
搜索引擎优化pdf
搜索引擎优化pdf(搜索引擎优化难题中最重要的一块:如果你的网站找不到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-03 12:01
正如我们之前提到的,搜索引擎是答录机。它们的存在是为了发现、理解和组织互联网内容,以便为搜索者提出的问题提供最相关的结果。
为了出现在搜索结果中,您的内容首先需要对搜索引擎可见。这可以说是搜索引擎优化难题中最重要的一块:如果找不到你的网站,你将无法出现在搜索引擎结果页面上。
一、搜索引擎是如何工作的?
搜索引擎通过三个主要功能工作:
1.。抓取:抓取工具抓取 Internet 的内容,检查它们找到的每个 URL 的代码/内容。
2.Index/收录:存储和整理爬取过程中发现的内容。页面一旦进入索引,就会作为相关查询的结果显示在运行中。
3. Ranking:提供最能回答搜索者查询的内容,即结果从相关性高到低排序。
二、什么是搜索引擎抓取?
爬网是一个发现过程,在这个过程中,搜索引擎会派出一组机器人(称为爬虫或蜘蛛)来寻找新的和更新的内容。内容可以不同——可以是网页、图片、视频、PDF等,但不管是什么格式,内容都是通过链接找到的。
谷歌机器人首先获取一些网页,然后根据这些网页上的链接寻找新的网址。沿着这条路径跳转链接,爬虫可以发现新的内容并将其添加到一个非常大的数据库中。当搜索者寻找信息时,谷歌会从数据库中选择匹配的内容并显示出来。
三、什么是搜索引擎收录?
搜索引擎处理并存储它们在 收录 中找到的信息。 收录 文件是一个巨大的数据库,收录了他们找到的所有内容,随时可供搜索者搜索和检索。
四、搜索引擎排名
当有人搜索时,搜索引擎会搜索他们的收录高度相关的内容,然后对内容进行排序,希望能解决搜索者的查询问题。这种根据相关性对搜索结果进行排序的方法称为排名。一般来说,您可以假设 网站 的排名越高,搜索引擎认为 网站 与查询的相关性就越高。
您可以在某些或所有站点上阻止搜索引擎爬虫,或指示搜索引擎避免将某些页面存储在它们的 收录 中。显然,有时这样做是有特定原因的。如果你想让你的内容被搜索者发现,你必须首先确保它可以被爬虫和 收录 访问。
5.爬行:搜索引擎能找到你的网页吗?
正如您刚刚了解到的,确保您的网站被抓取并且 收录 是在搜索结果页面上显示的先决条件。如果你已经有网站,建议先检查一下你的页面有多少被搜索引擎收录搜索到了。这将帮助您了解 Google 是否正在抓取并找到您希望它找到的所有 网站 页面。
查看收录 页面的一种方法是“站点:您的域名(不含)”,这是一种高级搜索运算符。转到 Google 并在搜索栏中输入“站点:”。这会将结果返回到 Google 在其 收录 中指定的站点:
Google 显示的结果数量并不准确,但它确实向您显示了您的哪些 网站 页面是 收录 以及它们在搜索结果中的显示方式。
要获得更准确的结果,请使用 Google Search Console 的 Google Search Console 中的 网站收录 覆盖率报告。如果您目前没有,可以注册一个免费的 Google Search Console 帐户。使用此工具,您可以为您的网站提交站点地图,并监控有多少提交的页面实际上 收录 在 Google 的索引中,以及其他内容。
如果您的 网站 没有出现在搜索结果中的任何位置,可能有以下几个原因:
您的 网站 是全新的,尚未被抓取。
您的 网站 未链接到任何外部 网站。
您的 网站 导航使搜索引擎机器人难以有效地抓取网站。
您的 网站 收录一些称为爬虫指令的基本代码,可防止搜索引擎抓取您的 网站。
您的 网站 已被 Google 处罚。 查看全部
搜索引擎优化pdf(搜索引擎优化难题中最重要的一块:如果你的网站找不到)
正如我们之前提到的,搜索引擎是答录机。它们的存在是为了发现、理解和组织互联网内容,以便为搜索者提出的问题提供最相关的结果。
为了出现在搜索结果中,您的内容首先需要对搜索引擎可见。这可以说是搜索引擎优化难题中最重要的一块:如果找不到你的网站,你将无法出现在搜索引擎结果页面上。
一、搜索引擎是如何工作的?
搜索引擎通过三个主要功能工作:
1.。抓取:抓取工具抓取 Internet 的内容,检查它们找到的每个 URL 的代码/内容。
2.Index/收录:存储和整理爬取过程中发现的内容。页面一旦进入索引,就会作为相关查询的结果显示在运行中。
3. Ranking:提供最能回答搜索者查询的内容,即结果从相关性高到低排序。
二、什么是搜索引擎抓取?
爬网是一个发现过程,在这个过程中,搜索引擎会派出一组机器人(称为爬虫或蜘蛛)来寻找新的和更新的内容。内容可以不同——可以是网页、图片、视频、PDF等,但不管是什么格式,内容都是通过链接找到的。
谷歌机器人首先获取一些网页,然后根据这些网页上的链接寻找新的网址。沿着这条路径跳转链接,爬虫可以发现新的内容并将其添加到一个非常大的数据库中。当搜索者寻找信息时,谷歌会从数据库中选择匹配的内容并显示出来。
三、什么是搜索引擎收录?
搜索引擎处理并存储它们在 收录 中找到的信息。 收录 文件是一个巨大的数据库,收录了他们找到的所有内容,随时可供搜索者搜索和检索。
四、搜索引擎排名
当有人搜索时,搜索引擎会搜索他们的收录高度相关的内容,然后对内容进行排序,希望能解决搜索者的查询问题。这种根据相关性对搜索结果进行排序的方法称为排名。一般来说,您可以假设 网站 的排名越高,搜索引擎认为 网站 与查询的相关性就越高。
您可以在某些或所有站点上阻止搜索引擎爬虫,或指示搜索引擎避免将某些页面存储在它们的 收录 中。显然,有时这样做是有特定原因的。如果你想让你的内容被搜索者发现,你必须首先确保它可以被爬虫和 收录 访问。
5.爬行:搜索引擎能找到你的网页吗?
正如您刚刚了解到的,确保您的网站被抓取并且 收录 是在搜索结果页面上显示的先决条件。如果你已经有网站,建议先检查一下你的页面有多少被搜索引擎收录搜索到了。这将帮助您了解 Google 是否正在抓取并找到您希望它找到的所有 网站 页面。
查看收录 页面的一种方法是“站点:您的域名(不含)”,这是一种高级搜索运算符。转到 Google 并在搜索栏中输入“站点:”。这会将结果返回到 Google 在其 收录 中指定的站点:
Google 显示的结果数量并不准确,但它确实向您显示了您的哪些 网站 页面是 收录 以及它们在搜索结果中的显示方式。
要获得更准确的结果,请使用 Google Search Console 的 Google Search Console 中的 网站收录 覆盖率报告。如果您目前没有,可以注册一个免费的 Google Search Console 帐户。使用此工具,您可以为您的网站提交站点地图,并监控有多少提交的页面实际上 收录 在 Google 的索引中,以及其他内容。
如果您的 网站 没有出现在搜索结果中的任何位置,可能有以下几个原因:
您的 网站 是全新的,尚未被抓取。
您的 网站 未链接到任何外部 网站。
您的 网站 导航使搜索引擎机器人难以有效地抓取网站。
您的 网站 收录一些称为爬虫指令的基本代码,可防止搜索引擎抓取您的 网站。
您的 网站 已被 Google 处罚。
搜索引擎优化pdf( wwwzgbjlycomwwwszygjjcom注重对网站进行查找引擎优化(1)_社会万象_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2022-01-03 04:15
wwwzgbjlycomwwwszygjjcom注重对网站进行查找引擎优化(1)_社会万象_光明网(组图))
wwwzgbjlycomwwwszygjjcom 如何关注百度搜索引擎优化 关注搜索引擎优化网站 所谓搜索引擎优化SearchEngineOptimization简称SEO,就是对齐各种搜索的搜索特征引擎,让网页描述合适搜索引擎的搜索条件,即搜索引擎友好度,然后让网站被搜索引擎录入,排名靠前。 SEO 的意图是 网站 对搜索引擎友好。让我们看看那些对搜索引擎不友好的人。 网站 是的有什么特点?第一页有很多图片或flash等RichMedia方法无法检索。第二页没有标题或标题不收录有用的关键字。第三页页面正文中有用的关键字较少。第四网站导航系统使搜索引擎无法理解第五多页,从而搜索引擎无法检索到第六页。搜索引擎输入的其他 网站 没有链接。第七个网站充斥着许多欺诈搜索引擎。过渡页上的文字、桥页、颜色和背景色等垃圾信息 第8个网站收录很多错误链接等 成都周边旅游当然适合搜索引擎友好的 网站 恰好与上述特性相反。查看wwwzgbjlycomwwwszygjjcom,找到引擎描述网站的方法,注重每一个细节的专业性。以真实的信息和有用的表达赢得搜索引擎的喜爱,进而获得更好的搜索引擎推广效果。具体来说,搜索引擎的优化主要在以下几个方面: 1、页面标题的标题是出现在阅读器左上角的文字。这是访问者看到的第一个信息。许多搜索引擎在互联网上占据主动。 @网站 搜索过程中记录的信息包括页面标题关键词等,因此页面标题对于网站的实现,以及为网站的阅读兴趣添加访问者,都非常有帮助。页面标题 标注方法如下: 2 合适的关键词 关键词:当你的网站被搜索引擎主动记录时,你为网站提供的50到100个关键词非常重要,因为当访问者正在搜索引擎搜索时,只要用的词是你的关键
文字中表示已经找到了网站人才,所以关键词应该尽量收录网站提供的信息,比如上面提到的网上新调查。 网站 其关键字 是网络实现 3 细化 网站 description网站 描述呈现在搜索引擎cdfcszcom 的搜索结果中。很大程度上决定了访问者能否通过搜索引擎的搜索结果。访问您的网站wwwzgbjlycomwwwszygjjcom,因此网站 描述应覆盖关键字定义的比例并更加突出。 网站 提升描述语句对访问者吸引力的关键点应该提取最重要的20个左右关键词是根据用户在实际工作中最关心的信息和网站提供的信息仔细编写不超过 250 字且收录空格的描述文本。 4 合理的导航说明。现在很多互联网公司都在做网站为了节省时间和精力,使用框架结构但不知道这是搜索引擎最讨厌的事情。即使你找到了网站的内容页面,也很难通过导航关键词程序进入其他导航页面。使用java 用flash导航很漂亮,但是搜索引擎在描述网站时找不到静态页面,不要用动态文字描述职位描述不要用图片,不要放大flash在 网站 的主页上。这不仅减慢了客户进入网站的速度,也不利于搜索引擎。 5 不要在站点准备好供大量读者访问之前过早注册站点。不要过早注册该网站。每个站点的建立可以是一个永无止境的过程。如果该网站仍处于测试期,通常会向观众开放。一个错误。当站点处于测试期时,wwwzgbjlycomwwwszygjjcom可以设置一些环境参数,防止被搜索引擎主动索引,即被Robot排除。其他人还没有做好充分的准备。 网站 给人的第一印象是不完美的印象。 网站用户往往不愿意在短时间内再次访问网站,而且不完善的注册需要更多的精力和费用,所以注册前一定要做好网站 网站准备工作 查看全部
搜索引擎优化pdf(
wwwzgbjlycomwwwszygjjcom注重对网站进行查找引擎优化(1)_社会万象_光明网(组图))

wwwzgbjlycomwwwszygjjcom 如何关注百度搜索引擎优化 关注搜索引擎优化网站 所谓搜索引擎优化SearchEngineOptimization简称SEO,就是对齐各种搜索的搜索特征引擎,让网页描述合适搜索引擎的搜索条件,即搜索引擎友好度,然后让网站被搜索引擎录入,排名靠前。 SEO 的意图是 网站 对搜索引擎友好。让我们看看那些对搜索引擎不友好的人。 网站 是的有什么特点?第一页有很多图片或flash等RichMedia方法无法检索。第二页没有标题或标题不收录有用的关键字。第三页页面正文中有用的关键字较少。第四网站导航系统使搜索引擎无法理解第五多页,从而搜索引擎无法检索到第六页。搜索引擎输入的其他 网站 没有链接。第七个网站充斥着许多欺诈搜索引擎。过渡页上的文字、桥页、颜色和背景色等垃圾信息 第8个网站收录很多错误链接等 成都周边旅游当然适合搜索引擎友好的 网站 恰好与上述特性相反。查看wwwzgbjlycomwwwszygjjcom,找到引擎描述网站的方法,注重每一个细节的专业性。以真实的信息和有用的表达赢得搜索引擎的喜爱,进而获得更好的搜索引擎推广效果。具体来说,搜索引擎的优化主要在以下几个方面: 1、页面标题的标题是出现在阅读器左上角的文字。这是访问者看到的第一个信息。许多搜索引擎在互联网上占据主动。 @网站 搜索过程中记录的信息包括页面标题关键词等,因此页面标题对于网站的实现,以及为网站的阅读兴趣添加访问者,都非常有帮助。页面标题 标注方法如下: 2 合适的关键词 关键词:当你的网站被搜索引擎主动记录时,你为网站提供的50到100个关键词非常重要,因为当访问者正在搜索引擎搜索时,只要用的词是你的关键

文字中表示已经找到了网站人才,所以关键词应该尽量收录网站提供的信息,比如上面提到的网上新调查。 网站 其关键字 是网络实现 3 细化 网站 description网站 描述呈现在搜索引擎cdfcszcom 的搜索结果中。很大程度上决定了访问者能否通过搜索引擎的搜索结果。访问您的网站wwwzgbjlycomwwwszygjjcom,因此网站 描述应覆盖关键字定义的比例并更加突出。 网站 提升描述语句对访问者吸引力的关键点应该提取最重要的20个左右关键词是根据用户在实际工作中最关心的信息和网站提供的信息仔细编写不超过 250 字且收录空格的描述文本。 4 合理的导航说明。现在很多互联网公司都在做网站为了节省时间和精力,使用框架结构但不知道这是搜索引擎最讨厌的事情。即使你找到了网站的内容页面,也很难通过导航关键词程序进入其他导航页面。使用java 用flash导航很漂亮,但是搜索引擎在描述网站时找不到静态页面,不要用动态文字描述职位描述不要用图片,不要放大flash在 网站 的主页上。这不仅减慢了客户进入网站的速度,也不利于搜索引擎。 5 不要在站点准备好供大量读者访问之前过早注册站点。不要过早注册该网站。每个站点的建立可以是一个永无止境的过程。如果该网站仍处于测试期,通常会向观众开放。一个错误。当站点处于测试期时,wwwzgbjlycomwwwszygjjcom可以设置一些环境参数,防止被搜索引擎主动索引,即被Robot排除。其他人还没有做好充分的准备。 网站 给人的第一印象是不完美的印象。 网站用户往往不愿意在短时间内再次访问网站,而且不完善的注册需要更多的精力和费用,所以注册前一定要做好网站 网站准备工作
搜索引擎优化pdf 搜索引擎优化pdf( 决算书暑假读一本好书辞职书个人欠款起诉书范文支部书记表态发言)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-03 04:14
决算书暑假读一本好书辞职书个人欠款起诉书范文支部书记表态发言)
搜索引擎优化魔法书结账本暑假阅读好书辞职信个人欠费起诉书范文分会书记发言SEOMagicBook豪威互动免费电子书wwwtimevnet目录关于本书1章1搜索引擎基础2章章节1.什么是搜索引擎2.1.搜索引擎的作用2.2.搜索引擎的定义4.2.搜索引擎的基本工作原理4.1.爬取5.2.索引5.3.排序5. 3. 搜索引擎分类 6. 1. 页面级搜索 6 2 垂直搜索 6 三元搜索引擎 6 4 目录搜索 6 5 综合搜索 7 第四节 搜索引擎的未来 7 1 更快 7 2 多元化 7 3 智能 7 4社交 7 5 个性化 8 5 栏目 主要搜索引擎介绍 8 1 谷歌 8 2 雅虎 12 3 百度 13 4 搜狗 15 5 中文搜索引擎列表 党员人数调查列表和毫米比表 教师职称等级列表 员工考核评分表一般年金现值系数表 16 第二章搜索引擎营销基础 17 第一节 什么是搜索引擎营销 17 1. 搜索引擎营销的定义 17 2. 搜索引擎营销的价值 17 3. 搜索引擎营销原理 18 第二节 特征19 1. 广泛使用 19 2. 用户主动性查询针对性强 19 三是获取新客户 19 四是竞争激烈 20 Page 1 搜索引擎优化魔法书 SEOM
agicBook 豪威互动免费电子书 wwwtimevnet 5 动态随时更新 20 6 门槛低高投资回报 20 栏目三搜索引擎营销目标 21 一被收录 21 二排名前21 三点击21 4. 客户转化 21 5. 提高品牌知名度 21 4. 搜索引擎营销的形式 22 1. 搜索引擎登录 22 2. 固定排名和广告 23 3. 结果付费 24 4. 自然排名 24 第三章 搜索基础引擎优化 25 第 1 节 为什么要进行搜索引擎优化 25 1. 搜索引擎优化的定义 25 2. 搜索引擎优化的价值 25 3. SEO 与 SEM 的关系 26 4. SEO 与付费排名的关系 26 节2. 搜索引擎对SEO的态度 27 1. Google 27 2. Yahoo 29 三百度 30 四搜狗 34 第三节 白帽SEO和黑帽SEO 37 第四节 搜索引擎优化的发展 39 一 SE的发展历程O 39 中国二搜索引擎优化 40 三搜索引擎优化的发展方向 42 第五节关于搜索引擎优化的一些看法 43 一是搜索引擎优化的法律 43 二 他会搜索
搜索引擎面临着这个任务。 43. 搜索引擎会不会人工干扰? 44.我的网站有很多高质量的原创内容,所以我不再需要SEO了。 44的技术,前六名网站做到了。我也向他们学习。 44. 七家SEO公司或SEO工具。保证排名。 44 八。排名稳定。 45 九。搜索引擎优化。访问量 45 十个竞争对手不能破坏我的排名 45 第四章 SEO 相关搜索引擎技术 46 页 2 搜索引擎优化魔法书 SEOMagicBook 豪威互动免费电子书 wwwtimevnet 第一节 搜索引擎机器人 46 一 什么是搜索引擎机器人 46 2 . 如何识别搜索引擎机器人的身份 47 第二节 超链接分析 47 1. 基本原理 48 2. 工作步骤 48 3. 搜索效果 49 4. 超链接分析技术的应用 49 5. 存在的缺陷 50 第三节 汉字分词50 1.什么是中文分词50 二中文分词含义与功能50 三中文分词技术51 四字拼图乘法口算100题七年级有理数混合运算100题计算机一级题库二元线性方程应用题真心话大冒险第53题五分中文分词
应用 53 六大中文搜索引擎技术 54 第四节 基于词义的文本分析 55 一种文本分析技术特点 55 两种文本分析应用 55 第五章网站的搜索引擎性能理解 57 第一节 基本查询 57 1 域名信息查询 57 2 域名历史查询 57 3 主机连接速度和 IP 地址查询 57 四个相同 IP 网站 查询 57 第二节 收录 查询 58 1 是否为 收录 58第二页收录 Number 58 第三部分Backlink 查询59 第四部分网页RANK 查询59 One GooglePageRank 查询59 第二SogouRank 查询59 Section 5 关键词 Ranking 查询59 Section VI ALEXA 查询60 1.什么是Alexa 60 2. Alexa 60 的主要数据 3. 用Alexa 60 检查什么 第六章 基于搜索引擎友好网站 设计 62 第一节域名策略 62 1. 不同后缀域名在搜索引擎中的权重 62 2. 域名基本常识 62 Page 3 Search Eng ine Optimization Magic Book SEOMagicBook Haowei Interactive 免费电子书 wwwtimevnet 关键词Strategy 6
9 4 中文网站域名拼音策略 70 5 小心注册被搜索引擎惩罚的域名 70 第二节 空间策略 71 1 安全要素 1 稳定性 71 2 安全要素 2 良好的共存环境 71 3 本节附录 72 第 3 节 网站 结构规划 72 第 4 节站点导航设计 73 第 5 节 IFRAMEJAVASCRIPT 和 AJAX73 1 IFRAME74 2 JS74 3 AJAX74 第 6 节 URL 设计 75 1 易于记忆 75 2 URL 静态 75> 3 URL 关键词@部署 78 第七节网页代码编译 80 一听WEB标准 篮球课程标准 党员活动室建设 尘肺病标准片 儿科分级护理标准 分级护理细化标准 80 第二代码的逻辑 80 第八节 面向搜索引擎的文案指导 81 1.网页标题 标题 81 2. 元元标记 84 3. 图片 ALT 替换文本 85 4. Robotstxt 85 5. 链接锚文本 89 6. 站点地图 xml 89 7. 版权和隐私97 第 9 节. 用户友好性检查 97 1. 链接可用性 97 2. 访问速度体验 97 3 查找信息的便利性 98 第 7 章创建搜索引擎喜欢的内容 查看全部
搜索引擎优化pdf 搜索引擎优化pdf(
决算书暑假读一本好书辞职书个人欠款起诉书范文支部书记表态发言)

搜索引擎优化魔法书结账本暑假阅读好书辞职信个人欠费起诉书范文分会书记发言SEOMagicBook豪威互动免费电子书wwwtimevnet目录关于本书1章1搜索引擎基础2章章节1.什么是搜索引擎2.1.搜索引擎的作用2.2.搜索引擎的定义4.2.搜索引擎的基本工作原理4.1.爬取5.2.索引5.3.排序5. 3. 搜索引擎分类 6. 1. 页面级搜索 6 2 垂直搜索 6 三元搜索引擎 6 4 目录搜索 6 5 综合搜索 7 第四节 搜索引擎的未来 7 1 更快 7 2 多元化 7 3 智能 7 4社交 7 5 个性化 8 5 栏目 主要搜索引擎介绍 8 1 谷歌 8 2 雅虎 12 3 百度 13 4 搜狗 15 5 中文搜索引擎列表 党员人数调查列表和毫米比表 教师职称等级列表 员工考核评分表一般年金现值系数表 16 第二章搜索引擎营销基础 17 第一节 什么是搜索引擎营销 17 1. 搜索引擎营销的定义 17 2. 搜索引擎营销的价值 17 3. 搜索引擎营销原理 18 第二节 特征19 1. 广泛使用 19 2. 用户主动性查询针对性强 19 三是获取新客户 19 四是竞争激烈 20 Page 1 搜索引擎优化魔法书 SEOM

agicBook 豪威互动免费电子书 wwwtimevnet 5 动态随时更新 20 6 门槛低高投资回报 20 栏目三搜索引擎营销目标 21 一被收录 21 二排名前21 三点击21 4. 客户转化 21 5. 提高品牌知名度 21 4. 搜索引擎营销的形式 22 1. 搜索引擎登录 22 2. 固定排名和广告 23 3. 结果付费 24 4. 自然排名 24 第三章 搜索基础引擎优化 25 第 1 节 为什么要进行搜索引擎优化 25 1. 搜索引擎优化的定义 25 2. 搜索引擎优化的价值 25 3. SEO 与 SEM 的关系 26 4. SEO 与付费排名的关系 26 节2. 搜索引擎对SEO的态度 27 1. Google 27 2. Yahoo 29 三百度 30 四搜狗 34 第三节 白帽SEO和黑帽SEO 37 第四节 搜索引擎优化的发展 39 一 SE的发展历程O 39 中国二搜索引擎优化 40 三搜索引擎优化的发展方向 42 第五节关于搜索引擎优化的一些看法 43 一是搜索引擎优化的法律 43 二 他会搜索

搜索引擎面临着这个任务。 43. 搜索引擎会不会人工干扰? 44.我的网站有很多高质量的原创内容,所以我不再需要SEO了。 44的技术,前六名网站做到了。我也向他们学习。 44. 七家SEO公司或SEO工具。保证排名。 44 八。排名稳定。 45 九。搜索引擎优化。访问量 45 十个竞争对手不能破坏我的排名 45 第四章 SEO 相关搜索引擎技术 46 页 2 搜索引擎优化魔法书 SEOMagicBook 豪威互动免费电子书 wwwtimevnet 第一节 搜索引擎机器人 46 一 什么是搜索引擎机器人 46 2 . 如何识别搜索引擎机器人的身份 47 第二节 超链接分析 47 1. 基本原理 48 2. 工作步骤 48 3. 搜索效果 49 4. 超链接分析技术的应用 49 5. 存在的缺陷 50 第三节 汉字分词50 1.什么是中文分词50 二中文分词含义与功能50 三中文分词技术51 四字拼图乘法口算100题七年级有理数混合运算100题计算机一级题库二元线性方程应用题真心话大冒险第53题五分中文分词

应用 53 六大中文搜索引擎技术 54 第四节 基于词义的文本分析 55 一种文本分析技术特点 55 两种文本分析应用 55 第五章网站的搜索引擎性能理解 57 第一节 基本查询 57 1 域名信息查询 57 2 域名历史查询 57 3 主机连接速度和 IP 地址查询 57 四个相同 IP 网站 查询 57 第二节 收录 查询 58 1 是否为 收录 58第二页收录 Number 58 第三部分Backlink 查询59 第四部分网页RANK 查询59 One GooglePageRank 查询59 第二SogouRank 查询59 Section 5 关键词 Ranking 查询59 Section VI ALEXA 查询60 1.什么是Alexa 60 2. Alexa 60 的主要数据 3. 用Alexa 60 检查什么 第六章 基于搜索引擎友好网站 设计 62 第一节域名策略 62 1. 不同后缀域名在搜索引擎中的权重 62 2. 域名基本常识 62 Page 3 Search Eng ine Optimization Magic Book SEOMagicBook Haowei Interactive 免费电子书 wwwtimevnet 关键词Strategy 6

9 4 中文网站域名拼音策略 70 5 小心注册被搜索引擎惩罚的域名 70 第二节 空间策略 71 1 安全要素 1 稳定性 71 2 安全要素 2 良好的共存环境 71 3 本节附录 72 第 3 节 网站 结构规划 72 第 4 节站点导航设计 73 第 5 节 IFRAMEJAVASCRIPT 和 AJAX73 1 IFRAME74 2 JS74 3 AJAX74 第 6 节 URL 设计 75 1 易于记忆 75 2 URL 静态 75> 3 URL 关键词@部署 78 第七节网页代码编译 80 一听WEB标准 篮球课程标准 党员活动室建设 尘肺病标准片 儿科分级护理标准 分级护理细化标准 80 第二代码的逻辑 80 第八节 面向搜索引擎的文案指导 81 1.网页标题 标题 81 2. 元元标记 84 3. 图片 ALT 替换文本 85 4. Robotstxt 85 5. 链接锚文本 89 6. 站点地图 xml 89 7. 版权和隐私97 第 9 节. 用户友好性检查 97 1. 链接可用性 97 2. 访问速度体验 97 3 查找信息的便利性 98 第 7 章创建搜索引擎喜欢的内容
搜索引擎优化pdf(“全局搜索”UKUI3.1版本即将发布,带给你更嗨的使用体验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-12-31 23:18
“全局搜索”UKUI3.版本1
即将推出
此版本的“全局搜索”功能
给用户全新的体验...
事实上,随着信息和效率的爆炸式增长,用户对“搜索”功能的依赖正在逐渐增加。因为“搜索”可以让用户快速找到他们想要的东西。
打开银河麒麟桌面操作系统V10 SP1,点击“全局搜索”输入框搜索相关信息。以前的版本支持拼音搜索和模糊搜索,可以快速查找系统应用、设置或用户目录中的文件,包括文本内容。随着“搜索”打开的应用程序或文件越来越多,主界面会显示【最近打开】和【大部分打开】,方便查找。
在“全局搜索”UKUI3.1版本中,除了上述原有版本功能外,Kylin团队对模块功能进行了改进升级,并增加了一些常用的搜索功能。
全新视觉升级,带给您更刺激的体验
UKUI3.1 版本拥有全新的视觉设计,整体页面更加简洁美观。同时,模块化展示搜索结果的效果更加清晰。将“垂直显示”改为“水平显示”,下滑更方便舒适。
01 增加记事本搜索功能
文档上的备忘录太多了,找到我想要的怎么办?不用担心,您只需要输入关键词即可查找笔记内容,即可快速找到内容记录,让您的办公更高效。
02 新的文本内容搜索格式
新增的文本内容搜索不仅支持pdf、docx、pptx、xlsx、doc、dot、wps、ppt、pps、dps等格式,还支持中英文搜索应用和设置,让您可以随意搜索不同格式的文本内容。
03 文件索引性能大幅优化
为了给您带来身临其境的工作体验,新版文件索引性能进行了大幅优化,减少了系统资源占用,提高了搜索效率。
不仅如此,新版本在架构上进一步优化,增加了插件接口,提供给社区爱好者进行扩展开发。目前已有不少社区爱好者加入了开源供应链照明计划社区UKUI-search聚合搜索插件项目。截至11月,该项目已通过中期和终审,顺利结束,并在UKUI社区建立了一个新项目UKUI-search-extensions。 “全局搜索”UKUI3.1版本虽然还未上线,但已经吸引了众多用户的关注。
“全局搜索”UKUI3.版本 1,
即将在 Ukylin 社区中测试体验,
你还在等什么?
欢迎下载安装体验! 查看全部
搜索引擎优化pdf(“全局搜索”UKUI3.1版本即将发布,带给你更嗨的使用体验)
“全局搜索”UKUI3.版本1
即将推出
此版本的“全局搜索”功能
给用户全新的体验...
事实上,随着信息和效率的爆炸式增长,用户对“搜索”功能的依赖正在逐渐增加。因为“搜索”可以让用户快速找到他们想要的东西。
打开银河麒麟桌面操作系统V10 SP1,点击“全局搜索”输入框搜索相关信息。以前的版本支持拼音搜索和模糊搜索,可以快速查找系统应用、设置或用户目录中的文件,包括文本内容。随着“搜索”打开的应用程序或文件越来越多,主界面会显示【最近打开】和【大部分打开】,方便查找。


