
文章定时自动采集
网站为什么不被百度收录?
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2020-08-13 00:52
首先我们网站发布一篇文章,最基本的目的是给用户看的,那么你最基本的保证就是这篇文章要是和网站内容相关的,而且对用户有需求的,是用户可能须要检索的内容,一篇和喷砂机网站主题毫无相关的文章是没有用户去访问的,就算是被用户无意间打开也只是篾一眼之后关掉,对网站优化的目的来说是毫无意义的,不能满足用户最基本的需求,没人去看,谈何被百度收录呢?
二、从网站用户体验度出发,保证文章页面的流畅性
优帮云在它的SEO实战密码中说过,用户能访问的地方,百度蜘蛛就可以抓取它,一个网页打开速率慢如蜗牛,不能显示完整的内容,作为访问者你会继续往下看吗?当然不会,保持网站页面打开的速率才能挺好的提升蜘蛛在网站上爬行的效率,进而提升收录,就如两个网站分别被置于国外服务器和美国服务器使用相同的SEO来优化它,最后放到国外服务器的网站排名比较靠前,道理一样。在这里就又要啰嗦点了,加快打开的速率方式好多,比如对CSS,js进行压缩,开启Gzip这种等等,其他的可以参考百度统计里的SEO建议里的说明。
三、从SEO角度出发,避免关键词拼凑嫌疑
很大一部分文章不被收录都是由于SEOer为了提升该页面的关键词,在文章中随便插入关键词,来达到关键词密度减小,自从2012年年初以来,百度就始终频频更新算法,对于那些三脚猫功夫,百度早早已不看在眼中了,搜索引擎仍然是顺应用户的,这种在网页中刻意的插入关键词,导致句子不能正常读通顺的文章肯定是会被淘汰的,更加不用说会收录你了。
四、从网站自身安全出发,保证网站不被采集
在中国是互联网的大国,网站也有无数,而且中国人喜欢懒惰,这就衍生出一些靠采集而活着的人,对于权重较低的网站,网上有类似的文章后,百度是不会再收录这种文章的,何况是相同的。古人云:”害人之心不可有,防人之心不可无”,对于这些采集人,我们惹不起,但我们躲的起,也防的起,因此在保证文章质量的情况下,文章依然没有被收录,可以通过标题的检索,来检测文章是否被镜像,如有可以调整代码结构,以及发布时间等方法来避免被镜像,例外随时对tt娱乐城网站进行代码漏洞检查,对后台程序升级到最新等等来避免网站被入侵篡改网站链接以及挂链接造成网站降权,直接影响文章的收录率。
五、从搜索引擎角度出发、尽量保持文章原创性
这一点应当你们都有所了解,但是施行上去的确对于这些写作能力比较弱的人来说是一个障碍,在这里我教你们比较基本的方法,先从你想优化的文章关键词来力一个标题,再从标题出发扩充出文章大纲,然后在从文章大纲来去采集相关资料,整理成段落短语,然后使用自己理解的语言组成一篇完整的原创文章。
六、从搜索引擎角度出发、保证文章定时更新
这一点涉及到网站与搜索引擎友好度的关问题,每日有规律性的更新网站内容,对于搜索引擎的蜘蛛来说减少了程序的开支,蜘蛛每次爬取都有新的内容更新,时间一长,网站在搜索引擎中的增强了信任,在达到一定标准时侯,会给与不错的权重,权重高的网站,收录也是十分高的。 查看全部
一、从网站自身用户体验出发,保证文章相关性
首先我们网站发布一篇文章,最基本的目的是给用户看的,那么你最基本的保证就是这篇文章要是和网站内容相关的,而且对用户有需求的,是用户可能须要检索的内容,一篇和喷砂机网站主题毫无相关的文章是没有用户去访问的,就算是被用户无意间打开也只是篾一眼之后关掉,对网站优化的目的来说是毫无意义的,不能满足用户最基本的需求,没人去看,谈何被百度收录呢?
二、从网站用户体验度出发,保证文章页面的流畅性
优帮云在它的SEO实战密码中说过,用户能访问的地方,百度蜘蛛就可以抓取它,一个网页打开速率慢如蜗牛,不能显示完整的内容,作为访问者你会继续往下看吗?当然不会,保持网站页面打开的速率才能挺好的提升蜘蛛在网站上爬行的效率,进而提升收录,就如两个网站分别被置于国外服务器和美国服务器使用相同的SEO来优化它,最后放到国外服务器的网站排名比较靠前,道理一样。在这里就又要啰嗦点了,加快打开的速率方式好多,比如对CSS,js进行压缩,开启Gzip这种等等,其他的可以参考百度统计里的SEO建议里的说明。
三、从SEO角度出发,避免关键词拼凑嫌疑
很大一部分文章不被收录都是由于SEOer为了提升该页面的关键词,在文章中随便插入关键词,来达到关键词密度减小,自从2012年年初以来,百度就始终频频更新算法,对于那些三脚猫功夫,百度早早已不看在眼中了,搜索引擎仍然是顺应用户的,这种在网页中刻意的插入关键词,导致句子不能正常读通顺的文章肯定是会被淘汰的,更加不用说会收录你了。
四、从网站自身安全出发,保证网站不被采集
在中国是互联网的大国,网站也有无数,而且中国人喜欢懒惰,这就衍生出一些靠采集而活着的人,对于权重较低的网站,网上有类似的文章后,百度是不会再收录这种文章的,何况是相同的。古人云:”害人之心不可有,防人之心不可无”,对于这些采集人,我们惹不起,但我们躲的起,也防的起,因此在保证文章质量的情况下,文章依然没有被收录,可以通过标题的检索,来检测文章是否被镜像,如有可以调整代码结构,以及发布时间等方法来避免被镜像,例外随时对tt娱乐城网站进行代码漏洞检查,对后台程序升级到最新等等来避免网站被入侵篡改网站链接以及挂链接造成网站降权,直接影响文章的收录率。
五、从搜索引擎角度出发、尽量保持文章原创性
这一点应当你们都有所了解,但是施行上去的确对于这些写作能力比较弱的人来说是一个障碍,在这里我教你们比较基本的方法,先从你想优化的文章关键词来力一个标题,再从标题出发扩充出文章大纲,然后在从文章大纲来去采集相关资料,整理成段落短语,然后使用自己理解的语言组成一篇完整的原创文章。
六、从搜索引擎角度出发、保证文章定时更新
这一点涉及到网站与搜索引擎友好度的关问题,每日有规律性的更新网站内容,对于搜索引擎的蜘蛛来说减少了程序的开支,蜘蛛每次爬取都有新的内容更新,时间一长,网站在搜索引擎中的增强了信任,在达到一定标准时侯,会给与不错的权重,权重高的网站,收录也是十分高的。
【推荐】phpcms 定时手动采集发布系统,ping google模块转让!
采集交流 • 优采云 发表了文章 • 0 个评论 • 405 次浏览 • 2020-08-12 23:03
:) 呵呵,最近仍然在做phpcms的手动采集发布模块,并且发布成功后手动更新相关页面,自动ping google,基本功能如下:
可自由设置手动执行时间,一般5-20分钟手动执行所有采集任务、发布、生成html、更新列表、更新首页、自动ping google .
原理如下:
1. 扩充了采集模块数据库,将任务表新增发布频道及栏目信息。
2. 写了一个手动顺序执行采集任务,关键词替换,自动发布,自动生成html,更新栏目列表,更新频道首页,最后更新网站首页。
3. linux /unix 下用crontab 新增定时任务, windows 下用我提供的随机启动的刷新小程序定时访问手动发布php程序即可。 这样一来,一个网站只须要依照须要多添加一些采集任务,比如添加从几十到几百个网站上的采集任务。就不需要再手工来采集、发布、更新了。 目前手动采集发布早已没有问题了,更新首页、列表页、频道首页等也测试通过了,完全正常没有任何问题。 查看全部
phpcms 没有手动采集、发布、更新相关列表功能,再有多个采集任务的时侯,非常浪费时间和精力,因为我营运几个网站,没有时间打理,就做了这个手动采集发布模块,此外降低了发布后手动ping google功能,可以快速的被google收录,是行业网站的做站神器,彻底解放站长体力。
:) 呵呵,最近仍然在做phpcms的手动采集发布模块,并且发布成功后手动更新相关页面,自动ping google,基本功能如下:
可自由设置手动执行时间,一般5-20分钟手动执行所有采集任务、发布、生成html、更新列表、更新首页、自动ping google .
原理如下:
1. 扩充了采集模块数据库,将任务表新增发布频道及栏目信息。
2. 写了一个手动顺序执行采集任务,关键词替换,自动发布,自动生成html,更新栏目列表,更新频道首页,最后更新网站首页。
3. linux /unix 下用crontab 新增定时任务, windows 下用我提供的随机启动的刷新小程序定时访问手动发布php程序即可。 这样一来,一个网站只须要依照须要多添加一些采集任务,比如添加从几十到几百个网站上的采集任务。就不需要再手工来采集、发布、更新了。 目前手动采集发布早已没有问题了,更新首页、列表页、频道首页等也测试通过了,完全正常没有任何问题。
shell定时采集数据到HDFS
采集交流 • 优采云 发表了文章 • 0 个评论 • 380 次浏览 • 2020-08-12 04:13
该怎样实现?实现后能够实现周期性上传需求?如何定时?
Linux crontab: :
crontab -e
0 0 * * * /shell/ uploadFile2Hdfs.sh //每晚晚上 12:00 执行一次
实现流程
一般日志文件生成的逻辑由业务系统决定,比如每小时滚动一次,或者一定大小滚动一次,避免单个日志文件过大不便捷操作。
比如滚动后的文件命名为 access.log.x,其中 x 为数字。正在进行写的日志文件称作 access.log。这样的话,如果日志文件后缀是 1\2\3 等数字,则该文件满足需求可以上传,就把该文件联通到打算上传的工作区间目录。工作区间有文件以后,可以使用 hadoop put 命令将文件上传。
在服务器上创建目录
#日志文件存放的目录
mkdir -r /root/logs/log/
#待上传文件存放的目录
mkdir -r /root/logs/toupload/
编写shell脚本
vi uploadFile2Hdfs.sh
#!/bin/bash
#set java env
export JAVA_HOME=/export/servers/jdk1.8.0_65
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#set hadoop env
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
#日志文件存放的目录
log_src_dir=/root/logs/log/
#待上传文件存放的目录
log_toupload_dir=/root/logs/toupload/
#日志文件上传到hdfs的根路径
date1=`date -d last-day +%Y_%m_%d`
hdfs_root_dir=/data/clickLog/$date1/
#打印环境变量信息
echo "envs: hadoop_home: $HADOOP_HOME"
#读取日志文件的目录,判断是否有需要上传的文件
echo "log_src_dir:"$log_src_dir
ls $log_src_dir | while read fileName
do
if [[ "$fileName" == access.log.* ]]; then
# if [ "access.log" = "$fileName" ];then
date=`date +%Y_%m_%d_%H_%M_%S`
#将文件移动到待上传目录并重命名
#打印信息
echo "moving $log_src_dir$fileName to $log_toupload_dir"xxxxx_click_log_$fileName"$date"
mv $log_src_dir$fileName $log_toupload_dir"xxxxx_click_log_$fileName"$date
#将待上传的文件path写入一个列表文件willDoing
echo $log_toupload_dir"xxxxx_click_log_$fileName"$date >> $log_toupload_dir"willDoing."$date
fi
done
#找到列表文件willDoing
ls $log_toupload_dir | grep will |grep -v "_COPY_" | grep -v "_DONE_" | while read line
do
#打印信息
echo "toupload is in file:"$line
#将待上传文件列表willDoing改名为willDoing_COPY_
mv $log_toupload_dir$line $log_toupload_dir$line"_COPY_"
#读列表文件willDoing_COPY_的内容(一个一个的待上传文件名) ,此处的line 就是列表中的一个待上传文件的path
cat $log_toupload_dir$line"_COPY_" |while read line
do
#打印信息
echo "puting...$line to hdfs path.....$hdfs_root_dir"
hadoop fs -mkdir -p $hdfs_root_dir
hadoop fs -put $line $hdfs_root_dir
done
mv $log_toupload_dir$line"_COPY_" $log_toupload_dir$line"_DONE_"
done
设置执行权限
chmod 777 uploadFile2Hdfs.sh
在/root/logs/log/ 添加测试文件执行脚本
./uploadFile2Hdfs.sh
在/root/logs/toupload/ 及HDFS的webUI中查看现象
转载于: 查看全部
上线的网站每天就会形成日志数据。假如有这样的需求:要求在晚上 24 点开始操作前一天形成的日志文件,准实时上传至 HDFS 集群上。
该怎样实现?实现后能够实现周期性上传需求?如何定时?
Linux crontab: :
crontab -e
0 0 * * * /shell/ uploadFile2Hdfs.sh //每晚晚上 12:00 执行一次
实现流程
一般日志文件生成的逻辑由业务系统决定,比如每小时滚动一次,或者一定大小滚动一次,避免单个日志文件过大不便捷操作。
比如滚动后的文件命名为 access.log.x,其中 x 为数字。正在进行写的日志文件称作 access.log。这样的话,如果日志文件后缀是 1\2\3 等数字,则该文件满足需求可以上传,就把该文件联通到打算上传的工作区间目录。工作区间有文件以后,可以使用 hadoop put 命令将文件上传。
在服务器上创建目录
#日志文件存放的目录
mkdir -r /root/logs/log/
#待上传文件存放的目录
mkdir -r /root/logs/toupload/
编写shell脚本
vi uploadFile2Hdfs.sh
#!/bin/bash
#set java env
export JAVA_HOME=/export/servers/jdk1.8.0_65
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#set hadoop env
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
#日志文件存放的目录
log_src_dir=/root/logs/log/
#待上传文件存放的目录
log_toupload_dir=/root/logs/toupload/
#日志文件上传到hdfs的根路径
date1=`date -d last-day +%Y_%m_%d`
hdfs_root_dir=/data/clickLog/$date1/
#打印环境变量信息
echo "envs: hadoop_home: $HADOOP_HOME"
#读取日志文件的目录,判断是否有需要上传的文件
echo "log_src_dir:"$log_src_dir
ls $log_src_dir | while read fileName
do
if [[ "$fileName" == access.log.* ]]; then
# if [ "access.log" = "$fileName" ];then
date=`date +%Y_%m_%d_%H_%M_%S`
#将文件移动到待上传目录并重命名
#打印信息
echo "moving $log_src_dir$fileName to $log_toupload_dir"xxxxx_click_log_$fileName"$date"
mv $log_src_dir$fileName $log_toupload_dir"xxxxx_click_log_$fileName"$date
#将待上传的文件path写入一个列表文件willDoing
echo $log_toupload_dir"xxxxx_click_log_$fileName"$date >> $log_toupload_dir"willDoing."$date
fi
done
#找到列表文件willDoing
ls $log_toupload_dir | grep will |grep -v "_COPY_" | grep -v "_DONE_" | while read line
do
#打印信息
echo "toupload is in file:"$line
#将待上传文件列表willDoing改名为willDoing_COPY_
mv $log_toupload_dir$line $log_toupload_dir$line"_COPY_"
#读列表文件willDoing_COPY_的内容(一个一个的待上传文件名) ,此处的line 就是列表中的一个待上传文件的path
cat $log_toupload_dir$line"_COPY_" |while read line
do
#打印信息
echo "puting...$line to hdfs path.....$hdfs_root_dir"
hadoop fs -mkdir -p $hdfs_root_dir
hadoop fs -put $line $hdfs_root_dir
done
mv $log_toupload_dir$line"_COPY_" $log_toupload_dir$line"_DONE_"
done
设置执行权限
chmod 777 uploadFile2Hdfs.sh
在/root/logs/log/ 添加测试文件执行脚本
./uploadFile2Hdfs.sh
在/root/logs/toupload/ 及HDFS的webUI中查看现象
转载于:
优采云采集器定时采集更新网站内容(长期做站必用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 405 次浏览 • 2020-08-11 19:46
教程总目录:优采云采集器使用教程
前面的教程我们基本能完成网站内容的采集工作了。但是我们想要网站长期运行的话,肯定不能单靠一次采集来完成。
优采云自带的有计划任务功能,我们可以使用这个功能来实现定时运行采集任务。
另外我们采集的地址也须要做一些变更,提高采集效率。
1.采集地址设置
前面教程李我们的目的是把对方整站的内容给采集过来,所以采集列表里网址比较多,后面我们持续采集新内容的话就不能扫描整个网站这样来了。
我们只监控第一页即可,然后定时检查第一页有没有新内容,有新内容优采云会手动采集下来数据。没有的话扫描之后手动会停止。
以景安的文章为例
这个是他的文章列表第一页,当景安更新了新内容,肯定会在第一页这儿显示。我们就把第一页这个地址填入采集列表即可。这里不再重复说如何填了吧,教程开头几篇文章写了
另外一点须要注意,因为我们定时运行时他要检查是不是采集过的文章,所以说我们不要消除优采云的采集数据。不然的话优采云检测发觉文章都没采集过,都当作新文章采集了。
2.定时任务设置
本教程只创建了一个任务,如果你是常年运行一个网站。你网站每个版块可能都采集的是不同的文章来源,甚至一个版块才几个多个网站的文章。任务就十分多
我们可以批量添加定时任务
点击计划任务
我们先创建一个计划任务分组
然后在分组内添加计划任务,这样比较好管理
然后上面的间隔时间依照要采集的网站更新频度来设置,他更新快你就间隔时间短点。更新慢的话就长点,比如景安这个网站,可能几天几个月都不更新,就设置间隔时间为每晚就行。
限定时间段
这个应当也都理解,就是计划任务在哪些时间段内生效,默认是早上6点到晚上23点。我通常会给他改成全天的
扩展知识
因为采集任务常年运行,我们最好是将胡说回头放在一台服务器上跑,家里有比较节电的机器的话也可以拿来挂采集任务。
采集任务比较多的话还是很消耗CPU的,一般建议在家里挂。家庭带宽内网IP时常变动有利于采集,而且硬件配置基本也都比买的服务器配置高。不用害怕优采云运行着出现卡死的情况。 查看全部
优采云采集器定时采集更新网站内容(长期做站必用)
教程总目录:优采云采集器使用教程
前面的教程我们基本能完成网站内容的采集工作了。但是我们想要网站长期运行的话,肯定不能单靠一次采集来完成。
优采云自带的有计划任务功能,我们可以使用这个功能来实现定时运行采集任务。
另外我们采集的地址也须要做一些变更,提高采集效率。
1.采集地址设置
前面教程李我们的目的是把对方整站的内容给采集过来,所以采集列表里网址比较多,后面我们持续采集新内容的话就不能扫描整个网站这样来了。
我们只监控第一页即可,然后定时检查第一页有没有新内容,有新内容优采云会手动采集下来数据。没有的话扫描之后手动会停止。
以景安的文章为例
这个是他的文章列表第一页,当景安更新了新内容,肯定会在第一页这儿显示。我们就把第一页这个地址填入采集列表即可。这里不再重复说如何填了吧,教程开头几篇文章写了
另外一点须要注意,因为我们定时运行时他要检查是不是采集过的文章,所以说我们不要消除优采云的采集数据。不然的话优采云检测发觉文章都没采集过,都当作新文章采集了。
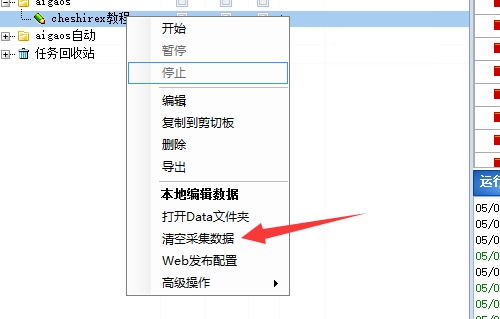
2.定时任务设置
本教程只创建了一个任务,如果你是常年运行一个网站。你网站每个版块可能都采集的是不同的文章来源,甚至一个版块才几个多个网站的文章。任务就十分多
我们可以批量添加定时任务
点击计划任务
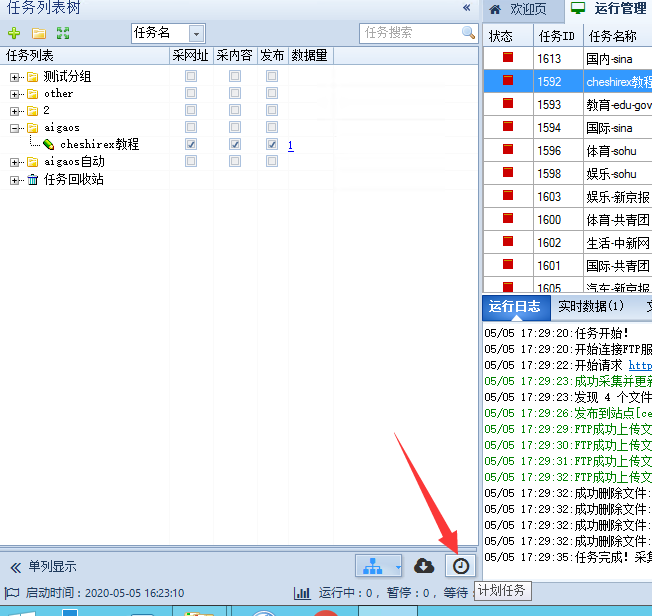
我们先创建一个计划任务分组
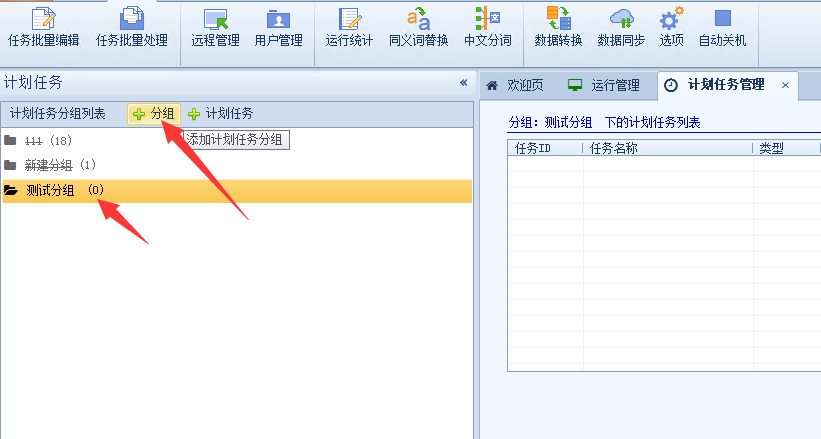
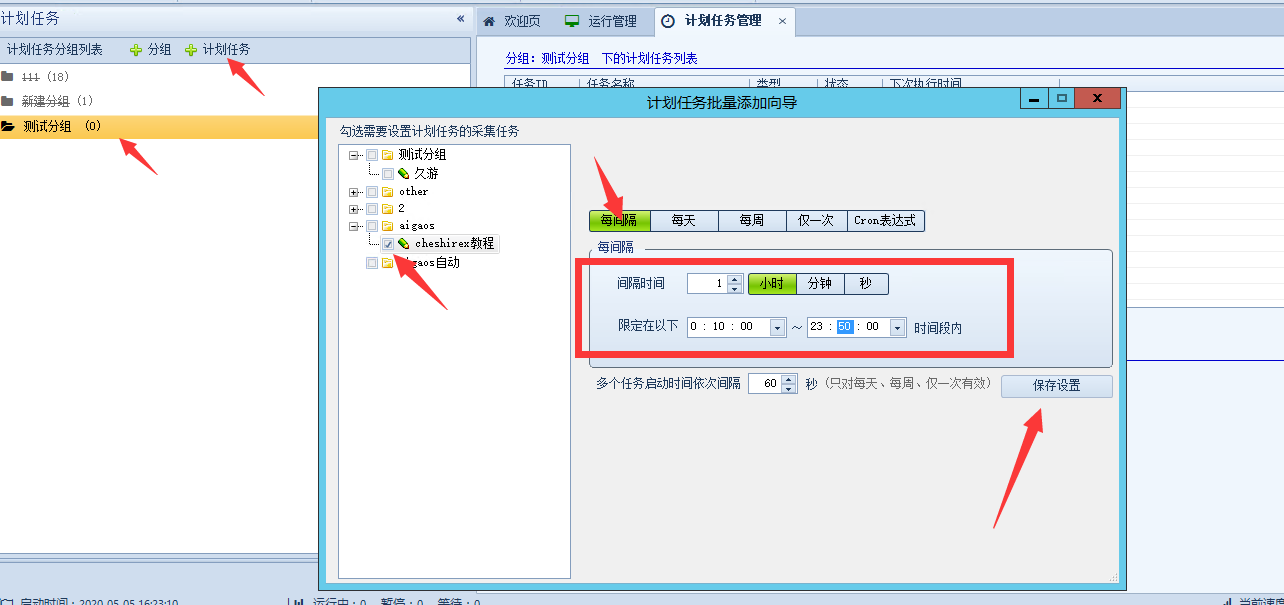
然后在分组内添加计划任务,这样比较好管理
然后上面的间隔时间依照要采集的网站更新频度来设置,他更新快你就间隔时间短点。更新慢的话就长点,比如景安这个网站,可能几天几个月都不更新,就设置间隔时间为每晚就行。
限定时间段
这个应当也都理解,就是计划任务在哪些时间段内生效,默认是早上6点到晚上23点。我通常会给他改成全天的
扩展知识
因为采集任务常年运行,我们最好是将胡说回头放在一台服务器上跑,家里有比较节电的机器的话也可以拿来挂采集任务。
采集任务比较多的话还是很消耗CPU的,一般建议在家里挂。家庭带宽内网IP时常变动有利于采集,而且硬件配置基本也都比买的服务器配置高。不用害怕优采云运行着出现卡死的情况。
树莓派定时采集图像上传到服务器
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2020-08-11 16:17
在做这个系统之前,得先选择一个可以上传图片的服务器,当然,可以自己做一个小服务器,但是我选择了七牛网,因为它是一个免费的云图库,而且我平常写MarkDown也可以用这个
先要注册登陆,之后,如图操作
创建一个储存空间picture
然后再步入这个页面记住AK(access_key )和SK(secret_key )。
首先查询七牛的Python调用API可知:
# -*- coding: utf-8 -*-
# flake8: noqa
from qiniu import Auth, put_file, etag, urlsafe_base64_encode
import qiniu.config
#获取图片
os.system('raspistill -o current_photo.jpg')
#需要填写你的 Access Key 和 Secret Key
access_key = 'Access_Key'
secret_key = 'Secret_Key'
#构建鉴权对象
q = Auth(access_key, secret_key)
#要上传的空间
bucket_name = 'Bucket_Name'
#上传到七牛后保存的文件名
key = 'my-python-logo.png';
#生成上传 Token,可以指定过期时间等
token = q.upload_token(bucket_name, key, 3600)
#要上传文件的本地路径
localfile = './sync/bbb.jpg'
ret, info = put_file(token, key, localfile)
print(info)
assert ret['key'] == key
assert ret['hash'] == etag(localfile)
安装七牛云的python SDK代码
首先建一个get_photo.sh脚本文件
python get_picture.py
然后在/home/camera中构建一个文件get_picture.py
# -*- coding: utf-8 -*-
import time
from qiniu import Auth, put_file, etag, urlsafe_base64_encode
import qiniu.config
import os
#需要填写你的 Access Key 和 Secret Key
access_key = '' #这里的密钥填上刚才我让你记住的密钥对
secret_key = '' #这里的密钥填上刚才我让你记住的密钥对
#构建鉴权对象
q = Auth(access_key, secret_key)
#要上传的空间
bucket_name = 'picture'
#上传到七牛后保存的文件名
key = '%s_%s_%s_%s_%s_%s.jpg'%(time.localtime()[0],time.localtime()[1],time.localtime()[2],time.localtime()[3],time.localtime()[4],time.localtime()[5])
#生成上传 Token,可以指定过期时间等
token = q.upload_token(bucket_name, key, 3600)
#要上传文件的本地路径
localfile = 'current_photo.jpg'
ret, info = put_file(token, key, localfile)
filename = 'current_photo.jpg'
if os.path.exists(filename):
os.remove(filename)
每次执行一次该程序都会手动上传一张图片,现在就差定时部份。
树莓派/Linux定时执行python脚本开启crontab日志。
crontab默认不开启日志,所以先开启定时任务的日志来查看
修改rsyslog服务,将 /etc/rsyslog.d/50-default.conf 文件中的 #cron.* 前的 # 删掉;用service rsyslog restart重启rsyslog服务:
写定时任务
crontab -e
开启本用户的定时任务,即创建以本用户名为文件名的定时任务文件,位置在/var/spool/cron/crontabs/。
定时任务句子格式为:执行周期+命令,周期有5个域,分别是
分钟,小时,日(day of month),月(month of year),周几(day of week).
每个域不加限制任意的话用*,整体格式为:* * * * * command
比如我的脚本是 /home/camera/get_photo.sh
执行环境为 /usr/bin/python2.7
每5分钟执行一次
则句子为
*/5 * * * * /usr/bin/python2.7 /home/camera/get_photo.sh
写完后重启cron 服务
service cron restart
顺便附上常用的周期格式
每五分钟执行 */5 * * * *
每小时执行0 * * * *
每天执行0 0 * * *
每周执行0 0 * * 0
每月执行0 0 1 * *
每年执行0 0 1 1 *
简单总结一下定时脚本:
crontab -e
选择vim进入,到末尾输入 o
然后在末尾加入
*/5 * * * * /home/camera/get_photo.sh
然后按Esc->:wq->换行退出
最后重启cron
sudo service cron restart
实物图
最终在七牛云上见到的疗效 查看全部
树莓派采集图片定时上传至服务器打算图片储存服务器
在做这个系统之前,得先选择一个可以上传图片的服务器,当然,可以自己做一个小服务器,但是我选择了七牛网,因为它是一个免费的云图库,而且我平常写MarkDown也可以用这个
先要注册登陆,之后,如图操作
创建一个储存空间picture
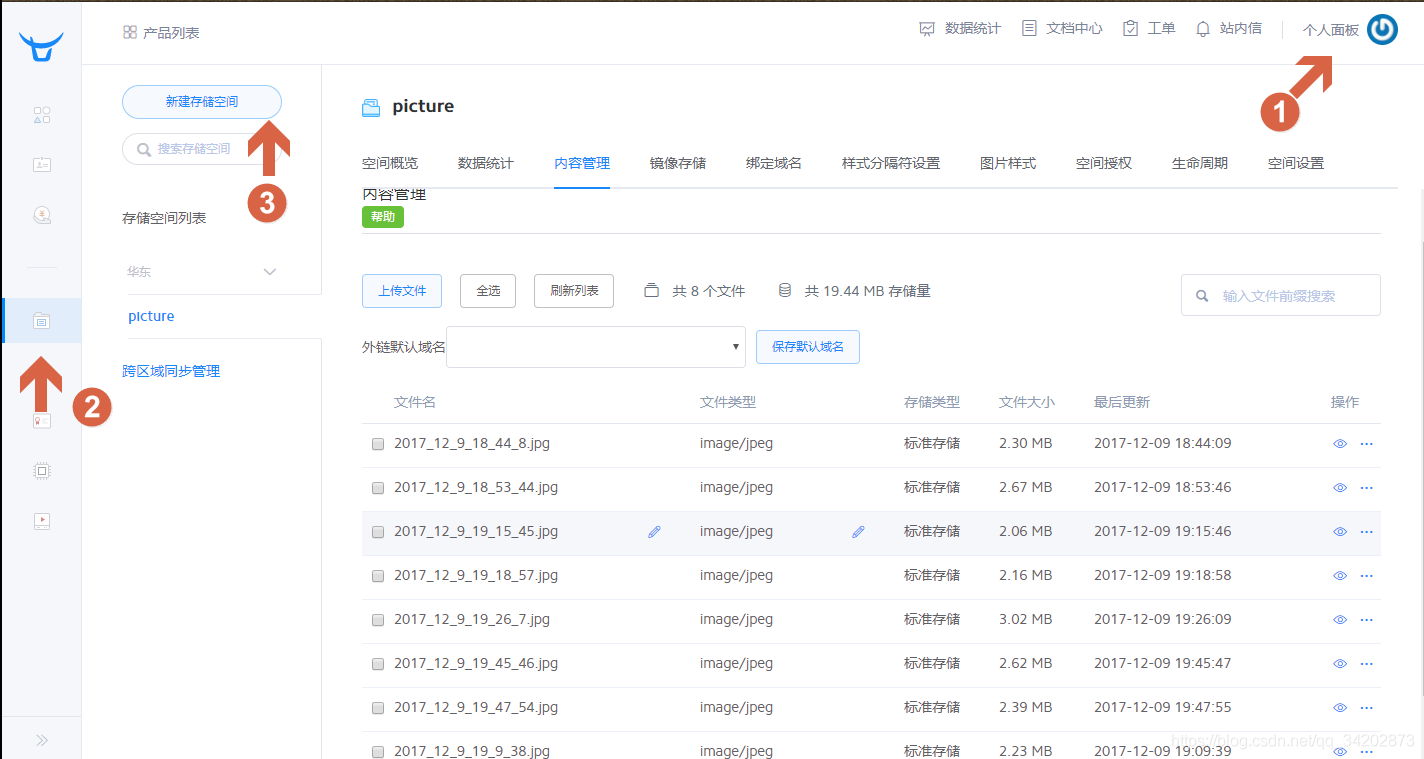
然后再步入这个页面记住AK(access_key )和SK(secret_key )。
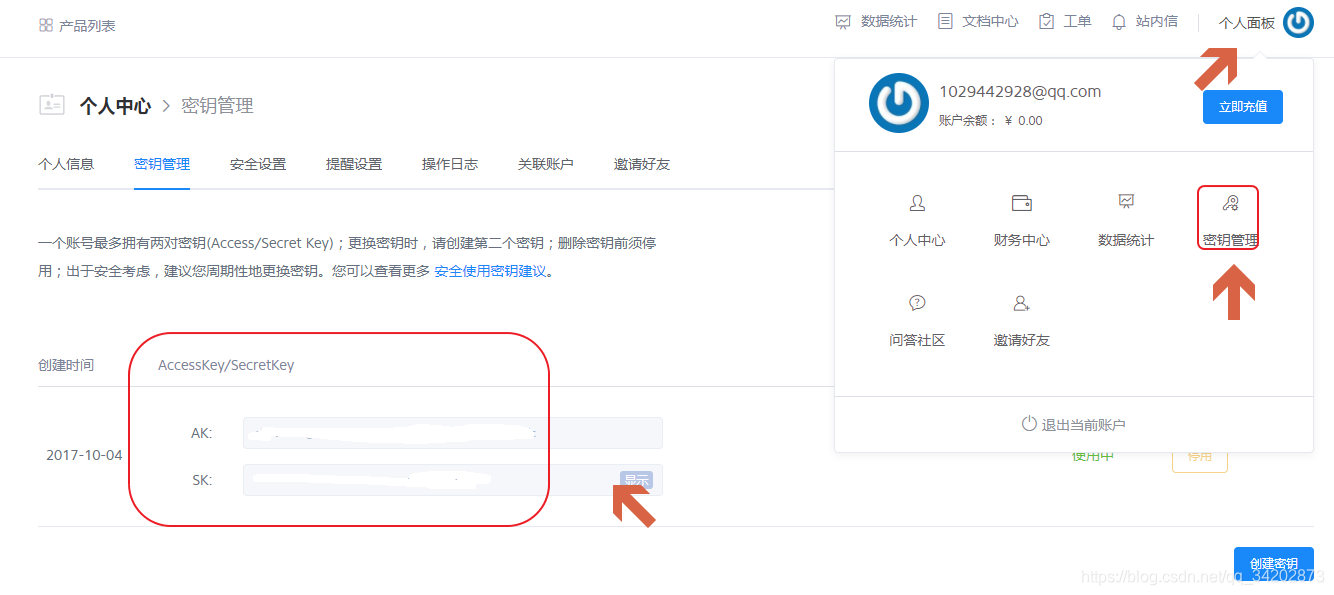
首先查询七牛的Python调用API可知:
# -*- coding: utf-8 -*-
# flake8: noqa
from qiniu import Auth, put_file, etag, urlsafe_base64_encode
import qiniu.config
#获取图片
os.system('raspistill -o current_photo.jpg')
#需要填写你的 Access Key 和 Secret Key
access_key = 'Access_Key'
secret_key = 'Secret_Key'
#构建鉴权对象
q = Auth(access_key, secret_key)
#要上传的空间
bucket_name = 'Bucket_Name'
#上传到七牛后保存的文件名
key = 'my-python-logo.png';
#生成上传 Token,可以指定过期时间等
token = q.upload_token(bucket_name, key, 3600)
#要上传文件的本地路径
localfile = './sync/bbb.jpg'
ret, info = put_file(token, key, localfile)
print(info)
assert ret['key'] == key
assert ret['hash'] == etag(localfile)
安装七牛云的python SDK代码
首先建一个get_photo.sh脚本文件
python get_picture.py
然后在/home/camera中构建一个文件get_picture.py
# -*- coding: utf-8 -*-
import time
from qiniu import Auth, put_file, etag, urlsafe_base64_encode
import qiniu.config
import os
#需要填写你的 Access Key 和 Secret Key
access_key = '' #这里的密钥填上刚才我让你记住的密钥对
secret_key = '' #这里的密钥填上刚才我让你记住的密钥对
#构建鉴权对象
q = Auth(access_key, secret_key)
#要上传的空间
bucket_name = 'picture'
#上传到七牛后保存的文件名
key = '%s_%s_%s_%s_%s_%s.jpg'%(time.localtime()[0],time.localtime()[1],time.localtime()[2],time.localtime()[3],time.localtime()[4],time.localtime()[5])
#生成上传 Token,可以指定过期时间等
token = q.upload_token(bucket_name, key, 3600)
#要上传文件的本地路径
localfile = 'current_photo.jpg'
ret, info = put_file(token, key, localfile)
filename = 'current_photo.jpg'
if os.path.exists(filename):
os.remove(filename)
每次执行一次该程序都会手动上传一张图片,现在就差定时部份。
树莓派/Linux定时执行python脚本开启crontab日志。
crontab默认不开启日志,所以先开启定时任务的日志来查看
修改rsyslog服务,将 /etc/rsyslog.d/50-default.conf 文件中的 #cron.* 前的 # 删掉;用service rsyslog restart重启rsyslog服务:
写定时任务
crontab -e
开启本用户的定时任务,即创建以本用户名为文件名的定时任务文件,位置在/var/spool/cron/crontabs/。
定时任务句子格式为:执行周期+命令,周期有5个域,分别是
分钟,小时,日(day of month),月(month of year),周几(day of week).
每个域不加限制任意的话用*,整体格式为:* * * * * command
比如我的脚本是 /home/camera/get_photo.sh
执行环境为 /usr/bin/python2.7
每5分钟执行一次
则句子为
*/5 * * * * /usr/bin/python2.7 /home/camera/get_photo.sh
写完后重启cron 服务
service cron restart
顺便附上常用的周期格式
每五分钟执行 */5 * * * *
每小时执行0 * * * *
每天执行0 0 * * *
每周执行0 0 * * 0
每月执行0 0 1 * *
每年执行0 0 1 1 *
简单总结一下定时脚本:
crontab -e
选择vim进入,到末尾输入 o
然后在末尾加入
*/5 * * * * /home/camera/get_photo.sh
然后按Esc->:wq->换行退出
最后重启cron
sudo service cron restart
实物图

