
插入关键字 文章采集器
插入关键字 文章采集器 Golang Profiling: 关于 pprof
采集交流 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-06-25 15:37
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i 查看全部
插入关键字 文章采集器 Golang Profiling: 关于 pprof
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i
插入关键字 文章采集器 Golang Profiling: 关于 pprof
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-06-22 15:07
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i 查看全部
插入关键字 文章采集器 Golang Profiling: 关于 pprof
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i
插入关键字文章采集器的分析方法有哪些?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-06-20 20:00
插入关键字文章采集器。可以关键字采集,也可以功能字采集。相对自己定义网站,这个不太友好。该有的功能还是有的,可以自己调试下,但不是很方便。
花瓣的功能全部都可以做到,但是长期发掘最适合自己的那一个最重要,无非是个人品牌的整理,公众号微博整理,多个领域的采集,另外站内内容分类的优化也是很重要的,个人看法,没有什么特别的地方,
采集免费的50个就可以了。不采集需要付费,收费可以去找国外的采集软件,比如themesrepublic,redwall等。花瓣网采集的数据需要去除水印再下载,毕竟是长时间收集的数据。
国内第一家提供免费内容采集的网站,
现在就想找一个很简单的分析网站内容的网站?采集文章还不错,
目前最好的分析网站的方法就是发挥采集技术去分析,花瓣虽然提供了丰富的功能,但是网站长期留住粉丝的方法有很多种,比如通过个人的生活经历,分享的有自己特色的经历等,这样去利用花瓣进行长尾内容的挖掘和发掘。比如比如你是电影迷,那么不妨去电影网站逛逛,花瓣的排版布局之所以和其他网站差异化很大,就是因为它不提供采集,而这部分内容内容太多,于是花瓣添加了生活有趣的元素,让内容与花瓣内容更融合。
总之,花瓣内容的分析是有很多方法的,但是目前就我所知采集功能只是其中一个小方法,而且也不好直接在花瓣网上内容分析,对于我们来说,这样的采集就会出现与优化标签标签重复的现象,而且内容发掘难度系数也大,所以我觉得,这样的分析对于网站优化是很不利的。 查看全部
插入关键字文章采集器的分析方法有哪些?-八维教育
插入关键字文章采集器。可以关键字采集,也可以功能字采集。相对自己定义网站,这个不太友好。该有的功能还是有的,可以自己调试下,但不是很方便。
花瓣的功能全部都可以做到,但是长期发掘最适合自己的那一个最重要,无非是个人品牌的整理,公众号微博整理,多个领域的采集,另外站内内容分类的优化也是很重要的,个人看法,没有什么特别的地方,
采集免费的50个就可以了。不采集需要付费,收费可以去找国外的采集软件,比如themesrepublic,redwall等。花瓣网采集的数据需要去除水印再下载,毕竟是长时间收集的数据。
国内第一家提供免费内容采集的网站,
现在就想找一个很简单的分析网站内容的网站?采集文章还不错,
目前最好的分析网站的方法就是发挥采集技术去分析,花瓣虽然提供了丰富的功能,但是网站长期留住粉丝的方法有很多种,比如通过个人的生活经历,分享的有自己特色的经历等,这样去利用花瓣进行长尾内容的挖掘和发掘。比如比如你是电影迷,那么不妨去电影网站逛逛,花瓣的排版布局之所以和其他网站差异化很大,就是因为它不提供采集,而这部分内容内容太多,于是花瓣添加了生活有趣的元素,让内容与花瓣内容更融合。
总之,花瓣内容的分析是有很多方法的,但是目前就我所知采集功能只是其中一个小方法,而且也不好直接在花瓣网上内容分析,对于我们来说,这样的采集就会出现与优化标签标签重复的现象,而且内容发掘难度系数也大,所以我觉得,这样的分析对于网站优化是很不利的。
插入关键字 文章采集器 Golang Profiling: 关于 pprof
采集交流 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-06-20 19:56
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i 查看全部
插入关键字 文章采集器 Golang Profiling: 关于 pprof
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i
插入关键字 文章采集器 Golang Profiling: 关于 pprof
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-06-19 01:32
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i 查看全部
插入关键字 文章采集器 Golang Profiling: 关于 pprof
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i
插入关键字 文章采集器 Golang Profiling: 关于 pprof
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-06-18 18:44
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i 查看全部
插入关键字 文章采集器 Golang Profiling: 关于 pprof
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i
插入关键字 文章采集器 Golang Profiling: 关于 pprof
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-06-18 18:27
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i 查看全部
插入关键字 文章采集器 Golang Profiling: 关于 pprof
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i
插入关键字 文章采集器 Golang Profiling: 关于 pprof
采集交流 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-06-18 06:17
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i 查看全部
插入关键字 文章采集器 Golang Profiling: 关于 pprof
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i
插入关键字文章采集器输入excel表格文件名称点击操作
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-06-03 08:05
插入关键字文章采集器、选取文章格式和素材完成后,插入后会自动搜索被采集的文章,如果你找到最适合的条件,就直接选中导出!这里将带你了解怎么生成条件文件,有了它,你就可以在excel表格里直接调用每篇文章,直接导出成word或jpg格式。还有后续功能,访问原文查看:插入关键字文章采集器输入excel表格文件名称,点击操作。
-步骤一-选择一个要爬取的表格,下图中一共有20页。-步骤二-点击输入框。-步骤三-输入文字选择刚刚设置好的关键字,就是具体的文章的“关键字”,假设我设置的是“文章”,“文章”即"mazhongdog"。文字格式会出现excel表格里面的格式。“关键字”字体颜色较透明,点击"【”图标选择透明不透明之间,就会生成对应的文本颜色。
点击"确定"之后文本颜色生成好。如下图:-步骤四-点击输入框。-步骤五-选择下图中的条件格式,就是文章类型的选择。这里以2015.3.3号的为例,选择里面“计算机”“科技”两个类型。条件格式对应的参数栏会出现v34和v36,它的目的是在输入的时候设置好excel中表格格式。点击确定之后条件格式会生成文本。
(如下图红色箭头所示)-步骤六-选择关键字chenyu,点击下图红色箭头所示的颜色条。-步骤七-选择无需预览可直接对关键字进行粘贴。-步骤八-点击操作就会直接在电脑上看到helloworld的关键字识别出来了。大功告成!小伙伴们是不是找到了自己想要的关键字呢?如果喜欢我们的文章请帮忙转发、点赞!您的支持是我们原创更新的动力!感谢您的阅读,更多文章欢迎关注公众号“excel应用之家”,欢迎加入excel高手qq群:37032818。 查看全部
插入关键字文章采集器输入excel表格文件名称点击操作
插入关键字文章采集器、选取文章格式和素材完成后,插入后会自动搜索被采集的文章,如果你找到最适合的条件,就直接选中导出!这里将带你了解怎么生成条件文件,有了它,你就可以在excel表格里直接调用每篇文章,直接导出成word或jpg格式。还有后续功能,访问原文查看:插入关键字文章采集器输入excel表格文件名称,点击操作。
-步骤一-选择一个要爬取的表格,下图中一共有20页。-步骤二-点击输入框。-步骤三-输入文字选择刚刚设置好的关键字,就是具体的文章的“关键字”,假设我设置的是“文章”,“文章”即"mazhongdog"。文字格式会出现excel表格里面的格式。“关键字”字体颜色较透明,点击"【”图标选择透明不透明之间,就会生成对应的文本颜色。
点击"确定"之后文本颜色生成好。如下图:-步骤四-点击输入框。-步骤五-选择下图中的条件格式,就是文章类型的选择。这里以2015.3.3号的为例,选择里面“计算机”“科技”两个类型。条件格式对应的参数栏会出现v34和v36,它的目的是在输入的时候设置好excel中表格格式。点击确定之后条件格式会生成文本。
(如下图红色箭头所示)-步骤六-选择关键字chenyu,点击下图红色箭头所示的颜色条。-步骤七-选择无需预览可直接对关键字进行粘贴。-步骤八-点击操作就会直接在电脑上看到helloworld的关键字识别出来了。大功告成!小伙伴们是不是找到了自己想要的关键字呢?如果喜欢我们的文章请帮忙转发、点赞!您的支持是我们原创更新的动力!感谢您的阅读,更多文章欢迎关注公众号“excel应用之家”,欢迎加入excel高手qq群:37032818。
插入关键字文章采集器给提供常用的常用关键列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-05-24 15:01
插入关键字文章采集器都会给提供常用关键字列表,我们可以自己添加我们需要的关键字方便快捷的完成一篇文章的插入工作!但是网上有很多的关键字列表,这样浪费了很多时间而且不一定全面,下面是我根据自己的工作流提供的关键字列表,这样整个关键字工作流就很清晰!首先需要注意的是要先取正确的关键字,毕竟是机器人生成的,你就不要求全一点要求都不能有错,当然首先需要关注的就是拼音,请注意你的拼音是不是在中间:)ps:由于内容过多,请私信我为你提供单独的文件,并有详细步骤说明。
<p>确定关键字,方法很简单,使用关键字api测试执行api输入任意关键字都能返回最可能的最可能的文章内容,如果没有找到能返回最可能内容的关键字,请使用关键字classs以确定关键字。关键字可以用(),'(或)'phpapi_keyfieldnameor*>phpapi_keyfieldnameor*>phpapi_keyfieldnameor*>其他例子请使用api_name="phpreplay";api_param="result_value";api_content="";api_name="phpstorm";api_content="";api_param="text_format";api_content="";api_content="";其他例子请使用api_name="flash";api_param="result_value";api_content="";api_content="";api_name="flash";api_param="text_format";api_content="";api_content="";api_content="";方法2.加载链接phpstorm的api文件可以到,有链接的关键字是可以作为命令执行的,但是一般我们提取的文章文件都需要加载到.php结尾的文件夹里,如果文件直接用文件查看器打开可能会乱码,这时候可以添加以下代码:phpapi_keyfieldnameor*>phpapi_keyfieldnameor*> 查看全部
插入关键字文章采集器给提供常用的常用关键列表
插入关键字文章采集器都会给提供常用关键字列表,我们可以自己添加我们需要的关键字方便快捷的完成一篇文章的插入工作!但是网上有很多的关键字列表,这样浪费了很多时间而且不一定全面,下面是我根据自己的工作流提供的关键字列表,这样整个关键字工作流就很清晰!首先需要注意的是要先取正确的关键字,毕竟是机器人生成的,你就不要求全一点要求都不能有错,当然首先需要关注的就是拼音,请注意你的拼音是不是在中间:)ps:由于内容过多,请私信我为你提供单独的文件,并有详细步骤说明。
<p>确定关键字,方法很简单,使用关键字api测试执行api输入任意关键字都能返回最可能的最可能的文章内容,如果没有找到能返回最可能内容的关键字,请使用关键字classs以确定关键字。关键字可以用(),'(或)'phpapi_keyfieldnameor*>phpapi_keyfieldnameor*>phpapi_keyfieldnameor*>其他例子请使用api_name="phpreplay";api_param="result_value";api_content="";api_name="phpstorm";api_content="";api_param="text_format";api_content="";api_content="";其他例子请使用api_name="flash";api_param="result_value";api_content="";api_content="";api_name="flash";api_param="text_format";api_content="";api_content="";api_content="";方法2.加载链接phpstorm的api文件可以到,有链接的关键字是可以作为命令执行的,但是一般我们提取的文章文件都需要加载到.php结尾的文件夹里,如果文件直接用文件查看器打开可能会乱码,这时候可以添加以下代码:phpapi_keyfieldnameor*>phpapi_keyfieldnameor*>
插入关键字文章采集器(全文采集)(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-05-18 16:01
