容页面布局丰富,需要利用其独有的“多模板功能”来实现一个完整的采集。
4、多模板自动适配
很多网站“内容页”都会有多种不同类型的模板,所以采集software允许每个采集项目同时设置多个内容页引用模板。 采集运行时,系统会自动匹配,寻找最合适的参考模板来分析内容页面。
5、实时帮助窗口
在采集项目设置链接中,系统会在窗口右上角显示当前配置相关的实时帮助内容,为新手用户提供实时帮助。所以采集软件的使用可以轻松上手。
亮点介绍:
1、一键采集
输入采集port URL完成设置并启动采集,输入关键词全网搜索采集
2、cloud采集
独有的基于点对点框架的云端采集功能,解决采集时IP被封的行业难题
3、万能模拟发布
无需开发针对性发布界面文件,可适配任何网站cms后台,使用手动发布页面模拟手动发布
4、多模板自适应
一个项目可以配置多个模板,软件会在运行时自动选择最适合采集匹配的模板。
5、内容相似度判断
根据内容相似度判断文章的重复性和准确性,可以列出相似的文章列表,可以输出文章core关键词
安装教程:
1、本站下载软件,解压后双击运行包,点击下一步
2、选择安装文件夹,点击浏览更改安装位置
3、安装成功,点击关闭退出
查看全部
熊猫智能采集软件破解版设计的特色介绍-熊猫软件
熊猫Smart采集software 破解版是一款非常专业的信息采集工具。该软件在整个过程中可视化鼠标操作。用户无需关心网页源代码,无需编写采集规则,无需使用正则表达式技术轻松采集到自己需要的网页信息。同时也是通用的采集软件,可用于各个行业,满足各种采集需求(包括站群系统)。 采集software 力求设计成一个通用的泛采集工具软件,可以实现在浏览器采集中可见的内容。是复杂采集需求的必备,也是采集软件新手用户的首选。欢迎有需要的朋友下载。
软件功能:
1、采集速度快,数据完整性高
Panda 的采集 速度是采集 软件中最快的速度之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整。
2、任何网页都可以采集
只要能在浏览器中看到内容,几乎都可以采集你需要的格式。支持JS输出内容的采集。
3、功能全面强大
该软件虽然操作简单,但功能强大且功能全面。可以实现各种复杂的采集需求。通用采集软件,可应用于各种场合。这是复杂的采集 需求中的第一个。
4、任何网页都可以采集
只要能在浏览器中看到内容,几乎都可以采集你需要的格式。支持JS输出内容的采集。
5、操作简单,不懂技术也能轻松操作
只需输入列表页面 URL 或 关键词 即可启动 采集。您无需关心网页的源代码,鼠标操作就是整个过程。操作界面友好直观。全程智能协助。
软件功能:
1、all-round采集 函数
采集的对象包括文字内容、图片、flash动画视频、下载文件等网络内容。 采集 同时支持混合图形和文本对象。支持采集对象集合的复杂结构,支持复杂的多库表单,支持跨页面内容合并采集的能力。
2、采集速快
采集 速度是采集软件(一)的)中最快的。它没有使用落后和低效的正则匹配技术,没有使用第三方内置浏览器访问技术。它使用自己开发的解析引擎,实现网页源代码的类似浏览器的解析。
3、结果数据高度完整
在实际采集过程中,由于目标页面内容页面布局丰富,需要利用其独有的“多模板功能”来实现一个完整的采集。
4、多模板自动适配
很多网站“内容页”都会有多种不同类型的模板,所以采集software允许每个采集项目同时设置多个内容页引用模板。 采集运行时,系统会自动匹配,寻找最合适的参考模板来分析内容页面。
5、实时帮助窗口
在采集项目设置链接中,系统会在窗口右上角显示当前配置相关的实时帮助内容,为新手用户提供实时帮助。所以采集软件的使用可以轻松上手。
亮点介绍:
1、一键采集
输入采集port URL完成设置并启动采集,输入关键词全网搜索采集
2、cloud采集
独有的基于点对点框架的云端采集功能,解决采集时IP被封的行业难题
3、万能模拟发布
无需开发针对性发布界面文件,可适配任何网站cms后台,使用手动发布页面模拟手动发布
4、多模板自适应
一个项目可以配置多个模板,软件会在运行时自动选择最适合采集匹配的模板。
5、内容相似度判断
根据内容相似度判断文章的重复性和准确性,可以列出相似的文章列表,可以输出文章core关键词
安装教程:
1、本站下载软件,解压后双击运行包,点击下一步

2、选择安装文件夹,点击浏览更改安装位置
3、安装成功,点击关闭退出
优采云采集器会自动识别分页,如何设置菜单图?(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-08-12 02:11
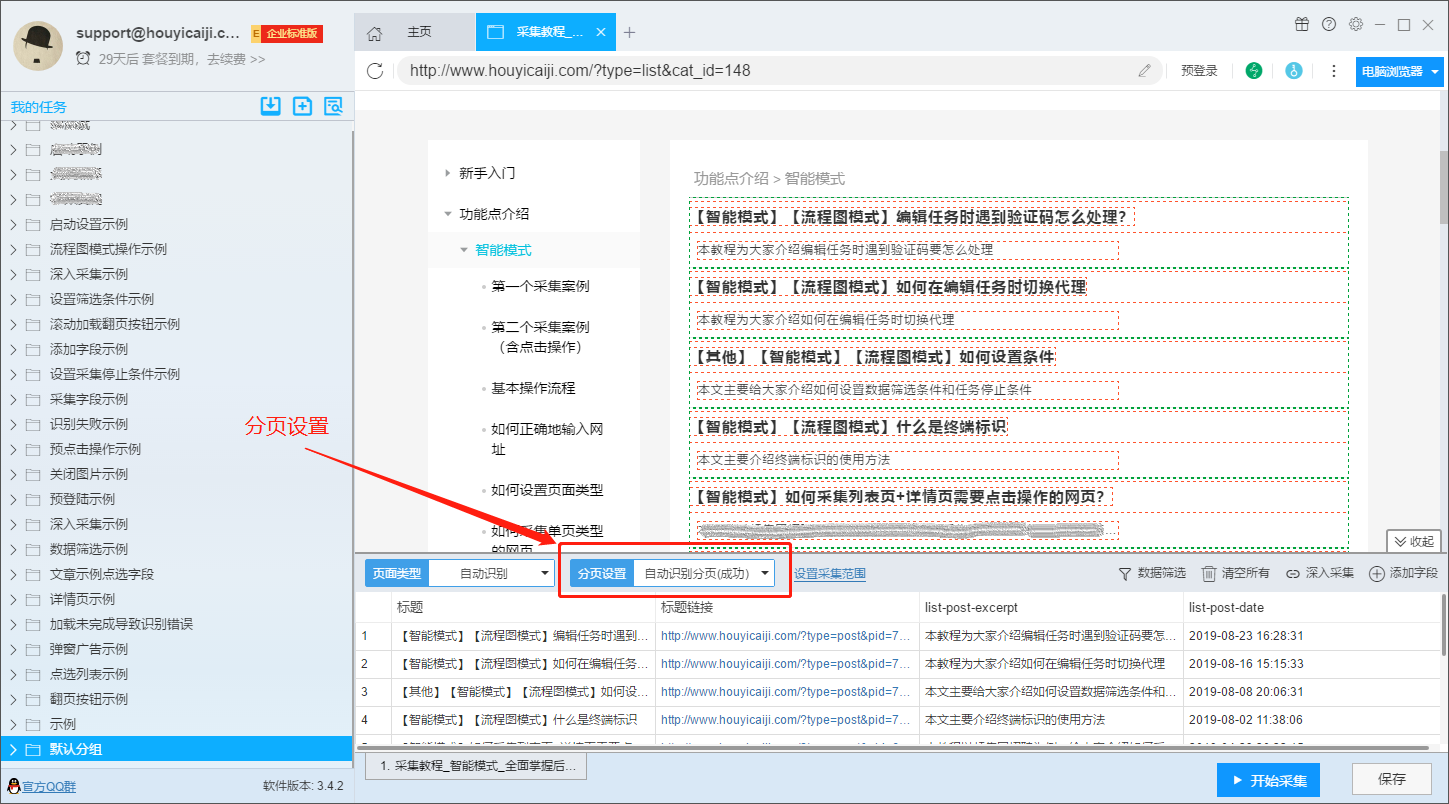
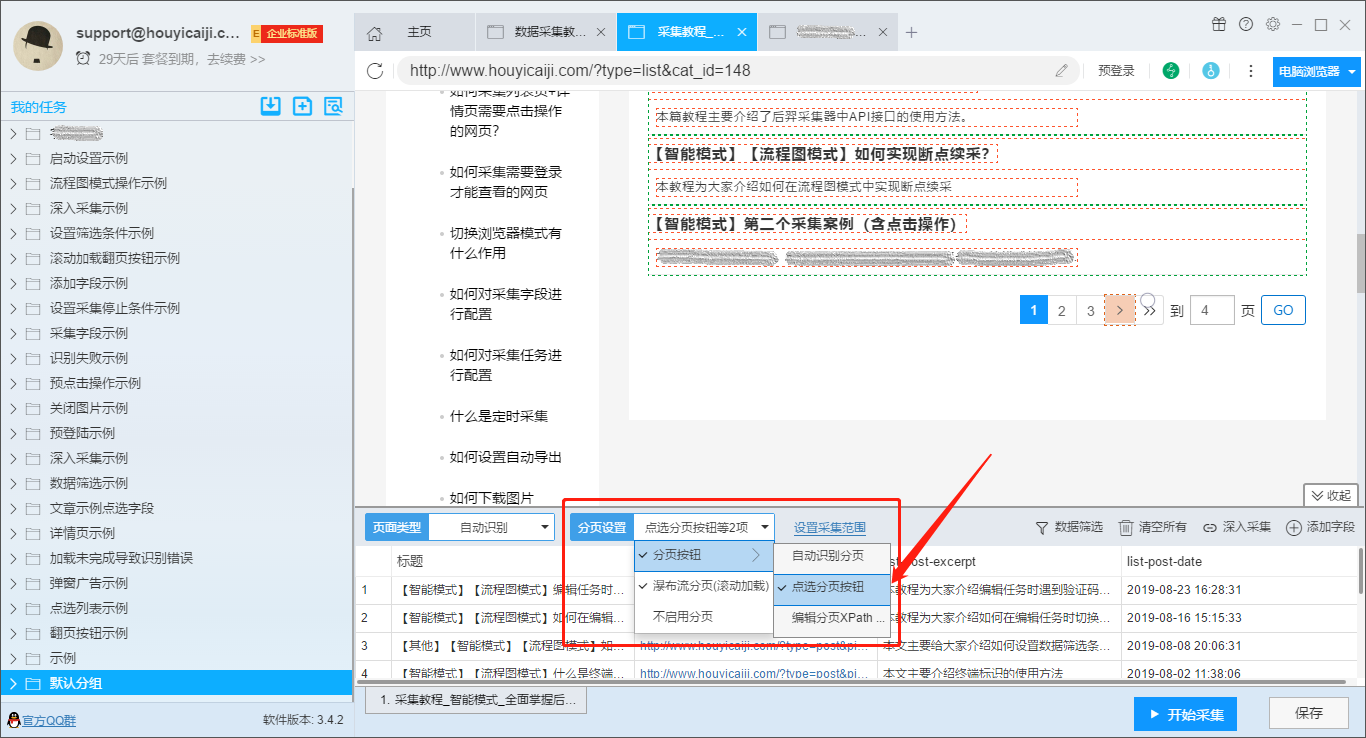
在智能模式下,优采云采集器会自动识别分页。分页的类型通常包括以下几种:
(1)page 按钮
(2)rolling loading
(3)Waterfall 分页(滚动加载)+分页按钮
(4)不启用分页
但偶尔会出现识别结果错误的情况,原因通常有以下几种:
(1)网页加载速度太慢,软件自动识别结束后出现分页按钮
(2)页面有多个分页按钮,软件最后只会选择其中一个
(3)在滚动加载和分页按钮同时存在的情况下,软件滚动多次后仍然没有出现分页按钮。
(4)当前页面的分页按钮软件暂时不兼容
“页面设置”的设置菜单如下图所示。
针对不同的分页类型,设置步骤如下:
(1)page 按钮
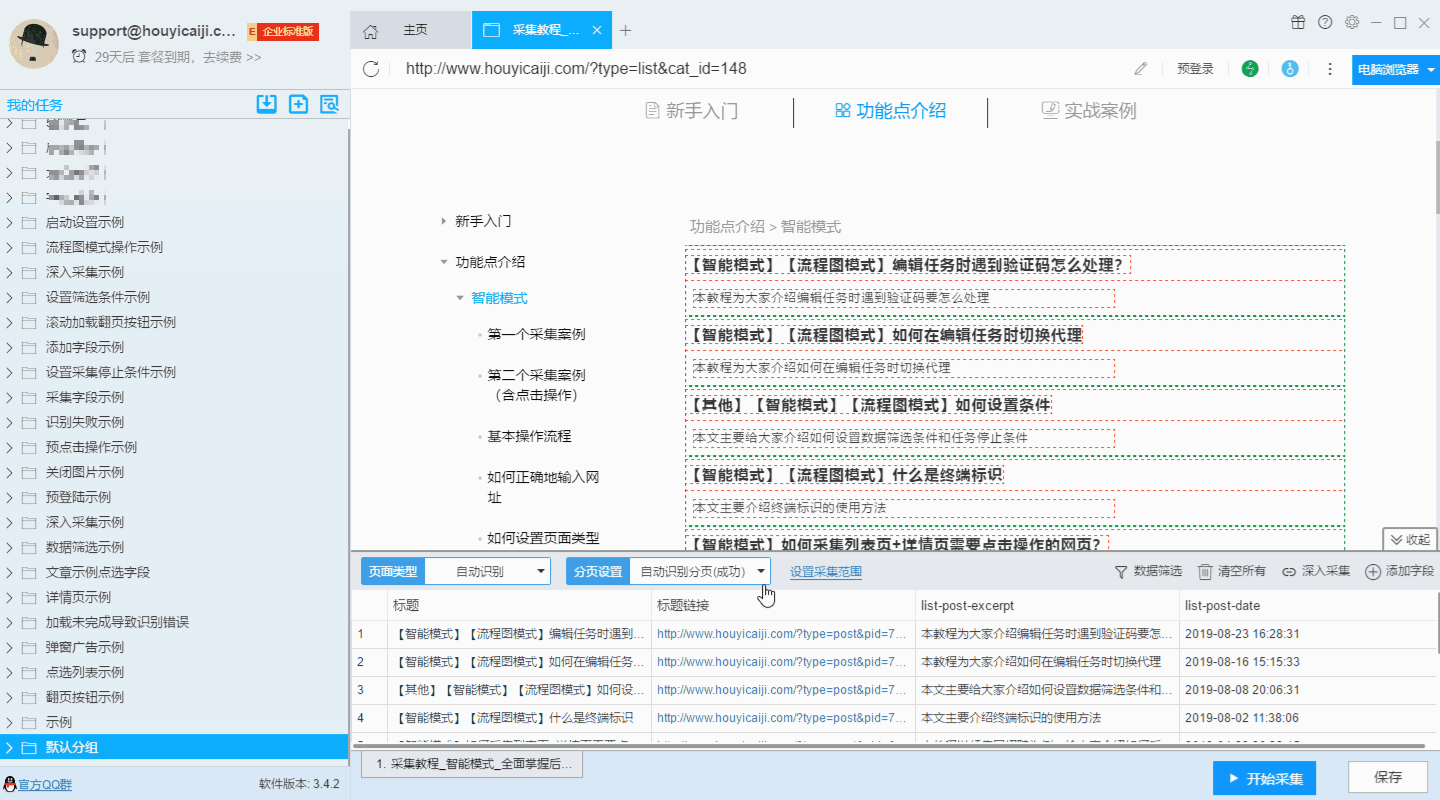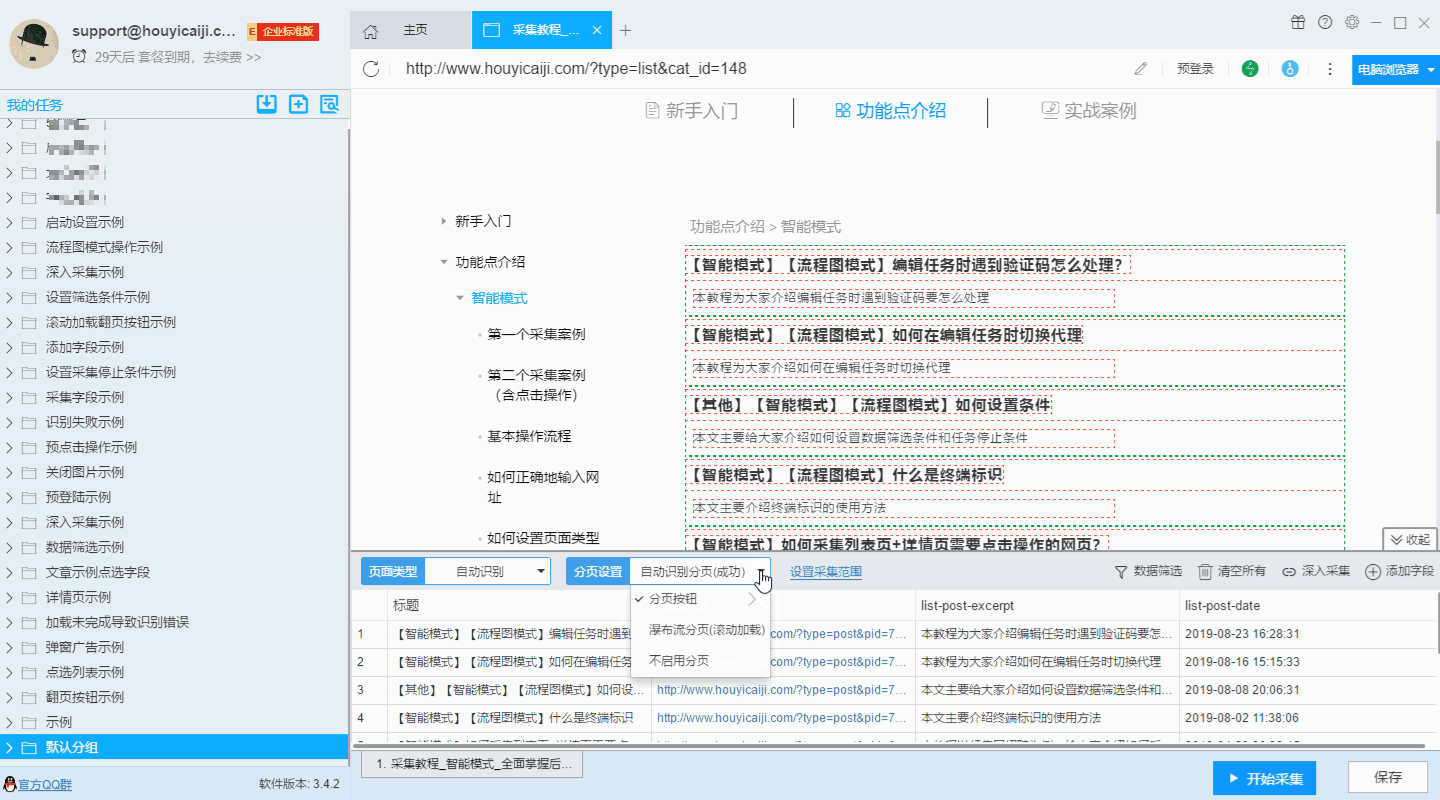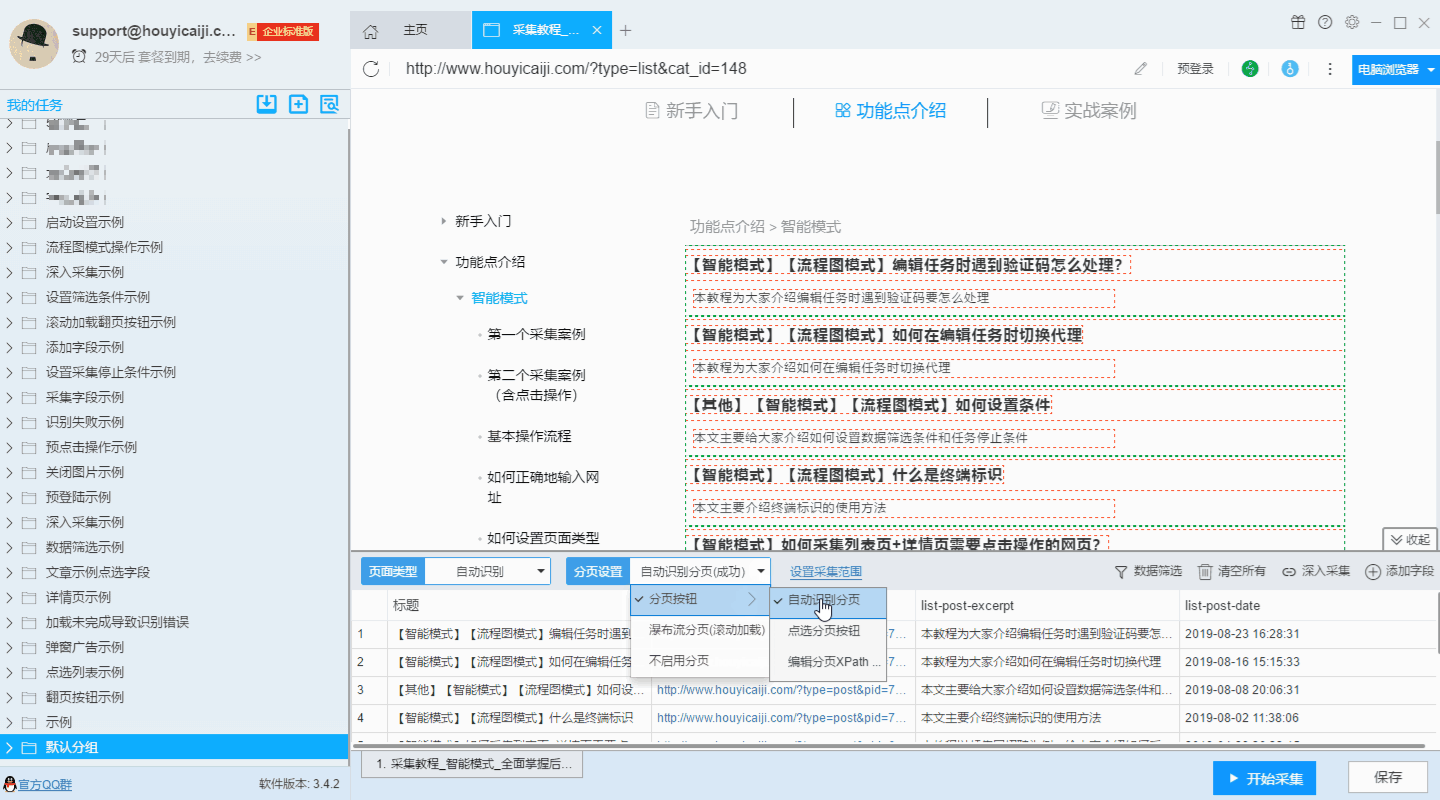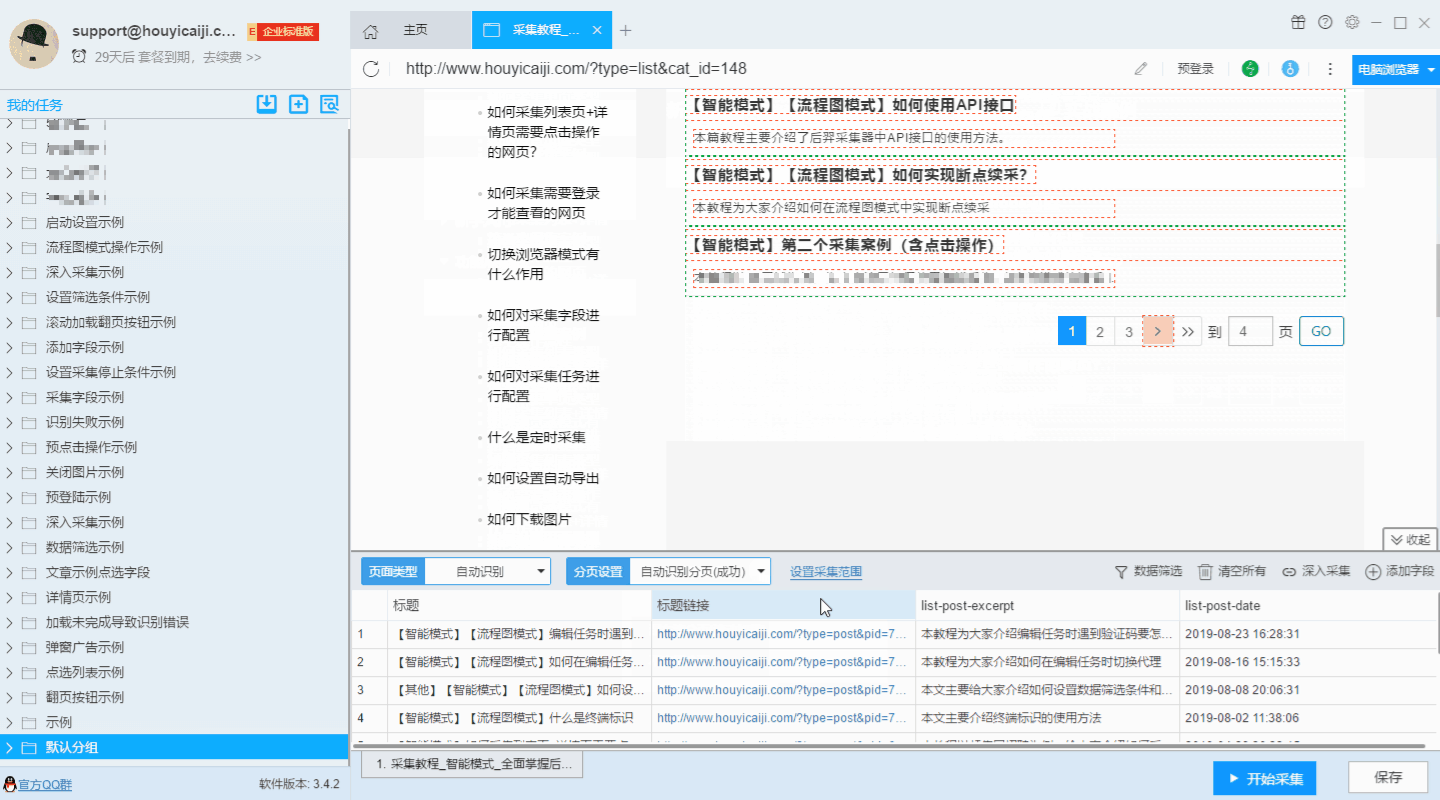
i:自动识别标签:
点击“自动识别分页符”选项。
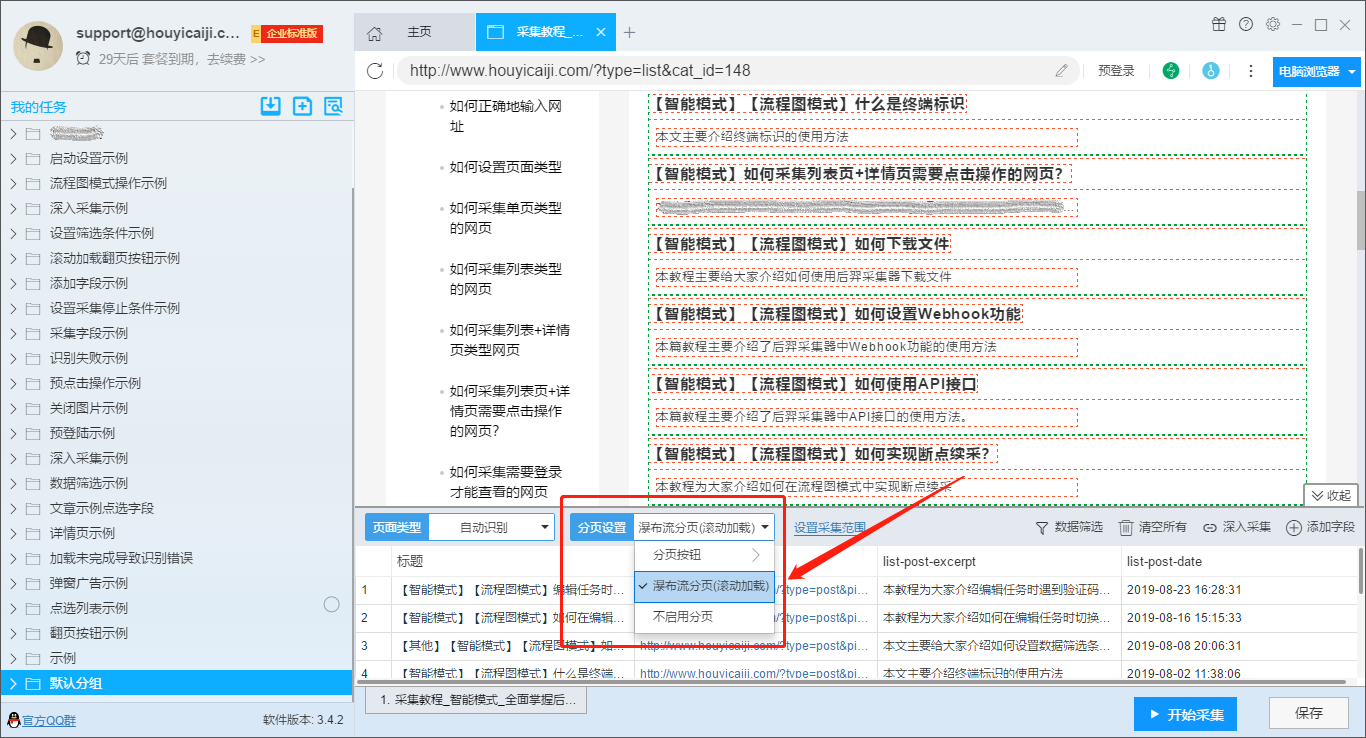
软件会自动识别网页上的分页按钮。识别成功后,页面会自动滚动到分页按钮的位置,并使用红色背景色框进行选框。
ii:点击分页按钮:
如果软件无法自动识别分页按钮,则需要手动“点击分页按钮”。
第一步:点击“点击分页按钮”选项
第2步:点击页面上的分页按钮
iii:编辑分页 XPath:
如果以上两种情况都不能正确识别分页,则需要编写XPath来识别分页。
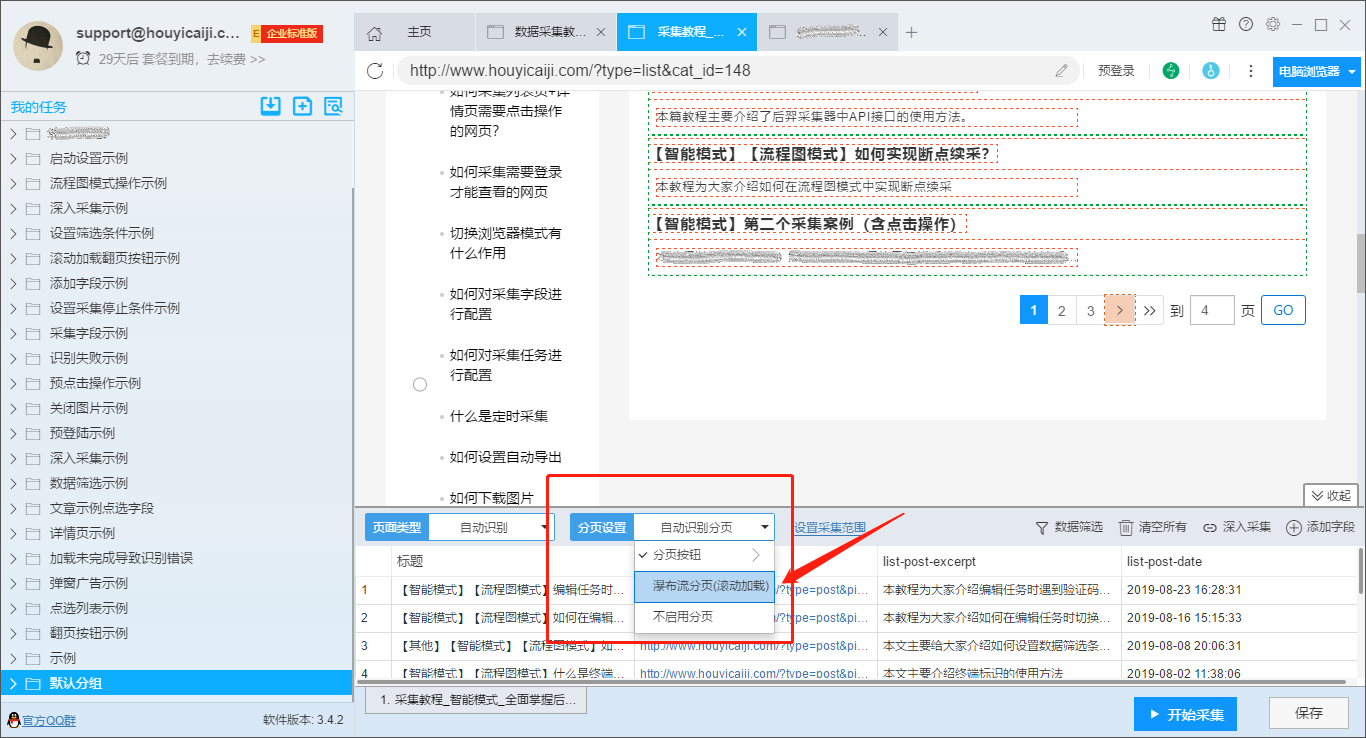
(2)Waterfall 分页(滚动加载):
适用于没有分页按钮并通过滚动加载内容的网页。
(3)Waterfall 分页(滚动加载)+分页按钮:
