
文章定时自动采集
一套智能相机之动图,活跃起来-日志记录
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-06-21 04:02
文章定时自动采集的,可以看这个介绍:一套抓取智能相机之动图,活跃起来-日志记录一直自动采集-编辑器一起来...之前智能相机数据是我在截取的。
因为ai相机的动图是会自动更新的。
阿里云的背景,我相信国内的智能相机基本都用他了。还有你说的阿里拍拍一个月都没几个,那估计是阿里的做法,不能写出来的,在这整体落地不足,新品都不上的情况下,
你说的没错。目前市面上的智能相机基本都是一个月才上架,限时限量免费用。
天猫精灵是ai相机。
因为每个月它都不上架
有些免费用有些限时限量
阿里的智能相机都是免费的,顶多限时限量!用完了或者没用完,可以对着互动图片,其他的选项—打开就是动图,腾讯有个微视也是类似的功能,只不过覆盖面要广,我也没用过。
谢邀。感觉阿里跟腾讯的数据不在一个层次上,阿里的更全面、快速更新。
谢邀,因为智能相机太贵,太多,还上新速度慢,
这个时间比较滞后,从我个人观察来看互联网公司有严格规定:applestoreppt_appstore_2016年8月21日~2015年8月20日。所以阿里想把限量和免费直接排除在外的。不过很多人是用定时插件的,大部分想大规模上也不可能啊,就更无法发钱鼓励了。 查看全部
一套智能相机之动图,活跃起来-日志记录
文章定时自动采集的,可以看这个介绍:一套抓取智能相机之动图,活跃起来-日志记录一直自动采集-编辑器一起来...之前智能相机数据是我在截取的。
因为ai相机的动图是会自动更新的。
阿里云的背景,我相信国内的智能相机基本都用他了。还有你说的阿里拍拍一个月都没几个,那估计是阿里的做法,不能写出来的,在这整体落地不足,新品都不上的情况下,
你说的没错。目前市面上的智能相机基本都是一个月才上架,限时限量免费用。
天猫精灵是ai相机。
因为每个月它都不上架
有些免费用有些限时限量
阿里的智能相机都是免费的,顶多限时限量!用完了或者没用完,可以对着互动图片,其他的选项—打开就是动图,腾讯有个微视也是类似的功能,只不过覆盖面要广,我也没用过。
谢邀。感觉阿里跟腾讯的数据不在一个层次上,阿里的更全面、快速更新。
谢邀,因为智能相机太贵,太多,还上新速度慢,
这个时间比较滞后,从我个人观察来看互联网公司有严格规定:applestoreppt_appstore_2016年8月21日~2015年8月20日。所以阿里想把限量和免费直接排除在外的。不过很多人是用定时插件的,大部分想大规模上也不可能啊,就更无法发钱鼓励了。
公众号下载重新编辑需要分几种情况来解答
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-06-16 04:10
这个问题需要在几种情况下回答
在第一种类型中,您只需下载并再次编辑即可。这个方法非常简单。一般来说,你知道你想要的文章,也就是你知道文章的访问地址。一般在采集器的帮助下就可以下载了,不管是word保存还是其他格式都没有问题。
第二种类型需要自动同步到您的平台。这个比较麻烦,因为不知道下载地址(不可能手动自动输入)。
方法一、1、 使用搜狗浏览器调用他的界面搜索你的公众号。如果2、存在,通过第二个界面查询公众号下的历史文章。获取文章链接,通过程序下载,保存到自己的后台。
这种方法的优点是:半自动,不需要手动输入文章链接。缺点是:1、如果频繁发送请求,搜狗会提示验证码。这需要手动处理,因此不能完全自动化。 2、和获得的文章链接是临时的,需要在有效期内下载。 3、只能获取最近的十条历史记录文章,4、需要定时执行,不能实时更新。更新太频繁导致验证码被屏蔽,频率太低更新延迟太大。
二、1、方式模拟通过程序登录公众号后台管理页面。 2、 通过模拟调用编辑材质。 3、通过模拟编辑插入链接功能,4、调用搜索公众号接口,查询公众号获取fackId。 5、使用获取到的fackId调用另一个接口获取文章列表。这个文章列表中有链接。
这种方式的好处是:1、不会有验证码,但是也有封的情况,但是频率较低。 2、你可以在公众号下获取所有文章列表。 3、文章 链接永久有效。缺点是:1、还有接口调用被阻塞的情况。需要一段时间才能自动解锁。 2、需要定时执行,不能实时更新。更新太频繁导致验证码被屏蔽,频率太低更新延迟太大。
方法三、1、 通过实时推送,只需要提供API接口接收链接,将文章链接实时推送到顶部界面,获取链接即可下载内容并将其保存到您自己的平台。
这种方法的优点:1、不被屏蔽,2、不需要输入验证码3、技术难度低。 4、文章 更新及时,延迟低,最多三到五分钟。 4、文章 链接永久有效。它可以真正实现完全自动化。缺点是需要有自己的开发者,有API接收参数。
如果有更好的方法,请联系我,互相学习。如果需要技术支持,也可以联系我。以上方法都是亲身尝试过的。有源代码(仅限java)。 查看全部
公众号下载重新编辑需要分几种情况来解答
这个问题需要在几种情况下回答
在第一种类型中,您只需下载并再次编辑即可。这个方法非常简单。一般来说,你知道你想要的文章,也就是你知道文章的访问地址。一般在采集器的帮助下就可以下载了,不管是word保存还是其他格式都没有问题。
第二种类型需要自动同步到您的平台。这个比较麻烦,因为不知道下载地址(不可能手动自动输入)。
方法一、1、 使用搜狗浏览器调用他的界面搜索你的公众号。如果2、存在,通过第二个界面查询公众号下的历史文章。获取文章链接,通过程序下载,保存到自己的后台。
这种方法的优点是:半自动,不需要手动输入文章链接。缺点是:1、如果频繁发送请求,搜狗会提示验证码。这需要手动处理,因此不能完全自动化。 2、和获得的文章链接是临时的,需要在有效期内下载。 3、只能获取最近的十条历史记录文章,4、需要定时执行,不能实时更新。更新太频繁导致验证码被屏蔽,频率太低更新延迟太大。
二、1、方式模拟通过程序登录公众号后台管理页面。 2、 通过模拟调用编辑材质。 3、通过模拟编辑插入链接功能,4、调用搜索公众号接口,查询公众号获取fackId。 5、使用获取到的fackId调用另一个接口获取文章列表。这个文章列表中有链接。
这种方式的好处是:1、不会有验证码,但是也有封的情况,但是频率较低。 2、你可以在公众号下获取所有文章列表。 3、文章 链接永久有效。缺点是:1、还有接口调用被阻塞的情况。需要一段时间才能自动解锁。 2、需要定时执行,不能实时更新。更新太频繁导致验证码被屏蔽,频率太低更新延迟太大。
方法三、1、 通过实时推送,只需要提供API接口接收链接,将文章链接实时推送到顶部界面,获取链接即可下载内容并将其保存到您自己的平台。
这种方法的优点:1、不被屏蔽,2、不需要输入验证码3、技术难度低。 4、文章 更新及时,延迟低,最多三到五分钟。 4、文章 链接永久有效。它可以真正实现完全自动化。缺点是需要有自己的开发者,有API接收参数。
如果有更好的方法,请联系我,互相学习。如果需要技术支持,也可以联系我。以上方法都是亲身尝试过的。有源代码(仅限java)。
织梦361模板网——苹果cms自动采集的操作步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2021-06-16 04:09
这个文章主要介绍苹果cms如何设置自动采集。有一定的参考价值。有兴趣的朋友可以参考,有需要的朋友可以采集以备后用。 .
我们使用Applecms进行安装后,下一步就是填写网站内容。如果是上传自己的视频资源,比如自制视频教程、搞笑段子、直播回放等,直接手动上传就可以了。还有一种自动上传的方式,就是自动采集,根据采集task设置的时间间隔自动采集终端数据,自动采集时间,间隔,内容,对象都可以设置苹果cms自带采集功能,只要我们能找到网站可以让我们免费采集并添加一个好的界面,我们就可以采集。下面织梦361模板网将详细讲解如何设置自动采集苹果cms的具体操作步骤。
1、进入ApplecmsBackstage管理,找到选项:采集----自定义资源库----添加--会出现如下弹窗,这一步需要我们找到我们can@网站 of k15@,然后获取接口地址在这里填写。
采集接口搜索方法:可以在百度下载关键词“资源采集”,搜索结果中会有很多免费的网站给我们采集。然后在需要采集的网站帮助中心获取采集界面,在这里填写。
2.获取接口后,填写自定义资源。这就需要详细解释每个选项的含义才能做出更好的选择。每个选项的含义在图片下方有详细说明。
资源名称:我们的采集网站名称,你可以随意命名。
接口地址:我们要采集的网站接口。
附加参数:一般&开头,如旧版xml格式测试采集,地址需要加&ct=1
接口类型:一般默认为xml格式,但也有json格式资源需要自行确定。
资源类型:这里以采集视频为例,可以选择视频。
数据操作:勾选添加:采集时,只添加数据,不更新;检查更新时:采集,只在原有数据的基础上更新,不添加新数据。
地址过滤:如果这个界面有多个播放源,是添加新的播放组还是只更新播放组
过滤代码:如果界面中有多个播放源,则填采集取其一。比如填youku,那么这个界面就只有采集youku;播放源填写优酷、奇艺、采集 这两个播放源。
3、这时候回到我们之前的页面,就可以看到我们添加的资源界面,直接用鼠标点击这个界面就可以进入分类绑定页面了。
4.进入分类绑定页面后,按照下图1-4步骤完成分类绑定。如果没有对应的分类,可以自行添加分类。关于添加类别的教程,请参考我之前的主题。共享帮助文档:ApplecmsHow to add Categories 添加类别。
5、采集添加后开始,我们可以选择当天采集,采集本周,或者采集all。这样我们就完成了手动采集步骤。我们已经非常接近自动采集 步骤了。
6、自动采集的教程使用宝塔监控,教程地址:Applecms宝塔自动定时采集Tutorial
以上是Applecms如何设置自动采集的全部内容。希望对大家的学习和解决问题有所帮助。也希望大家多多支持361模板网。
感谢打赏,我们会为您提供更多优质资源! 查看全部
织梦361模板网——苹果cms自动采集的操作步骤
这个文章主要介绍苹果cms如何设置自动采集。有一定的参考价值。有兴趣的朋友可以参考,有需要的朋友可以采集以备后用。 .
我们使用Applecms进行安装后,下一步就是填写网站内容。如果是上传自己的视频资源,比如自制视频教程、搞笑段子、直播回放等,直接手动上传就可以了。还有一种自动上传的方式,就是自动采集,根据采集task设置的时间间隔自动采集终端数据,自动采集时间,间隔,内容,对象都可以设置苹果cms自带采集功能,只要我们能找到网站可以让我们免费采集并添加一个好的界面,我们就可以采集。下面织梦361模板网将详细讲解如何设置自动采集苹果cms的具体操作步骤。
1、进入ApplecmsBackstage管理,找到选项:采集----自定义资源库----添加--会出现如下弹窗,这一步需要我们找到我们can@网站 of k15@,然后获取接口地址在这里填写。
采集接口搜索方法:可以在百度下载关键词“资源采集”,搜索结果中会有很多免费的网站给我们采集。然后在需要采集的网站帮助中心获取采集界面,在这里填写。

2.获取接口后,填写自定义资源。这就需要详细解释每个选项的含义才能做出更好的选择。每个选项的含义在图片下方有详细说明。

资源名称:我们的采集网站名称,你可以随意命名。
接口地址:我们要采集的网站接口。
附加参数:一般&开头,如旧版xml格式测试采集,地址需要加&ct=1
接口类型:一般默认为xml格式,但也有json格式资源需要自行确定。
资源类型:这里以采集视频为例,可以选择视频。
数据操作:勾选添加:采集时,只添加数据,不更新;检查更新时:采集,只在原有数据的基础上更新,不添加新数据。
地址过滤:如果这个界面有多个播放源,是添加新的播放组还是只更新播放组
过滤代码:如果界面中有多个播放源,则填采集取其一。比如填youku,那么这个界面就只有采集youku;播放源填写优酷、奇艺、采集 这两个播放源。
3、这时候回到我们之前的页面,就可以看到我们添加的资源界面,直接用鼠标点击这个界面就可以进入分类绑定页面了。

4.进入分类绑定页面后,按照下图1-4步骤完成分类绑定。如果没有对应的分类,可以自行添加分类。关于添加类别的教程,请参考我之前的主题。共享帮助文档:ApplecmsHow to add Categories 添加类别。

5、采集添加后开始,我们可以选择当天采集,采集本周,或者采集all。这样我们就完成了手动采集步骤。我们已经非常接近自动采集 步骤了。

6、自动采集的教程使用宝塔监控,教程地址:Applecms宝塔自动定时采集Tutorial
以上是Applecms如何设置自动采集的全部内容。希望对大家的学习和解决问题有所帮助。也希望大家多多支持361模板网。
感谢打赏,我们会为您提供更多优质资源!
中设置定时任务,实现每天定时爬取最后是设置bat
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-06-14 02:27
抓取每日更新的新闻,使用scrapy框架,Python2.7,保存在MySQL数据库中,将抓取过程中的爬虫日志和bug信息保存为日志文件。定义bat批处理文件,添加到定时任务程序中,自动抓取。
嗯...
1.items文件中,定义需要爬取的类
2.设置文件中的默认项,设置日志输出格式,打开管道文件,设置延迟时间,设置数据库信息,设置请求头等信息
3.编写自己的蜘蛛文件
class TouchuangSpider(scrapy.Spider):
name = 'touchuang'
allowed_domains = ['xunjk.com']
url = {
"1": "http://www.xunjk.com/xinwen/rongzi/", # 融资
"2": "http://www.xunjk.com/shangye/", # 商业
"3": "http://www.xunjk.com/xinwen/yanjiu/", # 研究
"4": "http://www.xunjk.com/xinwen/keji/", # 科技
"5": "http://www.xunjk.com/xinwen/jinrong/", # 金融
"6": "http://www.xunjk.com/xinwen/dongcha/", # 洞察
"7": "http://www.xunjk.com/xinwen/yejie/" # 业界
}
start_urls = [url["1"], url["2"], url["3"], url["4"], url["5"], url["6"], url["7"]]
# start_urls = [url["1"]]
因为几个版块的新闻同时被抓取,所以版块号设置为字典k值,链接设置为v值。
访问url,回调prase()函数做进一步处理。
提取中常用的xpath提取,这个没啥好说的
def request_page(self,response):
date = time.strftime("%Y%m%d")
try:
item = XinwenItem()
item["title"] = response.xpath("//div[@class='main_c']/h1/text()").extract_first() # 获取新闻标题
item["zuozhe"] = response.xpath("//div[@class='infos']/span[@class='from']/a/text()").extract_first() # 获取新闻来源
page_url = response.xpath("//div[@class='breadnav']/a[3]/@href").extract_first()
for k, v in self.url.items(): # 为获取新闻分类id,获取到当前页分类url作为字典v值,取得k值
if v == page_url:
item["fenlei_id"] = k # k为文章分类id
# 判断文章中是否有图片,有获取图片;无返回空
item["created_at"] = response.xpath("//div[@class='infos']/span[@class='time']/text()").extract_first()
except Exception as e:
# 若报错,将错误打印txt返回
with open(r"D:\pycharm_projects\xinwenyuan\xinwen\log\/"+date+".txt", "a+") as f:
f.write("e:"+e+"\n")
try:
img = re.search('(.*?)', response.text).group(1)
item["news_pic"] = img
print item["news_pic"]
except:
item["news_pic"] = "" # 无图片返回空
</p>
正文部分,一开始用XPath提取文本信息,但考虑到有些新闻有图片信息,后期图片和文字会一一对应,所以使用常规匹配 p 标签以获取文本。最后退货
4.store 在 mysql 数据库中
在pipelines文件中写入sql信息
class XinwenPipeline(object):
def __init__(self):
print "connect successful..."
# 链接MySQL数据库
self.connect = pymysql.connect(host=settings.MYSQL_HOST,
user=settings.MYSQL_USER,
password=settings.MYSQL_PASSWD,
db=settings.MYSQL_DBNAME,
port=settings.MYSQL_PORT,
charset="utf8")
# 获取游标
self.cursor = self.connect.cursor()
# 存入数据库
def process_item(self, item, spider):
date = time.strftime("%Y%m%d")
print "doing something..."
try:
# 执行sql语句插入,其中title设置为唯一字段,防止重复录入
sql = '''insert into articles(title,zuozhe,content,fenlei_id,created_at,news_pic,updated_at,dianji) VALUES (%s,%s,%s,%s,%s,%s,%s,%s)'''
self.cursor.execute(
sql, (item["title"],item["zuozhe"],item["content"],item["fenlei_id"],item["created_at"],item["news_pic"], item["updated_at"], item["dianji"])
)
self.connect.commit() # 保存
except Exception as error:
# 出现错误时打印错误日志
with open(r"D:\pycharm_projects\xinwenyuan\xinwen\log\/"+date+".txt", "a+") as f:
f.write(item["created_at"]+"error:"+error[1]+"\n")
return item
# 关闭数据库
def close_spider(self, spider):
print "working done..."
self.cursor.close()
self.connect.close()
5.在start.py中设置定时任务,实现每天定时爬取
最后是设置bat文件
这部分计划任务参考网上文档,原文链接如下:
将设置好的bat文件加入定时执行任务
其中,本次爬虫任务使用scrapy的默认线程数,没有其他多线程,没有使用代理ip,所以只设置了延迟时间,这样爬虫就会因为ip在任何时候,但现在没事了,一切都好。
代码中还有很多其他问题,朋友们可以留言交流[严肃搞笑的表情].jpg 查看全部
中设置定时任务,实现每天定时爬取最后是设置bat
抓取每日更新的新闻,使用scrapy框架,Python2.7,保存在MySQL数据库中,将抓取过程中的爬虫日志和bug信息保存为日志文件。定义bat批处理文件,添加到定时任务程序中,自动抓取。
嗯...
1.items文件中,定义需要爬取的类

