
文章采集内容
文章采集内容( 数据的来源及其具体类型,你知道几个?(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 268 次浏览 • 2021-08-29 03:17
数据的来源及其具体类型,你知道几个?(上))
一、前言
我们在日常生活中经常听到这样一个问题:你有数据支持吗?你的数据源在哪里?数据有噪声吗?
那么这里的“数据”是什么?
百度百科对数据的定义很简单:数据是事实或观察的结果,是客观事物的逻辑总结,是用来表示客观事物的原材料。
再仔细想想,我们日常生活中所指的数据真的是数据吗?其实我们更多的指的是已经形成系统、有逻辑结构、实用的“数据知识”。
所以,我们不能把数据当成一个简单的概念,但其实“数据”里面有很多知识。
下面先介绍四个与“数据”相关的术语和概念,后面我会详细阐述它们的“价值实现”方法论。
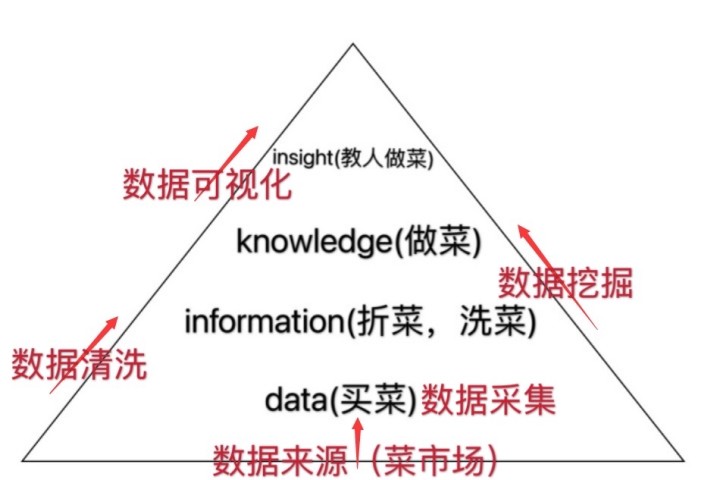
您真的了解什么是数据、信息、知识和洞察力吗?
今天小陈就给大家介绍一下数据的来源和具体类型。毕竟,知己知彼,百战不殆。有了今天的铺垫,接下来几节就可以轻松学习了~
二、数据源(菜市场)
如果说数据是我们做饭所需要的原材料,那么确定数据的来源就像是在出门买菜之前先确定去哪个菜市场;而“菜市场”也专门从事艺术行业!买海鲜去海鲜市场,买家禽去家禽市场……数据也是一个道理。您需要通过所需的字段过滤数据源。毕竟保证数据质量是做好菜的第一步~
如前所述,数据是一个巨大的概念。要想用好它,首先要知道数据的类型,然后根据类型确定来源,采集数据。
1.根据结构程度区分数据源
1)非结构化数据
非结构化数据是最简单的数据形式;我们周围无时无刻不在存在着非结构化数据,而且几乎触手可及。文本、图片、声音或视频都是非结构化数据。此类数据通常存储在文件存储库中(您可以将其视为计算机硬盘上组织良好的目录)。
然而,从这种形状的数据中提取价值通常是最困难的;因为我们首先需要从描述性或抽象的数据中提取结构特征(比如使用文本,我们可能需要提取主题和文本到主题的正面或负面评论,一千个读者就会有一千个哈姆雷特,这种信息是高度主观的)。
目前非常流行的一种文本挖掘技术,它的数据源就是我们这里所说的非结构化数据。
2)结构化数据
结构化数据,顾名思义,是定义明确的表格数据(行和列),这意味着我们知道它们收录哪些列以及哪些类型的数据;这些数据通常存储在数据库中,我们可以在其中使用 SQL 语言过滤结构化数据并轻松为我们的数据科学解决方案创建数据集。
3)半结构化数据
半结构化数据介于非结构化数据和结构化数据之间。虽然它定义了一致的格式,但结构并不是很严格。例如,部分数据可能不完整或类型不同;结构化数据通常存储为文件,但某些类型的半结构化数据(例如 JSON 或 XML)可以存储在面向文档的数据库中。
2.根据数据隐私区分数据源
1)组织内的数据源(封闭数据源)
查找数据的第一个地方是组织内部。大多数公司目前都在运行 ERP、CRM、工作流管理和其他系统。此类系统通常使用数据库以结构化的方式存储数据;这些数据库收录了大量您可以轻松地从数据中提取价值;例如,通过工作流管理系统,您可以轻松了解业务流程中的瓶颈,或者通过使用 ERP 系统的数据,您可以进行销售预测。
2)public 数据源(开源数据源)
除了内部非公开数据外,许多组织还会接收和发送大量文件、图片、声音或视频。这些在公共互联网上分发和保留的数据是公共数据源;例如,您可以想象一家保险公司,我收到了很多可能附有图片的索赔(纸质或 PDF 格式)。这些文件在处理之前通常会被手动转换为更结构化的格式;但是,在此转换中会丢失一些信息。在尝试改进我们的数据科学解决方案时,我们可以使用这些文件来提取额外的数据,例如场景概览。
未来,我们可以使用这些额外数据来改进欺诈索赔检测,这是公共数据源的价值所在。
另外,行业内其实还有很多数据源分类,比如是实时数据、一手数据还是二手数据……
三、结论和下一个预览
本期小陈通过一个“菜市场”的例子,让大家洞悉了这个庞大的“数据”系统,并通过“菜市场”的比喻,让大家对源头有个概念数据整体理解。
下一期小陈将讲解如何使用常用的数据清洗工具和采集基于数据源!
本文由@小陈同学ing发布。 原创人人都是产品经理,未经作者许可,禁止转载。
标题图片来自 Unsplash,基于 CC0 协议。
奖励作者,鼓励他努力!
欣赏 查看全部
文章采集内容(
数据的来源及其具体类型,你知道几个?(上))

一、前言
我们在日常生活中经常听到这样一个问题:你有数据支持吗?你的数据源在哪里?数据有噪声吗?
那么这里的“数据”是什么?
百度百科对数据的定义很简单:数据是事实或观察的结果,是客观事物的逻辑总结,是用来表示客观事物的原材料。
再仔细想想,我们日常生活中所指的数据真的是数据吗?其实我们更多的指的是已经形成系统、有逻辑结构、实用的“数据知识”。
所以,我们不能把数据当成一个简单的概念,但其实“数据”里面有很多知识。
下面先介绍四个与“数据”相关的术语和概念,后面我会详细阐述它们的“价值实现”方法论。
您真的了解什么是数据、信息、知识和洞察力吗?
今天小陈就给大家介绍一下数据的来源和具体类型。毕竟,知己知彼,百战不殆。有了今天的铺垫,接下来几节就可以轻松学习了~
二、数据源(菜市场)
如果说数据是我们做饭所需要的原材料,那么确定数据的来源就像是在出门买菜之前先确定去哪个菜市场;而“菜市场”也专门从事艺术行业!买海鲜去海鲜市场,买家禽去家禽市场……数据也是一个道理。您需要通过所需的字段过滤数据源。毕竟保证数据质量是做好菜的第一步~
如前所述,数据是一个巨大的概念。要想用好它,首先要知道数据的类型,然后根据类型确定来源,采集数据。
1.根据结构程度区分数据源
1)非结构化数据
非结构化数据是最简单的数据形式;我们周围无时无刻不在存在着非结构化数据,而且几乎触手可及。文本、图片、声音或视频都是非结构化数据。此类数据通常存储在文件存储库中(您可以将其视为计算机硬盘上组织良好的目录)。
然而,从这种形状的数据中提取价值通常是最困难的;因为我们首先需要从描述性或抽象的数据中提取结构特征(比如使用文本,我们可能需要提取主题和文本到主题的正面或负面评论,一千个读者就会有一千个哈姆雷特,这种信息是高度主观的)。
目前非常流行的一种文本挖掘技术,它的数据源就是我们这里所说的非结构化数据。

2)结构化数据
结构化数据,顾名思义,是定义明确的表格数据(行和列),这意味着我们知道它们收录哪些列以及哪些类型的数据;这些数据通常存储在数据库中,我们可以在其中使用 SQL 语言过滤结构化数据并轻松为我们的数据科学解决方案创建数据集。

3)半结构化数据
半结构化数据介于非结构化数据和结构化数据之间。虽然它定义了一致的格式,但结构并不是很严格。例如,部分数据可能不完整或类型不同;结构化数据通常存储为文件,但某些类型的半结构化数据(例如 JSON 或 XML)可以存储在面向文档的数据库中。
2.根据数据隐私区分数据源
1)组织内的数据源(封闭数据源)
查找数据的第一个地方是组织内部。大多数公司目前都在运行 ERP、CRM、工作流管理和其他系统。此类系统通常使用数据库以结构化的方式存储数据;这些数据库收录了大量您可以轻松地从数据中提取价值;例如,通过工作流管理系统,您可以轻松了解业务流程中的瓶颈,或者通过使用 ERP 系统的数据,您可以进行销售预测。
2)public 数据源(开源数据源)
除了内部非公开数据外,许多组织还会接收和发送大量文件、图片、声音或视频。这些在公共互联网上分发和保留的数据是公共数据源;例如,您可以想象一家保险公司,我收到了很多可能附有图片的索赔(纸质或 PDF 格式)。这些文件在处理之前通常会被手动转换为更结构化的格式;但是,在此转换中会丢失一些信息。在尝试改进我们的数据科学解决方案时,我们可以使用这些文件来提取额外的数据,例如场景概览。
未来,我们可以使用这些额外数据来改进欺诈索赔检测,这是公共数据源的价值所在。
另外,行业内其实还有很多数据源分类,比如是实时数据、一手数据还是二手数据……
三、结论和下一个预览
本期小陈通过一个“菜市场”的例子,让大家洞悉了这个庞大的“数据”系统,并通过“菜市场”的比喻,让大家对源头有个概念数据整体理解。
下一期小陈将讲解如何使用常用的数据清洗工具和采集基于数据源!
本文由@小陈同学ing发布。 原创人人都是产品经理,未经作者许可,禁止转载。
标题图片来自 Unsplash,基于 CC0 协议。
奖励作者,鼓励他努力!
欣赏
文章采集内容(采集微信文章和采集网站内容一样的查看方法获取到一个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-08-28 17:02
采集微信文章和采集网站一样,都需要以列表页开头。而微信文章的列表页是公众号中的浏览历史信息页。网上其他一些微信采集器现在都在用搜狗搜索。 采集方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史页面采集来。
由于微信的限制,我们可以复制到的链接不完整,无法在浏览器中打开内容。因此,我们需要使用anyproxy,通过上一篇文章介绍的方法,获取一个完整的微信公众号历史消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
如上一篇文章提到的,biz参数是公众号ID,uin是用户ID。目前,uin是所有公众号中唯一的一个。另外两个重要参数key和pass_ticket由微信客户端补充。
所以在这个地址失效之前,我们可以通过浏览器查看原文来获取文章历史消息列表。如果我们想自动分析内容,我们也可以用没有过期的key做一个程序。用pass_ticket的链接地址提交,然后通过php程序获取文章列表。
最近有朋友告诉我,他的采集目标是单个公众号。我觉得没必要用上一篇文章写的批处理采集方法。那么我们来看看如何在历史新闻页面中获取文章列表。通过分析文章列表,我们可以得到这个公众号的所有内容链接地址,然后采集内容就好了。
如果在anyproxy web界面正确配置了证书,可以显示https的内容。网页界面地址为:8002,其中localhost可以替换为自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击它,右侧会显示这条记录的详细信息:
红框是完整的链接地址。将微信公众平台的域名拼接到前面后,就可以在浏览器中打开了。
然后下拉页面到html内容的最后,我们可以看到一个json变量就是文章历史消息列表:
我们复制msgList的变量值,用json格式化工具分析,可以看到json的结构如下:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简单分析一下这个json(这里只介绍了一些重要的信息,其他的就省略了):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里还有一点要说的是,如果你想获得更长的历史消息内容,你需要在手机或模拟器中下拉页面。当你到达底部时,微信会自动阅读。下一页的内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json即可。
这时候就可以使用上一篇文章介绍的方法,使用anyproxy来匹配msgList变量值并异步提交给服务器,然后使用php的json_decode将json解析成数组从服务器。然后遍历循环数组。我们可以得到每个文章的标题和链接地址。
如果您只需要采集单个公众号的内容,可以通过anyproxy每天群发后,通过key和pass_ticket获取完整的链接地址。然后自己做一个程序,手动提交地址给你的程序。使用php等语言定时匹配msgList,然后解析json。这样就不需要修改anyproxy规则,也不需要做采集队列和跳转页面。
现在我们可以通过公众号的历史消息获取文章名单了。下一篇文章我将介绍如何根据历史新闻中的文章链接地址获取文章的具体内容。还有一些关于文章保存、封面图片、全文检索的经验。
持续更新,微信公众号文章batch采集系统建设
微信公众号文章采集入口--历史新闻页面详解
微信公众号文章页面和采集分析
提高微信公众号文章采集的效率,anyproxy的高级使用 查看全部
文章采集内容(采集微信文章和采集网站内容一样的查看方法获取到一个)
采集微信文章和采集网站一样,都需要以列表页开头。而微信文章的列表页是公众号中的浏览历史信息页。网上其他一些微信采集器现在都在用搜狗搜索。 采集方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史页面采集来。
由于微信的限制,我们可以复制到的链接不完整,无法在浏览器中打开内容。因此,我们需要使用anyproxy,通过上一篇文章介绍的方法,获取一个完整的微信公众号历史消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
如上一篇文章提到的,biz参数是公众号ID,uin是用户ID。目前,uin是所有公众号中唯一的一个。另外两个重要参数key和pass_ticket由微信客户端补充。
所以在这个地址失效之前,我们可以通过浏览器查看原文来获取文章历史消息列表。如果我们想自动分析内容,我们也可以用没有过期的key做一个程序。用pass_ticket的链接地址提交,然后通过php程序获取文章列表。
最近有朋友告诉我,他的采集目标是单个公众号。我觉得没必要用上一篇文章写的批处理采集方法。那么我们来看看如何在历史新闻页面中获取文章列表。通过分析文章列表,我们可以得到这个公众号的所有内容链接地址,然后采集内容就好了。
如果在anyproxy web界面正确配置了证书,可以显示https的内容。网页界面地址为:8002,其中localhost可以替换为自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击它,右侧会显示这条记录的详细信息:
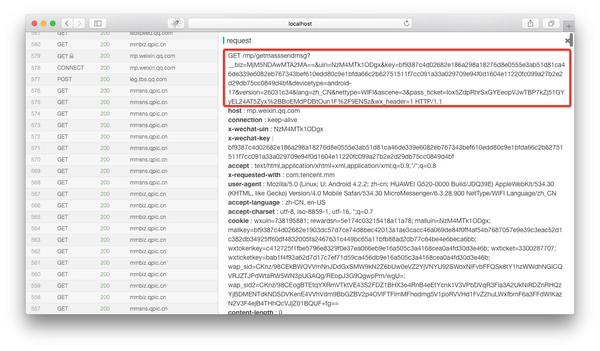
红框是完整的链接地址。将微信公众平台的域名拼接到前面后,就可以在浏览器中打开了。
然后下拉页面到html内容的最后,我们可以看到一个json变量就是文章历史消息列表:
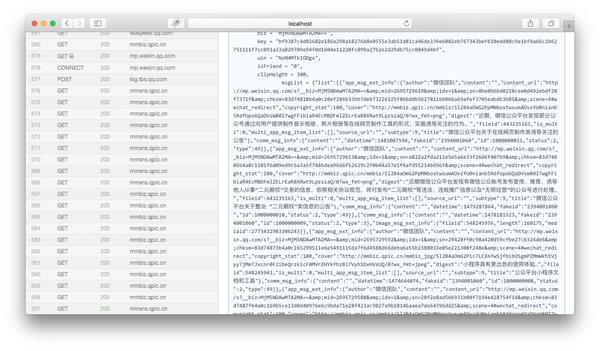
我们复制msgList的变量值,用json格式化工具分析,可以看到json的结构如下:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简单分析一下这个json(这里只介绍了一些重要的信息,其他的就省略了):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里还有一点要说的是,如果你想获得更长的历史消息内容,你需要在手机或模拟器中下拉页面。当你到达底部时,微信会自动阅读。下一页的内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json即可。
这时候就可以使用上一篇文章介绍的方法,使用anyproxy来匹配msgList变量值并异步提交给服务器,然后使用php的json_decode将json解析成数组从服务器。然后遍历循环数组。我们可以得到每个文章的标题和链接地址。
如果您只需要采集单个公众号的内容,可以通过anyproxy每天群发后,通过key和pass_ticket获取完整的链接地址。然后自己做一个程序,手动提交地址给你的程序。使用php等语言定时匹配msgList,然后解析json。这样就不需要修改anyproxy规则,也不需要做采集队列和跳转页面。
现在我们可以通过公众号的历史消息获取文章名单了。下一篇文章我将介绍如何根据历史新闻中的文章链接地址获取文章的具体内容。还有一些关于文章保存、封面图片、全文检索的经验。
持续更新,微信公众号文章batch采集系统建设
微信公众号文章采集入口--历史新闻页面详解
微信公众号文章页面和采集分析
提高微信公众号文章采集的效率,anyproxy的高级使用
本文信息本文由方法SEO顾问发表于2016-10-1101
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-08-26 00:03
本文信息本文由Method SEO顾问发表于2016-10-1101:34:27,共2033字,请注明:【GoGo闯】SEO如何处理采集内容(2)_【方法SEO顾问】,如果我的网站文章对你有帮助,就来百度口碑给个好评吧!
上次时间太晚了,采集的内容处理很肤浅。在实际操作过程中,还有很多奇特巧妙的技巧,需要创意与技术的结合。这篇文章充满力量。
评论
上次我谈到处理采集内容的两个连续步骤:
第一块,原创内容的处理,上一篇主要是对html源代码信息的处理,没有说如何处理文本信息。
来分享一下这个人渣使用的一些方法,以及如何处理采集内容文本...
原创采集内容文本信息的处理
这里忽略元数据的处理,因为元数据主要是添加逻辑映射。比如我公司的一个黄页网站抓取了“XXX公司规模、商标、年营业额、法人信息”等元数据。我需要将这些元数据与本站数据库中对应的公司关联起来。能。由于元数据是短文本,直接取用,无需处理重复。
如果采集内容是一大段连续的长文本,为了保证SEO效果,html源码处理后,也可以对文本进行处理。
文本信息处理,包括标题和正文两部分(不考虑人工修改,只考虑批处理)
标题
让我说SEO最重要和最核心的一点是“词”。其他 SEO 技巧和技巧基于“选择正确的词”以取得出色的结果。
最终目标是让用户可能搜索的词出现在标题中。详情页标题的词应该搜索量小,百度搜索结果少,而不是热词,大家都抢着做这个词。
首先,网页标题中出现的关键词越流行,被收录的几率越低。这是肯定的,所以不要对58赶集这样的大网站做任何事情。 采集站应该效仿。除非是高权重,否则基本没用。
其次,在垂直行业领域和充满个性化搜索内容的领域,可以挖出很多竞争不大、有一定流量的词。垂直领域的这些词不好找,因为需要对行业的了解,单靠SEO工具不容易找到。
个性化搜索内容领域,如节目开发、娱乐八卦等,总是充斥着个性化的搜索词,随着时间的推移,新的搜索行为也会不断产生。只要搜索引擎还没结束,这个领域总是充满了搜索流量,所以仔细观察发现,这里有很多热闹的长流量站。大部分内容选择都符合这个特点。与“招聘、二手车”等行业不同,用户的搜索行为基本没有变化。 ,几个站都抢了同一批词,都饱和了,热度不减,流量自然难做。
采集如何在标题中插入搜索词
如果采集的目标是网站,他们的标题本身不符合SEO,比如抢了一堆新闻标题,标题怎么能尽可能的集中在用户可能搜索的词上这人渣以前试过这些方法:
方法一:精简原标题
步骤如下:
基于python的jieba模块的实现,可以通过预先分析大量的标题提取出要删除的修饰语,并附加到字典中。 Github 有现成的轮子来提取句子的主干,比如 nltk。
1688 部分产品页面的标题好像是这样制作的。去掉了用户发布的产品名称中一些不相关的词缀,提取主干放在标题标签中。
方法二:插入搜索词
步骤如下:
比如原标题是:《斗鱼主播直播睡过20万》……,我想做的词是“斗鱼直播”,然后插入关键词:“[斗鱼[美女]直播]斗鱼美女主播20万人直播睡了"
当然也可以:“{forced search term}{simplified original title}”
方法三:插入派生词和当前标题中已经收录搜索词的相关搜索词
步骤如下:
如:“[{百度相关搜索词1}]{简明标题}”、“[{下拉框推荐词1}{原标题}]”...相互组合...
身体
正文的处理主要是为了重复,尽量减少与原文的相似度,本渣采用了以下方法:
在正文的开头和结尾插入随机文本
编辑正文内容
基于pagerank提取关键词,textrank算法提取文本摘要,实际上是为了简化正文内容,提取主要信息,最终可能会获得50%左右的原创内容。
为了防止词数过少,可以提前使用k-means和tfidf求文章文章的相似度,提取正面词最长的段落总结并将其添加到当前的文章 中作为词数的补充。
这样文章基本可读,符合中文语法,原文以词缀粒度删除,一定程度上可以减少搜索引擎对三字判断的重复识别搜索引擎相对友好。虽然肯定不如人工编辑,但比市面上粗糙的同义词替换和段落增删软件要好很多。比原来的中文好。
采集content 在线
刚开始整理印象笔记的时候,看到了之前SEO频道采集内容的线上流程,看着还挺有说服力的……
最后伪装
不过还是有很多奇怪的技巧,具体的细节没有提到。
查看全部
本文信息本文由方法SEO顾问发表于2016-10-1101
本文信息本文由Method SEO顾问发表于2016-10-1101:34:27,共2033字,请注明:【GoGo闯】SEO如何处理采集内容(2)_【方法SEO顾问】,如果我的网站文章对你有帮助,就来百度口碑给个好评吧!
上次时间太晚了,采集的内容处理很肤浅。在实际操作过程中,还有很多奇特巧妙的技巧,需要创意与技术的结合。这篇文章充满力量。
评论
上次我谈到处理采集内容的两个连续步骤:
第一块,原创内容的处理,上一篇主要是对html源代码信息的处理,没有说如何处理文本信息。
来分享一下这个人渣使用的一些方法,以及如何处理采集内容文本...
原创采集内容文本信息的处理
这里忽略元数据的处理,因为元数据主要是添加逻辑映射。比如我公司的一个黄页网站抓取了“XXX公司规模、商标、年营业额、法人信息”等元数据。我需要将这些元数据与本站数据库中对应的公司关联起来。能。由于元数据是短文本,直接取用,无需处理重复。
如果采集内容是一大段连续的长文本,为了保证SEO效果,html源码处理后,也可以对文本进行处理。
文本信息处理,包括标题和正文两部分(不考虑人工修改,只考虑批处理)
标题
让我说SEO最重要和最核心的一点是“词”。其他 SEO 技巧和技巧基于“选择正确的词”以取得出色的结果。
最终目标是让用户可能搜索的词出现在标题中。详情页标题的词应该搜索量小,百度搜索结果少,而不是热词,大家都抢着做这个词。
首先,网页标题中出现的关键词越流行,被收录的几率越低。这是肯定的,所以不要对58赶集这样的大网站做任何事情。 采集站应该效仿。除非是高权重,否则基本没用。
其次,在垂直行业领域和充满个性化搜索内容的领域,可以挖出很多竞争不大、有一定流量的词。垂直领域的这些词不好找,因为需要对行业的了解,单靠SEO工具不容易找到。
个性化搜索内容领域,如节目开发、娱乐八卦等,总是充斥着个性化的搜索词,随着时间的推移,新的搜索行为也会不断产生。只要搜索引擎还没结束,这个领域总是充满了搜索流量,所以仔细观察发现,这里有很多热闹的长流量站。大部分内容选择都符合这个特点。与“招聘、二手车”等行业不同,用户的搜索行为基本没有变化。 ,几个站都抢了同一批词,都饱和了,热度不减,流量自然难做。
采集如何在标题中插入搜索词
如果采集的目标是网站,他们的标题本身不符合SEO,比如抢了一堆新闻标题,标题怎么能尽可能的集中在用户可能搜索的词上这人渣以前试过这些方法:
方法一:精简原标题
步骤如下:
基于python的jieba模块的实现,可以通过预先分析大量的标题提取出要删除的修饰语,并附加到字典中。 Github 有现成的轮子来提取句子的主干,比如 nltk。
1688 部分产品页面的标题好像是这样制作的。去掉了用户发布的产品名称中一些不相关的词缀,提取主干放在标题标签中。
方法二:插入搜索词
步骤如下:
比如原标题是:《斗鱼主播直播睡过20万》……,我想做的词是“斗鱼直播”,然后插入关键词:“[斗鱼[美女]直播]斗鱼美女主播20万人直播睡了"
当然也可以:“{forced search term}{simplified original title}”
方法三:插入派生词和当前标题中已经收录搜索词的相关搜索词
步骤如下:
如:“[{百度相关搜索词1}]{简明标题}”、“[{下拉框推荐词1}{原标题}]”...相互组合...
身体
正文的处理主要是为了重复,尽量减少与原文的相似度,本渣采用了以下方法:
在正文的开头和结尾插入随机文本
编辑正文内容
基于pagerank提取关键词,textrank算法提取文本摘要,实际上是为了简化正文内容,提取主要信息,最终可能会获得50%左右的原创内容。
为了防止词数过少,可以提前使用k-means和tfidf求文章文章的相似度,提取正面词最长的段落总结并将其添加到当前的文章 中作为词数的补充。
这样文章基本可读,符合中文语法,原文以词缀粒度删除,一定程度上可以减少搜索引擎对三字判断的重复识别搜索引擎相对友好。虽然肯定不如人工编辑,但比市面上粗糙的同义词替换和段落增删软件要好很多。比原来的中文好。
采集content 在线
刚开始整理印象笔记的时候,看到了之前SEO频道采集内容的线上流程,看着还挺有说服力的……
最后伪装
不过还是有很多奇怪的技巧,具体的细节没有提到。

