
抓取ajax动态网页java
浅谈Python网络爬虫
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-05-09 23:59
(2)数据解析:了解HTML结构、JSON和XML数据格式,CSS选择器、Xpath路径表达式、正则表达式等,目的是从响应中提取出所需的数据;
(3)数据入库:MySQL,SQLite、Redis等数据库,便于数据的存储;
相关技术
以上是学习爬虫的基本要求,在实际的应用中,也应考虑如何使用多线程提高效率、如何做任务调度、如何应对反爬虫,如何实现分布式爬虫等等。本文介绍的比较有限,仅供参考。
六 python相关库
在爬虫实现上,除了scrapy框架之外,python有许多与此相关的库可供使用。其中,在数据抓取方面包括: urllib2(urllib3)、requests、mechanize、selenium、splinter;在数据解析方包括:lxml、beautifulsoup4、re、pyquery。
对于数据抓取,涉及的过程主要是模拟浏览器向服务器发送构造好的http请求,常见类型有:get/post。其中,urllib2(urllib3)、requests、mechanize用来获取URL对应的原始响应内容;而selenium、splinter通过加载浏览器驱动,获取浏览器渲染之后的响应内容,模拟程度更高。
具体选择哪种类库,应根据实际需求决定,如考虑效率、对方的反爬虫手段等。通常,能使用urllib2(urllib3)、requests、mechanize等解决的尽量不用selenium、splinter,因为后者因需要加载浏览器而导致效率较低。
对于数据解析,主要是从响应页面里提取所需的数据,常用方法有:xpath路径表达式、CSS选择器、正则表达式等。其中,xpath路径表达式、CSS选择器主要用于提取结构化的数据,而正则表达式主要用于提取非结构化的数据。相应的库有lxml、beautifulsoup4、re、pyquery。
类库
文档
数 据 抓 取
urllib2
requests
mechanize
splinter
selenium
数 据 解 析
lxml
beautifulsoup4
re
pyquery
相关库文档
七.相关介绍
1 数据抓取
(1)urllib2
urllib2是python自带的一个访问网页及本地文件的库,通常需要与urllib一起使用。因为urllib提供了urlencode方法用来对发送的数据进行编码,而urllib2没有对应的方法。
以下是对urllib2简易封装的说明,主要是将相关的特性集中在了一个类函数里面,避免一些繁琐的配置工作。
urllib2封装说明
(2)requests和mechanize
requests是Python的第三方库,基于urllib,但比urllib更加方便,接口简单。其特点包括, 关于http请求:支持自定义请求头,支持设置代理、支持重定向、支持保持会话[request.Session()]、支持超时设置、对post数据自动urlencode; 关于http响应:可直接从响应中获得详细的数据,无需人工配置,包括:状态码、自动解码的响应内容、响应头中的各个字段;还内置JSON解码器。
mechanize是对urllib2部分功能的替换,能够更好的模拟浏览器行为,在web访问控制方面做得很全面。其特点包括:支持cookie设置、代理设置、重定向设置、简单的表单填写、浏览器历史记录和重载、referer头的添加(可选)、自动遵守robots.txt、自动处理HTTP-EQUIV和刷新等。
对requests和mechanize简易封装后的接口与urllib2一样,也是将相关特性集中在了一个类函数里面,这里不在重复说明,可参考所给代码。
(3)splinter和selenium
selenium(python)和splinter可以很好的模拟浏览器行为,二者通过加载浏览器驱动工作。在采集信息方面,降低了分析网络请求的麻烦,一般只需要知道数据页面对应的URL即可。由于要加载浏览器,所以效率方面相对较低。
默认情况下,优先使用的是Firefox浏览器。这里列出chrome和pantomjs(无头浏览器)驱动的下载地址,方便查找。
chrome和pantomjs驱动地址:
chrome :
pantomjs :
2 数据解析
对于数据解析,可用的库有lxml、beautifulsoup4、re、pyquery。其中,beautifulsoup4比较常用些。除了这些库的使用,可了解一下xpath路径表达式、CSS选择器、正则表达式的语法,便于从网页中提取数据。其中,chrome浏览器自带生成Xpath的功能。
chrome查看元素的xpath
如果能够基于网络分析,抓取到所需数据对应的页面,接下来,从页面中提取数据的工作就相对明确很多。具体的使用方法可参考文档,这里不在详细介绍。
八 反爬虫
1. 基本的反爬虫手段,主要是检测请求头中的字段,比如:User-Agent、referer等。针对这种情况,只要在请求中带上对应的字段即可。所构造http请求的各个字段最好跟在浏览器中发送的完全一样,但也不是必须。
2. 基于用户行为的反爬虫手段,主要是在后台对访问的IP(或User-Agent)进行统计,当超过某一设定的阈值,给予封锁。针对这种情况,可通过使用代理服务器解决,每隔几次请求,切换一下所用代理的IP地址(或通过使用User-Agent列表解决,每次从列表里随机选择一个使用)。这样的反爬虫方法可能会误伤用户。
3. 希望抓取的数据是如果通过ajax请求得到的,假如通过网络分析能够找到该ajax请求,也能分析出请求所需的具体参数,则直接模拟相应的http请求,即可从响应中得到对应的数据。这种情况,跟普通的请求没有什么区别。
4. 基于Java的反爬虫手段,主要是在响应数据页面之前,先返回一段带有Java代码的页面,用于验证访问者有无Java的执行环境,以确定使用的是不是浏览器。
通常情况下,这段JS代码执行后,会发送一个带参数key的请求,后台通过判断key的值来决定是响应真实的页面,还是响应伪造或错误的页面。因为key参数是动态生成的,每次都不一样,难以分析出其生成方法,使得无法构造对应的http请求。
比如网站 ,使用就是这种方式,具体可参见 。
在首次访问网站时,响应的JS内容会发送带yundun参数的请求,而yundun参数每次都不一样。
动态参数yundun
目前测试时,该Java代码执行后,发送的请求不再带有yundun参数,而是动态生成一个cookie,在随后的请求中带上该cookie,作用类似于yundun参数。
动态cookie
针对这样的反爬虫方法,爬虫方面需要能够解析执行Java,具体的方法可使用selenium或splinter,通过加载浏览器来实现。 查看全部
浅谈Python网络爬虫
(2)数据解析:了解HTML结构、JSON和XML数据格式,CSS选择器、Xpath路径表达式、正则表达式等,目的是从响应中提取出所需的数据;
(3)数据入库:MySQL,SQLite、Redis等数据库,便于数据的存储;
相关技术
以上是学习爬虫的基本要求,在实际的应用中,也应考虑如何使用多线程提高效率、如何做任务调度、如何应对反爬虫,如何实现分布式爬虫等等。本文介绍的比较有限,仅供参考。
六 python相关库
在爬虫实现上,除了scrapy框架之外,python有许多与此相关的库可供使用。其中,在数据抓取方面包括: urllib2(urllib3)、requests、mechanize、selenium、splinter;在数据解析方包括:lxml、beautifulsoup4、re、pyquery。
对于数据抓取,涉及的过程主要是模拟浏览器向服务器发送构造好的http请求,常见类型有:get/post。其中,urllib2(urllib3)、requests、mechanize用来获取URL对应的原始响应内容;而selenium、splinter通过加载浏览器驱动,获取浏览器渲染之后的响应内容,模拟程度更高。
具体选择哪种类库,应根据实际需求决定,如考虑效率、对方的反爬虫手段等。通常,能使用urllib2(urllib3)、requests、mechanize等解决的尽量不用selenium、splinter,因为后者因需要加载浏览器而导致效率较低。
对于数据解析,主要是从响应页面里提取所需的数据,常用方法有:xpath路径表达式、CSS选择器、正则表达式等。其中,xpath路径表达式、CSS选择器主要用于提取结构化的数据,而正则表达式主要用于提取非结构化的数据。相应的库有lxml、beautifulsoup4、re、pyquery。
类库
文档
数 据 抓 取
urllib2
requests
mechanize
splinter
selenium
数 据 解 析
lxml
beautifulsoup4
re
pyquery
相关库文档
七.相关介绍
1 数据抓取
(1)urllib2
urllib2是python自带的一个访问网页及本地文件的库,通常需要与urllib一起使用。因为urllib提供了urlencode方法用来对发送的数据进行编码,而urllib2没有对应的方法。
以下是对urllib2简易封装的说明,主要是将相关的特性集中在了一个类函数里面,避免一些繁琐的配置工作。
urllib2封装说明
(2)requests和mechanize
requests是Python的第三方库,基于urllib,但比urllib更加方便,接口简单。其特点包括, 关于http请求:支持自定义请求头,支持设置代理、支持重定向、支持保持会话[request.Session()]、支持超时设置、对post数据自动urlencode; 关于http响应:可直接从响应中获得详细的数据,无需人工配置,包括:状态码、自动解码的响应内容、响应头中的各个字段;还内置JSON解码器。
mechanize是对urllib2部分功能的替换,能够更好的模拟浏览器行为,在web访问控制方面做得很全面。其特点包括:支持cookie设置、代理设置、重定向设置、简单的表单填写、浏览器历史记录和重载、referer头的添加(可选)、自动遵守robots.txt、自动处理HTTP-EQUIV和刷新等。
对requests和mechanize简易封装后的接口与urllib2一样,也是将相关特性集中在了一个类函数里面,这里不在重复说明,可参考所给代码。
(3)splinter和selenium
selenium(python)和splinter可以很好的模拟浏览器行为,二者通过加载浏览器驱动工作。在采集信息方面,降低了分析网络请求的麻烦,一般只需要知道数据页面对应的URL即可。由于要加载浏览器,所以效率方面相对较低。
默认情况下,优先使用的是Firefox浏览器。这里列出chrome和pantomjs(无头浏览器)驱动的下载地址,方便查找。
chrome和pantomjs驱动地址:
chrome :
pantomjs :
2 数据解析
对于数据解析,可用的库有lxml、beautifulsoup4、re、pyquery。其中,beautifulsoup4比较常用些。除了这些库的使用,可了解一下xpath路径表达式、CSS选择器、正则表达式的语法,便于从网页中提取数据。其中,chrome浏览器自带生成Xpath的功能。
chrome查看元素的xpath
如果能够基于网络分析,抓取到所需数据对应的页面,接下来,从页面中提取数据的工作就相对明确很多。具体的使用方法可参考文档,这里不在详细介绍。
八 反爬虫
1. 基本的反爬虫手段,主要是检测请求头中的字段,比如:User-Agent、referer等。针对这种情况,只要在请求中带上对应的字段即可。所构造http请求的各个字段最好跟在浏览器中发送的完全一样,但也不是必须。
2. 基于用户行为的反爬虫手段,主要是在后台对访问的IP(或User-Agent)进行统计,当超过某一设定的阈值,给予封锁。针对这种情况,可通过使用代理服务器解决,每隔几次请求,切换一下所用代理的IP地址(或通过使用User-Agent列表解决,每次从列表里随机选择一个使用)。这样的反爬虫方法可能会误伤用户。
3. 希望抓取的数据是如果通过ajax请求得到的,假如通过网络分析能够找到该ajax请求,也能分析出请求所需的具体参数,则直接模拟相应的http请求,即可从响应中得到对应的数据。这种情况,跟普通的请求没有什么区别。
4. 基于Java的反爬虫手段,主要是在响应数据页面之前,先返回一段带有Java代码的页面,用于验证访问者有无Java的执行环境,以确定使用的是不是浏览器。
通常情况下,这段JS代码执行后,会发送一个带参数key的请求,后台通过判断key的值来决定是响应真实的页面,还是响应伪造或错误的页面。因为key参数是动态生成的,每次都不一样,难以分析出其生成方法,使得无法构造对应的http请求。
比如网站 ,使用就是这种方式,具体可参见 。
在首次访问网站时,响应的JS内容会发送带yundun参数的请求,而yundun参数每次都不一样。
动态参数yundun
目前测试时,该Java代码执行后,发送的请求不再带有yundun参数,而是动态生成一个cookie,在随后的请求中带上该cookie,作用类似于yundun参数。
动态cookie
针对这样的反爬虫方法,爬虫方面需要能够解析执行Java,具体的方法可使用selenium或splinter,通过加载浏览器来实现。
抓取ajax动态网页java(点题外话吧,京东图书模拟浏览器的一些事儿)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-20 06:19
让我先离题。刚开始学爬虫的时候,有一次学长给我一个请求,要抓取京东图书的相关资料。嗯,因为我真的是刚开始学爬,用豆瓣练的很成功。我抓取了大约 500 条电影评论,然后将它们存储在 mysql 中。. . .
然后充满信心地开始工作。. 首先查看网页源代码。. . ? ? ? 我需要的不在源代码中!!!然后我问了校长。前辈告诉我这是AJAX生成的数据,我听完就去查数据。发现网上的信息在说明一个道理。对于动态页面,使用 PhantomJs 进行爬取,但是这样效率很低。作为一名优秀的程序员,当时看到“低效率”这两个字,心里是绝对不允许的,于是我就用抓包的方法去查看AJAX数据所在的URL。对于这种模拟浏览器方法一直搁置到现在。
但既然你知道了这一点,就没有理由不学习它。所以花点时间看了一下在Java中使用PhantomJs的资料,现在就分享给大家。
顺便说一句,其实作为一个网络爬虫,90%的页面数据都是通过抓包获取的。所以我还是鼓励大家直接请求自己需要的数据所在的URL。毕竟,这种方法虽然方便,但效率低下。
使用 AJAX 进行 JS 渲染
在学习这个东西之前,我们首先要了解什么是JS渲染,什么是AJAX,以及为什么我们在网页源码中取不到这两种数据。
根据我的理解,JS渲染和AJAX是相辅相成的关系。AJAX负责从服务器端异步获取数据,然后用JS渲染数据,最后呈现给用户。由于在Java中,HttpClient只能请求一个简单的静态页面,无法请求页面满载后JS调用相关代码生成的异步数据,所以我们无法通过HttpClient直接获取AJAX和JS渲染生成的数据。这时候根据上面的推荐,可以直接抓包获取AJAX数据所在的URL,或者使用本文提到的PhantomJs渲染引擎。
三大JS渲染引擎对比
在互联网上搜索信息时,我们常常被五花八门的答案弄得不知所措。这个时候要保持冷静的心情,二要考虑搜索问题的相关姿势,必要时要科学上网。
先不说本文提到的JS渲染引擎。只说Java爬虫中的HTTP请求库,可以有多种描述方式,Java自带的HttpURLConnection类,HttpClient第三方库等等,当然网上有这么多。方法,我们要选择,那么我们肯定要选择一个强大而简单的类库。这时候我们应该在网上搜索两个类库的相关对比,做出更好的选择,而不是随便挑一个就学,这样很可能投入的学习成本与回报不成正比。
那么相信大家在准备用JS引擎模拟浏览器的时候,看到的不光是PhantomJs,还有Selenium和HtmlUnit,它们的功能是一样的。那么我们该如何选择呢?下图摘自其他网友的博客:
HtmlUnitSeleniumPhantomJs
内置Rhinojs浏览器引擎,没有浏览器使用这个内核,解析速度一般,JS/CSS解析差,没有浏览器界面。
Selenium + WebDriver = Selenium是基于本地安装的浏览器,需要打开浏览器,需要参考对应的WebDriver,并正确配置webdriver的路径参数,这在爬取大量js时显然是不合适的渲染页面。
神器,短小精悍,可以本地运行,也可以作为服务器运行,基于webkit内核,性能和性能都不错,可以完美解析大部分页面。
这就是我选择谈论 PhantomJs 的原因。
PhantomJs 和 Selenium 经常成对出现在 Internet 上。原因是 Selenium 封装了 PhantomJs 的一些功能,而 Selenium 提供了 Python 接口模块。在 Python 语言中,Selenium 可以很好地使用,PhantomJs 可以间接使用。然而,是时候放弃 Selenium+PhantomJs 了。一个原因是封装的接口很久没有更新(没人维护),第二个原因是Selenium只实现了PhantomJs的一部分功能,很不完善。
PhantomJ 的使用
我使用的是Ubuntu16.04的开发环境。关于 PhantomJs + Selenium 的环境部署,网上有很多资料。这里给大家介绍一个链接,我就不详细解释了:Ubuntu install phantomjs
PhantomJs和Selenium的介绍我就不赘述了,你可以直接百度。我们直接看一下如何在Java中使用PhantomJs吧~
如果您不使用 Maven,请在线下载第三方 jar。我们需要的Maven依赖如下:
org.seleniumhq.selenium
selenium-java
2.53.1
com.github.detro.ghostdriver
phantomjsdriver
1.1.0
接下来,我们来看看程序应该怎么写:
1.设置请求头
//设置必要参数
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持(第二参数表明的是你的phantomjs引擎所在的路径,使用whereis phantomjs可以查看)
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY, "/usr/local/bin/phantomjs");
2.创建phantomjs浏览器对象
//创建无界面浏览器对象
PhantomJSDriver driver = new PhantomJSDriver(dcaps);
3.设置隐式等待
//设置隐性等待
driver.manage().timeouts().implicitlyWait(1, TimeUnit.SECONDS);
因为加载页面需要一段时间,如果页面没有加载,搜索到元素,肯定是找不到。最好的方法是设置默认等待时间。如果找不到页面元素,请稍等片刻,然后再次查找,直到超时。
以上三点是使用 PhantomJs 时需要注意的地方。大家可以看一下大致的整体方案:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import java.util.concurrent.TimeUnit;
/**
* Created by hg_yi on 17-10-11.
*/
public class phantomjs {
public static void main(String[] args) {
//设置必要参数
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持(第二参数表明的是你的phantomjs引擎所在的路径)
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,
"/usr/bin/phantomjs-2.1.1-linux-x86_64/bin/phantomjs");
//创建无界面浏览器对象
PhantomJSDriver driver = new PhantomJSDriver(dcaps);
//设置隐性等待(作用于全局)
driver.manage().timeouts().implicitlyWait(1, TimeUnit.SECONDS);
//打开页面
driver.get("--------------------------------");
//查找元素
WebElement element = driver.findElement(By.id("img_valiCode"));
System.out.println(element.getAttribute("src"));
}
}
成功抓取了网页源码中没有的数据~
关于上面用到的PhantomJSDriver类的相关API,你可以直接看这个资料,应该可以满足你的日常需求:webdriver API中文版(WebDriver API也适用于PhantomJSDriver)。
PhantomJs 的性能优化
我们都知道使用PhantomJs这样的无头浏览器来爬取网页源码是非常耗时的,所以当我们决定使用这个工具并且对爬取速度有一定要求的时候,就需要掌握PhantomJs的性能优化。能力。
1.设置参数
google、百度了半天,也看了一些官方文档,但是还是找不到PhantomJs相关的Java调用API文档。好吧,我们先扔一个Python,然后找到这个区域的内容再添加吧~~
【phantomjs系列】Selenium+Phantomjs性能优化
题外话:实际上是用于 Java 网络爬虫。. . 我真的很想投诉。建议刚开始学爬虫的人改用Python爬虫~~对于Java爬虫,我只能说一句话:学习难,学习周期长,投入与收益不成正比!!! 查看全部
抓取ajax动态网页java(点题外话吧,京东图书模拟浏览器的一些事儿)
让我先离题。刚开始学爬虫的时候,有一次学长给我一个请求,要抓取京东图书的相关资料。嗯,因为我真的是刚开始学爬,用豆瓣练的很成功。我抓取了大约 500 条电影评论,然后将它们存储在 mysql 中。. . .
然后充满信心地开始工作。. 首先查看网页源代码。. . ? ? ? 我需要的不在源代码中!!!然后我问了校长。前辈告诉我这是AJAX生成的数据,我听完就去查数据。发现网上的信息在说明一个道理。对于动态页面,使用 PhantomJs 进行爬取,但是这样效率很低。作为一名优秀的程序员,当时看到“低效率”这两个字,心里是绝对不允许的,于是我就用抓包的方法去查看AJAX数据所在的URL。对于这种模拟浏览器方法一直搁置到现在。
但既然你知道了这一点,就没有理由不学习它。所以花点时间看了一下在Java中使用PhantomJs的资料,现在就分享给大家。
顺便说一句,其实作为一个网络爬虫,90%的页面数据都是通过抓包获取的。所以我还是鼓励大家直接请求自己需要的数据所在的URL。毕竟,这种方法虽然方便,但效率低下。
使用 AJAX 进行 JS 渲染
在学习这个东西之前,我们首先要了解什么是JS渲染,什么是AJAX,以及为什么我们在网页源码中取不到这两种数据。
根据我的理解,JS渲染和AJAX是相辅相成的关系。AJAX负责从服务器端异步获取数据,然后用JS渲染数据,最后呈现给用户。由于在Java中,HttpClient只能请求一个简单的静态页面,无法请求页面满载后JS调用相关代码生成的异步数据,所以我们无法通过HttpClient直接获取AJAX和JS渲染生成的数据。这时候根据上面的推荐,可以直接抓包获取AJAX数据所在的URL,或者使用本文提到的PhantomJs渲染引擎。
三大JS渲染引擎对比
在互联网上搜索信息时,我们常常被五花八门的答案弄得不知所措。这个时候要保持冷静的心情,二要考虑搜索问题的相关姿势,必要时要科学上网。
先不说本文提到的JS渲染引擎。只说Java爬虫中的HTTP请求库,可以有多种描述方式,Java自带的HttpURLConnection类,HttpClient第三方库等等,当然网上有这么多。方法,我们要选择,那么我们肯定要选择一个强大而简单的类库。这时候我们应该在网上搜索两个类库的相关对比,做出更好的选择,而不是随便挑一个就学,这样很可能投入的学习成本与回报不成正比。
那么相信大家在准备用JS引擎模拟浏览器的时候,看到的不光是PhantomJs,还有Selenium和HtmlUnit,它们的功能是一样的。那么我们该如何选择呢?下图摘自其他网友的博客:
HtmlUnitSeleniumPhantomJs
内置Rhinojs浏览器引擎,没有浏览器使用这个内核,解析速度一般,JS/CSS解析差,没有浏览器界面。
Selenium + WebDriver = Selenium是基于本地安装的浏览器,需要打开浏览器,需要参考对应的WebDriver,并正确配置webdriver的路径参数,这在爬取大量js时显然是不合适的渲染页面。
神器,短小精悍,可以本地运行,也可以作为服务器运行,基于webkit内核,性能和性能都不错,可以完美解析大部分页面。
这就是我选择谈论 PhantomJs 的原因。
PhantomJs 和 Selenium 经常成对出现在 Internet 上。原因是 Selenium 封装了 PhantomJs 的一些功能,而 Selenium 提供了 Python 接口模块。在 Python 语言中,Selenium 可以很好地使用,PhantomJs 可以间接使用。然而,是时候放弃 Selenium+PhantomJs 了。一个原因是封装的接口很久没有更新(没人维护),第二个原因是Selenium只实现了PhantomJs的一部分功能,很不完善。
PhantomJ 的使用
我使用的是Ubuntu16.04的开发环境。关于 PhantomJs + Selenium 的环境部署,网上有很多资料。这里给大家介绍一个链接,我就不详细解释了:Ubuntu install phantomjs
PhantomJs和Selenium的介绍我就不赘述了,你可以直接百度。我们直接看一下如何在Java中使用PhantomJs吧~
如果您不使用 Maven,请在线下载第三方 jar。我们需要的Maven依赖如下:
org.seleniumhq.selenium
selenium-java
2.53.1
com.github.detro.ghostdriver
phantomjsdriver
1.1.0
接下来,我们来看看程序应该怎么写:
1.设置请求头
//设置必要参数
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持(第二参数表明的是你的phantomjs引擎所在的路径,使用whereis phantomjs可以查看)
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY, "/usr/local/bin/phantomjs");
2.创建phantomjs浏览器对象
//创建无界面浏览器对象
PhantomJSDriver driver = new PhantomJSDriver(dcaps);
3.设置隐式等待
//设置隐性等待
driver.manage().timeouts().implicitlyWait(1, TimeUnit.SECONDS);
因为加载页面需要一段时间,如果页面没有加载,搜索到元素,肯定是找不到。最好的方法是设置默认等待时间。如果找不到页面元素,请稍等片刻,然后再次查找,直到超时。
以上三点是使用 PhantomJs 时需要注意的地方。大家可以看一下大致的整体方案:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import java.util.concurrent.TimeUnit;
/**
* Created by hg_yi on 17-10-11.
*/
public class phantomjs {
public static void main(String[] args) {
//设置必要参数
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持(第二参数表明的是你的phantomjs引擎所在的路径)
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,
"/usr/bin/phantomjs-2.1.1-linux-x86_64/bin/phantomjs");
//创建无界面浏览器对象
PhantomJSDriver driver = new PhantomJSDriver(dcaps);
//设置隐性等待(作用于全局)
driver.manage().timeouts().implicitlyWait(1, TimeUnit.SECONDS);
//打开页面
driver.get("--------------------------------");
//查找元素
WebElement element = driver.findElement(By.id("img_valiCode"));
System.out.println(element.getAttribute("src"));
}
}
成功抓取了网页源码中没有的数据~
关于上面用到的PhantomJSDriver类的相关API,你可以直接看这个资料,应该可以满足你的日常需求:webdriver API中文版(WebDriver API也适用于PhantomJSDriver)。
PhantomJs 的性能优化
我们都知道使用PhantomJs这样的无头浏览器来爬取网页源码是非常耗时的,所以当我们决定使用这个工具并且对爬取速度有一定要求的时候,就需要掌握PhantomJs的性能优化。能力。
1.设置参数
google、百度了半天,也看了一些官方文档,但是还是找不到PhantomJs相关的Java调用API文档。好吧,我们先扔一个Python,然后找到这个区域的内容再添加吧~~
【phantomjs系列】Selenium+Phantomjs性能优化
题外话:实际上是用于 Java 网络爬虫。. . 我真的很想投诉。建议刚开始学爬虫的人改用Python爬虫~~对于Java爬虫,我只能说一句话:学习难,学习周期长,投入与收益不成正比!!!
抓取ajax动态网页java(HTML源码中的内容由前端的JS动态生成的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-04-19 03:29
)
我们之前爬取的大部分网页都是从 HTML 静态生成的内容,而我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样的。
网站的部分内容是由前端JS动态生成的。由于网页上显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中是找不到的。例如今日头条:
浏览器渲染的网页如下图所示:
看源码,如下图:
网页的新闻在 HTML 源代码中是找不到的,都是 JS 动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方法:
这里只介绍第一种方法。有一篇专门的文章介绍了 Selenium 的使用。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例来说明:
1、来自JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”选项卡后,有很多响应,所以让我们过滤并仅查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现少了很多链接,点一个就可以看到了:
我们选择city,预览中有一串json数据:
让我们再次点击查看:
原来是一个城市列表,应该是用来加载区域新闻的。
现在你大概明白如何找到 JS 请求的接口了吧?但是刚才我们没有找到想要的消息,我们再看一遍:
有一个焦点,我们点击它看看:
首页图片新闻呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这应该是热搜关键词
这是图片新闻下的新闻。
我们打开一个界面链接看看:
返回一堆乱码,但查看响应是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法请求数据接口并得到响应
2、请求和解析数据接口数据
先完整代码:
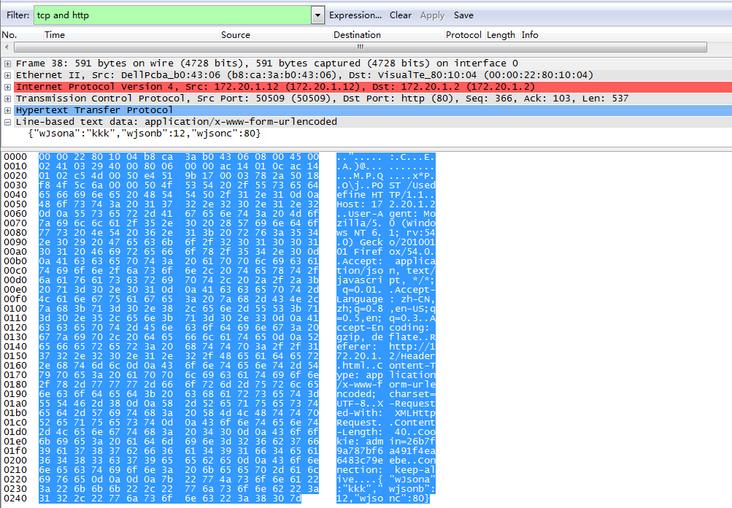
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:
像往常一样,对代码做一点解释:
代码分为四部分,
第 1 部分:介绍相关库
# coding:utf-8
import requests
import json
第 2 部分:向数据接口发出 http 请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
抓取ajax动态网页java(HTML源码中的内容由前端的JS动态生成的应用
)
我们之前爬取的大部分网页都是从 HTML 静态生成的内容,而我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样的。
网站的部分内容是由前端JS动态生成的。由于网页上显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中是找不到的。例如今日头条:
浏览器渲染的网页如下图所示:

看源码,如下图:

网页的新闻在 HTML 源代码中是找不到的,都是 JS 动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方法:
这里只介绍第一种方法。有一篇专门的文章介绍了 Selenium 的使用。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例来说明:
1、来自JS请求的数据接口
F12 打开网页调试工具

网页调试工具
选择“网络”选项卡后,有很多响应,所以让我们过滤并仅查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现少了很多链接,点一个就可以看到了:
我们选择city,预览中有一串json数据:

让我们再次点击查看:

原来是一个城市列表,应该是用来加载区域新闻的。
现在你大概明白如何找到 JS 请求的接口了吧?但是刚才我们没有找到想要的消息,我们再看一遍:
有一个焦点,我们点击它看看:

首页图片新闻呈现的数据是一样的,所以数据应该是有的。
查看其他链接:

这应该是热搜关键词

这是图片新闻下的新闻。
我们打开一个界面链接看看:

返回一堆乱码,但查看响应是正常的编码数据:

有了对应的数据接口,我们就可以模仿前面的方法请求数据接口并得到响应
2、请求和解析数据接口数据
先完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:

像往常一样,对代码做一点解释:
代码分为四部分,
第 1 部分:介绍相关库
# coding:utf-8
import requests
import json
第 2 部分:向数据接口发出 http 请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
抓取ajax动态网页java(rvest从R中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-04-16 12:31
背景信息目前,我正在使用 rvest 从 R 中的一些 网站 中抓取产品信息。这适用于所有 网站 s,除了一个 网站 内容似乎是动态加载的通过 angularJS(?),因此不能迭代(例如通过 URL 参数)加载(就像我对其他 网站 所做的那样)。具体网址如下:
请记住,我在我的计算机上没有管理员权限,仅实施不需要或仅授予管理员权限一次的解决方案
期望的输出 最后,R 中的一个表收录产品信息(例如标签、价格、评级)=> 但是,在这个问题中,我完全需要帮助来动态加载和存储 网站。我可以自己处理 R 中的后处理。如果你能把我推向正确的方向,那就太好了。也许我下面列出的方法之一是正确的,但我似乎无法将这些转移到指定的 网站。
目前的方法,我发现 phantomJS 是一个无头浏览器,应该能够处理这个问题。我对 Java 脚本几乎一无所知,而且语法(至少对我而言)与我更习惯的语言(R、Matlab、SQL)非常不同,而且我真的很难在其他语言中实现可能在我的代码中其他地方工作的方法。基于这个例子(非常感谢),我设法从使用以下代码显示的第一页中至少检索到信息:
回复:
<p>require(rvest)
## change Phantom.js scrape file
url 查看全部
抓取ajax动态网页java(rvest从R中的应用)
背景信息目前,我正在使用 rvest 从 R 中的一些 网站 中抓取产品信息。这适用于所有 网站 s,除了一个 网站 内容似乎是动态加载的通过 angularJS(?),因此不能迭代(例如通过 URL 参数)加载(就像我对其他 网站 所做的那样)。具体网址如下:
请记住,我在我的计算机上没有管理员权限,仅实施不需要或仅授予管理员权限一次的解决方案
期望的输出 最后,R 中的一个表收录产品信息(例如标签、价格、评级)=> 但是,在这个问题中,我完全需要帮助来动态加载和存储 网站。我可以自己处理 R 中的后处理。如果你能把我推向正确的方向,那就太好了。也许我下面列出的方法之一是正确的,但我似乎无法将这些转移到指定的 网站。
目前的方法,我发现 phantomJS 是一个无头浏览器,应该能够处理这个问题。我对 Java 脚本几乎一无所知,而且语法(至少对我而言)与我更习惯的语言(R、Matlab、SQL)非常不同,而且我真的很难在其他语言中实现可能在我的代码中其他地方工作的方法。基于这个例子(非常感谢),我设法从使用以下代码显示的第一页中至少检索到信息:
回复:
<p>require(rvest)
## change Phantom.js scrape file
url
抓取ajax动态网页java( 推荐:《PHP视频教JAVA中应用AJAX的中文乱码的解决办法方法》 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-04-13 22:14
推荐:《PHP视频教JAVA中应用AJAX的中文乱码的解决办法方法》
)
如何去除php中的nbsp:首先创建一个PHP代码示例文件;然后通过 "preg_replace("/(\s|\ \;||\xc2\xa0)/", " ", strip_tags ($val));" 方法删除所有nbsp。推荐:"PHP视频教学
JAVA中使用AJAX解决中文乱码问题:1、Ajax提交使用escape或encodeURI方式,必须使用两次; 2、后台java使用[.URLDecoder]类的decode方法。 【相关学习推荐:java基础知识】
java ajax提交返回值中文乱码如何解决:1、在RequestMapping的并发配置中添加代码[products=text/html;charset=UTF-8];2、在在[mvc:annotation-driven]文件中添加代码。
1、什么是AJAX,为什么要使用Ajax(请谈谈你对Ajax的理解) 什么是ajax:AJAX是“Asynchronous JavaScript and XML”的缩写。他提到了一种用于创建交互式 Web 应用程序的 Web 开发技术。 ajax包
运行java类文件方法:1、用main方法执行类文件,命令行为[java]; 2、执行的class文件被打包,在class文件中使用[package],命令行为[java .CLASS]。运行
【相关学习推荐:Java基础教程】需要通过ajax异步刷新页面,验证用户输入的账号密码是否存在于数据库中。技术栈JSP+Servlet+Oracle具体代码JSP部分:
【相关视频推荐:ajax视频教程】环境:eclipse+struts要达到的效果:点击按钮提交数据到后台再返回前台显示数据index.jsp
了解 Ajax 封装
2020-09-24
相关学习推荐:ajax前言的上一篇文章文章讲了ajax的原理、功能和实现。但是他们只实现了一个ajax请求响应操作。浏览器和服务器之间不会只有一个请求响应。如果你添加一个请求响应100次,那么你需要写100次。
ajax 19 个经典面试题1、什么是AJAX,为什么要使用Ajax(请谈谈你对Ajax 的了解) 什么是ajax:AJAX 是“Asynchronous JavaScript and XML”的缩写。他提到了一种创建交互式网络应用程序的方法
Java学习步骤为:1、进入Java语言基础学习阶段;2、掌握面向对象语言的通用性;3、精通JDK核心API编程技术;< @k43@ >精通SQL语句; 5、精通JDBC API; 6、理解迭代的含义; 7、手掌
中国网科技7月24日消息 今天,工信部发布了今年第三批侵犯用户权益的APP通知。报道称,截至目前,仍有58个APP未完成整改。对于有问题的APP,应在7月30日前完成整改
开发和运行一个java程序的三个主要步骤是:1、编辑源程序;2、生成字节码;3、解释和运行字节码。 Java是一种面向对象的编程语言,具有简单、面向对象、安全、健壮、多线程、可移植性等特点
了解 ajax
2020-09-23
相关文章推荐:ajax视频教程1.1 ajax是什么:Ajax是“Asynchronous Javascript And XML”(异步JavaScript和XML),是指用于创建交互式Web应用的网页开发技术。 Ajax=异步 JavaScript
【相关学习推荐:Java基础课程】1、什么是JSONP一般来说,位于的网页无法与不在的服务器通信,HTML元素除外。
1:什么是ajax? ajax的作用是什么?异步 javascript 和 xml AJAX 是一种用于创建快速和动态网页的技术。 ajax用于与后台交互2:原生js ajax请求有多少步?分别是什么//创建XMLHttp
查看全部
抓取ajax动态网页java(
推荐:《PHP视频教JAVA中应用AJAX的中文乱码的解决办法方法》
)
如何去除php中的nbsp:首先创建一个PHP代码示例文件;然后通过 "preg_replace("/(\s|\ \;||\xc2\xa0)/", " ", strip_tags ($val));" 方法删除所有nbsp。推荐:"PHP视频教学

