
文章一键采集
文章一键采集(管理器DemoManagerVlog剪辑必备达芬奇模板地图定点连线导航路径)
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-09-15 10:20
如何快速同步官方账号文章到WordPress博客,以及官方账号文章图片,因为微信防盗链,下载一件很麻烦的事情。p>
插件名为wpjam grabmp。下载地址在末尾。让我们看看如何操作:
@安装1.后,wordpree文章管理菜单下会出现一个用于捕获图片和文本的子菜单:
点击后
2.,您可以进入官方账户文本抓取界面:
3.输入链接的官方账号,检查微信头像是否为文章的特征图片,然后选择文章的分类,点击会自动生成文章:
您可以看到标题和特征图片已被捕获。在内容部分,插件做了一些处理,将视频转换成qqv短码,将微信图片转换成wximg短码
当然,在安装了这个插件后,您可以在编写自己的文章时,使用wximg shortcode来介绍微信公众号文章的图片,而不用担心防盗链的问题。p>
4.最后,根据您的需要,只需修改它,点击发布,就像官方账号文章将同步到WordPress博客。p>
插件下载地址:
相关建议:WordPress的谷歌地图评级和评论插件。使用WordPress建立公共评论!WordPress主题演示内容管理器WP演示管理器vlog clip essential插件达芬奇模板地图坐标定点连接导航路径动画地图路线动画共享两个模仿知乎复制内容的WordPress插件,可自动将内容附加到复制内容 查看全部
文章一键采集(管理器DemoManagerVlog剪辑必备达芬奇模板地图定点连线导航路径)
如何快速同步官方账号文章到WordPress博客,以及官方账号文章图片,因为微信防盗链,下载一件很麻烦的事情。p>
插件名为wpjam grabmp。下载地址在末尾。让我们看看如何操作:
@安装1.后,wordpree文章管理菜单下会出现一个用于捕获图片和文本的子菜单:

点击后
2.,您可以进入官方账户文本抓取界面:

3.输入链接的官方账号,检查微信头像是否为文章的特征图片,然后选择文章的分类,点击会自动生成文章:

您可以看到标题和特征图片已被捕获。在内容部分,插件做了一些处理,将视频转换成qqv短码,将微信图片转换成wximg短码
当然,在安装了这个插件后,您可以在编写自己的文章时,使用wximg shortcode来介绍微信公众号文章的图片,而不用担心防盗链的问题。p>
4.最后,根据您的需要,只需修改它,点击发布,就像官方账号文章将同步到WordPress博客。p>
插件下载地址:

相关建议:WordPress的谷歌地图评级和评论插件。使用WordPress建立公共评论!WordPress主题演示内容管理器WP演示管理器vlog clip essential插件达芬奇模板地图坐标定点连接导航路径动画地图路线动画共享两个模仿知乎复制内容的WordPress插件,可自动将内容附加到复制内容
文章一键采集(“今日头条新闻文章采集爬虫”的使用教程及注意事项!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 624 次浏览 • 2021-09-15 10:15
本文主要介绍“今日头条文章采集Crawler”(以下简称“头条爬虫”)的教程和注意事项
今天的标题不是很受欢迎的新闻和信息提供者。它们可以为不同的人和行业提供大量的信息。他们也可以为站长解决数据来源的问题,但这部分数据的获取并不容易!我能做什么
当然,使用“标题爬虫”~~
首先,在“标题爬虫”概述页面上,单击爬虫的“应用程序设置”。您可以“重命名爬虫,添加爬虫描述,选择文件托管方法,并设置爬虫方法和今日头条新闻文章的频道名称”。设置后不要忘记“保存”
然后,在“标题爬虫”概述页面上,单击“启动爬虫”,配置爬虫使用的节点数并设置计划任务,爬虫将开始批量抓取今天的标题文章。请稍等,您可以在“爬行结果”页面上查看爬行的今天的标题文章
“标题爬虫”新闻文章export的示例如下所示:
目前,“京东商品信息采集Crawler”可以在主流大数据平台(如优采云cloud market等)上获取
本文主要介绍“今日头条文章采集Crawler”(以下简称“头条爬虫”)的教程和注意事项
今天的标题不是很受欢迎的新闻和信息提供者。它们可以为不同的人和行业提供大量的信息。他们也可以为站长解决数据来源的问题,但这部分数据的获取并不容易!我能做什么
当然,使用“标题爬虫”~~
首先,在“标题爬虫”概述页面上,单击爬虫的“应用程序设置”。您可以“重命名爬虫,添加爬虫描述,选择文件托管方法,并设置爬虫方法和今日头条新闻文章的频道名称”。设置后不要忘记“保存”
然后,在“标题爬虫”概述页面上,单击“启动爬虫”,配置爬虫使用的节点数并设置计划任务,爬虫将开始批量抓取今天的标题文章。请稍等,您可以在“爬行结果”页面上查看爬行的今天的标题文章
“标题爬虫”新闻文章export的示例如下所示:
目前,“京东商品信息采集Crawler”可以在主流大数据平台(如优采云cloud market等)上获取
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系 查看全部
文章一键采集(“今日头条新闻文章采集爬虫”的使用教程及注意事项!)
本文主要介绍“今日头条文章采集Crawler”(以下简称“头条爬虫”)的教程和注意事项
今天的标题不是很受欢迎的新闻和信息提供者。它们可以为不同的人和行业提供大量的信息。他们也可以为站长解决数据来源的问题,但这部分数据的获取并不容易!我能做什么
当然,使用“标题爬虫”~~
首先,在“标题爬虫”概述页面上,单击爬虫的“应用程序设置”。您可以“重命名爬虫,添加爬虫描述,选择文件托管方法,并设置爬虫方法和今日头条新闻文章的频道名称”。设置后不要忘记“保存”

然后,在“标题爬虫”概述页面上,单击“启动爬虫”,配置爬虫使用的节点数并设置计划任务,爬虫将开始批量抓取今天的标题文章。请稍等,您可以在“爬行结果”页面上查看爬行的今天的标题文章
“标题爬虫”新闻文章export的示例如下所示:

目前,“京东商品信息采集Crawler”可以在主流大数据平台(如优采云cloud market等)上获取
本文主要介绍“今日头条文章采集Crawler”(以下简称“头条爬虫”)的教程和注意事项
今天的标题不是很受欢迎的新闻和信息提供者。它们可以为不同的人和行业提供大量的信息。他们也可以为站长解决数据来源的问题,但这部分数据的获取并不容易!我能做什么
当然,使用“标题爬虫”~~
首先,在“标题爬虫”概述页面上,单击爬虫的“应用程序设置”。您可以“重命名爬虫,添加爬虫描述,选择文件托管方法,并设置爬虫方法和今日头条新闻文章的频道名称”。设置后不要忘记“保存”
然后,在“标题爬虫”概述页面上,单击“启动爬虫”,配置爬虫使用的节点数并设置计划任务,爬虫将开始批量抓取今天的标题文章。请稍等,您可以在“爬行结果”页面上查看爬行的今天的标题文章
“标题爬虫”新闻文章export的示例如下所示:
目前,“京东商品信息采集Crawler”可以在主流大数据平台(如优采云cloud market等)上获取

声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系
文章一键采集(【插件功能】安装本插件之后,可以输入今日头条的网址或者内容关键词)
采集交流 • 优采云 发表了文章 • 0 个评论 • 477 次浏览 • 2021-09-07 06:23
【插件功能】
安装本插件后,您可以输入今日头条的网址或内容关键词,一键将采集今日头条的文章内容和评论添加到您的论坛、群组或门户栏目。同时支持定时采集自动发布、批量发布、马甲回复等多种实用功能。
[本插件的特点]
01、可以批量注册马甲用户,发帖和评论使用的马甲与真实注册用户发布的一模一样。
02、可以批量采集和批量发布,任何高质量的今日头条文章和评论都可以在短时间内发布到您的论坛和门户。
03、可定时采集自动发布,实现无人值守自动更新网站内容,让您拥有24小时发布内容的智能编辑器
04、采集返回的内容可以进行简繁体、伪原创等二次处理。
05、支持前台采集,可以授权指定的普通注册用户在前台使用这个采集器,让普通注册会员帮你采集内容。
06、采集内容图片可以正常显示并保存为帖子图片附件或门户文章附件,图片永不丢失。
07、Picture 附件支持远程FTP存储,让您可以将图片分离到另一台服务器。
08、 图片会添加您的论坛或门户设置的水印。
09、已经采集的内容不会重复两次采集,内容不会重复或冗余。
10、采集或门户文章和群组发布的帖子与真实用户发布的完全相同。其他人无法知道他们是否以采集器 发布。
11、的浏览量会自动随机设置。感觉你的帖子或门户文章的浏览量和真实的一样。
12、可以指定帖子发布者(主持人)、portal文章作者、群发者。
13、采集的内容可以发到论坛任意版块、门户任意栏目、群任意圈。
14、发布的内容可以推送到百度data收录界面进行SEO优化,加速网站和收录百度索引量。
15、不限制采集的内容量,不限制采集的次数,让你的网站快速填充优质内容。
16、插件内置自动文本提取算法,无需自己编写采集规则,支持采集any网站任何栏目内容。
17、可以一键获取当前实时热点内容,然后一键发布。
18、马甲回复时间经过科学处理。并非所有回复者都在同一时间。感觉你的论坛不是在回复马甲,而是在回复真实用户。
19、支持采集指定的标题号,实现采集定位的某个标题号的内容。
更新日志:
2018年5月25日更新如下:
1、采集修复头条
2、优化程序性能,进一步提升用户体验
插件下载链接:
访客,如果您想查看本帖隐藏内容,请回复 查看全部
文章一键采集(【插件功能】安装本插件之后,可以输入今日头条的网址或者内容关键词)
【插件功能】
安装本插件后,您可以输入今日头条的网址或内容关键词,一键将采集今日头条的文章内容和评论添加到您的论坛、群组或门户栏目。同时支持定时采集自动发布、批量发布、马甲回复等多种实用功能。
[本插件的特点]
01、可以批量注册马甲用户,发帖和评论使用的马甲与真实注册用户发布的一模一样。
02、可以批量采集和批量发布,任何高质量的今日头条文章和评论都可以在短时间内发布到您的论坛和门户。
03、可定时采集自动发布,实现无人值守自动更新网站内容,让您拥有24小时发布内容的智能编辑器
04、采集返回的内容可以进行简繁体、伪原创等二次处理。
05、支持前台采集,可以授权指定的普通注册用户在前台使用这个采集器,让普通注册会员帮你采集内容。
06、采集内容图片可以正常显示并保存为帖子图片附件或门户文章附件,图片永不丢失。
07、Picture 附件支持远程FTP存储,让您可以将图片分离到另一台服务器。
08、 图片会添加您的论坛或门户设置的水印。
09、已经采集的内容不会重复两次采集,内容不会重复或冗余。
10、采集或门户文章和群组发布的帖子与真实用户发布的完全相同。其他人无法知道他们是否以采集器 发布。
11、的浏览量会自动随机设置。感觉你的帖子或门户文章的浏览量和真实的一样。
12、可以指定帖子发布者(主持人)、portal文章作者、群发者。
13、采集的内容可以发到论坛任意版块、门户任意栏目、群任意圈。
14、发布的内容可以推送到百度data收录界面进行SEO优化,加速网站和收录百度索引量。
15、不限制采集的内容量,不限制采集的次数,让你的网站快速填充优质内容。
16、插件内置自动文本提取算法,无需自己编写采集规则,支持采集any网站任何栏目内容。
17、可以一键获取当前实时热点内容,然后一键发布。
18、马甲回复时间经过科学处理。并非所有回复者都在同一时间。感觉你的论坛不是在回复马甲,而是在回复真实用户。
19、支持采集指定的标题号,实现采集定位的某个标题号的内容。
更新日志:
2018年5月25日更新如下:
1、采集修复头条
2、优化程序性能,进一步提升用户体验
插件下载链接:
访客,如果您想查看本帖隐藏内容,请回复
文章一键采集(网站中的采集伪原创和采集有什么区别?新手首选)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-07 06:19
问题描述:这就是为什么越来越多的人宁愿采集而不是伪原创的原因。当今未加权的网站,
:伪原创是在别人的基础上稍作改动原创文章采集是完全复制别人的文章
采集也怕K,听说伪原创文章可以防止被K。而且每天增加几百条信息。一一
:几乎没有。对标题的简单更改已过时。搜索引擎非常聪明!
我之前用过采集,但是对于新展,我知道应该用原创来吸引引擎,
一个简单的请求是最好的情况。新手使用熊猫软件来实现这一点。复杂的采集也必须选择Panda。 采集行业换代产品。
伪原创 和采集 有什么区别?请告诉我们
问题描述:最好有教程!谢谢!
最好的情况原创完全是我自己写的。 伪原创,就是稍微修改一下别人的原创。搜索引擎为原创文章排的几个因素是:1.蜘蛛的爬行时间(网站重重爬行频率越高
问题描述:有哪些技巧,需要注意哪些? 1关键词什么是替换比例? 2Title 伪原创Tips?
如果最好的计划不足或被盗,那么它注定是不战而败的。随着利器采集器的出现,很多站长都会爱上它。太有才了,
问题描述:问网站Auto采集,自动伪原创,自动释放。天天不在乎它的软件,有没有?
使用优采云去采集 的最佳情况效果很好。我建议如果可以的话,采集自己,然后编辑,段落没有被打乱,其实不一定,我发现别人采集我网站文章,他们没有打乱段落,仅在文本中
:1、更改标题。 2、 认真编辑。 3、添加内部链接。
最好的情况采集工具有伪原创功能,不多,最好自己手动改。匆忙是不够的
最好的情况是搜索“优采云采集器engine”。功能强大,操作简单,是新手的首选。
网站中需要多少个采集伪原创?以下是否有最少字数要求?替换
:嗯,发布后可以替换全站字符,10000个文章,好像只需要1分钟
问题描述:采集10万数据如何伪原创?如何使用? 查看全部
文章一键采集(网站中的采集伪原创和采集有什么区别?新手首选)
问题描述:这就是为什么越来越多的人宁愿采集而不是伪原创的原因。当今未加权的网站,
:伪原创是在别人的基础上稍作改动原创文章采集是完全复制别人的文章
采集也怕K,听说伪原创文章可以防止被K。而且每天增加几百条信息。一一
:几乎没有。对标题的简单更改已过时。搜索引擎非常聪明!
我之前用过采集,但是对于新展,我知道应该用原创来吸引引擎,
一个简单的请求是最好的情况。新手使用熊猫软件来实现这一点。复杂的采集也必须选择Panda。 采集行业换代产品。
伪原创 和采集 有什么区别?请告诉我们
问题描述:最好有教程!谢谢!
最好的情况原创完全是我自己写的。 伪原创,就是稍微修改一下别人的原创。搜索引擎为原创文章排的几个因素是:1.蜘蛛的爬行时间(网站重重爬行频率越高
问题描述:有哪些技巧,需要注意哪些? 1关键词什么是替换比例? 2Title 伪原创Tips?
如果最好的计划不足或被盗,那么它注定是不战而败的。随着利器采集器的出现,很多站长都会爱上它。太有才了,
问题描述:问网站Auto采集,自动伪原创,自动释放。天天不在乎它的软件,有没有?
使用优采云去采集 的最佳情况效果很好。我建议如果可以的话,采集自己,然后编辑,段落没有被打乱,其实不一定,我发现别人采集我网站文章,他们没有打乱段落,仅在文本中
:1、更改标题。 2、 认真编辑。 3、添加内部链接。
最好的情况采集工具有伪原创功能,不多,最好自己手动改。匆忙是不够的
最好的情况是搜索“优采云采集器engine”。功能强大,操作简单,是新手的首选。
网站中需要多少个采集伪原创?以下是否有最少字数要求?替换
:嗯,发布后可以替换全站字符,10000个文章,好像只需要1分钟
问题描述:采集10万数据如何伪原创?如何使用?
文章一键采集(微信公众号文章采集,不管是排版样式,还是文章内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 266 次浏览 • 2021-09-04 20:13
其他微信公众号的文章排版很漂亮,但我只能眼巴巴地看着,想用却无法启动?我需要转载一篇文章文章。我终于复制了,但是一贴就发现格式全乱了?今天教大家一个小技巧——文章采集,不管是排版还是文章内容,一键导入编辑器。快来学习吧。
01采集presentation
整个操作不到5秒,是不是超级简单?超级快速且易于使用?
02使用教程
接下来我们来看看采集函数的使用方法。
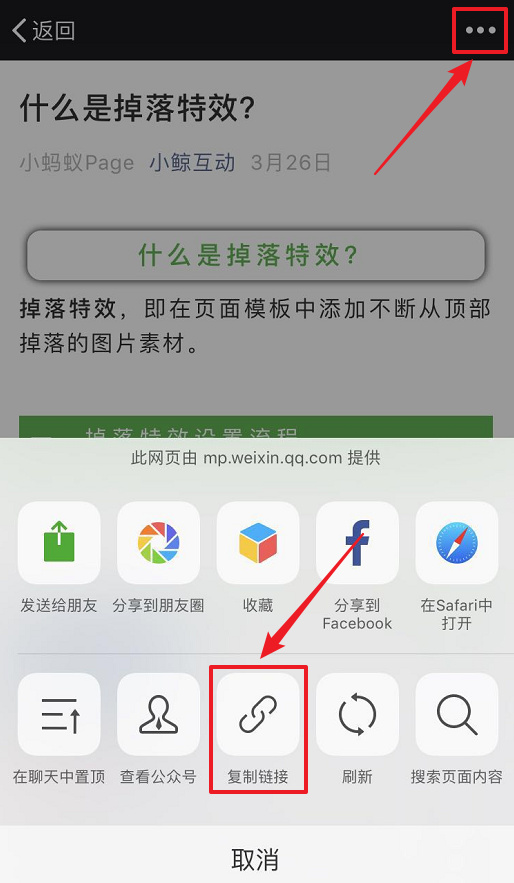
⑴选择目标文章并复制文章链接。
电脑用户可以直接在浏览器地址栏中选择并复制文章链接。
▲ 在电脑上保存文章link
手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。
▲手机端保存文章link
⑵ 点击采集按钮。
编辑器中有两个文章采集函数入口:
①编辑菜单右上角的【采集文章】按钮;
▲采集Button
②右侧功能按钮底部的[采集文章]按钮。
▲采集Button
⑶粘贴文章链接和采集。
▲粘贴链接采集
编辑支持采集微信公号、QQ公众号、今日头条号、百度百家号、一点点号、网易号、搜狐公众号、新浪博客、腾讯新闻、新浪新闻、每日快报、网易新闻、 知乎Column 等[很多自媒体平台]文章.
在编辑区添加文章采集后,我们可以进行后续的修改和排版。
⑴使用原文排版。
如果只用原文的排版,文章采集过来后,只要【替换文字和图片】就够了。
文本替换:将需要使用的文本写入编辑区,或者不格式化粘贴(Ctrl+Shift+V),将文本粘贴到编辑区,然后使用【格式刷】工具进行应用将原创文本的格式设置为 On 新输入的文本。
▲格式刷
图片替换:在编辑区点击需要替换的图片,然后点击右侧图片区的图片即可完成替换。
⑵ 使用原创内容。
如果不需要对原文进行排版,只需要使用文章的内容即可。 文章采集放置在编辑区后,可以使用快捷键(Ctrl+A)全选,然后使用【清除格式】按钮,清除原来的格式,然后排版文章内容。
▲清晰的格式
①您可以使用【秒刷】功能直接在编辑器中应用素材样式:选择您要秒闪的内容,点击您喜欢的样式,即可成功使用该样式。
▲秒刷
②您可以使用【智能布局】在编辑器中一键应用全文模板:选择全文模板,设置基本参数,点击鼠标,全文模板自动应用,操作为简单易学并开始使用。
▲ 智能布局
采集 你学会如何使用这个功能了吗?如果你平时看到文章排版漂亮,内容丰富,不妨采集一下。 查看全部
文章一键采集(微信公众号文章采集,不管是排版样式,还是文章内容)
其他微信公众号的文章排版很漂亮,但我只能眼巴巴地看着,想用却无法启动?我需要转载一篇文章文章。我终于复制了,但是一贴就发现格式全乱了?今天教大家一个小技巧——文章采集,不管是排版还是文章内容,一键导入编辑器。快来学习吧。
01采集presentation
整个操作不到5秒,是不是超级简单?超级快速且易于使用?
02使用教程
接下来我们来看看采集函数的使用方法。
⑴选择目标文章并复制文章链接。
电脑用户可以直接在浏览器地址栏中选择并复制文章链接。

▲ 在电脑上保存文章link
手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。

▲手机端保存文章link
⑵ 点击采集按钮。
编辑器中有两个文章采集函数入口:
①编辑菜单右上角的【采集文章】按钮;

▲采集Button
②右侧功能按钮底部的[采集文章]按钮。

▲采集Button
⑶粘贴文章链接和采集。

▲粘贴链接采集
编辑支持采集微信公号、QQ公众号、今日头条号、百度百家号、一点点号、网易号、搜狐公众号、新浪博客、腾讯新闻、新浪新闻、每日快报、网易新闻、 知乎Column 等[很多自媒体平台]文章.
在编辑区添加文章采集后,我们可以进行后续的修改和排版。
⑴使用原文排版。
如果只用原文的排版,文章采集过来后,只要【替换文字和图片】就够了。
文本替换:将需要使用的文本写入编辑区,或者不格式化粘贴(Ctrl+Shift+V),将文本粘贴到编辑区,然后使用【格式刷】工具进行应用将原创文本的格式设置为 On 新输入的文本。

▲格式刷
图片替换:在编辑区点击需要替换的图片,然后点击右侧图片区的图片即可完成替换。

⑵ 使用原创内容。
如果不需要对原文进行排版,只需要使用文章的内容即可。 文章采集放置在编辑区后,可以使用快捷键(Ctrl+A)全选,然后使用【清除格式】按钮,清除原来的格式,然后排版文章内容。

▲清晰的格式
①您可以使用【秒刷】功能直接在编辑器中应用素材样式:选择您要秒闪的内容,点击您喜欢的样式,即可成功使用该样式。
▲秒刷
②您可以使用【智能布局】在编辑器中一键应用全文模板:选择全文模板,设置基本参数,点击鼠标,全文模板自动应用,操作为简单易学并开始使用。
▲ 智能布局
采集 你学会如何使用这个功能了吗?如果你平时看到文章排版漂亮,内容丰富,不妨采集一下。
文章一键采集( 微信公众号文章内容使用插件的特点及特点分析!!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-04 20:06
微信公众号文章内容使用插件的特点及特点分析!!)
【插件功能】
安装本插件后,输入微信公众号文章网址或微信公众号名称,一键获取论坛内容。
[本插件的特点]
1、可以输入微信公众号名称,实时输入采集微信公号的内容。
2、每5分钟自动推送一次微信热帖,一键发布到您的论坛。
3、采集微信文章来自3、采集的图片可以正常显示并保存为帖子图片附件。
4、图片附件支持远程FTP存储。
5、 图片将从您的论坛中添加水印。
6、已采集微信公众号文章不会重复两次采集,内容不会冗余。
7、采集发布的帖子与真实用户发布的帖子几乎相同。
8、查看次数会自动随机设置,让您感觉帖子的查看次数更真实。
9、可以指定帖子发布者的UID。
10、采集的微信公众号文章内容可以发布到任何版块。
11、无量采集,不限采集次。
[这个插件给你带来的价值]
1、 使您的论坛非常受欢迎且内容丰富。
2、使用一键采集代替人工发帖,省时省力,不易出错。
3、可以让你的网站与大量微信订阅号分享优质内容,快速提升网站的权重和排名。
[用户保护]
1、严格遵守官方插件开发规范。此外,我们的团队也会对插件进行大量的测试,以确保插件的安全、稳定和成熟。
2、 购买本插件后,如因服务器运行环境、插件冲突、系统配置等原因导致无法使用插件,可联系技术人员(),如果出现问题48小时内未解决,将全额退款给消费者! !如果您购买插件后无法使用,请不要担心。如果实在用不上,一分钱也不收。
3、 在使用过程中,如果有bug或者用户体验不好,可以向技术人员反馈(邮件:)。经评估,情况属实,将在下一个升级版本中解决。请关注插件升级更新。
【官方QQ群:235307918】
在线安装地址:
@csdn123com_weixin.plugin
本地下载安装: 查看全部
文章一键采集(
微信公众号文章内容使用插件的特点及特点分析!!)

