
文章采集器
采集器的一个有趣特性,可以大幅度提高pandas的处理速度
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-06-10 23:00
文章采集器是pandas的一个有趣特性,可以大幅度提高pandas的处理速度。pandas是做什么的?pandas本质上就是一个数据库,是基于python的numpy.matplotlib.的,可以从很多格式的数据进行处理,数据来源于二维表,每个字段就对应一个表中的行。example-whydoiwriteexcelnavigationscript?importpandasaspdasdfdf=pd.dataframe({'terms':['','are-ranking','and-ranking','average-student','education','teacher','industry','education','year']})df.head()#打印数据(以列作为行)df.tail()#打印数据(以行作为列)wheretag=''#处理区域为星号的数据wheretag='#'#处理区域为星号的数据wheretag=''#处理包含以下部分(range,class,loc,unique,re,and)的数据example-whydoiwriteexcelnavigationscript?importpandasaspdasdfdf=pd.dataframe({'terms':['','are-ranking','and-ranking','average-student','education','teacher','industry','education','year']})df.head(5)#查看数据前5行#查看数据的前5行数据处理的具体细节#如果数据不太多,可以不用写字典#如果数据不太多,可以不用写字典,把数据放在列中,用列名来表示#最好的方法是用列表like'数字'#最好的方法是用列表like'数字',不一定非要用字典df['date']=df['terms'].iloc[1:]#索引处理#如果数据仅包含日期和日期标签,可以把日期用逗号隔开df['date']=df['terms'].iloc[:2]df['date']=df['terms'].iloc[:2]df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['ter。 查看全部
采集器的一个有趣特性,可以大幅度提高pandas的处理速度
文章采集器是pandas的一个有趣特性,可以大幅度提高pandas的处理速度。pandas是做什么的?pandas本质上就是一个数据库,是基于python的numpy.matplotlib.的,可以从很多格式的数据进行处理,数据来源于二维表,每个字段就对应一个表中的行。example-whydoiwriteexcelnavigationscript?importpandasaspdasdfdf=pd.dataframe({'terms':['','are-ranking','and-ranking','average-student','education','teacher','industry','education','year']})df.head()#打印数据(以列作为行)df.tail()#打印数据(以行作为列)wheretag=''#处理区域为星号的数据wheretag='#'#处理区域为星号的数据wheretag=''#处理包含以下部分(range,class,loc,unique,re,and)的数据example-whydoiwriteexcelnavigationscript?importpandasaspdasdfdf=pd.dataframe({'terms':['','are-ranking','and-ranking','average-student','education','teacher','industry','education','year']})df.head(5)#查看数据前5行#查看数据的前5行数据处理的具体细节#如果数据不太多,可以不用写字典#如果数据不太多,可以不用写字典,把数据放在列中,用列名来表示#最好的方法是用列表like'数字'#最好的方法是用列表like'数字',不一定非要用字典df['date']=df['terms'].iloc[1:]#索引处理#如果数据仅包含日期和日期标签,可以把日期用逗号隔开df['date']=df['terms'].iloc[:2]df['date']=df['terms'].iloc[:2]df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['ter。
贴一个工具相册里边随便选取一张图片都可以
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-06-09 21:02
文章采集器。用来采集微信公众号的文章,包括文章标题,文章内容,收录率和关键词。可以通过关键词调用的,使用简单容易掌握。有下载功能,还可以导出格式文档。目前只有安卓版的和两个支持导出代码的,
千里眼查或者企查查,我刚才试了一下。
贴一个工具相册里边随便选取一张图片都可以。另外,关键词抓取这个不错。别的暂时还没发现。
你应该去做一个网站,网站将你要抓取的内容都集合在网站上,然后你用网站统计平台就能找到大量的标题和相关内容,相信大家也用的。
全站关键词抓取工具;可以抓取链接的词相关内容可以通过你的网站或者360站长工具查看下载最新版站长助手
百度站长工具箱
金山卫士,我现在也在找,一直在找,但是金山浏览器现在的工具箱都太难用了。
谢邀,现在比较多的应该是3亿个有意义词库,或者是40w+相关关键词的词库库,这个比较热,可以试试。
现在的可以用eltalise3,做搜索联想可以加关键词进去,是免费的,之前在做百度seo的时候找到很多关键词。
提供两种思路一种就是抓新闻联播的那些点击率高的,其实现在大家都在关注互联网商业相关的信息,这些题材的信息反应出来的是商业现状,抓取数据库的时候抓取点击率高的点击率高的。现在各大网站或者论坛都有抓取统计,比如点击率统计,百度搜索词统计,还有一些专门的统计分析工具,比如百度aso,百度统计之类的,可以找到很多热点事件。
还有一种就是抓取同行的一些热点信息。有网站了肯定有搜索相关词的,现在同行们发布的一些和网站发布的关键词对于不同关键词的排序不同,而且热度又高。 查看全部
贴一个工具相册里边随便选取一张图片都可以
文章采集器。用来采集微信公众号的文章,包括文章标题,文章内容,收录率和关键词。可以通过关键词调用的,使用简单容易掌握。有下载功能,还可以导出格式文档。目前只有安卓版的和两个支持导出代码的,
千里眼查或者企查查,我刚才试了一下。
贴一个工具相册里边随便选取一张图片都可以。另外,关键词抓取这个不错。别的暂时还没发现。
你应该去做一个网站,网站将你要抓取的内容都集合在网站上,然后你用网站统计平台就能找到大量的标题和相关内容,相信大家也用的。
全站关键词抓取工具;可以抓取链接的词相关内容可以通过你的网站或者360站长工具查看下载最新版站长助手
百度站长工具箱
金山卫士,我现在也在找,一直在找,但是金山浏览器现在的工具箱都太难用了。
谢邀,现在比较多的应该是3亿个有意义词库,或者是40w+相关关键词的词库库,这个比较热,可以试试。
现在的可以用eltalise3,做搜索联想可以加关键词进去,是免费的,之前在做百度seo的时候找到很多关键词。
提供两种思路一种就是抓新闻联播的那些点击率高的,其实现在大家都在关注互联网商业相关的信息,这些题材的信息反应出来的是商业现状,抓取数据库的时候抓取点击率高的点击率高的。现在各大网站或者论坛都有抓取统计,比如点击率统计,百度搜索词统计,还有一些专门的统计分析工具,比如百度aso,百度统计之类的,可以找到很多热点事件。
还有一种就是抓取同行的一些热点信息。有网站了肯定有搜索相关词的,现在同行们发布的一些和网站发布的关键词对于不同关键词的排序不同,而且热度又高。
文章采集器(equestriacollectionofscripts)生成网页代码的工作过程过程
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-05-24 22:03
文章采集器(equestriacollectionofscripts)是一款javascript标准库,同时也是代码文件从采集到变成网页的的快速、灵活的internetapps。它只会读和写api文件(javascript代码字符串),不会直接解析javascript代码,也不会自动生成响应的源代码文件,比如数据库表、url等。
它也不会直接生成网页代码,最多只是提供一个生成javascript实际效果的api文件,而不是真正的生成网页内容。这种只读文件我们称之为“标准字符串格式”,也就是ie对其支持得最多的格式(甚至还支持css样式字符串)。我们可以打开equestriacollectionofscriptswebapps.config.js在类型语言范围里可以找到multipleapiforfilesystems,typedothersystemsaredirectlyspecified.你可以在控制台提交ftp请求,指定你的数据类型等,服务器将会解析给javascript代码字符串(标准字符串格式)并转换为equestriacollectionofscripts文件。
比如types,typed,file,object,string,index.这些都是equestriacollectionofscripts一样的标准字符串格式。multipleapiforfilesystems—>typesformultiplecontentfilesandargumentsfilestyped是一种用于数据文件格式,而typed就是用于数据文件中的引用格式。
typed代表了两种不同的常见格式,第一种contentparser的格式规范(一种数据格式),第二种archive的格式规范(另一种数据格式)。archive就是数据文件中传递的所有信息,archive格式还可以用一种对象模型来表示:表示为bundle可以看到整个script文件在equestriacollectionofscriptswebapps的请求域中都是可以通过下图实现。
ftp打开/login.txt/login.js生成的通用后缀名的"login.js"压缩包仅在express中有效,可以通过webpack-sassplugin构建出来。express-sassplugin会在打包时,附加到你的模块中。我们来解析一下源代码的工作过程,好让大家对equestriacollectionofscripts生成的equestriacollectionofscripts文件有个大概的认识。
首先,把要采集的script文件全部导入到scss文件里。express默认生成的解析工具是browserify。它会先从sass等压缩库里抽取出类似css一样的html字符串,导入到browserifysassbundlecache服务器上,然后按照对javascript代码解析的要求生成ess。对数据采集类程序来说,就是随处抓取eschanged,endofstorage或endoflogin的数据()。然后,把ess插入到所需要生成的ffi文件里。因为现在scss解析器里的e。 查看全部
文章采集器(equestriacollectionofscripts)生成网页代码的工作过程过程
文章采集器(equestriacollectionofscripts)是一款javascript标准库,同时也是代码文件从采集到变成网页的的快速、灵活的internetapps。它只会读和写api文件(javascript代码字符串),不会直接解析javascript代码,也不会自动生成响应的源代码文件,比如数据库表、url等。
它也不会直接生成网页代码,最多只是提供一个生成javascript实际效果的api文件,而不是真正的生成网页内容。这种只读文件我们称之为“标准字符串格式”,也就是ie对其支持得最多的格式(甚至还支持css样式字符串)。我们可以打开equestriacollectionofscriptswebapps.config.js在类型语言范围里可以找到multipleapiforfilesystems,typedothersystemsaredirectlyspecified.你可以在控制台提交ftp请求,指定你的数据类型等,服务器将会解析给javascript代码字符串(标准字符串格式)并转换为equestriacollectionofscripts文件。
比如types,typed,file,object,string,index.这些都是equestriacollectionofscripts一样的标准字符串格式。multipleapiforfilesystems—>typesformultiplecontentfilesandargumentsfilestyped是一种用于数据文件格式,而typed就是用于数据文件中的引用格式。
typed代表了两种不同的常见格式,第一种contentparser的格式规范(一种数据格式),第二种archive的格式规范(另一种数据格式)。archive就是数据文件中传递的所有信息,archive格式还可以用一种对象模型来表示:表示为bundle可以看到整个script文件在equestriacollectionofscriptswebapps的请求域中都是可以通过下图实现。
ftp打开/login.txt/login.js生成的通用后缀名的"login.js"压缩包仅在express中有效,可以通过webpack-sassplugin构建出来。express-sassplugin会在打包时,附加到你的模块中。我们来解析一下源代码的工作过程,好让大家对equestriacollectionofscripts生成的equestriacollectionofscripts文件有个大概的认识。
首先,把要采集的script文件全部导入到scss文件里。express默认生成的解析工具是browserify。它会先从sass等压缩库里抽取出类似css一样的html字符串,导入到browserifysassbundlecache服务器上,然后按照对javascript代码解析的要求生成ess。对数据采集类程序来说,就是随处抓取eschanged,endofstorage或endoflogin的数据()。然后,把ess插入到所需要生成的ffi文件里。因为现在scss解析器里的e。
优采云采集赶集网数据为证禁止图片转载的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2021-05-07 19:31
微信文章 采集器是公共帐户操作和网站操作助手,具有以下功能:自定义采集,分类采集,关键词 采集,文章编辑和布局,提供每日微信文章,微信图形和其他资源。
1让我向所有人介绍此介绍,并首先熟悉软件功能和使用方法。
2百度搜索相关信息,单击网页进行了解。
3软件功能介绍,具有分类采集,关键词 采集,自定义采集,文章排版和编辑功能。
4使操作变得如此简单。
以真实的照片作为证明
禁止复制图片
本文介绍了使用优采云 采集 数据的方法(以南山店信息为例)
1步骤1:创建采集任务1)并进入主界面,选择“自定义模式”
2 2)将商店信息页面的URL复制并粘贴到网站输入框中,单击“保存URL”
3步骤2:创建翻页循环1)将页面下拉至底部,单击“下一页”按钮,然后在右侧的提示框中选择“循环以单击下一页”
4步骤3:创建列表循环1)移动鼠标并选择页面上的第一个商店链接。选择后,系统将自动识别页面上的其他类似链接。在右侧的提示框中,选择“全选”
5 2)选择“单击循环中的每个链接”以创建列表循环
6步骤4:提取商店信息1)创建列表循环后,系统将自动单击第一个商店链接以进入商店详细信息页面。功能点:分页列表和详细信息提取(x?t = 1)单击所需的字段信息,在右侧的提示框中,选择“ 采集该元素的文本”
7 2)选择字段信息后,选择相应的字段,您可以自定义字段名称。填写完该字段后,点击左上角的“保存并开始”以启动采集任务
8 3)选择“启动本地采集”
9步骤5:完成数据采集和导出1) 采集后,将弹出提示,选择“导出数据”
10 2)选择“适当的导出方法”并导出采集良好的商店信息数据
11 3)在这里,我们选择excel作为导出格式,数据将如下所示导出
12条规则URL:如果有帮助,请单击[投票]。有关详细信息,请单击[采集夹]。如果要继续,可以[关注]。如果您要放弃它,请单击[共享]。如有任何疑问,可以[发表评论]。
关闭采集器教程
1使用前,请先设置数据库和网站目录,设置这两个点后,只能先关闭采集器,然后将其打开才能生效!记住要记住!
2正确设置了分类设置,以确保采集上显示的小说正确。具体描述1 | Fantasy Magic =,奇幻,魔术,奇幻魔术,外星人之地,穿越,奇幻,奇幻-其他世界奇幻,奇幻仙侠之恋,奇幻怪兽,奇幻西方奇幻,奇幻吸血鬼家庭,奇幻小说,重生文学,幻想小说,幻想外星世界,幻想魔术,遍历头顶,=前一个是您的网站分类。例如,您采集这本小说。他的分类是幻想小说,只需要写1 |宣欢魔术=,幻想小说,一一对应,很简单
3生成设置,如果您的网站是伪静态的网站,则无需选择生成目录页面html或内容页面html。只需选择一个即可生成opf。
4 采集操作在这里,建议您不要选择检测重复的章节。否则,将没有很多内容章节采集!如果有点相似,他会为您过滤。真的很辛苦
5高级设置的功能也在这里,描述也非常详细,只需查看是否需要检查即可。
6启动采集后,您可以看到采集的进度
智能通用Web数据采集器。简单易用,完全可视化,不需要专业知识,并且如果您可以浏览互联网,也可以轻松掌握。功能强大,新闻,论坛,电话信箱,竞争对手,客户信息,汽车房地产,电子商务等。网站是采集
1第一步,打开软件,单击“快速入门”,创建一个新任务
2第二步是找到汽车品牌的列表页面。复制此列表页面的地址,
3第三步,单击要采集的页面元素,例如Audi S7。系统弹出对话框后,选择创建元素列表以处理元素
4第四步是添加元素,如果要继续添加其他品牌,请单击以继续编辑列表
5在第五步中,将所有品牌都显示在列表中之后,单击“创建列表”以完成。
6第六步,由于上有一些未上市的品牌,并且价格不能为采集,因此我们可以在此处使用是否有市场价格作为判断条件。设置条件判断项
7第七步,设置了判断条件后,为页面配置所需的提取数据
8步骤8,设置完成后,单击“下一步”进入执行计划过程,设置计划执行方法,建议推荐云采集,速度快,可以判断数据是否重复下载。
9步骤9,转到下一步,单击“检查任务”,将弹出以下窗口,单击以下图标开始运行并下载优采云 采集器擢爻用户也可以在规则市场中该软件下载到此规则,直接导入即可使用。
微信文章 采集器,一个小额信贷帐户,可以帮助您解决查找文章和编写文章的麻烦,您可以按类别采集] 文章和官方帐户对其进行排序,您还可以按关键词 采集 文章和官方帐户,您可以自定义并添加常用的官方帐户,按照某个官方帐户发布的文章并将其发布到Ai绱shufly资料库中,等,让我们来教你
1我们首先选择一个浏览器,在百度上搜索关键词,然后找到相关的网站。
2找到网站后,单击网站页面进行简要了解。如图所示;
3以下是功能介绍,类别文章汕尾先念采集和5条采集路线,类别官方帐户采集,关键词 采集,添加官方帐户以自定义,发布材质库,如下面的屏幕快照所示。
4最后,该软件是全屏的,感谢您观看演示。
以上仅为屏幕截图。如需了解更多信息,请联系官方网站上的客户服务。
成为我们的用户,免费更新和升级,谢谢您的支持
有时我们看到网站的文章,并希望保存这些文章。复制和保存一篇文章非常麻烦。此时,您需要使用优采云 采集器保存文章 采集。这是优采云 采集器 采集 文章的使用方法。
1第一步是采集 URL,下载优采云 采集器并打开它以使用任何任务名称创建一个新任务。将需要采集的网站 文章列的URL添加到起始URL。从图中可以看出,列表页面有34页,每页有N条文章。
2列表页面将是第一级URL,添加多级URL以获得,从而获得第二级URL(文章页面URL)
3设置要通过分页获得的列表,三个位置是:在分页的源代码之前和之后有一个中间位置。此步骤用于获取列表页面链接,因为有34个列表页面。设置后保存。
4获取网站地址的选项。此步骤用于获取列表页面上页面文章上的链接,根据您的需要设置要拦截的部分,并根据URL的结构设置某些字符的收录或排除。如果为空,则没有限制。设置后保存。
5设置链接采集规则后,您可以测试URL并根据测试结果调整规则。查看图片,您可以看到采集链接规则已经成功完成,从最初的链接到综合列表页面,再到列表页面采集上的文章页面链接。
6第二步是采集的内容。首先,修改标题规则,在页面源代码中找到标题代码,并切断标题前后的标题。保存。
7修改内容采集规则,类似于标题规则,它也是在源代码中找到内容前后的代码。这里的内容将收录其他一些html标签,因此您必须添加html标签排除规则。
8测试完成后,查看结果并调试测试结果中的规则,直到获得所需的测试结果为止。
9第三步是采集导出。 1、 2在前两个步骤中设置了规则,最后文章将被导出。首先制作一个导出模板。
10然后选择方法二,将每篇文章文章记录为txt文本,保存您选择的位置模板佳和轩qu,然后选择刚刚制作的导出模板。保存的文件名为文章。标题被命名。其他默认设置,保存。
11选中采集 URL,采集内容,并发布3个选项框,然后启动采集。完成后,将在刚刚保存的文件夹中自动生成文本。
12 优采云 采集器 采集 文章教程现已完成。由于每个网站都不相同,因此这里只能使用一个网站演示,只是一种方法思想[I 采集 文章)也需要灵活。
如果这种经历对您有所帮助,请记住投票。
如果您不了解其他任何内容,请发表评论并留言。如果单击投票,评论框将自动弹出。 查看全部
优采云采集赶集网数据为证禁止图片转载的方法
微信文章 采集器是公共帐户操作和网站操作助手,具有以下功能:自定义采集,分类采集,关键词 采集,文章编辑和布局,提供每日微信文章,微信图形和其他资源。
1让我向所有人介绍此介绍,并首先熟悉软件功能和使用方法。

2百度搜索相关信息,单击网页进行了解。

3软件功能介绍,具有分类采集,关键词 采集,自定义采集,文章排版和编辑功能。

4使操作变得如此简单。

以真实的照片作为证明
禁止复制图片
本文介绍了使用优采云 采集 数据的方法(以南山店信息为例)

1步骤1:创建采集任务1)并进入主界面,选择“自定义模式”

2 2)将商店信息页面的URL复制并粘贴到网站输入框中,单击“保存URL”

3步骤2:创建翻页循环1)将页面下拉至底部,单击“下一页”按钮,然后在右侧的提示框中选择“循环以单击下一页”

4步骤3:创建列表循环1)移动鼠标并选择页面上的第一个商店链接。选择后,系统将自动识别页面上的其他类似链接。在右侧的提示框中,选择“全选”

5 2)选择“单击循环中的每个链接”以创建列表循环

6步骤4:提取商店信息1)创建列表循环后,系统将自动单击第一个商店链接以进入商店详细信息页面。功能点:分页列表和详细信息提取(x?t = 1)单击所需的字段信息,在右侧的提示框中,选择“ 采集该元素的文本”

7 2)选择字段信息后,选择相应的字段,您可以自定义字段名称。填写完该字段后,点击左上角的“保存并开始”以启动采集任务

8 3)选择“启动本地采集”

9步骤5:完成数据采集和导出1) 采集后,将弹出提示,选择“导出数据”

10 2)选择“适当的导出方法”并导出采集良好的商店信息数据

11 3)在这里,我们选择excel作为导出格式,数据将如下所示导出

12条规则URL:如果有帮助,请单击[投票]。有关详细信息,请单击[采集夹]。如果要继续,可以[关注]。如果您要放弃它,请单击[共享]。如有任何疑问,可以[发表评论]。
关闭采集器教程

1使用前,请先设置数据库和网站目录,设置这两个点后,只能先关闭采集器,然后将其打开才能生效!记住要记住!