JAVA中使用AJAX解决中文乱码问题:1、Ajax提交使用escape或encodeURI方式,必须使用两次; 2、后台java使用[.URLDecoder]类的decode方法。 【相关学习推荐:java基础知识】
java ajax提交返回值中文乱码如何解决:1、在RequestMapping的并发配置中添加代码[products=text/html;charset=UTF-8];2、在在[mvc:annotation-driven]文件中添加代码。
1、什么是AJAX,为什么要使用Ajax(请谈谈你对Ajax的理解) 什么是ajax:AJAX是“Asynchronous JavaScript and XML”的缩写。他提到了一种用于创建交互式 Web 应用程序的 Web 开发技术。 ajax包
运行java类文件方法:1、用main方法执行类文件,命令行为[java]; 2、执行的class文件被打包,在class文件中使用[package],命令行为[java .CLASS]。运行
【相关学习推荐:Java基础教程】需要通过ajax异步刷新页面,验证用户输入的账号密码是否存在于数据库中。技术栈JSP+Servlet+Oracle具体代码JSP部分:
【相关视频推荐:ajax视频教程】环境:eclipse+struts要达到的效果:点击按钮提交数据到后台再返回前台显示数据index.jsp
了解 Ajax 封装
2020-09-24
相关学习推荐:ajax前言的上一篇文章文章讲了ajax的原理、功能和实现。但是他们只实现了一个ajax请求响应操作。浏览器和服务器之间不会只有一个请求响应。如果你添加一个请求响应100次,那么你需要写100次。
ajax 19 个经典面试题1、什么是AJAX,为什么要使用Ajax(请谈谈你对Ajax 的了解) 什么是ajax:AJAX 是“Asynchronous JavaScript and XML”的缩写。他提到了一种创建交互式网络应用程序的方法
Java学习步骤为:1、进入Java语言基础学习阶段;2、掌握面向对象语言的通用性;3、精通JDK核心API编程技术;< @k43@ >精通SQL语句; 5、精通JDBC API; 6、理解迭代的含义; 7、手掌
中国网科技7月24日消息 今天,工信部发布了今年第三批侵犯用户权益的APP通知。报道称,截至目前,仍有58个APP未完成整改。对于有问题的APP,应在7月30日前完成整改
开发和运行一个java程序的三个主要步骤是:1、编辑源程序;2、生成字节码;3、解释和运行字节码。 Java是一种面向对象的编程语言,具有简单、面向对象、安全、健壮、多线程、可移植性等特点
了解 ajax
2020-09-23
相关文章推荐:ajax视频教程1.1 ajax是什么:Ajax是“Asynchronous Javascript And XML”(异步JavaScript和XML),是指用于创建交互式Web应用的网页开发技术。 Ajax=异步 JavaScript
【相关学习推荐:Java基础课程】1、什么是JSONP一般来说,位于的网页无法与不在的服务器通信,HTML元素除外。
1:什么是ajax? ajax的作用是什么?异步 javascript 和 xml AJAX 是一种用于创建快速和动态网页的技术。 ajax用于与后台交互2:原生js ajax请求有多少步?分别是什么//创建XMLHttp
抓取ajax动态网页java(什么是静态网页,什么事动态网页呢?济南网站建设 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-11 12:25
)
对于很多网站建筑专业的程序员来说,你问他们什么是静态页面,就像问大人“1+2等于多少”一样简单,但是对于那些不知道网站@ > 程序 还是有不少人分不清“静态页面”和“动态页面”。
那么什么是静态网页,什么是动态网页呢?让我给你解释一下:
1、静态网页:
在网站的设计中,静态网页是标准的HTML(标记语言)文件,文件扩展名为.htm、.html,可以收录文本、图像、声音、FLASH动画、脚本和ActiveX控件以及JAVA小程序等。静态网页是构建网站的基础,早期的网站一般都是由静态网页制作而成。与动态网页相比,静态网页是指没有后台数据库、不收录程序、非交互性的网页。静态网页更新比较麻烦,适用于一般更新较少的显示类型网站。
优点:网址稳定;访问速度快;每个网页都是一个独立的文件,保存在服务器上;内容稳定,易于被搜索引擎检索,对搜索引擎友好,有利于SEO。
缺点:缺乏交互性;没有数据库支持,网站 信息太多,网站 制作难度很大。
2、动态网页
一种与静态网页相对应的网页编程技术,可以与后台数据库交互、数据传输、URL后缀,不是.html等静态网页常见的网页制作格式,一般是.aspx、. asp、.jsp、.php、.perl、.cgi等为后缀,动态网址中有标志性符号。
优点:交互性强;有数据库支持,网站构建难度降低,可大大减少网站维护工作量;可实现用户登录、注册等多项功能;
缺点:访问速度慢,用户体验差;搜索引擎难以抓取,但现在很多搜索引擎已经开始支持动态网页的抓取。
因此,无论是静态网页还是动态网页,都各有优缺点。不能说所有的静态页面都是为了搜索引擎优化,或者动态页面都是为了维护方便。济南网站建站专家()提醒大家,选择建站方案需要根据自己的需要采用动静结合的方法进行网站施工。动态和静态 Web 内容共存于同一个 网站 上也很常见。
查看全部
抓取ajax动态网页java(什么是静态网页,什么事动态网页呢?济南网站建设
)
对于很多网站建筑专业的程序员来说,你问他们什么是静态页面,就像问大人“1+2等于多少”一样简单,但是对于那些不知道网站@ > 程序 还是有不少人分不清“静态页面”和“动态页面”。
那么什么是静态网页,什么是动态网页呢?让我给你解释一下:
1、静态网页:
在网站的设计中,静态网页是标准的HTML(标记语言)文件,文件扩展名为.htm、.html,可以收录文本、图像、声音、FLASH动画、脚本和ActiveX控件以及JAVA小程序等。静态网页是构建网站的基础,早期的网站一般都是由静态网页制作而成。与动态网页相比,静态网页是指没有后台数据库、不收录程序、非交互性的网页。静态网页更新比较麻烦,适用于一般更新较少的显示类型网站。
优点:网址稳定;访问速度快;每个网页都是一个独立的文件,保存在服务器上;内容稳定,易于被搜索引擎检索,对搜索引擎友好,有利于SEO。
缺点:缺乏交互性;没有数据库支持,网站 信息太多,网站 制作难度很大。
2、动态网页
一种与静态网页相对应的网页编程技术,可以与后台数据库交互、数据传输、URL后缀,不是.html等静态网页常见的网页制作格式,一般是.aspx、. asp、.jsp、.php、.perl、.cgi等为后缀,动态网址中有标志性符号。
优点:交互性强;有数据库支持,网站构建难度降低,可大大减少网站维护工作量;可实现用户登录、注册等多项功能;
缺点:访问速度慢,用户体验差;搜索引擎难以抓取,但现在很多搜索引擎已经开始支持动态网页的抓取。
因此,无论是静态网页还是动态网页,都各有优缺点。不能说所有的静态页面都是为了搜索引擎优化,或者动态页面都是为了维护方便。济南网站建站专家()提醒大家,选择建站方案需要根据自己的需要采用动静结合的方法进行网站施工。动态和静态 Web 内容共存于同一个 网站 上也很常见。

抓取ajax动态网页java(什么是ajax呢,简单来说,就是加载一个网页完毕)
网站优化 • 优采云 发表了文章 • 0 个评论 • 369 次浏览 • 2022-04-11 05:30
什么是ajax?简单来说就是加载一个网页后,还是看不到一些信息,需要点击一个按钮才能看到数据,或者有些网页的页面数据很多,而你在点击下一页,网页的url地址没有变,但是内容变了,可以说是ajax了。如果你还是不明白,我给你看百度百科的解释,这里是解释。
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML(标准通用标记语言的子集)。
Ajax 是一种用于创建快速和动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页部分的技术。[
Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
让我们谈谈一个例子。我爬过的最难的ajax页面是网易云音乐的评论。如果你有兴趣,你可以看看。
这里的评论都是ajax加载的,其他抢到今日头条妹子图片的也是ajax加载的,不过我简化了。还有很多,就不多说了,先说说我今天要说的ajax网站吧!
这是肯德基的门面信息
这里有很多页的数据,每页的数据都是ajax加载的。如果直接用python去请求上面的url,估计是拿不到任何数据的。如果你不相信,你可以试试。这时候,我们照常打开开发者工具。首先清除所有请求,勾选连续日志,然后点击下一页,你会看到
上面的请求就是ajax请求的网页,里面会有我们需要的数据。让我们看看是什么样的请求
这是一个发布请求。请求成功状态码是 200。请求 url 也在那里。以下来自 data 是我们需要发布的数据。很容易猜到pageIndex就是页数,所以我们可以改变这个值来翻页。
这个网页分析完了,这就是ajax动态网页的解决方案,是不是觉得很简单,其实不然,但是这个网页还是比较简单的,因为form的数据(来自data) 没有加密,如果是加密的话,估计你找个js文件看看参数是怎么加密的。这是我之前写的网易云音乐评论的爬取。看着这些被混淆的js寻找加密方法有时会让人头疼,所以人们经常选择使用selenium进行爬虫,但是使用这些会降低爬虫的性能,所以这种方法在工作中是不允许的。所以必须学会如何处理这些ajax。
粘贴代码
import requests
page = 1
while True:
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': '广州',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
response = requests.post(url, data=data)
print(response.json())
if response.json().get('Table1', ''):
page += 1
else:
break复制代码
可以看到,如果从数据中移除,不用十行代码就可以把所有的数据都爬下来,所以这个网站很适合练习,大家可以试试。
写在最后
在下一篇文章我会写一个复杂的ajax请求,这个网站
不知道有多少人想看,想看的就给个赞吧!或者你可以自己试试 查看全部
抓取ajax动态网页java(什么是ajax呢,简单来说,就是加载一个网页完毕)
什么是ajax?简单来说就是加载一个网页后,还是看不到一些信息,需要点击一个按钮才能看到数据,或者有些网页的页面数据很多,而你在点击下一页,网页的url地址没有变,但是内容变了,可以说是ajax了。如果你还是不明白,我给你看百度百科的解释,这里是解释。
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML(标准通用标记语言的子集)。
Ajax 是一种用于创建快速和动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页部分的技术。[
Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
让我们谈谈一个例子。我爬过的最难的ajax页面是网易云音乐的评论。如果你有兴趣,你可以看看。
这里的评论都是ajax加载的,其他抢到今日头条妹子图片的也是ajax加载的,不过我简化了。还有很多,就不多说了,先说说我今天要说的ajax网站吧!
这是肯德基的门面信息
这里有很多页的数据,每页的数据都是ajax加载的。如果直接用python去请求上面的url,估计是拿不到任何数据的。如果你不相信,你可以试试。这时候,我们照常打开开发者工具。首先清除所有请求,勾选连续日志,然后点击下一页,你会看到
上面的请求就是ajax请求的网页,里面会有我们需要的数据。让我们看看是什么样的请求
这是一个发布请求。请求成功状态码是 200。请求 url 也在那里。以下来自 data 是我们需要发布的数据。很容易猜到pageIndex就是页数,所以我们可以改变这个值来翻页。
这个网页分析完了,这就是ajax动态网页的解决方案,是不是觉得很简单,其实不然,但是这个网页还是比较简单的,因为form的数据(来自data) 没有加密,如果是加密的话,估计你找个js文件看看参数是怎么加密的。这是我之前写的网易云音乐评论的爬取。看着这些被混淆的js寻找加密方法有时会让人头疼,所以人们经常选择使用selenium进行爬虫,但是使用这些会降低爬虫的性能,所以这种方法在工作中是不允许的。所以必须学会如何处理这些ajax。
粘贴代码
import requests
page = 1
while True:
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': '广州',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
response = requests.post(url, data=data)
print(response.json())
if response.json().get('Table1', ''):
page += 1
else:
break复制代码
可以看到,如果从数据中移除,不用十行代码就可以把所有的数据都爬下来,所以这个网站很适合练习,大家可以试试。
写在最后
在下一篇文章我会写一个复杂的ajax请求,这个网站
不知道有多少人想看,想看的就给个赞吧!或者你可以自己试试
抓取ajax动态网页java(接着高级查询中的字段都是在前台写好的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-07 09:26
继续上一个高级查询。下拉框中的字段都写在前台。这对于系统的灵活性来说是一个很大的缺点。
解决方案:
在数据库中创建类型字典表。在数据库表的下拉框中对应要添加的项目的中英文名称。
下拉框动态绑定数据库表中的必填字段。
高级查询
在高级查询点击事件中,除了显示查询框外,还为下拉框的绑定字段添加了一个功能。这是 addItems()。
实现代码:
//动态绑定下拉框项
function addItems() {
$.ajax({
url: "addItem.ashx/GetItem", //后台webservice里的方法名称
type: "post",
dataType: "json",
contentType: "application/json",
traditional: true,
success: function (data) {
for (var i in data) {
var jsonObj =data[i];
var optionstring = "";
for (var j = 0; j < jsonObj.length; j++) {
optionstring += "" + jsonObj[j].chinesename + "";
}
$("#dpdField1").html("请选择... "+optionstring);
}
},
error: function (msg) {
alert("出错了!");
}
});
};
背景代码:
public void ProcessRequest(HttpContext context)
{
//context.Response.ContentType = "text/plain";
//context.Response.Write("Hello World");
GetItem(context);
}
public void GetItem(HttpContext context)
{
string ReturnValue = string.Empty;
BasicInformationFacade basicInformationFacade = new BasicInformationFacade(); //实例化基础信息外观
DataTable dt = new DataTable();
dt = basicInformationFacade.itemsQuery(); //根据查询条件获取结果
ReturnValue = DataTableJson(dt);
context.Response.ContentType = "text/plain";
context.Response.Write(ReturnValue);
//return ReturnValue;
}
#region dataTable转换成Json格式
///
/// dataTable转换成Json格式
///
///
///
public string DataTableJson(DataTable dt)
{
StringBuilder jsonBuilder = new StringBuilder();
jsonBuilder.Append("{\"");
jsonBuilder.Append(dt.TableName.ToString());
jsonBuilder.Append("\":[");
for (int i = 0; i < dt.Rows.Count; i++)
{
jsonBuilder.Append("{");
for (int j = 0; j < dt.Columns.Count; j++)
{
jsonBuilder.Append("\"");
jsonBuilder.Append(dt.Columns[j].ColumnName);
jsonBuilder.Append("\":\"");
jsonBuilder.Append(dt.Rows[i][j].ToString());
jsonBuilder.Append("\",");
}
jsonBuilder.Remove(jsonBuilder.Length - 1, 1);
jsonBuilder.Append("},");
}
jsonBuilder.Remove(jsonBuilder.Length - 1, 1);
jsonBuilder.Append("]");
jsonBuilder.Append("}");
return jsonBuilder.ToString();
}
#endregion
使用ajax和json将数据源绑定到首页中的select。后台通过两个函数获取数据库表的数据,并将数据转换为Json格式返回给前台。前台收到数据后,解析数据,在下拉框中获取需要绑定的字段。绑定时,下拉框的每一项分别绑定一个文本和一个值。显示文本供用户选择。value值是用户选择一个字段,获取该字段的值,进行后台查询字段。 查看全部
抓取ajax动态网页java(接着高级查询中的字段都是在前台写好的)
继续上一个高级查询。下拉框中的字段都写在前台。这对于系统的灵活性来说是一个很大的缺点。
解决方案:
在数据库中创建类型字典表。在数据库表的下拉框中对应要添加的项目的中英文名称。
下拉框动态绑定数据库表中的必填字段。
高级查询
在高级查询点击事件中,除了显示查询框外,还为下拉框的绑定字段添加了一个功能。这是 addItems()。
实现代码:
//动态绑定下拉框项
function addItems() {
$.ajax({
url: "addItem.ashx/GetItem", //后台webservice里的方法名称
type: "post",
dataType: "json",
contentType: "application/json",
traditional: true,
success: function (data) {
for (var i in data) {
var jsonObj =data[i];
var optionstring = "";
for (var j = 0; j < jsonObj.length; j++) {
optionstring += "" + jsonObj[j].chinesename + "";
}
$("#dpdField1").html("请选择... "+optionstring);
}
},
error: function (msg) {
alert("出错了!");
}
});
};
背景代码:
public void ProcessRequest(HttpContext context)
{
//context.Response.ContentType = "text/plain";
//context.Response.Write("Hello World");
GetItem(context);
}
public void GetItem(HttpContext context)
{
string ReturnValue = string.Empty;
BasicInformationFacade basicInformationFacade = new BasicInformationFacade(); //实例化基础信息外观
DataTable dt = new DataTable();
dt = basicInformationFacade.itemsQuery(); //根据查询条件获取结果
ReturnValue = DataTableJson(dt);
context.Response.ContentType = "text/plain";
context.Response.Write(ReturnValue);
//return ReturnValue;
}
#region dataTable转换成Json格式
///
/// dataTable转换成Json格式
///
///
///
public string DataTableJson(DataTable dt)
{
StringBuilder jsonBuilder = new StringBuilder();
jsonBuilder.Append("{\"");
jsonBuilder.Append(dt.TableName.ToString());
jsonBuilder.Append("\":[");
for (int i = 0; i < dt.Rows.Count; i++)
{
jsonBuilder.Append("{");
for (int j = 0; j < dt.Columns.Count; j++)
{
jsonBuilder.Append("\"");
jsonBuilder.Append(dt.Columns[j].ColumnName);
jsonBuilder.Append("\":\"");
jsonBuilder.Append(dt.Rows[i][j].ToString());
jsonBuilder.Append("\",");
}
jsonBuilder.Remove(jsonBuilder.Length - 1, 1);
jsonBuilder.Append("},");
}
jsonBuilder.Remove(jsonBuilder.Length - 1, 1);
jsonBuilder.Append("]");
jsonBuilder.Append("}");
return jsonBuilder.ToString();
}
#endregion
使用ajax和json将数据源绑定到首页中的select。后台通过两个函数获取数据库表的数据,并将数据转换为Json格式返回给前台。前台收到数据后,解析数据,在下拉框中获取需要绑定的字段。绑定时,下拉框的每一项分别绑定一个文本和一个值。显示文本供用户选择。value值是用户选择一个字段,获取该字段的值,进行后台查询字段。
抓取ajax动态网页java(部分干部不想抓不会抓致问题拖炸|问责_新浪新闻拼出的评论通道(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-04-05 13:02
ajax页面是动态生成的,不能直接抓到。不过,也不是没有办法。通常,通过找到ajax通道的地址,仍然可以得到ajax通道的内容。
你可以从ajax所在的页面找到线索。当然,每一页都不一样,所以不要问我怎么死的。
给大家一个思路:使用火狐浏览器监控页面信息。当您点击请求时,会出现频道地址信息。
当然,如果你获得了与某个请求相关的渠道信息知识,你也必须分析它们的一般公式。
以新浪新闻网为例,大家可能会更好理解:我已经从爬取的页面中获取了国内的新闻、标题、正文、日期,但我还想获取评论的信息(评论是动态生成的) )。所以,我对爬取页面进行解析,因为这个标签有两个改变新闻评论频道的信息:channel和newsid。等等等等
就是这么想的,终于找到评论页了。比如标题------------中纪委:有的干部不想抓,但不抓,但不敢惹问题被拖上来 | 天天要闻 中纪委| 问责制_新浪新闻
拼出来的评论频道是/page/info?format=json&channel=gn&newsid=1-1-31456214&group=0&compress=1&ie=gbk&oe=gbk&page=1&page_size=10
然后你解析页面内容,然后转码得到评论内容。
我说,不知道你懂不懂怎么做?
这是我作为网络爬虫的一点经验。我尝试了各种方法,包括引入第三方jar,但效果都不是很好。终于得到了这样的体验,毫无保留地与大家分享。
谢谢
不同的情况
一般简单的网页都是通过get参数进行分页的。在这种情况下,通过构造url来进行分页。
有的网站是通过post参数分页的,然后使用代码post到网站的对应参数
更复杂的ajax分页需要通过抓包来实现
ajax页面是动态生成的,不能直接抓到。不过,也不是没有办法。通常,通过找到ajax通道的地址,仍然可以得到ajax通道的内容。你可以从ajax所在的页面找到线索。当然,每一页都不一样,所以不要问我怎么死的。给大家一个思路:使用火狐浏览器监控页面信息
如何使用java抓取ajax页面的内容- :如果不能抓取,只能通过ajax提交参数来获取。可以写个js获取页面内容,然后通过ajax传给后台java程序
Java如何爬取ajax生成的页面?- :当时遇到的一个情况是ajax返回了很多json,然后前端js动态解析出来,目的是获取解析出来的数据,这样比较直观。使用 Selenium webdriver,一个自动化测试的东西,也是可以的。
如何使用JAVA爬取AJAX加载的页面-:1.一般简单的网页都是通过get参数进行分页的。这种情况下,分页是通过构造url来完成的;post参数进行分页,然后使用代码中对应的参数post到网站;3.更复杂的ajax分页需要通过抓包来实现。
java如何获取收录ajax-的网页数据: ajax数据的获取方式有两种: 1. 定义与参数相同的变量,即可获取对应的名称 2. 即可获取对应的值通过request:也可以获取一些cookie和session的值,可以通过它们对应的方法获取。
如何爬取ajax输出的页面数据-:在js代码中找到提交的url地址和参数,然后在浏览器中打开。。就是这样。
如何抓取ajax加载的页面-:查看其ajax提交的相关信息,在浏览器上输入其url及其参数,返回的内容就是ajax加载的内容,但有的只是简单的返回数据,有的返回with html 数据。
如何抓取ajax加载的页面-:如果要通用,只能通过浏览器启动。在windows上,可以使用程序调用IE浏览器接口获取页面文档,也可以使用chrome或firefox插件形式获取文档。采集 的信息随后被发布到服务器。Linux下可以使用phantomjs来操作webt来获取文档的内容。Phantomjs有很多优点:不依赖X,可以工作在文本模式,官网上叫headless;可以抓取页面截图;可以监控网络传输;可以禁用图像加载;自定义 cookie、自定义标头信息等。
java后台获取网页ajax数据并返回数据的简单源码-:1新建一个servlet,在xml中配置对应(一般是自动的)2创建服务方法3接受参数,做操作,返回数据如向SomeServlet发送ajax请求的页面 $.post("SomeServlet的请求路径",{param:"param"},function(data){ //data是json形式的返回数据 alert...
如何抓取 AJAX网站- 的内容: 手动刷新 DOMMetaStudio 左侧栏的 DOM 树是在 HTML 文档加载后自动生成的。如果 HTML 文档中的 Javascript 代码在 HTML 加载后修改了 DOM 内容,很有可能没有反映在 MetaStudio 的 DOM 树中。这时候,如果你使用反向...
Java后台获取网页ajax数据并返回数据简单源码-:1新建servlet对应xml中的配置(一般自动)
2 创建服务方法
3 接受参数,做操作,返回数据
例如,页面向 SomeServlet 发送 ajax 请求
$.post("SomeServlet 请求路径",{param:"param"},function(data){
//data是返回的数字... 查看全部
抓取ajax动态网页java(部分干部不想抓不会抓致问题拖炸|问责_新浪新闻拼出的评论通道(组图))
ajax页面是动态生成的,不能直接抓到。不过,也不是没有办法。通常,通过找到ajax通道的地址,仍然可以得到ajax通道的内容。
你可以从ajax所在的页面找到线索。当然,每一页都不一样,所以不要问我怎么死的。
给大家一个思路:使用火狐浏览器监控页面信息。当您点击请求时,会出现频道地址信息。
当然,如果你获得了与某个请求相关的渠道信息知识,你也必须分析它们的一般公式。
以新浪新闻网为例,大家可能会更好理解:我已经从爬取的页面中获取了国内的新闻、标题、正文、日期,但我还想获取评论的信息(评论是动态生成的) )。所以,我对爬取页面进行解析,因为这个标签有两个改变新闻评论频道的信息:channel和newsid。等等等等
就是这么想的,终于找到评论页了。比如标题------------中纪委:有的干部不想抓,但不抓,但不敢惹问题被拖上来 | 天天要闻 中纪委| 问责制_新浪新闻
拼出来的评论频道是/page/info?format=json&channel=gn&newsid=1-1-31456214&group=0&compress=1&ie=gbk&oe=gbk&page=1&page_size=10
然后你解析页面内容,然后转码得到评论内容。
我说,不知道你懂不懂怎么做?
这是我作为网络爬虫的一点经验。我尝试了各种方法,包括引入第三方jar,但效果都不是很好。终于得到了这样的体验,毫无保留地与大家分享。
谢谢
不同的情况
一般简单的网页都是通过get参数进行分页的。在这种情况下,通过构造url来进行分页。
有的网站是通过post参数分页的,然后使用代码post到网站的对应参数
更复杂的ajax分页需要通过抓包来实现
ajax页面是动态生成的,不能直接抓到。不过,也不是没有办法。通常,通过找到ajax通道的地址,仍然可以得到ajax通道的内容。你可以从ajax所在的页面找到线索。当然,每一页都不一样,所以不要问我怎么死的。给大家一个思路:使用火狐浏览器监控页面信息
如何使用java抓取ajax页面的内容- :如果不能抓取,只能通过ajax提交参数来获取。可以写个js获取页面内容,然后通过ajax传给后台java程序
Java如何爬取ajax生成的页面?- :当时遇到的一个情况是ajax返回了很多json,然后前端js动态解析出来,目的是获取解析出来的数据,这样比较直观。使用 Selenium webdriver,一个自动化测试的东西,也是可以的。
如何使用JAVA爬取AJAX加载的页面-:1.一般简单的网页都是通过get参数进行分页的。这种情况下,分页是通过构造url来完成的;post参数进行分页,然后使用代码中对应的参数post到网站;3.更复杂的ajax分页需要通过抓包来实现。
java如何获取收录ajax-的网页数据: ajax数据的获取方式有两种: 1. 定义与参数相同的变量,即可获取对应的名称 2. 即可获取对应的值通过request:也可以获取一些cookie和session的值,可以通过它们对应的方法获取。
如何爬取ajax输出的页面数据-:在js代码中找到提交的url地址和参数,然后在浏览器中打开。。就是这样。
如何抓取ajax加载的页面-:查看其ajax提交的相关信息,在浏览器上输入其url及其参数,返回的内容就是ajax加载的内容,但有的只是简单的返回数据,有的返回with html 数据。
如何抓取ajax加载的页面-:如果要通用,只能通过浏览器启动。在windows上,可以使用程序调用IE浏览器接口获取页面文档,也可以使用chrome或firefox插件形式获取文档。采集 的信息随后被发布到服务器。Linux下可以使用phantomjs来操作webt来获取文档的内容。Phantomjs有很多优点:不依赖X,可以工作在文本模式,官网上叫headless;可以抓取页面截图;可以监控网络传输;可以禁用图像加载;自定义 cookie、自定义标头信息等。
java后台获取网页ajax数据并返回数据的简单源码-:1新建一个servlet,在xml中配置对应(一般是自动的)2创建服务方法3接受参数,做操作,返回数据如向SomeServlet发送ajax请求的页面 $.post("SomeServlet的请求路径",{param:"param"},function(data){ //data是json形式的返回数据 alert...
如何抓取 AJAX网站- 的内容: 手动刷新 DOMMetaStudio 左侧栏的 DOM 树是在 HTML 文档加载后自动生成的。如果 HTML 文档中的 Javascript 代码在 HTML 加载后修改了 DOM 内容,很有可能没有反映在 MetaStudio 的 DOM 树中。这时候,如果你使用反向...
Java后台获取网页ajax数据并返回数据简单源码-:1新建servlet对应xml中的配置(一般自动)
2 创建服务方法
3 接受参数,做操作,返回数据
例如,页面向 SomeServlet 发送 ajax 请求
$.post("SomeServlet 请求路径",{param:"param"},function(data){
//data是返回的数字...
抓取ajax动态网页java(Web网络爬虫系统的功能及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-04 00:07
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。广泛应用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的页面的所有内容来获取或更新这些网站@的内容和检索方式>。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。另外,爬虫爬取的所有网页都会被系统存储,进行一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的第一个控制器。主要负责根据系统发送的URL链接分配线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列;
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接放到待爬取的URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4 部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。
2.3.5 OPIC 政策方针
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.6 大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都安装在“解析器”安装点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人理解错了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。这个Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。事实上,这是针对Nutch的声誉。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人已经解决了困难和复杂的问题(如DOM树解析定位、字符集检测、海量URL去重等),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫是否可以使用代理,爬虫是否可以爬取重复数据,爬虫是否可以爬取JS生成的信息?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,通常可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的代理放入一个全局数组中,并编写代码让代理随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?另一个爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习**的成本会比较大。而且你不能只计算一个人的学习成本。如果软件需要一个团队来开发或交接,那是很多人学习的成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,和更少的信息)。
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度,几乎每个大型门户网站网站都有自己的搜索引擎。有几十个名字和成千上万个未知的名字。对于内容驱动的网站,网络爬虫的赞助是不可避免的。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
[评论:它经常很容易被忽视。通过对请求的抓包分析,确定referer并添加到程序中模拟访问请求的header中]
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。
喜欢
不喜欢
你对这个答案的评价是什么? 查看全部
抓取ajax动态网页java(Web网络爬虫系统的功能及应用)
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。广泛应用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的页面的所有内容来获取或更新这些网站@的内容和检索方式>。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。另外,爬虫爬取的所有网页都会被系统存储,进行一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的第一个控制器。主要负责根据系统发送的URL链接分配线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列;
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接放到待爬取的URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4 部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。
2.3.5 OPIC 政策方针
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.6 大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都安装在“解析器”安装点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人理解错了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。这个Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。事实上,这是针对Nutch的声誉。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人已经解决了困难和复杂的问题(如DOM树解析定位、字符集检测、海量URL去重等),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫是否可以使用代理,爬虫是否可以爬取重复数据,爬虫是否可以爬取JS生成的信息?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,通常可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的代理放入一个全局数组中,并编写代码让代理随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?另一个爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习**的成本会比较大。而且你不能只计算一个人的学习成本。如果软件需要一个团队来开发或交接,那是很多人学习的成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,和更少的信息)。
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度,几乎每个大型门户网站网站都有自己的搜索引擎。有几十个名字和成千上万个未知的名字。对于内容驱动的网站,网络爬虫的赞助是不可避免的。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
[评论:它经常很容易被忽视。通过对请求的抓包分析,确定referer并添加到程序中模拟访问请求的header中]
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。
喜欢
不喜欢
你对这个答案的评价是什么?
抓取ajax动态网页java( 在线地图后台服务数据的多样展示方法--CrapperMap地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-03-30 11:04
在线地图后台服务数据的多样展示方法--CrapperMap地址)
爬取数据后台服务
在线地图后台服务
数据一直是数据源,是 GIS 系统非常重要的组成部分。获取公共数据或在后台处理并发布它很重要。
CrapperMap地址 这是一个大佬搭建的WebGIS系统,据说是在开源的基础上做的。前端相当丰富,用户可以添加各种图层,WMS图层,WMTS或者geoJson等,动态静态切片,标注图层。并且可以进行图层管理,包括 wgs84 和 Mars 坐标的比较示例。它包括一些气象数据的显示。例如,本网站提供符合OGC标准的wms和tms数据服务的地址。我们可以根据需要在地图上添加相应的图层来显示这些气象数据!是不是很棒!
上图是CrapperMap系统的截图
上图:通过 WMS 服务加载的 IEM 气象数据
另外诺基亚HERE地图也很不错,基于WebGL的3D视图更是震撼。3D模型具有多级显示机制,效率很高,配色很好。猜测是根据城市的机载 LiDAR 数据创建模型,并根据点数对其进行分级,从点云渲染 3D 模型,借助照片纹理......
在数据获取方面,目前最流行的在线资源是影像底图、街道底图,或者一些可以直接使用或通过分析获得的 POI 搜索和路线导航服务。但是有些数据不是我们可以直接使用的形式,不是OGC标准服务,也不是Json的形式。是一些零散的实时数据(表格或列表形式的站点数据),那么我们需要从门户网站或一些地址中抓取。或者我们要下载所需的数据切片。那么在未来,我们将研究数据的实时捕获!
继上次提到的各种数据之后,最近发现地理信息系统必须建立在信息系统的基础上。地理数据以外的信息要合理处理,注意网页中地理数据的各种展示方式。包括表格、图表、动态地图等。在这里,我发现了几个有用的插件,可以帮助更好地呈现数据。
是一款非常不错的jquery表单插件,界面美观,功能强大。默认分页和排序。符合Jquery的风格,界面比easyUI更加现代大气。如何提供表单信息以供下载的问题仍有待研究。Highchart是一款非常好用的图表插件,基于JS,动态效果极佳,时间线、折线图、条形图等各种统计图表,并提供图表下载。另外,网站的设计开发过程中还有一些需要注意的问题。主页面与分层页面(子页面)的关系是通过Tabs选项卡触发页面切换(切换:对应页面根据函数中的指令进行重定向,而子页面的切换可以通过替换Iframe下的subpage.src来实现)。多字段查询是一个重要部分。它在后台转换为Json并返回到前端。一些表单插件只有简单的单字段查询。 查看全部
抓取ajax动态网页java(
在线地图后台服务数据的多样展示方法--CrapperMap地址)
爬取数据后台服务
在线地图后台服务
数据一直是数据源,是 GIS 系统非常重要的组成部分。获取公共数据或在后台处理并发布它很重要。
CrapperMap地址 这是一个大佬搭建的WebGIS系统,据说是在开源的基础上做的。前端相当丰富,用户可以添加各种图层,WMS图层,WMTS或者geoJson等,动态静态切片,标注图层。并且可以进行图层管理,包括 wgs84 和 Mars 坐标的比较示例。它包括一些气象数据的显示。例如,本网站提供符合OGC标准的wms和tms数据服务的地址。我们可以根据需要在地图上添加相应的图层来显示这些气象数据!是不是很棒!

