
文章采集文章采集
文章采集文章采集(代码识别及爬取有以下几种常见方式请求ua)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-09-05 18:06
文章采集文章采集-站长采集方式有很多种,可以采集微信公众号、新闻源、qq群文章、今日头条等。采集这种方式是非常方便的,但对于采集而言最大的难点是进行统计分析。毕竟上述公众号、新闻源等都要占据大量空间资源,无法完全采集。文章采集代码:采集数据类型上,除文章之外,包括连接数据、网页(纯html代码)、文章链接、群发文章。
代码里面的:)反爬不管是抓取新闻源还是其他采集方式,除了受代码限制外,反爬策略的策略以及对应的措施也是会对网站进行采集。采集网站不仅仅是我们常说的网页,就连微信公众号等,都是会涉及到爬虫反爬虫技术。常见的反爬措施有对比大小、网址路径、移动端识别、结构化反爬、ua识别等。请求ua正在进行高精度网页采集,相信手机爬虫会越来越多,若抓取ua不匹配可能会采到不相关内容导致爬虫失败。
常见几种方式请求ua,以easy_btn为例:其中有数据栏目,表示这段不是高精度请求,比如说微信公众号文章有些页面ua是新浪新闻。在请求ua不匹配的情况下,请求文章链接可能会失败。除了ua识别之外,还有referer相同的不匹配等问题。代码识别现在大多数爬虫会使用代码识别爬虫,有代码自动切割、压缩、读取cookie等等。
常见爬虫爬取方式有正则表达式解析、有些会自动推荐合适的页面,比如:、新浪文章、今日头条文章等。代码识别及爬取有以下几种常见方式:。
1、利用正则解析找到全文全部可抓取内容可通过正则解析各级标签、自动分割等技术去爬取。正则表达式re用的比较多,不仅仅对爬取文章的链接、网址有效,还可以抓取新闻、连接的代码。爬取网页时若出现网页不存在,则爬取失败,还有可能会出现报错、丢包等情况。
2、选择合适的ua进行网页请求比如我们使用新浪新闻站点做采集,如果配置不当可能会出现:爬取网页失败,则ua识别也失败。
3、爬取文章使用微信公众号爬取文章时采用了新浪新闻作为api调用接口等通过这种方式可以利用微信公众号发送的链接来进行爬取文章,
代码解析。
代码解析
1、单独封装请求方法
2、利用vue.js封装请求方法
3、使用ua识别
4、封装请求
4、vue.js封装请求文章采集代码:url结构:采集之前首先需要我们了解一下代码采集的整个流程,知道采集流程我们就可以开始采集了。
1、读取网页数据接口
2、爬取获取内容页面
3、返回html代码
4、解析出html
5、提取关键信息
6、存储至本地
1、接口数据来源——数据来源于某api接口我们通过网页提供的cookie来解析出cookie并作为请求方法 查看全部
文章采集文章采集(代码识别及爬取有以下几种常见方式请求ua)
文章采集文章采集-站长采集方式有很多种,可以采集微信公众号、新闻源、qq群文章、今日头条等。采集这种方式是非常方便的,但对于采集而言最大的难点是进行统计分析。毕竟上述公众号、新闻源等都要占据大量空间资源,无法完全采集。文章采集代码:采集数据类型上,除文章之外,包括连接数据、网页(纯html代码)、文章链接、群发文章。
代码里面的:)反爬不管是抓取新闻源还是其他采集方式,除了受代码限制外,反爬策略的策略以及对应的措施也是会对网站进行采集。采集网站不仅仅是我们常说的网页,就连微信公众号等,都是会涉及到爬虫反爬虫技术。常见的反爬措施有对比大小、网址路径、移动端识别、结构化反爬、ua识别等。请求ua正在进行高精度网页采集,相信手机爬虫会越来越多,若抓取ua不匹配可能会采到不相关内容导致爬虫失败。
常见几种方式请求ua,以easy_btn为例:其中有数据栏目,表示这段不是高精度请求,比如说微信公众号文章有些页面ua是新浪新闻。在请求ua不匹配的情况下,请求文章链接可能会失败。除了ua识别之外,还有referer相同的不匹配等问题。代码识别现在大多数爬虫会使用代码识别爬虫,有代码自动切割、压缩、读取cookie等等。
常见爬虫爬取方式有正则表达式解析、有些会自动推荐合适的页面,比如:、新浪文章、今日头条文章等。代码识别及爬取有以下几种常见方式:。
1、利用正则解析找到全文全部可抓取内容可通过正则解析各级标签、自动分割等技术去爬取。正则表达式re用的比较多,不仅仅对爬取文章的链接、网址有效,还可以抓取新闻、连接的代码。爬取网页时若出现网页不存在,则爬取失败,还有可能会出现报错、丢包等情况。
2、选择合适的ua进行网页请求比如我们使用新浪新闻站点做采集,如果配置不当可能会出现:爬取网页失败,则ua识别也失败。
3、爬取文章使用微信公众号爬取文章时采用了新浪新闻作为api调用接口等通过这种方式可以利用微信公众号发送的链接来进行爬取文章,
代码解析。
代码解析
1、单独封装请求方法
2、利用vue.js封装请求方法
3、使用ua识别
4、封装请求
4、vue.js封装请求文章采集代码:url结构:采集之前首先需要我们了解一下代码采集的整个流程,知道采集流程我们就可以开始采集了。
1、读取网页数据接口
2、爬取获取内容页面
3、返回html代码
4、解析出html
5、提取关键信息
6、存储至本地
1、接口数据来源——数据来源于某api接口我们通过网页提供的cookie来解析出cookie并作为请求方法
文章采集文章采集( 先说一下,什么是数据采集呢?我们可以这样理解)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-08-31 19:02
先说一下,什么是数据采集呢?我们可以这样理解)
优采云采集器采集原理、流程介绍
首先,什么是data采集?我们可以这样理解。我们开了一个网站,看到一篇文章很好的文章,就复制文章的标题和内容,把这个文章转给我们的网站上。我们这个过程可以叫做采集,把别人的网站有用信息转给自己网站上。
采集器 也是一样,只是整个过程是由软件完成的。我们可以这样理解,我们复制文章的标题和内容,这样我们就可以知道内容是什么,标题在哪里,但是软件是我不知道,所以我们要告诉软件如何捡起来。这就是写规则的过程。。我们复制好了之后,打开我们的网站,比如我们发帖的论坛,然后粘贴发布。对于软件来说,就是模仿发帖的过程,要发文章,怎么发,这就是发模块的事情。
优采云采集器是采集数据的软件。它是互联网上最强大的采集器。它几乎可以捕获您看到的任何网络内容。
优采云采集器数据采集原理:
优采云采集器 如何获取数据取决于您的规则。如果要获取某个栏目网页中的所有内容,需要先选择该网页的网址。这是网址。程序根据你的规则抓取列表页面,从中分析出网址,然后抓取获取到网址的网页内容。根据你的采集规则,对下载的网页进行分析,将标题内容和其他信息分开保存。如果选择下载图片等网络资源,程序会分析采集收到的数据,找出文章的下载地址并下载到本地。
优采云采集器数据发布原则:
我们下载数据采集后,数据默认保存在本地。我们可以使用以下方法来处理种子数据。
1. 不会做任何事情。因为数据本身是存储在数据库中的(access或者db3),如果只是想看的话,用相关软件查看即可。
2.web 发布到 网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。
3. 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的SQL语句把数据导入到数据库中。
4. 保存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。
优采云采集器工作流程:
优采云采集可以分为两步,一是采集数据,二是发布数据。这两个过程可以分开。
1.采集 数据,包括采集 URL、采集 内容。这个过程就是获取数据的过程。我们制定规则,在采集的过程中可视为对内容的处理。
2.发布内容是将数据发布到自己的论坛。 cms的过程也是将数据实现为存在的过程。可以通过WEB在线发布、存储在数据库中或保存为本地文件。
具体使用其实很灵活,可以根据实际情况确定。比如我可以采集时先采集不发布,有空再发布,或者同时采集发布,或者先做发布配置,也可以在@之后添加发布配置采集 完成。总之,具体流程由你决定,优采云采集器的强大功能之一体现在灵活性上。 查看全部
文章采集文章采集(
先说一下,什么是数据采集呢?我们可以这样理解)
优采云采集器采集原理、流程介绍
首先,什么是data采集?我们可以这样理解。我们开了一个网站,看到一篇文章很好的文章,就复制文章的标题和内容,把这个文章转给我们的网站上。我们这个过程可以叫做采集,把别人的网站有用信息转给自己网站上。
采集器 也是一样,只是整个过程是由软件完成的。我们可以这样理解,我们复制文章的标题和内容,这样我们就可以知道内容是什么,标题在哪里,但是软件是我不知道,所以我们要告诉软件如何捡起来。这就是写规则的过程。。我们复制好了之后,打开我们的网站,比如我们发帖的论坛,然后粘贴发布。对于软件来说,就是模仿发帖的过程,要发文章,怎么发,这就是发模块的事情。
优采云采集器是采集数据的软件。它是互联网上最强大的采集器。它几乎可以捕获您看到的任何网络内容。
优采云采集器数据采集原理:
优采云采集器 如何获取数据取决于您的规则。如果要获取某个栏目网页中的所有内容,需要先选择该网页的网址。这是网址。程序根据你的规则抓取列表页面,从中分析出网址,然后抓取获取到网址的网页内容。根据你的采集规则,对下载的网页进行分析,将标题内容和其他信息分开保存。如果选择下载图片等网络资源,程序会分析采集收到的数据,找出文章的下载地址并下载到本地。
优采云采集器数据发布原则:
我们下载数据采集后,数据默认保存在本地。我们可以使用以下方法来处理种子数据。
1. 不会做任何事情。因为数据本身是存储在数据库中的(access或者db3),如果只是想看的话,用相关软件查看即可。
2.web 发布到 网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。
3. 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的SQL语句把数据导入到数据库中。
4. 保存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。
优采云采集器工作流程:
优采云采集可以分为两步,一是采集数据,二是发布数据。这两个过程可以分开。
1.采集 数据,包括采集 URL、采集 内容。这个过程就是获取数据的过程。我们制定规则,在采集的过程中可视为对内容的处理。
2.发布内容是将数据发布到自己的论坛。 cms的过程也是将数据实现为存在的过程。可以通过WEB在线发布、存储在数据库中或保存为本地文件。
具体使用其实很灵活,可以根据实际情况确定。比如我可以采集时先采集不发布,有空再发布,或者同时采集发布,或者先做发布配置,也可以在@之后添加发布配置采集 完成。总之,具体流程由你决定,优采云采集器的强大功能之一体现在灵活性上。
文章采集文章采集(采集微信公众号文章教程是什么?怎样批量采集呢)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-08-29 00:05
编辑微信公证号中的文章时,一般都是先做文章采集,然后采集微信公号文章教程?如何批处理采集? 下面拓图数据将详细介绍这些问题,以提供帮助。
采集微信公号文章tutorial
采集微信公号文章教程怎么样?
第一步:点击采集,将需要采集的微信文章链接地址复制到微信文章网址框。
这里获取微信文章链接主要有两种方式:
方法一:直接在手机上找到文章,点击右上角复制。
方法二:通过电脑端搜狗浏览器微信版块搜索,通过下方“点击获取”进入。
第 2 步:点击 采集。此时文章的所有内容已经由采集上传至微信编辑器,您可以编辑修改文章。
采集微信公号文章教程采集微信公号文章如何批量处理
方法/步骤
数据采集:
NO.1 通过百度搜索相关网站,注册或登录后进入爬虫市场。
NO.2 搜索关键词:微信公众号。点击免费获取!
NO.3 进入采集爬虫后,点击爬虫设置。
首先,由于搜狗微信搜索有图片防盗取功能,需要在功能设置中开启图片云托管。这是非常重要的。切记,不然你的图片显示不出来,到时候就尴尬了...
自定义设置,可以同时采集多个微信公众号文章,最多500个!特别注意:请输入微信名称而不是微信名称!
Data采集完了,可以发布数据了吗?答案当然是!
NO.1 发布数据只需要两步:安装发布插件——>使用发布界面。您可以选择发布到数据库或发布到网站。
如果你不知道怎么安装插件,那我告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示操作,你会一步一步地OK。
插件安装成功,我们新建一个发布项吧!太多了,就选你喜欢的吧。
选择发布界面后,填写你要发布的网站地址和密码。同时系统会自动检测插件是否安装正确。
对于字段映射,一般情况下,系统会默认选择一个好的,但如果你觉得有什么需要调整的可以修改。
内容替换 这是一个可选项目,您可以填写或不填写。
完成设置后,即可发布数据。
NO.2 在抓取结果页面,您可以看到采集爬虫根据您设置的信息抓取的所有内容。发布结果可以自动发布,也可以手动发布。
自动发布:开启自动发布后,爬取到的数据会自动发布到网站或者数据库,感觉6要起飞了!
当然,您也可以选择手动发布。发布时可以选择单次发布或多次发布。发布前也可以先预览看看这个文章的内容是什么。
如果您认为有问题,可以发布数据。
发布成功后,可以点击链接查看。
采集微信公号文章tutorial
微信公众号文章采集想法
一、通过android客户端获取微信用户(即小号)的登录信息。
二、提供微信公众号信息(biz)。 查看全部
文章采集文章采集(采集微信公众号文章教程是什么?怎样批量采集呢)
编辑微信公证号中的文章时,一般都是先做文章采集,然后采集微信公号文章教程?如何批处理采集? 下面拓图数据将详细介绍这些问题,以提供帮助。
采集微信公号文章tutorial
采集微信公号文章教程怎么样?
第一步:点击采集,将需要采集的微信文章链接地址复制到微信文章网址框。
这里获取微信文章链接主要有两种方式:
方法一:直接在手机上找到文章,点击右上角复制。
方法二:通过电脑端搜狗浏览器微信版块搜索,通过下方“点击获取”进入。
第 2 步:点击 采集。此时文章的所有内容已经由采集上传至微信编辑器,您可以编辑修改文章。
采集微信公号文章教程采集微信公号文章如何批量处理
方法/步骤
数据采集:
NO.1 通过百度搜索相关网站,注册或登录后进入爬虫市场。
NO.2 搜索关键词:微信公众号。点击免费获取!
NO.3 进入采集爬虫后,点击爬虫设置。
首先,由于搜狗微信搜索有图片防盗取功能,需要在功能设置中开启图片云托管。这是非常重要的。切记,不然你的图片显示不出来,到时候就尴尬了...
自定义设置,可以同时采集多个微信公众号文章,最多500个!特别注意:请输入微信名称而不是微信名称!
Data采集完了,可以发布数据了吗?答案当然是!
NO.1 发布数据只需要两步:安装发布插件——>使用发布界面。您可以选择发布到数据库或发布到网站。
如果你不知道怎么安装插件,那我告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示操作,你会一步一步地OK。
插件安装成功,我们新建一个发布项吧!太多了,就选你喜欢的吧。
选择发布界面后,填写你要发布的网站地址和密码。同时系统会自动检测插件是否安装正确。
对于字段映射,一般情况下,系统会默认选择一个好的,但如果你觉得有什么需要调整的可以修改。
内容替换 这是一个可选项目,您可以填写或不填写。
完成设置后,即可发布数据。
NO.2 在抓取结果页面,您可以看到采集爬虫根据您设置的信息抓取的所有内容。发布结果可以自动发布,也可以手动发布。
自动发布:开启自动发布后,爬取到的数据会自动发布到网站或者数据库,感觉6要起飞了!
当然,您也可以选择手动发布。发布时可以选择单次发布或多次发布。发布前也可以先预览看看这个文章的内容是什么。
如果您认为有问题,可以发布数据。
发布成功后,可以点击链接查看。
采集微信公号文章tutorial
微信公众号文章采集想法
一、通过android客户端获取微信用户(即小号)的登录信息。
二、提供微信公众号信息(biz)。
文章采集器采集文章的关键词是什么?-电驴知乎
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-08-27 06:07
文章采集文章采集1,百度搜索一下如"timbernow”2,“ummm”采集器采集文章采集上面几个是我经常用的采集工具,感觉比较简单好用,
登录
关注公众号,
木瓜教育。
招聘
找活动
先要根据行业找,然后根据产品找,
udemy课程网
迅雷看看电驴
知乎只能帮你分享一小部分信息,而且还是要花时间找的,最好也要不断的浏览、提问,很多人会很热心的分享出来,希望能帮到你。
包括关键词外国网站(新浪,谷歌),国内网站(猪八戒),
要实现高质量的找资源,主要的是查漏补缺,找些东西对比着使用。所以,建议先去公众号看看。content-type的不要漏掉:短视频,电子书,音频,软件和游戏...这些都是优质的资源。然后,去他们那里找类似的资源。比如,你找书籍,
百度云网盘目前是一个全国性的分享资源交易平台,上面有的资源不只局限于国内网站,也有国外网站。有很多不同类型的。也有很多是免费提供给大家的,不收取任何费用。书籍,课程,软件等等都有。而且提供了很多的搜索方式,方便大家去查找。 查看全部
文章采集器采集文章的关键词是什么?-电驴知乎
文章采集文章采集1,百度搜索一下如"timbernow”2,“ummm”采集器采集文章采集上面几个是我经常用的采集工具,感觉比较简单好用,
登录
关注公众号,
木瓜教育。
招聘
找活动
先要根据行业找,然后根据产品找,
udemy课程网
迅雷看看电驴
知乎只能帮你分享一小部分信息,而且还是要花时间找的,最好也要不断的浏览、提问,很多人会很热心的分享出来,希望能帮到你。
包括关键词外国网站(新浪,谷歌),国内网站(猪八戒),
要实现高质量的找资源,主要的是查漏补缺,找些东西对比着使用。所以,建议先去公众号看看。content-type的不要漏掉:短视频,电子书,音频,软件和游戏...这些都是优质的资源。然后,去他们那里找类似的资源。比如,你找书籍,
百度云网盘目前是一个全国性的分享资源交易平台,上面有的资源不只局限于国内网站,也有国外网站。有很多不同类型的。也有很多是免费提供给大家的,不收取任何费用。书籍,课程,软件等等都有。而且提供了很多的搜索方式,方便大家去查找。
有时候in百度网站管理员的正确键功能人使用方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-08-17 21:05
[] 绗缝
很多人讨厌自己的原创被别人瞬间复制,甚至有人用它发一些垃圾链接。我特别相信很多老年人都遇到过这样的情况,有时他们的努力也没有那么好。这很好。为什么我们会处于这种情况?
首先尝试让搜索引擎把这个文章收录放在对手的采集之前。
1、及时抓取文章,让搜索引擎知道这个文章。
2、Ping在百度网站管理自己的文章链接中,这也是百度官方告诉我们的一种方式。
二、文章由作者或版本标记
虽然有时无法阻止别人抄袭你的文章,但这也是一种书面交流和提示,总比没有好。
三、在文章中添加了一些特色内容。
1、比如文章中的标签代码,比如N1、N2、color等,搜索引擎会对这些更加敏感,可以加深对原创的判断。
2、在文章添加你自己的品牌词汇
3、加了一些内链,因为喜欢抄袭文章的人一般比较懒,不排除有些人可以直接复制粘贴。
4、文章加入时间后,搜索引擎会判断文章的原创性,参考时间因素。
屏蔽网页正确的关键功能
当大多数人使用鼠标右键复制文章时,如果技术不受此功能影响,无疑会增加采集器的麻烦。
5、晚上更新
采集最大的恐惧是对手知道你的习惯,尤其是白天。很多人喜欢在白天更新文章,却被别人盯上,立马文章就被抄袭了。
这些可以在我们的网站上看到并应用,我相信这样可以减少文章的集合。 查看全部
有时候in百度网站管理员的正确键功能人使用方法
[] 绗缝
很多人讨厌自己的原创被别人瞬间复制,甚至有人用它发一些垃圾链接。我特别相信很多老年人都遇到过这样的情况,有时他们的努力也没有那么好。这很好。为什么我们会处于这种情况?