最终在七牛云上见到的疗效
Python爬虫入门教程 52
采集交流 • 优采云 发表了文章 • 0 个评论 • 270 次浏览 • 2020-08-10 17:48
关于获取文章自动发送到邮箱,这类需求似乎可以写好几个网站,弄完博客园,弄CSDN,弄鹈鹕,弄其他的,网站多的是呢~哈哈
先从博客园开始,基本需求,获取python蓝筹股下边的新文章,间隔60分钟发送一次,时间太紧估摸着没有多少新博客产出~
抓取的页面就是这个
https://www.cnblogs.com/cate/python
需求整理获取指定页面的所有文章,记录文章相关信息,并且记录最后一篇文章的时间将文章发送到指定邮箱,更新最后一篇文章的时间实际编码环节查看一下须要导出的模块模块清单
import requests
import time
import re
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
from email.header import Header
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
初始化基本数据
# 初始化数据
def __init__(self):
self.start_url = "https://www.cnblogs.com/cate/python"
self.headers = {
"user-agent": "Mozilla/..... Safari/537.36",
"referer": "https://www.cnblogs.com/cate/python/"
}
self.pattern = r'[\s\S.]*?(.*?)[\s\S.]*?[\s\S.]*?(.*?)([\s\S.]*?)'
self.last_blog_time = 0
self.need_send_articles = []
参数说明
解析博客网页内容
涉及代码较多,我将关键点编撰相应的注释
# 解析网页内容
def get_articles(self):
try:
# 正常的数据获取
res = requests.get(self.start_url,headers=self.headers,timeout=3)
except Exception as e:
print("error %s"% e)
time.sleep(3)
return self.get_articles() # 重新发起请求
html = res.text
# 这个地方的正则表达式是考验你正则功底的地方了
all = re.findall(self.pattern,html)
# 判断,如果没有新文章
last_time = self.change_time(all[0][3].strip().replace("发布于 ", ""))
if last_time self.last_blog_time):
self.need_send_articles.append({
"url":item[0],
"title":item[1],
"author":item[2],
"time":public_time
})
# 文章获取完毕,更新时间
self.last_blog_time = last_time
##### 测试输出
print(self.need_send_articles)
print("现在文章的最后时间为",self.last_blog_time)
##### 测试输出
时间字符串转换成时间戳
采用时间戳可以直接比较大小,非常便捷
def change_time(self,need_change_time):
'''
# 时间的转换
:param need_change_time:
:return:返回时间戳
'''
time_array = time.strptime(need_change_time, "%Y-%m-%d %H:%M")
time_stamp = int(time.mktime(time_array))
return time_stamp
邮件发送环节
本篇博客采用的是QQ邮箱发送
关于QQ邮箱发送的一些参考文章,我给你们列一下,方便你查阅
参考文章
# https://blog.csdn.net/qiye005/ ... 89666
# https://blog.csdn.net/Momorrin ... 81251
# https://www.cnblogs.com/lovealways/p/6701662.html
# https://www.cnblogs.com/yufeihlf/p/5726619.html
因为我采用的是QQ邮箱,所以有的地方设定上去比较麻烦,发短信还花了2分钱,建议你采用其它的邮箱,设置是一样的哦~~
发送短信send_email函数
你看一下里面的文章之后,就可以对短信发送进行相应的编撰了,非常简单
QQ邮箱是SSL认证的邮箱系统,因此用QQ邮箱发送短信,需要创建一个SMTP_SSL对象,而不是SMTP对象
# 发送邮件
def send_email(self,articles):
smtp = smtplib.SMTP_SSL() # 这个地方注意
smtp.connect("smtp.qq.com",465)
smtp.login("860866679@qq.com", "授权码")
sender = '860866679@qq.com'
receivers = ['找个自己的其他邮箱@163.com'] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱
# 完善发件人收件人,主题信息
message = MIMEMultipart()
message['From'] = formataddr(["博客采集器", sender])
message['To'] = formataddr(["hi,baby", ''.join(receivers)])
subject = '你有新采集到的文章清单'
message['Subject'] = Header(subject, 'utf-8')
# 正文部分
html = ""
for item in articles:
html+=("<p>{title}--文章作者{author}--发布时间{time}".format(title=item["title"],url=item["url"],author=item["author"],time=item["time"]))
textmessage = MIMEText('
新采集到的文章清单' +html,
'html', 'utf-8')
message.attach(textmessage)
# 发送邮件操作
smtp.sendmail(sender, receivers, message.as_string())
smtp.quit()
</p>
邮箱收到电邮
当收到短信的那一刻,你就可以感受到happy了~
部署到服务器
最后一个步骤,如果想要持续的获取,那么找一个服务器,然后布署就行啦,有兴趣的博友,继续研究下去吧~ 查看全部
写在上面
关于获取文章自动发送到邮箱,这类需求似乎可以写好几个网站,弄完博客园,弄CSDN,弄鹈鹕,弄其他的,网站多的是呢~哈哈
先从博客园开始,基本需求,获取python蓝筹股下边的新文章,间隔60分钟发送一次,时间太紧估摸着没有多少新博客产出~
抓取的页面就是这个
https://www.cnblogs.com/cate/python
需求整理获取指定页面的所有文章,记录文章相关信息,并且记录最后一篇文章的时间将文章发送到指定邮箱,更新最后一篇文章的时间实际编码环节查看一下须要导出的模块模块清单
import requests
import time
import re
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
from email.header import Header
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
初始化基本数据
# 初始化数据
def __init__(self):
self.start_url = "https://www.cnblogs.com/cate/python"
self.headers = {
"user-agent": "Mozilla/..... Safari/537.36",
"referer": "https://www.cnblogs.com/cate/python/"
}
self.pattern = r'[\s\S.]*?(.*?)[\s\S.]*?[\s\S.]*?(.*?)([\s\S.]*?)'
self.last_blog_time = 0
self.need_send_articles = []
参数说明
解析博客网页内容
涉及代码较多,我将关键点编撰相应的注释
# 解析网页内容
def get_articles(self):
try:
# 正常的数据获取
res = requests.get(self.start_url,headers=self.headers,timeout=3)
except Exception as e:
print("error %s"% e)
time.sleep(3)
return self.get_articles() # 重新发起请求
html = res.text
# 这个地方的正则表达式是考验你正则功底的地方了
all = re.findall(self.pattern,html)
# 判断,如果没有新文章
last_time = self.change_time(all[0][3].strip().replace("发布于 ", ""))
if last_time self.last_blog_time):
self.need_send_articles.append({
"url":item[0],
"title":item[1],
"author":item[2],
"time":public_time
})
# 文章获取完毕,更新时间
self.last_blog_time = last_time
##### 测试输出
print(self.need_send_articles)
print("现在文章的最后时间为",self.last_blog_time)
##### 测试输出
时间字符串转换成时间戳
采用时间戳可以直接比较大小,非常便捷
def change_time(self,need_change_time):
'''
# 时间的转换
:param need_change_time:
:return:返回时间戳
'''
time_array = time.strptime(need_change_time, "%Y-%m-%d %H:%M")
time_stamp = int(time.mktime(time_array))
return time_stamp
邮件发送环节
本篇博客采用的是QQ邮箱发送
关于QQ邮箱发送的一些参考文章,我给你们列一下,方便你查阅
参考文章
# https://blog.csdn.net/qiye005/ ... 89666
# https://blog.csdn.net/Momorrin ... 81251
# https://www.cnblogs.com/lovealways/p/6701662.html
# https://www.cnblogs.com/yufeihlf/p/5726619.html
因为我采用的是QQ邮箱,所以有的地方设定上去比较麻烦,发短信还花了2分钱,建议你采用其它的邮箱,设置是一样的哦~~
发送短信send_email函数
你看一下里面的文章之后,就可以对短信发送进行相应的编撰了,非常简单
QQ邮箱是SSL认证的邮箱系统,因此用QQ邮箱发送短信,需要创建一个SMTP_SSL对象,而不是SMTP对象
# 发送邮件
def send_email(self,articles):
smtp = smtplib.SMTP_SSL() # 这个地方注意
smtp.connect("smtp.qq.com",465)
smtp.login("860866679@qq.com", "授权码")
sender = '860866679@qq.com'
receivers = ['找个自己的其他邮箱@163.com'] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱
# 完善发件人收件人,主题信息
message = MIMEMultipart()
message['From'] = formataddr(["博客采集器", sender])
message['To'] = formataddr(["hi,baby", ''.join(receivers)])
subject = '你有新采集到的文章清单'
message['Subject'] = Header(subject, 'utf-8')
# 正文部分
html = ""
for item in articles:
html+=("<p>{title}--文章作者{author}--发布时间{time}".format(title=item["title"],url=item["url"],author=item["author"],time=item["time"]))
textmessage = MIMEText('
新采集到的文章清单' +html,
'html', 'utf-8')
message.attach(textmessage)
# 发送邮件操作
smtp.sendmail(sender, receivers, message.as_string())
smtp.quit()
</p>
邮箱收到电邮
当收到短信的那一刻,你就可以感受到happy了~
部署到服务器
最后一个步骤,如果想要持续的获取,那么找一个服务器,然后布署就行啦,有兴趣的博友,继续研究下去吧~
下载 SEO商务营销王 的人还下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2020-08-10 16:23
软件功能概述及原理介绍
智能spider系统(采集)
只须要设置好采集目标站及采集规则,可以自动或定时手动采集目标站的内容,更可以同步目标站更新采集,采用蜘蛛内核模拟蜘蛛抓取网站内容而不会被屏蔽,强大的正则轻松采集你想要的一切信息,包括短信、QQ及手机号码等,不仅仅是想要的,还能过滤掉一切不想要的内容;
高度伪原创系统
如果您认为采集的文章不够原创,那我们强悍的伪原创系统可以解决这个问题,程序会按你的要求执行包括手动去头斩尾,自动在文章前和尾部加入原创文字、段落随机插入短语或图片、同意词替换、完整文章分多页及相同专题多页合并等独家技术,最大程度降低文章相似度,使搜索引擎判定为高权重的原创文章;
多任务定时手动采集发布系统(无人值守)
您可以按照须要自由设置采集的时间及发布文章的时间间隔,尽量科学的全手动管理您的网站,您只要定时的查看下发布的内容及软件输出提示,根据搜索引擎变化调整采集及发布的时间间隔;
强大的内链系统(SEO)
网站内部链接对于SEO乃重中之重,本系统可自由设置须要重点排行的关键字,并在发布的时侯手动生成专题页,并将文章中出现的... 查看全部
SEO商务营销王中英文网站全手动更新系统拥有CMS+SEO技术+ 中英文关键词分析+蜘蛛爬虫+网页智能信息抓取技术,目前支持织梦(DEDECMS)、帝国(EmpireCMS)、Wordpress、Z-blog、动易、5UCKS、discuz、phpwind等系统的数据手动导出并手动生成静态页,软件按照预设信息手动采集并发布,每天定时定量可定目标站手动维护更新内容,是站长流量获取的绝佳工具。
软件功能概述及原理介绍
智能spider系统(采集)
只须要设置好采集目标站及采集规则,可以自动或定时手动采集目标站的内容,更可以同步目标站更新采集,采用蜘蛛内核模拟蜘蛛抓取网站内容而不会被屏蔽,强大的正则轻松采集你想要的一切信息,包括短信、QQ及手机号码等,不仅仅是想要的,还能过滤掉一切不想要的内容;
高度伪原创系统
如果您认为采集的文章不够原创,那我们强悍的伪原创系统可以解决这个问题,程序会按你的要求执行包括手动去头斩尾,自动在文章前和尾部加入原创文字、段落随机插入短语或图片、同意词替换、完整文章分多页及相同专题多页合并等独家技术,最大程度降低文章相似度,使搜索引擎判定为高权重的原创文章;
多任务定时手动采集发布系统(无人值守)
您可以按照须要自由设置采集的时间及发布文章的时间间隔,尽量科学的全手动管理您的网站,您只要定时的查看下发布的内容及软件输出提示,根据搜索引擎变化调整采集及发布的时间间隔;
强大的内链系统(SEO)
网站内部链接对于SEO乃重中之重,本系统可自由设置须要重点排行的关键字,并在发布的时侯手动生成专题页,并将文章中出现的...
Nginx 访问统计 增加html静态网页显示 每晚定时更新
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2020-08-09 16:44
如果你希望这样简单的统计下自己小网站的访问量可以象我这样简单操作下:
1. 修改Nginx 导出日志
whereis nginx
cd /etc/nginx/
ls -l
sudo vim nginx.conf
修改nginx access_log 到指定目录
2. 写脚本 对日志进行统计并写入html,并清空日志
#!/bin/bash
cd /home/ubuntu/Blog
date1=`date +%F`
date2=`date +%r`
ips=`awk '{print $1"
"}' access.log|sort | uniq -c |sort -n -k 1 -r|head -n 10`
pv=`awk '{print $7}' access.log | wc -l`
ip=`awk '{print $1}' access.log | sort -n | uniq -c | wc -l`
html=`awk '{print $7"
"}' access.log|sort | uniq -c |grep -v '.jpg'|grep -v '.ico'|grep -v '.php'|grep -v '.do'|grep -v '400'|grep -v '.svg'|grep -v 'cgi-bin'|grep -v '.css'|grep -v '.js'|grep -v '.png'|grep -v '.jsp'|grep -v '.gif' |sort -n -k 1 -r | head -n 20`
echo "
--------${date1}--${date2}-------------
Pv is $pv
Ip is $ip
$ips ...
$html ...
----------
" >> count.html | sort -rn count.html | sed -i '31d' count.html | sort -r
:> access.log
:> error.log
3.脚本每晚晚上定时执行
crontab -e # 添加每天凌晨12:01 执行脚本
01 00 * * * /home/ubuntu/Blog/statistics.sh
4.如果有须要的话网页只能特定ip访问 查看全部
想统计自己网站的访问量,之前试过百度统计,在每位网页降低一些文件,百度会自己帮忙搜集统计。其实假如你自己网站就是用Nginx挂在服务器上的,他自己才会帮你统计,你只须要把他整理下就可以。我简单整理了下,可以看先疗效:

如果你希望这样简单的统计下自己小网站的访问量可以象我这样简单操作下:
1. 修改Nginx 导出日志
whereis nginx
cd /etc/nginx/
ls -l
sudo vim nginx.conf
修改nginx access_log 到指定目录

2. 写脚本 对日志进行统计并写入html,并清空日志
#!/bin/bash
cd /home/ubuntu/Blog
date1=`date +%F`
date2=`date +%r`
ips=`awk '{print $1"
"}' access.log|sort | uniq -c |sort -n -k 1 -r|head -n 10`
pv=`awk '{print $7}' access.log | wc -l`
ip=`awk '{print $1}' access.log | sort -n | uniq -c | wc -l`
html=`awk '{print $7"
"}' access.log|sort | uniq -c |grep -v '.jpg'|grep -v '.ico'|grep -v '.php'|grep -v '.do'|grep -v '400'|grep -v '.svg'|grep -v 'cgi-bin'|grep -v '.css'|grep -v '.js'|grep -v '.png'|grep -v '.jsp'|grep -v '.gif' |sort -n -k 1 -r | head -n 20`
echo "
--------${date1}--${date2}-------------
Pv is $pv
Ip is $ip
$ips ...
$html ...
----------
" >> count.html | sort -rn count.html | sed -i '31d' count.html | sort -r
:> access.log
:> error.log

3.脚本每晚晚上定时执行
crontab -e # 添加每天凌晨12:01 执行脚本
01 00 * * * /home/ubuntu/Blog/statistics.sh

4.如果有须要的话网页只能特定ip访问
Apache Camel 与 Spring Boot 集成
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2020-08-09 16:05
本项目主要是通过在Spring平台上配置Camel、FTP,实现定时从FTP服务器下载文件到本地、解析文件、存入数据库等功能。
2、搭建空项目:
Spring Boot有几种手动生成空项目的机制:CLI、Spring tool suite、网站Spring Initializr,我们选择第三个。
访问网站,如右图
在dependencies添加依赖包的时侯,在框中输入camle、jdbc、mysql会手动弹出提示,确认即为选中,如下图:
点击 generate project按键,生成项目,并将其导出到ecipse,在pom.xml中添加camel-ftp依赖,注意版本号选择与camel-spring-boot-stater的相同
org.apache.camel
camel-ftp
2.18.0
完整版的pom.xml文件如下:
org.apache.camel
camel-spring-boot-starter
2.18.0
org.apache.camel
camel-ftp
2.18.0
org.springframework.boot
spring-boot-starter-jdbc
mysql
mysql-connector-java
runtime
org.springframework.boot
spring-boot-starter-test
test
待所有依赖jar下载到本地,基础项目搭建完成3、配置Camel完成从ftp服务器定时下载文件到本地在application.properties中配置远程FTP服务器的地址、端口、用户名和密码等信息
ftp.server.info=sftp://172.16.20.133:22/../home/temp/data?username=root&password=root&delay=5s&move=done&readLock=rename
ftp.local.dir=file:C:/ftp/test
注意:sftp服务器的文件位置是相对于root登陆后的相对地址(被这儿坑到了),delay=5s是每隔5秒钟扫描ftp服务器上是否有新文件生成,如果有下载到本地,并将服务器上的文件转移到done文件夹(/home/temp/data/done),readLock=rename可以制止camel读取正在被写入的文件
配置路由,完成文件下载
@Component
public class DownloadRouteDemo extends RouteBuilder {
private static Logger logger = LoggerFactory.getLogger( DownloadRouteDemo.class );
@Value("${ftp.server.info}")
private String sftpServer;
@Value("${ftp.local.dir}")
private String downloadLocation;
@Override
public void configure() throws Exception {
from( sftpServer ).to( downloadLocation ).log(LoggingLevel.INFO, logger, "Downloaded file ${file:name} complete.");
}
}
注意:要承继camel的RouteBulider,重写configure方式,大意是从ftp服务器下载文件到本地,并输出文件名(运行时所需必要信息都配置在application.properties文件中)
为了使java进程在后台运行,需要在application.properties文件中降低如下配置
camel.springboot.main-run-controller=true
从ftp服务器下载文件的所有工作都已完成,运行CamelFtpSpringApplication.java,如果你的ftp服务器相应的位置上有文件,就会下载到本地所配置的文件夹下4、通过camel定时解析本地文件并保存到数据库在application.properties中降低如下配置
route.parserfile.info = {{ftp.local.dir}}?delay=10s&move=done&readLock=rename
route.parserfile.dir = {{ftp.local.dir}}/done
注意两个花括弧是引用其他变量的配置
编写解析文件、入库程序等处理器
@Component
public class LocationFileProcessor implements Processor {
private static Logger logger = LoggerFactory.getLogger( LocationFileProcessor.class );
@Value("${ftp.local.dir}")
private String fileDir;
@Autowired
OrderService orderService;//业务逻辑处理组件
@Override
public void process(Exchange exchange) throws Exception {
GenericFileMessage inFileMessage = (GenericFileMessage) exchange.getIn();
String fileName = inFileMessage.getGenericFile().getFileName();//文件名
String splitTag = File.separator;//系统文件分隔符
logger.info(fileDir + splitTag + fileName);//文件的绝对路径
orderService.process(fileDir + splitTag + fileName);//解析入库等操作
}
}
配置路由,完成业务逻辑的串联
@Component
public class LocalTransformRoute extends RouteBuilder {
private static Logger logger = LoggerFactory.getLogger( LocalTransformRoute.class );
@Value("${route.parserfile.info}")
private String location;
@Value("${route.parserfile.dir}")
private String locationDir;
@Autowired
LocationFileProcessor locationFileProcessor;
@Override
public void configure() throws Exception {
from( location ).process( locationFileProcessor ).to( locationDir ).log(LoggingLevel.INFO, logger, "tirans file ${file:name} complete.");
}
}
注意,比前面的路由多了process配置,即业务逻辑处理配置
至此,所有工作都已完成,重新执行CamelFtpSpringApplication.java即可实现ftp文件定时下载、业务处理等(其中省去了好多,例如入库操作等)备注:只是camle spring ftp的一个演示demo,要运用于生产,还有很多须要建立的地方
转载至:
转载于: 查看全部
1、概要:
本项目主要是通过在Spring平台上配置Camel、FTP,实现定时从FTP服务器下载文件到本地、解析文件、存入数据库等功能。
2、搭建空项目:
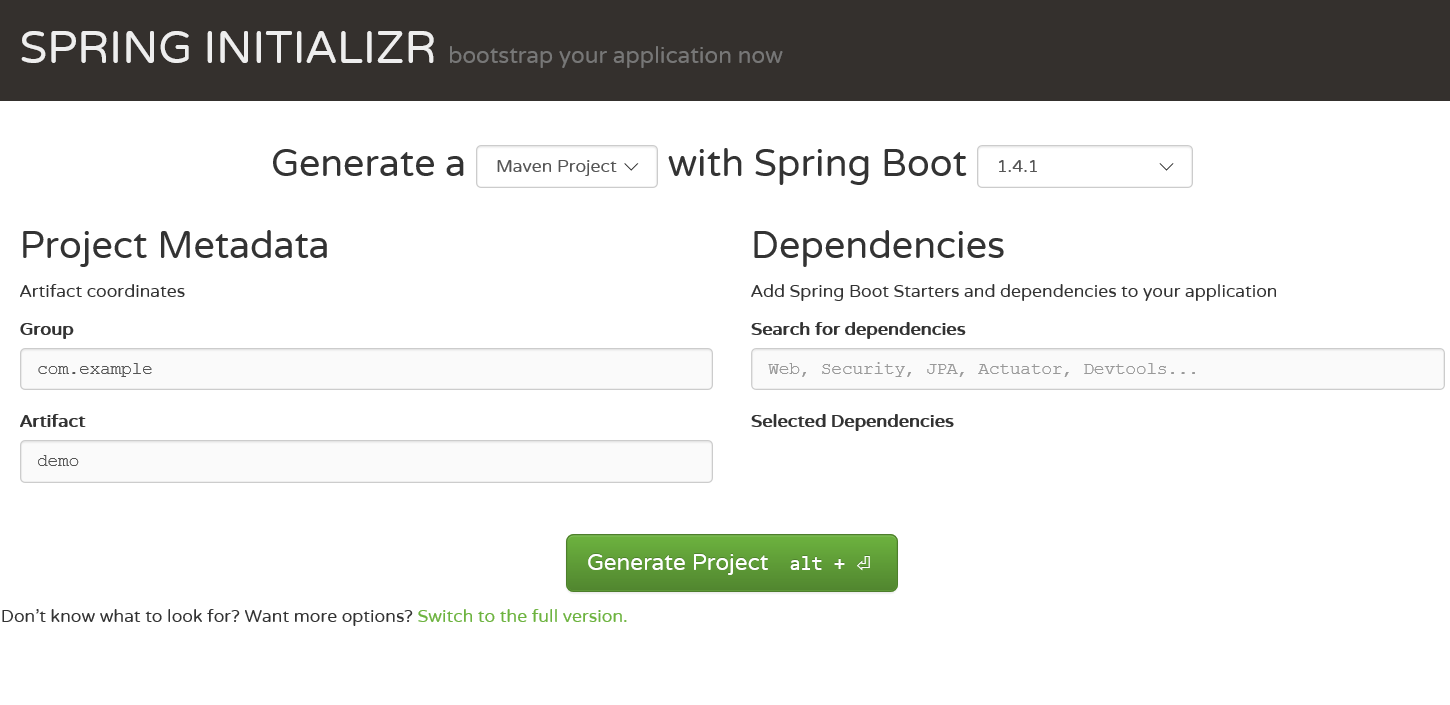
Spring Boot有几种手动生成空项目的机制:CLI、Spring tool suite、网站Spring Initializr,我们选择第三个。
访问网站,如右图
在dependencies添加依赖包的时侯,在框中输入camle、jdbc、mysql会手动弹出提示,确认即为选中,如下图:
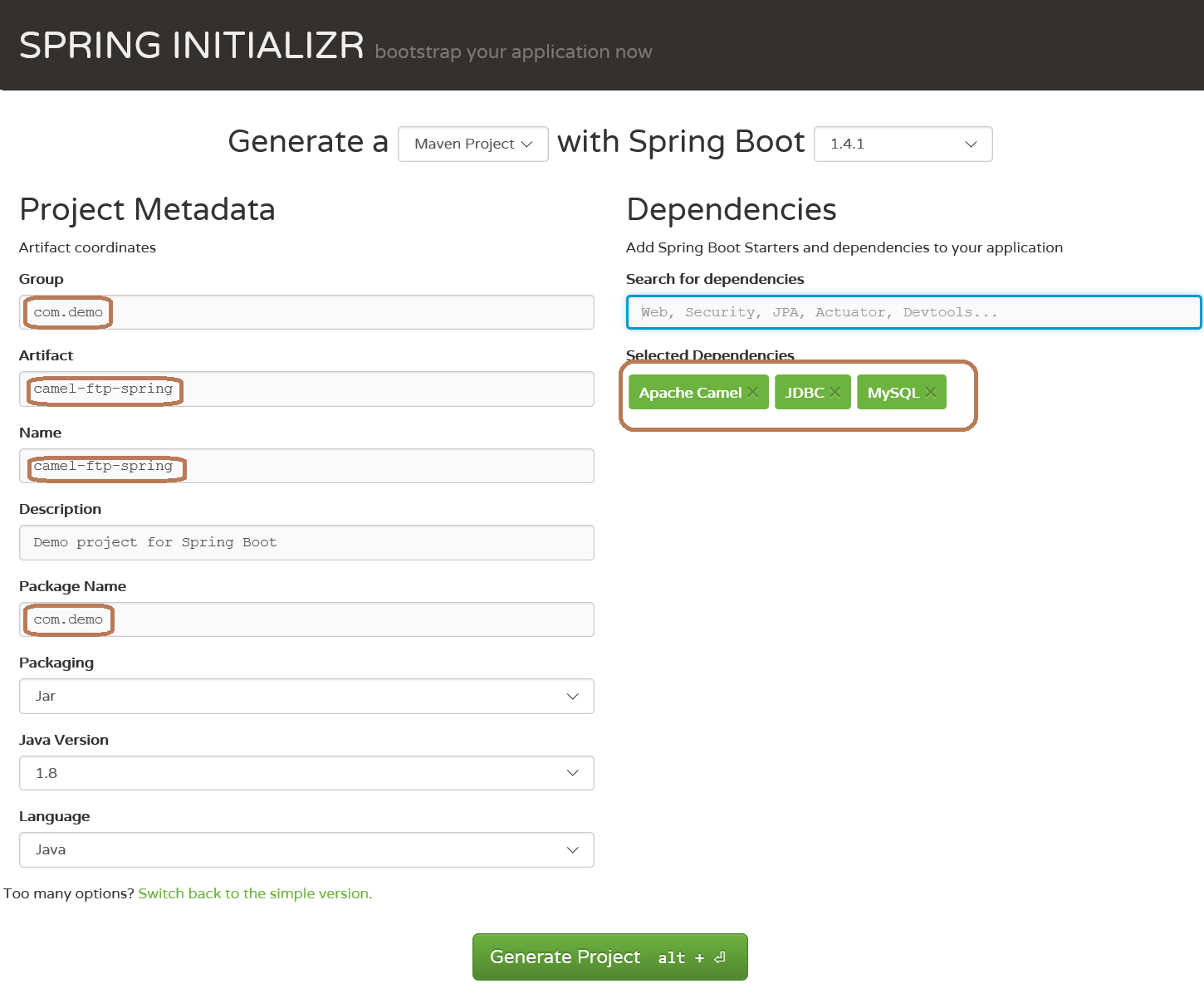
点击 generate project按键,生成项目,并将其导出到ecipse,在pom.xml中添加camel-ftp依赖,注意版本号选择与camel-spring-boot-stater的相同
org.apache.camel
camel-ftp
2.18.0
完整版的pom.xml文件如下:

org.apache.camel
camel-spring-boot-starter
2.18.0
org.apache.camel
camel-ftp
2.18.0
org.springframework.boot
spring-boot-starter-jdbc
mysql
mysql-connector-java
runtime
org.springframework.boot
spring-boot-starter-test
test
待所有依赖jar下载到本地,基础项目搭建完成3、配置Camel完成从ftp服务器定时下载文件到本地在application.properties中配置远程FTP服务器的地址、端口、用户名和密码等信息
ftp.server.info=sftp://172.16.20.133:22/../home/temp/data?username=root&password=root&delay=5s&move=done&readLock=rename
ftp.local.dir=file:C:/ftp/test
注意:sftp服务器的文件位置是相对于root登陆后的相对地址(被这儿坑到了),delay=5s是每隔5秒钟扫描ftp服务器上是否有新文件生成,如果有下载到本地,并将服务器上的文件转移到done文件夹(/home/temp/data/done),readLock=rename可以制止camel读取正在被写入的文件
配置路由,完成文件下载
@Component
public class DownloadRouteDemo extends RouteBuilder {
private static Logger logger = LoggerFactory.getLogger( DownloadRouteDemo.class );
@Value("${ftp.server.info}")
private String sftpServer;
@Value("${ftp.local.dir}")
private String downloadLocation;
@Override
public void configure() throws Exception {
from( sftpServer ).to( downloadLocation ).log(LoggingLevel.INFO, logger, "Downloaded file ${file:name} complete.");
}
}
注意:要承继camel的RouteBulider,重写configure方式,大意是从ftp服务器下载文件到本地,并输出文件名(运行时所需必要信息都配置在application.properties文件中)
为了使java进程在后台运行,需要在application.properties文件中降低如下配置
camel.springboot.main-run-controller=true
从ftp服务器下载文件的所有工作都已完成,运行CamelFtpSpringApplication.java,如果你的ftp服务器相应的位置上有文件,就会下载到本地所配置的文件夹下4、通过camel定时解析本地文件并保存到数据库在application.properties中降低如下配置
route.parserfile.info = {{ftp.local.dir}}?delay=10s&move=done&readLock=rename
route.parserfile.dir = {{ftp.local.dir}}/done
注意两个花括弧是引用其他变量的配置
编写解析文件、入库程序等处理器
@Component
public class LocationFileProcessor implements Processor {
private static Logger logger = LoggerFactory.getLogger( LocationFileProcessor.class );
@Value("${ftp.local.dir}")
private String fileDir;
@Autowired
OrderService orderService;//业务逻辑处理组件
@Override
public void process(Exchange exchange) throws Exception {
GenericFileMessage inFileMessage = (GenericFileMessage) exchange.getIn();
String fileName = inFileMessage.getGenericFile().getFileName();//文件名
String splitTag = File.separator;//系统文件分隔符
logger.info(fileDir + splitTag + fileName);//文件的绝对路径
orderService.process(fileDir + splitTag + fileName);//解析入库等操作
}
}
配置路由,完成业务逻辑的串联
@Component
public class LocalTransformRoute extends RouteBuilder {
private static Logger logger = LoggerFactory.getLogger( LocalTransformRoute.class );
@Value("${route.parserfile.info}")
private String location;
@Value("${route.parserfile.dir}")
private String locationDir;
@Autowired
LocationFileProcessor locationFileProcessor;
@Override
public void configure() throws Exception {
from( location ).process( locationFileProcessor ).to( locationDir ).log(LoggingLevel.INFO, logger, "tirans file ${file:name} complete.");
}
}
注意,比前面的路由多了process配置,即业务逻辑处理配置
至此,所有工作都已完成,重新执行CamelFtpSpringApplication.java即可实现ftp文件定时下载、业务处理等(其中省去了好多,例如入库操作等)备注:只是camle spring ftp的一个演示demo,要运用于生产,还有很多须要建立的地方
转载至:
转载于:
Knative 驾驭篇:带你 '纵横驰骋' Knative
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-09 15:33
注:本文基于最新 Knative v0.11.0 版本代码剖析
KPA 实现流程图
在 Knative 中,创建一个 Revision 会相应的创建 PodAutoScaler 资源。在KPA中通过操作 PodAutoScaler 资源,对当前的 Revision 中的 POD 进行扩缩容。
针对里面的流程实现,我们从三横两纵的维度进行分析其实现机制。
三横KPA 控制器
通过Revision 创建PodAutoScaler, 在 KPA 控制器中主要包括两个资源(Decider 和 Metric)和一个操作(Scale)。主要代码如下
func (c *Reconciler) reconcile(ctx context.Context, pa *pav1alpha1.PodAutoscaler) error {
......
decider, err := c.reconcileDecider(ctx, pa, pa.Status.MetricsServiceName)
if err != nil {
return fmt.Errorf("error reconciling Decider: %w", err)
}
if err := c.ReconcileMetric(ctx, pa, pa.Status.MetricsServiceName); err != nil {
return fmt.Errorf("error reconciling Metric: %w", err)
}
// Metrics services are no longer needed as we use the private services now.
if err := c.DeleteMetricsServices(ctx, pa); err != nil {
return err
}
// Get the appropriate current scale from the metric, and right size
// the scaleTargetRef based on it.
want, err := c.scaler.Scale(ctx, pa, sks, decider.Status.DesiredScale)
if err != nil {
return fmt.Errorf("error scaling target: %w", err)
}
......
}
这里先介绍一下两个资源:
再看一下Scale操作,在Scale方式中,根据扩缩容POD数、最小实例数和最大实例数确定最终须要扩容的POD实例数,然后更改deployment的Replicas值,最终实现POD的扩缩容, 代码实现如下:
// Scale attempts to scale the given PA's target reference to the desired scale.
func (ks *scaler) Scale(ctx context.Context, pa *pav1alpha1.PodAutoscaler, sks *nv1a1.ServerlessService, desiredScale int32) (int32, error) {
......
min, max := pa.ScaleBounds()
if newScale := applyBounds(min, max, desiredScale); newScale != desiredScale {
logger.Debugf("Adjusting desiredScale to meet the min and max bounds before applying: %d -> %d", desiredScale, newScale)
desiredScale = newScale
}
desiredScale, shouldApplyScale := ks.handleScaleToZero(ctx, pa, sks, desiredScale)
if !shouldApplyScale {
return desiredScale, nil
}
ps, err := resources.GetScaleResource(pa.Namespace, pa.Spec.ScaleTargetRef, ks.psInformerFactory)
if err != nil {
return desiredScale, fmt.Errorf("failed to get scale target %v: %w", pa.Spec.ScaleTargetRef, err)
}
currentScale := int32(1)
if ps.Spec.Replicas != nil {
currentScale = *ps.Spec.Replicas
}
if desiredScale == currentScale {
return desiredScale, nil
}
logger.Infof("Scaling from %d to %d", currentScale, desiredScale)
return ks.applyScale(ctx, pa, desiredScale, ps)
}
根据指标定时估算 POD 数
这是一个关于Decider的故事。Decider创建以后会同时创建下来一个定时器,该定时器默认每隔 2 秒(可以通过TickInterval 参数配置)会调用Scale方式,该Scale方式实现如下:
func (a *Autoscaler) Scale(ctx context.Context, now time.Time) (desiredPodCount int32, excessBC int32, validScale bool) {
......
metricName := spec.ScalingMetric
var observedStableValue, observedPanicValue float64
switch spec.ScalingMetric {
case autoscaling.RPS:
observedStableValue, observedPanicValue, err = a.metricClient.StableAndPanicRPS(metricKey, now)
a.reporter.ReportStableRPS(observedStableValue)
a.reporter.ReportPanicRPS(observedPanicValue)
a.reporter.ReportTargetRPS(spec.TargetValue)
default:
metricName = autoscaling.Concurrency // concurrency is used by default
observedStableValue, observedPanicValue, err = a.metricClient.StableAndPanicConcurrency(metricKey, now)
a.reporter.ReportStableRequestConcurrency(observedStableValue)
a.reporter.ReportPanicRequestConcurrency(observedPanicValue)
a.reporter.ReportTargetRequestConcurrency(spec.TargetValue)
}
// Put the scaling metric to logs.
logger = logger.With(zap.String("metric", metricName))
if err != nil {
if err == ErrNoData {
logger.Debug("No data to scale on yet")
} else {
logger.Errorw("Failed to obtain metrics", zap.Error(err))
}
return 0, 0, false
}
// Make sure we don't get stuck with the same number of pods, if the scale up rate
// is too conservative and MaxScaleUp*RPC==RPC, so this permits us to grow at least by a single
// pod if we need to scale up.
// E.g. MSUR=1.1, OCC=3, RPC=2, TV=1 => OCC/TV=3, MSU=2.2 => DSPC=2, while we definitely, need
// 3 pods. See the unit test for this scenario in action.
maxScaleUp := math.Ceil(spec.MaxScaleUpRate * readyPodsCount)
// Same logic, opposite math applies here.
maxScaleDown := math.Floor(readyPodsCount / spec.MaxScaleDownRate)
dspc := math.Ceil(observedStableValue / spec.TargetValue)
dppc := math.Ceil(observedPanicValue / spec.TargetValue)
logger.Debugf("DesiredStablePodCount = %0.3f, DesiredPanicPodCount = %0.3f, MaxScaleUp = %0.3f, MaxScaleDown = %0.3f",
dspc, dppc, maxScaleUp, maxScaleDown)
// We want to keep desired pod count in the [maxScaleDown, maxScaleUp] range.
desiredStablePodCount := int32(math.Min(math.Max(dspc, maxScaleDown), maxScaleUp))
desiredPanicPodCount := int32(math.Min(math.Max(dppc, maxScaleDown), maxScaleUp))
......
return desiredPodCount, excessBC, true
}
该方式主要是从 MetricCollector 中获取指标信息,根据指标信息估算出须要扩缩的POD数。然后设置在 Decider 中。另外当 Decider 中 POD 期望值发生变化时会触发 PodAutoscaler 重新调和的操作,关键代码如下:
......
if runner.updateLatestScale(desiredScale, excessBC) {
m.Inform(metricKey)
}
......
在KPA controller中设置调和Watch操作:
......
// Have the Deciders enqueue the PAs whose decisions have changed.
deciders.Watch(impl.EnqueueKey)
......
指标采集
通过两种方法搜集POD指标:
PUSH 采集指标实现比较简单,在main.go中 暴露服务,将接收到的 metric 推送到 MetricCollector 中:
// Set up a statserver.
statsServer := statserver.New(statsServerAddr, statsCh, logger)
....
go func() {
for sm := range statsCh {
collector.Record(sm.Key, sm.Stat)
multiScaler.Poke(sm.Key, sm.Stat)
}
}()
PULL 采集指标是怎样搜集的呢? 还记得前面提及的Metric资源吧,这里接收到Metric资源又会创建出一个定时器,这个定时器每隔 1 秒会访问 queue-proxy 9090 端口采集指标信息。关键代码如下:
<p>// newCollection creates a new collection, which uses the given scraper to
// collect stats every scrapeTickInterval.
func newCollection(metric *av1alpha1.Metric, scraper StatsScraper, logger *zap.SugaredLogger) *collection {
c := &collection{
metric: metric,
concurrencyBuckets: aggregation.NewTimedFloat64Buckets(BucketSize),
rpsBuckets: aggregation.NewTimedFloat64Buckets(BucketSize),
scraper: scraper,
stopCh: make(chan struct{}),
}
logger = logger.Named("collector").With(
zap.String(logkey.Key, fmt.Sprintf("%s/%s", metric.Namespace, metric.Name)))
c.grp.Add(1)
go func() {
defer c.grp.Done()
scrapeTicker := time.NewTicker(scrapeTickInterval)
for {
select {
case 查看全部
Knative 中提供了手动扩缩容灵活的实现机制,本文从 三横两纵 的维度带你深入了解 KPA 自动扩缩容的实现机制。让你轻松驾驭 Knative 自动扩缩容。
注:本文基于最新 Knative v0.11.0 版本代码剖析
KPA 实现流程图