上图是CrapperMap系统的截图

上图:通过 WMS 服务加载的 IEM 气象数据
另外诺基亚HERE地图也很不错,基于WebGL的3D视图更是震撼。3D模型具有多级显示机制,效率很高,配色很好。猜测是根据城市的机载 LiDAR 数据创建模型,并根据点数对其进行分级,从点云渲染 3D 模型,借助照片纹理......

在数据获取方面,目前最流行的在线资源是影像底图、街道底图,或者一些可以直接使用或通过分析获得的 POI 搜索和路线导航服务。但是有些数据不是我们可以直接使用的形式,不是OGC标准服务,也不是Json的形式。是一些零散的实时数据(表格或列表形式的站点数据),那么我们需要从门户网站或一些地址中抓取。或者我们要下载所需的数据切片。那么在未来,我们将研究数据的实时捕获!
继上次提到的各种数据之后,最近发现地理信息系统必须建立在信息系统的基础上。地理数据以外的信息要合理处理,注意网页中地理数据的各种展示方式。包括表格、图表、动态地图等。在这里,我发现了几个有用的插件,可以帮助更好地呈现数据。
是一款非常不错的jquery表单插件,界面美观,功能强大。默认分页和排序。符合Jquery的风格,界面比easyUI更加现代大气。如何提供表单信息以供下载的问题仍有待研究。Highchart是一款非常好用的图表插件,基于JS,动态效果极佳,时间线、折线图、条形图等各种统计图表,并提供图表下载。另外,网站的设计开发过程中还有一些需要注意的问题。主页面与分层页面(子页面)的关系是通过Tabs选项卡触发页面切换(切换:对应页面根据函数中的指令进行重定向,而子页面的切换可以通过替换Iframe下的subpage.src来实现)。多字段查询是一个重要部分。它在后台转换为Json并返回到前端。一些表单插件只有简单的单字段查询。
抓取ajax动态网页java(同步交互的不足之处和异步不用的优点和缺点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-03-30 05:07
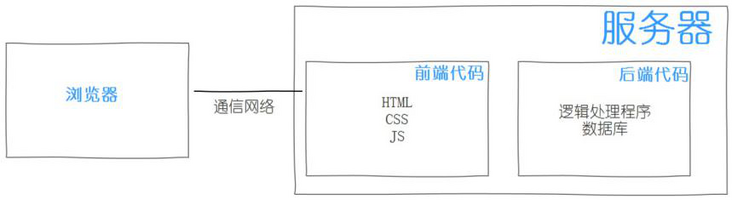
1、了解同步和异步交互(1)什么是同步交互
首先,用户向 HTTP 服务器提交处理请求。然后,服务器收到请求后,按照预先编写的程序中的业务逻辑进行处理,例如与数据库服务器交换数据信息。最后,服务端响应请求,将结果返回给客户端,返回一个HTML展示在浏览器中,通常带有CSS样式的富页面展示效果。
优点:可以保留浏览器后退按钮的正常功能。在动态更新页面的情况下,用户可以回到之前的页面状态,浏览器可以记住历史中的静态页面,而用户通常希望当点击返回按钮时,可以取消之前的操作并且同步交互这个需求就可以实现了。
缺点:同步交互的不足会给用户带来不连贯的体验。服务器处理请求时,用户只能等待状态,页面中的显示内容只能为空白。因为已经跳转到新的页面,所以页面上原来的信息无法保存,很多信息需要重新填写。
(2)什么是异步交互
指发送请求不等待返回,随时可以发送下一个请求,即不等待。在某些情况下,我们更喜欢在我们的项目开发中不需要等待的异步交互方法。将用户请求放入消息队列并反馈给用户,系统迁移过程已经启动,可以关闭浏览器。然后程序慢慢写入数据库。这是异步的。异步不需要等待所有操作完成,并响应用户请求。也就是先响应用户请求,再慢慢写数据库,用户体验更好。
优点:可以同时进行前端用户操作和后端服务器操作,充分利用用户操作之间的间隔时间完成操作页面不跳转,响应返回的数据直接上原创页面,并保留该页面的原创信息。
缺点:可能会破坏浏览器后退按钮的正常行为。在动态更新页面的情况下,用户无法回到之前的页面状态,因为浏览器只能记录始终是当前页面的静态页面。用户通常希望单击后退按钮能够取消之前的操作,但在 AJAX 等异步程序中,这是不可能的。
2、AJAX简介
AJAX 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种 Web 开发技术,用于创建交互式、快速和动态的 Web 应用程序,可以在不重新加载整个网页的情况下更新部分网页。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
AJAX关键技术
使用 CSS 构建用户界面样式,负责页面布局和美术。
使用DOM进行动态展示和交互,本地修改页面。 查看全部
抓取ajax动态网页java(同步交互的不足之处和异步不用的优点和缺点)
1、了解同步和异步交互(1)什么是同步交互
首先,用户向 HTTP 服务器提交处理请求。然后,服务器收到请求后,按照预先编写的程序中的业务逻辑进行处理,例如与数据库服务器交换数据信息。最后,服务端响应请求,将结果返回给客户端,返回一个HTML展示在浏览器中,通常带有CSS样式的富页面展示效果。
优点:可以保留浏览器后退按钮的正常功能。在动态更新页面的情况下,用户可以回到之前的页面状态,浏览器可以记住历史中的静态页面,而用户通常希望当点击返回按钮时,可以取消之前的操作并且同步交互这个需求就可以实现了。
缺点:同步交互的不足会给用户带来不连贯的体验。服务器处理请求时,用户只能等待状态,页面中的显示内容只能为空白。因为已经跳转到新的页面,所以页面上原来的信息无法保存,很多信息需要重新填写。

(2)什么是异步交互
指发送请求不等待返回,随时可以发送下一个请求,即不等待。在某些情况下,我们更喜欢在我们的项目开发中不需要等待的异步交互方法。将用户请求放入消息队列并反馈给用户,系统迁移过程已经启动,可以关闭浏览器。然后程序慢慢写入数据库。这是异步的。异步不需要等待所有操作完成,并响应用户请求。也就是先响应用户请求,再慢慢写数据库,用户体验更好。
优点:可以同时进行前端用户操作和后端服务器操作,充分利用用户操作之间的间隔时间完成操作页面不跳转,响应返回的数据直接上原创页面,并保留该页面的原创信息。
缺点:可能会破坏浏览器后退按钮的正常行为。在动态更新页面的情况下,用户无法回到之前的页面状态,因为浏览器只能记录始终是当前页面的静态页面。用户通常希望单击后退按钮能够取消之前的操作,但在 AJAX 等异步程序中,这是不可能的。
2、AJAX简介
AJAX 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种 Web 开发技术,用于创建交互式、快速和动态的 Web 应用程序,可以在不重新加载整个网页的情况下更新部分网页。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
AJAX关键技术
使用 CSS 构建用户界面样式,负责页面布局和美术。
使用DOM进行动态展示和交互,本地修改页面。
抓取ajax动态网页java(下图显示GET请求到文件后继续请求了多个JS、CSS文件前端与后端浏览器 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-03-25 06:20
)
下图是对HTML文件的GET请求后继续请求多个JS和CSS文件
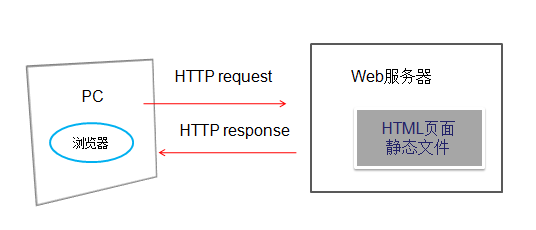
前端和后端
浏览器显示的网页是web前端界面,它为用户提供了一个与网站交互的可视化界面,而web后端服务主要是指在浏览器中进行的逻辑操作和数据处理。 server,为前端提供访问服务。. 所谓的前端和后端只是从代码执行的位置来区分的。前端代码在用户面前执行,后端代码在远程服务器上执行。但是,无论前端代码还是后端代码,都是存储在服务器上的,只有在浏览器请求时才从服务器发送出去。
AJAX 简介
在上述web应用的工作原理中,我们通过HTTP协议访问一个存在于服务器上的文件。服务器可以找到该文件并将其内容封装成一个HTTP请求,并以消息体的形式返回给客户端。但是,这种方法只能访问静态页面,不能与后端数据库交互。由于用户需要通过web前端与后端数据库进行实时交互,因此网页也需要动态更新。如果每次更新一个数据都是通过重新获取Html文件来实现的,势必会导致网络负载变重,页面加载变慢。而Ajax技术可以很好的解决这个问题。
Ajax,异步 JavaScript 和 XML,是一种用于创建交互式网页的技术,它可以更新网页的某些部分,而无需重新加载整个网页。目前 jQuery 库提供了几种与 AJAX 相关的方法。通过 jQuery AJAX 方法,可以使用 HTTP Get 和 HTTP Post 从远程服务器请求文本、HTML、XML 或 JSON,并且可以将这些外部数据直接加载到网页的选定元素中。
作为 Web 开发者广泛使用的 JavaScript 封装库之一,jQuery 库可以极大地简化我们的 JavaScript 编程,缓解浏览器不兼容带来的影响。有必要了解网页在不同浏览器中的兼容性测试。这也是很多工作。我们可以通过一个简单的例子看到 jQuery 库的优势:
$("p.neat").addClass("ohmy").show("slow");
有了上面的短代码,开发者就可以遍历所有“整洁”的类
元素,然后将“ohmy”类添加到它,同时缓慢地为每个段落设置动画。开发者无需检查客户端浏览器类型,无需编写循环代码,无需编写复杂的动画功能,只需一行代码即可实现上述效果。jQuery 的口号“用最少的代码做最多的事情”名副其实,并将 JavaScript 带到了更高的水平。
JSON格式介绍
对于交互式数据格式,这里使用JSON(JavaScript Object Notation),这是一种轻量级的数据交换格式,它使用完全独立于编程语言的文本格式来存储和表示数据。JSON键值的层次结构简洁明了,易读易写,使JSON成为一种理想的数据交换语言。一个理解 JSON 数据格式的例子:
{//JSON 键/值对
“'wJsona'”:“kkk”
“'wjsonb'”:“12”
“'wjsonc”:“80”
}
代码
下面介绍前端jQuery .ajax() 请求JSON数据的方法。代码如下:
函数 useTestFun() {
$.ajax({
url: "/Usedefine",//获取数据的URL
数据:JSON.stringify({
'wJsona':"kkk",
'wjsonb':12,
'wjsonc':80,
}),
type: "POST",//HTTP请求方式
dataType:'JSON',//获取数据执行方式
成功:功能(数据){
if(data.status == 'True'){//传入JSON对象格式
alert('连接成功');
}
别的{
$("#labletip").show();
}
},
错误:函数(错误){
alert('连接失败');
}
});
}
在数据传输过程中,JSON是以文本即字符串的形式传输的,而JS对JSON对象进行操作,所以JSON对象与JSON字符串的转换是关键,可以使用JSON.stringify() convert 将 JSON 对象转换为 JSON 字符串,使用 JSON.parse() 将 JSON 字符串转换为 JSON 对象。
JSON 字符串:var str1 = '{ "name": "cxh", "sex": "man" }';
JSON 对象:var str2 = { "name": "cxh", "sex": "man" };
var obj = str.parseJSON(); //从JSON字符串转换为JSON对象
var obj = JSON.parse(str); //从JSON字符串转换为JSON对象
var last = obj.toJSONString(); //将JSON对象转换为JSON字符
var last = JSON.stringify(obj); //将JSON对象转换为JSON字符
下面展示了HTTP协议中JSON数据的传输格式。后端服务器可以使用第三方 JSON 库来处理 JSON 数据。返回 JSON 数据时,将 HTTP 协议的 Content-Type 字段设置为“application/json”。
查看全部
抓取ajax动态网页java(下图显示GET请求到文件后继续请求了多个JS、CSS文件前端与后端浏览器
)
下图是对HTML文件的GET请求后继续请求多个JS和CSS文件
前端和后端
浏览器显示的网页是web前端界面,它为用户提供了一个与网站交互的可视化界面,而web后端服务主要是指在浏览器中进行的逻辑操作和数据处理。 server,为前端提供访问服务。. 所谓的前端和后端只是从代码执行的位置来区分的。前端代码在用户面前执行,后端代码在远程服务器上执行。但是,无论前端代码还是后端代码,都是存储在服务器上的,只有在浏览器请求时才从服务器发送出去。
AJAX 简介
在上述web应用的工作原理中,我们通过HTTP协议访问一个存在于服务器上的文件。服务器可以找到该文件并将其内容封装成一个HTTP请求,并以消息体的形式返回给客户端。但是,这种方法只能访问静态页面,不能与后端数据库交互。由于用户需要通过web前端与后端数据库进行实时交互,因此网页也需要动态更新。如果每次更新一个数据都是通过重新获取Html文件来实现的,势必会导致网络负载变重,页面加载变慢。而Ajax技术可以很好的解决这个问题。
Ajax,异步 JavaScript 和 XML,是一种用于创建交互式网页的技术,它可以更新网页的某些部分,而无需重新加载整个网页。目前 jQuery 库提供了几种与 AJAX 相关的方法。通过 jQuery AJAX 方法,可以使用 HTTP Get 和 HTTP Post 从远程服务器请求文本、HTML、XML 或 JSON,并且可以将这些外部数据直接加载到网页的选定元素中。
作为 Web 开发者广泛使用的 JavaScript 封装库之一,jQuery 库可以极大地简化我们的 JavaScript 编程,缓解浏览器不兼容带来的影响。有必要了解网页在不同浏览器中的兼容性测试。这也是很多工作。我们可以通过一个简单的例子看到 jQuery 库的优势:
$("p.neat").addClass("ohmy").show("slow");
有了上面的短代码,开发者就可以遍历所有“整洁”的类
元素,然后将“ohmy”类添加到它,同时缓慢地为每个段落设置动画。开发者无需检查客户端浏览器类型,无需编写循环代码,无需编写复杂的动画功能,只需一行代码即可实现上述效果。jQuery 的口号“用最少的代码做最多的事情”名副其实,并将 JavaScript 带到了更高的水平。
JSON格式介绍
对于交互式数据格式,这里使用JSON(JavaScript Object Notation),这是一种轻量级的数据交换格式,它使用完全独立于编程语言的文本格式来存储和表示数据。JSON键值的层次结构简洁明了,易读易写,使JSON成为一种理想的数据交换语言。一个理解 JSON 数据格式的例子:
{//JSON 键/值对
“'wJsona'”:“kkk”
“'wjsonb'”:“12”
“'wjsonc”:“80”
}
代码
下面介绍前端jQuery .ajax() 请求JSON数据的方法。代码如下:
函数 useTestFun() {
$.ajax({
url: "/Usedefine",//获取数据的URL
数据:JSON.stringify({
'wJsona':"kkk",
'wjsonb':12,
'wjsonc':80,
}),
type: "POST",//HTTP请求方式
dataType:'JSON',//获取数据执行方式
成功:功能(数据){
if(data.status == 'True'){//传入JSON对象格式
alert('连接成功');
}
别的{
$("#labletip").show();
}
},
错误:函数(错误){
alert('连接失败');
}
});
}
在数据传输过程中,JSON是以文本即字符串的形式传输的,而JS对JSON对象进行操作,所以JSON对象与JSON字符串的转换是关键,可以使用JSON.stringify() convert 将 JSON 对象转换为 JSON 字符串,使用 JSON.parse() 将 JSON 字符串转换为 JSON 对象。
JSON 字符串:var str1 = '{ "name": "cxh", "sex": "man" }';
JSON 对象:var str2 = { "name": "cxh", "sex": "man" };
var obj = str.parseJSON(); //从JSON字符串转换为JSON对象
var obj = JSON.parse(str); //从JSON字符串转换为JSON对象
var last = obj.toJSONString(); //将JSON对象转换为JSON字符
var last = JSON.stringify(obj); //将JSON对象转换为JSON字符
下面展示了HTTP协议中JSON数据的传输格式。后端服务器可以使用第三方 JSON 库来处理 JSON 数据。返回 JSON 数据时,将 HTTP 协议的 Content-Type 字段设置为“application/json”。
抓取ajax动态网页java(通过Python抓取深层网络数据库,一次性搜索20个名称)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-03-22 01:37
深层网络收录法庭记录、人口普查数据,可能还有旧报纸的档案。它主要是一个高度权威的学术数据库和政府档案。深度网络比表层网络更容易和更快地审计资源,但深度网络无法看穿表层网络。通过下面的冰山图,我们可以很清楚地知道表层网、深层网和暗网之间的层级关系。
通过Python爬取深度网络数据库,我们可以一次搜索多个数据库,比在每个网站上一次搜索一个要方便快捷得多,并且可以同时对数据库进行多个搜索,即一次搜索一个名称 20 次。
开放网络数据是指任何人都可以使用、重用和重新分配的一类数据,包括地理位置数据、交通数据和文化数据。
新闻服务 NPR 的 网站 是开放网络数据库的一个例子。如果您想要所有提及“互联网”一词的 NPR 文章,您可以从 网站 内部或 google 网站 搜外(通过谷歌搜索 "" 和 "internet" )。任何一种方法都可以获得关于 关键词 的 文章 列表。
图片来源:图片网可作为商业图片
相比之下,迈阿密-戴德县财产记录数据库是深度网络的一部分,简单的 关键词 搜索不会产生太多信息。假设你想获取迈阿密戴德县一个名叫“史密斯”的人的财产记录,你会怎么做?
直接在 Google 搜索“迈阿密戴德县史密斯房产记录”只会返回迈阿密戴德县房产查询网站。但是如果你想抓取一个开放的网络数据库,它是相对简单的。
比如你想爬取NPR提到“互联网”的文章,可以先使用网站的搜索功能,在搜索框中输入“互联网”,然后用关键词 结果页面。
我们也可以编写一个python脚本来爬取上述URL处的页面。这揭示了 网站 的搜索 URL 格式。输入搜索功能的关键字将出现在新网址的“search?query=”部分之后。
URL 可以通过分析 POST 请求中的请求体得到。点击F12键或右键“检查”查看网络的基本信息(进入后需要刷新页面)。
有关 F12/check 元素的更多信息,您可以点击下面的图片链接阅读文章“探索 Google Chrome 的神秘用法,F12!” 》
同样,如果你想搜索这个网站的其他信息,只需将上面URL中“=”后面的关键词替换为新的目标关键词即可。
如何使用 python 抓取深层网络数据?
为了使用 Python 从深度网络数据库中抓取信息,我们将向数据库服务器发送一个请求,该请求模仿 网站 向服务器发送请求的方式,就好像您实际上是通过 网站 提交搜索一样。
在这一点上,有人可能想知道为什么我们应该使用 python 而不仅仅是 网站,因为使用 python 我们可以一次搜索大量数据库。假设我们正在研究某人,而您想知道他们是否有法律问题。
因此,我们可以在法庭记录中搜索它们,搜索法庭记录的手动过程将需要我们搜索大量数据库,因为法院管辖权重叠并且每个数据库都有单独的数据库。
如何抓取深度网络数据库:使用“参数”
您可以使用以下名为 Basic_Scraper 的简单 Python 脚本来抓取您选择的数据库。该脚本通过向 url 标识的位置发送信息(参数)来工作。
# Basic_Scraper
import requests
params = {'firstname': 'John', 'lastname': 'Smith'}
r = requests.post("http://FAKE-WEBSITE-URL/processing.php", data=params)
print(r.text)
您需要输入 url、输入名称以及要查询的任何数据。这个怎么做?首先,导航到要抓取的 网站 的搜索页面。
我们可以使用一个随机的商业注册表作为深度网络数据库的示例。对于本演练,我使用的是 Chrome 浏览器,但任何浏览器都可以,浏览器功能的名称可能略有不同。
我们想使用 html-viewer 来查看 网站search 函数的 html 代码。网站 有一个注册表搜索栏,因此我们右键单击文本区域(您输入搜索词的位置)并单击“检查”。在开发者工具的浏览器中打开一个窗口,在功能选项卡下,网站 的 html 可见,搜索栏文本区域的 html 代码突出显示。请参阅下面的屏幕截图。
这标识了数据库搜索功能的“输入”元素或标签,我们将使用我们的代码和示例脚本 Basic_Scraper 中的“参数”来模拟它。html 告诉我们该元素被标识为“FindBox”,这与示例脚本中的标识符“firstname”相关。
其次,输入一个随机搜索词“Jack”,然后按 ENTER 键查看示例搜索如何影响 html。该网页现在列出了标题中带有“Jack”一词的公司。浏览器的 html 查看器显示搜索功能的代码已被刷新,并且一些新内容已添加到输入元素中。如下面屏幕截图的第二行所示,该元素具有额外的文本,内容为“value="jack"”。
现在我们知道如何识别搜索函数的参数及其值了。这在 Python 中称为字典,因为有一个键 (FindBox) 和一个关联的值 (jack)。因此,为了从带有“Jack”一词的公司中抓取该数据库,我们将示例脚本的参数更改为:
参数 = {'FindBox': 'Jack'}
第三,我们通过 POST 请求将此信息发布到数据库的服务器。但是我们需要确定一个 url 来发送我们的请求。
输入网页源代码,在HTML中找到form标签的“action”,其内容类似于“action=”后跟一个url。这将识别您将用于发送信息的 url。它将为您提供完整的 URL 或只是尾随部分。
例如,它可能读取“action=/processing.php”,它确认相关的 url 以 processing.php 结尾。有时你只是将它添加到搜索页面的 url 的末尾,或者有时你会用它来替换 url 的最后一段。
最终产品(URL)将被粘贴到上面的脚本中,在脚本中留下括号,它说:
在我们的示例数据库中,目标 url 与我们之前访问的网页的 url 相同。因此,我们向带有参数的 url 发送 POST 请求,并将响应分配给值 r。它应该如下所示:
然后我们可以输入“print(r)”查看对应的状态码来判断服务器的对应状态。如果状态码为“200”,则表示返回数据成功。这时候我们也可以输入“print(r.text)”来获取文本类型的对应内容。这些响应内容与我们在 网站 上发起 HTTP 请求时看到的响应正文的结果是一致的。
与任何 python 脚本一样,如果遇到问题,请尝试从命令行运行它并尝试输入 python3 而不是 python 并确保没有多余的行或换行符(在不小心按 enter 并在新行上开始文本之后) # 是后面的注释。
import requests
from bs4 import BeautifulSoup
#Scraping data
params = {'FindBox': 'Jack'}
r = requests.post('http://cr.justice.gov.lb/searc ... 39%3B, params)
print(r)
print(r.text)
然后,我们将收到结果数据作为响应,如下所示:
下面是同一脚本的一个版本,在末尾添加了一个部分来解析数据。这样,脚本不会检索大量数据,而只会列出您的搜索结果。
# commercial registry scraper
import requests
from bs4 import BeautifulSoup
#Scraping data
params = {'FindBox': 'Jack'}
r = requests.post('http://cr.justice.gov.lb/searc ... 39%3B, params)
html = r.text
#Parse the data
bs = BeautifulSoup(html, 'html.parser')
companies = bs.find_all('div', {'class' : {'res_line1' }})
dates = bs.find_all('div', {'class' : {'res_line2' }})
for company in companies:
link = bs.find('a')
for link in company:
articleUrl = (link.attrs['href'])
for date in dates:
print(company.get_text(),
'registration date and region:', date.get_text(),
'registration link:', ('http://cr.justice.gov.lb/search/{}'.format(articleUrl)))
此添加会解析数据,以便结果列出每个公司的名称、注册号以及指向其在目录中的文件的链接。结果如下所示:
第二部分,标题为#Parse the data,使用 Python 的 BeatifulSoup 库使响应数据更易于理解。BeautifulSoup 是一个用于解析 html(以及其他东西)的复杂工具,它已经写了一整本书,所以我们不会在本 文章 中讨论它。此处仅用于简化响应数据。
如何爬取深层网络数据库:模拟浏览器操作
以上方法通常用于查看浏览器开发者工具,分析服务器在向数据库提交HTTP请求时的响应状态。
但是在我们实际工作中,如果提交某个关键词搜索相关信息,空白搜索页面的URL和输入关键词后的结果URL是一样的,也就是说上面的这里可以使用方法。不起作用。
这是因为在实际的动态网页中,Ajax请求的很多参数都是加密的,用户通过分析Ajax请求很难得到真实的URL,而且有些动态加载的数据不是Ajax生成的。这时可以使用 Selenium 模拟浏览器的方法来获取网页动态加载和渲染的数据。
Selenium 是一种自动化测试工具,可驱动浏览器执行特定操作(如点击、输入等)。同时,还可以获取浏览器当前渲染的页面内容,以便在可见的情况下进行爬取。Python 提供了 Selenium 库来实现操作。
特此声明:本文旨在分享交流学习的工具。请读者在合理合法的范围内使用,时刻牢记合法红线,不要利用该工具和技术做任何违法的事情。
本文文章为傅云原创内容,未经授权禁止转载
富韵原创IP形象设计,原创请勿盗用,侵权必究 查看全部
抓取ajax动态网页java(通过Python抓取深层网络数据库,一次性搜索20个名称)
深层网络收录法庭记录、人口普查数据,可能还有旧报纸的档案。它主要是一个高度权威的学术数据库和政府档案。深度网络比表层网络更容易和更快地审计资源,但深度网络无法看穿表层网络。通过下面的冰山图,我们可以很清楚地知道表层网、深层网和暗网之间的层级关系。
通过Python爬取深度网络数据库,我们可以一次搜索多个数据库,比在每个网站上一次搜索一个要方便快捷得多,并且可以同时对数据库进行多个搜索,即一次搜索一个名称 20 次。
开放网络数据是指任何人都可以使用、重用和重新分配的一类数据,包括地理位置数据、交通数据和文化数据。
新闻服务 NPR 的 网站 是开放网络数据库的一个例子。如果您想要所有提及“互联网”一词的 NPR 文章,您可以从 网站 内部或 google 网站 搜外(通过谷歌搜索 "" 和 "internet" )。任何一种方法都可以获得关于 关键词 的 文章 列表。
图片来源:图片网可作为商业图片
相比之下,迈阿密-戴德县财产记录数据库是深度网络的一部分,简单的 关键词 搜索不会产生太多信息。假设你想获取迈阿密戴德县一个名叫“史密斯”的人的财产记录,你会怎么做?
直接在 Google 搜索“迈阿密戴德县史密斯房产记录”只会返回迈阿密戴德县房产查询网站。但是如果你想抓取一个开放的网络数据库,它是相对简单的。
比如你想爬取NPR提到“互联网”的文章,可以先使用网站的搜索功能,在搜索框中输入“互联网”,然后用关键词 结果页面。
我们也可以编写一个python脚本来爬取上述URL处的页面。这揭示了 网站 的搜索 URL 格式。输入搜索功能的关键字将出现在新网址的“search?query=”部分之后。
URL 可以通过分析 POST 请求中的请求体得到。点击F12键或右键“检查”查看网络的基本信息(进入后需要刷新页面)。
有关 F12/check 元素的更多信息,您可以点击下面的图片链接阅读文章“探索 Google Chrome 的神秘用法,F12!” 》
同样,如果你想搜索这个网站的其他信息,只需将上面URL中“=”后面的关键词替换为新的目标关键词即可。
如何使用 python 抓取深层网络数据?
为了使用 Python 从深度网络数据库中抓取信息,我们将向数据库服务器发送一个请求,该请求模仿 网站 向服务器发送请求的方式,就好像您实际上是通过 网站 提交搜索一样。
在这一点上,有人可能想知道为什么我们应该使用 python 而不仅仅是 网站,因为使用 python 我们可以一次搜索大量数据库。假设我们正在研究某人,而您想知道他们是否有法律问题。
因此,我们可以在法庭记录中搜索它们,搜索法庭记录的手动过程将需要我们搜索大量数据库,因为法院管辖权重叠并且每个数据库都有单独的数据库。
如何抓取深度网络数据库:使用“参数”
您可以使用以下名为 Basic_Scraper 的简单 Python 脚本来抓取您选择的数据库。该脚本通过向 url 标识的位置发送信息(参数)来工作。
# Basic_Scraper
import requests
params = {'firstname': 'John', 'lastname': 'Smith'}
r = requests.post("http://FAKE-WEBSITE-URL/processing.php", data=params)
print(r.text)
您需要输入 url、输入名称以及要查询的任何数据。这个怎么做?首先,导航到要抓取的 网站 的搜索页面。
我们可以使用一个随机的商业注册表作为深度网络数据库的示例。对于本演练,我使用的是 Chrome 浏览器,但任何浏览器都可以,浏览器功能的名称可能略有不同。
我们想使用 html-viewer 来查看 网站search 函数的 html 代码。网站 有一个注册表搜索栏,因此我们右键单击文本区域(您输入搜索词的位置)并单击“检查”。在开发者工具的浏览器中打开一个窗口,在功能选项卡下,网站 的 html 可见,搜索栏文本区域的 html 代码突出显示。请参阅下面的屏幕截图。
这标识了数据库搜索功能的“输入”元素或标签,我们将使用我们的代码和示例脚本 Basic_Scraper 中的“参数”来模拟它。html 告诉我们该元素被标识为“FindBox”,这与示例脚本中的标识符“firstname”相关。
其次,输入一个随机搜索词“Jack”,然后按 ENTER 键查看示例搜索如何影响 html。该网页现在列出了标题中带有“Jack”一词的公司。浏览器的 html 查看器显示搜索功能的代码已被刷新,并且一些新内容已添加到输入元素中。如下面屏幕截图的第二行所示,该元素具有额外的文本,内容为“value="jack"”。
现在我们知道如何识别搜索函数的参数及其值了。这在 Python 中称为字典,因为有一个键 (FindBox) 和一个关联的值 (jack)。因此,为了从带有“Jack”一词的公司中抓取该数据库,我们将示例脚本的参数更改为:
参数 = {'FindBox': 'Jack'}
第三,我们通过 POST 请求将此信息发布到数据库的服务器。但是我们需要确定一个 url 来发送我们的请求。
输入网页源代码,在HTML中找到form标签的“action”,其内容类似于“action=”后跟一个url。这将识别您将用于发送信息的 url。它将为您提供完整的 URL 或只是尾随部分。
例如,它可能读取“action=/processing.php”,它确认相关的 url 以 processing.php 结尾。有时你只是将它添加到搜索页面的 url 的末尾,或者有时你会用它来替换 url 的最后一段。
最终产品(URL)将被粘贴到上面的脚本中,在脚本中留下括号,它说:
在我们的示例数据库中,目标 url 与我们之前访问的网页的 url 相同。因此,我们向带有参数的 url 发送 POST 请求,并将响应分配给值 r。它应该如下所示:
然后我们可以输入“print(r)”查看对应的状态码来判断服务器的对应状态。如果状态码为“200”,则表示返回数据成功。这时候我们也可以输入“print(r.text)”来获取文本类型的对应内容。这些响应内容与我们在 网站 上发起 HTTP 请求时看到的响应正文的结果是一致的。
与任何 python 脚本一样,如果遇到问题,请尝试从命令行运行它并尝试输入 python3 而不是 python 并确保没有多余的行或换行符(在不小心按 enter 并在新行上开始文本之后) # 是后面的注释。
import requests
from bs4 import BeautifulSoup
#Scraping data
params = {'FindBox': 'Jack'}
r = requests.post('http://cr.justice.gov.lb/searc ... 39%3B, params)
print(r)
print(r.text)
然后,我们将收到结果数据作为响应,如下所示:
下面是同一脚本的一个版本,在末尾添加了一个部分来解析数据。这样,脚本不会检索大量数据,而只会列出您的搜索结果。
# commercial registry scraper
import requests
from bs4 import BeautifulSoup
#Scraping data
params = {'FindBox': 'Jack'}
r = requests.post('http://cr.justice.gov.lb/searc ... 39%3B, params)
html = r.text
#Parse the data
bs = BeautifulSoup(html, 'html.parser')
companies = bs.find_all('div', {'class' : {'res_line1' }})
dates = bs.find_all('div', {'class' : {'res_line2' }})
for company in companies:
link = bs.find('a')
for link in company:
articleUrl = (link.attrs['href'])
for date in dates:
print(company.get_text(),
'registration date and region:', date.get_text(),
'registration link:', ('http://cr.justice.gov.lb/search/{}'.format(articleUrl)))
此添加会解析数据,以便结果列出每个公司的名称、注册号以及指向其在目录中的文件的链接。结果如下所示:
第二部分,标题为#Parse the data,使用 Python 的 BeatifulSoup 库使响应数据更易于理解。BeautifulSoup 是一个用于解析 html(以及其他东西)的复杂工具,它已经写了一整本书,所以我们不会在本 文章 中讨论它。此处仅用于简化响应数据。
如何爬取深层网络数据库:模拟浏览器操作
以上方法通常用于查看浏览器开发者工具,分析服务器在向数据库提交HTTP请求时的响应状态。
但是在我们实际工作中,如果提交某个关键词搜索相关信息,空白搜索页面的URL和输入关键词后的结果URL是一样的,也就是说上面的这里可以使用方法。不起作用。
这是因为在实际的动态网页中,Ajax请求的很多参数都是加密的,用户通过分析Ajax请求很难得到真实的URL,而且有些动态加载的数据不是Ajax生成的。这时可以使用 Selenium 模拟浏览器的方法来获取网页动态加载和渲染的数据。
Selenium 是一种自动化测试工具,可驱动浏览器执行特定操作(如点击、输入等)。同时,还可以获取浏览器当前渲染的页面内容,以便在可见的情况下进行爬取。Python 提供了 Selenium 库来实现操作。
特此声明:本文旨在分享交流学习的工具。请读者在合理合法的范围内使用,时刻牢记合法红线,不要利用该工具和技术做任何违法的事情。
本文文章为傅云原创内容,未经授权禁止转载
富韵原创IP形象设计,原创请勿盗用,侵权必究
抓取ajax动态网页java(AJAX即“AsynchronousJavascriptAndXML”(异步JavaScript和XML)封装了ajax)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-03-17 00:27
AJAX 是“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
AJAX = 异步和 XML(标准通用标记语言的子集)。
AJAX 是一种用于创建快速和动态网页的技术。
AJAX 不是一种新的编程语言,而是一种使用现有标准的新方法。
AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
如果内容需要更新,传统网页(没有 AJAX)必须重新加载整个网页。
使用ajax传输对象、集合、数组等(xml)
jquery包封装ajax相关
package com.maya.ajax;
import java.io.IOException;
import java.util.ArrayList;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.maya.user.Users;
/**
* Servlet implementation class TestAjax2
*/
@WebServlet("/testajax2")
public class TestAjax2 extends HttpServlet {
private static final long serialVersionUID = 1L;
/**
* @see HttpServlet#HttpServlet()
*/
public TestAjax2() {
super();
// TODO Auto-generated constructor stub
}
/**
* @see HttpServlet#doGet(HttpServletRequest request, HttpServletResponse response)
*/
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setCharacterEncoding("utf-8");
response.setCharacterEncoding("utf-8");
Users user=new Users();
user.setName("张三");
user.setSex("男");
user.setAge(23);
Users user1=new Users();
user1.setName("李四");
user1.setSex("女");
user1.setAge(24);
Users user2=new Users();
user2.setName("王五");
user2.setSex("男");
user2.setAge(25);
ArrayList list=new ArrayList();
list.add(user);
list.add(user1);
list.add(user2);
response.getWriter().append("");
response.getWriter().append("");
for(Users u:list){
response.getWriter().append("");
response.getWriter().append(""+u.getName()+"");
response.getWriter().append(""+u.getSex()+"");
response.getWriter().append(""+u.getAge()+"");
response.getWriter().append("");
}
response.getWriter().append("");
}
/**
* @see HttpServlet#doPost(HttpServletRequest request, HttpServletResponse response)
*/
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// TODO Auto-generated method stub
doGet(request, response);
}
}
HTML页面:
<p>
Insert title here
$(document).ready(function(){
$("#ss").click(function(){
$.ajax({
url:"testajax2",
data:{},
type:"POST",
dataType:"XML",
success:function(httpdata){
var s=$(httpdata).find("user");
for(var i=0;i 查看全部
抓取ajax动态网页java(AJAX即“AsynchronousJavascriptAndXML”(异步JavaScript和XML)封装了ajax)
AJAX 是“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
AJAX = 异步和 XML(标准通用标记语言的子集)。
AJAX 是一种用于创建快速和动态网页的技术。
AJAX 不是一种新的编程语言,而是一种使用现有标准的新方法。
AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
如果内容需要更新,传统网页(没有 AJAX)必须重新加载整个网页。
使用ajax传输对象、集合、数组等(xml)
jquery包封装ajax相关
package com.maya.ajax;
import java.io.IOException;
import java.util.ArrayList;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.maya.user.Users;
/**
* Servlet implementation class TestAjax2
*/
@WebServlet("/testajax2")
public class TestAjax2 extends HttpServlet {
private static final long serialVersionUID = 1L;
/**
* @see HttpServlet#HttpServlet()
*/
public TestAjax2() {
super();
// TODO Auto-generated constructor stub
}
/**
* @see HttpServlet#doGet(HttpServletRequest request, HttpServletResponse response)
*/
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setCharacterEncoding("utf-8");
response.setCharacterEncoding("utf-8");
Users user=new Users();
user.setName("张三");
user.setSex("男");
user.setAge(23);
Users user1=new Users();
user1.setName("李四");
user1.setSex("女");
user1.setAge(24);
Users user2=new Users();
user2.setName("王五");
user2.setSex("男");
user2.setAge(25);
ArrayList list=new ArrayList();
list.add(user);
list.add(user1);
list.add(user2);
response.getWriter().append("");
response.getWriter().append("");
for(Users u:list){
response.getWriter().append("");
response.getWriter().append(""+u.getName()+"");
response.getWriter().append(""+u.getSex()+"");
response.getWriter().append(""+u.getAge()+"");
response.getWriter().append("");
}
response.getWriter().append("");
}
/**
* @see HttpServlet#doPost(HttpServletRequest request, HttpServletResponse response)
*/
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// TODO Auto-generated method stub
doGet(request, response);
}
}
HTML页面:
<p>
Insert title here
$(document).ready(function(){
$("#ss").click(function(){
$.ajax({
url:"testajax2",
data:{},
type:"POST",
dataType:"XML",
success:function(httpdata){
var s=$(httpdata).find("user");
for(var i=0;i
抓取ajax动态网页java(一个毛病有些301从定向引起的毛病是因为301(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-15 03:04
当 网站 上的页面(例如,当用户在浏览器中访问您的页面或 Google 机器人抓取该页面时)向您的服务器发出请求时,服务器会返回一个 HTTP 状态代码以响应该请求。
如果它显示 403 状态,您可以忽略它,这意味着您的主机正在阻止 Google bot 抓取。有关所有 HTTP 状态代码的列表,请参阅 Google HTTP 状态代码帮助页面。
2、站点地图中的错误
站点地图错误通常会导致 404 错误页面,或者在当前地图中返回 404 错误页面。如果出现 404 错误页面,请检查站点地图中的所有链接,
Google 将继续抓取您已删除的站点地图,这令人沮丧,但有一些方法可以解决它:确保已在管理工具中删除旧的站点地图。如果您不想被抓取,请确保旧站点地图呈现 404 或重定向到新站点地图。
谷歌员工 Susan Moskwa 解释说:
防止 Google bot 抓取的最好方法是让这些 URL(例如旧站点地图)显示 404,当我们看到一个 URL 多次显示 404 时,Google bot 将停止抓取。
三、重定向错误
一些故障是由重定向的 301 引起的。执行重定向后的注意事项:
1:确保它们返回正确的 HTTP 状态代码。
2:确保您没有任何循环重定向。
3:确保重定向指向一个有效的网页,而不是404页面,或者其他错误页面,比如503(服务器错误)或者403(停止爬取)
4:确保重定向不指向空页面。
四、404 错误
404错误可能出现在以下几个方面:
1:删除网站上的网页;
2:更改了网页名称;
4:链接到不存在的页面;
5:其他网站链接到你的网站最后一个不存在的页面;
6:网站迁移到域名不完全匹配的新网站。
五、受 robots.txt 限制
另一个原因是 robots.txt 文件阻止了 Google bot 抓取。如果出现大量爬取问题,第一步应该是检查robots.txt
6、软404问题
通常,当有人请求一个不存在的页面时,服务器会返回一个 404 (Not Found) 错误。如果响应请求的页面不存在,除了返回 404 代码外,服务器还会显示 404 页面。这更像是一个标准的“找不到文件”消息,或者是一个旨在向用户提供更多信息的自定义页面。页面内容与服务器返回的 HTTP 响应完全无关。仅仅因为页面显示 404 文件未找到消息并不意味着它是 404 页面。
七、超时
网站超时也是爬取失败的原因之一。如果超时,Google bot 将停止抓取。超时的故障类型有:
1:DNS超时,可以使用Nslookup命令检测DNS,DNS超时的最大原因是域名服务商的DNS服务器不稳定。
2:URL超时,特定页面出现故障,而不是整个域。
3:robots.txt超时,如果你网站有robots.txt,但是服务器超时,Google bot会认为该文件不存在。
4:动态网页响应时间过长,页面加载时间过长。 查看全部
抓取ajax动态网页java(一个毛病有些301从定向引起的毛病是因为301(组图))
当 网站 上的页面(例如,当用户在浏览器中访问您的页面或 Google 机器人抓取该页面时)向您的服务器发出请求时,服务器会返回一个 HTTP 状态代码以响应该请求。
如果它显示 403 状态,您可以忽略它,这意味着您的主机正在阻止 Google bot 抓取。有关所有 HTTP 状态代码的列表,请参阅 Google HTTP 状态代码帮助页面。
2、站点地图中的错误
站点地图错误通常会导致 404 错误页面,或者在当前地图中返回 404 错误页面。如果出现 404 错误页面,请检查站点地图中的所有链接,
Google 将继续抓取您已删除的站点地图,这令人沮丧,但有一些方法可以解决它:确保已在管理工具中删除旧的站点地图。如果您不想被抓取,请确保旧站点地图呈现 404 或重定向到新站点地图。
谷歌员工 Susan Moskwa 解释说:
防止 Google bot 抓取的最好方法是让这些 URL(例如旧站点地图)显示 404,当我们看到一个 URL 多次显示 404 时,Google bot 将停止抓取。
三、重定向错误
一些故障是由重定向的 301 引起的。执行重定向后的注意事项:
1:确保它们返回正确的 HTTP 状态代码。
2:确保您没有任何循环重定向。
3:确保重定向指向一个有效的网页,而不是404页面,或者其他错误页面,比如503(服务器错误)或者403(停止爬取)
4:确保重定向不指向空页面。
四、404 错误
404错误可能出现在以下几个方面:
1:删除网站上的网页;
2:更改了网页名称;
4:链接到不存在的页面;
5:其他网站链接到你的网站最后一个不存在的页面;
6:网站迁移到域名不完全匹配的新网站。
五、受 robots.txt 限制
另一个原因是 robots.txt 文件阻止了 Google bot 抓取。如果出现大量爬取问题,第一步应该是检查robots.txt
6、软404问题
通常,当有人请求一个不存在的页面时,服务器会返回一个 404 (Not Found) 错误。如果响应请求的页面不存在,除了返回 404 代码外,服务器还会显示 404 页面。这更像是一个标准的“找不到文件”消息,或者是一个旨在向用户提供更多信息的自定义页面。页面内容与服务器返回的 HTTP 响应完全无关。仅仅因为页面显示 404 文件未找到消息并不意味着它是 404 页面。

