
文章cms采集
齐博CMS自带采集体验系列之DedeCMSv5.7系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 464 次浏览 • 2021-06-05 21:15
cms自带采集生活系列文章已完成三期:
cms自带采集PHPcmsV9体验系列
cms自带采集Dedecmsv5.7体验系列
cms自带采集测试系列cmsv6.6
今天的第四期,来感受一下齐博cms自己的采集,齐博cms原名PHP168网站管理,是大学时期由“龙城”创建的,也就是在2003年系统于2010年12月1日更名为奇博软件,自2003年10月V1.0版本发布以来,历经多次版本升级,现已发展成为最成熟的“核心+模块+插件” ”架构系统,成为国内领先的开源PHP系统。涉及电子政务、媒体新闻门户、大型企业信息化、电子商务B2B等高端互联网应用,为数以万计的免费和付费用户提供了应用平台。
同理,今天我们来体验采集自带的Qibocms全站系统的文章采集和群图采集功能。目标网站还是和之前的文章一样,所以比较好。
一、文章采集
1、Title 和 URL采集
采集target网站:
任意填写规则名称,以及所属类别,采集不影响内容。
List网站也有两种添加方式,一种是手动输入多页,另一种是有规律连续的多页。分析目标站的列表页URL,得到列表页的规则,用[page]代替换号就够了,所以我们选择“规则连续多页”,填写[page].shtml,然后填写开始和结束页码以及每次更改的渐变。 (温馨提示:在整个采集设置过程中,所有通配符都不需要手动填写,可以点击旁边官方说明中的通配符自动复制,直接粘贴即可)
同时奇博也考虑到网站list页面第一页的一些URL规则不符合整体更改规则,所以在后面有一个文本框填写不规则第一页。我们采集目标的第一页符合整体规律,所以留空。
采集内容页地址和内容页标题。奇博cms自带采集和别人不同:采集title不在内容页采集,而是在采集list页文章url而且还直接放了锚文本文本采集 是标题。您只需要定义这个指向内容页面的锚文本规则。其中{url=*}表示标题URL通配符,{title=*}表示标题通配符,{*}表示不需要的内容通配符。分析我们的目标站,我们可以得到以下规则:
{title=*}{*}
其实这个设计有点瑕疵。比如为了让列表页更美观,有的网站限制了列表页标题字数,然后控制文章双标题中副标题字数显示它在列表页面上。并且主标题出现在内容页面上。
接下来可以勾选“显示不常用的高级设置”来进一步设置采集 URL。其实还有几个功能还是比较常用的,比如设置不能收录在链接中或者必须收录在过滤器中的字符。当它干扰链接时也很常见。另外,其他替换标题字符、链接字符、指定截取区域可以参考页面左侧的说明。这种头尾正则语法的设置,对用户的要求更高。如果您不熟悉 PHP,请谨慎使用。
设置好后点击“test采集title”
如图,我们采集去内容页地址和对应的标题。然后关闭测试页面,点击“下一步”,设置内容采集rule。 查看全部
齐博CMS自带采集体验系列之DedeCMSv5.7系统
cms自带采集生活系列文章已完成三期:
cms自带采集PHPcmsV9体验系列
cms自带采集Dedecmsv5.7体验系列
cms自带采集测试系列cmsv6.6
今天的第四期,来感受一下齐博cms自己的采集,齐博cms原名PHP168网站管理,是大学时期由“龙城”创建的,也就是在2003年系统于2010年12月1日更名为奇博软件,自2003年10月V1.0版本发布以来,历经多次版本升级,现已发展成为最成熟的“核心+模块+插件” ”架构系统,成为国内领先的开源PHP系统。涉及电子政务、媒体新闻门户、大型企业信息化、电子商务B2B等高端互联网应用,为数以万计的免费和付费用户提供了应用平台。
同理,今天我们来体验采集自带的Qibocms全站系统的文章采集和群图采集功能。目标网站还是和之前的文章一样,所以比较好。
一、文章采集
1、Title 和 URL采集
采集target网站:
任意填写规则名称,以及所属类别,采集不影响内容。
List网站也有两种添加方式,一种是手动输入多页,另一种是有规律连续的多页。分析目标站的列表页URL,得到列表页的规则,用[page]代替换号就够了,所以我们选择“规则连续多页”,填写[page].shtml,然后填写开始和结束页码以及每次更改的渐变。 (温馨提示:在整个采集设置过程中,所有通配符都不需要手动填写,可以点击旁边官方说明中的通配符自动复制,直接粘贴即可)

同时奇博也考虑到网站list页面第一页的一些URL规则不符合整体更改规则,所以在后面有一个文本框填写不规则第一页。我们采集目标的第一页符合整体规律,所以留空。

采集内容页地址和内容页标题。奇博cms自带采集和别人不同:采集title不在内容页采集,而是在采集list页文章url而且还直接放了锚文本文本采集 是标题。您只需要定义这个指向内容页面的锚文本规则。其中{url=*}表示标题URL通配符,{title=*}表示标题通配符,{*}表示不需要的内容通配符。分析我们的目标站,我们可以得到以下规则:
{title=*}{*}
其实这个设计有点瑕疵。比如为了让列表页更美观,有的网站限制了列表页标题字数,然后控制文章双标题中副标题字数显示它在列表页面上。并且主标题出现在内容页面上。

接下来可以勾选“显示不常用的高级设置”来进一步设置采集 URL。其实还有几个功能还是比较常用的,比如设置不能收录在链接中或者必须收录在过滤器中的字符。当它干扰链接时也很常见。另外,其他替换标题字符、链接字符、指定截取区域可以参考页面左侧的说明。这种头尾正则语法的设置,对用户的要求更高。如果您不熟悉 PHP,请谨慎使用。

设置好后点击“test采集title”

如图,我们采集去内容页地址和对应的标题。然后关闭测试页面,点击“下一步”,设置内容采集rule。
如何添加采集苹果cms自定义资源库(图文教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 749 次浏览 • 2021-05-20 22:23
1,今天,我将教您如何添加采集 Apple cms自定义资源库;输入背景,让我们以资源站为例,可以从网站所需的位置获取界面采集。通常在网站的帮助中心内:添加方法如下图所示(如果添加&ct = 1)后测试不成功,则需要填写其他参数。
2,我没有在这里填写,只要测试界面成功,就直接保存即可。如果测试失败,请填写其他参数&ct = 1),如果仍然无法正常工作,请检查采集界面是否填写错误
3。成功添加资源接口后,需要对资源进行分类和绑定:单击高清资源链接,进入绑定页面进行分类和绑定。
4。进入类别绑定页面后,单击未绑定页面,类别绑定将自动弹出。如果找不到对应的类别,则可以先绑定到相似的类别,也可以参考主题网络上的上一个共享。教程:Apple cms如何添加自定义分类的详细教程
5,绑定后,其余为采集。将其拉到页面底部。有一个采集按钮可以在采集天(需要采集的视频前面打勾)和采集这一天的所有三个选项选择采集。
6,选择后,进入自动采集页面。如果绑定采集成功,它将以绿色和红色显示。如果绑定不成功,请跳过采集,因此在绑定时必须小心绑定。
7,结束语:网站应该在最后一个采集结束后才具有视频数据。此时,这也是一个使很多人感到困惑的地方。 采集结束后无法播放!为什么是这样?这是因为您没有添加播放器。
每个资源站都有自己的单独播放器和分析程序。也就是说,您采集的资源只能与其播放器一起播放。通常可以在网站的帮助中心找到玩家,并提供详细的说明。
如果采集之后您不能玩,请参考以下教程:在Apple cms 采集之后导入并添加播放器。
转载: 查看全部
如何添加采集苹果cms自定义资源库(图文教程)
1,今天,我将教您如何添加采集 Apple cms自定义资源库;输入背景,让我们以资源站为例,可以从网站所需的位置获取界面采集。通常在网站的帮助中心内:添加方法如下图所示(如果添加&ct = 1)后测试不成功,则需要填写其他参数。

2,我没有在这里填写,只要测试界面成功,就直接保存即可。如果测试失败,请填写其他参数&ct = 1),如果仍然无法正常工作,请检查采集界面是否填写错误

3。成功添加资源接口后,需要对资源进行分类和绑定:单击高清资源链接,进入绑定页面进行分类和绑定。

4。进入类别绑定页面后,单击未绑定页面,类别绑定将自动弹出。如果找不到对应的类别,则可以先绑定到相似的类别,也可以参考主题网络上的上一个共享。教程:Apple cms如何添加自定义分类的详细教程


5,绑定后,其余为采集。将其拉到页面底部。有一个采集按钮可以在采集天(需要采集的视频前面打勾)和采集这一天的所有三个选项选择采集。

6,选择后,进入自动采集页面。如果绑定采集成功,它将以绿色和红色显示。如果绑定不成功,请跳过采集,因此在绑定时必须小心绑定。

7,结束语:网站应该在最后一个采集结束后才具有视频数据。此时,这也是一个使很多人感到困惑的地方。 采集结束后无法播放!为什么是这样?这是因为您没有添加播放器。
每个资源站都有自己的单独播放器和分析程序。也就是说,您采集的资源只能与其播放器一起播放。通常可以在网站的帮助中心找到玩家,并提供详细的说明。
如果采集之后您不能玩,请参考以下教程:在Apple cms 采集之后导入并添加播放器。
转载:
CMS内容管理系统特点易用性CMS的界面尽量模拟Windows软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-05-20 01:22
cms内容管理系统Internet内容管理平台
cms内容管理系统的功能
易于使用
cms的界面尽可能地模拟Windows软件的操作习惯,提供右键单击菜单,支持拖放操作以及图形按钮和菜单。
强大的编辑器
1) cms提供了一个功能强大且易于使用的在线编辑器。
2) cms支持在线运行Office前端功能,并直接使用Office功能作为编辑器。
3)支持以其他格式批量输入文档。
灵活性
1)对于不同类型的信息,cms允许您为每个通道设置表单并添加扩展字段。字段类型支持文本,列表,图片,日期,文件,标签等。从而可以实现对任意结构信息的管理。
2)为了输出信息,cms使用在模板中插入脚本的技术来输出任何格式的任意数据。
3)发布结果,cms支持RSS标准,XML格式,并自动转换为UTF8编码。这样,数据可以以丰富的形式显示,内容和形式可以完美地结合在一起。
4) cms可以灵活地定义生成文件的后缀,命名规则,图像上传目录等。
模板技术
模板技术是衡量cms系统的重要指标。 cms采用脚本技术,在HTML中插入脚本并可以访问COM,其技术与流行的ASP,.Net和其他技术一致。示例:
就模板制作方法而言,cms提供了DreamWeaver插件。在图形模式下,您可以通过拖放来插入预定义的代码。
在模板可扩展性方面,在cms中,当系统预先提供的插件不能满足要求时,可以手动编写脚本以实现所需的功能。
工作流程支持
在cms中,文章发布的基本过程是:
内容录入→记录→编辑→审阅→签发→发布,可以被拒绝,也可以进行重做。当固定流程不符合要求时,您可以自定义工作流程并根据渠道指定是否使用工作流程。
支持小组协作,用于更多内容的电子出版物。
自动化采集
除了为用户提供输入文章的界面外,内容管理系统还应提供自动化的采集功能。 cms企业版系统本身具有采集模块(某些采集功能目前正在开发中),它支持三种自动化方法采集,数据库采集,文件采集和网页采集,可以设置采集来源,采集目的地,采集频率等。
特殊主题管理,页面管理
cms提供了特殊的主题管理功能,可以由频道编辑器推荐给主题,或者可以由主题编辑器对其进行排序和提取。
cms提供特殊页面管理功能,专门用于管理特殊页面,例如网站主页,版权页面和联系信息页面。
可移植性
cms提供了专用的数据库导入和导出工具,用于将数据库导入HB cms数据库迁移工具,该工具可以自动将原创内容库导入到cms内容库中。 查看全部
CMS内容管理系统特点易用性CMS的界面尽量模拟Windows软件
cms内容管理系统Internet内容管理平台
cms内容管理系统的功能
易于使用
cms的界面尽可能地模拟Windows软件的操作习惯,提供右键单击菜单,支持拖放操作以及图形按钮和菜单。
强大的编辑器
1) cms提供了一个功能强大且易于使用的在线编辑器。
2) cms支持在线运行Office前端功能,并直接使用Office功能作为编辑器。
3)支持以其他格式批量输入文档。
灵活性
1)对于不同类型的信息,cms允许您为每个通道设置表单并添加扩展字段。字段类型支持文本,列表,图片,日期,文件,标签等。从而可以实现对任意结构信息的管理。
2)为了输出信息,cms使用在模板中插入脚本的技术来输出任何格式的任意数据。
3)发布结果,cms支持RSS标准,XML格式,并自动转换为UTF8编码。这样,数据可以以丰富的形式显示,内容和形式可以完美地结合在一起。
4) cms可以灵活地定义生成文件的后缀,命名规则,图像上传目录等。
模板技术
模板技术是衡量cms系统的重要指标。 cms采用脚本技术,在HTML中插入脚本并可以访问COM,其技术与流行的ASP,.Net和其他技术一致。示例:
就模板制作方法而言,cms提供了DreamWeaver插件。在图形模式下,您可以通过拖放来插入预定义的代码。
在模板可扩展性方面,在cms中,当系统预先提供的插件不能满足要求时,可以手动编写脚本以实现所需的功能。
工作流程支持
在cms中,文章发布的基本过程是:
内容录入→记录→编辑→审阅→签发→发布,可以被拒绝,也可以进行重做。当固定流程不符合要求时,您可以自定义工作流程并根据渠道指定是否使用工作流程。
支持小组协作,用于更多内容的电子出版物。
自动化采集
除了为用户提供输入文章的界面外,内容管理系统还应提供自动化的采集功能。 cms企业版系统本身具有采集模块(某些采集功能目前正在开发中),它支持三种自动化方法采集,数据库采集,文件采集和网页采集,可以设置采集来源,采集目的地,采集频率等。
特殊主题管理,页面管理
cms提供了特殊的主题管理功能,可以由频道编辑器推荐给主题,或者可以由主题编辑器对其进行排序和提取。
cms提供特殊页面管理功能,专门用于管理特殊页面,例如网站主页,版权页面和联系信息页面。
可移植性
cms提供了专用的数据库导入和导出工具,用于将数据库导入HB cms数据库迁移工具,该工具可以自动将原创内容库导入到cms内容库中。
什么是采集;采集功能怎么使用呢;对cms采集作以下对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2021-02-17 09:01
什么是采集;如何使用采集的功能;比较cms 采集如下:DEDE cms,php168,Empire cms,优采云; 采集的优缺点;向新手推荐方法
图片4851-1:
关于采集的优缺点,这主要取决于个人的想法。基本上,家用cms系统具有采集,由于其便利性和选择性,它已被网站管理员普遍接受。 [k15之后],无需花时间思考如何创建网站内容。当然采集不好,因为每个人都去采集。可以说,大量的内容物已经积累形成垃圾圈。当然,搜索引擎也拒绝了收录或被k丢弃。在这里,我们将不讨论采集的优缺点,因为我也很矛盾。尽管我认为采集不够好,但我仍然每天都使用它。以下只是我个人的看法,希望对新手有所帮助。
什么是采集
采集意味着我们将他人网站上的内容获取到我们自己的网站中。您可以先按Ctrl + C,再按Ctrl + V。但是复制和粘贴之间的区别在于它是分批的和智能的。您在一分钟内可以手动复制多少文章?可以想象,当然,我们必须将文章标题和内容,甚至发布时间,作者等分开。如果使用采集,则将有所不同。如果性能允许,则可以是每分钟采集数百篇文章文章。这大大减少了网站管理员的时间。
如何使用采集功能
国内cms通常具有采集功能,并且正在不断完善。还有一些论坛和博客程序以前没有采集功能,有些人会开发采集插件。
因为我更喜欢使用(织梦)的dede cms,所以我对其他cms系统了解不多,但是Internet上有许多相关的教程。您可以自己找到它并阅读以下内容。此外,还有哪些其他程序具有自己的采集,我们可以在百度上查看它们,例如php16 8、 php cms,Empire cms,Dongyi,Xinyun等。
接下来,我将讨论一个更强大的采集器,即优采云,优采云 采集器用于批处理采集网页,论坛等,直接保存到数据库或发布到网站一种工具,他们可以根据用户设置的规则自动采集原创网页,以获取格式网页中所需的内容。
那么如何使用这些采集器?如果要使用cms程序,则只需在安装完成后编写采集规则。如果是优采云,则有两种方法,一种是编写采集规则,第二种是编写用于连接网站的发布模块,然后您可以采集 +将内容发布到网站上去。
比较cms 采集如下
DEDE cms:功能强大,新手需要学习更多才能掌握它。该功能非常强大,我相信使用它的任何人都会知道它。但是DEDE具有单词替换功能,只要您导入单词替换数据即可执行替换操作,这对于伪原创更好。
php168:
1.随新浪新闻采集系统提供,该系统非常方便和免费采集新浪国内,国际,社会,娱乐,技术,金融,军事,体育新闻。
2.可以自由添加采集个参数,并且可以共享采集个参数,您可以导出采集个参数并与其他人共享。
3.可以轻松获得采集像奇虎这样的新闻,这意味着您可以建立像奇虎这样的电台。
帝国cms:
1.易于使用:无需知道任何程序,只需将相应的标签添加到相应的内容中
2.多重过滤:可以将同一链接设置为不重复采集;设置采集个关键字(采集除外);内容字符替换;广告过滤;过滤相似信息;过滤具有相同标题的信息;您可以设置采集的前几条记录。
php cms:整个站点内容页面的一般规则(请注意,这是内容页面,这是文章的详细显示页面)。如果在此处设置,将来添加采集个任务时,此规则将自动继承,这将节省大量工作。
优采云:强大的自定义参数,但是新手可以按照官方教程逐步进行操作。对于这样的采集软件,通常,只要网站程序中没有采集功能,或者该功能不够强大不能满足他们的要求,朋友就可以去看看。就个人而言,优采云是一款相对不错的采集软件。
采集的优缺点
尽管文章中未提及,但这里是对新手朋友的仔细分析。
优点:完成许多文章发行版可能需要少量时间。一个小时内可以发布成千上万的文章文章。减少了网站的维护和编写时间,并为网站管理员提供了便利。
缺点:内容是高度重复的,因为您是采集别人的文章,所以即使您是伪原创,您和其他人的文章也会重复很多,如果100个人,请考虑一下使用它伪原创工具,与采集不一样吗?我们不要谈论伪原创工具的优缺点。如果互联网充满了文章,但可读性没有任何价值,那么您认为网站可以保留客户吗? 网站内容的重复结果只有收录少,排名低。
新手推荐方法
我在互联网上看到一些人说,网站很容易做,只需安装该程序,然后采集就可以了。还有什么要说的采集更适合新手,个人认为这是胡说八道,网站不可读,有价值文章,您认为您可以保留这样的客户吗?我希望新手尽可能少地使用采集,并充实更有价值的文章,这是您的原创 文章,而不是发牢骚的采集。我希望这些对新手有用。
1.新手使用采集,那么将会有惯性,即使在将来,即使他们驻足,他们也会选择采集器。
2.为新手建立网站是一个学习过程。重要的是自己写文章。不要说您是否有写能力,或者如果您不能写,那么更改其他人的文章是件好事。这不仅比伪原创程序高,而且可读性更高。最重要的是,新手朋友可以不断学习和提高他们的知识。
3.误导了新手建立网站的观点。最初构建网站是为了为网民服务,并为自己带来好处。在使用了采集之后,尤其是那些曾经使用过的伪原创工具之后,无论网民是否喜欢它,它都值得期待。这会使新手目光短浅,不利于长期发展。
4.不利于新手学习seo。如果使用采集器,则基本上不需要seo。 seo是理论+实践的过程。只有在实践中论证理论并改变他们的错误观点,我们才能真正掌握SEO的核心部分。
我个人认为,新手会尽力用自己的双手写作文章。尽管写作效果不好,但我相信将来会更好。如果您想赚钱,请不要使用采集器,因为不是您在线赚钱。很简单不要以为如果您构建网站,就会有钱。如果此方法在头两年有效,那么现在将不起作用。如果您想赚钱,则必须有一个过程。因此,对于新手来说,您可以每天写一篇文章文章,然后继续学习和练习。我相信目标会越来越接近您。 查看全部
什么是采集;采集功能怎么使用呢;对cms采集作以下对比
什么是采集;如何使用采集的功能;比较cms 采集如下:DEDE cms,php168,Empire cms,优采云; 采集的优缺点;向新手推荐方法

图片4851-1:
关于采集的优缺点,这主要取决于个人的想法。基本上,家用cms系统具有采集,由于其便利性和选择性,它已被网站管理员普遍接受。 [k15之后],无需花时间思考如何创建网站内容。当然采集不好,因为每个人都去采集。可以说,大量的内容物已经积累形成垃圾圈。当然,搜索引擎也拒绝了收录或被k丢弃。在这里,我们将不讨论采集的优缺点,因为我也很矛盾。尽管我认为采集不够好,但我仍然每天都使用它。以下只是我个人的看法,希望对新手有所帮助。
什么是采集
采集意味着我们将他人网站上的内容获取到我们自己的网站中。您可以先按Ctrl + C,再按Ctrl + V。但是复制和粘贴之间的区别在于它是分批的和智能的。您在一分钟内可以手动复制多少文章?可以想象,当然,我们必须将文章标题和内容,甚至发布时间,作者等分开。如果使用采集,则将有所不同。如果性能允许,则可以是每分钟采集数百篇文章文章。这大大减少了网站管理员的时间。
如何使用采集功能
国内cms通常具有采集功能,并且正在不断完善。还有一些论坛和博客程序以前没有采集功能,有些人会开发采集插件。
因为我更喜欢使用(织梦)的dede cms,所以我对其他cms系统了解不多,但是Internet上有许多相关的教程。您可以自己找到它并阅读以下内容。此外,还有哪些其他程序具有自己的采集,我们可以在百度上查看它们,例如php16 8、 php cms,Empire cms,Dongyi,Xinyun等。
接下来,我将讨论一个更强大的采集器,即优采云,优采云 采集器用于批处理采集网页,论坛等,直接保存到数据库或发布到网站一种工具,他们可以根据用户设置的规则自动采集原创网页,以获取格式网页中所需的内容。
那么如何使用这些采集器?如果要使用cms程序,则只需在安装完成后编写采集规则。如果是优采云,则有两种方法,一种是编写采集规则,第二种是编写用于连接网站的发布模块,然后您可以采集 +将内容发布到网站上去。
比较cms 采集如下
DEDE cms:功能强大,新手需要学习更多才能掌握它。该功能非常强大,我相信使用它的任何人都会知道它。但是DEDE具有单词替换功能,只要您导入单词替换数据即可执行替换操作,这对于伪原创更好。
php168:
1.随新浪新闻采集系统提供,该系统非常方便和免费采集新浪国内,国际,社会,娱乐,技术,金融,军事,体育新闻。
2.可以自由添加采集个参数,并且可以共享采集个参数,您可以导出采集个参数并与其他人共享。
3.可以轻松获得采集像奇虎这样的新闻,这意味着您可以建立像奇虎这样的电台。
帝国cms:
1.易于使用:无需知道任何程序,只需将相应的标签添加到相应的内容中
2.多重过滤:可以将同一链接设置为不重复采集;设置采集个关键字(采集除外);内容字符替换;广告过滤;过滤相似信息;过滤具有相同标题的信息;您可以设置采集的前几条记录。
php cms:整个站点内容页面的一般规则(请注意,这是内容页面,这是文章的详细显示页面)。如果在此处设置,将来添加采集个任务时,此规则将自动继承,这将节省大量工作。
优采云:强大的自定义参数,但是新手可以按照官方教程逐步进行操作。对于这样的采集软件,通常,只要网站程序中没有采集功能,或者该功能不够强大不能满足他们的要求,朋友就可以去看看。就个人而言,优采云是一款相对不错的采集软件。
采集的优缺点
尽管文章中未提及,但这里是对新手朋友的仔细分析。
优点:完成许多文章发行版可能需要少量时间。一个小时内可以发布成千上万的文章文章。减少了网站的维护和编写时间,并为网站管理员提供了便利。
缺点:内容是高度重复的,因为您是采集别人的文章,所以即使您是伪原创,您和其他人的文章也会重复很多,如果100个人,请考虑一下使用它伪原创工具,与采集不一样吗?我们不要谈论伪原创工具的优缺点。如果互联网充满了文章,但可读性没有任何价值,那么您认为网站可以保留客户吗? 网站内容的重复结果只有收录少,排名低。
新手推荐方法
我在互联网上看到一些人说,网站很容易做,只需安装该程序,然后采集就可以了。还有什么要说的采集更适合新手,个人认为这是胡说八道,网站不可读,有价值文章,您认为您可以保留这样的客户吗?我希望新手尽可能少地使用采集,并充实更有价值的文章,这是您的原创 文章,而不是发牢骚的采集。我希望这些对新手有用。
1.新手使用采集,那么将会有惯性,即使在将来,即使他们驻足,他们也会选择采集器。
2.为新手建立网站是一个学习过程。重要的是自己写文章。不要说您是否有写能力,或者如果您不能写,那么更改其他人的文章是件好事。这不仅比伪原创程序高,而且可读性更高。最重要的是,新手朋友可以不断学习和提高他们的知识。
3.误导了新手建立网站的观点。最初构建网站是为了为网民服务,并为自己带来好处。在使用了采集之后,尤其是那些曾经使用过的伪原创工具之后,无论网民是否喜欢它,它都值得期待。这会使新手目光短浅,不利于长期发展。
4.不利于新手学习seo。如果使用采集器,则基本上不需要seo。 seo是理论+实践的过程。只有在实践中论证理论并改变他们的错误观点,我们才能真正掌握SEO的核心部分。
我个人认为,新手会尽力用自己的双手写作文章。尽管写作效果不好,但我相信将来会更好。如果您想赚钱,请不要使用采集器,因为不是您在线赚钱。很简单不要以为如果您构建网站,就会有钱。如果此方法在头两年有效,那么现在将不起作用。如果您想赚钱,则必须有一个过程。因此,对于新手来说,您可以每天写一篇文章文章,然后继续学习和练习。我相信目标会越来越接近您。
官方数据:大数据目标栏目整体采集发布到CMS文章系统的指定栏目
采集交流 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2020-12-27 09:19
作为整体的大数据目标列采集已发布到cms文章系统的指定列(实际战斗)准备:要下载采集器,您还需要下载Microsoft .NET Framework v2.0并在下载页面上注册帐号:根据需要填写注册信息,然后按确认进行注册,然后转到注册过程中填写的电子邮件地址以完成注册验证。软件安装:首先安装Microsoft.NET Framework v2.0,然后安装优采云采集器软件。 4:登录到软件单击桌面采集软件图标登录到该软件。首次登录时,该软件将自动升级,然后在您刚注册时填写信息。然后,我们完成了软件的下载,注册和安装。大数据目标列整体采集已发布到文章系统的指定列,我们首先登录采集软件并找到采集数据网站列页面(中间部分)标明域名),然后单击采集软件。项目管理在左上角-选择新项目(标准)以跳出项目名称并编写视频采集(您可以随意填写)其他默认值很好,单击左下角的下一个设置,然后在标题列表页面的起始地址采集地址中输入所需的地址,然后单击以开始预分析,然后弹出提示点:是,软件会自动找到标题页面的下一页和最后一页链接以及翻页次数。并列出了相应的值(我们是整体采集,所以我选择标题列表页面的页数为29),然后单击“下一步”进入内容选择页面以查看软件是否找到了我们的内容链接(在框中红色),然后单击下一步设置以进入内容页面模板管理。我选择了方法1,使用自定义模板(我个人喜欢使用此模板,可以使用有用的模板,而不能使用任何模板)使用此页面时忽略)要设置采集的内容,因为它是整个采集列,请在中间部分添加一个新模板,然后输入所需的内容页面的地址采集,(即,您想要采集 文章页面内容的详细信息)然后单击以添加一个新模板,我选择了“ fine”,然后单击以开始分析,采集自动为我们采集了标题和文本,但是还需要设置所需的标题和文本,然后我们选择[对于k15的内容],在表格中单击以启动所需的单词采集 文章,文章在右侧的红色区域中,但不完整,因此我们需要使用复合语句,单击[表中的k13],然后选择将采集存储表保存在采集中在下面的[]中,相应的字段名称是文本,检查复合句子,如果文章的内容不完整,请继续在表中单击。 采集 文章的内容,然后重复上述操作,直到文章的内容完成,并且我们的采集的工作在这里完成。
下一步,我将测试采集:该软件已经很容易地批处理采集到文章的标题和内容,让我进行最后一步并将其发布到我的网站: ,右键单击要发布到网站的列,然后执行以下步骤,最后选择数据模拟发布以启用模拟WEB发布采集的功能。选择发布机制采集后,可以同时进行发布,并且其他默认设置也可以,然后在登录参数设置和定义字段UserName =中填写网站用于后台登录的用户名,密码和身份验证代码。 =用户名PWD ==密码AdminLoginCode ==身份验证代码,我们可以轻松地验证并登录网站背景,下一步是设置发布页面,我们必须登录网站,找到背景地址发布文章页面,在文章系统上单击以填写文章,后台地址栏中显示的地址不是我们要发布文章页面的确切地址。我们想在后台发布文章页面,右键单击并选择属性,以便获得文章页面的确切地址,如图中红色圆圈所示。它是发布页面的特定地址。我们将其复制并粘贴到WEB发布页面的地址中。然后采集软件会一次自动分析并列出发布页面表的值。首先,选择要发布的文章对应的列,单击并按OK,选择疾病,然后设置文章的标题和文本,然后选择方法1从采集的结果中进行选择,[刚刚测试的k13]已成功发布,并且设置完成。稍后,按确认按钮,然后进入采集发布的最后阶段,单击开始和运行按钮,嘿,开心一点,然后源源不断的信息将存储在采集中。 查看全部
官方数据:大数据目标栏目整体采集发布到CMS文章系统的指定栏目
作为整体的大数据目标列采集已发布到cms文章系统的指定列(实际战斗)准备:要下载采集器,您还需要下载Microsoft .NET Framework v2.0并在下载页面上注册帐号:根据需要填写注册信息,然后按确认进行注册,然后转到注册过程中填写的电子邮件地址以完成注册验证。软件安装:首先安装Microsoft.NET Framework v2.0,然后安装优采云采集器软件。 4:登录到软件单击桌面采集软件图标登录到该软件。首次登录时,该软件将自动升级,然后在您刚注册时填写信息。然后,我们完成了软件的下载,注册和安装。大数据目标列整体采集已发布到文章系统的指定列,我们首先登录采集软件并找到采集数据网站列页面(中间部分)标明域名),然后单击采集软件。项目管理在左上角-选择新项目(标准)以跳出项目名称并编写视频采集(您可以随意填写)其他默认值很好,单击左下角的下一个设置,然后在标题列表页面的起始地址采集地址中输入所需的地址,然后单击以开始预分析,然后弹出提示点:是,软件会自动找到标题页面的下一页和最后一页链接以及翻页次数。并列出了相应的值(我们是整体采集,所以我选择标题列表页面的页数为29),然后单击“下一步”进入内容选择页面以查看软件是否找到了我们的内容链接(在框中红色),然后单击下一步设置以进入内容页面模板管理。我选择了方法1,使用自定义模板(我个人喜欢使用此模板,可以使用有用的模板,而不能使用任何模板)使用此页面时忽略)要设置采集的内容,因为它是整个采集列,请在中间部分添加一个新模板,然后输入所需的内容页面的地址采集,(即,您想要采集 文章页面内容的详细信息)然后单击以添加一个新模板,我选择了“ fine”,然后单击以开始分析,采集自动为我们采集了标题和文本,但是还需要设置所需的标题和文本,然后我们选择[对于k15的内容],在表格中单击以启动所需的单词采集 文章,文章在右侧的红色区域中,但不完整,因此我们需要使用复合语句,单击[表中的k13],然后选择将采集存储表保存在采集中在下面的[]中,相应的字段名称是文本,检查复合句子,如果文章的内容不完整,请继续在表中单击。 采集 文章的内容,然后重复上述操作,直到文章的内容完成,并且我们的采集的工作在这里完成。
下一步,我将测试采集:该软件已经很容易地批处理采集到文章的标题和内容,让我进行最后一步并将其发布到我的网站: ,右键单击要发布到网站的列,然后执行以下步骤,最后选择数据模拟发布以启用模拟WEB发布采集的功能。选择发布机制采集后,可以同时进行发布,并且其他默认设置也可以,然后在登录参数设置和定义字段UserName =中填写网站用于后台登录的用户名,密码和身份验证代码。 =用户名PWD ==密码AdminLoginCode ==身份验证代码,我们可以轻松地验证并登录网站背景,下一步是设置发布页面,我们必须登录网站,找到背景地址发布文章页面,在文章系统上单击以填写文章,后台地址栏中显示的地址不是我们要发布文章页面的确切地址。我们想在后台发布文章页面,右键单击并选择属性,以便获得文章页面的确切地址,如图中红色圆圈所示。它是发布页面的特定地址。我们将其复制并粘贴到WEB发布页面的地址中。然后采集软件会一次自动分析并列出发布页面表的值。首先,选择要发布的文章对应的列,单击并按OK,选择疾病,然后设置文章的标题和文本,然后选择方法1从采集的结果中进行选择,[刚刚测试的k13]已成功发布,并且设置完成。稍后,按确认按钮,然后进入采集发布的最后阶段,单击开始和运行按钮,嘿,开心一点,然后源源不断的信息将存储在采集中。
安全解决方案:帝国CMS-采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2020-11-30 10:17
Empire cms 采集实际上非常简单,只需使用Empire cms 采集插件即可完成。这里以7.0为例
进入后台cms帝国,选择“列”菜单,然后在左侧菜单中选择“ 采集管理”
打开“管理采集个节点”
您可以看到所有现有的采集条规则节点
开始在下面添加新的采集规则
点击添加节点按钮
在中间,系统将提示您选择要创建的列,然后单击要创建的列,例如国际新闻。好吧,只需单击并进入。出现的界面具有第一个节点的名称,因为上面创建的是国际新闻。在这里,填写国际新闻的父节点,无需关注(只需将其保留)
页面采集的地址通常用于选择新闻列表页面,该页面可以从新浪国际新闻复制。例如,可以在地址栏中复制国际新闻多面的地址。
采集页面地址方法二,不在乎是否填写内容,页面地址前缀写为
图片/ FLASH地址前缀(内容)~~~这里拦截内容介绍,不必费心开始填写采集常规内容,那么您需要查看网页的源代码。
信息页面的常规链接
无需填写标题图片的常规性:打开内容页面,然后在您刚才的大栏中打开文章
常规字幕:~~~常规信息源不需要编写新闻正文常规:
确定提交!
让我们预览一下是否有错误
单击“预览” 采集输入节点预览结果:
采集内容页面列表
采集内容页面页面:
预览采集节点后,返回“管理节点”,单击“启动采集”链接以启动采集
系统位于采集
采集完成后,将显示本地临时存储信息。此时,可以修改或删除临时存储信息
要查看采集的信息并将其存储在仓库中,请单击“存储所有信息”按钮
确定操作
提示完成信息存储
信息存储在数据库中后,单击管理信息
我们刚刚进入采集数据库就可以看到新闻信息
到目前为止,所有采集信息均已完成。帝国cms 采集非常强大,您需要自己进行探索。
注意:
通常,在2种情况下采集不可用:
在1、列表页面上选择的采集区域的规则不正确
2、详细信息页面常规错误
可以通过预览逐项找到原因,基本上可以找到采集,包括伪静态信息。 查看全部
帝国cms-采集
Empire cms 采集实际上非常简单,只需使用Empire cms 采集插件即可完成。这里以7.0为例
进入后台cms帝国,选择“列”菜单,然后在左侧菜单中选择“ 采集管理”