在“全局搜索”UKUI3.1版本中,除了上述原有版本功能外,Kylin团队对模块功能进行了改进升级,并增加了一些常用的搜索功能。
全新视觉升级,带给您更刺激的体验
UKUI3.1 版本拥有全新的视觉设计,整体页面更加简洁美观。同时,模块化展示搜索结果的效果更加清晰。将“垂直显示”改为“水平显示”,下滑更方便舒适。
01 增加记事本搜索功能
文档上的备忘录太多了,找到我想要的怎么办?不用担心,您只需要输入关键词即可查找笔记内容,即可快速找到内容记录,让您的办公更高效。
02 新的文本内容搜索格式
新增的文本内容搜索不仅支持pdf、docx、pptx、xlsx、doc、dot、wps、ppt、pps、dps等格式,还支持中英文搜索应用和设置,让您可以随意搜索不同格式的文本内容。
03 文件索引性能大幅优化
为了给您带来身临其境的工作体验,新版文件索引性能进行了大幅优化,减少了系统资源占用,提高了搜索效率。
不仅如此,新版本在架构上进一步优化,增加了插件接口,提供给社区爱好者进行扩展开发。目前已有不少社区爱好者加入了开源供应链照明计划社区UKUI-search聚合搜索插件项目。截至11月,该项目已通过中期和终审,顺利结束,并在UKUI社区建立了一个新项目UKUI-search-extensions。 “全局搜索”UKUI3.1版本虽然还未上线,但已经吸引了众多用户的关注。
“全局搜索”UKUI3.版本 1,
即将在 Ukylin 社区中测试体验,
你还在等什么?
欢迎下载安装体验!
搜索引擎优化pdf(6个支持M1的文件搜索工具,效果非常的不错)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-12-30 12:07
哪个文件搜索工具更好?别着急,今天小编为大家带来了6款支持M1的文件搜索工具。每个文件搜索工具都可以帮助用户更快更好地搜索他们想要的文件。使用起来非常简单方便,效果非常好。还不错,快来和小编一起看看吧!
1.HoudahSpot for Mac 多功能文件搜索软件
Mac 上哪款文件搜索软件好用?HoudahSpot for mac 是 Mac os 平台上的一个工具,可以帮助用户更快更好地搜索他们想要的文件。HoudahSpot for mac 是一款多功能文件搜索工具,建立在 Apple 强大的 Spotlight 引擎之上。非常简单方便,效果非常好。
%3D%3D
2.EasyFind for Mac 一个简单的文件搜索工具
哪里有一个简单的 macOS 文件搜索工具?该站点提供 Mac 版 EasyFind(一个简单的文件搜索工具)。EasyFind for Mac 主要用于搜索收录
目标关键词的特殊文件、隐藏文件和文档。它还显示每个文件的目录位置。EasyFind for Mac 的搜索功能非常强大,操作也非常简单。.
%3D%3D
3.ProFind for mac 文件搜索工具
Mac 上哪个文件搜索工具好用?ProFind mac版是一款Macos上的文件搜索软件,功能强大,性能卓越,可为macOS提供高级文件搜索。并支持自然语言查询、应用程序启动、隐藏位置搜索、脚本编写等。此外,您可以在不可见的文件夹和包中搜索,搜索任何磁盘类型。
%3D%3D
4.Find Any File for Mac 文件搜索软件
Find Any File for Mac 是一款适用于 Mac 的文件搜索工具。查找任何文件 Mac 可以按名称、创建或修改日期、大小或类型以及创建者代码(不是内容)搜索本地磁盘上的文件。您甚至可以搜索未被 Spotlight 索引的磁盘,包括服务器卷。
%3D%3D
5.PDF Search for Mac pdf文件搜索工具
PDF Search Mac特别版是Mac平台上一款PDF文件的快速搜索工具,可以搜索相关性,让您在上千个PDF文档中第一时间找到最相关的页面,提高工作效率!
%3D%3D
6.VisualGrep for Mac 非索引文件搜索工具
VisualGrep for Mac 是一种非索引文件搜索工具,支持带有过滤器和许多文件夹遍历选项的文件。此更新修复了 Big Sur 中的 UI 错误。
%3D%3D
以上就是小编为大家带来的6款支持M1的文件搜索工具合集。我希望它会对你有所帮助。macz有更多实用的Mac教程! 查看全部
搜索引擎优化pdf(6个支持M1的文件搜索工具,效果非常的不错)
哪个文件搜索工具更好?别着急,今天小编为大家带来了6款支持M1的文件搜索工具。每个文件搜索工具都可以帮助用户更快更好地搜索他们想要的文件。使用起来非常简单方便,效果非常好。还不错,快来和小编一起看看吧!
1.HoudahSpot for Mac 多功能文件搜索软件
Mac 上哪款文件搜索软件好用?HoudahSpot for mac 是 Mac os 平台上的一个工具,可以帮助用户更快更好地搜索他们想要的文件。HoudahSpot for mac 是一款多功能文件搜索工具,建立在 Apple 强大的 Spotlight 引擎之上。非常简单方便,效果非常好。
%3D%3D
2.EasyFind for Mac 一个简单的文件搜索工具
哪里有一个简单的 macOS 文件搜索工具?该站点提供 Mac 版 EasyFind(一个简单的文件搜索工具)。EasyFind for Mac 主要用于搜索收录
目标关键词的特殊文件、隐藏文件和文档。它还显示每个文件的目录位置。EasyFind for Mac 的搜索功能非常强大,操作也非常简单。.
%3D%3D
3.ProFind for mac 文件搜索工具
Mac 上哪个文件搜索工具好用?ProFind mac版是一款Macos上的文件搜索软件,功能强大,性能卓越,可为macOS提供高级文件搜索。并支持自然语言查询、应用程序启动、隐藏位置搜索、脚本编写等。此外,您可以在不可见的文件夹和包中搜索,搜索任何磁盘类型。
%3D%3D
4.Find Any File for Mac 文件搜索软件
Find Any File for Mac 是一款适用于 Mac 的文件搜索工具。查找任何文件 Mac 可以按名称、创建或修改日期、大小或类型以及创建者代码(不是内容)搜索本地磁盘上的文件。您甚至可以搜索未被 Spotlight 索引的磁盘,包括服务器卷。
%3D%3D
5.PDF Search for Mac pdf文件搜索工具
PDF Search Mac特别版是Mac平台上一款PDF文件的快速搜索工具,可以搜索相关性,让您在上千个PDF文档中第一时间找到最相关的页面,提高工作效率!
%3D%3D
6.VisualGrep for Mac 非索引文件搜索工具
VisualGrep for Mac 是一种非索引文件搜索工具,支持带有过滤器和许多文件夹遍历选项的文件。此更新修复了 Big Sur 中的 UI 错误。
%3D%3D
以上就是小编为大家带来的6款支持M1的文件搜索工具合集。我希望它会对你有所帮助。macz有更多实用的Mac教程!
搜索引擎优化pdf(几个无损压缩PDF的好用方法,手机也能免费转换 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-30 02:05
)
PDF是一种常用的文档格式。它具有较高的安全性,易于传输和存储,但在处理上也存在很多麻烦。比如我们在工作中经常会遇到PDF文件过大的问题。这时候我们就需要对PDF文件进行压缩。许多人发现很难面对这个问题,不知道从哪里开始。今天,让我们学习一些无损PDF压缩的有用方法。
一、speedpdf 在线压缩
优点:在线压缩不需要安装软件,手机也可以使用
方法:
1、 搜索speedpdf,找到并打开这个在线转换工具。除了我们想要的PDF压缩,其他日常的PDF转Word也可以免费转换。选择压缩 PDF 以输入压缩。无需注册登录,可直接免费办理;
2、 然后添加需要压缩的PDF文件后,下面的列表会显示上传的PDF文件,点击convert开始压缩。右键单击网页上的任意位置,将其翻译成简体中文网页。
3、 完成后点击下载。
二、快速乐趣
优点:客户端一键批量操作,省时高效
方法:
1、 极乐转换器下载安装后,在PDF工具中选择PDF压缩进入;
2、 将所有需要压缩的PDF批量添加或拖拽到压缩页面后,点击页面左下角的输出路径修改压缩后的PDF的保存位置,点击开始压缩一键压缩所有当前添加的PDF文档。
3、 除了我们上一步修改的保存位置,还可以查看转换完成后的所有压缩记录,右键任意文档选择打开查看。
查看全部
搜索引擎优化pdf(几个无损压缩PDF的好用方法,手机也能免费转换
)
PDF是一种常用的文档格式。它具有较高的安全性,易于传输和存储,但在处理上也存在很多麻烦。比如我们在工作中经常会遇到PDF文件过大的问题。这时候我们就需要对PDF文件进行压缩。许多人发现很难面对这个问题,不知道从哪里开始。今天,让我们学习一些无损PDF压缩的有用方法。
一、speedpdf 在线压缩
优点:在线压缩不需要安装软件,手机也可以使用
方法:
1、 搜索speedpdf,找到并打开这个在线转换工具。除了我们想要的PDF压缩,其他日常的PDF转Word也可以免费转换。选择压缩 PDF 以输入压缩。无需注册登录,可直接免费办理;
2、 然后添加需要压缩的PDF文件后,下面的列表会显示上传的PDF文件,点击convert开始压缩。右键单击网页上的任意位置,将其翻译成简体中文网页。
3、 完成后点击下载。
二、快速乐趣
优点:客户端一键批量操作,省时高效
方法:
1、 极乐转换器下载安装后,在PDF工具中选择PDF压缩进入;
2、 将所有需要压缩的PDF批量添加或拖拽到压缩页面后,点击页面左下角的输出路径修改压缩后的PDF的保存位置,点击开始压缩一键压缩所有当前添加的PDF文档。
3、 除了我们上一步修改的保存位置,还可以查看转换完成后的所有压缩记录,右键任意文档选择打开查看。
搜索引擎优化pdf(全文搜索首先搞清楚第一个问题的开发过程及解决办法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2021-12-30 00:09
最近项目组安排了一个任务,项目中用到了全文搜索,基于全文搜索Solr
但是Solr搜索云项目不稳定,经常查询不到数据。需要手动全量同步,由其他团队维护。依赖性太强了。Solr 服务一旦出现故障,我们的项目就因为所有的依赖关系而基本瘫痪。查询没有结果数据。
所以考虑开发一个适配层,如果Solr搜索有问题,自动切换到新的搜索:ElasticSearch(ES)
其实这个问题可以通过Solr集群或者服务容错设计来解决。但是不管设计本身的合理性,leader需要开发,所以我从头开始搭建ES服务,因为之前没接触过ES,所以通过这个系列记录了我的开发过程。
什么是全文搜索
首先澄清第一个问题:什么是全文搜索引擎?
百度百科中的定义:
全文搜索引擎是目前应用广泛的主流搜索引擎。其工作原理是计算机索引程序扫描文章中的每个词,为每个词建立索引,并指示该词在文章中的编号和位置。
当用户进行查询时,搜索程序会根据预先建立的索引进行搜索,并将搜索结果反馈给用户的搜索方法。这个过程类似于通过字典中的搜索词列表查找字符的过程。
从定义上,我们已经可以大致了解全文检索的思想了。为了更详细的讲解,先从生活中的数据说起。
在我们的生活中有两种类型的数据:结构化数据和非结构化数据。
当然,有些地方还会有第三种:半结构化数据,如XML、HTML等,可以根据需要处理为结构化数据,也可以提取纯文本作为非结构化数据处理。
根据两类数据分类,搜索也分为两类:
对于结构化数据,我们一般可以通过关系数据库(mysql、oracle等)的表进行存储和搜索,或者创建索引。对于非结构化数据,即搜索全文数据,主要有两种方法:顺序扫描法、全文搜索法
顺序扫描:也可以通过文字名称知道一般的搜索方式,即在顺序扫描中搜索特定的关键字。
比如给你一份报纸,找出报纸上“RNG”这个词出现在什么地方。您肯定需要从头到尾扫描报纸并标记关键字出现的部分和出现的位置。
这种方法无疑是最耗时、效果最差的。如果报纸的排版很小,而且有很多版块甚至是多份报纸,你扫了一眼就差不多了。
全文搜索:非结构化数据的顺序扫描很慢。我们可以优化它吗?想办法让我们的非结构化数据有一定的结构还不够吗?
我们将非结构化数据中的部分信息提取出来,重新组织起来,使其具有一定的结构,然后搜索具有一定结构的数据,从而达到比较快速搜索的目的。
这种方式构成了全文检索的基本思想。这部分信息是从非结构化数据中提取出来然后重新组织起来的,我们称之为索引。
以阅读报纸为例。我们要关注最近英雄联盟S8全球总决赛的消息。如果我们都是RNG的粉丝,如何快速找到RNG新闻的报纸和栏目?
全文检索法:从所有报纸的所有版块中提取关键词,如“EDG”、“RNG”、“FW”、“团队”、“英雄联盟”等,然后对这些关键词进行索引,并通过索引,我们可以对应出现在关键词中的报纸和栏目。
为什么要使用全文搜索引擎
那么第二个问题是,为什么要使用搜索引擎?
我们所有的数据都在数据库中,Oracle、SQL Server等数据库也可以提供查询检索或聚类分析功能。直接通过数据库查询还不够吗?
事实上,我们的大部分查询功能都可以通过数据库查询来获得。如果查询效率低,还可以通过建立数据库索引、优化SQL等方式来提高效率,甚至可以通过引入缓存来加快数据返回速度。如果数据量较大,可以拆分数据库和表来分担查询压力。
那为什么还需要全文搜索引擎呢?我们主要分析以下原因:
第三个问题:什么时候使用全文搜索引擎?
搜索到的数据对象是大量的非结构化文本数据。文件记录数达到数十万或数百万甚至更多。支持大量基于交互式文本的查询。具有非常灵活要求的全文搜索查询。对高度相关的搜索结果有特殊要求,但没有可用的关系数据库来满足这些要求。对不同记录类型、非文本数据操作或安全事务处理的要求相对较少的情况。Lucene、Solr 还是 ElasticSearch?
目前主流的搜索引擎大概有:Lucene、Solr、ElasticSearch。
他们的索引创建是根据倒排索引的方法来生成索引的,什么是倒排索引?
我们先来看看维基百科的解释:
维基百科
倒排索引(英文:Inverted index),也常被称为倒排索引、倒排文件或倒排文件,是一种索引方法,用于在全文搜索下存储文档或组中的某个词 存储的映射文档中的位置。它是文档检索系统中最常用的数据结构。
接下来,我们就来看看这三种主流的使用倒排索引的全文搜索引擎。
琉森
Lucene 是一个 Java 全文搜索引擎,完全用 Java 编写。Lucene 不是一个完整的应用程序,而是一个代码库和 API,可轻松用于向应用程序添加搜索功能。
Lucene 通过简单的 API 提供了强大的功能:
可扩展的高性能索引
强大、准确、高效的搜索算法
跨平台解决方案
但是Lucene只是一个框架。要充分利用其功能,需要使用JAVA,并在程序中集成Lucene。理解它是如何工作的需要大量的学习和理解,而要熟练地使用 Lucene 确实很复杂。
索尔
Apache Solr 是一个基于名为 Lucene 的 Java 库的开源搜索平台。它以用户友好的方式提供了Apache Lucene的搜索功能。
它提供分布式索引、复制、负载平衡查询以及自动故障转移和恢复。如果部署得当,管理得当,它可以成为一个高度可靠、可扩展、容错的搜索引擎。
许多互联网巨头,如 Netflix、eBay、Instagram 和亚马逊 (CloudSearch) 都使用 Solr,因为它能够索引和搜索多个站点。
主要功能列表包括:
弹性搜索
Elasticsearch 是一个基于 Apache Lucene 库的开源 RESTful 搜索引擎,在 Solr 几年后推出。
它提供了一个分布式、多租户全文搜索引擎,带有 HTTP Web 接口(REST)和非结构化 JSON 文档。
Elasticsearch 的官方客户端库提供 Java、Groovy、PHP、Ruby、Perl、Python、.NET 和 Javascript。
分布式搜索引擎收录
的索引可以分为段,每个段可以有多个副本。每个 Elasticsearch 节点可以有一个或多个分片,它的引擎也可以充当协调器,将操作委托给正确的分片。
Elasticsearch 可以通过近乎实时的搜索进行扩展。它的主要功能之一是多租户。主要功能列表包括:
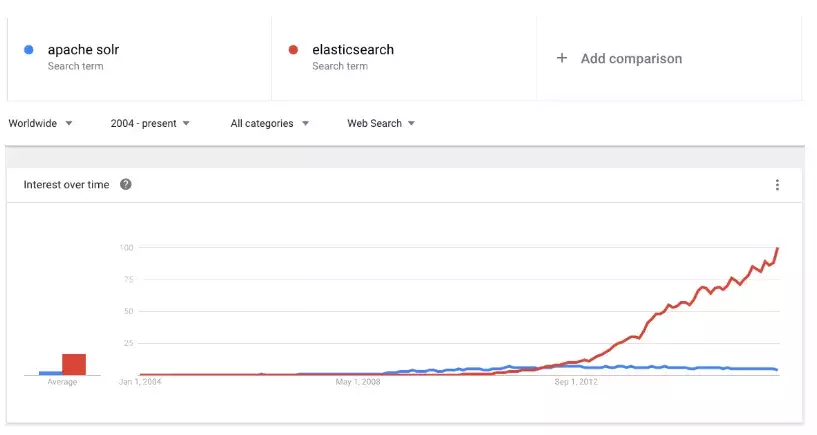
Elasticsearch vs. Solr,如何选择?
由于Lucene的复杂性,一般很少将其作为搜索的首选。排除部分公司需要自己开发搜索框架,底层需要依赖Lucene。所以这里我们重点分析Elasticsearch和Solr。
Elasticsearch 与 Solr。哪一个更好?它们有何不同?你应该使用哪一个?
历史比较
Apache Solr 是一个成熟的项目,拥有庞大而活跃的开发和用户社区,以及 Apache 品牌。Solr 于 2006 年首次发布开源。它长期以来一直统治着搜索引擎领域,是任何需要搜索功能的人的首选引擎。
它的成熟转化为丰富的功能,而不仅仅是简单的文本索引和搜索;如分面、分组、强大的过滤、可插入的文档处理、可插入的搜索链组件、语言检测等。
Solr 多年来一直统治着搜索领域。然后,在 2010 年左右,Elasticsearch 成为市场上的另一种选择。当时,它远不如 Solr 稳定,没有 Solr 的功能深度,没有分享想法,品牌等。
Elasticsearch虽然很年轻,但也有自己的一些优势。Elasticsearch 建立在更现代的原则之上,针对更现代的用例,旨在更轻松地处理大型索引和高查询率。
另外,因为它太年轻,没有社区可以合作,它可以在没有任何共识或与其他人(用户或开发者)合作,向后兼容,或任何其他更成熟的软件通常必须处理的情况下自由前进。
所以在Solr之前就公开了一些非常流行的功能(比如near real-time search,英文:Near Real-Time Search)。
从技术上讲,NRT 搜索的能力确实来自 Lucene,它是 Solr 和 Elasticsearch 使用的基本搜索库。
讽刺的是,因为 Elasticsearch 首先公开了 NRT 搜索,人们将 NRT 搜索与 Elasticsearch 联系起来,尽管 Solr 和 Lucene 都是同一个 Apache 项目的一部分,所以人们首先会期望 Solr 有如此苛刻的功能。
功能差异对比
这两个搜索引擎都是流行的高级开源搜索引擎。它们都是围绕核心底层搜索库-Lucene构建的
但它们是不同的。像所有事物一样,每个事物都有其优点和缺点,并且根据您的需求和期望,每个事物都可能更好或更糟。
那么,话不多说,先来看看不同之处:
综合比较
另外,我们从以下几个方面进行分析:
总结
所以问题是,它是 Solr 还是 Elasticsearch?
很难找到明确的答案。无论您选择 Solr 还是 Elasticsearch,您首先需要了解正确的用例和未来的需求。总结它们的每个属性。记住:
总之,两者都是功能丰富的搜索引擎,只要设计和实现得当,它们都可以提供或多或少相同的性能。本文整体内容大致如下图所示,由园友ReyCG精心绘制和提供。
欢迎工作一到五年的Java工程师加入Java程序员的开发:721575865
本群免费提供Java架构学习资料(高可用、高并发、高性能和分布式、JVM性能调优、Spring源码、MyBatis、Netty、Redis、Kafka、Mysql、Zookeeper、Tomcat、Docker、Dubbo、Nginx等框架知识点)合理利用自己的时间分分秒秒地学习提升自己,不要用“没时间”来掩饰自己的精神懒惰!趁年轻努力,给未来的自己一个交代! 查看全部
搜索引擎优化pdf(全文搜索首先搞清楚第一个问题的开发过程及解决办法!)
最近项目组安排了一个任务,项目中用到了全文搜索,基于全文搜索Solr
但是Solr搜索云项目不稳定,经常查询不到数据。需要手动全量同步,由其他团队维护。依赖性太强了。Solr 服务一旦出现故障,我们的项目就因为所有的依赖关系而基本瘫痪。查询没有结果数据。
所以考虑开发一个适配层,如果Solr搜索有问题,自动切换到新的搜索:ElasticSearch(ES)
其实这个问题可以通过Solr集群或者服务容错设计来解决。但是不管设计本身的合理性,leader需要开发,所以我从头开始搭建ES服务,因为之前没接触过ES,所以通过这个系列记录了我的开发过程。
什么是全文搜索
首先澄清第一个问题:什么是全文搜索引擎?
百度百科中的定义:
全文搜索引擎是目前应用广泛的主流搜索引擎。其工作原理是计算机索引程序扫描文章中的每个词,为每个词建立索引,并指示该词在文章中的编号和位置。
当用户进行查询时,搜索程序会根据预先建立的索引进行搜索,并将搜索结果反馈给用户的搜索方法。这个过程类似于通过字典中的搜索词列表查找字符的过程。
从定义上,我们已经可以大致了解全文检索的思想了。为了更详细的讲解,先从生活中的数据说起。
在我们的生活中有两种类型的数据:结构化数据和非结构化数据。
当然,有些地方还会有第三种:半结构化数据,如XML、HTML等,可以根据需要处理为结构化数据,也可以提取纯文本作为非结构化数据处理。
根据两类数据分类,搜索也分为两类:
对于结构化数据,我们一般可以通过关系数据库(mysql、oracle等)的表进行存储和搜索,或者创建索引。对于非结构化数据,即搜索全文数据,主要有两种方法:顺序扫描法、全文搜索法
顺序扫描:也可以通过文字名称知道一般的搜索方式,即在顺序扫描中搜索特定的关键字。
比如给你一份报纸,找出报纸上“RNG”这个词出现在什么地方。您肯定需要从头到尾扫描报纸并标记关键字出现的部分和出现的位置。
这种方法无疑是最耗时、效果最差的。如果报纸的排版很小,而且有很多版块甚至是多份报纸,你扫了一眼就差不多了。
全文搜索:非结构化数据的顺序扫描很慢。我们可以优化它吗?想办法让我们的非结构化数据有一定的结构还不够吗?
我们将非结构化数据中的部分信息提取出来,重新组织起来,使其具有一定的结构,然后搜索具有一定结构的数据,从而达到比较快速搜索的目的。
这种方式构成了全文检索的基本思想。这部分信息是从非结构化数据中提取出来然后重新组织起来的,我们称之为索引。
以阅读报纸为例。我们要关注最近英雄联盟S8全球总决赛的消息。如果我们都是RNG的粉丝,如何快速找到RNG新闻的报纸和栏目?
全文检索法:从所有报纸的所有版块中提取关键词,如“EDG”、“RNG”、“FW”、“团队”、“英雄联盟”等,然后对这些关键词进行索引,并通过索引,我们可以对应出现在关键词中的报纸和栏目。
为什么要使用全文搜索引擎
那么第二个问题是,为什么要使用搜索引擎?
我们所有的数据都在数据库中,Oracle、SQL Server等数据库也可以提供查询检索或聚类分析功能。直接通过数据库查询还不够吗?
事实上,我们的大部分查询功能都可以通过数据库查询来获得。如果查询效率低,还可以通过建立数据库索引、优化SQL等方式来提高效率,甚至可以通过引入缓存来加快数据返回速度。如果数据量较大,可以拆分数据库和表来分担查询压力。
那为什么还需要全文搜索引擎呢?我们主要分析以下原因:
第三个问题:什么时候使用全文搜索引擎?
搜索到的数据对象是大量的非结构化文本数据。文件记录数达到数十万或数百万甚至更多。支持大量基于交互式文本的查询。具有非常灵活要求的全文搜索查询。对高度相关的搜索结果有特殊要求,但没有可用的关系数据库来满足这些要求。对不同记录类型、非文本数据操作或安全事务处理的要求相对较少的情况。Lucene、Solr 还是 ElasticSearch?
目前主流的搜索引擎大概有:Lucene、Solr、ElasticSearch。

他们的索引创建是根据倒排索引的方法来生成索引的,什么是倒排索引?
我们先来看看维基百科的解释:
维基百科
倒排索引(英文:Inverted index),也常被称为倒排索引、倒排文件或倒排文件,是一种索引方法,用于在全文搜索下存储文档或组中的某个词 存储的映射文档中的位置。它是文档检索系统中最常用的数据结构。
接下来,我们就来看看这三种主流的使用倒排索引的全文搜索引擎。
琉森
Lucene 是一个 Java 全文搜索引擎,完全用 Java 编写。Lucene 不是一个完整的应用程序,而是一个代码库和 API,可轻松用于向应用程序添加搜索功能。
Lucene 通过简单的 API 提供了强大的功能:
可扩展的高性能索引
强大、准确、高效的搜索算法
跨平台解决方案
但是Lucene只是一个框架。要充分利用其功能,需要使用JAVA,并在程序中集成Lucene。理解它是如何工作的需要大量的学习和理解,而要熟练地使用 Lucene 确实很复杂。
索尔
Apache Solr 是一个基于名为 Lucene 的 Java 库的开源搜索平台。它以用户友好的方式提供了Apache Lucene的搜索功能。
它提供分布式索引、复制、负载平衡查询以及自动故障转移和恢复。如果部署得当,管理得当,它可以成为一个高度可靠、可扩展、容错的搜索引擎。
许多互联网巨头,如 Netflix、eBay、Instagram 和亚马逊 (CloudSearch) 都使用 Solr,因为它能够索引和搜索多个站点。
主要功能列表包括:
弹性搜索
Elasticsearch 是一个基于 Apache Lucene 库的开源 RESTful 搜索引擎,在 Solr 几年后推出。
它提供了一个分布式、多租户全文搜索引擎,带有 HTTP Web 接口(REST)和非结构化 JSON 文档。
Elasticsearch 的官方客户端库提供 Java、Groovy、PHP、Ruby、Perl、Python、.NET 和 Javascript。
分布式搜索引擎收录
的索引可以分为段,每个段可以有多个副本。每个 Elasticsearch 节点可以有一个或多个分片,它的引擎也可以充当协调器,将操作委托给正确的分片。
Elasticsearch 可以通过近乎实时的搜索进行扩展。它的主要功能之一是多租户。主要功能列表包括:
Elasticsearch vs. Solr,如何选择?
由于Lucene的复杂性,一般很少将其作为搜索的首选。排除部分公司需要自己开发搜索框架,底层需要依赖Lucene。所以这里我们重点分析Elasticsearch和Solr。
Elasticsearch 与 Solr。哪一个更好?它们有何不同?你应该使用哪一个?