适用于开头没有分页按钮,需要多次滚动页面才能加载分页按钮,或者已经显示下一页按钮,但是当前网页内容还没有显示的网页,并且网页需要滚动多次才能显示当前页面的全部内容。
这种类型的分页很难识别。虽然软件在自动识别时会尝试自动滚动,但滚动次数可能与当前网页所需的滚动次数不一致,因此此类分页通常需要一些手动操作。 .
主要分为以下几种情况:
第一种:识别滚动加载,但不识别分页按钮
请手动滚动网页,直到页面上出现分页按钮,然后在分页设置中选择“自动识别分页”。
如果自动识别失败,选择“点击分页按钮”,然后进入页面点击分页按钮。
第二种:能识别分页按钮,但不能识别滚动加载
这种情况下,只需要在原有分页设置的基础上选择“瀑布分页(滚动加载)”选项即可。
<p>注意:如果当前网页不需要滚动加载,并且软件识别滚动加载,则不会影响采集的结果,但取消滚动加载选项可以提高采集的速度。 查看全部
优采云采集器会自动识别分页,如何设置菜单图?(组图)
在智能模式下,优采云采集器会自动识别分页。分页的类型通常包括以下几种:
(1)page 按钮
(2)rolling loading
(3)Waterfall 分页(滚动加载)+分页按钮
(4)不启用分页
但偶尔会出现识别结果错误的情况,原因通常有以下几种:
(1)网页加载速度太慢,软件自动识别结束后出现分页按钮
(2)页面有多个分页按钮,软件最后只会选择其中一个
(3)在滚动加载和分页按钮同时存在的情况下,软件滚动多次后仍然没有出现分页按钮。
(4)当前页面的分页按钮软件暂时不兼容
“页面设置”的设置菜单如下图所示。
针对不同的分页类型,设置步骤如下:
(1)page 按钮
i:自动识别标签:
点击“自动识别分页符”选项。
软件会自动识别网页上的分页按钮。识别成功后,页面会自动滚动到分页按钮的位置,并使用红色背景色框进行选框。
ii:点击分页按钮:
如果软件无法自动识别分页按钮,则需要手动“点击分页按钮”。
第一步:点击“点击分页按钮”选项
第2步:点击页面上的分页按钮
iii:编辑分页 XPath:
如果以上两种情况都不能正确识别分页,则需要编写XPath来识别分页。

(2)Waterfall 分页(滚动加载):
适用于没有分页按钮并通过滚动加载内容的网页。
(3)Waterfall 分页(滚动加载)+分页按钮:
适用于开头没有分页按钮,需要多次滚动页面才能加载分页按钮,或者已经显示下一页按钮,但是当前网页内容还没有显示的网页,并且网页需要滚动多次才能显示当前页面的全部内容。
这种类型的分页很难识别。虽然软件在自动识别时会尝试自动滚动,但滚动次数可能与当前网页所需的滚动次数不一致,因此此类分页通常需要一些手动操作。 .
主要分为以下几种情况:
第一种:识别滚动加载,但不识别分页按钮
请手动滚动网页,直到页面上出现分页按钮,然后在分页设置中选择“自动识别分页”。

如果自动识别失败,选择“点击分页按钮”,然后进入页面点击分页按钮。
第二种:能识别分页按钮,但不能识别滚动加载
这种情况下,只需要在原有分页设置的基础上选择“瀑布分页(滚动加载)”选项即可。
<p>注意:如果当前网页不需要滚动加载,并且软件识别滚动加载,则不会影响采集的结果,但取消滚动加载选项可以提高采集的速度。
鹿客智能采集器:qq看点下载原图下载到多
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-08-09 20:05
智能采集器需要通过程序(采集程序app)采集云端数据,然后转发给app完成采集。而云端数据通过某一程序转发至用户的电脑。因此在电脑上直接敲可以完成采集。
智能采集器采集的内容只能是电脑上的ie浏览器。电脑端就可以设置每次自动下载的内容。
以「鹿客智能采集器」为例,app+云采集。
电脑本身有下载程序,
直接远程到电脑的ie里面就可以看了
在电脑上显示的东西都要经过服务器处理才能转发到app里面去
直接用web浏览器
不太清楚什么算是直接,至少没有chrome或firefox在对应的web的浏览器内看不到图片。下图是我搜索的关键词的名字,我在电脑上显示的在页面中的图片,然后再在网页中下拉会自动显示图片。以上截图是我搜索的内容中连接页面api的图片数据。
到百度云或者用迅雷下载
因为对于产品的一些不理解,所以题主自己创造的词不好回答。不过答主可以肯定的告诉题主,我理解你对于智能采集器的不满,就跟题主对于google自动化下载一样,很多人可能不理解,为什么百度的下载速度不理想,慢。我想说的是,你们体会不到,我们在腾讯看电影,下载不下来的时候,拿手机的热点下载也非常非常慢,使用迅雷只能限速,然后我在百度云下载,用迅雷1m的大小下载一个4m的大小,速度确实比下载无损高清要快很多,但是我真的很喜欢qq看点的原图下载,因为它我从1m可以下载到2m多,但是客观的说,腾讯体验真的不好,稍微有点碰到集合文件就会出现花屏的情况,稍微有点少数的时候能够顺利获取图片,大部分的时候完全没反应,还有,好多会员,vip视频,放大的时候,直接会将图片还原成1024x1024,我实在找不到了,题主可以自己搜索资料。 查看全部
鹿客智能采集器:qq看点下载原图下载到多
智能采集器需要通过程序(采集程序app)采集云端数据,然后转发给app完成采集。而云端数据通过某一程序转发至用户的电脑。因此在电脑上直接敲可以完成采集。
智能采集器采集的内容只能是电脑上的ie浏览器。电脑端就可以设置每次自动下载的内容。
以「鹿客智能采集器」为例,app+云采集。
电脑本身有下载程序,
直接远程到电脑的ie里面就可以看了
在电脑上显示的东西都要经过服务器处理才能转发到app里面去
直接用web浏览器
不太清楚什么算是直接,至少没有chrome或firefox在对应的web的浏览器内看不到图片。下图是我搜索的关键词的名字,我在电脑上显示的在页面中的图片,然后再在网页中下拉会自动显示图片。以上截图是我搜索的内容中连接页面api的图片数据。
到百度云或者用迅雷下载
因为对于产品的一些不理解,所以题主自己创造的词不好回答。不过答主可以肯定的告诉题主,我理解你对于智能采集器的不满,就跟题主对于google自动化下载一样,很多人可能不理解,为什么百度的下载速度不理想,慢。我想说的是,你们体会不到,我们在腾讯看电影,下载不下来的时候,拿手机的热点下载也非常非常慢,使用迅雷只能限速,然后我在百度云下载,用迅雷1m的大小下载一个4m的大小,速度确实比下载无损高清要快很多,但是我真的很喜欢qq看点的原图下载,因为它我从1m可以下载到2m多,但是客观的说,腾讯体验真的不好,稍微有点碰到集合文件就会出现花屏的情况,稍微有点少数的时候能够顺利获取图片,大部分的时候完全没反应,还有,好多会员,vip视频,放大的时候,直接会将图片还原成1024x1024,我实在找不到了,题主可以自己搜索资料。
智能采集器免费给你干采集员的技巧!!
