
文章采集调用
文章采集调用 Java 中拼接 String 的 N 种方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2022-05-01 09:32
1. 前言
Java 提供了拼接 String 字符串的多种方式,不过有时候如果我们不注意 null 字符串的话,可能会把 null 拼接到结果当中,很明显这不是我们想要的。
在这篇文章中,将介绍一些在拼接 String 时避免 null 值的几种方式。
2. 问题复现
如果我们想要拼接 String 数组,可以简单的使用 + 运算符进行拼接,但是可能会遇到 null 值。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />String result = "";<br /><br />for (String value : values) {<br /> result = result + value;<br />}<br />
这会将所有元素拼接到结果字符串中,如下所示:
https://www.wdbyte.comnull<br />
但是,我们已经发现问题了,最后的 null 值作为字符串也拼接了下来,这显然不是我们想要的。
同样,即使我们在 Java 8 或更高版本上运行,然后使用String.join() 静态方法拼接字符串,一样会得到带有 null 值的输出。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />String result = String.join("", values);<br />// output: https://www.wdbyte.comnull<br />
下面看看一些可以避免 null 值被拼接下来的方法,我的期待的输出结果应该是:
https://www.wdbyte.com<br />
3. 使用 + 运算符
加法符号 + 可以拼接 String 字符串,那么我们只需要在拼接时进行 null 判断就可以把 null 值替换为空字符串了。
for (String value : values) {<br /> result = result + (value == null ? "" : value);<br />}<br />
然而,我们知道 String 是一个不可变对象,使用 + 号会频繁的创建字符串对象,每次都会在内存中创建一个新的字符串,所以使用 + 符号来拼接字符串的性能消耗是很高的。
为了方便后续的代码演示,我们抽取一个可以传入字符串,返回一个非 null 字符串的方法。
public String nullToString(String value) {<br /> return value == null ? "" : value;<br />}<br />
因此上面的代码可以改为调用这个方法:
for (String value : values) {<br /> result = result + nullToString(value);<br />}<br />
4. 使用 String.concat()
String.concat() 是 String 类自带的一个方法,使用这种方式拼接字符串十分方便。
for (String value : values) {<br /> result = result.concat(getNonNullString(value));<br />}<br />
因为调用了 nullToString() 方法,因此得到的结果中没有 null 值。
5. 使用 StringBuilder
StringBuilder 类提供了很多有用且方便的 String 构建方法。其中比较常用的是 append() 方法,使用 append() 来拼接字符串,同时结合 nullToString() 方法来避免 null 值。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />StringBuilder result = new StringBuilder();<br />for (String value : values) {<br /> result = result.append(nullToString(value));<br />}<br />
可以得到如下结果:
https://www.wdbyte.com<br />
6. 使用 StringJoiner 类 (Java 8+)
StringJoiner 类提供了更强大的字符串拼接功能,不仅可以指定拼接时的分隔符,还可以指定拼接时的前缀和后缀,这里我们可以使用它的 add()方法来拼接字符串。
同样的会用 nullToString() 方法来避免 null 值。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />StringJoiner result = new StringJoiner("");<br />for (String value : values) {<br /> result = result.add(nullToString(value));<br />}<br />
7. 使用 Streams.filter (Java 8+)
Stream API 是 Java 8 引入的功能强大的流式操作类,可以进行常见的过滤、映射、遍历、分组、统计等操作。其中的过滤操作 filter 可以接收一个 Predicate 函数,Predicate 函数接口同之前介绍的 Function (opens new window)接口一样,是一个函数式接口,它可以接受一个泛型 参数,返回值为布尔类型,Predicate 常用于数据过滤。
因此,我们可以定义一个Predicate 来检查为 null 的字符串,然后传递给 Stream API 的 filter() 方法。
最后再使用 Collectors.joining() 方法拼接剩余的非 null 字符串。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />String result = Arrays.stream(values)<br /> .filter(Objects::nonNull)<br /> .collect(Collectors.joining());<br />
8. 总结
这篇文章介绍了拼接非 null 字符串的几种方式,不同的方式可能适合不同的场景,不过要注意拼接String 字符串是一项昂贵的操作,下面是使用 JMH 对几种拼接方式进行基准测试的结果。
Benchmark Mode Cnt Score Error Units<br />StringConcat.operateAdd thrpt 25 13635005.992 ± 549759.774 ops/s<br />StringConcat.String.concat thrpt 25 7465193.417 ± 667928.552 ops/s<br />StringConcat.StringBuilder thrpt 25 13949781.608 ± 142001.421 ops/s<br />StringConcat.StringJoiner thrpt 25 9502405.473 ± 211977.433 ops/s<br />StringConcat.StreamFilter thrpt 25 8998396.107 ± 649033.722 ops/s<br />
可以看到 StringBuilder 的性能是最好的,实际使用时要结合具体场景,然后选择最低的性能开销方式。
<p data-darkmode-bgcolor="rgb(36, 36, 36)" data-darkmode-original-bgcolor="rgb(255, 255, 255)" data-darkmode-color="rgb(106, 104, 111)" data-darkmode-original-color="rgb(106, 104, 111)" data-darkmode-bgcolor-15923650965579="rgb(36, 36, 36)" data-darkmode-original-bgcolor-15923650965579="rgb(255, 255, 255)" data-darkmode-color-15923650965579="rgb(106, 104, 111)" data-darkmode-original-color-15923650965579="rgb(106, 104, 111)" style="margin-right: 0em;margin-left: 0em;outline: 0px;color: rgb(106, 104, 111);">1. SQL优化万能公式:5 大步骤 + 10 个案例
2. 大型 SaaS 平台产品架构设计
3. Spring Cloud 分布式日志采集方案,建议收藏!
4. POI 导出 Excel:字体颜色、行列自适应、锁住、合并单元格、一文搞定……
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。</p>
<p data-tool="mdnice编辑器" style="margin-top: 10px;margin-bottom: 10px;padding-top: 8px;padding-bottom: 8px;outline: 0px;white-space: normal;font-family: -apple-system, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-align: right;line-height: 1.6;color: rgb(63, 63, 63);">PS:因公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。
点“在看”支持小哈呀,谢谢啦<strong style="outline: 0px;font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;color: rgb(0, 128, 255);font-size: 15px;"></strong></p> 查看全部
文章采集调用 Java 中拼接 String 的 N 种方式
1. 前言
Java 提供了拼接 String 字符串的多种方式,不过有时候如果我们不注意 null 字符串的话,可能会把 null 拼接到结果当中,很明显这不是我们想要的。
在这篇文章中,将介绍一些在拼接 String 时避免 null 值的几种方式。
2. 问题复现
如果我们想要拼接 String 数组,可以简单的使用 + 运算符进行拼接,但是可能会遇到 null 值。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />String result = "";<br /><br />for (String value : values) {<br /> result = result + value;<br />}<br />
这会将所有元素拼接到结果字符串中,如下所示:
https://www.wdbyte.comnull<br />
但是,我们已经发现问题了,最后的 null 值作为字符串也拼接了下来,这显然不是我们想要的。
同样,即使我们在 Java 8 或更高版本上运行,然后使用String.join() 静态方法拼接字符串,一样会得到带有 null 值的输出。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />String result = String.join("", values);<br />// output: https://www.wdbyte.comnull<br />
下面看看一些可以避免 null 值被拼接下来的方法,我的期待的输出结果应该是:
https://www.wdbyte.com<br />
3. 使用 + 运算符
加法符号 + 可以拼接 String 字符串,那么我们只需要在拼接时进行 null 判断就可以把 null 值替换为空字符串了。
for (String value : values) {<br /> result = result + (value == null ? "" : value);<br />}<br />
然而,我们知道 String 是一个不可变对象,使用 + 号会频繁的创建字符串对象,每次都会在内存中创建一个新的字符串,所以使用 + 符号来拼接字符串的性能消耗是很高的。
为了方便后续的代码演示,我们抽取一个可以传入字符串,返回一个非 null 字符串的方法。
public String nullToString(String value) {<br /> return value == null ? "" : value;<br />}<br />
因此上面的代码可以改为调用这个方法:
for (String value : values) {<br /> result = result + nullToString(value);<br />}<br />
4. 使用 String.concat()
String.concat() 是 String 类自带的一个方法,使用这种方式拼接字符串十分方便。
for (String value : values) {<br /> result = result.concat(getNonNullString(value));<br />}<br />
因为调用了 nullToString() 方法,因此得到的结果中没有 null 值。
5. 使用 StringBuilder
StringBuilder 类提供了很多有用且方便的 String 构建方法。其中比较常用的是 append() 方法,使用 append() 来拼接字符串,同时结合 nullToString() 方法来避免 null 值。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />StringBuilder result = new StringBuilder();<br />for (String value : values) {<br /> result = result.append(nullToString(value));<br />}<br />
可以得到如下结果:
https://www.wdbyte.com<br />
6. 使用 StringJoiner 类 (Java 8+)
StringJoiner 类提供了更强大的字符串拼接功能,不仅可以指定拼接时的分隔符,还可以指定拼接时的前缀和后缀,这里我们可以使用它的 add()方法来拼接字符串。
同样的会用 nullToString() 方法来避免 null 值。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />StringJoiner result = new StringJoiner("");<br />for (String value : values) {<br /> result = result.add(nullToString(value));<br />}<br />
7. 使用 Streams.filter (Java 8+)
Stream API 是 Java 8 引入的功能强大的流式操作类,可以进行常见的过滤、映射、遍历、分组、统计等操作。其中的过滤操作 filter 可以接收一个 Predicate 函数,Predicate 函数接口同之前介绍的 Function (opens new window)接口一样,是一个函数式接口,它可以接受一个泛型 参数,返回值为布尔类型,Predicate 常用于数据过滤。
因此,我们可以定义一个Predicate 来检查为 null 的字符串,然后传递给 Stream API 的 filter() 方法。
最后再使用 Collectors.joining() 方法拼接剩余的非 null 字符串。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />String result = Arrays.stream(values)<br /> .filter(Objects::nonNull)<br /> .collect(Collectors.joining());<br />
8. 总结
这篇文章介绍了拼接非 null 字符串的几种方式,不同的方式可能适合不同的场景,不过要注意拼接String 字符串是一项昂贵的操作,下面是使用 JMH 对几种拼接方式进行基准测试的结果。
Benchmark Mode Cnt Score Error Units<br />StringConcat.operateAdd thrpt 25 13635005.992 ± 549759.774 ops/s<br />StringConcat.String.concat thrpt 25 7465193.417 ± 667928.552 ops/s<br />StringConcat.StringBuilder thrpt 25 13949781.608 ± 142001.421 ops/s<br />StringConcat.StringJoiner thrpt 25 9502405.473 ± 211977.433 ops/s<br />StringConcat.StreamFilter thrpt 25 8998396.107 ± 649033.722 ops/s<br />
可以看到 StringBuilder 的性能是最好的,实际使用时要结合具体场景,然后选择最低的性能开销方式。
2. 大型 SaaS 平台产品架构设计
3. Spring Cloud 分布式日志采集方案,建议收藏!
4. POI 导出 Excel:字体颜色、行列自适应、锁住、合并单元格、一文搞定……
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。</p>
<p data-tool="mdnice编辑器" style="margin-top: 10px;margin-bottom: 10px;padding-top: 8px;padding-bottom: 8px;outline: 0px;white-space: normal;font-family: -apple-system, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-align: right;line-height: 1.6;color: rgb(63, 63, 63);">PS:因公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。
点“在看”支持小哈呀,谢谢啦<strong style="outline: 0px;font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;color: rgb(0, 128, 255);font-size: 15px;"></strong></p>
数据治理 | 数据分析与清洗工具:Pandas 数据类型转换(赠送本文同款数据!
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-05-01 09:11
Part1前言上期文章中,我们介绍了数据中的各种类型的缺失值以及如何处理这些缺失值;同时也介绍了常见的数据重复问题并奉上了处理重复数据的方法。这些处理方法对大家的数据治理、数据分析工作都有着至关重要的作用。本期文章将会继续学习 Pandas 工具,学习如何转换数据类型。读完本文后,灵活转换数据类型将不再是问题!本文中所有 Python 代码均在集成开发环境 Visual Studio Code (VScode) 中使用交互式开发环境 Jupyter Notebook 编写。Part2为什么需要做数据类型转换数据的含义与数据的类型是息息相关的,正确的数据类型能够支撑数据含义的正确表示。当一些数据的类型出现错乱时,它们的含义也会变得“诡异”。请看下面几个例子:
错误示范
正确示范
原因解析
今年是 2022.0年
今年是 2022 年
2022 作为一个年份时,应该保存为整数型或者字符型,而不是浮点型(小数型)数字 2022.0
圆周率保留两位小数的结果是3
圆周率保留两位小数的结果是 3.14
圆周率保留两位小数应该是浮点数 3.14,如果转为整数型,其结果就会是 3
1 + 1 = 11
1 + 1 = 2
1 + 1 = 11 实际上是字符串拼接,即 '1' + '1' 得到了 '11'
[0, 1, 2] 的第一个元素是[
[0, 1, 2] 的第一个元素是 0
列表 [0, 1, 2] 被保存为字符型,它的真面目是 "[0, 1, 2]",这个字符串的第一个元素是 '[' 而不是 0
我们早已经知道,Python 中字符串是用英文引号引起来的,就像是 'Python',"Python"。你可能会觉得,既然如此,数字型数据和字符型数据不就不容易搞混了吗?例如,数字 2022 和 字符串 "2022" ,很容易就能区分。然而,实际的情况却是,容易搞混,很容易搞混!这是因为在 Pandas 中,所有字符数据前后的引号都不会显示出来,如果显示出了引号,那么这些引号也是字符串中的字符。所以使用 Pandas 处理数据,为了避免类似的情况出现,学习数据类型转换是非常有必要的。Part3类型转换大多数时候,数据中不同字段的数据类型是不一定全都一样;同一个字段中,数据的类型是一般是一致的。所以进行数据类型转换时不需要一个一个对数据值做类型转换,直接操作一个字段会更加方便。我们使用本期赠送的数据作为介绍 Pandas 的示例数据,使用 Excel 打开数据【5G 产业全国各省市分年度专利申请、专利授权情况(2000-2019.9).xlsx】,如下图所示:
赠送的数据中没有缺失值,其中值为数字的字段在 Excel 中是数字类型;我们使用 Pandas 读取 Excel 或者 csv 数据时,系统会自动地将每个字段读取为合适的数据类型。如果需要自定义一些(或者所有)字段的类型,我们也可以自己指定每个字段的数据类型(数据必须满足指定类型的格式,例如我们不可以将 “省份名” 字段设置为 整数型)。使用 Pandas 读取这个 Excel 数据,代码和输出如下:
# 数据存储的路径<br />path = './5G 产业全国各省市分年度专利申请、专利授权情况(2000-2019.9).xlsx'<br /># 这里指定字段的数据类型<br />columns_type = {'年份':'str', <br /> '省份名':'str', <br /> '省份行政代码':'int', <br /> '专利申请':'int', <br /> '专利授权':'int', <br /> '专利类型':'str'}<br /># dtype 参数用于指定字段的类型,如果不需要特意指定字段的类型,不使用 dtype 参数即可<br />data = pd.read_excel(path, dtype=columns_type)<br />data<br />
读取数据后我们使用 Pandas 中的相关方法生成一个新的列,这一列中的数据是一个包含专利申请、专利授权和专利类型的列表。操作代码和新生成的数据如下:
# 根据专利申请、专利授权和专利类型三个字段得到一个新字段<br />data['列表'] = data.apply(lambda X: [X['专利申请'], X['专利授权'], X['专利类型']] ,axis=1)<br />data<br />
将新生成的数据保存为 csv 文件后再读取,读取时我们故意将部分字段读取为错误的类型,随后使用错误的数据来给大家演示如何进行数据类型的转换。
# 将刚刚新生成的数据保存为 csv 文件<br /># 参数 index=False 的含义是,不讲数据索引写入 csv 文件中<br />data.to_csv('新数据.csv', index=False)<br /><br /># 使用错误的字段类型重新读取数据<br /># 我们将年份读取为浮点型(小数型),将专利申请读取为字符型<br />wrong_type = {'年份':'float', <br /> '专利申请':'str'}<br />DATA = pd.read_csv('新数据.csv', dtype=wrong_type)<br /><br /># 查看专利申请字段类型<br />print(DATA.专利申请.dtype) # 输出:object,说明该字段含有字符型数据<br />DATA<br />
可以看到,“年份” 字段中所有的年份都变为小数型;通过代码也判断出 “专利申请” 字段不再是整数型,而是字符型,因为 DataFrame 中的字符型数据不会显示两端的引号,所以无法目测其类型。那么这种内容为数字的字符型数据会给我们什么麻烦呢?假设我们需要使用 专利授权/ 专利申请 来计算专利授权率时 ,会发现整数和字符之间无法运算。如果这两个字段中的值的都是字符型,那么两者只能进行加法运算,例如:“45” + “8” == “458”,这恐怕更不是我们想要的结果。接下来我们使用数据类型转换的方法来纠正这些错误的数据。1使用 astype() 转换基本类型Pandas 专门为类型转换提供了一个 astype() 方法,这个方法可以将数据类型转换为希望的类型,既可以操作 Series,又可以操作 DataFrame,使用时只需要传入转换后的类型即可。我们在往期的文章中提到过,Pandas 中绝大多数涉及到数据修改的方法,他们都不会直接修改原始的数据,而是返回一个新的数据。astype()也是一样的,默认返回一个新的数据。场景 1:将数据中的年份字段转换为整数型
# 将字段类型由浮点型(小数型)转换为整数型 int<br /># 返回一个新数据,调用该方法的是一个 Series,返回值也将是一个 Series<br />DATA['年份'].astype(int)<br />
希望类型转换操作在原始数据中生效可以使用下面的代码。
# 将新生的数据重新赋值给原始数据即可<br /># 赋值操作不会返回任何值<br />DATA['年份'] = DATA['年份'].astype(int)<br /># 输出查看转换后的数据<br />DATA<br />
场景 2:将数据中所有内容转换为字符型数据,转换后的数据命名为ALL_STR
# 将类型转换为字符型数据后的新数据命名为 ALL_STR<br />ALL_STR = DATA.astype(str)<br /># 查看新数据的信息<br />ALL_STR.info()<br />
所有的字段类型都变为 object,说明所有字段中都含有字符型数据,操作生效。另外,当字段中存在无法转换的数据值时,可以指定参数 errors='ignore' 来忽略无法转换的数据值。假如我们希望将所有字段都转换为浮点型(小数型),但是字符型数据 “北京” 、“45”、“发明专利” 等字符型数据无法转换为浮点型,我们则可以使用下面的代码来转换可以转换的字段:
# 指定参数 errors='ignore',忽略无法转换的数据值<br />DATA.astype(float, errors='ignore')<br />
可以看到,除了一些字符型数据之外,其他的数字类型数据都被转换为浮点型(小数型)数据。同样地,如果不进行赋值操作,那么就会返回一个新的数据,而原始数据不会发生变化。2使用 eval() 转换特殊类型astype() 方法多用于浮点型 float、整数型 int 和 字符型 str 的转换操作。当涉及到字符型转化为列表,字典等 Python 的组合数据类型时,则需要使用 Python 自带的方法 eval() 。该函数可以去掉字符串最外侧的引号,并按照 Python 语句方式执行去掉引号后的字符内容。下面我们举例介绍一下 eval() 的用法。
# 对字符串 '12' 做转换<br />eval('12') # 得到整数:12<br /><br /># 对字符串 '12.5' 做转换<br />eval('12.5') # 得到浮点数:12.5<br /><br /># 对字符串 '12+5' 做转换<br />eval('12+5') # 得到整数:17<br /><br /># 定义变量 a 后对字符串 'a' 做转换<br />a = '20'<br />eval('a') # 得到 a 的值:20<br /><br /># 对字符串 "[11,12,'列表元素']" 做转换<br />eval("[11,12,'列表元素']") # 得到列表:[11, 12, '列表元素']<br /><br /># 定义变量 m,n 后对字符串 '[m,n,m-50]' 做转换<br />m=100<br />n='某个字符串'<br />eval("[m,n,m-50]") # 得到列表:[100, '某个字符串', 50]<br />
根据上面的例子可以看出,eval() 确实可以去掉字符串最外侧的引号,并按照 Python 语句方式执行去掉引号后的字符内容。这个方法不仅可以转换列表形式的字符串,对诸如字典、元组以及集合等 Python 数据类型形式的字符串,该方法依然可用。场景 3:将数据中“列表”字段转换为 Python 列表类型由于 eval() 方法操作的是字符串对象,一次只接受一个需要转化的对象,当需要使用它来对 DataFrame 的一整个字段做转换操作时,需要借助循环或者其他的 Pandas 方法。
# 输出查看转换之前"列表"字段最后一个值的类型,原始的类型为 str 型<br />print(type(DATA['列表'].values[-1]))<br /># 输出:,确认是字符型<br /><br /># 方法 1:借助 for 循环<br />for i in DATA.index:<br /> # 遍历数据的索引<br /> # 根据索引找到待转换的数据<br /> Target = DATA.loc[i,'列表']<br /> # 将转换后的数据重新赋值给原来位置的数据值<br /> DATA['列表'][i] = eval(Target)<br /> <br /># 输出查看"列表"字段最后一个值的类型,若为列表,说明转换成功<br />print(type(DATA['列表'].values[-1]))<br /># 输出:,转换成功<br /><br /># 方法 2:借助 Pandas 方法 map()。不再输出查看类型<br />DATA['列表'] = DATA['列表'].map(eval)<br /><br /># 方法 3:借助 Pandas 方法 apply()。不再输出查看类型<br />DATA['列表'] = DATA['列表'].apply(eval)<br />
后面两种方法可以实现 方法 1 同样的效果,且代码量更少。Part4总结本期文章中,我们介绍了数据类型错误带来的影响,同时也介绍了转换字段数据类型的方法。使用类型转换方法可以在基本的数据类型之间进行合理的转换。同时也介绍了转换特殊数据类型的方法。学习这些可以让我们灵活地转换数据的类型,避免类型错乱带来的麻烦。在最后的 场景3中,我们使用了map() 和 apply() 两个方法,使用更少的代码完成了同样的功能。下期文章我们将会继续介绍 Pandas,学习如何使用以上两种方法来根据已有的数据生成新的数据列(数据列衍生)。
查看全部
数据治理 | 数据分析与清洗工具:Pandas 数据类型转换(赠送本文同款数据!
Part1前言上期文章中,我们介绍了数据中的各种类型的缺失值以及如何处理这些缺失值;同时也介绍了常见的数据重复问题并奉上了处理重复数据的方法。这些处理方法对大家的数据治理、数据分析工作都有着至关重要的作用。本期文章将会继续学习 Pandas 工具,学习如何转换数据类型。读完本文后,灵活转换数据类型将不再是问题!本文中所有 Python 代码均在集成开发环境 Visual Studio Code (VScode) 中使用交互式开发环境 Jupyter Notebook 编写。Part2为什么需要做数据类型转换数据的含义与数据的类型是息息相关的,正确的数据类型能够支撑数据含义的正确表示。当一些数据的类型出现错乱时,它们的含义也会变得“诡异”。请看下面几个例子:
错误示范
正确示范
原因解析
今年是 2022.0年
今年是 2022 年
2022 作为一个年份时,应该保存为整数型或者字符型,而不是浮点型(小数型)数字 2022.0
圆周率保留两位小数的结果是3
圆周率保留两位小数的结果是 3.14
圆周率保留两位小数应该是浮点数 3.14,如果转为整数型,其结果就会是 3
1 + 1 = 11
1 + 1 = 2
1 + 1 = 11 实际上是字符串拼接,即 '1' + '1' 得到了 '11'
[0, 1, 2] 的第一个元素是[
[0, 1, 2] 的第一个元素是 0
列表 [0, 1, 2] 被保存为字符型,它的真面目是 "[0, 1, 2]",这个字符串的第一个元素是 '[' 而不是 0
我们早已经知道,Python 中字符串是用英文引号引起来的,就像是 'Python',"Python"。你可能会觉得,既然如此,数字型数据和字符型数据不就不容易搞混了吗?例如,数字 2022 和 字符串 "2022" ,很容易就能区分。然而,实际的情况却是,容易搞混,很容易搞混!这是因为在 Pandas 中,所有字符数据前后的引号都不会显示出来,如果显示出了引号,那么这些引号也是字符串中的字符。所以使用 Pandas 处理数据,为了避免类似的情况出现,学习数据类型转换是非常有必要的。Part3类型转换大多数时候,数据中不同字段的数据类型是不一定全都一样;同一个字段中,数据的类型是一般是一致的。所以进行数据类型转换时不需要一个一个对数据值做类型转换,直接操作一个字段会更加方便。我们使用本期赠送的数据作为介绍 Pandas 的示例数据,使用 Excel 打开数据【5G 产业全国各省市分年度专利申请、专利授权情况(2000-2019.9).xlsx】,如下图所示:
赠送的数据中没有缺失值,其中值为数字的字段在 Excel 中是数字类型;我们使用 Pandas 读取 Excel 或者 csv 数据时,系统会自动地将每个字段读取为合适的数据类型。如果需要自定义一些(或者所有)字段的类型,我们也可以自己指定每个字段的数据类型(数据必须满足指定类型的格式,例如我们不可以将 “省份名” 字段设置为 整数型)。使用 Pandas 读取这个 Excel 数据,代码和输出如下:
# 数据存储的路径<br />path = './5G 产业全国各省市分年度专利申请、专利授权情况(2000-2019.9).xlsx'<br /># 这里指定字段的数据类型<br />columns_type = {'年份':'str', <br /> '省份名':'str', <br /> '省份行政代码':'int', <br /> '专利申请':'int', <br /> '专利授权':'int', <br /> '专利类型':'str'}<br /># dtype 参数用于指定字段的类型,如果不需要特意指定字段的类型,不使用 dtype 参数即可<br />data = pd.read_excel(path, dtype=columns_type)<br />data<br />
读取数据后我们使用 Pandas 中的相关方法生成一个新的列,这一列中的数据是一个包含专利申请、专利授权和专利类型的列表。操作代码和新生成的数据如下:
# 根据专利申请、专利授权和专利类型三个字段得到一个新字段<br />data['列表'] = data.apply(lambda X: [X['专利申请'], X['专利授权'], X['专利类型']] ,axis=1)<br />data<br />
将新生成的数据保存为 csv 文件后再读取,读取时我们故意将部分字段读取为错误的类型,随后使用错误的数据来给大家演示如何进行数据类型的转换。
# 将刚刚新生成的数据保存为 csv 文件<br /># 参数 index=False 的含义是,不讲数据索引写入 csv 文件中<br />data.to_csv('新数据.csv', index=False)<br /><br /># 使用错误的字段类型重新读取数据<br /># 我们将年份读取为浮点型(小数型),将专利申请读取为字符型<br />wrong_type = {'年份':'float', <br /> '专利申请':'str'}<br />DATA = pd.read_csv('新数据.csv', dtype=wrong_type)<br /><br /># 查看专利申请字段类型<br />print(DATA.专利申请.dtype) # 输出:object,说明该字段含有字符型数据<br />DATA<br />
可以看到,“年份” 字段中所有的年份都变为小数型;通过代码也判断出 “专利申请” 字段不再是整数型,而是字符型,因为 DataFrame 中的字符型数据不会显示两端的引号,所以无法目测其类型。那么这种内容为数字的字符型数据会给我们什么麻烦呢?假设我们需要使用 专利授权/ 专利申请 来计算专利授权率时 ,会发现整数和字符之间无法运算。如果这两个字段中的值的都是字符型,那么两者只能进行加法运算,例如:“45” + “8” == “458”,这恐怕更不是我们想要的结果。接下来我们使用数据类型转换的方法来纠正这些错误的数据。1使用 astype() 转换基本类型Pandas 专门为类型转换提供了一个 astype() 方法,这个方法可以将数据类型转换为希望的类型,既可以操作 Series,又可以操作 DataFrame,使用时只需要传入转换后的类型即可。我们在往期的文章中提到过,Pandas 中绝大多数涉及到数据修改的方法,他们都不会直接修改原始的数据,而是返回一个新的数据。astype()也是一样的,默认返回一个新的数据。场景 1:将数据中的年份字段转换为整数型
# 将字段类型由浮点型(小数型)转换为整数型 int<br /># 返回一个新数据,调用该方法的是一个 Series,返回值也将是一个 Series<br />DATA['年份'].astype(int)<br />
希望类型转换操作在原始数据中生效可以使用下面的代码。
# 将新生的数据重新赋值给原始数据即可<br /># 赋值操作不会返回任何值<br />DATA['年份'] = DATA['年份'].astype(int)<br /># 输出查看转换后的数据<br />DATA<br />
场景 2:将数据中所有内容转换为字符型数据,转换后的数据命名为ALL_STR
# 将类型转换为字符型数据后的新数据命名为 ALL_STR<br />ALL_STR = DATA.astype(str)<br /># 查看新数据的信息<br />ALL_STR.info()<br />
所有的字段类型都变为 object,说明所有字段中都含有字符型数据,操作生效。另外,当字段中存在无法转换的数据值时,可以指定参数 errors='ignore' 来忽略无法转换的数据值。假如我们希望将所有字段都转换为浮点型(小数型),但是字符型数据 “北京” 、“45”、“发明专利” 等字符型数据无法转换为浮点型,我们则可以使用下面的代码来转换可以转换的字段:
# 指定参数 errors='ignore',忽略无法转换的数据值<br />DATA.astype(float, errors='ignore')<br />
可以看到,除了一些字符型数据之外,其他的数字类型数据都被转换为浮点型(小数型)数据。同样地,如果不进行赋值操作,那么就会返回一个新的数据,而原始数据不会发生变化。2使用 eval() 转换特殊类型astype() 方法多用于浮点型 float、整数型 int 和 字符型 str 的转换操作。当涉及到字符型转化为列表,字典等 Python 的组合数据类型时,则需要使用 Python 自带的方法 eval() 。该函数可以去掉字符串最外侧的引号,并按照 Python 语句方式执行去掉引号后的字符内容。下面我们举例介绍一下 eval() 的用法。
# 对字符串 '12' 做转换<br />eval('12') # 得到整数:12<br /><br /># 对字符串 '12.5' 做转换<br />eval('12.5') # 得到浮点数:12.5<br /><br /># 对字符串 '12+5' 做转换<br />eval('12+5') # 得到整数:17<br /><br /># 定义变量 a 后对字符串 'a' 做转换<br />a = '20'<br />eval('a') # 得到 a 的值:20<br /><br /># 对字符串 "[11,12,'列表元素']" 做转换<br />eval("[11,12,'列表元素']") # 得到列表:[11, 12, '列表元素']<br /><br /># 定义变量 m,n 后对字符串 '[m,n,m-50]' 做转换<br />m=100<br />n='某个字符串'<br />eval("[m,n,m-50]") # 得到列表:[100, '某个字符串', 50]<br />
根据上面的例子可以看出,eval() 确实可以去掉字符串最外侧的引号,并按照 Python 语句方式执行去掉引号后的字符内容。这个方法不仅可以转换列表形式的字符串,对诸如字典、元组以及集合等 Python 数据类型形式的字符串,该方法依然可用。场景 3:将数据中“列表”字段转换为 Python 列表类型由于 eval() 方法操作的是字符串对象,一次只接受一个需要转化的对象,当需要使用它来对 DataFrame 的一整个字段做转换操作时,需要借助循环或者其他的 Pandas 方法。
# 输出查看转换之前"列表"字段最后一个值的类型,原始的类型为 str 型<br />print(type(DATA['列表'].values[-1]))<br /># 输出:,确认是字符型<br /><br /># 方法 1:借助 for 循环<br />for i in DATA.index:<br /> # 遍历数据的索引<br /> # 根据索引找到待转换的数据<br /> Target = DATA.loc[i,'列表']<br /> # 将转换后的数据重新赋值给原来位置的数据值<br /> DATA['列表'][i] = eval(Target)<br /> <br /># 输出查看"列表"字段最后一个值的类型,若为列表,说明转换成功<br />print(type(DATA['列表'].values[-1]))<br /># 输出:,转换成功<br /><br /># 方法 2:借助 Pandas 方法 map()。不再输出查看类型<br />DATA['列表'] = DATA['列表'].map(eval)<br /><br /># 方法 3:借助 Pandas 方法 apply()。不再输出查看类型<br />DATA['列表'] = DATA['列表'].apply(eval)<br />
后面两种方法可以实现 方法 1 同样的效果,且代码量更少。Part4总结本期文章中,我们介绍了数据类型错误带来的影响,同时也介绍了转换字段数据类型的方法。使用类型转换方法可以在基本的数据类型之间进行合理的转换。同时也介绍了转换特殊数据类型的方法。学习这些可以让我们灵活地转换数据的类型,避免类型错乱带来的麻烦。在最后的 场景3中,我们使用了map() 和 apply() 两个方法,使用更少的代码完成了同样的功能。下期文章我们将会继续介绍 Pandas,学习如何使用以上两种方法来根据已有的数据生成新的数据列(数据列衍生)。
Crack App | 某搜索 App 中关于 x 信文章检索功能的加密参数
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-04-30 02:25
点击上方“咸鱼学Python”,选择“加为星标”
第一时间关注Python技术干货!
图源:极简壁纸
今日目标
今天的目标是很多读者朋友在采集微信文章时常用站的 app 版本
aHR0cHM6Ly93d3cud2FuZG91amlhLmNvbS9zZWFyY2gvNjU1NTQ3NDYwMzMwMTAyMDk0MQ==
抓包分析
抓包使用的是 Charles + Postern 的组合
使用大黄鸟 app 抓包也是可以的,Charles 看着会更舒服一些
打开 app 搜索任意内容,切换到微信栏目就可以抓到以下的请求包了
点击这个请求可以看到请求参数还有请求的结果都是加密的
请求的参数是k、v、u、r、g、p的名字,所以通过参数名检索的方法很难定位到很准确的结果
静态分析定位逻辑
apk 包推荐使用 jadx 1.2 打开,用 1.3 搜索的时候老是崩溃
通过以请求链接的部分v2.get作为搜索关键词可以定位到下面的搜索结果
最后一个搜索的结果和我们的请求链接最匹配
点进去可以看到下面的内容
可以看到图中红框的部分应该是请求的部分,红框下面是返回的部分
分别经过了encrypt和decrypt两个方法
先讲讲我是怎么确定是这两个方法的
红框部分中定义了一个hashMap,通其中put了一个Content-Length,这个搞过 js 逆向的都知道,这个是代表了请求提交内容的长度
这个长度是通过encrypt.length得到的,而encrypt是通过ScEncryptWall.encrypt(str, str2, str3);得到的
而返回部分的代码是在判断了f0.b得出的,在f0.b的判断中有一关于response success的输出,进一步确认了我们的判断
所以这里的encrypt和decrypt两个方法是分析的重点
进一步追进去可以看到这两个方法都是native方法,定义在libSCoreTools.so里面
动态调试确认逻辑
既然是 native 方法,通过 IDA 分析这几个也是导出方法,这里 hook 的方法就很多了。
我们直接用frida hook看下出入参看看是不是符合我们在上一部分的猜想
先看encrypt
function hook_encrypt(){<br /> Java.perform(function () {<br /> var ScEncryptWall = Java.use('包名.类名');<br /> ScEncryptWall.encrypt.implementation = function (str1,str2,str3) {<br /> console.log('str1: ', str1);<br /> console.log('str2: ', str2);<br /> console.log('str3: ', str3);<br /> var res = this.encrypt(str1, str2, str3);<br /> console.log('res: ', res);<br /> return res;<br /> }<br /> })<br />}<br />setImmediate(hook_encrypt)<br />
通过hook可以得到以下结果
str1 = 请求的 url<br />str2 = 请求提交的参数(明文)<br />str3 = 空<br />
返回的结果就是加密好的参数了
同样的hook decrypt
function hook_decrypt(){<br /> Java.perform(function () {<br /> var ScEncryptWall = Java.use('包名.类名');<br /> ScEncryptWall.decrypt.implementation = function (data) {<br /> console.log('data: ', data);<br /> var res = this.decrypt(a);<br /> console.log('res: ', Java.use('java.lang.String').$new(res));<br /> return res;<br /> }<br /> })<br />}<br />setImmediate(hook_decrypt)<br />
打印结果如下
参数是请求的返回值,解密的结果是列表页的内容
完事~,Python RPC 调用一下就可以爽爽的采集相关的文章了 查看全部
Crack App | 某搜索 App 中关于 x 信文章检索功能的加密参数
点击上方“咸鱼学Python”,选择“加为星标”
第一时间关注Python技术干货!
图源:极简壁纸
今日目标
今天的目标是很多读者朋友在采集微信文章时常用站的 app 版本
aHR0cHM6Ly93d3cud2FuZG91amlhLmNvbS9zZWFyY2gvNjU1NTQ3NDYwMzMwMTAyMDk0MQ==
抓包分析
抓包使用的是 Charles + Postern 的组合
使用大黄鸟 app 抓包也是可以的,Charles 看着会更舒服一些
打开 app 搜索任意内容,切换到微信栏目就可以抓到以下的请求包了
点击这个请求可以看到请求参数还有请求的结果都是加密的
请求的参数是k、v、u、r、g、p的名字,所以通过参数名检索的方法很难定位到很准确的结果
静态分析定位逻辑
apk 包推荐使用 jadx 1.2 打开,用 1.3 搜索的时候老是崩溃
通过以请求链接的部分v2.get作为搜索关键词可以定位到下面的搜索结果
最后一个搜索的结果和我们的请求链接最匹配
点进去可以看到下面的内容
可以看到图中红框的部分应该是请求的部分,红框下面是返回的部分
分别经过了encrypt和decrypt两个方法
先讲讲我是怎么确定是这两个方法的
红框部分中定义了一个hashMap,通其中put了一个Content-Length,这个搞过 js 逆向的都知道,这个是代表了请求提交内容的长度
这个长度是通过encrypt.length得到的,而encrypt是通过ScEncryptWall.encrypt(str, str2, str3);得到的
而返回部分的代码是在判断了f0.b得出的,在f0.b的判断中有一关于response success的输出,进一步确认了我们的判断
所以这里的encrypt和decrypt两个方法是分析的重点
进一步追进去可以看到这两个方法都是native方法,定义在libSCoreTools.so里面
动态调试确认逻辑
既然是 native 方法,通过 IDA 分析这几个也是导出方法,这里 hook 的方法就很多了。
我们直接用frida hook看下出入参看看是不是符合我们在上一部分的猜想
先看encrypt
function hook_encrypt(){<br /> Java.perform(function () {<br /> var ScEncryptWall = Java.use('包名.类名');<br /> ScEncryptWall.encrypt.implementation = function (str1,str2,str3) {<br /> console.log('str1: ', str1);<br /> console.log('str2: ', str2);<br /> console.log('str3: ', str3);<br /> var res = this.encrypt(str1, str2, str3);<br /> console.log('res: ', res);<br /> return res;<br /> }<br /> })<br />}<br />setImmediate(hook_encrypt)<br />
通过hook可以得到以下结果
str1 = 请求的 url<br />str2 = 请求提交的参数(明文)<br />str3 = 空<br />
返回的结果就是加密好的参数了
同样的hook decrypt
function hook_decrypt(){<br /> Java.perform(function () {<br /> var ScEncryptWall = Java.use('包名.类名');<br /> ScEncryptWall.decrypt.implementation = function (data) {<br /> console.log('data: ', data);<br /> var res = this.decrypt(a);<br /> console.log('res: ', Java.use('java.lang.String').$new(res));<br /> return res;<br /> }<br /> })<br />}<br />setImmediate(hook_decrypt)<br />
打印结果如下
参数是请求的返回值,解密的结果是列表页的内容
完事~,Python RPC 调用一下就可以爽爽的采集相关的文章了
微信公众号视频批量下载软件--视频批量下载的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 386 次浏览 • 2022-04-29 14:13
大家好,这是余夫第 011篇原创文章,关注余夫持续分享实用软件和各种实用资料,第一时间获取更多的软件和资料。
注意本公众号介绍的所有下载视频的软件,视频下载的前提是你的视频必须是已经付费购买了课程或者是免费视频,只有可以正常播放才能下载。
微信公众号的视频分为两种
一种是自己上传到微信公众号里面的视频,以我自己的公众号视频为例如下图
这种就是直接上传到公众号里面的原创视频,这种视频可以直接复制链接到浏览器里面通过插件可以直接下载。
这个文章介绍的下载方法就可以实现单个下载
视频少的话可以用上面单个的一个一个的下载,那要是上百个视频就需要使用批量下载了。
这样直接就可以批量下载速度很快100个视频也就是几分钟的事。有需要下载的可以联系我代下载。
另外一种是调用的腾讯视频的链接,如下面这种就是调用腾讯视频。
这种的可以直接复制链接到浏览器里面里面去播放,选择分辨率高的来播放,idm的插件也可以直接识别到点击下载就可以了。
也可以批量采集链接复制到软件里面来下载。使用爬虫插件直接批量获取链接
直接复制链接到软件里面就可以实现批量下载了。
这样就把公众号的视频下载下来了。 音频是样的道理,文章也是可以下载,过2天讲下文章怎么下载的。 查看全部
微信公众号视频批量下载软件--视频批量下载的方法
大家好,这是余夫第 011篇原创文章,关注余夫持续分享实用软件和各种实用资料,第一时间获取更多的软件和资料。
注意本公众号介绍的所有下载视频的软件,视频下载的前提是你的视频必须是已经付费购买了课程或者是免费视频,只有可以正常播放才能下载。
微信公众号的视频分为两种
一种是自己上传到微信公众号里面的视频,以我自己的公众号视频为例如下图
这种就是直接上传到公众号里面的原创视频,这种视频可以直接复制链接到浏览器里面通过插件可以直接下载。
这个文章介绍的下载方法就可以实现单个下载
视频少的话可以用上面单个的一个一个的下载,那要是上百个视频就需要使用批量下载了。
这样直接就可以批量下载速度很快100个视频也就是几分钟的事。有需要下载的可以联系我代下载。
另外一种是调用的腾讯视频的链接,如下面这种就是调用腾讯视频。
这种的可以直接复制链接到浏览器里面里面去播放,选择分辨率高的来播放,idm的插件也可以直接识别到点击下载就可以了。
也可以批量采集链接复制到软件里面来下载。使用爬虫插件直接批量获取链接
直接复制链接到软件里面就可以实现批量下载了。
这样就把公众号的视频下载下来了。 音频是样的道理,文章也是可以下载,过2天讲下文章怎么下载的。
调用链追踪系统在伴鱼:Opentelemetry最佳实践案例分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-04-29 14:06
搭建可靠的链路追踪系统
在正式介绍前,简单交代一下背景:2015 年,在伴鱼服务端起步之时,技术团队就做出统一使用 Go 语言的决定。这个决定的影响主要体现在:
早期实践对接 Jaeger
2019 年,公司内部的微服务数量逐步增加,调用关系日趋复杂,工程师做性能分析、问题排查的难度变大。这时亟需一套调用链追踪系统帮助我们增强对服务端全貌的了解。经过调研后,我们决定采用同样基于 Go 语言搭建的、由 CNCF 孵化的项目Jaeger。当时,服务的开发和治理都尚未引入 context,不论进程内部调用还是跨进程调用,都没有上下文传递。因此早期引入调用链追踪的工作重心就落在了服务及服务治理框架的改造,包括:
部署方面:测试环境采用 all-in-one,线上环境采用 direct-to-storage 方案。整个过程前后大约耗时一个月,我们在 2019 年 Q3 上线了第一版调用链追踪系统。配合广泛被采用的 prometheus + grafana 以及 ELK,我们在微服务群的可观测性上终于凑齐了调用链 (traces)、日志 (logs) 和监控指标 (metrics) 三个要素。
下图是第一版调用链追踪系统的数据上报通路示意图。服务运行在容器中,通过 opentracing 的 sdk 埋点,Jaeger 的 go-sdk 上报到宿主机上的 Jaeger-agent,后者再将数据进一步上报到 Jaeger-collector,最终将调用链数据写入 ES,建立索引,即图中的 Jaeger backends。
遇到的问题
Jaeger 支持三种采样方式:
调用链通路改造使用场景
2020 年,我们不断收到业务研发的反馈:能不能全量采集 trace?
这促使我们开始重新思考如何改进调用链追踪系统。我们做了一个简单的容量预估:目前 Jaeger 每天写入 ES 的数据量接近 100GB/天,如果要全量采集 trace 数据,保守假设平均每个 HTTP API 服务的总 QPS 为 100,那么完整存下全量数据需要 10TB/天;乐观假设 100 名服务器研发每人每天查看 1 条 trace,每条 trace 的平均大小为 1KB,则整体信噪比千万分之一。可以看出,这件事情本身的 ROI 很低,考虑到未来业务会持续增长,存储这些数据的价值也会继续降低,因此全量采集的方案被放弃。退一步想:全量采集真的是本质需求吗?实际上并非如此,我们想要的其实是「有意思」的 trace 全采,「没意思」的 trace 不采。
根据 理论篇 中介绍的应用场景,实际上第一版调用链追踪系统只支持了稳态分析,而业务研发亟需的是异常检测。要同时支持这两种场景,我们必须借助尾部连贯采样 (tail-based coherent sampling)。相对于头部连贯采样在第一个 span 处就做出是否采样的决定,尾部连贯采样可以让我们在获取 (接近) 完整的 trace 信息后再做出判断。理想情况下,只要能合理地制定采样的判断逻辑,我们的调用链追踪系统就能做到「有意思」的 trace 全采,「没意思」的 trace 不采。
架构设计
Jaeger 团队从 2017 年就开始讨论引入 tail-based sampling 的可能性,但至今未有定论。在一次与 Jaeger 工程师 jpkrohling 的一对一沟通中,对方也证实了目前 Jaeger 尚没有相关的支持计划。因此,我们不得不另辟蹊径。经过一番调研,我们找到了刚刚进驻 CNCF SandBox 的OpenTelemetry,它的opentelemetry-collector子项目恰好能支持我们在现有架构上引入尾部连贯采样。
OpenTelemetry Collector
整个 OpenTelemetry 项目目的在于统一市面上可观测性数据 (telemetry data) 的标准,同时提供推动这些标准实施的组件和工具。opentelemetry-collector 就是这个生态中的一个重要组件,它的架构图如下:
collector 内部有 4 个核心组件:
opentelemetry-collector 项目被拆成两部分:主项目 opentelemetry-collector 和社区贡献项目 opentelemetry-collector-contrib,前者负责管理核心逻辑、数据结构以及通用的 Receivers、Processors、Exporters、Extensions 实现,后者则负责接收一些社区贡献的组件,当然贡献者主要都来自于可观测性 SaaS 解决方案供应商,如 DataDog、Splunk、LightStep 以及一些公有云厂商。opentelemtry-collector 项目的插件化管理方式,使得定制化开发 Receiver、Processor、Exporter 的成本很低,我们在做概念验证时,基本可以在一两个小时内开发并测试完毕一个组件。除此之外,opentelemetry-collector-contrib 还提供了开箱即用的tailsamplingprocessor。
由于 opentelemetry-collector 是 OpenTelemetry 团队推动标准实施的重要组件,且 OpenTelemetry 本身并没有提供独立的数据存储、索引实现的计划,因此它在与市面上流行的调用链追踪框架,如 Zipkin、Jaeger、OpenCensus,的兼容性上下了很大功夫。通过 Receivers 和 Exporters 的使用,我们可以用它替换 jaeger-agent,也可以放在 jaeger-agent 与 jaeger-collector 之间,必要时还可以在 jaeger-agent 和 jaeger-collector 之间部署多层 collectors。除此之外,如果有一天想换掉 jaeger-backend,比如新发布的 Grafana Tempo,我们也能很轻松的完成,并且利用多个 Pipelines 或一个 Pipeline 多个 Exporters 灰度上线,逐步替换。
上报通路
基于以上的调研和现有的架构,我们设计了第二版调用链追踪的架构,如下图所示:
用一组 opentelemetry-collector 替换 jaeger-agent,即图中的 otel-agent;同时在 otel-agent 与 jaeger-collector 之间增加另一组 opentelemetry-collector,即图中的 otel-collector。otel-agent 收集宿主机上不同服务上报的 trace 数据,打包批量发送给 otel-collector,后者负责做尾部连贯采样,将「有意思」的 trace 继续输出到原始架构中的 jaeger-collector,后者负责将数据投入 ElasticSearch 中,建立索引。
这里还有一个问题需要解决:整个架构做到高可用,势必要部署多个 otel-collector 实例,如果使用简单的负载均衡策略,不同 otel-agents、以及单个 otel-agent 不同时刻上报的数据,可能被随机上报到某个 otel-collector 实例,这就意味着,同一个 trace 的不同 spans 无法集中到同一个 otel-collector 实例上,既会导致同一个 trace 的不同 spans 的决定不一致,即不是连贯采样;也会导致尾部采样时提供判断的数据不全。解决方案很简单:让 otel-agent 按照 traceID 做负载均衡。
在调研阶段我们正好看到 opentelemetry-collector 社区也有此支持计划,并且前面提到的工程师 jpkrohling 正在通过增加loadbalancingexporter解决它,虽然直接使用 bleeding edge 的版本有一定的风险,我们还是决定尝试。在概念验证阶段,我们也的确发现了新功能的若干问题,但通过反馈的方式一一解决,最终获得了可以按预期执行尾部连贯采样的调用链追踪系统。
采样规则
尾部连贯采样的数据通路已经准备就绪,下一步就是确定和实施采样规则。
「有意思」的调用链
什么是「有意思」的调用链?研发在分析、排障过程中想查询的任何调用链就是「有意思」的调用链。但落实到代码的必须是确定性的规则,根据日常排障经验,我们先确定了以下三种情形:
满足任意条件,就认为这个调用链「有意思」。在伴鱼,只要服务打印了 ERROR 级别的日志就会触发报警,研发人员就会收到 im 消息或电话报警,如果能保证触发报警的调用链数据必采,研发人员的排障体验就会有很大的提升;我们的 DBA 团队认为超过 200ms 的查询请求都被判定为慢查询,如果能保证这些请求的调用链必采,就能大大方便研发排查导致慢查询的请求;对于在线服务来说,时延过高会令用户体验下降,但具体高到什么程度会引发明显的体验下降我们暂时没有数据支撑,因此先配置为 1s,支持随时修改阈值。
当然,以上条件并不绝对,我们可以在之后的实践根据反馈调整、新增规则,如单个请求引起的数据库、缓存查询次数超过某阈值等。
采样流水线
在第二版系统中,我们期望同时支持稳态分析与异常检测,因此采样过程既要按概率或限流方式采集一部分 trace,也需要按上文拟定的「有意思」 规则采集令一部分 trace。截止到本文撰写前,tailsamplingprocessor支持 4 种策略:
「按概率或限流采集一部分 trace」可以利用rate_limiting实现吗?rate_limiting只能按照每秒通过的 spans 个数限流,但 spans 数量在高峰期、低峰期、业务所处阶段都不一样,每个 trace 的平均 spans 数量也会随着微服务群规模以及依赖关系发生变化,因此设置 spans_per_second 将让我们很难对这个参数的最终效果合理评估,因此直接使用rate_limiting的方案被否决。
「按规则采集另一部分 trace」可以直接使用numeric_attribute和string_attribute实现吗?span 中还存在布尔 (bool) 类型的 tag,以「在调用链上如果打印了 ERROR 级别日志」为例,按照规范我们会记录span.SetTag("error" , true),但 tailsamplingprocessor 并未支持bool_attribute;此外,未来我们可能会有更复杂的组合条件,这时仅靠numeric_attribute和string_attribute也无法实现。
经过再三分析,我们最终决定利用 Processors 的链式结构,组合多个 Processor 完成采样,流水线如下图所示:
其中probattr负责在 trace 级别按概率抽样,anomaly 负责分析每个 trace 是否符合「有意思」的规则,如果命中二者之一,trace 就会被打上标记,即sampling.priority。最后在tailsamplingprocessor上配置一条规则即可,如下所示:
tail_sampling:<br /> policies:<br /> [<br /> {<br /> name: sample_with_high_priority,<br /> type: numeric_attribute,<br /> numeric_attribute: { key: "sampling.priority", min_value: 1, max_value: 1 }<br /> }<br /> ]
这里sampling.priority是整数类型,当前取值只有 0 和 1。按上面的配置,所以sampling.priority = 1的trace 都会被采集。后期可以增加更多的采集优先级,在必要的时候可以多采样 (upsampling) 或降采样 (downsampling)。
部署实施
采样规则确立后,整个解决方案就已跑通,下一步就是进入部署实施阶段。
上线准备基础库改造
动态更新 Tracer在第一版系统中,每个进程启动时会从 apollo 上获取采样配置,传递给 Jaeger sdk,后者利用配置初始化 GlobalTracer。GlobalTracer 会在 trace 的第一个 span 出现时,决定是否采集,并把这个决定传递下去,即头部连贯采样。在实施新架构时,我们需要 Jaeger sdk 将所有 trace 数据尽数上报。为了让这个过程更加平滑,我们对 Jaeger sdk 配置做出两方面改造:
支持对每个服务下发不同的采样配置,方便灰度发布 支持动态更新采样配置,使采样策略配置不依赖发布
日志库改造为了保证打印过 ERROR 级别日志的调用链必采,我们也在通用日志库的相应位置上给 span 打上 error 标签。
监控看板配置
opentelemetry-collector 内部利用 OpenCensus sdk 埋了很多有用的监控指标,并按照 Open Metrics 规范暴露数据。因为指标数量并不多,我们将大多数指标都配置了到 Grafana 看板中,包括:
xxx_receiver_accepted/refused_spans这里的 xxx 指代任意一个 pipeline 中使用的 receiver。实际上这里有两个具体指标:receiver 接收的 spans 数量和 receiver 拒绝的 spans 数量。二者可以与其它指标结合,分析系统在当前状况下的入口流量瓶颈。
xxx_exporter_send(failed)_spans这里的 xxx 指代任意一个 pipeline 中使用的 exporter。实际上这里有两个具体指标:exporter 发送成功的 spans 数量和 exporter 发送失败的 spans 数量。二者可以与其它指标结合,分析系统在当前状况下的出口流量瓶颈。
otelcol_processor_tail_sampling_sampling_trace_dropped_too_early要介绍上面这个指标,需要简单了解tailsamplingprocessor的工作原理。在分布式环境中,tailsamplingprocessor永远无法确定一个 trace 的所有 spans 在当前时刻是否收集完毕,因此需要设置一个超时时间,即 这里 的decision_wait,下面假设decision_wait = 5s。Trace Data 进入 processor 后,会被分别放入两个数据结构:
一个固定大小的队列和一个哈希表,二者合起来实现 trace data 的 LRU cache。同时 processor 会将所有进入到其中的 traces 按照每秒一个 batch 组织起来,内部一共维持 5 个 batch (decision_wait)。每隔一秒钟,将最老的 batch 取出来,对其中的 traces 分别判断是否符合采样规则,符合则将其传递给后续的 processors:
如果在做采样决策时,发现相应的 trace 已经被 LRU cache 清出,则认为「trace dropped too early」,后者意味着tailsamplingprocessor已经超负荷。理论上这个指标如果不等于 0,尾部连贯采样功能就处于异常状态。
灰度方案
上文提到过,实施改造需要让 Jaeger sdk 全量上报 trace。由于「是否上报」这个决定在请求入口服务 (即 HTTP 服务) 做出,并会随着跨进程调用传播到下游服务,同时伴鱼服务端内部的入口服务已经按照业务拆分,因此灰度的过程就可以按入口服务进行,从流量小的、级别低入口服务开始上线观察,再逐渐加入流量大的、级别高的入口服务,最终默认打开全量采样,并在这个过程中发现、解决潜在问题。
资源消耗优化
新版架构所需资源与旧版差别不大:
在逐步上线到所有入口服务之前,我们做了比较充分的风险评估。开启全量采集后,主要增加了宿主机的网络 i/o,在千兆网卡 (约 300MB/s) 支持下,增加后的 i/o 量远远未达到瓶颈。实施过程中,业务团队也确实没有感知。不过在灰度上线过程中,我们也发现并解决了若干问题。
热点服务问题
不同服务的请求量不同。个别服务的上报量过大会导致不同 otel-agent 的流量不均衡,在高峰期造成 otel-agent 的 CPU 经常超过预警线。我们通过增加热点服务实例,减小单个实例的请求量的方式,间接地均衡了每个 otel-agent 承载的流量。
过滤下推
在生产环境中,我们默认维持最近 7 天的 trace 数据。在分析 ES 中索引jaeger-span-* 的过程中,意料之中地,我们看到了 power law 的存在:
仔细分析可以发现,50% 以上的 span 都属于apolloConfigCenter.*。熟悉 apollo 的研发应该知道,通常 apollo sdk 会通过长轮询的方式从元数据中心拉取配置信息,并缓存到本地,而服务在应用层获取配置都是通过本地缓存获取。因此实际上这里的所有apolloConfigCenter.*只是本地访问,而不是跨进程调用,span 数据价值比较低,可以忽略。于是我们开发了通过正则匹配 spanName 过滤 span 的 processor,并部署到 otel-agent 上,我们称之为过滤下推。部署上线后,ES 索引体积下降超过 50%,目前每天索引体积为 40-50 GB;otel-collector 和 otel-agent 的 CPU 消耗也降低了接近 50%。
制定 SLO
在伴鱼服务端内,线上问题排查的第一入口通常是 im 消息,报警平台会将导致报警的 traceID 以及日志注入到消息中,并提供一个链接页面,方便研发快速查看报警相关的调用链信息及其在整个调用链上每个服务打印的日志。基于此我们制定新版调用链追踪系统的SLO:
名称
研发关心的 trace 数据采集成功率
SLI 规范
研发关心且被采集的 trace 个数/研发关心的 trace 个数
SLI 实现
包含 trace 数据的服务报警信息条数/服务报警信息条数
查询
sum(alertmanager_alert_total{trace_exists="true"})/sum(alertmanager_alert_total)
目标
99%
目前我们刚刚在报警平台中支持此 SLI 的埋点。目前还有个别服务尚未升级相关依赖,因此该指标尚不能反映所有服务的情况,我们会继续推动各服务全面升级,按照以上 SLO 来要求新版系统。
总结
借助开源项目,我们得以通过花费极少的人力,解决当前伴鱼内部调用链追踪应用的稳态分析及异常检测需求,同时也为开源项目和社区做出微小的贡献。调用链追踪是可观测性平台的重要组件,未来我们将继续把一些精力放在 telemetry data 的整合上,为研发提供更全面、一致的服务观测分析体验。
介绍
文章原创来自于伴鱼技术团队的郑鹤。
伴鱼少儿英语是目前飞速成长的互联网在线英语教育品牌之一。我们期望打造更创新、更酷、让学英语更有效的新一代互联网产品。转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Hi,我是老蒋。这里是中国Opentelemetry官方开源社区组织。我们定期分享精彩的Opentelemetry 落地案例,请大家持续关注
参考 查看全部
调用链追踪系统在伴鱼:Opentelemetry最佳实践案例分享
搭建可靠的链路追踪系统
在正式介绍前,简单交代一下背景:2015 年,在伴鱼服务端起步之时,技术团队就做出统一使用 Go 语言的决定。这个决定的影响主要体现在:
早期实践对接 Jaeger
2019 年,公司内部的微服务数量逐步增加,调用关系日趋复杂,工程师做性能分析、问题排查的难度变大。这时亟需一套调用链追踪系统帮助我们增强对服务端全貌的了解。经过调研后,我们决定采用同样基于 Go 语言搭建的、由 CNCF 孵化的项目Jaeger。当时,服务的开发和治理都尚未引入 context,不论进程内部调用还是跨进程调用,都没有上下文传递。因此早期引入调用链追踪的工作重心就落在了服务及服务治理框架的改造,包括:
部署方面:测试环境采用 all-in-one,线上环境采用 direct-to-storage 方案。整个过程前后大约耗时一个月,我们在 2019 年 Q3 上线了第一版调用链追踪系统。配合广泛被采用的 prometheus + grafana 以及 ELK,我们在微服务群的可观测性上终于凑齐了调用链 (traces)、日志 (logs) 和监控指标 (metrics) 三个要素。
下图是第一版调用链追踪系统的数据上报通路示意图。服务运行在容器中,通过 opentracing 的 sdk 埋点,Jaeger 的 go-sdk 上报到宿主机上的 Jaeger-agent,后者再将数据进一步上报到 Jaeger-collector,最终将调用链数据写入 ES,建立索引,即图中的 Jaeger backends。
遇到的问题
Jaeger 支持三种采样方式:
调用链通路改造使用场景
2020 年,我们不断收到业务研发的反馈:能不能全量采集 trace?
这促使我们开始重新思考如何改进调用链追踪系统。我们做了一个简单的容量预估:目前 Jaeger 每天写入 ES 的数据量接近 100GB/天,如果要全量采集 trace 数据,保守假设平均每个 HTTP API 服务的总 QPS 为 100,那么完整存下全量数据需要 10TB/天;乐观假设 100 名服务器研发每人每天查看 1 条 trace,每条 trace 的平均大小为 1KB,则整体信噪比千万分之一。可以看出,这件事情本身的 ROI 很低,考虑到未来业务会持续增长,存储这些数据的价值也会继续降低,因此全量采集的方案被放弃。退一步想:全量采集真的是本质需求吗?实际上并非如此,我们想要的其实是「有意思」的 trace 全采,「没意思」的 trace 不采。
根据 理论篇 中介绍的应用场景,实际上第一版调用链追踪系统只支持了稳态分析,而业务研发亟需的是异常检测。要同时支持这两种场景,我们必须借助尾部连贯采样 (tail-based coherent sampling)。相对于头部连贯采样在第一个 span 处就做出是否采样的决定,尾部连贯采样可以让我们在获取 (接近) 完整的 trace 信息后再做出判断。理想情况下,只要能合理地制定采样的判断逻辑,我们的调用链追踪系统就能做到「有意思」的 trace 全采,「没意思」的 trace 不采。
架构设计
Jaeger 团队从 2017 年就开始讨论引入 tail-based sampling 的可能性,但至今未有定论。在一次与 Jaeger 工程师 jpkrohling 的一对一沟通中,对方也证实了目前 Jaeger 尚没有相关的支持计划。因此,我们不得不另辟蹊径。经过一番调研,我们找到了刚刚进驻 CNCF SandBox 的OpenTelemetry,它的opentelemetry-collector子项目恰好能支持我们在现有架构上引入尾部连贯采样。
OpenTelemetry Collector
整个 OpenTelemetry 项目目的在于统一市面上可观测性数据 (telemetry data) 的标准,同时提供推动这些标准实施的组件和工具。opentelemetry-collector 就是这个生态中的一个重要组件,它的架构图如下:
collector 内部有 4 个核心组件:
opentelemetry-collector 项目被拆成两部分:主项目 opentelemetry-collector 和社区贡献项目 opentelemetry-collector-contrib,前者负责管理核心逻辑、数据结构以及通用的 Receivers、Processors、Exporters、Extensions 实现,后者则负责接收一些社区贡献的组件,当然贡献者主要都来自于可观测性 SaaS 解决方案供应商,如 DataDog、Splunk、LightStep 以及一些公有云厂商。opentelemtry-collector 项目的插件化管理方式,使得定制化开发 Receiver、Processor、Exporter 的成本很低,我们在做概念验证时,基本可以在一两个小时内开发并测试完毕一个组件。除此之外,opentelemetry-collector-contrib 还提供了开箱即用的tailsamplingprocessor。
由于 opentelemetry-collector 是 OpenTelemetry 团队推动标准实施的重要组件,且 OpenTelemetry 本身并没有提供独立的数据存储、索引实现的计划,因此它在与市面上流行的调用链追踪框架,如 Zipkin、Jaeger、OpenCensus,的兼容性上下了很大功夫。通过 Receivers 和 Exporters 的使用,我们可以用它替换 jaeger-agent,也可以放在 jaeger-agent 与 jaeger-collector 之间,必要时还可以在 jaeger-agent 和 jaeger-collector 之间部署多层 collectors。除此之外,如果有一天想换掉 jaeger-backend,比如新发布的 Grafana Tempo,我们也能很轻松的完成,并且利用多个 Pipelines 或一个 Pipeline 多个 Exporters 灰度上线,逐步替换。
上报通路
基于以上的调研和现有的架构,我们设计了第二版调用链追踪的架构,如下图所示:
用一组 opentelemetry-collector 替换 jaeger-agent,即图中的 otel-agent;同时在 otel-agent 与 jaeger-collector 之间增加另一组 opentelemetry-collector,即图中的 otel-collector。otel-agent 收集宿主机上不同服务上报的 trace 数据,打包批量发送给 otel-collector,后者负责做尾部连贯采样,将「有意思」的 trace 继续输出到原始架构中的 jaeger-collector,后者负责将数据投入 ElasticSearch 中,建立索引。
这里还有一个问题需要解决:整个架构做到高可用,势必要部署多个 otel-collector 实例,如果使用简单的负载均衡策略,不同 otel-agents、以及单个 otel-agent 不同时刻上报的数据,可能被随机上报到某个 otel-collector 实例,这就意味着,同一个 trace 的不同 spans 无法集中到同一个 otel-collector 实例上,既会导致同一个 trace 的不同 spans 的决定不一致,即不是连贯采样;也会导致尾部采样时提供判断的数据不全。解决方案很简单:让 otel-agent 按照 traceID 做负载均衡。
在调研阶段我们正好看到 opentelemetry-collector 社区也有此支持计划,并且前面提到的工程师 jpkrohling 正在通过增加loadbalancingexporter解决它,虽然直接使用 bleeding edge 的版本有一定的风险,我们还是决定尝试。在概念验证阶段,我们也的确发现了新功能的若干问题,但通过反馈的方式一一解决,最终获得了可以按预期执行尾部连贯采样的调用链追踪系统。
采样规则
尾部连贯采样的数据通路已经准备就绪,下一步就是确定和实施采样规则。
「有意思」的调用链
什么是「有意思」的调用链?研发在分析、排障过程中想查询的任何调用链就是「有意思」的调用链。但落实到代码的必须是确定性的规则,根据日常排障经验,我们先确定了以下三种情形:
满足任意条件,就认为这个调用链「有意思」。在伴鱼,只要服务打印了 ERROR 级别的日志就会触发报警,研发人员就会收到 im 消息或电话报警,如果能保证触发报警的调用链数据必采,研发人员的排障体验就会有很大的提升;我们的 DBA 团队认为超过 200ms 的查询请求都被判定为慢查询,如果能保证这些请求的调用链必采,就能大大方便研发排查导致慢查询的请求;对于在线服务来说,时延过高会令用户体验下降,但具体高到什么程度会引发明显的体验下降我们暂时没有数据支撑,因此先配置为 1s,支持随时修改阈值。
当然,以上条件并不绝对,我们可以在之后的实践根据反馈调整、新增规则,如单个请求引起的数据库、缓存查询次数超过某阈值等。
采样流水线
在第二版系统中,我们期望同时支持稳态分析与异常检测,因此采样过程既要按概率或限流方式采集一部分 trace,也需要按上文拟定的「有意思」 规则采集令一部分 trace。截止到本文撰写前,tailsamplingprocessor支持 4 种策略:
「按概率或限流采集一部分 trace」可以利用rate_limiting实现吗?rate_limiting只能按照每秒通过的 spans 个数限流,但 spans 数量在高峰期、低峰期、业务所处阶段都不一样,每个 trace 的平均 spans 数量也会随着微服务群规模以及依赖关系发生变化,因此设置 spans_per_second 将让我们很难对这个参数的最终效果合理评估,因此直接使用rate_limiting的方案被否决。
「按规则采集另一部分 trace」可以直接使用numeric_attribute和string_attribute实现吗?span 中还存在布尔 (bool) 类型的 tag,以「在调用链上如果打印了 ERROR 级别日志」为例,按照规范我们会记录span.SetTag("error" , true),但 tailsamplingprocessor 并未支持bool_attribute;此外,未来我们可能会有更复杂的组合条件,这时仅靠numeric_attribute和string_attribute也无法实现。
经过再三分析,我们最终决定利用 Processors 的链式结构,组合多个 Processor 完成采样,流水线如下图所示:
其中probattr负责在 trace 级别按概率抽样,anomaly 负责分析每个 trace 是否符合「有意思」的规则,如果命中二者之一,trace 就会被打上标记,即sampling.priority。最后在tailsamplingprocessor上配置一条规则即可,如下所示:
tail_sampling:<br /> policies:<br /> [<br /> {<br /> name: sample_with_high_priority,<br /> type: numeric_attribute,<br /> numeric_attribute: { key: "sampling.priority", min_value: 1, max_value: 1 }<br /> }<br /> ]
这里sampling.priority是整数类型,当前取值只有 0 和 1。按上面的配置,所以sampling.priority = 1的trace 都会被采集。后期可以增加更多的采集优先级,在必要的时候可以多采样 (upsampling) 或降采样 (downsampling)。
部署实施
采样规则确立后,整个解决方案就已跑通,下一步就是进入部署实施阶段。
上线准备基础库改造
动态更新 Tracer在第一版系统中,每个进程启动时会从 apollo 上获取采样配置,传递给 Jaeger sdk,后者利用配置初始化 GlobalTracer。GlobalTracer 会在 trace 的第一个 span 出现时,决定是否采集,并把这个决定传递下去,即头部连贯采样。在实施新架构时,我们需要 Jaeger sdk 将所有 trace 数据尽数上报。为了让这个过程更加平滑,我们对 Jaeger sdk 配置做出两方面改造:
支持对每个服务下发不同的采样配置,方便灰度发布 支持动态更新采样配置,使采样策略配置不依赖发布
日志库改造为了保证打印过 ERROR 级别日志的调用链必采,我们也在通用日志库的相应位置上给 span 打上 error 标签。
监控看板配置
opentelemetry-collector 内部利用 OpenCensus sdk 埋了很多有用的监控指标,并按照 Open Metrics 规范暴露数据。因为指标数量并不多,我们将大多数指标都配置了到 Grafana 看板中,包括:
xxx_receiver_accepted/refused_spans这里的 xxx 指代任意一个 pipeline 中使用的 receiver。实际上这里有两个具体指标:receiver 接收的 spans 数量和 receiver 拒绝的 spans 数量。二者可以与其它指标结合,分析系统在当前状况下的入口流量瓶颈。
xxx_exporter_send(failed)_spans这里的 xxx 指代任意一个 pipeline 中使用的 exporter。实际上这里有两个具体指标:exporter 发送成功的 spans 数量和 exporter 发送失败的 spans 数量。二者可以与其它指标结合,分析系统在当前状况下的出口流量瓶颈。
otelcol_processor_tail_sampling_sampling_trace_dropped_too_early要介绍上面这个指标,需要简单了解tailsamplingprocessor的工作原理。在分布式环境中,tailsamplingprocessor永远无法确定一个 trace 的所有 spans 在当前时刻是否收集完毕,因此需要设置一个超时时间,即 这里 的decision_wait,下面假设decision_wait = 5s。Trace Data 进入 processor 后,会被分别放入两个数据结构:
一个固定大小的队列和一个哈希表,二者合起来实现 trace data 的 LRU cache。同时 processor 会将所有进入到其中的 traces 按照每秒一个 batch 组织起来,内部一共维持 5 个 batch (decision_wait)。每隔一秒钟,将最老的 batch 取出来,对其中的 traces 分别判断是否符合采样规则,符合则将其传递给后续的 processors:
如果在做采样决策时,发现相应的 trace 已经被 LRU cache 清出,则认为「trace dropped too early」,后者意味着tailsamplingprocessor已经超负荷。理论上这个指标如果不等于 0,尾部连贯采样功能就处于异常状态。
灰度方案
上文提到过,实施改造需要让 Jaeger sdk 全量上报 trace。由于「是否上报」这个决定在请求入口服务 (即 HTTP 服务) 做出,并会随着跨进程调用传播到下游服务,同时伴鱼服务端内部的入口服务已经按照业务拆分,因此灰度的过程就可以按入口服务进行,从流量小的、级别低入口服务开始上线观察,再逐渐加入流量大的、级别高的入口服务,最终默认打开全量采样,并在这个过程中发现、解决潜在问题。
资源消耗优化
新版架构所需资源与旧版差别不大:
在逐步上线到所有入口服务之前,我们做了比较充分的风险评估。开启全量采集后,主要增加了宿主机的网络 i/o,在千兆网卡 (约 300MB/s) 支持下,增加后的 i/o 量远远未达到瓶颈。实施过程中,业务团队也确实没有感知。不过在灰度上线过程中,我们也发现并解决了若干问题。
热点服务问题
不同服务的请求量不同。个别服务的上报量过大会导致不同 otel-agent 的流量不均衡,在高峰期造成 otel-agent 的 CPU 经常超过预警线。我们通过增加热点服务实例,减小单个实例的请求量的方式,间接地均衡了每个 otel-agent 承载的流量。
过滤下推
在生产环境中,我们默认维持最近 7 天的 trace 数据。在分析 ES 中索引jaeger-span-* 的过程中,意料之中地,我们看到了 power law 的存在:
仔细分析可以发现,50% 以上的 span 都属于apolloConfigCenter.*。熟悉 apollo 的研发应该知道,通常 apollo sdk 会通过长轮询的方式从元数据中心拉取配置信息,并缓存到本地,而服务在应用层获取配置都是通过本地缓存获取。因此实际上这里的所有apolloConfigCenter.*只是本地访问,而不是跨进程调用,span 数据价值比较低,可以忽略。于是我们开发了通过正则匹配 spanName 过滤 span 的 processor,并部署到 otel-agent 上,我们称之为过滤下推。部署上线后,ES 索引体积下降超过 50%,目前每天索引体积为 40-50 GB;otel-collector 和 otel-agent 的 CPU 消耗也降低了接近 50%。
制定 SLO
在伴鱼服务端内,线上问题排查的第一入口通常是 im 消息,报警平台会将导致报警的 traceID 以及日志注入到消息中,并提供一个链接页面,方便研发快速查看报警相关的调用链信息及其在整个调用链上每个服务打印的日志。基于此我们制定新版调用链追踪系统的SLO:
名称
研发关心的 trace 数据采集成功率
SLI 规范
研发关心且被采集的 trace 个数/研发关心的 trace 个数
SLI 实现
包含 trace 数据的服务报警信息条数/服务报警信息条数
查询
sum(alertmanager_alert_total{trace_exists="true"})/sum(alertmanager_alert_total)
目标
99%
目前我们刚刚在报警平台中支持此 SLI 的埋点。目前还有个别服务尚未升级相关依赖,因此该指标尚不能反映所有服务的情况,我们会继续推动各服务全面升级,按照以上 SLO 来要求新版系统。
总结
借助开源项目,我们得以通过花费极少的人力,解决当前伴鱼内部调用链追踪应用的稳态分析及异常检测需求,同时也为开源项目和社区做出微小的贡献。调用链追踪是可观测性平台的重要组件,未来我们将继续把一些精力放在 telemetry data 的整合上,为研发提供更全面、一致的服务观测分析体验。
介绍
文章原创来自于伴鱼技术团队的郑鹤。
伴鱼少儿英语是目前飞速成长的互联网在线英语教育品牌之一。我们期望打造更创新、更酷、让学英语更有效的新一代互联网产品。转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Hi,我是老蒋。这里是中国Opentelemetry官方开源社区组织。我们定期分享精彩的Opentelemetry 落地案例,请大家持续关注
参考
文章采集调用(中国的股票市场上盈利,每周都有单个股票盈利2)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-04-18 07:10
目标:在中国股市盈利,单只股票每周盈利2%,月总盈利超过2%
计划实现:Pycharm + Anaconda3 + Python3 + Django + AKShare + MongoDB
当前实现:Pycharm + Anaconda3 + Python3 + Flask + AKShare
未来可能会用到:MongoDB、SQLAlchemy、baostock、Tushare
机器学习将在未来的实践中逐步使用。
实现方法
上一篇文章写过采集的方法。本文文章收录完整代码和调用代码。
使用后台执行的方法。
gupiao.py如下:
import akshare as ak
import threading
import datetime
import os
from threading import Thread
def get_start():
start_stock_daily()
# 这里就是核心了,调用这部分就会自动下载 深圳A股 的所有股票的历史记录
def start_stock_daily(indicator="A股列表", folder="sz_a", prefix="sz"):
file_path = "D:/work/data/" + folder + "/"
file_path_name = get_sz_a(file_path, indicator)
print(file_path_name)
num = 0
with open(file_path_name, "r", encoding='UTF-8') as stock_lines:
for stock_line in stock_lines.readlines():
num = num + 1
if num == 1:
continue
stock_line_arr = stock_line.split("|")
symbol = prefix + stock_line_arr[5]
print("股票信息=" + symbol + "||" + stock_line_arr[6])
stock_csv = get_stock_daily(file_path, symbol)
print("stock_csv=" + stock_csv)
# 获得深圳主板A股列表,每天获取一次不重复获取
# file_path 需要全路径,以 | 进行间隔
# indicator 可选参数 "A股列表", "B股列表", "AB股列表", "上市公司列表", "主板", "中小企业板", "创业板"
def get_sz_a(file_path, indicator="A股列表"):
today = datetime.datetime.today()
file_name = "sz_a_" + today.strftime('%Y%m%d') + ".csv"
if not os.path.exists(file_path): # 如果路径不存在则创建
os.makedirs(file_path)
if os.path.exists(file_path + file_name):
print("今日已经获取无需再次获取," + today.strftime('%Y%m%d'))
return file_path + file_name
stock_info_sz_df = ak.stock_info_sz_name_code(indicator=indicator)
stock_info_sz_df.to_csv(file_path + file_name, sep="|")
print('获取深圳主板A股列表并存储为CSV!' + today.strftime('%Y%m%d'))
return file_path + file_name
# 根据股票代码获取股票历史数据
# symbol 股票代码 需要前缀 sh 上海 sz 深圳,例如:sz300846
def get_stock_daily(file_path, symbol):
stock_zh_a_daily_hfq_df = ak.stock_zh_a_daily(symbol=symbol) # 返回不复权的数据
file_name = symbol + '.csv'
stock_zh_a_daily_hfq_df.to_csv(file_path + file_name)
return file_path + file_name
调用下载的部分,注意我随便写的名字,请根据情况修改,app.py如下:
from flask import Flask
import akshare as ak
import gupiao
import datetime
import os
from concurrent.futures import ThreadPoolExecutor
import time
executor = ThreadPoolExecutor(2)
app = Flask(__name__)
@app.route('/test_thread')
def test_thread():
executor.submit(gupiao.get_start)
return "thread is running at background !!!"
if __name__ == '__main__':
app.run()
使用Flask框架,生成一个项目,然后在app.py中创建一个gupiao.py,并运行该项目。
在浏览器中访问:5000/test_thread
可以在后台看到图片,整个深圳A股的下载时间大约是2小时到3小时。
历史股票数据
如图下载到本地
历史股票数据
爬取数据部分完成,接下来就是过滤了。 查看全部
文章采集调用(中国的股票市场上盈利,每周都有单个股票盈利2)
目标:在中国股市盈利,单只股票每周盈利2%,月总盈利超过2%
计划实现:Pycharm + Anaconda3 + Python3 + Django + AKShare + MongoDB
当前实现:Pycharm + Anaconda3 + Python3 + Flask + AKShare
未来可能会用到:MongoDB、SQLAlchemy、baostock、Tushare
机器学习将在未来的实践中逐步使用。
实现方法
上一篇文章写过采集的方法。本文文章收录完整代码和调用代码。
使用后台执行的方法。
gupiao.py如下:
import akshare as ak
import threading
import datetime
import os
from threading import Thread
def get_start():
start_stock_daily()
# 这里就是核心了,调用这部分就会自动下载 深圳A股 的所有股票的历史记录
def start_stock_daily(indicator="A股列表", folder="sz_a", prefix="sz"):
file_path = "D:/work/data/" + folder + "/"
file_path_name = get_sz_a(file_path, indicator)
print(file_path_name)
num = 0
with open(file_path_name, "r", encoding='UTF-8') as stock_lines:
for stock_line in stock_lines.readlines():
num = num + 1
if num == 1:
continue
stock_line_arr = stock_line.split("|")
symbol = prefix + stock_line_arr[5]
print("股票信息=" + symbol + "||" + stock_line_arr[6])
stock_csv = get_stock_daily(file_path, symbol)
print("stock_csv=" + stock_csv)
# 获得深圳主板A股列表,每天获取一次不重复获取
# file_path 需要全路径,以 | 进行间隔
# indicator 可选参数 "A股列表", "B股列表", "AB股列表", "上市公司列表", "主板", "中小企业板", "创业板"
def get_sz_a(file_path, indicator="A股列表"):
today = datetime.datetime.today()
file_name = "sz_a_" + today.strftime('%Y%m%d') + ".csv"
if not os.path.exists(file_path): # 如果路径不存在则创建
os.makedirs(file_path)
if os.path.exists(file_path + file_name):
print("今日已经获取无需再次获取," + today.strftime('%Y%m%d'))
return file_path + file_name
stock_info_sz_df = ak.stock_info_sz_name_code(indicator=indicator)
stock_info_sz_df.to_csv(file_path + file_name, sep="|")
print('获取深圳主板A股列表并存储为CSV!' + today.strftime('%Y%m%d'))
return file_path + file_name
# 根据股票代码获取股票历史数据
# symbol 股票代码 需要前缀 sh 上海 sz 深圳,例如:sz300846
def get_stock_daily(file_path, symbol):
stock_zh_a_daily_hfq_df = ak.stock_zh_a_daily(symbol=symbol) # 返回不复权的数据
file_name = symbol + '.csv'
stock_zh_a_daily_hfq_df.to_csv(file_path + file_name)
return file_path + file_name
调用下载的部分,注意我随便写的名字,请根据情况修改,app.py如下:
from flask import Flask
import akshare as ak
import gupiao
import datetime
import os
from concurrent.futures import ThreadPoolExecutor
import time
executor = ThreadPoolExecutor(2)
app = Flask(__name__)
@app.route('/test_thread')
def test_thread():
executor.submit(gupiao.get_start)
return "thread is running at background !!!"
if __name__ == '__main__':
app.run()
使用Flask框架,生成一个项目,然后在app.py中创建一个gupiao.py,并运行该项目。
在浏览器中访问:5000/test_thread
可以在后台看到图片,整个深圳A股的下载时间大约是2小时到3小时。
历史股票数据
如图下载到本地
历史股票数据
爬取数据部分完成,接下来就是过滤了。
文章采集调用(如何使用采集功能去采集一个图片类的网站(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2022-04-17 17:12
前言:本文章主要介绍如何使用采集函数来采集一个图片类网站。本次选择的目标站点为:战酷网名作鉴赏栏目,网址为:. 本文将介绍如何处理收录 采集 分页的页面以及如何使用简单的过滤规则。本文分为三部分:第一部分主要介绍如何进入采集界面以及添加新采集节点的第一步:设置基本信息和URL索引页面规则;第二部分,主要是引入新的采集节点的第二步:设置字段获取规则;第三节主要介绍采集如何指定节点以及如何导出采集内容。
进入下面的第一部分。
1.1进入采集节点管理界面
如图1),在后台管理界面主菜单点击“采集”,再点击“采集节点管理”进入采集节点管理界面,如图(图2).
图 1 - 后台管理界面
图2-采集节点管理界面
1.2. 添加新节点
在采集节点管理界面,点击左下角“添加新节点”或右上角“添加新节点”(如图2),可以输入“选择内容模型”界面,如(如图3),
图 3 - 选择内容模型界面
在“选择内容模型”界面的下拉列表框中,有“普通文章”和“图片采集”可供选择。
根据页面类型为采集,选择对应的内容模型。本文选择“图片采集”,点击确定,即可进入“添加采集节点:第一步设置基本信息和URL索引页面规则”界面,如图(图4)@ > ,
图4 - 添加采集节点:第一步设置基本信息和URL索引页面规则
1.2.1 设置节点基本信息
图 5 - 节点基本信息
如图(图5),这里只是获取“目标页面代码”的方法,其他设置请参考前面的文章。具体操作步骤:
(a) 打开 采集: 所针对的目标页面;
(b) 右击选择“查看源文件”找到“charset”,如图(图6),
图 6 - 查看源文件
等号后面的代码就是需要填写的“编码格式”,这里是“utf-8”。
填写后,如图(图7),
图 7 - 设置后节点的基本信息
检查后,进入下一步。
1.2.2 设置列表URL获取规则
图 8 - 列出 URL 获取规则
如(图8),这里是设置采集的文章列表页的匹配规则。具体步骤:
(a) 首先,回到打开的列表页面,找到浏览器的URL地址栏中显示的URL和页面的分页符部分。如(图9)和(图10))所示,
图 9 - 浏览器的 URL 地址栏
图 10 - 页面提要
(b) 点击“2”打开文章列表页面的第二页,再次找到浏览器的URL地址栏显示的URL和页面的换页部分,如图(图12)和(如图13),
图 11 - 第二页的 URL
图 12 - 第二页上的换页
(c) 在打开的列表页第二页,点击(1)返回列表页第一页,页面换页部分同上图10,只是浏览器URL地址栏显示的URL与上图9不同,如图(图13),
图 13 - 第一个页面的 URL
(d) 由(b)和(c)可知,这里采集的列表页的URL遵循如下规则:
!0!0!200!(*)!1!0!0/. 为了安全起见,请为自己测试更多列表页面。规则确定后,在“匹配网址”中,填写列表页后面的规则。
(e) 最后,根据需要指定采集的页码或常规数,并设置其递增规则。
至此,“List URL获取规则”部分就设置好了。最终结果,如图(图14)@>,
图 14 - 设置后的 URL 获取规则列表
确认无误后,进行下一步。
1.2.3设置文章网址匹配规则
图 15 - 文章 URL 匹配规则
下面是设置采集列表页的匹配规则。
具体步骤:
(a)对于“区域开始的HTML”,可以在已打开的列表首页,单击右键后选择“查看源文件”查找出第一篇文章的标题“高清壁纸”来获得,如(图16)所示,
图 16 - 查看源文件中第一个 文章 的标题
通过观察不难看出,“”是整个列表的结尾,后面的“”是页面的分页符。所以,在“HTML 结尾区域”中,应该用“”填充,意思是到第一个结尾。
(c) 观察图16和图17中文章的标题部分,可以发现标题的链接地址收录“=.html”。因此,在“必须收录”中,填写“=.html”。
至此,“文章URL匹配规则”就设置好了。填写后,如图(图18),
图 18 - 文章 设置后的 URL 匹配规则
通过以上三个小节,已经设置了添加采集节点的第一步。设置后的最终结果,如图(图19),
图19 - 设置后新增采集节点:第一步设置基本信息和URL索引页面规则
全部完成并勾选后,点击“保存信息并进入下一步”。如果前面设置正确,点击后会进入“添加采集节点:测试URL索引页面规则设置的基本信息和URL获取规则测试”页面,看到对应的文章列表地址. 如图(图20),
图 20 - URL 获取规则测试
确认无误后,点击“保存信息并进入下一步”。否则,单击“返回上一步进行更改”。
到这里,第一节就结束了。进入下面的第二部分。. . 查看全部
文章采集调用(如何使用采集功能去采集一个图片类的网站(组图))
前言:本文章主要介绍如何使用采集函数来采集一个图片类网站。本次选择的目标站点为:战酷网名作鉴赏栏目,网址为:. 本文将介绍如何处理收录 采集 分页的页面以及如何使用简单的过滤规则。本文分为三部分:第一部分主要介绍如何进入采集界面以及添加新采集节点的第一步:设置基本信息和URL索引页面规则;第二部分,主要是引入新的采集节点的第二步:设置字段获取规则;第三节主要介绍采集如何指定节点以及如何导出采集内容。
进入下面的第一部分。
1.1进入采集节点管理界面
如图1),在后台管理界面主菜单点击“采集”,再点击“采集节点管理”进入采集节点管理界面,如图(图2).