打开“管理采集个节点”

您可以看到所有现有的采集条规则节点
开始在下面添加新的采集规则

点击添加节点按钮
在中间,系统将提示您选择要创建的列,然后单击要创建的列,例如国际新闻。好吧,只需单击并进入。出现的界面具有第一个节点的名称,因为上面创建的是国际新闻。在这里,填写国际新闻的父节点,无需关注(只需将其保留)

页面采集的地址通常用于选择新闻列表页面,该页面可以从新浪国际新闻复制。例如,可以在地址栏中复制国际新闻多面的地址。

采集页面地址方法二,不在乎是否填写内容,页面地址前缀写为

图片/ FLASH地址前缀(内容)~~~这里拦截内容介绍,不必费心开始填写采集常规内容,那么您需要查看网页的源代码。

信息页面的常规链接

无需填写标题图片的常规性:打开内容页面,然后在您刚才的大栏中打开文章


常规字幕:~~~常规信息源不需要编写新闻正文常规:
确定提交!

让我们预览一下是否有错误

单击“预览” 采集输入节点预览结果:

采集内容页面列表

采集内容页面页面:

预览采集节点后,返回“管理节点”,单击“启动采集”链接以启动采集

系统位于采集

采集完成后,将显示本地临时存储信息。此时,可以修改或删除临时存储信息

要查看采集的信息并将其存储在仓库中,请单击“存储所有信息”按钮

确定操作

提示完成信息存储

信息存储在数据库中后,单击管理信息

我们刚刚进入采集数据库就可以看到新闻信息

到目前为止,所有采集信息均已完成。帝国cms 采集非常强大,您需要自己进行探索。
注意:
通常,在2种情况下采集不可用:
在1、列表页面上选择的采集区域的规则不正确
2、详细信息页面常规错误
可以通过预览逐项找到原因,基本上可以找到采集,包括伪静态信息。
汇总:2016-2017年帝国cms文章采集教程(1)
采集交流 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2020-10-23 13:03
Empirecms是一个网站构建系统,我们使用越来越多的PHP。在网站建设过程中,如果您没有任何信息,则只能重复手动复制和粘贴,这既费时又费力,因此我们必须使用Empirecms随附的采集功能来完成信息输入。为了了解Empirecms采集的功能,我们以“新浪新闻”专栏为例进行实际战斗采集。一、添加采集节点1、添加节点:2、选择要添加的列采集:3、输入添加节点的形式:4、在节点名称框中输入名称,然后将采集的新浪新闻列表地址复制到此处:5、我发现了很多选择,例如“ 采集页面地址方法二,内容页面地址前缀...”,暂时忽略他,我将解释他们一个接一个,只需将其转到“常规信息链接区域”即可:6、这是为采集常规设置的列表信息链接区域,我们单击以查看新浪地区的新闻列表“来源7、将源文件代码复制到Dreamweaver中,在Dreamweaver中选择信息链接区域到采集:8、切换到Dreamweaver代码模式,这是信息链接区域:9、获取信息链接区域规则:10、获取信息页面链接规则:1 1、注意:例如,如果信息页面链接是相对地址,则“内容页面地址前缀”应添加域名:1 2、现在采集标题和内容内容页面的t:1 3、检查新闻页面“源文件”并找到标题标签:1 4、获取标题规则:1 5、这是采集的内容区域:1 6、获取新闻内容规则:(注意:新闻内容规则中的d_id =“ *”使用通配符,因为每个新闻文章的d_id值都不同,所以可以使用*替换它,而“ *”可以替换任何字符
)1 7、单击提交按钮以完成整个采集节点:二、预览采集节点是否正确1、提交按钮并返回到管理节点:2、单击“ Preview” 采集,输入节点预览结果:3、 采集内容页面列表4、 采集内容页面页面:三、采集 1、预览采集节点正确后,然后返回到“管理节点”,单击“启动采集”链接将启动采集:2、系统位于采集:3、 采集完成3、之后,采集将显示本地临时存储信息,然后可以执行临时存储信息。修改或删除:4、修改后的信息页面如图所示:5、查看采集的信息并将其存储在仓库中,单击“在所有信息中存储按钮”:6、确认操作:7、存储中的信息完成提示:将信息存储在数据库中后,单击“管理信息”:我们可以看到收录新闻的新闻信息st存储在采集中:最后,转到“数据更新”以刷新主页,列和内容页面以完成网站采集的信息。由于Empirecms采集非常强大,因此我暂时无法完成。下一个讲座将继续说明其他功能的用法和技术。本文的组织者,请保留链接以供转载,谢谢! 13 1414 查看全部
2016-2017 Empirecms文章采集教程(1)
Empirecms是一个网站构建系统,我们使用越来越多的PHP。在网站建设过程中,如果您没有任何信息,则只能重复手动复制和粘贴,这既费时又费力,因此我们必须使用Empirecms随附的采集功能来完成信息输入。为了了解Empirecms采集的功能,我们以“新浪新闻”专栏为例进行实际战斗采集。一、添加采集节点1、添加节点:2、选择要添加的列采集:3、输入添加节点的形式:4、在节点名称框中输入名称,然后将采集的新浪新闻列表地址复制到此处:5、我发现了很多选择,例如“ 采集页面地址方法二,内容页面地址前缀...”,暂时忽略他,我将解释他们一个接一个,只需将其转到“常规信息链接区域”即可:6、这是为采集常规设置的列表信息链接区域,我们单击以查看新浪地区的新闻列表“来源7、将源文件代码复制到Dreamweaver中,在Dreamweaver中选择信息链接区域到采集:8、切换到Dreamweaver代码模式,这是信息链接区域:9、获取信息链接区域规则:10、获取信息页面链接规则:1 1、注意:例如,如果信息页面链接是相对地址,则“内容页面地址前缀”应添加域名:1 2、现在采集标题和内容内容页面的t:1 3、检查新闻页面“源文件”并找到标题标签:1 4、获取标题规则:1 5、这是采集的内容区域:1 6、获取新闻内容规则:(注意:新闻内容规则中的d_id =“ *”使用通配符,因为每个新闻文章的d_id值都不同,所以可以使用*替换它,而“ *”可以替换任何字符
)1 7、单击提交按钮以完成整个采集节点:二、预览采集节点是否正确1、提交按钮并返回到管理节点:2、单击“ Preview” 采集,输入节点预览结果:3、 采集内容页面列表4、 采集内容页面页面:三、采集 1、预览采集节点正确后,然后返回到“管理节点”,单击“启动采集”链接将启动采集:2、系统位于采集:3、 采集完成3、之后,采集将显示本地临时存储信息,然后可以执行临时存储信息。修改或删除:4、修改后的信息页面如图所示:5、查看采集的信息并将其存储在仓库中,单击“在所有信息中存储按钮”:6、确认操作:7、存储中的信息完成提示:将信息存储在数据库中后,单击“管理信息”:我们可以看到收录新闻的新闻信息st存储在采集中:最后,转到“数据更新”以刷新主页,列和内容页面以完成网站采集的信息。由于Empirecms采集非常强大,因此我暂时无法完成。下一个讲座将继续说明其他功能的用法和技术。本文的组织者,请保留链接以供转载,谢谢! 13 1414
详细描述:帝国文章分页帝国CMS采集文章-分页采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2020-10-11 11:01
下一页导航是分页采集的难点。它需要所有页面都符合分页规则。如果您不熟悉它,我们可以使用第1页和第2页上的代码进行比较分析。确定分页规则。
1、让我们以网站的以下内容分页为例:
您可以看到此新闻共有20页。
2、查看源代码:
除了已到达采集的第一页之外,该页还包括第二,第三,第四,第五,第六,第七,第八和第20页,但第9至19页未列出。目前,我们将使用第1页和第2页上的代码进行比较和分析,以确定页面规则:
([1)第1页代码:
([2)第2页代码:
从这两张图片中,您可以看到它们具有相同的“页面区域开始代码”,“页面链接”格式,“页面区域结束代码”,然后可以确定“页面区域规则性”和“页面链接”规律性”。
3、定期获取分页区域([!-smallpageallzz-]):
4、获得页面链接规则性([!-pageallzz-]):
5、为了便于显示本教程,我在新闻文本中用采集代替了采集的内容,请预览结果:
注意:
一、在第一页的HTML代码中,当全部列出了内容分页链接时,我们使用“全部列出”。在第一页的HTML代码中,如果未列出所有内容分页链接,我们将使用“上下导航”。
当二、使用所有公式时,采集具有正确的规则,但出现莫名其妙的重复页面。在这种情况下,您可以使用替换方法将其过滤掉(我们将在下一堂课中讨论它)。
当三、使用向上和向下页面导航样式时,始终会选择第一页,而其他页面甚至都看不到阴影。这是因为分页区域经常([!-smallpagezz--])拦截错误。
当四、使用向上和向下页面导航样式时,可以采集转到前几页,但是随后的前几页将重复该循环直至结束。这也是因为分页区域常规([!-smallpagezz--])拦截错误,拦截范围太大,导致前几个页面链接的重复拦截。
帝国文章分页帝国cms如何在文章分页中实现页面标题导航
帝国文章分页
问:我的网站是由cms帝国制作的,我想实现的是在文章的内容页面被分页之后,在文章之前或之后的文章之后添加页面导航。 :
本文导航:
第1页:首页的标题
第2页:第二页的字幕
类似于PHP cms中的内容页面页面标题导航:
可以使用英皇cms内置标签,但这是一个下拉跳转菜单,而不是文本链接。 SEO效果可能不是很好。请问,我可以将哪个标签称为Empire cms?或者告诉我如何修改实现,谢谢!
答案:我只是看着它。为了实现内容页面的页面标题导航,似乎只能通过实现内置标签来实现内置标签。我模仿了此标签的实现原理,并添加了[!-title.pagetitles--]页面标题导航标签可以满足您的需求,但是您需要修改/ e /中的functions.php文件和t_functions.php文件。类/目录。 (版本帝国cmsv6.5)
屏幕截图如下:
以下是实现Empire cms文章页面标题导航的详细方法,该方法仍适用于6.6版本:
第一步:在t_functions.php的第241行之后添加以下代码:(此函数用于提取文章中的页面标题并生成链接)
//返回目录页面标题导航
function sys_ShowTextPageTitles($ thispagenum,$ dolink,$ add,$ filetype,$ n_r){
if($ thispagenum == 1)
{
返回'';
}
$ pagetitles ='';
for($ j = 1; $ j = 2 && $ ti_r [0])
{
$ title = $ ti_r [0];
}
其他
{
$ title = $ add [title]。'('。$ j。')';
}
$ plink = $ add [文件名] .'_'。$ j。$ filetype;
}
$ pagetitles。='
在其前面添加以下代码:
//分页标题导航下降的叶子添加
if(strstr($ newstemptext,'[!-title.pagetitles-]'))
{
$ pagetitles = sys_ShowTextPageTitles($ thispagenum,$ dolink,$ add,$ filetype,$ n_r);
// echo $ pagetitles; exit;
}
第3步:在functions.php文件的2229行附近找到以下代码:
$ titleselect = str_replace(“?”。$ j。“”>“,”?“。$ j。”“ selected>”,$ dotitleselect);
在以下行中添加以下代码:
$ pagetitles = str_replace('class =“ page_current”','',$ pagetitles);
$ pagetitles = str_replace('id =“'。$ j。'”','id =“'。$ j。'”',$ pagetitles); //秋天的落叶添加
步骤4:在functions.php文件中的2362行附近找到以下代码:
$ string = str_replace('',$ titleselect,$ string);
在其后添加以下代码:
$ string = str_replace('[!-title.pagetitles-]',$ pagetitles,$ string); //网站管理员知道-落叶添加
然后,您可以在内容页面模板中使用[!-title.pagetitles--]标记来调用文章页面导航,并将当前页面标题CSS添加到style.css文件中,例如.page_current。 {color:#CC3300;}。
以上修改适用于生成静态页面的内容页面,不是生成静态页面,请在e / action / ShowInfo.php文件中对其进行修改,这时不多说,估计不生成静态页面的人更少 查看全部
帝国文章寻呼帝国cms采集文章-寻呼采集
下一页导航是分页采集的难点。它需要所有页面都符合分页规则。如果您不熟悉它,我们可以使用第1页和第2页上的代码进行比较分析。确定分页规则。
1、让我们以网站的以下内容分页为例:
您可以看到此新闻共有20页。
2、查看源代码:
除了已到达采集的第一页之外,该页还包括第二,第三,第四,第五,第六,第七,第八和第20页,但第9至19页未列出。目前,我们将使用第1页和第2页上的代码进行比较和分析,以确定页面规则:
([1)第1页代码:
([2)第2页代码:
从这两张图片中,您可以看到它们具有相同的“页面区域开始代码”,“页面链接”格式,“页面区域结束代码”,然后可以确定“页面区域规则性”和“页面链接”规律性”。
3、定期获取分页区域([!-smallpageallzz-]):
4、获得页面链接规则性([!-pageallzz-]):
5、为了便于显示本教程,我在新闻文本中用采集代替了采集的内容,请预览结果:
注意:
一、在第一页的HTML代码中,当全部列出了内容分页链接时,我们使用“全部列出”。在第一页的HTML代码中,如果未列出所有内容分页链接,我们将使用“上下导航”。
当二、使用所有公式时,采集具有正确的规则,但出现莫名其妙的重复页面。在这种情况下,您可以使用替换方法将其过滤掉(我们将在下一堂课中讨论它)。
当三、使用向上和向下页面导航样式时,始终会选择第一页,而其他页面甚至都看不到阴影。这是因为分页区域经常([!-smallpagezz--])拦截错误。
当四、使用向上和向下页面导航样式时,可以采集转到前几页,但是随后的前几页将重复该循环直至结束。这也是因为分页区域常规([!-smallpagezz--])拦截错误,拦截范围太大,导致前几个页面链接的重复拦截。
帝国文章分页帝国cms如何在文章分页中实现页面标题导航
帝国文章分页