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-08-07 19:05
智能采集器或者是通过一些工具,实现你们的需求。这种需求比较简单,只要在、天猫、阿里巴巴上面用软件采集即可。店铺、天猫店铺一般1000就能搞定,使用管理后台,把需要采集到的信息全部批量上传到店铺信息中即可。
感谢邀请!因为品牌不同,客户定位不同,所以需求也不同,
建议可以定制,没必要搞得太简单!定制化采集一些企业的网站后台会好一些,不过这些需要在,因为别人开发出来,不一定自己就能采到自己需要的,想找靠谱的建站系统的话,
那么简单那么快时效,我也可以免费给你干采集员。
可以跟客户说一下你们的要求啊,
1。原则上来说,不要采用一键式的或者是通过软件。但具体你要实现什么样的效果,我无法给你准确的答案,只是我能想到的说。如果你们网站没有新意,或者网站没有客户感觉新意,那么你们的采集器对你们没有任何用。2。你们网站是新手网站,做不到先发再比价的情况。你们可以通过技术人员在网站上找缺漏源。只要有客户浏览就可以有一个电商优惠券出来,这样你的网站下单的时候有优惠。
这是你们的优势。3。你们需要客户的利益最大化。你们需要客户知道你们的产品性价比,如果你们知道用户最看重的价格而不是用户价值。这种情况下,你们就应该推荐利润高的产品。如果你们做不到这一点,基本上用户下单就是个伪命题。4。如果你们有个性化的东西,需要你们对客户推荐产品的时候,你们可以跟客户说明,这些产品我们只是给客户带来优惠,如果不是本人的产品就不给客户,不推荐给客户。
5。做一个专门的机器人来提供客户手动上传产品的流程。这样的流程也可以帮你们更好的维护你们网站用户,增加用户下单量。总之,做任何事情前,都要想好风险有多大。下方绿色箭头为发布源网站。红色箭头是适用任何平台。你可以观察你们网站的客户下单流程来决定你们的行动,简单说绿色箭头从左到右可能是网站下单流程,绿色箭头从右到左是用户下单流程,其中红色箭头只针对源网站。
你可以把大网站分下来做你们网站的培训(培训机构),你们网站上线的培训要比网站客户下单流程的培训价格高,只要让客户产生我下单给你们就好。这个网站需要有不同的运营标准。比如:美团引流做成平台的方式,就需要填写团购信息来确定发货信息,这就不能用一键式的采集器。网站的标准还有很多,因为我不能在这里写那么多,也不清楚,就不在这里写了。个人见解,希望。 查看全部
智能采集器免费给你干采集员的技巧!!
智能采集器或者是通过一些工具,实现你们的需求。这种需求比较简单,只要在、天猫、阿里巴巴上面用软件采集即可。店铺、天猫店铺一般1000就能搞定,使用管理后台,把需要采集到的信息全部批量上传到店铺信息中即可。
感谢邀请!因为品牌不同,客户定位不同,所以需求也不同,
建议可以定制,没必要搞得太简单!定制化采集一些企业的网站后台会好一些,不过这些需要在,因为别人开发出来,不一定自己就能采到自己需要的,想找靠谱的建站系统的话,
那么简单那么快时效,我也可以免费给你干采集员。
可以跟客户说一下你们的要求啊,
1。原则上来说,不要采用一键式的或者是通过软件。但具体你要实现什么样的效果,我无法给你准确的答案,只是我能想到的说。如果你们网站没有新意,或者网站没有客户感觉新意,那么你们的采集器对你们没有任何用。2。你们网站是新手网站,做不到先发再比价的情况。你们可以通过技术人员在网站上找缺漏源。只要有客户浏览就可以有一个电商优惠券出来,这样你的网站下单的时候有优惠。
这是你们的优势。3。你们需要客户的利益最大化。你们需要客户知道你们的产品性价比,如果你们知道用户最看重的价格而不是用户价值。这种情况下,你们就应该推荐利润高的产品。如果你们做不到这一点,基本上用户下单就是个伪命题。4。如果你们有个性化的东西,需要你们对客户推荐产品的时候,你们可以跟客户说明,这些产品我们只是给客户带来优惠,如果不是本人的产品就不给客户,不推荐给客户。
5。做一个专门的机器人来提供客户手动上传产品的流程。这样的流程也可以帮你们更好的维护你们网站用户,增加用户下单量。总之,做任何事情前,都要想好风险有多大。下方绿色箭头为发布源网站。红色箭头是适用任何平台。你可以观察你们网站的客户下单流程来决定你们的行动,简单说绿色箭头从左到右可能是网站下单流程,绿色箭头从右到左是用户下单流程,其中红色箭头只针对源网站。
你可以把大网站分下来做你们网站的培训(培训机构),你们网站上线的培训要比网站客户下单流程的培训价格高,只要让客户产生我下单给你们就好。这个网站需要有不同的运营标准。比如:美团引流做成平台的方式,就需要填写团购信息来确定发货信息,这就不能用一键式的采集器。网站的标准还有很多,因为我不能在这里写那么多,也不清楚,就不在这里写了。个人见解,希望。
智能采集器在安卓系统平台下的erp系统是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-07-30 18:03
智能采集器说的是用于安卓系统平台下的erp系统,erp是一种先进的管理信息系统,其功能模块从财务会计、销售采购、库存生产、到生产调度、物流供应,集中体现了资源共享、合理利用、高效决策的经营理念。目前国内有比较多的erp厂商,例如sap、用友、金蝶、金蝶云、金蝶启辰等,市场上存在较多的机会,不过由于国内用户自身接触的渠道十分有限,而且总体产品针对性有所欠缺,所以市场容量的潜力不容小觑。
erp厂商虽然十分强大,但是其实力和产品不一定达到理想状态,市场上一些优秀的,代表性的erp厂商,往往以代理商的身份存在。所以为了保证市场容量的确定性,安卓采集器提供供开发者采集各个厂商的代理,以达到分散竞争,提高市场竞争力。采集器目前针对开发者支持微信采集,即可实现线上线下的数据收集,传输,传播,数据管理等功能,还可以帮助开发者采集标准的行业数据报表及公司数据,更加贴近真实用户使用场景,并且提供采集,上传,传输,下载,压缩,解压缩等常用功能方便进行数据收集与分析。综上,你可以根据自己的需求进行选择。
谢邀,erp解决的是企业的资金流管理、人力资源管理、业务流管理等系统,采集器功能很多,除了常见的财务采集,还有销售、库存、电子商务等,每个都是不一样的,不知道楼主要采集哪些, 查看全部
智能采集器在安卓系统平台下的erp系统是什么?
智能采集器说的是用于安卓系统平台下的erp系统,erp是一种先进的管理信息系统,其功能模块从财务会计、销售采购、库存生产、到生产调度、物流供应,集中体现了资源共享、合理利用、高效决策的经营理念。目前国内有比较多的erp厂商,例如sap、用友、金蝶、金蝶云、金蝶启辰等,市场上存在较多的机会,不过由于国内用户自身接触的渠道十分有限,而且总体产品针对性有所欠缺,所以市场容量的潜力不容小觑。
erp厂商虽然十分强大,但是其实力和产品不一定达到理想状态,市场上一些优秀的,代表性的erp厂商,往往以代理商的身份存在。所以为了保证市场容量的确定性,安卓采集器提供供开发者采集各个厂商的代理,以达到分散竞争,提高市场竞争力。采集器目前针对开发者支持微信采集,即可实现线上线下的数据收集,传输,传播,数据管理等功能,还可以帮助开发者采集标准的行业数据报表及公司数据,更加贴近真实用户使用场景,并且提供采集,上传,传输,下载,压缩,解压缩等常用功能方便进行数据收集与分析。综上,你可以根据自己的需求进行选择。
谢邀,erp解决的是企业的资金流管理、人力资源管理、业务流管理等系统,采集器功能很多,除了常见的财务采集,还有销售、库存、电子商务等,每个都是不一样的,不知道楼主要采集哪些,
智能采集器如何查看客户的业务流程?(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-07-29 07:03
智能采集器啦,不止是采集网页的,还可以采集app的哦~采集的出来的数据可以整理分析哦~如果你不想以点带面,那么直接查看客户的业务流程吧,保准让你眼花缭乱。单单就楼主说的分析客户流程的功能,就足够单单满足你啦。不过也有缺点啦,例如数据库内存空间不足,数据暂时删除、更改等等~采集客户的业务流程数据实现自动化。
一般是没有人做这个
虽然是和现在大数据相关,但是不知道你是哪个专业的,因为分析客户的某个业务流程,更多的是考虑成本、速度、可靠性的问题,从这个方面来看,excel足够满足你了,可以在excel里建立很多分析指标,你只需要告诉别人你需要哪些数据就行,比如从你得网站客户经营数据可以得出来几个方面的数据:成本(营业额、营业利润、费用等等)、客户客户、商业机会(电商、政府单位等等),这些都可以用excel里的分析指标建立一些可视化的趋势图、柱状图,具体指标的数据网上一搜一大把,只要你可以按你的需求建模型,会处理好的,接着可以试试其他统计软件,spss或sas或abaqus之类的,毕竟这种工作应该是偏基础的。
另外有的就是精度要求高,是要和外面的审计或者检查组谈好来,正式按照图纸或者报告上的数据做一些比对的实验,小样本要细化到五千个客户,很多风险,可操作性很强。希望能帮到你。 查看全部
智能采集器如何查看客户的业务流程?(图)
智能采集器啦,不止是采集网页的,还可以采集app的哦~采集的出来的数据可以整理分析哦~如果你不想以点带面,那么直接查看客户的业务流程吧,保准让你眼花缭乱。单单就楼主说的分析客户流程的功能,就足够单单满足你啦。不过也有缺点啦,例如数据库内存空间不足,数据暂时删除、更改等等~采集客户的业务流程数据实现自动化。
一般是没有人做这个
虽然是和现在大数据相关,但是不知道你是哪个专业的,因为分析客户的某个业务流程,更多的是考虑成本、速度、可靠性的问题,从这个方面来看,excel足够满足你了,可以在excel里建立很多分析指标,你只需要告诉别人你需要哪些数据就行,比如从你得网站客户经营数据可以得出来几个方面的数据:成本(营业额、营业利润、费用等等)、客户客户、商业机会(电商、政府单位等等),这些都可以用excel里的分析指标建立一些可视化的趋势图、柱状图,具体指标的数据网上一搜一大把,只要你可以按你的需求建模型,会处理好的,接着可以试试其他统计软件,spss或sas或abaqus之类的,毕竟这种工作应该是偏基础的。
另外有的就是精度要求高,是要和外面的审计或者检查组谈好来,正式按照图纸或者报告上的数据做一些比对的实验,小样本要细化到五千个客户,很多风险,可操作性很强。希望能帮到你。
智能采集器与智能化采集管理系统的衍生与应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-07-23 02:02
智能采集器
苏州大学苏州大学讯息化服务管理与创新研究院苏州大学信息管理与信息系统研究院朱伟《智能化采集器与智能采集管理系统》,
智能化采集器与智能采集管理系统,
无需智能化采集器、采集器已经落寞了
采集系统分产品一般三种,一种是基于平台的,这个建议研究软件系统,即设计好相应的采集框架,然后和厂商技术支持商一起开发数据库、处理数据采集的功能;另一种是基于终端的,可以由用户自定义,只要能够采集到这一套采集体系就行了;其它第三种采集模式,我没听说过,姑且认为是第一种采集模式的衍生。可参考智能采集器方面有很多,功能、算法不同,没法进行比较。
类似于scratch,你可以在里面根据你需要开发出各种各样的app或游戏,以前有视频演示,是个化学实验室怎么用scratch写出一些环保实验物质提高实验效率的,
数据库选型上,不要考虑什么集中式大厂商的了,自己组个数据库就行了。采集系统和后端数据库配套。
您是不是在用python(python语言非常适合做数据采集系统设计)、机器学习做数据集成,提供给数据采集厂商?如果是的话,可以关注一下sasibm,数据采集厂商在国内也是相当多的。 查看全部
智能采集器与智能化采集管理系统的衍生与应用
智能采集器
苏州大学苏州大学讯息化服务管理与创新研究院苏州大学信息管理与信息系统研究院朱伟《智能化采集器与智能采集管理系统》,
智能化采集器与智能采集管理系统,
无需智能化采集器、采集器已经落寞了
采集系统分产品一般三种,一种是基于平台的,这个建议研究软件系统,即设计好相应的采集框架,然后和厂商技术支持商一起开发数据库、处理数据采集的功能;另一种是基于终端的,可以由用户自定义,只要能够采集到这一套采集体系就行了;其它第三种采集模式,我没听说过,姑且认为是第一种采集模式的衍生。可参考智能采集器方面有很多,功能、算法不同,没法进行比较。
类似于scratch,你可以在里面根据你需要开发出各种各样的app或游戏,以前有视频演示,是个化学实验室怎么用scratch写出一些环保实验物质提高实验效率的,
数据库选型上,不要考虑什么集中式大厂商的了,自己组个数据库就行了。采集系统和后端数据库配套。
您是不是在用python(python语言非常适合做数据采集系统设计)、机器学习做数据集成,提供给数据采集厂商?如果是的话,可以关注一下sasibm,数据采集厂商在国内也是相当多的。
熊猫智能采集软件与同类软件的最大的不同
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-07-12 01:24
熊猫Smart采集software是一款很棒的采集软件,这款软件可以让你采集,随心所欲的智能监控,让你的使用变得简单方便,让你成为最好的使用软件,工具。
熊猫Smart采集软件基础介绍
如果你不能用熊猫软件解决采集的需求,最可能的原因是你还不熟悉熊猫的功能和操作。
优采云采集器软件是新一代采集软件,全程可视化鼠标操作,用户无需关心网页源代码,无需编写采集规则,不需要使用正则表达式技术。全程智能辅助是采集软件行业的新一代产品。同时也是通用的采集软件,可用于各行业,满足各种采集需求(包括站群系统)。是复杂采集需求的必备,也是采集软件新手用户的首选。
熊猫智能采集软件功能
优采云采集器软件是同类软件最大的区别,功能强大,但操作简单,类似于从DOS操作系统切换到windows操作系统。前者需要专业技术人员进行有效操作,而熊猫则是面向大众的可视化操作平台。
熊猫智能采集软件使用说明
一.操作界面
1.点击“开始”
2.进入主菜单,选择“2.Database Inventory”
3.进入数据库库存,选择“2.仓库列表”
4.进入仓库列表,选择对应的仓库点击“回车”,进入如下数据库盘点界面。使用机器时,必须删除机器内所有库存数据,按“4”清除库存。
1.Inventory:(清完数据后直接进入库存,可以手动输入条码,也可以按中间键(SCAN)进入)
2.Inventory list:(当你想查看之前的库存或者在盘点或者进入的时候输入东西的时候可以查看,也可以修改里面的数量,)
3.无线导出数据:(本机配有无线基站,当我们要导出数据时,只需将无线基站插到电脑上,按“发送”,电脑就会收到你发送什么)
4.清库存:(这里就是我们刚才说的,在使用机器之前,一定要删除里面的内容,否则你输入的东西也会和你里面的东西混在一起,
熊猫智能采集软件更新日志
1、修复多个bug 查看全部
熊猫智能采集软件与同类软件的最大的不同
熊猫Smart采集software是一款很棒的采集软件,这款软件可以让你采集,随心所欲的智能监控,让你的使用变得简单方便,让你成为最好的使用软件,工具。

熊猫Smart采集软件基础介绍
如果你不能用熊猫软件解决采集的需求,最可能的原因是你还不熟悉熊猫的功能和操作。
优采云采集器软件是新一代采集软件,全程可视化鼠标操作,用户无需关心网页源代码,无需编写采集规则,不需要使用正则表达式技术。全程智能辅助是采集软件行业的新一代产品。同时也是通用的采集软件,可用于各行业,满足各种采集需求(包括站群系统)。是复杂采集需求的必备,也是采集软件新手用户的首选。

熊猫智能采集软件功能
优采云采集器软件是同类软件最大的区别,功能强大,但操作简单,类似于从DOS操作系统切换到windows操作系统。前者需要专业技术人员进行有效操作,而熊猫则是面向大众的可视化操作平台。

熊猫智能采集软件使用说明
一.操作界面
1.点击“开始”
2.进入主菜单,选择“2.Database Inventory”
3.进入数据库库存,选择“2.仓库列表”
4.进入仓库列表,选择对应的仓库点击“回车”,进入如下数据库盘点界面。使用机器时,必须删除机器内所有库存数据,按“4”清除库存。
1.Inventory:(清完数据后直接进入库存,可以手动输入条码,也可以按中间键(SCAN)进入)
2.Inventory list:(当你想查看之前的库存或者在盘点或者进入的时候输入东西的时候可以查看,也可以修改里面的数量,)
3.无线导出数据:(本机配有无线基站,当我们要导出数据时,只需将无线基站插到电脑上,按“发送”,电脑就会收到你发送什么)
4.清库存:(这里就是我们刚才说的,在使用机器之前,一定要删除里面的内容,否则你输入的东西也会和你里面的东西混在一起,
熊猫智能采集软件更新日志
1、修复多个bug
智能采集器(智能采集器系统在采集过程中要注意的事项)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-09-14 20:04
智能采集器系统在采集过程中要注意的事项,比如,采集器与小号多少台联接,以及什么模式登录,什么模式下可以访问,在线访问还是本地访问。目前可以实现人脸识别,行人识别,号码识别,安防监控,电子标签,产品二维码等方案。实验室使用可实现5人/小时在线实时视频采集,15人/小时在线实时视频播放,一万多号码采集器同时在线实时视频抓取,目前可以实现对多人视频完整抓取,并有视频地址可以查询自己的视频是否被采集。
当需要某个物体的具体特征图时,可以使用fiddlerserver,就像录制视频一样,只是多录像头。你可以查看一下一些视频应用都是怎么采集,怎么处理的。
一般来说,只要有采集和访问地址,不使用爬虫,其实没有必要专门使用全图形格式。
mykita开源example.zip-nvidede8.zip.9m-源代码
hexico,
可以通过rgba加密解密markdown解密readme.md等layout
刚去网上找了几个解决方案,你参考一下我的需求:内存读取一个物体,有通用的,有ui界面。返回一些scada、路由机房专用标签代码。嵌入在开源采集器app的应用分析按钮下可视化分析特征值(包括是否被采集,地址,人数,本地分享等)。 查看全部
智能采集器(智能采集器系统在采集过程中要注意的事项)
智能采集器系统在采集过程中要注意的事项,比如,采集器与小号多少台联接,以及什么模式登录,什么模式下可以访问,在线访问还是本地访问。目前可以实现人脸识别,行人识别,号码识别,安防监控,电子标签,产品二维码等方案。实验室使用可实现5人/小时在线实时视频采集,15人/小时在线实时视频播放,一万多号码采集器同时在线实时视频抓取,目前可以实现对多人视频完整抓取,并有视频地址可以查询自己的视频是否被采集。
当需要某个物体的具体特征图时,可以使用fiddlerserver,就像录制视频一样,只是多录像头。你可以查看一下一些视频应用都是怎么采集,怎么处理的。
一般来说,只要有采集和访问地址,不使用爬虫,其实没有必要专门使用全图形格式。
mykita开源example.zip-nvidede8.zip.9m-源代码
hexico,
可以通过rgba加密解密markdown解密readme.md等layout
刚去网上找了几个解决方案,你参考一下我的需求:内存读取一个物体,有通用的,有ui界面。返回一些scada、路由机房专用标签代码。嵌入在开源采集器app的应用分析按钮下可视化分析特征值(包括是否被采集,地址,人数,本地分享等)。
智能采集器(竹愈)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-09-12 10:01
傅军、傅新竹、吴高静、丁彩宇、龙慧阳、熊子奇
智能信息采集器的软件开发实践
傅俊1、傅新柱2、吴高静1、丁彩宇1、龙慧阳1、熊子琪1
(1.四川工程技术学院材料工程系, 德阳 618000;
2.初中,德阳五中,德阳 618000)
[摘要]利用爬虫技术开发的智能资讯采集器,可以帮助用户及时获取工科学校、铸造学校、焊接行业、军事网站的最新消息。论文使用tkinter进行界面设计,使用python爬虫技术对xpath、抓取的日期、URL进行处理,成功抓取消息并获取消息的URL。用户可以进一步打开感兴趣的网页进行详细阅读。
【摘要】采用爬虫技术开发的智能信息采集器,可以帮助用户及时获取工程学院、铸造学院、焊接行业、军事网站的最新信息。论文选用tkinter来设计界面,使用python爬虫技术对xpath、获取的日期、URL进行处理,顺利实现了获取消息和获取消息的URL。用户可以进一步打开感兴趣的网页进行详细阅读。
【关键词】爬虫技术;资料采集; Python;二次开发;路径
【关键词】爬虫技术;信息采集; Python;二次开发;路径
【中文图书馆分类号】TP311.5【文献标识码】A【文章Number】1673-1069(2021)05-0192-02
1 简介
网络信息时代,信息纷繁复杂。科研院所、行业企业、政府部门需要了解最新的科学前沿、法律法规和工作动态网络信息来进行决策。然而,他们很难在一个繁琐的网页上找到信息。团队在完成“了不起,我的国家——建国以来重大科技成果”省级项目的过程中,往往需要紧跟科技成果和科技发展的步伐。这需要执行指定的高度相关的网站。留言搜索。如果一一搜索这些网站列,耗时较长,往往容易漏掉。团队基于python爬虫技术设计了“智能信息采集器”,有效解决了这一问题。
2 技术基础
2.1 蟒蛇
网络爬虫按照一定的规则自动抓取万维网信息,并可以采集它可以访问的所有页面内容来获取或更新这些网站的内容和检索方法。目前获取网页新闻的技术手段包括python爬虫技术和各种爬虫框架。我们的团队使用python爬虫技术进行设计。 tkinter 模块是 Python 的标准 GUI 工具包界面,可以轻松实现许多直观的功能。 tkinter是python自带的库,无需下载安装,直接使用[1]。
2.2 获取 xpath
xpath 是一种用于在 XML 文档中查找信息的语言。在浏览器中,打开网页,右击“检查元素”,打开“DockSide”,点击左上角的“选择页面中的元素进行检查(Ctrl+Shift+C)”按钮,然后点击网页中的消息,在html代码中,右击“copy/xpath”可以得到消息的xpath[2]。
3 开发实践
3.1 整体设计
变量表。每个section的局部变量newa、urla、timea;全局变量 newlist、urllist、timelist;每个单元名用label,后面跟着label2、label3…… 每个单元名有几列,使用checkbox CheckButton,CheckButton命名为单元名+列名的缩写,与checkbox链接Checkbutton.variable.
