
抓取网页flash视频
谷歌开发者服务器上的mp4tag加速成功解决(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-08-13 11:47
抓取网页flash视频,生成mp4文件,下载时另外下载txt文件另存为xxxxxxxxx.mp4,下载完成后,文件位置没有xxxxxxxxx.mp4,换一个文件夹重新下载即可。
我也是搜到这里,不知道有没有人遇到这种情况,我把原视频添加到屏幕截图,另存为xxx.mp4,重启软件就解决了。
我也是搜到这里,重新下载了mp4文件,但是还是出现了别的乱七八糟的东西,重新下载也解决不了。后来在网上看到mp4tag中解决了很多这种问题,看了好久资料有个哥们推荐了一个叫优视点的,说还挺好用的,下载后要解压缩才能转换mp4,用起来挺麻烦的。于是我就试试这个,看看能不能解决,点击右键“打开方式”,这就出现了选择解压缩方式了,我用的是itunesitunes-download里面直接选mp4tag,解压缩,上传就好了,这个下好后解压缩也麻烦。
还有个方法就是装个格式工厂,也是下载下来解压缩,上传就可以了。顺便说一下,刚下好的mp4tag也要试试转换转换,这会跟原视频编码不同。
我之前用的格式工厂,解压后要转换方法是点击存储图标,点击媒体文件--选择opencs3--选择格式工厂的mp4即可,选择后开始转换转换之前建议下载并解压缩。
今天我用开源项目->谷歌开发者服务器上的mp4tag加速,刚刚成功解决。图是我上午截图拍的。不想放代码截图的,需要上传谷歌开发者服务器。还有,pr一定要及时发过来!今天专门去重新刷了一遍,以后遇到这种问题上谷歌开发者服务器,推荐写maps.exe的人去对比一下在chromecanarycanarysettings中加入之前项目的useragent。 查看全部
谷歌开发者服务器上的mp4tag加速成功解决(组图)
抓取网页flash视频,生成mp4文件,下载时另外下载txt文件另存为xxxxxxxxx.mp4,下载完成后,文件位置没有xxxxxxxxx.mp4,换一个文件夹重新下载即可。

我也是搜到这里,不知道有没有人遇到这种情况,我把原视频添加到屏幕截图,另存为xxx.mp4,重启软件就解决了。
我也是搜到这里,重新下载了mp4文件,但是还是出现了别的乱七八糟的东西,重新下载也解决不了。后来在网上看到mp4tag中解决了很多这种问题,看了好久资料有个哥们推荐了一个叫优视点的,说还挺好用的,下载后要解压缩才能转换mp4,用起来挺麻烦的。于是我就试试这个,看看能不能解决,点击右键“打开方式”,这就出现了选择解压缩方式了,我用的是itunesitunes-download里面直接选mp4tag,解压缩,上传就好了,这个下好后解压缩也麻烦。

还有个方法就是装个格式工厂,也是下载下来解压缩,上传就可以了。顺便说一下,刚下好的mp4tag也要试试转换转换,这会跟原视频编码不同。
我之前用的格式工厂,解压后要转换方法是点击存储图标,点击媒体文件--选择opencs3--选择格式工厂的mp4即可,选择后开始转换转换之前建议下载并解压缩。
今天我用开源项目->谷歌开发者服务器上的mp4tag加速,刚刚成功解决。图是我上午截图拍的。不想放代码截图的,需要上传谷歌开发者服务器。还有,pr一定要及时发过来!今天专门去重新刷了一遍,以后遇到这种问题上谷歌开发者服务器,推荐写maps.exe的人去对比一下在chromecanarycanarysettings中加入之前项目的useragent。
Python爬虫教程:Python爬取视频之日本爱情电影
网站优化 • 优采云 发表了文章 • 0 个评论 • 454 次浏览 • 2022-06-18 22:51
肉身翻墙后,感受一下外面的肮脏世界。墙内的朋友叫苦不迭,由于某些原因,VPN能用的越来越少。上周我的好朋友狗子和我哭诉说自己常用的一个VPN终于也寿终正寝了,要和众多的日本小姐姐说再见了。作为“外面人”,我还是要帮他一把……
初探
狗子给我的网站还算良心,只跳了五个弹窗就消停了。
然后看到的就是各种穿不起衣服的女生的卖惨视频,我赶紧闭上眼睛,默念了几句我佛慈悲。
Tokyo真的有那么hot?
给狗子发了一张大的截图,狗子用涂鸦给我圈出了其中一个。
我和狗子说“等着吧”
(放心网站截图我是打了码也不敢放的。。。)
点进去之后,可以在线播放。
右下角有一个 Download 按钮,点击之后需要注册付费。
当时我就火了,这种卖惨视频毒害我兄弟精神,还敢收钱?!
自己动手,丰衣足食!
环境 & 依赖
Win10 64bit
IDE: PyCharm
Python 3.6
python-site-packegs: requests + BeautifulSoup + lxml + re + m3u8
在已经安装pip的环境下均可直接命令行安装
网站解析
将链接复制到Chrome浏览器打开
(我平时用猎豹,也是Chrome内核,界面比较舒服,但是这个时候必须大喊一声谷歌大法好)
菜单——更多工具——开发者选项(或者快捷键F12)进入Chrome内置的开发者模式
大概界面是这样
(唉打码真的累。。。。)
然后,根据提示,逐层深入标签找到视频的具体位置
这个网站存放的位置是 …->flash->video_container->video-player
显然视频就放在这个这个video-player中
在这个标签中,有一个名字为 source 的链接,src=”#%@就不告诉你#@¥”
Easy好吧!
这点小把戏还难得到我?我已经准备和狗子要红包了
复制该链接到地址栏粘贴并转到,然后,神奇的一幕出现了!!
What???
这是什么???
为啥这么小???
科普概念如上,那也就是说,m3u8记录了真实的视频所在的地址。
Network Traffic
想要从源码直接获得真实下载地址怕是行不通了。
这时候再和我一起读“谷歌大法好!”
很简单,浏览器在服务器中Get到视频呈现到我们面前,那这个过程必定经过了解析这一步。
那我们也可以利用浏览器这个功能来进行解析
依旧在开发者模式,最上面一行的导航栏,刚刚我们在Elements选项卡,现在切换到Network
我们监听视频播放的时候的封包应该就可以得到真实的视频地址了,试试看!
我们惊喜的发现,一个又一个的 .ts 文件正在载入了
(如果在图片里发现任何url请友情提醒我谢谢不然怕是水表难保)
知识点!这都是知识点!(敲黑板!)
点开其中的一个.ts文件看一下
这里可以看到请求头,虽然url被我走心的码掉了,但这就是真实的视频地址了
复制这个URL到地址栏,下载
9s。。。。。
每一个小视频只有9s,难道要一个又一个的去复制吗?
视频片段爬取
答案是当然不用。
这里我们要请出网络数据采集界的装逼王:Python爬虫!!!
首先进行初始化,包括路径设置,请求头的伪装等。
采集部分主要是将requests的get方法放到了for循环当中
这样做可行的原因在于,在Network监听的图中我们可以看到.ts文件的命名是具有规律的 seg-i-v1-a1,将i作为循环数
那么问题又来了,我怎么知道循环什么时候结束呢?也就是说我怎么知道i的大小呢?
等等,我好像记得在视频播放的框框右下角有时间来着?
在开发者模式中再次回到Element选项卡,定位到视频框右下角的时间,标签为duration,这里的时间格式是 时:分:秒格式的,我们可以计算得到总时长的秒数
但是呢,这样需要我们先获取这个时间,然后再进行字符串的拆解,再进行数学运算,太复杂了吧,狗子已经在微信催我了
Ctrl+F全局搜索duration
Yes!!!
好了,可以点击运行然后去喝杯咖啡,哦不,我喜欢喝茶。
一杯茶的功夫,回来之后已经下载完成。我打开文件夹check一下,发现从编号312之后的clip都是只有573字节,打开播放的话,显示的是数据损坏。
没关系,从312开始继续下载吧。然而下载得到的结果还是一样的573字节,而且下了两百多个之后出现了拒绝访问错误。
动态代理
显然我的IP被封了。之前的多个小项目,或是因为网站防护不够严格,或是因为数据条目数量较少,一直没有遇到过这种情况,这次的数据量增加,面对这种情况采取两种措施,一种是休眠策略,另一种是动态代理。现在我的IP已经被封了,所以休眠也为时已晚,必须采用动态IP了。
主要代码如下所示
合并文件
然后,我们得到了几百个9s的.ts小视频
然后,在cmd命令行下,我们进入到这些小视频所在的路径
执行
copy/b %s\*.ts %s\new.ts
很快,我们就得到了合成好的视频文件
当然这个前提是这几百个.ts文件是按顺序排列好的。
成果如下
优化—调用DOS命令 + 解析m3u8
为了尽可能的减少人的操作,让程序做更多的事
我们要把尽量多的操作写在code中
引用os模块进行文件夹切换,在程序中直接执行合并命令
并且,在判断合并完成后,使用清除几百个ts文件
这样,我们运行程序后,就真的可以去喝一杯茶,回来之后看到的就是没有任何多余的一个完整的最终视频
也就是说,要获得一个完整的视频,我们现在需要输入视频网页链接,还需要使用chrome的network解析得到真实下载地址。第二个部分显然不够友好,还有提升空间。
所以第一个尝试是,可不可以有一个工具或者一个包能嗅探到指定网页的network traffic,因为我们刚刚已经看到真实地址其实就在requestHeader中,关键在于怎样让程序自动获取。
查阅资料后,尝试了Selenium + PhantomJS的组合模拟浏览器访问,用一个叫做browsermobProxy的工具嗅探保存HAR(HTTP archive)。在这个上面花费了不少时间,但是关于browsermobProxy的资料实在是太少了,即使是在google上,搜到的也都是基于java的一些资料,面向的python的API也是很久没有更新维护了。此路不通。
在放弃之前,我又看一篇网站的源码,再次把目光投向了m3u8,上面讲到这个文件应该是包含文件真实地址的索引,索引能不能把在这上面做些文章呢?
Python不愧是万金油语言,packages多到令人发指,m3u8处理也是早就有熟肉。
pip install m3u8
这是一个比较小众的包,没有什么手册,只能自己读源码。
这个class中已经封装好了不少可以直接供使用的数据类型,回头抽时间可以写一写这个包的手册。
现在,我们可以从requests获取的源码中,首先找到m3u8的下载地址,首先下载到本地,然后用m3u8包进行解析,获取真实下载地址。
并且,解析可以得到所有地址,意味着可以省略上面的获取duration计算碎片数目的步骤。
最终
最终,我们现在终于可以,把视频网页链接丢进url中,点击运行,然后就可以去喝茶了。
再来总结一下实现这个的几个关键点:
- 网页解析
- m3u8解析
- 动态代理设置
- DOS命令行的调用
动手是最好的老师,尤其这种网站,兼具趣味性和挑战性,就是身体一天不如一天。。。
完整代码
# -*- coding:utf-8 -*-import requestsfrom bs4 import BeautifulSoupimport osimport lxmlimport timeimport randomimport reimport m3u8<br />class ViedeoCrawler(): def __init__(self): self.url = "" self.down_path = r"F:\Spider\VideoSpider\DOWN" self.final_path = r"F:\Spider\VideoSpider\FINAL" try: self.name = re.findall(r'/[A-Za-z]*-[0-9]*',self.url)[0][1:] except: self.name = "uncensord" self.headers = { 'Connection': 'Keep-Alive', 'Accept': 'text/html, application/xhtml+xml, */*', 'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3', 'User-Agent':'Mozilla/5.0 (Linux; U; Android 6.0; zh-CN; MZ-m2 note Build/MRA58K) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/40.0.2214.89 MZBrowser/6.5.506 UWS/2.10.1.22 Mobile Safari/537.36' }<br /> def get_ip_list(self): print("正在获取代理列表...") url = 'http://www.xicidaili.com/nn/' html = requests.get(url=url, headers=self.headers).text soup = BeautifulSoup(html, 'lxml') ips = soup.find(id='ip_list').find_all('tr') ip_list = [] for i in range(1, len(ips)): ip_info = ips[i] tds = ip_info.find_all('td') ip_list.append(tds[1].text + ':' + tds[2].text) print("代理列表抓取成功.") return ip_list<br /> def get_random_ip(self,ip_list): print("正在设置随机代理...") proxy_list = [] for ip in ip_list: proxy_list.append('http://' + ip) proxy_ip = random.choice(proxy_list) proxies = {'http': proxy_ip} print("代理设置成功.") return proxies<br /> def get_uri_from_m3u8(self,realAdr): print("正在解析真实下载地址...") with open('temp.m3u8', 'wb') as file: file.write(requests.get(realAdr).content) m3u8Obj = m3u8.load('temp.m3u8') print("解析完成.") return m3u8Obj.segments<br /> def run(self): print("Start!") start_time = time.time() os.chdir(self.down_path) html = requests.get(self.url).text bsObj = BeautifulSoup(html, 'lxml') realAdr = bsObj.find(id="video-player").find("source")['src']<br /> # duration = bsObj.find('meta', {'property': "video:duration"})['content'].replace("\"", "") # limit = int(duration) // 10 + 3<br /> ip_list = self.get_ip_list() proxies = self.get_random_ip(ip_list) uriList = self.get_uri_from_m3u8(realAdr) i = 1 # count for key in uriList: if i%50==0: print("休眠10s") time.sleep(10) if i0==0: print("更换代理IP") proxies = self.get_random_ip(ip_list) try: resp = requests.get(key.uri, headers = self.headers, proxies=proxies) except Exception as e: print(e) return if i < 10: name = ('clip00%d.ts' % i) elif i > 100: name = ('clip%d.ts' % i) else: name = ('clip0%d.ts' % i) with open(name,'wb') as f: f.write(resp.content) print('正在下载clip%d' % i) i = i+1 print("下载完成!总共耗时 %d s" % (time.time()-start_time)) print("接下来进行合并……") os.system('copy/b %s\\*.ts %s\\%s.ts' % (self.down_path,self.final_path, self.name)) print("合并完成,请您欣赏!") y = input("请检查文件完整性,并确认是否要删除碎片源文件?(y/n)") if y=='y': files = os.listdir(self.down_path) for filena in files: del_file = self.down_path + '\\' + filena os.remove(del_file) print("碎片文件已经删除完成") else: print("不删除,程序结束。")<br />if __name__=='__main__': crawler = ViedeoCrawler() crawler.run()
搜索下方加老师微信 查看全部
Python爬虫教程:Python爬取视频之日本爱情电影
肉身翻墙后,感受一下外面的肮脏世界。墙内的朋友叫苦不迭,由于某些原因,VPN能用的越来越少。上周我的好朋友狗子和我哭诉说自己常用的一个VPN终于也寿终正寝了,要和众多的日本小姐姐说再见了。作为“外面人”,我还是要帮他一把……
初探
狗子给我的网站还算良心,只跳了五个弹窗就消停了。
然后看到的就是各种穿不起衣服的女生的卖惨视频,我赶紧闭上眼睛,默念了几句我佛慈悲。
Tokyo真的有那么hot?