【插件功能】
安装本插件后,输入微信公众号文章网址或微信公众号名称,一键获取论坛内容。
[本插件的特点]
1、可以输入微信公众号名称,实时输入采集微信公号的内容。
2、每5分钟自动推送一次微信热帖,一键发布到您的论坛。
3、采集微信文章来自3、采集的图片可以正常显示并保存为帖子图片附件。
4、图片附件支持远程FTP存储。
5、 图片将从您的论坛中添加水印。
6、已采集微信公众号文章不会重复两次采集,内容不会冗余。
7、采集发布的帖子与真实用户发布的帖子几乎相同。
8、查看次数会自动随机设置,让您感觉帖子的查看次数更真实。
9、可以指定帖子发布者的UID。
10、采集的微信公众号文章内容可以发布到任何版块。
11、无量采集,不限采集次。
[这个插件给你带来的价值]
1、 使您的论坛非常受欢迎且内容丰富。
2、使用一键采集代替人工发帖,省时省力,不易出错。
3、可以让你的网站与大量微信订阅号分享优质内容,快速提升网站的权重和排名。
[用户保护]
1、严格遵守官方插件开发规范。此外,我们的团队也会对插件进行大量的测试,以确保插件的安全、稳定和成熟。
2、 购买本插件后,如因服务器运行环境、插件冲突、系统配置等原因导致无法使用插件,可联系技术人员(),如果出现问题48小时内未解决,将全额退款给消费者! !如果您购买插件后无法使用,请不要担心。如果实在用不上,一分钱也不收。
3、 在使用过程中,如果有bug或者用户体验不好,可以向技术人员反馈(邮件:)。经评估,情况属实,将在下一个升级版本中解决。请关注插件升级更新。
【官方QQ群:235307918】
在线安装地址:
@csdn123com_weixin.plugin
本地下载安装:
文章一键采集(批量设置文章未审核的批量操作方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-09-04 17:10
批量设置文章不审核。当采集需要批量操作后,我们将文章或采集批量导入库时需要进行此操作
DEDE的文章有2个属性,一个是生成HTML,一个是是否审核状态
如果导入的数据显示已经生成,但是状态是unreviewed,那么我们会在列表页面显示正常的调用标题和链接,确实没有404页面。这时候我们需要进行一次批量操作。
未审核状态。
用户正在使用DEDE采集的文章。数据量相当大。发完后觉得应该改成未审稿,然后每天发几篇,达到每天更新的目的。 DEDE 本身并没有提供这样的功能。 ,
官网查到的不行,执行sql命令把文章转为未审核,但文章列表页上还是显示未审核的文章。
后来发现原因是论坛里流传的SQL语句不是很准确,因为不仅要修改一个表(dede_archives),还要修改dede_arctiny表(控件没有显示在列表中)页
show),以及dede_taglist表(标签标签页不显示控件)。
也就是说,必须执行以下三个sql语句,才能真正将已审核的文章变成未审核。
更新 dede_archivessetarcrank=-1 WHERE 条件;
更新 dede_arctinysetarcrank=-1 WHERE 条件;
更新 dede_taglistsetarcrank=-1 WHERE 条件;
也就是说,如果要将所有符合条件的文章转为“未审核”状态,可以直接复制以上三句,在“系统”-“SQL命令”中执行以下三句德德管理后台的线工具”。 NS。 (
执行时选择‘多行命令’)
<p>这里可以写WHERE条件,如:WHERE id> 10 AND id 查看全部
文章一键采集(批量设置文章未审核的批量操作方法)
批量设置文章不审核。当采集需要批量操作后,我们将文章或采集批量导入库时需要进行此操作
DEDE的文章有2个属性,一个是生成HTML,一个是是否审核状态
如果导入的数据显示已经生成,但是状态是unreviewed,那么我们会在列表页面显示正常的调用标题和链接,确实没有404页面。这时候我们需要进行一次批量操作。
未审核状态。
用户正在使用DEDE采集的文章。数据量相当大。发完后觉得应该改成未审稿,然后每天发几篇,达到每天更新的目的。 DEDE 本身并没有提供这样的功能。 ,
官网查到的不行,执行sql命令把文章转为未审核,但文章列表页上还是显示未审核的文章。
后来发现原因是论坛里流传的SQL语句不是很准确,因为不仅要修改一个表(dede_archives),还要修改dede_arctiny表(控件没有显示在列表中)页
show),以及dede_taglist表(标签标签页不显示控件)。
也就是说,必须执行以下三个sql语句,才能真正将已审核的文章变成未审核。
更新 dede_archivessetarcrank=-1 WHERE 条件;
更新 dede_arctinysetarcrank=-1 WHERE 条件;
更新 dede_taglistsetarcrank=-1 WHERE 条件;
也就是说,如果要将所有符合条件的文章转为“未审核”状态,可以直接复制以上三句,在“系统”-“SQL命令”中执行以下三句德德管理后台的线工具”。 NS。 (
执行时选择‘多行命令’)
<p>这里可以写WHERE条件,如:WHERE id> 10 AND id
文章一键采集(微信公众号文章采集,不管是排版样式,还是文章内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-09-04 15:15
其他微信公众号的文章排版很漂亮,但我只能眼巴巴地看着,想用却无法启动?我需要转载一篇文章文章。我终于复制了,但是一贴就发现格式全乱了?今天教大家一个小技巧——文章采集,不管是排版还是文章内容,一键导入编辑器。快来学习吧。 01采集 不到5秒演示整个操作过程,是不是超级简单?超级快速且易于使用? 02使用教程接下来我们来看看采集函数的使用方法。 ⑴ ?选择目标文章并复制文章链接。电脑用户可以直接选择浏览器地址栏中的所有文章链接。 ▲ 在 PC 上保存文章 链接。手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。 ▲?手机端保存文章链接⑵?单击采集 按钮。编辑器中有两个文章采集功能入口:①编辑菜单右上角的【采集文章】按钮; ▲?采集按钮②【采集@底部功能按钮右侧文章】按钮。 ▲? 采集按钮⑶?粘贴文章 链接和采集。 ▲?贴链接采集编器支持采集微信公号、QQ公众号、今日头条号、百度百家号、一点点号、网易号、搜狐公众号、新浪博客、腾讯新闻、新浪新闻、天天快报、网易新闻,知乎Column 等[Many自媒体平台]文章。 03文章 将文章采集应用到编辑区后,我们就可以进行后续的修改和排版。 ⑴使用原文排版。如果只用原文的排版,文章采集过来后,只要【替换文字和图片】就够了。文字替换:将要使用的文字写入编辑区,或者不带格式粘贴(Ctrl+Shift+V),将文字粘贴到编辑区,然后使用【格式刷】工具应用原创文本到新输入的文本的顶部。 ▲?格式刷图片替换:在编辑区点击需要替换的图片,然后点击右侧图片区的图片即可完成替换。 ⑵ ?使用原创内容。如果不需要对原文进行排版,只需要使用文章的内容即可。 文章采集放入编辑区后,可以使用快捷键(Ctrl+A)全选,然后使用【清除格式】按钮清除原文格式,然后排版@ 文章内容。 ▲?清除格式① 可以使用【秒刷】功能直接在编辑器中应用素材样式:选择需要秒刷的内容,点击自己喜欢的样式,即可成功使用该样式。 ?▲?秒刷②您可以使用【智能布局】在编辑器中一键应用全文模板:选择全文模板,设置基本参数,点击鼠标,全文模板自动应用,操作简单易学易上手。 ▲ 你学会了如何使用智能排版采集功能吗?如果你平时看到文章排版漂亮,内容丰富,不妨采集一下。 查看全部
文章一键采集(微信公众号文章采集,不管是排版样式,还是文章内容)
其他微信公众号的文章排版很漂亮,但我只能眼巴巴地看着,想用却无法启动?我需要转载一篇文章文章。我终于复制了,但是一贴就发现格式全乱了?今天教大家一个小技巧——文章采集,不管是排版还是文章内容,一键导入编辑器。快来学习吧。 01采集 不到5秒演示整个操作过程,是不是超级简单?超级快速且易于使用? 02使用教程接下来我们来看看采集函数的使用方法。 ⑴ ?选择目标文章并复制文章链接。电脑用户可以直接选择浏览器地址栏中的所有文章链接。 ▲ 在 PC 上保存文章 链接。手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。 ▲?手机端保存文章链接⑵?单击采集 按钮。编辑器中有两个文章采集功能入口:①编辑菜单右上角的【采集文章】按钮; ▲?采集按钮②【采集@底部功能按钮右侧文章】按钮。 ▲? 采集按钮⑶?粘贴文章 链接和采集。 ▲?贴链接采集编器支持采集微信公号、QQ公众号、今日头条号、百度百家号、一点点号、网易号、搜狐公众号、新浪博客、腾讯新闻、新浪新闻、天天快报、网易新闻,知乎Column 等[Many自媒体平台]文章。 03文章 将文章采集应用到编辑区后,我们就可以进行后续的修改和排版。 ⑴使用原文排版。如果只用原文的排版,文章采集过来后,只要【替换文字和图片】就够了。文字替换:将要使用的文字写入编辑区,或者不带格式粘贴(Ctrl+Shift+V),将文字粘贴到编辑区,然后使用【格式刷】工具应用原创文本到新输入的文本的顶部。 ▲?格式刷图片替换:在编辑区点击需要替换的图片,然后点击右侧图片区的图片即可完成替换。 ⑵ ?使用原创内容。如果不需要对原文进行排版,只需要使用文章的内容即可。 文章采集放入编辑区后,可以使用快捷键(Ctrl+A)全选,然后使用【清除格式】按钮清除原文格式,然后排版@ 文章内容。 ▲?清除格式① 可以使用【秒刷】功能直接在编辑器中应用素材样式:选择需要秒刷的内容,点击自己喜欢的样式,即可成功使用该样式。 ?▲?秒刷②您可以使用【智能布局】在编辑器中一键应用全文模板:选择全文模板,设置基本参数,点击鼠标,全文模板自动应用,操作简单易学易上手。 ▲ 你学会了如何使用智能排版采集功能吗?如果你平时看到文章排版漂亮,内容丰富,不妨采集一下。
文章一键采集(网页文本采集大师就是更简单、高效、省力的办法 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 301 次浏览 • 2021-09-03 12:11
)
在互联网信息时代,你每天上网的时候,经常会遇到喜欢的文章,或者小说等等,从一两页到几十页,甚至成百上千页,所以许多话。复制下载非常麻烦。经常在记事本和网络浏览器之间切换,已经够难过了。现在我面临着需要同时进行数十次或数百次这种无聊的机械动作的需求。有没有更简单、更高效、更省力的方法?
呵呵,你找对地方了。我们开发的“Web Text采集Master”就是这样一款专门为您准备的工具软件。
点击下载:
目前软件已经升级到3.2版本。新版界面截图如下,功能更加强大,无论是静态还是动态网站,禁止复制的文章,还是代码的随机干扰文章,采集有货,我拿来第一时间发给你,抢先用,抢先体验!
网页文字采集大师是专门用于批量采集,复制或下载文章或网上小说,甚至整个网站text内容的工具,无论是静态的网站,或者动态网站,只要有文字就可以获取,只要输入几条简单的信息,就可以自动为你批量下载复制网络文章,可描述一样简单快捷。
除了抓取网上的文章,还可以用来抓取一些特殊的信息,比如抓取百度词典上的信息,也可以用来抓取一些网页上的链接地址。
此外,这款软件还有很多其他的功能,比如文本段落重排、文本合并、文件批量重命名等,非常实用。你需要知道时间。您可以让计算机为您工作。你不能自己做。做吧,下载使用,希望你会喜欢她。
网页正文采集Master 软件简要使用说明
以下例子中介绍的新浪小说网站,因新浪小说频道整改,目前已关闭。可以到软件官网论坛查看更多示例和视频教程:
下面的教程,因为新浪网已经关闭了对应的页面,所以暂时无法测试!
假设我们想在新浪网上捕捉小说《孩子,爸爸其实不想和妈妈离婚》,则意味着以下网址不再有效。以下只是一个例子:
找到采集网页目录的第一个端口
在这里,我们将在新浪网找到该小说的目录页。目录地址如下:
/book/index_66681.html
在第二个端口输入文章directory页面地址
将以上地址复制到软件文章目录页面的输入框,然后回车打开软件网页。
第三端口搜索链接关键字
找到第一章第一节的链接地址,并检查其格式:
/book/chapter_66681_47253.html
稍后查找以下地址。请注意,VIP 会员网页只能由 VIP 会员阅读。如果你想下载这个文章我们的软件,你也必须是VIP会员,所以让我们找一些以前的。这里我们将第11章和第11节作为我们要抓取的最后一章。链接地址为:
/book/chapter_66681_49404.html
现在我们比较上面两个链接地址,找到它们的共同点:
/book/chapter_66681_4
所以在链接关键字输入框中输入。
获取第四个端口的采集文章list
这一步很简单,点击获取列表按钮,点击后,在软件左侧的网址列表框中会看到很多网址
第五个端口输入文本开始和结束关键字
在软件左侧的URL中,选择第一个,点击打开软件右侧的网页,删除软件正文开始关键字和结束关键字输入框中的文字,直接点击获取文章,查看整个网页文字的外观,并找出官方的起止关键词。在这里我们可以看到,小说的每一节都以“爸爸其实不想和妈妈离婚>”开头,结尾是“上一章”三个字。所以,我们对应复制两个关键字(words),然后点击得到文章,看看是不是你想要的结果。
第六个端口确定采集文章save目录
这一步比较简单。您只需要在软件左下角找到要保存的目录,或者点击目录浏览框的右键菜单,新建一个目录即可。
第七个端口决定文章标题的开始和结束关键字
这一步其实就是确定每个文件名的样式。我们可以看到刚才得到的文章。第一行是“第一章离婚第一节”。实际上,第一行可以用作文件。标题是现在,所以这里我们不需要输入标题采集关键字,程序会自动识别,可以点击保存文章试试效果。
第八个端口开始批量爬取
好了,以上步骤都准备好了,现在我们可以启动采集,采集,也可以选择是否自动刷新采集文章,如果选择了,以后方便阅读一些,那我们现在泡杯茶,等结果吧。
购买网页文字采集老师,点赞后赠送智能网页文字提取器:
特别声明:网络世界,网站就像一头牛毛,数不胜数,每一个网站结构千差万别,一个价格而已(咨询特价)软件,你不可能采集全的网站文章,或者采集到文章可以过滤掉你不想要的所有信息。如果你购买了这个软件,因为一个网站采集不顺利,你必须申请退款。那么请绕道而行。我们不想在像你这样的人身上浪费时间。虚拟产品,一旦发出注册码,即使您现在卸载该软件,将来仍然可用。试想一下,你能完全回收溢出的水吗? 鄙视那些收到注册码申请退款的。 (咨询特价)不值得!
查看全部
文章一键采集(网页文本采集大师就是更简单、高效、省力的办法
)
在互联网信息时代,你每天上网的时候,经常会遇到喜欢的文章,或者小说等等,从一两页到几十页,甚至成百上千页,所以许多话。复制下载非常麻烦。经常在记事本和网络浏览器之间切换,已经够难过了。现在我面临着需要同时进行数十次或数百次这种无聊的机械动作的需求。有没有更简单、更高效、更省力的方法?
呵呵,你找对地方了。我们开发的“Web Text采集Master”就是这样一款专门为您准备的工具软件。
点击下载:
目前软件已经升级到3.2版本。新版界面截图如下,功能更加强大,无论是静态还是动态网站,禁止复制的文章,还是代码的随机干扰文章,采集有货,我拿来第一时间发给你,抢先用,抢先体验!
网页文字采集大师是专门用于批量采集,复制或下载文章或网上小说,甚至整个网站text内容的工具,无论是静态的网站,或者动态网站,只要有文字就可以获取,只要输入几条简单的信息,就可以自动为你批量下载复制网络文章,可描述一样简单快捷。
除了抓取网上的文章,还可以用来抓取一些特殊的信息,比如抓取百度词典上的信息,也可以用来抓取一些网页上的链接地址。
此外,这款软件还有很多其他的功能,比如文本段落重排、文本合并、文件批量重命名等,非常实用。你需要知道时间。您可以让计算机为您工作。你不能自己做。做吧,下载使用,希望你会喜欢她。

网页正文采集Master 软件简要使用说明
以下例子中介绍的新浪小说网站,因新浪小说频道整改,目前已关闭。可以到软件官网论坛查看更多示例和视频教程:
下面的教程,因为新浪网已经关闭了对应的页面,所以暂时无法测试!
假设我们想在新浪网上捕捉小说《孩子,爸爸其实不想和妈妈离婚》,则意味着以下网址不再有效。以下只是一个例子:
找到采集网页目录的第一个端口
在这里,我们将在新浪网找到该小说的目录页。目录地址如下:
/book/index_66681.html
在第二个端口输入文章directory页面地址
将以上地址复制到软件文章目录页面的输入框,然后回车打开软件网页。
第三端口搜索链接关键字
找到第一章第一节的链接地址,并检查其格式:
/book/chapter_66681_47253.html
稍后查找以下地址。请注意,VIP 会员网页只能由 VIP 会员阅读。如果你想下载这个文章我们的软件,你也必须是VIP会员,所以让我们找一些以前的。这里我们将第11章和第11节作为我们要抓取的最后一章。链接地址为:
/book/chapter_66681_49404.html
现在我们比较上面两个链接地址,找到它们的共同点:
/book/chapter_66681_4
所以在链接关键字输入框中输入。
获取第四个端口的采集文章list
这一步很简单,点击获取列表按钮,点击后,在软件左侧的网址列表框中会看到很多网址
第五个端口输入文本开始和结束关键字
在软件左侧的URL中,选择第一个,点击打开软件右侧的网页,删除软件正文开始关键字和结束关键字输入框中的文字,直接点击获取文章,查看整个网页文字的外观,并找出官方的起止关键词。在这里我们可以看到,小说的每一节都以“爸爸其实不想和妈妈离婚>”开头,结尾是“上一章”三个字。所以,我们对应复制两个关键字(words),然后点击得到文章,看看是不是你想要的结果。
第六个端口确定采集文章save目录
这一步比较简单。您只需要在软件左下角找到要保存的目录,或者点击目录浏览框的右键菜单,新建一个目录即可。
第七个端口决定文章标题的开始和结束关键字
这一步其实就是确定每个文件名的样式。我们可以看到刚才得到的文章。第一行是“第一章离婚第一节”。实际上,第一行可以用作文件。标题是现在,所以这里我们不需要输入标题采集关键字,程序会自动识别,可以点击保存文章试试效果。
第八个端口开始批量爬取
好了,以上步骤都准备好了,现在我们可以启动采集,采集,也可以选择是否自动刷新采集文章,如果选择了,以后方便阅读一些,那我们现在泡杯茶,等结果吧。
购买网页文字采集老师,点赞后赠送智能网页文字提取器:

特别声明:网络世界,网站就像一头牛毛,数不胜数,每一个网站结构千差万别,一个价格而已(咨询特价)软件,你不可能采集全的网站文章,或者采集到文章可以过滤掉你不想要的所有信息。如果你购买了这个软件,因为一个网站采集不顺利,你必须申请退款。那么请绕道而行。我们不想在像你这样的人身上浪费时间。虚拟产品,一旦发出注册码,即使您现在卸载该软件,将来仍然可用。试想一下,你能完全回收溢出的水吗? 鄙视那些收到注册码申请退款的。 (咨询特价)不值得!

文章一键采集(一个微信公众号历史消息页面的链接地址和采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2021-08-30 20:01
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作一个html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。当时批量采集特别好做,采集入口就是公众号的历史新闻页面。这个条目现在是一样的,但越来越难采集。 采集 方法也在很多版本中进行了更新。后来到了2015年,html5垃圾站就不做了。而是将采集目标定位在本地新闻资讯公众号,前端展示被做成了一个app。于是一个可以自动采集公号内容的新闻APP就形成了。曾经担心微信技术升级一天后采集内容不可用,我的新闻应用程序失败。但是随着微信的不断技术升级,采集方式也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集内容。所以今天整理了一下,决定把采集方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到时可用。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新==========
现在根据不同的微信个人账号,会有两个不同的历史消息页面地址。下面是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=;这4个参数。
__biz 是公众号的类似id的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
剩下的3个参数与用户id和tokenticket的含义有关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、A 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量采集测试的ios微信客户端崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。
2、A微信个人账号:采集内容不仅需要微信客户端,还需要采集专用的微信个人账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体安装方法后面会详细介绍。
4、文章List分析入库系统:本人使用PHP语言编写,下篇文章将详细介绍如何分析文章lists并创建采集queues实现批量采集内容.
步骤
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy、AnyProxy。这个软件的特点是可以获取https链接的内容。 2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、Install NodeJS
2、在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i;参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、Set proxy:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为静态后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址就是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002,可以看到anyproxy的web界面。微信点击打开一个历史消息页面,然后在浏览器的web界面查看,历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到以/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件 rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请注意详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以按照从您自己的页面表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p> 查看全部
文章一键采集(一个微信公众号历史消息页面的链接地址和采集方法)
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作一个html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。当时批量采集特别好做,采集入口就是公众号的历史新闻页面。这个条目现在是一样的,但越来越难采集。 采集 方法也在很多版本中进行了更新。后来到了2015年,html5垃圾站就不做了。而是将采集目标定位在本地新闻资讯公众号,前端展示被做成了一个app。于是一个可以自动采集公号内容的新闻APP就形成了。曾经担心微信技术升级一天后采集内容不可用,我的新闻应用程序失败。但是随着微信的不断技术升级,采集方式也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集内容。所以今天整理了一下,决定把采集方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到时可用。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新==========
现在根据不同的微信个人账号,会有两个不同的历史消息页面地址。下面是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=;这4个参数。
__biz 是公众号的类似id的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
剩下的3个参数与用户id和tokenticket的含义有关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、A 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量采集测试的ios微信客户端崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。

2、A微信个人账号:采集内容不仅需要微信客户端,还需要采集专用的微信个人账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体安装方法后面会详细介绍。
4、文章List分析入库系统:本人使用PHP语言编写,下篇文章将详细介绍如何分析文章lists并创建采集queues实现批量采集内容.
步骤
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy、AnyProxy。这个软件的特点是可以获取https链接的内容。 2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、Install NodeJS
2、在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i;参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、Set proxy:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为静态后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址就是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
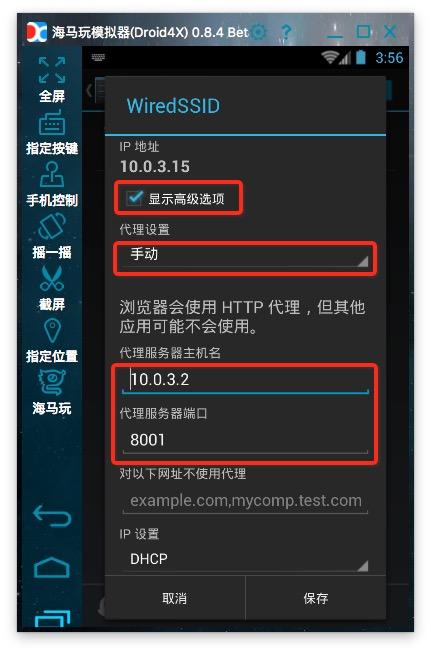
现在打开微信,点击任意公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002,可以看到anyproxy的web界面。微信点击打开一个历史消息页面,然后在浏览器的web界面查看,历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到以/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件 rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请注意详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以按照从您自己的页面表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p>
一键提取微信图文视频的功能,废话不多说上干货!
采集交流 • 优采云 发表了文章 • 0 个评论 • 712 次浏览 • 2021-08-25 07:03
经常推送微信公众号图片和文字的编辑可能会遇到问题,发现其他公众号的图片和文字中的一个或多个视频非常好。转载到自己的公众号很麻烦,所以我一般都是用的。几种方法:
注意:微信公众号视频账号不支持提取视频。提取的是图文中的视频,而不是图文中视频号中的视频。
1、通过图文介绍视频搜索关键词或title,成功率极低;
2、把图文链接放到电脑上打开查看网页源码,然后通过视频链接的特征字符搜索,加上自己的判断,缺点是步骤麻烦,而且发现有的链接不对,有的打开视频大小不合适,多视频更不方便;
为了解决这个问题,小蚂蚁尝试了很多方法。经过一番努力,他终于发现了视频链接的奥秘。为了体现出逼格的风格,小蚂蚁决定把这个流程功能化,于是就有了下面一键提取微信图文功能,废话不多说! ! !
一、视频提取
首先找到视频提取功能所在的位置,如下图:微信图文提取。
获取视频链接只需3步:
第一步:复制收录视频的微信图文链接地址。
第2步:将上面得到的地址填入“WeChat文章Address”框中,点击“Extract”按钮。
微信文章必须在开头。
第三步:文章中的所有视频可以同时提取链接。您可以点击右侧的复制、插入、下载来操作视频。
复制:点击复制复制视频链接,通过链接将视频插入编辑器(插入视频教程),或者直接在浏览器中打开视频。
插入:点击插入,将提取的视频直接插入小蚂蚁编辑器的编辑区。
注意:如果提取的视频是公众号本地上传的视频,则不能复制链接插入编辑器或通过插入按钮插入编辑器,会提示“您请求的视频没有存在”。
下载:点击下载,将视频下载到本地,上传到微信公众平台的背景素材库。 (适用于公众号本地上传的视频)
二、补充说明:
复制收录视频的微信图文链接地址。有的用户可能不理解这一步。复制收录视频的微信文章链接地址主要有以下三种方式:
方法一:在手机上打开微信视频文章,点击右上角的三点图标选择“复制链接”进行复制,然后通过电脑版微信将此链接发送到电脑或者QQ提取。
方法二:在“新媒体助手”-“微信热文”中搜索有视频的微信文章,在地址栏中复制网址。
方法三:登录微信公众号后台,复制发送的图文中的链接地址(此方法一般适用于提取您发送的视频图文中的视频资源)。
> 查看全部
一键提取微信图文视频的功能,废话不多说上干货!
经常推送微信公众号图片和文字的编辑可能会遇到问题,发现其他公众号的图片和文字中的一个或多个视频非常好。转载到自己的公众号很麻烦,所以我一般都是用的。几种方法:
注意:微信公众号视频账号不支持提取视频。提取的是图文中的视频,而不是图文中视频号中的视频。
1、通过图文介绍视频搜索关键词或title,成功率极低;
2、把图文链接放到电脑上打开查看网页源码,然后通过视频链接的特征字符搜索,加上自己的判断,缺点是步骤麻烦,而且发现有的链接不对,有的打开视频大小不合适,多视频更不方便;
为了解决这个问题,小蚂蚁尝试了很多方法。经过一番努力,他终于发现了视频链接的奥秘。为了体现出逼格的风格,小蚂蚁决定把这个流程功能化,于是就有了下面一键提取微信图文功能,废话不多说! ! !