2正确设置了分类设置,以确保采集上显示的小说正确。具体描述1 | Fantasy Magic =,奇幻,魔术,奇幻魔术,外星人之地,穿越,奇幻,奇幻-其他世界奇幻,奇幻仙侠之恋,奇幻怪兽,奇幻西方奇幻,奇幻吸血鬼家庭,奇幻小说,重生文学,幻想小说,幻想外星世界,幻想魔术,遍历头顶,=前一个是您的网站分类。例如,您采集这本小说。他的分类是幻想小说,只需要写1 |宣欢魔术=,幻想小说,一一对应,很简单

3生成设置,如果您的网站是伪静态的网站,则无需选择生成目录页面html或内容页面html。只需选择一个即可生成opf。

4 采集操作在这里,建议您不要选择检测重复的章节。否则,将没有很多内容章节采集!如果有点相似,他会为您过滤。真的很辛苦

5高级设置的功能也在这里,描述也非常详细,只需查看是否需要检查即可。

6启动采集后,您可以看到采集的进度

智能通用Web数据采集器。简单易用,完全可视化,不需要专业知识,并且如果您可以浏览互联网,也可以轻松掌握。功能强大,新闻,论坛,电话信箱,竞争对手,客户信息,汽车房地产,电子商务等。网站是采集
1第一步,打开软件,单击“快速入门”,创建一个新任务

2第二步是找到汽车品牌的列表页面。复制此列表页面的地址,

3第三步,单击要采集的页面元素,例如Audi S7。系统弹出对话框后,选择创建元素列表以处理元素

4第四步是添加元素,如果要继续添加其他品牌,请单击以继续编辑列表

5在第五步中,将所有品牌都显示在列表中之后,单击“创建列表”以完成。

6第六步,由于上有一些未上市的品牌,并且价格不能为采集,因此我们可以在此处使用是否有市场价格作为判断条件。设置条件判断项
7第七步,设置了判断条件后,为页面配置所需的提取数据

8步骤8,设置完成后,单击“下一步”进入执行计划过程,设置计划执行方法,建议推荐云采集,速度快,可以判断数据是否重复下载。

9步骤9,转到下一步,单击“检查任务”,将弹出以下窗口,单击以下图标开始运行并下载优采云 采集器擢爻用户也可以在规则市场中该软件下载到此规则,直接导入即可使用。

微信文章 采集器,一个小额信贷帐户,可以帮助您解决查找文章和编写文章的麻烦,您可以按类别采集] 文章和官方帐户对其进行排序,您还可以按关键词 采集 文章和官方帐户,您可以自定义并添加常用的官方帐户,按照某个官方帐户发布的文章并将其发布到Ai绱shufly资料库中,等,让我们来教你
1我们首先选择一个浏览器,在百度上搜索关键词,然后找到相关的网站。

2找到网站后,单击网站页面进行简要了解。如图所示;

3以下是功能介绍,类别文章汕尾先念采集和5条采集路线,类别官方帐户采集,关键词 采集,添加官方帐户以自定义,发布材质库,如下面的屏幕快照所示。

4最后,该软件是全屏的,感谢您观看演示。

以上仅为屏幕截图。如需了解更多信息,请联系官方网站上的客户服务。
成为我们的用户,免费更新和升级,谢谢您的支持
有时我们看到网站的文章,并希望保存这些文章。复制和保存一篇文章非常麻烦。此时,您需要使用优采云 采集器保存文章 采集。这是优采云 采集器 采集 文章的使用方法。
1第一步是采集 URL,下载优采云 采集器并打开它以使用任何任务名称创建一个新任务。将需要采集的网站 文章列的URL添加到起始URL。从图中可以看出,列表页面有34页,每页有N条文章。

2列表页面将是第一级URL,添加多级URL以获得,从而获得第二级URL(文章页面URL)

3设置要通过分页获得的列表,三个位置是:在分页的源代码之前和之后有一个中间位置。此步骤用于获取列表页面链接,因为有34个列表页面。设置后保存。

4获取网站地址的选项。此步骤用于获取列表页面上页面文章上的链接,根据您的需要设置要拦截的部分,并根据URL的结构设置某些字符的收录或排除。如果为空,则没有限制。设置后保存。

5设置链接采集规则后,您可以测试URL并根据测试结果调整规则。查看图片,您可以看到采集链接规则已经成功完成,从最初的链接到综合列表页面,再到列表页面采集上的文章页面链接。

6第二步是采集的内容。首先,修改标题规则,在页面源代码中找到标题代码,并切断标题前后的标题。保存。

7修改内容采集规则,类似于标题规则,它也是在源代码中找到内容前后的代码。这里的内容将收录其他一些html标签,因此您必须添加html标签排除规则。

8测试完成后,查看结果并调试测试结果中的规则,直到获得所需的测试结果为止。

9第三步是采集导出。 1、 2在前两个步骤中设置了规则,最后文章将被导出。首先制作一个导出模板。

10然后选择方法二,将每篇文章文章记录为txt文本,保存您选择的位置模板佳和轩qu,然后选择刚刚制作的导出模板。保存的文件名为文章。标题被命名。其他默认设置,保存。