给狗子发了一张大的截图,狗子用涂鸦给我圈出了其中一个。
我和狗子说“等着吧”
(放心网站截图我是打了码也不敢放的。。。)
点进去之后,可以在线播放。
右下角有一个 Download 按钮,点击之后需要注册付费。
当时我就火了,这种卖惨视频毒害我兄弟精神,还敢收钱?!
自己动手,丰衣足食!
环境 & 依赖
Win10 64bit
IDE: PyCharm
Python 3.6
python-site-packegs: requests + BeautifulSoup + lxml + re + m3u8
在已经安装pip的环境下均可直接命令行安装
网站解析
将链接复制到Chrome浏览器打开
(我平时用猎豹,也是Chrome内核,界面比较舒服,但是这个时候必须大喊一声谷歌大法好)
菜单——更多工具——开发者选项(或者快捷键F12)进入Chrome内置的开发者模式
大概界面是这样
(唉打码真的累。。。。)
然后,根据提示,逐层深入标签找到视频的具体位置
这个网站存放的位置是 …->flash->video_container->video-player
显然视频就放在这个这个video-player中
在这个标签中,有一个名字为 source 的链接,src=”#%@就不告诉你#@¥”
Easy好吧!
这点小把戏还难得到我?我已经准备和狗子要红包了
复制该链接到地址栏粘贴并转到,然后,神奇的一幕出现了!!
What???
这是什么???
为啥这么小???
科普概念如上,那也就是说,m3u8记录了真实的视频所在的地址。
Network Traffic
想要从源码直接获得真实下载地址怕是行不通了。
这时候再和我一起读“谷歌大法好!”
很简单,浏览器在服务器中Get到视频呈现到我们面前,那这个过程必定经过了解析这一步。
那我们也可以利用浏览器这个功能来进行解析
依旧在开发者模式,最上面一行的导航栏,刚刚我们在Elements选项卡,现在切换到Network
我们监听视频播放的时候的封包应该就可以得到真实的视频地址了,试试看!
我们惊喜的发现,一个又一个的 .ts 文件正在载入了
(如果在图片里发现任何url请友情提醒我谢谢不然怕是水表难保)
知识点!这都是知识点!(敲黑板!)
点开其中的一个.ts文件看一下
这里可以看到请求头,虽然url被我走心的码掉了,但这就是真实的视频地址了
复制这个URL到地址栏,下载
9s。。。。。
每一个小视频只有9s,难道要一个又一个的去复制吗?
视频片段爬取
答案是当然不用。
这里我们要请出网络数据采集界的装逼王:Python爬虫!!!
首先进行初始化,包括路径设置,请求头的伪装等。
采集部分主要是将requests的get方法放到了for循环当中
这样做可行的原因在于,在Network监听的图中我们可以看到.ts文件的命名是具有规律的 seg-i-v1-a1,将i作为循环数
那么问题又来了,我怎么知道循环什么时候结束呢?也就是说我怎么知道i的大小呢?
等等,我好像记得在视频播放的框框右下角有时间来着?
在开发者模式中再次回到Element选项卡,定位到视频框右下角的时间,标签为duration,这里的时间格式是 时:分:秒格式的,我们可以计算得到总时长的秒数
但是呢,这样需要我们先获取这个时间,然后再进行字符串的拆解,再进行数学运算,太复杂了吧,狗子已经在微信催我了
Ctrl+F全局搜索duration
Yes!!!
好了,可以点击运行然后去喝杯咖啡,哦不,我喜欢喝茶。
一杯茶的功夫,回来之后已经下载完成。我打开文件夹check一下,发现从编号312之后的clip都是只有573字节,打开播放的话,显示的是数据损坏。
没关系,从312开始继续下载吧。然而下载得到的结果还是一样的573字节,而且下了两百多个之后出现了拒绝访问错误。
动态代理
显然我的IP被封了。之前的多个小项目,或是因为网站防护不够严格,或是因为数据条目数量较少,一直没有遇到过这种情况,这次的数据量增加,面对这种情况采取两种措施,一种是休眠策略,另一种是动态代理。现在我的IP已经被封了,所以休眠也为时已晚,必须采用动态IP了。
主要代码如下所示
合并文件
然后,我们得到了几百个9s的.ts小视频
然后,在cmd命令行下,我们进入到这些小视频所在的路径
执行
copy/b %s\*.ts %s\new.ts
很快,我们就得到了合成好的视频文件
当然这个前提是这几百个.ts文件是按顺序排列好的。
成果如下
优化—调用DOS命令 + 解析m3u8
为了尽可能的减少人的操作,让程序做更多的事
我们要把尽量多的操作写在code中
引用os模块进行文件夹切换,在程序中直接执行合并命令
并且,在判断合并完成后,使用清除几百个ts文件
这样,我们运行程序后,就真的可以去喝一杯茶,回来之后看到的就是没有任何多余的一个完整的最终视频
也就是说,要获得一个完整的视频,我们现在需要输入视频网页链接,还需要使用chrome的network解析得到真实下载地址。第二个部分显然不够友好,还有提升空间。
所以第一个尝试是,可不可以有一个工具或者一个包能嗅探到指定网页的network traffic,因为我们刚刚已经看到真实地址其实就在requestHeader中,关键在于怎样让程序自动获取。
查阅资料后,尝试了Selenium + PhantomJS的组合模拟浏览器访问,用一个叫做browsermobProxy的工具嗅探保存HAR(HTTP archive)。在这个上面花费了不少时间,但是关于browsermobProxy的资料实在是太少了,即使是在google上,搜到的也都是基于java的一些资料,面向的python的API也是很久没有更新维护了。此路不通。
在放弃之前,我又看一篇网站的源码,再次把目光投向了m3u8,上面讲到这个文件应该是包含文件真实地址的索引,索引能不能把在这上面做些文章呢?
Python不愧是万金油语言,packages多到令人发指,m3u8处理也是早就有熟肉。
pip install m3u8
这是一个比较小众的包,没有什么手册,只能自己读源码。
这个class中已经封装好了不少可以直接供使用的数据类型,回头抽时间可以写一写这个包的手册。
现在,我们可以从requests获取的源码中,首先找到m3u8的下载地址,首先下载到本地,然后用m3u8包进行解析,获取真实下载地址。
并且,解析可以得到所有地址,意味着可以省略上面的获取duration计算碎片数目的步骤。
最终
最终,我们现在终于可以,把视频网页链接丢进url中,点击运行,然后就可以去喝茶了。
再来总结一下实现这个的几个关键点:
- 网页解析
- m3u8解析
- 动态代理设置
- DOS命令行的调用
动手是最好的老师,尤其这种网站,兼具趣味性和挑战性,就是身体一天不如一天。。。
完整代码
# -*- coding:utf-8 -*-import requestsfrom bs4 import BeautifulSoupimport osimport lxmlimport timeimport randomimport reimport m3u8<br />class ViedeoCrawler(): def __init__(self): self.url = "" self.down_path = r"F:\Spider\VideoSpider\DOWN" self.final_path = r"F:\Spider\VideoSpider\FINAL" try: self.name = re.findall(r'/[A-Za-z]*-[0-9]*',self.url)[0][1:] except: self.name = "uncensord" self.headers = { 'Connection': 'Keep-Alive', 'Accept': 'text/html, application/xhtml+xml, */*', 'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3', 'User-Agent':'Mozilla/5.0 (Linux; U; Android 6.0; zh-CN; MZ-m2 note Build/MRA58K) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/40.0.2214.89 MZBrowser/6.5.506 UWS/2.10.1.22 Mobile Safari/537.36' }<br /> def get_ip_list(self): print("正在获取代理列表...") url = 'http://www.xicidaili.com/nn/' html = requests.get(url=url, headers=self.headers).text soup = BeautifulSoup(html, 'lxml') ips = soup.find(id='ip_list').find_all('tr') ip_list = [] for i in range(1, len(ips)): ip_info = ips[i] tds = ip_info.find_all('td') ip_list.append(tds[1].text + ':' + tds[2].text) print("代理列表抓取成功.") return ip_list<br /> def get_random_ip(self,ip_list): print("正在设置随机代理...") proxy_list = [] for ip in ip_list: proxy_list.append('http://' + ip) proxy_ip = random.choice(proxy_list) proxies = {'http': proxy_ip} print("代理设置成功.") return proxies<br /> def get_uri_from_m3u8(self,realAdr): print("正在解析真实下载地址...") with open('temp.m3u8', 'wb') as file: file.write(requests.get(realAdr).content) m3u8Obj = m3u8.load('temp.m3u8') print("解析完成.") return m3u8Obj.segments<br /> def run(self): print("Start!") start_time = time.time() os.chdir(self.down_path) html = requests.get(self.url).text bsObj = BeautifulSoup(html, 'lxml') realAdr = bsObj.find(id="video-player").find("source")['src']<br /> # duration = bsObj.find('meta', {'property': "video:duration"})['content'].replace("\"", "") # limit = int(duration) // 10 + 3<br /> ip_list = self.get_ip_list() proxies = self.get_random_ip(ip_list) uriList = self.get_uri_from_m3u8(realAdr) i = 1 # count for key in uriList: if i%50==0: print("休眠10s") time.sleep(10) if i0==0: print("更换代理IP") proxies = self.get_random_ip(ip_list) try: resp = requests.get(key.uri, headers = self.headers, proxies=proxies) except Exception as e: print(e) return if i < 10: name = ('clip00%d.ts' % i) elif i > 100: name = ('clip%d.ts' % i) else: name = ('clip0%d.ts' % i) with open(name,'wb') as f: f.write(resp.content) print('正在下载clip%d' % i) i = i+1 print("下载完成!总共耗时 %d s" % (time.time()-start_time)) print("接下来进行合并……") os.system('copy/b %s\\*.ts %s\\%s.ts' % (self.down_path,self.final_path, self.name)) print("合并完成,请您欣赏!") y = input("请检查文件完整性,并确认是否要删除碎片源文件?(y/n)") if y=='y': files = os.listdir(self.down_path) for filena in files: del_file = self.down_path + '\\' + filena os.remove(del_file) print("碎片文件已经删除完成") else: print("不删除,程序结束。")<br />if __name__=='__main__': crawler = ViedeoCrawler() crawler.run()
搜索下方加老师微信
Python爬取视频之日本爱情电影
网站优化 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2022-06-17 17:13
点击上方蓝色“Python开发与人工智能”,选择“设为星标”
学最好的别人,做最好的我们
肉身翻墙后,感受一下外面的肮脏世界。墙内的朋友叫苦不迭,由于某些原因,VPN能用的越来越少。上周我的好朋友狗子和我哭诉说自己常用的一个VPN终于也寿终正寝了,要和众多的日本小姐姐说再见了。作为“外面人”,我还是要帮他一把……
作者:永无乡<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />源自:https://blog.csdn.net/JosephPa ... %3Bbr style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
初探
狗子给我的网站还算良心,只跳了五个弹窗就消停了。
然后看到的就是各种穿不起衣服的女生的卖惨视频,我赶紧闭上眼睛,默念了几句我佛慈悲。
Tokyo真的有那么hot?
给狗子发了一张大的截图,狗子用涂鸦给我圈出了其中一个。
我和狗子说“等着吧”
(放心网站截图我是打了码也不敢放的。。。)
点进去之后,可以在线播放。
右下角有一个 Download 按钮,点击之后需要注册付费。
当时我就火了,这种卖惨视频毒害我兄弟精神,还敢收钱?!
自己动手,丰衣足食!
环境 & 依赖
Win10 64bit
IDE: PyCharm
Python 3.6
python-site-packegs: requests + BeautifulSoup + lxml + re + m3u8
在已经安装pip的环境下均可直接命令行安装
网站解析
将链接复制到Chrome浏览器打开
(我平时用猎豹,也是Chrome内核,界面比较舒服,但是这个时候必须大喊一声谷歌大法好)
菜单——更多工具——开发者选项(或者快捷键F12)进入Chrome内置的开发者模式
大概界面是这样
(唉打码真的累。。。。)
然后,根据提示,逐层深入标签找到视频所在具体位置
这个网站存放的位置是 …->flash->video_container->video-player
显然视频就放在这个这个video-player中
在这个标签中,有一个名字为 source 的链接,src=”#%@就不告诉你#@¥”
Easy好吧!
这点小把戏还难得到我?我已经准备和狗子要红包了
复制该链接到地址栏粘贴并转到,然后,神奇的一幕出现了!!
What???
这是什么???
为啥这么小???
科普概念如上,那也就是说,m3u8记录了真实的视频所在的地址。
Network Traffic
想要从源码直接获得真实下载地址怕是行不通了。
这时候再和我一起读“谷歌大法好!”
很简单,浏览器在服务器中Get到视频呈现到我们面前,那这个过程必定经过了解析这一步。
那我们也可以利用浏览器这个功能来进行解析
依旧在开发者模式,最上面一行的导航栏,刚刚我们在Elements选项卡,现在切换到Network
我们监听视频播放的时候的封包应该就可以得到真实的视频地址了,试试看!
我们惊喜的发现,一个又一个的 .ts 文件正在载入了
(如果在图片里发现任何url请友情提醒我谢谢不然怕是水表难保)
知识点!这都是知识点!(敲黑板!)
点开其中的一个.ts文件看一下
这里可以看到请求头,虽然url被我走心的码掉了,但这就是真实的视频地址了
复制这个URL到地址栏,下载
9s。。。。。
每一个小视频只有9s,难道要一个又一个的去复制吗?
视频片段爬取
答案是当然不用。
这里我们要请出网络数据采集界的装逼王:Python爬虫!!!
首先进行初始化,包括路径设置,请求头的伪装等。
采集部分主要是将requests的get方法放到了for循环当中
这样做可行的原因在于,在Network监听的图中我们可以看到.ts文件的命名是具有规律的 seg-i-v1-a1,将i作为循环数
那么问题又来了,我怎么知道循环什么时候结束呢?也就是说我怎么知道i的大小呢?
等等,我好像记得在视频播放的框框右下角有时间来着?