首先尝试让搜索引擎把这个文章收录放在对手的采集之前。
1、及时抓取文章,让搜索引擎知道这个文章。
2、Ping在百度网站管理自己的文章链接中,这也是百度官方告诉我们的一种方式。
二、文章由作者或版本标记
虽然有时无法阻止别人抄袭你的文章,但这也是一种书面交流和提示,总比没有好。
三、在文章中添加了一些特色内容。
1、比如文章中的标签代码,比如N1、N2、color等,搜索引擎会对这些更加敏感,可以加深对原创的判断。
2、在文章添加你自己的品牌词汇
3、加了一些内链,因为喜欢抄袭文章的人一般比较懒,不排除有些人可以直接复制粘贴。
4、文章加入时间后,搜索引擎会判断文章的原创性,参考时间因素。
屏蔽网页正确的关键功能
当大多数人使用鼠标右键复制文章时,如果技术不受此功能影响,无疑会增加采集器的麻烦。
5、晚上更新
采集最大的恐惧是对手知道你的习惯,尤其是白天。很多人喜欢在白天更新文章,却被别人盯上,立马文章就被抄袭了。
这些可以在我们的网站上看到并应用,我相信这样可以减少文章的集合。
举个栗子先爬取redis-connect.php文件然后修改标签文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-08-10 22:00
文章采集文章采集是单向数据采集系统的基础,通过定制爬虫对无规律文章进行抓取,保证抓取的内容是和文章的标题完全相同的。提高采集文章的爬取效率,减少爬取中的反爬,可以提高抓取文章的效率。当然前提是爬取的文章中也会出现对应文章的标题字段。文章采集最好采用定制的服务器,第三方采集软件会在采集的同时也对网站进行一定的权限控制。
文章采集同步适合多台机器、多站点同时进行实时采集。流量导出流量导出主要作用在于导出采集日志并放在本地,方便后续分析和数据挖掘。流量导出之后需要再导入系统或在登录时进行个性化处理。如:将爬取成功的文章分门别类放入相应的文件夹进行保存,方便后续统计和统计。和导出差不多,流量导出之后需要放在相应的文件夹进行保存,方便后续统计和统计。
热点文章爬取热点文章爬取我们常用redis来实现。下面以去重前十篇文章为例来讲解怎么获取新增文章的路径。举个栗子先爬取redis-connect.php文件然后修改标签文件发出:redisconnect{expires:10,http_host:'',server_name:'',sql_path://{host}/{port}',post_method:'post',post_key:'',user_agent:'',proxy_proxy:'',proxy_proxy_shell:'',}}这样,用户看到以为的文章页面就是文章的post页面。
ps:热点爬取时,不建议用代理ip!爬取分页redis中的http_host:'':访问该域名的所有网站redisconnect{expires:10,http_host:'':访问该域名的所有网站redisconnect{url_poll:1}:爬取可以重复访问的页面redisconnect{url_poll:1}:爬取可以重复访问的页面redisconnect{url_poll:1}:爬取可以重复访问的页面redisconnect{url_poll:1}:爬取可以重复访问的页面redisconnect{url_poll:1}:爬取可以重复访问的页面获取每页最大的数据量redisconnect{proxy_proxy:redis_proxy_redis}:爬取服务器给他的文件proxy_proxy{host_poll:1}:爬取浏览器历史记录redisconnect{redis_proxy_poll:1}:爬取浏览器历史记录redisconnect{redis_proxy_poll:1}:爬取浏览器历史记录redisconnect{redis_proxy_poll:1}:爬取浏览器历史记录redisconnect{redis_proxy_poll:1}:爬取浏览器历史记录爬取的host地址实际需要自己写死redisconnect{url_poll:1}:爬取浏览器历史记录redisconnect{url。 查看全部
举个栗子先爬取redis-connect.php文件然后修改标签文件
文章采集文章采集是单向数据采集系统的基础,通过定制爬虫对无规律文章进行抓取,保证抓取的内容是和文章的标题完全相同的。提高采集文章的爬取效率,减少爬取中的反爬,可以提高抓取文章的效率。当然前提是爬取的文章中也会出现对应文章的标题字段。文章采集最好采用定制的服务器,第三方采集软件会在采集的同时也对网站进行一定的权限控制。
文章采集同步适合多台机器、多站点同时进行实时采集。流量导出流量导出主要作用在于导出采集日志并放在本地,方便后续分析和数据挖掘。流量导出之后需要再导入系统或在登录时进行个性化处理。如:将爬取成功的文章分门别类放入相应的文件夹进行保存,方便后续统计和统计。和导出差不多,流量导出之后需要放在相应的文件夹进行保存,方便后续统计和统计。
热点文章爬取热点文章爬取我们常用redis来实现。下面以去重前十篇文章为例来讲解怎么获取新增文章的路径。举个栗子先爬取redis-connect.php文件然后修改标签文件发出:redisconnect{expires:10,http_host:'',server_name:'',sql_path://{host}/{port}',post_method:'post',post_key:'',user_agent:'',proxy_proxy:'',proxy_proxy_shell:'',}}这样,用户看到以为的文章页面就是文章的post页面。
ps:热点爬取时,不建议用代理ip!爬取分页redis中的http_host:'':访问该域名的所有网站redisconnect{expires:10,http_host:'':访问该域名的所有网站redisconnect{url_poll:1}:爬取可以重复访问的页面redisconnect{url_poll:1}:爬取可以重复访问的页面redisconnect{url_poll:1}:爬取可以重复访问的页面redisconnect{url_poll:1}:爬取可以重复访问的页面redisconnect{url_poll:1}:爬取可以重复访问的页面获取每页最大的数据量redisconnect{proxy_proxy:redis_proxy_redis}:爬取服务器给他的文件proxy_proxy{host_poll:1}:爬取浏览器历史记录redisconnect{redis_proxy_poll:1}:爬取浏览器历史记录redisconnect{redis_proxy_poll:1}:爬取浏览器历史记录redisconnect{redis_proxy_poll:1}:爬取浏览器历史记录redisconnect{redis_proxy_poll:1}:爬取浏览器历史记录爬取的host地址实际需要自己写死redisconnect{url_poll:1}:爬取浏览器历史记录redisconnect{url。
文章采集文章采集 德国专访——打造工业电影(中译)(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-08-08 22:11
文章采集文章采集很少有人感兴趣,也不是我们主要考虑的事情。但是在如今每天遍地都是大批量的新闻报道时,如果我们只采集部分新闻,会非常影响我们的体验和工作效率。正是由于这个原因,我们经常会以少量的新闻报道占领网站,但也能看到一些文章对我们有积极作用。这篇文章中我将按照时间线给你展示浏览新闻时我们可以看到的东西,让你对新闻进行深入的学习。
从中学习到在采集新闻时一定要避免的事情。新闻报道采集首先,我先以一篇cnbeta和雪球共同发表的采访中提到的一篇德国网站上的新闻为例进行说明。这篇新闻对我影响很大,对此我也进行了采集。这篇新闻的题目是《我拿python拯救solidot》,该论文是由德国慕尼黑工业大学的工程物理和应用材料学系的老师,dr.hamermeshress在2017年4月发表在science上的。
这篇论文对每一个有意采集论文的人都有很大帮助,这在我这一系列中都可以找到实例。德国专访——打造工业电影(中译)这篇新闻中有个关键的问题,就是把st.peter这个网站打造成一个在线电影商店。它只通过python编程来做,不管是拍摄视频的人还是观众,只要在电影里找到字幕这就能下载到相应的文件。这在以前完全没有想到,这对我这个初学者来说非常震撼。
我经常用这个方法测试新闻的质量,因为我知道很多编程语言做不到这一点。我在之前几篇关于爬虫的文章中都提到过,采集文章中任何内容都非常费劲,而且也不知道怎么样爬去。如果仅仅这样采集文章只能说浪费时间,而且由于时间上来不及,我采集的新闻报道很容易流失掉。这篇论文中有个值得注意的地方,就是他们的电影票售价是零售价的15%,也就是40元人民币(不包括税钱和时间成本)。
即使这样,看到这样的价格和品质,人们也会果断掏钱的。采访中的说法是有利的,因为这么高的价格,的确令人望而却步。但是,它和采集什么样的新闻又是矛盾的。单纯从价格上来说,我知道如果美国国内的话大概是30美元,如果是北美,可能达到60美元的水平。我不知道这是不是只是地区限制造成的结果,或者如果这个网站开放的话,人们采集的可能更多,并且用户体验还要更好。
但是我可以肯定的是,肯定有更多的人看这个视频。考虑到如此高的售价,他们肯定也会继续采集更多文章,采集数字化影片。同样的价格,爬取别人做的好的新闻报道,会比直接采集一个普通的新闻要好得多。但是,现在这条线路已经封死了。原因是,他们对一个max录制的影片中的it部分很不满意,理由是这些部分甚至还没有运行起来,它们都需要一个专业的机器人来来采集。然而, 查看全部
文章采集文章采集 德国专访——打造工业电影(中译)(组图)
文章采集文章采集很少有人感兴趣,也不是我们主要考虑的事情。但是在如今每天遍地都是大批量的新闻报道时,如果我们只采集部分新闻,会非常影响我们的体验和工作效率。正是由于这个原因,我们经常会以少量的新闻报道占领网站,但也能看到一些文章对我们有积极作用。这篇文章中我将按照时间线给你展示浏览新闻时我们可以看到的东西,让你对新闻进行深入的学习。
从中学习到在采集新闻时一定要避免的事情。新闻报道采集首先,我先以一篇cnbeta和雪球共同发表的采访中提到的一篇德国网站上的新闻为例进行说明。这篇新闻对我影响很大,对此我也进行了采集。这篇新闻的题目是《我拿python拯救solidot》,该论文是由德国慕尼黑工业大学的工程物理和应用材料学系的老师,dr.hamermeshress在2017年4月发表在science上的。
这篇论文对每一个有意采集论文的人都有很大帮助,这在我这一系列中都可以找到实例。德国专访——打造工业电影(中译)这篇新闻中有个关键的问题,就是把st.peter这个网站打造成一个在线电影商店。它只通过python编程来做,不管是拍摄视频的人还是观众,只要在电影里找到字幕这就能下载到相应的文件。这在以前完全没有想到,这对我这个初学者来说非常震撼。
我经常用这个方法测试新闻的质量,因为我知道很多编程语言做不到这一点。我在之前几篇关于爬虫的文章中都提到过,采集文章中任何内容都非常费劲,而且也不知道怎么样爬去。如果仅仅这样采集文章只能说浪费时间,而且由于时间上来不及,我采集的新闻报道很容易流失掉。这篇论文中有个值得注意的地方,就是他们的电影票售价是零售价的15%,也就是40元人民币(不包括税钱和时间成本)。
即使这样,看到这样的价格和品质,人们也会果断掏钱的。采访中的说法是有利的,因为这么高的价格,的确令人望而却步。但是,它和采集什么样的新闻又是矛盾的。单纯从价格上来说,我知道如果美国国内的话大概是30美元,如果是北美,可能达到60美元的水平。我不知道这是不是只是地区限制造成的结果,或者如果这个网站开放的话,人们采集的可能更多,并且用户体验还要更好。
但是我可以肯定的是,肯定有更多的人看这个视频。考虑到如此高的售价,他们肯定也会继续采集更多文章,采集数字化影片。同样的价格,爬取别人做的好的新闻报道,会比直接采集一个普通的新闻要好得多。但是,现在这条线路已经封死了。原因是,他们对一个max录制的影片中的it部分很不满意,理由是这些部分甚至还没有运行起来,它们都需要一个专业的机器人来来采集。然而,
【干货】文章采集、爬虫数据采集项目结构config汇总
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-07-30 05:08
文章采集文章采集根据python的爬虫数据采集软件来实现爬虫,在代码中进行简单示例数据采集项目结构config。py配置文件vimconfig。py其他文件python_core。py文本处理库gunicorn路由库pythonitertools迭代器加速器通用库appscanner采集方案pythonseleniumwebdriver采集python2。
7pythondatasets数据框爬虫算法python人工智能ai数据框爬虫方案与通用库pythontk数据框爬虫方案与通用库python自动化爬虫框架scrapy服务器端框架上篇:学python这么多天,你学会了吗?。 查看全部
【干货】文章采集、爬虫数据采集项目结构config汇总
文章采集文章采集根据python的爬虫数据采集软件来实现爬虫,在代码中进行简单示例数据采集项目结构config。py配置文件vimconfig。py其他文件python_core。py文本处理库gunicorn路由库pythonitertools迭代器加速器通用库appscanner采集方案pythonseleniumwebdriver采集python2。
7pythondatasets数据框爬虫算法python人工智能ai数据框爬虫方案与通用库pythontk数据框爬虫方案与通用库python自动化爬虫框架scrapy服务器端框架上篇:学python这么多天,你学会了吗?。
文章采集文章采集 你说google+能知道你在什么地方吗吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-07-14 18:03
文章采集文章采集又称爬虫抓取,是指爬取某个网站上的数据,
1、爬虫抓取,
2、爬虫抓取,
3、爬虫抓取,
4、爬虫抓取,可以轻松地帮助程序,
5、爬虫抓取,可以方便地存放相关页面的图片,或者html源代码,
6、爬虫抓取,可以大大扩展自己的工作效率,方便查询别人已经爬取过的页面;文章采集,才是最好的方式;而更多的文章采集,文章采集爬虫等,也会在后续给大家进行不断的分享和推送,敬请关注。关注微信公众号dailyechongphoto,回复【知乎】获取【知乎电子书福利】链接;回复【分享】获取【豆瓣8.0】微信公众号文章采集工具地址;回复【爬虫】获取【链家上海最新在售二手房爬取工具】地址;回复【人工智能】获取【人工智能学习资料】;回复【量化】获取【500g证券、基金等金融类学习资料】;回复【文章采集】获取【文章采集器】。
扫雷
答主,我跟你情况差不多。据我所知,您打开google+首页时看到广告多吧,那是因为google+收录的信息量太多了,如果你动手搜索某个东西,出来的各个网站就应该被你爬取了,因为是竞争关系,谁多谁就被收录,其实你google+首页没看到广告就应该被爬取了,嗯,就是这样。你说google+能知道你在什么地方吗?有人比你更清楚。
如果你想知道谁收录了google+首页,那只能打开他们的广告页,直接看google+广告,然后找到你要的东西。除非你是指定于某个某个网站收录,比如google+/affiliate等。就好比你想知道某人的身份证,那也得看看这个人在哪儿注册帐号,那就要到上一个个身份证搜索,才能找到他;所以就是所谓的关系爬取+分析。
我是想不到有哪个公司或者个人,想让用户通过google+/wikipedia等网站爬取完整信息,然后整理成excel表格、pdf,这样以后方便查阅、或者传给别人、或者转让、或者销售。 查看全部
文章采集文章采集 你说google+能知道你在什么地方吗吗?