七、超时
网站超时也是爬取失败的原因之一。如果超时,Google bot 将停止抓取。超时的故障类型有:
1:DNS超时,可以使用Nslookup命令检测DNS,DNS超时的最大原因是域名服务商的DNS服务器不稳定。
2:URL超时,特定页面出现故障,而不是整个域。
3:robots.txt超时,如果你网站有robots.txt,但是服务器超时,Google bot会认为该文件不存在。
4:动态网页响应时间过长,页面加载时间过长。
抓取ajax动态网页java(爬取苏宁酷开电视价格代码如下:(导入jsoup包) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2022-03-14 14:04
)
最近因为工作需要,开始学习爬虫。对于静态加载的页面,爬取并不难,但是遇到ajax动态加载的页面,动态加载的信息是爬不出来的!
对于ajax动态加载的数据爬取,一般有两种方式:
1.因为js渲染页面的数据也是从后端获取的,而且基本上都是AJAX获取的,所以分析AJAX请求,找到对应的数据
请求也更可行。而且相对于页面样式,这个界面是不太可能改变的。缺点是找到请求,并且
仿真是一个比较困难的过程,需要比较多的分析经验
2.在爬取阶段,爬虫内置浏览器内核,爬取前执行js渲染页面。这方面对应的工具有Selenium,
HtmlUnit 或 PhantomJs。但这些工具都存在一定的效率问题,同时也不是那么稳定。好处是写规则
对于第二种方法,我测试过,只有Selenium可以成功爬到ajax动态加载的页面,但是每次请求页面都会弹出浏览器窗口,这对后面的项目部署到浏览器很不利!所以推荐第一种方法,代码也是第一种方法。
爬取苏宁酷开电视价格代码如下:
(导入jsoup包我就不多说了,自己百度吧!)
//然后就是模拟ajax请求,当然了,根据规律,需要将"datasku"的属性值替换下面链接中的"133537397"和"0000000000"值
Document
document1=Jsoup.connect("http://ds.suning.cn/ds/general ... 6quot;)
.ignoreContentType(true)
.data("query", "Java")
.userAgent("Mozilla")
.cookie("auth", "token")
.timeout(3000)
.get();
//打印出模拟ajax请求返回的数据,一个json格式的数据,对它进行解析就可以了
System.out.println(document1.text()); 查看全部
抓取ajax动态网页java(爬取苏宁酷开电视价格代码如下:(导入jsoup包)
)
最近因为工作需要,开始学习爬虫。对于静态加载的页面,爬取并不难,但是遇到ajax动态加载的页面,动态加载的信息是爬不出来的!
对于ajax动态加载的数据爬取,一般有两种方式:
1.因为js渲染页面的数据也是从后端获取的,而且基本上都是AJAX获取的,所以分析AJAX请求,找到对应的数据
请求也更可行。而且相对于页面样式,这个界面是不太可能改变的。缺点是找到请求,并且
仿真是一个比较困难的过程,需要比较多的分析经验
2.在爬取阶段,爬虫内置浏览器内核,爬取前执行js渲染页面。这方面对应的工具有Selenium,
HtmlUnit 或 PhantomJs。但这些工具都存在一定的效率问题,同时也不是那么稳定。好处是写规则
对于第二种方法,我测试过,只有Selenium可以成功爬到ajax动态加载的页面,但是每次请求页面都会弹出浏览器窗口,这对后面的项目部署到浏览器很不利!所以推荐第一种方法,代码也是第一种方法。
爬取苏宁酷开电视价格代码如下:
(导入jsoup包我就不多说了,自己百度吧!)
//然后就是模拟ajax请求,当然了,根据规律,需要将"datasku"的属性值替换下面链接中的"133537397"和"0000000000"值
Document
document1=Jsoup.connect("http://ds.suning.cn/ds/general ... 6quot;)
.ignoreContentType(true)
.data("query", "Java")
.userAgent("Mozilla")
.cookie("auth", "token")
.timeout(3000)
.get();
//打印出模拟ajax请求返回的数据,一个json格式的数据,对它进行解析就可以了
System.out.println(document1.text());
抓取ajax动态网页java(Web页面不用打断交互流程进行重新加裁,你还不知道?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-03-12 20:11
Ajax(异步 JavaScript 和 XML)是一种结合 Java 技术、XML 和 JavaScript 的编程技术,允许您构建基于 Java 技术的 Web 应用程序并打破使用页面重新加载的惯例。
Ajax,异步 JavaScript 和 XML,是一种 Web 应用程序开发方法,它使用客户端脚本与 Web 服务器交换数据。这样,可以在不中断交互流程进行重新编辑的情况下动态更新网页。使用 Ajax,您可以创建接近本地桌面应用程序的直接、高度可用、更丰富和更动态的 Web 用户界面界面。
Ajax 不是一种技术,它更像是一种模式——一种识别和描述有用设计技术的方法。对于许多不熟悉它的开发人员来说,这是一种新的感觉,但是实现 Ajax 的所有组件都已经存在多年了。
当前的热议是由于 2004 年和 2005 年出现了一些非常动态的基于 Ajax 的 WebUI,尤其是 Google 的 GMail 和 Maps 应用程序,以及照片共享 网站Flickr。这些 UI 充分利用了后端通道,也被一些开发人员称为“Web2.0”,并导致对 Ajax 应用程序的兴趣激增。
更好的购物车
您可以使用 Ajax 来增强传统的 Web 应用程序,通过消除页面加载使交互更加顺畅。为了演示它,我将使用一个简单的购物车来动态更新添加的项目。结合在线商店,这种方法允许我们继续浏览并将商品挑选到购物车中,而无需等待页面在点击后重新加载。
尽管本文中的代码是针对购物车示例的,但所展示的技术也可以在其他 Ajax 应用程序中使用。购物车示例中使用的 HTML 代码如清单 1 所示。我将在整个 文章 中引用此 HTML 代码。
阿贾克斯进程
Ajax 交互从一个名为 XMLHttpRequest 的 JavaScript 对象开始。顾名思义,它允许客户端脚本执行 HTTP 请求并解析 XML 格式的服务器响应。Ajax 处理的第一步是创建 XMLHttpRequest 的实例。使用 HTTP 方法(GET 或 POST)处理请求并将目标 URL 设置为 XMLHttpRequest 对象。
现在,还记得最初是如何异步处理 Ajax 的吗?当你发送一个 HTTP 请求时,你不希望浏览器挂起等待服务器的响应,相反,你希望页面继续响应用户的界面交互,当它们真正到达时服务器响应处理它们。
为此,您可以使用 XMLHttpRequest 注册回调函数并异步调度 XMLHttpRequest 请求。控制权立即返回给浏览器,当服务器响应到达时会调用回调函数。
在 Java Web 服务器上,传入请求与任何其他 HttpServletRequest 相同。解析请求参数后,servlet 执行必要的应用程序逻辑,将响应序列化为 XML,并将其写回 HttpServletResponse。
回到客户端,现在将调用注册在 XMLHttpRequest 上的回调函数来处理服务器返回的 XML 文档。最后,JavaScript 用于通过更新用户界面以响应从服务器传输的数据来操作页面的 HTMLDOM。图 1 是 Ajax 进程的序列图。
图 1:Ajax 处理流程
您现在应该对 Ajax 进程有一个高级视图。我将进入这些步骤中的每一个,并更详细地了解发生了什么。如果找不到合适的位置,请返回并查看图 1,此外 - 由于 Ajax 方法的异步特性,序列图并不直接。 查看全部
抓取ajax动态网页java(Web页面不用打断交互流程进行重新加裁,你还不知道?)
Ajax(异步 JavaScript 和 XML)是一种结合 Java 技术、XML 和 JavaScript 的编程技术,允许您构建基于 Java 技术的 Web 应用程序并打破使用页面重新加载的惯例。
Ajax,异步 JavaScript 和 XML,是一种 Web 应用程序开发方法,它使用客户端脚本与 Web 服务器交换数据。这样,可以在不中断交互流程进行重新编辑的情况下动态更新网页。使用 Ajax,您可以创建接近本地桌面应用程序的直接、高度可用、更丰富和更动态的 Web 用户界面界面。
Ajax 不是一种技术,它更像是一种模式——一种识别和描述有用设计技术的方法。对于许多不熟悉它的开发人员来说,这是一种新的感觉,但是实现 Ajax 的所有组件都已经存在多年了。
当前的热议是由于 2004 年和 2005 年出现了一些非常动态的基于 Ajax 的 WebUI,尤其是 Google 的 GMail 和 Maps 应用程序,以及照片共享 网站Flickr。这些 UI 充分利用了后端通道,也被一些开发人员称为“Web2.0”,并导致对 Ajax 应用程序的兴趣激增。
更好的购物车
您可以使用 Ajax 来增强传统的 Web 应用程序,通过消除页面加载使交互更加顺畅。为了演示它,我将使用一个简单的购物车来动态更新添加的项目。结合在线商店,这种方法允许我们继续浏览并将商品挑选到购物车中,而无需等待页面在点击后重新加载。
尽管本文中的代码是针对购物车示例的,但所展示的技术也可以在其他 Ajax 应用程序中使用。购物车示例中使用的 HTML 代码如清单 1 所示。我将在整个 文章 中引用此 HTML 代码。
阿贾克斯进程
Ajax 交互从一个名为 XMLHttpRequest 的 JavaScript 对象开始。顾名思义,它允许客户端脚本执行 HTTP 请求并解析 XML 格式的服务器响应。Ajax 处理的第一步是创建 XMLHttpRequest 的实例。使用 HTTP 方法(GET 或 POST)处理请求并将目标 URL 设置为 XMLHttpRequest 对象。
现在,还记得最初是如何异步处理 Ajax 的吗?当你发送一个 HTTP 请求时,你不希望浏览器挂起等待服务器的响应,相反,你希望页面继续响应用户的界面交互,当它们真正到达时服务器响应处理它们。
为此,您可以使用 XMLHttpRequest 注册回调函数并异步调度 XMLHttpRequest 请求。控制权立即返回给浏览器,当服务器响应到达时会调用回调函数。
在 Java Web 服务器上,传入请求与任何其他 HttpServletRequest 相同。解析请求参数后,servlet 执行必要的应用程序逻辑,将响应序列化为 XML,并将其写回 HttpServletResponse。
回到客户端,现在将调用注册在 XMLHttpRequest 上的回调函数来处理服务器返回的 XML 文档。最后,JavaScript 用于通过更新用户界面以响应从服务器传输的数据来操作页面的 HTMLDOM。图 1 是 Ajax 进程的序列图。

图 1:Ajax 处理流程
您现在应该对 Ajax 进程有一个高级视图。我将进入这些步骤中的每一个,并更详细地了解发生了什么。如果找不到合适的位置,请返回并查看图 1,此外 - 由于 Ajax 方法的异步特性,序列图并不直接。
抓取ajax动态网页java(如何一次性把网站中的ajax获取这里介绍的文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-03-10 14:11
通常情况下,通过网络爬虫挖出来的网页的静态内容基本上就是网页的静态内容,而动态ajax号的内容是我个人不知道ajax怎么弄进去的网站 一次
这里介绍的是某个网站中的某个ajax刷新某个表,期望数据,提供其他操作,比如下载:
假设我们需要挖掘某个网站:
示例:网站 中的那些 pdf 文件,并下载它们
首先:需要分析网页构成的结果;看看它是如何被读取和处理的。 ajax解决方案到此结束(其他异同,ajax只对数据进行一次性数据请求)
具体操作已经通过案例主要介绍了:
先分析ajax使用的请求url的含义和请求中需要的参数,然后给出响应的参数
/**
* 获取某个请求的内容
* @param url 请求的地址
* @param code 请求的编码,不传就代表UTF-8
* @return 请求响应的内容
* @throws IOException
*/
public static String fetch_url(String url, String code) throws IOException {
BufferedReader bis = null;
InputStream is = null;
InputStreamReader inputStreamReader = null;
try {
URLConnection connection = new URL(url).openConnection();
connection.setConnectTimeout(20000);
connection.setReadTimeout(20000);
connection.setUseCaches(false);
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11");
is = connection.getInputStream();
inputStreamReader = new InputStreamReader(is, code);
bis = new BufferedReader(inputStreamReader);
String line = null;
StringBuffer result = new StringBuffer();
while ((line = bis.readLine()) != null) {
result.append(line);
}
return result.toString();
} finally {
if (inputStreamReader != null) {
try {
inputStreamReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (bis != null) {
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (is != null) {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
通过上面的url请求,观察响应的数据格式,这里响应的数据测试格式为json格式
/**
* 数据转化成json格式
* @param s
*/
public static void getJSON(String s) {
JSONObject object = JSONObject.fromObject(s);
JSONArray array = JSONArray.fromObject(object.get("disclosureInfos"));
//System.out.println(array);
String filePath = object.getString("filePath");//解析数据中的某一个值
//System.out.println(array.size());
List listFilePath = getJSONArray(array,filePath);//将数据解析成条数
/*System.out.println(listFilePath);
System.out.println(listFilePath.size());*/
writer(listFilePath);//根据数据的内容开始挖取下载
}
大量数据需要下载,一个一个
public static void writer(List listFilePath) {
for (String string : listFilePath) {
downloadFile(string);
}
}
从格式数据中解析json数据
/**
* 解析文件url
* @param array
* @return
*/
public static List getJSONArray(JSONArray array,String filePath) {
List listFilePath = new ArrayList();
for (Object object : array) {
JSONObject ob = JSONObject.fromObject(object);
filePath = filePath + ob.get("filePath").toString();
// System.out.println(filePath);
listFilePath.add(filePath);
}
return listFilePath;
}
文件下载处理
/* 下载 url 指向的网页 */
public static String downloadFile(String url) {
String filePath = null;
/* 1.生成 HttpClinet 对象并设置参数 */
HttpClient httpClient = new HttpClient();
// 设置 Http 连接超时 5s
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(5000);
/* 2.生成 GetMethod 对象并设置参数 */
GetMethod getMethod = new GetMethod(url);
// 设置 get 请求超时 5s
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, 5000);
// 设置请求重试处理
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER, new DefaultHttpMethodRetryHandler());
/* 3.执行 HTTP GET 请求 */
try {
int statusCode = httpClient.executeMethod(getMethod);
// 判断访问的状态码
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: " + getMethod.getStatusLine());
filePath = null;
}
/* 4.处理 HTTP 响应内容 */
byte[] responseBody = getMethod.getResponseBody();// 读取为字节数组
// 根据网页 url 生成保存时的文件名
filePath = "e:\\spider\\";
String fileName = getFileNameByUrl(url, getMethod.getResponseHeader("Content-Type").getValue());
saveToLocal(responseBody, filePath,fileName);
} catch (HttpException e) {
// 发生致命的异常,可能是协议不对或者返回的内容有问题
System.out.println("Please check your provided http address!");
e.printStackTrace();
} catch (IOException e) {
// 发生网络异常
e.printStackTrace();
} finally {
// 释放连接
getMethod.releaseConnection();
}
return filePath;
}
确认文件名和文件格式
/**
* 根据 url 和网页类型生成需要保存的网页的文件名 去除掉 url 中非文件名字符
*/
public static String getFileNameByUrl(String url, String contentType) {
// remove http://
url = url.substring(7);
// text/html类型
if (contentType.indexOf("html") != -1) {
url = url.replaceAll("[\\?/:*|\"]", "_") + ".html";
return url;
}
// 如application/pdf类型
else {
return url.replaceAll("[\\?/:*|\"]", "_") + "." + contentType.substring(contentType.lastIndexOf("/") + 1);
}
}
保存要写入的文件地址
/**
* 保存网页字节数组到本地文件 filePath 为要保存的文件的相对地址
*/
private static void saveToLocal(byte[] data, String fileDir,String fileName) {
try {
File fileNew=new File(fileDir+"\\"+fileName);//new 一个文件 构造参数是字符串
File rootFile=fileNew.getParentFile();//得到父文件夹
if( !fileNew.exists()) {
rootFile.mkdirs();
fileNew.createNewFile();
}
DataOutputStream out = new DataOutputStream(new FileOutputStream(fileNew));
for (int i = 0; i < data.length; i++)
out.write(data[i]);
out.flush();
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
测试,这里写一个测试URL,网站地址和URL参数可能会发生变化,需要适当调整
public static void main(String[] args) throws Exception{
String s = fetch_url("http://www.neeq.cc/controller/ ... ot%3B, "utf-8");
//System.out.println(s);
getJSON(s);
}
完(欢迎转载) 查看全部
抓取ajax动态网页java(如何一次性把网站中的ajax获取这里介绍的文件)
通常情况下,通过网络爬虫挖出来的网页的静态内容基本上就是网页的静态内容,而动态ajax号的内容是我个人不知道ajax怎么弄进去的网站 一次
这里介绍的是某个网站中的某个ajax刷新某个表,期望数据,提供其他操作,比如下载:
假设我们需要挖掘某个网站:
示例:网站 中的那些 pdf 文件,并下载它们
首先:需要分析网页构成的结果;看看它是如何被读取和处理的。 ajax解决方案到此结束(其他异同,ajax只对数据进行一次性数据请求)
具体操作已经通过案例主要介绍了:
先分析ajax使用的请求url的含义和请求中需要的参数,然后给出响应的参数
/**
* 获取某个请求的内容
* @param url 请求的地址
* @param code 请求的编码,不传就代表UTF-8
* @return 请求响应的内容
* @throws IOException
*/
public static String fetch_url(String url, String code) throws IOException {
BufferedReader bis = null;
InputStream is = null;
InputStreamReader inputStreamReader = null;
try {
URLConnection connection = new URL(url).openConnection();
connection.setConnectTimeout(20000);
connection.setReadTimeout(20000);
connection.setUseCaches(false);
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11");
is = connection.getInputStream();
inputStreamReader = new InputStreamReader(is, code);
bis = new BufferedReader(inputStreamReader);
String line = null;
StringBuffer result = new StringBuffer();
while ((line = bis.readLine()) != null) {
result.append(line);
}
return result.toString();
} finally {
if (inputStreamReader != null) {
try {
inputStreamReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (bis != null) {
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (is != null) {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
通过上面的url请求,观察响应的数据格式,这里响应的数据测试格式为json格式
/**
* 数据转化成json格式
* @param s
*/
public static void getJSON(String s) {
JSONObject object = JSONObject.fromObject(s);
JSONArray array = JSONArray.fromObject(object.get("disclosureInfos"));
//System.out.println(array);
String filePath = object.getString("filePath");//解析数据中的某一个值
//System.out.println(array.size());
List listFilePath = getJSONArray(array,filePath);//将数据解析成条数
/*System.out.println(listFilePath);
System.out.println(listFilePath.size());*/
writer(listFilePath);//根据数据的内容开始挖取下载
}
大量数据需要下载,一个一个
public static void writer(List listFilePath) {
for (String string : listFilePath) {
downloadFile(string);
}
}
从格式数据中解析json数据
/**
* 解析文件url
* @param array
* @return
*/
public static List getJSONArray(JSONArray array,String filePath) {
List listFilePath = new ArrayList();
for (Object object : array) {
JSONObject ob = JSONObject.fromObject(object);
filePath = filePath + ob.get("filePath").toString();
// System.out.println(filePath);
listFilePath.add(filePath);
}
return listFilePath;
}
文件下载处理
/* 下载 url 指向的网页 */
public static String downloadFile(String url) {
String filePath = null;
/* 1.生成 HttpClinet 对象并设置参数 */
HttpClient httpClient = new HttpClient();
// 设置 Http 连接超时 5s
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(5000);
/* 2.生成 GetMethod 对象并设置参数 */
GetMethod getMethod = new GetMethod(url);
// 设置 get 请求超时 5s
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, 5000);
// 设置请求重试处理
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER, new DefaultHttpMethodRetryHandler());
/* 3.执行 HTTP GET 请求 */
try {
int statusCode = httpClient.executeMethod(getMethod);
// 判断访问的状态码
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: " + getMethod.getStatusLine());
filePath = null;
}
/* 4.处理 HTTP 响应内容 */
byte[] responseBody = getMethod.getResponseBody();// 读取为字节数组
// 根据网页 url 生成保存时的文件名
filePath = "e:\\spider\\";
String fileName = getFileNameByUrl(url, getMethod.getResponseHeader("Content-Type").getValue());
saveToLocal(responseBody, filePath,fileName);
} catch (HttpException e) {
// 发生致命的异常,可能是协议不对或者返回的内容有问题
System.out.println("Please check your provided http address!");
e.printStackTrace();
} catch (IOException e) {
// 发生网络异常
e.printStackTrace();
} finally {
// 释放连接
getMethod.releaseConnection();
}
return filePath;
}
确认文件名和文件格式
/**
* 根据 url 和网页类型生成需要保存的网页的文件名 去除掉 url 中非文件名字符
*/
public static String getFileNameByUrl(String url, String contentType) {
// remove http://
url = url.substring(7);
// text/html类型
if (contentType.indexOf("html") != -1) {
url = url.replaceAll("[\\?/:*|\"]", "_") + ".html";
return url;
}
// 如application/pdf类型
else {
return url.replaceAll("[\\?/:*|\"]", "_") + "." + contentType.substring(contentType.lastIndexOf("/") + 1);
}
}
保存要写入的文件地址
/**
* 保存网页字节数组到本地文件 filePath 为要保存的文件的相对地址
*/
private static void saveToLocal(byte[] data, String fileDir,String fileName) {
try {
File fileNew=new File(fileDir+"\\"+fileName);//new 一个文件 构造参数是字符串
File rootFile=fileNew.getParentFile();//得到父文件夹
if( !fileNew.exists()) {
rootFile.mkdirs();
fileNew.createNewFile();
}
DataOutputStream out = new DataOutputStream(new FileOutputStream(fileNew));
for (int i = 0; i < data.length; i++)
out.write(data[i]);
out.flush();
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
测试,这里写一个测试URL,网站地址和URL参数可能会发生变化,需要适当调整
public static void main(String[] args) throws Exception{
String s = fetch_url("http://www.neeq.cc/controller/ ... ot%3B, "utf-8");
//System.out.println(s);
getJSON(s);
}
完(欢迎转载)
抓取ajax动态网页java( 小金子学院目录最新收录:家常小知识:熬中药要先清洗吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-03-05 15:18
小金子学院目录最新收录:家常小知识:熬中药要先清洗吗)
小金子学院最新目录收录:家常知识:中药需要先清洗吗?
网站对未被搜索引擎搜索的页面的引用收录
1、网页使用框架:框架内的内容通常不会被搜索引擎抓取。
2、图片太多,文字太少。
3、提交页面转到另一个网站:搜索引擎可能会完全跳过此页面。
4、提交过于频繁:一个月提交2次以上,很多搜索引擎受不了,认为你在提交垃圾邮件。
5、网站关键词密度太大:可惜搜索引擎并没有说明密度到底有多高,一般认为100字的描述收录3-4个关键词 是最好的。
6、文字颜色与背景颜色相同:搜索引擎认为你在堆积关键词来欺骗它。
7、动态网页:网站的内容管理系统方便了网页更新,但给大部分搜索引擎带来了麻烦。很多搜索引擎不对动态页面收费,或者只对一级页面收费,不会深度收费。这时候应该考虑使用WEB服务器的重写技术,将动态页面的url映射成与静态页面的url类似的格式。搜索引擎误认为是静态页面,会收费。
8、网站传输服务器:搜索引擎通常只识别IP地址。转换主机或域名时,IP/DNS 地址会发生变化。这时候需要重新提交网站。
9、免费网站空间:一些搜索引擎拒绝从免费空间中索引网站,抱怨很多垃圾和质量差。
10、Crawling 网站Not Online:如果主机不稳定,就会发生这种情况。更糟糕的是,即使 网站 已经是 收录,重新抓取并发现它处于脱机状态也会完全删除 网站。
11、不正确地阻止robots indexing网站:有两种方式来阻止robots:宿主服务器根目录下的简单文本文件;带有某种 META 标签的网页。
12、使用大量Flash、DHTML、cookies、JavaScript、Java或密码访问的网页,搜索引擎很难从此类网页中提取内容。
13、搜索引擎无法解析你的DNS:新域名注册后需要1-2天才能生效,所以不要一注册域名就提交网站 .
14、网站的链接宽度太小:链接宽度太小,搜索引擎很难找到你。这个时候可以考虑将网站登录到知名的分类,或者多做几个友好的链接。
15、服务器速度太慢:网络带宽太小,网页下载速度太慢,或者网页太复杂,可能导致搜索引擎在文字内容还没出来之前就挂了成立。
16、关键字问题:如果你的META标签中提到的关键字没有出现在文本中,搜索引擎可能会认为它是垃圾关键字。
医学院⊙▽㊦1㊧公司名称
特别的
医学院⊙▽㊦1㊧公司名称
特别的
小金子。com
上一篇:一些改进和增强的方法网站
显示:网站没有被搜索引擎搜索到的页面的参考描述收录
下一篇:再谈交换友情链接的六大要点
特别提醒,本信息由本站会员xjz001提供。
如需转载,请注明出处,数据来源为小金字类:
"网站不被搜索引擎搜索的页面参考说明收录"感谢您的支持!
»如果您觉得“网站页面未被搜索引擎收录的参考描述”,相关信息不全,请点击这里协作更新!
1 查看全部
抓取ajax动态网页java(
小金子学院目录最新收录:家常小知识:熬中药要先清洗吗)

小金子学院最新目录收录:家常知识:中药需要先清洗吗?
网站对未被搜索引擎搜索的页面的引用收录
1、网页使用框架:框架内的内容通常不会被搜索引擎抓取。
2、图片太多,文字太少。
3、提交页面转到另一个网站:搜索引擎可能会完全跳过此页面。
4、提交过于频繁:一个月提交2次以上,很多搜索引擎受不了,认为你在提交垃圾邮件。
5、网站关键词密度太大:可惜搜索引擎并没有说明密度到底有多高,一般认为100字的描述收录3-4个关键词 是最好的。
6、文字颜色与背景颜色相同:搜索引擎认为你在堆积关键词来欺骗它。
7、动态网页:网站的内容管理系统方便了网页更新,但给大部分搜索引擎带来了麻烦。很多搜索引擎不对动态页面收费,或者只对一级页面收费,不会深度收费。这时候应该考虑使用WEB服务器的重写技术,将动态页面的url映射成与静态页面的url类似的格式。搜索引擎误认为是静态页面,会收费。
8、网站传输服务器:搜索引擎通常只识别IP地址。转换主机或域名时,IP/DNS 地址会发生变化。这时候需要重新提交网站。
9、免费网站空间:一些搜索引擎拒绝从免费空间中索引网站,抱怨很多垃圾和质量差。
10、Crawling 网站Not Online:如果主机不稳定,就会发生这种情况。更糟糕的是,即使 网站 已经是 收录,重新抓取并发现它处于脱机状态也会完全删除 网站。
11、不正确地阻止robots indexing网站:有两种方式来阻止robots:宿主服务器根目录下的简单文本文件;带有某种 META 标签的网页。
12、使用大量Flash、DHTML、cookies、JavaScript、Java或密码访问的网页,搜索引擎很难从此类网页中提取内容。
13、搜索引擎无法解析你的DNS:新域名注册后需要1-2天才能生效,所以不要一注册域名就提交网站 .
14、网站的链接宽度太小:链接宽度太小,搜索引擎很难找到你。这个时候可以考虑将网站登录到知名的分类,或者多做几个友好的链接。
15、服务器速度太慢:网络带宽太小,网页下载速度太慢,或者网页太复杂,可能导致搜索引擎在文字内容还没出来之前就挂了成立。
16、关键字问题:如果你的META标签中提到的关键字没有出现在文本中,搜索引擎可能会认为它是垃圾关键字。
医学院⊙▽㊦1㊧公司名称
特别的
医学院⊙▽㊦1㊧公司名称
特别的
小金子。com
上一篇:一些改进和增强的方法网站
显示:网站没有被搜索引擎搜索到的页面的参考描述收录
下一篇:再谈交换友情链接的六大要点
特别提醒,本信息由本站会员xjz001提供。
如需转载,请注明出处,数据来源为小金字类:
"网站不被搜索引擎搜索的页面参考说明收录"感谢您的支持!
»如果您觉得“网站页面未被搜索引擎收录的参考描述”,相关信息不全,请点击这里协作更新!