问:我的网站是由cms帝国制作的,我想实现的是在文章的内容页面被分页之后,在文章之前或之后的文章之后添加页面导航。 :
本文导航:
第1页:首页的标题
第2页:第二页的字幕
类似于PHP cms中的内容页面页面标题导航:
可以使用英皇cms内置标签,但这是一个下拉跳转菜单,而不是文本链接。 SEO效果可能不是很好。请问,我可以将哪个标签称为Empire cms?或者告诉我如何修改实现,谢谢!
答案:我只是看着它。为了实现内容页面的页面标题导航,似乎只能通过实现内置标签来实现内置标签。我模仿了此标签的实现原理,并添加了[!-title.pagetitles--]页面标题导航标签可以满足您的需求,但是您需要修改/ e /中的functions.php文件和t_functions.php文件。类/目录。 (版本帝国cmsv6.5)
屏幕截图如下:
以下是实现Empire cms文章页面标题导航的详细方法,该方法仍适用于6.6版本:
第一步:在t_functions.php的第241行之后添加以下代码:(此函数用于提取文章中的页面标题并生成链接)
//返回目录页面标题导航
function sys_ShowTextPageTitles($ thispagenum,$ dolink,$ add,$ filetype,$ n_r){
if($ thispagenum == 1)
{
返回'';
}
$ pagetitles ='';
for($ j = 1; $ j = 2 && $ ti_r [0])
{
$ title = $ ti_r [0];
}
其他
{
$ title = $ add [title]。'('。$ j。')';
}
$ plink = $ add [文件名] .'_'。$ j。$ filetype;
}
$ pagetitles。='
在其前面添加以下代码:
//分页标题导航下降的叶子添加
if(strstr($ newstemptext,'[!-title.pagetitles-]'))
{
$ pagetitles = sys_ShowTextPageTitles($ thispagenum,$ dolink,$ add,$ filetype,$ n_r);
// echo $ pagetitles; exit;
}
第3步:在functions.php文件的2229行附近找到以下代码:
$ titleselect = str_replace(“?”。$ j。“”>“,”?“。$ j。”“ selected>”,$ dotitleselect);
在以下行中添加以下代码:
$ pagetitles = str_replace('class =“ page_current”','',$ pagetitles);
$ pagetitles = str_replace('id =“'。$ j。'”','id =“'。$ j。'”',$ pagetitles); //秋天的落叶添加
步骤4:在functions.php文件中的2362行附近找到以下代码:
$ string = str_replace('',$ titleselect,$ string);
在其后添加以下代码:
$ string = str_replace('[!-title.pagetitles-]',$ pagetitles,$ string); //网站管理员知道-落叶添加
然后,您可以在内容页面模板中使用[!-title.pagetitles--]标记来调用文章页面导航,并将当前页面标题CSS添加到style.css文件中,例如.page_current。 {color:#CC3300;}。
以上修改适用于生成静态页面的内容页面,不是生成静态页面,请在e / action / ShowInfo.php文件中对其进行修改,这时不多说,估计不生成静态页面的人更少
技术文章:杰奇CMS小说关关采集器配置教程(文字+视频) 免费下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 532 次浏览 • 2020-09-07 02:40
[Jie Qi cms Novel Guan Guan 采集器 Configuration Tutorial Video]我不知道何时获得它。我看到该视频可能是V9版本,但是您可以参考当前流行的主要版本。由于许多设置技术是相同的,因此我们在这里共享它们。顺便说一句,我还发布了我采集的教程的文本版本,以供您参考。
目录介绍
规则文件夹,日志文件夹:
规则是我们推迟采集条规则的地方;
log是一个日志文件,也就是说,当采集器出错时,它将记录错误的信息。当我们看到这一点时,我们知道采集在哪里错误;
现在,我们单击开关以关闭采集器,直接打开NovelSpider.exe,然后可以启动开关采集器。 (注意:打开过程会有点慢,因此请单击一次并稍等片刻。请勿单击再次打开,否则一段时间采集器后将打开多个级别!)
在某些级别上会有一个提示框,因此我们不在乎。
系统设置
打开后,我们应立即修改“设置(S)”→系统设置。 :
1.修改本地网站目录,例如,我的目录位于D:\ xiaoshuo
2.再次修改数据库连接字符串
DataSource = 12 7. 0. 0. 1;
Database =数据库名称;
UserID =数据库管理用户名;
Password =数据库管理密码;
port = 3306;
charset = gbk
上面的设置是为了关闭采集器,这是您第一次使用它,您需要对其进行设置,而无需在设置后再次进行设置。
分类设置
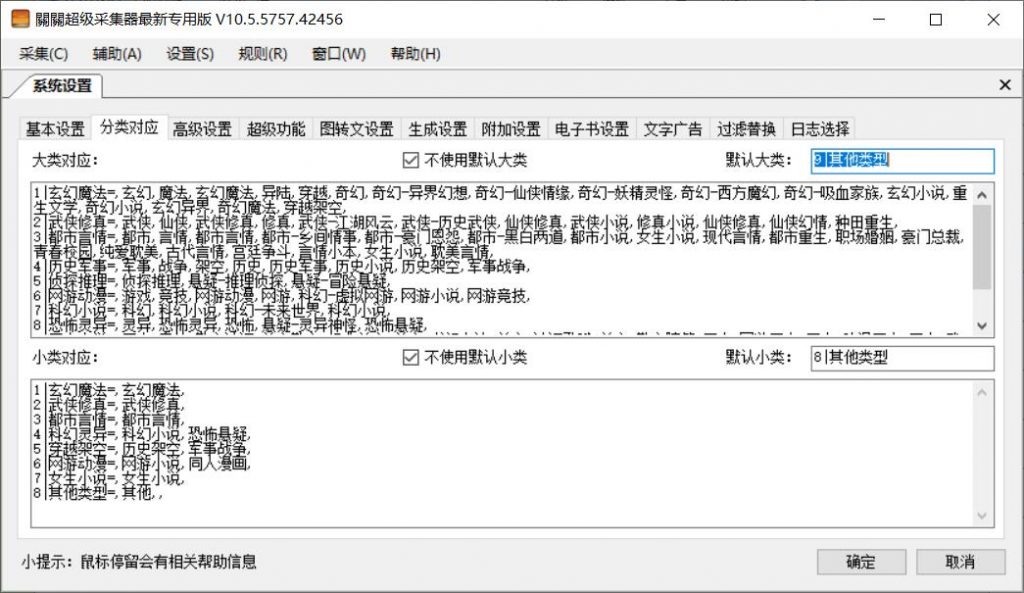
首先:类别设置通常对应于类别,这些对应于您的网站类别。例如
1 | Fantasy Fantasy =,幻想,幻想,魔术,魔术,幻想魔术,幻想幻想,幻想小说,幻想·魔术,幻想世界,幻想幻想,
1是您的网站第一个蓝色稻米幻想幻想。等号是采集目标网站可能遇到的分类之后,越详细越好,某些模板网站对应于您的幻想幻想。如果您没有幻想模板,只需添加它即可。
第二个:是设置中的一代
默认情况下无需修改。第一个生成的内容页面html是您的网站小说目录页面的html。如果您网站使用伪静态,则不需要生成它。生成的第二个内容页面html是单击小说的内容以查看小说的文本章节。这与上面的第一个相同。如果您网站使用伪静态,则不需要生成它。
如果要构建静态小说网站,则需要生成它,这非常消耗硬盘。通常,一千本小说需要几GB的空间。
第三:生成全文阅读。不用担心,通常不使用。
第四:生成OPF。必须生成此文件,否则无法打开网站,并且如果未生成您的小说网站,也会出现打开错误。只需在此处打勾。不用担心其他设置,没有特殊要求您将无法使用它们。 (注意:[Settings-e-book settings]不需要控制,默认值就足够了,因此不要选择对勾,设置中的图片设置也是默认值,因此不要选择对勾。)
第五:文字广告。如果要在新颖内容中添加广告,则可以在此处添加内容。您需要选择第一个存储章节以添加文字广告。实际的存储空间会将您的广告添加到您采集下的小说中,这些路径的txt文件中的文件/ article / txt / 0/1
这是您的小说,是一部移动版本,因此您需要选择第一本。添加广告时,您会在章节阅读中看到它,但不要使用这些功能。
第六:其他[过滤和替换],[文本到图片]。无需控制
第七:日志选择。勾选所有人。这是采集遇到的错误的日志。您可以基于此消除错误。
规则测试
单击规则进入规则管理器,我们选择我们不能做的三角形符号,下拉并选择要测试的规则,单击右侧的加载,然后单击“测试规则”,如果出现“是要获取ID和小说名称”,则会弹出一个界面
这是为了获得包括小说名称分类介绍和封面在内的小说信息内容。
某些网站信息不完整采集。如果我们采集回来,它将显得不完整。这没有作用。您可以阅读小说的主要章节。然后是获得采集的章节,这是获得小说的内容。
这是一个很好的采集规则。我们可以使用采集规则更新采集小说。
如何采集
通常,我们使用标准的采集模式。
当我们单击“ 采集 –标准采集模式”时,有时会出现错误消息。无论我们单击采集框架中的规则,它都会出现在正确的位置,并且还会出现一些其他提示。忽略他,只需单击[继续]。
输入标准采集后输入正确的姿势后,通常使用第一个根据目标测站页面获取编号。编写此规则时,将根据目标电台的最新更新小说进行设置,采集更新时将自动采集对方的小说,并且还将关注其他人的小说网站。
1.根据目标台的ID 采集设置ID范围,直到通常另一方的书采集的特殊采集是采集时才使用。
2.根据目标台ID 采集,当特殊采集是另一方的书采集时,直到通常需要采集时才很少使用它。
3.点击了他的网站的小说ID 采集,在点击之前,他必须先更新其中一部网站小说,但是模板网站可能没有这本书,因此采集看起来非常好慢。很少使用,基本上没有用。
4.在日志记录的底部,必须选择此项以记录采集新颖信息,这些信息无缘无故不会出现在采集中。还必须选择循环采集。如果这是自动采集,请确保采集器自动循环另一方的采集。循环时间设置取决于您自己的需求。我通常将其设置为十分钟。如果您想将采集设置为零。
设置采集
[添加新书]:添加书时添加;
[谨慎使用]:以下两个单词是比较模板站的章节名称。如果正确,请继续。 采集如果不正确,将其清空,然后单击采集。不要使用它,这会导致严重的问题。有时候,意外清空我在百度收录上使用过的页面是一个悲剧。对于其他一些功能,可以阅读文字;
[设置2]:这是比较章节的选择,无论如何,它们几乎是相同的,为什么我没有什么不同?您可以默认;
[空章节的处理方法]:这意味着模板站点上的某些小说是空的,具体取决于您的需要,但是请注意,您不应选择第二本来跳过本章,因为跳过本章会留下章节名称为空,下次采集,如果将较少的章节名称与模板站进行比较,则该章节名称将无法更新书籍;
[章节安排]:这取决于目标站的图,这更加复杂。我给您的采集规则按目标电台的顺序排列。不要选择任何东西,通常使用[目标电台顺序]和[按照章节ID的顺序],不要使用其他内容。这两个不会有问题,我将为您提供默认设置;
[过滤器设置]:取决于您需要设置的内容,字面意思很明确;
[删除水印]:这基本上是不必要的;
[Agent],[Progress]:通常将上述三个数字设置为000;
这样,采集很快。代理IP是您阻止的目标站点的采集,然后在Internet上找到一些代理,打开代理功能,然后单击采集。
我已经在这里讨论了其中一些功能,而其他功能则是一些辅助功能,您以后可以进一步了解。
下一步,进行设置,然后单击以启动采集。选择规则,然后选择要按采集 采集输入的内容,然后单击以开始;
如果出现提示“成功启动采集模式”,则可以查看网站是否已更新。
PS:如果文本教程不能使您清楚地了解操作方法,请下载视频以帮助理解。
此资源的下载价格为0. 1德国货币,请先登录
打开VIP会员并免费下载所有站点资源!该程序仅用于测试,不能用于商业用途!如有任何疑问,请联系我们! 查看全部
节气cms Novel Guan Guan 采集器配置教程(文字+视频)免费下载
[Jie Qi cms Novel Guan Guan 采集器 Configuration Tutorial Video]我不知道何时获得它。我看到该视频可能是V9版本,但是您可以参考当前流行的主要版本。由于许多设置技术是相同的,因此我们在这里共享它们。顺便说一句,我还发布了我采集的教程的文本版本,以供您参考。
目录介绍
规则文件夹,日志文件夹:
规则是我们推迟采集条规则的地方;
log是一个日志文件,也就是说,当采集器出错时,它将记录错误的信息。当我们看到这一点时,我们知道采集在哪里错误;
现在,我们单击开关以关闭采集器,直接打开NovelSpider.exe,然后可以启动开关采集器。 (注意:打开过程会有点慢,因此请单击一次并稍等片刻。请勿单击再次打开,否则一段时间采集器后将打开多个级别!)
在某些级别上会有一个提示框,因此我们不在乎。
系统设置
打开后,我们应立即修改“设置(S)”→系统设置。 :
1.修改本地网站目录,例如,我的目录位于D:\ xiaoshuo
2.再次修改数据库连接字符串
DataSource = 12 7. 0. 0. 1;
Database =数据库名称;
UserID =数据库管理用户名;
Password =数据库管理密码;
port = 3306;
charset = gbk
上面的设置是为了关闭采集器,这是您第一次使用它,您需要对其进行设置,而无需在设置后再次进行设置。
分类设置
首先:类别设置通常对应于类别,这些对应于您的网站类别。例如
1 | Fantasy Fantasy =,幻想,幻想,魔术,魔术,幻想魔术,幻想幻想,幻想小说,幻想·魔术,幻想世界,幻想幻想,
1是您的网站第一个蓝色稻米幻想幻想。等号是采集目标网站可能遇到的分类之后,越详细越好,某些模板网站对应于您的幻想幻想。如果您没有幻想模板,只需添加它即可。
第二个:是设置中的一代
默认情况下无需修改。第一个生成的内容页面html是您的网站小说目录页面的html。如果您网站使用伪静态,则不需要生成它。生成的第二个内容页面html是单击小说的内容以查看小说的文本章节。这与上面的第一个相同。如果您网站使用伪静态,则不需要生成它。
如果要构建静态小说网站,则需要生成它,这非常消耗硬盘。通常,一千本小说需要几GB的空间。
第三:生成全文阅读。不用担心,通常不使用。
第四:生成OPF。必须生成此文件,否则无法打开网站,并且如果未生成您的小说网站,也会出现打开错误。只需在此处打勾。不用担心其他设置,没有特殊要求您将无法使用它们。 (注意:[Settings-e-book settings]不需要控制,默认值就足够了,因此不要选择对勾,设置中的图片设置也是默认值,因此不要选择对勾。)
第五:文字广告。如果要在新颖内容中添加广告,则可以在此处添加内容。您需要选择第一个存储章节以添加文字广告。实际的存储空间会将您的广告添加到您采集下的小说中,这些路径的txt文件中的文件/ article / txt / 0/1
这是您的小说,是一部移动版本,因此您需要选择第一本。添加广告时,您会在章节阅读中看到它,但不要使用这些功能。
第六:其他[过滤和替换],[文本到图片]。无需控制
第七:日志选择。勾选所有人。这是采集遇到的错误的日志。您可以基于此消除错误。
规则测试
单击规则进入规则管理器,我们选择我们不能做的三角形符号,下拉并选择要测试的规则,单击右侧的加载,然后单击“测试规则”,如果出现“是要获取ID和小说名称”,则会弹出一个界面
这是为了获得包括小说名称分类介绍和封面在内的小说信息内容。
某些网站信息不完整采集。如果我们采集回来,它将显得不完整。这没有作用。您可以阅读小说的主要章节。然后是获得采集的章节,这是获得小说的内容。
这是一个很好的采集规则。我们可以使用采集规则更新采集小说。
如何采集
通常,我们使用标准的采集模式。
当我们单击“ 采集 –标准采集模式”时,有时会出现错误消息。无论我们单击采集框架中的规则,它都会出现在正确的位置,并且还会出现一些其他提示。忽略他,只需单击[继续]。
输入标准采集后输入正确的姿势后,通常使用第一个根据目标测站页面获取编号。编写此规则时,将根据目标电台的最新更新小说进行设置,采集更新时将自动采集对方的小说,并且还将关注其他人的小说网站。
1.根据目标台的ID 采集设置ID范围,直到通常另一方的书采集的特殊采集是采集时才使用。
2.根据目标台ID 采集,当特殊采集是另一方的书采集时,直到通常需要采集时才很少使用它。
3.点击了他的网站的小说ID 采集,在点击之前,他必须先更新其中一部网站小说,但是模板网站可能没有这本书,因此采集看起来非常好慢。很少使用,基本上没有用。
4.在日志记录的底部,必须选择此项以记录采集新颖信息,这些信息无缘无故不会出现在采集中。还必须选择循环采集。如果这是自动采集,请确保采集器自动循环另一方的采集。循环时间设置取决于您自己的需求。我通常将其设置为十分钟。如果您想将采集设置为零。
设置采集
[添加新书]:添加书时添加;
[谨慎使用]:以下两个单词是比较模板站的章节名称。如果正确,请继续。 采集如果不正确,将其清空,然后单击采集。不要使用它,这会导致严重的问题。有时候,意外清空我在百度收录上使用过的页面是一个悲剧。对于其他一些功能,可以阅读文字;
[设置2]:这是比较章节的选择,无论如何,它们几乎是相同的,为什么我没有什么不同?您可以默认;
[空章节的处理方法]:这意味着模板站点上的某些小说是空的,具体取决于您的需要,但是请注意,您不应选择第二本来跳过本章,因为跳过本章会留下章节名称为空,下次采集,如果将较少的章节名称与模板站进行比较,则该章节名称将无法更新书籍;
[章节安排]:这取决于目标站的图,这更加复杂。我给您的采集规则按目标电台的顺序排列。不要选择任何东西,通常使用[目标电台顺序]和[按照章节ID的顺序],不要使用其他内容。这两个不会有问题,我将为您提供默认设置;
[过滤器设置]:取决于您需要设置的内容,字面意思很明确;
[删除水印]:这基本上是不必要的;
[Agent],[Progress]:通常将上述三个数字设置为000;
这样,采集很快。代理IP是您阻止的目标站点的采集,然后在Internet上找到一些代理,打开代理功能,然后单击采集。
我已经在这里讨论了其中一些功能,而其他功能则是一些辅助功能,您以后可以进一步了解。
下一步,进行设置,然后单击以启动采集。选择规则,然后选择要按采集 采集输入的内容,然后单击以开始;
如果出现提示“成功启动采集模式”,则可以查看网站是否已更新。
PS:如果文本教程不能使您清楚地了解操作方法,请下载视频以帮助理解。
此资源的下载价格为0. 1德国货币,请先登录
打开VIP会员并免费下载所有站点资源!该程序仅用于测试,不能用于商业用途!如有任何疑问,请联系我们!
帝国cms文章采集教程(1).doc
采集交流 • 优采云 发表了文章 • 0 个评论 • 370 次浏览 • 2020-08-28 07:17
文档介绍:帝国cms是我们用得比较多得PHP的建站系统,在建站过程中,如果自己没有信息源,只能靠手工不断的重复copy和粘贴,这样费时吃力,于是我们就要使用帝国cms自带的采集功能来完成信息的录入。为了深入了解帝国cms采集功能,下面我们以“新浪各地新闻”栏目为例来进行实战采集。一、增加采集节点1、添加节点:2、选择要降低采集的栏目:3、进入降低节点表单:4、在节点名称框里起个名子,然后把要采集的新浪各地新闻列表地址copy过来:5、下来发觉很多选项,如“采集页面地址方法二,内容页地址前缀。。。”先不要理他,后面再一一解读,直接拉到“信息链接区域正则”这里:6、这里是设置采集的列表信息链接区域正则,我们点击查看新浪各地新闻列表“源文件”:7、把源文件代码copy到Dreamweaver里,在Dreamweaver里选取要采集的信息链接区域:8、切换到Dreamweaver代码形式,就是信息链接区域:9、得到信息链接区域正则:10、得到信息页链接正则:11、注意:如果信息页链接是相对地址,例如,那么“内容页地址前缀”要加域名:12、现在要采集内容页的标题和内容:13、查看新闻页“源文件”,找title标签:14、取得标题正则:15、这里是要采集的内容区域:16、取得新闻内容正则:(注意:新闻内容正则里的d_id=‘*’用了转义,因为每一篇新闻的d_id值是不同的,所以可以用*来替代它,“*”可以替代任意字符。)17、点击递交按键就完成了整个采集节点:二、预览采集节点是否正确1、提交按键后返回管理节点:2、点击“预览”采集,进入节点预览结果:3、采集内容页列表4、采集内容页页面:三、采集1、预览采集节点无误后,然后返回“管理节点”,点击“开始采集”链接就开始进行采集:2、系统正在采集中:3、采集完后显示本地临时入库的信息,这时可以对临时入库的信息进行更改或则删掉:4、修改信息页面如图:5、对采集的信息进行初审并入库,点击“入库全部信息按键”: 查看全部
帝国cms文章采集教程(1).doc
文档介绍:帝国cms是我们用得比较多得PHP的建站系统,在建站过程中,如果自己没有信息源,只能靠手工不断的重复copy和粘贴,这样费时吃力,于是我们就要使用帝国cms自带的采集功能来完成信息的录入。为了深入了解帝国cms采集功能,下面我们以“新浪各地新闻”栏目为例来进行实战采集。一、增加采集节点1、添加节点:2、选择要降低采集的栏目:3、进入降低节点表单:4、在节点名称框里起个名子,然后把要采集的新浪各地新闻列表地址copy过来:5、下来发觉很多选项,如“采集页面地址方法二,内容页地址前缀。。。”先不要理他,后面再一一解读,直接拉到“信息链接区域正则”这里:6、这里是设置采集的列表信息链接区域正则,我们点击查看新浪各地新闻列表“源文件”:7、把源文件代码copy到Dreamweaver里,在Dreamweaver里选取要采集的信息链接区域:8、切换到Dreamweaver代码形式,就是信息链接区域:9、得到信息链接区域正则:10、得到信息页链接正则:11、注意:如果信息页链接是相对地址,例如,那么“内容页地址前缀”要加域名:12、现在要采集内容页的标题和内容:13、查看新闻页“源文件”,找title标签:14、取得标题正则:15、这里是要采集的内容区域:16、取得新闻内容正则:(注意:新闻内容正则里的d_id=‘*’用了转义,因为每一篇新闻的d_id值是不同的,所以可以用*来替代它,“*”可以替代任意字符。)17、点击递交按键就完成了整个采集节点:二、预览采集节点是否正确1、提交按键后返回管理节点:2、点击“预览”采集,进入节点预览结果:3、采集内容页列表4、采集内容页页面:三、采集1、预览采集节点无误后,然后返回“管理节点”,点击“开始采集”链接就开始进行采集:2、系统正在采集中:3、采集完后显示本地临时入库的信息,这时可以对临时入库的信息进行更改或则删掉:4、修改信息页面如图:5、对采集的信息进行初审并入库,点击“入库全部信息按键”:
苹果cms自定义资源库采集教程
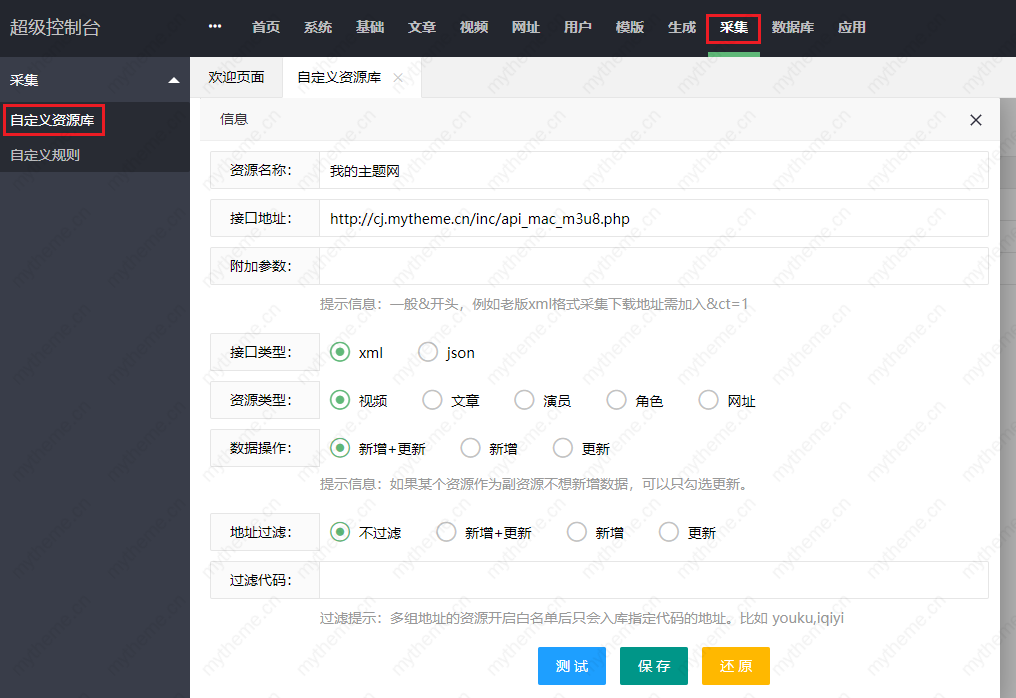
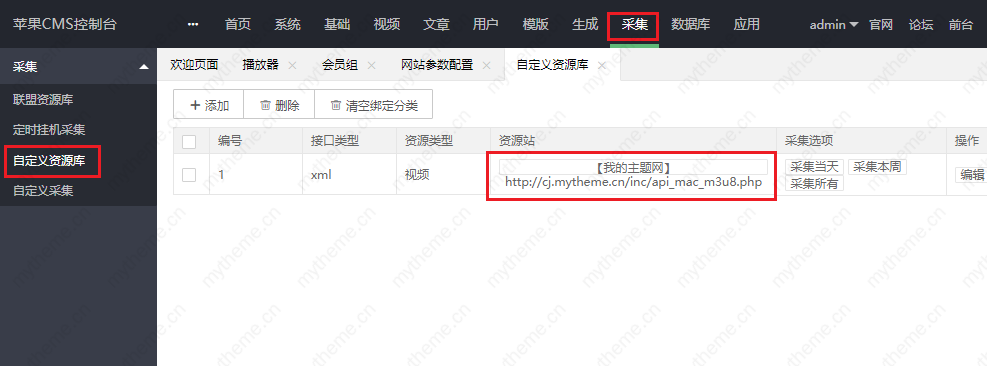
采集交流 • 优采云 发表了文章 • 0 个评论 • 606 次浏览 • 2020-08-27 16:16
1,今天教你们怎样添加采集自定义资源库;进入后台我们随意以某资源站为例,接口可以到你要采集的网站上获取就可以了 一般都在网站的帮助中心:添加方式如下图(添加后进行测试不成功须要填写附加参数 &ct=1)
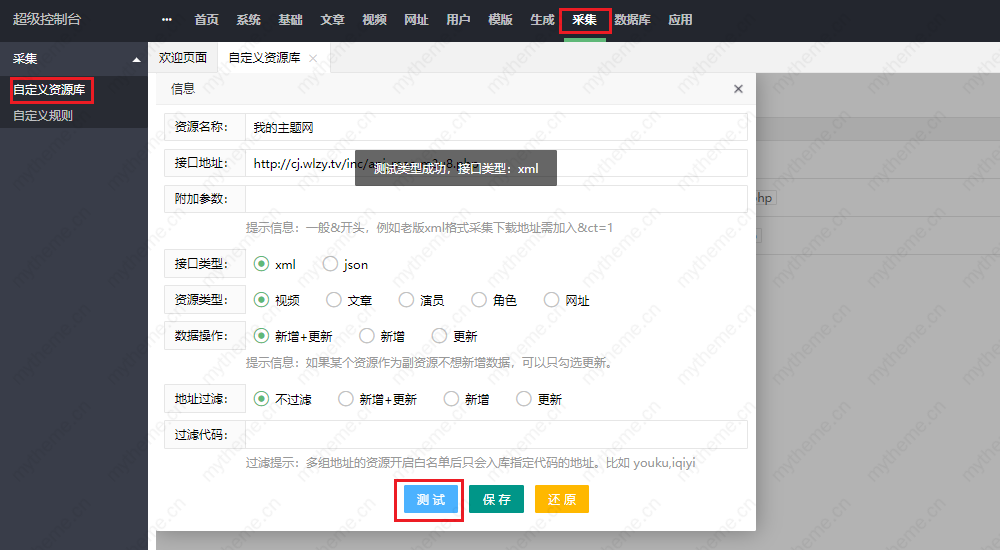
2,我这儿没有填写只要测试插口成功 就直接保存就可以了 如果测试失败就填写附加参数 &ct=1)如果还不行检测采集接口是不是填写错误
3,添加资源插口成功后须要对资源进行分类绑定 :点击高清资源链接步入绑定页面进行分类绑定
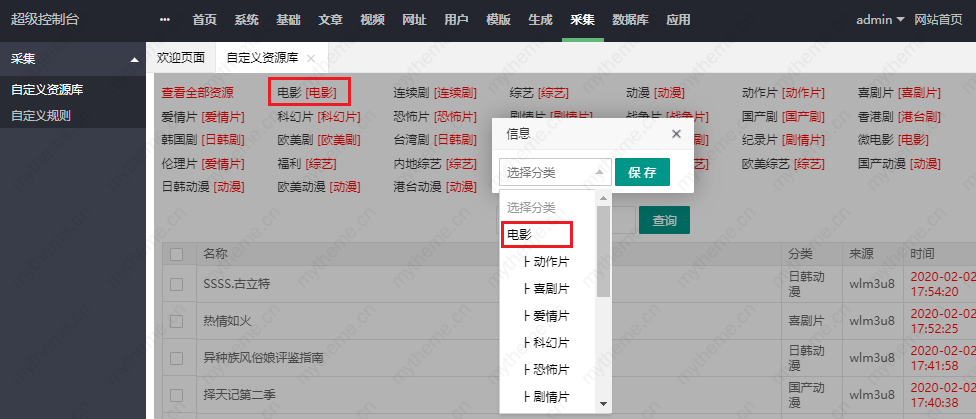
4,进入分类绑定页面后 点击没有绑定的页面会手动弹出分类绑定,如果找不到相对应的可以先绑定到相像的类目或是自定义添加分类
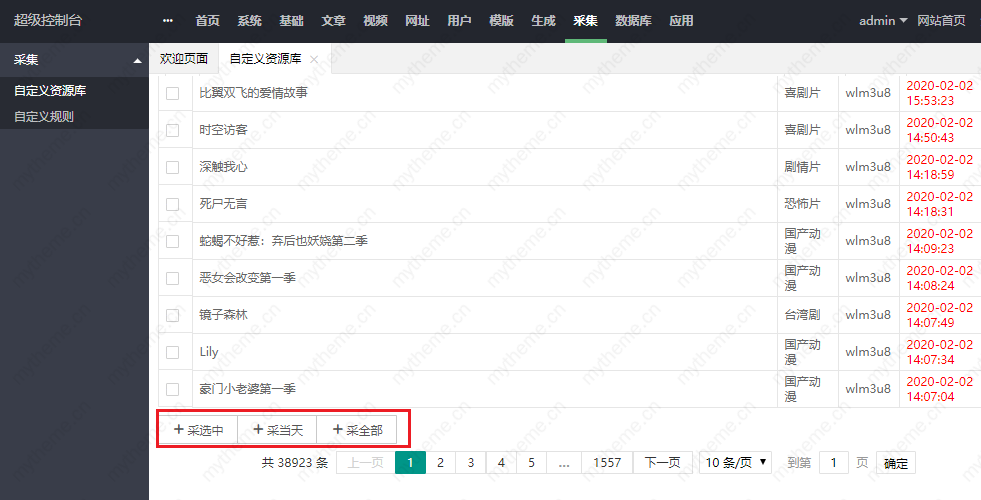
5,绑定后剩下就是采集了 拉到页面的顶部 有采集按钮 可以采集当天 采集选中(在须要采集的视频上面打勾)还有采集全部三种选择
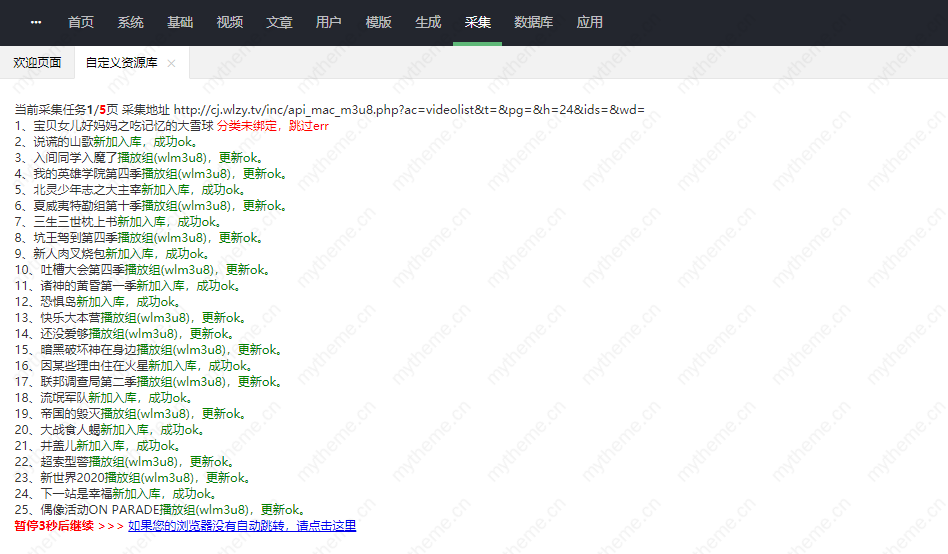
6,选择后步入手动采集页面 如果绑定的采集成功后显示红色 红色的则是没绑定成功跳过采集,所以在绑定的时侯要认真绑定。
结束语:最后采集完后网站就应当有视频数据了 这个时侯也是很多人苦恼的地方 采集完了播放不了!这是为什么呢?因为你没添加播放器引起的。
每个资源站都有自己单独的播放器和解析 也就是你采集谁家的资源就必须要用谁家的播放器才可以进行播放。播放器通常都在网站的帮助中心查找,都有详尽的说明。 查看全部
苹果cms自定义资源库采集教程
1,今天教你们怎样添加采集自定义资源库;进入后台我们随意以某资源站为例,接口可以到你要采集的网站上获取就可以了 一般都在网站的帮助中心:添加方式如下图(添加后进行测试不成功须要填写附加参数 &ct=1)
2,我这儿没有填写只要测试插口成功 就直接保存就可以了 如果测试失败就填写附加参数 &ct=1)如果还不行检测采集接口是不是填写错误
3,添加资源插口成功后须要对资源进行分类绑定 :点击高清资源链接步入绑定页面进行分类绑定
4,进入分类绑定页面后 点击没有绑定的页面会手动弹出分类绑定,如果找不到相对应的可以先绑定到相像的类目或是自定义添加分类
5,绑定后剩下就是采集了 拉到页面的顶部 有采集按钮 可以采集当天 采集选中(在须要采集的视频上面打勾)还有采集全部三种选择
6,选择后步入手动采集页面 如果绑定的采集成功后显示红色 红色的则是没绑定成功跳过采集,所以在绑定的时侯要认真绑定。
结束语:最后采集完后网站就应当有视频数据了 这个时侯也是很多人苦恼的地方 采集完了播放不了!这是为什么呢?因为你没添加播放器引起的。
每个资源站都有自己单独的播放器和解析 也就是你采集谁家的资源就必须要用谁家的播放器才可以进行播放。播放器通常都在网站的帮助中心查找,都有详尽的说明。
SiteServer CMS信息采集概述
采集交流 • 优采云 发表了文章 • 0 个评论 • 329 次浏览 • 2020-08-27 15:04
Web是一个巨大的资源宝库,目前页面数量已超过400亿,每小时还以惊人的速率下降,里面有你须要的大量有价值的信息,例如潜在顾客的列表与联系信息,竞争产品的价钱列表,实时金融新闻,供求信息,论文摘要等等。 可是因为关键信息都是以半结构化或自由文本方式存在于大量的HTML网页中,很难直接加以借助。
SiteServer CMS 信息采集功能的主要目标就是解决网路信息的采集问题,系统通过一些订制的采集逻辑,自动从指定网站或数据库中获取内容并保存到网站中。
一、主要功能
SiteServer CMS 提供强悍的信息采集功能模块,用户只须要告诉系统目标网页并简单地设置页面规则,很快就可以直接得到所须要的数据了。
除了典型的Web页面信息采集外,系统还提供数据库信息采集与单文件页采集功能:
Web页面信息采集用于手动从指定网站中获取内容;
数据库信息采集用于手动从指定数据库中获取内容;
单文件页采集用于将指定网页采集到本地的对应文件中。
二、系统特征
结果数据高度确切
对目标网站进行信息手动抓取,支持HTML页面内各类数据的采集,如文本信息、图片、附件、日期等
用户对每类信息自定义来源与分类
可以下载图片与各种文件
支持定时任务,可以与SiteServer CMS 定时模块相配合,定期抽取目标网站
支持记录惟一索引,避免相同信息重复入库
支持智能替换功能,可以将内容中嵌入的所有的无关部份如广告消除 查看全部
SiteServer CMS信息采集概述
Web是一个巨大的资源宝库,目前页面数量已超过400亿,每小时还以惊人的速率下降,里面有你须要的大量有价值的信息,例如潜在顾客的列表与联系信息,竞争产品的价钱列表,实时金融新闻,供求信息,论文摘要等等。 可是因为关键信息都是以半结构化或自由文本方式存在于大量的HTML网页中,很难直接加以借助。
SiteServer CMS 信息采集功能的主要目标就是解决网路信息的采集问题,系统通过一些订制的采集逻辑,自动从指定网站或数据库中获取内容并保存到网站中。
一、主要功能
SiteServer CMS 提供强悍的信息采集功能模块,用户只须要告诉系统目标网页并简单地设置页面规则,很快就可以直接得到所须要的数据了。
除了典型的Web页面信息采集外,系统还提供数据库信息采集与单文件页采集功能:
Web页面信息采集用于手动从指定网站中获取内容;
数据库信息采集用于手动从指定数据库中获取内容;
单文件页采集用于将指定网页采集到本地的对应文件中。
二、系统特征
结果数据高度确切
对目标网站进行信息手动抓取,支持HTML页面内各类数据的采集,如文本信息、图片、附件、日期等
用户对每类信息自定义来源与分类
可以下载图片与各种文件
支持定时任务,可以与SiteServer CMS 定时模块相配合,定期抽取目标网站
支持记录惟一索引,避免相同信息重复入库
支持智能替换功能,可以将内容中嵌入的所有的无关部份如广告消除
织梦CMS采集侠破解版提示本域名以被锁定的最新解除方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 305 次浏览 • 2020-08-27 05:36
是一款帮助网站进行手动更新采集文章的工具,不但能采集其它网站的内容,还支持伪静态设置,搜索引擎优化,自动内链,自动生成网站地图等。
织梦采集侠破解版提示本域名以被锁定的最新解除方式
只需一分钟,立即开始采集,而且结合简单、健壮、灵活、开源的dedecms程序
根据用户设定的关键词进行泛采集,实现不对指定的一个或几个被采集站点进行采集
只须要输入RSS地址即可便捷的 采集到目标网站内容,无需编撰采集规则,方便简单
提供列表URL和文章URL即采集指定网站或栏目内容,便可精确采集标题、正文、作者、来源
可预先设定是采集任务,然后全手动完成进行伪原创,导入,生成,操作无需人工干预
我们为商业用户提供的远程触发采集服务,新站无有人访问即可定时定量采集更新
采集侠亦可按照您的须要每晚在您设置的时间段内定时定量初审更新
自动生成sitemap,自动推送百度插口,确保百度及时收录到您的网站,提供网站排名
市面上好多织梦CMS采集侠破解版用户,偶尔会遇见被锁定域名未能正常使用的问题,现在提供下解除锁定的教程,方法也很简单,三步就搞定了。
第一步:
找到网站根目录data文件夹
第二步:
打开data文件夹找到admin文件夹
第三步:
打开admin文件夹删掉 oo.txt文件即可。 查看全部
织梦CMS采集侠破解版提示本域名以被锁定的最新解除方式
是一款帮助网站进行手动更新采集文章的工具,不但能采集其它网站的内容,还支持伪静态设置,搜索引擎优化,自动内链,自动生成网站地图等。
织梦采集侠破解版提示本域名以被锁定的最新解除方式
只需一分钟,立即开始采集,而且结合简单、健壮、灵活、开源的dedecms程序