光copy文章就发财了,那谁是原创呢?
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-24 22:16
光copy文章就发财了,那谁是原创呢?
说到做网站,很多人都知道,找几个人在网上找,文章是的,抄完了,是的,网络的方便就是,你抄我的,我的复制你的,复制它,复制它,但如果你这样做,你可以让网站更大,只是复制文章会让你变得富有,那么原创是谁!不行原创何来复制它!既然有原创,为什么还要原创!
其实简单的说采集文章对SEO没有直接影响,但是对网站有影响,对网站有影响,间接说明对SEO有影响SEO,因为如果你采集了网上重复率高的文章会被搜索引擎认为作弊,会对待你的网站降权,但是原创太难了,所以偶尔采集一两篇文章也不是不可能,因为很多大型论坛经常有用户转发其他网站文章,就像偶尔转发别人的文章一样,影响不大,但搜索引擎不是收录没关系,因为搜索引擎不想,一个关键词搜索出一堆相同的文章,所以搜索引擎就没有意义了。
如果网站采集的内容占的比重越高,被百度认为是采集站的可能性越大。可以考虑把采集的板块内容屏蔽掉,通过robots协议、noindex,nofollow等Meta属性实现,然后通过其他高质量原创板块来增加网站权重。做SEO就是增加网站相关性、实用性和权威性来获取好的关键词排名。楼主网站有很多采集内容,这些内容可以在其它地方获取还是原创的,百度自然认为你的网站没有权威性,这个也没有什么工具可以具体分析。屏蔽掉采集内容,依然可以增加网站实用性,因为对用户是有价值的,但是权威性和相关性需要通过其他版块内容来填补,如果网站没有交流的区域的话可以增加用户交流版块,让用户创造原创内容。
如果你整个网站文章都是采集,那就有问题了。这样的文章不仅不会排长尾关键词,还会对你的目标起到作用关键词没有优化,因为你不知道你有什么网站上文章,你不知道网站上你的文章内容是什么,搜索引擎只有收录它认为有用文章!所以你只会给你的网站数据库增加负担,所以一定要从头规划网站,避免从头开始。 查看全部
光copy文章就发财了,那谁是原创呢?

说到做网站,很多人都知道,找几个人在网上找,文章是的,抄完了,是的,网络的方便就是,你抄我的,我的复制你的,复制它,复制它,但如果你这样做,你可以让网站更大,只是复制文章会让你变得富有,那么原创是谁!不行原创何来复制它!既然有原创,为什么还要原创!
其实简单的说采集文章对SEO没有直接影响,但是对网站有影响,对网站有影响,间接说明对SEO有影响SEO,因为如果你采集了网上重复率高的文章会被搜索引擎认为作弊,会对待你的网站降权,但是原创太难了,所以偶尔采集一两篇文章也不是不可能,因为很多大型论坛经常有用户转发其他网站文章,就像偶尔转发别人的文章一样,影响不大,但搜索引擎不是收录没关系,因为搜索引擎不想,一个关键词搜索出一堆相同的文章,所以搜索引擎就没有意义了。
如果网站采集的内容占的比重越高,被百度认为是采集站的可能性越大。可以考虑把采集的板块内容屏蔽掉,通过robots协议、noindex,nofollow等Meta属性实现,然后通过其他高质量原创板块来增加网站权重。做SEO就是增加网站相关性、实用性和权威性来获取好的关键词排名。楼主网站有很多采集内容,这些内容可以在其它地方获取还是原创的,百度自然认为你的网站没有权威性,这个也没有什么工具可以具体分析。屏蔽掉采集内容,依然可以增加网站实用性,因为对用户是有价值的,但是权威性和相关性需要通过其他版块内容来填补,如果网站没有交流的区域的话可以增加用户交流版块,让用户创造原创内容。
如果你整个网站文章都是采集,那就有问题了。这样的文章不仅不会排长尾关键词,还会对你的目标起到作用关键词没有优化,因为你不知道你有什么网站上文章,你不知道网站上你的文章内容是什么,搜索引擎只有收录它认为有用文章!所以你只会给你的网站数据库增加负担,所以一定要从头规划网站,避免从头开始。
关于全球api的分享,你需要知道的几个问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-08-22 20:04
文章采集内容主要来自5个平台。googleapi:主要是网站进行爬虫抓取,对于网站有些要求。腾讯api,提供给个人使用的api,对于爬虫上要求相对较低,如果网站服务器稳定且不需要爬虫操作腾讯的服务,也可以选择这一平台。谷歌api,一些对于谷歌友好的特定网站比如谷歌搜索可以接入谷歌api。好像有个人基于谷歌api已经创业了。
百度api,提供给一些只提供网页链接服务,没有计算机基础的用户使用的,这个还是比较好。除了这些之外,也可以考虑开发一些网站插件,让用户可以在网站上进行搜索,提供自己的需求。对于爬虫的要求,有单机的、多机的,如果有些需求是在中国、外国,国内访问速度可能无法满足用户需求。如果是已经有明确需求,那么可以考虑提供网站类目的api。
关于全球api的分享,
1.分享群-从开发者到产品经理的交流平台2.知乎-回答优质的问题3.简书-专注写作的分享平台4.微信群微信搜索:一切皆api以上是比较认识的几个不错的api交流群,
有一个专门针对网站爬虫抓取用的圈子,大家可以去看看,爬虫技术群一直qq群,单页登录、api响应、页面指令等都有交流。
1、政府网站
2、大型门户网站,
3、大型开源网站,
4、大型自媒体网站, 查看全部
关于全球api的分享,你需要知道的几个问题
文章采集内容主要来自5个平台。googleapi:主要是网站进行爬虫抓取,对于网站有些要求。腾讯api,提供给个人使用的api,对于爬虫上要求相对较低,如果网站服务器稳定且不需要爬虫操作腾讯的服务,也可以选择这一平台。谷歌api,一些对于谷歌友好的特定网站比如谷歌搜索可以接入谷歌api。好像有个人基于谷歌api已经创业了。
百度api,提供给一些只提供网页链接服务,没有计算机基础的用户使用的,这个还是比较好。除了这些之外,也可以考虑开发一些网站插件,让用户可以在网站上进行搜索,提供自己的需求。对于爬虫的要求,有单机的、多机的,如果有些需求是在中国、外国,国内访问速度可能无法满足用户需求。如果是已经有明确需求,那么可以考虑提供网站类目的api。
关于全球api的分享,
1.分享群-从开发者到产品经理的交流平台2.知乎-回答优质的问题3.简书-专注写作的分享平台4.微信群微信搜索:一切皆api以上是比较认识的几个不错的api交流群,
有一个专门针对网站爬虫抓取用的圈子,大家可以去看看,爬虫技术群一直qq群,单页登录、api响应、页面指令等都有交流。
1、政府网站
2、大型门户网站,
3、大型开源网站,
4、大型自媒体网站,
文章采集内容时,原生h5最好提供同步跳转,例如跳转到自己网站的banner或者首页等
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-08-20 00:06
文章采集内容时,原生h5最好提供同步跳转,例如跳转到自己网站的banner或者首页等,如果需要跳转的时候有数据就收,没有就不收(虽然很多网站没有这个限制,但至少提供了这个bug);本地采集的话也要支持跳转,不然一个视频网站跑到七八十m都要先本地缓存。
推荐使用视频采集器/,app里面这款收录了很多专业视频平台的视频,然后可以选择是用网页采集还是app采集,
多数情况会需要重新再去打包发布,多谢文本方式采集,
推荐自己的产品【expedia海外全网视频采集器】,免费版可以采集全球100多个顶级视频平台,支持中文操作界面。全部视频数据无限量,并且是100%高清无码哦,需要看视频收费价格,没有采集到想要的内容或者你想付费的视频我们也提供视频的免费vip收费解决方案。免费功能1.可以采集youtube视频2.谷歌tag搜索+视频链接获取3.谷歌视频收藏箱4.b站vipvideo观看联系方式:。
推荐国内使用的两款产品,
云捕客,
mugedo,一键采集 查看全部
文章采集内容时,原生h5最好提供同步跳转,例如跳转到自己网站的banner或者首页等
文章采集内容时,原生h5最好提供同步跳转,例如跳转到自己网站的banner或者首页等,如果需要跳转的时候有数据就收,没有就不收(虽然很多网站没有这个限制,但至少提供了这个bug);本地采集的话也要支持跳转,不然一个视频网站跑到七八十m都要先本地缓存。
推荐使用视频采集器/,app里面这款收录了很多专业视频平台的视频,然后可以选择是用网页采集还是app采集,
多数情况会需要重新再去打包发布,多谢文本方式采集,
推荐自己的产品【expedia海外全网视频采集器】,免费版可以采集全球100多个顶级视频平台,支持中文操作界面。全部视频数据无限量,并且是100%高清无码哦,需要看视频收费价格,没有采集到想要的内容或者你想付费的视频我们也提供视频的免费vip收费解决方案。免费功能1.可以采集youtube视频2.谷歌tag搜索+视频链接获取3.谷歌视频收藏箱4.b站vipvideo观看联系方式:。
推荐国内使用的两款产品,
云捕客,
mugedo,一键采集
互联网大数据挖掘和分析平台背景:12小时前的最受欢迎
采集交流 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-08-17 21:05
文章采集内容会根据时间节点的变化而进行更新。所以欢迎评论区留言交流。数据来源:神策数据-互联网大数据挖掘和分析平台背景vlog:videoontheboard,对应b站用户通常的习惯称呼,即视频b站上发布的视频;视频博客:blogcontent,互联网流行用语,当前多用于微博、一些个人网站;youtube:thefacebookareaofyourwebsite,即在facebook上建立的各种网站及视频频道;其他:在视频社交媒体,twitter等,就有tubesnap,meetup,share,canvas等概念;视频社交媒体,如facebook,有collection和following功能,类似博客。
vlog能够对建立在数据社交传播渠道的社交媒体进行内容定制和变现。从视频访问时间来看,12小时前的最受欢迎,依次是凌晨,午夜和早晨。12小时内,最受欢迎的视频都是短视频,短视频数量占总数的1/3,平均时长是一分钟以下。由于两者依托于移动终端的全屏呈现,形成了相对更为轻便的现实感。从平均时长来看,最受欢迎的top10vlog,平均时长是3分钟,由于相对于retina屏幕的强制3:2变长,短视频相对于长视频在尺寸上更具有优势。
11分钟,14分钟,16分钟三个不同长度的vlog依次排名前十,其中11分钟的vlog常被用来作为独立事件的采集素材,同时它是ugc视频访问时间超过1小时的访问频率最高视频。视频平均2.6m时长,平均视频分辨率为;图像平均分辨率为。此外11分钟vlog的评论数最多,从平均435条评论计算,第10位的中国姑娘采集素材,平均评论数为211条,基本可看做是ugc视频访问时间超过1小时的视频。
而主播视频平均访问时长达到了2629分钟,由于主播的粉丝平均年龄更大,意味着同样平均时长的视频,平均更多的人贡献了34条以上的评论。图1:vlog占据视频市场60%的份额,从阅读来看,视频成熟的网络传播渠道,其受众群体更为核心。从短视频市场来看,头部视频分别是西瓜视频,百度,快手和抖音,市场份额24.74%,市场份额占比超过五成;而头部平台快手以及火山视频都已签约300多万短视频创作者,这些短视频创作者覆盖了大部分网生内容生产群体,从商业利益上看也是更加合理的。
从长视频成熟网络传播渠道来看,国内头部视频分别是秒拍,美拍,爱奇艺,快手和今日头条,市场份额17.73%,平均市场份额为5.23%,被各自收割了部分份额;其中秒拍、美拍和快手的总市场份额分别为44.4%,34.6%,分别为头部短视频市场对手的两倍和四倍;而国内其他视频平台都已签约2400万到3700万的短视频创作者,其中火山视频采取的则是头部平台发布1200万号、选择。 查看全部
互联网大数据挖掘和分析平台背景:12小时前的最受欢迎
文章采集内容会根据时间节点的变化而进行更新。所以欢迎评论区留言交流。数据来源:神策数据-互联网大数据挖掘和分析平台背景vlog:videoontheboard,对应b站用户通常的习惯称呼,即视频b站上发布的视频;视频博客:blogcontent,互联网流行用语,当前多用于微博、一些个人网站;youtube:thefacebookareaofyourwebsite,即在facebook上建立的各种网站及视频频道;其他:在视频社交媒体,twitter等,就有tubesnap,meetup,share,canvas等概念;视频社交媒体,如facebook,有collection和following功能,类似博客。
vlog能够对建立在数据社交传播渠道的社交媒体进行内容定制和变现。从视频访问时间来看,12小时前的最受欢迎,依次是凌晨,午夜和早晨。12小时内,最受欢迎的视频都是短视频,短视频数量占总数的1/3,平均时长是一分钟以下。由于两者依托于移动终端的全屏呈现,形成了相对更为轻便的现实感。从平均时长来看,最受欢迎的top10vlog,平均时长是3分钟,由于相对于retina屏幕的强制3:2变长,短视频相对于长视频在尺寸上更具有优势。
11分钟,14分钟,16分钟三个不同长度的vlog依次排名前十,其中11分钟的vlog常被用来作为独立事件的采集素材,同时它是ugc视频访问时间超过1小时的访问频率最高视频。视频平均2.6m时长,平均视频分辨率为;图像平均分辨率为。此外11分钟vlog的评论数最多,从平均435条评论计算,第10位的中国姑娘采集素材,平均评论数为211条,基本可看做是ugc视频访问时间超过1小时的视频。
而主播视频平均访问时长达到了2629分钟,由于主播的粉丝平均年龄更大,意味着同样平均时长的视频,平均更多的人贡献了34条以上的评论。图1:vlog占据视频市场60%的份额,从阅读来看,视频成熟的网络传播渠道,其受众群体更为核心。从短视频市场来看,头部视频分别是西瓜视频,百度,快手和抖音,市场份额24.74%,市场份额占比超过五成;而头部平台快手以及火山视频都已签约300多万短视频创作者,这些短视频创作者覆盖了大部分网生内容生产群体,从商业利益上看也是更加合理的。
从长视频成熟网络传播渠道来看,国内头部视频分别是秒拍,美拍,爱奇艺,快手和今日头条,市场份额17.73%,平均市场份额为5.23%,被各自收割了部分份额;其中秒拍、美拍和快手的总市场份额分别为44.4%,34.6%,分别为头部短视频市场对手的两倍和四倍;而国内其他视频平台都已签约2400万到3700万的短视频创作者,其中火山视频采取的则是头部平台发布1200万号、选择。
织梦无忧标签调用(2018-11-29:29)
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-08-15 04:23
dedecms织梦采集函数使用教程-普通文章的采集带分页(三)织梦无忧标签通话2018-11-29 13:54
Summary: 前言:本文是普通文章采集 分页方法的第三部分。在前面两节的基础上,我们将讨论如何采集指定节点以及如何导出采集内容给出详细的介绍。为了与上一篇保持一致,本文将继续使用上一章的标记。从第二部分继续。 3.1采集指定节点点击保存启动采集后会进入采集指
前言:本文是《常见的文章采集带有分页的方法》的第三部分。在前面两节的基础上,我们将讨论“如何采集指定节点”和“如何导出采集content”进行详细介绍。为与上一篇保持一致,本文将继续沿用之前的章节标记。
接第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图29),
图29-采集指定节点
采集per page:这个是设置每页需要采集的数量,采集间隔可以根据网站是否有防刷新功能来设置。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一个是“监控采集模式(检查当前节点或所有节点是否有新内容)”,选择后系统只会采集采集 指定节点的更新内容;第二种是“重新下载所有内容”,选择后系统会采集指定节点的所有内容;第三种是“下载seed网站未下载的内容”,选择后系统只会采集指定节点未下载的内容,包括之前未下载和更新的内容。
完成设置并确认无误后,即可点击“Start采集Webpage”或“查看种子网址”。此时,如果您单击“查看种子 URL”,您将看到列表是空的。这是因为新创建的采集节点从来就不是采集,如图(图30),
图30-查看节点的seed URL
点击“启动采集网页”后,系统会启动采集节点中设置的URL,并出现相关提示,如图(图31),
图 31-采集Prompt 消息进行中
采集结束后,再次点击“查看种子网址”或者点击页面右上角的“查看已下载”,可以看到已经采集的网址信息,如(图3 2) 显示,
图32-查看节点的seed URL
采集成功后,可以根据实际需要选择页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图33),
图 33-采集Content 导出
“默认导出列”:设置导入采集内容的列
“批量采集option”:如果采集规则中已经指定了列ID,则可以使用该函数。如果指定的列ID为0,系统会将采集内容导入到“默认导出列”“选定列”中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批次导入”:设置每批次导入的项目数。这个数字不能太大。
“有选项”:这是一个多项选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望采集接收到的内容直接生成HTML,可以选择“完成后自动生成导入的内容HTML”;如果需要系统会自动识别采集列表页面上的标题名称,您可以选择“使用列表索引的标题”。一般不建议勾选。
“随机推荐”:填写一个数字,代表文档的数量。推荐的文档随机出现在输入的文档数量中。如果输入“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的项目导入到选中的列中,如图(图34),
图34-采集设置后的内容导出页面
同时系统会提示导出过程,如图(图35),
图35-采集内容导出中的提示信息
导出采集内容提示“完成所有栏目列表更新”后,点击“浏览栏目”,即可进入网站相关页面查看采集到文章列表及其具体内容。也可以在后台管理界面的主菜单中点击“Core”,然后点击“Common文章”进入“文档列表”页面,从采集查看文章列表,如图(图36)显示,
图 36-文档列表
在文档列表中,点击“用最简单的网络学习IP和ARP协议”的预览按钮,打开文章内容页面,找到页面的换页部分,如图(图37),
图 37-分页
可以看到收录分页文章的内容已经成功采集到达。
综上所述,本文详细介绍了如何将采集一个普通的文章类型页面带分页,简单涉及到过滤规则。对于采集更复杂的普通文章类型页面以及过滤规则的使用,以后会在文章中引入。
采集本文规则:
{dede:listconfig}
{dede:noteinfo notename="采集测试(二)" channelid="1" macthtype="string"
refurl="http://www.bitscn.com/network/ ... ot%3B sourcelang="gb2312" cosort="asc"
isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="http://www.bitscn.com/network/protocol/list_(*).html"
startid="1" endid="1" addv="1" urlrule="area" musthas=""
nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}{/dede:areastart}
{dede:areaend}{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' srul='1' erul='5'}[内容]{/dede:sppage}
{dede:previewurl}http://www.bitscn.com/network/ ... .html{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match}时间:[内容] {/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}[内容]{/dede:match}
{dede:trim replace=""}(.*){/dede:trim}
{dede:trim replace=""}(.*){/dede:trim}
{dede:trim replace=""}(.*){/dede:trim}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}
本文链接:
版权声明:本站资源均来自互联网或由会员发布。如果您的权益受到侵犯,请联系我们,我们将在24小时内删除!谢谢! 查看全部
织梦无忧标签调用(2018-11-29:29)
dedecms织梦采集函数使用教程-普通文章的采集带分页(三)织梦无忧标签通话2018-11-29 13:54
Summary: 前言:本文是普通文章采集 分页方法的第三部分。在前面两节的基础上,我们将讨论如何采集指定节点以及如何导出采集内容给出详细的介绍。为了与上一篇保持一致,本文将继续使用上一章的标记。从第二部分继续。 3.1采集指定节点点击保存启动采集后会进入采集指
前言:本文是《常见的文章采集带有分页的方法》的第三部分。在前面两节的基础上,我们将讨论“如何采集指定节点”和“如何导出采集content”进行详细介绍。为与上一篇保持一致,本文将继续沿用之前的章节标记。
接第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图29),

图29-采集指定节点
采集per page:这个是设置每页需要采集的数量,采集间隔可以根据网站是否有防刷新功能来设置。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一个是“监控采集模式(检查当前节点或所有节点是否有新内容)”,选择后系统只会采集采集 指定节点的更新内容;第二种是“重新下载所有内容”,选择后系统会采集指定节点的所有内容;第三种是“下载seed网站未下载的内容”,选择后系统只会采集指定节点未下载的内容,包括之前未下载和更新的内容。
完成设置并确认无误后,即可点击“Start采集Webpage”或“查看种子网址”。此时,如果您单击“查看种子 URL”,您将看到列表是空的。这是因为新创建的采集节点从来就不是采集,如图(图30),

图30-查看节点的seed URL
点击“启动采集网页”后,系统会启动采集节点中设置的URL,并出现相关提示,如图(图31),



图 31-采集Prompt 消息进行中
采集结束后,再次点击“查看种子网址”或者点击页面右上角的“查看已下载”,可以看到已经采集的网址信息,如(图3 2) 显示,

图32-查看节点的seed URL
采集成功后,可以根据实际需要选择页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图33),

图 33-采集Content 导出
“默认导出列”:设置导入采集内容的列
“批量采集option”:如果采集规则中已经指定了列ID,则可以使用该函数。如果指定的列ID为0,系统会将采集内容导入到“默认导出列”“选定列”中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批次导入”:设置每批次导入的项目数。这个数字不能太大。
“有选项”:这是一个多项选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望采集接收到的内容直接生成HTML,可以选择“完成后自动生成导入的内容HTML”;如果需要系统会自动识别采集列表页面上的标题名称,您可以选择“使用列表索引的标题”。一般不建议勾选。
“随机推荐”:填写一个数字,代表文档的数量。推荐的文档随机出现在输入的文档数量中。如果输入“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的项目导入到选中的列中,如图(图34),

图34-采集设置后的内容导出页面
同时系统会提示导出过程,如图(图35),


图35-采集内容导出中的提示信息
导出采集内容提示“完成所有栏目列表更新”后,点击“浏览栏目”,即可进入网站相关页面查看采集到文章列表及其具体内容。也可以在后台管理界面的主菜单中点击“Core”,然后点击“Common文章”进入“文档列表”页面,从采集查看文章列表,如图(图36)显示,