插入关键字文章采集器(全文采集)目前有两种采集方式1.机器采集:只采集标题,一天采集5000条数据,机器采集相对较慢2.网站采集:不采集标题,还可以采集网站的各种内容,但是网站采集的内容没有机器采集精准,且机器采集的数据存在数据失真情况采集器,一般搜索百度+标题可以找到网站地址,最快速度的是采集器去采集快速采集器-网站采集。看到网站上有个观点或文章标题就知道文章在那个网站采集的。
专门的有两个:地址栏打开就显示出网站链接的采集器,比如说reex。
百度即可有关页面的post数据可以通过railix来自动的爬。另外很多网站都支持ip段爬,可以自行发动,爬一个出来,访问过的ip和session都可以用他分析出来,然后自己找爬虫clone,自己写。
自己没爬过,所以很难发言,不过还是有方法的,这里有我的方法,
就是百度搜网站名,直接下载抓包工具,根据抓包信息来数据就行了。
我知道一款,推荐给你。
有的,有一些网站是没有getselect,如果需要再get到的方式爬回来,有的时候时间来不及了。小编来告诉你,“不会采集,不会生成”的人都有谁,有哪些又快速,
网站可以去百度各个网站上直接去下载带采集功能的文章,直接读取就可以了!如果是第三方网站,用采集器是可以生成网站的链接地址让你爬。 查看全部
插入关键字文章采集器(全文采集)(图)
插入关键字文章采集器(全文采集)目前有两种采集方式1.机器采集:只采集标题,一天采集5000条数据,机器采集相对较慢2.网站采集:不采集标题,还可以采集网站的各种内容,但是网站采集的内容没有机器采集精准,且机器采集的数据存在数据失真情况采集器,一般搜索百度+标题可以找到网站地址,最快速度的是采集器去采集快速采集器-网站采集。看到网站上有个观点或文章标题就知道文章在那个网站采集的。
专门的有两个:地址栏打开就显示出网站链接的采集器,比如说reex。
百度即可有关页面的post数据可以通过railix来自动的爬。另外很多网站都支持ip段爬,可以自行发动,爬一个出来,访问过的ip和session都可以用他分析出来,然后自己找爬虫clone,自己写。
自己没爬过,所以很难发言,不过还是有方法的,这里有我的方法,
就是百度搜网站名,直接下载抓包工具,根据抓包信息来数据就行了。
我知道一款,推荐给你。
有的,有一些网站是没有getselect,如果需要再get到的方式爬回来,有的时候时间来不及了。小编来告诉你,“不会采集,不会生成”的人都有谁,有哪些又快速,
网站可以去百度各个网站上直接去下载带采集功能的文章,直接读取就可以了!如果是第三方网站,用采集器是可以生成网站的链接地址让你爬。
插入关键字文章采集器,api接口文章大全(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-05-07 20:00
插入关键字文章采集器,api接口文章大全,api开放平台文章智能推荐引擎,智能新闻推荐_v2ex
采集需要关键字的邮箱,把需要的内容集中起来(文章),通过api接口提供者提供的api对接到需要的地方,一般api接口服务器。
采集我们产品api数据和抓取抓力推荐可以试试“蜜蜂推荐”,直接购买单个账号,可对接很多个网站内容。
uc微信订阅号中的文章
三款基于信息流的app新闻站点搜狗网易
微信公众号文章不是很多都采集的么
一是采集新闻源,类似一些网站经常发布的采集器;二是新闻源解析,百度搜索搜新闻源,自己创建自己的网站库存,解析其文章,可加上自己的标签。三是视频采集与下载,公众号文章都会有视频及相关下载;还有一些文章站点的二维码生成的方式提供。
一个app来源统计,
在米饭采集器,
我会告诉你看到过有个人把新闻源api给开源了嘛,你去试试看吧,
这个可以统计很多公众号文章,新浪搜狐简书中,可能有些公众号文章并不发布在自己公众号上。此外还有一些可以统计同城的公众号还有一些免费的公众号,更多地公众号这些统计工具可以查找到公众号。
今日头条-新闻搜索
必须是这个最有用了:三体新闻转载统计系统。 查看全部
插入关键字文章采集器,api接口文章大全(组图)
插入关键字文章采集器,api接口文章大全,api开放平台文章智能推荐引擎,智能新闻推荐_v2ex
采集需要关键字的邮箱,把需要的内容集中起来(文章),通过api接口提供者提供的api对接到需要的地方,一般api接口服务器。
采集我们产品api数据和抓取抓力推荐可以试试“蜜蜂推荐”,直接购买单个账号,可对接很多个网站内容。
uc微信订阅号中的文章
三款基于信息流的app新闻站点搜狗网易
微信公众号文章不是很多都采集的么
一是采集新闻源,类似一些网站经常发布的采集器;二是新闻源解析,百度搜索搜新闻源,自己创建自己的网站库存,解析其文章,可加上自己的标签。三是视频采集与下载,公众号文章都会有视频及相关下载;还有一些文章站点的二维码生成的方式提供。
一个app来源统计,
在米饭采集器,
我会告诉你看到过有个人把新闻源api给开源了嘛,你去试试看吧,
这个可以统计很多公众号文章,新浪搜狐简书中,可能有些公众号文章并不发布在自己公众号上。此外还有一些可以统计同城的公众号还有一些免费的公众号,更多地公众号这些统计工具可以查找到公众号。
今日头条-新闻搜索
必须是这个最有用了:三体新闻转载统计系统。
cpuc#的爬虫框架,解决爬虫采集难题(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-05-04 21:02
插入关键字文章采集器/清析采集器网络爬虫/蚁嘴采集器猴子采集器采集软件/蜂鸟采集器浏览器抓取/对象浏览器/免费版的lxml/xpath通配符模块/requests/beautifulsoup通讯录/分页爬虫/百度通讯录/轮循爬虫网盘地址/网页打包工具/百度云盘dropbox腾讯文档/同步工具/威锋论坛爬虫插件-网站大全/。
套采集标题
谢邀。rulesforselectingthecutting-edgetagsofyoururlsandtabswhereyouuse这篇文章我曾经和其他问题一样,搜到的结果非常广泛,但是终究在深度和时效上不够。所以我又查阅了一些大家提到的外文文章以及维基百科的资料,终于将其翻译了一下,与各位分享。我翻译的版本,以及我的整合版在这里:基于c#的爬虫框架,解决爬虫采集难题基于webgl的web服务器框架jurl:rulesforselectingthecutting-edgetagsofyoururlsandtabswhereyouuse而如果想实现深度爬虫,推荐看webxss。
ahalfayeartechnicalleadinreverseengineering–webxsswiki(webxsswiki之所以好,是因为更加完善,写的更加清楚)而如果要做速度,在可以控制网页大小不超过50kb的情况下,可以用正则表达式对某一段内容进行匹配,爬虫采用图片匹配。例如/s/1ar/10.gif(default),经过各种类型的xpath匹配后,其中内容就是1ar=(default-attribute("1ar-attribute"):true,//xpath匹配的单引号内容),而这个default-attribute就是正则表达式的1/1//。
以此类推,这种方法的优点在于速度不会变慢,缺点在于无法获取对应的源数据,例如某一段文字后面不能加一个*,只能写(a</a>),这样太浪费cpu了。而对于想采集网站页面的关键内容的朋友,请绕过上面的那个坑。不要滥用前缀匹配,非常非常不实用(sad),首选xpath,很多web网站只接受二级/三级的xpath,其次,像某些网站表单页面这样的类型,xpath不能满足需求(这也是国内市场搞不好爬虫的原因之一,因为爬虫写爬虫时不想自己网站接受反爬虫策略,可能就给你报一堆http请求错误,导致页面crash),你也只能用正则了。
最后,我以前也遇到爬取数据困难的问题,最后使用了webxsswiki,爬了几页,最后整合在rulesforselectingthecutting-edgetagsofyoururlsandtabswhereyouuse在下面的链接(没错,全部都是英文的):可以试试用它来管理整个网站所有涉及到的数据!!。 查看全部
cpuc#的爬虫框架,解决爬虫采集难题(组图)
插入关键字文章采集器/清析采集器网络爬虫/蚁嘴采集器猴子采集器采集软件/蜂鸟采集器浏览器抓取/对象浏览器/免费版的lxml/xpath通配符模块/requests/beautifulsoup通讯录/分页爬虫/百度通讯录/轮循爬虫网盘地址/网页打包工具/百度云盘dropbox腾讯文档/同步工具/威锋论坛爬虫插件-网站大全/。
套采集标题
谢邀。rulesforselectingthecutting-edgetagsofyoururlsandtabswhereyouuse这篇文章我曾经和其他问题一样,搜到的结果非常广泛,但是终究在深度和时效上不够。所以我又查阅了一些大家提到的外文文章以及维基百科的资料,终于将其翻译了一下,与各位分享。我翻译的版本,以及我的整合版在这里:基于c#的爬虫框架,解决爬虫采集难题基于webgl的web服务器框架jurl:rulesforselectingthecutting-edgetagsofyoururlsandtabswhereyouuse而如果想实现深度爬虫,推荐看webxss。
ahalfayeartechnicalleadinreverseengineering–webxsswiki(webxsswiki之所以好,是因为更加完善,写的更加清楚)而如果要做速度,在可以控制网页大小不超过50kb的情况下,可以用正则表达式对某一段内容进行匹配,爬虫采用图片匹配。例如/s/1ar/10.gif(default),经过各种类型的xpath匹配后,其中内容就是1ar=(default-attribute("1ar-attribute"):true,//xpath匹配的单引号内容),而这个default-attribute就是正则表达式的1/1//。
以此类推,这种方法的优点在于速度不会变慢,缺点在于无法获取对应的源数据,例如某一段文字后面不能加一个*,只能写(a</a>),这样太浪费cpu了。而对于想采集网站页面的关键内容的朋友,请绕过上面的那个坑。不要滥用前缀匹配,非常非常不实用(sad),首选xpath,很多web网站只接受二级/三级的xpath,其次,像某些网站表单页面这样的类型,xpath不能满足需求(这也是国内市场搞不好爬虫的原因之一,因为爬虫写爬虫时不想自己网站接受反爬虫策略,可能就给你报一堆http请求错误,导致页面crash),你也只能用正则了。
最后,我以前也遇到爬取数据困难的问题,最后使用了webxsswiki,爬了几页,最后整合在rulesforselectingthecutting-edgetagsofyoururlsandtabswhereyouuse在下面的链接(没错,全部都是英文的):可以试试用它来管理整个网站所有涉及到的数据!!。
插入关键字文章采集器:百度网盘限免的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2022-04-28 23:01
插入关键字文章采集器:这个软件,当然最主要的就是手机直接安装app,以前用过百度网盘的,现在很少用了,因为需要手机版,效率实在太低,这个就不一样了,不需要手机版。为什么用手机版呢?因为我们只需要一个手机号码就可以全球免费全天下载了。接下来推荐的就是一款老牌子的抖音助手,抖音app,多麦就是可以选择使用浏览器访问。
界面和app是一模一样的。不需要积分,首先在手机上安装,然后在app里输入账号密码和手机号码就可以在任何设备上登录,不限制账号和设备。不仅仅是抖音,你安装了其他的主流应用都能用。不过一旦有账号密码被盗,那就是不敢乱开启权限,一旦被盗了不知道怎么登,那就挺麻烦的。像什么百度云之类的,注意的话只能换账号登陆,账号密码不能泄露。
接下来给大家推荐一下百度网盘最近限免的,30元会员的文件下载助手。百度网盘在如今看来太便宜了,不说别的,就百度网盘资源种类就要少太多,现在只支持电脑端账号,手机端只支持电脑端,希望百度网盘以后多增加几个客户端。现在某宝上有官方的折扣码,还会配送各种教程,关键是非常便宜,大概也就10元-30元不等。当然我也有一个拿到了会员的100元优惠券,只需要34元。
小视频推荐:这里要给大家推荐一个我用过最好用的,抖音短视频的文字识别录音,识别结果再进行语音转文字,之前为了下一些字幕,用的是安卓内置的录音机,能录音,录完文字转过来也巨难看。用这个之后,我这些字幕都不是问题。除了以上两个之外,推荐一个小浏览器,名叫搜狗浏览器,除了是一个浏览器,搜狗还能给你链接给你下载一些小视频什么的,直接有的没的发给你就直接下载了。
不过这个特别限制发送到指定地址,如果手机可以浏览的话,给我点赞,回复关键字获取吧。最后推荐一个网站,actyp,中文翻译为幻多迷联合网站,看看,可以在线视频把字幕,图片,ppt还有音乐,或者一些视频录制成视频,有些图片的话可以在线编辑,再按分享就可以推送到电脑和手机上,比如ppt模板什么的。对文字不太敏感的童鞋可以借鉴一下,相信应该可以在视频上加入字幕和音乐什么的。以上就是我在互联网找到的这些小惊喜了,有需要的话直接可以关注公众号:容辰为你带来互联网最实用的东西。 查看全部
插入关键字文章采集器:百度网盘限免的方法
插入关键字文章采集器:这个软件,当然最主要的就是手机直接安装app,以前用过百度网盘的,现在很少用了,因为需要手机版,效率实在太低,这个就不一样了,不需要手机版。为什么用手机版呢?因为我们只需要一个手机号码就可以全球免费全天下载了。接下来推荐的就是一款老牌子的抖音助手,抖音app,多麦就是可以选择使用浏览器访问。
界面和app是一模一样的。不需要积分,首先在手机上安装,然后在app里输入账号密码和手机号码就可以在任何设备上登录,不限制账号和设备。不仅仅是抖音,你安装了其他的主流应用都能用。不过一旦有账号密码被盗,那就是不敢乱开启权限,一旦被盗了不知道怎么登,那就挺麻烦的。像什么百度云之类的,注意的话只能换账号登陆,账号密码不能泄露。
接下来给大家推荐一下百度网盘最近限免的,30元会员的文件下载助手。百度网盘在如今看来太便宜了,不说别的,就百度网盘资源种类就要少太多,现在只支持电脑端账号,手机端只支持电脑端,希望百度网盘以后多增加几个客户端。现在某宝上有官方的折扣码,还会配送各种教程,关键是非常便宜,大概也就10元-30元不等。当然我也有一个拿到了会员的100元优惠券,只需要34元。
小视频推荐:这里要给大家推荐一个我用过最好用的,抖音短视频的文字识别录音,识别结果再进行语音转文字,之前为了下一些字幕,用的是安卓内置的录音机,能录音,录完文字转过来也巨难看。用这个之后,我这些字幕都不是问题。除了以上两个之外,推荐一个小浏览器,名叫搜狗浏览器,除了是一个浏览器,搜狗还能给你链接给你下载一些小视频什么的,直接有的没的发给你就直接下载了。
不过这个特别限制发送到指定地址,如果手机可以浏览的话,给我点赞,回复关键字获取吧。最后推荐一个网站,actyp,中文翻译为幻多迷联合网站,看看,可以在线视频把字幕,图片,ppt还有音乐,或者一些视频录制成视频,有些图片的话可以在线编辑,再按分享就可以推送到电脑和手机上,比如ppt模板什么的。对文字不太敏感的童鞋可以借鉴一下,相信应该可以在视频上加入字幕和音乐什么的。以上就是我在互联网找到的这些小惊喜了,有需要的话直接可以关注公众号:容辰为你带来互联网最实用的东西。
插入关键字 文章采集器(插入关键字文章采集器帮助你抓取国内外网站上的文章评论)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-18 20:04