在 Knative 中,创建一个 Revision 会相应的创建 PodAutoScaler 资源。在KPA中通过操作 PodAutoScaler 资源,对当前的 Revision 中的 POD 进行扩缩容。
针对里面的流程实现,我们从三横两纵的维度进行分析其实现机制。
三横KPA 控制器
通过Revision 创建PodAutoScaler, 在 KPA 控制器中主要包括两个资源(Decider 和 Metric)和一个操作(Scale)。主要代码如下
func (c *Reconciler) reconcile(ctx context.Context, pa *pav1alpha1.PodAutoscaler) error {
......
decider, err := c.reconcileDecider(ctx, pa, pa.Status.MetricsServiceName)
if err != nil {
return fmt.Errorf("error reconciling Decider: %w", err)
}
if err := c.ReconcileMetric(ctx, pa, pa.Status.MetricsServiceName); err != nil {
return fmt.Errorf("error reconciling Metric: %w", err)
}
// Metrics services are no longer needed as we use the private services now.
if err := c.DeleteMetricsServices(ctx, pa); err != nil {
return err
}
// Get the appropriate current scale from the metric, and right size
// the scaleTargetRef based on it.
want, err := c.scaler.Scale(ctx, pa, sks, decider.Status.DesiredScale)
if err != nil {
return fmt.Errorf("error scaling target: %w", err)
}
......
}
这里先介绍一下两个资源:
再看一下Scale操作,在Scale方式中,根据扩缩容POD数、最小实例数和最大实例数确定最终须要扩容的POD实例数,然后更改deployment的Replicas值,最终实现POD的扩缩容, 代码实现如下:
// Scale attempts to scale the given PA's target reference to the desired scale.
func (ks *scaler) Scale(ctx context.Context, pa *pav1alpha1.PodAutoscaler, sks *nv1a1.ServerlessService, desiredScale int32) (int32, error) {
......
min, max := pa.ScaleBounds()
if newScale := applyBounds(min, max, desiredScale); newScale != desiredScale {
logger.Debugf("Adjusting desiredScale to meet the min and max bounds before applying: %d -> %d", desiredScale, newScale)
desiredScale = newScale
}
desiredScale, shouldApplyScale := ks.handleScaleToZero(ctx, pa, sks, desiredScale)
if !shouldApplyScale {
return desiredScale, nil
}
ps, err := resources.GetScaleResource(pa.Namespace, pa.Spec.ScaleTargetRef, ks.psInformerFactory)
if err != nil {
return desiredScale, fmt.Errorf("failed to get scale target %v: %w", pa.Spec.ScaleTargetRef, err)
}
currentScale := int32(1)
if ps.Spec.Replicas != nil {
currentScale = *ps.Spec.Replicas
}
if desiredScale == currentScale {
return desiredScale, nil
}
logger.Infof("Scaling from %d to %d", currentScale, desiredScale)
return ks.applyScale(ctx, pa, desiredScale, ps)
}
根据指标定时估算 POD 数
这是一个关于Decider的故事。Decider创建以后会同时创建下来一个定时器,该定时器默认每隔 2 秒(可以通过TickInterval 参数配置)会调用Scale方式,该Scale方式实现如下:
func (a *Autoscaler) Scale(ctx context.Context, now time.Time) (desiredPodCount int32, excessBC int32, validScale bool) {
......
metricName := spec.ScalingMetric
var observedStableValue, observedPanicValue float64
switch spec.ScalingMetric {
case autoscaling.RPS:
observedStableValue, observedPanicValue, err = a.metricClient.StableAndPanicRPS(metricKey, now)
a.reporter.ReportStableRPS(observedStableValue)
a.reporter.ReportPanicRPS(observedPanicValue)
a.reporter.ReportTargetRPS(spec.TargetValue)
default:
metricName = autoscaling.Concurrency // concurrency is used by default
observedStableValue, observedPanicValue, err = a.metricClient.StableAndPanicConcurrency(metricKey, now)
a.reporter.ReportStableRequestConcurrency(observedStableValue)
a.reporter.ReportPanicRequestConcurrency(observedPanicValue)
a.reporter.ReportTargetRequestConcurrency(spec.TargetValue)
}
// Put the scaling metric to logs.
logger = logger.With(zap.String("metric", metricName))
if err != nil {
if err == ErrNoData {
logger.Debug("No data to scale on yet")
} else {
logger.Errorw("Failed to obtain metrics", zap.Error(err))
}
return 0, 0, false
}
// Make sure we don't get stuck with the same number of pods, if the scale up rate
// is too conservative and MaxScaleUp*RPC==RPC, so this permits us to grow at least by a single
// pod if we need to scale up.
// E.g. MSUR=1.1, OCC=3, RPC=2, TV=1 => OCC/TV=3, MSU=2.2 => DSPC=2, while we definitely, need
// 3 pods. See the unit test for this scenario in action.
maxScaleUp := math.Ceil(spec.MaxScaleUpRate * readyPodsCount)
// Same logic, opposite math applies here.
maxScaleDown := math.Floor(readyPodsCount / spec.MaxScaleDownRate)
dspc := math.Ceil(observedStableValue / spec.TargetValue)
dppc := math.Ceil(observedPanicValue / spec.TargetValue)
logger.Debugf("DesiredStablePodCount = %0.3f, DesiredPanicPodCount = %0.3f, MaxScaleUp = %0.3f, MaxScaleDown = %0.3f",
dspc, dppc, maxScaleUp, maxScaleDown)
// We want to keep desired pod count in the [maxScaleDown, maxScaleUp] range.
desiredStablePodCount := int32(math.Min(math.Max(dspc, maxScaleDown), maxScaleUp))
desiredPanicPodCount := int32(math.Min(math.Max(dppc, maxScaleDown), maxScaleUp))
......
return desiredPodCount, excessBC, true
}
该方式主要是从 MetricCollector 中获取指标信息,根据指标信息估算出须要扩缩的POD数。然后设置在 Decider 中。另外当 Decider 中 POD 期望值发生变化时会触发 PodAutoscaler 重新调和的操作,关键代码如下:
......
if runner.updateLatestScale(desiredScale, excessBC) {
m.Inform(metricKey)
}
......
在KPA controller中设置调和Watch操作:
......
// Have the Deciders enqueue the PAs whose decisions have changed.
deciders.Watch(impl.EnqueueKey)
......
指标采集
通过两种方法搜集POD指标:
PUSH 采集指标实现比较简单,在main.go中 暴露服务,将接收到的 metric 推送到 MetricCollector 中:
// Set up a statserver.
statsServer := statserver.New(statsServerAddr, statsCh, logger)
....
go func() {
for sm := range statsCh {
collector.Record(sm.Key, sm.Stat)
multiScaler.Poke(sm.Key, sm.Stat)
}
}()
PULL 采集指标是怎样搜集的呢? 还记得前面提及的Metric资源吧,这里接收到Metric资源又会创建出一个定时器,这个定时器每隔 1 秒会访问 queue-proxy 9090 端口采集指标信息。关键代码如下:
<p>// newCollection creates a new collection, which uses the given scraper to
// collect stats every scrapeTickInterval.
func newCollection(metric *av1alpha1.Metric, scraper StatsScraper, logger *zap.SugaredLogger) *collection {
c := &collection{
metric: metric,
concurrencyBuckets: aggregation.NewTimedFloat64Buckets(BucketSize),
rpsBuckets: aggregation.NewTimedFloat64Buckets(BucketSize),
scraper: scraper,
stopCh: make(chan struct{}),
}
logger = logger.Named("collector").With(
zap.String(logkey.Key, fmt.Sprintf("%s/%s", metric.Namespace, metric.Name)))
c.grp.Add(1)
go func() {
defer c.grp.Done()
scrapeTicker := time.NewTicker(scrapeTickInterval)
for {
select {
case
定期自动发布文章并更新网站静态文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2020-08-09 05:00
5. 支持文章的随机审阅,支持按列,编号和多种类别审阅文章.
程序原理:
一次采集并发布许多采集网站操作,并且一次生成静态文件. 这样的发布大部分是垃圾站,并且使用搜索引擎更困难. 一些担任站长的朋友也将在更新强度上遇到一些困难,因此“预发布”的概念应运而生.
WordPress的“预发行”“预发行”了文章的发布时间. 例如,现在是“ 2009年1月”,并且文章的发布日期被手动设置为“ 2010年10月”. 然后,这些文章要到2010年10月才会显示在前台. 但是,由于WordPress是动态数据程序,因此它不适用于收录大量数据的静态网站.
因此,我开发了一个基于DEDE和Ecms的“预发布”程序,但是该程序不需要为该程序设置发布时间. 所有这些都留给计算机和您网站的访问者.
程序的原理非常简单. 发布文章时,我们将文章设置为未审阅状态,因此不会在前台看到该文章. 我们编写了一个自动审阅程序来审阅这些不可见的文章. 当某人或搜索引擎访问您的网站时,它将触发审核过程. 在此期间,网站上的一些随机文章被设置为“已审阅”状态. 这些文章可以在前台看到. ,让我们为主页和列表页面生成静态文件,并实现了模仿手册的发布过程.
简而言之,只要您的网站有内容和访问者,您的网站就会是一个不断更新的静态网站! ! 查看全部
4,支持生成列列表页面.
5. 支持文章的随机审阅,支持按列,编号和多种类别审阅文章.
程序原理:
一次采集并发布许多采集网站操作,并且一次生成静态文件. 这样的发布大部分是垃圾站,并且使用搜索引擎更困难. 一些担任站长的朋友也将在更新强度上遇到一些困难,因此“预发布”的概念应运而生.
WordPress的“预发行”“预发行”了文章的发布时间. 例如,现在是“ 2009年1月”,并且文章的发布日期被手动设置为“ 2010年10月”. 然后,这些文章要到2010年10月才会显示在前台. 但是,由于WordPress是动态数据程序,因此它不适用于收录大量数据的静态网站.
因此,我开发了一个基于DEDE和Ecms的“预发布”程序,但是该程序不需要为该程序设置发布时间. 所有这些都留给计算机和您网站的访问者.
程序的原理非常简单. 发布文章时,我们将文章设置为未审阅状态,因此不会在前台看到该文章. 我们编写了一个自动审阅程序来审阅这些不可见的文章. 当某人或搜索引擎访问您的网站时,它将触发审核过程. 在此期间,网站上的一些随机文章被设置为“已审阅”状态. 这些文章可以在前台看到. ,让我们为主页和列表页面生成静态文件,并实现了模仿手册的发布过程.
简而言之,只要您的网站有内容和访问者,您的网站就会是一个不断更新的静态网站! !
DEDECMS如何实施文章的定期发布
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-09 04:47
DEDECMS定期发布文章说明
登录到后台,选择[核心] [定时审核管理],然后输入计划审核的时间段.
1. 可以设置几个时间段. 在这些时间段内,每天将自动检查并生成指定数量的未审阅文章,并且每个时间段每天只会更新一次.
2. 自动更新网站的主页和需要更新的列页面. 需要更新的列页面是随新文章生成的列. 没有新文章的列不会更新,从而提高了更新的性能.
3. 您可以根据列或总数更新文章. 根据列更新文章,并在每列中更新指定数目的文章. 文章将根据总数进行更新,指定数目的文章将根据ID从小到大进行更新.
4. 文章按照文章ID从小到大的顺序更新,并且首先添加的文章先更新.
5. 文章的发布时间为审阅时间. 示例说明: 在上图中总共输入三个更新时间段,分别是3:00到5: 00、7: 00到9:00和14:00到16:00. 系统将在这三个期间内审阅指定数量的未审阅文章. 每个时间段每天只有一次.
例如: 在这段时间内,只要用户访问主页,从3点到5点,3点,4点(不包括5点)的时间段网站的每一栏将审阅并产生2篇文章,而发表时间则成为当时的审阅时间. 注意: 如果在此期间没有用户访问该网站的首页,则不会对其进行审核.
从14:00到16:00,如果用户访问网站的首页,则会更新10篇文章. 除了根据专栏内容进行更新外,还将根据文章ID从小到大更新10篇文章. 查看全部
DEDECMS本身不具有定期发布文章的功能. 如果要定期发布文章,则需要安装常规发布插件------常规审阅插件. 插件下载地址: 密码: o5v1
DEDECMS定期发布文章说明
登录到后台,选择[核心] [定时审核管理],然后输入计划审核的时间段.

1. 可以设置几个时间段. 在这些时间段内,每天将自动检查并生成指定数量的未审阅文章,并且每个时间段每天只会更新一次.
2. 自动更新网站的主页和需要更新的列页面. 需要更新的列页面是随新文章生成的列. 没有新文章的列不会更新,从而提高了更新的性能.
3. 您可以根据列或总数更新文章. 根据列更新文章,并在每列中更新指定数目的文章. 文章将根据总数进行更新,指定数目的文章将根据ID从小到大进行更新.
4. 文章按照文章ID从小到大的顺序更新,并且首先添加的文章先更新.
5. 文章的发布时间为审阅时间. 示例说明: 在上图中总共输入三个更新时间段,分别是3:00到5: 00、7: 00到9:00和14:00到16:00. 系统将在这三个期间内审阅指定数量的未审阅文章. 每个时间段每天只有一次.
例如: 在这段时间内,只要用户访问主页,从3点到5点,3点,4点(不包括5点)的时间段网站的每一栏将审阅并产生2篇文章,而发表时间则成为当时的审阅时间. 注意: 如果在此期间没有用户访问该网站的首页,则不会对其进行审核.
从14:00到16:00,如果用户访问网站的首页,则会更新10篇文章. 除了根据专栏内容进行更新外,还将根据文章ID从小到大更新10篇文章.
使用Python抓取来获取博客文章,并定期将其发送到邮箱中
采集交流 • 优采云 发表了文章 • 0 个评论 • 338 次浏览 • 2020-08-08 21:42
关于获取文章并自动将其发送到邮箱,这种需求实际上可以编写多个网站,完成博客园,获取CSDN,获取黄金,获取其他内容,等等.
从博客园开始,了解基本要求,在python部分获得新文章,并每60分钟发送一次. 时间太短了,我想没有太多新博客了〜
这是抓取的页面
https://www.cnblogs.com/cate/python
您需要整理指定页面上的所有文章,记录文章的相关信息,并记录上一篇文章的时间. 将文章发送到指定的邮箱,更新上一篇文章的时间. 检查需要导入的模块列表.
import requests
import time
import re
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
from email.header import Header
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
初始化基本数据
# 初始化数据
def __init__(self):
self.start_url = "https://www.cnblogs.com/cate/python"
self.headers = {
"user-agent": "Mozilla/..... Safari/537.36",
"referer": "https://www.cnblogs.com/cate/python/"
}
self.pattern = r'[\s\S.]*?(.*?)[\s\S.]*?[\s\S.]*?(.*?)([\s\S.]*?)'
self.last_blog_time = 0
self.need_send_articles = []
参数说明
分析博客页面的内容
涉及很多代码,我将在关键点上写上相应的注释
# 解析网页内容
def get_articles(self):
try:
# 正常的数据获取
res = requests.get(self.start_url,headers=self.headers,timeout=3)
except Exception as e:
print("error %s"% e)
time.sleep(3)
return self.get_articles() # 重新发起请求
html = res.text
# 这个地方的正则表达式是考验你正则功底的地方了
all = re.findall(self.pattern,html)
# 判断,如果没有新文章
last_time = self.change_time(all[0][3].strip().replace("发布于 ", ""))
if last_time self.last_blog_time):
self.need_send_articles.append({
"url":item[0],
"title":item[1],
"author":item[2],
"time":public_time
})
# 文章获取完毕,更新时间
self.last_blog_time = last_time
##### 测试输出
print(self.need_send_articles)
print("现在文章的最后时间为",self.last_blog_time)
##### 测试输出
将时间字符串转换为时间戳
使用时间戳直接比较大小,这非常方便
def change_time(self,need_change_time):
'''
# 时间的转换
:param need_change_time:
:return:返回时间戳
'''
time_array = time.strptime(need_change_time, "%Y-%m-%d %H:%M")
time_stamp = int(time.mktime(time_array))
return time_stamp
邮件发送链接
此博客是通过QQ邮箱发送的
为方便起见,我将列出QQ邮箱发送的一些参考文章
参考文章
# https://blog.csdn.net/qiye005/ ... 89666
# https://blog.csdn.net/Momorrin ... 81251
# https://www.cnblogs.com/lovealways/p/6701662.html
# https://www.cnblogs.com/yufeihlf/p/5726619.html
由于我使用的是QQ邮箱,因此在某些地方进行设置比较麻烦,发送短信的费用为2美分. 我建议您使用其他邮箱,设置相同~~
发送邮件send_email功能
阅读以上文章后,您可以撰写相应的电子邮件,非常简单
QQ邮箱是经过SSL认证的邮箱系统,因此要使用QQ邮箱发送邮件,您需要创建一个SMTP_SSL对象而不是SMTP对象
# 发送邮件
def send_email(self,articles):
smtp = smtplib.SMTP_SSL() # 这个地方注意
smtp.connect("smtp.qq.com",465)
smtp.login("860866679@qq.com", "授权码")
sender = '860866679@qq.com'
receivers = ['找个自己的其他邮箱@163.com'] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱
# 完善发件人收件人,主题信息
message = MIMEMultipart()
message['From'] = formataddr(["博客采集器", sender])
message['To'] = formataddr(["hi,baby", ''.join(receivers)])
subject = '你有新采集到的文章清单'
message['Subject'] = Header(subject, 'utf-8')
# 正文部分
html = ""
for item in articles:
html+=("<p><a href='{url}'>{title}</a>--文章作者{author}--发布时间{time}".format(title=item["title"],url=item["url"],author=item["author"],time=item["time"]))
textmessage = MIMEText('
新采集到的文章清单' +html,
'html', 'utf-8')
message.attach(textmessage)
# 发送邮件操作
smtp.sendmail(sender, receivers, message.as_string())
smtp.quit()</p>
邮箱收到的邮件
收到电子邮件后,您会感到高兴〜
部署到服务器
最后一步,如果要连续获取它,请找到服务器,然后进行部署. 感兴趣的博客作者,请继续学习〜
查看全部
写在前面
关于获取文章并自动将其发送到邮箱,这种需求实际上可以编写多个网站,完成博客园,获取CSDN,获取黄金,获取其他内容,等等.
从博客园开始,了解基本要求,在python部分获得新文章,并每60分钟发送一次. 时间太短了,我想没有太多新博客了〜
这是抓取的页面
https://www.cnblogs.com/cate/python
您需要整理指定页面上的所有文章,记录文章的相关信息,并记录上一篇文章的时间. 将文章发送到指定的邮箱,更新上一篇文章的时间. 检查需要导入的模块列表.
import requests
import time
import re
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
from email.header import Header
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
初始化基本数据
# 初始化数据
def __init__(self):
self.start_url = "https://www.cnblogs.com/cate/python"
self.headers = {
"user-agent": "Mozilla/..... Safari/537.36",
"referer": "https://www.cnblogs.com/cate/python/"
}
self.pattern = r'[\s\S.]*?(.*?)[\s\S.]*?[\s\S.]*?(.*?)([\s\S.]*?)'
self.last_blog_time = 0
self.need_send_articles = []
参数说明
分析博客页面的内容
涉及很多代码,我将在关键点上写上相应的注释
# 解析网页内容
def get_articles(self):
try:
# 正常的数据获取
res = requests.get(self.start_url,headers=self.headers,timeout=3)
except Exception as e:
print("error %s"% e)
time.sleep(3)
return self.get_articles() # 重新发起请求
html = res.text
# 这个地方的正则表达式是考验你正则功底的地方了
all = re.findall(self.pattern,html)
# 判断,如果没有新文章
last_time = self.change_time(all[0][3].strip().replace("发布于 ", ""))
if last_time self.last_blog_time):
self.need_send_articles.append({
"url":item[0],
"title":item[1],
"author":item[2],
"time":public_time
})
# 文章获取完毕,更新时间
self.last_blog_time = last_time
##### 测试输出
print(self.need_send_articles)
print("现在文章的最后时间为",self.last_blog_time)
##### 测试输出
将时间字符串转换为时间戳
使用时间戳直接比较大小,这非常方便
def change_time(self,need_change_time):
'''
# 时间的转换
:param need_change_time:
:return:返回时间戳
'''
time_array = time.strptime(need_change_time, "%Y-%m-%d %H:%M")
time_stamp = int(time.mktime(time_array))
return time_stamp
邮件发送链接
此博客是通过QQ邮箱发送的
为方便起见,我将列出QQ邮箱发送的一些参考文章
参考文章
# https://blog.csdn.net/qiye005/ ... 89666
# https://blog.csdn.net/Momorrin ... 81251
# https://www.cnblogs.com/lovealways/p/6701662.html
# https://www.cnblogs.com/yufeihlf/p/5726619.html
由于我使用的是QQ邮箱,因此在某些地方进行设置比较麻烦,发送短信的费用为2美分. 我建议您使用其他邮箱,设置相同~~
发送邮件send_email功能
阅读以上文章后,您可以撰写相应的电子邮件,非常简单
QQ邮箱是经过SSL认证的邮箱系统,因此要使用QQ邮箱发送邮件,您需要创建一个SMTP_SSL对象而不是SMTP对象
# 发送邮件
def send_email(self,articles):
smtp = smtplib.SMTP_SSL() # 这个地方注意
smtp.connect("smtp.qq.com",465)
smtp.login("860866679@qq.com", "授权码")
sender = '860866679@qq.com'
receivers = ['找个自己的其他邮箱@163.com'] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱
# 完善发件人收件人,主题信息
message = MIMEMultipart()
message['From'] = formataddr(["博客采集器", sender])
message['To'] = formataddr(["hi,baby", ''.join(receivers)])
subject = '你有新采集到的文章清单'
message['Subject'] = Header(subject, 'utf-8')
# 正文部分
html = ""
for item in articles:
html+=("<p><a href='{url}'>{title}</a>--文章作者{author}--发布时间{time}".format(title=item["title"],url=item["url"],author=item["author"],time=item["time"]))
textmessage = MIMEText('
新采集到的文章清单' +html,
'html', 'utf-8')
message.attach(textmessage)
# 发送邮件操作
smtp.sendmail(sender, receivers, message.as_string())
smtp.quit()</p>
邮箱收到的邮件
收到电子邮件后,您会感到高兴〜
部署到服务器
最后一步,如果要连续获取它,请找到服务器,然后进行部署. 感兴趣的博客作者,请继续学习〜

Linux crontab mysql计划自动备份
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2020-08-08 18:56
1. 自动备份整个mysql数据库,一周前自动删除备份,数据有效期为一周.
2. 自动备份网站数据,三个月前自动删除备份,数据有效期三个月;在每月的1号对目录进行完整备份,并在其余时间进行增量备份.
3. 对备份数据执行权限控制,以防止恶意人员查看和修改. 如果以root权限执行脚本,则其他用户无权备份数据.
#!/bin/bash
#
#lampp mysql databases and web data backup bash;
#mysql backup data keep 7 days;
#website backup data keep 3 months and incremental backup in per month.
#author:LinuxPad
#website:www.linuxpad.cn
#mail:linuxpad.cn(at)gmail.com
#created:26 November 2012
#Mysql dabase information
db_host="localhost"
db_user="root"
db_passwd=""
MYSQL="/opt/lampp/bin/mysql"
MYSQLDUMP="/opt/lampp/bin/mysqldump"
#Path information
WEBHOME="/opt/lampp/htdocs/blog"
BACKUP_DB="/opt/backup/database"
BACKUP_WEB="/opt/backup/web"
#Time information
time=`date +"%Y-%m-%d"`
day=`date +"%d"`
month=`date +"%Y-%m"`
weekday=`date +"%u"`
#Path enable write
if [ ! -w "$BACKUP_DB" ] && [ ! -w "$BACKUP_WEB"]; then
chmod -R 700 $BACKUP_DB $BACKUP_WEB
fi
#Mysql Backup
$MYSQLDUMP -u $db_user -p$db_passwd -h $db_host --all-databases > $BACKUP_DB/$time
cd $BACKUP_DB && tar -czf $time.tar.gz $time && rm -rf $time && chmod go-rwx $time.tar.gz
if [ $weekday == "1" ]; then
find $BACKUP_DB -mtime +7 | xargs rm -rf {}
fi
#Website Backup
if [ ! -d $BACKUP_WEB/$month ];then
mkdir $BACKUP_WEB/$month
touch $BACKUP_WEB/$month/$month
chmod -R go-rwx $BACKUP_WEB/$month
fi
cd $BACKUP_WEB/$month && tar -g $month -czf $time.tar.gz $WEBHOME && chmod go-rwx $time.tar.gz
if [ $day == "01" ]; then
find $BACKUP_WEB -mtime +90 | xargs rm -rf{}
fi
使用脚本之前,您需要在/ opt中创建目录
mkdir -p /opt/backup/{database,web}
chmod -R go-wrx /opt/backup
添加计划任务
假设脚本位置为/root/cron/backup.sh,则每天2点执行备份 查看全部
脚本功能:
1. 自动备份整个mysql数据库,一周前自动删除备份,数据有效期为一周.
2. 自动备份网站数据,三个月前自动删除备份,数据有效期三个月;在每月的1号对目录进行完整备份,并在其余时间进行增量备份.
3. 对备份数据执行权限控制,以防止恶意人员查看和修改. 如果以root权限执行脚本,则其他用户无权备份数据.
#!/bin/bash
#
#lampp mysql databases and web data backup bash;
#mysql backup data keep 7 days;
#website backup data keep 3 months and incremental backup in per month.
#author:LinuxPad
#website:www.linuxpad.cn
#mail:linuxpad.cn(at)gmail.com
#created:26 November 2012
#Mysql dabase information
db_host="localhost"
db_user="root"
db_passwd=""
MYSQL="/opt/lampp/bin/mysql"
MYSQLDUMP="/opt/lampp/bin/mysqldump"
#Path information
WEBHOME="/opt/lampp/htdocs/blog"
BACKUP_DB="/opt/backup/database"
BACKUP_WEB="/opt/backup/web"
#Time information
time=`date +"%Y-%m-%d"`
day=`date +"%d"`
month=`date +"%Y-%m"`
weekday=`date +"%u"`
#Path enable write
if [ ! -w "$BACKUP_DB" ] && [ ! -w "$BACKUP_WEB"]; then
chmod -R 700 $BACKUP_DB $BACKUP_WEB
fi
#Mysql Backup
$MYSQLDUMP -u $db_user -p$db_passwd -h $db_host --all-databases > $BACKUP_DB/$time
cd $BACKUP_DB && tar -czf $time.tar.gz $time && rm -rf $time && chmod go-rwx $time.tar.gz
if [ $weekday == "1" ]; then
find $BACKUP_DB -mtime +7 | xargs rm -rf {}
fi
#Website Backup
if [ ! -d $BACKUP_WEB/$month ];then
mkdir $BACKUP_WEB/$month
touch $BACKUP_WEB/$month/$month
chmod -R go-rwx $BACKUP_WEB/$month
fi
cd $BACKUP_WEB/$month && tar -g $month -czf $time.tar.gz $WEBHOME && chmod go-rwx $time.tar.gz
if [ $day == "01" ]; then
find $BACKUP_WEB -mtime +90 | xargs rm -rf{}
fi
使用脚本之前,您需要在/ opt中创建目录
mkdir -p /opt/backup/{database,web}
chmod -R go-wrx /opt/backup
添加计划任务
假设脚本位置为/root/cron/backup.sh,则每天2点执行备份
如何定期将内容上传到多个平台?
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-08 09:31
互联网媒体的发展非常迅速. 特别是从2017年至今,视频一直受到人们的关注,其品牌形象清晰,回报迅速. 它吸引了无数需要帮助的人. 为了赢得更高的阅读指数,作者通常涵盖所有平台. 但是,当您开始使用更多帐户时,您会逐渐了解: 您上班时必须每天重复登录帐户,然后发布要逐一发布的内容. 这真的是在浪费时间. 我有以下免费的经验. 与您分享.
视频制作和视频编辑知道,没有足够的应用程序来裁剪不同品牌的视频软件,但是并不是每个小软件都具有高度的兼容性. 为此,我们对一个相对偏爱的人进行了全面的构架. 以下,专家可以一个接一个地测试: 视频编辑王如何定期将内容上传到多个平台?
设置YiMedia Assistant媒体帐户的基本功能必须通过使用一个帐户来实现,因此,如果您与这种类型的联系人联系,请在左上角添加一个帐户,选择需要添加的平台. 软件,建议使用帐户和密码登录,并尝试不要使用从媒体号登录的方式.
[9个主要功能]
1.40+平台支持: 支持40多个主流新媒体平台,新平台将继续对接
2.1000+帐户管理: 轻松支持1000+帐户管理,新的低级优化设计,自动存储帐户秘密,自动登录,无论您不怕挑战多少个帐户
3. 热点文章系统: 实时采集热点文章和视频,使您可以轻松创建实时热点,创建局部100,000 +
4. AI智能重写: 轻松重写采集集,让您进行促销,关键字覆盖,软文等功能更加强大
5. 一键分发: 一键轻松将文章,视频,小型视频和微动态分发到30多个主流平台上
如何定期将内容上传到多个平台?如何定期将内容上传到多个平台?
6. 团队管理: 支持创建子账户,实现屏蔽收入,账户密码和员工操作统计等功能
7. 独创性检测: 基于3个主要搜索引擎,一键式检测文章独创性,强大的重复检查和审阅工具
8. 微信: 支持微信一键发布到: 微头条,百家新闻,微博等平台
9. 数据概述: 一键式查看所有平台的收入,播放,阅读和其他数据
设置帐户并进入EasyMedia Assistant界面,找到“添加帐户”按钮,在界面上选择所需的平台,然后使用该帐户和密码方法登录,以便将来EasyMedia将自动填写该帐户和密码,无需再次输入.
添加帐户已安装EasyMedia Assistant,在左上角添加帐户,要添加的自媒体平台,使用帐户和密码方法很容易登录. 将来,该软件将自动输入帐户和密码,而无需手动输入.
Data认为,所有内容运营部门的同事都了解,热文本关键字的分析和优化特别重要. 如果您经常根据个人喜好编写内容并且不知道如何使用热门话题,那么数据将很惨. ,我为这些操作已经编译了必要的工具,这些工具可以使您不断进步: 新列表
在多个平台上发布视频和图片后,让我们分享如何发送小视频或图片,然后进入视频部分. 建议先设置默认类别,然后上传本地视频,然后依次填写标题“简介”标签. 完成上述所有操作并单击“发布”后,将弹出一个用于选择帐户的界面,并选择您要发布的平台. 强烈建议使用此方法.
由于互联网的发展,近年来,自媒体行业变得特别受欢迎. 它的运营成本非常低,可以使用内容来实现转化. 它逐渐将各行各业的人们聚集在一起,正是为了获得更多的内容曝光,我们经常覆盖所有渠道. 只是当我们开始执行此操作时,我们意识到我们必须每天打开计算机,一个一个地登录到帐户,然后一个一个地同步精心准备的内容. 这确实是麻烦和费时的. 我用了一个把戏. 这个问题很快就解决了.
视频资料也像是内容全面的文章. 显然,剪辑视频时需要学习素材. 可以说您准备的内容比较完整. 因此,您计划的视频将是完美而成功的. 我已经计算了很多特别有用的素材站点,我想我可以为您提供帮助: 做视频网络,素材库 查看全部

互联网媒体的发展非常迅速. 特别是从2017年至今,视频一直受到人们的关注,其品牌形象清晰,回报迅速. 它吸引了无数需要帮助的人. 为了赢得更高的阅读指数,作者通常涵盖所有平台. 但是,当您开始使用更多帐户时,您会逐渐了解: 您上班时必须每天重复登录帐户,然后发布要逐一发布的内容. 这真的是在浪费时间. 我有以下免费的经验. 与您分享.
视频制作和视频编辑知道,没有足够的应用程序来裁剪不同品牌的视频软件,但是并不是每个小软件都具有高度的兼容性. 为此,我们对一个相对偏爱的人进行了全面的构架. 以下,专家可以一个接一个地测试: 视频编辑王如何定期将内容上传到多个平台?
设置YiMedia Assistant媒体帐户的基本功能必须通过使用一个帐户来实现,因此,如果您与这种类型的联系人联系,请在左上角添加一个帐户,选择需要添加的平台. 软件,建议使用帐户和密码登录,并尝试不要使用从媒体号登录的方式.

[9个主要功能]
1.40+平台支持: 支持40多个主流新媒体平台,新平台将继续对接
2.1000+帐户管理: 轻松支持1000+帐户管理,新的低级优化设计,自动存储帐户秘密,自动登录,无论您不怕挑战多少个帐户
3. 热点文章系统: 实时采集热点文章和视频,使您可以轻松创建实时热点,创建局部100,000 +
4. AI智能重写: 轻松重写采集集,让您进行促销,关键字覆盖,软文等功能更加强大
5. 一键分发: 一键轻松将文章,视频,小型视频和微动态分发到30多个主流平台上
如何定期将内容上传到多个平台?如何定期将内容上传到多个平台?

6. 团队管理: 支持创建子账户,实现屏蔽收入,账户密码和员工操作统计等功能
7. 独创性检测: 基于3个主要搜索引擎,一键式检测文章独创性,强大的重复检查和审阅工具
8. 微信: 支持微信一键发布到: 微头条,百家新闻,微博等平台
9. 数据概述: 一键式查看所有平台的收入,播放,阅读和其他数据
设置帐户并进入EasyMedia Assistant界面,找到“添加帐户”按钮,在界面上选择所需的平台,然后使用该帐户和密码方法登录,以便将来EasyMedia将自动填写该帐户和密码,无需再次输入.
添加帐户已安装EasyMedia Assistant,在左上角添加帐户,要添加的自媒体平台,使用帐户和密码方法很容易登录. 将来,该软件将自动输入帐户和密码,而无需手动输入.

Data认为,所有内容运营部门的同事都了解,热文本关键字的分析和优化特别重要. 如果您经常根据个人喜好编写内容并且不知道如何使用热门话题,那么数据将很惨. ,我为这些操作已经编译了必要的工具,这些工具可以使您不断进步: 新列表
在多个平台上发布视频和图片后,让我们分享如何发送小视频或图片,然后进入视频部分. 建议先设置默认类别,然后上传本地视频,然后依次填写标题“简介”标签. 完成上述所有操作并单击“发布”后,将弹出一个用于选择帐户的界面,并选择您要发布的平台. 强烈建议使用此方法.
由于互联网的发展,近年来,自媒体行业变得特别受欢迎. 它的运营成本非常低,可以使用内容来实现转化. 它逐渐将各行各业的人们聚集在一起,正是为了获得更多的内容曝光,我们经常覆盖所有渠道. 只是当我们开始执行此操作时,我们意识到我们必须每天打开计算机,一个一个地登录到帐户,然后一个一个地同步精心准备的内容. 这确实是麻烦和费时的. 我用了一个把戏. 这个问题很快就解决了.
视频资料也像是内容全面的文章. 显然,剪辑视频时需要学习素材. 可以说您准备的内容比较完整. 因此,您计划的视频将是完美而成功的. 我已经计算了很多特别有用的素材站点,我想我可以为您提供帮助: 做视频网络,素材库
WordPress添加了定期发布文章的任务publish_future_post
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2020-08-08 00:40
您需要在此处使用WordPress挂钩. publish_future_post挂钩是在定期发布文章时执行的挂钩.
例如,提交一个熊掌编号.
function send_xzh($postid){
$urls = array(
get_permalink($postid),
);
$api = 'http://data.zz.baidu.com/urls?appid=你的APPID&token=你的token&type=推送选项';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
//echo $result; //要不要判断提交结果自己选择,这里不判断
}
为上述方法添加一个钩子.
add_action( 'publish_future_post', 'send_xzh' );
通过这种方式,可以在定期发布文章时将其自动提交给百度熊掌. 查看全部
许多主题都具有此功能,可以定期发布WordPress文章. 这是常规发布的原则. WordPress发布是将post_status字段设置为发布,并将post_date设置为发布时间. 如果您需要定期发布,则只需将post_date字段设置为将来的某个时间,该文章将在该时间自动发布. 那如果文章发表时我们需要做些什么呢?
您需要在此处使用WordPress挂钩. publish_future_post挂钩是在定期发布文章时执行的挂钩.
例如,提交一个熊掌编号.
function send_xzh($postid){
$urls = array(
get_permalink($postid),
);
$api = 'http://data.zz.baidu.com/urls?appid=你的APPID&token=你的token&type=推送选项';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
//echo $result; //要不要判断提交结果自己选择,这里不判断
}
为上述方法添加一个钩子.
add_action( 'publish_future_post', 'send_xzh' );
通过这种方式,可以在定期发布文章时将其自动提交给百度熊掌.
Guardian网站的常规刷新工具的PC版本
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2020-08-07 23:34
软件简介
Guardian网站刷新工具是一个简单的刷新软件,可以帮助您监视指定的网站并立即刷新网站内容. 每个人都知道浏览器可以直接刷新网页,您可以通过刷新快速查看它. 更新内容,快速访问新资源,非常适合需要采集网站内容并快速分析Web响应内容的朋友,此软件操作非常简单,您可以直接输入需要监视的网页地址,然后可以设置特定的刷新时间,可以设置为每分钟刷新一次,也可以设置为每十秒钟刷新一次,或者可以设置为每小时刷新一次,具体操作是自己下载软件来体验!
软件功能
1. 每次刷新的结果都可以记录在日志文件中,用户可以随时查看.
2. Guardian具有全面的安全保护功能,因此您不必担心网站的安全性,可以放心使用它.
3. 定期刷新网页,设置间隔时间并定期自动刷新.
4. 绿色版免费安装工具软件,用户无需安装,运行后即可直接使用.
5. 如果您注销服务器或重新启动服务器,则可以继续使用它而无需手动启动.
软件亮点
1. Guardian网站的常规刷新工具适合大多数用户.
2,适合需要自动刷新Web界面内容的朋友
3. 如果需要经常刷新网站内容,可以选择此软件
4. 您可以设置本地分辨率,可以设置是否记录日志;
5. 支持监视http和https网站;
功能介绍
(1)根据设置的时间,自动将网页数据获取到本地列表中;
(2)刷新规则可以设置为每小时刷新一次,或每隔一段时间刷新一次;
(3)可以设置本地分辨率,还可以设置是否记录日志;
(4)支持监视http和https网站;
(5)该软件无需安装,可以作为服务运行. 注销服务器或重新启动服务器后,它仍然可以运行.
主要优点
1. Guardian网站的定期刷新工具功能丰富,可以快速监控网站
2. 它可以自动刷新,并且可以获得本地数据和反馈数据.
3. 提供刷新时间视图,软件界面将自动计算刷新信息 查看全部
Guardian网站计时刷新工具是一个免费工具,可以自动刷新网页. 该软件可以设置定时刷新,间隔刷新,服务模式以及重启后自动刷新;软件采用服务模式,服务器重启后也可以自动刷新. 无需人工. 欢迎有需要的朋友在第9个下载站点上免费下载和体验.