图 1 - 后台管理界面

图2-采集节点管理界面
1.2. 添加新节点
在采集节点管理界面,点击左下角“添加新节点”或右上角“添加新节点”(如图2),可以输入“选择内容模型”界面,如(如图3),

图 3 - 选择内容模型界面
在“选择内容模型”界面的下拉列表框中,有“普通文章”和“图片采集”可供选择。
根据页面类型为采集,选择对应的内容模型。本文选择“图片采集”,点击确定,即可进入“添加采集节点:第一步设置基本信息和URL索引页面规则”界面,如图(图4)@ > ,

图4 - 添加采集节点:第一步设置基本信息和URL索引页面规则
1.2.1 设置节点基本信息

图 5 - 节点基本信息
如图(图5),这里只是获取“目标页面代码”的方法,其他设置请参考前面的文章。具体操作步骤:
(a) 打开 采集: 所针对的目标页面;
(b) 右击选择“查看源文件”找到“charset”,如图(图6),

图 6 - 查看源文件
等号后面的代码就是需要填写的“编码格式”,这里是“utf-8”。
填写后,如图(图7),

图 7 - 设置后节点的基本信息
检查后,进入下一步。
1.2.2 设置列表URL获取规则

图 8 - 列出 URL 获取规则
如(图8),这里是设置采集的文章列表页的匹配规则。具体步骤:
(a) 首先,回到打开的列表页面,找到浏览器的URL地址栏中显示的URL和页面的分页符部分。如(图9)和(图10))所示,

图 9 - 浏览器的 URL 地址栏

图 10 - 页面提要
(b) 点击“2”打开文章列表页面的第二页,再次找到浏览器的URL地址栏显示的URL和页面的换页部分,如图(图12)和(如图13),

图 11 - 第二页的 URL

图 12 - 第二页上的换页
(c) 在打开的列表页第二页,点击(1)返回列表页第一页,页面换页部分同上图10,只是浏览器URL地址栏显示的URL与上图9不同,如图(图13),

图 13 - 第一个页面的 URL
(d) 由(b)和(c)可知,这里采集的列表页的URL遵循如下规则:
!0!0!200!(*)!1!0!0/. 为了安全起见,请为自己测试更多列表页面。规则确定后,在“匹配网址”中,填写列表页后面的规则。
(e) 最后,根据需要指定采集的页码或常规数,并设置其递增规则。
至此,“List URL获取规则”部分就设置好了。最终结果,如图(图14)@>,

图 14 - 设置后的 URL 获取规则列表
确认无误后,进行下一步。
1.2.3设置文章网址匹配规则

图 15 - 文章 URL 匹配规则
下面是设置采集列表页的匹配规则。
具体步骤:
(a)对于“区域开始的HTML”,可以在已打开的列表首页,单击右键后选择“查看源文件”查找出第一篇文章的标题“高清壁纸”来获得,如(图16)所示,

图 16 - 查看源文件中第一个 文章 的标题
通过观察不难看出,“”是整个列表的结尾,后面的“”是页面的分页符。所以,在“HTML 结尾区域”中,应该用“”填充,意思是到第一个结尾。
(c) 观察图16和图17中文章的标题部分,可以发现标题的链接地址收录“=.html”。因此,在“必须收录”中,填写“=.html”。
至此,“文章URL匹配规则”就设置好了。填写后,如图(图18),

图 18 - 文章 设置后的 URL 匹配规则
通过以上三个小节,已经设置了添加采集节点的第一步。设置后的最终结果,如图(图19),

图19 - 设置后新增采集节点:第一步设置基本信息和URL索引页面规则
全部完成并勾选后,点击“保存信息并进入下一步”。如果前面设置正确,点击后会进入“添加采集节点:测试URL索引页面规则设置的基本信息和URL获取规则测试”页面,看到对应的文章列表地址. 如图(图20),