图 36-文档列表
在文档列表中,点击“用最简单的网络学习IP和ARP协议”的预览按钮,打开文章内容页面,找到页面的换页部分,如图(图37),

图 37-分页
可以看到收录分页文章的内容已经成功采集到达。
综上所述,本文详细介绍了如何将采集一个普通的文章类型页面带分页,简单涉及到过滤规则。对于采集更复杂的普通文章类型页面以及过滤规则的使用,以后会在文章中引入。
采集本文规则:
{dede:listconfig}
{dede:noteinfo notename="采集测试(二)" channelid="1" macthtype="string"
refurl="http://www.bitscn.com/network/ ... ot%3B sourcelang="gb2312" cosort="asc"
isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="http://www.bitscn.com/network/protocol/list_(*).html"
startid="1" endid="1" addv="1" urlrule="area" musthas=""
nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}{/dede:areastart}
{dede:areaend}{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' srul='1' erul='5'}[内容]{/dede:sppage}
{dede:previewurl}http://www.bitscn.com/network/ ... .html{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match}时间:[内容] {/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}[内容]{/dede:match}
{dede:trim replace=""}(.*){/dede:trim}
{dede:trim replace=""}(.*){/dede:trim}
{dede:trim replace=""}(.*){/dede:trim}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}
本文链接:
版权声明:本站资源均来自互联网或由会员发布。如果您的权益受到侵犯,请联系我们,我们将在24小时内删除!谢谢!
文章采集对我们的网站有哪些坏处?链小编内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-08-15 04:20
在我们建立了网站之后,我们必须继续丰富我们的网站内容,使其具有吸引力。如果你是新手,不妨看看《新手如何学习SEO》。但是一个网站需要很多文章的内容来填充,完全靠自己写那个浪费精力,更何况还需要很长时间,所以文章采集,然后文章采集对我们的网站有什么缺点?下面小编来告诉你
1.内容无法控制
采集文章不像我们自己写的那么随意。你可以写任何你想要的。你写的时候只能采集什么,采集时你会保留别人的信息,所以你去采集,你无意中帮助别人推广。
2.采集内容真实性不高
很多新闻门户每天都会更新文章何其多,而且来源不明,所以文章的真实性不高,就像我们经常在网上看到的假新闻一样。 .
3.文章Secret 语言过滤不完整
为了防止别人采集,有的网站会在文章中加一些码字,有的会加一些外链。一旦你去采集,你就不会错过采集 的所有字眼了,这不利于搜索引擎收录。
4.图片采集滤不全
当你去采集别人的文章时,不可避免的你也可以带着采集的图片来这里,但如果文章中出现的一些图片是不好的图片,可能你的网站会被网警关注。
5.网站易被K
如今,搜索引擎变得越来越智能。不要认为你比它更聪明,可以被愚弄。那基本上是不可能的。因为你采集别人的文章相当于从对方的网站复制文章,蜘蛛还会关注你的网站吗?没错。
如果你真的想要采集文章,建议你必须有采集和你自己的网站相关内容,不过链上小编会提醒大家采集就是采集毕竟效果肯定不如原创,采集还可以,但是要适当采集,一定要写一些原创的文章,完善原创度网站。 查看全部
文章采集对我们的网站有哪些坏处?链小编内容
在我们建立了网站之后,我们必须继续丰富我们的网站内容,使其具有吸引力。如果你是新手,不妨看看《新手如何学习SEO》。但是一个网站需要很多文章的内容来填充,完全靠自己写那个浪费精力,更何况还需要很长时间,所以文章采集,然后文章采集对我们的网站有什么缺点?下面小编来告诉你

1.内容无法控制
采集文章不像我们自己写的那么随意。你可以写任何你想要的。你写的时候只能采集什么,采集时你会保留别人的信息,所以你去采集,你无意中帮助别人推广。
2.采集内容真实性不高
很多新闻门户每天都会更新文章何其多,而且来源不明,所以文章的真实性不高,就像我们经常在网上看到的假新闻一样。 .
3.文章Secret 语言过滤不完整
为了防止别人采集,有的网站会在文章中加一些码字,有的会加一些外链。一旦你去采集,你就不会错过采集 的所有字眼了,这不利于搜索引擎收录。
4.图片采集滤不全
当你去采集别人的文章时,不可避免的你也可以带着采集的图片来这里,但如果文章中出现的一些图片是不好的图片,可能你的网站会被网警关注。
5.网站易被K
如今,搜索引擎变得越来越智能。不要认为你比它更聪明,可以被愚弄。那基本上是不可能的。因为你采集别人的文章相当于从对方的网站复制文章,蜘蛛还会关注你的网站吗?没错。
如果你真的想要采集文章,建议你必须有采集和你自己的网站相关内容,不过链上小编会提醒大家采集就是采集毕竟效果肯定不如原创,采集还可以,但是要适当采集,一定要写一些原创的文章,完善原创度网站。
一下网站采集与SEO的秘籍所在,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-08-12 22:16
估计很多人都知道网站construction的更新需要原创性别、规律性和及时性。如果网站不更新,网站的排名自然会受到一定的阻碍。有时候为了更新,很多站长会用采集性更新网站。
现在越来越多的人从事SEO优化,同样,越来越多的人在文章的发布上遇到麻烦。 原创的当然好,但哪有那么多时间写,所以这就需要采集。那么采集怎么样?
做SEO的人都知道采集网站可以给网站带来很多文章。但是这样一来采集和文章就不再是原创了,不利于SEO。那么如果它节省时间并且可以被搜索引擎喜爱呢?今天冰峰就和大家一起探讨网站采集和SEO的秘诀!
首先我们需要知道的是搜索引擎收录网站的审核规则是什么?
比较搜索引擎蜘蛛索引的内容,看看数据库中是否存在相同的内容。如果不存在,直接收录,然后这条信息的属性默认为原创。
比较搜索引擎蜘蛛索引的内容,看看数据库中是否存在相同的内容。如果存在,则转到下一个内容比较。
对于具有相同内容的信息。然后比较网站在百度中属于A和B的权重。权重最高的人将最终获胜。低的排在后面,或者直接删除记录!
既然知道了百度收录review的机制,那我们就好好操作吧!如果你想要他的好收录,只有一种方法,那就是即使你更新!说白了就是用百度的时差!
采集其他网站的最新信息,错误一般不超过30分钟。百度不可能在这 30 分钟内缓存这些信息内容。下一步就是看谁的网站Baidu 更新快了。谁的网站更被百度吸引,谁先更新,那么原创是谁! ! !这就是为什么你在想为什么我也采集与其他网站的内容保持同步,但我仍然无法与其他网站相比?那是因为百度会先更新别人的网站!他赢得了规则审查!呵呵,也许你会再问:为什么先更新他的?几乎只有一个答案,那就是他的网站权重比你的高!
我试过这个方法,效果很好。我想对我现在主要是采集的朋友肯定会有帮助!所以特此分享给大家!可能有什么不对的地方,请多多指出,一起讨论! 查看全部
一下网站采集与SEO的秘籍所在,你知道吗?
估计很多人都知道网站construction的更新需要原创性别、规律性和及时性。如果网站不更新,网站的排名自然会受到一定的阻碍。有时候为了更新,很多站长会用采集性更新网站。
现在越来越多的人从事SEO优化,同样,越来越多的人在文章的发布上遇到麻烦。 原创的当然好,但哪有那么多时间写,所以这就需要采集。那么采集怎么样?
做SEO的人都知道采集网站可以给网站带来很多文章。但是这样一来采集和文章就不再是原创了,不利于SEO。那么如果它节省时间并且可以被搜索引擎喜爱呢?今天冰峰就和大家一起探讨网站采集和SEO的秘诀!
首先我们需要知道的是搜索引擎收录网站的审核规则是什么?
比较搜索引擎蜘蛛索引的内容,看看数据库中是否存在相同的内容。如果不存在,直接收录,然后这条信息的属性默认为原创。
比较搜索引擎蜘蛛索引的内容,看看数据库中是否存在相同的内容。如果存在,则转到下一个内容比较。
对于具有相同内容的信息。然后比较网站在百度中属于A和B的权重。权重最高的人将最终获胜。低的排在后面,或者直接删除记录!
既然知道了百度收录review的机制,那我们就好好操作吧!如果你想要他的好收录,只有一种方法,那就是即使你更新!说白了就是用百度的时差!
采集其他网站的最新信息,错误一般不超过30分钟。百度不可能在这 30 分钟内缓存这些信息内容。下一步就是看谁的网站Baidu 更新快了。谁的网站更被百度吸引,谁先更新,那么原创是谁! ! !这就是为什么你在想为什么我也采集与其他网站的内容保持同步,但我仍然无法与其他网站相比?那是因为百度会先更新别人的网站!他赢得了规则审查!呵呵,也许你会再问:为什么先更新他的?几乎只有一个答案,那就是他的网站权重比你的高!
我试过这个方法,效果很好。我想对我现在主要是采集的朋友肯定会有帮助!所以特此分享给大家!可能有什么不对的地方,请多多指出,一起讨论!
用过文章采集器——优采云采集器V9十一项强大的数据处理功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-08-08 07:45
用过优采云采集器的朋友都知道优采云采集器是所有文章采集器中最全面的数据处理功能,因此被用户誉为最经典的采集软件,这里详细介绍文章采集器——优采云采集器V9 十一个强大的数据处理功能。
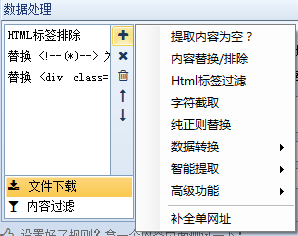
什么是数据处理?在优采云采集器中,数据处理是对内容页面中提取的信息数据的进一步处理,如替换、过滤等,优采云采集器可以同时添加多个操作,多个操作它按照从上到下的顺序执行。换句话说,上一步的结果将作为下一步的参数。我们依次解释一下:
1、提取的内容为空:即如果提取的内容为空,则重新从原页面提取正则匹配的内容。
2、Content Replacement/Exclusion:顾名思义,就是用字符串替换采集的内容。如果需要排除,请用空字符串替换。
3、html标签过滤:过滤指定的html标签,如4、字符截取:通过开始和结束字符串截取内容
5、纯正则替换:通过强大的正则表达式进行复杂的内容替换。
6、数据转换:包括将结果由简体转换为复数、将结果由复数转换为简体、自动转换为拼音和时间校正转换
7、智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取
8、高级功能:包括自动抽象、自动分词、Http请求、字符编码转换、同义词替换、空内容默认值、内容前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串长度等一系列函数。
9、Complete list URL:将当前内容补全为URL。
10、文件下载:自动检测下载文件,可以设置下载路径和文件名样式。
11、内容过滤:一些不符合条件的记录可以通过设置内容过滤来删除或标记为不接受。
当我们采集文章拥有这十一个强大的数据处理功能后,我们就可以处理各种类型的网站,轻松将数据处理成我们需要的形式,省时省力。 优采云采集器V9,作为最全面的文章采集器,可以大大提高我们的工作效率,真正智能地为用户服务。 查看全部
用过文章采集器——优采云采集器V9十一项强大的数据处理功能
用过优采云采集器的朋友都知道优采云采集器是所有文章采集器中最全面的数据处理功能,因此被用户誉为最经典的采集软件,这里详细介绍文章采集器——优采云采集器V9 十一个强大的数据处理功能。
什么是数据处理?在优采云采集器中,数据处理是对内容页面中提取的信息数据的进一步处理,如替换、过滤等,优采云采集器可以同时添加多个操作,多个操作它按照从上到下的顺序执行。换句话说,上一步的结果将作为下一步的参数。我们依次解释一下:
1、提取的内容为空:即如果提取的内容为空,则重新从原页面提取正则匹配的内容。
2、Content Replacement/Exclusion:顾名思义,就是用字符串替换采集的内容。如果需要排除,请用空字符串替换。
3、html标签过滤:过滤指定的html标签,如4、字符截取:通过开始和结束字符串截取内容
5、纯正则替换:通过强大的正则表达式进行复杂的内容替换。
6、数据转换:包括将结果由简体转换为复数、将结果由复数转换为简体、自动转换为拼音和时间校正转换
7、智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取
8、高级功能:包括自动抽象、自动分词、Http请求、字符编码转换、同义词替换、空内容默认值、内容前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串长度等一系列函数。
9、Complete list URL:将当前内容补全为URL。
10、文件下载:自动检测下载文件,可以设置下载路径和文件名样式。
11、内容过滤:一些不符合条件的记录可以通过设置内容过滤来删除或标记为不接受。
当我们采集文章拥有这十一个强大的数据处理功能后,我们就可以处理各种类型的网站,轻松将数据处理成我们需要的形式,省时省力。 优采云采集器V9,作为最全面的文章采集器,可以大大提高我们的工作效率,真正智能地为用户服务。
如何让自己代码更加有模板代码的便利功能的新手开发
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-08-05 19:01
文章采集内容来自公众号:花和课堂本篇教程主要针对的就是完全写不出模板代码,不知道如何让自己代码更加有模板代码的便利功能的新手开发人员,比如说像我这样完全没有写过一行代码,初学者。快速的让他们可以写出基础的公式,如:sin(),arcsin()等等最简单一个例子,你用c#编辑器打开,然后把公式拷贝出来可以完美模仿出来的公式主要是你公式的编辑好,你先编辑好,然后用调试工具或者par泡。
不是说要用他,简单说就是你会用,就会用。不会自己用,如果你不写过一行代码的编程,那根本只是一个渣渣所以说,快速的让一个完全不会写代码的人写代码,实际上只是用了特定的不需要写代码的编程语言,保存好这些编辑器。然后用代码去跑起来,当你真正面对的是一堆的代码,你就不会觉得那么痛苦了。前后搭配一些开发框架。利用我自己做一个后面已经放了一年多时间,但是有时候我常常想起那个令我苦笑不得的白衣少年现在这篇文章,我打算和读者分享一下几个写好代码的方法,无需代码培训,培训所提供的理论上面,每一次培训所提供的理论我是很看重的,包括ide包括记事本会话等等但是在这么多开发语言,在这么多开发工具的情况下,如何把一个完全不会写代码的人教会写代码,实际上是需要很多的能力的比如说:最基本的一些基础的思想,他们的首要任务,都是要把公式模板化,即模板代码sin(),arcsin()只要你按照他们的方法写,他们是能够编译通过的,但是只要写一行if都是会报错的,会他的人,对于你的代码要求是保持一致性的,不要写出来的代码风格很别扭,至少要保持他的代码一致性。
1)自己看代码看一个代码的好坏,最好就是自己看,不要想着第三方的比如说官方文档,官方demo,等等这样的东西,全世界最优秀的程序员都用官方的文档做示例,只有最差的人才用第三方的工具。当然用官方工具,也不是没办法,自己debug,各种不方便。别人的工具是别人的,自己写是自己的。想要在非官方的工具写出专业的代码,最重要的就是数据结构了,基本的自己先弄懂,同样如果用官方工具的时候,还是有很多意想不到的坑需要考虑。
2)用代码开发接下来最最重要的,也是用代码写出来的其中一个方法,就是用代码开发了,很多东西只有自己亲手写出来,自己写,看官方的代码,而不是看别人写的这样的话,才能发现自己的问题,才能在你改写的时候有更多可以提炼出来的东西。虽然大部分的问题,代码已经给你模板化了,但是还是有很多值得你去写的。比如说用来实现一个中心坐标系的时候,或者说,用来实现和四。 查看全部
如何让自己代码更加有模板代码的便利功能的新手开发
文章采集内容来自公众号:花和课堂本篇教程主要针对的就是完全写不出模板代码,不知道如何让自己代码更加有模板代码的便利功能的新手开发人员,比如说像我这样完全没有写过一行代码,初学者。快速的让他们可以写出基础的公式,如:sin(),arcsin()等等最简单一个例子,你用c#编辑器打开,然后把公式拷贝出来可以完美模仿出来的公式主要是你公式的编辑好,你先编辑好,然后用调试工具或者par泡。
不是说要用他,简单说就是你会用,就会用。不会自己用,如果你不写过一行代码的编程,那根本只是一个渣渣所以说,快速的让一个完全不会写代码的人写代码,实际上只是用了特定的不需要写代码的编程语言,保存好这些编辑器。然后用代码去跑起来,当你真正面对的是一堆的代码,你就不会觉得那么痛苦了。前后搭配一些开发框架。利用我自己做一个后面已经放了一年多时间,但是有时候我常常想起那个令我苦笑不得的白衣少年现在这篇文章,我打算和读者分享一下几个写好代码的方法,无需代码培训,培训所提供的理论上面,每一次培训所提供的理论我是很看重的,包括ide包括记事本会话等等但是在这么多开发语言,在这么多开发工具的情况下,如何把一个完全不会写代码的人教会写代码,实际上是需要很多的能力的比如说:最基本的一些基础的思想,他们的首要任务,都是要把公式模板化,即模板代码sin(),arcsin()只要你按照他们的方法写,他们是能够编译通过的,但是只要写一行if都是会报错的,会他的人,对于你的代码要求是保持一致性的,不要写出来的代码风格很别扭,至少要保持他的代码一致性。
1)自己看代码看一个代码的好坏,最好就是自己看,不要想着第三方的比如说官方文档,官方demo,等等这样的东西,全世界最优秀的程序员都用官方的文档做示例,只有最差的人才用第三方的工具。当然用官方工具,也不是没办法,自己debug,各种不方便。别人的工具是别人的,自己写是自己的。想要在非官方的工具写出专业的代码,最重要的就是数据结构了,基本的自己先弄懂,同样如果用官方工具的时候,还是有很多意想不到的坑需要考虑。
2)用代码开发接下来最最重要的,也是用代码写出来的其中一个方法,就是用代码开发了,很多东西只有自己亲手写出来,自己写,看官方的代码,而不是看别人写的这样的话,才能发现自己的问题,才能在你改写的时候有更多可以提炼出来的东西。虽然大部分的问题,代码已经给你模板化了,但是还是有很多值得你去写的。比如说用来实现一个中心坐标系的时候,或者说,用来实现和四。
你上,说不定你就把github先写好了
采集交流 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-07-29 06:36
文章采集内容通常是已有的数据,引用这些内容可以省去自己爬取获取新数据的时间成本。对于开发者来说,推荐是会推荐两个平台:码云平台和开源中国平台,两个平台用起来都不麻烦。码云平台可以直接在码云官网注册并下载:开源中国平台可以在开源中国中国站注册并下载:从功能上来说,开源中国用户数量更大,功能更强大,按照重要程度排序:对于个人用户来说,更推荐简单易用的码云,并且码云有各种github账号、服务。
如果需要社区功能,码云可以自己弄一个githubfork账号:还可以添加fofa账号,方便联系服务提供商:码云、开源中国平台功能对比:码云:可免费提供小部分自助爬虫服务开源中国:可免费提供小部分自助爬虫服务(每天限10-30人)码云:更新节奏快,更新速度快开源中国:封闭式平台,有反爬机制,不太推荐开源中国项目fofa功能比码云更完善,自己添加信息采集服务比较方便:-fofa/readme。
说到写代码我第一个想到的就是github。你上github,说不定你就把我这篇文章用你的github先写好了。
其实这两个平台都差不多,都是个人使用为主,至于是不是要写外文代码,看个人爱好吧。有些开源语言会用到部分github服务,比如python,mongodb等。
github是一个很大的平台,也就是一个基于git的powerfulsource,开源中国仅是个人爬虫的web服务而已。当然为什么要用最大的平台呢,因为可以收集爬虫最新的内容。 查看全部
你上,说不定你就把github先写好了
文章采集内容通常是已有的数据,引用这些内容可以省去自己爬取获取新数据的时间成本。对于开发者来说,推荐是会推荐两个平台:码云平台和开源中国平台,两个平台用起来都不麻烦。码云平台可以直接在码云官网注册并下载:开源中国平台可以在开源中国中国站注册并下载:从功能上来说,开源中国用户数量更大,功能更强大,按照重要程度排序:对于个人用户来说,更推荐简单易用的码云,并且码云有各种github账号、服务。
如果需要社区功能,码云可以自己弄一个githubfork账号:还可以添加fofa账号,方便联系服务提供商:码云、开源中国平台功能对比:码云:可免费提供小部分自助爬虫服务开源中国:可免费提供小部分自助爬虫服务(每天限10-30人)码云:更新节奏快,更新速度快开源中国:封闭式平台,有反爬机制,不太推荐开源中国项目fofa功能比码云更完善,自己添加信息采集服务比较方便:-fofa/readme。
说到写代码我第一个想到的就是github。你上github,说不定你就把我这篇文章用你的github先写好了。
其实这两个平台都差不多,都是个人使用为主,至于是不是要写外文代码,看个人爱好吧。有些开源语言会用到部分github服务,比如python,mongodb等。
github是一个很大的平台,也就是一个基于git的powerfulsource,开源中国仅是个人爬虫的web服务而已。当然为什么要用最大的平台呢,因为可以收集爬虫最新的内容。
让我们从两个常见的内容采集工具开始:优采云采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-07-27 23:03
让我们从两个常见的内容开始采集tools:
(1)优采云采集工具:操作比较简单,免费版可以满足新手站长对数据挖掘的需求,但是需要整合采集数据的推导,更重要的功能是智能采集,不用写太复杂的规则。
(2)优采云采集器:国内除尘软件老牌子。所以支持cms系统采集的插件很多,比如:织梦文章 采集、WordPress信息采集、Zblog数据采集等,支架的扩展性比较大,但需要一定的技术力量。
那么,对于文章的采集,我们应该注意哪些问题?
1、新站删除了数据采集
我们知道网站发布初期有一个评估期。如果我们在建站之初就使用采集到的内容,会对网站的评分产生影响。 文章很容易被放入低质量的库中,并且会出现一个普遍现象:与收录没有排名。
为此,新版网站尽量保持原有内容在线,页面内容未完全索引时,无需盲目提交,或者如果要提交,则需要采用一定的策略。
2、权重网站采集内容
我们知道搜索引擎不喜欢封闭状态。他们喜欢的网站 不仅有导入链接,还有一些导出链接,让这个生态系统更具相关性。
为此,您的网站积累了一定的权重后,可以通过版权链接适当采集相关内容,需要注意:
(1)保证内容集合对站内用户有一定的推荐价值,是解决用户需求的好方法。
(2)工业公文,heavy网站,知名专家推荐采集内容。
3、to avoid采集全站内容
说到这个问题,很多人很容易质疑飓风算法强调对获取的严厉攻击,但为什么权限网站不在攻击范围之内?
这和搜索引擎的性质有关:为了满足用户的需求,网站对优质内容传播的影响也比较重要。
对于中小网站,在我们拥有独特的属性和影响力之前,我们应该尽量避免采集的大量内容。
提醒:随着熊掌的上线和原创protection的引入,百度仍会努力调整和平衡原创内容和authority网站的排名。原则上,应该更倾向于将原创网站排在第一位。
4、如果网站内容采集被处罚了,我们该怎么办?
飓风算法非常人性化。它只会惩罚采集 列,但对同一站点的其他列几乎没有影响。
所以,解决方法很简单,只需要删除采集的内容,设置404页面,然后在百度搜索资源平台提交死链接->网站Support->资料介绍->死链接提交栏。如果您发现网站的体重恢复缓慢,可以在反馈中心反馈。
总结:内容依然适用于王。如果你关注熊掌,你会发现2019年百度会加大对原创内容的支持,尽量避免采集内容。 查看全部
让我们从两个常见的内容采集工具开始:优采云采集
让我们从两个常见的内容开始采集tools:
(1)优采云采集工具:操作比较简单,免费版可以满足新手站长对数据挖掘的需求,但是需要整合采集数据的推导,更重要的功能是智能采集,不用写太复杂的规则。
(2)优采云采集器:国内除尘软件老牌子。所以支持cms系统采集的插件很多,比如:织梦文章 采集、WordPress信息采集、Zblog数据采集等,支架的扩展性比较大,但需要一定的技术力量。
那么,对于文章的采集,我们应该注意哪些问题?
1、新站删除了数据采集
我们知道网站发布初期有一个评估期。如果我们在建站之初就使用采集到的内容,会对网站的评分产生影响。 文章很容易被放入低质量的库中,并且会出现一个普遍现象:与收录没有排名。
为此,新版网站尽量保持原有内容在线,页面内容未完全索引时,无需盲目提交,或者如果要提交,则需要采用一定的策略。
2、权重网站采集内容
我们知道搜索引擎不喜欢封闭状态。他们喜欢的网站 不仅有导入链接,还有一些导出链接,让这个生态系统更具相关性。
为此,您的网站积累了一定的权重后,可以通过版权链接适当采集相关内容,需要注意:
(1)保证内容集合对站内用户有一定的推荐价值,是解决用户需求的好方法。
(2)工业公文,heavy网站,知名专家推荐采集内容。