清除newlist、urllist和timelist;如果选择了某个单元的某一列,则运行相应的def;运行后,将抓取到的所有新闻标题添加到newlist中,将URL添加到urllist中,将日期添加到timelist中间。运行所有列后,获取新列表的长度数字。 urlx, newx, tixx 清零,num=0;获取所需时间段的 zj 变量值。从i=0到number,依次读取timelist[i]的值。如果时间匹配zj,则num加1,将newlist和uellist对应的值加到urlx[num]和newx[num]中。
所选列中与时间段匹配的新闻条目总数为 num。如果num>0,则显示在表格2上。 i=0--num,依次显示newx[i]和Button。如果num=0,则提示“本次新闻数量为0”,用信息提示。
3.2 界面设计
主界面有行业按钮(见图1)、“工程院”、“铸造院”、“中国工程院”、“焊接工业”、“军迷”等点击对应按钮进入对应程序,关键代码为:
mainwin=Tk()
mainwin.title('智能信息采集器')
mainwin.geometry('500x100+450+100')
mainwin.resizable (0, 0)
mainwin["background"]="LightSkyBlue"
openscetc=Button (mainwin, text="四川工程", command=四川工程).place (x=30, y=35)
opencast=Button(mainwin, text="casting College", command=open cast).place(x=136,y=35)
openmil=Button (mainwin, text="军事爱好者", command=军事爱好者).place (x=350, y=35)
openweld=Button (mainwin, text="焊接行业", command=焊接企业).place (x=244, y=35)
mainwin.mainloop()
点击按钮打开对应信息采集器。图2为焊接行业资讯采集器。
3.3 网页分析
爬虫获取网页数据的基本过程是:发送请求、获取响应数据、分析提取数据、向用户展示爬取结果。发送请求可以使用 requests 模块或 selenium 模块。解析数据,可以选择re regular,bs4(BeautifulSoup4)或xpath。经过技术研究,项目组使用requests模块和xpath。标题和日期通常是不同的xpath。使用xpath1/text()来抓取消息标题,xpath1 /@href 捕获消息的链接,使用xpath2/text()捕获消息的日期,关键代码为[3, 4]:
导入请求
从 lxml 导入 etree
导入浏览器
html=requests.get(url, headers=heade)
html.encoding='简体中文'
news=etree.HTML (html.text)
newstitle=news.xpath('xpath1/text()') #获取消息标题
newsurl=news.xpath('xpath1/@href') #抓取新闻链接
newsdate=news.xpath('xpath2/text()') #抓取新闻的日期
3.4 xpath 处理
在DockSide中得到的xpath有很多种,需要根据情况进行处理。以下是三种常见的 xpath 类型:
①一页上有一个xpath。最简单的情况是复制网页上的两条消息,比较方括号中的数字,删除数字改变的方括号,然后就可以抓取xpath下的所有消息了。 ②同一页面有多个xpath。按照①的方法去掉括号后,只能抓取到网页上的部分消息。这时候把没有抓到的xpath复制过来,一一比较,再次运行,直到抓到所有的消息。 ③只保留根xpath。在DockSide中获取到的xpath通常有几个层次,但是由于站群系统的不同,无法爬取成功。解决办法是只留下根xpath 就可以成功爬取。
3.5 获取网址
xpath/@href 方法获取的URL中,需要打印才能观察。通常有两种情况:①获取完整的URL,直接使用; ②只抓取网页过时的部分,可以通过预设的preurl解决。
3.6 获取日期
xpath2/text()捕获的消息日期日期统一为yyyy-mm-dd格式。也通过打印观察,通常有以下三种情况: ①分隔符不是破折号。对于 yyyy/mm/dd、yyyy year mm、month 和 dd 形式的日期,将其替换为 replace。 date=date.replace('/','-').replace(('year','-').replace((month'','-').replace(('day','')②开头和结尾还有其他字符,对于格式[yyyy-mm-dd]的日期,也使用replace。 date=date.replace('[','').replace((']', '-') ③收录时间,对于2021-01-31 10:01形式的日期数据,只剩下年月日,然后截取前10个字符 date=date[0:10]
3.7 时间段处理
消息时间段分为今天、最近三天、本周和上个月。确定 time.mktime(今天)和 timeStamp 之间的差异。
today=time.localtime(time.time())
today=int(time.mktime(today))
timeArray=time.strptime(timelist,'%Y-%m-%d')
timeStamp=int(time.mktime(timeArray))
shij=(today-timeStamp)/(24*3600)
图3为图2中“焊接质量检测+中国工程焊接协会+焊接之家+近一个月”的搜索结果。
4 结论
应用爬虫技术开发智能信息采集器,可用于采集四川工程学院、铸造院校、焊接行业、军事网站的最新网络新闻,满足不同用户的需求。免费提供给用户后,深受用户欢迎。
科学技术日新月异。您可以利用这些技术开发一些适合自己使用的小程序,以满足您的个性化需求。利用该项目技术开发的作品参加了一系列大学生比赛,并多次获奖。
[参考文献]
[1] 戴元,郑传兴。基于Python的南京二手房数据抓取与分析[J].计算机时代,2021 (1): 37-40+45.
[2] 李文华.网络爬虫技术原理解析[J].福建计算机, 2021, 37 (1):95-96.
[3] 许景贤,林金成,程雨萌。基于Selenium框架的反爬虫程序设计与实现[J].福建计算机, 2021, 37 (1):26-29.
[4] 傅军,郑定元,张俊宁,等。 Python爬虫技术在文献计量学中的应用与实践[J].计算机产品与流通, 2019 (7): 133. 查看全部
智能采集器(竹愈)
傅军、傅新竹、吴高静、丁彩宇、龙慧阳、熊子奇
智能信息采集器的软件开发实践
傅俊1、傅新柱2、吴高静1、丁彩宇1、龙慧阳1、熊子琪1
(1.四川工程技术学院材料工程系, 德阳 618000;
2.初中,德阳五中,德阳 618000)
[摘要]利用爬虫技术开发的智能资讯采集器,可以帮助用户及时获取工科学校、铸造学校、焊接行业、军事网站的最新消息。论文使用tkinter进行界面设计,使用python爬虫技术对xpath、抓取的日期、URL进行处理,成功抓取消息并获取消息的URL。用户可以进一步打开感兴趣的网页进行详细阅读。
【摘要】采用爬虫技术开发的智能信息采集器,可以帮助用户及时获取工程学院、铸造学院、焊接行业、军事网站的最新信息。论文选用tkinter来设计界面,使用python爬虫技术对xpath、获取的日期、URL进行处理,顺利实现了获取消息和获取消息的URL。用户可以进一步打开感兴趣的网页进行详细阅读。
【关键词】爬虫技术;资料采集; Python;二次开发;路径
【关键词】爬虫技术;信息采集; Python;二次开发;路径
【中文图书馆分类号】TP311.5【文献标识码】A【文章Number】1673-1069(2021)05-0192-02
1 简介
网络信息时代,信息纷繁复杂。科研院所、行业企业、政府部门需要了解最新的科学前沿、法律法规和工作动态网络信息来进行决策。然而,他们很难在一个繁琐的网页上找到信息。团队在完成“了不起,我的国家——建国以来重大科技成果”省级项目的过程中,往往需要紧跟科技成果和科技发展的步伐。这需要执行指定的高度相关的网站。留言搜索。如果一一搜索这些网站列,耗时较长,往往容易漏掉。团队基于python爬虫技术设计了“智能信息采集器”,有效解决了这一问题。
2 技术基础
2.1 蟒蛇
网络爬虫按照一定的规则自动抓取万维网信息,并可以采集它可以访问的所有页面内容来获取或更新这些网站的内容和检索方法。目前获取网页新闻的技术手段包括python爬虫技术和各种爬虫框架。我们的团队使用python爬虫技术进行设计。 tkinter 模块是 Python 的标准 GUI 工具包界面,可以轻松实现许多直观的功能。 tkinter是python自带的库,无需下载安装,直接使用[1]。
2.2 获取 xpath
xpath 是一种用于在 XML 文档中查找信息的语言。在浏览器中,打开网页,右击“检查元素”,打开“DockSide”,点击左上角的“选择页面中的元素进行检查(Ctrl+Shift+C)”按钮,然后点击网页中的消息,在html代码中,右击“copy/xpath”可以得到消息的xpath[2]。
3 开发实践
3.1 整体设计
变量表。每个section的局部变量newa、urla、timea;全局变量 newlist、urllist、timelist;每个单元名用label,后面跟着label2、label3…… 每个单元名有几列,使用checkbox CheckButton,CheckButton命名为单元名+列名的缩写,与checkbox链接Checkbutton.variable.
清除newlist、urllist和timelist;如果选择了某个单元的某一列,则运行相应的def;运行后,将抓取到的所有新闻标题添加到newlist中,将URL添加到urllist中,将日期添加到timelist中间。运行所有列后,获取新列表的长度数字。 urlx, newx, tixx 清零,num=0;获取所需时间段的 zj 变量值。从i=0到number,依次读取timelist[i]的值。如果时间匹配zj,则num加1,将newlist和uellist对应的值加到urlx[num]和newx[num]中。
所选列中与时间段匹配的新闻条目总数为 num。如果num>0,则显示在表格2上。 i=0--num,依次显示newx[i]和Button。如果num=0,则提示“本次新闻数量为0”,用信息提示。
3.2 界面设计
主界面有行业按钮(见图1)、“工程院”、“铸造院”、“中国工程院”、“焊接工业”、“军迷”等点击对应按钮进入对应程序,关键代码为:
mainwin=Tk()
mainwin.title('智能信息采集器')
mainwin.geometry('500x100+450+100')
mainwin.resizable (0, 0)
mainwin["background"]="LightSkyBlue"
openscetc=Button (mainwin, text="四川工程", command=四川工程).place (x=30, y=35)
opencast=Button(mainwin, text="casting College", command=open cast).place(x=136,y=35)
openmil=Button (mainwin, text="军事爱好者", command=军事爱好者).place (x=350, y=35)
openweld=Button (mainwin, text="焊接行业", command=焊接企业).place (x=244, y=35)
mainwin.mainloop()
点击按钮打开对应信息采集器。图2为焊接行业资讯采集器。
3.3 网页分析
爬虫获取网页数据的基本过程是:发送请求、获取响应数据、分析提取数据、向用户展示爬取结果。发送请求可以使用 requests 模块或 selenium 模块。解析数据,可以选择re regular,bs4(BeautifulSoup4)或xpath。经过技术研究,项目组使用requests模块和xpath。标题和日期通常是不同的xpath。使用xpath1/text()来抓取消息标题,xpath1 /@href 捕获消息的链接,使用xpath2/text()捕获消息的日期,关键代码为[3, 4]:
导入请求
从 lxml 导入 etree
导入浏览器
html=requests.get(url, headers=heade)
html.encoding='简体中文'
news=etree.HTML (html.text)
newstitle=news.xpath('xpath1/text()') #获取消息标题
newsurl=news.xpath('xpath1/@href') #抓取新闻链接
newsdate=news.xpath('xpath2/text()') #抓取新闻的日期
3.4 xpath 处理
在DockSide中得到的xpath有很多种,需要根据情况进行处理。以下是三种常见的 xpath 类型:
①一页上有一个xpath。最简单的情况是复制网页上的两条消息,比较方括号中的数字,删除数字改变的方括号,然后就可以抓取xpath下的所有消息了。 ②同一页面有多个xpath。按照①的方法去掉括号后,只能抓取到网页上的部分消息。这时候把没有抓到的xpath复制过来,一一比较,再次运行,直到抓到所有的消息。 ③只保留根xpath。在DockSide中获取到的xpath通常有几个层次,但是由于站群系统的不同,无法爬取成功。解决办法是只留下根xpath 就可以成功爬取。
3.5 获取网址
xpath/@href 方法获取的URL中,需要打印才能观察。通常有两种情况:①获取完整的URL,直接使用; ②只抓取网页过时的部分,可以通过预设的preurl解决。
3.6 获取日期
xpath2/text()捕获的消息日期日期统一为yyyy-mm-dd格式。也通过打印观察,通常有以下三种情况: ①分隔符不是破折号。对于 yyyy/mm/dd、yyyy year mm、month 和 dd 形式的日期,将其替换为 replace。 date=date.replace('/','-').replace(('year','-').replace((month'','-').replace(('day','')②开头和结尾还有其他字符,对于格式[yyyy-mm-dd]的日期,也使用replace。 date=date.replace('[','').replace((']', '-') ③收录时间,对于2021-01-31 10:01形式的日期数据,只剩下年月日,然后截取前10个字符 date=date[0:10]
3.7 时间段处理
消息时间段分为今天、最近三天、本周和上个月。确定 time.mktime(今天)和 timeStamp 之间的差异。
today=time.localtime(time.time())
today=int(time.mktime(today))
timeArray=time.strptime(timelist,'%Y-%m-%d')
timeStamp=int(time.mktime(timeArray))
shij=(today-timeStamp)/(24*3600)
图3为图2中“焊接质量检测+中国工程焊接协会+焊接之家+近一个月”的搜索结果。
4 结论
应用爬虫技术开发智能信息采集器,可用于采集四川工程学院、铸造院校、焊接行业、军事网站的最新网络新闻,满足不同用户的需求。免费提供给用户后,深受用户欢迎。
科学技术日新月异。您可以利用这些技术开发一些适合自己使用的小程序,以满足您的个性化需求。利用该项目技术开发的作品参加了一系列大学生比赛,并多次获奖。
[参考文献]
[1] 戴元,郑传兴。基于Python的南京二手房数据抓取与分析[J].计算机时代,2021 (1): 37-40+45.
[2] 李文华.网络爬虫技术原理解析[J].福建计算机, 2021, 37 (1):95-96.
[3] 许景贤,林金成,程雨萌。基于Selenium框架的反爬虫程序设计与实现[J].福建计算机, 2021, 37 (1):26-29.
[4] 傅军,郑定元,张俊宁,等。 Python爬虫技术在文献计量学中的应用与实践[J].计算机产品与流通, 2019 (7): 133.