图 20 - URL 获取规则测试
确认无误后,点击“保存信息并进入下一步”。否则,单击“返回上一步进行更改”。
到这里,第一节就结束了。进入下面的第二部分。. .
文章采集调用(跑到图文加工店,说给点素材,中年老板:骚年你来对了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-15 08:38
我去了图形加工店,要了一些材料。中年老板:骚年,你说得对,我们这里有很多存货。我们拥有您需要的一切,无论是否为 JPG、PSD、AI、AE、AV……
我去了菜市场,给我举了一些例子。水果卖家:朋友知道货。今天刚到的李子很清爽。缺点是太甜了!隔壁卖糖炒栗子的小伙伸了伸脖子:大哥,带个刚出锅的袋子!
嗯……定义很重要,所以我们今天说的就是阅读中获得的文本内容,写作、演讲、推理等参考和引用的材料和例子。
其实很多大牛都写过管理自己的知识库,整理自己的知识体系文章等文章,素材和例子只是其中很小的一部分。和那些大牛相比,这次我只关注材料和例子。这个入口点非常小。如果你已经建立了自己完整的知识框架和结构,非常欢迎你给我意见和批评,面带微笑。
一、素材和例子有什么用1.征服观众
在写作或演讲时,通常围绕一个主题,你所要做的就是让读者或听众理解并接受你所说的话。如果你像教科书一样一个一个地遵守规则,你可能会失去很多观众。这种情况在演讲时尤其明显。当你偶尔低头在台上寻求所谓的眼神交流和互动感,发现台下很多人都只是笑眯眯地盯着桌子看,你应该明白你说的没那么有趣他们作为微博或朋友圈。
适当的书面或口语引用可以帮助最大程度地防止这种情况发生。在写作中引用例子可以帮助读者避免长时间阅读的疲劳,同时加深对内容的理解;演讲中生动的例子更有意义,使你表达的内容更容易被听众接受和理解。此外,成人注意力的时间曲线有其特定的规律。举两个生动的例子,在听众精力下降、容易分心的时候,可以瞬间重新集中注意力,保证演讲的良好效果。
2.已关注
你身边应该有几个这样的朋友。饭桌上,谈山,如切瓜切菜。上至天文地理玄学玄学,三体四书五道口,下至官民悲喜肉离奇故事,五花八门。境界中,入流而不入流的,如果被TA接管了,也别想带回去。如果你也想成为党的中心(当然,最好排除个人自我宣传的内容),一个反驳大片的引用,那么素材和例子的采集可以让你玩得更轻松. 李笑来老师在《花时间做朋友》中提到,父亲在公共场合总是能言善辩。一时间,他原以为父亲是个记忆力极好的人,后来才发现,父亲的秘密,其实是一本写满记录的笔记本。所谓口才,就是根据采集到的资料和例子,什么时候可以应用到什么场合。
3.生理原因(个人原因)
英语中有一句话:在我的舌尖上,字面意思是“在我的舌尖上”。它实际上意味着这些话在嘴唇上,但我突然想不起来了。在专注于采集资料和例子之前,我有很多类似的经历。我清楚地记得,前一天,甚至几个小时前,我碰巧看到了一个可以支持我观点的例子,但我不记得细节和来源了。孤歌独娘,没有结果。这时候,我会感到后背和喉咙有刺的不适感,相当难受。我认为这种感觉来自于没有保存适当的材料或示例的遗憾。
因此,采集和整理资料和例子已经成为我的日常习惯之一。“书籍只有在使用时才会被使用。” 古人早就发出过类似的感叹。事实上,对于掌握了很多新工具和新方法的现代人来说,采集和整理资料和实例其实并没有想象中的那么麻烦。
二、如何采集资料和例子1.采集资料和例子
由于我说的采集整理主要是针对文字内容,所以采集资料和例子的主要来源如下:
(1)书籍
如今,知识产权的保护普遍受到重视。很多书的内容不能直接在网上获取,只能在阅读后摘录和总结。
- 电子书
目前国内外新书趋势是电子版和纸质版同步推出。电子版通常比较便宜,可以直接在亚马逊等官网购买。尤其是刚出版的新书,基本上只能找到付费版(各种号称免费的网站往往最后都指向付费版网址)。对于已经上架一段时间的书籍,会有各种免费的电子版流出,其中大部分是PDF,但质量参差不齐。还有一件事,我找电子书的建议是,如果5-10分钟内没有找到合适的版本,基本可以放弃。不值得花更多宝贵的时间在无法保证的免费和优质内容上,并直接购买电子书。版本性价比更高,付费也体现了对知识的尊重。
以目前主流的亚马逊官网为例,购买完成后会自动推送到KINDLE。为了方便后续的整理和检索,我会使用CALIBER软件和DEDRM插件将亚马逊下载的AZW3格式转换成EPUB格式,然后把书放进书里。所需内容采集在印象笔记中(仅供学习参考,绝不参与D版盈利),让大量摘抄和引用的内容轻松复制到印象笔记保存和同步,不易丢失和容易搜索。
- 纸质书
有的书比较经典但年代久远,多次再版都没有电子版;还有非小说类的书,因为我个人喜欢边看书边写读书笔记,所以买了纸质版。对于这种纸质书,做长篇摘录很不方便,手工摘录也相当耗时。幸运的是,我在某宝上找到了一款手持扫描笔,可以快速将纸张内容扫描成可编辑的文本格式,比手动输入效率高出很多倍。以前看过万维刚的《没想到》。其中有许多科学证据的例子。段落很长。钱是不能存的。对于纸质书阅读量大、喜欢做阅读笔记的朋友来说,扫描笔是个值得推荐的工具。
(2)微信内容
微信是大多数人使用频率最高的手机应用,用得上不用说。我关联了印象笔记和有道云笔记这两个官方微信账号。我一般把值得采集的内容随时保存在云端,然后在电脑上整理总结。
(3)网页内容
当我浏览网页时,我也会保存我发现的好内容。复制粘贴部分太麻烦了。为此,我使用了印象笔记的网页剪辑插件。可以选择整页,网页正文,或者去广告等等,形式多样,非常体贴。
(4)其他
其他来源不是我采集整理资料的主流渠道,比如微信聊天记录等,我靠谷歌度娘的一些技巧整理成文字保存。
2.材料和例子的组织
采集后一定要整理好,否则起不到任何价值。整理的目的是为了更好的使用,单靠大脑很难把采集到的所有内容都记住。作为一个85后,我经常听到90后说:“哎呀!怎么记不住了?年纪大了,脑子就不行了。” 更习惯了)。事实上,人的大脑就像一台电脑。存储容量有一定的上限。此外,人脑也有遗忘机制。对于长时间不使用的内容,大脑会选择忘记释放存储空间让经常使用的模块运行。因此,我们需要将采集到的资料和实例进行更有效的整理,以方便后续的高效调用,减轻大脑的负担,
以印象笔记为例。完成采集动作后,你的印象笔记现在应该有相当多的内容了,但是它们是杂乱无章的。这时候,你需要做三件事:
第一步是取名字。这是最直接的内容分类方法,也是最原创的信息搜索渠道。我通常给内容命名的方式是:日期+类型+一般内容摘要,例如:20161011知乎LIVE-詹老师——一种不需要意志力的习惯养成方法,这样不管我怎么想“猎鹰”、“习惯”、“知乎”或日期,可以找到这个材料。
第二步是分类。采集到的内容按照类型设置成文件夹并进行相应分类,就像在电脑上为各种文档创建文件夹一样。我现在常用的文件夹有:个人(存放个人内容和其他私密内容,可选择加密)、日常工作(与工作相关的资料或内容)、学习(与学习、写作、成长等相关)等。此设置的优点是,当您不记得要搜索的具体内容,但可以确定需要查找的一般类别时,您可以过滤掉其他大类并缩小搜索范围。但是,当内容积累到一定程度时,这样的分类范围还是太粗,不够细。此时,
第三步也是最重要的一步是添加标签!标签!标签!(重要的事情说三遍)按文件夹分类的材料有一个巨大的缺陷。一份资料或例子只能归入一个文件夹。如果要放到第二个文件夹,只能复制粘贴一次。. 数据本质上是复杂的。复制粘贴会导致多个重复的搜索结果,并且会白白占用宝贵的云存储空间。强烈不推荐。因此,此时需要对素材或示例做的是添加标签,而不是添加一个标签,而是添加尽可能多的标签,并根据该素材所能穷尽的所有相关特性进行标记. 例如:之前在简书上看到一篇文章文章《经验:我如何找到电子书》,它教你如何搜索你需要的电子书或电子版资料。我把这个文章按类别放在study文件夹里,但其实我在工作中也用到了电子资料的搜索技巧。所以我给这个文章加了“e-book”、“search”、“resource”、“skill”等几个标签,方便以后写文章来明确调用资源,找电子书,在普及工作技能等角度的时候可以找到这个文章。
标记有两个非常大的好处。首先,打标签可以帮助你思考反刍:除了解释原创内容之外,这个材料或例子还能用于哪些其他方面?它还可以用来支持哪些其他论点?这与上面提到的相同。李笑来老师和他的父亲,通过记录和思考,在什么时间、什么地点、什么情况下记下了笔记本上的内容。是“思维拓展”的简化版,也可以体现来这里帮助你进一步理解内容。二是通过打标签会有很多意想不到的“惊喜”。我之前写过《学会花钱》这本书的书评。当我分析涉及概率论的章节时,我点击了我标记为“
三、调用的方法
所谓调用就是搜索所有你认为你能想到的关键词来找到你想要的内容,其中一些在上一篇文章中已经提到过。可以确定,文件名的搜索是最直接的。如果没有,可以在大类中搜索,缩小范围,或者使用标签叠加的方法进行多维搜索。目前我最常用的方法是确定大类,然后使用多个标签叠加搜索的方法,这种方法是最具方向性的。如果您想在搜索时获得灵感,仅使用一个关键字浏览或单击一组单独的标签通常会给您带来意想不到的东西。
李敖拆书的著名例子就是材料采集和转移的最好例子。以下文字来自对他的采访:
我很少忘记读过的书,李敖,为什么?方法很好。有什么办法?无情。所有的剪刀和美工刀都用了,当这本书被肢解时,它被切开。这个页面我需要,这个段落我需要,我按类别分开。背面呢?复印一份,或者一开始买两本书,剪开整理一下,想看的部分留着。结果一本书写完了,书也被肢解了。我就是这样看书的。
分类是如何划分的?我有很多自己制作的剪辑,我在剪辑上写下并分类所有信息。读完一本书,全都进了我的文件夹。我可以分出上千个班级,分得很细。例如,按照图书馆的分类,有哲学类和宗教类;宗教类别进一步分为佛教、道教和天主教。我,李敖,可以分为更多的细节。天主教徒可以细分,神父是一类。牧师也可以细分。同性恋神父是一类,世俗神父是另一类。女同性恋是一类,修女是世俗的,是另一类。
书中的任何相关内容都会进入我的个人资料。输入什么?当我想写小说时,我需要这些信息,打开信息,然后就写出来。或者发生了什么事,这与修女是同性恋有关。我想表达我对新闻的想法,带来新闻,打开我的数据,合并两者,文章马上就写出来。
也就是说,看完这本书,我被五匹马撕成了八块。但我被迷住了。我不记得这些材料。我小心翼翼地把它们挂起来,放在文件夹里。我的记忆只需要记住这些标题。标题是根据我的习惯划分的。基本上都是翻译成英文单词,排列成英文字母,偶尔也有一些中文。"
四、备注
在明确了材料采集的方法和好处之后,有两点需要注意:
1.确认是真的。
逻辑中有一个重要的概念:“合乎逻辑就是符合真理”。如果采集的材料和例子来自歪曲事实或报道,那么即使它符合你的观点,支持你的说法,也没有任何意义,甚至会产生相反的效果,让读者或听众觉得你是一个无法区分的人。对真假撒谎的人,从而大大降低了你观点的可信度。此外,即使材料是真实的,也很可能是时间敏感的。因此,在使用素材或示例时,一定要记得检查内容是否真实,是否仍然准确,并及时更新筛选。如果涉及收录日期或数据的新闻、历史、人文等,
2.通知消息来源。
引用示例时,在不引用来源的情况下表达内容会让人感到缺乏信任。如果读者或听众对您引用的材料或示例特别感兴趣,他们可能希望通过这些资源了解更详细的内容。因此,在引用资料或例子时,尽量告知出处,同时不影响表达的流畅性。
五、总结
查看有关采集和组织示例的所需要点:
——为什么要注意资料和例子的采集
1.征服全场
2.已关注
3.(个人原因)
- 采集和组织方法
1.采集来源
(1)书籍 - 电子版、纸质版
(2)微信
(3) 网页
(4)其他
- 调用方法
文件名、类别、标签覆盖
- 防范措施
1.确认真相
2.通知来源
话虽如此,我只是想把我采集整理的习惯分享给大家,让分享好的东西更有意义。无论是写作、口语、推理,还是丰富对话、获取知识,还是成为一个有趣的人,好的材料和例子都是非常有帮助的。“好记性不如坏笔”,在这个时代应该改为“好记性不如坏手指”。虽然一开始可能看起来有些麻烦,但当你意识到经常采集和整理的好处时,你绝对不会停下来。想到通过采集整理,就可以控制这么大的素材库供自己使用,是多么有趣啊。
你为什么不也试试呢? 查看全部
文章采集调用(跑到图文加工店,说给点素材,中年老板:骚年你来对了)
我去了图形加工店,要了一些材料。中年老板:骚年,你说得对,我们这里有很多存货。我们拥有您需要的一切,无论是否为 JPG、PSD、AI、AE、AV……
我去了菜市场,给我举了一些例子。水果卖家:朋友知道货。今天刚到的李子很清爽。缺点是太甜了!隔壁卖糖炒栗子的小伙伸了伸脖子:大哥,带个刚出锅的袋子!
嗯……定义很重要,所以我们今天说的就是阅读中获得的文本内容,写作、演讲、推理等参考和引用的材料和例子。
其实很多大牛都写过管理自己的知识库,整理自己的知识体系文章等文章,素材和例子只是其中很小的一部分。和那些大牛相比,这次我只关注材料和例子。这个入口点非常小。如果你已经建立了自己完整的知识框架和结构,非常欢迎你给我意见和批评,面带微笑。
一、素材和例子有什么用1.征服观众
在写作或演讲时,通常围绕一个主题,你所要做的就是让读者或听众理解并接受你所说的话。如果你像教科书一样一个一个地遵守规则,你可能会失去很多观众。这种情况在演讲时尤其明显。当你偶尔低头在台上寻求所谓的眼神交流和互动感,发现台下很多人都只是笑眯眯地盯着桌子看,你应该明白你说的没那么有趣他们作为微博或朋友圈。
适当的书面或口语引用可以帮助最大程度地防止这种情况发生。在写作中引用例子可以帮助读者避免长时间阅读的疲劳,同时加深对内容的理解;演讲中生动的例子更有意义,使你表达的内容更容易被听众接受和理解。此外,成人注意力的时间曲线有其特定的规律。举两个生动的例子,在听众精力下降、容易分心的时候,可以瞬间重新集中注意力,保证演讲的良好效果。
2.已关注
你身边应该有几个这样的朋友。饭桌上,谈山,如切瓜切菜。上至天文地理玄学玄学,三体四书五道口,下至官民悲喜肉离奇故事,五花八门。境界中,入流而不入流的,如果被TA接管了,也别想带回去。如果你也想成为党的中心(当然,最好排除个人自我宣传的内容),一个反驳大片的引用,那么素材和例子的采集可以让你玩得更轻松. 李笑来老师在《花时间做朋友》中提到,父亲在公共场合总是能言善辩。一时间,他原以为父亲是个记忆力极好的人,后来才发现,父亲的秘密,其实是一本写满记录的笔记本。所谓口才,就是根据采集到的资料和例子,什么时候可以应用到什么场合。
3.生理原因(个人原因)
英语中有一句话:在我的舌尖上,字面意思是“在我的舌尖上”。它实际上意味着这些话在嘴唇上,但我突然想不起来了。在专注于采集资料和例子之前,我有很多类似的经历。我清楚地记得,前一天,甚至几个小时前,我碰巧看到了一个可以支持我观点的例子,但我不记得细节和来源了。孤歌独娘,没有结果。这时候,我会感到后背和喉咙有刺的不适感,相当难受。我认为这种感觉来自于没有保存适当的材料或示例的遗憾。
因此,采集和整理资料和例子已经成为我的日常习惯之一。“书籍只有在使用时才会被使用。” 古人早就发出过类似的感叹。事实上,对于掌握了很多新工具和新方法的现代人来说,采集和整理资料和实例其实并没有想象中的那么麻烦。
二、如何采集资料和例子1.采集资料和例子
由于我说的采集整理主要是针对文字内容,所以采集资料和例子的主要来源如下:
(1)书籍
如今,知识产权的保护普遍受到重视。很多书的内容不能直接在网上获取,只能在阅读后摘录和总结。
- 电子书
目前国内外新书趋势是电子版和纸质版同步推出。电子版通常比较便宜,可以直接在亚马逊等官网购买。尤其是刚出版的新书,基本上只能找到付费版(各种号称免费的网站往往最后都指向付费版网址)。对于已经上架一段时间的书籍,会有各种免费的电子版流出,其中大部分是PDF,但质量参差不齐。还有一件事,我找电子书的建议是,如果5-10分钟内没有找到合适的版本,基本可以放弃。不值得花更多宝贵的时间在无法保证的免费和优质内容上,并直接购买电子书。版本性价比更高,付费也体现了对知识的尊重。
以目前主流的亚马逊官网为例,购买完成后会自动推送到KINDLE。为了方便后续的整理和检索,我会使用CALIBER软件和DEDRM插件将亚马逊下载的AZW3格式转换成EPUB格式,然后把书放进书里。所需内容采集在印象笔记中(仅供学习参考,绝不参与D版盈利),让大量摘抄和引用的内容轻松复制到印象笔记保存和同步,不易丢失和容易搜索。
- 纸质书
有的书比较经典但年代久远,多次再版都没有电子版;还有非小说类的书,因为我个人喜欢边看书边写读书笔记,所以买了纸质版。对于这种纸质书,做长篇摘录很不方便,手工摘录也相当耗时。幸运的是,我在某宝上找到了一款手持扫描笔,可以快速将纸张内容扫描成可编辑的文本格式,比手动输入效率高出很多倍。以前看过万维刚的《没想到》。其中有许多科学证据的例子。段落很长。钱是不能存的。对于纸质书阅读量大、喜欢做阅读笔记的朋友来说,扫描笔是个值得推荐的工具。
(2)微信内容
微信是大多数人使用频率最高的手机应用,用得上不用说。我关联了印象笔记和有道云笔记这两个官方微信账号。我一般把值得采集的内容随时保存在云端,然后在电脑上整理总结。
(3)网页内容
当我浏览网页时,我也会保存我发现的好内容。复制粘贴部分太麻烦了。为此,我使用了印象笔记的网页剪辑插件。可以选择整页,网页正文,或者去广告等等,形式多样,非常体贴。
(4)其他
其他来源不是我采集整理资料的主流渠道,比如微信聊天记录等,我靠谷歌度娘的一些技巧整理成文字保存。
2.材料和例子的组织
采集后一定要整理好,否则起不到任何价值。整理的目的是为了更好的使用,单靠大脑很难把采集到的所有内容都记住。作为一个85后,我经常听到90后说:“哎呀!怎么记不住了?年纪大了,脑子就不行了。” 更习惯了)。事实上,人的大脑就像一台电脑。存储容量有一定的上限。此外,人脑也有遗忘机制。对于长时间不使用的内容,大脑会选择忘记释放存储空间让经常使用的模块运行。因此,我们需要将采集到的资料和实例进行更有效的整理,以方便后续的高效调用,减轻大脑的负担,
以印象笔记为例。完成采集动作后,你的印象笔记现在应该有相当多的内容了,但是它们是杂乱无章的。这时候,你需要做三件事:
第一步是取名字。这是最直接的内容分类方法,也是最原创的信息搜索渠道。我通常给内容命名的方式是:日期+类型+一般内容摘要,例如:20161011知乎LIVE-詹老师——一种不需要意志力的习惯养成方法,这样不管我怎么想“猎鹰”、“习惯”、“知乎”或日期,可以找到这个材料。
第二步是分类。采集到的内容按照类型设置成文件夹并进行相应分类,就像在电脑上为各种文档创建文件夹一样。我现在常用的文件夹有:个人(存放个人内容和其他私密内容,可选择加密)、日常工作(与工作相关的资料或内容)、学习(与学习、写作、成长等相关)等。此设置的优点是,当您不记得要搜索的具体内容,但可以确定需要查找的一般类别时,您可以过滤掉其他大类并缩小搜索范围。但是,当内容积累到一定程度时,这样的分类范围还是太粗,不够细。此时,
第三步也是最重要的一步是添加标签!标签!标签!(重要的事情说三遍)按文件夹分类的材料有一个巨大的缺陷。一份资料或例子只能归入一个文件夹。如果要放到第二个文件夹,只能复制粘贴一次。. 数据本质上是复杂的。复制粘贴会导致多个重复的搜索结果,并且会白白占用宝贵的云存储空间。强烈不推荐。因此,此时需要对素材或示例做的是添加标签,而不是添加一个标签,而是添加尽可能多的标签,并根据该素材所能穷尽的所有相关特性进行标记. 例如:之前在简书上看到一篇文章文章《经验:我如何找到电子书》,它教你如何搜索你需要的电子书或电子版资料。我把这个文章按类别放在study文件夹里,但其实我在工作中也用到了电子资料的搜索技巧。所以我给这个文章加了“e-book”、“search”、“resource”、“skill”等几个标签,方便以后写文章来明确调用资源,找电子书,在普及工作技能等角度的时候可以找到这个文章。
标记有两个非常大的好处。首先,打标签可以帮助你思考反刍:除了解释原创内容之外,这个材料或例子还能用于哪些其他方面?它还可以用来支持哪些其他论点?这与上面提到的相同。李笑来老师和他的父亲,通过记录和思考,在什么时间、什么地点、什么情况下记下了笔记本上的内容。是“思维拓展”的简化版,也可以体现来这里帮助你进一步理解内容。二是通过打标签会有很多意想不到的“惊喜”。我之前写过《学会花钱》这本书的书评。当我分析涉及概率论的章节时,我点击了我标记为“
三、调用的方法
所谓调用就是搜索所有你认为你能想到的关键词来找到你想要的内容,其中一些在上一篇文章中已经提到过。可以确定,文件名的搜索是最直接的。如果没有,可以在大类中搜索,缩小范围,或者使用标签叠加的方法进行多维搜索。目前我最常用的方法是确定大类,然后使用多个标签叠加搜索的方法,这种方法是最具方向性的。如果您想在搜索时获得灵感,仅使用一个关键字浏览或单击一组单独的标签通常会给您带来意想不到的东西。
李敖拆书的著名例子就是材料采集和转移的最好例子。以下文字来自对他的采访:
我很少忘记读过的书,李敖,为什么?方法很好。有什么办法?无情。所有的剪刀和美工刀都用了,当这本书被肢解时,它被切开。这个页面我需要,这个段落我需要,我按类别分开。背面呢?复印一份,或者一开始买两本书,剪开整理一下,想看的部分留着。结果一本书写完了,书也被肢解了。我就是这样看书的。
分类是如何划分的?我有很多自己制作的剪辑,我在剪辑上写下并分类所有信息。读完一本书,全都进了我的文件夹。我可以分出上千个班级,分得很细。例如,按照图书馆的分类,有哲学类和宗教类;宗教类别进一步分为佛教、道教和天主教。我,李敖,可以分为更多的细节。天主教徒可以细分,神父是一类。牧师也可以细分。同性恋神父是一类,世俗神父是另一类。女同性恋是一类,修女是世俗的,是另一类。
书中的任何相关内容都会进入我的个人资料。输入什么?当我想写小说时,我需要这些信息,打开信息,然后就写出来。或者发生了什么事,这与修女是同性恋有关。我想表达我对新闻的想法,带来新闻,打开我的数据,合并两者,文章马上就写出来。
也就是说,看完这本书,我被五匹马撕成了八块。但我被迷住了。我不记得这些材料。我小心翼翼地把它们挂起来,放在文件夹里。我的记忆只需要记住这些标题。标题是根据我的习惯划分的。基本上都是翻译成英文单词,排列成英文字母,偶尔也有一些中文。"
四、备注
在明确了材料采集的方法和好处之后,有两点需要注意:
1.确认是真的。
逻辑中有一个重要的概念:“合乎逻辑就是符合真理”。如果采集的材料和例子来自歪曲事实或报道,那么即使它符合你的观点,支持你的说法,也没有任何意义,甚至会产生相反的效果,让读者或听众觉得你是一个无法区分的人。对真假撒谎的人,从而大大降低了你观点的可信度。此外,即使材料是真实的,也很可能是时间敏感的。因此,在使用素材或示例时,一定要记得检查内容是否真实,是否仍然准确,并及时更新筛选。如果涉及收录日期或数据的新闻、历史、人文等,
2.通知消息来源。
引用示例时,在不引用来源的情况下表达内容会让人感到缺乏信任。如果读者或听众对您引用的材料或示例特别感兴趣,他们可能希望通过这些资源了解更详细的内容。因此,在引用资料或例子时,尽量告知出处,同时不影响表达的流畅性。
五、总结
查看有关采集和组织示例的所需要点:
——为什么要注意资料和例子的采集
1.征服全场
2.已关注
3.(个人原因)
- 采集和组织方法
1.采集来源
(1)书籍 - 电子版、纸质版
(2)微信
(3) 网页
(4)其他
- 调用方法
文件名、类别、标签覆盖
- 防范措施
1.确认真相
2.通知来源
话虽如此,我只是想把我采集整理的习惯分享给大家,让分享好的东西更有意义。无论是写作、口语、推理,还是丰富对话、获取知识,还是成为一个有趣的人,好的材料和例子都是非常有帮助的。“好记性不如坏笔”,在这个时代应该改为“好记性不如坏手指”。虽然一开始可能看起来有些麻烦,但当你意识到经常采集和整理的好处时,你绝对不会停下来。想到通过采集整理,就可以控制这么大的素材库供自己使用,是多么有趣啊。
你为什么不也试试呢?
文章采集调用(注意事项雷电模拟器要用3.96.0版本的,用7.1版本我的思路)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-04-14 20:26
一、算法
算法确实好用,但是破解的难度大家应该都知道。随着版本的更新,算法会经常发生变化,你的软件也会随着变化而更新,这样会增加开发成本。,你不得不说采集效率!就个人而言,我不认为它快得多。毕竟,访问的频率也是有限的。访问后不能更改代理,对吗?这个多少钱?
二、浏览器
不知道大家有没有发现,用户的主页是用浏览器打开的,但是用户的作品却完全没有显示出来。相信很多人的算法都是通过网页版获取的,所以这就造成了一个现象,网页版的算法,往往需要多次请求才能返回一组数据。当然,不排除有通过APP逆向获得的大神。这种情况我就不在这里讨论了,因为我也是半桶水倒过来。
三、捕获(提琴手)
Fiddler 可以说是 TCP 之外非常常见的抓包工具。证书安装好后,什么都不用做。缺点是没有API可以调用,除非你重新开发。一个调用第三方的dll库,我们在自己的程序中调用这个dll,把自己当做代理服务器,所有经过的请求都会先经过我这边,这样我就可以处理数据了。
四、备注
迅雷模拟器使用3.96.0版本,apk使用7.1版本
我的思路:
1.使用Fiddler做代理服务器,具体代码和dll库可以百度。
2.用模拟器操作,安装证书,挂代理,你刷你的视频,我的服务器会自动过滤数据,留下有用的
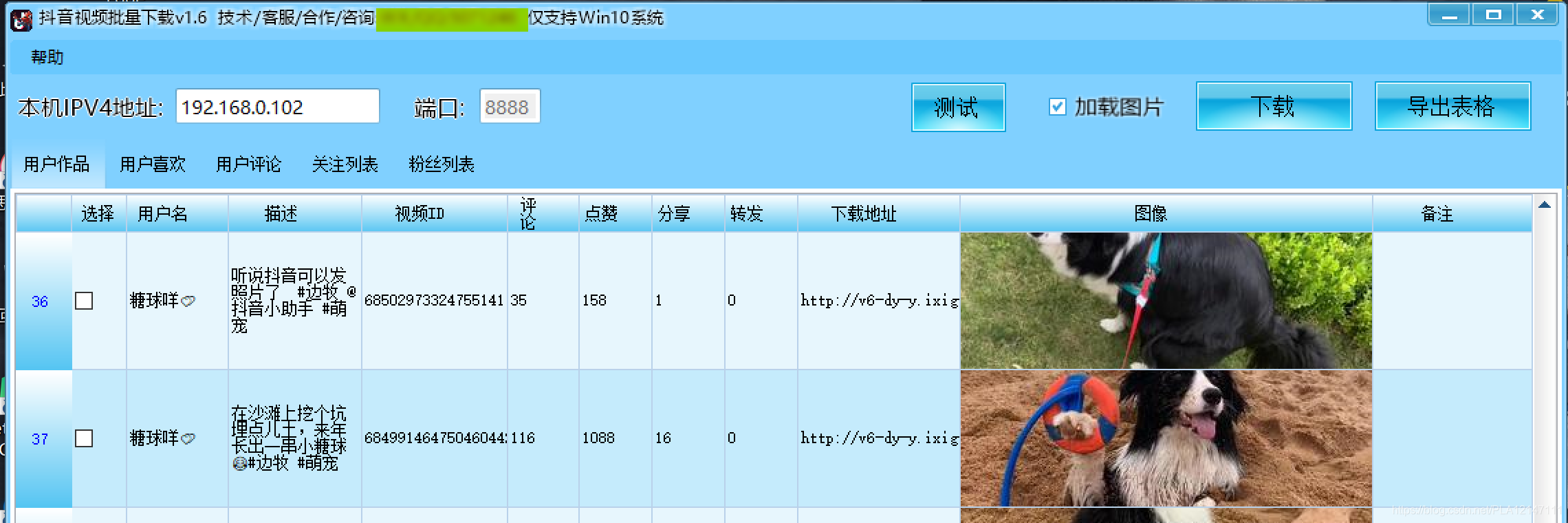
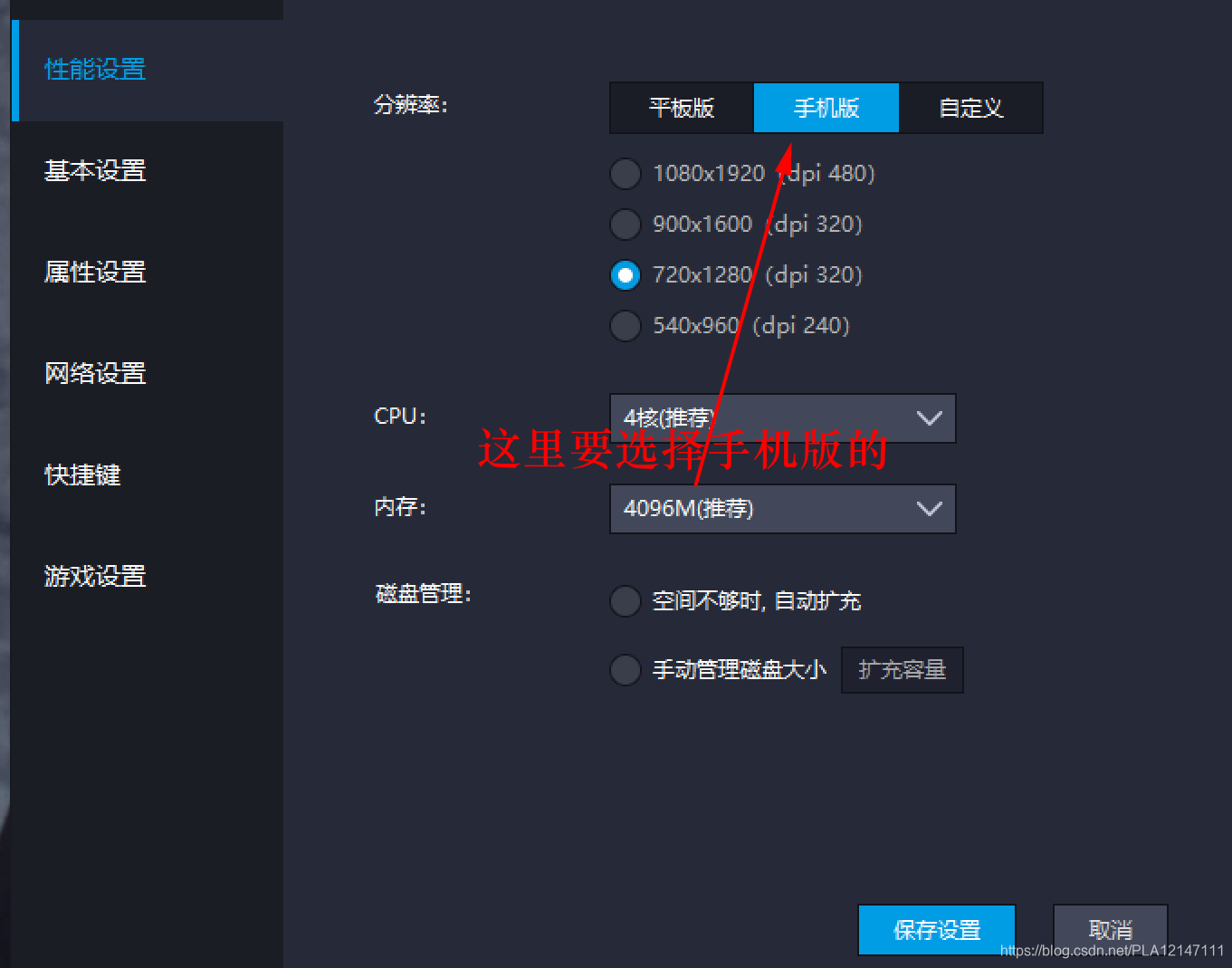
(1)配置模拟器,模拟器选择手机版本,分辨率可选
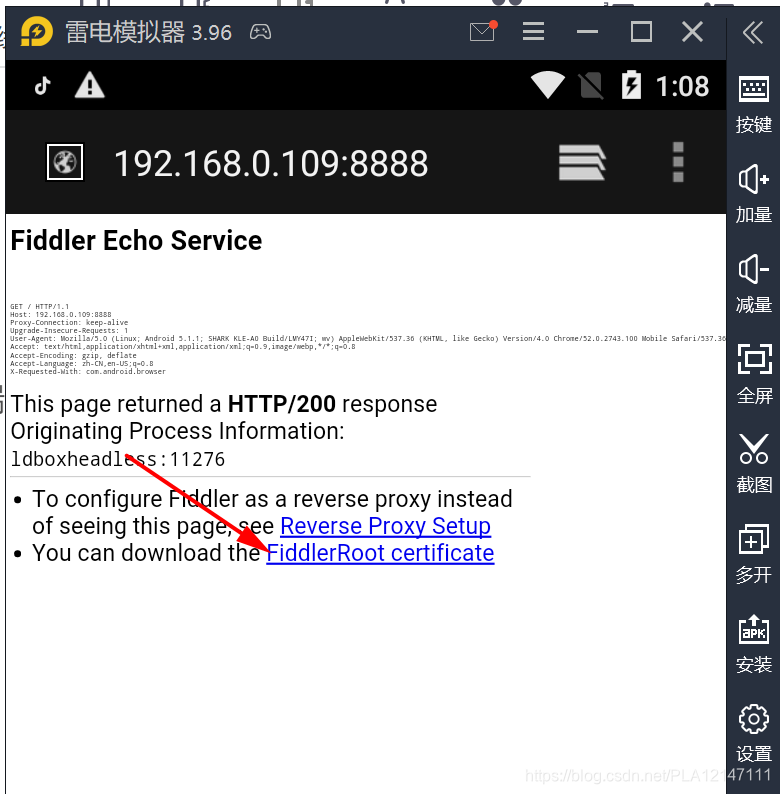
(2)使用模拟器中的浏览器打开软件上的链接(地址:端口),例如(192.168.0.109:8888)@ > 继续安装证书
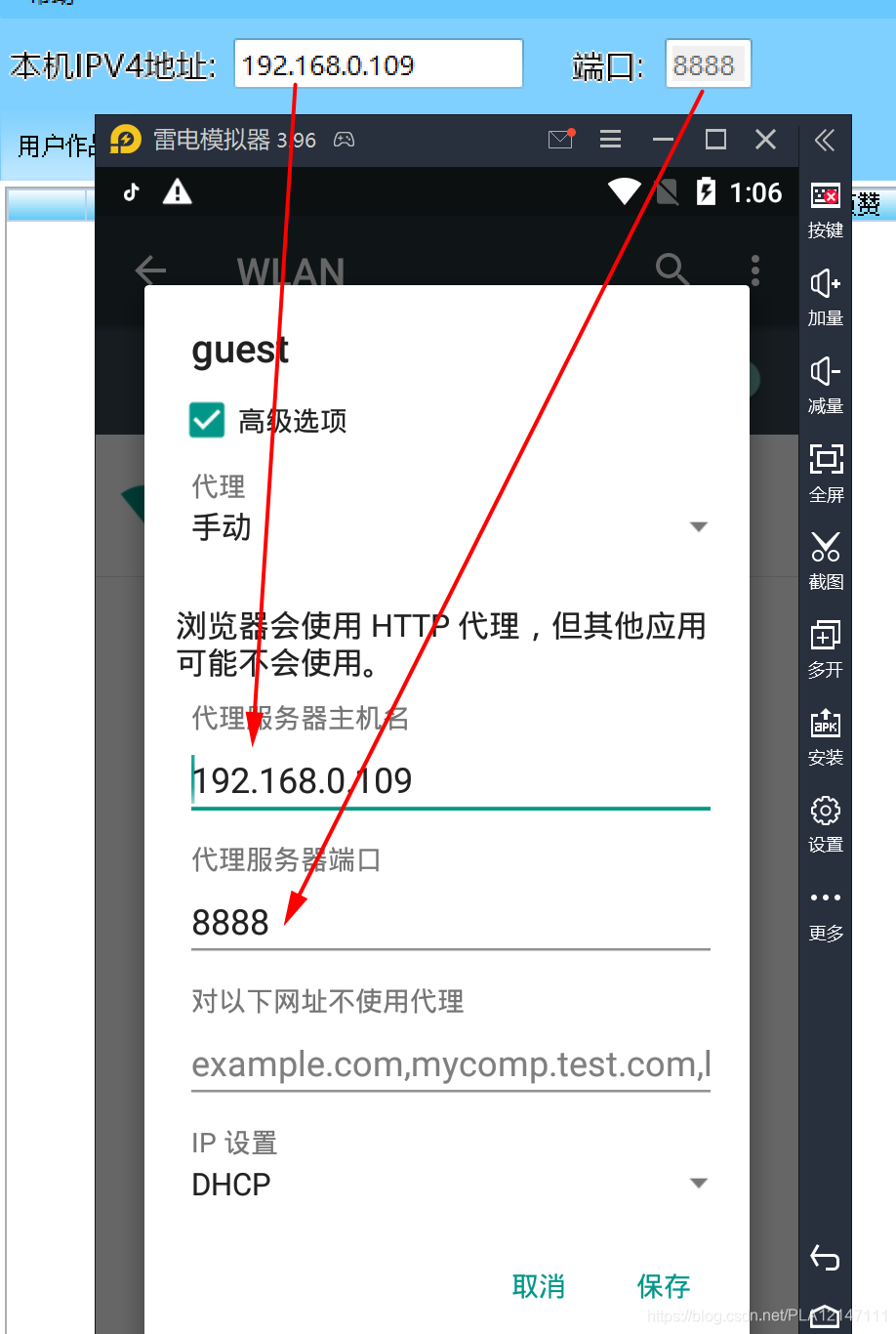
(3)配置模拟器网络代理
就这么简单,不知道你看懂Get了吗?这个方法,不管你放在什么app上,都是可行的,只要你要抓的数据是通过http或者https传输的,那么这个方法是可以的,但是在模拟器段,你可能要写一个脚本操作请求的触发器。与破解算法相比,自动化脚本可不是小菜一碟。
关于抖音在模拟器中无法正常显示数据,可以下载7.1版本的apk,不屏蔽模拟器的7.1版本。
这是我自己的批量去水印下载的示例。有兴趣的可以自行下载试用。有问题或者需要更多功能可以私信我交流。下载后右键属性解锁,否则可能无法正常使用。
对了,win7系统可能不行,因为很多win7 Fiddler证书无法正常安装,所以软件不能抓取https,这个可以自己测试。 查看全部
文章采集调用(注意事项雷电模拟器要用3.96.0版本的,用7.1版本我的思路)
一、算法
算法确实好用,但是破解的难度大家应该都知道。随着版本的更新,算法会经常发生变化,你的软件也会随着变化而更新,这样会增加开发成本。,你不得不说采集效率!就个人而言,我不认为它快得多。毕竟,访问的频率也是有限的。访问后不能更改代理,对吗?这个多少钱?
二、浏览器
不知道大家有没有发现,用户的主页是用浏览器打开的,但是用户的作品却完全没有显示出来。相信很多人的算法都是通过网页版获取的,所以这就造成了一个现象,网页版的算法,往往需要多次请求才能返回一组数据。当然,不排除有通过APP逆向获得的大神。这种情况我就不在这里讨论了,因为我也是半桶水倒过来。
三、捕获(提琴手)
Fiddler 可以说是 TCP 之外非常常见的抓包工具。证书安装好后,什么都不用做。缺点是没有API可以调用,除非你重新开发。一个调用第三方的dll库,我们在自己的程序中调用这个dll,把自己当做代理服务器,所有经过的请求都会先经过我这边,这样我就可以处理数据了。
四、备注
迅雷模拟器使用3.96.0版本,apk使用7.1版本
我的思路:
1.使用Fiddler做代理服务器,具体代码和dll库可以百度。
2.用模拟器操作,安装证书,挂代理,你刷你的视频,我的服务器会自动过滤数据,留下有用的
(1)配置模拟器,模拟器选择手机版本,分辨率可选
(2)使用模拟器中的浏览器打开软件上的链接(地址:端口),例如(192.168.0.109:8888)@ > 继续安装证书
(3)配置模拟器网络代理
就这么简单,不知道你看懂Get了吗?这个方法,不管你放在什么app上,都是可行的,只要你要抓的数据是通过http或者https传输的,那么这个方法是可以的,但是在模拟器段,你可能要写一个脚本操作请求的触发器。与破解算法相比,自动化脚本可不是小菜一碟。
关于抖音在模拟器中无法正常显示数据,可以下载7.1版本的apk,不屏蔽模拟器的7.1版本。
这是我自己的批量去水印下载的示例。有兴趣的可以自行下载试用。有问题或者需要更多功能可以私信我交流。下载后右键属性解锁,否则可能无法正常使用。
对了,win7系统可能不行,因为很多win7 Fiddler证书无法正常安装,所以软件不能抓取https,这个可以自己测试。
文章采集调用(2.采集支持调用奶盘API接口(组图)采集数据 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-04-14 17:06
)
优采云采集支持调用奶盘API接口,处理采集的数据标题和内容等;
温馨提示:第三方API接入功能需要用户提供第三方接口账号信息(即用户需要注册第三方接口,调用第三方接口产生的一切费用自理)由用户);
详细使用步骤
1. 创建奶盘API接口配置一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==最后点击【奶锅】 Open API] 创建接口配置;
二、配置API接口信息:
【Purchased Authorized User】和【Purchased Authorization Code】是从后台获取API授权信息,填写优采云;
【API版】是奶锅网购买对应的套餐:百度优化版、AI智能版;
注意:由于牛奶托盘每次调用限制为最多65000个字符(包括html代码),当内容长度超过时,优采云会被分割多次调用。这个操作会增加api调用次数,开销也会相应增加。这是用户需要承担的成本。使用前一定要注意!!!
2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==,点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击【+添加API处理规则]创建API处理规则;
二、API处理规则配置:
3. API 处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
一、手动执行API处理规则:
在采集任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译等工具】按钮==选择【第三方API执行】栏==选择对应的API处理规则= ="执行(数据范围有两种执行方式,根据发布状态批量执行和根据列表中选择的数据执行);
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡【自动执行第三方API配置】==勾选【采集,自动执行API】选项==选择要执行的API处理规则= ="选择API接口处理的数据范围(一般选择'待释放',all会导致所有数据重复执行),最后点击保存;
4. API处理结果并发布一、查看API接口处理结果:
API接口处理后的内容会保存为一个新的字段,如:标题处理后的新字段:`title_milk tray`,内容处理后的新字段:`content_milk tray`,在【结果数据&发布】和可以查看数据预览界面。
提示:执行 API 处理规则需要一段时间。执行完成后,页面会自动刷新,并出现API接口处理的新字段;
二、API接口处理后的内容发布
发布文章前,修改发布目标第二步的映射字段,重新选择标题和内容到API接口处理后添加的对应字段`title_milk tray'和`content_milk tray';
提示:如果发布目标中无法选择新字段,请在任务下复制或新建发布目标,然后在新发布目标中选择新字段即可。详细教程请参考发布目标中不能选择的字段。
5. 奶盘-API接口常见问题及解决方法一、API处理规则和SEO规则如何结合使用?
系统默认对title和content字段进行SEO功能,需要修改为SEO规则中的`title_milk tray'和`content_milk tray'字段;
查看全部
文章采集调用(2.采集支持调用奶盘API接口(组图)采集数据
)
优采云采集支持调用奶盘API接口,处理采集的数据标题和内容等;
温馨提示:第三方API接入功能需要用户提供第三方接口账号信息(即用户需要注册第三方接口,调用第三方接口产生的一切费用自理)由用户);
详细使用步骤
1. 创建奶盘API接口配置一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==最后点击【奶锅】 Open API] 创建接口配置;

二、配置API接口信息:
【Purchased Authorized User】和【Purchased Authorization Code】是从后台获取API授权信息,填写优采云;
【API版】是奶锅网购买对应的套餐:百度优化版、AI智能版;


注意:由于牛奶托盘每次调用限制为最多65000个字符(包括html代码),当内容长度超过时,优采云会被分割多次调用。这个操作会增加api调用次数,开销也会相应增加。这是用户需要承担的成本。使用前一定要注意!!!
2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==,点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击【+添加API处理规则]创建API处理规则;

二、API处理规则配置:

3. API 处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
一、手动执行API处理规则:
在采集任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译等工具】按钮==选择【第三方API执行】栏==选择对应的API处理规则= ="执行(数据范围有两种执行方式,根据发布状态批量执行和根据列表中选择的数据执行);

二、自动执行API处理规则:

启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡【自动执行第三方API配置】==勾选【采集,自动执行API】选项==选择要执行的API处理规则= ="选择API接口处理的数据范围(一般选择'待释放',all会导致所有数据重复执行),最后点击保存;
4. API处理结果并发布一、查看API接口处理结果:
API接口处理后的内容会保存为一个新的字段,如:标题处理后的新字段:`title_milk tray`,内容处理后的新字段:`content_milk tray`,在【结果数据&发布】和可以查看数据预览界面。
提示:执行 API 处理规则需要一段时间。执行完成后,页面会自动刷新,并出现API接口处理的新字段;

二、API接口处理后的内容发布
发布文章前,修改发布目标第二步的映射字段,重新选择标题和内容到API接口处理后添加的对应字段`title_milk tray'和`content_milk tray';

提示:如果发布目标中无法选择新字段,请在任务下复制或新建发布目标,然后在新发布目标中选择新字段即可。详细教程请参考发布目标中不能选择的字段。
5. 奶盘-API接口常见问题及解决方法一、API处理规则和SEO规则如何结合使用?
系统默认对title和content字段进行SEO功能,需要修改为SEO规则中的`title_milk tray'和`content_milk tray'字段;

文章采集调用( 开发环境JDK1.8.0javassist本章本章GA本章涉及源码的开发)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-13 14:15
开发环境JDK1.8.0javassist本章本章GA本章涉及源码的开发)
一、前言
字节码编程插桩技术常结合Javaagent技术用于系统的非侵入式监控,可以替代方法中的硬编码操作。例如,您需要监控一个方法,包括;方法信息、执行时间、输入输出参数、执行链接、异常。那么就非常适合用这样的技术手段进行加工。
为了体现这部分的核心内容,本文将只使用Javassist技术对一段方法字节码进行instrument,最后输出该方法的执行信息,如下;
Method - 后续字节码增强操作的测试方法
public Integer strToInt(String str01, String str02) {
return Integer.parseInt(str01);
}
监控 - 方法的字节码增强后,输出监控信息
监控 - Begin
方法:org.itstack.demo.javassist.ApiTest.strToInt
入参:["str01","str02"] 入参[类型]:["java.lang.String","java.lang.String"] 入数[值]:["1","2"]
出参:java.lang.Integer 出参[值]:1
耗时:59(s)
监控 - End
有了这样的监控方案,我们基本上可以输出方法执行过程中的所有信息。然后通过后期的改进,将监控信息显示在界面上,并实时发出警报。不仅提高了系统的监控质量,也便于研发排查和定位问题。
这很好!然后我们一步步开始使用javassist进行字节码插桩,就达到了我们的监控效果。
二、开发环境JDK 1.8.0javassist 3.12.1.GA本章涉及的源码为:itstack-demo-bytecode -1-04,可以关注公众号:bugstack 虫洞栈,回复源码下载即可。您将获得下载链接列表。打开后第十七期“因为我有很多开源代码”,记得给个Star!三、技术实现1. 获取方法的基本信息1.1 获取类
ClassPool pool = ClassPool.getDefault();
// 获取类
CtClass ctClass = pool.get(org.itstack.demo.javassist.ApiTest.class.getName());
ctClass.replaceClassName("ApiTest", "ApiTest02");
String clazzName = ctClass.getName();
通过类名获取类信息,这里可以替换类名。它还包括一些其他操作来获取类中的属性,例如;ctClass.getSimpleName()、ctClass.getAnnotations() 等等。
1.2 如何获得
CtMethod ctMethod = ctClass.getDeclaredMethod("strToInt");
String methodName = ctMethod.getName();
通过getDeclaredMethod获取方法的CtMethod的内容。之后,您可以获取方法名称等信息。
1.3 方法信息
MethodInfo methodInfo = ctMethod.getMethodInfo();
MethodInfo 收录方法信息;名称、类型等
1.4 种方法类型
boolean isStatic = (methodInfo.getAccessFlags() & AccessFlag.STATIC) != 0;
通过methodInfo.getAccessFlags()获取方法的标识符,然后使用AND运算AccessFlag.STATIC判断该方法是否为静态方法。因为静态方法会影响后续参数名的获取,所以静态方法的第一个参数就是this,需要排除。
1.5 方法:输入参数信息{name and type}
CodeAttribute codeAttribute = methodInfo.getCodeAttribute();
LocalVariableAttribute attr = (LocalVariableAttribute) codeAttribute.getAttribute(LocalVariableAttribute.tag);
CtClass[] parameterTypes = ctMethod.getParameterTypes();
1.6 方法;参数信息
CtClass returnType = ctMethod.getReturnType();
String returnTypeName = returnType.getName();
对于方法的参数信息,只需要获取参数类型即可。
1.7 输出所有获取的信息
System.out.println("类名:" + clazzName);
System.out.println("方法:" + methodName);
System.out.println("类型:" + (isStatic ? "静态方法" : "非静态方法"));
System.out.println("描述:" + methodInfo.getDescriptor());
System.out.println("入参[名称]:" + attr.variableName(1) + "," + attr.variableName(2));
System.out.println("入参[类型]:" + parameterTypes[0].getName() + "," + parameterTypes[1].getName());
System.out.println("出参[类型]:" + returnTypeName);
输出结果
类名:org.itstack.demo.javassist.ApiTest
方法:strToInt
类型:非静态方法
描述:(Ljava/lang/String;Ljava/lang/String;)Ljava/lang/Integer;
入参[名称]:str01,str02
入参[类型]:java.lang.String,java.lang.String
出参[类型]:java.lang.Integer
以上,输出信息为监控方法做准备。从上面可以记录方法的基本描述和输入参数的数量。尤其是入参的个数,因为后面需要用到$1来获取没有给入参的值。
2. 方法字节码检测
需要通过字节码检测来更改的原创方法;
public class ApiTest {
public Integer strToInt(String str01, String str02) {
return Integer.parseInt(str01);
}
}
2.1 先标记基础属性
在监控的情况下,不可能将每次调用的所有方法信息都汇总输出。这不仅仅是性能问题,这些都是固定信息,不需要每次方法执行都输出。
这很好!然后在编译方法时,会为每个方法生成一个唯一的ID,并将方法的固定信息与ID关联起来。也可以通过ID将监控数据传递到外部。
// 方法:生成方法唯一标识ID
int idx = Monitor.generateMethodId(clazzName, methodName, parameterNameList, parameterTypeList, returnTypeName);
生成ID的过程
public static final int MAX_NUM = 1024 * 32;
private final static AtomicInteger index = new AtomicInteger(0);
private final static AtomicReferenceArray methodTagArr = new AtomicReferenceArray(MAX_NUM);
public static int generateMethodId(String clazzName, String methodName, List parameterNameList, List parameterTypeList, String returnType) {
MethodDescription methodDescription = new MethodDescription();
methodDescription.setClazzName(clazzName);
methodDescription.setMethodName(methodName);
methodDescription.setParameterNameList(parameterNameList);
methodDescription.setParameterTypeList(parameterTypeList);
methodDescription.setReturnType(returnType);
int methodId = index.getAndIncrement();
if (methodId > MAX_NUM) return -1;
methodTagArr.set(methodId, methodDescription);
return methodId;
}
2.2 字节码检测增加入口方法时间
// 定义属性
ctMethod.addLocalVariable("startNanos", CtClass.longType);
// 方法前加强
ctMethod.insertBefore("{ startNanos = System.nanoTime(); }");
final类类方法
public class ApiTest {
public Integer strToInt(String str01, String str02) {
long startNanos = System.nanoTime();
return Integer.parseInt(str01);
}
}
2.3 字节码检测添加输入和输出
// 定义属性
ctMethod.addLocalVariable("parameterValues", pool.get(Object[].class.getName()));
// 方法前加强
ctMethod.insertBefore("{ parameterValues = new Object[]{" + parameters.toString() + "}; }");
final类类方法
public Integer strToInt(String str01, String str02) {
Object[] var10000 = new Object[]{str01, str02};
long startNanos = System.nanoTime();
return Integer.parseInt(str01);
}
2.4 定义监控方法
因为我们需要向外部输出监控信息。然后我们在这里定义一个静态方法,让字节码增强的方法调用,并输出监控信息。
public static void point(final int methodId, final long startNanos, Object[] parameterValues, Object returnValues) {
MethodDescription method = methodTagArr.get(methodId);
System.out.println("监控 - Begin");
System.out.println("方法:" + method.getClazzName() + "." + method.getMethodName());
System.out.println("入参:" + JSON.toJSONString(method.getParameterNameList()) + " 入参[类型]:" + JSON.toJSONString(method.getParameterTypeList()) + " 入数[值]:" + JSON.toJSONString(parameterValues));
System.out.println("出参:" + method.getReturnType() + " 出参[值]:" + JSON.toJSONString(returnValues));
System.out.println("耗时:" + (System.nanoTime() - startNanos) / 1000000 + "(s)");
System.out.println("监控 - End\r\n");
}
public static void point(final int methodId, Throwable throwable) {
MethodDescription method = methodTagArr.get(methodId);
System.out.println("监控 - Begin");
System.out.println("方法:" + method.getClazzName() + "." + method.getMethodName());
System.out.println("异常:" + throwable.getMessage());
System.out.println("监控 - End\r\n");
}
2.5 字节码检测调用监控方法
// 方法后加强
ctMethod.insertAfter("{ org.itstack.demo.javassist.Monitor.point(" + idx + ", startNanos, parameterValues, $_);}", false); // 如果返回类型非对象类型,$_ 需要进行类型转换
final类类方法
public Integer strToInt(String str01, String str02) {
Object[] parameterValues = new Object[]{str01, str02};
long startNanos = System.nanoTime();
Integer var7 = Integer.parseInt(str01);
Monitor.point(0, startNanos, parameterValues, var7);
return var7;
}
2.6 字节码检测将 TryCatch 添加到方法中
以上instrumentation内容,如果只是正常调用,是没有问题的。但是如果方法抛出异常,那么此时就无法采集到监控信息。所以你还需要将 TryCatch 添加到方法中。
// 方法;添加TryCatch
ctMethod.addCatch("{ org.itstack.demo.javassist.Monitor.point(" + idx + ", $e); throw $e; }", ClassPool.getDefault().get("java.lang.Exception")); // 添加异常捕获
final类类方法
public Integer strToInt(String str01, String str02) {
try {
Object[] parameterValues = new Object[]{str01, str02};
long startNanos = System.nanoTime();
Integer var7 = Integer.parseInt(str01);
Monitor.point(0, startNanos, parameterValues, var7);
return var7;
} catch (Exception var9) {
Monitor.point(0, var9);
throw var9;
}
}
四、测试结果
下一步是执行我们的调用来测试修改后的方法字节码。通过不同的输入参数验证监测结果;
// 测试调用
byte[] bytes = ctClass.toBytecode();
Class clazzNew = new GenerateClazzMethod().defineClass("org.itstack.demo.javassist.ApiTest", bytes, 0, bytes.length);
// 反射获取 main 方法
Method method = clazzNew.getMethod("strToInt", String.class, String.class);
Object obj_01 = method.invoke(clazzNew.newInstance(), "1", "2");
System.out.println("正确入参:" + obj_01);
Object obj_02 = method.invoke(clazzNew.newInstance(), "a", "b");
System.out.println("异常入参:" + obj_02);
测试结果
监控 - Begin
方法:org.itstack.demo.javassist.ApiTest.strToInt
入参:["str01","str02"] 入参[类型]:["java.lang.String","java.lang.String"] 入数[值]:["1","2"]
出参:java.lang.Integer 出参[值]:1
耗时:63(s)
监控 - End
正确入参:1
监控 - Begin
方法:org.itstack.demo.javassist.ApiTest.strToInt
异常:For input string: "a"
监控 - End
五、总结 查看全部
文章采集调用(
开发环境JDK1.8.0javassist本章本章GA本章涉及源码的开发)