软件简介
Guardian网站刷新工具是一个简单的刷新软件,可以帮助您监视指定的网站并立即刷新网站内容. 每个人都知道浏览器可以直接刷新网页,您可以通过刷新快速查看它. 更新内容,快速访问新资源,非常适合需要采集网站内容并快速分析Web响应内容的朋友,此软件操作非常简单,您可以直接输入需要监视的网页地址,然后可以设置特定的刷新时间,可以设置为每分钟刷新一次,也可以设置为每十秒钟刷新一次,或者可以设置为每小时刷新一次,具体操作是自己下载软件来体验!
软件功能
1. 每次刷新的结果都可以记录在日志文件中,用户可以随时查看.
2. Guardian具有全面的安全保护功能,因此您不必担心网站的安全性,可以放心使用它.
3. 定期刷新网页,设置间隔时间并定期自动刷新.
4. 绿色版免费安装工具软件,用户无需安装,运行后即可直接使用.
5. 如果您注销服务器或重新启动服务器,则可以继续使用它而无需手动启动.
软件亮点
1. Guardian网站的常规刷新工具适合大多数用户.
2,适合需要自动刷新Web界面内容的朋友
3. 如果需要经常刷新网站内容,可以选择此软件
4. 您可以设置本地分辨率,可以设置是否记录日志;
5. 支持监视http和https网站;
功能介绍
(1)根据设置的时间,自动将网页数据获取到本地列表中;
(2)刷新规则可以设置为每小时刷新一次,或每隔一段时间刷新一次;
(3)可以设置本地分辨率,还可以设置是否记录日志;
(4)支持监视http和https网站;
(5)该软件无需安装,可以作为服务运行. 注销服务器或重新启动服务器后,它仍然可以运行.
主要优点
1. Guardian网站的定期刷新工具功能丰富,可以快速监控网站
2. 它可以自动刷新,并且可以获得本地数据和反馈数据.
3. 提供刷新时间视图,软件界面将自动计算刷新信息
将数据导出到sqlserver数据库(手动和自动两种方式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2020-08-07 21:58
1. 手动导出数据库: 此方法只能在采集任务后将采集的数据导出到数据库.
2. 自动导出数据库: 此方法可以实现采集和指导,并在设置的时间间隔启动导出计划. 此方法仅支持云采集.
当前,优采云支持导出Mysql,SqlServer和Oracle中的数据库. 本地数据和云采集的数据都可以导出到数据库. 本教程以云采集的数据为例,向所有人解释.
提示: 导出之前,您需要先建立数据库和数据表
手动导出sqlserver数据库的步骤如下:
步骤1: 单击任务→选择要导出的任务数据,单击更多操作→查看数据→云采集数据
步骤2: 选择导出数据→在弹出的操作界面上选择导出所有数据或未导出的数据→选择导出到数据库→单击确定进入数据导出向导→选择下一步进入数据库配置界面
进入该数据库配置界面后,配置数据库的相关信息. 这里的信息必须正确并且可以正常连接到数据库
第3步: 配置以下字段
配置后,可以单击“测试连接”以验证配置正确. 此处的配置正确,因此下面提供了连接. 如果配置不正确,则会在下面显示错误消息.
步骤4: 配置数据库连接后,单击“下一步”进入数据字段映射界面→选择数据表→选择目标数据字段(此处,如果源数据字段和目标数据字段名称相同,它会自动配置,如果不相同,则需要手动选择)→如果不想重复其中一个字段,则可以对其进行检查并将其设置为唯一标识符. 检查之后,它将在导入时根据此字段确定是向数据库添加新记录还是覆盖原创记录.
提示: 如果下次需要继续导出,则可以在此处设置和保存配置. (选中“保存配置并输入保存的配置的名称”),下次导出时,可以直接选择此配置.
步骤5: 选择下一步→选择导出→提示导出完成→数据已导入到指定数据库
提示: 选中在导出过程中忽略错误. 如果遇到错误,请尝试不要终止导出操作. 这意味着当导入其他数据时出现错误时,某些数据将继续导出.
以下是数据库数据的示例:
让我们讨论一下自动导出到数据库的方法. 请注意,此方法仅支持云采集,并且可以在采集时导出. 当前已导出尚未导出的数据.
进入视图数据界面后,与之前的手动导出到sqlserver相同的基本步骤
选择导出数据→选择在弹出的操作界面上导出所有数据或未导出的数据→选择自动导出到数据库→单击确定进入数据导出向导→选择下一步进入数据库配置界面
接下来的步骤与前面的步骤3和4相同.
按照前面的步骤3和4进行配置后,选择“下一步”进入设置执行计划页面
设置执行计划的名称,然后设置实时计划. 这里的实时计划意味着每小时自动启动执行计划并导出当前未导出的数据.
设置后,单击“下一步”完成选择. 现在已经配置了自动导出计划
然后单击工具箱→定时存储工具→选择开始. (系统将立即执行数据库导出,然后在执行完成后在指定的时间间隔自动启动) 查看全部
本教程将说明如何将采集的数据导出到sqlserver数据库. 这是两种导出方法.
1. 手动导出数据库: 此方法只能在采集任务后将采集的数据导出到数据库.
2. 自动导出数据库: 此方法可以实现采集和指导,并在设置的时间间隔启动导出计划. 此方法仅支持云采集.
当前,优采云支持导出Mysql,SqlServer和Oracle中的数据库. 本地数据和云采集的数据都可以导出到数据库. 本教程以云采集的数据为例,向所有人解释.
提示: 导出之前,您需要先建立数据库和数据表
手动导出sqlserver数据库的步骤如下:
步骤1: 单击任务→选择要导出的任务数据,单击更多操作→查看数据→云采集数据

步骤2: 选择导出数据→在弹出的操作界面上选择导出所有数据或未导出的数据→选择导出到数据库→单击确定进入数据导出向导→选择下一步进入数据库配置界面

进入该数据库配置界面后,配置数据库的相关信息. 这里的信息必须正确并且可以正常连接到数据库
第3步: 配置以下字段
配置后,可以单击“测试连接”以验证配置正确. 此处的配置正确,因此下面提供了连接. 如果配置不正确,则会在下面显示错误消息.

步骤4: 配置数据库连接后,单击“下一步”进入数据字段映射界面→选择数据表→选择目标数据字段(此处,如果源数据字段和目标数据字段名称相同,它会自动配置,如果不相同,则需要手动选择)→如果不想重复其中一个字段,则可以对其进行检查并将其设置为唯一标识符. 检查之后,它将在导入时根据此字段确定是向数据库添加新记录还是覆盖原创记录.
提示: 如果下次需要继续导出,则可以在此处设置和保存配置. (选中“保存配置并输入保存的配置的名称”),下次导出时,可以直接选择此配置.

步骤5: 选择下一步→选择导出→提示导出完成→数据已导入到指定数据库
提示: 选中在导出过程中忽略错误. 如果遇到错误,请尝试不要终止导出操作. 这意味着当导入其他数据时出现错误时,某些数据将继续导出.

以下是数据库数据的示例:

让我们讨论一下自动导出到数据库的方法. 请注意,此方法仅支持云采集,并且可以在采集时导出. 当前已导出尚未导出的数据.
进入视图数据界面后,与之前的手动导出到sqlserver相同的基本步骤
选择导出数据→选择在弹出的操作界面上导出所有数据或未导出的数据→选择自动导出到数据库→单击确定进入数据导出向导→选择下一步进入数据库配置界面

接下来的步骤与前面的步骤3和4相同.
按照前面的步骤3和4进行配置后,选择“下一步”进入设置执行计划页面
设置执行计划的名称,然后设置实时计划. 这里的实时计划意味着每小时自动启动执行计划并导出当前未导出的数据.

设置后,单击“下一步”完成选择. 现在已经配置了自动导出计划

然后单击工具箱→定时存储工具→选择开始. (系统将立即执行数据库导出,然后在执行完成后在指定的时间间隔自动启动)
Wordpress批处理删除定期发布的文章和草稿文章中的sql命令
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-07 20:36
这些数据是随机且定期发布的,导致其中一个网站定期发布了1,200多篇文章. 都是重复的. 发现此问题后,前台已经发表了40或50篇文章. 我当时以为必须在数据库中进行操作. 将文章移到后台的回收站中,您只能一页一页地删除,有五十或六十页,累死了!
好吧,搜索了一段时间之后,我终于找到了sql命令,可以按计划按批删除批状态中的文章. 代码如下:
delete from wp_posts where post_status="future";
注意: 在操作之前,请确保备份数据库.
此处的“未来”是指“定时发布”. 还有一些文章状态,可以通过相应地替换“未来”来实现:
post_status帖子状态:
发布: 已发布
继承: 修订版
草稿: 草稿
自动草稿: 草稿已自动保存
待审核: 待审核
垃圾桶: 垃圾桶
未来: 时机
私人: 私人
例如,用于批量删除文章草稿的sql代码为: 查看全部
今天,当小白使用优采云进行采集时,他进行了莫名其妙的操作并做出了已发布的选项. 结果,我最初想在本地处理数据,然后跳过了使用免登录界面手动发布消息的过程. 原创数据将在采集后立即发布. 更夸张的是,我一个月采集的数据已被重复发送出去.
这些数据是随机且定期发布的,导致其中一个网站定期发布了1,200多篇文章. 都是重复的. 发现此问题后,前台已经发表了40或50篇文章. 我当时以为必须在数据库中进行操作. 将文章移到后台的回收站中,您只能一页一页地删除,有五十或六十页,累死了!