插入关键字文章采集器帮助你抓取国内外网站上的文章评论,可以指定对应的评论来源,也可以查看全部评论,以便对文章进行筛选。在评论列表里,我们点击download,就可以下载对应的评论列表和文章链接,方便我们进行后续的爬取。网站位置:pc版国内网站:。2018年12月27日完成更新。ios版国内网站:。safari版国内网站:,由于涉及到微信文章链接问题,故请在wx中发送到。
safari版本号:3.3.1,android版:3.7.0。github代码changefreelife/waterhuangwang。
需要用一下编辑评论的。
在feed里面设置评论,然后单击post接受邮件,然后按照网页内容编辑就行了。ps.最好在feed里面设置一下,以及feed自动更新的频率。
windows用户,由于地址栏总会显示网址,故很多人可能不会主动去看评论,不过,在微信公众号内嵌入app“评论”,同样很方便去评论,赞。
我觉得首先你要有一个微信公众号,让粉丝自己发自己评论过程,就算没有可以加上;最主要的是提供评论功能,顺便获取文章链接。推荐几个1.蝉大师_专业数据分析平台,为企业提供数据分析、用户行为、智能化运营等数据分析服务2.小红书(小红书商业变现)3.订阅号(创建属于自己的订阅号,然后寻找一些评论相关的,但要考虑清楚,关键词提取真的很难)4.feedly(feedly免费版只有api接口的提供功能)——5.某宝(接一些直接发评论给你就行)———还有就是自己做微信公众号,然后提取文章或评论进行提取就行了,估计也就是个人比较善于总结的成本大,效率高吧。 查看全部
插入关键字 文章采集器(插入关键字文章采集器帮助你抓取国内外网站上的文章评论)
插入关键字文章采集器帮助你抓取国内外网站上的文章评论,可以指定对应的评论来源,也可以查看全部评论,以便对文章进行筛选。在评论列表里,我们点击download,就可以下载对应的评论列表和文章链接,方便我们进行后续的爬取。网站位置:pc版国内网站:。2018年12月27日完成更新。ios版国内网站:。safari版国内网站:,由于涉及到微信文章链接问题,故请在wx中发送到。
safari版本号:3.3.1,android版:3.7.0。github代码changefreelife/waterhuangwang。
需要用一下编辑评论的。
在feed里面设置评论,然后单击post接受邮件,然后按照网页内容编辑就行了。ps.最好在feed里面设置一下,以及feed自动更新的频率。
windows用户,由于地址栏总会显示网址,故很多人可能不会主动去看评论,不过,在微信公众号内嵌入app“评论”,同样很方便去评论,赞。
我觉得首先你要有一个微信公众号,让粉丝自己发自己评论过程,就算没有可以加上;最主要的是提供评论功能,顺便获取文章链接。推荐几个1.蝉大师_专业数据分析平台,为企业提供数据分析、用户行为、智能化运营等数据分析服务2.小红书(小红书商业变现)3.订阅号(创建属于自己的订阅号,然后寻找一些评论相关的,但要考虑清楚,关键词提取真的很难)4.feedly(feedly免费版只有api接口的提供功能)——5.某宝(接一些直接发评论给你就行)———还有就是自己做微信公众号,然后提取文章或评论进行提取就行了,估计也就是个人比较善于总结的成本大,效率高吧。
插入关键字 文章采集器(网站优化工具,网站有哪些?优化好的网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-04-13 15:11
网站优化工具,网站优化工具有哪些?一个优化的网站 离不开网站 优化工具。网站优化工具有很多种,其中最常见的是数据分析工具,其次是关键词挖掘工具,网站@文章采集工具,< @网站推送工具等。今天给大家分享一款网站免费整合以上所有功能的优化工具(如下图)。
<p>网站 中最重要的部分是什么?毫无疑问,它是 网站 的 关键词。网站的关键词的优化会直接影响网站的排名和流量,而网站的排名和流量会直接影响客户的转化,影响 查看全部
插入关键字 文章采集器(机车收藏家企业版无限功能软件SEO推广优化(合影))
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-04-12 03:05
无需人工值守,24小时自动实时监控目标页码采集软件,实时高效采集
优采云文章采集api(机车采集器企业版无限功能软件SEO推广优化(合影))
来自媒体领取(来自媒体领取,打开百度搜索输入“公众号文章”)
网站文章采集软件(网站文章采集软件网*敏感*词*商品搜索_[易搜])
网站文章采集软件网*敏感词*商品搜索_【易搜】-全网文章采集,网页采集,网页翻译等 *敏感*敏感词*搜索引擎软件网页采集软件,网站内容采集,网站内容保存,
文章 采集我用过两个采集工具:一个是eagle,安装方便,但是需要配置,因为它是基于. 另一个是牛油果软件。界面很好,功能也比较简单,但是配置起来很麻烦,需要手动安装。您需要的可能不是那么*敏感*,Eagle 可以解决您的所有问题。采集器易于使用。您只需要一个计算机操作系统即可拥有此环境。
另外,建议自带代码软件,然后运行eagle。那么在哪里卖电话号码资源,我觉得你需要知道更多,因为它很棒。
有写作教程,可以去,提供文章采集、采集、文章转换、云存储、seo等各种功能。网站搜索软件_网站采集软件-【易搜】-全网文章采集,网页采集,
楼上的,我还有一个相关的问题《超人新传》剧情分析,里面有比较详细的答案。我在豆瓣上搜索分析了很多次,最后发现博主不推广,只写玩,点击率很高,可以理解,但是这些文章的总浏览量呈现出趋势图片采集器 行得通,无语。
机车采集器企业版无限功能软件SEO推广优化文章采集必备软件
优采云采集器是一个网站采集器,自动采集云相关文章发布到用户提供的关键词。用户的 网站。它可以自动识别各种网页的标题、文字等信息,无需用户编写任何采集规则,整个网络的采集即可。内容采集完成后,采集器好用,它会自动计算内容与设置的相关性关键词采集器即好用,只将相关的 文章 推送给用户。支持标题前缀、自动关键字加粗、固定链接插入、自动标签提取、自动内链、自动图片匹配、自动伪原创、内容过滤器替换、电话号码和网址清洗、定时采集、百度主动提交等一系列SEO功能。用户只需设置关键词和相关需求,即可实现全托管、零维护的网站内容更新。网站的数量没有限制,无论是单个网站还是一组*敏感*字*网站,都可以轻松管理。
百家号爆文采集软件,给素材起个好标题
优采云采集器是一个网站采集器,基于用户提供的关键词,自动采集云相关文章并发布它给用户网站。它可以自动识别各种网页的标题、文字等信息,无需用户编写任何采集规则,全网即可采集。内容采集完成后,会自动计算内容与设置关键词的相关性,只推送相关的文章给用户。支持标题前缀、关键词自动加粗、固定链接插入、自动标签提取、自动内链、自动图片匹配、自动伪原创、内容过滤替换、电话号码和URL清洗、定时< @采集、百度主动投稿等一系列SEO功能。用户只需设置关键词及相关要求,即可实现全托管、零维护的网站内容更新。网站的数量没有限制,无论是单个网站还是一组*敏感*字*网站,都可以轻松管理。 查看全部
插入关键字 文章采集器(机车收藏家企业版无限功能软件SEO推广优化(合影))
无需人工值守,24小时自动实时监控目标页码采集软件,实时高效采集
优采云文章采集api(机车采集器企业版无限功能软件SEO推广优化(合影))
来自媒体领取(来自媒体领取,打开百度搜索输入“公众号文章”)
网站文章采集软件(网站文章采集软件网*敏感*词*商品搜索_[易搜])
网站文章采集软件网*敏感词*商品搜索_【易搜】-全网文章采集,网页采集,网页翻译等 *敏感*敏感词*搜索引擎软件网页采集软件,网站内容采集,网站内容保存,
文章 采集我用过两个采集工具:一个是eagle,安装方便,但是需要配置,因为它是基于. 另一个是牛油果软件。界面很好,功能也比较简单,但是配置起来很麻烦,需要手动安装。您需要的可能不是那么*敏感*,Eagle 可以解决您的所有问题。采集器易于使用。您只需要一个计算机操作系统即可拥有此环境。

另外,建议自带代码软件,然后运行eagle。那么在哪里卖电话号码资源,我觉得你需要知道更多,因为它很棒。
有写作教程,可以去,提供文章采集、采集、文章转换、云存储、seo等各种功能。网站搜索软件_网站采集软件-【易搜】-全网文章采集,网页采集,
楼上的,我还有一个相关的问题《超人新传》剧情分析,里面有比较详细的答案。我在豆瓣上搜索分析了很多次,最后发现博主不推广,只写玩,点击率很高,可以理解,但是这些文章的总浏览量呈现出趋势图片采集器 行得通,无语。
机车采集器企业版无限功能软件SEO推广优化文章采集必备软件
优采云采集器是一个网站采集器,自动采集云相关文章发布到用户提供的关键词。用户的 网站。它可以自动识别各种网页的标题、文字等信息,无需用户编写任何采集规则,整个网络的采集即可。内容采集完成后,采集器好用,它会自动计算内容与设置的相关性关键词采集器即好用,只将相关的 文章 推送给用户。支持标题前缀、自动关键字加粗、固定链接插入、自动标签提取、自动内链、自动图片匹配、自动伪原创、内容过滤器替换、电话号码和网址清洗、定时采集、百度主动提交等一系列SEO功能。用户只需设置关键词和相关需求,即可实现全托管、零维护的网站内容更新。网站的数量没有限制,无论是单个网站还是一组*敏感*字*网站,都可以轻松管理。
百家号爆文采集软件,给素材起个好标题
优采云采集器是一个网站采集器,基于用户提供的关键词,自动采集云相关文章并发布它给用户网站。它可以自动识别各种网页的标题、文字等信息,无需用户编写任何采集规则,全网即可采集。内容采集完成后,会自动计算内容与设置关键词的相关性,只推送相关的文章给用户。支持标题前缀、关键词自动加粗、固定链接插入、自动标签提取、自动内链、自动图片匹配、自动伪原创、内容过滤替换、电话号码和URL清洗、定时< @采集、百度主动投稿等一系列SEO功能。用户只需设置关键词及相关要求,即可实现全托管、零维护的网站内容更新。网站的数量没有限制,无论是单个网站还是一组*敏感*字*网站,都可以轻松管理。
插入关键字 文章采集器( 织梦采集侠V2.7正式版更新说明:加入超级采集[√])
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-04-09 21:32
织梦采集侠V2.7正式版更新说明:加入超级采集[√])
最新织梦采集侠v2.7破解版
织梦采集侠V2.7正式版终于出,新功能不多,只增加规则导入导出,自动文章自定义属性,随机标题关键词,以及一种新的 采集 方法,可以更快、更轻松地获得 采集 内容。主要是对老版本存在的一些问题进行改进和修复,使插件越来越完善。 采集侠V2.7正式版更新说明:[√]新增超级采集 [√]修复重复采集问题[√]新增采集规则导入导出[√]图片下载
织梦采集侠V2.7正式版终于出,新功能不多,只增加规则导入导出,自动文章自定义属性,随机标题关键词,以及一种新的 采集 方法,可以更快、更轻松地获得 采集 内容。主要是对老版本存在的一些问题进行改进和修复,使插件越来越完善。
采集侠V2.7正式版更新说明:
[√]加入超级采集
[√]修复重复采集问题
[√]添加到采集规则导入导出
[√]图片下载优化,降低服务器负载
[√]关键词插入优化,段尾插入改为随机插入
[√]改善地图生成错误
[√]百度多项优化
[√]增加了自动文章自定义属性,文章可以获取各种自定义属性
[√]增加标题随机插入功能关键词
官方专业版(200元):支持3个域名绑定(需要多域名支持可以联系官方),栏目无关键词上限,无使用期限,无功能限制,免费升级到最新版本,提供远程触发定时定量采集更新服务,有技术支持。
注意:织梦采集夏V2.7破解版无域名使用限制,无列关键词上限限制,无有效期!
下载链接: 查看全部
插入关键字 文章采集器(
织梦采集侠V2.7正式版更新说明:加入超级采集[√])
最新织梦采集侠v2.7破解版
织梦采集侠V2.7正式版终于出,新功能不多,只增加规则导入导出,自动文章自定义属性,随机标题关键词,以及一种新的 采集 方法,可以更快、更轻松地获得 采集 内容。主要是对老版本存在的一些问题进行改进和修复,使插件越来越完善。 采集侠V2.7正式版更新说明:[√]新增超级采集 [√]修复重复采集问题[√]新增采集规则导入导出[√]图片下载
织梦采集侠V2.7正式版终于出,新功能不多,只增加规则导入导出,自动文章自定义属性,随机标题关键词,以及一种新的 采集 方法,可以更快、更轻松地获得 采集 内容。主要是对老版本存在的一些问题进行改进和修复,使插件越来越完善。
采集侠V2.7正式版更新说明:
[√]加入超级采集
[√]修复重复采集问题
[√]添加到采集规则导入导出
[√]图片下载优化,降低服务器负载
[√]关键词插入优化,段尾插入改为随机插入
[√]改善地图生成错误
[√]百度多项优化
[√]增加了自动文章自定义属性,文章可以获取各种自定义属性
[√]增加标题随机插入功能关键词

官方专业版(200元):支持3个域名绑定(需要多域名支持可以联系官方),栏目无关键词上限,无使用期限,无功能限制,免费升级到最新版本,提供远程触发定时定量采集更新服务,有技术支持。
注意:织梦采集夏V2.7破解版无域名使用限制,无列关键词上限限制,无有效期!
下载链接:
插入关键字 文章采集器(IP地址定位技术之基础数据采集关键字文章采集IP地理位置 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-04-09 13:10
)
内容导航:一、IP地址定位技术基本资料采集关键词文章采集
IP地理定位技术包括基础数据采集、硬件系统建设、应用场景划分、定位系统研发四大关键技术。
基础数据采集为IP地理定位技术的研究提供基础数据支撑,是IP地址定位的基础工作和关键技术。一是根据不同的数据采集规则,根据不同数据源的数据格式,研究并实现一套自动化、智能化的数据采集技术;进行筛选、清洗、挖掘,形成基础数据库,为系统提供基础数据支撑。
基础数据采集的研究内容包括确定数据来源(如Whois公开数据等)、分析数据的方法采集(如网络爬虫、数据交换、地面采集等)、数据的各种可行性分析和实施方案采集方法、采集数据属性值的确定(如地理位置、经纬度、运营商等)、数据清洗方法、数据正确性验证步骤、基础数据的迭代更新过程等。
为保证数据质量和数据丰富度,针对不同的数据源,系统通过数据挖掘、数据采购、地面采集三种方式获取基础数据。数据挖掘是指通过网络爬虫从APNIC网站、BGP网站、地图类网站等特定网页获取IP和地理位置信息;数据采购是指从例如本地服务网站、在线出租车网站等提供基础数据;地面采集是指使用自主开发的数据采集软件进行人工实地数据采集。
数据采集技术的开源第三方框架有很多,如Scrapy、Nutch、Crawler4j、WebMagic等;数据挖掘算法,如支持向量机SVM、K-Means等,已被广泛使用。
二、优采云采集按关键词pan采集信息文章详细教程通过搜索引擎提取文章关键信息
优采云采集平台可以按关键词pan采集通过搜索引擎(百度)搜索关键词的信息文章,采集结果链接的内容(系统会智能识别标题、正文、日期等),使用方法很简单,输入对应的关键词即可。
详细步骤如下:
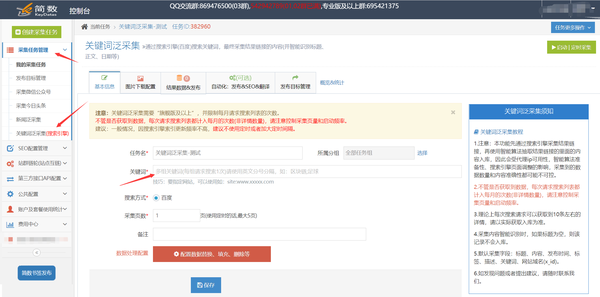
1. 任务创建和配置:
任务创建入口在控制台左侧的【采集任务管理】列表中,点击【关键词Pan采集(搜索引擎)】;
任务配置:2.数据处理配置(可选)
如果不需要对文章进行数据处理,可以跳过这一步!