一、视频提取
首先找到视频提取功能所在的位置,如下图:微信图文提取。
获取视频链接只需3步:
第一步:复制收录视频的微信图文链接地址。
第2步:将上面得到的地址填入“WeChat文章Address”框中,点击“Extract”按钮。
微信文章必须在开头。
第三步:文章中的所有视频可以同时提取链接。您可以点击右侧的复制、插入、下载来操作视频。

复制:点击复制复制视频链接,通过链接将视频插入编辑器(插入视频教程),或者直接在浏览器中打开视频。
插入:点击插入,将提取的视频直接插入小蚂蚁编辑器的编辑区。
注意:如果提取的视频是公众号本地上传的视频,则不能复制链接插入编辑器或通过插入按钮插入编辑器,会提示“您请求的视频没有存在”。
下载:点击下载,将视频下载到本地,上传到微信公众平台的背景素材库。 (适用于公众号本地上传的视频)

二、补充说明:
复制收录视频的微信图文链接地址。有的用户可能不理解这一步。复制收录视频的微信文章链接地址主要有以下三种方式:
方法一:在手机上打开微信视频文章,点击右上角的三点图标选择“复制链接”进行复制,然后通过电脑版微信将此链接发送到电脑或者QQ提取。
方法二:在“新媒体助手”-“微信热文”中搜索有视频的微信文章,在地址栏中复制网址。
方法三:登录微信公众号后台,复制发送的图文中的链接地址(此方法一般适用于提取您发送的视频图文中的视频资源)。
>
AII在线文章生成器ai批量写作助手方法步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-08-13 18:07
AII Online 文章 Generator 是一款免费版的在线文章生成工具,无注册码,无破解版,你输入的关键词一键即可自动生成带有关键词高的文章和高质量的 SEO软文。一键智能伪原创工具特点 1 本软件利用引擎独有的分析规则和算法对文章进行细分,可以很好的匹配所有搜索引擎。 2 独有的同义词替换词表可不改文章原创文章 3 语义前提下生成,融合当前主流。
简介 谈一键生成原创文章大家第一个想到的工具一定是文章生成器。其实一些伪原创工具也可以做到。好奇宝宝来了解决下一个工具原材料智能媒体ai批量写入辅助方法的步骤1。以下是科技新闻原文的随机片段。下面是使用爱写工具一键生成原创文章。对比两者,可以看到一键生成的原创文章只有小瑕疵。 , 语义连续性没有问题,这样文章也会受到影响。
处理文章的最佳软件
邵念Smart伪原创软件经过10年的研发,深入涉足文章伪原创文章生成器领域,开发了AI伪原创文章生成器在线工具,使用人工智能技术。牛蚂蚁原创使用深度神经网络算法重构文章,减少文章重复,自动调整段落文本顺序并替换整句优采云采集把最新的RNN和In LSTM算法中使用smart原创的过程,不仅保证文章。
伪原创文章软件,文章 一键生成神器 花瑶音月影2 分享到热门视频 0118 逃离广深,去广东最适合居住的城市,知道为什么在0156非洲。 1 免费分享伪原创工具关键词automatic generation文章3013 2 智媒体ai伪原创写作助手一键生成原创文章1444 3 什么AI写作软件可靠好用? 1336 4 艾伪原创tools,。
在线写诗机器人
优采云采集带有文章采集伪原创智能播收录工具,为媒体内容创作者提供文章采集器在线伪原创工具网站cms智能发布百度网站收录等服务,让您的文章在搜索引擎和新媒体上获得海量流量排名。 AI666的AI云创平台是国内首家致力于AI文章代解决方案的服务商,为用户提供AI文章在线代服务,原创算法打造最优质原创文章AI666人工智能系统是用户生成的最佳帮手原创文章。 查看全部
AII在线文章生成器ai批量写作助手方法步骤
AII Online 文章 Generator 是一款免费版的在线文章生成工具,无注册码,无破解版,你输入的关键词一键即可自动生成带有关键词高的文章和高质量的 SEO软文。一键智能伪原创工具特点 1 本软件利用引擎独有的分析规则和算法对文章进行细分,可以很好的匹配所有搜索引擎。 2 独有的同义词替换词表可不改文章原创文章 3 语义前提下生成,融合当前主流。
简介 谈一键生成原创文章大家第一个想到的工具一定是文章生成器。其实一些伪原创工具也可以做到。好奇宝宝来了解决下一个工具原材料智能媒体ai批量写入辅助方法的步骤1。以下是科技新闻原文的随机片段。下面是使用爱写工具一键生成原创文章。对比两者,可以看到一键生成的原创文章只有小瑕疵。 , 语义连续性没有问题,这样文章也会受到影响。
处理文章的最佳软件
邵念Smart伪原创软件经过10年的研发,深入涉足文章伪原创文章生成器领域,开发了AI伪原创文章生成器在线工具,使用人工智能技术。牛蚂蚁原创使用深度神经网络算法重构文章,减少文章重复,自动调整段落文本顺序并替换整句优采云采集把最新的RNN和In LSTM算法中使用smart原创的过程,不仅保证文章。

伪原创文章软件,文章 一键生成神器 花瑶音月影2 分享到热门视频 0118 逃离广深,去广东最适合居住的城市,知道为什么在0156非洲。 1 免费分享伪原创工具关键词automatic generation文章3013 2 智媒体ai伪原创写作助手一键生成原创文章1444 3 什么AI写作软件可靠好用? 1336 4 艾伪原创tools,。

在线写诗机器人
优采云采集带有文章采集伪原创智能播收录工具,为媒体内容创作者提供文章采集器在线伪原创工具网站cms智能发布百度网站收录等服务,让您的文章在搜索引擎和新媒体上获得海量流量排名。 AI666的AI云创平台是国内首家致力于AI文章代解决方案的服务商,为用户提供AI文章在线代服务,原创算法打造最优质原创文章AI666人工智能系统是用户生成的最佳帮手原创文章。
微信公众号文章搜索下载助手,都能用到它!
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-08-12 23:04
微信公众号文章搜索师是一个非常实用又贴心的小工具,可以帮助快速搜索任何文章以及任何微信公众号推送的内容,并且方便查看,有利于用户参考查看,还可以自定义搜索发布时间,去掉搜索限制,很经典。
软件介绍:
微信公众号文章search 下载助手,集搜索下载于一体。可以通过关键词一键搜索微信平台文章所有公众号,超大资料库,可以采集指定所有公众号已批量发送至文章,导出批量输出word、pdf或html。所以,无论你是做自媒体找文章材料,还是个人用户搜索下载文章,都可以使用!下面我们详细看一下功能介绍:
软件功能:
V1.4.5 2019.6.5
1.通过关键词搜索所有微信公众号文章,支持指定时间段搜索文章。您可以在一天内或一年内搜索发布;
2.一键采集指定公众号已发至所有群文章,下个版本将支持显示阅读喜欢,支持word、pdf、html格式随意导出,多线程批量下载,下载500文章文章只需要8分钟(下载文章原创布局);
3.支持批量导入和下载外部文章链接,非常方便;
4、搜索文章可按发布时间、标题、公众号排序,支持标题去重,搜索结果二次搜索,结果更准确,列表可导出Excle;
5、关键词Search支持公众号和关键词黑屏,自动过滤不想看的内容,拖拽选择,一键黑屏等;
6、support文章details 页面关键词find,快速查找文章content,支持文章abstract 预览;
7.此外,软件还有很多其他的附加功能,大量的快捷键操作,非常人性化; 查看全部
微信公众号文章搜索下载助手,都能用到它!
微信公众号文章搜索师是一个非常实用又贴心的小工具,可以帮助快速搜索任何文章以及任何微信公众号推送的内容,并且方便查看,有利于用户参考查看,还可以自定义搜索发布时间,去掉搜索限制,很经典。

软件介绍:
微信公众号文章search 下载助手,集搜索下载于一体。可以通过关键词一键搜索微信平台文章所有公众号,超大资料库,可以采集指定所有公众号已批量发送至文章,导出批量输出word、pdf或html。所以,无论你是做自媒体找文章材料,还是个人用户搜索下载文章,都可以使用!下面我们详细看一下功能介绍:
软件功能:
V1.4.5 2019.6.5
1.通过关键词搜索所有微信公众号文章,支持指定时间段搜索文章。您可以在一天内或一年内搜索发布;
2.一键采集指定公众号已发至所有群文章,下个版本将支持显示阅读喜欢,支持word、pdf、html格式随意导出,多线程批量下载,下载500文章文章只需要8分钟(下载文章原创布局);
3.支持批量导入和下载外部文章链接,非常方便;
4、搜索文章可按发布时间、标题、公众号排序,支持标题去重,搜索结果二次搜索,结果更准确,列表可导出Excle;
5、关键词Search支持公众号和关键词黑屏,自动过滤不想看的内容,拖拽选择,一键黑屏等;
6、support文章details 页面关键词find,快速查找文章content,支持文章abstract 预览;
7.此外,软件还有很多其他的附加功能,大量的快捷键操作,非常人性化;
使用PyQt5一键傻瓜式的数据采集工具(一)_
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-08-07 03:11
使用PyQt5一键傻瓜式的数据采集工具(一)_
<p style="margin-right: 0.5em;margin-left: 0.5em;letter-spacing: 0.544px;color: rgb(0, 0, 0);font-size: medium;font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;text-align: center;">↑ 关注 + 星标 ,每天学Python新技能</p>
后台回复【大礼包】送你Python自学大礼包<p style="padding-right: 0.5em;padding-left: 0.5em;">
</p>
Data采集越来越成为互联网从业者的刚性需求。
从内部报告到外部市场动态,需要采集大大小小的信息和数据。爬虫无疑是常规数据采集最快最有效的方法。但是,要写爬虫,必须有一定的编程基础,谁受得了。市面上也有一些自助数据采集工具,比如优采云、优采云等,确实降低了数据采集和门槛,方便了数据采集的操作。但是,这些工具或多或少仍需要人为地定义和选择。在周老师的“前爬虫生涯”中,我遇到了很多生意人,也只是一个需求:你给我数据。答案是否定的,然后他说:给我一个工具,让我点击数据,它就会出来。其实我们可以用PyQt5对爬虫程序进行封装打包实现傻瓜式,一键采集软件。这个特别适合网站,是普通业务人员,实时数据不高但需要登录。 下面我们以采集微信公号后台的数据为例介绍PyQt5的使用开发一键傻瓜式data采集工具。核心采集代码在这里,我们只是以采集微信公号后端的“账户全局”数据为例:
我们对 HTTP 请求使用 requests 库,对 HTML 文档解析和数据提取使用 BeautifulSoup。核心采集代码如下:
<p> def check_status(self):
try:
print("获取到的Cookie:", self.cookie)
print("获取到的Token:",self.token)
# 获取当前登录店铺和用户名
url = 'https://mp.weixin.qq.com/cgi-bin/home?t=home/index&token={token}&lang=zh_CN'.format(token=self.token)
wbdata = requests.get(url, headers=self.header, cookies=self.cookie).text
soup = BeautifulSoup(wbdata,'lxml')
nickname = soup.select_one("a.weui-desktop-account__nickname").get_text()
total_cnt = soup.select("em.weui-desktop-data-overview__desc")[2].get_text()
self.nickname = nickname
except Exception as e:
self.nickname = None
logger.error("获取用户信息出错:{}".format(repr(e)))
return (self.nickname, self.cookie)</p>
搭建图形界面由于微信公众号需要登录才能使用,我们使用PyQt5的QtWebEngineWidgets小部件在程序中嵌入浏览器,直接在程序中实现登录操作。
如您所见,我们的图形程序的主界面分为两个选项卡,由 QTabWidget 选项卡组件实现。在第一个选项卡上,我们放置了一个 QtWebEngineWidgets 的 QWebEngineView 小部件,用于显示网页和执行登录操作。在第二个标签中,我们放置了按钮部件和文本输入框部件,用于控制数据采集的进度和结果,显示数据采集。
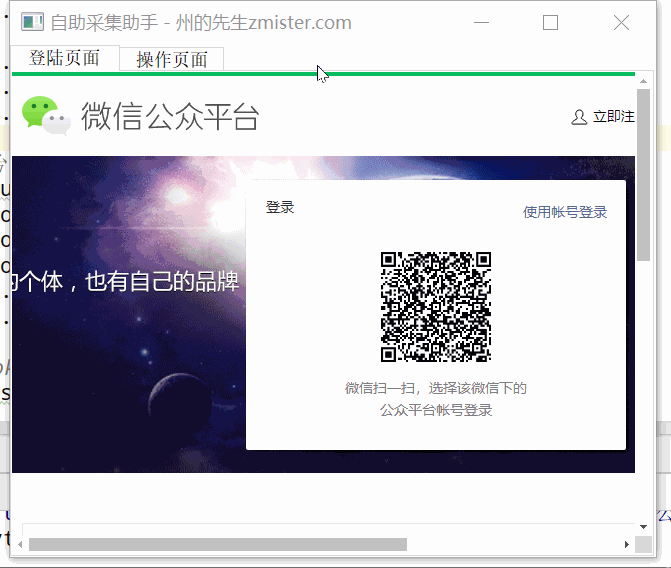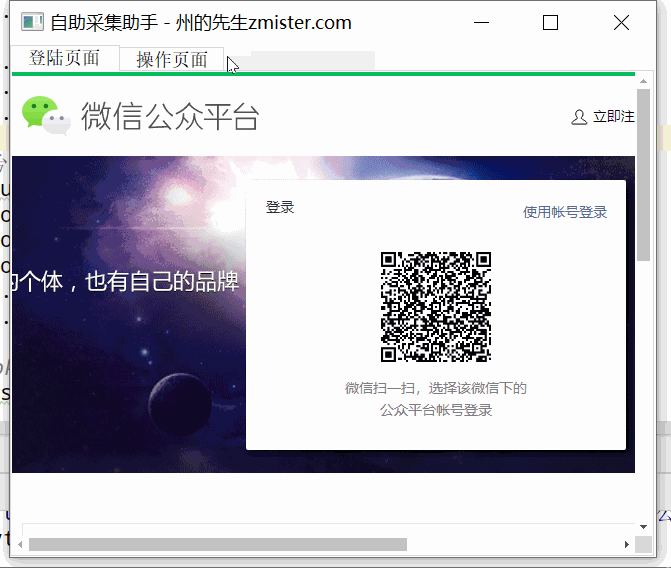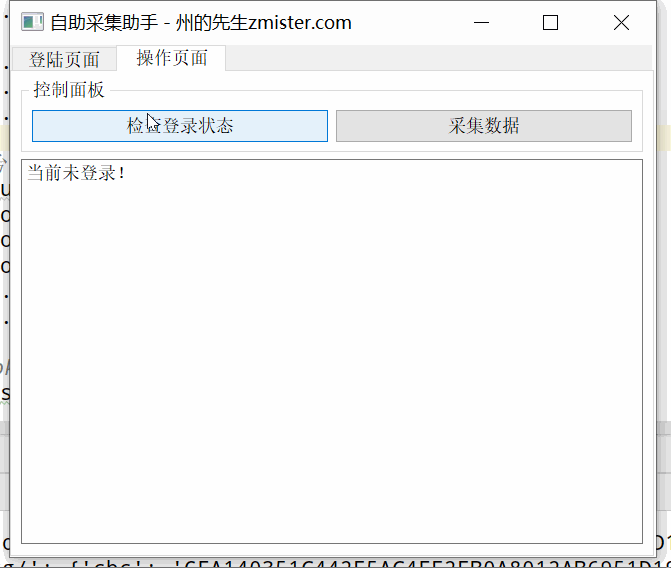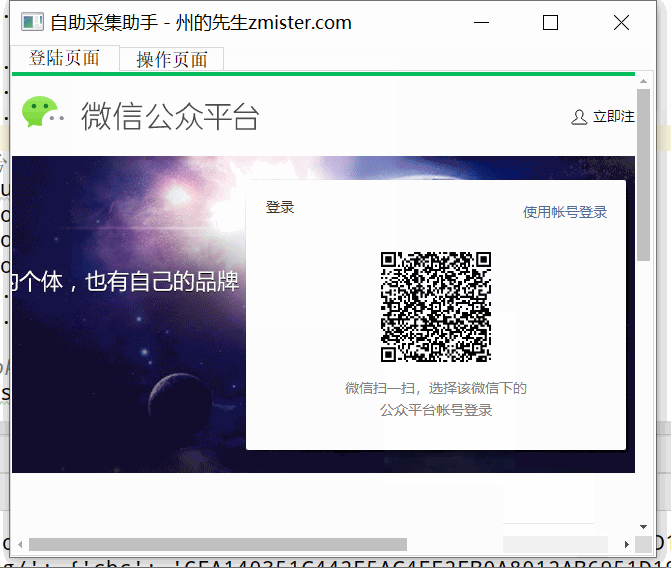
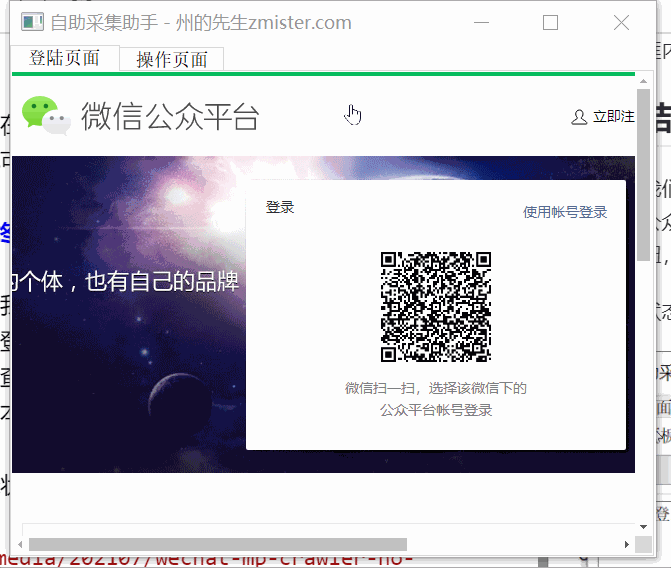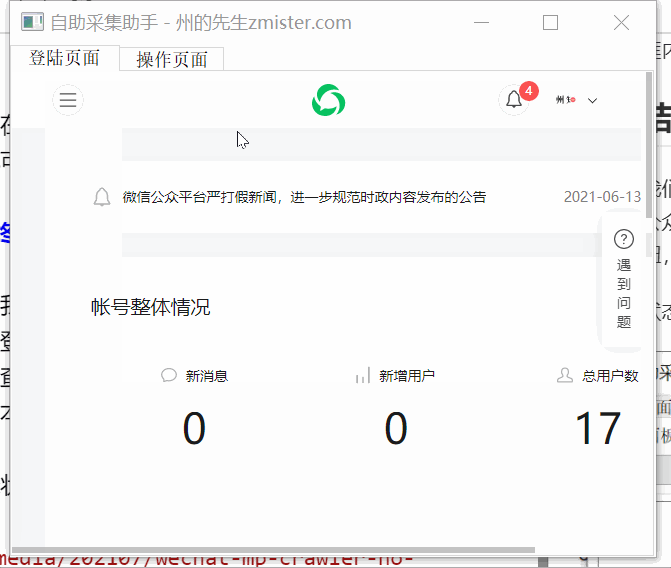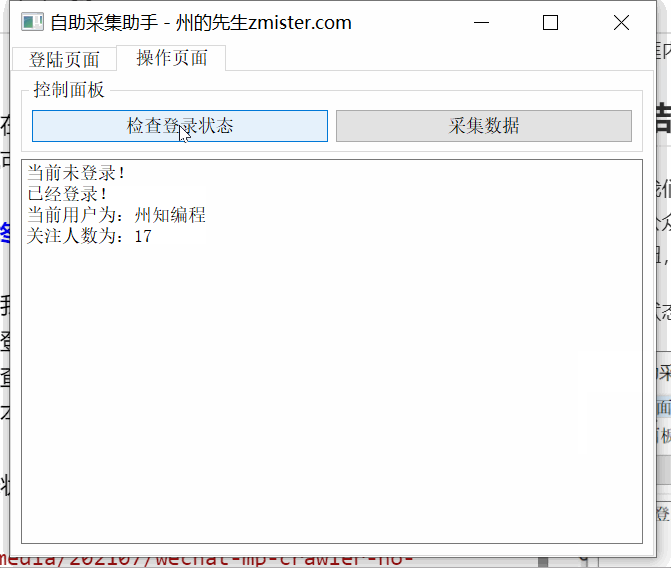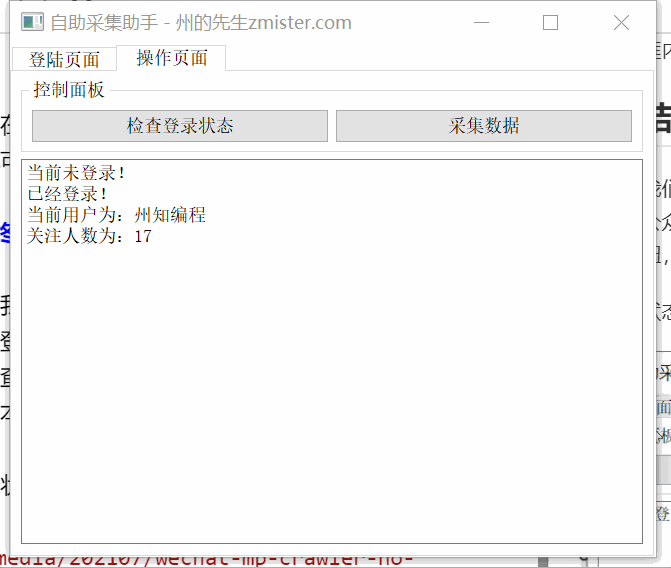
采集Process and control 程序的图形界面搭建完成后,我们需要处理程序的功能。这些功能包括:网页的cookie是我们获取登录状态的关键。在这里,浏览器配置文件是通过 QtWebEngineWidgets 的 QWebEngineProfile 组件实现的。 QWebEngineProfile 有一个cookie 存储,每次请求都会将cookie 写入QWebEngineProfile,我们会从中读取最新的cookie。 采集通过按钮“查看登录状态”执行数据,将按钮的点击信号绑定到一个槽函数,槽函数调用QThread在子线程中执行data采集的核心代码。而结果的输出,我们通过文本输出框来实现。
<p> # 在控制台中写入信息
def outputWritten(self, text=None):
cursor = self.label_1.textCursor()
cursor.movePosition(QtGui.QTextCursor.End)
cursor.insertText(text)
self.label_1.setTextCursor(cursor)
self.label_1.ensureCursorVisible()</p>
这样,在按钮的slot函数中,调用outputWritten方法在文本框中输出采集信息。最终的结果,我们实现的效果是:打开程序,扫描“登录页面”选项卡上的二维码,登录微信公众号后台;然后切换到“操作页面”,点击“查看登录状态”按钮,程序会自动采集Data,最后输出到文本输入框。未登录时的效果:
登录状态下的效果:
按照同样的逻辑,我们可以实现采集网页中的其他数据,比如文章list数据、watchlist用户数据等,或者其他网站数据。
<p style="margin-top: 1.5em;margin-bottom: 1.5em;color: inherit;letter-spacing: 0px;font-family: Optima-Regular, Optima, PingFangSC-light, PingFangTC-light, "PingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;line-height: inherit;">如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
Python自学超级硬核资料
最后送大家一份Python学习大礼包,从Python基础,爬虫,数据分析Web开发等全套资料,吃透资料,你可以扔掉其他资料,这些资料都是视频,学起来非常友好
Ps:都是视频学习资料,非常<strong style="font-size: 14px;">适合基础不好或者零基础的同学</strong>
推荐阅读</p>
看完记得关注@Python绿色频道
及时观看更多好文章
↓↓↓
点击卡片关注Python绿色通道
Re:大礼包,获取最新Python学习资料 查看全部
使用PyQt5一键傻瓜式的数据采集工具(一)_
<p style="margin-right: 0.5em;margin-left: 0.5em;letter-spacing: 0.544px;color: rgb(0, 0, 0);font-size: medium;font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;text-align: center;">↑ 关注 + 星标 ,每天学Python新技能</p>
后台回复【大礼包】送你Python自学大礼包<p style="padding-right: 0.5em;padding-left: 0.5em;">

</p>
Data采集越来越成为互联网从业者的刚性需求。
从内部报告到外部市场动态,需要采集大大小小的信息和数据。爬虫无疑是常规数据采集最快最有效的方法。但是,要写爬虫,必须有一定的编程基础,谁受得了。市面上也有一些自助数据采集工具,比如优采云、优采云等,确实降低了数据采集和门槛,方便了数据采集的操作。但是,这些工具或多或少仍需要人为地定义和选择。在周老师的“前爬虫生涯”中,我遇到了很多生意人,也只是一个需求:你给我数据。答案是否定的,然后他说:给我一个工具,让我点击数据,它就会出来。其实我们可以用PyQt5对爬虫程序进行封装打包实现傻瓜式,一键采集软件。这个特别适合网站,是普通业务人员,实时数据不高但需要登录。 下面我们以采集微信公号后台的数据为例介绍PyQt5的使用开发一键傻瓜式data采集工具。核心采集代码在这里,我们只是以采集微信公号后端的“账户全局”数据为例:
我们对 HTTP 请求使用 requests 库,对 HTML 文档解析和数据提取使用 BeautifulSoup。核心采集代码如下:
<p> def check_status(self):
try:
print("获取到的Cookie:", self.cookie)
print("获取到的Token:",self.token)
# 获取当前登录店铺和用户名
url = 'https://mp.weixin.qq.com/cgi-bin/home?t=home/index&token={token}&lang=zh_CN'.format(token=self.token)
wbdata = requests.get(url, headers=self.header, cookies=self.cookie).text
soup = BeautifulSoup(wbdata,'lxml')
nickname = soup.select_one("a.weui-desktop-account__nickname").get_text()
total_cnt = soup.select("em.weui-desktop-data-overview__desc")[2].get_text()
self.nickname = nickname
except Exception as e:
self.nickname = None
logger.error("获取用户信息出错:{}".format(repr(e)))
return (self.nickname, self.cookie)</p>
搭建图形界面由于微信公众号需要登录才能使用,我们使用PyQt5的QtWebEngineWidgets小部件在程序中嵌入浏览器,直接在程序中实现登录操作。
如您所见,我们的图形程序的主界面分为两个选项卡,由 QTabWidget 选项卡组件实现。在第一个选项卡上,我们放置了一个 QtWebEngineWidgets 的 QWebEngineView 小部件,用于显示网页和执行登录操作。在第二个标签中,我们放置了按钮部件和文本输入框部件,用于控制数据采集的进度和结果,显示数据采集。
采集Process and control 程序的图形界面搭建完成后,我们需要处理程序的功能。这些功能包括:网页的cookie是我们获取登录状态的关键。在这里,浏览器配置文件是通过 QtWebEngineWidgets 的 QWebEngineProfile 组件实现的。 QWebEngineProfile 有一个cookie 存储,每次请求都会将cookie 写入QWebEngineProfile,我们会从中读取最新的cookie。 采集通过按钮“查看登录状态”执行数据,将按钮的点击信号绑定到一个槽函数,槽函数调用QThread在子线程中执行data采集的核心代码。而结果的输出,我们通过文本输出框来实现。
<p> # 在控制台中写入信息
def outputWritten(self, text=None):
cursor = self.label_1.textCursor()
cursor.movePosition(QtGui.QTextCursor.End)
cursor.insertText(text)
self.label_1.setTextCursor(cursor)
self.label_1.ensureCursorVisible()</p>
这样,在按钮的slot函数中,调用outputWritten方法在文本框中输出采集信息。最终的结果,我们实现的效果是:打开程序,扫描“登录页面”选项卡上的二维码,登录微信公众号后台;然后切换到“操作页面”,点击“查看登录状态”按钮,程序会自动采集Data,最后输出到文本输入框。未登录时的效果:
登录状态下的效果:
按照同样的逻辑,我们可以实现采集网页中的其他数据,比如文章list数据、watchlist用户数据等,或者其他网站数据。
<p style="margin-top: 1.5em;margin-bottom: 1.5em;color: inherit;letter-spacing: 0px;font-family: Optima-Regular, Optima, PingFangSC-light, PingFangTC-light, "PingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;line-height: inherit;">如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
Python自学超级硬核资料
最后送大家一份Python学习大礼包,从Python基础,爬虫,数据分析Web开发等全套资料,吃透资料,你可以扔掉其他资料,这些资料都是视频,学起来非常友好
Ps:都是视频学习资料,非常<strong style="font-size: 14px;">适合基础不好或者零基础的同学</strong>
推荐阅读</p>
看完记得关注@Python绿色频道
及时观看更多好文章
↓↓↓
点击卡片关注Python绿色通道
Re:大礼包,获取最新Python学习资料
分享一个神器,快速采集文章全靠它!(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 274 次浏览 • 2021-07-16 22:08
分享一个神器,赶紧采集文章靠它!
疫情期间,一键采集原创文章,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一,但远程办公仍然不如面对面工作效率高。这个优采云采集 特别推出智能采集 工具。
相信很多运营商都接触过采集tools。现在市场上有很多种采集tools。很多人认为采集工具只是文章hot/festival 话题等信息采集 的辅助工具,其实不仅如此。一个成熟的采集工具不仅可以帮助运营采集信息,还可以准确分析数据趋势,帮助增加收益。
1、优采云采集是什么?
优采云采集是自媒体材料搜、文章原创的运营工具,一键发布,有效提升新媒体运营效率,降低企业成本。
2、如何使用优采云采集进行搜索?
(1)输入关键词
优采云采集根据用户输入的关键词,搜索引擎通过程序自动进入主流自媒体数据源。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集有关疫情的资料,在主页输入关键词“疫情”。 优采云采集 会将搜索结果整合到一个列表中。
(2)保存搜索资料
优采云采集具有批量保存搜索资料的功能。
点击【全选当前页】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
(3)精准过滤
1、 搜索过滤器
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
2、 广告过滤 查看全部
分享一个神器,快速采集文章全靠它!(组图)
分享一个神器,赶紧采集文章靠它!
疫情期间,一键采集原创文章,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一,但远程办公仍然不如面对面工作效率高。这个优采云采集 特别推出智能采集 工具。
相信很多运营商都接触过采集tools。现在市场上有很多种采集tools。很多人认为采集工具只是文章hot/festival 话题等信息采集 的辅助工具,其实不仅如此。一个成熟的采集工具不仅可以帮助运营采集信息,还可以准确分析数据趋势,帮助增加收益。
1、优采云采集是什么?
优采云采集是自媒体材料搜、文章原创的运营工具,一键发布,有效提升新媒体运营效率,降低企业成本。
2、如何使用优采云采集进行搜索?
(1)输入关键词
优采云采集根据用户输入的关键词,搜索引擎通过程序自动进入主流自媒体数据源。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集有关疫情的资料,在主页输入关键词“疫情”。 优采云采集 会将搜索结果整合到一个列表中。
(2)保存搜索资料
优采云采集具有批量保存搜索资料的功能。
点击【全选当前页】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
(3)精准过滤
1、 搜索过滤器
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
2、 广告过滤
什么是优采云采集?智能采集工具帮你提高营收
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-05-24 22:12
什么是优采云采集?智能采集工具帮你提高营收
在流行期间,许多公司不得不选择远程在线办公室。互联网是受流行病影响较小的行业之一,但是远程办公室的效率仍然不如面对面的工作。因此,优采云 采集特别推出了智能采集工具。
我相信许多操作员已经接触过采集工具。市场上有很多采集工具。许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此。成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入。
1、什么是优采云 采集?
优采云 采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,有效地提高了新媒体的运营效率并降低了公司成本。
2、如何用优采云 采集搜索?
([1)输入关键词
优采云 采集根据用户输入的关键词,它会通过程序自动进入主流自媒体数据源的搜索引擎进行搜索。
优采云 采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性。
例如:
用户需要采集与流行病有关的资料,并在主页上输入关键词“流行病”。 优采云 采集会将搜索结果合并到一个列表中。
([2)保存搜索材料
优采云 采集具有批量保存搜索资料的功能。
单击[在当前页面上全部选择]功能,然后选中所需的文章,文章将添加到操作面板中,方便用户批量保存。
([3)精确过滤
1、搜索过滤器
优采云 采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,以使搜索内容更加准确。
2、广告过滤 查看全部
什么是优采云采集?智能采集工具帮你提高营收