1
浅谈Python网络爬虫
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-05-09 23:59
(2)数据解析:了解HTML结构、JSON和XML数据格式,CSS选择器、Xpath路径表达式、正则表达式等,目的是从响应中提取出所需的数据;
(3)数据入库:MySQL,SQLite、Redis等数据库,便于数据的存储;
相关技术
以上是学习爬虫的基本要求,在实际的应用中,也应考虑如何使用多线程提高效率、如何做任务调度、如何应对反爬虫,如何实现分布式爬虫等等。本文介绍的比较有限,仅供参考。
六 python相关库
在爬虫实现上,除了scrapy框架之外,python有许多与此相关的库可供使用。其中,在数据抓取方面包括: urllib2(urllib3)、requests、mechanize、selenium、splinter;在数据解析方包括:lxml、beautifulsoup4、re、pyquery。
对于数据抓取,涉及的过程主要是模拟浏览器向服务器发送构造好的http请求,常见类型有:get/post。其中,urllib2(urllib3)、requests、mechanize用来获取URL对应的原始响应内容;而selenium、splinter通过加载浏览器驱动,获取浏览器渲染之后的响应内容,模拟程度更高。
具体选择哪种类库,应根据实际需求决定,如考虑效率、对方的反爬虫手段等。通常,能使用urllib2(urllib3)、requests、mechanize等解决的尽量不用selenium、splinter,因为后者因需要加载浏览器而导致效率较低。
对于数据解析,主要是从响应页面里提取所需的数据,常用方法有:xpath路径表达式、CSS选择器、正则表达式等。其中,xpath路径表达式、CSS选择器主要用于提取结构化的数据,而正则表达式主要用于提取非结构化的数据。相应的库有lxml、beautifulsoup4、re、pyquery。
类库
文档
数 据 抓 取
urllib2
requests
mechanize
splinter
selenium
数 据 解 析
lxml
beautifulsoup4
re
pyquery
相关库文档
七.相关介绍
1 数据抓取
(1)urllib2
urllib2是python自带的一个访问网页及本地文件的库,通常需要与urllib一起使用。因为urllib提供了urlencode方法用来对发送的数据进行编码,而urllib2没有对应的方法。
以下是对urllib2简易封装的说明,主要是将相关的特性集中在了一个类函数里面,避免一些繁琐的配置工作。
urllib2封装说明
(2)requests和mechanize
requests是Python的第三方库,基于urllib,但比urllib更加方便,接口简单。其特点包括, 关于http请求:支持自定义请求头,支持设置代理、支持重定向、支持保持会话[request.Session()]、支持超时设置、对post数据自动urlencode; 关于http响应:可直接从响应中获得详细的数据,无需人工配置,包括:状态码、自动解码的响应内容、响应头中的各个字段;还内置JSON解码器。
mechanize是对urllib2部分功能的替换,能够更好的模拟浏览器行为,在web访问控制方面做得很全面。其特点包括:支持cookie设置、代理设置、重定向设置、简单的表单填写、浏览器历史记录和重载、referer头的添加(可选)、自动遵守robots.txt、自动处理HTTP-EQUIV和刷新等。
对requests和mechanize简易封装后的接口与urllib2一样,也是将相关特性集中在了一个类函数里面,这里不在重复说明,可参考所给代码。
(3)splinter和selenium
selenium(python)和splinter可以很好的模拟浏览器行为,二者通过加载浏览器驱动工作。在采集信息方面,降低了分析网络请求的麻烦,一般只需要知道数据页面对应的URL即可。由于要加载浏览器,所以效率方面相对较低。
默认情况下,优先使用的是Firefox浏览器。这里列出chrome和pantomjs(无头浏览器)驱动的下载地址,方便查找。
chrome和pantomjs驱动地址:
chrome :
pantomjs :
2 数据解析
对于数据解析,可用的库有lxml、beautifulsoup4、re、pyquery。其中,beautifulsoup4比较常用些。除了这些库的使用,可了解一下xpath路径表达式、CSS选择器、正则表达式的语法,便于从网页中提取数据。其中,chrome浏览器自带生成Xpath的功能。
chrome查看元素的xpath
如果能够基于网络分析,抓取到所需数据对应的页面,接下来,从页面中提取数据的工作就相对明确很多。具体的使用方法可参考文档,这里不在详细介绍。
八 反爬虫
1. 基本的反爬虫手段,主要是检测请求头中的字段,比如:User-Agent、referer等。针对这种情况,只要在请求中带上对应的字段即可。所构造http请求的各个字段最好跟在浏览器中发送的完全一样,但也不是必须。
2. 基于用户行为的反爬虫手段,主要是在后台对访问的IP(或User-Agent)进行统计,当超过某一设定的阈值,给予封锁。针对这种情况,可通过使用代理服务器解决,每隔几次请求,切换一下所用代理的IP地址(或通过使用User-Agent列表解决,每次从列表里随机选择一个使用)。这样的反爬虫方法可能会误伤用户。
3. 希望抓取的数据是如果通过ajax请求得到的,假如通过网络分析能够找到该ajax请求,也能分析出请求所需的具体参数,则直接模拟相应的http请求,即可从响应中得到对应的数据。这种情况,跟普通的请求没有什么区别。
4. 基于Java的反爬虫手段,主要是在响应数据页面之前,先返回一段带有Java代码的页面,用于验证访问者有无Java的执行环境,以确定使用的是不是浏览器。
通常情况下,这段JS代码执行后,会发送一个带参数key的请求,后台通过判断key的值来决定是响应真实的页面,还是响应伪造或错误的页面。因为key参数是动态生成的,每次都不一样,难以分析出其生成方法,使得无法构造对应的http请求。
比如网站 ,使用就是这种方式,具体可参见 。
在首次访问网站时,响应的JS内容会发送带yundun参数的请求,而yundun参数每次都不一样。
动态参数yundun
目前测试时,该Java代码执行后,发送的请求不再带有yundun参数,而是动态生成一个cookie,在随后的请求中带上该cookie,作用类似于yundun参数。
动态cookie
针对这样的反爬虫方法,爬虫方面需要能够解析执行Java,具体的方法可使用selenium或splinter,通过加载浏览器来实现。 查看全部
浅谈Python网络爬虫
(2)数据解析:了解HTML结构、JSON和XML数据格式,CSS选择器、Xpath路径表达式、正则表达式等,目的是从响应中提取出所需的数据;
(3)数据入库:MySQL,SQLite、Redis等数据库,便于数据的存储;
相关技术
以上是学习爬虫的基本要求,在实际的应用中,也应考虑如何使用多线程提高效率、如何做任务调度、如何应对反爬虫,如何实现分布式爬虫等等。本文介绍的比较有限,仅供参考。
六 python相关库
在爬虫实现上,除了scrapy框架之外,python有许多与此相关的库可供使用。其中,在数据抓取方面包括: urllib2(urllib3)、requests、mechanize、selenium、splinter;在数据解析方包括:lxml、beautifulsoup4、re、pyquery。
对于数据抓取,涉及的过程主要是模拟浏览器向服务器发送构造好的http请求,常见类型有:get/post。其中,urllib2(urllib3)、requests、mechanize用来获取URL对应的原始响应内容;而selenium、splinter通过加载浏览器驱动,获取浏览器渲染之后的响应内容,模拟程度更高。
具体选择哪种类库,应根据实际需求决定,如考虑效率、对方的反爬虫手段等。通常,能使用urllib2(urllib3)、requests、mechanize等解决的尽量不用selenium、splinter,因为后者因需要加载浏览器而导致效率较低。
对于数据解析,主要是从响应页面里提取所需的数据,常用方法有:xpath路径表达式、CSS选择器、正则表达式等。其中,xpath路径表达式、CSS选择器主要用于提取结构化的数据,而正则表达式主要用于提取非结构化的数据。相应的库有lxml、beautifulsoup4、re、pyquery。
类库
文档
数 据 抓 取
urllib2
requests
mechanize
splinter
selenium
数 据 解 析
lxml
beautifulsoup4
re
pyquery
相关库文档
七.相关介绍
1 数据抓取
(1)urllib2
urllib2是python自带的一个访问网页及本地文件的库,通常需要与urllib一起使用。因为urllib提供了urlencode方法用来对发送的数据进行编码,而urllib2没有对应的方法。
以下是对urllib2简易封装的说明,主要是将相关的特性集中在了一个类函数里面,避免一些繁琐的配置工作。
urllib2封装说明
(2)requests和mechanize
requests是Python的第三方库,基于urllib,但比urllib更加方便,接口简单。其特点包括, 关于http请求:支持自定义请求头,支持设置代理、支持重定向、支持保持会话[request.Session()]、支持超时设置、对post数据自动urlencode; 关于http响应:可直接从响应中获得详细的数据,无需人工配置,包括:状态码、自动解码的响应内容、响应头中的各个字段;还内置JSON解码器。
mechanize是对urllib2部分功能的替换,能够更好的模拟浏览器行为,在web访问控制方面做得很全面。其特点包括:支持cookie设置、代理设置、重定向设置、简单的表单填写、浏览器历史记录和重载、referer头的添加(可选)、自动遵守robots.txt、自动处理HTTP-EQUIV和刷新等。
对requests和mechanize简易封装后的接口与urllib2一样,也是将相关特性集中在了一个类函数里面,这里不在重复说明,可参考所给代码。
(3)splinter和selenium
selenium(python)和splinter可以很好的模拟浏览器行为,二者通过加载浏览器驱动工作。在采集信息方面,降低了分析网络请求的麻烦,一般只需要知道数据页面对应的URL即可。由于要加载浏览器,所以效率方面相对较低。
默认情况下,优先使用的是Firefox浏览器。这里列出chrome和pantomjs(无头浏览器)驱动的下载地址,方便查找。
chrome和pantomjs驱动地址:
chrome :
pantomjs :
2 数据解析
对于数据解析,可用的库有lxml、beautifulsoup4、re、pyquery。其中,beautifulsoup4比较常用些。除了这些库的使用,可了解一下xpath路径表达式、CSS选择器、正则表达式的语法,便于从网页中提取数据。其中,chrome浏览器自带生成Xpath的功能。
chrome查看元素的xpath
如果能够基于网络分析,抓取到所需数据对应的页面,接下来,从页面中提取数据的工作就相对明确很多。具体的使用方法可参考文档,这里不在详细介绍。
八 反爬虫
1. 基本的反爬虫手段,主要是检测请求头中的字段,比如:User-Agent、referer等。针对这种情况,只要在请求中带上对应的字段即可。所构造http请求的各个字段最好跟在浏览器中发送的完全一样,但也不是必须。
2. 基于用户行为的反爬虫手段,主要是在后台对访问的IP(或User-Agent)进行统计,当超过某一设定的阈值,给予封锁。针对这种情况,可通过使用代理服务器解决,每隔几次请求,切换一下所用代理的IP地址(或通过使用User-Agent列表解决,每次从列表里随机选择一个使用)。这样的反爬虫方法可能会误伤用户。
3. 希望抓取的数据是如果通过ajax请求得到的,假如通过网络分析能够找到该ajax请求,也能分析出请求所需的具体参数,则直接模拟相应的http请求,即可从响应中得到对应的数据。这种情况,跟普通的请求没有什么区别。
4. 基于Java的反爬虫手段,主要是在响应数据页面之前,先返回一段带有Java代码的页面,用于验证访问者有无Java的执行环境,以确定使用的是不是浏览器。
通常情况下,这段JS代码执行后,会发送一个带参数key的请求,后台通过判断key的值来决定是响应真实的页面,还是响应伪造或错误的页面。因为key参数是动态生成的,每次都不一样,难以分析出其生成方法,使得无法构造对应的http请求。
比如网站 ,使用就是这种方式,具体可参见 。
在首次访问网站时,响应的JS内容会发送带yundun参数的请求,而yundun参数每次都不一样。
动态参数yundun
目前测试时,该Java代码执行后,发送的请求不再带有yundun参数,而是动态生成一个cookie,在随后的请求中带上该cookie,作用类似于yundun参数。
动态cookie
针对这样的反爬虫方法,爬虫方面需要能够解析执行Java,具体的方法可使用selenium或splinter,通过加载浏览器来实现。
抓取ajax动态网页java(点题外话吧,京东图书模拟浏览器的一些事儿)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-20 06:19
让我先离题。刚开始学爬虫的时候,有一次学长给我一个请求,要抓取京东图书的相关资料。嗯,因为我真的是刚开始学爬,用豆瓣练的很成功。我抓取了大约 500 条电影评论,然后将它们存储在 mysql 中。. . .
然后充满信心地开始工作。. 首先查看网页源代码。. . ? ? ? 我需要的不在源代码中!!!然后我问了校长。前辈告诉我这是AJAX生成的数据,我听完就去查数据。发现网上的信息在说明一个道理。对于动态页面,使用 PhantomJs 进行爬取,但是这样效率很低。作为一名优秀的程序员,当时看到“低效率”这两个字,心里是绝对不允许的,于是我就用抓包的方法去查看AJAX数据所在的URL。对于这种模拟浏览器方法一直搁置到现在。
但既然你知道了这一点,就没有理由不学习它。所以花点时间看了一下在Java中使用PhantomJs的资料,现在就分享给大家。
顺便说一句,其实作为一个网络爬虫,90%的页面数据都是通过抓包获取的。所以我还是鼓励大家直接请求自己需要的数据所在的URL。毕竟,这种方法虽然方便,但效率低下。
使用 AJAX 进行 JS 渲染
在学习这个东西之前,我们首先要了解什么是JS渲染,什么是AJAX,以及为什么我们在网页源码中取不到这两种数据。
根据我的理解,JS渲染和AJAX是相辅相成的关系。AJAX负责从服务器端异步获取数据,然后用JS渲染数据,最后呈现给用户。由于在Java中,HttpClient只能请求一个简单的静态页面,无法请求页面满载后JS调用相关代码生成的异步数据,所以我们无法通过HttpClient直接获取AJAX和JS渲染生成的数据。这时候根据上面的推荐,可以直接抓包获取AJAX数据所在的URL,或者使用本文提到的PhantomJs渲染引擎。
三大JS渲染引擎对比
在互联网上搜索信息时,我们常常被五花八门的答案弄得不知所措。这个时候要保持冷静的心情,二要考虑搜索问题的相关姿势,必要时要科学上网。
先不说本文提到的JS渲染引擎。只说Java爬虫中的HTTP请求库,可以有多种描述方式,Java自带的HttpURLConnection类,HttpClient第三方库等等,当然网上有这么多。方法,我们要选择,那么我们肯定要选择一个强大而简单的类库。这时候我们应该在网上搜索两个类库的相关对比,做出更好的选择,而不是随便挑一个就学,这样很可能投入的学习成本与回报不成正比。
那么相信大家在准备用JS引擎模拟浏览器的时候,看到的不光是PhantomJs,还有Selenium和HtmlUnit,它们的功能是一样的。那么我们该如何选择呢?下图摘自其他网友的博客:
HtmlUnitSeleniumPhantomJs
内置Rhinojs浏览器引擎,没有浏览器使用这个内核,解析速度一般,JS/CSS解析差,没有浏览器界面。
Selenium + WebDriver = Selenium是基于本地安装的浏览器,需要打开浏览器,需要参考对应的WebDriver,并正确配置webdriver的路径参数,这在爬取大量js时显然是不合适的渲染页面。
神器,短小精悍,可以本地运行,也可以作为服务器运行,基于webkit内核,性能和性能都不错,可以完美解析大部分页面。
这就是我选择谈论 PhantomJs 的原因。
PhantomJs 和 Selenium 经常成对出现在 Internet 上。原因是 Selenium 封装了 PhantomJs 的一些功能,而 Selenium 提供了 Python 接口模块。在 Python 语言中,Selenium 可以很好地使用,PhantomJs 可以间接使用。然而,是时候放弃 Selenium+PhantomJs 了。一个原因是封装的接口很久没有更新(没人维护),第二个原因是Selenium只实现了PhantomJs的一部分功能,很不完善。
PhantomJ 的使用
我使用的是Ubuntu16.04的开发环境。关于 PhantomJs + Selenium 的环境部署,网上有很多资料。这里给大家介绍一个链接,我就不详细解释了:Ubuntu install phantomjs
PhantomJs和Selenium的介绍我就不赘述了,你可以直接百度。我们直接看一下如何在Java中使用PhantomJs吧~
如果您不使用 Maven,请在线下载第三方 jar。我们需要的Maven依赖如下:
org.seleniumhq.selenium
selenium-java
2.53.1
com.github.detro.ghostdriver
phantomjsdriver
1.1.0
接下来,我们来看看程序应该怎么写:
1.设置请求头
//设置必要参数
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持(第二参数表明的是你的phantomjs引擎所在的路径,使用whereis phantomjs可以查看)
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY, "/usr/local/bin/phantomjs");
2.创建phantomjs浏览器对象
//创建无界面浏览器对象
PhantomJSDriver driver = new PhantomJSDriver(dcaps);
3.设置隐式等待
//设置隐性等待
driver.manage().timeouts().implicitlyWait(1, TimeUnit.SECONDS);
因为加载页面需要一段时间,如果页面没有加载,搜索到元素,肯定是找不到。最好的方法是设置默认等待时间。如果找不到页面元素,请稍等片刻,然后再次查找,直到超时。
以上三点是使用 PhantomJs 时需要注意的地方。大家可以看一下大致的整体方案:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import java.util.concurrent.TimeUnit;
/**
* Created by hg_yi on 17-10-11.
*/
public class phantomjs {
public static void main(String[] args) {
//设置必要参数
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持(第二参数表明的是你的phantomjs引擎所在的路径)
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,
"/usr/bin/phantomjs-2.1.1-linux-x86_64/bin/phantomjs");
//创建无界面浏览器对象
PhantomJSDriver driver = new PhantomJSDriver(dcaps);
//设置隐性等待(作用于全局)
driver.manage().timeouts().implicitlyWait(1, TimeUnit.SECONDS);
//打开页面
driver.get("--------------------------------");
//查找元素
WebElement element = driver.findElement(By.id("img_valiCode"));
System.out.println(element.getAttribute("src"));
}
}
成功抓取了网页源码中没有的数据~
关于上面用到的PhantomJSDriver类的相关API,你可以直接看这个资料,应该可以满足你的日常需求:webdriver API中文版(WebDriver API也适用于PhantomJSDriver)。
PhantomJs 的性能优化
我们都知道使用PhantomJs这样的无头浏览器来爬取网页源码是非常耗时的,所以当我们决定使用这个工具并且对爬取速度有一定要求的时候,就需要掌握PhantomJs的性能优化。能力。
1.设置参数
google、百度了半天,也看了一些官方文档,但是还是找不到PhantomJs相关的Java调用API文档。好吧,我们先扔一个Python,然后找到这个区域的内容再添加吧~~
【phantomjs系列】Selenium+Phantomjs性能优化
题外话:实际上是用于 Java 网络爬虫。. . 我真的很想投诉。建议刚开始学爬虫的人改用Python爬虫~~对于Java爬虫,我只能说一句话:学习难,学习周期长,投入与收益不成正比!!! 查看全部
抓取ajax动态网页java(点题外话吧,京东图书模拟浏览器的一些事儿)
让我先离题。刚开始学爬虫的时候,有一次学长给我一个请求,要抓取京东图书的相关资料。嗯,因为我真的是刚开始学爬,用豆瓣练的很成功。我抓取了大约 500 条电影评论,然后将它们存储在 mysql 中。. . .
然后充满信心地开始工作。. 首先查看网页源代码。. . ? ? ? 我需要的不在源代码中!!!然后我问了校长。前辈告诉我这是AJAX生成的数据,我听完就去查数据。发现网上的信息在说明一个道理。对于动态页面,使用 PhantomJs 进行爬取,但是这样效率很低。作为一名优秀的程序员,当时看到“低效率”这两个字,心里是绝对不允许的,于是我就用抓包的方法去查看AJAX数据所在的URL。对于这种模拟浏览器方法一直搁置到现在。
但既然你知道了这一点,就没有理由不学习它。所以花点时间看了一下在Java中使用PhantomJs的资料,现在就分享给大家。
顺便说一句,其实作为一个网络爬虫,90%的页面数据都是通过抓包获取的。所以我还是鼓励大家直接请求自己需要的数据所在的URL。毕竟,这种方法虽然方便,但效率低下。
使用 AJAX 进行 JS 渲染
在学习这个东西之前,我们首先要了解什么是JS渲染,什么是AJAX,以及为什么我们在网页源码中取不到这两种数据。
根据我的理解,JS渲染和AJAX是相辅相成的关系。AJAX负责从服务器端异步获取数据,然后用JS渲染数据,最后呈现给用户。由于在Java中,HttpClient只能请求一个简单的静态页面,无法请求页面满载后JS调用相关代码生成的异步数据,所以我们无法通过HttpClient直接获取AJAX和JS渲染生成的数据。这时候根据上面的推荐,可以直接抓包获取AJAX数据所在的URL,或者使用本文提到的PhantomJs渲染引擎。
三大JS渲染引擎对比
在互联网上搜索信息时,我们常常被五花八门的答案弄得不知所措。这个时候要保持冷静的心情,二要考虑搜索问题的相关姿势,必要时要科学上网。
先不说本文提到的JS渲染引擎。只说Java爬虫中的HTTP请求库,可以有多种描述方式,Java自带的HttpURLConnection类,HttpClient第三方库等等,当然网上有这么多。方法,我们要选择,那么我们肯定要选择一个强大而简单的类库。这时候我们应该在网上搜索两个类库的相关对比,做出更好的选择,而不是随便挑一个就学,这样很可能投入的学习成本与回报不成正比。
那么相信大家在准备用JS引擎模拟浏览器的时候,看到的不光是PhantomJs,还有Selenium和HtmlUnit,它们的功能是一样的。那么我们该如何选择呢?下图摘自其他网友的博客:
HtmlUnitSeleniumPhantomJs
内置Rhinojs浏览器引擎,没有浏览器使用这个内核,解析速度一般,JS/CSS解析差,没有浏览器界面。
Selenium + WebDriver = Selenium是基于本地安装的浏览器,需要打开浏览器,需要参考对应的WebDriver,并正确配置webdriver的路径参数,这在爬取大量js时显然是不合适的渲染页面。
神器,短小精悍,可以本地运行,也可以作为服务器运行,基于webkit内核,性能和性能都不错,可以完美解析大部分页面。
这就是我选择谈论 PhantomJs 的原因。
PhantomJs 和 Selenium 经常成对出现在 Internet 上。原因是 Selenium 封装了 PhantomJs 的一些功能,而 Selenium 提供了 Python 接口模块。在 Python 语言中,Selenium 可以很好地使用,PhantomJs 可以间接使用。然而,是时候放弃 Selenium+PhantomJs 了。一个原因是封装的接口很久没有更新(没人维护),第二个原因是Selenium只实现了PhantomJs的一部分功能,很不完善。
PhantomJ 的使用
我使用的是Ubuntu16.04的开发环境。关于 PhantomJs + Selenium 的环境部署,网上有很多资料。这里给大家介绍一个链接,我就不详细解释了:Ubuntu install phantomjs
PhantomJs和Selenium的介绍我就不赘述了,你可以直接百度。我们直接看一下如何在Java中使用PhantomJs吧~
如果您不使用 Maven,请在线下载第三方 jar。我们需要的Maven依赖如下:
org.seleniumhq.selenium
selenium-java
2.53.1
com.github.detro.ghostdriver
phantomjsdriver
1.1.0
接下来,我们来看看程序应该怎么写:
1.设置请求头
//设置必要参数
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持(第二参数表明的是你的phantomjs引擎所在的路径,使用whereis phantomjs可以查看)
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY, "/usr/local/bin/phantomjs");
2.创建phantomjs浏览器对象
//创建无界面浏览器对象
PhantomJSDriver driver = new PhantomJSDriver(dcaps);
3.设置隐式等待
//设置隐性等待
driver.manage().timeouts().implicitlyWait(1, TimeUnit.SECONDS);
因为加载页面需要一段时间,如果页面没有加载,搜索到元素,肯定是找不到。最好的方法是设置默认等待时间。如果找不到页面元素,请稍等片刻,然后再次查找,直到超时。
以上三点是使用 PhantomJs 时需要注意的地方。大家可以看一下大致的整体方案:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import java.util.concurrent.TimeUnit;
/**
* Created by hg_yi on 17-10-11.
*/
public class phantomjs {
public static void main(String[] args) {
//设置必要参数
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持(第二参数表明的是你的phantomjs引擎所在的路径)
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,
"/usr/bin/phantomjs-2.1.1-linux-x86_64/bin/phantomjs");
//创建无界面浏览器对象
PhantomJSDriver driver = new PhantomJSDriver(dcaps);
//设置隐性等待(作用于全局)
driver.manage().timeouts().implicitlyWait(1, TimeUnit.SECONDS);
//打开页面
driver.get("--------------------------------");
//查找元素
WebElement element = driver.findElement(By.id("img_valiCode"));
System.out.println(element.getAttribute("src"));
}
}
成功抓取了网页源码中没有的数据~
关于上面用到的PhantomJSDriver类的相关API,你可以直接看这个资料,应该可以满足你的日常需求:webdriver API中文版(WebDriver API也适用于PhantomJSDriver)。
PhantomJs 的性能优化
我们都知道使用PhantomJs这样的无头浏览器来爬取网页源码是非常耗时的,所以当我们决定使用这个工具并且对爬取速度有一定要求的时候,就需要掌握PhantomJs的性能优化。能力。
1.设置参数
google、百度了半天,也看了一些官方文档,但是还是找不到PhantomJs相关的Java调用API文档。好吧,我们先扔一个Python,然后找到这个区域的内容再添加吧~~
【phantomjs系列】Selenium+Phantomjs性能优化
题外话:实际上是用于 Java 网络爬虫。. . 我真的很想投诉。建议刚开始学爬虫的人改用Python爬虫~~对于Java爬虫,我只能说一句话:学习难,学习周期长,投入与收益不成正比!!!
抓取ajax动态网页java(HTML源码中的内容由前端的JS动态生成的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-04-19 03:29
)
我们之前爬取的大部分网页都是从 HTML 静态生成的内容,而我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样的。
网站的部分内容是由前端JS动态生成的。由于网页上显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中是找不到的。例如今日头条:
浏览器渲染的网页如下图所示:
看源码,如下图:
网页的新闻在 HTML 源代码中是找不到的,都是 JS 动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方法:
这里只介绍第一种方法。有一篇专门的文章介绍了 Selenium 的使用。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例来说明:
1、来自JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”选项卡后,有很多响应,所以让我们过滤并仅查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现少了很多链接,点一个就可以看到了:
我们选择city,预览中有一串json数据:
让我们再次点击查看:
原来是一个城市列表,应该是用来加载区域新闻的。
现在你大概明白如何找到 JS 请求的接口了吧?但是刚才我们没有找到想要的消息,我们再看一遍:
有一个焦点,我们点击它看看:
首页图片新闻呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这应该是热搜关键词
这是图片新闻下的新闻。
我们打开一个界面链接看看:
返回一堆乱码,但查看响应是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法请求数据接口并得到响应
2、请求和解析数据接口数据
先完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:
像往常一样,对代码做一点解释:
代码分为四部分,
第 1 部分:介绍相关库
# coding:utf-8
import requests
import json
第 2 部分:向数据接口发出 http 请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
抓取ajax动态网页java(HTML源码中的内容由前端的JS动态生成的应用
)
我们之前爬取的大部分网页都是从 HTML 静态生成的内容,而我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样的。
网站的部分内容是由前端JS动态生成的。由于网页上显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中是找不到的。例如今日头条:
浏览器渲染的网页如下图所示:
看源码,如下图:
网页的新闻在 HTML 源代码中是找不到的,都是 JS 动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方法:
这里只介绍第一种方法。有一篇专门的文章介绍了 Selenium 的使用。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例来说明:
1、来自JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”选项卡后,有很多响应,所以让我们过滤并仅查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现少了很多链接,点一个就可以看到了:
我们选择city,预览中有一串json数据:
让我们再次点击查看:
原来是一个城市列表,应该是用来加载区域新闻的。
现在你大概明白如何找到 JS 请求的接口了吧?但是刚才我们没有找到想要的消息,我们再看一遍:
有一个焦点,我们点击它看看:
首页图片新闻呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这应该是热搜关键词
这是图片新闻下的新闻。
我们打开一个界面链接看看:
返回一堆乱码,但查看响应是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法请求数据接口并得到响应
2、请求和解析数据接口数据
先完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:
像往常一样,对代码做一点解释:
代码分为四部分,
第 1 部分:介绍相关库
# coding:utf-8
import requests
import json
第 2 部分:向数据接口发出 http 请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
抓取ajax动态网页java(rvest从R中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-04-16 12:31
背景信息目前,我正在使用 rvest 从 R 中的一些 网站 中抓取产品信息。这适用于所有 网站 s,除了一个 网站 内容似乎是动态加载的通过 angularJS(?),因此不能迭代(例如通过 URL 参数)加载(就像我对其他 网站 所做的那样)。具体网址如下:
请记住,我在我的计算机上没有管理员权限,仅实施不需要或仅授予管理员权限一次的解决方案
期望的输出 最后,R 中的一个表收录产品信息(例如标签、价格、评级)=> 但是,在这个问题中,我完全需要帮助来动态加载和存储 网站。我可以自己处理 R 中的后处理。如果你能把我推向正确的方向,那就太好了。也许我下面列出的方法之一是正确的,但我似乎无法将这些转移到指定的 网站。
目前的方法,我发现 phantomJS 是一个无头浏览器,应该能够处理这个问题。我对 Java 脚本几乎一无所知,而且语法(至少对我而言)与我更习惯的语言(R、Matlab、SQL)非常不同,而且我真的很难在其他语言中实现可能在我的代码中其他地方工作的方法。基于这个例子(非常感谢),我设法从使用以下代码显示的第一页中至少检索到信息:
回复:
<p>require(rvest)
## change Phantom.js scrape file
url 查看全部
抓取ajax动态网页java(rvest从R中的应用)
背景信息目前,我正在使用 rvest 从 R 中的一些 网站 中抓取产品信息。这适用于所有 网站 s,除了一个 网站 内容似乎是动态加载的通过 angularJS(?),因此不能迭代(例如通过 URL 参数)加载(就像我对其他 网站 所做的那样)。具体网址如下:
请记住,我在我的计算机上没有管理员权限,仅实施不需要或仅授予管理员权限一次的解决方案
期望的输出 最后,R 中的一个表收录产品信息(例如标签、价格、评级)=> 但是,在这个问题中,我完全需要帮助来动态加载和存储 网站。我可以自己处理 R 中的后处理。如果你能把我推向正确的方向,那就太好了。也许我下面列出的方法之一是正确的,但我似乎无法将这些转移到指定的 网站。
目前的方法,我发现 phantomJS 是一个无头浏览器,应该能够处理这个问题。我对 Java 脚本几乎一无所知,而且语法(至少对我而言)与我更习惯的语言(R、Matlab、SQL)非常不同,而且我真的很难在其他语言中实现可能在我的代码中其他地方工作的方法。基于这个例子(非常感谢),我设法从使用以下代码显示的第一页中至少检索到信息:
回复:
<p>require(rvest)
## change Phantom.js scrape file
url
抓取ajax动态网页java( 推荐:《PHP视频教JAVA中应用AJAX的中文乱码的解决办法方法》 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-04-13 22:14
推荐:《PHP视频教JAVA中应用AJAX的中文乱码的解决办法方法》
)
如何去除php中的nbsp:首先创建一个PHP代码示例文件;然后通过 "preg_replace("/(\s|\ \;||\xc2\xa0)/", " ", strip_tags ($val));" 方法删除所有nbsp。推荐:"PHP视频教学
JAVA中使用AJAX解决中文乱码问题:1、Ajax提交使用escape或encodeURI方式,必须使用两次; 2、后台java使用[.URLDecoder]类的decode方法。 【相关学习推荐:java基础知识】
java ajax提交返回值中文乱码如何解决:1、在RequestMapping的并发配置中添加代码[products=text/html;charset=UTF-8];2、在在[mvc:annotation-driven]文件中添加代码。
1、什么是AJAX,为什么要使用Ajax(请谈谈你对Ajax的理解) 什么是ajax:AJAX是“Asynchronous JavaScript and XML”的缩写。他提到了一种用于创建交互式 Web 应用程序的 Web 开发技术。 ajax包
运行java类文件方法:1、用main方法执行类文件,命令行为[java]; 2、执行的class文件被打包,在class文件中使用[package],命令行为[java .CLASS]。运行
【相关学习推荐:Java基础教程】需要通过ajax异步刷新页面,验证用户输入的账号密码是否存在于数据库中。技术栈JSP+Servlet+Oracle具体代码JSP部分:
【相关视频推荐:ajax视频教程】环境:eclipse+struts要达到的效果:点击按钮提交数据到后台再返回前台显示数据index.jsp
了解 Ajax 封装
2020-09-24
相关学习推荐:ajax前言的上一篇文章文章讲了ajax的原理、功能和实现。但是他们只实现了一个ajax请求响应操作。浏览器和服务器之间不会只有一个请求响应。如果你添加一个请求响应100次,那么你需要写100次。
ajax 19 个经典面试题1、什么是AJAX,为什么要使用Ajax(请谈谈你对Ajax 的了解) 什么是ajax:AJAX 是“Asynchronous JavaScript and XML”的缩写。他提到了一种创建交互式网络应用程序的方法
Java学习步骤为:1、进入Java语言基础学习阶段;2、掌握面向对象语言的通用性;3、精通JDK核心API编程技术;< @k43@ >精通SQL语句; 5、精通JDBC API; 6、理解迭代的含义; 7、手掌
中国网科技7月24日消息 今天,工信部发布了今年第三批侵犯用户权益的APP通知。报道称,截至目前,仍有58个APP未完成整改。对于有问题的APP,应在7月30日前完成整改
开发和运行一个java程序的三个主要步骤是:1、编辑源程序;2、生成字节码;3、解释和运行字节码。 Java是一种面向对象的编程语言,具有简单、面向对象、安全、健壮、多线程、可移植性等特点
了解 ajax
2020-09-23
相关文章推荐:ajax视频教程1.1 ajax是什么:Ajax是“Asynchronous Javascript And XML”(异步JavaScript和XML),是指用于创建交互式Web应用的网页开发技术。 Ajax=异步 JavaScript
【相关学习推荐:Java基础课程】1、什么是JSONP一般来说,位于的网页无法与不在的服务器通信,HTML元素除外。
1:什么是ajax? ajax的作用是什么?异步 javascript 和 xml AJAX 是一种用于创建快速和动态网页的技术。 ajax用于与后台交互2:原生js ajax请求有多少步?分别是什么//创建XMLHttp
查看全部
抓取ajax动态网页java(
推荐:《PHP视频教JAVA中应用AJAX的中文乱码的解决办法方法》
)
如何去除php中的nbsp:首先创建一个PHP代码示例文件;然后通过 "preg_replace("/(\s|\ \;||\xc2\xa0)/", " ", strip_tags ($val));" 方法删除所有nbsp。推荐:"PHP视频教学
JAVA中使用AJAX解决中文乱码问题:1、Ajax提交使用escape或encodeURI方式,必须使用两次; 2、后台java使用[.URLDecoder]类的decode方法。 【相关学习推荐:java基础知识】
java ajax提交返回值中文乱码如何解决:1、在RequestMapping的并发配置中添加代码[products=text/html;charset=UTF-8];2、在在[mvc:annotation-driven]文件中添加代码。
1、什么是AJAX,为什么要使用Ajax(请谈谈你对Ajax的理解) 什么是ajax:AJAX是“Asynchronous JavaScript and XML”的缩写。他提到了一种用于创建交互式 Web 应用程序的 Web 开发技术。 ajax包
运行java类文件方法:1、用main方法执行类文件,命令行为[java]; 2、执行的class文件被打包,在class文件中使用[package],命令行为[java .CLASS]。运行
【相关学习推荐:Java基础教程】需要通过ajax异步刷新页面,验证用户输入的账号密码是否存在于数据库中。技术栈JSP+Servlet+Oracle具体代码JSP部分:
【相关视频推荐:ajax视频教程】环境:eclipse+struts要达到的效果:点击按钮提交数据到后台再返回前台显示数据index.jsp
了解 Ajax 封装
2020-09-24
相关学习推荐:ajax前言的上一篇文章文章讲了ajax的原理、功能和实现。但是他们只实现了一个ajax请求响应操作。浏览器和服务器之间不会只有一个请求响应。如果你添加一个请求响应100次,那么你需要写100次。
ajax 19 个经典面试题1、什么是AJAX,为什么要使用Ajax(请谈谈你对Ajax 的了解) 什么是ajax:AJAX 是“Asynchronous JavaScript and XML”的缩写。他提到了一种创建交互式网络应用程序的方法
Java学习步骤为:1、进入Java语言基础学习阶段;2、掌握面向对象语言的通用性;3、精通JDK核心API编程技术;< @k43@ >精通SQL语句; 5、精通JDBC API; 6、理解迭代的含义; 7、手掌
中国网科技7月24日消息 今天,工信部发布了今年第三批侵犯用户权益的APP通知。报道称,截至目前,仍有58个APP未完成整改。对于有问题的APP,应在7月30日前完成整改