智能采集器(我个人推荐telegraphfacebook的网站返回数据量是相对大一些)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-09-11 07:04
智能采集器可以只要cto水平高,能够合理指定采集类型和一些特殊策略,就能得到不错的数据结果,一些次一点的数据相对是比较丰富的,但另一方面也有限制,像一些文本类的数据如果不涉及很多相关性但又可以得到很好的结果就是不错的,但是百分比方式返回的数据虽然能得到粗略数据,但要得到精确的结果的话能返回的数据会很有限。
有个同学在里面做采集,他说做的比之前做的etl的效果差很多,但感觉跟人工还是相差不大的。要说不足是cto没什么特别高级的水平,靠机器学习的成本很高,特别是对的编程能力要求很高,如果没有专门做过人工智能的数据类型处理,机器学习的能力不会太强,要说有更好的选择,其实成熟稳定的chatclient也不错,而且即使不在里面做深度学习,也可以直接应用fb特别推荐的另一个网站telegraph里面的tags来采集数据,毕竟他们自己算法用的很多,得到的数据还是相对比较精准。
如果你不是搞技术的,只是想采集一些个人信息的话,不用担心这点,像你在豆瓣app里看到我发的东西,我其实是只用了一个返回链接而已,但这个返回的并不是你个人信息,只是app返回的一个链接,不同于google给你的是google的presentation里用的,即使是其他软件,只要是一个被分类到newswebsite里的,自己就可以获取个人信息,这个是可以自己做主动选择的。
我个人推荐telegraph,facebook的网站返回数据量是相对大一些,如果你看我发的东西更多,觉得新奇的,可以直接post个人信息到telegraph去。p.s.其实豆瓣app本身也是个隐私数据库,这一点我觉得他们需要考虑一下,用手机登录他们是不需要再次收集你的任何数据,这可能会增加获取的难度和成本。 查看全部
智能采集器(我个人推荐telegraphfacebook的网站返回数据量是相对大一些)
智能采集器可以只要cto水平高,能够合理指定采集类型和一些特殊策略,就能得到不错的数据结果,一些次一点的数据相对是比较丰富的,但另一方面也有限制,像一些文本类的数据如果不涉及很多相关性但又可以得到很好的结果就是不错的,但是百分比方式返回的数据虽然能得到粗略数据,但要得到精确的结果的话能返回的数据会很有限。
有个同学在里面做采集,他说做的比之前做的etl的效果差很多,但感觉跟人工还是相差不大的。要说不足是cto没什么特别高级的水平,靠机器学习的成本很高,特别是对的编程能力要求很高,如果没有专门做过人工智能的数据类型处理,机器学习的能力不会太强,要说有更好的选择,其实成熟稳定的chatclient也不错,而且即使不在里面做深度学习,也可以直接应用fb特别推荐的另一个网站telegraph里面的tags来采集数据,毕竟他们自己算法用的很多,得到的数据还是相对比较精准。
如果你不是搞技术的,只是想采集一些个人信息的话,不用担心这点,像你在豆瓣app里看到我发的东西,我其实是只用了一个返回链接而已,但这个返回的并不是你个人信息,只是app返回的一个链接,不同于google给你的是google的presentation里用的,即使是其他软件,只要是一个被分类到newswebsite里的,自己就可以获取个人信息,这个是可以自己做主动选择的。
我个人推荐telegraph,facebook的网站返回数据量是相对大一些,如果你看我发的东西更多,觉得新奇的,可以直接post个人信息到telegraph去。p.s.其实豆瓣app本身也是个隐私数据库,这一点我觉得他们需要考虑一下,用手机登录他们是不需要再次收集你的任何数据,这可能会增加获取的难度和成本。
智能采集器(智能采集器如何找到接口的痛点?行云管家教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-09 19:07
智能采集器是为了解决部分行业找不到采集接口的痛点而出现的,不仅提供接口,还提供后台统计、分析、授权、搜索等功能,能帮助解决企业不知道如何找到接口的痛点,是一个非常强大的采集器。
我买了一个行云采集器的app,产品功能挺全的,使用蛮方便的,你可以看看我写的教程。
做个水果网站好像用的行云管家的html采集器,这个产品蛮好用的,用的也挺顺手的。
同问题,
行云管家很厉害的,是国内某著名大公司出品的一款很不错的新型互联网数据采集工具,
应该可以问问???
推荐用一个p2p平台:。它是一个免费互联网数据采集和挖掘平台。做网站、做app什么的都可以用。或者做博客网站去外链等。特别方便。
行云管家真的很好用,有几个方面我真的非常喜欢:①采集接口多:常用的七八十个,大多是对大型网站的采集。②上传文件速度快:文件上传非常快。③自带全文搜索:几个关键词就能搜索到想要的东西。④采集匹配度高:主要针对企业的信息收集,而不是普通小网站。
可以考虑下联想企业网,没有用过,但是被他的宣传吓到了,希望是我想太多。只是拿他来举个例子,主要体现对接合作的。 查看全部
智能采集器(智能采集器如何找到接口的痛点?行云管家教程)
智能采集器是为了解决部分行业找不到采集接口的痛点而出现的,不仅提供接口,还提供后台统计、分析、授权、搜索等功能,能帮助解决企业不知道如何找到接口的痛点,是一个非常强大的采集器。
我买了一个行云采集器的app,产品功能挺全的,使用蛮方便的,你可以看看我写的教程。
做个水果网站好像用的行云管家的html采集器,这个产品蛮好用的,用的也挺顺手的。
同问题,
行云管家很厉害的,是国内某著名大公司出品的一款很不错的新型互联网数据采集工具,
应该可以问问???
推荐用一个p2p平台:。它是一个免费互联网数据采集和挖掘平台。做网站、做app什么的都可以用。或者做博客网站去外链等。特别方便。
行云管家真的很好用,有几个方面我真的非常喜欢:①采集接口多:常用的七八十个,大多是对大型网站的采集。②上传文件速度快:文件上传非常快。③自带全文搜索:几个关键词就能搜索到想要的东西。④采集匹配度高:主要针对企业的信息收集,而不是普通小网站。
可以考虑下联想企业网,没有用过,但是被他的宣传吓到了,希望是我想太多。只是拿他来举个例子,主要体现对接合作的。
智能采集器(百度影音自带的一键采集spider功能文件分类过多容易造成采集错误)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-09-08 09:07
智能采集器关键是通过控制采集端口速率为200mbps,实现全国范围内所有网站一键采集,采集效率比较高。
国内来说,是采集开发平台做快数的团队做的比较好些,如采数科技,
快数采集器一键采集神器!完美解决大文件、大图片、多账号采集。目前获得125万用户使用,粉丝数超过100万,开发团队有60人,为了给新用户更好的体验和服务,提供免费有效的技术支持。
为了采到更好的网站地址,百度搜了一圈,baiduspider能采到。
米采2.0基于spider+diy极客+http2,相对较新,安装也比较方便,而且支持跨区域spider爬取,如果文件较大的话可以提供单spider模式。
百度影音自带的一键采集spider功能
文件分类过多容易造成采集错误,智能采集最大程度上避免了问题,通过一个规则实现多个功能,
我们公司正在做这方面的探索,个人对一些集采集,云采集的公司比较推荐。有人说智能采集采集一些新闻内容(视频,音频等)效率不高,集采集,云采集更加高效。最近在研究m站的集采集(需要vps才能采集,发现上也有一些集采集服务商,模仿这个模式)。最后针对m站这块,综合各方面, 查看全部
智能采集器(百度影音自带的一键采集spider功能文件分类过多容易造成采集错误)
智能采集器关键是通过控制采集端口速率为200mbps,实现全国范围内所有网站一键采集,采集效率比较高。
国内来说,是采集开发平台做快数的团队做的比较好些,如采数科技,
快数采集器一键采集神器!完美解决大文件、大图片、多账号采集。目前获得125万用户使用,粉丝数超过100万,开发团队有60人,为了给新用户更好的体验和服务,提供免费有效的技术支持。
为了采到更好的网站地址,百度搜了一圈,baiduspider能采到。
米采2.0基于spider+diy极客+http2,相对较新,安装也比较方便,而且支持跨区域spider爬取,如果文件较大的话可以提供单spider模式。
百度影音自带的一键采集spider功能
文件分类过多容易造成采集错误,智能采集最大程度上避免了问题,通过一个规则实现多个功能,
我们公司正在做这方面的探索,个人对一些集采集,云采集的公司比较推荐。有人说智能采集采集一些新闻内容(视频,音频等)效率不高,集采集,云采集更加高效。最近在研究m站的集采集(需要vps才能采集,发现上也有一些集采集服务商,模仿这个模式)。最后针对m站这块,综合各方面,
智能采集器(智能采集器,电商企业需要做的开发,复制粘贴)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-09-03 16:36
智能采集器,就像机器人采集商品一样,可以任意浏览、扫码、识别、购买、推送信息,就像扫描码一样,更人性化。使用起来简单,易上手,一步实现全网商品的采集以及识别,还可以对识别到的商品进行编辑、推送、关联微信公众号,等操作。另外,还有一些现成的商品数据可以下载,电商企业需要做的开发,复制粘贴使用起来是很方便的。功能:。
1、采集全网海量自媒体平台
2、识别商品,
3、后台商品一键编辑、修改、查看
4、手机端多端打开,
5、手机端多端同步登录,
微信搜索“有货”小程序,选择“市场”,输入需要进行采集的商品,完成以后点击“确认”,商品信息就会全部采集到小程序里,前提是要扫描二维码进行登录。另外还有各种价格、佣金信息,甚至有图片、视频等等,可供商家选择。
我们商掌门采集大众点评、微信、京东上的商品信息已经很长时间了,采集技术之所以能够成功,不是看采集软件的采集速度。小程序尚未上线,我们还有很长的路要走。另外,大部分商家,小程序不适合需要非常专业的采集软件,我们的采集软件,需要各种各样的数据接口、分发接口,数据采集相关的传输技术等,不是我们这个方向要解决的问题。
等到小程序正式上线,我们将全力做好。好的采集软件,采集速度越快的,在其他方面不具备优势,更容易让人离开。不如当用户第一次购买我们产品时,先进去体验下。 查看全部
智能采集器(智能采集器,电商企业需要做的开发,复制粘贴)
智能采集器,就像机器人采集商品一样,可以任意浏览、扫码、识别、购买、推送信息,就像扫描码一样,更人性化。使用起来简单,易上手,一步实现全网商品的采集以及识别,还可以对识别到的商品进行编辑、推送、关联微信公众号,等操作。另外,还有一些现成的商品数据可以下载,电商企业需要做的开发,复制粘贴使用起来是很方便的。功能:。
1、采集全网海量自媒体平台
2、识别商品,
3、后台商品一键编辑、修改、查看
4、手机端多端打开,
5、手机端多端同步登录,
微信搜索“有货”小程序,选择“市场”,输入需要进行采集的商品,完成以后点击“确认”,商品信息就会全部采集到小程序里,前提是要扫描二维码进行登录。另外还有各种价格、佣金信息,甚至有图片、视频等等,可供商家选择。
我们商掌门采集大众点评、微信、京东上的商品信息已经很长时间了,采集技术之所以能够成功,不是看采集软件的采集速度。小程序尚未上线,我们还有很长的路要走。另外,大部分商家,小程序不适合需要非常专业的采集软件,我们的采集软件,需要各种各样的数据接口、分发接口,数据采集相关的传输技术等,不是我们这个方向要解决的问题。
等到小程序正式上线,我们将全力做好。好的采集软件,采集速度越快的,在其他方面不具备优势,更容易让人离开。不如当用户第一次购买我们产品时,先进去体验下。
智能采集器(熊猫智能采集软件是一款快速专业的采集工具,功能强大,操作简单)
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-08-29 15:11
熊猫智能采集软件是一款快速专业的采集工具,功能强大,操作简单,轻松帮助用户实现批量采集,下载、复制互联网资源,欢迎有需要的朋友下载使用!
Panda Smart采集软件介绍
优采云采集器软件是新一代采集软件,鼠标操作全过程可视化,用户无需关心网页源代码,无需编写采集规则,不需要使用正则表达式技术。全程智能辅助是采集软件行业的新一代产品。同时也是通用的采集软件,可用于各行业,满足各种采集需求。是采集复杂需求的必备,也是采集软件新手用户的首选。
熊猫智能采集器功能
操作简单,不懂技术也能轻松操作
只需输入列表页面 URL 或 关键词 即可启动 采集。您无需关心网页的源代码,鼠标操作就是整个过程。操作界面友好直观。全程智能协助。
全面强大的功能
该软件虽然操作简单,但功能强大且功能全面。可以实现各种复杂的采集需求。多功能采集软件,可应用于各种场合。是复杂采集需求的首选。
任何网页都可以采集
只要能在浏览器中看到内容,几乎都可以采集你需要的格式。支持JS输出内容的采集。
采集 速度快,数据完整性高
Panda 的采集 速度是采集 软件中最快的速度之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整。
熊猫智能采集Function
全方位的采集功能
采集的对象包括文字内容、图片、flash动画视频、下载文件等网络内容。 采集 同时支持混合图形和文本对象。支持复杂结构化的采集对象集合,支持复杂的多库表单,支持跨页面内容合并采集的能力。
采集速快
使用我们自己开发的解析引擎,实现网页源代码的类似浏览器的解析。分解网页的视觉内容元素,在此基础上进行机器学习和批量采集匹配。经过实际测试,比传统的正则匹配方式采集快2~5倍。比第三方内置浏览器采集快10-20倍。
结果数据的高度完整性
在实际采集过程中,由于目标页面具有丰富的内容页面格式,这时候就需要借助pandas独有的“多模板功能”来实现一个完整的采集。页面上采集的内容为100%采集。
多模板自动适配
很多网站“内容页”都会有多种不同类型的模板,所以优采云采集器软件允许每个采集项目同时设置多个内容页引用模板,在采集处运行时,系统会自动匹配找到最合适的参考模板来分析内容页面。
实时帮助窗口
在采集项目设置链接中,系统会在窗口右上角显示当前配置相关的实时帮助内容,为新手用户提供实时帮助。因此,优采云采集器 软件可以轻松使用。全程智能辅助,即使是第一次接触优采云采集器软件,配置采集项目也更加轻松。 查看全部
智能采集器(熊猫智能采集软件是一款快速专业的采集工具,功能强大,操作简单)
熊猫智能采集软件是一款快速专业的采集工具,功能强大,操作简单,轻松帮助用户实现批量采集,下载、复制互联网资源,欢迎有需要的朋友下载使用!
Panda Smart采集软件介绍
优采云采集器软件是新一代采集软件,鼠标操作全过程可视化,用户无需关心网页源代码,无需编写采集规则,不需要使用正则表达式技术。全程智能辅助是采集软件行业的新一代产品。同时也是通用的采集软件,可用于各行业,满足各种采集需求。是采集复杂需求的必备,也是采集软件新手用户的首选。
熊猫智能采集器功能
操作简单,不懂技术也能轻松操作
只需输入列表页面 URL 或 关键词 即可启动 采集。您无需关心网页的源代码,鼠标操作就是整个过程。操作界面友好直观。全程智能协助。
全面强大的功能
该软件虽然操作简单,但功能强大且功能全面。可以实现各种复杂的采集需求。多功能采集软件,可应用于各种场合。是复杂采集需求的首选。
任何网页都可以采集
只要能在浏览器中看到内容,几乎都可以采集你需要的格式。支持JS输出内容的采集。
采集 速度快,数据完整性高
Panda 的采集 速度是采集 软件中最快的速度之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整。
熊猫智能采集Function
全方位的采集功能
采集的对象包括文字内容、图片、flash动画视频、下载文件等网络内容。 采集 同时支持混合图形和文本对象。支持复杂结构化的采集对象集合,支持复杂的多库表单,支持跨页面内容合并采集的能力。
采集速快
使用我们自己开发的解析引擎,实现网页源代码的类似浏览器的解析。分解网页的视觉内容元素,在此基础上进行机器学习和批量采集匹配。经过实际测试,比传统的正则匹配方式采集快2~5倍。比第三方内置浏览器采集快10-20倍。
结果数据的高度完整性
在实际采集过程中,由于目标页面具有丰富的内容页面格式,这时候就需要借助pandas独有的“多模板功能”来实现一个完整的采集。页面上采集的内容为100%采集。
多模板自动适配
很多网站“内容页”都会有多种不同类型的模板,所以优采云采集器软件允许每个采集项目同时设置多个内容页引用模板,在采集处运行时,系统会自动匹配找到最合适的参考模板来分析内容页面。
实时帮助窗口
在采集项目设置链接中,系统会在窗口右上角显示当前配置相关的实时帮助内容,为新手用户提供实时帮助。因此,优采云采集器 软件可以轻松使用。全程智能辅助,即使是第一次接触优采云采集器软件,配置采集项目也更加轻松。
智能采集器(优化啦·智能信息采集器软件特点:1.智能邮箱采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-08-28 00:16
优化。智讯采集器是基于爬取搜索引擎邮件资源开发的一款功能强大的采集软件。来自采集、QQ的邮箱地址具有很强的定向性,排除你与目标受众无关的Email,会让你得到的邮箱列表更有针对性,发送的效果自然会更好。优化。智能信息采集器提供强大的邮箱地址、导出、去重功能。是邮箱营销和QQ营销的必备软件!
优化·智能信息采集器软件特点:
1.智慧邮采集器是一款功能强大、易于使用且友好的专业邮件按钮搜索器。
2.通过页面多平台智能分析,深度挖掘所有页面的邮箱地址,扣号,准确率99%。
3. 根据设定的目标关键词,软件会自动从搜索引擎结果中采集 对应的邮箱地址。 采集发送的邮件地址非常准确,更符合精准邮件营销的理念。
4. 根据设定的目标关键词,软件自动从搜索引擎结果中检索出采集对应的所有扣号。 采集收到的扣号非常准确,更适合扣精准营销。想法。
客户信息采集器是一个强大的客户挖掘工具。使用本软件挖掘客户时,用户只需要输入关键词软件即可自动采集在线客户信息并过滤,最终过滤结果显示供客户参考。
优化·智能信息采集器使用提醒:
提醒:部分杀毒软件返回误报,加入白名单正常使用即可。 查看全部
智能采集器(优化啦·智能信息采集器软件特点:1.智能邮箱采集器)
优化。智讯采集器是基于爬取搜索引擎邮件资源开发的一款功能强大的采集软件。来自采集、QQ的邮箱地址具有很强的定向性,排除你与目标受众无关的Email,会让你得到的邮箱列表更有针对性,发送的效果自然会更好。优化。智能信息采集器提供强大的邮箱地址、导出、去重功能。是邮箱营销和QQ营销的必备软件!
优化·智能信息采集器软件特点:
1.智慧邮采集器是一款功能强大、易于使用且友好的专业邮件按钮搜索器。
2.通过页面多平台智能分析,深度挖掘所有页面的邮箱地址,扣号,准确率99%。
3. 根据设定的目标关键词,软件会自动从搜索引擎结果中采集 对应的邮箱地址。 采集发送的邮件地址非常准确,更符合精准邮件营销的理念。
4. 根据设定的目标关键词,软件自动从搜索引擎结果中检索出采集对应的所有扣号。 采集收到的扣号非常准确,更适合扣精准营销。想法。
客户信息采集器是一个强大的客户挖掘工具。使用本软件挖掘客户时,用户只需要输入关键词软件即可自动采集在线客户信息并过滤,最终过滤结果显示供客户参考。
优化·智能信息采集器使用提醒:
提醒:部分杀毒软件返回误报,加入白名单正常使用即可。
优采云软件开发智能文章采集系统介绍及功能介绍(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-08-26 02:05
优采云智能文章采集系统是优采云software开发的网站文章采集器系统。软件内置智能分块算法,可以直接将html代码和主要内容分开,只需要输入网站网址,软件就可以轻松准确地将采集网站中的所有文章 @。除了采集文章功能,软件还有强大的原创功能,可以将采集收到的内容处理两次,直接发布到你的网站,或者直接导出到txt格式本地化,功能非常强大,适合每一位站长下载使用。
软件功能
1、智能区块算法采集任何内容站点,真的傻瓜式采集
智能块算法自动提取网页正文内容,无需配置源码规则,真的傻瓜式采集;
自动去噪,可自动过滤标题内容中的图片\URL\电话\QQ\email等信息;
可以针对全球任何小语种,任意编码文章采集,无乱码;
多任务(多站点/列)多线程同步采集,支持代理采集,快速高效;
指定任何文章内容类网站采集,而不是文章源
2、Powerful 伪原创function
内置中文分词功能,强大的近义词和同义词数据库引擎,替换效率高;
自带英文分词词库和语料库,支持TBS模式批量原创,保持句子语义流畅;
标题和内容可以伪原创单独处理;
3、内置主流cmsrelease接口
可直接导出为TXT文件,可根据标题或序号生成文件名。
支持wordpress、zblog、dedecms、phpcms等国内外主流cms自动发布;
支持多线程、多任务同时发布;
功能介绍
1、Content 区块自动识别并自动提取任意页面内容
自动识别html代码并过滤正文内容,完整率95%以上,只要是基于内容的页面,都可以自动提取。
2、使用代理IP模拟真实蜘蛛头采集防止同一IP采集被过多限制
目前很多大规模网站对同一个IP的访问过于频繁会被限制。软件可以使用采集的代理IP绕过限制,同时模拟真实蜘蛛爬取采集页面,最大可能受到网站采集某个大频率的限制。
3、任何编码和小语种采集全球小语种采集,无乱码
一般网页采集乱码都是编码不正确造成的。本软件内置所有全球编码格式,可以选择不同的编码采集,确保任何语言和任意编码采集都不会出现乱码。
4、中英文伪原创处理多种原创模式,对搜索引擎收录有好处
中文采用内置同义词和同义词数据库替换模式,英文采用伪原创强大的TBS预测数据库,保证句子前后流畅。同一篇文章文章的内容每次原创之后都会改变。
5、多种导出/发布模式,灵活的内容导出和发布
可以根据序列号或标题为文件名直接以TXT格式导出到本地,也可以直接使用内置发布接口发布到当前主流的几个内容cms程序,目前支持dedecms、wordpress、zblog 等
常见问题
1、是否可以在任何网站上采集?