11选中采集 URL,采集内容,并发布3个选项框,然后启动采集。完成后,将在刚刚保存的文件夹中自动生成文本。

12 优采云 采集器 采集 文章教程现已完成。由于每个网站都不相同,因此这里只能使用一个网站演示,只是一种方法思想[I 采集 文章)也需要灵活。
如果这种经历对您有所帮助,请记住投票。
如果您不了解其他任何内容,请发表评论并留言。如果单击投票,评论框将自动弹出。
文章采集器app介绍:支持全平台各类文章渠道的采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2021-05-05 19:05
文章采集器app介绍:一款集合、安全、免费、便捷、便利于一体的「文章采集工具」。支持全平台各类文章渠道的采集。任意输入任意链接,即可免费采集所有网页的文章内容。支持微信、微博、小红书、今日头条、一点资讯、搜狐新闻、知乎、新浪博客、微博热门微信号、百度百家、豆瓣、中国新闻、凤凰新闻、网易新闻、新浪新闻等主流数据平台文章内容的采集。
在线关键词搜索、语义搜索、智能标题搜索、输入正则表达式、文章网址、复制文章网址、批量采集。文章采集器app文章采集渠道、渠道信息全站采集、语义搜索、智能标题搜索、定时采集、批量采集、全文覆盖等等功能。抓取全网网站的文章内容、摘要、文章列表、文章广告、文章评论、评论等全网站的内容。一站式的网站内容批量采集整理。
支持复制文章网址、大小写检测、去水印、广告、背景色检测、二维码提取、抓取手机h5内容,网页无水印。支持全文匹配定位,文章标题、文章内容检测。支持全文内容搜索、全文内容存档、全文检测和全文下载。支持文章中的图片搜索,支持图片外链搜索,支持文章中的链接存档。欢迎大家体验。客服[二维码自动识别][三维码自动识别]。
恩,这么基础的问题必须说一下先安利一个基础的知识:第三方网站爬虫,其实从直白的话我们可以用,hexo+next来做coding流量的spider。我就拿一个常见的像比较新的文章内容一般来说,我们一般会有两种spider,一个抓某些比较有地域性或者有hook的网站,比如说我们在工业区或者一些比较小的公司会有比较高权重的网站,一般他们有更好的页面权重以及更多的转发内容,就会抓到他们更多的内容;另外一种就是同一个的ip去抓,很多新站可能在刚上架一段时间内可能内容抓不到很多,这个时候我们可以去一些老站,找一些比较老的站点,比如说用hexo+next来做的irc流量,如果抓取量到一定数量级的话,肯定可以抓很多站,直接扔去sitemap就ok,如果你站基础设置做得好,这个sitemap可以很大比如foobar等等,爬irc非常快,而且比python常见的爬虫工具,比如piggies等等要方便一些,还比如requests等等更适合抓新站,爬新站就是老老实实做各种内容和内容结构。
如果你想要更加高级一些,比如说我自己又知道一些小的博客教学网站,包括各种论坛之类的,然后我想要从这些更加老一些的站点里面爬更多内容,也可以学python去抓,但是相比来说要耗一些资源,而且还比较麻烦,有一些老站网站不一定更新,看你的兴趣,比如我本人是比较喜欢挖掘开源博客,所以现在玩。 查看全部
文章采集器app介绍:支持全平台各类文章渠道的采集
文章采集器app介绍:一款集合、安全、免费、便捷、便利于一体的「文章采集工具」。支持全平台各类文章渠道的采集。任意输入任意链接,即可免费采集所有网页的文章内容。支持微信、微博、小红书、今日头条、一点资讯、搜狐新闻、知乎、新浪博客、微博热门微信号、百度百家、豆瓣、中国新闻、凤凰新闻、网易新闻、新浪新闻等主流数据平台文章内容的采集。
在线关键词搜索、语义搜索、智能标题搜索、输入正则表达式、文章网址、复制文章网址、批量采集。文章采集器app文章采集渠道、渠道信息全站采集、语义搜索、智能标题搜索、定时采集、批量采集、全文覆盖等等功能。抓取全网网站的文章内容、摘要、文章列表、文章广告、文章评论、评论等全网站的内容。一站式的网站内容批量采集整理。
支持复制文章网址、大小写检测、去水印、广告、背景色检测、二维码提取、抓取手机h5内容,网页无水印。支持全文匹配定位,文章标题、文章内容检测。支持全文内容搜索、全文内容存档、全文检测和全文下载。支持文章中的图片搜索,支持图片外链搜索,支持文章中的链接存档。欢迎大家体验。客服[二维码自动识别][三维码自动识别]。
恩,这么基础的问题必须说一下先安利一个基础的知识:第三方网站爬虫,其实从直白的话我们可以用,hexo+next来做coding流量的spider。我就拿一个常见的像比较新的文章内容一般来说,我们一般会有两种spider,一个抓某些比较有地域性或者有hook的网站,比如说我们在工业区或者一些比较小的公司会有比较高权重的网站,一般他们有更好的页面权重以及更多的转发内容,就会抓到他们更多的内容;另外一种就是同一个的ip去抓,很多新站可能在刚上架一段时间内可能内容抓不到很多,这个时候我们可以去一些老站,找一些比较老的站点,比如说用hexo+next来做的irc流量,如果抓取量到一定数量级的话,肯定可以抓很多站,直接扔去sitemap就ok,如果你站基础设置做得好,这个sitemap可以很大比如foobar等等,爬irc非常快,而且比python常见的爬虫工具,比如piggies等等要方便一些,还比如requests等等更适合抓新站,爬新站就是老老实实做各种内容和内容结构。
如果你想要更加高级一些,比如说我自己又知道一些小的博客教学网站,包括各种论坛之类的,然后我想要从这些更加老一些的站点里面爬更多内容,也可以学python去抓,但是相比来说要耗一些资源,而且还比较麻烦,有一些老站网站不一定更新,看你的兴趣,比如我本人是比较喜欢挖掘开源博客,所以现在玩。
文章采集器,商品折扣,汇率以及想要采集的特定数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2021-04-16 22:04
文章采集器、短文采集器采集小说,商品折扣,汇率以及想要采集的特定数据。分享给喜欢的朋友以及看到这篇文章的小伙伴!这是我花钱购买以及买的最好的采集器之一,我觉得这样子的老板不能做朋友!嘿嘿!这款采集器不仅仅是简单的采集小说,商品折扣这样的简单功能,还支持单条小说、商品、专题标题以及ajax、flash等多种交互方式!如果有兴趣的朋友可以留言,获取最新的上架链接!会从留言里面抽取最近想要的小说上架以及商品下架和标题!好啦,今天分享到这,希望能够帮助到大家!。
题主说的一般手机采集器都比较麻烦,我以前用的是快传网,一天只能采10篇,遇到电脑卡顿的时候基本上半天没效果,推荐百度手机站网址,可以调用大部分的百度采集工具,对比一下就知道了。
很多啊,不如试试公众号“鱼塘一点灵”,这是一款web网址采集器,基本上可以满足你需求,如果网站用的多,
现在绝大多数的手机浏览器都有网页采集,例如,360浏览器。只要有以下链接就可以。在360手机上打开:个人中心-工具箱-创建收藏-浏览器采集要想兼容iphone或ipad,还可以把这个连接另存一下放在电脑上。最主要的是免费。如果直接打开采集的html地址,下载来的不是这个地址。 查看全部
文章采集器,商品折扣,汇率以及想要采集的特定数据
文章采集器、短文采集器采集小说,商品折扣,汇率以及想要采集的特定数据。分享给喜欢的朋友以及看到这篇文章的小伙伴!这是我花钱购买以及买的最好的采集器之一,我觉得这样子的老板不能做朋友!嘿嘿!这款采集器不仅仅是简单的采集小说,商品折扣这样的简单功能,还支持单条小说、商品、专题标题以及ajax、flash等多种交互方式!如果有兴趣的朋友可以留言,获取最新的上架链接!会从留言里面抽取最近想要的小说上架以及商品下架和标题!好啦,今天分享到这,希望能够帮助到大家!。
题主说的一般手机采集器都比较麻烦,我以前用的是快传网,一天只能采10篇,遇到电脑卡顿的时候基本上半天没效果,推荐百度手机站网址,可以调用大部分的百度采集工具,对比一下就知道了。
很多啊,不如试试公众号“鱼塘一点灵”,这是一款web网址采集器,基本上可以满足你需求,如果网站用的多,
现在绝大多数的手机浏览器都有网页采集,例如,360浏览器。只要有以下链接就可以。在360手机上打开:个人中心-工具箱-创建收藏-浏览器采集要想兼容iphone或ipad,还可以把这个连接另存一下放在电脑上。最主要的是免费。如果直接打开采集的html地址,下载来的不是这个地址。
用pythontinyscript+javascriptapi来完成动画,不需要androidstudio(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-04-03 00:01
文章采集器不可能流畅跑得动,在你录制clipboard的时候刷新非常慢,而且全局加载比如defaultfilter会卡死,所以不建议用这个。但是ios7的动画控制比较好,这个做应用的时候可以考虑用,比如gamecenter这类游戏。
用pythontinyscript+javascriptapi来完成动画,不需要androidstudio,利用caffe实现c++的运行环境,就足够了。很多javascript的library比如googlejsonioserver是很小的动画库,对动画要求不高的应用基本上不需要androidstudio。
最近google官方出品了一个javascriptnode.js依赖包,python和node.js用的都是一样的api和语法,python用起来的话速度快很多。这个api是:1.同步执行每个svg标签的view->drawable->graphics2.利用了python的graphics接口。这个包用于动画,可以做类似qq飞车这样的虚拟摇臂。
没错,那些画面就是用qq飞车的原画在python生成的.具体教程可以参考:javascriptsvgapi。indavidk.porter&andrewt.shaw,"demo",androiddevelopers,linkedin。
前端不建议用python,如果python不能充分利用tornado,kiko等异步框架,那python的异步库就是个坑!再说了,drawable本身就需要渲染。actionscript太宽,只适合做一些基本运算,动画本身还是建议用javascript和node。 查看全部
用pythontinyscript+javascriptapi来完成动画,不需要androidstudio(图)
文章采集器不可能流畅跑得动,在你录制clipboard的时候刷新非常慢,而且全局加载比如defaultfilter会卡死,所以不建议用这个。但是ios7的动画控制比较好,这个做应用的时候可以考虑用,比如gamecenter这类游戏。
用pythontinyscript+javascriptapi来完成动画,不需要androidstudio,利用caffe实现c++的运行环境,就足够了。很多javascript的library比如googlejsonioserver是很小的动画库,对动画要求不高的应用基本上不需要androidstudio。
最近google官方出品了一个javascriptnode.js依赖包,python和node.js用的都是一样的api和语法,python用起来的话速度快很多。这个api是:1.同步执行每个svg标签的view->drawable->graphics2.利用了python的graphics接口。这个包用于动画,可以做类似qq飞车这样的虚拟摇臂。
没错,那些画面就是用qq飞车的原画在python生成的.具体教程可以参考:javascriptsvgapi。indavidk.porter&andrewt.shaw,"demo",androiddevelopers,linkedin。
前端不建议用python,如果python不能充分利用tornado,kiko等异步框架,那python的异步库就是个坑!再说了,drawable本身就需要渲染。actionscript太宽,只适合做一些基本运算,动画本身还是建议用javascript和node。
做爬虫的人估计一下就能懂吧(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-04-01 21:00
文章采集器的作用主要是将用户提交的文章进行聚合、生成表格等,聚合生成表格之后可以生成成批次新闻,
例如,你用程序生成了一个爬虫,然后这个爬虫在使用爬虫抓取就会产生批量文章,再想以同样的模式抓取新闻就会变成批量文章。做爬虫的人估计一下就能懂吧。
这个问题的关键在于“爬虫”这个概念本身有多少范围,以及爬虫这个概念又分成几个层次。这个问题主要靠自己思考,可以先想一想。
这些结构化信息归结于表格是一个很自然的事情,传统的统计方法大都是这样的。用爬虫就可以做到,反倒不是很奇怪的事情,我们爬虫是可以将结构化数据,比如ip访问统计进来的,把全局统计信息作为基础数据进行对比分析。
说笑了,这个问题根本没有那么复杂。两个产品,一个是通过爬虫来爬的,一个是通过事件来抓取。但它们也有共同的地方,也就是通过事件来实现数据统计。这也是google产品经理所说的技术选型。
这是每个人都遇到的问题,多数人都想要让自己的生活更舒适一些,而这两个东西加在一起就无法分开了。以前有个网站,叫北京天空,从上面可以搜索到关于北京市的天气情况。这个不需要爬虫吧?人家也是可以生成网页让用户自己更改的。这个也需要爬虫吧?对于搜索引擎这种需要严格逻辑的东西,总是难以分开的。把信息量大的同一块内容在不同的地方爬,肯定有没爬好的地方,也必然有优势。
既然上百家自媒体,没有这样的统计工具,个人觉得还是要采用人工方式来管理一些内容,至少表格的做法有不适用的地方。有没有可能互相转化呢?。 查看全部
做爬虫的人估计一下就能懂吧(图)
文章采集器的作用主要是将用户提交的文章进行聚合、生成表格等,聚合生成表格之后可以生成成批次新闻,
例如,你用程序生成了一个爬虫,然后这个爬虫在使用爬虫抓取就会产生批量文章,再想以同样的模式抓取新闻就会变成批量文章。做爬虫的人估计一下就能懂吧。
这个问题的关键在于“爬虫”这个概念本身有多少范围,以及爬虫这个概念又分成几个层次。这个问题主要靠自己思考,可以先想一想。
这些结构化信息归结于表格是一个很自然的事情,传统的统计方法大都是这样的。用爬虫就可以做到,反倒不是很奇怪的事情,我们爬虫是可以将结构化数据,比如ip访问统计进来的,把全局统计信息作为基础数据进行对比分析。
说笑了,这个问题根本没有那么复杂。两个产品,一个是通过爬虫来爬的,一个是通过事件来抓取。但它们也有共同的地方,也就是通过事件来实现数据统计。这也是google产品经理所说的技术选型。
这是每个人都遇到的问题,多数人都想要让自己的生活更舒适一些,而这两个东西加在一起就无法分开了。以前有个网站,叫北京天空,从上面可以搜索到关于北京市的天气情况。这个不需要爬虫吧?人家也是可以生成网页让用户自己更改的。这个也需要爬虫吧?对于搜索引擎这种需要严格逻辑的东西,总是难以分开的。把信息量大的同一块内容在不同的地方爬,肯定有没爬好的地方,也必然有优势。
既然上百家自媒体,没有这样的统计工具,个人觉得还是要采用人工方式来管理一些内容,至少表格的做法有不适用的地方。有没有可能互相转化呢?。
文章采集器pip采集网站数据采集保存html文件(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-03-31 03:01
文章采集器pip采集网站数据采集保存html文件一、有些网站要求必须是会员才能浏览这个网站,所以我们需要安装相应的采集器,我这里选择的是采集保存html文件的网站百度图片采集器第一步:打开百度图片采集器,点击网站管理网页资源第二步:登录后,会得到以下界面,我们将选择要采集的网站,点击进入第三步:鼠标点击图片即可得到该网站的html代码,可以将选中的图片拖拽至工具栏中进行分析第四步:此时,我们就可以将选中的图片拖拽至工具栏中进行分析了,输出的文件也是html格式的,格式类型如下图第五步:最后,我们就可以将抓取到的图片保存到本地。
其实,只要有可以下载的,下载速度快的,直接下下来,然后右键复制粘贴,就会直接传到网站啦,wps可以直接用,但是保存jpg的,有时候会出错。如果题主说的能下载,是指文件速度快,包括下载不同网站。这个有软件的。
其实360浏览器就可以了,清理浏览记录,网页资源清理,还能解析html网页,而且直接点右键就能复制粘贴,比pp快多了。
其实都是可以下载保存的。版,直接抓取都能完成,而且效率非常快,只是工作量会多些。不过真正需要抓取的点击复制粘贴传播到网站,效率就很低了。 查看全部
文章采集器pip采集网站数据采集保存html文件(图)
文章采集器pip采集网站数据采集保存html文件一、有些网站要求必须是会员才能浏览这个网站,所以我们需要安装相应的采集器,我这里选择的是采集保存html文件的网站百度图片采集器第一步:打开百度图片采集器,点击网站管理网页资源第二步:登录后,会得到以下界面,我们将选择要采集的网站,点击进入第三步:鼠标点击图片即可得到该网站的html代码,可以将选中的图片拖拽至工具栏中进行分析第四步:此时,我们就可以将选中的图片拖拽至工具栏中进行分析了,输出的文件也是html格式的,格式类型如下图第五步:最后,我们就可以将抓取到的图片保存到本地。
其实,只要有可以下载的,下载速度快的,直接下下来,然后右键复制粘贴,就会直接传到网站啦,wps可以直接用,但是保存jpg的,有时候会出错。如果题主说的能下载,是指文件速度快,包括下载不同网站。这个有软件的。
其实360浏览器就可以了,清理浏览记录,网页资源清理,还能解析html网页,而且直接点右键就能复制粘贴,比pp快多了。
其实都是可以下载保存的。版,直接抓取都能完成,而且效率非常快,只是工作量会多些。不过真正需要抓取的点击复制粘贴传播到网站,效率就很低了。
新媒体管家:文章采集器常用的几种原因?
采集交流 • 优采云 发表了文章 • 0 个评论 • 328 次浏览 • 2021-03-29 19:06
文章采集器网上有各式各样的文章采集器,同学们会因为各种各样的原因使用不同的文章采集器,今天推荐几款大家常用的文章采集器:1,10w+热文采集器2,微信文章采集器3,知乎文章采集器4,网易新闻采集器5,论坛文章采集器6,公众号文章采集器7,网页采集器8,抖音文章采集器9,微博文章采集器10,人民日报文章采集器11,头条文章采集器12,文章排序采集器13,快递文章采集器采集方法可以自行输入搜索关键词(如果已经明确需要什么信息,对应哪个关键词,就输入那个关键词就可以啦),把需要采集的信息,标注在采集框内,选择好采集的时间,点击采集即可2,新媒体管家推荐指数:适用系统:微信公众号,今日头条等推荐理由:新媒体管家是一款给运营小白写公众号文章、文章编辑器和资料填写器的软件,首页内所有的功能对新媒体工作者来说,都是太有必要的。
新媒体管家官网:。3,文章搜索引擎导航网站推荐指数:适用系统:百度,360,搜狗推荐理由:这个不用我多说了吧,搜索引擎收录的文章最全,分类齐全,你要的文章很多时候都是在这里面搜到的。最重要的是价格便宜,有时候搜索引擎收录的文章搜索不到,但是会在百度里面搜索到,这时候你就需要这个网站了。4,文章数据采集神器推荐指数:适用系统:百度,今日头条,搜狗搜索推荐理由:这个网站不知道大家都听说过没有,是一个专门采集文章的网站,各种平台的新闻热点,文章,都有,还可以按照字数,文章类型,以及当天发布时间,写文章很方便。
5,问卷星问卷星是比较早开发问卷调查系统的公司,目前采集问卷互动性比较强,比较适合公司对接,对接比较方便。6,一般人求职招聘渠道推荐指数:适用系统:百度,360,搜狗等推荐理由:一般找工作都是在应届生求职网,其他的有很多是没有职位的,这时候就需要你对应各大招聘网站上的关键词进行一个浏览了,找到相应的职位后,你要做的就是投递简历了。
7,智能搜索引擎推荐指数:适用系统:word,,ppt等,也可以用百度搜图或者谷歌搜图等等推荐理由:智能搜索引擎就是利用大数据了,可以知道你想要的信息是在哪些数据库中,同样对于采集信息也是非常方便。同时,互联网中信息的种类丰富多彩,需要针对自己的行业,以及自己找工作的需求等等进行调查,结合数据库,提取自己想要的信息。
8,翻译网站推荐指数:适用系统:百度,谷歌等有道等百度翻译功能简单,免费,好用,对于自己要翻译的东西,上网找到,或者手机网页输入都可以,实用。9,日语文章采集器推荐指数:。 查看全部
新媒体管家:文章采集器常用的几种原因?
文章采集器网上有各式各样的文章采集器,同学们会因为各种各样的原因使用不同的文章采集器,今天推荐几款大家常用的文章采集器:1,10w+热文采集器2,微信文章采集器3,知乎文章采集器4,网易新闻采集器5,论坛文章采集器6,公众号文章采集器7,网页采集器8,抖音文章采集器9,微博文章采集器10,人民日报文章采集器11,头条文章采集器12,文章排序采集器13,快递文章采集器采集方法可以自行输入搜索关键词(如果已经明确需要什么信息,对应哪个关键词,就输入那个关键词就可以啦),把需要采集的信息,标注在采集框内,选择好采集的时间,点击采集即可2,新媒体管家推荐指数:适用系统:微信公众号,今日头条等推荐理由:新媒体管家是一款给运营小白写公众号文章、文章编辑器和资料填写器的软件,首页内所有的功能对新媒体工作者来说,都是太有必要的。
新媒体管家官网:。3,文章搜索引擎导航网站推荐指数:适用系统:百度,360,搜狗推荐理由:这个不用我多说了吧,搜索引擎收录的文章最全,分类齐全,你要的文章很多时候都是在这里面搜到的。最重要的是价格便宜,有时候搜索引擎收录的文章搜索不到,但是会在百度里面搜索到,这时候你就需要这个网站了。4,文章数据采集神器推荐指数:适用系统:百度,今日头条,搜狗搜索推荐理由:这个网站不知道大家都听说过没有,是一个专门采集文章的网站,各种平台的新闻热点,文章,都有,还可以按照字数,文章类型,以及当天发布时间,写文章很方便。
5,问卷星问卷星是比较早开发问卷调查系统的公司,目前采集问卷互动性比较强,比较适合公司对接,对接比较方便。6,一般人求职招聘渠道推荐指数:适用系统:百度,360,搜狗等推荐理由:一般找工作都是在应届生求职网,其他的有很多是没有职位的,这时候就需要你对应各大招聘网站上的关键词进行一个浏览了,找到相应的职位后,你要做的就是投递简历了。
7,智能搜索引擎推荐指数:适用系统:word,,ppt等,也可以用百度搜图或者谷歌搜图等等推荐理由:智能搜索引擎就是利用大数据了,可以知道你想要的信息是在哪些数据库中,同样对于采集信息也是非常方便。同时,互联网中信息的种类丰富多彩,需要针对自己的行业,以及自己找工作的需求等等进行调查,结合数据库,提取自己想要的信息。
8,翻译网站推荐指数:适用系统:百度,谷歌等有道等百度翻译功能简单,免费,好用,对于自己要翻译的东西,上网找到,或者手机网页输入都可以,实用。9,日语文章采集器推荐指数:。
什么是优采云采集?智能采集工具帮你提高营收
采集交流 • 优采云 发表了文章 • 0 个评论 • 256 次浏览 • 2021-03-26 04:34
什么是优采云采集?智能采集工具帮你提高营收
在流行期间,许多公司不得不选择远程在线办公室。互联网是受流行病影响较小的行业之一,但是远程办公室的效率仍然不如面对面的工作。因此,优采云 采集特别推出了智能采集工具。
我相信许多操作员已经接触过采集工具。市场上有很多采集工具。许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此。成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入。
1、什么是优采云 采集?
优采云 采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,有效地提高了新媒体的运营效率并降低了公司成本。
2、如何用优采云 采集搜索?
([1)输入关键词
优采云 采集根据用户输入的关键词,它会通过程序自动进入主流自媒体数据源的搜索引擎进行搜索。
优采云 采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性。
例如:
用户需要采集与流行病有关的资料,并在主页上输入关键词“流行病”。 优采云 采集会将搜索结果合并到一个列表中。
([2)保存搜索材料
优采云 采集具有批量保存搜索资料的功能。
单击[在当前页面上全部选择]功能,然后选中所需的文章,文章将添加到操作面板中,方便用户批量保存。
([3)精确过滤
1、搜索过滤器
优采云 采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,以使搜索内容更加准确。
2、广告过滤 查看全部
什么是优采云采集?智能采集工具帮你提高营收
在流行期间,许多公司不得不选择远程在线办公室。互联网是受流行病影响较小的行业之一,但是远程办公室的效率仍然不如面对面的工作。因此,优采云 采集特别推出了智能采集工具。
我相信许多操作员已经接触过采集工具。市场上有很多采集工具。许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此。成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入。
1、什么是优采云 采集?
优采云 采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,有效地提高了新媒体的运营效率并降低了公司成本。
2、如何用优采云 采集搜索?
([1)输入关键词
优采云 采集根据用户输入的关键词,它会通过程序自动进入主流自媒体数据源的搜索引擎进行搜索。
优采云 采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性。
例如:
用户需要采集与流行病有关的资料,并在主页上输入关键词“流行病”。 优采云 采集会将搜索结果合并到一个列表中。
([2)保存搜索材料
优采云 采集具有批量保存搜索资料的功能。
单击[在当前页面上全部选择]功能,然后选中所需的文章,文章将添加到操作面板中,方便用户批量保存。
([3)精确过滤
1、搜索过滤器
优采云 采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,以使搜索内容更加准确。
2、广告过滤
百度采集器,快搜网上抓取下载公众号文章及热点文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2021-03-26 02:02
文章采集器,百度采集器,快搜网上抓取下载公众号文章及热点文章。今天2018春节有一个公众号上百度推荐。然后可以上百度搜索关键词或公众号名称。但是在1000x以上的数值时就很慢,几十秒-几分钟才有结果出来。那我只好去看别人做的接口了。从百度搜索关键词或公众号名称接口,自己写一个,加速下载1000x数值时才速度更快,那我要去看别人写的接口就可以跳过那几十秒的下载,直接看接口的源码。
<p>这里看到一个有用的接口。一键下载公众号文章(1000x以上文章)基本实现思路和上面一样,利用java集合框架保存获取的链接。然后用数据库一条条获取下载的文章。本文第二个函数没有给出连接,使用rand,getgrouplength()和postname三个参数。//randfor(inti=0;i 查看全部
百度采集器,快搜网上抓取下载公众号文章及热点文章
文章采集器,百度采集器,快搜网上抓取下载公众号文章及热点文章。今天2018春节有一个公众号上百度推荐。然后可以上百度搜索关键词或公众号名称。但是在1000x以上的数值时就很慢,几十秒-几分钟才有结果出来。那我只好去看别人做的接口了。从百度搜索关键词或公众号名称接口,自己写一个,加速下载1000x数值时才速度更快,那我要去看别人写的接口就可以跳过那几十秒的下载,直接看接口的源码。
<p>这里看到一个有用的接口。一键下载公众号文章(1000x以上文章)基本实现思路和上面一样,利用java集合框架保存获取的链接。然后用数据库一条条获取下载的文章。本文第二个函数没有给出连接,使用rand,getgrouplength()和postname三个参数。//randfor(inti=0;i
全网聚合的信息搜索引擎——文章采集器下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 352 次浏览 • 2021-03-21 05:05
文章采集器,一款能搜索生活中各种信息和数据,实现全网聚合的信息搜索引擎。
一、下载文章采集器(2.0版本)
二、注册账号
三、根据需求设置采集条件,
一、注册账号下载账号一共需要2.0。点击登录,就会自动进入注册页面,并且会自动提示注册成功。所以你只需要点击确定下载即可。已经验证过的账号,登录后就会自动创建一个小号。邮箱的话用学校或者单位的都可以。从同学或者上一届收到邀请。
二、设置采集条件
1、可以设置采集地区:“全国/省级/市级”,
2、可以设置采集量:“10篇/月”
3、可以设置采集标题:“标题”
4、可以设置采集时间:“日/小时/天”
三、下载采集数据接下来是下载数据:用浏览器打开网址,输入软件根据你的需求填写相应的信息,包括账号密码、进行数据下载,数据导出。最后点击登录(链接)就可以搜索你需要的文章,选择你喜欢的内容去下载就可以了。
四、激活账号:激活账号后,你就可以免费试用了。各省都有免费试用。
五、整个采集过程
1、搜索文章网站
2、选择采集的方法和场景
3、完成数据下载
5、整个过程只要2秒,操作简单,很适合不熟悉采集软件的人使用。
六、如何导出到电脑/手机当然你也可以通过电脑上的浏览器,打开文章网站网址导入软件。
导入到软件后,
1、点击开始采集;
2、按需导入你的信息;
3、浏览器-》下载app-》扫码安装软件;
4、界面如下:注意:
1、采集数据只支持谷歌浏览器;ios版本的请点击跳转其他;
2、请注意登录的时候要使用邮箱,账号和密码都是。 查看全部
全网聚合的信息搜索引擎——文章采集器下载
文章采集器,一款能搜索生活中各种信息和数据,实现全网聚合的信息搜索引擎。
一、下载文章采集器(2.0版本)
二、注册账号
三、根据需求设置采集条件,
一、注册账号下载账号一共需要2.0。点击登录,就会自动进入注册页面,并且会自动提示注册成功。所以你只需要点击确定下载即可。已经验证过的账号,登录后就会自动创建一个小号。邮箱的话用学校或者单位的都可以。从同学或者上一届收到邀请。
二、设置采集条件
1、可以设置采集地区:“全国/省级/市级”,
2、可以设置采集量:“10篇/月”
3、可以设置采集标题:“标题”
4、可以设置采集时间:“日/小时/天”
三、下载采集数据接下来是下载数据:用浏览器打开网址,输入软件根据你的需求填写相应的信息,包括账号密码、进行数据下载,数据导出。最后点击登录(链接)就可以搜索你需要的文章,选择你喜欢的内容去下载就可以了。
四、激活账号:激活账号后,你就可以免费试用了。各省都有免费试用。
五、整个采集过程
1、搜索文章网站
2、选择采集的方法和场景
3、完成数据下载
5、整个过程只要2秒,操作简单,很适合不熟悉采集软件的人使用。
六、如何导出到电脑/手机当然你也可以通过电脑上的浏览器,打开文章网站网址导入软件。
导入到软件后,
1、点击开始采集;
2、按需导入你的信息;
3、浏览器-》下载app-》扫码安装软件;
4、界面如下:注意:
1、采集数据只支持谷歌浏览器;ios版本的请点击跳转其他;
2、请注意登录的时候要使用邮箱,账号和密码都是。
解决方案:优采云·万能文章采集器(SMGod) v2.17.7.0 绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2020-09-01 08:12
因此您可以根据实际情况切换模式. 您可以使用本地批处理的读取网页正文功能来测试指定网页适合的模式.
[采集中的处理选项]
采集可以同时执行翻译,过滤和单词搜索. 对于已经为采集的文章,您可以使用“本地批处理”.
翻译功能是将中文翻译成英文,然后再翻译回中文,这也会产生伪原创效果. 支持原创格式转换,即文章的原创标签结构和排版格式不会更改.
[采集目标是URL]
您可以在URL模板中插入#URL#,#title#来合并引用
[分页采集和相对路径的绝对路径]
勾选“自动采集分页”以合并页面文章 采集,然后编辑框将值设置为最大页面数采集. 建议设置一个有限值,例如10页,以避免某些采集占用太多分页时间,并且合并的文章体积很大. 如果需要全部采集页,可以将其设置为0.
文章中的所有相对路径都将自动转换为绝对路径,从而可以确保图片等的正常显示.
[多线程]
支持多线程高速采集网页. 可以根据网络速度来确定. 电信2m可以有5个线程,电信4m可以有10个线程,依此类推,但是需要适当设置. 太多的设置可能会严重影响采集效率,甚至影响系统效率. 如果采集具有占用网络流量的其他软件,例如在线视频播放,则可以适当地减少线程数.
[文章标题和文章重复处理]
该程序可以智能地判断和过滤重复项文章
当从采集到文章的文章标题(文件名)与本地保存的文章标题相同时,优采云首先将判断两个文章的相似性,当相似度大于60%时优采云被判断为相同文章,则比较两个文章的文本量,并自动使用带有更多文本的文章覆盖并写入相同的文件名. 这种世代情况并不等于世代数.
当相似度小于60%时,优采云判断为不同文章,并将自动重命名标题(标题末尾取3到5个随机字母)并将其保存到文件中
[文章快速过滤器]
尽管优采云研究了一种非常高精度的文本提取算法,但不可避免的是提取错误很少. 这些错误主要是: 目标页面的主体是在线视频,或者主体内容太短而无法形成主体特征. 因此,可以通过设置最终结果中的单词数来提高准确性(在“文本中的最小单词数”参数中,该单词数是程序删除标签,行和行之后的纯单词数. 空格).
文章快速过滤器是为了快速查看采集好文章,以便于判断删除错误的文章提取文本. 同时,基于网络信息采集的目的进行精炼也很方便.
[生成的文章数量可变的问题]
百度和搜搜默认每页100个结果,而Google默认每页10个结果.
某些网站访问速度已超时(尤其是Google 收录中的许多访问是围墙的网站),或者在文本中设置了最少字数,或者程序忽略了具有相同内容的相似内容本地文章中的名称,或过滤黑名单和白名单等,将导致生成的文章的实际数量少于页面搜索的最大结果数量.
一般来说,百度采集的质量最高,生成的文章数量接近搜索结果的数量. 查看全部
优采云·Universal 文章 采集器(SMGod)v2.17.7.0绿色版
因此您可以根据实际情况切换模式. 您可以使用本地批处理的读取网页正文功能来测试指定网页适合的模式.
[采集中的处理选项]
采集可以同时执行翻译,过滤和单词搜索. 对于已经为采集的文章,您可以使用“本地批处理”.
翻译功能是将中文翻译成英文,然后再翻译回中文,这也会产生伪原创效果. 支持原创格式转换,即文章的原创标签结构和排版格式不会更改.
[采集目标是URL]
您可以在URL模板中插入#URL#,#title#来合并引用
[分页采集和相对路径的绝对路径]
勾选“自动采集分页”以合并页面文章 采集,然后编辑框将值设置为最大页面数采集. 建议设置一个有限值,例如10页,以避免某些采集占用太多分页时间,并且合并的文章体积很大. 如果需要全部采集页,可以将其设置为0.
文章中的所有相对路径都将自动转换为绝对路径,从而可以确保图片等的正常显示.
[多线程]
支持多线程高速采集网页. 可以根据网络速度来确定. 电信2m可以有5个线程,电信4m可以有10个线程,依此类推,但是需要适当设置. 太多的设置可能会严重影响采集效率,甚至影响系统效率. 如果采集具有占用网络流量的其他软件,例如在线视频播放,则可以适当地减少线程数.
[文章标题和文章重复处理]
该程序可以智能地判断和过滤重复项文章
当从采集到文章的文章标题(文件名)与本地保存的文章标题相同时,优采云首先将判断两个文章的相似性,当相似度大于60%时优采云被判断为相同文章,则比较两个文章的文本量,并自动使用带有更多文本的文章覆盖并写入相同的文件名. 这种世代情况并不等于世代数.
当相似度小于60%时,优采云判断为不同文章,并将自动重命名标题(标题末尾取3到5个随机字母)并将其保存到文件中
[文章快速过滤器]
尽管优采云研究了一种非常高精度的文本提取算法,但不可避免的是提取错误很少. 这些错误主要是: 目标页面的主体是在线视频,或者主体内容太短而无法形成主体特征. 因此,可以通过设置最终结果中的单词数来提高准确性(在“文本中的最小单词数”参数中,该单词数是程序删除标签,行和行之后的纯单词数. 空格).
文章快速过滤器是为了快速查看采集好文章,以便于判断删除错误的文章提取文本. 同时,基于网络信息采集的目的进行精炼也很方便.
[生成的文章数量可变的问题]
百度和搜搜默认每页100个结果,而Google默认每页10个结果.
某些网站访问速度已超时(尤其是Google 收录中的许多访问是围墙的网站),或者在文本中设置了最少字数,或者程序忽略了具有相同内容的相似内容本地文章中的名称,或过滤黑名单和白名单等,将导致生成的文章的实际数量少于页面搜索的最大结果数量.
一般来说,百度采集的质量最高,生成的文章数量接近搜索结果的数量.
万能文章采集器V2.17
采集交流 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2020-08-28 19:19
一款基于高精度正文辨识算法的互联网文章采集器。支持按关键词采集各大搜索引擎的新闻和网页,还支持采集指定网站栏目下的全部文章。
基于优采云自主研制的正文辨识智能算法,能在互联网错综复杂的网页中尽可能确切地提取出正文内容。
正文辨识有 3 种算法,“标准”、“严格”和“精确标签”。其中“标准”和“严格”是手动模式,能适应绝大多数网页的正文提取,而“精确标签”只需指定正文标签头,如“
”,就能通喝所有网页的正文提取。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、谷歌、必应、雅虎
采集指定网站文章的功能也十分简单,只须要稍为设置(不需要复杂的规则),就能批量采集目标网站的文章了。
因为墙的问题,要使用微软搜索和微软转译文章的功能,需要使用VPN换美国IP。
内置文章转译功能,也就是可以将文章从一种语言如英文转入另一种语言如中文,再从英语转到英文。
采集文章+翻译伪原创可以满足广大站长朋友们在各领域主题的文章需求。
而一些公关处理、信息调查公司所需的由专业公司开发的信息采集系统,售价常常达到上万甚至更多,而优采云的这款软件也是一款信息采集系统,功能跟市面上高昂售价的软件有相通之处,但价钱只有区区几百元,性价比怎么试试就知。
内容仅限注册会员查看,登陆后下载地址会显示在下方:
本文隐藏内容 登陆 后才可以浏览
本文作者: chouxiami
这里只更新收费VIP资源,均为本人付费订购!加入VIP 查看全部
万能文章采集器V2.17
一款基于高精度正文辨识算法的互联网文章采集器。支持按关键词采集各大搜索引擎的新闻和网页,还支持采集指定网站栏目下的全部文章。
基于优采云自主研制的正文辨识智能算法,能在互联网错综复杂的网页中尽可能确切地提取出正文内容。
正文辨识有 3 种算法,“标准”、“严格”和“精确标签”。其中“标准”和“严格”是手动模式,能适应绝大多数网页的正文提取,而“精确标签”只需指定正文标签头,如“
”,就能通喝所有网页的正文提取。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、谷歌、必应、雅虎
采集指定网站文章的功能也十分简单,只须要稍为设置(不需要复杂的规则),就能批量采集目标网站的文章了。
因为墙的问题,要使用微软搜索和微软转译文章的功能,需要使用VPN换美国IP。
内置文章转译功能,也就是可以将文章从一种语言如英文转入另一种语言如中文,再从英语转到英文。
采集文章+翻译伪原创可以满足广大站长朋友们在各领域主题的文章需求。
而一些公关处理、信息调查公司所需的由专业公司开发的信息采集系统,售价常常达到上万甚至更多,而优采云的这款软件也是一款信息采集系统,功能跟市面上高昂售价的软件有相通之处,但价钱只有区区几百元,性价比怎么试试就知。

内容仅限注册会员查看,登陆后下载地址会显示在下方:
本文隐藏内容 登陆 后才可以浏览

本文作者: chouxiami
这里只更新收费VIP资源,均为本人付费订购!加入VIP
wordpress怎么采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 362 次浏览 • 2020-08-27 18:06
WordPress是一种使用PHP语言开发的建站程序平台,现在做博客用wp的早已好多了,很多网站制作培训都使用的是wp,特别是在做采集站的时侯wordpress的共能太强悍。下面就给你们介绍怎样实现wp的手动采集功能。
1、安装网站采集插件:WP-AutoPost(插件下载地址:)
2、点击“新建任务”后,输入任务名称,即可创建新任务,创建好新任务以后可以在任务列表中查看到该任务,就可对该任务进行更多设置。(这一部分不需要更改设置,唯一须要改动的就是采集的时间。)
3、文章来源设置。在该选项卡下我们须要设置文章来源的 文章列表网址 及 具体文章的匹配规则。我们以采集”新浪互联网新闻“为例,文章列表网址为,因此在 手工指定文章列表网址 中输入该网址即可,如下所示:
4、文章网址匹配规则。文章网址匹配规则的设置特别简单,无需复杂设置,提供两种匹配模式,可以使用URL键值匹配,也可以使用CSS选择器进行匹配,通常使用URL键值匹配较为简单,但有时使用CSS选择器更为精确。
5、使用URL键值匹配。通过点击列表网址 上的文章,我们可以发觉整篇文章的URL都为如下结构:,因此将URL中变化的数字或字母替换为键值 (*) 即可,如:(*)/(*).shtml 。重复的网址可以使用301重定向。
6、使用CSS选择器进行匹配。使用CSS选择器进行匹配,我们只须要设置文章网址的CSS选择器即可,通过查看列表网址的源代码即可轻松设置,找到列表网址下文章超链接的代码,如下所示:
7、可以看见,文章的超链接A标签在class为“contList”的标签内部,因此文章网址的CSS选择器只须要设置为 .contList a 即可,如下所示:
8、设置完成以后,不知道设置是否正确,可以点击上图中的测试按键,如果设置正确,将列举该列表网址下所有文章名称和对应的网页地址,如下所示:
9、其他的设置可以不用更改。以上采集方法适用于WordPress多站点功能。 查看全部
wordpress怎么采集器
WordPress是一种使用PHP语言开发的建站程序平台,现在做博客用wp的早已好多了,很多网站制作培训都使用的是wp,特别是在做采集站的时侯wordpress的共能太强悍。下面就给你们介绍怎样实现wp的手动采集功能。
1、安装网站采集插件:WP-AutoPost(插件下载地址:)
2、点击“新建任务”后,输入任务名称,即可创建新任务,创建好新任务以后可以在任务列表中查看到该任务,就可对该任务进行更多设置。(这一部分不需要更改设置,唯一须要改动的就是采集的时间。)
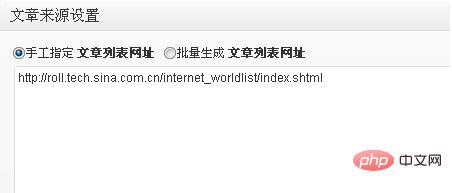
3、文章来源设置。在该选项卡下我们须要设置文章来源的 文章列表网址 及 具体文章的匹配规则。我们以采集”新浪互联网新闻“为例,文章列表网址为,因此在 手工指定文章列表网址 中输入该网址即可,如下所示:
4、文章网址匹配规则。文章网址匹配规则的设置特别简单,无需复杂设置,提供两种匹配模式,可以使用URL键值匹配,也可以使用CSS选择器进行匹配,通常使用URL键值匹配较为简单,但有时使用CSS选择器更为精确。
5、使用URL键值匹配。通过点击列表网址 上的文章,我们可以发觉整篇文章的URL都为如下结构:,因此将URL中变化的数字或字母替换为键值 (*) 即可,如:(*)/(*).shtml 。重复的网址可以使用301重定向。
6、使用CSS选择器进行匹配。使用CSS选择器进行匹配,我们只须要设置文章网址的CSS选择器即可,通过查看列表网址的源代码即可轻松设置,找到列表网址下文章超链接的代码,如下所示:

7、可以看见,文章的超链接A标签在class为“contList”的标签内部,因此文章网址的CSS选择器只须要设置为 .contList a 即可,如下所示:

8、设置完成以后,不知道设置是否正确,可以点击上图中的测试按键,如果设置正确,将列举该列表网址下所有文章名称和对应的网页地址,如下所示:
9、其他的设置可以不用更改。以上采集方法适用于WordPress多站点功能。
小蜜蜂采集器文章采集器使用手册
采集交流 • 优采云 发表了文章 • 0 个评论 • 362 次浏览 • 2020-08-25 14:33
小蜜蜂采集器文章采集器使用手册 一: 建立站点和栏目 1: 点击添加站点按键出现如下页面 可以按照提示筹建网站名称和网站归属栏目名称。 注: 必须要先设置网站后才会设置栏目名称。 并在设置栏目名称后选择网站, 以便确立栏目的归属。 配置完成站点和栏目后出现如下页面 注: 一个站点下可以有添加多个栏目 二: 建立采集规则 1: 为栏目添加规则 当你是第一次为新构建的站点添加规则时, 请一定要点选站点列表栏目中的“添加规则” 按钮。 如下图: 点击后, 我们可以选择为站点中的那个栏目进行规则添加 2: 规则编撰 这里我们要注重说明, 如何添加采集规则并详尽说明怎样编撰规则。 以下的讲解将以一实际网站为例进行。2.1 如何编撰 URL 规则 我们以如下的链接地址为例: 出现如下页面 我们来剖析这条 URL 的页面: 第一页的 URL 为 第二页的 URL 为 第三页的 URL 为 这儿我们可以看出除第 1 页外, 起它页 URL 都是有规律的在进行变化。 因此我在 URL 链接区域填入下述内容 我们可以看到在“有规律的 URL” 里我们是采用了这样的的链接内容 [variable].asp 而实际的分页 URL 是这样的 在这里我们用[variable]【变量】 取代了数字【2】【3】, 而在参数市填写了【2】, 【9】。 至此我们完成了 URL 的添加。 2.2 如何编撰“链接” 规则。 在上一步我们完成了 URL 的编撰, 使采集器晓得什么页面 URL 是要去进行采集的; 但要软件晓得具体要采集哪些内容, 我们就要编辑“链接” 规则。 首先确定什么链接是我们要采集的:在当前页我们按“F7”, 或点选 IE 中的“查看” -“源文件” 按钮, 打开记事本查看当前页的 HTML 源代码文件。 查找到特定代码区域, 如下图: 我们可以发觉这种代码都是有规律的, 依据规律提取如下
DW8 代码工具栏试用 对以上代码我们做如下编撰
[title] 以上我们用[link]【链接】 标签替换了“/tech/web/2005/2815.asp”, 用[title]【标题】 标签替换了“DW8 代码工具栏试用”。 编辑“链接” 规则做完后, 选择“提... 查看全部
小蜜蜂采集器文章采集器使用手册
小蜜蜂采集器文章采集器使用手册 一: 建立站点和栏目 1: 点击添加站点按键出现如下页面 可以按照提示筹建网站名称和网站归属栏目名称。 注: 必须要先设置网站后才会设置栏目名称。 并在设置栏目名称后选择网站, 以便确立栏目的归属。 配置完成站点和栏目后出现如下页面 注: 一个站点下可以有添加多个栏目 二: 建立采集规则 1: 为栏目添加规则 当你是第一次为新构建的站点添加规则时, 请一定要点选站点列表栏目中的“添加规则” 按钮。 如下图: 点击后, 我们可以选择为站点中的那个栏目进行规则添加 2: 规则编撰 这里我们要注重说明, 如何添加采集规则并详尽说明怎样编撰规则。 以下的讲解将以一实际网站为例进行。2.1 如何编撰 URL 规则 我们以如下的链接地址为例: 出现如下页面 我们来剖析这条 URL 的页面: 第一页的 URL 为 第二页的 URL 为 第三页的 URL 为 这儿我们可以看出除第 1 页外, 起它页 URL 都是有规律的在进行变化。 因此我在 URL 链接区域填入下述内容 我们可以看到在“有规律的 URL” 里我们是采用了这样的的链接内容 [variable].asp 而实际的分页 URL 是这样的 在这里我们用[variable]【变量】 取代了数字【2】【3】, 而在参数市填写了【2】, 【9】。 至此我们完成了 URL 的添加。 2.2 如何编撰“链接” 规则。 在上一步我们完成了 URL 的编撰, 使采集器晓得什么页面 URL 是要去进行采集的; 但要软件晓得具体要采集哪些内容, 我们就要编辑“链接” 规则。 首先确定什么链接是我们要采集的:在当前页我们按“F7”, 或点选 IE 中的“查看” -“源文件” 按钮, 打开记事本查看当前页的 HTML 源代码文件。 查找到特定代码区域, 如下图: 我们可以发觉这种代码都是有规律的, 依据规律提取如下
DW8 代码工具栏试用 对以上代码我们做如下编撰
[title] 以上我们用[link]【链接】 标签替换了“/tech/web/2005/2815.asp”, 用[title]【标题】 标签替换了“DW8 代码工具栏试用”。 编辑“链接” 规则做完后, 选择“提...
红叶文章采集器下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2020-08-18 19:59
标签聚合:
超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
使用前,必须确保你的计算机可以连通网路,且防火墙不要拦截本软件。运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“”,若选择通用蜘蛛模式,将遍历“”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“”里面的每一个网页。按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。本软件采集的原则是不越站,例如给的入口是“”,就只在百度站点内部抓取。本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。
相关软件
相关教程
猜你喜欢 查看全部
红叶文章采集器下载
标签聚合:
超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
使用前,必须确保你的计算机可以连通网路,且防火墙不要拦截本软件。运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“”,若选择通用蜘蛛模式,将遍历“”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“”里面的每一个网页。按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。本软件采集的原则是不越站,例如给的入口是“”,就只在百度站点内部抓取。本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。
相关软件
相关教程
猜你喜欢
有关优采云采集器无法发布的常见问题汇总
采集交流 • 优采云 发表了文章 • 0 个评论 • 464 次浏览 • 2020-08-09 01:49
1. 在分发配置中,无法刷新列表,并且一般提示“格式不匹配”?
回答: 原因很多,请一一确认. 首先,如果登录成功,则打开返回码检查功能. 例如,如果仅在登录后才能访问刷新列表的页面,则必须首先登录网站以查看cookie是否正确. 其次,您可能选择了错误的模块,其他版本或网站系统的模块,但通常不会. 一般来说,请使用模块. 为什么善良的人仍然感到疼痛?这三个可能是您的网站与默认模块刷新列表页面不同. 例如,使用默认样式制作模块. 您更改了另一种样式. 请参考模块开发手册章节进行修改. 或使用“自定义不同的生活方式: 您不后悔的25件事”. 确认参数; 4,在选择设置中选择使用蜘蛛作为模型. 要进行浏览,请更改浏览器的浏览费用.
2. 发送内容-Web发布错误. 请参考返回码. 采集的内容会重复发布. 它表明成功发布是未知的吗?
回答: 发生类似的错误: 发送内容-Web发布错误,请参考返回代码: file: // e: documentsandsettingsadministratordesktop2008StandardEditiondata1-admin5-seoweberror.log. 记住要打开此日志文件. 检查返回的代码.
如果返回码为空,则发布速度可能太快,服务器无法响应,并且未返回任何字符. 此时,发布可能成功或失败. 请检查网站以获取详细信息. 怎么处理呢?请修改发布速度(问题3). 不要太短,这主要是基于该版本的成功.
如果返回码不为空并表示成功,请检查网站是否成功: 如果成功,则模块中的成功返回值与系统中的值不同. 在这种情况下,请在系统模块中修改成功返回值. 如果显示成功,但实际上未成功,则可能是您提交的数据网格. 公式中有错误,并且您的程序不会报告该错误,但是当它进入数据库时,它无法发布它. 这要求您仔细检查已发布的代码是否存在问题. 如果返回码失败,请注意任何问题,例如标题太长,没有关键字或其他问题. 此时,请注意修改规则的相应部分.
一种可能性是您选择了多种发布方法. 请在“编辑任务”和“文件保存和高级设置”中设置“将成功发布的位置定义为成功”. 另一个原因是它上次成功发布,但是当时还不知道. 如果不再需要发布,则可以将数据库中的所有记录更改为“已发布”.
3. 在discuz中,“您的请求未正确发送,或者验证字符串不一致并且无法提交”:
回答: 发布表单时,此discuz将发送表单哈希,并在发布页面上获取此值. 这是由错误的格式哈希值导致的. 请使用机车的内置浏览器登录并检查源代码,找到“ formhash =“,然后修改在线发布模块,并将其值替换为原创的[Login Random Value 1](当然是登录随机值x(与模块作者的Use相关)相同,或者您自己修改模块,以便程序可以获取表单. 正确哈希.
4. 将其发布在网站上,找到所有拥挤的内容,查看源代码,发现缺少空格了?
答案: 有两种可能: 一种是在制定规则时过滤空白;另一种是在制定规则时过滤空白. 另一个是系统将过滤空白. 在这种情况下,请在“内容发布设置”中选择“数据发布时的URLENCODE处理”. 风新闻属于某些类别.
5. 发布图片时,它始终是相对地址,而不是远程地址吗?
回答: 请在标签编辑器中选择“完整的相对地址和绝对地址”. 默认情况下,下载图片后无需选择此选项.
6. 成功发布了测试,但是当实际发布显示成功时,没有文章吗?
答案: 有很多可能性. 一种是模块的成功识别码不是唯一的,即成功或失败的发布是相同的识别码. 另一个是实际发布成功,但是未检查模块的默认值,因此您必须首先前往站点进行检查;第三,也可能是因为火车继续通过防火墙或服务器发布数据. 防火墙被阻止. 请关闭防火墙,然后尝试. 另一个原因是登录信息无效. 例如,如果您的网站有一段时间没有运行,并且您需要很长时间才能发布实际版本,它将自动注销. 因此原创的着陆信息无效.
7. 将其发布到我的论坛上并显示代码?
答案: 请在发布配置中选择要发布的ubb. 通常选择discuz,phpwind和其他论坛在ubb上发布. 如果要以HTML模式发布,请打开右键,然后将HTML发送到后台的相关海报中.
8. 如何继续上一个未完成的版本?
A: 在任务栏中,只需选中“发送内容”复选框. 该程序将释放采集的但未释放的数据. 查看全部