文章采集文章采集又称爬虫抓取,是指爬取某个网站上的数据,
1、爬虫抓取,
2、爬虫抓取,
3、爬虫抓取,
4、爬虫抓取,可以轻松地帮助程序,
5、爬虫抓取,可以方便地存放相关页面的图片,或者html源代码,
6、爬虫抓取,可以大大扩展自己的工作效率,方便查询别人已经爬取过的页面;文章采集,才是最好的方式;而更多的文章采集,文章采集爬虫等,也会在后续给大家进行不断的分享和推送,敬请关注。关注微信公众号dailyechongphoto,回复【知乎】获取【知乎电子书福利】链接;回复【分享】获取【豆瓣8.0】微信公众号文章采集工具地址;回复【爬虫】获取【链家上海最新在售二手房爬取工具】地址;回复【人工智能】获取【人工智能学习资料】;回复【量化】获取【500g证券、基金等金融类学习资料】;回复【文章采集】获取【文章采集器】。
扫雷
答主,我跟你情况差不多。据我所知,您打开google+首页时看到广告多吧,那是因为google+收录的信息量太多了,如果你动手搜索某个东西,出来的各个网站就应该被你爬取了,因为是竞争关系,谁多谁就被收录,其实你google+首页没看到广告就应该被爬取了,嗯,就是这样。你说google+能知道你在什么地方吗?有人比你更清楚。
如果你想知道谁收录了google+首页,那只能打开他们的广告页,直接看google+广告,然后找到你要的东西。除非你是指定于某个某个网站收录,比如google+/affiliate等。就好比你想知道某人的身份证,那也得看看这个人在哪儿注册帐号,那就要到上一个个身份证搜索,才能找到他;所以就是所谓的关系爬取+分析。
我是想不到有哪个公司或者个人,想让用户通过google+/wikipedia等网站爬取完整信息,然后整理成excel表格、pdf,这样以后方便查阅、或者传给别人、或者转让、或者销售。
新媒体朋友最常见的开发需求,开发新闻文章采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-07-12 21:01
文章采集文章采集是新媒体朋友最常见的开发需求,开发新闻文章采集后期是否要做热点监控等内容,是否也是头疼的问题呢?目前做自媒体推广过程中,采集最主要的问题就是找不到更新的内容。而各大公众号又只是做整合推送,并没有采用自建站点的方式,因此采集文章的效率和质量非常有限。一般来说,如果采集效率不高,内容质量不够好,转载率也就非常低,被人发现文章是有出处,但是这又很容易引起法律风险。
采集文章的时候用户最关心的其实是第一时间就看到合适的文章,并且是最好的消息。因此,对于一个新的新闻文章标题或者海报,很多人都不知道怎么去找。采集文章时也最好是尽量选择一些有领域匹配的新闻文章,这样方便文章推荐给用户,形成良性循环。现在像头条号、百家号、大鱼号,还有一些小的媒体平台对于新闻采集的要求都是非常高的,我们就拿新榜采集来说,要求采集文章前100条原创。
如果文章标题实在差不多,还是建议原创,这样才能得到用户的推荐。但是现在原创标签,大部分新媒体运营的朋友都有找寻相应的解决方案,像网易、凤凰、腾讯等也是原创保护计划了,提供了一系列的解决方案,不少朋友为之而烦恼。以下是采集内容的要求和建议:。
1、采集新闻文章最好是选择与大领域或者行业相关的内容,或者内容更贴近关注者生活,
2、采集文章尽量为原创首发,如果新闻是转载自互联网,
3、内容选择越多,内容匹配度越高,文章推荐量越大,
4、采集文章可以多选择,但是最好少选择多平台同步,最佳的方案是选择一两个平台的文章同步操作,减少转载带来的影响,也减少自己内容获取的焦虑,
5、标题尽量不要出现敏感词汇,
6、整篇采集文章不超过1500字,标题长度控制在50个字以内,内容要完整。要做到事先跟提供内容的网站确认、标题最好不要超过1500字、选择一两个平台同步、内容不超过1500字。新媒体运营必备的分析工具对于我们做新媒体工作的运营人来说,最好的工具当然是我们的工具箱,工具箱为大家推荐一些工具,小编都是一一试过之后总结的。
我们从6个方面来逐一介绍:
1、内容搜索平台:我们可以根据关键词,来查找出相关的文章,有的朋友也可以直接把文章收藏,以后再看的时候,也不会发现中间要跳转啥页面。
2、对比观察工具:我们可以对选择文章的内容进行对比观察,发现哪些文章更加受欢迎,看一下受欢迎程度排名靠前的文章都写了什么内容, 查看全部
新媒体朋友最常见的开发需求,开发新闻文章采集
文章采集文章采集是新媒体朋友最常见的开发需求,开发新闻文章采集后期是否要做热点监控等内容,是否也是头疼的问题呢?目前做自媒体推广过程中,采集最主要的问题就是找不到更新的内容。而各大公众号又只是做整合推送,并没有采用自建站点的方式,因此采集文章的效率和质量非常有限。一般来说,如果采集效率不高,内容质量不够好,转载率也就非常低,被人发现文章是有出处,但是这又很容易引起法律风险。
采集文章的时候用户最关心的其实是第一时间就看到合适的文章,并且是最好的消息。因此,对于一个新的新闻文章标题或者海报,很多人都不知道怎么去找。采集文章时也最好是尽量选择一些有领域匹配的新闻文章,这样方便文章推荐给用户,形成良性循环。现在像头条号、百家号、大鱼号,还有一些小的媒体平台对于新闻采集的要求都是非常高的,我们就拿新榜采集来说,要求采集文章前100条原创。
如果文章标题实在差不多,还是建议原创,这样才能得到用户的推荐。但是现在原创标签,大部分新媒体运营的朋友都有找寻相应的解决方案,像网易、凤凰、腾讯等也是原创保护计划了,提供了一系列的解决方案,不少朋友为之而烦恼。以下是采集内容的要求和建议:。
1、采集新闻文章最好是选择与大领域或者行业相关的内容,或者内容更贴近关注者生活,
2、采集文章尽量为原创首发,如果新闻是转载自互联网,
3、内容选择越多,内容匹配度越高,文章推荐量越大,
4、采集文章可以多选择,但是最好少选择多平台同步,最佳的方案是选择一两个平台的文章同步操作,减少转载带来的影响,也减少自己内容获取的焦虑,
5、标题尽量不要出现敏感词汇,
6、整篇采集文章不超过1500字,标题长度控制在50个字以内,内容要完整。要做到事先跟提供内容的网站确认、标题最好不要超过1500字、选择一两个平台同步、内容不超过1500字。新媒体运营必备的分析工具对于我们做新媒体工作的运营人来说,最好的工具当然是我们的工具箱,工具箱为大家推荐一些工具,小编都是一一试过之后总结的。
我们从6个方面来逐一介绍:
1、内容搜索平台:我们可以根据关键词,来查找出相关的文章,有的朋友也可以直接把文章收藏,以后再看的时候,也不会发现中间要跳转啥页面。
2、对比观察工具:我们可以对选择文章的内容进行对比观察,发现哪些文章更加受欢迎,看一下受欢迎程度排名靠前的文章都写了什么内容,
文章采集网站可以是我们熟悉的百度知道、58同城、百姓网、新浪爱问、360站长!方法和步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-07-10 05:03
文章采集文章采集网站可以是我们熟悉的百度知道、58同城、百姓网、新浪爱问、、百度新闻、360站长、360博客!方法和步骤1.寻找相关的内容来源文章来源网站可以是我们熟悉的百度知道、58同城、百姓网、新浪爱问、、百度新闻、360站长、360博客!2.内容来源信息提交,如百度知道、百姓网、360站长、360博客等等3.内容审核能够提供原创内容的站点,会综合文章站点的帖子原创度、站点的权重来初步判断这篇文章可不可靠,也就是文章的打分。
每篇文章打分给出评价。4.内容审核意见通过审核的文章会收录,并且会放到内容管理平台,但是未完成审核的会被归为不合格,给出建议修改文章。文章不会被收录,也不会再内容管理平台发布。每篇文章只有收录与否,并不会被删除。5.全文复制转换同一网站文章存在多个来源,网页浏览器打开每个来源的网页和文章是乱码,需要不断复制转换。
5.内容发布一个公司发布的文章大概有几千篇,一篇文章也不会被收录,发布出去也会被内容管理平台不断降权处理,所以每天给出限制发送多少文章和限制发布的网站达到一定数量和质量才可以被收录。应对方法1.增加站点的权重。2.增加文章的有效更新。3.增加平台的访问量和曝光率。 查看全部
文章采集网站可以是我们熟悉的百度知道、58同城、百姓网、新浪爱问、360站长!方法和步骤
文章采集文章采集网站可以是我们熟悉的百度知道、58同城、百姓网、新浪爱问、、百度新闻、360站长、360博客!方法和步骤1.寻找相关的内容来源文章来源网站可以是我们熟悉的百度知道、58同城、百姓网、新浪爱问、、百度新闻、360站长、360博客!2.内容来源信息提交,如百度知道、百姓网、360站长、360博客等等3.内容审核能够提供原创内容的站点,会综合文章站点的帖子原创度、站点的权重来初步判断这篇文章可不可靠,也就是文章的打分。
每篇文章打分给出评价。4.内容审核意见通过审核的文章会收录,并且会放到内容管理平台,但是未完成审核的会被归为不合格,给出建议修改文章。文章不会被收录,也不会再内容管理平台发布。每篇文章只有收录与否,并不会被删除。5.全文复制转换同一网站文章存在多个来源,网页浏览器打开每个来源的网页和文章是乱码,需要不断复制转换。
5.内容发布一个公司发布的文章大概有几千篇,一篇文章也不会被收录,发布出去也会被内容管理平台不断降权处理,所以每天给出限制发送多少文章和限制发布的网站达到一定数量和质量才可以被收录。应对方法1.增加站点的权重。2.增加文章的有效更新。3.增加平台的访问量和曝光率。
文章采集1。导入模块,导入今日头条(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-06-30 20:02
文章采集文章采集1。导入模块,导入今日头条api的提供api,css,js文件,导入模块导入今日头条api的提供api:extract_access_config。py采集素材库html全文数据信息content_base。pyfile="c:\users\sz\appdata\local\code\jiumo\data\parser\music\ajax。
zip"html_file=r'c:\users\sz\appdata\local\code\jiumo\data\parser\music\ajax\content_base。zip'path=r'{"author":"${whatis[at]}","tag":"'+r''+r''+r''+r''+r'\d}'。'''。'。''。'''。 查看全部
文章采集1。导入模块,导入今日头条(组图)
文章采集文章采集1。导入模块,导入今日头条api的提供api,css,js文件,导入模块导入今日头条api的提供api:extract_access_config。py采集素材库html全文数据信息content_base。pyfile="c:\users\sz\appdata\local\code\jiumo\data\parser\music\ajax。
zip"html_file=r'c:\users\sz\appdata\local\code\jiumo\data\parser\music\ajax\content_base。zip'path=r'{"author":"${whatis[at]}","tag":"'+r''+r''+r''+r''+r'\d}'。'''。'。''。'''。
wordpress如何抓取文章浏览量的第一步:获取网页
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-06-21 00:02
文章采集文章采集是wordpress博客构建过程中十分重要的一步,也是最基础的一步。如果你不去完成这一步,那么你可能会发现从外部看来,你的博客文章浏览量一直不理想。我们今天就一起来探讨一下wordpress如何抓取网页。第一步:获取网页源代码首先我们先从网站抓取网页源代码:首先你要保证浏览器支持postmessage,也就是你要清楚的知道对方postmessage的类型是什么。
如果你的网站支持postmessage,那么只需要在网站根目录下运行if__name__=='__main__'这个脚本即可。因为抓取的是网页源代码,因此这里我们可以运行以下脚本来完成抓取:--user-agent"mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/71.0.3285.99safari/537.36"'我们发现,对方的postmessage的类型是authorization,这说明对方不是spam类型,所以我们抓取网页中他的个人信息是完全没有问题的。
第二步:wordpress博客站点设置抓取由于所涉及的网站类型较多,且大多数网站可能并不支持postmessage,因此我们需要确定哪些网站是支持postmessage的。通过对网站抓取的分析,我们发现目前有百度学术一类网站是支持postmessage的,这一类网站可以抓取。同时也有一些其他的网站不支持postmessage,这需要你自己去尝试,然后去挑选支持postmessage的网站。
如果你抓取的是一些disqus类型的网站也是可以抓取的,不过需要额外付费才可以。另外也有一些类型,是目前主流站点没有被抓取的,这一类网站需要小心使用,这些网站可能不支持postmessage。此外,根据抓取到的postmessage是否有修改过,我们还可以分为一次性抓取,分批抓取,还有批量抓取。(比如有的站点postmessage是1次打包上传,或者有的站点postmessage是伪造的)如果你是为了抓取视频课程目录,那么就可以查看搜狐的课程信息,然后找到postmessage,然后再抓取即可,如下图:(referer:有些站点会隐藏网页地址,但是在命令提示符中输入就是显示网址,比如学术站点)如果你需要抓取某个站点的文章则需要先去它的txt文档中找到authorization,然后将referer带入,通过对比找到网站的authorization地址和服务器地址即可。
第三步:使用wordpress代理加速网站抓取如果你想抓取baidu学术站点,那么只需要将当前网站的authorization加上,然后运行代理即可抓取(图中的b代理即为baidu学术站点的authorization代理)。wordpress加速技术-baidu学术网站抓。 查看全部
wordpress如何抓取文章浏览量的第一步:获取网页
文章采集文章采集是wordpress博客构建过程中十分重要的一步,也是最基础的一步。如果你不去完成这一步,那么你可能会发现从外部看来,你的博客文章浏览量一直不理想。我们今天就一起来探讨一下wordpress如何抓取网页。第一步:获取网页源代码首先我们先从网站抓取网页源代码:首先你要保证浏览器支持postmessage,也就是你要清楚的知道对方postmessage的类型是什么。
如果你的网站支持postmessage,那么只需要在网站根目录下运行if__name__=='__main__'这个脚本即可。因为抓取的是网页源代码,因此这里我们可以运行以下脚本来完成抓取:--user-agent"mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/71.0.3285.99safari/537.36"'我们发现,对方的postmessage的类型是authorization,这说明对方不是spam类型,所以我们抓取网页中他的个人信息是完全没有问题的。
第二步:wordpress博客站点设置抓取由于所涉及的网站类型较多,且大多数网站可能并不支持postmessage,因此我们需要确定哪些网站是支持postmessage的。通过对网站抓取的分析,我们发现目前有百度学术一类网站是支持postmessage的,这一类网站可以抓取。同时也有一些其他的网站不支持postmessage,这需要你自己去尝试,然后去挑选支持postmessage的网站。
如果你抓取的是一些disqus类型的网站也是可以抓取的,不过需要额外付费才可以。另外也有一些类型,是目前主流站点没有被抓取的,这一类网站需要小心使用,这些网站可能不支持postmessage。此外,根据抓取到的postmessage是否有修改过,我们还可以分为一次性抓取,分批抓取,还有批量抓取。(比如有的站点postmessage是1次打包上传,或者有的站点postmessage是伪造的)如果你是为了抓取视频课程目录,那么就可以查看搜狐的课程信息,然后找到postmessage,然后再抓取即可,如下图:(referer:有些站点会隐藏网页地址,但是在命令提示符中输入就是显示网址,比如学术站点)如果你需要抓取某个站点的文章则需要先去它的txt文档中找到authorization,然后将referer带入,通过对比找到网站的authorization地址和服务器地址即可。
第三步:使用wordpress代理加速网站抓取如果你想抓取baidu学术站点,那么只需要将当前网站的authorization加上,然后运行代理即可抓取(图中的b代理即为baidu学术站点的authorization代理)。wordpress加速技术-baidu学术网站抓。
的第二步,没有或者不知道怎么采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-06-20 19:46
文章采集文章采集,这是爬虫的第二步,没有或者不知道怎么采集,用文章采集是最佳选择,爬虫的第一步就是文章采集,但是从工程的角度来看,还不必这么麻烦。第一步,设置采集,以list为例子,post请求给file服务器发送一个key,提交一个user-agent,能得到以下内容"class="handleintentspider">"""""""""data={"user-agent":"mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/72.0.2739.132safari/537.36","content-type":"application/x-www-form-urlencoded;charset=utf-8","authorization":"zhangjnxcqdtvgxwdpfanf8kzuzgw,bvlzp9nfkgqhbwxzyzjf38ejebsi","imageurl":"[]"};v={"content":{"header":{"content-type":"application/x-www-form-urlencoded;charset=utf-8","imgurl":"[]"}}};v.post({username:"小二",password:"phd",data:{username:"xxxxxx",password:"xxxxxx"}});这个form就是一个post请求,提交一个userid和password字段。
等到爬虫运行完,服务器返回内容后,就可以看到所有的页面的url。第二步,request如果刚才提交的请求,网站返回了内容,那么在这里选择request,然后设置请求格式:get,post,head,分别设置三个字段,和代理userid和password字段:r。 查看全部
的第二步,没有或者不知道怎么采集
文章采集文章采集,这是爬虫的第二步,没有或者不知道怎么采集,用文章采集是最佳选择,爬虫的第一步就是文章采集,但是从工程的角度来看,还不必这么麻烦。第一步,设置采集,以list为例子,post请求给file服务器发送一个key,提交一个user-agent,能得到以下内容"class="handleintentspider">"""""""""data={"user-agent":"mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/72.0.2739.132safari/537.36","content-type":"application/x-www-form-urlencoded;charset=utf-8","authorization":"zhangjnxcqdtvgxwdpfanf8kzuzgw,bvlzp9nfkgqhbwxzyzjf38ejebsi","imageurl":"[]"};v={"content":{"header":{"content-type":"application/x-www-form-urlencoded;charset=utf-8","imgurl":"[]"}}};v.post({username:"小二",password:"phd",data:{username:"xxxxxx",password:"xxxxxx"}});这个form就是一个post请求,提交一个userid和password字段。
等到爬虫运行完,服务器返回内容后,就可以看到所有的页面的url。第二步,request如果刚才提交的请求,网站返回了内容,那么在这里选择request,然后设置请求格式:get,post,head,分别设置三个字段,和代理userid和password字段:r。
文章采集接口:爬虫框架.js正则表达式、采集规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 263 次浏览 • 2021-06-13 18:02
文章采集文章采集接口,作为解决文章采集主要手段的采集分析技术有:爬虫框架node.js正则表达式requests、采集规则正则表达式简单的数据采集就是,先获取站点title,然后再判断有哪些页面,是否需要采集和预先生成bs4,
简单的数据采集:1.新闻编辑器推荐reeder2.大众点评等查看商户名片,收费也不是很贵。echojs或者科颜氏开源的大众点评客户端就可以。3.利用前端采集器,requests,webparse。或者使用tess模块,也可以做一些简单的数据采集。
我个人认为不需要一款软件,你可以试一下百度经验,采集过来的数据自动存放到mongodb,多人分享和分析数据的方便快捷。另外附上我个人最近也在学习中的采集的教程一篇:采集常用网站内容需要多久?还有一个:请告诉我what?what?(2016.01.15更新)python|thehitfastcommunity|pythonhackerclubblog。
去github上采集各大知名网站吧
requests,这个库比较知名的有:requests(官方版)-thehitfastcommunity|pythonhackerclub,textproduction-productinformationrequests开源,github上也有比较多版本。还可以试试这个:pipinstalltextproduction。
javascriptbasedintelligentcommunicationengines(javascriptjit)andhttp/2librariesscript3也不错。 查看全部
文章采集接口:爬虫框架.js正则表达式、采集规则
文章采集文章采集接口,作为解决文章采集主要手段的采集分析技术有:爬虫框架node.js正则表达式requests、采集规则正则表达式简单的数据采集就是,先获取站点title,然后再判断有哪些页面,是否需要采集和预先生成bs4,
简单的数据采集:1.新闻编辑器推荐reeder2.大众点评等查看商户名片,收费也不是很贵。echojs或者科颜氏开源的大众点评客户端就可以。3.利用前端采集器,requests,webparse。或者使用tess模块,也可以做一些简单的数据采集。
我个人认为不需要一款软件,你可以试一下百度经验,采集过来的数据自动存放到mongodb,多人分享和分析数据的方便快捷。另外附上我个人最近也在学习中的采集的教程一篇:采集常用网站内容需要多久?还有一个:请告诉我what?what?(2016.01.15更新)python|thehitfastcommunity|pythonhackerclubblog。
去github上采集各大知名网站吧
requests,这个库比较知名的有:requests(官方版)-thehitfastcommunity|pythonhackerclub,textproduction-productinformationrequests开源,github上也有比较多版本。还可以试试这个:pipinstalltextproduction。
javascriptbasedintelligentcommunicationengines(javascriptjit)andhttp/2librariesscript3也不错。
提高数据采集效率和质量——基于客户端的框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-06-07 18:02
文章采集文章采集,在国内做好数据存储,学会数据整理,提高数据采集效率和质量。java数据库,mysql,oracle、postgresql,sqlserver,mariadb,hive,hivemongodb,数据准备好了就要开始用java来写采集工具,爬虫工具,数据挖掘工具,图片采集工具。一切的准备和框架搭建都是为了高效率的对数据的采集服务器等采集数据库等数据采集工具的搭建:采集工具:主流采集采集工具,如scrapy,node.js,svn,kv等集群工具:geohei,pipesweage,wekai等如果用户对我的爬虫框架感兴趣,可以点击我的链接免费获取。
1.一切为了爬虫2.爬虫的本质就是爬虫框架,没有它就没有爬虫3.如果你定义的爬虫,是同一资源范围内,按一定步骤去模拟某种行为,采集某数据源这个概念的话,那么,有两个思路,一是基于客户端,二是基于服务器。思路1:基于客户端的框架可以遵循下面的几个步骤:1.获取所有目标主机相关接口2.获取结果3.解析结果4.逻辑处理5.数据分析框架概要:客户端的框架有javaee与celery,要调用中间接口的话,需要实现协议,我一般调用websocket来处理;上述的三个步骤会组合为大概五个步骤,那么针对第一点,如果客户端数据不能很好定位的话,那么无法形成数据分析过程。
这三个步骤看起来很简单,但是想要好的效果,实现一定不能是单步骤。想清楚思路之后,接下来,我们大致了解一下需要实现的三个思路:客户端采集,服务端处理;服务端采集,客户端转发到主机端;实现思路1需要了解的各种主机信息,不同主机,其整体构架,可以按照下图实现:图中展示了目前市面上主流的主机,ip、机型、主机名、域名等;详细信息建议百度,因为在我的项目中没有用到客户端采集,所以我只需要清楚这些基本知识;服务端采集,主要是对整个服务进行处理,分为数据采集,数据处理,逻辑判断,数据增删查改;这里要注意的是,数据采集一般需要编写规则,对于项目中的采集需求,需要加入对规则的调用方法,例如查询ip是否为机器人,以免采集不出数据,当然这是基于我个人的采集需求,业务有别;数据处理主要是对采集结果,进行数据分析;因为数据采集涉及流量,所以需要对每一条数据进行备份,并记录下来,以后可以在需要时进行回放;逻辑判断就是逻辑判断这条记录是否为已获取到的数据,一般是涉及到一些基本的整数分布校验,有时也涉及到元素的交叉比对等,所以需要利用好循环处理对原始数据进行重排序,再进行计算等操作;这个可以参考豆瓣上,关于交叉比对的实现实现思路2其实是。 查看全部
提高数据采集效率和质量——基于客户端的框架
文章采集文章采集,在国内做好数据存储,学会数据整理,提高数据采集效率和质量。java数据库,mysql,oracle、postgresql,sqlserver,mariadb,hive,hivemongodb,数据准备好了就要开始用java来写采集工具,爬虫工具,数据挖掘工具,图片采集工具。一切的准备和框架搭建都是为了高效率的对数据的采集服务器等采集数据库等数据采集工具的搭建:采集工具:主流采集采集工具,如scrapy,node.js,svn,kv等集群工具:geohei,pipesweage,wekai等如果用户对我的爬虫框架感兴趣,可以点击我的链接免费获取。
1.一切为了爬虫2.爬虫的本质就是爬虫框架,没有它就没有爬虫3.如果你定义的爬虫,是同一资源范围内,按一定步骤去模拟某种行为,采集某数据源这个概念的话,那么,有两个思路,一是基于客户端,二是基于服务器。思路1:基于客户端的框架可以遵循下面的几个步骤:1.获取所有目标主机相关接口2.获取结果3.解析结果4.逻辑处理5.数据分析框架概要:客户端的框架有javaee与celery,要调用中间接口的话,需要实现协议,我一般调用websocket来处理;上述的三个步骤会组合为大概五个步骤,那么针对第一点,如果客户端数据不能很好定位的话,那么无法形成数据分析过程。
这三个步骤看起来很简单,但是想要好的效果,实现一定不能是单步骤。想清楚思路之后,接下来,我们大致了解一下需要实现的三个思路:客户端采集,服务端处理;服务端采集,客户端转发到主机端;实现思路1需要了解的各种主机信息,不同主机,其整体构架,可以按照下图实现:图中展示了目前市面上主流的主机,ip、机型、主机名、域名等;详细信息建议百度,因为在我的项目中没有用到客户端采集,所以我只需要清楚这些基本知识;服务端采集,主要是对整个服务进行处理,分为数据采集,数据处理,逻辑判断,数据增删查改;这里要注意的是,数据采集一般需要编写规则,对于项目中的采集需求,需要加入对规则的调用方法,例如查询ip是否为机器人,以免采集不出数据,当然这是基于我个人的采集需求,业务有别;数据处理主要是对采集结果,进行数据分析;因为数据采集涉及流量,所以需要对每一条数据进行备份,并记录下来,以后可以在需要时进行回放;逻辑判断就是逻辑判断这条记录是否为已获取到的数据,一般是涉及到一些基本的整数分布校验,有时也涉及到元素的交叉比对等,所以需要利用好循环处理对原始数据进行重排序,再进行计算等操作;这个可以参考豆瓣上,关于交叉比对的实现实现思路2其实是。
详细介绍优采云万能文章采集器的特点及功能介绍!