开发和运行一个java程序的三个主要步骤是:1、编辑源程序;2、生成字节码;3、解释和运行字节码。 Java是一种面向对象的编程语言,具有简单、面向对象、安全、健壮、多线程、可移植性等特点
了解 ajax
2020-09-23
相关文章推荐:ajax视频教程1.1 ajax是什么:Ajax是“Asynchronous Javascript And XML”(异步JavaScript和XML),是指用于创建交互式Web应用的网页开发技术。 Ajax=异步 JavaScript
【相关学习推荐:Java基础课程】1、什么是JSONP一般来说,位于的网页无法与不在的服务器通信,HTML元素除外。
1:什么是ajax? ajax的作用是什么?异步 javascript 和 xml AJAX 是一种用于创建快速和动态网页的技术。 ajax用于与后台交互2:原生js ajax请求有多少步?分别是什么//创建XMLHttp
抓取ajax动态网页java(什么是静态网页,什么事动态网页呢?济南网站建设 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-11 12:25
)
对于很多网站建筑专业的程序员来说,你问他们什么是静态页面,就像问大人“1+2等于多少”一样简单,但是对于那些不知道网站@ > 程序 还是有不少人分不清“静态页面”和“动态页面”。
那么什么是静态网页,什么是动态网页呢?让我给你解释一下:
1、静态网页:
在网站的设计中,静态网页是标准的HTML(标记语言)文件,文件扩展名为.htm、.html,可以收录文本、图像、声音、FLASH动画、脚本和ActiveX控件以及JAVA小程序等。静态网页是构建网站的基础,早期的网站一般都是由静态网页制作而成。与动态网页相比,静态网页是指没有后台数据库、不收录程序、非交互性的网页。静态网页更新比较麻烦,适用于一般更新较少的显示类型网站。
优点:网址稳定;访问速度快;每个网页都是一个独立的文件,保存在服务器上;内容稳定,易于被搜索引擎检索,对搜索引擎友好,有利于SEO。
缺点:缺乏交互性;没有数据库支持,网站 信息太多,网站 制作难度很大。
2、动态网页
一种与静态网页相对应的网页编程技术,可以与后台数据库交互、数据传输、URL后缀,不是.html等静态网页常见的网页制作格式,一般是.aspx、. asp、.jsp、.php、.perl、.cgi等为后缀,动态网址中有标志性符号。
优点:交互性强;有数据库支持,网站构建难度降低,可大大减少网站维护工作量;可实现用户登录、注册等多项功能;
缺点:访问速度慢,用户体验差;搜索引擎难以抓取,但现在很多搜索引擎已经开始支持动态网页的抓取。
因此,无论是静态网页还是动态网页,都各有优缺点。不能说所有的静态页面都是为了搜索引擎优化,或者动态页面都是为了维护方便。济南网站建站专家()提醒大家,选择建站方案需要根据自己的需要采用动静结合的方法进行网站施工。动态和静态 Web 内容共存于同一个 网站 上也很常见。
查看全部
抓取ajax动态网页java(什么是静态网页,什么事动态网页呢?济南网站建设
)
对于很多网站建筑专业的程序员来说,你问他们什么是静态页面,就像问大人“1+2等于多少”一样简单,但是对于那些不知道网站@ > 程序 还是有不少人分不清“静态页面”和“动态页面”。
那么什么是静态网页,什么是动态网页呢?让我给你解释一下:
1、静态网页:
在网站的设计中,静态网页是标准的HTML(标记语言)文件,文件扩展名为.htm、.html,可以收录文本、图像、声音、FLASH动画、脚本和ActiveX控件以及JAVA小程序等。静态网页是构建网站的基础,早期的网站一般都是由静态网页制作而成。与动态网页相比,静态网页是指没有后台数据库、不收录程序、非交互性的网页。静态网页更新比较麻烦,适用于一般更新较少的显示类型网站。
优点:网址稳定;访问速度快;每个网页都是一个独立的文件,保存在服务器上;内容稳定,易于被搜索引擎检索,对搜索引擎友好,有利于SEO。
缺点:缺乏交互性;没有数据库支持,网站 信息太多,网站 制作难度很大。
2、动态网页
一种与静态网页相对应的网页编程技术,可以与后台数据库交互、数据传输、URL后缀,不是.html等静态网页常见的网页制作格式,一般是.aspx、. asp、.jsp、.php、.perl、.cgi等为后缀,动态网址中有标志性符号。
优点:交互性强;有数据库支持,网站构建难度降低,可大大减少网站维护工作量;可实现用户登录、注册等多项功能;
缺点:访问速度慢,用户体验差;搜索引擎难以抓取,但现在很多搜索引擎已经开始支持动态网页的抓取。
因此,无论是静态网页还是动态网页,都各有优缺点。不能说所有的静态页面都是为了搜索引擎优化,或者动态页面都是为了维护方便。济南网站建站专家()提醒大家,选择建站方案需要根据自己的需要采用动静结合的方法进行网站施工。动态和静态 Web 内容共存于同一个 网站 上也很常见。
抓取ajax动态网页java(什么是ajax呢,简单来说,就是加载一个网页完毕)
网站优化 • 优采云 发表了文章 • 0 个评论 • 369 次浏览 • 2022-04-11 05:30
什么是ajax?简单来说就是加载一个网页后,还是看不到一些信息,需要点击一个按钮才能看到数据,或者有些网页的页面数据很多,而你在点击下一页,网页的url地址没有变,但是内容变了,可以说是ajax了。如果你还是不明白,我给你看百度百科的解释,这里是解释。
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML(标准通用标记语言的子集)。
Ajax 是一种用于创建快速和动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页部分的技术。[
Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
让我们谈谈一个例子。我爬过的最难的ajax页面是网易云音乐的评论。如果你有兴趣,你可以看看。
这里的评论都是ajax加载的,其他抢到今日头条妹子图片的也是ajax加载的,不过我简化了。还有很多,就不多说了,先说说我今天要说的ajax网站吧!
这是肯德基的门面信息
这里有很多页的数据,每页的数据都是ajax加载的。如果直接用python去请求上面的url,估计是拿不到任何数据的。如果你不相信,你可以试试。这时候,我们照常打开开发者工具。首先清除所有请求,勾选连续日志,然后点击下一页,你会看到
上面的请求就是ajax请求的网页,里面会有我们需要的数据。让我们看看是什么样的请求
这是一个发布请求。请求成功状态码是 200。请求 url 也在那里。以下来自 data 是我们需要发布的数据。很容易猜到pageIndex就是页数,所以我们可以改变这个值来翻页。
这个网页分析完了,这就是ajax动态网页的解决方案,是不是觉得很简单,其实不然,但是这个网页还是比较简单的,因为form的数据(来自data) 没有加密,如果是加密的话,估计你找个js文件看看参数是怎么加密的。这是我之前写的网易云音乐评论的爬取。看着这些被混淆的js寻找加密方法有时会让人头疼,所以人们经常选择使用selenium进行爬虫,但是使用这些会降低爬虫的性能,所以这种方法在工作中是不允许的。所以必须学会如何处理这些ajax。
粘贴代码
import requests
page = 1
while True:
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': '广州',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
response = requests.post(url, data=data)
print(response.json())
if response.json().get('Table1', ''):
page += 1
else:
break复制代码
可以看到,如果从数据中移除,不用十行代码就可以把所有的数据都爬下来,所以这个网站很适合练习,大家可以试试。
写在最后
在下一篇文章我会写一个复杂的ajax请求,这个网站
不知道有多少人想看,想看的就给个赞吧!或者你可以自己试试 查看全部
抓取ajax动态网页java(什么是ajax呢,简单来说,就是加载一个网页完毕)
什么是ajax?简单来说就是加载一个网页后,还是看不到一些信息,需要点击一个按钮才能看到数据,或者有些网页的页面数据很多,而你在点击下一页,网页的url地址没有变,但是内容变了,可以说是ajax了。如果你还是不明白,我给你看百度百科的解释,这里是解释。
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML(标准通用标记语言的子集)。
Ajax 是一种用于创建快速和动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页部分的技术。[
Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
让我们谈谈一个例子。我爬过的最难的ajax页面是网易云音乐的评论。如果你有兴趣,你可以看看。
这里的评论都是ajax加载的,其他抢到今日头条妹子图片的也是ajax加载的,不过我简化了。还有很多,就不多说了,先说说我今天要说的ajax网站吧!
这是肯德基的门面信息
这里有很多页的数据,每页的数据都是ajax加载的。如果直接用python去请求上面的url,估计是拿不到任何数据的。如果你不相信,你可以试试。这时候,我们照常打开开发者工具。首先清除所有请求,勾选连续日志,然后点击下一页,你会看到
上面的请求就是ajax请求的网页,里面会有我们需要的数据。让我们看看是什么样的请求
这是一个发布请求。请求成功状态码是 200。请求 url 也在那里。以下来自 data 是我们需要发布的数据。很容易猜到pageIndex就是页数,所以我们可以改变这个值来翻页。
这个网页分析完了,这就是ajax动态网页的解决方案,是不是觉得很简单,其实不然,但是这个网页还是比较简单的,因为form的数据(来自data) 没有加密,如果是加密的话,估计你找个js文件看看参数是怎么加密的。这是我之前写的网易云音乐评论的爬取。看着这些被混淆的js寻找加密方法有时会让人头疼,所以人们经常选择使用selenium进行爬虫,但是使用这些会降低爬虫的性能,所以这种方法在工作中是不允许的。所以必须学会如何处理这些ajax。
粘贴代码
import requests
page = 1
while True:
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': '广州',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
response = requests.post(url, data=data)
print(response.json())
if response.json().get('Table1', ''):
page += 1
else:
break复制代码
可以看到,如果从数据中移除,不用十行代码就可以把所有的数据都爬下来,所以这个网站很适合练习,大家可以试试。
写在最后
在下一篇文章我会写一个复杂的ajax请求,这个网站
不知道有多少人想看,想看的就给个赞吧!或者你可以自己试试
抓取ajax动态网页java(接着高级查询中的字段都是在前台写好的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-07 09:26
继续上一个高级查询。下拉框中的字段都写在前台。这对于系统的灵活性来说是一个很大的缺点。
解决方案:
在数据库中创建类型字典表。在数据库表的下拉框中对应要添加的项目的中英文名称。
下拉框动态绑定数据库表中的必填字段。
高级查询
在高级查询点击事件中,除了显示查询框外,还为下拉框的绑定字段添加了一个功能。这是 addItems()。
实现代码:
//动态绑定下拉框项
function addItems() {
$.ajax({
url: "addItem.ashx/GetItem", //后台webservice里的方法名称
type: "post",
dataType: "json",
contentType: "application/json",
traditional: true,
success: function (data) {
for (var i in data) {
var jsonObj =data[i];
var optionstring = "";
for (var j = 0; j < jsonObj.length; j++) {
optionstring += "" + jsonObj[j].chinesename + "";
}
$("#dpdField1").html("请选择... "+optionstring);
}
},
error: function (msg) {
alert("出错了!");
}
});
};
背景代码:
public void ProcessRequest(HttpContext context)
{
//context.Response.ContentType = "text/plain";
//context.Response.Write("Hello World");
GetItem(context);
}
public void GetItem(HttpContext context)
{
string ReturnValue = string.Empty;
BasicInformationFacade basicInformationFacade = new BasicInformationFacade(); //实例化基础信息外观
DataTable dt = new DataTable();
dt = basicInformationFacade.itemsQuery(); //根据查询条件获取结果
ReturnValue = DataTableJson(dt);
context.Response.ContentType = "text/plain";
context.Response.Write(ReturnValue);
//return ReturnValue;
}
#region dataTable转换成Json格式
///
/// dataTable转换成Json格式
///
///
///
public string DataTableJson(DataTable dt)
{
StringBuilder jsonBuilder = new StringBuilder();
jsonBuilder.Append("{\"");
jsonBuilder.Append(dt.TableName.ToString());
jsonBuilder.Append("\":[");
for (int i = 0; i < dt.Rows.Count; i++)
{
jsonBuilder.Append("{");
for (int j = 0; j < dt.Columns.Count; j++)
{
jsonBuilder.Append("\"");
jsonBuilder.Append(dt.Columns[j].ColumnName);
jsonBuilder.Append("\":\"");
jsonBuilder.Append(dt.Rows[i][j].ToString());
jsonBuilder.Append("\",");
}
jsonBuilder.Remove(jsonBuilder.Length - 1, 1);
jsonBuilder.Append("},");
}
jsonBuilder.Remove(jsonBuilder.Length - 1, 1);
jsonBuilder.Append("]");
jsonBuilder.Append("}");
return jsonBuilder.ToString();
}
#endregion
使用ajax和json将数据源绑定到首页中的select。后台通过两个函数获取数据库表的数据,并将数据转换为Json格式返回给前台。前台收到数据后,解析数据,在下拉框中获取需要绑定的字段。绑定时,下拉框的每一项分别绑定一个文本和一个值。显示文本供用户选择。value值是用户选择一个字段,获取该字段的值,进行后台查询字段。 查看全部
抓取ajax动态网页java(接着高级查询中的字段都是在前台写好的)
继续上一个高级查询。下拉框中的字段都写在前台。这对于系统的灵活性来说是一个很大的缺点。
解决方案:
在数据库中创建类型字典表。在数据库表的下拉框中对应要添加的项目的中英文名称。
下拉框动态绑定数据库表中的必填字段。
高级查询
在高级查询点击事件中,除了显示查询框外,还为下拉框的绑定字段添加了一个功能。这是 addItems()。
实现代码:
//动态绑定下拉框项
function addItems() {
$.ajax({
url: "addItem.ashx/GetItem", //后台webservice里的方法名称
type: "post",
dataType: "json",
contentType: "application/json",
traditional: true,
success: function (data) {
for (var i in data) {
var jsonObj =data[i];
var optionstring = "";
for (var j = 0; j < jsonObj.length; j++) {
optionstring += "" + jsonObj[j].chinesename + "";
}
$("#dpdField1").html("请选择... "+optionstring);
}
},
error: function (msg) {
alert("出错了!");
}
});
};
背景代码:
public void ProcessRequest(HttpContext context)
{
//context.Response.ContentType = "text/plain";
//context.Response.Write("Hello World");
GetItem(context);
}
public void GetItem(HttpContext context)
{
string ReturnValue = string.Empty;
BasicInformationFacade basicInformationFacade = new BasicInformationFacade(); //实例化基础信息外观
DataTable dt = new DataTable();
dt = basicInformationFacade.itemsQuery(); //根据查询条件获取结果
ReturnValue = DataTableJson(dt);
context.Response.ContentType = "text/plain";
context.Response.Write(ReturnValue);
//return ReturnValue;
}
#region dataTable转换成Json格式
///
/// dataTable转换成Json格式
///
///
///
public string DataTableJson(DataTable dt)
{
StringBuilder jsonBuilder = new StringBuilder();
jsonBuilder.Append("{\"");
jsonBuilder.Append(dt.TableName.ToString());
jsonBuilder.Append("\":[");
for (int i = 0; i < dt.Rows.Count; i++)
{
jsonBuilder.Append("{");
for (int j = 0; j < dt.Columns.Count; j++)
{
jsonBuilder.Append("\"");
jsonBuilder.Append(dt.Columns[j].ColumnName);
jsonBuilder.Append("\":\"");
jsonBuilder.Append(dt.Rows[i][j].ToString());
jsonBuilder.Append("\",");
}
jsonBuilder.Remove(jsonBuilder.Length - 1, 1);
jsonBuilder.Append("},");
}
jsonBuilder.Remove(jsonBuilder.Length - 1, 1);
jsonBuilder.Append("]");
jsonBuilder.Append("}");
return jsonBuilder.ToString();
}
#endregion
使用ajax和json将数据源绑定到首页中的select。后台通过两个函数获取数据库表的数据,并将数据转换为Json格式返回给前台。前台收到数据后,解析数据,在下拉框中获取需要绑定的字段。绑定时,下拉框的每一项分别绑定一个文本和一个值。显示文本供用户选择。value值是用户选择一个字段,获取该字段的值,进行后台查询字段。
抓取ajax动态网页java(部分干部不想抓不会抓致问题拖炸|问责_新浪新闻拼出的评论通道(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-04-05 13:02
ajax页面是动态生成的,不能直接抓到。不过,也不是没有办法。通常,通过找到ajax通道的地址,仍然可以得到ajax通道的内容。
你可以从ajax所在的页面找到线索。当然,每一页都不一样,所以不要问我怎么死的。
给大家一个思路:使用火狐浏览器监控页面信息。当您点击请求时,会出现频道地址信息。
当然,如果你获得了与某个请求相关的渠道信息知识,你也必须分析它们的一般公式。
以新浪新闻网为例,大家可能会更好理解:我已经从爬取的页面中获取了国内的新闻、标题、正文、日期,但我还想获取评论的信息(评论是动态生成的) )。所以,我对爬取页面进行解析,因为这个标签有两个改变新闻评论频道的信息:channel和newsid。等等等等
就是这么想的,终于找到评论页了。比如标题------------中纪委:有的干部不想抓,但不抓,但不敢惹问题被拖上来 | 天天要闻 中纪委| 问责制_新浪新闻
拼出来的评论频道是/page/info?format=json&channel=gn&newsid=1-1-31456214&group=0&compress=1&ie=gbk&oe=gbk&page=1&page_size=10
然后你解析页面内容,然后转码得到评论内容。
我说,不知道你懂不懂怎么做?
这是我作为网络爬虫的一点经验。我尝试了各种方法,包括引入第三方jar,但效果都不是很好。终于得到了这样的体验,毫无保留地与大家分享。
谢谢
不同的情况
一般简单的网页都是通过get参数进行分页的。在这种情况下,通过构造url来进行分页。
有的网站是通过post参数分页的,然后使用代码post到网站的对应参数
更复杂的ajax分页需要通过抓包来实现
ajax页面是动态生成的,不能直接抓到。不过,也不是没有办法。通常,通过找到ajax通道的地址,仍然可以得到ajax通道的内容。你可以从ajax所在的页面找到线索。当然,每一页都不一样,所以不要问我怎么死的。给大家一个思路:使用火狐浏览器监控页面信息
如何使用java抓取ajax页面的内容- :如果不能抓取,只能通过ajax提交参数来获取。可以写个js获取页面内容,然后通过ajax传给后台java程序
Java如何爬取ajax生成的页面?- :当时遇到的一个情况是ajax返回了很多json,然后前端js动态解析出来,目的是获取解析出来的数据,这样比较直观。使用 Selenium webdriver,一个自动化测试的东西,也是可以的。
如何使用JAVA爬取AJAX加载的页面-:1.一般简单的网页都是通过get参数进行分页的。这种情况下,分页是通过构造url来完成的;post参数进行分页,然后使用代码中对应的参数post到网站;3.更复杂的ajax分页需要通过抓包来实现。
java如何获取收录ajax-的网页数据: ajax数据的获取方式有两种: 1. 定义与参数相同的变量,即可获取对应的名称 2. 即可获取对应的值通过request:也可以获取一些cookie和session的值,可以通过它们对应的方法获取。
如何爬取ajax输出的页面数据-:在js代码中找到提交的url地址和参数,然后在浏览器中打开。。就是这样。
如何抓取ajax加载的页面-:查看其ajax提交的相关信息,在浏览器上输入其url及其参数,返回的内容就是ajax加载的内容,但有的只是简单的返回数据,有的返回with html 数据。
如何抓取ajax加载的页面-:如果要通用,只能通过浏览器启动。在windows上,可以使用程序调用IE浏览器接口获取页面文档,也可以使用chrome或firefox插件形式获取文档。采集 的信息随后被发布到服务器。Linux下可以使用phantomjs来操作webt来获取文档的内容。Phantomjs有很多优点:不依赖X,可以工作在文本模式,官网上叫headless;可以抓取页面截图;可以监控网络传输;可以禁用图像加载;自定义 cookie、自定义标头信息等。
java后台获取网页ajax数据并返回数据的简单源码-:1新建一个servlet,在xml中配置对应(一般是自动的)2创建服务方法3接受参数,做操作,返回数据如向SomeServlet发送ajax请求的页面 $.post("SomeServlet的请求路径",{param:"param"},function(data){ //data是json形式的返回数据 alert...
如何抓取 AJAX网站- 的内容: 手动刷新 DOMMetaStudio 左侧栏的 DOM 树是在 HTML 文档加载后自动生成的。如果 HTML 文档中的 Javascript 代码在 HTML 加载后修改了 DOM 内容,很有可能没有反映在 MetaStudio 的 DOM 树中。这时候,如果你使用反向...
Java后台获取网页ajax数据并返回数据简单源码-:1新建servlet对应xml中的配置(一般自动)
2 创建服务方法
3 接受参数,做操作,返回数据
例如,页面向 SomeServlet 发送 ajax 请求
$.post("SomeServlet 请求路径",{param:"param"},function(data){
//data是返回的数字... 查看全部
抓取ajax动态网页java(部分干部不想抓不会抓致问题拖炸|问责_新浪新闻拼出的评论通道(组图))
ajax页面是动态生成的,不能直接抓到。不过,也不是没有办法。通常,通过找到ajax通道的地址,仍然可以得到ajax通道的内容。
你可以从ajax所在的页面找到线索。当然,每一页都不一样,所以不要问我怎么死的。
给大家一个思路:使用火狐浏览器监控页面信息。当您点击请求时,会出现频道地址信息。
当然,如果你获得了与某个请求相关的渠道信息知识,你也必须分析它们的一般公式。
以新浪新闻网为例,大家可能会更好理解:我已经从爬取的页面中获取了国内的新闻、标题、正文、日期,但我还想获取评论的信息(评论是动态生成的) )。所以,我对爬取页面进行解析,因为这个标签有两个改变新闻评论频道的信息:channel和newsid。等等等等
就是这么想的,终于找到评论页了。比如标题------------中纪委:有的干部不想抓,但不抓,但不敢惹问题被拖上来 | 天天要闻 中纪委| 问责制_新浪新闻
拼出来的评论频道是/page/info?format=json&channel=gn&newsid=1-1-31456214&group=0&compress=1&ie=gbk&oe=gbk&page=1&page_size=10
然后你解析页面内容,然后转码得到评论内容。
我说,不知道你懂不懂怎么做?
这是我作为网络爬虫的一点经验。我尝试了各种方法,包括引入第三方jar,但效果都不是很好。终于得到了这样的体验,毫无保留地与大家分享。
谢谢
不同的情况
一般简单的网页都是通过get参数进行分页的。在这种情况下,通过构造url来进行分页。
有的网站是通过post参数分页的,然后使用代码post到网站的对应参数
更复杂的ajax分页需要通过抓包来实现
ajax页面是动态生成的,不能直接抓到。不过,也不是没有办法。通常,通过找到ajax通道的地址,仍然可以得到ajax通道的内容。你可以从ajax所在的页面找到线索。当然,每一页都不一样,所以不要问我怎么死的。给大家一个思路:使用火狐浏览器监控页面信息
如何使用java抓取ajax页面的内容- :如果不能抓取,只能通过ajax提交参数来获取。可以写个js获取页面内容,然后通过ajax传给后台java程序
Java如何爬取ajax生成的页面?- :当时遇到的一个情况是ajax返回了很多json,然后前端js动态解析出来,目的是获取解析出来的数据,这样比较直观。使用 Selenium webdriver,一个自动化测试的东西,也是可以的。
如何使用JAVA爬取AJAX加载的页面-:1.一般简单的网页都是通过get参数进行分页的。这种情况下,分页是通过构造url来完成的;post参数进行分页,然后使用代码中对应的参数post到网站;3.更复杂的ajax分页需要通过抓包来实现。
java如何获取收录ajax-的网页数据: ajax数据的获取方式有两种: 1. 定义与参数相同的变量,即可获取对应的名称 2. 即可获取对应的值通过request:也可以获取一些cookie和session的值,可以通过它们对应的方法获取。
如何爬取ajax输出的页面数据-:在js代码中找到提交的url地址和参数,然后在浏览器中打开。。就是这样。
如何抓取ajax加载的页面-:查看其ajax提交的相关信息,在浏览器上输入其url及其参数,返回的内容就是ajax加载的内容,但有的只是简单的返回数据,有的返回with html 数据。
如何抓取ajax加载的页面-:如果要通用,只能通过浏览器启动。在windows上,可以使用程序调用IE浏览器接口获取页面文档,也可以使用chrome或firefox插件形式获取文档。采集 的信息随后被发布到服务器。Linux下可以使用phantomjs来操作webt来获取文档的内容。Phantomjs有很多优点:不依赖X,可以工作在文本模式,官网上叫headless;可以抓取页面截图;可以监控网络传输;可以禁用图像加载;自定义 cookie、自定义标头信息等。
java后台获取网页ajax数据并返回数据的简单源码-:1新建一个servlet,在xml中配置对应(一般是自动的)2创建服务方法3接受参数,做操作,返回数据如向SomeServlet发送ajax请求的页面 $.post("SomeServlet的请求路径",{param:"param"},function(data){ //data是json形式的返回数据 alert...
如何抓取 AJAX网站- 的内容: 手动刷新 DOMMetaStudio 左侧栏的 DOM 树是在 HTML 文档加载后自动生成的。如果 HTML 文档中的 Javascript 代码在 HTML 加载后修改了 DOM 内容,很有可能没有反映在 MetaStudio 的 DOM 树中。这时候,如果你使用反向...
Java后台获取网页ajax数据并返回数据简单源码-:1新建servlet对应xml中的配置(一般自动)
2 创建服务方法
3 接受参数,做操作,返回数据
例如,页面向 SomeServlet 发送 ajax 请求
$.post("SomeServlet 请求路径",{param:"param"},function(data){
//data是返回的数字...
抓取ajax动态网页java(Web网络爬虫系统的功能及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-04 00:07
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。广泛应用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的页面的所有内容来获取或更新这些网站@的内容和检索方式>。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。另外,爬虫爬取的所有网页都会被系统存储,进行一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的第一个控制器。主要负责根据系统发送的URL链接分配线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列;
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接放到待爬取的URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4 部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。
2.3.5 OPIC 政策方针
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.6 大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都安装在“解析器”安装点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人理解错了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。这个Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。事实上,这是针对Nutch的声誉。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人已经解决了困难和复杂的问题(如DOM树解析定位、字符集检测、海量URL去重等),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫是否可以使用代理,爬虫是否可以爬取重复数据,爬虫是否可以爬取JS生成的信息?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,通常可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的代理放入一个全局数组中,并编写代码让代理随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?另一个爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习**的成本会比较大。而且你不能只计算一个人的学习成本。如果软件需要一个团队来开发或交接,那是很多人学习的成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,和更少的信息)。
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度,几乎每个大型门户网站网站都有自己的搜索引擎。有几十个名字和成千上万个未知的名字。对于内容驱动的网站,网络爬虫的赞助是不可避免的。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
[评论:它经常很容易被忽视。通过对请求的抓包分析,确定referer并添加到程序中模拟访问请求的header中]
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。
喜欢
不喜欢
你对这个答案的评价是什么? 查看全部
抓取ajax动态网页java(Web网络爬虫系统的功能及应用)
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。广泛应用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的页面的所有内容来获取或更新这些网站@的内容和检索方式>。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。另外,爬虫爬取的所有网页都会被系统存储,进行一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的第一个控制器。主要负责根据系统发送的URL链接分配线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列;
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接放到待爬取的URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4 部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。
2.3.5 OPIC 政策方针
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.6 大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都安装在“解析器”安装点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人理解错了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。这个Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。事实上,这是针对Nutch的声誉。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人已经解决了困难和复杂的问题(如DOM树解析定位、字符集检测、海量URL去重等),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫是否可以使用代理,爬虫是否可以爬取重复数据,爬虫是否可以爬取JS生成的信息?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,通常可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的代理放入一个全局数组中,并编写代码让代理随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?另一个爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习**的成本会比较大。而且你不能只计算一个人的学习成本。如果软件需要一个团队来开发或交接,那是很多人学习的成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,和更少的信息)。
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度,几乎每个大型门户网站网站都有自己的搜索引擎。有几十个名字和成千上万个未知的名字。对于内容驱动的网站,网络爬虫的赞助是不可避免的。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
[评论:它经常很容易被忽视。通过对请求的抓包分析,确定referer并添加到程序中模拟访问请求的header中]
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。
喜欢
不喜欢
你对这个答案的评价是什么?
抓取ajax动态网页java( 在线地图后台服务数据的多样展示方法--CrapperMap地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-03-30 11:04
在线地图后台服务数据的多样展示方法--CrapperMap地址)
爬取数据后台服务
在线地图后台服务
数据一直是数据源,是 GIS 系统非常重要的组成部分。获取公共数据或在后台处理并发布它很重要。
CrapperMap地址 这是一个大佬搭建的WebGIS系统,据说是在开源的基础上做的。前端相当丰富,用户可以添加各种图层,WMS图层,WMTS或者geoJson等,动态静态切片,标注图层。并且可以进行图层管理,包括 wgs84 和 Mars 坐标的比较示例。它包括一些气象数据的显示。例如,本网站提供符合OGC标准的wms和tms数据服务的地址。我们可以根据需要在地图上添加相应的图层来显示这些气象数据!是不是很棒!
上图是CrapperMap系统的截图
上图:通过 WMS 服务加载的 IEM 气象数据
另外诺基亚HERE地图也很不错,基于WebGL的3D视图更是震撼。3D模型具有多级显示机制,效率很高,配色很好。猜测是根据城市的机载 LiDAR 数据创建模型,并根据点数对其进行分级,从点云渲染 3D 模型,借助照片纹理......
在数据获取方面,目前最流行的在线资源是影像底图、街道底图,或者一些可以直接使用或通过分析获得的 POI 搜索和路线导航服务。但是有些数据不是我们可以直接使用的形式,不是OGC标准服务,也不是Json的形式。是一些零散的实时数据(表格或列表形式的站点数据),那么我们需要从门户网站或一些地址中抓取。或者我们要下载所需的数据切片。那么在未来,我们将研究数据的实时捕获!
继上次提到的各种数据之后,最近发现地理信息系统必须建立在信息系统的基础上。地理数据以外的信息要合理处理,注意网页中地理数据的各种展示方式。包括表格、图表、动态地图等。在这里,我发现了几个有用的插件,可以帮助更好地呈现数据。
是一款非常不错的jquery表单插件,界面美观,功能强大。默认分页和排序。符合Jquery的风格,界面比easyUI更加现代大气。如何提供表单信息以供下载的问题仍有待研究。Highchart是一款非常好用的图表插件,基于JS,动态效果极佳,时间线、折线图、条形图等各种统计图表,并提供图表下载。另外,网站的设计开发过程中还有一些需要注意的问题。主页面与分层页面(子页面)的关系是通过Tabs选项卡触发页面切换(切换:对应页面根据函数中的指令进行重定向,而子页面的切换可以通过替换Iframe下的subpage.src来实现)。多字段查询是一个重要部分。它在后台转换为Json并返回到前端。一些表单插件只有简单的单字段查询。 查看全部
抓取ajax动态网页java(
在线地图后台服务数据的多样展示方法--CrapperMap地址)
爬取数据后台服务
在线地图后台服务
数据一直是数据源,是 GIS 系统非常重要的组成部分。获取公共数据或在后台处理并发布它很重要。
CrapperMap地址 这是一个大佬搭建的WebGIS系统,据说是在开源的基础上做的。前端相当丰富,用户可以添加各种图层,WMS图层,WMTS或者geoJson等,动态静态切片,标注图层。并且可以进行图层管理,包括 wgs84 和 Mars 坐标的比较示例。它包括一些气象数据的显示。例如,本网站提供符合OGC标准的wms和tms数据服务的地址。我们可以根据需要在地图上添加相应的图层来显示这些气象数据!是不是很棒!
上图是CrapperMap系统的截图
上图:通过 WMS 服务加载的 IEM 气象数据
另外诺基亚HERE地图也很不错,基于WebGL的3D视图更是震撼。3D模型具有多级显示机制,效率很高,配色很好。猜测是根据城市的机载 LiDAR 数据创建模型,并根据点数对其进行分级,从点云渲染 3D 模型,借助照片纹理......
在数据获取方面,目前最流行的在线资源是影像底图、街道底图,或者一些可以直接使用或通过分析获得的 POI 搜索和路线导航服务。但是有些数据不是我们可以直接使用的形式,不是OGC标准服务,也不是Json的形式。是一些零散的实时数据(表格或列表形式的站点数据),那么我们需要从门户网站或一些地址中抓取。或者我们要下载所需的数据切片。那么在未来,我们将研究数据的实时捕获!
继上次提到的各种数据之后,最近发现地理信息系统必须建立在信息系统的基础上。地理数据以外的信息要合理处理,注意网页中地理数据的各种展示方式。包括表格、图表、动态地图等。在这里,我发现了几个有用的插件,可以帮助更好地呈现数据。
是一款非常不错的jquery表单插件,界面美观,功能强大。默认分页和排序。符合Jquery的风格,界面比easyUI更加现代大气。如何提供表单信息以供下载的问题仍有待研究。Highchart是一款非常好用的图表插件,基于JS,动态效果极佳,时间线、折线图、条形图等各种统计图表,并提供图表下载。另外,网站的设计开发过程中还有一些需要注意的问题。主页面与分层页面(子页面)的关系是通过Tabs选项卡触发页面切换(切换:对应页面根据函数中的指令进行重定向,而子页面的切换可以通过替换Iframe下的subpage.src来实现)。多字段查询是一个重要部分。它在后台转换为Json并返回到前端。一些表单插件只有简单的单字段查询。