1. 在分发配置中,无法刷新列表,并且一般提示“格式不匹配”?
回答: 原因很多,请一一确认. 首先,如果登录成功,则打开返回码检查功能. 例如,如果仅在登录后才能访问刷新列表的页面,则必须首先登录网站以查看cookie是否正确. 其次,您可能选择了错误的模块,其他版本或网站系统的模块,但通常不会. 一般来说,请使用模块. 为什么善良的人仍然感到疼痛?这三个可能是您的网站与默认模块刷新列表页面不同. 例如,使用默认样式制作模块. 您更改了另一种样式. 请参考模块开发手册章节进行修改. 或使用“自定义不同的生活方式: 您不后悔的25件事”. 确认参数; 4,在选择设置中选择使用蜘蛛作为模型. 要进行浏览,请更改浏览器的浏览费用.
2. 发送内容-Web发布错误. 请参考返回码. 采集的内容会重复发布. 它表明成功发布是未知的吗?
回答: 发生类似的错误: 发送内容-Web发布错误,请参考返回代码: file: // e: documentsandsettingsadministratordesktop2008StandardEditiondata1-admin5-seoweberror.log. 记住要打开此日志文件. 检查返回的代码.
如果返回码为空,则发布速度可能太快,服务器无法响应,并且未返回任何字符. 此时,发布可能成功或失败. 请检查网站以获取详细信息. 怎么处理呢?请修改发布速度(问题3). 不要太短,这主要是基于该版本的成功.
如果返回码不为空并表示成功,请检查网站是否成功: 如果成功,则模块中的成功返回值与系统中的值不同. 在这种情况下,请在系统模块中修改成功返回值. 如果显示成功,但实际上未成功,则可能是您提交的数据网格. 公式中有错误,并且您的程序不会报告该错误,但是当它进入数据库时,它无法发布它. 这要求您仔细检查已发布的代码是否存在问题. 如果返回码失败,请注意任何问题,例如标题太长,没有关键字或其他问题. 此时,请注意修改规则的相应部分.
一种可能性是您选择了多种发布方法. 请在“编辑任务”和“文件保存和高级设置”中设置“将成功发布的位置定义为成功”. 另一个原因是它上次成功发布,但是当时还不知道. 如果不再需要发布,则可以将数据库中的所有记录更改为“已发布”.
3. 在discuz中,“您的请求未正确发送,或者验证字符串不一致并且无法提交”:
回答: 发布表单时,此discuz将发送表单哈希,并在发布页面上获取此值. 这是由错误的格式哈希值导致的. 请使用机车的内置浏览器登录并检查源代码,找到“ formhash =“,然后修改在线发布模块,并将其值替换为原创的[Login Random Value 1](当然是登录随机值x(与模块作者的Use相关)相同,或者您自己修改模块,以便程序可以获取表单. 正确哈希.
4. 将其发布在网站上,找到所有拥挤的内容,查看源代码,发现缺少空格了?
答案: 有两种可能: 一种是在制定规则时过滤空白;另一种是在制定规则时过滤空白. 另一个是系统将过滤空白. 在这种情况下,请在“内容发布设置”中选择“数据发布时的URLENCODE处理”. 风新闻属于某些类别.
5. 发布图片时,它始终是相对地址,而不是远程地址吗?
回答: 请在标签编辑器中选择“完整的相对地址和绝对地址”. 默认情况下,下载图片后无需选择此选项.
6. 成功发布了测试,但是当实际发布显示成功时,没有文章吗?
答案: 有很多可能性. 一种是模块的成功识别码不是唯一的,即成功或失败的发布是相同的识别码. 另一个是实际发布成功,但是未检查模块的默认值,因此您必须首先前往站点进行检查;第三,也可能是因为火车继续通过防火墙或服务器发布数据. 防火墙被阻止. 请关闭防火墙,然后尝试. 另一个原因是登录信息无效. 例如,如果您的网站有一段时间没有运行,并且您需要很长时间才能发布实际版本,它将自动注销. 因此原创的着陆信息无效.
7. 将其发布到我的论坛上并显示代码?
答案: 请在发布配置中选择要发布的ubb. 通常选择discuz,phpwind和其他论坛在ubb上发布. 如果要以HTML模式发布,请打开右键,然后将HTML发送到后台的相关海报中.
8. 如何继续上一个未完成的版本?
A: 在任务栏中,只需选中“发送内容”复选框. 该程序将释放采集的但未释放的数据.
优采云通用文章采集器(网站管理员工具)v1.12特别版
采集交流 • 优采云 发表了文章 • 0 个评论 • 628 次浏览 • 2020-08-08 04:16
获取过程中的处理选项
在采集过程中可以同时执行翻译,过滤和单词搜索等处理. 所采集的文章可以通过“本地批处理”进行处理.
翻译功能是将中文翻译成英文,然后再翻译回中文,从而产生伪原创效果. 支持原创格式翻译,即不要更改文章的原创标签结构和排版格式.
采集目标是URL
您可以在URL模板中插入#URL#,#title#来合并引用
页面采集和相对路径转换为绝对路径
勾选“自动采集和分页”以合并分页的文章. 编辑框的设置值为最大采集页数. 建议设置一个有限的值(例如10页),以免出现分页时间过长的集合,并且合并后的文章过大. 如果需要采集所有页面,可以将其设置为0.
文章中的所有相对路径将自动转换为绝对路径,这样可以确保图片等的正常显示.
多线程
支持网页的多线程高速采集. 可以根据网络速度来确定. 电信2m可以有5个线程,电信4m可以有10个线程,依此类推,但是需要适当设置. 太多的设置可能会严重影响采集效率甚至系统效率. 如果在采集过程中运行了占用流量的其他软件(例如在线视频播放),则可以适当减少线程数.
处理重复的文章标题和文章内容
该程序可以智能地判断和过滤重复的文章
当采集到的文章的标题(文件名)与本地保存的文章的标题相同时,优采云将首先判断这两篇文章的相似性. 当相似度大于60%时,优采云将确定同一文章,然后比较这两篇文章的文本量,并自动使用收录更多文本的文章来覆盖和写入相同的文件名. 这种世代情况并不等于世代数.
当相似度低于60%时,优采云判断这是另一篇文章,并将自动重命名标题(标题末尾取3到5个随机字母)并将其保存到文件中.
快速文章过滤器
尽管优采云研究了非常精确的人体提取算法,但提取错误仍然很少. 这些错误主要是: 目标页面的主体是在线视频,或者主体内容太短而无法形成主体特征. 因此,可以通过设置最终结果中的单词数来提高准确性(在“最小字符数”参数中,该单词数是程序删除标签,行和空格后的纯文本单词数) ).
文章快速过滤器用于快速查看采集到的文章,并有助于判断和删除文本错误的文章. 同时,基于网络信息采集的目的,方便了细化和选择过程.
生成的文章数量可变的问题
百度和搜搜默认每页100个结果,而Google默认每页10个结果.
某些网站已超时(特别是Google所收录的许多网站被阻止),或在文本中设置了最少字数,或者该程序忽略了具有相同名称,黑名单和白名单的内容相似的本地文章等会导致实际生成的文章数低于每次页面搜索的最大结果数.
总的来说,百度的质量是最好的,生成的文章数量接近搜索结果的数量.
更新日志:
1.12: 继续增强Web批处理列URL采集器识别文章URL的能力,并支持多种地址格式的同时匹配.
1.11: 增强了Web批处理列URL采集器识别文章URL的能力.
1.10: 解决了翻译功能无法翻译的问题. 查看全部
因此您可以根据实际情况切换模式. 您可以使用本地批处理的读取网页正文功能来测试指定网页适合的模式.
获取过程中的处理选项
在采集过程中可以同时执行翻译,过滤和单词搜索等处理. 所采集的文章可以通过“本地批处理”进行处理.
翻译功能是将中文翻译成英文,然后再翻译回中文,从而产生伪原创效果. 支持原创格式翻译,即不要更改文章的原创标签结构和排版格式.
采集目标是URL
您可以在URL模板中插入#URL#,#title#来合并引用
页面采集和相对路径转换为绝对路径
勾选“自动采集和分页”以合并分页的文章. 编辑框的设置值为最大采集页数. 建议设置一个有限的值(例如10页),以免出现分页时间过长的集合,并且合并后的文章过大. 如果需要采集所有页面,可以将其设置为0.
文章中的所有相对路径将自动转换为绝对路径,这样可以确保图片等的正常显示.
多线程
支持网页的多线程高速采集. 可以根据网络速度来确定. 电信2m可以有5个线程,电信4m可以有10个线程,依此类推,但是需要适当设置. 太多的设置可能会严重影响采集效率甚至系统效率. 如果在采集过程中运行了占用流量的其他软件(例如在线视频播放),则可以适当减少线程数.
处理重复的文章标题和文章内容
该程序可以智能地判断和过滤重复的文章
当采集到的文章的标题(文件名)与本地保存的文章的标题相同时,优采云将首先判断这两篇文章的相似性. 当相似度大于60%时,优采云将确定同一文章,然后比较这两篇文章的文本量,并自动使用收录更多文本的文章来覆盖和写入相同的文件名. 这种世代情况并不等于世代数.
当相似度低于60%时,优采云判断这是另一篇文章,并将自动重命名标题(标题末尾取3到5个随机字母)并将其保存到文件中.
快速文章过滤器
尽管优采云研究了非常精确的人体提取算法,但提取错误仍然很少. 这些错误主要是: 目标页面的主体是在线视频,或者主体内容太短而无法形成主体特征. 因此,可以通过设置最终结果中的单词数来提高准确性(在“最小字符数”参数中,该单词数是程序删除标签,行和空格后的纯文本单词数) ).
文章快速过滤器用于快速查看采集到的文章,并有助于判断和删除文本错误的文章. 同时,基于网络信息采集的目的,方便了细化和选择过程.
生成的文章数量可变的问题
百度和搜搜默认每页100个结果,而Google默认每页10个结果.
某些网站已超时(特别是Google所收录的许多网站被阻止),或在文本中设置了最少字数,或者该程序忽略了具有相同名称,黑名单和白名单的内容相似的本地文章等会导致实际生成的文章数低于每次页面搜索的最大结果数.
总的来说,百度的质量是最好的,生成的文章数量接近搜索结果的数量.
更新日志:
1.12: 继续增强Web批处理列URL采集器识别文章URL的能力,并支持多种地址格式的同时匹配.
1.11: 增强了Web批处理列URL采集器识别文章URL的能力.
1.10: 解决了翻译功能无法翻译的问题.
采集器的一个有趣特性,可以大幅度提高pandas的处理速度
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-06-10 23:00
文章采集器是pandas的一个有趣特性,可以大幅度提高pandas的处理速度。pandas是做什么的?pandas本质上就是一个数据库,是基于python的numpy.matplotlib.的,可以从很多格式的数据进行处理,数据来源于二维表,每个字段就对应一个表中的行。example-whydoiwriteexcelnavigationscript?importpandasaspdasdfdf=pd.dataframe({'terms':['','are-ranking','and-ranking','average-student','education','teacher','industry','education','year']})df.head()#打印数据(以列作为行)df.tail()#打印数据(以行作为列)wheretag=''#处理区域为星号的数据wheretag='#'#处理区域为星号的数据wheretag=''#处理包含以下部分(range,class,loc,unique,re,and)的数据example-whydoiwriteexcelnavigationscript?importpandasaspdasdfdf=pd.dataframe({'terms':['','are-ranking','and-ranking','average-student','education','teacher','industry','education','year']})df.head(5)#查看数据前5行#查看数据的前5行数据处理的具体细节#如果数据不太多,可以不用写字典#如果数据不太多,可以不用写字典,把数据放在列中,用列名来表示#最好的方法是用列表like'数字'#最好的方法是用列表like'数字',不一定非要用字典df['date']=df['terms'].iloc[1:]#索引处理#如果数据仅包含日期和日期标签,可以把日期用逗号隔开df['date']=df['terms'].iloc[:2]df['date']=df['terms'].iloc[:2]df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['ter。 查看全部
采集器的一个有趣特性,可以大幅度提高pandas的处理速度
文章采集器是pandas的一个有趣特性,可以大幅度提高pandas的处理速度。pandas是做什么的?pandas本质上就是一个数据库,是基于python的numpy.matplotlib.的,可以从很多格式的数据进行处理,数据来源于二维表,每个字段就对应一个表中的行。example-whydoiwriteexcelnavigationscript?importpandasaspdasdfdf=pd.dataframe({'terms':['','are-ranking','and-ranking','average-student','education','teacher','industry','education','year']})df.head()#打印数据(以列作为行)df.tail()#打印数据(以行作为列)wheretag=''#处理区域为星号的数据wheretag='#'#处理区域为星号的数据wheretag=''#处理包含以下部分(range,class,loc,unique,re,and)的数据example-whydoiwriteexcelnavigationscript?importpandasaspdasdfdf=pd.dataframe({'terms':['','are-ranking','and-ranking','average-student','education','teacher','industry','education','year']})df.head(5)#查看数据前5行#查看数据的前5行数据处理的具体细节#如果数据不太多,可以不用写字典#如果数据不太多,可以不用写字典,把数据放在列中,用列名来表示#最好的方法是用列表like'数字'#最好的方法是用列表like'数字',不一定非要用字典df['date']=df['terms'].iloc[1:]#索引处理#如果数据仅包含日期和日期标签,可以把日期用逗号隔开df['date']=df['terms'].iloc[:2]df['date']=df['terms'].iloc[:2]df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['terms']df['date']=df['ter。
贴一个工具相册里边随便选取一张图片都可以
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-06-09 21:02
文章采集器。用来采集微信公众号的文章,包括文章标题,文章内容,收录率和关键词。可以通过关键词调用的,使用简单容易掌握。有下载功能,还可以导出格式文档。目前只有安卓版的和两个支持导出代码的,
千里眼查或者企查查,我刚才试了一下。
贴一个工具相册里边随便选取一张图片都可以。另外,关键词抓取这个不错。别的暂时还没发现。
你应该去做一个网站,网站将你要抓取的内容都集合在网站上,然后你用网站统计平台就能找到大量的标题和相关内容,相信大家也用的。
全站关键词抓取工具;可以抓取链接的词相关内容可以通过你的网站或者360站长工具查看下载最新版站长助手
百度站长工具箱
金山卫士,我现在也在找,一直在找,但是金山浏览器现在的工具箱都太难用了。
谢邀,现在比较多的应该是3亿个有意义词库,或者是40w+相关关键词的词库库,这个比较热,可以试试。
现在的可以用eltalise3,做搜索联想可以加关键词进去,是免费的,之前在做百度seo的时候找到很多关键词。
提供两种思路一种就是抓新闻联播的那些点击率高的,其实现在大家都在关注互联网商业相关的信息,这些题材的信息反应出来的是商业现状,抓取数据库的时候抓取点击率高的点击率高的。现在各大网站或者论坛都有抓取统计,比如点击率统计,百度搜索词统计,还有一些专门的统计分析工具,比如百度aso,百度统计之类的,可以找到很多热点事件。
还有一种就是抓取同行的一些热点信息。有网站了肯定有搜索相关词的,现在同行们发布的一些和网站发布的关键词对于不同关键词的排序不同,而且热度又高。 查看全部
贴一个工具相册里边随便选取一张图片都可以
文章采集器。用来采集微信公众号的文章,包括文章标题,文章内容,收录率和关键词。可以通过关键词调用的,使用简单容易掌握。有下载功能,还可以导出格式文档。目前只有安卓版的和两个支持导出代码的,
千里眼查或者企查查,我刚才试了一下。
贴一个工具相册里边随便选取一张图片都可以。另外,关键词抓取这个不错。别的暂时还没发现。
你应该去做一个网站,网站将你要抓取的内容都集合在网站上,然后你用网站统计平台就能找到大量的标题和相关内容,相信大家也用的。
全站关键词抓取工具;可以抓取链接的词相关内容可以通过你的网站或者360站长工具查看下载最新版站长助手
百度站长工具箱
金山卫士,我现在也在找,一直在找,但是金山浏览器现在的工具箱都太难用了。
谢邀,现在比较多的应该是3亿个有意义词库,或者是40w+相关关键词的词库库,这个比较热,可以试试。
现在的可以用eltalise3,做搜索联想可以加关键词进去,是免费的,之前在做百度seo的时候找到很多关键词。
提供两种思路一种就是抓新闻联播的那些点击率高的,其实现在大家都在关注互联网商业相关的信息,这些题材的信息反应出来的是商业现状,抓取数据库的时候抓取点击率高的点击率高的。现在各大网站或者论坛都有抓取统计,比如点击率统计,百度搜索词统计,还有一些专门的统计分析工具,比如百度aso,百度统计之类的,可以找到很多热点事件。
还有一种就是抓取同行的一些热点信息。有网站了肯定有搜索相关词的,现在同行们发布的一些和网站发布的关键词对于不同关键词的排序不同,而且热度又高。
文章采集器(equestriacollectionofscripts)生成网页代码的工作过程过程
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-05-24 22:03
文章采集器(equestriacollectionofscripts)是一款javascript标准库,同时也是代码文件从采集到变成网页的的快速、灵活的internetapps。它只会读和写api文件(javascript代码字符串),不会直接解析javascript代码,也不会自动生成响应的源代码文件,比如数据库表、url等。
它也不会直接生成网页代码,最多只是提供一个生成javascript实际效果的api文件,而不是真正的生成网页内容。这种只读文件我们称之为“标准字符串格式”,也就是ie对其支持得最多的格式(甚至还支持css样式字符串)。我们可以打开equestriacollectionofscriptswebapps.config.js在类型语言范围里可以找到multipleapiforfilesystems,typedothersystemsaredirectlyspecified.你可以在控制台提交ftp请求,指定你的数据类型等,服务器将会解析给javascript代码字符串(标准字符串格式)并转换为equestriacollectionofscripts文件。
比如types,typed,file,object,string,index.这些都是equestriacollectionofscripts一样的标准字符串格式。multipleapiforfilesystems—>typesformultiplecontentfilesandargumentsfilestyped是一种用于数据文件格式,而typed就是用于数据文件中的引用格式。
typed代表了两种不同的常见格式,第一种contentparser的格式规范(一种数据格式),第二种archive的格式规范(另一种数据格式)。archive就是数据文件中传递的所有信息,archive格式还可以用一种对象模型来表示:表示为bundle可以看到整个script文件在equestriacollectionofscriptswebapps的请求域中都是可以通过下图实现。
ftp打开/login.txt/login.js生成的通用后缀名的"login.js"压缩包仅在express中有效,可以通过webpack-sassplugin构建出来。express-sassplugin会在打包时,附加到你的模块中。我们来解析一下源代码的工作过程,好让大家对equestriacollectionofscripts生成的equestriacollectionofscripts文件有个大概的认识。
首先,把要采集的script文件全部导入到scss文件里。express默认生成的解析工具是browserify。它会先从sass等压缩库里抽取出类似css一样的html字符串,导入到browserifysassbundlecache服务器上,然后按照对javascript代码解析的要求生成ess。对数据采集类程序来说,就是随处抓取eschanged,endofstorage或endoflogin的数据()。然后,把ess插入到所需要生成的ffi文件里。因为现在scss解析器里的e。 查看全部
文章采集器(equestriacollectionofscripts)生成网页代码的工作过程过程
文章采集器(equestriacollectionofscripts)是一款javascript标准库,同时也是代码文件从采集到变成网页的的快速、灵活的internetapps。它只会读和写api文件(javascript代码字符串),不会直接解析javascript代码,也不会自动生成响应的源代码文件,比如数据库表、url等。
它也不会直接生成网页代码,最多只是提供一个生成javascript实际效果的api文件,而不是真正的生成网页内容。这种只读文件我们称之为“标准字符串格式”,也就是ie对其支持得最多的格式(甚至还支持css样式字符串)。我们可以打开equestriacollectionofscriptswebapps.config.js在类型语言范围里可以找到multipleapiforfilesystems,typedothersystemsaredirectlyspecified.你可以在控制台提交ftp请求,指定你的数据类型等,服务器将会解析给javascript代码字符串(标准字符串格式)并转换为equestriacollectionofscripts文件。
比如types,typed,file,object,string,index.这些都是equestriacollectionofscripts一样的标准字符串格式。multipleapiforfilesystems—>typesformultiplecontentfilesandargumentsfilestyped是一种用于数据文件格式,而typed就是用于数据文件中的引用格式。
typed代表了两种不同的常见格式,第一种contentparser的格式规范(一种数据格式),第二种archive的格式规范(另一种数据格式)。archive就是数据文件中传递的所有信息,archive格式还可以用一种对象模型来表示:表示为bundle可以看到整个script文件在equestriacollectionofscriptswebapps的请求域中都是可以通过下图实现。
ftp打开/login.txt/login.js生成的通用后缀名的"login.js"压缩包仅在express中有效,可以通过webpack-sassplugin构建出来。express-sassplugin会在打包时,附加到你的模块中。我们来解析一下源代码的工作过程,好让大家对equestriacollectionofscripts生成的equestriacollectionofscripts文件有个大概的认识。
首先,把要采集的script文件全部导入到scss文件里。express默认生成的解析工具是browserify。它会先从sass等压缩库里抽取出类似css一样的html字符串,导入到browserifysassbundlecache服务器上,然后按照对javascript代码解析的要求生成ess。对数据采集类程序来说,就是随处抓取eschanged,endofstorage或endoflogin的数据()。然后,把ess插入到所需要生成的ffi文件里。因为现在scss解析器里的e。
优采云采集赶集网数据为证禁止图片转载的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2021-05-07 19:31
微信文章 采集器是公共帐户操作和网站操作助手,具有以下功能:自定义采集,分类采集,关键词 采集,文章编辑和布局,提供每日微信文章,微信图形和其他资源。
1让我向所有人介绍此介绍,并首先熟悉软件功能和使用方法。
2百度搜索相关信息,单击网页进行了解。
3软件功能介绍,具有分类采集,关键词 采集,自定义采集,文章排版和编辑功能。
4使操作变得如此简单。
以真实的照片作为证明
禁止复制图片
本文介绍了使用优采云 采集 数据的方法(以南山店信息为例)
1步骤1:创建采集任务1)并进入主界面,选择“自定义模式”
2 2)将商店信息页面的URL复制并粘贴到网站输入框中,单击“保存URL”
3步骤2:创建翻页循环1)将页面下拉至底部,单击“下一页”按钮,然后在右侧的提示框中选择“循环以单击下一页”
4步骤3:创建列表循环1)移动鼠标并选择页面上的第一个商店链接。选择后,系统将自动识别页面上的其他类似链接。在右侧的提示框中,选择“全选”
5 2)选择“单击循环中的每个链接”以创建列表循环