一、前言
字节码编程插桩技术常结合Javaagent技术用于系统的非侵入式监控,可以替代方法中的硬编码操作。例如,您需要监控一个方法,包括;方法信息、执行时间、输入输出参数、执行链接、异常。那么就非常适合用这样的技术手段进行加工。
为了体现这部分的核心内容,本文将只使用Javassist技术对一段方法字节码进行instrument,最后输出该方法的执行信息,如下;
Method - 后续字节码增强操作的测试方法
public Integer strToInt(String str01, String str02) {
return Integer.parseInt(str01);
}
监控 - 方法的字节码增强后,输出监控信息
监控 - Begin
方法:org.itstack.demo.javassist.ApiTest.strToInt
入参:["str01","str02"] 入参[类型]:["java.lang.String","java.lang.String"] 入数[值]:["1","2"]
出参:java.lang.Integer 出参[值]:1
耗时:59(s)
监控 - End
有了这样的监控方案,我们基本上可以输出方法执行过程中的所有信息。然后通过后期的改进,将监控信息显示在界面上,并实时发出警报。不仅提高了系统的监控质量,也便于研发排查和定位问题。
这很好!然后我们一步步开始使用javassist进行字节码插桩,就达到了我们的监控效果。
二、开发环境JDK 1.8.0javassist 3.12.1.GA本章涉及的源码为:itstack-demo-bytecode -1-04,可以关注公众号:bugstack 虫洞栈,回复源码下载即可。您将获得下载链接列表。打开后第十七期“因为我有很多开源代码”,记得给个Star!三、技术实现1. 获取方法的基本信息1.1 获取类
ClassPool pool = ClassPool.getDefault();
// 获取类
CtClass ctClass = pool.get(org.itstack.demo.javassist.ApiTest.class.getName());
ctClass.replaceClassName("ApiTest", "ApiTest02");
String clazzName = ctClass.getName();
通过类名获取类信息,这里可以替换类名。它还包括一些其他操作来获取类中的属性,例如;ctClass.getSimpleName()、ctClass.getAnnotations() 等等。
1.2 如何获得
CtMethod ctMethod = ctClass.getDeclaredMethod("strToInt");
String methodName = ctMethod.getName();
通过getDeclaredMethod获取方法的CtMethod的内容。之后,您可以获取方法名称等信息。
1.3 方法信息
MethodInfo methodInfo = ctMethod.getMethodInfo();
MethodInfo 收录方法信息;名称、类型等
1.4 种方法类型
boolean isStatic = (methodInfo.getAccessFlags() & AccessFlag.STATIC) != 0;
通过methodInfo.getAccessFlags()获取方法的标识符,然后使用AND运算AccessFlag.STATIC判断该方法是否为静态方法。因为静态方法会影响后续参数名的获取,所以静态方法的第一个参数就是this,需要排除。
1.5 方法:输入参数信息{name and type}
CodeAttribute codeAttribute = methodInfo.getCodeAttribute();
LocalVariableAttribute attr = (LocalVariableAttribute) codeAttribute.getAttribute(LocalVariableAttribute.tag);
CtClass[] parameterTypes = ctMethod.getParameterTypes();
1.6 方法;参数信息
CtClass returnType = ctMethod.getReturnType();
String returnTypeName = returnType.getName();
对于方法的参数信息,只需要获取参数类型即可。
1.7 输出所有获取的信息
System.out.println("类名:" + clazzName);
System.out.println("方法:" + methodName);
System.out.println("类型:" + (isStatic ? "静态方法" : "非静态方法"));
System.out.println("描述:" + methodInfo.getDescriptor());
System.out.println("入参[名称]:" + attr.variableName(1) + "," + attr.variableName(2));
System.out.println("入参[类型]:" + parameterTypes[0].getName() + "," + parameterTypes[1].getName());
System.out.println("出参[类型]:" + returnTypeName);
输出结果
类名:org.itstack.demo.javassist.ApiTest
方法:strToInt
类型:非静态方法
描述:(Ljava/lang/String;Ljava/lang/String;)Ljava/lang/Integer;
入参[名称]:str01,str02
入参[类型]:java.lang.String,java.lang.String
出参[类型]:java.lang.Integer
以上,输出信息为监控方法做准备。从上面可以记录方法的基本描述和输入参数的数量。尤其是入参的个数,因为后面需要用到$1来获取没有给入参的值。
2. 方法字节码检测
需要通过字节码检测来更改的原创方法;
public class ApiTest {
public Integer strToInt(String str01, String str02) {
return Integer.parseInt(str01);
}
}
2.1 先标记基础属性
在监控的情况下,不可能将每次调用的所有方法信息都汇总输出。这不仅仅是性能问题,这些都是固定信息,不需要每次方法执行都输出。
这很好!然后在编译方法时,会为每个方法生成一个唯一的ID,并将方法的固定信息与ID关联起来。也可以通过ID将监控数据传递到外部。
// 方法:生成方法唯一标识ID
int idx = Monitor.generateMethodId(clazzName, methodName, parameterNameList, parameterTypeList, returnTypeName);
生成ID的过程
public static final int MAX_NUM = 1024 * 32;
private final static AtomicInteger index = new AtomicInteger(0);
private final static AtomicReferenceArray methodTagArr = new AtomicReferenceArray(MAX_NUM);
public static int generateMethodId(String clazzName, String methodName, List parameterNameList, List parameterTypeList, String returnType) {
MethodDescription methodDescription = new MethodDescription();
methodDescription.setClazzName(clazzName);
methodDescription.setMethodName(methodName);
methodDescription.setParameterNameList(parameterNameList);
methodDescription.setParameterTypeList(parameterTypeList);
methodDescription.setReturnType(returnType);
int methodId = index.getAndIncrement();
if (methodId > MAX_NUM) return -1;
methodTagArr.set(methodId, methodDescription);
return methodId;
}
2.2 字节码检测增加入口方法时间
// 定义属性
ctMethod.addLocalVariable("startNanos", CtClass.longType);
// 方法前加强
ctMethod.insertBefore("{ startNanos = System.nanoTime(); }");
final类类方法
public class ApiTest {
public Integer strToInt(String str01, String str02) {
long startNanos = System.nanoTime();
return Integer.parseInt(str01);
}
}
2.3 字节码检测添加输入和输出
// 定义属性
ctMethod.addLocalVariable("parameterValues", pool.get(Object[].class.getName()));
// 方法前加强
ctMethod.insertBefore("{ parameterValues = new Object[]{" + parameters.toString() + "}; }");
final类类方法
public Integer strToInt(String str01, String str02) {
Object[] var10000 = new Object[]{str01, str02};
long startNanos = System.nanoTime();
return Integer.parseInt(str01);
}
2.4 定义监控方法
因为我们需要向外部输出监控信息。然后我们在这里定义一个静态方法,让字节码增强的方法调用,并输出监控信息。
public static void point(final int methodId, final long startNanos, Object[] parameterValues, Object returnValues) {
MethodDescription method = methodTagArr.get(methodId);
System.out.println("监控 - Begin");
System.out.println("方法:" + method.getClazzName() + "." + method.getMethodName());
System.out.println("入参:" + JSON.toJSONString(method.getParameterNameList()) + " 入参[类型]:" + JSON.toJSONString(method.getParameterTypeList()) + " 入数[值]:" + JSON.toJSONString(parameterValues));
System.out.println("出参:" + method.getReturnType() + " 出参[值]:" + JSON.toJSONString(returnValues));
System.out.println("耗时:" + (System.nanoTime() - startNanos) / 1000000 + "(s)");
System.out.println("监控 - End\r\n");
}
public static void point(final int methodId, Throwable throwable) {
MethodDescription method = methodTagArr.get(methodId);
System.out.println("监控 - Begin");
System.out.println("方法:" + method.getClazzName() + "." + method.getMethodName());
System.out.println("异常:" + throwable.getMessage());
System.out.println("监控 - End\r\n");
}
2.5 字节码检测调用监控方法
// 方法后加强
ctMethod.insertAfter("{ org.itstack.demo.javassist.Monitor.point(" + idx + ", startNanos, parameterValues, $_);}", false); // 如果返回类型非对象类型,$_ 需要进行类型转换
final类类方法
public Integer strToInt(String str01, String str02) {
Object[] parameterValues = new Object[]{str01, str02};
long startNanos = System.nanoTime();
Integer var7 = Integer.parseInt(str01);
Monitor.point(0, startNanos, parameterValues, var7);
return var7;
}
2.6 字节码检测将 TryCatch 添加到方法中
以上instrumentation内容,如果只是正常调用,是没有问题的。但是如果方法抛出异常,那么此时就无法采集到监控信息。所以你还需要将 TryCatch 添加到方法中。
// 方法;添加TryCatch
ctMethod.addCatch("{ org.itstack.demo.javassist.Monitor.point(" + idx + ", $e); throw $e; }", ClassPool.getDefault().get("java.lang.Exception")); // 添加异常捕获
final类类方法
public Integer strToInt(String str01, String str02) {
try {
Object[] parameterValues = new Object[]{str01, str02};
long startNanos = System.nanoTime();
Integer var7 = Integer.parseInt(str01);
Monitor.point(0, startNanos, parameterValues, var7);
return var7;
} catch (Exception var9) {
Monitor.point(0, var9);
throw var9;
}
}
四、测试结果
下一步是执行我们的调用来测试修改后的方法字节码。通过不同的输入参数验证监测结果;
// 测试调用
byte[] bytes = ctClass.toBytecode();
Class clazzNew = new GenerateClazzMethod().defineClass("org.itstack.demo.javassist.ApiTest", bytes, 0, bytes.length);
// 反射获取 main 方法
Method method = clazzNew.getMethod("strToInt", String.class, String.class);
Object obj_01 = method.invoke(clazzNew.newInstance(), "1", "2");
System.out.println("正确入参:" + obj_01);
Object obj_02 = method.invoke(clazzNew.newInstance(), "a", "b");
System.out.println("异常入参:" + obj_02);
测试结果
监控 - Begin
方法:org.itstack.demo.javassist.ApiTest.strToInt
入参:["str01","str02"] 入参[类型]:["java.lang.String","java.lang.String"] 入数[值]:["1","2"]
出参:java.lang.Integer 出参[值]:1
耗时:63(s)
监控 - End
正确入参:1
监控 - Begin
方法:org.itstack.demo.javassist.ApiTest.strToInt
异常:For input string: "a"
监控 - End
五、总结
文章采集调用(优采云采集+伪原创错误博客分享《《》)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-04-13 05:18
优采云 是一个非常有用的文章采集 工具,但它也是一个很多人不知道的文章 构建工具。优采云采集+伪原创 方法已经流行了这么多年,仍然被大量的人使用,构建 原创文章 将使网站 改变更好的质量。今天,bug 博客( )分享了“优采云采集如何量产原创文章”。我希望能有所帮助。
优采云构建原创文章
一、优采云采集+伪原创
报错博客先讲优采云采集伪原创的操作方法。查找更好的信息网站采集一些较新的文章、采集有互联网热词,如百度搜索热点、抖音热点、微信博热搜和很快。
标题不要重复,不建议直接伪原创标题。最好手动编辑标题。内容 伪原创 应该是可读的。如果不可读,不建议使用那种工具,因为这个内容已经发了很久了,网站活不了多久了。
优采云采集+伪原创的形式确实可以创作很多内容,但是也应该考虑在网站中发布一些原创文章提高百度信心,让您事半功倍。
二、优采云构建原创文章
与其 优采云 构造 原创文章 不如调用内容,然后使用 文章 正文内容格式调用那些单词和句子。如何将这些单词和句子很好地呈现给用户和搜索引擎,不仅具有一定的可读性,而且具有看似实用的功能。这是错误博客的示例。当 爱站 网络对 网站 进行数据查询时,该页面是一个类似于 原创文章 的新页面,通过调用各种数据形成。页面,这样的页面有很好的排名。当这种页面出现在搜索引擎中时,很多人会选择点击,而且可能会停留很长时间。这是一个成功的案例。
当然,错误博客并没有那么有能力做出这样一种形式的页面来调用各种数据,但是我们可以根据自己的能力来构建这样一个原创页面,这样大量的内容页面就会不被我们使用。搜索引擎的罢工也可能会受到鼓励,毕竟这个页面非常实用。 查看全部
文章采集调用(优采云采集+伪原创错误博客分享《《》)
优采云 是一个非常有用的文章采集 工具,但它也是一个很多人不知道的文章 构建工具。优采云采集+伪原创 方法已经流行了这么多年,仍然被大量的人使用,构建 原创文章 将使网站 改变更好的质量。今天,bug 博客( )分享了“优采云采集如何量产原创文章”。我希望能有所帮助。
优采云构建原创文章
一、优采云采集+伪原创
报错博客先讲优采云采集伪原创的操作方法。查找更好的信息网站采集一些较新的文章、采集有互联网热词,如百度搜索热点、抖音热点、微信博热搜和很快。
标题不要重复,不建议直接伪原创标题。最好手动编辑标题。内容 伪原创 应该是可读的。如果不可读,不建议使用那种工具,因为这个内容已经发了很久了,网站活不了多久了。
优采云采集+伪原创的形式确实可以创作很多内容,但是也应该考虑在网站中发布一些原创文章提高百度信心,让您事半功倍。
二、优采云构建原创文章
与其 优采云 构造 原创文章 不如调用内容,然后使用 文章 正文内容格式调用那些单词和句子。如何将这些单词和句子很好地呈现给用户和搜索引擎,不仅具有一定的可读性,而且具有看似实用的功能。这是错误博客的示例。当 爱站 网络对 网站 进行数据查询时,该页面是一个类似于 原创文章 的新页面,通过调用各种数据形成。页面,这样的页面有很好的排名。当这种页面出现在搜索引擎中时,很多人会选择点击,而且可能会停留很长时间。这是一个成功的案例。
当然,错误博客并没有那么有能力做出这样一种形式的页面来调用各种数据,但是我们可以根据自己的能力来构建这样一个原创页面,这样大量的内容页面就会不被我们使用。搜索引擎的罢工也可能会受到鼓励,毕竟这个页面非常实用。
文章采集调用(R语言爬虫格式的json格式,寻找新的方法!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-04-12 19:35
==========背景===================
最近一直在用R语言爬,但是有些网站是动态json格式的。每次都找到重定向的 URL 很麻烦。因此,我正在寻找一种新方法,构建一个浏览器,在浏览器中查找 URL。于是出现了以下问题:
==========执行步骤分割线============
1、cmd enable java -jar selenium-server-standalone-2.53.0.jar //启动selenium
2、R 控制台
> library("Rwebdriver", lib.loc="C:/Program Files/R/R-3.2.3/library")
加载所需的包:RCurl
加载所需的包:bitops
加载所需包:RJSONIO
> library("XML", lib.loc="\\\\CNDOUW0000/Users/CNLeeWi/R/win-library/3.2")
> start_session(root = "" ,browser = "firefox")
函数错误(类型、msg、asError = TRUE):
无法连接到 localhost 端口 80:连接被拒绝
==========相关信息链接================== 查看全部
文章采集调用(R语言爬虫格式的json格式,寻找新的方法!)
==========背景===================
最近一直在用R语言爬,但是有些网站是动态json格式的。每次都找到重定向的 URL 很麻烦。因此,我正在寻找一种新方法,构建一个浏览器,在浏览器中查找 URL。于是出现了以下问题:
==========执行步骤分割线============
1、cmd enable java -jar selenium-server-standalone-2.53.0.jar //启动selenium
2、R 控制台
> library("Rwebdriver", lib.loc="C:/Program Files/R/R-3.2.3/library")
加载所需的包:RCurl
加载所需的包:bitops
加载所需包:RJSONIO
> library("XML", lib.loc="\\\\CNDOUW0000/Users/CNLeeWi/R/win-library/3.2")
> start_session(root = "" ,browser = "firefox")
函数错误(类型、msg、asError = TRUE):
无法连接到 localhost 端口 80:连接被拒绝
==========相关信息链接==================
文章采集调用(天弘基金(余额宝)移动平台首席架构师负责人)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-04-12 17:31
近年来,APM进入了快速发展的快车道。作为APM的核心功能,分布式环境下的自动应用发现和动态调用链路分析也被广泛应用于APM的推广。一些不足暴露出来:完全基于运行状态的分析模式决定了只能获取与实际调用的逻辑链接,大量未被掩埋或未被触发的调用逻辑成为无法触及的“失落的世界” . 撞。找到这部分“失落的世界”对于我们了解分布式环境中应用程序的全貌非常重要。天鸿基金移动平台团队在这方面进行了一些创新探索。我们跳出了传统APM的惯性思维,扫描分析海量代码中的调用关系,得到分布式环境下“前中后”站的完整调用链,并在此基础上叠加动态调用链,构建精细化APM监控。通过这个话题,我将结合我们的实践,详细介绍“静态调用链路发现”的技术和手段,并探讨如何在运维和开发场景中将其与现有的APM能力相结合。-->观众受益:1、了解分布式环境下APM的“优”与“差”。2、了解构建“静态呼叫链路发现”能力的技术和手段。3、 学习如何用创新思维拓展APM的应用场景。--> 个人介绍:天弘基金(月宝)移动平台首席架构师李鑫,负责移动平台整体技术架构设计。曾任当当网架构师,负责电商后端运营产品平台整体技术架构及研发团队管理;华为云计算专家,主导华为软件各类云计算产品和服务的设计、规划和建设。个人技术涉及大规模分布式应用与治理、中间件云化与服务化(PaaS)、APM监控、基础开发平台等领域, 查看全部
文章采集调用(天弘基金(余额宝)移动平台首席架构师负责人)
近年来,APM进入了快速发展的快车道。作为APM的核心功能,分布式环境下的自动应用发现和动态调用链路分析也被广泛应用于APM的推广。一些不足暴露出来:完全基于运行状态的分析模式决定了只能获取与实际调用的逻辑链接,大量未被掩埋或未被触发的调用逻辑成为无法触及的“失落的世界” . 撞。找到这部分“失落的世界”对于我们了解分布式环境中应用程序的全貌非常重要。天鸿基金移动平台团队在这方面进行了一些创新探索。我们跳出了传统APM的惯性思维,扫描分析海量代码中的调用关系,得到分布式环境下“前中后”站的完整调用链,并在此基础上叠加动态调用链,构建精细化APM监控。通过这个话题,我将结合我们的实践,详细介绍“静态调用链路发现”的技术和手段,并探讨如何在运维和开发场景中将其与现有的APM能力相结合。-->观众受益:1、了解分布式环境下APM的“优”与“差”。2、了解构建“静态呼叫链路发现”能力的技术和手段。3、 学习如何用创新思维拓展APM的应用场景。--> 个人介绍:天弘基金(月宝)移动平台首席架构师李鑫,负责移动平台整体技术架构设计。曾任当当网架构师,负责电商后端运营产品平台整体技术架构及研发团队管理;华为云计算专家,主导华为软件各类云计算产品和服务的设计、规划和建设。个人技术涉及大规模分布式应用与治理、中间件云化与服务化(PaaS)、APM监控、基础开发平台等领域,
文章采集调用(一个企业网站被百度降权了怎么办?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-04-12 06:32
去年年底,一位客户要求我帮助创建一家公司网站。考虑到 网站 将来会推广搜索引擎,网站 在 SEO 中必须是搜索引擎友好的。最后我选择了DeDecms,它可以在URL、PageTitle、TextBlock、LinkBlock、Auto Sitemap、Related Article中做早期的SEO布局。所以在栏目规划、版面设计、模板制作阶段,我将各种SEO元素充分融入到整个制作阶段,希望网站上线后,能够快速积累搜索排名权重。尤其是在模板代码编写方面,可以有效控制链接输出和导入,尽可能提高内部链接的相关性和关键词的匹配位置,去除无用的网页噪音信息,
果然,网站正式发布后,网站收录的占比迅速达到70%,大部分产品终端页面为收录,部分信息页面为收录 ,更重要的是:行业关键词排名和产品关键词排名进步很快;整个网站在SEO运营中呈现良性发展态势。客户端开始接管网站并正常更新站点内容,按照设定的时间表,一切应该都进行得很顺利。
不过最近网站SEO的表现开始下滑,网页数量收录首当其冲。百度统计后台显示的页面索引与搜索框中site命令返回的结果数量有显着差异。site 命令显示 Only 2 pages are 收录,都是首页,首页有 www 和没有 www 的两个版本。另外,信息正常更新后,百度索引很快,短时间内可以通过site命令返回结果,但过了一会儿发现收录无效。基于以上情况,我认为网站已经被百度降级了。
为了找到问题所在,我研究了各种因素,发现:
(1)除了正常更新网站的内容外,企业端也在积极运营外链,建外链是好事,但是用错了方式参与资源站的链轮;
(2)网上有相同模板、相同内容、不同品牌的仿站,而百度上的仿站收录也只有首页,“惊人的相似” ”给客户网站。
1、关于链轮问题,幸好我及时发现并制止了这种行为。由于参与sprocket的产品页面只有几个,时间不长,应该不会有这么大的影响,更何况自己的资源站。.
2、关于重复站点,非常少见。大多数人会自觉地在网站内容或组织形式上形成差异;而如果客户网站有这样的SEO症状,恐怕关键就在于仿网站,当我看到仿网站的时候,我完全无语了。除了公司的品牌名称不同,网站我都太了解了;本来想吐槽的,但回头看,现在网络不流行了。是不是到处都有抄袭的趋势?或许习惯了就好,但我不能忍受的是模板100%模仿,数据完整采集没事,拜托,你敢不敢放是99 % 相同的网站作为一个整体发布?你TMD搞SEO,不知道类似网站!你的TMD模仿站也可以模仿我过去写的自动更新的网站地图文件sitemap.php!做SEO伤不起啊。
吐槽回吐槽,问题还是要解决,采用了几个方法:
1、调整模板数据调用规则和新内容块布局
新的内容块会使页面主题关键词更加分散,并调整数据调用规则,使仿站点的数据与自己页面的数据不同,减少复制网站的负面影响@>搜索引擎优化问题。
2、想办法阻止内容采集
DeDecms本身就有防止采集混淆字符串的功能,但是这种防止采集的方法对SEO来说是非常不利的。您不希望搜索蜘蛛看到网页中有许多隐藏的隐藏对象。文字,而这些文字会影响蜘蛛对信息块主题的判断,影响关键词的排名。事实上,DeDecms并没有根本的办法来阻止采集,而且是一尺高。高一章,只要通过页面发布你的信息,总能找到采集的方法;我根据网上搜集的资料采用了两种方法,只能放最基本的采集。>:
(1)方法一:复制网页正文内容时自动添加版权信息
JavaScript 代码
将上面的代码放在文章页面模板中文本末尾之后。这个方法我测试过,只对IE浏览器有效,对火狐、傲游、谷歌浏览器无效。
(2)方法二:使页面代码唯一
一般别人采集时,要获取内容的起始码和结束码,而且必须是唯一的,所以填写的起始码多为:
. 这样,我们在这个类后面加上文章的ID值,改成这个
,其中{dede:field.id/}获取dedecms中当前文章的ID值,那么每个生成的文章的ID值都不一样,这里的起始代码为也不同,所以其他人将无法采集,并且您一次只能选择一件。
当我们制作模板时,在body标签附近
变成
,注意空格+{dede:field.id/},所以div的class没有变,但是
,此代码在每个文章的内容页面中是唯一的,或者在html标签中插入id={dede:field.id/},例如:
并且,这里的{dede:field.id/}是在dedecms中获取当前文章的ID值,这样别人就无法采集了,只有一个可以一次采集。当然,其他人可以使用过滤规则来移除,但是如果我在所有类中插入文档ID,或者插入id=文档ID。然后他只能采集整个页面,然后过滤,使得采集更加复杂。
缺点:如果{dede:field.id/}插入的不够多,其他人可以用过滤规则过滤掉。但是对于一些站群采集软件来说,这个招数就足以阻止他们采集了!
3、升级DeDecms到最新版本
DeDecms老版本有漏洞,很容易被黑,要么嵌入各种广告代码,要么无缘无故添加太多隐藏链接,所以一定要升级到最新版本。
上一篇:织梦cms:错误的解决方法:check Snooping out of bounds
下一步:设置dedecms标签[field:global.autoindex/]的初始值 查看全部
文章采集调用(一个企业网站被百度降权了怎么办?(图))
去年年底,一位客户要求我帮助创建一家公司网站。考虑到 网站 将来会推广搜索引擎,网站 在 SEO 中必须是搜索引擎友好的。最后我选择了DeDecms,它可以在URL、PageTitle、TextBlock、LinkBlock、Auto Sitemap、Related Article中做早期的SEO布局。所以在栏目规划、版面设计、模板制作阶段,我将各种SEO元素充分融入到整个制作阶段,希望网站上线后,能够快速积累搜索排名权重。尤其是在模板代码编写方面,可以有效控制链接输出和导入,尽可能提高内部链接的相关性和关键词的匹配位置,去除无用的网页噪音信息,
果然,网站正式发布后,网站收录的占比迅速达到70%,大部分产品终端页面为收录,部分信息页面为收录 ,更重要的是:行业关键词排名和产品关键词排名进步很快;整个网站在SEO运营中呈现良性发展态势。客户端开始接管网站并正常更新站点内容,按照设定的时间表,一切应该都进行得很顺利。
不过最近网站SEO的表现开始下滑,网页数量收录首当其冲。百度统计后台显示的页面索引与搜索框中site命令返回的结果数量有显着差异。site 命令显示 Only 2 pages are 收录,都是首页,首页有 www 和没有 www 的两个版本。另外,信息正常更新后,百度索引很快,短时间内可以通过site命令返回结果,但过了一会儿发现收录无效。基于以上情况,我认为网站已经被百度降级了。
为了找到问题所在,我研究了各种因素,发现:
(1)除了正常更新网站的内容外,企业端也在积极运营外链,建外链是好事,但是用错了方式参与资源站的链轮;
(2)网上有相同模板、相同内容、不同品牌的仿站,而百度上的仿站收录也只有首页,“惊人的相似” ”给客户网站。
1、关于链轮问题,幸好我及时发现并制止了这种行为。由于参与sprocket的产品页面只有几个,时间不长,应该不会有这么大的影响,更何况自己的资源站。.
2、关于重复站点,非常少见。大多数人会自觉地在网站内容或组织形式上形成差异;而如果客户网站有这样的SEO症状,恐怕关键就在于仿网站,当我看到仿网站的时候,我完全无语了。除了公司的品牌名称不同,网站我都太了解了;本来想吐槽的,但回头看,现在网络不流行了。是不是到处都有抄袭的趋势?或许习惯了就好,但我不能忍受的是模板100%模仿,数据完整采集没事,拜托,你敢不敢放是99 % 相同的网站作为一个整体发布?你TMD搞SEO,不知道类似网站!你的TMD模仿站也可以模仿我过去写的自动更新的网站地图文件sitemap.php!做SEO伤不起啊。
吐槽回吐槽,问题还是要解决,采用了几个方法:
1、调整模板数据调用规则和新内容块布局
新的内容块会使页面主题关键词更加分散,并调整数据调用规则,使仿站点的数据与自己页面的数据不同,减少复制网站的负面影响@>搜索引擎优化问题。
2、想办法阻止内容采集
DeDecms本身就有防止采集混淆字符串的功能,但是这种防止采集的方法对SEO来说是非常不利的。您不希望搜索蜘蛛看到网页中有许多隐藏的隐藏对象。文字,而这些文字会影响蜘蛛对信息块主题的判断,影响关键词的排名。事实上,DeDecms并没有根本的办法来阻止采集,而且是一尺高。高一章,只要通过页面发布你的信息,总能找到采集的方法;我根据网上搜集的资料采用了两种方法,只能放最基本的采集。>:
(1)方法一:复制网页正文内容时自动添加版权信息
JavaScript 代码
将上面的代码放在文章页面模板中文本末尾之后。这个方法我测试过,只对IE浏览器有效,对火狐、傲游、谷歌浏览器无效。
(2)方法二:使页面代码唯一
一般别人采集时,要获取内容的起始码和结束码,而且必须是唯一的,所以填写的起始码多为:
. 这样,我们在这个类后面加上文章的ID值,改成这个
,其中{dede:field.id/}获取dedecms中当前文章的ID值,那么每个生成的文章的ID值都不一样,这里的起始代码为也不同,所以其他人将无法采集,并且您一次只能选择一件。
当我们制作模板时,在body标签附近
变成
,注意空格+{dede:field.id/},所以div的class没有变,但是
,此代码在每个文章的内容页面中是唯一的,或者在html标签中插入id={dede:field.id/},例如:
并且,这里的{dede:field.id/}是在dedecms中获取当前文章的ID值,这样别人就无法采集了,只有一个可以一次采集。当然,其他人可以使用过滤规则来移除,但是如果我在所有类中插入文档ID,或者插入id=文档ID。然后他只能采集整个页面,然后过滤,使得采集更加复杂。
缺点:如果{dede:field.id/}插入的不够多,其他人可以用过滤规则过滤掉。但是对于一些站群采集软件来说,这个招数就足以阻止他们采集了!
3、升级DeDecms到最新版本
DeDecms老版本有漏洞,很容易被黑,要么嵌入各种广告代码,要么无缘无故添加太多隐藏链接,所以一定要升级到最新版本。
上一篇:织梦cms:错误的解决方法:check Snooping out of bounds
下一步:设置dedecms标签[field:global.autoindex/]的初始值
文章采集调用(1.用python爬取代理批量采集实现方法:anyproxy+js)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-04-11 13:02
微信公众号文章爬取方法整理1.用python爬取
php
实现方法:通过微信提供的公众号文章调用接口,实现抓取公众号文章html的功能
步骤:java
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookies,达到登录的效果;Python
2.使用webdriver功能需要安装对应浏览器的驱动插件。我在这里使用谷歌浏览器进行测试:
谷歌浏览器版本是 52.0.2743.6 ;
chromedriver版本为:V2.23
注意:谷歌浏览器版本和chromedriver需要对应,否则启动时会报错。【附:selenium的chromedriver和chrome版本映射表(更新为v2.30))】web
3.微信公众号登录地址:chrome
4.微信公众号文章界面地址可以在微信公众号后台创建图文信息,从超链接函数中获取:数据库
5.搜索公众号api
6.获取要爬取公众号的fakeid浏览器
7.选择要爬取的公众号,获取文章接口地址微信
8.文章列表翻页和内容获取
2.AnyProxy 代理批量采集
实现方式:anyproxy+js
实现方式:anyproxy+java+webmagic
3.FiddlerCore
实现方式:抓包工具,Fiddler4
经过多个账号的抓包分析,可以确认:
_biz:这个14位的字符串是每一个公众号的“id”,搜狗的微信平台能够得到
uin:与访问者有关,微信号id
key:和所访问的公众号有关
步:
1、编写按钮向导脚本,在手机端自动点击公众号文章的列表页面,即“查看历史消息”;
2、使用fiddler代理劫持手机访问,将URL转发到php编写的本地网页;
3、将接收到的URL备份到php网页上的数据库中;
4、使用python从数据库中检索URL,然后进行正常爬取。
在爬升过程中发现了一个问题:
如果只是想爬文章的内容,貌似没有访问频率限制,但是如果你想爬读点赞数,达到一定频率后,返回值会变成null,我设置的时间间隔为10秒,可以正常取到。在这个频率下,一个小时只能取到 360 条,没有实际意义。
4.青波新榜
如果你只是想看数据,你可以不花钱只看每日清单。如果你需要访问自己的系统,他们也提供了一个api接口 查看全部
文章采集调用(1.用python爬取代理批量采集实现方法:anyproxy+js)
微信公众号文章爬取方法整理1.用python爬取
php
实现方法:通过微信提供的公众号文章调用接口,实现抓取公众号文章html的功能
步骤:java
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookies,达到登录的效果;Python
2.使用webdriver功能需要安装对应浏览器的驱动插件。我在这里使用谷歌浏览器进行测试:
谷歌浏览器版本是 52.0.2743.6 ;
chromedriver版本为:V2.23
注意:谷歌浏览器版本和chromedriver需要对应,否则启动时会报错。【附:selenium的chromedriver和chrome版本映射表(更新为v2.30))】web
3.微信公众号登录地址:chrome
4.微信公众号文章界面地址可以在微信公众号后台创建图文信息,从超链接函数中获取:数据库
5.搜索公众号api
6.获取要爬取公众号的fakeid浏览器
7.选择要爬取的公众号,获取文章接口地址微信
8.文章列表翻页和内容获取
2.AnyProxy 代理批量采集
实现方式:anyproxy+js
实现方式:anyproxy+java+webmagic
3.FiddlerCore
实现方式:抓包工具,Fiddler4
经过多个账号的抓包分析,可以确认:
_biz:这个14位的字符串是每一个公众号的“id”,搜狗的微信平台能够得到
uin:与访问者有关,微信号id
key:和所访问的公众号有关
步:
1、编写按钮向导脚本,在手机端自动点击公众号文章的列表页面,即“查看历史消息”;
2、使用fiddler代理劫持手机访问,将URL转发到php编写的本地网页;
3、将接收到的URL备份到php网页上的数据库中;
4、使用python从数据库中检索URL,然后进行正常爬取。
在爬升过程中发现了一个问题:
如果只是想爬文章的内容,貌似没有访问频率限制,但是如果你想爬读点赞数,达到一定频率后,返回值会变成null,我设置的时间间隔为10秒,可以正常取到。在这个频率下,一个小时只能取到 360 条,没有实际意义。
4.青波新榜
如果你只是想看数据,你可以不花钱只看每日清单。如果你需要访问自己的系统,他们也提供了一个api接口
文章采集调用(设为“星标”,好文章不错过!(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-04-10 19:27
设置为“star”,所以文章不要错过!
1 服务跟踪系统的意义
1.1 快速定位请求失败的原因
在微服务架构下,有很多服务。如果上游请求失败,要找出是哪个应用程序导致它是一场噩梦!
如果有系统,它可以跟踪记录用户请求发起了哪些调用,处理了哪些服务,并记录了每次调用所涉及的服务的详细信息。如果调用失败,可以通过日志快速定位问题!
1.2 优化系统瓶颈
通过记录调用经过的每个环节的耗时,可以快速定位整个系统的瓶颈点。比如你访问xxx网站的首页,发现速度很慢,可能是运营商网络延迟、网关系统异常、服务异常、缓存或者DB异常。通过服务跟踪,可以从上帝视角看到整个系统的瓶颈点,然后针对性的优化。
1.3 优化链接调用
分析调用经过的路径,评估是否合理,每个依赖是否必要,是否可以通过业务优化减少服务依赖。
一般情况下,服务部署在多个数据中心,实现异地容灾。此时服务A经常调用另一个数据中心的服务B,而不会调用同一个数据中心的服务B。
跨数据中心的呼叫会根据距离有一定的网络延迟,这对于某些业务来说是无法接受的。通过分析调用链,可以识别和优化跨数据中心的服务调用。
1.4 生成网络拓扑
通过记录的链路信息,可以生成系统的网络调用拓扑图,可以反映系统依赖哪些服务,服务之间的调用关系是什么,一目了然。
服务调用的详细信息也可以标注在网络拓扑图上,也可以起到服务监控的作用。
1.5 数据透传
业务中经常有需求,期望从调用开始就可以传递一些用户数据,让系统中的每个服务都能获取到这些信息。比如一个业务要做一些A/B测试,想把A/B测试的切换逻辑一路向下通过服务跟踪系统,经过的每一层服务都可以得到切换值,从而可以统一A/B测试。.
2 服务跟踪系统原理
服务跟踪系统的鼻祖:Google 的论文 Dapper, a Large-Scale Distributed Systems Tracing Infrastructure 详细解释了服务跟踪系统的实现原理。
2.1 核心概念
跟踪标识
全局唯一的 64 位整数,用于标识特定的请求 ID。
它在 RPC 调用的网络链路中不断传输,将一个请求在系统中经过的所有路径串联起来。
跨度ID
它用于标识一个RPC调用在分布式请求中的位置,以及区分系统中不同服务之间的调用顺序。
当用户的请求进入系统时,在RPC调用网络第一层A时spanId初始值为0,进入下一层RPC调用B时spanId为0.1,并继续进入下一层RPC调用在C中,spanId为0.1.1,与B同层的RPC调用E的spanId为0.2,这样某个RPC请求就可以通过spanId在系统中定位到调用中的位置,以及它的上下游依赖是谁。这类似于霍夫曼编码。
注解
用于自定义业务的嵌入点数据。可以是业务感兴趣并想上传到后端的数据,比如一个请求的用户UID。
商家自定义一些自己感兴趣的数据,除了上传traceId、spanId等基本信息外,添加一些自己感兴趣的信息。
3 服务跟踪系统的实施
服务跟踪系统可分为三层:
3.1 个数据采集图层
在系统的不同模块中嵌入点,采集数据并上报给数据处理层进行处理。
那么如何掩埋数据呢?结合下图来了解数据嵌入的过程。
以红框圈出的A调用B的过程为例,一个RPC请求可以分为四个阶段。
CS(Client Send)阶段:客户端发起请求并生成调用的上下文
SR(Server Recieve)阶段:服务器接收请求并生成上下文
SS(Server Send)阶段:服务器返回请求。在此阶段,将报告服务器上下文数据。下图显示上报数据为:traceId=123456, spanId=0.1, appKey=B, method=B.method, start=103, duration=38
CR(Client Recieve)阶段:客户端接收返回的结果。此阶段将报告客户端上下文数据。上报数据为:traceid=123456,spanId=0.1,appKey=A,method=B.method,start=103,duration=38。
3.2 数据处理层
按需计算data采集层上报的数据,然后存储在地面上供查询使用。
据我所知,数据处理需求一般分为两类,一类是实时计算需求,一类是离线计算需求。
实时计算要求需要较高的计算效率。一般要求采集到的链路数据可以秒级聚合,实时查询。但是,离线计算的需求并不需要那么高的计算效率。一般可以在小时级别完成链路数据的聚合计算,一般用于数据汇总统计。对于这两类不同的数据处理需求,所使用的计算方式和存储也是不同的。
3.3 数据表示层
数据展示层的作用是将处理后的链接信息以图形方式展示给用户。
主要使用以下两个图形:
调用链接图
从这张图中可以看出:
在实际项目中,调用链路图主要用于故障定位。例如,如果用户调用失败,可以通过调用链路图查询用户调用经过了哪些链路,以及调用失败的层级。造成的。
呼叫拓扑
呼叫拓扑图是全局视图图。在实际项目中,主要用于全局监控,以发现系统中的异常点并快速做出决策。比如某个服务突然出现异常,在调用链路拓扑图中可以看出该服务的调用时间增加了,可以用红色图案标注,用于监控和告警。
参考
过去推荐
厂家如何解决数值精度/舍入/溢出问题
大厂数据库事务实践——事务生效后能否正确回滚?
在线问题事迹(一)数据库事务没有生效? 查看全部
文章采集调用(设为“星标”,好文章不错过!(组图))
设置为“star”,所以文章不要错过!

1 服务跟踪系统的意义

1.1 快速定位请求失败的原因

在微服务架构下,有很多服务。如果上游请求失败,要找出是哪个应用程序导致它是一场噩梦!

如果有系统,它可以跟踪记录用户请求发起了哪些调用,处理了哪些服务,并记录了每次调用所涉及的服务的详细信息。如果调用失败,可以通过日志快速定位问题!
1.2 优化系统瓶颈
通过记录调用经过的每个环节的耗时,可以快速定位整个系统的瓶颈点。比如你访问xxx网站的首页,发现速度很慢,可能是运营商网络延迟、网关系统异常、服务异常、缓存或者DB异常。通过服务跟踪,可以从上帝视角看到整个系统的瓶颈点,然后针对性的优化。
1.3 优化链接调用
分析调用经过的路径,评估是否合理,每个依赖是否必要,是否可以通过业务优化减少服务依赖。
一般情况下,服务部署在多个数据中心,实现异地容灾。此时服务A经常调用另一个数据中心的服务B,而不会调用同一个数据中心的服务B。
跨数据中心的呼叫会根据距离有一定的网络延迟,这对于某些业务来说是无法接受的。通过分析调用链,可以识别和优化跨数据中心的服务调用。
1.4 生成网络拓扑
通过记录的链路信息,可以生成系统的网络调用拓扑图,可以反映系统依赖哪些服务,服务之间的调用关系是什么,一目了然。
服务调用的详细信息也可以标注在网络拓扑图上,也可以起到服务监控的作用。
1.5 数据透传
业务中经常有需求,期望从调用开始就可以传递一些用户数据,让系统中的每个服务都能获取到这些信息。比如一个业务要做一些A/B测试,想把A/B测试的切换逻辑一路向下通过服务跟踪系统,经过的每一层服务都可以得到切换值,从而可以统一A/B测试。.
2 服务跟踪系统原理
服务跟踪系统的鼻祖:Google 的论文 Dapper, a Large-Scale Distributed Systems Tracing Infrastructure 详细解释了服务跟踪系统的实现原理。
2.1 核心概念
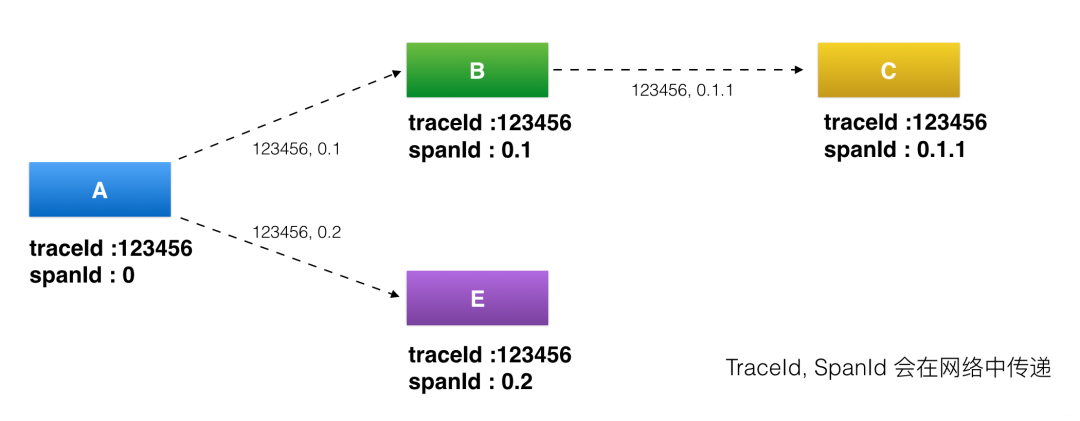

跟踪标识

全局唯一的 64 位整数,用于标识特定的请求 ID。
它在 RPC 调用的网络链路中不断传输,将一个请求在系统中经过的所有路径串联起来。
跨度ID
它用于标识一个RPC调用在分布式请求中的位置,以及区分系统中不同服务之间的调用顺序。
当用户的请求进入系统时,在RPC调用网络第一层A时spanId初始值为0,进入下一层RPC调用B时spanId为0.1,并继续进入下一层RPC调用在C中,spanId为0.1.1,与B同层的RPC调用E的spanId为0.2,这样某个RPC请求就可以通过spanId在系统中定位到调用中的位置,以及它的上下游依赖是谁。这类似于霍夫曼编码。
注解
用于自定义业务的嵌入点数据。可以是业务感兴趣并想上传到后端的数据,比如一个请求的用户UID。
商家自定义一些自己感兴趣的数据,除了上传traceId、spanId等基本信息外,添加一些自己感兴趣的信息。
3 服务跟踪系统的实施
服务跟踪系统可分为三层:
3.1 个数据采集图层
在系统的不同模块中嵌入点,采集数据并上报给数据处理层进行处理。
那么如何掩埋数据呢?结合下图来了解数据嵌入的过程。
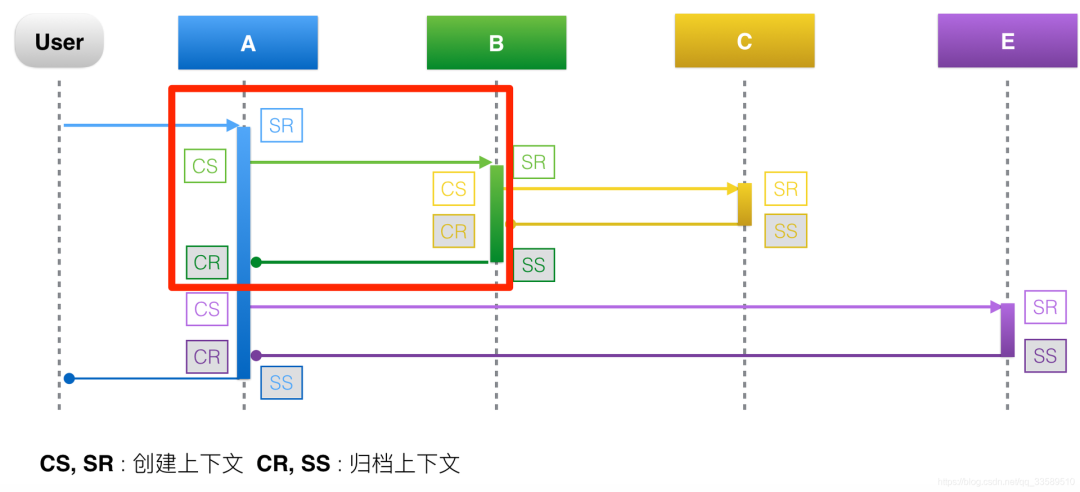
以红框圈出的A调用B的过程为例,一个RPC请求可以分为四个阶段。
CS(Client Send)阶段:客户端发起请求并生成调用的上下文
SR(Server Recieve)阶段:服务器接收请求并生成上下文
SS(Server Send)阶段:服务器返回请求。在此阶段,将报告服务器上下文数据。下图显示上报数据为:traceId=123456, spanId=0.1, appKey=B, method=B.method, start=103, duration=38
CR(Client Recieve)阶段:客户端接收返回的结果。此阶段将报告客户端上下文数据。上报数据为:traceid=123456,spanId=0.1,appKey=A,method=B.method,start=103,duration=38。