在开发者模式中再次回到Element选项卡,定位到视频框右下角的时间,标签为duration,这里的时间格式是 时:分:秒格式的,我们可以计算得到总时长的秒数
但是呢,这样需要我们先获取这个时间,然后再进行字符串的拆解,再进行数学运算,太复杂了吧,狗子已经在微信催我了
Ctrl+F全局搜索duration
Yes!!!
好了,可以点击运行然后去喝杯咖啡,哦不,我喜欢喝茶。
一杯茶的功夫,回来之后已经下载完成。我打开文件夹check一下,发现从编号312之后的clip都是只有573字节,打开播放的话,显示的是数据损坏。
没关系,从312开始继续下载吧。然而下载得到的结果还是一样的573字节,而且下了两百多个之后出现了拒绝访问错误。
动态代理
显然我的IP被封了。之前的多个小项目,或是因为网站防护不够严格,或是因为数据条目数量较少,一直没有遇到过这种情况,这次的数据量增加,面对这种情况采取两种措施,一种是休眠策略,另一种是动态代理。现在我的IP已经被封了,所以休眠也为时已晚,必须采用动态IP了。
主要代码如下所示
合并文件
然后,我们得到了几百个9s的.ts小视频
然后,在cmd命令行下,我们进入到这些小视频所在的路径
执行
copy/b %s\*.ts %s\new.ts
很快,我们就得到了合成好的视频文件
当然这个前提是这几百个.ts文件是按顺序排列好的。
成果如下
优化—调用DOS命令 + 解析m3u8
为了尽可能的减少人的操作,让程序做更多的事
我们要把尽量多的操作写在code中
引用os模块进行文件夹切换,在程序中直接执行合并命令
并且,在判断合并完成后,使用清除几百个ts文件
这样,我们运行程序后,就真的可以去喝一杯茶,回来之后看到的就是没有任何多余的一个完整的最终视频
也就是说,要获得一个完整的视频,我们现在需要输入视频网页链接,还需要使用chrome的network解析得到真实下载地址。第二个部分显然不够友好,还有提升空间。
所以第一个尝试是,可不可以有一个工具或者一个包能嗅探到指定网页的network traffic,因为我们刚刚已经看到真实地址其实就在requestHeader中,关键在于怎样让程序自动获取。
查阅资料后,尝试了Selenium + PhantomJS的组合模拟浏览器访问,用一个叫做browsermobProxy的工具嗅探保存HAR(HTTP archive)。在这个上面花费了不少时间,但是关于browsermobProxy的资料实在是太少了,即使是在google上,搜到的也都是基于java的一些资料,面向的python的API也是很久没有更新维护了。此路不通。
在放弃之前,我又看一篇网站的源码,再次把目光投向了m3u8,上面讲到这个文件应该是包含文件真实地址的索引,索引能不能把在这上面做些文章呢?
Python不愧是万金油语言,packages多到令人发指,m3u8处理也是早就有熟肉。
pip install m3u8
这是一个比较小众的包,没有什么手册,只能自己读源码。
这个class中已经封装好了不少可以直接供使用的数据类型,回头抽时间可以写一写这个包的手册。
现在,我们可以从requests获取的源码中,首先找到m3u8的下载地址,首先下载到本地,然后用m3u8包进行解析,获取真实下载地址。
并且,解析可以得到所有地址,意味着可以省略上面的获取duration计算碎片数目的步骤。
最终
最终,我们现在终于可以,把视频网页链接丢进url中,点击运行,然后就可以去喝茶了。
再来总结一下实现这个的几个关键点:
- 网页解析
- m3u8解析
- 动态代理设置
- DOS命令行的调用
动手是最好的老师,尤其这种网站,兼具趣味性和挑战性,就是身体一天不如一天。。。
完整代码
# -*- coding:utf-8 -*-<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import requests<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />from bs4 import BeautifulSoup<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import os<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import lxml<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import time<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import random<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import re<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import m3u8<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />class ViedeoCrawler():<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def __init__(self):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.url = ""<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.down_path = r"F:\Spider\VideoSpider\DOWN"<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.final_path = r"F:\Spider\VideoSpider\FINAL"<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> try:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.name = re.findall(r'/[A-Za-z]*-[0-9]*',self.url)[0][1:]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> except:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.name = "uncensord"<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.headers = {<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 'Connection': 'Keep-Alive',<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 'Accept': 'text/html, application/xhtml+xml, */*',<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 'User-Agent':'Mozilla/5.0 (Linux; U; Android 6.0; zh-CN; MZ-m2 note Build/MRA58K) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/40.0.2214.89 MZBrowser/6.5.506 UWS/2.10.1.22 Mobile Safari/537.36'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def get_ip_list(self):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("正在获取代理列表...")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> url = 'http://www.xicidaili.com/nn/'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> html = requests.get(url=url, headers=self.headers).text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> soup = BeautifulSoup(html, 'lxml')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ips = soup.find(id='ip_list').find_all('tr')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ip_list = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> for i in range(1, len(ips)):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ip_info = ips[i]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> tds = ip_info.find_all('td')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ip_list.append(tds[1].text + ':' + tds[2].text)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("代理列表抓取成功.")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> return ip_list<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def get_random_ip(self,ip_list):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("正在设置随机代理...")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxy_list = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> for ip in ip_list:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxy_list.append('http://' + ip)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxy_ip = random.choice(proxy_list)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxies = {'http': proxy_ip}<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("代理设置成功.")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> return proxies<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def get_uri_from_m3u8(self,realAdr):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("正在解析真实下载地址...")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> with open('temp.m3u8', 'wb') as file:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> file.write(requests.get(realAdr).content)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> m3u8Obj = m3u8.load('temp.m3u8')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("解析完成.")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> return m3u8Obj.segments<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def run(self):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("Start!")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> start_time = time.time()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> os.chdir(self.down_path)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> html = requests.get(self.url).text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> bsObj = BeautifulSoup(html, 'lxml')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> realAdr = bsObj.find(id="video-player").find("source")['src']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> # duration = bsObj.find('meta', {'property': "video:duration"})['content'].replace("\"", "")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> # limit = int(duration) // 10 + 3<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ip_list = self.get_ip_list()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxies = self.get_random_ip(ip_list)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> uriList = self.get_uri_from_m3u8(realAdr)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> i = 1 # count<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> for key in uriList:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if i%50==0:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("休眠10s")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> time.sleep(10)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if i%120==0:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("更换代理IP")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxies = self.get_random_ip(ip_list)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> try:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> resp = requests.get(key.uri, headers = self.headers, proxies=proxies)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> except Exception as e:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print(e)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> return<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if i 100:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> name = ('clip%d.ts' % i)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> else:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> name = ('clip0%d.ts' % i)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> with open(name,'wb') as f:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> f.write(resp.content)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print('正在下载clip%d' % i)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> i = i+1<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("下载完成!总共耗时 %d s" % (time.time()-start_time))<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("接下来进行合并……")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> os.system('copy/b %s\\*.ts %s\\%s.ts' % (self.down_path,self.final_path, self.name))<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("合并完成,请您欣赏!")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> y = input("请检查文件完整性,并确认是否要删除碎片源文件?(y/n)")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if y=='y':<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> files = os.listdir(self.down_path)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> for filena in files:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> del_file = self.down_path + '\\' + filena<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> os.remove(del_file)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("碎片文件已经删除完成")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> else:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("不删除,程序结束。")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />if __name__=='__main__':<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> crawler = ViedeoCrawler()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> crawler.run()
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜。
-END-
<p style="max-width: 100%;min-height: 1em;text-align: center;box-sizing: border-box !important;overflow-wrap: break-word !important;">
\
<br />
<br style="max-width: 100%;color: rgb(0, 0, 0);font-family: Optima-Regular, Optima, PingFangSC-light, PingFangTC-light, "PingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;white-space: normal;background-color: rgb(255, 255, 255);box-sizing: border-box !important;overflow-wrap: break-word !important;" />
往期推荐
Python面试题【BAT版】
用一个实战项目快速入门VUE3.0!
最强程序员成长攻略指南!
<br /></p> 查看全部
Python爬取视频之日本爱情电影
点击上方蓝色“Python开发与人工智能”,选择“设为星标”
学最好的别人,做最好的我们
肉身翻墙后,感受一下外面的肮脏世界。墙内的朋友叫苦不迭,由于某些原因,VPN能用的越来越少。上周我的好朋友狗子和我哭诉说自己常用的一个VPN终于也寿终正寝了,要和众多的日本小姐姐说再见了。作为“外面人”,我还是要帮他一把……
作者:永无乡<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />源自:https://blog.csdn.net/JosephPa ... %3Bbr style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
初探
狗子给我的网站还算良心,只跳了五个弹窗就消停了。
然后看到的就是各种穿不起衣服的女生的卖惨视频,我赶紧闭上眼睛,默念了几句我佛慈悲。
Tokyo真的有那么hot?
给狗子发了一张大的截图,狗子用涂鸦给我圈出了其中一个。
我和狗子说“等着吧”
(放心网站截图我是打了码也不敢放的。。。)
点进去之后,可以在线播放。
右下角有一个 Download 按钮,点击之后需要注册付费。
当时我就火了,这种卖惨视频毒害我兄弟精神,还敢收钱?!
自己动手,丰衣足食!
环境 & 依赖
Win10 64bit
IDE: PyCharm
Python 3.6
python-site-packegs: requests + BeautifulSoup + lxml + re + m3u8
在已经安装pip的环境下均可直接命令行安装
网站解析
将链接复制到Chrome浏览器打开
(我平时用猎豹,也是Chrome内核,界面比较舒服,但是这个时候必须大喊一声谷歌大法好)
菜单——更多工具——开发者选项(或者快捷键F12)进入Chrome内置的开发者模式
大概界面是这样
(唉打码真的累。。。。)
然后,根据提示,逐层深入标签找到视频所在具体位置
这个网站存放的位置是 …->flash->video_container->video-player
显然视频就放在这个这个video-player中
在这个标签中,有一个名字为 source 的链接,src=”#%@就不告诉你#@¥”
Easy好吧!
这点小把戏还难得到我?我已经准备和狗子要红包了
复制该链接到地址栏粘贴并转到,然后,神奇的一幕出现了!!
What???
这是什么???
为啥这么小???
科普概念如上,那也就是说,m3u8记录了真实的视频所在的地址。
Network Traffic
想要从源码直接获得真实下载地址怕是行不通了。
这时候再和我一起读“谷歌大法好!”
很简单,浏览器在服务器中Get到视频呈现到我们面前,那这个过程必定经过了解析这一步。
那我们也可以利用浏览器这个功能来进行解析
依旧在开发者模式,最上面一行的导航栏,刚刚我们在Elements选项卡,现在切换到Network
我们监听视频播放的时候的封包应该就可以得到真实的视频地址了,试试看!
我们惊喜的发现,一个又一个的 .ts 文件正在载入了
(如果在图片里发现任何url请友情提醒我谢谢不然怕是水表难保)
知识点!这都是知识点!(敲黑板!)
点开其中的一个.ts文件看一下
这里可以看到请求头,虽然url被我走心的码掉了,但这就是真实的视频地址了
复制这个URL到地址栏,下载
9s。。。。。
每一个小视频只有9s,难道要一个又一个的去复制吗?
视频片段爬取
答案是当然不用。
这里我们要请出网络数据采集界的装逼王:Python爬虫!!!
首先进行初始化,包括路径设置,请求头的伪装等。
采集部分主要是将requests的get方法放到了for循环当中
这样做可行的原因在于,在Network监听的图中我们可以看到.ts文件的命名是具有规律的 seg-i-v1-a1,将i作为循环数
那么问题又来了,我怎么知道循环什么时候结束呢?也就是说我怎么知道i的大小呢?
等等,我好像记得在视频播放的框框右下角有时间来着?
在开发者模式中再次回到Element选项卡,定位到视频框右下角的时间,标签为duration,这里的时间格式是 时:分:秒格式的,我们可以计算得到总时长的秒数
但是呢,这样需要我们先获取这个时间,然后再进行字符串的拆解,再进行数学运算,太复杂了吧,狗子已经在微信催我了
Ctrl+F全局搜索duration
Yes!!!
好了,可以点击运行然后去喝杯咖啡,哦不,我喜欢喝茶。
一杯茶的功夫,回来之后已经下载完成。我打开文件夹check一下,发现从编号312之后的clip都是只有573字节,打开播放的话,显示的是数据损坏。
没关系,从312开始继续下载吧。然而下载得到的结果还是一样的573字节,而且下了两百多个之后出现了拒绝访问错误。
动态代理
显然我的IP被封了。之前的多个小项目,或是因为网站防护不够严格,或是因为数据条目数量较少,一直没有遇到过这种情况,这次的数据量增加,面对这种情况采取两种措施,一种是休眠策略,另一种是动态代理。现在我的IP已经被封了,所以休眠也为时已晚,必须采用动态IP了。
主要代码如下所示
合并文件
然后,我们得到了几百个9s的.ts小视频
然后,在cmd命令行下,我们进入到这些小视频所在的路径
执行
copy/b %s\*.ts %s\new.ts
很快,我们就得到了合成好的视频文件
当然这个前提是这几百个.ts文件是按顺序排列好的。
成果如下
优化—调用DOS命令 + 解析m3u8
为了尽可能的减少人的操作,让程序做更多的事
我们要把尽量多的操作写在code中
引用os模块进行文件夹切换,在程序中直接执行合并命令
并且,在判断合并完成后,使用清除几百个ts文件
这样,我们运行程序后,就真的可以去喝一杯茶,回来之后看到的就是没有任何多余的一个完整的最终视频
也就是说,要获得一个完整的视频,我们现在需要输入视频网页链接,还需要使用chrome的network解析得到真实下载地址。第二个部分显然不够友好,还有提升空间。
所以第一个尝试是,可不可以有一个工具或者一个包能嗅探到指定网页的network traffic,因为我们刚刚已经看到真实地址其实就在requestHeader中,关键在于怎样让程序自动获取。
查阅资料后,尝试了Selenium + PhantomJS的组合模拟浏览器访问,用一个叫做browsermobProxy的工具嗅探保存HAR(HTTP archive)。在这个上面花费了不少时间,但是关于browsermobProxy的资料实在是太少了,即使是在google上,搜到的也都是基于java的一些资料,面向的python的API也是很久没有更新维护了。此路不通。
在放弃之前,我又看一篇网站的源码,再次把目光投向了m3u8,上面讲到这个文件应该是包含文件真实地址的索引,索引能不能把在这上面做些文章呢?