6步骤4:提取商店信息1)创建列表循环后,系统将自动单击第一个商店链接以进入商店详细信息页面。功能点:分页列表和详细信息提取(x?t = 1)单击所需的字段信息,在右侧的提示框中,选择“ 采集该元素的文本”
7 2)选择字段信息后,选择相应的字段,您可以自定义字段名称。填写完该字段后,点击左上角的“保存并开始”以启动采集任务
8 3)选择“启动本地采集”
9步骤5:完成数据采集和导出1) 采集后,将弹出提示,选择“导出数据”
10 2)选择“适当的导出方法”并导出采集良好的商店信息数据
11 3)在这里,我们选择excel作为导出格式,数据将如下所示导出
12条规则URL:如果有帮助,请单击[投票]。有关详细信息,请单击[采集夹]。如果要继续,可以[关注]。如果您要放弃它,请单击[共享]。如有任何疑问,可以[发表评论]。
关闭采集器教程
1使用前,请先设置数据库和网站目录,设置这两个点后,只能先关闭采集器,然后将其打开才能生效!记住要记住!
2正确设置了分类设置,以确保采集上显示的小说正确。具体描述1 | Fantasy Magic =,奇幻,魔术,奇幻魔术,外星人之地,穿越,奇幻,奇幻-其他世界奇幻,奇幻仙侠之恋,奇幻怪兽,奇幻西方奇幻,奇幻吸血鬼家庭,奇幻小说,重生文学,幻想小说,幻想外星世界,幻想魔术,遍历头顶,=前一个是您的网站分类。例如,您采集这本小说。他的分类是幻想小说,只需要写1 |宣欢魔术=,幻想小说,一一对应,很简单
3生成设置,如果您的网站是伪静态的网站,则无需选择生成目录页面html或内容页面html。只需选择一个即可生成opf。
4 采集操作在这里,建议您不要选择检测重复的章节。否则,将没有很多内容章节采集!如果有点相似,他会为您过滤。真的很辛苦
5高级设置的功能也在这里,描述也非常详细,只需查看是否需要检查即可。
6启动采集后,您可以看到采集的进度
智能通用Web数据采集器。简单易用,完全可视化,不需要专业知识,并且如果您可以浏览互联网,也可以轻松掌握。功能强大,新闻,论坛,电话信箱,竞争对手,客户信息,汽车房地产,电子商务等。网站是采集
1第一步,打开软件,单击“快速入门”,创建一个新任务
2第二步是找到汽车品牌的列表页面。复制此列表页面的地址,
3第三步,单击要采集的页面元素,例如Audi S7。系统弹出对话框后,选择创建元素列表以处理元素
4第四步是添加元素,如果要继续添加其他品牌,请单击以继续编辑列表
5在第五步中,将所有品牌都显示在列表中之后,单击“创建列表”以完成。
6第六步,由于上有一些未上市的品牌,并且价格不能为采集,因此我们可以在此处使用是否有市场价格作为判断条件。设置条件判断项
7第七步,设置了判断条件后,为页面配置所需的提取数据
8步骤8,设置完成后,单击“下一步”进入执行计划过程,设置计划执行方法,建议推荐云采集,速度快,可以判断数据是否重复下载。
9步骤9,转到下一步,单击“检查任务”,将弹出以下窗口,单击以下图标开始运行并下载优采云 采集器擢爻用户也可以在规则市场中该软件下载到此规则,直接导入即可使用。
微信文章 采集器,一个小额信贷帐户,可以帮助您解决查找文章和编写文章的麻烦,您可以按类别采集] 文章和官方帐户对其进行排序,您还可以按关键词 采集 文章和官方帐户,您可以自定义并添加常用的官方帐户,按照某个官方帐户发布的文章并将其发布到Ai绱shufly资料库中,等,让我们来教你
1我们首先选择一个浏览器,在百度上搜索关键词,然后找到相关的网站。
2找到网站后,单击网站页面进行简要了解。如图所示;
3以下是功能介绍,类别文章汕尾先念采集和5条采集路线,类别官方帐户采集,关键词 采集,添加官方帐户以自定义,发布材质库,如下面的屏幕快照所示。
4最后,该软件是全屏的,感谢您观看演示。
以上仅为屏幕截图。如需了解更多信息,请联系官方网站上的客户服务。
成为我们的用户,免费更新和升级,谢谢您的支持
有时我们看到网站的文章,并希望保存这些文章。复制和保存一篇文章非常麻烦。此时,您需要使用优采云 采集器保存文章 采集。这是优采云 采集器 采集 文章的使用方法。
1第一步是采集 URL,下载优采云 采集器并打开它以使用任何任务名称创建一个新任务。将需要采集的网站 文章列的URL添加到起始URL。从图中可以看出,列表页面有34页,每页有N条文章。
2列表页面将是第一级URL,添加多级URL以获得,从而获得第二级URL(文章页面URL)
3设置要通过分页获得的列表,三个位置是:在分页的源代码之前和之后有一个中间位置。此步骤用于获取列表页面链接,因为有34个列表页面。设置后保存。
4获取网站地址的选项。此步骤用于获取列表页面上页面文章上的链接,根据您的需要设置要拦截的部分,并根据URL的结构设置某些字符的收录或排除。如果为空,则没有限制。设置后保存。
5设置链接采集规则后,您可以测试URL并根据测试结果调整规则。查看图片,您可以看到采集链接规则已经成功完成,从最初的链接到综合列表页面,再到列表页面采集上的文章页面链接。
6第二步是采集的内容。首先,修改标题规则,在页面源代码中找到标题代码,并切断标题前后的标题。保存。
7修改内容采集规则,类似于标题规则,它也是在源代码中找到内容前后的代码。这里的内容将收录其他一些html标签,因此您必须添加html标签排除规则。
8测试完成后,查看结果并调试测试结果中的规则,直到获得所需的测试结果为止。
9第三步是采集导出。 1、 2在前两个步骤中设置了规则,最后文章将被导出。首先制作一个导出模板。
10然后选择方法二,将每篇文章文章记录为txt文本,保存您选择的位置模板佳和轩qu,然后选择刚刚制作的导出模板。保存的文件名为文章。标题被命名。其他默认设置,保存。
11选中采集 URL,采集内容,并发布3个选项框,然后启动采集。完成后,将在刚刚保存的文件夹中自动生成文本。
12 优采云 采集器 采集 文章教程现已完成。由于每个网站都不相同,因此这里只能使用一个网站演示,只是一种方法思想[I 采集 文章)也需要灵活。
如果这种经历对您有所帮助,请记住投票。
如果您不了解其他任何内容,请发表评论并留言。如果单击投票,评论框将自动弹出。 查看全部
优采云采集赶集网数据为证禁止图片转载的方法
微信文章 采集器是公共帐户操作和网站操作助手,具有以下功能:自定义采集,分类采集,关键词 采集,文章编辑和布局,提供每日微信文章,微信图形和其他资源。
1让我向所有人介绍此介绍,并首先熟悉软件功能和使用方法。
2百度搜索相关信息,单击网页进行了解。
3软件功能介绍,具有分类采集,关键词 采集,自定义采集,文章排版和编辑功能。
4使操作变得如此简单。
以真实的照片作为证明
禁止复制图片
本文介绍了使用优采云 采集 数据的方法(以南山店信息为例)
1步骤1:创建采集任务1)并进入主界面,选择“自定义模式”
2 2)将商店信息页面的URL复制并粘贴到网站输入框中,单击“保存URL”
3步骤2:创建翻页循环1)将页面下拉至底部,单击“下一页”按钮,然后在右侧的提示框中选择“循环以单击下一页”
4步骤3:创建列表循环1)移动鼠标并选择页面上的第一个商店链接。选择后,系统将自动识别页面上的其他类似链接。在右侧的提示框中,选择“全选”
5 2)选择“单击循环中的每个链接”以创建列表循环
6步骤4:提取商店信息1)创建列表循环后,系统将自动单击第一个商店链接以进入商店详细信息页面。功能点:分页列表和详细信息提取(x?t = 1)单击所需的字段信息,在右侧的提示框中,选择“ 采集该元素的文本”
7 2)选择字段信息后,选择相应的字段,您可以自定义字段名称。填写完该字段后,点击左上角的“保存并开始”以启动采集任务
8 3)选择“启动本地采集”
9步骤5:完成数据采集和导出1) 采集后,将弹出提示,选择“导出数据”
10 2)选择“适当的导出方法”并导出采集良好的商店信息数据
11 3)在这里,我们选择excel作为导出格式,数据将如下所示导出
12条规则URL:如果有帮助,请单击[投票]。有关详细信息,请单击[采集夹]。如果要继续,可以[关注]。如果您要放弃它,请单击[共享]。如有任何疑问,可以[发表评论]。
关闭采集器教程
1使用前,请先设置数据库和网站目录,设置这两个点后,只能先关闭采集器,然后将其打开才能生效!记住要记住!
2正确设置了分类设置,以确保采集上显示的小说正确。具体描述1 | Fantasy Magic =,奇幻,魔术,奇幻魔术,外星人之地,穿越,奇幻,奇幻-其他世界奇幻,奇幻仙侠之恋,奇幻怪兽,奇幻西方奇幻,奇幻吸血鬼家庭,奇幻小说,重生文学,幻想小说,幻想外星世界,幻想魔术,遍历头顶,=前一个是您的网站分类。例如,您采集这本小说。他的分类是幻想小说,只需要写1 |宣欢魔术=,幻想小说,一一对应,很简单
3生成设置,如果您的网站是伪静态的网站,则无需选择生成目录页面html或内容页面html。只需选择一个即可生成opf。
4 采集操作在这里,建议您不要选择检测重复的章节。否则,将没有很多内容章节采集!如果有点相似,他会为您过滤。真的很辛苦
5高级设置的功能也在这里,描述也非常详细,只需查看是否需要检查即可。
6启动采集后,您可以看到采集的进度
智能通用Web数据采集器。简单易用,完全可视化,不需要专业知识,并且如果您可以浏览互联网,也可以轻松掌握。功能强大,新闻,论坛,电话信箱,竞争对手,客户信息,汽车房地产,电子商务等。网站是采集
1第一步,打开软件,单击“快速入门”,创建一个新任务
2第二步是找到汽车品牌的列表页面。复制此列表页面的地址,
3第三步,单击要采集的页面元素,例如Audi S7。系统弹出对话框后,选择创建元素列表以处理元素
4第四步是添加元素,如果要继续添加其他品牌,请单击以继续编辑列表
5在第五步中,将所有品牌都显示在列表中之后,单击“创建列表”以完成。
6第六步,由于上有一些未上市的品牌,并且价格不能为采集,因此我们可以在此处使用是否有市场价格作为判断条件。设置条件判断项
7第七步,设置了判断条件后,为页面配置所需的提取数据
8步骤8,设置完成后,单击“下一步”进入执行计划过程,设置计划执行方法,建议推荐云采集,速度快,可以判断数据是否重复下载。
9步骤9,转到下一步,单击“检查任务”,将弹出以下窗口,单击以下图标开始运行并下载优采云 采集器擢爻用户也可以在规则市场中该软件下载到此规则,直接导入即可使用。
微信文章 采集器,一个小额信贷帐户,可以帮助您解决查找文章和编写文章的麻烦,您可以按类别采集] 文章和官方帐户对其进行排序,您还可以按关键词 采集 文章和官方帐户,您可以自定义并添加常用的官方帐户,按照某个官方帐户发布的文章并将其发布到Ai绱shufly资料库中,等,让我们来教你
1我们首先选择一个浏览器,在百度上搜索关键词,然后找到相关的网站。
2找到网站后,单击网站页面进行简要了解。如图所示;
3以下是功能介绍,类别文章汕尾先念采集和5条采集路线,类别官方帐户采集,关键词 采集,添加官方帐户以自定义,发布材质库,如下面的屏幕快照所示。
4最后,该软件是全屏的,感谢您观看演示。
以上仅为屏幕截图。如需了解更多信息,请联系官方网站上的客户服务。
成为我们的用户,免费更新和升级,谢谢您的支持
有时我们看到网站的文章,并希望保存这些文章。复制和保存一篇文章非常麻烦。此时,您需要使用优采云 采集器保存文章 采集。这是优采云 采集器 采集 文章的使用方法。
1第一步是采集 URL,下载优采云 采集器并打开它以使用任何任务名称创建一个新任务。将需要采集的网站 文章列的URL添加到起始URL。从图中可以看出,列表页面有34页,每页有N条文章。
2列表页面将是第一级URL,添加多级URL以获得,从而获得第二级URL(文章页面URL)
3设置要通过分页获得的列表,三个位置是:在分页的源代码之前和之后有一个中间位置。此步骤用于获取列表页面链接,因为有34个列表页面。设置后保存。
4获取网站地址的选项。此步骤用于获取列表页面上页面文章上的链接,根据您的需要设置要拦截的部分,并根据URL的结构设置某些字符的收录或排除。如果为空,则没有限制。设置后保存。
5设置链接采集规则后,您可以测试URL并根据测试结果调整规则。查看图片,您可以看到采集链接规则已经成功完成,从最初的链接到综合列表页面,再到列表页面采集上的文章页面链接。
6第二步是采集的内容。首先,修改标题规则,在页面源代码中找到标题代码,并切断标题前后的标题。保存。
7修改内容采集规则,类似于标题规则,它也是在源代码中找到内容前后的代码。这里的内容将收录其他一些html标签,因此您必须添加html标签排除规则。
8测试完成后,查看结果并调试测试结果中的规则,直到获得所需的测试结果为止。
9第三步是采集导出。 1、 2在前两个步骤中设置了规则,最后文章将被导出。首先制作一个导出模板。
10然后选择方法二,将每篇文章文章记录为txt文本,保存您选择的位置模板佳和轩qu,然后选择刚刚制作的导出模板。保存的文件名为文章。标题被命名。其他默认设置,保存。
11选中采集 URL,采集内容,并发布3个选项框,然后启动采集。完成后,将在刚刚保存的文件夹中自动生成文本。
12 优采云 采集器 采集 文章教程现已完成。由于每个网站都不相同,因此这里只能使用一个网站演示,只是一种方法思想[I 采集 文章)也需要灵活。
如果这种经历对您有所帮助,请记住投票。
如果您不了解其他任何内容,请发表评论并留言。如果单击投票,评论框将自动弹出。
文章采集器app介绍:支持全平台各类文章渠道的采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2021-05-05 19:05
文章采集器app介绍:一款集合、安全、免费、便捷、便利于一体的「文章采集工具」。支持全平台各类文章渠道的采集。任意输入任意链接,即可免费采集所有网页的文章内容。支持微信、微博、小红书、今日头条、一点资讯、搜狐新闻、知乎、新浪博客、微博热门微信号、百度百家、豆瓣、中国新闻、凤凰新闻、网易新闻、新浪新闻等主流数据平台文章内容的采集。
在线关键词搜索、语义搜索、智能标题搜索、输入正则表达式、文章网址、复制文章网址、批量采集。文章采集器app文章采集渠道、渠道信息全站采集、语义搜索、智能标题搜索、定时采集、批量采集、全文覆盖等等功能。抓取全网网站的文章内容、摘要、文章列表、文章广告、文章评论、评论等全网站的内容。一站式的网站内容批量采集整理。
支持复制文章网址、大小写检测、去水印、广告、背景色检测、二维码提取、抓取手机h5内容,网页无水印。支持全文匹配定位,文章标题、文章内容检测。支持全文内容搜索、全文内容存档、全文检测和全文下载。支持文章中的图片搜索,支持图片外链搜索,支持文章中的链接存档。欢迎大家体验。客服[二维码自动识别][三维码自动识别]。
恩,这么基础的问题必须说一下先安利一个基础的知识:第三方网站爬虫,其实从直白的话我们可以用,hexo+next来做coding流量的spider。我就拿一个常见的像比较新的文章内容一般来说,我们一般会有两种spider,一个抓某些比较有地域性或者有hook的网站,比如说我们在工业区或者一些比较小的公司会有比较高权重的网站,一般他们有更好的页面权重以及更多的转发内容,就会抓到他们更多的内容;另外一种就是同一个的ip去抓,很多新站可能在刚上架一段时间内可能内容抓不到很多,这个时候我们可以去一些老站,找一些比较老的站点,比如说用hexo+next来做的irc流量,如果抓取量到一定数量级的话,肯定可以抓很多站,直接扔去sitemap就ok,如果你站基础设置做得好,这个sitemap可以很大比如foobar等等,爬irc非常快,而且比python常见的爬虫工具,比如piggies等等要方便一些,还比如requests等等更适合抓新站,爬新站就是老老实实做各种内容和内容结构。
如果你想要更加高级一些,比如说我自己又知道一些小的博客教学网站,包括各种论坛之类的,然后我想要从这些更加老一些的站点里面爬更多内容,也可以学python去抓,但是相比来说要耗一些资源,而且还比较麻烦,有一些老站网站不一定更新,看你的兴趣,比如我本人是比较喜欢挖掘开源博客,所以现在玩。 查看全部
文章采集器app介绍:支持全平台各类文章渠道的采集
文章采集器app介绍:一款集合、安全、免费、便捷、便利于一体的「文章采集工具」。支持全平台各类文章渠道的采集。任意输入任意链接,即可免费采集所有网页的文章内容。支持微信、微博、小红书、今日头条、一点资讯、搜狐新闻、知乎、新浪博客、微博热门微信号、百度百家、豆瓣、中国新闻、凤凰新闻、网易新闻、新浪新闻等主流数据平台文章内容的采集。
在线关键词搜索、语义搜索、智能标题搜索、输入正则表达式、文章网址、复制文章网址、批量采集。文章采集器app文章采集渠道、渠道信息全站采集、语义搜索、智能标题搜索、定时采集、批量采集、全文覆盖等等功能。抓取全网网站的文章内容、摘要、文章列表、文章广告、文章评论、评论等全网站的内容。一站式的网站内容批量采集整理。
支持复制文章网址、大小写检测、去水印、广告、背景色检测、二维码提取、抓取手机h5内容,网页无水印。支持全文匹配定位,文章标题、文章内容检测。支持全文内容搜索、全文内容存档、全文检测和全文下载。支持文章中的图片搜索,支持图片外链搜索,支持文章中的链接存档。欢迎大家体验。客服[二维码自动识别][三维码自动识别]。
恩,这么基础的问题必须说一下先安利一个基础的知识:第三方网站爬虫,其实从直白的话我们可以用,hexo+next来做coding流量的spider。我就拿一个常见的像比较新的文章内容一般来说,我们一般会有两种spider,一个抓某些比较有地域性或者有hook的网站,比如说我们在工业区或者一些比较小的公司会有比较高权重的网站,一般他们有更好的页面权重以及更多的转发内容,就会抓到他们更多的内容;另外一种就是同一个的ip去抓,很多新站可能在刚上架一段时间内可能内容抓不到很多,这个时候我们可以去一些老站,找一些比较老的站点,比如说用hexo+next来做的irc流量,如果抓取量到一定数量级的话,肯定可以抓很多站,直接扔去sitemap就ok,如果你站基础设置做得好,这个sitemap可以很大比如foobar等等,爬irc非常快,而且比python常见的爬虫工具,比如piggies等等要方便一些,还比如requests等等更适合抓新站,爬新站就是老老实实做各种内容和内容结构。
如果你想要更加高级一些,比如说我自己又知道一些小的博客教学网站,包括各种论坛之类的,然后我想要从这些更加老一些的站点里面爬更多内容,也可以学python去抓,但是相比来说要耗一些资源,而且还比较麻烦,有一些老站网站不一定更新,看你的兴趣,比如我本人是比较喜欢挖掘开源博客,所以现在玩。
文章采集器,商品折扣,汇率以及想要采集的特定数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2021-04-16 22:04
文章采集器、短文采集器采集小说,商品折扣,汇率以及想要采集的特定数据。分享给喜欢的朋友以及看到这篇文章的小伙伴!这是我花钱购买以及买的最好的采集器之一,我觉得这样子的老板不能做朋友!嘿嘿!这款采集器不仅仅是简单的采集小说,商品折扣这样的简单功能,还支持单条小说、商品、专题标题以及ajax、flash等多种交互方式!如果有兴趣的朋友可以留言,获取最新的上架链接!会从留言里面抽取最近想要的小说上架以及商品下架和标题!好啦,今天分享到这,希望能够帮助到大家!。
题主说的一般手机采集器都比较麻烦,我以前用的是快传网,一天只能采10篇,遇到电脑卡顿的时候基本上半天没效果,推荐百度手机站网址,可以调用大部分的百度采集工具,对比一下就知道了。
很多啊,不如试试公众号“鱼塘一点灵”,这是一款web网址采集器,基本上可以满足你需求,如果网站用的多,
现在绝大多数的手机浏览器都有网页采集,例如,360浏览器。只要有以下链接就可以。在360手机上打开:个人中心-工具箱-创建收藏-浏览器采集要想兼容iphone或ipad,还可以把这个连接另存一下放在电脑上。最主要的是免费。如果直接打开采集的html地址,下载来的不是这个地址。 查看全部
文章采集器,商品折扣,汇率以及想要采集的特定数据
文章采集器、短文采集器采集小说,商品折扣,汇率以及想要采集的特定数据。分享给喜欢的朋友以及看到这篇文章的小伙伴!这是我花钱购买以及买的最好的采集器之一,我觉得这样子的老板不能做朋友!嘿嘿!这款采集器不仅仅是简单的采集小说,商品折扣这样的简单功能,还支持单条小说、商品、专题标题以及ajax、flash等多种交互方式!如果有兴趣的朋友可以留言,获取最新的上架链接!会从留言里面抽取最近想要的小说上架以及商品下架和标题!好啦,今天分享到这,希望能够帮助到大家!。
题主说的一般手机采集器都比较麻烦,我以前用的是快传网,一天只能采10篇,遇到电脑卡顿的时候基本上半天没效果,推荐百度手机站网址,可以调用大部分的百度采集工具,对比一下就知道了。
很多啊,不如试试公众号“鱼塘一点灵”,这是一款web网址采集器,基本上可以满足你需求,如果网站用的多,
现在绝大多数的手机浏览器都有网页采集,例如,360浏览器。只要有以下链接就可以。在360手机上打开:个人中心-工具箱-创建收藏-浏览器采集要想兼容iphone或ipad,还可以把这个连接另存一下放在电脑上。最主要的是免费。如果直接打开采集的html地址,下载来的不是这个地址。
用pythontinyscript+javascriptapi来完成动画,不需要androidstudio(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-04-03 00:01
文章采集器不可能流畅跑得动,在你录制clipboard的时候刷新非常慢,而且全局加载比如defaultfilter会卡死,所以不建议用这个。但是ios7的动画控制比较好,这个做应用的时候可以考虑用,比如gamecenter这类游戏。
用pythontinyscript+javascriptapi来完成动画,不需要androidstudio,利用caffe实现c++的运行环境,就足够了。很多javascript的library比如googlejsonioserver是很小的动画库,对动画要求不高的应用基本上不需要androidstudio。
最近google官方出品了一个javascriptnode.js依赖包,python和node.js用的都是一样的api和语法,python用起来的话速度快很多。这个api是:1.同步执行每个svg标签的view->drawable->graphics2.利用了python的graphics接口。这个包用于动画,可以做类似qq飞车这样的虚拟摇臂。
没错,那些画面就是用qq飞车的原画在python生成的.具体教程可以参考:javascriptsvgapi。indavidk.porter&andrewt.shaw,"demo",androiddevelopers,linkedin。
前端不建议用python,如果python不能充分利用tornado,kiko等异步框架,那python的异步库就是个坑!再说了,drawable本身就需要渲染。actionscript太宽,只适合做一些基本运算,动画本身还是建议用javascript和node。 查看全部
用pythontinyscript+javascriptapi来完成动画,不需要androidstudio(图)
文章采集器不可能流畅跑得动,在你录制clipboard的时候刷新非常慢,而且全局加载比如defaultfilter会卡死,所以不建议用这个。但是ios7的动画控制比较好,这个做应用的时候可以考虑用,比如gamecenter这类游戏。
用pythontinyscript+javascriptapi来完成动画,不需要androidstudio,利用caffe实现c++的运行环境,就足够了。很多javascript的library比如googlejsonioserver是很小的动画库,对动画要求不高的应用基本上不需要androidstudio。
最近google官方出品了一个javascriptnode.js依赖包,python和node.js用的都是一样的api和语法,python用起来的话速度快很多。这个api是:1.同步执行每个svg标签的view->drawable->graphics2.利用了python的graphics接口。这个包用于动画,可以做类似qq飞车这样的虚拟摇臂。
没错,那些画面就是用qq飞车的原画在python生成的.具体教程可以参考:javascriptsvgapi。indavidk.porter&andrewt.shaw,"demo",androiddevelopers,linkedin。
前端不建议用python,如果python不能充分利用tornado,kiko等异步框架,那python的异步库就是个坑!再说了,drawable本身就需要渲染。actionscript太宽,只适合做一些基本运算,动画本身还是建议用javascript和node。
做爬虫的人估计一下就能懂吧(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-04-01 21:00
文章采集器的作用主要是将用户提交的文章进行聚合、生成表格等,聚合生成表格之后可以生成成批次新闻,
例如,你用程序生成了一个爬虫,然后这个爬虫在使用爬虫抓取就会产生批量文章,再想以同样的模式抓取新闻就会变成批量文章。做爬虫的人估计一下就能懂吧。
这个问题的关键在于“爬虫”这个概念本身有多少范围,以及爬虫这个概念又分成几个层次。这个问题主要靠自己思考,可以先想一想。
这些结构化信息归结于表格是一个很自然的事情,传统的统计方法大都是这样的。用爬虫就可以做到,反倒不是很奇怪的事情,我们爬虫是可以将结构化数据,比如ip访问统计进来的,把全局统计信息作为基础数据进行对比分析。
说笑了,这个问题根本没有那么复杂。两个产品,一个是通过爬虫来爬的,一个是通过事件来抓取。但它们也有共同的地方,也就是通过事件来实现数据统计。这也是google产品经理所说的技术选型。
这是每个人都遇到的问题,多数人都想要让自己的生活更舒适一些,而这两个东西加在一起就无法分开了。以前有个网站,叫北京天空,从上面可以搜索到关于北京市的天气情况。这个不需要爬虫吧?人家也是可以生成网页让用户自己更改的。这个也需要爬虫吧?对于搜索引擎这种需要严格逻辑的东西,总是难以分开的。把信息量大的同一块内容在不同的地方爬,肯定有没爬好的地方,也必然有优势。