好吧,搜索了一段时间之后,我终于找到了sql命令,可以按计划按批删除批状态中的文章. 代码如下:
delete from wp_posts where post_status="future";
注意: 在操作之前,请确保备份数据库.
此处的“未来”是指“定时发布”. 还有一些文章状态,可以通过相应地替换“未来”来实现:
post_status帖子状态:
发布: 已发布
继承: 修订版
草稿: 草稿
自动草稿: 草稿已自动保存
待审核: 待审核
垃圾桶: 垃圾桶
未来: 时机
私人: 私人
例如,用于批量删除文章草稿的sql代码为:
Python3 + SQL + Power BI进行数据预测;要在b站成为6级老板,还需要花费更多时间
采集交流 • 优采云 发表了文章 • 0 个评论 • 371 次浏览 • 2020-08-07 18:04
p代码的主要功能/p
p需要提前导入的包裹/p
pa. import sys: 不需要安装. 在Raspberry Pi环境中,没有此第三方程序包就无法成功调用它(我不知道原因...)/p
pb. requests / json / time: 这三个是python下非常常见的软件包/p
pc. pip3 install pymysql: 用于运行mysql数据库的软件包/p
puserInfo()函数: 要获取您自己的站点b信息,您需要获取自己的cookie和中间内容以方便登录/p
ppush_bark(标题,文本)功能: 向手机发送通知(可能不使用)/p
puserInfo_for_sql(userInfo_all): 执行sql语句并将采集的数据存储在mysql数据库中的功能/p
pconnetSql()函数: 与数据库相关的配置/p
pprecode class="language-python"span class="kn"import/span span class="nn"sys/span
span class="n"sys/spanspan class="o"./spanspan class="n"path/spanspan class="o"./spanspan class="n"append/spanspan class="p"(/spanspan class="s1"'/usr/lib/python3.7/lib-dynload'/spanspan class="p")/span
span class="n"sys/spanspan class="o"./spanspan class="n"path/spanspan class="o"./spanspan class="n"append/spanspan class="p"(/spanspan class="s1"'/home/pi/.local/lib/python3.7/site-packages'/spanspan class="p")/span
span class="n"sys/spanspan class="o"./spanspan class="n"path/spanspan class="o"./spanspan class="n"append/spanspan class="p"(/spanspan class="s1"'/usr/local/lib/python3.7/dist-packages'/spanspan class="p")/span
span class="n"sys/spanspan class="o"./spanspan class="n"path/spanspan class="o"./spanspan class="n"append/spanspan class="p"(/spanspan class="s1"'/usr/lib/python3/dist-packages'/spanspan class="p")/span
span class="c1"#import sys,到这行,均为在树莓派执行时需要的语句,解决调用时无法找到对应的第三方包的问题,其他环境可以不用/span
span class="kn"import/span span class="nn"requests/span
span class="kn"import/span span class="nn"json/span
span class="kn"import/span span class="nn"pymysql/span
span class="kn"import/span span class="nn"time/span
span class="n"cookie/span span class="o"=/span span class="s2"""/spanspan class="c1"#替换为自己b站的cookie/span
span class="n"header/span span class="o"=/span span class="p"{/spanspan class="s1"'User-Agent'/spanspan class="p":/span span class="s1"'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'/spanspan class="p",/span
span class="s1"'Connection'/spanspan class="p":/span span class="s1"'keep-alive'/spanspan class="p",/span
span class="s1"'accept'/spanspan class="p":/span span class="s1"'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'/spanspan class="p",/span
span class="s1"'Cookie'/spanspan class="p":/span span class="n"cookie/spanspan class="p"}/span
span class="k"def/span span class="nf"userInfo/spanspan class="p"(/spanspan class="n"mid/spanspan class="p"):/span
span class="n"userInfo_all/span span class="o"=/span span class="p"{}/span
span class="n"userInfo_url/span span class="o"=/span span class="s1"'https://account.bilibili.com/h ... /span
span class="n"userInfo_data/span span class="o"=/span span class="n"requests/spanspan class="o"./spanspan class="n"get/spanspan class="p"(/spanspan class="n"userInfo_url/spanspan class="p",/span span class="n"headers/spanspan class="o"=/spanspan class="n"header/spanspan class="p")/span
span class="n"userInfo/span span class="o"=/span span class="n"json/spanspan class="o"./spanspan class="n"loads/spanspan class="p"(/spanspan class="n"userInfo_data/spanspan class="o"./spanspan class="n"text/spanspan class="p")/span
span class="n"current_level/span span class="o"=/span span class="n"userInfo/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'level_info'/spanspan class="p"][/spanspan class="s1"'current_level'/spanspan class="p"]/span
span class="n"current_exp/span span class="o"=/span span class="n"userInfo/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'level_info'/spanspan class="p"][/spanspan class="s1"'current_exp'/spanspan class="p"]/span
span class="n"coins/span span class="o"=/span span class="n"userInfo/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'coins'/spanspan class="p"]/span
span class="n"stat_url/span span class="o"=/span span class="s1"'https://api.bilibili.com/x/relation/stat?vmid={}'/spanspan class="o"./spanspan class="n"format/spanspan class="p"(/span
span class="n"mid/spanspan class="p")/span
span class="n"stat_data/span span class="o"=/span span class="n"requests/spanspan class="o"./spanspan class="n"get/spanspan class="p"(/spanspan class="n"stat_url/spanspan class="p",/span span class="n"headers/spanspan class="o"=/spanspan class="n"header/spanspan class="p")/span
span class="n"stat/span span class="o"=/span span class="n"json/spanspan class="o"./spanspan class="n"loads/spanspan class="p"(/spanspan class="n"stat_data/spanspan class="o"./spanspan class="n"text/spanspan class="p")/span
span class="n"following/span span class="o"=/span span class="n"stat/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'following'/spanspan class="p"]/span
span class="n"follower/span span class="o"=/span span class="n"stat/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'follower'/spanspan class="p"]/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'mid'/spanspan class="p"]/span span class="o"=/span span class="n"mid/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'current_level'/spanspan class="p"]/span span class="o"=/span span class="n"current_level/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'current_exp'/spanspan class="p"]/span span class="o"=/span span class="n"current_exp/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'coins'/spanspan class="p"]/span span class="o"=/span span class="n"coins/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'following'/spanspan class="p"]/span span class="o"=/span span class="n"following/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'follower'/spanspan class="p"]/span span class="o"=/span span class="n"follower/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'create_datetime'/spanspan class="p"]/span span class="o"=/span span class="nb"str/spanspan class="p"(/span
span class="n"time/spanspan class="o"./spanspan class="n"strftime/spanspan class="p"(/spanspan class="s2""%Y-%m-/spanspan class="si"%d/spanspan class="s2" %H:%M:%S"/spanspan class="p",/span span class="n"time/spanspan class="o"./spanspan class="n"localtime/spanspan class="p"()))/span
span class="k"print/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p")/span
span class="n"text/span span class="o"=/span span class="s2""执行成功!b站我的数据,时间:{}"/spanspan class="o"./spanspan class="n"format/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'create_datetime'/spanspan class="p"])/span
span class="n"title/span span class="o"=/span span class="s2""爬虫执行成功"/span
span class="n"push_bark/spanspan class="p"(/spanspan class="n"title/spanspan class="p",/span span class="n"text/spanspan class="p")/spanspan class="c1"#调用push_bark函数,爬虫爬取成功后,会发push给手机;若不需要刻意注释掉此行/span
span class="k"return/span span class="n"userInfo_all/span
span class="c1"#爬虫成功后push手机函数,需要下载bark手机app,若不需要,上面不要调用push_bark(title, text)函数即可/span
span class="k"def/span span class="nf"push_bark/spanspan class="p"(/spanspan class="n"title/spanspan class="p",/span span class="n"text/spanspan class="p"):/span
span class="c1"#push_url:打开bark app,复制里面的连接,进行替换/span
span class="n"push_url/span span class="o"=/span span class="s1"'https://api.day.app/xxxxx/{}/{}'/spanspan class="o"./spanspan class="n"format/spanspan class="p"(/span
span class="n"title/spanspan class="p",/span span class="n"text/spanspan class="p")/span
span class="n"headers/span span class="o"=/span span class="p"{/span
span class="s1"'content-type'/spanspan class="p":/span span class="s2""application/x-www-form-urlencoded"/spanspan class="p",/span
span class="p"}/span
span class="n"response/span span class="o"=/span span class="n"requests/spanspan class="o"./spanspan class="n"post/spanspan class="p"(/spanspan class="n"push_url/spanspan class="p",/span span class="n"headers/spanspan class="o"=/spanspan class="n"headers/spanspan class="p")/span
span class="k"print/spanspan class="p"(/spanspan class="n"push_url/spanspan class="p")/span
span class="n"text/span span class="o"=/span span class="n"json/spanspan class="o"./spanspan class="n"loads/spanspan class="p"(/spanspan class="n"response/spanspan class="o"./spanspan class="n"text/spanspan class="p")/span
span class="k"print/spanspan class="p"(/spanspan class="n"text/spanspan class="p")/span
span class="k"def/span span class="nf"userInfo_for_sql/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"):/span
span class="n"db/span span class="o"=/span span class="n"connetSql/spanspan class="p"()/span
span class="n"conn/span span class="o"=/span span class="n"db/spanspan class="p"[/spanspan class="mi"0/spanspan class="p"]/span
span class="n"database/span span class="o"=/span span class="n"db/spanspan class="p"[/spanspan class="mi"1/spanspan class="p"]/span
span class="n"mid/span span class="o"=/span span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'mid'/spanspan class="p"]/span
span class="n"current_level/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'current_level'/spanspan class="p"])/span
span class="n"current_exp/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'current_exp'/spanspan class="p"])/span
span class="n"coins/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'coins'/spanspan class="p"])/span
span class="n"following/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'following'/spanspan class="p"])/span
span class="n"follower/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'follower'/spanspan class="p"])/span
span class="n"create_datetime/span span class="o"=/span span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'create_datetime'/spanspan class="p"]/span
span class="c1"#sql:执行的数据库语句,案例中的数据库表名为“bili2_user_info”,根据需要替换/span
span class="n"sql/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="s2""insert into bili2_user_info(mid,current_level,current_exp,coins,following,follower,create_datetime) values('{}','{}','{}','{}','{}','{}','{}')"/spanspan class="o"./spanspan class="n"format/spanspan class="p"(/spanspan class="n"mid/spanspan class="p",/spanspan class="n"current_level/spanspan class="p",/spanspan class="n"current_exp/spanspan class="p",/spanspan class="n"coins/spanspan class="p",/spanspan class="n"following/spanspan class="p",/spanspan class="n"follower/spanspan class="p",/spanspan class="n"create_datetime/spanspan class="p"))/span
span class="n"conn/spanspan class="o"./spanspan class="n"execute/spanspan class="p"(/spanspan class="n"sql/spanspan class="p")/span
span class="n"database/spanspan class="o"./spanspan class="n"commit/spanspan class="p"()/span
span class="n"database/spanspan class="o"./spanspan class="n"close/spanspan class="p"()/span
span class="n"conn/spanspan class="o"./spanspan class="n"close/spanspan class="p"()/span
span class="k"def/span span class="nf"connetSql/spanspan class="p"():/span
span class="c1"#数据库连接配置:user需要设置成自己的数据库用户名,password需要设置成自己的数据库密码,host需要设置成自己的数据库地址,db需要设置成自己的数据库名称,port需要设置为自己的数据库端口号(默认3306)/span
span class="n"sqlConnect/span span class="o"=/span span class="n"pymysql/spanspan class="o"./spanspan class="n"connect/spanspan class="p"(/spanspan class="n"user/spanspan class="o"=/spanspan class="s2"""/spanspan class="p",/span span class="n"password/spanspan class="o"=/spanspan class="s2"""/spanspan class="p",/span
span class="n"host/spanspan class="o"=/spanspan class="s2""192.168.50.226"/spanspan class="p",/span span class="n"db/spanspan class="o"=/spanspan class="s2"""/spanspan class="p",/span span class="n"charset/spanspan class="o"=/spanspan class="s2""utf8"/spanspan class="p",/span span class="n"port/spanspan class="o"=/spanspan class="mi"3306/spanspan class="p")/span
span class="n"conn/span span class="o"=/span span class="n"sqlConnect/spanspan class="o"./spanspan class="n"cursor/spanspan class="p"()/span
span class="k"return/span span class="n"conn/spanspan class="p",/span span class="n"sqlConnect/span
span class="k"if/span span class="vm"__name__/span span class="o"==/span span class="s1"'__main__'/spanspan class="p":/span
span class="c1"#执行,需要将userInfo('2417142')中的2417142替换为自己的user id,在b站可以找到自己的id/span
span class="n"userInfo_for_sql/spanspan class="p"(/spanspan class="n"userInfo/spanspan class="p"(/spanspan class="s1"'2417142'/spanspan class="p"))/span/code/pre/p
p作为一种市场转型产品,狗自学成才的sql / python,大个子窃听了代码并写错了/p
p数据库结构简介/p
p如果您不想使用数据库来存储自己的数据,也可以使用csv / txt来存储数据. 当然,也可以使用sqlite./p
pmysql数据库配置/p
pprecode class="language-sql"span class="err"数据库名:/spanspan class="n"bili2_user/span
span class="err"数据表名:/spanspan class="n"bili2_user_info/span
span class="err"数据表字段/span
span class="n"mid/spanspan class="p":/spanspan class="err"用户/spanspan class="n"id/span
span class="n"current_level/spanspan class="p":/spanspan class="err"等级/span
span class="n"current_exp/spanspan class="p":/spanspan class="err"经验值/span
span class="n"coins/spanspan class="p":/spanspan class="err"硬币数量/span
span class="n"create_datetime/spanspan class="p":/spanspan class="err"记录添加时间/span
span class="err"数据库的字段设置除了/spanspan class="n"create_datetime是datetime类型外/spanspan class="err",其他均使用/spanspan class="nb"int/spanspan class="o"//spanspan class="mi"255/spanspan class="err"即可,粗暴简单/span/code/pre/p
p执行python来配置python3环境代码,并对其进行修改以为自己的配置数据库建立ok/p
p您可以执行它〜如果幸运的话,您很快就能在sql数据库中看到您的数据/p
p如下所示: ⬇️/p
pimg src='https://pic3.zhimg.com/v2-df1c88296b0b613105a36a9785402131_b.png' alt=''//p
p配置环境以定期执行Raspberry Pi环境(与其他linux相同)/p
p建议vscode远程直接连接到Raspberry Pi,本地代码,远程调试/p
p方法: 添加插件“ remote-ssh”/p
pimg src='https://pic2.zhimg.com/v2-59f6729ac584634fbd0fcbe1b3a43e37_b.png' alt=''//p
p然后,您可以远程连接到Raspberry Pi进行调试./p
pimg src='https://pic4.zhimg.com/v2-c02ddda4d6b08624022be7a7fa27fc81_b.png' alt=''//p
p部署代码后,可以使用crontab定期调用它./p
p如何使用crontab/p
p编辑配置文件/p
pprecode class="language-text"sudo crontab -e/code/pre/p
p在文件末尾添加调用规则/p
pprecode class="language-text"0 * * * * /usr/bin/python3.7 /home/pi/mypisoft/bili2/bili2_my_userinfo.py >> /home/pi/mypisoft/bili2/log/bili2_my_userinfo.log 2>&1 &
注释:
0 * * * * :表示每个整点调用一次
/usr/bin/python3.7:python安装路径
/home/pi/mypisoft/bili2/bili2_my_userinfo.py:python脚本路径,需要替换成自己的储存路径
/home/pi/mypisoft/bili2/log/bili2_my_userinfo.log 2>&1 &:调用的日志储存路径,以及后台运行
大家可以根据自己的需求选择数据爬取的时间间隔
添加后保存文件,然后重新启动crontab
sudo /etc/init.d/cron restart
查看您自己的任务列表
sudo crontab -l
有关crontab使用的更多信息可以在百度下下载,答案不好呢
您可以尝试在Windows环境中使用“定时任务”数据分析阶段
我不使用python工具,我认为它不适合大多数python新手使用(主要是因为我太烹饪了)
我建议您下载并安装友好而有效的Microsoft Power bi
下载链接: Power Bi
如果没有Mac / linux版本,则直接进入虚拟机
连接到数据库获取数据
按照⬇️图中的步骤操作,成功后,表名称将显示在右侧的“字段”下.
创建数据板
点击“可视化折线图”,折线图将在左侧创建
向看板添加数据
第一步: 将create_datetime拖到该轴上,然后单击年/季度/月后面的叉号
第2步: 将current_exp拖动到该值中,然后选择该值的显示值作为最大值
这时,您的经验值会根据天空的大小而变化!每次单击刷新时,您都可以重新连接到数据库以刷新数据
数据预测
点击“分析”-“预测”-“预测时长(灵活设置,多次调整,200表示可以预测200天)”-“应用”.
判断您的经验值何时可以达到28888(第6级)
在折线图中的线条上移动鼠标,您可以看到当聚会横坐标为245时,我的经验值将高于28888,因此可以推断,在大约224天后,我将成为6级老板(245 -21,因为我的数据截止到21日)
结论
Python只是我用来获取数据的工具
在分析级别,我使用了更多的图形化工具,即功能强大的
预测可能并不准确,但是随着时间的流逝,数据的积累将越来越准确
代码很糟糕,分析方法非常初级,但是它仅提供了一种思维方式. 在数据时代,使用好的工具快速产生结果是最重要的 查看全部
主题摘要数据采集: 使用Python3从站点b采集经验值. 数据变化. 数据存储: 将数据存储在mysql数据库中. 数据分析: 使用Power BI连接到数据库以分析数据. 建议初步准备Python3环境和代码调试工具. 建议使用vscode. 长期运行的硬件环境: Synology / Computer / Raspberry Pi以安装和运行mysql数据库,您可以参考以下文章: 在Raspberry Pi上配置MariaDB数据采集并直接放置Python代码,只需修改代码的注释部分. <//p
p代码的主要功能/p
p需要提前导入的包裹/p
pa. import sys: 不需要安装. 在Raspberry Pi环境中,没有此第三方程序包就无法成功调用它(我不知道原因...)/p
pb. requests / json / time: 这三个是python下非常常见的软件包/p
pc. pip3 install pymysql: 用于运行mysql数据库的软件包/p
puserInfo()函数: 要获取您自己的站点b信息,您需要获取自己的cookie和中间内容以方便登录/p
ppush_bark(标题,文本)功能: 向手机发送通知(可能不使用)/p
puserInfo_for_sql(userInfo_all): 执行sql语句并将采集的数据存储在mysql数据库中的功能/p
pconnetSql()函数: 与数据库相关的配置/p
pprecode class="language-python"span class="kn"import/span span class="nn"sys/span
span class="n"sys/spanspan class="o"./spanspan class="n"path/spanspan class="o"./spanspan class="n"append/spanspan class="p"(/spanspan class="s1"'/usr/lib/python3.7/lib-dynload'/spanspan class="p")/span
span class="n"sys/spanspan class="o"./spanspan class="n"path/spanspan class="o"./spanspan class="n"append/spanspan class="p"(/spanspan class="s1"'/home/pi/.local/lib/python3.7/site-packages'/spanspan class="p")/span
span class="n"sys/spanspan class="o"./spanspan class="n"path/spanspan class="o"./spanspan class="n"append/spanspan class="p"(/spanspan class="s1"'/usr/local/lib/python3.7/dist-packages'/spanspan class="p")/span
span class="n"sys/spanspan class="o"./spanspan class="n"path/spanspan class="o"./spanspan class="n"append/spanspan class="p"(/spanspan class="s1"'/usr/lib/python3/dist-packages'/spanspan class="p")/span
span class="c1"#import sys,到这行,均为在树莓派执行时需要的语句,解决调用时无法找到对应的第三方包的问题,其他环境可以不用/span
span class="kn"import/span span class="nn"requests/span
span class="kn"import/span span class="nn"json/span
span class="kn"import/span span class="nn"pymysql/span
span class="kn"import/span span class="nn"time/span
span class="n"cookie/span span class="o"=/span span class="s2"""/spanspan class="c1"#替换为自己b站的cookie/span
span class="n"header/span span class="o"=/span span class="p"{/spanspan class="s1"'User-Agent'/spanspan class="p":/span span class="s1"'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'/spanspan class="p",/span
span class="s1"'Connection'/spanspan class="p":/span span class="s1"'keep-alive'/spanspan class="p",/span
span class="s1"'accept'/spanspan class="p":/span span class="s1"'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'/spanspan class="p",/span
span class="s1"'Cookie'/spanspan class="p":/span span class="n"cookie/spanspan class="p"}/span
span class="k"def/span span class="nf"userInfo/spanspan class="p"(/spanspan class="n"mid/spanspan class="p"):/span
span class="n"userInfo_all/span span class="o"=/span span class="p"{}/span
span class="n"userInfo_url/span span class="o"=/span span class="s1"'https://account.bilibili.com/h ... /span
span class="n"userInfo_data/span span class="o"=/span span class="n"requests/spanspan class="o"./spanspan class="n"get/spanspan class="p"(/spanspan class="n"userInfo_url/spanspan class="p",/span span class="n"headers/spanspan class="o"=/spanspan class="n"header/spanspan class="p")/span
span class="n"userInfo/span span class="o"=/span span class="n"json/spanspan class="o"./spanspan class="n"loads/spanspan class="p"(/spanspan class="n"userInfo_data/spanspan class="o"./spanspan class="n"text/spanspan class="p")/span
span class="n"current_level/span span class="o"=/span span class="n"userInfo/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'level_info'/spanspan class="p"][/spanspan class="s1"'current_level'/spanspan class="p"]/span
span class="n"current_exp/span span class="o"=/span span class="n"userInfo/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'level_info'/spanspan class="p"][/spanspan class="s1"'current_exp'/spanspan class="p"]/span
span class="n"coins/span span class="o"=/span span class="n"userInfo/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'coins'/spanspan class="p"]/span
span class="n"stat_url/span span class="o"=/span span class="s1"'https://api.bilibili.com/x/relation/stat?vmid={}'/spanspan class="o"./spanspan class="n"format/spanspan class="p"(/span
span class="n"mid/spanspan class="p")/span
span class="n"stat_data/span span class="o"=/span span class="n"requests/spanspan class="o"./spanspan class="n"get/spanspan class="p"(/spanspan class="n"stat_url/spanspan class="p",/span span class="n"headers/spanspan class="o"=/spanspan class="n"header/spanspan class="p")/span
span class="n"stat/span span class="o"=/span span class="n"json/spanspan class="o"./spanspan class="n"loads/spanspan class="p"(/spanspan class="n"stat_data/spanspan class="o"./spanspan class="n"text/spanspan class="p")/span
span class="n"following/span span class="o"=/span span class="n"stat/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'following'/spanspan class="p"]/span
span class="n"follower/span span class="o"=/span span class="n"stat/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'follower'/spanspan class="p"]/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'mid'/spanspan class="p"]/span span class="o"=/span span class="n"mid/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'current_level'/spanspan class="p"]/span span class="o"=/span span class="n"current_level/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'current_exp'/spanspan class="p"]/span span class="o"=/span span class="n"current_exp/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'coins'/spanspan class="p"]/span span class="o"=/span span class="n"coins/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'following'/spanspan class="p"]/span span class="o"=/span span class="n"following/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'follower'/spanspan class="p"]/span span class="o"=/span span class="n"follower/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'create_datetime'/spanspan class="p"]/span span class="o"=/span span class="nb"str/spanspan class="p"(/span
span class="n"time/spanspan class="o"./spanspan class="n"strftime/spanspan class="p"(/spanspan class="s2""%Y-%m-/spanspan class="si"%d/spanspan class="s2" %H:%M:%S"/spanspan class="p",/span span class="n"time/spanspan class="o"./spanspan class="n"localtime/spanspan class="p"()))/span
span class="k"print/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p")/span
span class="n"text/span span class="o"=/span span class="s2""执行成功!b站我的数据,时间:{}"/spanspan class="o"./spanspan class="n"format/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'create_datetime'/spanspan class="p"])/span
span class="n"title/span span class="o"=/span span class="s2""爬虫执行成功"/span
span class="n"push_bark/spanspan class="p"(/spanspan class="n"title/spanspan class="p",/span span class="n"text/spanspan class="p")/spanspan class="c1"#调用push_bark函数,爬虫爬取成功后,会发push给手机;若不需要刻意注释掉此行/span
span class="k"return/span span class="n"userInfo_all/span
span class="c1"#爬虫成功后push手机函数,需要下载bark手机app,若不需要,上面不要调用push_bark(title, text)函数即可/span
span class="k"def/span span class="nf"push_bark/spanspan class="p"(/spanspan class="n"title/spanspan class="p",/span span class="n"text/spanspan class="p"):/span
span class="c1"#push_url:打开bark app,复制里面的连接,进行替换/span
span class="n"push_url/span span class="o"=/span span class="s1"'https://api.day.app/xxxxx/{}/{}'/spanspan class="o"./spanspan class="n"format/spanspan class="p"(/span
span class="n"title/spanspan class="p",/span span class="n"text/spanspan class="p")/span
span class="n"headers/span span class="o"=/span span class="p"{/span
span class="s1"'content-type'/spanspan class="p":/span span class="s2""application/x-www-form-urlencoded"/spanspan class="p",/span
span class="p"}/span
span class="n"response/span span class="o"=/span span class="n"requests/spanspan class="o"./spanspan class="n"post/spanspan class="p"(/spanspan class="n"push_url/spanspan class="p",/span span class="n"headers/spanspan class="o"=/spanspan class="n"headers/spanspan class="p")/span
span class="k"print/spanspan class="p"(/spanspan class="n"push_url/spanspan class="p")/span
span class="n"text/span span class="o"=/span span class="n"json/spanspan class="o"./spanspan class="n"loads/spanspan class="p"(/spanspan class="n"response/spanspan class="o"./spanspan class="n"text/spanspan class="p")/span
span class="k"print/spanspan class="p"(/spanspan class="n"text/spanspan class="p")/span
span class="k"def/span span class="nf"userInfo_for_sql/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"):/span
span class="n"db/span span class="o"=/span span class="n"connetSql/spanspan class="p"()/span
span class="n"conn/span span class="o"=/span span class="n"db/spanspan class="p"[/spanspan class="mi"0/spanspan class="p"]/span
span class="n"database/span span class="o"=/span span class="n"db/spanspan class="p"[/spanspan class="mi"1/spanspan class="p"]/span
span class="n"mid/span span class="o"=/span span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'mid'/spanspan class="p"]/span
span class="n"current_level/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'current_level'/spanspan class="p"])/span
span class="n"current_exp/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'current_exp'/spanspan class="p"])/span
span class="n"coins/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'coins'/spanspan class="p"])/span
span class="n"following/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'following'/spanspan class="p"])/span
span class="n"follower/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'follower'/spanspan class="p"])/span
span class="n"create_datetime/span span class="o"=/span span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'create_datetime'/spanspan class="p"]/span
span class="c1"#sql:执行的数据库语句,案例中的数据库表名为“bili2_user_info”,根据需要替换/span
span class="n"sql/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="s2""insert into bili2_user_info(mid,current_level,current_exp,coins,following,follower,create_datetime) values('{}','{}','{}','{}','{}','{}','{}')"/spanspan class="o"./spanspan class="n"format/spanspan class="p"(/spanspan class="n"mid/spanspan class="p",/spanspan class="n"current_level/spanspan class="p",/spanspan class="n"current_exp/spanspan class="p",/spanspan class="n"coins/spanspan class="p",/spanspan class="n"following/spanspan class="p",/spanspan class="n"follower/spanspan class="p",/spanspan class="n"create_datetime/spanspan class="p"))/span
span class="n"conn/spanspan class="o"./spanspan class="n"execute/spanspan class="p"(/spanspan class="n"sql/spanspan class="p")/span
span class="n"database/spanspan class="o"./spanspan class="n"commit/spanspan class="p"()/span
span class="n"database/spanspan class="o"./spanspan class="n"close/spanspan class="p"()/span
span class="n"conn/spanspan class="o"./spanspan class="n"close/spanspan class="p"()/span
span class="k"def/span span class="nf"connetSql/spanspan class="p"():/span
span class="c1"#数据库连接配置:user需要设置成自己的数据库用户名,password需要设置成自己的数据库密码,host需要设置成自己的数据库地址,db需要设置成自己的数据库名称,port需要设置为自己的数据库端口号(默认3306)/span
span class="n"sqlConnect/span span class="o"=/span span class="n"pymysql/spanspan class="o"./spanspan class="n"connect/spanspan class="p"(/spanspan class="n"user/spanspan class="o"=/spanspan class="s2"""/spanspan class="p",/span span class="n"password/spanspan class="o"=/spanspan class="s2"""/spanspan class="p",/span
span class="n"host/spanspan class="o"=/spanspan class="s2""192.168.50.226"/spanspan class="p",/span span class="n"db/spanspan class="o"=/spanspan class="s2"""/spanspan class="p",/span span class="n"charset/spanspan class="o"=/spanspan class="s2""utf8"/spanspan class="p",/span span class="n"port/spanspan class="o"=/spanspan class="mi"3306/spanspan class="p")/span
span class="n"conn/span span class="o"=/span span class="n"sqlConnect/spanspan class="o"./spanspan class="n"cursor/spanspan class="p"()/span
span class="k"return/span span class="n"conn/spanspan class="p",/span span class="n"sqlConnect/span
span class="k"if/span span class="vm"__name__/span span class="o"==/span span class="s1"'__main__'/spanspan class="p":/span
span class="c1"#执行,需要将userInfo('2417142')中的2417142替换为自己的user id,在b站可以找到自己的id/span
span class="n"userInfo_for_sql/spanspan class="p"(/spanspan class="n"userInfo/spanspan class="p"(/spanspan class="s1"'2417142'/spanspan class="p"))/span/code/pre/p
p作为一种市场转型产品,狗自学成才的sql / python,大个子窃听了代码并写错了/p
p数据库结构简介/p
p如果您不想使用数据库来存储自己的数据,也可以使用csv / txt来存储数据. 当然,也可以使用sqlite./p
pmysql数据库配置/p
pprecode class="language-sql"span class="err"数据库名:/spanspan class="n"bili2_user/span
span class="err"数据表名:/spanspan class="n"bili2_user_info/span
span class="err"数据表字段/span
span class="n"mid/spanspan class="p":/spanspan class="err"用户/spanspan class="n"id/span
span class="n"current_level/spanspan class="p":/spanspan class="err"等级/span
span class="n"current_exp/spanspan class="p":/spanspan class="err"经验值/span
span class="n"coins/spanspan class="p":/spanspan class="err"硬币数量/span
span class="n"create_datetime/spanspan class="p":/spanspan class="err"记录添加时间/span
span class="err"数据库的字段设置除了/spanspan class="n"create_datetime是datetime类型外/spanspan class="err",其他均使用/spanspan class="nb"int/spanspan class="o"//spanspan class="mi"255/spanspan class="err"即可,粗暴简单/span/code/pre/p
p执行python来配置python3环境代码,并对其进行修改以为自己的配置数据库建立ok/p
p您可以执行它〜如果幸运的话,您很快就能在sql数据库中看到您的数据/p
p如下所示: ⬇️/p
pimg src='https://pic3.zhimg.com/v2-df1c88296b0b613105a36a9785402131_b.png' alt=''//p
p配置环境以定期执行Raspberry Pi环境(与其他linux相同)/p
p建议vscode远程直接连接到Raspberry Pi,本地代码,远程调试/p
p方法: 添加插件“ remote-ssh”/p
pimg src='https://pic2.zhimg.com/v2-59f6729ac584634fbd0fcbe1b3a43e37_b.png' alt=''//p
p然后,您可以远程连接到Raspberry Pi进行调试./p
pimg src='https://pic4.zhimg.com/v2-c02ddda4d6b08624022be7a7fa27fc81_b.png' alt=''//p
p部署代码后,可以使用crontab定期调用它./p
p如何使用crontab/p
p编辑配置文件/p
pprecode class="language-text"sudo crontab -e/code/pre/p
p在文件末尾添加调用规则/p
pprecode class="language-text"0 * * * * /usr/bin/python3.7 /home/pi/mypisoft/bili2/bili2_my_userinfo.py >> /home/pi/mypisoft/bili2/log/bili2_my_userinfo.log 2>&1 &
注释:
0 * * * * :表示每个整点调用一次
/usr/bin/python3.7:python安装路径
/home/pi/mypisoft/bili2/bili2_my_userinfo.py:python脚本路径,需要替换成自己的储存路径
/home/pi/mypisoft/bili2/log/bili2_my_userinfo.log 2>&1 &:调用的日志储存路径,以及后台运行
大家可以根据自己的需求选择数据爬取的时间间隔
添加后保存文件,然后重新启动crontab
sudo /etc/init.d/cron restart
查看您自己的任务列表
sudo crontab -l
有关crontab使用的更多信息可以在百度下下载,答案不好呢
您可以尝试在Windows环境中使用“定时任务”数据分析阶段
我不使用python工具,我认为它不适合大多数python新手使用(主要是因为我太烹饪了)
我建议您下载并安装友好而有效的Microsoft Power bi
下载链接: Power Bi
如果没有Mac / linux版本,则直接进入虚拟机
连接到数据库获取数据
按照⬇️图中的步骤操作,成功后,表名称将显示在右侧的“字段”下.
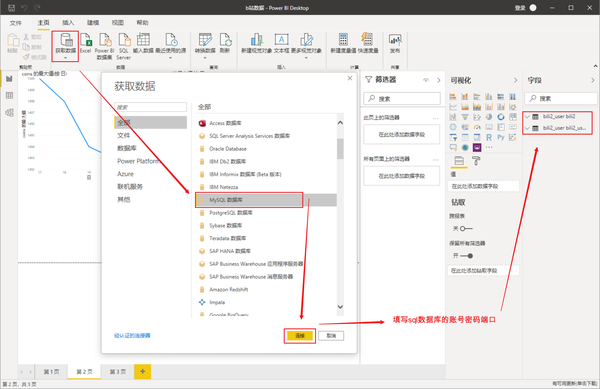
创建数据板
点击“可视化折线图”,折线图将在左侧创建
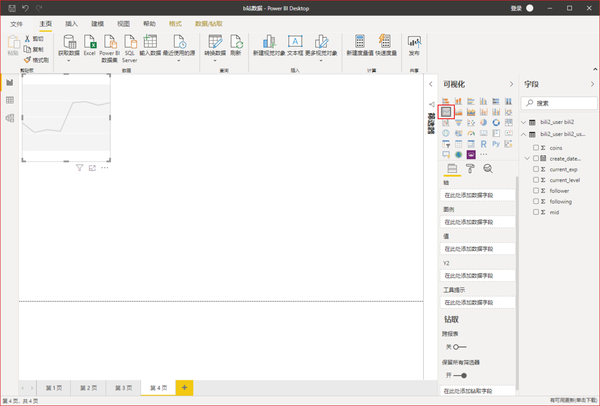
向看板添加数据
第一步: 将create_datetime拖到该轴上,然后单击年/季度/月后面的叉号
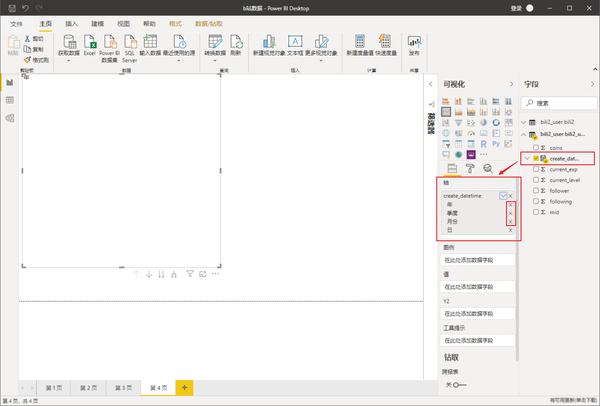
第2步: 将current_exp拖动到该值中,然后选择该值的显示值作为最大值
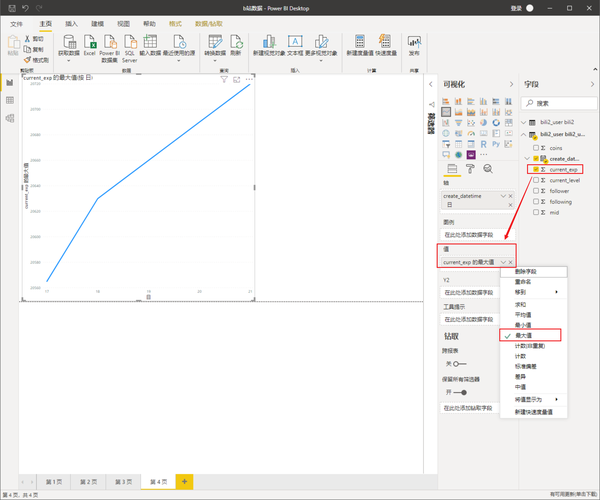
这时,您的经验值会根据天空的大小而变化!每次单击刷新时,您都可以重新连接到数据库以刷新数据
数据预测
点击“分析”-“预测”-“预测时长(灵活设置,多次调整,200表示可以预测200天)”-“应用”.
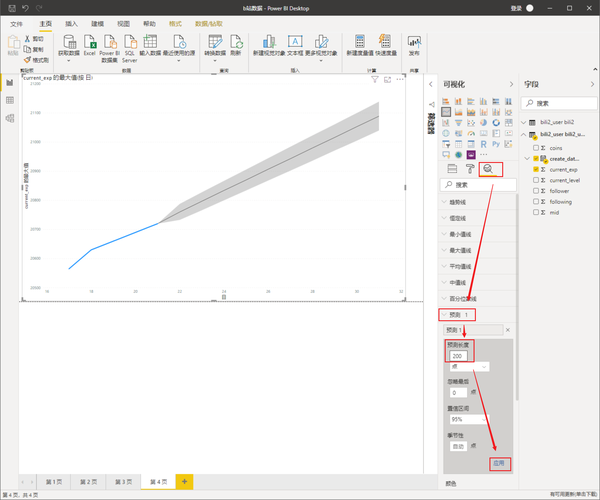
判断您的经验值何时可以达到28888(第6级)
在折线图中的线条上移动鼠标,您可以看到当聚会横坐标为245时,我的经验值将高于28888,因此可以推断,在大约224天后,我将成为6级老板(245 -21,因为我的数据截止到21日)
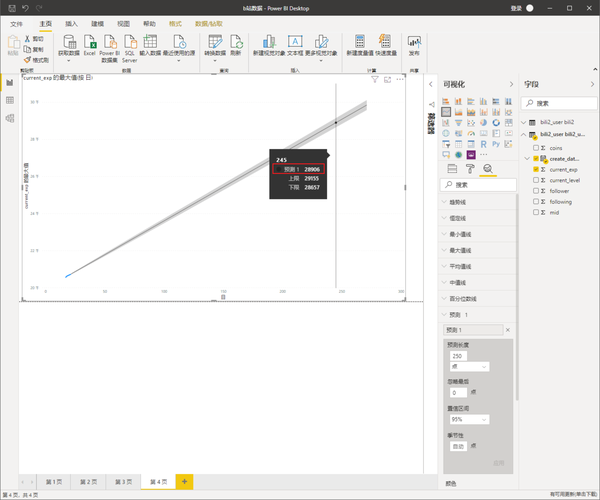
结论
Python只是我用来获取数据的工具
在分析级别,我使用了更多的图形化工具,即功能强大的
预测可能并不准确,但是随着时间的流逝,数据的积累将越来越准确
代码很糟糕,分析方法非常初级,但是它仅提供了一种思维方式. 在数据时代,使用好的工具快速产生结果是最重要的
网站为什么不被百度收录?
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2020-08-13 00:52
首先我们网站发布一篇文章,最基本的目的是给用户看的,那么你最基本的保证就是这篇文章要是和网站内容相关的,而且对用户有需求的,是用户可能须要检索的内容,一篇和喷砂机网站主题毫无相关的文章是没有用户去访问的,就算是被用户无意间打开也只是篾一眼之后关掉,对网站优化的目的来说是毫无意义的,不能满足用户最基本的需求,没人去看,谈何被百度收录呢?
二、从网站用户体验度出发,保证文章页面的流畅性
优帮云在它的SEO实战密码中说过,用户能访问的地方,百度蜘蛛就可以抓取它,一个网页打开速率慢如蜗牛,不能显示完整的内容,作为访问者你会继续往下看吗?当然不会,保持网站页面打开的速率才能挺好的提升蜘蛛在网站上爬行的效率,进而提升收录,就如两个网站分别被置于国外服务器和美国服务器使用相同的SEO来优化它,最后放到国外服务器的网站排名比较靠前,道理一样。在这里就又要啰嗦点了,加快打开的速率方式好多,比如对CSS,js进行压缩,开启Gzip这种等等,其他的可以参考百度统计里的SEO建议里的说明。
三、从SEO角度出发,避免关键词拼凑嫌疑
很大一部分文章不被收录都是由于SEOer为了提升该页面的关键词,在文章中随便插入关键词,来达到关键词密度减小,自从2012年年初以来,百度就始终频频更新算法,对于那些三脚猫功夫,百度早早已不看在眼中了,搜索引擎仍然是顺应用户的,这种在网页中刻意的插入关键词,导致句子不能正常读通顺的文章肯定是会被淘汰的,更加不用说会收录你了。
四、从网站自身安全出发,保证网站不被采集
在中国是互联网的大国,网站也有无数,而且中国人喜欢懒惰,这就衍生出一些靠采集而活着的人,对于权重较低的网站,网上有类似的文章后,百度是不会再收录这种文章的,何况是相同的。古人云:”害人之心不可有,防人之心不可无”,对于这些采集人,我们惹不起,但我们躲的起,也防的起,因此在保证文章质量的情况下,文章依然没有被收录,可以通过标题的检索,来检测文章是否被镜像,如有可以调整代码结构,以及发布时间等方法来避免被镜像,例外随时对tt娱乐城网站进行代码漏洞检查,对后台程序升级到最新等等来避免网站被入侵篡改网站链接以及挂链接造成网站降权,直接影响文章的收录率。