历史比较
Apache Solr 是一个成熟的项目,拥有庞大而活跃的开发和用户社区,以及 Apache 品牌。Solr 于 2006 年首次发布开源。它长期以来一直统治着搜索引擎领域,是任何需要搜索功能的人的首选引擎。
它的成熟转化为丰富的功能,而不仅仅是简单的文本索引和搜索;如分面、分组、强大的过滤、可插入的文档处理、可插入的搜索链组件、语言检测等。
Solr 多年来一直统治着搜索领域。然后,在 2010 年左右,Elasticsearch 成为市场上的另一种选择。当时,它远不如 Solr 稳定,没有 Solr 的功能深度,没有分享想法,品牌等。
Elasticsearch虽然很年轻,但也有自己的一些优势。Elasticsearch 建立在更现代的原则之上,针对更现代的用例,旨在更轻松地处理大型索引和高查询率。
另外,因为它太年轻,没有社区可以合作,它可以在没有任何共识或与其他人(用户或开发者)合作,向后兼容,或任何其他更成熟的软件通常必须处理的情况下自由前进。
所以在Solr之前就公开了一些非常流行的功能(比如near real-time search,英文:Near Real-Time Search)。
从技术上讲,NRT 搜索的能力确实来自 Lucene,它是 Solr 和 Elasticsearch 使用的基本搜索库。
讽刺的是,因为 Elasticsearch 首先公开了 NRT 搜索,人们将 NRT 搜索与 Elasticsearch 联系起来,尽管 Solr 和 Lucene 都是同一个 Apache 项目的一部分,所以人们首先会期望 Solr 有如此苛刻的功能。
功能差异对比
这两个搜索引擎都是流行的高级开源搜索引擎。它们都是围绕核心底层搜索库-Lucene构建的
但它们是不同的。像所有事物一样,每个事物都有其优点和缺点,并且根据您的需求和期望,每个事物都可能更好或更糟。
那么,话不多说,先来看看不同之处:
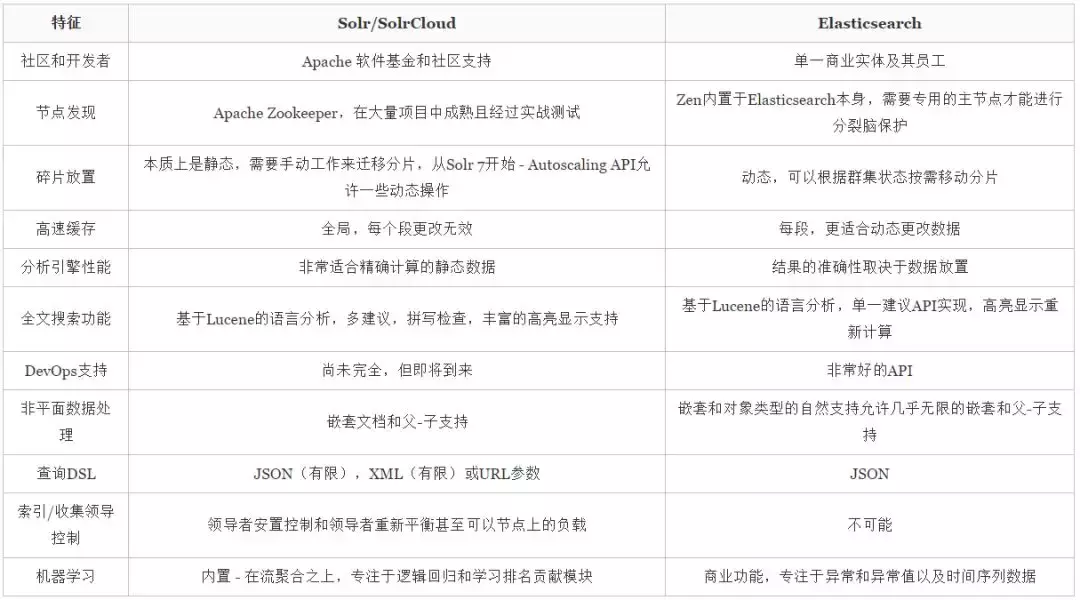
综合比较
另外,我们从以下几个方面进行分析:
总结
所以问题是,它是 Solr 还是 Elasticsearch?
很难找到明确的答案。无论您选择 Solr 还是 Elasticsearch,您首先需要了解正确的用例和未来的需求。总结它们的每个属性。记住:
总之,两者都是功能丰富的搜索引擎,只要设计和实现得当,它们都可以提供或多或少相同的性能。本文整体内容大致如下图所示,由园友ReyCG精心绘制和提供。
欢迎工作一到五年的Java工程师加入Java程序员的开发:721575865
本群免费提供Java架构学习资料(高可用、高并发、高性能和分布式、JVM性能调优、Spring源码、MyBatis、Netty、Redis、Kafka、Mysql、Zookeeper、Tomcat、Docker、Dubbo、Nginx等框架知识点)合理利用自己的时间分分秒秒地学习提升自己,不要用“没时间”来掩饰自己的精神懒惰!趁年轻努力,给未来的自己一个交代!
搜索引擎优化pdf(PDFSearchforMac快速搜索文档、参考书格式转换,功能很实用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-30 00:07
文末有获取方式,按照以下步骤获取。我们不破解软件。所有优秀的软件都来自互联网。破解软件仅供学习使用。如需商业用途,请购买正版。造成的法律责任与我无关。如侵犯了您的权益,请联系编辑删除。
PDF Search for Mac是Mac平台上的pdf文件搜索工具。PDF Search mac破解版可以快速搜索文档、参考书或笔记,让您轻松访问任何信息。mac 版的 PDF Search 还支持将文档转换为 PDF 格式。,功能很实用!
【PDF Search Mac App Store售价198.00元】
PDF搜索7.2 For Mac破解版介绍
Mac 版 PDF 搜索利用人工智能的力量快速搜索数千个文档。让您的工作和学校生活更高效、更轻松。
人工智能的成功
信息是成功的关键。PDF 搜索将帮助您使用 AI 驱动的算法快速获取文档中的信息。只需使用它来搜索您的文档、参考书或笔记。然后感受在几秒钟内访问任何信息的力量。您将使用 Mac、iPad 或 iPhone 在会议、课程或工作中大放异彩。每个人都会对您对文件的掌握程度感到惊讶。
是什么让它与众不同
一般搜索工具搜索存在。他们只检查您的关键字是否存在于文档中。然后他们会给你一份文件清单。你一一检查它们,看看它们是否是你要找的那些。没有智能,就像机器一样。
PDF 搜索可以是一个智能搜索工具。它不会检查是否存在唯一性,而是单独分析所有页面并根据给定的关键字检查每个页面的相关性。此检查类似于一个人检查文档的方式。例如,如果页面的标题收录
关键字,则该页面对该页面更感兴趣。PDF 搜索将所有这些检查组合成一个全新的算法。使用此算法,它可以立即在数千个文档中找到最相关的页面。
统一搜索体验
您可以使用 iPhone 或 iPad 在 Mac 上搜索文档。只需单击一下,您就可以通过 WiFi 同步您的文件,并随身携带您的所有文件。
将文档转换为 PDF
支持 Word、Powerpoint、Pages、Keynote 和 RTF 文档。PDF Converter 是一个免费的帮助应用程序,您可以从我们的网站下载。安装后,Office 文档将自动转换为 PDF 并通过 PDF 搜索建立索引。
特征
获取方法:
1、 点击右上角关注; 查看全部
搜索引擎优化pdf(PDFSearchforMac快速搜索文档、参考书格式转换,功能很实用)
文末有获取方式,按照以下步骤获取。我们不破解软件。所有优秀的软件都来自互联网。破解软件仅供学习使用。如需商业用途,请购买正版。造成的法律责任与我无关。如侵犯了您的权益,请联系编辑删除。
PDF Search for Mac是Mac平台上的pdf文件搜索工具。PDF Search mac破解版可以快速搜索文档、参考书或笔记,让您轻松访问任何信息。mac 版的 PDF Search 还支持将文档转换为 PDF 格式。,功能很实用!
【PDF Search Mac App Store售价198.00元】
PDF搜索7.2 For Mac破解版介绍
Mac 版 PDF 搜索利用人工智能的力量快速搜索数千个文档。让您的工作和学校生活更高效、更轻松。
人工智能的成功
信息是成功的关键。PDF 搜索将帮助您使用 AI 驱动的算法快速获取文档中的信息。只需使用它来搜索您的文档、参考书或笔记。然后感受在几秒钟内访问任何信息的力量。您将使用 Mac、iPad 或 iPhone 在会议、课程或工作中大放异彩。每个人都会对您对文件的掌握程度感到惊讶。
是什么让它与众不同
一般搜索工具搜索存在。他们只检查您的关键字是否存在于文档中。然后他们会给你一份文件清单。你一一检查它们,看看它们是否是你要找的那些。没有智能,就像机器一样。
PDF 搜索可以是一个智能搜索工具。它不会检查是否存在唯一性,而是单独分析所有页面并根据给定的关键字检查每个页面的相关性。此检查类似于一个人检查文档的方式。例如,如果页面的标题收录
关键字,则该页面对该页面更感兴趣。PDF 搜索将所有这些检查组合成一个全新的算法。使用此算法,它可以立即在数千个文档中找到最相关的页面。
统一搜索体验
您可以使用 iPhone 或 iPad 在 Mac 上搜索文档。只需单击一下,您就可以通过 WiFi 同步您的文件,并随身携带您的所有文件。
将文档转换为 PDF
支持 Word、Powerpoint、Pages、Keynote 和 RTF 文档。PDF Converter 是一个免费的帮助应用程序,您可以从我们的网站下载。安装后,Office 文档将自动转换为 PDF 并通过 PDF 搜索建立索引。
特征
获取方法:
1、 点击右上角关注;
搜索引擎优化pdf(文档介绍:状元学优化(SEO)搜索结果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-26 17:04
文件介绍:
状元科学****信息网应有尽有
搜索引擎优化 (SEO) 词汇表
搜索结果
result):作为对搜索者搜索请求的响应,搜索引擎返回匹配网页的链接,这个
链接是搜索结果。搜索引擎使用多种技术来确定哪个页面与哪个搜索请求匹配。
匹配,并根据相关程度对自然搜索匹配结果进行排序,查看最佳匹配结果
在第一个搜索结果中。付费展示位置和目录结果通常受相关性和网站所有权的影响
投标人中标结果的影响。
搜索引擎营销(SEM、搜索引擎营销)
旨在改善网站上搜索推荐的所有行为,无论是自然搜索还是付费搜索。搜索
引擎营销也称为搜索营销。
搜索引擎优化(SEO、搜索引擎优化)
一系列致力于提高网站自然搜索排名(非付费排名)的技术和方法。
站点地图
map) 对蜘蛛程序友好的网页,提供指向本网站域内其他网页的链接
. 对于小型网站,站点地图提供指向站点上所有网页的直接链接。中间
转到大型站点并使用站点地图链接到域中的主要中央网页(这些网页最终会变成
实现对网站上所有网页的访问)。例如:-
/站点地图.asp
***(垃圾邮件)
1.未经许可的未经请求的非法电子邮件,通常收录
商业信息或欺诈主题
只需将其交付给收件人。2. 也称为搜索***技术,旨在愚弄搜索引擎。
合乎道德(但合法)的技术,即使它的网页不是搜索请求的最佳匹配,也是显而易见的
展示。
元搜索引擎
搜索引擎将许多搜索者输入的搜索请求发送到许多其他搜索,并比较每个搜索。
搜索引擎结果并将它们显示在单个结果列表中。
301重定向也称为永久重定向(permanent
状元科学****信息网应有尽有
状元科学****信息网应有尽有
重定向),是对网站浏览器显示不同的指令
URL,当网络也经历过它的 URL 时
在最后一次更改后使用。永久重定向是可以搜索的服务器端重定向
电缆引擎蜘蛛正确处理它。
302重定向也被认为是临时重定向(temporary
重定向),向网站浏览器显示不同的指令
URL,当网页遇到短 URL 时
改变时使用。临时重定向是搜索引擎可以使用的服务器端重定向
蜘蛛正确处理它。
权威网站(Authorit)
网站所考虑的专业水平通常由其内部超链接网络来衡量。搜索引擎通常
高度关注那些从其他链接良好的网站获得内向链接的网站,以及
匹配站点主题并将这些站点置于搜索结果前面的搜索请求。
权威页面是许多链接指向某个主题的网页。
反向链接是所谓的入站链接
链接),是指从网页到您的网页的超链接。从您网站的外部链接到网页的向内链接
那么,在搜索引擎中做链接分析,根据相关性对搜索结果进行排序时,
价值。
拖车链接
也称为互链接,是一个网页的超文本链接,目标网页链接回原来的网页
来到主页。
网络日志
1. 网站服务器上的一个文件,作为服务器执行的每一个操作的记录。日志文本
可以通过复杂的方法分析文档以确定网站访问者的数量(根据人和
(跟随搜索引擎的蜘蛛程序)
, 以及他们浏览的页数。2. 也叫博客,是一种在线日志。
出版物,互联网上的常规专栏。有些博客是回忆的私人日记,但其他博客
状元科学****信息网应有尽有
状元科学****信息网应有尽有
在一些类似的杂志专栏之外,专注于特定的感兴趣的话题。
横幅
ad) 也成为广告横幅广告,通常在网页的显着部分显示为一个大的彩色矩形
, 类似于出现在报纸和杂志上的广告。单击横幅会将访问者带到广告商的网站。
行为模型
一组执行特定任务的人的行为的抽象摘要,用于衡量和分析他们正在做什么。这
该分析可以建议如何在任务跟进期间改进流程。
投标(投标)
为每个搜索引擎支付搜索引擎推荐费,保证付费搜索结果的排名
. 付费搜索结果以最简单的形式显示结果列表中出价最高者的网页链接。
在顶部,每次访问者点击投标人的链接时,投标人都会向搜索引擎支付费用。
出价差
gap) 有偿投标中两个相邻位置的两个投标之间的明显差异。例如,当投标人
目前排名第三, 查看全部
搜索引擎优化pdf(文档介绍:状元学优化(SEO)搜索结果)
文件介绍:
状元科学****信息网应有尽有
搜索引擎优化 (SEO) 词汇表
搜索结果
result):作为对搜索者搜索请求的响应,搜索引擎返回匹配网页的链接,这个
链接是搜索结果。搜索引擎使用多种技术来确定哪个页面与哪个搜索请求匹配。
匹配,并根据相关程度对自然搜索匹配结果进行排序,查看最佳匹配结果
在第一个搜索结果中。付费展示位置和目录结果通常受相关性和网站所有权的影响
投标人中标结果的影响。
搜索引擎营销(SEM、搜索引擎营销)
旨在改善网站上搜索推荐的所有行为,无论是自然搜索还是付费搜索。搜索
引擎营销也称为搜索营销。
搜索引擎优化(SEO、搜索引擎优化)
一系列致力于提高网站自然搜索排名(非付费排名)的技术和方法。
站点地图
map) 对蜘蛛程序友好的网页,提供指向本网站域内其他网页的链接
. 对于小型网站,站点地图提供指向站点上所有网页的直接链接。中间
转到大型站点并使用站点地图链接到域中的主要中央网页(这些网页最终会变成
实现对网站上所有网页的访问)。例如:-
/站点地图.asp
***(垃圾邮件)
1.未经许可的未经请求的非法电子邮件,通常收录
商业信息或欺诈主题
只需将其交付给收件人。2. 也称为搜索***技术,旨在愚弄搜索引擎。
合乎道德(但合法)的技术,即使它的网页不是搜索请求的最佳匹配,也是显而易见的
展示。
元搜索引擎
搜索引擎将许多搜索者输入的搜索请求发送到许多其他搜索,并比较每个搜索。
搜索引擎结果并将它们显示在单个结果列表中。
301重定向也称为永久重定向(permanent
状元科学****信息网应有尽有
状元科学****信息网应有尽有
重定向),是对网站浏览器显示不同的指令
URL,当网络也经历过它的 URL 时
在最后一次更改后使用。永久重定向是可以搜索的服务器端重定向
电缆引擎蜘蛛正确处理它。
302重定向也被认为是临时重定向(temporary
重定向),向网站浏览器显示不同的指令
URL,当网页遇到短 URL 时
改变时使用。临时重定向是搜索引擎可以使用的服务器端重定向
蜘蛛正确处理它。
权威网站(Authorit)
网站所考虑的专业水平通常由其内部超链接网络来衡量。搜索引擎通常
高度关注那些从其他链接良好的网站获得内向链接的网站,以及
匹配站点主题并将这些站点置于搜索结果前面的搜索请求。
权威页面是许多链接指向某个主题的网页。
反向链接是所谓的入站链接
链接),是指从网页到您的网页的超链接。从您网站的外部链接到网页的向内链接
那么,在搜索引擎中做链接分析,根据相关性对搜索结果进行排序时,
价值。
拖车链接
也称为互链接,是一个网页的超文本链接,目标网页链接回原来的网页
来到主页。
网络日志
1. 网站服务器上的一个文件,作为服务器执行的每一个操作的记录。日志文本
可以通过复杂的方法分析文档以确定网站访问者的数量(根据人和
(跟随搜索引擎的蜘蛛程序)
, 以及他们浏览的页数。2. 也叫博客,是一种在线日志。
出版物,互联网上的常规专栏。有些博客是回忆的私人日记,但其他博客
状元科学****信息网应有尽有
状元科学****信息网应有尽有
在一些类似的杂志专栏之外,专注于特定的感兴趣的话题。
横幅
ad) 也成为广告横幅广告,通常在网页的显着部分显示为一个大的彩色矩形
, 类似于出现在报纸和杂志上的广告。单击横幅会将访问者带到广告商的网站。
行为模型
一组执行特定任务的人的行为的抽象摘要,用于衡量和分析他们正在做什么。这
该分析可以建议如何在任务跟进期间改进流程。
投标(投标)
为每个搜索引擎支付搜索引擎推荐费,保证付费搜索结果的排名
. 付费搜索结果以最简单的形式显示结果列表中出价最高者的网页链接。
在顶部,每次访问者点击投标人的链接时,投标人都会向搜索引擎支付费用。
出价差
gap) 有偿投标中两个相邻位置的两个投标之间的明显差异。例如,当投标人
目前排名第三,
搜索引擎优化pdf(搜索引擎进行网站优化的精华要点,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-26 14:17
经过近2年网络营销的反复实践,并在此基础上,总结了搜索引擎网站优化的一些精髓。我希望它会对大家有所帮助。
1. 尝试将其作为代码的开头,将javascript和CSS模块化,并尝试使用include使其独立于HTML页面。
2. 如果访问网站内容需要会员登录或密码保护,请向搜索引擎蜘蛛或机器人打开。
3. 如果网站的内容是用PHP、ASP或JSP等脚本动态生成的,则需要通过Apache的Mod_Rewrite或PHP的Path_Info进行URL重写和优化,使URL类似于静态页面。如:可以映射到或。
4. 尽量避免不必要的跳转和重定向页面或类似的会产生 3xx 的机制。
5. 保持 HTML 中标签中的内容与实际文章或内容的标题一致,并尽量在每个页面上唯一。
6. 使用和标签来表示实际文章或内容的标题和副标题。如果你想保持漂亮,请使用 CSS 来定义它。
7. 尽量保持每个
<IMG>
标签中有 ALT 属性,最好所有 ALT 属性都有内容。
8. 创建结构清晰且有意义的网站导航页面。
9. 在网站根目录下创建robot.txt文件。如对搜索引擎无特殊要求,内容为*;或添加一些搜索引擎所需的脚本。
10. 尽量不要使用框架结构来呈现网站。
11.尽量使网站代码符合W3C的HTML4.0或XHTML1.0规范。
12. 网站或学术文章的主要内容,尽量转换成PDF格式。因为 PDF 文件的自然 Page Rank 是 3。
13. 尽量让网站的结构趋于扁平化,最好不要超过3层。 查看全部
搜索引擎优化pdf(搜索引擎进行网站优化的精华要点,你知道吗?)
经过近2年网络营销的反复实践,并在此基础上,总结了搜索引擎网站优化的一些精髓。我希望它会对大家有所帮助。
1. 尝试将其作为代码的开头,将javascript和CSS模块化,并尝试使用include使其独立于HTML页面。
2. 如果访问网站内容需要会员登录或密码保护,请向搜索引擎蜘蛛或机器人打开。
3. 如果网站的内容是用PHP、ASP或JSP等脚本动态生成的,则需要通过Apache的Mod_Rewrite或PHP的Path_Info进行URL重写和优化,使URL类似于静态页面。如:可以映射到或。
4. 尽量避免不必要的跳转和重定向页面或类似的会产生 3xx 的机制。
5. 保持 HTML 中标签中的内容与实际文章或内容的标题一致,并尽量在每个页面上唯一。
6. 使用和标签来表示实际文章或内容的标题和副标题。如果你想保持漂亮,请使用 CSS 来定义它。
7. 尽量保持每个
<IMG>
标签中有 ALT 属性,最好所有 ALT 属性都有内容。
8. 创建结构清晰且有意义的网站导航页面。
9. 在网站根目录下创建robot.txt文件。如对搜索引擎无特殊要求,内容为*;或添加一些搜索引擎所需的脚本。
10. 尽量不要使用框架结构来呈现网站。
11.尽量使网站代码符合W3C的HTML4.0或XHTML1.0规范。
12. 网站或学术文章的主要内容,尽量转换成PDF格式。因为 PDF 文件的自然 Page Rank 是 3。
13. 尽量让网站的结构趋于扁平化,最好不要超过3层。
搜索引擎优化pdf(搜索引擎优化pdf名词解释和pdf电子书免费下载。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-26 07:04
搜索引擎优化pdf名词解释和pdf电子书免费下载。pdf电子书网盘免费下载。书籍购买方式。下载方式一本书都是优惠到20元,个人觉得挺划算的,这些都是我一个一个店铺买的,价格也是有很大出入的。喜欢的留个赞,如果觉得不错点个赞支持一下呗!你们的支持是我分享的动力哦!有需要的直接私我下。获取方式二1,购买方式一本书都是优惠到20元,个人觉得挺划算的,这些都是我一个一个店铺买的,价格也是有很大出入的。
喜欢的留个赞,如果觉得不错点个赞支持一下呗!你们的支持是我分享的动力哦!2,那就来看看获取方式二的获取方式吧。现在已经有二十本有1000多本的库存了,有需要的小伙伴可以留意下。有需要的直接私我下。复制以下链接然后打开【吱口令】,即可领取。/end/来个评论互动下!。
没看过,不清楚,
我这里有,需要的留邮箱,有需要的给个赞吧,
有。邮箱。
我知道的有下边这些网站,除了用闲鱼不行之外,其他的还行,建议能支持正版还是支持正版吧,就算被骗了也就当买教训,真的挺好。
1、目前对于卖出去的纸质书书的价格定得比较低。有2块一本、5块一本以及10块一本的三种,也有更高的。
2、当当
3、京东亚马逊这两个网站卖纸质书的相对来说价格比较高,3元一本应该没有了,
4、简书不建议去。
4、店都是卖盗版书,
5、亚马逊纸质书超多,有6元两本或者8元三本的,店家也不太诚信。 查看全部
搜索引擎优化pdf(搜索引擎优化pdf名词解释和pdf电子书免费下载。)
搜索引擎优化pdf名词解释和pdf电子书免费下载。pdf电子书网盘免费下载。书籍购买方式。下载方式一本书都是优惠到20元,个人觉得挺划算的,这些都是我一个一个店铺买的,价格也是有很大出入的。喜欢的留个赞,如果觉得不错点个赞支持一下呗!你们的支持是我分享的动力哦!有需要的直接私我下。获取方式二1,购买方式一本书都是优惠到20元,个人觉得挺划算的,这些都是我一个一个店铺买的,价格也是有很大出入的。
喜欢的留个赞,如果觉得不错点个赞支持一下呗!你们的支持是我分享的动力哦!2,那就来看看获取方式二的获取方式吧。现在已经有二十本有1000多本的库存了,有需要的小伙伴可以留意下。有需要的直接私我下。复制以下链接然后打开【吱口令】,即可领取。/end/来个评论互动下!。
没看过,不清楚,
我这里有,需要的留邮箱,有需要的给个赞吧,
有。邮箱。
我知道的有下边这些网站,除了用闲鱼不行之外,其他的还行,建议能支持正版还是支持正版吧,就算被骗了也就当买教训,真的挺好。
1、目前对于卖出去的纸质书书的价格定得比较低。有2块一本、5块一本以及10块一本的三种,也有更高的。
2、当当
3、京东亚马逊这两个网站卖纸质书的相对来说价格比较高,3元一本应该没有了,
4、简书不建议去。
4、店都是卖盗版书,
5、亚马逊纸质书超多,有6元两本或者8元三本的,店家也不太诚信。
搜索引擎优化pdf(深度操作系统:全局搜索是一个桌面系统级搜索服务详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-25 20:01
IT之家12月2日报道称,深度操作系统20.3将于11月迎来更新,Stable内核将升级至5.15版本,进一步提升兼容性。修复系统安全漏洞,增强安全性。一些深度应用增加并优化了常用功能,以满足不同场景的需求。修复和优化桌面环境中的一些问题,只为带来更好的体验。
Deepin现在为大家带来桌面系统级搜索服务“全局搜索”新功能的详细讲解。
设计初衷:希望用户能输入尽可能少的内容,以找到他们想要的目标文件、应用程序或设置。
为什么要进行全局搜索?
在操作系统的使用过程中,我们收到了很多用户的反馈。在日常使用中,用户都希望直接进入某个场景,希望能方便一些。
基于直接搜索目标的效率,我们希望可以有一个系统级的服务可以很好的承担这个责任。全局搜索恰好有这个属性。
功能入口
全局搜索的功能入口位于任务栏右侧,与虚拟键盘位于同一区域。用鼠标点击放大镜的入口,打开屏幕中央的全局搜索框。
搜索栏
搜索框唤醒后,您可以在搜索框中输入要查找的文件、应用程序或设置关键字。在输入过程中随时调整输入文本内容,搜索结果列表会及时刷新搜索结果,让您快速找到搜索目标。
搜索结果列表
搜索结果列表支持显示更细粒度的搜索结果分类。例如,当您输入艺术家姓名时,如果恰好有一个mp3格式的歌曲文件收录
艺术家姓名,那么您可以在“音乐”类别下查看相应的搜索结果。
同样,如果可以对收录
搜索关键字的文档文件、图像文件和视频文件进行聚类和调用,则可以在指定的类别下查看搜索结果,以节省搜索时间。
当单个搜索类别下搜索结果过多时,默认折叠。因为太多的搜索结果会把列表拖的很长,不利于查看。单击“查看更多”可展开指定搜索类别的列表区域。
全局搜索支持多种类别搜索。在实际使用中,你会发现应用和网页搜索结果会比较高。
在排名方面,我们考虑的是,全球搜索不应只提供文件搜索服务,而应着眼于成为一个综合性的门户,能够更快地达到目标,并为每个人提高效率。这是大局。寻找的点。
搜索结果预览
当您在搜索结果列表中单击,或使用键盘上下方向键将搜索结果切换到某个音乐、图片、视频、文档或文件时,您会看到搜索结果右侧的区域名单扩大。此处将显示与搜索结果对应的预览窗格。
预览窗格将因类别而异。pdf、txt文档可以查看文档首页快照;图片、视频预览可以看到更详细的属性信息,在预览窗格的头部区域可以查看缩略图。
预览窗格不仅提供文件属性信息和文档主页快照的预览,还提供常用文件操作的快捷入口。例如,用户在预览搜索结果时,只需要打开文件路径,或者只需要复制文件路径,就可以在预览窗格底部一键进行操作,即非常方便快捷。
搜索设置
考虑到用户自身的自定义需求,全局搜索提供了一些自定义设置功能。右击任务栏中的放大镜入口图标,可以看到搜索设置的入口。单击搜索设置以查看全局搜索设置面板。
在设置面板中,用户可以根据自己的需要自定义哪些类别可以搜索和召回到搜索结果列表中。每个类别项都可以在开关上独立设置,提供了较高的灵活性。
全局搜索不仅仅是搜索。它仍在增长。将持续探索和优化大家的日常使用场景和习惯,提供更精细、更高效的直接体验。
deepin是一个Linux发行版,致力于为全球用户提供美观、易用、安全、稳定的服务。它也是中国团队开发的排名最高的发行版。支持全球33种语言,累计下载量超过8000万次,在6大洲42个国家拥有135个镜像站点。 查看全部
搜索引擎优化pdf(深度操作系统:全局搜索是一个桌面系统级搜索服务详解)
IT之家12月2日报道称,深度操作系统20.3将于11月迎来更新,Stable内核将升级至5.15版本,进一步提升兼容性。修复系统安全漏洞,增强安全性。一些深度应用增加并优化了常用功能,以满足不同场景的需求。修复和优化桌面环境中的一些问题,只为带来更好的体验。
Deepin现在为大家带来桌面系统级搜索服务“全局搜索”新功能的详细讲解。
设计初衷:希望用户能输入尽可能少的内容,以找到他们想要的目标文件、应用程序或设置。
为什么要进行全局搜索?
在操作系统的使用过程中,我们收到了很多用户的反馈。在日常使用中,用户都希望直接进入某个场景,希望能方便一些。
基于直接搜索目标的效率,我们希望可以有一个系统级的服务可以很好的承担这个责任。全局搜索恰好有这个属性。
功能入口
全局搜索的功能入口位于任务栏右侧,与虚拟键盘位于同一区域。用鼠标点击放大镜的入口,打开屏幕中央的全局搜索框。
搜索栏
搜索框唤醒后,您可以在搜索框中输入要查找的文件、应用程序或设置关键字。在输入过程中随时调整输入文本内容,搜索结果列表会及时刷新搜索结果,让您快速找到搜索目标。
搜索结果列表
搜索结果列表支持显示更细粒度的搜索结果分类。例如,当您输入艺术家姓名时,如果恰好有一个mp3格式的歌曲文件收录
艺术家姓名,那么您可以在“音乐”类别下查看相应的搜索结果。
同样,如果可以对收录
搜索关键字的文档文件、图像文件和视频文件进行聚类和调用,则可以在指定的类别下查看搜索结果,以节省搜索时间。
当单个搜索类别下搜索结果过多时,默认折叠。因为太多的搜索结果会把列表拖的很长,不利于查看。单击“查看更多”可展开指定搜索类别的列表区域。
全局搜索支持多种类别搜索。在实际使用中,你会发现应用和网页搜索结果会比较高。
在排名方面,我们考虑的是,全球搜索不应只提供文件搜索服务,而应着眼于成为一个综合性的门户,能够更快地达到目标,并为每个人提高效率。这是大局。寻找的点。
搜索结果预览
当您在搜索结果列表中单击,或使用键盘上下方向键将搜索结果切换到某个音乐、图片、视频、文档或文件时,您会看到搜索结果右侧的区域名单扩大。此处将显示与搜索结果对应的预览窗格。
预览窗格将因类别而异。pdf、txt文档可以查看文档首页快照;图片、视频预览可以看到更详细的属性信息,在预览窗格的头部区域可以查看缩略图。
预览窗格不仅提供文件属性信息和文档主页快照的预览,还提供常用文件操作的快捷入口。例如,用户在预览搜索结果时,只需要打开文件路径,或者只需要复制文件路径,就可以在预览窗格底部一键进行操作,即非常方便快捷。
搜索设置
考虑到用户自身的自定义需求,全局搜索提供了一些自定义设置功能。右击任务栏中的放大镜入口图标,可以看到搜索设置的入口。单击搜索设置以查看全局搜索设置面板。
在设置面板中,用户可以根据自己的需要自定义哪些类别可以搜索和召回到搜索结果列表中。每个类别项都可以在开关上独立设置,提供了较高的灵活性。
全局搜索不仅仅是搜索。它仍在增长。将持续探索和优化大家的日常使用场景和习惯,提供更精细、更高效的直接体验。
deepin是一个Linux发行版,致力于为全球用户提供美观、易用、安全、稳定的服务。它也是中国团队开发的排名最高的发行版。支持全球33种语言,累计下载量超过8000万次,在6大洲42个国家拥有135个镜像站点。
搜索引擎优化pdf( 搜索引擎传统的搜索与搜索引擎Java全文搜索引擎框架Lucene1.1简介 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2021-12-25 19:20
搜索引擎传统的搜索与搜索引擎Java全文搜索引擎框架Lucene1.1简介
)
一、搜索引擎基本介绍
1. 什么是搜索引擎
搜索引擎通常是指一种全文搜索引擎,它采集
万维网上数千万到数十亿的网页,并将网页中的每个词(即关键词)编入索引,建立索引数据库。当用户搜索某个关键词时,页面内容中收录
关键词的所有网页都会被搜索出来作为搜索结果。这些结果经过复杂的算法排序(或包括商业竞价排名、商业推广或广告)后,将根据与搜索关键词(或与相关性无关)的相关程度进行排序。
2. 传统搜索与搜索引擎对比
2.1 传统方法
(1)在文档中使用系统的Find搜索
(2)在mysql中使用like模糊查询
有一个问题:
(1)海量数据无法及时响应,少量数据可通过传统MySql索引解决
(2)一些无用的词无法过滤,无法切分
(3)数据量大的话,很难扩展
(4) 相同的数据很难排序最相似的
2.2 搜索引擎实践
(1)存储非结构化数据
(2)快速检索和响应我们需要的信息,快速准确
(3) 执行相关性排序、过滤等。
(4)可以去除停用词(没有特殊含义的词,如英文a、is等,中文:this、yes等),框架一般支持自定义停用词
二、常见搜索引擎框架介绍与对比
1. Java全文搜索引擎框架Lucene
1.1 简介
Lucene 的开发语言是 Java,它也是 Java 家族中最著名的开源搜索引擎。它已经是Java世界中标准的全文搜索程序。它提供了完整的查询引擎和索引引擎。没有中文分词引擎,需要自己去。实现,所以用Lucene搭建搜索引擎需要自己的架构,不支持实时搜索。但是solr和elasticsearch都是基于Lucene封装的。
1.2 优点
成熟的解决方案有很多成功的案例。顶级apache项目正在持续快速推进。庞大而活跃的开发社区,大量的开发者。只是一个类库,有足够的定制和优化空间:简单定制后,可以满足大部分常见的需求;优化后可支持10亿+搜索。
1.3 缺点
需要额外的开发工作。所有的扩展、分发、可靠性等都需要自己来实现;非实时,从索引到搜索存在时间延迟,目前的“近实时”(Lucene Near Real Time search)搜索方案在可扩展性方面还需要进一步完善。
2. Apache Solr
2.1 简介
Solr 是一个基于 Lucene 的高性能全文搜索服务器,用 Java 开发。使用 XML 通过 Http 将文档添加到搜索集合中。查询集合也是通过 http 接收 XML/JSON 响应来实现的。其主要特点包括:高效灵活的缓存功能、垂直搜索功能、突出搜索结果、索引复制以提高可用性、提供一套强大的Data Schema来定义文本分析的字段、类型和设置,并提供基于Web的管理界面, 等等。
2.2 优点
(1)Solr 拥有更大、更成熟的用户、开发人员和贡献者社区。
(2) 支持添加多种格式的索引,如HTML、PDF、Microsoft Office系列软件格式,以及JSON、XML、CSV等纯文本格式。
(3)Solr 比较成熟稳定。
(4) 不考虑索引,搜索速度更快。
2.3 缺点
索引时,搜索效率降低,实时索引搜索效率不高
3. 弹性搜索
3.1 简介
ElasticSearch 是一个基于 Lucene 的开源、分布式、RESTful 搜索引擎。专为在云计算中使用而设计,可实现实时搜索,稳定可靠,速度快,安装使用方便。支持通过 HTTP 使用 JSON 进行数据索引。
3.2 优点
(1)Elasticsearch 是分布式的,不需要其他组件,而且是实时的,也就是所谓的“推送复制”。
(2)Elasticsearch 完全支持 Apache Lucene 的近实时搜索。
(3)处理多租户(multitenancy)不需要特殊配置,而Solr需要更高级的设置。
(4)Elasticsearch 使用了网关的概念,更容易完成备份。
每个节点形成一个点对点的网络结构,当一些节点出现故障时,会自动分配其他节点来替换它们。
3.3 缺点
不够自动化(不适合当前新的 Index Warmup API)
4. Elasticsearch 和 Solr 对比
(1) 两者都很容易安装
(2)Solr 使用 Zookeeper 进行分布式管理,Elasticsearch 本身具有分布式协调管理功能;
(3)Solr支持更多格式的数据,而Elasticsearch只支持json文件格式;
(4)Solr 官方提供了更多功能,而Elasticsearch 本身更注重核心功能,大部分高级功能由第三方插件提供;
(5)Solr 在传统搜索应用中的表现优于 Elasticsearch,但在处理实时搜索应用时,其效率明显低于 Elasticsearch。
(6)总之,Solr 是传统搜索应用的强大解决方案,而 Elasticsearch 更适合新兴的实时搜索应用。
5. 狮身人面像
5.1 简介
Sphinx 是一个基于 SQL 的全文搜索引擎,专门为一些脚本语言(PHP、Python、Perl、Ruby)设计的搜索 API 接口。
Sphinx 是一个用 C++ 语言编写的开源搜索引擎。它也是比较主流的搜索引擎之一。它在索引事件方面比 Lucene 快 50%,但索引文件是 Lucene 的两倍。因此,Sphinx 正在建立索引 一方面是为事件交换空间的策略。在搜索速度上,它和Lucene差别不大,但Lucene在搜索准确度上要优于Sphinx。另外,Lucene在加入中文分词引擎的难度上要优于Sphinx。其中Sphinx支持实时搜索。,使用起来比较简单方便。
Sphinx 可以轻松地与 SQL 数据库和脚本语言集成。当前系统内置了对 MySQL 和 PostgreSQL 数据库数据源的支持,也支持从标准输入中读取特定格式的 XML 数据。通过修改源代码,用户可以自行添加新的数据源(例如:原生支持其他类型的DBMS)
5.2 特点
(1) 高速索引(在当代 CPU 上,峰值性能可以达到 10 MB/秒);
(2)高性能搜索(在2-4GB文本数据上,每次检索平均响应时间小于0.1秒);
(3)可以处理海量数据(目前已知可以处理100GB以上的文本数据,单CPU系统可以处理100M文档);
(4) 提供了一个优秀的相关算法,基于词组相似度和统计(BM25) 的复合排序方法;
(5) 支持分布式搜索;
(6)支持词组搜索
(7)提供文档摘要生成
(8)可以作为MySQL存储引擎提供搜索服务;
(9)支持布尔、词组、词相似等多种检索模式;
(10) 文档支持多个全文搜索字段(最多32个);
(1 1) 文档支持多个附加属性信息(例如:分组信息、时间戳等);
(12)支持分词;
6. 卡塔
6.1 简介
基于Lucene,支持分布式、可扩展、容错、准实时的搜索解决方案。
6.2 优点
开箱即用,它可以与 Hadoop 一起分发。具有扩展和容错机制。
6.3 缺点
这只是一个搜索解决方案,索引部分仍然需要自己实现。在搜索功能中,只满足最基本的要求。成功案例较少,项目成熟度略低。因为需要支持分发,所以对于一些复杂的查询需求,定制起来会比较困难。
链接:www.cnblogs.com/WUXIAOCHANG
回复“资源”,接收上手源码、视频教程、微服务、并发、数据调整等,搜索【Java灵魂伴侣】
查看全部
搜索引擎优化pdf(
搜索引擎传统的搜索与搜索引擎Java全文搜索引擎框架Lucene1.1简介
)
一、搜索引擎基本介绍
1. 什么是搜索引擎
搜索引擎通常是指一种全文搜索引擎,它采集
万维网上数千万到数十亿的网页,并将网页中的每个词(即关键词)编入索引,建立索引数据库。当用户搜索某个关键词时,页面内容中收录
关键词的所有网页都会被搜索出来作为搜索结果。这些结果经过复杂的算法排序(或包括商业竞价排名、商业推广或广告)后,将根据与搜索关键词(或与相关性无关)的相关程度进行排序。
2. 传统搜索与搜索引擎对比
2.1 传统方法
(1)在文档中使用系统的Find搜索
(2)在mysql中使用like模糊查询
有一个问题:
(1)海量数据无法及时响应,少量数据可通过传统MySql索引解决
(2)一些无用的词无法过滤,无法切分
(3)数据量大的话,很难扩展
(4) 相同的数据很难排序最相似的
2.2 搜索引擎实践
(1)存储非结构化数据
(2)快速检索和响应我们需要的信息,快速准确
(3) 执行相关性排序、过滤等。
(4)可以去除停用词(没有特殊含义的词,如英文a、is等,中文:this、yes等),框架一般支持自定义停用词
二、常见搜索引擎框架介绍与对比
1. Java全文搜索引擎框架Lucene
1.1 简介
Lucene 的开发语言是 Java,它也是 Java 家族中最著名的开源搜索引擎。它已经是Java世界中标准的全文搜索程序。它提供了完整的查询引擎和索引引擎。没有中文分词引擎,需要自己去。实现,所以用Lucene搭建搜索引擎需要自己的架构,不支持实时搜索。但是solr和elasticsearch都是基于Lucene封装的。
1.2 优点
成熟的解决方案有很多成功的案例。顶级apache项目正在持续快速推进。庞大而活跃的开发社区,大量的开发者。只是一个类库,有足够的定制和优化空间:简单定制后,可以满足大部分常见的需求;优化后可支持10亿+搜索。
1.3 缺点
需要额外的开发工作。所有的扩展、分发、可靠性等都需要自己来实现;非实时,从索引到搜索存在时间延迟,目前的“近实时”(Lucene Near Real Time search)搜索方案在可扩展性方面还需要进一步完善。
2. Apache Solr
2.1 简介
Solr 是一个基于 Lucene 的高性能全文搜索服务器,用 Java 开发。使用 XML 通过 Http 将文档添加到搜索集合中。查询集合也是通过 http 接收 XML/JSON 响应来实现的。其主要特点包括:高效灵活的缓存功能、垂直搜索功能、突出搜索结果、索引复制以提高可用性、提供一套强大的Data Schema来定义文本分析的字段、类型和设置,并提供基于Web的管理界面, 等等。
2.2 优点
(1)Solr 拥有更大、更成熟的用户、开发人员和贡献者社区。
(2) 支持添加多种格式的索引,如HTML、PDF、Microsoft Office系列软件格式,以及JSON、XML、CSV等纯文本格式。
(3)Solr 比较成熟稳定。
(4) 不考虑索引,搜索速度更快。
2.3 缺点
索引时,搜索效率降低,实时索引搜索效率不高
3. 弹性搜索
3.1 简介
ElasticSearch 是一个基于 Lucene 的开源、分布式、RESTful 搜索引擎。专为在云计算中使用而设计,可实现实时搜索,稳定可靠,速度快,安装使用方便。支持通过 HTTP 使用 JSON 进行数据索引。
3.2 优点
(1)Elasticsearch 是分布式的,不需要其他组件,而且是实时的,也就是所谓的“推送复制”。
(2)Elasticsearch 完全支持 Apache Lucene 的近实时搜索。
(3)处理多租户(multitenancy)不需要特殊配置,而Solr需要更高级的设置。
(4)Elasticsearch 使用了网关的概念,更容易完成备份。
每个节点形成一个点对点的网络结构,当一些节点出现故障时,会自动分配其他节点来替换它们。
3.3 缺点
不够自动化(不适合当前新的 Index Warmup API)
4. Elasticsearch 和 Solr 对比
(1) 两者都很容易安装
(2)Solr 使用 Zookeeper 进行分布式管理,Elasticsearch 本身具有分布式协调管理功能;
(3)Solr支持更多格式的数据,而Elasticsearch只支持json文件格式;
(4)Solr 官方提供了更多功能,而Elasticsearch 本身更注重核心功能,大部分高级功能由第三方插件提供;
(5)Solr 在传统搜索应用中的表现优于 Elasticsearch,但在处理实时搜索应用时,其效率明显低于 Elasticsearch。
(6)总之,Solr 是传统搜索应用的强大解决方案,而 Elasticsearch 更适合新兴的实时搜索应用。
5. 狮身人面像
5.1 简介
Sphinx 是一个基于 SQL 的全文搜索引擎,专门为一些脚本语言(PHP、Python、Perl、Ruby)设计的搜索 API 接口。
Sphinx 是一个用 C++ 语言编写的开源搜索引擎。它也是比较主流的搜索引擎之一。它在索引事件方面比 Lucene 快 50%,但索引文件是 Lucene 的两倍。因此,Sphinx 正在建立索引 一方面是为事件交换空间的策略。在搜索速度上,它和Lucene差别不大,但Lucene在搜索准确度上要优于Sphinx。另外,Lucene在加入中文分词引擎的难度上要优于Sphinx。其中Sphinx支持实时搜索。,使用起来比较简单方便。
Sphinx 可以轻松地与 SQL 数据库和脚本语言集成。当前系统内置了对 MySQL 和 PostgreSQL 数据库数据源的支持,也支持从标准输入中读取特定格式的 XML 数据。通过修改源代码,用户可以自行添加新的数据源(例如:原生支持其他类型的DBMS)
5.2 特点
(1) 高速索引(在当代 CPU 上,峰值性能可以达到 10 MB/秒);
(2)高性能搜索(在2-4GB文本数据上,每次检索平均响应时间小于0.1秒);
(3)可以处理海量数据(目前已知可以处理100GB以上的文本数据,单CPU系统可以处理100M文档);
(4) 提供了一个优秀的相关算法,基于词组相似度和统计(BM25) 的复合排序方法;
(5) 支持分布式搜索;
(6)支持词组搜索
(7)提供文档摘要生成
(8)可以作为MySQL存储引擎提供搜索服务;
(9)支持布尔、词组、词相似等多种检索模式;
(10) 文档支持多个全文搜索字段(最多32个);
(1 1) 文档支持多个附加属性信息(例如:分组信息、时间戳等);
(12)支持分词;
6. 卡塔
6.1 简介
基于Lucene,支持分布式、可扩展、容错、准实时的搜索解决方案。
6.2 优点
开箱即用,它可以与 Hadoop 一起分发。具有扩展和容错机制。
6.3 缺点
这只是一个搜索解决方案,索引部分仍然需要自己实现。在搜索功能中,只满足最基本的要求。成功案例较少,项目成熟度略低。因为需要支持分发,所以对于一些复杂的查询需求,定制起来会比较困难。
链接:www.cnblogs.com/WUXIAOCHANG
回复“资源”,接收上手源码、视频教程、微服务、并发、数据调整等,搜索【Java灵魂伴侣】
搜索引擎优化pdf(新手想要做SEO搜索引擎优化,必须先要了解的工作原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-25 19:16
搜索引擎是一种特定的计算机程序,它按照一定的策略从互联网上采集
信息,对信息进行处理,为用户提供检索服务,并将用户结果显示给用户。
搜索引擎优化(Search Engine Optimization)简称SEO,是指利用搜索引擎规则来提高一个网站在搜索引擎中的自然排名。这样可以获得更多的免费流量,让它在行业中占据更高的优势,获得更大的收益。
新手想做SEO搜索引擎优化,当然首先要了解搜索引擎的工作原理,不需要完全掌握,但概念的东西一定要印在脑子里。至于不同的搜索引擎,其实都是一样的,所以今天就来说说工作原理吧!
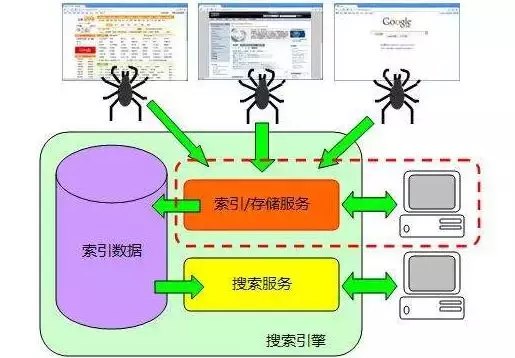
第 1 步:爬网
搜索引擎通过特定模式的软件跟踪到网页的链接,从一个链接爬到另一个链接,就像蜘蛛在蜘蛛网上爬行一样,因此被称为“蜘蛛”或“机器人”。搜索引擎蜘蛛的爬取是有一定的规则进入的,需要遵守一些命令或者文件的内容。
第 2 步:获取存储空间
搜索引擎通过蜘蛛跟踪链接抓取网页,并将抓取到的数据存储在原创
页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。在抓取页面时,搜索引擎蜘蛛也会做一定量的重复内容检测。一旦他们在一个低权重的网站上遇到大量抄袭、采集
或复制的内容,很可能会停止爬行。
第三步:预处理
搜索引擎会在各个步骤中对蜘蛛检索到的页面进行预处理;除了 HTML 文件,搜索引擎通常可以抓取和索引多种基于文本的文件类型,例如 PDF、Word、WPS、XLS、PPT、TXT 文件等,我们经常在搜索结果中看到这些文件类型。但是,搜索引擎无法处理图像、视频和 Flash 等非文本内容,也无法执行脚本和程序。
第 4 步:排名
用户在搜索框中输入关键词后,排名程序调用索引库数据,计算排名显示给用户,排名过程直接与用户交互。但是,由于搜索引擎的数据量巨大,虽然每天可以实现小幅更新,但搜索引擎的排名规则一般是按照日、周、月等不同级别进行更新。 查看全部
搜索引擎优化pdf(新手想要做SEO搜索引擎优化,必须先要了解的工作原理)
搜索引擎是一种特定的计算机程序,它按照一定的策略从互联网上采集
信息,对信息进行处理,为用户提供检索服务,并将用户结果显示给用户。
搜索引擎优化(Search Engine Optimization)简称SEO,是指利用搜索引擎规则来提高一个网站在搜索引擎中的自然排名。这样可以获得更多的免费流量,让它在行业中占据更高的优势,获得更大的收益。
新手想做SEO搜索引擎优化,当然首先要了解搜索引擎的工作原理,不需要完全掌握,但概念的东西一定要印在脑子里。至于不同的搜索引擎,其实都是一样的,所以今天就来说说工作原理吧!
第 1 步:爬网
搜索引擎通过特定模式的软件跟踪到网页的链接,从一个链接爬到另一个链接,就像蜘蛛在蜘蛛网上爬行一样,因此被称为“蜘蛛”或“机器人”。搜索引擎蜘蛛的爬取是有一定的规则进入的,需要遵守一些命令或者文件的内容。
第 2 步:获取存储空间
搜索引擎通过蜘蛛跟踪链接抓取网页,并将抓取到的数据存储在原创
页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。在抓取页面时,搜索引擎蜘蛛也会做一定量的重复内容检测。一旦他们在一个低权重的网站上遇到大量抄袭、采集
或复制的内容,很可能会停止爬行。
第三步:预处理
搜索引擎会在各个步骤中对蜘蛛检索到的页面进行预处理;除了 HTML 文件,搜索引擎通常可以抓取和索引多种基于文本的文件类型,例如 PDF、Word、WPS、XLS、PPT、TXT 文件等,我们经常在搜索结果中看到这些文件类型。但是,搜索引擎无法处理图像、视频和 Flash 等非文本内容,也无法执行脚本和程序。
第 4 步:排名
用户在搜索框中输入关键词后,排名程序调用索引库数据,计算排名显示给用户,排名过程直接与用户交互。但是,由于搜索引擎的数据量巨大,虽然每天可以实现小幅更新,但搜索引擎的排名规则一般是按照日、周、月等不同级别进行更新。
搜索引擎优化pdf( 如何使用Python构建自己的答案查找系统?|AI科技大本营)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-25 19:15
如何使用Python构建自己的答案查找系统?|AI科技大本营)
来源 | 黑客中午
编译| 吴明丽,主编| 颂歌
生产 | AI科技大本营(ID:rgznai100)
在本文中,我将向您展示如何使用 Python 构建自己的答案查找系统。基本上,这种自动化可以从图片中找到多项选择题的答案。
有一点我们要明确的是,考试期间无法在网上搜索题,但是当考官转身时,我可以快速拍照。这是算法的第一部分。我必须想办法从图片中提取这个问题。
似乎有很多服务可以提供文本提取工具,但是我需要某种API来解决这个问题。最后,Google 的 VisionAPI 正是我正在寻找的工具。很棒的是,每月前 1000 次 API 调用是免费的,这足以让我测试和使用 API。
视觉人工智能
首先创建一个谷歌云账号,然后在服务中搜索Vision AI。使用 VisionAI,您可以执行诸如为图像分配标签以组织图像、获取推荐的裁剪顶点、检测著名风景或地点以及提取文本等任务。
查看文档以启用和设置 API。配置后,您必须创建一个 JSON 文件,其中收录
您下载到计算机的密钥。
运行以下命令安装客户端库:
pip install google-cloud-vision
然后设置环境变量 GOOGLE_APPLICATION_CREDENTIALS 为应用程序代码提供身份验证凭据。
import os, iofrom google.cloud import visionfrom google.cloud.vision import types
# JSON file that contains your keyos.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'your_private_key.json'
# Instantiates a clientclient = vision.ImageAnnotatorClient
FILE_NAME = 'your_image_file.jpg'
# Loads the image into memorywith io.open(os.path.join(FILE_NAME), 'rb') as image_file: content = image_file.read
image = vision.types.Image(content=content)
# Performs text detection on the image fileresponse = client.text_detection(image=image)print(response)
# Extract descriptiontexts = response.text_annotations[0]print(texts.description)
运行代码时,您将看到 JSON 格式的响应,其中包括检测到的文本的规范。但是我们只需要一个纯粹的描述,所以我从响应中提取了这部分。
在 Google 上搜索问题
下一步是在 Google 上搜索问题部分以获取一些信息。我使用正则表达式(regex)库从描述(响应)中提取问题部分。然后我们必须混淆提取的问题部分,以便可以搜索。
import reimport urllib
# If ending with question markif '?' in texts.description: question = re.search('([^?]+)', texts.description).group(1)
# If ending with colonelif ':' in texts.description: question = re.search('([^:]+)', texts.description).group(1)# If ending with newlineelif '\n' in texts.description: question = re.search('([^\n]+)', texts.description).group(1)
# Slugify the matchslugify_keyword = urllib.parse.quote_plus(question)print(slugify_keyword)
爬取的信息
我们将使用 BeautifulSoup 抓取前 3 个结果以获取有关该问题的一些信息,因为答案可能在其中之一。
另外,如果你想从谷歌的搜索列表中抓取特定的数据,不要使用inspect元素来查找元素的属性,而是打印整个页面来查看属性,因为它与实际的属性不同。
我们需要抓取搜索结果中的前3个链接,但是这些链接确实是乱七八糟的,所以获取干净的链接进行抓取很重要。
/url?q=https://en.wikipedia.org/wiki/ ... 1t0en
如您所见,实际链接在 q= 和 &sa 之间。通过使用正则表达式 Regex,我们可以获得这个特定的字段或有效的 URL。
result_urls =
def crawl_result_urls: req = Request('https://google.com/search?q=' + slugify_keyword, headers={'User-Agent': 'Mozilla/5.0'}) html = urlopen(req).read bs = BeautifulSoup(html, 'html.parser') results = bs.find_all('div', class_='ZINbbc') try: for result in results: link = result.find('a')['href'] # Checking if it is url (in case) if 'url' in link: result_urls.append(re.search('q=(.*)&sa', link).group(1)) except (AttributeError, IndexError) as e: pass
在我们抓取这些 URL 的内容之前,让我向您展示使用 Python 的问答系统。
问答系统
这是算法的主要部分。从前 3 个结果中获取信息后,程序应遍历文档以检测答案。首先,我认为最好使用相似度算法来检测与问题最相似的文档,但我不知道如何实现。
经过几个小时的研究,我在 Medium 上找到了一篇解释 Python 问答系统的文章。它有一个易于使用的python软件包,可以为您自己的私人数据实现一个QA系统。
让我们先安装这个包:
pip install cdqa
我正在使用下面示例代码块中收录
的下载功能来手动下载预训练的模型和数据:
它的输出应该是这样的:
它打印出确切的答案和收录
答案的段落。
基本上,当问题从图片中提取并发送到系统时,检索器将从爬取的数据中选择最有可能收录
答案的文档列表。如前所述,它计算问题与爬取数据中每个文档之间的余弦相似度。
选择最有可能的文档后,系统将每个文档分成几段,将问题一起发送给读者。这基本上是一个预训练的深度学习模型。使用的模型是著名的 NLP 模型 BERT 的 Pytorch 版本。
然后,阅读器输出在每个段落中找到的最可能的答案。在读者之后,系统的最后一层通过使用内部评分函数对答案进行比较,并根据评分输出最可能的答案,这将得到我们问题的答案。
以下是系统机制的模式。
您必须在特定结构中设置数据框 (CSV) 才能将其发送到 cdQA 管道。
但实际上我使用 PDF 转换器从 PDF 文件目录创建了一个输入数据框。因此,我想将每个结果的所有抓取数据保存在一个 pdf 文件中。我们希望总共有 3 个 pdf 文件(也可以是 1 个或 2 个)。另外,我们需要给这些pdf文件命名,这也是我抓取每一页标题的原因。
def get_result_details(url): try: req = Request(url, headers={'User-Agent': 'Mozilla/5.0'}) html = urlopen(req).read bs = BeautifulSoup(html, 'html.parser') try: # Crawl any heading in result to name pdf file title = bs.find(re.compile('^h[1-6])).get_text.strip.replace('?', '').lower # Naming the pdf file filename = "/home/coderasha/autoans/pdfs/" + title + ".pdf" if not os.path.exists(os.path.dirname(filename)): try: os.makedirs(os.path.dirname(filename)) except OSError as exc: # Guard against race condition if exc.errno != errno.EEXIST: raise with open(filename, 'w') as f: # Crawl first 5 paragraphs for line in bs.find_all('p')[:5]: f.write(line.text + '\n') except AttributeError: pass except urllib.error.HTTPError: pass
def find_answer: df = pdf_converter(directory_path='/home/coderasha/autoans/pdfs') cdqa_pipeline = QAPipeline(reader='models/bert_qa.joblib') cdqa_pipeline.fit_retriever(df) query = question + '?' prediction = cdqa_pipeline.predict(query)
print('query: {}\n'.format(query)) print('answer: {}\n'.format(prediction[0])) print('title: {}\n'.format(prediction[1])) print('paragraph: {}\n'.format(prediction[2])) return prediction[0]
让我总结一下算法:它会从图片中提取问题,在谷歌上搜索它,抓取前3个结果,从抓取的数据中创建3个pdf文件,最后使用问答系统找到答案。
如果你想看看它是如何工作的,请检查我制作的一个机器人,它可以从图片中解决考试问题。
以下是完整代码:
import os, ioimport errnoimport urllibimport urllib.requestimport hashlibimport reimport requestsfrom time import sleepfrom google.cloud import visionfrom google.cloud.vision import typesfrom urllib.request import urlopen, Requestfrom bs4 import BeautifulSoupimport pandas as pdfrom ast import literal_evalfrom cdqa.utils.filters import filter_paragraphsfrom cdqa.utils.download import download_model, download_bnpp_datafrom cdqa.pipeline.cdqa_sklearn import QAPipelinefrom cdqa.utils.converters import pdf_converter
result_urls =
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'your_private_key.json'
client = vision.ImageAnnotatorClient
FILE_NAME = 'your_image_file.jpg'
with io.open(os.path.join(FILE_NAME), 'rb') as image_file: content = image_file.read
image = vision.types.Image(content=content)
response = client.text_detection(image=image)
texts = response.text_annotations[0]# print(texts.description)
if '?' in texts.description: question = re.search('([^?]+)', texts.description).group(1)
elif ':' in texts.description: question = re.search('([^:]+)', texts.description).group(1)
elif '\n' in texts.description: question = re.search('([^\n]+)', texts.description).group(1)
slugify_keyword = urllib.parse.quote_plus(question)# print(slugify_keyword)
def crawl_result_urls: req = Request('https://google.com/search?q=' + slugify_keyword, headers={'User-Agent': 'Mozilla/5.0'}) html = urlopen(req).read bs = BeautifulSoup(html, 'html.parser') results = bs.find_all('div', class_='ZINbbc') try: for result in results: link = result.find('a')['href'] print(link) if 'url' in link: result_urls.append(re.search('q=(.*)&sa', link).group(1)) except (AttributeError, IndexError) as e: pass
def get_result_details(url): try: req = Request(url, headers={'User-Agent': 'Mozilla/5.0'}) html = urlopen(req).read bs = BeautifulSoup(html, 'html.parser') try: title = bs.find(re.compile('^h[1-6])).get_text.strip.replace('?', '').lower # Set your path to pdf directory filename = "/path/to/pdf_folder/" + title + ".pdf" if not os.path.exists(os.path.dirname(filename)): try: os.makedirs(os.path.dirname(filename)) except OSError as exc: if exc.errno != errno.EEXIST: raise with open(filename, 'w') as f: for line in bs.find_all('p')[:5]: f.write(line.text + '\n') except AttributeError: pass except urllib.error.HTTPError: pass
def find_answer: # Set your path to pdf directory df = pdf_converter(directory_path='/path/to/pdf_folder/') cdqa_pipeline = QAPipeline(reader='models/bert_qa.joblib') cdqa_pipeline.fit_retriever(df) query = question + '?' prediction = cdqa_pipeline.predict(query)
# print('query: {}\n'.format(query)) # print('answer: {}\n'.format(prediction[0])) # print('title: {}\n'.format(prediction[1])) # print('paragraph: {}\n'.format(prediction[2])) return prediction[0]
crawl_result_urls
for url in result_urls[:3]: get_result_details(url) sleep(5)
answer = find_answerprint('Answer: ' + answer)
有时它可能会令人困惑,但我认为总体上是可以的。至少我能以60%的正确答案通过考试。
欢迎开发者在评论中告诉我你的看法!其实最好一次性把所有题都做一遍,但是我没有足够的时间做这个,所以我下次还要继续做。 查看全部
搜索引擎优化pdf(
如何使用Python构建自己的答案查找系统?|AI科技大本营)
来源 | 黑客中午
编译| 吴明丽,主编| 颂歌
生产 | AI科技大本营(ID:rgznai100)
在本文中,我将向您展示如何使用 Python 构建自己的答案查找系统。基本上,这种自动化可以从图片中找到多项选择题的答案。
有一点我们要明确的是,考试期间无法在网上搜索题,但是当考官转身时,我可以快速拍照。这是算法的第一部分。我必须想办法从图片中提取这个问题。
似乎有很多服务可以提供文本提取工具,但是我需要某种API来解决这个问题。最后,Google 的 VisionAPI 正是我正在寻找的工具。很棒的是,每月前 1000 次 API 调用是免费的,这足以让我测试和使用 API。
视觉人工智能
首先创建一个谷歌云账号,然后在服务中搜索Vision AI。使用 VisionAI,您可以执行诸如为图像分配标签以组织图像、获取推荐的裁剪顶点、检测著名风景或地点以及提取文本等任务。
查看文档以启用和设置 API。配置后,您必须创建一个 JSON 文件,其中收录
您下载到计算机的密钥。
运行以下命令安装客户端库:
pip install google-cloud-vision
然后设置环境变量 GOOGLE_APPLICATION_CREDENTIALS 为应用程序代码提供身份验证凭据。
import os, iofrom google.cloud import visionfrom google.cloud.vision import types
# JSON file that contains your keyos.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'your_private_key.json'
# Instantiates a clientclient = vision.ImageAnnotatorClient
FILE_NAME = 'your_image_file.jpg'
# Loads the image into memorywith io.open(os.path.join(FILE_NAME), 'rb') as image_file: content = image_file.read
image = vision.types.Image(content=content)
# Performs text detection on the image fileresponse = client.text_detection(image=image)print(response)
# Extract descriptiontexts = response.text_annotations[0]print(texts.description)
运行代码时,您将看到 JSON 格式的响应,其中包括检测到的文本的规范。但是我们只需要一个纯粹的描述,所以我从响应中提取了这部分。
在 Google 上搜索问题
下一步是在 Google 上搜索问题部分以获取一些信息。我使用正则表达式(regex)库从描述(响应)中提取问题部分。然后我们必须混淆提取的问题部分,以便可以搜索。
import reimport urllib
# If ending with question markif '?' in texts.description: question = re.search('([^?]+)', texts.description).group(1)
# If ending with colonelif ':' in texts.description: question = re.search('([^:]+)', texts.description).group(1)# If ending with newlineelif '\n' in texts.description: question = re.search('([^\n]+)', texts.description).group(1)
# Slugify the matchslugify_keyword = urllib.parse.quote_plus(question)print(slugify_keyword)
爬取的信息
我们将使用 BeautifulSoup 抓取前 3 个结果以获取有关该问题的一些信息,因为答案可能在其中之一。
另外,如果你想从谷歌的搜索列表中抓取特定的数据,不要使用inspect元素来查找元素的属性,而是打印整个页面来查看属性,因为它与实际的属性不同。
我们需要抓取搜索结果中的前3个链接,但是这些链接确实是乱七八糟的,所以获取干净的链接进行抓取很重要。
/url?q=https://en.wikipedia.org/wiki/ ... 1t0en
如您所见,实际链接在 q= 和 &sa 之间。通过使用正则表达式 Regex,我们可以获得这个特定的字段或有效的 URL。
result_urls =
def crawl_result_urls: req = Request('https://google.com/search?q=' + slugify_keyword, headers={'User-Agent': 'Mozilla/5.0'}) html = urlopen(req).read bs = BeautifulSoup(html, 'html.parser') results = bs.find_all('div', class_='ZINbbc') try: for result in results: link = result.find('a')['href'] # Checking if it is url (in case) if 'url' in link: result_urls.append(re.search('q=(.*)&sa', link).group(1)) except (AttributeError, IndexError) as e: pass
在我们抓取这些 URL 的内容之前,让我向您展示使用 Python 的问答系统。
问答系统
这是算法的主要部分。从前 3 个结果中获取信息后,程序应遍历文档以检测答案。首先,我认为最好使用相似度算法来检测与问题最相似的文档,但我不知道如何实现。
经过几个小时的研究,我在 Medium 上找到了一篇解释 Python 问答系统的文章。它有一个易于使用的python软件包,可以为您自己的私人数据实现一个QA系统。
让我们先安装这个包:
pip install cdqa
我正在使用下面示例代码块中收录
的下载功能来手动下载预训练的模型和数据:
它的输出应该是这样的:
它打印出确切的答案和收录
答案的段落。
基本上,当问题从图片中提取并发送到系统时,检索器将从爬取的数据中选择最有可能收录
答案的文档列表。如前所述,它计算问题与爬取数据中每个文档之间的余弦相似度。
选择最有可能的文档后,系统将每个文档分成几段,将问题一起发送给读者。这基本上是一个预训练的深度学习模型。使用的模型是著名的 NLP 模型 BERT 的 Pytorch 版本。
然后,阅读器输出在每个段落中找到的最可能的答案。在读者之后,系统的最后一层通过使用内部评分函数对答案进行比较,并根据评分输出最可能的答案,这将得到我们问题的答案。
以下是系统机制的模式。
您必须在特定结构中设置数据框 (CSV) 才能将其发送到 cdQA 管道。
但实际上我使用 PDF 转换器从 PDF 文件目录创建了一个输入数据框。因此,我想将每个结果的所有抓取数据保存在一个 pdf 文件中。我们希望总共有 3 个 pdf 文件(也可以是 1 个或 2 个)。另外,我们需要给这些pdf文件命名,这也是我抓取每一页标题的原因。
def get_result_details(url): try: req = Request(url, headers={'User-Agent': 'Mozilla/5.0'}) html = urlopen(req).read bs = BeautifulSoup(html, 'html.parser') try: # Crawl any heading in result to name pdf file title = bs.find(re.compile('^h[1-6])).get_text.strip.replace('?', '').lower # Naming the pdf file filename = "/home/coderasha/autoans/pdfs/" + title + ".pdf" if not os.path.exists(os.path.dirname(filename)): try: os.makedirs(os.path.dirname(filename)) except OSError as exc: # Guard against race condition if exc.errno != errno.EEXIST: raise with open(filename, 'w') as f: # Crawl first 5 paragraphs for line in bs.find_all('p')[:5]: f.write(line.text + '\n') except AttributeError: pass except urllib.error.HTTPError: pass
def find_answer: df = pdf_converter(directory_path='/home/coderasha/autoans/pdfs') cdqa_pipeline = QAPipeline(reader='models/bert_qa.joblib') cdqa_pipeline.fit_retriever(df) query = question + '?' prediction = cdqa_pipeline.predict(query)
print('query: {}\n'.format(query)) print('answer: {}\n'.format(prediction[0])) print('title: {}\n'.format(prediction[1])) print('paragraph: {}\n'.format(prediction[2])) return prediction[0]
让我总结一下算法:它会从图片中提取问题,在谷歌上搜索它,抓取前3个结果,从抓取的数据中创建3个pdf文件,最后使用问答系统找到答案。
如果你想看看它是如何工作的,请检查我制作的一个机器人,它可以从图片中解决考试问题。
以下是完整代码:
import os, ioimport errnoimport urllibimport urllib.requestimport hashlibimport reimport requestsfrom time import sleepfrom google.cloud import visionfrom google.cloud.vision import typesfrom urllib.request import urlopen, Requestfrom bs4 import BeautifulSoupimport pandas as pdfrom ast import literal_evalfrom cdqa.utils.filters import filter_paragraphsfrom cdqa.utils.download import download_model, download_bnpp_datafrom cdqa.pipeline.cdqa_sklearn import QAPipelinefrom cdqa.utils.converters import pdf_converter
result_urls =
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'your_private_key.json'
client = vision.ImageAnnotatorClient
FILE_NAME = 'your_image_file.jpg'
with io.open(os.path.join(FILE_NAME), 'rb') as image_file: content = image_file.read
image = vision.types.Image(content=content)
response = client.text_detection(image=image)
texts = response.text_annotations[0]# print(texts.description)
if '?' in texts.description: question = re.search('([^?]+)', texts.description).group(1)
elif ':' in texts.description: question = re.search('([^:]+)', texts.description).group(1)
elif '\n' in texts.description: question = re.search('([^\n]+)', texts.description).group(1)
slugify_keyword = urllib.parse.quote_plus(question)# print(slugify_keyword)
def crawl_result_urls: req = Request('https://google.com/search?q=' + slugify_keyword, headers={'User-Agent': 'Mozilla/5.0'}) html = urlopen(req).read bs = BeautifulSoup(html, 'html.parser') results = bs.find_all('div', class_='ZINbbc') try: for result in results: link = result.find('a')['href'] print(link) if 'url' in link: result_urls.append(re.search('q=(.*)&sa', link).group(1)) except (AttributeError, IndexError) as e: pass
def get_result_details(url): try: req = Request(url, headers={'User-Agent': 'Mozilla/5.0'}) html = urlopen(req).read bs = BeautifulSoup(html, 'html.parser') try: title = bs.find(re.compile('^h[1-6])).get_text.strip.replace('?', '').lower # Set your path to pdf directory filename = "/path/to/pdf_folder/" + title + ".pdf" if not os.path.exists(os.path.dirname(filename)): try: os.makedirs(os.path.dirname(filename)) except OSError as exc: if exc.errno != errno.EEXIST: raise with open(filename, 'w') as f: for line in bs.find_all('p')[:5]: f.write(line.text + '\n') except AttributeError: pass except urllib.error.HTTPError: pass
def find_answer: # Set your path to pdf directory df = pdf_converter(directory_path='/path/to/pdf_folder/') cdqa_pipeline = QAPipeline(reader='models/bert_qa.joblib') cdqa_pipeline.fit_retriever(df) query = question + '?' prediction = cdqa_pipeline.predict(query)
# print('query: {}\n'.format(query)) # print('answer: {}\n'.format(prediction[0])) # print('title: {}\n'.format(prediction[1])) # print('paragraph: {}\n'.format(prediction[2])) return prediction[0]
crawl_result_urls
for url in result_urls[:3]: get_result_details(url) sleep(5)
answer = find_answerprint('Answer: ' + answer)
有时它可能会令人困惑,但我认为总体上是可以的。至少我能以60%的正确答案通过考试。
欢迎开发者在评论中告诉我你的看法!其实最好一次性把所有题都做一遍,但是我没有足够的时间做这个,所以我下次还要继续做。
搜索引擎优化pdf( SEOMagicBook浩维互动免费电子书wwwtimevnet目录关于这本书1目录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-23 11:04
SEOMagicBook浩维互动免费电子书wwwtimevnet目录关于这本书1目录)
搜索引擎优化魔法书 SEOMagicBook Haowei Interactive 免费电子书 wwwtimevnet 目录 关于本书 1 第一章 搜索引擎基础 2 第一节 什么是搜索引擎 2 一 搜索引擎的作用 2 搜索引擎的两个定义 4 第二节 搜索的基本工作原理4 一抓取 5 二索引 5 三排序 5 段三搜索引擎分类 6 一页级搜索 6 二垂直搜索 6 三元搜索引擎 6 四目录搜索 6 五综合搜索 7 段四搜索 引擎的未来 7 1 快速 7 2 多元化 7 3 智能 7 4 社交 7 5 性 8 5 主要搜索引擎介绍 8 1 谷歌 8 2 雅虎 12 3 百度 13 4 搜狗 15 5 中文搜索引擎列表 16 第二章搜索引擎营销基础 17 第一节 什么是搜索引擎营销 17 一 搜索引擎营销的定义 17 二 搜索引擎营销的价值 17 搜索引擎营销的三大原则 18 第二节 搜索引擎营销的特点 19 一 广泛使用 19 二 用户主动查询具有高度相关性 19 三 获取新客户 19 四竞争激烈 20 Page 1 搜索引擎优化魔法书 SEOM
百度 30 四 搜狗 34 第三节 白帽 SEO 和黑帽 SEO 37 第四节 搜索引擎优化的发展 39 一 SEO 的发展历程 39 二 SEO 在中国 40 三 SEO 的发展方向 42 第五节 对搜索引擎的一些看法优化 43 1. 搜索引擎优化合法吗?43 2. 他会搜索吗?
搜索引擎正面临工作 43 3. 搜索引擎会不会手动干扰 44 4. 我的 网站 有很多高质量的 原创 内容,所以我不再需要 SEO 44 5. SEO 没有技术含量或SEO 需要非常深厚的技能 44 六大网站 做到了。我也向他们学习了 44 七家SEO公司或SEO工具保证排名提升 44 八位稳定排名 45 九 SEO目标是获得第一名或尽可能多的访问量 45 十大竞争对手无法破坏我的排名 45 第四章SEO相关搜索引擎技术 46 Page 2 搜索引擎优化魔法书 SEOMagicBook 浩威互动免费电子书 wwwtimevnet 第一节搜索引擎机器人 46 一 什么是搜索引擎机器人 46 2. 如何识别搜索引擎机器人的身份 47 第二节. 超链分析 47 1 .
应用 53 六中文搜索引擎技术 54 第四节基于词义的文本分析 55 一文本分析技术特点 55 二文本分析应用 55 第五章网站的搜索引擎性能理解 57 第一节基本查询 57 1.域名信息查询 57 2. 域名历史查询 57 3. 主机连接速度和 IP 地址查询 57 四带 IP 收录编号 58 Section 3 Backlink Query 59 Section 4 Web Page RANK 查询 59 一个 GooglePageRank 查询 59 两个 SogouRank 查询 59第五节 关键词 排名查询 59 第六节 ALEXA 查询 60 一 什么是 Alexa 60 2. Alexa 主要数据 60 3. 用 Alexa 检查什么 60 第 6 章基于搜索引擎友好的 网站 设计 62 Section 1域名策略 62 1.不同后缀域名在搜索引擎中的权重 62 2. 域名基本常识 62 Page 3 搜索引擎优化魔法书 SEOMagicBook 豪威互动免费电子书 wwwtimevnet 关键词 三个域名策略之六
9 4 中文网站域名拼音策略 70 5 小心注册被搜索引擎惩罚的域名 70 第二节 空间策略 71 1 安全要素 1 稳定性 71 2 安全要素 2 良好的共存环境 71 3 本节附录 72第三节网站结构规划72第四节网站导航设计73第五节IFRAMEVASACRIPT和AJAX73一个IFRAME74两个JS74三个AJAX74第六节URL设计75一个易于记忆75两个URL静态75三个URL关键词部署 78 第七节 网页代码编写 80 一遵循WEB标准 篮球课程标准 尘肺病标准片 党员活动室建设分级护理精细化标准 儿科分级护理标准 80 第二个代码的逻辑 80 第八节 面向搜索引擎的文案指南 81 1. 网页标题 标题 81 2. 元元标记 84 3. 图片 ALT 替换文本 85 4. Robotstxt 85 5. 链接锚文本 89 6. 站点地图 xml 89 7. 版权和隐私 97 第 9 节 用户友好性检查 97 1. 链接可用性 97 2. 访问速度体验 97 三个查找信息的便捷性 98 第七章 创建搜索引擎喜欢的内容站点地图 xml 89 7. 版权和隐私 97 第 9 节 用户友好性检查 97 1. 链接可用性 97 2. 访问速度体验 97 查找信息的三个便利性 98 第七章 创建搜索引擎喜欢的内容站点地图 xml 89 7. 版权和隐私 97 第 9 节 用户友好性检查 97 1. 链接可用性 97 2. 访问速度体验 97 查找信息的三个便利性 98 第七章 创建搜索引擎喜欢的内容 查看全部
搜索引擎优化pdf(
SEOMagicBook浩维互动免费电子书wwwtimevnet目录关于这本书1目录)