只要是本站主要内容,如论坛、博客、文章站等都可以采集、优采云智能文章采集系统会自动识别正文块并自动提取正文内容。
2、采集的文章乱七八糟?
优采云智能文章采集系统是针对指定的网站采集,得到的文章是原页面文章的正文内容,不是源码的文本字符网页,但干净的原创文章Content。 查看全部
优采云软件开发智能文章采集系统介绍及功能介绍(组图)
优采云智能文章采集系统是优采云software开发的网站文章采集器系统。软件内置智能分块算法,可以直接将html代码和主要内容分开,只需要输入网站网址,软件就可以轻松准确地将采集网站中的所有文章 @。除了采集文章功能,软件还有强大的原创功能,可以将采集收到的内容处理两次,直接发布到你的网站,或者直接导出到txt格式本地化,功能非常强大,适合每一位站长下载使用。
软件功能
1、智能区块算法采集任何内容站点,真的傻瓜式采集
智能块算法自动提取网页正文内容,无需配置源码规则,真的傻瓜式采集;
自动去噪,可自动过滤标题内容中的图片\URL\电话\QQ\email等信息;
可以针对全球任何小语种,任意编码文章采集,无乱码;
多任务(多站点/列)多线程同步采集,支持代理采集,快速高效;
指定任何文章内容类网站采集,而不是文章源
2、Powerful 伪原创function
内置中文分词功能,强大的近义词和同义词数据库引擎,替换效率高;
自带英文分词词库和语料库,支持TBS模式批量原创,保持句子语义流畅;
标题和内容可以伪原创单独处理;
3、内置主流cmsrelease接口
可直接导出为TXT文件,可根据标题或序号生成文件名。
支持wordpress、zblog、dedecms、phpcms等国内外主流cms自动发布;
支持多线程、多任务同时发布;
功能介绍
1、Content 区块自动识别并自动提取任意页面内容
自动识别html代码并过滤正文内容,完整率95%以上,只要是基于内容的页面,都可以自动提取。
2、使用代理IP模拟真实蜘蛛头采集防止同一IP采集被过多限制
目前很多大规模网站对同一个IP的访问过于频繁会被限制。软件可以使用采集的代理IP绕过限制,同时模拟真实蜘蛛爬取采集页面,最大可能受到网站采集某个大频率的限制。
3、任何编码和小语种采集全球小语种采集,无乱码
一般网页采集乱码都是编码不正确造成的。本软件内置所有全球编码格式,可以选择不同的编码采集,确保任何语言和任意编码采集都不会出现乱码。
4、中英文伪原创处理多种原创模式,对搜索引擎收录有好处
中文采用内置同义词和同义词数据库替换模式,英文采用伪原创强大的TBS预测数据库,保证句子前后流畅。同一篇文章文章的内容每次原创之后都会改变。
5、多种导出/发布模式,灵活的内容导出和发布
可以根据序列号或标题为文件名直接以TXT格式导出到本地,也可以直接使用内置发布接口发布到当前主流的几个内容cms程序,目前支持dedecms、wordpress、zblog 等
常见问题
1、是否可以在任何网站上采集?
只要是本站主要内容,如论坛、博客、文章站等都可以采集、优采云智能文章采集系统会自动识别正文块并自动提取正文内容。
2、采集的文章乱七八糟?
优采云智能文章采集系统是针对指定的网站采集,得到的文章是原页面文章的正文内容,不是源码的文本字符网页,但干净的原创文章Content。
智能采集器如何开发多种聚合搜索、采集方案?
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-08-25 01:06
智能采集器,可以进行聚合搜索、采集分析,针对不同的行业可以开发多种聚合采集方案,如网站采集、app采集、小程序采集、内容聚合等。打开智能采集器,以“采五颜六色”为例子,进行一次安装教程说明操作说明:进入pc端,点击上方“采五颜六色”里面的五种功能进行一个下载。打开我们的电脑,双击我们刚刚准备好的采集器,找到我们需要搜索的内容。
点击五颜六色中的“采集源地址”,点击保存,然后可以开始搜索了,或者点击文中的“采集源地址”,返回到智能采集器里,点击搜索源地址。在我们前面的操作页面,可以看到是我们的模拟浏览器在浏览网页。点击浏览器里面的“全部浏览器”,然后找到我们需要搜索的链接,或者百度地址。点击网址上方的“realpage”点击点击即可播放样式,点击我们准备好的搜索源地址即可开始搜索了。
智能采集器可以免费使用1个月,保存之后文件如何打包呢?答案很简单,我们直接把下载的文件上传到我们的百度云里就可以了。不会有一点点的乱码吧!搜索完之后,如果需要特别的效果,或者需要我们自己想要这样的效果的,直接购买。如果你没有购买的话,那我们要怎么找呢?要怎么样才能开通花呗呢?我们把有搜索词的样式拖到智能采集器,或者直接把文件拖到里面,就可以开通花呗了。
打开花呗还款智能采集器,扫码也可以开通花呗呀,或者说是扫码就开通花呗也可以,管理访客,也可以自己添加访客,不管是通过微信还是别的方式添加访客,添加方式都一样的。只要我们购买了花呗,在我们有花呗的界面会有一个“添加花呗”,我们可以在里面把自己的花呗添加进去,但是现在花呗是一分钱都可以购买的。想了解更多,那就来找我吧!喜欢记得点赞哦!。 查看全部
智能采集器如何开发多种聚合搜索、采集方案?
智能采集器,可以进行聚合搜索、采集分析,针对不同的行业可以开发多种聚合采集方案,如网站采集、app采集、小程序采集、内容聚合等。打开智能采集器,以“采五颜六色”为例子,进行一次安装教程说明操作说明:进入pc端,点击上方“采五颜六色”里面的五种功能进行一个下载。打开我们的电脑,双击我们刚刚准备好的采集器,找到我们需要搜索的内容。
点击五颜六色中的“采集源地址”,点击保存,然后可以开始搜索了,或者点击文中的“采集源地址”,返回到智能采集器里,点击搜索源地址。在我们前面的操作页面,可以看到是我们的模拟浏览器在浏览网页。点击浏览器里面的“全部浏览器”,然后找到我们需要搜索的链接,或者百度地址。点击网址上方的“realpage”点击点击即可播放样式,点击我们准备好的搜索源地址即可开始搜索了。
智能采集器可以免费使用1个月,保存之后文件如何打包呢?答案很简单,我们直接把下载的文件上传到我们的百度云里就可以了。不会有一点点的乱码吧!搜索完之后,如果需要特别的效果,或者需要我们自己想要这样的效果的,直接购买。如果你没有购买的话,那我们要怎么找呢?要怎么样才能开通花呗呢?我们把有搜索词的样式拖到智能采集器,或者直接把文件拖到里面,就可以开通花呗了。
打开花呗还款智能采集器,扫码也可以开通花呗呀,或者说是扫码就开通花呗也可以,管理访客,也可以自己添加访客,不管是通过微信还是别的方式添加访客,添加方式都一样的。只要我们购买了花呗,在我们有花呗的界面会有一个“添加花呗”,我们可以在里面把自己的花呗添加进去,但是现在花呗是一分钱都可以购买的。想了解更多,那就来找我吧!喜欢记得点赞哦!。
智能采集器 竹愈
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-08-18 06:02
傅军、傅新竹、吴高静、丁彩宇、龙慧阳、熊子奇
智能信息采集器的软件开发实践
傅俊1、傅新柱2、吴高静1、丁彩宇1、龙慧阳1、熊子琪1
(1.四川工程技术学院材料工程系, 德阳 618000;
2.初中,德阳五中,德阳 618000)
[摘要]利用爬虫技术开发的智能资讯采集器,可以帮助用户及时获取工科学校、铸造学校、焊接行业、军事网站的最新消息。论文使用tkinter进行界面设计,使用python爬虫技术对xpath、抓取的日期、URL进行处理,成功抓取消息并获取消息的URL。用户可以进一步打开感兴趣的网页进行详细阅读。
【摘要】采用爬虫技术开发的智能信息采集器,可以帮助用户及时获取工程学院、铸造学院、焊接行业、军事网站的最新信息。论文选用tkinter来设计界面,使用python爬虫技术对xpath、获取的日期、URL进行处理,顺利实现了获取消息和获取消息的URL。用户可以进一步打开感兴趣的网页进行详细阅读。
【关键词】爬虫技术;资料采集; Python;二次开发;路径
【关键词】爬虫技术;信息采集; Python;二次开发;路径
【中文图书馆分类号】TP311.5【文献标识码】A【文章Number】1673-1069(2021)05-0192-02
1 简介
网络信息时代,信息纷繁复杂。科研院所、行业企业和政府部门需要了解最新的科学前沿、法律法规和工作动态网络信息来进行决策。然而,他们很难在一个繁琐的网页上找到信息。团队在完成“了不起,我国——建国以来重大科技成果”省级项目的过程中,往往需要紧跟科技成果和科技发展的步伐。这需要执行指定的高度相关的网站。留言搜索。如果一一搜索这些网站列,耗时较长,往往容易漏掉。团队基于python爬虫技术设计了“智能信息采集器”,有效解决了这一问题。
2 技术基础
2.1 蟒蛇
网络爬虫按照一定的规则自动抓取万维网信息,并可以采集它可以访问的所有页面内容来获取或更新这些网站的内容和检索方法。目前获取网页新闻的技术手段包括python爬虫技术和各种爬虫框架。我们的团队使用python爬虫技术进行设计。 tkinter 模块是 Python 的标准 GUI 工具包界面,可以轻松实现许多直观的功能。 tkinter是python自带的库,无需下载安装,直接使用[1]。
2.2 获取 xpath
xpath 是一种用于在 XML 文档中查找信息的语言。在浏览器中,打开网页,右击“检查元素”,打开“DockSide”,点击左上角的“选择页面中的元素进行检查(Ctrl+Shift+C)”按钮,然后点击网页中的消息,在html代码中,右击“copy/xpath”可以得到消息的xpath[2]。
3 开发实践
3.1 整体设计
变量表。每个section的局部变量newa、urla、timea;全局变量 newlist、urllist、timelist;每个单元名用label,后面跟着label2、label3……每个单元名下面有几列,使用checkbox CheckButton,CheckButton命名为单元名+列名的缩写,链接复选框 Checkbutton.variable。
清除newlist、urllist和timelist;如果选择了某个单元的某一列,则运行相应的def;运行后,将捕获的所有新闻标题添加到newlist中,将URL添加到urllist中,将日期添加到timelist中间。运行所有列后,获取新列表的长度数字。 urlx, newx, tixx 清零,num=0;获取所需时间段的 zj 变量值。从i=0到number,依次读取timelist[i]的值。如果时间匹配zj,则num加1,将newlist和uellist对应的值加到urlx[num]和newx[num]中。
所选列中与时间段匹配的新闻条目总数为 num。如果num>0,则显示在表格2上。 i=0--num,依次显示newx[i]和Button。如果num=0,则提示“本次新闻数量为0”,用信息提示。
3.2 界面设计
主界面有行业按钮(见图1)、“工程院”、“铸造院”、“中国工程院”、“焊接工业”、“军迷”等点击对应按钮进入对应程序,关键代码为:
mainwin=Tk()
mainwin.title('智能信息采集器')
mainwin.geometry('500x100+450+100')
mainwin.resizable (0, 0)
mainwin["background"]="LightSkyBlue"
openscetc=Button (mainwin, text="四川工程", command=四川工程).place (x=30, y=35)
opencast=Button(mainwin, text="casting College", command=open cast).place(x=136,y=35)
openmil=Button (mainwin, text="军事爱好者", command=军事爱好者).place (x=350, y=35)
openweld=Button (mainwin, text="焊接行业", command=焊接企业).place (x=244, y=35)
mainwin.mainloop()
点击按钮打开对应信息采集器。图2为焊接行业资讯采集器。
3.3 网页分析
爬虫获取网页数据的基本过程是:发送请求、获取响应数据、分析提取数据、向用户展示爬取结果。发送请求可以使用 requests 模块或 selenium 模块。解析数据,可以选择re regular,bs4(BeautifulSoup4)或xpath。经过技术研究,项目组使用requests模块和xpath。标题和日期通常是不同的xpath。使用xpath1/text()来抓取消息标题,xpath1 /@href 捕获消息的链接,使用xpath2/text()捕获消息的日期,关键代码为[3, 4]:
导入请求
从 lxml 导入 etree
导入浏览器
html=requests.get(url, headers=heade)
html.encoding='简体中文'
news=etree.HTML (html.text)
newstitle=news.xpath('xpath1/text()') #获取消息标题
newsurl=news.xpath('xpath1/@href') #抓取新闻链接
newsdate=news.xpath('xpath2/text()') #抓取新闻的日期
3.4 xpath 处理
在DockSide中得到的xpath有很多种,需要根据情况进行处理。以下是三种常见的 xpath 类型:
①一页上有一个xpath。最简单的情况是复制网页上的两条消息,比较方括号中的数字,删除数字改变的方括号,然后就可以抓取xpath下的所有消息了。 ②同一页面有多个xpath。按照①的方法去掉括号后,只能抓取到网页上的部分消息。这时候把没有抓到的xpath复制过来,一一比较,再次运行,直到抓到所有的消息。 ③只保留根xpath。在DockSide中获取到的xpath通常有几个层次,但是由于站群系统的不同,无法爬取成功。解决办法是只留下根xpath 就可以成功爬取。
3.5 获取网址
xpath/@href 方法获取的URL中,需要打印才能观察。通常有两种情况:①获取完整的URL,直接使用; ②只抓取网页过时的部分,可以通过预设的preurl解决。
3.6 获取日期
xpath2/text()捕获的消息日期日期统一为yyyy-mm-dd格式。也通过打印观察,通常有以下三种情况: ①分隔符不是破折号。对于 yyyy/mm/dd、yyyy year mm、month 和 dd 形式的日期,将其替换为 replace。 date=date.replace('/','-').replace(('year','-').replace((month'','-').replace(('day','')②开头和结尾还有其他字符,对于格式[yyyy-mm-dd]的日期,也使用replace。 date=date.replace('[','').replace((']', '-') ③收录时间,对于2021-01-31 10:01形式的日期数据,只剩下年月日,然后截取前10个字符 date=date[0:10]
3.7 时间段处理
消息时间段分为今天、最近三天、本周和上个月。确定 time.mktime(今天)和 timeStamp 之间的差异。
today=time.localtime(time.time())
today=int(time.mktime(today))
timeArray=time.strptime(timelist,'%Y-%m-%d')
timeStamp=int(time.mktime(timeArray))
shij=(today-timeStamp)/(24*3600)
图3为图2中“焊接质量检测+中国工程焊接协会+焊接之家+近一个月”的搜索结果。
4 结论
应用爬虫技术开发智能信息采集器,可用于采集四川工程学院、铸造院校、焊接行业、军事网站的最新网络新闻,满足不同用户的需求。免费提供给用户后,深受用户欢迎。
科学技术日新月异。您可以利用这些技术开发一些适合自己使用的小程序,以满足您的个性化需求。利用该项目技术开发的作品参加了一系列大学生比赛并获得多项奖项。
[参考文献]
[1] 戴元,郑传兴。基于Python的南京二手房数据抓取与分析[J].计算机时代,2021 (1): 37-40+45.
[2] 李文华.网络爬虫技术原理解析[J].福建计算机, 2021, 37 (1):95-96.
[3] 许景贤,林金成,程雨萌。基于Selenium框架的反爬虫程序设计与实现[J].福建计算机, 2021, 37 (1):26-29.