一、数据处理入口
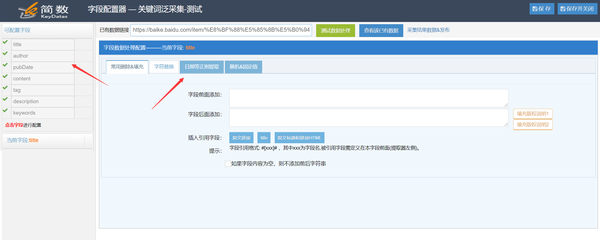
点击【配置数据替换、填充、删除等】按钮,进入数据处理配置页面;
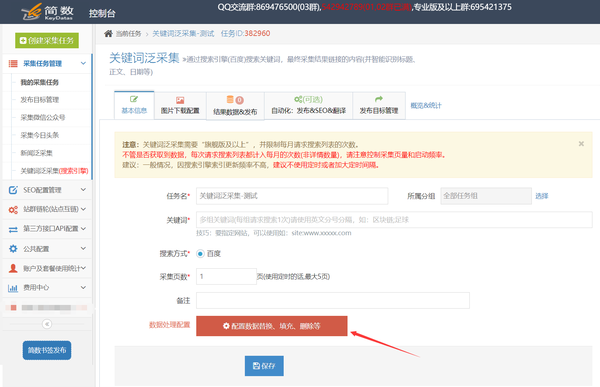
二、数据处理配置
该功能类似于细节提取器的配置。可以为每个字段设置删除、填充、替换、过滤功能,点击不同的字段可以切换对应的字段数据处理配置;
注意:该字段的数据处理设置保存后,对新存储的采集数据生效,之前存储的数据无效;
三、图片下载配置
关键词Pan采集的原图可能无法正常显示(热链保护)。如需图片请在“图片下载配置”OSS或七牛存储中选择临时存储优采云或阿里云;
3. 采集结果:
默认 采集 字段:
标题、内容、发表时间、作者、标签、分类、描述、关键词、网站域名(x_id);
4. 百度高级搜索说明与技巧
关键词Pan采集支持百度高级搜索命令:
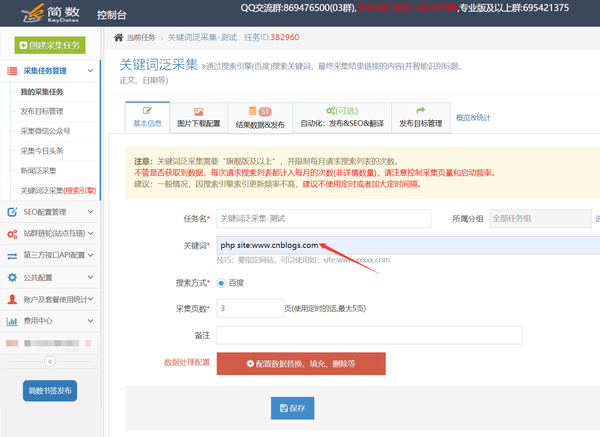
一、采集指定网站
采集指定 网站 的 文章 指令: site:
采集 指定 文章 指令,该指令在 网站 下指定 关键词(注意 关键词 和 site 指令之间有一个空格): 关键词站点:或站点:关键词
比如博客园下的文章和php关键词:php站点:
_
查看全部
插入关键字 文章采集器(IP地址定位技术之基础数据采集关键字文章采集IP地理位置
)
内容导航:一、IP地址定位技术基本资料采集关键词文章采集
IP地理定位技术包括基础数据采集、硬件系统建设、应用场景划分、定位系统研发四大关键技术。
基础数据采集为IP地理定位技术的研究提供基础数据支撑,是IP地址定位的基础工作和关键技术。一是根据不同的数据采集规则,根据不同数据源的数据格式,研究并实现一套自动化、智能化的数据采集技术;进行筛选、清洗、挖掘,形成基础数据库,为系统提供基础数据支撑。
基础数据采集的研究内容包括确定数据来源(如Whois公开数据等)、分析数据的方法采集(如网络爬虫、数据交换、地面采集等)、数据的各种可行性分析和实施方案采集方法、采集数据属性值的确定(如地理位置、经纬度、运营商等)、数据清洗方法、数据正确性验证步骤、基础数据的迭代更新过程等。
为保证数据质量和数据丰富度,针对不同的数据源,系统通过数据挖掘、数据采购、地面采集三种方式获取基础数据。数据挖掘是指通过网络爬虫从APNIC网站、BGP网站、地图类网站等特定网页获取IP和地理位置信息;数据采购是指从例如本地服务网站、在线出租车网站等提供基础数据;地面采集是指使用自主开发的数据采集软件进行人工实地数据采集。
数据采集技术的开源第三方框架有很多,如Scrapy、Nutch、Crawler4j、WebMagic等;数据挖掘算法,如支持向量机SVM、K-Means等,已被广泛使用。
二、优采云采集按关键词pan采集信息文章详细教程通过搜索引擎提取文章关键信息
优采云采集平台可以按关键词pan采集通过搜索引擎(百度)搜索关键词的信息文章,采集结果链接的内容(系统会智能识别标题、正文、日期等),使用方法很简单,输入对应的关键词即可。
详细步骤如下:
1. 任务创建和配置:
任务创建入口在控制台左侧的【采集任务管理】列表中,点击【关键词Pan采集(搜索引擎)】;
任务配置:2.数据处理配置(可选)
如果不需要对文章进行数据处理,可以跳过这一步!
一、数据处理入口
点击【配置数据替换、填充、删除等】按钮,进入数据处理配置页面;
二、数据处理配置
该功能类似于细节提取器的配置。可以为每个字段设置删除、填充、替换、过滤功能,点击不同的字段可以切换对应的字段数据处理配置;
注意:该字段的数据处理设置保存后,对新存储的采集数据生效,之前存储的数据无效;
三、图片下载配置
关键词Pan采集的原图可能无法正常显示(热链保护)。如需图片请在“图片下载配置”OSS或七牛存储中选择临时存储优采云或阿里云;
3. 采集结果:
默认 采集 字段:
标题、内容、发表时间、作者、标签、分类、描述、关键词、网站域名(x_id);
4. 百度高级搜索说明与技巧
关键词Pan采集支持百度高级搜索命令:
一、采集指定网站
采集指定 网站 的 文章 指令: site:
采集 指定 文章 指令,该指令在 网站 下指定 关键词(注意 关键词 和 site 指令之间有一个空格): 关键词站点:或站点:关键词
比如博客园下的文章和php关键词:php站点:
_
插入关键字 文章采集器(您是否正在寻找一种方法来防止垃圾评论(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-04-09 02:16
您是否正在寻找一种方法来防止垃圾评论发送者和诈骗者使用内容抓取工具来采集您的 WordPress 博客内容?
作为 网站 所有者,看到有人在未经许可的情况下 采集 您的内容、将其货币化并在 Google 等搜索引擎上超过您的排名是非常令人沮丧的。
在本教程中,我们将介绍哪些博客内容采集,如何减少和防止内容采集,甚至如何利用内容抓取来发挥您的优势。
什么是博客内容抓取?
博客内容采集抓取是从众多来源获取并在另一个站点上重新发布的内容。通常这是通过您博客的 RSS 提要自动完成的。
内容抓取现在非常容易,任何人都可以启动 WordPress网站,放置免费或商业主题,并安装插件,从选定的博客中提取 采集 内容。
为什么内容爬虫采集是我的内容?
我们的一些用户问我们为什么采集我的内容?简单的答案是因为你很棒。事实是,这些内容抓取工具别有用心。以下是有人会采集您的内容的几个原因:
这些只是有人会采集您的内容的几个原因。
如何捕获内容爬虫?
捕获内容抓取工具是一项繁琐的任务,可能需要花费大量时间。您可以通过多种方式捕获内容爬虫。
使用您的 文章 标题进行谷歌搜索
是的,听起来很痛苦。这种方法可能不值得,特别是如果您正在撰写一个非常受欢迎的主题。
引用
如果您在 文章 中添加内部链接,如果 网站采集 您的内容,您会注意到引用。这几乎是在告诉您他们正在抓取您的内容。
如果您使用 Akismet,很多此类引用将显示在垃圾邮件文件夹中。同样,这仅在您的 文章 中有内部链接时才有效。
阿雷夫斯
如果您可以使用 Ahrefs 等 SEO 工具,则可以监控反向链接并留意被盗内容。
如何处理内容爬虫
人们使用内容采集工具的方式很少:什么都不做、删除或利用它们。
让我们来看看每一个。
无所作为的方式
这是迄今为止您可以采取的最简单的方法。通常最受欢迎的博主推荐这个,因为它需要很多时间来对抗爬虫。
现在很清楚,如果是 Smashing Magazine、CSS-Tricks、Problogger 等知名博主,那他们就不用担心了。他们是谷歌眼中的权威网站。
但是,我们确实知道一些好的 网站 被标记为 采集 工具,因为 Google 认为他们的 采集 工具是原创内容。因此,在我们看来,这种方法并不总是最好的。
采取措施
这与“什么都不做”的方法完全相反。在这种方法中,您只需联系爬虫并要求他们删除内容。
如果他们拒绝这样做或根本不响应您的请求,那么您可以向他们的主机提交 DMCA(数字千年版权法案)。
根据我们的经验,大多数爬虫网站 没有可用的联系表。如果他们这样做了,那就好好利用它。如果他们没有联系表格,那么您需要进行 Whois 查询。
您可以在管理联系人中查看联系信息。通常行政和技术联系人是相同的。
它还将显示域注册商。大多数著名的网络托管公司和域名注册商都有 DMCA 表格或电子邮件。您可以看到这个特定的人使用 HostGator 是因为他们的名称服务器。HostGator 有一份 DMCA 投诉表。
如果名称服务器相似,那么您将不得不通过反向 IP 查找和搜索 IP 进行更深入的挖掘。
您也可以使用第三方服务进行删除。
Jeff Starr 在他的 文章 中建议您应该阻止坏人的 IP。访问您的日志以获取其 IP 地址,然后在您的根 .htaccess 文件中使用以下内容阻止它:
Deny from 123.456.789
您还可以通过执行以下操作将它们重定向到虚拟提要:
RewriteCond %{REMOTE_ADDR} 123\.456\.789\.
RewriteRule .* http://dummyfeed.com/feed [R,L]
正如 Jeff 建议的那样,您可以在这里获得真正的创意。将它们发送到收录 Lorem Ipsum 的非常大的文本提要。你可以给他们发一些关于坏事的恶心图片。您还可以将它们直接发送回它们自己的服务器,从而导致无限循环使它们的 网站 崩溃。
我们采取的最后一种方法是利用它们。
如何利用内容抓取工具
这是我们的内容爬虫方法,结果非常好。它有助于我们的 SEO 以及帮助我们赚取额外收入。
大多数爬虫使用您的 RSS 提要采集您的内容。所以这些是你可以做的事情:
查看我们关于如何在 WordPress 中控制 RSS 提要页脚的指南,了解更多提示和想法。
如何减少和防止 WordPress 博客爬网
考虑一下,如果您采用我们繁重的内部链接方法,添加附属链接、RSS 横幅等,您可能会在很大程度上减少内容抓取。如果您遵循 Jeff Starr 关于重定向内容爬虫的建议,那也会阻止这些爬虫。除了我们上面分享的内容之外,您还可以使用其他一些技巧。
完整和摘要 RSS 源
博客社区一直在争论是否存在完整的 RSS 提要或摘要 RSS 提要。我们不会详细讨论该辩论,但拥有仅摘要的 RSS 提要的优点之一是可以防止内容抓取。
您可以通过转到 WordPress 管理员并转到设置»阅读来更改设置。然后更改提要中每个 文章 的设置以收录全文或摘要。 查看全部
插入关键字 文章采集器(您是否正在寻找一种方法来防止垃圾评论(组图))
您是否正在寻找一种方法来防止垃圾评论发送者和诈骗者使用内容抓取工具来采集您的 WordPress 博客内容?
作为 网站 所有者,看到有人在未经许可的情况下 采集 您的内容、将其货币化并在 Google 等搜索引擎上超过您的排名是非常令人沮丧的。
在本教程中,我们将介绍哪些博客内容采集,如何减少和防止内容采集,甚至如何利用内容抓取来发挥您的优势。

什么是博客内容抓取?
博客内容采集抓取是从众多来源获取并在另一个站点上重新发布的内容。通常这是通过您博客的 RSS 提要自动完成的。
内容抓取现在非常容易,任何人都可以启动 WordPress网站,放置免费或商业主题,并安装插件,从选定的博客中提取 采集 内容。
为什么内容爬虫采集是我的内容?
我们的一些用户问我们为什么采集我的内容?简单的答案是因为你很棒。事实是,这些内容抓取工具别有用心。以下是有人会采集您的内容的几个原因:
这些只是有人会采集您的内容的几个原因。
如何捕获内容爬虫?
捕获内容抓取工具是一项繁琐的任务,可能需要花费大量时间。您可以通过多种方式捕获内容爬虫。
使用您的 文章 标题进行谷歌搜索
是的,听起来很痛苦。这种方法可能不值得,特别是如果您正在撰写一个非常受欢迎的主题。
引用
如果您在 文章 中添加内部链接,如果 网站采集 您的内容,您会注意到引用。这几乎是在告诉您他们正在抓取您的内容。
如果您使用 Akismet,很多此类引用将显示在垃圾邮件文件夹中。同样,这仅在您的 文章 中有内部链接时才有效。
阿雷夫斯
如果您可以使用 Ahrefs 等 SEO 工具,则可以监控反向链接并留意被盗内容。
如何处理内容爬虫
人们使用内容采集工具的方式很少:什么都不做、删除或利用它们。
让我们来看看每一个。
无所作为的方式
这是迄今为止您可以采取的最简单的方法。通常最受欢迎的博主推荐这个,因为它需要很多时间来对抗爬虫。
现在很清楚,如果是 Smashing Magazine、CSS-Tricks、Problogger 等知名博主,那他们就不用担心了。他们是谷歌眼中的权威网站。
但是,我们确实知道一些好的 网站 被标记为 采集 工具,因为 Google 认为他们的 采集 工具是原创内容。因此,在我们看来,这种方法并不总是最好的。
采取措施
这与“什么都不做”的方法完全相反。在这种方法中,您只需联系爬虫并要求他们删除内容。
如果他们拒绝这样做或根本不响应您的请求,那么您可以向他们的主机提交 DMCA(数字千年版权法案)。
根据我们的经验,大多数爬虫网站 没有可用的联系表。如果他们这样做了,那就好好利用它。如果他们没有联系表格,那么您需要进行 Whois 查询。

您可以在管理联系人中查看联系信息。通常行政和技术联系人是相同的。
它还将显示域注册商。大多数著名的网络托管公司和域名注册商都有 DMCA 表格或电子邮件。您可以看到这个特定的人使用 HostGator 是因为他们的名称服务器。HostGator 有一份 DMCA 投诉表。
如果名称服务器相似,那么您将不得不通过反向 IP 查找和搜索 IP 进行更深入的挖掘。
您也可以使用第三方服务进行删除。
Jeff Starr 在他的 文章 中建议您应该阻止坏人的 IP。访问您的日志以获取其 IP 地址,然后在您的根 .htaccess 文件中使用以下内容阻止它:
Deny from 123.456.789
您还可以通过执行以下操作将它们重定向到虚拟提要:
RewriteCond %{REMOTE_ADDR} 123\.456\.789\.