根据用户设定的关键词进行泛采集,实现不对指定的一个或几个被采集站点进行采集
只须要输入RSS地址即可便捷的 采集到目标网站内容,无需编撰采集规则,方便简单
提供列表URL和文章URL即采集指定网站或栏目内容,便可精确采集标题、正文、作者、来源
可预先设定是采集任务,然后全手动完成进行伪原创,导入,生成,操作无需人工干预
我们为商业用户提供的远程触发采集服务,新站无有人访问即可定时定量采集更新
采集侠亦可按照您的须要每晚在您设置的时间段内定时定量初审更新
自动生成sitemap,自动推送百度插口,确保百度及时收录到您的网站,提供网站排名
市面上好多织梦CMS采集侠破解版用户,偶尔会遇见被锁定域名未能正常使用的问题,现在提供下解除锁定的教程,方法也很简单,三步就搞定了。
第一步:
找到网站根目录data文件夹
第二步:
打开data文件夹找到admin文件夹
第三步:
打开admin文件夹删掉 oo.txt文件即可。
动易SiteFactory采集流程第一步
采集交流 • 优采云 发表了文章 • 0 个评论 • 476 次浏览 • 2020-08-27 03:46
本节将以采集动易官方网站“公司动态”栏目为例讲解添加采集项目并进行信息采集的全过程。
如果您第一次接触采集功能,请认真阅读操作步骤及并理解相关说明,按以下步骤一一操作以完善所需采集的项目。
14.2.1 第一步:采集项目设置
依次点击“内容管理”->“采集管理”->“采集管理”功能链接,在出现的管理界面中,单击两侧管理操作导航中“添加采集项目”功能链接,系统出现“添加采集项目设置”管理界面,以设置所需新建的采集项目的名称、采集网站、编码等基本设置信息。
重要参数说明:
·项目名称:填写自定义采集项目的名称(如“动易公司动态”)。
·对应本站栏目:点选设置所采集的数据保存到本站所对应的栏目节点名(如“文章中心”)。
·对应内容模型:点选设置对应栏目的模型(如“文章模型”)。
温馨提示:若后续在采集项目完成后,再修改了所对应的模型,系统将手动删掉采集第三步所有数组的规则。
·采集网站:填写所需采集目标网站的名称(如“动易官网”)。
·采集URL:填写采集网页的网址(以 开头,如“”)。
·编码选择:提供GB2312、UTF-8和Big5三种编码格式。国内的网站基本都是GB2312,若采集香港、台湾的网站请选择Big5编码,若采集海外网站则选择UTF-8编码(如“动易技术中心”选择“GB2312” 编码)。
·指定采集数量:指定采集的数目,不指定为采集全部数据。
·采集顺序:设置按升序或乱序形式进行采集(系统默认为逆序采集)。
·采集简介:填写本采集项目的简略介绍信息(如“动易官方网站动易公司动态信息”)。
设置好相关选项后,单击页面顶部“下一步”功能按键进行采集列表项目信息设置。
温馨提示:若目标网站的信息须要登陆后才可查阅与采集,请参阅动易技术中心中的相关说明以进行设置。 查看全部
动易SiteFactory采集流程第一步
本节将以采集动易官方网站“公司动态”栏目为例讲解添加采集项目并进行信息采集的全过程。
如果您第一次接触采集功能,请认真阅读操作步骤及并理解相关说明,按以下步骤一一操作以完善所需采集的项目。
14.2.1 第一步:采集项目设置
依次点击“内容管理”->“采集管理”->“采集管理”功能链接,在出现的管理界面中,单击两侧管理操作导航中“添加采集项目”功能链接,系统出现“添加采集项目设置”管理界面,以设置所需新建的采集项目的名称、采集网站、编码等基本设置信息。

重要参数说明:
·项目名称:填写自定义采集项目的名称(如“动易公司动态”)。
·对应本站栏目:点选设置所采集的数据保存到本站所对应的栏目节点名(如“文章中心”)。
·对应内容模型:点选设置对应栏目的模型(如“文章模型”)。

温馨提示:若后续在采集项目完成后,再修改了所对应的模型,系统将手动删掉采集第三步所有数组的规则。
·采集网站:填写所需采集目标网站的名称(如“动易官网”)。
·采集URL:填写采集网页的网址(以 开头,如“”)。
·编码选择:提供GB2312、UTF-8和Big5三种编码格式。国内的网站基本都是GB2312,若采集香港、台湾的网站请选择Big5编码,若采集海外网站则选择UTF-8编码(如“动易技术中心”选择“GB2312” 编码)。
·指定采集数量:指定采集的数目,不指定为采集全部数据。
·采集顺序:设置按升序或乱序形式进行采集(系统默认为逆序采集)。
·采集简介:填写本采集项目的简略介绍信息(如“动易官方网站动易公司动态信息”)。
设置好相关选项后,单击页面顶部“下一步”功能按键进行采集列表项目信息设置。

温馨提示:若目标网站的信息须要登陆后才可查阅与采集,请参阅动易技术中心中的相关说明以进行设置。
如何把DEDECMS采集文章变成“原创”的文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2020-08-26 18:13
关键字描述:文章 变成 原创 采集 如何 &ldquo 标题 &rdquo 词组 句子
到xkzzz来学习的,多是中小网站的站长,他们使用DedeCms产品的不在少数。今天,我想注重说说关于“辅助插件”的功能及使用。当然,我不会去说dede自带的这些插件,因为来这儿的站长都是dedecms好手,我想分享一下我们自己开发的一个小插件------如何把采集来的文章变成“原创”的文章!
产生原创标题的原理
首先,请看截图。
此插件页面和dede自带的其他插件风格相同,功能是把标题弄成独有的标题。原理是这样的:通常,我们在百度里搜索某篇文章的标题,百度会返回好多相同的文章,显然这篇文章被转载了好多次。我们晓得,在内容重复的情况下,百度会根据站点的权重进行排序。权重越高的站点,搜索结果排的位置就越靠前。所以,尽管你的站点也被搜到了,但是结果太可能靠后。采集别人的文章虽然省事,但带来的疗效不一定好,原因就在这里。
一个标题,说白了就是一句话。句子由成语组成,在不影响语句意思的前提下,换个相仿的词句,那么,在搜索引擎看来,这个短语就成了不同于原先语句的短语。换句话说,你形成了一个原创的标题。这特别重要。原创的内容,是搜索引擎最喜欢的东西。
就像冯巩每年新年晚宴上场前常说的一句话,亲爱的听众朋友们,“我想死大家啦”,当他被朱军逼着不使再说这句话时,冯巩说出了“你们使我想死啦”。意思其实没变,句子却变了。插件的原理,就是这样的。
插件的用法
“当前的标题”和“原来的标题”开始都载入某篇文章的标题,后者不可改变,为黄色。下面的“优化建议”根据现有语句里的词句,去词库---随时添加的---里搜索带有相同词句的反义词租。比如,“玩赏犬训练中的注意事项”,注意事项和注意要点、关注点的构词相仿,训练和调教的构词相仿,所以,这句话可以换成“玩赏犬训练中的注意要点”、“玩赏犬训练中的关注点”等等。
从图中见到,有个添加相仿单词的大大按键,我们通过这个功能向词库里添加新发现的反义词组,或点击“edit”按钮,去编辑现有的反义词组。一般情况下,刚开始的时侯,词库里的反义词组较少,优化建议一般为空,这就须要我们拆开语句,根据网站内容填写反义词组。随着单词数目的增多,和语句关联的反义词组出现的频度会越来越多,人工录入单词的次数也会大大增加,然后,编辑次数相应降低,从而让现有词库最优化满足本网站需要。
根据我们实际使用情况,作为一个宠物方面的行业网站,编辑人员仅在维护1天之后,就积累了300多个反义词组,如果每位短语按3个估算,那么当日共积累了逾1000个熟语。接下来的几天,编辑只须要通过快捷键“Ctrl U”动态替换标题,就可以了。
在页面的下方是“看看百度收录情况”,此按键将把用反义词替换后的标题在百度里的搜索情况,按列显示在下边,图中显示了7条。这样,编辑人员就有了指导根据------越是搜不到的标题,越是接近于原创的标题。
其他方面就不介绍了。
插件评价
自我觉得,此功能很过投机取巧。但是从搜索引擎优化的角度看,它不能不算做一条捷径。我曾看见好多编辑人员(不局限于我们公司),在做着类似的工作。
另一方面,从用户的利益看,我们应当有节制地使用,程序不是万能的,能为用户带来真正有用信息的文章才是好文章,这个宗旨不能丢。
在和同事的聊天中获知,有些站长早就这样做了,这里,我也希望有这方面经验的站长,能够抽时间,给你们分享一下。
本文标题: 如何把DEDECMS采集文章变成“原创”的文章
本文地址: 查看全部
如何把DEDECMS采集文章变成“原创”的文章
关键字描述:文章 变成 原创 采集 如何 &ldquo 标题 &rdquo 词组 句子
到xkzzz来学习的,多是中小网站的站长,他们使用DedeCms产品的不在少数。今天,我想注重说说关于“辅助插件”的功能及使用。当然,我不会去说dede自带的这些插件,因为来这儿的站长都是dedecms好手,我想分享一下我们自己开发的一个小插件------如何把采集来的文章变成“原创”的文章!
产生原创标题的原理
首先,请看截图。

此插件页面和dede自带的其他插件风格相同,功能是把标题弄成独有的标题。原理是这样的:通常,我们在百度里搜索某篇文章的标题,百度会返回好多相同的文章,显然这篇文章被转载了好多次。我们晓得,在内容重复的情况下,百度会根据站点的权重进行排序。权重越高的站点,搜索结果排的位置就越靠前。所以,尽管你的站点也被搜到了,但是结果太可能靠后。采集别人的文章虽然省事,但带来的疗效不一定好,原因就在这里。
一个标题,说白了就是一句话。句子由成语组成,在不影响语句意思的前提下,换个相仿的词句,那么,在搜索引擎看来,这个短语就成了不同于原先语句的短语。换句话说,你形成了一个原创的标题。这特别重要。原创的内容,是搜索引擎最喜欢的东西。
就像冯巩每年新年晚宴上场前常说的一句话,亲爱的听众朋友们,“我想死大家啦”,当他被朱军逼着不使再说这句话时,冯巩说出了“你们使我想死啦”。意思其实没变,句子却变了。插件的原理,就是这样的。
插件的用法
“当前的标题”和“原来的标题”开始都载入某篇文章的标题,后者不可改变,为黄色。下面的“优化建议”根据现有语句里的词句,去词库---随时添加的---里搜索带有相同词句的反义词租。比如,“玩赏犬训练中的注意事项”,注意事项和注意要点、关注点的构词相仿,训练和调教的构词相仿,所以,这句话可以换成“玩赏犬训练中的注意要点”、“玩赏犬训练中的关注点”等等。
从图中见到,有个添加相仿单词的大大按键,我们通过这个功能向词库里添加新发现的反义词组,或点击“edit”按钮,去编辑现有的反义词组。一般情况下,刚开始的时侯,词库里的反义词组较少,优化建议一般为空,这就须要我们拆开语句,根据网站内容填写反义词组。随着单词数目的增多,和语句关联的反义词组出现的频度会越来越多,人工录入单词的次数也会大大增加,然后,编辑次数相应降低,从而让现有词库最优化满足本网站需要。
根据我们实际使用情况,作为一个宠物方面的行业网站,编辑人员仅在维护1天之后,就积累了300多个反义词组,如果每位短语按3个估算,那么当日共积累了逾1000个熟语。接下来的几天,编辑只须要通过快捷键“Ctrl U”动态替换标题,就可以了。
在页面的下方是“看看百度收录情况”,此按键将把用反义词替换后的标题在百度里的搜索情况,按列显示在下边,图中显示了7条。这样,编辑人员就有了指导根据------越是搜不到的标题,越是接近于原创的标题。
其他方面就不介绍了。
插件评价
自我觉得,此功能很过投机取巧。但是从搜索引擎优化的角度看,它不能不算做一条捷径。我曾看见好多编辑人员(不局限于我们公司),在做着类似的工作。
另一方面,从用户的利益看,我们应当有节制地使用,程序不是万能的,能为用户带来真正有用信息的文章才是好文章,这个宗旨不能丢。
在和同事的聊天中获知,有些站长早就这样做了,这里,我也希望有这方面经验的站长,能够抽时间,给你们分享一下。
本文标题: 如何把DEDECMS采集文章变成“原创”的文章
本文地址:
帝国CMS采集文章-分页采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 290 次浏览 • 2020-08-26 08:58
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。 不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:(1)全部列举式(2)上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以"中华网内容分页()"为例:
可以看见这条新闻总共有3条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:
可以看见这条新闻总共有20条分页。
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:
(2)第2页代码:
从这两幅图片可以见到她们有着相同的"分页区域开始代码","分页链接"格式,"分页区域结束代码",那么就可以确定"分页区域正则","分页链接正则"。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
5、为了便捷教程显示,newstext我采集了标题而不是采集内容,预览结果:
注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用"全部列出式"。
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。 在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用"上下页导航式"。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时,老是采到第1页,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。 查看全部
帝国CMS采集文章-分页采集
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。 不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:(1)全部列举式(2)上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以"中华网内容分页()"为例:
可以看见这条新闻总共有3条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:
可以看见这条新闻总共有20条分页。
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:
(2)第2页代码:
从这两幅图片可以见到她们有着相同的"分页区域开始代码","分页链接"格式,"分页区域结束代码",那么就可以确定"分页区域正则","分页链接正则"。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
5、为了便捷教程显示,newstext我采集了标题而不是采集内容,预览结果:
注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用"全部列出式"。
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。 在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用"上下页导航式"。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时,老是采到第1页,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
实例教你使用帝国CMS采集图文教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 468 次浏览 • 2020-08-26 00:35
本节通过采集简单的页面作为采集教程实例。
每个系统模型都有自己的采集,无论是外置的还是用户自定义的系统模型,新闻系统有新闻系统采集,下载系统有下载系统采集等等。
下面讲解新闻系统模型的采集,其它系统模型采集基本雷同,用户可举一反三。
采集页面地址
本例要采集的页面地址:
开始采集
采集一般步骤:
1、增加采集节点;
2、预览采集正则是否正确;
3、开始采集;
4、对采集的数据进行初审并入库;
5、生成栏目及内容HTML页面。
一、增加采集节点:
1、登录后台->“栏目”>“采集管理”>“增加采集节点”;
2、“选择要降低采集的栏目”(选择终极栏目);
3、“选择要降低采集的栏目”后步入降低采集节点页面;
4、打开要采集的列表页面:
点击查看“源文件”
点击查看,列表页源代码为如下:
5、开始设置采集节点及列表页正则:
(1)、输入节点名称:采集实例
(2)、采集页面地址:
(3)、由列表页的源代码:“”,我们得出“内容页地址前缀”为:
(4)、设置“信息页链接正则”:由列表页的源代码得出。
图1:页面源代码
图2:得出的信息页链接正则
6、点击采集的内容页页面并查看源文件:
图1:内容页页面
图2:内容页源代码
7、设置内容页内容正则:(标题及内容正则)
(1)、标题正则:由源代码内容我们得出“新闻标题”正则为:
图1:页面源代码
图2:得出的标题正则
(2)、内容正则:由源代码内容我们得出“新闻内容”正则为:
图1:页面源代码
图2:得出的新闻内容正则
8、点击“提交”按钮即可降低节点完毕,整个表单最终疗效如下:
[点击查看]
二、预览采集正则是否正确:
1、上面降低采集节点后,我们返回“管理节点”页面,如下:
2、点击“预览”采集,进入节点正则预览与验证:
图1:采集页面地址列表
图2:信息链接列表
图3:采集的内容页内容
3、上面链接列表页及内容页内容预览无误后方可进行采集操作。
三、开始采集:
1、上面的采集节点正则预览无误后,我们返回“管理节点”页面:
2、点击里面的“开始采集”链接,开始进行采集;
3、采集信息完成后,系统会转向采集入库页面,如下:
四、对采集的数据进行初审并入库:
即可完成入库操作:
管理栏目信息也可以看见我们刚刚入库的信息:
五、生成栏目及内容HTML页面:
点击“系统”>“数据更新”>“数据更新中心”,进入数据更新中心页面: 查看全部
实例教你使用帝国CMS采集图文教程
本节通过采集简单的页面作为采集教程实例。
每个系统模型都有自己的采集,无论是外置的还是用户自定义的系统模型,新闻系统有新闻系统采集,下载系统有下载系统采集等等。
下面讲解新闻系统模型的采集,其它系统模型采集基本雷同,用户可举一反三。
采集页面地址
本例要采集的页面地址:
开始采集
采集一般步骤:
1、增加采集节点;
2、预览采集正则是否正确;
3、开始采集;
4、对采集的数据进行初审并入库;
5、生成栏目及内容HTML页面。
一、增加采集节点:
1、登录后台->“栏目”>“采集管理”>“增加采集节点”;
2、“选择要降低采集的栏目”(选择终极栏目);

3、“选择要降低采集的栏目”后步入降低采集节点页面;
4、打开要采集的列表页面:

点击查看“源文件”

点击查看,列表页源代码为如下:

5、开始设置采集节点及列表页正则:
(1)、输入节点名称:采集实例

(2)、采集页面地址:

(3)、由列表页的源代码:“”,我们得出“内容页地址前缀”为:

(4)、设置“信息页链接正则”:由列表页的源代码得出。
图1:页面源代码

图2:得出的信息页链接正则

6、点击采集的内容页页面并查看源文件:
图1:内容页页面

图2:内容页源代码

7、设置内容页内容正则:(标题及内容正则)
(1)、标题正则:由源代码内容我们得出“新闻标题”正则为:
图1:页面源代码

图2:得出的标题正则

(2)、内容正则:由源代码内容我们得出“新闻内容”正则为:
图1:页面源代码

图2:得出的新闻内容正则

8、点击“提交”按钮即可降低节点完毕,整个表单最终疗效如下:
[点击查看]
二、预览采集正则是否正确:
1、上面降低采集节点后,我们返回“管理节点”页面,如下:

2、点击“预览”采集,进入节点正则预览与验证:
图1:采集页面地址列表

图2:信息链接列表

图3:采集的内容页内容

3、上面链接列表页及内容页内容预览无误后方可进行采集操作。
三、开始采集:
1、上面的采集节点正则预览无误后,我们返回“管理节点”页面:

2、点击里面的“开始采集”链接,开始进行采集;
3、采集信息完成后,系统会转向采集入库页面,如下:

四、对采集的数据进行初审并入库:

即可完成入库操作:

管理栏目信息也可以看见我们刚刚入库的信息:

五、生成栏目及内容HTML页面:
点击“系统”>“数据更新”>“数据更新中心”,进入数据更新中心页面:
织梦cms(dedecms)采集文章二
采集交流 • 优采云 发表了文章 • 0 个评论 • 573 次浏览 • 2020-08-25 09:46
网页内容获取规则。系统会默认一个采集url为预览网址,另外内容分页导航所在的区域匹配规则也太灵活,除了和phpcms一样有全“部列举的分页列表模式”、“上下页方式或不完整的分页列表模式”外,还多了一个“分页列表规则”。
各数组内容采集,dedecms的内容匹配规则和phpcms一样:“起始无重复HTML[内容]结尾无重复HTML”,[内容]即为所采内容。过滤规则是{dede:trim replace=""}规则{/dede:trim},多个规则的话一个一行,如果要替换成指定的值,则只要在replace=""的冒号里设置即可。
其中,内容摘要、关键字、缩略图系统会用正则进行手动匹配,我们只需设置过滤内容即可。其余数组分别设置匹配规则和过滤规则,系统同样自带了几个常用的过滤规则,但是点击“常用规则”后为弹出小窗口模式,稍微有点不便捷。针对本测试的标题采集,以下两种形式都是可以的,如图:
文章作者、文章来源和发布时间数组一样采集,但是此版本dedecms在这几个数组下没有“自定义处理插口”了,如果有的话会稍显灵活,例如设置固定值可直接用“@me="固定值"”实现。现在不能用自定义处理插口设定固定值,也没有数组值设置,只能通过采集网页某一固定值之后用替换。如图:
dedecms的文章内容采集非常强悍,除了匹配规则和过滤规则,还有个“自定义处理插口”。如果你有php基础的话,可以通过此功能对采集结果@me进行各类处理,强大到不行啊。以后小编会专门发一篇此功能的讲解文章。最后,不能直接在采集管理处新增采集字段,只能在对应内容模型管理中降低数组,采集管理会手动降低。如小编在“普通文章”内容模型那降低了一个“chinaz数组”,则采集设置中手动增了一个“chinaz数组”项目。
保存并测试,查看列表测试信息和网页规则测试,检查是否正确,无误后确定并开始采集。进入采集指定节点设置页面,因为小编之前有测试一遍,所以有60个历史种子网址,即小编之前早已采集了60个网址,另外还有几个选项你们按需求选择。
点开始采集网页,出现此采集提示信息显示采集进度,不知道是小编人品不好还是dede采集本身缺点,经常会浏览器没反应,采集停止在那,只有自动点击了就会继续。 查看全部
织梦cms(dedecms)采集文章二
网页内容获取规则。系统会默认一个采集url为预览网址,另外内容分页导航所在的区域匹配规则也太灵活,除了和phpcms一样有全“部列举的分页列表模式”、“上下页方式或不完整的分页列表模式”外,还多了一个“分页列表规则”。

各数组内容采集,dedecms的内容匹配规则和phpcms一样:“起始无重复HTML[内容]结尾无重复HTML”,[内容]即为所采内容。过滤规则是{dede:trim replace=""}规则{/dede:trim},多个规则的话一个一行,如果要替换成指定的值,则只要在replace=""的冒号里设置即可。
其中,内容摘要、关键字、缩略图系统会用正则进行手动匹配,我们只需设置过滤内容即可。其余数组分别设置匹配规则和过滤规则,系统同样自带了几个常用的过滤规则,但是点击“常用规则”后为弹出小窗口模式,稍微有点不便捷。针对本测试的标题采集,以下两种形式都是可以的,如图:


文章作者、文章来源和发布时间数组一样采集,但是此版本dedecms在这几个数组下没有“自定义处理插口”了,如果有的话会稍显灵活,例如设置固定值可直接用“@me="固定值"”实现。现在不能用自定义处理插口设定固定值,也没有数组值设置,只能通过采集网页某一固定值之后用替换。如图:

dedecms的文章内容采集非常强悍,除了匹配规则和过滤规则,还有个“自定义处理插口”。如果你有php基础的话,可以通过此功能对采集结果@me进行各类处理,强大到不行啊。以后小编会专门发一篇此功能的讲解文章。最后,不能直接在采集管理处新增采集字段,只能在对应内容模型管理中降低数组,采集管理会手动降低。如小编在“普通文章”内容模型那降低了一个“chinaz数组”,则采集设置中手动增了一个“chinaz数组”项目。

保存并测试,查看列表测试信息和网页规则测试,检查是否正确,无误后确定并开始采集。进入采集指定节点设置页面,因为小编之前有测试一遍,所以有60个历史种子网址,即小编之前早已采集了60个网址,另外还有几个选项你们按需求选择。


点开始采集网页,出现此采集提示信息显示采集进度,不知道是小编人品不好还是dede采集本身缺点,经常会浏览器没反应,采集停止在那,只有自动点击了就会继续。
优采云CMS采集器绿色版(采集CMS工具) v1.0 免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2020-08-25 07:21
需要快捷采集CMS工具?优采云CMS采集器绿色版肯定就是您要找的软件啊!直接能够在网站和峰会里面开始自己的文章内容采集!非常简单的一键采集数据功能等着您进行是使用!还能够手动采集图面手动添加水印等等!优采云CMS采集器绿色版使在做相关工作的朋友们才能节约大量的时间和精力!
优采云CMS采集器绿色版功能说明
可采集别人网站和峰会的所有文章或内容并伪原创后发布到自己网站,可以每日采集最新文章,自动维护网站的发帖量等,可实现资源手动本地化,图片手动本地并添加水印等,日采集发布可达到上万篇。目前全面支持DEDECMS(织梦)、ECMS(帝国)、PHPCMS、PHP168、PowerEasy(动易)、SupeSite、5U、DIY-Page、Zoomla!逐浪CMS、目前包括CMS采集大挪移、维护王和同步更新王,JEECMS等主流CMS程序的采集和发布任务。
优采云CMS采集器绿色版特征介绍
可以在你的峰会一次注册成千上万个会员,让你的新峰会一开始都会有大量的会员;
可以一口气采集网站/论坛的主题和回复全部内容,80%的网站/论坛均可以采集 ,支持把文章内容保存到本地后再发布;
支持按UBB代码和源代码以及UBB和源代码相结合的三种形式编撰采集规则,最大限度的便捷了用户的使用习惯和选择;
具备万能破解功能,对于富含干扰码的文章、帖子,可以对它们内容中的干扰码进行完全屏蔽;
可将发贴和跟帖ID分割设置,让一部分会员全部发主题,让另外一部分会员全部回复,ID号会员抽选发布;
经过7年多的不断建立和升级,优采云采集器目前早已支持了国外大部分主流的建站程序,完全可以使您从繁杂的网站维护管理中解放下来,优采云采集器每套包括采集维护王和采集大挪移,配合使用具备以下实用功能:
可以使会员在设定的时间内同时上线,轻松实现万人在线火热峰会疗效(部分按IP算在线人数的峰会不支持,如DVbbs/PHPWind);
支持将某网站论坛A蓝筹股或栏目内容批量采集转发到自己网站或者峰会指定蓝筹股。
可以同时向网站或峰会的多个版块一起批量发帖;
可以针对峰会的某一主题分类进行发贴; 查看全部
优采云CMS采集器绿色版(采集CMS工具) v1.0 免费版
需要快捷采集CMS工具?优采云CMS采集器绿色版肯定就是您要找的软件啊!直接能够在网站和峰会里面开始自己的文章内容采集!非常简单的一键采集数据功能等着您进行是使用!还能够手动采集图面手动添加水印等等!优采云CMS采集器绿色版使在做相关工作的朋友们才能节约大量的时间和精力!