[4] 傅军,郑定元,张俊宁,等。 Python爬虫技术在文献计量学中的应用与实践[J].计算机产品与流通, 2019 (7): 133. 查看全部
智能采集器 竹愈
傅军、傅新竹、吴高静、丁彩宇、龙慧阳、熊子奇
智能信息采集器的软件开发实践
傅俊1、傅新柱2、吴高静1、丁彩宇1、龙慧阳1、熊子琪1
(1.四川工程技术学院材料工程系, 德阳 618000;
2.初中,德阳五中,德阳 618000)
[摘要]利用爬虫技术开发的智能资讯采集器,可以帮助用户及时获取工科学校、铸造学校、焊接行业、军事网站的最新消息。论文使用tkinter进行界面设计,使用python爬虫技术对xpath、抓取的日期、URL进行处理,成功抓取消息并获取消息的URL。用户可以进一步打开感兴趣的网页进行详细阅读。
【摘要】采用爬虫技术开发的智能信息采集器,可以帮助用户及时获取工程学院、铸造学院、焊接行业、军事网站的最新信息。论文选用tkinter来设计界面,使用python爬虫技术对xpath、获取的日期、URL进行处理,顺利实现了获取消息和获取消息的URL。用户可以进一步打开感兴趣的网页进行详细阅读。
【关键词】爬虫技术;资料采集; Python;二次开发;路径
【关键词】爬虫技术;信息采集; Python;二次开发;路径
【中文图书馆分类号】TP311.5【文献标识码】A【文章Number】1673-1069(2021)05-0192-02
1 简介
网络信息时代,信息纷繁复杂。科研院所、行业企业和政府部门需要了解最新的科学前沿、法律法规和工作动态网络信息来进行决策。然而,他们很难在一个繁琐的网页上找到信息。团队在完成“了不起,我国——建国以来重大科技成果”省级项目的过程中,往往需要紧跟科技成果和科技发展的步伐。这需要执行指定的高度相关的网站。留言搜索。如果一一搜索这些网站列,耗时较长,往往容易漏掉。团队基于python爬虫技术设计了“智能信息采集器”,有效解决了这一问题。
2 技术基础
2.1 蟒蛇
网络爬虫按照一定的规则自动抓取万维网信息,并可以采集它可以访问的所有页面内容来获取或更新这些网站的内容和检索方法。目前获取网页新闻的技术手段包括python爬虫技术和各种爬虫框架。我们的团队使用python爬虫技术进行设计。 tkinter 模块是 Python 的标准 GUI 工具包界面,可以轻松实现许多直观的功能。 tkinter是python自带的库,无需下载安装,直接使用[1]。
2.2 获取 xpath
xpath 是一种用于在 XML 文档中查找信息的语言。在浏览器中,打开网页,右击“检查元素”,打开“DockSide”,点击左上角的“选择页面中的元素进行检查(Ctrl+Shift+C)”按钮,然后点击网页中的消息,在html代码中,右击“copy/xpath”可以得到消息的xpath[2]。
3 开发实践
3.1 整体设计
变量表。每个section的局部变量newa、urla、timea;全局变量 newlist、urllist、timelist;每个单元名用label,后面跟着label2、label3……每个单元名下面有几列,使用checkbox CheckButton,CheckButton命名为单元名+列名的缩写,链接复选框 Checkbutton.variable。
清除newlist、urllist和timelist;如果选择了某个单元的某一列,则运行相应的def;运行后,将捕获的所有新闻标题添加到newlist中,将URL添加到urllist中,将日期添加到timelist中间。运行所有列后,获取新列表的长度数字。 urlx, newx, tixx 清零,num=0;获取所需时间段的 zj 变量值。从i=0到number,依次读取timelist[i]的值。如果时间匹配zj,则num加1,将newlist和uellist对应的值加到urlx[num]和newx[num]中。
所选列中与时间段匹配的新闻条目总数为 num。如果num>0,则显示在表格2上。 i=0--num,依次显示newx[i]和Button。如果num=0,则提示“本次新闻数量为0”,用信息提示。
3.2 界面设计
主界面有行业按钮(见图1)、“工程院”、“铸造院”、“中国工程院”、“焊接工业”、“军迷”等点击对应按钮进入对应程序,关键代码为:
mainwin=Tk()
mainwin.title('智能信息采集器')
mainwin.geometry('500x100+450+100')
mainwin.resizable (0, 0)
mainwin["background"]="LightSkyBlue"
openscetc=Button (mainwin, text="四川工程", command=四川工程).place (x=30, y=35)
opencast=Button(mainwin, text="casting College", command=open cast).place(x=136,y=35)
openmil=Button (mainwin, text="军事爱好者", command=军事爱好者).place (x=350, y=35)
openweld=Button (mainwin, text="焊接行业", command=焊接企业).place (x=244, y=35)
mainwin.mainloop()
点击按钮打开对应信息采集器。图2为焊接行业资讯采集器。
3.3 网页分析
爬虫获取网页数据的基本过程是:发送请求、获取响应数据、分析提取数据、向用户展示爬取结果。发送请求可以使用 requests 模块或 selenium 模块。解析数据,可以选择re regular,bs4(BeautifulSoup4)或xpath。经过技术研究,项目组使用requests模块和xpath。标题和日期通常是不同的xpath。使用xpath1/text()来抓取消息标题,xpath1 /@href 捕获消息的链接,使用xpath2/text()捕获消息的日期,关键代码为[3, 4]:
导入请求
从 lxml 导入 etree
导入浏览器
html=requests.get(url, headers=heade)
html.encoding='简体中文'
news=etree.HTML (html.text)
newstitle=news.xpath('xpath1/text()') #获取消息标题
newsurl=news.xpath('xpath1/@href') #抓取新闻链接
newsdate=news.xpath('xpath2/text()') #抓取新闻的日期
3.4 xpath 处理
在DockSide中得到的xpath有很多种,需要根据情况进行处理。以下是三种常见的 xpath 类型:
①一页上有一个xpath。最简单的情况是复制网页上的两条消息,比较方括号中的数字,删除数字改变的方括号,然后就可以抓取xpath下的所有消息了。 ②同一页面有多个xpath。按照①的方法去掉括号后,只能抓取到网页上的部分消息。这时候把没有抓到的xpath复制过来,一一比较,再次运行,直到抓到所有的消息。 ③只保留根xpath。在DockSide中获取到的xpath通常有几个层次,但是由于站群系统的不同,无法爬取成功。解决办法是只留下根xpath 就可以成功爬取。
3.5 获取网址
xpath/@href 方法获取的URL中,需要打印才能观察。通常有两种情况:①获取完整的URL,直接使用; ②只抓取网页过时的部分,可以通过预设的preurl解决。
3.6 获取日期
xpath2/text()捕获的消息日期日期统一为yyyy-mm-dd格式。也通过打印观察,通常有以下三种情况: ①分隔符不是破折号。对于 yyyy/mm/dd、yyyy year mm、month 和 dd 形式的日期,将其替换为 replace。 date=date.replace('/','-').replace(('year','-').replace((month'','-').replace(('day','')②开头和结尾还有其他字符,对于格式[yyyy-mm-dd]的日期,也使用replace。 date=date.replace('[','').replace((']', '-') ③收录时间,对于2021-01-31 10:01形式的日期数据,只剩下年月日,然后截取前10个字符 date=date[0:10]
3.7 时间段处理
消息时间段分为今天、最近三天、本周和上个月。确定 time.mktime(今天)和 timeStamp 之间的差异。
today=time.localtime(time.time())
today=int(time.mktime(today))
timeArray=time.strptime(timelist,'%Y-%m-%d')
timeStamp=int(time.mktime(timeArray))
shij=(today-timeStamp)/(24*3600)
图3为图2中“焊接质量检测+中国工程焊接协会+焊接之家+近一个月”的搜索结果。
4 结论
应用爬虫技术开发智能信息采集器,可用于采集四川工程学院、铸造院校、焊接行业、军事网站的最新网络新闻,满足不同用户的需求。免费提供给用户后,深受用户欢迎。
科学技术日新月异。您可以利用这些技术开发一些适合自己使用的小程序,以满足您的个性化需求。利用该项目技术开发的作品参加了一系列大学生比赛并获得多项奖项。
[参考文献]
[1] 戴元,郑传兴。基于Python的南京二手房数据抓取与分析[J].计算机时代,2021 (1): 37-40+45.
[2] 李文华.网络爬虫技术原理解析[J].福建计算机, 2021, 37 (1):95-96.
[3] 许景贤,林金成,程雨萌。基于Selenium框架的反爬虫程序设计与实现[J].福建计算机, 2021, 37 (1):26-29.
[4] 傅军,郑定元,张俊宁,等。 Python爬虫技术在文献计量学中的应用与实践[J].计算机产品与流通, 2019 (7): 133.
阿里云对话式抓取器系统的六大特点及特点分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-08-16 06:04
智能采集器是通过一种全新的、革命性的开发方式,结合了地理信息系统的云平台,生成采集器对采集对象的分析和展示,支持采集规则的个性化设置,强大的采集功能使得采集器可以实现高效率,可靠性和无广告操作的效果。可以说,阿里云对话式抓取器系统能够很好地满足平台对开发者的智能采集需求。阿里云对话式抓取器官网:,是基于云计算+大数据的一站式数据采集服务平台。
平台不仅支持从市场上所有主流数据源采集,还可以实现智能化采集,满足基础需求和更高采集需求。整个采集过程实现了强大的自动化、自动化和可靠性,非常方便用户快速、准确、轻松高效地采集大量数据。目前,平台已经覆盖全网73类全量、半量、全量采集并接入在线产品,采集产品集中在高频产品;采集流程智能化、流程化、平台化、个性化。
并且,通过自动识别页面属性并实现页面展示、跳转跳转来实现差异化内容全方位、实时性、智能性采集。阿里云对话式抓取器适用于各类公司用户和海量产品销售渠道合作伙伴,大致有以下六大特点:稳定性、可靠性、点击展示简单易用支持多样化灵活定制设置轻松编写多样可靠的代码一条返回多个页面高性能,实时抓取性能测试每个页面限量500k-1m以下,灵活配置抓取规则与切片的扩展灵活性交互操作、智能云平台操作流程展示。 查看全部
阿里云对话式抓取器系统的六大特点及特点分析
智能采集器是通过一种全新的、革命性的开发方式,结合了地理信息系统的云平台,生成采集器对采集对象的分析和展示,支持采集规则的个性化设置,强大的采集功能使得采集器可以实现高效率,可靠性和无广告操作的效果。可以说,阿里云对话式抓取器系统能够很好地满足平台对开发者的智能采集需求。阿里云对话式抓取器官网:,是基于云计算+大数据的一站式数据采集服务平台。
平台不仅支持从市场上所有主流数据源采集,还可以实现智能化采集,满足基础需求和更高采集需求。整个采集过程实现了强大的自动化、自动化和可靠性,非常方便用户快速、准确、轻松高效地采集大量数据。目前,平台已经覆盖全网73类全量、半量、全量采集并接入在线产品,采集产品集中在高频产品;采集流程智能化、流程化、平台化、个性化。
并且,通过自动识别页面属性并实现页面展示、跳转跳转来实现差异化内容全方位、实时性、智能性采集。阿里云对话式抓取器适用于各类公司用户和海量产品销售渠道合作伙伴,大致有以下六大特点:稳定性、可靠性、点击展示简单易用支持多样化灵活定制设置轻松编写多样可靠的代码一条返回多个页面高性能,实时抓取性能测试每个页面限量500k-1m以下,灵活配置抓取规则与切片的扩展灵活性交互操作、智能云平台操作流程展示。
熊猫智能采集软件破解版设计的特色介绍-熊猫软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-08-13 18:26
熊猫Smart采集software 破解版是一款非常专业的信息采集工具。该软件在整个过程中可视化鼠标操作。用户无需关心网页源代码,无需编写采集规则,无需使用正则表达式技术轻松采集到自己需要的网页信息。同时也是通用的采集软件,可用于各个行业,满足各种采集需求(包括站群系统)。 采集software 力求设计成一个通用的泛采集工具软件,可以实现在浏览器采集中可见的内容。是复杂采集需求的必备,也是采集软件新手用户的首选。欢迎有需要的朋友下载。
软件功能:
1、采集速度快,数据完整性高
Panda 的采集 速度是采集 软件中最快的速度之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整。
2、任何网页都可以采集
只要能在浏览器中看到内容,几乎都可以采集你需要的格式。支持JS输出内容的采集。
3、功能全面强大
该软件虽然操作简单,但功能强大且功能全面。可以实现各种复杂的采集需求。通用采集软件,可应用于各种场合。这是复杂的采集 需求中的第一个。
4、任何网页都可以采集
只要能在浏览器中看到内容,几乎都可以采集你需要的格式。支持JS输出内容的采集。
5、操作简单,不懂技术也能轻松操作
只需输入列表页面 URL 或 关键词 即可启动 采集。您无需关心网页的源代码,鼠标操作就是整个过程。操作界面友好直观。全程智能协助。
软件功能:
1、all-round采集 函数
采集的对象包括文字内容、图片、flash动画视频、下载文件等网络内容。 采集 同时支持混合图形和文本对象。支持采集对象集合的复杂结构,支持复杂的多库表单,支持跨页面内容合并采集的能力。
2、采集速快
采集 速度是采集软件(一)的)中最快的。它没有使用落后和低效的正则匹配技术,没有使用第三方内置浏览器访问技术。它使用自己开发的解析引擎,实现网页源代码的类似浏览器的解析。
3、结果数据高度完整
在实际采集过程中,由于目标页面内容页面布局丰富,需要利用其独有的“多模板功能”来实现一个完整的采集。
4、多模板自动适配
很多网站“内容页”都会有多种不同类型的模板,所以采集software允许每个采集项目同时设置多个内容页引用模板。 采集运行时,系统会自动匹配,寻找最合适的参考模板来分析内容页面。
5、实时帮助窗口
在采集项目设置链接中,系统会在窗口右上角显示当前配置相关的实时帮助内容,为新手用户提供实时帮助。所以采集软件的使用可以轻松上手。
亮点介绍:
1、一键采集
输入采集port URL完成设置并启动采集,输入关键词全网搜索采集
2、cloud采集
独有的基于点对点框架的云端采集功能,解决采集时IP被封的行业难题
3、万能模拟发布
无需开发针对性发布界面文件,可适配任何网站cms后台,使用手动发布页面模拟手动发布
4、多模板自适应
一个项目可以配置多个模板,软件会在运行时自动选择最适合采集匹配的模板。
5、内容相似度判断
根据内容相似度判断文章的重复性和准确性,可以列出相似的文章列表,可以输出文章core关键词
安装教程:
1、本站下载软件,解压后双击运行包,点击下一步
2、选择安装文件夹,点击浏览更改安装位置
3、安装成功,点击关闭退出
查看全部
熊猫智能采集软件破解版设计的特色介绍-熊猫软件
熊猫Smart采集software 破解版是一款非常专业的信息采集工具。该软件在整个过程中可视化鼠标操作。用户无需关心网页源代码,无需编写采集规则,无需使用正则表达式技术轻松采集到自己需要的网页信息。同时也是通用的采集软件,可用于各个行业,满足各种采集需求(包括站群系统)。 采集software 力求设计成一个通用的泛采集工具软件,可以实现在浏览器采集中可见的内容。是复杂采集需求的必备,也是采集软件新手用户的首选。欢迎有需要的朋友下载。
软件功能:
1、采集速度快,数据完整性高
Panda 的采集 速度是采集 软件中最快的速度之一。独有的多模板功能+智能纠错模式,保证结果数据100%完整。
2、任何网页都可以采集
只要能在浏览器中看到内容,几乎都可以采集你需要的格式。支持JS输出内容的采集。
3、功能全面强大
该软件虽然操作简单,但功能强大且功能全面。可以实现各种复杂的采集需求。通用采集软件,可应用于各种场合。这是复杂的采集 需求中的第一个。
4、任何网页都可以采集
只要能在浏览器中看到内容,几乎都可以采集你需要的格式。支持JS输出内容的采集。
5、操作简单,不懂技术也能轻松操作
只需输入列表页面 URL 或 关键词 即可启动 采集。您无需关心网页的源代码,鼠标操作就是整个过程。操作界面友好直观。全程智能协助。
软件功能:
1、all-round采集 函数
采集的对象包括文字内容、图片、flash动画视频、下载文件等网络内容。 采集 同时支持混合图形和文本对象。支持采集对象集合的复杂结构,支持复杂的多库表单,支持跨页面内容合并采集的能力。
2、采集速快
采集 速度是采集软件(一)的)中最快的。它没有使用落后和低效的正则匹配技术,没有使用第三方内置浏览器访问技术。它使用自己开发的解析引擎,实现网页源代码的类似浏览器的解析。
3、结果数据高度完整
在实际采集过程中,由于目标页面内容页面布局丰富,需要利用其独有的“多模板功能”来实现一个完整的采集。
4、多模板自动适配
很多网站“内容页”都会有多种不同类型的模板,所以采集software允许每个采集项目同时设置多个内容页引用模板。 采集运行时,系统会自动匹配,寻找最合适的参考模板来分析内容页面。
5、实时帮助窗口
在采集项目设置链接中,系统会在窗口右上角显示当前配置相关的实时帮助内容,为新手用户提供实时帮助。所以采集软件的使用可以轻松上手。
亮点介绍:
1、一键采集
输入采集port URL完成设置并启动采集,输入关键词全网搜索采集
2、cloud采集
独有的基于点对点框架的云端采集功能,解决采集时IP被封的行业难题
3、万能模拟发布
无需开发针对性发布界面文件,可适配任何网站cms后台,使用手动发布页面模拟手动发布
4、多模板自适应
一个项目可以配置多个模板,软件会在运行时自动选择最适合采集匹配的模板。
5、内容相似度判断
根据内容相似度判断文章的重复性和准确性,可以列出相似的文章列表,可以输出文章core关键词
安装教程:
1、本站下载软件,解压后双击运行包,点击下一步
2、选择安装文件夹,点击浏览更改安装位置
3、安装成功,点击关闭退出
优采云采集器会自动识别分页,如何设置菜单图?(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-08-12 02:11
在智能模式下,优采云采集器会自动识别分页。分页的类型通常包括以下几种:
(1)page 按钮
(2)rolling loading
(3)Waterfall 分页(滚动加载)+分页按钮
(4)不启用分页
但偶尔会出现识别结果错误的情况,原因通常有以下几种:
(1)网页加载速度太慢,软件自动识别结束后出现分页按钮
(2)页面有多个分页按钮,软件最后只会选择其中一个
(3)在滚动加载和分页按钮同时存在的情况下,软件滚动多次后仍然没有出现分页按钮。
(4)当前页面的分页按钮软件暂时不兼容
“页面设置”的设置菜单如下图所示。
针对不同的分页类型,设置步骤如下:
(1)page 按钮
i:自动识别标签:
点击“自动识别分页符”选项。
软件会自动识别网页上的分页按钮。识别成功后,页面会自动滚动到分页按钮的位置,并使用红色背景色框进行选框。
ii:点击分页按钮:
如果软件无法自动识别分页按钮,则需要手动“点击分页按钮”。
第一步:点击“点击分页按钮”选项
第2步:点击页面上的分页按钮
iii:编辑分页 XPath:
如果以上两种情况都不能正确识别分页,则需要编写XPath来识别分页。
(2)Waterfall 分页(滚动加载):
适用于没有分页按钮并通过滚动加载内容的网页。
(3)Waterfall 分页(滚动加载)+分页按钮:
适用于开头没有分页按钮,需要多次滚动页面才能加载分页按钮,或者已经显示下一页按钮,但是当前网页内容还没有显示的网页,并且网页需要滚动多次才能显示当前页面的全部内容。
这种类型的分页很难识别。虽然软件在自动识别时会尝试自动滚动,但滚动次数可能与当前网页所需的滚动次数不一致,因此此类分页通常需要一些手动操作。 .
主要分为以下几种情况:
第一种:识别滚动加载,但不识别分页按钮
请手动滚动网页,直到页面上出现分页按钮,然后在分页设置中选择“自动识别分页”。
如果自动识别失败,选择“点击分页按钮”,然后进入页面点击分页按钮。
第二种:能识别分页按钮,但不能识别滚动加载
这种情况下,只需要在原有分页设置的基础上选择“瀑布分页(滚动加载)”选项即可。
<p>注意:如果当前网页不需要滚动加载,并且软件识别滚动加载,则不会影响采集的结果,但取消滚动加载选项可以提高采集的速度。 查看全部
优采云采集器会自动识别分页,如何设置菜单图?(组图)
在智能模式下,优采云采集器会自动识别分页。分页的类型通常包括以下几种:
(1)page 按钮
(2)rolling loading
(3)Waterfall 分页(滚动加载)+分页按钮
(4)不启用分页
但偶尔会出现识别结果错误的情况,原因通常有以下几种:
(1)网页加载速度太慢,软件自动识别结束后出现分页按钮
(2)页面有多个分页按钮,软件最后只会选择其中一个
(3)在滚动加载和分页按钮同时存在的情况下,软件滚动多次后仍然没有出现分页按钮。
(4)当前页面的分页按钮软件暂时不兼容
“页面设置”的设置菜单如下图所示。
针对不同的分页类型,设置步骤如下:
(1)page 按钮
i:自动识别标签:
点击“自动识别分页符”选项。
软件会自动识别网页上的分页按钮。识别成功后,页面会自动滚动到分页按钮的位置,并使用红色背景色框进行选框。
ii:点击分页按钮:
如果软件无法自动识别分页按钮,则需要手动“点击分页按钮”。
第一步:点击“点击分页按钮”选项
第2步:点击页面上的分页按钮
iii:编辑分页 XPath:
如果以上两种情况都不能正确识别分页,则需要编写XPath来识别分页。
(2)Waterfall 分页(滚动加载):
适用于没有分页按钮并通过滚动加载内容的网页。
(3)Waterfall 分页(滚动加载)+分页按钮:
适用于开头没有分页按钮,需要多次滚动页面才能加载分页按钮,或者已经显示下一页按钮,但是当前网页内容还没有显示的网页,并且网页需要滚动多次才能显示当前页面的全部内容。
这种类型的分页很难识别。虽然软件在自动识别时会尝试自动滚动,但滚动次数可能与当前网页所需的滚动次数不一致,因此此类分页通常需要一些手动操作。 .