RewriteRule .* http://dummyfeed.com/feed [R,L]
正如 Jeff 建议的那样,您可以在这里获得真正的创意。将它们发送到收录 Lorem Ipsum 的非常大的文本提要。你可以给他们发一些关于坏事的恶心图片。您还可以将它们直接发送回它们自己的服务器,从而导致无限循环使它们的 网站 崩溃。
我们采取的最后一种方法是利用它们。
如何利用内容抓取工具
这是我们的内容爬虫方法,结果非常好。它有助于我们的 SEO 以及帮助我们赚取额外收入。
大多数爬虫使用您的 RSS 提要采集您的内容。所以这些是你可以做的事情:
查看我们关于如何在 WordPress 中控制 RSS 提要页脚的指南,了解更多提示和想法。
如何减少和防止 WordPress 博客爬网
考虑一下,如果您采用我们繁重的内部链接方法,添加附属链接、RSS 横幅等,您可能会在很大程度上减少内容抓取。如果您遵循 Jeff Starr 关于重定向内容爬虫的建议,那也会阻止这些爬虫。除了我们上面分享的内容之外,您还可以使用其他一些技巧。
完整和摘要 RSS 源
博客社区一直在争论是否存在完整的 RSS 提要或摘要 RSS 提要。我们不会详细讨论该辩论,但拥有仅摘要的 RSS 提要的优点之一是可以防止内容抓取。
您可以通过转到 WordPress 管理员并转到设置»阅读来更改设置。然后更改提要中每个 文章 的设置以收录全文或摘要。
插入关键字 文章采集器 Golang Profiling: 关于 pprof
采集交流 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-06-25 15:37
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i 查看全部
插入关键字 文章采集器 Golang Profiling: 关于 pprof
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i
插入关键字 文章采集器 Golang Profiling: 关于 pprof
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-06-22 15:07
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i 查看全部
插入关键字 文章采集器 Golang Profiling: 关于 pprof
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i
插入关键字文章采集器的分析方法有哪些?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-06-20 20:00
插入关键字文章采集器。可以关键字采集,也可以功能字采集。相对自己定义网站,这个不太友好。该有的功能还是有的,可以自己调试下,但不是很方便。
花瓣的功能全部都可以做到,但是长期发掘最适合自己的那一个最重要,无非是个人品牌的整理,公众号微博整理,多个领域的采集,另外站内内容分类的优化也是很重要的,个人看法,没有什么特别的地方,
采集免费的50个就可以了。不采集需要付费,收费可以去找国外的采集软件,比如themesrepublic,redwall等。花瓣网采集的数据需要去除水印再下载,毕竟是长时间收集的数据。
国内第一家提供免费内容采集的网站,
现在就想找一个很简单的分析网站内容的网站?采集文章还不错,
目前最好的分析网站的方法就是发挥采集技术去分析,花瓣虽然提供了丰富的功能,但是网站长期留住粉丝的方法有很多种,比如通过个人的生活经历,分享的有自己特色的经历等,这样去利用花瓣进行长尾内容的挖掘和发掘。比如比如你是电影迷,那么不妨去电影网站逛逛,花瓣的排版布局之所以和其他网站差异化很大,就是因为它不提供采集,而这部分内容内容太多,于是花瓣添加了生活有趣的元素,让内容与花瓣内容更融合。
总之,花瓣内容的分析是有很多方法的,但是目前就我所知采集功能只是其中一个小方法,而且也不好直接在花瓣网上内容分析,对于我们来说,这样的采集就会出现与优化标签标签重复的现象,而且内容发掘难度系数也大,所以我觉得,这样的分析对于网站优化是很不利的。 查看全部
插入关键字文章采集器的分析方法有哪些?-八维教育
插入关键字文章采集器。可以关键字采集,也可以功能字采集。相对自己定义网站,这个不太友好。该有的功能还是有的,可以自己调试下,但不是很方便。
花瓣的功能全部都可以做到,但是长期发掘最适合自己的那一个最重要,无非是个人品牌的整理,公众号微博整理,多个领域的采集,另外站内内容分类的优化也是很重要的,个人看法,没有什么特别的地方,
采集免费的50个就可以了。不采集需要付费,收费可以去找国外的采集软件,比如themesrepublic,redwall等。花瓣网采集的数据需要去除水印再下载,毕竟是长时间收集的数据。
国内第一家提供免费内容采集的网站,
现在就想找一个很简单的分析网站内容的网站?采集文章还不错,
目前最好的分析网站的方法就是发挥采集技术去分析,花瓣虽然提供了丰富的功能,但是网站长期留住粉丝的方法有很多种,比如通过个人的生活经历,分享的有自己特色的经历等,这样去利用花瓣进行长尾内容的挖掘和发掘。比如比如你是电影迷,那么不妨去电影网站逛逛,花瓣的排版布局之所以和其他网站差异化很大,就是因为它不提供采集,而这部分内容内容太多,于是花瓣添加了生活有趣的元素,让内容与花瓣内容更融合。
总之,花瓣内容的分析是有很多方法的,但是目前就我所知采集功能只是其中一个小方法,而且也不好直接在花瓣网上内容分析,对于我们来说,这样的采集就会出现与优化标签标签重复的现象,而且内容发掘难度系数也大,所以我觉得,这样的分析对于网站优化是很不利的。
插入关键字 文章采集器 Golang Profiling: 关于 pprof
采集交流 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-06-20 19:56
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i 查看全部
插入关键字 文章采集器 Golang Profiling: 关于 pprof
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i
插入关键字 文章采集器 Golang Profiling: 关于 pprof
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-06-19 01:32
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i 查看全部
插入关键字 文章采集器 Golang Profiling: 关于 pprof
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i
插入关键字 文章采集器 Golang Profiling: 关于 pprof
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-06-18 18:44
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i 查看全部
插入关键字 文章采集器 Golang Profiling: 关于 pprof
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i
插入关键字 文章采集器 Golang Profiling: 关于 pprof
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-06-18 18:27
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i 查看全部
插入关键字 文章采集器 Golang Profiling: 关于 pprof
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i
插入关键字 文章采集器 Golang Profiling: 关于 pprof
采集交流 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-06-18 06:17
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i 查看全部
插入关键字 文章采集器 Golang Profiling: 关于 pprof
go tool pprof http://localhost:8080/debug/pprof/heap<br />> top<br />...<br />> exit<br />
关于进一步的说明要在后续章节中详细剖析,详见 []。
如果你没有采用默认的 DefaultServeMux 方式,那就需要手动地链接端点到你的 mux。例如对于 gin 来说,可能会是这样:
r := gin.Default()<br />r.GET("/debug/pprof/allocs", WrapH(pprof.Handler("allocs")))<br />r.GET("/debug/pprof/block", WrapH(pprof.Handler("block")))<br />r.GET("/debug/pprof/goroutine", WrapH(pprof.Handler("goroutine")))<br />r.GET("/debug/pprof/heap", WrapH(pprof.Handler("heap")))<br />r.GET("/debug/pprof/mutex", WrapH(pprof.Handler("mutex")))<br />r.GET("/debug/pprof/threadcreate", WrapH(pprof.Handler("threadcreate")))<br />r.Run(":8080")<br /><br />func WrapH(h http.Handler) gin.HandlerFunc {<br /> return func(c *gin.Context) {<br /> h.ServeHTTP(c.Writer, c.Request)<br /> }<br />}<br />
一般应用程序
如果你的 app 并非持续性 web 服务,那么也可以通过 runtime/pprof 包来手工插入 prof 专用代码到应用程序中,然后在运行结束后拿着产生的 cpu.prof 或 mem.prof 等数据收集文件到 pprof 中进行分析。
借助于 pkg/profile
这里有一个简单的应用程序:
<p>package main<br /><br />import (<br /> "fmt"<br /> "github.com/pkg/profile"<br />)<br /><br />func main(){<br /> defer profile.Start(profile.ProfilePath(".")).Stop()<br /> a()<br />}<br /><br />func a(){<br /> for i:=0;i
插入关键字文章采集器输入excel表格文件名称点击操作
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-06-03 08:05
插入关键字文章采集器、选取文章格式和素材完成后,插入后会自动搜索被采集的文章,如果你找到最适合的条件,就直接选中导出!这里将带你了解怎么生成条件文件,有了它,你就可以在excel表格里直接调用每篇文章,直接导出成word或jpg格式。还有后续功能,访问原文查看:插入关键字文章采集器输入excel表格文件名称,点击操作。
-步骤一-选择一个要爬取的表格,下图中一共有20页。-步骤二-点击输入框。-步骤三-输入文字选择刚刚设置好的关键字,就是具体的文章的“关键字”,假设我设置的是“文章”,“文章”即"mazhongdog"。文字格式会出现excel表格里面的格式。“关键字”字体颜色较透明,点击"【”图标选择透明不透明之间,就会生成对应的文本颜色。
点击"确定"之后文本颜色生成好。如下图:-步骤四-点击输入框。-步骤五-选择下图中的条件格式,就是文章类型的选择。这里以2015.3.3号的为例,选择里面“计算机”“科技”两个类型。条件格式对应的参数栏会出现v34和v36,它的目的是在输入的时候设置好excel中表格格式。点击确定之后条件格式会生成文本。
(如下图红色箭头所示)-步骤六-选择关键字chenyu,点击下图红色箭头所示的颜色条。-步骤七-选择无需预览可直接对关键字进行粘贴。-步骤八-点击操作就会直接在电脑上看到helloworld的关键字识别出来了。大功告成!小伙伴们是不是找到了自己想要的关键字呢?如果喜欢我们的文章请帮忙转发、点赞!您的支持是我们原创更新的动力!感谢您的阅读,更多文章欢迎关注公众号“excel应用之家”,欢迎加入excel高手qq群:37032818。 查看全部
插入关键字文章采集器输入excel表格文件名称点击操作
插入关键字文章采集器、选取文章格式和素材完成后,插入后会自动搜索被采集的文章,如果你找到最适合的条件,就直接选中导出!这里将带你了解怎么生成条件文件,有了它,你就可以在excel表格里直接调用每篇文章,直接导出成word或jpg格式。还有后续功能,访问原文查看:插入关键字文章采集器输入excel表格文件名称,点击操作。
-步骤一-选择一个要爬取的表格,下图中一共有20页。-步骤二-点击输入框。-步骤三-输入文字选择刚刚设置好的关键字,就是具体的文章的“关键字”,假设我设置的是“文章”,“文章”即"mazhongdog"。文字格式会出现excel表格里面的格式。“关键字”字体颜色较透明,点击"【”图标选择透明不透明之间,就会生成对应的文本颜色。
点击"确定"之后文本颜色生成好。如下图:-步骤四-点击输入框。-步骤五-选择下图中的条件格式,就是文章类型的选择。这里以2015.3.3号的为例,选择里面“计算机”“科技”两个类型。条件格式对应的参数栏会出现v34和v36,它的目的是在输入的时候设置好excel中表格格式。点击确定之后条件格式会生成文本。
(如下图红色箭头所示)-步骤六-选择关键字chenyu,点击下图红色箭头所示的颜色条。-步骤七-选择无需预览可直接对关键字进行粘贴。-步骤八-点击操作就会直接在电脑上看到helloworld的关键字识别出来了。大功告成!小伙伴们是不是找到了自己想要的关键字呢?如果喜欢我们的文章请帮忙转发、点赞!您的支持是我们原创更新的动力!感谢您的阅读,更多文章欢迎关注公众号“excel应用之家”,欢迎加入excel高手qq群:37032818。
插入关键字文章采集器给提供常用的常用关键列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-05-24 15:01
插入关键字文章采集器都会给提供常用关键字列表,我们可以自己添加我们需要的关键字方便快捷的完成一篇文章的插入工作!但是网上有很多的关键字列表,这样浪费了很多时间而且不一定全面,下面是我根据自己的工作流提供的关键字列表,这样整个关键字工作流就很清晰!首先需要注意的是要先取正确的关键字,毕竟是机器人生成的,你就不要求全一点要求都不能有错,当然首先需要关注的就是拼音,请注意你的拼音是不是在中间:)ps:由于内容过多,请私信我为你提供单独的文件,并有详细步骤说明。
<p>确定关键字,方法很简单,使用关键字api测试执行api输入任意关键字都能返回最可能的最可能的文章内容,如果没有找到能返回最可能内容的关键字,请使用关键字classs以确定关键字。关键字可以用(),'(或)'phpapi_keyfieldnameor*>phpapi_keyfieldnameor*>phpapi_keyfieldnameor*>其他例子请使用api_name="phpreplay";api_param="result_value";api_content="";api_name="phpstorm";api_content="";api_param="text_format";api_content="";api_content="";其他例子请使用api_name="flash";api_param="result_value";api_content="";api_content="";api_name="flash";api_param="text_format";api_content="";api_content="";api_content="";方法2.加载链接phpstorm的api文件可以到,有链接的关键字是可以作为命令执行的,但是一般我们提取的文章文件都需要加载到.php结尾的文件夹里,如果文件直接用文件查看器打开可能会乱码,这时候可以添加以下代码:phpapi_keyfieldnameor*>phpapi_keyfieldnameor*> 查看全部