搜索引擎优化魔法书 SEOMagicBook Haowei Interactive 免费电子书 wwwtimevnet 目录 关于本书 1 第一章 搜索引擎基础 2 第一节 什么是搜索引擎 2 一 搜索引擎的作用 2 搜索引擎的两个定义 4 第二节 搜索的基本工作原理4 一抓取 5 二索引 5 三排序 5 段三搜索引擎分类 6 一页级搜索 6 二垂直搜索 6 三元搜索引擎 6 四目录搜索 6 五综合搜索 7 段四搜索 引擎的未来 7 1 快速 7 2 多元化 7 3 智能 7 4 社交 7 5 性 8 5 主要搜索引擎介绍 8 1 谷歌 8 2 雅虎 12 3 百度 13 4 搜狗 15 5 中文搜索引擎列表 16 第二章搜索引擎营销基础 17 第一节 什么是搜索引擎营销 17 一 搜索引擎营销的定义 17 二 搜索引擎营销的价值 17 搜索引擎营销的三大原则 18 第二节 搜索引擎营销的特点 19 一 广泛使用 19 二 用户主动查询具有高度相关性 19 三 获取新客户 19 四竞争激烈 20 Page 1 搜索引擎优化魔法书 SEOM

百度 30 四 搜狗 34 第三节 白帽 SEO 和黑帽 SEO 37 第四节 搜索引擎优化的发展 39 一 SEO 的发展历程 39 二 SEO 在中国 40 三 SEO 的发展方向 42 第五节 对搜索引擎的一些看法优化 43 1. 搜索引擎优化合法吗?43 2. 他会搜索吗?

搜索引擎正面临工作 43 3. 搜索引擎会不会手动干扰 44 4. 我的 网站 有很多高质量的 原创 内容,所以我不再需要 SEO 44 5. SEO 没有技术含量或SEO 需要非常深厚的技能 44 六大网站 做到了。我也向他们学习了 44 七家SEO公司或SEO工具保证排名提升 44 八位稳定排名 45 九 SEO目标是获得第一名或尽可能多的访问量 45 十大竞争对手无法破坏我的排名 45 第四章SEO相关搜索引擎技术 46 Page 2 搜索引擎优化魔法书 SEOMagicBook 浩威互动免费电子书 wwwtimevnet 第一节搜索引擎机器人 46 一 什么是搜索引擎机器人 46 2. 如何识别搜索引擎机器人的身份 47 第二节. 超链分析 47 1 .

应用 53 六中文搜索引擎技术 54 第四节基于词义的文本分析 55 一文本分析技术特点 55 二文本分析应用 55 第五章网站的搜索引擎性能理解 57 第一节基本查询 57 1.域名信息查询 57 2. 域名历史查询 57 3. 主机连接速度和 IP 地址查询 57 四带 IP 收录编号 58 Section 3 Backlink Query 59 Section 4 Web Page RANK 查询 59 一个 GooglePageRank 查询 59 两个 SogouRank 查询 59第五节 关键词 排名查询 59 第六节 ALEXA 查询 60 一 什么是 Alexa 60 2. Alexa 主要数据 60 3. 用 Alexa 检查什么 60 第 6 章基于搜索引擎友好的 网站 设计 62 Section 1域名策略 62 1.不同后缀域名在搜索引擎中的权重 62 2. 域名基本常识 62 Page 3 搜索引擎优化魔法书 SEOMagicBook 豪威互动免费电子书 wwwtimevnet 关键词 三个域名策略之六

9 4 中文网站域名拼音策略 70 5 小心注册被搜索引擎惩罚的域名 70 第二节 空间策略 71 1 安全要素 1 稳定性 71 2 安全要素 2 良好的共存环境 71 3 本节附录 72第三节网站结构规划72第四节网站导航设计73第五节IFRAMEVASACRIPT和AJAX73一个IFRAME74两个JS74三个AJAX74第六节URL设计75一个易于记忆75两个URL静态75三个URL关键词部署 78 第七节 网页代码编写 80 一遵循WEB标准 篮球课程标准 尘肺病标准片 党员活动室建设分级护理精细化标准 儿科分级护理标准 80 第二个代码的逻辑 80 第八节 面向搜索引擎的文案指南 81 1. 网页标题 标题 81 2. 元元标记 84 3. 图片 ALT 替换文本 85 4. Robotstxt 85 5. 链接锚文本 89 6. 站点地图 xml 89 7. 版权和隐私 97 第 9 节 用户友好性检查 97 1. 链接可用性 97 2. 访问速度体验 97 三个查找信息的便捷性 98 第七章 创建搜索引擎喜欢的内容站点地图 xml 89 7. 版权和隐私 97 第 9 节 用户友好性检查 97 1. 链接可用性 97 2. 访问速度体验 97 查找信息的三个便利性 98 第七章 创建搜索引擎喜欢的内容站点地图 xml 89 7. 版权和隐私 97 第 9 节 用户友好性检查 97 1. 链接可用性 97 2. 访问速度体验 97 查找信息的三个便利性 98 第七章 创建搜索引擎喜欢的内容
搜索引擎优化pdf(文档格式有TXT、WORD、PDF等,对这些文档的搜索引擎优化方法比较简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-21 13:00
目前常用的文档格式有TXT、WORD、PDF等,这些文档的搜索引擎优化方法比较简单,只要文档标题和文档首页前面的一些文字信息包括关键词,针对网页进行了优化。这个想法是一样的。这些任务只需要在我们写文档的时候顺便完成。
目前常用的文档格式有TXT、WORD、PDF等,这些文档的搜索引擎优化方法比较简单,只要文档标题和文档首页前面的一些文字信息包括关键词,针对网页进行了优化。这个想法是一样的。这些任务只需要在写文档的时候顺便完成。当大家对这些问题都不够重视的时候,就一点点
目前常用的文档格式有TXT、WORD、PDF等,这些文档的搜索引擎优化方法比较简单,只要文档标题和文档首页前面的一些文字信息包括关键词,针对网页进行了优化。这个想法是一样的。这些任务只需要在我们写文档的时候顺便完成。当大家对这些问题都不够重视时,只要稍加注意,就能获得更好的搜索排名效果。随着类似文档的逐渐增多,可能需要更复杂的优化方法,但在这方面似乎没有更有效的方法可以借鉴。
基于三大搜索引擎的PDF文档权重非常高。PDF 文档可以添加指向其内容的链接。在GOOGLE的策略中,文档相对于普通的HTML文件有着先天的优势。GOOGLE给出原创PDF文件PR=3的高权重主要有以下三个原因:1、一般人们会把比较重要的文件和文本做成PDF格式,导致PDF的识别度高搜索引擎提供的文件。2、 PDF文件的打开方式是html,在web客户端上方便阅读。3、PDF文件易于下载,易于传播,并且在传播过程中不会被扭曲或修改(相对于DOC等)。
如何制作pdf文件?大家应该都在思考吧!前面说过,PDF文件优化的思路和网页优化的思路是一样的,比如:在标题和内容中适当的收录关键词,以提高内容的相关性,使用H1进行标题格式,重要内容以粗体或大号显示等。另外,对于PDF文档,需要对文件属性做一些优化。要制作PDF文件,使用Acrobat软件太麻烦了。我一般用WORD直接导出生成PDF格式,简单实用。文件属性的优化主要包括:文件描述、文件元数据描述文件、文件属性、描述、标题、作者、主题、描述描述、关键词关键字、描述作者描述编写者、
你可以看看Adobe Acrobat6.0的使用说明,两套关键词重要性分析,哪一个关键词最有可能得到搜索引擎的关注?我们知道元数据(metadata)有很多种存储格式,但是Adobe使用的是XML格式,用记事本打开PDF文件,可以发现关键词区域在“文件属性说明”下输入的关键词 " 以逗号分隔,如:关键词(关键词1,关键词2,关键词3,...),我们在"文档元数据描述" 关键词 下关键词 区域输入的内容格式为:关键词1关键词2关键词3 根据这个格式,搜索引擎是更有可能抓取“属性描述”下关键词区域中的“文件信息”。因此,我们建议列出该区域最相关的关键词 网站。如果要使用PDF文件中的图片,最好在每张图片下方添加一行说明,并且最好收录目标关键词,类似于html中的图片。
还有一点就是pdf文件是对网站的内外链的很好的补充。这时候可以花点时间整理一下网上公布的技术文章,做成pdf。文档。
html 中文网站 题外话,最近发现我的一个页面的PR值达到了7,这个页面是FLASH页面:
以上就是网页PDF文档优化制作方法的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
搜索引擎优化pdf(文档格式有TXT、WORD、PDF等,对这些文档的搜索引擎优化方法比较简单)
目前常用的文档格式有TXT、WORD、PDF等,这些文档的搜索引擎优化方法比较简单,只要文档标题和文档首页前面的一些文字信息包括关键词,针对网页进行了优化。这个想法是一样的。这些任务只需要在我们写文档的时候顺便完成。
目前常用的文档格式有TXT、WORD、PDF等,这些文档的搜索引擎优化方法比较简单,只要文档标题和文档首页前面的一些文字信息包括关键词,针对网页进行了优化。这个想法是一样的。这些任务只需要在写文档的时候顺便完成。当大家对这些问题都不够重视的时候,就一点点
目前常用的文档格式有TXT、WORD、PDF等,这些文档的搜索引擎优化方法比较简单,只要文档标题和文档首页前面的一些文字信息包括关键词,针对网页进行了优化。这个想法是一样的。这些任务只需要在我们写文档的时候顺便完成。当大家对这些问题都不够重视时,只要稍加注意,就能获得更好的搜索排名效果。随着类似文档的逐渐增多,可能需要更复杂的优化方法,但在这方面似乎没有更有效的方法可以借鉴。
基于三大搜索引擎的PDF文档权重非常高。PDF 文档可以添加指向其内容的链接。在GOOGLE的策略中,文档相对于普通的HTML文件有着先天的优势。GOOGLE给出原创PDF文件PR=3的高权重主要有以下三个原因:1、一般人们会把比较重要的文件和文本做成PDF格式,导致PDF的识别度高搜索引擎提供的文件。2、 PDF文件的打开方式是html,在web客户端上方便阅读。3、PDF文件易于下载,易于传播,并且在传播过程中不会被扭曲或修改(相对于DOC等)。
如何制作pdf文件?大家应该都在思考吧!前面说过,PDF文件优化的思路和网页优化的思路是一样的,比如:在标题和内容中适当的收录关键词,以提高内容的相关性,使用H1进行标题格式,重要内容以粗体或大号显示等。另外,对于PDF文档,需要对文件属性做一些优化。要制作PDF文件,使用Acrobat软件太麻烦了。我一般用WORD直接导出生成PDF格式,简单实用。文件属性的优化主要包括:文件描述、文件元数据描述文件、文件属性、描述、标题、作者、主题、描述描述、关键词关键字、描述作者描述编写者、
你可以看看Adobe Acrobat6.0的使用说明,两套关键词重要性分析,哪一个关键词最有可能得到搜索引擎的关注?我们知道元数据(metadata)有很多种存储格式,但是Adobe使用的是XML格式,用记事本打开PDF文件,可以发现关键词区域在“文件属性说明”下输入的关键词 " 以逗号分隔,如:关键词(关键词1,关键词2,关键词3,...),我们在"文档元数据描述" 关键词 下关键词 区域输入的内容格式为:关键词1关键词2关键词3 根据这个格式,搜索引擎是更有可能抓取“属性描述”下关键词区域中的“文件信息”。因此,我们建议列出该区域最相关的关键词 网站。如果要使用PDF文件中的图片,最好在每张图片下方添加一行说明,并且最好收录目标关键词,类似于html中的图片。
还有一点就是pdf文件是对网站的内外链的很好的补充。这时候可以花点时间整理一下网上公布的技术文章,做成pdf。文档。
html 中文网站 题外话,最近发现我的一个页面的PR值达到了7,这个页面是FLASH页面:
以上就是网页PDF文档优化制作方法的详细内容。更多详情请关注其他相关html中文网站文章!
搜索引擎优化pdf(软文推广目前大大小小的网站使用的一个重要的推广方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-20 04:08
文档介绍:file:///C|/Users/cysell/Desktop/优采云采集新闻来源/搜索引擎优化从何入手..htm[2014/5/17 22:49:49 ]搜索引擎优化(SEO)就是对一个网站进行优化以获得更高的排名,通过对搜索引擎基于网站的内链和内容以及外链的一些计算来优化的过程。网赚现在说说搜索引擎优化的一般步骤和内容。一.内容搜索引擎优化是一个庞大而综合的系统工程,但可以概括为以下几个部分,一般包括标签、描述、alt、文本和链接。1. 标题标签是网站的一个代码,其中最重要的是顶部标题标签的各种标签。标题标签在网站的索引中起着重要的作用。首先,搜索引擎将根据标题标签确定特定网页的相关性。因此,它在标题标签中收录关键字。标题标签中过度使用重复的关键词会被搜索引擎惩罚。2.元标签描述和关键字标签。说明很重要。正确使用这些标签可以帮助访问者了解您的 网站 的主要观点是什么。3.ALT标签 这些标签有助于描述网页中图片的内容,使搜索引擎更容易理解图片的内容。二.链接建设 链接建设的目的是增加网站的权重,吸引网络流量和搜索引擎蜘蛛。如果你离开你的网站
三.软文推广当前大大小小的网站使用的一个重要的推广方式是软文,推广网站学写软文是必须的,软文的推广力度明显加大。一个好的软文可以不断为你添加链接。四.网站以上所有方法都是根据网站内容必须有价值,网站内容必须与你的网站主题相关,如果无关紧要,上面的做法再好,也无济于事。file:///C|/Users/cysell/Desktop/优采云采集新闻来源/从哪里开始搜索引擎优化..htm[2014/5/17 22:49:49]一般个人网站 大约 90% 的网络流量是由搜索引擎带来的。所以在做搜索引擎的时候,每个单独的网站管理员都必须做功课。文章创,转载请保留链接,谢谢!================================================== ==================== 【2014年怎么赚钱-微信朋友圈赚钱】你的手机只要装了微信软件就可以赚钱!!!如何通过微信赚钱?怎么用微信赚钱?你怎么能保证你能得到你赚到的钱?微信赚钱的方式无外乎几种:1、公众号靠广告赚钱,2、微信群广告赚钱,3、朋友圈赚钱广告,这三招帮你赚RMB!!我们来谈谈如何在微信朋友圈赚钱?如果你的微信好友超过200人可以赚钱,因为这 200 或更多人是你的客户,他们可以为你创造价值,你可以从中赚钱。赚取人民币。通过将广告分享到您的朋友圈,您的朋友将看到该广告 查看全部
搜索引擎优化pdf(软文推广目前大大小小的网站使用的一个重要的推广方式)
文档介绍:file:///C|/Users/cysell/Desktop/优采云采集新闻来源/搜索引擎优化从何入手..htm[2014/5/17 22:49:49 ]搜索引擎优化(SEO)就是对一个网站进行优化以获得更高的排名,通过对搜索引擎基于网站的内链和内容以及外链的一些计算来优化的过程。网赚现在说说搜索引擎优化的一般步骤和内容。一.内容搜索引擎优化是一个庞大而综合的系统工程,但可以概括为以下几个部分,一般包括标签、描述、alt、文本和链接。1. 标题标签是网站的一个代码,其中最重要的是顶部标题标签的各种标签。标题标签在网站的索引中起着重要的作用。首先,搜索引擎将根据标题标签确定特定网页的相关性。因此,它在标题标签中收录关键字。标题标签中过度使用重复的关键词会被搜索引擎惩罚。2.元标签描述和关键字标签。说明很重要。正确使用这些标签可以帮助访问者了解您的 网站 的主要观点是什么。3.ALT标签 这些标签有助于描述网页中图片的内容,使搜索引擎更容易理解图片的内容。二.链接建设 链接建设的目的是增加网站的权重,吸引网络流量和搜索引擎蜘蛛。如果你离开你的网站
三.软文推广当前大大小小的网站使用的一个重要的推广方式是软文,推广网站学写软文是必须的,软文的推广力度明显加大。一个好的软文可以不断为你添加链接。四.网站以上所有方法都是根据网站内容必须有价值,网站内容必须与你的网站主题相关,如果无关紧要,上面的做法再好,也无济于事。file:///C|/Users/cysell/Desktop/优采云采集新闻来源/从哪里开始搜索引擎优化..htm[2014/5/17 22:49:49]一般个人网站 大约 90% 的网络流量是由搜索引擎带来的。所以在做搜索引擎的时候,每个单独的网站管理员都必须做功课。文章创,转载请保留链接,谢谢!================================================== ==================== 【2014年怎么赚钱-微信朋友圈赚钱】你的手机只要装了微信软件就可以赚钱!!!如何通过微信赚钱?怎么用微信赚钱?你怎么能保证你能得到你赚到的钱?微信赚钱的方式无外乎几种:1、公众号靠广告赚钱,2、微信群广告赚钱,3、朋友圈赚钱广告,这三招帮你赚RMB!!我们来谈谈如何在微信朋友圈赚钱?如果你的微信好友超过200人可以赚钱,因为这 200 或更多人是你的客户,他们可以为你创造价值,你可以从中赚钱。赚取人民币。通过将广告分享到您的朋友圈,您的朋友将看到该广告
搜索引擎优化pdf(我知道的只有一个,不知道会不会弹窗转换,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-20 00:03
搜索引擎优化pdf,现在pdf每天的处理量,已经达到了几十gb了,一般小文档的处理,都必须通过图片来完成,需要转换的pdf文档在4000张以上,pdf转jpg文件,还是pdf转ppt的话,就更为庞大了,页数,页面尺寸,当然有大有小,为了更精确的完成优化师的工作量,处理处理页面多的pdf,一般都需要转换后再次pdf,这就是pdf转换器adobeacrobat来完成转换工作了。
虽然有些转换器最高的内容可以达到4g,但是再次压缩的话,按照以上的规则,还是会在10m以内的,虽然普通的工具可以把图片的大小压缩到10多mm,但还是不能达到4g的,有的转换器即使像转转大师压缩率可以达到99%,那也是要牺牲部分页面大小的,毕竟页面尺寸和页面缩放还是直接决定pdf的大小的,不可能真的把页面也压缩到只有一个像素的大小的。文章来源于网络,如有侵权请联系删除。
我知道的只有一个,不会弹窗转换,不知道会不会切换首页,虽然一个可以收费.adobeacrobat具体步骤请参照:我需要哪些安装包和破解工具?
ocr,识别为文字后翻译成pdf,查询转换器,可以帮你变废为宝。或者学习写pdf,编辑pdf内容。
pdf转换器,现在基本上市面上能见到的类型的转换器, 查看全部
搜索引擎优化pdf(我知道的只有一个,不知道会不会弹窗转换,)
搜索引擎优化pdf,现在pdf每天的处理量,已经达到了几十gb了,一般小文档的处理,都必须通过图片来完成,需要转换的pdf文档在4000张以上,pdf转jpg文件,还是pdf转ppt的话,就更为庞大了,页数,页面尺寸,当然有大有小,为了更精确的完成优化师的工作量,处理处理页面多的pdf,一般都需要转换后再次pdf,这就是pdf转换器adobeacrobat来完成转换工作了。
虽然有些转换器最高的内容可以达到4g,但是再次压缩的话,按照以上的规则,还是会在10m以内的,虽然普通的工具可以把图片的大小压缩到10多mm,但还是不能达到4g的,有的转换器即使像转转大师压缩率可以达到99%,那也是要牺牲部分页面大小的,毕竟页面尺寸和页面缩放还是直接决定pdf的大小的,不可能真的把页面也压缩到只有一个像素的大小的。文章来源于网络,如有侵权请联系删除。
我知道的只有一个,不会弹窗转换,不知道会不会切换首页,虽然一个可以收费.adobeacrobat具体步骤请参照:我需要哪些安装包和破解工具?
ocr,识别为文字后翻译成pdf,查询转换器,可以帮你变废为宝。或者学习写pdf,编辑pdf内容。
pdf转换器,现在基本上市面上能见到的类型的转换器,
搜索引擎优化pdf(如何使用SEO对PDF文件进行排名?58的建议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2021-12-19 18:28
PDF文件是科研机构和企业在日常工作中经常使用的文件,可以是学术研究报告或企业的产品描述文件。
如果你的 网站 经常使用 PDF 文件作为使用说明书,在实践中,我们需要 PDF 文件来对搜索引擎进行排名。
如何使用 SEO 对 PDF 文件进行排名?
针对以往科研机构和国内教育机构优化的经验,织梦58通常对通过SEO优化PDF文件提出以下建议:
1、PDF 目录
规范的PDF文件存储目录,一有利于提高抓捕百度爬虫的频率,二是更好的管理文档,尤其是PDF文件数量比较大的时候。
2、PDF 格式
确保PDF文件的内容格式以文本形式存在,可以适当使用表格,但最好简化表格内容,尽量避免使用纯图片格式。
目前百度完全可以分析PDF文件的文本内容,当然也包括PDF中的链接。
3、PDF 标题
如果使用命令filetype:pdf,在百度的搜索结果中,你会发现pdf文件的标题是可识别的,并显示在搜索结果中。
因此,在设置PDF标题时,需要参考页面标题和标题标签的设计方法,在创建PDF时尽量在“文档属性”中标注标题内容。
4、PDF 大小
针对PDF文件的大小,我们不仅强调PDF文件的大小不能太大,而且建议尽可能合理控制PDF文件的字数。
严重影响搜索引擎的分析和索引,也影响页面加载速度。
5、PDF 超链接
理论上,百度可以识别PDF文件中的超链接,所以在建立PDF文件数据库时,可以正确使用PDF中的链接来引导蜘蛛爬行。例如:指向PDF文件目录的首页,或者指向网站核心关键字的链接。
6、PDF 策略
如果你在做一些行业研究,你会发现对于相关的话题,用户对PDF文件有很多潜在的需求,比如:SEO电子书。当然,你也可以定期整理这些内容,上传到网站合理的专栏上发布。
有助于提高目标网站在行业中的相关性。
7、PDF 设计
如果你是基于搜索引擎的角度,你还是需要注意PDF的设计,尤其是它在手机上的展示,注意搜索引擎的友好度,这有助于提高它在手机上的排名电话。
8、PDF 内容
在设计PDF内容的时候,我们需要保证PDF内容的主题与网站的核心内容高度相关,我们尽量查看PDF文件的标题。如果有一定的相关性,就会出现大量的病例。
我们有必要把它写到网页中,并使用网页的标题作为标签标题,并且在内容页中,不要跟踪所有的pdf链接,这是一种比较特殊的情况。 查看全部
搜索引擎优化pdf(如何使用SEO对PDF文件进行排名?58的建议)
PDF文件是科研机构和企业在日常工作中经常使用的文件,可以是学术研究报告或企业的产品描述文件。
如果你的 网站 经常使用 PDF 文件作为使用说明书,在实践中,我们需要 PDF 文件来对搜索引擎进行排名。
如何使用 SEO 对 PDF 文件进行排名?
针对以往科研机构和国内教育机构优化的经验,织梦58通常对通过SEO优化PDF文件提出以下建议:
1、PDF 目录
规范的PDF文件存储目录,一有利于提高抓捕百度爬虫的频率,二是更好的管理文档,尤其是PDF文件数量比较大的时候。
2、PDF 格式
确保PDF文件的内容格式以文本形式存在,可以适当使用表格,但最好简化表格内容,尽量避免使用纯图片格式。
目前百度完全可以分析PDF文件的文本内容,当然也包括PDF中的链接。
3、PDF 标题
如果使用命令filetype:pdf,在百度的搜索结果中,你会发现pdf文件的标题是可识别的,并显示在搜索结果中。
因此,在设置PDF标题时,需要参考页面标题和标题标签的设计方法,在创建PDF时尽量在“文档属性”中标注标题内容。