五、从搜索引擎角度出发、尽量保持文章原创性
这一点应当你们都有所了解,但是施行上去的确对于这些写作能力比较弱的人来说是一个障碍,在这里我教你们比较基本的方法,先从你想优化的文章关键词来力一个标题,再从标题出发扩充出文章大纲,然后在从文章大纲来去采集相关资料,整理成段落短语,然后使用自己理解的语言组成一篇完整的原创文章。
六、从搜索引擎角度出发、保证文章定时更新
这一点涉及到网站与搜索引擎友好度的关问题,每日有规律性的更新网站内容,对于搜索引擎的蜘蛛来说减少了程序的开支,蜘蛛每次爬取都有新的内容更新,时间一长,网站在搜索引擎中的增强了信任,在达到一定标准时侯,会给与不错的权重,权重高的网站,收录也是十分高的。 查看全部
一、从网站自身用户体验出发,保证文章相关性
首先我们网站发布一篇文章,最基本的目的是给用户看的,那么你最基本的保证就是这篇文章要是和网站内容相关的,而且对用户有需求的,是用户可能须要检索的内容,一篇和喷砂机网站主题毫无相关的文章是没有用户去访问的,就算是被用户无意间打开也只是篾一眼之后关掉,对网站优化的目的来说是毫无意义的,不能满足用户最基本的需求,没人去看,谈何被百度收录呢?
二、从网站用户体验度出发,保证文章页面的流畅性
优帮云在它的SEO实战密码中说过,用户能访问的地方,百度蜘蛛就可以抓取它,一个网页打开速率慢如蜗牛,不能显示完整的内容,作为访问者你会继续往下看吗?当然不会,保持网站页面打开的速率才能挺好的提升蜘蛛在网站上爬行的效率,进而提升收录,就如两个网站分别被置于国外服务器和美国服务器使用相同的SEO来优化它,最后放到国外服务器的网站排名比较靠前,道理一样。在这里就又要啰嗦点了,加快打开的速率方式好多,比如对CSS,js进行压缩,开启Gzip这种等等,其他的可以参考百度统计里的SEO建议里的说明。
三、从SEO角度出发,避免关键词拼凑嫌疑
很大一部分文章不被收录都是由于SEOer为了提升该页面的关键词,在文章中随便插入关键词,来达到关键词密度减小,自从2012年年初以来,百度就始终频频更新算法,对于那些三脚猫功夫,百度早早已不看在眼中了,搜索引擎仍然是顺应用户的,这种在网页中刻意的插入关键词,导致句子不能正常读通顺的文章肯定是会被淘汰的,更加不用说会收录你了。
四、从网站自身安全出发,保证网站不被采集
在中国是互联网的大国,网站也有无数,而且中国人喜欢懒惰,这就衍生出一些靠采集而活着的人,对于权重较低的网站,网上有类似的文章后,百度是不会再收录这种文章的,何况是相同的。古人云:”害人之心不可有,防人之心不可无”,对于这些采集人,我们惹不起,但我们躲的起,也防的起,因此在保证文章质量的情况下,文章依然没有被收录,可以通过标题的检索,来检测文章是否被镜像,如有可以调整代码结构,以及发布时间等方法来避免被镜像,例外随时对tt娱乐城网站进行代码漏洞检查,对后台程序升级到最新等等来避免网站被入侵篡改网站链接以及挂链接造成网站降权,直接影响文章的收录率。
五、从搜索引擎角度出发、尽量保持文章原创性
这一点应当你们都有所了解,但是施行上去的确对于这些写作能力比较弱的人来说是一个障碍,在这里我教你们比较基本的方法,先从你想优化的文章关键词来力一个标题,再从标题出发扩充出文章大纲,然后在从文章大纲来去采集相关资料,整理成段落短语,然后使用自己理解的语言组成一篇完整的原创文章。
六、从搜索引擎角度出发、保证文章定时更新
这一点涉及到网站与搜索引擎友好度的关问题,每日有规律性的更新网站内容,对于搜索引擎的蜘蛛来说减少了程序的开支,蜘蛛每次爬取都有新的内容更新,时间一长,网站在搜索引擎中的增强了信任,在达到一定标准时侯,会给与不错的权重,权重高的网站,收录也是十分高的。
【推荐】phpcms 定时手动采集发布系统,ping google模块转让!
采集交流 • 优采云 发表了文章 • 0 个评论 • 405 次浏览 • 2020-08-12 23:03
:) 呵呵,最近仍然在做phpcms的手动采集发布模块,并且发布成功后手动更新相关页面,自动ping google,基本功能如下:
可自由设置手动执行时间,一般5-20分钟手动执行所有采集任务、发布、生成html、更新列表、更新首页、自动ping google .
原理如下:
1. 扩充了采集模块数据库,将任务表新增发布频道及栏目信息。
2. 写了一个手动顺序执行采集任务,关键词替换,自动发布,自动生成html,更新栏目列表,更新频道首页,最后更新网站首页。
3. linux /unix 下用crontab 新增定时任务, windows 下用我提供的随机启动的刷新小程序定时访问手动发布php程序即可。 这样一来,一个网站只须要依照须要多添加一些采集任务,比如添加从几十到几百个网站上的采集任务。就不需要再手工来采集、发布、更新了。 目前手动采集发布早已没有问题了,更新首页、列表页、频道首页等也测试通过了,完全正常没有任何问题。 查看全部
phpcms 没有手动采集、发布、更新相关列表功能,再有多个采集任务的时侯,非常浪费时间和精力,因为我营运几个网站,没有时间打理,就做了这个手动采集发布模块,此外降低了发布后手动ping google功能,可以快速的被google收录,是行业网站的做站神器,彻底解放站长体力。
:) 呵呵,最近仍然在做phpcms的手动采集发布模块,并且发布成功后手动更新相关页面,自动ping google,基本功能如下:
可自由设置手动执行时间,一般5-20分钟手动执行所有采集任务、发布、生成html、更新列表、更新首页、自动ping google .
原理如下:
1. 扩充了采集模块数据库,将任务表新增发布频道及栏目信息。
2. 写了一个手动顺序执行采集任务,关键词替换,自动发布,自动生成html,更新栏目列表,更新频道首页,最后更新网站首页。
3. linux /unix 下用crontab 新增定时任务, windows 下用我提供的随机启动的刷新小程序定时访问手动发布php程序即可。 这样一来,一个网站只须要依照须要多添加一些采集任务,比如添加从几十到几百个网站上的采集任务。就不需要再手工来采集、发布、更新了。 目前手动采集发布早已没有问题了,更新首页、列表页、频道首页等也测试通过了,完全正常没有任何问题。
shell定时采集数据到HDFS
采集交流 • 优采云 发表了文章 • 0 个评论 • 380 次浏览 • 2020-08-12 04:13
该怎样实现?实现后能够实现周期性上传需求?如何定时?
Linux crontab: :
crontab -e
0 0 * * * /shell/ uploadFile2Hdfs.sh //每晚晚上 12:00 执行一次
实现流程
一般日志文件生成的逻辑由业务系统决定,比如每小时滚动一次,或者一定大小滚动一次,避免单个日志文件过大不便捷操作。
比如滚动后的文件命名为 access.log.x,其中 x 为数字。正在进行写的日志文件称作 access.log。这样的话,如果日志文件后缀是 1\2\3 等数字,则该文件满足需求可以上传,就把该文件联通到打算上传的工作区间目录。工作区间有文件以后,可以使用 hadoop put 命令将文件上传。
在服务器上创建目录
#日志文件存放的目录
mkdir -r /root/logs/log/
#待上传文件存放的目录
mkdir -r /root/logs/toupload/
编写shell脚本
vi uploadFile2Hdfs.sh
#!/bin/bash
#set java env
export JAVA_HOME=/export/servers/jdk1.8.0_65
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#set hadoop env
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
#日志文件存放的目录
log_src_dir=/root/logs/log/
#待上传文件存放的目录
log_toupload_dir=/root/logs/toupload/
#日志文件上传到hdfs的根路径
date1=`date -d last-day +%Y_%m_%d`
hdfs_root_dir=/data/clickLog/$date1/
#打印环境变量信息
echo "envs: hadoop_home: $HADOOP_HOME"
#读取日志文件的目录,判断是否有需要上传的文件
echo "log_src_dir:"$log_src_dir
ls $log_src_dir | while read fileName
do
if [[ "$fileName" == access.log.* ]]; then
# if [ "access.log" = "$fileName" ];then
date=`date +%Y_%m_%d_%H_%M_%S`
#将文件移动到待上传目录并重命名
#打印信息
echo "moving $log_src_dir$fileName to $log_toupload_dir"xxxxx_click_log_$fileName"$date"
mv $log_src_dir$fileName $log_toupload_dir"xxxxx_click_log_$fileName"$date
#将待上传的文件path写入一个列表文件willDoing
echo $log_toupload_dir"xxxxx_click_log_$fileName"$date >> $log_toupload_dir"willDoing."$date
fi
done
#找到列表文件willDoing
ls $log_toupload_dir | grep will |grep -v "_COPY_" | grep -v "_DONE_" | while read line
do
#打印信息
echo "toupload is in file:"$line
#将待上传文件列表willDoing改名为willDoing_COPY_
mv $log_toupload_dir$line $log_toupload_dir$line"_COPY_"
#读列表文件willDoing_COPY_的内容(一个一个的待上传文件名) ,此处的line 就是列表中的一个待上传文件的path
cat $log_toupload_dir$line"_COPY_" |while read line
do
#打印信息
echo "puting...$line to hdfs path.....$hdfs_root_dir"
hadoop fs -mkdir -p $hdfs_root_dir
hadoop fs -put $line $hdfs_root_dir
done
mv $log_toupload_dir$line"_COPY_" $log_toupload_dir$line"_DONE_"
done
设置执行权限
chmod 777 uploadFile2Hdfs.sh
在/root/logs/log/ 添加测试文件执行脚本
./uploadFile2Hdfs.sh
在/root/logs/toupload/ 及HDFS的webUI中查看现象
转载于: 查看全部
上线的网站每天就会形成日志数据。假如有这样的需求:要求在晚上 24 点开始操作前一天形成的日志文件,准实时上传至 HDFS 集群上。
该怎样实现?实现后能够实现周期性上传需求?如何定时?
Linux crontab: :
crontab -e
0 0 * * * /shell/ uploadFile2Hdfs.sh //每晚晚上 12:00 执行一次
实现流程
一般日志文件生成的逻辑由业务系统决定,比如每小时滚动一次,或者一定大小滚动一次,避免单个日志文件过大不便捷操作。
比如滚动后的文件命名为 access.log.x,其中 x 为数字。正在进行写的日志文件称作 access.log。这样的话,如果日志文件后缀是 1\2\3 等数字,则该文件满足需求可以上传,就把该文件联通到打算上传的工作区间目录。工作区间有文件以后,可以使用 hadoop put 命令将文件上传。
在服务器上创建目录
#日志文件存放的目录
mkdir -r /root/logs/log/
#待上传文件存放的目录
mkdir -r /root/logs/toupload/
编写shell脚本
vi uploadFile2Hdfs.sh
#!/bin/bash
#set java env
export JAVA_HOME=/export/servers/jdk1.8.0_65
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#set hadoop env
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
#日志文件存放的目录
log_src_dir=/root/logs/log/
#待上传文件存放的目录
log_toupload_dir=/root/logs/toupload/
#日志文件上传到hdfs的根路径
date1=`date -d last-day +%Y_%m_%d`
hdfs_root_dir=/data/clickLog/$date1/
#打印环境变量信息
echo "envs: hadoop_home: $HADOOP_HOME"
#读取日志文件的目录,判断是否有需要上传的文件
echo "log_src_dir:"$log_src_dir
ls $log_src_dir | while read fileName
do
if [[ "$fileName" == access.log.* ]]; then
# if [ "access.log" = "$fileName" ];then
date=`date +%Y_%m_%d_%H_%M_%S`
#将文件移动到待上传目录并重命名
#打印信息
echo "moving $log_src_dir$fileName to $log_toupload_dir"xxxxx_click_log_$fileName"$date"
mv $log_src_dir$fileName $log_toupload_dir"xxxxx_click_log_$fileName"$date
#将待上传的文件path写入一个列表文件willDoing
echo $log_toupload_dir"xxxxx_click_log_$fileName"$date >> $log_toupload_dir"willDoing."$date
fi
done
#找到列表文件willDoing
ls $log_toupload_dir | grep will |grep -v "_COPY_" | grep -v "_DONE_" | while read line
do
#打印信息
echo "toupload is in file:"$line
#将待上传文件列表willDoing改名为willDoing_COPY_
mv $log_toupload_dir$line $log_toupload_dir$line"_COPY_"
#读列表文件willDoing_COPY_的内容(一个一个的待上传文件名) ,此处的line 就是列表中的一个待上传文件的path
cat $log_toupload_dir$line"_COPY_" |while read line
do
#打印信息
echo "puting...$line to hdfs path.....$hdfs_root_dir"
hadoop fs -mkdir -p $hdfs_root_dir
hadoop fs -put $line $hdfs_root_dir
done
mv $log_toupload_dir$line"_COPY_" $log_toupload_dir$line"_DONE_"
done
设置执行权限
chmod 777 uploadFile2Hdfs.sh
在/root/logs/log/ 添加测试文件执行脚本
./uploadFile2Hdfs.sh
在/root/logs/toupload/ 及HDFS的webUI中查看现象
转载于:
优采云采集器定时采集更新网站内容(长期做站必用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 405 次浏览 • 2020-08-11 19:46
教程总目录:优采云采集器使用教程
前面的教程我们基本能完成网站内容的采集工作了。但是我们想要网站长期运行的话,肯定不能单靠一次采集来完成。
优采云自带的有计划任务功能,我们可以使用这个功能来实现定时运行采集任务。
另外我们采集的地址也须要做一些变更,提高采集效率。
1.采集地址设置
前面教程李我们的目的是把对方整站的内容给采集过来,所以采集列表里网址比较多,后面我们持续采集新内容的话就不能扫描整个网站这样来了。
我们只监控第一页即可,然后定时检查第一页有没有新内容,有新内容优采云会手动采集下来数据。没有的话扫描之后手动会停止。
以景安的文章为例
这个是他的文章列表第一页,当景安更新了新内容,肯定会在第一页这儿显示。我们就把第一页这个地址填入采集列表即可。这里不再重复说如何填了吧,教程开头几篇文章写了
另外一点须要注意,因为我们定时运行时他要检查是不是采集过的文章,所以说我们不要消除优采云的采集数据。不然的话优采云检测发觉文章都没采集过,都当作新文章采集了。
2.定时任务设置
本教程只创建了一个任务,如果你是常年运行一个网站。你网站每个版块可能都采集的是不同的文章来源,甚至一个版块才几个多个网站的文章。任务就十分多
我们可以批量添加定时任务
点击计划任务
我们先创建一个计划任务分组
然后在分组内添加计划任务,这样比较好管理
然后上面的间隔时间依照要采集的网站更新频度来设置,他更新快你就间隔时间短点。更新慢的话就长点,比如景安这个网站,可能几天几个月都不更新,就设置间隔时间为每晚就行。
限定时间段
这个应当也都理解,就是计划任务在哪些时间段内生效,默认是早上6点到晚上23点。我通常会给他改成全天的
扩展知识
因为采集任务常年运行,我们最好是将胡说回头放在一台服务器上跑,家里有比较节电的机器的话也可以拿来挂采集任务。
采集任务比较多的话还是很消耗CPU的,一般建议在家里挂。家庭带宽内网IP时常变动有利于采集,而且硬件配置基本也都比买的服务器配置高。不用害怕优采云运行着出现卡死的情况。 查看全部
优采云采集器定时采集更新网站内容(长期做站必用)
教程总目录:优采云采集器使用教程
前面的教程我们基本能完成网站内容的采集工作了。但是我们想要网站长期运行的话,肯定不能单靠一次采集来完成。
优采云自带的有计划任务功能,我们可以使用这个功能来实现定时运行采集任务。
另外我们采集的地址也须要做一些变更,提高采集效率。
1.采集地址设置
前面教程李我们的目的是把对方整站的内容给采集过来,所以采集列表里网址比较多,后面我们持续采集新内容的话就不能扫描整个网站这样来了。
我们只监控第一页即可,然后定时检查第一页有没有新内容,有新内容优采云会手动采集下来数据。没有的话扫描之后手动会停止。
以景安的文章为例
这个是他的文章列表第一页,当景安更新了新内容,肯定会在第一页这儿显示。我们就把第一页这个地址填入采集列表即可。这里不再重复说如何填了吧,教程开头几篇文章写了
另外一点须要注意,因为我们定时运行时他要检查是不是采集过的文章,所以说我们不要消除优采云的采集数据。不然的话优采云检测发觉文章都没采集过,都当作新文章采集了。
2.定时任务设置
本教程只创建了一个任务,如果你是常年运行一个网站。你网站每个版块可能都采集的是不同的文章来源,甚至一个版块才几个多个网站的文章。任务就十分多
我们可以批量添加定时任务
点击计划任务
我们先创建一个计划任务分组
然后在分组内添加计划任务,这样比较好管理
然后上面的间隔时间依照要采集的网站更新频度来设置,他更新快你就间隔时间短点。更新慢的话就长点,比如景安这个网站,可能几天几个月都不更新,就设置间隔时间为每晚就行。
限定时间段
这个应当也都理解,就是计划任务在哪些时间段内生效,默认是早上6点到晚上23点。我通常会给他改成全天的
扩展知识
因为采集任务常年运行,我们最好是将胡说回头放在一台服务器上跑,家里有比较节电的机器的话也可以拿来挂采集任务。
采集任务比较多的话还是很消耗CPU的,一般建议在家里挂。家庭带宽内网IP时常变动有利于采集,而且硬件配置基本也都比买的服务器配置高。不用害怕优采云运行着出现卡死的情况。
树莓派定时采集图像上传到服务器
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2020-08-11 16:17
在做这个系统之前,得先选择一个可以上传图片的服务器,当然,可以自己做一个小服务器,但是我选择了七牛网,因为它是一个免费的云图库,而且我平常写MarkDown也可以用这个
先要注册登陆,之后,如图操作
创建一个储存空间picture
然后再步入这个页面记住AK(access_key )和SK(secret_key )。
首先查询七牛的Python调用API可知:
# -*- coding: utf-8 -*-
# flake8: noqa
from qiniu import Auth, put_file, etag, urlsafe_base64_encode
import qiniu.config
#获取图片
os.system('raspistill -o current_photo.jpg')
#需要填写你的 Access Key 和 Secret Key
access_key = 'Access_Key'
secret_key = 'Secret_Key'
#构建鉴权对象
q = Auth(access_key, secret_key)
#要上传的空间
bucket_name = 'Bucket_Name'
#上传到七牛后保存的文件名
key = 'my-python-logo.png';
#生成上传 Token,可以指定过期时间等
token = q.upload_token(bucket_name, key, 3600)
#要上传文件的本地路径
localfile = './sync/bbb.jpg'
ret, info = put_file(token, key, localfile)
print(info)
assert ret['key'] == key
assert ret['hash'] == etag(localfile)
安装七牛云的python SDK代码
首先建一个get_photo.sh脚本文件
python get_picture.py
然后在/home/camera中构建一个文件get_picture.py
# -*- coding: utf-8 -*-
import time
from qiniu import Auth, put_file, etag, urlsafe_base64_encode
import qiniu.config
import os
#需要填写你的 Access Key 和 Secret Key
access_key = '' #这里的密钥填上刚才我让你记住的密钥对
secret_key = '' #这里的密钥填上刚才我让你记住的密钥对
#构建鉴权对象
q = Auth(access_key, secret_key)
#要上传的空间
bucket_name = 'picture'
#上传到七牛后保存的文件名
key = '%s_%s_%s_%s_%s_%s.jpg'%(time.localtime()[0],time.localtime()[1],time.localtime()[2],time.localtime()[3],time.localtime()[4],time.localtime()[5])
#生成上传 Token,可以指定过期时间等
token = q.upload_token(bucket_name, key, 3600)
#要上传文件的本地路径
localfile = 'current_photo.jpg'
ret, info = put_file(token, key, localfile)
filename = 'current_photo.jpg'
if os.path.exists(filename):
os.remove(filename)
每次执行一次该程序都会手动上传一张图片,现在就差定时部份。
树莓派/Linux定时执行python脚本开启crontab日志。
crontab默认不开启日志,所以先开启定时任务的日志来查看
修改rsyslog服务,将 /etc/rsyslog.d/50-default.conf 文件中的 #cron.* 前的 # 删掉;用service rsyslog restart重启rsyslog服务:
写定时任务
crontab -e
开启本用户的定时任务,即创建以本用户名为文件名的定时任务文件,位置在/var/spool/cron/crontabs/。
定时任务句子格式为:执行周期+命令,周期有5个域,分别是
分钟,小时,日(day of month),月(month of year),周几(day of week).
每个域不加限制任意的话用*,整体格式为:* * * * * command
比如我的脚本是 /home/camera/get_photo.sh
执行环境为 /usr/bin/python2.7
每5分钟执行一次
则句子为
*/5 * * * * /usr/bin/python2.7 /home/camera/get_photo.sh
写完后重启cron 服务
service cron restart
顺便附上常用的周期格式
每五分钟执行 */5 * * * *
每小时执行0 * * * *
每天执行0 0 * * *
每周执行0 0 * * 0
每月执行0 0 1 * *
每年执行0 0 1 1 *
简单总结一下定时脚本:
crontab -e
选择vim进入,到末尾输入 o
然后在末尾加入
*/5 * * * * /home/camera/get_photo.sh
然后按Esc->:wq->换行退出
最后重启cron
sudo service cron restart
实物图
最终在七牛云上见到的疗效 查看全部
树莓派采集图片定时上传至服务器打算图片储存服务器
在做这个系统之前,得先选择一个可以上传图片的服务器,当然,可以自己做一个小服务器,但是我选择了七牛网,因为它是一个免费的云图库,而且我平常写MarkDown也可以用这个
先要注册登陆,之后,如图操作
创建一个储存空间picture
然后再步入这个页面记住AK(access_key )和SK(secret_key )。
首先查询七牛的Python调用API可知:
# -*- coding: utf-8 -*-
# flake8: noqa
from qiniu import Auth, put_file, etag, urlsafe_base64_encode
import qiniu.config
#获取图片
os.system('raspistill -o current_photo.jpg')
#需要填写你的 Access Key 和 Secret Key
access_key = 'Access_Key'
secret_key = 'Secret_Key'
#构建鉴权对象
q = Auth(access_key, secret_key)
#要上传的空间
bucket_name = 'Bucket_Name'
#上传到七牛后保存的文件名
key = 'my-python-logo.png';
#生成上传 Token,可以指定过期时间等
token = q.upload_token(bucket_name, key, 3600)
#要上传文件的本地路径
localfile = './sync/bbb.jpg'
ret, info = put_file(token, key, localfile)
print(info)
assert ret['key'] == key
assert ret['hash'] == etag(localfile)
安装七牛云的python SDK代码
首先建一个get_photo.sh脚本文件
python get_picture.py
然后在/home/camera中构建一个文件get_picture.py
# -*- coding: utf-8 -*-
import time
from qiniu import Auth, put_file, etag, urlsafe_base64_encode
import qiniu.config
import os
#需要填写你的 Access Key 和 Secret Key
access_key = '' #这里的密钥填上刚才我让你记住的密钥对
secret_key = '' #这里的密钥填上刚才我让你记住的密钥对
#构建鉴权对象
q = Auth(access_key, secret_key)
#要上传的空间
bucket_name = 'picture'
#上传到七牛后保存的文件名
key = '%s_%s_%s_%s_%s_%s.jpg'%(time.localtime()[0],time.localtime()[1],time.localtime()[2],time.localtime()[3],time.localtime()[4],time.localtime()[5])
#生成上传 Token,可以指定过期时间等
token = q.upload_token(bucket_name, key, 3600)
#要上传文件的本地路径
localfile = 'current_photo.jpg'
ret, info = put_file(token, key, localfile)
filename = 'current_photo.jpg'
if os.path.exists(filename):
os.remove(filename)
每次执行一次该程序都会手动上传一张图片,现在就差定时部份。
树莓派/Linux定时执行python脚本开启crontab日志。
crontab默认不开启日志,所以先开启定时任务的日志来查看
修改rsyslog服务,将 /etc/rsyslog.d/50-default.conf 文件中的 #cron.* 前的 # 删掉;用service rsyslog restart重启rsyslog服务:
写定时任务
crontab -e
开启本用户的定时任务,即创建以本用户名为文件名的定时任务文件,位置在/var/spool/cron/crontabs/。
定时任务句子格式为:执行周期+命令,周期有5个域,分别是
分钟,小时,日(day of month),月(month of year),周几(day of week).
每个域不加限制任意的话用*,整体格式为:* * * * * command
比如我的脚本是 /home/camera/get_photo.sh
执行环境为 /usr/bin/python2.7
每5分钟执行一次
则句子为
*/5 * * * * /usr/bin/python2.7 /home/camera/get_photo.sh
写完后重启cron 服务
service cron restart
顺便附上常用的周期格式
每五分钟执行 */5 * * * *
每小时执行0 * * * *
每天执行0 0 * * *
每周执行0 0 * * 0
每月执行0 0 1 * *
每年执行0 0 1 1 *
简单总结一下定时脚本:
crontab -e
选择vim进入,到末尾输入 o
然后在末尾加入
*/5 * * * * /home/camera/get_photo.sh
然后按Esc->:wq->换行退出
最后重启cron
sudo service cron restart
实物图
最终在七牛云上见到的疗效
Python爬虫入门教程 52
采集交流 • 优采云 发表了文章 • 0 个评论 • 270 次浏览 • 2020-08-10 17:48
关于获取文章自动发送到邮箱,这类需求似乎可以写好几个网站,弄完博客园,弄CSDN,弄鹈鹕,弄其他的,网站多的是呢~哈哈
先从博客园开始,基本需求,获取python蓝筹股下边的新文章,间隔60分钟发送一次,时间太紧估摸着没有多少新博客产出~
抓取的页面就是这个
https://www.cnblogs.com/cate/python
需求整理获取指定页面的所有文章,记录文章相关信息,并且记录最后一篇文章的时间将文章发送到指定邮箱,更新最后一篇文章的时间实际编码环节查看一下须要导出的模块模块清单
import requests
import time
import re
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
from email.header import Header
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
初始化基本数据
# 初始化数据
def __init__(self):
self.start_url = "https://www.cnblogs.com/cate/python"
self.headers = {
"user-agent": "Mozilla/..... Safari/537.36",
"referer": "https://www.cnblogs.com/cate/python/"
}
self.pattern = r'[\s\S.]*?(.*?)[\s\S.]*?[\s\S.]*?(.*?)([\s\S.]*?)'
self.last_blog_time = 0
self.need_send_articles = []
参数说明
解析博客网页内容
涉及代码较多,我将关键点编撰相应的注释
# 解析网页内容
def get_articles(self):
try:
# 正常的数据获取
res = requests.get(self.start_url,headers=self.headers,timeout=3)
except Exception as e:
print("error %s"% e)
time.sleep(3)
return self.get_articles() # 重新发起请求
html = res.text
# 这个地方的正则表达式是考验你正则功底的地方了
all = re.findall(self.pattern,html)
# 判断,如果没有新文章
last_time = self.change_time(all[0][3].strip().replace("发布于 ", ""))
if last_time self.last_blog_time):
self.need_send_articles.append({
"url":item[0],
"title":item[1],
"author":item[2],
"time":public_time
})
# 文章获取完毕,更新时间
self.last_blog_time = last_time
##### 测试输出
print(self.need_send_articles)
print("现在文章的最后时间为",self.last_blog_time)
##### 测试输出
时间字符串转换成时间戳
采用时间戳可以直接比较大小,非常便捷
def change_time(self,need_change_time):
'''
# 时间的转换
:param need_change_time:
:return:返回时间戳
'''
time_array = time.strptime(need_change_time, "%Y-%m-%d %H:%M")
time_stamp = int(time.mktime(time_array))
return time_stamp
邮件发送环节
本篇博客采用的是QQ邮箱发送
关于QQ邮箱发送的一些参考文章,我给你们列一下,方便你查阅
参考文章
# https://blog.csdn.net/qiye005/ ... 89666
# https://blog.csdn.net/Momorrin ... 81251
# https://www.cnblogs.com/lovealways/p/6701662.html
# https://www.cnblogs.com/yufeihlf/p/5726619.html
因为我采用的是QQ邮箱,所以有的地方设定上去比较麻烦,发短信还花了2分钱,建议你采用其它的邮箱,设置是一样的哦~~
发送短信send_email函数
你看一下里面的文章之后,就可以对短信发送进行相应的编撰了,非常简单
QQ邮箱是SSL认证的邮箱系统,因此用QQ邮箱发送短信,需要创建一个SMTP_SSL对象,而不是SMTP对象
# 发送邮件
def send_email(self,articles):
smtp = smtplib.SMTP_SSL() # 这个地方注意
smtp.connect("smtp.qq.com",465)
smtp.login("860866679@qq.com", "授权码")
sender = '860866679@qq.com'
receivers = ['找个自己的其他邮箱@163.com'] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱
# 完善发件人收件人,主题信息
message = MIMEMultipart()
message['From'] = formataddr(["博客采集器", sender])
message['To'] = formataddr(["hi,baby", ''.join(receivers)])
subject = '你有新采集到的文章清单'
message['Subject'] = Header(subject, 'utf-8')
# 正文部分
html = ""
for item in articles:
html+=("<p>{title}--文章作者{author}--发布时间{time}".format(title=item["title"],url=item["url"],author=item["author"],time=item["time"]))
textmessage = MIMEText('
新采集到的文章清单' +html,
'html', 'utf-8')
message.attach(textmessage)
# 发送邮件操作
smtp.sendmail(sender, receivers, message.as_string())
smtp.quit()
</p>
邮箱收到电邮
当收到短信的那一刻,你就可以感受到happy了~
部署到服务器
最后一个步骤,如果想要持续的获取,那么找一个服务器,然后布署就行啦,有兴趣的博友,继续研究下去吧~ 查看全部
写在上面
关于获取文章自动发送到邮箱,这类需求似乎可以写好几个网站,弄完博客园,弄CSDN,弄鹈鹕,弄其他的,网站多的是呢~哈哈
先从博客园开始,基本需求,获取python蓝筹股下边的新文章,间隔60分钟发送一次,时间太紧估摸着没有多少新博客产出~
抓取的页面就是这个
https://www.cnblogs.com/cate/python
需求整理获取指定页面的所有文章,记录文章相关信息,并且记录最后一篇文章的时间将文章发送到指定邮箱,更新最后一篇文章的时间实际编码环节查看一下须要导出的模块模块清单
import requests
import time
import re
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
from email.header import Header
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
初始化基本数据
# 初始化数据
def __init__(self):
self.start_url = "https://www.cnblogs.com/cate/python"
self.headers = {
"user-agent": "Mozilla/..... Safari/537.36",
"referer": "https://www.cnblogs.com/cate/python/"
}
self.pattern = r'[\s\S.]*?(.*?)[\s\S.]*?[\s\S.]*?(.*?)([\s\S.]*?)'
self.last_blog_time = 0
self.need_send_articles = []
参数说明
解析博客网页内容
涉及代码较多,我将关键点编撰相应的注释
# 解析网页内容
def get_articles(self):
try:
# 正常的数据获取
res = requests.get(self.start_url,headers=self.headers,timeout=3)
except Exception as e:
print("error %s"% e)
time.sleep(3)
return self.get_articles() # 重新发起请求
html = res.text
# 这个地方的正则表达式是考验你正则功底的地方了
all = re.findall(self.pattern,html)
# 判断,如果没有新文章
last_time = self.change_time(all[0][3].strip().replace("发布于 ", ""))
if last_time self.last_blog_time):
self.need_send_articles.append({
"url":item[0],
"title":item[1],
"author":item[2],
"time":public_time
})
# 文章获取完毕,更新时间
self.last_blog_time = last_time
##### 测试输出
print(self.need_send_articles)
print("现在文章的最后时间为",self.last_blog_time)
##### 测试输出
时间字符串转换成时间戳
采用时间戳可以直接比较大小,非常便捷
def change_time(self,need_change_time):
'''
# 时间的转换
:param need_change_time:
:return:返回时间戳
'''
time_array = time.strptime(need_change_time, "%Y-%m-%d %H:%M")
time_stamp = int(time.mktime(time_array))
return time_stamp
邮件发送环节
本篇博客采用的是QQ邮箱发送
关于QQ邮箱发送的一些参考文章,我给你们列一下,方便你查阅
参考文章
# https://blog.csdn.net/qiye005/ ... 89666
# https://blog.csdn.net/Momorrin ... 81251
# https://www.cnblogs.com/lovealways/p/6701662.html
# https://www.cnblogs.com/yufeihlf/p/5726619.html
因为我采用的是QQ邮箱,所以有的地方设定上去比较麻烦,发短信还花了2分钱,建议你采用其它的邮箱,设置是一样的哦~~
发送短信send_email函数
你看一下里面的文章之后,就可以对短信发送进行相应的编撰了,非常简单
QQ邮箱是SSL认证的邮箱系统,因此用QQ邮箱发送短信,需要创建一个SMTP_SSL对象,而不是SMTP对象
# 发送邮件
def send_email(self,articles):
smtp = smtplib.SMTP_SSL() # 这个地方注意
smtp.connect("smtp.qq.com",465)
smtp.login("860866679@qq.com", "授权码")
sender = '860866679@qq.com'
receivers = ['找个自己的其他邮箱@163.com'] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱
# 完善发件人收件人,主题信息
message = MIMEMultipart()
message['From'] = formataddr(["博客采集器", sender])
message['To'] = formataddr(["hi,baby", ''.join(receivers)])
subject = '你有新采集到的文章清单'
message['Subject'] = Header(subject, 'utf-8')
# 正文部分
html = ""
for item in articles:
html+=("<p>{title}--文章作者{author}--发布时间{time}".format(title=item["title"],url=item["url"],author=item["author"],time=item["time"]))
textmessage = MIMEText('
新采集到的文章清单' +html,
'html', 'utf-8')
message.attach(textmessage)
# 发送邮件操作
smtp.sendmail(sender, receivers, message.as_string())
smtp.quit()
</p>
邮箱收到电邮
当收到短信的那一刻,你就可以感受到happy了~
部署到服务器
最后一个步骤,如果想要持续的获取,那么找一个服务器,然后布署就行啦,有兴趣的博友,继续研究下去吧~
下载 SEO商务营销王 的人还下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2020-08-10 16:23
软件功能概述及原理介绍
智能spider系统(采集)
只须要设置好采集目标站及采集规则,可以自动或定时手动采集目标站的内容,更可以同步目标站更新采集,采用蜘蛛内核模拟蜘蛛抓取网站内容而不会被屏蔽,强大的正则轻松采集你想要的一切信息,包括短信、QQ及手机号码等,不仅仅是想要的,还能过滤掉一切不想要的内容;
高度伪原创系统
如果您认为采集的文章不够原创,那我们强悍的伪原创系统可以解决这个问题,程序会按你的要求执行包括手动去头斩尾,自动在文章前和尾部加入原创文字、段落随机插入短语或图片、同意词替换、完整文章分多页及相同专题多页合并等独家技术,最大程度降低文章相似度,使搜索引擎判定为高权重的原创文章;
多任务定时手动采集发布系统(无人值守)
您可以按照须要自由设置采集的时间及发布文章的时间间隔,尽量科学的全手动管理您的网站,您只要定时的查看下发布的内容及软件输出提示,根据搜索引擎变化调整采集及发布的时间间隔;
强大的内链系统(SEO)
网站内部链接对于SEO乃重中之重,本系统可自由设置须要重点排行的关键字,并在发布的时侯手动生成专题页,并将文章中出现的... 查看全部
SEO商务营销王中英文网站全手动更新系统拥有CMS+SEO技术+ 中英文关键词分析+蜘蛛爬虫+网页智能信息抓取技术,目前支持织梦(DEDECMS)、帝国(EmpireCMS)、Wordpress、Z-blog、动易、5UCKS、discuz、phpwind等系统的数据手动导出并手动生成静态页,软件按照预设信息手动采集并发布,每天定时定量可定目标站手动维护更新内容,是站长流量获取的绝佳工具。
软件功能概述及原理介绍
智能spider系统(采集)
只须要设置好采集目标站及采集规则,可以自动或定时手动采集目标站的内容,更可以同步目标站更新采集,采用蜘蛛内核模拟蜘蛛抓取网站内容而不会被屏蔽,强大的正则轻松采集你想要的一切信息,包括短信、QQ及手机号码等,不仅仅是想要的,还能过滤掉一切不想要的内容;
高度伪原创系统
如果您认为采集的文章不够原创,那我们强悍的伪原创系统可以解决这个问题,程序会按你的要求执行包括手动去头斩尾,自动在文章前和尾部加入原创文字、段落随机插入短语或图片、同意词替换、完整文章分多页及相同专题多页合并等独家技术,最大程度降低文章相似度,使搜索引擎判定为高权重的原创文章;
多任务定时手动采集发布系统(无人值守)
您可以按照须要自由设置采集的时间及发布文章的时间间隔,尽量科学的全手动管理您的网站,您只要定时的查看下发布的内容及软件输出提示,根据搜索引擎变化调整采集及发布的时间间隔;
强大的内链系统(SEO)
网站内部链接对于SEO乃重中之重,本系统可自由设置须要重点排行的关键字,并在发布的时侯手动生成专题页,并将文章中出现的...
Nginx 访问统计 增加html静态网页显示 每晚定时更新
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2020-08-09 16:44
如果你希望这样简单的统计下自己小网站的访问量可以象我这样简单操作下:
1. 修改Nginx 导出日志
whereis nginx
cd /etc/nginx/
ls -l
sudo vim nginx.conf
修改nginx access_log 到指定目录
2. 写脚本 对日志进行统计并写入html,并清空日志
#!/bin/bash
cd /home/ubuntu/Blog
date1=`date +%F`
date2=`date +%r`
ips=`awk '{print $1"
"}' access.log|sort | uniq -c |sort -n -k 1 -r|head -n 10`
pv=`awk '{print $7}' access.log | wc -l`
ip=`awk '{print $1}' access.log | sort -n | uniq -c | wc -l`
html=`awk '{print $7"
"}' access.log|sort | uniq -c |grep -v '.jpg'|grep -v '.ico'|grep -v '.php'|grep -v '.do'|grep -v '400'|grep -v '.svg'|grep -v 'cgi-bin'|grep -v '.css'|grep -v '.js'|grep -v '.png'|grep -v '.jsp'|grep -v '.gif' |sort -n -k 1 -r | head -n 20`
echo "
--------${date1}--${date2}-------------
Pv is $pv
Ip is $ip
$ips ...
$html ...
----------
" >> count.html | sort -rn count.html | sed -i '31d' count.html | sort -r
:> access.log
:> error.log
3.脚本每晚晚上定时执行
crontab -e # 添加每天凌晨12:01 执行脚本
01 00 * * * /home/ubuntu/Blog/statistics.sh
4.如果有须要的话网页只能特定ip访问 查看全部
想统计自己网站的访问量,之前试过百度统计,在每位网页降低一些文件,百度会自己帮忙搜集统计。其实假如你自己网站就是用Nginx挂在服务器上的,他自己才会帮你统计,你只须要把他整理下就可以。我简单整理了下,可以看先疗效:
如果你希望这样简单的统计下自己小网站的访问量可以象我这样简单操作下:
1. 修改Nginx 导出日志
whereis nginx
cd /etc/nginx/
ls -l
sudo vim nginx.conf
修改nginx access_log 到指定目录
2. 写脚本 对日志进行统计并写入html,并清空日志
#!/bin/bash
cd /home/ubuntu/Blog
date1=`date +%F`
date2=`date +%r`
ips=`awk '{print $1"
"}' access.log|sort | uniq -c |sort -n -k 1 -r|head -n 10`
pv=`awk '{print $7}' access.log | wc -l`
ip=`awk '{print $1}' access.log | sort -n | uniq -c | wc -l`
html=`awk '{print $7"
"}' access.log|sort | uniq -c |grep -v '.jpg'|grep -v '.ico'|grep -v '.php'|grep -v '.do'|grep -v '400'|grep -v '.svg'|grep -v 'cgi-bin'|grep -v '.css'|grep -v '.js'|grep -v '.png'|grep -v '.jsp'|grep -v '.gif' |sort -n -k 1 -r | head -n 20`
echo "
--------${date1}--${date2}-------------
Pv is $pv
Ip is $ip
$ips ...
$html ...
----------
" >> count.html | sort -rn count.html | sed -i '31d' count.html | sort -r
:> access.log
:> error.log
3.脚本每晚晚上定时执行
crontab -e # 添加每天凌晨12:01 执行脚本
01 00 * * * /home/ubuntu/Blog/statistics.sh
4.如果有须要的话网页只能特定ip访问
Apache Camel 与 Spring Boot 集成
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2020-08-09 16:05
本项目主要是通过在Spring平台上配置Camel、FTP,实现定时从FTP服务器下载文件到本地、解析文件、存入数据库等功能。
2、搭建空项目:
Spring Boot有几种手动生成空项目的机制:CLI、Spring tool suite、网站Spring Initializr,我们选择第三个。
访问网站,如右图
在dependencies添加依赖包的时侯,在框中输入camle、jdbc、mysql会手动弹出提示,确认即为选中,如下图:
点击 generate project按键,生成项目,并将其导出到ecipse,在pom.xml中添加camel-ftp依赖,注意版本号选择与camel-spring-boot-stater的相同
org.apache.camel
camel-ftp
2.18.0
完整版的pom.xml文件如下:
org.apache.camel
camel-spring-boot-starter
2.18.0
org.apache.camel
camel-ftp
2.18.0
org.springframework.boot
spring-boot-starter-jdbc
mysql
mysql-connector-java
runtime
org.springframework.boot
spring-boot-starter-test
test
待所有依赖jar下载到本地,基础项目搭建完成3、配置Camel完成从ftp服务器定时下载文件到本地在application.properties中配置远程FTP服务器的地址、端口、用户名和密码等信息
ftp.server.info=sftp://172.16.20.133:22/../home/temp/data?username=root&password=root&delay=5s&move=done&readLock=rename
ftp.local.dir=file:C:/ftp/test
注意:sftp服务器的文件位置是相对于root登陆后的相对地址(被这儿坑到了),delay=5s是每隔5秒钟扫描ftp服务器上是否有新文件生成,如果有下载到本地,并将服务器上的文件转移到done文件夹(/home/temp/data/done),readLock=rename可以制止camel读取正在被写入的文件
配置路由,完成文件下载
@Component
public class DownloadRouteDemo extends RouteBuilder {
private static Logger logger = LoggerFactory.getLogger( DownloadRouteDemo.class );
@Value("${ftp.server.info}")
private String sftpServer;
@Value("${ftp.local.dir}")
private String downloadLocation;
@Override
public void configure() throws Exception {
from( sftpServer ).to( downloadLocation ).log(LoggingLevel.INFO, logger, "Downloaded file ${file:name} complete.");
}
}
注意:要承继camel的RouteBulider,重写configure方式,大意是从ftp服务器下载文件到本地,并输出文件名(运行时所需必要信息都配置在application.properties文件中)
为了使java进程在后台运行,需要在application.properties文件中降低如下配置
camel.springboot.main-run-controller=true
从ftp服务器下载文件的所有工作都已完成,运行CamelFtpSpringApplication.java,如果你的ftp服务器相应的位置上有文件,就会下载到本地所配置的文件夹下4、通过camel定时解析本地文件并保存到数据库在application.properties中降低如下配置
route.parserfile.info = {{ftp.local.dir}}?delay=10s&move=done&readLock=rename
route.parserfile.dir = {{ftp.local.dir}}/done
注意两个花括弧是引用其他变量的配置
编写解析文件、入库程序等处理器
@Component
public class LocationFileProcessor implements Processor {
private static Logger logger = LoggerFactory.getLogger( LocationFileProcessor.class );
@Value("${ftp.local.dir}")
private String fileDir;
@Autowired
OrderService orderService;//业务逻辑处理组件
@Override
public void process(Exchange exchange) throws Exception {
GenericFileMessage inFileMessage = (GenericFileMessage) exchange.getIn();
String fileName = inFileMessage.getGenericFile().getFileName();//文件名
String splitTag = File.separator;//系统文件分隔符
logger.info(fileDir + splitTag + fileName);//文件的绝对路径
orderService.process(fileDir + splitTag + fileName);//解析入库等操作
}
}
配置路由,完成业务逻辑的串联
@Component
public class LocalTransformRoute extends RouteBuilder {
private static Logger logger = LoggerFactory.getLogger( LocalTransformRoute.class );
@Value("${route.parserfile.info}")
private String location;
@Value("${route.parserfile.dir}")
private String locationDir;
@Autowired
LocationFileProcessor locationFileProcessor;
@Override
public void configure() throws Exception {
from( location ).process( locationFileProcessor ).to( locationDir ).log(LoggingLevel.INFO, logger, "tirans file ${file:name} complete.");
}
}
注意,比前面的路由多了process配置,即业务逻辑处理配置
至此,所有工作都已完成,重新执行CamelFtpSpringApplication.java即可实现ftp文件定时下载、业务处理等(其中省去了好多,例如入库操作等)备注:只是camle spring ftp的一个演示demo,要运用于生产,还有很多须要建立的地方
转载至:
转载于: 查看全部
1、概要:
本项目主要是通过在Spring平台上配置Camel、FTP,实现定时从FTP服务器下载文件到本地、解析文件、存入数据库等功能。
2、搭建空项目:
Spring Boot有几种手动生成空项目的机制:CLI、Spring tool suite、网站Spring Initializr,我们选择第三个。
访问网站,如右图
在dependencies添加依赖包的时侯,在框中输入camle、jdbc、mysql会手动弹出提示,确认即为选中,如下图:
点击 generate project按键,生成项目,并将其导出到ecipse,在pom.xml中添加camel-ftp依赖,注意版本号选择与camel-spring-boot-stater的相同
org.apache.camel
camel-ftp
2.18.0
完整版的pom.xml文件如下:
org.apache.camel
camel-spring-boot-starter
2.18.0
org.apache.camel
camel-ftp
2.18.0
org.springframework.boot
spring-boot-starter-jdbc
mysql
mysql-connector-java
runtime
org.springframework.boot
spring-boot-starter-test
test
待所有依赖jar下载到本地,基础项目搭建完成3、配置Camel完成从ftp服务器定时下载文件到本地在application.properties中配置远程FTP服务器的地址、端口、用户名和密码等信息
ftp.server.info=sftp://172.16.20.133:22/../home/temp/data?username=root&password=root&delay=5s&move=done&readLock=rename
ftp.local.dir=file:C:/ftp/test
注意:sftp服务器的文件位置是相对于root登陆后的相对地址(被这儿坑到了),delay=5s是每隔5秒钟扫描ftp服务器上是否有新文件生成,如果有下载到本地,并将服务器上的文件转移到done文件夹(/home/temp/data/done),readLock=rename可以制止camel读取正在被写入的文件
配置路由,完成文件下载
@Component
public class DownloadRouteDemo extends RouteBuilder {
private static Logger logger = LoggerFactory.getLogger( DownloadRouteDemo.class );
@Value("${ftp.server.info}")
private String sftpServer;
@Value("${ftp.local.dir}")
private String downloadLocation;
@Override
public void configure() throws Exception {
from( sftpServer ).to( downloadLocation ).log(LoggingLevel.INFO, logger, "Downloaded file ${file:name} complete.");
}
}
注意:要承继camel的RouteBulider,重写configure方式,大意是从ftp服务器下载文件到本地,并输出文件名(运行时所需必要信息都配置在application.properties文件中)
为了使java进程在后台运行,需要在application.properties文件中降低如下配置
camel.springboot.main-run-controller=true
从ftp服务器下载文件的所有工作都已完成,运行CamelFtpSpringApplication.java,如果你的ftp服务器相应的位置上有文件,就会下载到本地所配置的文件夹下4、通过camel定时解析本地文件并保存到数据库在application.properties中降低如下配置
route.parserfile.info = {{ftp.local.dir}}?delay=10s&move=done&readLock=rename
route.parserfile.dir = {{ftp.local.dir}}/done
注意两个花括弧是引用其他变量的配置
编写解析文件、入库程序等处理器
@Component
public class LocationFileProcessor implements Processor {
private static Logger logger = LoggerFactory.getLogger( LocationFileProcessor.class );
@Value("${ftp.local.dir}")
private String fileDir;
@Autowired
OrderService orderService;//业务逻辑处理组件
@Override
public void process(Exchange exchange) throws Exception {
GenericFileMessage inFileMessage = (GenericFileMessage) exchange.getIn();
String fileName = inFileMessage.getGenericFile().getFileName();//文件名
String splitTag = File.separator;//系统文件分隔符
logger.info(fileDir + splitTag + fileName);//文件的绝对路径
orderService.process(fileDir + splitTag + fileName);//解析入库等操作
}
}
配置路由,完成业务逻辑的串联
@Component
public class LocalTransformRoute extends RouteBuilder {
private static Logger logger = LoggerFactory.getLogger( LocalTransformRoute.class );
@Value("${route.parserfile.info}")
private String location;
@Value("${route.parserfile.dir}")
private String locationDir;
@Autowired
LocationFileProcessor locationFileProcessor;
@Override
public void configure() throws Exception {
from( location ).process( locationFileProcessor ).to( locationDir ).log(LoggingLevel.INFO, logger, "tirans file ${file:name} complete.");
}
}
注意,比前面的路由多了process配置,即业务逻辑处理配置
至此,所有工作都已完成,重新执行CamelFtpSpringApplication.java即可实现ftp文件定时下载、业务处理等(其中省去了好多,例如入库操作等)备注:只是camle spring ftp的一个演示demo,要运用于生产,还有很多须要建立的地方
转载至:
转载于:
Knative 驾驭篇:带你 '纵横驰骋' Knative
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-09 15:33
注:本文基于最新 Knative v0.11.0 版本代码剖析
KPA 实现流程图
在 Knative 中,创建一个 Revision 会相应的创建 PodAutoScaler 资源。在KPA中通过操作 PodAutoScaler 资源,对当前的 Revision 中的 POD 进行扩缩容。
针对里面的流程实现,我们从三横两纵的维度进行分析其实现机制。
三横KPA 控制器
通过Revision 创建PodAutoScaler, 在 KPA 控制器中主要包括两个资源(Decider 和 Metric)和一个操作(Scale)。主要代码如下
func (c *Reconciler) reconcile(ctx context.Context, pa *pav1alpha1.PodAutoscaler) error {
......
decider, err := c.reconcileDecider(ctx, pa, pa.Status.MetricsServiceName)
if err != nil {
return fmt.Errorf("error reconciling Decider: %w", err)
}
if err := c.ReconcileMetric(ctx, pa, pa.Status.MetricsServiceName); err != nil {
return fmt.Errorf("error reconciling Metric: %w", err)
}
// Metrics services are no longer needed as we use the private services now.
if err := c.DeleteMetricsServices(ctx, pa); err != nil {
return err
}
// Get the appropriate current scale from the metric, and right size
// the scaleTargetRef based on it.
want, err := c.scaler.Scale(ctx, pa, sks, decider.Status.DesiredScale)
if err != nil {
return fmt.Errorf("error scaling target: %w", err)
}
......
}
这里先介绍一下两个资源:
再看一下Scale操作,在Scale方式中,根据扩缩容POD数、最小实例数和最大实例数确定最终须要扩容的POD实例数,然后更改deployment的Replicas值,最终实现POD的扩缩容, 代码实现如下:
// Scale attempts to scale the given PA's target reference to the desired scale.
func (ks *scaler) Scale(ctx context.Context, pa *pav1alpha1.PodAutoscaler, sks *nv1a1.ServerlessService, desiredScale int32) (int32, error) {
......
min, max := pa.ScaleBounds()
if newScale := applyBounds(min, max, desiredScale); newScale != desiredScale {
logger.Debugf("Adjusting desiredScale to meet the min and max bounds before applying: %d -> %d", desiredScale, newScale)
desiredScale = newScale
}
desiredScale, shouldApplyScale := ks.handleScaleToZero(ctx, pa, sks, desiredScale)
if !shouldApplyScale {
return desiredScale, nil
}
ps, err := resources.GetScaleResource(pa.Namespace, pa.Spec.ScaleTargetRef, ks.psInformerFactory)
if err != nil {
return desiredScale, fmt.Errorf("failed to get scale target %v: %w", pa.Spec.ScaleTargetRef, err)
}
currentScale := int32(1)
if ps.Spec.Replicas != nil {
currentScale = *ps.Spec.Replicas
}
if desiredScale == currentScale {
return desiredScale, nil
}
logger.Infof("Scaling from %d to %d", currentScale, desiredScale)
return ks.applyScale(ctx, pa, desiredScale, ps)
}
根据指标定时估算 POD 数
这是一个关于Decider的故事。Decider创建以后会同时创建下来一个定时器,该定时器默认每隔 2 秒(可以通过TickInterval 参数配置)会调用Scale方式,该Scale方式实现如下:
func (a *Autoscaler) Scale(ctx context.Context, now time.Time) (desiredPodCount int32, excessBC int32, validScale bool) {
......
metricName := spec.ScalingMetric
var observedStableValue, observedPanicValue float64
switch spec.ScalingMetric {
case autoscaling.RPS:
observedStableValue, observedPanicValue, err = a.metricClient.StableAndPanicRPS(metricKey, now)
a.reporter.ReportStableRPS(observedStableValue)
a.reporter.ReportPanicRPS(observedPanicValue)
a.reporter.ReportTargetRPS(spec.TargetValue)
default:
metricName = autoscaling.Concurrency // concurrency is used by default
observedStableValue, observedPanicValue, err = a.metricClient.StableAndPanicConcurrency(metricKey, now)
a.reporter.ReportStableRequestConcurrency(observedStableValue)
a.reporter.ReportPanicRequestConcurrency(observedPanicValue)
a.reporter.ReportTargetRequestConcurrency(spec.TargetValue)
}
// Put the scaling metric to logs.
logger = logger.With(zap.String("metric", metricName))
if err != nil {
if err == ErrNoData {
logger.Debug("No data to scale on yet")
} else {
logger.Errorw("Failed to obtain metrics", zap.Error(err))
}
return 0, 0, false
}
// Make sure we don't get stuck with the same number of pods, if the scale up rate
// is too conservative and MaxScaleUp*RPC==RPC, so this permits us to grow at least by a single
// pod if we need to scale up.
// E.g. MSUR=1.1, OCC=3, RPC=2, TV=1 => OCC/TV=3, MSU=2.2 => DSPC=2, while we definitely, need
// 3 pods. See the unit test for this scenario in action.
maxScaleUp := math.Ceil(spec.MaxScaleUpRate * readyPodsCount)
// Same logic, opposite math applies here.
maxScaleDown := math.Floor(readyPodsCount / spec.MaxScaleDownRate)
dspc := math.Ceil(observedStableValue / spec.TargetValue)
dppc := math.Ceil(observedPanicValue / spec.TargetValue)
logger.Debugf("DesiredStablePodCount = %0.3f, DesiredPanicPodCount = %0.3f, MaxScaleUp = %0.3f, MaxScaleDown = %0.3f",
dspc, dppc, maxScaleUp, maxScaleDown)
// We want to keep desired pod count in the [maxScaleDown, maxScaleUp] range.
desiredStablePodCount := int32(math.Min(math.Max(dspc, maxScaleDown), maxScaleUp))
desiredPanicPodCount := int32(math.Min(math.Max(dppc, maxScaleDown), maxScaleUp))
......
return desiredPodCount, excessBC, true
}
该方式主要是从 MetricCollector 中获取指标信息,根据指标信息估算出须要扩缩的POD数。然后设置在 Decider 中。另外当 Decider 中 POD 期望值发生变化时会触发 PodAutoscaler 重新调和的操作,关键代码如下:
......
if runner.updateLatestScale(desiredScale, excessBC) {
m.Inform(metricKey)
}
......
在KPA controller中设置调和Watch操作:
......
// Have the Deciders enqueue the PAs whose decisions have changed.
deciders.Watch(impl.EnqueueKey)
......
指标采集
通过两种方法搜集POD指标:
PUSH 采集指标实现比较简单,在main.go中 暴露服务,将接收到的 metric 推送到 MetricCollector 中:
// Set up a statserver.
statsServer := statserver.New(statsServerAddr, statsCh, logger)
....
go func() {
for sm := range statsCh {
collector.Record(sm.Key, sm.Stat)
multiScaler.Poke(sm.Key, sm.Stat)
}
}()
PULL 采集指标是怎样搜集的呢? 还记得前面提及的Metric资源吧,这里接收到Metric资源又会创建出一个定时器,这个定时器每隔 1 秒会访问 queue-proxy 9090 端口采集指标信息。关键代码如下:
<p>// newCollection creates a new collection, which uses the given scraper to
// collect stats every scrapeTickInterval.
func newCollection(metric *av1alpha1.Metric, scraper StatsScraper, logger *zap.SugaredLogger) *collection {
c := &collection{
metric: metric,
concurrencyBuckets: aggregation.NewTimedFloat64Buckets(BucketSize),
rpsBuckets: aggregation.NewTimedFloat64Buckets(BucketSize),
scraper: scraper,
stopCh: make(chan struct{}),
}
logger = logger.Named("collector").With(
zap.String(logkey.Key, fmt.Sprintf("%s/%s", metric.Namespace, metric.Name)))
c.grp.Add(1)
go func() {
defer c.grp.Done()
scrapeTicker := time.NewTicker(scrapeTickInterval)
for {
select {
case 查看全部
Knative 中提供了手动扩缩容灵活的实现机制,本文从 三横两纵 的维度带你深入了解 KPA 自动扩缩容的实现机制。让你轻松驾驭 Knative 自动扩缩容。
注:本文基于最新 Knative v0.11.0 版本代码剖析
KPA 实现流程图
在 Knative 中,创建一个 Revision 会相应的创建 PodAutoScaler 资源。在KPA中通过操作 PodAutoScaler 资源,对当前的 Revision 中的 POD 进行扩缩容。
针对里面的流程实现,我们从三横两纵的维度进行分析其实现机制。
三横KPA 控制器
通过Revision 创建PodAutoScaler, 在 KPA 控制器中主要包括两个资源(Decider 和 Metric)和一个操作(Scale)。主要代码如下
func (c *Reconciler) reconcile(ctx context.Context, pa *pav1alpha1.PodAutoscaler) error {
......
decider, err := c.reconcileDecider(ctx, pa, pa.Status.MetricsServiceName)
if err != nil {
return fmt.Errorf("error reconciling Decider: %w", err)
}
if err := c.ReconcileMetric(ctx, pa, pa.Status.MetricsServiceName); err != nil {
return fmt.Errorf("error reconciling Metric: %w", err)
}
// Metrics services are no longer needed as we use the private services now.
if err := c.DeleteMetricsServices(ctx, pa); err != nil {
return err
}
// Get the appropriate current scale from the metric, and right size
// the scaleTargetRef based on it.
want, err := c.scaler.Scale(ctx, pa, sks, decider.Status.DesiredScale)
if err != nil {
return fmt.Errorf("error scaling target: %w", err)
}
......
}
这里先介绍一下两个资源:
再看一下Scale操作,在Scale方式中,根据扩缩容POD数、最小实例数和最大实例数确定最终须要扩容的POD实例数,然后更改deployment的Replicas值,最终实现POD的扩缩容, 代码实现如下:
// Scale attempts to scale the given PA's target reference to the desired scale.
func (ks *scaler) Scale(ctx context.Context, pa *pav1alpha1.PodAutoscaler, sks *nv1a1.ServerlessService, desiredScale int32) (int32, error) {
......
min, max := pa.ScaleBounds()
if newScale := applyBounds(min, max, desiredScale); newScale != desiredScale {
logger.Debugf("Adjusting desiredScale to meet the min and max bounds before applying: %d -> %d", desiredScale, newScale)
desiredScale = newScale
}
desiredScale, shouldApplyScale := ks.handleScaleToZero(ctx, pa, sks, desiredScale)
if !shouldApplyScale {
return desiredScale, nil
}
ps, err := resources.GetScaleResource(pa.Namespace, pa.Spec.ScaleTargetRef, ks.psInformerFactory)
if err != nil {
return desiredScale, fmt.Errorf("failed to get scale target %v: %w", pa.Spec.ScaleTargetRef, err)
}
currentScale := int32(1)
if ps.Spec.Replicas != nil {
currentScale = *ps.Spec.Replicas
}
if desiredScale == currentScale {
return desiredScale, nil
}
logger.Infof("Scaling from %d to %d", currentScale, desiredScale)
return ks.applyScale(ctx, pa, desiredScale, ps)
}
根据指标定时估算 POD 数
这是一个关于Decider的故事。Decider创建以后会同时创建下来一个定时器,该定时器默认每隔 2 秒(可以通过TickInterval 参数配置)会调用Scale方式,该Scale方式实现如下:
func (a *Autoscaler) Scale(ctx context.Context, now time.Time) (desiredPodCount int32, excessBC int32, validScale bool) {
......
metricName := spec.ScalingMetric
var observedStableValue, observedPanicValue float64
switch spec.ScalingMetric {
case autoscaling.RPS:
observedStableValue, observedPanicValue, err = a.metricClient.StableAndPanicRPS(metricKey, now)
a.reporter.ReportStableRPS(observedStableValue)
a.reporter.ReportPanicRPS(observedPanicValue)
a.reporter.ReportTargetRPS(spec.TargetValue)
default:
metricName = autoscaling.Concurrency // concurrency is used by default
observedStableValue, observedPanicValue, err = a.metricClient.StableAndPanicConcurrency(metricKey, now)
a.reporter.ReportStableRequestConcurrency(observedStableValue)
a.reporter.ReportPanicRequestConcurrency(observedPanicValue)
a.reporter.ReportTargetRequestConcurrency(spec.TargetValue)
}
// Put the scaling metric to logs.
logger = logger.With(zap.String("metric", metricName))
if err != nil {
if err == ErrNoData {
logger.Debug("No data to scale on yet")
} else {
logger.Errorw("Failed to obtain metrics", zap.Error(err))
}
return 0, 0, false
}
// Make sure we don't get stuck with the same number of pods, if the scale up rate
// is too conservative and MaxScaleUp*RPC==RPC, so this permits us to grow at least by a single
// pod if we need to scale up.
// E.g. MSUR=1.1, OCC=3, RPC=2, TV=1 => OCC/TV=3, MSU=2.2 => DSPC=2, while we definitely, need
// 3 pods. See the unit test for this scenario in action.
maxScaleUp := math.Ceil(spec.MaxScaleUpRate * readyPodsCount)
// Same logic, opposite math applies here.
maxScaleDown := math.Floor(readyPodsCount / spec.MaxScaleDownRate)
dspc := math.Ceil(observedStableValue / spec.TargetValue)
dppc := math.Ceil(observedPanicValue / spec.TargetValue)
logger.Debugf("DesiredStablePodCount = %0.3f, DesiredPanicPodCount = %0.3f, MaxScaleUp = %0.3f, MaxScaleDown = %0.3f",
dspc, dppc, maxScaleUp, maxScaleDown)
// We want to keep desired pod count in the [maxScaleDown, maxScaleUp] range.
desiredStablePodCount := int32(math.Min(math.Max(dspc, maxScaleDown), maxScaleUp))
desiredPanicPodCount := int32(math.Min(math.Max(dppc, maxScaleDown), maxScaleUp))
......
return desiredPodCount, excessBC, true
}
该方式主要是从 MetricCollector 中获取指标信息,根据指标信息估算出须要扩缩的POD数。然后设置在 Decider 中。另外当 Decider 中 POD 期望值发生变化时会触发 PodAutoscaler 重新调和的操作,关键代码如下:
......
if runner.updateLatestScale(desiredScale, excessBC) {
m.Inform(metricKey)
}
......
在KPA controller中设置调和Watch操作:
......
// Have the Deciders enqueue the PAs whose decisions have changed.
deciders.Watch(impl.EnqueueKey)
......
指标采集
通过两种方法搜集POD指标:
PUSH 采集指标实现比较简单,在main.go中 暴露服务,将接收到的 metric 推送到 MetricCollector 中:
// Set up a statserver.
statsServer := statserver.New(statsServerAddr, statsCh, logger)
....
go func() {
for sm := range statsCh {
collector.Record(sm.Key, sm.Stat)
multiScaler.Poke(sm.Key, sm.Stat)
}
}()
PULL 采集指标是怎样搜集的呢? 还记得前面提及的Metric资源吧,这里接收到Metric资源又会创建出一个定时器,这个定时器每隔 1 秒会访问 queue-proxy 9090 端口采集指标信息。关键代码如下:
<p>// newCollection creates a new collection, which uses the given scraper to
// collect stats every scrapeTickInterval.
func newCollection(metric *av1alpha1.Metric, scraper StatsScraper, logger *zap.SugaredLogger) *collection {
c := &collection{
metric: metric,
concurrencyBuckets: aggregation.NewTimedFloat64Buckets(BucketSize),
rpsBuckets: aggregation.NewTimedFloat64Buckets(BucketSize),
scraper: scraper,
stopCh: make(chan struct{}),
}
logger = logger.Named("collector").With(
zap.String(logkey.Key, fmt.Sprintf("%s/%s", metric.Namespace, metric.Name)))
c.grp.Add(1)
go func() {
defer c.grp.Done()
scrapeTicker := time.NewTicker(scrapeTickInterval)
for {
select {
case
定期自动发布文章并更新网站静态文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2020-08-09 05:00
5. 支持文章的随机审阅,支持按列,编号和多种类别审阅文章.
程序原理:
一次采集并发布许多采集网站操作,并且一次生成静态文件. 这样的发布大部分是垃圾站,并且使用搜索引擎更困难. 一些担任站长的朋友也将在更新强度上遇到一些困难,因此“预发布”的概念应运而生.
WordPress的“预发行”“预发行”了文章的发布时间. 例如,现在是“ 2009年1月”,并且文章的发布日期被手动设置为“ 2010年10月”. 然后,这些文章要到2010年10月才会显示在前台. 但是,由于WordPress是动态数据程序,因此它不适用于收录大量数据的静态网站.
因此,我开发了一个基于DEDE和Ecms的“预发布”程序,但是该程序不需要为该程序设置发布时间. 所有这些都留给计算机和您网站的访问者.
程序的原理非常简单. 发布文章时,我们将文章设置为未审阅状态,因此不会在前台看到该文章. 我们编写了一个自动审阅程序来审阅这些不可见的文章. 当某人或搜索引擎访问您的网站时,它将触发审核过程. 在此期间,网站上的一些随机文章被设置为“已审阅”状态. 这些文章可以在前台看到. ,让我们为主页和列表页面生成静态文件,并实现了模仿手册的发布过程.
简而言之,只要您的网站有内容和访问者,您的网站就会是一个不断更新的静态网站! ! 查看全部
4,支持生成列列表页面.
5. 支持文章的随机审阅,支持按列,编号和多种类别审阅文章.
程序原理:
一次采集并发布许多采集网站操作,并且一次生成静态文件. 这样的发布大部分是垃圾站,并且使用搜索引擎更困难. 一些担任站长的朋友也将在更新强度上遇到一些困难,因此“预发布”的概念应运而生.
WordPress的“预发行”“预发行”了文章的发布时间. 例如,现在是“ 2009年1月”,并且文章的发布日期被手动设置为“ 2010年10月”. 然后,这些文章要到2010年10月才会显示在前台. 但是,由于WordPress是动态数据程序,因此它不适用于收录大量数据的静态网站.
因此,我开发了一个基于DEDE和Ecms的“预发布”程序,但是该程序不需要为该程序设置发布时间. 所有这些都留给计算机和您网站的访问者.
程序的原理非常简单. 发布文章时,我们将文章设置为未审阅状态,因此不会在前台看到该文章. 我们编写了一个自动审阅程序来审阅这些不可见的文章. 当某人或搜索引擎访问您的网站时,它将触发审核过程. 在此期间,网站上的一些随机文章被设置为“已审阅”状态. 这些文章可以在前台看到. ,让我们为主页和列表页面生成静态文件,并实现了模仿手册的发布过程.
简而言之,只要您的网站有内容和访问者,您的网站就会是一个不断更新的静态网站! !
DEDECMS如何实施文章的定期发布
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-09 04:47
DEDECMS定期发布文章说明
登录到后台,选择[核心] [定时审核管理],然后输入计划审核的时间段.
1. 可以设置几个时间段. 在这些时间段内,每天将自动检查并生成指定数量的未审阅文章,并且每个时间段每天只会更新一次.
2. 自动更新网站的主页和需要更新的列页面. 需要更新的列页面是随新文章生成的列. 没有新文章的列不会更新,从而提高了更新的性能.
3. 您可以根据列或总数更新文章. 根据列更新文章,并在每列中更新指定数目的文章. 文章将根据总数进行更新,指定数目的文章将根据ID从小到大进行更新.
4. 文章按照文章ID从小到大的顺序更新,并且首先添加的文章先更新.
5. 文章的发布时间为审阅时间. 示例说明: 在上图中总共输入三个更新时间段,分别是3:00到5: 00、7: 00到9:00和14:00到16:00. 系统将在这三个期间内审阅指定数量的未审阅文章. 每个时间段每天只有一次.
例如: 在这段时间内,只要用户访问主页,从3点到5点,3点,4点(不包括5点)的时间段网站的每一栏将审阅并产生2篇文章,而发表时间则成为当时的审阅时间. 注意: 如果在此期间没有用户访问该网站的首页,则不会对其进行审核.
从14:00到16:00,如果用户访问网站的首页,则会更新10篇文章. 除了根据专栏内容进行更新外,还将根据文章ID从小到大更新10篇文章. 查看全部
DEDECMS本身不具有定期发布文章的功能. 如果要定期发布文章,则需要安装常规发布插件------常规审阅插件. 插件下载地址: 密码: o5v1
DEDECMS定期发布文章说明
登录到后台,选择[核心] [定时审核管理],然后输入计划审核的时间段.
1. 可以设置几个时间段. 在这些时间段内,每天将自动检查并生成指定数量的未审阅文章,并且每个时间段每天只会更新一次.
2. 自动更新网站的主页和需要更新的列页面. 需要更新的列页面是随新文章生成的列. 没有新文章的列不会更新,从而提高了更新的性能.
3. 您可以根据列或总数更新文章. 根据列更新文章,并在每列中更新指定数目的文章. 文章将根据总数进行更新,指定数目的文章将根据ID从小到大进行更新.
4. 文章按照文章ID从小到大的顺序更新,并且首先添加的文章先更新.
5. 文章的发布时间为审阅时间. 示例说明: 在上图中总共输入三个更新时间段,分别是3:00到5: 00、7: 00到9:00和14:00到16:00. 系统将在这三个期间内审阅指定数量的未审阅文章. 每个时间段每天只有一次.
例如: 在这段时间内,只要用户访问主页,从3点到5点,3点,4点(不包括5点)的时间段网站的每一栏将审阅并产生2篇文章,而发表时间则成为当时的审阅时间. 注意: 如果在此期间没有用户访问该网站的首页,则不会对其进行审核.
从14:00到16:00,如果用户访问网站的首页,则会更新10篇文章. 除了根据专栏内容进行更新外,还将根据文章ID从小到大更新10篇文章.
使用Python抓取来获取博客文章,并定期将其发送到邮箱中
采集交流 • 优采云 发表了文章 • 0 个评论 • 338 次浏览 • 2020-08-08 21:42
关于获取文章并自动将其发送到邮箱,这种需求实际上可以编写多个网站,完成博客园,获取CSDN,获取黄金,获取其他内容,等等.
从博客园开始,了解基本要求,在python部分获得新文章,并每60分钟发送一次. 时间太短了,我想没有太多新博客了〜
这是抓取的页面
https://www.cnblogs.com/cate/python
您需要整理指定页面上的所有文章,记录文章的相关信息,并记录上一篇文章的时间. 将文章发送到指定的邮箱,更新上一篇文章的时间. 检查需要导入的模块列表.
import requests
import time
import re
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
from email.header import Header
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
初始化基本数据
# 初始化数据
def __init__(self):
self.start_url = "https://www.cnblogs.com/cate/python"
self.headers = {
"user-agent": "Mozilla/..... Safari/537.36",
"referer": "https://www.cnblogs.com/cate/python/"
}
self.pattern = r'[\s\S.]*?(.*?)[\s\S.]*?[\s\S.]*?(.*?)([\s\S.]*?)'
self.last_blog_time = 0
self.need_send_articles = []
参数说明
分析博客页面的内容
涉及很多代码,我将在关键点上写上相应的注释
# 解析网页内容
def get_articles(self):
try:
# 正常的数据获取
res = requests.get(self.start_url,headers=self.headers,timeout=3)
except Exception as e:
print("error %s"% e)
time.sleep(3)
return self.get_articles() # 重新发起请求
html = res.text
# 这个地方的正则表达式是考验你正则功底的地方了
all = re.findall(self.pattern,html)
# 判断,如果没有新文章
last_time = self.change_time(all[0][3].strip().replace("发布于 ", ""))
if last_time self.last_blog_time):
self.need_send_articles.append({
"url":item[0],
"title":item[1],
"author":item[2],
"time":public_time
})
# 文章获取完毕,更新时间
self.last_blog_time = last_time
##### 测试输出
print(self.need_send_articles)
print("现在文章的最后时间为",self.last_blog_time)
##### 测试输出
将时间字符串转换为时间戳
使用时间戳直接比较大小,这非常方便
def change_time(self,need_change_time):
'''
# 时间的转换
:param need_change_time:
:return:返回时间戳
'''
time_array = time.strptime(need_change_time, "%Y-%m-%d %H:%M")
time_stamp = int(time.mktime(time_array))
return time_stamp
邮件发送链接
此博客是通过QQ邮箱发送的
为方便起见,我将列出QQ邮箱发送的一些参考文章
参考文章
# https://blog.csdn.net/qiye005/ ... 89666
# https://blog.csdn.net/Momorrin ... 81251
# https://www.cnblogs.com/lovealways/p/6701662.html
# https://www.cnblogs.com/yufeihlf/p/5726619.html
由于我使用的是QQ邮箱,因此在某些地方进行设置比较麻烦,发送短信的费用为2美分. 我建议您使用其他邮箱,设置相同~~
发送邮件send_email功能
阅读以上文章后,您可以撰写相应的电子邮件,非常简单
QQ邮箱是经过SSL认证的邮箱系统,因此要使用QQ邮箱发送邮件,您需要创建一个SMTP_SSL对象而不是SMTP对象
# 发送邮件
def send_email(self,articles):
smtp = smtplib.SMTP_SSL() # 这个地方注意
smtp.connect("smtp.qq.com",465)
smtp.login("860866679@qq.com", "授权码")
sender = '860866679@qq.com'
receivers = ['找个自己的其他邮箱@163.com'] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱
# 完善发件人收件人,主题信息
message = MIMEMultipart()
message['From'] = formataddr(["博客采集器", sender])
message['To'] = formataddr(["hi,baby", ''.join(receivers)])
subject = '你有新采集到的文章清单'
message['Subject'] = Header(subject, 'utf-8')
# 正文部分
html = ""
for item in articles:
html+=("<p><a href='{url}'>{title}</a>--文章作者{author}--发布时间{time}".format(title=item["title"],url=item["url"],author=item["author"],time=item["time"]))
textmessage = MIMEText('
新采集到的文章清单' +html,
'html', 'utf-8')
message.attach(textmessage)
# 发送邮件操作
smtp.sendmail(sender, receivers, message.as_string())
smtp.quit()</p>
邮箱收到的邮件
收到电子邮件后,您会感到高兴〜
部署到服务器
最后一步,如果要连续获取它,请找到服务器,然后进行部署. 感兴趣的博客作者,请继续学习〜
查看全部
写在前面
关于获取文章并自动将其发送到邮箱,这种需求实际上可以编写多个网站,完成博客园,获取CSDN,获取黄金,获取其他内容,等等.
从博客园开始,了解基本要求,在python部分获得新文章,并每60分钟发送一次. 时间太短了,我想没有太多新博客了〜
这是抓取的页面
https://www.cnblogs.com/cate/python
您需要整理指定页面上的所有文章,记录文章的相关信息,并记录上一篇文章的时间. 将文章发送到指定的邮箱,更新上一篇文章的时间. 检查需要导入的模块列表.
import requests
import time
import re
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
from email.header import Header
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
初始化基本数据
# 初始化数据
def __init__(self):
self.start_url = "https://www.cnblogs.com/cate/python"
self.headers = {
"user-agent": "Mozilla/..... Safari/537.36",
"referer": "https://www.cnblogs.com/cate/python/"
}
self.pattern = r'[\s\S.]*?(.*?)[\s\S.]*?[\s\S.]*?(.*?)([\s\S.]*?)'
self.last_blog_time = 0
self.need_send_articles = []
参数说明
分析博客页面的内容
涉及很多代码,我将在关键点上写上相应的注释
# 解析网页内容
def get_articles(self):
try:
# 正常的数据获取
res = requests.get(self.start_url,headers=self.headers,timeout=3)
except Exception as e:
print("error %s"% e)
time.sleep(3)
return self.get_articles() # 重新发起请求
html = res.text
# 这个地方的正则表达式是考验你正则功底的地方了
all = re.findall(self.pattern,html)
# 判断,如果没有新文章
last_time = self.change_time(all[0][3].strip().replace("发布于 ", ""))
if last_time self.last_blog_time):
self.need_send_articles.append({
"url":item[0],
"title":item[1],
"author":item[2],
"time":public_time
})
# 文章获取完毕,更新时间
self.last_blog_time = last_time
##### 测试输出
print(self.need_send_articles)
print("现在文章的最后时间为",self.last_blog_time)
##### 测试输出
将时间字符串转换为时间戳
使用时间戳直接比较大小,这非常方便
def change_time(self,need_change_time):
'''
# 时间的转换
:param need_change_time:
:return:返回时间戳
'''
time_array = time.strptime(need_change_time, "%Y-%m-%d %H:%M")
time_stamp = int(time.mktime(time_array))
return time_stamp
邮件发送链接
此博客是通过QQ邮箱发送的
为方便起见,我将列出QQ邮箱发送的一些参考文章
参考文章
# https://blog.csdn.net/qiye005/ ... 89666
# https://blog.csdn.net/Momorrin ... 81251
# https://www.cnblogs.com/lovealways/p/6701662.html
# https://www.cnblogs.com/yufeihlf/p/5726619.html
由于我使用的是QQ邮箱,因此在某些地方进行设置比较麻烦,发送短信的费用为2美分. 我建议您使用其他邮箱,设置相同~~
发送邮件send_email功能
阅读以上文章后,您可以撰写相应的电子邮件,非常简单
QQ邮箱是经过SSL认证的邮箱系统,因此要使用QQ邮箱发送邮件,您需要创建一个SMTP_SSL对象而不是SMTP对象
# 发送邮件
def send_email(self,articles):
smtp = smtplib.SMTP_SSL() # 这个地方注意
smtp.connect("smtp.qq.com",465)
smtp.login("860866679@qq.com", "授权码")
sender = '860866679@qq.com'
receivers = ['找个自己的其他邮箱@163.com'] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱
# 完善发件人收件人,主题信息
message = MIMEMultipart()
message['From'] = formataddr(["博客采集器", sender])
message['To'] = formataddr(["hi,baby", ''.join(receivers)])
subject = '你有新采集到的文章清单'
message['Subject'] = Header(subject, 'utf-8')
# 正文部分
html = ""
for item in articles:
html+=("<p><a href='{url}'>{title}</a>--文章作者{author}--发布时间{time}".format(title=item["title"],url=item["url"],author=item["author"],time=item["time"]))
textmessage = MIMEText('
新采集到的文章清单' +html,
'html', 'utf-8')
message.attach(textmessage)
# 发送邮件操作
smtp.sendmail(sender, receivers, message.as_string())
smtp.quit()</p>
邮箱收到的邮件
收到电子邮件后,您会感到高兴〜
部署到服务器
最后一步,如果要连续获取它,请找到服务器,然后进行部署. 感兴趣的博客作者,请继续学习〜
Linux crontab mysql计划自动备份
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2020-08-08 18:56
1. 自动备份整个mysql数据库,一周前自动删除备份,数据有效期为一周.
2. 自动备份网站数据,三个月前自动删除备份,数据有效期三个月;在每月的1号对目录进行完整备份,并在其余时间进行增量备份.
3. 对备份数据执行权限控制,以防止恶意人员查看和修改. 如果以root权限执行脚本,则其他用户无权备份数据.
#!/bin/bash
#
#lampp mysql databases and web data backup bash;
#mysql backup data keep 7 days;
#website backup data keep 3 months and incremental backup in per month.
#author:LinuxPad
#website:www.linuxpad.cn
#mail:linuxpad.cn(at)gmail.com
#created:26 November 2012
#Mysql dabase information
db_host="localhost"
db_user="root"
db_passwd=""
MYSQL="/opt/lampp/bin/mysql"
MYSQLDUMP="/opt/lampp/bin/mysqldump"
#Path information
WEBHOME="/opt/lampp/htdocs/blog"
BACKUP_DB="/opt/backup/database"
BACKUP_WEB="/opt/backup/web"
#Time information
time=`date +"%Y-%m-%d"`
day=`date +"%d"`
month=`date +"%Y-%m"`
weekday=`date +"%u"`
#Path enable write
if [ ! -w "$BACKUP_DB" ] && [ ! -w "$BACKUP_WEB"]; then
chmod -R 700 $BACKUP_DB $BACKUP_WEB
fi
#Mysql Backup
$MYSQLDUMP -u $db_user -p$db_passwd -h $db_host --all-databases > $BACKUP_DB/$time
cd $BACKUP_DB && tar -czf $time.tar.gz $time && rm -rf $time && chmod go-rwx $time.tar.gz
if [ $weekday == "1" ]; then
find $BACKUP_DB -mtime +7 | xargs rm -rf {}
fi
#Website Backup
if [ ! -d $BACKUP_WEB/$month ];then
mkdir $BACKUP_WEB/$month
touch $BACKUP_WEB/$month/$month
chmod -R go-rwx $BACKUP_WEB/$month
fi
cd $BACKUP_WEB/$month && tar -g $month -czf $time.tar.gz $WEBHOME && chmod go-rwx $time.tar.gz
if [ $day == "01" ]; then
find $BACKUP_WEB -mtime +90 | xargs rm -rf{}
fi
使用脚本之前,您需要在/ opt中创建目录
mkdir -p /opt/backup/{database,web}
chmod -R go-wrx /opt/backup
添加计划任务
假设脚本位置为/root/cron/backup.sh,则每天2点执行备份 查看全部
脚本功能:
1. 自动备份整个mysql数据库,一周前自动删除备份,数据有效期为一周.
2. 自动备份网站数据,三个月前自动删除备份,数据有效期三个月;在每月的1号对目录进行完整备份,并在其余时间进行增量备份.
3. 对备份数据执行权限控制,以防止恶意人员查看和修改. 如果以root权限执行脚本,则其他用户无权备份数据.
#!/bin/bash
#
#lampp mysql databases and web data backup bash;
#mysql backup data keep 7 days;
#website backup data keep 3 months and incremental backup in per month.
#author:LinuxPad
#website:www.linuxpad.cn
#mail:linuxpad.cn(at)gmail.com
#created:26 November 2012
#Mysql dabase information
db_host="localhost"
db_user="root"
db_passwd=""
MYSQL="/opt/lampp/bin/mysql"
MYSQLDUMP="/opt/lampp/bin/mysqldump"
#Path information
WEBHOME="/opt/lampp/htdocs/blog"
BACKUP_DB="/opt/backup/database"
BACKUP_WEB="/opt/backup/web"
#Time information
time=`date +"%Y-%m-%d"`
day=`date +"%d"`
month=`date +"%Y-%m"`
weekday=`date +"%u"`
#Path enable write
if [ ! -w "$BACKUP_DB" ] && [ ! -w "$BACKUP_WEB"]; then
chmod -R 700 $BACKUP_DB $BACKUP_WEB
fi
#Mysql Backup
$MYSQLDUMP -u $db_user -p$db_passwd -h $db_host --all-databases > $BACKUP_DB/$time
cd $BACKUP_DB && tar -czf $time.tar.gz $time && rm -rf $time && chmod go-rwx $time.tar.gz
if [ $weekday == "1" ]; then
find $BACKUP_DB -mtime +7 | xargs rm -rf {}
fi
#Website Backup
if [ ! -d $BACKUP_WEB/$month ];then
mkdir $BACKUP_WEB/$month
touch $BACKUP_WEB/$month/$month
chmod -R go-rwx $BACKUP_WEB/$month
fi
cd $BACKUP_WEB/$month && tar -g $month -czf $time.tar.gz $WEBHOME && chmod go-rwx $time.tar.gz
if [ $day == "01" ]; then
find $BACKUP_WEB -mtime +90 | xargs rm -rf{}
fi
使用脚本之前,您需要在/ opt中创建目录
mkdir -p /opt/backup/{database,web}
chmod -R go-wrx /opt/backup
添加计划任务
假设脚本位置为/root/cron/backup.sh,则每天2点执行备份
如何定期将内容上传到多个平台?
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-08 09:31
互联网媒体的发展非常迅速. 特别是从2017年至今,视频一直受到人们的关注,其品牌形象清晰,回报迅速. 它吸引了无数需要帮助的人. 为了赢得更高的阅读指数,作者通常涵盖所有平台. 但是,当您开始使用更多帐户时,您会逐渐了解: 您上班时必须每天重复登录帐户,然后发布要逐一发布的内容. 这真的是在浪费时间. 我有以下免费的经验. 与您分享.
视频制作和视频编辑知道,没有足够的应用程序来裁剪不同品牌的视频软件,但是并不是每个小软件都具有高度的兼容性. 为此,我们对一个相对偏爱的人进行了全面的构架. 以下,专家可以一个接一个地测试: 视频编辑王如何定期将内容上传到多个平台?
设置YiMedia Assistant媒体帐户的基本功能必须通过使用一个帐户来实现,因此,如果您与这种类型的联系人联系,请在左上角添加一个帐户,选择需要添加的平台. 软件,建议使用帐户和密码登录,并尝试不要使用从媒体号登录的方式.
[9个主要功能]
1.40+平台支持: 支持40多个主流新媒体平台,新平台将继续对接
2.1000+帐户管理: 轻松支持1000+帐户管理,新的低级优化设计,自动存储帐户秘密,自动登录,无论您不怕挑战多少个帐户
3. 热点文章系统: 实时采集热点文章和视频,使您可以轻松创建实时热点,创建局部100,000 +
4. AI智能重写: 轻松重写采集集,让您进行促销,关键字覆盖,软文等功能更加强大
5. 一键分发: 一键轻松将文章,视频,小型视频和微动态分发到30多个主流平台上
如何定期将内容上传到多个平台?如何定期将内容上传到多个平台?
6. 团队管理: 支持创建子账户,实现屏蔽收入,账户密码和员工操作统计等功能
7. 独创性检测: 基于3个主要搜索引擎,一键式检测文章独创性,强大的重复检查和审阅工具
8. 微信: 支持微信一键发布到: 微头条,百家新闻,微博等平台
9. 数据概述: 一键式查看所有平台的收入,播放,阅读和其他数据
设置帐户并进入EasyMedia Assistant界面,找到“添加帐户”按钮,在界面上选择所需的平台,然后使用该帐户和密码方法登录,以便将来EasyMedia将自动填写该帐户和密码,无需再次输入.
添加帐户已安装EasyMedia Assistant,在左上角添加帐户,要添加的自媒体平台,使用帐户和密码方法很容易登录. 将来,该软件将自动输入帐户和密码,而无需手动输入.
Data认为,所有内容运营部门的同事都了解,热文本关键字的分析和优化特别重要. 如果您经常根据个人喜好编写内容并且不知道如何使用热门话题,那么数据将很惨. ,我为这些操作已经编译了必要的工具,这些工具可以使您不断进步: 新列表
在多个平台上发布视频和图片后,让我们分享如何发送小视频或图片,然后进入视频部分. 建议先设置默认类别,然后上传本地视频,然后依次填写标题“简介”标签. 完成上述所有操作并单击“发布”后,将弹出一个用于选择帐户的界面,并选择您要发布的平台. 强烈建议使用此方法.
由于互联网的发展,近年来,自媒体行业变得特别受欢迎. 它的运营成本非常低,可以使用内容来实现转化. 它逐渐将各行各业的人们聚集在一起,正是为了获得更多的内容曝光,我们经常覆盖所有渠道. 只是当我们开始执行此操作时,我们意识到我们必须每天打开计算机,一个一个地登录到帐户,然后一个一个地同步精心准备的内容. 这确实是麻烦和费时的. 我用了一个把戏. 这个问题很快就解决了.
视频资料也像是内容全面的文章. 显然,剪辑视频时需要学习素材. 可以说您准备的内容比较完整. 因此,您计划的视频将是完美而成功的. 我已经计算了很多特别有用的素材站点,我想我可以为您提供帮助: 做视频网络,素材库 查看全部
互联网媒体的发展非常迅速. 特别是从2017年至今,视频一直受到人们的关注,其品牌形象清晰,回报迅速. 它吸引了无数需要帮助的人. 为了赢得更高的阅读指数,作者通常涵盖所有平台. 但是,当您开始使用更多帐户时,您会逐渐了解: 您上班时必须每天重复登录帐户,然后发布要逐一发布的内容. 这真的是在浪费时间. 我有以下免费的经验. 与您分享.
视频制作和视频编辑知道,没有足够的应用程序来裁剪不同品牌的视频软件,但是并不是每个小软件都具有高度的兼容性. 为此,我们对一个相对偏爱的人进行了全面的构架. 以下,专家可以一个接一个地测试: 视频编辑王如何定期将内容上传到多个平台?
设置YiMedia Assistant媒体帐户的基本功能必须通过使用一个帐户来实现,因此,如果您与这种类型的联系人联系,请在左上角添加一个帐户,选择需要添加的平台. 软件,建议使用帐户和密码登录,并尝试不要使用从媒体号登录的方式.
[9个主要功能]
1.40+平台支持: 支持40多个主流新媒体平台,新平台将继续对接
2.1000+帐户管理: 轻松支持1000+帐户管理,新的低级优化设计,自动存储帐户秘密,自动登录,无论您不怕挑战多少个帐户
3. 热点文章系统: 实时采集热点文章和视频,使您可以轻松创建实时热点,创建局部100,000 +
4. AI智能重写: 轻松重写采集集,让您进行促销,关键字覆盖,软文等功能更加强大
5. 一键分发: 一键轻松将文章,视频,小型视频和微动态分发到30多个主流平台上
如何定期将内容上传到多个平台?如何定期将内容上传到多个平台?
6. 团队管理: 支持创建子账户,实现屏蔽收入,账户密码和员工操作统计等功能
7. 独创性检测: 基于3个主要搜索引擎,一键式检测文章独创性,强大的重复检查和审阅工具
8. 微信: 支持微信一键发布到: 微头条,百家新闻,微博等平台
9. 数据概述: 一键式查看所有平台的收入,播放,阅读和其他数据
设置帐户并进入EasyMedia Assistant界面,找到“添加帐户”按钮,在界面上选择所需的平台,然后使用该帐户和密码方法登录,以便将来EasyMedia将自动填写该帐户和密码,无需再次输入.
添加帐户已安装EasyMedia Assistant,在左上角添加帐户,要添加的自媒体平台,使用帐户和密码方法很容易登录. 将来,该软件将自动输入帐户和密码,而无需手动输入.
Data认为,所有内容运营部门的同事都了解,热文本关键字的分析和优化特别重要. 如果您经常根据个人喜好编写内容并且不知道如何使用热门话题,那么数据将很惨. ,我为这些操作已经编译了必要的工具,这些工具可以使您不断进步: 新列表
在多个平台上发布视频和图片后,让我们分享如何发送小视频或图片,然后进入视频部分. 建议先设置默认类别,然后上传本地视频,然后依次填写标题“简介”标签. 完成上述所有操作并单击“发布”后,将弹出一个用于选择帐户的界面,并选择您要发布的平台. 强烈建议使用此方法.
由于互联网的发展,近年来,自媒体行业变得特别受欢迎. 它的运营成本非常低,可以使用内容来实现转化. 它逐渐将各行各业的人们聚集在一起,正是为了获得更多的内容曝光,我们经常覆盖所有渠道. 只是当我们开始执行此操作时,我们意识到我们必须每天打开计算机,一个一个地登录到帐户,然后一个一个地同步精心准备的内容. 这确实是麻烦和费时的. 我用了一个把戏. 这个问题很快就解决了.
视频资料也像是内容全面的文章. 显然,剪辑视频时需要学习素材. 可以说您准备的内容比较完整. 因此,您计划的视频将是完美而成功的. 我已经计算了很多特别有用的素材站点,我想我可以为您提供帮助: 做视频网络,素材库
WordPress添加了定期发布文章的任务publish_future_post
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2020-08-08 00:40
您需要在此处使用WordPress挂钩. publish_future_post挂钩是在定期发布文章时执行的挂钩.
例如,提交一个熊掌编号.
function send_xzh($postid){
$urls = array(
get_permalink($postid),
);
$api = 'http://data.zz.baidu.com/urls?appid=你的APPID&token=你的token&type=推送选项';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
//echo $result; //要不要判断提交结果自己选择,这里不判断
}
为上述方法添加一个钩子.
add_action( 'publish_future_post', 'send_xzh' );
通过这种方式,可以在定期发布文章时将其自动提交给百度熊掌. 查看全部
许多主题都具有此功能,可以定期发布WordPress文章. 这是常规发布的原则. WordPress发布是将post_status字段设置为发布,并将post_date设置为发布时间. 如果您需要定期发布,则只需将post_date字段设置为将来的某个时间,该文章将在该时间自动发布. 那如果文章发表时我们需要做些什么呢?
您需要在此处使用WordPress挂钩. publish_future_post挂钩是在定期发布文章时执行的挂钩.
例如,提交一个熊掌编号.
function send_xzh($postid){
$urls = array(
get_permalink($postid),
);
$api = 'http://data.zz.baidu.com/urls?appid=你的APPID&token=你的token&type=推送选项';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
//echo $result; //要不要判断提交结果自己选择,这里不判断
}
为上述方法添加一个钩子.
add_action( 'publish_future_post', 'send_xzh' );
通过这种方式,可以在定期发布文章时将其自动提交给百度熊掌.
Guardian网站的常规刷新工具的PC版本
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2020-08-07 23:34
软件简介
Guardian网站刷新工具是一个简单的刷新软件,可以帮助您监视指定的网站并立即刷新网站内容. 每个人都知道浏览器可以直接刷新网页,您可以通过刷新快速查看它. 更新内容,快速访问新资源,非常适合需要采集网站内容并快速分析Web响应内容的朋友,此软件操作非常简单,您可以直接输入需要监视的网页地址,然后可以设置特定的刷新时间,可以设置为每分钟刷新一次,也可以设置为每十秒钟刷新一次,或者可以设置为每小时刷新一次,具体操作是自己下载软件来体验!
软件功能
1. 每次刷新的结果都可以记录在日志文件中,用户可以随时查看.
2. Guardian具有全面的安全保护功能,因此您不必担心网站的安全性,可以放心使用它.
3. 定期刷新网页,设置间隔时间并定期自动刷新.
4. 绿色版免费安装工具软件,用户无需安装,运行后即可直接使用.
5. 如果您注销服务器或重新启动服务器,则可以继续使用它而无需手动启动.
软件亮点
1. Guardian网站的常规刷新工具适合大多数用户.
2,适合需要自动刷新Web界面内容的朋友
3. 如果需要经常刷新网站内容,可以选择此软件
4. 您可以设置本地分辨率,可以设置是否记录日志;
5. 支持监视http和https网站;
功能介绍
(1)根据设置的时间,自动将网页数据获取到本地列表中;
(2)刷新规则可以设置为每小时刷新一次,或每隔一段时间刷新一次;
(3)可以设置本地分辨率,还可以设置是否记录日志;
(4)支持监视http和https网站;
(5)该软件无需安装,可以作为服务运行. 注销服务器或重新启动服务器后,它仍然可以运行.
主要优点
1. Guardian网站的定期刷新工具功能丰富,可以快速监控网站
2. 它可以自动刷新,并且可以获得本地数据和反馈数据.
3. 提供刷新时间视图,软件界面将自动计算刷新信息 查看全部
Guardian网站计时刷新工具是一个免费工具,可以自动刷新网页. 该软件可以设置定时刷新,间隔刷新,服务模式以及重启后自动刷新;软件采用服务模式,服务器重启后也可以自动刷新. 无需人工. 欢迎有需要的朋友在第9个下载站点上免费下载和体验.
软件简介
Guardian网站刷新工具是一个简单的刷新软件,可以帮助您监视指定的网站并立即刷新网站内容. 每个人都知道浏览器可以直接刷新网页,您可以通过刷新快速查看它. 更新内容,快速访问新资源,非常适合需要采集网站内容并快速分析Web响应内容的朋友,此软件操作非常简单,您可以直接输入需要监视的网页地址,然后可以设置特定的刷新时间,可以设置为每分钟刷新一次,也可以设置为每十秒钟刷新一次,或者可以设置为每小时刷新一次,具体操作是自己下载软件来体验!
软件功能
1. 每次刷新的结果都可以记录在日志文件中,用户可以随时查看.
2. Guardian具有全面的安全保护功能,因此您不必担心网站的安全性,可以放心使用它.
3. 定期刷新网页,设置间隔时间并定期自动刷新.
4. 绿色版免费安装工具软件,用户无需安装,运行后即可直接使用.
5. 如果您注销服务器或重新启动服务器,则可以继续使用它而无需手动启动.
软件亮点
1. Guardian网站的常规刷新工具适合大多数用户.
2,适合需要自动刷新Web界面内容的朋友
3. 如果需要经常刷新网站内容,可以选择此软件
4. 您可以设置本地分辨率,可以设置是否记录日志;
5. 支持监视http和https网站;
功能介绍
(1)根据设置的时间,自动将网页数据获取到本地列表中;
(2)刷新规则可以设置为每小时刷新一次,或每隔一段时间刷新一次;
(3)可以设置本地分辨率,还可以设置是否记录日志;
(4)支持监视http和https网站;
(5)该软件无需安装,可以作为服务运行. 注销服务器或重新启动服务器后,它仍然可以运行.
主要优点
1. Guardian网站的定期刷新工具功能丰富,可以快速监控网站
2. 它可以自动刷新,并且可以获得本地数据和反馈数据.
3. 提供刷新时间视图,软件界面将自动计算刷新信息
将数据导出到sqlserver数据库(手动和自动两种方式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2020-08-07 21:58
1. 手动导出数据库: 此方法只能在采集任务后将采集的数据导出到数据库.
2. 自动导出数据库: 此方法可以实现采集和指导,并在设置的时间间隔启动导出计划. 此方法仅支持云采集.
当前,优采云支持导出Mysql,SqlServer和Oracle中的数据库. 本地数据和云采集的数据都可以导出到数据库. 本教程以云采集的数据为例,向所有人解释.
提示: 导出之前,您需要先建立数据库和数据表
手动导出sqlserver数据库的步骤如下:
步骤1: 单击任务→选择要导出的任务数据,单击更多操作→查看数据→云采集数据
步骤2: 选择导出数据→在弹出的操作界面上选择导出所有数据或未导出的数据→选择导出到数据库→单击确定进入数据导出向导→选择下一步进入数据库配置界面
进入该数据库配置界面后,配置数据库的相关信息. 这里的信息必须正确并且可以正常连接到数据库
第3步: 配置以下字段
配置后,可以单击“测试连接”以验证配置正确. 此处的配置正确,因此下面提供了连接. 如果配置不正确,则会在下面显示错误消息.
步骤4: 配置数据库连接后,单击“下一步”进入数据字段映射界面→选择数据表→选择目标数据字段(此处,如果源数据字段和目标数据字段名称相同,它会自动配置,如果不相同,则需要手动选择)→如果不想重复其中一个字段,则可以对其进行检查并将其设置为唯一标识符. 检查之后,它将在导入时根据此字段确定是向数据库添加新记录还是覆盖原创记录.
提示: 如果下次需要继续导出,则可以在此处设置和保存配置. (选中“保存配置并输入保存的配置的名称”),下次导出时,可以直接选择此配置.
步骤5: 选择下一步→选择导出→提示导出完成→数据已导入到指定数据库
提示: 选中在导出过程中忽略错误. 如果遇到错误,请尝试不要终止导出操作. 这意味着当导入其他数据时出现错误时,某些数据将继续导出.
以下是数据库数据的示例:
让我们讨论一下自动导出到数据库的方法. 请注意,此方法仅支持云采集,并且可以在采集时导出. 当前已导出尚未导出的数据.
进入视图数据界面后,与之前的手动导出到sqlserver相同的基本步骤
选择导出数据→选择在弹出的操作界面上导出所有数据或未导出的数据→选择自动导出到数据库→单击确定进入数据导出向导→选择下一步进入数据库配置界面
接下来的步骤与前面的步骤3和4相同.
按照前面的步骤3和4进行配置后,选择“下一步”进入设置执行计划页面
设置执行计划的名称,然后设置实时计划. 这里的实时计划意味着每小时自动启动执行计划并导出当前未导出的数据.
设置后,单击“下一步”完成选择. 现在已经配置了自动导出计划
然后单击工具箱→定时存储工具→选择开始. (系统将立即执行数据库导出,然后在执行完成后在指定的时间间隔自动启动) 查看全部
本教程将说明如何将采集的数据导出到sqlserver数据库. 这是两种导出方法.
1. 手动导出数据库: 此方法只能在采集任务后将采集的数据导出到数据库.
2. 自动导出数据库: 此方法可以实现采集和指导,并在设置的时间间隔启动导出计划. 此方法仅支持云采集.
当前,优采云支持导出Mysql,SqlServer和Oracle中的数据库. 本地数据和云采集的数据都可以导出到数据库. 本教程以云采集的数据为例,向所有人解释.
提示: 导出之前,您需要先建立数据库和数据表
手动导出sqlserver数据库的步骤如下:
步骤1: 单击任务→选择要导出的任务数据,单击更多操作→查看数据→云采集数据
步骤2: 选择导出数据→在弹出的操作界面上选择导出所有数据或未导出的数据→选择导出到数据库→单击确定进入数据导出向导→选择下一步进入数据库配置界面
进入该数据库配置界面后,配置数据库的相关信息. 这里的信息必须正确并且可以正常连接到数据库
第3步: 配置以下字段
配置后,可以单击“测试连接”以验证配置正确. 此处的配置正确,因此下面提供了连接. 如果配置不正确,则会在下面显示错误消息.
步骤4: 配置数据库连接后,单击“下一步”进入数据字段映射界面→选择数据表→选择目标数据字段(此处,如果源数据字段和目标数据字段名称相同,它会自动配置,如果不相同,则需要手动选择)→如果不想重复其中一个字段,则可以对其进行检查并将其设置为唯一标识符. 检查之后,它将在导入时根据此字段确定是向数据库添加新记录还是覆盖原创记录.
提示: 如果下次需要继续导出,则可以在此处设置和保存配置. (选中“保存配置并输入保存的配置的名称”),下次导出时,可以直接选择此配置.
步骤5: 选择下一步→选择导出→提示导出完成→数据已导入到指定数据库
提示: 选中在导出过程中忽略错误. 如果遇到错误,请尝试不要终止导出操作. 这意味着当导入其他数据时出现错误时,某些数据将继续导出.
以下是数据库数据的示例:
让我们讨论一下自动导出到数据库的方法. 请注意,此方法仅支持云采集,并且可以在采集时导出. 当前已导出尚未导出的数据.
进入视图数据界面后,与之前的手动导出到sqlserver相同的基本步骤
选择导出数据→选择在弹出的操作界面上导出所有数据或未导出的数据→选择自动导出到数据库→单击确定进入数据导出向导→选择下一步进入数据库配置界面
接下来的步骤与前面的步骤3和4相同.
按照前面的步骤3和4进行配置后,选择“下一步”进入设置执行计划页面
设置执行计划的名称,然后设置实时计划. 这里的实时计划意味着每小时自动启动执行计划并导出当前未导出的数据.
设置后,单击“下一步”完成选择. 现在已经配置了自动导出计划
然后单击工具箱→定时存储工具→选择开始. (系统将立即执行数据库导出,然后在执行完成后在指定的时间间隔自动启动)
Wordpress批处理删除定期发布的文章和草稿文章中的sql命令
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-07 20:36
这些数据是随机且定期发布的,导致其中一个网站定期发布了1,200多篇文章. 都是重复的. 发现此问题后,前台已经发表了40或50篇文章. 我当时以为必须在数据库中进行操作. 将文章移到后台的回收站中,您只能一页一页地删除,有五十或六十页,累死了!
好吧,搜索了一段时间之后,我终于找到了sql命令,可以按计划按批删除批状态中的文章. 代码如下:
delete from wp_posts where post_status="future";
注意: 在操作之前,请确保备份数据库.
此处的“未来”是指“定时发布”. 还有一些文章状态,可以通过相应地替换“未来”来实现:
post_status帖子状态:
发布: 已发布
继承: 修订版
草稿: 草稿
自动草稿: 草稿已自动保存
待审核: 待审核
垃圾桶: 垃圾桶
未来: 时机
私人: 私人
例如,用于批量删除文章草稿的sql代码为: 查看全部
今天,当小白使用优采云进行采集时,他进行了莫名其妙的操作并做出了已发布的选项. 结果,我最初想在本地处理数据,然后跳过了使用免登录界面手动发布消息的过程. 原创数据将在采集后立即发布. 更夸张的是,我一个月采集的数据已被重复发送出去.
这些数据是随机且定期发布的,导致其中一个网站定期发布了1,200多篇文章. 都是重复的. 发现此问题后,前台已经发表了40或50篇文章. 我当时以为必须在数据库中进行操作. 将文章移到后台的回收站中,您只能一页一页地删除,有五十或六十页,累死了!
好吧,搜索了一段时间之后,我终于找到了sql命令,可以按计划按批删除批状态中的文章. 代码如下:
delete from wp_posts where post_status="future";
注意: 在操作之前,请确保备份数据库.
此处的“未来”是指“定时发布”. 还有一些文章状态,可以通过相应地替换“未来”来实现:
post_status帖子状态:
发布: 已发布
继承: 修订版
草稿: 草稿
自动草稿: 草稿已自动保存
待审核: 待审核
垃圾桶: 垃圾桶
未来: 时机
私人: 私人
例如,用于批量删除文章草稿的sql代码为:
Python3 + SQL + Power BI进行数据预测;要在b站成为6级老板,还需要花费更多时间
采集交流 • 优采云 发表了文章 • 0 个评论 • 371 次浏览 • 2020-08-07 18:04
p代码的主要功能/p
p需要提前导入的包裹/p
pa. import sys: 不需要安装. 在Raspberry Pi环境中,没有此第三方程序包就无法成功调用它(我不知道原因...)/p
pb. requests / json / time: 这三个是python下非常常见的软件包/p
pc. pip3 install pymysql: 用于运行mysql数据库的软件包/p
puserInfo()函数: 要获取您自己的站点b信息,您需要获取自己的cookie和中间内容以方便登录/p
ppush_bark(标题,文本)功能: 向手机发送通知(可能不使用)/p
puserInfo_for_sql(userInfo_all): 执行sql语句并将采集的数据存储在mysql数据库中的功能/p
pconnetSql()函数: 与数据库相关的配置/p
pprecode class="language-python"span class="kn"import/span span class="nn"sys/span
span class="n"sys/spanspan class="o"./spanspan class="n"path/spanspan class="o"./spanspan class="n"append/spanspan class="p"(/spanspan class="s1"'/usr/lib/python3.7/lib-dynload'/spanspan class="p")/span
span class="n"sys/spanspan class="o"./spanspan class="n"path/spanspan class="o"./spanspan class="n"append/spanspan class="p"(/spanspan class="s1"'/home/pi/.local/lib/python3.7/site-packages'/spanspan class="p")/span
span class="n"sys/spanspan class="o"./spanspan class="n"path/spanspan class="o"./spanspan class="n"append/spanspan class="p"(/spanspan class="s1"'/usr/local/lib/python3.7/dist-packages'/spanspan class="p")/span
span class="n"sys/spanspan class="o"./spanspan class="n"path/spanspan class="o"./spanspan class="n"append/spanspan class="p"(/spanspan class="s1"'/usr/lib/python3/dist-packages'/spanspan class="p")/span
span class="c1"#import sys,到这行,均为在树莓派执行时需要的语句,解决调用时无法找到对应的第三方包的问题,其他环境可以不用/span
span class="kn"import/span span class="nn"requests/span
span class="kn"import/span span class="nn"json/span
span class="kn"import/span span class="nn"pymysql/span
span class="kn"import/span span class="nn"time/span
span class="n"cookie/span span class="o"=/span span class="s2"""/spanspan class="c1"#替换为自己b站的cookie/span
span class="n"header/span span class="o"=/span span class="p"{/spanspan class="s1"'User-Agent'/spanspan class="p":/span span class="s1"'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'/spanspan class="p",/span
span class="s1"'Connection'/spanspan class="p":/span span class="s1"'keep-alive'/spanspan class="p",/span
span class="s1"'accept'/spanspan class="p":/span span class="s1"'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'/spanspan class="p",/span
span class="s1"'Cookie'/spanspan class="p":/span span class="n"cookie/spanspan class="p"}/span
span class="k"def/span span class="nf"userInfo/spanspan class="p"(/spanspan class="n"mid/spanspan class="p"):/span
span class="n"userInfo_all/span span class="o"=/span span class="p"{}/span
span class="n"userInfo_url/span span class="o"=/span span class="s1"'https://account.bilibili.com/h ... /span
span class="n"userInfo_data/span span class="o"=/span span class="n"requests/spanspan class="o"./spanspan class="n"get/spanspan class="p"(/spanspan class="n"userInfo_url/spanspan class="p",/span span class="n"headers/spanspan class="o"=/spanspan class="n"header/spanspan class="p")/span
span class="n"userInfo/span span class="o"=/span span class="n"json/spanspan class="o"./spanspan class="n"loads/spanspan class="p"(/spanspan class="n"userInfo_data/spanspan class="o"./spanspan class="n"text/spanspan class="p")/span
span class="n"current_level/span span class="o"=/span span class="n"userInfo/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'level_info'/spanspan class="p"][/spanspan class="s1"'current_level'/spanspan class="p"]/span
span class="n"current_exp/span span class="o"=/span span class="n"userInfo/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'level_info'/spanspan class="p"][/spanspan class="s1"'current_exp'/spanspan class="p"]/span
span class="n"coins/span span class="o"=/span span class="n"userInfo/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'coins'/spanspan class="p"]/span
span class="n"stat_url/span span class="o"=/span span class="s1"'https://api.bilibili.com/x/relation/stat?vmid={}'/spanspan class="o"./spanspan class="n"format/spanspan class="p"(/span
span class="n"mid/spanspan class="p")/span
span class="n"stat_data/span span class="o"=/span span class="n"requests/spanspan class="o"./spanspan class="n"get/spanspan class="p"(/spanspan class="n"stat_url/spanspan class="p",/span span class="n"headers/spanspan class="o"=/spanspan class="n"header/spanspan class="p")/span
span class="n"stat/span span class="o"=/span span class="n"json/spanspan class="o"./spanspan class="n"loads/spanspan class="p"(/spanspan class="n"stat_data/spanspan class="o"./spanspan class="n"text/spanspan class="p")/span
span class="n"following/span span class="o"=/span span class="n"stat/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'following'/spanspan class="p"]/span
span class="n"follower/span span class="o"=/span span class="n"stat/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'follower'/spanspan class="p"]/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'mid'/spanspan class="p"]/span span class="o"=/span span class="n"mid/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'current_level'/spanspan class="p"]/span span class="o"=/span span class="n"current_level/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'current_exp'/spanspan class="p"]/span span class="o"=/span span class="n"current_exp/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'coins'/spanspan class="p"]/span span class="o"=/span span class="n"coins/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'following'/spanspan class="p"]/span span class="o"=/span span class="n"following/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'follower'/spanspan class="p"]/span span class="o"=/span span class="n"follower/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'create_datetime'/spanspan class="p"]/span span class="o"=/span span class="nb"str/spanspan class="p"(/span
span class="n"time/spanspan class="o"./spanspan class="n"strftime/spanspan class="p"(/spanspan class="s2""%Y-%m-/spanspan class="si"%d/spanspan class="s2" %H:%M:%S"/spanspan class="p",/span span class="n"time/spanspan class="o"./spanspan class="n"localtime/spanspan class="p"()))/span
span class="k"print/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p")/span
span class="n"text/span span class="o"=/span span class="s2""执行成功!b站我的数据,时间:{}"/spanspan class="o"./spanspan class="n"format/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'create_datetime'/spanspan class="p"])/span
span class="n"title/span span class="o"=/span span class="s2""爬虫执行成功"/span
span class="n"push_bark/spanspan class="p"(/spanspan class="n"title/spanspan class="p",/span span class="n"text/spanspan class="p")/spanspan class="c1"#调用push_bark函数,爬虫爬取成功后,会发push给手机;若不需要刻意注释掉此行/span
span class="k"return/span span class="n"userInfo_all/span
span class="c1"#爬虫成功后push手机函数,需要下载bark手机app,若不需要,上面不要调用push_bark(title, text)函数即可/span
span class="k"def/span span class="nf"push_bark/spanspan class="p"(/spanspan class="n"title/spanspan class="p",/span span class="n"text/spanspan class="p"):/span
span class="c1"#push_url:打开bark app,复制里面的连接,进行替换/span
span class="n"push_url/span span class="o"=/span span class="s1"'https://api.day.app/xxxxx/{}/{}'/spanspan class="o"./spanspan class="n"format/spanspan class="p"(/span
span class="n"title/spanspan class="p",/span span class="n"text/spanspan class="p")/span
span class="n"headers/span span class="o"=/span span class="p"{/span
span class="s1"'content-type'/spanspan class="p":/span span class="s2""application/x-www-form-urlencoded"/spanspan class="p",/span
span class="p"}/span
span class="n"response/span span class="o"=/span span class="n"requests/spanspan class="o"./spanspan class="n"post/spanspan class="p"(/spanspan class="n"push_url/spanspan class="p",/span span class="n"headers/spanspan class="o"=/spanspan class="n"headers/spanspan class="p")/span
span class="k"print/spanspan class="p"(/spanspan class="n"push_url/spanspan class="p")/span
span class="n"text/span span class="o"=/span span class="n"json/spanspan class="o"./spanspan class="n"loads/spanspan class="p"(/spanspan class="n"response/spanspan class="o"./spanspan class="n"text/spanspan class="p")/span
span class="k"print/spanspan class="p"(/spanspan class="n"text/spanspan class="p")/span
span class="k"def/span span class="nf"userInfo_for_sql/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"):/span
span class="n"db/span span class="o"=/span span class="n"connetSql/spanspan class="p"()/span
span class="n"conn/span span class="o"=/span span class="n"db/spanspan class="p"[/spanspan class="mi"0/spanspan class="p"]/span
span class="n"database/span span class="o"=/span span class="n"db/spanspan class="p"[/spanspan class="mi"1/spanspan class="p"]/span
span class="n"mid/span span class="o"=/span span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'mid'/spanspan class="p"]/span
span class="n"current_level/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'current_level'/spanspan class="p"])/span
span class="n"current_exp/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'current_exp'/spanspan class="p"])/span
span class="n"coins/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'coins'/spanspan class="p"])/span
span class="n"following/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'following'/spanspan class="p"])/span
span class="n"follower/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'follower'/spanspan class="p"])/span
span class="n"create_datetime/span span class="o"=/span span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'create_datetime'/spanspan class="p"]/span
span class="c1"#sql:执行的数据库语句,案例中的数据库表名为“bili2_user_info”,根据需要替换/span
span class="n"sql/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="s2""insert into bili2_user_info(mid,current_level,current_exp,coins,following,follower,create_datetime) values('{}','{}','{}','{}','{}','{}','{}')"/spanspan class="o"./spanspan class="n"format/spanspan class="p"(/spanspan class="n"mid/spanspan class="p",/spanspan class="n"current_level/spanspan class="p",/spanspan class="n"current_exp/spanspan class="p",/spanspan class="n"coins/spanspan class="p",/spanspan class="n"following/spanspan class="p",/spanspan class="n"follower/spanspan class="p",/spanspan class="n"create_datetime/spanspan class="p"))/span
span class="n"conn/spanspan class="o"./spanspan class="n"execute/spanspan class="p"(/spanspan class="n"sql/spanspan class="p")/span
span class="n"database/spanspan class="o"./spanspan class="n"commit/spanspan class="p"()/span
span class="n"database/spanspan class="o"./spanspan class="n"close/spanspan class="p"()/span
span class="n"conn/spanspan class="o"./spanspan class="n"close/spanspan class="p"()/span
span class="k"def/span span class="nf"connetSql/spanspan class="p"():/span
span class="c1"#数据库连接配置:user需要设置成自己的数据库用户名,password需要设置成自己的数据库密码,host需要设置成自己的数据库地址,db需要设置成自己的数据库名称,port需要设置为自己的数据库端口号(默认3306)/span
span class="n"sqlConnect/span span class="o"=/span span class="n"pymysql/spanspan class="o"./spanspan class="n"connect/spanspan class="p"(/spanspan class="n"user/spanspan class="o"=/spanspan class="s2"""/spanspan class="p",/span span class="n"password/spanspan class="o"=/spanspan class="s2"""/spanspan class="p",/span
span class="n"host/spanspan class="o"=/spanspan class="s2""192.168.50.226"/spanspan class="p",/span span class="n"db/spanspan class="o"=/spanspan class="s2"""/spanspan class="p",/span span class="n"charset/spanspan class="o"=/spanspan class="s2""utf8"/spanspan class="p",/span span class="n"port/spanspan class="o"=/spanspan class="mi"3306/spanspan class="p")/span
span class="n"conn/span span class="o"=/span span class="n"sqlConnect/spanspan class="o"./spanspan class="n"cursor/spanspan class="p"()/span
span class="k"return/span span class="n"conn/spanspan class="p",/span span class="n"sqlConnect/span
span class="k"if/span span class="vm"__name__/span span class="o"==/span span class="s1"'__main__'/spanspan class="p":/span
span class="c1"#执行,需要将userInfo('2417142')中的2417142替换为自己的user id,在b站可以找到自己的id/span
span class="n"userInfo_for_sql/spanspan class="p"(/spanspan class="n"userInfo/spanspan class="p"(/spanspan class="s1"'2417142'/spanspan class="p"))/span/code/pre/p
p作为一种市场转型产品,狗自学成才的sql / python,大个子窃听了代码并写错了/p
p数据库结构简介/p
p如果您不想使用数据库来存储自己的数据,也可以使用csv / txt来存储数据. 当然,也可以使用sqlite./p
pmysql数据库配置/p
pprecode class="language-sql"span class="err"数据库名:/spanspan class="n"bili2_user/span
span class="err"数据表名:/spanspan class="n"bili2_user_info/span
span class="err"数据表字段/span
span class="n"mid/spanspan class="p":/spanspan class="err"用户/spanspan class="n"id/span
span class="n"current_level/spanspan class="p":/spanspan class="err"等级/span
span class="n"current_exp/spanspan class="p":/spanspan class="err"经验值/span
span class="n"coins/spanspan class="p":/spanspan class="err"硬币数量/span
span class="n"create_datetime/spanspan class="p":/spanspan class="err"记录添加时间/span
span class="err"数据库的字段设置除了/spanspan class="n"create_datetime是datetime类型外/spanspan class="err",其他均使用/spanspan class="nb"int/spanspan class="o"//spanspan class="mi"255/spanspan class="err"即可,粗暴简单/span/code/pre/p
p执行python来配置python3环境代码,并对其进行修改以为自己的配置数据库建立ok/p
p您可以执行它〜如果幸运的话,您很快就能在sql数据库中看到您的数据/p
p如下所示: ⬇️/p
pimg src='https://pic3.zhimg.com/v2-df1c88296b0b613105a36a9785402131_b.png' alt=''//p
p配置环境以定期执行Raspberry Pi环境(与其他linux相同)/p
p建议vscode远程直接连接到Raspberry Pi,本地代码,远程调试/p
p方法: 添加插件“ remote-ssh”/p
pimg src='https://pic2.zhimg.com/v2-59f6729ac584634fbd0fcbe1b3a43e37_b.png' alt=''//p
p然后,您可以远程连接到Raspberry Pi进行调试./p
pimg src='https://pic4.zhimg.com/v2-c02ddda4d6b08624022be7a7fa27fc81_b.png' alt=''//p
p部署代码后,可以使用crontab定期调用它./p
p如何使用crontab/p
p编辑配置文件/p
pprecode class="language-text"sudo crontab -e/code/pre/p
p在文件末尾添加调用规则/p
pprecode class="language-text"0 * * * * /usr/bin/python3.7 /home/pi/mypisoft/bili2/bili2_my_userinfo.py >> /home/pi/mypisoft/bili2/log/bili2_my_userinfo.log 2>&1 &
注释:
0 * * * * :表示每个整点调用一次
/usr/bin/python3.7:python安装路径
/home/pi/mypisoft/bili2/bili2_my_userinfo.py:python脚本路径,需要替换成自己的储存路径
/home/pi/mypisoft/bili2/log/bili2_my_userinfo.log 2>&1 &:调用的日志储存路径,以及后台运行
大家可以根据自己的需求选择数据爬取的时间间隔
添加后保存文件,然后重新启动crontab
sudo /etc/init.d/cron restart
查看您自己的任务列表
sudo crontab -l
有关crontab使用的更多信息可以在百度下下载,答案不好呢
您可以尝试在Windows环境中使用“定时任务”数据分析阶段
我不使用python工具,我认为它不适合大多数python新手使用(主要是因为我太烹饪了)
我建议您下载并安装友好而有效的Microsoft Power bi
下载链接: Power Bi
如果没有Mac / linux版本,则直接进入虚拟机
连接到数据库获取数据
按照⬇️图中的步骤操作,成功后,表名称将显示在右侧的“字段”下.
创建数据板
点击“可视化折线图”,折线图将在左侧创建
向看板添加数据
第一步: 将create_datetime拖到该轴上,然后单击年/季度/月后面的叉号
第2步: 将current_exp拖动到该值中,然后选择该值的显示值作为最大值
这时,您的经验值会根据天空的大小而变化!每次单击刷新时,您都可以重新连接到数据库以刷新数据
数据预测
点击“分析”-“预测”-“预测时长(灵活设置,多次调整,200表示可以预测200天)”-“应用”.
判断您的经验值何时可以达到28888(第6级)
在折线图中的线条上移动鼠标,您可以看到当聚会横坐标为245时,我的经验值将高于28888,因此可以推断,在大约224天后,我将成为6级老板(245 -21,因为我的数据截止到21日)
结论
Python只是我用来获取数据的工具
在分析级别,我使用了更多的图形化工具,即功能强大的
预测可能并不准确,但是随着时间的流逝,数据的积累将越来越准确
代码很糟糕,分析方法非常初级,但是它仅提供了一种思维方式. 在数据时代,使用好的工具快速产生结果是最重要的 查看全部
主题摘要数据采集: 使用Python3从站点b采集经验值. 数据变化. 数据存储: 将数据存储在mysql数据库中. 数据分析: 使用Power BI连接到数据库以分析数据. 建议初步准备Python3环境和代码调试工具. 建议使用vscode. 长期运行的硬件环境: Synology / Computer / Raspberry Pi以安装和运行mysql数据库,您可以参考以下文章: 在Raspberry Pi上配置MariaDB数据采集并直接放置Python代码,只需修改代码的注释部分. <//p
p代码的主要功能/p
p需要提前导入的包裹/p
pa. import sys: 不需要安装. 在Raspberry Pi环境中,没有此第三方程序包就无法成功调用它(我不知道原因...)/p
pb. requests / json / time: 这三个是python下非常常见的软件包/p
pc. pip3 install pymysql: 用于运行mysql数据库的软件包/p
puserInfo()函数: 要获取您自己的站点b信息,您需要获取自己的cookie和中间内容以方便登录/p
ppush_bark(标题,文本)功能: 向手机发送通知(可能不使用)/p
puserInfo_for_sql(userInfo_all): 执行sql语句并将采集的数据存储在mysql数据库中的功能/p
pconnetSql()函数: 与数据库相关的配置/p
pprecode class="language-python"span class="kn"import/span span class="nn"sys/span
span class="n"sys/spanspan class="o"./spanspan class="n"path/spanspan class="o"./spanspan class="n"append/spanspan class="p"(/spanspan class="s1"'/usr/lib/python3.7/lib-dynload'/spanspan class="p")/span
span class="n"sys/spanspan class="o"./spanspan class="n"path/spanspan class="o"./spanspan class="n"append/spanspan class="p"(/spanspan class="s1"'/home/pi/.local/lib/python3.7/site-packages'/spanspan class="p")/span
span class="n"sys/spanspan class="o"./spanspan class="n"path/spanspan class="o"./spanspan class="n"append/spanspan class="p"(/spanspan class="s1"'/usr/local/lib/python3.7/dist-packages'/spanspan class="p")/span
span class="n"sys/spanspan class="o"./spanspan class="n"path/spanspan class="o"./spanspan class="n"append/spanspan class="p"(/spanspan class="s1"'/usr/lib/python3/dist-packages'/spanspan class="p")/span
span class="c1"#import sys,到这行,均为在树莓派执行时需要的语句,解决调用时无法找到对应的第三方包的问题,其他环境可以不用/span
span class="kn"import/span span class="nn"requests/span
span class="kn"import/span span class="nn"json/span
span class="kn"import/span span class="nn"pymysql/span
span class="kn"import/span span class="nn"time/span
span class="n"cookie/span span class="o"=/span span class="s2"""/spanspan class="c1"#替换为自己b站的cookie/span
span class="n"header/span span class="o"=/span span class="p"{/spanspan class="s1"'User-Agent'/spanspan class="p":/span span class="s1"'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'/spanspan class="p",/span
span class="s1"'Connection'/spanspan class="p":/span span class="s1"'keep-alive'/spanspan class="p",/span
span class="s1"'accept'/spanspan class="p":/span span class="s1"'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'/spanspan class="p",/span
span class="s1"'Cookie'/spanspan class="p":/span span class="n"cookie/spanspan class="p"}/span
span class="k"def/span span class="nf"userInfo/spanspan class="p"(/spanspan class="n"mid/spanspan class="p"):/span
span class="n"userInfo_all/span span class="o"=/span span class="p"{}/span
span class="n"userInfo_url/span span class="o"=/span span class="s1"'https://account.bilibili.com/h ... /span
span class="n"userInfo_data/span span class="o"=/span span class="n"requests/spanspan class="o"./spanspan class="n"get/spanspan class="p"(/spanspan class="n"userInfo_url/spanspan class="p",/span span class="n"headers/spanspan class="o"=/spanspan class="n"header/spanspan class="p")/span
span class="n"userInfo/span span class="o"=/span span class="n"json/spanspan class="o"./spanspan class="n"loads/spanspan class="p"(/spanspan class="n"userInfo_data/spanspan class="o"./spanspan class="n"text/spanspan class="p")/span
span class="n"current_level/span span class="o"=/span span class="n"userInfo/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'level_info'/spanspan class="p"][/spanspan class="s1"'current_level'/spanspan class="p"]/span
span class="n"current_exp/span span class="o"=/span span class="n"userInfo/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'level_info'/spanspan class="p"][/spanspan class="s1"'current_exp'/spanspan class="p"]/span
span class="n"coins/span span class="o"=/span span class="n"userInfo/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'coins'/spanspan class="p"]/span
span class="n"stat_url/span span class="o"=/span span class="s1"'https://api.bilibili.com/x/relation/stat?vmid={}'/spanspan class="o"./spanspan class="n"format/spanspan class="p"(/span
span class="n"mid/spanspan class="p")/span
span class="n"stat_data/span span class="o"=/span span class="n"requests/spanspan class="o"./spanspan class="n"get/spanspan class="p"(/spanspan class="n"stat_url/spanspan class="p",/span span class="n"headers/spanspan class="o"=/spanspan class="n"header/spanspan class="p")/span
span class="n"stat/span span class="o"=/span span class="n"json/spanspan class="o"./spanspan class="n"loads/spanspan class="p"(/spanspan class="n"stat_data/spanspan class="o"./spanspan class="n"text/spanspan class="p")/span
span class="n"following/span span class="o"=/span span class="n"stat/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'following'/spanspan class="p"]/span
span class="n"follower/span span class="o"=/span span class="n"stat/spanspan class="p"[/spanspan class="s1"'data'/spanspan class="p"][/spanspan class="s1"'follower'/spanspan class="p"]/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'mid'/spanspan class="p"]/span span class="o"=/span span class="n"mid/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'current_level'/spanspan class="p"]/span span class="o"=/span span class="n"current_level/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'current_exp'/spanspan class="p"]/span span class="o"=/span span class="n"current_exp/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'coins'/spanspan class="p"]/span span class="o"=/span span class="n"coins/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'following'/spanspan class="p"]/span span class="o"=/span span class="n"following/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'follower'/spanspan class="p"]/span span class="o"=/span span class="n"follower/span
span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'create_datetime'/spanspan class="p"]/span span class="o"=/span span class="nb"str/spanspan class="p"(/span
span class="n"time/spanspan class="o"./spanspan class="n"strftime/spanspan class="p"(/spanspan class="s2""%Y-%m-/spanspan class="si"%d/spanspan class="s2" %H:%M:%S"/spanspan class="p",/span span class="n"time/spanspan class="o"./spanspan class="n"localtime/spanspan class="p"()))/span
span class="k"print/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p")/span
span class="n"text/span span class="o"=/span span class="s2""执行成功!b站我的数据,时间:{}"/spanspan class="o"./spanspan class="n"format/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'create_datetime'/spanspan class="p"])/span
span class="n"title/span span class="o"=/span span class="s2""爬虫执行成功"/span
span class="n"push_bark/spanspan class="p"(/spanspan class="n"title/spanspan class="p",/span span class="n"text/spanspan class="p")/spanspan class="c1"#调用push_bark函数,爬虫爬取成功后,会发push给手机;若不需要刻意注释掉此行/span
span class="k"return/span span class="n"userInfo_all/span
span class="c1"#爬虫成功后push手机函数,需要下载bark手机app,若不需要,上面不要调用push_bark(title, text)函数即可/span
span class="k"def/span span class="nf"push_bark/spanspan class="p"(/spanspan class="n"title/spanspan class="p",/span span class="n"text/spanspan class="p"):/span
span class="c1"#push_url:打开bark app,复制里面的连接,进行替换/span
span class="n"push_url/span span class="o"=/span span class="s1"'https://api.day.app/xxxxx/{}/{}'/spanspan class="o"./spanspan class="n"format/spanspan class="p"(/span
span class="n"title/spanspan class="p",/span span class="n"text/spanspan class="p")/span
span class="n"headers/span span class="o"=/span span class="p"{/span
span class="s1"'content-type'/spanspan class="p":/span span class="s2""application/x-www-form-urlencoded"/spanspan class="p",/span
span class="p"}/span
span class="n"response/span span class="o"=/span span class="n"requests/spanspan class="o"./spanspan class="n"post/spanspan class="p"(/spanspan class="n"push_url/spanspan class="p",/span span class="n"headers/spanspan class="o"=/spanspan class="n"headers/spanspan class="p")/span
span class="k"print/spanspan class="p"(/spanspan class="n"push_url/spanspan class="p")/span
span class="n"text/span span class="o"=/span span class="n"json/spanspan class="o"./spanspan class="n"loads/spanspan class="p"(/spanspan class="n"response/spanspan class="o"./spanspan class="n"text/spanspan class="p")/span
span class="k"print/spanspan class="p"(/spanspan class="n"text/spanspan class="p")/span
span class="k"def/span span class="nf"userInfo_for_sql/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"):/span
span class="n"db/span span class="o"=/span span class="n"connetSql/spanspan class="p"()/span
span class="n"conn/span span class="o"=/span span class="n"db/spanspan class="p"[/spanspan class="mi"0/spanspan class="p"]/span
span class="n"database/span span class="o"=/span span class="n"db/spanspan class="p"[/spanspan class="mi"1/spanspan class="p"]/span
span class="n"mid/span span class="o"=/span span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'mid'/spanspan class="p"]/span
span class="n"current_level/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'current_level'/spanspan class="p"])/span
span class="n"current_exp/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'current_exp'/spanspan class="p"])/span
span class="n"coins/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'coins'/spanspan class="p"])/span
span class="n"following/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'following'/spanspan class="p"])/span
span class="n"follower/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'follower'/spanspan class="p"])/span
span class="n"create_datetime/span span class="o"=/span span class="n"userInfo_all/spanspan class="p"[/spanspan class="s1"'create_datetime'/spanspan class="p"]/span
span class="c1"#sql:执行的数据库语句,案例中的数据库表名为“bili2_user_info”,根据需要替换/span
span class="n"sql/span span class="o"=/span span class="nb"str/spanspan class="p"(/spanspan class="s2""insert into bili2_user_info(mid,current_level,current_exp,coins,following,follower,create_datetime) values('{}','{}','{}','{}','{}','{}','{}')"/spanspan class="o"./spanspan class="n"format/spanspan class="p"(/spanspan class="n"mid/spanspan class="p",/spanspan class="n"current_level/spanspan class="p",/spanspan class="n"current_exp/spanspan class="p",/spanspan class="n"coins/spanspan class="p",/spanspan class="n"following/spanspan class="p",/spanspan class="n"follower/spanspan class="p",/spanspan class="n"create_datetime/spanspan class="p"))/span
span class="n"conn/spanspan class="o"./spanspan class="n"execute/spanspan class="p"(/spanspan class="n"sql/spanspan class="p")/span
span class="n"database/spanspan class="o"./spanspan class="n"commit/spanspan class="p"()/span
span class="n"database/spanspan class="o"./spanspan class="n"close/spanspan class="p"()/span
span class="n"conn/spanspan class="o"./spanspan class="n"close/spanspan class="p"()/span
span class="k"def/span span class="nf"connetSql/spanspan class="p"():/span
span class="c1"#数据库连接配置:user需要设置成自己的数据库用户名,password需要设置成自己的数据库密码,host需要设置成自己的数据库地址,db需要设置成自己的数据库名称,port需要设置为自己的数据库端口号(默认3306)/span
span class="n"sqlConnect/span span class="o"=/span span class="n"pymysql/spanspan class="o"./spanspan class="n"connect/spanspan class="p"(/spanspan class="n"user/spanspan class="o"=/spanspan class="s2"""/spanspan class="p",/span span class="n"password/spanspan class="o"=/spanspan class="s2"""/spanspan class="p",/span
span class="n"host/spanspan class="o"=/spanspan class="s2""192.168.50.226"/spanspan class="p",/span span class="n"db/spanspan class="o"=/spanspan class="s2"""/spanspan class="p",/span span class="n"charset/spanspan class="o"=/spanspan class="s2""utf8"/spanspan class="p",/span span class="n"port/spanspan class="o"=/spanspan class="mi"3306/spanspan class="p")/span
span class="n"conn/span span class="o"=/span span class="n"sqlConnect/spanspan class="o"./spanspan class="n"cursor/spanspan class="p"()/span
span class="k"return/span span class="n"conn/spanspan class="p",/span span class="n"sqlConnect/span
span class="k"if/span span class="vm"__name__/span span class="o"==/span span class="s1"'__main__'/spanspan class="p":/span
span class="c1"#执行,需要将userInfo('2417142')中的2417142替换为自己的user id,在b站可以找到自己的id/span
span class="n"userInfo_for_sql/spanspan class="p"(/spanspan class="n"userInfo/spanspan class="p"(/spanspan class="s1"'2417142'/spanspan class="p"))/span/code/pre/p
p作为一种市场转型产品,狗自学成才的sql / python,大个子窃听了代码并写错了/p
p数据库结构简介/p
p如果您不想使用数据库来存储自己的数据,也可以使用csv / txt来存储数据. 当然,也可以使用sqlite./p
pmysql数据库配置/p
pprecode class="language-sql"span class="err"数据库名:/spanspan class="n"bili2_user/span
span class="err"数据表名:/spanspan class="n"bili2_user_info/span
span class="err"数据表字段/span
span class="n"mid/spanspan class="p":/spanspan class="err"用户/spanspan class="n"id/span
span class="n"current_level/spanspan class="p":/spanspan class="err"等级/span
span class="n"current_exp/spanspan class="p":/spanspan class="err"经验值/span
span class="n"coins/spanspan class="p":/spanspan class="err"硬币数量/span
span class="n"create_datetime/spanspan class="p":/spanspan class="err"记录添加时间/span
span class="err"数据库的字段设置除了/spanspan class="n"create_datetime是datetime类型外/spanspan class="err",其他均使用/spanspan class="nb"int/spanspan class="o"//spanspan class="mi"255/spanspan class="err"即可,粗暴简单/span/code/pre/p
p执行python来配置python3环境代码,并对其进行修改以为自己的配置数据库建立ok/p
p您可以执行它〜如果幸运的话,您很快就能在sql数据库中看到您的数据/p
p如下所示: ⬇️/p
pimg src='https://pic3.zhimg.com/v2-df1c88296b0b613105a36a9785402131_b.png' alt=''//p
p配置环境以定期执行Raspberry Pi环境(与其他linux相同)/p
p建议vscode远程直接连接到Raspberry Pi,本地代码,远程调试/p
p方法: 添加插件“ remote-ssh”/p
pimg src='https://pic2.zhimg.com/v2-59f6729ac584634fbd0fcbe1b3a43e37_b.png' alt=''//p
p然后,您可以远程连接到Raspberry Pi进行调试./p
pimg src='https://pic4.zhimg.com/v2-c02ddda4d6b08624022be7a7fa27fc81_b.png' alt=''//p
p部署代码后,可以使用crontab定期调用它./p
p如何使用crontab/p
p编辑配置文件/p
pprecode class="language-text"sudo crontab -e/code/pre/p
p在文件末尾添加调用规则/p
pprecode class="language-text"0 * * * * /usr/bin/python3.7 /home/pi/mypisoft/bili2/bili2_my_userinfo.py >> /home/pi/mypisoft/bili2/log/bili2_my_userinfo.log 2>&1 &
注释:
0 * * * * :表示每个整点调用一次
/usr/bin/python3.7:python安装路径
/home/pi/mypisoft/bili2/bili2_my_userinfo.py:python脚本路径,需要替换成自己的储存路径
/home/pi/mypisoft/bili2/log/bili2_my_userinfo.log 2>&1 &:调用的日志储存路径,以及后台运行
大家可以根据自己的需求选择数据爬取的时间间隔
添加后保存文件,然后重新启动crontab
sudo /etc/init.d/cron restart
查看您自己的任务列表
sudo crontab -l
有关crontab使用的更多信息可以在百度下下载,答案不好呢
您可以尝试在Windows环境中使用“定时任务”数据分析阶段
我不使用python工具,我认为它不适合大多数python新手使用(主要是因为我太烹饪了)
我建议您下载并安装友好而有效的Microsoft Power bi
下载链接: Power Bi
如果没有Mac / linux版本,则直接进入虚拟机
连接到数据库获取数据
按照⬇️图中的步骤操作,成功后,表名称将显示在右侧的“字段”下.
创建数据板
点击“可视化折线图”,折线图将在左侧创建
向看板添加数据
第一步: 将create_datetime拖到该轴上,然后单击年/季度/月后面的叉号
第2步: 将current_exp拖动到该值中,然后选择该值的显示值作为最大值
这时,您的经验值会根据天空的大小而变化!每次单击刷新时,您都可以重新连接到数据库以刷新数据
数据预测
点击“分析”-“预测”-“预测时长(灵活设置,多次调整,200表示可以预测200天)”-“应用”.
判断您的经验值何时可以达到28888(第6级)
在折线图中的线条上移动鼠标,您可以看到当聚会横坐标为245时,我的经验值将高于28888,因此可以推断,在大约224天后,我将成为6级老板(245 -21,因为我的数据截止到21日)
结论
Python只是我用来获取数据的工具
在分析级别,我使用了更多的图形化工具,即功能强大的
预测可能并不准确,但是随着时间的流逝,数据的积累将越来越准确
代码很糟糕,分析方法非常初级,但是它仅提供了一种思维方式. 在数据时代,使用好的工具快速产生结果是最重要的