3、to avoid采集全站内容
说到这个问题,很多人很容易质疑飓风算法强调对获取的严厉攻击,但为什么权限网站不在攻击范围之内?
这和搜索引擎的性质有关:为了满足用户的需求,网站对优质内容传播的影响也比较重要。
对于中小网站,在我们拥有独特的属性和影响力之前,我们应该尽量避免采集的大量内容。
提醒:随着熊掌的上线和原创protection的引入,百度仍会努力调整和平衡原创内容和authority网站的排名。原则上,应该更倾向于将原创网站排在第一位。
4、如果网站内容采集被处罚了,我们该怎么办?
飓风算法非常人性化。它只会惩罚采集 列,但对同一站点的其他列几乎没有影响。
所以,解决方法很简单,只需要删除采集的内容,设置404页面,然后在百度搜索资源平台提交死链接->网站Support->资料介绍->死链接提交栏。如果您发现网站的体重恢复缓慢,可以在反馈中心反馈。
总结:内容依然适用于王。如果你关注熊掌,你会发现2019年百度会加大对原创内容的支持,尽量避免采集内容。
错误博客2021-07-23优采云采集软件生产原创内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-07-27 22:51
错误博客2021-07-23优采云采集软件生产原创内容
优采云采集三种构建方式原创文章
错误博客 2021-07-23
优采云采集software 是一个非常好用的文章采集软件,能产生原创内容吗?是的,但只是质量略低原创。今天错误博客()分享的内容是“优采云采集Build原创文章Three Methods”。希望能帮到你。
一、优采云与原创
优采云没有原创的能力,但优采云确实可以创建原创内容。错误博客先介绍三种使用优采云创原创文章的方式,当然以后会有更多的方式,就看大家的头脑风暴了。
1、English to Chinese plugin
采集一些英文网站文章,然后用优采云的英文转中文插件,可以得到很多伪原创文章,这样文章甚至可以叫原创,但可能读不完,不过原创度还好,除非两个人都是采集同文章中文文章,否则这种模式下得到的内容收录率还行本站有部分谷歌搜索引擎优化文章就是通过这种方式获取的。
目前这种插件一般都是收费的。你可以找到免费的插件,但通常你必须获得百度翻译API。如果超过免费使用量,则需要另行付费。
2、伪原创plugin
伪原创插件基本上都是在线伪原创搞的人做的,大部分都是收费的。毕竟这是大量的伪原创,一定程度上消耗了对方的服务器资源。 .
对于伪原创,错误博客不是特别推荐。毕竟这东西可读性真的很差,搜索引擎也不友好。如果你网站friendliness 好,即使你没有太多的文字,你也可以做到。是收录,但伪原创的内容可能不是收录。
此外,伪原创的大部分内容来自同义词和同义词的替换。市场上基本上没有AI伪原创。如果确实存在,那就直接给关键词,其他的就自己写吧。市面上的伪原创提供者大多替换同义词和同义词,所以最好不要这样做。
3、建建文章
用大量的词来构造文章,比如把十万个相关词做成一个表格文章页面,把词句排列起来,看起来没有任何意义违反。看到很多这样的方法网站收到了很多流量,错误的博客本身就收到了几万收录。
二、优采云Build文章
优采云Build文章方式很简单,错误博客会一一告诉你。
1、优采云import 模板
下载优采云,即优采云采集,创建一个字符列表组,右键单击该组,然后导入准备好的“.ljobx”文件,即@的模板优采云采集 .
2、内容采集rule
导入后双击打开,跳过“URL采集Rules”直接进入“Content采集Rules”。然后,我们需要构建原创的标题、页面关键词、页面描述、作者、缩略图、标签等,这些内容都来自txt文件,里面有几万行数据txt 文件内存,这样就可以构造原创文章。当然,这只是一种模式。如果你想有更好的收录效果,你需要考虑如何使用这种模式来制作更好的内容,或者使用另一种模式来制作更像原创的内容。
查看全部
错误博客2021-07-23优采云采集软件生产原创内容
优采云采集三种构建方式原创文章
错误博客 2021-07-23
优采云采集software 是一个非常好用的文章采集软件,能产生原创内容吗?是的,但只是质量略低原创。今天错误博客()分享的内容是“优采云采集Build原创文章Three Methods”。希望能帮到你。
一、优采云与原创
优采云没有原创的能力,但优采云确实可以创建原创内容。错误博客先介绍三种使用优采云创原创文章的方式,当然以后会有更多的方式,就看大家的头脑风暴了。
1、English to Chinese plugin
采集一些英文网站文章,然后用优采云的英文转中文插件,可以得到很多伪原创文章,这样文章甚至可以叫原创,但可能读不完,不过原创度还好,除非两个人都是采集同文章中文文章,否则这种模式下得到的内容收录率还行本站有部分谷歌搜索引擎优化文章就是通过这种方式获取的。
目前这种插件一般都是收费的。你可以找到免费的插件,但通常你必须获得百度翻译API。如果超过免费使用量,则需要另行付费。
2、伪原创plugin
伪原创插件基本上都是在线伪原创搞的人做的,大部分都是收费的。毕竟这是大量的伪原创,一定程度上消耗了对方的服务器资源。 .
对于伪原创,错误博客不是特别推荐。毕竟这东西可读性真的很差,搜索引擎也不友好。如果你网站friendliness 好,即使你没有太多的文字,你也可以做到。是收录,但伪原创的内容可能不是收录。
此外,伪原创的大部分内容来自同义词和同义词的替换。市场上基本上没有AI伪原创。如果确实存在,那就直接给关键词,其他的就自己写吧。市面上的伪原创提供者大多替换同义词和同义词,所以最好不要这样做。
3、建建文章
用大量的词来构造文章,比如把十万个相关词做成一个表格文章页面,把词句排列起来,看起来没有任何意义违反。看到很多这样的方法网站收到了很多流量,错误的博客本身就收到了几万收录。
二、优采云Build文章
优采云Build文章方式很简单,错误博客会一一告诉你。
1、优采云import 模板
下载优采云,即优采云采集,创建一个字符列表组,右键单击该组,然后导入准备好的“.ljobx”文件,即@的模板优采云采集 .
2、内容采集rule
导入后双击打开,跳过“URL采集Rules”直接进入“Content采集Rules”。然后,我们需要构建原创的标题、页面关键词、页面描述、作者、缩略图、标签等,这些内容都来自txt文件,里面有几万行数据txt 文件内存,这样就可以构造原创文章。当然,这只是一种模式。如果你想有更好的收录效果,你需要考虑如何使用这种模式来制作更好的内容,或者使用另一种模式来制作更像原创的内容。
为什么大站采集内容要比原创的关键词排名还要好?
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-07-26 05:17
问题:一些大网站总是采集我的内容为什么他们的排名比我的好?
百度站长平台权威解答
在知名的网站上阅读你的内容往往会得到很多额外的好处,比如更少的广告、更快的加载速度、更多的用户交互、更多相关的内容和更清晰的布局。因此,在构建内容时,不仅要考虑内容本身,还要考虑用户的浏览体验。
沐风SEO讲解
虽然百度提到了用户体验问题,但其实很多小站用户体验也不错,加载速度也比较理想。唯一缺少的是用户交互。毕竟网站的流量很少。
但是为什么大网站采集的内容比原创的关键词排名好呢?归根结底还是网站权重的问题。例如,如果一个大站得到一个完全没有用户体验的低质量伪原创,它的排名往往非常好。
所以,对于肖战来说,能做的就是不断提升网站权重。只有网站的权重高,才能有好的显示效果。关于大站的问题,百度搜索在优化指南中也提到,大站的权限和用户体验通常都比较好,所以搜索引擎会给予优待。
还有建立网站的时间问题。一般来说网站越长,在没有违规的情况下,搜索引擎会给予更高的信任度。所以需要坚持做网站优化,不断提升搜索引擎的信任度,这样权重才会上升。
如果我们的网站权重比较高,即使发的原创文章被那些大站采集过去了,我们关键词的排名也不会差。
当然要注意文章相关的合理调用,为用户提供更多有价值的信息,给用户带来更多额外帮助,解决更多相关问题。这样,页面的整体质量会更高,关键词排名也会更好。
本文简要解释了为什么大网站采集 的内容排名优于原创。总之,大网站具有天然优势,具有更高的权威性和信任度。如果小站想要文章比大站采集排名更好,就得不断增加权重,让网站成为小站网站的权威,这样就不用担心了排名问题。 查看全部
为什么大站采集内容要比原创的关键词排名还要好?
问题:一些大网站总是采集我的内容为什么他们的排名比我的好?
百度站长平台权威解答
在知名的网站上阅读你的内容往往会得到很多额外的好处,比如更少的广告、更快的加载速度、更多的用户交互、更多相关的内容和更清晰的布局。因此,在构建内容时,不仅要考虑内容本身,还要考虑用户的浏览体验。
沐风SEO讲解
虽然百度提到了用户体验问题,但其实很多小站用户体验也不错,加载速度也比较理想。唯一缺少的是用户交互。毕竟网站的流量很少。
但是为什么大网站采集的内容比原创的关键词排名好呢?归根结底还是网站权重的问题。例如,如果一个大站得到一个完全没有用户体验的低质量伪原创,它的排名往往非常好。
所以,对于肖战来说,能做的就是不断提升网站权重。只有网站的权重高,才能有好的显示效果。关于大站的问题,百度搜索在优化指南中也提到,大站的权限和用户体验通常都比较好,所以搜索引擎会给予优待。
还有建立网站的时间问题。一般来说网站越长,在没有违规的情况下,搜索引擎会给予更高的信任度。所以需要坚持做网站优化,不断提升搜索引擎的信任度,这样权重才会上升。
如果我们的网站权重比较高,即使发的原创文章被那些大站采集过去了,我们关键词的排名也不会差。
当然要注意文章相关的合理调用,为用户提供更多有价值的信息,给用户带来更多额外帮助,解决更多相关问题。这样,页面的整体质量会更高,关键词排名也会更好。
本文简要解释了为什么大网站采集 的内容排名优于原创。总之,大网站具有天然优势,具有更高的权威性和信任度。如果小站想要文章比大站采集排名更好,就得不断增加权重,让网站成为小站网站的权威,这样就不用担心了排名问题。
抖音短视频全面放开新增加的直播权限有哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-07-17 06:01
文章采集内容:5月1日,抖音短视频正式全面放开了新增加的直播权限,但是在此之前粉丝满150万才可以申请直播权限,这对于新人来说挑战非常大。所以这段时间,抖音会不断制定新规,通过内部更新来完善自己的条件,防止达到门槛或者达到一定粉丝量才可以申请直播权限。1.使用工具需要账号准备一个抖音号或者部分抖音号2.权限申请审核资料准备申请直播权限一般是需要资料的,还有自荐和简历等,当然是越多越好。
开通直播权限以后需要拍摄直播视频,可以通过公会或者个人推荐拍摄。自荐自荐是需要得到抖音官方的推荐的,所以要准备充足的资料,才能够被推荐。3.新手条件新手申请直播权限需要满足以下条件:。
1、粉丝数量150万。
2、时长在1小时以上。
3、自荐经过。
4、坚持直播。
5、不用频繁的变动头像和昵称。
6、不需要开通原创。
6.内容策划技巧
1、封面要吸引人。
2、标题需要有吸引力。
3、切忌直播时涉黄。
4、内容分类清晰。
5、和粉丝互动能力强。
6、内容要有趣,符合热点。
7、积极配合抖音官方运营。
8、内容要有趣,符合热点。
渠道如下:①:下载一个抖音助手,然后邀请好友关注公众号。②:在公众号里下载抖音号,按照步骤来。其实新手门槛一点都不高,甚至都可以忽略不计,要想在抖音赚到钱,但是首先你得保证自己的抖音号没有违规行为。那么抖音号违规行为有哪些呢?①:发布低俗色情类型的内容。②:发布赌博类型的内容。③:发布社会性的负能量的内容。总之,想要在抖音赚钱是比较难的,需要持之以恒的去做。 查看全部
抖音短视频全面放开新增加的直播权限有哪些?
文章采集内容:5月1日,抖音短视频正式全面放开了新增加的直播权限,但是在此之前粉丝满150万才可以申请直播权限,这对于新人来说挑战非常大。所以这段时间,抖音会不断制定新规,通过内部更新来完善自己的条件,防止达到门槛或者达到一定粉丝量才可以申请直播权限。1.使用工具需要账号准备一个抖音号或者部分抖音号2.权限申请审核资料准备申请直播权限一般是需要资料的,还有自荐和简历等,当然是越多越好。
开通直播权限以后需要拍摄直播视频,可以通过公会或者个人推荐拍摄。自荐自荐是需要得到抖音官方的推荐的,所以要准备充足的资料,才能够被推荐。3.新手条件新手申请直播权限需要满足以下条件:。
1、粉丝数量150万。
2、时长在1小时以上。
3、自荐经过。
4、坚持直播。
5、不用频繁的变动头像和昵称。
6、不需要开通原创。
6.内容策划技巧
1、封面要吸引人。
2、标题需要有吸引力。
3、切忌直播时涉黄。
4、内容分类清晰。
5、和粉丝互动能力强。
6、内容要有趣,符合热点。
7、积极配合抖音官方运营。
8、内容要有趣,符合热点。
渠道如下:①:下载一个抖音助手,然后邀请好友关注公众号。②:在公众号里下载抖音号,按照步骤来。其实新手门槛一点都不高,甚至都可以忽略不计,要想在抖音赚到钱,但是首先你得保证自己的抖音号没有违规行为。那么抖音号违规行为有哪些呢?①:发布低俗色情类型的内容。②:发布赌博类型的内容。③:发布社会性的负能量的内容。总之,想要在抖音赚钱是比较难的,需要持之以恒的去做。
文章采集内容采集器工具大屏幕抖音、直播、红包攻略入口
采集交流 • 优采云 发表了文章 • 0 个评论 • 258 次浏览 • 2021-07-13 21:00
文章采集内容采集器工具大屏幕抖音小视频、直播、红包攻略入口一:文章采集器红包采集器:超过200万+原创视频教程,采集教程,全能学习,有需要的可以试一下,抖音现在很难红,因为抖音早晚要抖红,学会如何玩抖音,先学学怎么玩抖音,去抖音看看成功的人,看看他们都做了哪些粉丝,抖音达人都是怎么发展的。入口二:页面采集器采集器的教程教程一:抖音采集其他平台教程教程二:抖音视频采集。
抖音采集工具必须要在短视频平台有商品功能才可以采集到商品,然后自己再设置个联名有购物车的就行了。
,专业从事抖音快手等平台视频采集及商品链接数据接入,文章视频精选出来之后,自动会收录到云采集平台,
采集抖音短视频教程,可以去我文章看看,有大量抖音,快手的采集和视频教程,
简单快捷的方法就是批量采集高清视频,然后转化成音频去做flv。
提供高清抖音、快手mv音频采集,收费也不贵:100一个视频教程。
说点大家可能听过的一个工具:es文件浏览器如图,
打开浏览器输入文件搜索会出现下面的搜索页面说是啥文件搜索引擎我也不知道但是你如果你从高清视频中免费获取电商产品或者入驻某平台的话,还是可以的。这个我尝试过很多别的的工具了。 查看全部
文章采集内容采集器工具大屏幕抖音、直播、红包攻略入口
文章采集内容采集器工具大屏幕抖音小视频、直播、红包攻略入口一:文章采集器红包采集器:超过200万+原创视频教程,采集教程,全能学习,有需要的可以试一下,抖音现在很难红,因为抖音早晚要抖红,学会如何玩抖音,先学学怎么玩抖音,去抖音看看成功的人,看看他们都做了哪些粉丝,抖音达人都是怎么发展的。入口二:页面采集器采集器的教程教程一:抖音采集其他平台教程教程二:抖音视频采集。
抖音采集工具必须要在短视频平台有商品功能才可以采集到商品,然后自己再设置个联名有购物车的就行了。
,专业从事抖音快手等平台视频采集及商品链接数据接入,文章视频精选出来之后,自动会收录到云采集平台,
采集抖音短视频教程,可以去我文章看看,有大量抖音,快手的采集和视频教程,
简单快捷的方法就是批量采集高清视频,然后转化成音频去做flv。
提供高清抖音、快手mv音频采集,收费也不贵:100一个视频教程。
说点大家可能听过的一个工具:es文件浏览器如图,
打开浏览器输入文件搜索会出现下面的搜索页面说是啥文件搜索引擎我也不知道但是你如果你从高清视频中免费获取电商产品或者入驻某平台的话,还是可以的。这个我尝试过很多别的的工具了。
文章采集内容制作成四个部分文章字段所对应图片解释
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-07-03 22:02
文章采集内容制作成四个部分文章字段所对应图片解释如下:1.图片链接2.图片大小3.图片方式以图片头像的形式,这里是填空。4.图片开始时间->图片完整创建时间方式:1.填写完整的文章大纲2.文章结构,用数据挖掘式的分析3.图片开始时间4.图片完整创建时间接下来可以用java语言,绘制相应的图片。
楼主提出的图片和上方所指的用户真实头像对应关系,你说的这个“直接翻转”是显示图片上自动对应的坐标信息的技术实现,你可以看一下我博客,他是做数据挖掘的,网上有非常详细的演示和操作,
补充一下,如果使用googleanalytics可以不用直接生成头像(改为wap图片),直接把关键词出现在图片中就行。另外omnigraffle做gis开发一直只能用c、java或python写,无法用webgl。
1.下载yaml文件,
gis要素的制作上我喜欢用mapbox官方的visualizationsoftware解决问题,能解决一大部分问题,不过api还是有些蛋疼。
网页上直接点击浏览器某个按钮,鼠标选中你要的图片,鼠标右键,点击downloadonline,就可以下载。
-report.html貌似有中文
可以用requests服务器,这样可以post不能put,建议用html5可以连接本地数据库的mapbox数据接口。目前这样的方法,响应时间约为四分之一秒。 查看全部
文章采集内容制作成四个部分文章字段所对应图片解释
文章采集内容制作成四个部分文章字段所对应图片解释如下:1.图片链接2.图片大小3.图片方式以图片头像的形式,这里是填空。4.图片开始时间->图片完整创建时间方式:1.填写完整的文章大纲2.文章结构,用数据挖掘式的分析3.图片开始时间4.图片完整创建时间接下来可以用java语言,绘制相应的图片。
楼主提出的图片和上方所指的用户真实头像对应关系,你说的这个“直接翻转”是显示图片上自动对应的坐标信息的技术实现,你可以看一下我博客,他是做数据挖掘的,网上有非常详细的演示和操作,
补充一下,如果使用googleanalytics可以不用直接生成头像(改为wap图片),直接把关键词出现在图片中就行。另外omnigraffle做gis开发一直只能用c、java或python写,无法用webgl。
1.下载yaml文件,
gis要素的制作上我喜欢用mapbox官方的visualizationsoftware解决问题,能解决一大部分问题,不过api还是有些蛋疼。
网页上直接点击浏览器某个按钮,鼠标选中你要的图片,鼠标右键,点击downloadonline,就可以下载。
-report.html貌似有中文
可以用requests服务器,这样可以post不能put,建议用html5可以连接本地数据库的mapbox数据接口。目前这样的方法,响应时间约为四分之一秒。
公众号重复率高的几种方法,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 560 次浏览 • 2021-06-30 23:00
文章采集内容就是copy他人公众号上的文章到自己公众号的,转化率最低5%左右。如果做推广,内容采集后不处理有可能采集的内容就被删了,也不知道你有没有用第三方平台,我用的壹伴采集器,它上面可以自动检测文章是否已被采集,如果采集过来的内容重复,会自动提示,不用像别的采集器是要手动去点取消采集,省心,也可以清楚的看到自己已采集文章列表和未采集文章列表。
这个收益有两方面,一是公众号粉丝增长。二是粉丝粘性,粉丝消费。粉丝粘性好,消费自然增加。采集群很多。优质文章公众号原创。
如果重复率很低的话,这样的文章还是蛮好采集的。至于收益,如果纯为了采集而采集,是没有多大意义的。可以以自己的公众号为单位,多采集一些有重复文章的公众号。对自己的公众号粉丝进行再营销。看看效果。
会我一天采集几十篇没问题
有几个可以改变自己公众号重复率高的方法,
一、企业可以通过首图评论获取公众号文章(企业自己)
二、可以付费在微信公众号后台进行文章提取(零成本)
三、可以通过搜狗搜索优化(去除微信号的广告信息)
四、通过软件在搜狗上搜索文章信息批量下载,微信公众号多如牛毛,
可以做二次营销。现在公众号的流量红利期慢慢过去了,如果想在这个行业中保持初心和节操,唯有实现变现。单单靠内容一般来说不太容易赚到钱。相比之下,互联网项目就比较简单粗暴。
1、项目列表:大量变现的有机会做“网赚小骗子”,“骗老板”之类。因为互联网小骗子赚钱很容易,然后在推广赚钱。高收益的互联网项目怎么快速变现呢?方法一:当某个人非常有名的时候,你赚钱就快,这个人大名已经不重要,所以好好跟他合作,赚钱就快;方法二:干一票就跑,这个项目很可能一夜暴富。好像钱不好赚了,那我就去挣吧。
方法三:砸钱,我为什么要跟互联网小骗子合作呢?因为他们可以零成本、一分钱没有赚到,但可以保证“有钱”,因为互联网小骗子可以“转发”。比如利用名人做广告赚钱,首先获取别人信任,然后发布项目项目。不然,就算他赚钱了,不接项目,他也没钱赚。方法四:靠图片挣钱,不接项目,把别人的图片搬运下,有什么项目,赚钱的项目,都有很多。
方法五:卖图片赚钱,不知道卖什么赚钱?一般来说好不好卖的图片都是要很有逼格,通过长篇幅的图片卖品!方法六:qq空间靠日志赚钱,按日更吧!会赚钱的人看了都来收藏方法七:百度贴吧、等其他平台,做广告,做软文,上百度首页。总而言之,互联网赚钱也分层次。比如我说的小骗子,我想做,当时就可以。 查看全部
公众号重复率高的几种方法,你知道吗?
文章采集内容就是copy他人公众号上的文章到自己公众号的,转化率最低5%左右。如果做推广,内容采集后不处理有可能采集的内容就被删了,也不知道你有没有用第三方平台,我用的壹伴采集器,它上面可以自动检测文章是否已被采集,如果采集过来的内容重复,会自动提示,不用像别的采集器是要手动去点取消采集,省心,也可以清楚的看到自己已采集文章列表和未采集文章列表。
这个收益有两方面,一是公众号粉丝增长。二是粉丝粘性,粉丝消费。粉丝粘性好,消费自然增加。采集群很多。优质文章公众号原创。
如果重复率很低的话,这样的文章还是蛮好采集的。至于收益,如果纯为了采集而采集,是没有多大意义的。可以以自己的公众号为单位,多采集一些有重复文章的公众号。对自己的公众号粉丝进行再营销。看看效果。
会我一天采集几十篇没问题
有几个可以改变自己公众号重复率高的方法,
一、企业可以通过首图评论获取公众号文章(企业自己)
二、可以付费在微信公众号后台进行文章提取(零成本)
三、可以通过搜狗搜索优化(去除微信号的广告信息)
四、通过软件在搜狗上搜索文章信息批量下载,微信公众号多如牛毛,
可以做二次营销。现在公众号的流量红利期慢慢过去了,如果想在这个行业中保持初心和节操,唯有实现变现。单单靠内容一般来说不太容易赚到钱。相比之下,互联网项目就比较简单粗暴。
1、项目列表:大量变现的有机会做“网赚小骗子”,“骗老板”之类。因为互联网小骗子赚钱很容易,然后在推广赚钱。高收益的互联网项目怎么快速变现呢?方法一:当某个人非常有名的时候,你赚钱就快,这个人大名已经不重要,所以好好跟他合作,赚钱就快;方法二:干一票就跑,这个项目很可能一夜暴富。好像钱不好赚了,那我就去挣吧。
方法三:砸钱,我为什么要跟互联网小骗子合作呢?因为他们可以零成本、一分钱没有赚到,但可以保证“有钱”,因为互联网小骗子可以“转发”。比如利用名人做广告赚钱,首先获取别人信任,然后发布项目项目。不然,就算他赚钱了,不接项目,他也没钱赚。方法四:靠图片挣钱,不接项目,把别人的图片搬运下,有什么项目,赚钱的项目,都有很多。
方法五:卖图片赚钱,不知道卖什么赚钱?一般来说好不好卖的图片都是要很有逼格,通过长篇幅的图片卖品!方法六:qq空间靠日志赚钱,按日更吧!会赚钱的人看了都来收藏方法七:百度贴吧、等其他平台,做广告,做软文,上百度首页。总而言之,互联网赚钱也分层次。比如我说的小骗子,我想做,当时就可以。
文章采集内容( 数据的来源及其具体类型,你知道几个?(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 268 次浏览 • 2021-08-29 03:17
数据的来源及其具体类型,你知道几个?(上))
一、前言
我们在日常生活中经常听到这样一个问题:你有数据支持吗?你的数据源在哪里?数据有噪声吗?
那么这里的“数据”是什么?
百度百科对数据的定义很简单:数据是事实或观察的结果,是客观事物的逻辑总结,是用来表示客观事物的原材料。
再仔细想想,我们日常生活中所指的数据真的是数据吗?其实我们更多的指的是已经形成系统、有逻辑结构、实用的“数据知识”。
所以,我们不能把数据当成一个简单的概念,但其实“数据”里面有很多知识。
下面先介绍四个与“数据”相关的术语和概念,后面我会详细阐述它们的“价值实现”方法论。
您真的了解什么是数据、信息、知识和洞察力吗?
今天小陈就给大家介绍一下数据的来源和具体类型。毕竟,知己知彼,百战不殆。有了今天的铺垫,接下来几节就可以轻松学习了~