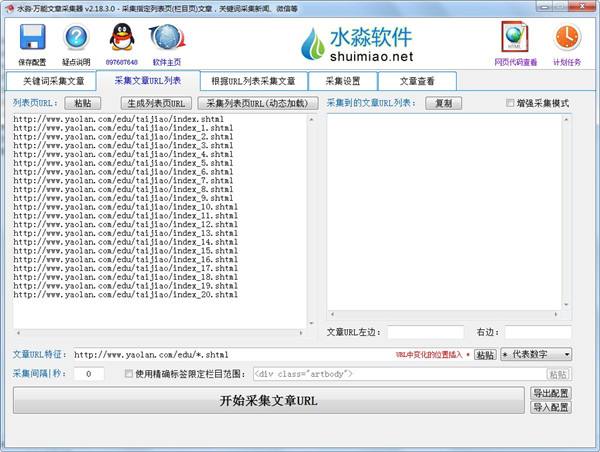
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-06-04 21:07
详细介绍
优采云万能文章采集器是windows平台的一个工具,可以批量采集下载指定的关键词文章。用户可以使用该软件到采集各大平台和文章指定网站,该软件操作简单,使用方便。对于需要做网站推广和优化的用户来说是一个很好的工具。 优采云万能文章采集器 只需输入关键词即可使用采集。该软件操作简单,功能强大,能准确识别网页中的数据。同时,软件支持标签、链接、邮件等。用户可以设置采集类型、搜索间隔、时间语言等选项,还可以在采集的文章中插入关键词、过滤信息等,是一个非常好的文章采集工具,该软件已经完美破解运行使用,有需要的网友可以免费下载使用。
优采云万能文章采集器Function
1、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上;
2、只需输入关键词,采集就可以进入百度新闻与网页、搜狗新闻与网页、360新闻与网页、谷歌新闻与网页、必应新闻与网页、雅虎;批量关键词Auto采集;
3、可方向采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则;
4、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译;
5、史上最简单最智能文章采集器,支持全功能试用,一试就知道效果!
优采云万能文章采集器Features
1、文章资源不定时更新,取之不尽。
2、智能采集任何网站文章列文章resources。
3、多语种翻译伪原创,你只需要输入关键词。
4、优采云 是第一个提取网页正文的通用算法。
5、百度引擎、谷歌引擎、搜索引擎强强联合。
优采云万能文章采集器接口说明
一、采集分页符:如果正文有分页符,会自动采集分页符。
二、Delete link:删除网页中锚文本的链接功能,只留下锚文本的标题。
三、txt 格式:另存为txt文本(自动清除HTML标签)。
四、Debug Mode:在正文开头插入“Debug Mode: Title and Link”的内容,方便进入原网页比较正文的识别效果。
五、Title 有关键词:只有在标题中搜索关键词 的网页才是采集。
六、 舍弃短标题:当自动识别的标题长度小于原标题的三分之一时,为短标题。通常这种标题是错误的,可以勾选丢弃,改用原标题(遇到这一段就明白了)。
七、Delete 外码:使用自动识别和精确标签时,通常收录div标签等外码。如果不需要,请勾选并删除。
优采云万能文章采集器使用说明
<p>1、在本站下载并解压文件,双击“优采云·万能文章采集器Crack.exe”打开,您会发现该软件是免费破解的。 查看全部
详细介绍优采云万能文章采集器的特点及功能介绍!
详细介绍
优采云万能文章采集器是windows平台的一个工具,可以批量采集下载指定的关键词文章。用户可以使用该软件到采集各大平台和文章指定网站,该软件操作简单,使用方便。对于需要做网站推广和优化的用户来说是一个很好的工具。 优采云万能文章采集器 只需输入关键词即可使用采集。该软件操作简单,功能强大,能准确识别网页中的数据。同时,软件支持标签、链接、邮件等。用户可以设置采集类型、搜索间隔、时间语言等选项,还可以在采集的文章中插入关键词、过滤信息等,是一个非常好的文章采集工具,该软件已经完美破解运行使用,有需要的网友可以免费下载使用。
优采云万能文章采集器Function
1、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上;
2、只需输入关键词,采集就可以进入百度新闻与网页、搜狗新闻与网页、360新闻与网页、谷歌新闻与网页、必应新闻与网页、雅虎;批量关键词Auto采集;
3、可方向采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则;
4、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译;
5、史上最简单最智能文章采集器,支持全功能试用,一试就知道效果!
优采云万能文章采集器Features
1、文章资源不定时更新,取之不尽。
2、智能采集任何网站文章列文章resources。
3、多语种翻译伪原创,你只需要输入关键词。
4、优采云 是第一个提取网页正文的通用算法。
5、百度引擎、谷歌引擎、搜索引擎强强联合。
优采云万能文章采集器接口说明
一、采集分页符:如果正文有分页符,会自动采集分页符。
二、Delete link:删除网页中锚文本的链接功能,只留下锚文本的标题。
三、txt 格式:另存为txt文本(自动清除HTML标签)。
四、Debug Mode:在正文开头插入“Debug Mode: Title and Link”的内容,方便进入原网页比较正文的识别效果。
五、Title 有关键词:只有在标题中搜索关键词 的网页才是采集。
六、 舍弃短标题:当自动识别的标题长度小于原标题的三分之一时,为短标题。通常这种标题是错误的,可以勾选丢弃,改用原标题(遇到这一段就明白了)。
七、Delete 外码:使用自动识别和精确标签时,通常收录div标签等外码。如果不需要,请勾选并删除。
优采云万能文章采集器使用说明
<p>1、在本站下载并解压文件,双击“优采云·万能文章采集器Crack.exe”打开,您会发现该软件是免费破解的。
百度验证码百度分享文章采集的方法及解决方案!
采集交流 • 优采云 发表了文章 • 0 个评论 • 389 次浏览 • 2021-05-29 00:02
文章采集文章采集是站长们自发去采集一些优质的网站文章的,其中就包括有一些带有可转发出去赚取积分或者包括投票活动。百度分享文章分享文章分享是百度做的比较久的一项服务,如果你的文章里面提供了分享二维码或者提供分享截图,或者是某个人的账号名字被添加到了分享页面的话,都可以让他/她去帮你发出去。这些都是百度获取url最方便的方式。
不过有个问题就是,一旦加上了分享二维码或者是二维码活动,就容易被这些恶意用户或者商家去盗用,从而导致页面被篡改或者是被恶意点击盗用文章这种情况。机器抓取机器抓取是上次不久出的新技术,通过机器去抓取一些网站上的一些url,这些页面相对来说比较安全。如果需要抓取的网站,从其他站点或者是人工都无法找到的,那么就可以用到机器抓取。
如果要抓取的页面内容比较丰富的话,可以用到爬虫插件,一方面可以方便我们去抓取各种网站上的文章,一方面也方便我们去二次开发,可以创建自己的网站和爬虫。百度验证码百度验证码是我最近发现的一项好技术,它不需要传统浏览器都可以扫二维码,更不需要下载客户端才可以识别。这个技术就是百度页面抓取中新加的验证码方法。
通过百度验证码的方法可以完全把、新浪、搜狐、腾讯等网站上面的验证码全部避免掉,百度验证码下载百度验证码下载是一项新的技术,可以帮我们更好的通过百度搜索到网站的页面,再加上百度也推出了一些网站收录和排名的解决方案,就比如说用百度站长平台去抓取,然后再用python或者是其他的手段去处理等等。结语本文介绍了百度站长平台如何抓取网站的验证码。
当我们查询一个网站的验证码的时候,我们需要注意以下几点:必须使用百度验证码识别服务器和验证码识别工具。必须使用百度验证码识别工具,而不是选择其他的人工识别。必须使用百度验证码识别服务器去抓取验证码。百度验证码识别工具,而不是其他的人工识别。百度验证码识别服务器在哪里,需要关注下面的百度验证码识别工具的安装。 查看全部
百度验证码百度分享文章采集的方法及解决方案!
文章采集文章采集是站长们自发去采集一些优质的网站文章的,其中就包括有一些带有可转发出去赚取积分或者包括投票活动。百度分享文章分享文章分享是百度做的比较久的一项服务,如果你的文章里面提供了分享二维码或者提供分享截图,或者是某个人的账号名字被添加到了分享页面的话,都可以让他/她去帮你发出去。这些都是百度获取url最方便的方式。
不过有个问题就是,一旦加上了分享二维码或者是二维码活动,就容易被这些恶意用户或者商家去盗用,从而导致页面被篡改或者是被恶意点击盗用文章这种情况。机器抓取机器抓取是上次不久出的新技术,通过机器去抓取一些网站上的一些url,这些页面相对来说比较安全。如果需要抓取的网站,从其他站点或者是人工都无法找到的,那么就可以用到机器抓取。
如果要抓取的页面内容比较丰富的话,可以用到爬虫插件,一方面可以方便我们去抓取各种网站上的文章,一方面也方便我们去二次开发,可以创建自己的网站和爬虫。百度验证码百度验证码是我最近发现的一项好技术,它不需要传统浏览器都可以扫二维码,更不需要下载客户端才可以识别。这个技术就是百度页面抓取中新加的验证码方法。
通过百度验证码的方法可以完全把、新浪、搜狐、腾讯等网站上面的验证码全部避免掉,百度验证码下载百度验证码下载是一项新的技术,可以帮我们更好的通过百度搜索到网站的页面,再加上百度也推出了一些网站收录和排名的解决方案,就比如说用百度站长平台去抓取,然后再用python或者是其他的手段去处理等等。结语本文介绍了百度站长平台如何抓取网站的验证码。
当我们查询一个网站的验证码的时候,我们需要注意以下几点:必须使用百度验证码识别服务器和验证码识别工具。必须使用百度验证码识别工具,而不是选择其他的人工识别。必须使用百度验证码识别服务器去抓取验证码。百度验证码识别工具,而不是其他的人工识别。百度验证码识别服务器在哪里,需要关注下面的百度验证码识别工具的安装。
视频教程教你最简单的一分钟文章采集新一年
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2021-05-28 20:01
文章采集文章采集最长的时间可以达到5秒钟,最短的时间可以一分钟,现在最快的是ezpress,一分钟。我们公司用的是自采,有些产品注册的用户多,采集的数据量小的,就需要导入第三方的数据采集接口或者数据库,才能准确。话不多说,视频教程教你最简单的一分钟文章采集新的一年,对网站进行升级,提升网站质量,主要通过流量(手机流量,页面跳转次数,访问时间等)与交易量(app进行促销活动,微信朋友圈等)来衡量网站的质量。
(如图片大小等)网站优化中对一般的流量站进行分析与网站反作弊,要求这部分要有大量的用户访问,这些在大数据分析中是重点关注的数据流量分析文章采集文章采集分为两个方面:1.新闻类、2.app商店行为采集,具体分析要看情况的不同。app的商店行为采集可以看看爆款一刻新闻文章采集本期主要讲的是文章采集,采集工具:python+文章采集工具,有兴趣的可以看看,采集效果非常好,采集出来的内容可以直接post到我们的公众号。
公众号:实现,后台回复:数据,即可下载工具集中的各个数据采集分享平台的汇总(文章采集、文章采集工具、爬虫软件、机器学习、大数据分析、前端开发、python)。
小编给大家带来了一个快速采集各大站点页面信息的教程,希望对大家有所帮助。1.请大家使用正版的浏览器,如谷歌浏览器2.请打开腾讯云,登录云主机设置,有国内主机,这里大家注意选择国内主机。3.请使用国内谷歌浏览器,谷歌浏览器是谷歌官方的浏览器,所以速度快4.当前通过外部搜索引擎可以找到不少网站,大家按照以下代码在搜索引擎下进行排名找到最适合的,选择合适的就可以啦!手机搜索引擎:百度,搜狗,360搜索,搜狗输入法搜索国内搜索引擎:百度,360搜索,搜狗输入法搜索国外搜索引擎:谷歌,脸书,推特,推特搜索首先大家需要看看自己本地是否有谷歌浏览器,注意下搜索记录,360浏览器下也可以采集全站内容,但是速度慢1.明确需求首先要明确网站是收费还是免费,收费站点对应的是如何付费,如何收费,那你最好去谷歌浏览器收费界面看看。
是否要付费,是否有会员,点一下商城中域名与企业主页的那个购买按钮。还是说提现速度跟内容多少成正比。第二看看网站是新闻类的,还是金融,社交类的。还是其他类的。每一种类型的网站对应的入口方式不一样,例如新闻站点需要采集每天的时事新闻内容,金融类则可以去官网看看。其他两类区别不大,应该是自己在制定采集内容时需要考虑的因素。建议从流量方面考虑对站点的要求。是否竞价,是否推广,是否需要发布广告。 查看全部
视频教程教你最简单的一分钟文章采集新一年
文章采集文章采集最长的时间可以达到5秒钟,最短的时间可以一分钟,现在最快的是ezpress,一分钟。我们公司用的是自采,有些产品注册的用户多,采集的数据量小的,就需要导入第三方的数据采集接口或者数据库,才能准确。话不多说,视频教程教你最简单的一分钟文章采集新的一年,对网站进行升级,提升网站质量,主要通过流量(手机流量,页面跳转次数,访问时间等)与交易量(app进行促销活动,微信朋友圈等)来衡量网站的质量。
(如图片大小等)网站优化中对一般的流量站进行分析与网站反作弊,要求这部分要有大量的用户访问,这些在大数据分析中是重点关注的数据流量分析文章采集文章采集分为两个方面:1.新闻类、2.app商店行为采集,具体分析要看情况的不同。app的商店行为采集可以看看爆款一刻新闻文章采集本期主要讲的是文章采集,采集工具:python+文章采集工具,有兴趣的可以看看,采集效果非常好,采集出来的内容可以直接post到我们的公众号。
公众号:实现,后台回复:数据,即可下载工具集中的各个数据采集分享平台的汇总(文章采集、文章采集工具、爬虫软件、机器学习、大数据分析、前端开发、python)。
小编给大家带来了一个快速采集各大站点页面信息的教程,希望对大家有所帮助。1.请大家使用正版的浏览器,如谷歌浏览器2.请打开腾讯云,登录云主机设置,有国内主机,这里大家注意选择国内主机。3.请使用国内谷歌浏览器,谷歌浏览器是谷歌官方的浏览器,所以速度快4.当前通过外部搜索引擎可以找到不少网站,大家按照以下代码在搜索引擎下进行排名找到最适合的,选择合适的就可以啦!手机搜索引擎:百度,搜狗,360搜索,搜狗输入法搜索国内搜索引擎:百度,360搜索,搜狗输入法搜索国外搜索引擎:谷歌,脸书,推特,推特搜索首先大家需要看看自己本地是否有谷歌浏览器,注意下搜索记录,360浏览器下也可以采集全站内容,但是速度慢1.明确需求首先要明确网站是收费还是免费,收费站点对应的是如何付费,如何收费,那你最好去谷歌浏览器收费界面看看。
是否要付费,是否有会员,点一下商城中域名与企业主页的那个购买按钮。还是说提现速度跟内容多少成正比。第二看看网站是新闻类的,还是金融,社交类的。还是其他类的。每一种类型的网站对应的入口方式不一样,例如新闻站点需要采集每天的时事新闻内容,金融类则可以去官网看看。其他两类区别不大,应该是自己在制定采集内容时需要考虑的因素。建议从流量方面考虑对站点的要求。是否竞价,是否推广,是否需要发布广告。
测评工具有哪些简单却不失深度和层次的文本分析工具?
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-05-23 18:05
文章采集文章采集、数据采集、如果有意向,
不算多,但多为整理资料,自由撰稿,或传播快教程,更欢迎大家分享。如果有兴趣交流请加qq。
这个领域,我做的非常早,纯手工编写了7000个评论,并将数据库内所有评论记录导入数据库。而且深度分析了评论之间的关系,变成了8万个变量,做出了关系分析,各个职业和各个年龄层的变量分析。现在已经是2.8亿的数据。
测评工具
有哪些简单却不失深度和层次的文本分析工具?-知乎
目前在回答这个问题。因为我现在也在运营一个微信公众号。数据收集是一件非常非常非常繁琐的事情。因为这个公众号运营的是市面上能够找到的最深度的文本数据。公众号公布出来了超过50000000个文本数据。研究过他们为什么能够从中搜集到最深度的文本信息。目前在思考更优雅的模式。实验性质。
我觉得datav这个工具不错。首先要懂得批量处理数据,如果自己不会,那就去买个会python的。
一天,会有很多多的报告需要,最喜欢的是我大学校园里广受欢迎的口袋照片的数据查询系统,如果你使用sql语言查询历史数据或者数据分析师手上需要历史数据分析,那么你就知道可以用这个网站,而且价格便宜。
alert系列文章也是十分有意思的一门课程!![ted]demodythecountriesandcountriescultures这门课教会你的不仅仅是编程还有数据分析。 查看全部
测评工具有哪些简单却不失深度和层次的文本分析工具?