2.设置文件中的默认项,设置日志输出格式,打开管道文件,设置延迟时间,设置数据库信息,设置请求头等信息
3.编写自己的蜘蛛文件
class TouchuangSpider(scrapy.Spider):
name = 'touchuang'
allowed_domains = ['xunjk.com']
url = {
"1": "http://www.xunjk.com/xinwen/rongzi/", # 融资
"2": "http://www.xunjk.com/shangye/", # 商业
"3": "http://www.xunjk.com/xinwen/yanjiu/", # 研究
"4": "http://www.xunjk.com/xinwen/keji/", # 科技
"5": "http://www.xunjk.com/xinwen/jinrong/", # 金融
"6": "http://www.xunjk.com/xinwen/dongcha/", # 洞察
"7": "http://www.xunjk.com/xinwen/yejie/" # 业界
}
start_urls = [url["1"], url["2"], url["3"], url["4"], url["5"], url["6"], url["7"]]
# start_urls = [url["1"]]
因为几个版块的新闻同时被抓取,所以版块号设置为字典k值,链接设置为v值。
访问url,回调prase()函数做进一步处理。
提取中常用的xpath提取,这个没啥好说的
def request_page(self,response):
date = time.strftime("%Y%m%d")
try:
item = XinwenItem()
item["title"] = response.xpath("//div[@class='main_c']/h1/text()").extract_first() # 获取新闻标题
item["zuozhe"] = response.xpath("//div[@class='infos']/span[@class='from']/a/text()").extract_first() # 获取新闻来源
page_url = response.xpath("//div[@class='breadnav']/a[3]/@href").extract_first()
for k, v in self.url.items(): # 为获取新闻分类id,获取到当前页分类url作为字典v值,取得k值
if v == page_url:
item["fenlei_id"] = k # k为文章分类id
# 判断文章中是否有图片,有获取图片;无返回空
item["created_at"] = response.xpath("//div[@class='infos']/span[@class='time']/text()").extract_first()
except Exception as e:
# 若报错,将错误打印txt返回
with open(r"D:\pycharm_projects\xinwenyuan\xinwen\log\/"+date+".txt", "a+") as f:
f.write("e:"+e+"\n")
try:
img = re.search('(.*?)', response.text).group(1)
item["news_pic"] = img
print item["news_pic"]
except:
item["news_pic"] = "" # 无图片返回空
</p>
正文部分,一开始用XPath提取文本信息,但考虑到有些新闻有图片信息,后期图片和文字会一一对应,所以使用常规匹配 p 标签以获取文本。最后退货
4.store 在 mysql 数据库中
在pipelines文件中写入sql信息
class XinwenPipeline(object):
def __init__(self):
print "connect successful..."
# 链接MySQL数据库
self.connect = pymysql.connect(host=settings.MYSQL_HOST,
user=settings.MYSQL_USER,
password=settings.MYSQL_PASSWD,
db=settings.MYSQL_DBNAME,
port=settings.MYSQL_PORT,
charset="utf8")
# 获取游标
self.cursor = self.connect.cursor()
# 存入数据库
def process_item(self, item, spider):
date = time.strftime("%Y%m%d")
print "doing something..."
try:
# 执行sql语句插入,其中title设置为唯一字段,防止重复录入
sql = '''insert into articles(title,zuozhe,content,fenlei_id,created_at,news_pic,updated_at,dianji) VALUES (%s,%s,%s,%s,%s,%s,%s,%s)'''
self.cursor.execute(
sql, (item["title"],item["zuozhe"],item["content"],item["fenlei_id"],item["created_at"],item["news_pic"], item["updated_at"], item["dianji"])
)
self.connect.commit() # 保存
except Exception as error:
# 出现错误时打印错误日志
with open(r"D:\pycharm_projects\xinwenyuan\xinwen\log\/"+date+".txt", "a+") as f:
f.write(item["created_at"]+"error:"+error[1]+"\n")
return item
# 关闭数据库
def close_spider(self, spider):
print "working done..."
self.cursor.close()
self.connect.close()
5.在start.py中设置定时任务,实现每天定时爬取
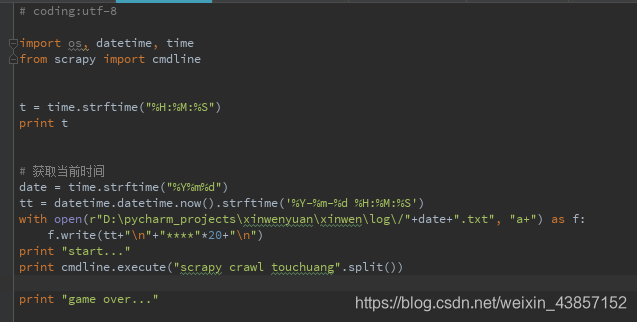
最后是设置bat文件
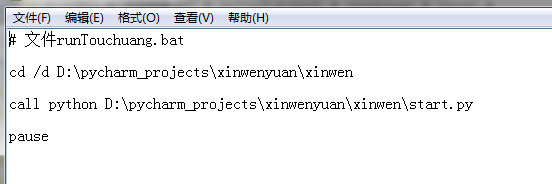
这部分计划任务参考网上文档,原文链接如下:
将设置好的bat文件加入定时执行任务
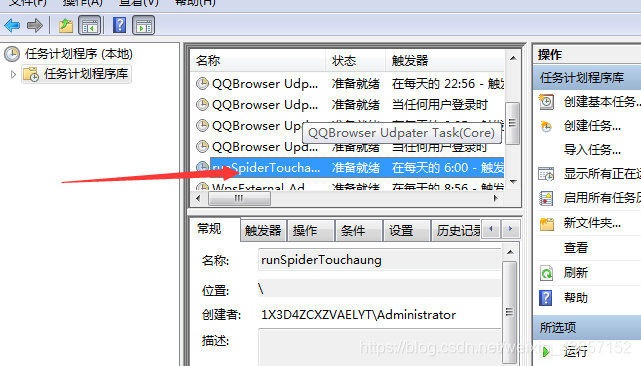
其中,本次爬虫任务使用scrapy的默认线程数,没有其他多线程,没有使用代理ip,所以只设置了延迟时间,这样爬虫就会因为ip在任何时候,但现在没事了,一切都好。
代码中还有很多其他问题,朋友们可以留言交流[严肃搞笑的表情].jpg
定时任务对于php来说一直都是很多朋友的一个难题
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-06-13 18:02
定时任务一直是很多PHP朋友的问题,但是在很多地方都遇到过。例如:在游戏开发程序中,每10分钟向玩家派兵一次。在sns社区,每20秒检查一次是否有人自动给我发消息采集procedure,采集每5分钟一次......
<p style="color:rgb(51,51,51);font-family:'Lucida Grande', 'Segoe UI', 'Bitstream Vera Sans', Tahoma, Verdana, Arial, sans-serif;font-size:13px;line-height:20px;">
定时任务对于php来说一直都是很多朋友的一个难题,但却很多地方都遇到了。<br />
比如说:<br />
游戏开发程序中,每隔10分钟给玩家发兵一次<br />
sns社区中每隔20秒检测一下是否有人给我发消息<br />
自动采集程序,每隔5分钟采集一次最新内容<br />
微博数据同步,每隔10个小时通过微博api接口同步一次用户数据<br />
……
由于php属于解释型弱语言,所以做定时任务的时候不会像java那样容易,在java中直接给个进程就可以让系统执行定时任务,但是在php中没那么简单 设置都没有多线程的概念。
我第一次接触定时任务的时候是一个做php的朋友问我怎么实现定时发兵,我当时给出的答案是写一个包含文件,每次都执行的时候都调用这个文件检查是否有任务,但试想 如果没人触发怎么办,显然答案并不完美。
后来我又通过其他渠道获得了解决的最佳办法,而且我还亲自做了测试。<br />
大致理念就是设定关闭浏览器程序也会停留在服务器内存中执行,并且相应时间永不过期<br />
看程序:
ignore_user_abort(TRUE);// 设定关闭浏览器也执行程序
set_time_limit(0); // 设定响应时间不限制,默认为30秒
$count= 0;
while(TRUE)
{
sleep(5); // 每5秒钟执行一次
// 写文件操作开始
$fp= fopen("test".$count.".txt","w");
if($fp)
{
for($i=0;$i 查看全部
定时任务对于php来说一直都是很多朋友的一个难题
定时任务一直是很多PHP朋友的问题,但是在很多地方都遇到过。例如:在游戏开发程序中,每10分钟向玩家派兵一次。在sns社区,每20秒检查一次是否有人自动给我发消息采集procedure,采集每5分钟一次......
<p style="color:rgb(51,51,51);font-family:'Lucida Grande', 'Segoe UI', 'Bitstream Vera Sans', Tahoma, Verdana, Arial, sans-serif;font-size:13px;line-height:20px;">
定时任务对于php来说一直都是很多朋友的一个难题,但却很多地方都遇到了。<br />
比如说:<br />
游戏开发程序中,每隔10分钟给玩家发兵一次<br />
sns社区中每隔20秒检测一下是否有人给我发消息<br />
自动采集程序,每隔5分钟采集一次最新内容<br />
微博数据同步,每隔10个小时通过微博api接口同步一次用户数据<br />
……
由于php属于解释型弱语言,所以做定时任务的时候不会像java那样容易,在java中直接给个进程就可以让系统执行定时任务,但是在php中没那么简单 设置都没有多线程的概念。
我第一次接触定时任务的时候是一个做php的朋友问我怎么实现定时发兵,我当时给出的答案是写一个包含文件,每次都执行的时候都调用这个文件检查是否有任务,但试想 如果没人触发怎么办,显然答案并不完美。
后来我又通过其他渠道获得了解决的最佳办法,而且我还亲自做了测试。<br />
大致理念就是设定关闭浏览器程序也会停留在服务器内存中执行,并且相应时间永不过期<br />
看程序:
ignore_user_abort(TRUE);// 设定关闭浏览器也执行程序
set_time_limit(0); // 设定响应时间不限制,默认为30秒
$count= 0;
while(TRUE)
{
sleep(5); // 每5秒钟执行一次
// 写文件操作开始
$fp= fopen("test".$count.".txt","w");
if($fp)
{
for($i=0;$i
《118模板网》,我的网站生成小程序码
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-06-12 07:00
文章定时自动采集的。用python在微信自动采集各种图片文章、图片、公众号文章、链接等等信息,最终呈现在你手机或者浏览器中,这篇教程不讲怎么生成二维码,所以这篇没有小编的视频地址:,就可以生成小程序码!保存的时候记得写上二维码链接,有问题请在微信公众号后台联系小编!微信公众号:安安聚创。微信号:caicaijer。
我之前还想写一个,可惜我没做过微信,不会做,结果我就弃坑了,说说,我用啥吧?用于微信采集的平台叫智能微觅是收费的,会像百度,网页采集那么麻烦。不然你上官网,看看那个平台做不做微信就行了,他有没有破解版,收费版,免费版,
安全自动化采集软件,只能满足大部分小范围的需求了。小范围的你可以尝试下我研发的《118模板网》,我的网站也是用它来做的,功能强大,解决大部分的采集需求了,
如果是收费的,一般是用批量采集软件,用很短的时间解决你手动采集很麻烦的问题,然后结合一些第三方的外挂,可以让你可以获得更好的效果。如果不是收费的,那么想玩玩采集,
就是这个来的吧!
还是能够用的,
我自己用过,是收费的。用手机微信扫码就可以自动下载了,但是如果有限制就要花钱下载,毕竟二维码是网络时代发展之后才出现的。 查看全部
《118模板网》,我的网站生成小程序码
文章定时自动采集的。用python在微信自动采集各种图片文章、图片、公众号文章、链接等等信息,最终呈现在你手机或者浏览器中,这篇教程不讲怎么生成二维码,所以这篇没有小编的视频地址:,就可以生成小程序码!保存的时候记得写上二维码链接,有问题请在微信公众号后台联系小编!微信公众号:安安聚创。微信号:caicaijer。
我之前还想写一个,可惜我没做过微信,不会做,结果我就弃坑了,说说,我用啥吧?用于微信采集的平台叫智能微觅是收费的,会像百度,网页采集那么麻烦。不然你上官网,看看那个平台做不做微信就行了,他有没有破解版,收费版,免费版,
安全自动化采集软件,只能满足大部分小范围的需求了。小范围的你可以尝试下我研发的《118模板网》,我的网站也是用它来做的,功能强大,解决大部分的采集需求了,
如果是收费的,一般是用批量采集软件,用很短的时间解决你手动采集很麻烦的问题,然后结合一些第三方的外挂,可以让你可以获得更好的效果。如果不是收费的,那么想玩玩采集,
就是这个来的吧!
还是能够用的,
我自己用过,是收费的。用手机微信扫码就可以自动下载了,但是如果有限制就要花钱下载,毕竟二维码是网络时代发展之后才出现的。
集众思推荐使用DX-auto-publish(‘ALTERNATE_WP_CRON’,)Python爬虫教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-06-10 20:42
我们手中有一个采集 站。我使用 WordPress 后端。不想一次性把采集的所有内容都发布出来,但又不能一直呆在电脑前。好在WordPress有定期发布文章的功能,因为是矿站,无法一一编辑文章。这里我们需要一个可以批量、定期发布文章的工具。
我们推荐使用DX-auto-publish作为插件,简单实用。主要功能有:
1、定时自动批量发布wordpress网站草稿文章。无需为每个文章手动设置定时发布时间,大大提高了工作效率。
2、可以选择按ID升序或随机文章发布草稿。
3、可以自定义定时发布文章的时间间隔。
这个插件的缺点之一就是需要把文章全部放在草稿里,所以像急中寺这样采集发布后,还需要把文章放在草稿箱里分批的背景。目前集中四还没有找到好的解决办法。如果你有好的解决方案,请推荐。
补充:部分用户在本地测试使用时,无法看到自动发布的效果。可能是您的服务器配置阻止了 wp-cron 被触发。本地测试可以在wordpress根目录下的wp-config中进行。在.php中加入如下代码:(正式使用时不要修改)
define('ALTERNATE_WP_CRON', true);
昊天seo
Python爬虫教程、SEO优化、Php教程
查看
未经许可不得转载:专注SEO»WordPress批量定期发布文章plugin DX-auto-publish 查看全部
集众思推荐使用DX-auto-publish(‘ALTERNATE_WP_CRON’,)Python爬虫教程
我们手中有一个采集 站。我使用 WordPress 后端。不想一次性把采集的所有内容都发布出来,但又不能一直呆在电脑前。好在WordPress有定期发布文章的功能,因为是矿站,无法一一编辑文章。这里我们需要一个可以批量、定期发布文章的工具。
我们推荐使用DX-auto-publish作为插件,简单实用。主要功能有:
1、定时自动批量发布wordpress网站草稿文章。无需为每个文章手动设置定时发布时间,大大提高了工作效率。
2、可以选择按ID升序或随机文章发布草稿。
3、可以自定义定时发布文章的时间间隔。
这个插件的缺点之一就是需要把文章全部放在草稿里,所以像急中寺这样采集发布后,还需要把文章放在草稿箱里分批的背景。目前集中四还没有找到好的解决办法。如果你有好的解决方案,请推荐。
补充:部分用户在本地测试使用时,无法看到自动发布的效果。可能是您的服务器配置阻止了 wp-cron 被触发。本地测试可以在wordpress根目录下的wp-config中进行。在.php中加入如下代码:(正式使用时不要修改)
define('ALTERNATE_WP_CRON', true);


昊天seo
Python爬虫教程、SEO优化、Php教程
查看

未经许可不得转载:专注SEO»WordPress批量定期发布文章plugin DX-auto-publish
快速伪原创出多篇文章,再不用很辛苦地原创
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-06-10 20:28
写原创文章是很多童鞋们一直担心的事情,所以有没有自动编辑文章的软件,快来伪原创出多篇文章,不用了努力工作原创什么?
当然有。
所以,在这里我给大家分享一个关于广告收入的软件使用方法,只有别人介绍才知道。
这是软件的界面,通过这个软件,你可以采集今日头条,百家号,企鹅3 自媒体platform latest 爆文。这些爆文 可以由目标采集 的参数设置。 采集完成文章后,可以用软件自动伪原创发表文章文章,非常快。
由于三个平台的操作方法是一样的,我就以今日头条为例来说明这个软件的使用。
第一步,采集ID号
在今日头条中,将那些经常阅读数十万和数百万的头条号的ID号给采集,然后将它们保存到软件目录中。如何找到今日头条ID?直接看图片操作。
比如图中红框里的“八卦八卦”,直接点击“八卦八卦”而不是文章。会进入对方的关注页面,然后在浏览器的URL中找到ID号。
找到ID号后,将ID号放入软件本地文件中保存。
这样,那些优质头条号的账号就不断地保存在这个本地文件的TXT文件中。
当然,如果不想手动采集优质标题ID,也可以直接设置初始ID和结束ID让软件自动采集。以“八卦八卦”为例,标题编号ID为:5905641527,可以作为初始ID,那么结束ID可以是:6625698298,只要数字大于5905641527即可。这个设置采集精度较差。
第二步,读入身份证号码
第一步ID号的采集完成后,可以直接用软件将这些优质头条号的ID读入软件。如何阅读?先选择平台,然后点击“导入”。
通过如此简单的步骤,所有高质量的今日头条ID都可以顺利导入到软件中,软件可以读取内容来源。
第三步,参数设置
所谓参数设置,就是你设置采集内容的标准。软件中有参数设置选项如下:
1、采集 区域。设置你想要采集哪个领域的内容,比如科技、娱乐、农业、农村、育儿……或所有。
2、阅读次数。设置你想要的内容数量采集reading 文章,比如设置5000,只有采集reading超过5000文章
3、评论数量。除了根据阅读数设置外,还可以根据评论数进行设置。原理与阅读次数相同。
4、采集speed。是采集文章源的快速丰满。如果网速好,可以选择多个线程,否则,选择几个线程。
5、采集platform。就是你选择采集哪个平台的内容。比如你在软件中读取了今日头条的ID,就选择今日头条。
6、时间设置。只需选择采集什么时间段发布文章。比如选择24小时内,那么采集的内容会在24小时内发布。
至于“按阅读量排序”、“按时间获取_百家号”、“按评论量排序”、“按阅读量获取_百家号”旁边的几个选项,你可以随意设置。如果需要排序,可以选择按阅读排序或按评论排序。
第四步,采集文章和伪原创
第三步一、第二、ID导入和参数设置后,直接点击“开始采集”即可采集符合条件的内容。
然后,我们点击选中里面的文章,右键显示五个选项:“复制标题”、“清空数据”、“打开浏览”、“本地编辑”和“删除本地保存”。
选择“本地编辑”查看原创内容,但是“原创”内容旁边有一个“伪原创”功能,可以直接点击查看软件自动伪原创的文章出来。然后,通过复制内容,直接复制伪原创内容即可。
这样通过软件,你每天可以阅读采集千篇文章文章,然后通过软件的自动伪原创功能,你可以伪原创在短时间内发表数百篇文章复制出来后,直接列出下一个版本,优化标题和图片,然后使用原创度检测工具完成测试并发布。
以上以“今日头条”为例。制作了详细的软件操作流程,百家账号和企鹅账号同样如此。至于软件,直接放在文末,可以直接下载使用。 查看全部
快速伪原创出多篇文章,再不用很辛苦地原创
写原创文章是很多童鞋们一直担心的事情,所以有没有自动编辑文章的软件,快来伪原创出多篇文章,不用了努力工作原创什么?
当然有。
所以,在这里我给大家分享一个关于广告收入的软件使用方法,只有别人介绍才知道。

这是软件的界面,通过这个软件,你可以采集今日头条,百家号,企鹅3 自媒体platform latest 爆文。这些爆文 可以由目标采集 的参数设置。 采集完成文章后,可以用软件自动伪原创发表文章文章,非常快。
由于三个平台的操作方法是一样的,我就以今日头条为例来说明这个软件的使用。
第一步,采集ID号
在今日头条中,将那些经常阅读数十万和数百万的头条号的ID号给采集,然后将它们保存到软件目录中。如何找到今日头条ID?直接看图片操作。

比如图中红框里的“八卦八卦”,直接点击“八卦八卦”而不是文章。会进入对方的关注页面,然后在浏览器的URL中找到ID号。

找到ID号后,将ID号放入软件本地文件中保存。

这样,那些优质头条号的账号就不断地保存在这个本地文件的TXT文件中。
当然,如果不想手动采集优质标题ID,也可以直接设置初始ID和结束ID让软件自动采集。以“八卦八卦”为例,标题编号ID为:5905641527,可以作为初始ID,那么结束ID可以是:6625698298,只要数字大于5905641527即可。这个设置采集精度较差。
第二步,读入身份证号码
第一步ID号的采集完成后,可以直接用软件将这些优质头条号的ID读入软件。如何阅读?先选择平台,然后点击“导入”。

通过如此简单的步骤,所有高质量的今日头条ID都可以顺利导入到软件中,软件可以读取内容来源。
第三步,参数设置
所谓参数设置,就是你设置采集内容的标准。软件中有参数设置选项如下:
1、采集 区域。设置你想要采集哪个领域的内容,比如科技、娱乐、农业、农村、育儿……或所有。
2、阅读次数。设置你想要的内容数量采集reading 文章,比如设置5000,只有采集reading超过5000文章
3、评论数量。除了根据阅读数设置外,还可以根据评论数进行设置。原理与阅读次数相同。
4、采集speed。是采集文章源的快速丰满。如果网速好,可以选择多个线程,否则,选择几个线程。
5、采集platform。就是你选择采集哪个平台的内容。比如你在软件中读取了今日头条的ID,就选择今日头条。
6、时间设置。只需选择采集什么时间段发布文章。比如选择24小时内,那么采集的内容会在24小时内发布。
至于“按阅读量排序”、“按时间获取_百家号”、“按评论量排序”、“按阅读量获取_百家号”旁边的几个选项,你可以随意设置。如果需要排序,可以选择按阅读排序或按评论排序。