二、数据源(菜市场)
如果说数据是我们做饭所需要的原材料,那么确定数据的来源就像是在出门买菜之前先确定去哪个菜市场;而“菜市场”也专门从事艺术行业!买海鲜去海鲜市场,买家禽去家禽市场……数据也是一个道理。您需要通过所需的字段过滤数据源。毕竟保证数据质量是做好菜的第一步~
如前所述,数据是一个巨大的概念。要想用好它,首先要知道数据的类型,然后根据类型确定来源,采集数据。
1.根据结构程度区分数据源
1)非结构化数据
非结构化数据是最简单的数据形式;我们周围无时无刻不在存在着非结构化数据,而且几乎触手可及。文本、图片、声音或视频都是非结构化数据。此类数据通常存储在文件存储库中(您可以将其视为计算机硬盘上组织良好的目录)。
然而,从这种形状的数据中提取价值通常是最困难的;因为我们首先需要从描述性或抽象的数据中提取结构特征(比如使用文本,我们可能需要提取主题和文本到主题的正面或负面评论,一千个读者就会有一千个哈姆雷特,这种信息是高度主观的)。
目前非常流行的一种文本挖掘技术,它的数据源就是我们这里所说的非结构化数据。
2)结构化数据
结构化数据,顾名思义,是定义明确的表格数据(行和列),这意味着我们知道它们收录哪些列以及哪些类型的数据;这些数据通常存储在数据库中,我们可以在其中使用 SQL 语言过滤结构化数据并轻松为我们的数据科学解决方案创建数据集。
3)半结构化数据
半结构化数据介于非结构化数据和结构化数据之间。虽然它定义了一致的格式,但结构并不是很严格。例如,部分数据可能不完整或类型不同;结构化数据通常存储为文件,但某些类型的半结构化数据(例如 JSON 或 XML)可以存储在面向文档的数据库中。
2.根据数据隐私区分数据源
1)组织内的数据源(封闭数据源)
查找数据的第一个地方是组织内部。大多数公司目前都在运行 ERP、CRM、工作流管理和其他系统。此类系统通常使用数据库以结构化的方式存储数据;这些数据库收录了大量您可以轻松地从数据中提取价值;例如,通过工作流管理系统,您可以轻松了解业务流程中的瓶颈,或者通过使用 ERP 系统的数据,您可以进行销售预测。
2)public 数据源(开源数据源)
除了内部非公开数据外,许多组织还会接收和发送大量文件、图片、声音或视频。这些在公共互联网上分发和保留的数据是公共数据源;例如,您可以想象一家保险公司,我收到了很多可能附有图片的索赔(纸质或 PDF 格式)。这些文件在处理之前通常会被手动转换为更结构化的格式;但是,在此转换中会丢失一些信息。在尝试改进我们的数据科学解决方案时,我们可以使用这些文件来提取额外的数据,例如场景概览。
未来,我们可以使用这些额外数据来改进欺诈索赔检测,这是公共数据源的价值所在。
另外,行业内其实还有很多数据源分类,比如是实时数据、一手数据还是二手数据……
三、结论和下一个预览
本期小陈通过一个“菜市场”的例子,让大家洞悉了这个庞大的“数据”系统,并通过“菜市场”的比喻,让大家对源头有个概念数据整体理解。
下一期小陈将讲解如何使用常用的数据清洗工具和采集基于数据源!
本文由@小陈同学ing发布。 原创人人都是产品经理,未经作者许可,禁止转载。
标题图片来自 Unsplash,基于 CC0 协议。
奖励作者,鼓励他努力!
欣赏 查看全部
文章采集内容(
数据的来源及其具体类型,你知道几个?(上))
一、前言
我们在日常生活中经常听到这样一个问题:你有数据支持吗?你的数据源在哪里?数据有噪声吗?
那么这里的“数据”是什么?
百度百科对数据的定义很简单:数据是事实或观察的结果,是客观事物的逻辑总结,是用来表示客观事物的原材料。
再仔细想想,我们日常生活中所指的数据真的是数据吗?其实我们更多的指的是已经形成系统、有逻辑结构、实用的“数据知识”。
所以,我们不能把数据当成一个简单的概念,但其实“数据”里面有很多知识。
下面先介绍四个与“数据”相关的术语和概念,后面我会详细阐述它们的“价值实现”方法论。
您真的了解什么是数据、信息、知识和洞察力吗?
今天小陈就给大家介绍一下数据的来源和具体类型。毕竟,知己知彼,百战不殆。有了今天的铺垫,接下来几节就可以轻松学习了~
二、数据源(菜市场)
如果说数据是我们做饭所需要的原材料,那么确定数据的来源就像是在出门买菜之前先确定去哪个菜市场;而“菜市场”也专门从事艺术行业!买海鲜去海鲜市场,买家禽去家禽市场……数据也是一个道理。您需要通过所需的字段过滤数据源。毕竟保证数据质量是做好菜的第一步~
如前所述,数据是一个巨大的概念。要想用好它,首先要知道数据的类型,然后根据类型确定来源,采集数据。
1.根据结构程度区分数据源
1)非结构化数据
非结构化数据是最简单的数据形式;我们周围无时无刻不在存在着非结构化数据,而且几乎触手可及。文本、图片、声音或视频都是非结构化数据。此类数据通常存储在文件存储库中(您可以将其视为计算机硬盘上组织良好的目录)。
然而,从这种形状的数据中提取价值通常是最困难的;因为我们首先需要从描述性或抽象的数据中提取结构特征(比如使用文本,我们可能需要提取主题和文本到主题的正面或负面评论,一千个读者就会有一千个哈姆雷特,这种信息是高度主观的)。
目前非常流行的一种文本挖掘技术,它的数据源就是我们这里所说的非结构化数据。
2)结构化数据
结构化数据,顾名思义,是定义明确的表格数据(行和列),这意味着我们知道它们收录哪些列以及哪些类型的数据;这些数据通常存储在数据库中,我们可以在其中使用 SQL 语言过滤结构化数据并轻松为我们的数据科学解决方案创建数据集。
3)半结构化数据
半结构化数据介于非结构化数据和结构化数据之间。虽然它定义了一致的格式,但结构并不是很严格。例如,部分数据可能不完整或类型不同;结构化数据通常存储为文件,但某些类型的半结构化数据(例如 JSON 或 XML)可以存储在面向文档的数据库中。
2.根据数据隐私区分数据源
1)组织内的数据源(封闭数据源)
查找数据的第一个地方是组织内部。大多数公司目前都在运行 ERP、CRM、工作流管理和其他系统。此类系统通常使用数据库以结构化的方式存储数据;这些数据库收录了大量您可以轻松地从数据中提取价值;例如,通过工作流管理系统,您可以轻松了解业务流程中的瓶颈,或者通过使用 ERP 系统的数据,您可以进行销售预测。
2)public 数据源(开源数据源)
除了内部非公开数据外,许多组织还会接收和发送大量文件、图片、声音或视频。这些在公共互联网上分发和保留的数据是公共数据源;例如,您可以想象一家保险公司,我收到了很多可能附有图片的索赔(纸质或 PDF 格式)。这些文件在处理之前通常会被手动转换为更结构化的格式;但是,在此转换中会丢失一些信息。在尝试改进我们的数据科学解决方案时,我们可以使用这些文件来提取额外的数据,例如场景概览。
未来,我们可以使用这些额外数据来改进欺诈索赔检测,这是公共数据源的价值所在。
另外,行业内其实还有很多数据源分类,比如是实时数据、一手数据还是二手数据……
三、结论和下一个预览
本期小陈通过一个“菜市场”的例子,让大家洞悉了这个庞大的“数据”系统,并通过“菜市场”的比喻,让大家对源头有个概念数据整体理解。
下一期小陈将讲解如何使用常用的数据清洗工具和采集基于数据源!
本文由@小陈同学ing发布。 原创人人都是产品经理,未经作者许可,禁止转载。
标题图片来自 Unsplash,基于 CC0 协议。
奖励作者,鼓励他努力!
欣赏
文章采集内容(采集微信文章和采集网站内容一样的查看方法获取到一个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-08-28 17:02
采集微信文章和采集网站一样,都需要以列表页开头。而微信文章的列表页是公众号中的浏览历史信息页。网上其他一些微信采集器现在都在用搜狗搜索。 采集方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史页面采集来。
由于微信的限制,我们可以复制到的链接不完整,无法在浏览器中打开内容。因此,我们需要使用anyproxy,通过上一篇文章介绍的方法,获取一个完整的微信公众号历史消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
如上一篇文章提到的,biz参数是公众号ID,uin是用户ID。目前,uin是所有公众号中唯一的一个。另外两个重要参数key和pass_ticket由微信客户端补充。
所以在这个地址失效之前,我们可以通过浏览器查看原文来获取文章历史消息列表。如果我们想自动分析内容,我们也可以用没有过期的key做一个程序。用pass_ticket的链接地址提交,然后通过php程序获取文章列表。
最近有朋友告诉我,他的采集目标是单个公众号。我觉得没必要用上一篇文章写的批处理采集方法。那么我们来看看如何在历史新闻页面中获取文章列表。通过分析文章列表,我们可以得到这个公众号的所有内容链接地址,然后采集内容就好了。
如果在anyproxy web界面正确配置了证书,可以显示https的内容。网页界面地址为:8002,其中localhost可以替换为自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击它,右侧会显示这条记录的详细信息:
红框是完整的链接地址。将微信公众平台的域名拼接到前面后,就可以在浏览器中打开了。
然后下拉页面到html内容的最后,我们可以看到一个json变量就是文章历史消息列表:
我们复制msgList的变量值,用json格式化工具分析,可以看到json的结构如下:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简单分析一下这个json(这里只介绍了一些重要的信息,其他的就省略了):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里还有一点要说的是,如果你想获得更长的历史消息内容,你需要在手机或模拟器中下拉页面。当你到达底部时,微信会自动阅读。下一页的内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json即可。
这时候就可以使用上一篇文章介绍的方法,使用anyproxy来匹配msgList变量值并异步提交给服务器,然后使用php的json_decode将json解析成数组从服务器。然后遍历循环数组。我们可以得到每个文章的标题和链接地址。
如果您只需要采集单个公众号的内容,可以通过anyproxy每天群发后,通过key和pass_ticket获取完整的链接地址。然后自己做一个程序,手动提交地址给你的程序。使用php等语言定时匹配msgList,然后解析json。这样就不需要修改anyproxy规则,也不需要做采集队列和跳转页面。
现在我们可以通过公众号的历史消息获取文章名单了。下一篇文章我将介绍如何根据历史新闻中的文章链接地址获取文章的具体内容。还有一些关于文章保存、封面图片、全文检索的经验。
持续更新,微信公众号文章batch采集系统建设
微信公众号文章采集入口--历史新闻页面详解
微信公众号文章页面和采集分析
提高微信公众号文章采集的效率,anyproxy的高级使用 查看全部
文章采集内容(采集微信文章和采集网站内容一样的查看方法获取到一个)
采集微信文章和采集网站一样,都需要以列表页开头。而微信文章的列表页是公众号中的浏览历史信息页。网上其他一些微信采集器现在都在用搜狗搜索。 采集方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史页面采集来。
由于微信的限制,我们可以复制到的链接不完整,无法在浏览器中打开内容。因此,我们需要使用anyproxy,通过上一篇文章介绍的方法,获取一个完整的微信公众号历史消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
如上一篇文章提到的,biz参数是公众号ID,uin是用户ID。目前,uin是所有公众号中唯一的一个。另外两个重要参数key和pass_ticket由微信客户端补充。
所以在这个地址失效之前,我们可以通过浏览器查看原文来获取文章历史消息列表。如果我们想自动分析内容,我们也可以用没有过期的key做一个程序。用pass_ticket的链接地址提交,然后通过php程序获取文章列表。
最近有朋友告诉我,他的采集目标是单个公众号。我觉得没必要用上一篇文章写的批处理采集方法。那么我们来看看如何在历史新闻页面中获取文章列表。通过分析文章列表,我们可以得到这个公众号的所有内容链接地址,然后采集内容就好了。
如果在anyproxy web界面正确配置了证书,可以显示https的内容。网页界面地址为:8002,其中localhost可以替换为自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击它,右侧会显示这条记录的详细信息:
红框是完整的链接地址。将微信公众平台的域名拼接到前面后,就可以在浏览器中打开了。
然后下拉页面到html内容的最后,我们可以看到一个json变量就是文章历史消息列表:
我们复制msgList的变量值,用json格式化工具分析,可以看到json的结构如下:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简单分析一下这个json(这里只介绍了一些重要的信息,其他的就省略了):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里还有一点要说的是,如果你想获得更长的历史消息内容,你需要在手机或模拟器中下拉页面。当你到达底部时,微信会自动阅读。下一页的内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json即可。
这时候就可以使用上一篇文章介绍的方法,使用anyproxy来匹配msgList变量值并异步提交给服务器,然后使用php的json_decode将json解析成数组从服务器。然后遍历循环数组。我们可以得到每个文章的标题和链接地址。
如果您只需要采集单个公众号的内容,可以通过anyproxy每天群发后,通过key和pass_ticket获取完整的链接地址。然后自己做一个程序,手动提交地址给你的程序。使用php等语言定时匹配msgList,然后解析json。这样就不需要修改anyproxy规则,也不需要做采集队列和跳转页面。
现在我们可以通过公众号的历史消息获取文章名单了。下一篇文章我将介绍如何根据历史新闻中的文章链接地址获取文章的具体内容。还有一些关于文章保存、封面图片、全文检索的经验。
持续更新,微信公众号文章batch采集系统建设
微信公众号文章采集入口--历史新闻页面详解
微信公众号文章页面和采集分析
提高微信公众号文章采集的效率,anyproxy的高级使用
本文信息本文由方法SEO顾问发表于2016-10-1101
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-08-26 00:03
本文信息本文由Method SEO顾问发表于2016-10-1101:34:27,共2033字,请注明:【GoGo闯】SEO如何处理采集内容(2)_【方法SEO顾问】,如果我的网站文章对你有帮助,就来百度口碑给个好评吧!
上次时间太晚了,采集的内容处理很肤浅。在实际操作过程中,还有很多奇特巧妙的技巧,需要创意与技术的结合。这篇文章充满力量。
评论
上次我谈到处理采集内容的两个连续步骤:
第一块,原创内容的处理,上一篇主要是对html源代码信息的处理,没有说如何处理文本信息。
来分享一下这个人渣使用的一些方法,以及如何处理采集内容文本...
原创采集内容文本信息的处理
这里忽略元数据的处理,因为元数据主要是添加逻辑映射。比如我公司的一个黄页网站抓取了“XXX公司规模、商标、年营业额、法人信息”等元数据。我需要将这些元数据与本站数据库中对应的公司关联起来。能。由于元数据是短文本,直接取用,无需处理重复。
如果采集内容是一大段连续的长文本,为了保证SEO效果,html源码处理后,也可以对文本进行处理。
文本信息处理,包括标题和正文两部分(不考虑人工修改,只考虑批处理)
标题
让我说SEO最重要和最核心的一点是“词”。其他 SEO 技巧和技巧基于“选择正确的词”以取得出色的结果。
最终目标是让用户可能搜索的词出现在标题中。详情页标题的词应该搜索量小,百度搜索结果少,而不是热词,大家都抢着做这个词。
首先,网页标题中出现的关键词越流行,被收录的几率越低。这是肯定的,所以不要对58赶集这样的大网站做任何事情。 采集站应该效仿。除非是高权重,否则基本没用。
其次,在垂直行业领域和充满个性化搜索内容的领域,可以挖出很多竞争不大、有一定流量的词。垂直领域的这些词不好找,因为需要对行业的了解,单靠SEO工具不容易找到。
个性化搜索内容领域,如节目开发、娱乐八卦等,总是充斥着个性化的搜索词,随着时间的推移,新的搜索行为也会不断产生。只要搜索引擎还没结束,这个领域总是充满了搜索流量,所以仔细观察发现,这里有很多热闹的长流量站。大部分内容选择都符合这个特点。与“招聘、二手车”等行业不同,用户的搜索行为基本没有变化。 ,几个站都抢了同一批词,都饱和了,热度不减,流量自然难做。
采集如何在标题中插入搜索词
如果采集的目标是网站,他们的标题本身不符合SEO,比如抢了一堆新闻标题,标题怎么能尽可能的集中在用户可能搜索的词上这人渣以前试过这些方法:
方法一:精简原标题
步骤如下:
基于python的jieba模块的实现,可以通过预先分析大量的标题提取出要删除的修饰语,并附加到字典中。 Github 有现成的轮子来提取句子的主干,比如 nltk。
1688 部分产品页面的标题好像是这样制作的。去掉了用户发布的产品名称中一些不相关的词缀,提取主干放在标题标签中。
方法二:插入搜索词
步骤如下:
比如原标题是:《斗鱼主播直播睡过20万》……,我想做的词是“斗鱼直播”,然后插入关键词:“[斗鱼[美女]直播]斗鱼美女主播20万人直播睡了"
当然也可以:“{forced search term}{simplified original title}”
方法三:插入派生词和当前标题中已经收录搜索词的相关搜索词
步骤如下:
如:“[{百度相关搜索词1}]{简明标题}”、“[{下拉框推荐词1}{原标题}]”...相互组合...
身体
正文的处理主要是为了重复,尽量减少与原文的相似度,本渣采用了以下方法:
在正文的开头和结尾插入随机文本
编辑正文内容
基于pagerank提取关键词,textrank算法提取文本摘要,实际上是为了简化正文内容,提取主要信息,最终可能会获得50%左右的原创内容。
为了防止词数过少,可以提前使用k-means和tfidf求文章文章的相似度,提取正面词最长的段落总结并将其添加到当前的文章 中作为词数的补充。
这样文章基本可读,符合中文语法,原文以词缀粒度删除,一定程度上可以减少搜索引擎对三字判断的重复识别搜索引擎相对友好。虽然肯定不如人工编辑,但比市面上粗糙的同义词替换和段落增删软件要好很多。比原来的中文好。
采集content 在线
刚开始整理印象笔记的时候,看到了之前SEO频道采集内容的线上流程,看着还挺有说服力的……
最后伪装
不过还是有很多奇怪的技巧,具体的细节没有提到。
查看全部
本文信息本文由方法SEO顾问发表于2016-10-1101
本文信息本文由Method SEO顾问发表于2016-10-1101:34:27,共2033字,请注明:【GoGo闯】SEO如何处理采集内容(2)_【方法SEO顾问】,如果我的网站文章对你有帮助,就来百度口碑给个好评吧!
上次时间太晚了,采集的内容处理很肤浅。在实际操作过程中,还有很多奇特巧妙的技巧,需要创意与技术的结合。这篇文章充满力量。
评论
上次我谈到处理采集内容的两个连续步骤:
第一块,原创内容的处理,上一篇主要是对html源代码信息的处理,没有说如何处理文本信息。
来分享一下这个人渣使用的一些方法,以及如何处理采集内容文本...
原创采集内容文本信息的处理
这里忽略元数据的处理,因为元数据主要是添加逻辑映射。比如我公司的一个黄页网站抓取了“XXX公司规模、商标、年营业额、法人信息”等元数据。我需要将这些元数据与本站数据库中对应的公司关联起来。能。由于元数据是短文本,直接取用,无需处理重复。
如果采集内容是一大段连续的长文本,为了保证SEO效果,html源码处理后,也可以对文本进行处理。
文本信息处理,包括标题和正文两部分(不考虑人工修改,只考虑批处理)
标题
让我说SEO最重要和最核心的一点是“词”。其他 SEO 技巧和技巧基于“选择正确的词”以取得出色的结果。
最终目标是让用户可能搜索的词出现在标题中。详情页标题的词应该搜索量小,百度搜索结果少,而不是热词,大家都抢着做这个词。
首先,网页标题中出现的关键词越流行,被收录的几率越低。这是肯定的,所以不要对58赶集这样的大网站做任何事情。 采集站应该效仿。除非是高权重,否则基本没用。
其次,在垂直行业领域和充满个性化搜索内容的领域,可以挖出很多竞争不大、有一定流量的词。垂直领域的这些词不好找,因为需要对行业的了解,单靠SEO工具不容易找到。
个性化搜索内容领域,如节目开发、娱乐八卦等,总是充斥着个性化的搜索词,随着时间的推移,新的搜索行为也会不断产生。只要搜索引擎还没结束,这个领域总是充满了搜索流量,所以仔细观察发现,这里有很多热闹的长流量站。大部分内容选择都符合这个特点。与“招聘、二手车”等行业不同,用户的搜索行为基本没有变化。 ,几个站都抢了同一批词,都饱和了,热度不减,流量自然难做。
采集如何在标题中插入搜索词
如果采集的目标是网站,他们的标题本身不符合SEO,比如抢了一堆新闻标题,标题怎么能尽可能的集中在用户可能搜索的词上这人渣以前试过这些方法:
方法一:精简原标题
步骤如下:
基于python的jieba模块的实现,可以通过预先分析大量的标题提取出要删除的修饰语,并附加到字典中。 Github 有现成的轮子来提取句子的主干,比如 nltk。
1688 部分产品页面的标题好像是这样制作的。去掉了用户发布的产品名称中一些不相关的词缀,提取主干放在标题标签中。
方法二:插入搜索词
步骤如下:
比如原标题是:《斗鱼主播直播睡过20万》……,我想做的词是“斗鱼直播”,然后插入关键词:“[斗鱼[美女]直播]斗鱼美女主播20万人直播睡了"
当然也可以:“{forced search term}{simplified original title}”
方法三:插入派生词和当前标题中已经收录搜索词的相关搜索词
步骤如下:
如:“[{百度相关搜索词1}]{简明标题}”、“[{下拉框推荐词1}{原标题}]”...相互组合...
身体
正文的处理主要是为了重复,尽量减少与原文的相似度,本渣采用了以下方法:
在正文的开头和结尾插入随机文本
编辑正文内容
基于pagerank提取关键词,textrank算法提取文本摘要,实际上是为了简化正文内容,提取主要信息,最终可能会获得50%左右的原创内容。
为了防止词数过少,可以提前使用k-means和tfidf求文章文章的相似度,提取正面词最长的段落总结并将其添加到当前的文章 中作为词数的补充。
这样文章基本可读,符合中文语法,原文以词缀粒度删除,一定程度上可以减少搜索引擎对三字判断的重复识别搜索引擎相对友好。虽然肯定不如人工编辑,但比市面上粗糙的同义词替换和段落增删软件要好很多。比原来的中文好。
采集content 在线
刚开始整理印象笔记的时候,看到了之前SEO频道采集内容的线上流程,看着还挺有说服力的……
最后伪装
不过还是有很多奇怪的技巧,具体的细节没有提到。
光copy文章就发财了,那谁是原创呢?
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-24 22:16
光copy文章就发财了,那谁是原创呢?
说到做网站,很多人都知道,找几个人在网上找,文章是的,抄完了,是的,网络的方便就是,你抄我的,我的复制你的,复制它,复制它,但如果你这样做,你可以让网站更大,只是复制文章会让你变得富有,那么原创是谁!不行原创何来复制它!既然有原创,为什么还要原创!
其实简单的说采集文章对SEO没有直接影响,但是对网站有影响,对网站有影响,间接说明对SEO有影响SEO,因为如果你采集了网上重复率高的文章会被搜索引擎认为作弊,会对待你的网站降权,但是原创太难了,所以偶尔采集一两篇文章也不是不可能,因为很多大型论坛经常有用户转发其他网站文章,就像偶尔转发别人的文章一样,影响不大,但搜索引擎不是收录没关系,因为搜索引擎不想,一个关键词搜索出一堆相同的文章,所以搜索引擎就没有意义了。
如果网站采集的内容占的比重越高,被百度认为是采集站的可能性越大。可以考虑把采集的板块内容屏蔽掉,通过robots协议、noindex,nofollow等Meta属性实现,然后通过其他高质量原创板块来增加网站权重。做SEO就是增加网站相关性、实用性和权威性来获取好的关键词排名。楼主网站有很多采集内容,这些内容可以在其它地方获取还是原创的,百度自然认为你的网站没有权威性,这个也没有什么工具可以具体分析。屏蔽掉采集内容,依然可以增加网站实用性,因为对用户是有价值的,但是权威性和相关性需要通过其他版块内容来填补,如果网站没有交流的区域的话可以增加用户交流版块,让用户创造原创内容。