Python不愧是万金油语言,packages多到令人发指,m3u8处理也是早就有熟肉。
pip install m3u8
这是一个比较小众的包,没有什么手册,只能自己读源码。
这个class中已经封装好了不少可以直接供使用的数据类型,回头抽时间可以写一写这个包的手册。
现在,我们可以从requests获取的源码中,首先找到m3u8的下载地址,首先下载到本地,然后用m3u8包进行解析,获取真实下载地址。
并且,解析可以得到所有地址,意味着可以省略上面的获取duration计算碎片数目的步骤。
最终
最终,我们现在终于可以,把视频网页链接丢进url中,点击运行,然后就可以去喝茶了。
再来总结一下实现这个的几个关键点:
- 网页解析
- m3u8解析
- 动态代理设置
- DOS命令行的调用
动手是最好的老师,尤其这种网站,兼具趣味性和挑战性,就是身体一天不如一天。。。
完整代码
# -*- coding:utf-8 -*-<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import requests<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />from bs4 import BeautifulSoup<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import os<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import lxml<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import time<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import random<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import re<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import m3u8<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />class ViedeoCrawler():<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def __init__(self):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.url = ""<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.down_path = r"F:\Spider\VideoSpider\DOWN"<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.final_path = r"F:\Spider\VideoSpider\FINAL"<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> try:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.name = re.findall(r'/[A-Za-z]*-[0-9]*',self.url)[0][1:]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> except:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.name = "uncensord"<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.headers = {<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 'Connection': 'Keep-Alive',<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 'Accept': 'text/html, application/xhtml+xml, */*',<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 'User-Agent':'Mozilla/5.0 (Linux; U; Android 6.0; zh-CN; MZ-m2 note Build/MRA58K) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/40.0.2214.89 MZBrowser/6.5.506 UWS/2.10.1.22 Mobile Safari/537.36'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def get_ip_list(self):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("正在获取代理列表...")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> url = 'http://www.xicidaili.com/nn/'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> html = requests.get(url=url, headers=self.headers).text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> soup = BeautifulSoup(html, 'lxml')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ips = soup.find(id='ip_list').find_all('tr')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ip_list = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> for i in range(1, len(ips)):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ip_info = ips[i]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> tds = ip_info.find_all('td')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ip_list.append(tds[1].text + ':' + tds[2].text)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("代理列表抓取成功.")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> return ip_list<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def get_random_ip(self,ip_list):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("正在设置随机代理...")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxy_list = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> for ip in ip_list:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxy_list.append('http://' + ip)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxy_ip = random.choice(proxy_list)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxies = {'http': proxy_ip}<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("代理设置成功.")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> return proxies<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def get_uri_from_m3u8(self,realAdr):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("正在解析真实下载地址...")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> with open('temp.m3u8', 'wb') as file:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> file.write(requests.get(realAdr).content)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> m3u8Obj = m3u8.load('temp.m3u8')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("解析完成.")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> return m3u8Obj.segments<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def run(self):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("Start!")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> start_time = time.time()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> os.chdir(self.down_path)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> html = requests.get(self.url).text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> bsObj = BeautifulSoup(html, 'lxml')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> realAdr = bsObj.find(id="video-player").find("source")['src']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> # duration = bsObj.find('meta', {'property': "video:duration"})['content'].replace("\"", "")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> # limit = int(duration) // 10 + 3<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ip_list = self.get_ip_list()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxies = self.get_random_ip(ip_list)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> uriList = self.get_uri_from_m3u8(realAdr)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> i = 1 # count<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> for key in uriList:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if i%50==0:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("休眠10s")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> time.sleep(10)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if i%120==0:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("更换代理IP")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxies = self.get_random_ip(ip_list)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> try:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> resp = requests.get(key.uri, headers = self.headers, proxies=proxies)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> except Exception as e:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print(e)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> return<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if i 100:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> name = ('clip%d.ts' % i)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> else:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> name = ('clip0%d.ts' % i)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> with open(name,'wb') as f:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> f.write(resp.content)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print('正在下载clip%d' % i)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> i = i+1<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("下载完成!总共耗时 %d s" % (time.time()-start_time))<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("接下来进行合并……")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> os.system('copy/b %s\\*.ts %s\\%s.ts' % (self.down_path,self.final_path, self.name))<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("合并完成,请您欣赏!")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> y = input("请检查文件完整性,并确认是否要删除碎片源文件?(y/n)")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if y=='y':<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> files = os.listdir(self.down_path)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> for filena in files:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> del_file = self.down_path + '\\' + filena<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> os.remove(del_file)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("碎片文件已经删除完成")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> else:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("不删除,程序结束。")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />if __name__=='__main__':<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> crawler = ViedeoCrawler()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> crawler.run()
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜。
-END-
<p style="max-width: 100%;min-height: 1em;text-align: center;box-sizing: border-box !important;overflow-wrap: break-word !important;">
<br />
<br style="max-width: 100%;color: rgb(0, 0, 0);font-family: Optima-Regular, Optima, PingFangSC-light, PingFangTC-light, "PingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;white-space: normal;background-color: rgb(255, 255, 255);box-sizing: border-box !important;overflow-wrap: break-word !important;" />
往期推荐
Python面试题【BAT版】
用一个实战项目快速入门VUE3.0!
最强程序员成长攻略指南!
<br /></p>
[音视频] 下载M3U8加密视频文件
网站优化 • 优采云 发表了文章 • 0 个评论 • 474 次浏览 • 2022-06-10 10:40
0. 网页视频播放器的演进
随着浏览器的逐步迭代,网页播放视频方案也一直不断演进。从早期的MediaPlayer到Flash,再到video标签,我们可以更方便的在网页中播放视频。
1. HLS协议
在浏览器中,HLS协议的video标签是没有保存功能的(源码地址)。所以不能直接在浏览器中下载媒体文件,但是仅仅这一点是不够的,用户可以方便的拿到云存储上的视频地址,下载到本地即可以播放。所以HLS又提供了一套视频流加密的方案,这样云存储中存放的视频流也是加密的,由浏览器负责一边进行解密一边播放。
M3U8作为HLS协议的载体,也是我们后续分析的主要对象。详细的M3U8文件格式的介绍网上有很多,可以参照文档m3u8文件格式详解
下面列出一段未加密的样例传送门
没有加密的M3U8视频流
可以使用ffmpeg工具将视频保存到本地
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "https://node.imgio.in/demo/birds.m3u8" -c copy -copyts "birds.ts"
含有加密KEY的样例传送门
加密的M3U8视频流
因为样例中的解密KEY没有做鉴权,我们同样可以将视频保存到本地
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "https://cdn.theoplayer.com/vid ... ot%3B -c copy -copyts "index.ts"
2. 加密策略
浏览器在解析M3U8协议文件时候,如果发现文件中指定了加密策略,就使用当前的网络环境访问该地址,获取对应的解密KEY。从云存储中读取到ts流之后,使用KEY和IV进行解密,然后在网页上播放。由于视频流一般是部署在OSS或者CDN,方便让用户下载,通常这类服务器是不会做鉴权策略的,于是对视频的保护就转变成了对解密KEY的保护。
2.1 refer检测