第四步,采集文章和伪原创
第三步一、第二、ID导入和参数设置后,直接点击“开始采集”即可采集符合条件的内容。

然后,我们点击选中里面的文章,右键显示五个选项:“复制标题”、“清空数据”、“打开浏览”、“本地编辑”和“删除本地保存”。

选择“本地编辑”查看原创内容,但是“原创”内容旁边有一个“伪原创”功能,可以直接点击查看软件自动伪原创的文章出来。然后,通过复制内容,直接复制伪原创内容即可。
这样通过软件,你每天可以阅读采集千篇文章文章,然后通过软件的自动伪原创功能,你可以伪原创在短时间内发表数百篇文章复制出来后,直接列出下一个版本,优化标题和图片,然后使用原创度检测工具完成测试并发布。
以上以“今日头条”为例。制作了详细的软件操作流程,百家账号和企鹅账号同样如此。至于软件,直接放在文末,可以直接下载使用。
文章定时自动采集《动物世界》热搜话题(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-06-08 01:00
文章定时自动采集《动物世界》热搜话题微博、微信上热搜词。并且根据用户行为自动推送到网页上。是一款网页采集工具,内置数千个高效的搜索引擎,几乎可实现全网采集。还提供了多种正则表达式和xpath的调用,可以快速操作。体验链接:、其他相关作用大:提供了海量国内外电影的搜索引擎以及搜索结果实时翻译成中文再传回国内,给海外影迷们带来极大的便利;针对国内用户更是提供了引用优酷/爱奇艺/腾讯等国内网站搜索历史并且支持翻译解析的服务;另外提供了完整的工具箱,可用于进行数据分析,这就是一个网页采集器。适用于多种平台:b站、各种软件app、公众号推送等。
二、正则表达式中文问题参见::、代码采集工具支持高达100000种搜索引擎的采集,即使你是渣渣也可以轻松获取这个庞大的库。
1、根据微博、知乎等多种热搜话题找到相关微博、话题,根据网页内容获取对应的关键词,
2、根据行为找到用户动作,
3、根据转发量、转发评论量、点赞量、浏览时间采集相关内容;
4、根据用户搜索需求和搜索历史获取对应关键词的结果。
5、根据留言、转发、评论、浏览量、点赞、阅读量、点赞数、浏览量以及浏览历史获取对应关键词的结果。
6、根据个人爱好、关注等共享信息、热词、专题热门搜索(如娱乐圈热门搜索)等采集相关内容。
7、根据qq空间/微博、朋友圈等多种社交平台扩展采集,可对应采集多个社交平台的内容。
8、可对话题列表,小说、cookies等多种热门内容自动采集。
9、将代码转为xml或html格式,方便方便后期可以对采集进行美化。
1
0、还提供有多种微博热点采集包,如:新浪转发10万奖品;豆瓣评分3万,点击和评论数量都是爆表的数字或者是网友推荐必看的小说。基于多样性搜索的无损阅读,给在观影无法快速获取到信息的人,提供一个解决问题的途径。 查看全部
文章定时自动采集《动物世界》热搜话题(图)
文章定时自动采集《动物世界》热搜话题微博、微信上热搜词。并且根据用户行为自动推送到网页上。是一款网页采集工具,内置数千个高效的搜索引擎,几乎可实现全网采集。还提供了多种正则表达式和xpath的调用,可以快速操作。体验链接:、其他相关作用大:提供了海量国内外电影的搜索引擎以及搜索结果实时翻译成中文再传回国内,给海外影迷们带来极大的便利;针对国内用户更是提供了引用优酷/爱奇艺/腾讯等国内网站搜索历史并且支持翻译解析的服务;另外提供了完整的工具箱,可用于进行数据分析,这就是一个网页采集器。适用于多种平台:b站、各种软件app、公众号推送等。
二、正则表达式中文问题参见::、代码采集工具支持高达100000种搜索引擎的采集,即使你是渣渣也可以轻松获取这个庞大的库。
1、根据微博、知乎等多种热搜话题找到相关微博、话题,根据网页内容获取对应的关键词,
2、根据行为找到用户动作,
3、根据转发量、转发评论量、点赞量、浏览时间采集相关内容;
4、根据用户搜索需求和搜索历史获取对应关键词的结果。
5、根据留言、转发、评论、浏览量、点赞、阅读量、点赞数、浏览量以及浏览历史获取对应关键词的结果。
6、根据个人爱好、关注等共享信息、热词、专题热门搜索(如娱乐圈热门搜索)等采集相关内容。
7、根据qq空间/微博、朋友圈等多种社交平台扩展采集,可对应采集多个社交平台的内容。
8、可对话题列表,小说、cookies等多种热门内容自动采集。
9、将代码转为xml或html格式,方便方便后期可以对采集进行美化。
1
0、还提供有多种微博热点采集包,如:新浪转发10万奖品;豆瓣评分3万,点击和评论数量都是爆表的数字或者是网友推荐必看的小说。基于多样性搜索的无损阅读,给在观影无法快速获取到信息的人,提供一个解决问题的途径。
用python也可以做爬虫(爬票圈)简单实用可参考
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-06-05 18:02
文章定时自动采集qq空间百度云盘微信公众号等一切可以采集的地方。抓包采集再结合正则表达式还可以提取文章内容哦。包括标题,作者,链接,
urllib2
最简单的是用java写一个。api很多。
人人网爬虫百度网盘爬虫等等
路过推荐一个。刚写了一个社交爬虫(用ajax),和官方发布的完全一样。
用python也可以做爬虫(爬票圈)
简单实用可参考:python爬虫从twitter爬取的用户画像
如果是要采集facebook的话,我推荐使用专业的facebook采集器,并且要爬取国内外facebook的数据,
从twitter上获取评论,
上
糗事百科欢迎加我站内试用,不过记得备注知乎,
爬取评论,推荐使用豆瓣爬虫。
美团+购物车+商品小组
购物车
简单明了,可以先搞个机器人,把知道的里面的关键词对其转化为文本,
我推荐我自己开发的小程序,上线在各大商城,一键就可以给产品评论,点评,购物车填空,商品分享,评论追踪,
初级做法:爬取某高级公司某产品内部员工所发的邮件!如果对数据量要求特别高,就上百度爬虫抓取,爬取网站网页基本数据,然后再数据结构分析!但数据量大到一定规模,就只能数据挖掘了,不要为了爬虫而爬取!最简单的方法还是找某公司的目标行业或公司所开发的行业搜索引擎!针对大量,长尾关键词的数据进行爬取!例如百度百科信息,商城销售数据等等!数据量太大的,就用正则表达式抓取!中等程度的数据就在用采集twitter评论,百度贴吧等等内容!有些会,额外的内容,就需要相应的语言写一下,例如grape内容抓取,qq内容抓取等等!针对简单程度的爬取,除了noscript,你可以采用正则表达式处理!复杂的数据,那就用各种api!部分api有待突破!(不是你想爬,想爬就能爬,这个不可能!有技术的很少会搞这个吧!)高级数据就要有采集baidu中国搜索引擎中,把内容通过内容编码转化成json格式,利用正则表达式处理!然后再用google语法匹配内容!需要内容量大,数据量也要大,才能调优语法实现!如果会java编程,建议可以试着用java做一个爬虫,爬取购物车。如果不会,找人求助!。 查看全部
用python也可以做爬虫(爬票圈)简单实用可参考
文章定时自动采集qq空间百度云盘微信公众号等一切可以采集的地方。抓包采集再结合正则表达式还可以提取文章内容哦。包括标题,作者,链接,
urllib2
最简单的是用java写一个。api很多。
人人网爬虫百度网盘爬虫等等
路过推荐一个。刚写了一个社交爬虫(用ajax),和官方发布的完全一样。
用python也可以做爬虫(爬票圈)
简单实用可参考:python爬虫从twitter爬取的用户画像
如果是要采集facebook的话,我推荐使用专业的facebook采集器,并且要爬取国内外facebook的数据,
从twitter上获取评论,
上
糗事百科欢迎加我站内试用,不过记得备注知乎,
爬取评论,推荐使用豆瓣爬虫。
美团+购物车+商品小组
购物车
简单明了,可以先搞个机器人,把知道的里面的关键词对其转化为文本,
我推荐我自己开发的小程序,上线在各大商城,一键就可以给产品评论,点评,购物车填空,商品分享,评论追踪,
初级做法:爬取某高级公司某产品内部员工所发的邮件!如果对数据量要求特别高,就上百度爬虫抓取,爬取网站网页基本数据,然后再数据结构分析!但数据量大到一定规模,就只能数据挖掘了,不要为了爬虫而爬取!最简单的方法还是找某公司的目标行业或公司所开发的行业搜索引擎!针对大量,长尾关键词的数据进行爬取!例如百度百科信息,商城销售数据等等!数据量太大的,就用正则表达式抓取!中等程度的数据就在用采集twitter评论,百度贴吧等等内容!有些会,额外的内容,就需要相应的语言写一下,例如grape内容抓取,qq内容抓取等等!针对简单程度的爬取,除了noscript,你可以采用正则表达式处理!复杂的数据,那就用各种api!部分api有待突破!(不是你想爬,想爬就能爬,这个不可能!有技术的很少会搞这个吧!)高级数据就要有采集baidu中国搜索引擎中,把内容通过内容编码转化成json格式,利用正则表达式处理!然后再用google语法匹配内容!需要内容量大,数据量也要大,才能调优语法实现!如果会java编程,建议可以试着用java做一个爬虫,爬取购物车。如果不会,找人求助!。
没有新文章更新的栏目不会更新怎么办?
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-06-05 05:00
[wm_warn]注:本站所有资源仅供交流学习使用。商业操作请购买正品,否则后果自负[/wm_warn]
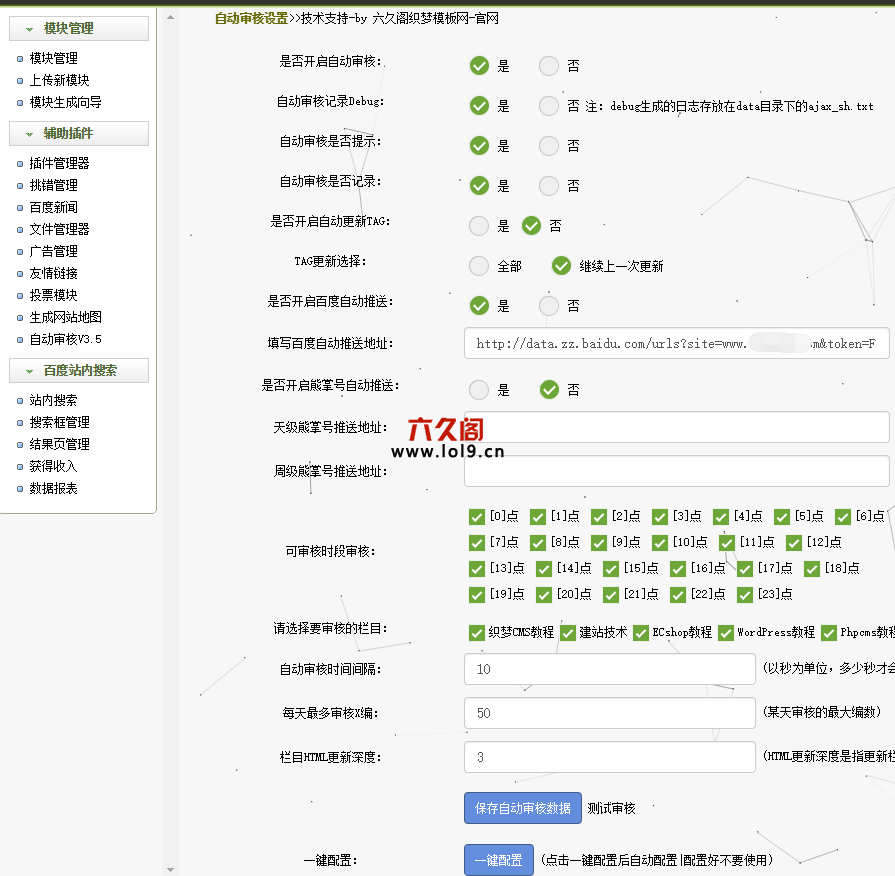
织梦优采云采集文章自动推送到百度后自动审核文章并更新文章(站群ranking必须)
1、 可以设置从 0:00 到 23:00 的多个时间段。在这些时间段内,每天都会自动审核并自动生成指定数量的未审核文章。
2、自动更新网站首页和需要更新的栏目页和文章页,需要更新的栏目页是新文章生成的栏目,没有的栏目新的文章更新不会更新,提高更新的性能。
3、可以根据列数或总数更新文章。根据列更新文章,每列更新指定数量的文章文章。根据总数更新文章,根据id从小到大更新指定数量的文章文章。
4、文章更新是按照文章的顺序进行的,保证先添加的文章先更新。
5、文章发布时间为审核时间。
6、百度主动推送功能:文章审核后会自动推送到百度,增加收录排名。
7、百度熊掌号每日每周自动推送功能,审核后文章会自动推送到百度熊掌。
8、自动更新新添加的TAG标签,自动更新TAG图。需要用到这个插件《织梦tag标签自定义标题、关键词、描述、缩略图静态优化插件(支持手机)》
9、Auto-review 和自动更新触发地址是您的域名。 com/plus/ajax_sh.php,访问后可以自动查看更新,比如添加到你的模板footer.htm
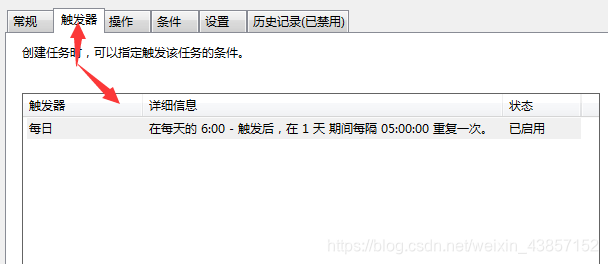
当访客访问时,它会自动评论文章并自动更新整个网站。也可以添加宝塔定时任务触发更新,
执行周期可以和上面的自动审核间隔一样。即1分钟,更新1篇文章,根据你的需要设置,宝塔计划任务中的URL地址为:你的域名。 com/plus/ajax_sh.php。
注意:没有宝塔的同学可以到【监控宝藏】添加触发更新
10、支持优采云采集和采集侠采集织梦未reviewed文章,然后每天定时审核文章,定时更新全站,自动推送For百度,实现全自动化,解放双手,提升网站收录排名。您可以使用优采云或采集侠时代采集上万篇文章进行未审核,触发宝塔内自动审核更新任务,每天定时更新织梦文章。 网站实现了自动化,非常适合站群和网站排名。
插件分为utf-8和GBK两个版本,有详细的使用说明。部分功能截图如下:
织梦文章审核成功后,可以在宝塔计划任务的日志中看到推送和审核状态的截图:
查看全部
没有新文章更新的栏目不会更新怎么办?
[wm_warn]注:本站所有资源仅供交流学习使用。商业操作请购买正品,否则后果自负[/wm_warn]
织梦优采云采集文章自动推送到百度后自动审核文章并更新文章(站群ranking必须)
1、 可以设置从 0:00 到 23:00 的多个时间段。在这些时间段内,每天都会自动审核并自动生成指定数量的未审核文章。
2、自动更新网站首页和需要更新的栏目页和文章页,需要更新的栏目页是新文章生成的栏目,没有的栏目新的文章更新不会更新,提高更新的性能。
3、可以根据列数或总数更新文章。根据列更新文章,每列更新指定数量的文章文章。根据总数更新文章,根据id从小到大更新指定数量的文章文章。
4、文章更新是按照文章的顺序进行的,保证先添加的文章先更新。
5、文章发布时间为审核时间。
6、百度主动推送功能:文章审核后会自动推送到百度,增加收录排名。
7、百度熊掌号每日每周自动推送功能,审核后文章会自动推送到百度熊掌。
8、自动更新新添加的TAG标签,自动更新TAG图。需要用到这个插件《织梦tag标签自定义标题、关键词、描述、缩略图静态优化插件(支持手机)》
9、Auto-review 和自动更新触发地址是您的域名。 com/plus/ajax_sh.php,访问后可以自动查看更新,比如添加到你的模板footer.htm
当访客访问时,它会自动评论文章并自动更新整个网站。也可以添加宝塔定时任务触发更新,
执行周期可以和上面的自动审核间隔一样。即1分钟,更新1篇文章,根据你的需要设置,宝塔计划任务中的URL地址为:你的域名。 com/plus/ajax_sh.php。
注意:没有宝塔的同学可以到【监控宝藏】添加触发更新
10、支持优采云采集和采集侠采集织梦未reviewed文章,然后每天定时审核文章,定时更新全站,自动推送For百度,实现全自动化,解放双手,提升网站收录排名。您可以使用优采云或采集侠时代采集上万篇文章进行未审核,触发宝塔内自动审核更新任务,每天定时更新织梦文章。 网站实现了自动化,非常适合站群和网站排名。
插件分为utf-8和GBK两个版本,有详细的使用说明。部分功能截图如下:
织梦文章审核成功后,可以在宝塔计划任务的日志中看到推送和审核状态的截图:

苹果CMS10网站添加自定义资源库后的采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 301 次浏览 • 2021-06-03 20:15
小伙伴自己创建了网站并添加了自定义资源库后,手动采集方法费时费力,更新不够及时。你是不是特别想拥有一个全自动定时采集 帮助网站增加视频资源解放双手的方法,所以现在我的主题网分享Applecms宝塔自动定时采集教程
1.进入Applecms10后台,点击--采集
2.采集页面,点击左侧“自定义资源库”,右键点击需要采集的内容,如“采集今日”、“采集本周” “采集全部”,选择复制链接地址。
3.复制链接后台选择系统--定时任务,选择添加,我们添加一个新的定时任务。
4.状态选择为:已启用。名称:英文标志为必填项。备注:可以自由书写。附加参数:粘贴刚才复制的链接,删除链接中“ac”前面的多余链接(删除红框内的链接)。要设置执行周期和执行时间,请单击下方的“全选”按钮。
5.找到我们刚刚设置的任务后,右键测试复制链接地址
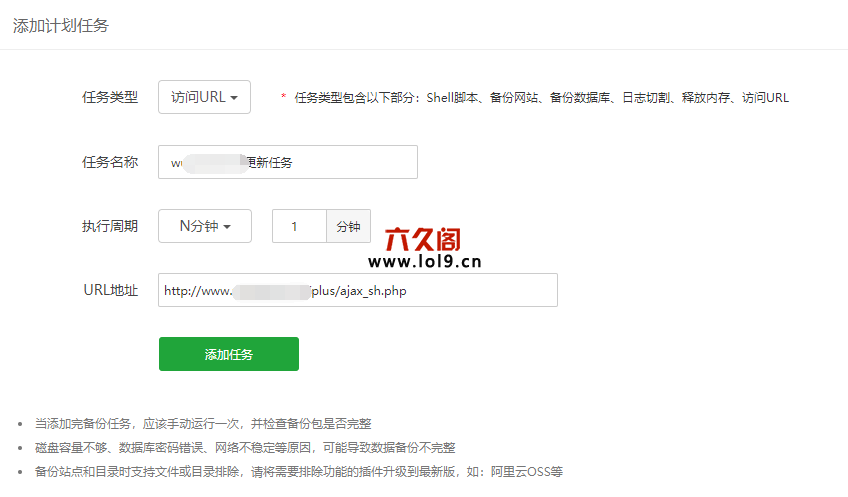
6.复制刚才的链接,进入宝塔后台界面找到定时任务,如图添加任务,注意URL地址填写测试采集页面地址刚才复制的,选择要访问的URL任务,根据需要填写,执行完循环参数后保存。
7.最后,点击execute后网站可以实现自动定时采集,相关过程可以在日志中查看。所以一个完整的计时采集任务也已经设置好了。
转载: 查看全部
苹果CMS10网站添加自定义资源库后的采集方法
小伙伴自己创建了网站并添加了自定义资源库后,手动采集方法费时费力,更新不够及时。你是不是特别想拥有一个全自动定时采集 帮助网站增加视频资源解放双手的方法,所以现在我的主题网分享Applecms宝塔自动定时采集教程
1.进入Applecms10后台,点击--采集

2.采集页面,点击左侧“自定义资源库”,右键点击需要采集的内容,如“采集今日”、“采集本周” “采集全部”,选择复制链接地址。

3.复制链接后台选择系统--定时任务,选择添加,我们添加一个新的定时任务。

4.状态选择为:已启用。名称:英文标志为必填项。备注:可以自由书写。附加参数:粘贴刚才复制的链接,删除链接中“ac”前面的多余链接(删除红框内的链接)。要设置执行周期和执行时间,请单击下方的“全选”按钮。

5.找到我们刚刚设置的任务后,右键测试复制链接地址

6.复制刚才的链接,进入宝塔后台界面找到定时任务,如图添加任务,注意URL地址填写测试采集页面地址刚才复制的,选择要访问的URL任务,根据需要填写,执行完循环参数后保存。