3.2 数据处理层
按需计算data采集层上报的数据,然后存储在地面上供查询使用。
据我所知,数据处理需求一般分为两类,一类是实时计算需求,一类是离线计算需求。
实时计算要求需要较高的计算效率。一般要求采集到的链路数据可以秒级聚合,实时查询。但是,离线计算的需求并不需要那么高的计算效率。一般可以在小时级别完成链路数据的聚合计算,一般用于数据汇总统计。对于这两类不同的数据处理需求,所使用的计算方式和存储也是不同的。
3.3 数据表示层
数据展示层的作用是将处理后的链接信息以图形方式展示给用户。
主要使用以下两个图形:
调用链接图
从这张图中可以看出:
在实际项目中,调用链路图主要用于故障定位。例如,如果用户调用失败,可以通过调用链路图查询用户调用经过了哪些链路,以及调用失败的层级。造成的。
呼叫拓扑
呼叫拓扑图是全局视图图。在实际项目中,主要用于全局监控,以发现系统中的异常点并快速做出决策。比如某个服务突然出现异常,在调用链路拓扑图中可以看出该服务的调用时间增加了,可以用红色图案标注,用于监控和告警。
参考
过去推荐
厂家如何解决数值精度/舍入/溢出问题
大厂数据库事务实践——事务生效后能否正确回滚?
在线问题事迹(一)数据库事务没有生效?
文章采集调用(这部分资料大部分都是都是:如何编程经验总结了一下,效果并不好)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-04-10 19:23
主机:ubuntu 10.10 开发板:Tiny6410 交叉编译工具链:atm-linux-gcc 4.3.2qt 版本:QtEmbedded-4.5.2 - arm 最近在Tiny6410上编程摄像头的时候,从网上找了很多资料学习,但是效果不好,因为网上大部分资料都不是很详细,如果有V4L2编程经验的话. 都差不多,不过对于我这种刚入门的人来说太麻烦了。这部分信息大部分是:1、详细介绍如何编程V4L2,但没有提供源代码示例。2、提供了源代码,但注释很少。难以阅读。于是总结了一篇文章文章,总结了编程心得,这些例子可以在Tiny6410开发板上运行,也可以直接在ubuntu 10.10上运行,可以使用的摄像头有OV9650、USB接口OV301等,只需对源码稍作改动即可。关于 videodevice 是我在网上找到的一条资料。我觉得他写的很好,所以也收录在里面供大家参考。如果您有任何问题,请与我联系。我的邮箱是:我要注意:我上次上传的代码不是我上次修改的代码,虽然没有问题,但是我还是觉得再上传一次就好了,就是不知道怎么改删除之前上传的代码,只能重新发送。关于 videodevice 是我在网上找到的一条资料。我觉得他写的很好,所以也收录在里面供大家参考。如果您有任何问题,请与我联系。我的邮箱是:我要注意:我上次上传的代码不是我上次修改的代码,虽然没有问题,但是我还是觉得再上传一次就好了,就是不知道怎么改删除之前上传的代码,只能重新发送。关于 videodevice 是我在网上找到的一条资料。我觉得他写的很好,所以也收录在里面供大家参考。如果您有任何问题,请与我联系。我的邮箱是:我要注意:我上次上传的代码不是我上次修改的代码,虽然没有问题,但是我还是觉得再上传一次就好了,就是不知道怎么改删除之前上传的代码,只能重新发送。 查看全部
文章采集调用(这部分资料大部分都是都是:如何编程经验总结了一下,效果并不好)
主机:ubuntu 10.10 开发板:Tiny6410 交叉编译工具链:atm-linux-gcc 4.3.2qt 版本:QtEmbedded-4.5.2 - arm 最近在Tiny6410上编程摄像头的时候,从网上找了很多资料学习,但是效果不好,因为网上大部分资料都不是很详细,如果有V4L2编程经验的话. 都差不多,不过对于我这种刚入门的人来说太麻烦了。这部分信息大部分是:1、详细介绍如何编程V4L2,但没有提供源代码示例。2、提供了源代码,但注释很少。难以阅读。于是总结了一篇文章文章,总结了编程心得,这些例子可以在Tiny6410开发板上运行,也可以直接在ubuntu 10.10上运行,可以使用的摄像头有OV9650、USB接口OV301等,只需对源码稍作改动即可。关于 videodevice 是我在网上找到的一条资料。我觉得他写的很好,所以也收录在里面供大家参考。如果您有任何问题,请与我联系。我的邮箱是:我要注意:我上次上传的代码不是我上次修改的代码,虽然没有问题,但是我还是觉得再上传一次就好了,就是不知道怎么改删除之前上传的代码,只能重新发送。关于 videodevice 是我在网上找到的一条资料。我觉得他写的很好,所以也收录在里面供大家参考。如果您有任何问题,请与我联系。我的邮箱是:我要注意:我上次上传的代码不是我上次修改的代码,虽然没有问题,但是我还是觉得再上传一次就好了,就是不知道怎么改删除之前上传的代码,只能重新发送。关于 videodevice 是我在网上找到的一条资料。我觉得他写的很好,所以也收录在里面供大家参考。如果您有任何问题,请与我联系。我的邮箱是:我要注意:我上次上传的代码不是我上次修改的代码,虽然没有问题,但是我还是觉得再上传一次就好了,就是不知道怎么改删除之前上传的代码,只能重新发送。
文章采集调用(文章采集调用服务的xml格式的接口,无需restfulapi)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-09 23:03
文章采集调用服务的xml格式的接口,无需restfulapi,一切交给c++,或者用epoll、select等异步网络调用即可.现有文章内容抓取及商品xml接口通过开发一个简单的爬虫,能够最大限度的节省url请求和返回的访问成本。本小节以杭州某地的某线索网站为例讲解如何开发一个简单的爬虫。由于杭州市的所有信息全部都在这一小块地图上,爬虫必须读取这些数据,可以很快速的进行数据采集。
爬虫的实现要先针对这个网站的数据进行分析,得到每个url对应的vi信息即当前页内容,以及当前页内容对应的url之前的所有历史价格数据。得到每个url对应的vi信息即当前页内容对应的url之前的所有历史价格数据爬虫的代码是通过两个c++的源文件完成。以杭州市某的某线索网站为例(杭州市的网址则在此网址后面存放),可以理解爬虫只需要通过url完成第一步所有的任务,然后解析所有url的内容返回给服务端即可。
<p>有了数据,接下来就是网站的代码实现,以及如何抓取数据了。爬虫的代码:#include#include#includeusingnamespacestd;constintmaxpage=10;//一页的长度#includeintmain(){void*path;stringfilename;charcontent[]="/";charcontent[]="\n";string[]arrays;present_content(path);filename=0;file_tindex;charlines[]=path.size();char[]next;for(index=0;index 查看全部
文章采集调用(文章采集调用服务的xml格式的接口,无需restfulapi)
文章采集调用服务的xml格式的接口,无需restfulapi,一切交给c++,或者用epoll、select等异步网络调用即可.现有文章内容抓取及商品xml接口通过开发一个简单的爬虫,能够最大限度的节省url请求和返回的访问成本。本小节以杭州某地的某线索网站为例讲解如何开发一个简单的爬虫。由于杭州市的所有信息全部都在这一小块地图上,爬虫必须读取这些数据,可以很快速的进行数据采集。
爬虫的实现要先针对这个网站的数据进行分析,得到每个url对应的vi信息即当前页内容,以及当前页内容对应的url之前的所有历史价格数据。得到每个url对应的vi信息即当前页内容对应的url之前的所有历史价格数据爬虫的代码是通过两个c++的源文件完成。以杭州市某的某线索网站为例(杭州市的网址则在此网址后面存放),可以理解爬虫只需要通过url完成第一步所有的任务,然后解析所有url的内容返回给服务端即可。
<p>有了数据,接下来就是网站的代码实现,以及如何抓取数据了。爬虫的代码:#include#include#includeusingnamespacestd;constintmaxpage=10;//一页的长度#includeintmain(){void*path;stringfilename;charcontent[]="/";charcontent[]="\n";string[]arrays;present_content(path);filename=0;file_tindex;charlines[]=path.size();char[]next;for(index=0;index
文章采集调用(通过SpringBootActuatorWebAPI监控应用状态actuatorWeb)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-04-09 18:42
环境需求案例:通过 Spring Boot Actuator Web API 监控应用状态
执行器提供了一个健康端点,用于获取有关应用程序健康的详细信息。
官方文档地址:#health
URL地址是:
/执行器/健康
返回结果(JSON数据格式):
{
"status": "UP",
"components": {
"custom": {
"status": "UP",
"details": {
"app": "Alive and Kicking",
"error": "Nothing! I'm good."
}
},
"diskSpace": {
"status": "UP",
"details": {
"total": 52776349696,
"free": 43368595456,
"threshold": 10485760
}
},
"ping": {
"status": "UP"
}
}
}
配置监控项
建议使用Zabbix的主监控项+从属监控项(相关项)实现采集一次多个数据调用,减少API调用次数。
第一步:创建主监控项
创建监控项,修改如下配置:
如果API接口需要认证,可以设置HTTP认证。使用宏变量支持用户名和密码。
配置完成后,点击下方测试,点击获取值并测试,查看是否可以正确获取数据。
第二步:创建依赖监控项(相关项)
假设您需要监控应用程序的状态和磁盘的剩余空间。
指标 1:监控应用程序状态
JSONPath语法说明参考官方文档:
创建监控项,修改如下配置:
将步骤添加到“进程”选项卡:
点击下面的Test all steps来验证配置,在value中填入主监控项test获取的数据,点击Test查看是否可以正确获取数据。
指标 2:监控磁盘剩余空间
创建监控项,修改如下配置:
将步骤添加到“进程”选项卡:
点击下面的Test all steps来验证配置,在value中填入主监控项test获取的数据,点击Test查看是否可以正确获取数据。
检查最新数据是否正常采集
注:依赖监控项(相关项)的数据更新周期由主监控项设置的更新周期决定
至此,监控项的配置已经完成,接下来就可以根据实际情况配置相应的触发器了。
配置模板时,可以将主监控项中的URL配置为宏宏变量,例如:{$HOST}:{$PORT}/actuator/health,这样可以在链接时为不同的主机设置宏变量模板(用户名和密码也可以这样配置)。 查看全部
文章采集调用(通过SpringBootActuatorWebAPI监控应用状态actuatorWeb)
环境需求案例:通过 Spring Boot Actuator Web API 监控应用状态
执行器提供了一个健康端点,用于获取有关应用程序健康的详细信息。
官方文档地址:#health
URL地址是:
/执行器/健康
返回结果(JSON数据格式):
{
"status": "UP",
"components": {
"custom": {
"status": "UP",
"details": {
"app": "Alive and Kicking",
"error": "Nothing! I'm good."
}
},
"diskSpace": {
"status": "UP",
"details": {
"total": 52776349696,
"free": 43368595456,
"threshold": 10485760
}
},
"ping": {
"status": "UP"
}
}
}
配置监控项
建议使用Zabbix的主监控项+从属监控项(相关项)实现采集一次多个数据调用,减少API调用次数。
第一步:创建主监控项
创建监控项,修改如下配置:
如果API接口需要认证,可以设置HTTP认证。使用宏变量支持用户名和密码。
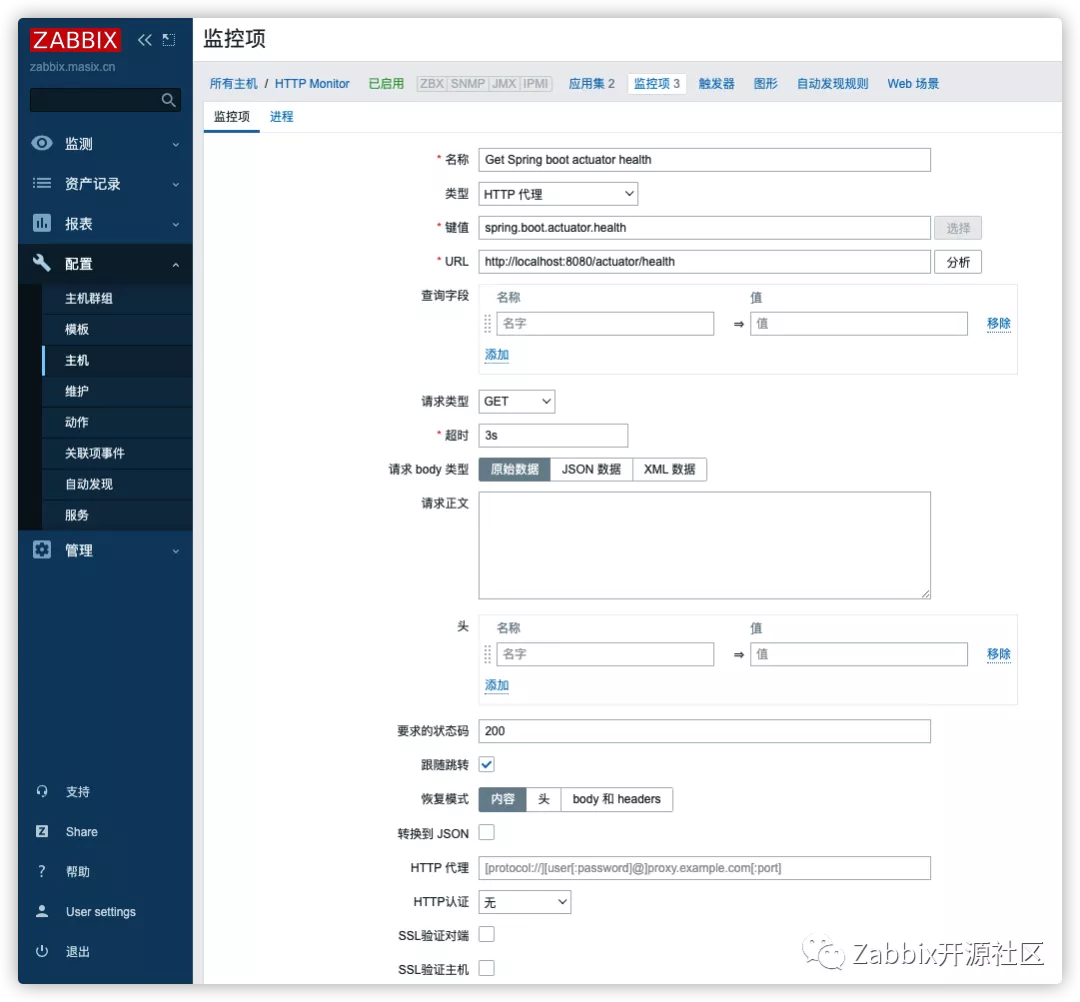
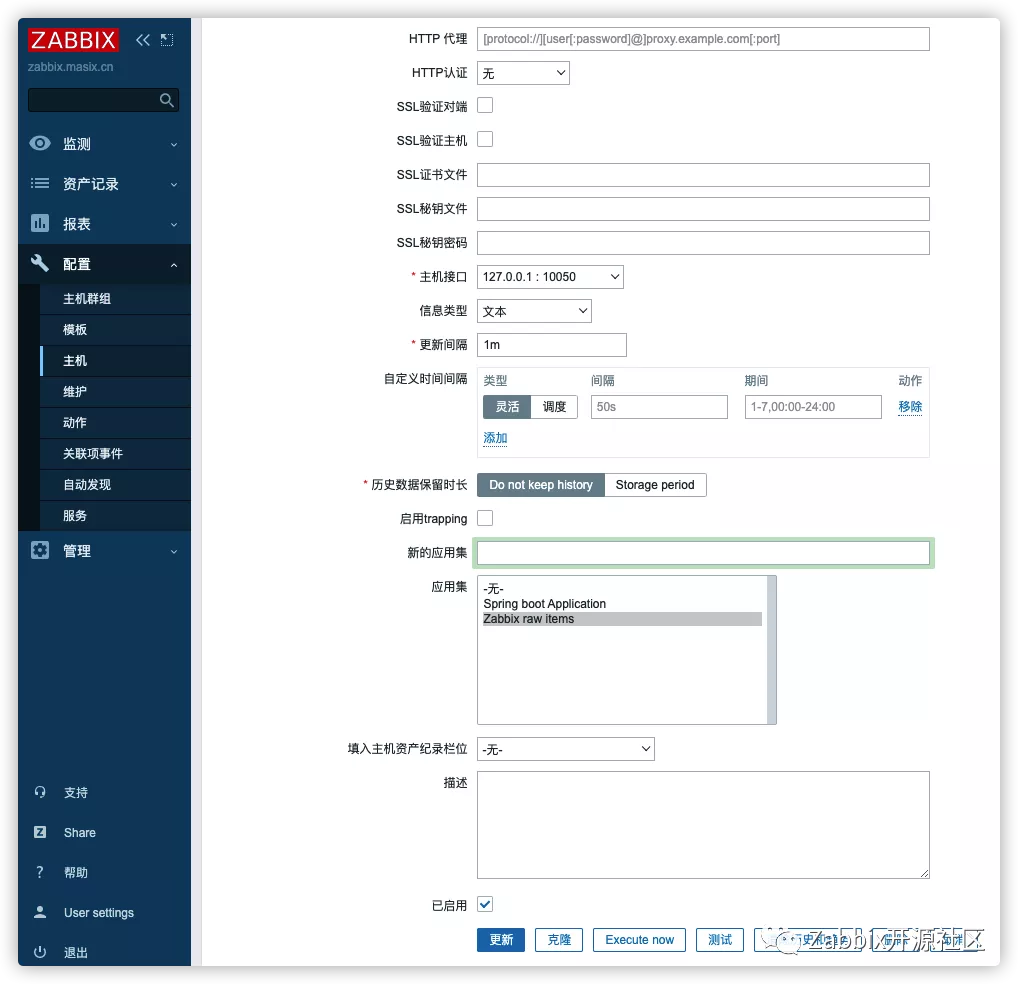
配置完成后,点击下方测试,点击获取值并测试,查看是否可以正确获取数据。
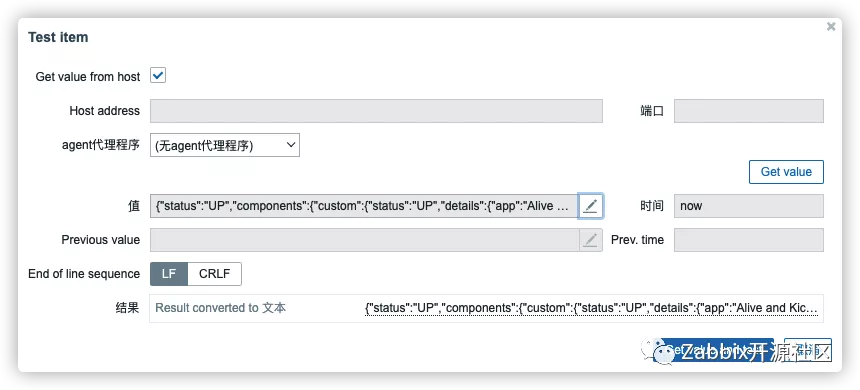
第二步:创建依赖监控项(相关项)
假设您需要监控应用程序的状态和磁盘的剩余空间。
指标 1:监控应用程序状态
JSONPath语法说明参考官方文档:
创建监控项,修改如下配置:
将步骤添加到“进程”选项卡:
点击下面的Test all steps来验证配置,在value中填入主监控项test获取的数据,点击Test查看是否可以正确获取数据。
指标 2:监控磁盘剩余空间
创建监控项,修改如下配置:
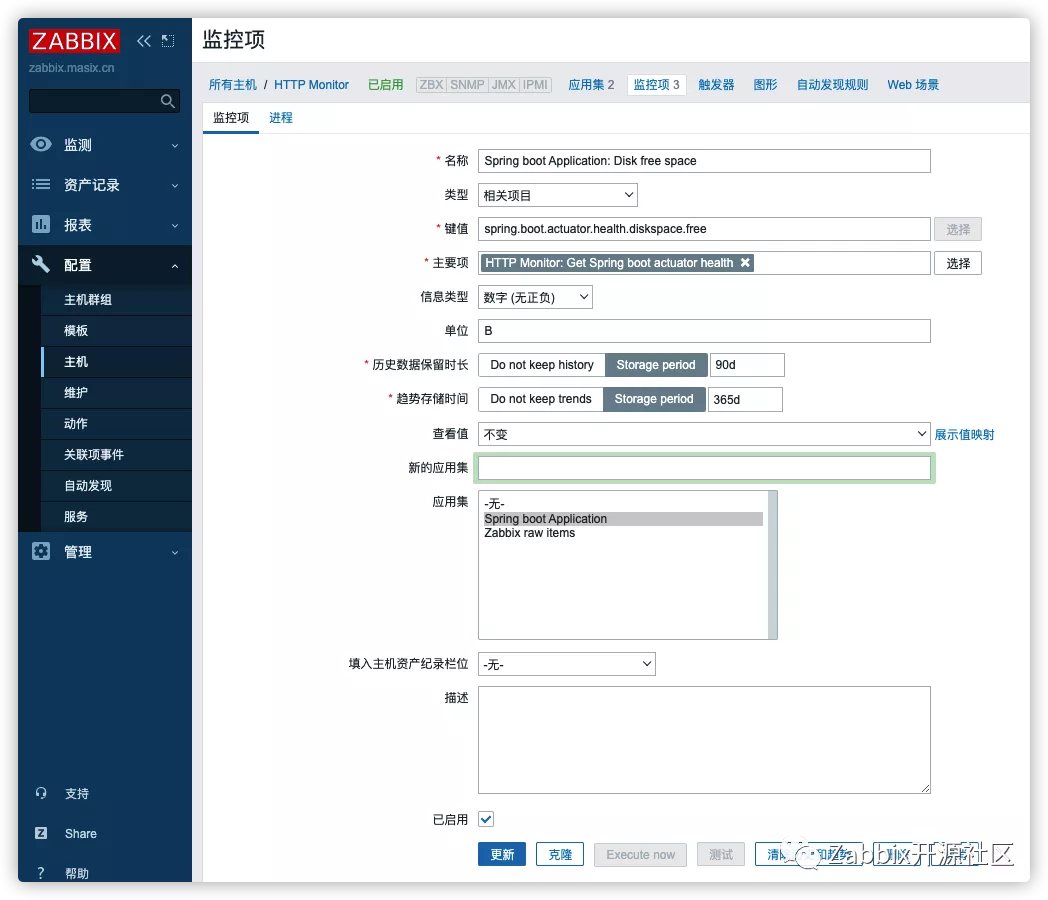
将步骤添加到“进程”选项卡:
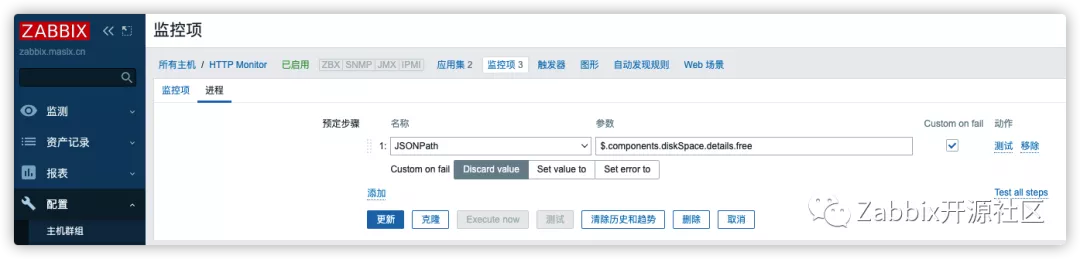
点击下面的Test all steps来验证配置,在value中填入主监控项test获取的数据,点击Test查看是否可以正确获取数据。
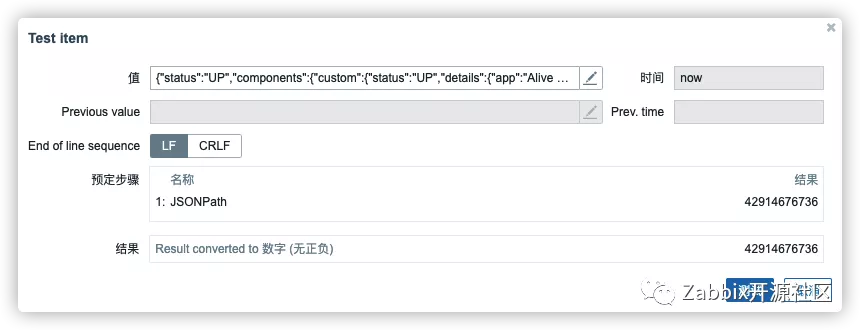
检查最新数据是否正常采集
注:依赖监控项(相关项)的数据更新周期由主监控项设置的更新周期决定
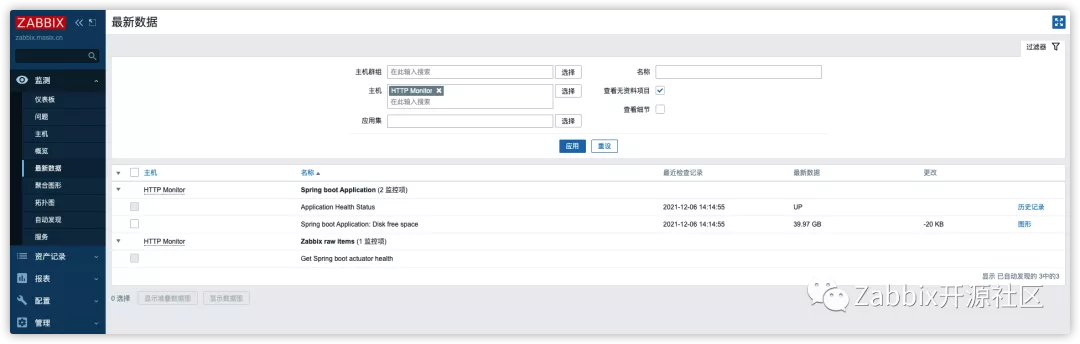
至此,监控项的配置已经完成,接下来就可以根据实际情况配置相应的触发器了。
配置模板时,可以将主监控项中的URL配置为宏宏变量,例如:{$HOST}:{$PORT}/actuator/health,这样可以在链接时为不同的主机设置宏变量模板(用户名和密码也可以这样配置)。
文章采集调用 Java 中拼接 String 的 N 种方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2022-05-01 09:32
1. 前言
Java 提供了拼接 String 字符串的多种方式,不过有时候如果我们不注意 null 字符串的话,可能会把 null 拼接到结果当中,很明显这不是我们想要的。
在这篇文章中,将介绍一些在拼接 String 时避免 null 值的几种方式。
2. 问题复现
如果我们想要拼接 String 数组,可以简单的使用 + 运算符进行拼接,但是可能会遇到 null 值。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />String result = "";<br /><br />for (String value : values) {<br /> result = result + value;<br />}<br />
这会将所有元素拼接到结果字符串中,如下所示:
https://www.wdbyte.comnull<br />
但是,我们已经发现问题了,最后的 null 值作为字符串也拼接了下来,这显然不是我们想要的。
同样,即使我们在 Java 8 或更高版本上运行,然后使用String.join() 静态方法拼接字符串,一样会得到带有 null 值的输出。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />String result = String.join("", values);<br />// output: https://www.wdbyte.comnull<br />
下面看看一些可以避免 null 值被拼接下来的方法,我的期待的输出结果应该是:
https://www.wdbyte.com<br />
3. 使用 + 运算符
加法符号 + 可以拼接 String 字符串,那么我们只需要在拼接时进行 null 判断就可以把 null 值替换为空字符串了。
for (String value : values) {<br /> result = result + (value == null ? "" : value);<br />}<br />
然而,我们知道 String 是一个不可变对象,使用 + 号会频繁的创建字符串对象,每次都会在内存中创建一个新的字符串,所以使用 + 符号来拼接字符串的性能消耗是很高的。
为了方便后续的代码演示,我们抽取一个可以传入字符串,返回一个非 null 字符串的方法。
public String nullToString(String value) {<br /> return value == null ? "" : value;<br />}<br />
因此上面的代码可以改为调用这个方法:
for (String value : values) {<br /> result = result + nullToString(value);<br />}<br />
4. 使用 String.concat()
String.concat() 是 String 类自带的一个方法,使用这种方式拼接字符串十分方便。
for (String value : values) {<br /> result = result.concat(getNonNullString(value));<br />}<br />
因为调用了 nullToString() 方法,因此得到的结果中没有 null 值。
5. 使用 StringBuilder
StringBuilder 类提供了很多有用且方便的 String 构建方法。其中比较常用的是 append() 方法,使用 append() 来拼接字符串,同时结合 nullToString() 方法来避免 null 值。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />StringBuilder result = new StringBuilder();<br />for (String value : values) {<br /> result = result.append(nullToString(value));<br />}<br />
可以得到如下结果:
https://www.wdbyte.com<br />
6. 使用 StringJoiner 类 (Java 8+)
StringJoiner 类提供了更强大的字符串拼接功能,不仅可以指定拼接时的分隔符,还可以指定拼接时的前缀和后缀,这里我们可以使用它的 add()方法来拼接字符串。
同样的会用 nullToString() 方法来避免 null 值。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />StringJoiner result = new StringJoiner("");<br />for (String value : values) {<br /> result = result.add(nullToString(value));<br />}<br />
7. 使用 Streams.filter (Java 8+)
Stream API 是 Java 8 引入的功能强大的流式操作类,可以进行常见的过滤、映射、遍历、分组、统计等操作。其中的过滤操作 filter 可以接收一个 Predicate 函数,Predicate 函数接口同之前介绍的 Function (opens new window)接口一样,是一个函数式接口,它可以接受一个泛型 参数,返回值为布尔类型,Predicate 常用于数据过滤。
因此,我们可以定义一个Predicate 来检查为 null 的字符串,然后传递给 Stream API 的 filter() 方法。
最后再使用 Collectors.joining() 方法拼接剩余的非 null 字符串。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />String result = Arrays.stream(values)<br /> .filter(Objects::nonNull)<br /> .collect(Collectors.joining());<br />
8. 总结
这篇文章介绍了拼接非 null 字符串的几种方式,不同的方式可能适合不同的场景,不过要注意拼接String 字符串是一项昂贵的操作,下面是使用 JMH 对几种拼接方式进行基准测试的结果。
Benchmark Mode Cnt Score Error Units<br />StringConcat.operateAdd thrpt 25 13635005.992 ± 549759.774 ops/s<br />StringConcat.String.concat thrpt 25 7465193.417 ± 667928.552 ops/s<br />StringConcat.StringBuilder thrpt 25 13949781.608 ± 142001.421 ops/s<br />StringConcat.StringJoiner thrpt 25 9502405.473 ± 211977.433 ops/s<br />StringConcat.StreamFilter thrpt 25 8998396.107 ± 649033.722 ops/s<br />
可以看到 StringBuilder 的性能是最好的,实际使用时要结合具体场景,然后选择最低的性能开销方式。
<p data-darkmode-bgcolor="rgb(36, 36, 36)" data-darkmode-original-bgcolor="rgb(255, 255, 255)" data-darkmode-color="rgb(106, 104, 111)" data-darkmode-original-color="rgb(106, 104, 111)" data-darkmode-bgcolor-15923650965579="rgb(36, 36, 36)" data-darkmode-original-bgcolor-15923650965579="rgb(255, 255, 255)" data-darkmode-color-15923650965579="rgb(106, 104, 111)" data-darkmode-original-color-15923650965579="rgb(106, 104, 111)" style="margin-right: 0em;margin-left: 0em;outline: 0px;color: rgb(106, 104, 111);">1. SQL优化万能公式:5 大步骤 + 10 个案例
2. 大型 SaaS 平台产品架构设计
3. Spring Cloud 分布式日志采集方案,建议收藏!
4. POI 导出 Excel:字体颜色、行列自适应、锁住、合并单元格、一文搞定……
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。</p>
<p data-tool="mdnice编辑器" style="margin-top: 10px;margin-bottom: 10px;padding-top: 8px;padding-bottom: 8px;outline: 0px;white-space: normal;font-family: -apple-system, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-align: right;line-height: 1.6;color: rgb(63, 63, 63);">PS:因公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。
点“在看”支持小哈呀,谢谢啦<strong style="outline: 0px;font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;color: rgb(0, 128, 255);font-size: 15px;"></strong></p> 查看全部
文章采集调用 Java 中拼接 String 的 N 种方式
1. 前言
Java 提供了拼接 String 字符串的多种方式,不过有时候如果我们不注意 null 字符串的话,可能会把 null 拼接到结果当中,很明显这不是我们想要的。
在这篇文章中,将介绍一些在拼接 String 时避免 null 值的几种方式。
2. 问题复现
如果我们想要拼接 String 数组,可以简单的使用 + 运算符进行拼接,但是可能会遇到 null 值。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />String result = "";<br /><br />for (String value : values) {<br /> result = result + value;<br />}<br />
这会将所有元素拼接到结果字符串中,如下所示:
https://www.wdbyte.comnull<br />
但是,我们已经发现问题了,最后的 null 值作为字符串也拼接了下来,这显然不是我们想要的。
同样,即使我们在 Java 8 或更高版本上运行,然后使用String.join() 静态方法拼接字符串,一样会得到带有 null 值的输出。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />String result = String.join("", values);<br />// output: https://www.wdbyte.comnull<br />
下面看看一些可以避免 null 值被拼接下来的方法,我的期待的输出结果应该是:
https://www.wdbyte.com<br />
3. 使用 + 运算符
加法符号 + 可以拼接 String 字符串,那么我们只需要在拼接时进行 null 判断就可以把 null 值替换为空字符串了。
for (String value : values) {<br /> result = result + (value == null ? "" : value);<br />}<br />
然而,我们知道 String 是一个不可变对象,使用 + 号会频繁的创建字符串对象,每次都会在内存中创建一个新的字符串,所以使用 + 符号来拼接字符串的性能消耗是很高的。
为了方便后续的代码演示,我们抽取一个可以传入字符串,返回一个非 null 字符串的方法。
public String nullToString(String value) {<br /> return value == null ? "" : value;<br />}<br />
因此上面的代码可以改为调用这个方法:
for (String value : values) {<br /> result = result + nullToString(value);<br />}<br />
4. 使用 String.concat()
String.concat() 是 String 类自带的一个方法,使用这种方式拼接字符串十分方便。
for (String value : values) {<br /> result = result.concat(getNonNullString(value));<br />}<br />
因为调用了 nullToString() 方法,因此得到的结果中没有 null 值。
5. 使用 StringBuilder
StringBuilder 类提供了很多有用且方便的 String 构建方法。其中比较常用的是 append() 方法,使用 append() 来拼接字符串,同时结合 nullToString() 方法来避免 null 值。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />StringBuilder result = new StringBuilder();<br />for (String value : values) {<br /> result = result.append(nullToString(value));<br />}<br />
可以得到如下结果:
https://www.wdbyte.com<br />
6. 使用 StringJoiner 类 (Java 8+)
StringJoiner 类提供了更强大的字符串拼接功能,不仅可以指定拼接时的分隔符,还可以指定拼接时的前缀和后缀,这里我们可以使用它的 add()方法来拼接字符串。
同样的会用 nullToString() 方法来避免 null 值。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />StringJoiner result = new StringJoiner("");<br />for (String value : values) {<br /> result = result.add(nullToString(value));<br />}<br />
7. 使用 Streams.filter (Java 8+)
Stream API 是 Java 8 引入的功能强大的流式操作类,可以进行常见的过滤、映射、遍历、分组、统计等操作。其中的过滤操作 filter 可以接收一个 Predicate 函数,Predicate 函数接口同之前介绍的 Function (opens new window)接口一样,是一个函数式接口,它可以接受一个泛型 参数,返回值为布尔类型,Predicate 常用于数据过滤。
因此,我们可以定义一个Predicate 来检查为 null 的字符串,然后传递给 Stream API 的 filter() 方法。
最后再使用 Collectors.joining() 方法拼接剩余的非 null 字符串。
String[] values = {"https", "://", "www.", "wdbyte", ".com", null};<br />String result = Arrays.stream(values)<br /> .filter(Objects::nonNull)<br /> .collect(Collectors.joining());<br />
8. 总结
这篇文章介绍了拼接非 null 字符串的几种方式,不同的方式可能适合不同的场景,不过要注意拼接String 字符串是一项昂贵的操作,下面是使用 JMH 对几种拼接方式进行基准测试的结果。
Benchmark Mode Cnt Score Error Units<br />StringConcat.operateAdd thrpt 25 13635005.992 ± 549759.774 ops/s<br />StringConcat.String.concat thrpt 25 7465193.417 ± 667928.552 ops/s<br />StringConcat.StringBuilder thrpt 25 13949781.608 ± 142001.421 ops/s<br />StringConcat.StringJoiner thrpt 25 9502405.473 ± 211977.433 ops/s<br />StringConcat.StreamFilter thrpt 25 8998396.107 ± 649033.722 ops/s<br />
可以看到 StringBuilder 的性能是最好的,实际使用时要结合具体场景,然后选择最低的性能开销方式。
2. 大型 SaaS 平台产品架构设计
3. Spring Cloud 分布式日志采集方案,建议收藏!
4. POI 导出 Excel:字体颜色、行列自适应、锁住、合并单元格、一文搞定……
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。</p>
<p data-tool="mdnice编辑器" style="margin-top: 10px;margin-bottom: 10px;padding-top: 8px;padding-bottom: 8px;outline: 0px;white-space: normal;font-family: -apple-system, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;text-align: right;line-height: 1.6;color: rgb(63, 63, 63);">PS:因公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。
点“在看”支持小哈呀,谢谢啦<strong style="outline: 0px;font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;color: rgb(0, 128, 255);font-size: 15px;"></strong></p>
数据治理 | 数据分析与清洗工具:Pandas 数据类型转换(赠送本文同款数据!
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-05-01 09:11
Part1前言上期文章中,我们介绍了数据中的各种类型的缺失值以及如何处理这些缺失值;同时也介绍了常见的数据重复问题并奉上了处理重复数据的方法。这些处理方法对大家的数据治理、数据分析工作都有着至关重要的作用。本期文章将会继续学习 Pandas 工具,学习如何转换数据类型。读完本文后,灵活转换数据类型将不再是问题!本文中所有 Python 代码均在集成开发环境 Visual Studio Code (VScode) 中使用交互式开发环境 Jupyter Notebook 编写。Part2为什么需要做数据类型转换数据的含义与数据的类型是息息相关的,正确的数据类型能够支撑数据含义的正确表示。当一些数据的类型出现错乱时,它们的含义也会变得“诡异”。请看下面几个例子:
错误示范
正确示范
原因解析
今年是 2022.0年
今年是 2022 年
2022 作为一个年份时,应该保存为整数型或者字符型,而不是浮点型(小数型)数字 2022.0
圆周率保留两位小数的结果是3
圆周率保留两位小数的结果是 3.14
圆周率保留两位小数应该是浮点数 3.14,如果转为整数型,其结果就会是 3
1 + 1 = 11
1 + 1 = 2
1 + 1 = 11 实际上是字符串拼接,即 '1' + '1' 得到了 '11'
[0, 1, 2] 的第一个元素是[
[0, 1, 2] 的第一个元素是 0
列表 [0, 1, 2] 被保存为字符型,它的真面目是 "[0, 1, 2]",这个字符串的第一个元素是 '[' 而不是 0
我们早已经知道,Python 中字符串是用英文引号引起来的,就像是 'Python',"Python"。你可能会觉得,既然如此,数字型数据和字符型数据不就不容易搞混了吗?例如,数字 2022 和 字符串 "2022" ,很容易就能区分。然而,实际的情况却是,容易搞混,很容易搞混!这是因为在 Pandas 中,所有字符数据前后的引号都不会显示出来,如果显示出了引号,那么这些引号也是字符串中的字符。所以使用 Pandas 处理数据,为了避免类似的情况出现,学习数据类型转换是非常有必要的。Part3类型转换大多数时候,数据中不同字段的数据类型是不一定全都一样;同一个字段中,数据的类型是一般是一致的。所以进行数据类型转换时不需要一个一个对数据值做类型转换,直接操作一个字段会更加方便。我们使用本期赠送的数据作为介绍 Pandas 的示例数据,使用 Excel 打开数据【5G 产业全国各省市分年度专利申请、专利授权情况(2000-2019.9).xlsx】,如下图所示:
赠送的数据中没有缺失值,其中值为数字的字段在 Excel 中是数字类型;我们使用 Pandas 读取 Excel 或者 csv 数据时,系统会自动地将每个字段读取为合适的数据类型。如果需要自定义一些(或者所有)字段的类型,我们也可以自己指定每个字段的数据类型(数据必须满足指定类型的格式,例如我们不可以将 “省份名” 字段设置为 整数型)。使用 Pandas 读取这个 Excel 数据,代码和输出如下:
# 数据存储的路径<br />path = './5G 产业全国各省市分年度专利申请、专利授权情况(2000-2019.9).xlsx'<br /># 这里指定字段的数据类型<br />columns_type = {'年份':'str', <br /> '省份名':'str', <br /> '省份行政代码':'int', <br /> '专利申请':'int', <br /> '专利授权':'int', <br /> '专利类型':'str'}<br /># dtype 参数用于指定字段的类型,如果不需要特意指定字段的类型,不使用 dtype 参数即可<br />data = pd.read_excel(path, dtype=columns_type)<br />data<br />
读取数据后我们使用 Pandas 中的相关方法生成一个新的列,这一列中的数据是一个包含专利申请、专利授权和专利类型的列表。操作代码和新生成的数据如下:
# 根据专利申请、专利授权和专利类型三个字段得到一个新字段<br />data['列表'] = data.apply(lambda X: [X['专利申请'], X['专利授权'], X['专利类型']] ,axis=1)<br />data<br />
将新生成的数据保存为 csv 文件后再读取,读取时我们故意将部分字段读取为错误的类型,随后使用错误的数据来给大家演示如何进行数据类型的转换。
# 将刚刚新生成的数据保存为 csv 文件<br /># 参数 index=False 的含义是,不讲数据索引写入 csv 文件中<br />data.to_csv('新数据.csv', index=False)<br /><br /># 使用错误的字段类型重新读取数据<br /># 我们将年份读取为浮点型(小数型),将专利申请读取为字符型<br />wrong_type = {'年份':'float', <br /> '专利申请':'str'}<br />DATA = pd.read_csv('新数据.csv', dtype=wrong_type)<br /><br /># 查看专利申请字段类型<br />print(DATA.专利申请.dtype) # 输出:object,说明该字段含有字符型数据<br />DATA<br />
可以看到,“年份” 字段中所有的年份都变为小数型;通过代码也判断出 “专利申请” 字段不再是整数型,而是字符型,因为 DataFrame 中的字符型数据不会显示两端的引号,所以无法目测其类型。那么这种内容为数字的字符型数据会给我们什么麻烦呢?假设我们需要使用 专利授权/ 专利申请 来计算专利授权率时 ,会发现整数和字符之间无法运算。如果这两个字段中的值的都是字符型,那么两者只能进行加法运算,例如:“45” + “8” == “458”,这恐怕更不是我们想要的结果。接下来我们使用数据类型转换的方法来纠正这些错误的数据。1使用 astype() 转换基本类型Pandas 专门为类型转换提供了一个 astype() 方法,这个方法可以将数据类型转换为希望的类型,既可以操作 Series,又可以操作 DataFrame,使用时只需要传入转换后的类型即可。我们在往期的文章中提到过,Pandas 中绝大多数涉及到数据修改的方法,他们都不会直接修改原始的数据,而是返回一个新的数据。astype()也是一样的,默认返回一个新的数据。场景 1:将数据中的年份字段转换为整数型
# 将字段类型由浮点型(小数型)转换为整数型 int<br /># 返回一个新数据,调用该方法的是一个 Series,返回值也将是一个 Series<br />DATA['年份'].astype(int)<br />
希望类型转换操作在原始数据中生效可以使用下面的代码。
# 将新生的数据重新赋值给原始数据即可<br /># 赋值操作不会返回任何值<br />DATA['年份'] = DATA['年份'].astype(int)<br /># 输出查看转换后的数据<br />DATA<br />
场景 2:将数据中所有内容转换为字符型数据,转换后的数据命名为ALL_STR
# 将类型转换为字符型数据后的新数据命名为 ALL_STR<br />ALL_STR = DATA.astype(str)<br /># 查看新数据的信息<br />ALL_STR.info()<br />
所有的字段类型都变为 object,说明所有字段中都含有字符型数据,操作生效。另外,当字段中存在无法转换的数据值时,可以指定参数 errors='ignore' 来忽略无法转换的数据值。假如我们希望将所有字段都转换为浮点型(小数型),但是字符型数据 “北京” 、“45”、“发明专利” 等字符型数据无法转换为浮点型,我们则可以使用下面的代码来转换可以转换的字段:
# 指定参数 errors='ignore',忽略无法转换的数据值<br />DATA.astype(float, errors='ignore')<br />
可以看到,除了一些字符型数据之外,其他的数字类型数据都被转换为浮点型(小数型)数据。同样地,如果不进行赋值操作,那么就会返回一个新的数据,而原始数据不会发生变化。2使用 eval() 转换特殊类型astype() 方法多用于浮点型 float、整数型 int 和 字符型 str 的转换操作。当涉及到字符型转化为列表,字典等 Python 的组合数据类型时,则需要使用 Python 自带的方法 eval() 。该函数可以去掉字符串最外侧的引号,并按照 Python 语句方式执行去掉引号后的字符内容。下面我们举例介绍一下 eval() 的用法。
# 对字符串 '12' 做转换<br />eval('12') # 得到整数:12<br /><br /># 对字符串 '12.5' 做转换<br />eval('12.5') # 得到浮点数:12.5<br /><br /># 对字符串 '12+5' 做转换<br />eval('12+5') # 得到整数:17<br /><br /># 定义变量 a 后对字符串 'a' 做转换<br />a = '20'<br />eval('a') # 得到 a 的值:20<br /><br /># 对字符串 "[11,12,'列表元素']" 做转换<br />eval("[11,12,'列表元素']") # 得到列表:[11, 12, '列表元素']<br /><br /># 定义变量 m,n 后对字符串 '[m,n,m-50]' 做转换<br />m=100<br />n='某个字符串'<br />eval("[m,n,m-50]") # 得到列表:[100, '某个字符串', 50]<br />
根据上面的例子可以看出,eval() 确实可以去掉字符串最外侧的引号,并按照 Python 语句方式执行去掉引号后的字符内容。这个方法不仅可以转换列表形式的字符串,对诸如字典、元组以及集合等 Python 数据类型形式的字符串,该方法依然可用。场景 3:将数据中“列表”字段转换为 Python 列表类型由于 eval() 方法操作的是字符串对象,一次只接受一个需要转化的对象,当需要使用它来对 DataFrame 的一整个字段做转换操作时,需要借助循环或者其他的 Pandas 方法。
# 输出查看转换之前"列表"字段最后一个值的类型,原始的类型为 str 型<br />print(type(DATA['列表'].values[-1]))<br /># 输出:,确认是字符型<br /><br /># 方法 1:借助 for 循环<br />for i in DATA.index:<br /> # 遍历数据的索引<br /> # 根据索引找到待转换的数据<br /> Target = DATA.loc[i,'列表']<br /> # 将转换后的数据重新赋值给原来位置的数据值<br /> DATA['列表'][i] = eval(Target)<br /> <br /># 输出查看"列表"字段最后一个值的类型,若为列表,说明转换成功<br />print(type(DATA['列表'].values[-1]))<br /># 输出:,转换成功<br /><br /># 方法 2:借助 Pandas 方法 map()。不再输出查看类型<br />DATA['列表'] = DATA['列表'].map(eval)<br /><br /># 方法 3:借助 Pandas 方法 apply()。不再输出查看类型<br />DATA['列表'] = DATA['列表'].apply(eval)<br />
后面两种方法可以实现 方法 1 同样的效果,且代码量更少。Part4总结本期文章中,我们介绍了数据类型错误带来的影响,同时也介绍了转换字段数据类型的方法。使用类型转换方法可以在基本的数据类型之间进行合理的转换。同时也介绍了转换特殊数据类型的方法。学习这些可以让我们灵活地转换数据的类型,避免类型错乱带来的麻烦。在最后的 场景3中,我们使用了map() 和 apply() 两个方法,使用更少的代码完成了同样的功能。下期文章我们将会继续介绍 Pandas,学习如何使用以上两种方法来根据已有的数据生成新的数据列(数据列衍生)。
查看全部
数据治理 | 数据分析与清洗工具:Pandas 数据类型转换(赠送本文同款数据!
Part1前言上期文章中,我们介绍了数据中的各种类型的缺失值以及如何处理这些缺失值;同时也介绍了常见的数据重复问题并奉上了处理重复数据的方法。这些处理方法对大家的数据治理、数据分析工作都有着至关重要的作用。本期文章将会继续学习 Pandas 工具,学习如何转换数据类型。读完本文后,灵活转换数据类型将不再是问题!本文中所有 Python 代码均在集成开发环境 Visual Studio Code (VScode) 中使用交互式开发环境 Jupyter Notebook 编写。Part2为什么需要做数据类型转换数据的含义与数据的类型是息息相关的,正确的数据类型能够支撑数据含义的正确表示。当一些数据的类型出现错乱时,它们的含义也会变得“诡异”。请看下面几个例子:
错误示范
正确示范
原因解析
今年是 2022.0年
今年是 2022 年
2022 作为一个年份时,应该保存为整数型或者字符型,而不是浮点型(小数型)数字 2022.0
圆周率保留两位小数的结果是3
圆周率保留两位小数的结果是 3.14
圆周率保留两位小数应该是浮点数 3.14,如果转为整数型,其结果就会是 3
1 + 1 = 11
1 + 1 = 2
1 + 1 = 11 实际上是字符串拼接,即 '1' + '1' 得到了 '11'
[0, 1, 2] 的第一个元素是[
[0, 1, 2] 的第一个元素是 0
列表 [0, 1, 2] 被保存为字符型,它的真面目是 "[0, 1, 2]",这个字符串的第一个元素是 '[' 而不是 0
我们早已经知道,Python 中字符串是用英文引号引起来的,就像是 'Python',"Python"。你可能会觉得,既然如此,数字型数据和字符型数据不就不容易搞混了吗?例如,数字 2022 和 字符串 "2022" ,很容易就能区分。然而,实际的情况却是,容易搞混,很容易搞混!这是因为在 Pandas 中,所有字符数据前后的引号都不会显示出来,如果显示出了引号,那么这些引号也是字符串中的字符。所以使用 Pandas 处理数据,为了避免类似的情况出现,学习数据类型转换是非常有必要的。Part3类型转换大多数时候,数据中不同字段的数据类型是不一定全都一样;同一个字段中,数据的类型是一般是一致的。所以进行数据类型转换时不需要一个一个对数据值做类型转换,直接操作一个字段会更加方便。我们使用本期赠送的数据作为介绍 Pandas 的示例数据,使用 Excel 打开数据【5G 产业全国各省市分年度专利申请、专利授权情况(2000-2019.9).xlsx】,如下图所示:
赠送的数据中没有缺失值,其中值为数字的字段在 Excel 中是数字类型;我们使用 Pandas 读取 Excel 或者 csv 数据时,系统会自动地将每个字段读取为合适的数据类型。如果需要自定义一些(或者所有)字段的类型,我们也可以自己指定每个字段的数据类型(数据必须满足指定类型的格式,例如我们不可以将 “省份名” 字段设置为 整数型)。使用 Pandas 读取这个 Excel 数据,代码和输出如下:
# 数据存储的路径<br />path = './5G 产业全国各省市分年度专利申请、专利授权情况(2000-2019.9).xlsx'<br /># 这里指定字段的数据类型<br />columns_type = {'年份':'str', <br /> '省份名':'str', <br /> '省份行政代码':'int', <br /> '专利申请':'int', <br /> '专利授权':'int', <br /> '专利类型':'str'}<br /># dtype 参数用于指定字段的类型,如果不需要特意指定字段的类型,不使用 dtype 参数即可<br />data = pd.read_excel(path, dtype=columns_type)<br />data<br />
读取数据后我们使用 Pandas 中的相关方法生成一个新的列,这一列中的数据是一个包含专利申请、专利授权和专利类型的列表。操作代码和新生成的数据如下:
# 根据专利申请、专利授权和专利类型三个字段得到一个新字段<br />data['列表'] = data.apply(lambda X: [X['专利申请'], X['专利授权'], X['专利类型']] ,axis=1)<br />data<br />
将新生成的数据保存为 csv 文件后再读取,读取时我们故意将部分字段读取为错误的类型,随后使用错误的数据来给大家演示如何进行数据类型的转换。
# 将刚刚新生成的数据保存为 csv 文件<br /># 参数 index=False 的含义是,不讲数据索引写入 csv 文件中<br />data.to_csv('新数据.csv', index=False)<br /><br /># 使用错误的字段类型重新读取数据<br /># 我们将年份读取为浮点型(小数型),将专利申请读取为字符型<br />wrong_type = {'年份':'float', <br /> '专利申请':'str'}<br />DATA = pd.read_csv('新数据.csv', dtype=wrong_type)<br /><br /># 查看专利申请字段类型<br />print(DATA.专利申请.dtype) # 输出:object,说明该字段含有字符型数据<br />DATA<br />
可以看到,“年份” 字段中所有的年份都变为小数型;通过代码也判断出 “专利申请” 字段不再是整数型,而是字符型,因为 DataFrame 中的字符型数据不会显示两端的引号,所以无法目测其类型。那么这种内容为数字的字符型数据会给我们什么麻烦呢?假设我们需要使用 专利授权/ 专利申请 来计算专利授权率时 ,会发现整数和字符之间无法运算。如果这两个字段中的值的都是字符型,那么两者只能进行加法运算,例如:“45” + “8” == “458”,这恐怕更不是我们想要的结果。接下来我们使用数据类型转换的方法来纠正这些错误的数据。1使用 astype() 转换基本类型Pandas 专门为类型转换提供了一个 astype() 方法,这个方法可以将数据类型转换为希望的类型,既可以操作 Series,又可以操作 DataFrame,使用时只需要传入转换后的类型即可。我们在往期的文章中提到过,Pandas 中绝大多数涉及到数据修改的方法,他们都不会直接修改原始的数据,而是返回一个新的数据。astype()也是一样的,默认返回一个新的数据。场景 1:将数据中的年份字段转换为整数型
# 将字段类型由浮点型(小数型)转换为整数型 int<br /># 返回一个新数据,调用该方法的是一个 Series,返回值也将是一个 Series<br />DATA['年份'].astype(int)<br />
希望类型转换操作在原始数据中生效可以使用下面的代码。
# 将新生的数据重新赋值给原始数据即可<br /># 赋值操作不会返回任何值<br />DATA['年份'] = DATA['年份'].astype(int)<br /># 输出查看转换后的数据<br />DATA<br />
场景 2:将数据中所有内容转换为字符型数据,转换后的数据命名为ALL_STR
# 将类型转换为字符型数据后的新数据命名为 ALL_STR<br />ALL_STR = DATA.astype(str)<br /># 查看新数据的信息<br />ALL_STR.info()<br />
所有的字段类型都变为 object,说明所有字段中都含有字符型数据,操作生效。另外,当字段中存在无法转换的数据值时,可以指定参数 errors='ignore' 来忽略无法转换的数据值。假如我们希望将所有字段都转换为浮点型(小数型),但是字符型数据 “北京” 、“45”、“发明专利” 等字符型数据无法转换为浮点型,我们则可以使用下面的代码来转换可以转换的字段:
# 指定参数 errors='ignore',忽略无法转换的数据值<br />DATA.astype(float, errors='ignore')<br />
可以看到,除了一些字符型数据之外,其他的数字类型数据都被转换为浮点型(小数型)数据。同样地,如果不进行赋值操作,那么就会返回一个新的数据,而原始数据不会发生变化。2使用 eval() 转换特殊类型astype() 方法多用于浮点型 float、整数型 int 和 字符型 str 的转换操作。当涉及到字符型转化为列表,字典等 Python 的组合数据类型时,则需要使用 Python 自带的方法 eval() 。该函数可以去掉字符串最外侧的引号,并按照 Python 语句方式执行去掉引号后的字符内容。下面我们举例介绍一下 eval() 的用法。
# 对字符串 '12' 做转换<br />eval('12') # 得到整数:12<br /><br /># 对字符串 '12.5' 做转换<br />eval('12.5') # 得到浮点数:12.5<br /><br /># 对字符串 '12+5' 做转换<br />eval('12+5') # 得到整数:17<br /><br /># 定义变量 a 后对字符串 'a' 做转换<br />a = '20'<br />eval('a') # 得到 a 的值:20<br /><br /># 对字符串 "[11,12,'列表元素']" 做转换<br />eval("[11,12,'列表元素']") # 得到列表:[11, 12, '列表元素']<br /><br /># 定义变量 m,n 后对字符串 '[m,n,m-50]' 做转换<br />m=100<br />n='某个字符串'<br />eval("[m,n,m-50]") # 得到列表:[100, '某个字符串', 50]<br />
根据上面的例子可以看出,eval() 确实可以去掉字符串最外侧的引号,并按照 Python 语句方式执行去掉引号后的字符内容。这个方法不仅可以转换列表形式的字符串,对诸如字典、元组以及集合等 Python 数据类型形式的字符串,该方法依然可用。场景 3:将数据中“列表”字段转换为 Python 列表类型由于 eval() 方法操作的是字符串对象,一次只接受一个需要转化的对象,当需要使用它来对 DataFrame 的一整个字段做转换操作时,需要借助循环或者其他的 Pandas 方法。
# 输出查看转换之前"列表"字段最后一个值的类型,原始的类型为 str 型<br />print(type(DATA['列表'].values[-1]))<br /># 输出:,确认是字符型<br /><br /># 方法 1:借助 for 循环<br />for i in DATA.index:<br /> # 遍历数据的索引<br /> # 根据索引找到待转换的数据<br /> Target = DATA.loc[i,'列表']<br /> # 将转换后的数据重新赋值给原来位置的数据值<br /> DATA['列表'][i] = eval(Target)<br /> <br /># 输出查看"列表"字段最后一个值的类型,若为列表,说明转换成功<br />print(type(DATA['列表'].values[-1]))<br /># 输出:,转换成功<br /><br /># 方法 2:借助 Pandas 方法 map()。不再输出查看类型<br />DATA['列表'] = DATA['列表'].map(eval)<br /><br /># 方法 3:借助 Pandas 方法 apply()。不再输出查看类型<br />DATA['列表'] = DATA['列表'].apply(eval)<br />
后面两种方法可以实现 方法 1 同样的效果,且代码量更少。Part4总结本期文章中,我们介绍了数据类型错误带来的影响,同时也介绍了转换字段数据类型的方法。使用类型转换方法可以在基本的数据类型之间进行合理的转换。同时也介绍了转换特殊数据类型的方法。学习这些可以让我们灵活地转换数据的类型,避免类型错乱带来的麻烦。在最后的 场景3中,我们使用了map() 和 apply() 两个方法,使用更少的代码完成了同样的功能。下期文章我们将会继续介绍 Pandas,学习如何使用以上两种方法来根据已有的数据生成新的数据列(数据列衍生)。
Crack App | 某搜索 App 中关于 x 信文章检索功能的加密参数
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-04-30 02:25
点击上方“咸鱼学Python”,选择“加为星标”
第一时间关注Python技术干货!
图源:极简壁纸
今日目标
今天的目标是很多读者朋友在采集微信文章时常用站的 app 版本
aHR0cHM6Ly93d3cud2FuZG91amlhLmNvbS9zZWFyY2gvNjU1NTQ3NDYwMzMwMTAyMDk0MQ==
抓包分析
抓包使用的是 Charles + Postern 的组合
使用大黄鸟 app 抓包也是可以的,Charles 看着会更舒服一些
打开 app 搜索任意内容,切换到微信栏目就可以抓到以下的请求包了
点击这个请求可以看到请求参数还有请求的结果都是加密的
请求的参数是k、v、u、r、g、p的名字,所以通过参数名检索的方法很难定位到很准确的结果
静态分析定位逻辑
apk 包推荐使用 jadx 1.2 打开,用 1.3 搜索的时候老是崩溃
通过以请求链接的部分v2.get作为搜索关键词可以定位到下面的搜索结果
最后一个搜索的结果和我们的请求链接最匹配
点进去可以看到下面的内容
可以看到图中红框的部分应该是请求的部分,红框下面是返回的部分
分别经过了encrypt和decrypt两个方法
先讲讲我是怎么确定是这两个方法的
红框部分中定义了一个hashMap,通其中put了一个Content-Length,这个搞过 js 逆向的都知道,这个是代表了请求提交内容的长度
这个长度是通过encrypt.length得到的,而encrypt是通过ScEncryptWall.encrypt(str, str2, str3);得到的
而返回部分的代码是在判断了f0.b得出的,在f0.b的判断中有一关于response success的输出,进一步确认了我们的判断
所以这里的encrypt和decrypt两个方法是分析的重点
进一步追进去可以看到这两个方法都是native方法,定义在libSCoreTools.so里面
动态调试确认逻辑
既然是 native 方法,通过 IDA 分析这几个也是导出方法,这里 hook 的方法就很多了。
我们直接用frida hook看下出入参看看是不是符合我们在上一部分的猜想
先看encrypt
function hook_encrypt(){<br /> Java.perform(function () {<br /> var ScEncryptWall = Java.use('包名.类名');<br /> ScEncryptWall.encrypt.implementation = function (str1,str2,str3) {<br /> console.log('str1: ', str1);<br /> console.log('str2: ', str2);<br /> console.log('str3: ', str3);<br /> var res = this.encrypt(str1, str2, str3);<br /> console.log('res: ', res);<br /> return res;<br /> }<br /> })<br />}<br />setImmediate(hook_encrypt)<br />