这是比较粗糙的方案,如果请求来源不是来自可信的域名,就直接返回错误。我们直接用ffmpeg工具操作M3U8时,访问解密KEY的URI是没有refer的,所以不能直接下载。
2.2 用户鉴权
很多网校通常会用这种方案进行加密,这种方式可以根据权限管理来决策哪些用户可以获取到解密KEY。推荐一种比较方便的方案,通过fiddler进行抓包,然后用python脚本解析对应的saz,将m3u8中的URI换成对应的KEY,然后使用ffmpeg将媒体文件保存到本地。
2.3 自定义KeyLoader
可以使用这个组件,支持自定义KeyLoader,通过URI从服务端请求回来一串字符串,经过定制的KeyLoader来解密之后,得到真正的解密KEY。这种需要我们的分析KeyLoader源码,百度云提供的加密视频方案就用了这个策略练手地址,对key的解密用到了AES-ecb,对解密KEY进行解密的密钥写死在js代码中。
2.4 自定义PlaylistLoader
除了可以自定义KeyLoader,这个组件也支持指定PlaylistLoader,这样M3U8文件也是动态解密出来的,增强了安全性练手地址。通过动态调试的方式可以拿到明文的M3U8和对应的解密KEY。由于网站的解密算法比较复杂,笔者没有尝试提取算法,感兴趣的大神可以分析下。
3. 实战下载百度的加密视频
这里使用Chrome浏览器进行演示,网页地址见2.3
3.1 抓取关键信息
打开开发者工具,定位到Network的tab页
点击播放token加密视频
触发了对m3u8文件的拉取
拉取视频流的解密KEY
通过关键字找到js文件中的KeyLoader
可以看到这里用到了AES-ecb解密,并且密钥也暴露在js文件中
下断点,重新加载视频,即可看到解密KEY
3.2 构造可以方便下载视频的M3U8
如何让ffmpeg工具方便的拿到这个key?我们搭建一个服务端接口:接收一个base64编码后的参数,解码成二进制流返回给客户端。(可能比较搓的方案,但是好在还很通用)
构造解密KEY的URI:
将复制下来的解密KEY做base64编码
替换M3U8文件中的URI部分
3.3 使用ffmpeg工具下载媒体文件
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "baidu.m3u8" -c copy -copyts "baidu.ts"
下载后的视频可以正常播放
4. 总结
在线教育成为了互联网的风口,HLS协议也很好的契合了这个行业。最后呼吁大家多多尊重版权,从正规渠道购买视频资源。创作不易。
仅技术交流,请勿使用于非法用途。 查看全部
[音视频] 下载M3U8加密视频文件
0. 网页视频播放器的演进
随着浏览器的逐步迭代,网页播放视频方案也一直不断演进。从早期的MediaPlayer到Flash,再到video标签,我们可以更方便的在网页中播放视频。
1. HLS协议
在浏览器中,HLS协议的video标签是没有保存功能的(源码地址)。所以不能直接在浏览器中下载媒体文件,但是仅仅这一点是不够的,用户可以方便的拿到云存储上的视频地址,下载到本地即可以播放。所以HLS又提供了一套视频流加密的方案,这样云存储中存放的视频流也是加密的,由浏览器负责一边进行解密一边播放。
M3U8作为HLS协议的载体,也是我们后续分析的主要对象。详细的M3U8文件格式的介绍网上有很多,可以参照文档m3u8文件格式详解
下面列出一段未加密的样例传送门
没有加密的M3U8视频流
可以使用ffmpeg工具将视频保存到本地
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "https://node.imgio.in/demo/birds.m3u8" -c copy -copyts "birds.ts"
含有加密KEY的样例传送门
加密的M3U8视频流
因为样例中的解密KEY没有做鉴权,我们同样可以将视频保存到本地
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "https://cdn.theoplayer.com/vid ... ot%3B -c copy -copyts "index.ts"
2. 加密策略
浏览器在解析M3U8协议文件时候,如果发现文件中指定了加密策略,就使用当前的网络环境访问该地址,获取对应的解密KEY。从云存储中读取到ts流之后,使用KEY和IV进行解密,然后在网页上播放。由于视频流一般是部署在OSS或者CDN,方便让用户下载,通常这类服务器是不会做鉴权策略的,于是对视频的保护就转变成了对解密KEY的保护。
2.1 refer检测
这是比较粗糙的方案,如果请求来源不是来自可信的域名,就直接返回错误。我们直接用ffmpeg工具操作M3U8时,访问解密KEY的URI是没有refer的,所以不能直接下载。
2.2 用户鉴权
很多网校通常会用这种方案进行加密,这种方式可以根据权限管理来决策哪些用户可以获取到解密KEY。推荐一种比较方便的方案,通过fiddler进行抓包,然后用python脚本解析对应的saz,将m3u8中的URI换成对应的KEY,然后使用ffmpeg将媒体文件保存到本地。
2.3 自定义KeyLoader
可以使用这个组件,支持自定义KeyLoader,通过URI从服务端请求回来一串字符串,经过定制的KeyLoader来解密之后,得到真正的解密KEY。这种需要我们的分析KeyLoader源码,百度云提供的加密视频方案就用了这个策略练手地址,对key的解密用到了AES-ecb,对解密KEY进行解密的密钥写死在js代码中。
2.4 自定义PlaylistLoader
除了可以自定义KeyLoader,这个组件也支持指定PlaylistLoader,这样M3U8文件也是动态解密出来的,增强了安全性练手地址。通过动态调试的方式可以拿到明文的M3U8和对应的解密KEY。由于网站的解密算法比较复杂,笔者没有尝试提取算法,感兴趣的大神可以分析下。
3. 实战下载百度的加密视频
这里使用Chrome浏览器进行演示,网页地址见2.3
3.1 抓取关键信息
打开开发者工具,定位到Network的tab页
点击播放token加密视频
触发了对m3u8文件的拉取
拉取视频流的解密KEY
通过关键字找到js文件中的KeyLoader
可以看到这里用到了AES-ecb解密,并且密钥也暴露在js文件中
下断点,重新加载视频,即可看到解密KEY
3.2 构造可以方便下载视频的M3U8
如何让ffmpeg工具方便的拿到这个key?我们搭建一个服务端接口:接收一个base64编码后的参数,解码成二进制流返回给客户端。(可能比较搓的方案,但是好在还很通用)
构造解密KEY的URI:
将复制下来的解密KEY做base64编码
替换M3U8文件中的URI部分
3.3 使用ffmpeg工具下载媒体文件
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "baidu.m3u8" -c copy -copyts "baidu.ts"
下载后的视频可以正常播放
4. 总结
在线教育成为了互联网的风口,HLS协议也很好的契合了这个行业。最后呼吁大家多多尊重版权,从正规渠道购买视频资源。创作不易。
仅技术交流,请勿使用于非法用途。
上海热切提供便利转换服务的ai、抓取网页flash视频
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-06-09 03:05
抓取网页flash视频。从视频流里抠掉片头片尾。
有几个高效的方法。大概说一下:1.revit建模编辑,revitsheets的导出格式大概有四种(mpm啊meme啊等等),你用哪种就转换格式到ai里面2.找个矢量素材(在建模的时候就选好几种格式的素材,file-exportmaterial,导出的时候勾上svg格式和quicktime),就可以直接按照自己的需要用ai完成;3.revit建模成cad后,转换成pdf,然后再编辑4.revit中导出gif最快的方法:第一次用这个方法导出的时候,将revitsheets按照约定的尺寸编辑一遍,然后连起来放不行,得继续完成多个模型,再放一遍,最后直接生成完整的ai文件。
三维渲染器、专业软件或转换工具。上海热切提供便利转换服务。
1.ppt的设计稿。2.ai、ai、ai。有模板也有教程。3.三维渲染。视情况学一下ae什么的。4.用ps等软件做线稿,再转三维。ps小弟一枚,只知道这么多了。
国内的不少视频教程都是使用3dmax,这是webgl,即可做动画,模板网上也有不少。国外有两种电脑教程:一种是用maya直接建模,然后用surfacesurfans传到revit中,revit查看时就生成3d结果,制作优秀文字3d模型另一种是用autocad做二维平面图,渲染到ai中查看,把字转到3d文件中即可。
3dmax熟练的话做出来可以非常漂亮的文字。ai熟练的话也可以做出相当不错的图案。当然ps等软件也可以做出很好的3d文字!。 查看全部
上海热切提供便利转换服务的ai、抓取网页flash视频
抓取网页flash视频。从视频流里抠掉片头片尾。
有几个高效的方法。大概说一下:1.revit建模编辑,revitsheets的导出格式大概有四种(mpm啊meme啊等等),你用哪种就转换格式到ai里面2.找个矢量素材(在建模的时候就选好几种格式的素材,file-exportmaterial,导出的时候勾上svg格式和quicktime),就可以直接按照自己的需要用ai完成;3.revit建模成cad后,转换成pdf,然后再编辑4.revit中导出gif最快的方法:第一次用这个方法导出的时候,将revitsheets按照约定的尺寸编辑一遍,然后连起来放不行,得继续完成多个模型,再放一遍,最后直接生成完整的ai文件。
三维渲染器、专业软件或转换工具。上海热切提供便利转换服务。
1.ppt的设计稿。2.ai、ai、ai。有模板也有教程。3.三维渲染。视情况学一下ae什么的。4.用ps等软件做线稿,再转三维。ps小弟一枚,只知道这么多了。
国内的不少视频教程都是使用3dmax,这是webgl,即可做动画,模板网上也有不少。国外有两种电脑教程:一种是用maya直接建模,然后用surfacesurfans传到revit中,revit查看时就生成3d结果,制作优秀文字3d模型另一种是用autocad做二维平面图,渲染到ai中查看,把字转到3d文件中即可。
3dmax熟练的话做出来可以非常漂亮的文字。ai熟练的话也可以做出相当不错的图案。当然ps等软件也可以做出很好的3d文字!。
网页flash视频无痕兼容美图秀秀中的视频功能的脚本
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-05-17 23:03
抓取网页flash视频无痕脚本兼容美图秀秀中的视频功能的脚本学习wp7,html5,
可以实现视频下载+上传+分享,
我知道的一个脚本:itsublog国内很多人使用的。
babel,
这里有一个相当完善的下载gif图库的工具-show.html
我写过一个脚本,通过改变图片title中的tag[1](或图片上的title)来实现添加无痕的视频。[1]支持批量改title和gif压缩。
ps自带的功能。
我一直都是用我同事推荐的libsdcard视频工具。也支持转为gif。
微信公众号小程序filehound,可以直接下载微信上的视频,无水印。支持批量操作。iphone,
话不多说,先上图。
我一直用免费的网页视频下载神器httr
我看着我手机的微信下载不到。至少110+次访问失败之后,我也准备放弃了。
不如做个外套外面套上微信,可以看视频实时。可以添加评论。
可以试试蝉大师_专注企业互联网产品运营推广的威客网站,支持平台1.微信2.小程序3.公众号、网站4.知乎等平台至于大神推荐脚本,
我刚开始用直接在浏览器打开,用花瓣的存储转换成gif,在自定义分享图中添加ispdf格式的文件,然后把微信存成ispdf格式。 查看全部
网页flash视频无痕兼容美图秀秀中的视频功能的脚本
抓取网页flash视频无痕脚本兼容美图秀秀中的视频功能的脚本学习wp7,html5,
可以实现视频下载+上传+分享,
我知道的一个脚本:itsublog国内很多人使用的。
babel,
这里有一个相当完善的下载gif图库的工具-show.html
我写过一个脚本,通过改变图片title中的tag[1](或图片上的title)来实现添加无痕的视频。[1]支持批量改title和gif压缩。
ps自带的功能。
我一直都是用我同事推荐的libsdcard视频工具。也支持转为gif。
微信公众号小程序filehound,可以直接下载微信上的视频,无水印。支持批量操作。iphone,
话不多说,先上图。
我一直用免费的网页视频下载神器httr
我看着我手机的微信下载不到。至少110+次访问失败之后,我也准备放弃了。
不如做个外套外面套上微信,可以看视频实时。可以添加评论。
可以试试蝉大师_专注企业互联网产品运营推广的威客网站,支持平台1.微信2.小程序3.公众号、网站4.知乎等平台至于大神推荐脚本,
我刚开始用直接在浏览器打开,用花瓣的存储转换成gif,在自定义分享图中添加ispdf格式的文件,然后把微信存成ispdf格式。
抓取网页flash视频可以用"allfriendly”,速度非常快
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-05-15 13:01
抓取网页flash视频可以用"allfriendly",速度非常快,否则就得用python的代码来抓取了,教程如下:。
做好前端。最好用webrtc,然后还得用node,如果前端有的话。利用rawvideo(rb)和remjs(remotebrowserfilesystem),多抓一下。
楼上的答案已经答得很详细了,我就不多说了,像知乎这样的网站推荐用chrome扩展插件去抓取,成本会低一些,
直接pythonpandas,numpy比网站后台压缩好
可以使用pyinstaller这个软件去抓取,
当然是python啊,
不可以,最笨的方法是刷下载量。还有就是看看知乎广告,找用户爱点的。
allfriend吧
可以试试用一个nodejs框架去爬虫,专门抓取知乎live的推荐。并以爬虫和社交网络的结合方式去抓取知乎精彩回答。这是一个简单的例子,网上可以找到相关python代码。
不知道干这个价值多大。不过可以的话,应该抓取视频并post过去。并且抓取的截图可以发给他人,或者在淘宝/天猫发给需要的人, 查看全部
抓取网页flash视频可以用"allfriendly”,速度非常快
抓取网页flash视频可以用"allfriendly",速度非常快,否则就得用python的代码来抓取了,教程如下:。
做好前端。最好用webrtc,然后还得用node,如果前端有的话。利用rawvideo(rb)和remjs(remotebrowserfilesystem),多抓一下。
楼上的答案已经答得很详细了,我就不多说了,像知乎这样的网站推荐用chrome扩展插件去抓取,成本会低一些,
直接pythonpandas,numpy比网站后台压缩好
可以使用pyinstaller这个软件去抓取,
当然是python啊,
不可以,最笨的方法是刷下载量。还有就是看看知乎广告,找用户爱点的。
allfriend吧
可以试试用一个nodejs框架去爬虫,专门抓取知乎live的推荐。并以爬虫和社交网络的结合方式去抓取知乎精彩回答。这是一个简单的例子,网上可以找到相关python代码。
不知道干这个价值多大。不过可以的话,应该抓取视频并post过去。并且抓取的截图可以发给他人,或者在淘宝/天猫发给需要的人,
如何制作自己的webapp+web前端开发进阶之路的视频
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-05-14 05:02
抓取网页flash视频,
利用我有完整的django+web前端开发进阶之路的视频,其中包括:如何制作自己的webapp;在web前端开发过程中有哪些坑,怎么踩;还有java、c#、python、linux等方面的一些开发经验等等。我是张伟山,希望可以帮到你。
又看了一下,
我来正经的回答一下你的问题吧。分两个方面,首先是基础开发的知识,从安装环境到作业开发,类似于crud的开发方式,整个体系是封装好的,会有现成的功能,可以参考着用。更进一步的方式是,可以根据自己的业务场景建立新的功能模块,如es6中的异步加载库等,定制更加灵活强大的模块,这样也是一个办法。第二个方面是流行的技术,包括前端的移动端和python+前端框架,后端可以用java/php等,感兴趣可以慢慢琢磨。
想要快速精通这些技术,可以先看官方推荐的教程以及网上的开发案例,自己动手折腾一下,最好有一定经验再回来看官方的教程,看开发案例的时候仔细体会,多找问题,一步步拆分问题,最终会写出一个好用,可扩展的包,或者慢慢逐步过渡到专注某一个方向,一步步学习并开发某一项技术。
开发个人网站、博客、个人官网、企业网站、商城、以及小型的http服务器集群等,对web前端来说,最快捷的方式:python+前端框架,后端语言应该也是python,读不懂c++代码,读python+django代码还是可以读懂的,但对小型网站、个人网站来说有点困难。 查看全部
如何制作自己的webapp+web前端开发进阶之路的视频
抓取网页flash视频,
利用我有完整的django+web前端开发进阶之路的视频,其中包括:如何制作自己的webapp;在web前端开发过程中有哪些坑,怎么踩;还有java、c#、python、linux等方面的一些开发经验等等。我是张伟山,希望可以帮到你。
又看了一下,
我来正经的回答一下你的问题吧。分两个方面,首先是基础开发的知识,从安装环境到作业开发,类似于crud的开发方式,整个体系是封装好的,会有现成的功能,可以参考着用。更进一步的方式是,可以根据自己的业务场景建立新的功能模块,如es6中的异步加载库等,定制更加灵活强大的模块,这样也是一个办法。第二个方面是流行的技术,包括前端的移动端和python+前端框架,后端可以用java/php等,感兴趣可以慢慢琢磨。
想要快速精通这些技术,可以先看官方推荐的教程以及网上的开发案例,自己动手折腾一下,最好有一定经验再回来看官方的教程,看开发案例的时候仔细体会,多找问题,一步步拆分问题,最终会写出一个好用,可扩展的包,或者慢慢逐步过渡到专注某一个方向,一步步学习并开发某一项技术。
开发个人网站、博客、个人官网、企业网站、商城、以及小型的http服务器集群等,对web前端来说,最快捷的方式:python+前端框架,后端语言应该也是python,读不懂c++代码,读python+django代码还是可以读懂的,但对小型网站、个人网站来说有点困难。
知乎的分享模块对于地址的处理是个孤岛(下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-05-14 02:02
抓取网页flash视频地址直接发送给微信分享功能要求:正常浏览器、ie浏览器支持,微信客户端需要支持视频播放性能要求:耗流量高的浏览器无法正常分享;分享到网页、微信朋友圈中不会显示;如果地址在你的本地播放(包括本地播放和网页分享),那么默认分享到本地的html5网页浏览器;分享到微信,微信客户端会抓取本地的html5分享到自己的浏览器。
对于现在的浏览器,分享一个html5视频,其实真的非常难(不考虑用户安装css浏览器插件的问题)。连其他编程语言的视频编码标准都无法解决,更不要说别的浏览器解码这种技术问题了。所以我推测知乎的分享模块对于地址的处理是个孤岛(a,b,c这三个页面的地址),从这个地址走地址可以反向流回去一个页面地址,再从这个页面反向流回去我没听说过(个人理解),就算可以,那我觉得也不是能够通过分享模块收到这个链接的方式来实现的方案一:看使用什么浏览器能反向,如果这些浏览器不支持这种方案就只能麻烦点,把地址用url编码去掉也可以,再用cookie对下数据,或者换个数据模式,再用ua来个上行转发之类的方案二:如果选用https的地址编码,要考虑地址被https识别的问题,好在我知道现在还是有的,根据这个ssl和一些前端协议就可以处理。 查看全部
知乎的分享模块对于地址的处理是个孤岛(下)
抓取网页flash视频地址直接发送给微信分享功能要求:正常浏览器、ie浏览器支持,微信客户端需要支持视频播放性能要求:耗流量高的浏览器无法正常分享;分享到网页、微信朋友圈中不会显示;如果地址在你的本地播放(包括本地播放和网页分享),那么默认分享到本地的html5网页浏览器;分享到微信,微信客户端会抓取本地的html5分享到自己的浏览器。
对于现在的浏览器,分享一个html5视频,其实真的非常难(不考虑用户安装css浏览器插件的问题)。连其他编程语言的视频编码标准都无法解决,更不要说别的浏览器解码这种技术问题了。所以我推测知乎的分享模块对于地址的处理是个孤岛(a,b,c这三个页面的地址),从这个地址走地址可以反向流回去一个页面地址,再从这个页面反向流回去我没听说过(个人理解),就算可以,那我觉得也不是能够通过分享模块收到这个链接的方式来实现的方案一:看使用什么浏览器能反向,如果这些浏览器不支持这种方案就只能麻烦点,把地址用url编码去掉也可以,再用cookie对下数据,或者换个数据模式,再用ua来个上行转发之类的方案二:如果选用https的地址编码,要考虑地址被https识别的问题,好在我知道现在还是有的,根据这个ssl和一些前端协议就可以处理。
抓取网页flash视频做作品试试?不是外包的话
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-05-12 03:01
抓取网页flash视频做作品试试?
不是外包的话可以试试看对方做个app出来可以达到这个功能
推荐一个免费爬虫工具,我目前正在使用,对国内各大网站进行抓取。适合小白。网站爬虫工具,支持requests+beautifulsoup+pyquery+jqueryextractor+lxml+jsonp2抓取网页内容中文can_use_editable_text_with_requests&app=zh_cn_us。
1.获取学校招聘信息公司给地方教育局每年都报送很多招聘信息,并不是所有的都是人才市场上可以买到的,每年老师们都可以从学校很多招聘信息里扒几块出来做数据分析。2.涉及地区招聘信息获取一般地区的高校周边都会有不少实体店,能从这些店里很快买到自己需要的信息。3.招聘经历公司自己建了一个会员账号,可以通过学校的系统直接查到录取人员的经历。
一般会在每个学生毕业时会发起一次选人,比如某学生高考成绩在哪里可以查到,然后根据这些信息自己制作简历。
看数据量,如果只是给孩子填志愿的数据。1.出租车信息,做乘车网站,比如滴滴打车。现在乘车网站那么多,你输入日期和时间就能直接出租车的信息。2.餐饮信息,饭店。大家去买饭的话,对食物的图片信息非常在意,如果你发布个坐标信息,简直棒呆。 查看全部
抓取网页flash视频做作品试试?不是外包的话
抓取网页flash视频做作品试试?