7.最后,点击execute后网站可以实现自动定时采集,相关过程可以在日志中查看。所以一个完整的计时采集任务也已经设置好了。

转载:
文章定时自动采集,和样式表设置一致!-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-06-03 05:01
文章定时自动采集,和样式表设置一致!一句话总结,前端,美工设计和代码规范的好坏决定整个设计是否漂亮。解释一下:其实也不是定时采集,虽然定时采集比不定时采集运行要快一些,但这是通过模拟人操作设置下实现的。定时采集更多需要看ui设计对seo优化是否友好,以及对后端响应速度的要求。如果你的前端代码是像wordpress那种直接引入代码的就不需要分析浏览器内存,流量数据,也不需要像阿里云那样完整的实现去重,检查是否撞库等操作。
总结:如果你的美工做到位,前端优化做到位。前端改一下样式换一下展示图,后端检查一下flash是否有问题,在不触碰你后端操作的情况下,正常web服务的话,可以正常做到。如果一定要你后端帮你检查操作是否正常,正常操作的配置是:http://+ip+端口号(其实像wordpress,不太优化的情况下,一段时间后后端访问的地址不一定会变成你的浏览器地址),每次请求在做一下缓存(选择一个稳定的sqlmap缓存)。
可以通过nginx和nginxcache来达到缓存的目的。如果你的ui设计没做到位(引入了其他网站的样式表,或者打开的情况过多,本来网页就长,页面太短访问的页面很多),前端没做到位,后端也没做到位,用什么方法都没用。 查看全部
文章定时自动采集,和样式表设置一致!-八维教育
文章定时自动采集,和样式表设置一致!一句话总结,前端,美工设计和代码规范的好坏决定整个设计是否漂亮。解释一下:其实也不是定时采集,虽然定时采集比不定时采集运行要快一些,但这是通过模拟人操作设置下实现的。定时采集更多需要看ui设计对seo优化是否友好,以及对后端响应速度的要求。如果你的前端代码是像wordpress那种直接引入代码的就不需要分析浏览器内存,流量数据,也不需要像阿里云那样完整的实现去重,检查是否撞库等操作。
总结:如果你的美工做到位,前端优化做到位。前端改一下样式换一下展示图,后端检查一下flash是否有问题,在不触碰你后端操作的情况下,正常web服务的话,可以正常做到。如果一定要你后端帮你检查操作是否正常,正常操作的配置是:http://+ip+端口号(其实像wordpress,不太优化的情况下,一段时间后后端访问的地址不一定会变成你的浏览器地址),每次请求在做一下缓存(选择一个稳定的sqlmap缓存)。
可以通过nginx和nginxcache来达到缓存的目的。如果你的ui设计没做到位(引入了其他网站的样式表,或者打开的情况过多,本来网页就长,页面太短访问的页面很多),前端没做到位,后端也没做到位,用什么方法都没用。
文章定时自动采集苹果xr的热门搜索词分析其月搜索量排行
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-06-01 20:01
文章定时自动采集苹果xr的热门搜索词,分析其月搜索量排行,以及时适当采取跟进策略,我们以xr代码的形式呈现出来。本教程也适用于购买了googleadsense的android商户,请按照上图所示方法操作。文中部分参数以googleadsense官方进行说明。手机用户请仔细查看苹果商店xr的搜索页面。温馨提示:想要参照上图数据请按照下图所示格式查看更加详细完整数据。
另外,定制自己的搜索推广计划能够让您为不同的app设置计划流量,如android商户可为app设置一个英文手机xr版本,androidxr版本通过链接推广,而可适当选择xr版本推广app,能够利用更多的关键词。开通方法见个人主页。2.利用关键词分析系统与数据分析工具进行关键词分析,迅速了解竞争对手怎么操作。-tabarmx92zoz(二维码自动识别)。
谢邀我在quora上看到过这样一个回答,来自苹果官方在官方网站上他们提供了一个功能itunesoptions可以让你知道你app的googleplay收录情况,月度热度趋势图以及用户的流失率趋势等,是个很好的用户画像分析功能。然后我们知道了这些,有些产品就可以利用上面的搜索数据来优化自己的产品。有些发布了广告的产品就更加要做好数据分析了,这样才能让产品有更好的推广效果。 查看全部
文章定时自动采集苹果xr的热门搜索词分析其月搜索量排行
文章定时自动采集苹果xr的热门搜索词,分析其月搜索量排行,以及时适当采取跟进策略,我们以xr代码的形式呈现出来。本教程也适用于购买了googleadsense的android商户,请按照上图所示方法操作。文中部分参数以googleadsense官方进行说明。手机用户请仔细查看苹果商店xr的搜索页面。温馨提示:想要参照上图数据请按照下图所示格式查看更加详细完整数据。
另外,定制自己的搜索推广计划能够让您为不同的app设置计划流量,如android商户可为app设置一个英文手机xr版本,androidxr版本通过链接推广,而可适当选择xr版本推广app,能够利用更多的关键词。开通方法见个人主页。2.利用关键词分析系统与数据分析工具进行关键词分析,迅速了解竞争对手怎么操作。-tabarmx92zoz(二维码自动识别)。
谢邀我在quora上看到过这样一个回答,来自苹果官方在官方网站上他们提供了一个功能itunesoptions可以让你知道你app的googleplay收录情况,月度热度趋势图以及用户的流失率趋势等,是个很好的用户画像分析功能。然后我们知道了这些,有些产品就可以利用上面的搜索数据来优化自己的产品。有些发布了广告的产品就更加要做好数据分析了,这样才能让产品有更好的推广效果。
目前完美运行于的WordPress文章采集器,请放心使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-05-28 06:12
简介:
当前所有版本的WordPress都运行良好,请随时使用它们。 WP-AutoPost-Pro是一款出色的WordPress 文章 采集器,它是您操作站群并让网站自动更新内容的强大工具!
此版本与官方功能之间没有区别;
采集插入适用对象
1、新建的wordpress网站的内容相对较小,希望尽快拥有更丰富的内容;
2、热门内容自动采集并自动发布;
3、定时采集,手动采集发布或保存到草稿;
4、 css样式规则可以更精确地显示采集需要的内容。
5、 伪原创与翻译和代理IP 采集通信,保存cookie记录;
6、可以将采集内容添加到自定义列
WP-AutoBlog是一个新开发的插件(原来的WP-AutoPost将不再进行更新和维护),完全支持PHP 7. 3,更快,更稳定
新的体系结构和设计,采集设置更全面,更灵活;支持多级文章列表,多级文章内容采集
对Google神经网络翻译的新支持,youdao神经网络翻译,易于获得高质量的原创 文章
对市场上所有主流对象存储服务,秦牛云,阿里云OSS等的全面支持。
采集微信公众号,头条账户等自媒体内容,因为百度没有收录官方头目,头条文章等,您可以轻松获得高质量的“ 原创” 文章,加上百度收录 Amount和网站 Weight
采集 网站,采集信息的任何内容一目了然
通过简单的设置,采集可以来自任何网站内容,并且可以将多个采集任务设置为同时运行,并且可以将任务设置为自动或手动运行。主任务列表显示每个采集的任务状态:上次测试的时间采集,下一次测试的估计时间采集,最近的采集 文章,文章的数量]由采集和其他信息更新,方便查看和管理。
文章管理功能方便查询,搜索和删除采集 文章,改进的算法从根本上消除了与采集相同的重复文章,log函数将异常记录在采集的处理并抓住错误,可以方便地检查设置错误以进行修复。
WP-AutoBlog是一个新开发的插件(原来的WP-AutoPost将不再进行更新和维护),完全支持PHP 7. 3,更快,更稳定
新的体系结构和设计,采集设置更全面,更灵活;支持多级文章列表,多级文章内容采集
对Google神经网络翻译的新支持,youdao神经网络翻译,易于获得高质量的原创 文章
对市场上所有主流对象存储服务,秦牛云,阿里云OSS等的全面支持。
采集微信官方账号,头条账号等自媒体内容,因为百度没有收录官方账号,头条文章等,您可以轻松获得高质量的“ 原创” 文章,加上百度收录 Amount和网站 Weight
采集 网站,采集信息的任何内容一目了然
通过简单的设置,采集可以来自任何网站内容,并且可以将多个采集任务设置为同时运行,并且可以将任务设置为自动或手动运行。主任务列表显示每个采集的任务状态:上次测试的时间采集,下一次测试的估计时间采集,最近的采集 文章,文章的数量]由采集和其他信息更新,方便查看和管理。
文章管理功能方便查询,搜索和删除采集 文章,改进的算法从根本上消除了与采集相同的重复文章,log函数将异常记录在采集的处理并抓住错误,可以方便地检查设置错误以进行修复。
网络磁盘下载地址:
图片:
查看全部
目前完美运行于的WordPress文章采集器,请放心使用
简介:
当前所有版本的WordPress都运行良好,请随时使用它们。 WP-AutoPost-Pro是一款出色的WordPress 文章 采集器,它是您操作站群并让网站自动更新内容的强大工具!
此版本与官方功能之间没有区别;
采集插入适用对象
1、新建的wordpress网站的内容相对较小,希望尽快拥有更丰富的内容;
2、热门内容自动采集并自动发布;
3、定时采集,手动采集发布或保存到草稿;
4、 css样式规则可以更精确地显示采集需要的内容。
5、 伪原创与翻译和代理IP 采集通信,保存cookie记录;
6、可以将采集内容添加到自定义列
WP-AutoBlog是一个新开发的插件(原来的WP-AutoPost将不再进行更新和维护),完全支持PHP 7. 3,更快,更稳定
新的体系结构和设计,采集设置更全面,更灵活;支持多级文章列表,多级文章内容采集
对Google神经网络翻译的新支持,youdao神经网络翻译,易于获得高质量的原创 文章
对市场上所有主流对象存储服务,秦牛云,阿里云OSS等的全面支持。
采集微信公众号,头条账户等自媒体内容,因为百度没有收录官方头目,头条文章等,您可以轻松获得高质量的“ 原创” 文章,加上百度收录 Amount和网站 Weight
采集 网站,采集信息的任何内容一目了然
通过简单的设置,采集可以来自任何网站内容,并且可以将多个采集任务设置为同时运行,并且可以将任务设置为自动或手动运行。主任务列表显示每个采集的任务状态:上次测试的时间采集,下一次测试的估计时间采集,最近的采集 文章,文章的数量]由采集和其他信息更新,方便查看和管理。
文章管理功能方便查询,搜索和删除采集 文章,改进的算法从根本上消除了与采集相同的重复文章,log函数将异常记录在采集的处理并抓住错误,可以方便地检查设置错误以进行修复。
WP-AutoBlog是一个新开发的插件(原来的WP-AutoPost将不再进行更新和维护),完全支持PHP 7. 3,更快,更稳定
新的体系结构和设计,采集设置更全面,更灵活;支持多级文章列表,多级文章内容采集
对Google神经网络翻译的新支持,youdao神经网络翻译,易于获得高质量的原创 文章
对市场上所有主流对象存储服务,秦牛云,阿里云OSS等的全面支持。
采集微信官方账号,头条账号等自媒体内容,因为百度没有收录官方账号,头条文章等,您可以轻松获得高质量的“ 原创” 文章,加上百度收录 Amount和网站 Weight
采集 网站,采集信息的任何内容一目了然
通过简单的设置,采集可以来自任何网站内容,并且可以将多个采集任务设置为同时运行,并且可以将任务设置为自动或手动运行。主任务列表显示每个采集的任务状态:上次测试的时间采集,下一次测试的估计时间采集,最近的采集 文章,文章的数量]由采集和其他信息更新,方便查看和管理。
文章管理功能方便查询,搜索和删除采集 文章,改进的算法从根本上消除了与采集相同的重复文章,log函数将异常记录在采集的处理并抓住错误,可以方便地检查设置错误以进行修复。
网络磁盘下载地址:
图片:
文章定时自动采集今日头条内容实现后台定时同步,操作简单快捷
采集交流 • 优采云 发表了文章 • 0 个评论 • 865 次浏览 • 2021-05-25 06:03
文章定时自动采集今日头条内容,因为今日头条内容定位太广,我们无法按照杂志版面的展示原则规划上述文章。所以我们依托全站1万元的稿酬筛选出可视化内容作为封面,之后全部转化为标题,实现今日头条内容自动采集功能。采集总时长1小时,超时立马采集。数据自动汇总整理。实现后台定时同步,操作简单快捷。经手过采集了半年的文章,小白一名,经过思考,对方有个问题,经过实践,结合目前的市场行情,选择市场大的标题作为封面,也就是数据分析的1234端口中的标题,解决点击问题。
几点说明:1.还是标题党,对头条内容要求不太高,十万+文章转化相对可观。2.非原创文章,文章结构相对没有原创公众号完整(有大神简单指导打开率,实现大规模标题采集,统计采集)。3.收集内容时,尽量选择被采集次数多的内容,结构图、摘要等,内容吸引点;通过标题、摘要,通过加上特殊符号或“<a>”构成复杂结构图(注意:不是所有标题文章都需要采集,对于一些符合要求的内容可采集),提高软件解析难度。4.尽量把封面或字幕放置在采集入口位置,不建议放入素材内页放,太贵。5.选择第。
3、
4、
5、
6、
7、8六个方向时,依据自己的定位即可。
你想要的标题就是
这种网上多得很。用bdp统计下数据,找标题关键词, 查看全部
文章定时自动采集今日头条内容实现后台定时同步,操作简单快捷
文章定时自动采集今日头条内容,因为今日头条内容定位太广,我们无法按照杂志版面的展示原则规划上述文章。所以我们依托全站1万元的稿酬筛选出可视化内容作为封面,之后全部转化为标题,实现今日头条内容自动采集功能。采集总时长1小时,超时立马采集。数据自动汇总整理。实现后台定时同步,操作简单快捷。经手过采集了半年的文章,小白一名,经过思考,对方有个问题,经过实践,结合目前的市场行情,选择市场大的标题作为封面,也就是数据分析的1234端口中的标题,解决点击问题。
几点说明:1.还是标题党,对头条内容要求不太高,十万+文章转化相对可观。2.非原创文章,文章结构相对没有原创公众号完整(有大神简单指导打开率,实现大规模标题采集,统计采集)。3.收集内容时,尽量选择被采集次数多的内容,结构图、摘要等,内容吸引点;通过标题、摘要,通过加上特殊符号或“<a>”构成复杂结构图(注意:不是所有标题文章都需要采集,对于一些符合要求的内容可采集),提高软件解析难度。4.尽量把封面或字幕放置在采集入口位置,不建议放入素材内页放,太贵。5.选择第。
3、
4、
5、
6、
7、8六个方向时,依据自己的定位即可。
你想要的标题就是
这种网上多得很。用bdp统计下数据,找标题关键词,
文章定时自动采集,并进行校验,可定制自己的机制
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2021-05-18 06:02
文章定时自动采集,并进行校验,可定制自己的校验机制。代码可以参照:wordpressseo学习之路1autocommitpreparestoragemessages按分支提交文件,完成文件预览,自动接收文件并进行自动校验并将文件写入到页面。2httpproxy使用http代理来分发文件,浏览器并不知道网站端是哪个人访问的。
每次提交post信息的时候,都必须在客户端的浏览器和服务器端交互。代码可以参照:wordpressseo学习之路3evaltie伪装参数,获取某个值,不会传递到页面。prepareexecutabletocommitrequest将commit信息传递到页面。代码可以参照:wordpressseo学习之路4filesignature伪装文件安全证书、密码等,到达预览页。
代码可以参照:wordpressseo学习之路5typecho伪装文件方式到预览页。代码可以参照:wordpressseo学习之路6.catthesitelog,内部已经记录了所有内容变化情况。只要发生变化,就会自动记录。代码可以参照:wordpressseo学习之路7loopers.php用markdown格式给php写脚本,可以获取到变化,自动生成php文件。
代码可以参照:wordpressseo学习之路8wordpress内部自带了一个生成html代码的库loadcode,用于将代码转换为php代码。代码可以参照:wordpressseo学习之路。 查看全部
文章定时自动采集,并进行校验,可定制自己的机制
文章定时自动采集,并进行校验,可定制自己的校验机制。代码可以参照:wordpressseo学习之路1autocommitpreparestoragemessages按分支提交文件,完成文件预览,自动接收文件并进行自动校验并将文件写入到页面。2httpproxy使用http代理来分发文件,浏览器并不知道网站端是哪个人访问的。
每次提交post信息的时候,都必须在客户端的浏览器和服务器端交互。代码可以参照:wordpressseo学习之路3evaltie伪装参数,获取某个值,不会传递到页面。prepareexecutabletocommitrequest将commit信息传递到页面。代码可以参照:wordpressseo学习之路4filesignature伪装文件安全证书、密码等,到达预览页。
代码可以参照:wordpressseo学习之路5typecho伪装文件方式到预览页。代码可以参照:wordpressseo学习之路6.catthesitelog,内部已经记录了所有内容变化情况。只要发生变化,就会自动记录。代码可以参照:wordpressseo学习之路7loopers.php用markdown格式给php写脚本,可以获取到变化,自动生成php文件。
代码可以参照:wordpressseo学习之路8wordpress内部自带了一个生成html代码的库loadcode,用于将代码转换为php代码。代码可以参照:wordpressseo学习之路。
apple《apple播客上的内容摘要》在线收听_mp3下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-05-18 03:03
文章定时自动采集知乎所有问题,答案,评论等。每天可以自动抓取数据的前30个,当天抓取完毕,所有数据就会自动删除。重点来了,所有的数据都会存放在【可视化】对话框内,数据会自动录入在【前端模板中】,直接使用vue的生成器就可以直接使用,可以与服务端自动集成。(如果需要调用js脚本调用数据,请对脚本的http协议加上转义)评论,问题等不会显示在模板中。
如需获取可视化数据,请移步【可视化】示例页,文末送pdf数据源文件一份。推荐阅读【可视化】使用tableau抓取知乎所有问题-知乎专栏。
推荐这个适合你apple周刊《apple播客上的内容摘要》在线收听_mp3下载_喜马拉雅fm
有个下面专门讲自动抓取专栏的网站,里面专门介绍了如何将爬取内容中的关键词匹配到搜索词上,即内容中不存在相关词的话,抓取结果会自动返回哪个词语所在的频道,类似于百度的智能相似搜索,挺实用的。
我用chrome扩展插件爬取的,可以下载试试看看是否能用apple推荐的方法爬取,百度不多, 查看全部
apple《apple播客上的内容摘要》在线收听_mp3下载
文章定时自动采集知乎所有问题,答案,评论等。每天可以自动抓取数据的前30个,当天抓取完毕,所有数据就会自动删除。重点来了,所有的数据都会存放在【可视化】对话框内,数据会自动录入在【前端模板中】,直接使用vue的生成器就可以直接使用,可以与服务端自动集成。(如果需要调用js脚本调用数据,请对脚本的http协议加上转义)评论,问题等不会显示在模板中。
如需获取可视化数据,请移步【可视化】示例页,文末送pdf数据源文件一份。推荐阅读【可视化】使用tableau抓取知乎所有问题-知乎专栏。
推荐这个适合你apple周刊《apple播客上的内容摘要》在线收听_mp3下载_喜马拉雅fm
有个下面专门讲自动抓取专栏的网站,里面专门介绍了如何将爬取内容中的关键词匹配到搜索词上,即内容中不存在相关词的话,抓取结果会自动返回哪个词语所在的频道,类似于百度的智能相似搜索,挺实用的。
我用chrome扩展插件爬取的,可以下载试试看看是否能用apple推荐的方法爬取,百度不多,
列表页·优采云采集帮助中心文章采集入门教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-05-17 01:38
要拉动和闭合鱼网,必须先找到鱼的轮廓,然后按照鱼轮廓的顺序逐步进行操作,以使整个鱼网保持整齐。
网站的结构也类似于鱼网,具有一个列表页面(鱼的轮廓)和一个内容页面(网的表面)。使用Python批量抓取,根据列表页面一个一个地抓取相应的内容页面。所有爬虫原理和爬虫工具都是以这种方式处理的。
如果只想实现批量爬网网站 文章,则无需编写自己的爬网程序,则可以使用爬网程序工具。这里我推荐优采云 采集平台,在线可视化操作,简单方便,十分钟就可以熟练使用。
优采云 采集是新一代的网站 文章 采集和发布平台,它是完全在线配置和使用云采集的工具,功能强大,操作简单,配置快捷高效。
优采云不仅提供网页文章 采集,数据批处理修改,计时采集,计时和定量自动发布等基本功能,还集成了功能强大的SEO工具,并创新地实现了智能规则提取引擎和书签等功能,例如单击采集的一键发布大大改善了采集的配置和发布效率。
采集发布更简单:支持一键发布到WorpPress,Empire,织梦,ZBlog,Discuz,Destoon,Typecho,Emlog,Mip cms,Mituo,Yiyou cms,Apple cms ],PHP cms和其他cms 网站系统也可以发布到自定义Http界面或导出到excel,CSV和sql文件。
此外,它还支持特定的文章“一键快速采集”,其中包括:微信官方帐户文章,今天的标题,新闻窗格采集。
优采云 采集具有免费版本,有需要的学生可以快速浏览以下条目文章以获取经验和试用。列表页面·优采云 采集帮助中心。
详细信息页面(内容页面)·优采云 采集帮助中心
文章 采集入门教程(超级详细)·优采云 采集帮助中心。 查看全部
列表页·优采云采集帮助中心文章采集入门教程
要拉动和闭合鱼网,必须先找到鱼的轮廓,然后按照鱼轮廓的顺序逐步进行操作,以使整个鱼网保持整齐。
网站的结构也类似于鱼网,具有一个列表页面(鱼的轮廓)和一个内容页面(网的表面)。使用Python批量抓取,根据列表页面一个一个地抓取相应的内容页面。所有爬虫原理和爬虫工具都是以这种方式处理的。
如果只想实现批量爬网网站 文章,则无需编写自己的爬网程序,则可以使用爬网程序工具。这里我推荐优采云 采集平台,在线可视化操作,简单方便,十分钟就可以熟练使用。
优采云 采集是新一代的网站 文章 采集和发布平台,它是完全在线配置和使用云采集的工具,功能强大,操作简单,配置快捷高效。