4、PDF 大小
针对PDF文件的大小,我们不仅强调PDF文件的大小不能太大,而且建议尽可能合理控制PDF文件的字数。
严重影响搜索引擎的分析和索引,也影响页面加载速度。
5、PDF 超链接
理论上,百度可以识别PDF文件中的超链接,所以在建立PDF文件数据库时,可以正确使用PDF中的链接来引导蜘蛛爬行。例如:指向PDF文件目录的首页,或者指向网站核心关键字的链接。
6、PDF 策略
如果你在做一些行业研究,你会发现对于相关的话题,用户对PDF文件有很多潜在的需求,比如:SEO电子书。当然,你也可以定期整理这些内容,上传到网站合理的专栏上发布。
有助于提高目标网站在行业中的相关性。
7、PDF 设计
如果你是基于搜索引擎的角度,你还是需要注意PDF的设计,尤其是它在手机上的展示,注意搜索引擎的友好度,这有助于提高它在手机上的排名电话。
8、PDF 内容
在设计PDF内容的时候,我们需要保证PDF内容的主题与网站的核心内容高度相关,我们尽量查看PDF文件的标题。如果有一定的相关性,就会出现大量的病例。
我们有必要把它写到网页中,并使用网页的标题作为标签标题,并且在内容页中,不要跟踪所有的pdf链接,这是一种比较特殊的情况。
搜索引擎优化pdf(搜索引擎优化难题中最重要的一块:如果你的网站找不到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-03 12:01
正如我们之前提到的,搜索引擎是答录机。它们的存在是为了发现、理解和组织互联网内容,以便为搜索者提出的问题提供最相关的结果。
为了出现在搜索结果中,您的内容首先需要对搜索引擎可见。这可以说是搜索引擎优化难题中最重要的一块:如果找不到你的网站,你将无法出现在搜索引擎结果页面上。
一、搜索引擎是如何工作的?
搜索引擎通过三个主要功能工作:
1.。抓取:抓取工具抓取 Internet 的内容,检查它们找到的每个 URL 的代码/内容。
2.Index/收录:存储和整理爬取过程中发现的内容。页面一旦进入索引,就会作为相关查询的结果显示在运行中。
3. Ranking:提供最能回答搜索者查询的内容,即结果从相关性高到低排序。
二、什么是搜索引擎抓取?
爬网是一个发现过程,在这个过程中,搜索引擎会派出一组机器人(称为爬虫或蜘蛛)来寻找新的和更新的内容。内容可以不同——可以是网页、图片、视频、PDF等,但不管是什么格式,内容都是通过链接找到的。
谷歌机器人首先获取一些网页,然后根据这些网页上的链接寻找新的网址。沿着这条路径跳转链接,爬虫可以发现新的内容并将其添加到一个非常大的数据库中。当搜索者寻找信息时,谷歌会从数据库中选择匹配的内容并显示出来。
三、什么是搜索引擎收录?
搜索引擎处理并存储它们在 收录 中找到的信息。 收录 文件是一个巨大的数据库,收录了他们找到的所有内容,随时可供搜索者搜索和检索。
四、搜索引擎排名
当有人搜索时,搜索引擎会搜索他们的收录高度相关的内容,然后对内容进行排序,希望能解决搜索者的查询问题。这种根据相关性对搜索结果进行排序的方法称为排名。一般来说,您可以假设 网站 的排名越高,搜索引擎认为 网站 与查询的相关性就越高。
您可以在某些或所有站点上阻止搜索引擎爬虫,或指示搜索引擎避免将某些页面存储在它们的 收录 中。显然,有时这样做是有特定原因的。如果你想让你的内容被搜索者发现,你必须首先确保它可以被爬虫和 收录 访问。
5.爬行:搜索引擎能找到你的网页吗?
正如您刚刚了解到的,确保您的网站被抓取并且 收录 是在搜索结果页面上显示的先决条件。如果你已经有网站,建议先检查一下你的页面有多少被搜索引擎收录搜索到了。这将帮助您了解 Google 是否正在抓取并找到您希望它找到的所有 网站 页面。
查看收录 页面的一种方法是“站点:您的域名(不含)”,这是一种高级搜索运算符。转到 Google 并在搜索栏中输入“站点:”。这会将结果返回到 Google 在其 收录 中指定的站点:
Google 显示的结果数量并不准确,但它确实向您显示了您的哪些 网站 页面是 收录 以及它们在搜索结果中的显示方式。
要获得更准确的结果,请使用 Google Search Console 的 Google Search Console 中的 网站收录 覆盖率报告。如果您目前没有,可以注册一个免费的 Google Search Console 帐户。使用此工具,您可以为您的网站提交站点地图,并监控有多少提交的页面实际上 收录 在 Google 的索引中,以及其他内容。
如果您的 网站 没有出现在搜索结果中的任何位置,可能有以下几个原因:
您的 网站 是全新的,尚未被抓取。
您的 网站 未链接到任何外部 网站。
您的 网站 导航使搜索引擎机器人难以有效地抓取网站。
您的 网站 收录一些称为爬虫指令的基本代码,可防止搜索引擎抓取您的 网站。
您的 网站 已被 Google 处罚。 查看全部
搜索引擎优化pdf(搜索引擎优化难题中最重要的一块:如果你的网站找不到)
正如我们之前提到的,搜索引擎是答录机。它们的存在是为了发现、理解和组织互联网内容,以便为搜索者提出的问题提供最相关的结果。
为了出现在搜索结果中,您的内容首先需要对搜索引擎可见。这可以说是搜索引擎优化难题中最重要的一块:如果找不到你的网站,你将无法出现在搜索引擎结果页面上。
一、搜索引擎是如何工作的?
搜索引擎通过三个主要功能工作:
1.。抓取:抓取工具抓取 Internet 的内容,检查它们找到的每个 URL 的代码/内容。
2.Index/收录:存储和整理爬取过程中发现的内容。页面一旦进入索引,就会作为相关查询的结果显示在运行中。
3. Ranking:提供最能回答搜索者查询的内容,即结果从相关性高到低排序。
二、什么是搜索引擎抓取?
爬网是一个发现过程,在这个过程中,搜索引擎会派出一组机器人(称为爬虫或蜘蛛)来寻找新的和更新的内容。内容可以不同——可以是网页、图片、视频、PDF等,但不管是什么格式,内容都是通过链接找到的。
谷歌机器人首先获取一些网页,然后根据这些网页上的链接寻找新的网址。沿着这条路径跳转链接,爬虫可以发现新的内容并将其添加到一个非常大的数据库中。当搜索者寻找信息时,谷歌会从数据库中选择匹配的内容并显示出来。
三、什么是搜索引擎收录?
搜索引擎处理并存储它们在 收录 中找到的信息。 收录 文件是一个巨大的数据库,收录了他们找到的所有内容,随时可供搜索者搜索和检索。
四、搜索引擎排名
当有人搜索时,搜索引擎会搜索他们的收录高度相关的内容,然后对内容进行排序,希望能解决搜索者的查询问题。这种根据相关性对搜索结果进行排序的方法称为排名。一般来说,您可以假设 网站 的排名越高,搜索引擎认为 网站 与查询的相关性就越高。
您可以在某些或所有站点上阻止搜索引擎爬虫,或指示搜索引擎避免将某些页面存储在它们的 收录 中。显然,有时这样做是有特定原因的。如果你想让你的内容被搜索者发现,你必须首先确保它可以被爬虫和 收录 访问。
5.爬行:搜索引擎能找到你的网页吗?
正如您刚刚了解到的,确保您的网站被抓取并且 收录 是在搜索结果页面上显示的先决条件。如果你已经有网站,建议先检查一下你的页面有多少被搜索引擎收录搜索到了。这将帮助您了解 Google 是否正在抓取并找到您希望它找到的所有 网站 页面。
查看收录 页面的一种方法是“站点:您的域名(不含)”,这是一种高级搜索运算符。转到 Google 并在搜索栏中输入“站点:”。这会将结果返回到 Google 在其 收录 中指定的站点:
Google 显示的结果数量并不准确,但它确实向您显示了您的哪些 网站 页面是 收录 以及它们在搜索结果中的显示方式。
要获得更准确的结果,请使用 Google Search Console 的 Google Search Console 中的 网站收录 覆盖率报告。如果您目前没有,可以注册一个免费的 Google Search Console 帐户。使用此工具,您可以为您的网站提交站点地图,并监控有多少提交的页面实际上 收录 在 Google 的索引中,以及其他内容。
如果您的 网站 没有出现在搜索结果中的任何位置,可能有以下几个原因:
您的 网站 是全新的,尚未被抓取。
您的 网站 未链接到任何外部 网站。
您的 网站 导航使搜索引擎机器人难以有效地抓取网站。
您的 网站 收录一些称为爬虫指令的基本代码,可防止搜索引擎抓取您的 网站。
您的 网站 已被 Google 处罚。
搜索引擎优化pdf( wwwzgbjlycomwwwszygjjcom注重对网站进行查找引擎优化(1)_社会万象_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2022-01-03 04:15
wwwzgbjlycomwwwszygjjcom注重对网站进行查找引擎优化(1)_社会万象_光明网(组图))
wwwzgbjlycomwwwszygjjcom 如何关注百度搜索引擎优化 关注搜索引擎优化网站 所谓搜索引擎优化SearchEngineOptimization简称SEO,就是对齐各种搜索的搜索特征引擎,让网页描述合适搜索引擎的搜索条件,即搜索引擎友好度,然后让网站被搜索引擎录入,排名靠前。 SEO 的意图是 网站 对搜索引擎友好。让我们看看那些对搜索引擎不友好的人。 网站 是的有什么特点?第一页有很多图片或flash等RichMedia方法无法检索。第二页没有标题或标题不收录有用的关键字。第三页页面正文中有用的关键字较少。第四网站导航系统使搜索引擎无法理解第五多页,从而搜索引擎无法检索到第六页。搜索引擎输入的其他 网站 没有链接。第七个网站充斥着许多欺诈搜索引擎。过渡页上的文字、桥页、颜色和背景色等垃圾信息 第8个网站收录很多错误链接等 成都周边旅游当然适合搜索引擎友好的 网站 恰好与上述特性相反。查看wwwzgbjlycomwwwszygjjcom,找到引擎描述网站的方法,注重每一个细节的专业性。以真实的信息和有用的表达赢得搜索引擎的喜爱,进而获得更好的搜索引擎推广效果。具体来说,搜索引擎的优化主要在以下几个方面: 1、页面标题的标题是出现在阅读器左上角的文字。这是访问者看到的第一个信息。许多搜索引擎在互联网上占据主动。 @网站 搜索过程中记录的信息包括页面标题关键词等,因此页面标题对于网站的实现,以及为网站的阅读兴趣添加访问者,都非常有帮助。页面标题 标注方法如下: 2 合适的关键词 关键词:当你的网站被搜索引擎主动记录时,你为网站提供的50到100个关键词非常重要,因为当访问者正在搜索引擎搜索时,只要用的词是你的关键
文字中表示已经找到了网站人才,所以关键词应该尽量收录网站提供的信息,比如上面提到的网上新调查。 网站 其关键字 是网络实现 3 细化 网站 description网站 描述呈现在搜索引擎cdfcszcom 的搜索结果中。很大程度上决定了访问者能否通过搜索引擎的搜索结果。访问您的网站wwwzgbjlycomwwwszygjjcom,因此网站 描述应覆盖关键字定义的比例并更加突出。 网站 提升描述语句对访问者吸引力的关键点应该提取最重要的20个左右关键词是根据用户在实际工作中最关心的信息和网站提供的信息仔细编写不超过 250 字且收录空格的描述文本。 4 合理的导航说明。现在很多互联网公司都在做网站为了节省时间和精力,使用框架结构但不知道这是搜索引擎最讨厌的事情。即使你找到了网站的内容页面,也很难通过导航关键词程序进入其他导航页面。使用java 用flash导航很漂亮,但是搜索引擎在描述网站时找不到静态页面,不要用动态文字描述职位描述不要用图片,不要放大flash在 网站 的主页上。这不仅减慢了客户进入网站的速度,也不利于搜索引擎。 5 不要在站点准备好供大量读者访问之前过早注册站点。不要过早注册该网站。每个站点的建立可以是一个永无止境的过程。如果该网站仍处于测试期,通常会向观众开放。一个错误。当站点处于测试期时,wwwzgbjlycomwwwszygjjcom可以设置一些环境参数,防止被搜索引擎主动索引,即被Robot排除。其他人还没有做好充分的准备。 网站 给人的第一印象是不完美的印象。 网站用户往往不愿意在短时间内再次访问网站,而且不完善的注册需要更多的精力和费用,所以注册前一定要做好网站 网站准备工作 查看全部
搜索引擎优化pdf(
wwwzgbjlycomwwwszygjjcom注重对网站进行查找引擎优化(1)_社会万象_光明网(组图))
wwwzgbjlycomwwwszygjjcom 如何关注百度搜索引擎优化 关注搜索引擎优化网站 所谓搜索引擎优化SearchEngineOptimization简称SEO,就是对齐各种搜索的搜索特征引擎,让网页描述合适搜索引擎的搜索条件,即搜索引擎友好度,然后让网站被搜索引擎录入,排名靠前。 SEO 的意图是 网站 对搜索引擎友好。让我们看看那些对搜索引擎不友好的人。 网站 是的有什么特点?第一页有很多图片或flash等RichMedia方法无法检索。第二页没有标题或标题不收录有用的关键字。第三页页面正文中有用的关键字较少。第四网站导航系统使搜索引擎无法理解第五多页,从而搜索引擎无法检索到第六页。搜索引擎输入的其他 网站 没有链接。第七个网站充斥着许多欺诈搜索引擎。过渡页上的文字、桥页、颜色和背景色等垃圾信息 第8个网站收录很多错误链接等 成都周边旅游当然适合搜索引擎友好的 网站 恰好与上述特性相反。查看wwwzgbjlycomwwwszygjjcom,找到引擎描述网站的方法,注重每一个细节的专业性。以真实的信息和有用的表达赢得搜索引擎的喜爱,进而获得更好的搜索引擎推广效果。具体来说,搜索引擎的优化主要在以下几个方面: 1、页面标题的标题是出现在阅读器左上角的文字。这是访问者看到的第一个信息。许多搜索引擎在互联网上占据主动。 @网站 搜索过程中记录的信息包括页面标题关键词等,因此页面标题对于网站的实现,以及为网站的阅读兴趣添加访问者,都非常有帮助。页面标题 标注方法如下: 2 合适的关键词 关键词:当你的网站被搜索引擎主动记录时,你为网站提供的50到100个关键词非常重要,因为当访问者正在搜索引擎搜索时,只要用的词是你的关键
文字中表示已经找到了网站人才,所以关键词应该尽量收录网站提供的信息,比如上面提到的网上新调查。 网站 其关键字 是网络实现 3 细化 网站 description网站 描述呈现在搜索引擎cdfcszcom 的搜索结果中。很大程度上决定了访问者能否通过搜索引擎的搜索结果。访问您的网站wwwzgbjlycomwwwszygjjcom,因此网站 描述应覆盖关键字定义的比例并更加突出。 网站 提升描述语句对访问者吸引力的关键点应该提取最重要的20个左右关键词是根据用户在实际工作中最关心的信息和网站提供的信息仔细编写不超过 250 字且收录空格的描述文本。 4 合理的导航说明。现在很多互联网公司都在做网站为了节省时间和精力,使用框架结构但不知道这是搜索引擎最讨厌的事情。即使你找到了网站的内容页面,也很难通过导航关键词程序进入其他导航页面。使用java 用flash导航很漂亮,但是搜索引擎在描述网站时找不到静态页面,不要用动态文字描述职位描述不要用图片,不要放大flash在 网站 的主页上。这不仅减慢了客户进入网站的速度,也不利于搜索引擎。 5 不要在站点准备好供大量读者访问之前过早注册站点。不要过早注册该网站。每个站点的建立可以是一个永无止境的过程。如果该网站仍处于测试期,通常会向观众开放。一个错误。当站点处于测试期时,wwwzgbjlycomwwwszygjjcom可以设置一些环境参数,防止被搜索引擎主动索引,即被Robot排除。其他人还没有做好充分的准备。 网站 给人的第一印象是不完美的印象。 网站用户往往不愿意在短时间内再次访问网站,而且不完善的注册需要更多的精力和费用,所以注册前一定要做好网站 网站准备工作
搜索引擎优化pdf 搜索引擎优化pdf( 决算书暑假读一本好书辞职书个人欠款起诉书范文支部书记表态发言)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-03 04:14
决算书暑假读一本好书辞职书个人欠款起诉书范文支部书记表态发言)
搜索引擎优化魔法书结账本暑假阅读好书辞职信个人欠费起诉书范文分会书记发言SEOMagicBook豪威互动免费电子书wwwtimevnet目录关于本书1章1搜索引擎基础2章章节1.什么是搜索引擎2.1.搜索引擎的作用2.2.搜索引擎的定义4.2.搜索引擎的基本工作原理4.1.爬取5.2.索引5.3.排序5. 3. 搜索引擎分类 6. 1. 页面级搜索 6 2 垂直搜索 6 三元搜索引擎 6 4 目录搜索 6 5 综合搜索 7 第四节 搜索引擎的未来 7 1 更快 7 2 多元化 7 3 智能 7 4社交 7 5 个性化 8 5 栏目 主要搜索引擎介绍 8 1 谷歌 8 2 雅虎 12 3 百度 13 4 搜狗 15 5 中文搜索引擎列表 党员人数调查列表和毫米比表 教师职称等级列表 员工考核评分表一般年金现值系数表 16 第二章搜索引擎营销基础 17 第一节 什么是搜索引擎营销 17 1. 搜索引擎营销的定义 17 2. 搜索引擎营销的价值 17 3. 搜索引擎营销原理 18 第二节 特征19 1. 广泛使用 19 2. 用户主动性查询针对性强 19 三是获取新客户 19 四是竞争激烈 20 Page 1 搜索引擎优化魔法书 SEOM
agicBook 豪威互动免费电子书 wwwtimevnet 5 动态随时更新 20 6 门槛低高投资回报 20 栏目三搜索引擎营销目标 21 一被收录 21 二排名前21 三点击21 4. 客户转化 21 5. 提高品牌知名度 21 4. 搜索引擎营销的形式 22 1. 搜索引擎登录 22 2. 固定排名和广告 23 3. 结果付费 24 4. 自然排名 24 第三章 搜索基础引擎优化 25 第 1 节 为什么要进行搜索引擎优化 25 1. 搜索引擎优化的定义 25 2. 搜索引擎优化的价值 25 3. SEO 与 SEM 的关系 26 4. SEO 与付费排名的关系 26 节2. 搜索引擎对SEO的态度 27 1. Google 27 2. Yahoo 29 三百度 30 四搜狗 34 第三节 白帽SEO和黑帽SEO 37 第四节 搜索引擎优化的发展 39 一 SE的发展历程O 39 中国二搜索引擎优化 40 三搜索引擎优化的发展方向 42 第五节关于搜索引擎优化的一些看法 43 一是搜索引擎优化的法律 43 二 他会搜索
搜索引擎面临着这个任务。 43. 搜索引擎会不会人工干扰? 44.我的网站有很多高质量的原创内容,所以我不再需要SEO了。 44的技术,前六名网站做到了。我也向他们学习。 44. 七家SEO公司或SEO工具。保证排名。 44 八。排名稳定。 45 九。搜索引擎优化。访问量 45 十个竞争对手不能破坏我的排名 45 第四章 SEO 相关搜索引擎技术 46 页 2 搜索引擎优化魔法书 SEOMagicBook 豪威互动免费电子书 wwwtimevnet 第一节 搜索引擎机器人 46 一 什么是搜索引擎机器人 46 2 . 如何识别搜索引擎机器人的身份 47 第二节 超链接分析 47 1. 基本原理 48 2. 工作步骤 48 3. 搜索效果 49 4. 超链接分析技术的应用 49 5. 存在的缺陷 50 第三节 汉字分词50 1.什么是中文分词50 二中文分词含义与功能50 三中文分词技术51 四字拼图乘法口算100题七年级有理数混合运算100题计算机一级题库二元线性方程应用题真心话大冒险第53题五分中文分词
应用 53 六大中文搜索引擎技术 54 第四节 基于词义的文本分析 55 一种文本分析技术特点 55 两种文本分析应用 55 第五章网站的搜索引擎性能理解 57 第一节 基本查询 57 1 域名信息查询 57 2 域名历史查询 57 3 主机连接速度和 IP 地址查询 57 四个相同 IP 网站 查询 57 第二节 收录 查询 58 1 是否为 收录 58第二页收录 Number 58 第三部分Backlink 查询59 第四部分网页RANK 查询59 One GooglePageRank 查询59 第二SogouRank 查询59 Section 5 关键词 Ranking 查询59 Section VI ALEXA 查询60 1.什么是Alexa 60 2. Alexa 60 的主要数据 3. 用Alexa 60 检查什么 第六章 基于搜索引擎友好网站 设计 62 第一节域名策略 62 1. 不同后缀域名在搜索引擎中的权重 62 2. 域名基本常识 62 Page 3 Search Eng ine Optimization Magic Book SEOMagicBook Haowei Interactive 免费电子书 wwwtimevnet 关键词Strategy 6
9 4 中文网站域名拼音策略 70 5 小心注册被搜索引擎惩罚的域名 70 第二节 空间策略 71 1 安全要素 1 稳定性 71 2 安全要素 2 良好的共存环境 71 3 本节附录 72 第 3 节 网站 结构规划 72 第 4 节站点导航设计 73 第 5 节 IFRAMEJAVASCRIPT 和 AJAX73 1 IFRAME74 2 JS74 3 AJAX74 第 6 节 URL 设计 75 1 易于记忆 75 2 URL 静态 75> 3 URL 关键词@部署 78 第七节网页代码编译 80 一听WEB标准 篮球课程标准 党员活动室建设 尘肺病标准片 儿科分级护理标准 分级护理细化标准 80 第二代码的逻辑 80 第八节 面向搜索引擎的文案指导 81 1.网页标题 标题 81 2. 元元标记 84 3. 图片 ALT 替换文本 85 4. Robotstxt 85 5. 链接锚文本 89 6. 站点地图 xml 89 7. 版权和隐私97 第 9 节. 用户友好性检查 97 1. 链接可用性 97 2. 访问速度体验 97 3 查找信息的便利性 98 第 7 章创建搜索引擎喜欢的内容 查看全部
搜索引擎优化pdf 搜索引擎优化pdf(
决算书暑假读一本好书辞职书个人欠款起诉书范文支部书记表态发言)
搜索引擎优化魔法书结账本暑假阅读好书辞职信个人欠费起诉书范文分会书记发言SEOMagicBook豪威互动免费电子书wwwtimevnet目录关于本书1章1搜索引擎基础2章章节1.什么是搜索引擎2.1.搜索引擎的作用2.2.搜索引擎的定义4.2.搜索引擎的基本工作原理4.1.爬取5.2.索引5.3.排序5. 3. 搜索引擎分类 6. 1. 页面级搜索 6 2 垂直搜索 6 三元搜索引擎 6 4 目录搜索 6 5 综合搜索 7 第四节 搜索引擎的未来 7 1 更快 7 2 多元化 7 3 智能 7 4社交 7 5 个性化 8 5 栏目 主要搜索引擎介绍 8 1 谷歌 8 2 雅虎 12 3 百度 13 4 搜狗 15 5 中文搜索引擎列表 党员人数调查列表和毫米比表 教师职称等级列表 员工考核评分表一般年金现值系数表 16 第二章搜索引擎营销基础 17 第一节 什么是搜索引擎营销 17 1. 搜索引擎营销的定义 17 2. 搜索引擎营销的价值 17 3. 搜索引擎营销原理 18 第二节 特征19 1. 广泛使用 19 2. 用户主动性查询针对性强 19 三是获取新客户 19 四是竞争激烈 20 Page 1 搜索引擎优化魔法书 SEOM
agicBook 豪威互动免费电子书 wwwtimevnet 5 动态随时更新 20 6 门槛低高投资回报 20 栏目三搜索引擎营销目标 21 一被收录 21 二排名前21 三点击21 4. 客户转化 21 5. 提高品牌知名度 21 4. 搜索引擎营销的形式 22 1. 搜索引擎登录 22 2. 固定排名和广告 23 3. 结果付费 24 4. 自然排名 24 第三章 搜索基础引擎优化 25 第 1 节 为什么要进行搜索引擎优化 25 1. 搜索引擎优化的定义 25 2. 搜索引擎优化的价值 25 3. SEO 与 SEM 的关系 26 4. SEO 与付费排名的关系 26 节2. 搜索引擎对SEO的态度 27 1. Google 27 2. Yahoo 29 三百度 30 四搜狗 34 第三节 白帽SEO和黑帽SEO 37 第四节 搜索引擎优化的发展 39 一 SE的发展历程O 39 中国二搜索引擎优化 40 三搜索引擎优化的发展方向 42 第五节关于搜索引擎优化的一些看法 43 一是搜索引擎优化的法律 43 二 他会搜索
搜索引擎面临着这个任务。 43. 搜索引擎会不会人工干扰? 44.我的网站有很多高质量的原创内容,所以我不再需要SEO了。 44的技术,前六名网站做到了。我也向他们学习。 44. 七家SEO公司或SEO工具。保证排名。 44 八。排名稳定。 45 九。搜索引擎优化。访问量 45 十个竞争对手不能破坏我的排名 45 第四章 SEO 相关搜索引擎技术 46 页 2 搜索引擎优化魔法书 SEOMagicBook 豪威互动免费电子书 wwwtimevnet 第一节 搜索引擎机器人 46 一 什么是搜索引擎机器人 46 2 . 如何识别搜索引擎机器人的身份 47 第二节 超链接分析 47 1. 基本原理 48 2. 工作步骤 48 3. 搜索效果 49 4. 超链接分析技术的应用 49 5. 存在的缺陷 50 第三节 汉字分词50 1.什么是中文分词50 二中文分词含义与功能50 三中文分词技术51 四字拼图乘法口算100题七年级有理数混合运算100题计算机一级题库二元线性方程应用题真心话大冒险第53题五分中文分词
应用 53 六大中文搜索引擎技术 54 第四节 基于词义的文本分析 55 一种文本分析技术特点 55 两种文本分析应用 55 第五章网站的搜索引擎性能理解 57 第一节 基本查询 57 1 域名信息查询 57 2 域名历史查询 57 3 主机连接速度和 IP 地址查询 57 四个相同 IP 网站 查询 57 第二节 收录 查询 58 1 是否为 收录 58第二页收录 Number 58 第三部分Backlink 查询59 第四部分网页RANK 查询59 One GooglePageRank 查询59 第二SogouRank 查询59 Section 5 关键词 Ranking 查询59 Section VI ALEXA 查询60 1.什么是Alexa 60 2. Alexa 60 的主要数据 3. 用Alexa 60 检查什么 第六章 基于搜索引擎友好网站 设计 62 第一节域名策略 62 1. 不同后缀域名在搜索引擎中的权重 62 2. 域名基本常识 62 Page 3 Search Eng ine Optimization Magic Book SEOMagicBook Haowei Interactive 免费电子书 wwwtimevnet 关键词Strategy 6
9 4 中文网站域名拼音策略 70 5 小心注册被搜索引擎惩罚的域名 70 第二节 空间策略 71 1 安全要素 1 稳定性 71 2 安全要素 2 良好的共存环境 71 3 本节附录 72 第 3 节 网站 结构规划 72 第 4 节站点导航设计 73 第 5 节 IFRAMEJAVASCRIPT 和 AJAX73 1 IFRAME74 2 JS74 3 AJAX74 第 6 节 URL 设计 75 1 易于记忆 75 2 URL 静态 75> 3 URL 关键词@部署 78 第七节网页代码编译 80 一听WEB标准 篮球课程标准 党员活动室建设 尘肺病标准片 儿科分级护理标准 分级护理细化标准 80 第二代码的逻辑 80 第八节 面向搜索引擎的文案指导 81 1.网页标题 标题 81 2. 元元标记 84 3. 图片 ALT 替换文本 85 4. Robotstxt 85 5. 链接锚文本 89 6. 站点地图 xml 89 7. 版权和隐私97 第 9 节. 用户友好性检查 97 1. 链接可用性 97 2. 访问速度体验 97 3 查找信息的便利性 98 第 7 章创建搜索引擎喜欢的内容
搜索引擎优化pdf(“全局搜索”UKUI3.1版本即将发布,带给你更嗨的使用体验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-12-31 23:18
“全局搜索”UKUI3.版本1
即将推出
此版本的“全局搜索”功能
给用户全新的体验...
事实上,随着信息和效率的爆炸式增长,用户对“搜索”功能的依赖正在逐渐增加。因为“搜索”可以让用户快速找到他们想要的东西。
打开银河麒麟桌面操作系统V10 SP1,点击“全局搜索”输入框搜索相关信息。以前的版本支持拼音搜索和模糊搜索,可以快速查找系统应用、设置或用户目录中的文件,包括文本内容。随着“搜索”打开的应用程序或文件越来越多,主界面会显示【最近打开】和【大部分打开】,方便查找。
在“全局搜索”UKUI3.1版本中,除了上述原有版本功能外,Kylin团队对模块功能进行了改进升级,并增加了一些常用的搜索功能。
全新视觉升级,带给您更刺激的体验
UKUI3.1 版本拥有全新的视觉设计,整体页面更加简洁美观。同时,模块化展示搜索结果的效果更加清晰。将“垂直显示”改为“水平显示”,下滑更方便舒适。
01 增加记事本搜索功能
文档上的备忘录太多了,找到我想要的怎么办?不用担心,您只需要输入关键词即可查找笔记内容,即可快速找到内容记录,让您的办公更高效。
02 新的文本内容搜索格式
新增的文本内容搜索不仅支持pdf、docx、pptx、xlsx、doc、dot、wps、ppt、pps、dps等格式,还支持中英文搜索应用和设置,让您可以随意搜索不同格式的文本内容。
03 文件索引性能大幅优化
为了给您带来身临其境的工作体验,新版文件索引性能进行了大幅优化,减少了系统资源占用,提高了搜索效率。
不仅如此,新版本在架构上进一步优化,增加了插件接口,提供给社区爱好者进行扩展开发。目前已有不少社区爱好者加入了开源供应链照明计划社区UKUI-search聚合搜索插件项目。截至11月,该项目已通过中期和终审,顺利结束,并在UKUI社区建立了一个新项目UKUI-search-extensions。 “全局搜索”UKUI3.1版本虽然还未上线,但已经吸引了众多用户的关注。
“全局搜索”UKUI3.版本 1,
即将在 Ukylin 社区中测试体验,
你还在等什么?
欢迎下载安装体验! 查看全部
搜索引擎优化pdf(“全局搜索”UKUI3.1版本即将发布,带给你更嗨的使用体验)
“全局搜索”UKUI3.版本1
即将推出
此版本的“全局搜索”功能
给用户全新的体验...
事实上,随着信息和效率的爆炸式增长,用户对“搜索”功能的依赖正在逐渐增加。因为“搜索”可以让用户快速找到他们想要的东西。
打开银河麒麟桌面操作系统V10 SP1,点击“全局搜索”输入框搜索相关信息。以前的版本支持拼音搜索和模糊搜索,可以快速查找系统应用、设置或用户目录中的文件,包括文本内容。随着“搜索”打开的应用程序或文件越来越多,主界面会显示【最近打开】和【大部分打开】,方便查找。
在“全局搜索”UKUI3.1版本中,除了上述原有版本功能外,Kylin团队对模块功能进行了改进升级,并增加了一些常用的搜索功能。
全新视觉升级,带给您更刺激的体验
UKUI3.1 版本拥有全新的视觉设计,整体页面更加简洁美观。同时,模块化展示搜索结果的效果更加清晰。将“垂直显示”改为“水平显示”,下滑更方便舒适。
01 增加记事本搜索功能
文档上的备忘录太多了,找到我想要的怎么办?不用担心,您只需要输入关键词即可查找笔记内容,即可快速找到内容记录,让您的办公更高效。
02 新的文本内容搜索格式
新增的文本内容搜索不仅支持pdf、docx、pptx、xlsx、doc、dot、wps、ppt、pps、dps等格式,还支持中英文搜索应用和设置,让您可以随意搜索不同格式的文本内容。
03 文件索引性能大幅优化
为了给您带来身临其境的工作体验,新版文件索引性能进行了大幅优化,减少了系统资源占用,提高了搜索效率。
不仅如此,新版本在架构上进一步优化,增加了插件接口,提供给社区爱好者进行扩展开发。目前已有不少社区爱好者加入了开源供应链照明计划社区UKUI-search聚合搜索插件项目。截至11月,该项目已通过中期和终审,顺利结束,并在UKUI社区建立了一个新项目UKUI-search-extensions。 “全局搜索”UKUI3.1版本虽然还未上线,但已经吸引了众多用户的关注。
“全局搜索”UKUI3.版本 1,
即将在 Ukylin 社区中测试体验,
你还在等什么?
欢迎下载安装体验!
搜索引擎优化pdf(6个支持M1的文件搜索工具,效果非常的不错)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-12-30 12:07
哪个文件搜索工具更好?别着急,今天小编为大家带来了6款支持M1的文件搜索工具。每个文件搜索工具都可以帮助用户更快更好地搜索他们想要的文件。使用起来非常简单方便,效果非常好。还不错,快来和小编一起看看吧!
1.HoudahSpot for Mac 多功能文件搜索软件
Mac 上哪款文件搜索软件好用?HoudahSpot for mac 是 Mac os 平台上的一个工具,可以帮助用户更快更好地搜索他们想要的文件。HoudahSpot for mac 是一款多功能文件搜索工具,建立在 Apple 强大的 Spotlight 引擎之上。非常简单方便,效果非常好。
%3D%3D
2.EasyFind for Mac 一个简单的文件搜索工具
哪里有一个简单的 macOS 文件搜索工具?该站点提供 Mac 版 EasyFind(一个简单的文件搜索工具)。EasyFind for Mac 主要用于搜索收录
目标关键词的特殊文件、隐藏文件和文档。它还显示每个文件的目录位置。EasyFind for Mac 的搜索功能非常强大,操作也非常简单。.
%3D%3D
3.ProFind for mac 文件搜索工具
Mac 上哪个文件搜索工具好用?ProFind mac版是一款Macos上的文件搜索软件,功能强大,性能卓越,可为macOS提供高级文件搜索。并支持自然语言查询、应用程序启动、隐藏位置搜索、脚本编写等。此外,您可以在不可见的文件夹和包中搜索,搜索任何磁盘类型。
%3D%3D
4.Find Any File for Mac 文件搜索软件
Find Any File for Mac 是一款适用于 Mac 的文件搜索工具。查找任何文件 Mac 可以按名称、创建或修改日期、大小或类型以及创建者代码(不是内容)搜索本地磁盘上的文件。您甚至可以搜索未被 Spotlight 索引的磁盘,包括服务器卷。
%3D%3D
5.PDF Search for Mac pdf文件搜索工具
PDF Search Mac特别版是Mac平台上一款PDF文件的快速搜索工具,可以搜索相关性,让您在上千个PDF文档中第一时间找到最相关的页面,提高工作效率!
%3D%3D
6.VisualGrep for Mac 非索引文件搜索工具
VisualGrep for Mac 是一种非索引文件搜索工具,支持带有过滤器和许多文件夹遍历选项的文件。此更新修复了 Big Sur 中的 UI 错误。
%3D%3D
以上就是小编为大家带来的6款支持M1的文件搜索工具合集。我希望它会对你有所帮助。macz有更多实用的Mac教程! 查看全部
搜索引擎优化pdf(6个支持M1的文件搜索工具,效果非常的不错)
哪个文件搜索工具更好?别着急,今天小编为大家带来了6款支持M1的文件搜索工具。每个文件搜索工具都可以帮助用户更快更好地搜索他们想要的文件。使用起来非常简单方便,效果非常好。还不错,快来和小编一起看看吧!
1.HoudahSpot for Mac 多功能文件搜索软件
Mac 上哪款文件搜索软件好用?HoudahSpot for mac 是 Mac os 平台上的一个工具,可以帮助用户更快更好地搜索他们想要的文件。HoudahSpot for mac 是一款多功能文件搜索工具,建立在 Apple 强大的 Spotlight 引擎之上。非常简单方便,效果非常好。
%3D%3D
2.EasyFind for Mac 一个简单的文件搜索工具
哪里有一个简单的 macOS 文件搜索工具?该站点提供 Mac 版 EasyFind(一个简单的文件搜索工具)。EasyFind for Mac 主要用于搜索收录
目标关键词的特殊文件、隐藏文件和文档。它还显示每个文件的目录位置。EasyFind for Mac 的搜索功能非常强大,操作也非常简单。.
%3D%3D
3.ProFind for mac 文件搜索工具
Mac 上哪个文件搜索工具好用?ProFind mac版是一款Macos上的文件搜索软件,功能强大,性能卓越,可为macOS提供高级文件搜索。并支持自然语言查询、应用程序启动、隐藏位置搜索、脚本编写等。此外,您可以在不可见的文件夹和包中搜索,搜索任何磁盘类型。
%3D%3D
4.Find Any File for Mac 文件搜索软件
Find Any File for Mac 是一款适用于 Mac 的文件搜索工具。查找任何文件 Mac 可以按名称、创建或修改日期、大小或类型以及创建者代码(不是内容)搜索本地磁盘上的文件。您甚至可以搜索未被 Spotlight 索引的磁盘,包括服务器卷。
%3D%3D
5.PDF Search for Mac pdf文件搜索工具
PDF Search Mac特别版是Mac平台上一款PDF文件的快速搜索工具,可以搜索相关性,让您在上千个PDF文档中第一时间找到最相关的页面,提高工作效率!
%3D%3D
6.VisualGrep for Mac 非索引文件搜索工具
VisualGrep for Mac 是一种非索引文件搜索工具,支持带有过滤器和许多文件夹遍历选项的文件。此更新修复了 Big Sur 中的 UI 错误。
%3D%3D
以上就是小编为大家带来的6款支持M1的文件搜索工具合集。我希望它会对你有所帮助。macz有更多实用的Mac教程!
搜索引擎优化pdf(几个无损压缩PDF的好用方法,手机也能免费转换 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-30 02:05
)
PDF是一种常用的文档格式。它具有较高的安全性,易于传输和存储,但在处理上也存在很多麻烦。比如我们在工作中经常会遇到PDF文件过大的问题。这时候我们就需要对PDF文件进行压缩。许多人发现很难面对这个问题,不知道从哪里开始。今天,让我们学习一些无损PDF压缩的有用方法。
一、speedpdf 在线压缩
优点:在线压缩不需要安装软件,手机也可以使用
方法:
1、 搜索speedpdf,找到并打开这个在线转换工具。除了我们想要的PDF压缩,其他日常的PDF转Word也可以免费转换。选择压缩 PDF 以输入压缩。无需注册登录,可直接免费办理;
2、 然后添加需要压缩的PDF文件后,下面的列表会显示上传的PDF文件,点击convert开始压缩。右键单击网页上的任意位置,将其翻译成简体中文网页。
3、 完成后点击下载。
二、快速乐趣
优点:客户端一键批量操作,省时高效
方法:
1、 极乐转换器下载安装后,在PDF工具中选择PDF压缩进入;
2、 将所有需要压缩的PDF批量添加或拖拽到压缩页面后,点击页面左下角的输出路径修改压缩后的PDF的保存位置,点击开始压缩一键压缩所有当前添加的PDF文档。
3、 除了我们上一步修改的保存位置,还可以查看转换完成后的所有压缩记录,右键任意文档选择打开查看。
查看全部
搜索引擎优化pdf(几个无损压缩PDF的好用方法,手机也能免费转换
)
PDF是一种常用的文档格式。它具有较高的安全性,易于传输和存储,但在处理上也存在很多麻烦。比如我们在工作中经常会遇到PDF文件过大的问题。这时候我们就需要对PDF文件进行压缩。许多人发现很难面对这个问题,不知道从哪里开始。今天,让我们学习一些无损PDF压缩的有用方法。
一、speedpdf 在线压缩
优点:在线压缩不需要安装软件,手机也可以使用
方法:
1、 搜索speedpdf,找到并打开这个在线转换工具。除了我们想要的PDF压缩,其他日常的PDF转Word也可以免费转换。选择压缩 PDF 以输入压缩。无需注册登录,可直接免费办理;
2、 然后添加需要压缩的PDF文件后,下面的列表会显示上传的PDF文件,点击convert开始压缩。右键单击网页上的任意位置,将其翻译成简体中文网页。
3、 完成后点击下载。
二、快速乐趣
优点:客户端一键批量操作,省时高效
方法:
1、 极乐转换器下载安装后,在PDF工具中选择PDF压缩进入;
2、 将所有需要压缩的PDF批量添加或拖拽到压缩页面后,点击页面左下角的输出路径修改压缩后的PDF的保存位置,点击开始压缩一键压缩所有当前添加的PDF文档。
3、 除了我们上一步修改的保存位置,还可以查看转换完成后的所有压缩记录,右键任意文档选择打开查看。
搜索引擎优化pdf(全文搜索首先搞清楚第一个问题的开发过程及解决办法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2021-12-30 00:09
最近项目组安排了一个任务,项目中用到了全文搜索,基于全文搜索Solr
但是Solr搜索云项目不稳定,经常查询不到数据。需要手动全量同步,由其他团队维护。依赖性太强了。Solr 服务一旦出现故障,我们的项目就因为所有的依赖关系而基本瘫痪。查询没有结果数据。
所以考虑开发一个适配层,如果Solr搜索有问题,自动切换到新的搜索:ElasticSearch(ES)
其实这个问题可以通过Solr集群或者服务容错设计来解决。但是不管设计本身的合理性,leader需要开发,所以我从头开始搭建ES服务,因为之前没接触过ES,所以通过这个系列记录了我的开发过程。
什么是全文搜索
首先澄清第一个问题:什么是全文搜索引擎?
百度百科中的定义:
全文搜索引擎是目前应用广泛的主流搜索引擎。其工作原理是计算机索引程序扫描文章中的每个词,为每个词建立索引,并指示该词在文章中的编号和位置。
当用户进行查询时,搜索程序会根据预先建立的索引进行搜索,并将搜索结果反馈给用户的搜索方法。这个过程类似于通过字典中的搜索词列表查找字符的过程。
从定义上,我们已经可以大致了解全文检索的思想了。为了更详细的讲解,先从生活中的数据说起。
在我们的生活中有两种类型的数据:结构化数据和非结构化数据。
当然,有些地方还会有第三种:半结构化数据,如XML、HTML等,可以根据需要处理为结构化数据,也可以提取纯文本作为非结构化数据处理。
根据两类数据分类,搜索也分为两类:
对于结构化数据,我们一般可以通过关系数据库(mysql、oracle等)的表进行存储和搜索,或者创建索引。对于非结构化数据,即搜索全文数据,主要有两种方法:顺序扫描法、全文搜索法
顺序扫描:也可以通过文字名称知道一般的搜索方式,即在顺序扫描中搜索特定的关键字。