优采云CMS采集器绿色版功能说明
可采集别人网站和峰会的所有文章或内容并伪原创后发布到自己网站,可以每日采集最新文章,自动维护网站的发帖量等,可实现资源手动本地化,图片手动本地并添加水印等,日采集发布可达到上万篇。目前全面支持DEDECMS(织梦)、ECMS(帝国)、PHPCMS、PHP168、PowerEasy(动易)、SupeSite、5U、DIY-Page、Zoomla!逐浪CMS、目前包括CMS采集大挪移、维护王和同步更新王,JEECMS等主流CMS程序的采集和发布任务。
优采云CMS采集器绿色版特征介绍
可以在你的峰会一次注册成千上万个会员,让你的新峰会一开始都会有大量的会员;
可以一口气采集网站/论坛的主题和回复全部内容,80%的网站/论坛均可以采集 ,支持把文章内容保存到本地后再发布;
支持按UBB代码和源代码以及UBB和源代码相结合的三种形式编撰采集规则,最大限度的便捷了用户的使用习惯和选择;
具备万能破解功能,对于富含干扰码的文章、帖子,可以对它们内容中的干扰码进行完全屏蔽;
可将发贴和跟帖ID分割设置,让一部分会员全部发主题,让另外一部分会员全部回复,ID号会员抽选发布;
经过7年多的不断建立和升级,优采云采集器目前早已支持了国外大部分主流的建站程序,完全可以使您从繁杂的网站维护管理中解放下来,优采云采集器每套包括采集维护王和采集大挪移,配合使用具备以下实用功能:
可以使会员在设定的时间内同时上线,轻松实现万人在线火热峰会疗效(部分按IP算在线人数的峰会不支持,如DVbbs/PHPWind);
支持将某网站论坛A蓝筹股或栏目内容批量采集转发到自己网站或者峰会指定蓝筹股。
可以同时向网站或峰会的多个版块一起批量发帖;
可以针对峰会的某一主题分类进行发贴;
飞飞CMS最新模板,影视含文章140模板
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2020-08-20 02:38
购买须知:
A:嗯,对的,我们承诺演示效果图均和网站一模一样,如有不同,全额退票!并且我们的模板和数据都没有留侧门,请放心使用!
因为模板具有可复制性和可传播性,模板一旦发货,(除和演示效果图不一样),其它不支持退货,所以勿必请您一定看清楚后再订购;
A:我们的模板价钱代表着这个行业的最高价位。原因1)我们是正版的模板商,所有模板全部自主开发,因为我们的模板均为全新制做,纯手写代码精简优化,每套模板有配套的教程。2)我们仍然在降价,是因为我们的模板质量和系统优化仍然在提高,请不要单纯的比价钱,应该比它的价值。我们的模板是加了大量实用的插件的,如果你买了优价的模板再想实现我们的一些功能疗效,需要再花钱找人开发,那样最终的价钱虽然比我们的还高,而且一个站在多处找人开发,容易乱套,更没有保障。
A:购买模板 即得到整站全部源码,并且后台源码全部开源,不加密。只要自己有技术人员,可以任意更改的。(个别产品可能有部份文件加密,但不影响更改)
A:模板基本上全是后台控制的,个别后台管理不便捷的地方我们也做到了一个单独的库文件里,并且提供了安装教程,您完全可以自己任意更改的。一般小更改是免费的,如果涉及一定工作量的更改,我们是合理计费的。如果您能自己更改的最好自己更改,我们也不想加收您的费用,我们那边服务压力非常大,希望您能理解。
A:我们的演示全是模板的实际疗效截图,确保为你提供模板真实疗效。网上总有人想尽一切办法偷取我们的模板数据,所以没办法只能暂时采用的这些一比一截图演示方式,给您带来不便,希望能理解,我们仍然在为怎样使顾客能感受到模板真实的疗效而努力。我们承诺演示效果图均和网站一模一样,如有不同,全额退票! 查看全部
飞飞CMS最新模板,影视含文章140模板
购买须知:
A:嗯,对的,我们承诺演示效果图均和网站一模一样,如有不同,全额退票!并且我们的模板和数据都没有留侧门,请放心使用!
因为模板具有可复制性和可传播性,模板一旦发货,(除和演示效果图不一样),其它不支持退货,所以勿必请您一定看清楚后再订购;
A:我们的模板价钱代表着这个行业的最高价位。原因1)我们是正版的模板商,所有模板全部自主开发,因为我们的模板均为全新制做,纯手写代码精简优化,每套模板有配套的教程。2)我们仍然在降价,是因为我们的模板质量和系统优化仍然在提高,请不要单纯的比价钱,应该比它的价值。我们的模板是加了大量实用的插件的,如果你买了优价的模板再想实现我们的一些功能疗效,需要再花钱找人开发,那样最终的价钱虽然比我们的还高,而且一个站在多处找人开发,容易乱套,更没有保障。
A:购买模板 即得到整站全部源码,并且后台源码全部开源,不加密。只要自己有技术人员,可以任意更改的。(个别产品可能有部份文件加密,但不影响更改)
A:模板基本上全是后台控制的,个别后台管理不便捷的地方我们也做到了一个单独的库文件里,并且提供了安装教程,您完全可以自己任意更改的。一般小更改是免费的,如果涉及一定工作量的更改,我们是合理计费的。如果您能自己更改的最好自己更改,我们也不想加收您的费用,我们那边服务压力非常大,希望您能理解。
A:我们的演示全是模板的实际疗效截图,确保为你提供模板真实疗效。网上总有人想尽一切办法偷取我们的模板数据,所以没办法只能暂时采用的这些一比一截图演示方式,给您带来不便,希望能理解,我们仍然在为怎样使顾客能感受到模板真实的疗效而努力。我们承诺演示效果图均和网站一模一样,如有不同,全额退票!
齐博CMS自带采集体验系列之DedeCMSv5.7系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 464 次浏览 • 2021-06-05 21:15
cms自带采集生活系列文章已完成三期:
cms自带采集PHPcmsV9体验系列
cms自带采集Dedecmsv5.7体验系列
cms自带采集测试系列cmsv6.6
今天的第四期,来感受一下齐博cms自己的采集,齐博cms原名PHP168网站管理,是大学时期由“龙城”创建的,也就是在2003年系统于2010年12月1日更名为奇博软件,自2003年10月V1.0版本发布以来,历经多次版本升级,现已发展成为最成熟的“核心+模块+插件” ”架构系统,成为国内领先的开源PHP系统。涉及电子政务、媒体新闻门户、大型企业信息化、电子商务B2B等高端互联网应用,为数以万计的免费和付费用户提供了应用平台。
同理,今天我们来体验采集自带的Qibocms全站系统的文章采集和群图采集功能。目标网站还是和之前的文章一样,所以比较好。
一、文章采集
1、Title 和 URL采集
采集target网站:
任意填写规则名称,以及所属类别,采集不影响内容。
List网站也有两种添加方式,一种是手动输入多页,另一种是有规律连续的多页。分析目标站的列表页URL,得到列表页的规则,用[page]代替换号就够了,所以我们选择“规则连续多页”,填写[page].shtml,然后填写开始和结束页码以及每次更改的渐变。 (温馨提示:在整个采集设置过程中,所有通配符都不需要手动填写,可以点击旁边官方说明中的通配符自动复制,直接粘贴即可)
同时奇博也考虑到网站list页面第一页的一些URL规则不符合整体更改规则,所以在后面有一个文本框填写不规则第一页。我们采集目标的第一页符合整体规律,所以留空。
采集内容页地址和内容页标题。奇博cms自带采集和别人不同:采集title不在内容页采集,而是在采集list页文章url而且还直接放了锚文本文本采集 是标题。您只需要定义这个指向内容页面的锚文本规则。其中{url=*}表示标题URL通配符,{title=*}表示标题通配符,{*}表示不需要的内容通配符。分析我们的目标站,我们可以得到以下规则:
{title=*}{*}
其实这个设计有点瑕疵。比如为了让列表页更美观,有的网站限制了列表页标题字数,然后控制文章双标题中副标题字数显示它在列表页面上。并且主标题出现在内容页面上。
接下来可以勾选“显示不常用的高级设置”来进一步设置采集 URL。其实还有几个功能还是比较常用的,比如设置不能收录在链接中或者必须收录在过滤器中的字符。当它干扰链接时也很常见。另外,其他替换标题字符、链接字符、指定截取区域可以参考页面左侧的说明。这种头尾正则语法的设置,对用户的要求更高。如果您不熟悉 PHP,请谨慎使用。
设置好后点击“test采集title”
如图,我们采集去内容页地址和对应的标题。然后关闭测试页面,点击“下一步”,设置内容采集rule。 查看全部
齐博CMS自带采集体验系列之DedeCMSv5.7系统
cms自带采集生活系列文章已完成三期:
cms自带采集PHPcmsV9体验系列
cms自带采集Dedecmsv5.7体验系列
cms自带采集测试系列cmsv6.6
今天的第四期,来感受一下齐博cms自己的采集,齐博cms原名PHP168网站管理,是大学时期由“龙城”创建的,也就是在2003年系统于2010年12月1日更名为奇博软件,自2003年10月V1.0版本发布以来,历经多次版本升级,现已发展成为最成熟的“核心+模块+插件” ”架构系统,成为国内领先的开源PHP系统。涉及电子政务、媒体新闻门户、大型企业信息化、电子商务B2B等高端互联网应用,为数以万计的免费和付费用户提供了应用平台。
同理,今天我们来体验采集自带的Qibocms全站系统的文章采集和群图采集功能。目标网站还是和之前的文章一样,所以比较好。
一、文章采集
1、Title 和 URL采集
采集target网站:
任意填写规则名称,以及所属类别,采集不影响内容。
List网站也有两种添加方式,一种是手动输入多页,另一种是有规律连续的多页。分析目标站的列表页URL,得到列表页的规则,用[page]代替换号就够了,所以我们选择“规则连续多页”,填写[page].shtml,然后填写开始和结束页码以及每次更改的渐变。 (温馨提示:在整个采集设置过程中,所有通配符都不需要手动填写,可以点击旁边官方说明中的通配符自动复制,直接粘贴即可)
同时奇博也考虑到网站list页面第一页的一些URL规则不符合整体更改规则,所以在后面有一个文本框填写不规则第一页。我们采集目标的第一页符合整体规律,所以留空。
采集内容页地址和内容页标题。奇博cms自带采集和别人不同:采集title不在内容页采集,而是在采集list页文章url而且还直接放了锚文本文本采集 是标题。您只需要定义这个指向内容页面的锚文本规则。其中{url=*}表示标题URL通配符,{title=*}表示标题通配符,{*}表示不需要的内容通配符。分析我们的目标站,我们可以得到以下规则:
{title=*}{*}
其实这个设计有点瑕疵。比如为了让列表页更美观,有的网站限制了列表页标题字数,然后控制文章双标题中副标题字数显示它在列表页面上。并且主标题出现在内容页面上。
接下来可以勾选“显示不常用的高级设置”来进一步设置采集 URL。其实还有几个功能还是比较常用的,比如设置不能收录在链接中或者必须收录在过滤器中的字符。当它干扰链接时也很常见。另外,其他替换标题字符、链接字符、指定截取区域可以参考页面左侧的说明。这种头尾正则语法的设置,对用户的要求更高。如果您不熟悉 PHP,请谨慎使用。
设置好后点击“test采集title”
如图,我们采集去内容页地址和对应的标题。然后关闭测试页面,点击“下一步”,设置内容采集rule。
如何添加采集苹果cms自定义资源库(图文教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 749 次浏览 • 2021-05-20 22:23
1,今天,我将教您如何添加采集 Apple cms自定义资源库;输入背景,让我们以资源站为例,可以从网站所需的位置获取界面采集。通常在网站的帮助中心内:添加方法如下图所示(如果添加&ct = 1)后测试不成功,则需要填写其他参数。
2,我没有在这里填写,只要测试界面成功,就直接保存即可。如果测试失败,请填写其他参数&ct = 1),如果仍然无法正常工作,请检查采集界面是否填写错误
3。成功添加资源接口后,需要对资源进行分类和绑定:单击高清资源链接,进入绑定页面进行分类和绑定。
4。进入类别绑定页面后,单击未绑定页面,类别绑定将自动弹出。如果找不到对应的类别,则可以先绑定到相似的类别,也可以参考主题网络上的上一个共享。教程:Apple cms如何添加自定义分类的详细教程
5,绑定后,其余为采集。将其拉到页面底部。有一个采集按钮可以在采集天(需要采集的视频前面打勾)和采集这一天的所有三个选项选择采集。
6,选择后,进入自动采集页面。如果绑定采集成功,它将以绿色和红色显示。如果绑定不成功,请跳过采集,因此在绑定时必须小心绑定。
7,结束语:网站应该在最后一个采集结束后才具有视频数据。此时,这也是一个使很多人感到困惑的地方。 采集结束后无法播放!为什么是这样?这是因为您没有添加播放器。
每个资源站都有自己的单独播放器和分析程序。也就是说,您采集的资源只能与其播放器一起播放。通常可以在网站的帮助中心找到玩家,并提供详细的说明。
如果采集之后您不能玩,请参考以下教程:在Apple cms 采集之后导入并添加播放器。
转载: 查看全部
如何添加采集苹果cms自定义资源库(图文教程)
1,今天,我将教您如何添加采集 Apple cms自定义资源库;输入背景,让我们以资源站为例,可以从网站所需的位置获取界面采集。通常在网站的帮助中心内:添加方法如下图所示(如果添加&ct = 1)后测试不成功,则需要填写其他参数。
2,我没有在这里填写,只要测试界面成功,就直接保存即可。如果测试失败,请填写其他参数&ct = 1),如果仍然无法正常工作,请检查采集界面是否填写错误
3。成功添加资源接口后,需要对资源进行分类和绑定:单击高清资源链接,进入绑定页面进行分类和绑定。
4。进入类别绑定页面后,单击未绑定页面,类别绑定将自动弹出。如果找不到对应的类别,则可以先绑定到相似的类别,也可以参考主题网络上的上一个共享。教程:Apple cms如何添加自定义分类的详细教程
5,绑定后,其余为采集。将其拉到页面底部。有一个采集按钮可以在采集天(需要采集的视频前面打勾)和采集这一天的所有三个选项选择采集。
6,选择后,进入自动采集页面。如果绑定采集成功,它将以绿色和红色显示。如果绑定不成功,请跳过采集,因此在绑定时必须小心绑定。
7,结束语:网站应该在最后一个采集结束后才具有视频数据。此时,这也是一个使很多人感到困惑的地方。 采集结束后无法播放!为什么是这样?这是因为您没有添加播放器。
每个资源站都有自己的单独播放器和分析程序。也就是说,您采集的资源只能与其播放器一起播放。通常可以在网站的帮助中心找到玩家,并提供详细的说明。
如果采集之后您不能玩,请参考以下教程:在Apple cms 采集之后导入并添加播放器。
转载:
CMS内容管理系统特点易用性CMS的界面尽量模拟Windows软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-05-20 01:22
cms内容管理系统Internet内容管理平台
cms内容管理系统的功能
易于使用
cms的界面尽可能地模拟Windows软件的操作习惯,提供右键单击菜单,支持拖放操作以及图形按钮和菜单。
强大的编辑器
1) cms提供了一个功能强大且易于使用的在线编辑器。
2) cms支持在线运行Office前端功能,并直接使用Office功能作为编辑器。
3)支持以其他格式批量输入文档。
灵活性
1)对于不同类型的信息,cms允许您为每个通道设置表单并添加扩展字段。字段类型支持文本,列表,图片,日期,文件,标签等。从而可以实现对任意结构信息的管理。
2)为了输出信息,cms使用在模板中插入脚本的技术来输出任何格式的任意数据。
3)发布结果,cms支持RSS标准,XML格式,并自动转换为UTF8编码。这样,数据可以以丰富的形式显示,内容和形式可以完美地结合在一起。
4) cms可以灵活地定义生成文件的后缀,命名规则,图像上传目录等。
模板技术
模板技术是衡量cms系统的重要指标。 cms采用脚本技术,在HTML中插入脚本并可以访问COM,其技术与流行的ASP,.Net和其他技术一致。示例:
就模板制作方法而言,cms提供了DreamWeaver插件。在图形模式下,您可以通过拖放来插入预定义的代码。
在模板可扩展性方面,在cms中,当系统预先提供的插件不能满足要求时,可以手动编写脚本以实现所需的功能。
工作流程支持
在cms中,文章发布的基本过程是:
内容录入→记录→编辑→审阅→签发→发布,可以被拒绝,也可以进行重做。当固定流程不符合要求时,您可以自定义工作流程并根据渠道指定是否使用工作流程。
支持小组协作,用于更多内容的电子出版物。
自动化采集
除了为用户提供输入文章的界面外,内容管理系统还应提供自动化的采集功能。 cms企业版系统本身具有采集模块(某些采集功能目前正在开发中),它支持三种自动化方法采集,数据库采集,文件采集和网页采集,可以设置采集来源,采集目的地,采集频率等。
特殊主题管理,页面管理
cms提供了特殊的主题管理功能,可以由频道编辑器推荐给主题,或者可以由主题编辑器对其进行排序和提取。
cms提供特殊页面管理功能,专门用于管理特殊页面,例如网站主页,版权页面和联系信息页面。
可移植性
cms提供了专用的数据库导入和导出工具,用于将数据库导入HB cms数据库迁移工具,该工具可以自动将原创内容库导入到cms内容库中。 查看全部
CMS内容管理系统特点易用性CMS的界面尽量模拟Windows软件
cms内容管理系统Internet内容管理平台
cms内容管理系统的功能
易于使用
cms的界面尽可能地模拟Windows软件的操作习惯,提供右键单击菜单,支持拖放操作以及图形按钮和菜单。
强大的编辑器
1) cms提供了一个功能强大且易于使用的在线编辑器。
2) cms支持在线运行Office前端功能,并直接使用Office功能作为编辑器。
3)支持以其他格式批量输入文档。
灵活性
1)对于不同类型的信息,cms允许您为每个通道设置表单并添加扩展字段。字段类型支持文本,列表,图片,日期,文件,标签等。从而可以实现对任意结构信息的管理。
2)为了输出信息,cms使用在模板中插入脚本的技术来输出任何格式的任意数据。
3)发布结果,cms支持RSS标准,XML格式,并自动转换为UTF8编码。这样,数据可以以丰富的形式显示,内容和形式可以完美地结合在一起。
4) cms可以灵活地定义生成文件的后缀,命名规则,图像上传目录等。
模板技术
模板技术是衡量cms系统的重要指标。 cms采用脚本技术,在HTML中插入脚本并可以访问COM,其技术与流行的ASP,.Net和其他技术一致。示例:
就模板制作方法而言,cms提供了DreamWeaver插件。在图形模式下,您可以通过拖放来插入预定义的代码。
在模板可扩展性方面,在cms中,当系统预先提供的插件不能满足要求时,可以手动编写脚本以实现所需的功能。
工作流程支持
在cms中,文章发布的基本过程是:
内容录入→记录→编辑→审阅→签发→发布,可以被拒绝,也可以进行重做。当固定流程不符合要求时,您可以自定义工作流程并根据渠道指定是否使用工作流程。
支持小组协作,用于更多内容的电子出版物。
自动化采集
除了为用户提供输入文章的界面外,内容管理系统还应提供自动化的采集功能。 cms企业版系统本身具有采集模块(某些采集功能目前正在开发中),它支持三种自动化方法采集,数据库采集,文件采集和网页采集,可以设置采集来源,采集目的地,采集频率等。
特殊主题管理,页面管理
cms提供了特殊的主题管理功能,可以由频道编辑器推荐给主题,或者可以由主题编辑器对其进行排序和提取。
cms提供特殊页面管理功能,专门用于管理特殊页面,例如网站主页,版权页面和联系信息页面。
可移植性
cms提供了专用的数据库导入和导出工具,用于将数据库导入HB cms数据库迁移工具,该工具可以自动将原创内容库导入到cms内容库中。
什么是采集;采集功能怎么使用呢;对cms采集作以下对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2021-02-17 09:01
什么是采集;如何使用采集的功能;比较cms 采集如下:DEDE cms,php168,Empire cms,优采云; 采集的优缺点;向新手推荐方法
图片4851-1:
关于采集的优缺点,这主要取决于个人的想法。基本上,家用cms系统具有采集,由于其便利性和选择性,它已被网站管理员普遍接受。 [k15之后],无需花时间思考如何创建网站内容。当然采集不好,因为每个人都去采集。可以说,大量的内容物已经积累形成垃圾圈。当然,搜索引擎也拒绝了收录或被k丢弃。在这里,我们将不讨论采集的优缺点,因为我也很矛盾。尽管我认为采集不够好,但我仍然每天都使用它。以下只是我个人的看法,希望对新手有所帮助。
什么是采集
采集意味着我们将他人网站上的内容获取到我们自己的网站中。您可以先按Ctrl + C,再按Ctrl + V。但是复制和粘贴之间的区别在于它是分批的和智能的。您在一分钟内可以手动复制多少文章?可以想象,当然,我们必须将文章标题和内容,甚至发布时间,作者等分开。如果使用采集,则将有所不同。如果性能允许,则可以是每分钟采集数百篇文章文章。这大大减少了网站管理员的时间。
如何使用采集功能
国内cms通常具有采集功能,并且正在不断完善。还有一些论坛和博客程序以前没有采集功能,有些人会开发采集插件。
因为我更喜欢使用(织梦)的dede cms,所以我对其他cms系统了解不多,但是Internet上有许多相关的教程。您可以自己找到它并阅读以下内容。此外,还有哪些其他程序具有自己的采集,我们可以在百度上查看它们,例如php16 8、 php cms,Empire cms,Dongyi,Xinyun等。
接下来,我将讨论一个更强大的采集器,即优采云,优采云 采集器用于批处理采集网页,论坛等,直接保存到数据库或发布到网站一种工具,他们可以根据用户设置的规则自动采集原创网页,以获取格式网页中所需的内容。
那么如何使用这些采集器?如果要使用cms程序,则只需在安装完成后编写采集规则。如果是优采云,则有两种方法,一种是编写采集规则,第二种是编写用于连接网站的发布模块,然后您可以采集 +将内容发布到网站上去。
比较cms 采集如下
DEDE cms:功能强大,新手需要学习更多才能掌握它。该功能非常强大,我相信使用它的任何人都会知道它。但是DEDE具有单词替换功能,只要您导入单词替换数据即可执行替换操作,这对于伪原创更好。
php168:
1.随新浪新闻采集系统提供,该系统非常方便和免费采集新浪国内,国际,社会,娱乐,技术,金融,军事,体育新闻。
2.可以自由添加采集个参数,并且可以共享采集个参数,您可以导出采集个参数并与其他人共享。
3.可以轻松获得采集像奇虎这样的新闻,这意味着您可以建立像奇虎这样的电台。
帝国cms:
1.易于使用:无需知道任何程序,只需将相应的标签添加到相应的内容中
2.多重过滤:可以将同一链接设置为不重复采集;设置采集个关键字(采集除外);内容字符替换;广告过滤;过滤相似信息;过滤具有相同标题的信息;您可以设置采集的前几条记录。
php cms:整个站点内容页面的一般规则(请注意,这是内容页面,这是文章的详细显示页面)。如果在此处设置,将来添加采集个任务时,此规则将自动继承,这将节省大量工作。
优采云:强大的自定义参数,但是新手可以按照官方教程逐步进行操作。对于这样的采集软件,通常,只要网站程序中没有采集功能,或者该功能不够强大不能满足他们的要求,朋友就可以去看看。就个人而言,优采云是一款相对不错的采集软件。
采集的优缺点
尽管文章中未提及,但这里是对新手朋友的仔细分析。
优点:完成许多文章发行版可能需要少量时间。一个小时内可以发布成千上万的文章文章。减少了网站的维护和编写时间,并为网站管理员提供了便利。
缺点:内容是高度重复的,因为您是采集别人的文章,所以即使您是伪原创,您和其他人的文章也会重复很多,如果100个人,请考虑一下使用它伪原创工具,与采集不一样吗?我们不要谈论伪原创工具的优缺点。如果互联网充满了文章,但可读性没有任何价值,那么您认为网站可以保留客户吗? 网站内容的重复结果只有收录少,排名低。
新手推荐方法
我在互联网上看到一些人说,网站很容易做,只需安装该程序,然后采集就可以了。还有什么要说的采集更适合新手,个人认为这是胡说八道,网站不可读,有价值文章,您认为您可以保留这样的客户吗?我希望新手尽可能少地使用采集,并充实更有价值的文章,这是您的原创 文章,而不是发牢骚的采集。我希望这些对新手有用。
1.新手使用采集,那么将会有惯性,即使在将来,即使他们驻足,他们也会选择采集器。
2.为新手建立网站是一个学习过程。重要的是自己写文章。不要说您是否有写能力,或者如果您不能写,那么更改其他人的文章是件好事。这不仅比伪原创程序高,而且可读性更高。最重要的是,新手朋友可以不断学习和提高他们的知识。
3.误导了新手建立网站的观点。最初构建网站是为了为网民服务,并为自己带来好处。在使用了采集之后,尤其是那些曾经使用过的伪原创工具之后,无论网民是否喜欢它,它都值得期待。这会使新手目光短浅,不利于长期发展。
4.不利于新手学习seo。如果使用采集器,则基本上不需要seo。 seo是理论+实践的过程。只有在实践中论证理论并改变他们的错误观点,我们才能真正掌握SEO的核心部分。
我个人认为,新手会尽力用自己的双手写作文章。尽管写作效果不好,但我相信将来会更好。如果您想赚钱,请不要使用采集器,因为不是您在线赚钱。很简单不要以为如果您构建网站,就会有钱。如果此方法在头两年有效,那么现在将不起作用。如果您想赚钱,则必须有一个过程。因此,对于新手来说,您可以每天写一篇文章文章,然后继续学习和练习。我相信目标会越来越接近您。 查看全部
什么是采集;采集功能怎么使用呢;对cms采集作以下对比
什么是采集;如何使用采集的功能;比较cms 采集如下:DEDE cms,php168,Empire cms,优采云; 采集的优缺点;向新手推荐方法
图片4851-1:
关于采集的优缺点,这主要取决于个人的想法。基本上,家用cms系统具有采集,由于其便利性和选择性,它已被网站管理员普遍接受。 [k15之后],无需花时间思考如何创建网站内容。当然采集不好,因为每个人都去采集。可以说,大量的内容物已经积累形成垃圾圈。当然,搜索引擎也拒绝了收录或被k丢弃。在这里,我们将不讨论采集的优缺点,因为我也很矛盾。尽管我认为采集不够好,但我仍然每天都使用它。以下只是我个人的看法,希望对新手有所帮助。
什么是采集
采集意味着我们将他人网站上的内容获取到我们自己的网站中。您可以先按Ctrl + C,再按Ctrl + V。但是复制和粘贴之间的区别在于它是分批的和智能的。您在一分钟内可以手动复制多少文章?可以想象,当然,我们必须将文章标题和内容,甚至发布时间,作者等分开。如果使用采集,则将有所不同。如果性能允许,则可以是每分钟采集数百篇文章文章。这大大减少了网站管理员的时间。
如何使用采集功能
国内cms通常具有采集功能,并且正在不断完善。还有一些论坛和博客程序以前没有采集功能,有些人会开发采集插件。
因为我更喜欢使用(织梦)的dede cms,所以我对其他cms系统了解不多,但是Internet上有许多相关的教程。您可以自己找到它并阅读以下内容。此外,还有哪些其他程序具有自己的采集,我们可以在百度上查看它们,例如php16 8、 php cms,Empire cms,Dongyi,Xinyun等。
接下来,我将讨论一个更强大的采集器,即优采云,优采云 采集器用于批处理采集网页,论坛等,直接保存到数据库或发布到网站一种工具,他们可以根据用户设置的规则自动采集原创网页,以获取格式网页中所需的内容。
那么如何使用这些采集器?如果要使用cms程序,则只需在安装完成后编写采集规则。如果是优采云,则有两种方法,一种是编写采集规则,第二种是编写用于连接网站的发布模块,然后您可以采集 +将内容发布到网站上去。
比较cms 采集如下
DEDE cms:功能强大,新手需要学习更多才能掌握它。该功能非常强大,我相信使用它的任何人都会知道它。但是DEDE具有单词替换功能,只要您导入单词替换数据即可执行替换操作,这对于伪原创更好。
php168:
1.随新浪新闻采集系统提供,该系统非常方便和免费采集新浪国内,国际,社会,娱乐,技术,金融,军事,体育新闻。
2.可以自由添加采集个参数,并且可以共享采集个参数,您可以导出采集个参数并与其他人共享。
3.可以轻松获得采集像奇虎这样的新闻,这意味着您可以建立像奇虎这样的电台。
帝国cms:
1.易于使用:无需知道任何程序,只需将相应的标签添加到相应的内容中
2.多重过滤:可以将同一链接设置为不重复采集;设置采集个关键字(采集除外);内容字符替换;广告过滤;过滤相似信息;过滤具有相同标题的信息;您可以设置采集的前几条记录。
php cms:整个站点内容页面的一般规则(请注意,这是内容页面,这是文章的详细显示页面)。如果在此处设置,将来添加采集个任务时,此规则将自动继承,这将节省大量工作。
优采云:强大的自定义参数,但是新手可以按照官方教程逐步进行操作。对于这样的采集软件,通常,只要网站程序中没有采集功能,或者该功能不够强大不能满足他们的要求,朋友就可以去看看。就个人而言,优采云是一款相对不错的采集软件。
采集的优缺点
尽管文章中未提及,但这里是对新手朋友的仔细分析。
优点:完成许多文章发行版可能需要少量时间。一个小时内可以发布成千上万的文章文章。减少了网站的维护和编写时间,并为网站管理员提供了便利。
缺点:内容是高度重复的,因为您是采集别人的文章,所以即使您是伪原创,您和其他人的文章也会重复很多,如果100个人,请考虑一下使用它伪原创工具,与采集不一样吗?我们不要谈论伪原创工具的优缺点。如果互联网充满了文章,但可读性没有任何价值,那么您认为网站可以保留客户吗? 网站内容的重复结果只有收录少,排名低。
新手推荐方法