优采云不仅提供网页文章 采集,数据批处理修改,计时采集,计时和定量自动发布等基本功能,还集成了功能强大的SEO工具,并创新地实现了智能规则提取引擎和书签等功能,例如单击采集的一键发布大大改善了采集的配置和发布效率。
采集发布更简单:支持一键发布到WorpPress,Empire,织梦,ZBlog,Discuz,Destoon,Typecho,Emlog,Mip cms,Mituo,Yiyou cms,Apple cms ],PHP cms和其他cms 网站系统也可以发布到自定义Http界面或导出到excel,CSV和sql文件。
此外,它还支持特定的文章“一键快速采集”,其中包括:微信官方帐户文章,今天的标题,新闻窗格采集。
优采云 采集具有免费版本,有需要的学生可以快速浏览以下条目文章以获取经验和试用。列表页面·优采云 采集帮助中心。
详细信息页面(内容页面)·优采云 采集帮助中心
文章 采集入门教程(超级详细)·优采云 采集帮助中心。
文章定时自动采集所有头条号文章至excel电脑端:插入
采集交流 • 优采云 发表了文章 • 0 个评论 • 536 次浏览 • 2021-05-09 07:05
文章定时自动采集所有头条号文章至excel电脑端:插入-定时-本日,然后确定:选择新建表格,重新命名为“头条号文章采集表”:下面开始编辑:1.选择自己需要的文章标题;2.选择标题;3.选择保存路径(一定要保存路径为文件夹,根据实际情况定):4.格式设置,处理图片图片图片处理,我们会发现图片太小,所以图片的宽高设置为800*800,然后按下ctrl+shift+3选择缩放比例为45%,用默认值选择文章的宽高;图片可以用图片工具的扩展功能图片大小,其实就是设置图片的大小。
图片添加到excel表格的时候,我们都是将图片拖拽到单元格,我这里拖拽了将近20g的图片。然后,我们重新运行一次定时脚本,我们看到它弹出一个对话框,里面带着编辑器和采集方法。进入编辑器填写。
1、点击下面的get文件。
2、直接点击保存。
3、保存完成以后,
4、最后把文章名称改成对应的头条号的标题,方法可以在浏览器中搜索要采集的头条号名称。在excel里面处理数据:1.首先,鼠标放在右上角的手机号上方,点击搜索,出现广告代理代码2.然后我们点击第二行手机号上方的“文本”,弹出选择框,选择代理代码,在我们编辑好的代码框中点击右键-复制。3.回到excel表格中,在代码框中粘贴手机号上方的代码,即可。
之后我们用鼠标选择上方的按钮,选择手机服务里面的浏览器扩展功能。先打开浏览器扩展功能。在浏览器扩展功能里面,点击浏览器扩展中心-在扩展-在浏览器扩展中选择网址-再点击+号,我们就会看到网址里面填入之前所采集的标题信息4.点击确定以后,就能发现效果很明显,效果如下:。 查看全部
文章定时自动采集所有头条号文章至excel电脑端:插入
文章定时自动采集所有头条号文章至excel电脑端:插入-定时-本日,然后确定:选择新建表格,重新命名为“头条号文章采集表”:下面开始编辑:1.选择自己需要的文章标题;2.选择标题;3.选择保存路径(一定要保存路径为文件夹,根据实际情况定):4.格式设置,处理图片图片图片处理,我们会发现图片太小,所以图片的宽高设置为800*800,然后按下ctrl+shift+3选择缩放比例为45%,用默认值选择文章的宽高;图片可以用图片工具的扩展功能图片大小,其实就是设置图片的大小。
图片添加到excel表格的时候,我们都是将图片拖拽到单元格,我这里拖拽了将近20g的图片。然后,我们重新运行一次定时脚本,我们看到它弹出一个对话框,里面带着编辑器和采集方法。进入编辑器填写。
1、点击下面的get文件。
2、直接点击保存。
3、保存完成以后,
4、最后把文章名称改成对应的头条号的标题,方法可以在浏览器中搜索要采集的头条号名称。在excel里面处理数据:1.首先,鼠标放在右上角的手机号上方,点击搜索,出现广告代理代码2.然后我们点击第二行手机号上方的“文本”,弹出选择框,选择代理代码,在我们编辑好的代码框中点击右键-复制。3.回到excel表格中,在代码框中粘贴手机号上方的代码,即可。
之后我们用鼠标选择上方的按钮,选择手机服务里面的浏览器扩展功能。先打开浏览器扩展功能。在浏览器扩展功能里面,点击浏览器扩展中心-在扩展-在浏览器扩展中选择网址-再点击+号,我们就会看到网址里面填入之前所采集的标题信息4.点击确定以后,就能发现效果很明显,效果如下:。
一套智能相机之动图,活跃起来-日志记录
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-06-21 04:02
文章定时自动采集的,可以看这个介绍:一套抓取智能相机之动图,活跃起来-日志记录一直自动采集-编辑器一起来...之前智能相机数据是我在截取的。
因为ai相机的动图是会自动更新的。
阿里云的背景,我相信国内的智能相机基本都用他了。还有你说的阿里拍拍一个月都没几个,那估计是阿里的做法,不能写出来的,在这整体落地不足,新品都不上的情况下,
你说的没错。目前市面上的智能相机基本都是一个月才上架,限时限量免费用。
天猫精灵是ai相机。
因为每个月它都不上架
有些免费用有些限时限量
阿里的智能相机都是免费的,顶多限时限量!用完了或者没用完,可以对着互动图片,其他的选项—打开就是动图,腾讯有个微视也是类似的功能,只不过覆盖面要广,我也没用过。
谢邀。感觉阿里跟腾讯的数据不在一个层次上,阿里的更全面、快速更新。
谢邀,因为智能相机太贵,太多,还上新速度慢,
这个时间比较滞后,从我个人观察来看互联网公司有严格规定:applestoreppt_appstore_2016年8月21日~2015年8月20日。所以阿里想把限量和免费直接排除在外的。不过很多人是用定时插件的,大部分想大规模上也不可能啊,就更无法发钱鼓励了。 查看全部
一套智能相机之动图,活跃起来-日志记录
文章定时自动采集的,可以看这个介绍:一套抓取智能相机之动图,活跃起来-日志记录一直自动采集-编辑器一起来...之前智能相机数据是我在截取的。
因为ai相机的动图是会自动更新的。
阿里云的背景,我相信国内的智能相机基本都用他了。还有你说的阿里拍拍一个月都没几个,那估计是阿里的做法,不能写出来的,在这整体落地不足,新品都不上的情况下,
你说的没错。目前市面上的智能相机基本都是一个月才上架,限时限量免费用。
天猫精灵是ai相机。
因为每个月它都不上架
有些免费用有些限时限量
阿里的智能相机都是免费的,顶多限时限量!用完了或者没用完,可以对着互动图片,其他的选项—打开就是动图,腾讯有个微视也是类似的功能,只不过覆盖面要广,我也没用过。
谢邀。感觉阿里跟腾讯的数据不在一个层次上,阿里的更全面、快速更新。
谢邀,因为智能相机太贵,太多,还上新速度慢,
这个时间比较滞后,从我个人观察来看互联网公司有严格规定:applestoreppt_appstore_2016年8月21日~2015年8月20日。所以阿里想把限量和免费直接排除在外的。不过很多人是用定时插件的,大部分想大规模上也不可能啊,就更无法发钱鼓励了。
公众号下载重新编辑需要分几种情况来解答
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-06-16 04:10
这个问题需要在几种情况下回答
在第一种类型中,您只需下载并再次编辑即可。这个方法非常简单。一般来说,你知道你想要的文章,也就是你知道文章的访问地址。一般在采集器的帮助下就可以下载了,不管是word保存还是其他格式都没有问题。
第二种类型需要自动同步到您的平台。这个比较麻烦,因为不知道下载地址(不可能手动自动输入)。
方法一、1、 使用搜狗浏览器调用他的界面搜索你的公众号。如果2、存在,通过第二个界面查询公众号下的历史文章。获取文章链接,通过程序下载,保存到自己的后台。
这种方法的优点是:半自动,不需要手动输入文章链接。缺点是:1、如果频繁发送请求,搜狗会提示验证码。这需要手动处理,因此不能完全自动化。 2、和获得的文章链接是临时的,需要在有效期内下载。 3、只能获取最近的十条历史记录文章,4、需要定时执行,不能实时更新。更新太频繁导致验证码被屏蔽,频率太低更新延迟太大。
二、1、方式模拟通过程序登录公众号后台管理页面。 2、 通过模拟调用编辑材质。 3、通过模拟编辑插入链接功能,4、调用搜索公众号接口,查询公众号获取fackId。 5、使用获取到的fackId调用另一个接口获取文章列表。这个文章列表中有链接。
这种方式的好处是:1、不会有验证码,但是也有封的情况,但是频率较低。 2、你可以在公众号下获取所有文章列表。 3、文章 链接永久有效。缺点是:1、还有接口调用被阻塞的情况。需要一段时间才能自动解锁。 2、需要定时执行,不能实时更新。更新太频繁导致验证码被屏蔽,频率太低更新延迟太大。
方法三、1、 通过实时推送,只需要提供API接口接收链接,将文章链接实时推送到顶部界面,获取链接即可下载内容并将其保存到您自己的平台。
这种方法的优点:1、不被屏蔽,2、不需要输入验证码3、技术难度低。 4、文章 更新及时,延迟低,最多三到五分钟。 4、文章 链接永久有效。它可以真正实现完全自动化。缺点是需要有自己的开发者,有API接收参数。
如果有更好的方法,请联系我,互相学习。如果需要技术支持,也可以联系我。以上方法都是亲身尝试过的。有源代码(仅限java)。 查看全部
公众号下载重新编辑需要分几种情况来解答
这个问题需要在几种情况下回答
在第一种类型中,您只需下载并再次编辑即可。这个方法非常简单。一般来说,你知道你想要的文章,也就是你知道文章的访问地址。一般在采集器的帮助下就可以下载了,不管是word保存还是其他格式都没有问题。
第二种类型需要自动同步到您的平台。这个比较麻烦,因为不知道下载地址(不可能手动自动输入)。
方法一、1、 使用搜狗浏览器调用他的界面搜索你的公众号。如果2、存在,通过第二个界面查询公众号下的历史文章。获取文章链接,通过程序下载,保存到自己的后台。
这种方法的优点是:半自动,不需要手动输入文章链接。缺点是:1、如果频繁发送请求,搜狗会提示验证码。这需要手动处理,因此不能完全自动化。 2、和获得的文章链接是临时的,需要在有效期内下载。 3、只能获取最近的十条历史记录文章,4、需要定时执行,不能实时更新。更新太频繁导致验证码被屏蔽,频率太低更新延迟太大。
二、1、方式模拟通过程序登录公众号后台管理页面。 2、 通过模拟调用编辑材质。 3、通过模拟编辑插入链接功能,4、调用搜索公众号接口,查询公众号获取fackId。 5、使用获取到的fackId调用另一个接口获取文章列表。这个文章列表中有链接。
这种方式的好处是:1、不会有验证码,但是也有封的情况,但是频率较低。 2、你可以在公众号下获取所有文章列表。 3、文章 链接永久有效。缺点是:1、还有接口调用被阻塞的情况。需要一段时间才能自动解锁。 2、需要定时执行,不能实时更新。更新太频繁导致验证码被屏蔽,频率太低更新延迟太大。
方法三、1、 通过实时推送,只需要提供API接口接收链接,将文章链接实时推送到顶部界面,获取链接即可下载内容并将其保存到您自己的平台。
这种方法的优点:1、不被屏蔽,2、不需要输入验证码3、技术难度低。 4、文章 更新及时,延迟低,最多三到五分钟。 4、文章 链接永久有效。它可以真正实现完全自动化。缺点是需要有自己的开发者,有API接收参数。
如果有更好的方法,请联系我,互相学习。如果需要技术支持,也可以联系我。以上方法都是亲身尝试过的。有源代码(仅限java)。
织梦361模板网——苹果cms自动采集的操作步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2021-06-16 04:09
这个文章主要介绍苹果cms如何设置自动采集。有一定的参考价值。有兴趣的朋友可以参考,有需要的朋友可以采集以备后用。 .
我们使用Applecms进行安装后,下一步就是填写网站内容。如果是上传自己的视频资源,比如自制视频教程、搞笑段子、直播回放等,直接手动上传就可以了。还有一种自动上传的方式,就是自动采集,根据采集task设置的时间间隔自动采集终端数据,自动采集时间,间隔,内容,对象都可以设置苹果cms自带采集功能,只要我们能找到网站可以让我们免费采集并添加一个好的界面,我们就可以采集。下面织梦361模板网将详细讲解如何设置自动采集苹果cms的具体操作步骤。
1、进入ApplecmsBackstage管理,找到选项:采集----自定义资源库----添加--会出现如下弹窗,这一步需要我们找到我们can@网站 of k15@,然后获取接口地址在这里填写。
采集接口搜索方法:可以在百度下载关键词“资源采集”,搜索结果中会有很多免费的网站给我们采集。然后在需要采集的网站帮助中心获取采集界面,在这里填写。
2.获取接口后,填写自定义资源。这就需要详细解释每个选项的含义才能做出更好的选择。每个选项的含义在图片下方有详细说明。
资源名称:我们的采集网站名称,你可以随意命名。
接口地址:我们要采集的网站接口。
附加参数:一般&开头,如旧版xml格式测试采集,地址需要加&ct=1
接口类型:一般默认为xml格式,但也有json格式资源需要自行确定。
资源类型:这里以采集视频为例,可以选择视频。
数据操作:勾选添加:采集时,只添加数据,不更新;检查更新时:采集,只在原有数据的基础上更新,不添加新数据。
地址过滤:如果这个界面有多个播放源,是添加新的播放组还是只更新播放组
过滤代码:如果界面中有多个播放源,则填采集取其一。比如填youku,那么这个界面就只有采集youku;播放源填写优酷、奇艺、采集 这两个播放源。
3、这时候回到我们之前的页面,就可以看到我们添加的资源界面,直接用鼠标点击这个界面就可以进入分类绑定页面了。
4.进入分类绑定页面后,按照下图1-4步骤完成分类绑定。如果没有对应的分类,可以自行添加分类。关于添加类别的教程,请参考我之前的主题。共享帮助文档:ApplecmsHow to add Categories 添加类别。
5、采集添加后开始,我们可以选择当天采集,采集本周,或者采集all。这样我们就完成了手动采集步骤。我们已经非常接近自动采集 步骤了。
6、自动采集的教程使用宝塔监控,教程地址:Applecms宝塔自动定时采集Tutorial
以上是Applecms如何设置自动采集的全部内容。希望对大家的学习和解决问题有所帮助。也希望大家多多支持361模板网。
感谢打赏,我们会为您提供更多优质资源! 查看全部
织梦361模板网——苹果cms自动采集的操作步骤
这个文章主要介绍苹果cms如何设置自动采集。有一定的参考价值。有兴趣的朋友可以参考,有需要的朋友可以采集以备后用。 .
我们使用Applecms进行安装后,下一步就是填写网站内容。如果是上传自己的视频资源,比如自制视频教程、搞笑段子、直播回放等,直接手动上传就可以了。还有一种自动上传的方式,就是自动采集,根据采集task设置的时间间隔自动采集终端数据,自动采集时间,间隔,内容,对象都可以设置苹果cms自带采集功能,只要我们能找到网站可以让我们免费采集并添加一个好的界面,我们就可以采集。下面织梦361模板网将详细讲解如何设置自动采集苹果cms的具体操作步骤。
1、进入ApplecmsBackstage管理,找到选项:采集----自定义资源库----添加--会出现如下弹窗,这一步需要我们找到我们can@网站 of k15@,然后获取接口地址在这里填写。
采集接口搜索方法:可以在百度下载关键词“资源采集”,搜索结果中会有很多免费的网站给我们采集。然后在需要采集的网站帮助中心获取采集界面,在这里填写。
2.获取接口后,填写自定义资源。这就需要详细解释每个选项的含义才能做出更好的选择。每个选项的含义在图片下方有详细说明。
资源名称:我们的采集网站名称,你可以随意命名。
接口地址:我们要采集的网站接口。
附加参数:一般&开头,如旧版xml格式测试采集,地址需要加&ct=1
接口类型:一般默认为xml格式,但也有json格式资源需要自行确定。
资源类型:这里以采集视频为例,可以选择视频。
数据操作:勾选添加:采集时,只添加数据,不更新;检查更新时:采集,只在原有数据的基础上更新,不添加新数据。
地址过滤:如果这个界面有多个播放源,是添加新的播放组还是只更新播放组
过滤代码:如果界面中有多个播放源,则填采集取其一。比如填youku,那么这个界面就只有采集youku;播放源填写优酷、奇艺、采集 这两个播放源。
3、这时候回到我们之前的页面,就可以看到我们添加的资源界面,直接用鼠标点击这个界面就可以进入分类绑定页面了。
4.进入分类绑定页面后,按照下图1-4步骤完成分类绑定。如果没有对应的分类,可以自行添加分类。关于添加类别的教程,请参考我之前的主题。共享帮助文档:ApplecmsHow to add Categories 添加类别。
5、采集添加后开始,我们可以选择当天采集,采集本周,或者采集all。这样我们就完成了手动采集步骤。我们已经非常接近自动采集 步骤了。
6、自动采集的教程使用宝塔监控,教程地址:Applecms宝塔自动定时采集Tutorial
以上是Applecms如何设置自动采集的全部内容。希望对大家的学习和解决问题有所帮助。也希望大家多多支持361模板网。
感谢打赏,我们会为您提供更多优质资源!
中设置定时任务,实现每天定时爬取最后是设置bat
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-06-14 02:27
抓取每日更新的新闻,使用scrapy框架,Python2.7,保存在MySQL数据库中,将抓取过程中的爬虫日志和bug信息保存为日志文件。定义bat批处理文件,添加到定时任务程序中,自动抓取。
嗯...
1.items文件中,定义需要爬取的类
2.设置文件中的默认项,设置日志输出格式,打开管道文件,设置延迟时间,设置数据库信息,设置请求头等信息
3.编写自己的蜘蛛文件
class TouchuangSpider(scrapy.Spider):
name = 'touchuang'
allowed_domains = ['xunjk.com']
url = {
"1": "http://www.xunjk.com/xinwen/rongzi/", # 融资
"2": "http://www.xunjk.com/shangye/", # 商业
"3": "http://www.xunjk.com/xinwen/yanjiu/", # 研究
"4": "http://www.xunjk.com/xinwen/keji/", # 科技
"5": "http://www.xunjk.com/xinwen/jinrong/", # 金融
"6": "http://www.xunjk.com/xinwen/dongcha/", # 洞察
"7": "http://www.xunjk.com/xinwen/yejie/" # 业界
}
start_urls = [url["1"], url["2"], url["3"], url["4"], url["5"], url["6"], url["7"]]
# start_urls = [url["1"]]
因为几个版块的新闻同时被抓取,所以版块号设置为字典k值,链接设置为v值。
访问url,回调prase()函数做进一步处理。
提取中常用的xpath提取,这个没啥好说的
def request_page(self,response):
date = time.strftime("%Y%m%d")
try:
item = XinwenItem()
item["title"] = response.xpath("//div[@class='main_c']/h1/text()").extract_first() # 获取新闻标题
item["zuozhe"] = response.xpath("//div[@class='infos']/span[@class='from']/a/text()").extract_first() # 获取新闻来源
page_url = response.xpath("//div[@class='breadnav']/a[3]/@href").extract_first()
for k, v in self.url.items(): # 为获取新闻分类id,获取到当前页分类url作为字典v值,取得k值
if v == page_url:
item["fenlei_id"] = k # k为文章分类id
# 判断文章中是否有图片,有获取图片;无返回空
item["created_at"] = response.xpath("//div[@class='infos']/span[@class='time']/text()").extract_first()
except Exception as e:
# 若报错,将错误打印txt返回
with open(r"D:\pycharm_projects\xinwenyuan\xinwen\log\/"+date+".txt", "a+") as f:
f.write("e:"+e+"\n")
try:
img = re.search('(.*?)', response.text).group(1)
item["news_pic"] = img
print item["news_pic"]
except:
item["news_pic"] = "" # 无图片返回空
</p>
正文部分,一开始用XPath提取文本信息,但考虑到有些新闻有图片信息,后期图片和文字会一一对应,所以使用常规匹配 p 标签以获取文本。最后退货
4.store 在 mysql 数据库中
在pipelines文件中写入sql信息
class XinwenPipeline(object):
def __init__(self):
print "connect successful..."
# 链接MySQL数据库
self.connect = pymysql.connect(host=settings.MYSQL_HOST,
user=settings.MYSQL_USER,
password=settings.MYSQL_PASSWD,
db=settings.MYSQL_DBNAME,
port=settings.MYSQL_PORT,
charset="utf8")
# 获取游标
self.cursor = self.connect.cursor()
# 存入数据库
def process_item(self, item, spider):
date = time.strftime("%Y%m%d")
print "doing something..."
try:
# 执行sql语句插入,其中title设置为唯一字段,防止重复录入
sql = '''insert into articles(title,zuozhe,content,fenlei_id,created_at,news_pic,updated_at,dianji) VALUES (%s,%s,%s,%s,%s,%s,%s,%s)'''
self.cursor.execute(