比如给你一份报纸,找出报纸上“RNG”这个词出现在什么地方。您肯定需要从头到尾扫描报纸并标记关键字出现的部分和出现的位置。
这种方法无疑是最耗时、效果最差的。如果报纸的排版很小,而且有很多版块甚至是多份报纸,你扫了一眼就差不多了。
全文搜索:非结构化数据的顺序扫描很慢。我们可以优化它吗?想办法让我们的非结构化数据有一定的结构还不够吗?
我们将非结构化数据中的部分信息提取出来,重新组织起来,使其具有一定的结构,然后搜索具有一定结构的数据,从而达到比较快速搜索的目的。
这种方式构成了全文检索的基本思想。这部分信息是从非结构化数据中提取出来然后重新组织起来的,我们称之为索引。
以阅读报纸为例。我们要关注最近英雄联盟S8全球总决赛的消息。如果我们都是RNG的粉丝,如何快速找到RNG新闻的报纸和栏目?
全文检索法:从所有报纸的所有版块中提取关键词,如“EDG”、“RNG”、“FW”、“团队”、“英雄联盟”等,然后对这些关键词进行索引,并通过索引,我们可以对应出现在关键词中的报纸和栏目。
为什么要使用全文搜索引擎
那么第二个问题是,为什么要使用搜索引擎?
我们所有的数据都在数据库中,Oracle、SQL Server等数据库也可以提供查询检索或聚类分析功能。直接通过数据库查询还不够吗?
事实上,我们的大部分查询功能都可以通过数据库查询来获得。如果查询效率低,还可以通过建立数据库索引、优化SQL等方式来提高效率,甚至可以通过引入缓存来加快数据返回速度。如果数据量较大,可以拆分数据库和表来分担查询压力。
那为什么还需要全文搜索引擎呢?我们主要分析以下原因:
第三个问题:什么时候使用全文搜索引擎?
搜索到的数据对象是大量的非结构化文本数据。文件记录数达到数十万或数百万甚至更多。支持大量基于交互式文本的查询。具有非常灵活要求的全文搜索查询。对高度相关的搜索结果有特殊要求,但没有可用的关系数据库来满足这些要求。对不同记录类型、非文本数据操作或安全事务处理的要求相对较少的情况。Lucene、Solr 还是 ElasticSearch?
目前主流的搜索引擎大概有:Lucene、Solr、ElasticSearch。
他们的索引创建是根据倒排索引的方法来生成索引的,什么是倒排索引?
我们先来看看维基百科的解释:
维基百科
倒排索引(英文:Inverted index),也常被称为倒排索引、倒排文件或倒排文件,是一种索引方法,用于在全文搜索下存储文档或组中的某个词 存储的映射文档中的位置。它是文档检索系统中最常用的数据结构。
接下来,我们就来看看这三种主流的使用倒排索引的全文搜索引擎。
琉森
Lucene 是一个 Java 全文搜索引擎,完全用 Java 编写。Lucene 不是一个完整的应用程序,而是一个代码库和 API,可轻松用于向应用程序添加搜索功能。
Lucene 通过简单的 API 提供了强大的功能:
可扩展的高性能索引
强大、准确、高效的搜索算法
跨平台解决方案
但是Lucene只是一个框架。要充分利用其功能,需要使用JAVA,并在程序中集成Lucene。理解它是如何工作的需要大量的学习和理解,而要熟练地使用 Lucene 确实很复杂。
索尔
Apache Solr 是一个基于名为 Lucene 的 Java 库的开源搜索平台。它以用户友好的方式提供了Apache Lucene的搜索功能。
它提供分布式索引、复制、负载平衡查询以及自动故障转移和恢复。如果部署得当,管理得当,它可以成为一个高度可靠、可扩展、容错的搜索引擎。
许多互联网巨头,如 Netflix、eBay、Instagram 和亚马逊 (CloudSearch) 都使用 Solr,因为它能够索引和搜索多个站点。
主要功能列表包括:
弹性搜索
Elasticsearch 是一个基于 Apache Lucene 库的开源 RESTful 搜索引擎,在 Solr 几年后推出。
它提供了一个分布式、多租户全文搜索引擎,带有 HTTP Web 接口(REST)和非结构化 JSON 文档。
Elasticsearch 的官方客户端库提供 Java、Groovy、PHP、Ruby、Perl、Python、.NET 和 Javascript。
分布式搜索引擎收录
的索引可以分为段,每个段可以有多个副本。每个 Elasticsearch 节点可以有一个或多个分片,它的引擎也可以充当协调器,将操作委托给正确的分片。
Elasticsearch 可以通过近乎实时的搜索进行扩展。它的主要功能之一是多租户。主要功能列表包括:
Elasticsearch vs. Solr,如何选择?
由于Lucene的复杂性,一般很少将其作为搜索的首选。排除部分公司需要自己开发搜索框架,底层需要依赖Lucene。所以这里我们重点分析Elasticsearch和Solr。
Elasticsearch 与 Solr。哪一个更好?它们有何不同?你应该使用哪一个?
历史比较
Apache Solr 是一个成熟的项目,拥有庞大而活跃的开发和用户社区,以及 Apache 品牌。Solr 于 2006 年首次发布开源。它长期以来一直统治着搜索引擎领域,是任何需要搜索功能的人的首选引擎。
它的成熟转化为丰富的功能,而不仅仅是简单的文本索引和搜索;如分面、分组、强大的过滤、可插入的文档处理、可插入的搜索链组件、语言检测等。
Solr 多年来一直统治着搜索领域。然后,在 2010 年左右,Elasticsearch 成为市场上的另一种选择。当时,它远不如 Solr 稳定,没有 Solr 的功能深度,没有分享想法,品牌等。
Elasticsearch虽然很年轻,但也有自己的一些优势。Elasticsearch 建立在更现代的原则之上,针对更现代的用例,旨在更轻松地处理大型索引和高查询率。
另外,因为它太年轻,没有社区可以合作,它可以在没有任何共识或与其他人(用户或开发者)合作,向后兼容,或任何其他更成熟的软件通常必须处理的情况下自由前进。
所以在Solr之前就公开了一些非常流行的功能(比如near real-time search,英文:Near Real-Time Search)。
从技术上讲,NRT 搜索的能力确实来自 Lucene,它是 Solr 和 Elasticsearch 使用的基本搜索库。
讽刺的是,因为 Elasticsearch 首先公开了 NRT 搜索,人们将 NRT 搜索与 Elasticsearch 联系起来,尽管 Solr 和 Lucene 都是同一个 Apache 项目的一部分,所以人们首先会期望 Solr 有如此苛刻的功能。
功能差异对比
这两个搜索引擎都是流行的高级开源搜索引擎。它们都是围绕核心底层搜索库-Lucene构建的
但它们是不同的。像所有事物一样,每个事物都有其优点和缺点,并且根据您的需求和期望,每个事物都可能更好或更糟。
那么,话不多说,先来看看不同之处:
综合比较
另外,我们从以下几个方面进行分析:
总结
所以问题是,它是 Solr 还是 Elasticsearch?
很难找到明确的答案。无论您选择 Solr 还是 Elasticsearch,您首先需要了解正确的用例和未来的需求。总结它们的每个属性。记住:
总之,两者都是功能丰富的搜索引擎,只要设计和实现得当,它们都可以提供或多或少相同的性能。本文整体内容大致如下图所示,由园友ReyCG精心绘制和提供。
欢迎工作一到五年的Java工程师加入Java程序员的开发:721575865
本群免费提供Java架构学习资料(高可用、高并发、高性能和分布式、JVM性能调优、Spring源码、MyBatis、Netty、Redis、Kafka、Mysql、Zookeeper、Tomcat、Docker、Dubbo、Nginx等框架知识点)合理利用自己的时间分分秒秒地学习提升自己,不要用“没时间”来掩饰自己的精神懒惰!趁年轻努力,给未来的自己一个交代! 查看全部
搜索引擎优化pdf(全文搜索首先搞清楚第一个问题的开发过程及解决办法!)
最近项目组安排了一个任务,项目中用到了全文搜索,基于全文搜索Solr
但是Solr搜索云项目不稳定,经常查询不到数据。需要手动全量同步,由其他团队维护。依赖性太强了。Solr 服务一旦出现故障,我们的项目就因为所有的依赖关系而基本瘫痪。查询没有结果数据。
所以考虑开发一个适配层,如果Solr搜索有问题,自动切换到新的搜索:ElasticSearch(ES)
其实这个问题可以通过Solr集群或者服务容错设计来解决。但是不管设计本身的合理性,leader需要开发,所以我从头开始搭建ES服务,因为之前没接触过ES,所以通过这个系列记录了我的开发过程。
什么是全文搜索
首先澄清第一个问题:什么是全文搜索引擎?
百度百科中的定义:
全文搜索引擎是目前应用广泛的主流搜索引擎。其工作原理是计算机索引程序扫描文章中的每个词,为每个词建立索引,并指示该词在文章中的编号和位置。
当用户进行查询时,搜索程序会根据预先建立的索引进行搜索,并将搜索结果反馈给用户的搜索方法。这个过程类似于通过字典中的搜索词列表查找字符的过程。
从定义上,我们已经可以大致了解全文检索的思想了。为了更详细的讲解,先从生活中的数据说起。
在我们的生活中有两种类型的数据:结构化数据和非结构化数据。
当然,有些地方还会有第三种:半结构化数据,如XML、HTML等,可以根据需要处理为结构化数据,也可以提取纯文本作为非结构化数据处理。
根据两类数据分类,搜索也分为两类:
对于结构化数据,我们一般可以通过关系数据库(mysql、oracle等)的表进行存储和搜索,或者创建索引。对于非结构化数据,即搜索全文数据,主要有两种方法:顺序扫描法、全文搜索法
顺序扫描:也可以通过文字名称知道一般的搜索方式,即在顺序扫描中搜索特定的关键字。
比如给你一份报纸,找出报纸上“RNG”这个词出现在什么地方。您肯定需要从头到尾扫描报纸并标记关键字出现的部分和出现的位置。
这种方法无疑是最耗时、效果最差的。如果报纸的排版很小,而且有很多版块甚至是多份报纸,你扫了一眼就差不多了。
全文搜索:非结构化数据的顺序扫描很慢。我们可以优化它吗?想办法让我们的非结构化数据有一定的结构还不够吗?
我们将非结构化数据中的部分信息提取出来,重新组织起来,使其具有一定的结构,然后搜索具有一定结构的数据,从而达到比较快速搜索的目的。
这种方式构成了全文检索的基本思想。这部分信息是从非结构化数据中提取出来然后重新组织起来的,我们称之为索引。
以阅读报纸为例。我们要关注最近英雄联盟S8全球总决赛的消息。如果我们都是RNG的粉丝,如何快速找到RNG新闻的报纸和栏目?
全文检索法:从所有报纸的所有版块中提取关键词,如“EDG”、“RNG”、“FW”、“团队”、“英雄联盟”等,然后对这些关键词进行索引,并通过索引,我们可以对应出现在关键词中的报纸和栏目。
为什么要使用全文搜索引擎
那么第二个问题是,为什么要使用搜索引擎?
我们所有的数据都在数据库中,Oracle、SQL Server等数据库也可以提供查询检索或聚类分析功能。直接通过数据库查询还不够吗?
事实上,我们的大部分查询功能都可以通过数据库查询来获得。如果查询效率低,还可以通过建立数据库索引、优化SQL等方式来提高效率,甚至可以通过引入缓存来加快数据返回速度。如果数据量较大,可以拆分数据库和表来分担查询压力。
那为什么还需要全文搜索引擎呢?我们主要分析以下原因:
第三个问题:什么时候使用全文搜索引擎?
搜索到的数据对象是大量的非结构化文本数据。文件记录数达到数十万或数百万甚至更多。支持大量基于交互式文本的查询。具有非常灵活要求的全文搜索查询。对高度相关的搜索结果有特殊要求,但没有可用的关系数据库来满足这些要求。对不同记录类型、非文本数据操作或安全事务处理的要求相对较少的情况。Lucene、Solr 还是 ElasticSearch?
目前主流的搜索引擎大概有:Lucene、Solr、ElasticSearch。
他们的索引创建是根据倒排索引的方法来生成索引的,什么是倒排索引?
我们先来看看维基百科的解释:
维基百科
倒排索引(英文:Inverted index),也常被称为倒排索引、倒排文件或倒排文件,是一种索引方法,用于在全文搜索下存储文档或组中的某个词 存储的映射文档中的位置。它是文档检索系统中最常用的数据结构。
接下来,我们就来看看这三种主流的使用倒排索引的全文搜索引擎。
琉森
Lucene 是一个 Java 全文搜索引擎,完全用 Java 编写。Lucene 不是一个完整的应用程序,而是一个代码库和 API,可轻松用于向应用程序添加搜索功能。
Lucene 通过简单的 API 提供了强大的功能:
可扩展的高性能索引
强大、准确、高效的搜索算法
跨平台解决方案
但是Lucene只是一个框架。要充分利用其功能,需要使用JAVA,并在程序中集成Lucene。理解它是如何工作的需要大量的学习和理解,而要熟练地使用 Lucene 确实很复杂。
索尔
Apache Solr 是一个基于名为 Lucene 的 Java 库的开源搜索平台。它以用户友好的方式提供了Apache Lucene的搜索功能。
它提供分布式索引、复制、负载平衡查询以及自动故障转移和恢复。如果部署得当,管理得当,它可以成为一个高度可靠、可扩展、容错的搜索引擎。
许多互联网巨头,如 Netflix、eBay、Instagram 和亚马逊 (CloudSearch) 都使用 Solr,因为它能够索引和搜索多个站点。
主要功能列表包括:
弹性搜索
Elasticsearch 是一个基于 Apache Lucene 库的开源 RESTful 搜索引擎,在 Solr 几年后推出。
它提供了一个分布式、多租户全文搜索引擎,带有 HTTP Web 接口(REST)和非结构化 JSON 文档。
Elasticsearch 的官方客户端库提供 Java、Groovy、PHP、Ruby、Perl、Python、.NET 和 Javascript。
分布式搜索引擎收录
的索引可以分为段,每个段可以有多个副本。每个 Elasticsearch 节点可以有一个或多个分片,它的引擎也可以充当协调器,将操作委托给正确的分片。
Elasticsearch 可以通过近乎实时的搜索进行扩展。它的主要功能之一是多租户。主要功能列表包括:
Elasticsearch vs. Solr,如何选择?
由于Lucene的复杂性,一般很少将其作为搜索的首选。排除部分公司需要自己开发搜索框架,底层需要依赖Lucene。所以这里我们重点分析Elasticsearch和Solr。
Elasticsearch 与 Solr。哪一个更好?它们有何不同?你应该使用哪一个?
历史比较
Apache Solr 是一个成熟的项目,拥有庞大而活跃的开发和用户社区,以及 Apache 品牌。Solr 于 2006 年首次发布开源。它长期以来一直统治着搜索引擎领域,是任何需要搜索功能的人的首选引擎。
它的成熟转化为丰富的功能,而不仅仅是简单的文本索引和搜索;如分面、分组、强大的过滤、可插入的文档处理、可插入的搜索链组件、语言检测等。
Solr 多年来一直统治着搜索领域。然后,在 2010 年左右,Elasticsearch 成为市场上的另一种选择。当时,它远不如 Solr 稳定,没有 Solr 的功能深度,没有分享想法,品牌等。
Elasticsearch虽然很年轻,但也有自己的一些优势。Elasticsearch 建立在更现代的原则之上,针对更现代的用例,旨在更轻松地处理大型索引和高查询率。
另外,因为它太年轻,没有社区可以合作,它可以在没有任何共识或与其他人(用户或开发者)合作,向后兼容,或任何其他更成熟的软件通常必须处理的情况下自由前进。
所以在Solr之前就公开了一些非常流行的功能(比如near real-time search,英文:Near Real-Time Search)。
从技术上讲,NRT 搜索的能力确实来自 Lucene,它是 Solr 和 Elasticsearch 使用的基本搜索库。
讽刺的是,因为 Elasticsearch 首先公开了 NRT 搜索,人们将 NRT 搜索与 Elasticsearch 联系起来,尽管 Solr 和 Lucene 都是同一个 Apache 项目的一部分,所以人们首先会期望 Solr 有如此苛刻的功能。
功能差异对比
这两个搜索引擎都是流行的高级开源搜索引擎。它们都是围绕核心底层搜索库-Lucene构建的
但它们是不同的。像所有事物一样,每个事物都有其优点和缺点,并且根据您的需求和期望,每个事物都可能更好或更糟。
那么,话不多说,先来看看不同之处:
综合比较
另外,我们从以下几个方面进行分析:
总结
所以问题是,它是 Solr 还是 Elasticsearch?
很难找到明确的答案。无论您选择 Solr 还是 Elasticsearch,您首先需要了解正确的用例和未来的需求。总结它们的每个属性。记住:
总之,两者都是功能丰富的搜索引擎,只要设计和实现得当,它们都可以提供或多或少相同的性能。本文整体内容大致如下图所示,由园友ReyCG精心绘制和提供。
欢迎工作一到五年的Java工程师加入Java程序员的开发:721575865
本群免费提供Java架构学习资料(高可用、高并发、高性能和分布式、JVM性能调优、Spring源码、MyBatis、Netty、Redis、Kafka、Mysql、Zookeeper、Tomcat、Docker、Dubbo、Nginx等框架知识点)合理利用自己的时间分分秒秒地学习提升自己,不要用“没时间”来掩饰自己的精神懒惰!趁年轻努力,给未来的自己一个交代!
搜索引擎优化pdf(PDFSearchforMac快速搜索文档、参考书格式转换,功能很实用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-30 00:07
文末有获取方式,按照以下步骤获取。我们不破解软件。所有优秀的软件都来自互联网。破解软件仅供学习使用。如需商业用途,请购买正版。造成的法律责任与我无关。如侵犯了您的权益,请联系编辑删除。
PDF Search for Mac是Mac平台上的pdf文件搜索工具。PDF Search mac破解版可以快速搜索文档、参考书或笔记,让您轻松访问任何信息。mac 版的 PDF Search 还支持将文档转换为 PDF 格式。,功能很实用!
【PDF Search Mac App Store售价198.00元】
PDF搜索7.2 For Mac破解版介绍
Mac 版 PDF 搜索利用人工智能的力量快速搜索数千个文档。让您的工作和学校生活更高效、更轻松。
人工智能的成功
信息是成功的关键。PDF 搜索将帮助您使用 AI 驱动的算法快速获取文档中的信息。只需使用它来搜索您的文档、参考书或笔记。然后感受在几秒钟内访问任何信息的力量。您将使用 Mac、iPad 或 iPhone 在会议、课程或工作中大放异彩。每个人都会对您对文件的掌握程度感到惊讶。
是什么让它与众不同
一般搜索工具搜索存在。他们只检查您的关键字是否存在于文档中。然后他们会给你一份文件清单。你一一检查它们,看看它们是否是你要找的那些。没有智能,就像机器一样。
PDF 搜索可以是一个智能搜索工具。它不会检查是否存在唯一性,而是单独分析所有页面并根据给定的关键字检查每个页面的相关性。此检查类似于一个人检查文档的方式。例如,如果页面的标题收录
关键字,则该页面对该页面更感兴趣。PDF 搜索将所有这些检查组合成一个全新的算法。使用此算法,它可以立即在数千个文档中找到最相关的页面。
统一搜索体验
您可以使用 iPhone 或 iPad 在 Mac 上搜索文档。只需单击一下,您就可以通过 WiFi 同步您的文件,并随身携带您的所有文件。
将文档转换为 PDF
支持 Word、Powerpoint、Pages、Keynote 和 RTF 文档。PDF Converter 是一个免费的帮助应用程序,您可以从我们的网站下载。安装后,Office 文档将自动转换为 PDF 并通过 PDF 搜索建立索引。
特征
获取方法:
1、 点击右上角关注; 查看全部
搜索引擎优化pdf(PDFSearchforMac快速搜索文档、参考书格式转换,功能很实用)
文末有获取方式,按照以下步骤获取。我们不破解软件。所有优秀的软件都来自互联网。破解软件仅供学习使用。如需商业用途,请购买正版。造成的法律责任与我无关。如侵犯了您的权益,请联系编辑删除。
PDF Search for Mac是Mac平台上的pdf文件搜索工具。PDF Search mac破解版可以快速搜索文档、参考书或笔记,让您轻松访问任何信息。mac 版的 PDF Search 还支持将文档转换为 PDF 格式。,功能很实用!
【PDF Search Mac App Store售价198.00元】
PDF搜索7.2 For Mac破解版介绍
Mac 版 PDF 搜索利用人工智能的力量快速搜索数千个文档。让您的工作和学校生活更高效、更轻松。
人工智能的成功
信息是成功的关键。PDF 搜索将帮助您使用 AI 驱动的算法快速获取文档中的信息。只需使用它来搜索您的文档、参考书或笔记。然后感受在几秒钟内访问任何信息的力量。您将使用 Mac、iPad 或 iPhone 在会议、课程或工作中大放异彩。每个人都会对您对文件的掌握程度感到惊讶。
是什么让它与众不同
一般搜索工具搜索存在。他们只检查您的关键字是否存在于文档中。然后他们会给你一份文件清单。你一一检查它们,看看它们是否是你要找的那些。没有智能,就像机器一样。
PDF 搜索可以是一个智能搜索工具。它不会检查是否存在唯一性,而是单独分析所有页面并根据给定的关键字检查每个页面的相关性。此检查类似于一个人检查文档的方式。例如,如果页面的标题收录
关键字,则该页面对该页面更感兴趣。PDF 搜索将所有这些检查组合成一个全新的算法。使用此算法,它可以立即在数千个文档中找到最相关的页面。
统一搜索体验
您可以使用 iPhone 或 iPad 在 Mac 上搜索文档。只需单击一下,您就可以通过 WiFi 同步您的文件,并随身携带您的所有文件。
将文档转换为 PDF
支持 Word、Powerpoint、Pages、Keynote 和 RTF 文档。PDF Converter 是一个免费的帮助应用程序,您可以从我们的网站下载。安装后,Office 文档将自动转换为 PDF 并通过 PDF 搜索建立索引。
特征
获取方法:
1、 点击右上角关注;
搜索引擎优化pdf(文档介绍:状元学优化(SEO)搜索结果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-26 17:04
文件介绍:
状元科学****信息网应有尽有
搜索引擎优化 (SEO) 词汇表
搜索结果
result):作为对搜索者搜索请求的响应,搜索引擎返回匹配网页的链接,这个
链接是搜索结果。搜索引擎使用多种技术来确定哪个页面与哪个搜索请求匹配。
匹配,并根据相关程度对自然搜索匹配结果进行排序,查看最佳匹配结果
在第一个搜索结果中。付费展示位置和目录结果通常受相关性和网站所有权的影响
投标人中标结果的影响。
搜索引擎营销(SEM、搜索引擎营销)
旨在改善网站上搜索推荐的所有行为,无论是自然搜索还是付费搜索。搜索
引擎营销也称为搜索营销。
搜索引擎优化(SEO、搜索引擎优化)
一系列致力于提高网站自然搜索排名(非付费排名)的技术和方法。
站点地图
map) 对蜘蛛程序友好的网页,提供指向本网站域内其他网页的链接
. 对于小型网站,站点地图提供指向站点上所有网页的直接链接。中间
转到大型站点并使用站点地图链接到域中的主要中央网页(这些网页最终会变成
实现对网站上所有网页的访问)。例如:-
/站点地图.asp
***(垃圾邮件)
1.未经许可的未经请求的非法电子邮件,通常收录
商业信息或欺诈主题
只需将其交付给收件人。2. 也称为搜索***技术,旨在愚弄搜索引擎。
合乎道德(但合法)的技术,即使它的网页不是搜索请求的最佳匹配,也是显而易见的
展示。
元搜索引擎
搜索引擎将许多搜索者输入的搜索请求发送到许多其他搜索,并比较每个搜索。
搜索引擎结果并将它们显示在单个结果列表中。
301重定向也称为永久重定向(permanent
状元科学****信息网应有尽有
状元科学****信息网应有尽有
重定向),是对网站浏览器显示不同的指令
URL,当网络也经历过它的 URL 时
在最后一次更改后使用。永久重定向是可以搜索的服务器端重定向
电缆引擎蜘蛛正确处理它。
302重定向也被认为是临时重定向(temporary
重定向),向网站浏览器显示不同的指令
URL,当网页遇到短 URL 时
改变时使用。临时重定向是搜索引擎可以使用的服务器端重定向
蜘蛛正确处理它。
权威网站(Authorit)
网站所考虑的专业水平通常由其内部超链接网络来衡量。搜索引擎通常
高度关注那些从其他链接良好的网站获得内向链接的网站,以及
匹配站点主题并将这些站点置于搜索结果前面的搜索请求。
权威页面是许多链接指向某个主题的网页。
反向链接是所谓的入站链接
链接),是指从网页到您的网页的超链接。从您网站的外部链接到网页的向内链接
那么,在搜索引擎中做链接分析,根据相关性对搜索结果进行排序时,
价值。
拖车链接
也称为互链接,是一个网页的超文本链接,目标网页链接回原来的网页
来到主页。
网络日志
1. 网站服务器上的一个文件,作为服务器执行的每一个操作的记录。日志文本
可以通过复杂的方法分析文档以确定网站访问者的数量(根据人和
(跟随搜索引擎的蜘蛛程序)
, 以及他们浏览的页数。2. 也叫博客,是一种在线日志。
出版物,互联网上的常规专栏。有些博客是回忆的私人日记,但其他博客
状元科学****信息网应有尽有
状元科学****信息网应有尽有
在一些类似的杂志专栏之外,专注于特定的感兴趣的话题。
横幅
ad) 也成为广告横幅广告,通常在网页的显着部分显示为一个大的彩色矩形
, 类似于出现在报纸和杂志上的广告。单击横幅会将访问者带到广告商的网站。
行为模型
一组执行特定任务的人的行为的抽象摘要,用于衡量和分析他们正在做什么。这
该分析可以建议如何在任务跟进期间改进流程。
投标(投标)
为每个搜索引擎支付搜索引擎推荐费,保证付费搜索结果的排名
. 付费搜索结果以最简单的形式显示结果列表中出价最高者的网页链接。
在顶部,每次访问者点击投标人的链接时,投标人都会向搜索引擎支付费用。
出价差
gap) 有偿投标中两个相邻位置的两个投标之间的明显差异。例如,当投标人
目前排名第三, 查看全部
搜索引擎优化pdf(文档介绍:状元学优化(SEO)搜索结果)
文件介绍:
状元科学****信息网应有尽有
搜索引擎优化 (SEO) 词汇表
搜索结果
result):作为对搜索者搜索请求的响应,搜索引擎返回匹配网页的链接,这个
链接是搜索结果。搜索引擎使用多种技术来确定哪个页面与哪个搜索请求匹配。
匹配,并根据相关程度对自然搜索匹配结果进行排序,查看最佳匹配结果
在第一个搜索结果中。付费展示位置和目录结果通常受相关性和网站所有权的影响
投标人中标结果的影响。
搜索引擎营销(SEM、搜索引擎营销)
旨在改善网站上搜索推荐的所有行为,无论是自然搜索还是付费搜索。搜索
引擎营销也称为搜索营销。
搜索引擎优化(SEO、搜索引擎优化)
一系列致力于提高网站自然搜索排名(非付费排名)的技术和方法。
站点地图
map) 对蜘蛛程序友好的网页,提供指向本网站域内其他网页的链接
. 对于小型网站,站点地图提供指向站点上所有网页的直接链接。中间
转到大型站点并使用站点地图链接到域中的主要中央网页(这些网页最终会变成
实现对网站上所有网页的访问)。例如:-
/站点地图.asp
***(垃圾邮件)
1.未经许可的未经请求的非法电子邮件,通常收录
商业信息或欺诈主题
只需将其交付给收件人。2. 也称为搜索***技术,旨在愚弄搜索引擎。
合乎道德(但合法)的技术,即使它的网页不是搜索请求的最佳匹配,也是显而易见的
展示。
元搜索引擎
搜索引擎将许多搜索者输入的搜索请求发送到许多其他搜索,并比较每个搜索。
搜索引擎结果并将它们显示在单个结果列表中。
301重定向也称为永久重定向(permanent
状元科学****信息网应有尽有
状元科学****信息网应有尽有
重定向),是对网站浏览器显示不同的指令
URL,当网络也经历过它的 URL 时
在最后一次更改后使用。永久重定向是可以搜索的服务器端重定向
电缆引擎蜘蛛正确处理它。
302重定向也被认为是临时重定向(temporary
重定向),向网站浏览器显示不同的指令
URL,当网页遇到短 URL 时
改变时使用。临时重定向是搜索引擎可以使用的服务器端重定向
蜘蛛正确处理它。
权威网站(Authorit)
网站所考虑的专业水平通常由其内部超链接网络来衡量。搜索引擎通常
高度关注那些从其他链接良好的网站获得内向链接的网站,以及
匹配站点主题并将这些站点置于搜索结果前面的搜索请求。
权威页面是许多链接指向某个主题的网页。
反向链接是所谓的入站链接
链接),是指从网页到您的网页的超链接。从您网站的外部链接到网页的向内链接
那么,在搜索引擎中做链接分析,根据相关性对搜索结果进行排序时,
价值。
拖车链接
也称为互链接,是一个网页的超文本链接,目标网页链接回原来的网页
来到主页。
网络日志
1. 网站服务器上的一个文件,作为服务器执行的每一个操作的记录。日志文本
可以通过复杂的方法分析文档以确定网站访问者的数量(根据人和
(跟随搜索引擎的蜘蛛程序)
, 以及他们浏览的页数。2. 也叫博客,是一种在线日志。
出版物,互联网上的常规专栏。有些博客是回忆的私人日记,但其他博客
状元科学****信息网应有尽有
状元科学****信息网应有尽有
在一些类似的杂志专栏之外,专注于特定的感兴趣的话题。
横幅
ad) 也成为广告横幅广告,通常在网页的显着部分显示为一个大的彩色矩形
, 类似于出现在报纸和杂志上的广告。单击横幅会将访问者带到广告商的网站。
行为模型
一组执行特定任务的人的行为的抽象摘要,用于衡量和分析他们正在做什么。这
该分析可以建议如何在任务跟进期间改进流程。
投标(投标)
为每个搜索引擎支付搜索引擎推荐费,保证付费搜索结果的排名
. 付费搜索结果以最简单的形式显示结果列表中出价最高者的网页链接。
在顶部,每次访问者点击投标人的链接时,投标人都会向搜索引擎支付费用。
出价差
gap) 有偿投标中两个相邻位置的两个投标之间的明显差异。例如,当投标人
目前排名第三,
搜索引擎优化pdf(搜索引擎进行网站优化的精华要点,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-26 14:17
经过近2年网络营销的反复实践,并在此基础上,总结了搜索引擎网站优化的一些精髓。我希望它会对大家有所帮助。
1. 尝试将其作为代码的开头,将javascript和CSS模块化,并尝试使用include使其独立于HTML页面。
2. 如果访问网站内容需要会员登录或密码保护,请向搜索引擎蜘蛛或机器人打开。
3. 如果网站的内容是用PHP、ASP或JSP等脚本动态生成的,则需要通过Apache的Mod_Rewrite或PHP的Path_Info进行URL重写和优化,使URL类似于静态页面。如:可以映射到或。
4. 尽量避免不必要的跳转和重定向页面或类似的会产生 3xx 的机制。
5. 保持 HTML 中标签中的内容与实际文章或内容的标题一致,并尽量在每个页面上唯一。
6. 使用和标签来表示实际文章或内容的标题和副标题。如果你想保持漂亮,请使用 CSS 来定义它。
7. 尽量保持每个
<IMG>
标签中有 ALT 属性,最好所有 ALT 属性都有内容。
8. 创建结构清晰且有意义的网站导航页面。
9. 在网站根目录下创建robot.txt文件。如对搜索引擎无特殊要求,内容为*;或添加一些搜索引擎所需的脚本。
10. 尽量不要使用框架结构来呈现网站。
11.尽量使网站代码符合W3C的HTML4.0或XHTML1.0规范。
12. 网站或学术文章的主要内容,尽量转换成PDF格式。因为 PDF 文件的自然 Page Rank 是 3。
13. 尽量让网站的结构趋于扁平化,最好不要超过3层。 查看全部
搜索引擎优化pdf(搜索引擎进行网站优化的精华要点,你知道吗?)
经过近2年网络营销的反复实践,并在此基础上,总结了搜索引擎网站优化的一些精髓。我希望它会对大家有所帮助。
1. 尝试将其作为代码的开头,将javascript和CSS模块化,并尝试使用include使其独立于HTML页面。
2. 如果访问网站内容需要会员登录或密码保护,请向搜索引擎蜘蛛或机器人打开。
3. 如果网站的内容是用PHP、ASP或JSP等脚本动态生成的,则需要通过Apache的Mod_Rewrite或PHP的Path_Info进行URL重写和优化,使URL类似于静态页面。如:可以映射到或。
4. 尽量避免不必要的跳转和重定向页面或类似的会产生 3xx 的机制。
5. 保持 HTML 中标签中的内容与实际文章或内容的标题一致,并尽量在每个页面上唯一。
6. 使用和标签来表示实际文章或内容的标题和副标题。如果你想保持漂亮,请使用 CSS 来定义它。
7. 尽量保持每个
<IMG>
标签中有 ALT 属性,最好所有 ALT 属性都有内容。
8. 创建结构清晰且有意义的网站导航页面。
9. 在网站根目录下创建robot.txt文件。如对搜索引擎无特殊要求,内容为*;或添加一些搜索引擎所需的脚本。
10. 尽量不要使用框架结构来呈现网站。
11.尽量使网站代码符合W3C的HTML4.0或XHTML1.0规范。
12. 网站或学术文章的主要内容,尽量转换成PDF格式。因为 PDF 文件的自然 Page Rank 是 3。
13. 尽量让网站的结构趋于扁平化,最好不要超过3层。
搜索引擎优化pdf(搜索引擎优化pdf名词解释和pdf电子书免费下载。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-26 07:04
搜索引擎优化pdf名词解释和pdf电子书免费下载。pdf电子书网盘免费下载。书籍购买方式。下载方式一本书都是优惠到20元,个人觉得挺划算的,这些都是我一个一个店铺买的,价格也是有很大出入的。喜欢的留个赞,如果觉得不错点个赞支持一下呗!你们的支持是我分享的动力哦!有需要的直接私我下。获取方式二1,购买方式一本书都是优惠到20元,个人觉得挺划算的,这些都是我一个一个店铺买的,价格也是有很大出入的。
喜欢的留个赞,如果觉得不错点个赞支持一下呗!你们的支持是我分享的动力哦!2,那就来看看获取方式二的获取方式吧。现在已经有二十本有1000多本的库存了,有需要的小伙伴可以留意下。有需要的直接私我下。复制以下链接然后打开【吱口令】,即可领取。/end/来个评论互动下!。
没看过,不清楚,
我这里有,需要的留邮箱,有需要的给个赞吧,
有。邮箱。
我知道的有下边这些网站,除了用闲鱼不行之外,其他的还行,建议能支持正版还是支持正版吧,就算被骗了也就当买教训,真的挺好。
1、目前对于卖出去的纸质书书的价格定得比较低。有2块一本、5块一本以及10块一本的三种,也有更高的。
2、当当
3、京东亚马逊这两个网站卖纸质书的相对来说价格比较高,3元一本应该没有了,
4、简书不建议去。
4、店都是卖盗版书,
5、亚马逊纸质书超多,有6元两本或者8元三本的,店家也不太诚信。 查看全部
搜索引擎优化pdf(搜索引擎优化pdf名词解释和pdf电子书免费下载。)
搜索引擎优化pdf名词解释和pdf电子书免费下载。pdf电子书网盘免费下载。书籍购买方式。下载方式一本书都是优惠到20元,个人觉得挺划算的,这些都是我一个一个店铺买的,价格也是有很大出入的。喜欢的留个赞,如果觉得不错点个赞支持一下呗!你们的支持是我分享的动力哦!有需要的直接私我下。获取方式二1,购买方式一本书都是优惠到20元,个人觉得挺划算的,这些都是我一个一个店铺买的,价格也是有很大出入的。
喜欢的留个赞,如果觉得不错点个赞支持一下呗!你们的支持是我分享的动力哦!2,那就来看看获取方式二的获取方式吧。现在已经有二十本有1000多本的库存了,有需要的小伙伴可以留意下。有需要的直接私我下。复制以下链接然后打开【吱口令】,即可领取。/end/来个评论互动下!。
没看过,不清楚,
我这里有,需要的留邮箱,有需要的给个赞吧,
有。邮箱。
我知道的有下边这些网站,除了用闲鱼不行之外,其他的还行,建议能支持正版还是支持正版吧,就算被骗了也就当买教训,真的挺好。
1、目前对于卖出去的纸质书书的价格定得比较低。有2块一本、5块一本以及10块一本的三种,也有更高的。
2、当当
3、京东亚马逊这两个网站卖纸质书的相对来说价格比较高,3元一本应该没有了,
4、简书不建议去。
4、店都是卖盗版书,
5、亚马逊纸质书超多,有6元两本或者8元三本的,店家也不太诚信。
搜索引擎优化pdf(深度操作系统:全局搜索是一个桌面系统级搜索服务详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-25 20:01
IT之家12月2日报道称,深度操作系统20.3将于11月迎来更新,Stable内核将升级至5.15版本,进一步提升兼容性。修复系统安全漏洞,增强安全性。一些深度应用增加并优化了常用功能,以满足不同场景的需求。修复和优化桌面环境中的一些问题,只为带来更好的体验。
Deepin现在为大家带来桌面系统级搜索服务“全局搜索”新功能的详细讲解。
设计初衷:希望用户能输入尽可能少的内容,以找到他们想要的目标文件、应用程序或设置。
为什么要进行全局搜索?
在操作系统的使用过程中,我们收到了很多用户的反馈。在日常使用中,用户都希望直接进入某个场景,希望能方便一些。
基于直接搜索目标的效率,我们希望可以有一个系统级的服务可以很好的承担这个责任。全局搜索恰好有这个属性。
功能入口
全局搜索的功能入口位于任务栏右侧,与虚拟键盘位于同一区域。用鼠标点击放大镜的入口,打开屏幕中央的全局搜索框。
搜索栏
搜索框唤醒后,您可以在搜索框中输入要查找的文件、应用程序或设置关键字。在输入过程中随时调整输入文本内容,搜索结果列表会及时刷新搜索结果,让您快速找到搜索目标。
搜索结果列表
搜索结果列表支持显示更细粒度的搜索结果分类。例如,当您输入艺术家姓名时,如果恰好有一个mp3格式的歌曲文件收录
艺术家姓名,那么您可以在“音乐”类别下查看相应的搜索结果。
同样,如果可以对收录
搜索关键字的文档文件、图像文件和视频文件进行聚类和调用,则可以在指定的类别下查看搜索结果,以节省搜索时间。
当单个搜索类别下搜索结果过多时,默认折叠。因为太多的搜索结果会把列表拖的很长,不利于查看。单击“查看更多”可展开指定搜索类别的列表区域。
全局搜索支持多种类别搜索。在实际使用中,你会发现应用和网页搜索结果会比较高。
在排名方面,我们考虑的是,全球搜索不应只提供文件搜索服务,而应着眼于成为一个综合性的门户,能够更快地达到目标,并为每个人提高效率。这是大局。寻找的点。
搜索结果预览
当您在搜索结果列表中单击,或使用键盘上下方向键将搜索结果切换到某个音乐、图片、视频、文档或文件时,您会看到搜索结果右侧的区域名单扩大。此处将显示与搜索结果对应的预览窗格。
预览窗格将因类别而异。pdf、txt文档可以查看文档首页快照;图片、视频预览可以看到更详细的属性信息,在预览窗格的头部区域可以查看缩略图。
预览窗格不仅提供文件属性信息和文档主页快照的预览,还提供常用文件操作的快捷入口。例如,用户在预览搜索结果时,只需要打开文件路径,或者只需要复制文件路径,就可以在预览窗格底部一键进行操作,即非常方便快捷。
搜索设置
考虑到用户自身的自定义需求,全局搜索提供了一些自定义设置功能。右击任务栏中的放大镜入口图标,可以看到搜索设置的入口。单击搜索设置以查看全局搜索设置面板。
在设置面板中,用户可以根据自己的需要自定义哪些类别可以搜索和召回到搜索结果列表中。每个类别项都可以在开关上独立设置,提供了较高的灵活性。
全局搜索不仅仅是搜索。它仍在增长。将持续探索和优化大家的日常使用场景和习惯,提供更精细、更高效的直接体验。
deepin是一个Linux发行版,致力于为全球用户提供美观、易用、安全、稳定的服务。它也是中国团队开发的排名最高的发行版。支持全球33种语言,累计下载量超过8000万次,在6大洲42个国家拥有135个镜像站点。 查看全部
搜索引擎优化pdf(深度操作系统:全局搜索是一个桌面系统级搜索服务详解)
IT之家12月2日报道称,深度操作系统20.3将于11月迎来更新,Stable内核将升级至5.15版本,进一步提升兼容性。修复系统安全漏洞,增强安全性。一些深度应用增加并优化了常用功能,以满足不同场景的需求。修复和优化桌面环境中的一些问题,只为带来更好的体验。
Deepin现在为大家带来桌面系统级搜索服务“全局搜索”新功能的详细讲解。
设计初衷:希望用户能输入尽可能少的内容,以找到他们想要的目标文件、应用程序或设置。
为什么要进行全局搜索?
在操作系统的使用过程中,我们收到了很多用户的反馈。在日常使用中,用户都希望直接进入某个场景,希望能方便一些。
基于直接搜索目标的效率,我们希望可以有一个系统级的服务可以很好的承担这个责任。全局搜索恰好有这个属性。
功能入口
全局搜索的功能入口位于任务栏右侧,与虚拟键盘位于同一区域。用鼠标点击放大镜的入口,打开屏幕中央的全局搜索框。
搜索栏
搜索框唤醒后,您可以在搜索框中输入要查找的文件、应用程序或设置关键字。在输入过程中随时调整输入文本内容,搜索结果列表会及时刷新搜索结果,让您快速找到搜索目标。
搜索结果列表
搜索结果列表支持显示更细粒度的搜索结果分类。例如,当您输入艺术家姓名时,如果恰好有一个mp3格式的歌曲文件收录
艺术家姓名,那么您可以在“音乐”类别下查看相应的搜索结果。
同样,如果可以对收录
搜索关键字的文档文件、图像文件和视频文件进行聚类和调用,则可以在指定的类别下查看搜索结果,以节省搜索时间。
当单个搜索类别下搜索结果过多时,默认折叠。因为太多的搜索结果会把列表拖的很长,不利于查看。单击“查看更多”可展开指定搜索类别的列表区域。
全局搜索支持多种类别搜索。在实际使用中,你会发现应用和网页搜索结果会比较高。
在排名方面,我们考虑的是,全球搜索不应只提供文件搜索服务,而应着眼于成为一个综合性的门户,能够更快地达到目标,并为每个人提高效率。这是大局。寻找的点。
搜索结果预览
当您在搜索结果列表中单击,或使用键盘上下方向键将搜索结果切换到某个音乐、图片、视频、文档或文件时,您会看到搜索结果右侧的区域名单扩大。此处将显示与搜索结果对应的预览窗格。
预览窗格将因类别而异。pdf、txt文档可以查看文档首页快照;图片、视频预览可以看到更详细的属性信息,在预览窗格的头部区域可以查看缩略图。
预览窗格不仅提供文件属性信息和文档主页快照的预览,还提供常用文件操作的快捷入口。例如,用户在预览搜索结果时,只需要打开文件路径,或者只需要复制文件路径,就可以在预览窗格底部一键进行操作,即非常方便快捷。
搜索设置
考虑到用户自身的自定义需求,全局搜索提供了一些自定义设置功能。右击任务栏中的放大镜入口图标,可以看到搜索设置的入口。单击搜索设置以查看全局搜索设置面板。