抓取ajax动态网页java(同步交互的不足之处和异步不用的优点和缺点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-03-30 05:07
1、了解同步和异步交互(1)什么是同步交互
首先,用户向 HTTP 服务器提交处理请求。然后,服务器收到请求后,按照预先编写的程序中的业务逻辑进行处理,例如与数据库服务器交换数据信息。最后,服务端响应请求,将结果返回给客户端,返回一个HTML展示在浏览器中,通常带有CSS样式的富页面展示效果。
优点:可以保留浏览器后退按钮的正常功能。在动态更新页面的情况下,用户可以回到之前的页面状态,浏览器可以记住历史中的静态页面,而用户通常希望当点击返回按钮时,可以取消之前的操作并且同步交互这个需求就可以实现了。
缺点:同步交互的不足会给用户带来不连贯的体验。服务器处理请求时,用户只能等待状态,页面中的显示内容只能为空白。因为已经跳转到新的页面,所以页面上原来的信息无法保存,很多信息需要重新填写。
(2)什么是异步交互
指发送请求不等待返回,随时可以发送下一个请求,即不等待。在某些情况下,我们更喜欢在我们的项目开发中不需要等待的异步交互方法。将用户请求放入消息队列并反馈给用户,系统迁移过程已经启动,可以关闭浏览器。然后程序慢慢写入数据库。这是异步的。异步不需要等待所有操作完成,并响应用户请求。也就是先响应用户请求,再慢慢写数据库,用户体验更好。
优点:可以同时进行前端用户操作和后端服务器操作,充分利用用户操作之间的间隔时间完成操作页面不跳转,响应返回的数据直接上原创页面,并保留该页面的原创信息。
缺点:可能会破坏浏览器后退按钮的正常行为。在动态更新页面的情况下,用户无法回到之前的页面状态,因为浏览器只能记录始终是当前页面的静态页面。用户通常希望单击后退按钮能够取消之前的操作,但在 AJAX 等异步程序中,这是不可能的。
2、AJAX简介
AJAX 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种 Web 开发技术,用于创建交互式、快速和动态的 Web 应用程序,可以在不重新加载整个网页的情况下更新部分网页。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
AJAX关键技术
使用 CSS 构建用户界面样式,负责页面布局和美术。
使用DOM进行动态展示和交互,本地修改页面。 查看全部
抓取ajax动态网页java(同步交互的不足之处和异步不用的优点和缺点)
1、了解同步和异步交互(1)什么是同步交互
首先,用户向 HTTP 服务器提交处理请求。然后,服务器收到请求后,按照预先编写的程序中的业务逻辑进行处理,例如与数据库服务器交换数据信息。最后,服务端响应请求,将结果返回给客户端,返回一个HTML展示在浏览器中,通常带有CSS样式的富页面展示效果。
优点:可以保留浏览器后退按钮的正常功能。在动态更新页面的情况下,用户可以回到之前的页面状态,浏览器可以记住历史中的静态页面,而用户通常希望当点击返回按钮时,可以取消之前的操作并且同步交互这个需求就可以实现了。
缺点:同步交互的不足会给用户带来不连贯的体验。服务器处理请求时,用户只能等待状态,页面中的显示内容只能为空白。因为已经跳转到新的页面,所以页面上原来的信息无法保存,很多信息需要重新填写。
(2)什么是异步交互
指发送请求不等待返回,随时可以发送下一个请求,即不等待。在某些情况下,我们更喜欢在我们的项目开发中不需要等待的异步交互方法。将用户请求放入消息队列并反馈给用户,系统迁移过程已经启动,可以关闭浏览器。然后程序慢慢写入数据库。这是异步的。异步不需要等待所有操作完成,并响应用户请求。也就是先响应用户请求,再慢慢写数据库,用户体验更好。
优点:可以同时进行前端用户操作和后端服务器操作,充分利用用户操作之间的间隔时间完成操作页面不跳转,响应返回的数据直接上原创页面,并保留该页面的原创信息。
缺点:可能会破坏浏览器后退按钮的正常行为。在动态更新页面的情况下,用户无法回到之前的页面状态,因为浏览器只能记录始终是当前页面的静态页面。用户通常希望单击后退按钮能够取消之前的操作,但在 AJAX 等异步程序中,这是不可能的。
2、AJAX简介
AJAX 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种 Web 开发技术,用于创建交互式、快速和动态的 Web 应用程序,可以在不重新加载整个网页的情况下更新部分网页。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
AJAX关键技术
使用 CSS 构建用户界面样式,负责页面布局和美术。
使用DOM进行动态展示和交互,本地修改页面。
抓取ajax动态网页java(下图显示GET请求到文件后继续请求了多个JS、CSS文件前端与后端浏览器 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-03-25 06:20
)
下图是对HTML文件的GET请求后继续请求多个JS和CSS文件
前端和后端
浏览器显示的网页是web前端界面,它为用户提供了一个与网站交互的可视化界面,而web后端服务主要是指在浏览器中进行的逻辑操作和数据处理。 server,为前端提供访问服务。. 所谓的前端和后端只是从代码执行的位置来区分的。前端代码在用户面前执行,后端代码在远程服务器上执行。但是,无论前端代码还是后端代码,都是存储在服务器上的,只有在浏览器请求时才从服务器发送出去。
AJAX 简介
在上述web应用的工作原理中,我们通过HTTP协议访问一个存在于服务器上的文件。服务器可以找到该文件并将其内容封装成一个HTTP请求,并以消息体的形式返回给客户端。但是,这种方法只能访问静态页面,不能与后端数据库交互。由于用户需要通过web前端与后端数据库进行实时交互,因此网页也需要动态更新。如果每次更新一个数据都是通过重新获取Html文件来实现的,势必会导致网络负载变重,页面加载变慢。而Ajax技术可以很好的解决这个问题。
Ajax,异步 JavaScript 和 XML,是一种用于创建交互式网页的技术,它可以更新网页的某些部分,而无需重新加载整个网页。目前 jQuery 库提供了几种与 AJAX 相关的方法。通过 jQuery AJAX 方法,可以使用 HTTP Get 和 HTTP Post 从远程服务器请求文本、HTML、XML 或 JSON,并且可以将这些外部数据直接加载到网页的选定元素中。
作为 Web 开发者广泛使用的 JavaScript 封装库之一,jQuery 库可以极大地简化我们的 JavaScript 编程,缓解浏览器不兼容带来的影响。有必要了解网页在不同浏览器中的兼容性测试。这也是很多工作。我们可以通过一个简单的例子看到 jQuery 库的优势:
$("p.neat").addClass("ohmy").show("slow");
有了上面的短代码,开发者就可以遍历所有“整洁”的类
元素,然后将“ohmy”类添加到它,同时缓慢地为每个段落设置动画。开发者无需检查客户端浏览器类型,无需编写循环代码,无需编写复杂的动画功能,只需一行代码即可实现上述效果。jQuery 的口号“用最少的代码做最多的事情”名副其实,并将 JavaScript 带到了更高的水平。
JSON格式介绍
对于交互式数据格式,这里使用JSON(JavaScript Object Notation),这是一种轻量级的数据交换格式,它使用完全独立于编程语言的文本格式来存储和表示数据。JSON键值的层次结构简洁明了,易读易写,使JSON成为一种理想的数据交换语言。一个理解 JSON 数据格式的例子:
{//JSON 键/值对
“'wJsona'”:“kkk”
“'wjsonb'”:“12”
“'wjsonc”:“80”
}
代码
下面介绍前端jQuery .ajax() 请求JSON数据的方法。代码如下:
函数 useTestFun() {
$.ajax({
url: "/Usedefine",//获取数据的URL
数据:JSON.stringify({
'wJsona':"kkk",
'wjsonb':12,
'wjsonc':80,
}),
type: "POST",//HTTP请求方式
dataType:'JSON',//获取数据执行方式
成功:功能(数据){
if(data.status == 'True'){//传入JSON对象格式
alert('连接成功');
}
别的{
$("#labletip").show();
}
},
错误:函数(错误){
alert('连接失败');
}
});
}
在数据传输过程中,JSON是以文本即字符串的形式传输的,而JS对JSON对象进行操作,所以JSON对象与JSON字符串的转换是关键,可以使用JSON.stringify() convert 将 JSON 对象转换为 JSON 字符串,使用 JSON.parse() 将 JSON 字符串转换为 JSON 对象。
JSON 字符串:var str1 = '{ "name": "cxh", "sex": "man" }';
JSON 对象:var str2 = { "name": "cxh", "sex": "man" };
var obj = str.parseJSON(); //从JSON字符串转换为JSON对象
var obj = JSON.parse(str); //从JSON字符串转换为JSON对象
var last = obj.toJSONString(); //将JSON对象转换为JSON字符
var last = JSON.stringify(obj); //将JSON对象转换为JSON字符
下面展示了HTTP协议中JSON数据的传输格式。后端服务器可以使用第三方 JSON 库来处理 JSON 数据。返回 JSON 数据时,将 HTTP 协议的 Content-Type 字段设置为“application/json”。
查看全部
抓取ajax动态网页java(下图显示GET请求到文件后继续请求了多个JS、CSS文件前端与后端浏览器
)
下图是对HTML文件的GET请求后继续请求多个JS和CSS文件
前端和后端
浏览器显示的网页是web前端界面,它为用户提供了一个与网站交互的可视化界面,而web后端服务主要是指在浏览器中进行的逻辑操作和数据处理。 server,为前端提供访问服务。. 所谓的前端和后端只是从代码执行的位置来区分的。前端代码在用户面前执行,后端代码在远程服务器上执行。但是,无论前端代码还是后端代码,都是存储在服务器上的,只有在浏览器请求时才从服务器发送出去。
AJAX 简介
在上述web应用的工作原理中,我们通过HTTP协议访问一个存在于服务器上的文件。服务器可以找到该文件并将其内容封装成一个HTTP请求,并以消息体的形式返回给客户端。但是,这种方法只能访问静态页面,不能与后端数据库交互。由于用户需要通过web前端与后端数据库进行实时交互,因此网页也需要动态更新。如果每次更新一个数据都是通过重新获取Html文件来实现的,势必会导致网络负载变重,页面加载变慢。而Ajax技术可以很好的解决这个问题。
Ajax,异步 JavaScript 和 XML,是一种用于创建交互式网页的技术,它可以更新网页的某些部分,而无需重新加载整个网页。目前 jQuery 库提供了几种与 AJAX 相关的方法。通过 jQuery AJAX 方法,可以使用 HTTP Get 和 HTTP Post 从远程服务器请求文本、HTML、XML 或 JSON,并且可以将这些外部数据直接加载到网页的选定元素中。
作为 Web 开发者广泛使用的 JavaScript 封装库之一,jQuery 库可以极大地简化我们的 JavaScript 编程,缓解浏览器不兼容带来的影响。有必要了解网页在不同浏览器中的兼容性测试。这也是很多工作。我们可以通过一个简单的例子看到 jQuery 库的优势:
$("p.neat").addClass("ohmy").show("slow");
有了上面的短代码,开发者就可以遍历所有“整洁”的类
元素,然后将“ohmy”类添加到它,同时缓慢地为每个段落设置动画。开发者无需检查客户端浏览器类型,无需编写循环代码,无需编写复杂的动画功能,只需一行代码即可实现上述效果。jQuery 的口号“用最少的代码做最多的事情”名副其实,并将 JavaScript 带到了更高的水平。
JSON格式介绍
对于交互式数据格式,这里使用JSON(JavaScript Object Notation),这是一种轻量级的数据交换格式,它使用完全独立于编程语言的文本格式来存储和表示数据。JSON键值的层次结构简洁明了,易读易写,使JSON成为一种理想的数据交换语言。一个理解 JSON 数据格式的例子:
{//JSON 键/值对
“'wJsona'”:“kkk”
“'wjsonb'”:“12”
“'wjsonc”:“80”
}
代码
下面介绍前端jQuery .ajax() 请求JSON数据的方法。代码如下:
函数 useTestFun() {
$.ajax({
url: "/Usedefine",//获取数据的URL
数据:JSON.stringify({
'wJsona':"kkk",
'wjsonb':12,
'wjsonc':80,
}),
type: "POST",//HTTP请求方式
dataType:'JSON',//获取数据执行方式
成功:功能(数据){
if(data.status == 'True'){//传入JSON对象格式
alert('连接成功');
}
别的{
$("#labletip").show();
}
},
错误:函数(错误){
alert('连接失败');
}
});
}
在数据传输过程中,JSON是以文本即字符串的形式传输的,而JS对JSON对象进行操作,所以JSON对象与JSON字符串的转换是关键,可以使用JSON.stringify() convert 将 JSON 对象转换为 JSON 字符串,使用 JSON.parse() 将 JSON 字符串转换为 JSON 对象。
JSON 字符串:var str1 = '{ "name": "cxh", "sex": "man" }';
JSON 对象:var str2 = { "name": "cxh", "sex": "man" };
var obj = str.parseJSON(); //从JSON字符串转换为JSON对象
var obj = JSON.parse(str); //从JSON字符串转换为JSON对象
var last = obj.toJSONString(); //将JSON对象转换为JSON字符
var last = JSON.stringify(obj); //将JSON对象转换为JSON字符
下面展示了HTTP协议中JSON数据的传输格式。后端服务器可以使用第三方 JSON 库来处理 JSON 数据。返回 JSON 数据时,将 HTTP 协议的 Content-Type 字段设置为“application/json”。
抓取ajax动态网页java(通过Python抓取深层网络数据库,一次性搜索20个名称)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-03-22 01:37
深层网络收录法庭记录、人口普查数据,可能还有旧报纸的档案。它主要是一个高度权威的学术数据库和政府档案。深度网络比表层网络更容易和更快地审计资源,但深度网络无法看穿表层网络。通过下面的冰山图,我们可以很清楚地知道表层网、深层网和暗网之间的层级关系。
通过Python爬取深度网络数据库,我们可以一次搜索多个数据库,比在每个网站上一次搜索一个要方便快捷得多,并且可以同时对数据库进行多个搜索,即一次搜索一个名称 20 次。
开放网络数据是指任何人都可以使用、重用和重新分配的一类数据,包括地理位置数据、交通数据和文化数据。
新闻服务 NPR 的 网站 是开放网络数据库的一个例子。如果您想要所有提及“互联网”一词的 NPR 文章,您可以从 网站 内部或 google 网站 搜外(通过谷歌搜索 "" 和 "internet" )。任何一种方法都可以获得关于 关键词 的 文章 列表。
图片来源:图片网可作为商业图片
相比之下,迈阿密-戴德县财产记录数据库是深度网络的一部分,简单的 关键词 搜索不会产生太多信息。假设你想获取迈阿密戴德县一个名叫“史密斯”的人的财产记录,你会怎么做?
直接在 Google 搜索“迈阿密戴德县史密斯房产记录”只会返回迈阿密戴德县房产查询网站。但是如果你想抓取一个开放的网络数据库,它是相对简单的。
比如你想爬取NPR提到“互联网”的文章,可以先使用网站的搜索功能,在搜索框中输入“互联网”,然后用关键词 结果页面。
我们也可以编写一个python脚本来爬取上述URL处的页面。这揭示了 网站 的搜索 URL 格式。输入搜索功能的关键字将出现在新网址的“search?query=”部分之后。
URL 可以通过分析 POST 请求中的请求体得到。点击F12键或右键“检查”查看网络的基本信息(进入后需要刷新页面)。
有关 F12/check 元素的更多信息,您可以点击下面的图片链接阅读文章“探索 Google Chrome 的神秘用法,F12!” 》
同样,如果你想搜索这个网站的其他信息,只需将上面URL中“=”后面的关键词替换为新的目标关键词即可。
如何使用 python 抓取深层网络数据?
为了使用 Python 从深度网络数据库中抓取信息,我们将向数据库服务器发送一个请求,该请求模仿 网站 向服务器发送请求的方式,就好像您实际上是通过 网站 提交搜索一样。
在这一点上,有人可能想知道为什么我们应该使用 python 而不仅仅是 网站,因为使用 python 我们可以一次搜索大量数据库。假设我们正在研究某人,而您想知道他们是否有法律问题。
因此,我们可以在法庭记录中搜索它们,搜索法庭记录的手动过程将需要我们搜索大量数据库,因为法院管辖权重叠并且每个数据库都有单独的数据库。
如何抓取深度网络数据库:使用“参数”
您可以使用以下名为 Basic_Scraper 的简单 Python 脚本来抓取您选择的数据库。该脚本通过向 url 标识的位置发送信息(参数)来工作。
# Basic_Scraper
import requests
params = {'firstname': 'John', 'lastname': 'Smith'}
r = requests.post("http://FAKE-WEBSITE-URL/processing.php", data=params)
print(r.text)
您需要输入 url、输入名称以及要查询的任何数据。这个怎么做?首先,导航到要抓取的 网站 的搜索页面。
我们可以使用一个随机的商业注册表作为深度网络数据库的示例。对于本演练,我使用的是 Chrome 浏览器,但任何浏览器都可以,浏览器功能的名称可能略有不同。
我们想使用 html-viewer 来查看 网站search 函数的 html 代码。网站 有一个注册表搜索栏,因此我们右键单击文本区域(您输入搜索词的位置)并单击“检查”。在开发者工具的浏览器中打开一个窗口,在功能选项卡下,网站 的 html 可见,搜索栏文本区域的 html 代码突出显示。请参阅下面的屏幕截图。
这标识了数据库搜索功能的“输入”元素或标签,我们将使用我们的代码和示例脚本 Basic_Scraper 中的“参数”来模拟它。html 告诉我们该元素被标识为“FindBox”,这与示例脚本中的标识符“firstname”相关。
其次,输入一个随机搜索词“Jack”,然后按 ENTER 键查看示例搜索如何影响 html。该网页现在列出了标题中带有“Jack”一词的公司。浏览器的 html 查看器显示搜索功能的代码已被刷新,并且一些新内容已添加到输入元素中。如下面屏幕截图的第二行所示,该元素具有额外的文本,内容为“value="jack"”。
现在我们知道如何识别搜索函数的参数及其值了。这在 Python 中称为字典,因为有一个键 (FindBox) 和一个关联的值 (jack)。因此,为了从带有“Jack”一词的公司中抓取该数据库,我们将示例脚本的参数更改为:
参数 = {'FindBox': 'Jack'}
第三,我们通过 POST 请求将此信息发布到数据库的服务器。但是我们需要确定一个 url 来发送我们的请求。
输入网页源代码,在HTML中找到form标签的“action”,其内容类似于“action=”后跟一个url。这将识别您将用于发送信息的 url。它将为您提供完整的 URL 或只是尾随部分。
例如,它可能读取“action=/processing.php”,它确认相关的 url 以 processing.php 结尾。有时你只是将它添加到搜索页面的 url 的末尾,或者有时你会用它来替换 url 的最后一段。
最终产品(URL)将被粘贴到上面的脚本中,在脚本中留下括号,它说:
在我们的示例数据库中,目标 url 与我们之前访问的网页的 url 相同。因此,我们向带有参数的 url 发送 POST 请求,并将响应分配给值 r。它应该如下所示:
然后我们可以输入“print(r)”查看对应的状态码来判断服务器的对应状态。如果状态码为“200”,则表示返回数据成功。这时候我们也可以输入“print(r.text)”来获取文本类型的对应内容。这些响应内容与我们在 网站 上发起 HTTP 请求时看到的响应正文的结果是一致的。
与任何 python 脚本一样,如果遇到问题,请尝试从命令行运行它并尝试输入 python3 而不是 python 并确保没有多余的行或换行符(在不小心按 enter 并在新行上开始文本之后) # 是后面的注释。
import requests
from bs4 import BeautifulSoup
#Scraping data
params = {'FindBox': 'Jack'}
r = requests.post('http://cr.justice.gov.lb/searc ... 39%3B, params)
print(r)
print(r.text)
然后,我们将收到结果数据作为响应,如下所示:
下面是同一脚本的一个版本,在末尾添加了一个部分来解析数据。这样,脚本不会检索大量数据,而只会列出您的搜索结果。
# commercial registry scraper
import requests
from bs4 import BeautifulSoup
#Scraping data
params = {'FindBox': 'Jack'}
r = requests.post('http://cr.justice.gov.lb/searc ... 39%3B, params)
html = r.text
#Parse the data
bs = BeautifulSoup(html, 'html.parser')
companies = bs.find_all('div', {'class' : {'res_line1' }})
dates = bs.find_all('div', {'class' : {'res_line2' }})
for company in companies:
link = bs.find('a')
for link in company:
articleUrl = (link.attrs['href'])
for date in dates:
print(company.get_text(),
'registration date and region:', date.get_text(),
'registration link:', ('http://cr.justice.gov.lb/search/{}'.format(articleUrl)))
此添加会解析数据,以便结果列出每个公司的名称、注册号以及指向其在目录中的文件的链接。结果如下所示:
第二部分,标题为#Parse the data,使用 Python 的 BeatifulSoup 库使响应数据更易于理解。BeautifulSoup 是一个用于解析 html(以及其他东西)的复杂工具,它已经写了一整本书,所以我们不会在本 文章 中讨论它。此处仅用于简化响应数据。
如何爬取深层网络数据库:模拟浏览器操作
以上方法通常用于查看浏览器开发者工具,分析服务器在向数据库提交HTTP请求时的响应状态。
但是在我们实际工作中,如果提交某个关键词搜索相关信息,空白搜索页面的URL和输入关键词后的结果URL是一样的,也就是说上面的这里可以使用方法。不起作用。
这是因为在实际的动态网页中,Ajax请求的很多参数都是加密的,用户通过分析Ajax请求很难得到真实的URL,而且有些动态加载的数据不是Ajax生成的。这时可以使用 Selenium 模拟浏览器的方法来获取网页动态加载和渲染的数据。
Selenium 是一种自动化测试工具,可驱动浏览器执行特定操作(如点击、输入等)。同时,还可以获取浏览器当前渲染的页面内容,以便在可见的情况下进行爬取。Python 提供了 Selenium 库来实现操作。
特此声明:本文旨在分享交流学习的工具。请读者在合理合法的范围内使用,时刻牢记合法红线,不要利用该工具和技术做任何违法的事情。
本文文章为傅云原创内容,未经授权禁止转载
富韵原创IP形象设计,原创请勿盗用,侵权必究 查看全部
抓取ajax动态网页java(通过Python抓取深层网络数据库,一次性搜索20个名称)
深层网络收录法庭记录、人口普查数据,可能还有旧报纸的档案。它主要是一个高度权威的学术数据库和政府档案。深度网络比表层网络更容易和更快地审计资源,但深度网络无法看穿表层网络。通过下面的冰山图,我们可以很清楚地知道表层网、深层网和暗网之间的层级关系。
通过Python爬取深度网络数据库,我们可以一次搜索多个数据库,比在每个网站上一次搜索一个要方便快捷得多,并且可以同时对数据库进行多个搜索,即一次搜索一个名称 20 次。
开放网络数据是指任何人都可以使用、重用和重新分配的一类数据,包括地理位置数据、交通数据和文化数据。
新闻服务 NPR 的 网站 是开放网络数据库的一个例子。如果您想要所有提及“互联网”一词的 NPR 文章,您可以从 网站 内部或 google 网站 搜外(通过谷歌搜索 "" 和 "internet" )。任何一种方法都可以获得关于 关键词 的 文章 列表。
图片来源:图片网可作为商业图片
相比之下,迈阿密-戴德县财产记录数据库是深度网络的一部分,简单的 关键词 搜索不会产生太多信息。假设你想获取迈阿密戴德县一个名叫“史密斯”的人的财产记录,你会怎么做?
直接在 Google 搜索“迈阿密戴德县史密斯房产记录”只会返回迈阿密戴德县房产查询网站。但是如果你想抓取一个开放的网络数据库,它是相对简单的。
比如你想爬取NPR提到“互联网”的文章,可以先使用网站的搜索功能,在搜索框中输入“互联网”,然后用关键词 结果页面。
我们也可以编写一个python脚本来爬取上述URL处的页面。这揭示了 网站 的搜索 URL 格式。输入搜索功能的关键字将出现在新网址的“search?query=”部分之后。
URL 可以通过分析 POST 请求中的请求体得到。点击F12键或右键“检查”查看网络的基本信息(进入后需要刷新页面)。
有关 F12/check 元素的更多信息,您可以点击下面的图片链接阅读文章“探索 Google Chrome 的神秘用法,F12!” 》
同样,如果你想搜索这个网站的其他信息,只需将上面URL中“=”后面的关键词替换为新的目标关键词即可。
如何使用 python 抓取深层网络数据?
为了使用 Python 从深度网络数据库中抓取信息,我们将向数据库服务器发送一个请求,该请求模仿 网站 向服务器发送请求的方式,就好像您实际上是通过 网站 提交搜索一样。
在这一点上,有人可能想知道为什么我们应该使用 python 而不仅仅是 网站,因为使用 python 我们可以一次搜索大量数据库。假设我们正在研究某人,而您想知道他们是否有法律问题。
因此,我们可以在法庭记录中搜索它们,搜索法庭记录的手动过程将需要我们搜索大量数据库,因为法院管辖权重叠并且每个数据库都有单独的数据库。
如何抓取深度网络数据库:使用“参数”
您可以使用以下名为 Basic_Scraper 的简单 Python 脚本来抓取您选择的数据库。该脚本通过向 url 标识的位置发送信息(参数)来工作。
# Basic_Scraper
import requests
params = {'firstname': 'John', 'lastname': 'Smith'}
r = requests.post("http://FAKE-WEBSITE-URL/processing.php", data=params)
print(r.text)
您需要输入 url、输入名称以及要查询的任何数据。这个怎么做?首先,导航到要抓取的 网站 的搜索页面。
我们可以使用一个随机的商业注册表作为深度网络数据库的示例。对于本演练,我使用的是 Chrome 浏览器,但任何浏览器都可以,浏览器功能的名称可能略有不同。
我们想使用 html-viewer 来查看 网站search 函数的 html 代码。网站 有一个注册表搜索栏,因此我们右键单击文本区域(您输入搜索词的位置)并单击“检查”。在开发者工具的浏览器中打开一个窗口,在功能选项卡下,网站 的 html 可见,搜索栏文本区域的 html 代码突出显示。请参阅下面的屏幕截图。
这标识了数据库搜索功能的“输入”元素或标签,我们将使用我们的代码和示例脚本 Basic_Scraper 中的“参数”来模拟它。html 告诉我们该元素被标识为“FindBox”,这与示例脚本中的标识符“firstname”相关。
其次,输入一个随机搜索词“Jack”,然后按 ENTER 键查看示例搜索如何影响 html。该网页现在列出了标题中带有“Jack”一词的公司。浏览器的 html 查看器显示搜索功能的代码已被刷新,并且一些新内容已添加到输入元素中。如下面屏幕截图的第二行所示,该元素具有额外的文本,内容为“value="jack"”。
现在我们知道如何识别搜索函数的参数及其值了。这在 Python 中称为字典,因为有一个键 (FindBox) 和一个关联的值 (jack)。因此,为了从带有“Jack”一词的公司中抓取该数据库,我们将示例脚本的参数更改为:
参数 = {'FindBox': 'Jack'}
第三,我们通过 POST 请求将此信息发布到数据库的服务器。但是我们需要确定一个 url 来发送我们的请求。
输入网页源代码,在HTML中找到form标签的“action”,其内容类似于“action=”后跟一个url。这将识别您将用于发送信息的 url。它将为您提供完整的 URL 或只是尾随部分。
例如,它可能读取“action=/processing.php”,它确认相关的 url 以 processing.php 结尾。有时你只是将它添加到搜索页面的 url 的末尾,或者有时你会用它来替换 url 的最后一段。
最终产品(URL)将被粘贴到上面的脚本中,在脚本中留下括号,它说:
在我们的示例数据库中,目标 url 与我们之前访问的网页的 url 相同。因此,我们向带有参数的 url 发送 POST 请求,并将响应分配给值 r。它应该如下所示:
然后我们可以输入“print(r)”查看对应的状态码来判断服务器的对应状态。如果状态码为“200”,则表示返回数据成功。这时候我们也可以输入“print(r.text)”来获取文本类型的对应内容。这些响应内容与我们在 网站 上发起 HTTP 请求时看到的响应正文的结果是一致的。
与任何 python 脚本一样,如果遇到问题,请尝试从命令行运行它并尝试输入 python3 而不是 python 并确保没有多余的行或换行符(在不小心按 enter 并在新行上开始文本之后) # 是后面的注释。
import requests
from bs4 import BeautifulSoup
#Scraping data
params = {'FindBox': 'Jack'}
r = requests.post('http://cr.justice.gov.lb/searc ... 39%3B, params)
print(r)
print(r.text)
然后,我们将收到结果数据作为响应,如下所示:
下面是同一脚本的一个版本,在末尾添加了一个部分来解析数据。这样,脚本不会检索大量数据,而只会列出您的搜索结果。
# commercial registry scraper
import requests
from bs4 import BeautifulSoup
#Scraping data
params = {'FindBox': 'Jack'}
r = requests.post('http://cr.justice.gov.lb/searc ... 39%3B, params)
html = r.text
#Parse the data
bs = BeautifulSoup(html, 'html.parser')
companies = bs.find_all('div', {'class' : {'res_line1' }})
dates = bs.find_all('div', {'class' : {'res_line2' }})
for company in companies:
link = bs.find('a')
for link in company:
articleUrl = (link.attrs['href'])
for date in dates:
print(company.get_text(),
'registration date and region:', date.get_text(),
'registration link:', ('http://cr.justice.gov.lb/search/{}'.format(articleUrl)))
此添加会解析数据,以便结果列出每个公司的名称、注册号以及指向其在目录中的文件的链接。结果如下所示:
第二部分,标题为#Parse the data,使用 Python 的 BeatifulSoup 库使响应数据更易于理解。BeautifulSoup 是一个用于解析 html(以及其他东西)的复杂工具,它已经写了一整本书,所以我们不会在本 文章 中讨论它。此处仅用于简化响应数据。
如何爬取深层网络数据库:模拟浏览器操作
以上方法通常用于查看浏览器开发者工具,分析服务器在向数据库提交HTTP请求时的响应状态。
但是在我们实际工作中,如果提交某个关键词搜索相关信息,空白搜索页面的URL和输入关键词后的结果URL是一样的,也就是说上面的这里可以使用方法。不起作用。
这是因为在实际的动态网页中,Ajax请求的很多参数都是加密的,用户通过分析Ajax请求很难得到真实的URL,而且有些动态加载的数据不是Ajax生成的。这时可以使用 Selenium 模拟浏览器的方法来获取网页动态加载和渲染的数据。
Selenium 是一种自动化测试工具,可驱动浏览器执行特定操作(如点击、输入等)。同时,还可以获取浏览器当前渲染的页面内容,以便在可见的情况下进行爬取。Python 提供了 Selenium 库来实现操作。
特此声明:本文旨在分享交流学习的工具。请读者在合理合法的范围内使用,时刻牢记合法红线,不要利用该工具和技术做任何违法的事情。
本文文章为傅云原创内容,未经授权禁止转载
富韵原创IP形象设计,原创请勿盗用,侵权必究
抓取ajax动态网页java(AJAX即“AsynchronousJavascriptAndXML”(异步JavaScript和XML)封装了ajax)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-03-17 00:27
AJAX 是“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
AJAX = 异步和 XML(标准通用标记语言的子集)。
AJAX 是一种用于创建快速和动态网页的技术。
AJAX 不是一种新的编程语言,而是一种使用现有标准的新方法。
AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
如果内容需要更新,传统网页(没有 AJAX)必须重新加载整个网页。
使用ajax传输对象、集合、数组等(xml)
jquery包封装ajax相关
package com.maya.ajax;
import java.io.IOException;
import java.util.ArrayList;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.maya.user.Users;
/**
* Servlet implementation class TestAjax2
*/
@WebServlet("/testajax2")
public class TestAjax2 extends HttpServlet {
private static final long serialVersionUID = 1L;
/**
* @see HttpServlet#HttpServlet()
*/
public TestAjax2() {
super();
// TODO Auto-generated constructor stub
}
/**
* @see HttpServlet#doGet(HttpServletRequest request, HttpServletResponse response)
*/
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setCharacterEncoding("utf-8");
response.setCharacterEncoding("utf-8");
Users user=new Users();
user.setName("张三");
user.setSex("男");
user.setAge(23);
Users user1=new Users();
user1.setName("李四");
user1.setSex("女");
user1.setAge(24);
Users user2=new Users();
user2.setName("王五");
user2.setSex("男");
user2.setAge(25);
ArrayList list=new ArrayList();
list.add(user);
list.add(user1);
list.add(user2);
response.getWriter().append("");
response.getWriter().append("");
for(Users u:list){
response.getWriter().append("");
response.getWriter().append(""+u.getName()+"");
response.getWriter().append(""+u.getSex()+"");
response.getWriter().append(""+u.getAge()+"");
response.getWriter().append("");
}
response.getWriter().append("");
}
/**
* @see HttpServlet#doPost(HttpServletRequest request, HttpServletResponse response)
*/
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// TODO Auto-generated method stub
doGet(request, response);
}
}
HTML页面:
<p>
Insert title here
$(document).ready(function(){
$("#ss").click(function(){
$.ajax({
url:"testajax2",
data:{},
type:"POST",
dataType:"XML",
success:function(httpdata){
var s=$(httpdata).find("user");
for(var i=0;i 查看全部
抓取ajax动态网页java(AJAX即“AsynchronousJavascriptAndXML”(异步JavaScript和XML)封装了ajax)
AJAX 是“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
AJAX = 异步和 XML(标准通用标记语言的子集)。
AJAX 是一种用于创建快速和动态网页的技术。
AJAX 不是一种新的编程语言,而是一种使用现有标准的新方法。
AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
如果内容需要更新,传统网页(没有 AJAX)必须重新加载整个网页。
使用ajax传输对象、集合、数组等(xml)
jquery包封装ajax相关
package com.maya.ajax;
import java.io.IOException;
import java.util.ArrayList;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.maya.user.Users;
/**
* Servlet implementation class TestAjax2
*/
@WebServlet("/testajax2")
public class TestAjax2 extends HttpServlet {
private static final long serialVersionUID = 1L;
/**
* @see HttpServlet#HttpServlet()
*/
public TestAjax2() {
super();
// TODO Auto-generated constructor stub
}
/**
* @see HttpServlet#doGet(HttpServletRequest request, HttpServletResponse response)
*/
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setCharacterEncoding("utf-8");
response.setCharacterEncoding("utf-8");
Users user=new Users();
user.setName("张三");
user.setSex("男");
user.setAge(23);
Users user1=new Users();
user1.setName("李四");
user1.setSex("女");
user1.setAge(24);
Users user2=new Users();
user2.setName("王五");
user2.setSex("男");
user2.setAge(25);
ArrayList list=new ArrayList();
list.add(user);
list.add(user1);
list.add(user2);
response.getWriter().append("");
response.getWriter().append("");
for(Users u:list){
response.getWriter().append("");
response.getWriter().append(""+u.getName()+"");
response.getWriter().append(""+u.getSex()+"");
response.getWriter().append(""+u.getAge()+"");
response.getWriter().append("");
}
response.getWriter().append("");
}
/**
* @see HttpServlet#doPost(HttpServletRequest request, HttpServletResponse response)
*/
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// TODO Auto-generated method stub
doGet(request, response);
}
}
HTML页面:
<p>
Insert title here
$(document).ready(function(){
$("#ss").click(function(){
$.ajax({
url:"testajax2",
data:{},
type:"POST",
dataType:"XML",
success:function(httpdata){
var s=$(httpdata).find("user");
for(var i=0;i