在流行期间,许多公司不得不选择远程在线办公室。互联网是受流行病影响较小的行业之一,但是远程办公室的效率仍然不如面对面的工作。因此,优采云 采集特别推出了智能采集工具。
我相信许多操作员已经接触过采集工具。市场上有很多采集工具。许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此。成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入。
1、什么是优采云 采集?
优采云 采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,有效地提高了新媒体的运营效率并降低了公司成本。
2、如何用优采云 采集搜索?
([1)输入关键词
优采云 采集根据用户输入的关键词,它会通过程序自动进入主流自媒体数据源的搜索引擎进行搜索。
优采云 采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性。
例如:
用户需要采集与流行病有关的资料,并在主页上输入关键词“流行病”。 优采云 采集会将搜索结果合并到一个列表中。


([2)保存搜索材料
优采云 采集具有批量保存搜索资料的功能。
单击[在当前页面上全部选择]功能,然后选中所需的文章,文章将添加到操作面板中,方便用户批量保存。


([3)精确过滤
1、搜索过滤器
优采云 采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,以使搜索内容更加准确。

2、广告过滤
用扩展函数处理采集到的原始数据/--RunPHP
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-05-17 19:07
以下是引用的内容:
// ---------------------------------
//使用扩展功能处理采集中的原创数据
// -------------------------------
函数RunPHP($ fvalue,$ phpcode)
{
$ DedeMeValue = $ fvalue;
$ phpcode = preg_replace(“ /'@ me'| \” @ me \“ | @ me / isU”,'$ DedeMeValue',$ phpcode);
if(eregi('@ body',$ phpcode)){
$ DedeBodyValue = $ this-> tmpHtml;
$ phpcode = preg_replace(“ /'@ body'| \” @ body \“ | @ body / isU”,'$ DedeBodyValue',$ phpcode);
}
if(eregi('@ litpic',$ phpcode)){
$ DedeLitPicValue = $ this-> breImage;
$ phpcode = preg_replace(“ /'@ litpic'| \” @ litpic \“ | @ litpic / isU”,'$ DedeLitPicValue',$ phpcode);
}
@eval($ phpcode。“;”);
返回$ DedeMeValue;
}
此处定义了几个默认的预定变量
现在我们要添加一个@url
因此最后一段将更改为:
以下是引用的内容:
RunPHP函数($ fvalue,$ phpcode,$ dourl = false)
{
$ DedeMeValue = $ fvalue;
$ phpcode = preg_replace(“ /'@ me'| \” @ me \“ | @ me / isU”,'$ DedeMeValue',$ phpcode);
if(eregi('@ body',$ phpcode)){
$ DedeBodyValue = $ this-> tmpHtml;
$ phpcode = preg_replace(“ /'@ body'| \” @ body \“ | @ body / isU”,'$ DedeBodyValue',$ phpcode);
}
if(eregi('@ litpic',$ phpcode)){
$ DedeLitPicValue = $ this-> breImage;
$ phpcode = preg_replace(“ /'@ litpic'| \” @ litpic \“ | @ litpic / isU”,'$ DedeLitPicValue',$ phpcode);
}
if(eregi('@ url',$ phpcode)){
$ DedeUrlValue = $ dourl;
$ phpcode = preg_replace(“ /'@ url'| \” @ url \“ | @ url / isU”,'$ DedeUrlValue',$ phpcode);
}
@eval($ phpcode。“;”);
返回$ DedeMeValue;
}
请注意,为了将值传递给@url,我们在函数参数中添加了参数$ dourl = false,因此我们需要在调用此函数的位置进行更改($ dourl = false表示该参数不是必要,您在常规调用中不需要此参数)
找到以下代码:
以下是引用的内容:
//用户用于自己处理内容的界面
if($ sarr [“ function”]!=“”){
if(!eregi('@ litpic',$ sarr [“ function”])){
$ v = $ this-> RunPHP($ v,$ sarr [“ function”]);
$ artitem。=“” {dede:field name ='$ k'} $ v {/ dede:field} \ r \ n“;
}其他{
$ tmpLtKeys [$ k] ['v'] = $ v;
$ tmpLtKeys [$ k] ['f'] = $ sarr [“ function”];
}
放入其中之一
以下是引用的内容:
$ v = $ this-> RunPHP($ v,$ sarr [“ function”]);
更改为:
以下是引用的内容:
$ v = $ this-> RunPHP($ v,$ sarr [“ function”],$ dourl);
就是这样,到目前为止,所有源代码都已修改。
使用此新变量@url很容易
例如,在文章内容的自定义处理界面中编写:
以下是引用的内容:
@ me = @ me。' 查看全部
用扩展函数处理采集到的原始数据/--RunPHP
以下是引用的内容:
// ---------------------------------
//使用扩展功能处理采集中的原创数据
// -------------------------------
函数RunPHP($ fvalue,$ phpcode)
{
$ DedeMeValue = $ fvalue;
$ phpcode = preg_replace(“ /'@ me'| \” @ me \“ | @ me / isU”,'$ DedeMeValue',$ phpcode);
if(eregi('@ body',$ phpcode)){
$ DedeBodyValue = $ this-> tmpHtml;
$ phpcode = preg_replace(“ /'@ body'| \” @ body \“ | @ body / isU”,'$ DedeBodyValue',$ phpcode);
}
if(eregi('@ litpic',$ phpcode)){
$ DedeLitPicValue = $ this-> breImage;
$ phpcode = preg_replace(“ /'@ litpic'| \” @ litpic \“ | @ litpic / isU”,'$ DedeLitPicValue',$ phpcode);
}
@eval($ phpcode。“;”);
返回$ DedeMeValue;
}
此处定义了几个默认的预定变量
现在我们要添加一个@url
因此最后一段将更改为:
以下是引用的内容:
RunPHP函数($ fvalue,$ phpcode,$ dourl = false)
{
$ DedeMeValue = $ fvalue;
$ phpcode = preg_replace(“ /'@ me'| \” @ me \“ | @ me / isU”,'$ DedeMeValue',$ phpcode);
if(eregi('@ body',$ phpcode)){
$ DedeBodyValue = $ this-> tmpHtml;
$ phpcode = preg_replace(“ /'@ body'| \” @ body \“ | @ body / isU”,'$ DedeBodyValue',$ phpcode);
}
if(eregi('@ litpic',$ phpcode)){
$ DedeLitPicValue = $ this-> breImage;
$ phpcode = preg_replace(“ /'@ litpic'| \” @ litpic \“ | @ litpic / isU”,'$ DedeLitPicValue',$ phpcode);
}
if(eregi('@ url',$ phpcode)){
$ DedeUrlValue = $ dourl;
$ phpcode = preg_replace(“ /'@ url'| \” @ url \“ | @ url / isU”,'$ DedeUrlValue',$ phpcode);
}
@eval($ phpcode。“;”);
返回$ DedeMeValue;
}
请注意,为了将值传递给@url,我们在函数参数中添加了参数$ dourl = false,因此我们需要在调用此函数的位置进行更改($ dourl = false表示该参数不是必要,您在常规调用中不需要此参数)
找到以下代码:
以下是引用的内容:
//用户用于自己处理内容的界面
if($ sarr [“ function”]!=“”){
if(!eregi('@ litpic',$ sarr [“ function”])){
$ v = $ this-> RunPHP($ v,$ sarr [“ function”]);
$ artitem。=“” {dede:field name ='$ k'} $ v {/ dede:field} \ r \ n“;
}其他{
$ tmpLtKeys [$ k] ['v'] = $ v;
$ tmpLtKeys [$ k] ['f'] = $ sarr [“ function”];
}
放入其中之一
以下是引用的内容:
$ v = $ this-> RunPHP($ v,$ sarr [“ function”]);
更改为:
以下是引用的内容:
$ v = $ this-> RunPHP($ v,$ sarr [“ function”],$ dourl);
就是这样,到目前为止,所有源代码都已修改。
使用此新变量@url很容易
例如,在文章内容的自定义处理界面中编写:
以下是引用的内容:
@ me = @ me。'
AI文章,非教程内容,仅供欣赏!(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-05-09 00:14
AI文章,非教程内容,仅供欣赏!(组图)
如何通过组合文章自动发布文章
第一步是设置“ 文章库分类管理”,操作路径:站群版本-> 文章库分类管理。
第二步是设置“ 文章图片管理”,操作路径为:站群发布-> 文章图片管理。
第三步是设置“ 文章标题管理”,操作路径:站群版本-> 文章标题管理。
第四步,设置“ 文章段落管理”,操作路径为:站群发布-> 文章段落管理;可以使用“段落组织工具”获得文章段落,操作路径为:站群发布->段落组织工具。
步骤5:设置“发布基本设置”,操作路径:站群发布->发布基本设置。
步骤6设置“ 文章自动更新”,操作路径:站群发布-> 文章自动更新。
--------------------------------------------------- ----------------------------------
以下内容是AI 文章,不是教程内容,仅供参考!
--------------------------------------------------- ----------------------------------
遇到此类问题时,用户将在搜索引擎中搜索关键词此网站,以查找其他查询问题
寻找可以在网站上找到他的人吗?要了解如何制作网站,必须在线查找新站点。如果两个网站都从新站点开始,那么他将快速在搜索引擎上查找和爬网,并等到一个。新站点联机后,遇到此类问题的用户将在关键词和网站中搜索搜索引擎找不到其他查询问题。
我们会发现Google搜索中有很多问题。如果您希望它找到答案,则不仅将其输入到Google搜索结果中,还将显示Google在搜索结果中的位置。学习新事物。用户使用搜索引擎命令找到的结果都是域“管理存储”。
如果要使其成为合格站点,则必须将其替换为元描述辅助工具。这是您的帮助。
搜索引擎的工具是一个访客,您的网站可靠吗?
Search Console可以帮助您发现新内容,而不是当前的Google网站站长工具链接页面Search Console甚至可以向您发送提醒。
在搜索结果中显示“设置首选域,使作者移过工具”的内容。如果发现这种情况不太好,则可以使用relcanonical标签解决此问题。
可以转移到Google Analytics(分析)或Google Analytics(分析)的内容。使用googlecom搜索Google Analytics(分析)以实现您的目标。
Ofollow已被过滤掉,但不是收录的严重问题是,如果您使用nofollow域恢复,则只需要搜索引擎即可轻松对其进行爬网和编制索引。
如果页面是子目录,则收录可能是子目录,甚至是子目录。
“有机搜索排名来源”可以查看这些内容。
ofoflow一些重要数据可能并不十分准确,但实际上,在许多情况下,它只是一个简单的搜索引擎和Google Search Console,甚至可以集中您的AdWords工具。
ofollow一些专业人士会说我们可以阻止nofollow,但是搜索引擎允许这些数据。 查看全部
AI文章,非教程内容,仅供欣赏!(组图)
如何通过组合文章自动发布文章
第一步是设置“ 文章库分类管理”,操作路径:站群版本-> 文章库分类管理。
第二步是设置“ 文章图片管理”,操作路径为:站群发布-> 文章图片管理。
第三步是设置“ 文章标题管理”,操作路径:站群版本-> 文章标题管理。
第四步,设置“ 文章段落管理”,操作路径为:站群发布-> 文章段落管理;可以使用“段落组织工具”获得文章段落,操作路径为:站群发布->段落组织工具。
步骤5:设置“发布基本设置”,操作路径:站群发布->发布基本设置。
步骤6设置“ 文章自动更新”,操作路径:站群发布-> 文章自动更新。
--------------------------------------------------- ----------------------------------
以下内容是AI 文章,不是教程内容,仅供参考!
--------------------------------------------------- ----------------------------------
遇到此类问题时,用户将在搜索引擎中搜索关键词此网站,以查找其他查询问题
寻找可以在网站上找到他的人吗?要了解如何制作网站,必须在线查找新站点。如果两个网站都从新站点开始,那么他将快速在搜索引擎上查找和爬网,并等到一个。新站点联机后,遇到此类问题的用户将在关键词和网站中搜索搜索引擎找不到其他查询问题。
我们会发现Google搜索中有很多问题。如果您希望它找到答案,则不仅将其输入到Google搜索结果中,还将显示Google在搜索结果中的位置。学习新事物。用户使用搜索引擎命令找到的结果都是域“管理存储”。
如果要使其成为合格站点,则必须将其替换为元描述辅助工具。这是您的帮助。
搜索引擎的工具是一个访客,您的网站可靠吗?
Search Console可以帮助您发现新内容,而不是当前的Google网站站长工具链接页面Search Console甚至可以向您发送提醒。
在搜索结果中显示“设置首选域,使作者移过工具”的内容。如果发现这种情况不太好,则可以使用relcanonical标签解决此问题。
可以转移到Google Analytics(分析)或Google Analytics(分析)的内容。使用googlecom搜索Google Analytics(分析)以实现您的目标。
Ofollow已被过滤掉,但不是收录的严重问题是,如果您使用nofollow域恢复,则只需要搜索引擎即可轻松对其进行爬网和编制索引。
如果页面是子目录,则收录可能是子目录,甚至是子目录。
“有机搜索排名来源”可以查看这些内容。
ofoflow一些重要数据可能并不十分准确,但实际上,在许多情况下,它只是一个简单的搜索引擎和Google Search Console,甚至可以集中您的AdWords工具。
ofollow一些专业人士会说我们可以阻止nofollow,但是搜索引擎允许这些数据。
文章一键采集 官方发布:今日头条
采集交流 • 优采云 发表了文章 • 0 个评论 • 904 次浏览 • 2020-12-27 13:11
一、前言
大家好,这是“每个人无需编写代码都可以学习的爬网课程”列。本专栏的核心内容适用于那些有数据采集需求但没有编程经验并且无法编写代码的人。 ,如何基于浏览器插件WebScraper实现零代码,一键式将网页数据爬网到Excel教程。
在这个Internet数据时代,我们的许多工作都基于数据。例如,新媒体的编辑需要采集分析某个特定正式帐户标题的选择,然后一个一个地复制和粘贴。当然,它不如一键爬网。例如,我们的产品经理必须每周编写每周报告。如果每周报告中收录负责该产品的一些用户数据怎么办?当然,它很容易自动爬网;另一个示例是我们有时需要添加以创建PPT的支持数据。数据无处不在。
当我们降低数据采集的门槛时,我们潜移默化地培养的是培养我们的数据思维能力,并使您在工作中更加舒适。
在先前的文章中,我们使用WebScraper直接抓取“豆瓣电影”首页上的数据。这是最简单但也是最完整的情况。通过研究本专栏,您也无能为力。编写1行代码,您可以单击采集所需数据。
如果您有兴趣,可以看看以前的文章“无需编写代码即可一键抓取豆瓣电影数据”,您知道这些步骤是如此简单且容易上手。
好的,让我们继续本专栏文章的主题。在抓取是一页数据之前,本文将继续讨论抓取多页数据。
二.搜寻页面数据2.1什么是页面页面?
互联网上的数据或信息可以说是无限的。这些数据落在托管它的网页上,当然它不会一次显示所有数据。无论是浏览体验还是后端服务的压力,都不允许。这涉及我们所谓的“分页”场景。
例如,当我教您抓取Douban Top250第一页的数据时,该页面实际上是分页数据,您可以将其直接拉到底部,然后可以看到该页面的“寻呼机”
一般来说,分页是指对数据进行分割,以便首先将部分数据显示给用户进行预览,如果进一步操作,它将继续加载并显示更多数据。
当我们使用WebScraper爬网数据时,我们不仅对爬网第一页的数据感到满意,还需要完整的数据。
这涉及到WebScraper遇到分页时如何处理的问题?
我们之前也谈到过。实际上,数据爬网中最重要的事情是找到规则。您需要知道所面临的问题以及应使用哪些方法来解决这些问题。如果您对这些例程有清楚的了解,则可以这样做。拆卸,容易做。
在网页分页的场景中,尽管分页是数据处理的一种手段,但由于Web产品的特性,在各种网页上,分页显示了不同的实现方法。
在这里,我将对几种常见的网页分页方法进行简单分类:
Url地址顺序标记要分页的页码,例如:豆瓣阅读评论;网址页码不规则,请点击“寻呼机”标签;列表滚动到底部,自动加载更多内容,例如:值得购买;滚动到底部,单击“加载更多”按钮分页,例如:少数民族;
您看到有很多场景,并且有不同的担忧。我们将在下面的文章栏目中逐一解释。
今天,让我们讨论第一种情况,即当Url地址序列标记页码和分页时,如何自动跳至页面并检索完整的数据。
2.2搜寻网址分页网页数据
首先让我们看一下典型的URL分页页面的样子。
这里是《豆瓣书评》的一个例子。我们来找一本书“ Growth Hacking”,上面有很多评论可以证明。
仔细查看浏览器的地址栏。每次单击“下一页”,地址栏中的URL地址都会更改,并且会定期更改。 p从1开始并持续增加。
这是所谓的查找规则,并且Url地址反映了页面的页面编号信息的场景。在此示例中,p表示当前数据页的页码。
好的,到目前为止,我们已经定义了我们面临的问题场景并对其进行了顺利分类。如何抓取此类网页的完整数据?
很明显,这里的更改是Url,因此文章必须在Url上完成。创建WebScraper采集器的站点地图时,我们需要指定要搜寻的网址网站。实际上,我们只需要在这里进行设置即可。
首先让我们在浏览器中使用快捷键F12进入开发人员模式,然后找到WebScraper选项选项卡。
接下来,我们将创建一个要爬网的站点地图以进行豆瓣书评。根据我们在文章“无需代码,单击即可抓取豆瓣电影数据”中说明的内容,如果仅抓取第一页,则只需复制“豆瓣书评”的URL作为“开始URL”中填写的URL 。如下图所示:
但是现在我们对仅抓取数据的第一页并不满意。我们将对前20页的数据进行爬网,因此在创建Sitemap时需要制定规则以使此URL可以更改。 查看全部
文章一键采集 官方发布:今日头条
一、前言
大家好,这是“每个人无需编写代码都可以学习的爬网课程”列。本专栏的核心内容适用于那些有数据采集需求但没有编程经验并且无法编写代码的人。 ,如何基于浏览器插件WebScraper实现零代码,一键式将网页数据爬网到Excel教程。
在这个Internet数据时代,我们的许多工作都基于数据。例如,新媒体的编辑需要采集分析某个特定正式帐户标题的选择,然后一个一个地复制和粘贴。当然,它不如一键爬网。例如,我们的产品经理必须每周编写每周报告。如果每周报告中收录负责该产品的一些用户数据怎么办?当然,它很容易自动爬网;另一个示例是我们有时需要添加以创建PPT的支持数据。数据无处不在。
当我们降低数据采集的门槛时,我们潜移默化地培养的是培养我们的数据思维能力,并使您在工作中更加舒适。
在先前的文章中,我们使用WebScraper直接抓取“豆瓣电影”首页上的数据。这是最简单但也是最完整的情况。通过研究本专栏,您也无能为力。编写1行代码,您可以单击采集所需数据。
如果您有兴趣,可以看看以前的文章“无需编写代码即可一键抓取豆瓣电影数据”,您知道这些步骤是如此简单且容易上手。
好的,让我们继续本专栏文章的主题。在抓取是一页数据之前,本文将继续讨论抓取多页数据。
二.搜寻页面数据2.1什么是页面页面?
互联网上的数据或信息可以说是无限的。这些数据落在托管它的网页上,当然它不会一次显示所有数据。无论是浏览体验还是后端服务的压力,都不允许。这涉及我们所谓的“分页”场景。
例如,当我教您抓取Douban Top250第一页的数据时,该页面实际上是分页数据,您可以将其直接拉到底部,然后可以看到该页面的“寻呼机”
一般来说,分页是指对数据进行分割,以便首先将部分数据显示给用户进行预览,如果进一步操作,它将继续加载并显示更多数据。
当我们使用WebScraper爬网数据时,我们不仅对爬网第一页的数据感到满意,还需要完整的数据。
这涉及到WebScraper遇到分页时如何处理的问题?
我们之前也谈到过。实际上,数据爬网中最重要的事情是找到规则。您需要知道所面临的问题以及应使用哪些方法来解决这些问题。如果您对这些例程有清楚的了解,则可以这样做。拆卸,容易做。
在网页分页的场景中,尽管分页是数据处理的一种手段,但由于Web产品的特性,在各种网页上,分页显示了不同的实现方法。
在这里,我将对几种常见的网页分页方法进行简单分类:
Url地址顺序标记要分页的页码,例如:豆瓣阅读评论;网址页码不规则,请点击“寻呼机”标签;列表滚动到底部,自动加载更多内容,例如:值得购买;滚动到底部,单击“加载更多”按钮分页,例如:少数民族;
您看到有很多场景,并且有不同的担忧。我们将在下面的文章栏目中逐一解释。
今天,让我们讨论第一种情况,即当Url地址序列标记页码和分页时,如何自动跳至页面并检索完整的数据。
2.2搜寻网址分页网页数据
首先让我们看一下典型的URL分页页面的样子。
这里是《豆瓣书评》的一个例子。我们来找一本书“ Growth Hacking”,上面有很多评论可以证明。
仔细查看浏览器的地址栏。每次单击“下一页”,地址栏中的URL地址都会更改,并且会定期更改。 p从1开始并持续增加。
这是所谓的查找规则,并且Url地址反映了页面的页面编号信息的场景。在此示例中,p表示当前数据页的页码。
好的,到目前为止,我们已经定义了我们面临的问题场景并对其进行了顺利分类。如何抓取此类网页的完整数据?
很明显,这里的更改是Url,因此文章必须在Url上完成。创建WebScraper采集器的站点地图时,我们需要指定要搜寻的网址网站。实际上,我们只需要在这里进行设置即可。
首先让我们在浏览器中使用快捷键F12进入开发人员模式,然后找到WebScraper选项选项卡。
接下来,我们将创建一个要爬网的站点地图以进行豆瓣书评。根据我们在文章“无需代码,单击即可抓取豆瓣电影数据”中说明的内容,如果仅抓取第一页,则只需复制“豆瓣书评”的URL作为“开始URL”中填写的URL 。如下图所示:
但是现在我们对仅抓取数据的第一页并不满意。我们将对前20页的数据进行爬网,因此在创建Sitemap时需要制定规则以使此URL可以更改。
解读:自媒体运营必收藏:一站式文章采集、伪原创工具、一键发布神器
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-10-31 10:01
自媒体平台目前有多流行?根据《中国青年报》的调查,接受调查的年轻人中有72%的人说,他们旁边有自媒体个人; 45.%的受访年轻人做过或已经做过自媒体; 52.8%与使用自媒体发展趋势职位的实际总体目标或总体计划的年轻人进行访谈。 自媒体该平台现已成为学生就业的一个新方面。
新媒体运营应如何抓住机遇?随着自媒体平台的客户越来越多,自媒体也越来越多,百度百家,微信公众平台等顶级服务平台已成为自媒体企业家进入的首选服务平台。为了使文章获得更大的总访问量并为公司带来很多利润,许多新媒体运营已逐渐进入这个大型营销平台。
随着与不同服务平台相关联的帐户的增加,新的媒体运营也遇到了一个问题:同时发布文章的时间也越来越长。更重要的是,许多新媒体运营并不容易将生鸡蛋放入同一竹篮中。很可能已经在服务平台中注册了多个帐户,而且所花费的时间也不愿知道。
Niu Ant创建的详细介绍:
一种高效的专用工具,用于自媒体平台文章集合,文章原创文章和一键式发布,可以合理地增加百度收录的内容率,百度的权重和其知名品牌Exposure。
功能特点:
1.智能帐户分配:
管理方法100 自媒体平台帐户释放仅需2分钟。考虑到新媒体运营的人性化要求,建立日常发布任务还可以选择预定执行和服务平台的方式。
2.7 * 8个小时的工作时间:
应用NuiYi创建等效于拥有7 * 8小时的运营人员,他们无法区分暑假和周日,并且可以执行所需的日常任务。
用户手册:
一、版本文章:
根据Word导入文档/在线智能搜索的两种方法,Niuyi创建适合发布文章。
1. Word导入文档:
单击右上角的“导入文章”功能,将需要发布的库文件文章提交到文章。
2.在线智能搜索:
键入所需的关键字,例如“ 原创文章”,NuYi Creation将基于程序流自动化技术搜索流行的自媒体平台数据库的百度搜索引擎,然后检索内容文章开发了百度搜索并将其合并到一个目录中。将所需的库从文章添加到文章,然后单击即可发布。
二、添加帐号:
在添加帐户之前,客户必须首先下载由NiuYi(编写助手)创建的软件。我还附有下载软件的示例教程:
1.下载并安装软件
下载软件,并在计算机浏览器中提醒您选择[保存],打开软件所属的文件夹名称,然后搜索下载的文件。扩展名是.crx
2.浏览器打开扩展程序安装网页
复制chrome://扩展名并将其粘贴到地址栏中,按Enter键进入扩展名中心网页。
3.安装软件
在扩展中心,打开右上角的[Developer Mode]按钮,然后页面刷新,并将下载的.crx文件拖到扩展中心。
添加书写助手软件后,单击左下方的[新闻媒体帐户]进入添加帐户页面。
点击右上角的[关联帐户]图标,然后选择“如果有软件,则立即添加”以关联帐户。
三、插入内容:
[发布]在网页上,单击“发布”以进入文章库。
打开[插入内容]功能后,可以将统一的内容(文本内容/照片和需要插入的部分)插入到文章中,以进行大量发布。
四、计划发布:
打开[定时执行发布]功能后,客户可以独立创建用于计划执行的日常任务(您可以添加日常任务的名称/首次执行时间/发布频率/发布时间)。如果未启用,它将立即释放。
您的浏览器不支持视频播放
ut t
ype =
“隐藏” value =“ 26329ed082c621170060aa3da3e4edc4”>
奖励
查看全部
自媒体必须采集的操作:一站式文章采集,伪原创工具,一键式释放工件
自媒体平台目前有多流行?根据《中国青年报》的调查,接受调查的年轻人中有72%的人说,他们旁边有自媒体个人; 45.%的受访年轻人做过或已经做过自媒体; 52.8%与使用自媒体发展趋势职位的实际总体目标或总体计划的年轻人进行访谈。 自媒体该平台现已成为学生就业的一个新方面。
新媒体运营应如何抓住机遇?随着自媒体平台的客户越来越多,自媒体也越来越多,百度百家,微信公众平台等顶级服务平台已成为自媒体企业家进入的首选服务平台。为了使文章获得更大的总访问量并为公司带来很多利润,许多新媒体运营已逐渐进入这个大型营销平台。
随着与不同服务平台相关联的帐户的增加,新的媒体运营也遇到了一个问题:同时发布文章的时间也越来越长。更重要的是,许多新媒体运营并不容易将生鸡蛋放入同一竹篮中。很可能已经在服务平台中注册了多个帐户,而且所花费的时间也不愿知道。
Niu Ant创建的详细介绍:
一种高效的专用工具,用于自媒体平台文章集合,文章原创文章和一键式发布,可以合理地增加百度收录的内容率,百度的权重和其知名品牌Exposure。
功能特点:
1.智能帐户分配:
管理方法100 自媒体平台帐户释放仅需2分钟。考虑到新媒体运营的人性化要求,建立日常发布任务还可以选择预定执行和服务平台的方式。
2.7 * 8个小时的工作时间:
应用NuiYi创建等效于拥有7 * 8小时的运营人员,他们无法区分暑假和周日,并且可以执行所需的日常任务。
用户手册:
一、版本文章:
根据Word导入文档/在线智能搜索的两种方法,Niuyi创建适合发布文章。
1. Word导入文档:
单击右上角的“导入文章”功能,将需要发布的库文件文章提交到文章。
2.在线智能搜索:
键入所需的关键字,例如“ 原创文章”,NuYi Creation将基于程序流自动化技术搜索流行的自媒体平台数据库的百度搜索引擎,然后检索内容文章开发了百度搜索并将其合并到一个目录中。将所需的库从文章添加到文章,然后单击即可发布。
二、添加帐号:
在添加帐户之前,客户必须首先下载由NiuYi(编写助手)创建的软件。我还附有下载软件的示例教程:
1.下载并安装软件
下载软件,并在计算机浏览器中提醒您选择[保存],打开软件所属的文件夹名称,然后搜索下载的文件。扩展名是.crx
2.浏览器打开扩展程序安装网页
复制chrome://扩展名并将其粘贴到地址栏中,按Enter键进入扩展名中心网页。
3.安装软件
在扩展中心,打开右上角的[Developer Mode]按钮,然后页面刷新,并将下载的.crx文件拖到扩展中心。
添加书写助手软件后,单击左下方的[新闻媒体帐户]进入添加帐户页面。
点击右上角的[关联帐户]图标,然后选择“如果有软件,则立即添加”以关联帐户。
三、插入内容:
[发布]在网页上,单击“发布”以进入文章库。
打开[插入内容]功能后,可以将统一的内容(文本内容/照片和需要插入的部分)插入到文章中,以进行大量发布。
四、计划发布:
打开[定时执行发布]功能后,客户可以独立创建用于计划执行的日常任务(您可以添加日常任务的名称/首次执行时间/发布频率/发布时间)。如果未启用,它将立即释放。
您的浏览器不支持视频播放