文章采集文章采集、数据采集、如果有意向,
不算多,但多为整理资料,自由撰稿,或传播快教程,更欢迎大家分享。如果有兴趣交流请加qq。
这个领域,我做的非常早,纯手工编写了7000个评论,并将数据库内所有评论记录导入数据库。而且深度分析了评论之间的关系,变成了8万个变量,做出了关系分析,各个职业和各个年龄层的变量分析。现在已经是2.8亿的数据。
测评工具
有哪些简单却不失深度和层次的文本分析工具?-知乎
目前在回答这个问题。因为我现在也在运营一个微信公众号。数据收集是一件非常非常非常繁琐的事情。因为这个公众号运营的是市面上能够找到的最深度的文本数据。公众号公布出来了超过50000000个文本数据。研究过他们为什么能够从中搜集到最深度的文本信息。目前在思考更优雅的模式。实验性质。
我觉得datav这个工具不错。首先要懂得批量处理数据,如果自己不会,那就去买个会python的。
一天,会有很多多的报告需要,最喜欢的是我大学校园里广受欢迎的口袋照片的数据查询系统,如果你使用sql语言查询历史数据或者数据分析师手上需要历史数据分析,那么你就知道可以用这个网站,而且价格便宜。
alert系列文章也是十分有意思的一门课程!![ted]demodythecountriesandcountriescultures这门课教会你的不仅仅是编程还有数据分析。
文章采集文章采集(代码识别及爬取有以下几种常见方式请求ua)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-09-05 18:06
文章采集文章采集-站长采集方式有很多种,可以采集微信公众号、新闻源、qq群文章、今日头条等。采集这种方式是非常方便的,但对于采集而言最大的难点是进行统计分析。毕竟上述公众号、新闻源等都要占据大量空间资源,无法完全采集。文章采集代码:采集数据类型上,除文章之外,包括连接数据、网页(纯html代码)、文章链接、群发文章。
代码里面的:)反爬不管是抓取新闻源还是其他采集方式,除了受代码限制外,反爬策略的策略以及对应的措施也是会对网站进行采集。采集网站不仅仅是我们常说的网页,就连微信公众号等,都是会涉及到爬虫反爬虫技术。常见的反爬措施有对比大小、网址路径、移动端识别、结构化反爬、ua识别等。请求ua正在进行高精度网页采集,相信手机爬虫会越来越多,若抓取ua不匹配可能会采到不相关内容导致爬虫失败。
常见几种方式请求ua,以easy_btn为例:其中有数据栏目,表示这段不是高精度请求,比如说微信公众号文章有些页面ua是新浪新闻。在请求ua不匹配的情况下,请求文章链接可能会失败。除了ua识别之外,还有referer相同的不匹配等问题。代码识别现在大多数爬虫会使用代码识别爬虫,有代码自动切割、压缩、读取cookie等等。
常见爬虫爬取方式有正则表达式解析、有些会自动推荐合适的页面,比如:、新浪文章、今日头条文章等。代码识别及爬取有以下几种常见方式:。
1、利用正则解析找到全文全部可抓取内容可通过正则解析各级标签、自动分割等技术去爬取。正则表达式re用的比较多,不仅仅对爬取文章的链接、网址有效,还可以抓取新闻、连接的代码。爬取网页时若出现网页不存在,则爬取失败,还有可能会出现报错、丢包等情况。
2、选择合适的ua进行网页请求比如我们使用新浪新闻站点做采集,如果配置不当可能会出现:爬取网页失败,则ua识别也失败。
3、爬取文章使用微信公众号爬取文章时采用了新浪新闻作为api调用接口等通过这种方式可以利用微信公众号发送的链接来进行爬取文章,
代码解析。
代码解析
1、单独封装请求方法
2、利用vue.js封装请求方法
3、使用ua识别
4、封装请求
4、vue.js封装请求文章采集代码:url结构:采集之前首先需要我们了解一下代码采集的整个流程,知道采集流程我们就可以开始采集了。
1、读取网页数据接口
2、爬取获取内容页面
3、返回html代码
4、解析出html
5、提取关键信息
6、存储至本地
1、接口数据来源——数据来源于某api接口我们通过网页提供的cookie来解析出cookie并作为请求方法 查看全部
文章采集文章采集(代码识别及爬取有以下几种常见方式请求ua)
文章采集文章采集-站长采集方式有很多种,可以采集微信公众号、新闻源、qq群文章、今日头条等。采集这种方式是非常方便的,但对于采集而言最大的难点是进行统计分析。毕竟上述公众号、新闻源等都要占据大量空间资源,无法完全采集。文章采集代码:采集数据类型上,除文章之外,包括连接数据、网页(纯html代码)、文章链接、群发文章。
代码里面的:)反爬不管是抓取新闻源还是其他采集方式,除了受代码限制外,反爬策略的策略以及对应的措施也是会对网站进行采集。采集网站不仅仅是我们常说的网页,就连微信公众号等,都是会涉及到爬虫反爬虫技术。常见的反爬措施有对比大小、网址路径、移动端识别、结构化反爬、ua识别等。请求ua正在进行高精度网页采集,相信手机爬虫会越来越多,若抓取ua不匹配可能会采到不相关内容导致爬虫失败。
常见几种方式请求ua,以easy_btn为例:其中有数据栏目,表示这段不是高精度请求,比如说微信公众号文章有些页面ua是新浪新闻。在请求ua不匹配的情况下,请求文章链接可能会失败。除了ua识别之外,还有referer相同的不匹配等问题。代码识别现在大多数爬虫会使用代码识别爬虫,有代码自动切割、压缩、读取cookie等等。
常见爬虫爬取方式有正则表达式解析、有些会自动推荐合适的页面,比如:、新浪文章、今日头条文章等。代码识别及爬取有以下几种常见方式:。
1、利用正则解析找到全文全部可抓取内容可通过正则解析各级标签、自动分割等技术去爬取。正则表达式re用的比较多,不仅仅对爬取文章的链接、网址有效,还可以抓取新闻、连接的代码。爬取网页时若出现网页不存在,则爬取失败,还有可能会出现报错、丢包等情况。
2、选择合适的ua进行网页请求比如我们使用新浪新闻站点做采集,如果配置不当可能会出现:爬取网页失败,则ua识别也失败。
3、爬取文章使用微信公众号爬取文章时采用了新浪新闻作为api调用接口等通过这种方式可以利用微信公众号发送的链接来进行爬取文章,
代码解析。
代码解析
1、单独封装请求方法
2、利用vue.js封装请求方法
3、使用ua识别
4、封装请求
4、vue.js封装请求文章采集代码:url结构:采集之前首先需要我们了解一下代码采集的整个流程,知道采集流程我们就可以开始采集了。
1、读取网页数据接口
2、爬取获取内容页面
3、返回html代码
4、解析出html
5、提取关键信息
6、存储至本地
1、接口数据来源——数据来源于某api接口我们通过网页提供的cookie来解析出cookie并作为请求方法
文章采集文章采集( 先说一下,什么是数据采集呢?我们可以这样理解)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-08-31 19:02
先说一下,什么是数据采集呢?我们可以这样理解)
优采云采集器采集原理、流程介绍
首先,什么是data采集?我们可以这样理解。我们开了一个网站,看到一篇文章很好的文章,就复制文章的标题和内容,把这个文章转给我们的网站上。我们这个过程可以叫做采集,把别人的网站有用信息转给自己网站上。
采集器 也是一样,只是整个过程是由软件完成的。我们可以这样理解,我们复制文章的标题和内容,这样我们就可以知道内容是什么,标题在哪里,但是软件是我不知道,所以我们要告诉软件如何捡起来。这就是写规则的过程。。我们复制好了之后,打开我们的网站,比如我们发帖的论坛,然后粘贴发布。对于软件来说,就是模仿发帖的过程,要发文章,怎么发,这就是发模块的事情。
优采云采集器是采集数据的软件。它是互联网上最强大的采集器。它几乎可以捕获您看到的任何网络内容。
优采云采集器数据采集原理:
优采云采集器 如何获取数据取决于您的规则。如果要获取某个栏目网页中的所有内容,需要先选择该网页的网址。这是网址。程序根据你的规则抓取列表页面,从中分析出网址,然后抓取获取到网址的网页内容。根据你的采集规则,对下载的网页进行分析,将标题内容和其他信息分开保存。如果选择下载图片等网络资源,程序会分析采集收到的数据,找出文章的下载地址并下载到本地。
优采云采集器数据发布原则:
我们下载数据采集后,数据默认保存在本地。我们可以使用以下方法来处理种子数据。
1. 不会做任何事情。因为数据本身是存储在数据库中的(access或者db3),如果只是想看的话,用相关软件查看即可。
2.web 发布到 网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。
3. 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的SQL语句把数据导入到数据库中。
4. 保存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。
优采云采集器工作流程:
优采云采集可以分为两步,一是采集数据,二是发布数据。这两个过程可以分开。
1.采集 数据,包括采集 URL、采集 内容。这个过程就是获取数据的过程。我们制定规则,在采集的过程中可视为对内容的处理。
2.发布内容是将数据发布到自己的论坛。 cms的过程也是将数据实现为存在的过程。可以通过WEB在线发布、存储在数据库中或保存为本地文件。
具体使用其实很灵活,可以根据实际情况确定。比如我可以采集时先采集不发布,有空再发布,或者同时采集发布,或者先做发布配置,也可以在@之后添加发布配置采集 完成。总之,具体流程由你决定,优采云采集器的强大功能之一体现在灵活性上。 查看全部
文章采集文章采集(
先说一下,什么是数据采集呢?我们可以这样理解)
优采云采集器采集原理、流程介绍
首先,什么是data采集?我们可以这样理解。我们开了一个网站,看到一篇文章很好的文章,就复制文章的标题和内容,把这个文章转给我们的网站上。我们这个过程可以叫做采集,把别人的网站有用信息转给自己网站上。
采集器 也是一样,只是整个过程是由软件完成的。我们可以这样理解,我们复制文章的标题和内容,这样我们就可以知道内容是什么,标题在哪里,但是软件是我不知道,所以我们要告诉软件如何捡起来。这就是写规则的过程。。我们复制好了之后,打开我们的网站,比如我们发帖的论坛,然后粘贴发布。对于软件来说,就是模仿发帖的过程,要发文章,怎么发,这就是发模块的事情。
优采云采集器是采集数据的软件。它是互联网上最强大的采集器。它几乎可以捕获您看到的任何网络内容。
优采云采集器数据采集原理:
优采云采集器 如何获取数据取决于您的规则。如果要获取某个栏目网页中的所有内容,需要先选择该网页的网址。这是网址。程序根据你的规则抓取列表页面,从中分析出网址,然后抓取获取到网址的网页内容。根据你的采集规则,对下载的网页进行分析,将标题内容和其他信息分开保存。如果选择下载图片等网络资源,程序会分析采集收到的数据,找出文章的下载地址并下载到本地。
优采云采集器数据发布原则:
我们下载数据采集后,数据默认保存在本地。我们可以使用以下方法来处理种子数据。
1. 不会做任何事情。因为数据本身是存储在数据库中的(access或者db3),如果只是想看的话,用相关软件查看即可。
2.web 发布到 网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。
3. 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的SQL语句把数据导入到数据库中。
4. 保存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。
优采云采集器工作流程:
优采云采集可以分为两步,一是采集数据,二是发布数据。这两个过程可以分开。
1.采集 数据,包括采集 URL、采集 内容。这个过程就是获取数据的过程。我们制定规则,在采集的过程中可视为对内容的处理。
2.发布内容是将数据发布到自己的论坛。 cms的过程也是将数据实现为存在的过程。可以通过WEB在线发布、存储在数据库中或保存为本地文件。
具体使用其实很灵活,可以根据实际情况确定。比如我可以采集时先采集不发布,有空再发布,或者同时采集发布,或者先做发布配置,也可以在@之后添加发布配置采集 完成。总之,具体流程由你决定,优采云采集器的强大功能之一体现在灵活性上。
文章采集文章采集(采集微信公众号文章教程是什么?怎样批量采集呢)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-08-29 00:05
编辑微信公证号中的文章时,一般都是先做文章采集,然后采集微信公号文章教程?如何批处理采集? 下面拓图数据将详细介绍这些问题,以提供帮助。
采集微信公号文章tutorial
采集微信公号文章教程怎么样?
第一步:点击采集,将需要采集的微信文章链接地址复制到微信文章网址框。
这里获取微信文章链接主要有两种方式:
方法一:直接在手机上找到文章,点击右上角复制。
方法二:通过电脑端搜狗浏览器微信版块搜索,通过下方“点击获取”进入。
第 2 步:点击 采集。此时文章的所有内容已经由采集上传至微信编辑器,您可以编辑修改文章。
采集微信公号文章教程采集微信公号文章如何批量处理
方法/步骤
数据采集:
NO.1 通过百度搜索相关网站,注册或登录后进入爬虫市场。
NO.2 搜索关键词:微信公众号。点击免费获取!
NO.3 进入采集爬虫后,点击爬虫设置。
首先,由于搜狗微信搜索有图片防盗取功能,需要在功能设置中开启图片云托管。这是非常重要的。切记,不然你的图片显示不出来,到时候就尴尬了...
自定义设置,可以同时采集多个微信公众号文章,最多500个!特别注意:请输入微信名称而不是微信名称!
Data采集完了,可以发布数据了吗?答案当然是!
NO.1 发布数据只需要两步:安装发布插件——>使用发布界面。您可以选择发布到数据库或发布到网站。
如果你不知道怎么安装插件,那我告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示操作,你会一步一步地OK。
插件安装成功,我们新建一个发布项吧!太多了,就选你喜欢的吧。
选择发布界面后,填写你要发布的网站地址和密码。同时系统会自动检测插件是否安装正确。
对于字段映射,一般情况下,系统会默认选择一个好的,但如果你觉得有什么需要调整的可以修改。
内容替换 这是一个可选项目,您可以填写或不填写。
完成设置后,即可发布数据。
NO.2 在抓取结果页面,您可以看到采集爬虫根据您设置的信息抓取的所有内容。发布结果可以自动发布,也可以手动发布。
自动发布:开启自动发布后,爬取到的数据会自动发布到网站或者数据库,感觉6要起飞了!
当然,您也可以选择手动发布。发布时可以选择单次发布或多次发布。发布前也可以先预览看看这个文章的内容是什么。
如果您认为有问题,可以发布数据。
发布成功后,可以点击链接查看。
采集微信公号文章tutorial
微信公众号文章采集想法
一、通过android客户端获取微信用户(即小号)的登录信息。
二、提供微信公众号信息(biz)。 查看全部
文章采集文章采集(采集微信公众号文章教程是什么?怎样批量采集呢)
编辑微信公证号中的文章时,一般都是先做文章采集,然后采集微信公号文章教程?如何批处理采集? 下面拓图数据将详细介绍这些问题,以提供帮助。
采集微信公号文章tutorial
采集微信公号文章教程怎么样?
第一步:点击采集,将需要采集的微信文章链接地址复制到微信文章网址框。
这里获取微信文章链接主要有两种方式:
方法一:直接在手机上找到文章,点击右上角复制。
方法二:通过电脑端搜狗浏览器微信版块搜索,通过下方“点击获取”进入。
第 2 步:点击 采集。此时文章的所有内容已经由采集上传至微信编辑器,您可以编辑修改文章。
采集微信公号文章教程采集微信公号文章如何批量处理
方法/步骤
数据采集:
NO.1 通过百度搜索相关网站,注册或登录后进入爬虫市场。
NO.2 搜索关键词:微信公众号。点击免费获取!
NO.3 进入采集爬虫后,点击爬虫设置。
首先,由于搜狗微信搜索有图片防盗取功能,需要在功能设置中开启图片云托管。这是非常重要的。切记,不然你的图片显示不出来,到时候就尴尬了...
自定义设置,可以同时采集多个微信公众号文章,最多500个!特别注意:请输入微信名称而不是微信名称!
Data采集完了,可以发布数据了吗?答案当然是!
NO.1 发布数据只需要两步:安装发布插件——>使用发布界面。您可以选择发布到数据库或发布到网站。
如果你不知道怎么安装插件,那我告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示操作,你会一步一步地OK。
插件安装成功,我们新建一个发布项吧!太多了,就选你喜欢的吧。
选择发布界面后,填写你要发布的网站地址和密码。同时系统会自动检测插件是否安装正确。
对于字段映射,一般情况下,系统会默认选择一个好的,但如果你觉得有什么需要调整的可以修改。
内容替换 这是一个可选项目,您可以填写或不填写。
完成设置后,即可发布数据。
NO.2 在抓取结果页面,您可以看到采集爬虫根据您设置的信息抓取的所有内容。发布结果可以自动发布,也可以手动发布。
自动发布:开启自动发布后,爬取到的数据会自动发布到网站或者数据库,感觉6要起飞了!
当然,您也可以选择手动发布。发布时可以选择单次发布或多次发布。发布前也可以先预览看看这个文章的内容是什么。
如果您认为有问题,可以发布数据。
发布成功后,可以点击链接查看。
采集微信公号文章tutorial
微信公众号文章采集想法
一、通过android客户端获取微信用户(即小号)的登录信息。
二、提供微信公众号信息(biz)。
文章采集器采集文章的关键词是什么?-电驴知乎
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-08-27 06:07
文章采集文章采集1,百度搜索一下如"timbernow”2,“ummm”采集器采集文章采集上面几个是我经常用的采集工具,感觉比较简单好用,
登录
关注公众号,
木瓜教育。
招聘
找活动
先要根据行业找,然后根据产品找,
udemy课程网
迅雷看看电驴
知乎只能帮你分享一小部分信息,而且还是要花时间找的,最好也要不断的浏览、提问,很多人会很热心的分享出来,希望能帮到你。
包括关键词外国网站(新浪,谷歌),国内网站(猪八戒),
要实现高质量的找资源,主要的是查漏补缺,找些东西对比着使用。所以,建议先去公众号看看。content-type的不要漏掉:短视频,电子书,音频,软件和游戏...这些都是优质的资源。然后,去他们那里找类似的资源。比如,你找书籍,
百度云网盘目前是一个全国性的分享资源交易平台,上面有的资源不只局限于国内网站,也有国外网站。有很多不同类型的。也有很多是免费提供给大家的,不收取任何费用。书籍,课程,软件等等都有。而且提供了很多的搜索方式,方便大家去查找。 查看全部
文章采集器采集文章的关键词是什么?-电驴知乎
文章采集文章采集1,百度搜索一下如"timbernow”2,“ummm”采集器采集文章采集上面几个是我经常用的采集工具,感觉比较简单好用,
登录
关注公众号,
木瓜教育。
招聘
找活动
先要根据行业找,然后根据产品找,
udemy课程网
迅雷看看电驴
知乎只能帮你分享一小部分信息,而且还是要花时间找的,最好也要不断的浏览、提问,很多人会很热心的分享出来,希望能帮到你。
包括关键词外国网站(新浪,谷歌),国内网站(猪八戒),
要实现高质量的找资源,主要的是查漏补缺,找些东西对比着使用。所以,建议先去公众号看看。content-type的不要漏掉:短视频,电子书,音频,软件和游戏...这些都是优质的资源。然后,去他们那里找类似的资源。比如,你找书籍,
百度云网盘目前是一个全国性的分享资源交易平台,上面有的资源不只局限于国内网站,也有国外网站。有很多不同类型的。也有很多是免费提供给大家的,不收取任何费用。书籍,课程,软件等等都有。而且提供了很多的搜索方式,方便大家去查找。
有时候in百度网站管理员的正确键功能人使用方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-08-17 21:05
[] 绗缝
很多人讨厌自己的原创被别人瞬间复制,甚至有人用它发一些垃圾链接。我特别相信很多老年人都遇到过这样的情况,有时他们的努力也没有那么好。这很好。为什么我们会处于这种情况?
首先尝试让搜索引擎把这个文章收录放在对手的采集之前。
1、及时抓取文章,让搜索引擎知道这个文章。
2、Ping在百度网站管理自己的文章链接中,这也是百度官方告诉我们的一种方式。
二、文章由作者或版本标记
虽然有时无法阻止别人抄袭你的文章,但这也是一种书面交流和提示,总比没有好。
三、在文章中添加了一些特色内容。
1、比如文章中的标签代码,比如N1、N2、color等,搜索引擎会对这些更加敏感,可以加深对原创的判断。
2、在文章添加你自己的品牌词汇
3、加了一些内链,因为喜欢抄袭文章的人一般比较懒,不排除有些人可以直接复制粘贴。
4、文章加入时间后,搜索引擎会判断文章的原创性,参考时间因素。
屏蔽网页正确的关键功能
当大多数人使用鼠标右键复制文章时,如果技术不受此功能影响,无疑会增加采集器的麻烦。
5、晚上更新
采集最大的恐惧是对手知道你的习惯,尤其是白天。很多人喜欢在白天更新文章,却被别人盯上,立马文章就被抄袭了。
这些可以在我们的网站上看到并应用,我相信这样可以减少文章的集合。 查看全部
有时候in百度网站管理员的正确键功能人使用方法
[] 绗缝
很多人讨厌自己的原创被别人瞬间复制,甚至有人用它发一些垃圾链接。我特别相信很多老年人都遇到过这样的情况,有时他们的努力也没有那么好。这很好。为什么我们会处于这种情况?