如果你整个网站文章都是采集,那就有问题了。这样的文章不仅不会排长尾关键词,还会对你的目标起到作用关键词没有优化,因为你不知道你有什么网站上文章,你不知道网站上你的文章内容是什么,搜索引擎只有收录它认为有用文章!所以你只会给你的网站数据库增加负担,所以一定要从头规划网站,避免从头开始。 查看全部
光copy文章就发财了,那谁是原创呢?
说到做网站,很多人都知道,找几个人在网上找,文章是的,抄完了,是的,网络的方便就是,你抄我的,我的复制你的,复制它,复制它,但如果你这样做,你可以让网站更大,只是复制文章会让你变得富有,那么原创是谁!不行原创何来复制它!既然有原创,为什么还要原创!
其实简单的说采集文章对SEO没有直接影响,但是对网站有影响,对网站有影响,间接说明对SEO有影响SEO,因为如果你采集了网上重复率高的文章会被搜索引擎认为作弊,会对待你的网站降权,但是原创太难了,所以偶尔采集一两篇文章也不是不可能,因为很多大型论坛经常有用户转发其他网站文章,就像偶尔转发别人的文章一样,影响不大,但搜索引擎不是收录没关系,因为搜索引擎不想,一个关键词搜索出一堆相同的文章,所以搜索引擎就没有意义了。
如果网站采集的内容占的比重越高,被百度认为是采集站的可能性越大。可以考虑把采集的板块内容屏蔽掉,通过robots协议、noindex,nofollow等Meta属性实现,然后通过其他高质量原创板块来增加网站权重。做SEO就是增加网站相关性、实用性和权威性来获取好的关键词排名。楼主网站有很多采集内容,这些内容可以在其它地方获取还是原创的,百度自然认为你的网站没有权威性,这个也没有什么工具可以具体分析。屏蔽掉采集内容,依然可以增加网站实用性,因为对用户是有价值的,但是权威性和相关性需要通过其他版块内容来填补,如果网站没有交流的区域的话可以增加用户交流版块,让用户创造原创内容。
如果你整个网站文章都是采集,那就有问题了。这样的文章不仅不会排长尾关键词,还会对你的目标起到作用关键词没有优化,因为你不知道你有什么网站上文章,你不知道网站上你的文章内容是什么,搜索引擎只有收录它认为有用文章!所以你只会给你的网站数据库增加负担,所以一定要从头规划网站,避免从头开始。
关于全球api的分享,你需要知道的几个问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-08-22 20:04
文章采集内容主要来自5个平台。googleapi:主要是网站进行爬虫抓取,对于网站有些要求。腾讯api,提供给个人使用的api,对于爬虫上要求相对较低,如果网站服务器稳定且不需要爬虫操作腾讯的服务,也可以选择这一平台。谷歌api,一些对于谷歌友好的特定网站比如谷歌搜索可以接入谷歌api。好像有个人基于谷歌api已经创业了。
百度api,提供给一些只提供网页链接服务,没有计算机基础的用户使用的,这个还是比较好。除了这些之外,也可以考虑开发一些网站插件,让用户可以在网站上进行搜索,提供自己的需求。对于爬虫的要求,有单机的、多机的,如果有些需求是在中国、外国,国内访问速度可能无法满足用户需求。如果是已经有明确需求,那么可以考虑提供网站类目的api。
关于全球api的分享,
1.分享群-从开发者到产品经理的交流平台2.知乎-回答优质的问题3.简书-专注写作的分享平台4.微信群微信搜索:一切皆api以上是比较认识的几个不错的api交流群,
有一个专门针对网站爬虫抓取用的圈子,大家可以去看看,爬虫技术群一直qq群,单页登录、api响应、页面指令等都有交流。
1、政府网站
2、大型门户网站,
3、大型开源网站,
4、大型自媒体网站, 查看全部
关于全球api的分享,你需要知道的几个问题
文章采集内容主要来自5个平台。googleapi:主要是网站进行爬虫抓取,对于网站有些要求。腾讯api,提供给个人使用的api,对于爬虫上要求相对较低,如果网站服务器稳定且不需要爬虫操作腾讯的服务,也可以选择这一平台。谷歌api,一些对于谷歌友好的特定网站比如谷歌搜索可以接入谷歌api。好像有个人基于谷歌api已经创业了。
百度api,提供给一些只提供网页链接服务,没有计算机基础的用户使用的,这个还是比较好。除了这些之外,也可以考虑开发一些网站插件,让用户可以在网站上进行搜索,提供自己的需求。对于爬虫的要求,有单机的、多机的,如果有些需求是在中国、外国,国内访问速度可能无法满足用户需求。如果是已经有明确需求,那么可以考虑提供网站类目的api。
关于全球api的分享,
1.分享群-从开发者到产品经理的交流平台2.知乎-回答优质的问题3.简书-专注写作的分享平台4.微信群微信搜索:一切皆api以上是比较认识的几个不错的api交流群,
有一个专门针对网站爬虫抓取用的圈子,大家可以去看看,爬虫技术群一直qq群,单页登录、api响应、页面指令等都有交流。
1、政府网站
2、大型门户网站,
3、大型开源网站,
4、大型自媒体网站,
文章采集内容时,原生h5最好提供同步跳转,例如跳转到自己网站的banner或者首页等
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-08-20 00:06
文章采集内容时,原生h5最好提供同步跳转,例如跳转到自己网站的banner或者首页等,如果需要跳转的时候有数据就收,没有就不收(虽然很多网站没有这个限制,但至少提供了这个bug);本地采集的话也要支持跳转,不然一个视频网站跑到七八十m都要先本地缓存。
推荐使用视频采集器/,app里面这款收录了很多专业视频平台的视频,然后可以选择是用网页采集还是app采集,
多数情况会需要重新再去打包发布,多谢文本方式采集,
推荐自己的产品【expedia海外全网视频采集器】,免费版可以采集全球100多个顶级视频平台,支持中文操作界面。全部视频数据无限量,并且是100%高清无码哦,需要看视频收费价格,没有采集到想要的内容或者你想付费的视频我们也提供视频的免费vip收费解决方案。免费功能1.可以采集youtube视频2.谷歌tag搜索+视频链接获取3.谷歌视频收藏箱4.b站vipvideo观看联系方式:。
推荐国内使用的两款产品,
云捕客,
mugedo,一键采集 查看全部
文章采集内容时,原生h5最好提供同步跳转,例如跳转到自己网站的banner或者首页等
文章采集内容时,原生h5最好提供同步跳转,例如跳转到自己网站的banner或者首页等,如果需要跳转的时候有数据就收,没有就不收(虽然很多网站没有这个限制,但至少提供了这个bug);本地采集的话也要支持跳转,不然一个视频网站跑到七八十m都要先本地缓存。
推荐使用视频采集器/,app里面这款收录了很多专业视频平台的视频,然后可以选择是用网页采集还是app采集,
多数情况会需要重新再去打包发布,多谢文本方式采集,
推荐自己的产品【expedia海外全网视频采集器】,免费版可以采集全球100多个顶级视频平台,支持中文操作界面。全部视频数据无限量,并且是100%高清无码哦,需要看视频收费价格,没有采集到想要的内容或者你想付费的视频我们也提供视频的免费vip收费解决方案。免费功能1.可以采集youtube视频2.谷歌tag搜索+视频链接获取3.谷歌视频收藏箱4.b站vipvideo观看联系方式:。
推荐国内使用的两款产品,
云捕客,
mugedo,一键采集
互联网大数据挖掘和分析平台背景:12小时前的最受欢迎
采集交流 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-08-17 21:05
文章采集内容会根据时间节点的变化而进行更新。所以欢迎评论区留言交流。数据来源:神策数据-互联网大数据挖掘和分析平台背景vlog:videoontheboard,对应b站用户通常的习惯称呼,即视频b站上发布的视频;视频博客:blogcontent,互联网流行用语,当前多用于微博、一些个人网站;youtube:thefacebookareaofyourwebsite,即在facebook上建立的各种网站及视频频道;其他:在视频社交媒体,twitter等,就有tubesnap,meetup,share,canvas等概念;视频社交媒体,如facebook,有collection和following功能,类似博客。
vlog能够对建立在数据社交传播渠道的社交媒体进行内容定制和变现。从视频访问时间来看,12小时前的最受欢迎,依次是凌晨,午夜和早晨。12小时内,最受欢迎的视频都是短视频,短视频数量占总数的1/3,平均时长是一分钟以下。由于两者依托于移动终端的全屏呈现,形成了相对更为轻便的现实感。从平均时长来看,最受欢迎的top10vlog,平均时长是3分钟,由于相对于retina屏幕的强制3:2变长,短视频相对于长视频在尺寸上更具有优势。
11分钟,14分钟,16分钟三个不同长度的vlog依次排名前十,其中11分钟的vlog常被用来作为独立事件的采集素材,同时它是ugc视频访问时间超过1小时的访问频率最高视频。视频平均2.6m时长,平均视频分辨率为;图像平均分辨率为。此外11分钟vlog的评论数最多,从平均435条评论计算,第10位的中国姑娘采集素材,平均评论数为211条,基本可看做是ugc视频访问时间超过1小时的视频。
而主播视频平均访问时长达到了2629分钟,由于主播的粉丝平均年龄更大,意味着同样平均时长的视频,平均更多的人贡献了34条以上的评论。图1:vlog占据视频市场60%的份额,从阅读来看,视频成熟的网络传播渠道,其受众群体更为核心。从短视频市场来看,头部视频分别是西瓜视频,百度,快手和抖音,市场份额24.74%,市场份额占比超过五成;而头部平台快手以及火山视频都已签约300多万短视频创作者,这些短视频创作者覆盖了大部分网生内容生产群体,从商业利益上看也是更加合理的。
从长视频成熟网络传播渠道来看,国内头部视频分别是秒拍,美拍,爱奇艺,快手和今日头条,市场份额17.73%,平均市场份额为5.23%,被各自收割了部分份额;其中秒拍、美拍和快手的总市场份额分别为44.4%,34.6%,分别为头部短视频市场对手的两倍和四倍;而国内其他视频平台都已签约2400万到3700万的短视频创作者,其中火山视频采取的则是头部平台发布1200万号、选择。 查看全部
互联网大数据挖掘和分析平台背景:12小时前的最受欢迎
文章采集内容会根据时间节点的变化而进行更新。所以欢迎评论区留言交流。数据来源:神策数据-互联网大数据挖掘和分析平台背景vlog:videoontheboard,对应b站用户通常的习惯称呼,即视频b站上发布的视频;视频博客:blogcontent,互联网流行用语,当前多用于微博、一些个人网站;youtube:thefacebookareaofyourwebsite,即在facebook上建立的各种网站及视频频道;其他:在视频社交媒体,twitter等,就有tubesnap,meetup,share,canvas等概念;视频社交媒体,如facebook,有collection和following功能,类似博客。
vlog能够对建立在数据社交传播渠道的社交媒体进行内容定制和变现。从视频访问时间来看,12小时前的最受欢迎,依次是凌晨,午夜和早晨。12小时内,最受欢迎的视频都是短视频,短视频数量占总数的1/3,平均时长是一分钟以下。由于两者依托于移动终端的全屏呈现,形成了相对更为轻便的现实感。从平均时长来看,最受欢迎的top10vlog,平均时长是3分钟,由于相对于retina屏幕的强制3:2变长,短视频相对于长视频在尺寸上更具有优势。
11分钟,14分钟,16分钟三个不同长度的vlog依次排名前十,其中11分钟的vlog常被用来作为独立事件的采集素材,同时它是ugc视频访问时间超过1小时的访问频率最高视频。视频平均2.6m时长,平均视频分辨率为;图像平均分辨率为。此外11分钟vlog的评论数最多,从平均435条评论计算,第10位的中国姑娘采集素材,平均评论数为211条,基本可看做是ugc视频访问时间超过1小时的视频。
而主播视频平均访问时长达到了2629分钟,由于主播的粉丝平均年龄更大,意味着同样平均时长的视频,平均更多的人贡献了34条以上的评论。图1:vlog占据视频市场60%的份额,从阅读来看,视频成熟的网络传播渠道,其受众群体更为核心。从短视频市场来看,头部视频分别是西瓜视频,百度,快手和抖音,市场份额24.74%,市场份额占比超过五成;而头部平台快手以及火山视频都已签约300多万短视频创作者,这些短视频创作者覆盖了大部分网生内容生产群体,从商业利益上看也是更加合理的。
从长视频成熟网络传播渠道来看,国内头部视频分别是秒拍,美拍,爱奇艺,快手和今日头条,市场份额17.73%,平均市场份额为5.23%,被各自收割了部分份额;其中秒拍、美拍和快手的总市场份额分别为44.4%,34.6%,分别为头部短视频市场对手的两倍和四倍;而国内其他视频平台都已签约2400万到3700万的短视频创作者,其中火山视频采取的则是头部平台发布1200万号、选择。
织梦无忧标签调用(2018-11-29:29)
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-08-15 04:23
dedecms织梦采集函数使用教程-普通文章的采集带分页(三)织梦无忧标签通话2018-11-29 13:54
Summary: 前言:本文是普通文章采集 分页方法的第三部分。在前面两节的基础上,我们将讨论如何采集指定节点以及如何导出采集内容给出详细的介绍。为了与上一篇保持一致,本文将继续使用上一章的标记。从第二部分继续。 3.1采集指定节点点击保存启动采集后会进入采集指
前言:本文是《常见的文章采集带有分页的方法》的第三部分。在前面两节的基础上,我们将讨论“如何采集指定节点”和“如何导出采集content”进行详细介绍。为与上一篇保持一致,本文将继续沿用之前的章节标记。
接第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图29),
图29-采集指定节点
采集per page:这个是设置每页需要采集的数量,采集间隔可以根据网站是否有防刷新功能来设置。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一个是“监控采集模式(检查当前节点或所有节点是否有新内容)”,选择后系统只会采集采集 指定节点的更新内容;第二种是“重新下载所有内容”,选择后系统会采集指定节点的所有内容;第三种是“下载seed网站未下载的内容”,选择后系统只会采集指定节点未下载的内容,包括之前未下载和更新的内容。
完成设置并确认无误后,即可点击“Start采集Webpage”或“查看种子网址”。此时,如果您单击“查看种子 URL”,您将看到列表是空的。这是因为新创建的采集节点从来就不是采集,如图(图30),
图30-查看节点的seed URL
点击“启动采集网页”后,系统会启动采集节点中设置的URL,并出现相关提示,如图(图31),
图 31-采集Prompt 消息进行中
采集结束后,再次点击“查看种子网址”或者点击页面右上角的“查看已下载”,可以看到已经采集的网址信息,如(图3 2) 显示,
图32-查看节点的seed URL
采集成功后,可以根据实际需要选择页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图33),
图 33-采集Content 导出
“默认导出列”:设置导入采集内容的列
“批量采集option”:如果采集规则中已经指定了列ID,则可以使用该函数。如果指定的列ID为0,系统会将采集内容导入到“默认导出列”“选定列”中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批次导入”:设置每批次导入的项目数。这个数字不能太大。
“有选项”:这是一个多项选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望采集接收到的内容直接生成HTML,可以选择“完成后自动生成导入的内容HTML”;如果需要系统会自动识别采集列表页面上的标题名称,您可以选择“使用列表索引的标题”。一般不建议勾选。
“随机推荐”:填写一个数字,代表文档的数量。推荐的文档随机出现在输入的文档数量中。如果输入“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的项目导入到选中的列中,如图(图34),
图34-采集设置后的内容导出页面
同时系统会提示导出过程,如图(图35),
图35-采集内容导出中的提示信息
导出采集内容提示“完成所有栏目列表更新”后,点击“浏览栏目”,即可进入网站相关页面查看采集到文章列表及其具体内容。也可以在后台管理界面的主菜单中点击“Core”,然后点击“Common文章”进入“文档列表”页面,从采集查看文章列表,如图(图36)显示,
图 36-文档列表
在文档列表中,点击“用最简单的网络学习IP和ARP协议”的预览按钮,打开文章内容页面,找到页面的换页部分,如图(图37),
图 37-分页
可以看到收录分页文章的内容已经成功采集到达。
综上所述,本文详细介绍了如何将采集一个普通的文章类型页面带分页,简单涉及到过滤规则。对于采集更复杂的普通文章类型页面以及过滤规则的使用,以后会在文章中引入。
采集本文规则:
{dede:listconfig}
{dede:noteinfo notename="采集测试(二)" channelid="1" macthtype="string"
refurl="http://www.bitscn.com/network/ ... ot%3B sourcelang="gb2312" cosort="asc"
isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="http://www.bitscn.com/network/protocol/list_(*).html"
startid="1" endid="1" addv="1" urlrule="area" musthas=""
nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}{/dede:areastart}
{dede:areaend}{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' srul='1' erul='5'}[内容]{/dede:sppage}
{dede:previewurl}http://www.bitscn.com/network/ ... .html{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match}时间:[内容] {/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}[内容]{/dede:match}
{dede:trim replace=""}(.*){/dede:trim}
{dede:trim replace=""}(.*){/dede:trim}
{dede:trim replace=""}(.*){/dede:trim}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}
本文链接:
版权声明:本站资源均来自互联网或由会员发布。如果您的权益受到侵犯,请联系我们,我们将在24小时内删除!谢谢! 查看全部
织梦无忧标签调用(2018-11-29:29)
dedecms织梦采集函数使用教程-普通文章的采集带分页(三)织梦无忧标签通话2018-11-29 13:54
Summary: 前言:本文是普通文章采集 分页方法的第三部分。在前面两节的基础上,我们将讨论如何采集指定节点以及如何导出采集内容给出详细的介绍。为了与上一篇保持一致,本文将继续使用上一章的标记。从第二部分继续。 3.1采集指定节点点击保存启动采集后会进入采集指
前言:本文是《常见的文章采集带有分页的方法》的第三部分。在前面两节的基础上,我们将讨论“如何采集指定节点”和“如何导出采集content”进行详细介绍。为与上一篇保持一致,本文将继续沿用之前的章节标记。
接第二部分。
3.1采集指定节点
点击“保存并启动采集”后,会进入“采集指定节点”界面,如图(图29),
图29-采集指定节点
采集per page:这个是设置每页需要采集的数量,采集间隔可以根据网站是否有防刷新功能来设置。
特殊选项:设置是否检测重复图片,默认为“检测”。
附加选项:该选项有3种采集模式可供选择:第一个是“监控采集模式(检查当前节点或所有节点是否有新内容)”,选择后系统只会采集采集 指定节点的更新内容;第二种是“重新下载所有内容”,选择后系统会采集指定节点的所有内容;第三种是“下载seed网站未下载的内容”,选择后系统只会采集指定节点未下载的内容,包括之前未下载和更新的内容。
完成设置并确认无误后,即可点击“Start采集Webpage”或“查看种子网址”。此时,如果您单击“查看种子 URL”,您将看到列表是空的。这是因为新创建的采集节点从来就不是采集,如图(图30),
图30-查看节点的seed URL
点击“启动采集网页”后,系统会启动采集节点中设置的URL,并出现相关提示,如图(图31),
图 31-采集Prompt 消息进行中
采集结束后,再次点击“查看种子网址”或者点击页面右上角的“查看已下载”,可以看到已经采集的网址信息,如(图3 2) 显示,
图32-查看节点的seed URL
采集成功后,可以根据实际需要选择页面右上角的“采集节点管理”或“导出数据”。点击“导出数据”后,可以进入“采集管理>采集内容导出”界面,如图(图33),
图 33-采集Content 导出
“默认导出列”:设置导入采集内容的列
“批量采集option”:如果采集规则中已经指定了列ID,则可以使用该函数。如果指定的列ID为0,系统会将采集内容导入到“默认导出列”“选定列”中。
“发布选项”:有发布为“普通文档”和“另存为草稿”的选项。
“每批次导入”:设置每批次导入的项目数。这个数字不能太大。
“有选项”:这是一个多项选择。如果不想采集重复文章标题,可以选择“排除重复标题”;如果希望采集接收到的内容直接生成HTML,可以选择“完成后自动生成导入的内容HTML”;如果需要系统会自动识别采集列表页面上的标题名称,您可以选择“使用列表索引的标题”。一般不建议勾选。
“随机推荐”:填写一个数字,代表文档的数量。推荐的文档随机出现在输入的文档数量中。如果输入“0”,则表示不推荐。
设置完成后,可以点击“确定”将下载的项目导入到选中的列中,如图(图34),
图34-采集设置后的内容导出页面
同时系统会提示导出过程,如图(图35),
图35-采集内容导出中的提示信息
导出采集内容提示“完成所有栏目列表更新”后,点击“浏览栏目”,即可进入网站相关页面查看采集到文章列表及其具体内容。也可以在后台管理界面的主菜单中点击“Core”,然后点击“Common文章”进入“文档列表”页面,从采集查看文章列表,如图(图36)显示,
图 36-文档列表
在文档列表中,点击“用最简单的网络学习IP和ARP协议”的预览按钮,打开文章内容页面,找到页面的换页部分,如图(图37),
图 37-分页
可以看到收录分页文章的内容已经成功采集到达。
综上所述,本文详细介绍了如何将采集一个普通的文章类型页面带分页,简单涉及到过滤规则。对于采集更复杂的普通文章类型页面以及过滤规则的使用,以后会在文章中引入。
采集本文规则:
{dede:listconfig}
{dede:noteinfo notename="采集测试(二)" channelid="1" macthtype="string"
refurl="http://www.bitscn.com/network/ ... ot%3B sourcelang="gb2312" cosort="asc"
isref="no" exptime="10" usemore="0" /}
{dede:listrule sourcetype="batch" rssurl="http://" regxurl="http://www.bitscn.com/network/protocol/list_(*).html"
startid="1" endid="1" addv="1" urlrule="area" musthas=""
nothas="" listpic="1" usemore="0"}
{dede:addurls}{/dede:addurls}
{dede:batchrule}{/dede:batchrule}
{dede:regxrule}{/dede:regxrule}