抓取ajax动态网页java(一个毛病有些301从定向引起的毛病是因为301(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-15 03:04
当 网站 上的页面(例如,当用户在浏览器中访问您的页面或 Google 机器人抓取该页面时)向您的服务器发出请求时,服务器会返回一个 HTTP 状态代码以响应该请求。
如果它显示 403 状态,您可以忽略它,这意味着您的主机正在阻止 Google bot 抓取。有关所有 HTTP 状态代码的列表,请参阅 Google HTTP 状态代码帮助页面。
2、站点地图中的错误
站点地图错误通常会导致 404 错误页面,或者在当前地图中返回 404 错误页面。如果出现 404 错误页面,请检查站点地图中的所有链接,
Google 将继续抓取您已删除的站点地图,这令人沮丧,但有一些方法可以解决它:确保已在管理工具中删除旧的站点地图。如果您不想被抓取,请确保旧站点地图呈现 404 或重定向到新站点地图。
谷歌员工 Susan Moskwa 解释说:
防止 Google bot 抓取的最好方法是让这些 URL(例如旧站点地图)显示 404,当我们看到一个 URL 多次显示 404 时,Google bot 将停止抓取。
三、重定向错误
一些故障是由重定向的 301 引起的。执行重定向后的注意事项:
1:确保它们返回正确的 HTTP 状态代码。
2:确保您没有任何循环重定向。
3:确保重定向指向一个有效的网页,而不是404页面,或者其他错误页面,比如503(服务器错误)或者403(停止爬取)
4:确保重定向不指向空页面。
四、404 错误
404错误可能出现在以下几个方面:
1:删除网站上的网页;
2:更改了网页名称;
4:链接到不存在的页面;
5:其他网站链接到你的网站最后一个不存在的页面;
6:网站迁移到域名不完全匹配的新网站。
五、受 robots.txt 限制
另一个原因是 robots.txt 文件阻止了 Google bot 抓取。如果出现大量爬取问题,第一步应该是检查robots.txt
6、软404问题
通常,当有人请求一个不存在的页面时,服务器会返回一个 404 (Not Found) 错误。如果响应请求的页面不存在,除了返回 404 代码外,服务器还会显示 404 页面。这更像是一个标准的“找不到文件”消息,或者是一个旨在向用户提供更多信息的自定义页面。页面内容与服务器返回的 HTTP 响应完全无关。仅仅因为页面显示 404 文件未找到消息并不意味着它是 404 页面。
七、超时
网站超时也是爬取失败的原因之一。如果超时,Google bot 将停止抓取。超时的故障类型有:
1:DNS超时,可以使用Nslookup命令检测DNS,DNS超时的最大原因是域名服务商的DNS服务器不稳定。
2:URL超时,特定页面出现故障,而不是整个域。
3:robots.txt超时,如果你网站有robots.txt,但是服务器超时,Google bot会认为该文件不存在。
4:动态网页响应时间过长,页面加载时间过长。 查看全部
抓取ajax动态网页java(一个毛病有些301从定向引起的毛病是因为301(组图))
当 网站 上的页面(例如,当用户在浏览器中访问您的页面或 Google 机器人抓取该页面时)向您的服务器发出请求时,服务器会返回一个 HTTP 状态代码以响应该请求。
如果它显示 403 状态,您可以忽略它,这意味着您的主机正在阻止 Google bot 抓取。有关所有 HTTP 状态代码的列表,请参阅 Google HTTP 状态代码帮助页面。
2、站点地图中的错误
站点地图错误通常会导致 404 错误页面,或者在当前地图中返回 404 错误页面。如果出现 404 错误页面,请检查站点地图中的所有链接,
Google 将继续抓取您已删除的站点地图,这令人沮丧,但有一些方法可以解决它:确保已在管理工具中删除旧的站点地图。如果您不想被抓取,请确保旧站点地图呈现 404 或重定向到新站点地图。
谷歌员工 Susan Moskwa 解释说:
防止 Google bot 抓取的最好方法是让这些 URL(例如旧站点地图)显示 404,当我们看到一个 URL 多次显示 404 时,Google bot 将停止抓取。
三、重定向错误
一些故障是由重定向的 301 引起的。执行重定向后的注意事项:
1:确保它们返回正确的 HTTP 状态代码。
2:确保您没有任何循环重定向。
3:确保重定向指向一个有效的网页,而不是404页面,或者其他错误页面,比如503(服务器错误)或者403(停止爬取)
4:确保重定向不指向空页面。
四、404 错误
404错误可能出现在以下几个方面:
1:删除网站上的网页;
2:更改了网页名称;
4:链接到不存在的页面;
5:其他网站链接到你的网站最后一个不存在的页面;
6:网站迁移到域名不完全匹配的新网站。
五、受 robots.txt 限制
另一个原因是 robots.txt 文件阻止了 Google bot 抓取。如果出现大量爬取问题,第一步应该是检查robots.txt
6、软404问题
通常,当有人请求一个不存在的页面时,服务器会返回一个 404 (Not Found) 错误。如果响应请求的页面不存在,除了返回 404 代码外,服务器还会显示 404 页面。这更像是一个标准的“找不到文件”消息,或者是一个旨在向用户提供更多信息的自定义页面。页面内容与服务器返回的 HTTP 响应完全无关。仅仅因为页面显示 404 文件未找到消息并不意味着它是 404 页面。
七、超时
网站超时也是爬取失败的原因之一。如果超时,Google bot 将停止抓取。超时的故障类型有:
1:DNS超时,可以使用Nslookup命令检测DNS,DNS超时的最大原因是域名服务商的DNS服务器不稳定。
2:URL超时,特定页面出现故障,而不是整个域。
3:robots.txt超时,如果你网站有robots.txt,但是服务器超时,Google bot会认为该文件不存在。
4:动态网页响应时间过长,页面加载时间过长。
抓取ajax动态网页java(爬取苏宁酷开电视价格代码如下:(导入jsoup包) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2022-03-14 14:04
)
最近因为工作需要,开始学习爬虫。对于静态加载的页面,爬取并不难,但是遇到ajax动态加载的页面,动态加载的信息是爬不出来的!
对于ajax动态加载的数据爬取,一般有两种方式:
1.因为js渲染页面的数据也是从后端获取的,而且基本上都是AJAX获取的,所以分析AJAX请求,找到对应的数据
请求也更可行。而且相对于页面样式,这个界面是不太可能改变的。缺点是找到请求,并且
仿真是一个比较困难的过程,需要比较多的分析经验
2.在爬取阶段,爬虫内置浏览器内核,爬取前执行js渲染页面。这方面对应的工具有Selenium,
HtmlUnit 或 PhantomJs。但这些工具都存在一定的效率问题,同时也不是那么稳定。好处是写规则
对于第二种方法,我测试过,只有Selenium可以成功爬到ajax动态加载的页面,但是每次请求页面都会弹出浏览器窗口,这对后面的项目部署到浏览器很不利!所以推荐第一种方法,代码也是第一种方法。
爬取苏宁酷开电视价格代码如下:
(导入jsoup包我就不多说了,自己百度吧!)
//然后就是模拟ajax请求,当然了,根据规律,需要将"datasku"的属性值替换下面链接中的"133537397"和"0000000000"值
Document
document1=Jsoup.connect("http://ds.suning.cn/ds/general ... 6quot;)
.ignoreContentType(true)
.data("query", "Java")
.userAgent("Mozilla")
.cookie("auth", "token")
.timeout(3000)
.get();
//打印出模拟ajax请求返回的数据,一个json格式的数据,对它进行解析就可以了
System.out.println(document1.text()); 查看全部
抓取ajax动态网页java(爬取苏宁酷开电视价格代码如下:(导入jsoup包)
)
最近因为工作需要,开始学习爬虫。对于静态加载的页面,爬取并不难,但是遇到ajax动态加载的页面,动态加载的信息是爬不出来的!
对于ajax动态加载的数据爬取,一般有两种方式:
1.因为js渲染页面的数据也是从后端获取的,而且基本上都是AJAX获取的,所以分析AJAX请求,找到对应的数据
请求也更可行。而且相对于页面样式,这个界面是不太可能改变的。缺点是找到请求,并且
仿真是一个比较困难的过程,需要比较多的分析经验
2.在爬取阶段,爬虫内置浏览器内核,爬取前执行js渲染页面。这方面对应的工具有Selenium,
HtmlUnit 或 PhantomJs。但这些工具都存在一定的效率问题,同时也不是那么稳定。好处是写规则
对于第二种方法,我测试过,只有Selenium可以成功爬到ajax动态加载的页面,但是每次请求页面都会弹出浏览器窗口,这对后面的项目部署到浏览器很不利!所以推荐第一种方法,代码也是第一种方法。
爬取苏宁酷开电视价格代码如下:
(导入jsoup包我就不多说了,自己百度吧!)
//然后就是模拟ajax请求,当然了,根据规律,需要将"datasku"的属性值替换下面链接中的"133537397"和"0000000000"值
Document
document1=Jsoup.connect("http://ds.suning.cn/ds/general ... 6quot;)
.ignoreContentType(true)
.data("query", "Java")
.userAgent("Mozilla")
.cookie("auth", "token")
.timeout(3000)
.get();
//打印出模拟ajax请求返回的数据,一个json格式的数据,对它进行解析就可以了
System.out.println(document1.text());
抓取ajax动态网页java(Web页面不用打断交互流程进行重新加裁,你还不知道?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-03-12 20:11
Ajax(异步 JavaScript 和 XML)是一种结合 Java 技术、XML 和 JavaScript 的编程技术,允许您构建基于 Java 技术的 Web 应用程序并打破使用页面重新加载的惯例。
Ajax,异步 JavaScript 和 XML,是一种 Web 应用程序开发方法,它使用客户端脚本与 Web 服务器交换数据。这样,可以在不中断交互流程进行重新编辑的情况下动态更新网页。使用 Ajax,您可以创建接近本地桌面应用程序的直接、高度可用、更丰富和更动态的 Web 用户界面界面。
Ajax 不是一种技术,它更像是一种模式——一种识别和描述有用设计技术的方法。对于许多不熟悉它的开发人员来说,这是一种新的感觉,但是实现 Ajax 的所有组件都已经存在多年了。
当前的热议是由于 2004 年和 2005 年出现了一些非常动态的基于 Ajax 的 WebUI,尤其是 Google 的 GMail 和 Maps 应用程序,以及照片共享 网站Flickr。这些 UI 充分利用了后端通道,也被一些开发人员称为“Web2.0”,并导致对 Ajax 应用程序的兴趣激增。
更好的购物车
您可以使用 Ajax 来增强传统的 Web 应用程序,通过消除页面加载使交互更加顺畅。为了演示它,我将使用一个简单的购物车来动态更新添加的项目。结合在线商店,这种方法允许我们继续浏览并将商品挑选到购物车中,而无需等待页面在点击后重新加载。
尽管本文中的代码是针对购物车示例的,但所展示的技术也可以在其他 Ajax 应用程序中使用。购物车示例中使用的 HTML 代码如清单 1 所示。我将在整个 文章 中引用此 HTML 代码。
阿贾克斯进程
Ajax 交互从一个名为 XMLHttpRequest 的 JavaScript 对象开始。顾名思义,它允许客户端脚本执行 HTTP 请求并解析 XML 格式的服务器响应。Ajax 处理的第一步是创建 XMLHttpRequest 的实例。使用 HTTP 方法(GET 或 POST)处理请求并将目标 URL 设置为 XMLHttpRequest 对象。
现在,还记得最初是如何异步处理 Ajax 的吗?当你发送一个 HTTP 请求时,你不希望浏览器挂起等待服务器的响应,相反,你希望页面继续响应用户的界面交互,当它们真正到达时服务器响应处理它们。
为此,您可以使用 XMLHttpRequest 注册回调函数并异步调度 XMLHttpRequest 请求。控制权立即返回给浏览器,当服务器响应到达时会调用回调函数。
在 Java Web 服务器上,传入请求与任何其他 HttpServletRequest 相同。解析请求参数后,servlet 执行必要的应用程序逻辑,将响应序列化为 XML,并将其写回 HttpServletResponse。
回到客户端,现在将调用注册在 XMLHttpRequest 上的回调函数来处理服务器返回的 XML 文档。最后,JavaScript 用于通过更新用户界面以响应从服务器传输的数据来操作页面的 HTMLDOM。图 1 是 Ajax 进程的序列图。
图 1:Ajax 处理流程
您现在应该对 Ajax 进程有一个高级视图。我将进入这些步骤中的每一个,并更详细地了解发生了什么。如果找不到合适的位置,请返回并查看图 1,此外 - 由于 Ajax 方法的异步特性,序列图并不直接。 查看全部
抓取ajax动态网页java(Web页面不用打断交互流程进行重新加裁,你还不知道?)
Ajax(异步 JavaScript 和 XML)是一种结合 Java 技术、XML 和 JavaScript 的编程技术,允许您构建基于 Java 技术的 Web 应用程序并打破使用页面重新加载的惯例。
Ajax,异步 JavaScript 和 XML,是一种 Web 应用程序开发方法,它使用客户端脚本与 Web 服务器交换数据。这样,可以在不中断交互流程进行重新编辑的情况下动态更新网页。使用 Ajax,您可以创建接近本地桌面应用程序的直接、高度可用、更丰富和更动态的 Web 用户界面界面。
Ajax 不是一种技术,它更像是一种模式——一种识别和描述有用设计技术的方法。对于许多不熟悉它的开发人员来说,这是一种新的感觉,但是实现 Ajax 的所有组件都已经存在多年了。
当前的热议是由于 2004 年和 2005 年出现了一些非常动态的基于 Ajax 的 WebUI,尤其是 Google 的 GMail 和 Maps 应用程序,以及照片共享 网站Flickr。这些 UI 充分利用了后端通道,也被一些开发人员称为“Web2.0”,并导致对 Ajax 应用程序的兴趣激增。
更好的购物车
您可以使用 Ajax 来增强传统的 Web 应用程序,通过消除页面加载使交互更加顺畅。为了演示它,我将使用一个简单的购物车来动态更新添加的项目。结合在线商店,这种方法允许我们继续浏览并将商品挑选到购物车中,而无需等待页面在点击后重新加载。
尽管本文中的代码是针对购物车示例的,但所展示的技术也可以在其他 Ajax 应用程序中使用。购物车示例中使用的 HTML 代码如清单 1 所示。我将在整个 文章 中引用此 HTML 代码。
阿贾克斯进程
Ajax 交互从一个名为 XMLHttpRequest 的 JavaScript 对象开始。顾名思义,它允许客户端脚本执行 HTTP 请求并解析 XML 格式的服务器响应。Ajax 处理的第一步是创建 XMLHttpRequest 的实例。使用 HTTP 方法(GET 或 POST)处理请求并将目标 URL 设置为 XMLHttpRequest 对象。
现在,还记得最初是如何异步处理 Ajax 的吗?当你发送一个 HTTP 请求时,你不希望浏览器挂起等待服务器的响应,相反,你希望页面继续响应用户的界面交互,当它们真正到达时服务器响应处理它们。
为此,您可以使用 XMLHttpRequest 注册回调函数并异步调度 XMLHttpRequest 请求。控制权立即返回给浏览器,当服务器响应到达时会调用回调函数。
在 Java Web 服务器上,传入请求与任何其他 HttpServletRequest 相同。解析请求参数后,servlet 执行必要的应用程序逻辑,将响应序列化为 XML,并将其写回 HttpServletResponse。
回到客户端,现在将调用注册在 XMLHttpRequest 上的回调函数来处理服务器返回的 XML 文档。最后,JavaScript 用于通过更新用户界面以响应从服务器传输的数据来操作页面的 HTMLDOM。图 1 是 Ajax 进程的序列图。
图 1:Ajax 处理流程
您现在应该对 Ajax 进程有一个高级视图。我将进入这些步骤中的每一个,并更详细地了解发生了什么。如果找不到合适的位置,请返回并查看图 1,此外 - 由于 Ajax 方法的异步特性,序列图并不直接。
抓取ajax动态网页java(如何一次性把网站中的ajax获取这里介绍的文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-03-10 14:11
通常情况下,通过网络爬虫挖出来的网页的静态内容基本上就是网页的静态内容,而动态ajax号的内容是我个人不知道ajax怎么弄进去的网站 一次
这里介绍的是某个网站中的某个ajax刷新某个表,期望数据,提供其他操作,比如下载:
假设我们需要挖掘某个网站:
示例:网站 中的那些 pdf 文件,并下载它们
首先:需要分析网页构成的结果;看看它是如何被读取和处理的。 ajax解决方案到此结束(其他异同,ajax只对数据进行一次性数据请求)
具体操作已经通过案例主要介绍了:
先分析ajax使用的请求url的含义和请求中需要的参数,然后给出响应的参数
/**
* 获取某个请求的内容
* @param url 请求的地址
* @param code 请求的编码,不传就代表UTF-8
* @return 请求响应的内容
* @throws IOException
*/
public static String fetch_url(String url, String code) throws IOException {
BufferedReader bis = null;
InputStream is = null;
InputStreamReader inputStreamReader = null;
try {
URLConnection connection = new URL(url).openConnection();
connection.setConnectTimeout(20000);
connection.setReadTimeout(20000);
connection.setUseCaches(false);
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11");
is = connection.getInputStream();
inputStreamReader = new InputStreamReader(is, code);
bis = new BufferedReader(inputStreamReader);
String line = null;
StringBuffer result = new StringBuffer();
while ((line = bis.readLine()) != null) {
result.append(line);
}
return result.toString();
} finally {
if (inputStreamReader != null) {
try {
inputStreamReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (bis != null) {
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (is != null) {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
通过上面的url请求,观察响应的数据格式,这里响应的数据测试格式为json格式
/**
* 数据转化成json格式
* @param s
*/
public static void getJSON(String s) {
JSONObject object = JSONObject.fromObject(s);
JSONArray array = JSONArray.fromObject(object.get("disclosureInfos"));
//System.out.println(array);
String filePath = object.getString("filePath");//解析数据中的某一个值
//System.out.println(array.size());
List listFilePath = getJSONArray(array,filePath);//将数据解析成条数
/*System.out.println(listFilePath);
System.out.println(listFilePath.size());*/
writer(listFilePath);//根据数据的内容开始挖取下载
}
大量数据需要下载,一个一个
public static void writer(List listFilePath) {
for (String string : listFilePath) {
downloadFile(string);
}
}
从格式数据中解析json数据
/**
* 解析文件url
* @param array
* @return
*/
public static List getJSONArray(JSONArray array,String filePath) {
List listFilePath = new ArrayList();
for (Object object : array) {
JSONObject ob = JSONObject.fromObject(object);
filePath = filePath + ob.get("filePath").toString();
// System.out.println(filePath);
listFilePath.add(filePath);
}
return listFilePath;
}
文件下载处理
/* 下载 url 指向的网页 */
public static String downloadFile(String url) {
String filePath = null;
/* 1.生成 HttpClinet 对象并设置参数 */
HttpClient httpClient = new HttpClient();
// 设置 Http 连接超时 5s
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(5000);
/* 2.生成 GetMethod 对象并设置参数 */
GetMethod getMethod = new GetMethod(url);
// 设置 get 请求超时 5s
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, 5000);
// 设置请求重试处理
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER, new DefaultHttpMethodRetryHandler());
/* 3.执行 HTTP GET 请求 */
try {
int statusCode = httpClient.executeMethod(getMethod);
// 判断访问的状态码
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: " + getMethod.getStatusLine());
filePath = null;
}
/* 4.处理 HTTP 响应内容 */
byte[] responseBody = getMethod.getResponseBody();// 读取为字节数组
// 根据网页 url 生成保存时的文件名
filePath = "e:\\spider\\";
String fileName = getFileNameByUrl(url, getMethod.getResponseHeader("Content-Type").getValue());
saveToLocal(responseBody, filePath,fileName);
} catch (HttpException e) {
// 发生致命的异常,可能是协议不对或者返回的内容有问题
System.out.println("Please check your provided http address!");
e.printStackTrace();
} catch (IOException e) {
// 发生网络异常
e.printStackTrace();
} finally {
// 释放连接
getMethod.releaseConnection();
}
return filePath;
}
确认文件名和文件格式
/**
* 根据 url 和网页类型生成需要保存的网页的文件名 去除掉 url 中非文件名字符
*/
public static String getFileNameByUrl(String url, String contentType) {
// remove http://
url = url.substring(7);
// text/html类型
if (contentType.indexOf("html") != -1) {
url = url.replaceAll("[\\?/:*|\"]", "_") + ".html";
return url;
}
// 如application/pdf类型
else {
return url.replaceAll("[\\?/:*|\"]", "_") + "." + contentType.substring(contentType.lastIndexOf("/") + 1);
}
}
保存要写入的文件地址
/**
* 保存网页字节数组到本地文件 filePath 为要保存的文件的相对地址
*/
private static void saveToLocal(byte[] data, String fileDir,String fileName) {
try {
File fileNew=new File(fileDir+"\\"+fileName);//new 一个文件 构造参数是字符串
File rootFile=fileNew.getParentFile();//得到父文件夹
if( !fileNew.exists()) {
rootFile.mkdirs();
fileNew.createNewFile();
}
DataOutputStream out = new DataOutputStream(new FileOutputStream(fileNew));
for (int i = 0; i < data.length; i++)
out.write(data[i]);
out.flush();
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
测试,这里写一个测试URL,网站地址和URL参数可能会发生变化,需要适当调整
public static void main(String[] args) throws Exception{
String s = fetch_url("http://www.neeq.cc/controller/ ... ot%3B, "utf-8");
//System.out.println(s);
getJSON(s);
}
完(欢迎转载) 查看全部
抓取ajax动态网页java(如何一次性把网站中的ajax获取这里介绍的文件)
通常情况下,通过网络爬虫挖出来的网页的静态内容基本上就是网页的静态内容,而动态ajax号的内容是我个人不知道ajax怎么弄进去的网站 一次
这里介绍的是某个网站中的某个ajax刷新某个表,期望数据,提供其他操作,比如下载:
假设我们需要挖掘某个网站:
示例:网站 中的那些 pdf 文件,并下载它们
首先:需要分析网页构成的结果;看看它是如何被读取和处理的。 ajax解决方案到此结束(其他异同,ajax只对数据进行一次性数据请求)
具体操作已经通过案例主要介绍了:
先分析ajax使用的请求url的含义和请求中需要的参数,然后给出响应的参数
/**
* 获取某个请求的内容
* @param url 请求的地址
* @param code 请求的编码,不传就代表UTF-8
* @return 请求响应的内容
* @throws IOException
*/
public static String fetch_url(String url, String code) throws IOException {
BufferedReader bis = null;
InputStream is = null;
InputStreamReader inputStreamReader = null;
try {
URLConnection connection = new URL(url).openConnection();
connection.setConnectTimeout(20000);
connection.setReadTimeout(20000);
connection.setUseCaches(false);
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11");
is = connection.getInputStream();
inputStreamReader = new InputStreamReader(is, code);
bis = new BufferedReader(inputStreamReader);
String line = null;
StringBuffer result = new StringBuffer();
while ((line = bis.readLine()) != null) {
result.append(line);
}
return result.toString();
} finally {
if (inputStreamReader != null) {
try {
inputStreamReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (bis != null) {
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (is != null) {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
通过上面的url请求,观察响应的数据格式,这里响应的数据测试格式为json格式
/**
* 数据转化成json格式
* @param s
*/
public static void getJSON(String s) {
JSONObject object = JSONObject.fromObject(s);
JSONArray array = JSONArray.fromObject(object.get("disclosureInfos"));
//System.out.println(array);
String filePath = object.getString("filePath");//解析数据中的某一个值
//System.out.println(array.size());
List listFilePath = getJSONArray(array,filePath);//将数据解析成条数
/*System.out.println(listFilePath);
System.out.println(listFilePath.size());*/
writer(listFilePath);//根据数据的内容开始挖取下载
}
大量数据需要下载,一个一个
public static void writer(List listFilePath) {
for (String string : listFilePath) {
downloadFile(string);
}
}
从格式数据中解析json数据
/**
* 解析文件url
* @param array
* @return
*/
public static List getJSONArray(JSONArray array,String filePath) {
List listFilePath = new ArrayList();
for (Object object : array) {
JSONObject ob = JSONObject.fromObject(object);
filePath = filePath + ob.get("filePath").toString();
// System.out.println(filePath);
listFilePath.add(filePath);
}
return listFilePath;
}
文件下载处理
/* 下载 url 指向的网页 */
public static String downloadFile(String url) {
String filePath = null;
/* 1.生成 HttpClinet 对象并设置参数 */
HttpClient httpClient = new HttpClient();
// 设置 Http 连接超时 5s
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(5000);
/* 2.生成 GetMethod 对象并设置参数 */
GetMethod getMethod = new GetMethod(url);
// 设置 get 请求超时 5s
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, 5000);
// 设置请求重试处理
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER, new DefaultHttpMethodRetryHandler());
/* 3.执行 HTTP GET 请求 */
try {
int statusCode = httpClient.executeMethod(getMethod);
// 判断访问的状态码
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: " + getMethod.getStatusLine());
filePath = null;
}
/* 4.处理 HTTP 响应内容 */
byte[] responseBody = getMethod.getResponseBody();// 读取为字节数组
// 根据网页 url 生成保存时的文件名
filePath = "e:\\spider\\";
String fileName = getFileNameByUrl(url, getMethod.getResponseHeader("Content-Type").getValue());
saveToLocal(responseBody, filePath,fileName);
} catch (HttpException e) {
// 发生致命的异常,可能是协议不对或者返回的内容有问题
System.out.println("Please check your provided http address!");
e.printStackTrace();
} catch (IOException e) {
// 发生网络异常
e.printStackTrace();
} finally {
// 释放连接
getMethod.releaseConnection();
}
return filePath;
}
确认文件名和文件格式
/**
* 根据 url 和网页类型生成需要保存的网页的文件名 去除掉 url 中非文件名字符
*/
public static String getFileNameByUrl(String url, String contentType) {
// remove http://
url = url.substring(7);
// text/html类型
if (contentType.indexOf("html") != -1) {
url = url.replaceAll("[\\?/:*|\"]", "_") + ".html";
return url;
}
// 如application/pdf类型
else {
return url.replaceAll("[\\?/:*|\"]", "_") + "." + contentType.substring(contentType.lastIndexOf("/") + 1);
}
}
保存要写入的文件地址
/**
* 保存网页字节数组到本地文件 filePath 为要保存的文件的相对地址
*/
private static void saveToLocal(byte[] data, String fileDir,String fileName) {
try {
File fileNew=new File(fileDir+"\\"+fileName);//new 一个文件 构造参数是字符串
File rootFile=fileNew.getParentFile();//得到父文件夹
if( !fileNew.exists()) {
rootFile.mkdirs();
fileNew.createNewFile();
}
DataOutputStream out = new DataOutputStream(new FileOutputStream(fileNew));
for (int i = 0; i < data.length; i++)
out.write(data[i]);
out.flush();
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
测试,这里写一个测试URL,网站地址和URL参数可能会发生变化,需要适当调整
public static void main(String[] args) throws Exception{
String s = fetch_url("http://www.neeq.cc/controller/ ... ot%3B, "utf-8");
//System.out.println(s);
getJSON(s);
}
完(欢迎转载)
抓取ajax动态网页java( 小金子学院目录最新收录:家常小知识:熬中药要先清洗吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-03-05 15:18
小金子学院目录最新收录:家常小知识:熬中药要先清洗吗)
小金子学院最新目录收录:家常知识:中药需要先清洗吗?
网站对未被搜索引擎搜索的页面的引用收录
1、网页使用框架:框架内的内容通常不会被搜索引擎抓取。
2、图片太多,文字太少。
3、提交页面转到另一个网站:搜索引擎可能会完全跳过此页面。
4、提交过于频繁:一个月提交2次以上,很多搜索引擎受不了,认为你在提交垃圾邮件。
5、网站关键词密度太大:可惜搜索引擎并没有说明密度到底有多高,一般认为100字的描述收录3-4个关键词 是最好的。
6、文字颜色与背景颜色相同:搜索引擎认为你在堆积关键词来欺骗它。
7、动态网页:网站的内容管理系统方便了网页更新,但给大部分搜索引擎带来了麻烦。很多搜索引擎不对动态页面收费,或者只对一级页面收费,不会深度收费。这时候应该考虑使用WEB服务器的重写技术,将动态页面的url映射成与静态页面的url类似的格式。搜索引擎误认为是静态页面,会收费。
8、网站传输服务器:搜索引擎通常只识别IP地址。转换主机或域名时,IP/DNS 地址会发生变化。这时候需要重新提交网站。
9、免费网站空间:一些搜索引擎拒绝从免费空间中索引网站,抱怨很多垃圾和质量差。
10、Crawling 网站Not Online:如果主机不稳定,就会发生这种情况。更糟糕的是,即使 网站 已经是 收录,重新抓取并发现它处于脱机状态也会完全删除 网站。
11、不正确地阻止robots indexing网站:有两种方式来阻止robots:宿主服务器根目录下的简单文本文件;带有某种 META 标签的网页。
12、使用大量Flash、DHTML、cookies、JavaScript、Java或密码访问的网页,搜索引擎很难从此类网页中提取内容。
13、搜索引擎无法解析你的DNS:新域名注册后需要1-2天才能生效,所以不要一注册域名就提交网站 .
14、网站的链接宽度太小:链接宽度太小,搜索引擎很难找到你。这个时候可以考虑将网站登录到知名的分类,或者多做几个友好的链接。
15、服务器速度太慢:网络带宽太小,网页下载速度太慢,或者网页太复杂,可能导致搜索引擎在文字内容还没出来之前就挂了成立。
16、关键字问题:如果你的META标签中提到的关键字没有出现在文本中,搜索引擎可能会认为它是垃圾关键字。
医学院⊙▽㊦1㊧公司名称
特别的
医学院⊙▽㊦1㊧公司名称
特别的
小金子。com
上一篇:一些改进和增强的方法网站
显示:网站没有被搜索引擎搜索到的页面的参考描述收录
下一篇:再谈交换友情链接的六大要点
特别提醒,本信息由本站会员xjz001提供。
如需转载,请注明出处,数据来源为小金字类:
"网站不被搜索引擎搜索的页面参考说明收录"感谢您的支持!
»如果您觉得“网站页面未被搜索引擎收录的参考描述”,相关信息不全,请点击这里协作更新!
1 查看全部
抓取ajax动态网页java(
小金子学院目录最新收录:家常小知识:熬中药要先清洗吗)
小金子学院最新目录收录:家常知识:中药需要先清洗吗?
网站对未被搜索引擎搜索的页面的引用收录
1、网页使用框架:框架内的内容通常不会被搜索引擎抓取。
2、图片太多,文字太少。
3、提交页面转到另一个网站:搜索引擎可能会完全跳过此页面。
4、提交过于频繁:一个月提交2次以上,很多搜索引擎受不了,认为你在提交垃圾邮件。
5、网站关键词密度太大:可惜搜索引擎并没有说明密度到底有多高,一般认为100字的描述收录3-4个关键词 是最好的。
6、文字颜色与背景颜色相同:搜索引擎认为你在堆积关键词来欺骗它。
7、动态网页:网站的内容管理系统方便了网页更新,但给大部分搜索引擎带来了麻烦。很多搜索引擎不对动态页面收费,或者只对一级页面收费,不会深度收费。这时候应该考虑使用WEB服务器的重写技术,将动态页面的url映射成与静态页面的url类似的格式。搜索引擎误认为是静态页面,会收费。
8、网站传输服务器:搜索引擎通常只识别IP地址。转换主机或域名时,IP/DNS 地址会发生变化。这时候需要重新提交网站。
9、免费网站空间:一些搜索引擎拒绝从免费空间中索引网站,抱怨很多垃圾和质量差。
10、Crawling 网站Not Online:如果主机不稳定,就会发生这种情况。更糟糕的是,即使 网站 已经是 收录,重新抓取并发现它处于脱机状态也会完全删除 网站。
11、不正确地阻止robots indexing网站:有两种方式来阻止robots:宿主服务器根目录下的简单文本文件;带有某种 META 标签的网页。
12、使用大量Flash、DHTML、cookies、JavaScript、Java或密码访问的网页,搜索引擎很难从此类网页中提取内容。
13、搜索引擎无法解析你的DNS:新域名注册后需要1-2天才能生效,所以不要一注册域名就提交网站 .
14、网站的链接宽度太小:链接宽度太小,搜索引擎很难找到你。这个时候可以考虑将网站登录到知名的分类,或者多做几个友好的链接。
15、服务器速度太慢:网络带宽太小,网页下载速度太慢,或者网页太复杂,可能导致搜索引擎在文字内容还没出来之前就挂了成立。
16、关键字问题:如果你的META标签中提到的关键字没有出现在文本中,搜索引擎可能会认为它是垃圾关键字。
医学院⊙▽㊦1㊧公司名称
特别的
医学院⊙▽㊦1㊧公司名称
特别的
小金子。com
上一篇:一些改进和增强的方法网站
显示:网站没有被搜索引擎搜索到的页面的参考描述收录
下一篇:再谈交换友情链接的六大要点
特别提醒,本信息由本站会员xjz001提供。
如需转载,请注明出处,数据来源为小金字类:
"网站不被搜索引擎搜索的页面参考说明收录"感谢您的支持!
»如果您觉得“网站页面未被搜索引擎收录的参考描述”,相关信息不全,请点击这里协作更新!
1