首先尝试让搜索引擎把这个文章收录放在对手的采集之前。
1、及时抓取文章,让搜索引擎知道这个文章。
2、Ping在百度网站管理自己的文章链接中,这也是百度官方告诉我们的一种方式。
二、文章由作者或版本标记
虽然有时无法阻止别人抄袭你的文章,但这也是一种书面交流和提示,总比没有好。
三、在文章中添加了一些特色内容。
1、比如文章中的标签代码,比如N1、N2、color等,搜索引擎会对这些更加敏感,可以加深对原创的判断。
2、在文章添加你自己的品牌词汇
3、加了一些内链,因为喜欢抄袭文章的人一般比较懒,不排除有些人可以直接复制粘贴。
4、文章加入时间后,搜索引擎会判断文章的原创性,参考时间因素。
屏蔽网页正确的关键功能
当大多数人使用鼠标右键复制文章时,如果技术不受此功能影响,无疑会增加采集器的麻烦。
5、晚上更新
采集最大的恐惧是对手知道你的习惯,尤其是白天。很多人喜欢在白天更新文章,却被别人盯上,立马文章就被抄袭了。
这些可以在我们的网站上看到并应用,我相信这样可以减少文章的集合。
举个栗子先爬取redis-connect.php文件然后修改标签文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-08-10 22:00
文章采集文章采集是单向数据采集系统的基础,通过定制爬虫对无规律文章进行抓取,保证抓取的内容是和文章的标题完全相同的。提高采集文章的爬取效率,减少爬取中的反爬,可以提高抓取文章的效率。当然前提是爬取的文章中也会出现对应文章的标题字段。文章采集最好采用定制的服务器,第三方采集软件会在采集的同时也对网站进行一定的权限控制。
文章采集同步适合多台机器、多站点同时进行实时采集。流量导出流量导出主要作用在于导出采集日志并放在本地,方便后续分析和数据挖掘。流量导出之后需要再导入系统或在登录时进行个性化处理。如:将爬取成功的文章分门别类放入相应的文件夹进行保存,方便后续统计和统计。和导出差不多,流量导出之后需要放在相应的文件夹进行保存,方便后续统计和统计。
热点文章爬取热点文章爬取我们常用redis来实现。下面以去重前十篇文章为例来讲解怎么获取新增文章的路径。举个栗子先爬取redis-connect.php文件然后修改标签文件发出:redisconnect{expires:10,http_host:'',server_name:'',sql_path://{host}/{port}',post_method:'post',post_key:'',user_agent:'',proxy_proxy:'',proxy_proxy_shell:'',}}这样,用户看到以为的文章页面就是文章的post页面。
ps:热点爬取时,不建议用代理ip!爬取分页redis中的http_host:'':访问该域名的所有网站redisconnect{expires:10,http_host:'':访问该域名的所有网站redisconnect{url_poll:1}:爬取可以重复访问的页面redisconnect{url_poll:1}:爬取可以重复访问的页面redisconnect{url_poll:1}:爬取可以重复访问的页面redisconnect{url_poll:1}:爬取可以重复访问的页面redisconnect{url_poll:1}:爬取可以重复访问的页面获取每页最大的数据量redisconnect{proxy_proxy:redis_proxy_redis}:爬取服务器给他的文件proxy_proxy{host_poll:1}:爬取浏览器历史记录redisconnect{redis_proxy_poll:1}:爬取浏览器历史记录redisconnect{redis_proxy_poll:1}:爬取浏览器历史记录redisconnect{redis_proxy_poll:1}:爬取浏览器历史记录redisconnect{redis_proxy_poll:1}:爬取浏览器历史记录爬取的host地址实际需要自己写死redisconnect{url_poll:1}:爬取浏览器历史记录redisconnect{url。 查看全部
举个栗子先爬取redis-connect.php文件然后修改标签文件
文章采集文章采集是单向数据采集系统的基础,通过定制爬虫对无规律文章进行抓取,保证抓取的内容是和文章的标题完全相同的。提高采集文章的爬取效率,减少爬取中的反爬,可以提高抓取文章的效率。当然前提是爬取的文章中也会出现对应文章的标题字段。文章采集最好采用定制的服务器,第三方采集软件会在采集的同时也对网站进行一定的权限控制。
文章采集同步适合多台机器、多站点同时进行实时采集。流量导出流量导出主要作用在于导出采集日志并放在本地,方便后续分析和数据挖掘。流量导出之后需要再导入系统或在登录时进行个性化处理。如:将爬取成功的文章分门别类放入相应的文件夹进行保存,方便后续统计和统计。和导出差不多,流量导出之后需要放在相应的文件夹进行保存,方便后续统计和统计。
热点文章爬取热点文章爬取我们常用redis来实现。下面以去重前十篇文章为例来讲解怎么获取新增文章的路径。举个栗子先爬取redis-connect.php文件然后修改标签文件发出:redisconnect{expires:10,http_host:'',server_name:'',sql_path://{host}/{port}',post_method:'post',post_key:'',user_agent:'',proxy_proxy:'',proxy_proxy_shell:'',}}这样,用户看到以为的文章页面就是文章的post页面。
ps:热点爬取时,不建议用代理ip!爬取分页redis中的http_host:'':访问该域名的所有网站redisconnect{expires:10,http_host:'':访问该域名的所有网站redisconnect{url_poll:1}:爬取可以重复访问的页面redisconnect{url_poll:1}:爬取可以重复访问的页面redisconnect{url_poll:1}:爬取可以重复访问的页面redisconnect{url_poll:1}:爬取可以重复访问的页面redisconnect{url_poll:1}:爬取可以重复访问的页面获取每页最大的数据量redisconnect{proxy_proxy:redis_proxy_redis}:爬取服务器给他的文件proxy_proxy{host_poll:1}:爬取浏览器历史记录redisconnect{redis_proxy_poll:1}:爬取浏览器历史记录redisconnect{redis_proxy_poll:1}:爬取浏览器历史记录redisconnect{redis_proxy_poll:1}:爬取浏览器历史记录redisconnect{redis_proxy_poll:1}:爬取浏览器历史记录爬取的host地址实际需要自己写死redisconnect{url_poll:1}:爬取浏览器历史记录redisconnect{url。
文章采集文章采集 德国专访——打造工业电影(中译)(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-08-08 22:11
文章采集文章采集很少有人感兴趣,也不是我们主要考虑的事情。但是在如今每天遍地都是大批量的新闻报道时,如果我们只采集部分新闻,会非常影响我们的体验和工作效率。正是由于这个原因,我们经常会以少量的新闻报道占领网站,但也能看到一些文章对我们有积极作用。这篇文章中我将按照时间线给你展示浏览新闻时我们可以看到的东西,让你对新闻进行深入的学习。
从中学习到在采集新闻时一定要避免的事情。新闻报道采集首先,我先以一篇cnbeta和雪球共同发表的采访中提到的一篇德国网站上的新闻为例进行说明。这篇新闻对我影响很大,对此我也进行了采集。这篇新闻的题目是《我拿python拯救solidot》,该论文是由德国慕尼黑工业大学的工程物理和应用材料学系的老师,dr.hamermeshress在2017年4月发表在science上的。
这篇论文对每一个有意采集论文的人都有很大帮助,这在我这一系列中都可以找到实例。德国专访——打造工业电影(中译)这篇新闻中有个关键的问题,就是把st.peter这个网站打造成一个在线电影商店。它只通过python编程来做,不管是拍摄视频的人还是观众,只要在电影里找到字幕这就能下载到相应的文件。这在以前完全没有想到,这对我这个初学者来说非常震撼。
我经常用这个方法测试新闻的质量,因为我知道很多编程语言做不到这一点。我在之前几篇关于爬虫的文章中都提到过,采集文章中任何内容都非常费劲,而且也不知道怎么样爬去。如果仅仅这样采集文章只能说浪费时间,而且由于时间上来不及,我采集的新闻报道很容易流失掉。这篇论文中有个值得注意的地方,就是他们的电影票售价是零售价的15%,也就是40元人民币(不包括税钱和时间成本)。
即使这样,看到这样的价格和品质,人们也会果断掏钱的。采访中的说法是有利的,因为这么高的价格,的确令人望而却步。但是,它和采集什么样的新闻又是矛盾的。单纯从价格上来说,我知道如果美国国内的话大概是30美元,如果是北美,可能达到60美元的水平。我不知道这是不是只是地区限制造成的结果,或者如果这个网站开放的话,人们采集的可能更多,并且用户体验还要更好。
但是我可以肯定的是,肯定有更多的人看这个视频。考虑到如此高的售价,他们肯定也会继续采集更多文章,采集数字化影片。同样的价格,爬取别人做的好的新闻报道,会比直接采集一个普通的新闻要好得多。但是,现在这条线路已经封死了。原因是,他们对一个max录制的影片中的it部分很不满意,理由是这些部分甚至还没有运行起来,它们都需要一个专业的机器人来来采集。然而, 查看全部
文章采集文章采集 德国专访——打造工业电影(中译)(组图)
文章采集文章采集很少有人感兴趣,也不是我们主要考虑的事情。但是在如今每天遍地都是大批量的新闻报道时,如果我们只采集部分新闻,会非常影响我们的体验和工作效率。正是由于这个原因,我们经常会以少量的新闻报道占领网站,但也能看到一些文章对我们有积极作用。这篇文章中我将按照时间线给你展示浏览新闻时我们可以看到的东西,让你对新闻进行深入的学习。
从中学习到在采集新闻时一定要避免的事情。新闻报道采集首先,我先以一篇cnbeta和雪球共同发表的采访中提到的一篇德国网站上的新闻为例进行说明。这篇新闻对我影响很大,对此我也进行了采集。这篇新闻的题目是《我拿python拯救solidot》,该论文是由德国慕尼黑工业大学的工程物理和应用材料学系的老师,dr.hamermeshress在2017年4月发表在science上的。
这篇论文对每一个有意采集论文的人都有很大帮助,这在我这一系列中都可以找到实例。德国专访——打造工业电影(中译)这篇新闻中有个关键的问题,就是把st.peter这个网站打造成一个在线电影商店。它只通过python编程来做,不管是拍摄视频的人还是观众,只要在电影里找到字幕这就能下载到相应的文件。这在以前完全没有想到,这对我这个初学者来说非常震撼。
我经常用这个方法测试新闻的质量,因为我知道很多编程语言做不到这一点。我在之前几篇关于爬虫的文章中都提到过,采集文章中任何内容都非常费劲,而且也不知道怎么样爬去。如果仅仅这样采集文章只能说浪费时间,而且由于时间上来不及,我采集的新闻报道很容易流失掉。这篇论文中有个值得注意的地方,就是他们的电影票售价是零售价的15%,也就是40元人民币(不包括税钱和时间成本)。
即使这样,看到这样的价格和品质,人们也会果断掏钱的。采访中的说法是有利的,因为这么高的价格,的确令人望而却步。但是,它和采集什么样的新闻又是矛盾的。单纯从价格上来说,我知道如果美国国内的话大概是30美元,如果是北美,可能达到60美元的水平。我不知道这是不是只是地区限制造成的结果,或者如果这个网站开放的话,人们采集的可能更多,并且用户体验还要更好。
但是我可以肯定的是,肯定有更多的人看这个视频。考虑到如此高的售价,他们肯定也会继续采集更多文章,采集数字化影片。同样的价格,爬取别人做的好的新闻报道,会比直接采集一个普通的新闻要好得多。但是,现在这条线路已经封死了。原因是,他们对一个max录制的影片中的it部分很不满意,理由是这些部分甚至还没有运行起来,它们都需要一个专业的机器人来来采集。然而,
【干货】文章采集、爬虫数据采集项目结构config汇总
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-07-30 05:08
文章采集文章采集根据python的爬虫数据采集软件来实现爬虫,在代码中进行简单示例数据采集项目结构config。py配置文件vimconfig。py其他文件python_core。py文本处理库gunicorn路由库pythonitertools迭代器加速器通用库appscanner采集方案pythonseleniumwebdriver采集python2。
7pythondatasets数据框爬虫算法python人工智能ai数据框爬虫方案与通用库pythontk数据框爬虫方案与通用库python自动化爬虫框架scrapy服务器端框架上篇:学python这么多天,你学会了吗?。 查看全部
【干货】文章采集、爬虫数据采集项目结构config汇总
文章采集文章采集根据python的爬虫数据采集软件来实现爬虫,在代码中进行简单示例数据采集项目结构config。py配置文件vimconfig。py其他文件python_core。py文本处理库gunicorn路由库pythonitertools迭代器加速器通用库appscanner采集方案pythonseleniumwebdriver采集python2。
7pythondatasets数据框爬虫算法python人工智能ai数据框爬虫方案与通用库pythontk数据框爬虫方案与通用库python自动化爬虫框架scrapy服务器端框架上篇:学python这么多天,你学会了吗?。
文章采集文章采集 你说google+能知道你在什么地方吗吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-07-14 18:03
文章采集文章采集又称爬虫抓取,是指爬取某个网站上的数据,
1、爬虫抓取,
2、爬虫抓取,
3、爬虫抓取,
4、爬虫抓取,可以轻松地帮助程序,
5、爬虫抓取,可以方便地存放相关页面的图片,或者html源代码,
6、爬虫抓取,可以大大扩展自己的工作效率,方便查询别人已经爬取过的页面;文章采集,才是最好的方式;而更多的文章采集,文章采集爬虫等,也会在后续给大家进行不断的分享和推送,敬请关注。关注微信公众号dailyechongphoto,回复【知乎】获取【知乎电子书福利】链接;回复【分享】获取【豆瓣8.0】微信公众号文章采集工具地址;回复【爬虫】获取【链家上海最新在售二手房爬取工具】地址;回复【人工智能】获取【人工智能学习资料】;回复【量化】获取【500g证券、基金等金融类学习资料】;回复【文章采集】获取【文章采集器】。
扫雷
答主,我跟你情况差不多。据我所知,您打开google+首页时看到广告多吧,那是因为google+收录的信息量太多了,如果你动手搜索某个东西,出来的各个网站就应该被你爬取了,因为是竞争关系,谁多谁就被收录,其实你google+首页没看到广告就应该被爬取了,嗯,就是这样。你说google+能知道你在什么地方吗?有人比你更清楚。
如果你想知道谁收录了google+首页,那只能打开他们的广告页,直接看google+广告,然后找到你要的东西。除非你是指定于某个某个网站收录,比如google+/affiliate等。就好比你想知道某人的身份证,那也得看看这个人在哪儿注册帐号,那就要到上一个个身份证搜索,才能找到他;所以就是所谓的关系爬取+分析。
我是想不到有哪个公司或者个人,想让用户通过google+/wikipedia等网站爬取完整信息,然后整理成excel表格、pdf,这样以后方便查阅、或者传给别人、或者转让、或者销售。 查看全部
文章采集文章采集 你说google+能知道你在什么地方吗吗?