我在互联网上看到一些人说,网站很容易做,只需安装该程序,然后采集就可以了。还有什么要说的采集更适合新手,个人认为这是胡说八道,网站不可读,有价值文章,您认为您可以保留这样的客户吗?我希望新手尽可能少地使用采集,并充实更有价值的文章,这是您的原创 文章,而不是发牢骚的采集。我希望这些对新手有用。
1.新手使用采集,那么将会有惯性,即使在将来,即使他们驻足,他们也会选择采集器。
2.为新手建立网站是一个学习过程。重要的是自己写文章。不要说您是否有写能力,或者如果您不能写,那么更改其他人的文章是件好事。这不仅比伪原创程序高,而且可读性更高。最重要的是,新手朋友可以不断学习和提高他们的知识。
3.误导了新手建立网站的观点。最初构建网站是为了为网民服务,并为自己带来好处。在使用了采集之后,尤其是那些曾经使用过的伪原创工具之后,无论网民是否喜欢它,它都值得期待。这会使新手目光短浅,不利于长期发展。
4.不利于新手学习seo。如果使用采集器,则基本上不需要seo。 seo是理论+实践的过程。只有在实践中论证理论并改变他们的错误观点,我们才能真正掌握SEO的核心部分。
我个人认为,新手会尽力用自己的双手写作文章。尽管写作效果不好,但我相信将来会更好。如果您想赚钱,请不要使用采集器,因为不是您在线赚钱。很简单不要以为如果您构建网站,就会有钱。如果此方法在头两年有效,那么现在将不起作用。如果您想赚钱,则必须有一个过程。因此,对于新手来说,您可以每天写一篇文章文章,然后继续学习和练习。我相信目标会越来越接近您。
官方数据:大数据目标栏目整体采集发布到CMS文章系统的指定栏目
采集交流 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2020-12-27 09:19
作为整体的大数据目标列采集已发布到cms文章系统的指定列(实际战斗)准备:要下载采集器,您还需要下载Microsoft .NET Framework v2.0并在下载页面上注册帐号:根据需要填写注册信息,然后按确认进行注册,然后转到注册过程中填写的电子邮件地址以完成注册验证。软件安装:首先安装Microsoft.NET Framework v2.0,然后安装优采云采集器软件。 4:登录到软件单击桌面采集软件图标登录到该软件。首次登录时,该软件将自动升级,然后在您刚注册时填写信息。然后,我们完成了软件的下载,注册和安装。大数据目标列整体采集已发布到文章系统的指定列,我们首先登录采集软件并找到采集数据网站列页面(中间部分)标明域名),然后单击采集软件。项目管理在左上角-选择新项目(标准)以跳出项目名称并编写视频采集(您可以随意填写)其他默认值很好,单击左下角的下一个设置,然后在标题列表页面的起始地址采集地址中输入所需的地址,然后单击以开始预分析,然后弹出提示点:是,软件会自动找到标题页面的下一页和最后一页链接以及翻页次数。并列出了相应的值(我们是整体采集,所以我选择标题列表页面的页数为29),然后单击“下一步”进入内容选择页面以查看软件是否找到了我们的内容链接(在框中红色),然后单击下一步设置以进入内容页面模板管理。我选择了方法1,使用自定义模板(我个人喜欢使用此模板,可以使用有用的模板,而不能使用任何模板)使用此页面时忽略)要设置采集的内容,因为它是整个采集列,请在中间部分添加一个新模板,然后输入所需的内容页面的地址采集,(即,您想要采集 文章页面内容的详细信息)然后单击以添加一个新模板,我选择了“ fine”,然后单击以开始分析,采集自动为我们采集了标题和文本,但是还需要设置所需的标题和文本,然后我们选择[对于k15的内容],在表格中单击以启动所需的单词采集 文章,文章在右侧的红色区域中,但不完整,因此我们需要使用复合语句,单击[表中的k13],然后选择将采集存储表保存在采集中在下面的[]中,相应的字段名称是文本,检查复合句子,如果文章的内容不完整,请继续在表中单击。 采集 文章的内容,然后重复上述操作,直到文章的内容完成,并且我们的采集的工作在这里完成。
下一步,我将测试采集:该软件已经很容易地批处理采集到文章的标题和内容,让我进行最后一步并将其发布到我的网站: ,右键单击要发布到网站的列,然后执行以下步骤,最后选择数据模拟发布以启用模拟WEB发布采集的功能。选择发布机制采集后,可以同时进行发布,并且其他默认设置也可以,然后在登录参数设置和定义字段UserName =中填写网站用于后台登录的用户名,密码和身份验证代码。 =用户名PWD ==密码AdminLoginCode ==身份验证代码,我们可以轻松地验证并登录网站背景,下一步是设置发布页面,我们必须登录网站,找到背景地址发布文章页面,在文章系统上单击以填写文章,后台地址栏中显示的地址不是我们要发布文章页面的确切地址。我们想在后台发布文章页面,右键单击并选择属性,以便获得文章页面的确切地址,如图中红色圆圈所示。它是发布页面的特定地址。我们将其复制并粘贴到WEB发布页面的地址中。然后采集软件会一次自动分析并列出发布页面表的值。首先,选择要发布的文章对应的列,单击并按OK,选择疾病,然后设置文章的标题和文本,然后选择方法1从采集的结果中进行选择,[刚刚测试的k13]已成功发布,并且设置完成。稍后,按确认按钮,然后进入采集发布的最后阶段,单击开始和运行按钮,嘿,开心一点,然后源源不断的信息将存储在采集中。 查看全部
官方数据:大数据目标栏目整体采集发布到CMS文章系统的指定栏目
作为整体的大数据目标列采集已发布到cms文章系统的指定列(实际战斗)准备:要下载采集器,您还需要下载Microsoft .NET Framework v2.0并在下载页面上注册帐号:根据需要填写注册信息,然后按确认进行注册,然后转到注册过程中填写的电子邮件地址以完成注册验证。软件安装:首先安装Microsoft.NET Framework v2.0,然后安装优采云采集器软件。 4:登录到软件单击桌面采集软件图标登录到该软件。首次登录时,该软件将自动升级,然后在您刚注册时填写信息。然后,我们完成了软件的下载,注册和安装。大数据目标列整体采集已发布到文章系统的指定列,我们首先登录采集软件并找到采集数据网站列页面(中间部分)标明域名),然后单击采集软件。项目管理在左上角-选择新项目(标准)以跳出项目名称并编写视频采集(您可以随意填写)其他默认值很好,单击左下角的下一个设置,然后在标题列表页面的起始地址采集地址中输入所需的地址,然后单击以开始预分析,然后弹出提示点:是,软件会自动找到标题页面的下一页和最后一页链接以及翻页次数。并列出了相应的值(我们是整体采集,所以我选择标题列表页面的页数为29),然后单击“下一步”进入内容选择页面以查看软件是否找到了我们的内容链接(在框中红色),然后单击下一步设置以进入内容页面模板管理。我选择了方法1,使用自定义模板(我个人喜欢使用此模板,可以使用有用的模板,而不能使用任何模板)使用此页面时忽略)要设置采集的内容,因为它是整个采集列,请在中间部分添加一个新模板,然后输入所需的内容页面的地址采集,(即,您想要采集 文章页面内容的详细信息)然后单击以添加一个新模板,我选择了“ fine”,然后单击以开始分析,采集自动为我们采集了标题和文本,但是还需要设置所需的标题和文本,然后我们选择[对于k15的内容],在表格中单击以启动所需的单词采集 文章,文章在右侧的红色区域中,但不完整,因此我们需要使用复合语句,单击[表中的k13],然后选择将采集存储表保存在采集中在下面的[]中,相应的字段名称是文本,检查复合句子,如果文章的内容不完整,请继续在表中单击。 采集 文章的内容,然后重复上述操作,直到文章的内容完成,并且我们的采集的工作在这里完成。
下一步,我将测试采集:该软件已经很容易地批处理采集到文章的标题和内容,让我进行最后一步并将其发布到我的网站: ,右键单击要发布到网站的列,然后执行以下步骤,最后选择数据模拟发布以启用模拟WEB发布采集的功能。选择发布机制采集后,可以同时进行发布,并且其他默认设置也可以,然后在登录参数设置和定义字段UserName =中填写网站用于后台登录的用户名,密码和身份验证代码。 =用户名PWD ==密码AdminLoginCode ==身份验证代码,我们可以轻松地验证并登录网站背景,下一步是设置发布页面,我们必须登录网站,找到背景地址发布文章页面,在文章系统上单击以填写文章,后台地址栏中显示的地址不是我们要发布文章页面的确切地址。我们想在后台发布文章页面,右键单击并选择属性,以便获得文章页面的确切地址,如图中红色圆圈所示。它是发布页面的特定地址。我们将其复制并粘贴到WEB发布页面的地址中。然后采集软件会一次自动分析并列出发布页面表的值。首先,选择要发布的文章对应的列,单击并按OK,选择疾病,然后设置文章的标题和文本,然后选择方法1从采集的结果中进行选择,[刚刚测试的k13]已成功发布,并且设置完成。稍后,按确认按钮,然后进入采集发布的最后阶段,单击开始和运行按钮,嘿,开心一点,然后源源不断的信息将存储在采集中。
安全解决方案:帝国CMS-采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2020-11-30 10:17
Empire cms 采集实际上非常简单,只需使用Empire cms 采集插件即可完成。这里以7.0为例
进入后台cms帝国,选择“列”菜单,然后在左侧菜单中选择“ 采集管理”
打开“管理采集个节点”
您可以看到所有现有的采集条规则节点
开始在下面添加新的采集规则
点击添加节点按钮
在中间,系统将提示您选择要创建的列,然后单击要创建的列,例如国际新闻。好吧,只需单击并进入。出现的界面具有第一个节点的名称,因为上面创建的是国际新闻。在这里,填写国际新闻的父节点,无需关注(只需将其保留)
页面采集的地址通常用于选择新闻列表页面,该页面可以从新浪国际新闻复制。例如,可以在地址栏中复制国际新闻多面的地址。
采集页面地址方法二,不在乎是否填写内容,页面地址前缀写为
图片/ FLASH地址前缀(内容)~~~这里拦截内容介绍,不必费心开始填写采集常规内容,那么您需要查看网页的源代码。
信息页面的常规链接
无需填写标题图片的常规性:打开内容页面,然后在您刚才的大栏中打开文章
常规字幕:~~~常规信息源不需要编写新闻正文常规:
确定提交!
让我们预览一下是否有错误
单击“预览” 采集输入节点预览结果:
采集内容页面列表
采集内容页面页面:
预览采集节点后,返回“管理节点”,单击“启动采集”链接以启动采集
系统位于采集
采集完成后,将显示本地临时存储信息。此时,可以修改或删除临时存储信息
要查看采集的信息并将其存储在仓库中,请单击“存储所有信息”按钮
确定操作
提示完成信息存储
信息存储在数据库中后,单击管理信息
我们刚刚进入采集数据库就可以看到新闻信息
到目前为止,所有采集信息均已完成。帝国cms 采集非常强大,您需要自己进行探索。
注意:
通常,在2种情况下采集不可用:
在1、列表页面上选择的采集区域的规则不正确
2、详细信息页面常规错误
可以通过预览逐项找到原因,基本上可以找到采集,包括伪静态信息。 查看全部
帝国cms-采集
Empire cms 采集实际上非常简单,只需使用Empire cms 采集插件即可完成。这里以7.0为例
进入后台cms帝国,选择“列”菜单,然后在左侧菜单中选择“ 采集管理”
打开“管理采集个节点”
您可以看到所有现有的采集条规则节点
开始在下面添加新的采集规则
点击添加节点按钮
在中间,系统将提示您选择要创建的列,然后单击要创建的列,例如国际新闻。好吧,只需单击并进入。出现的界面具有第一个节点的名称,因为上面创建的是国际新闻。在这里,填写国际新闻的父节点,无需关注(只需将其保留)
页面采集的地址通常用于选择新闻列表页面,该页面可以从新浪国际新闻复制。例如,可以在地址栏中复制国际新闻多面的地址。
采集页面地址方法二,不在乎是否填写内容,页面地址前缀写为
图片/ FLASH地址前缀(内容)~~~这里拦截内容介绍,不必费心开始填写采集常规内容,那么您需要查看网页的源代码。
信息页面的常规链接
无需填写标题图片的常规性:打开内容页面,然后在您刚才的大栏中打开文章
常规字幕:~~~常规信息源不需要编写新闻正文常规:
确定提交!
让我们预览一下是否有错误
单击“预览” 采集输入节点预览结果:
采集内容页面列表
采集内容页面页面:
预览采集节点后,返回“管理节点”,单击“启动采集”链接以启动采集
系统位于采集
采集完成后,将显示本地临时存储信息。此时,可以修改或删除临时存储信息
要查看采集的信息并将其存储在仓库中,请单击“存储所有信息”按钮
确定操作
提示完成信息存储
信息存储在数据库中后,单击管理信息
我们刚刚进入采集数据库就可以看到新闻信息
到目前为止,所有采集信息均已完成。帝国cms 采集非常强大,您需要自己进行探索。
注意:
通常,在2种情况下采集不可用:
在1、列表页面上选择的采集区域的规则不正确
2、详细信息页面常规错误
可以通过预览逐项找到原因,基本上可以找到采集,包括伪静态信息。
汇总:2016-2017年帝国cms文章采集教程(1)
采集交流 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2020-10-23 13:03
Empirecms是一个网站构建系统,我们使用越来越多的PHP。在网站建设过程中,如果您没有任何信息,则只能重复手动复制和粘贴,这既费时又费力,因此我们必须使用Empirecms随附的采集功能来完成信息输入。为了了解Empirecms采集的功能,我们以“新浪新闻”专栏为例进行实际战斗采集。一、添加采集节点1、添加节点:2、选择要添加的列采集:3、输入添加节点的形式:4、在节点名称框中输入名称,然后将采集的新浪新闻列表地址复制到此处:5、我发现了很多选择,例如“ 采集页面地址方法二,内容页面地址前缀...”,暂时忽略他,我将解释他们一个接一个,只需将其转到“常规信息链接区域”即可:6、这是为采集常规设置的列表信息链接区域,我们单击以查看新浪地区的新闻列表“来源7、将源文件代码复制到Dreamweaver中,在Dreamweaver中选择信息链接区域到采集:8、切换到Dreamweaver代码模式,这是信息链接区域:9、获取信息链接区域规则:10、获取信息页面链接规则:1 1、注意:例如,如果信息页面链接是相对地址,则“内容页面地址前缀”应添加域名:1 2、现在采集标题和内容内容页面的t:1 3、检查新闻页面“源文件”并找到标题标签:1 4、获取标题规则:1 5、这是采集的内容区域:1 6、获取新闻内容规则:(注意:新闻内容规则中的d_id =“ *”使用通配符,因为每个新闻文章的d_id值都不同,所以可以使用*替换它,而“ *”可以替换任何字符
)1 7、单击提交按钮以完成整个采集节点:二、预览采集节点是否正确1、提交按钮并返回到管理节点:2、单击“ Preview” 采集,输入节点预览结果:3、 采集内容页面列表4、 采集内容页面页面:三、采集 1、预览采集节点正确后,然后返回到“管理节点”,单击“启动采集”链接将启动采集:2、系统位于采集:3、 采集完成3、之后,采集将显示本地临时存储信息,然后可以执行临时存储信息。修改或删除:4、修改后的信息页面如图所示:5、查看采集的信息并将其存储在仓库中,单击“在所有信息中存储按钮”:6、确认操作:7、存储中的信息完成提示:将信息存储在数据库中后,单击“管理信息”:我们可以看到收录新闻的新闻信息st存储在采集中:最后,转到“数据更新”以刷新主页,列和内容页面以完成网站采集的信息。由于Empirecms采集非常强大,因此我暂时无法完成。下一个讲座将继续说明其他功能的用法和技术。本文的组织者,请保留链接以供转载,谢谢! 13 1414 查看全部
2016-2017 Empirecms文章采集教程(1)
Empirecms是一个网站构建系统,我们使用越来越多的PHP。在网站建设过程中,如果您没有任何信息,则只能重复手动复制和粘贴,这既费时又费力,因此我们必须使用Empirecms随附的采集功能来完成信息输入。为了了解Empirecms采集的功能,我们以“新浪新闻”专栏为例进行实际战斗采集。一、添加采集节点1、添加节点:2、选择要添加的列采集:3、输入添加节点的形式:4、在节点名称框中输入名称,然后将采集的新浪新闻列表地址复制到此处:5、我发现了很多选择,例如“ 采集页面地址方法二,内容页面地址前缀...”,暂时忽略他,我将解释他们一个接一个,只需将其转到“常规信息链接区域”即可:6、这是为采集常规设置的列表信息链接区域,我们单击以查看新浪地区的新闻列表“来源7、将源文件代码复制到Dreamweaver中,在Dreamweaver中选择信息链接区域到采集:8、切换到Dreamweaver代码模式,这是信息链接区域:9、获取信息链接区域规则:10、获取信息页面链接规则:1 1、注意:例如,如果信息页面链接是相对地址,则“内容页面地址前缀”应添加域名:1 2、现在采集标题和内容内容页面的t:1 3、检查新闻页面“源文件”并找到标题标签:1 4、获取标题规则:1 5、这是采集的内容区域:1 6、获取新闻内容规则:(注意:新闻内容规则中的d_id =“ *”使用通配符,因为每个新闻文章的d_id值都不同,所以可以使用*替换它,而“ *”可以替换任何字符
)1 7、单击提交按钮以完成整个采集节点:二、预览采集节点是否正确1、提交按钮并返回到管理节点:2、单击“ Preview” 采集,输入节点预览结果:3、 采集内容页面列表4、 采集内容页面页面:三、采集 1、预览采集节点正确后,然后返回到“管理节点”,单击“启动采集”链接将启动采集:2、系统位于采集:3、 采集完成3、之后,采集将显示本地临时存储信息,然后可以执行临时存储信息。修改或删除:4、修改后的信息页面如图所示:5、查看采集的信息并将其存储在仓库中,单击“在所有信息中存储按钮”:6、确认操作:7、存储中的信息完成提示:将信息存储在数据库中后,单击“管理信息”:我们可以看到收录新闻的新闻信息st存储在采集中:最后,转到“数据更新”以刷新主页,列和内容页面以完成网站采集的信息。由于Empirecms采集非常强大,因此我暂时无法完成。下一个讲座将继续说明其他功能的用法和技术。本文的组织者,请保留链接以供转载,谢谢! 13 1414
详细描述:帝国文章分页帝国CMS采集文章-分页采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2020-10-11 11:01
下一页导航是分页采集的难点。它需要所有页面都符合分页规则。如果您不熟悉它,我们可以使用第1页和第2页上的代码进行比较分析。确定分页规则。
1、让我们以网站的以下内容分页为例:
您可以看到此新闻共有20页。
2、查看源代码:
除了已到达采集的第一页之外,该页还包括第二,第三,第四,第五,第六,第七,第八和第20页,但第9至19页未列出。目前,我们将使用第1页和第2页上的代码进行比较和分析,以确定页面规则:
([1)第1页代码:
([2)第2页代码:
从这两张图片中,您可以看到它们具有相同的“页面区域开始代码”,“页面链接”格式,“页面区域结束代码”,然后可以确定“页面区域规则性”和“页面链接”规律性”。
3、定期获取分页区域([!-smallpageallzz-]):
4、获得页面链接规则性([!-pageallzz-]):
5、为了便于显示本教程,我在新闻文本中用采集代替了采集的内容,请预览结果:
注意:
一、在第一页的HTML代码中,当全部列出了内容分页链接时,我们使用“全部列出”。在第一页的HTML代码中,如果未列出所有内容分页链接,我们将使用“上下导航”。
当二、使用所有公式时,采集具有正确的规则,但出现莫名其妙的重复页面。在这种情况下,您可以使用替换方法将其过滤掉(我们将在下一堂课中讨论它)。
当三、使用向上和向下页面导航样式时,始终会选择第一页,而其他页面甚至都看不到阴影。这是因为分页区域经常([!-smallpagezz--])拦截错误。
当四、使用向上和向下页面导航样式时,可以采集转到前几页,但是随后的前几页将重复该循环直至结束。这也是因为分页区域常规([!-smallpagezz--])拦截错误,拦截范围太大,导致前几个页面链接的重复拦截。
帝国文章分页帝国cms如何在文章分页中实现页面标题导航
帝国文章分页
问:我的网站是由cms帝国制作的,我想实现的是在文章的内容页面被分页之后,在文章之前或之后的文章之后添加页面导航。 :
本文导航:
第1页:首页的标题
第2页:第二页的字幕
类似于PHP cms中的内容页面页面标题导航:
可以使用英皇cms内置标签,但这是一个下拉跳转菜单,而不是文本链接。 SEO效果可能不是很好。请问,我可以将哪个标签称为Empire cms?或者告诉我如何修改实现,谢谢!
答案:我只是看着它。为了实现内容页面的页面标题导航,似乎只能通过实现内置标签来实现内置标签。我模仿了此标签的实现原理,并添加了[!-title.pagetitles--]页面标题导航标签可以满足您的需求,但是您需要修改/ e /中的functions.php文件和t_functions.php文件。类/目录。 (版本帝国cmsv6.5)
屏幕截图如下:
以下是实现Empire cms文章页面标题导航的详细方法,该方法仍适用于6.6版本:
第一步:在t_functions.php的第241行之后添加以下代码:(此函数用于提取文章中的页面标题并生成链接)
//返回目录页面标题导航
function sys_ShowTextPageTitles($ thispagenum,$ dolink,$ add,$ filetype,$ n_r){
if($ thispagenum == 1)
{
返回'';
}
$ pagetitles ='';
for($ j = 1; $ j = 2 && $ ti_r [0])
{
$ title = $ ti_r [0];
}
其他
{
$ title = $ add [title]。'('。$ j。')';
}
$ plink = $ add [文件名] .'_'。$ j。$ filetype;
}
$ pagetitles。='
在其前面添加以下代码:
//分页标题导航下降的叶子添加
if(strstr($ newstemptext,'[!-title.pagetitles-]'))
{
$ pagetitles = sys_ShowTextPageTitles($ thispagenum,$ dolink,$ add,$ filetype,$ n_r);
// echo $ pagetitles; exit;
}
第3步:在functions.php文件的2229行附近找到以下代码:
$ titleselect = str_replace(“?”。$ j。“”>“,”?“。$ j。”“ selected>”,$ dotitleselect);
在以下行中添加以下代码:
$ pagetitles = str_replace('class =“ page_current”','',$ pagetitles);
$ pagetitles = str_replace('id =“'。$ j。'”','id =“'。$ j。'”',$ pagetitles); //秋天的落叶添加
步骤4:在functions.php文件中的2362行附近找到以下代码:
$ string = str_replace('',$ titleselect,$ string);
在其后添加以下代码:
$ string = str_replace('[!-title.pagetitles-]',$ pagetitles,$ string); //网站管理员知道-落叶添加
然后,您可以在内容页面模板中使用[!-title.pagetitles--]标记来调用文章页面导航,并将当前页面标题CSS添加到style.css文件中,例如.page_current。 {color:#CC3300;}。
以上修改适用于生成静态页面的内容页面,不是生成静态页面,请在e / action / ShowInfo.php文件中对其进行修改,这时不多说,估计不生成静态页面的人更少 查看全部
帝国文章寻呼帝国cms采集文章-寻呼采集
下一页导航是分页采集的难点。它需要所有页面都符合分页规则。如果您不熟悉它,我们可以使用第1页和第2页上的代码进行比较分析。确定分页规则。
1、让我们以网站的以下内容分页为例:
您可以看到此新闻共有20页。
2、查看源代码:
除了已到达采集的第一页之外,该页还包括第二,第三,第四,第五,第六,第七,第八和第20页,但第9至19页未列出。目前,我们将使用第1页和第2页上的代码进行比较和分析,以确定页面规则:
([1)第1页代码:
([2)第2页代码:
从这两张图片中,您可以看到它们具有相同的“页面区域开始代码”,“页面链接”格式,“页面区域结束代码”,然后可以确定“页面区域规则性”和“页面链接”规律性”。
3、定期获取分页区域([!-smallpageallzz-]):
4、获得页面链接规则性([!-pageallzz-]):
5、为了便于显示本教程,我在新闻文本中用采集代替了采集的内容,请预览结果:
注意:
一、在第一页的HTML代码中,当全部列出了内容分页链接时,我们使用“全部列出”。在第一页的HTML代码中,如果未列出所有内容分页链接,我们将使用“上下导航”。
当二、使用所有公式时,采集具有正确的规则,但出现莫名其妙的重复页面。在这种情况下,您可以使用替换方法将其过滤掉(我们将在下一堂课中讨论它)。
当三、使用向上和向下页面导航样式时,始终会选择第一页,而其他页面甚至都看不到阴影。这是因为分页区域经常([!-smallpagezz--])拦截错误。
当四、使用向上和向下页面导航样式时,可以采集转到前几页,但是随后的前几页将重复该循环直至结束。这也是因为分页区域常规([!-smallpagezz--])拦截错误,拦截范围太大,导致前几个页面链接的重复拦截。
帝国文章分页帝国cms如何在文章分页中实现页面标题导航
帝国文章分页
问:我的网站是由cms帝国制作的,我想实现的是在文章的内容页面被分页之后,在文章之前或之后的文章之后添加页面导航。 :
本文导航:
第1页:首页的标题
第2页:第二页的字幕
类似于PHP cms中的内容页面页面标题导航:
可以使用英皇cms内置标签,但这是一个下拉跳转菜单,而不是文本链接。 SEO效果可能不是很好。请问,我可以将哪个标签称为Empire cms?或者告诉我如何修改实现,谢谢!
答案:我只是看着它。为了实现内容页面的页面标题导航,似乎只能通过实现内置标签来实现内置标签。我模仿了此标签的实现原理,并添加了[!-title.pagetitles--]页面标题导航标签可以满足您的需求,但是您需要修改/ e /中的functions.php文件和t_functions.php文件。类/目录。 (版本帝国cmsv6.5)
屏幕截图如下:
以下是实现Empire cms文章页面标题导航的详细方法,该方法仍适用于6.6版本:
第一步:在t_functions.php的第241行之后添加以下代码:(此函数用于提取文章中的页面标题并生成链接)
//返回目录页面标题导航
function sys_ShowTextPageTitles($ thispagenum,$ dolink,$ add,$ filetype,$ n_r){
if($ thispagenum == 1)
{
返回'';
}
$ pagetitles ='';
for($ j = 1; $ j = 2 && $ ti_r [0])
{
$ title = $ ti_r [0];
}
其他
{
$ title = $ add [title]。'('。$ j。')';
}
$ plink = $ add [文件名] .'_'。$ j。$ filetype;
}
$ pagetitles。='
在其前面添加以下代码:
//分页标题导航下降的叶子添加
if(strstr($ newstemptext,'[!-title.pagetitles-]'))
{
$ pagetitles = sys_ShowTextPageTitles($ thispagenum,$ dolink,$ add,$ filetype,$ n_r);
// echo $ pagetitles; exit;
}
第3步:在functions.php文件的2229行附近找到以下代码:
$ titleselect = str_replace(“?”。$ j。“”>“,”?“。$ j。”“ selected>”,$ dotitleselect);
在以下行中添加以下代码:
$ pagetitles = str_replace('class =“ page_current”','',$ pagetitles);
$ pagetitles = str_replace('id =“'。$ j。'”','id =“'。$ j。'”',$ pagetitles); //秋天的落叶添加
步骤4:在functions.php文件中的2362行附近找到以下代码:
$ string = str_replace('',$ titleselect,$ string);
在其后添加以下代码:
$ string = str_replace('[!-title.pagetitles-]',$ pagetitles,$ string); //网站管理员知道-落叶添加
然后,您可以在内容页面模板中使用[!-title.pagetitles--]标记来调用文章页面导航,并将当前页面标题CSS添加到style.css文件中,例如.page_current。 {color:#CC3300;}。
以上修改适用于生成静态页面的内容页面,不是生成静态页面,请在e / action / ShowInfo.php文件中对其进行修改,这时不多说,估计不生成静态页面的人更少