主要分为以下几种情况:
第一种:识别滚动加载,但不识别分页按钮
请手动滚动网页,直到页面上出现分页按钮,然后在分页设置中选择“自动识别分页”。
如果自动识别失败,选择“点击分页按钮”,然后进入页面点击分页按钮。
第二种:能识别分页按钮,但不能识别滚动加载
这种情况下,只需要在原有分页设置的基础上选择“瀑布分页(滚动加载)”选项即可。
<p>注意:如果当前网页不需要滚动加载,并且软件识别滚动加载,则不会影响采集的结果,但取消滚动加载选项可以提高采集的速度。
鹿客智能采集器:qq看点下载原图下载到多
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-08-09 20:05
智能采集器需要通过程序(采集程序app)采集云端数据,然后转发给app完成采集。而云端数据通过某一程序转发至用户的电脑。因此在电脑上直接敲可以完成采集。
智能采集器采集的内容只能是电脑上的ie浏览器。电脑端就可以设置每次自动下载的内容。
以「鹿客智能采集器」为例,app+云采集。
电脑本身有下载程序,
直接远程到电脑的ie里面就可以看了
在电脑上显示的东西都要经过服务器处理才能转发到app里面去
直接用web浏览器
不太清楚什么算是直接,至少没有chrome或firefox在对应的web的浏览器内看不到图片。下图是我搜索的关键词的名字,我在电脑上显示的在页面中的图片,然后再在网页中下拉会自动显示图片。以上截图是我搜索的内容中连接页面api的图片数据。
到百度云或者用迅雷下载
因为对于产品的一些不理解,所以题主自己创造的词不好回答。不过答主可以肯定的告诉题主,我理解你对于智能采集器的不满,就跟题主对于google自动化下载一样,很多人可能不理解,为什么百度的下载速度不理想,慢。我想说的是,你们体会不到,我们在腾讯看电影,下载不下来的时候,拿手机的热点下载也非常非常慢,使用迅雷只能限速,然后我在百度云下载,用迅雷1m的大小下载一个4m的大小,速度确实比下载无损高清要快很多,但是我真的很喜欢qq看点的原图下载,因为它我从1m可以下载到2m多,但是客观的说,腾讯体验真的不好,稍微有点碰到集合文件就会出现花屏的情况,稍微有点少数的时候能够顺利获取图片,大部分的时候完全没反应,还有,好多会员,vip视频,放大的时候,直接会将图片还原成1024x1024,我实在找不到了,题主可以自己搜索资料。 查看全部
鹿客智能采集器:qq看点下载原图下载到多
智能采集器需要通过程序(采集程序app)采集云端数据,然后转发给app完成采集。而云端数据通过某一程序转发至用户的电脑。因此在电脑上直接敲可以完成采集。
智能采集器采集的内容只能是电脑上的ie浏览器。电脑端就可以设置每次自动下载的内容。
以「鹿客智能采集器」为例,app+云采集。
电脑本身有下载程序,
直接远程到电脑的ie里面就可以看了
在电脑上显示的东西都要经过服务器处理才能转发到app里面去
直接用web浏览器
不太清楚什么算是直接,至少没有chrome或firefox在对应的web的浏览器内看不到图片。下图是我搜索的关键词的名字,我在电脑上显示的在页面中的图片,然后再在网页中下拉会自动显示图片。以上截图是我搜索的内容中连接页面api的图片数据。
到百度云或者用迅雷下载
因为对于产品的一些不理解,所以题主自己创造的词不好回答。不过答主可以肯定的告诉题主,我理解你对于智能采集器的不满,就跟题主对于google自动化下载一样,很多人可能不理解,为什么百度的下载速度不理想,慢。我想说的是,你们体会不到,我们在腾讯看电影,下载不下来的时候,拿手机的热点下载也非常非常慢,使用迅雷只能限速,然后我在百度云下载,用迅雷1m的大小下载一个4m的大小,速度确实比下载无损高清要快很多,但是我真的很喜欢qq看点的原图下载,因为它我从1m可以下载到2m多,但是客观的说,腾讯体验真的不好,稍微有点碰到集合文件就会出现花屏的情况,稍微有点少数的时候能够顺利获取图片,大部分的时候完全没反应,还有,好多会员,vip视频,放大的时候,直接会将图片还原成1024x1024,我实在找不到了,题主可以自己搜索资料。
智能采集器免费给你干采集员的技巧!!
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-08-07 19:05
智能采集器或者是通过一些工具,实现你们的需求。这种需求比较简单,只要在、天猫、阿里巴巴上面用软件采集即可。店铺、天猫店铺一般1000就能搞定,使用管理后台,把需要采集到的信息全部批量上传到店铺信息中即可。
感谢邀请!因为品牌不同,客户定位不同,所以需求也不同,
建议可以定制,没必要搞得太简单!定制化采集一些企业的网站后台会好一些,不过这些需要在,因为别人开发出来,不一定自己就能采到自己需要的,想找靠谱的建站系统的话,
那么简单那么快时效,我也可以免费给你干采集员。
可以跟客户说一下你们的要求啊,
1。原则上来说,不要采用一键式的或者是通过软件。但具体你要实现什么样的效果,我无法给你准确的答案,只是我能想到的说。如果你们网站没有新意,或者网站没有客户感觉新意,那么你们的采集器对你们没有任何用。2。你们网站是新手网站,做不到先发再比价的情况。你们可以通过技术人员在网站上找缺漏源。只要有客户浏览就可以有一个电商优惠券出来,这样你的网站下单的时候有优惠。
这是你们的优势。3。你们需要客户的利益最大化。你们需要客户知道你们的产品性价比,如果你们知道用户最看重的价格而不是用户价值。这种情况下,你们就应该推荐利润高的产品。如果你们做不到这一点,基本上用户下单就是个伪命题。4。如果你们有个性化的东西,需要你们对客户推荐产品的时候,你们可以跟客户说明,这些产品我们只是给客户带来优惠,如果不是本人的产品就不给客户,不推荐给客户。
5。做一个专门的机器人来提供客户手动上传产品的流程。这样的流程也可以帮你们更好的维护你们网站用户,增加用户下单量。总之,做任何事情前,都要想好风险有多大。下方绿色箭头为发布源网站。红色箭头是适用任何平台。你可以观察你们网站的客户下单流程来决定你们的行动,简单说绿色箭头从左到右可能是网站下单流程,绿色箭头从右到左是用户下单流程,其中红色箭头只针对源网站。
你可以把大网站分下来做你们网站的培训(培训机构),你们网站上线的培训要比网站客户下单流程的培训价格高,只要让客户产生我下单给你们就好。这个网站需要有不同的运营标准。比如:美团引流做成平台的方式,就需要填写团购信息来确定发货信息,这就不能用一键式的采集器。网站的标准还有很多,因为我不能在这里写那么多,也不清楚,就不在这里写了。个人见解,希望。 查看全部
智能采集器免费给你干采集员的技巧!!
智能采集器或者是通过一些工具,实现你们的需求。这种需求比较简单,只要在、天猫、阿里巴巴上面用软件采集即可。店铺、天猫店铺一般1000就能搞定,使用管理后台,把需要采集到的信息全部批量上传到店铺信息中即可。
感谢邀请!因为品牌不同,客户定位不同,所以需求也不同,
建议可以定制,没必要搞得太简单!定制化采集一些企业的网站后台会好一些,不过这些需要在,因为别人开发出来,不一定自己就能采到自己需要的,想找靠谱的建站系统的话,
那么简单那么快时效,我也可以免费给你干采集员。
可以跟客户说一下你们的要求啊,
1。原则上来说,不要采用一键式的或者是通过软件。但具体你要实现什么样的效果,我无法给你准确的答案,只是我能想到的说。如果你们网站没有新意,或者网站没有客户感觉新意,那么你们的采集器对你们没有任何用。2。你们网站是新手网站,做不到先发再比价的情况。你们可以通过技术人员在网站上找缺漏源。只要有客户浏览就可以有一个电商优惠券出来,这样你的网站下单的时候有优惠。
这是你们的优势。3。你们需要客户的利益最大化。你们需要客户知道你们的产品性价比,如果你们知道用户最看重的价格而不是用户价值。这种情况下,你们就应该推荐利润高的产品。如果你们做不到这一点,基本上用户下单就是个伪命题。4。如果你们有个性化的东西,需要你们对客户推荐产品的时候,你们可以跟客户说明,这些产品我们只是给客户带来优惠,如果不是本人的产品就不给客户,不推荐给客户。
5。做一个专门的机器人来提供客户手动上传产品的流程。这样的流程也可以帮你们更好的维护你们网站用户,增加用户下单量。总之,做任何事情前,都要想好风险有多大。下方绿色箭头为发布源网站。红色箭头是适用任何平台。你可以观察你们网站的客户下单流程来决定你们的行动,简单说绿色箭头从左到右可能是网站下单流程,绿色箭头从右到左是用户下单流程,其中红色箭头只针对源网站。
你可以把大网站分下来做你们网站的培训(培训机构),你们网站上线的培训要比网站客户下单流程的培训价格高,只要让客户产生我下单给你们就好。这个网站需要有不同的运营标准。比如:美团引流做成平台的方式,就需要填写团购信息来确定发货信息,这就不能用一键式的采集器。网站的标准还有很多,因为我不能在这里写那么多,也不清楚,就不在这里写了。个人见解,希望。
智能采集器在安卓系统平台下的erp系统是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-07-30 18:03
智能采集器说的是用于安卓系统平台下的erp系统,erp是一种先进的管理信息系统,其功能模块从财务会计、销售采购、库存生产、到生产调度、物流供应,集中体现了资源共享、合理利用、高效决策的经营理念。目前国内有比较多的erp厂商,例如sap、用友、金蝶、金蝶云、金蝶启辰等,市场上存在较多的机会,不过由于国内用户自身接触的渠道十分有限,而且总体产品针对性有所欠缺,所以市场容量的潜力不容小觑。
erp厂商虽然十分强大,但是其实力和产品不一定达到理想状态,市场上一些优秀的,代表性的erp厂商,往往以代理商的身份存在。所以为了保证市场容量的确定性,安卓采集器提供供开发者采集各个厂商的代理,以达到分散竞争,提高市场竞争力。采集器目前针对开发者支持微信采集,即可实现线上线下的数据收集,传输,传播,数据管理等功能,还可以帮助开发者采集标准的行业数据报表及公司数据,更加贴近真实用户使用场景,并且提供采集,上传,传输,下载,压缩,解压缩等常用功能方便进行数据收集与分析。综上,你可以根据自己的需求进行选择。
谢邀,erp解决的是企业的资金流管理、人力资源管理、业务流管理等系统,采集器功能很多,除了常见的财务采集,还有销售、库存、电子商务等,每个都是不一样的,不知道楼主要采集哪些, 查看全部
智能采集器在安卓系统平台下的erp系统是什么?
智能采集器说的是用于安卓系统平台下的erp系统,erp是一种先进的管理信息系统,其功能模块从财务会计、销售采购、库存生产、到生产调度、物流供应,集中体现了资源共享、合理利用、高效决策的经营理念。目前国内有比较多的erp厂商,例如sap、用友、金蝶、金蝶云、金蝶启辰等,市场上存在较多的机会,不过由于国内用户自身接触的渠道十分有限,而且总体产品针对性有所欠缺,所以市场容量的潜力不容小觑。
erp厂商虽然十分强大,但是其实力和产品不一定达到理想状态,市场上一些优秀的,代表性的erp厂商,往往以代理商的身份存在。所以为了保证市场容量的确定性,安卓采集器提供供开发者采集各个厂商的代理,以达到分散竞争,提高市场竞争力。采集器目前针对开发者支持微信采集,即可实现线上线下的数据收集,传输,传播,数据管理等功能,还可以帮助开发者采集标准的行业数据报表及公司数据,更加贴近真实用户使用场景,并且提供采集,上传,传输,下载,压缩,解压缩等常用功能方便进行数据收集与分析。综上,你可以根据自己的需求进行选择。
谢邀,erp解决的是企业的资金流管理、人力资源管理、业务流管理等系统,采集器功能很多,除了常见的财务采集,还有销售、库存、电子商务等,每个都是不一样的,不知道楼主要采集哪些,
智能采集器如何查看客户的业务流程?(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-07-29 07:03
智能采集器啦,不止是采集网页的,还可以采集app的哦~采集的出来的数据可以整理分析哦~如果你不想以点带面,那么直接查看客户的业务流程吧,保准让你眼花缭乱。单单就楼主说的分析客户流程的功能,就足够单单满足你啦。不过也有缺点啦,例如数据库内存空间不足,数据暂时删除、更改等等~采集客户的业务流程数据实现自动化。
一般是没有人做这个
虽然是和现在大数据相关,但是不知道你是哪个专业的,因为分析客户的某个业务流程,更多的是考虑成本、速度、可靠性的问题,从这个方面来看,excel足够满足你了,可以在excel里建立很多分析指标,你只需要告诉别人你需要哪些数据就行,比如从你得网站客户经营数据可以得出来几个方面的数据:成本(营业额、营业利润、费用等等)、客户客户、商业机会(电商、政府单位等等),这些都可以用excel里的分析指标建立一些可视化的趋势图、柱状图,具体指标的数据网上一搜一大把,只要你可以按你的需求建模型,会处理好的,接着可以试试其他统计软件,spss或sas或abaqus之类的,毕竟这种工作应该是偏基础的。
另外有的就是精度要求高,是要和外面的审计或者检查组谈好来,正式按照图纸或者报告上的数据做一些比对的实验,小样本要细化到五千个客户,很多风险,可操作性很强。希望能帮到你。 查看全部
智能采集器如何查看客户的业务流程?(图)
智能采集器啦,不止是采集网页的,还可以采集app的哦~采集的出来的数据可以整理分析哦~如果你不想以点带面,那么直接查看客户的业务流程吧,保准让你眼花缭乱。单单就楼主说的分析客户流程的功能,就足够单单满足你啦。不过也有缺点啦,例如数据库内存空间不足,数据暂时删除、更改等等~采集客户的业务流程数据实现自动化。
一般是没有人做这个
虽然是和现在大数据相关,但是不知道你是哪个专业的,因为分析客户的某个业务流程,更多的是考虑成本、速度、可靠性的问题,从这个方面来看,excel足够满足你了,可以在excel里建立很多分析指标,你只需要告诉别人你需要哪些数据就行,比如从你得网站客户经营数据可以得出来几个方面的数据:成本(营业额、营业利润、费用等等)、客户客户、商业机会(电商、政府单位等等),这些都可以用excel里的分析指标建立一些可视化的趋势图、柱状图,具体指标的数据网上一搜一大把,只要你可以按你的需求建模型,会处理好的,接着可以试试其他统计软件,spss或sas或abaqus之类的,毕竟这种工作应该是偏基础的。
另外有的就是精度要求高,是要和外面的审计或者检查组谈好来,正式按照图纸或者报告上的数据做一些比对的实验,小样本要细化到五千个客户,很多风险,可操作性很强。希望能帮到你。
智能采集器与智能化采集管理系统的衍生与应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-07-23 02:02
智能采集器
苏州大学苏州大学讯息化服务管理与创新研究院苏州大学信息管理与信息系统研究院朱伟《智能化采集器与智能采集管理系统》,
智能化采集器与智能采集管理系统,
无需智能化采集器、采集器已经落寞了
采集系统分产品一般三种,一种是基于平台的,这个建议研究软件系统,即设计好相应的采集框架,然后和厂商技术支持商一起开发数据库、处理数据采集的功能;另一种是基于终端的,可以由用户自定义,只要能够采集到这一套采集体系就行了;其它第三种采集模式,我没听说过,姑且认为是第一种采集模式的衍生。可参考智能采集器方面有很多,功能、算法不同,没法进行比较。
类似于scratch,你可以在里面根据你需要开发出各种各样的app或游戏,以前有视频演示,是个化学实验室怎么用scratch写出一些环保实验物质提高实验效率的,
数据库选型上,不要考虑什么集中式大厂商的了,自己组个数据库就行了。采集系统和后端数据库配套。
您是不是在用python(python语言非常适合做数据采集系统设计)、机器学习做数据集成,提供给数据采集厂商?如果是的话,可以关注一下sasibm,数据采集厂商在国内也是相当多的。 查看全部
智能采集器与智能化采集管理系统的衍生与应用
智能采集器
苏州大学苏州大学讯息化服务管理与创新研究院苏州大学信息管理与信息系统研究院朱伟《智能化采集器与智能采集管理系统》,
智能化采集器与智能采集管理系统,
无需智能化采集器、采集器已经落寞了
采集系统分产品一般三种,一种是基于平台的,这个建议研究软件系统,即设计好相应的采集框架,然后和厂商技术支持商一起开发数据库、处理数据采集的功能;另一种是基于终端的,可以由用户自定义,只要能够采集到这一套采集体系就行了;其它第三种采集模式,我没听说过,姑且认为是第一种采集模式的衍生。可参考智能采集器方面有很多,功能、算法不同,没法进行比较。
类似于scratch,你可以在里面根据你需要开发出各种各样的app或游戏,以前有视频演示,是个化学实验室怎么用scratch写出一些环保实验物质提高实验效率的,
数据库选型上,不要考虑什么集中式大厂商的了,自己组个数据库就行了。采集系统和后端数据库配套。
您是不是在用python(python语言非常适合做数据采集系统设计)、机器学习做数据集成,提供给数据采集厂商?如果是的话,可以关注一下sasibm,数据采集厂商在国内也是相当多的。
熊猫智能采集软件与同类软件的最大的不同
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-07-12 01:24
熊猫Smart采集software是一款很棒的采集软件,这款软件可以让你采集,随心所欲的智能监控,让你的使用变得简单方便,让你成为最好的使用软件,工具。
熊猫Smart采集软件基础介绍
如果你不能用熊猫软件解决采集的需求,最可能的原因是你还不熟悉熊猫的功能和操作。
优采云采集器软件是新一代采集软件,全程可视化鼠标操作,用户无需关心网页源代码,无需编写采集规则,不需要使用正则表达式技术。全程智能辅助是采集软件行业的新一代产品。同时也是通用的采集软件,可用于各行业,满足各种采集需求(包括站群系统)。是复杂采集需求的必备,也是采集软件新手用户的首选。
熊猫智能采集软件功能
优采云采集器软件是同类软件最大的区别,功能强大,但操作简单,类似于从DOS操作系统切换到windows操作系统。前者需要专业技术人员进行有效操作,而熊猫则是面向大众的可视化操作平台。
熊猫智能采集软件使用说明
一.操作界面
1.点击“开始”
2.进入主菜单,选择“2.Database Inventory”
3.进入数据库库存,选择“2.仓库列表”
4.进入仓库列表,选择对应的仓库点击“回车”,进入如下数据库盘点界面。使用机器时,必须删除机器内所有库存数据,按“4”清除库存。
1.Inventory:(清完数据后直接进入库存,可以手动输入条码,也可以按中间键(SCAN)进入)
2.Inventory list:(当你想查看之前的库存或者在盘点或者进入的时候输入东西的时候可以查看,也可以修改里面的数量,)
3.无线导出数据:(本机配有无线基站,当我们要导出数据时,只需将无线基站插到电脑上,按“发送”,电脑就会收到你发送什么)
4.清库存:(这里就是我们刚才说的,在使用机器之前,一定要删除里面的内容,否则你输入的东西也会和你里面的东西混在一起,
熊猫智能采集软件更新日志
1、修复多个bug 查看全部
熊猫智能采集软件与同类软件的最大的不同
熊猫Smart采集software是一款很棒的采集软件,这款软件可以让你采集,随心所欲的智能监控,让你的使用变得简单方便,让你成为最好的使用软件,工具。
熊猫Smart采集软件基础介绍
如果你不能用熊猫软件解决采集的需求,最可能的原因是你还不熟悉熊猫的功能和操作。
优采云采集器软件是新一代采集软件,全程可视化鼠标操作,用户无需关心网页源代码,无需编写采集规则,不需要使用正则表达式技术。全程智能辅助是采集软件行业的新一代产品。同时也是通用的采集软件,可用于各行业,满足各种采集需求(包括站群系统)。是复杂采集需求的必备,也是采集软件新手用户的首选。
熊猫智能采集软件功能
优采云采集器软件是同类软件最大的区别,功能强大,但操作简单,类似于从DOS操作系统切换到windows操作系统。前者需要专业技术人员进行有效操作,而熊猫则是面向大众的可视化操作平台。
熊猫智能采集软件使用说明
一.操作界面
1.点击“开始”
2.进入主菜单,选择“2.Database Inventory”
3.进入数据库库存,选择“2.仓库列表”
4.进入仓库列表,选择对应的仓库点击“回车”,进入如下数据库盘点界面。使用机器时,必须删除机器内所有库存数据,按“4”清除库存。
1.Inventory:(清完数据后直接进入库存,可以手动输入条码,也可以按中间键(SCAN)进入)
2.Inventory list:(当你想查看之前的库存或者在盘点或者进入的时候输入东西的时候可以查看,也可以修改里面的数量,)
3.无线导出数据:(本机配有无线基站,当我们要导出数据时,只需将无线基站插到电脑上,按“发送”,电脑就会收到你发送什么)
4.清库存:(这里就是我们刚才说的,在使用机器之前,一定要删除里面的内容,否则你输入的东西也会和你里面的东西混在一起,
熊猫智能采集软件更新日志
1、修复多个bug