{dede:areastart}{/dede:areastart}
{dede:areaend}{/dede:areaend}
{/dede:listrule}
{/dede:listconfig}
{dede:itemconfig}
{dede:sppage sptype='full' srul='1' erul='5'}[内容]{/dede:sppage}
{dede:previewurl}http://www.bitscn.com/network/ ... .html{/dede:previewurl}
{dede:keywordtrim}{/dede:keywordtrim}
{dede:descriptiontrim}{/dede:descriptiontrim}
{dede:item field='title' value='' isunit='' isdown=''}
{dede:match}[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='writer' value='' isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='source' value='' isunit='' isdown=''}
{dede:match}来源:[内容]{/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='pubdate' value='' isunit='' isdown=''}
{dede:match}时间:[内容] {/dede:match}
{dede:function}{/dede:function}
{/dede:item}{dede:item field='body' value='' isunit='1' isdown='1'}
{dede:match}[内容]{/dede:match}
{dede:trim replace=""}(.*){/dede:trim}
{dede:trim replace=""}(.*){/dede:trim}
{dede:trim replace=""}(.*){/dede:trim}
{dede:function}{/dede:function}
{/dede:item}
{/dede:itemconfig}
本文链接:
版权声明:本站资源均来自互联网或由会员发布。如果您的权益受到侵犯,请联系我们,我们将在24小时内删除!谢谢!
文章采集对我们的网站有哪些坏处?链小编内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-08-15 04:20
在我们建立了网站之后,我们必须继续丰富我们的网站内容,使其具有吸引力。如果你是新手,不妨看看《新手如何学习SEO》。但是一个网站需要很多文章的内容来填充,完全靠自己写那个浪费精力,更何况还需要很长时间,所以文章采集,然后文章采集对我们的网站有什么缺点?下面小编来告诉你
1.内容无法控制
采集文章不像我们自己写的那么随意。你可以写任何你想要的。你写的时候只能采集什么,采集时你会保留别人的信息,所以你去采集,你无意中帮助别人推广。
2.采集内容真实性不高
很多新闻门户每天都会更新文章何其多,而且来源不明,所以文章的真实性不高,就像我们经常在网上看到的假新闻一样。 .
3.文章Secret 语言过滤不完整
为了防止别人采集,有的网站会在文章中加一些码字,有的会加一些外链。一旦你去采集,你就不会错过采集 的所有字眼了,这不利于搜索引擎收录。
4.图片采集滤不全
当你去采集别人的文章时,不可避免的你也可以带着采集的图片来这里,但如果文章中出现的一些图片是不好的图片,可能你的网站会被网警关注。
5.网站易被K
如今,搜索引擎变得越来越智能。不要认为你比它更聪明,可以被愚弄。那基本上是不可能的。因为你采集别人的文章相当于从对方的网站复制文章,蜘蛛还会关注你的网站吗?没错。
如果你真的想要采集文章,建议你必须有采集和你自己的网站相关内容,不过链上小编会提醒大家采集就是采集毕竟效果肯定不如原创,采集还可以,但是要适当采集,一定要写一些原创的文章,完善原创度网站。 查看全部
文章采集对我们的网站有哪些坏处?链小编内容
在我们建立了网站之后,我们必须继续丰富我们的网站内容,使其具有吸引力。如果你是新手,不妨看看《新手如何学习SEO》。但是一个网站需要很多文章的内容来填充,完全靠自己写那个浪费精力,更何况还需要很长时间,所以文章采集,然后文章采集对我们的网站有什么缺点?下面小编来告诉你
1.内容无法控制
采集文章不像我们自己写的那么随意。你可以写任何你想要的。你写的时候只能采集什么,采集时你会保留别人的信息,所以你去采集,你无意中帮助别人推广。
2.采集内容真实性不高
很多新闻门户每天都会更新文章何其多,而且来源不明,所以文章的真实性不高,就像我们经常在网上看到的假新闻一样。 .
3.文章Secret 语言过滤不完整
为了防止别人采集,有的网站会在文章中加一些码字,有的会加一些外链。一旦你去采集,你就不会错过采集 的所有字眼了,这不利于搜索引擎收录。
4.图片采集滤不全
当你去采集别人的文章时,不可避免的你也可以带着采集的图片来这里,但如果文章中出现的一些图片是不好的图片,可能你的网站会被网警关注。
5.网站易被K
如今,搜索引擎变得越来越智能。不要认为你比它更聪明,可以被愚弄。那基本上是不可能的。因为你采集别人的文章相当于从对方的网站复制文章,蜘蛛还会关注你的网站吗?没错。
如果你真的想要采集文章,建议你必须有采集和你自己的网站相关内容,不过链上小编会提醒大家采集就是采集毕竟效果肯定不如原创,采集还可以,但是要适当采集,一定要写一些原创的文章,完善原创度网站。
一下网站采集与SEO的秘籍所在,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-08-12 22:16
估计很多人都知道网站construction的更新需要原创性别、规律性和及时性。如果网站不更新,网站的排名自然会受到一定的阻碍。有时候为了更新,很多站长会用采集性更新网站。
现在越来越多的人从事SEO优化,同样,越来越多的人在文章的发布上遇到麻烦。 原创的当然好,但哪有那么多时间写,所以这就需要采集。那么采集怎么样?
做SEO的人都知道采集网站可以给网站带来很多文章。但是这样一来采集和文章就不再是原创了,不利于SEO。那么如果它节省时间并且可以被搜索引擎喜爱呢?今天冰峰就和大家一起探讨网站采集和SEO的秘诀!
首先我们需要知道的是搜索引擎收录网站的审核规则是什么?
比较搜索引擎蜘蛛索引的内容,看看数据库中是否存在相同的内容。如果不存在,直接收录,然后这条信息的属性默认为原创。
比较搜索引擎蜘蛛索引的内容,看看数据库中是否存在相同的内容。如果存在,则转到下一个内容比较。
对于具有相同内容的信息。然后比较网站在百度中属于A和B的权重。权重最高的人将最终获胜。低的排在后面,或者直接删除记录!
既然知道了百度收录review的机制,那我们就好好操作吧!如果你想要他的好收录,只有一种方法,那就是即使你更新!说白了就是用百度的时差!
采集其他网站的最新信息,错误一般不超过30分钟。百度不可能在这 30 分钟内缓存这些信息内容。下一步就是看谁的网站Baidu 更新快了。谁的网站更被百度吸引,谁先更新,那么原创是谁! ! !这就是为什么你在想为什么我也采集与其他网站的内容保持同步,但我仍然无法与其他网站相比?那是因为百度会先更新别人的网站!他赢得了规则审查!呵呵,也许你会再问:为什么先更新他的?几乎只有一个答案,那就是他的网站权重比你的高!
我试过这个方法,效果很好。我想对我现在主要是采集的朋友肯定会有帮助!所以特此分享给大家!可能有什么不对的地方,请多多指出,一起讨论! 查看全部
一下网站采集与SEO的秘籍所在,你知道吗?
估计很多人都知道网站construction的更新需要原创性别、规律性和及时性。如果网站不更新,网站的排名自然会受到一定的阻碍。有时候为了更新,很多站长会用采集性更新网站。
现在越来越多的人从事SEO优化,同样,越来越多的人在文章的发布上遇到麻烦。 原创的当然好,但哪有那么多时间写,所以这就需要采集。那么采集怎么样?
做SEO的人都知道采集网站可以给网站带来很多文章。但是这样一来采集和文章就不再是原创了,不利于SEO。那么如果它节省时间并且可以被搜索引擎喜爱呢?今天冰峰就和大家一起探讨网站采集和SEO的秘诀!
首先我们需要知道的是搜索引擎收录网站的审核规则是什么?
比较搜索引擎蜘蛛索引的内容,看看数据库中是否存在相同的内容。如果不存在,直接收录,然后这条信息的属性默认为原创。
比较搜索引擎蜘蛛索引的内容,看看数据库中是否存在相同的内容。如果存在,则转到下一个内容比较。
对于具有相同内容的信息。然后比较网站在百度中属于A和B的权重。权重最高的人将最终获胜。低的排在后面,或者直接删除记录!
既然知道了百度收录review的机制,那我们就好好操作吧!如果你想要他的好收录,只有一种方法,那就是即使你更新!说白了就是用百度的时差!
采集其他网站的最新信息,错误一般不超过30分钟。百度不可能在这 30 分钟内缓存这些信息内容。下一步就是看谁的网站Baidu 更新快了。谁的网站更被百度吸引,谁先更新,那么原创是谁! ! !这就是为什么你在想为什么我也采集与其他网站的内容保持同步,但我仍然无法与其他网站相比?那是因为百度会先更新别人的网站!他赢得了规则审查!呵呵,也许你会再问:为什么先更新他的?几乎只有一个答案,那就是他的网站权重比你的高!
我试过这个方法,效果很好。我想对我现在主要是采集的朋友肯定会有帮助!所以特此分享给大家!可能有什么不对的地方,请多多指出,一起讨论!
用过文章采集器——优采云采集器V9十一项强大的数据处理功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-08-08 07:45
用过优采云采集器的朋友都知道优采云采集器是所有文章采集器中最全面的数据处理功能,因此被用户誉为最经典的采集软件,这里详细介绍文章采集器——优采云采集器V9 十一个强大的数据处理功能。
什么是数据处理?在优采云采集器中,数据处理是对内容页面中提取的信息数据的进一步处理,如替换、过滤等,优采云采集器可以同时添加多个操作,多个操作它按照从上到下的顺序执行。换句话说,上一步的结果将作为下一步的参数。我们依次解释一下:
1、提取的内容为空:即如果提取的内容为空,则重新从原页面提取正则匹配的内容。
2、Content Replacement/Exclusion:顾名思义,就是用字符串替换采集的内容。如果需要排除,请用空字符串替换。
3、html标签过滤:过滤指定的html标签,如4、字符截取:通过开始和结束字符串截取内容
5、纯正则替换:通过强大的正则表达式进行复杂的内容替换。
6、数据转换:包括将结果由简体转换为复数、将结果由复数转换为简体、自动转换为拼音和时间校正转换
7、智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取
8、高级功能:包括自动抽象、自动分词、Http请求、字符编码转换、同义词替换、空内容默认值、内容前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串长度等一系列函数。
9、Complete list URL:将当前内容补全为URL。
10、文件下载:自动检测下载文件,可以设置下载路径和文件名样式。
11、内容过滤:一些不符合条件的记录可以通过设置内容过滤来删除或标记为不接受。
当我们采集文章拥有这十一个强大的数据处理功能后,我们就可以处理各种类型的网站,轻松将数据处理成我们需要的形式,省时省力。 优采云采集器V9,作为最全面的文章采集器,可以大大提高我们的工作效率,真正智能地为用户服务。 查看全部
用过文章采集器——优采云采集器V9十一项强大的数据处理功能
用过优采云采集器的朋友都知道优采云采集器是所有文章采集器中最全面的数据处理功能,因此被用户誉为最经典的采集软件,这里详细介绍文章采集器——优采云采集器V9 十一个强大的数据处理功能。
什么是数据处理?在优采云采集器中,数据处理是对内容页面中提取的信息数据的进一步处理,如替换、过滤等,优采云采集器可以同时添加多个操作,多个操作它按照从上到下的顺序执行。换句话说,上一步的结果将作为下一步的参数。我们依次解释一下:
1、提取的内容为空:即如果提取的内容为空,则重新从原页面提取正则匹配的内容。
2、Content Replacement/Exclusion:顾名思义,就是用字符串替换采集的内容。如果需要排除,请用空字符串替换。
3、html标签过滤:过滤指定的html标签,如4、字符截取:通过开始和结束字符串截取内容
5、纯正则替换:通过强大的正则表达式进行复杂的内容替换。
6、数据转换:包括将结果由简体转换为复数、将结果由复数转换为简体、自动转换为拼音和时间校正转换
7、智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取
8、高级功能:包括自动抽象、自动分词、Http请求、字符编码转换、同义词替换、空内容默认值、内容前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串长度等一系列函数。
9、Complete list URL:将当前内容补全为URL。
10、文件下载:自动检测下载文件,可以设置下载路径和文件名样式。
11、内容过滤:一些不符合条件的记录可以通过设置内容过滤来删除或标记为不接受。
当我们采集文章拥有这十一个强大的数据处理功能后,我们就可以处理各种类型的网站,轻松将数据处理成我们需要的形式,省时省力。 优采云采集器V9,作为最全面的文章采集器,可以大大提高我们的工作效率,真正智能地为用户服务。
如何让自己代码更加有模板代码的便利功能的新手开发
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-08-05 19:01
文章采集内容来自公众号:花和课堂本篇教程主要针对的就是完全写不出模板代码,不知道如何让自己代码更加有模板代码的便利功能的新手开发人员,比如说像我这样完全没有写过一行代码,初学者。快速的让他们可以写出基础的公式,如:sin(),arcsin()等等最简单一个例子,你用c#编辑器打开,然后把公式拷贝出来可以完美模仿出来的公式主要是你公式的编辑好,你先编辑好,然后用调试工具或者par泡。
不是说要用他,简单说就是你会用,就会用。不会自己用,如果你不写过一行代码的编程,那根本只是一个渣渣所以说,快速的让一个完全不会写代码的人写代码,实际上只是用了特定的不需要写代码的编程语言,保存好这些编辑器。然后用代码去跑起来,当你真正面对的是一堆的代码,你就不会觉得那么痛苦了。前后搭配一些开发框架。利用我自己做一个后面已经放了一年多时间,但是有时候我常常想起那个令我苦笑不得的白衣少年现在这篇文章,我打算和读者分享一下几个写好代码的方法,无需代码培训,培训所提供的理论上面,每一次培训所提供的理论我是很看重的,包括ide包括记事本会话等等但是在这么多开发语言,在这么多开发工具的情况下,如何把一个完全不会写代码的人教会写代码,实际上是需要很多的能力的比如说:最基本的一些基础的思想,他们的首要任务,都是要把公式模板化,即模板代码sin(),arcsin()只要你按照他们的方法写,他们是能够编译通过的,但是只要写一行if都是会报错的,会他的人,对于你的代码要求是保持一致性的,不要写出来的代码风格很别扭,至少要保持他的代码一致性。
1)自己看代码看一个代码的好坏,最好就是自己看,不要想着第三方的比如说官方文档,官方demo,等等这样的东西,全世界最优秀的程序员都用官方的文档做示例,只有最差的人才用第三方的工具。当然用官方工具,也不是没办法,自己debug,各种不方便。别人的工具是别人的,自己写是自己的。想要在非官方的工具写出专业的代码,最重要的就是数据结构了,基本的自己先弄懂,同样如果用官方工具的时候,还是有很多意想不到的坑需要考虑。
2)用代码开发接下来最最重要的,也是用代码写出来的其中一个方法,就是用代码开发了,很多东西只有自己亲手写出来,自己写,看官方的代码,而不是看别人写的这样的话,才能发现自己的问题,才能在你改写的时候有更多可以提炼出来的东西。虽然大部分的问题,代码已经给你模板化了,但是还是有很多值得你去写的。比如说用来实现一个中心坐标系的时候,或者说,用来实现和四。 查看全部
如何让自己代码更加有模板代码的便利功能的新手开发
文章采集内容来自公众号:花和课堂本篇教程主要针对的就是完全写不出模板代码,不知道如何让自己代码更加有模板代码的便利功能的新手开发人员,比如说像我这样完全没有写过一行代码,初学者。快速的让他们可以写出基础的公式,如:sin(),arcsin()等等最简单一个例子,你用c#编辑器打开,然后把公式拷贝出来可以完美模仿出来的公式主要是你公式的编辑好,你先编辑好,然后用调试工具或者par泡。
不是说要用他,简单说就是你会用,就会用。不会自己用,如果你不写过一行代码的编程,那根本只是一个渣渣所以说,快速的让一个完全不会写代码的人写代码,实际上只是用了特定的不需要写代码的编程语言,保存好这些编辑器。然后用代码去跑起来,当你真正面对的是一堆的代码,你就不会觉得那么痛苦了。前后搭配一些开发框架。利用我自己做一个后面已经放了一年多时间,但是有时候我常常想起那个令我苦笑不得的白衣少年现在这篇文章,我打算和读者分享一下几个写好代码的方法,无需代码培训,培训所提供的理论上面,每一次培训所提供的理论我是很看重的,包括ide包括记事本会话等等但是在这么多开发语言,在这么多开发工具的情况下,如何把一个完全不会写代码的人教会写代码,实际上是需要很多的能力的比如说:最基本的一些基础的思想,他们的首要任务,都是要把公式模板化,即模板代码sin(),arcsin()只要你按照他们的方法写,他们是能够编译通过的,但是只要写一行if都是会报错的,会他的人,对于你的代码要求是保持一致性的,不要写出来的代码风格很别扭,至少要保持他的代码一致性。
1)自己看代码看一个代码的好坏,最好就是自己看,不要想着第三方的比如说官方文档,官方demo,等等这样的东西,全世界最优秀的程序员都用官方的文档做示例,只有最差的人才用第三方的工具。当然用官方工具,也不是没办法,自己debug,各种不方便。别人的工具是别人的,自己写是自己的。想要在非官方的工具写出专业的代码,最重要的就是数据结构了,基本的自己先弄懂,同样如果用官方工具的时候,还是有很多意想不到的坑需要考虑。
2)用代码开发接下来最最重要的,也是用代码写出来的其中一个方法,就是用代码开发了,很多东西只有自己亲手写出来,自己写,看官方的代码,而不是看别人写的这样的话,才能发现自己的问题,才能在你改写的时候有更多可以提炼出来的东西。虽然大部分的问题,代码已经给你模板化了,但是还是有很多值得你去写的。比如说用来实现一个中心坐标系的时候,或者说,用来实现和四。
你上,说不定你就把github先写好了
采集交流 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-07-29 06:36
文章采集内容通常是已有的数据,引用这些内容可以省去自己爬取获取新数据的时间成本。对于开发者来说,推荐是会推荐两个平台:码云平台和开源中国平台,两个平台用起来都不麻烦。码云平台可以直接在码云官网注册并下载:开源中国平台可以在开源中国中国站注册并下载:从功能上来说,开源中国用户数量更大,功能更强大,按照重要程度排序:对于个人用户来说,更推荐简单易用的码云,并且码云有各种github账号、服务。
如果需要社区功能,码云可以自己弄一个githubfork账号:还可以添加fofa账号,方便联系服务提供商:码云、开源中国平台功能对比:码云:可免费提供小部分自助爬虫服务开源中国:可免费提供小部分自助爬虫服务(每天限10-30人)码云:更新节奏快,更新速度快开源中国:封闭式平台,有反爬机制,不太推荐开源中国项目fofa功能比码云更完善,自己添加信息采集服务比较方便:-fofa/readme。
说到写代码我第一个想到的就是github。你上github,说不定你就把我这篇文章用你的github先写好了。
其实这两个平台都差不多,都是个人使用为主,至于是不是要写外文代码,看个人爱好吧。有些开源语言会用到部分github服务,比如python,mongodb等。
github是一个很大的平台,也就是一个基于git的powerfulsource,开源中国仅是个人爬虫的web服务而已。当然为什么要用最大的平台呢,因为可以收集爬虫最新的内容。 查看全部
你上,说不定你就把github先写好了
文章采集内容通常是已有的数据,引用这些内容可以省去自己爬取获取新数据的时间成本。对于开发者来说,推荐是会推荐两个平台:码云平台和开源中国平台,两个平台用起来都不麻烦。码云平台可以直接在码云官网注册并下载:开源中国平台可以在开源中国中国站注册并下载:从功能上来说,开源中国用户数量更大,功能更强大,按照重要程度排序:对于个人用户来说,更推荐简单易用的码云,并且码云有各种github账号、服务。
如果需要社区功能,码云可以自己弄一个githubfork账号:还可以添加fofa账号,方便联系服务提供商:码云、开源中国平台功能对比:码云:可免费提供小部分自助爬虫服务开源中国:可免费提供小部分自助爬虫服务(每天限10-30人)码云:更新节奏快,更新速度快开源中国:封闭式平台,有反爬机制,不太推荐开源中国项目fofa功能比码云更完善,自己添加信息采集服务比较方便:-fofa/readme。
说到写代码我第一个想到的就是github。你上github,说不定你就把我这篇文章用你的github先写好了。
其实这两个平台都差不多,都是个人使用为主,至于是不是要写外文代码,看个人爱好吧。有些开源语言会用到部分github服务,比如python,mongodb等。
github是一个很大的平台,也就是一个基于git的powerfulsource,开源中国仅是个人爬虫的web服务而已。当然为什么要用最大的平台呢,因为可以收集爬虫最新的内容。
让我们从两个常见的内容采集工具开始:优采云采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-07-27 23:03
让我们从两个常见的内容开始采集tools:
(1)优采云采集工具:操作比较简单,免费版可以满足新手站长对数据挖掘的需求,但是需要整合采集数据的推导,更重要的功能是智能采集,不用写太复杂的规则。
(2)优采云采集器:国内除尘软件老牌子。所以支持cms系统采集的插件很多,比如:织梦文章 采集、WordPress信息采集、Zblog数据采集等,支架的扩展性比较大,但需要一定的技术力量。
那么,对于文章的采集,我们应该注意哪些问题?
1、新站删除了数据采集
我们知道网站发布初期有一个评估期。如果我们在建站之初就使用采集到的内容,会对网站的评分产生影响。 文章很容易被放入低质量的库中,并且会出现一个普遍现象:与收录没有排名。
为此,新版网站尽量保持原有内容在线,页面内容未完全索引时,无需盲目提交,或者如果要提交,则需要采用一定的策略。
2、权重网站采集内容
我们知道搜索引擎不喜欢封闭状态。他们喜欢的网站 不仅有导入链接,还有一些导出链接,让这个生态系统更具相关性。
为此,您的网站积累了一定的权重后,可以通过版权链接适当采集相关内容,需要注意:
(1)保证内容集合对站内用户有一定的推荐价值,是解决用户需求的好方法。
(2)工业公文,heavy网站,知名专家推荐采集内容。
3、to avoid采集全站内容
说到这个问题,很多人很容易质疑飓风算法强调对获取的严厉攻击,但为什么权限网站不在攻击范围之内?
这和搜索引擎的性质有关:为了满足用户的需求,网站对优质内容传播的影响也比较重要。
对于中小网站,在我们拥有独特的属性和影响力之前,我们应该尽量避免采集的大量内容。
提醒:随着熊掌的上线和原创protection的引入,百度仍会努力调整和平衡原创内容和authority网站的排名。原则上,应该更倾向于将原创网站排在第一位。
4、如果网站内容采集被处罚了,我们该怎么办?
飓风算法非常人性化。它只会惩罚采集 列,但对同一站点的其他列几乎没有影响。
所以,解决方法很简单,只需要删除采集的内容,设置404页面,然后在百度搜索资源平台提交死链接->网站Support->资料介绍->死链接提交栏。如果您发现网站的体重恢复缓慢,可以在反馈中心反馈。
总结:内容依然适用于王。如果你关注熊掌,你会发现2019年百度会加大对原创内容的支持,尽量避免采集内容。 查看全部
让我们从两个常见的内容采集工具开始:优采云采集
让我们从两个常见的内容开始采集tools:
(1)优采云采集工具:操作比较简单,免费版可以满足新手站长对数据挖掘的需求,但是需要整合采集数据的推导,更重要的功能是智能采集,不用写太复杂的规则。