通过hook可以得到以下结果
str1 = 请求的 url<br />str2 = 请求提交的参数(明文)<br />str3 = 空<br />
返回的结果就是加密好的参数了
同样的hook decrypt
function hook_decrypt(){<br /> Java.perform(function () {<br /> var ScEncryptWall = Java.use('包名.类名');<br /> ScEncryptWall.decrypt.implementation = function (data) {<br /> console.log('data: ', data);<br /> var res = this.decrypt(a);<br /> console.log('res: ', Java.use('java.lang.String').$new(res));<br /> return res;<br /> }<br /> })<br />}<br />setImmediate(hook_decrypt)<br />
打印结果如下
参数是请求的返回值,解密的结果是列表页的内容
完事~,Python RPC 调用一下就可以爽爽的采集相关的文章了 查看全部
Crack App | 某搜索 App 中关于 x 信文章检索功能的加密参数
点击上方“咸鱼学Python”,选择“加为星标”
第一时间关注Python技术干货!
图源:极简壁纸
今日目标
今天的目标是很多读者朋友在采集微信文章时常用站的 app 版本
aHR0cHM6Ly93d3cud2FuZG91amlhLmNvbS9zZWFyY2gvNjU1NTQ3NDYwMzMwMTAyMDk0MQ==
抓包分析
抓包使用的是 Charles + Postern 的组合
使用大黄鸟 app 抓包也是可以的,Charles 看着会更舒服一些
打开 app 搜索任意内容,切换到微信栏目就可以抓到以下的请求包了
点击这个请求可以看到请求参数还有请求的结果都是加密的
请求的参数是k、v、u、r、g、p的名字,所以通过参数名检索的方法很难定位到很准确的结果
静态分析定位逻辑
apk 包推荐使用 jadx 1.2 打开,用 1.3 搜索的时候老是崩溃
通过以请求链接的部分v2.get作为搜索关键词可以定位到下面的搜索结果
最后一个搜索的结果和我们的请求链接最匹配
点进去可以看到下面的内容
可以看到图中红框的部分应该是请求的部分,红框下面是返回的部分
分别经过了encrypt和decrypt两个方法
先讲讲我是怎么确定是这两个方法的
红框部分中定义了一个hashMap,通其中put了一个Content-Length,这个搞过 js 逆向的都知道,这个是代表了请求提交内容的长度
这个长度是通过encrypt.length得到的,而encrypt是通过ScEncryptWall.encrypt(str, str2, str3);得到的
而返回部分的代码是在判断了f0.b得出的,在f0.b的判断中有一关于response success的输出,进一步确认了我们的判断
所以这里的encrypt和decrypt两个方法是分析的重点
进一步追进去可以看到这两个方法都是native方法,定义在libSCoreTools.so里面
动态调试确认逻辑
既然是 native 方法,通过 IDA 分析这几个也是导出方法,这里 hook 的方法就很多了。
我们直接用frida hook看下出入参看看是不是符合我们在上一部分的猜想
先看encrypt
function hook_encrypt(){<br /> Java.perform(function () {<br /> var ScEncryptWall = Java.use('包名.类名');<br /> ScEncryptWall.encrypt.implementation = function (str1,str2,str3) {<br /> console.log('str1: ', str1);<br /> console.log('str2: ', str2);<br /> console.log('str3: ', str3);<br /> var res = this.encrypt(str1, str2, str3);<br /> console.log('res: ', res);<br /> return res;<br /> }<br /> })<br />}<br />setImmediate(hook_encrypt)<br />
通过hook可以得到以下结果
str1 = 请求的 url<br />str2 = 请求提交的参数(明文)<br />str3 = 空<br />
返回的结果就是加密好的参数了
同样的hook decrypt
function hook_decrypt(){<br /> Java.perform(function () {<br /> var ScEncryptWall = Java.use('包名.类名');<br /> ScEncryptWall.decrypt.implementation = function (data) {<br /> console.log('data: ', data);<br /> var res = this.decrypt(a);<br /> console.log('res: ', Java.use('java.lang.String').$new(res));<br /> return res;<br /> }<br /> })<br />}<br />setImmediate(hook_decrypt)<br />
打印结果如下
参数是请求的返回值,解密的结果是列表页的内容
完事~,Python RPC 调用一下就可以爽爽的采集相关的文章了
微信公众号视频批量下载软件--视频批量下载的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 386 次浏览 • 2022-04-29 14:13
大家好,这是余夫第 011篇原创文章,关注余夫持续分享实用软件和各种实用资料,第一时间获取更多的软件和资料。
注意本公众号介绍的所有下载视频的软件,视频下载的前提是你的视频必须是已经付费购买了课程或者是免费视频,只有可以正常播放才能下载。
微信公众号的视频分为两种
一种是自己上传到微信公众号里面的视频,以我自己的公众号视频为例如下图
这种就是直接上传到公众号里面的原创视频,这种视频可以直接复制链接到浏览器里面通过插件可以直接下载。
这个文章介绍的下载方法就可以实现单个下载
视频少的话可以用上面单个的一个一个的下载,那要是上百个视频就需要使用批量下载了。
这样直接就可以批量下载速度很快100个视频也就是几分钟的事。有需要下载的可以联系我代下载。
另外一种是调用的腾讯视频的链接,如下面这种就是调用腾讯视频。
这种的可以直接复制链接到浏览器里面里面去播放,选择分辨率高的来播放,idm的插件也可以直接识别到点击下载就可以了。
也可以批量采集链接复制到软件里面来下载。使用爬虫插件直接批量获取链接
直接复制链接到软件里面就可以实现批量下载了。
这样就把公众号的视频下载下来了。 音频是样的道理,文章也是可以下载,过2天讲下文章怎么下载的。 查看全部
微信公众号视频批量下载软件--视频批量下载的方法
大家好,这是余夫第 011篇原创文章,关注余夫持续分享实用软件和各种实用资料,第一时间获取更多的软件和资料。
注意本公众号介绍的所有下载视频的软件,视频下载的前提是你的视频必须是已经付费购买了课程或者是免费视频,只有可以正常播放才能下载。
微信公众号的视频分为两种
一种是自己上传到微信公众号里面的视频,以我自己的公众号视频为例如下图
这种就是直接上传到公众号里面的原创视频,这种视频可以直接复制链接到浏览器里面通过插件可以直接下载。
这个文章介绍的下载方法就可以实现单个下载
视频少的话可以用上面单个的一个一个的下载,那要是上百个视频就需要使用批量下载了。
这样直接就可以批量下载速度很快100个视频也就是几分钟的事。有需要下载的可以联系我代下载。
另外一种是调用的腾讯视频的链接,如下面这种就是调用腾讯视频。
这种的可以直接复制链接到浏览器里面里面去播放,选择分辨率高的来播放,idm的插件也可以直接识别到点击下载就可以了。
也可以批量采集链接复制到软件里面来下载。使用爬虫插件直接批量获取链接
直接复制链接到软件里面就可以实现批量下载了。
这样就把公众号的视频下载下来了。 音频是样的道理,文章也是可以下载,过2天讲下文章怎么下载的。
调用链追踪系统在伴鱼:Opentelemetry最佳实践案例分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-04-29 14:06
搭建可靠的链路追踪系统
在正式介绍前,简单交代一下背景:2015 年,在伴鱼服务端起步之时,技术团队就做出统一使用 Go 语言的决定。这个决定的影响主要体现在:
早期实践对接 Jaeger
2019 年,公司内部的微服务数量逐步增加,调用关系日趋复杂,工程师做性能分析、问题排查的难度变大。这时亟需一套调用链追踪系统帮助我们增强对服务端全貌的了解。经过调研后,我们决定采用同样基于 Go 语言搭建的、由 CNCF 孵化的项目Jaeger。当时,服务的开发和治理都尚未引入 context,不论进程内部调用还是跨进程调用,都没有上下文传递。因此早期引入调用链追踪的工作重心就落在了服务及服务治理框架的改造,包括:
部署方面:测试环境采用 all-in-one,线上环境采用 direct-to-storage 方案。整个过程前后大约耗时一个月,我们在 2019 年 Q3 上线了第一版调用链追踪系统。配合广泛被采用的 prometheus + grafana 以及 ELK,我们在微服务群的可观测性上终于凑齐了调用链 (traces)、日志 (logs) 和监控指标 (metrics) 三个要素。
下图是第一版调用链追踪系统的数据上报通路示意图。服务运行在容器中,通过 opentracing 的 sdk 埋点,Jaeger 的 go-sdk 上报到宿主机上的 Jaeger-agent,后者再将数据进一步上报到 Jaeger-collector,最终将调用链数据写入 ES,建立索引,即图中的 Jaeger backends。
遇到的问题
Jaeger 支持三种采样方式:
调用链通路改造使用场景
2020 年,我们不断收到业务研发的反馈:能不能全量采集 trace?
这促使我们开始重新思考如何改进调用链追踪系统。我们做了一个简单的容量预估:目前 Jaeger 每天写入 ES 的数据量接近 100GB/天,如果要全量采集 trace 数据,保守假设平均每个 HTTP API 服务的总 QPS 为 100,那么完整存下全量数据需要 10TB/天;乐观假设 100 名服务器研发每人每天查看 1 条 trace,每条 trace 的平均大小为 1KB,则整体信噪比千万分之一。可以看出,这件事情本身的 ROI 很低,考虑到未来业务会持续增长,存储这些数据的价值也会继续降低,因此全量采集的方案被放弃。退一步想:全量采集真的是本质需求吗?实际上并非如此,我们想要的其实是「有意思」的 trace 全采,「没意思」的 trace 不采。
根据 理论篇 中介绍的应用场景,实际上第一版调用链追踪系统只支持了稳态分析,而业务研发亟需的是异常检测。要同时支持这两种场景,我们必须借助尾部连贯采样 (tail-based coherent sampling)。相对于头部连贯采样在第一个 span 处就做出是否采样的决定,尾部连贯采样可以让我们在获取 (接近) 完整的 trace 信息后再做出判断。理想情况下,只要能合理地制定采样的判断逻辑,我们的调用链追踪系统就能做到「有意思」的 trace 全采,「没意思」的 trace 不采。
架构设计
Jaeger 团队从 2017 年就开始讨论引入 tail-based sampling 的可能性,但至今未有定论。在一次与 Jaeger 工程师 jpkrohling 的一对一沟通中,对方也证实了目前 Jaeger 尚没有相关的支持计划。因此,我们不得不另辟蹊径。经过一番调研,我们找到了刚刚进驻 CNCF SandBox 的OpenTelemetry,它的opentelemetry-collector子项目恰好能支持我们在现有架构上引入尾部连贯采样。
OpenTelemetry Collector
整个 OpenTelemetry 项目目的在于统一市面上可观测性数据 (telemetry data) 的标准,同时提供推动这些标准实施的组件和工具。opentelemetry-collector 就是这个生态中的一个重要组件,它的架构图如下:
collector 内部有 4 个核心组件:
opentelemetry-collector 项目被拆成两部分:主项目 opentelemetry-collector 和社区贡献项目 opentelemetry-collector-contrib,前者负责管理核心逻辑、数据结构以及通用的 Receivers、Processors、Exporters、Extensions 实现,后者则负责接收一些社区贡献的组件,当然贡献者主要都来自于可观测性 SaaS 解决方案供应商,如 DataDog、Splunk、LightStep 以及一些公有云厂商。opentelemtry-collector 项目的插件化管理方式,使得定制化开发 Receiver、Processor、Exporter 的成本很低,我们在做概念验证时,基本可以在一两个小时内开发并测试完毕一个组件。除此之外,opentelemetry-collector-contrib 还提供了开箱即用的tailsamplingprocessor。
由于 opentelemetry-collector 是 OpenTelemetry 团队推动标准实施的重要组件,且 OpenTelemetry 本身并没有提供独立的数据存储、索引实现的计划,因此它在与市面上流行的调用链追踪框架,如 Zipkin、Jaeger、OpenCensus,的兼容性上下了很大功夫。通过 Receivers 和 Exporters 的使用,我们可以用它替换 jaeger-agent,也可以放在 jaeger-agent 与 jaeger-collector 之间,必要时还可以在 jaeger-agent 和 jaeger-collector 之间部署多层 collectors。除此之外,如果有一天想换掉 jaeger-backend,比如新发布的 Grafana Tempo,我们也能很轻松的完成,并且利用多个 Pipelines 或一个 Pipeline 多个 Exporters 灰度上线,逐步替换。
上报通路
基于以上的调研和现有的架构,我们设计了第二版调用链追踪的架构,如下图所示:
用一组 opentelemetry-collector 替换 jaeger-agent,即图中的 otel-agent;同时在 otel-agent 与 jaeger-collector 之间增加另一组 opentelemetry-collector,即图中的 otel-collector。otel-agent 收集宿主机上不同服务上报的 trace 数据,打包批量发送给 otel-collector,后者负责做尾部连贯采样,将「有意思」的 trace 继续输出到原始架构中的 jaeger-collector,后者负责将数据投入 ElasticSearch 中,建立索引。
这里还有一个问题需要解决:整个架构做到高可用,势必要部署多个 otel-collector 实例,如果使用简单的负载均衡策略,不同 otel-agents、以及单个 otel-agent 不同时刻上报的数据,可能被随机上报到某个 otel-collector 实例,这就意味着,同一个 trace 的不同 spans 无法集中到同一个 otel-collector 实例上,既会导致同一个 trace 的不同 spans 的决定不一致,即不是连贯采样;也会导致尾部采样时提供判断的数据不全。解决方案很简单:让 otel-agent 按照 traceID 做负载均衡。
在调研阶段我们正好看到 opentelemetry-collector 社区也有此支持计划,并且前面提到的工程师 jpkrohling 正在通过增加loadbalancingexporter解决它,虽然直接使用 bleeding edge 的版本有一定的风险,我们还是决定尝试。在概念验证阶段,我们也的确发现了新功能的若干问题,但通过反馈的方式一一解决,最终获得了可以按预期执行尾部连贯采样的调用链追踪系统。
采样规则
尾部连贯采样的数据通路已经准备就绪,下一步就是确定和实施采样规则。
「有意思」的调用链
什么是「有意思」的调用链?研发在分析、排障过程中想查询的任何调用链就是「有意思」的调用链。但落实到代码的必须是确定性的规则,根据日常排障经验,我们先确定了以下三种情形:
满足任意条件,就认为这个调用链「有意思」。在伴鱼,只要服务打印了 ERROR 级别的日志就会触发报警,研发人员就会收到 im 消息或电话报警,如果能保证触发报警的调用链数据必采,研发人员的排障体验就会有很大的提升;我们的 DBA 团队认为超过 200ms 的查询请求都被判定为慢查询,如果能保证这些请求的调用链必采,就能大大方便研发排查导致慢查询的请求;对于在线服务来说,时延过高会令用户体验下降,但具体高到什么程度会引发明显的体验下降我们暂时没有数据支撑,因此先配置为 1s,支持随时修改阈值。
当然,以上条件并不绝对,我们可以在之后的实践根据反馈调整、新增规则,如单个请求引起的数据库、缓存查询次数超过某阈值等。
采样流水线
在第二版系统中,我们期望同时支持稳态分析与异常检测,因此采样过程既要按概率或限流方式采集一部分 trace,也需要按上文拟定的「有意思」 规则采集令一部分 trace。截止到本文撰写前,tailsamplingprocessor支持 4 种策略:
「按概率或限流采集一部分 trace」可以利用rate_limiting实现吗?rate_limiting只能按照每秒通过的 spans 个数限流,但 spans 数量在高峰期、低峰期、业务所处阶段都不一样,每个 trace 的平均 spans 数量也会随着微服务群规模以及依赖关系发生变化,因此设置 spans_per_second 将让我们很难对这个参数的最终效果合理评估,因此直接使用rate_limiting的方案被否决。
「按规则采集另一部分 trace」可以直接使用numeric_attribute和string_attribute实现吗?span 中还存在布尔 (bool) 类型的 tag,以「在调用链上如果打印了 ERROR 级别日志」为例,按照规范我们会记录span.SetTag("error" , true),但 tailsamplingprocessor 并未支持bool_attribute;此外,未来我们可能会有更复杂的组合条件,这时仅靠numeric_attribute和string_attribute也无法实现。
经过再三分析,我们最终决定利用 Processors 的链式结构,组合多个 Processor 完成采样,流水线如下图所示:
其中probattr负责在 trace 级别按概率抽样,anomaly 负责分析每个 trace 是否符合「有意思」的规则,如果命中二者之一,trace 就会被打上标记,即sampling.priority。最后在tailsamplingprocessor上配置一条规则即可,如下所示:
tail_sampling:<br /> policies:<br /> [<br /> {<br /> name: sample_with_high_priority,<br /> type: numeric_attribute,<br /> numeric_attribute: { key: "sampling.priority", min_value: 1, max_value: 1 }<br /> }<br /> ]
这里sampling.priority是整数类型,当前取值只有 0 和 1。按上面的配置,所以sampling.priority = 1的trace 都会被采集。后期可以增加更多的采集优先级,在必要的时候可以多采样 (upsampling) 或降采样 (downsampling)。
部署实施
采样规则确立后,整个解决方案就已跑通,下一步就是进入部署实施阶段。
上线准备基础库改造
动态更新 Tracer在第一版系统中,每个进程启动时会从 apollo 上获取采样配置,传递给 Jaeger sdk,后者利用配置初始化 GlobalTracer。GlobalTracer 会在 trace 的第一个 span 出现时,决定是否采集,并把这个决定传递下去,即头部连贯采样。在实施新架构时,我们需要 Jaeger sdk 将所有 trace 数据尽数上报。为了让这个过程更加平滑,我们对 Jaeger sdk 配置做出两方面改造:
支持对每个服务下发不同的采样配置,方便灰度发布 支持动态更新采样配置,使采样策略配置不依赖发布
日志库改造为了保证打印过 ERROR 级别日志的调用链必采,我们也在通用日志库的相应位置上给 span 打上 error 标签。
监控看板配置
opentelemetry-collector 内部利用 OpenCensus sdk 埋了很多有用的监控指标,并按照 Open Metrics 规范暴露数据。因为指标数量并不多,我们将大多数指标都配置了到 Grafana 看板中,包括:
xxx_receiver_accepted/refused_spans这里的 xxx 指代任意一个 pipeline 中使用的 receiver。实际上这里有两个具体指标:receiver 接收的 spans 数量和 receiver 拒绝的 spans 数量。二者可以与其它指标结合,分析系统在当前状况下的入口流量瓶颈。
xxx_exporter_send(failed)_spans这里的 xxx 指代任意一个 pipeline 中使用的 exporter。实际上这里有两个具体指标:exporter 发送成功的 spans 数量和 exporter 发送失败的 spans 数量。二者可以与其它指标结合,分析系统在当前状况下的出口流量瓶颈。
otelcol_processor_tail_sampling_sampling_trace_dropped_too_early要介绍上面这个指标,需要简单了解tailsamplingprocessor的工作原理。在分布式环境中,tailsamplingprocessor永远无法确定一个 trace 的所有 spans 在当前时刻是否收集完毕,因此需要设置一个超时时间,即 这里 的decision_wait,下面假设decision_wait = 5s。Trace Data 进入 processor 后,会被分别放入两个数据结构:
一个固定大小的队列和一个哈希表,二者合起来实现 trace data 的 LRU cache。同时 processor 会将所有进入到其中的 traces 按照每秒一个 batch 组织起来,内部一共维持 5 个 batch (decision_wait)。每隔一秒钟,将最老的 batch 取出来,对其中的 traces 分别判断是否符合采样规则,符合则将其传递给后续的 processors:
如果在做采样决策时,发现相应的 trace 已经被 LRU cache 清出,则认为「trace dropped too early」,后者意味着tailsamplingprocessor已经超负荷。理论上这个指标如果不等于 0,尾部连贯采样功能就处于异常状态。
灰度方案
上文提到过,实施改造需要让 Jaeger sdk 全量上报 trace。由于「是否上报」这个决定在请求入口服务 (即 HTTP 服务) 做出,并会随着跨进程调用传播到下游服务,同时伴鱼服务端内部的入口服务已经按照业务拆分,因此灰度的过程就可以按入口服务进行,从流量小的、级别低入口服务开始上线观察,再逐渐加入流量大的、级别高的入口服务,最终默认打开全量采样,并在这个过程中发现、解决潜在问题。
资源消耗优化
新版架构所需资源与旧版差别不大:
在逐步上线到所有入口服务之前,我们做了比较充分的风险评估。开启全量采集后,主要增加了宿主机的网络 i/o,在千兆网卡 (约 300MB/s) 支持下,增加后的 i/o 量远远未达到瓶颈。实施过程中,业务团队也确实没有感知。不过在灰度上线过程中,我们也发现并解决了若干问题。
热点服务问题
不同服务的请求量不同。个别服务的上报量过大会导致不同 otel-agent 的流量不均衡,在高峰期造成 otel-agent 的 CPU 经常超过预警线。我们通过增加热点服务实例,减小单个实例的请求量的方式,间接地均衡了每个 otel-agent 承载的流量。
过滤下推
在生产环境中,我们默认维持最近 7 天的 trace 数据。在分析 ES 中索引jaeger-span-* 的过程中,意料之中地,我们看到了 power law 的存在:
仔细分析可以发现,50% 以上的 span 都属于apolloConfigCenter.*。熟悉 apollo 的研发应该知道,通常 apollo sdk 会通过长轮询的方式从元数据中心拉取配置信息,并缓存到本地,而服务在应用层获取配置都是通过本地缓存获取。因此实际上这里的所有apolloConfigCenter.*只是本地访问,而不是跨进程调用,span 数据价值比较低,可以忽略。于是我们开发了通过正则匹配 spanName 过滤 span 的 processor,并部署到 otel-agent 上,我们称之为过滤下推。部署上线后,ES 索引体积下降超过 50%,目前每天索引体积为 40-50 GB;otel-collector 和 otel-agent 的 CPU 消耗也降低了接近 50%。
制定 SLO
在伴鱼服务端内,线上问题排查的第一入口通常是 im 消息,报警平台会将导致报警的 traceID 以及日志注入到消息中,并提供一个链接页面,方便研发快速查看报警相关的调用链信息及其在整个调用链上每个服务打印的日志。基于此我们制定新版调用链追踪系统的SLO:
名称
研发关心的 trace 数据采集成功率
SLI 规范
研发关心且被采集的 trace 个数/研发关心的 trace 个数
SLI 实现
包含 trace 数据的服务报警信息条数/服务报警信息条数
查询
sum(alertmanager_alert_total{trace_exists="true"})/sum(alertmanager_alert_total)
目标
99%
目前我们刚刚在报警平台中支持此 SLI 的埋点。目前还有个别服务尚未升级相关依赖,因此该指标尚不能反映所有服务的情况,我们会继续推动各服务全面升级,按照以上 SLO 来要求新版系统。
总结
借助开源项目,我们得以通过花费极少的人力,解决当前伴鱼内部调用链追踪应用的稳态分析及异常检测需求,同时也为开源项目和社区做出微小的贡献。调用链追踪是可观测性平台的重要组件,未来我们将继续把一些精力放在 telemetry data 的整合上,为研发提供更全面、一致的服务观测分析体验。
介绍
文章原创来自于伴鱼技术团队的郑鹤。
伴鱼少儿英语是目前飞速成长的互联网在线英语教育品牌之一。我们期望打造更创新、更酷、让学英语更有效的新一代互联网产品。转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Hi,我是老蒋。这里是中国Opentelemetry官方开源社区组织。我们定期分享精彩的Opentelemetry 落地案例,请大家持续关注
参考 查看全部
调用链追踪系统在伴鱼:Opentelemetry最佳实践案例分享
搭建可靠的链路追踪系统
在正式介绍前,简单交代一下背景:2015 年,在伴鱼服务端起步之时,技术团队就做出统一使用 Go 语言的决定。这个决定的影响主要体现在:
早期实践对接 Jaeger
2019 年,公司内部的微服务数量逐步增加,调用关系日趋复杂,工程师做性能分析、问题排查的难度变大。这时亟需一套调用链追踪系统帮助我们增强对服务端全貌的了解。经过调研后,我们决定采用同样基于 Go 语言搭建的、由 CNCF 孵化的项目Jaeger。当时,服务的开发和治理都尚未引入 context,不论进程内部调用还是跨进程调用,都没有上下文传递。因此早期引入调用链追踪的工作重心就落在了服务及服务治理框架的改造,包括:
部署方面:测试环境采用 all-in-one,线上环境采用 direct-to-storage 方案。整个过程前后大约耗时一个月,我们在 2019 年 Q3 上线了第一版调用链追踪系统。配合广泛被采用的 prometheus + grafana 以及 ELK,我们在微服务群的可观测性上终于凑齐了调用链 (traces)、日志 (logs) 和监控指标 (metrics) 三个要素。
下图是第一版调用链追踪系统的数据上报通路示意图。服务运行在容器中,通过 opentracing 的 sdk 埋点,Jaeger 的 go-sdk 上报到宿主机上的 Jaeger-agent,后者再将数据进一步上报到 Jaeger-collector,最终将调用链数据写入 ES,建立索引,即图中的 Jaeger backends。
遇到的问题
Jaeger 支持三种采样方式:
调用链通路改造使用场景
2020 年,我们不断收到业务研发的反馈:能不能全量采集 trace?
这促使我们开始重新思考如何改进调用链追踪系统。我们做了一个简单的容量预估:目前 Jaeger 每天写入 ES 的数据量接近 100GB/天,如果要全量采集 trace 数据,保守假设平均每个 HTTP API 服务的总 QPS 为 100,那么完整存下全量数据需要 10TB/天;乐观假设 100 名服务器研发每人每天查看 1 条 trace,每条 trace 的平均大小为 1KB,则整体信噪比千万分之一。可以看出,这件事情本身的 ROI 很低,考虑到未来业务会持续增长,存储这些数据的价值也会继续降低,因此全量采集的方案被放弃。退一步想:全量采集真的是本质需求吗?实际上并非如此,我们想要的其实是「有意思」的 trace 全采,「没意思」的 trace 不采。
根据 理论篇 中介绍的应用场景,实际上第一版调用链追踪系统只支持了稳态分析,而业务研发亟需的是异常检测。要同时支持这两种场景,我们必须借助尾部连贯采样 (tail-based coherent sampling)。相对于头部连贯采样在第一个 span 处就做出是否采样的决定,尾部连贯采样可以让我们在获取 (接近) 完整的 trace 信息后再做出判断。理想情况下,只要能合理地制定采样的判断逻辑,我们的调用链追踪系统就能做到「有意思」的 trace 全采,「没意思」的 trace 不采。
架构设计
Jaeger 团队从 2017 年就开始讨论引入 tail-based sampling 的可能性,但至今未有定论。在一次与 Jaeger 工程师 jpkrohling 的一对一沟通中,对方也证实了目前 Jaeger 尚没有相关的支持计划。因此,我们不得不另辟蹊径。经过一番调研,我们找到了刚刚进驻 CNCF SandBox 的OpenTelemetry,它的opentelemetry-collector子项目恰好能支持我们在现有架构上引入尾部连贯采样。
OpenTelemetry Collector
整个 OpenTelemetry 项目目的在于统一市面上可观测性数据 (telemetry data) 的标准,同时提供推动这些标准实施的组件和工具。opentelemetry-collector 就是这个生态中的一个重要组件,它的架构图如下:
collector 内部有 4 个核心组件:
opentelemetry-collector 项目被拆成两部分:主项目 opentelemetry-collector 和社区贡献项目 opentelemetry-collector-contrib,前者负责管理核心逻辑、数据结构以及通用的 Receivers、Processors、Exporters、Extensions 实现,后者则负责接收一些社区贡献的组件,当然贡献者主要都来自于可观测性 SaaS 解决方案供应商,如 DataDog、Splunk、LightStep 以及一些公有云厂商。opentelemtry-collector 项目的插件化管理方式,使得定制化开发 Receiver、Processor、Exporter 的成本很低,我们在做概念验证时,基本可以在一两个小时内开发并测试完毕一个组件。除此之外,opentelemetry-collector-contrib 还提供了开箱即用的tailsamplingprocessor。
由于 opentelemetry-collector 是 OpenTelemetry 团队推动标准实施的重要组件,且 OpenTelemetry 本身并没有提供独立的数据存储、索引实现的计划,因此它在与市面上流行的调用链追踪框架,如 Zipkin、Jaeger、OpenCensus,的兼容性上下了很大功夫。通过 Receivers 和 Exporters 的使用,我们可以用它替换 jaeger-agent,也可以放在 jaeger-agent 与 jaeger-collector 之间,必要时还可以在 jaeger-agent 和 jaeger-collector 之间部署多层 collectors。除此之外,如果有一天想换掉 jaeger-backend,比如新发布的 Grafana Tempo,我们也能很轻松的完成,并且利用多个 Pipelines 或一个 Pipeline 多个 Exporters 灰度上线,逐步替换。
上报通路
基于以上的调研和现有的架构,我们设计了第二版调用链追踪的架构,如下图所示:
用一组 opentelemetry-collector 替换 jaeger-agent,即图中的 otel-agent;同时在 otel-agent 与 jaeger-collector 之间增加另一组 opentelemetry-collector,即图中的 otel-collector。otel-agent 收集宿主机上不同服务上报的 trace 数据,打包批量发送给 otel-collector,后者负责做尾部连贯采样,将「有意思」的 trace 继续输出到原始架构中的 jaeger-collector,后者负责将数据投入 ElasticSearch 中,建立索引。
这里还有一个问题需要解决:整个架构做到高可用,势必要部署多个 otel-collector 实例,如果使用简单的负载均衡策略,不同 otel-agents、以及单个 otel-agent 不同时刻上报的数据,可能被随机上报到某个 otel-collector 实例,这就意味着,同一个 trace 的不同 spans 无法集中到同一个 otel-collector 实例上,既会导致同一个 trace 的不同 spans 的决定不一致,即不是连贯采样;也会导致尾部采样时提供判断的数据不全。解决方案很简单:让 otel-agent 按照 traceID 做负载均衡。
在调研阶段我们正好看到 opentelemetry-collector 社区也有此支持计划,并且前面提到的工程师 jpkrohling 正在通过增加loadbalancingexporter解决它,虽然直接使用 bleeding edge 的版本有一定的风险,我们还是决定尝试。在概念验证阶段,我们也的确发现了新功能的若干问题,但通过反馈的方式一一解决,最终获得了可以按预期执行尾部连贯采样的调用链追踪系统。
采样规则
尾部连贯采样的数据通路已经准备就绪,下一步就是确定和实施采样规则。
「有意思」的调用链
什么是「有意思」的调用链?研发在分析、排障过程中想查询的任何调用链就是「有意思」的调用链。但落实到代码的必须是确定性的规则,根据日常排障经验,我们先确定了以下三种情形:
满足任意条件,就认为这个调用链「有意思」。在伴鱼,只要服务打印了 ERROR 级别的日志就会触发报警,研发人员就会收到 im 消息或电话报警,如果能保证触发报警的调用链数据必采,研发人员的排障体验就会有很大的提升;我们的 DBA 团队认为超过 200ms 的查询请求都被判定为慢查询,如果能保证这些请求的调用链必采,就能大大方便研发排查导致慢查询的请求;对于在线服务来说,时延过高会令用户体验下降,但具体高到什么程度会引发明显的体验下降我们暂时没有数据支撑,因此先配置为 1s,支持随时修改阈值。
当然,以上条件并不绝对,我们可以在之后的实践根据反馈调整、新增规则,如单个请求引起的数据库、缓存查询次数超过某阈值等。
采样流水线
在第二版系统中,我们期望同时支持稳态分析与异常检测,因此采样过程既要按概率或限流方式采集一部分 trace,也需要按上文拟定的「有意思」 规则采集令一部分 trace。截止到本文撰写前,tailsamplingprocessor支持 4 种策略:
「按概率或限流采集一部分 trace」可以利用rate_limiting实现吗?rate_limiting只能按照每秒通过的 spans 个数限流,但 spans 数量在高峰期、低峰期、业务所处阶段都不一样,每个 trace 的平均 spans 数量也会随着微服务群规模以及依赖关系发生变化,因此设置 spans_per_second 将让我们很难对这个参数的最终效果合理评估,因此直接使用rate_limiting的方案被否决。
「按规则采集另一部分 trace」可以直接使用numeric_attribute和string_attribute实现吗?span 中还存在布尔 (bool) 类型的 tag,以「在调用链上如果打印了 ERROR 级别日志」为例,按照规范我们会记录span.SetTag("error" , true),但 tailsamplingprocessor 并未支持bool_attribute;此外,未来我们可能会有更复杂的组合条件,这时仅靠numeric_attribute和string_attribute也无法实现。
经过再三分析,我们最终决定利用 Processors 的链式结构,组合多个 Processor 完成采样,流水线如下图所示:
其中probattr负责在 trace 级别按概率抽样,anomaly 负责分析每个 trace 是否符合「有意思」的规则,如果命中二者之一,trace 就会被打上标记,即sampling.priority。最后在tailsamplingprocessor上配置一条规则即可,如下所示:
tail_sampling:<br /> policies:<br /> [<br /> {<br /> name: sample_with_high_priority,<br /> type: numeric_attribute,<br /> numeric_attribute: { key: "sampling.priority", min_value: 1, max_value: 1 }<br /> }<br /> ]
这里sampling.priority是整数类型,当前取值只有 0 和 1。按上面的配置,所以sampling.priority = 1的trace 都会被采集。后期可以增加更多的采集优先级,在必要的时候可以多采样 (upsampling) 或降采样 (downsampling)。
部署实施
采样规则确立后,整个解决方案就已跑通,下一步就是进入部署实施阶段。
上线准备基础库改造
动态更新 Tracer在第一版系统中,每个进程启动时会从 apollo 上获取采样配置,传递给 Jaeger sdk,后者利用配置初始化 GlobalTracer。GlobalTracer 会在 trace 的第一个 span 出现时,决定是否采集,并把这个决定传递下去,即头部连贯采样。在实施新架构时,我们需要 Jaeger sdk 将所有 trace 数据尽数上报。为了让这个过程更加平滑,我们对 Jaeger sdk 配置做出两方面改造:
支持对每个服务下发不同的采样配置,方便灰度发布 支持动态更新采样配置,使采样策略配置不依赖发布
日志库改造为了保证打印过 ERROR 级别日志的调用链必采,我们也在通用日志库的相应位置上给 span 打上 error 标签。
监控看板配置
opentelemetry-collector 内部利用 OpenCensus sdk 埋了很多有用的监控指标,并按照 Open Metrics 规范暴露数据。因为指标数量并不多,我们将大多数指标都配置了到 Grafana 看板中,包括:
xxx_receiver_accepted/refused_spans这里的 xxx 指代任意一个 pipeline 中使用的 receiver。实际上这里有两个具体指标:receiver 接收的 spans 数量和 receiver 拒绝的 spans 数量。二者可以与其它指标结合,分析系统在当前状况下的入口流量瓶颈。
xxx_exporter_send(failed)_spans这里的 xxx 指代任意一个 pipeline 中使用的 exporter。实际上这里有两个具体指标:exporter 发送成功的 spans 数量和 exporter 发送失败的 spans 数量。二者可以与其它指标结合,分析系统在当前状况下的出口流量瓶颈。
otelcol_processor_tail_sampling_sampling_trace_dropped_too_early要介绍上面这个指标,需要简单了解tailsamplingprocessor的工作原理。在分布式环境中,tailsamplingprocessor永远无法确定一个 trace 的所有 spans 在当前时刻是否收集完毕,因此需要设置一个超时时间,即 这里 的decision_wait,下面假设decision_wait = 5s。Trace Data 进入 processor 后,会被分别放入两个数据结构:
一个固定大小的队列和一个哈希表,二者合起来实现 trace data 的 LRU cache。同时 processor 会将所有进入到其中的 traces 按照每秒一个 batch 组织起来,内部一共维持 5 个 batch (decision_wait)。每隔一秒钟,将最老的 batch 取出来,对其中的 traces 分别判断是否符合采样规则,符合则将其传递给后续的 processors:
如果在做采样决策时,发现相应的 trace 已经被 LRU cache 清出,则认为「trace dropped too early」,后者意味着tailsamplingprocessor已经超负荷。理论上这个指标如果不等于 0,尾部连贯采样功能就处于异常状态。
灰度方案
上文提到过,实施改造需要让 Jaeger sdk 全量上报 trace。由于「是否上报」这个决定在请求入口服务 (即 HTTP 服务) 做出,并会随着跨进程调用传播到下游服务,同时伴鱼服务端内部的入口服务已经按照业务拆分,因此灰度的过程就可以按入口服务进行,从流量小的、级别低入口服务开始上线观察,再逐渐加入流量大的、级别高的入口服务,最终默认打开全量采样,并在这个过程中发现、解决潜在问题。
资源消耗优化
新版架构所需资源与旧版差别不大:
在逐步上线到所有入口服务之前,我们做了比较充分的风险评估。开启全量采集后,主要增加了宿主机的网络 i/o,在千兆网卡 (约 300MB/s) 支持下,增加后的 i/o 量远远未达到瓶颈。实施过程中,业务团队也确实没有感知。不过在灰度上线过程中,我们也发现并解决了若干问题。
热点服务问题
不同服务的请求量不同。个别服务的上报量过大会导致不同 otel-agent 的流量不均衡,在高峰期造成 otel-agent 的 CPU 经常超过预警线。我们通过增加热点服务实例,减小单个实例的请求量的方式,间接地均衡了每个 otel-agent 承载的流量。
过滤下推
在生产环境中,我们默认维持最近 7 天的 trace 数据。在分析 ES 中索引jaeger-span-* 的过程中,意料之中地,我们看到了 power law 的存在:
仔细分析可以发现,50% 以上的 span 都属于apolloConfigCenter.*。熟悉 apollo 的研发应该知道,通常 apollo sdk 会通过长轮询的方式从元数据中心拉取配置信息,并缓存到本地,而服务在应用层获取配置都是通过本地缓存获取。因此实际上这里的所有apolloConfigCenter.*只是本地访问,而不是跨进程调用,span 数据价值比较低,可以忽略。于是我们开发了通过正则匹配 spanName 过滤 span 的 processor,并部署到 otel-agent 上,我们称之为过滤下推。部署上线后,ES 索引体积下降超过 50%,目前每天索引体积为 40-50 GB;otel-collector 和 otel-agent 的 CPU 消耗也降低了接近 50%。
制定 SLO
在伴鱼服务端内,线上问题排查的第一入口通常是 im 消息,报警平台会将导致报警的 traceID 以及日志注入到消息中,并提供一个链接页面,方便研发快速查看报警相关的调用链信息及其在整个调用链上每个服务打印的日志。基于此我们制定新版调用链追踪系统的SLO:
名称
研发关心的 trace 数据采集成功率
SLI 规范
研发关心且被采集的 trace 个数/研发关心的 trace 个数
SLI 实现
包含 trace 数据的服务报警信息条数/服务报警信息条数
查询
sum(alertmanager_alert_total{trace_exists="true"})/sum(alertmanager_alert_total)
目标
99%
目前我们刚刚在报警平台中支持此 SLI 的埋点。目前还有个别服务尚未升级相关依赖,因此该指标尚不能反映所有服务的情况,我们会继续推动各服务全面升级,按照以上 SLO 来要求新版系统。
总结
借助开源项目,我们得以通过花费极少的人力,解决当前伴鱼内部调用链追踪应用的稳态分析及异常检测需求,同时也为开源项目和社区做出微小的贡献。调用链追踪是可观测性平台的重要组件,未来我们将继续把一些精力放在 telemetry data 的整合上,为研发提供更全面、一致的服务观测分析体验。
介绍
文章原创来自于伴鱼技术团队的郑鹤。
伴鱼少儿英语是目前飞速成长的互联网在线英语教育品牌之一。我们期望打造更创新、更酷、让学英语更有效的新一代互联网产品。转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Hi,我是老蒋。这里是中国Opentelemetry官方开源社区组织。我们定期分享精彩的Opentelemetry 落地案例,请大家持续关注
参考
文章采集调用(中国的股票市场上盈利,每周都有单个股票盈利2)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-04-18 07:10
目标:在中国股市盈利,单只股票每周盈利2%,月总盈利超过2%
计划实现:Pycharm + Anaconda3 + Python3 + Django + AKShare + MongoDB
当前实现:Pycharm + Anaconda3 + Python3 + Flask + AKShare
未来可能会用到:MongoDB、SQLAlchemy、baostock、Tushare
机器学习将在未来的实践中逐步使用。
实现方法
上一篇文章写过采集的方法。本文文章收录完整代码和调用代码。
使用后台执行的方法。
gupiao.py如下:
import akshare as ak
import threading
import datetime
import os
from threading import Thread
def get_start():
start_stock_daily()
# 这里就是核心了,调用这部分就会自动下载 深圳A股 的所有股票的历史记录
def start_stock_daily(indicator="A股列表", folder="sz_a", prefix="sz"):
file_path = "D:/work/data/" + folder + "/"
file_path_name = get_sz_a(file_path, indicator)
print(file_path_name)
num = 0
with open(file_path_name, "r", encoding='UTF-8') as stock_lines:
for stock_line in stock_lines.readlines():
num = num + 1
if num == 1:
continue
stock_line_arr = stock_line.split("|")
symbol = prefix + stock_line_arr[5]
print("股票信息=" + symbol + "||" + stock_line_arr[6])
stock_csv = get_stock_daily(file_path, symbol)
print("stock_csv=" + stock_csv)
# 获得深圳主板A股列表,每天获取一次不重复获取
# file_path 需要全路径,以 | 进行间隔
# indicator 可选参数 "A股列表", "B股列表", "AB股列表", "上市公司列表", "主板", "中小企业板", "创业板"
def get_sz_a(file_path, indicator="A股列表"):
today = datetime.datetime.today()
file_name = "sz_a_" + today.strftime('%Y%m%d') + ".csv"
if not os.path.exists(file_path): # 如果路径不存在则创建
os.makedirs(file_path)
if os.path.exists(file_path + file_name):
print("今日已经获取无需再次获取," + today.strftime('%Y%m%d'))
return file_path + file_name
stock_info_sz_df = ak.stock_info_sz_name_code(indicator=indicator)
stock_info_sz_df.to_csv(file_path + file_name, sep="|")
print('获取深圳主板A股列表并存储为CSV!' + today.strftime('%Y%m%d'))
return file_path + file_name
# 根据股票代码获取股票历史数据
# symbol 股票代码 需要前缀 sh 上海 sz 深圳,例如:sz300846
def get_stock_daily(file_path, symbol):
stock_zh_a_daily_hfq_df = ak.stock_zh_a_daily(symbol=symbol) # 返回不复权的数据
file_name = symbol + '.csv'
stock_zh_a_daily_hfq_df.to_csv(file_path + file_name)
return file_path + file_name
调用下载的部分,注意我随便写的名字,请根据情况修改,app.py如下:
from flask import Flask
import akshare as ak
import gupiao
import datetime
import os
from concurrent.futures import ThreadPoolExecutor
import time
executor = ThreadPoolExecutor(2)
app = Flask(__name__)
@app.route('/test_thread')
def test_thread():
executor.submit(gupiao.get_start)
return "thread is running at background !!!"
if __name__ == '__main__':
app.run()
使用Flask框架,生成一个项目,然后在app.py中创建一个gupiao.py,并运行该项目。
在浏览器中访问:5000/test_thread
可以在后台看到图片,整个深圳A股的下载时间大约是2小时到3小时。
历史股票数据
如图下载到本地
历史股票数据
爬取数据部分完成,接下来就是过滤了。 查看全部
文章采集调用(中国的股票市场上盈利,每周都有单个股票盈利2)
目标:在中国股市盈利,单只股票每周盈利2%,月总盈利超过2%
计划实现:Pycharm + Anaconda3 + Python3 + Django + AKShare + MongoDB
当前实现:Pycharm + Anaconda3 + Python3 + Flask + AKShare
未来可能会用到:MongoDB、SQLAlchemy、baostock、Tushare
机器学习将在未来的实践中逐步使用。
实现方法
上一篇文章写过采集的方法。本文文章收录完整代码和调用代码。
使用后台执行的方法。
gupiao.py如下:
import akshare as ak
import threading
import datetime
import os
from threading import Thread
def get_start():
start_stock_daily()
# 这里就是核心了,调用这部分就会自动下载 深圳A股 的所有股票的历史记录
def start_stock_daily(indicator="A股列表", folder="sz_a", prefix="sz"):
file_path = "D:/work/data/" + folder + "/"
file_path_name = get_sz_a(file_path, indicator)
print(file_path_name)
num = 0
with open(file_path_name, "r", encoding='UTF-8') as stock_lines:
for stock_line in stock_lines.readlines():
num = num + 1
if num == 1:
continue
stock_line_arr = stock_line.split("|")
symbol = prefix + stock_line_arr[5]
print("股票信息=" + symbol + "||" + stock_line_arr[6])
stock_csv = get_stock_daily(file_path, symbol)
print("stock_csv=" + stock_csv)
# 获得深圳主板A股列表,每天获取一次不重复获取
# file_path 需要全路径,以 | 进行间隔
# indicator 可选参数 "A股列表", "B股列表", "AB股列表", "上市公司列表", "主板", "中小企业板", "创业板"
def get_sz_a(file_path, indicator="A股列表"):
today = datetime.datetime.today()
file_name = "sz_a_" + today.strftime('%Y%m%d') + ".csv"
if not os.path.exists(file_path): # 如果路径不存在则创建
os.makedirs(file_path)
if os.path.exists(file_path + file_name):
print("今日已经获取无需再次获取," + today.strftime('%Y%m%d'))
return file_path + file_name
stock_info_sz_df = ak.stock_info_sz_name_code(indicator=indicator)
stock_info_sz_df.to_csv(file_path + file_name, sep="|")
print('获取深圳主板A股列表并存储为CSV!' + today.strftime('%Y%m%d'))
return file_path + file_name
# 根据股票代码获取股票历史数据
# symbol 股票代码 需要前缀 sh 上海 sz 深圳,例如:sz300846
def get_stock_daily(file_path, symbol):
stock_zh_a_daily_hfq_df = ak.stock_zh_a_daily(symbol=symbol) # 返回不复权的数据
file_name = symbol + '.csv'
stock_zh_a_daily_hfq_df.to_csv(file_path + file_name)
return file_path + file_name
调用下载的部分,注意我随便写的名字,请根据情况修改,app.py如下:
from flask import Flask
import akshare as ak
import gupiao
import datetime
import os
from concurrent.futures import ThreadPoolExecutor
import time
executor = ThreadPoolExecutor(2)
app = Flask(__name__)
@app.route('/test_thread')
def test_thread():
executor.submit(gupiao.get_start)
return "thread is running at background !!!"
if __name__ == '__main__':
app.run()
使用Flask框架,生成一个项目,然后在app.py中创建一个gupiao.py,并运行该项目。
在浏览器中访问:5000/test_thread
可以在后台看到图片,整个深圳A股的下载时间大约是2小时到3小时。
历史股票数据
如图下载到本地
历史股票数据
爬取数据部分完成,接下来就是过滤了。
文章采集调用(如何使用采集功能去采集一个图片类的网站(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2022-04-17 17:12
前言:本文章主要介绍如何使用采集函数来采集一个图片类网站。本次选择的目标站点为:战酷网名作鉴赏栏目,网址为:. 本文将介绍如何处理收录 采集 分页的页面以及如何使用简单的过滤规则。本文分为三部分:第一部分主要介绍如何进入采集界面以及添加新采集节点的第一步:设置基本信息和URL索引页面规则;第二部分,主要是引入新的采集节点的第二步:设置字段获取规则;第三节主要介绍采集如何指定节点以及如何导出采集内容。
进入下面的第一部分。
1.1进入采集节点管理界面
如图1),在后台管理界面主菜单点击“采集”,再点击“采集节点管理”进入采集节点管理界面,如图(图2).
图 1 - 后台管理界面
图2-采集节点管理界面
1.2. 添加新节点
在采集节点管理界面,点击左下角“添加新节点”或右上角“添加新节点”(如图2),可以输入“选择内容模型”界面,如(如图3),
图 3 - 选择内容模型界面
在“选择内容模型”界面的下拉列表框中,有“普通文章”和“图片采集”可供选择。
根据页面类型为采集,选择对应的内容模型。本文选择“图片采集”,点击确定,即可进入“添加采集节点:第一步设置基本信息和URL索引页面规则”界面,如图(图4)@ > ,
图4 - 添加采集节点:第一步设置基本信息和URL索引页面规则
1.2.1 设置节点基本信息
图 5 - 节点基本信息
如图(图5),这里只是获取“目标页面代码”的方法,其他设置请参考前面的文章。具体操作步骤:
(a) 打开 采集: 所针对的目标页面;
(b) 右击选择“查看源文件”找到“charset”,如图(图6),
图 6 - 查看源文件
等号后面的代码就是需要填写的“编码格式”,这里是“utf-8”。
填写后,如图(图7),
图 7 - 设置后节点的基本信息
检查后,进入下一步。
1.2.2 设置列表URL获取规则
图 8 - 列出 URL 获取规则
如(图8),这里是设置采集的文章列表页的匹配规则。具体步骤:
(a) 首先,回到打开的列表页面,找到浏览器的URL地址栏中显示的URL和页面的分页符部分。如(图9)和(图10))所示,
图 9 - 浏览器的 URL 地址栏
图 10 - 页面提要
(b) 点击“2”打开文章列表页面的第二页,再次找到浏览器的URL地址栏显示的URL和页面的换页部分,如图(图12)和(如图13),
图 11 - 第二页的 URL
图 12 - 第二页上的换页
(c) 在打开的列表页第二页,点击(1)返回列表页第一页,页面换页部分同上图10,只是浏览器URL地址栏显示的URL与上图9不同,如图(图13),
图 13 - 第一个页面的 URL
(d) 由(b)和(c)可知,这里采集的列表页的URL遵循如下规则:
!0!0!200!(*)!1!0!0/. 为了安全起见,请为自己测试更多列表页面。规则确定后,在“匹配网址”中,填写列表页后面的规则。
(e) 最后,根据需要指定采集的页码或常规数,并设置其递增规则。
至此,“List URL获取规则”部分就设置好了。最终结果,如图(图14)@>,
图 14 - 设置后的 URL 获取规则列表
确认无误后,进行下一步。
1.2.3设置文章网址匹配规则
图 15 - 文章 URL 匹配规则
下面是设置采集列表页的匹配规则。
具体步骤:
(a)对于“区域开始的HTML”,可以在已打开的列表首页,单击右键后选择“查看源文件”查找出第一篇文章的标题“高清壁纸”来获得,如(图16)所示,