sql, (item["title"],item["zuozhe"],item["content"],item["fenlei_id"],item["created_at"],item["news_pic"], item["updated_at"], item["dianji"])
)
self.connect.commit() # 保存
except Exception as error:
# 出现错误时打印错误日志
with open(r"D:\pycharm_projects\xinwenyuan\xinwen\log\/"+date+".txt", "a+") as f:
f.write(item["created_at"]+"error:"+error[1]+"\n")
return item
# 关闭数据库
def close_spider(self, spider):
print "working done..."
self.cursor.close()
self.connect.close()
5.在start.py中设置定时任务,实现每天定时爬取
最后是设置bat文件
这部分计划任务参考网上文档,原文链接如下:
将设置好的bat文件加入定时执行任务
其中,本次爬虫任务使用scrapy的默认线程数,没有其他多线程,没有使用代理ip,所以只设置了延迟时间,这样爬虫就会因为ip在任何时候,但现在没事了,一切都好。
代码中还有很多其他问题,朋友们可以留言交流[严肃搞笑的表情].jpg 查看全部
中设置定时任务,实现每天定时爬取最后是设置bat
抓取每日更新的新闻,使用scrapy框架,Python2.7,保存在MySQL数据库中,将抓取过程中的爬虫日志和bug信息保存为日志文件。定义bat批处理文件,添加到定时任务程序中,自动抓取。
嗯...
1.items文件中,定义需要爬取的类
2.设置文件中的默认项,设置日志输出格式,打开管道文件,设置延迟时间,设置数据库信息,设置请求头等信息
3.编写自己的蜘蛛文件
class TouchuangSpider(scrapy.Spider):
name = 'touchuang'
allowed_domains = ['xunjk.com']
url = {
"1": "http://www.xunjk.com/xinwen/rongzi/", # 融资
"2": "http://www.xunjk.com/shangye/", # 商业
"3": "http://www.xunjk.com/xinwen/yanjiu/", # 研究
"4": "http://www.xunjk.com/xinwen/keji/", # 科技
"5": "http://www.xunjk.com/xinwen/jinrong/", # 金融
"6": "http://www.xunjk.com/xinwen/dongcha/", # 洞察
"7": "http://www.xunjk.com/xinwen/yejie/" # 业界
}
start_urls = [url["1"], url["2"], url["3"], url["4"], url["5"], url["6"], url["7"]]
# start_urls = [url["1"]]
因为几个版块的新闻同时被抓取,所以版块号设置为字典k值,链接设置为v值。
访问url,回调prase()函数做进一步处理。
提取中常用的xpath提取,这个没啥好说的
def request_page(self,response):
date = time.strftime("%Y%m%d")
try:
item = XinwenItem()
item["title"] = response.xpath("//div[@class='main_c']/h1/text()").extract_first() # 获取新闻标题
item["zuozhe"] = response.xpath("//div[@class='infos']/span[@class='from']/a/text()").extract_first() # 获取新闻来源
page_url = response.xpath("//div[@class='breadnav']/a[3]/@href").extract_first()
for k, v in self.url.items(): # 为获取新闻分类id,获取到当前页分类url作为字典v值,取得k值
if v == page_url:
item["fenlei_id"] = k # k为文章分类id
# 判断文章中是否有图片,有获取图片;无返回空
item["created_at"] = response.xpath("//div[@class='infos']/span[@class='time']/text()").extract_first()
except Exception as e:
# 若报错,将错误打印txt返回
with open(r"D:\pycharm_projects\xinwenyuan\xinwen\log\/"+date+".txt", "a+") as f:
f.write("e:"+e+"\n")
try:
img = re.search('(.*?)', response.text).group(1)
item["news_pic"] = img
print item["news_pic"]
except:
item["news_pic"] = "" # 无图片返回空
</p>
正文部分,一开始用XPath提取文本信息,但考虑到有些新闻有图片信息,后期图片和文字会一一对应,所以使用常规匹配 p 标签以获取文本。最后退货
4.store 在 mysql 数据库中
在pipelines文件中写入sql信息
class XinwenPipeline(object):
def __init__(self):
print "connect successful..."
# 链接MySQL数据库
self.connect = pymysql.connect(host=settings.MYSQL_HOST,
user=settings.MYSQL_USER,
password=settings.MYSQL_PASSWD,
db=settings.MYSQL_DBNAME,
port=settings.MYSQL_PORT,
charset="utf8")
# 获取游标
self.cursor = self.connect.cursor()
# 存入数据库
def process_item(self, item, spider):
date = time.strftime("%Y%m%d")
print "doing something..."
try:
# 执行sql语句插入,其中title设置为唯一字段,防止重复录入
sql = '''insert into articles(title,zuozhe,content,fenlei_id,created_at,news_pic,updated_at,dianji) VALUES (%s,%s,%s,%s,%s,%s,%s,%s)'''
self.cursor.execute(
sql, (item["title"],item["zuozhe"],item["content"],item["fenlei_id"],item["created_at"],item["news_pic"], item["updated_at"], item["dianji"])
)
self.connect.commit() # 保存
except Exception as error:
# 出现错误时打印错误日志
with open(r"D:\pycharm_projects\xinwenyuan\xinwen\log\/"+date+".txt", "a+") as f:
f.write(item["created_at"]+"error:"+error[1]+"\n")
return item
# 关闭数据库
def close_spider(self, spider):
print "working done..."
self.cursor.close()
self.connect.close()
5.在start.py中设置定时任务,实现每天定时爬取
最后是设置bat文件
这部分计划任务参考网上文档,原文链接如下:
将设置好的bat文件加入定时执行任务
其中,本次爬虫任务使用scrapy的默认线程数,没有其他多线程,没有使用代理ip,所以只设置了延迟时间,这样爬虫就会因为ip在任何时候,但现在没事了,一切都好。
代码中还有很多其他问题,朋友们可以留言交流[严肃搞笑的表情].jpg
定时任务对于php来说一直都是很多朋友的一个难题
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-06-13 18:02
定时任务一直是很多PHP朋友的问题,但是在很多地方都遇到过。例如:在游戏开发程序中,每10分钟向玩家派兵一次。在sns社区,每20秒检查一次是否有人自动给我发消息采集procedure,采集每5分钟一次......
<p style="color:rgb(51,51,51);font-family:'Lucida Grande', 'Segoe UI', 'Bitstream Vera Sans', Tahoma, Verdana, Arial, sans-serif;font-size:13px;line-height:20px;">
定时任务对于php来说一直都是很多朋友的一个难题,但却很多地方都遇到了。<br />
比如说:<br />
游戏开发程序中,每隔10分钟给玩家发兵一次<br />
sns社区中每隔20秒检测一下是否有人给我发消息<br />
自动采集程序,每隔5分钟采集一次最新内容<br />
微博数据同步,每隔10个小时通过微博api接口同步一次用户数据<br />
……
由于php属于解释型弱语言,所以做定时任务的时候不会像java那样容易,在java中直接给个进程就可以让系统执行定时任务,但是在php中没那么简单 设置都没有多线程的概念。
我第一次接触定时任务的时候是一个做php的朋友问我怎么实现定时发兵,我当时给出的答案是写一个包含文件,每次都执行的时候都调用这个文件检查是否有任务,但试想 如果没人触发怎么办,显然答案并不完美。
后来我又通过其他渠道获得了解决的最佳办法,而且我还亲自做了测试。<br />
大致理念就是设定关闭浏览器程序也会停留在服务器内存中执行,并且相应时间永不过期<br />
看程序:
ignore_user_abort(TRUE);// 设定关闭浏览器也执行程序
set_time_limit(0); // 设定响应时间不限制,默认为30秒
$count= 0;
while(TRUE)
{
sleep(5); // 每5秒钟执行一次
// 写文件操作开始
$fp= fopen("test".$count.".txt","w");
if($fp)
{
for($i=0;$i 查看全部
定时任务对于php来说一直都是很多朋友的一个难题
定时任务一直是很多PHP朋友的问题,但是在很多地方都遇到过。例如:在游戏开发程序中,每10分钟向玩家派兵一次。在sns社区,每20秒检查一次是否有人自动给我发消息采集procedure,采集每5分钟一次......
<p style="color:rgb(51,51,51);font-family:'Lucida Grande', 'Segoe UI', 'Bitstream Vera Sans', Tahoma, Verdana, Arial, sans-serif;font-size:13px;line-height:20px;">
定时任务对于php来说一直都是很多朋友的一个难题,但却很多地方都遇到了。<br />
比如说:<br />
游戏开发程序中,每隔10分钟给玩家发兵一次<br />
sns社区中每隔20秒检测一下是否有人给我发消息<br />
自动采集程序,每隔5分钟采集一次最新内容<br />
微博数据同步,每隔10个小时通过微博api接口同步一次用户数据<br />
……
由于php属于解释型弱语言,所以做定时任务的时候不会像java那样容易,在java中直接给个进程就可以让系统执行定时任务,但是在php中没那么简单 设置都没有多线程的概念。
我第一次接触定时任务的时候是一个做php的朋友问我怎么实现定时发兵,我当时给出的答案是写一个包含文件,每次都执行的时候都调用这个文件检查是否有任务,但试想 如果没人触发怎么办,显然答案并不完美。
后来我又通过其他渠道获得了解决的最佳办法,而且我还亲自做了测试。<br />
大致理念就是设定关闭浏览器程序也会停留在服务器内存中执行,并且相应时间永不过期<br />
看程序:
ignore_user_abort(TRUE);// 设定关闭浏览器也执行程序
set_time_limit(0); // 设定响应时间不限制,默认为30秒
$count= 0;
while(TRUE)
{
sleep(5); // 每5秒钟执行一次
// 写文件操作开始
$fp= fopen("test".$count.".txt","w");
if($fp)
{
for($i=0;$i
《118模板网》,我的网站生成小程序码
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-06-12 07:00
文章定时自动采集的。用python在微信自动采集各种图片文章、图片、公众号文章、链接等等信息,最终呈现在你手机或者浏览器中,这篇教程不讲怎么生成二维码,所以这篇没有小编的视频地址:,就可以生成小程序码!保存的时候记得写上二维码链接,有问题请在微信公众号后台联系小编!微信公众号:安安聚创。微信号:caicaijer。
我之前还想写一个,可惜我没做过微信,不会做,结果我就弃坑了,说说,我用啥吧?用于微信采集的平台叫智能微觅是收费的,会像百度,网页采集那么麻烦。不然你上官网,看看那个平台做不做微信就行了,他有没有破解版,收费版,免费版,
安全自动化采集软件,只能满足大部分小范围的需求了。小范围的你可以尝试下我研发的《118模板网》,我的网站也是用它来做的,功能强大,解决大部分的采集需求了,
如果是收费的,一般是用批量采集软件,用很短的时间解决你手动采集很麻烦的问题,然后结合一些第三方的外挂,可以让你可以获得更好的效果。如果不是收费的,那么想玩玩采集,
就是这个来的吧!
还是能够用的,
我自己用过,是收费的。用手机微信扫码就可以自动下载了,但是如果有限制就要花钱下载,毕竟二维码是网络时代发展之后才出现的。 查看全部
《118模板网》,我的网站生成小程序码
文章定时自动采集的。用python在微信自动采集各种图片文章、图片、公众号文章、链接等等信息,最终呈现在你手机或者浏览器中,这篇教程不讲怎么生成二维码,所以这篇没有小编的视频地址:,就可以生成小程序码!保存的时候记得写上二维码链接,有问题请在微信公众号后台联系小编!微信公众号:安安聚创。微信号:caicaijer。
我之前还想写一个,可惜我没做过微信,不会做,结果我就弃坑了,说说,我用啥吧?用于微信采集的平台叫智能微觅是收费的,会像百度,网页采集那么麻烦。不然你上官网,看看那个平台做不做微信就行了,他有没有破解版,收费版,免费版,
安全自动化采集软件,只能满足大部分小范围的需求了。小范围的你可以尝试下我研发的《118模板网》,我的网站也是用它来做的,功能强大,解决大部分的采集需求了,
如果是收费的,一般是用批量采集软件,用很短的时间解决你手动采集很麻烦的问题,然后结合一些第三方的外挂,可以让你可以获得更好的效果。如果不是收费的,那么想玩玩采集,
就是这个来的吧!
还是能够用的,
我自己用过,是收费的。用手机微信扫码就可以自动下载了,但是如果有限制就要花钱下载,毕竟二维码是网络时代发展之后才出现的。
集众思推荐使用DX-auto-publish(‘ALTERNATE_WP_CRON’,)Python爬虫教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-06-10 20:42
我们手中有一个采集 站。我使用 WordPress 后端。不想一次性把采集的所有内容都发布出来,但又不能一直呆在电脑前。好在WordPress有定期发布文章的功能,因为是矿站,无法一一编辑文章。这里我们需要一个可以批量、定期发布文章的工具。
我们推荐使用DX-auto-publish作为插件,简单实用。主要功能有:
1、定时自动批量发布wordpress网站草稿文章。无需为每个文章手动设置定时发布时间,大大提高了工作效率。
2、可以选择按ID升序或随机文章发布草稿。
3、可以自定义定时发布文章的时间间隔。
这个插件的缺点之一就是需要把文章全部放在草稿里,所以像急中寺这样采集发布后,还需要把文章放在草稿箱里分批的背景。目前集中四还没有找到好的解决办法。如果你有好的解决方案,请推荐。
补充:部分用户在本地测试使用时,无法看到自动发布的效果。可能是您的服务器配置阻止了 wp-cron 被触发。本地测试可以在wordpress根目录下的wp-config中进行。在.php中加入如下代码:(正式使用时不要修改)
define('ALTERNATE_WP_CRON', true);
昊天seo
Python爬虫教程、SEO优化、Php教程
查看
未经许可不得转载:专注SEO»WordPress批量定期发布文章plugin DX-auto-publish 查看全部
集众思推荐使用DX-auto-publish(‘ALTERNATE_WP_CRON’,)Python爬虫教程
我们手中有一个采集 站。我使用 WordPress 后端。不想一次性把采集的所有内容都发布出来,但又不能一直呆在电脑前。好在WordPress有定期发布文章的功能,因为是矿站,无法一一编辑文章。这里我们需要一个可以批量、定期发布文章的工具。
我们推荐使用DX-auto-publish作为插件,简单实用。主要功能有:
1、定时自动批量发布wordpress网站草稿文章。无需为每个文章手动设置定时发布时间,大大提高了工作效率。
2、可以选择按ID升序或随机文章发布草稿。
3、可以自定义定时发布文章的时间间隔。
这个插件的缺点之一就是需要把文章全部放在草稿里,所以像急中寺这样采集发布后,还需要把文章放在草稿箱里分批的背景。目前集中四还没有找到好的解决办法。如果你有好的解决方案,请推荐。
补充:部分用户在本地测试使用时,无法看到自动发布的效果。可能是您的服务器配置阻止了 wp-cron 被触发。本地测试可以在wordpress根目录下的wp-config中进行。在.php中加入如下代码:(正式使用时不要修改)
define('ALTERNATE_WP_CRON', true);
昊天seo
Python爬虫教程、SEO优化、Php教程
查看
未经许可不得转载:专注SEO»WordPress批量定期发布文章plugin DX-auto-publish
快速伪原创出多篇文章,再不用很辛苦地原创
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-06-10 20:28
写原创文章是很多童鞋们一直担心的事情,所以有没有自动编辑文章的软件,快来伪原创出多篇文章,不用了努力工作原创什么?
当然有。
所以,在这里我给大家分享一个关于广告收入的软件使用方法,只有别人介绍才知道。
这是软件的界面,通过这个软件,你可以采集今日头条,百家号,企鹅3 自媒体platform latest 爆文。这些爆文 可以由目标采集 的参数设置。 采集完成文章后,可以用软件自动伪原创发表文章文章,非常快。
由于三个平台的操作方法是一样的,我就以今日头条为例来说明这个软件的使用。
第一步,采集ID号
在今日头条中,将那些经常阅读数十万和数百万的头条号的ID号给采集,然后将它们保存到软件目录中。如何找到今日头条ID?直接看图片操作。
比如图中红框里的“八卦八卦”,直接点击“八卦八卦”而不是文章。会进入对方的关注页面,然后在浏览器的URL中找到ID号。
找到ID号后,将ID号放入软件本地文件中保存。
这样,那些优质头条号的账号就不断地保存在这个本地文件的TXT文件中。
当然,如果不想手动采集优质标题ID,也可以直接设置初始ID和结束ID让软件自动采集。以“八卦八卦”为例,标题编号ID为:5905641527,可以作为初始ID,那么结束ID可以是:6625698298,只要数字大于5905641527即可。这个设置采集精度较差。
第二步,读入身份证号码
第一步ID号的采集完成后,可以直接用软件将这些优质头条号的ID读入软件。如何阅读?先选择平台,然后点击“导入”。
通过如此简单的步骤,所有高质量的今日头条ID都可以顺利导入到软件中,软件可以读取内容来源。
第三步,参数设置
所谓参数设置,就是你设置采集内容的标准。软件中有参数设置选项如下:
1、采集 区域。设置你想要采集哪个领域的内容,比如科技、娱乐、农业、农村、育儿……或所有。
2、阅读次数。设置你想要的内容数量采集reading 文章,比如设置5000,只有采集reading超过5000文章
3、评论数量。除了根据阅读数设置外,还可以根据评论数进行设置。原理与阅读次数相同。
4、采集speed。是采集文章源的快速丰满。如果网速好,可以选择多个线程,否则,选择几个线程。
5、采集platform。就是你选择采集哪个平台的内容。比如你在软件中读取了今日头条的ID,就选择今日头条。
6、时间设置。只需选择采集什么时间段发布文章。比如选择24小时内,那么采集的内容会在24小时内发布。
至于“按阅读量排序”、“按时间获取_百家号”、“按评论量排序”、“按阅读量获取_百家号”旁边的几个选项,你可以随意设置。如果需要排序,可以选择按阅读排序或按评论排序。
第四步,采集文章和伪原创
第三步一、第二、ID导入和参数设置后,直接点击“开始采集”即可采集符合条件的内容。
然后,我们点击选中里面的文章,右键显示五个选项:“复制标题”、“清空数据”、“打开浏览”、“本地编辑”和“删除本地保存”。
选择“本地编辑”查看原创内容,但是“原创”内容旁边有一个“伪原创”功能,可以直接点击查看软件自动伪原创的文章出来。然后,通过复制内容,直接复制伪原创内容即可。
这样通过软件,你每天可以阅读采集千篇文章文章,然后通过软件的自动伪原创功能,你可以伪原创在短时间内发表数百篇文章复制出来后,直接列出下一个版本,优化标题和图片,然后使用原创度检测工具完成测试并发布。
以上以“今日头条”为例。制作了详细的软件操作流程,百家账号和企鹅账号同样如此。至于软件,直接放在文末,可以直接下载使用。 查看全部
快速伪原创出多篇文章,再不用很辛苦地原创
写原创文章是很多童鞋们一直担心的事情,所以有没有自动编辑文章的软件,快来伪原创出多篇文章,不用了努力工作原创什么?
当然有。