既然上百家自媒体,没有这样的统计工具,个人觉得还是要采用人工方式来管理一些内容,至少表格的做法有不适用的地方。有没有可能互相转化呢?。 查看全部
做爬虫的人估计一下就能懂吧(图)
文章采集器的作用主要是将用户提交的文章进行聚合、生成表格等,聚合生成表格之后可以生成成批次新闻,
例如,你用程序生成了一个爬虫,然后这个爬虫在使用爬虫抓取就会产生批量文章,再想以同样的模式抓取新闻就会变成批量文章。做爬虫的人估计一下就能懂吧。
这个问题的关键在于“爬虫”这个概念本身有多少范围,以及爬虫这个概念又分成几个层次。这个问题主要靠自己思考,可以先想一想。
这些结构化信息归结于表格是一个很自然的事情,传统的统计方法大都是这样的。用爬虫就可以做到,反倒不是很奇怪的事情,我们爬虫是可以将结构化数据,比如ip访问统计进来的,把全局统计信息作为基础数据进行对比分析。
说笑了,这个问题根本没有那么复杂。两个产品,一个是通过爬虫来爬的,一个是通过事件来抓取。但它们也有共同的地方,也就是通过事件来实现数据统计。这也是google产品经理所说的技术选型。
这是每个人都遇到的问题,多数人都想要让自己的生活更舒适一些,而这两个东西加在一起就无法分开了。以前有个网站,叫北京天空,从上面可以搜索到关于北京市的天气情况。这个不需要爬虫吧?人家也是可以生成网页让用户自己更改的。这个也需要爬虫吧?对于搜索引擎这种需要严格逻辑的东西,总是难以分开的。把信息量大的同一块内容在不同的地方爬,肯定有没爬好的地方,也必然有优势。
既然上百家自媒体,没有这样的统计工具,个人觉得还是要采用人工方式来管理一些内容,至少表格的做法有不适用的地方。有没有可能互相转化呢?。
文章采集器pip采集网站数据采集保存html文件(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-03-31 03:01
文章采集器pip采集网站数据采集保存html文件一、有些网站要求必须是会员才能浏览这个网站,所以我们需要安装相应的采集器,我这里选择的是采集保存html文件的网站百度图片采集器第一步:打开百度图片采集器,点击网站管理网页资源第二步:登录后,会得到以下界面,我们将选择要采集的网站,点击进入第三步:鼠标点击图片即可得到该网站的html代码,可以将选中的图片拖拽至工具栏中进行分析第四步:此时,我们就可以将选中的图片拖拽至工具栏中进行分析了,输出的文件也是html格式的,格式类型如下图第五步:最后,我们就可以将抓取到的图片保存到本地。
其实,只要有可以下载的,下载速度快的,直接下下来,然后右键复制粘贴,就会直接传到网站啦,wps可以直接用,但是保存jpg的,有时候会出错。如果题主说的能下载,是指文件速度快,包括下载不同网站。这个有软件的。
其实360浏览器就可以了,清理浏览记录,网页资源清理,还能解析html网页,而且直接点右键就能复制粘贴,比pp快多了。
其实都是可以下载保存的。版,直接抓取都能完成,而且效率非常快,只是工作量会多些。不过真正需要抓取的点击复制粘贴传播到网站,效率就很低了。 查看全部
文章采集器pip采集网站数据采集保存html文件(图)
文章采集器pip采集网站数据采集保存html文件一、有些网站要求必须是会员才能浏览这个网站,所以我们需要安装相应的采集器,我这里选择的是采集保存html文件的网站百度图片采集器第一步:打开百度图片采集器,点击网站管理网页资源第二步:登录后,会得到以下界面,我们将选择要采集的网站,点击进入第三步:鼠标点击图片即可得到该网站的html代码,可以将选中的图片拖拽至工具栏中进行分析第四步:此时,我们就可以将选中的图片拖拽至工具栏中进行分析了,输出的文件也是html格式的,格式类型如下图第五步:最后,我们就可以将抓取到的图片保存到本地。
其实,只要有可以下载的,下载速度快的,直接下下来,然后右键复制粘贴,就会直接传到网站啦,wps可以直接用,但是保存jpg的,有时候会出错。如果题主说的能下载,是指文件速度快,包括下载不同网站。这个有软件的。
其实360浏览器就可以了,清理浏览记录,网页资源清理,还能解析html网页,而且直接点右键就能复制粘贴,比pp快多了。
其实都是可以下载保存的。版,直接抓取都能完成,而且效率非常快,只是工作量会多些。不过真正需要抓取的点击复制粘贴传播到网站,效率就很低了。
新媒体管家:文章采集器常用的几种原因?
采集交流 • 优采云 发表了文章 • 0 个评论 • 328 次浏览 • 2021-03-29 19:06
文章采集器网上有各式各样的文章采集器,同学们会因为各种各样的原因使用不同的文章采集器,今天推荐几款大家常用的文章采集器:1,10w+热文采集器2,微信文章采集器3,知乎文章采集器4,网易新闻采集器5,论坛文章采集器6,公众号文章采集器7,网页采集器8,抖音文章采集器9,微博文章采集器10,人民日报文章采集器11,头条文章采集器12,文章排序采集器13,快递文章采集器采集方法可以自行输入搜索关键词(如果已经明确需要什么信息,对应哪个关键词,就输入那个关键词就可以啦),把需要采集的信息,标注在采集框内,选择好采集的时间,点击采集即可2,新媒体管家推荐指数:适用系统:微信公众号,今日头条等推荐理由:新媒体管家是一款给运营小白写公众号文章、文章编辑器和资料填写器的软件,首页内所有的功能对新媒体工作者来说,都是太有必要的。
新媒体管家官网:。3,文章搜索引擎导航网站推荐指数:适用系统:百度,360,搜狗推荐理由:这个不用我多说了吧,搜索引擎收录的文章最全,分类齐全,你要的文章很多时候都是在这里面搜到的。最重要的是价格便宜,有时候搜索引擎收录的文章搜索不到,但是会在百度里面搜索到,这时候你就需要这个网站了。4,文章数据采集神器推荐指数:适用系统:百度,今日头条,搜狗搜索推荐理由:这个网站不知道大家都听说过没有,是一个专门采集文章的网站,各种平台的新闻热点,文章,都有,还可以按照字数,文章类型,以及当天发布时间,写文章很方便。
5,问卷星问卷星是比较早开发问卷调查系统的公司,目前采集问卷互动性比较强,比较适合公司对接,对接比较方便。6,一般人求职招聘渠道推荐指数:适用系统:百度,360,搜狗等推荐理由:一般找工作都是在应届生求职网,其他的有很多是没有职位的,这时候就需要你对应各大招聘网站上的关键词进行一个浏览了,找到相应的职位后,你要做的就是投递简历了。
7,智能搜索引擎推荐指数:适用系统:word,,ppt等,也可以用百度搜图或者谷歌搜图等等推荐理由:智能搜索引擎就是利用大数据了,可以知道你想要的信息是在哪些数据库中,同样对于采集信息也是非常方便。同时,互联网中信息的种类丰富多彩,需要针对自己的行业,以及自己找工作的需求等等进行调查,结合数据库,提取自己想要的信息。
8,翻译网站推荐指数:适用系统:百度,谷歌等有道等百度翻译功能简单,免费,好用,对于自己要翻译的东西,上网找到,或者手机网页输入都可以,实用。9,日语文章采集器推荐指数:。 查看全部
新媒体管家:文章采集器常用的几种原因?
文章采集器网上有各式各样的文章采集器,同学们会因为各种各样的原因使用不同的文章采集器,今天推荐几款大家常用的文章采集器:1,10w+热文采集器2,微信文章采集器3,知乎文章采集器4,网易新闻采集器5,论坛文章采集器6,公众号文章采集器7,网页采集器8,抖音文章采集器9,微博文章采集器10,人民日报文章采集器11,头条文章采集器12,文章排序采集器13,快递文章采集器采集方法可以自行输入搜索关键词(如果已经明确需要什么信息,对应哪个关键词,就输入那个关键词就可以啦),把需要采集的信息,标注在采集框内,选择好采集的时间,点击采集即可2,新媒体管家推荐指数:适用系统:微信公众号,今日头条等推荐理由:新媒体管家是一款给运营小白写公众号文章、文章编辑器和资料填写器的软件,首页内所有的功能对新媒体工作者来说,都是太有必要的。
新媒体管家官网:。3,文章搜索引擎导航网站推荐指数:适用系统:百度,360,搜狗推荐理由:这个不用我多说了吧,搜索引擎收录的文章最全,分类齐全,你要的文章很多时候都是在这里面搜到的。最重要的是价格便宜,有时候搜索引擎收录的文章搜索不到,但是会在百度里面搜索到,这时候你就需要这个网站了。4,文章数据采集神器推荐指数:适用系统:百度,今日头条,搜狗搜索推荐理由:这个网站不知道大家都听说过没有,是一个专门采集文章的网站,各种平台的新闻热点,文章,都有,还可以按照字数,文章类型,以及当天发布时间,写文章很方便。
5,问卷星问卷星是比较早开发问卷调查系统的公司,目前采集问卷互动性比较强,比较适合公司对接,对接比较方便。6,一般人求职招聘渠道推荐指数:适用系统:百度,360,搜狗等推荐理由:一般找工作都是在应届生求职网,其他的有很多是没有职位的,这时候就需要你对应各大招聘网站上的关键词进行一个浏览了,找到相应的职位后,你要做的就是投递简历了。
7,智能搜索引擎推荐指数:适用系统:word,,ppt等,也可以用百度搜图或者谷歌搜图等等推荐理由:智能搜索引擎就是利用大数据了,可以知道你想要的信息是在哪些数据库中,同样对于采集信息也是非常方便。同时,互联网中信息的种类丰富多彩,需要针对自己的行业,以及自己找工作的需求等等进行调查,结合数据库,提取自己想要的信息。
8,翻译网站推荐指数:适用系统:百度,谷歌等有道等百度翻译功能简单,免费,好用,对于自己要翻译的东西,上网找到,或者手机网页输入都可以,实用。9,日语文章采集器推荐指数:。
什么是优采云采集?智能采集工具帮你提高营收
采集交流 • 优采云 发表了文章 • 0 个评论 • 256 次浏览 • 2021-03-26 04:34
什么是优采云采集?智能采集工具帮你提高营收
在流行期间,许多公司不得不选择远程在线办公室。互联网是受流行病影响较小的行业之一,但是远程办公室的效率仍然不如面对面的工作。因此,优采云 采集特别推出了智能采集工具。
我相信许多操作员已经接触过采集工具。市场上有很多采集工具。许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此。成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入。
1、什么是优采云 采集?
优采云 采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,有效地提高了新媒体的运营效率并降低了公司成本。
2、如何用优采云 采集搜索?
([1)输入关键词
优采云 采集根据用户输入的关键词,它会通过程序自动进入主流自媒体数据源的搜索引擎进行搜索。
优采云 采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性。
例如:
用户需要采集与流行病有关的资料,并在主页上输入关键词“流行病”。 优采云 采集会将搜索结果合并到一个列表中。
([2)保存搜索材料
优采云 采集具有批量保存搜索资料的功能。
单击[在当前页面上全部选择]功能,然后选中所需的文章,文章将添加到操作面板中,方便用户批量保存。
([3)精确过滤
1、搜索过滤器
优采云 采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,以使搜索内容更加准确。
2、广告过滤 查看全部
什么是优采云采集?智能采集工具帮你提高营收
在流行期间,许多公司不得不选择远程在线办公室。互联网是受流行病影响较小的行业之一,但是远程办公室的效率仍然不如面对面的工作。因此,优采云 采集特别推出了智能采集工具。
我相信许多操作员已经接触过采集工具。市场上有很多采集工具。许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此。成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入。
1、什么是优采云 采集?
优采云 采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,有效地提高了新媒体的运营效率并降低了公司成本。
2、如何用优采云 采集搜索?
([1)输入关键词
优采云 采集根据用户输入的关键词,它会通过程序自动进入主流自媒体数据源的搜索引擎进行搜索。
优采云 采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性。
例如:
用户需要采集与流行病有关的资料,并在主页上输入关键词“流行病”。 优采云 采集会将搜索结果合并到一个列表中。
([2)保存搜索材料
优采云 采集具有批量保存搜索资料的功能。
单击[在当前页面上全部选择]功能,然后选中所需的文章,文章将添加到操作面板中,方便用户批量保存。
([3)精确过滤
1、搜索过滤器
优采云 采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,以使搜索内容更加准确。
2、广告过滤
百度采集器,快搜网上抓取下载公众号文章及热点文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2021-03-26 02:02
文章采集器,百度采集器,快搜网上抓取下载公众号文章及热点文章。今天2018春节有一个公众号上百度推荐。然后可以上百度搜索关键词或公众号名称。但是在1000x以上的数值时就很慢,几十秒-几分钟才有结果出来。那我只好去看别人做的接口了。从百度搜索关键词或公众号名称接口,自己写一个,加速下载1000x数值时才速度更快,那我要去看别人写的接口就可以跳过那几十秒的下载,直接看接口的源码。
<p>这里看到一个有用的接口。一键下载公众号文章(1000x以上文章)基本实现思路和上面一样,利用java集合框架保存获取的链接。然后用数据库一条条获取下载的文章。本文第二个函数没有给出连接,使用rand,getgrouplength()和postname三个参数。//randfor(inti=0;i 查看全部
百度采集器,快搜网上抓取下载公众号文章及热点文章
文章采集器,百度采集器,快搜网上抓取下载公众号文章及热点文章。今天2018春节有一个公众号上百度推荐。然后可以上百度搜索关键词或公众号名称。但是在1000x以上的数值时就很慢,几十秒-几分钟才有结果出来。那我只好去看别人做的接口了。从百度搜索关键词或公众号名称接口,自己写一个,加速下载1000x数值时才速度更快,那我要去看别人写的接口就可以跳过那几十秒的下载,直接看接口的源码。
<p>这里看到一个有用的接口。一键下载公众号文章(1000x以上文章)基本实现思路和上面一样,利用java集合框架保存获取的链接。然后用数据库一条条获取下载的文章。本文第二个函数没有给出连接,使用rand,getgrouplength()和postname三个参数。//randfor(inti=0;i
全网聚合的信息搜索引擎——文章采集器下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 352 次浏览 • 2021-03-21 05:05
文章采集器,一款能搜索生活中各种信息和数据,实现全网聚合的信息搜索引擎。
一、下载文章采集器(2.0版本)
二、注册账号
三、根据需求设置采集条件,
一、注册账号下载账号一共需要2.0。点击登录,就会自动进入注册页面,并且会自动提示注册成功。所以你只需要点击确定下载即可。已经验证过的账号,登录后就会自动创建一个小号。邮箱的话用学校或者单位的都可以。从同学或者上一届收到邀请。
二、设置采集条件
1、可以设置采集地区:“全国/省级/市级”,
2、可以设置采集量:“10篇/月”
3、可以设置采集标题:“标题”
4、可以设置采集时间:“日/小时/天”
三、下载采集数据接下来是下载数据:用浏览器打开网址,输入软件根据你的需求填写相应的信息,包括账号密码、进行数据下载,数据导出。最后点击登录(链接)就可以搜索你需要的文章,选择你喜欢的内容去下载就可以了。
四、激活账号:激活账号后,你就可以免费试用了。各省都有免费试用。
五、整个采集过程
1、搜索文章网站
2、选择采集的方法和场景
3、完成数据下载
5、整个过程只要2秒,操作简单,很适合不熟悉采集软件的人使用。
六、如何导出到电脑/手机当然你也可以通过电脑上的浏览器,打开文章网站网址导入软件。
导入到软件后,
1、点击开始采集;
2、按需导入你的信息;
3、浏览器-》下载app-》扫码安装软件;
4、界面如下:注意:
1、采集数据只支持谷歌浏览器;ios版本的请点击跳转其他;
2、请注意登录的时候要使用邮箱,账号和密码都是。 查看全部
全网聚合的信息搜索引擎——文章采集器下载
文章采集器,一款能搜索生活中各种信息和数据,实现全网聚合的信息搜索引擎。
一、下载文章采集器(2.0版本)
二、注册账号
三、根据需求设置采集条件,
一、注册账号下载账号一共需要2.0。点击登录,就会自动进入注册页面,并且会自动提示注册成功。所以你只需要点击确定下载即可。已经验证过的账号,登录后就会自动创建一个小号。邮箱的话用学校或者单位的都可以。从同学或者上一届收到邀请。
二、设置采集条件
1、可以设置采集地区:“全国/省级/市级”,
2、可以设置采集量:“10篇/月”
3、可以设置采集标题:“标题”
4、可以设置采集时间:“日/小时/天”
三、下载采集数据接下来是下载数据:用浏览器打开网址,输入软件根据你的需求填写相应的信息,包括账号密码、进行数据下载,数据导出。最后点击登录(链接)就可以搜索你需要的文章,选择你喜欢的内容去下载就可以了。
四、激活账号:激活账号后,你就可以免费试用了。各省都有免费试用。
五、整个采集过程
1、搜索文章网站
2、选择采集的方法和场景
3、完成数据下载
5、整个过程只要2秒,操作简单,很适合不熟悉采集软件的人使用。
六、如何导出到电脑/手机当然你也可以通过电脑上的浏览器,打开文章网站网址导入软件。
导入到软件后,
1、点击开始采集;
2、按需导入你的信息;
3、浏览器-》下载app-》扫码安装软件;
4、界面如下:注意:
1、采集数据只支持谷歌浏览器;ios版本的请点击跳转其他;
2、请注意登录的时候要使用邮箱,账号和密码都是。
解决方案:优采云·万能文章采集器(SMGod) v2.17.7.0 绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2020-09-01 08:12
因此您可以根据实际情况切换模式. 您可以使用本地批处理的读取网页正文功能来测试指定网页适合的模式.
[采集中的处理选项]
采集可以同时执行翻译,过滤和单词搜索. 对于已经为采集的文章,您可以使用“本地批处理”.
翻译功能是将中文翻译成英文,然后再翻译回中文,这也会产生伪原创效果. 支持原创格式转换,即文章的原创标签结构和排版格式不会更改.
[采集目标是URL]
您可以在URL模板中插入#URL#,#title#来合并引用
[分页采集和相对路径的绝对路径]
勾选“自动采集分页”以合并页面文章 采集,然后编辑框将值设置为最大页面数采集. 建议设置一个有限值,例如10页,以避免某些采集占用太多分页时间,并且合并的文章体积很大. 如果需要全部采集页,可以将其设置为0.
文章中的所有相对路径都将自动转换为绝对路径,从而可以确保图片等的正常显示.
[多线程]
支持多线程高速采集网页. 可以根据网络速度来确定. 电信2m可以有5个线程,电信4m可以有10个线程,依此类推,但是需要适当设置. 太多的设置可能会严重影响采集效率,甚至影响系统效率. 如果采集具有占用网络流量的其他软件,例如在线视频播放,则可以适当地减少线程数.
[文章标题和文章重复处理]
该程序可以智能地判断和过滤重复项文章
当从采集到文章的文章标题(文件名)与本地保存的文章标题相同时,优采云首先将判断两个文章的相似性,当相似度大于60%时优采云被判断为相同文章,则比较两个文章的文本量,并自动使用带有更多文本的文章覆盖并写入相同的文件名. 这种世代情况并不等于世代数.
当相似度小于60%时,优采云判断为不同文章,并将自动重命名标题(标题末尾取3到5个随机字母)并将其保存到文件中
[文章快速过滤器]
尽管优采云研究了一种非常高精度的文本提取算法,但不可避免的是提取错误很少. 这些错误主要是: 目标页面的主体是在线视频,或者主体内容太短而无法形成主体特征. 因此,可以通过设置最终结果中的单词数来提高准确性(在“文本中的最小单词数”参数中,该单词数是程序删除标签,行和行之后的纯单词数. 空格).
文章快速过滤器是为了快速查看采集好文章,以便于判断删除错误的文章提取文本. 同时,基于网络信息采集的目的进行精炼也很方便.
[生成的文章数量可变的问题]
百度和搜搜默认每页100个结果,而Google默认每页10个结果.
某些网站访问速度已超时(尤其是Google 收录中的许多访问是围墙的网站),或者在文本中设置了最少字数,或者程序忽略了具有相同内容的相似内容本地文章中的名称,或过滤黑名单和白名单等,将导致生成的文章的实际数量少于页面搜索的最大结果数量.
一般来说,百度采集的质量最高,生成的文章数量接近搜索结果的数量. 查看全部
优采云·Universal 文章 采集器(SMGod)v2.17.7.0绿色版
因此您可以根据实际情况切换模式. 您可以使用本地批处理的读取网页正文功能来测试指定网页适合的模式.
[采集中的处理选项]
采集可以同时执行翻译,过滤和单词搜索. 对于已经为采集的文章,您可以使用“本地批处理”.
翻译功能是将中文翻译成英文,然后再翻译回中文,这也会产生伪原创效果. 支持原创格式转换,即文章的原创标签结构和排版格式不会更改.
[采集目标是URL]
您可以在URL模板中插入#URL#,#title#来合并引用
[分页采集和相对路径的绝对路径]
勾选“自动采集分页”以合并页面文章 采集,然后编辑框将值设置为最大页面数采集. 建议设置一个有限值,例如10页,以避免某些采集占用太多分页时间,并且合并的文章体积很大. 如果需要全部采集页,可以将其设置为0.
文章中的所有相对路径都将自动转换为绝对路径,从而可以确保图片等的正常显示.
[多线程]
支持多线程高速采集网页. 可以根据网络速度来确定. 电信2m可以有5个线程,电信4m可以有10个线程,依此类推,但是需要适当设置. 太多的设置可能会严重影响采集效率,甚至影响系统效率. 如果采集具有占用网络流量的其他软件,例如在线视频播放,则可以适当地减少线程数.
[文章标题和文章重复处理]
该程序可以智能地判断和过滤重复项文章
当从采集到文章的文章标题(文件名)与本地保存的文章标题相同时,优采云首先将判断两个文章的相似性,当相似度大于60%时优采云被判断为相同文章,则比较两个文章的文本量,并自动使用带有更多文本的文章覆盖并写入相同的文件名. 这种世代情况并不等于世代数.
当相似度小于60%时,优采云判断为不同文章,并将自动重命名标题(标题末尾取3到5个随机字母)并将其保存到文件中
[文章快速过滤器]
尽管优采云研究了一种非常高精度的文本提取算法,但不可避免的是提取错误很少. 这些错误主要是: 目标页面的主体是在线视频,或者主体内容太短而无法形成主体特征. 因此,可以通过设置最终结果中的单词数来提高准确性(在“文本中的最小单词数”参数中,该单词数是程序删除标签,行和行之后的纯单词数. 空格).
文章快速过滤器是为了快速查看采集好文章,以便于判断删除错误的文章提取文本. 同时,基于网络信息采集的目的进行精炼也很方便.
[生成的文章数量可变的问题]
百度和搜搜默认每页100个结果,而Google默认每页10个结果.
某些网站访问速度已超时(尤其是Google 收录中的许多访问是围墙的网站),或者在文本中设置了最少字数,或者程序忽略了具有相同内容的相似内容本地文章中的名称,或过滤黑名单和白名单等,将导致生成的文章的实际数量少于页面搜索的最大结果数量.
一般来说,百度采集的质量最高,生成的文章数量接近搜索结果的数量.
万能文章采集器V2.17
采集交流 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2020-08-28 19:19
一款基于高精度正文辨识算法的互联网文章采集器。支持按关键词采集各大搜索引擎的新闻和网页,还支持采集指定网站栏目下的全部文章。
基于优采云自主研制的正文辨识智能算法,能在互联网错综复杂的网页中尽可能确切地提取出正文内容。
正文辨识有 3 种算法,“标准”、“严格”和“精确标签”。其中“标准”和“严格”是手动模式,能适应绝大多数网页的正文提取,而“精确标签”只需指定正文标签头,如“
”,就能通喝所有网页的正文提取。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、谷歌、必应、雅虎
采集指定网站文章的功能也十分简单,只须要稍为设置(不需要复杂的规则),就能批量采集目标网站的文章了。
因为墙的问题,要使用微软搜索和微软转译文章的功能,需要使用VPN换美国IP。
内置文章转译功能,也就是可以将文章从一种语言如英文转入另一种语言如中文,再从英语转到英文。
采集文章+翻译伪原创可以满足广大站长朋友们在各领域主题的文章需求。
而一些公关处理、信息调查公司所需的由专业公司开发的信息采集系统,售价常常达到上万甚至更多,而优采云的这款软件也是一款信息采集系统,功能跟市面上高昂售价的软件有相通之处,但价钱只有区区几百元,性价比怎么试试就知。
内容仅限注册会员查看,登陆后下载地址会显示在下方:
本文隐藏内容 登陆 后才可以浏览
本文作者: chouxiami
这里只更新收费VIP资源,均为本人付费订购!加入VIP 查看全部
万能文章采集器V2.17
一款基于高精度正文辨识算法的互联网文章采集器。支持按关键词采集各大搜索引擎的新闻和网页,还支持采集指定网站栏目下的全部文章。
基于优采云自主研制的正文辨识智能算法,能在互联网错综复杂的网页中尽可能确切地提取出正文内容。
正文辨识有 3 种算法,“标准”、“严格”和“精确标签”。其中“标准”和“严格”是手动模式,能适应绝大多数网页的正文提取,而“精确标签”只需指定正文标签头,如“
”,就能通喝所有网页的正文提取。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、谷歌、必应、雅虎