图 16 - 查看源文件中第一个 文章 的标题
通过观察不难看出,“”是整个列表的结尾,后面的“”是页面的分页符。所以,在“HTML 结尾区域”中,应该用“”填充,意思是到第一个结尾。
(c) 观察图16和图17中文章的标题部分,可以发现标题的链接地址收录“=.html”。因此,在“必须收录”中,填写“=.html”。
至此,“文章URL匹配规则”就设置好了。填写后,如图(图18),
图 18 - 文章 设置后的 URL 匹配规则
通过以上三个小节,已经设置了添加采集节点的第一步。设置后的最终结果,如图(图19),
图19 - 设置后新增采集节点:第一步设置基本信息和URL索引页面规则
全部完成并勾选后,点击“保存信息并进入下一步”。如果前面设置正确,点击后会进入“添加采集节点:测试URL索引页面规则设置的基本信息和URL获取规则测试”页面,看到对应的文章列表地址. 如图(图20),
图 20 - URL 获取规则测试
确认无误后,点击“保存信息并进入下一步”。否则,单击“返回上一步进行更改”。
到这里,第一节就结束了。进入下面的第二部分。. . 查看全部
文章采集调用(如何使用采集功能去采集一个图片类的网站(组图))
前言:本文章主要介绍如何使用采集函数来采集一个图片类网站。本次选择的目标站点为:战酷网名作鉴赏栏目,网址为:. 本文将介绍如何处理收录 采集 分页的页面以及如何使用简单的过滤规则。本文分为三部分:第一部分主要介绍如何进入采集界面以及添加新采集节点的第一步:设置基本信息和URL索引页面规则;第二部分,主要是引入新的采集节点的第二步:设置字段获取规则;第三节主要介绍采集如何指定节点以及如何导出采集内容。
进入下面的第一部分。
1.1进入采集节点管理界面
如图1),在后台管理界面主菜单点击“采集”,再点击“采集节点管理”进入采集节点管理界面,如图(图2).
图 1 - 后台管理界面
图2-采集节点管理界面
1.2. 添加新节点
在采集节点管理界面,点击左下角“添加新节点”或右上角“添加新节点”(如图2),可以输入“选择内容模型”界面,如(如图3),
图 3 - 选择内容模型界面
在“选择内容模型”界面的下拉列表框中,有“普通文章”和“图片采集”可供选择。
根据页面类型为采集,选择对应的内容模型。本文选择“图片采集”,点击确定,即可进入“添加采集节点:第一步设置基本信息和URL索引页面规则”界面,如图(图4)@ > ,
图4 - 添加采集节点:第一步设置基本信息和URL索引页面规则
1.2.1 设置节点基本信息
图 5 - 节点基本信息
如图(图5),这里只是获取“目标页面代码”的方法,其他设置请参考前面的文章。具体操作步骤:
(a) 打开 采集: 所针对的目标页面;
(b) 右击选择“查看源文件”找到“charset”,如图(图6),
图 6 - 查看源文件
等号后面的代码就是需要填写的“编码格式”,这里是“utf-8”。
填写后,如图(图7),
图 7 - 设置后节点的基本信息
检查后,进入下一步。
1.2.2 设置列表URL获取规则
图 8 - 列出 URL 获取规则
如(图8),这里是设置采集的文章列表页的匹配规则。具体步骤:
(a) 首先,回到打开的列表页面,找到浏览器的URL地址栏中显示的URL和页面的分页符部分。如(图9)和(图10))所示,
图 9 - 浏览器的 URL 地址栏
图 10 - 页面提要
(b) 点击“2”打开文章列表页面的第二页,再次找到浏览器的URL地址栏显示的URL和页面的换页部分,如图(图12)和(如图13),
图 11 - 第二页的 URL
图 12 - 第二页上的换页
(c) 在打开的列表页第二页,点击(1)返回列表页第一页,页面换页部分同上图10,只是浏览器URL地址栏显示的URL与上图9不同,如图(图13),
图 13 - 第一个页面的 URL
(d) 由(b)和(c)可知,这里采集的列表页的URL遵循如下规则:
!0!0!200!(*)!1!0!0/. 为了安全起见,请为自己测试更多列表页面。规则确定后,在“匹配网址”中,填写列表页后面的规则。
(e) 最后,根据需要指定采集的页码或常规数,并设置其递增规则。
至此,“List URL获取规则”部分就设置好了。最终结果,如图(图14)@>,
图 14 - 设置后的 URL 获取规则列表
确认无误后,进行下一步。
1.2.3设置文章网址匹配规则
图 15 - 文章 URL 匹配规则
下面是设置采集列表页的匹配规则。
具体步骤:
(a)对于“区域开始的HTML”,可以在已打开的列表首页,单击右键后选择“查看源文件”查找出第一篇文章的标题“高清壁纸”来获得,如(图16)所示,
图 16 - 查看源文件中第一个 文章 的标题
通过观察不难看出,“”是整个列表的结尾,后面的“”是页面的分页符。所以,在“HTML 结尾区域”中,应该用“”填充,意思是到第一个结尾。
(c) 观察图16和图17中文章的标题部分,可以发现标题的链接地址收录“=.html”。因此,在“必须收录”中,填写“=.html”。
至此,“文章URL匹配规则”就设置好了。填写后,如图(图18),
图 18 - 文章 设置后的 URL 匹配规则
通过以上三个小节,已经设置了添加采集节点的第一步。设置后的最终结果,如图(图19),
图19 - 设置后新增采集节点:第一步设置基本信息和URL索引页面规则
全部完成并勾选后,点击“保存信息并进入下一步”。如果前面设置正确,点击后会进入“添加采集节点:测试URL索引页面规则设置的基本信息和URL获取规则测试”页面,看到对应的文章列表地址. 如图(图20),
图 20 - URL 获取规则测试
确认无误后,点击“保存信息并进入下一步”。否则,单击“返回上一步进行更改”。
到这里,第一节就结束了。进入下面的第二部分。. .
文章采集调用(跑到图文加工店,说给点素材,中年老板:骚年你来对了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-15 08:38
我去了图形加工店,要了一些材料。中年老板:骚年,你说得对,我们这里有很多存货。我们拥有您需要的一切,无论是否为 JPG、PSD、AI、AE、AV……
我去了菜市场,给我举了一些例子。水果卖家:朋友知道货。今天刚到的李子很清爽。缺点是太甜了!隔壁卖糖炒栗子的小伙伸了伸脖子:大哥,带个刚出锅的袋子!
嗯……定义很重要,所以我们今天说的就是阅读中获得的文本内容,写作、演讲、推理等参考和引用的材料和例子。
其实很多大牛都写过管理自己的知识库,整理自己的知识体系文章等文章,素材和例子只是其中很小的一部分。和那些大牛相比,这次我只关注材料和例子。这个入口点非常小。如果你已经建立了自己完整的知识框架和结构,非常欢迎你给我意见和批评,面带微笑。
一、素材和例子有什么用1.征服观众
在写作或演讲时,通常围绕一个主题,你所要做的就是让读者或听众理解并接受你所说的话。如果你像教科书一样一个一个地遵守规则,你可能会失去很多观众。这种情况在演讲时尤其明显。当你偶尔低头在台上寻求所谓的眼神交流和互动感,发现台下很多人都只是笑眯眯地盯着桌子看,你应该明白你说的没那么有趣他们作为微博或朋友圈。
适当的书面或口语引用可以帮助最大程度地防止这种情况发生。在写作中引用例子可以帮助读者避免长时间阅读的疲劳,同时加深对内容的理解;演讲中生动的例子更有意义,使你表达的内容更容易被听众接受和理解。此外,成人注意力的时间曲线有其特定的规律。举两个生动的例子,在听众精力下降、容易分心的时候,可以瞬间重新集中注意力,保证演讲的良好效果。
2.已关注
你身边应该有几个这样的朋友。饭桌上,谈山,如切瓜切菜。上至天文地理玄学玄学,三体四书五道口,下至官民悲喜肉离奇故事,五花八门。境界中,入流而不入流的,如果被TA接管了,也别想带回去。如果你也想成为党的中心(当然,最好排除个人自我宣传的内容),一个反驳大片的引用,那么素材和例子的采集可以让你玩得更轻松. 李笑来老师在《花时间做朋友》中提到,父亲在公共场合总是能言善辩。一时间,他原以为父亲是个记忆力极好的人,后来才发现,父亲的秘密,其实是一本写满记录的笔记本。所谓口才,就是根据采集到的资料和例子,什么时候可以应用到什么场合。
3.生理原因(个人原因)
英语中有一句话:在我的舌尖上,字面意思是“在我的舌尖上”。它实际上意味着这些话在嘴唇上,但我突然想不起来了。在专注于采集资料和例子之前,我有很多类似的经历。我清楚地记得,前一天,甚至几个小时前,我碰巧看到了一个可以支持我观点的例子,但我不记得细节和来源了。孤歌独娘,没有结果。这时候,我会感到后背和喉咙有刺的不适感,相当难受。我认为这种感觉来自于没有保存适当的材料或示例的遗憾。
因此,采集和整理资料和例子已经成为我的日常习惯之一。“书籍只有在使用时才会被使用。” 古人早就发出过类似的感叹。事实上,对于掌握了很多新工具和新方法的现代人来说,采集和整理资料和实例其实并没有想象中的那么麻烦。
二、如何采集资料和例子1.采集资料和例子
由于我说的采集整理主要是针对文字内容,所以采集资料和例子的主要来源如下:
(1)书籍
如今,知识产权的保护普遍受到重视。很多书的内容不能直接在网上获取,只能在阅读后摘录和总结。
- 电子书
目前国内外新书趋势是电子版和纸质版同步推出。电子版通常比较便宜,可以直接在亚马逊等官网购买。尤其是刚出版的新书,基本上只能找到付费版(各种号称免费的网站往往最后都指向付费版网址)。对于已经上架一段时间的书籍,会有各种免费的电子版流出,其中大部分是PDF,但质量参差不齐。还有一件事,我找电子书的建议是,如果5-10分钟内没有找到合适的版本,基本可以放弃。不值得花更多宝贵的时间在无法保证的免费和优质内容上,并直接购买电子书。版本性价比更高,付费也体现了对知识的尊重。
以目前主流的亚马逊官网为例,购买完成后会自动推送到KINDLE。为了方便后续的整理和检索,我会使用CALIBER软件和DEDRM插件将亚马逊下载的AZW3格式转换成EPUB格式,然后把书放进书里。所需内容采集在印象笔记中(仅供学习参考,绝不参与D版盈利),让大量摘抄和引用的内容轻松复制到印象笔记保存和同步,不易丢失和容易搜索。
- 纸质书
有的书比较经典但年代久远,多次再版都没有电子版;还有非小说类的书,因为我个人喜欢边看书边写读书笔记,所以买了纸质版。对于这种纸质书,做长篇摘录很不方便,手工摘录也相当耗时。幸运的是,我在某宝上找到了一款手持扫描笔,可以快速将纸张内容扫描成可编辑的文本格式,比手动输入效率高出很多倍。以前看过万维刚的《没想到》。其中有许多科学证据的例子。段落很长。钱是不能存的。对于纸质书阅读量大、喜欢做阅读笔记的朋友来说,扫描笔是个值得推荐的工具。
(2)微信内容
微信是大多数人使用频率最高的手机应用,用得上不用说。我关联了印象笔记和有道云笔记这两个官方微信账号。我一般把值得采集的内容随时保存在云端,然后在电脑上整理总结。
(3)网页内容
当我浏览网页时,我也会保存我发现的好内容。复制粘贴部分太麻烦了。为此,我使用了印象笔记的网页剪辑插件。可以选择整页,网页正文,或者去广告等等,形式多样,非常体贴。
(4)其他
其他来源不是我采集整理资料的主流渠道,比如微信聊天记录等,我靠谷歌度娘的一些技巧整理成文字保存。
2.材料和例子的组织
采集后一定要整理好,否则起不到任何价值。整理的目的是为了更好的使用,单靠大脑很难把采集到的所有内容都记住。作为一个85后,我经常听到90后说:“哎呀!怎么记不住了?年纪大了,脑子就不行了。” 更习惯了)。事实上,人的大脑就像一台电脑。存储容量有一定的上限。此外,人脑也有遗忘机制。对于长时间不使用的内容,大脑会选择忘记释放存储空间让经常使用的模块运行。因此,我们需要将采集到的资料和实例进行更有效的整理,以方便后续的高效调用,减轻大脑的负担,
以印象笔记为例。完成采集动作后,你的印象笔记现在应该有相当多的内容了,但是它们是杂乱无章的。这时候,你需要做三件事:
第一步是取名字。这是最直接的内容分类方法,也是最原创的信息搜索渠道。我通常给内容命名的方式是:日期+类型+一般内容摘要,例如:20161011知乎LIVE-詹老师——一种不需要意志力的习惯养成方法,这样不管我怎么想“猎鹰”、“习惯”、“知乎”或日期,可以找到这个材料。
第二步是分类。采集到的内容按照类型设置成文件夹并进行相应分类,就像在电脑上为各种文档创建文件夹一样。我现在常用的文件夹有:个人(存放个人内容和其他私密内容,可选择加密)、日常工作(与工作相关的资料或内容)、学习(与学习、写作、成长等相关)等。此设置的优点是,当您不记得要搜索的具体内容,但可以确定需要查找的一般类别时,您可以过滤掉其他大类并缩小搜索范围。但是,当内容积累到一定程度时,这样的分类范围还是太粗,不够细。此时,
第三步也是最重要的一步是添加标签!标签!标签!(重要的事情说三遍)按文件夹分类的材料有一个巨大的缺陷。一份资料或例子只能归入一个文件夹。如果要放到第二个文件夹,只能复制粘贴一次。. 数据本质上是复杂的。复制粘贴会导致多个重复的搜索结果,并且会白白占用宝贵的云存储空间。强烈不推荐。因此,此时需要对素材或示例做的是添加标签,而不是添加一个标签,而是添加尽可能多的标签,并根据该素材所能穷尽的所有相关特性进行标记. 例如:之前在简书上看到一篇文章文章《经验:我如何找到电子书》,它教你如何搜索你需要的电子书或电子版资料。我把这个文章按类别放在study文件夹里,但其实我在工作中也用到了电子资料的搜索技巧。所以我给这个文章加了“e-book”、“search”、“resource”、“skill”等几个标签,方便以后写文章来明确调用资源,找电子书,在普及工作技能等角度的时候可以找到这个文章。
标记有两个非常大的好处。首先,打标签可以帮助你思考反刍:除了解释原创内容之外,这个材料或例子还能用于哪些其他方面?它还可以用来支持哪些其他论点?这与上面提到的相同。李笑来老师和他的父亲,通过记录和思考,在什么时间、什么地点、什么情况下记下了笔记本上的内容。是“思维拓展”的简化版,也可以体现来这里帮助你进一步理解内容。二是通过打标签会有很多意想不到的“惊喜”。我之前写过《学会花钱》这本书的书评。当我分析涉及概率论的章节时,我点击了我标记为“
三、调用的方法
所谓调用就是搜索所有你认为你能想到的关键词来找到你想要的内容,其中一些在上一篇文章中已经提到过。可以确定,文件名的搜索是最直接的。如果没有,可以在大类中搜索,缩小范围,或者使用标签叠加的方法进行多维搜索。目前我最常用的方法是确定大类,然后使用多个标签叠加搜索的方法,这种方法是最具方向性的。如果您想在搜索时获得灵感,仅使用一个关键字浏览或单击一组单独的标签通常会给您带来意想不到的东西。
李敖拆书的著名例子就是材料采集和转移的最好例子。以下文字来自对他的采访:
我很少忘记读过的书,李敖,为什么?方法很好。有什么办法?无情。所有的剪刀和美工刀都用了,当这本书被肢解时,它被切开。这个页面我需要,这个段落我需要,我按类别分开。背面呢?复印一份,或者一开始买两本书,剪开整理一下,想看的部分留着。结果一本书写完了,书也被肢解了。我就是这样看书的。
分类是如何划分的?我有很多自己制作的剪辑,我在剪辑上写下并分类所有信息。读完一本书,全都进了我的文件夹。我可以分出上千个班级,分得很细。例如,按照图书馆的分类,有哲学类和宗教类;宗教类别进一步分为佛教、道教和天主教。我,李敖,可以分为更多的细节。天主教徒可以细分,神父是一类。牧师也可以细分。同性恋神父是一类,世俗神父是另一类。女同性恋是一类,修女是世俗的,是另一类。
书中的任何相关内容都会进入我的个人资料。输入什么?当我想写小说时,我需要这些信息,打开信息,然后就写出来。或者发生了什么事,这与修女是同性恋有关。我想表达我对新闻的想法,带来新闻,打开我的数据,合并两者,文章马上就写出来。
也就是说,看完这本书,我被五匹马撕成了八块。但我被迷住了。我不记得这些材料。我小心翼翼地把它们挂起来,放在文件夹里。我的记忆只需要记住这些标题。标题是根据我的习惯划分的。基本上都是翻译成英文单词,排列成英文字母,偶尔也有一些中文。"
四、备注
在明确了材料采集的方法和好处之后,有两点需要注意:
1.确认是真的。
逻辑中有一个重要的概念:“合乎逻辑就是符合真理”。如果采集的材料和例子来自歪曲事实或报道,那么即使它符合你的观点,支持你的说法,也没有任何意义,甚至会产生相反的效果,让读者或听众觉得你是一个无法区分的人。对真假撒谎的人,从而大大降低了你观点的可信度。此外,即使材料是真实的,也很可能是时间敏感的。因此,在使用素材或示例时,一定要记得检查内容是否真实,是否仍然准确,并及时更新筛选。如果涉及收录日期或数据的新闻、历史、人文等,
2.通知消息来源。
引用示例时,在不引用来源的情况下表达内容会让人感到缺乏信任。如果读者或听众对您引用的材料或示例特别感兴趣,他们可能希望通过这些资源了解更详细的内容。因此,在引用资料或例子时,尽量告知出处,同时不影响表达的流畅性。
五、总结
查看有关采集和组织示例的所需要点:
——为什么要注意资料和例子的采集
1.征服全场
2.已关注
3.(个人原因)
- 采集和组织方法
1.采集来源
(1)书籍 - 电子版、纸质版
(2)微信
(3) 网页
(4)其他
- 调用方法
文件名、类别、标签覆盖
- 防范措施
1.确认真相
2.通知来源
话虽如此,我只是想把我采集整理的习惯分享给大家,让分享好的东西更有意义。无论是写作、口语、推理,还是丰富对话、获取知识,还是成为一个有趣的人,好的材料和例子都是非常有帮助的。“好记性不如坏笔”,在这个时代应该改为“好记性不如坏手指”。虽然一开始可能看起来有些麻烦,但当你意识到经常采集和整理的好处时,你绝对不会停下来。想到通过采集整理,就可以控制这么大的素材库供自己使用,是多么有趣啊。
你为什么不也试试呢? 查看全部
文章采集调用(跑到图文加工店,说给点素材,中年老板:骚年你来对了)
我去了图形加工店,要了一些材料。中年老板:骚年,你说得对,我们这里有很多存货。我们拥有您需要的一切,无论是否为 JPG、PSD、AI、AE、AV……
我去了菜市场,给我举了一些例子。水果卖家:朋友知道货。今天刚到的李子很清爽。缺点是太甜了!隔壁卖糖炒栗子的小伙伸了伸脖子:大哥,带个刚出锅的袋子!
嗯……定义很重要,所以我们今天说的就是阅读中获得的文本内容,写作、演讲、推理等参考和引用的材料和例子。
其实很多大牛都写过管理自己的知识库,整理自己的知识体系文章等文章,素材和例子只是其中很小的一部分。和那些大牛相比,这次我只关注材料和例子。这个入口点非常小。如果你已经建立了自己完整的知识框架和结构,非常欢迎你给我意见和批评,面带微笑。
一、素材和例子有什么用1.征服观众
在写作或演讲时,通常围绕一个主题,你所要做的就是让读者或听众理解并接受你所说的话。如果你像教科书一样一个一个地遵守规则,你可能会失去很多观众。这种情况在演讲时尤其明显。当你偶尔低头在台上寻求所谓的眼神交流和互动感,发现台下很多人都只是笑眯眯地盯着桌子看,你应该明白你说的没那么有趣他们作为微博或朋友圈。
适当的书面或口语引用可以帮助最大程度地防止这种情况发生。在写作中引用例子可以帮助读者避免长时间阅读的疲劳,同时加深对内容的理解;演讲中生动的例子更有意义,使你表达的内容更容易被听众接受和理解。此外,成人注意力的时间曲线有其特定的规律。举两个生动的例子,在听众精力下降、容易分心的时候,可以瞬间重新集中注意力,保证演讲的良好效果。
2.已关注
你身边应该有几个这样的朋友。饭桌上,谈山,如切瓜切菜。上至天文地理玄学玄学,三体四书五道口,下至官民悲喜肉离奇故事,五花八门。境界中,入流而不入流的,如果被TA接管了,也别想带回去。如果你也想成为党的中心(当然,最好排除个人自我宣传的内容),一个反驳大片的引用,那么素材和例子的采集可以让你玩得更轻松. 李笑来老师在《花时间做朋友》中提到,父亲在公共场合总是能言善辩。一时间,他原以为父亲是个记忆力极好的人,后来才发现,父亲的秘密,其实是一本写满记录的笔记本。所谓口才,就是根据采集到的资料和例子,什么时候可以应用到什么场合。
3.生理原因(个人原因)
英语中有一句话:在我的舌尖上,字面意思是“在我的舌尖上”。它实际上意味着这些话在嘴唇上,但我突然想不起来了。在专注于采集资料和例子之前,我有很多类似的经历。我清楚地记得,前一天,甚至几个小时前,我碰巧看到了一个可以支持我观点的例子,但我不记得细节和来源了。孤歌独娘,没有结果。这时候,我会感到后背和喉咙有刺的不适感,相当难受。我认为这种感觉来自于没有保存适当的材料或示例的遗憾。
因此,采集和整理资料和例子已经成为我的日常习惯之一。“书籍只有在使用时才会被使用。” 古人早就发出过类似的感叹。事实上,对于掌握了很多新工具和新方法的现代人来说,采集和整理资料和实例其实并没有想象中的那么麻烦。
二、如何采集资料和例子1.采集资料和例子
由于我说的采集整理主要是针对文字内容,所以采集资料和例子的主要来源如下:
(1)书籍
如今,知识产权的保护普遍受到重视。很多书的内容不能直接在网上获取,只能在阅读后摘录和总结。
- 电子书
目前国内外新书趋势是电子版和纸质版同步推出。电子版通常比较便宜,可以直接在亚马逊等官网购买。尤其是刚出版的新书,基本上只能找到付费版(各种号称免费的网站往往最后都指向付费版网址)。对于已经上架一段时间的书籍,会有各种免费的电子版流出,其中大部分是PDF,但质量参差不齐。还有一件事,我找电子书的建议是,如果5-10分钟内没有找到合适的版本,基本可以放弃。不值得花更多宝贵的时间在无法保证的免费和优质内容上,并直接购买电子书。版本性价比更高,付费也体现了对知识的尊重。
以目前主流的亚马逊官网为例,购买完成后会自动推送到KINDLE。为了方便后续的整理和检索,我会使用CALIBER软件和DEDRM插件将亚马逊下载的AZW3格式转换成EPUB格式,然后把书放进书里。所需内容采集在印象笔记中(仅供学习参考,绝不参与D版盈利),让大量摘抄和引用的内容轻松复制到印象笔记保存和同步,不易丢失和容易搜索。
- 纸质书
有的书比较经典但年代久远,多次再版都没有电子版;还有非小说类的书,因为我个人喜欢边看书边写读书笔记,所以买了纸质版。对于这种纸质书,做长篇摘录很不方便,手工摘录也相当耗时。幸运的是,我在某宝上找到了一款手持扫描笔,可以快速将纸张内容扫描成可编辑的文本格式,比手动输入效率高出很多倍。以前看过万维刚的《没想到》。其中有许多科学证据的例子。段落很长。钱是不能存的。对于纸质书阅读量大、喜欢做阅读笔记的朋友来说,扫描笔是个值得推荐的工具。
(2)微信内容
微信是大多数人使用频率最高的手机应用,用得上不用说。我关联了印象笔记和有道云笔记这两个官方微信账号。我一般把值得采集的内容随时保存在云端,然后在电脑上整理总结。
(3)网页内容
当我浏览网页时,我也会保存我发现的好内容。复制粘贴部分太麻烦了。为此,我使用了印象笔记的网页剪辑插件。可以选择整页,网页正文,或者去广告等等,形式多样,非常体贴。
(4)其他
其他来源不是我采集整理资料的主流渠道,比如微信聊天记录等,我靠谷歌度娘的一些技巧整理成文字保存。
2.材料和例子的组织
采集后一定要整理好,否则起不到任何价值。整理的目的是为了更好的使用,单靠大脑很难把采集到的所有内容都记住。作为一个85后,我经常听到90后说:“哎呀!怎么记不住了?年纪大了,脑子就不行了。” 更习惯了)。事实上,人的大脑就像一台电脑。存储容量有一定的上限。此外,人脑也有遗忘机制。对于长时间不使用的内容,大脑会选择忘记释放存储空间让经常使用的模块运行。因此,我们需要将采集到的资料和实例进行更有效的整理,以方便后续的高效调用,减轻大脑的负担,
以印象笔记为例。完成采集动作后,你的印象笔记现在应该有相当多的内容了,但是它们是杂乱无章的。这时候,你需要做三件事:
第一步是取名字。这是最直接的内容分类方法,也是最原创的信息搜索渠道。我通常给内容命名的方式是:日期+类型+一般内容摘要,例如:20161011知乎LIVE-詹老师——一种不需要意志力的习惯养成方法,这样不管我怎么想“猎鹰”、“习惯”、“知乎”或日期,可以找到这个材料。
第二步是分类。采集到的内容按照类型设置成文件夹并进行相应分类,就像在电脑上为各种文档创建文件夹一样。我现在常用的文件夹有:个人(存放个人内容和其他私密内容,可选择加密)、日常工作(与工作相关的资料或内容)、学习(与学习、写作、成长等相关)等。此设置的优点是,当您不记得要搜索的具体内容,但可以确定需要查找的一般类别时,您可以过滤掉其他大类并缩小搜索范围。但是,当内容积累到一定程度时,这样的分类范围还是太粗,不够细。此时,
第三步也是最重要的一步是添加标签!标签!标签!(重要的事情说三遍)按文件夹分类的材料有一个巨大的缺陷。一份资料或例子只能归入一个文件夹。如果要放到第二个文件夹,只能复制粘贴一次。. 数据本质上是复杂的。复制粘贴会导致多个重复的搜索结果,并且会白白占用宝贵的云存储空间。强烈不推荐。因此,此时需要对素材或示例做的是添加标签,而不是添加一个标签,而是添加尽可能多的标签,并根据该素材所能穷尽的所有相关特性进行标记. 例如:之前在简书上看到一篇文章文章《经验:我如何找到电子书》,它教你如何搜索你需要的电子书或电子版资料。我把这个文章按类别放在study文件夹里,但其实我在工作中也用到了电子资料的搜索技巧。所以我给这个文章加了“e-book”、“search”、“resource”、“skill”等几个标签,方便以后写文章来明确调用资源,找电子书,在普及工作技能等角度的时候可以找到这个文章。
标记有两个非常大的好处。首先,打标签可以帮助你思考反刍:除了解释原创内容之外,这个材料或例子还能用于哪些其他方面?它还可以用来支持哪些其他论点?这与上面提到的相同。李笑来老师和他的父亲,通过记录和思考,在什么时间、什么地点、什么情况下记下了笔记本上的内容。是“思维拓展”的简化版,也可以体现来这里帮助你进一步理解内容。二是通过打标签会有很多意想不到的“惊喜”。我之前写过《学会花钱》这本书的书评。当我分析涉及概率论的章节时,我点击了我标记为“
三、调用的方法
所谓调用就是搜索所有你认为你能想到的关键词来找到你想要的内容,其中一些在上一篇文章中已经提到过。可以确定,文件名的搜索是最直接的。如果没有,可以在大类中搜索,缩小范围,或者使用标签叠加的方法进行多维搜索。目前我最常用的方法是确定大类,然后使用多个标签叠加搜索的方法,这种方法是最具方向性的。如果您想在搜索时获得灵感,仅使用一个关键字浏览或单击一组单独的标签通常会给您带来意想不到的东西。
李敖拆书的著名例子就是材料采集和转移的最好例子。以下文字来自对他的采访:
我很少忘记读过的书,李敖,为什么?方法很好。有什么办法?无情。所有的剪刀和美工刀都用了,当这本书被肢解时,它被切开。这个页面我需要,这个段落我需要,我按类别分开。背面呢?复印一份,或者一开始买两本书,剪开整理一下,想看的部分留着。结果一本书写完了,书也被肢解了。我就是这样看书的。
分类是如何划分的?我有很多自己制作的剪辑,我在剪辑上写下并分类所有信息。读完一本书,全都进了我的文件夹。我可以分出上千个班级,分得很细。例如,按照图书馆的分类,有哲学类和宗教类;宗教类别进一步分为佛教、道教和天主教。我,李敖,可以分为更多的细节。天主教徒可以细分,神父是一类。牧师也可以细分。同性恋神父是一类,世俗神父是另一类。女同性恋是一类,修女是世俗的,是另一类。
书中的任何相关内容都会进入我的个人资料。输入什么?当我想写小说时,我需要这些信息,打开信息,然后就写出来。或者发生了什么事,这与修女是同性恋有关。我想表达我对新闻的想法,带来新闻,打开我的数据,合并两者,文章马上就写出来。
也就是说,看完这本书,我被五匹马撕成了八块。但我被迷住了。我不记得这些材料。我小心翼翼地把它们挂起来,放在文件夹里。我的记忆只需要记住这些标题。标题是根据我的习惯划分的。基本上都是翻译成英文单词,排列成英文字母,偶尔也有一些中文。"
四、备注
在明确了材料采集的方法和好处之后,有两点需要注意:
1.确认是真的。
逻辑中有一个重要的概念:“合乎逻辑就是符合真理”。如果采集的材料和例子来自歪曲事实或报道,那么即使它符合你的观点,支持你的说法,也没有任何意义,甚至会产生相反的效果,让读者或听众觉得你是一个无法区分的人。对真假撒谎的人,从而大大降低了你观点的可信度。此外,即使材料是真实的,也很可能是时间敏感的。因此,在使用素材或示例时,一定要记得检查内容是否真实,是否仍然准确,并及时更新筛选。如果涉及收录日期或数据的新闻、历史、人文等,
2.通知消息来源。
引用示例时,在不引用来源的情况下表达内容会让人感到缺乏信任。如果读者或听众对您引用的材料或示例特别感兴趣,他们可能希望通过这些资源了解更详细的内容。因此,在引用资料或例子时,尽量告知出处,同时不影响表达的流畅性。
五、总结
查看有关采集和组织示例的所需要点:
——为什么要注意资料和例子的采集
1.征服全场
2.已关注
3.(个人原因)
- 采集和组织方法
1.采集来源
(1)书籍 - 电子版、纸质版
(2)微信
(3) 网页
(4)其他
- 调用方法
文件名、类别、标签覆盖
- 防范措施
1.确认真相
2.通知来源
话虽如此,我只是想把我采集整理的习惯分享给大家,让分享好的东西更有意义。无论是写作、口语、推理,还是丰富对话、获取知识,还是成为一个有趣的人,好的材料和例子都是非常有帮助的。“好记性不如坏笔”,在这个时代应该改为“好记性不如坏手指”。虽然一开始可能看起来有些麻烦,但当你意识到经常采集和整理的好处时,你绝对不会停下来。想到通过采集整理,就可以控制这么大的素材库供自己使用,是多么有趣啊。
你为什么不也试试呢?
文章采集调用(注意事项雷电模拟器要用3.96.0版本的,用7.1版本我的思路)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-04-14 20:26
一、算法
算法确实好用,但是破解的难度大家应该都知道。随着版本的更新,算法会经常发生变化,你的软件也会随着变化而更新,这样会增加开发成本。,你不得不说采集效率!就个人而言,我不认为它快得多。毕竟,访问的频率也是有限的。访问后不能更改代理,对吗?这个多少钱?
二、浏览器
不知道大家有没有发现,用户的主页是用浏览器打开的,但是用户的作品却完全没有显示出来。相信很多人的算法都是通过网页版获取的,所以这就造成了一个现象,网页版的算法,往往需要多次请求才能返回一组数据。当然,不排除有通过APP逆向获得的大神。这种情况我就不在这里讨论了,因为我也是半桶水倒过来。
三、捕获(提琴手)
Fiddler 可以说是 TCP 之外非常常见的抓包工具。证书安装好后,什么都不用做。缺点是没有API可以调用,除非你重新开发。一个调用第三方的dll库,我们在自己的程序中调用这个dll,把自己当做代理服务器,所有经过的请求都会先经过我这边,这样我就可以处理数据了。
四、备注
迅雷模拟器使用3.96.0版本,apk使用7.1版本
我的思路:
1.使用Fiddler做代理服务器,具体代码和dll库可以百度。
2.用模拟器操作,安装证书,挂代理,你刷你的视频,我的服务器会自动过滤数据,留下有用的
(1)配置模拟器,模拟器选择手机版本,分辨率可选
(2)使用模拟器中的浏览器打开软件上的链接(地址:端口),例如(192.168.0.109:8888)@ > 继续安装证书
(3)配置模拟器网络代理
就这么简单,不知道你看懂Get了吗?这个方法,不管你放在什么app上,都是可行的,只要你要抓的数据是通过http或者https传输的,那么这个方法是可以的,但是在模拟器段,你可能要写一个脚本操作请求的触发器。与破解算法相比,自动化脚本可不是小菜一碟。
关于抖音在模拟器中无法正常显示数据,可以下载7.1版本的apk,不屏蔽模拟器的7.1版本。
这是我自己的批量去水印下载的示例。有兴趣的可以自行下载试用。有问题或者需要更多功能可以私信我交流。下载后右键属性解锁,否则可能无法正常使用。
对了,win7系统可能不行,因为很多win7 Fiddler证书无法正常安装,所以软件不能抓取https,这个可以自己测试。 查看全部
文章采集调用(注意事项雷电模拟器要用3.96.0版本的,用7.1版本我的思路)
一、算法
算法确实好用,但是破解的难度大家应该都知道。随着版本的更新,算法会经常发生变化,你的软件也会随着变化而更新,这样会增加开发成本。,你不得不说采集效率!就个人而言,我不认为它快得多。毕竟,访问的频率也是有限的。访问后不能更改代理,对吗?这个多少钱?
二、浏览器
不知道大家有没有发现,用户的主页是用浏览器打开的,但是用户的作品却完全没有显示出来。相信很多人的算法都是通过网页版获取的,所以这就造成了一个现象,网页版的算法,往往需要多次请求才能返回一组数据。当然,不排除有通过APP逆向获得的大神。这种情况我就不在这里讨论了,因为我也是半桶水倒过来。
三、捕获(提琴手)
Fiddler 可以说是 TCP 之外非常常见的抓包工具。证书安装好后,什么都不用做。缺点是没有API可以调用,除非你重新开发。一个调用第三方的dll库,我们在自己的程序中调用这个dll,把自己当做代理服务器,所有经过的请求都会先经过我这边,这样我就可以处理数据了。
四、备注
迅雷模拟器使用3.96.0版本,apk使用7.1版本
我的思路:
1.使用Fiddler做代理服务器,具体代码和dll库可以百度。
2.用模拟器操作,安装证书,挂代理,你刷你的视频,我的服务器会自动过滤数据,留下有用的
(1)配置模拟器,模拟器选择手机版本,分辨率可选
(2)使用模拟器中的浏览器打开软件上的链接(地址:端口),例如(192.168.0.109:8888)@ > 继续安装证书
(3)配置模拟器网络代理
就这么简单,不知道你看懂Get了吗?这个方法,不管你放在什么app上,都是可行的,只要你要抓的数据是通过http或者https传输的,那么这个方法是可以的,但是在模拟器段,你可能要写一个脚本操作请求的触发器。与破解算法相比,自动化脚本可不是小菜一碟。
关于抖音在模拟器中无法正常显示数据,可以下载7.1版本的apk,不屏蔽模拟器的7.1版本。
这是我自己的批量去水印下载的示例。有兴趣的可以自行下载试用。有问题或者需要更多功能可以私信我交流。下载后右键属性解锁,否则可能无法正常使用。
对了,win7系统可能不行,因为很多win7 Fiddler证书无法正常安装,所以软件不能抓取https,这个可以自己测试。
文章采集调用(2.采集支持调用奶盘API接口(组图)采集数据 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-04-14 17:06
)
优采云采集支持调用奶盘API接口,处理采集的数据标题和内容等;
温馨提示:第三方API接入功能需要用户提供第三方接口账号信息(即用户需要注册第三方接口,调用第三方接口产生的一切费用自理)由用户);
详细使用步骤
1. 创建奶盘API接口配置一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==最后点击【奶锅】 Open API] 创建接口配置;
二、配置API接口信息:
【Purchased Authorized User】和【Purchased Authorization Code】是从后台获取API授权信息,填写优采云;
【API版】是奶锅网购买对应的套餐:百度优化版、AI智能版;
注意:由于牛奶托盘每次调用限制为最多65000个字符(包括html代码),当内容长度超过时,优采云会被分割多次调用。这个操作会增加api调用次数,开销也会相应增加。这是用户需要承担的成本。使用前一定要注意!!!
2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==,点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击【+添加API处理规则]创建API处理规则;
二、API处理规则配置:
3. API 处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
一、手动执行API处理规则:
在采集任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译等工具】按钮==选择【第三方API执行】栏==选择对应的API处理规则= ="执行(数据范围有两种执行方式,根据发布状态批量执行和根据列表中选择的数据执行);
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡【自动执行第三方API配置】==勾选【采集,自动执行API】选项==选择要执行的API处理规则= ="选择API接口处理的数据范围(一般选择'待释放',all会导致所有数据重复执行),最后点击保存;
4. API处理结果并发布一、查看API接口处理结果:
API接口处理后的内容会保存为一个新的字段,如:标题处理后的新字段:`title_milk tray`,内容处理后的新字段:`content_milk tray`,在【结果数据&发布】和可以查看数据预览界面。
提示:执行 API 处理规则需要一段时间。执行完成后,页面会自动刷新,并出现API接口处理的新字段;
二、API接口处理后的内容发布
发布文章前,修改发布目标第二步的映射字段,重新选择标题和内容到API接口处理后添加的对应字段`title_milk tray'和`content_milk tray';
提示:如果发布目标中无法选择新字段,请在任务下复制或新建发布目标,然后在新发布目标中选择新字段即可。详细教程请参考发布目标中不能选择的字段。
5. 奶盘-API接口常见问题及解决方法一、API处理规则和SEO规则如何结合使用?
系统默认对title和content字段进行SEO功能,需要修改为SEO规则中的`title_milk tray'和`content_milk tray'字段;
查看全部
文章采集调用(2.采集支持调用奶盘API接口(组图)采集数据
)
优采云采集支持调用奶盘API接口,处理采集的数据标题和内容等;
温馨提示:第三方API接入功能需要用户提供第三方接口账号信息(即用户需要注册第三方接口,调用第三方接口产生的一切费用自理)由用户);
详细使用步骤
1. 创建奶盘API接口配置一、API配置入口:
点击控制台左侧列表中的【第三方服务配置】==点击【第三方内容API接入】==点击【第三方API配置管理】==最后点击【奶锅】 Open API] 创建接口配置;
二、配置API接口信息:
【Purchased Authorized User】和【Purchased Authorization Code】是从后台获取API授权信息,填写优采云;
【API版】是奶锅网购买对应的套餐:百度优化版、AI智能版;
注意:由于牛奶托盘每次调用限制为最多65000个字符(包括html代码),当内容长度超过时,优采云会被分割多次调用。这个操作会增加api调用次数,开销也会相应增加。这是用户需要承担的成本。使用前一定要注意!!!
2. 创建 API 处理规则
API处理规则,可以通过调用API接口设置处理哪些字段的内容;
一、API处理规则入口:
点击控制台左侧列表中的【第三方服务配置】==,点击【第三方内容API接入】==进入【API处理规则管理】页面,最后点击【+添加API处理规则]创建API处理规则;
二、API处理规则配置:
3. API 处理规则使用
API处理规则有两种使用方式:手动执行和自动执行:
一、手动执行API处理规则:
在采集任务的【结果数据&发布】选项卡中,点击【SEO&API&翻译等工具】按钮==选择【第三方API执行】栏==选择对应的API处理规则= ="执行(数据范围有两种执行方式,根据发布状态批量执行和根据列表中选择的数据执行);
二、自动执行API处理规则:
启用 API 处理的自动执行。任务完成后采集会自动执行API处理。一般配合定时采集和自动发布功能使用非常方便;
在任务的【自动化:发布&SEO&翻译】选项卡【自动执行第三方API配置】==勾选【采集,自动执行API】选项==选择要执行的API处理规则= ="选择API接口处理的数据范围(一般选择'待释放',all会导致所有数据重复执行),最后点击保存;
4. API处理结果并发布一、查看API接口处理结果:
API接口处理后的内容会保存为一个新的字段,如:标题处理后的新字段:`title_milk tray`,内容处理后的新字段:`content_milk tray`,在【结果数据&发布】和可以查看数据预览界面。
提示:执行 API 处理规则需要一段时间。执行完成后,页面会自动刷新,并出现API接口处理的新字段;
二、API接口处理后的内容发布
发布文章前,修改发布目标第二步的映射字段,重新选择标题和内容到API接口处理后添加的对应字段`title_milk tray'和`content_milk tray';
提示:如果发布目标中无法选择新字段,请在任务下复制或新建发布目标,然后在新发布目标中选择新字段即可。详细教程请参考发布目标中不能选择的字段。
5. 奶盘-API接口常见问题及解决方法一、API处理规则和SEO规则如何结合使用?
系统默认对title和content字段进行SEO功能,需要修改为SEO规则中的`title_milk tray'和`content_milk tray'字段;
文章采集调用( 开发环境JDK1.8.0javassist本章本章GA本章涉及源码的开发)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-13 14:15
开发环境JDK1.8.0javassist本章本章GA本章涉及源码的开发)
一、前言
字节码编程插桩技术常结合Javaagent技术用于系统的非侵入式监控,可以替代方法中的硬编码操作。例如,您需要监控一个方法,包括;方法信息、执行时间、输入输出参数、执行链接、异常。那么就非常适合用这样的技术手段进行加工。
为了体现这部分的核心内容,本文将只使用Javassist技术对一段方法字节码进行instrument,最后输出该方法的执行信息,如下;
Method - 后续字节码增强操作的测试方法
public Integer strToInt(String str01, String str02) {
return Integer.parseInt(str01);
}
监控 - 方法的字节码增强后,输出监控信息
监控 - Begin
方法:org.itstack.demo.javassist.ApiTest.strToInt
入参:["str01","str02"] 入参[类型]:["java.lang.String","java.lang.String"] 入数[值]:["1","2"]
出参:java.lang.Integer 出参[值]:1
耗时:59(s)
监控 - End
有了这样的监控方案,我们基本上可以输出方法执行过程中的所有信息。然后通过后期的改进,将监控信息显示在界面上,并实时发出警报。不仅提高了系统的监控质量,也便于研发排查和定位问题。
这很好!然后我们一步步开始使用javassist进行字节码插桩,就达到了我们的监控效果。
二、开发环境JDK 1.8.0javassist 3.12.1.GA本章涉及的源码为:itstack-demo-bytecode -1-04,可以关注公众号:bugstack 虫洞栈,回复源码下载即可。您将获得下载链接列表。打开后第十七期“因为我有很多开源代码”,记得给个Star!三、技术实现1. 获取方法的基本信息1.1 获取类
ClassPool pool = ClassPool.getDefault();
// 获取类
CtClass ctClass = pool.get(org.itstack.demo.javassist.ApiTest.class.getName());
ctClass.replaceClassName("ApiTest", "ApiTest02");
String clazzName = ctClass.getName();
通过类名获取类信息,这里可以替换类名。它还包括一些其他操作来获取类中的属性,例如;ctClass.getSimpleName()、ctClass.getAnnotations() 等等。
1.2 如何获得
CtMethod ctMethod = ctClass.getDeclaredMethod("strToInt");
String methodName = ctMethod.getName();
通过getDeclaredMethod获取方法的CtMethod的内容。之后,您可以获取方法名称等信息。
1.3 方法信息
MethodInfo methodInfo = ctMethod.getMethodInfo();
MethodInfo 收录方法信息;名称、类型等
1.4 种方法类型
boolean isStatic = (methodInfo.getAccessFlags() & AccessFlag.STATIC) != 0;
通过methodInfo.getAccessFlags()获取方法的标识符,然后使用AND运算AccessFlag.STATIC判断该方法是否为静态方法。因为静态方法会影响后续参数名的获取,所以静态方法的第一个参数就是this,需要排除。
1.5 方法:输入参数信息{name and type}
CodeAttribute codeAttribute = methodInfo.getCodeAttribute();
LocalVariableAttribute attr = (LocalVariableAttribute) codeAttribute.getAttribute(LocalVariableAttribute.tag);
CtClass[] parameterTypes = ctMethod.getParameterTypes();
1.6 方法;参数信息
CtClass returnType = ctMethod.getReturnType();
String returnTypeName = returnType.getName();
对于方法的参数信息,只需要获取参数类型即可。
1.7 输出所有获取的信息
System.out.println("类名:" + clazzName);
System.out.println("方法:" + methodName);
System.out.println("类型:" + (isStatic ? "静态方法" : "非静态方法"));
System.out.println("描述:" + methodInfo.getDescriptor());
System.out.println("入参[名称]:" + attr.variableName(1) + "," + attr.variableName(2));
System.out.println("入参[类型]:" + parameterTypes[0].getName() + "," + parameterTypes[1].getName());
System.out.println("出参[类型]:" + returnTypeName);
输出结果
类名:org.itstack.demo.javassist.ApiTest
方法:strToInt
类型:非静态方法
描述:(Ljava/lang/String;Ljava/lang/String;)Ljava/lang/Integer;
入参[名称]:str01,str02
入参[类型]:java.lang.String,java.lang.String
出参[类型]:java.lang.Integer
以上,输出信息为监控方法做准备。从上面可以记录方法的基本描述和输入参数的数量。尤其是入参的个数,因为后面需要用到$1来获取没有给入参的值。
2. 方法字节码检测
需要通过字节码检测来更改的原创方法;
public class ApiTest {
public Integer strToInt(String str01, String str02) {
return Integer.parseInt(str01);
}
}
2.1 先标记基础属性
在监控的情况下,不可能将每次调用的所有方法信息都汇总输出。这不仅仅是性能问题,这些都是固定信息,不需要每次方法执行都输出。
这很好!然后在编译方法时,会为每个方法生成一个唯一的ID,并将方法的固定信息与ID关联起来。也可以通过ID将监控数据传递到外部。
// 方法:生成方法唯一标识ID
int idx = Monitor.generateMethodId(clazzName, methodName, parameterNameList, parameterTypeList, returnTypeName);
生成ID的过程
public static final int MAX_NUM = 1024 * 32;
private final static AtomicInteger index = new AtomicInteger(0);
private final static AtomicReferenceArray methodTagArr = new AtomicReferenceArray(MAX_NUM);
public static int generateMethodId(String clazzName, String methodName, List parameterNameList, List parameterTypeList, String returnType) {
MethodDescription methodDescription = new MethodDescription();
methodDescription.setClazzName(clazzName);
methodDescription.setMethodName(methodName);
methodDescription.setParameterNameList(parameterNameList);
methodDescription.setParameterTypeList(parameterTypeList);
methodDescription.setReturnType(returnType);
int methodId = index.getAndIncrement();
if (methodId > MAX_NUM) return -1;
methodTagArr.set(methodId, methodDescription);
return methodId;
}
2.2 字节码检测增加入口方法时间
// 定义属性
ctMethod.addLocalVariable("startNanos", CtClass.longType);
// 方法前加强
ctMethod.insertBefore("{ startNanos = System.nanoTime(); }");
final类类方法
public class ApiTest {
public Integer strToInt(String str01, String str02) {
long startNanos = System.nanoTime();
return Integer.parseInt(str01);
}
}
2.3 字节码检测添加输入和输出
// 定义属性
ctMethod.addLocalVariable("parameterValues", pool.get(Object[].class.getName()));
// 方法前加强
ctMethod.insertBefore("{ parameterValues = new Object[]{" + parameters.toString() + "}; }");
final类类方法
public Integer strToInt(String str01, String str02) {
Object[] var10000 = new Object[]{str01, str02};
long startNanos = System.nanoTime();
return Integer.parseInt(str01);
}
2.4 定义监控方法
因为我们需要向外部输出监控信息。然后我们在这里定义一个静态方法,让字节码增强的方法调用,并输出监控信息。
public static void point(final int methodId, final long startNanos, Object[] parameterValues, Object returnValues) {
MethodDescription method = methodTagArr.get(methodId);
System.out.println("监控 - Begin");
System.out.println("方法:" + method.getClazzName() + "." + method.getMethodName());
System.out.println("入参:" + JSON.toJSONString(method.getParameterNameList()) + " 入参[类型]:" + JSON.toJSONString(method.getParameterTypeList()) + " 入数[值]:" + JSON.toJSONString(parameterValues));
System.out.println("出参:" + method.getReturnType() + " 出参[值]:" + JSON.toJSONString(returnValues));
System.out.println("耗时:" + (System.nanoTime() - startNanos) / 1000000 + "(s)");
System.out.println("监控 - End\r\n");
}
public static void point(final int methodId, Throwable throwable) {
MethodDescription method = methodTagArr.get(methodId);
System.out.println("监控 - Begin");
System.out.println("方法:" + method.getClazzName() + "." + method.getMethodName());
System.out.println("异常:" + throwable.getMessage());
System.out.println("监控 - End\r\n");
}
2.5 字节码检测调用监控方法
// 方法后加强
ctMethod.insertAfter("{ org.itstack.demo.javassist.Monitor.point(" + idx + ", startNanos, parameterValues, $_);}", false); // 如果返回类型非对象类型,$_ 需要进行类型转换
final类类方法
public Integer strToInt(String str01, String str02) {
Object[] parameterValues = new Object[]{str01, str02};
long startNanos = System.nanoTime();
Integer var7 = Integer.parseInt(str01);
Monitor.point(0, startNanos, parameterValues, var7);
return var7;
}
2.6 字节码检测将 TryCatch 添加到方法中
以上instrumentation内容,如果只是正常调用,是没有问题的。但是如果方法抛出异常,那么此时就无法采集到监控信息。所以你还需要将 TryCatch 添加到方法中。
// 方法;添加TryCatch
ctMethod.addCatch("{ org.itstack.demo.javassist.Monitor.point(" + idx + ", $e); throw $e; }", ClassPool.getDefault().get("java.lang.Exception")); // 添加异常捕获
final类类方法
public Integer strToInt(String str01, String str02) {
try {
Object[] parameterValues = new Object[]{str01, str02};
long startNanos = System.nanoTime();
Integer var7 = Integer.parseInt(str01);
Monitor.point(0, startNanos, parameterValues, var7);
return var7;
} catch (Exception var9) {
Monitor.point(0, var9);
throw var9;
}
}
四、测试结果
下一步是执行我们的调用来测试修改后的方法字节码。通过不同的输入参数验证监测结果;
// 测试调用
byte[] bytes = ctClass.toBytecode();
Class clazzNew = new GenerateClazzMethod().defineClass("org.itstack.demo.javassist.ApiTest", bytes, 0, bytes.length);
// 反射获取 main 方法
Method method = clazzNew.getMethod("strToInt", String.class, String.class);
Object obj_01 = method.invoke(clazzNew.newInstance(), "1", "2");
System.out.println("正确入参:" + obj_01);
Object obj_02 = method.invoke(clazzNew.newInstance(), "a", "b");
System.out.println("异常入参:" + obj_02);
测试结果
监控 - Begin
方法:org.itstack.demo.javassist.ApiTest.strToInt
入参:["str01","str02"] 入参[类型]:["java.lang.String","java.lang.String"] 入数[值]:["1","2"]
出参:java.lang.Integer 出参[值]:1
耗时:63(s)
监控 - End
正确入参:1
监控 - Begin
方法:org.itstack.demo.javassist.ApiTest.strToInt
异常:For input string: "a"
监控 - End
五、总结 查看全部
文章采集调用(
开发环境JDK1.8.0javassist本章本章GA本章涉及源码的开发)
一、前言
字节码编程插桩技术常结合Javaagent技术用于系统的非侵入式监控,可以替代方法中的硬编码操作。例如,您需要监控一个方法,包括;方法信息、执行时间、输入输出参数、执行链接、异常。那么就非常适合用这样的技术手段进行加工。
为了体现这部分的核心内容,本文将只使用Javassist技术对一段方法字节码进行instrument,最后输出该方法的执行信息,如下;
Method - 后续字节码增强操作的测试方法
public Integer strToInt(String str01, String str02) {
return Integer.parseInt(str01);
}
监控 - 方法的字节码增强后,输出监控信息
监控 - Begin
方法:org.itstack.demo.javassist.ApiTest.strToInt
入参:["str01","str02"] 入参[类型]:["java.lang.String","java.lang.String"] 入数[值]:["1","2"]
出参:java.lang.Integer 出参[值]:1
耗时:59(s)
监控 - End
有了这样的监控方案,我们基本上可以输出方法执行过程中的所有信息。然后通过后期的改进,将监控信息显示在界面上,并实时发出警报。不仅提高了系统的监控质量,也便于研发排查和定位问题。
这很好!然后我们一步步开始使用javassist进行字节码插桩,就达到了我们的监控效果。
二、开发环境JDK 1.8.0javassist 3.12.1.GA本章涉及的源码为:itstack-demo-bytecode -1-04,可以关注公众号:bugstack 虫洞栈,回复源码下载即可。您将获得下载链接列表。打开后第十七期“因为我有很多开源代码”,记得给个Star!三、技术实现1. 获取方法的基本信息1.1 获取类
ClassPool pool = ClassPool.getDefault();
// 获取类
CtClass ctClass = pool.get(org.itstack.demo.javassist.ApiTest.class.getName());
ctClass.replaceClassName("ApiTest", "ApiTest02");
String clazzName = ctClass.getName();
通过类名获取类信息,这里可以替换类名。它还包括一些其他操作来获取类中的属性,例如;ctClass.getSimpleName()、ctClass.getAnnotations() 等等。
1.2 如何获得
CtMethod ctMethod = ctClass.getDeclaredMethod("strToInt");
String methodName = ctMethod.getName();
通过getDeclaredMethod获取方法的CtMethod的内容。之后,您可以获取方法名称等信息。
1.3 方法信息
MethodInfo methodInfo = ctMethod.getMethodInfo();
MethodInfo 收录方法信息;名称、类型等
1.4 种方法类型
boolean isStatic = (methodInfo.getAccessFlags() & AccessFlag.STATIC) != 0;