不是外包的话可以试试看对方做个app出来可以达到这个功能
推荐一个免费爬虫工具,我目前正在使用,对国内各大网站进行抓取。适合小白。网站爬虫工具,支持requests+beautifulsoup+pyquery+jqueryextractor+lxml+jsonp2抓取网页内容中文can_use_editable_text_with_requests&app=zh_cn_us。
1.获取学校招聘信息公司给地方教育局每年都报送很多招聘信息,并不是所有的都是人才市场上可以买到的,每年老师们都可以从学校很多招聘信息里扒几块出来做数据分析。2.涉及地区招聘信息获取一般地区的高校周边都会有不少实体店,能从这些店里很快买到自己需要的信息。3.招聘经历公司自己建了一个会员账号,可以通过学校的系统直接查到录取人员的经历。
一般会在每个学生毕业时会发起一次选人,比如某学生高考成绩在哪里可以查到,然后根据这些信息自己制作简历。
看数据量,如果只是给孩子填志愿的数据。1.出租车信息,做乘车网站,比如滴滴打车。现在乘车网站那么多,你输入日期和时间就能直接出租车的信息。2.餐饮信息,饭店。大家去买饭的话,对食物的图片信息非常在意,如果你发布个坐标信息,简直棒呆。
了解搜索引擎来进行SEO
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-05-07 09:29
搜索引擎的工作的过程非常复杂,而简单的讲搜索引擎的工过程大体可以分成三个阶段。爬行和抓取:搜索引擎蜘蛛通过跟踪链接访问页面,获取页面HTML代码存入数据库。预处理:搜索赢球对抓取来的页面数据文字进行文字提取、中文分词、索引等处理,以备排名程序调用。排名:用户输入关键字后,排名调用索引库数据,计算相关性,然后按一定格式生成搜索结果页面。
爬行和抓取
爬行和抓取是搜索引擎工作的第一步,完成数据收集任务。
蜘蛛
搜索引擎用来爬行和访问页面的程序被称为蜘蛛(spider),也称为机器人(bot)。
蜘蛛代理名称:
百度蜘蛛:Baiduspider+(+) ·
雅虎中国蜘蛛:Mozilla/5.0 (compatible; Yahoo! Slurp China; ) ·
英文雅虎蜘蛛:Mozilla/5.0 (compatible; Yahoo! Slurp/3.0; )
Google 蜘蛛:Mozilla/5.0 (compatible; Googlebot/2.1; +) ·
微软 Bing 蜘蛛:msnbot/1.1 (+)·
搜狗蜘蛛: Sogou+web+robot+(+#07) ·
搜搜蜘蛛:Sosospider+(+) ·
有道蜘蛛:Mozilla/5.0 (compatible; YodaoBot/1.0; ; )
跟踪链接
为了抓取网上尽量多的页面,搜索引擎蜘蛛会跟踪页面上的链接,从一个页面爬到下一个页面,就好像蜘蛛在蜘蛛网上爬行那样,这也就是搜索引擎蜘蛛这个名称的由来。最简单的爬行遍历策略分为两种,一是深度优先,二是广度优先。
深度优先搜索
深度优先搜索就是在搜索树的每一层始终先只扩展一个子节点,不断地向纵深前进直到不能再前进(到达叶子节点或受到深度限制)时,才从当前节点返回到上一级节点,沿另一方向又继续前进。这种方法的搜索树是从树根开始一枝一枝逐渐形成的。
深度优先搜索亦称为纵向搜索。由于一个有解的问题树可能含有无穷分枝,深度优先搜索如果误入无穷分枝(即深度无限),则不可能找到目标节点。所以,深度优先搜索策略是不完备的。另外,应用此策略得到的解不一定是最佳解(最短路径)。
广度优先搜索
在深度优先搜索算法中,是深度越大的结点越先得到扩展。如果在搜索中把算法改为按结点的层次进行搜索, 本层的结点没有搜索处理完时,不能对下层结点进行处理,即深度越小的结点越先得到扩展,也就是说先产生 的结点先得以扩展处理,这种搜索算法称为广度优先搜索法。
在深度优先搜索算法中,是深度越大的结点越先得到扩展。如果在搜索中把算法改为按结点的层次进行搜索, 本层的结点没有搜索处理完时,不能对下层结点进行处理,即深度越小的结点越先得到扩展,也就是说先产生 的结点先得以扩展处理,这种搜索算法称为广度优先搜索法。
吸引蜘蛛
哪些页面被认为比较重要呢?有几方面影响因素:
· 网站和页面权重。质量高、资格老的网站被认为权重比较高,这种网站上的页面被爬行的深度也会比较高,所以会有更多内页被收录。
· 页面更新度。蜘蛛每次爬行都会把页面数据存储起来。如果第二次爬行发现页面与第一次收录的完全一样,说明页面没有更新,蜘蛛也就没有必要经常抓取。如果页面内容经常更新,蜘蛛就会更加频繁地访问这种页面,页面上出现的新链接,也自然会被蜘蛛更快跟踪,抓取新页面。
· 导入链接。无论是外部链接还是同一个网站的内部链接,要被蜘蛛抓取就必须有导入链接进入页面,否则蜘蛛根本没有机会知道页面的存在。高质量的导入链接也经常使页面上的导出链接被爬行深度增加。一般来说网站上权重最高的是首页,大部分外部链接是指向首页,蜘蛛访问最频繁的也是首页。离首页点击距离越近,页面权重越高,被蜘蛛爬行的机会也越大。
地址库
为了避免重复爬行和抓取网址,搜索引擎会建立一个地址库,记录已经被发现还没有抓取的页面,以及已经被抓取的页面。地址库中的uRL有几个来源:
(1)人工录入的种子网站。
(2)蜘蛛抓取页面后,从HTML中解析出新的链接uRL,与地址库中的数据进行对比,如果是地址库中没有的网址,就存入待访问地址库。
(3)站长通过搜索引擎网页提交表格提交进来的网址。
蜘蛛按重要性从待访问地址库中提取uRL,访问并抓取页面,然后把这个uRL从待访问地址库中删除,放进已访问地址库中。
大部分主流搜索引擎都提供一个表格,让站长提交网址。不过这些提交来的网址都只是存入地址库而已,是否收录还要看页面重要性如何。搜索引擎所收录的绝大部分页面是蜘蛛自己跟踪链接得到的。可以说提交页面基本t是毫无用处的,搜索引擎更喜欢自己沿着链接发现新页面。
文件存储搜索引擎蜘蛛抓取的数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML是完全一样的。每个uRI,都有一个独特的文件编号。
爬行时的复制内容检测
检测并删除复制内容通常是在下面介绍的预处理过程中进行的,但现在的蜘蛛在爬行和抓取文件时也会进行定程度的复制内容检测。遇到权重很低的网站上大量转载或抄袭内容时,很可能不再继续爬行。这也就是有的站长在日志文件中发现了蜘蛛,但页面从来没有被真正收录过的原因。
预处理
在一些SEO材料中,“预处理”也被简称为“索引”,因为索引是预处理最主要的步骤。
搜索引擎蜘蛛抓取的原始页面,并不能直接用于查询排名处理。搜索引擎数据库中的页面数都在数万亿级别以上,用户输入搜索词后,靠排名程序实时对这么多页面分析相关性,计算量太大,不可能在一两秒内返回排名结果。因此抓取来的页面必须经过预处理,为最后的查询排名做好准备。
和爬行抓取一样,预处理也是在后台提前完成的,用户搜索时感觉不到这个过程。
1.提取文字
现在的搜索引擎还是以文字内容为基础。蜘蛛抓取到的页面中的HTML代码,除了用户在浏览器上可以看到的可见文字外,还包含了大量的HTML格式标签、 JavaScript程序等无法用于排名的内容。搜索引擎预处理首先要做的就是从HTML文件中去除标签、程序,提取出可以用于排名处理的网页面文字内 容。
今天愚人节哈
除去HTML代码后,剩下的用于排名的文字只是这一行:
今天愚人节哈
除了可见文字,搜索引擎也会提取出一些特殊的包含文字信息的代码,如Meta标签中的文字、图片替代文字、Flash文件的替代文字、链接锚文字等。
2.中文分词
分词是中文搜索引擎特有的步骤。搜索引擎存储和处理页面及用户搜索都是以词为基础的。英文等语言单词与单词之间有空格分隔,搜索引擎索引程序可以直接把句子 划分为单词的集合。而中文词与词之间没有任何分隔符,一个句子中的所有字和词都是连在一起的。搜索引擎必须首先分辨哪几个字组成一个词,哪些字本身就是一 个词。比如“减肥方法”将被分词为“减肥”和“方法”两个词。
中文分词方法基本上有两种,一种是基于词典匹配,另一种是基于统计。
基于词典匹配的方法是指,将待分析的一段汉字与一个事先造好的词典中的词条进行匹配,在待分析汉字串中扫描到词典中已有的词条则匹配成功,或者说切分出一个单词。
按照扫描方向,基于词典的匹配法可以分为正向匹配和逆向匹配。按照匹配长度优先级的不同,又可以分为最大匹配和最小匹配。将扫描方向和长度优先混合,又可以产生正向最大匹配、逆向最大匹配等不同方法。
词典匹配方法计算简单,其准确度在很大程度上取决于词典的完整性和更新情况。
基于统计的分词方法指的是分析大量文字样本,计算出字与字相邻出现的统计概率,几个字相邻出现越多,就越可能形成一个单词。基于统计的方法的优势是对新出现的词反应更快速,也有利于消除歧义。
基于词典匹配和基于统计的分词方法各有优劣,实际使用中的分词系统都是混合使用两种方法的,快速高效,又能识别生词、新词,消除歧义。
中文分词的准确性往往影响搜索引擎排名的相关性。比如在百度搜索“搜索引擎优化”,从快照中可以看到,百度把“搜索引擎优化”这六个字当成一个词。
而在Google搜索同样的词,快照显示Google将其分切为“搜索引擎”和“优化”两个词。显然百度切分得更为合理,搜索引擎优化是一个完整的概念。Google分词时倾向于更为细碎。
这种分词上的不同很可能是一些关键词排名在不同搜索引擎有不同表现的原因之一。比如百度更喜欢将搜索词完整匹配地出现在页面上,也就是说搜索“够戏博客” 时,这四个字连续完整出现更容易在百度获得好的排名。Google就与此不同,不太要求完整匹配。一些页面出现“够戏”和“博客”两个词,但不必完整匹配 地出现,“够戏”出现在前面,“博客”出现在页面的其他地方,这样的页面在Google搜索“够戏博客”时,也可以获得不错的排名。
搜索引擎对页面的分词取决于词库的规模、准确性和分词算法的好坏,而不是取决于页面本身如何,所以SEO人员对分词所能做的很少。唯一能做的是在页面上用某种形 式提示搜索引擎,某几个字应该被当做一个词处理,尤其是可能产生歧义的时候,比如在页面标题、h1标签及黑体中出现关键词。如果页面是关于“和服”的内 容,那么可以把“和服”这两个字特意标为黑体。如果页面是关于“化妆和服装”,可以把“服装”两个字标为黑体。这样,搜索引擎对页面进行分析时就知道标为 黑体的应该是一个词。
3.去停止词
无论是英文还是中文,页面内容中都会有一些出现频率很 高,却对内容没有任何影响的词,如“的”、“地”、“得”之类的助词,“啊”、“哈”、“呀”之类的感叹词,“从而”、“以”、“却”之类的副词或介词。 这些词被称为停止词,因为它们对页面的主要意思没什么影响。英文中的常见停止词有the,a,an,to,of等。
搜索引擎在索引页面之前会去掉这些停止词,使索引数据主题更为突出,减少无谓的计算量。
4.消除噪声
绝 大部分页面上还有一部分内容对页面主题也没有什么贡献,比如版权声明文字、导航条、广告等。以常见的博客导航为例,几乎每个博客页面上都会出现文章分类、 历史存档等导航内容,但是这些页面本身与“分类”、“历史”这些词都没有任何关系。用户搜索“历史”、“分类”这些关键词时仅仅因为页面上有这些词出现而 返回博客帖子是毫无意义的,完全不相关。所以这些区块都属于噪声,对页面主题只能起到分散作用。
搜索引擎需要识别并消除这些噪声,排名时不使用噪声内容。消噪的基本方法是根据HTML标签对页面分块,区分出页头、导航、正文、页脚、广告等区域,在网站上大量重复出现的区块往往属于噪声。对页面进行消噪后,剩下的才是页面主体内容。
5.去重
搜索引擎还需要对页面进行去重处理。
同 一篇文章经常会重复出现在不同网站及同一个网站的不同网址上,搜索引擎并不喜欢这种重复性的内容。用户搜索时,如果在前两页看到的都是来自不同网站的同一 篇文章,用户体验就太差了,虽然都是内容相关的。搜索引擎希望只返回相同文章中的一篇,所以在进行索引前还需要识别和删除重复内容,这个过程就称为“去 重”。
去重的基本方法是对页面特征关键词计算指纹,也就是说从页面主体内容中选取最有代表性的一部分关键词(经常是出现频率最高的关键 词),然后计算这些关键词的数字指纹。这里的关键词选取是在分词、去停止词、消噪之后。实验表明,通常选取10个特征关键词就可以达到比较高的计算准确 性,再选取更多词对去重准确性提高的贡献也就不大了。
典型的指纹计算方法如MD5算法(信息摘要算法第五版)。这类指纹算法的特点是,输入(特征关键词)有任何微小的变化,都会导致计算出的指纹有很大差距。
了 解了搜索引擎的去重算法,SEO人员就应该知道简单地增加“的”、“地”、“得”、调换段落顺序这种所谓伪原创,并不能逃过搜索引擎的去重算法,因为这样 的操作无法改变文章的特征关键词。而且搜索引擎的去重算法很可能不止于页面级别,而是进行到段落级别,混合不同文章、交叉调换段落顺序也不能使转载和抄袭 变成原创。
6.正向索引
正向索引也可以简称为索引。
经过文字提取、分词、 消噪、去重后,搜索引擎得到的就是独特的、能反映页面主体内容的、以词为单位的内容。接下来搜索引擎索引程序就可以提取关键词,按照分词程序划分好的词, 把页面转换为一个关键词组成的集合,同时记录每一个关键词在页面上的出现频率、出现次数、格式(如出现在标题标签、黑体、H标签、锚文字等)、位置(如页 面第一段文字等)。这样,每一个页面都可以记录为一串关键词集合,其中每个关键词的词频、格式、位置等权重信息也都记录在案。
搜索引擎索引程序将页面及关键词形成词表结构存储进索引库。简化的索引词表形式如表2-1所示。
每个文件都对应一个文件ID,文件内容被表示为一串关键词的集合。实际上在搜索引擎索引库中,关键词也已经转换为关键词ID.这样的数据结构就称为正向索引。
7.倒排索引
正向索引还不能直接用于排名。假设用户搜索关键词2,如果只存在正向索引,排名程序需要扫描所有索引库中的文件,找出包含关键词2的文件,再进行相关性计算。这样的计算量无法满足实时返回排名结果的要求。
所以搜索引擎会将正向索引数据库重新构造为倒排索引,把文件对应到关键词的映射转换为关键词到文件的映射,如表2-2所示。
在倒排索引中关键词是主键,每个关键词都对应着一系列文件,这些文件中都出现了这个关键词。这样当用户搜索某个关键词时,排序程序在倒排索引中定位到这个关键词,就可以马上找出所有包含这个关键词的文件。
8.链接关系计算
链接关系计算也是预处理中很重要的一部分。现在所有的主流搜索引擎排名因素中都包含网页之间的链接流动信息。搜索引擎在抓取页面内容后,必须事前计算出:页 面上有哪些链接指向哪些其他页面,每个页面有哪些导入链接,链接使用了什么锚文字,这些复杂的链接指向关系形成了网站和页面的链接权重。
Google PR值就是这种链接关系的最主要体现之一。其他搜索引擎也都进行类似计算,虽然它们并不称为PR.