采集指定网站文章的功能也十分简单,只须要稍为设置(不需要复杂的规则),就能批量采集目标网站的文章了。
因为墙的问题,要使用微软搜索和微软转译文章的功能,需要使用VPN换美国IP。
内置文章转译功能,也就是可以将文章从一种语言如英文转入另一种语言如中文,再从英语转到英文。
采集文章+翻译伪原创可以满足广大站长朋友们在各领域主题的文章需求。
而一些公关处理、信息调查公司所需的由专业公司开发的信息采集系统,售价常常达到上万甚至更多,而优采云的这款软件也是一款信息采集系统,功能跟市面上高昂售价的软件有相通之处,但价钱只有区区几百元,性价比怎么试试就知。
内容仅限注册会员查看,登陆后下载地址会显示在下方:
本文隐藏内容 登陆 后才可以浏览
本文作者: chouxiami
这里只更新收费VIP资源,均为本人付费订购!加入VIP
wordpress怎么采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 362 次浏览 • 2020-08-27 18:06
WordPress是一种使用PHP语言开发的建站程序平台,现在做博客用wp的早已好多了,很多网站制作培训都使用的是wp,特别是在做采集站的时侯wordpress的共能太强悍。下面就给你们介绍怎样实现wp的手动采集功能。
1、安装网站采集插件:WP-AutoPost(插件下载地址:)
2、点击“新建任务”后,输入任务名称,即可创建新任务,创建好新任务以后可以在任务列表中查看到该任务,就可对该任务进行更多设置。(这一部分不需要更改设置,唯一须要改动的就是采集的时间。)
3、文章来源设置。在该选项卡下我们须要设置文章来源的 文章列表网址 及 具体文章的匹配规则。我们以采集”新浪互联网新闻“为例,文章列表网址为,因此在 手工指定文章列表网址 中输入该网址即可,如下所示:
4、文章网址匹配规则。文章网址匹配规则的设置特别简单,无需复杂设置,提供两种匹配模式,可以使用URL键值匹配,也可以使用CSS选择器进行匹配,通常使用URL键值匹配较为简单,但有时使用CSS选择器更为精确。
5、使用URL键值匹配。通过点击列表网址 上的文章,我们可以发觉整篇文章的URL都为如下结构:,因此将URL中变化的数字或字母替换为键值 (*) 即可,如:(*)/(*).shtml 。重复的网址可以使用301重定向。
6、使用CSS选择器进行匹配。使用CSS选择器进行匹配,我们只须要设置文章网址的CSS选择器即可,通过查看列表网址的源代码即可轻松设置,找到列表网址下文章超链接的代码,如下所示:
7、可以看见,文章的超链接A标签在class为“contList”的标签内部,因此文章网址的CSS选择器只须要设置为 .contList a 即可,如下所示:
8、设置完成以后,不知道设置是否正确,可以点击上图中的测试按键,如果设置正确,将列举该列表网址下所有文章名称和对应的网页地址,如下所示:
9、其他的设置可以不用更改。以上采集方法适用于WordPress多站点功能。 查看全部
wordpress怎么采集器
WordPress是一种使用PHP语言开发的建站程序平台,现在做博客用wp的早已好多了,很多网站制作培训都使用的是wp,特别是在做采集站的时侯wordpress的共能太强悍。下面就给你们介绍怎样实现wp的手动采集功能。
1、安装网站采集插件:WP-AutoPost(插件下载地址:)
2、点击“新建任务”后,输入任务名称,即可创建新任务,创建好新任务以后可以在任务列表中查看到该任务,就可对该任务进行更多设置。(这一部分不需要更改设置,唯一须要改动的就是采集的时间。)
3、文章来源设置。在该选项卡下我们须要设置文章来源的 文章列表网址 及 具体文章的匹配规则。我们以采集”新浪互联网新闻“为例,文章列表网址为,因此在 手工指定文章列表网址 中输入该网址即可,如下所示:
4、文章网址匹配规则。文章网址匹配规则的设置特别简单,无需复杂设置,提供两种匹配模式,可以使用URL键值匹配,也可以使用CSS选择器进行匹配,通常使用URL键值匹配较为简单,但有时使用CSS选择器更为精确。
5、使用URL键值匹配。通过点击列表网址 上的文章,我们可以发觉整篇文章的URL都为如下结构:,因此将URL中变化的数字或字母替换为键值 (*) 即可,如:(*)/(*).shtml 。重复的网址可以使用301重定向。
6、使用CSS选择器进行匹配。使用CSS选择器进行匹配,我们只须要设置文章网址的CSS选择器即可,通过查看列表网址的源代码即可轻松设置,找到列表网址下文章超链接的代码,如下所示:
7、可以看见,文章的超链接A标签在class为“contList”的标签内部,因此文章网址的CSS选择器只须要设置为 .contList a 即可,如下所示:
8、设置完成以后,不知道设置是否正确,可以点击上图中的测试按键,如果设置正确,将列举该列表网址下所有文章名称和对应的网页地址,如下所示:
9、其他的设置可以不用更改。以上采集方法适用于WordPress多站点功能。
小蜜蜂采集器文章采集器使用手册
采集交流 • 优采云 发表了文章 • 0 个评论 • 362 次浏览 • 2020-08-25 14:33
小蜜蜂采集器文章采集器使用手册 一: 建立站点和栏目 1: 点击添加站点按键出现如下页面 可以按照提示筹建网站名称和网站归属栏目名称。 注: 必须要先设置网站后才会设置栏目名称。 并在设置栏目名称后选择网站, 以便确立栏目的归属。 配置完成站点和栏目后出现如下页面 注: 一个站点下可以有添加多个栏目 二: 建立采集规则 1: 为栏目添加规则 当你是第一次为新构建的站点添加规则时, 请一定要点选站点列表栏目中的“添加规则” 按钮。 如下图: 点击后, 我们可以选择为站点中的那个栏目进行规则添加 2: 规则编撰 这里我们要注重说明, 如何添加采集规则并详尽说明怎样编撰规则。 以下的讲解将以一实际网站为例进行。2.1 如何编撰 URL 规则 我们以如下的链接地址为例: 出现如下页面 我们来剖析这条 URL 的页面: 第一页的 URL 为 第二页的 URL 为 第三页的 URL 为 这儿我们可以看出除第 1 页外, 起它页 URL 都是有规律的在进行变化。 因此我在 URL 链接区域填入下述内容 我们可以看到在“有规律的 URL” 里我们是采用了这样的的链接内容 [variable].asp 而实际的分页 URL 是这样的 在这里我们用[variable]【变量】 取代了数字【2】【3】, 而在参数市填写了【2】, 【9】。 至此我们完成了 URL 的添加。 2.2 如何编撰“链接” 规则。 在上一步我们完成了 URL 的编撰, 使采集器晓得什么页面 URL 是要去进行采集的; 但要软件晓得具体要采集哪些内容, 我们就要编辑“链接” 规则。 首先确定什么链接是我们要采集的:在当前页我们按“F7”, 或点选 IE 中的“查看” -“源文件” 按钮, 打开记事本查看当前页的 HTML 源代码文件。 查找到特定代码区域, 如下图: 我们可以发觉这种代码都是有规律的, 依据规律提取如下
DW8 代码工具栏试用 对以上代码我们做如下编撰
[title] 以上我们用[link]【链接】 标签替换了“/tech/web/2005/2815.asp”, 用[title]【标题】 标签替换了“DW8 代码工具栏试用”。 编辑“链接” 规则做完后, 选择“提... 查看全部
小蜜蜂采集器文章采集器使用手册
小蜜蜂采集器文章采集器使用手册 一: 建立站点和栏目 1: 点击添加站点按键出现如下页面 可以按照提示筹建网站名称和网站归属栏目名称。 注: 必须要先设置网站后才会设置栏目名称。 并在设置栏目名称后选择网站, 以便确立栏目的归属。 配置完成站点和栏目后出现如下页面 注: 一个站点下可以有添加多个栏目 二: 建立采集规则 1: 为栏目添加规则 当你是第一次为新构建的站点添加规则时, 请一定要点选站点列表栏目中的“添加规则” 按钮。 如下图: 点击后, 我们可以选择为站点中的那个栏目进行规则添加 2: 规则编撰 这里我们要注重说明, 如何添加采集规则并详尽说明怎样编撰规则。 以下的讲解将以一实际网站为例进行。2.1 如何编撰 URL 规则 我们以如下的链接地址为例: 出现如下页面 我们来剖析这条 URL 的页面: 第一页的 URL 为 第二页的 URL 为 第三页的 URL 为 这儿我们可以看出除第 1 页外, 起它页 URL 都是有规律的在进行变化。 因此我在 URL 链接区域填入下述内容 我们可以看到在“有规律的 URL” 里我们是采用了这样的的链接内容 [variable].asp 而实际的分页 URL 是这样的 在这里我们用[variable]【变量】 取代了数字【2】【3】, 而在参数市填写了【2】, 【9】。 至此我们完成了 URL 的添加。 2.2 如何编撰“链接” 规则。 在上一步我们完成了 URL 的编撰, 使采集器晓得什么页面 URL 是要去进行采集的; 但要软件晓得具体要采集哪些内容, 我们就要编辑“链接” 规则。 首先确定什么链接是我们要采集的:在当前页我们按“F7”, 或点选 IE 中的“查看” -“源文件” 按钮, 打开记事本查看当前页的 HTML 源代码文件。 查找到特定代码区域, 如下图: 我们可以发觉这种代码都是有规律的, 依据规律提取如下
DW8 代码工具栏试用 对以上代码我们做如下编撰
[title] 以上我们用[link]【链接】 标签替换了“/tech/web/2005/2815.asp”, 用[title]【标题】 标签替换了“DW8 代码工具栏试用”。 编辑“链接” 规则做完后, 选择“提...
红叶文章采集器下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2020-08-18 19:59
标签聚合:
超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
使用前,必须确保你的计算机可以连通网路,且防火墙不要拦截本软件。运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“”,若选择通用蜘蛛模式,将遍历“”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“”里面的每一个网页。按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。本软件采集的原则是不越站,例如给的入口是“”,就只在百度站点内部抓取。本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。
相关软件
相关教程
猜你喜欢 查看全部
红叶文章采集器下载
标签聚合:
超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
使用前,必须确保你的计算机可以连通网路,且防火墙不要拦截本软件。运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“”,若选择通用蜘蛛模式,将遍历“”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“”里面的每一个网页。按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。本软件采集的原则是不越站,例如给的入口是“”,就只在百度站点内部抓取。本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。
相关软件
相关教程
猜你喜欢
有关优采云采集器无法发布的常见问题汇总
采集交流 • 优采云 发表了文章 • 0 个评论 • 464 次浏览 • 2020-08-09 01:49
1. 在分发配置中,无法刷新列表,并且一般提示“格式不匹配”?
回答: 原因很多,请一一确认. 首先,如果登录成功,则打开返回码检查功能. 例如,如果仅在登录后才能访问刷新列表的页面,则必须首先登录网站以查看cookie是否正确. 其次,您可能选择了错误的模块,其他版本或网站系统的模块,但通常不会. 一般来说,请使用模块. 为什么善良的人仍然感到疼痛?这三个可能是您的网站与默认模块刷新列表页面不同. 例如,使用默认样式制作模块. 您更改了另一种样式. 请参考模块开发手册章节进行修改. 或使用“自定义不同的生活方式: 您不后悔的25件事”. 确认参数; 4,在选择设置中选择使用蜘蛛作为模型. 要进行浏览,请更改浏览器的浏览费用.
2. 发送内容-Web发布错误. 请参考返回码. 采集的内容会重复发布. 它表明成功发布是未知的吗?
回答: 发生类似的错误: 发送内容-Web发布错误,请参考返回代码: file: // e: documentsandsettingsadministratordesktop2008StandardEditiondata1-admin5-seoweberror.log. 记住要打开此日志文件. 检查返回的代码.
如果返回码为空,则发布速度可能太快,服务器无法响应,并且未返回任何字符. 此时,发布可能成功或失败. 请检查网站以获取详细信息. 怎么处理呢?请修改发布速度(问题3). 不要太短,这主要是基于该版本的成功.
如果返回码不为空并表示成功,请检查网站是否成功: 如果成功,则模块中的成功返回值与系统中的值不同. 在这种情况下,请在系统模块中修改成功返回值. 如果显示成功,但实际上未成功,则可能是您提交的数据网格. 公式中有错误,并且您的程序不会报告该错误,但是当它进入数据库时,它无法发布它. 这要求您仔细检查已发布的代码是否存在问题. 如果返回码失败,请注意任何问题,例如标题太长,没有关键字或其他问题. 此时,请注意修改规则的相应部分.
一种可能性是您选择了多种发布方法. 请在“编辑任务”和“文件保存和高级设置”中设置“将成功发布的位置定义为成功”. 另一个原因是它上次成功发布,但是当时还不知道. 如果不再需要发布,则可以将数据库中的所有记录更改为“已发布”.
3. 在discuz中,“您的请求未正确发送,或者验证字符串不一致并且无法提交”:
回答: 发布表单时,此discuz将发送表单哈希,并在发布页面上获取此值. 这是由错误的格式哈希值导致的. 请使用机车的内置浏览器登录并检查源代码,找到“ formhash =“,然后修改在线发布模块,并将其值替换为原创的[Login Random Value 1](当然是登录随机值x(与模块作者的Use相关)相同,或者您自己修改模块,以便程序可以获取表单. 正确哈希.
4. 将其发布在网站上,找到所有拥挤的内容,查看源代码,发现缺少空格了?
答案: 有两种可能: 一种是在制定规则时过滤空白;另一种是在制定规则时过滤空白. 另一个是系统将过滤空白. 在这种情况下,请在“内容发布设置”中选择“数据发布时的URLENCODE处理”. 风新闻属于某些类别.
5. 发布图片时,它始终是相对地址,而不是远程地址吗?
回答: 请在标签编辑器中选择“完整的相对地址和绝对地址”. 默认情况下,下载图片后无需选择此选项.
6. 成功发布了测试,但是当实际发布显示成功时,没有文章吗?
答案: 有很多可能性. 一种是模块的成功识别码不是唯一的,即成功或失败的发布是相同的识别码. 另一个是实际发布成功,但是未检查模块的默认值,因此您必须首先前往站点进行检查;第三,也可能是因为火车继续通过防火墙或服务器发布数据. 防火墙被阻止. 请关闭防火墙,然后尝试. 另一个原因是登录信息无效. 例如,如果您的网站有一段时间没有运行,并且您需要很长时间才能发布实际版本,它将自动注销. 因此原创的着陆信息无效.
7. 将其发布到我的论坛上并显示代码?
答案: 请在发布配置中选择要发布的ubb. 通常选择discuz,phpwind和其他论坛在ubb上发布. 如果要以HTML模式发布,请打开右键,然后将HTML发送到后台的相关海报中.
8. 如何继续上一个未完成的版本?
A: 在任务栏中,只需选中“发送内容”复选框. 该程序将释放采集的但未释放的数据. 查看全部
1. 在分发配置中,无法刷新列表,并且一般提示“格式不匹配”?
回答: 原因很多,请一一确认. 首先,如果登录成功,则打开返回码检查功能. 例如,如果仅在登录后才能访问刷新列表的页面,则必须首先登录网站以查看cookie是否正确. 其次,您可能选择了错误的模块,其他版本或网站系统的模块,但通常不会. 一般来说,请使用模块. 为什么善良的人仍然感到疼痛?这三个可能是您的网站与默认模块刷新列表页面不同. 例如,使用默认样式制作模块. 您更改了另一种样式. 请参考模块开发手册章节进行修改. 或使用“自定义不同的生活方式: 您不后悔的25件事”. 确认参数; 4,在选择设置中选择使用蜘蛛作为模型. 要进行浏览,请更改浏览器的浏览费用.
2. 发送内容-Web发布错误. 请参考返回码. 采集的内容会重复发布. 它表明成功发布是未知的吗?
回答: 发生类似的错误: 发送内容-Web发布错误,请参考返回代码: file: // e: documentsandsettingsadministratordesktop2008StandardEditiondata1-admin5-seoweberror.log. 记住要打开此日志文件. 检查返回的代码.
如果返回码为空,则发布速度可能太快,服务器无法响应,并且未返回任何字符. 此时,发布可能成功或失败. 请检查网站以获取详细信息. 怎么处理呢?请修改发布速度(问题3). 不要太短,这主要是基于该版本的成功.
如果返回码不为空并表示成功,请检查网站是否成功: 如果成功,则模块中的成功返回值与系统中的值不同. 在这种情况下,请在系统模块中修改成功返回值. 如果显示成功,但实际上未成功,则可能是您提交的数据网格. 公式中有错误,并且您的程序不会报告该错误,但是当它进入数据库时,它无法发布它. 这要求您仔细检查已发布的代码是否存在问题. 如果返回码失败,请注意任何问题,例如标题太长,没有关键字或其他问题. 此时,请注意修改规则的相应部分.
一种可能性是您选择了多种发布方法. 请在“编辑任务”和“文件保存和高级设置”中设置“将成功发布的位置定义为成功”. 另一个原因是它上次成功发布,但是当时还不知道. 如果不再需要发布,则可以将数据库中的所有记录更改为“已发布”.
3. 在discuz中,“您的请求未正确发送,或者验证字符串不一致并且无法提交”:
回答: 发布表单时,此discuz将发送表单哈希,并在发布页面上获取此值. 这是由错误的格式哈希值导致的. 请使用机车的内置浏览器登录并检查源代码,找到“ formhash =“,然后修改在线发布模块,并将其值替换为原创的[Login Random Value 1](当然是登录随机值x(与模块作者的Use相关)相同,或者您自己修改模块,以便程序可以获取表单. 正确哈希.
4. 将其发布在网站上,找到所有拥挤的内容,查看源代码,发现缺少空格了?
答案: 有两种可能: 一种是在制定规则时过滤空白;另一种是在制定规则时过滤空白. 另一个是系统将过滤空白. 在这种情况下,请在“内容发布设置”中选择“数据发布时的URLENCODE处理”. 风新闻属于某些类别.
5. 发布图片时,它始终是相对地址,而不是远程地址吗?
回答: 请在标签编辑器中选择“完整的相对地址和绝对地址”. 默认情况下,下载图片后无需选择此选项.
6. 成功发布了测试,但是当实际发布显示成功时,没有文章吗?
答案: 有很多可能性. 一种是模块的成功识别码不是唯一的,即成功或失败的发布是相同的识别码. 另一个是实际发布成功,但是未检查模块的默认值,因此您必须首先前往站点进行检查;第三,也可能是因为火车继续通过防火墙或服务器发布数据. 防火墙被阻止. 请关闭防火墙,然后尝试. 另一个原因是登录信息无效. 例如,如果您的网站有一段时间没有运行,并且您需要很长时间才能发布实际版本,它将自动注销. 因此原创的着陆信息无效.
7. 将其发布到我的论坛上并显示代码?
答案: 请在发布配置中选择要发布的ubb. 通常选择discuz,phpwind和其他论坛在ubb上发布. 如果要以HTML模式发布,请打开右键,然后将HTML发送到后台的相关海报中.
8. 如何继续上一个未完成的版本?
A: 在任务栏中,只需选中“发送内容”复选框. 该程序将释放采集的但未释放的数据.
优采云通用文章采集器(网站管理员工具)v1.12特别版
采集交流 • 优采云 发表了文章 • 0 个评论 • 628 次浏览 • 2020-08-08 04:16
获取过程中的处理选项
在采集过程中可以同时执行翻译,过滤和单词搜索等处理. 所采集的文章可以通过“本地批处理”进行处理.
翻译功能是将中文翻译成英文,然后再翻译回中文,从而产生伪原创效果. 支持原创格式翻译,即不要更改文章的原创标签结构和排版格式.
采集目标是URL
您可以在URL模板中插入#URL#,#title#来合并引用
页面采集和相对路径转换为绝对路径
勾选“自动采集和分页”以合并分页的文章. 编辑框的设置值为最大采集页数. 建议设置一个有限的值(例如10页),以免出现分页时间过长的集合,并且合并后的文章过大. 如果需要采集所有页面,可以将其设置为0.
文章中的所有相对路径将自动转换为绝对路径,这样可以确保图片等的正常显示.
多线程
支持网页的多线程高速采集. 可以根据网络速度来确定. 电信2m可以有5个线程,电信4m可以有10个线程,依此类推,但是需要适当设置. 太多的设置可能会严重影响采集效率甚至系统效率. 如果在采集过程中运行了占用流量的其他软件(例如在线视频播放),则可以适当减少线程数.
处理重复的文章标题和文章内容
该程序可以智能地判断和过滤重复的文章
当采集到的文章的标题(文件名)与本地保存的文章的标题相同时,优采云将首先判断这两篇文章的相似性. 当相似度大于60%时,优采云将确定同一文章,然后比较这两篇文章的文本量,并自动使用收录更多文本的文章来覆盖和写入相同的文件名. 这种世代情况并不等于世代数.
当相似度低于60%时,优采云判断这是另一篇文章,并将自动重命名标题(标题末尾取3到5个随机字母)并将其保存到文件中.
快速文章过滤器
尽管优采云研究了非常精确的人体提取算法,但提取错误仍然很少. 这些错误主要是: 目标页面的主体是在线视频,或者主体内容太短而无法形成主体特征. 因此,可以通过设置最终结果中的单词数来提高准确性(在“最小字符数”参数中,该单词数是程序删除标签,行和空格后的纯文本单词数) ).
文章快速过滤器用于快速查看采集到的文章,并有助于判断和删除文本错误的文章. 同时,基于网络信息采集的目的,方便了细化和选择过程.
生成的文章数量可变的问题
百度和搜搜默认每页100个结果,而Google默认每页10个结果.
某些网站已超时(特别是Google所收录的许多网站被阻止),或在文本中设置了最少字数,或者该程序忽略了具有相同名称,黑名单和白名单的内容相似的本地文章等会导致实际生成的文章数低于每次页面搜索的最大结果数.
总的来说,百度的质量是最好的,生成的文章数量接近搜索结果的数量.
更新日志:
1.12: 继续增强Web批处理列URL采集器识别文章URL的能力,并支持多种地址格式的同时匹配.
1.11: 增强了Web批处理列URL采集器识别文章URL的能力.
1.10: 解决了翻译功能无法翻译的问题. 查看全部
因此您可以根据实际情况切换模式. 您可以使用本地批处理的读取网页正文功能来测试指定网页适合的模式.
获取过程中的处理选项
在采集过程中可以同时执行翻译,过滤和单词搜索等处理. 所采集的文章可以通过“本地批处理”进行处理.
翻译功能是将中文翻译成英文,然后再翻译回中文,从而产生伪原创效果. 支持原创格式翻译,即不要更改文章的原创标签结构和排版格式.
采集目标是URL
您可以在URL模板中插入#URL#,#title#来合并引用
页面采集和相对路径转换为绝对路径
勾选“自动采集和分页”以合并分页的文章. 编辑框的设置值为最大采集页数. 建议设置一个有限的值(例如10页),以免出现分页时间过长的集合,并且合并后的文章过大. 如果需要采集所有页面,可以将其设置为0.
文章中的所有相对路径将自动转换为绝对路径,这样可以确保图片等的正常显示.
多线程
支持网页的多线程高速采集. 可以根据网络速度来确定. 电信2m可以有5个线程,电信4m可以有10个线程,依此类推,但是需要适当设置. 太多的设置可能会严重影响采集效率甚至系统效率. 如果在采集过程中运行了占用流量的其他软件(例如在线视频播放),则可以适当减少线程数.
处理重复的文章标题和文章内容
该程序可以智能地判断和过滤重复的文章
当采集到的文章的标题(文件名)与本地保存的文章的标题相同时,优采云将首先判断这两篇文章的相似性. 当相似度大于60%时,优采云将确定同一文章,然后比较这两篇文章的文本量,并自动使用收录更多文本的文章来覆盖和写入相同的文件名. 这种世代情况并不等于世代数.
当相似度低于60%时,优采云判断这是另一篇文章,并将自动重命名标题(标题末尾取3到5个随机字母)并将其保存到文件中.
快速文章过滤器
尽管优采云研究了非常精确的人体提取算法,但提取错误仍然很少. 这些错误主要是: 目标页面的主体是在线视频,或者主体内容太短而无法形成主体特征. 因此,可以通过设置最终结果中的单词数来提高准确性(在“最小字符数”参数中,该单词数是程序删除标签,行和空格后的纯文本单词数) ).
文章快速过滤器用于快速查看采集到的文章,并有助于判断和删除文本错误的文章. 同时,基于网络信息采集的目的,方便了细化和选择过程.
生成的文章数量可变的问题
百度和搜搜默认每页100个结果,而Google默认每页10个结果.
某些网站已超时(特别是Google所收录的许多网站被阻止),或在文本中设置了最少字数,或者该程序忽略了具有相同名称,黑名单和白名单的内容相似的本地文章等会导致实际生成的文章数低于每次页面搜索的最大结果数.
总的来说,百度的质量是最好的,生成的文章数量接近搜索结果的数量.
更新日志:
1.12: 继续增强Web批处理列URL采集器识别文章URL的能力,并支持多种地址格式的同时匹配.
1.11: 增强了Web批处理列URL采集器识别文章URL的能力.
1.10: 解决了翻译功能无法翻译的问题.