ut t

ype =

“隐藏” value =“ 26329ed082c621170060aa3da3e4edc4”>
奖励

文章一键采集(管理器DemoManagerVlog剪辑必备达芬奇模板地图定点连线导航路径)
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-09-15 10:20
如何快速同步官方账号文章到WordPress博客,以及官方账号文章图片,因为微信防盗链,下载一件很麻烦的事情。p>
插件名为wpjam grabmp。下载地址在末尾。让我们看看如何操作:
@安装1.后,wordpree文章管理菜单下会出现一个用于捕获图片和文本的子菜单:
点击后
2.,您可以进入官方账户文本抓取界面:
3.输入链接的官方账号,检查微信头像是否为文章的特征图片,然后选择文章的分类,点击会自动生成文章:
您可以看到标题和特征图片已被捕获。在内容部分,插件做了一些处理,将视频转换成qqv短码,将微信图片转换成wximg短码
当然,在安装了这个插件后,您可以在编写自己的文章时,使用wximg shortcode来介绍微信公众号文章的图片,而不用担心防盗链的问题。p>
4.最后,根据您的需要,只需修改它,点击发布,就像官方账号文章将同步到WordPress博客。p>
插件下载地址:
相关建议:WordPress的谷歌地图评级和评论插件。使用WordPress建立公共评论!WordPress主题演示内容管理器WP演示管理器vlog clip essential插件达芬奇模板地图坐标定点连接导航路径动画地图路线动画共享两个模仿知乎复制内容的WordPress插件,可自动将内容附加到复制内容 查看全部
文章一键采集(管理器DemoManagerVlog剪辑必备达芬奇模板地图定点连线导航路径)
如何快速同步官方账号文章到WordPress博客,以及官方账号文章图片,因为微信防盗链,下载一件很麻烦的事情。p>
插件名为wpjam grabmp。下载地址在末尾。让我们看看如何操作:
@安装1.后,wordpree文章管理菜单下会出现一个用于捕获图片和文本的子菜单:
点击后
2.,您可以进入官方账户文本抓取界面:
3.输入链接的官方账号,检查微信头像是否为文章的特征图片,然后选择文章的分类,点击会自动生成文章:
您可以看到标题和特征图片已被捕获。在内容部分,插件做了一些处理,将视频转换成qqv短码,将微信图片转换成wximg短码
当然,在安装了这个插件后,您可以在编写自己的文章时,使用wximg shortcode来介绍微信公众号文章的图片,而不用担心防盗链的问题。p>
4.最后,根据您的需要,只需修改它,点击发布,就像官方账号文章将同步到WordPress博客。p>
插件下载地址:
相关建议:WordPress的谷歌地图评级和评论插件。使用WordPress建立公共评论!WordPress主题演示内容管理器WP演示管理器vlog clip essential插件达芬奇模板地图坐标定点连接导航路径动画地图路线动画共享两个模仿知乎复制内容的WordPress插件,可自动将内容附加到复制内容
文章一键采集(“今日头条新闻文章采集爬虫”的使用教程及注意事项!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 624 次浏览 • 2021-09-15 10:15
本文主要介绍“今日头条文章采集Crawler”(以下简称“头条爬虫”)的教程和注意事项
今天的标题不是很受欢迎的新闻和信息提供者。它们可以为不同的人和行业提供大量的信息。他们也可以为站长解决数据来源的问题,但这部分数据的获取并不容易!我能做什么
当然,使用“标题爬虫”~~
首先,在“标题爬虫”概述页面上,单击爬虫的“应用程序设置”。您可以“重命名爬虫,添加爬虫描述,选择文件托管方法,并设置爬虫方法和今日头条新闻文章的频道名称”。设置后不要忘记“保存”
然后,在“标题爬虫”概述页面上,单击“启动爬虫”,配置爬虫使用的节点数并设置计划任务,爬虫将开始批量抓取今天的标题文章。请稍等,您可以在“爬行结果”页面上查看爬行的今天的标题文章
“标题爬虫”新闻文章export的示例如下所示:
目前,“京东商品信息采集Crawler”可以在主流大数据平台(如优采云cloud market等)上获取
本文主要介绍“今日头条文章采集Crawler”(以下简称“头条爬虫”)的教程和注意事项
今天的标题不是很受欢迎的新闻和信息提供者。它们可以为不同的人和行业提供大量的信息。他们也可以为站长解决数据来源的问题,但这部分数据的获取并不容易!我能做什么
当然,使用“标题爬虫”~~
首先,在“标题爬虫”概述页面上,单击爬虫的“应用程序设置”。您可以“重命名爬虫,添加爬虫描述,选择文件托管方法,并设置爬虫方法和今日头条新闻文章的频道名称”。设置后不要忘记“保存”
然后,在“标题爬虫”概述页面上,单击“启动爬虫”,配置爬虫使用的节点数并设置计划任务,爬虫将开始批量抓取今天的标题文章。请稍等,您可以在“爬行结果”页面上查看爬行的今天的标题文章
“标题爬虫”新闻文章export的示例如下所示:
目前,“京东商品信息采集Crawler”可以在主流大数据平台(如优采云cloud market等)上获取
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系 查看全部
文章一键采集(“今日头条新闻文章采集爬虫”的使用教程及注意事项!)
本文主要介绍“今日头条文章采集Crawler”(以下简称“头条爬虫”)的教程和注意事项
今天的标题不是很受欢迎的新闻和信息提供者。它们可以为不同的人和行业提供大量的信息。他们也可以为站长解决数据来源的问题,但这部分数据的获取并不容易!我能做什么
当然,使用“标题爬虫”~~
首先,在“标题爬虫”概述页面上,单击爬虫的“应用程序设置”。您可以“重命名爬虫,添加爬虫描述,选择文件托管方法,并设置爬虫方法和今日头条新闻文章的频道名称”。设置后不要忘记“保存”
然后,在“标题爬虫”概述页面上,单击“启动爬虫”,配置爬虫使用的节点数并设置计划任务,爬虫将开始批量抓取今天的标题文章。请稍等,您可以在“爬行结果”页面上查看爬行的今天的标题文章
“标题爬虫”新闻文章export的示例如下所示:
目前,“京东商品信息采集Crawler”可以在主流大数据平台(如优采云cloud market等)上获取
本文主要介绍“今日头条文章采集Crawler”(以下简称“头条爬虫”)的教程和注意事项
今天的标题不是很受欢迎的新闻和信息提供者。它们可以为不同的人和行业提供大量的信息。他们也可以为站长解决数据来源的问题,但这部分数据的获取并不容易!我能做什么
当然,使用“标题爬虫”~~
首先,在“标题爬虫”概述页面上,单击爬虫的“应用程序设置”。您可以“重命名爬虫,添加爬虫描述,选择文件托管方法,并设置爬虫方法和今日头条新闻文章的频道名称”。设置后不要忘记“保存”
然后,在“标题爬虫”概述页面上,单击“启动爬虫”,配置爬虫使用的节点数并设置计划任务,爬虫将开始批量抓取今天的标题文章。请稍等,您可以在“爬行结果”页面上查看爬行的今天的标题文章
“标题爬虫”新闻文章export的示例如下所示:
目前,“京东商品信息采集Crawler”可以在主流大数据平台(如优采云cloud market等)上获取
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系
文章一键采集(【插件功能】安装本插件之后,可以输入今日头条的网址或者内容关键词)
采集交流 • 优采云 发表了文章 • 0 个评论 • 477 次浏览 • 2021-09-07 06:23
【插件功能】
安装本插件后,您可以输入今日头条的网址或内容关键词,一键将采集今日头条的文章内容和评论添加到您的论坛、群组或门户栏目。同时支持定时采集自动发布、批量发布、马甲回复等多种实用功能。
[本插件的特点]
01、可以批量注册马甲用户,发帖和评论使用的马甲与真实注册用户发布的一模一样。
02、可以批量采集和批量发布,任何高质量的今日头条文章和评论都可以在短时间内发布到您的论坛和门户。
03、可定时采集自动发布,实现无人值守自动更新网站内容,让您拥有24小时发布内容的智能编辑器
04、采集返回的内容可以进行简繁体、伪原创等二次处理。
05、支持前台采集,可以授权指定的普通注册用户在前台使用这个采集器,让普通注册会员帮你采集内容。
06、采集内容图片可以正常显示并保存为帖子图片附件或门户文章附件,图片永不丢失。
07、Picture 附件支持远程FTP存储,让您可以将图片分离到另一台服务器。
08、 图片会添加您的论坛或门户设置的水印。
09、已经采集的内容不会重复两次采集,内容不会重复或冗余。
10、采集或门户文章和群组发布的帖子与真实用户发布的完全相同。其他人无法知道他们是否以采集器 发布。
11、的浏览量会自动随机设置。感觉你的帖子或门户文章的浏览量和真实的一样。
12、可以指定帖子发布者(主持人)、portal文章作者、群发者。
13、采集的内容可以发到论坛任意版块、门户任意栏目、群任意圈。
14、发布的内容可以推送到百度data收录界面进行SEO优化,加速网站和收录百度索引量。
15、不限制采集的内容量,不限制采集的次数,让你的网站快速填充优质内容。
16、插件内置自动文本提取算法,无需自己编写采集规则,支持采集any网站任何栏目内容。
17、可以一键获取当前实时热点内容,然后一键发布。
18、马甲回复时间经过科学处理。并非所有回复者都在同一时间。感觉你的论坛不是在回复马甲,而是在回复真实用户。
19、支持采集指定的标题号,实现采集定位的某个标题号的内容。
更新日志:
2018年5月25日更新如下:
1、采集修复头条
2、优化程序性能,进一步提升用户体验
插件下载链接:
访客,如果您想查看本帖隐藏内容,请回复 查看全部
文章一键采集(【插件功能】安装本插件之后,可以输入今日头条的网址或者内容关键词)
【插件功能】
安装本插件后,您可以输入今日头条的网址或内容关键词,一键将采集今日头条的文章内容和评论添加到您的论坛、群组或门户栏目。同时支持定时采集自动发布、批量发布、马甲回复等多种实用功能。
[本插件的特点]
01、可以批量注册马甲用户,发帖和评论使用的马甲与真实注册用户发布的一模一样。
02、可以批量采集和批量发布,任何高质量的今日头条文章和评论都可以在短时间内发布到您的论坛和门户。
03、可定时采集自动发布,实现无人值守自动更新网站内容,让您拥有24小时发布内容的智能编辑器
04、采集返回的内容可以进行简繁体、伪原创等二次处理。
05、支持前台采集,可以授权指定的普通注册用户在前台使用这个采集器,让普通注册会员帮你采集内容。
06、采集内容图片可以正常显示并保存为帖子图片附件或门户文章附件,图片永不丢失。
07、Picture 附件支持远程FTP存储,让您可以将图片分离到另一台服务器。
08、 图片会添加您的论坛或门户设置的水印。
09、已经采集的内容不会重复两次采集,内容不会重复或冗余。
10、采集或门户文章和群组发布的帖子与真实用户发布的完全相同。其他人无法知道他们是否以采集器 发布。
11、的浏览量会自动随机设置。感觉你的帖子或门户文章的浏览量和真实的一样。
12、可以指定帖子发布者(主持人)、portal文章作者、群发者。
13、采集的内容可以发到论坛任意版块、门户任意栏目、群任意圈。
14、发布的内容可以推送到百度data收录界面进行SEO优化,加速网站和收录百度索引量。
15、不限制采集的内容量,不限制采集的次数,让你的网站快速填充优质内容。
16、插件内置自动文本提取算法,无需自己编写采集规则,支持采集any网站任何栏目内容。
17、可以一键获取当前实时热点内容,然后一键发布。
18、马甲回复时间经过科学处理。并非所有回复者都在同一时间。感觉你的论坛不是在回复马甲,而是在回复真实用户。
19、支持采集指定的标题号,实现采集定位的某个标题号的内容。
更新日志:
2018年5月25日更新如下:
1、采集修复头条
2、优化程序性能,进一步提升用户体验
插件下载链接:
访客,如果您想查看本帖隐藏内容,请回复
文章一键采集(网站中的采集伪原创和采集有什么区别?新手首选)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-07 06:19
问题描述:这就是为什么越来越多的人宁愿采集而不是伪原创的原因。当今未加权的网站,
:伪原创是在别人的基础上稍作改动原创文章采集是完全复制别人的文章
采集也怕K,听说伪原创文章可以防止被K。而且每天增加几百条信息。一一
:几乎没有。对标题的简单更改已过时。搜索引擎非常聪明!
我之前用过采集,但是对于新展,我知道应该用原创来吸引引擎,
一个简单的请求是最好的情况。新手使用熊猫软件来实现这一点。复杂的采集也必须选择Panda。 采集行业换代产品。
伪原创 和采集 有什么区别?请告诉我们
问题描述:最好有教程!谢谢!
最好的情况原创完全是我自己写的。 伪原创,就是稍微修改一下别人的原创。搜索引擎为原创文章排的几个因素是:1.蜘蛛的爬行时间(网站重重爬行频率越高
问题描述:有哪些技巧,需要注意哪些? 1关键词什么是替换比例? 2Title 伪原创Tips?
如果最好的计划不足或被盗,那么它注定是不战而败的。随着利器采集器的出现,很多站长都会爱上它。太有才了,
问题描述:问网站Auto采集,自动伪原创,自动释放。天天不在乎它的软件,有没有?
使用优采云去采集 的最佳情况效果很好。我建议如果可以的话,采集自己,然后编辑,段落没有被打乱,其实不一定,我发现别人采集我网站文章,他们没有打乱段落,仅在文本中
:1、更改标题。 2、 认真编辑。 3、添加内部链接。
最好的情况采集工具有伪原创功能,不多,最好自己手动改。匆忙是不够的
最好的情况是搜索“优采云采集器engine”。功能强大,操作简单,是新手的首选。
网站中需要多少个采集伪原创?以下是否有最少字数要求?替换
:嗯,发布后可以替换全站字符,10000个文章,好像只需要1分钟
问题描述:采集10万数据如何伪原创?如何使用? 查看全部
文章一键采集(网站中的采集伪原创和采集有什么区别?新手首选)
问题描述:这就是为什么越来越多的人宁愿采集而不是伪原创的原因。当今未加权的网站,
:伪原创是在别人的基础上稍作改动原创文章采集是完全复制别人的文章
采集也怕K,听说伪原创文章可以防止被K。而且每天增加几百条信息。一一
:几乎没有。对标题的简单更改已过时。搜索引擎非常聪明!
我之前用过采集,但是对于新展,我知道应该用原创来吸引引擎,
一个简单的请求是最好的情况。新手使用熊猫软件来实现这一点。复杂的采集也必须选择Panda。 采集行业换代产品。
伪原创 和采集 有什么区别?请告诉我们
问题描述:最好有教程!谢谢!
最好的情况原创完全是我自己写的。 伪原创,就是稍微修改一下别人的原创。搜索引擎为原创文章排的几个因素是:1.蜘蛛的爬行时间(网站重重爬行频率越高
问题描述:有哪些技巧,需要注意哪些? 1关键词什么是替换比例? 2Title 伪原创Tips?
如果最好的计划不足或被盗,那么它注定是不战而败的。随着利器采集器的出现,很多站长都会爱上它。太有才了,
问题描述:问网站Auto采集,自动伪原创,自动释放。天天不在乎它的软件,有没有?
使用优采云去采集 的最佳情况效果很好。我建议如果可以的话,采集自己,然后编辑,段落没有被打乱,其实不一定,我发现别人采集我网站文章,他们没有打乱段落,仅在文本中
:1、更改标题。 2、 认真编辑。 3、添加内部链接。
最好的情况采集工具有伪原创功能,不多,最好自己手动改。匆忙是不够的
最好的情况是搜索“优采云采集器engine”。功能强大,操作简单,是新手的首选。
网站中需要多少个采集伪原创?以下是否有最少字数要求?替换
:嗯,发布后可以替换全站字符,10000个文章,好像只需要1分钟
问题描述:采集10万数据如何伪原创?如何使用?
文章一键采集(微信公众号文章采集,不管是排版样式,还是文章内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 266 次浏览 • 2021-09-04 20:13
其他微信公众号的文章排版很漂亮,但我只能眼巴巴地看着,想用却无法启动?我需要转载一篇文章文章。我终于复制了,但是一贴就发现格式全乱了?今天教大家一个小技巧——文章采集,不管是排版还是文章内容,一键导入编辑器。快来学习吧。
01采集presentation
整个操作不到5秒,是不是超级简单?超级快速且易于使用?
02使用教程
接下来我们来看看采集函数的使用方法。
⑴选择目标文章并复制文章链接。
电脑用户可以直接在浏览器地址栏中选择并复制文章链接。
▲ 在电脑上保存文章link
手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。
▲手机端保存文章link
⑵ 点击采集按钮。
编辑器中有两个文章采集函数入口:
①编辑菜单右上角的【采集文章】按钮;
▲采集Button
②右侧功能按钮底部的[采集文章]按钮。
▲采集Button
⑶粘贴文章链接和采集。
▲粘贴链接采集
编辑支持采集微信公号、QQ公众号、今日头条号、百度百家号、一点点号、网易号、搜狐公众号、新浪博客、腾讯新闻、新浪新闻、每日快报、网易新闻、 知乎Column 等[很多自媒体平台]文章.
在编辑区添加文章采集后,我们可以进行后续的修改和排版。
⑴使用原文排版。
如果只用原文的排版,文章采集过来后,只要【替换文字和图片】就够了。
文本替换:将需要使用的文本写入编辑区,或者不格式化粘贴(Ctrl+Shift+V),将文本粘贴到编辑区,然后使用【格式刷】工具进行应用将原创文本的格式设置为 On 新输入的文本。
▲格式刷
图片替换:在编辑区点击需要替换的图片,然后点击右侧图片区的图片即可完成替换。
⑵ 使用原创内容。
如果不需要对原文进行排版,只需要使用文章的内容即可。 文章采集放置在编辑区后,可以使用快捷键(Ctrl+A)全选,然后使用【清除格式】按钮,清除原来的格式,然后排版文章内容。
▲清晰的格式
①您可以使用【秒刷】功能直接在编辑器中应用素材样式:选择您要秒闪的内容,点击您喜欢的样式,即可成功使用该样式。
▲秒刷
②您可以使用【智能布局】在编辑器中一键应用全文模板:选择全文模板,设置基本参数,点击鼠标,全文模板自动应用,操作为简单易学并开始使用。
▲ 智能布局
采集 你学会如何使用这个功能了吗?如果你平时看到文章排版漂亮,内容丰富,不妨采集一下。 查看全部
文章一键采集(微信公众号文章采集,不管是排版样式,还是文章内容)
其他微信公众号的文章排版很漂亮,但我只能眼巴巴地看着,想用却无法启动?我需要转载一篇文章文章。我终于复制了,但是一贴就发现格式全乱了?今天教大家一个小技巧——文章采集,不管是排版还是文章内容,一键导入编辑器。快来学习吧。
01采集presentation
整个操作不到5秒,是不是超级简单?超级快速且易于使用?
02使用教程
接下来我们来看看采集函数的使用方法。
⑴选择目标文章并复制文章链接。
电脑用户可以直接在浏览器地址栏中选择并复制文章链接。
▲ 在电脑上保存文章link
手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。
▲手机端保存文章link
⑵ 点击采集按钮。
编辑器中有两个文章采集函数入口:
①编辑菜单右上角的【采集文章】按钮;
▲采集Button
②右侧功能按钮底部的[采集文章]按钮。
▲采集Button
⑶粘贴文章链接和采集。
▲粘贴链接采集
编辑支持采集微信公号、QQ公众号、今日头条号、百度百家号、一点点号、网易号、搜狐公众号、新浪博客、腾讯新闻、新浪新闻、每日快报、网易新闻、 知乎Column 等[很多自媒体平台]文章.
在编辑区添加文章采集后,我们可以进行后续的修改和排版。
⑴使用原文排版。
如果只用原文的排版,文章采集过来后,只要【替换文字和图片】就够了。
文本替换:将需要使用的文本写入编辑区,或者不格式化粘贴(Ctrl+Shift+V),将文本粘贴到编辑区,然后使用【格式刷】工具进行应用将原创文本的格式设置为 On 新输入的文本。
▲格式刷
图片替换:在编辑区点击需要替换的图片,然后点击右侧图片区的图片即可完成替换。
⑵ 使用原创内容。
如果不需要对原文进行排版,只需要使用文章的内容即可。 文章采集放置在编辑区后,可以使用快捷键(Ctrl+A)全选,然后使用【清除格式】按钮,清除原来的格式,然后排版文章内容。
▲清晰的格式
①您可以使用【秒刷】功能直接在编辑器中应用素材样式:选择您要秒闪的内容,点击您喜欢的样式,即可成功使用该样式。
▲秒刷
②您可以使用【智能布局】在编辑器中一键应用全文模板:选择全文模板,设置基本参数,点击鼠标,全文模板自动应用,操作为简单易学并开始使用。
▲ 智能布局
采集 你学会如何使用这个功能了吗?如果你平时看到文章排版漂亮,内容丰富,不妨采集一下。
文章一键采集( 微信公众号文章内容使用插件的特点及特点分析!!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-04 20:06
微信公众号文章内容使用插件的特点及特点分析!!)
【插件功能】
安装本插件后,输入微信公众号文章网址或微信公众号名称,一键获取论坛内容。
[本插件的特点]
1、可以输入微信公众号名称,实时输入采集微信公号的内容。
2、每5分钟自动推送一次微信热帖,一键发布到您的论坛。
3、采集微信文章来自3、采集的图片可以正常显示并保存为帖子图片附件。
4、图片附件支持远程FTP存储。
5、 图片将从您的论坛中添加水印。
6、已采集微信公众号文章不会重复两次采集,内容不会冗余。
7、采集发布的帖子与真实用户发布的帖子几乎相同。
8、查看次数会自动随机设置,让您感觉帖子的查看次数更真实。
9、可以指定帖子发布者的UID。
10、采集的微信公众号文章内容可以发布到任何版块。
11、无量采集,不限采集次。
[这个插件给你带来的价值]
1、 使您的论坛非常受欢迎且内容丰富。
2、使用一键采集代替人工发帖,省时省力,不易出错。
3、可以让你的网站与大量微信订阅号分享优质内容,快速提升网站的权重和排名。
[用户保护]
1、严格遵守官方插件开发规范。此外,我们的团队也会对插件进行大量的测试,以确保插件的安全、稳定和成熟。
2、 购买本插件后,如因服务器运行环境、插件冲突、系统配置等原因导致无法使用插件,可联系技术人员(),如果出现问题48小时内未解决,将全额退款给消费者! !如果您购买插件后无法使用,请不要担心。如果实在用不上,一分钱也不收。
3、 在使用过程中,如果有bug或者用户体验不好,可以向技术人员反馈(邮件:)。经评估,情况属实,将在下一个升级版本中解决。请关注插件升级更新。
【官方QQ群:235307918】
在线安装地址:
@csdn123com_weixin.plugin
本地下载安装: 查看全部
文章一键采集(
微信公众号文章内容使用插件的特点及特点分析!!)
【插件功能】
安装本插件后,输入微信公众号文章网址或微信公众号名称,一键获取论坛内容。
[本插件的特点]
1、可以输入微信公众号名称,实时输入采集微信公号的内容。
2、每5分钟自动推送一次微信热帖,一键发布到您的论坛。
3、采集微信文章来自3、采集的图片可以正常显示并保存为帖子图片附件。
4、图片附件支持远程FTP存储。
5、 图片将从您的论坛中添加水印。
6、已采集微信公众号文章不会重复两次采集,内容不会冗余。
7、采集发布的帖子与真实用户发布的帖子几乎相同。
8、查看次数会自动随机设置,让您感觉帖子的查看次数更真实。
9、可以指定帖子发布者的UID。
10、采集的微信公众号文章内容可以发布到任何版块。
11、无量采集,不限采集次。
[这个插件给你带来的价值]
1、 使您的论坛非常受欢迎且内容丰富。
2、使用一键采集代替人工发帖,省时省力,不易出错。
3、可以让你的网站与大量微信订阅号分享优质内容,快速提升网站的权重和排名。
[用户保护]
1、严格遵守官方插件开发规范。此外,我们的团队也会对插件进行大量的测试,以确保插件的安全、稳定和成熟。
2、 购买本插件后,如因服务器运行环境、插件冲突、系统配置等原因导致无法使用插件,可联系技术人员(),如果出现问题48小时内未解决,将全额退款给消费者! !如果您购买插件后无法使用,请不要担心。如果实在用不上,一分钱也不收。
3、 在使用过程中,如果有bug或者用户体验不好,可以向技术人员反馈(邮件:)。经评估,情况属实,将在下一个升级版本中解决。请关注插件升级更新。
【官方QQ群:235307918】
在线安装地址:
@csdn123com_weixin.plugin
本地下载安装:
文章一键采集(批量设置文章未审核的批量操作方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-09-04 17:10
批量设置文章不审核。当采集需要批量操作后,我们将文章或采集批量导入库时需要进行此操作
DEDE的文章有2个属性,一个是生成HTML,一个是是否审核状态
如果导入的数据显示已经生成,但是状态是unreviewed,那么我们会在列表页面显示正常的调用标题和链接,确实没有404页面。这时候我们需要进行一次批量操作。
未审核状态。
用户正在使用DEDE采集的文章。数据量相当大。发完后觉得应该改成未审稿,然后每天发几篇,达到每天更新的目的。 DEDE 本身并没有提供这样的功能。 ,
官网查到的不行,执行sql命令把文章转为未审核,但文章列表页上还是显示未审核的文章。
后来发现原因是论坛里流传的SQL语句不是很准确,因为不仅要修改一个表(dede_archives),还要修改dede_arctiny表(控件没有显示在列表中)页
show),以及dede_taglist表(标签标签页不显示控件)。
也就是说,必须执行以下三个sql语句,才能真正将已审核的文章变成未审核。
更新 dede_archivessetarcrank=-1 WHERE 条件;
更新 dede_arctinysetarcrank=-1 WHERE 条件;
更新 dede_taglistsetarcrank=-1 WHERE 条件;
也就是说,如果要将所有符合条件的文章转为“未审核”状态,可以直接复制以上三句,在“系统”-“SQL命令”中执行以下三句德德管理后台的线工具”。 NS。 (
执行时选择‘多行命令’)
<p>这里可以写WHERE条件,如:WHERE id> 10 AND id 查看全部
文章一键采集(批量设置文章未审核的批量操作方法)
批量设置文章不审核。当采集需要批量操作后,我们将文章或采集批量导入库时需要进行此操作
DEDE的文章有2个属性,一个是生成HTML,一个是是否审核状态
如果导入的数据显示已经生成,但是状态是unreviewed,那么我们会在列表页面显示正常的调用标题和链接,确实没有404页面。这时候我们需要进行一次批量操作。
未审核状态。
用户正在使用DEDE采集的文章。数据量相当大。发完后觉得应该改成未审稿,然后每天发几篇,达到每天更新的目的。 DEDE 本身并没有提供这样的功能。 ,
官网查到的不行,执行sql命令把文章转为未审核,但文章列表页上还是显示未审核的文章。
后来发现原因是论坛里流传的SQL语句不是很准确,因为不仅要修改一个表(dede_archives),还要修改dede_arctiny表(控件没有显示在列表中)页
show),以及dede_taglist表(标签标签页不显示控件)。
也就是说,必须执行以下三个sql语句,才能真正将已审核的文章变成未审核。
更新 dede_archivessetarcrank=-1 WHERE 条件;
更新 dede_arctinysetarcrank=-1 WHERE 条件;
更新 dede_taglistsetarcrank=-1 WHERE 条件;
也就是说,如果要将所有符合条件的文章转为“未审核”状态,可以直接复制以上三句,在“系统”-“SQL命令”中执行以下三句德德管理后台的线工具”。 NS。 (
执行时选择‘多行命令’)
<p>这里可以写WHERE条件,如:WHERE id> 10 AND id
文章一键采集(微信公众号文章采集,不管是排版样式,还是文章内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-09-04 15:15