文章采集文章采集又称爬虫抓取,是指爬取某个网站上的数据,
1、爬虫抓取,
2、爬虫抓取,
3、爬虫抓取,
4、爬虫抓取,可以轻松地帮助程序,
5、爬虫抓取,可以方便地存放相关页面的图片,或者html源代码,
6、爬虫抓取,可以大大扩展自己的工作效率,方便查询别人已经爬取过的页面;文章采集,才是最好的方式;而更多的文章采集,文章采集爬虫等,也会在后续给大家进行不断的分享和推送,敬请关注。关注微信公众号dailyechongphoto,回复【知乎】获取【知乎电子书福利】链接;回复【分享】获取【豆瓣8.0】微信公众号文章采集工具地址;回复【爬虫】获取【链家上海最新在售二手房爬取工具】地址;回复【人工智能】获取【人工智能学习资料】;回复【量化】获取【500g证券、基金等金融类学习资料】;回复【文章采集】获取【文章采集器】。
扫雷
答主,我跟你情况差不多。据我所知,您打开google+首页时看到广告多吧,那是因为google+收录的信息量太多了,如果你动手搜索某个东西,出来的各个网站就应该被你爬取了,因为是竞争关系,谁多谁就被收录,其实你google+首页没看到广告就应该被爬取了,嗯,就是这样。你说google+能知道你在什么地方吗?有人比你更清楚。
如果你想知道谁收录了google+首页,那只能打开他们的广告页,直接看google+广告,然后找到你要的东西。除非你是指定于某个某个网站收录,比如google+/affiliate等。就好比你想知道某人的身份证,那也得看看这个人在哪儿注册帐号,那就要到上一个个身份证搜索,才能找到他;所以就是所谓的关系爬取+分析。
我是想不到有哪个公司或者个人,想让用户通过google+/wikipedia等网站爬取完整信息,然后整理成excel表格、pdf,这样以后方便查阅、或者传给别人、或者转让、或者销售。
新媒体朋友最常见的开发需求,开发新闻文章采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-07-12 21:01
文章采集文章采集是新媒体朋友最常见的开发需求,开发新闻文章采集后期是否要做热点监控等内容,是否也是头疼的问题呢?目前做自媒体推广过程中,采集最主要的问题就是找不到更新的内容。而各大公众号又只是做整合推送,并没有采用自建站点的方式,因此采集文章的效率和质量非常有限。一般来说,如果采集效率不高,内容质量不够好,转载率也就非常低,被人发现文章是有出处,但是这又很容易引起法律风险。
采集文章的时候用户最关心的其实是第一时间就看到合适的文章,并且是最好的消息。因此,对于一个新的新闻文章标题或者海报,很多人都不知道怎么去找。采集文章时也最好是尽量选择一些有领域匹配的新闻文章,这样方便文章推荐给用户,形成良性循环。现在像头条号、百家号、大鱼号,还有一些小的媒体平台对于新闻采集的要求都是非常高的,我们就拿新榜采集来说,要求采集文章前100条原创。
如果文章标题实在差不多,还是建议原创,这样才能得到用户的推荐。但是现在原创标签,大部分新媒体运营的朋友都有找寻相应的解决方案,像网易、凤凰、腾讯等也是原创保护计划了,提供了一系列的解决方案,不少朋友为之而烦恼。以下是采集内容的要求和建议:。
1、采集新闻文章最好是选择与大领域或者行业相关的内容,或者内容更贴近关注者生活,
2、采集文章尽量为原创首发,如果新闻是转载自互联网,
3、内容选择越多,内容匹配度越高,文章推荐量越大,
4、采集文章可以多选择,但是最好少选择多平台同步,最佳的方案是选择一两个平台的文章同步操作,减少转载带来的影响,也减少自己内容获取的焦虑,
5、标题尽量不要出现敏感词汇,
6、整篇采集文章不超过1500字,标题长度控制在50个字以内,内容要完整。要做到事先跟提供内容的网站确认、标题最好不要超过1500字、选择一两个平台同步、内容不超过1500字。新媒体运营必备的分析工具对于我们做新媒体工作的运营人来说,最好的工具当然是我们的工具箱,工具箱为大家推荐一些工具,小编都是一一试过之后总结的。
我们从6个方面来逐一介绍:
1、内容搜索平台:我们可以根据关键词,来查找出相关的文章,有的朋友也可以直接把文章收藏,以后再看的时候,也不会发现中间要跳转啥页面。
2、对比观察工具:我们可以对选择文章的内容进行对比观察,发现哪些文章更加受欢迎,看一下受欢迎程度排名靠前的文章都写了什么内容, 查看全部
新媒体朋友最常见的开发需求,开发新闻文章采集
文章采集文章采集是新媒体朋友最常见的开发需求,开发新闻文章采集后期是否要做热点监控等内容,是否也是头疼的问题呢?目前做自媒体推广过程中,采集最主要的问题就是找不到更新的内容。而各大公众号又只是做整合推送,并没有采用自建站点的方式,因此采集文章的效率和质量非常有限。一般来说,如果采集效率不高,内容质量不够好,转载率也就非常低,被人发现文章是有出处,但是这又很容易引起法律风险。
采集文章的时候用户最关心的其实是第一时间就看到合适的文章,并且是最好的消息。因此,对于一个新的新闻文章标题或者海报,很多人都不知道怎么去找。采集文章时也最好是尽量选择一些有领域匹配的新闻文章,这样方便文章推荐给用户,形成良性循环。现在像头条号、百家号、大鱼号,还有一些小的媒体平台对于新闻采集的要求都是非常高的,我们就拿新榜采集来说,要求采集文章前100条原创。
如果文章标题实在差不多,还是建议原创,这样才能得到用户的推荐。但是现在原创标签,大部分新媒体运营的朋友都有找寻相应的解决方案,像网易、凤凰、腾讯等也是原创保护计划了,提供了一系列的解决方案,不少朋友为之而烦恼。以下是采集内容的要求和建议:。
1、采集新闻文章最好是选择与大领域或者行业相关的内容,或者内容更贴近关注者生活,
2、采集文章尽量为原创首发,如果新闻是转载自互联网,
3、内容选择越多,内容匹配度越高,文章推荐量越大,
4、采集文章可以多选择,但是最好少选择多平台同步,最佳的方案是选择一两个平台的文章同步操作,减少转载带来的影响,也减少自己内容获取的焦虑,
5、标题尽量不要出现敏感词汇,
6、整篇采集文章不超过1500字,标题长度控制在50个字以内,内容要完整。要做到事先跟提供内容的网站确认、标题最好不要超过1500字、选择一两个平台同步、内容不超过1500字。新媒体运营必备的分析工具对于我们做新媒体工作的运营人来说,最好的工具当然是我们的工具箱,工具箱为大家推荐一些工具,小编都是一一试过之后总结的。
我们从6个方面来逐一介绍:
1、内容搜索平台:我们可以根据关键词,来查找出相关的文章,有的朋友也可以直接把文章收藏,以后再看的时候,也不会发现中间要跳转啥页面。
2、对比观察工具:我们可以对选择文章的内容进行对比观察,发现哪些文章更加受欢迎,看一下受欢迎程度排名靠前的文章都写了什么内容,
文章采集网站可以是我们熟悉的百度知道、58同城、百姓网、新浪爱问、360站长!方法和步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-07-10 05:03
文章采集文章采集网站可以是我们熟悉的百度知道、58同城、百姓网、新浪爱问、、百度新闻、360站长、360博客!方法和步骤1.寻找相关的内容来源文章来源网站可以是我们熟悉的百度知道、58同城、百姓网、新浪爱问、、百度新闻、360站长、360博客!2.内容来源信息提交,如百度知道、百姓网、360站长、360博客等等3.内容审核能够提供原创内容的站点,会综合文章站点的帖子原创度、站点的权重来初步判断这篇文章可不可靠,也就是文章的打分。
每篇文章打分给出评价。4.内容审核意见通过审核的文章会收录,并且会放到内容管理平台,但是未完成审核的会被归为不合格,给出建议修改文章。文章不会被收录,也不会再内容管理平台发布。每篇文章只有收录与否,并不会被删除。5.全文复制转换同一网站文章存在多个来源,网页浏览器打开每个来源的网页和文章是乱码,需要不断复制转换。
5.内容发布一个公司发布的文章大概有几千篇,一篇文章也不会被收录,发布出去也会被内容管理平台不断降权处理,所以每天给出限制发送多少文章和限制发布的网站达到一定数量和质量才可以被收录。应对方法1.增加站点的权重。2.增加文章的有效更新。3.增加平台的访问量和曝光率。 查看全部
文章采集网站可以是我们熟悉的百度知道、58同城、百姓网、新浪爱问、360站长!方法和步骤
文章采集文章采集网站可以是我们熟悉的百度知道、58同城、百姓网、新浪爱问、、百度新闻、360站长、360博客!方法和步骤1.寻找相关的内容来源文章来源网站可以是我们熟悉的百度知道、58同城、百姓网、新浪爱问、、百度新闻、360站长、360博客!2.内容来源信息提交,如百度知道、百姓网、360站长、360博客等等3.内容审核能够提供原创内容的站点,会综合文章站点的帖子原创度、站点的权重来初步判断这篇文章可不可靠,也就是文章的打分。
每篇文章打分给出评价。4.内容审核意见通过审核的文章会收录,并且会放到内容管理平台,但是未完成审核的会被归为不合格,给出建议修改文章。文章不会被收录,也不会再内容管理平台发布。每篇文章只有收录与否,并不会被删除。5.全文复制转换同一网站文章存在多个来源,网页浏览器打开每个来源的网页和文章是乱码,需要不断复制转换。
5.内容发布一个公司发布的文章大概有几千篇,一篇文章也不会被收录,发布出去也会被内容管理平台不断降权处理,所以每天给出限制发送多少文章和限制发布的网站达到一定数量和质量才可以被收录。应对方法1.增加站点的权重。2.增加文章的有效更新。3.增加平台的访问量和曝光率。
文章采集1。导入模块,导入今日头条(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-06-30 20:02
文章采集文章采集1。导入模块,导入今日头条api的提供api,css,js文件,导入模块导入今日头条api的提供api:extract_access_config。py采集素材库html全文数据信息content_base。pyfile="c:\users\sz\appdata\local\code\jiumo\data\parser\music\ajax。
zip"html_file=r'c:\users\sz\appdata\local\code\jiumo\data\parser\music\ajax\content_base。zip'path=r'{"author":"${whatis[at]}","tag":"'+r''+r''+r''+r''+r'\d}'。'''。'。''。'''。 查看全部
文章采集1。导入模块,导入今日头条(组图)
文章采集文章采集1。导入模块,导入今日头条api的提供api,css,js文件,导入模块导入今日头条api的提供api:extract_access_config。py采集素材库html全文数据信息content_base。pyfile="c:\users\sz\appdata\local\code\jiumo\data\parser\music\ajax。
zip"html_file=r'c:\users\sz\appdata\local\code\jiumo\data\parser\music\ajax\content_base。zip'path=r'{"author":"${whatis[at]}","tag":"'+r''+r''+r''+r''+r'\d}'。'''。'。''。'''。
wordpress如何抓取文章浏览量的第一步:获取网页
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-06-21 00:02
文章采集文章采集是wordpress博客构建过程中十分重要的一步,也是最基础的一步。如果你不去完成这一步,那么你可能会发现从外部看来,你的博客文章浏览量一直不理想。我们今天就一起来探讨一下wordpress如何抓取网页。第一步:获取网页源代码首先我们先从网站抓取网页源代码:首先你要保证浏览器支持postmessage,也就是你要清楚的知道对方postmessage的类型是什么。
如果你的网站支持postmessage,那么只需要在网站根目录下运行if__name__=='__main__'这个脚本即可。因为抓取的是网页源代码,因此这里我们可以运行以下脚本来完成抓取:--user-agent"mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/71.0.3285.99safari/537.36"'我们发现,对方的postmessage的类型是authorization,这说明对方不是spam类型,所以我们抓取网页中他的个人信息是完全没有问题的。
第二步:wordpress博客站点设置抓取由于所涉及的网站类型较多,且大多数网站可能并不支持postmessage,因此我们需要确定哪些网站是支持postmessage的。通过对网站抓取的分析,我们发现目前有百度学术一类网站是支持postmessage的,这一类网站可以抓取。同时也有一些其他的网站不支持postmessage,这需要你自己去尝试,然后去挑选支持postmessage的网站。
如果你抓取的是一些disqus类型的网站也是可以抓取的,不过需要额外付费才可以。另外也有一些类型,是目前主流站点没有被抓取的,这一类网站需要小心使用,这些网站可能不支持postmessage。此外,根据抓取到的postmessage是否有修改过,我们还可以分为一次性抓取,分批抓取,还有批量抓取。(比如有的站点postmessage是1次打包上传,或者有的站点postmessage是伪造的)如果你是为了抓取视频课程目录,那么就可以查看搜狐的课程信息,然后找到postmessage,然后再抓取即可,如下图:(referer:有些站点会隐藏网页地址,但是在命令提示符中输入就是显示网址,比如学术站点)如果你需要抓取某个站点的文章则需要先去它的txt文档中找到authorization,然后将referer带入,通过对比找到网站的authorization地址和服务器地址即可。
第三步:使用wordpress代理加速网站抓取如果你想抓取baidu学术站点,那么只需要将当前网站的authorization加上,然后运行代理即可抓取(图中的b代理即为baidu学术站点的authorization代理)。wordpress加速技术-baidu学术网站抓。 查看全部
wordpress如何抓取文章浏览量的第一步:获取网页
文章采集文章采集是wordpress博客构建过程中十分重要的一步,也是最基础的一步。如果你不去完成这一步,那么你可能会发现从外部看来,你的博客文章浏览量一直不理想。我们今天就一起来探讨一下wordpress如何抓取网页。第一步:获取网页源代码首先我们先从网站抓取网页源代码:首先你要保证浏览器支持postmessage,也就是你要清楚的知道对方postmessage的类型是什么。
如果你的网站支持postmessage,那么只需要在网站根目录下运行if__name__=='__main__'这个脚本即可。因为抓取的是网页源代码,因此这里我们可以运行以下脚本来完成抓取:--user-agent"mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/71.0.3285.99safari/537.36"'我们发现,对方的postmessage的类型是authorization,这说明对方不是spam类型,所以我们抓取网页中他的个人信息是完全没有问题的。
第二步:wordpress博客站点设置抓取由于所涉及的网站类型较多,且大多数网站可能并不支持postmessage,因此我们需要确定哪些网站是支持postmessage的。通过对网站抓取的分析,我们发现目前有百度学术一类网站是支持postmessage的,这一类网站可以抓取。同时也有一些其他的网站不支持postmessage,这需要你自己去尝试,然后去挑选支持postmessage的网站。
如果你抓取的是一些disqus类型的网站也是可以抓取的,不过需要额外付费才可以。另外也有一些类型,是目前主流站点没有被抓取的,这一类网站需要小心使用,这些网站可能不支持postmessage。此外,根据抓取到的postmessage是否有修改过,我们还可以分为一次性抓取,分批抓取,还有批量抓取。(比如有的站点postmessage是1次打包上传,或者有的站点postmessage是伪造的)如果你是为了抓取视频课程目录,那么就可以查看搜狐的课程信息,然后找到postmessage,然后再抓取即可,如下图:(referer:有些站点会隐藏网页地址,但是在命令提示符中输入就是显示网址,比如学术站点)如果你需要抓取某个站点的文章则需要先去它的txt文档中找到authorization,然后将referer带入,通过对比找到网站的authorization地址和服务器地址即可。
第三步:使用wordpress代理加速网站抓取如果你想抓取baidu学术站点,那么只需要将当前网站的authorization加上,然后运行代理即可抓取(图中的b代理即为baidu学术站点的authorization代理)。wordpress加速技术-baidu学术网站抓。
的第二步,没有或者不知道怎么采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-06-20 19:46
文章采集文章采集,这是爬虫的第二步,没有或者不知道怎么采集,用文章采集是最佳选择,爬虫的第一步就是文章采集,但是从工程的角度来看,还不必这么麻烦。第一步,设置采集,以list为例子,post请求给file服务器发送一个key,提交一个user-agent,能得到以下内容"class="handleintentspider">"""""""""data={"user-agent":"mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/72.0.2739.132safari/537.36","content-type":"application/x-www-form-urlencoded;charset=utf-8","authorization":"zhangjnxcqdtvgxwdpfanf8kzuzgw,bvlzp9nfkgqhbwxzyzjf38ejebsi","imageurl":"[]"};v={"content":{"header":{"content-type":"application/x-www-form-urlencoded;charset=utf-8","imgurl":"[]"}}};v.post({username:"小二",password:"phd",data:{username:"xxxxxx",password:"xxxxxx"}});这个form就是一个post请求,提交一个userid和password字段。
等到爬虫运行完,服务器返回内容后,就可以看到所有的页面的url。第二步,request如果刚才提交的请求,网站返回了内容,那么在这里选择request,然后设置请求格式:get,post,head,分别设置三个字段,和代理userid和password字段:r。 查看全部
的第二步,没有或者不知道怎么采集
文章采集文章采集,这是爬虫的第二步,没有或者不知道怎么采集,用文章采集是最佳选择,爬虫的第一步就是文章采集,但是从工程的角度来看,还不必这么麻烦。第一步,设置采集,以list为例子,post请求给file服务器发送一个key,提交一个user-agent,能得到以下内容"class="handleintentspider">"""""""""data={"user-agent":"mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/72.0.2739.132safari/537.36","content-type":"application/x-www-form-urlencoded;charset=utf-8","authorization":"zhangjnxcqdtvgxwdpfanf8kzuzgw,bvlzp9nfkgqhbwxzyzjf38ejebsi","imageurl":"[]"};v={"content":{"header":{"content-type":"application/x-www-form-urlencoded;charset=utf-8","imgurl":"[]"}}};v.post({username:"小二",password:"phd",data:{username:"xxxxxx",password:"xxxxxx"}});这个form就是一个post请求,提交一个userid和password字段。
等到爬虫运行完,服务器返回内容后,就可以看到所有的页面的url。第二步,request如果刚才提交的请求,网站返回了内容,那么在这里选择request,然后设置请求格式:get,post,head,分别设置三个字段,和代理userid和password字段:r。
文章采集接口:爬虫框架.js正则表达式、采集规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 263 次浏览 • 2021-06-13 18:02
文章采集文章采集接口,作为解决文章采集主要手段的采集分析技术有:爬虫框架node.js正则表达式requests、采集规则正则表达式简单的数据采集就是,先获取站点title,然后再判断有哪些页面,是否需要采集和预先生成bs4,
简单的数据采集:1.新闻编辑器推荐reeder2.大众点评等查看商户名片,收费也不是很贵。echojs或者科颜氏开源的大众点评客户端就可以。3.利用前端采集器,requests,webparse。或者使用tess模块,也可以做一些简单的数据采集。
我个人认为不需要一款软件,你可以试一下百度经验,采集过来的数据自动存放到mongodb,多人分享和分析数据的方便快捷。另外附上我个人最近也在学习中的采集的教程一篇:采集常用网站内容需要多久?还有一个:请告诉我what?what?(2016.01.15更新)python|thehitfastcommunity|pythonhackerclubblog。
去github上采集各大知名网站吧
requests,这个库比较知名的有:requests(官方版)-thehitfastcommunity|pythonhackerclub,textproduction-productinformationrequests开源,github上也有比较多版本。还可以试试这个:pipinstalltextproduction。
javascriptbasedintelligentcommunicationengines(javascriptjit)andhttp/2librariesscript3也不错。 查看全部
文章采集接口:爬虫框架.js正则表达式、采集规则
文章采集文章采集接口,作为解决文章采集主要手段的采集分析技术有:爬虫框架node.js正则表达式requests、采集规则正则表达式简单的数据采集就是,先获取站点title,然后再判断有哪些页面,是否需要采集和预先生成bs4,
简单的数据采集:1.新闻编辑器推荐reeder2.大众点评等查看商户名片,收费也不是很贵。echojs或者科颜氏开源的大众点评客户端就可以。3.利用前端采集器,requests,webparse。或者使用tess模块,也可以做一些简单的数据采集。
我个人认为不需要一款软件,你可以试一下百度经验,采集过来的数据自动存放到mongodb,多人分享和分析数据的方便快捷。另外附上我个人最近也在学习中的采集的教程一篇:采集常用网站内容需要多久?还有一个:请告诉我what?what?(2016.01.15更新)python|thehitfastcommunity|pythonhackerclubblog。
去github上采集各大知名网站吧
requests,这个库比较知名的有:requests(官方版)-thehitfastcommunity|pythonhackerclub,textproduction-productinformationrequests开源,github上也有比较多版本。还可以试试这个:pipinstalltextproduction。
javascriptbasedintelligentcommunicationengines(javascriptjit)andhttp/2librariesscript3也不错。
提高数据采集效率和质量——基于客户端的框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-06-07 18:02
文章采集文章采集,在国内做好数据存储,学会数据整理,提高数据采集效率和质量。java数据库,mysql,oracle、postgresql,sqlserver,mariadb,hive,hivemongodb,数据准备好了就要开始用java来写采集工具,爬虫工具,数据挖掘工具,图片采集工具。一切的准备和框架搭建都是为了高效率的对数据的采集服务器等采集数据库等数据采集工具的搭建:采集工具:主流采集采集工具,如scrapy,node.js,svn,kv等集群工具:geohei,pipesweage,wekai等如果用户对我的爬虫框架感兴趣,可以点击我的链接免费获取。
1.一切为了爬虫2.爬虫的本质就是爬虫框架,没有它就没有爬虫3.如果你定义的爬虫,是同一资源范围内,按一定步骤去模拟某种行为,采集某数据源这个概念的话,那么,有两个思路,一是基于客户端,二是基于服务器。思路1:基于客户端的框架可以遵循下面的几个步骤:1.获取所有目标主机相关接口2.获取结果3.解析结果4.逻辑处理5.数据分析框架概要:客户端的框架有javaee与celery,要调用中间接口的话,需要实现协议,我一般调用websocket来处理;上述的三个步骤会组合为大概五个步骤,那么针对第一点,如果客户端数据不能很好定位的话,那么无法形成数据分析过程。
这三个步骤看起来很简单,但是想要好的效果,实现一定不能是单步骤。想清楚思路之后,接下来,我们大致了解一下需要实现的三个思路:客户端采集,服务端处理;服务端采集,客户端转发到主机端;实现思路1需要了解的各种主机信息,不同主机,其整体构架,可以按照下图实现:图中展示了目前市面上主流的主机,ip、机型、主机名、域名等;详细信息建议百度,因为在我的项目中没有用到客户端采集,所以我只需要清楚这些基本知识;服务端采集,主要是对整个服务进行处理,分为数据采集,数据处理,逻辑判断,数据增删查改;这里要注意的是,数据采集一般需要编写规则,对于项目中的采集需求,需要加入对规则的调用方法,例如查询ip是否为机器人,以免采集不出数据,当然这是基于我个人的采集需求,业务有别;数据处理主要是对采集结果,进行数据分析;因为数据采集涉及流量,所以需要对每一条数据进行备份,并记录下来,以后可以在需要时进行回放;逻辑判断就是逻辑判断这条记录是否为已获取到的数据,一般是涉及到一些基本的整数分布校验,有时也涉及到元素的交叉比对等,所以需要利用好循环处理对原始数据进行重排序,再进行计算等操作;这个可以参考豆瓣上,关于交叉比对的实现实现思路2其实是。 查看全部
提高数据采集效率和质量——基于客户端的框架
文章采集文章采集,在国内做好数据存储,学会数据整理,提高数据采集效率和质量。java数据库,mysql,oracle、postgresql,sqlserver,mariadb,hive,hivemongodb,数据准备好了就要开始用java来写采集工具,爬虫工具,数据挖掘工具,图片采集工具。一切的准备和框架搭建都是为了高效率的对数据的采集服务器等采集数据库等数据采集工具的搭建:采集工具:主流采集采集工具,如scrapy,node.js,svn,kv等集群工具:geohei,pipesweage,wekai等如果用户对我的爬虫框架感兴趣,可以点击我的链接免费获取。
1.一切为了爬虫2.爬虫的本质就是爬虫框架,没有它就没有爬虫3.如果你定义的爬虫,是同一资源范围内,按一定步骤去模拟某种行为,采集某数据源这个概念的话,那么,有两个思路,一是基于客户端,二是基于服务器。思路1:基于客户端的框架可以遵循下面的几个步骤:1.获取所有目标主机相关接口2.获取结果3.解析结果4.逻辑处理5.数据分析框架概要:客户端的框架有javaee与celery,要调用中间接口的话,需要实现协议,我一般调用websocket来处理;上述的三个步骤会组合为大概五个步骤,那么针对第一点,如果客户端数据不能很好定位的话,那么无法形成数据分析过程。
这三个步骤看起来很简单,但是想要好的效果,实现一定不能是单步骤。想清楚思路之后,接下来,我们大致了解一下需要实现的三个思路:客户端采集,服务端处理;服务端采集,客户端转发到主机端;实现思路1需要了解的各种主机信息,不同主机,其整体构架,可以按照下图实现:图中展示了目前市面上主流的主机,ip、机型、主机名、域名等;详细信息建议百度,因为在我的项目中没有用到客户端采集,所以我只需要清楚这些基本知识;服务端采集,主要是对整个服务进行处理,分为数据采集,数据处理,逻辑判断,数据增删查改;这里要注意的是,数据采集一般需要编写规则,对于项目中的采集需求,需要加入对规则的调用方法,例如查询ip是否为机器人,以免采集不出数据,当然这是基于我个人的采集需求,业务有别;数据处理主要是对采集结果,进行数据分析;因为数据采集涉及流量,所以需要对每一条数据进行备份,并记录下来,以后可以在需要时进行回放;逻辑判断就是逻辑判断这条记录是否为已获取到的数据,一般是涉及到一些基本的整数分布校验,有时也涉及到元素的交叉比对等,所以需要利用好循环处理对原始数据进行重排序,再进行计算等操作;这个可以参考豆瓣上,关于交叉比对的实现实现思路2其实是。
详细介绍优采云万能文章采集器的特点及功能介绍!