插入关键字文章采集器给提供常用的常用关键列表
插入关键字文章采集器都会给提供常用关键字列表,我们可以自己添加我们需要的关键字方便快捷的完成一篇文章的插入工作!但是网上有很多的关键字列表,这样浪费了很多时间而且不一定全面,下面是我根据自己的工作流提供的关键字列表,这样整个关键字工作流就很清晰!首先需要注意的是要先取正确的关键字,毕竟是机器人生成的,你就不要求全一点要求都不能有错,当然首先需要关注的就是拼音,请注意你的拼音是不是在中间:)ps:由于内容过多,请私信我为你提供单独的文件,并有详细步骤说明。
<p>确定关键字,方法很简单,使用关键字api测试执行api输入任意关键字都能返回最可能的最可能的文章内容,如果没有找到能返回最可能内容的关键字,请使用关键字classs以确定关键字。关键字可以用(),'(或)'phpapi_keyfieldnameor*>phpapi_keyfieldnameor*>phpapi_keyfieldnameor*>其他例子请使用api_name="phpreplay";api_param="result_value";api_content="";api_name="phpstorm";api_content="";api_param="text_format";api_content="";api_content="";其他例子请使用api_name="flash";api_param="result_value";api_content="";api_content="";api_name="flash";api_param="text_format";api_content="";api_content="";api_content="";方法2.加载链接phpstorm的api文件可以到,有链接的关键字是可以作为命令执行的,但是一般我们提取的文章文件都需要加载到.php结尾的文件夹里,如果文件直接用文件查看器打开可能会乱码,这时候可以添加以下代码:phpapi_keyfieldnameor*>phpapi_keyfieldnameor*>
插入关键字文章采集器(全文采集)(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-05-18 16:01
插入关键字文章采集器(全文采集)目前有两种采集方式1.机器采集:只采集标题,一天采集5000条数据,机器采集相对较慢2.网站采集:不采集标题,还可以采集网站的各种内容,但是网站采集的内容没有机器采集精准,且机器采集的数据存在数据失真情况采集器,一般搜索百度+标题可以找到网站地址,最快速度的是采集器去采集快速采集器-网站采集。看到网站上有个观点或文章标题就知道文章在那个网站采集的。
专门的有两个:地址栏打开就显示出网站链接的采集器,比如说reex。
百度即可有关页面的post数据可以通过railix来自动的爬。另外很多网站都支持ip段爬,可以自行发动,爬一个出来,访问过的ip和session都可以用他分析出来,然后自己找爬虫clone,自己写。
自己没爬过,所以很难发言,不过还是有方法的,这里有我的方法,
就是百度搜网站名,直接下载抓包工具,根据抓包信息来数据就行了。
我知道一款,推荐给你。
有的,有一些网站是没有getselect,如果需要再get到的方式爬回来,有的时候时间来不及了。小编来告诉你,“不会采集,不会生成”的人都有谁,有哪些又快速,
网站可以去百度各个网站上直接去下载带采集功能的文章,直接读取就可以了!如果是第三方网站,用采集器是可以生成网站的链接地址让你爬。 查看全部
插入关键字文章采集器(全文采集)(图)
插入关键字文章采集器(全文采集)目前有两种采集方式1.机器采集:只采集标题,一天采集5000条数据,机器采集相对较慢2.网站采集:不采集标题,还可以采集网站的各种内容,但是网站采集的内容没有机器采集精准,且机器采集的数据存在数据失真情况采集器,一般搜索百度+标题可以找到网站地址,最快速度的是采集器去采集快速采集器-网站采集。看到网站上有个观点或文章标题就知道文章在那个网站采集的。
专门的有两个:地址栏打开就显示出网站链接的采集器,比如说reex。
百度即可有关页面的post数据可以通过railix来自动的爬。另外很多网站都支持ip段爬,可以自行发动,爬一个出来,访问过的ip和session都可以用他分析出来,然后自己找爬虫clone,自己写。
自己没爬过,所以很难发言,不过还是有方法的,这里有我的方法,
就是百度搜网站名,直接下载抓包工具,根据抓包信息来数据就行了。
我知道一款,推荐给你。
有的,有一些网站是没有getselect,如果需要再get到的方式爬回来,有的时候时间来不及了。小编来告诉你,“不会采集,不会生成”的人都有谁,有哪些又快速,
网站可以去百度各个网站上直接去下载带采集功能的文章,直接读取就可以了!如果是第三方网站,用采集器是可以生成网站的链接地址让你爬。
插入关键字文章采集器,api接口文章大全(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-05-07 20:00
插入关键字文章采集器,api接口文章大全,api开放平台文章智能推荐引擎,智能新闻推荐_v2ex
采集需要关键字的邮箱,把需要的内容集中起来(文章),通过api接口提供者提供的api对接到需要的地方,一般api接口服务器。
采集我们产品api数据和抓取抓力推荐可以试试“蜜蜂推荐”,直接购买单个账号,可对接很多个网站内容。
uc微信订阅号中的文章
三款基于信息流的app新闻站点搜狗网易
微信公众号文章不是很多都采集的么
一是采集新闻源,类似一些网站经常发布的采集器;二是新闻源解析,百度搜索搜新闻源,自己创建自己的网站库存,解析其文章,可加上自己的标签。三是视频采集与下载,公众号文章都会有视频及相关下载;还有一些文章站点的二维码生成的方式提供。
一个app来源统计,
在米饭采集器,
我会告诉你看到过有个人把新闻源api给开源了嘛,你去试试看吧,
这个可以统计很多公众号文章,新浪搜狐简书中,可能有些公众号文章并不发布在自己公众号上。此外还有一些可以统计同城的公众号还有一些免费的公众号,更多地公众号这些统计工具可以查找到公众号。
今日头条-新闻搜索
必须是这个最有用了:三体新闻转载统计系统。 查看全部
插入关键字文章采集器,api接口文章大全(组图)
插入关键字文章采集器,api接口文章大全,api开放平台文章智能推荐引擎,智能新闻推荐_v2ex
采集需要关键字的邮箱,把需要的内容集中起来(文章),通过api接口提供者提供的api对接到需要的地方,一般api接口服务器。
采集我们产品api数据和抓取抓力推荐可以试试“蜜蜂推荐”,直接购买单个账号,可对接很多个网站内容。
uc微信订阅号中的文章
三款基于信息流的app新闻站点搜狗网易
微信公众号文章不是很多都采集的么
一是采集新闻源,类似一些网站经常发布的采集器;二是新闻源解析,百度搜索搜新闻源,自己创建自己的网站库存,解析其文章,可加上自己的标签。三是视频采集与下载,公众号文章都会有视频及相关下载;还有一些文章站点的二维码生成的方式提供。
一个app来源统计,
在米饭采集器,
我会告诉你看到过有个人把新闻源api给开源了嘛,你去试试看吧,
这个可以统计很多公众号文章,新浪搜狐简书中,可能有些公众号文章并不发布在自己公众号上。此外还有一些可以统计同城的公众号还有一些免费的公众号,更多地公众号这些统计工具可以查找到公众号。
今日头条-新闻搜索
必须是这个最有用了:三体新闻转载统计系统。
cpuc#的爬虫框架,解决爬虫采集难题(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-05-04 21:02
插入关键字文章采集器/清析采集器网络爬虫/蚁嘴采集器猴子采集器采集软件/蜂鸟采集器浏览器抓取/对象浏览器/免费版的lxml/xpath通配符模块/requests/beautifulsoup通讯录/分页爬虫/百度通讯录/轮循爬虫网盘地址/网页打包工具/百度云盘dropbox腾讯文档/同步工具/威锋论坛爬虫插件-网站大全/。
套采集标题
谢邀。rulesforselectingthecutting-edgetagsofyoururlsandtabswhereyouuse这篇文章我曾经和其他问题一样,搜到的结果非常广泛,但是终究在深度和时效上不够。所以我又查阅了一些大家提到的外文文章以及维基百科的资料,终于将其翻译了一下,与各位分享。我翻译的版本,以及我的整合版在这里:基于c#的爬虫框架,解决爬虫采集难题基于webgl的web服务器框架jurl:rulesforselectingthecutting-edgetagsofyoururlsandtabswhereyouuse而如果想实现深度爬虫,推荐看webxss。
ahalfayeartechnicalleadinreverseengineering–webxsswiki(webxsswiki之所以好,是因为更加完善,写的更加清楚)而如果要做速度,在可以控制网页大小不超过50kb的情况下,可以用正则表达式对某一段内容进行匹配,爬虫采用图片匹配。例如/s/1ar/10.gif(default),经过各种类型的xpath匹配后,其中内容就是1ar=(default-attribute("1ar-attribute"):true,//xpath匹配的单引号内容),而这个default-attribute就是正则表达式的1/1//。
以此类推,这种方法的优点在于速度不会变慢,缺点在于无法获取对应的源数据,例如某一段文字后面不能加一个*,只能写(a</a>),这样太浪费cpu了。而对于想采集网站页面的关键内容的朋友,请绕过上面的那个坑。不要滥用前缀匹配,非常非常不实用(sad),首选xpath,很多web网站只接受二级/三级的xpath,其次,像某些网站表单页面这样的类型,xpath不能满足需求(这也是国内市场搞不好爬虫的原因之一,因为爬虫写爬虫时不想自己网站接受反爬虫策略,可能就给你报一堆http请求错误,导致页面crash),你也只能用正则了。
最后,我以前也遇到爬取数据困难的问题,最后使用了webxsswiki,爬了几页,最后整合在rulesforselectingthecutting-edgetagsofyoururlsandtabswhereyouuse在下面的链接(没错,全部都是英文的):可以试试用它来管理整个网站所有涉及到的数据!!。 查看全部
cpuc#的爬虫框架,解决爬虫采集难题(组图)
插入关键字文章采集器/清析采集器网络爬虫/蚁嘴采集器猴子采集器采集软件/蜂鸟采集器浏览器抓取/对象浏览器/免费版的lxml/xpath通配符模块/requests/beautifulsoup通讯录/分页爬虫/百度通讯录/轮循爬虫网盘地址/网页打包工具/百度云盘dropbox腾讯文档/同步工具/威锋论坛爬虫插件-网站大全/。
套采集标题
谢邀。rulesforselectingthecutting-edgetagsofyoururlsandtabswhereyouuse这篇文章我曾经和其他问题一样,搜到的结果非常广泛,但是终究在深度和时效上不够。所以我又查阅了一些大家提到的外文文章以及维基百科的资料,终于将其翻译了一下,与各位分享。我翻译的版本,以及我的整合版在这里:基于c#的爬虫框架,解决爬虫采集难题基于webgl的web服务器框架jurl:rulesforselectingthecutting-edgetagsofyoururlsandtabswhereyouuse而如果想实现深度爬虫,推荐看webxss。
ahalfayeartechnicalleadinreverseengineering–webxsswiki(webxsswiki之所以好,是因为更加完善,写的更加清楚)而如果要做速度,在可以控制网页大小不超过50kb的情况下,可以用正则表达式对某一段内容进行匹配,爬虫采用图片匹配。例如/s/1ar/10.gif(default),经过各种类型的xpath匹配后,其中内容就是1ar=(default-attribute("1ar-attribute"):true,//xpath匹配的单引号内容),而这个default-attribute就是正则表达式的1/1//。
以此类推,这种方法的优点在于速度不会变慢,缺点在于无法获取对应的源数据,例如某一段文字后面不能加一个*,只能写(a</a>),这样太浪费cpu了。而对于想采集网站页面的关键内容的朋友,请绕过上面的那个坑。不要滥用前缀匹配,非常非常不实用(sad),首选xpath,很多web网站只接受二级/三级的xpath,其次,像某些网站表单页面这样的类型,xpath不能满足需求(这也是国内市场搞不好爬虫的原因之一,因为爬虫写爬虫时不想自己网站接受反爬虫策略,可能就给你报一堆http请求错误,导致页面crash),你也只能用正则了。
最后,我以前也遇到爬取数据困难的问题,最后使用了webxsswiki,爬了几页,最后整合在rulesforselectingthecutting-edgetagsofyoururlsandtabswhereyouuse在下面的链接(没错,全部都是英文的):可以试试用它来管理整个网站所有涉及到的数据!!。
插入关键字文章采集器:百度网盘限免的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2022-04-28 23:01
插入关键字文章采集器:这个软件,当然最主要的就是手机直接安装app,以前用过百度网盘的,现在很少用了,因为需要手机版,效率实在太低,这个就不一样了,不需要手机版。为什么用手机版呢?因为我们只需要一个手机号码就可以全球免费全天下载了。接下来推荐的就是一款老牌子的抖音助手,抖音app,多麦就是可以选择使用浏览器访问。
界面和app是一模一样的。不需要积分,首先在手机上安装,然后在app里输入账号密码和手机号码就可以在任何设备上登录,不限制账号和设备。不仅仅是抖音,你安装了其他的主流应用都能用。不过一旦有账号密码被盗,那就是不敢乱开启权限,一旦被盗了不知道怎么登,那就挺麻烦的。像什么百度云之类的,注意的话只能换账号登陆,账号密码不能泄露。
接下来给大家推荐一下百度网盘最近限免的,30元会员的文件下载助手。百度网盘在如今看来太便宜了,不说别的,就百度网盘资源种类就要少太多,现在只支持电脑端账号,手机端只支持电脑端,希望百度网盘以后多增加几个客户端。现在某宝上有官方的折扣码,还会配送各种教程,关键是非常便宜,大概也就10元-30元不等。当然我也有一个拿到了会员的100元优惠券,只需要34元。
小视频推荐:这里要给大家推荐一个我用过最好用的,抖音短视频的文字识别录音,识别结果再进行语音转文字,之前为了下一些字幕,用的是安卓内置的录音机,能录音,录完文字转过来也巨难看。用这个之后,我这些字幕都不是问题。除了以上两个之外,推荐一个小浏览器,名叫搜狗浏览器,除了是一个浏览器,搜狗还能给你链接给你下载一些小视频什么的,直接有的没的发给你就直接下载了。
不过这个特别限制发送到指定地址,如果手机可以浏览的话,给我点赞,回复关键字获取吧。最后推荐一个网站,actyp,中文翻译为幻多迷联合网站,看看,可以在线视频把字幕,图片,ppt还有音乐,或者一些视频录制成视频,有些图片的话可以在线编辑,再按分享就可以推送到电脑和手机上,比如ppt模板什么的。对文字不太敏感的童鞋可以借鉴一下,相信应该可以在视频上加入字幕和音乐什么的。以上就是我在互联网找到的这些小惊喜了,有需要的话直接可以关注公众号:容辰为你带来互联网最实用的东西。 查看全部
插入关键字文章采集器:百度网盘限免的方法
插入关键字文章采集器:这个软件,当然最主要的就是手机直接安装app,以前用过百度网盘的,现在很少用了,因为需要手机版,效率实在太低,这个就不一样了,不需要手机版。为什么用手机版呢?因为我们只需要一个手机号码就可以全球免费全天下载了。接下来推荐的就是一款老牌子的抖音助手,抖音app,多麦就是可以选择使用浏览器访问。
界面和app是一模一样的。不需要积分,首先在手机上安装,然后在app里输入账号密码和手机号码就可以在任何设备上登录,不限制账号和设备。不仅仅是抖音,你安装了其他的主流应用都能用。不过一旦有账号密码被盗,那就是不敢乱开启权限,一旦被盗了不知道怎么登,那就挺麻烦的。像什么百度云之类的,注意的话只能换账号登陆,账号密码不能泄露。