在设置面板中,用户可以根据自己的需要自定义哪些类别可以搜索和召回到搜索结果列表中。每个类别项都可以在开关上独立设置,提供了较高的灵活性。
全局搜索不仅仅是搜索。它仍在增长。将持续探索和优化大家的日常使用场景和习惯,提供更精细、更高效的直接体验。
deepin是一个Linux发行版,致力于为全球用户提供美观、易用、安全、稳定的服务。它也是中国团队开发的排名最高的发行版。支持全球33种语言,累计下载量超过8000万次,在6大洲42个国家拥有135个镜像站点。
搜索引擎优化pdf( 搜索引擎传统的搜索与搜索引擎Java全文搜索引擎框架Lucene1.1简介 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2021-12-25 19:20
搜索引擎传统的搜索与搜索引擎Java全文搜索引擎框架Lucene1.1简介
)
一、搜索引擎基本介绍
1. 什么是搜索引擎
搜索引擎通常是指一种全文搜索引擎,它采集
万维网上数千万到数十亿的网页,并将网页中的每个词(即关键词)编入索引,建立索引数据库。当用户搜索某个关键词时,页面内容中收录
关键词的所有网页都会被搜索出来作为搜索结果。这些结果经过复杂的算法排序(或包括商业竞价排名、商业推广或广告)后,将根据与搜索关键词(或与相关性无关)的相关程度进行排序。
2. 传统搜索与搜索引擎对比
2.1 传统方法
(1)在文档中使用系统的Find搜索
(2)在mysql中使用like模糊查询
有一个问题:
(1)海量数据无法及时响应,少量数据可通过传统MySql索引解决
(2)一些无用的词无法过滤,无法切分
(3)数据量大的话,很难扩展
(4) 相同的数据很难排序最相似的
2.2 搜索引擎实践
(1)存储非结构化数据
(2)快速检索和响应我们需要的信息,快速准确
(3) 执行相关性排序、过滤等。
(4)可以去除停用词(没有特殊含义的词,如英文a、is等,中文:this、yes等),框架一般支持自定义停用词
二、常见搜索引擎框架介绍与对比
1. Java全文搜索引擎框架Lucene
1.1 简介
Lucene 的开发语言是 Java,它也是 Java 家族中最著名的开源搜索引擎。它已经是Java世界中标准的全文搜索程序。它提供了完整的查询引擎和索引引擎。没有中文分词引擎,需要自己去。实现,所以用Lucene搭建搜索引擎需要自己的架构,不支持实时搜索。但是solr和elasticsearch都是基于Lucene封装的。
1.2 优点
成熟的解决方案有很多成功的案例。顶级apache项目正在持续快速推进。庞大而活跃的开发社区,大量的开发者。只是一个类库,有足够的定制和优化空间:简单定制后,可以满足大部分常见的需求;优化后可支持10亿+搜索。
1.3 缺点
需要额外的开发工作。所有的扩展、分发、可靠性等都需要自己来实现;非实时,从索引到搜索存在时间延迟,目前的“近实时”(Lucene Near Real Time search)搜索方案在可扩展性方面还需要进一步完善。
2. Apache Solr
2.1 简介
Solr 是一个基于 Lucene 的高性能全文搜索服务器,用 Java 开发。使用 XML 通过 Http 将文档添加到搜索集合中。查询集合也是通过 http 接收 XML/JSON 响应来实现的。其主要特点包括:高效灵活的缓存功能、垂直搜索功能、突出搜索结果、索引复制以提高可用性、提供一套强大的Data Schema来定义文本分析的字段、类型和设置,并提供基于Web的管理界面, 等等。
2.2 优点
(1)Solr 拥有更大、更成熟的用户、开发人员和贡献者社区。
(2) 支持添加多种格式的索引,如HTML、PDF、Microsoft Office系列软件格式,以及JSON、XML、CSV等纯文本格式。
(3)Solr 比较成熟稳定。
(4) 不考虑索引,搜索速度更快。
2.3 缺点
索引时,搜索效率降低,实时索引搜索效率不高
3. 弹性搜索
3.1 简介
ElasticSearch 是一个基于 Lucene 的开源、分布式、RESTful 搜索引擎。专为在云计算中使用而设计,可实现实时搜索,稳定可靠,速度快,安装使用方便。支持通过 HTTP 使用 JSON 进行数据索引。
3.2 优点
(1)Elasticsearch 是分布式的,不需要其他组件,而且是实时的,也就是所谓的“推送复制”。
(2)Elasticsearch 完全支持 Apache Lucene 的近实时搜索。
(3)处理多租户(multitenancy)不需要特殊配置,而Solr需要更高级的设置。
(4)Elasticsearch 使用了网关的概念,更容易完成备份。
每个节点形成一个点对点的网络结构,当一些节点出现故障时,会自动分配其他节点来替换它们。
3.3 缺点
不够自动化(不适合当前新的 Index Warmup API)
4. Elasticsearch 和 Solr 对比
(1) 两者都很容易安装
(2)Solr 使用 Zookeeper 进行分布式管理,Elasticsearch 本身具有分布式协调管理功能;
(3)Solr支持更多格式的数据,而Elasticsearch只支持json文件格式;
(4)Solr 官方提供了更多功能,而Elasticsearch 本身更注重核心功能,大部分高级功能由第三方插件提供;
(5)Solr 在传统搜索应用中的表现优于 Elasticsearch,但在处理实时搜索应用时,其效率明显低于 Elasticsearch。
(6)总之,Solr 是传统搜索应用的强大解决方案,而 Elasticsearch 更适合新兴的实时搜索应用。
5. 狮身人面像
5.1 简介
Sphinx 是一个基于 SQL 的全文搜索引擎,专门为一些脚本语言(PHP、Python、Perl、Ruby)设计的搜索 API 接口。
Sphinx 是一个用 C++ 语言编写的开源搜索引擎。它也是比较主流的搜索引擎之一。它在索引事件方面比 Lucene 快 50%,但索引文件是 Lucene 的两倍。因此,Sphinx 正在建立索引 一方面是为事件交换空间的策略。在搜索速度上,它和Lucene差别不大,但Lucene在搜索准确度上要优于Sphinx。另外,Lucene在加入中文分词引擎的难度上要优于Sphinx。其中Sphinx支持实时搜索。,使用起来比较简单方便。
Sphinx 可以轻松地与 SQL 数据库和脚本语言集成。当前系统内置了对 MySQL 和 PostgreSQL 数据库数据源的支持,也支持从标准输入中读取特定格式的 XML 数据。通过修改源代码,用户可以自行添加新的数据源(例如:原生支持其他类型的DBMS)
5.2 特点
(1) 高速索引(在当代 CPU 上,峰值性能可以达到 10 MB/秒);
(2)高性能搜索(在2-4GB文本数据上,每次检索平均响应时间小于0.1秒);
(3)可以处理海量数据(目前已知可以处理100GB以上的文本数据,单CPU系统可以处理100M文档);
(4) 提供了一个优秀的相关算法,基于词组相似度和统计(BM25) 的复合排序方法;
(5) 支持分布式搜索;
(6)支持词组搜索
(7)提供文档摘要生成
(8)可以作为MySQL存储引擎提供搜索服务;
(9)支持布尔、词组、词相似等多种检索模式;
(10) 文档支持多个全文搜索字段(最多32个);
(1 1) 文档支持多个附加属性信息(例如:分组信息、时间戳等);
(12)支持分词;
6. 卡塔
6.1 简介
基于Lucene,支持分布式、可扩展、容错、准实时的搜索解决方案。
6.2 优点
开箱即用,它可以与 Hadoop 一起分发。具有扩展和容错机制。
6.3 缺点
这只是一个搜索解决方案,索引部分仍然需要自己实现。在搜索功能中,只满足最基本的要求。成功案例较少,项目成熟度略低。因为需要支持分发,所以对于一些复杂的查询需求,定制起来会比较困难。
链接:www.cnblogs.com/WUXIAOCHANG
回复“资源”,接收上手源码、视频教程、微服务、并发、数据调整等,搜索【Java灵魂伴侣】
查看全部
搜索引擎优化pdf(
搜索引擎传统的搜索与搜索引擎Java全文搜索引擎框架Lucene1.1简介
)
一、搜索引擎基本介绍
1. 什么是搜索引擎
搜索引擎通常是指一种全文搜索引擎,它采集
万维网上数千万到数十亿的网页,并将网页中的每个词(即关键词)编入索引,建立索引数据库。当用户搜索某个关键词时,页面内容中收录
关键词的所有网页都会被搜索出来作为搜索结果。这些结果经过复杂的算法排序(或包括商业竞价排名、商业推广或广告)后,将根据与搜索关键词(或与相关性无关)的相关程度进行排序。
2. 传统搜索与搜索引擎对比
2.1 传统方法
(1)在文档中使用系统的Find搜索
(2)在mysql中使用like模糊查询
有一个问题:
(1)海量数据无法及时响应,少量数据可通过传统MySql索引解决
(2)一些无用的词无法过滤,无法切分
(3)数据量大的话,很难扩展
(4) 相同的数据很难排序最相似的
2.2 搜索引擎实践
(1)存储非结构化数据
(2)快速检索和响应我们需要的信息,快速准确
(3) 执行相关性排序、过滤等。
(4)可以去除停用词(没有特殊含义的词,如英文a、is等,中文:this、yes等),框架一般支持自定义停用词
二、常见搜索引擎框架介绍与对比
1. Java全文搜索引擎框架Lucene
1.1 简介
Lucene 的开发语言是 Java,它也是 Java 家族中最著名的开源搜索引擎。它已经是Java世界中标准的全文搜索程序。它提供了完整的查询引擎和索引引擎。没有中文分词引擎,需要自己去。实现,所以用Lucene搭建搜索引擎需要自己的架构,不支持实时搜索。但是solr和elasticsearch都是基于Lucene封装的。
1.2 优点
成熟的解决方案有很多成功的案例。顶级apache项目正在持续快速推进。庞大而活跃的开发社区,大量的开发者。只是一个类库,有足够的定制和优化空间:简单定制后,可以满足大部分常见的需求;优化后可支持10亿+搜索。
1.3 缺点
需要额外的开发工作。所有的扩展、分发、可靠性等都需要自己来实现;非实时,从索引到搜索存在时间延迟,目前的“近实时”(Lucene Near Real Time search)搜索方案在可扩展性方面还需要进一步完善。
2. Apache Solr
2.1 简介
Solr 是一个基于 Lucene 的高性能全文搜索服务器,用 Java 开发。使用 XML 通过 Http 将文档添加到搜索集合中。查询集合也是通过 http 接收 XML/JSON 响应来实现的。其主要特点包括:高效灵活的缓存功能、垂直搜索功能、突出搜索结果、索引复制以提高可用性、提供一套强大的Data Schema来定义文本分析的字段、类型和设置,并提供基于Web的管理界面, 等等。
2.2 优点
(1)Solr 拥有更大、更成熟的用户、开发人员和贡献者社区。
(2) 支持添加多种格式的索引,如HTML、PDF、Microsoft Office系列软件格式,以及JSON、XML、CSV等纯文本格式。
(3)Solr 比较成熟稳定。
(4) 不考虑索引,搜索速度更快。
2.3 缺点
索引时,搜索效率降低,实时索引搜索效率不高
3. 弹性搜索
3.1 简介
ElasticSearch 是一个基于 Lucene 的开源、分布式、RESTful 搜索引擎。专为在云计算中使用而设计,可实现实时搜索,稳定可靠,速度快,安装使用方便。支持通过 HTTP 使用 JSON 进行数据索引。
3.2 优点
(1)Elasticsearch 是分布式的,不需要其他组件,而且是实时的,也就是所谓的“推送复制”。
(2)Elasticsearch 完全支持 Apache Lucene 的近实时搜索。
(3)处理多租户(multitenancy)不需要特殊配置,而Solr需要更高级的设置。
(4)Elasticsearch 使用了网关的概念,更容易完成备份。
每个节点形成一个点对点的网络结构,当一些节点出现故障时,会自动分配其他节点来替换它们。
3.3 缺点
不够自动化(不适合当前新的 Index Warmup API)
4. Elasticsearch 和 Solr 对比
(1) 两者都很容易安装
(2)Solr 使用 Zookeeper 进行分布式管理,Elasticsearch 本身具有分布式协调管理功能;
(3)Solr支持更多格式的数据,而Elasticsearch只支持json文件格式;
(4)Solr 官方提供了更多功能,而Elasticsearch 本身更注重核心功能,大部分高级功能由第三方插件提供;
(5)Solr 在传统搜索应用中的表现优于 Elasticsearch,但在处理实时搜索应用时,其效率明显低于 Elasticsearch。
(6)总之,Solr 是传统搜索应用的强大解决方案,而 Elasticsearch 更适合新兴的实时搜索应用。
5. 狮身人面像
5.1 简介
Sphinx 是一个基于 SQL 的全文搜索引擎,专门为一些脚本语言(PHP、Python、Perl、Ruby)设计的搜索 API 接口。
Sphinx 是一个用 C++ 语言编写的开源搜索引擎。它也是比较主流的搜索引擎之一。它在索引事件方面比 Lucene 快 50%,但索引文件是 Lucene 的两倍。因此,Sphinx 正在建立索引 一方面是为事件交换空间的策略。在搜索速度上,它和Lucene差别不大,但Lucene在搜索准确度上要优于Sphinx。另外,Lucene在加入中文分词引擎的难度上要优于Sphinx。其中Sphinx支持实时搜索。,使用起来比较简单方便。
Sphinx 可以轻松地与 SQL 数据库和脚本语言集成。当前系统内置了对 MySQL 和 PostgreSQL 数据库数据源的支持,也支持从标准输入中读取特定格式的 XML 数据。通过修改源代码,用户可以自行添加新的数据源(例如:原生支持其他类型的DBMS)
5.2 特点
(1) 高速索引(在当代 CPU 上,峰值性能可以达到 10 MB/秒);
(2)高性能搜索(在2-4GB文本数据上,每次检索平均响应时间小于0.1秒);
(3)可以处理海量数据(目前已知可以处理100GB以上的文本数据,单CPU系统可以处理100M文档);
(4) 提供了一个优秀的相关算法,基于词组相似度和统计(BM25) 的复合排序方法;
(5) 支持分布式搜索;
(6)支持词组搜索
(7)提供文档摘要生成
(8)可以作为MySQL存储引擎提供搜索服务;
(9)支持布尔、词组、词相似等多种检索模式;
(10) 文档支持多个全文搜索字段(最多32个);
(1 1) 文档支持多个附加属性信息(例如:分组信息、时间戳等);
(12)支持分词;
6. 卡塔
6.1 简介
基于Lucene,支持分布式、可扩展、容错、准实时的搜索解决方案。
6.2 优点
开箱即用,它可以与 Hadoop 一起分发。具有扩展和容错机制。
6.3 缺点
这只是一个搜索解决方案,索引部分仍然需要自己实现。在搜索功能中,只满足最基本的要求。成功案例较少,项目成熟度略低。因为需要支持分发,所以对于一些复杂的查询需求,定制起来会比较困难。
链接:www.cnblogs.com/WUXIAOCHANG
回复“资源”,接收上手源码、视频教程、微服务、并发、数据调整等,搜索【Java灵魂伴侣】
搜索引擎优化pdf(新手想要做SEO搜索引擎优化,必须先要了解的工作原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-25 19:16
搜索引擎是一种特定的计算机程序,它按照一定的策略从互联网上采集
信息,对信息进行处理,为用户提供检索服务,并将用户结果显示给用户。
搜索引擎优化(Search Engine Optimization)简称SEO,是指利用搜索引擎规则来提高一个网站在搜索引擎中的自然排名。这样可以获得更多的免费流量,让它在行业中占据更高的优势,获得更大的收益。
新手想做SEO搜索引擎优化,当然首先要了解搜索引擎的工作原理,不需要完全掌握,但概念的东西一定要印在脑子里。至于不同的搜索引擎,其实都是一样的,所以今天就来说说工作原理吧!
第 1 步:爬网
搜索引擎通过特定模式的软件跟踪到网页的链接,从一个链接爬到另一个链接,就像蜘蛛在蜘蛛网上爬行一样,因此被称为“蜘蛛”或“机器人”。搜索引擎蜘蛛的爬取是有一定的规则进入的,需要遵守一些命令或者文件的内容。
第 2 步:获取存储空间
搜索引擎通过蜘蛛跟踪链接抓取网页,并将抓取到的数据存储在原创
页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。在抓取页面时,搜索引擎蜘蛛也会做一定量的重复内容检测。一旦他们在一个低权重的网站上遇到大量抄袭、采集
或复制的内容,很可能会停止爬行。
第三步:预处理
搜索引擎会在各个步骤中对蜘蛛检索到的页面进行预处理;除了 HTML 文件,搜索引擎通常可以抓取和索引多种基于文本的文件类型,例如 PDF、Word、WPS、XLS、PPT、TXT 文件等,我们经常在搜索结果中看到这些文件类型。但是,搜索引擎无法处理图像、视频和 Flash 等非文本内容,也无法执行脚本和程序。
第 4 步:排名
用户在搜索框中输入关键词后,排名程序调用索引库数据,计算排名显示给用户,排名过程直接与用户交互。但是,由于搜索引擎的数据量巨大,虽然每天可以实现小幅更新,但搜索引擎的排名规则一般是按照日、周、月等不同级别进行更新。 查看全部
搜索引擎优化pdf(新手想要做SEO搜索引擎优化,必须先要了解的工作原理)
搜索引擎是一种特定的计算机程序,它按照一定的策略从互联网上采集
信息,对信息进行处理,为用户提供检索服务,并将用户结果显示给用户。
搜索引擎优化(Search Engine Optimization)简称SEO,是指利用搜索引擎规则来提高一个网站在搜索引擎中的自然排名。这样可以获得更多的免费流量,让它在行业中占据更高的优势,获得更大的收益。
新手想做SEO搜索引擎优化,当然首先要了解搜索引擎的工作原理,不需要完全掌握,但概念的东西一定要印在脑子里。至于不同的搜索引擎,其实都是一样的,所以今天就来说说工作原理吧!
第 1 步:爬网
搜索引擎通过特定模式的软件跟踪到网页的链接,从一个链接爬到另一个链接,就像蜘蛛在蜘蛛网上爬行一样,因此被称为“蜘蛛”或“机器人”。搜索引擎蜘蛛的爬取是有一定的规则进入的,需要遵守一些命令或者文件的内容。
第 2 步:获取存储空间
搜索引擎通过蜘蛛跟踪链接抓取网页,并将抓取到的数据存储在原创
页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。在抓取页面时,搜索引擎蜘蛛也会做一定量的重复内容检测。一旦他们在一个低权重的网站上遇到大量抄袭、采集
或复制的内容,很可能会停止爬行。
第三步:预处理
搜索引擎会在各个步骤中对蜘蛛检索到的页面进行预处理;除了 HTML 文件,搜索引擎通常可以抓取和索引多种基于文本的文件类型,例如 PDF、Word、WPS、XLS、PPT、TXT 文件等,我们经常在搜索结果中看到这些文件类型。但是,搜索引擎无法处理图像、视频和 Flash 等非文本内容,也无法执行脚本和程序。
第 4 步:排名
用户在搜索框中输入关键词后,排名程序调用索引库数据,计算排名显示给用户,排名过程直接与用户交互。但是,由于搜索引擎的数据量巨大,虽然每天可以实现小幅更新,但搜索引擎的排名规则一般是按照日、周、月等不同级别进行更新。
搜索引擎优化pdf( 如何使用Python构建自己的答案查找系统?|AI科技大本营)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-25 19:15
如何使用Python构建自己的答案查找系统?|AI科技大本营)
来源 | 黑客中午
编译| 吴明丽,主编| 颂歌
生产 | AI科技大本营(ID:rgznai100)
在本文中,我将向您展示如何使用 Python 构建自己的答案查找系统。基本上,这种自动化可以从图片中找到多项选择题的答案。
有一点我们要明确的是,考试期间无法在网上搜索题,但是当考官转身时,我可以快速拍照。这是算法的第一部分。我必须想办法从图片中提取这个问题。
似乎有很多服务可以提供文本提取工具,但是我需要某种API来解决这个问题。最后,Google 的 VisionAPI 正是我正在寻找的工具。很棒的是,每月前 1000 次 API 调用是免费的,这足以让我测试和使用 API。
视觉人工智能
首先创建一个谷歌云账号,然后在服务中搜索Vision AI。使用 VisionAI,您可以执行诸如为图像分配标签以组织图像、获取推荐的裁剪顶点、检测著名风景或地点以及提取文本等任务。
查看文档以启用和设置 API。配置后,您必须创建一个 JSON 文件,其中收录
您下载到计算机的密钥。
运行以下命令安装客户端库:
pip install google-cloud-vision
然后设置环境变量 GOOGLE_APPLICATION_CREDENTIALS 为应用程序代码提供身份验证凭据。
import os, iofrom google.cloud import visionfrom google.cloud.vision import types
# JSON file that contains your keyos.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'your_private_key.json'
# Instantiates a clientclient = vision.ImageAnnotatorClient
FILE_NAME = 'your_image_file.jpg'
# Loads the image into memorywith io.open(os.path.join(FILE_NAME), 'rb') as image_file: content = image_file.read
image = vision.types.Image(content=content)
# Performs text detection on the image fileresponse = client.text_detection(image=image)print(response)
# Extract descriptiontexts = response.text_annotations[0]print(texts.description)
运行代码时,您将看到 JSON 格式的响应,其中包括检测到的文本的规范。但是我们只需要一个纯粹的描述,所以我从响应中提取了这部分。
在 Google 上搜索问题
下一步是在 Google 上搜索问题部分以获取一些信息。我使用正则表达式(regex)库从描述(响应)中提取问题部分。然后我们必须混淆提取的问题部分,以便可以搜索。
import reimport urllib
# If ending with question markif '?' in texts.description: question = re.search('([^?]+)', texts.description).group(1)
# If ending with colonelif ':' in texts.description: question = re.search('([^:]+)', texts.description).group(1)# If ending with newlineelif '\n' in texts.description: question = re.search('([^\n]+)', texts.description).group(1)
# Slugify the matchslugify_keyword = urllib.parse.quote_plus(question)print(slugify_keyword)
爬取的信息
我们将使用 BeautifulSoup 抓取前 3 个结果以获取有关该问题的一些信息,因为答案可能在其中之一。
另外,如果你想从谷歌的搜索列表中抓取特定的数据,不要使用inspect元素来查找元素的属性,而是打印整个页面来查看属性,因为它与实际的属性不同。
我们需要抓取搜索结果中的前3个链接,但是这些链接确实是乱七八糟的,所以获取干净的链接进行抓取很重要。
/url?q=https://en.wikipedia.org/wiki/ ... 1t0en
如您所见,实际链接在 q= 和 &sa 之间。通过使用正则表达式 Regex,我们可以获得这个特定的字段或有效的 URL。
result_urls =
def crawl_result_urls: req = Request('https://google.com/search?q=' + slugify_keyword, headers={'User-Agent': 'Mozilla/5.0'}) html = urlopen(req).read bs = BeautifulSoup(html, 'html.parser') results = bs.find_all('div', class_='ZINbbc') try: for result in results: link = result.find('a')['href'] # Checking if it is url (in case) if 'url' in link: result_urls.append(re.search('q=(.*)&sa', link).group(1)) except (AttributeError, IndexError) as e: pass
在我们抓取这些 URL 的内容之前,让我向您展示使用 Python 的问答系统。
问答系统
这是算法的主要部分。从前 3 个结果中获取信息后,程序应遍历文档以检测答案。首先,我认为最好使用相似度算法来检测与问题最相似的文档,但我不知道如何实现。
经过几个小时的研究,我在 Medium 上找到了一篇解释 Python 问答系统的文章。它有一个易于使用的python软件包,可以为您自己的私人数据实现一个QA系统。
让我们先安装这个包:
pip install cdqa
我正在使用下面示例代码块中收录
的下载功能来手动下载预训练的模型和数据:
它的输出应该是这样的:
它打印出确切的答案和收录
答案的段落。
基本上,当问题从图片中提取并发送到系统时,检索器将从爬取的数据中选择最有可能收录
答案的文档列表。如前所述,它计算问题与爬取数据中每个文档之间的余弦相似度。
选择最有可能的文档后,系统将每个文档分成几段,将问题一起发送给读者。这基本上是一个预训练的深度学习模型。使用的模型是著名的 NLP 模型 BERT 的 Pytorch 版本。
然后,阅读器输出在每个段落中找到的最可能的答案。在读者之后,系统的最后一层通过使用内部评分函数对答案进行比较,并根据评分输出最可能的答案,这将得到我们问题的答案。
以下是系统机制的模式。
您必须在特定结构中设置数据框 (CSV) 才能将其发送到 cdQA 管道。
但实际上我使用 PDF 转换器从 PDF 文件目录创建了一个输入数据框。因此,我想将每个结果的所有抓取数据保存在一个 pdf 文件中。我们希望总共有 3 个 pdf 文件(也可以是 1 个或 2 个)。另外,我们需要给这些pdf文件命名,这也是我抓取每一页标题的原因。
def get_result_details(url): try: req = Request(url, headers={'User-Agent': 'Mozilla/5.0'}) html = urlopen(req).read bs = BeautifulSoup(html, 'html.parser') try: # Crawl any heading in result to name pdf file title = bs.find(re.compile('^h[1-6])).get_text.strip.replace('?', '').lower # Naming the pdf file filename = "/home/coderasha/autoans/pdfs/" + title + ".pdf" if not os.path.exists(os.path.dirname(filename)): try: os.makedirs(os.path.dirname(filename)) except OSError as exc: # Guard against race condition if exc.errno != errno.EEXIST: raise with open(filename, 'w') as f: # Crawl first 5 paragraphs for line in bs.find_all('p')[:5]: f.write(line.text + '\n') except AttributeError: pass except urllib.error.HTTPError: pass
def find_answer: df = pdf_converter(directory_path='/home/coderasha/autoans/pdfs') cdqa_pipeline = QAPipeline(reader='models/bert_qa.joblib') cdqa_pipeline.fit_retriever(df) query = question + '?' prediction = cdqa_pipeline.predict(query)
print('query: {}\n'.format(query)) print('answer: {}\n'.format(prediction[0])) print('title: {}\n'.format(prediction[1])) print('paragraph: {}\n'.format(prediction[2])) return prediction[0]
让我总结一下算法:它会从图片中提取问题,在谷歌上搜索它,抓取前3个结果,从抓取的数据中创建3个pdf文件,最后使用问答系统找到答案。
如果你想看看它是如何工作的,请检查我制作的一个机器人,它可以从图片中解决考试问题。
以下是完整代码:
import os, ioimport errnoimport urllibimport urllib.requestimport hashlibimport reimport requestsfrom time import sleepfrom google.cloud import visionfrom google.cloud.vision import typesfrom urllib.request import urlopen, Requestfrom bs4 import BeautifulSoupimport pandas as pdfrom ast import literal_evalfrom cdqa.utils.filters import filter_paragraphsfrom cdqa.utils.download import download_model, download_bnpp_datafrom cdqa.pipeline.cdqa_sklearn import QAPipelinefrom cdqa.utils.converters import pdf_converter
result_urls =
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'your_private_key.json'
client = vision.ImageAnnotatorClient
FILE_NAME = 'your_image_file.jpg'
with io.open(os.path.join(FILE_NAME), 'rb') as image_file: content = image_file.read
image = vision.types.Image(content=content)
response = client.text_detection(image=image)
texts = response.text_annotations[0]# print(texts.description)
if '?' in texts.description: question = re.search('([^?]+)', texts.description).group(1)
elif ':' in texts.description: question = re.search('([^:]+)', texts.description).group(1)
elif '\n' in texts.description: question = re.search('([^\n]+)', texts.description).group(1)
slugify_keyword = urllib.parse.quote_plus(question)# print(slugify_keyword)
def crawl_result_urls: req = Request('https://google.com/search?q=' + slugify_keyword, headers={'User-Agent': 'Mozilla/5.0'}) html = urlopen(req).read bs = BeautifulSoup(html, 'html.parser') results = bs.find_all('div', class_='ZINbbc') try: for result in results: link = result.find('a')['href'] print(link) if 'url' in link: result_urls.append(re.search('q=(.*)&sa', link).group(1)) except (AttributeError, IndexError) as e: pass
def get_result_details(url): try: req = Request(url, headers={'User-Agent': 'Mozilla/5.0'}) html = urlopen(req).read bs = BeautifulSoup(html, 'html.parser') try: title = bs.find(re.compile('^h[1-6])).get_text.strip.replace('?', '').lower # Set your path to pdf directory filename = "/path/to/pdf_folder/" + title + ".pdf" if not os.path.exists(os.path.dirname(filename)): try: os.makedirs(os.path.dirname(filename)) except OSError as exc: if exc.errno != errno.EEXIST: raise with open(filename, 'w') as f: for line in bs.find_all('p')[:5]: f.write(line.text + '\n') except AttributeError: pass except urllib.error.HTTPError: pass
def find_answer: # Set your path to pdf directory df = pdf_converter(directory_path='/path/to/pdf_folder/') cdqa_pipeline = QAPipeline(reader='models/bert_qa.joblib') cdqa_pipeline.fit_retriever(df) query = question + '?' prediction = cdqa_pipeline.predict(query)
# print('query: {}\n'.format(query)) # print('answer: {}\n'.format(prediction[0])) # print('title: {}\n'.format(prediction[1])) # print('paragraph: {}\n'.format(prediction[2])) return prediction[0]
crawl_result_urls
for url in result_urls[:3]: get_result_details(url) sleep(5)
answer = find_answerprint('Answer: ' + answer)
有时它可能会令人困惑,但我认为总体上是可以的。至少我能以60%的正确答案通过考试。
欢迎开发者在评论中告诉我你的看法!其实最好一次性把所有题都做一遍,但是我没有足够的时间做这个,所以我下次还要继续做。 查看全部
搜索引擎优化pdf(
如何使用Python构建自己的答案查找系统?|AI科技大本营)
来源 | 黑客中午
编译| 吴明丽,主编| 颂歌
生产 | AI科技大本营(ID:rgznai100)
在本文中,我将向您展示如何使用 Python 构建自己的答案查找系统。基本上,这种自动化可以从图片中找到多项选择题的答案。
有一点我们要明确的是,考试期间无法在网上搜索题,但是当考官转身时,我可以快速拍照。这是算法的第一部分。我必须想办法从图片中提取这个问题。
似乎有很多服务可以提供文本提取工具,但是我需要某种API来解决这个问题。最后,Google 的 VisionAPI 正是我正在寻找的工具。很棒的是,每月前 1000 次 API 调用是免费的,这足以让我测试和使用 API。
视觉人工智能
首先创建一个谷歌云账号,然后在服务中搜索Vision AI。使用 VisionAI,您可以执行诸如为图像分配标签以组织图像、获取推荐的裁剪顶点、检测著名风景或地点以及提取文本等任务。
查看文档以启用和设置 API。配置后,您必须创建一个 JSON 文件,其中收录
您下载到计算机的密钥。
运行以下命令安装客户端库:
pip install google-cloud-vision
然后设置环境变量 GOOGLE_APPLICATION_CREDENTIALS 为应用程序代码提供身份验证凭据。
import os, iofrom google.cloud import visionfrom google.cloud.vision import types
# JSON file that contains your keyos.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'your_private_key.json'
# Instantiates a clientclient = vision.ImageAnnotatorClient
FILE_NAME = 'your_image_file.jpg'
# Loads the image into memorywith io.open(os.path.join(FILE_NAME), 'rb') as image_file: content = image_file.read
image = vision.types.Image(content=content)
# Performs text detection on the image fileresponse = client.text_detection(image=image)print(response)
# Extract descriptiontexts = response.text_annotations[0]print(texts.description)
运行代码时,您将看到 JSON 格式的响应,其中包括检测到的文本的规范。但是我们只需要一个纯粹的描述,所以我从响应中提取了这部分。
在 Google 上搜索问题
下一步是在 Google 上搜索问题部分以获取一些信息。我使用正则表达式(regex)库从描述(响应)中提取问题部分。然后我们必须混淆提取的问题部分,以便可以搜索。
import reimport urllib
# If ending with question markif '?' in texts.description: question = re.search('([^?]+)', texts.description).group(1)
# If ending with colonelif ':' in texts.description: question = re.search('([^:]+)', texts.description).group(1)# If ending with newlineelif '\n' in texts.description: question = re.search('([^\n]+)', texts.description).group(1)
# Slugify the matchslugify_keyword = urllib.parse.quote_plus(question)print(slugify_keyword)
爬取的信息
我们将使用 BeautifulSoup 抓取前 3 个结果以获取有关该问题的一些信息,因为答案可能在其中之一。
另外,如果你想从谷歌的搜索列表中抓取特定的数据,不要使用inspect元素来查找元素的属性,而是打印整个页面来查看属性,因为它与实际的属性不同。
我们需要抓取搜索结果中的前3个链接,但是这些链接确实是乱七八糟的,所以获取干净的链接进行抓取很重要。
/url?q=https://en.wikipedia.org/wiki/ ... 1t0en
如您所见,实际链接在 q= 和 &sa 之间。通过使用正则表达式 Regex,我们可以获得这个特定的字段或有效的 URL。
result_urls =