由于页面和链接数量巨大,网上的链接关系又时时处在更新中,因此链接关系及PR的计算要耗费很长时间。关于PR和链接分析,后面还有专门的章节介绍。
9.特殊文件处理
除 了HTML文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如PDF、Word、WPS、XLS、PPT、TXT文件等。我们在搜索结果 中也经常会看到这些文件类型。但目前的搜索引擎还不能处理图片、视频、Flash这类非文字内容,也不能执行脚本和程序。
虽然搜索引擎在识别图片及从Flash中提取文字内容方面有些进步,不过距离直接靠读取图片、视频、Flash内容返回结果的目标还很远。对图片、视频内容的排名还往往是依据与之相关的文字内容,详细情况可以参考后面的整合搜索部分。
排名
经过搜索引擎蜘蛛抓取的界面,搜索引擎程序 计算得到倒排索引后,收索引擎就准备好可以随时处理用户搜索了。用户在搜索框填入关键字后,排名程序调用索引库数据,计算排名显示给客户,排名过程是与客户直接互动的。 查看全部
了解搜索引擎来进行SEO
搜索引擎的工作的过程非常复杂,而简单的讲搜索引擎的工过程大体可以分成三个阶段。爬行和抓取:搜索引擎蜘蛛通过跟踪链接访问页面,获取页面HTML代码存入数据库。预处理:搜索赢球对抓取来的页面数据文字进行文字提取、中文分词、索引等处理,以备排名程序调用。排名:用户输入关键字后,排名调用索引库数据,计算相关性,然后按一定格式生成搜索结果页面。
爬行和抓取
爬行和抓取是搜索引擎工作的第一步,完成数据收集任务。
蜘蛛
搜索引擎用来爬行和访问页面的程序被称为蜘蛛(spider),也称为机器人(bot)。
蜘蛛代理名称:
百度蜘蛛:Baiduspider+(+) ·
雅虎中国蜘蛛:Mozilla/5.0 (compatible; Yahoo! Slurp China; ) ·
英文雅虎蜘蛛:Mozilla/5.0 (compatible; Yahoo! Slurp/3.0; )
Google 蜘蛛:Mozilla/5.0 (compatible; Googlebot/2.1; +) ·
微软 Bing 蜘蛛:msnbot/1.1 (+)·
搜狗蜘蛛: Sogou+web+robot+(+#07) ·
搜搜蜘蛛:Sosospider+(+) ·
有道蜘蛛:Mozilla/5.0 (compatible; YodaoBot/1.0; ; )
跟踪链接
为了抓取网上尽量多的页面,搜索引擎蜘蛛会跟踪页面上的链接,从一个页面爬到下一个页面,就好像蜘蛛在蜘蛛网上爬行那样,这也就是搜索引擎蜘蛛这个名称的由来。最简单的爬行遍历策略分为两种,一是深度优先,二是广度优先。
深度优先搜索
深度优先搜索就是在搜索树的每一层始终先只扩展一个子节点,不断地向纵深前进直到不能再前进(到达叶子节点或受到深度限制)时,才从当前节点返回到上一级节点,沿另一方向又继续前进。这种方法的搜索树是从树根开始一枝一枝逐渐形成的。
深度优先搜索亦称为纵向搜索。由于一个有解的问题树可能含有无穷分枝,深度优先搜索如果误入无穷分枝(即深度无限),则不可能找到目标节点。所以,深度优先搜索策略是不完备的。另外,应用此策略得到的解不一定是最佳解(最短路径)。
广度优先搜索
在深度优先搜索算法中,是深度越大的结点越先得到扩展。如果在搜索中把算法改为按结点的层次进行搜索, 本层的结点没有搜索处理完时,不能对下层结点进行处理,即深度越小的结点越先得到扩展,也就是说先产生 的结点先得以扩展处理,这种搜索算法称为广度优先搜索法。
在深度优先搜索算法中,是深度越大的结点越先得到扩展。如果在搜索中把算法改为按结点的层次进行搜索, 本层的结点没有搜索处理完时,不能对下层结点进行处理,即深度越小的结点越先得到扩展,也就是说先产生 的结点先得以扩展处理,这种搜索算法称为广度优先搜索法。
吸引蜘蛛
哪些页面被认为比较重要呢?有几方面影响因素:
· 网站和页面权重。质量高、资格老的网站被认为权重比较高,这种网站上的页面被爬行的深度也会比较高,所以会有更多内页被收录。
· 页面更新度。蜘蛛每次爬行都会把页面数据存储起来。如果第二次爬行发现页面与第一次收录的完全一样,说明页面没有更新,蜘蛛也就没有必要经常抓取。如果页面内容经常更新,蜘蛛就会更加频繁地访问这种页面,页面上出现的新链接,也自然会被蜘蛛更快跟踪,抓取新页面。
· 导入链接。无论是外部链接还是同一个网站的内部链接,要被蜘蛛抓取就必须有导入链接进入页面,否则蜘蛛根本没有机会知道页面的存在。高质量的导入链接也经常使页面上的导出链接被爬行深度增加。一般来说网站上权重最高的是首页,大部分外部链接是指向首页,蜘蛛访问最频繁的也是首页。离首页点击距离越近,页面权重越高,被蜘蛛爬行的机会也越大。
地址库
为了避免重复爬行和抓取网址,搜索引擎会建立一个地址库,记录已经被发现还没有抓取的页面,以及已经被抓取的页面。地址库中的uRL有几个来源:
(1)人工录入的种子网站。
(2)蜘蛛抓取页面后,从HTML中解析出新的链接uRL,与地址库中的数据进行对比,如果是地址库中没有的网址,就存入待访问地址库。
(3)站长通过搜索引擎网页提交表格提交进来的网址。
蜘蛛按重要性从待访问地址库中提取uRL,访问并抓取页面,然后把这个uRL从待访问地址库中删除,放进已访问地址库中。
大部分主流搜索引擎都提供一个表格,让站长提交网址。不过这些提交来的网址都只是存入地址库而已,是否收录还要看页面重要性如何。搜索引擎所收录的绝大部分页面是蜘蛛自己跟踪链接得到的。可以说提交页面基本t是毫无用处的,搜索引擎更喜欢自己沿着链接发现新页面。
文件存储搜索引擎蜘蛛抓取的数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML是完全一样的。每个uRI,都有一个独特的文件编号。
爬行时的复制内容检测
检测并删除复制内容通常是在下面介绍的预处理过程中进行的,但现在的蜘蛛在爬行和抓取文件时也会进行定程度的复制内容检测。遇到权重很低的网站上大量转载或抄袭内容时,很可能不再继续爬行。这也就是有的站长在日志文件中发现了蜘蛛,但页面从来没有被真正收录过的原因。
预处理
在一些SEO材料中,“预处理”也被简称为“索引”,因为索引是预处理最主要的步骤。
搜索引擎蜘蛛抓取的原始页面,并不能直接用于查询排名处理。搜索引擎数据库中的页面数都在数万亿级别以上,用户输入搜索词后,靠排名程序实时对这么多页面分析相关性,计算量太大,不可能在一两秒内返回排名结果。因此抓取来的页面必须经过预处理,为最后的查询排名做好准备。
和爬行抓取一样,预处理也是在后台提前完成的,用户搜索时感觉不到这个过程。
1.提取文字
现在的搜索引擎还是以文字内容为基础。蜘蛛抓取到的页面中的HTML代码,除了用户在浏览器上可以看到的可见文字外,还包含了大量的HTML格式标签、 JavaScript程序等无法用于排名的内容。搜索引擎预处理首先要做的就是从HTML文件中去除标签、程序,提取出可以用于排名处理的网页面文字内 容。
今天愚人节哈
除去HTML代码后,剩下的用于排名的文字只是这一行:
今天愚人节哈
除了可见文字,搜索引擎也会提取出一些特殊的包含文字信息的代码,如Meta标签中的文字、图片替代文字、Flash文件的替代文字、链接锚文字等。
2.中文分词
分词是中文搜索引擎特有的步骤。搜索引擎存储和处理页面及用户搜索都是以词为基础的。英文等语言单词与单词之间有空格分隔,搜索引擎索引程序可以直接把句子 划分为单词的集合。而中文词与词之间没有任何分隔符,一个句子中的所有字和词都是连在一起的。搜索引擎必须首先分辨哪几个字组成一个词,哪些字本身就是一 个词。比如“减肥方法”将被分词为“减肥”和“方法”两个词。
中文分词方法基本上有两种,一种是基于词典匹配,另一种是基于统计。
基于词典匹配的方法是指,将待分析的一段汉字与一个事先造好的词典中的词条进行匹配,在待分析汉字串中扫描到词典中已有的词条则匹配成功,或者说切分出一个单词。
按照扫描方向,基于词典的匹配法可以分为正向匹配和逆向匹配。按照匹配长度优先级的不同,又可以分为最大匹配和最小匹配。将扫描方向和长度优先混合,又可以产生正向最大匹配、逆向最大匹配等不同方法。
词典匹配方法计算简单,其准确度在很大程度上取决于词典的完整性和更新情况。
基于统计的分词方法指的是分析大量文字样本,计算出字与字相邻出现的统计概率,几个字相邻出现越多,就越可能形成一个单词。基于统计的方法的优势是对新出现的词反应更快速,也有利于消除歧义。
基于词典匹配和基于统计的分词方法各有优劣,实际使用中的分词系统都是混合使用两种方法的,快速高效,又能识别生词、新词,消除歧义。
中文分词的准确性往往影响搜索引擎排名的相关性。比如在百度搜索“搜索引擎优化”,从快照中可以看到,百度把“搜索引擎优化”这六个字当成一个词。
而在Google搜索同样的词,快照显示Google将其分切为“搜索引擎”和“优化”两个词。显然百度切分得更为合理,搜索引擎优化是一个完整的概念。Google分词时倾向于更为细碎。
这种分词上的不同很可能是一些关键词排名在不同搜索引擎有不同表现的原因之一。比如百度更喜欢将搜索词完整匹配地出现在页面上,也就是说搜索“够戏博客” 时,这四个字连续完整出现更容易在百度获得好的排名。Google就与此不同,不太要求完整匹配。一些页面出现“够戏”和“博客”两个词,但不必完整匹配 地出现,“够戏”出现在前面,“博客”出现在页面的其他地方,这样的页面在Google搜索“够戏博客”时,也可以获得不错的排名。
搜索引擎对页面的分词取决于词库的规模、准确性和分词算法的好坏,而不是取决于页面本身如何,所以SEO人员对分词所能做的很少。唯一能做的是在页面上用某种形 式提示搜索引擎,某几个字应该被当做一个词处理,尤其是可能产生歧义的时候,比如在页面标题、h1标签及黑体中出现关键词。如果页面是关于“和服”的内 容,那么可以把“和服”这两个字特意标为黑体。如果页面是关于“化妆和服装”,可以把“服装”两个字标为黑体。这样,搜索引擎对页面进行分析时就知道标为 黑体的应该是一个词。
3.去停止词
无论是英文还是中文,页面内容中都会有一些出现频率很 高,却对内容没有任何影响的词,如“的”、“地”、“得”之类的助词,“啊”、“哈”、“呀”之类的感叹词,“从而”、“以”、“却”之类的副词或介词。 这些词被称为停止词,因为它们对页面的主要意思没什么影响。英文中的常见停止词有the,a,an,to,of等。
搜索引擎在索引页面之前会去掉这些停止词,使索引数据主题更为突出,减少无谓的计算量。
4.消除噪声
绝 大部分页面上还有一部分内容对页面主题也没有什么贡献,比如版权声明文字、导航条、广告等。以常见的博客导航为例,几乎每个博客页面上都会出现文章分类、 历史存档等导航内容,但是这些页面本身与“分类”、“历史”这些词都没有任何关系。用户搜索“历史”、“分类”这些关键词时仅仅因为页面上有这些词出现而 返回博客帖子是毫无意义的,完全不相关。所以这些区块都属于噪声,对页面主题只能起到分散作用。
搜索引擎需要识别并消除这些噪声,排名时不使用噪声内容。消噪的基本方法是根据HTML标签对页面分块,区分出页头、导航、正文、页脚、广告等区域,在网站上大量重复出现的区块往往属于噪声。对页面进行消噪后,剩下的才是页面主体内容。
5.去重
搜索引擎还需要对页面进行去重处理。
同 一篇文章经常会重复出现在不同网站及同一个网站的不同网址上,搜索引擎并不喜欢这种重复性的内容。用户搜索时,如果在前两页看到的都是来自不同网站的同一 篇文章,用户体验就太差了,虽然都是内容相关的。搜索引擎希望只返回相同文章中的一篇,所以在进行索引前还需要识别和删除重复内容,这个过程就称为“去 重”。
去重的基本方法是对页面特征关键词计算指纹,也就是说从页面主体内容中选取最有代表性的一部分关键词(经常是出现频率最高的关键 词),然后计算这些关键词的数字指纹。这里的关键词选取是在分词、去停止词、消噪之后。实验表明,通常选取10个特征关键词就可以达到比较高的计算准确 性,再选取更多词对去重准确性提高的贡献也就不大了。
典型的指纹计算方法如MD5算法(信息摘要算法第五版)。这类指纹算法的特点是,输入(特征关键词)有任何微小的变化,都会导致计算出的指纹有很大差距。
了 解了搜索引擎的去重算法,SEO人员就应该知道简单地增加“的”、“地”、“得”、调换段落顺序这种所谓伪原创,并不能逃过搜索引擎的去重算法,因为这样 的操作无法改变文章的特征关键词。而且搜索引擎的去重算法很可能不止于页面级别,而是进行到段落级别,混合不同文章、交叉调换段落顺序也不能使转载和抄袭 变成原创。
6.正向索引
正向索引也可以简称为索引。
经过文字提取、分词、 消噪、去重后,搜索引擎得到的就是独特的、能反映页面主体内容的、以词为单位的内容。接下来搜索引擎索引程序就可以提取关键词,按照分词程序划分好的词, 把页面转换为一个关键词组成的集合,同时记录每一个关键词在页面上的出现频率、出现次数、格式(如出现在标题标签、黑体、H标签、锚文字等)、位置(如页 面第一段文字等)。这样,每一个页面都可以记录为一串关键词集合,其中每个关键词的词频、格式、位置等权重信息也都记录在案。
搜索引擎索引程序将页面及关键词形成词表结构存储进索引库。简化的索引词表形式如表2-1所示。
每个文件都对应一个文件ID,文件内容被表示为一串关键词的集合。实际上在搜索引擎索引库中,关键词也已经转换为关键词ID.这样的数据结构就称为正向索引。
7.倒排索引
正向索引还不能直接用于排名。假设用户搜索关键词2,如果只存在正向索引,排名程序需要扫描所有索引库中的文件,找出包含关键词2的文件,再进行相关性计算。这样的计算量无法满足实时返回排名结果的要求。
所以搜索引擎会将正向索引数据库重新构造为倒排索引,把文件对应到关键词的映射转换为关键词到文件的映射,如表2-2所示。
在倒排索引中关键词是主键,每个关键词都对应着一系列文件,这些文件中都出现了这个关键词。这样当用户搜索某个关键词时,排序程序在倒排索引中定位到这个关键词,就可以马上找出所有包含这个关键词的文件。
8.链接关系计算
链接关系计算也是预处理中很重要的一部分。现在所有的主流搜索引擎排名因素中都包含网页之间的链接流动信息。搜索引擎在抓取页面内容后,必须事前计算出:页 面上有哪些链接指向哪些其他页面,每个页面有哪些导入链接,链接使用了什么锚文字,这些复杂的链接指向关系形成了网站和页面的链接权重。
Google PR值就是这种链接关系的最主要体现之一。其他搜索引擎也都进行类似计算,虽然它们并不称为PR.