接下来给大家推荐一下百度网盘最近限免的,30元会员的文件下载助手。百度网盘在如今看来太便宜了,不说别的,就百度网盘资源种类就要少太多,现在只支持电脑端账号,手机端只支持电脑端,希望百度网盘以后多增加几个客户端。现在某宝上有官方的折扣码,还会配送各种教程,关键是非常便宜,大概也就10元-30元不等。当然我也有一个拿到了会员的100元优惠券,只需要34元。
小视频推荐:这里要给大家推荐一个我用过最好用的,抖音短视频的文字识别录音,识别结果再进行语音转文字,之前为了下一些字幕,用的是安卓内置的录音机,能录音,录完文字转过来也巨难看。用这个之后,我这些字幕都不是问题。除了以上两个之外,推荐一个小浏览器,名叫搜狗浏览器,除了是一个浏览器,搜狗还能给你链接给你下载一些小视频什么的,直接有的没的发给你就直接下载了。
不过这个特别限制发送到指定地址,如果手机可以浏览的话,给我点赞,回复关键字获取吧。最后推荐一个网站,actyp,中文翻译为幻多迷联合网站,看看,可以在线视频把字幕,图片,ppt还有音乐,或者一些视频录制成视频,有些图片的话可以在线编辑,再按分享就可以推送到电脑和手机上,比如ppt模板什么的。对文字不太敏感的童鞋可以借鉴一下,相信应该可以在视频上加入字幕和音乐什么的。以上就是我在互联网找到的这些小惊喜了,有需要的话直接可以关注公众号:容辰为你带来互联网最实用的东西。
插入关键字 文章采集器(插入关键字文章采集器帮助你抓取国内外网站上的文章评论)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-18 20:04
插入关键字文章采集器帮助你抓取国内外网站上的文章评论,可以指定对应的评论来源,也可以查看全部评论,以便对文章进行筛选。在评论列表里,我们点击download,就可以下载对应的评论列表和文章链接,方便我们进行后续的爬取。网站位置:pc版国内网站:。2018年12月27日完成更新。ios版国内网站:。safari版国内网站:,由于涉及到微信文章链接问题,故请在wx中发送到。
safari版本号:3.3.1,android版:3.7.0。github代码changefreelife/waterhuangwang。
需要用一下编辑评论的。
在feed里面设置评论,然后单击post接受邮件,然后按照网页内容编辑就行了。ps.最好在feed里面设置一下,以及feed自动更新的频率。
windows用户,由于地址栏总会显示网址,故很多人可能不会主动去看评论,不过,在微信公众号内嵌入app“评论”,同样很方便去评论,赞。
我觉得首先你要有一个微信公众号,让粉丝自己发自己评论过程,就算没有可以加上;最主要的是提供评论功能,顺便获取文章链接。推荐几个1.蝉大师_专业数据分析平台,为企业提供数据分析、用户行为、智能化运营等数据分析服务2.小红书(小红书商业变现)3.订阅号(创建属于自己的订阅号,然后寻找一些评论相关的,但要考虑清楚,关键词提取真的很难)4.feedly(feedly免费版只有api接口的提供功能)——5.某宝(接一些直接发评论给你就行)———还有就是自己做微信公众号,然后提取文章或评论进行提取就行了,估计也就是个人比较善于总结的成本大,效率高吧。 查看全部
插入关键字 文章采集器(插入关键字文章采集器帮助你抓取国内外网站上的文章评论)
插入关键字文章采集器帮助你抓取国内外网站上的文章评论,可以指定对应的评论来源,也可以查看全部评论,以便对文章进行筛选。在评论列表里,我们点击download,就可以下载对应的评论列表和文章链接,方便我们进行后续的爬取。网站位置:pc版国内网站:。2018年12月27日完成更新。ios版国内网站:。safari版国内网站:,由于涉及到微信文章链接问题,故请在wx中发送到。
safari版本号:3.3.1,android版:3.7.0。github代码changefreelife/waterhuangwang。
需要用一下编辑评论的。
在feed里面设置评论,然后单击post接受邮件,然后按照网页内容编辑就行了。ps.最好在feed里面设置一下,以及feed自动更新的频率。
windows用户,由于地址栏总会显示网址,故很多人可能不会主动去看评论,不过,在微信公众号内嵌入app“评论”,同样很方便去评论,赞。
我觉得首先你要有一个微信公众号,让粉丝自己发自己评论过程,就算没有可以加上;最主要的是提供评论功能,顺便获取文章链接。推荐几个1.蝉大师_专业数据分析平台,为企业提供数据分析、用户行为、智能化运营等数据分析服务2.小红书(小红书商业变现)3.订阅号(创建属于自己的订阅号,然后寻找一些评论相关的,但要考虑清楚,关键词提取真的很难)4.feedly(feedly免费版只有api接口的提供功能)——5.某宝(接一些直接发评论给你就行)———还有就是自己做微信公众号,然后提取文章或评论进行提取就行了,估计也就是个人比较善于总结的成本大,效率高吧。
插入关键字 文章采集器(网站优化工具,网站有哪些?优化好的网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-04-13 15:11
网站优化工具,网站优化工具有哪些?一个优化的网站 离不开网站 优化工具。网站优化工具有很多种,其中最常见的是数据分析工具,其次是关键词挖掘工具,网站@文章采集工具,< @网站推送工具等。今天给大家分享一款网站免费整合以上所有功能的优化工具(如下图)。
<p>网站 中最重要的部分是什么?毫无疑问,它是 网站 的 关键词。网站的关键词的优化会直接影响网站的排名和流量,而网站的排名和流量会直接影响客户的转化,影响 查看全部
插入关键字 文章采集器(机车收藏家企业版无限功能软件SEO推广优化(合影))
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-04-12 03:05
无需人工值守,24小时自动实时监控目标页码采集软件,实时高效采集
优采云文章采集api(机车采集器企业版无限功能软件SEO推广优化(合影))
来自媒体领取(来自媒体领取,打开百度搜索输入“公众号文章”)
网站文章采集软件(网站文章采集软件网*敏感*词*商品搜索_[易搜])
网站文章采集软件网*敏感词*商品搜索_【易搜】-全网文章采集,网页采集,网页翻译等 *敏感*敏感词*搜索引擎软件网页采集软件,网站内容采集,网站内容保存,
文章 采集我用过两个采集工具:一个是eagle,安装方便,但是需要配置,因为它是基于. 另一个是牛油果软件。界面很好,功能也比较简单,但是配置起来很麻烦,需要手动安装。您需要的可能不是那么*敏感*,Eagle 可以解决您的所有问题。采集器易于使用。您只需要一个计算机操作系统即可拥有此环境。
另外,建议自带代码软件,然后运行eagle。那么在哪里卖电话号码资源,我觉得你需要知道更多,因为它很棒。
有写作教程,可以去,提供文章采集、采集、文章转换、云存储、seo等各种功能。网站搜索软件_网站采集软件-【易搜】-全网文章采集,网页采集,
楼上的,我还有一个相关的问题《超人新传》剧情分析,里面有比较详细的答案。我在豆瓣上搜索分析了很多次,最后发现博主不推广,只写玩,点击率很高,可以理解,但是这些文章的总浏览量呈现出趋势图片采集器 行得通,无语。
机车采集器企业版无限功能软件SEO推广优化文章采集必备软件
优采云采集器是一个网站采集器,自动采集云相关文章发布到用户提供的关键词。用户的 网站。它可以自动识别各种网页的标题、文字等信息,无需用户编写任何采集规则,整个网络的采集即可。内容采集完成后,采集器好用,它会自动计算内容与设置的相关性关键词采集器即好用,只将相关的 文章 推送给用户。支持标题前缀、自动关键字加粗、固定链接插入、自动标签提取、自动内链、自动图片匹配、自动伪原创、内容过滤器替换、电话号码和网址清洗、定时采集、百度主动提交等一系列SEO功能。用户只需设置关键词和相关需求,即可实现全托管、零维护的网站内容更新。网站的数量没有限制,无论是单个网站还是一组*敏感*字*网站,都可以轻松管理。
百家号爆文采集软件,给素材起个好标题
优采云采集器是一个网站采集器,基于用户提供的关键词,自动采集云相关文章并发布它给用户网站。它可以自动识别各种网页的标题、文字等信息,无需用户编写任何采集规则,全网即可采集。内容采集完成后,会自动计算内容与设置关键词的相关性,只推送相关的文章给用户。支持标题前缀、关键词自动加粗、固定链接插入、自动标签提取、自动内链、自动图片匹配、自动伪原创、内容过滤替换、电话号码和URL清洗、定时< @采集、百度主动投稿等一系列SEO功能。用户只需设置关键词及相关要求,即可实现全托管、零维护的网站内容更新。网站的数量没有限制,无论是单个网站还是一组*敏感*字*网站,都可以轻松管理。 查看全部
插入关键字 文章采集器(机车收藏家企业版无限功能软件SEO推广优化(合影))
无需人工值守,24小时自动实时监控目标页码采集软件,实时高效采集
优采云文章采集api(机车采集器企业版无限功能软件SEO推广优化(合影))
来自媒体领取(来自媒体领取,打开百度搜索输入“公众号文章”)
网站文章采集软件(网站文章采集软件网*敏感*词*商品搜索_[易搜])
网站文章采集软件网*敏感词*商品搜索_【易搜】-全网文章采集,网页采集,网页翻译等 *敏感*敏感词*搜索引擎软件网页采集软件,网站内容采集,网站内容保存,
文章 采集我用过两个采集工具:一个是eagle,安装方便,但是需要配置,因为它是基于. 另一个是牛油果软件。界面很好,功能也比较简单,但是配置起来很麻烦,需要手动安装。您需要的可能不是那么*敏感*,Eagle 可以解决您的所有问题。采集器易于使用。您只需要一个计算机操作系统即可拥有此环境。
另外,建议自带代码软件,然后运行eagle。那么在哪里卖电话号码资源,我觉得你需要知道更多,因为它很棒。
有写作教程,可以去,提供文章采集、采集、文章转换、云存储、seo等各种功能。网站搜索软件_网站采集软件-【易搜】-全网文章采集,网页采集,
楼上的,我还有一个相关的问题《超人新传》剧情分析,里面有比较详细的答案。我在豆瓣上搜索分析了很多次,最后发现博主不推广,只写玩,点击率很高,可以理解,但是这些文章的总浏览量呈现出趋势图片采集器 行得通,无语。
机车采集器企业版无限功能软件SEO推广优化文章采集必备软件
优采云采集器是一个网站采集器,自动采集云相关文章发布到用户提供的关键词。用户的 网站。它可以自动识别各种网页的标题、文字等信息,无需用户编写任何采集规则,整个网络的采集即可。内容采集完成后,采集器好用,它会自动计算内容与设置的相关性关键词采集器即好用,只将相关的 文章 推送给用户。支持标题前缀、自动关键字加粗、固定链接插入、自动标签提取、自动内链、自动图片匹配、自动伪原创、内容过滤器替换、电话号码和网址清洗、定时采集、百度主动提交等一系列SEO功能。用户只需设置关键词和相关需求,即可实现全托管、零维护的网站内容更新。网站的数量没有限制,无论是单个网站还是一组*敏感*字*网站,都可以轻松管理。
百家号爆文采集软件,给素材起个好标题
优采云采集器是一个网站采集器,基于用户提供的关键词,自动采集云相关文章并发布它给用户网站。它可以自动识别各种网页的标题、文字等信息,无需用户编写任何采集规则,全网即可采集。内容采集完成后,会自动计算内容与设置关键词的相关性,只推送相关的文章给用户。支持标题前缀、关键词自动加粗、固定链接插入、自动标签提取、自动内链、自动图片匹配、自动伪原创、内容过滤替换、电话号码和URL清洗、定时< @采集、百度主动投稿等一系列SEO功能。用户只需设置关键词及相关要求,即可实现全托管、零维护的网站内容更新。网站的数量没有限制,无论是单个网站还是一组*敏感*字*网站,都可以轻松管理。
插入关键字 文章采集器( 织梦采集侠V2.7正式版更新说明:加入超级采集[√])
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-04-09 21:32
织梦采集侠V2.7正式版更新说明:加入超级采集[√])
最新织梦采集侠v2.7破解版
织梦采集侠V2.7正式版终于出,新功能不多,只增加规则导入导出,自动文章自定义属性,随机标题关键词,以及一种新的 采集 方法,可以更快、更轻松地获得 采集 内容。主要是对老版本存在的一些问题进行改进和修复,使插件越来越完善。 采集侠V2.7正式版更新说明:[√]新增超级采集 [√]修复重复采集问题[√]新增采集规则导入导出[√]图片下载
织梦采集侠V2.7正式版终于出,新功能不多,只增加规则导入导出,自动文章自定义属性,随机标题关键词,以及一种新的 采集 方法,可以更快、更轻松地获得 采集 内容。主要是对老版本存在的一些问题进行改进和修复,使插件越来越完善。
采集侠V2.7正式版更新说明:
[√]加入超级采集
[√]修复重复采集问题
[√]添加到采集规则导入导出
[√]图片下载优化,降低服务器负载
[√]关键词插入优化,段尾插入改为随机插入
[√]改善地图生成错误
[√]百度多项优化
[√]增加了自动文章自定义属性,文章可以获取各种自定义属性
[√]增加标题随机插入功能关键词
官方专业版(200元):支持3个域名绑定(需要多域名支持可以联系官方),栏目无关键词上限,无使用期限,无功能限制,免费升级到最新版本,提供远程触发定时定量采集更新服务,有技术支持。
注意:织梦采集夏V2.7破解版无域名使用限制,无列关键词上限限制,无有效期!
下载链接: 查看全部
插入关键字 文章采集器(
织梦采集侠V2.7正式版更新说明:加入超级采集[√])
最新织梦采集侠v2.7破解版
织梦采集侠V2.7正式版终于出,新功能不多,只增加规则导入导出,自动文章自定义属性,随机标题关键词,以及一种新的 采集 方法,可以更快、更轻松地获得 采集 内容。主要是对老版本存在的一些问题进行改进和修复,使插件越来越完善。 采集侠V2.7正式版更新说明:[√]新增超级采集 [√]修复重复采集问题[√]新增采集规则导入导出[√]图片下载
织梦采集侠V2.7正式版终于出,新功能不多,只增加规则导入导出,自动文章自定义属性,随机标题关键词,以及一种新的 采集 方法,可以更快、更轻松地获得 采集 内容。主要是对老版本存在的一些问题进行改进和修复,使插件越来越完善。
采集侠V2.7正式版更新说明:
[√]加入超级采集
[√]修复重复采集问题
[√]添加到采集规则导入导出
[√]图片下载优化,降低服务器负载
[√]关键词插入优化,段尾插入改为随机插入
[√]改善地图生成错误
[√]百度多项优化
[√]增加了自动文章自定义属性,文章可以获取各种自定义属性
[√]增加标题随机插入功能关键词
官方专业版(200元):支持3个域名绑定(需要多域名支持可以联系官方),栏目无关键词上限,无使用期限,无功能限制,免费升级到最新版本,提供远程触发定时定量采集更新服务,有技术支持。
注意:织梦采集夏V2.7破解版无域名使用限制,无列关键词上限限制,无有效期!
下载链接:
插入关键字 文章采集器(IP地址定位技术之基础数据采集关键字文章采集IP地理位置 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-04-09 13:10
)
内容导航:一、IP地址定位技术基本资料采集关键词文章采集
IP地理定位技术包括基础数据采集、硬件系统建设、应用场景划分、定位系统研发四大关键技术。
基础数据采集为IP地理定位技术的研究提供基础数据支撑,是IP地址定位的基础工作和关键技术。一是根据不同的数据采集规则,根据不同数据源的数据格式,研究并实现一套自动化、智能化的数据采集技术;进行筛选、清洗、挖掘,形成基础数据库,为系统提供基础数据支撑。
基础数据采集的研究内容包括确定数据来源(如Whois公开数据等)、分析数据的方法采集(如网络爬虫、数据交换、地面采集等)、数据的各种可行性分析和实施方案采集方法、采集数据属性值的确定(如地理位置、经纬度、运营商等)、数据清洗方法、数据正确性验证步骤、基础数据的迭代更新过程等。
为保证数据质量和数据丰富度,针对不同的数据源,系统通过数据挖掘、数据采购、地面采集三种方式获取基础数据。数据挖掘是指通过网络爬虫从APNIC网站、BGP网站、地图类网站等特定网页获取IP和地理位置信息;数据采购是指从例如本地服务网站、在线出租车网站等提供基础数据;地面采集是指使用自主开发的数据采集软件进行人工实地数据采集。
数据采集技术的开源第三方框架有很多,如Scrapy、Nutch、Crawler4j、WebMagic等;数据挖掘算法,如支持向量机SVM、K-Means等,已被广泛使用。
二、优采云采集按关键词pan采集信息文章详细教程通过搜索引擎提取文章关键信息
优采云采集平台可以按关键词pan采集通过搜索引擎(百度)搜索关键词的信息文章,采集结果链接的内容(系统会智能识别标题、正文、日期等),使用方法很简单,输入对应的关键词即可。
详细步骤如下:
1. 任务创建和配置:
任务创建入口在控制台左侧的【采集任务管理】列表中,点击【关键词Pan采集(搜索引擎)】;
任务配置:2.数据处理配置(可选)
如果不需要对文章进行数据处理,可以跳过这一步!