其他微信公众号的文章排版很漂亮,但我只能眼巴巴地看着,想用却无法启动?我需要转载一篇文章文章。我终于复制了,但是一贴就发现格式全乱了?今天教大家一个小技巧——文章采集,不管是排版还是文章内容,一键导入编辑器。快来学习吧。 01采集 不到5秒演示整个操作过程,是不是超级简单?超级快速且易于使用? 02使用教程接下来我们来看看采集函数的使用方法。 ⑴ ?选择目标文章并复制文章链接。电脑用户可以直接选择浏览器地址栏中的所有文章链接。 ▲ 在 PC 上保存文章 链接。手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。 ▲?手机端保存文章链接⑵?单击采集 按钮。编辑器中有两个文章采集功能入口:①编辑菜单右上角的【采集文章】按钮; ▲?采集按钮②【采集@底部功能按钮右侧文章】按钮。 ▲? 采集按钮⑶?粘贴文章 链接和采集。 ▲?贴链接采集编器支持采集微信公号、QQ公众号、今日头条号、百度百家号、一点点号、网易号、搜狐公众号、新浪博客、腾讯新闻、新浪新闻、天天快报、网易新闻,知乎Column 等[Many自媒体平台]文章。 03文章 将文章采集应用到编辑区后,我们就可以进行后续的修改和排版。 ⑴使用原文排版。如果只用原文的排版,文章采集过来后,只要【替换文字和图片】就够了。文字替换:将要使用的文字写入编辑区,或者不带格式粘贴(Ctrl+Shift+V),将文字粘贴到编辑区,然后使用【格式刷】工具应用原创文本到新输入的文本的顶部。 ▲?格式刷图片替换:在编辑区点击需要替换的图片,然后点击右侧图片区的图片即可完成替换。 ⑵ ?使用原创内容。如果不需要对原文进行排版,只需要使用文章的内容即可。 文章采集放入编辑区后,可以使用快捷键(Ctrl+A)全选,然后使用【清除格式】按钮清除原文格式,然后排版@ 文章内容。 ▲?清除格式① 可以使用【秒刷】功能直接在编辑器中应用素材样式:选择需要秒刷的内容,点击自己喜欢的样式,即可成功使用该样式。 ?▲?秒刷②您可以使用【智能布局】在编辑器中一键应用全文模板:选择全文模板,设置基本参数,点击鼠标,全文模板自动应用,操作简单易学易上手。 ▲ 你学会了如何使用智能排版采集功能吗?如果你平时看到文章排版漂亮,内容丰富,不妨采集一下。 查看全部
文章一键采集(微信公众号文章采集,不管是排版样式,还是文章内容)
其他微信公众号的文章排版很漂亮,但我只能眼巴巴地看着,想用却无法启动?我需要转载一篇文章文章。我终于复制了,但是一贴就发现格式全乱了?今天教大家一个小技巧——文章采集,不管是排版还是文章内容,一键导入编辑器。快来学习吧。 01采集 不到5秒演示整个操作过程,是不是超级简单?超级快速且易于使用? 02使用教程接下来我们来看看采集函数的使用方法。 ⑴ ?选择目标文章并复制文章链接。电脑用户可以直接选择浏览器地址栏中的所有文章链接。 ▲ 在 PC 上保存文章 链接。手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。 ▲?手机端保存文章链接⑵?单击采集 按钮。编辑器中有两个文章采集功能入口:①编辑菜单右上角的【采集文章】按钮; ▲?采集按钮②【采集@底部功能按钮右侧文章】按钮。 ▲? 采集按钮⑶?粘贴文章 链接和采集。 ▲?贴链接采集编器支持采集微信公号、QQ公众号、今日头条号、百度百家号、一点点号、网易号、搜狐公众号、新浪博客、腾讯新闻、新浪新闻、天天快报、网易新闻,知乎Column 等[Many自媒体平台]文章。 03文章 将文章采集应用到编辑区后,我们就可以进行后续的修改和排版。 ⑴使用原文排版。如果只用原文的排版,文章采集过来后,只要【替换文字和图片】就够了。文字替换:将要使用的文字写入编辑区,或者不带格式粘贴(Ctrl+Shift+V),将文字粘贴到编辑区,然后使用【格式刷】工具应用原创文本到新输入的文本的顶部。 ▲?格式刷图片替换:在编辑区点击需要替换的图片,然后点击右侧图片区的图片即可完成替换。 ⑵ ?使用原创内容。如果不需要对原文进行排版,只需要使用文章的内容即可。 文章采集放入编辑区后,可以使用快捷键(Ctrl+A)全选,然后使用【清除格式】按钮清除原文格式,然后排版@ 文章内容。 ▲?清除格式① 可以使用【秒刷】功能直接在编辑器中应用素材样式:选择需要秒刷的内容,点击自己喜欢的样式,即可成功使用该样式。 ?▲?秒刷②您可以使用【智能布局】在编辑器中一键应用全文模板:选择全文模板,设置基本参数,点击鼠标,全文模板自动应用,操作简单易学易上手。 ▲ 你学会了如何使用智能排版采集功能吗?如果你平时看到文章排版漂亮,内容丰富,不妨采集一下。
文章一键采集(网页文本采集大师就是更简单、高效、省力的办法 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 301 次浏览 • 2021-09-03 12:11
)
在互联网信息时代,你每天上网的时候,经常会遇到喜欢的文章,或者小说等等,从一两页到几十页,甚至成百上千页,所以许多话。复制下载非常麻烦。经常在记事本和网络浏览器之间切换,已经够难过了。现在我面临着需要同时进行数十次或数百次这种无聊的机械动作的需求。有没有更简单、更高效、更省力的方法?
呵呵,你找对地方了。我们开发的“Web Text采集Master”就是这样一款专门为您准备的工具软件。
点击下载:
目前软件已经升级到3.2版本。新版界面截图如下,功能更加强大,无论是静态还是动态网站,禁止复制的文章,还是代码的随机干扰文章,采集有货,我拿来第一时间发给你,抢先用,抢先体验!
网页文字采集大师是专门用于批量采集,复制或下载文章或网上小说,甚至整个网站text内容的工具,无论是静态的网站,或者动态网站,只要有文字就可以获取,只要输入几条简单的信息,就可以自动为你批量下载复制网络文章,可描述一样简单快捷。
除了抓取网上的文章,还可以用来抓取一些特殊的信息,比如抓取百度词典上的信息,也可以用来抓取一些网页上的链接地址。
此外,这款软件还有很多其他的功能,比如文本段落重排、文本合并、文件批量重命名等,非常实用。你需要知道时间。您可以让计算机为您工作。你不能自己做。做吧,下载使用,希望你会喜欢她。
网页正文采集Master 软件简要使用说明
以下例子中介绍的新浪小说网站,因新浪小说频道整改,目前已关闭。可以到软件官网论坛查看更多示例和视频教程:
下面的教程,因为新浪网已经关闭了对应的页面,所以暂时无法测试!
假设我们想在新浪网上捕捉小说《孩子,爸爸其实不想和妈妈离婚》,则意味着以下网址不再有效。以下只是一个例子:
找到采集网页目录的第一个端口
在这里,我们将在新浪网找到该小说的目录页。目录地址如下:
/book/index_66681.html
在第二个端口输入文章directory页面地址
将以上地址复制到软件文章目录页面的输入框,然后回车打开软件网页。
第三端口搜索链接关键字
找到第一章第一节的链接地址,并检查其格式:
/book/chapter_66681_47253.html
稍后查找以下地址。请注意,VIP 会员网页只能由 VIP 会员阅读。如果你想下载这个文章我们的软件,你也必须是VIP会员,所以让我们找一些以前的。这里我们将第11章和第11节作为我们要抓取的最后一章。链接地址为:
/book/chapter_66681_49404.html
现在我们比较上面两个链接地址,找到它们的共同点:
/book/chapter_66681_4
所以在链接关键字输入框中输入。
获取第四个端口的采集文章list
这一步很简单,点击获取列表按钮,点击后,在软件左侧的网址列表框中会看到很多网址
第五个端口输入文本开始和结束关键字
在软件左侧的URL中,选择第一个,点击打开软件右侧的网页,删除软件正文开始关键字和结束关键字输入框中的文字,直接点击获取文章,查看整个网页文字的外观,并找出官方的起止关键词。在这里我们可以看到,小说的每一节都以“爸爸其实不想和妈妈离婚>”开头,结尾是“上一章”三个字。所以,我们对应复制两个关键字(words),然后点击得到文章,看看是不是你想要的结果。
第六个端口确定采集文章save目录
这一步比较简单。您只需要在软件左下角找到要保存的目录,或者点击目录浏览框的右键菜单,新建一个目录即可。
第七个端口决定文章标题的开始和结束关键字
这一步其实就是确定每个文件名的样式。我们可以看到刚才得到的文章。第一行是“第一章离婚第一节”。实际上,第一行可以用作文件。标题是现在,所以这里我们不需要输入标题采集关键字,程序会自动识别,可以点击保存文章试试效果。
第八个端口开始批量爬取
好了,以上步骤都准备好了,现在我们可以启动采集,采集,也可以选择是否自动刷新采集文章,如果选择了,以后方便阅读一些,那我们现在泡杯茶,等结果吧。
购买网页文字采集老师,点赞后赠送智能网页文字提取器:
特别声明:网络世界,网站就像一头牛毛,数不胜数,每一个网站结构千差万别,一个价格而已(咨询特价)软件,你不可能采集全的网站文章,或者采集到文章可以过滤掉你不想要的所有信息。如果你购买了这个软件,因为一个网站采集不顺利,你必须申请退款。那么请绕道而行。我们不想在像你这样的人身上浪费时间。虚拟产品,一旦发出注册码,即使您现在卸载该软件,将来仍然可用。试想一下,你能完全回收溢出的水吗? 鄙视那些收到注册码申请退款的。 (咨询特价)不值得!
查看全部
文章一键采集(网页文本采集大师就是更简单、高效、省力的办法
)
在互联网信息时代,你每天上网的时候,经常会遇到喜欢的文章,或者小说等等,从一两页到几十页,甚至成百上千页,所以许多话。复制下载非常麻烦。经常在记事本和网络浏览器之间切换,已经够难过了。现在我面临着需要同时进行数十次或数百次这种无聊的机械动作的需求。有没有更简单、更高效、更省力的方法?
呵呵,你找对地方了。我们开发的“Web Text采集Master”就是这样一款专门为您准备的工具软件。
点击下载:
目前软件已经升级到3.2版本。新版界面截图如下,功能更加强大,无论是静态还是动态网站,禁止复制的文章,还是代码的随机干扰文章,采集有货,我拿来第一时间发给你,抢先用,抢先体验!
网页文字采集大师是专门用于批量采集,复制或下载文章或网上小说,甚至整个网站text内容的工具,无论是静态的网站,或者动态网站,只要有文字就可以获取,只要输入几条简单的信息,就可以自动为你批量下载复制网络文章,可描述一样简单快捷。
除了抓取网上的文章,还可以用来抓取一些特殊的信息,比如抓取百度词典上的信息,也可以用来抓取一些网页上的链接地址。
此外,这款软件还有很多其他的功能,比如文本段落重排、文本合并、文件批量重命名等,非常实用。你需要知道时间。您可以让计算机为您工作。你不能自己做。做吧,下载使用,希望你会喜欢她。
网页正文采集Master 软件简要使用说明
以下例子中介绍的新浪小说网站,因新浪小说频道整改,目前已关闭。可以到软件官网论坛查看更多示例和视频教程:
下面的教程,因为新浪网已经关闭了对应的页面,所以暂时无法测试!
假设我们想在新浪网上捕捉小说《孩子,爸爸其实不想和妈妈离婚》,则意味着以下网址不再有效。以下只是一个例子:
找到采集网页目录的第一个端口
在这里,我们将在新浪网找到该小说的目录页。目录地址如下:
/book/index_66681.html
在第二个端口输入文章directory页面地址
将以上地址复制到软件文章目录页面的输入框,然后回车打开软件网页。
第三端口搜索链接关键字
找到第一章第一节的链接地址,并检查其格式:
/book/chapter_66681_47253.html
稍后查找以下地址。请注意,VIP 会员网页只能由 VIP 会员阅读。如果你想下载这个文章我们的软件,你也必须是VIP会员,所以让我们找一些以前的。这里我们将第11章和第11节作为我们要抓取的最后一章。链接地址为:
/book/chapter_66681_49404.html
现在我们比较上面两个链接地址,找到它们的共同点:
/book/chapter_66681_4
所以在链接关键字输入框中输入。
获取第四个端口的采集文章list
这一步很简单,点击获取列表按钮,点击后,在软件左侧的网址列表框中会看到很多网址
第五个端口输入文本开始和结束关键字
在软件左侧的URL中,选择第一个,点击打开软件右侧的网页,删除软件正文开始关键字和结束关键字输入框中的文字,直接点击获取文章,查看整个网页文字的外观,并找出官方的起止关键词。在这里我们可以看到,小说的每一节都以“爸爸其实不想和妈妈离婚>”开头,结尾是“上一章”三个字。所以,我们对应复制两个关键字(words),然后点击得到文章,看看是不是你想要的结果。
第六个端口确定采集文章save目录
这一步比较简单。您只需要在软件左下角找到要保存的目录,或者点击目录浏览框的右键菜单,新建一个目录即可。
第七个端口决定文章标题的开始和结束关键字
这一步其实就是确定每个文件名的样式。我们可以看到刚才得到的文章。第一行是“第一章离婚第一节”。实际上,第一行可以用作文件。标题是现在,所以这里我们不需要输入标题采集关键字,程序会自动识别,可以点击保存文章试试效果。
第八个端口开始批量爬取
好了,以上步骤都准备好了,现在我们可以启动采集,采集,也可以选择是否自动刷新采集文章,如果选择了,以后方便阅读一些,那我们现在泡杯茶,等结果吧。
购买网页文字采集老师,点赞后赠送智能网页文字提取器:
特别声明:网络世界,网站就像一头牛毛,数不胜数,每一个网站结构千差万别,一个价格而已(咨询特价)软件,你不可能采集全的网站文章,或者采集到文章可以过滤掉你不想要的所有信息。如果你购买了这个软件,因为一个网站采集不顺利,你必须申请退款。那么请绕道而行。我们不想在像你这样的人身上浪费时间。虚拟产品,一旦发出注册码,即使您现在卸载该软件,将来仍然可用。试想一下,你能完全回收溢出的水吗? 鄙视那些收到注册码申请退款的。 (咨询特价)不值得!
文章一键采集(一个微信公众号历史消息页面的链接地址和采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2021-08-30 20:01
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作一个html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。当时批量采集特别好做,采集入口就是公众号的历史新闻页面。这个条目现在是一样的,但越来越难采集。 采集 方法也在很多版本中进行了更新。后来到了2015年,html5垃圾站就不做了。而是将采集目标定位在本地新闻资讯公众号,前端展示被做成了一个app。于是一个可以自动采集公号内容的新闻APP就形成了。曾经担心微信技术升级一天后采集内容不可用,我的新闻应用程序失败。但是随着微信的不断技术升级,采集方式也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集内容。所以今天整理了一下,决定把采集方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到时可用。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新==========
现在根据不同的微信个人账号,会有两个不同的历史消息页面地址。下面是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=;这4个参数。
__biz 是公众号的类似id的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
剩下的3个参数与用户id和tokenticket的含义有关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、A 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量采集测试的ios微信客户端崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。
2、A微信个人账号:采集内容不仅需要微信客户端,还需要采集专用的微信个人账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体安装方法后面会详细介绍。
4、文章List分析入库系统:本人使用PHP语言编写,下篇文章将详细介绍如何分析文章lists并创建采集queues实现批量采集内容.
步骤
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy、AnyProxy。这个软件的特点是可以获取https链接的内容。 2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、Install NodeJS
2、在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i;参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、Set proxy:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为静态后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址就是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002,可以看到anyproxy的web界面。微信点击打开一个历史消息页面,然后在浏览器的web界面查看,历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到以/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件 rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请注意详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以按照从您自己的页面表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p> 查看全部
文章一键采集(一个微信公众号历史消息页面的链接地址和采集方法)
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作一个html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。当时批量采集特别好做,采集入口就是公众号的历史新闻页面。这个条目现在是一样的,但越来越难采集。 采集 方法也在很多版本中进行了更新。后来到了2015年,html5垃圾站就不做了。而是将采集目标定位在本地新闻资讯公众号,前端展示被做成了一个app。于是一个可以自动采集公号内容的新闻APP就形成了。曾经担心微信技术升级一天后采集内容不可用,我的新闻应用程序失败。但是随着微信的不断技术升级,采集方式也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集内容。所以今天整理了一下,决定把采集方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到时可用。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新==========
现在根据不同的微信个人账号,会有两个不同的历史消息页面地址。下面是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=;这4个参数。
__biz 是公众号的类似id的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
剩下的3个参数与用户id和tokenticket的含义有关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、A 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量采集测试的ios微信客户端崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。
2、A微信个人账号:采集内容不仅需要微信客户端,还需要采集专用的微信个人账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体安装方法后面会详细介绍。
4、文章List分析入库系统:本人使用PHP语言编写,下篇文章将详细介绍如何分析文章lists并创建采集queues实现批量采集内容.
步骤
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy、AnyProxy。这个软件的特点是可以获取https链接的内容。 2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、Install NodeJS
2、在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、 启动 anyproxy 运行命令:sudo anyproxy -i;参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、Set proxy:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为静态后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址就是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002,可以看到anyproxy的web界面。微信点击打开一个历史消息页面,然后在浏览器的web界面查看,历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到以/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件 rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请注意详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以按照从您自己的页面表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次请原谅我不熟悉windows命令。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p>
一键提取微信图文视频的功能,废话不多说上干货!
采集交流 • 优采云 发表了文章 • 0 个评论 • 712 次浏览 • 2021-08-25 07:03
经常推送微信公众号图片和文字的编辑可能会遇到问题,发现其他公众号的图片和文字中的一个或多个视频非常好。转载到自己的公众号很麻烦,所以我一般都是用的。几种方法:
注意:微信公众号视频账号不支持提取视频。提取的是图文中的视频,而不是图文中视频号中的视频。
1、通过图文介绍视频搜索关键词或title,成功率极低;
2、把图文链接放到电脑上打开查看网页源码,然后通过视频链接的特征字符搜索,加上自己的判断,缺点是步骤麻烦,而且发现有的链接不对,有的打开视频大小不合适,多视频更不方便;
为了解决这个问题,小蚂蚁尝试了很多方法。经过一番努力,他终于发现了视频链接的奥秘。为了体现出逼格的风格,小蚂蚁决定把这个流程功能化,于是就有了下面一键提取微信图文功能,废话不多说! ! !
一、视频提取
首先找到视频提取功能所在的位置,如下图:微信图文提取。
获取视频链接只需3步:
第一步:复制收录视频的微信图文链接地址。
第2步:将上面得到的地址填入“WeChat文章Address”框中,点击“Extract”按钮。
微信文章必须在开头。
第三步:文章中的所有视频可以同时提取链接。您可以点击右侧的复制、插入、下载来操作视频。
复制:点击复制复制视频链接,通过链接将视频插入编辑器(插入视频教程),或者直接在浏览器中打开视频。
插入:点击插入,将提取的视频直接插入小蚂蚁编辑器的编辑区。
注意:如果提取的视频是公众号本地上传的视频,则不能复制链接插入编辑器或通过插入按钮插入编辑器,会提示“您请求的视频没有存在”。
下载:点击下载,将视频下载到本地,上传到微信公众平台的背景素材库。 (适用于公众号本地上传的视频)
二、补充说明:
复制收录视频的微信图文链接地址。有的用户可能不理解这一步。复制收录视频的微信文章链接地址主要有以下三种方式:
方法一:在手机上打开微信视频文章,点击右上角的三点图标选择“复制链接”进行复制,然后通过电脑版微信将此链接发送到电脑或者QQ提取。
方法二:在“新媒体助手”-“微信热文”中搜索有视频的微信文章,在地址栏中复制网址。
方法三:登录微信公众号后台,复制发送的图文中的链接地址(此方法一般适用于提取您发送的视频图文中的视频资源)。
> 查看全部
一键提取微信图文视频的功能,废话不多说上干货!
经常推送微信公众号图片和文字的编辑可能会遇到问题,发现其他公众号的图片和文字中的一个或多个视频非常好。转载到自己的公众号很麻烦,所以我一般都是用的。几种方法:
注意:微信公众号视频账号不支持提取视频。提取的是图文中的视频,而不是图文中视频号中的视频。
1、通过图文介绍视频搜索关键词或title,成功率极低;
2、把图文链接放到电脑上打开查看网页源码,然后通过视频链接的特征字符搜索,加上自己的判断,缺点是步骤麻烦,而且发现有的链接不对,有的打开视频大小不合适,多视频更不方便;
为了解决这个问题,小蚂蚁尝试了很多方法。经过一番努力,他终于发现了视频链接的奥秘。为了体现出逼格的风格,小蚂蚁决定把这个流程功能化,于是就有了下面一键提取微信图文功能,废话不多说! ! !
一、视频提取
首先找到视频提取功能所在的位置,如下图:微信图文提取。
获取视频链接只需3步:
第一步:复制收录视频的微信图文链接地址。
第2步:将上面得到的地址填入“WeChat文章Address”框中,点击“Extract”按钮。
微信文章必须在开头。
第三步:文章中的所有视频可以同时提取链接。您可以点击右侧的复制、插入、下载来操作视频。
复制:点击复制复制视频链接,通过链接将视频插入编辑器(插入视频教程),或者直接在浏览器中打开视频。
插入:点击插入,将提取的视频直接插入小蚂蚁编辑器的编辑区。
注意:如果提取的视频是公众号本地上传的视频,则不能复制链接插入编辑器或通过插入按钮插入编辑器,会提示“您请求的视频没有存在”。
下载:点击下载,将视频下载到本地,上传到微信公众平台的背景素材库。 (适用于公众号本地上传的视频)
二、补充说明:
复制收录视频的微信图文链接地址。有的用户可能不理解这一步。复制收录视频的微信文章链接地址主要有以下三种方式:
方法一:在手机上打开微信视频文章,点击右上角的三点图标选择“复制链接”进行复制,然后通过电脑版微信将此链接发送到电脑或者QQ提取。
方法二:在“新媒体助手”-“微信热文”中搜索有视频的微信文章,在地址栏中复制网址。
方法三:登录微信公众号后台,复制发送的图文中的链接地址(此方法一般适用于提取您发送的视频图文中的视频资源)。
>
AII在线文章生成器ai批量写作助手方法步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-08-13 18:07
AII Online 文章 Generator 是一款免费版的在线文章生成工具,无注册码,无破解版,你输入的关键词一键即可自动生成带有关键词高的文章和高质量的 SEO软文。一键智能伪原创工具特点 1 本软件利用引擎独有的分析规则和算法对文章进行细分,可以很好的匹配所有搜索引擎。 2 独有的同义词替换词表可不改文章原创文章 3 语义前提下生成,融合当前主流。
简介 谈一键生成原创文章大家第一个想到的工具一定是文章生成器。其实一些伪原创工具也可以做到。好奇宝宝来了解决下一个工具原材料智能媒体ai批量写入辅助方法的步骤1。以下是科技新闻原文的随机片段。下面是使用爱写工具一键生成原创文章。对比两者,可以看到一键生成的原创文章只有小瑕疵。 , 语义连续性没有问题,这样文章也会受到影响。
处理文章的最佳软件
邵念Smart伪原创软件经过10年的研发,深入涉足文章伪原创文章生成器领域,开发了AI伪原创文章生成器在线工具,使用人工智能技术。牛蚂蚁原创使用深度神经网络算法重构文章,减少文章重复,自动调整段落文本顺序并替换整句优采云采集把最新的RNN和In LSTM算法中使用smart原创的过程,不仅保证文章。
伪原创文章软件,文章 一键生成神器 花瑶音月影2 分享到热门视频 0118 逃离广深,去广东最适合居住的城市,知道为什么在0156非洲。 1 免费分享伪原创工具关键词automatic generation文章3013 2 智媒体ai伪原创写作助手一键生成原创文章1444 3 什么AI写作软件可靠好用? 1336 4 艾伪原创tools,。
在线写诗机器人