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-06-04 21:07
详细介绍
优采云万能文章采集器是windows平台的一个工具,可以批量采集下载指定的关键词文章。用户可以使用该软件到采集各大平台和文章指定网站,该软件操作简单,使用方便。对于需要做网站推广和优化的用户来说是一个很好的工具。 优采云万能文章采集器 只需输入关键词即可使用采集。该软件操作简单,功能强大,能准确识别网页中的数据。同时,软件支持标签、链接、邮件等。用户可以设置采集类型、搜索间隔、时间语言等选项,还可以在采集的文章中插入关键词、过滤信息等,是一个非常好的文章采集工具,该软件已经完美破解运行使用,有需要的网友可以免费下载使用。
优采云万能文章采集器Function
1、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上;
2、只需输入关键词,采集就可以进入百度新闻与网页、搜狗新闻与网页、360新闻与网页、谷歌新闻与网页、必应新闻与网页、雅虎;批量关键词Auto采集;
3、可方向采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则;
4、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译;
5、史上最简单最智能文章采集器,支持全功能试用,一试就知道效果!
优采云万能文章采集器Features
1、文章资源不定时更新,取之不尽。
2、智能采集任何网站文章列文章resources。
3、多语种翻译伪原创,你只需要输入关键词。
4、优采云 是第一个提取网页正文的通用算法。
5、百度引擎、谷歌引擎、搜索引擎强强联合。
优采云万能文章采集器接口说明
一、采集分页符:如果正文有分页符,会自动采集分页符。
二、Delete link:删除网页中锚文本的链接功能,只留下锚文本的标题。
三、txt 格式:另存为txt文本(自动清除HTML标签)。
四、Debug Mode:在正文开头插入“Debug Mode: Title and Link”的内容,方便进入原网页比较正文的识别效果。
五、Title 有关键词:只有在标题中搜索关键词 的网页才是采集。
六、 舍弃短标题:当自动识别的标题长度小于原标题的三分之一时,为短标题。通常这种标题是错误的,可以勾选丢弃,改用原标题(遇到这一段就明白了)。
七、Delete 外码:使用自动识别和精确标签时,通常收录div标签等外码。如果不需要,请勾选并删除。
优采云万能文章采集器使用说明
<p>1、在本站下载并解压文件,双击“优采云·万能文章采集器Crack.exe”打开,您会发现该软件是免费破解的。 查看全部
详细介绍优采云万能文章采集器的特点及功能介绍!
详细介绍
优采云万能文章采集器是windows平台的一个工具,可以批量采集下载指定的关键词文章。用户可以使用该软件到采集各大平台和文章指定网站,该软件操作简单,使用方便。对于需要做网站推广和优化的用户来说是一个很好的工具。 优采云万能文章采集器 只需输入关键词即可使用采集。该软件操作简单,功能强大,能准确识别网页中的数据。同时,软件支持标签、链接、邮件等。用户可以设置采集类型、搜索间隔、时间语言等选项,还可以在采集的文章中插入关键词、过滤信息等,是一个非常好的文章采集工具,该软件已经完美破解运行使用,有需要的网友可以免费下载使用。
优采云万能文章采集器Function
1、依托优采云software独家通用文本识别智能算法,可实现任意网页文本自动提取,准确率95%以上;
2、只需输入关键词,采集就可以进入百度新闻与网页、搜狗新闻与网页、360新闻与网页、谷歌新闻与网页、必应新闻与网页、雅虎;批量关键词Auto采集;
3、可方向采集指定网站列列表下的所有文章,智能匹配,无需编写复杂规则;
4、文章转翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译;
5、史上最简单最智能文章采集器,支持全功能试用,一试就知道效果!
优采云万能文章采集器Features
1、文章资源不定时更新,取之不尽。
2、智能采集任何网站文章列文章resources。
3、多语种翻译伪原创,你只需要输入关键词。
4、优采云 是第一个提取网页正文的通用算法。
5、百度引擎、谷歌引擎、搜索引擎强强联合。
优采云万能文章采集器接口说明
一、采集分页符:如果正文有分页符,会自动采集分页符。
二、Delete link:删除网页中锚文本的链接功能,只留下锚文本的标题。
三、txt 格式:另存为txt文本(自动清除HTML标签)。
四、Debug Mode:在正文开头插入“Debug Mode: Title and Link”的内容,方便进入原网页比较正文的识别效果。
五、Title 有关键词:只有在标题中搜索关键词 的网页才是采集。
六、 舍弃短标题:当自动识别的标题长度小于原标题的三分之一时,为短标题。通常这种标题是错误的,可以勾选丢弃,改用原标题(遇到这一段就明白了)。
七、Delete 外码:使用自动识别和精确标签时,通常收录div标签等外码。如果不需要,请勾选并删除。
优采云万能文章采集器使用说明
<p>1、在本站下载并解压文件,双击“优采云·万能文章采集器Crack.exe”打开,您会发现该软件是免费破解的。
百度验证码百度分享文章采集的方法及解决方案!
采集交流 • 优采云 发表了文章 • 0 个评论 • 389 次浏览 • 2021-05-29 00:02
文章采集文章采集是站长们自发去采集一些优质的网站文章的,其中就包括有一些带有可转发出去赚取积分或者包括投票活动。百度分享文章分享文章分享是百度做的比较久的一项服务,如果你的文章里面提供了分享二维码或者提供分享截图,或者是某个人的账号名字被添加到了分享页面的话,都可以让他/她去帮你发出去。这些都是百度获取url最方便的方式。
不过有个问题就是,一旦加上了分享二维码或者是二维码活动,就容易被这些恶意用户或者商家去盗用,从而导致页面被篡改或者是被恶意点击盗用文章这种情况。机器抓取机器抓取是上次不久出的新技术,通过机器去抓取一些网站上的一些url,这些页面相对来说比较安全。如果需要抓取的网站,从其他站点或者是人工都无法找到的,那么就可以用到机器抓取。
如果要抓取的页面内容比较丰富的话,可以用到爬虫插件,一方面可以方便我们去抓取各种网站上的文章,一方面也方便我们去二次开发,可以创建自己的网站和爬虫。百度验证码百度验证码是我最近发现的一项好技术,它不需要传统浏览器都可以扫二维码,更不需要下载客户端才可以识别。这个技术就是百度页面抓取中新加的验证码方法。
通过百度验证码的方法可以完全把、新浪、搜狐、腾讯等网站上面的验证码全部避免掉,百度验证码下载百度验证码下载是一项新的技术,可以帮我们更好的通过百度搜索到网站的页面,再加上百度也推出了一些网站收录和排名的解决方案,就比如说用百度站长平台去抓取,然后再用python或者是其他的手段去处理等等。结语本文介绍了百度站长平台如何抓取网站的验证码。
当我们查询一个网站的验证码的时候,我们需要注意以下几点:必须使用百度验证码识别服务器和验证码识别工具。必须使用百度验证码识别工具,而不是选择其他的人工识别。必须使用百度验证码识别服务器去抓取验证码。百度验证码识别工具,而不是其他的人工识别。百度验证码识别服务器在哪里,需要关注下面的百度验证码识别工具的安装。 查看全部
百度验证码百度分享文章采集的方法及解决方案!
文章采集文章采集是站长们自发去采集一些优质的网站文章的,其中就包括有一些带有可转发出去赚取积分或者包括投票活动。百度分享文章分享文章分享是百度做的比较久的一项服务,如果你的文章里面提供了分享二维码或者提供分享截图,或者是某个人的账号名字被添加到了分享页面的话,都可以让他/她去帮你发出去。这些都是百度获取url最方便的方式。
不过有个问题就是,一旦加上了分享二维码或者是二维码活动,就容易被这些恶意用户或者商家去盗用,从而导致页面被篡改或者是被恶意点击盗用文章这种情况。机器抓取机器抓取是上次不久出的新技术,通过机器去抓取一些网站上的一些url,这些页面相对来说比较安全。如果需要抓取的网站,从其他站点或者是人工都无法找到的,那么就可以用到机器抓取。
如果要抓取的页面内容比较丰富的话,可以用到爬虫插件,一方面可以方便我们去抓取各种网站上的文章,一方面也方便我们去二次开发,可以创建自己的网站和爬虫。百度验证码百度验证码是我最近发现的一项好技术,它不需要传统浏览器都可以扫二维码,更不需要下载客户端才可以识别。这个技术就是百度页面抓取中新加的验证码方法。
通过百度验证码的方法可以完全把、新浪、搜狐、腾讯等网站上面的验证码全部避免掉,百度验证码下载百度验证码下载是一项新的技术,可以帮我们更好的通过百度搜索到网站的页面,再加上百度也推出了一些网站收录和排名的解决方案,就比如说用百度站长平台去抓取,然后再用python或者是其他的手段去处理等等。结语本文介绍了百度站长平台如何抓取网站的验证码。
当我们查询一个网站的验证码的时候,我们需要注意以下几点:必须使用百度验证码识别服务器和验证码识别工具。必须使用百度验证码识别工具,而不是选择其他的人工识别。必须使用百度验证码识别服务器去抓取验证码。百度验证码识别工具,而不是其他的人工识别。百度验证码识别服务器在哪里,需要关注下面的百度验证码识别工具的安装。
视频教程教你最简单的一分钟文章采集新一年
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2021-05-28 20:01
文章采集文章采集最长的时间可以达到5秒钟,最短的时间可以一分钟,现在最快的是ezpress,一分钟。我们公司用的是自采,有些产品注册的用户多,采集的数据量小的,就需要导入第三方的数据采集接口或者数据库,才能准确。话不多说,视频教程教你最简单的一分钟文章采集新的一年,对网站进行升级,提升网站质量,主要通过流量(手机流量,页面跳转次数,访问时间等)与交易量(app进行促销活动,微信朋友圈等)来衡量网站的质量。
(如图片大小等)网站优化中对一般的流量站进行分析与网站反作弊,要求这部分要有大量的用户访问,这些在大数据分析中是重点关注的数据流量分析文章采集文章采集分为两个方面:1.新闻类、2.app商店行为采集,具体分析要看情况的不同。app的商店行为采集可以看看爆款一刻新闻文章采集本期主要讲的是文章采集,采集工具:python+文章采集工具,有兴趣的可以看看,采集效果非常好,采集出来的内容可以直接post到我们的公众号。
公众号:实现,后台回复:数据,即可下载工具集中的各个数据采集分享平台的汇总(文章采集、文章采集工具、爬虫软件、机器学习、大数据分析、前端开发、python)。
小编给大家带来了一个快速采集各大站点页面信息的教程,希望对大家有所帮助。1.请大家使用正版的浏览器,如谷歌浏览器2.请打开腾讯云,登录云主机设置,有国内主机,这里大家注意选择国内主机。3.请使用国内谷歌浏览器,谷歌浏览器是谷歌官方的浏览器,所以速度快4.当前通过外部搜索引擎可以找到不少网站,大家按照以下代码在搜索引擎下进行排名找到最适合的,选择合适的就可以啦!手机搜索引擎:百度,搜狗,360搜索,搜狗输入法搜索国内搜索引擎:百度,360搜索,搜狗输入法搜索国外搜索引擎:谷歌,脸书,推特,推特搜索首先大家需要看看自己本地是否有谷歌浏览器,注意下搜索记录,360浏览器下也可以采集全站内容,但是速度慢1.明确需求首先要明确网站是收费还是免费,收费站点对应的是如何付费,如何收费,那你最好去谷歌浏览器收费界面看看。
是否要付费,是否有会员,点一下商城中域名与企业主页的那个购买按钮。还是说提现速度跟内容多少成正比。第二看看网站是新闻类的,还是金融,社交类的。还是其他类的。每一种类型的网站对应的入口方式不一样,例如新闻站点需要采集每天的时事新闻内容,金融类则可以去官网看看。其他两类区别不大,应该是自己在制定采集内容时需要考虑的因素。建议从流量方面考虑对站点的要求。是否竞价,是否推广,是否需要发布广告。 查看全部
视频教程教你最简单的一分钟文章采集新一年
文章采集文章采集最长的时间可以达到5秒钟,最短的时间可以一分钟,现在最快的是ezpress,一分钟。我们公司用的是自采,有些产品注册的用户多,采集的数据量小的,就需要导入第三方的数据采集接口或者数据库,才能准确。话不多说,视频教程教你最简单的一分钟文章采集新的一年,对网站进行升级,提升网站质量,主要通过流量(手机流量,页面跳转次数,访问时间等)与交易量(app进行促销活动,微信朋友圈等)来衡量网站的质量。
(如图片大小等)网站优化中对一般的流量站进行分析与网站反作弊,要求这部分要有大量的用户访问,这些在大数据分析中是重点关注的数据流量分析文章采集文章采集分为两个方面:1.新闻类、2.app商店行为采集,具体分析要看情况的不同。app的商店行为采集可以看看爆款一刻新闻文章采集本期主要讲的是文章采集,采集工具:python+文章采集工具,有兴趣的可以看看,采集效果非常好,采集出来的内容可以直接post到我们的公众号。
公众号:实现,后台回复:数据,即可下载工具集中的各个数据采集分享平台的汇总(文章采集、文章采集工具、爬虫软件、机器学习、大数据分析、前端开发、python)。
小编给大家带来了一个快速采集各大站点页面信息的教程,希望对大家有所帮助。1.请大家使用正版的浏览器,如谷歌浏览器2.请打开腾讯云,登录云主机设置,有国内主机,这里大家注意选择国内主机。3.请使用国内谷歌浏览器,谷歌浏览器是谷歌官方的浏览器,所以速度快4.当前通过外部搜索引擎可以找到不少网站,大家按照以下代码在搜索引擎下进行排名找到最适合的,选择合适的就可以啦!手机搜索引擎:百度,搜狗,360搜索,搜狗输入法搜索国内搜索引擎:百度,360搜索,搜狗输入法搜索国外搜索引擎:谷歌,脸书,推特,推特搜索首先大家需要看看自己本地是否有谷歌浏览器,注意下搜索记录,360浏览器下也可以采集全站内容,但是速度慢1.明确需求首先要明确网站是收费还是免费,收费站点对应的是如何付费,如何收费,那你最好去谷歌浏览器收费界面看看。
是否要付费,是否有会员,点一下商城中域名与企业主页的那个购买按钮。还是说提现速度跟内容多少成正比。第二看看网站是新闻类的,还是金融,社交类的。还是其他类的。每一种类型的网站对应的入口方式不一样,例如新闻站点需要采集每天的时事新闻内容,金融类则可以去官网看看。其他两类区别不大,应该是自己在制定采集内容时需要考虑的因素。建议从流量方面考虑对站点的要求。是否竞价,是否推广,是否需要发布广告。
测评工具有哪些简单却不失深度和层次的文本分析工具?
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-05-23 18:05
文章采集文章采集、数据采集、如果有意向,
不算多,但多为整理资料,自由撰稿,或传播快教程,更欢迎大家分享。如果有兴趣交流请加qq。
这个领域,我做的非常早,纯手工编写了7000个评论,并将数据库内所有评论记录导入数据库。而且深度分析了评论之间的关系,变成了8万个变量,做出了关系分析,各个职业和各个年龄层的变量分析。现在已经是2.8亿的数据。
测评工具
有哪些简单却不失深度和层次的文本分析工具?-知乎
目前在回答这个问题。因为我现在也在运营一个微信公众号。数据收集是一件非常非常非常繁琐的事情。因为这个公众号运营的是市面上能够找到的最深度的文本数据。公众号公布出来了超过50000000个文本数据。研究过他们为什么能够从中搜集到最深度的文本信息。目前在思考更优雅的模式。实验性质。
我觉得datav这个工具不错。首先要懂得批量处理数据,如果自己不会,那就去买个会python的。
一天,会有很多多的报告需要,最喜欢的是我大学校园里广受欢迎的口袋照片的数据查询系统,如果你使用sql语言查询历史数据或者数据分析师手上需要历史数据分析,那么你就知道可以用这个网站,而且价格便宜。
alert系列文章也是十分有意思的一门课程!![ted]demodythecountriesandcountriescultures这门课教会你的不仅仅是编程还有数据分析。 查看全部
测评工具有哪些简单却不失深度和层次的文本分析工具?
文章采集文章采集、数据采集、如果有意向,
不算多,但多为整理资料,自由撰稿,或传播快教程,更欢迎大家分享。如果有兴趣交流请加qq。
这个领域,我做的非常早,纯手工编写了7000个评论,并将数据库内所有评论记录导入数据库。而且深度分析了评论之间的关系,变成了8万个变量,做出了关系分析,各个职业和各个年龄层的变量分析。现在已经是2.8亿的数据。
测评工具
有哪些简单却不失深度和层次的文本分析工具?-知乎
目前在回答这个问题。因为我现在也在运营一个微信公众号。数据收集是一件非常非常非常繁琐的事情。因为这个公众号运营的是市面上能够找到的最深度的文本数据。公众号公布出来了超过50000000个文本数据。研究过他们为什么能够从中搜集到最深度的文本信息。目前在思考更优雅的模式。实验性质。
我觉得datav这个工具不错。首先要懂得批量处理数据,如果自己不会,那就去买个会python的。
一天,会有很多多的报告需要,最喜欢的是我大学校园里广受欢迎的口袋照片的数据查询系统,如果你使用sql语言查询历史数据或者数据分析师手上需要历史数据分析,那么你就知道可以用这个网站,而且价格便宜。
alert系列文章也是十分有意思的一门课程!![ted]demodythecountriesandcountriescultures这门课教会你的不仅仅是编程还有数据分析。