一、数据处理入口
点击【配置数据替换、填充、删除等】按钮,进入数据处理配置页面;
二、数据处理配置
该功能类似于细节提取器的配置。可以为每个字段设置删除、填充、替换、过滤功能,点击不同的字段可以切换对应的字段数据处理配置;
注意:该字段的数据处理设置保存后,对新存储的采集数据生效,之前存储的数据无效;
三、图片下载配置
关键词Pan采集的原图可能无法正常显示(热链保护)。如需图片请在“图片下载配置”OSS或七牛存储中选择临时存储优采云或阿里云;
3. 采集结果:
默认 采集 字段:
标题、内容、发表时间、作者、标签、分类、描述、关键词、网站域名(x_id);
4. 百度高级搜索说明与技巧
关键词Pan采集支持百度高级搜索命令:
一、采集指定网站
采集指定 网站 的 文章 指令: site:
采集 指定 文章 指令,该指令在 网站 下指定 关键词(注意 关键词 和 site 指令之间有一个空格): 关键词站点:或站点:关键词
比如博客园下的文章和php关键词:php站点:
_
查看全部
插入关键字 文章采集器(IP地址定位技术之基础数据采集关键字文章采集IP地理位置
)
内容导航:一、IP地址定位技术基本资料采集关键词文章采集
IP地理定位技术包括基础数据采集、硬件系统建设、应用场景划分、定位系统研发四大关键技术。
基础数据采集为IP地理定位技术的研究提供基础数据支撑,是IP地址定位的基础工作和关键技术。一是根据不同的数据采集规则,根据不同数据源的数据格式,研究并实现一套自动化、智能化的数据采集技术;进行筛选、清洗、挖掘,形成基础数据库,为系统提供基础数据支撑。
基础数据采集的研究内容包括确定数据来源(如Whois公开数据等)、分析数据的方法采集(如网络爬虫、数据交换、地面采集等)、数据的各种可行性分析和实施方案采集方法、采集数据属性值的确定(如地理位置、经纬度、运营商等)、数据清洗方法、数据正确性验证步骤、基础数据的迭代更新过程等。
为保证数据质量和数据丰富度,针对不同的数据源,系统通过数据挖掘、数据采购、地面采集三种方式获取基础数据。数据挖掘是指通过网络爬虫从APNIC网站、BGP网站、地图类网站等特定网页获取IP和地理位置信息;数据采购是指从例如本地服务网站、在线出租车网站等提供基础数据;地面采集是指使用自主开发的数据采集软件进行人工实地数据采集。
数据采集技术的开源第三方框架有很多,如Scrapy、Nutch、Crawler4j、WebMagic等;数据挖掘算法,如支持向量机SVM、K-Means等,已被广泛使用。
二、优采云采集按关键词pan采集信息文章详细教程通过搜索引擎提取文章关键信息
优采云采集平台可以按关键词pan采集通过搜索引擎(百度)搜索关键词的信息文章,采集结果链接的内容(系统会智能识别标题、正文、日期等),使用方法很简单,输入对应的关键词即可。
详细步骤如下:
1. 任务创建和配置:
任务创建入口在控制台左侧的【采集任务管理】列表中,点击【关键词Pan采集(搜索引擎)】;
任务配置:2.数据处理配置(可选)
如果不需要对文章进行数据处理,可以跳过这一步!
一、数据处理入口
点击【配置数据替换、填充、删除等】按钮,进入数据处理配置页面;
二、数据处理配置
该功能类似于细节提取器的配置。可以为每个字段设置删除、填充、替换、过滤功能,点击不同的字段可以切换对应的字段数据处理配置;
注意:该字段的数据处理设置保存后,对新存储的采集数据生效,之前存储的数据无效;
三、图片下载配置
关键词Pan采集的原图可能无法正常显示(热链保护)。如需图片请在“图片下载配置”OSS或七牛存储中选择临时存储优采云或阿里云;
3. 采集结果:
默认 采集 字段:
标题、内容、发表时间、作者、标签、分类、描述、关键词、网站域名(x_id);
4. 百度高级搜索说明与技巧
关键词Pan采集支持百度高级搜索命令:
一、采集指定网站
采集指定 网站 的 文章 指令: site:
采集 指定 文章 指令,该指令在 网站 下指定 关键词(注意 关键词 和 site 指令之间有一个空格): 关键词站点:或站点:关键词
比如博客园下的文章和php关键词:php站点:
_
插入关键字 文章采集器(您是否正在寻找一种方法来防止垃圾评论(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-04-09 02:16
您是否正在寻找一种方法来防止垃圾评论发送者和诈骗者使用内容抓取工具来采集您的 WordPress 博客内容?
作为 网站 所有者,看到有人在未经许可的情况下 采集 您的内容、将其货币化并在 Google 等搜索引擎上超过您的排名是非常令人沮丧的。
在本教程中,我们将介绍哪些博客内容采集,如何减少和防止内容采集,甚至如何利用内容抓取来发挥您的优势。
什么是博客内容抓取?
博客内容采集抓取是从众多来源获取并在另一个站点上重新发布的内容。通常这是通过您博客的 RSS 提要自动完成的。
内容抓取现在非常容易,任何人都可以启动 WordPress网站,放置免费或商业主题,并安装插件,从选定的博客中提取 采集 内容。
为什么内容爬虫采集是我的内容?
我们的一些用户问我们为什么采集我的内容?简单的答案是因为你很棒。事实是,这些内容抓取工具别有用心。以下是有人会采集您的内容的几个原因:
这些只是有人会采集您的内容的几个原因。
如何捕获内容爬虫?
捕获内容抓取工具是一项繁琐的任务,可能需要花费大量时间。您可以通过多种方式捕获内容爬虫。
使用您的 文章 标题进行谷歌搜索
是的,听起来很痛苦。这种方法可能不值得,特别是如果您正在撰写一个非常受欢迎的主题。
引用
如果您在 文章 中添加内部链接,如果 网站采集 您的内容,您会注意到引用。这几乎是在告诉您他们正在抓取您的内容。
如果您使用 Akismet,很多此类引用将显示在垃圾邮件文件夹中。同样,这仅在您的 文章 中有内部链接时才有效。
阿雷夫斯
如果您可以使用 Ahrefs 等 SEO 工具,则可以监控反向链接并留意被盗内容。
如何处理内容爬虫
人们使用内容采集工具的方式很少:什么都不做、删除或利用它们。
让我们来看看每一个。
无所作为的方式
这是迄今为止您可以采取的最简单的方法。通常最受欢迎的博主推荐这个,因为它需要很多时间来对抗爬虫。
现在很清楚,如果是 Smashing Magazine、CSS-Tricks、Problogger 等知名博主,那他们就不用担心了。他们是谷歌眼中的权威网站。
但是,我们确实知道一些好的 网站 被标记为 采集 工具,因为 Google 认为他们的 采集 工具是原创内容。因此,在我们看来,这种方法并不总是最好的。
采取措施
这与“什么都不做”的方法完全相反。在这种方法中,您只需联系爬虫并要求他们删除内容。
如果他们拒绝这样做或根本不响应您的请求,那么您可以向他们的主机提交 DMCA(数字千年版权法案)。
根据我们的经验,大多数爬虫网站 没有可用的联系表。如果他们这样做了,那就好好利用它。如果他们没有联系表格,那么您需要进行 Whois 查询。
您可以在管理联系人中查看联系信息。通常行政和技术联系人是相同的。
它还将显示域注册商。大多数著名的网络托管公司和域名注册商都有 DMCA 表格或电子邮件。您可以看到这个特定的人使用 HostGator 是因为他们的名称服务器。HostGator 有一份 DMCA 投诉表。
如果名称服务器相似,那么您将不得不通过反向 IP 查找和搜索 IP 进行更深入的挖掘。
您也可以使用第三方服务进行删除。
Jeff Starr 在他的 文章 中建议您应该阻止坏人的 IP。访问您的日志以获取其 IP 地址,然后在您的根 .htaccess 文件中使用以下内容阻止它:
Deny from 123.456.789
您还可以通过执行以下操作将它们重定向到虚拟提要:
RewriteCond %{REMOTE_ADDR} 123\.456\.789\.
RewriteRule .* http://dummyfeed.com/feed [R,L]
正如 Jeff 建议的那样,您可以在这里获得真正的创意。将它们发送到收录 Lorem Ipsum 的非常大的文本提要。你可以给他们发一些关于坏事的恶心图片。您还可以将它们直接发送回它们自己的服务器,从而导致无限循环使它们的 网站 崩溃。
我们采取的最后一种方法是利用它们。
如何利用内容抓取工具
这是我们的内容爬虫方法,结果非常好。它有助于我们的 SEO 以及帮助我们赚取额外收入。
大多数爬虫使用您的 RSS 提要采集您的内容。所以这些是你可以做的事情:
查看我们关于如何在 WordPress 中控制 RSS 提要页脚的指南,了解更多提示和想法。
如何减少和防止 WordPress 博客爬网
考虑一下,如果您采用我们繁重的内部链接方法,添加附属链接、RSS 横幅等,您可能会在很大程度上减少内容抓取。如果您遵循 Jeff Starr 关于重定向内容爬虫的建议,那也会阻止这些爬虫。除了我们上面分享的内容之外,您还可以使用其他一些技巧。
完整和摘要 RSS 源
博客社区一直在争论是否存在完整的 RSS 提要或摘要 RSS 提要。我们不会详细讨论该辩论,但拥有仅摘要的 RSS 提要的优点之一是可以防止内容抓取。
您可以通过转到 WordPress 管理员并转到设置»阅读来更改设置。然后更改提要中每个 文章 的设置以收录全文或摘要。 查看全部
插入关键字 文章采集器(您是否正在寻找一种方法来防止垃圾评论(组图))
您是否正在寻找一种方法来防止垃圾评论发送者和诈骗者使用内容抓取工具来采集您的 WordPress 博客内容?
作为 网站 所有者,看到有人在未经许可的情况下 采集 您的内容、将其货币化并在 Google 等搜索引擎上超过您的排名是非常令人沮丧的。
在本教程中,我们将介绍哪些博客内容采集,如何减少和防止内容采集,甚至如何利用内容抓取来发挥您的优势。
什么是博客内容抓取?
博客内容采集抓取是从众多来源获取并在另一个站点上重新发布的内容。通常这是通过您博客的 RSS 提要自动完成的。
内容抓取现在非常容易,任何人都可以启动 WordPress网站,放置免费或商业主题,并安装插件,从选定的博客中提取 采集 内容。
为什么内容爬虫采集是我的内容?
我们的一些用户问我们为什么采集我的内容?简单的答案是因为你很棒。事实是,这些内容抓取工具别有用心。以下是有人会采集您的内容的几个原因:
这些只是有人会采集您的内容的几个原因。
如何捕获内容爬虫?
捕获内容抓取工具是一项繁琐的任务,可能需要花费大量时间。您可以通过多种方式捕获内容爬虫。
使用您的 文章 标题进行谷歌搜索
是的,听起来很痛苦。这种方法可能不值得,特别是如果您正在撰写一个非常受欢迎的主题。
引用
如果您在 文章 中添加内部链接,如果 网站采集 您的内容,您会注意到引用。这几乎是在告诉您他们正在抓取您的内容。
如果您使用 Akismet,很多此类引用将显示在垃圾邮件文件夹中。同样,这仅在您的 文章 中有内部链接时才有效。
阿雷夫斯
如果您可以使用 Ahrefs 等 SEO 工具,则可以监控反向链接并留意被盗内容。
如何处理内容爬虫
人们使用内容采集工具的方式很少:什么都不做、删除或利用它们。
让我们来看看每一个。
无所作为的方式
这是迄今为止您可以采取的最简单的方法。通常最受欢迎的博主推荐这个,因为它需要很多时间来对抗爬虫。
现在很清楚,如果是 Smashing Magazine、CSS-Tricks、Problogger 等知名博主,那他们就不用担心了。他们是谷歌眼中的权威网站。
但是,我们确实知道一些好的 网站 被标记为 采集 工具,因为 Google 认为他们的 采集 工具是原创内容。因此,在我们看来,这种方法并不总是最好的。
采取措施
这与“什么都不做”的方法完全相反。在这种方法中,您只需联系爬虫并要求他们删除内容。
如果他们拒绝这样做或根本不响应您的请求,那么您可以向他们的主机提交 DMCA(数字千年版权法案)。
根据我们的经验,大多数爬虫网站 没有可用的联系表。如果他们这样做了,那就好好利用它。如果他们没有联系表格,那么您需要进行 Whois 查询。
您可以在管理联系人中查看联系信息。通常行政和技术联系人是相同的。
它还将显示域注册商。大多数著名的网络托管公司和域名注册商都有 DMCA 表格或电子邮件。您可以看到这个特定的人使用 HostGator 是因为他们的名称服务器。HostGator 有一份 DMCA 投诉表。
如果名称服务器相似,那么您将不得不通过反向 IP 查找和搜索 IP 进行更深入的挖掘。
您也可以使用第三方服务进行删除。
Jeff Starr 在他的 文章 中建议您应该阻止坏人的 IP。访问您的日志以获取其 IP 地址,然后在您的根 .htaccess 文件中使用以下内容阻止它:
Deny from 123.456.789
您还可以通过执行以下操作将它们重定向到虚拟提要:
RewriteCond %{REMOTE_ADDR} 123\.456\.789\.
RewriteRule .* http://dummyfeed.com/feed [R,L]
正如 Jeff 建议的那样,您可以在这里获得真正的创意。将它们发送到收录 Lorem Ipsum 的非常大的文本提要。你可以给他们发一些关于坏事的恶心图片。您还可以将它们直接发送回它们自己的服务器,从而导致无限循环使它们的 网站 崩溃。
我们采取的最后一种方法是利用它们。
如何利用内容抓取工具
这是我们的内容爬虫方法,结果非常好。它有助于我们的 SEO 以及帮助我们赚取额外收入。
大多数爬虫使用您的 RSS 提要采集您的内容。所以这些是你可以做的事情:
查看我们关于如何在 WordPress 中控制 RSS 提要页脚的指南,了解更多提示和想法。
如何减少和防止 WordPress 博客爬网
考虑一下,如果您采用我们繁重的内部链接方法,添加附属链接、RSS 横幅等,您可能会在很大程度上减少内容抓取。如果您遵循 Jeff Starr 关于重定向内容爬虫的建议,那也会阻止这些爬虫。除了我们上面分享的内容之外,您还可以使用其他一些技巧。
完整和摘要 RSS 源
博客社区一直在争论是否存在完整的 RSS 提要或摘要 RSS 提要。我们不会详细讨论该辩论,但拥有仅摘要的 RSS 提要的优点之一是可以防止内容抓取。
您可以通过转到 WordPress 管理员并转到设置»阅读来更改设置。然后更改提要中每个 文章 的设置以收录全文或摘要。