优采云采集带有文章采集伪原创智能播收录工具,为媒体内容创作者提供文章采集器在线伪原创工具网站cms智能发布百度网站收录等服务,让您的文章在搜索引擎和新媒体上获得海量流量排名。 AI666的AI云创平台是国内首家致力于AI文章代解决方案的服务商,为用户提供AI文章在线代服务,原创算法打造最优质原创文章AI666人工智能系统是用户生成的最佳帮手原创文章。 查看全部
AII在线文章生成器ai批量写作助手方法步骤
AII Online 文章 Generator 是一款免费版的在线文章生成工具,无注册码,无破解版,你输入的关键词一键即可自动生成带有关键词高的文章和高质量的 SEO软文。一键智能伪原创工具特点 1 本软件利用引擎独有的分析规则和算法对文章进行细分,可以很好的匹配所有搜索引擎。 2 独有的同义词替换词表可不改文章原创文章 3 语义前提下生成,融合当前主流。
简介 谈一键生成原创文章大家第一个想到的工具一定是文章生成器。其实一些伪原创工具也可以做到。好奇宝宝来了解决下一个工具原材料智能媒体ai批量写入辅助方法的步骤1。以下是科技新闻原文的随机片段。下面是使用爱写工具一键生成原创文章。对比两者,可以看到一键生成的原创文章只有小瑕疵。 , 语义连续性没有问题,这样文章也会受到影响。
处理文章的最佳软件
邵念Smart伪原创软件经过10年的研发,深入涉足文章伪原创文章生成器领域,开发了AI伪原创文章生成器在线工具,使用人工智能技术。牛蚂蚁原创使用深度神经网络算法重构文章,减少文章重复,自动调整段落文本顺序并替换整句优采云采集把最新的RNN和In LSTM算法中使用smart原创的过程,不仅保证文章。
伪原创文章软件,文章 一键生成神器 花瑶音月影2 分享到热门视频 0118 逃离广深,去广东最适合居住的城市,知道为什么在0156非洲。 1 免费分享伪原创工具关键词automatic generation文章3013 2 智媒体ai伪原创写作助手一键生成原创文章1444 3 什么AI写作软件可靠好用? 1336 4 艾伪原创tools,。
在线写诗机器人
优采云采集带有文章采集伪原创智能播收录工具,为媒体内容创作者提供文章采集器在线伪原创工具网站cms智能发布百度网站收录等服务,让您的文章在搜索引擎和新媒体上获得海量流量排名。 AI666的AI云创平台是国内首家致力于AI文章代解决方案的服务商,为用户提供AI文章在线代服务,原创算法打造最优质原创文章AI666人工智能系统是用户生成的最佳帮手原创文章。
微信公众号文章搜索下载助手,都能用到它!
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-08-12 23:04
微信公众号文章搜索师是一个非常实用又贴心的小工具,可以帮助快速搜索任何文章以及任何微信公众号推送的内容,并且方便查看,有利于用户参考查看,还可以自定义搜索发布时间,去掉搜索限制,很经典。
软件介绍:
微信公众号文章search 下载助手,集搜索下载于一体。可以通过关键词一键搜索微信平台文章所有公众号,超大资料库,可以采集指定所有公众号已批量发送至文章,导出批量输出word、pdf或html。所以,无论你是做自媒体找文章材料,还是个人用户搜索下载文章,都可以使用!下面我们详细看一下功能介绍:
软件功能:
V1.4.5 2019.6.5
1.通过关键词搜索所有微信公众号文章,支持指定时间段搜索文章。您可以在一天内或一年内搜索发布;
2.一键采集指定公众号已发至所有群文章,下个版本将支持显示阅读喜欢,支持word、pdf、html格式随意导出,多线程批量下载,下载500文章文章只需要8分钟(下载文章原创布局);
3.支持批量导入和下载外部文章链接,非常方便;
4、搜索文章可按发布时间、标题、公众号排序,支持标题去重,搜索结果二次搜索,结果更准确,列表可导出Excle;
5、关键词Search支持公众号和关键词黑屏,自动过滤不想看的内容,拖拽选择,一键黑屏等;
6、support文章details 页面关键词find,快速查找文章content,支持文章abstract 预览;
7.此外,软件还有很多其他的附加功能,大量的快捷键操作,非常人性化; 查看全部
微信公众号文章搜索下载助手,都能用到它!
微信公众号文章搜索师是一个非常实用又贴心的小工具,可以帮助快速搜索任何文章以及任何微信公众号推送的内容,并且方便查看,有利于用户参考查看,还可以自定义搜索发布时间,去掉搜索限制,很经典。
软件介绍:
微信公众号文章search 下载助手,集搜索下载于一体。可以通过关键词一键搜索微信平台文章所有公众号,超大资料库,可以采集指定所有公众号已批量发送至文章,导出批量输出word、pdf或html。所以,无论你是做自媒体找文章材料,还是个人用户搜索下载文章,都可以使用!下面我们详细看一下功能介绍:
软件功能:
V1.4.5 2019.6.5
1.通过关键词搜索所有微信公众号文章,支持指定时间段搜索文章。您可以在一天内或一年内搜索发布;
2.一键采集指定公众号已发至所有群文章,下个版本将支持显示阅读喜欢,支持word、pdf、html格式随意导出,多线程批量下载,下载500文章文章只需要8分钟(下载文章原创布局);
3.支持批量导入和下载外部文章链接,非常方便;
4、搜索文章可按发布时间、标题、公众号排序,支持标题去重,搜索结果二次搜索,结果更准确,列表可导出Excle;
5、关键词Search支持公众号和关键词黑屏,自动过滤不想看的内容,拖拽选择,一键黑屏等;
6、support文章details 页面关键词find,快速查找文章content,支持文章abstract 预览;
7.此外,软件还有很多其他的附加功能,大量的快捷键操作,非常人性化;
使用PyQt5一键傻瓜式的数据采集工具(一)_
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-08-07 03:11
使用PyQt5一键傻瓜式的数据采集工具(一)_
<p style="margin-right: 0.5em;margin-left: 0.5em;letter-spacing: 0.544px;color: rgb(0, 0, 0);font-size: medium;font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;text-align: center;">↑ 关注 + 星标 ,每天学Python新技能</p>
后台回复【大礼包】送你Python自学大礼包<p style="padding-right: 0.5em;padding-left: 0.5em;">
</p>
Data采集越来越成为互联网从业者的刚性需求。
从内部报告到外部市场动态,需要采集大大小小的信息和数据。爬虫无疑是常规数据采集最快最有效的方法。但是,要写爬虫,必须有一定的编程基础,谁受得了。市面上也有一些自助数据采集工具,比如优采云、优采云等,确实降低了数据采集和门槛,方便了数据采集的操作。但是,这些工具或多或少仍需要人为地定义和选择。在周老师的“前爬虫生涯”中,我遇到了很多生意人,也只是一个需求:你给我数据。答案是否定的,然后他说:给我一个工具,让我点击数据,它就会出来。其实我们可以用PyQt5对爬虫程序进行封装打包实现傻瓜式,一键采集软件。这个特别适合网站,是普通业务人员,实时数据不高但需要登录。 下面我们以采集微信公号后台的数据为例介绍PyQt5的使用开发一键傻瓜式data采集工具。核心采集代码在这里,我们只是以采集微信公号后端的“账户全局”数据为例:
我们对 HTTP 请求使用 requests 库,对 HTML 文档解析和数据提取使用 BeautifulSoup。核心采集代码如下:
<p> def check_status(self):
try:
print("获取到的Cookie:", self.cookie)
print("获取到的Token:",self.token)
# 获取当前登录店铺和用户名
url = 'https://mp.weixin.qq.com/cgi-bin/home?t=home/index&token={token}&lang=zh_CN'.format(token=self.token)
wbdata = requests.get(url, headers=self.header, cookies=self.cookie).text
soup = BeautifulSoup(wbdata,'lxml')
nickname = soup.select_one("a.weui-desktop-account__nickname").get_text()
total_cnt = soup.select("em.weui-desktop-data-overview__desc")[2].get_text()
self.nickname = nickname
except Exception as e:
self.nickname = None
logger.error("获取用户信息出错:{}".format(repr(e)))
return (self.nickname, self.cookie)</p>
搭建图形界面由于微信公众号需要登录才能使用,我们使用PyQt5的QtWebEngineWidgets小部件在程序中嵌入浏览器,直接在程序中实现登录操作。
如您所见,我们的图形程序的主界面分为两个选项卡,由 QTabWidget 选项卡组件实现。在第一个选项卡上,我们放置了一个 QtWebEngineWidgets 的 QWebEngineView 小部件,用于显示网页和执行登录操作。在第二个标签中,我们放置了按钮部件和文本输入框部件,用于控制数据采集的进度和结果,显示数据采集。
采集Process and control 程序的图形界面搭建完成后,我们需要处理程序的功能。这些功能包括:网页的cookie是我们获取登录状态的关键。在这里,浏览器配置文件是通过 QtWebEngineWidgets 的 QWebEngineProfile 组件实现的。 QWebEngineProfile 有一个cookie 存储,每次请求都会将cookie 写入QWebEngineProfile,我们会从中读取最新的cookie。 采集通过按钮“查看登录状态”执行数据,将按钮的点击信号绑定到一个槽函数,槽函数调用QThread在子线程中执行data采集的核心代码。而结果的输出,我们通过文本输出框来实现。
<p> # 在控制台中写入信息
def outputWritten(self, text=None):
cursor = self.label_1.textCursor()
cursor.movePosition(QtGui.QTextCursor.End)
cursor.insertText(text)
self.label_1.setTextCursor(cursor)
self.label_1.ensureCursorVisible()</p>
这样,在按钮的slot函数中,调用outputWritten方法在文本框中输出采集信息。最终的结果,我们实现的效果是:打开程序,扫描“登录页面”选项卡上的二维码,登录微信公众号后台;然后切换到“操作页面”,点击“查看登录状态”按钮,程序会自动采集Data,最后输出到文本输入框。未登录时的效果:
登录状态下的效果:
按照同样的逻辑,我们可以实现采集网页中的其他数据,比如文章list数据、watchlist用户数据等,或者其他网站数据。
<p style="margin-top: 1.5em;margin-bottom: 1.5em;color: inherit;letter-spacing: 0px;font-family: Optima-Regular, Optima, PingFangSC-light, PingFangTC-light, "PingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;line-height: inherit;">如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
Python自学超级硬核资料
最后送大家一份Python学习大礼包,从Python基础,爬虫,数据分析Web开发等全套资料,吃透资料,你可以扔掉其他资料,这些资料都是视频,学起来非常友好
Ps:都是视频学习资料,非常<strong style="font-size: 14px;">适合基础不好或者零基础的同学</strong>
推荐阅读</p>
看完记得关注@Python绿色频道
及时观看更多好文章
↓↓↓
点击卡片关注Python绿色通道
Re:大礼包,获取最新Python学习资料 查看全部
使用PyQt5一键傻瓜式的数据采集工具(一)_
<p style="margin-right: 0.5em;margin-left: 0.5em;letter-spacing: 0.544px;color: rgb(0, 0, 0);font-size: medium;font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;text-align: center;">↑ 关注 + 星标 ,每天学Python新技能</p>
后台回复【大礼包】送你Python自学大礼包<p style="padding-right: 0.5em;padding-left: 0.5em;">
</p>
Data采集越来越成为互联网从业者的刚性需求。
从内部报告到外部市场动态,需要采集大大小小的信息和数据。爬虫无疑是常规数据采集最快最有效的方法。但是,要写爬虫,必须有一定的编程基础,谁受得了。市面上也有一些自助数据采集工具,比如优采云、优采云等,确实降低了数据采集和门槛,方便了数据采集的操作。但是,这些工具或多或少仍需要人为地定义和选择。在周老师的“前爬虫生涯”中,我遇到了很多生意人,也只是一个需求:你给我数据。答案是否定的,然后他说:给我一个工具,让我点击数据,它就会出来。其实我们可以用PyQt5对爬虫程序进行封装打包实现傻瓜式,一键采集软件。这个特别适合网站,是普通业务人员,实时数据不高但需要登录。 下面我们以采集微信公号后台的数据为例介绍PyQt5的使用开发一键傻瓜式data采集工具。核心采集代码在这里,我们只是以采集微信公号后端的“账户全局”数据为例:
我们对 HTTP 请求使用 requests 库,对 HTML 文档解析和数据提取使用 BeautifulSoup。核心采集代码如下:
<p> def check_status(self):
try:
print("获取到的Cookie:", self.cookie)
print("获取到的Token:",self.token)
# 获取当前登录店铺和用户名
url = 'https://mp.weixin.qq.com/cgi-bin/home?t=home/index&token={token}&lang=zh_CN'.format(token=self.token)
wbdata = requests.get(url, headers=self.header, cookies=self.cookie).text
soup = BeautifulSoup(wbdata,'lxml')
nickname = soup.select_one("a.weui-desktop-account__nickname").get_text()
total_cnt = soup.select("em.weui-desktop-data-overview__desc")[2].get_text()
self.nickname = nickname
except Exception as e:
self.nickname = None
logger.error("获取用户信息出错:{}".format(repr(e)))
return (self.nickname, self.cookie)</p>
搭建图形界面由于微信公众号需要登录才能使用,我们使用PyQt5的QtWebEngineWidgets小部件在程序中嵌入浏览器,直接在程序中实现登录操作。
如您所见,我们的图形程序的主界面分为两个选项卡,由 QTabWidget 选项卡组件实现。在第一个选项卡上,我们放置了一个 QtWebEngineWidgets 的 QWebEngineView 小部件,用于显示网页和执行登录操作。在第二个标签中,我们放置了按钮部件和文本输入框部件,用于控制数据采集的进度和结果,显示数据采集。
采集Process and control 程序的图形界面搭建完成后,我们需要处理程序的功能。这些功能包括:网页的cookie是我们获取登录状态的关键。在这里,浏览器配置文件是通过 QtWebEngineWidgets 的 QWebEngineProfile 组件实现的。 QWebEngineProfile 有一个cookie 存储,每次请求都会将cookie 写入QWebEngineProfile,我们会从中读取最新的cookie。 采集通过按钮“查看登录状态”执行数据,将按钮的点击信号绑定到一个槽函数,槽函数调用QThread在子线程中执行data采集的核心代码。而结果的输出,我们通过文本输出框来实现。
<p> # 在控制台中写入信息
def outputWritten(self, text=None):
cursor = self.label_1.textCursor()
cursor.movePosition(QtGui.QTextCursor.End)
cursor.insertText(text)
self.label_1.setTextCursor(cursor)
self.label_1.ensureCursorVisible()</p>
这样,在按钮的slot函数中,调用outputWritten方法在文本框中输出采集信息。最终的结果,我们实现的效果是:打开程序,扫描“登录页面”选项卡上的二维码,登录微信公众号后台;然后切换到“操作页面”,点击“查看登录状态”按钮,程序会自动采集Data,最后输出到文本输入框。未登录时的效果:
登录状态下的效果:
按照同样的逻辑,我们可以实现采集网页中的其他数据,比如文章list数据、watchlist用户数据等,或者其他网站数据。
<p style="margin-top: 1.5em;margin-bottom: 1.5em;color: inherit;letter-spacing: 0px;font-family: Optima-Regular, Optima, PingFangSC-light, PingFangTC-light, "PingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;line-height: inherit;">如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
Python自学超级硬核资料
最后送大家一份Python学习大礼包,从Python基础,爬虫,数据分析Web开发等全套资料,吃透资料,你可以扔掉其他资料,这些资料都是视频,学起来非常友好
Ps:都是视频学习资料,非常<strong style="font-size: 14px;">适合基础不好或者零基础的同学</strong>
推荐阅读</p>
看完记得关注@Python绿色频道
及时观看更多好文章
↓↓↓
点击卡片关注Python绿色通道
Re:大礼包,获取最新Python学习资料
分享一个神器,快速采集文章全靠它!(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 274 次浏览 • 2021-07-16 22:08
分享一个神器,赶紧采集文章靠它!
疫情期间,一键采集原创文章,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一,但远程办公仍然不如面对面工作效率高。这个优采云采集 特别推出智能采集 工具。
相信很多运营商都接触过采集tools。现在市场上有很多种采集tools。很多人认为采集工具只是文章hot/festival 话题等信息采集 的辅助工具,其实不仅如此。一个成熟的采集工具不仅可以帮助运营采集信息,还可以准确分析数据趋势,帮助增加收益。
1、优采云采集是什么?
优采云采集是自媒体材料搜、文章原创的运营工具,一键发布,有效提升新媒体运营效率,降低企业成本。
2、如何使用优采云采集进行搜索?
(1)输入关键词
优采云采集根据用户输入的关键词,搜索引擎通过程序自动进入主流自媒体数据源。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集有关疫情的资料,在主页输入关键词“疫情”。 优采云采集 会将搜索结果整合到一个列表中。
(2)保存搜索资料
优采云采集具有批量保存搜索资料的功能。
点击【全选当前页】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
(3)精准过滤
1、 搜索过滤器
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
2、 广告过滤 查看全部
分享一个神器,快速采集文章全靠它!(组图)
分享一个神器,赶紧采集文章靠它!
疫情期间,一键采集原创文章,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一,但远程办公仍然不如面对面工作效率高。这个优采云采集 特别推出智能采集 工具。
相信很多运营商都接触过采集tools。现在市场上有很多种采集tools。很多人认为采集工具只是文章hot/festival 话题等信息采集 的辅助工具,其实不仅如此。一个成熟的采集工具不仅可以帮助运营采集信息,还可以准确分析数据趋势,帮助增加收益。
1、优采云采集是什么?
优采云采集是自媒体材料搜、文章原创的运营工具,一键发布,有效提升新媒体运营效率,降低企业成本。
2、如何使用优采云采集进行搜索?
(1)输入关键词
优采云采集根据用户输入的关键词,搜索引擎通过程序自动进入主流自媒体数据源。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集有关疫情的资料,在主页输入关键词“疫情”。 优采云采集 会将搜索结果整合到一个列表中。
(2)保存搜索资料
优采云采集具有批量保存搜索资料的功能。
点击【全选当前页】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
(3)精准过滤
1、 搜索过滤器
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
2、 广告过滤
什么是优采云采集?智能采集工具帮你提高营收
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-05-24 22:12
什么是优采云采集?智能采集工具帮你提高营收
在流行期间,许多公司不得不选择远程在线办公室。互联网是受流行病影响较小的行业之一,但是远程办公室的效率仍然不如面对面的工作。因此,优采云 采集特别推出了智能采集工具。
我相信许多操作员已经接触过采集工具。市场上有很多采集工具。许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此。成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入。
1、什么是优采云 采集?
优采云 采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,有效地提高了新媒体的运营效率并降低了公司成本。
2、如何用优采云 采集搜索?
([1)输入关键词
优采云 采集根据用户输入的关键词,它会通过程序自动进入主流自媒体数据源的搜索引擎进行搜索。
优采云 采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性。
例如:
用户需要采集与流行病有关的资料,并在主页上输入关键词“流行病”。 优采云 采集会将搜索结果合并到一个列表中。
([2)保存搜索材料
优采云 采集具有批量保存搜索资料的功能。
单击[在当前页面上全部选择]功能,然后选中所需的文章,文章将添加到操作面板中,方便用户批量保存。
([3)精确过滤
1、搜索过滤器
优采云 采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,以使搜索内容更加准确。
2、广告过滤 查看全部
什么是优采云采集?智能采集工具帮你提高营收
在流行期间,许多公司不得不选择远程在线办公室。互联网是受流行病影响较小的行业之一,但是远程办公室的效率仍然不如面对面的工作。因此,优采云 采集特别推出了智能采集工具。
我相信许多操作员已经接触过采集工具。市场上有很多采集工具。许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此。成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入。
1、什么是优采云 采集?
优采云 采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,有效地提高了新媒体的运营效率并降低了公司成本。
2、如何用优采云 采集搜索?
([1)输入关键词
优采云 采集根据用户输入的关键词,它会通过程序自动进入主流自媒体数据源的搜索引擎进行搜索。
优采云 采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性。
例如:
用户需要采集与流行病有关的资料,并在主页上输入关键词“流行病”。 优采云 采集会将搜索结果合并到一个列表中。
([2)保存搜索材料
优采云 采集具有批量保存搜索资料的功能。
单击[在当前页面上全部选择]功能,然后选中所需的文章,文章将添加到操作面板中,方便用户批量保存。
([3)精确过滤
1、搜索过滤器
优采云 采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,以使搜索内容更加准确。
2、广告过滤
用扩展函数处理采集到的原始数据/--RunPHP
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-05-17 19:07
以下是引用的内容:
// ---------------------------------
//使用扩展功能处理采集中的原创数据
// -------------------------------
函数RunPHP($ fvalue,$ phpcode)
{
$ DedeMeValue = $ fvalue;
$ phpcode = preg_replace(“ /'@ me'| \” @ me \“ | @ me / isU”,'$ DedeMeValue',$ phpcode);
if(eregi('@ body',$ phpcode)){
$ DedeBodyValue = $ this-> tmpHtml;
$ phpcode = preg_replace(“ /'@ body'| \” @ body \“ | @ body / isU”,'$ DedeBodyValue',$ phpcode);
}
if(eregi('@ litpic',$ phpcode)){
$ DedeLitPicValue = $ this-> breImage;
$ phpcode = preg_replace(“ /'@ litpic'| \” @ litpic \“ | @ litpic / isU”,'$ DedeLitPicValue',$ phpcode);
}
@eval($ phpcode。“;”);
返回$ DedeMeValue;
}
此处定义了几个默认的预定变量
现在我们要添加一个@url
因此最后一段将更改为:
以下是引用的内容:
RunPHP函数($ fvalue,$ phpcode,$ dourl = false)
{
$ DedeMeValue = $ fvalue;
$ phpcode = preg_replace(“ /'@ me'| \” @ me \“ | @ me / isU”,'$ DedeMeValue',$ phpcode);
if(eregi('@ body',$ phpcode)){
$ DedeBodyValue = $ this-> tmpHtml;