技术文章:杰奇CMS小说关关采集器配置教程(文字+视频) 免费下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 532 次浏览 • 2020-09-07 02:40
[Jie Qi cms Novel Guan Guan 采集器 Configuration Tutorial Video]我不知道何时获得它。我看到该视频可能是V9版本,但是您可以参考当前流行的主要版本。由于许多设置技术是相同的,因此我们在这里共享它们。顺便说一句,我还发布了我采集的教程的文本版本,以供您参考。
目录介绍
规则文件夹,日志文件夹:
规则是我们推迟采集条规则的地方;
log是一个日志文件,也就是说,当采集器出错时,它将记录错误的信息。当我们看到这一点时,我们知道采集在哪里错误;
现在,我们单击开关以关闭采集器,直接打开NovelSpider.exe,然后可以启动开关采集器。 (注意:打开过程会有点慢,因此请单击一次并稍等片刻。请勿单击再次打开,否则一段时间采集器后将打开多个级别!)
在某些级别上会有一个提示框,因此我们不在乎。
系统设置
打开后,我们应立即修改“设置(S)”→系统设置。 :
1.修改本地网站目录,例如,我的目录位于D:\ xiaoshuo
2.再次修改数据库连接字符串
DataSource = 12 7. 0. 0. 1;
Database =数据库名称;
UserID =数据库管理用户名;
Password =数据库管理密码;
port = 3306;
charset = gbk
上面的设置是为了关闭采集器,这是您第一次使用它,您需要对其进行设置,而无需在设置后再次进行设置。
分类设置
首先:类别设置通常对应于类别,这些对应于您的网站类别。例如
1 | Fantasy Fantasy =,幻想,幻想,魔术,魔术,幻想魔术,幻想幻想,幻想小说,幻想·魔术,幻想世界,幻想幻想,
1是您的网站第一个蓝色稻米幻想幻想。等号是采集目标网站可能遇到的分类之后,越详细越好,某些模板网站对应于您的幻想幻想。如果您没有幻想模板,只需添加它即可。
第二个:是设置中的一代
默认情况下无需修改。第一个生成的内容页面html是您的网站小说目录页面的html。如果您网站使用伪静态,则不需要生成它。生成的第二个内容页面html是单击小说的内容以查看小说的文本章节。这与上面的第一个相同。如果您网站使用伪静态,则不需要生成它。
如果要构建静态小说网站,则需要生成它,这非常消耗硬盘。通常,一千本小说需要几GB的空间。
第三:生成全文阅读。不用担心,通常不使用。
第四:生成OPF。必须生成此文件,否则无法打开网站,并且如果未生成您的小说网站,也会出现打开错误。只需在此处打勾。不用担心其他设置,没有特殊要求您将无法使用它们。 (注意:[Settings-e-book settings]不需要控制,默认值就足够了,因此不要选择对勾,设置中的图片设置也是默认值,因此不要选择对勾。)
第五:文字广告。如果要在新颖内容中添加广告,则可以在此处添加内容。您需要选择第一个存储章节以添加文字广告。实际的存储空间会将您的广告添加到您采集下的小说中,这些路径的txt文件中的文件/ article / txt / 0/1
这是您的小说,是一部移动版本,因此您需要选择第一本。添加广告时,您会在章节阅读中看到它,但不要使用这些功能。
第六:其他[过滤和替换],[文本到图片]。无需控制
第七:日志选择。勾选所有人。这是采集遇到的错误的日志。您可以基于此消除错误。
规则测试
单击规则进入规则管理器,我们选择我们不能做的三角形符号,下拉并选择要测试的规则,单击右侧的加载,然后单击“测试规则”,如果出现“是要获取ID和小说名称”,则会弹出一个界面
这是为了获得包括小说名称分类介绍和封面在内的小说信息内容。
某些网站信息不完整采集。如果我们采集回来,它将显得不完整。这没有作用。您可以阅读小说的主要章节。然后是获得采集的章节,这是获得小说的内容。
这是一个很好的采集规则。我们可以使用采集规则更新采集小说。
如何采集
通常,我们使用标准的采集模式。
当我们单击“ 采集 –标准采集模式”时,有时会出现错误消息。无论我们单击采集框架中的规则,它都会出现在正确的位置,并且还会出现一些其他提示。忽略他,只需单击[继续]。
输入标准采集后输入正确的姿势后,通常使用第一个根据目标测站页面获取编号。编写此规则时,将根据目标电台的最新更新小说进行设置,采集更新时将自动采集对方的小说,并且还将关注其他人的小说网站。
1.根据目标台的ID 采集设置ID范围,直到通常另一方的书采集的特殊采集是采集时才使用。
2.根据目标台ID 采集,当特殊采集是另一方的书采集时,直到通常需要采集时才很少使用它。
3.点击了他的网站的小说ID 采集,在点击之前,他必须先更新其中一部网站小说,但是模板网站可能没有这本书,因此采集看起来非常好慢。很少使用,基本上没有用。
4.在日志记录的底部,必须选择此项以记录采集新颖信息,这些信息无缘无故不会出现在采集中。还必须选择循环采集。如果这是自动采集,请确保采集器自动循环另一方的采集。循环时间设置取决于您自己的需求。我通常将其设置为十分钟。如果您想将采集设置为零。
设置采集
[添加新书]:添加书时添加;
[谨慎使用]:以下两个单词是比较模板站的章节名称。如果正确,请继续。 采集如果不正确,将其清空,然后单击采集。不要使用它,这会导致严重的问题。有时候,意外清空我在百度收录上使用过的页面是一个悲剧。对于其他一些功能,可以阅读文字;
[设置2]:这是比较章节的选择,无论如何,它们几乎是相同的,为什么我没有什么不同?您可以默认;
[空章节的处理方法]:这意味着模板站点上的某些小说是空的,具体取决于您的需要,但是请注意,您不应选择第二本来跳过本章,因为跳过本章会留下章节名称为空,下次采集,如果将较少的章节名称与模板站进行比较,则该章节名称将无法更新书籍;
[章节安排]:这取决于目标站的图,这更加复杂。我给您的采集规则按目标电台的顺序排列。不要选择任何东西,通常使用[目标电台顺序]和[按照章节ID的顺序],不要使用其他内容。这两个不会有问题,我将为您提供默认设置;
[过滤器设置]:取决于您需要设置的内容,字面意思很明确;
[删除水印]:这基本上是不必要的;
[Agent],[Progress]:通常将上述三个数字设置为000;
这样,采集很快。代理IP是您阻止的目标站点的采集,然后在Internet上找到一些代理,打开代理功能,然后单击采集。
我已经在这里讨论了其中一些功能,而其他功能则是一些辅助功能,您以后可以进一步了解。
下一步,进行设置,然后单击以启动采集。选择规则,然后选择要按采集 采集输入的内容,然后单击以开始;
如果出现提示“成功启动采集模式”,则可以查看网站是否已更新。
PS:如果文本教程不能使您清楚地了解操作方法,请下载视频以帮助理解。
此资源的下载价格为0. 1德国货币,请先登录
打开VIP会员并免费下载所有站点资源!该程序仅用于测试,不能用于商业用途!如有任何疑问,请联系我们! 查看全部
节气cms Novel Guan Guan 采集器配置教程(文字+视频)免费下载
[Jie Qi cms Novel Guan Guan 采集器 Configuration Tutorial Video]我不知道何时获得它。我看到该视频可能是V9版本,但是您可以参考当前流行的主要版本。由于许多设置技术是相同的,因此我们在这里共享它们。顺便说一句,我还发布了我采集的教程的文本版本,以供您参考。
目录介绍
规则文件夹,日志文件夹:
规则是我们推迟采集条规则的地方;
log是一个日志文件,也就是说,当采集器出错时,它将记录错误的信息。当我们看到这一点时,我们知道采集在哪里错误;
现在,我们单击开关以关闭采集器,直接打开NovelSpider.exe,然后可以启动开关采集器。 (注意:打开过程会有点慢,因此请单击一次并稍等片刻。请勿单击再次打开,否则一段时间采集器后将打开多个级别!)
在某些级别上会有一个提示框,因此我们不在乎。
系统设置
打开后,我们应立即修改“设置(S)”→系统设置。 :
1.修改本地网站目录,例如,我的目录位于D:\ xiaoshuo
2.再次修改数据库连接字符串
DataSource = 12 7. 0. 0. 1;
Database =数据库名称;
UserID =数据库管理用户名;
Password =数据库管理密码;
port = 3306;
charset = gbk
上面的设置是为了关闭采集器,这是您第一次使用它,您需要对其进行设置,而无需在设置后再次进行设置。
分类设置
首先:类别设置通常对应于类别,这些对应于您的网站类别。例如
1 | Fantasy Fantasy =,幻想,幻想,魔术,魔术,幻想魔术,幻想幻想,幻想小说,幻想·魔术,幻想世界,幻想幻想,
1是您的网站第一个蓝色稻米幻想幻想。等号是采集目标网站可能遇到的分类之后,越详细越好,某些模板网站对应于您的幻想幻想。如果您没有幻想模板,只需添加它即可。
第二个:是设置中的一代
默认情况下无需修改。第一个生成的内容页面html是您的网站小说目录页面的html。如果您网站使用伪静态,则不需要生成它。生成的第二个内容页面html是单击小说的内容以查看小说的文本章节。这与上面的第一个相同。如果您网站使用伪静态,则不需要生成它。
如果要构建静态小说网站,则需要生成它,这非常消耗硬盘。通常,一千本小说需要几GB的空间。
第三:生成全文阅读。不用担心,通常不使用。
第四:生成OPF。必须生成此文件,否则无法打开网站,并且如果未生成您的小说网站,也会出现打开错误。只需在此处打勾。不用担心其他设置,没有特殊要求您将无法使用它们。 (注意:[Settings-e-book settings]不需要控制,默认值就足够了,因此不要选择对勾,设置中的图片设置也是默认值,因此不要选择对勾。)
第五:文字广告。如果要在新颖内容中添加广告,则可以在此处添加内容。您需要选择第一个存储章节以添加文字广告。实际的存储空间会将您的广告添加到您采集下的小说中,这些路径的txt文件中的文件/ article / txt / 0/1
这是您的小说,是一部移动版本,因此您需要选择第一本。添加广告时,您会在章节阅读中看到它,但不要使用这些功能。
第六:其他[过滤和替换],[文本到图片]。无需控制
第七:日志选择。勾选所有人。这是采集遇到的错误的日志。您可以基于此消除错误。
规则测试
单击规则进入规则管理器,我们选择我们不能做的三角形符号,下拉并选择要测试的规则,单击右侧的加载,然后单击“测试规则”,如果出现“是要获取ID和小说名称”,则会弹出一个界面
这是为了获得包括小说名称分类介绍和封面在内的小说信息内容。
某些网站信息不完整采集。如果我们采集回来,它将显得不完整。这没有作用。您可以阅读小说的主要章节。然后是获得采集的章节,这是获得小说的内容。
这是一个很好的采集规则。我们可以使用采集规则更新采集小说。
如何采集
通常,我们使用标准的采集模式。
当我们单击“ 采集 –标准采集模式”时,有时会出现错误消息。无论我们单击采集框架中的规则,它都会出现在正确的位置,并且还会出现一些其他提示。忽略他,只需单击[继续]。
输入标准采集后输入正确的姿势后,通常使用第一个根据目标测站页面获取编号。编写此规则时,将根据目标电台的最新更新小说进行设置,采集更新时将自动采集对方的小说,并且还将关注其他人的小说网站。
1.根据目标台的ID 采集设置ID范围,直到通常另一方的书采集的特殊采集是采集时才使用。
2.根据目标台ID 采集,当特殊采集是另一方的书采集时,直到通常需要采集时才很少使用它。
3.点击了他的网站的小说ID 采集,在点击之前,他必须先更新其中一部网站小说,但是模板网站可能没有这本书,因此采集看起来非常好慢。很少使用,基本上没有用。
4.在日志记录的底部,必须选择此项以记录采集新颖信息,这些信息无缘无故不会出现在采集中。还必须选择循环采集。如果这是自动采集,请确保采集器自动循环另一方的采集。循环时间设置取决于您自己的需求。我通常将其设置为十分钟。如果您想将采集设置为零。
设置采集
[添加新书]:添加书时添加;
[谨慎使用]:以下两个单词是比较模板站的章节名称。如果正确,请继续。 采集如果不正确,将其清空,然后单击采集。不要使用它,这会导致严重的问题。有时候,意外清空我在百度收录上使用过的页面是一个悲剧。对于其他一些功能,可以阅读文字;
[设置2]:这是比较章节的选择,无论如何,它们几乎是相同的,为什么我没有什么不同?您可以默认;
[空章节的处理方法]:这意味着模板站点上的某些小说是空的,具体取决于您的需要,但是请注意,您不应选择第二本来跳过本章,因为跳过本章会留下章节名称为空,下次采集,如果将较少的章节名称与模板站进行比较,则该章节名称将无法更新书籍;
[章节安排]:这取决于目标站的图,这更加复杂。我给您的采集规则按目标电台的顺序排列。不要选择任何东西,通常使用[目标电台顺序]和[按照章节ID的顺序],不要使用其他内容。这两个不会有问题,我将为您提供默认设置;
[过滤器设置]:取决于您需要设置的内容,字面意思很明确;
[删除水印]:这基本上是不必要的;
[Agent],[Progress]:通常将上述三个数字设置为000;
这样,采集很快。代理IP是您阻止的目标站点的采集,然后在Internet上找到一些代理,打开代理功能,然后单击采集。
我已经在这里讨论了其中一些功能,而其他功能则是一些辅助功能,您以后可以进一步了解。
下一步,进行设置,然后单击以启动采集。选择规则,然后选择要按采集 采集输入的内容,然后单击以开始;
如果出现提示“成功启动采集模式”,则可以查看网站是否已更新。
PS:如果文本教程不能使您清楚地了解操作方法,请下载视频以帮助理解。
此资源的下载价格为0. 1德国货币,请先登录
打开VIP会员并免费下载所有站点资源!该程序仅用于测试,不能用于商业用途!如有任何疑问,请联系我们!
帝国cms文章采集教程(1).doc
采集交流 • 优采云 发表了文章 • 0 个评论 • 370 次浏览 • 2020-08-28 07:17
文档介绍:帝国cms是我们用得比较多得PHP的建站系统,在建站过程中,如果自己没有信息源,只能靠手工不断的重复copy和粘贴,这样费时吃力,于是我们就要使用帝国cms自带的采集功能来完成信息的录入。为了深入了解帝国cms采集功能,下面我们以“新浪各地新闻”栏目为例来进行实战采集。一、增加采集节点1、添加节点:2、选择要降低采集的栏目:3、进入降低节点表单:4、在节点名称框里起个名子,然后把要采集的新浪各地新闻列表地址copy过来:5、下来发觉很多选项,如“采集页面地址方法二,内容页地址前缀。。。”先不要理他,后面再一一解读,直接拉到“信息链接区域正则”这里:6、这里是设置采集的列表信息链接区域正则,我们点击查看新浪各地新闻列表“源文件”:7、把源文件代码copy到Dreamweaver里,在Dreamweaver里选取要采集的信息链接区域:8、切换到Dreamweaver代码形式,就是信息链接区域:9、得到信息链接区域正则:10、得到信息页链接正则:11、注意:如果信息页链接是相对地址,例如,那么“内容页地址前缀”要加域名:12、现在要采集内容页的标题和内容:13、查看新闻页“源文件”,找title标签:14、取得标题正则:15、这里是要采集的内容区域:16、取得新闻内容正则:(注意:新闻内容正则里的d_id=‘*’用了转义,因为每一篇新闻的d_id值是不同的,所以可以用*来替代它,“*”可以替代任意字符。)17、点击递交按键就完成了整个采集节点:二、预览采集节点是否正确1、提交按键后返回管理节点:2、点击“预览”采集,进入节点预览结果:3、采集内容页列表4、采集内容页页面:三、采集1、预览采集节点无误后,然后返回“管理节点”,点击“开始采集”链接就开始进行采集:2、系统正在采集中:3、采集完后显示本地临时入库的信息,这时可以对临时入库的信息进行更改或则删掉:4、修改信息页面如图:5、对采集的信息进行初审并入库,点击“入库全部信息按键”: 查看全部
帝国cms文章采集教程(1).doc
文档介绍:帝国cms是我们用得比较多得PHP的建站系统,在建站过程中,如果自己没有信息源,只能靠手工不断的重复copy和粘贴,这样费时吃力,于是我们就要使用帝国cms自带的采集功能来完成信息的录入。为了深入了解帝国cms采集功能,下面我们以“新浪各地新闻”栏目为例来进行实战采集。一、增加采集节点1、添加节点:2、选择要降低采集的栏目:3、进入降低节点表单:4、在节点名称框里起个名子,然后把要采集的新浪各地新闻列表地址copy过来:5、下来发觉很多选项,如“采集页面地址方法二,内容页地址前缀。。。”先不要理他,后面再一一解读,直接拉到“信息链接区域正则”这里:6、这里是设置采集的列表信息链接区域正则,我们点击查看新浪各地新闻列表“源文件”:7、把源文件代码copy到Dreamweaver里,在Dreamweaver里选取要采集的信息链接区域:8、切换到Dreamweaver代码形式,就是信息链接区域:9、得到信息链接区域正则:10、得到信息页链接正则:11、注意:如果信息页链接是相对地址,例如,那么“内容页地址前缀”要加域名:12、现在要采集内容页的标题和内容:13、查看新闻页“源文件”,找title标签:14、取得标题正则:15、这里是要采集的内容区域:16、取得新闻内容正则:(注意:新闻内容正则里的d_id=‘*’用了转义,因为每一篇新闻的d_id值是不同的,所以可以用*来替代它,“*”可以替代任意字符。)17、点击递交按键就完成了整个采集节点:二、预览采集节点是否正确1、提交按键后返回管理节点:2、点击“预览”采集,进入节点预览结果:3、采集内容页列表4、采集内容页页面:三、采集1、预览采集节点无误后,然后返回“管理节点”,点击“开始采集”链接就开始进行采集:2、系统正在采集中:3、采集完后显示本地临时入库的信息,这时可以对临时入库的信息进行更改或则删掉:4、修改信息页面如图:5、对采集的信息进行初审并入库,点击“入库全部信息按键”:
苹果cms自定义资源库采集教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 606 次浏览 • 2020-08-27 16:16
1,今天教你们怎样添加采集自定义资源库;进入后台我们随意以某资源站为例,接口可以到你要采集的网站上获取就可以了 一般都在网站的帮助中心:添加方式如下图(添加后进行测试不成功须要填写附加参数 &ct=1)
2,我这儿没有填写只要测试插口成功 就直接保存就可以了 如果测试失败就填写附加参数 &ct=1)如果还不行检测采集接口是不是填写错误
3,添加资源插口成功后须要对资源进行分类绑定 :点击高清资源链接步入绑定页面进行分类绑定
4,进入分类绑定页面后 点击没有绑定的页面会手动弹出分类绑定,如果找不到相对应的可以先绑定到相像的类目或是自定义添加分类
5,绑定后剩下就是采集了 拉到页面的顶部 有采集按钮 可以采集当天 采集选中(在须要采集的视频上面打勾)还有采集全部三种选择
6,选择后步入手动采集页面 如果绑定的采集成功后显示红色 红色的则是没绑定成功跳过采集,所以在绑定的时侯要认真绑定。
结束语:最后采集完后网站就应当有视频数据了 这个时侯也是很多人苦恼的地方 采集完了播放不了!这是为什么呢?因为你没添加播放器引起的。
每个资源站都有自己单独的播放器和解析 也就是你采集谁家的资源就必须要用谁家的播放器才可以进行播放。播放器通常都在网站的帮助中心查找,都有详尽的说明。 查看全部
苹果cms自定义资源库采集教程
1,今天教你们怎样添加采集自定义资源库;进入后台我们随意以某资源站为例,接口可以到你要采集的网站上获取就可以了 一般都在网站的帮助中心:添加方式如下图(添加后进行测试不成功须要填写附加参数 &ct=1)
2,我这儿没有填写只要测试插口成功 就直接保存就可以了 如果测试失败就填写附加参数 &ct=1)如果还不行检测采集接口是不是填写错误
3,添加资源插口成功后须要对资源进行分类绑定 :点击高清资源链接步入绑定页面进行分类绑定
4,进入分类绑定页面后 点击没有绑定的页面会手动弹出分类绑定,如果找不到相对应的可以先绑定到相像的类目或是自定义添加分类
5,绑定后剩下就是采集了 拉到页面的顶部 有采集按钮 可以采集当天 采集选中(在须要采集的视频上面打勾)还有采集全部三种选择
6,选择后步入手动采集页面 如果绑定的采集成功后显示红色 红色的则是没绑定成功跳过采集,所以在绑定的时侯要认真绑定。
结束语:最后采集完后网站就应当有视频数据了 这个时侯也是很多人苦恼的地方 采集完了播放不了!这是为什么呢?因为你没添加播放器引起的。
每个资源站都有自己单独的播放器和解析 也就是你采集谁家的资源就必须要用谁家的播放器才可以进行播放。播放器通常都在网站的帮助中心查找,都有详尽的说明。
SiteServer CMS信息采集概述
采集交流 • 优采云 发表了文章 • 0 个评论 • 329 次浏览 • 2020-08-27 15:04
Web是一个巨大的资源宝库,目前页面数量已超过400亿,每小时还以惊人的速率下降,里面有你须要的大量有价值的信息,例如潜在顾客的列表与联系信息,竞争产品的价钱列表,实时金融新闻,供求信息,论文摘要等等。 可是因为关键信息都是以半结构化或自由文本方式存在于大量的HTML网页中,很难直接加以借助。
SiteServer CMS 信息采集功能的主要目标就是解决网路信息的采集问题,系统通过一些订制的采集逻辑,自动从指定网站或数据库中获取内容并保存到网站中。
一、主要功能
SiteServer CMS 提供强悍的信息采集功能模块,用户只须要告诉系统目标网页并简单地设置页面规则,很快就可以直接得到所须要的数据了。
除了典型的Web页面信息采集外,系统还提供数据库信息采集与单文件页采集功能:
Web页面信息采集用于手动从指定网站中获取内容;
数据库信息采集用于手动从指定数据库中获取内容;
单文件页采集用于将指定网页采集到本地的对应文件中。
二、系统特征
结果数据高度确切
对目标网站进行信息手动抓取,支持HTML页面内各类数据的采集,如文本信息、图片、附件、日期等
用户对每类信息自定义来源与分类
可以下载图片与各种文件
支持定时任务,可以与SiteServer CMS 定时模块相配合,定期抽取目标网站
支持记录惟一索引,避免相同信息重复入库
支持智能替换功能,可以将内容中嵌入的所有的无关部份如广告消除 查看全部
SiteServer CMS信息采集概述
Web是一个巨大的资源宝库,目前页面数量已超过400亿,每小时还以惊人的速率下降,里面有你须要的大量有价值的信息,例如潜在顾客的列表与联系信息,竞争产品的价钱列表,实时金融新闻,供求信息,论文摘要等等。 可是因为关键信息都是以半结构化或自由文本方式存在于大量的HTML网页中,很难直接加以借助。
SiteServer CMS 信息采集功能的主要目标就是解决网路信息的采集问题,系统通过一些订制的采集逻辑,自动从指定网站或数据库中获取内容并保存到网站中。
一、主要功能
SiteServer CMS 提供强悍的信息采集功能模块,用户只须要告诉系统目标网页并简单地设置页面规则,很快就可以直接得到所须要的数据了。
除了典型的Web页面信息采集外,系统还提供数据库信息采集与单文件页采集功能:
Web页面信息采集用于手动从指定网站中获取内容;
数据库信息采集用于手动从指定数据库中获取内容;
单文件页采集用于将指定网页采集到本地的对应文件中。
二、系统特征
结果数据高度确切
对目标网站进行信息手动抓取,支持HTML页面内各类数据的采集,如文本信息、图片、附件、日期等
用户对每类信息自定义来源与分类
可以下载图片与各种文件
支持定时任务,可以与SiteServer CMS 定时模块相配合,定期抽取目标网站
支持记录惟一索引,避免相同信息重复入库
支持智能替换功能,可以将内容中嵌入的所有的无关部份如广告消除
织梦CMS采集侠破解版提示本域名以被锁定的最新解除方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 305 次浏览 • 2020-08-27 05:36
是一款帮助网站进行手动更新采集文章的工具,不但能采集其它网站的内容,还支持伪静态设置,搜索引擎优化,自动内链,自动生成网站地图等。
织梦采集侠破解版提示本域名以被锁定的最新解除方式
只需一分钟,立即开始采集,而且结合简单、健壮、灵活、开源的dedecms程序
根据用户设定的关键词进行泛采集,实现不对指定的一个或几个被采集站点进行采集
只须要输入RSS地址即可便捷的 采集到目标网站内容,无需编撰采集规则,方便简单
提供列表URL和文章URL即采集指定网站或栏目内容,便可精确采集标题、正文、作者、来源
可预先设定是采集任务,然后全手动完成进行伪原创,导入,生成,操作无需人工干预
我们为商业用户提供的远程触发采集服务,新站无有人访问即可定时定量采集更新
采集侠亦可按照您的须要每晚在您设置的时间段内定时定量初审更新
自动生成sitemap,自动推送百度插口,确保百度及时收录到您的网站,提供网站排名
市面上好多织梦CMS采集侠破解版用户,偶尔会遇见被锁定域名未能正常使用的问题,现在提供下解除锁定的教程,方法也很简单,三步就搞定了。
第一步:
找到网站根目录data文件夹
第二步:
打开data文件夹找到admin文件夹
第三步:
打开admin文件夹删掉 oo.txt文件即可。 查看全部
织梦CMS采集侠破解版提示本域名以被锁定的最新解除方式
是一款帮助网站进行手动更新采集文章的工具,不但能采集其它网站的内容,还支持伪静态设置,搜索引擎优化,自动内链,自动生成网站地图等。
织梦采集侠破解版提示本域名以被锁定的最新解除方式
只需一分钟,立即开始采集,而且结合简单、健壮、灵活、开源的dedecms程序
根据用户设定的关键词进行泛采集,实现不对指定的一个或几个被采集站点进行采集
只须要输入RSS地址即可便捷的 采集到目标网站内容,无需编撰采集规则,方便简单
提供列表URL和文章URL即采集指定网站或栏目内容,便可精确采集标题、正文、作者、来源
可预先设定是采集任务,然后全手动完成进行伪原创,导入,生成,操作无需人工干预
我们为商业用户提供的远程触发采集服务,新站无有人访问即可定时定量采集更新
采集侠亦可按照您的须要每晚在您设置的时间段内定时定量初审更新
自动生成sitemap,自动推送百度插口,确保百度及时收录到您的网站,提供网站排名
市面上好多织梦CMS采集侠破解版用户,偶尔会遇见被锁定域名未能正常使用的问题,现在提供下解除锁定的教程,方法也很简单,三步就搞定了。
第一步:
找到网站根目录data文件夹
第二步:
打开data文件夹找到admin文件夹
第三步:
打开admin文件夹删掉 oo.txt文件即可。
动易SiteFactory采集流程第一步
采集交流 • 优采云 发表了文章 • 0 个评论 • 476 次浏览 • 2020-08-27 03:46
本节将以采集动易官方网站“公司动态”栏目为例讲解添加采集项目并进行信息采集的全过程。
如果您第一次接触采集功能,请认真阅读操作步骤及并理解相关说明,按以下步骤一一操作以完善所需采集的项目。
14.2.1 第一步:采集项目设置
依次点击“内容管理”->“采集管理”->“采集管理”功能链接,在出现的管理界面中,单击两侧管理操作导航中“添加采集项目”功能链接,系统出现“添加采集项目设置”管理界面,以设置所需新建的采集项目的名称、采集网站、编码等基本设置信息。
重要参数说明:
·项目名称:填写自定义采集项目的名称(如“动易公司动态”)。
·对应本站栏目:点选设置所采集的数据保存到本站所对应的栏目节点名(如“文章中心”)。
·对应内容模型:点选设置对应栏目的模型(如“文章模型”)。
温馨提示:若后续在采集项目完成后,再修改了所对应的模型,系统将手动删掉采集第三步所有数组的规则。
·采集网站:填写所需采集目标网站的名称(如“动易官网”)。
·采集URL:填写采集网页的网址(以 开头,如“”)。
·编码选择:提供GB2312、UTF-8和Big5三种编码格式。国内的网站基本都是GB2312,若采集香港、台湾的网站请选择Big5编码,若采集海外网站则选择UTF-8编码(如“动易技术中心”选择“GB2312” 编码)。
·指定采集数量:指定采集的数目,不指定为采集全部数据。
·采集顺序:设置按升序或乱序形式进行采集(系统默认为逆序采集)。
·采集简介:填写本采集项目的简略介绍信息(如“动易官方网站动易公司动态信息”)。
设置好相关选项后,单击页面顶部“下一步”功能按键进行采集列表项目信息设置。
温馨提示:若目标网站的信息须要登陆后才可查阅与采集,请参阅动易技术中心中的相关说明以进行设置。 查看全部
动易SiteFactory采集流程第一步
本节将以采集动易官方网站“公司动态”栏目为例讲解添加采集项目并进行信息采集的全过程。
如果您第一次接触采集功能,请认真阅读操作步骤及并理解相关说明,按以下步骤一一操作以完善所需采集的项目。
14.2.1 第一步:采集项目设置
依次点击“内容管理”->“采集管理”->“采集管理”功能链接,在出现的管理界面中,单击两侧管理操作导航中“添加采集项目”功能链接,系统出现“添加采集项目设置”管理界面,以设置所需新建的采集项目的名称、采集网站、编码等基本设置信息。
重要参数说明:
·项目名称:填写自定义采集项目的名称(如“动易公司动态”)。
·对应本站栏目:点选设置所采集的数据保存到本站所对应的栏目节点名(如“文章中心”)。
·对应内容模型:点选设置对应栏目的模型(如“文章模型”)。
温馨提示:若后续在采集项目完成后,再修改了所对应的模型,系统将手动删掉采集第三步所有数组的规则。
·采集网站:填写所需采集目标网站的名称(如“动易官网”)。
·采集URL:填写采集网页的网址(以 开头,如“”)。
·编码选择:提供GB2312、UTF-8和Big5三种编码格式。国内的网站基本都是GB2312,若采集香港、台湾的网站请选择Big5编码,若采集海外网站则选择UTF-8编码(如“动易技术中心”选择“GB2312” 编码)。