所以,在这里我给大家分享一个关于广告收入的软件使用方法,只有别人介绍才知道。
这是软件的界面,通过这个软件,你可以采集今日头条,百家号,企鹅3 自媒体platform latest 爆文。这些爆文 可以由目标采集 的参数设置。 采集完成文章后,可以用软件自动伪原创发表文章文章,非常快。
由于三个平台的操作方法是一样的,我就以今日头条为例来说明这个软件的使用。
第一步,采集ID号
在今日头条中,将那些经常阅读数十万和数百万的头条号的ID号给采集,然后将它们保存到软件目录中。如何找到今日头条ID?直接看图片操作。
比如图中红框里的“八卦八卦”,直接点击“八卦八卦”而不是文章。会进入对方的关注页面,然后在浏览器的URL中找到ID号。
找到ID号后,将ID号放入软件本地文件中保存。
这样,那些优质头条号的账号就不断地保存在这个本地文件的TXT文件中。
当然,如果不想手动采集优质标题ID,也可以直接设置初始ID和结束ID让软件自动采集。以“八卦八卦”为例,标题编号ID为:5905641527,可以作为初始ID,那么结束ID可以是:6625698298,只要数字大于5905641527即可。这个设置采集精度较差。
第二步,读入身份证号码
第一步ID号的采集完成后,可以直接用软件将这些优质头条号的ID读入软件。如何阅读?先选择平台,然后点击“导入”。
通过如此简单的步骤,所有高质量的今日头条ID都可以顺利导入到软件中,软件可以读取内容来源。
第三步,参数设置
所谓参数设置,就是你设置采集内容的标准。软件中有参数设置选项如下:
1、采集 区域。设置你想要采集哪个领域的内容,比如科技、娱乐、农业、农村、育儿……或所有。
2、阅读次数。设置你想要的内容数量采集reading 文章,比如设置5000,只有采集reading超过5000文章
3、评论数量。除了根据阅读数设置外,还可以根据评论数进行设置。原理与阅读次数相同。
4、采集speed。是采集文章源的快速丰满。如果网速好,可以选择多个线程,否则,选择几个线程。
5、采集platform。就是你选择采集哪个平台的内容。比如你在软件中读取了今日头条的ID,就选择今日头条。
6、时间设置。只需选择采集什么时间段发布文章。比如选择24小时内,那么采集的内容会在24小时内发布。
至于“按阅读量排序”、“按时间获取_百家号”、“按评论量排序”、“按阅读量获取_百家号”旁边的几个选项,你可以随意设置。如果需要排序,可以选择按阅读排序或按评论排序。
第四步,采集文章和伪原创
第三步一、第二、ID导入和参数设置后,直接点击“开始采集”即可采集符合条件的内容。
然后,我们点击选中里面的文章,右键显示五个选项:“复制标题”、“清空数据”、“打开浏览”、“本地编辑”和“删除本地保存”。
选择“本地编辑”查看原创内容,但是“原创”内容旁边有一个“伪原创”功能,可以直接点击查看软件自动伪原创的文章出来。然后,通过复制内容,直接复制伪原创内容即可。
这样通过软件,你每天可以阅读采集千篇文章文章,然后通过软件的自动伪原创功能,你可以伪原创在短时间内发表数百篇文章复制出来后,直接列出下一个版本,优化标题和图片,然后使用原创度检测工具完成测试并发布。
以上以“今日头条”为例。制作了详细的软件操作流程,百家账号和企鹅账号同样如此。至于软件,直接放在文末,可以直接下载使用。
文章定时自动采集《动物世界》热搜话题(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-06-08 01:00
文章定时自动采集《动物世界》热搜话题微博、微信上热搜词。并且根据用户行为自动推送到网页上。是一款网页采集工具,内置数千个高效的搜索引擎,几乎可实现全网采集。还提供了多种正则表达式和xpath的调用,可以快速操作。体验链接:、其他相关作用大:提供了海量国内外电影的搜索引擎以及搜索结果实时翻译成中文再传回国内,给海外影迷们带来极大的便利;针对国内用户更是提供了引用优酷/爱奇艺/腾讯等国内网站搜索历史并且支持翻译解析的服务;另外提供了完整的工具箱,可用于进行数据分析,这就是一个网页采集器。适用于多种平台:b站、各种软件app、公众号推送等。
二、正则表达式中文问题参见::、代码采集工具支持高达100000种搜索引擎的采集,即使你是渣渣也可以轻松获取这个庞大的库。
1、根据微博、知乎等多种热搜话题找到相关微博、话题,根据网页内容获取对应的关键词,
2、根据行为找到用户动作,
3、根据转发量、转发评论量、点赞量、浏览时间采集相关内容;
4、根据用户搜索需求和搜索历史获取对应关键词的结果。
5、根据留言、转发、评论、浏览量、点赞、阅读量、点赞数、浏览量以及浏览历史获取对应关键词的结果。
6、根据个人爱好、关注等共享信息、热词、专题热门搜索(如娱乐圈热门搜索)等采集相关内容。
7、根据qq空间/微博、朋友圈等多种社交平台扩展采集,可对应采集多个社交平台的内容。
8、可对话题列表,小说、cookies等多种热门内容自动采集。
9、将代码转为xml或html格式,方便方便后期可以对采集进行美化。
1
0、还提供有多种微博热点采集包,如:新浪转发10万奖品;豆瓣评分3万,点击和评论数量都是爆表的数字或者是网友推荐必看的小说。基于多样性搜索的无损阅读,给在观影无法快速获取到信息的人,提供一个解决问题的途径。 查看全部
文章定时自动采集《动物世界》热搜话题(图)
文章定时自动采集《动物世界》热搜话题微博、微信上热搜词。并且根据用户行为自动推送到网页上。是一款网页采集工具,内置数千个高效的搜索引擎,几乎可实现全网采集。还提供了多种正则表达式和xpath的调用,可以快速操作。体验链接:、其他相关作用大:提供了海量国内外电影的搜索引擎以及搜索结果实时翻译成中文再传回国内,给海外影迷们带来极大的便利;针对国内用户更是提供了引用优酷/爱奇艺/腾讯等国内网站搜索历史并且支持翻译解析的服务;另外提供了完整的工具箱,可用于进行数据分析,这就是一个网页采集器。适用于多种平台:b站、各种软件app、公众号推送等。
二、正则表达式中文问题参见::、代码采集工具支持高达100000种搜索引擎的采集,即使你是渣渣也可以轻松获取这个庞大的库。
1、根据微博、知乎等多种热搜话题找到相关微博、话题,根据网页内容获取对应的关键词,
2、根据行为找到用户动作,
3、根据转发量、转发评论量、点赞量、浏览时间采集相关内容;
4、根据用户搜索需求和搜索历史获取对应关键词的结果。
5、根据留言、转发、评论、浏览量、点赞、阅读量、点赞数、浏览量以及浏览历史获取对应关键词的结果。
6、根据个人爱好、关注等共享信息、热词、专题热门搜索(如娱乐圈热门搜索)等采集相关内容。
7、根据qq空间/微博、朋友圈等多种社交平台扩展采集,可对应采集多个社交平台的内容。
8、可对话题列表,小说、cookies等多种热门内容自动采集。
9、将代码转为xml或html格式,方便方便后期可以对采集进行美化。
1
0、还提供有多种微博热点采集包,如:新浪转发10万奖品;豆瓣评分3万,点击和评论数量都是爆表的数字或者是网友推荐必看的小说。基于多样性搜索的无损阅读,给在观影无法快速获取到信息的人,提供一个解决问题的途径。
用python也可以做爬虫(爬票圈)简单实用可参考
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-06-05 18:02
文章定时自动采集qq空间百度云盘微信公众号等一切可以采集的地方。抓包采集再结合正则表达式还可以提取文章内容哦。包括标题,作者,链接,
urllib2
最简单的是用java写一个。api很多。
人人网爬虫百度网盘爬虫等等
路过推荐一个。刚写了一个社交爬虫(用ajax),和官方发布的完全一样。
用python也可以做爬虫(爬票圈)
简单实用可参考:python爬虫从twitter爬取的用户画像
如果是要采集facebook的话,我推荐使用专业的facebook采集器,并且要爬取国内外facebook的数据,
从twitter上获取评论,
上
糗事百科欢迎加我站内试用,不过记得备注知乎,
爬取评论,推荐使用豆瓣爬虫。
美团+购物车+商品小组
购物车
简单明了,可以先搞个机器人,把知道的里面的关键词对其转化为文本,
我推荐我自己开发的小程序,上线在各大商城,一键就可以给产品评论,点评,购物车填空,商品分享,评论追踪,
初级做法:爬取某高级公司某产品内部员工所发的邮件!如果对数据量要求特别高,就上百度爬虫抓取,爬取网站网页基本数据,然后再数据结构分析!但数据量大到一定规模,就只能数据挖掘了,不要为了爬虫而爬取!最简单的方法还是找某公司的目标行业或公司所开发的行业搜索引擎!针对大量,长尾关键词的数据进行爬取!例如百度百科信息,商城销售数据等等!数据量太大的,就用正则表达式抓取!中等程度的数据就在用采集twitter评论,百度贴吧等等内容!有些会,额外的内容,就需要相应的语言写一下,例如grape内容抓取,qq内容抓取等等!针对简单程度的爬取,除了noscript,你可以采用正则表达式处理!复杂的数据,那就用各种api!部分api有待突破!(不是你想爬,想爬就能爬,这个不可能!有技术的很少会搞这个吧!)高级数据就要有采集baidu中国搜索引擎中,把内容通过内容编码转化成json格式,利用正则表达式处理!然后再用google语法匹配内容!需要内容量大,数据量也要大,才能调优语法实现!如果会java编程,建议可以试着用java做一个爬虫,爬取购物车。如果不会,找人求助!。 查看全部
用python也可以做爬虫(爬票圈)简单实用可参考
文章定时自动采集qq空间百度云盘微信公众号等一切可以采集的地方。抓包采集再结合正则表达式还可以提取文章内容哦。包括标题,作者,链接,
urllib2
最简单的是用java写一个。api很多。
人人网爬虫百度网盘爬虫等等
路过推荐一个。刚写了一个社交爬虫(用ajax),和官方发布的完全一样。
用python也可以做爬虫(爬票圈)
简单实用可参考:python爬虫从twitter爬取的用户画像
如果是要采集facebook的话,我推荐使用专业的facebook采集器,并且要爬取国内外facebook的数据,
从twitter上获取评论,
上
糗事百科欢迎加我站内试用,不过记得备注知乎,
爬取评论,推荐使用豆瓣爬虫。
美团+购物车+商品小组
购物车
简单明了,可以先搞个机器人,把知道的里面的关键词对其转化为文本,
我推荐我自己开发的小程序,上线在各大商城,一键就可以给产品评论,点评,购物车填空,商品分享,评论追踪,
初级做法:爬取某高级公司某产品内部员工所发的邮件!如果对数据量要求特别高,就上百度爬虫抓取,爬取网站网页基本数据,然后再数据结构分析!但数据量大到一定规模,就只能数据挖掘了,不要为了爬虫而爬取!最简单的方法还是找某公司的目标行业或公司所开发的行业搜索引擎!针对大量,长尾关键词的数据进行爬取!例如百度百科信息,商城销售数据等等!数据量太大的,就用正则表达式抓取!中等程度的数据就在用采集twitter评论,百度贴吧等等内容!有些会,额外的内容,就需要相应的语言写一下,例如grape内容抓取,qq内容抓取等等!针对简单程度的爬取,除了noscript,你可以采用正则表达式处理!复杂的数据,那就用各种api!部分api有待突破!(不是你想爬,想爬就能爬,这个不可能!有技术的很少会搞这个吧!)高级数据就要有采集baidu中国搜索引擎中,把内容通过内容编码转化成json格式,利用正则表达式处理!然后再用google语法匹配内容!需要内容量大,数据量也要大,才能调优语法实现!如果会java编程,建议可以试着用java做一个爬虫,爬取购物车。如果不会,找人求助!。
没有新文章更新的栏目不会更新怎么办?
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-06-05 05:00
[wm_warn]注:本站所有资源仅供交流学习使用。商业操作请购买正品,否则后果自负[/wm_warn]
织梦优采云采集文章自动推送到百度后自动审核文章并更新文章(站群ranking必须)
1、 可以设置从 0:00 到 23:00 的多个时间段。在这些时间段内,每天都会自动审核并自动生成指定数量的未审核文章。
2、自动更新网站首页和需要更新的栏目页和文章页,需要更新的栏目页是新文章生成的栏目,没有的栏目新的文章更新不会更新,提高更新的性能。
3、可以根据列数或总数更新文章。根据列更新文章,每列更新指定数量的文章文章。根据总数更新文章,根据id从小到大更新指定数量的文章文章。
4、文章更新是按照文章的顺序进行的,保证先添加的文章先更新。
5、文章发布时间为审核时间。
6、百度主动推送功能:文章审核后会自动推送到百度,增加收录排名。
7、百度熊掌号每日每周自动推送功能,审核后文章会自动推送到百度熊掌。
8、自动更新新添加的TAG标签,自动更新TAG图。需要用到这个插件《织梦tag标签自定义标题、关键词、描述、缩略图静态优化插件(支持手机)》
9、Auto-review 和自动更新触发地址是您的域名。 com/plus/ajax_sh.php,访问后可以自动查看更新,比如添加到你的模板footer.htm
当访客访问时,它会自动评论文章并自动更新整个网站。也可以添加宝塔定时任务触发更新,
执行周期可以和上面的自动审核间隔一样。即1分钟,更新1篇文章,根据你的需要设置,宝塔计划任务中的URL地址为:你的域名。 com/plus/ajax_sh.php。
注意:没有宝塔的同学可以到【监控宝藏】添加触发更新
10、支持优采云采集和采集侠采集织梦未reviewed文章,然后每天定时审核文章,定时更新全站,自动推送For百度,实现全自动化,解放双手,提升网站收录排名。您可以使用优采云或采集侠时代采集上万篇文章进行未审核,触发宝塔内自动审核更新任务,每天定时更新织梦文章。 网站实现了自动化,非常适合站群和网站排名。
插件分为utf-8和GBK两个版本,有详细的使用说明。部分功能截图如下:
织梦文章审核成功后,可以在宝塔计划任务的日志中看到推送和审核状态的截图:
查看全部
没有新文章更新的栏目不会更新怎么办?
[wm_warn]注:本站所有资源仅供交流学习使用。商业操作请购买正品,否则后果自负[/wm_warn]
织梦优采云采集文章自动推送到百度后自动审核文章并更新文章(站群ranking必须)
1、 可以设置从 0:00 到 23:00 的多个时间段。在这些时间段内,每天都会自动审核并自动生成指定数量的未审核文章。
2、自动更新网站首页和需要更新的栏目页和文章页,需要更新的栏目页是新文章生成的栏目,没有的栏目新的文章更新不会更新,提高更新的性能。
3、可以根据列数或总数更新文章。根据列更新文章,每列更新指定数量的文章文章。根据总数更新文章,根据id从小到大更新指定数量的文章文章。
4、文章更新是按照文章的顺序进行的,保证先添加的文章先更新。
5、文章发布时间为审核时间。
6、百度主动推送功能:文章审核后会自动推送到百度,增加收录排名。
7、百度熊掌号每日每周自动推送功能,审核后文章会自动推送到百度熊掌。
8、自动更新新添加的TAG标签,自动更新TAG图。需要用到这个插件《织梦tag标签自定义标题、关键词、描述、缩略图静态优化插件(支持手机)》
9、Auto-review 和自动更新触发地址是您的域名。 com/plus/ajax_sh.php,访问后可以自动查看更新,比如添加到你的模板footer.htm
当访客访问时,它会自动评论文章并自动更新整个网站。也可以添加宝塔定时任务触发更新,
执行周期可以和上面的自动审核间隔一样。即1分钟,更新1篇文章,根据你的需要设置,宝塔计划任务中的URL地址为:你的域名。 com/plus/ajax_sh.php。
注意:没有宝塔的同学可以到【监控宝藏】添加触发更新
10、支持优采云采集和采集侠采集织梦未reviewed文章,然后每天定时审核文章,定时更新全站,自动推送For百度,实现全自动化,解放双手,提升网站收录排名。您可以使用优采云或采集侠时代采集上万篇文章进行未审核,触发宝塔内自动审核更新任务,每天定时更新织梦文章。 网站实现了自动化,非常适合站群和网站排名。
插件分为utf-8和GBK两个版本,有详细的使用说明。部分功能截图如下:
织梦文章审核成功后,可以在宝塔计划任务的日志中看到推送和审核状态的截图:
苹果CMS10网站添加自定义资源库后的采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 301 次浏览 • 2021-06-03 20:15
小伙伴自己创建了网站并添加了自定义资源库后,手动采集方法费时费力,更新不够及时。你是不是特别想拥有一个全自动定时采集 帮助网站增加视频资源解放双手的方法,所以现在我的主题网分享Applecms宝塔自动定时采集教程
1.进入Applecms10后台,点击--采集
2.采集页面,点击左侧“自定义资源库”,右键点击需要采集的内容,如“采集今日”、“采集本周” “采集全部”,选择复制链接地址。
3.复制链接后台选择系统--定时任务,选择添加,我们添加一个新的定时任务。
4.状态选择为:已启用。名称:英文标志为必填项。备注:可以自由书写。附加参数:粘贴刚才复制的链接,删除链接中“ac”前面的多余链接(删除红框内的链接)。要设置执行周期和执行时间,请单击下方的“全选”按钮。
5.找到我们刚刚设置的任务后,右键测试复制链接地址
6.复制刚才的链接,进入宝塔后台界面找到定时任务,如图添加任务,注意URL地址填写测试采集页面地址刚才复制的,选择要访问的URL任务,根据需要填写,执行完循环参数后保存。
7.最后,点击execute后网站可以实现自动定时采集,相关过程可以在日志中查看。所以一个完整的计时采集任务也已经设置好了。
转载: 查看全部
苹果CMS10网站添加自定义资源库后的采集方法
小伙伴自己创建了网站并添加了自定义资源库后,手动采集方法费时费力,更新不够及时。你是不是特别想拥有一个全自动定时采集 帮助网站增加视频资源解放双手的方法,所以现在我的主题网分享Applecms宝塔自动定时采集教程
1.进入Applecms10后台,点击--采集
2.采集页面,点击左侧“自定义资源库”,右键点击需要采集的内容,如“采集今日”、“采集本周” “采集全部”,选择复制链接地址。
3.复制链接后台选择系统--定时任务,选择添加,我们添加一个新的定时任务。
4.状态选择为:已启用。名称:英文标志为必填项。备注:可以自由书写。附加参数:粘贴刚才复制的链接,删除链接中“ac”前面的多余链接(删除红框内的链接)。要设置执行周期和执行时间,请单击下方的“全选”按钮。
5.找到我们刚刚设置的任务后,右键测试复制链接地址
6.复制刚才的链接,进入宝塔后台界面找到定时任务,如图添加任务,注意URL地址填写测试采集页面地址刚才复制的,选择要访问的URL任务,根据需要填写,执行完循环参数后保存。
7.最后,点击execute后网站可以实现自动定时采集,相关过程可以在日志中查看。所以一个完整的计时采集任务也已经设置好了。
转载:
文章定时自动采集,和样式表设置一致!-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-06-03 05:01
文章定时自动采集,和样式表设置一致!一句话总结,前端,美工设计和代码规范的好坏决定整个设计是否漂亮。解释一下:其实也不是定时采集,虽然定时采集比不定时采集运行要快一些,但这是通过模拟人操作设置下实现的。定时采集更多需要看ui设计对seo优化是否友好,以及对后端响应速度的要求。如果你的前端代码是像wordpress那种直接引入代码的就不需要分析浏览器内存,流量数据,也不需要像阿里云那样完整的实现去重,检查是否撞库等操作。
总结:如果你的美工做到位,前端优化做到位。前端改一下样式换一下展示图,后端检查一下flash是否有问题,在不触碰你后端操作的情况下,正常web服务的话,可以正常做到。如果一定要你后端帮你检查操作是否正常,正常操作的配置是:http://+ip+端口号(其实像wordpress,不太优化的情况下,一段时间后后端访问的地址不一定会变成你的浏览器地址),每次请求在做一下缓存(选择一个稳定的sqlmap缓存)。
可以通过nginx和nginxcache来达到缓存的目的。如果你的ui设计没做到位(引入了其他网站的样式表,或者打开的情况过多,本来网页就长,页面太短访问的页面很多),前端没做到位,后端也没做到位,用什么方法都没用。 查看全部
文章定时自动采集,和样式表设置一致!-八维教育
文章定时自动采集,和样式表设置一致!一句话总结,前端,美工设计和代码规范的好坏决定整个设计是否漂亮。解释一下:其实也不是定时采集,虽然定时采集比不定时采集运行要快一些,但这是通过模拟人操作设置下实现的。定时采集更多需要看ui设计对seo优化是否友好,以及对后端响应速度的要求。如果你的前端代码是像wordpress那种直接引入代码的就不需要分析浏览器内存,流量数据,也不需要像阿里云那样完整的实现去重,检查是否撞库等操作。
总结:如果你的美工做到位,前端优化做到位。前端改一下样式换一下展示图,后端检查一下flash是否有问题,在不触碰你后端操作的情况下,正常web服务的话,可以正常做到。如果一定要你后端帮你检查操作是否正常,正常操作的配置是:http://+ip+端口号(其实像wordpress,不太优化的情况下,一段时间后后端访问的地址不一定会变成你的浏览器地址),每次请求在做一下缓存(选择一个稳定的sqlmap缓存)。
可以通过nginx和nginxcache来达到缓存的目的。如果你的ui设计没做到位(引入了其他网站的样式表,或者打开的情况过多,本来网页就长,页面太短访问的页面很多),前端没做到位,后端也没做到位,用什么方法都没用。
文章定时自动采集苹果xr的热门搜索词分析其月搜索量排行
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-06-01 20:01
文章定时自动采集苹果xr的热门搜索词,分析其月搜索量排行,以及时适当采取跟进策略,我们以xr代码的形式呈现出来。本教程也适用于购买了googleadsense的android商户,请按照上图所示方法操作。文中部分参数以googleadsense官方进行说明。手机用户请仔细查看苹果商店xr的搜索页面。温馨提示:想要参照上图数据请按照下图所示格式查看更加详细完整数据。
另外,定制自己的搜索推广计划能够让您为不同的app设置计划流量,如android商户可为app设置一个英文手机xr版本,androidxr版本通过链接推广,而可适当选择xr版本推广app,能够利用更多的关键词。开通方法见个人主页。2.利用关键词分析系统与数据分析工具进行关键词分析,迅速了解竞争对手怎么操作。-tabarmx92zoz(二维码自动识别)。
谢邀我在quora上看到过这样一个回答,来自苹果官方在官方网站上他们提供了一个功能itunesoptions可以让你知道你app的googleplay收录情况,月度热度趋势图以及用户的流失率趋势等,是个很好的用户画像分析功能。然后我们知道了这些,有些产品就可以利用上面的搜索数据来优化自己的产品。有些发布了广告的产品就更加要做好数据分析了,这样才能让产品有更好的推广效果。 查看全部