(2)优采云采集器:国内除尘软件老牌子。所以支持cms系统采集的插件很多,比如:织梦文章 采集、WordPress信息采集、Zblog数据采集等,支架的扩展性比较大,但需要一定的技术力量。
那么,对于文章的采集,我们应该注意哪些问题?
1、新站删除了数据采集
我们知道网站发布初期有一个评估期。如果我们在建站之初就使用采集到的内容,会对网站的评分产生影响。 文章很容易被放入低质量的库中,并且会出现一个普遍现象:与收录没有排名。
为此,新版网站尽量保持原有内容在线,页面内容未完全索引时,无需盲目提交,或者如果要提交,则需要采用一定的策略。
2、权重网站采集内容
我们知道搜索引擎不喜欢封闭状态。他们喜欢的网站 不仅有导入链接,还有一些导出链接,让这个生态系统更具相关性。
为此,您的网站积累了一定的权重后,可以通过版权链接适当采集相关内容,需要注意:
(1)保证内容集合对站内用户有一定的推荐价值,是解决用户需求的好方法。
(2)工业公文,heavy网站,知名专家推荐采集内容。
3、to avoid采集全站内容
说到这个问题,很多人很容易质疑飓风算法强调对获取的严厉攻击,但为什么权限网站不在攻击范围之内?
这和搜索引擎的性质有关:为了满足用户的需求,网站对优质内容传播的影响也比较重要。
对于中小网站,在我们拥有独特的属性和影响力之前,我们应该尽量避免采集的大量内容。
提醒:随着熊掌的上线和原创protection的引入,百度仍会努力调整和平衡原创内容和authority网站的排名。原则上,应该更倾向于将原创网站排在第一位。
4、如果网站内容采集被处罚了,我们该怎么办?
飓风算法非常人性化。它只会惩罚采集 列,但对同一站点的其他列几乎没有影响。
所以,解决方法很简单,只需要删除采集的内容,设置404页面,然后在百度搜索资源平台提交死链接->网站Support->资料介绍->死链接提交栏。如果您发现网站的体重恢复缓慢,可以在反馈中心反馈。
总结:内容依然适用于王。如果你关注熊掌,你会发现2019年百度会加大对原创内容的支持,尽量避免采集内容。
错误博客2021-07-23优采云采集软件生产原创内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-07-27 22:51
错误博客2021-07-23优采云采集软件生产原创内容
优采云采集三种构建方式原创文章
错误博客 2021-07-23
优采云采集software 是一个非常好用的文章采集软件,能产生原创内容吗?是的,但只是质量略低原创。今天错误博客()分享的内容是“优采云采集Build原创文章Three Methods”。希望能帮到你。
一、优采云与原创
优采云没有原创的能力,但优采云确实可以创建原创内容。错误博客先介绍三种使用优采云创原创文章的方式,当然以后会有更多的方式,就看大家的头脑风暴了。
1、English to Chinese plugin
采集一些英文网站文章,然后用优采云的英文转中文插件,可以得到很多伪原创文章,这样文章甚至可以叫原创,但可能读不完,不过原创度还好,除非两个人都是采集同文章中文文章,否则这种模式下得到的内容收录率还行本站有部分谷歌搜索引擎优化文章就是通过这种方式获取的。
目前这种插件一般都是收费的。你可以找到免费的插件,但通常你必须获得百度翻译API。如果超过免费使用量,则需要另行付费。
2、伪原创plugin
伪原创插件基本上都是在线伪原创搞的人做的,大部分都是收费的。毕竟这是大量的伪原创,一定程度上消耗了对方的服务器资源。 .
对于伪原创,错误博客不是特别推荐。毕竟这东西可读性真的很差,搜索引擎也不友好。如果你网站friendliness 好,即使你没有太多的文字,你也可以做到。是收录,但伪原创的内容可能不是收录。
此外,伪原创的大部分内容来自同义词和同义词的替换。市场上基本上没有AI伪原创。如果确实存在,那就直接给关键词,其他的就自己写吧。市面上的伪原创提供者大多替换同义词和同义词,所以最好不要这样做。
3、建建文章
用大量的词来构造文章,比如把十万个相关词做成一个表格文章页面,把词句排列起来,看起来没有任何意义违反。看到很多这样的方法网站收到了很多流量,错误的博客本身就收到了几万收录。
二、优采云Build文章
优采云Build文章方式很简单,错误博客会一一告诉你。
1、优采云import 模板
下载优采云,即优采云采集,创建一个字符列表组,右键单击该组,然后导入准备好的“.ljobx”文件,即@的模板优采云采集 .
2、内容采集rule
导入后双击打开,跳过“URL采集Rules”直接进入“Content采集Rules”。然后,我们需要构建原创的标题、页面关键词、页面描述、作者、缩略图、标签等,这些内容都来自txt文件,里面有几万行数据txt 文件内存,这样就可以构造原创文章。当然,这只是一种模式。如果你想有更好的收录效果,你需要考虑如何使用这种模式来制作更好的内容,或者使用另一种模式来制作更像原创的内容。
查看全部
错误博客2021-07-23优采云采集软件生产原创内容
优采云采集三种构建方式原创文章
错误博客 2021-07-23
优采云采集software 是一个非常好用的文章采集软件,能产生原创内容吗?是的,但只是质量略低原创。今天错误博客()分享的内容是“优采云采集Build原创文章Three Methods”。希望能帮到你。
一、优采云与原创
优采云没有原创的能力,但优采云确实可以创建原创内容。错误博客先介绍三种使用优采云创原创文章的方式,当然以后会有更多的方式,就看大家的头脑风暴了。
1、English to Chinese plugin
采集一些英文网站文章,然后用优采云的英文转中文插件,可以得到很多伪原创文章,这样文章甚至可以叫原创,但可能读不完,不过原创度还好,除非两个人都是采集同文章中文文章,否则这种模式下得到的内容收录率还行本站有部分谷歌搜索引擎优化文章就是通过这种方式获取的。
目前这种插件一般都是收费的。你可以找到免费的插件,但通常你必须获得百度翻译API。如果超过免费使用量,则需要另行付费。
2、伪原创plugin
伪原创插件基本上都是在线伪原创搞的人做的,大部分都是收费的。毕竟这是大量的伪原创,一定程度上消耗了对方的服务器资源。 .
对于伪原创,错误博客不是特别推荐。毕竟这东西可读性真的很差,搜索引擎也不友好。如果你网站friendliness 好,即使你没有太多的文字,你也可以做到。是收录,但伪原创的内容可能不是收录。
此外,伪原创的大部分内容来自同义词和同义词的替换。市场上基本上没有AI伪原创。如果确实存在,那就直接给关键词,其他的就自己写吧。市面上的伪原创提供者大多替换同义词和同义词,所以最好不要这样做。
3、建建文章
用大量的词来构造文章,比如把十万个相关词做成一个表格文章页面,把词句排列起来,看起来没有任何意义违反。看到很多这样的方法网站收到了很多流量,错误的博客本身就收到了几万收录。
二、优采云Build文章
优采云Build文章方式很简单,错误博客会一一告诉你。
1、优采云import 模板
下载优采云,即优采云采集,创建一个字符列表组,右键单击该组,然后导入准备好的“.ljobx”文件,即@的模板优采云采集 .
2、内容采集rule
导入后双击打开,跳过“URL采集Rules”直接进入“Content采集Rules”。然后,我们需要构建原创的标题、页面关键词、页面描述、作者、缩略图、标签等,这些内容都来自txt文件,里面有几万行数据txt 文件内存,这样就可以构造原创文章。当然,这只是一种模式。如果你想有更好的收录效果,你需要考虑如何使用这种模式来制作更好的内容,或者使用另一种模式来制作更像原创的内容。
为什么大站采集内容要比原创的关键词排名还要好?
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-07-26 05:17
问题:一些大网站总是采集我的内容为什么他们的排名比我的好?
百度站长平台权威解答
在知名的网站上阅读你的内容往往会得到很多额外的好处,比如更少的广告、更快的加载速度、更多的用户交互、更多相关的内容和更清晰的布局。因此,在构建内容时,不仅要考虑内容本身,还要考虑用户的浏览体验。
沐风SEO讲解
虽然百度提到了用户体验问题,但其实很多小站用户体验也不错,加载速度也比较理想。唯一缺少的是用户交互。毕竟网站的流量很少。
但是为什么大网站采集的内容比原创的关键词排名好呢?归根结底还是网站权重的问题。例如,如果一个大站得到一个完全没有用户体验的低质量伪原创,它的排名往往非常好。
所以,对于肖战来说,能做的就是不断提升网站权重。只有网站的权重高,才能有好的显示效果。关于大站的问题,百度搜索在优化指南中也提到,大站的权限和用户体验通常都比较好,所以搜索引擎会给予优待。
还有建立网站的时间问题。一般来说网站越长,在没有违规的情况下,搜索引擎会给予更高的信任度。所以需要坚持做网站优化,不断提升搜索引擎的信任度,这样权重才会上升。
如果我们的网站权重比较高,即使发的原创文章被那些大站采集过去了,我们关键词的排名也不会差。
当然要注意文章相关的合理调用,为用户提供更多有价值的信息,给用户带来更多额外帮助,解决更多相关问题。这样,页面的整体质量会更高,关键词排名也会更好。
本文简要解释了为什么大网站采集 的内容排名优于原创。总之,大网站具有天然优势,具有更高的权威性和信任度。如果小站想要文章比大站采集排名更好,就得不断增加权重,让网站成为小站网站的权威,这样就不用担心了排名问题。 查看全部
为什么大站采集内容要比原创的关键词排名还要好?
问题:一些大网站总是采集我的内容为什么他们的排名比我的好?
百度站长平台权威解答
在知名的网站上阅读你的内容往往会得到很多额外的好处,比如更少的广告、更快的加载速度、更多的用户交互、更多相关的内容和更清晰的布局。因此,在构建内容时,不仅要考虑内容本身,还要考虑用户的浏览体验。
沐风SEO讲解
虽然百度提到了用户体验问题,但其实很多小站用户体验也不错,加载速度也比较理想。唯一缺少的是用户交互。毕竟网站的流量很少。
但是为什么大网站采集的内容比原创的关键词排名好呢?归根结底还是网站权重的问题。例如,如果一个大站得到一个完全没有用户体验的低质量伪原创,它的排名往往非常好。
所以,对于肖战来说,能做的就是不断提升网站权重。只有网站的权重高,才能有好的显示效果。关于大站的问题,百度搜索在优化指南中也提到,大站的权限和用户体验通常都比较好,所以搜索引擎会给予优待。
还有建立网站的时间问题。一般来说网站越长,在没有违规的情况下,搜索引擎会给予更高的信任度。所以需要坚持做网站优化,不断提升搜索引擎的信任度,这样权重才会上升。
如果我们的网站权重比较高,即使发的原创文章被那些大站采集过去了,我们关键词的排名也不会差。
当然要注意文章相关的合理调用,为用户提供更多有价值的信息,给用户带来更多额外帮助,解决更多相关问题。这样,页面的整体质量会更高,关键词排名也会更好。
本文简要解释了为什么大网站采集 的内容排名优于原创。总之,大网站具有天然优势,具有更高的权威性和信任度。如果小站想要文章比大站采集排名更好,就得不断增加权重,让网站成为小站网站的权威,这样就不用担心了排名问题。
抖音短视频全面放开新增加的直播权限有哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-07-17 06:01
文章采集内容:5月1日,抖音短视频正式全面放开了新增加的直播权限,但是在此之前粉丝满150万才可以申请直播权限,这对于新人来说挑战非常大。所以这段时间,抖音会不断制定新规,通过内部更新来完善自己的条件,防止达到门槛或者达到一定粉丝量才可以申请直播权限。1.使用工具需要账号准备一个抖音号或者部分抖音号2.权限申请审核资料准备申请直播权限一般是需要资料的,还有自荐和简历等,当然是越多越好。
开通直播权限以后需要拍摄直播视频,可以通过公会或者个人推荐拍摄。自荐自荐是需要得到抖音官方的推荐的,所以要准备充足的资料,才能够被推荐。3.新手条件新手申请直播权限需要满足以下条件:。
1、粉丝数量150万。
2、时长在1小时以上。
3、自荐经过。
4、坚持直播。
5、不用频繁的变动头像和昵称。
6、不需要开通原创。
6.内容策划技巧
1、封面要吸引人。
2、标题需要有吸引力。
3、切忌直播时涉黄。
4、内容分类清晰。
5、和粉丝互动能力强。
6、内容要有趣,符合热点。
7、积极配合抖音官方运营。
8、内容要有趣,符合热点。
渠道如下:①:下载一个抖音助手,然后邀请好友关注公众号。②:在公众号里下载抖音号,按照步骤来。其实新手门槛一点都不高,甚至都可以忽略不计,要想在抖音赚到钱,但是首先你得保证自己的抖音号没有违规行为。那么抖音号违规行为有哪些呢?①:发布低俗色情类型的内容。②:发布赌博类型的内容。③:发布社会性的负能量的内容。总之,想要在抖音赚钱是比较难的,需要持之以恒的去做。 查看全部
抖音短视频全面放开新增加的直播权限有哪些?
文章采集内容:5月1日,抖音短视频正式全面放开了新增加的直播权限,但是在此之前粉丝满150万才可以申请直播权限,这对于新人来说挑战非常大。所以这段时间,抖音会不断制定新规,通过内部更新来完善自己的条件,防止达到门槛或者达到一定粉丝量才可以申请直播权限。1.使用工具需要账号准备一个抖音号或者部分抖音号2.权限申请审核资料准备申请直播权限一般是需要资料的,还有自荐和简历等,当然是越多越好。
开通直播权限以后需要拍摄直播视频,可以通过公会或者个人推荐拍摄。自荐自荐是需要得到抖音官方的推荐的,所以要准备充足的资料,才能够被推荐。3.新手条件新手申请直播权限需要满足以下条件:。
1、粉丝数量150万。
2、时长在1小时以上。
3、自荐经过。
4、坚持直播。
5、不用频繁的变动头像和昵称。
6、不需要开通原创。
6.内容策划技巧
1、封面要吸引人。
2、标题需要有吸引力。
3、切忌直播时涉黄。
4、内容分类清晰。
5、和粉丝互动能力强。
6、内容要有趣,符合热点。
7、积极配合抖音官方运营。
8、内容要有趣,符合热点。
渠道如下:①:下载一个抖音助手,然后邀请好友关注公众号。②:在公众号里下载抖音号,按照步骤来。其实新手门槛一点都不高,甚至都可以忽略不计,要想在抖音赚到钱,但是首先你得保证自己的抖音号没有违规行为。那么抖音号违规行为有哪些呢?①:发布低俗色情类型的内容。②:发布赌博类型的内容。③:发布社会性的负能量的内容。总之,想要在抖音赚钱是比较难的,需要持之以恒的去做。
文章采集内容采集器工具大屏幕抖音、直播、红包攻略入口
采集交流 • 优采云 发表了文章 • 0 个评论 • 258 次浏览 • 2021-07-13 21:00
文章采集内容采集器工具大屏幕抖音小视频、直播、红包攻略入口一:文章采集器红包采集器:超过200万+原创视频教程,采集教程,全能学习,有需要的可以试一下,抖音现在很难红,因为抖音早晚要抖红,学会如何玩抖音,先学学怎么玩抖音,去抖音看看成功的人,看看他们都做了哪些粉丝,抖音达人都是怎么发展的。入口二:页面采集器采集器的教程教程一:抖音采集其他平台教程教程二:抖音视频采集。
抖音采集工具必须要在短视频平台有商品功能才可以采集到商品,然后自己再设置个联名有购物车的就行了。
,专业从事抖音快手等平台视频采集及商品链接数据接入,文章视频精选出来之后,自动会收录到云采集平台,
采集抖音短视频教程,可以去我文章看看,有大量抖音,快手的采集和视频教程,
简单快捷的方法就是批量采集高清视频,然后转化成音频去做flv。
提供高清抖音、快手mv音频采集,收费也不贵:100一个视频教程。
说点大家可能听过的一个工具:es文件浏览器如图,
打开浏览器输入文件搜索会出现下面的搜索页面说是啥文件搜索引擎我也不知道但是你如果你从高清视频中免费获取电商产品或者入驻某平台的话,还是可以的。这个我尝试过很多别的的工具了。 查看全部
文章采集内容采集器工具大屏幕抖音、直播、红包攻略入口
文章采集内容采集器工具大屏幕抖音小视频、直播、红包攻略入口一:文章采集器红包采集器:超过200万+原创视频教程,采集教程,全能学习,有需要的可以试一下,抖音现在很难红,因为抖音早晚要抖红,学会如何玩抖音,先学学怎么玩抖音,去抖音看看成功的人,看看他们都做了哪些粉丝,抖音达人都是怎么发展的。入口二:页面采集器采集器的教程教程一:抖音采集其他平台教程教程二:抖音视频采集。
抖音采集工具必须要在短视频平台有商品功能才可以采集到商品,然后自己再设置个联名有购物车的就行了。
,专业从事抖音快手等平台视频采集及商品链接数据接入,文章视频精选出来之后,自动会收录到云采集平台,
采集抖音短视频教程,可以去我文章看看,有大量抖音,快手的采集和视频教程,
简单快捷的方法就是批量采集高清视频,然后转化成音频去做flv。
提供高清抖音、快手mv音频采集,收费也不贵:100一个视频教程。
说点大家可能听过的一个工具:es文件浏览器如图,
打开浏览器输入文件搜索会出现下面的搜索页面说是啥文件搜索引擎我也不知道但是你如果你从高清视频中免费获取电商产品或者入驻某平台的话,还是可以的。这个我尝试过很多别的的工具了。
文章采集内容制作成四个部分文章字段所对应图片解释
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-07-03 22:02
文章采集内容制作成四个部分文章字段所对应图片解释如下:1.图片链接2.图片大小3.图片方式以图片头像的形式,这里是填空。4.图片开始时间->图片完整创建时间方式:1.填写完整的文章大纲2.文章结构,用数据挖掘式的分析3.图片开始时间4.图片完整创建时间接下来可以用java语言,绘制相应的图片。
楼主提出的图片和上方所指的用户真实头像对应关系,你说的这个“直接翻转”是显示图片上自动对应的坐标信息的技术实现,你可以看一下我博客,他是做数据挖掘的,网上有非常详细的演示和操作,
补充一下,如果使用googleanalytics可以不用直接生成头像(改为wap图片),直接把关键词出现在图片中就行。另外omnigraffle做gis开发一直只能用c、java或python写,无法用webgl。
1.下载yaml文件,
gis要素的制作上我喜欢用mapbox官方的visualizationsoftware解决问题,能解决一大部分问题,不过api还是有些蛋疼。
网页上直接点击浏览器某个按钮,鼠标选中你要的图片,鼠标右键,点击downloadonline,就可以下载。
-report.html貌似有中文
可以用requests服务器,这样可以post不能put,建议用html5可以连接本地数据库的mapbox数据接口。目前这样的方法,响应时间约为四分之一秒。 查看全部
文章采集内容制作成四个部分文章字段所对应图片解释
文章采集内容制作成四个部分文章字段所对应图片解释如下:1.图片链接2.图片大小3.图片方式以图片头像的形式,这里是填空。4.图片开始时间->图片完整创建时间方式:1.填写完整的文章大纲2.文章结构,用数据挖掘式的分析3.图片开始时间4.图片完整创建时间接下来可以用java语言,绘制相应的图片。
楼主提出的图片和上方所指的用户真实头像对应关系,你说的这个“直接翻转”是显示图片上自动对应的坐标信息的技术实现,你可以看一下我博客,他是做数据挖掘的,网上有非常详细的演示和操作,
补充一下,如果使用googleanalytics可以不用直接生成头像(改为wap图片),直接把关键词出现在图片中就行。另外omnigraffle做gis开发一直只能用c、java或python写,无法用webgl。
1.下载yaml文件,
gis要素的制作上我喜欢用mapbox官方的visualizationsoftware解决问题,能解决一大部分问题,不过api还是有些蛋疼。
网页上直接点击浏览器某个按钮,鼠标选中你要的图片,鼠标右键,点击downloadonline,就可以下载。
-report.html貌似有中文
可以用requests服务器,这样可以post不能put,建议用html5可以连接本地数据库的mapbox数据接口。目前这样的方法,响应时间约为四分之一秒。
公众号重复率高的几种方法,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 560 次浏览 • 2021-06-30 23:00
文章采集内容就是copy他人公众号上的文章到自己公众号的,转化率最低5%左右。如果做推广,内容采集后不处理有可能采集的内容就被删了,也不知道你有没有用第三方平台,我用的壹伴采集器,它上面可以自动检测文章是否已被采集,如果采集过来的内容重复,会自动提示,不用像别的采集器是要手动去点取消采集,省心,也可以清楚的看到自己已采集文章列表和未采集文章列表。
这个收益有两方面,一是公众号粉丝增长。二是粉丝粘性,粉丝消费。粉丝粘性好,消费自然增加。采集群很多。优质文章公众号原创。
如果重复率很低的话,这样的文章还是蛮好采集的。至于收益,如果纯为了采集而采集,是没有多大意义的。可以以自己的公众号为单位,多采集一些有重复文章的公众号。对自己的公众号粉丝进行再营销。看看效果。
会我一天采集几十篇没问题
有几个可以改变自己公众号重复率高的方法,
一、企业可以通过首图评论获取公众号文章(企业自己)
二、可以付费在微信公众号后台进行文章提取(零成本)
三、可以通过搜狗搜索优化(去除微信号的广告信息)
四、通过软件在搜狗上搜索文章信息批量下载,微信公众号多如牛毛,
可以做二次营销。现在公众号的流量红利期慢慢过去了,如果想在这个行业中保持初心和节操,唯有实现变现。单单靠内容一般来说不太容易赚到钱。相比之下,互联网项目就比较简单粗暴。
1、项目列表:大量变现的有机会做“网赚小骗子”,“骗老板”之类。因为互联网小骗子赚钱很容易,然后在推广赚钱。高收益的互联网项目怎么快速变现呢?方法一:当某个人非常有名的时候,你赚钱就快,这个人大名已经不重要,所以好好跟他合作,赚钱就快;方法二:干一票就跑,这个项目很可能一夜暴富。好像钱不好赚了,那我就去挣吧。
方法三:砸钱,我为什么要跟互联网小骗子合作呢?因为他们可以零成本、一分钱没有赚到,但可以保证“有钱”,因为互联网小骗子可以“转发”。比如利用名人做广告赚钱,首先获取别人信任,然后发布项目项目。不然,就算他赚钱了,不接项目,他也没钱赚。方法四:靠图片挣钱,不接项目,把别人的图片搬运下,有什么项目,赚钱的项目,都有很多。
方法五:卖图片赚钱,不知道卖什么赚钱?一般来说好不好卖的图片都是要很有逼格,通过长篇幅的图片卖品!方法六:qq空间靠日志赚钱,按日更吧!会赚钱的人看了都来收藏方法七:百度贴吧、等其他平台,做广告,做软文,上百度首页。总而言之,互联网赚钱也分层次。比如我说的小骗子,我想做,当时就可以。 查看全部
公众号重复率高的几种方法,你知道吗?
文章采集内容就是copy他人公众号上的文章到自己公众号的,转化率最低5%左右。如果做推广,内容采集后不处理有可能采集的内容就被删了,也不知道你有没有用第三方平台,我用的壹伴采集器,它上面可以自动检测文章是否已被采集,如果采集过来的内容重复,会自动提示,不用像别的采集器是要手动去点取消采集,省心,也可以清楚的看到自己已采集文章列表和未采集文章列表。
这个收益有两方面,一是公众号粉丝增长。二是粉丝粘性,粉丝消费。粉丝粘性好,消费自然增加。采集群很多。优质文章公众号原创。
如果重复率很低的话,这样的文章还是蛮好采集的。至于收益,如果纯为了采集而采集,是没有多大意义的。可以以自己的公众号为单位,多采集一些有重复文章的公众号。对自己的公众号粉丝进行再营销。看看效果。
会我一天采集几十篇没问题
有几个可以改变自己公众号重复率高的方法,
一、企业可以通过首图评论获取公众号文章(企业自己)
二、可以付费在微信公众号后台进行文章提取(零成本)
三、可以通过搜狗搜索优化(去除微信号的广告信息)
四、通过软件在搜狗上搜索文章信息批量下载,微信公众号多如牛毛,
可以做二次营销。现在公众号的流量红利期慢慢过去了,如果想在这个行业中保持初心和节操,唯有实现变现。单单靠内容一般来说不太容易赚到钱。相比之下,互联网项目就比较简单粗暴。
1、项目列表:大量变现的有机会做“网赚小骗子”,“骗老板”之类。因为互联网小骗子赚钱很容易,然后在推广赚钱。高收益的互联网项目怎么快速变现呢?方法一:当某个人非常有名的时候,你赚钱就快,这个人大名已经不重要,所以好好跟他合作,赚钱就快;方法二:干一票就跑,这个项目很可能一夜暴富。好像钱不好赚了,那我就去挣吧。
方法三:砸钱,我为什么要跟互联网小骗子合作呢?因为他们可以零成本、一分钱没有赚到,但可以保证“有钱”,因为互联网小骗子可以“转发”。比如利用名人做广告赚钱,首先获取别人信任,然后发布项目项目。不然,就算他赚钱了,不接项目,他也没钱赚。方法四:靠图片挣钱,不接项目,把别人的图片搬运下,有什么项目,赚钱的项目,都有很多。
方法五:卖图片赚钱,不知道卖什么赚钱?一般来说好不好卖的图片都是要很有逼格,通过长篇幅的图片卖品!方法六:qq空间靠日志赚钱,按日更吧!会赚钱的人看了都来收藏方法七:百度贴吧、等其他平台,做广告,做软文,上百度首页。总而言之,互联网赚钱也分层次。比如我说的小骗子,我想做,当时就可以。