·指定采集数量:指定采集的数目,不指定为采集全部数据。
·采集顺序:设置按升序或乱序形式进行采集(系统默认为逆序采集)。
·采集简介:填写本采集项目的简略介绍信息(如“动易官方网站动易公司动态信息”)。
设置好相关选项后,单击页面顶部“下一步”功能按键进行采集列表项目信息设置。
温馨提示:若目标网站的信息须要登陆后才可查阅与采集,请参阅动易技术中心中的相关说明以进行设置。
如何把DEDECMS采集文章变成“原创”的文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2020-08-26 18:13
关键字描述:文章 变成 原创 采集 如何 &ldquo 标题 &rdquo 词组 句子
到xkzzz来学习的,多是中小网站的站长,他们使用DedeCms产品的不在少数。今天,我想注重说说关于“辅助插件”的功能及使用。当然,我不会去说dede自带的这些插件,因为来这儿的站长都是dedecms好手,我想分享一下我们自己开发的一个小插件------如何把采集来的文章变成“原创”的文章!
产生原创标题的原理
首先,请看截图。
此插件页面和dede自带的其他插件风格相同,功能是把标题弄成独有的标题。原理是这样的:通常,我们在百度里搜索某篇文章的标题,百度会返回好多相同的文章,显然这篇文章被转载了好多次。我们晓得,在内容重复的情况下,百度会根据站点的权重进行排序。权重越高的站点,搜索结果排的位置就越靠前。所以,尽管你的站点也被搜到了,但是结果太可能靠后。采集别人的文章虽然省事,但带来的疗效不一定好,原因就在这里。
一个标题,说白了就是一句话。句子由成语组成,在不影响语句意思的前提下,换个相仿的词句,那么,在搜索引擎看来,这个短语就成了不同于原先语句的短语。换句话说,你形成了一个原创的标题。这特别重要。原创的内容,是搜索引擎最喜欢的东西。
就像冯巩每年新年晚宴上场前常说的一句话,亲爱的听众朋友们,“我想死大家啦”,当他被朱军逼着不使再说这句话时,冯巩说出了“你们使我想死啦”。意思其实没变,句子却变了。插件的原理,就是这样的。
插件的用法
“当前的标题”和“原来的标题”开始都载入某篇文章的标题,后者不可改变,为黄色。下面的“优化建议”根据现有语句里的词句,去词库---随时添加的---里搜索带有相同词句的反义词租。比如,“玩赏犬训练中的注意事项”,注意事项和注意要点、关注点的构词相仿,训练和调教的构词相仿,所以,这句话可以换成“玩赏犬训练中的注意要点”、“玩赏犬训练中的关注点”等等。
从图中见到,有个添加相仿单词的大大按键,我们通过这个功能向词库里添加新发现的反义词组,或点击“edit”按钮,去编辑现有的反义词组。一般情况下,刚开始的时侯,词库里的反义词组较少,优化建议一般为空,这就须要我们拆开语句,根据网站内容填写反义词组。随着单词数目的增多,和语句关联的反义词组出现的频度会越来越多,人工录入单词的次数也会大大增加,然后,编辑次数相应降低,从而让现有词库最优化满足本网站需要。
根据我们实际使用情况,作为一个宠物方面的行业网站,编辑人员仅在维护1天之后,就积累了300多个反义词组,如果每位短语按3个估算,那么当日共积累了逾1000个熟语。接下来的几天,编辑只须要通过快捷键“Ctrl U”动态替换标题,就可以了。
在页面的下方是“看看百度收录情况”,此按键将把用反义词替换后的标题在百度里的搜索情况,按列显示在下边,图中显示了7条。这样,编辑人员就有了指导根据------越是搜不到的标题,越是接近于原创的标题。
其他方面就不介绍了。
插件评价
自我觉得,此功能很过投机取巧。但是从搜索引擎优化的角度看,它不能不算做一条捷径。我曾看见好多编辑人员(不局限于我们公司),在做着类似的工作。
另一方面,从用户的利益看,我们应当有节制地使用,程序不是万能的,能为用户带来真正有用信息的文章才是好文章,这个宗旨不能丢。
在和同事的聊天中获知,有些站长早就这样做了,这里,我也希望有这方面经验的站长,能够抽时间,给你们分享一下。
本文标题: 如何把DEDECMS采集文章变成“原创”的文章
本文地址: 查看全部
如何把DEDECMS采集文章变成“原创”的文章
关键字描述:文章 变成 原创 采集 如何 &ldquo 标题 &rdquo 词组 句子
到xkzzz来学习的,多是中小网站的站长,他们使用DedeCms产品的不在少数。今天,我想注重说说关于“辅助插件”的功能及使用。当然,我不会去说dede自带的这些插件,因为来这儿的站长都是dedecms好手,我想分享一下我们自己开发的一个小插件------如何把采集来的文章变成“原创”的文章!
产生原创标题的原理
首先,请看截图。
此插件页面和dede自带的其他插件风格相同,功能是把标题弄成独有的标题。原理是这样的:通常,我们在百度里搜索某篇文章的标题,百度会返回好多相同的文章,显然这篇文章被转载了好多次。我们晓得,在内容重复的情况下,百度会根据站点的权重进行排序。权重越高的站点,搜索结果排的位置就越靠前。所以,尽管你的站点也被搜到了,但是结果太可能靠后。采集别人的文章虽然省事,但带来的疗效不一定好,原因就在这里。
一个标题,说白了就是一句话。句子由成语组成,在不影响语句意思的前提下,换个相仿的词句,那么,在搜索引擎看来,这个短语就成了不同于原先语句的短语。换句话说,你形成了一个原创的标题。这特别重要。原创的内容,是搜索引擎最喜欢的东西。
就像冯巩每年新年晚宴上场前常说的一句话,亲爱的听众朋友们,“我想死大家啦”,当他被朱军逼着不使再说这句话时,冯巩说出了“你们使我想死啦”。意思其实没变,句子却变了。插件的原理,就是这样的。
插件的用法
“当前的标题”和“原来的标题”开始都载入某篇文章的标题,后者不可改变,为黄色。下面的“优化建议”根据现有语句里的词句,去词库---随时添加的---里搜索带有相同词句的反义词租。比如,“玩赏犬训练中的注意事项”,注意事项和注意要点、关注点的构词相仿,训练和调教的构词相仿,所以,这句话可以换成“玩赏犬训练中的注意要点”、“玩赏犬训练中的关注点”等等。
从图中见到,有个添加相仿单词的大大按键,我们通过这个功能向词库里添加新发现的反义词组,或点击“edit”按钮,去编辑现有的反义词组。一般情况下,刚开始的时侯,词库里的反义词组较少,优化建议一般为空,这就须要我们拆开语句,根据网站内容填写反义词组。随着单词数目的增多,和语句关联的反义词组出现的频度会越来越多,人工录入单词的次数也会大大增加,然后,编辑次数相应降低,从而让现有词库最优化满足本网站需要。
根据我们实际使用情况,作为一个宠物方面的行业网站,编辑人员仅在维护1天之后,就积累了300多个反义词组,如果每位短语按3个估算,那么当日共积累了逾1000个熟语。接下来的几天,编辑只须要通过快捷键“Ctrl U”动态替换标题,就可以了。
在页面的下方是“看看百度收录情况”,此按键将把用反义词替换后的标题在百度里的搜索情况,按列显示在下边,图中显示了7条。这样,编辑人员就有了指导根据------越是搜不到的标题,越是接近于原创的标题。
其他方面就不介绍了。
插件评价
自我觉得,此功能很过投机取巧。但是从搜索引擎优化的角度看,它不能不算做一条捷径。我曾看见好多编辑人员(不局限于我们公司),在做着类似的工作。
另一方面,从用户的利益看,我们应当有节制地使用,程序不是万能的,能为用户带来真正有用信息的文章才是好文章,这个宗旨不能丢。
在和同事的聊天中获知,有些站长早就这样做了,这里,我也希望有这方面经验的站长,能够抽时间,给你们分享一下。
本文标题: 如何把DEDECMS采集文章变成“原创”的文章
本文地址:
帝国CMS采集文章-分页采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 290 次浏览 • 2020-08-26 08:58
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。 不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:(1)全部列举式(2)上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以"中华网内容分页()"为例:
可以看见这条新闻总共有3条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:
可以看见这条新闻总共有20条分页。
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:
(2)第2页代码:
从这两幅图片可以见到她们有着相同的"分页区域开始代码","分页链接"格式,"分页区域结束代码",那么就可以确定"分页区域正则","分页链接正则"。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
5、为了便捷教程显示,newstext我采集了标题而不是采集内容,预览结果:
注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用"全部列出式"。
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。 在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用"上下页导航式"。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时,老是采到第1页,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。 查看全部
帝国CMS采集文章-分页采集
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。 不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:(1)全部列举式(2)上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以"中华网内容分页()"为例:
可以看见这条新闻总共有3条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:
可以看见这条新闻总共有20条分页。
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:
(2)第2页代码:
从这两幅图片可以见到她们有着相同的"分页区域开始代码","分页链接"格式,"分页区域结束代码",那么就可以确定"分页区域正则","分页链接正则"。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
5、为了便捷教程显示,newstext我采集了标题而不是采集内容,预览结果:
注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用"全部列出式"。
不少的朋友在采集过程中,列表页和内容页都能可以挺好地设定正则,但常常失败在内容分页正则上,主要是对内容分页正则不了解。帝国的内容分页方式有两种:全部列出式上下页导航式,但是这两种内容分页方式有哪些区别,采集内容分页时该用哪种,官方说得比较模糊,对此有些朋友倍感太头大,好的,我们先看下事例:。全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。可以看见这条新闻总共有3条分页。这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。 在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用"上下页导航式"。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时,老是采到第1页,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
实例教你使用帝国CMS采集图文教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 468 次浏览 • 2020-08-26 00:35
本节通过采集简单的页面作为采集教程实例。
每个系统模型都有自己的采集,无论是外置的还是用户自定义的系统模型,新闻系统有新闻系统采集,下载系统有下载系统采集等等。
下面讲解新闻系统模型的采集,其它系统模型采集基本雷同,用户可举一反三。
采集页面地址
本例要采集的页面地址:
开始采集
采集一般步骤:
1、增加采集节点;
2、预览采集正则是否正确;
3、开始采集;
4、对采集的数据进行初审并入库;
5、生成栏目及内容HTML页面。
一、增加采集节点:
1、登录后台->“栏目”>“采集管理”>“增加采集节点”;
2、“选择要降低采集的栏目”(选择终极栏目);
3、“选择要降低采集的栏目”后步入降低采集节点页面;
4、打开要采集的列表页面:
点击查看“源文件”
点击查看,列表页源代码为如下:
5、开始设置采集节点及列表页正则:
(1)、输入节点名称:采集实例
(2)、采集页面地址:
(3)、由列表页的源代码:“”,我们得出“内容页地址前缀”为:
(4)、设置“信息页链接正则”:由列表页的源代码得出。
图1:页面源代码
图2:得出的信息页链接正则
6、点击采集的内容页页面并查看源文件:
图1:内容页页面
图2:内容页源代码
7、设置内容页内容正则:(标题及内容正则)
(1)、标题正则:由源代码内容我们得出“新闻标题”正则为:
图1:页面源代码
图2:得出的标题正则
(2)、内容正则:由源代码内容我们得出“新闻内容”正则为:
图1:页面源代码
图2:得出的新闻内容正则
8、点击“提交”按钮即可降低节点完毕,整个表单最终疗效如下:
[点击查看]
二、预览采集正则是否正确:
1、上面降低采集节点后,我们返回“管理节点”页面,如下:
2、点击“预览”采集,进入节点正则预览与验证:
图1:采集页面地址列表
图2:信息链接列表
图3:采集的内容页内容
3、上面链接列表页及内容页内容预览无误后方可进行采集操作。
三、开始采集:
1、上面的采集节点正则预览无误后,我们返回“管理节点”页面:
2、点击里面的“开始采集”链接,开始进行采集;
3、采集信息完成后,系统会转向采集入库页面,如下:
四、对采集的数据进行初审并入库:
即可完成入库操作:
管理栏目信息也可以看见我们刚刚入库的信息:
五、生成栏目及内容HTML页面:
点击“系统”>“数据更新”>“数据更新中心”,进入数据更新中心页面: 查看全部
实例教你使用帝国CMS采集图文教程
本节通过采集简单的页面作为采集教程实例。
每个系统模型都有自己的采集,无论是外置的还是用户自定义的系统模型,新闻系统有新闻系统采集,下载系统有下载系统采集等等。
下面讲解新闻系统模型的采集,其它系统模型采集基本雷同,用户可举一反三。
采集页面地址
本例要采集的页面地址:
开始采集
采集一般步骤:
1、增加采集节点;
2、预览采集正则是否正确;
3、开始采集;
4、对采集的数据进行初审并入库;
5、生成栏目及内容HTML页面。
一、增加采集节点:
1、登录后台->“栏目”>“采集管理”>“增加采集节点”;
2、“选择要降低采集的栏目”(选择终极栏目);
3、“选择要降低采集的栏目”后步入降低采集节点页面;
4、打开要采集的列表页面:
点击查看“源文件”
点击查看,列表页源代码为如下:
5、开始设置采集节点及列表页正则:
(1)、输入节点名称:采集实例
(2)、采集页面地址:
(3)、由列表页的源代码:“”,我们得出“内容页地址前缀”为:
(4)、设置“信息页链接正则”:由列表页的源代码得出。
图1:页面源代码
图2:得出的信息页链接正则
6、点击采集的内容页页面并查看源文件:
图1:内容页页面
图2:内容页源代码
7、设置内容页内容正则:(标题及内容正则)
(1)、标题正则:由源代码内容我们得出“新闻标题”正则为:
图1:页面源代码
图2:得出的标题正则
(2)、内容正则:由源代码内容我们得出“新闻内容”正则为:
图1:页面源代码
图2:得出的新闻内容正则
8、点击“提交”按钮即可降低节点完毕,整个表单最终疗效如下:
[点击查看]
二、预览采集正则是否正确:
1、上面降低采集节点后,我们返回“管理节点”页面,如下:
2、点击“预览”采集,进入节点正则预览与验证:
图1:采集页面地址列表
图2:信息链接列表
图3:采集的内容页内容
3、上面链接列表页及内容页内容预览无误后方可进行采集操作。
三、开始采集:
1、上面的采集节点正则预览无误后,我们返回“管理节点”页面:
2、点击里面的“开始采集”链接,开始进行采集;
3、采集信息完成后,系统会转向采集入库页面,如下:
四、对采集的数据进行初审并入库:
即可完成入库操作:
管理栏目信息也可以看见我们刚刚入库的信息:
五、生成栏目及内容HTML页面:
点击“系统”>“数据更新”>“数据更新中心”,进入数据更新中心页面:
织梦cms(dedecms)采集文章二
采集交流 • 优采云 发表了文章 • 0 个评论 • 573 次浏览 • 2020-08-25 09:46
网页内容获取规则。系统会默认一个采集url为预览网址,另外内容分页导航所在的区域匹配规则也太灵活,除了和phpcms一样有全“部列举的分页列表模式”、“上下页方式或不完整的分页列表模式”外,还多了一个“分页列表规则”。
各数组内容采集,dedecms的内容匹配规则和phpcms一样:“起始无重复HTML[内容]结尾无重复HTML”,[内容]即为所采内容。过滤规则是{dede:trim replace=""}规则{/dede:trim},多个规则的话一个一行,如果要替换成指定的值,则只要在replace=""的冒号里设置即可。
其中,内容摘要、关键字、缩略图系统会用正则进行手动匹配,我们只需设置过滤内容即可。其余数组分别设置匹配规则和过滤规则,系统同样自带了几个常用的过滤规则,但是点击“常用规则”后为弹出小窗口模式,稍微有点不便捷。针对本测试的标题采集,以下两种形式都是可以的,如图:
文章作者、文章来源和发布时间数组一样采集,但是此版本dedecms在这几个数组下没有“自定义处理插口”了,如果有的话会稍显灵活,例如设置固定值可直接用“@me="固定值"”实现。现在不能用自定义处理插口设定固定值,也没有数组值设置,只能通过采集网页某一固定值之后用替换。如图:
dedecms的文章内容采集非常强悍,除了匹配规则和过滤规则,还有个“自定义处理插口”。如果你有php基础的话,可以通过此功能对采集结果@me进行各类处理,强大到不行啊。以后小编会专门发一篇此功能的讲解文章。最后,不能直接在采集管理处新增采集字段,只能在对应内容模型管理中降低数组,采集管理会手动降低。如小编在“普通文章”内容模型那降低了一个“chinaz数组”,则采集设置中手动增了一个“chinaz数组”项目。
保存并测试,查看列表测试信息和网页规则测试,检查是否正确,无误后确定并开始采集。进入采集指定节点设置页面,因为小编之前有测试一遍,所以有60个历史种子网址,即小编之前早已采集了60个网址,另外还有几个选项你们按需求选择。
点开始采集网页,出现此采集提示信息显示采集进度,不知道是小编人品不好还是dede采集本身缺点,经常会浏览器没反应,采集停止在那,只有自动点击了就会继续。 查看全部
织梦cms(dedecms)采集文章二
网页内容获取规则。系统会默认一个采集url为预览网址,另外内容分页导航所在的区域匹配规则也太灵活,除了和phpcms一样有全“部列举的分页列表模式”、“上下页方式或不完整的分页列表模式”外,还多了一个“分页列表规则”。
各数组内容采集,dedecms的内容匹配规则和phpcms一样:“起始无重复HTML[内容]结尾无重复HTML”,[内容]即为所采内容。过滤规则是{dede:trim replace=""}规则{/dede:trim},多个规则的话一个一行,如果要替换成指定的值,则只要在replace=""的冒号里设置即可。
其中,内容摘要、关键字、缩略图系统会用正则进行手动匹配,我们只需设置过滤内容即可。其余数组分别设置匹配规则和过滤规则,系统同样自带了几个常用的过滤规则,但是点击“常用规则”后为弹出小窗口模式,稍微有点不便捷。针对本测试的标题采集,以下两种形式都是可以的,如图:
文章作者、文章来源和发布时间数组一样采集,但是此版本dedecms在这几个数组下没有“自定义处理插口”了,如果有的话会稍显灵活,例如设置固定值可直接用“@me="固定值"”实现。现在不能用自定义处理插口设定固定值,也没有数组值设置,只能通过采集网页某一固定值之后用替换。如图:
dedecms的文章内容采集非常强悍,除了匹配规则和过滤规则,还有个“自定义处理插口”。如果你有php基础的话,可以通过此功能对采集结果@me进行各类处理,强大到不行啊。以后小编会专门发一篇此功能的讲解文章。最后,不能直接在采集管理处新增采集字段,只能在对应内容模型管理中降低数组,采集管理会手动降低。如小编在“普通文章”内容模型那降低了一个“chinaz数组”,则采集设置中手动增了一个“chinaz数组”项目。
保存并测试,查看列表测试信息和网页规则测试,检查是否正确,无误后确定并开始采集。进入采集指定节点设置页面,因为小编之前有测试一遍,所以有60个历史种子网址,即小编之前早已采集了60个网址,另外还有几个选项你们按需求选择。
点开始采集网页,出现此采集提示信息显示采集进度,不知道是小编人品不好还是dede采集本身缺点,经常会浏览器没反应,采集停止在那,只有自动点击了就会继续。
优采云CMS采集器绿色版(采集CMS工具) v1.0 免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2020-08-25 07:21
需要快捷采集CMS工具?优采云CMS采集器绿色版肯定就是您要找的软件啊!直接能够在网站和峰会里面开始自己的文章内容采集!非常简单的一键采集数据功能等着您进行是使用!还能够手动采集图面手动添加水印等等!优采云CMS采集器绿色版使在做相关工作的朋友们才能节约大量的时间和精力!
优采云CMS采集器绿色版功能说明
可采集别人网站和峰会的所有文章或内容并伪原创后发布到自己网站,可以每日采集最新文章,自动维护网站的发帖量等,可实现资源手动本地化,图片手动本地并添加水印等,日采集发布可达到上万篇。目前全面支持DEDECMS(织梦)、ECMS(帝国)、PHPCMS、PHP168、PowerEasy(动易)、SupeSite、5U、DIY-Page、Zoomla!逐浪CMS、目前包括CMS采集大挪移、维护王和同步更新王,JEECMS等主流CMS程序的采集和发布任务。
优采云CMS采集器绿色版特征介绍
可以在你的峰会一次注册成千上万个会员,让你的新峰会一开始都会有大量的会员;
可以一口气采集网站/论坛的主题和回复全部内容,80%的网站/论坛均可以采集 ,支持把文章内容保存到本地后再发布;
支持按UBB代码和源代码以及UBB和源代码相结合的三种形式编撰采集规则,最大限度的便捷了用户的使用习惯和选择;
具备万能破解功能,对于富含干扰码的文章、帖子,可以对它们内容中的干扰码进行完全屏蔽;
可将发贴和跟帖ID分割设置,让一部分会员全部发主题,让另外一部分会员全部回复,ID号会员抽选发布;
经过7年多的不断建立和升级,优采云采集器目前早已支持了国外大部分主流的建站程序,完全可以使您从繁杂的网站维护管理中解放下来,优采云采集器每套包括采集维护王和采集大挪移,配合使用具备以下实用功能:
可以使会员在设定的时间内同时上线,轻松实现万人在线火热峰会疗效(部分按IP算在线人数的峰会不支持,如DVbbs/PHPWind);
支持将某网站论坛A蓝筹股或栏目内容批量采集转发到自己网站或者峰会指定蓝筹股。
可以同时向网站或峰会的多个版块一起批量发帖;
可以针对峰会的某一主题分类进行发贴; 查看全部
优采云CMS采集器绿色版(采集CMS工具) v1.0 免费版
需要快捷采集CMS工具?优采云CMS采集器绿色版肯定就是您要找的软件啊!直接能够在网站和峰会里面开始自己的文章内容采集!非常简单的一键采集数据功能等着您进行是使用!还能够手动采集图面手动添加水印等等!优采云CMS采集器绿色版使在做相关工作的朋友们才能节约大量的时间和精力!
优采云CMS采集器绿色版功能说明
可采集别人网站和峰会的所有文章或内容并伪原创后发布到自己网站,可以每日采集最新文章,自动维护网站的发帖量等,可实现资源手动本地化,图片手动本地并添加水印等,日采集发布可达到上万篇。目前全面支持DEDECMS(织梦)、ECMS(帝国)、PHPCMS、PHP168、PowerEasy(动易)、SupeSite、5U、DIY-Page、Zoomla!逐浪CMS、目前包括CMS采集大挪移、维护王和同步更新王,JEECMS等主流CMS程序的采集和发布任务。
优采云CMS采集器绿色版特征介绍
可以在你的峰会一次注册成千上万个会员,让你的新峰会一开始都会有大量的会员;
可以一口气采集网站/论坛的主题和回复全部内容,80%的网站/论坛均可以采集 ,支持把文章内容保存到本地后再发布;
支持按UBB代码和源代码以及UBB和源代码相结合的三种形式编撰采集规则,最大限度的便捷了用户的使用习惯和选择;
具备万能破解功能,对于富含干扰码的文章、帖子,可以对它们内容中的干扰码进行完全屏蔽;
可将发贴和跟帖ID分割设置,让一部分会员全部发主题,让另外一部分会员全部回复,ID号会员抽选发布;
经过7年多的不断建立和升级,优采云采集器目前早已支持了国外大部分主流的建站程序,完全可以使您从繁杂的网站维护管理中解放下来,优采云采集器每套包括采集维护王和采集大挪移,配合使用具备以下实用功能:
可以使会员在设定的时间内同时上线,轻松实现万人在线火热峰会疗效(部分按IP算在线人数的峰会不支持,如DVbbs/PHPWind);
支持将某网站论坛A蓝筹股或栏目内容批量采集转发到自己网站或者峰会指定蓝筹股。
可以同时向网站或峰会的多个版块一起批量发帖;
可以针对峰会的某一主题分类进行发贴;
飞飞CMS最新模板,影视含文章140模板
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2020-08-20 02:38
购买须知:
A:嗯,对的,我们承诺演示效果图均和网站一模一样,如有不同,全额退票!并且我们的模板和数据都没有留侧门,请放心使用!
因为模板具有可复制性和可传播性,模板一旦发货,(除和演示效果图不一样),其它不支持退货,所以勿必请您一定看清楚后再订购;
A:我们的模板价钱代表着这个行业的最高价位。原因1)我们是正版的模板商,所有模板全部自主开发,因为我们的模板均为全新制做,纯手写代码精简优化,每套模板有配套的教程。2)我们仍然在降价,是因为我们的模板质量和系统优化仍然在提高,请不要单纯的比价钱,应该比它的价值。我们的模板是加了大量实用的插件的,如果你买了优价的模板再想实现我们的一些功能疗效,需要再花钱找人开发,那样最终的价钱虽然比我们的还高,而且一个站在多处找人开发,容易乱套,更没有保障。
A:购买模板 即得到整站全部源码,并且后台源码全部开源,不加密。只要自己有技术人员,可以任意更改的。(个别产品可能有部份文件加密,但不影响更改)
A:模板基本上全是后台控制的,个别后台管理不便捷的地方我们也做到了一个单独的库文件里,并且提供了安装教程,您完全可以自己任意更改的。一般小更改是免费的,如果涉及一定工作量的更改,我们是合理计费的。如果您能自己更改的最好自己更改,我们也不想加收您的费用,我们那边服务压力非常大,希望您能理解。
A:我们的演示全是模板的实际疗效截图,确保为你提供模板真实疗效。网上总有人想尽一切办法偷取我们的模板数据,所以没办法只能暂时采用的这些一比一截图演示方式,给您带来不便,希望能理解,我们仍然在为怎样使顾客能感受到模板真实的疗效而努力。我们承诺演示效果图均和网站一模一样,如有不同,全额退票! 查看全部
飞飞CMS最新模板,影视含文章140模板
购买须知:
A:嗯,对的,我们承诺演示效果图均和网站一模一样,如有不同,全额退票!并且我们的模板和数据都没有留侧门,请放心使用!
因为模板具有可复制性和可传播性,模板一旦发货,(除和演示效果图不一样),其它不支持退货,所以勿必请您一定看清楚后再订购;
A:我们的模板价钱代表着这个行业的最高价位。原因1)我们是正版的模板商,所有模板全部自主开发,因为我们的模板均为全新制做,纯手写代码精简优化,每套模板有配套的教程。2)我们仍然在降价,是因为我们的模板质量和系统优化仍然在提高,请不要单纯的比价钱,应该比它的价值。我们的模板是加了大量实用的插件的,如果你买了优价的模板再想实现我们的一些功能疗效,需要再花钱找人开发,那样最终的价钱虽然比我们的还高,而且一个站在多处找人开发,容易乱套,更没有保障。
A:购买模板 即得到整站全部源码,并且后台源码全部开源,不加密。只要自己有技术人员,可以任意更改的。(个别产品可能有部份文件加密,但不影响更改)
A:模板基本上全是后台控制的,个别后台管理不便捷的地方我们也做到了一个单独的库文件里,并且提供了安装教程,您完全可以自己任意更改的。一般小更改是免费的,如果涉及一定工作量的更改,我们是合理计费的。如果您能自己更改的最好自己更改,我们也不想加收您的费用,我们那边服务压力非常大,希望您能理解。
A:我们的演示全是模板的实际疗效截图,确保为你提供模板真实疗效。网上总有人想尽一切办法偷取我们的模板数据,所以没办法只能暂时采用的这些一比一截图演示方式,给您带来不便,希望能理解,我们仍然在为怎样使顾客能感受到模板真实的疗效而努力。我们承诺演示效果图均和网站一模一样,如有不同,全额退票!