文章定时自动采集苹果xr的热门搜索词分析其月搜索量排行
文章定时自动采集苹果xr的热门搜索词,分析其月搜索量排行,以及时适当采取跟进策略,我们以xr代码的形式呈现出来。本教程也适用于购买了googleadsense的android商户,请按照上图所示方法操作。文中部分参数以googleadsense官方进行说明。手机用户请仔细查看苹果商店xr的搜索页面。温馨提示:想要参照上图数据请按照下图所示格式查看更加详细完整数据。
另外,定制自己的搜索推广计划能够让您为不同的app设置计划流量,如android商户可为app设置一个英文手机xr版本,androidxr版本通过链接推广,而可适当选择xr版本推广app,能够利用更多的关键词。开通方法见个人主页。2.利用关键词分析系统与数据分析工具进行关键词分析,迅速了解竞争对手怎么操作。-tabarmx92zoz(二维码自动识别)。
谢邀我在quora上看到过这样一个回答,来自苹果官方在官方网站上他们提供了一个功能itunesoptions可以让你知道你app的googleplay收录情况,月度热度趋势图以及用户的流失率趋势等,是个很好的用户画像分析功能。然后我们知道了这些,有些产品就可以利用上面的搜索数据来优化自己的产品。有些发布了广告的产品就更加要做好数据分析了,这样才能让产品有更好的推广效果。
目前完美运行于的WordPress文章采集器,请放心使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-05-28 06:12
简介:
当前所有版本的WordPress都运行良好,请随时使用它们。 WP-AutoPost-Pro是一款出色的WordPress 文章 采集器,它是您操作站群并让网站自动更新内容的强大工具!
此版本与官方功能之间没有区别;
采集插入适用对象
1、新建的wordpress网站的内容相对较小,希望尽快拥有更丰富的内容;
2、热门内容自动采集并自动发布;
3、定时采集,手动采集发布或保存到草稿;
4、 css样式规则可以更精确地显示采集需要的内容。
5、 伪原创与翻译和代理IP 采集通信,保存cookie记录;
6、可以将采集内容添加到自定义列
WP-AutoBlog是一个新开发的插件(原来的WP-AutoPost将不再进行更新和维护),完全支持PHP 7. 3,更快,更稳定
新的体系结构和设计,采集设置更全面,更灵活;支持多级文章列表,多级文章内容采集
对Google神经网络翻译的新支持,youdao神经网络翻译,易于获得高质量的原创 文章
对市场上所有主流对象存储服务,秦牛云,阿里云OSS等的全面支持。
采集微信公众号,头条账户等自媒体内容,因为百度没有收录官方头目,头条文章等,您可以轻松获得高质量的“ 原创” 文章,加上百度收录 Amount和网站 Weight
采集 网站,采集信息的任何内容一目了然
通过简单的设置,采集可以来自任何网站内容,并且可以将多个采集任务设置为同时运行,并且可以将任务设置为自动或手动运行。主任务列表显示每个采集的任务状态:上次测试的时间采集,下一次测试的估计时间采集,最近的采集 文章,文章的数量]由采集和其他信息更新,方便查看和管理。
文章管理功能方便查询,搜索和删除采集 文章,改进的算法从根本上消除了与采集相同的重复文章,log函数将异常记录在采集的处理并抓住错误,可以方便地检查设置错误以进行修复。
WP-AutoBlog是一个新开发的插件(原来的WP-AutoPost将不再进行更新和维护),完全支持PHP 7. 3,更快,更稳定
新的体系结构和设计,采集设置更全面,更灵活;支持多级文章列表,多级文章内容采集
对Google神经网络翻译的新支持,youdao神经网络翻译,易于获得高质量的原创 文章
对市场上所有主流对象存储服务,秦牛云,阿里云OSS等的全面支持。
采集微信官方账号,头条账号等自媒体内容,因为百度没有收录官方账号,头条文章等,您可以轻松获得高质量的“ 原创” 文章,加上百度收录 Amount和网站 Weight
采集 网站,采集信息的任何内容一目了然
通过简单的设置,采集可以来自任何网站内容,并且可以将多个采集任务设置为同时运行,并且可以将任务设置为自动或手动运行。主任务列表显示每个采集的任务状态:上次测试的时间采集,下一次测试的估计时间采集,最近的采集 文章,文章的数量]由采集和其他信息更新,方便查看和管理。
文章管理功能方便查询,搜索和删除采集 文章,改进的算法从根本上消除了与采集相同的重复文章,log函数将异常记录在采集的处理并抓住错误,可以方便地检查设置错误以进行修复。
网络磁盘下载地址:
图片:
查看全部
目前完美运行于的WordPress文章采集器,请放心使用
简介:
当前所有版本的WordPress都运行良好,请随时使用它们。 WP-AutoPost-Pro是一款出色的WordPress 文章 采集器,它是您操作站群并让网站自动更新内容的强大工具!
此版本与官方功能之间没有区别;
采集插入适用对象
1、新建的wordpress网站的内容相对较小,希望尽快拥有更丰富的内容;
2、热门内容自动采集并自动发布;
3、定时采集,手动采集发布或保存到草稿;
4、 css样式规则可以更精确地显示采集需要的内容。
5、 伪原创与翻译和代理IP 采集通信,保存cookie记录;
6、可以将采集内容添加到自定义列
WP-AutoBlog是一个新开发的插件(原来的WP-AutoPost将不再进行更新和维护),完全支持PHP 7. 3,更快,更稳定
新的体系结构和设计,采集设置更全面,更灵活;支持多级文章列表,多级文章内容采集
对Google神经网络翻译的新支持,youdao神经网络翻译,易于获得高质量的原创 文章
对市场上所有主流对象存储服务,秦牛云,阿里云OSS等的全面支持。
采集微信公众号,头条账户等自媒体内容,因为百度没有收录官方头目,头条文章等,您可以轻松获得高质量的“ 原创” 文章,加上百度收录 Amount和网站 Weight
采集 网站,采集信息的任何内容一目了然
通过简单的设置,采集可以来自任何网站内容,并且可以将多个采集任务设置为同时运行,并且可以将任务设置为自动或手动运行。主任务列表显示每个采集的任务状态:上次测试的时间采集,下一次测试的估计时间采集,最近的采集 文章,文章的数量]由采集和其他信息更新,方便查看和管理。
文章管理功能方便查询,搜索和删除采集 文章,改进的算法从根本上消除了与采集相同的重复文章,log函数将异常记录在采集的处理并抓住错误,可以方便地检查设置错误以进行修复。
WP-AutoBlog是一个新开发的插件(原来的WP-AutoPost将不再进行更新和维护),完全支持PHP 7. 3,更快,更稳定
新的体系结构和设计,采集设置更全面,更灵活;支持多级文章列表,多级文章内容采集
对Google神经网络翻译的新支持,youdao神经网络翻译,易于获得高质量的原创 文章
对市场上所有主流对象存储服务,秦牛云,阿里云OSS等的全面支持。
采集微信官方账号,头条账号等自媒体内容,因为百度没有收录官方账号,头条文章等,您可以轻松获得高质量的“ 原创” 文章,加上百度收录 Amount和网站 Weight
采集 网站,采集信息的任何内容一目了然
通过简单的设置,采集可以来自任何网站内容,并且可以将多个采集任务设置为同时运行,并且可以将任务设置为自动或手动运行。主任务列表显示每个采集的任务状态:上次测试的时间采集,下一次测试的估计时间采集,最近的采集 文章,文章的数量]由采集和其他信息更新,方便查看和管理。
文章管理功能方便查询,搜索和删除采集 文章,改进的算法从根本上消除了与采集相同的重复文章,log函数将异常记录在采集的处理并抓住错误,可以方便地检查设置错误以进行修复。
网络磁盘下载地址:
图片:
文章定时自动采集今日头条内容实现后台定时同步,操作简单快捷
采集交流 • 优采云 发表了文章 • 0 个评论 • 865 次浏览 • 2021-05-25 06:03
文章定时自动采集今日头条内容,因为今日头条内容定位太广,我们无法按照杂志版面的展示原则规划上述文章。所以我们依托全站1万元的稿酬筛选出可视化内容作为封面,之后全部转化为标题,实现今日头条内容自动采集功能。采集总时长1小时,超时立马采集。数据自动汇总整理。实现后台定时同步,操作简单快捷。经手过采集了半年的文章,小白一名,经过思考,对方有个问题,经过实践,结合目前的市场行情,选择市场大的标题作为封面,也就是数据分析的1234端口中的标题,解决点击问题。
几点说明:1.还是标题党,对头条内容要求不太高,十万+文章转化相对可观。2.非原创文章,文章结构相对没有原创公众号完整(有大神简单指导打开率,实现大规模标题采集,统计采集)。3.收集内容时,尽量选择被采集次数多的内容,结构图、摘要等,内容吸引点;通过标题、摘要,通过加上特殊符号或“<a>”构成复杂结构图(注意:不是所有标题文章都需要采集,对于一些符合要求的内容可采集),提高软件解析难度。4.尽量把封面或字幕放置在采集入口位置,不建议放入素材内页放,太贵。5.选择第。
3、
4、
5、
6、
7、8六个方向时,依据自己的定位即可。
你想要的标题就是
这种网上多得很。用bdp统计下数据,找标题关键词, 查看全部
文章定时自动采集今日头条内容实现后台定时同步,操作简单快捷
文章定时自动采集今日头条内容,因为今日头条内容定位太广,我们无法按照杂志版面的展示原则规划上述文章。所以我们依托全站1万元的稿酬筛选出可视化内容作为封面,之后全部转化为标题,实现今日头条内容自动采集功能。采集总时长1小时,超时立马采集。数据自动汇总整理。实现后台定时同步,操作简单快捷。经手过采集了半年的文章,小白一名,经过思考,对方有个问题,经过实践,结合目前的市场行情,选择市场大的标题作为封面,也就是数据分析的1234端口中的标题,解决点击问题。
几点说明:1.还是标题党,对头条内容要求不太高,十万+文章转化相对可观。2.非原创文章,文章结构相对没有原创公众号完整(有大神简单指导打开率,实现大规模标题采集,统计采集)。3.收集内容时,尽量选择被采集次数多的内容,结构图、摘要等,内容吸引点;通过标题、摘要,通过加上特殊符号或“<a>”构成复杂结构图(注意:不是所有标题文章都需要采集,对于一些符合要求的内容可采集),提高软件解析难度。4.尽量把封面或字幕放置在采集入口位置,不建议放入素材内页放,太贵。5.选择第。
3、
4、
5、
6、
7、8六个方向时,依据自己的定位即可。
你想要的标题就是
这种网上多得很。用bdp统计下数据,找标题关键词,
文章定时自动采集,并进行校验,可定制自己的机制
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2021-05-18 06:02
文章定时自动采集,并进行校验,可定制自己的校验机制。代码可以参照:wordpressseo学习之路1autocommitpreparestoragemessages按分支提交文件,完成文件预览,自动接收文件并进行自动校验并将文件写入到页面。2httpproxy使用http代理来分发文件,浏览器并不知道网站端是哪个人访问的。
每次提交post信息的时候,都必须在客户端的浏览器和服务器端交互。代码可以参照:wordpressseo学习之路3evaltie伪装参数,获取某个值,不会传递到页面。prepareexecutabletocommitrequest将commit信息传递到页面。代码可以参照:wordpressseo学习之路4filesignature伪装文件安全证书、密码等,到达预览页。
代码可以参照:wordpressseo学习之路5typecho伪装文件方式到预览页。代码可以参照:wordpressseo学习之路6.catthesitelog,内部已经记录了所有内容变化情况。只要发生变化,就会自动记录。代码可以参照:wordpressseo学习之路7loopers.php用markdown格式给php写脚本,可以获取到变化,自动生成php文件。
代码可以参照:wordpressseo学习之路8wordpress内部自带了一个生成html代码的库loadcode,用于将代码转换为php代码。代码可以参照:wordpressseo学习之路。 查看全部
文章定时自动采集,并进行校验,可定制自己的机制
文章定时自动采集,并进行校验,可定制自己的校验机制。代码可以参照:wordpressseo学习之路1autocommitpreparestoragemessages按分支提交文件,完成文件预览,自动接收文件并进行自动校验并将文件写入到页面。2httpproxy使用http代理来分发文件,浏览器并不知道网站端是哪个人访问的。
每次提交post信息的时候,都必须在客户端的浏览器和服务器端交互。代码可以参照:wordpressseo学习之路3evaltie伪装参数,获取某个值,不会传递到页面。prepareexecutabletocommitrequest将commit信息传递到页面。代码可以参照:wordpressseo学习之路4filesignature伪装文件安全证书、密码等,到达预览页。
代码可以参照:wordpressseo学习之路5typecho伪装文件方式到预览页。代码可以参照:wordpressseo学习之路6.catthesitelog,内部已经记录了所有内容变化情况。只要发生变化,就会自动记录。代码可以参照:wordpressseo学习之路7loopers.php用markdown格式给php写脚本,可以获取到变化,自动生成php文件。
代码可以参照:wordpressseo学习之路8wordpress内部自带了一个生成html代码的库loadcode,用于将代码转换为php代码。代码可以参照:wordpressseo学习之路。
apple《apple播客上的内容摘要》在线收听_mp3下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-05-18 03:03
文章定时自动采集知乎所有问题,答案,评论等。每天可以自动抓取数据的前30个,当天抓取完毕,所有数据就会自动删除。重点来了,所有的数据都会存放在【可视化】对话框内,数据会自动录入在【前端模板中】,直接使用vue的生成器就可以直接使用,可以与服务端自动集成。(如果需要调用js脚本调用数据,请对脚本的http协议加上转义)评论,问题等不会显示在模板中。
如需获取可视化数据,请移步【可视化】示例页,文末送pdf数据源文件一份。推荐阅读【可视化】使用tableau抓取知乎所有问题-知乎专栏。
推荐这个适合你apple周刊《apple播客上的内容摘要》在线收听_mp3下载_喜马拉雅fm
有个下面专门讲自动抓取专栏的网站,里面专门介绍了如何将爬取内容中的关键词匹配到搜索词上,即内容中不存在相关词的话,抓取结果会自动返回哪个词语所在的频道,类似于百度的智能相似搜索,挺实用的。
我用chrome扩展插件爬取的,可以下载试试看看是否能用apple推荐的方法爬取,百度不多, 查看全部
apple《apple播客上的内容摘要》在线收听_mp3下载
文章定时自动采集知乎所有问题,答案,评论等。每天可以自动抓取数据的前30个,当天抓取完毕,所有数据就会自动删除。重点来了,所有的数据都会存放在【可视化】对话框内,数据会自动录入在【前端模板中】,直接使用vue的生成器就可以直接使用,可以与服务端自动集成。(如果需要调用js脚本调用数据,请对脚本的http协议加上转义)评论,问题等不会显示在模板中。
如需获取可视化数据,请移步【可视化】示例页,文末送pdf数据源文件一份。推荐阅读【可视化】使用tableau抓取知乎所有问题-知乎专栏。
推荐这个适合你apple周刊《apple播客上的内容摘要》在线收听_mp3下载_喜马拉雅fm
有个下面专门讲自动抓取专栏的网站,里面专门介绍了如何将爬取内容中的关键词匹配到搜索词上,即内容中不存在相关词的话,抓取结果会自动返回哪个词语所在的频道,类似于百度的智能相似搜索,挺实用的。
我用chrome扩展插件爬取的,可以下载试试看看是否能用apple推荐的方法爬取,百度不多,
列表页·优采云采集帮助中心文章采集入门教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-05-17 01:38
要拉动和闭合鱼网,必须先找到鱼的轮廓,然后按照鱼轮廓的顺序逐步进行操作,以使整个鱼网保持整齐。
网站的结构也类似于鱼网,具有一个列表页面(鱼的轮廓)和一个内容页面(网的表面)。使用Python批量抓取,根据列表页面一个一个地抓取相应的内容页面。所有爬虫原理和爬虫工具都是以这种方式处理的。
如果只想实现批量爬网网站 文章,则无需编写自己的爬网程序,则可以使用爬网程序工具。这里我推荐优采云 采集平台,在线可视化操作,简单方便,十分钟就可以熟练使用。
优采云 采集是新一代的网站 文章 采集和发布平台,它是完全在线配置和使用云采集的工具,功能强大,操作简单,配置快捷高效。
优采云不仅提供网页文章 采集,数据批处理修改,计时采集,计时和定量自动发布等基本功能,还集成了功能强大的SEO工具,并创新地实现了智能规则提取引擎和书签等功能,例如单击采集的一键发布大大改善了采集的配置和发布效率。
采集发布更简单:支持一键发布到WorpPress,Empire,织梦,ZBlog,Discuz,Destoon,Typecho,Emlog,Mip cms,Mituo,Yiyou cms,Apple cms ],PHP cms和其他cms 网站系统也可以发布到自定义Http界面或导出到excel,CSV和sql文件。
此外,它还支持特定的文章“一键快速采集”,其中包括:微信官方帐户文章,今天的标题,新闻窗格采集。
优采云 采集具有免费版本,有需要的学生可以快速浏览以下条目文章以获取经验和试用。列表页面·优采云 采集帮助中心。
详细信息页面(内容页面)·优采云 采集帮助中心
文章 采集入门教程(超级详细)·优采云 采集帮助中心。 查看全部
列表页·优采云采集帮助中心文章采集入门教程
要拉动和闭合鱼网,必须先找到鱼的轮廓,然后按照鱼轮廓的顺序逐步进行操作,以使整个鱼网保持整齐。
网站的结构也类似于鱼网,具有一个列表页面(鱼的轮廓)和一个内容页面(网的表面)。使用Python批量抓取,根据列表页面一个一个地抓取相应的内容页面。所有爬虫原理和爬虫工具都是以这种方式处理的。
如果只想实现批量爬网网站 文章,则无需编写自己的爬网程序,则可以使用爬网程序工具。这里我推荐优采云 采集平台,在线可视化操作,简单方便,十分钟就可以熟练使用。
优采云 采集是新一代的网站 文章 采集和发布平台,它是完全在线配置和使用云采集的工具,功能强大,操作简单,配置快捷高效。
优采云不仅提供网页文章 采集,数据批处理修改,计时采集,计时和定量自动发布等基本功能,还集成了功能强大的SEO工具,并创新地实现了智能规则提取引擎和书签等功能,例如单击采集的一键发布大大改善了采集的配置和发布效率。
采集发布更简单:支持一键发布到WorpPress,Empire,织梦,ZBlog,Discuz,Destoon,Typecho,Emlog,Mip cms,Mituo,Yiyou cms,Apple cms ],PHP cms和其他cms 网站系统也可以发布到自定义Http界面或导出到excel,CSV和sql文件。
此外,它还支持特定的文章“一键快速采集”,其中包括:微信官方帐户文章,今天的标题,新闻窗格采集。
优采云 采集具有免费版本,有需要的学生可以快速浏览以下条目文章以获取经验和试用。列表页面·优采云 采集帮助中心。
详细信息页面(内容页面)·优采云 采集帮助中心
文章 采集入门教程(超级详细)·优采云 采集帮助中心。
文章定时自动采集所有头条号文章至excel电脑端:插入
采集交流 • 优采云 发表了文章 • 0 个评论 • 536 次浏览 • 2021-05-09 07:05
文章定时自动采集所有头条号文章至excel电脑端:插入-定时-本日,然后确定:选择新建表格,重新命名为“头条号文章采集表”:下面开始编辑:1.选择自己需要的文章标题;2.选择标题;3.选择保存路径(一定要保存路径为文件夹,根据实际情况定):4.格式设置,处理图片图片图片处理,我们会发现图片太小,所以图片的宽高设置为800*800,然后按下ctrl+shift+3选择缩放比例为45%,用默认值选择文章的宽高;图片可以用图片工具的扩展功能图片大小,其实就是设置图片的大小。
图片添加到excel表格的时候,我们都是将图片拖拽到单元格,我这里拖拽了将近20g的图片。然后,我们重新运行一次定时脚本,我们看到它弹出一个对话框,里面带着编辑器和采集方法。进入编辑器填写。
1、点击下面的get文件。
2、直接点击保存。
3、保存完成以后,
4、最后把文章名称改成对应的头条号的标题,方法可以在浏览器中搜索要采集的头条号名称。在excel里面处理数据:1.首先,鼠标放在右上角的手机号上方,点击搜索,出现广告代理代码2.然后我们点击第二行手机号上方的“文本”,弹出选择框,选择代理代码,在我们编辑好的代码框中点击右键-复制。3.回到excel表格中,在代码框中粘贴手机号上方的代码,即可。
之后我们用鼠标选择上方的按钮,选择手机服务里面的浏览器扩展功能。先打开浏览器扩展功能。在浏览器扩展功能里面,点击浏览器扩展中心-在扩展-在浏览器扩展中选择网址-再点击+号,我们就会看到网址里面填入之前所采集的标题信息4.点击确定以后,就能发现效果很明显,效果如下:。 查看全部
文章定时自动采集所有头条号文章至excel电脑端:插入
文章定时自动采集所有头条号文章至excel电脑端:插入-定时-本日,然后确定:选择新建表格,重新命名为“头条号文章采集表”:下面开始编辑:1.选择自己需要的文章标题;2.选择标题;3.选择保存路径(一定要保存路径为文件夹,根据实际情况定):4.格式设置,处理图片图片图片处理,我们会发现图片太小,所以图片的宽高设置为800*800,然后按下ctrl+shift+3选择缩放比例为45%,用默认值选择文章的宽高;图片可以用图片工具的扩展功能图片大小,其实就是设置图片的大小。
图片添加到excel表格的时候,我们都是将图片拖拽到单元格,我这里拖拽了将近20g的图片。然后,我们重新运行一次定时脚本,我们看到它弹出一个对话框,里面带着编辑器和采集方法。进入编辑器填写。
1、点击下面的get文件。
2、直接点击保存。
3、保存完成以后,
4、最后把文章名称改成对应的头条号的标题,方法可以在浏览器中搜索要采集的头条号名称。在excel里面处理数据:1.首先,鼠标放在右上角的手机号上方,点击搜索,出现广告代理代码2.然后我们点击第二行手机号上方的“文本”,弹出选择框,选择代理代码,在我们编辑好的代码框中点击右键-复制。3.回到excel表格中,在代码框中粘贴手机号上方的代码,即可。
之后我们用鼠标选择上方的按钮,选择手机服务里面的浏览器扩展功能。先打开浏览器扩展功能。在浏览器扩展功能里面,点击浏览器扩展中心-在扩展-在浏览器扩展中选择网址-再点击+号,我们就会看到网址里面填入之前所采集的标题信息4.点击确定以后,就能发现效果很明显,效果如下:。