def crawl_result_urls: req = Request('https://google.com/search?q=' + slugify_keyword, headers={'User-Agent': 'Mozilla/5.0'}) html = urlopen(req).read bs = BeautifulSoup(html, 'html.parser') results = bs.find_all('div', class_='ZINbbc') try: for result in results: link = result.find('a')['href'] # Checking if it is url (in case) if 'url' in link: result_urls.append(re.search('q=(.*)&sa', link).group(1)) except (AttributeError, IndexError) as e: pass
在我们抓取这些 URL 的内容之前,让我向您展示使用 Python 的问答系统。
问答系统
这是算法的主要部分。从前 3 个结果中获取信息后,程序应遍历文档以检测答案。首先,我认为最好使用相似度算法来检测与问题最相似的文档,但我不知道如何实现。
经过几个小时的研究,我在 Medium 上找到了一篇解释 Python 问答系统的文章。它有一个易于使用的python软件包,可以为您自己的私人数据实现一个QA系统。
让我们先安装这个包:
pip install cdqa
我正在使用下面示例代码块中收录
的下载功能来手动下载预训练的模型和数据:
它的输出应该是这样的:
它打印出确切的答案和收录
答案的段落。
基本上,当问题从图片中提取并发送到系统时,检索器将从爬取的数据中选择最有可能收录
答案的文档列表。如前所述,它计算问题与爬取数据中每个文档之间的余弦相似度。
选择最有可能的文档后,系统将每个文档分成几段,将问题一起发送给读者。这基本上是一个预训练的深度学习模型。使用的模型是著名的 NLP 模型 BERT 的 Pytorch 版本。
然后,阅读器输出在每个段落中找到的最可能的答案。在读者之后,系统的最后一层通过使用内部评分函数对答案进行比较,并根据评分输出最可能的答案,这将得到我们问题的答案。
以下是系统机制的模式。
您必须在特定结构中设置数据框 (CSV) 才能将其发送到 cdQA 管道。
但实际上我使用 PDF 转换器从 PDF 文件目录创建了一个输入数据框。因此,我想将每个结果的所有抓取数据保存在一个 pdf 文件中。我们希望总共有 3 个 pdf 文件(也可以是 1 个或 2 个)。另外,我们需要给这些pdf文件命名,这也是我抓取每一页标题的原因。
def get_result_details(url): try: req = Request(url, headers={'User-Agent': 'Mozilla/5.0'}) html = urlopen(req).read bs = BeautifulSoup(html, 'html.parser') try: # Crawl any heading in result to name pdf file title = bs.find(re.compile('^h[1-6])).get_text.strip.replace('?', '').lower # Naming the pdf file filename = "/home/coderasha/autoans/pdfs/" + title + ".pdf" if not os.path.exists(os.path.dirname(filename)): try: os.makedirs(os.path.dirname(filename)) except OSError as exc: # Guard against race condition if exc.errno != errno.EEXIST: raise with open(filename, 'w') as f: # Crawl first 5 paragraphs for line in bs.find_all('p')[:5]: f.write(line.text + '\n') except AttributeError: pass except urllib.error.HTTPError: pass
def find_answer: df = pdf_converter(directory_path='/home/coderasha/autoans/pdfs') cdqa_pipeline = QAPipeline(reader='models/bert_qa.joblib') cdqa_pipeline.fit_retriever(df) query = question + '?' prediction = cdqa_pipeline.predict(query)
print('query: {}\n'.format(query)) print('answer: {}\n'.format(prediction[0])) print('title: {}\n'.format(prediction[1])) print('paragraph: {}\n'.format(prediction[2])) return prediction[0]
让我总结一下算法:它会从图片中提取问题,在谷歌上搜索它,抓取前3个结果,从抓取的数据中创建3个pdf文件,最后使用问答系统找到答案。
如果你想看看它是如何工作的,请检查我制作的一个机器人,它可以从图片中解决考试问题。
以下是完整代码:
import os, ioimport errnoimport urllibimport urllib.requestimport hashlibimport reimport requestsfrom time import sleepfrom google.cloud import visionfrom google.cloud.vision import typesfrom urllib.request import urlopen, Requestfrom bs4 import BeautifulSoupimport pandas as pdfrom ast import literal_evalfrom cdqa.utils.filters import filter_paragraphsfrom cdqa.utils.download import download_model, download_bnpp_datafrom cdqa.pipeline.cdqa_sklearn import QAPipelinefrom cdqa.utils.converters import pdf_converter
result_urls =
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'your_private_key.json'
client = vision.ImageAnnotatorClient
FILE_NAME = 'your_image_file.jpg'
with io.open(os.path.join(FILE_NAME), 'rb') as image_file: content = image_file.read
image = vision.types.Image(content=content)
response = client.text_detection(image=image)
texts = response.text_annotations[0]# print(texts.description)
if '?' in texts.description: question = re.search('([^?]+)', texts.description).group(1)
elif ':' in texts.description: question = re.search('([^:]+)', texts.description).group(1)
elif '\n' in texts.description: question = re.search('([^\n]+)', texts.description).group(1)
slugify_keyword = urllib.parse.quote_plus(question)# print(slugify_keyword)
def crawl_result_urls: req = Request('https://google.com/search?q=' + slugify_keyword, headers={'User-Agent': 'Mozilla/5.0'}) html = urlopen(req).read bs = BeautifulSoup(html, 'html.parser') results = bs.find_all('div', class_='ZINbbc') try: for result in results: link = result.find('a')['href'] print(link) if 'url' in link: result_urls.append(re.search('q=(.*)&sa', link).group(1)) except (AttributeError, IndexError) as e: pass
def get_result_details(url): try: req = Request(url, headers={'User-Agent': 'Mozilla/5.0'}) html = urlopen(req).read bs = BeautifulSoup(html, 'html.parser') try: title = bs.find(re.compile('^h[1-6])).get_text.strip.replace('?', '').lower # Set your path to pdf directory filename = "/path/to/pdf_folder/" + title + ".pdf" if not os.path.exists(os.path.dirname(filename)): try: os.makedirs(os.path.dirname(filename)) except OSError as exc: if exc.errno != errno.EEXIST: raise with open(filename, 'w') as f: for line in bs.find_all('p')[:5]: f.write(line.text + '\n') except AttributeError: pass except urllib.error.HTTPError: pass
def find_answer: # Set your path to pdf directory df = pdf_converter(directory_path='/path/to/pdf_folder/') cdqa_pipeline = QAPipeline(reader='models/bert_qa.joblib') cdqa_pipeline.fit_retriever(df) query = question + '?' prediction = cdqa_pipeline.predict(query)
# print('query: {}\n'.format(query)) # print('answer: {}\n'.format(prediction[0])) # print('title: {}\n'.format(prediction[1])) # print('paragraph: {}\n'.format(prediction[2])) return prediction[0]
crawl_result_urls
for url in result_urls[:3]: get_result_details(url) sleep(5)
answer = find_answerprint('Answer: ' + answer)
有时它可能会令人困惑,但我认为总体上是可以的。至少我能以60%的正确答案通过考试。
欢迎开发者在评论中告诉我你的看法!其实最好一次性把所有题都做一遍,但是我没有足够的时间做这个,所以我下次还要继续做。
搜索引擎优化pdf( SEOMagicBook浩维互动免费电子书wwwtimevnet目录关于这本书1目录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-23 11:04
SEOMagicBook浩维互动免费电子书wwwtimevnet目录关于这本书1目录)
搜索引擎优化魔法书 SEOMagicBook Haowei Interactive 免费电子书 wwwtimevnet 目录 关于本书 1 第一章 搜索引擎基础 2 第一节 什么是搜索引擎 2 一 搜索引擎的作用 2 搜索引擎的两个定义 4 第二节 搜索的基本工作原理4 一抓取 5 二索引 5 三排序 5 段三搜索引擎分类 6 一页级搜索 6 二垂直搜索 6 三元搜索引擎 6 四目录搜索 6 五综合搜索 7 段四搜索 引擎的未来 7 1 快速 7 2 多元化 7 3 智能 7 4 社交 7 5 性 8 5 主要搜索引擎介绍 8 1 谷歌 8 2 雅虎 12 3 百度 13 4 搜狗 15 5 中文搜索引擎列表 16 第二章搜索引擎营销基础 17 第一节 什么是搜索引擎营销 17 一 搜索引擎营销的定义 17 二 搜索引擎营销的价值 17 搜索引擎营销的三大原则 18 第二节 搜索引擎营销的特点 19 一 广泛使用 19 二 用户主动查询具有高度相关性 19 三 获取新客户 19 四竞争激烈 20 Page 1 搜索引擎优化魔法书 SEOM
百度 30 四 搜狗 34 第三节 白帽 SEO 和黑帽 SEO 37 第四节 搜索引擎优化的发展 39 一 SEO 的发展历程 39 二 SEO 在中国 40 三 SEO 的发展方向 42 第五节 对搜索引擎的一些看法优化 43 1. 搜索引擎优化合法吗?43 2. 他会搜索吗?
搜索引擎正面临工作 43 3. 搜索引擎会不会手动干扰 44 4. 我的 网站 有很多高质量的 原创 内容,所以我不再需要 SEO 44 5. SEO 没有技术含量或SEO 需要非常深厚的技能 44 六大网站 做到了。我也向他们学习了 44 七家SEO公司或SEO工具保证排名提升 44 八位稳定排名 45 九 SEO目标是获得第一名或尽可能多的访问量 45 十大竞争对手无法破坏我的排名 45 第四章SEO相关搜索引擎技术 46 Page 2 搜索引擎优化魔法书 SEOMagicBook 浩威互动免费电子书 wwwtimevnet 第一节搜索引擎机器人 46 一 什么是搜索引擎机器人 46 2. 如何识别搜索引擎机器人的身份 47 第二节. 超链分析 47 1 .
应用 53 六中文搜索引擎技术 54 第四节基于词义的文本分析 55 一文本分析技术特点 55 二文本分析应用 55 第五章网站的搜索引擎性能理解 57 第一节基本查询 57 1.域名信息查询 57 2. 域名历史查询 57 3. 主机连接速度和 IP 地址查询 57 四带 IP 收录编号 58 Section 3 Backlink Query 59 Section 4 Web Page RANK 查询 59 一个 GooglePageRank 查询 59 两个 SogouRank 查询 59第五节 关键词 排名查询 59 第六节 ALEXA 查询 60 一 什么是 Alexa 60 2. Alexa 主要数据 60 3. 用 Alexa 检查什么 60 第 6 章基于搜索引擎友好的 网站 设计 62 Section 1域名策略 62 1.不同后缀域名在搜索引擎中的权重 62 2. 域名基本常识 62 Page 3 搜索引擎优化魔法书 SEOMagicBook 豪威互动免费电子书 wwwtimevnet 关键词 三个域名策略之六
9 4 中文网站域名拼音策略 70 5 小心注册被搜索引擎惩罚的域名 70 第二节 空间策略 71 1 安全要素 1 稳定性 71 2 安全要素 2 良好的共存环境 71 3 本节附录 72第三节网站结构规划72第四节网站导航设计73第五节IFRAMEVASACRIPT和AJAX73一个IFRAME74两个JS74三个AJAX74第六节URL设计75一个易于记忆75两个URL静态75三个URL关键词部署 78 第七节 网页代码编写 80 一遵循WEB标准 篮球课程标准 尘肺病标准片 党员活动室建设分级护理精细化标准 儿科分级护理标准 80 第二个代码的逻辑 80 第八节 面向搜索引擎的文案指南 81 1. 网页标题 标题 81 2. 元元标记 84 3. 图片 ALT 替换文本 85 4. Robotstxt 85 5. 链接锚文本 89 6. 站点地图 xml 89 7. 版权和隐私 97 第 9 节 用户友好性检查 97 1. 链接可用性 97 2. 访问速度体验 97 三个查找信息的便捷性 98 第七章 创建搜索引擎喜欢的内容站点地图 xml 89 7. 版权和隐私 97 第 9 节 用户友好性检查 97 1. 链接可用性 97 2. 访问速度体验 97 查找信息的三个便利性 98 第七章 创建搜索引擎喜欢的内容站点地图 xml 89 7. 版权和隐私 97 第 9 节 用户友好性检查 97 1. 链接可用性 97 2. 访问速度体验 97 查找信息的三个便利性 98 第七章 创建搜索引擎喜欢的内容 查看全部
搜索引擎优化pdf(
SEOMagicBook浩维互动免费电子书wwwtimevnet目录关于这本书1目录)
搜索引擎优化魔法书 SEOMagicBook Haowei Interactive 免费电子书 wwwtimevnet 目录 关于本书 1 第一章 搜索引擎基础 2 第一节 什么是搜索引擎 2 一 搜索引擎的作用 2 搜索引擎的两个定义 4 第二节 搜索的基本工作原理4 一抓取 5 二索引 5 三排序 5 段三搜索引擎分类 6 一页级搜索 6 二垂直搜索 6 三元搜索引擎 6 四目录搜索 6 五综合搜索 7 段四搜索 引擎的未来 7 1 快速 7 2 多元化 7 3 智能 7 4 社交 7 5 性 8 5 主要搜索引擎介绍 8 1 谷歌 8 2 雅虎 12 3 百度 13 4 搜狗 15 5 中文搜索引擎列表 16 第二章搜索引擎营销基础 17 第一节 什么是搜索引擎营销 17 一 搜索引擎营销的定义 17 二 搜索引擎营销的价值 17 搜索引擎营销的三大原则 18 第二节 搜索引擎营销的特点 19 一 广泛使用 19 二 用户主动查询具有高度相关性 19 三 获取新客户 19 四竞争激烈 20 Page 1 搜索引擎优化魔法书 SEOM
百度 30 四 搜狗 34 第三节 白帽 SEO 和黑帽 SEO 37 第四节 搜索引擎优化的发展 39 一 SEO 的发展历程 39 二 SEO 在中国 40 三 SEO 的发展方向 42 第五节 对搜索引擎的一些看法优化 43 1. 搜索引擎优化合法吗?43 2. 他会搜索吗?
搜索引擎正面临工作 43 3. 搜索引擎会不会手动干扰 44 4. 我的 网站 有很多高质量的 原创 内容,所以我不再需要 SEO 44 5. SEO 没有技术含量或SEO 需要非常深厚的技能 44 六大网站 做到了。我也向他们学习了 44 七家SEO公司或SEO工具保证排名提升 44 八位稳定排名 45 九 SEO目标是获得第一名或尽可能多的访问量 45 十大竞争对手无法破坏我的排名 45 第四章SEO相关搜索引擎技术 46 Page 2 搜索引擎优化魔法书 SEOMagicBook 浩威互动免费电子书 wwwtimevnet 第一节搜索引擎机器人 46 一 什么是搜索引擎机器人 46 2. 如何识别搜索引擎机器人的身份 47 第二节. 超链分析 47 1 .
应用 53 六中文搜索引擎技术 54 第四节基于词义的文本分析 55 一文本分析技术特点 55 二文本分析应用 55 第五章网站的搜索引擎性能理解 57 第一节基本查询 57 1.域名信息查询 57 2. 域名历史查询 57 3. 主机连接速度和 IP 地址查询 57 四带 IP 收录编号 58 Section 3 Backlink Query 59 Section 4 Web Page RANK 查询 59 一个 GooglePageRank 查询 59 两个 SogouRank 查询 59第五节 关键词 排名查询 59 第六节 ALEXA 查询 60 一 什么是 Alexa 60 2. Alexa 主要数据 60 3. 用 Alexa 检查什么 60 第 6 章基于搜索引擎友好的 网站 设计 62 Section 1域名策略 62 1.不同后缀域名在搜索引擎中的权重 62 2. 域名基本常识 62 Page 3 搜索引擎优化魔法书 SEOMagicBook 豪威互动免费电子书 wwwtimevnet 关键词 三个域名策略之六
9 4 中文网站域名拼音策略 70 5 小心注册被搜索引擎惩罚的域名 70 第二节 空间策略 71 1 安全要素 1 稳定性 71 2 安全要素 2 良好的共存环境 71 3 本节附录 72第三节网站结构规划72第四节网站导航设计73第五节IFRAMEVASACRIPT和AJAX73一个IFRAME74两个JS74三个AJAX74第六节URL设计75一个易于记忆75两个URL静态75三个URL关键词部署 78 第七节 网页代码编写 80 一遵循WEB标准 篮球课程标准 尘肺病标准片 党员活动室建设分级护理精细化标准 儿科分级护理标准 80 第二个代码的逻辑 80 第八节 面向搜索引擎的文案指南 81 1. 网页标题 标题 81 2. 元元标记 84 3. 图片 ALT 替换文本 85 4. Robotstxt 85 5. 链接锚文本 89 6. 站点地图 xml 89 7. 版权和隐私 97 第 9 节 用户友好性检查 97 1. 链接可用性 97 2. 访问速度体验 97 三个查找信息的便捷性 98 第七章 创建搜索引擎喜欢的内容站点地图 xml 89 7. 版权和隐私 97 第 9 节 用户友好性检查 97 1. 链接可用性 97 2. 访问速度体验 97 查找信息的三个便利性 98 第七章 创建搜索引擎喜欢的内容站点地图 xml 89 7. 版权和隐私 97 第 9 节 用户友好性检查 97 1. 链接可用性 97 2. 访问速度体验 97 查找信息的三个便利性 98 第七章 创建搜索引擎喜欢的内容
搜索引擎优化pdf(文档格式有TXT、WORD、PDF等,对这些文档的搜索引擎优化方法比较简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-21 13:00
目前常用的文档格式有TXT、WORD、PDF等,这些文档的搜索引擎优化方法比较简单,只要文档标题和文档首页前面的一些文字信息包括关键词,针对网页进行了优化。这个想法是一样的。这些任务只需要在我们写文档的时候顺便完成。
目前常用的文档格式有TXT、WORD、PDF等,这些文档的搜索引擎优化方法比较简单,只要文档标题和文档首页前面的一些文字信息包括关键词,针对网页进行了优化。这个想法是一样的。这些任务只需要在写文档的时候顺便完成。当大家对这些问题都不够重视的时候,就一点点
目前常用的文档格式有TXT、WORD、PDF等,这些文档的搜索引擎优化方法比较简单,只要文档标题和文档首页前面的一些文字信息包括关键词,针对网页进行了优化。这个想法是一样的。这些任务只需要在我们写文档的时候顺便完成。当大家对这些问题都不够重视时,只要稍加注意,就能获得更好的搜索排名效果。随着类似文档的逐渐增多,可能需要更复杂的优化方法,但在这方面似乎没有更有效的方法可以借鉴。
基于三大搜索引擎的PDF文档权重非常高。PDF 文档可以添加指向其内容的链接。在GOOGLE的策略中,文档相对于普通的HTML文件有着先天的优势。GOOGLE给出原创PDF文件PR=3的高权重主要有以下三个原因:1、一般人们会把比较重要的文件和文本做成PDF格式,导致PDF的识别度高搜索引擎提供的文件。2、 PDF文件的打开方式是html,在web客户端上方便阅读。3、PDF文件易于下载,易于传播,并且在传播过程中不会被扭曲或修改(相对于DOC等)。
如何制作pdf文件?大家应该都在思考吧!前面说过,PDF文件优化的思路和网页优化的思路是一样的,比如:在标题和内容中适当的收录关键词,以提高内容的相关性,使用H1进行标题格式,重要内容以粗体或大号显示等。另外,对于PDF文档,需要对文件属性做一些优化。要制作PDF文件,使用Acrobat软件太麻烦了。我一般用WORD直接导出生成PDF格式,简单实用。文件属性的优化主要包括:文件描述、文件元数据描述文件、文件属性、描述、标题、作者、主题、描述描述、关键词关键字、描述作者描述编写者、
你可以看看Adobe Acrobat6.0的使用说明,两套关键词重要性分析,哪一个关键词最有可能得到搜索引擎的关注?我们知道元数据(metadata)有很多种存储格式,但是Adobe使用的是XML格式,用记事本打开PDF文件,可以发现关键词区域在“文件属性说明”下输入的关键词 " 以逗号分隔,如:关键词(关键词1,关键词2,关键词3,...),我们在"文档元数据描述" 关键词 下关键词 区域输入的内容格式为:关键词1关键词2关键词3 根据这个格式,搜索引擎是更有可能抓取“属性描述”下关键词区域中的“文件信息”。因此,我们建议列出该区域最相关的关键词 网站。如果要使用PDF文件中的图片,最好在每张图片下方添加一行说明,并且最好收录目标关键词,类似于html中的图片。
还有一点就是pdf文件是对网站的内外链的很好的补充。这时候可以花点时间整理一下网上公布的技术文章,做成pdf。文档。
html 中文网站 题外话,最近发现我的一个页面的PR值达到了7,这个页面是FLASH页面:
以上就是网页PDF文档优化制作方法的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
搜索引擎优化pdf(文档格式有TXT、WORD、PDF等,对这些文档的搜索引擎优化方法比较简单)
目前常用的文档格式有TXT、WORD、PDF等,这些文档的搜索引擎优化方法比较简单,只要文档标题和文档首页前面的一些文字信息包括关键词,针对网页进行了优化。这个想法是一样的。这些任务只需要在我们写文档的时候顺便完成。
目前常用的文档格式有TXT、WORD、PDF等,这些文档的搜索引擎优化方法比较简单,只要文档标题和文档首页前面的一些文字信息包括关键词,针对网页进行了优化。这个想法是一样的。这些任务只需要在写文档的时候顺便完成。当大家对这些问题都不够重视的时候,就一点点
目前常用的文档格式有TXT、WORD、PDF等,这些文档的搜索引擎优化方法比较简单,只要文档标题和文档首页前面的一些文字信息包括关键词,针对网页进行了优化。这个想法是一样的。这些任务只需要在我们写文档的时候顺便完成。当大家对这些问题都不够重视时,只要稍加注意,就能获得更好的搜索排名效果。随着类似文档的逐渐增多,可能需要更复杂的优化方法,但在这方面似乎没有更有效的方法可以借鉴。
基于三大搜索引擎的PDF文档权重非常高。PDF 文档可以添加指向其内容的链接。在GOOGLE的策略中,文档相对于普通的HTML文件有着先天的优势。GOOGLE给出原创PDF文件PR=3的高权重主要有以下三个原因:1、一般人们会把比较重要的文件和文本做成PDF格式,导致PDF的识别度高搜索引擎提供的文件。2、 PDF文件的打开方式是html,在web客户端上方便阅读。3、PDF文件易于下载,易于传播,并且在传播过程中不会被扭曲或修改(相对于DOC等)。
如何制作pdf文件?大家应该都在思考吧!前面说过,PDF文件优化的思路和网页优化的思路是一样的,比如:在标题和内容中适当的收录关键词,以提高内容的相关性,使用H1进行标题格式,重要内容以粗体或大号显示等。另外,对于PDF文档,需要对文件属性做一些优化。要制作PDF文件,使用Acrobat软件太麻烦了。我一般用WORD直接导出生成PDF格式,简单实用。文件属性的优化主要包括:文件描述、文件元数据描述文件、文件属性、描述、标题、作者、主题、描述描述、关键词关键字、描述作者描述编写者、
你可以看看Adobe Acrobat6.0的使用说明,两套关键词重要性分析,哪一个关键词最有可能得到搜索引擎的关注?我们知道元数据(metadata)有很多种存储格式,但是Adobe使用的是XML格式,用记事本打开PDF文件,可以发现关键词区域在“文件属性说明”下输入的关键词 " 以逗号分隔,如:关键词(关键词1,关键词2,关键词3,...),我们在"文档元数据描述" 关键词 下关键词 区域输入的内容格式为:关键词1关键词2关键词3 根据这个格式,搜索引擎是更有可能抓取“属性描述”下关键词区域中的“文件信息”。因此,我们建议列出该区域最相关的关键词 网站。如果要使用PDF文件中的图片,最好在每张图片下方添加一行说明,并且最好收录目标关键词,类似于html中的图片。
还有一点就是pdf文件是对网站的内外链的很好的补充。这时候可以花点时间整理一下网上公布的技术文章,做成pdf。文档。
html 中文网站 题外话,最近发现我的一个页面的PR值达到了7,这个页面是FLASH页面:
以上就是网页PDF文档优化制作方法的详细内容。更多详情请关注其他相关html中文网站文章!
搜索引擎优化pdf(软文推广目前大大小小的网站使用的一个重要的推广方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-20 04:08
文档介绍:file:///C|/Users/cysell/Desktop/优采云采集新闻来源/搜索引擎优化从何入手..htm[2014/5/17 22:49:49 ]搜索引擎优化(SEO)就是对一个网站进行优化以获得更高的排名,通过对搜索引擎基于网站的内链和内容以及外链的一些计算来优化的过程。网赚现在说说搜索引擎优化的一般步骤和内容。一.内容搜索引擎优化是一个庞大而综合的系统工程,但可以概括为以下几个部分,一般包括标签、描述、alt、文本和链接。1. 标题标签是网站的一个代码,其中最重要的是顶部标题标签的各种标签。标题标签在网站的索引中起着重要的作用。首先,搜索引擎将根据标题标签确定特定网页的相关性。因此,它在标题标签中收录关键字。标题标签中过度使用重复的关键词会被搜索引擎惩罚。2.元标签描述和关键字标签。说明很重要。正确使用这些标签可以帮助访问者了解您的 网站 的主要观点是什么。3.ALT标签 这些标签有助于描述网页中图片的内容,使搜索引擎更容易理解图片的内容。二.链接建设 链接建设的目的是增加网站的权重,吸引网络流量和搜索引擎蜘蛛。如果你离开你的网站
三.软文推广当前大大小小的网站使用的一个重要的推广方式是软文,推广网站学写软文是必须的,软文的推广力度明显加大。一个好的软文可以不断为你添加链接。四.网站以上所有方法都是根据网站内容必须有价值,网站内容必须与你的网站主题相关,如果无关紧要,上面的做法再好,也无济于事。file:///C|/Users/cysell/Desktop/优采云采集新闻来源/从哪里开始搜索引擎优化..htm[2014/5/17 22:49:49]一般个人网站 大约 90% 的网络流量是由搜索引擎带来的。所以在做搜索引擎的时候,每个单独的网站管理员都必须做功课。文章创,转载请保留链接,谢谢!================================================== ==================== 【2014年怎么赚钱-微信朋友圈赚钱】你的手机只要装了微信软件就可以赚钱!!!如何通过微信赚钱?怎么用微信赚钱?你怎么能保证你能得到你赚到的钱?微信赚钱的方式无外乎几种:1、公众号靠广告赚钱,2、微信群广告赚钱,3、朋友圈赚钱广告,这三招帮你赚RMB!!我们来谈谈如何在微信朋友圈赚钱?如果你的微信好友超过200人可以赚钱,因为这 200 或更多人是你的客户,他们可以为你创造价值,你可以从中赚钱。赚取人民币。通过将广告分享到您的朋友圈,您的朋友将看到该广告 查看全部
搜索引擎优化pdf(软文推广目前大大小小的网站使用的一个重要的推广方式)
文档介绍:file:///C|/Users/cysell/Desktop/优采云采集新闻来源/搜索引擎优化从何入手..htm[2014/5/17 22:49:49 ]搜索引擎优化(SEO)就是对一个网站进行优化以获得更高的排名,通过对搜索引擎基于网站的内链和内容以及外链的一些计算来优化的过程。网赚现在说说搜索引擎优化的一般步骤和内容。一.内容搜索引擎优化是一个庞大而综合的系统工程,但可以概括为以下几个部分,一般包括标签、描述、alt、文本和链接。1. 标题标签是网站的一个代码,其中最重要的是顶部标题标签的各种标签。标题标签在网站的索引中起着重要的作用。首先,搜索引擎将根据标题标签确定特定网页的相关性。因此,它在标题标签中收录关键字。标题标签中过度使用重复的关键词会被搜索引擎惩罚。2.元标签描述和关键字标签。说明很重要。正确使用这些标签可以帮助访问者了解您的 网站 的主要观点是什么。3.ALT标签 这些标签有助于描述网页中图片的内容,使搜索引擎更容易理解图片的内容。二.链接建设 链接建设的目的是增加网站的权重,吸引网络流量和搜索引擎蜘蛛。如果你离开你的网站
三.软文推广当前大大小小的网站使用的一个重要的推广方式是软文,推广网站学写软文是必须的,软文的推广力度明显加大。一个好的软文可以不断为你添加链接。四.网站以上所有方法都是根据网站内容必须有价值,网站内容必须与你的网站主题相关,如果无关紧要,上面的做法再好,也无济于事。file:///C|/Users/cysell/Desktop/优采云采集新闻来源/从哪里开始搜索引擎优化..htm[2014/5/17 22:49:49]一般个人网站 大约 90% 的网络流量是由搜索引擎带来的。所以在做搜索引擎的时候,每个单独的网站管理员都必须做功课。文章创,转载请保留链接,谢谢!================================================== ==================== 【2014年怎么赚钱-微信朋友圈赚钱】你的手机只要装了微信软件就可以赚钱!!!如何通过微信赚钱?怎么用微信赚钱?你怎么能保证你能得到你赚到的钱?微信赚钱的方式无外乎几种:1、公众号靠广告赚钱,2、微信群广告赚钱,3、朋友圈赚钱广告,这三招帮你赚RMB!!我们来谈谈如何在微信朋友圈赚钱?如果你的微信好友超过200人可以赚钱,因为这 200 或更多人是你的客户,他们可以为你创造价值,你可以从中赚钱。赚取人民币。通过将广告分享到您的朋友圈,您的朋友将看到该广告
搜索引擎优化pdf(我知道的只有一个,不知道会不会弹窗转换,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-20 00:03
搜索引擎优化pdf,现在pdf每天的处理量,已经达到了几十gb了,一般小文档的处理,都必须通过图片来完成,需要转换的pdf文档在4000张以上,pdf转jpg文件,还是pdf转ppt的话,就更为庞大了,页数,页面尺寸,当然有大有小,为了更精确的完成优化师的工作量,处理处理页面多的pdf,一般都需要转换后再次pdf,这就是pdf转换器adobeacrobat来完成转换工作了。
虽然有些转换器最高的内容可以达到4g,但是再次压缩的话,按照以上的规则,还是会在10m以内的,虽然普通的工具可以把图片的大小压缩到10多mm,但还是不能达到4g的,有的转换器即使像转转大师压缩率可以达到99%,那也是要牺牲部分页面大小的,毕竟页面尺寸和页面缩放还是直接决定pdf的大小的,不可能真的把页面也压缩到只有一个像素的大小的。文章来源于网络,如有侵权请联系删除。
我知道的只有一个,不会弹窗转换,不知道会不会切换首页,虽然一个可以收费.adobeacrobat具体步骤请参照:我需要哪些安装包和破解工具?
ocr,识别为文字后翻译成pdf,查询转换器,可以帮你变废为宝。或者学习写pdf,编辑pdf内容。
pdf转换器,现在基本上市面上能见到的类型的转换器, 查看全部
搜索引擎优化pdf(我知道的只有一个,不知道会不会弹窗转换,)
搜索引擎优化pdf,现在pdf每天的处理量,已经达到了几十gb了,一般小文档的处理,都必须通过图片来完成,需要转换的pdf文档在4000张以上,pdf转jpg文件,还是pdf转ppt的话,就更为庞大了,页数,页面尺寸,当然有大有小,为了更精确的完成优化师的工作量,处理处理页面多的pdf,一般都需要转换后再次pdf,这就是pdf转换器adobeacrobat来完成转换工作了。
虽然有些转换器最高的内容可以达到4g,但是再次压缩的话,按照以上的规则,还是会在10m以内的,虽然普通的工具可以把图片的大小压缩到10多mm,但还是不能达到4g的,有的转换器即使像转转大师压缩率可以达到99%,那也是要牺牲部分页面大小的,毕竟页面尺寸和页面缩放还是直接决定pdf的大小的,不可能真的把页面也压缩到只有一个像素的大小的。文章来源于网络,如有侵权请联系删除。
我知道的只有一个,不会弹窗转换,不知道会不会切换首页,虽然一个可以收费.adobeacrobat具体步骤请参照:我需要哪些安装包和破解工具?
ocr,识别为文字后翻译成pdf,查询转换器,可以帮你变废为宝。或者学习写pdf,编辑pdf内容。
pdf转换器,现在基本上市面上能见到的类型的转换器,
搜索引擎优化pdf(如何使用SEO对PDF文件进行排名?58的建议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2021-12-19 18:28
PDF文件是科研机构和企业在日常工作中经常使用的文件,可以是学术研究报告或企业的产品描述文件。
如果你的 网站 经常使用 PDF 文件作为使用说明书,在实践中,我们需要 PDF 文件来对搜索引擎进行排名。
如何使用 SEO 对 PDF 文件进行排名?
针对以往科研机构和国内教育机构优化的经验,织梦58通常对通过SEO优化PDF文件提出以下建议:
1、PDF 目录
规范的PDF文件存储目录,一有利于提高抓捕百度爬虫的频率,二是更好的管理文档,尤其是PDF文件数量比较大的时候。
2、PDF 格式
确保PDF文件的内容格式以文本形式存在,可以适当使用表格,但最好简化表格内容,尽量避免使用纯图片格式。
目前百度完全可以分析PDF文件的文本内容,当然也包括PDF中的链接。
3、PDF 标题
如果使用命令filetype:pdf,在百度的搜索结果中,你会发现pdf文件的标题是可识别的,并显示在搜索结果中。
因此,在设置PDF标题时,需要参考页面标题和标题标签的设计方法,在创建PDF时尽量在“文档属性”中标注标题内容。
4、PDF 大小
针对PDF文件的大小,我们不仅强调PDF文件的大小不能太大,而且建议尽可能合理控制PDF文件的字数。
严重影响搜索引擎的分析和索引,也影响页面加载速度。
5、PDF 超链接
理论上,百度可以识别PDF文件中的超链接,所以在建立PDF文件数据库时,可以正确使用PDF中的链接来引导蜘蛛爬行。例如:指向PDF文件目录的首页,或者指向网站核心关键字的链接。
6、PDF 策略
如果你在做一些行业研究,你会发现对于相关的话题,用户对PDF文件有很多潜在的需求,比如:SEO电子书。当然,你也可以定期整理这些内容,上传到网站合理的专栏上发布。
有助于提高目标网站在行业中的相关性。
7、PDF 设计
如果你是基于搜索引擎的角度,你还是需要注意PDF的设计,尤其是它在手机上的展示,注意搜索引擎的友好度,这有助于提高它在手机上的排名电话。
8、PDF 内容
在设计PDF内容的时候,我们需要保证PDF内容的主题与网站的核心内容高度相关,我们尽量查看PDF文件的标题。如果有一定的相关性,就会出现大量的病例。
我们有必要把它写到网页中,并使用网页的标题作为标签标题,并且在内容页中,不要跟踪所有的pdf链接,这是一种比较特殊的情况。 查看全部
搜索引擎优化pdf(如何使用SEO对PDF文件进行排名?58的建议)
PDF文件是科研机构和企业在日常工作中经常使用的文件,可以是学术研究报告或企业的产品描述文件。
如果你的 网站 经常使用 PDF 文件作为使用说明书,在实践中,我们需要 PDF 文件来对搜索引擎进行排名。
如何使用 SEO 对 PDF 文件进行排名?
针对以往科研机构和国内教育机构优化的经验,织梦58通常对通过SEO优化PDF文件提出以下建议:
1、PDF 目录
规范的PDF文件存储目录,一有利于提高抓捕百度爬虫的频率,二是更好的管理文档,尤其是PDF文件数量比较大的时候。
2、PDF 格式
确保PDF文件的内容格式以文本形式存在,可以适当使用表格,但最好简化表格内容,尽量避免使用纯图片格式。
目前百度完全可以分析PDF文件的文本内容,当然也包括PDF中的链接。
3、PDF 标题
如果使用命令filetype:pdf,在百度的搜索结果中,你会发现pdf文件的标题是可识别的,并显示在搜索结果中。
因此,在设置PDF标题时,需要参考页面标题和标题标签的设计方法,在创建PDF时尽量在“文档属性”中标注标题内容。
4、PDF 大小
针对PDF文件的大小,我们不仅强调PDF文件的大小不能太大,而且建议尽可能合理控制PDF文件的字数。
严重影响搜索引擎的分析和索引,也影响页面加载速度。
5、PDF 超链接
理论上,百度可以识别PDF文件中的超链接,所以在建立PDF文件数据库时,可以正确使用PDF中的链接来引导蜘蛛爬行。例如:指向PDF文件目录的首页,或者指向网站核心关键字的链接。
6、PDF 策略
如果你在做一些行业研究,你会发现对于相关的话题,用户对PDF文件有很多潜在的需求,比如:SEO电子书。当然,你也可以定期整理这些内容,上传到网站合理的专栏上发布。
有助于提高目标网站在行业中的相关性。
7、PDF 设计
如果你是基于搜索引擎的角度,你还是需要注意PDF的设计,尤其是它在手机上的展示,注意搜索引擎的友好度,这有助于提高它在手机上的排名电话。
8、PDF 内容
在设计PDF内容的时候,我们需要保证PDF内容的主题与网站的核心内容高度相关,我们尽量查看PDF文件的标题。如果有一定的相关性,就会出现大量的病例。
我们有必要把它写到网页中,并使用网页的标题作为标签标题,并且在内容页中,不要跟踪所有的pdf链接,这是一种比较特殊的情况。