通过methodInfo.getAccessFlags()获取方法的标识符,然后使用AND运算AccessFlag.STATIC判断该方法是否为静态方法。因为静态方法会影响后续参数名的获取,所以静态方法的第一个参数就是this,需要排除。
1.5 方法:输入参数信息{name and type}
CodeAttribute codeAttribute = methodInfo.getCodeAttribute();
LocalVariableAttribute attr = (LocalVariableAttribute) codeAttribute.getAttribute(LocalVariableAttribute.tag);
CtClass[] parameterTypes = ctMethod.getParameterTypes();
1.6 方法;参数信息
CtClass returnType = ctMethod.getReturnType();
String returnTypeName = returnType.getName();
对于方法的参数信息,只需要获取参数类型即可。
1.7 输出所有获取的信息
System.out.println("类名:" + clazzName);
System.out.println("方法:" + methodName);
System.out.println("类型:" + (isStatic ? "静态方法" : "非静态方法"));
System.out.println("描述:" + methodInfo.getDescriptor());
System.out.println("入参[名称]:" + attr.variableName(1) + "," + attr.variableName(2));
System.out.println("入参[类型]:" + parameterTypes[0].getName() + "," + parameterTypes[1].getName());
System.out.println("出参[类型]:" + returnTypeName);
输出结果
类名:org.itstack.demo.javassist.ApiTest
方法:strToInt
类型:非静态方法
描述:(Ljava/lang/String;Ljava/lang/String;)Ljava/lang/Integer;
入参[名称]:str01,str02
入参[类型]:java.lang.String,java.lang.String
出参[类型]:java.lang.Integer
以上,输出信息为监控方法做准备。从上面可以记录方法的基本描述和输入参数的数量。尤其是入参的个数,因为后面需要用到$1来获取没有给入参的值。
2. 方法字节码检测
需要通过字节码检测来更改的原创方法;
public class ApiTest {
public Integer strToInt(String str01, String str02) {
return Integer.parseInt(str01);
}
}
2.1 先标记基础属性
在监控的情况下,不可能将每次调用的所有方法信息都汇总输出。这不仅仅是性能问题,这些都是固定信息,不需要每次方法执行都输出。
这很好!然后在编译方法时,会为每个方法生成一个唯一的ID,并将方法的固定信息与ID关联起来。也可以通过ID将监控数据传递到外部。
// 方法:生成方法唯一标识ID
int idx = Monitor.generateMethodId(clazzName, methodName, parameterNameList, parameterTypeList, returnTypeName);
生成ID的过程
public static final int MAX_NUM = 1024 * 32;
private final static AtomicInteger index = new AtomicInteger(0);
private final static AtomicReferenceArray methodTagArr = new AtomicReferenceArray(MAX_NUM);
public static int generateMethodId(String clazzName, String methodName, List parameterNameList, List parameterTypeList, String returnType) {
MethodDescription methodDescription = new MethodDescription();
methodDescription.setClazzName(clazzName);
methodDescription.setMethodName(methodName);
methodDescription.setParameterNameList(parameterNameList);
methodDescription.setParameterTypeList(parameterTypeList);
methodDescription.setReturnType(returnType);
int methodId = index.getAndIncrement();
if (methodId > MAX_NUM) return -1;
methodTagArr.set(methodId, methodDescription);
return methodId;
}
2.2 字节码检测增加入口方法时间
// 定义属性
ctMethod.addLocalVariable("startNanos", CtClass.longType);
// 方法前加强
ctMethod.insertBefore("{ startNanos = System.nanoTime(); }");
final类类方法
public class ApiTest {
public Integer strToInt(String str01, String str02) {
long startNanos = System.nanoTime();
return Integer.parseInt(str01);
}
}
2.3 字节码检测添加输入和输出
// 定义属性
ctMethod.addLocalVariable("parameterValues", pool.get(Object[].class.getName()));
// 方法前加强
ctMethod.insertBefore("{ parameterValues = new Object[]{" + parameters.toString() + "}; }");
final类类方法
public Integer strToInt(String str01, String str02) {
Object[] var10000 = new Object[]{str01, str02};
long startNanos = System.nanoTime();
return Integer.parseInt(str01);
}
2.4 定义监控方法
因为我们需要向外部输出监控信息。然后我们在这里定义一个静态方法,让字节码增强的方法调用,并输出监控信息。
public static void point(final int methodId, final long startNanos, Object[] parameterValues, Object returnValues) {
MethodDescription method = methodTagArr.get(methodId);
System.out.println("监控 - Begin");
System.out.println("方法:" + method.getClazzName() + "." + method.getMethodName());
System.out.println("入参:" + JSON.toJSONString(method.getParameterNameList()) + " 入参[类型]:" + JSON.toJSONString(method.getParameterTypeList()) + " 入数[值]:" + JSON.toJSONString(parameterValues));
System.out.println("出参:" + method.getReturnType() + " 出参[值]:" + JSON.toJSONString(returnValues));
System.out.println("耗时:" + (System.nanoTime() - startNanos) / 1000000 + "(s)");
System.out.println("监控 - End\r\n");
}
public static void point(final int methodId, Throwable throwable) {
MethodDescription method = methodTagArr.get(methodId);
System.out.println("监控 - Begin");
System.out.println("方法:" + method.getClazzName() + "." + method.getMethodName());
System.out.println("异常:" + throwable.getMessage());
System.out.println("监控 - End\r\n");
}
2.5 字节码检测调用监控方法
// 方法后加强
ctMethod.insertAfter("{ org.itstack.demo.javassist.Monitor.point(" + idx + ", startNanos, parameterValues, $_);}", false); // 如果返回类型非对象类型,$_ 需要进行类型转换
final类类方法
public Integer strToInt(String str01, String str02) {
Object[] parameterValues = new Object[]{str01, str02};
long startNanos = System.nanoTime();
Integer var7 = Integer.parseInt(str01);
Monitor.point(0, startNanos, parameterValues, var7);
return var7;
}
2.6 字节码检测将 TryCatch 添加到方法中
以上instrumentation内容,如果只是正常调用,是没有问题的。但是如果方法抛出异常,那么此时就无法采集到监控信息。所以你还需要将 TryCatch 添加到方法中。
// 方法;添加TryCatch
ctMethod.addCatch("{ org.itstack.demo.javassist.Monitor.point(" + idx + ", $e); throw $e; }", ClassPool.getDefault().get("java.lang.Exception")); // 添加异常捕获
final类类方法
public Integer strToInt(String str01, String str02) {
try {
Object[] parameterValues = new Object[]{str01, str02};
long startNanos = System.nanoTime();
Integer var7 = Integer.parseInt(str01);
Monitor.point(0, startNanos, parameterValues, var7);
return var7;
} catch (Exception var9) {
Monitor.point(0, var9);
throw var9;
}
}
四、测试结果
下一步是执行我们的调用来测试修改后的方法字节码。通过不同的输入参数验证监测结果;
// 测试调用
byte[] bytes = ctClass.toBytecode();
Class clazzNew = new GenerateClazzMethod().defineClass("org.itstack.demo.javassist.ApiTest", bytes, 0, bytes.length);
// 反射获取 main 方法
Method method = clazzNew.getMethod("strToInt", String.class, String.class);
Object obj_01 = method.invoke(clazzNew.newInstance(), "1", "2");
System.out.println("正确入参:" + obj_01);
Object obj_02 = method.invoke(clazzNew.newInstance(), "a", "b");
System.out.println("异常入参:" + obj_02);
测试结果
监控 - Begin
方法:org.itstack.demo.javassist.ApiTest.strToInt
入参:["str01","str02"] 入参[类型]:["java.lang.String","java.lang.String"] 入数[值]:["1","2"]
出参:java.lang.Integer 出参[值]:1
耗时:63(s)
监控 - End
正确入参:1
监控 - Begin
方法:org.itstack.demo.javassist.ApiTest.strToInt
异常:For input string: "a"
监控 - End
五、总结
文章采集调用(优采云采集+伪原创错误博客分享《《》)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-04-13 05:18
优采云 是一个非常有用的文章采集 工具,但它也是一个很多人不知道的文章 构建工具。优采云采集+伪原创 方法已经流行了这么多年,仍然被大量的人使用,构建 原创文章 将使网站 改变更好的质量。今天,bug 博客( )分享了“优采云采集如何量产原创文章”。我希望能有所帮助。
优采云构建原创文章
一、优采云采集+伪原创
报错博客先讲优采云采集伪原创的操作方法。查找更好的信息网站采集一些较新的文章、采集有互联网热词,如百度搜索热点、抖音热点、微信博热搜和很快。
标题不要重复,不建议直接伪原创标题。最好手动编辑标题。内容 伪原创 应该是可读的。如果不可读,不建议使用那种工具,因为这个内容已经发了很久了,网站活不了多久了。
优采云采集+伪原创的形式确实可以创作很多内容,但是也应该考虑在网站中发布一些原创文章提高百度信心,让您事半功倍。
二、优采云构建原创文章
与其 优采云 构造 原创文章 不如调用内容,然后使用 文章 正文内容格式调用那些单词和句子。如何将这些单词和句子很好地呈现给用户和搜索引擎,不仅具有一定的可读性,而且具有看似实用的功能。这是错误博客的示例。当 爱站 网络对 网站 进行数据查询时,该页面是一个类似于 原创文章 的新页面,通过调用各种数据形成。页面,这样的页面有很好的排名。当这种页面出现在搜索引擎中时,很多人会选择点击,而且可能会停留很长时间。这是一个成功的案例。
当然,错误博客并没有那么有能力做出这样一种形式的页面来调用各种数据,但是我们可以根据自己的能力来构建这样一个原创页面,这样大量的内容页面就会不被我们使用。搜索引擎的罢工也可能会受到鼓励,毕竟这个页面非常实用。 查看全部
文章采集调用(优采云采集+伪原创错误博客分享《《》)
优采云 是一个非常有用的文章采集 工具,但它也是一个很多人不知道的文章 构建工具。优采云采集+伪原创 方法已经流行了这么多年,仍然被大量的人使用,构建 原创文章 将使网站 改变更好的质量。今天,bug 博客( )分享了“优采云采集如何量产原创文章”。我希望能有所帮助。
优采云构建原创文章
一、优采云采集+伪原创
报错博客先讲优采云采集伪原创的操作方法。查找更好的信息网站采集一些较新的文章、采集有互联网热词,如百度搜索热点、抖音热点、微信博热搜和很快。
标题不要重复,不建议直接伪原创标题。最好手动编辑标题。内容 伪原创 应该是可读的。如果不可读,不建议使用那种工具,因为这个内容已经发了很久了,网站活不了多久了。
优采云采集+伪原创的形式确实可以创作很多内容,但是也应该考虑在网站中发布一些原创文章提高百度信心,让您事半功倍。
二、优采云构建原创文章
与其 优采云 构造 原创文章 不如调用内容,然后使用 文章 正文内容格式调用那些单词和句子。如何将这些单词和句子很好地呈现给用户和搜索引擎,不仅具有一定的可读性,而且具有看似实用的功能。这是错误博客的示例。当 爱站 网络对 网站 进行数据查询时,该页面是一个类似于 原创文章 的新页面,通过调用各种数据形成。页面,这样的页面有很好的排名。当这种页面出现在搜索引擎中时,很多人会选择点击,而且可能会停留很长时间。这是一个成功的案例。
当然,错误博客并没有那么有能力做出这样一种形式的页面来调用各种数据,但是我们可以根据自己的能力来构建这样一个原创页面,这样大量的内容页面就会不被我们使用。搜索引擎的罢工也可能会受到鼓励,毕竟这个页面非常实用。
文章采集调用(R语言爬虫格式的json格式,寻找新的方法!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-04-12 19:35
==========背景===================
最近一直在用R语言爬,但是有些网站是动态json格式的。每次都找到重定向的 URL 很麻烦。因此,我正在寻找一种新方法,构建一个浏览器,在浏览器中查找 URL。于是出现了以下问题:
==========执行步骤分割线============
1、cmd enable java -jar selenium-server-standalone-2.53.0.jar //启动selenium
2、R 控制台
> library("Rwebdriver", lib.loc="C:/Program Files/R/R-3.2.3/library")
加载所需的包:RCurl
加载所需的包:bitops
加载所需包:RJSONIO
> library("XML", lib.loc="\\\\CNDOUW0000/Users/CNLeeWi/R/win-library/3.2")
> start_session(root = "" ,browser = "firefox")
函数错误(类型、msg、asError = TRUE):
无法连接到 localhost 端口 80:连接被拒绝
==========相关信息链接================== 查看全部
文章采集调用(R语言爬虫格式的json格式,寻找新的方法!)
==========背景===================
最近一直在用R语言爬,但是有些网站是动态json格式的。每次都找到重定向的 URL 很麻烦。因此,我正在寻找一种新方法,构建一个浏览器,在浏览器中查找 URL。于是出现了以下问题:
==========执行步骤分割线============
1、cmd enable java -jar selenium-server-standalone-2.53.0.jar //启动selenium
2、R 控制台
> library("Rwebdriver", lib.loc="C:/Program Files/R/R-3.2.3/library")
加载所需的包:RCurl
加载所需的包:bitops
加载所需包:RJSONIO
> library("XML", lib.loc="\\\\CNDOUW0000/Users/CNLeeWi/R/win-library/3.2")
> start_session(root = "" ,browser = "firefox")
函数错误(类型、msg、asError = TRUE):
无法连接到 localhost 端口 80:连接被拒绝
==========相关信息链接==================
文章采集调用(天弘基金(余额宝)移动平台首席架构师负责人)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-04-12 17:31
近年来,APM进入了快速发展的快车道。作为APM的核心功能,分布式环境下的自动应用发现和动态调用链路分析也被广泛应用于APM的推广。一些不足暴露出来:完全基于运行状态的分析模式决定了只能获取与实际调用的逻辑链接,大量未被掩埋或未被触发的调用逻辑成为无法触及的“失落的世界” . 撞。找到这部分“失落的世界”对于我们了解分布式环境中应用程序的全貌非常重要。天鸿基金移动平台团队在这方面进行了一些创新探索。我们跳出了传统APM的惯性思维,扫描分析海量代码中的调用关系,得到分布式环境下“前中后”站的完整调用链,并在此基础上叠加动态调用链,构建精细化APM监控。通过这个话题,我将结合我们的实践,详细介绍“静态调用链路发现”的技术和手段,并探讨如何在运维和开发场景中将其与现有的APM能力相结合。-->观众受益:1、了解分布式环境下APM的“优”与“差”。2、了解构建“静态呼叫链路发现”能力的技术和手段。3、 学习如何用创新思维拓展APM的应用场景。--> 个人介绍:天弘基金(月宝)移动平台首席架构师李鑫,负责移动平台整体技术架构设计。曾任当当网架构师,负责电商后端运营产品平台整体技术架构及研发团队管理;华为云计算专家,主导华为软件各类云计算产品和服务的设计、规划和建设。个人技术涉及大规模分布式应用与治理、中间件云化与服务化(PaaS)、APM监控、基础开发平台等领域, 查看全部
文章采集调用(天弘基金(余额宝)移动平台首席架构师负责人)
近年来,APM进入了快速发展的快车道。作为APM的核心功能,分布式环境下的自动应用发现和动态调用链路分析也被广泛应用于APM的推广。一些不足暴露出来:完全基于运行状态的分析模式决定了只能获取与实际调用的逻辑链接,大量未被掩埋或未被触发的调用逻辑成为无法触及的“失落的世界” . 撞。找到这部分“失落的世界”对于我们了解分布式环境中应用程序的全貌非常重要。天鸿基金移动平台团队在这方面进行了一些创新探索。我们跳出了传统APM的惯性思维,扫描分析海量代码中的调用关系,得到分布式环境下“前中后”站的完整调用链,并在此基础上叠加动态调用链,构建精细化APM监控。通过这个话题,我将结合我们的实践,详细介绍“静态调用链路发现”的技术和手段,并探讨如何在运维和开发场景中将其与现有的APM能力相结合。-->观众受益:1、了解分布式环境下APM的“优”与“差”。2、了解构建“静态呼叫链路发现”能力的技术和手段。3、 学习如何用创新思维拓展APM的应用场景。--> 个人介绍:天弘基金(月宝)移动平台首席架构师李鑫,负责移动平台整体技术架构设计。曾任当当网架构师,负责电商后端运营产品平台整体技术架构及研发团队管理;华为云计算专家,主导华为软件各类云计算产品和服务的设计、规划和建设。个人技术涉及大规模分布式应用与治理、中间件云化与服务化(PaaS)、APM监控、基础开发平台等领域,
文章采集调用(一个企业网站被百度降权了怎么办?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-04-12 06:32
去年年底,一位客户要求我帮助创建一家公司网站。考虑到 网站 将来会推广搜索引擎,网站 在 SEO 中必须是搜索引擎友好的。最后我选择了DeDecms,它可以在URL、PageTitle、TextBlock、LinkBlock、Auto Sitemap、Related Article中做早期的SEO布局。所以在栏目规划、版面设计、模板制作阶段,我将各种SEO元素充分融入到整个制作阶段,希望网站上线后,能够快速积累搜索排名权重。尤其是在模板代码编写方面,可以有效控制链接输出和导入,尽可能提高内部链接的相关性和关键词的匹配位置,去除无用的网页噪音信息,
果然,网站正式发布后,网站收录的占比迅速达到70%,大部分产品终端页面为收录,部分信息页面为收录 ,更重要的是:行业关键词排名和产品关键词排名进步很快;整个网站在SEO运营中呈现良性发展态势。客户端开始接管网站并正常更新站点内容,按照设定的时间表,一切应该都进行得很顺利。
不过最近网站SEO的表现开始下滑,网页数量收录首当其冲。百度统计后台显示的页面索引与搜索框中site命令返回的结果数量有显着差异。site 命令显示 Only 2 pages are 收录,都是首页,首页有 www 和没有 www 的两个版本。另外,信息正常更新后,百度索引很快,短时间内可以通过site命令返回结果,但过了一会儿发现收录无效。基于以上情况,我认为网站已经被百度降级了。
为了找到问题所在,我研究了各种因素,发现:
(1)除了正常更新网站的内容外,企业端也在积极运营外链,建外链是好事,但是用错了方式参与资源站的链轮;
(2)网上有相同模板、相同内容、不同品牌的仿站,而百度上的仿站收录也只有首页,“惊人的相似” ”给客户网站。
1、关于链轮问题,幸好我及时发现并制止了这种行为。由于参与sprocket的产品页面只有几个,时间不长,应该不会有这么大的影响,更何况自己的资源站。.
2、关于重复站点,非常少见。大多数人会自觉地在网站内容或组织形式上形成差异;而如果客户网站有这样的SEO症状,恐怕关键就在于仿网站,当我看到仿网站的时候,我完全无语了。除了公司的品牌名称不同,网站我都太了解了;本来想吐槽的,但回头看,现在网络不流行了。是不是到处都有抄袭的趋势?或许习惯了就好,但我不能忍受的是模板100%模仿,数据完整采集没事,拜托,你敢不敢放是99 % 相同的网站作为一个整体发布?你TMD搞SEO,不知道类似网站!你的TMD模仿站也可以模仿我过去写的自动更新的网站地图文件sitemap.php!做SEO伤不起啊。
吐槽回吐槽,问题还是要解决,采用了几个方法:
1、调整模板数据调用规则和新内容块布局
新的内容块会使页面主题关键词更加分散,并调整数据调用规则,使仿站点的数据与自己页面的数据不同,减少复制网站的负面影响@>搜索引擎优化问题。
2、想办法阻止内容采集
DeDecms本身就有防止采集混淆字符串的功能,但是这种防止采集的方法对SEO来说是非常不利的。您不希望搜索蜘蛛看到网页中有许多隐藏的隐藏对象。文字,而这些文字会影响蜘蛛对信息块主题的判断,影响关键词的排名。事实上,DeDecms并没有根本的办法来阻止采集,而且是一尺高。高一章,只要通过页面发布你的信息,总能找到采集的方法;我根据网上搜集的资料采用了两种方法,只能放最基本的采集。>:
(1)方法一:复制网页正文内容时自动添加版权信息
JavaScript 代码
将上面的代码放在文章页面模板中文本末尾之后。这个方法我测试过,只对IE浏览器有效,对火狐、傲游、谷歌浏览器无效。
(2)方法二:使页面代码唯一
一般别人采集时,要获取内容的起始码和结束码,而且必须是唯一的,所以填写的起始码多为:
. 这样,我们在这个类后面加上文章的ID值,改成这个
,其中{dede:field.id/}获取dedecms中当前文章的ID值,那么每个生成的文章的ID值都不一样,这里的起始代码为也不同,所以其他人将无法采集,并且您一次只能选择一件。
当我们制作模板时,在body标签附近
变成
,注意空格+{dede:field.id/},所以div的class没有变,但是
,此代码在每个文章的内容页面中是唯一的,或者在html标签中插入id={dede:field.id/},例如:
并且,这里的{dede:field.id/}是在dedecms中获取当前文章的ID值,这样别人就无法采集了,只有一个可以一次采集。当然,其他人可以使用过滤规则来移除,但是如果我在所有类中插入文档ID,或者插入id=文档ID。然后他只能采集整个页面,然后过滤,使得采集更加复杂。
缺点:如果{dede:field.id/}插入的不够多,其他人可以用过滤规则过滤掉。但是对于一些站群采集软件来说,这个招数就足以阻止他们采集了!
3、升级DeDecms到最新版本
DeDecms老版本有漏洞,很容易被黑,要么嵌入各种广告代码,要么无缘无故添加太多隐藏链接,所以一定要升级到最新版本。
上一篇:织梦cms:错误的解决方法:check Snooping out of bounds
下一步:设置dedecms标签[field:global.autoindex/]的初始值 查看全部
文章采集调用(一个企业网站被百度降权了怎么办?(图))
去年年底,一位客户要求我帮助创建一家公司网站。考虑到 网站 将来会推广搜索引擎,网站 在 SEO 中必须是搜索引擎友好的。最后我选择了DeDecms,它可以在URL、PageTitle、TextBlock、LinkBlock、Auto Sitemap、Related Article中做早期的SEO布局。所以在栏目规划、版面设计、模板制作阶段,我将各种SEO元素充分融入到整个制作阶段,希望网站上线后,能够快速积累搜索排名权重。尤其是在模板代码编写方面,可以有效控制链接输出和导入,尽可能提高内部链接的相关性和关键词的匹配位置,去除无用的网页噪音信息,
果然,网站正式发布后,网站收录的占比迅速达到70%,大部分产品终端页面为收录,部分信息页面为收录 ,更重要的是:行业关键词排名和产品关键词排名进步很快;整个网站在SEO运营中呈现良性发展态势。客户端开始接管网站并正常更新站点内容,按照设定的时间表,一切应该都进行得很顺利。
不过最近网站SEO的表现开始下滑,网页数量收录首当其冲。百度统计后台显示的页面索引与搜索框中site命令返回的结果数量有显着差异。site 命令显示 Only 2 pages are 收录,都是首页,首页有 www 和没有 www 的两个版本。另外,信息正常更新后,百度索引很快,短时间内可以通过site命令返回结果,但过了一会儿发现收录无效。基于以上情况,我认为网站已经被百度降级了。
为了找到问题所在,我研究了各种因素,发现:
(1)除了正常更新网站的内容外,企业端也在积极运营外链,建外链是好事,但是用错了方式参与资源站的链轮;
(2)网上有相同模板、相同内容、不同品牌的仿站,而百度上的仿站收录也只有首页,“惊人的相似” ”给客户网站。
1、关于链轮问题,幸好我及时发现并制止了这种行为。由于参与sprocket的产品页面只有几个,时间不长,应该不会有这么大的影响,更何况自己的资源站。.
2、关于重复站点,非常少见。大多数人会自觉地在网站内容或组织形式上形成差异;而如果客户网站有这样的SEO症状,恐怕关键就在于仿网站,当我看到仿网站的时候,我完全无语了。除了公司的品牌名称不同,网站我都太了解了;本来想吐槽的,但回头看,现在网络不流行了。是不是到处都有抄袭的趋势?或许习惯了就好,但我不能忍受的是模板100%模仿,数据完整采集没事,拜托,你敢不敢放是99 % 相同的网站作为一个整体发布?你TMD搞SEO,不知道类似网站!你的TMD模仿站也可以模仿我过去写的自动更新的网站地图文件sitemap.php!做SEO伤不起啊。
吐槽回吐槽,问题还是要解决,采用了几个方法:
1、调整模板数据调用规则和新内容块布局
新的内容块会使页面主题关键词更加分散,并调整数据调用规则,使仿站点的数据与自己页面的数据不同,减少复制网站的负面影响@>搜索引擎优化问题。
2、想办法阻止内容采集
DeDecms本身就有防止采集混淆字符串的功能,但是这种防止采集的方法对SEO来说是非常不利的。您不希望搜索蜘蛛看到网页中有许多隐藏的隐藏对象。文字,而这些文字会影响蜘蛛对信息块主题的判断,影响关键词的排名。事实上,DeDecms并没有根本的办法来阻止采集,而且是一尺高。高一章,只要通过页面发布你的信息,总能找到采集的方法;我根据网上搜集的资料采用了两种方法,只能放最基本的采集。>:
(1)方法一:复制网页正文内容时自动添加版权信息
JavaScript 代码
将上面的代码放在文章页面模板中文本末尾之后。这个方法我测试过,只对IE浏览器有效,对火狐、傲游、谷歌浏览器无效。
(2)方法二:使页面代码唯一
一般别人采集时,要获取内容的起始码和结束码,而且必须是唯一的,所以填写的起始码多为:
. 这样,我们在这个类后面加上文章的ID值,改成这个
,其中{dede:field.id/}获取dedecms中当前文章的ID值,那么每个生成的文章的ID值都不一样,这里的起始代码为也不同,所以其他人将无法采集,并且您一次只能选择一件。
当我们制作模板时,在body标签附近
变成
,注意空格+{dede:field.id/},所以div的class没有变,但是
,此代码在每个文章的内容页面中是唯一的,或者在html标签中插入id={dede:field.id/},例如:
并且,这里的{dede:field.id/}是在dedecms中获取当前文章的ID值,这样别人就无法采集了,只有一个可以一次采集。当然,其他人可以使用过滤规则来移除,但是如果我在所有类中插入文档ID,或者插入id=文档ID。然后他只能采集整个页面,然后过滤,使得采集更加复杂。
缺点:如果{dede:field.id/}插入的不够多,其他人可以用过滤规则过滤掉。但是对于一些站群采集软件来说,这个招数就足以阻止他们采集了!
3、升级DeDecms到最新版本
DeDecms老版本有漏洞,很容易被黑,要么嵌入各种广告代码,要么无缘无故添加太多隐藏链接,所以一定要升级到最新版本。
上一篇:织梦cms:错误的解决方法:check Snooping out of bounds
下一步:设置dedecms标签[field:global.autoindex/]的初始值
文章采集调用(1.用python爬取代理批量采集实现方法:anyproxy+js)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-04-11 13:02
微信公众号文章爬取方法整理1.用python爬取
php
实现方法:通过微信提供的公众号文章调用接口,实现抓取公众号文章html的功能
步骤:java
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookies,达到登录的效果;Python
2.使用webdriver功能需要安装对应浏览器的驱动插件。我在这里使用谷歌浏览器进行测试:
谷歌浏览器版本是 52.0.2743.6 ;
chromedriver版本为:V2.23
注意:谷歌浏览器版本和chromedriver需要对应,否则启动时会报错。【附:selenium的chromedriver和chrome版本映射表(更新为v2.30))】web
3.微信公众号登录地址:chrome
4.微信公众号文章界面地址可以在微信公众号后台创建图文信息,从超链接函数中获取:数据库
5.搜索公众号api
6.获取要爬取公众号的fakeid浏览器
7.选择要爬取的公众号,获取文章接口地址微信
8.文章列表翻页和内容获取
2.AnyProxy 代理批量采集
实现方式:anyproxy+js
实现方式:anyproxy+java+webmagic
3.FiddlerCore
实现方式:抓包工具,Fiddler4
经过多个账号的抓包分析,可以确认:
_biz:这个14位的字符串是每一个公众号的“id”,搜狗的微信平台能够得到
uin:与访问者有关,微信号id
key:和所访问的公众号有关
步:
1、编写按钮向导脚本,在手机端自动点击公众号文章的列表页面,即“查看历史消息”;
2、使用fiddler代理劫持手机访问,将URL转发到php编写的本地网页;
3、将接收到的URL备份到php网页上的数据库中;
4、使用python从数据库中检索URL,然后进行正常爬取。
在爬升过程中发现了一个问题:
如果只是想爬文章的内容,貌似没有访问频率限制,但是如果你想爬读点赞数,达到一定频率后,返回值会变成null,我设置的时间间隔为10秒,可以正常取到。在这个频率下,一个小时只能取到 360 条,没有实际意义。
4.青波新榜
如果你只是想看数据,你可以不花钱只看每日清单。如果你需要访问自己的系统,他们也提供了一个api接口 查看全部
文章采集调用(1.用python爬取代理批量采集实现方法:anyproxy+js)
微信公众号文章爬取方法整理1.用python爬取
php
实现方法:通过微信提供的公众号文章调用接口,实现抓取公众号文章html的功能
步骤:java
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookies,达到登录的效果;Python
2.使用webdriver功能需要安装对应浏览器的驱动插件。我在这里使用谷歌浏览器进行测试:
谷歌浏览器版本是 52.0.2743.6 ;
chromedriver版本为:V2.23
注意:谷歌浏览器版本和chromedriver需要对应,否则启动时会报错。【附:selenium的chromedriver和chrome版本映射表(更新为v2.30))】web
3.微信公众号登录地址:chrome
4.微信公众号文章界面地址可以在微信公众号后台创建图文信息,从超链接函数中获取:数据库
5.搜索公众号api
6.获取要爬取公众号的fakeid浏览器
7.选择要爬取的公众号,获取文章接口地址微信
8.文章列表翻页和内容获取
2.AnyProxy 代理批量采集
实现方式:anyproxy+js
实现方式:anyproxy+java+webmagic
3.FiddlerCore
实现方式:抓包工具,Fiddler4
经过多个账号的抓包分析,可以确认:
_biz:这个14位的字符串是每一个公众号的“id”,搜狗的微信平台能够得到
uin:与访问者有关,微信号id
key:和所访问的公众号有关
步:
1、编写按钮向导脚本,在手机端自动点击公众号文章的列表页面,即“查看历史消息”;
2、使用fiddler代理劫持手机访问,将URL转发到php编写的本地网页;
3、将接收到的URL备份到php网页上的数据库中;
4、使用python从数据库中检索URL,然后进行正常爬取。
在爬升过程中发现了一个问题:
如果只是想爬文章的内容,貌似没有访问频率限制,但是如果你想爬读点赞数,达到一定频率后,返回值会变成null,我设置的时间间隔为10秒,可以正常取到。在这个频率下,一个小时只能取到 360 条,没有实际意义。
4.青波新榜
如果你只是想看数据,你可以不花钱只看每日清单。如果你需要访问自己的系统,他们也提供了一个api接口
文章采集调用(设为“星标”,好文章不错过!(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-04-10 19:27
设置为“star”,所以文章不要错过!
1 服务跟踪系统的意义
1.1 快速定位请求失败的原因
在微服务架构下,有很多服务。如果上游请求失败,要找出是哪个应用程序导致它是一场噩梦!
如果有系统,它可以跟踪记录用户请求发起了哪些调用,处理了哪些服务,并记录了每次调用所涉及的服务的详细信息。如果调用失败,可以通过日志快速定位问题!
1.2 优化系统瓶颈
通过记录调用经过的每个环节的耗时,可以快速定位整个系统的瓶颈点。比如你访问xxx网站的首页,发现速度很慢,可能是运营商网络延迟、网关系统异常、服务异常、缓存或者DB异常。通过服务跟踪,可以从上帝视角看到整个系统的瓶颈点,然后针对性的优化。
1.3 优化链接调用
分析调用经过的路径,评估是否合理,每个依赖是否必要,是否可以通过业务优化减少服务依赖。
一般情况下,服务部署在多个数据中心,实现异地容灾。此时服务A经常调用另一个数据中心的服务B,而不会调用同一个数据中心的服务B。
跨数据中心的呼叫会根据距离有一定的网络延迟,这对于某些业务来说是无法接受的。通过分析调用链,可以识别和优化跨数据中心的服务调用。
1.4 生成网络拓扑
通过记录的链路信息,可以生成系统的网络调用拓扑图,可以反映系统依赖哪些服务,服务之间的调用关系是什么,一目了然。
服务调用的详细信息也可以标注在网络拓扑图上,也可以起到服务监控的作用。
1.5 数据透传
业务中经常有需求,期望从调用开始就可以传递一些用户数据,让系统中的每个服务都能获取到这些信息。比如一个业务要做一些A/B测试,想把A/B测试的切换逻辑一路向下通过服务跟踪系统,经过的每一层服务都可以得到切换值,从而可以统一A/B测试。.
2 服务跟踪系统原理
服务跟踪系统的鼻祖:Google 的论文 Dapper, a Large-Scale Distributed Systems Tracing Infrastructure 详细解释了服务跟踪系统的实现原理。
2.1 核心概念
跟踪标识
全局唯一的 64 位整数,用于标识特定的请求 ID。
它在 RPC 调用的网络链路中不断传输,将一个请求在系统中经过的所有路径串联起来。
跨度ID
它用于标识一个RPC调用在分布式请求中的位置,以及区分系统中不同服务之间的调用顺序。
当用户的请求进入系统时,在RPC调用网络第一层A时spanId初始值为0,进入下一层RPC调用B时spanId为0.1,并继续进入下一层RPC调用在C中,spanId为0.1.1,与B同层的RPC调用E的spanId为0.2,这样某个RPC请求就可以通过spanId在系统中定位到调用中的位置,以及它的上下游依赖是谁。这类似于霍夫曼编码。
注解
用于自定义业务的嵌入点数据。可以是业务感兴趣并想上传到后端的数据,比如一个请求的用户UID。
商家自定义一些自己感兴趣的数据,除了上传traceId、spanId等基本信息外,添加一些自己感兴趣的信息。
3 服务跟踪系统的实施
服务跟踪系统可分为三层:
3.1 个数据采集图层
在系统的不同模块中嵌入点,采集数据并上报给数据处理层进行处理。
那么如何掩埋数据呢?结合下图来了解数据嵌入的过程。
以红框圈出的A调用B的过程为例,一个RPC请求可以分为四个阶段。
CS(Client Send)阶段:客户端发起请求并生成调用的上下文
SR(Server Recieve)阶段:服务器接收请求并生成上下文
SS(Server Send)阶段:服务器返回请求。在此阶段,将报告服务器上下文数据。下图显示上报数据为:traceId=123456, spanId=0.1, appKey=B, method=B.method, start=103, duration=38
CR(Client Recieve)阶段:客户端接收返回的结果。此阶段将报告客户端上下文数据。上报数据为:traceid=123456,spanId=0.1,appKey=A,method=B.method,start=103,duration=38。
3.2 数据处理层
按需计算data采集层上报的数据,然后存储在地面上供查询使用。
据我所知,数据处理需求一般分为两类,一类是实时计算需求,一类是离线计算需求。
实时计算要求需要较高的计算效率。一般要求采集到的链路数据可以秒级聚合,实时查询。但是,离线计算的需求并不需要那么高的计算效率。一般可以在小时级别完成链路数据的聚合计算,一般用于数据汇总统计。对于这两类不同的数据处理需求,所使用的计算方式和存储也是不同的。
3.3 数据表示层
数据展示层的作用是将处理后的链接信息以图形方式展示给用户。
主要使用以下两个图形:
调用链接图
从这张图中可以看出:
在实际项目中,调用链路图主要用于故障定位。例如,如果用户调用失败,可以通过调用链路图查询用户调用经过了哪些链路,以及调用失败的层级。造成的。
呼叫拓扑
呼叫拓扑图是全局视图图。在实际项目中,主要用于全局监控,以发现系统中的异常点并快速做出决策。比如某个服务突然出现异常,在调用链路拓扑图中可以看出该服务的调用时间增加了,可以用红色图案标注,用于监控和告警。
参考
过去推荐
厂家如何解决数值精度/舍入/溢出问题
大厂数据库事务实践——事务生效后能否正确回滚?
在线问题事迹(一)数据库事务没有生效? 查看全部
文章采集调用(设为“星标”,好文章不错过!(组图))
设置为“star”,所以文章不要错过!
1 服务跟踪系统的意义
1.1 快速定位请求失败的原因
在微服务架构下,有很多服务。如果上游请求失败,要找出是哪个应用程序导致它是一场噩梦!
如果有系统,它可以跟踪记录用户请求发起了哪些调用,处理了哪些服务,并记录了每次调用所涉及的服务的详细信息。如果调用失败,可以通过日志快速定位问题!
1.2 优化系统瓶颈
通过记录调用经过的每个环节的耗时,可以快速定位整个系统的瓶颈点。比如你访问xxx网站的首页,发现速度很慢,可能是运营商网络延迟、网关系统异常、服务异常、缓存或者DB异常。通过服务跟踪,可以从上帝视角看到整个系统的瓶颈点,然后针对性的优化。
1.3 优化链接调用
分析调用经过的路径,评估是否合理,每个依赖是否必要,是否可以通过业务优化减少服务依赖。
一般情况下,服务部署在多个数据中心,实现异地容灾。此时服务A经常调用另一个数据中心的服务B,而不会调用同一个数据中心的服务B。
跨数据中心的呼叫会根据距离有一定的网络延迟,这对于某些业务来说是无法接受的。通过分析调用链,可以识别和优化跨数据中心的服务调用。
1.4 生成网络拓扑
通过记录的链路信息,可以生成系统的网络调用拓扑图,可以反映系统依赖哪些服务,服务之间的调用关系是什么,一目了然。
服务调用的详细信息也可以标注在网络拓扑图上,也可以起到服务监控的作用。
1.5 数据透传
业务中经常有需求,期望从调用开始就可以传递一些用户数据,让系统中的每个服务都能获取到这些信息。比如一个业务要做一些A/B测试,想把A/B测试的切换逻辑一路向下通过服务跟踪系统,经过的每一层服务都可以得到切换值,从而可以统一A/B测试。.
2 服务跟踪系统原理
服务跟踪系统的鼻祖:Google 的论文 Dapper, a Large-Scale Distributed Systems Tracing Infrastructure 详细解释了服务跟踪系统的实现原理。
2.1 核心概念
跟踪标识
全局唯一的 64 位整数,用于标识特定的请求 ID。
它在 RPC 调用的网络链路中不断传输,将一个请求在系统中经过的所有路径串联起来。
跨度ID
它用于标识一个RPC调用在分布式请求中的位置,以及区分系统中不同服务之间的调用顺序。
当用户的请求进入系统时,在RPC调用网络第一层A时spanId初始值为0,进入下一层RPC调用B时spanId为0.1,并继续进入下一层RPC调用在C中,spanId为0.1.1,与B同层的RPC调用E的spanId为0.2,这样某个RPC请求就可以通过spanId在系统中定位到调用中的位置,以及它的上下游依赖是谁。这类似于霍夫曼编码。
注解
用于自定义业务的嵌入点数据。可以是业务感兴趣并想上传到后端的数据,比如一个请求的用户UID。
商家自定义一些自己感兴趣的数据,除了上传traceId、spanId等基本信息外,添加一些自己感兴趣的信息。
3 服务跟踪系统的实施
服务跟踪系统可分为三层:
3.1 个数据采集图层
在系统的不同模块中嵌入点,采集数据并上报给数据处理层进行处理。
那么如何掩埋数据呢?结合下图来了解数据嵌入的过程。
以红框圈出的A调用B的过程为例,一个RPC请求可以分为四个阶段。
CS(Client Send)阶段:客户端发起请求并生成调用的上下文
SR(Server Recieve)阶段:服务器接收请求并生成上下文
SS(Server Send)阶段:服务器返回请求。在此阶段,将报告服务器上下文数据。下图显示上报数据为:traceId=123456, spanId=0.1, appKey=B, method=B.method, start=103, duration=38
CR(Client Recieve)阶段:客户端接收返回的结果。此阶段将报告客户端上下文数据。上报数据为:traceid=123456,spanId=0.1,appKey=A,method=B.method,start=103,duration=38。
3.2 数据处理层
按需计算data采集层上报的数据,然后存储在地面上供查询使用。
据我所知,数据处理需求一般分为两类,一类是实时计算需求,一类是离线计算需求。
实时计算要求需要较高的计算效率。一般要求采集到的链路数据可以秒级聚合,实时查询。但是,离线计算的需求并不需要那么高的计算效率。一般可以在小时级别完成链路数据的聚合计算,一般用于数据汇总统计。对于这两类不同的数据处理需求,所使用的计算方式和存储也是不同的。
3.3 数据表示层
数据展示层的作用是将处理后的链接信息以图形方式展示给用户。
主要使用以下两个图形:
调用链接图
从这张图中可以看出:
在实际项目中,调用链路图主要用于故障定位。例如,如果用户调用失败,可以通过调用链路图查询用户调用经过了哪些链路,以及调用失败的层级。造成的。
呼叫拓扑
呼叫拓扑图是全局视图图。在实际项目中,主要用于全局监控,以发现系统中的异常点并快速做出决策。比如某个服务突然出现异常,在调用链路拓扑图中可以看出该服务的调用时间增加了,可以用红色图案标注,用于监控和告警。
参考
过去推荐
厂家如何解决数值精度/舍入/溢出问题
大厂数据库事务实践——事务生效后能否正确回滚?
在线问题事迹(一)数据库事务没有生效?
文章采集调用(这部分资料大部分都是都是:如何编程经验总结了一下,效果并不好)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-04-10 19:23
主机:ubuntu 10.10 开发板:Tiny6410 交叉编译工具链:atm-linux-gcc 4.3.2qt 版本:QtEmbedded-4.5.2 - arm 最近在Tiny6410上编程摄像头的时候,从网上找了很多资料学习,但是效果不好,因为网上大部分资料都不是很详细,如果有V4L2编程经验的话. 都差不多,不过对于我这种刚入门的人来说太麻烦了。这部分信息大部分是:1、详细介绍如何编程V4L2,但没有提供源代码示例。2、提供了源代码,但注释很少。难以阅读。于是总结了一篇文章文章,总结了编程心得,这些例子可以在Tiny6410开发板上运行,也可以直接在ubuntu 10.10上运行,可以使用的摄像头有OV9650、USB接口OV301等,只需对源码稍作改动即可。关于 videodevice 是我在网上找到的一条资料。我觉得他写的很好,所以也收录在里面供大家参考。如果您有任何问题,请与我联系。我的邮箱是:我要注意:我上次上传的代码不是我上次修改的代码,虽然没有问题,但是我还是觉得再上传一次就好了,就是不知道怎么改删除之前上传的代码,只能重新发送。关于 videodevice 是我在网上找到的一条资料。我觉得他写的很好,所以也收录在里面供大家参考。如果您有任何问题,请与我联系。我的邮箱是:我要注意:我上次上传的代码不是我上次修改的代码,虽然没有问题,但是我还是觉得再上传一次就好了,就是不知道怎么改删除之前上传的代码,只能重新发送。关于 videodevice 是我在网上找到的一条资料。我觉得他写的很好,所以也收录在里面供大家参考。如果您有任何问题,请与我联系。我的邮箱是:我要注意:我上次上传的代码不是我上次修改的代码,虽然没有问题,但是我还是觉得再上传一次就好了,就是不知道怎么改删除之前上传的代码,只能重新发送。 查看全部
文章采集调用(这部分资料大部分都是都是:如何编程经验总结了一下,效果并不好)
主机:ubuntu 10.10 开发板:Tiny6410 交叉编译工具链:atm-linux-gcc 4.3.2qt 版本:QtEmbedded-4.5.2 - arm 最近在Tiny6410上编程摄像头的时候,从网上找了很多资料学习,但是效果不好,因为网上大部分资料都不是很详细,如果有V4L2编程经验的话. 都差不多,不过对于我这种刚入门的人来说太麻烦了。这部分信息大部分是:1、详细介绍如何编程V4L2,但没有提供源代码示例。2、提供了源代码,但注释很少。难以阅读。于是总结了一篇文章文章,总结了编程心得,这些例子可以在Tiny6410开发板上运行,也可以直接在ubuntu 10.10上运行,可以使用的摄像头有OV9650、USB接口OV301等,只需对源码稍作改动即可。关于 videodevice 是我在网上找到的一条资料。我觉得他写的很好,所以也收录在里面供大家参考。如果您有任何问题,请与我联系。我的邮箱是:我要注意:我上次上传的代码不是我上次修改的代码,虽然没有问题,但是我还是觉得再上传一次就好了,就是不知道怎么改删除之前上传的代码,只能重新发送。关于 videodevice 是我在网上找到的一条资料。我觉得他写的很好,所以也收录在里面供大家参考。如果您有任何问题,请与我联系。我的邮箱是:我要注意:我上次上传的代码不是我上次修改的代码,虽然没有问题,但是我还是觉得再上传一次就好了,就是不知道怎么改删除之前上传的代码,只能重新发送。关于 videodevice 是我在网上找到的一条资料。我觉得他写的很好,所以也收录在里面供大家参考。如果您有任何问题,请与我联系。我的邮箱是:我要注意:我上次上传的代码不是我上次修改的代码,虽然没有问题,但是我还是觉得再上传一次就好了,就是不知道怎么改删除之前上传的代码,只能重新发送。
文章采集调用(文章采集调用服务的xml格式的接口,无需restfulapi)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-09 23:03
文章采集调用服务的xml格式的接口,无需restfulapi,一切交给c++,或者用epoll、select等异步网络调用即可.现有文章内容抓取及商品xml接口通过开发一个简单的爬虫,能够最大限度的节省url请求和返回的访问成本。本小节以杭州某地的某线索网站为例讲解如何开发一个简单的爬虫。由于杭州市的所有信息全部都在这一小块地图上,爬虫必须读取这些数据,可以很快速的进行数据采集。
爬虫的实现要先针对这个网站的数据进行分析,得到每个url对应的vi信息即当前页内容,以及当前页内容对应的url之前的所有历史价格数据。得到每个url对应的vi信息即当前页内容对应的url之前的所有历史价格数据爬虫的代码是通过两个c++的源文件完成。以杭州市某的某线索网站为例(杭州市的网址则在此网址后面存放),可以理解爬虫只需要通过url完成第一步所有的任务,然后解析所有url的内容返回给服务端即可。
<p>有了数据,接下来就是网站的代码实现,以及如何抓取数据了。爬虫的代码:#include#include#includeusingnamespacestd;constintmaxpage=10;//一页的长度#includeintmain(){void*path;stringfilename;charcontent[]="/";charcontent[]="\n";string[]arrays;present_content(path);filename=0;file_tindex;charlines[]=path.size();char[]next;for(index=0;index 查看全部
文章采集调用(文章采集调用服务的xml格式的接口,无需restfulapi)
文章采集调用服务的xml格式的接口,无需restfulapi,一切交给c++,或者用epoll、select等异步网络调用即可.现有文章内容抓取及商品xml接口通过开发一个简单的爬虫,能够最大限度的节省url请求和返回的访问成本。本小节以杭州某地的某线索网站为例讲解如何开发一个简单的爬虫。由于杭州市的所有信息全部都在这一小块地图上,爬虫必须读取这些数据,可以很快速的进行数据采集。
爬虫的实现要先针对这个网站的数据进行分析,得到每个url对应的vi信息即当前页内容,以及当前页内容对应的url之前的所有历史价格数据。得到每个url对应的vi信息即当前页内容对应的url之前的所有历史价格数据爬虫的代码是通过两个c++的源文件完成。以杭州市某的某线索网站为例(杭州市的网址则在此网址后面存放),可以理解爬虫只需要通过url完成第一步所有的任务,然后解析所有url的内容返回给服务端即可。
<p>有了数据,接下来就是网站的代码实现,以及如何抓取数据了。爬虫的代码:#include#include#includeusingnamespacestd;constintmaxpage=10;//一页的长度#includeintmain(){void*path;stringfilename;charcontent[]="/";charcontent[]="\n";string[]arrays;present_content(path);filename=0;file_tindex;charlines[]=path.size();char[]next;for(index=0;index
文章采集调用(通过SpringBootActuatorWebAPI监控应用状态actuatorWeb)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-04-09 18:42
环境需求案例:通过 Spring Boot Actuator Web API 监控应用状态
执行器提供了一个健康端点,用于获取有关应用程序健康的详细信息。
官方文档地址:#health
URL地址是:
/执行器/健康
返回结果(JSON数据格式):
{
"status": "UP",
"components": {
"custom": {
"status": "UP",
"details": {
"app": "Alive and Kicking",
"error": "Nothing! I'm good."
}
},
"diskSpace": {
"status": "UP",
"details": {
"total": 52776349696,
"free": 43368595456,
"threshold": 10485760
}
},
"ping": {
"status": "UP"
}
}
}
配置监控项
建议使用Zabbix的主监控项+从属监控项(相关项)实现采集一次多个数据调用,减少API调用次数。
第一步:创建主监控项
创建监控项,修改如下配置:
如果API接口需要认证,可以设置HTTP认证。使用宏变量支持用户名和密码。
配置完成后,点击下方测试,点击获取值并测试,查看是否可以正确获取数据。
第二步:创建依赖监控项(相关项)
假设您需要监控应用程序的状态和磁盘的剩余空间。
指标 1:监控应用程序状态
JSONPath语法说明参考官方文档:
创建监控项,修改如下配置:
将步骤添加到“进程”选项卡:
点击下面的Test all steps来验证配置,在value中填入主监控项test获取的数据,点击Test查看是否可以正确获取数据。
指标 2:监控磁盘剩余空间
创建监控项,修改如下配置:
将步骤添加到“进程”选项卡:
点击下面的Test all steps来验证配置,在value中填入主监控项test获取的数据,点击Test查看是否可以正确获取数据。
检查最新数据是否正常采集
注:依赖监控项(相关项)的数据更新周期由主监控项设置的更新周期决定
至此,监控项的配置已经完成,接下来就可以根据实际情况配置相应的触发器了。
配置模板时,可以将主监控项中的URL配置为宏宏变量,例如:{$HOST}:{$PORT}/actuator/health,这样可以在链接时为不同的主机设置宏变量模板(用户名和密码也可以这样配置)。 查看全部
文章采集调用(通过SpringBootActuatorWebAPI监控应用状态actuatorWeb)
环境需求案例:通过 Spring Boot Actuator Web API 监控应用状态
执行器提供了一个健康端点,用于获取有关应用程序健康的详细信息。
官方文档地址:#health
URL地址是:
/执行器/健康
返回结果(JSON数据格式):
{
"status": "UP",
"components": {
"custom": {
"status": "UP",
"details": {
"app": "Alive and Kicking",
"error": "Nothing! I'm good."
}
},
"diskSpace": {
"status": "UP",
"details": {
"total": 52776349696,
"free": 43368595456,
"threshold": 10485760
}
},
"ping": {
"status": "UP"
}
}
}
配置监控项
建议使用Zabbix的主监控项+从属监控项(相关项)实现采集一次多个数据调用,减少API调用次数。
第一步:创建主监控项
创建监控项,修改如下配置:
如果API接口需要认证,可以设置HTTP认证。使用宏变量支持用户名和密码。
配置完成后,点击下方测试,点击获取值并测试,查看是否可以正确获取数据。
第二步:创建依赖监控项(相关项)
假设您需要监控应用程序的状态和磁盘的剩余空间。
指标 1:监控应用程序状态
JSONPath语法说明参考官方文档:
创建监控项,修改如下配置:
将步骤添加到“进程”选项卡:
点击下面的Test all steps来验证配置,在value中填入主监控项test获取的数据,点击Test查看是否可以正确获取数据。
指标 2:监控磁盘剩余空间
创建监控项,修改如下配置:
将步骤添加到“进程”选项卡:
点击下面的Test all steps来验证配置,在value中填入主监控项test获取的数据,点击Test查看是否可以正确获取数据。
检查最新数据是否正常采集
注:依赖监控项(相关项)的数据更新周期由主监控项设置的更新周期决定
至此,监控项的配置已经完成,接下来就可以根据实际情况配置相应的触发器了。
配置模板时,可以将主监控项中的URL配置为宏宏变量,例如:{$HOST}:{$PORT}/actuator/health,这样可以在链接时为不同的主机设置宏变量模板(用户名和密码也可以这样配置)。