$ phpcode = preg_replace(“ /'@ body'| \” @ body \“ | @ body / isU”,'$ DedeBodyValue',$ phpcode);
}
if(eregi('@ litpic',$ phpcode)){
$ DedeLitPicValue = $ this-> breImage;
$ phpcode = preg_replace(“ /'@ litpic'| \” @ litpic \“ | @ litpic / isU”,'$ DedeLitPicValue',$ phpcode);
}
if(eregi('@ url',$ phpcode)){
$ DedeUrlValue = $ dourl;
$ phpcode = preg_replace(“ /'@ url'| \” @ url \“ | @ url / isU”,'$ DedeUrlValue',$ phpcode);
}
@eval($ phpcode。“;”);
返回$ DedeMeValue;
}
请注意,为了将值传递给@url,我们在函数参数中添加了参数$ dourl = false,因此我们需要在调用此函数的位置进行更改($ dourl = false表示该参数不是必要,您在常规调用中不需要此参数)
找到以下代码:
以下是引用的内容:
//用户用于自己处理内容的界面
if($ sarr [“ function”]!=“”){
if(!eregi('@ litpic',$ sarr [“ function”])){
$ v = $ this-> RunPHP($ v,$ sarr [“ function”]);
$ artitem。=“” {dede:field name ='$ k'} $ v {/ dede:field} \ r \ n“;
}其他{
$ tmpLtKeys [$ k] ['v'] = $ v;
$ tmpLtKeys [$ k] ['f'] = $ sarr [“ function”];
}
放入其中之一
以下是引用的内容:
$ v = $ this-> RunPHP($ v,$ sarr [“ function”]);
更改为:
以下是引用的内容:
$ v = $ this-> RunPHP($ v,$ sarr [“ function”],$ dourl);
就是这样,到目前为止,所有源代码都已修改。
使用此新变量@url很容易
例如,在文章内容的自定义处理界面中编写:
以下是引用的内容:
@ me = @ me。' 查看全部
用扩展函数处理采集到的原始数据/--RunPHP
以下是引用的内容:
// ---------------------------------
//使用扩展功能处理采集中的原创数据
// -------------------------------
函数RunPHP($ fvalue,$ phpcode)
{
$ DedeMeValue = $ fvalue;
$ phpcode = preg_replace(“ /'@ me'| \” @ me \“ | @ me / isU”,'$ DedeMeValue',$ phpcode);
if(eregi('@ body',$ phpcode)){
$ DedeBodyValue = $ this-> tmpHtml;
$ phpcode = preg_replace(“ /'@ body'| \” @ body \“ | @ body / isU”,'$ DedeBodyValue',$ phpcode);
}
if(eregi('@ litpic',$ phpcode)){
$ DedeLitPicValue = $ this-> breImage;
$ phpcode = preg_replace(“ /'@ litpic'| \” @ litpic \“ | @ litpic / isU”,'$ DedeLitPicValue',$ phpcode);
}
@eval($ phpcode。“;”);
返回$ DedeMeValue;
}
此处定义了几个默认的预定变量
现在我们要添加一个@url
因此最后一段将更改为:
以下是引用的内容:
RunPHP函数($ fvalue,$ phpcode,$ dourl = false)
{
$ DedeMeValue = $ fvalue;
$ phpcode = preg_replace(“ /'@ me'| \” @ me \“ | @ me / isU”,'$ DedeMeValue',$ phpcode);
if(eregi('@ body',$ phpcode)){
$ DedeBodyValue = $ this-> tmpHtml;
$ phpcode = preg_replace(“ /'@ body'| \” @ body \“ | @ body / isU”,'$ DedeBodyValue',$ phpcode);
}
if(eregi('@ litpic',$ phpcode)){
$ DedeLitPicValue = $ this-> breImage;
$ phpcode = preg_replace(“ /'@ litpic'| \” @ litpic \“ | @ litpic / isU”,'$ DedeLitPicValue',$ phpcode);
}
if(eregi('@ url',$ phpcode)){
$ DedeUrlValue = $ dourl;
$ phpcode = preg_replace(“ /'@ url'| \” @ url \“ | @ url / isU”,'$ DedeUrlValue',$ phpcode);
}
@eval($ phpcode。“;”);
返回$ DedeMeValue;
}
请注意,为了将值传递给@url,我们在函数参数中添加了参数$ dourl = false,因此我们需要在调用此函数的位置进行更改($ dourl = false表示该参数不是必要,您在常规调用中不需要此参数)
找到以下代码:
以下是引用的内容:
//用户用于自己处理内容的界面
if($ sarr [“ function”]!=“”){
if(!eregi('@ litpic',$ sarr [“ function”])){
$ v = $ this-> RunPHP($ v,$ sarr [“ function”]);
$ artitem。=“” {dede:field name ='$ k'} $ v {/ dede:field} \ r \ n“;
}其他{
$ tmpLtKeys [$ k] ['v'] = $ v;
$ tmpLtKeys [$ k] ['f'] = $ sarr [“ function”];
}
放入其中之一
以下是引用的内容:
$ v = $ this-> RunPHP($ v,$ sarr [“ function”]);
更改为:
以下是引用的内容:
$ v = $ this-> RunPHP($ v,$ sarr [“ function”],$ dourl);
就是这样,到目前为止,所有源代码都已修改。
使用此新变量@url很容易
例如,在文章内容的自定义处理界面中编写:
以下是引用的内容:
@ me = @ me。'
AI文章,非教程内容,仅供欣赏!(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-05-09 00:14
AI文章,非教程内容,仅供欣赏!(组图)
如何通过组合文章自动发布文章
第一步是设置“ 文章库分类管理”,操作路径:站群版本-> 文章库分类管理。
第二步是设置“ 文章图片管理”,操作路径为:站群发布-> 文章图片管理。
第三步是设置“ 文章标题管理”,操作路径:站群版本-> 文章标题管理。
第四步,设置“ 文章段落管理”,操作路径为:站群发布-> 文章段落管理;可以使用“段落组织工具”获得文章段落,操作路径为:站群发布->段落组织工具。
步骤5:设置“发布基本设置”,操作路径:站群发布->发布基本设置。
步骤6设置“ 文章自动更新”,操作路径:站群发布-> 文章自动更新。
--------------------------------------------------- ----------------------------------
以下内容是AI 文章,不是教程内容,仅供参考!
--------------------------------------------------- ----------------------------------
遇到此类问题时,用户将在搜索引擎中搜索关键词此网站,以查找其他查询问题
寻找可以在网站上找到他的人吗?要了解如何制作网站,必须在线查找新站点。如果两个网站都从新站点开始,那么他将快速在搜索引擎上查找和爬网,并等到一个。新站点联机后,遇到此类问题的用户将在关键词和网站中搜索搜索引擎找不到其他查询问题。
我们会发现Google搜索中有很多问题。如果您希望它找到答案,则不仅将其输入到Google搜索结果中,还将显示Google在搜索结果中的位置。学习新事物。用户使用搜索引擎命令找到的结果都是域“管理存储”。
如果要使其成为合格站点,则必须将其替换为元描述辅助工具。这是您的帮助。
搜索引擎的工具是一个访客,您的网站可靠吗?
Search Console可以帮助您发现新内容,而不是当前的Google网站站长工具链接页面Search Console甚至可以向您发送提醒。
在搜索结果中显示“设置首选域,使作者移过工具”的内容。如果发现这种情况不太好,则可以使用relcanonical标签解决此问题。
可以转移到Google Analytics(分析)或Google Analytics(分析)的内容。使用googlecom搜索Google Analytics(分析)以实现您的目标。
Ofollow已被过滤掉,但不是收录的严重问题是,如果您使用nofollow域恢复,则只需要搜索引擎即可轻松对其进行爬网和编制索引。
如果页面是子目录,则收录可能是子目录,甚至是子目录。
“有机搜索排名来源”可以查看这些内容。
ofoflow一些重要数据可能并不十分准确,但实际上,在许多情况下,它只是一个简单的搜索引擎和Google Search Console,甚至可以集中您的AdWords工具。
ofollow一些专业人士会说我们可以阻止nofollow,但是搜索引擎允许这些数据。 查看全部
AI文章,非教程内容,仅供欣赏!(组图)
如何通过组合文章自动发布文章
第一步是设置“ 文章库分类管理”,操作路径:站群版本-> 文章库分类管理。
第二步是设置“ 文章图片管理”,操作路径为:站群发布-> 文章图片管理。
第三步是设置“ 文章标题管理”,操作路径:站群版本-> 文章标题管理。
第四步,设置“ 文章段落管理”,操作路径为:站群发布-> 文章段落管理;可以使用“段落组织工具”获得文章段落,操作路径为:站群发布->段落组织工具。
步骤5:设置“发布基本设置”,操作路径:站群发布->发布基本设置。
步骤6设置“ 文章自动更新”,操作路径:站群发布-> 文章自动更新。
--------------------------------------------------- ----------------------------------
以下内容是AI 文章,不是教程内容,仅供参考!
--------------------------------------------------- ----------------------------------
遇到此类问题时,用户将在搜索引擎中搜索关键词此网站,以查找其他查询问题
寻找可以在网站上找到他的人吗?要了解如何制作网站,必须在线查找新站点。如果两个网站都从新站点开始,那么他将快速在搜索引擎上查找和爬网,并等到一个。新站点联机后,遇到此类问题的用户将在关键词和网站中搜索搜索引擎找不到其他查询问题。
我们会发现Google搜索中有很多问题。如果您希望它找到答案,则不仅将其输入到Google搜索结果中,还将显示Google在搜索结果中的位置。学习新事物。用户使用搜索引擎命令找到的结果都是域“管理存储”。
如果要使其成为合格站点,则必须将其替换为元描述辅助工具。这是您的帮助。
搜索引擎的工具是一个访客,您的网站可靠吗?
Search Console可以帮助您发现新内容,而不是当前的Google网站站长工具链接页面Search Console甚至可以向您发送提醒。
在搜索结果中显示“设置首选域,使作者移过工具”的内容。如果发现这种情况不太好,则可以使用relcanonical标签解决此问题。
可以转移到Google Analytics(分析)或Google Analytics(分析)的内容。使用googlecom搜索Google Analytics(分析)以实现您的目标。
Ofollow已被过滤掉,但不是收录的严重问题是,如果您使用nofollow域恢复,则只需要搜索引擎即可轻松对其进行爬网和编制索引。
如果页面是子目录,则收录可能是子目录,甚至是子目录。
“有机搜索排名来源”可以查看这些内容。
ofoflow一些重要数据可能并不十分准确,但实际上,在许多情况下,它只是一个简单的搜索引擎和Google Search Console,甚至可以集中您的AdWords工具。
ofollow一些专业人士会说我们可以阻止nofollow,但是搜索引擎允许这些数据。
文章一键采集 官方发布:今日头条
采集交流 • 优采云 发表了文章 • 0 个评论 • 904 次浏览 • 2020-12-27 13:11
一、前言
大家好,这是“每个人无需编写代码都可以学习的爬网课程”列。本专栏的核心内容适用于那些有数据采集需求但没有编程经验并且无法编写代码的人。 ,如何基于浏览器插件WebScraper实现零代码,一键式将网页数据爬网到Excel教程。
在这个Internet数据时代,我们的许多工作都基于数据。例如,新媒体的编辑需要采集分析某个特定正式帐户标题的选择,然后一个一个地复制和粘贴。当然,它不如一键爬网。例如,我们的产品经理必须每周编写每周报告。如果每周报告中收录负责该产品的一些用户数据怎么办?当然,它很容易自动爬网;另一个示例是我们有时需要添加以创建PPT的支持数据。数据无处不在。
当我们降低数据采集的门槛时,我们潜移默化地培养的是培养我们的数据思维能力,并使您在工作中更加舒适。
在先前的文章中,我们使用WebScraper直接抓取“豆瓣电影”首页上的数据。这是最简单但也是最完整的情况。通过研究本专栏,您也无能为力。编写1行代码,您可以单击采集所需数据。
如果您有兴趣,可以看看以前的文章“无需编写代码即可一键抓取豆瓣电影数据”,您知道这些步骤是如此简单且容易上手。
好的,让我们继续本专栏文章的主题。在抓取是一页数据之前,本文将继续讨论抓取多页数据。
二.搜寻页面数据2.1什么是页面页面?
互联网上的数据或信息可以说是无限的。这些数据落在托管它的网页上,当然它不会一次显示所有数据。无论是浏览体验还是后端服务的压力,都不允许。这涉及我们所谓的“分页”场景。
例如,当我教您抓取Douban Top250第一页的数据时,该页面实际上是分页数据,您可以将其直接拉到底部,然后可以看到该页面的“寻呼机”
一般来说,分页是指对数据进行分割,以便首先将部分数据显示给用户进行预览,如果进一步操作,它将继续加载并显示更多数据。
当我们使用WebScraper爬网数据时,我们不仅对爬网第一页的数据感到满意,还需要完整的数据。
这涉及到WebScraper遇到分页时如何处理的问题?
我们之前也谈到过。实际上,数据爬网中最重要的事情是找到规则。您需要知道所面临的问题以及应使用哪些方法来解决这些问题。如果您对这些例程有清楚的了解,则可以这样做。拆卸,容易做。
在网页分页的场景中,尽管分页是数据处理的一种手段,但由于Web产品的特性,在各种网页上,分页显示了不同的实现方法。
在这里,我将对几种常见的网页分页方法进行简单分类:
Url地址顺序标记要分页的页码,例如:豆瓣阅读评论;网址页码不规则,请点击“寻呼机”标签;列表滚动到底部,自动加载更多内容,例如:值得购买;滚动到底部,单击“加载更多”按钮分页,例如:少数民族;
您看到有很多场景,并且有不同的担忧。我们将在下面的文章栏目中逐一解释。
今天,让我们讨论第一种情况,即当Url地址序列标记页码和分页时,如何自动跳至页面并检索完整的数据。
2.2搜寻网址分页网页数据
首先让我们看一下典型的URL分页页面的样子。
这里是《豆瓣书评》的一个例子。我们来找一本书“ Growth Hacking”,上面有很多评论可以证明。
仔细查看浏览器的地址栏。每次单击“下一页”,地址栏中的URL地址都会更改,并且会定期更改。 p从1开始并持续增加。
这是所谓的查找规则,并且Url地址反映了页面的页面编号信息的场景。在此示例中,p表示当前数据页的页码。
好的,到目前为止,我们已经定义了我们面临的问题场景并对其进行了顺利分类。如何抓取此类网页的完整数据?
很明显,这里的更改是Url,因此文章必须在Url上完成。创建WebScraper采集器的站点地图时,我们需要指定要搜寻的网址网站。实际上,我们只需要在这里进行设置即可。
首先让我们在浏览器中使用快捷键F12进入开发人员模式,然后找到WebScraper选项选项卡。
接下来,我们将创建一个要爬网的站点地图以进行豆瓣书评。根据我们在文章“无需代码,单击即可抓取豆瓣电影数据”中说明的内容,如果仅抓取第一页,则只需复制“豆瓣书评”的URL作为“开始URL”中填写的URL 。如下图所示:
但是现在我们对仅抓取数据的第一页并不满意。我们将对前20页的数据进行爬网,因此在创建Sitemap时需要制定规则以使此URL可以更改。 查看全部
文章一键采集 官方发布:今日头条
一、前言
大家好,这是“每个人无需编写代码都可以学习的爬网课程”列。本专栏的核心内容适用于那些有数据采集需求但没有编程经验并且无法编写代码的人。 ,如何基于浏览器插件WebScraper实现零代码,一键式将网页数据爬网到Excel教程。
在这个Internet数据时代,我们的许多工作都基于数据。例如,新媒体的编辑需要采集分析某个特定正式帐户标题的选择,然后一个一个地复制和粘贴。当然,它不如一键爬网。例如,我们的产品经理必须每周编写每周报告。如果每周报告中收录负责该产品的一些用户数据怎么办?当然,它很容易自动爬网;另一个示例是我们有时需要添加以创建PPT的支持数据。数据无处不在。
当我们降低数据采集的门槛时,我们潜移默化地培养的是培养我们的数据思维能力,并使您在工作中更加舒适。
在先前的文章中,我们使用WebScraper直接抓取“豆瓣电影”首页上的数据。这是最简单但也是最完整的情况。通过研究本专栏,您也无能为力。编写1行代码,您可以单击采集所需数据。
如果您有兴趣,可以看看以前的文章“无需编写代码即可一键抓取豆瓣电影数据”,您知道这些步骤是如此简单且容易上手。
好的,让我们继续本专栏文章的主题。在抓取是一页数据之前,本文将继续讨论抓取多页数据。
二.搜寻页面数据2.1什么是页面页面?
互联网上的数据或信息可以说是无限的。这些数据落在托管它的网页上,当然它不会一次显示所有数据。无论是浏览体验还是后端服务的压力,都不允许。这涉及我们所谓的“分页”场景。
例如,当我教您抓取Douban Top250第一页的数据时,该页面实际上是分页数据,您可以将其直接拉到底部,然后可以看到该页面的“寻呼机”
一般来说,分页是指对数据进行分割,以便首先将部分数据显示给用户进行预览,如果进一步操作,它将继续加载并显示更多数据。
当我们使用WebScraper爬网数据时,我们不仅对爬网第一页的数据感到满意,还需要完整的数据。
这涉及到WebScraper遇到分页时如何处理的问题?
我们之前也谈到过。实际上,数据爬网中最重要的事情是找到规则。您需要知道所面临的问题以及应使用哪些方法来解决这些问题。如果您对这些例程有清楚的了解,则可以这样做。拆卸,容易做。
在网页分页的场景中,尽管分页是数据处理的一种手段,但由于Web产品的特性,在各种网页上,分页显示了不同的实现方法。
在这里,我将对几种常见的网页分页方法进行简单分类:
Url地址顺序标记要分页的页码,例如:豆瓣阅读评论;网址页码不规则,请点击“寻呼机”标签;列表滚动到底部,自动加载更多内容,例如:值得购买;滚动到底部,单击“加载更多”按钮分页,例如:少数民族;
您看到有很多场景,并且有不同的担忧。我们将在下面的文章栏目中逐一解释。
今天,让我们讨论第一种情况,即当Url地址序列标记页码和分页时,如何自动跳至页面并检索完整的数据。
2.2搜寻网址分页网页数据
首先让我们看一下典型的URL分页页面的样子。
这里是《豆瓣书评》的一个例子。我们来找一本书“ Growth Hacking”,上面有很多评论可以证明。
仔细查看浏览器的地址栏。每次单击“下一页”,地址栏中的URL地址都会更改,并且会定期更改。 p从1开始并持续增加。
这是所谓的查找规则,并且Url地址反映了页面的页面编号信息的场景。在此示例中,p表示当前数据页的页码。
好的,到目前为止,我们已经定义了我们面临的问题场景并对其进行了顺利分类。如何抓取此类网页的完整数据?
很明显,这里的更改是Url,因此文章必须在Url上完成。创建WebScraper采集器的站点地图时,我们需要指定要搜寻的网址网站。实际上,我们只需要在这里进行设置即可。
首先让我们在浏览器中使用快捷键F12进入开发人员模式,然后找到WebScraper选项选项卡。
接下来,我们将创建一个要爬网的站点地图以进行豆瓣书评。根据我们在文章“无需代码,单击即可抓取豆瓣电影数据”中说明的内容,如果仅抓取第一页,则只需复制“豆瓣书评”的URL作为“开始URL”中填写的URL 。如下图所示:
但是现在我们对仅抓取数据的第一页并不满意。我们将对前20页的数据进行爬网,因此在创建Sitemap时需要制定规则以使此URL可以更改。
解读:自媒体运营必收藏:一站式文章采集、伪原创工具、一键发布神器
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-10-31 10:01
自媒体平台目前有多流行?根据《中国青年报》的调查,接受调查的年轻人中有72%的人说,他们旁边有自媒体个人; 45.%的受访年轻人做过或已经做过自媒体; 52.8%与使用自媒体发展趋势职位的实际总体目标或总体计划的年轻人进行访谈。 自媒体该平台现已成为学生就业的一个新方面。
新媒体运营应如何抓住机遇?随着自媒体平台的客户越来越多,自媒体也越来越多,百度百家,微信公众平台等顶级服务平台已成为自媒体企业家进入的首选服务平台。为了使文章获得更大的总访问量并为公司带来很多利润,许多新媒体运营已逐渐进入这个大型营销平台。
随着与不同服务平台相关联的帐户的增加,新的媒体运营也遇到了一个问题:同时发布文章的时间也越来越长。更重要的是,许多新媒体运营并不容易将生鸡蛋放入同一竹篮中。很可能已经在服务平台中注册了多个帐户,而且所花费的时间也不愿知道。
Niu Ant创建的详细介绍:
一种高效的专用工具,用于自媒体平台文章集合,文章原创文章和一键式发布,可以合理地增加百度收录的内容率,百度的权重和其知名品牌Exposure。
功能特点:
1.智能帐户分配:
管理方法100 自媒体平台帐户释放仅需2分钟。考虑到新媒体运营的人性化要求,建立日常发布任务还可以选择预定执行和服务平台的方式。
2.7 * 8个小时的工作时间:
应用NuiYi创建等效于拥有7 * 8小时的运营人员,他们无法区分暑假和周日,并且可以执行所需的日常任务。
用户手册:
一、版本文章:
根据Word导入文档/在线智能搜索的两种方法,Niuyi创建适合发布文章。
1. Word导入文档:
单击右上角的“导入文章”功能,将需要发布的库文件文章提交到文章。
2.在线智能搜索:
键入所需的关键字,例如“ 原创文章”,NuYi Creation将基于程序流自动化技术搜索流行的自媒体平台数据库的百度搜索引擎,然后检索内容文章开发了百度搜索并将其合并到一个目录中。将所需的库从文章添加到文章,然后单击即可发布。
二、添加帐号:
在添加帐户之前,客户必须首先下载由NiuYi(编写助手)创建的软件。我还附有下载软件的示例教程:
1.下载并安装软件
下载软件,并在计算机浏览器中提醒您选择[保存],打开软件所属的文件夹名称,然后搜索下载的文件。扩展名是.crx
2.浏览器打开扩展程序安装网页
复制chrome://扩展名并将其粘贴到地址栏中,按Enter键进入扩展名中心网页。
3.安装软件
在扩展中心,打开右上角的[Developer Mode]按钮,然后页面刷新,并将下载的.crx文件拖到扩展中心。
添加书写助手软件后,单击左下方的[新闻媒体帐户]进入添加帐户页面。
点击右上角的[关联帐户]图标,然后选择“如果有软件,则立即添加”以关联帐户。
三、插入内容:
[发布]在网页上,单击“发布”以进入文章库。
打开[插入内容]功能后,可以将统一的内容(文本内容/照片和需要插入的部分)插入到文章中,以进行大量发布。
四、计划发布:
打开[定时执行发布]功能后,客户可以独立创建用于计划执行的日常任务(您可以添加日常任务的名称/首次执行时间/发布频率/发布时间)。如果未启用,它将立即释放。
您的浏览器不支持视频播放
ut t
ype =
“隐藏” value =“ 26329ed082c621170060aa3da3e4edc4”>
奖励
查看全部
自媒体必须采集的操作:一站式文章采集,伪原创工具,一键式释放工件
自媒体平台目前有多流行?根据《中国青年报》的调查,接受调查的年轻人中有72%的人说,他们旁边有自媒体个人; 45.%的受访年轻人做过或已经做过自媒体; 52.8%与使用自媒体发展趋势职位的实际总体目标或总体计划的年轻人进行访谈。 自媒体该平台现已成为学生就业的一个新方面。
新媒体运营应如何抓住机遇?随着自媒体平台的客户越来越多,自媒体也越来越多,百度百家,微信公众平台等顶级服务平台已成为自媒体企业家进入的首选服务平台。为了使文章获得更大的总访问量并为公司带来很多利润,许多新媒体运营已逐渐进入这个大型营销平台。
随着与不同服务平台相关联的帐户的增加,新的媒体运营也遇到了一个问题:同时发布文章的时间也越来越长。更重要的是,许多新媒体运营并不容易将生鸡蛋放入同一竹篮中。很可能已经在服务平台中注册了多个帐户,而且所花费的时间也不愿知道。
Niu Ant创建的详细介绍:
一种高效的专用工具,用于自媒体平台文章集合,文章原创文章和一键式发布,可以合理地增加百度收录的内容率,百度的权重和其知名品牌Exposure。
功能特点:
1.智能帐户分配:
管理方法100 自媒体平台帐户释放仅需2分钟。考虑到新媒体运营的人性化要求,建立日常发布任务还可以选择预定执行和服务平台的方式。
2.7 * 8个小时的工作时间:
应用NuiYi创建等效于拥有7 * 8小时的运营人员,他们无法区分暑假和周日,并且可以执行所需的日常任务。
用户手册:
一、版本文章:
根据Word导入文档/在线智能搜索的两种方法,Niuyi创建适合发布文章。
1. Word导入文档:
单击右上角的“导入文章”功能,将需要发布的库文件文章提交到文章。
2.在线智能搜索:
键入所需的关键字,例如“ 原创文章”,NuYi Creation将基于程序流自动化技术搜索流行的自媒体平台数据库的百度搜索引擎,然后检索内容文章开发了百度搜索并将其合并到一个目录中。将所需的库从文章添加到文章,然后单击即可发布。
二、添加帐号:
在添加帐户之前,客户必须首先下载由NiuYi(编写助手)创建的软件。我还附有下载软件的示例教程:
1.下载并安装软件
下载软件,并在计算机浏览器中提醒您选择[保存],打开软件所属的文件夹名称,然后搜索下载的文件。扩展名是.crx
2.浏览器打开扩展程序安装网页
复制chrome://扩展名并将其粘贴到地址栏中,按Enter键进入扩展名中心网页。
3.安装软件
在扩展中心,打开右上角的[Developer Mode]按钮,然后页面刷新,并将下载的.crx文件拖到扩展中心。
添加书写助手软件后,单击左下方的[新闻媒体帐户]进入添加帐户页面。
点击右上角的[关联帐户]图标,然后选择“如果有软件,则立即添加”以关联帐户。
三、插入内容:
[发布]在网页上,单击“发布”以进入文章库。
打开[插入内容]功能后,可以将统一的内容(文本内容/照片和需要插入的部分)插入到文章中,以进行大量发布。
四、计划发布:
打开[定时执行发布]功能后,客户可以独立创建用于计划执行的日常任务(您可以添加日常任务的名称/首次执行时间/发布频率/发布时间)。如果未启用,它将立即释放。
您的浏览器不支持视频播放
ut t
ype =
“隐藏” value =“ 26329ed082c621170060aa3da3e4edc4”>
奖励