由于页面和链接数量巨大,网上的链接关系又时时处在更新中,因此链接关系及PR的计算要耗费很长时间。关于PR和链接分析,后面还有专门的章节介绍。
9.特殊文件处理
除 了HTML文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如PDF、Word、WPS、XLS、PPT、TXT文件等。我们在搜索结果 中也经常会看到这些文件类型。但目前的搜索引擎还不能处理图片、视频、Flash这类非文字内容,也不能执行脚本和程序。
虽然搜索引擎在识别图片及从Flash中提取文字内容方面有些进步,不过距离直接靠读取图片、视频、Flash内容返回结果的目标还很远。对图片、视频内容的排名还往往是依据与之相关的文字内容,详细情况可以参考后面的整合搜索部分。
排名
经过搜索引擎蜘蛛抓取的界面,搜索引擎程序 计算得到倒排索引后,收索引擎就准备好可以随时处理用户搜索了。用户在搜索框填入关键字后,排名程序调用索引库数据,计算排名显示给客户,排名过程是与客户直接互动的。
如何在网页测试中叠加多个被试的眼动追踪数据?
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-05-07 09:17
在多数网页研究中,给被试者分配的任务通常包含浏览某个网站或浏览某个网页应用。在浏览的过程中,他们并不是被动地观看按指定顺序和时长呈现的刺激材料,而是会与呈现的刺激材料进行交互,这样每个被试者的结果都是独一无二的。因此如果要对这些被试者的体验进行对比就会很繁琐,并且多被试的眼动数据自动叠加是一项很有挑战性的工作。
例如,在浏览网页时,一些被试者可能在某个页面的停留时间比其他被试者长,他们可能会跳转到其他页面,多次播放和停止网页内的视频等。如果一个或两个被试者在浏览一个页面时花了很多的时间,那么他们的注视点数量可能会增加,这会对叠加的数据带来影响。页面中还有可能会包含一些动态内容,例如下拉菜单,弹出窗口和flash动画内容,这些都会对数据的自动叠加带来一些挑战。
在进行网页眼动数据采集时,对这些不同的挑战要保持足够的注意并做出相应的分析做好准备。本文将介绍通过Pro Lab软件实现对网页实验项目中多被试者的眼动追踪数据叠加的方法和步骤。我们将对能够自动叠加数据和手动叠加数据的案例进行着重阐述。
1
通过自动网页导航TOI兴趣区间叠加数据
在使用网页元素进行测试时,Pro Lab软件会记录观察窗*区域的测试过程的视频并同时提取所有打开的独立的URL的完整页面屏幕截图。软件还会保存与页面导航时间相关的TOI信息和事件(确定TOI的开始和结束点)在分析过程中,你可以通过这些视频记录来观察被试者的行为并发现可用性问题并找到诠释问题的方法,或可以通过屏幕截图与相应的TOI将眼动追踪数据叠加到每个网页上。例如,将数据叠加到一张热点图上时,Pro Lab软件使用屏幕截图作为数据叠加的背景图像并使用两个TOI事件来确定叠加在热点图上的数据范围。
*观察窗是指被试者在浏览网页时呈现在当前屏幕上的那部分网页。
如果在测试中被试者多次访问同一个网页,那么每次访问都将生成相同的开始和结束事件并作为属于相同的兴趣区间TOI的不同时间片段和屏幕截图被记录下来。默认情况下,当你选择了一个兴趣区间TOI,Pro Lab软件会按所有属于该兴趣区间TOI的时间片段来叠加数据。
图1. 对相同的网页进行多次访问的数据是如何被叠加到相同的网页导航兴趣区间(TOI)的。
接下来,我们将分步骤介绍创建数据叠加可视化结果和根据网页导航兴趣区间TOI提取眼动追踪统计指标的方法。
将数据叠加到热点图上的操作步骤:
1. 点击Visualization按钮,可以在Project Overview界面或从顶部导航栏中的Analyze下拉列表中找到该按钮。
2. 在界面右侧打开工具栏中的Visualization Type和Settings工具,并选择Heat Map。
3. 选择创建热点图所使用的眼动数据过滤器。请参考Pro Lab用户手册附录部分 “Appendix B Gaze Filters’ functions and effects” 进一步了解眼动数据过滤器。
4. 进入Times of Interest工具并选择与要创建热点图的网页相对应的网页导航。为了帮你高效地进行兴趣区间TOI的选择,软件将呈现网页的名称和缩略图。
5.切换到Recordings工具并选择或取消选择要叠加到热点图上的记录。
6. 选择热点图的创建方式- 绝对计数, 相对计数,绝对时间或相对时间。(请参阅Pro Lab 用户手册附录部分“Appendix C Calculating heat maps” 进一步了解热点图的不同创建方式)。
7. 叠加了多个记录的数据的热点图创建ok。
提取眼动追踪统计指标的步骤:
1. 打开AOI选项卡来创建你的AOI兴趣区。
2. 在Media Selection部分选择目标网页图像。
3. 为要分析的元素描绘兴趣区域。
4. 如果你想跨多个兴趣区来叠加数据,也可以创建AOI标签并将每个AOI进行标记(兴趣区组)。
5. 切换到Metrics Export选项卡。
6. 在Settings面板点击Export Format下拉列表选择数据输出的格式。选择Interval based TSV file (default).tsv格式将按照页面的每次访问来切分数据或选择Excel report for the.xlsx格式导出汇总报告。
7. 选择要包含在导出数据文件中的统计指标(可选的统计指标按第2步的选择有所不同)。
8. 选择导出使用的眼动数据过滤器。请参考Pro Lab用户手册附录部分 “Appendix B Gaze Filters’ functions and effects” 进一步了解眼动数据过滤器。
9. 选择记录。选择导出全部记录或按照需要选择相应的记录进行导出。
10. 选择Participant variables可根据被试变量对数据做进一步筛选。
11. 选择网页导航兴趣区间TOI。
12. 选择第1-4步创建的AOI兴趣区和兴趣区标签。
13. 可选择Web Navigation Event types来导出与事件相关的统计指标。
14. 点击Export开始数据导出。
2
使用自定义兴趣区间TOI叠加数据的操作步骤
如果你的研究需要将数据叠加到带有少量或没有动态元素的网页上,你可以使用网页导航兴趣区间TOI和相应的屏幕截图来叠加数据。但如果网页包含较多动态元素,你就会面临三个挑战:
1. 浏览器不支持某些动态内容**
2. 网页截图无法呈现某些网页的动态元素***
3. 在网页访问期间如果用户花了一些时间与动态元素进行交互和观察,那么这期间采集到的眼动数据可能会错误地叠加到网页图像上。
** 例如,Pro Lab内嵌浏览器目前不支持 Flash动画元素。
***唯一的例外是网页的固定元素,Tobii Pro Lab软件能够追踪这些元素并正确叠加数据。固定元素是指网页中与浏览窗口位置相关而不是与网页本身位置相关的元素。当被试者将包含固定元素的网页向下滚动时,这些元素仍停留在网页截图中固定的位置不变,而其他的元素则会相应地移动。这些元素在网页截图中的位置是固定的。任何在这些元素上的眼动数据都将被叠加到屏幕截图中相应元素的位置,无论这些元素真正被看到时处于什么位置。这样可以更真实地展现注视点。
上面列出的挑战也说明了系统生成的网页导航兴趣区间TOI可能无法满足你的研究需求,因为将会有一部分眼动数据无法正确叠加到自动生成的网页截图所无法呈现的元素上,即一部份数据是视觉上无意义的。而这部分数据应该属于被试与动态元素的交互行为。例如,如果被试在网页中打开了一个下拉菜单,那么观察该菜单的视觉模式将会被记录并叠加到网页截图上,但在网页截图上,该菜单是不可见的。其他类型的动态元素也会出现这种情况,例如不会生成独立URL的弹出窗口或跨越屏幕呈现的元素。
如前文所述,在眼动测试数据采集期间,Pro Lab也会捕捉整个浏览环节中观察窗部分的视频。该视频也可以在后期回放记录时被回放出来。该视频其实就是被试者网页浏览行为的屏幕记录,因此你可以在回放中看到不同的动态元素和被试者对这些元素的观察与交互行为。在数据分析期间,你可以使用该视频在时间轴上创建事件作为被试者与这些元素交互的开始和结束标记。创建好这些事件后,就可以进一步通过它们来创建与视频帧相关的自定义兴趣区间TOI。自定义兴趣区间TOI可将与动态内容的交互相关的视觉浏览行为数据进行叠加,而视频的帧图像可作为带有动态内容的网页的数据叠加背景图像。将自定义兴趣区间TOI和帧图像结合,就可以实现叠加了多被试数据的可视化结果生成并创建兴趣区来提取眼动追踪统计指标。
在上一个例子中,当被试者与一个下拉菜单进行交互时,你可能需要标记两个事件,例如,下拉菜单打开和下拉菜单关闭,然后通过这两个事件作为开始点和结束点,结合一帧视频图像来创建自定义兴趣区间TOI。帧图像需要在视频中该下拉菜单处于打开状态时截取。然后重复这个步骤,在其他记录中创建相应的兴趣区间TOI,然后在Visualization工具中选择按自定义兴趣区间TOI来创建热点图等可视化结果。这样,生成的热点图就将展示出叠加了多被试数据的对下拉菜单的视觉观察行为。下面将按步骤介绍基于视频帧的自定义兴趣区间TOI的创建方法。
创建自定义兴趣区间TOI的操作步骤:
1. 打开一条记录
2. 创建一个或两个自定义事件来确定兴趣区间TOI的开始点和结束点,例如,每当用户打开下拉菜单和关闭该菜单。
3. 将鼠标指针移到打开的菜单中视频的一帧,然后点击位于记录的计时器右侧的创建帧图像的图标并选择Create Toi with frame选项。如前文所述,帧与网页截图的功能相同。
4. 在Create custom Time of Interest 窗口中选择在第1步中创建的开始和结束点。
5. 将Media重命名为对分析有意义的描述性名称。
6. 点击OK 创建兴趣区间TOI。
7. 重复第1步和第2步为其他记录定义兴趣区间TOI的开始和结束点。
创建了与帧相关联的自定义兴趣区间TOI后,你就可以像使用网页导航兴趣区间TOI一样使用这些自定义的兴趣区间TOI来生成可视化结果并提取基于多被试的叠加的眼动统计指标了。
这种分析流程的局限性在于网页的动态内容需要适应观察窗。如果被试需要通过滚动操作来与元素进行交互,那么这种方案就不可行,因为你无法将观察行为汇总到一个单独的视频帧上。
3
结语
在网页的眼动测试中叠加多个被试的数据在概念上和技术上都具有挑战性,对如今包含大量动态内容的网页来说更是如此。
从概念上看,由于动态内容使每个被试在一个网页的交互数据都不同,所以很难在几个不同被试之间进行数据对比;而从技术上看,很难有效地捕捉用于创建热点图的眼动数据,因为 内容是不断变化的——尤其是仅当页面的某些部分发生变化。
在研究的准备阶段,你就需要充分考虑到这些可能会面临的挑战并针对每个难点确定可行的分析方案和流程。这样你才能更现实际地预估为数据分析工作投入的时间和资源。
表1.不同的网页动态元素与跨多被试数据叠加的相应流程/功能汇总
网页动态内容
Pro Lab 分析元素
无
网页截图相关联的网页导航兴趣区间TOI
事件自动生成,自动抓取整幅网页图像
可展开的元素与不需要滚动的内容(适应观察窗)
视频帧相关联的自定义兴趣区间TOI
需手动添加事件并从视频中选择背景帧
可展开的元素与需要滚动的内容(不会自适应观察窗)
手动叠加 (请参见用户手册第8.2 章节)
需要通过手动Coding的方式将注视点叠加到视觉编码方案表单或导入的网页图像上
固定元素
网页导航兴趣区间TOI相关联的网页截图
事件自动生成,自动抓取整幅网页图像
生成新URL的弹出元素
网页导航兴趣区间TOI相关联的网页截图
事件自动生成,自动抓取整幅网页图像
不生成新URL的弹出元素
视频帧相关联的自定义兴趣区间TOI
需手动添加事件并从视频中选择背景帧
嵌入式mp4视频内容
暂时无法分析 (浏览器不支持)
在视频记录中不可见
嵌入式Flash动画内容
暂时无法分析 (浏览器不支持)
在视频记录中不可见
-The end-
你可能还想看:
探究人类行为
我们通过领先的眼动追踪解决方案帮助商业和科研专家获得人类行为的真实洞察力。我们的眼动追踪研究产品和服务正在被全球超过2,000家企业和1,500所研究机构所使用。
查看全部
如何在网页测试中叠加多个被试的眼动追踪数据?
在多数网页研究中,给被试者分配的任务通常包含浏览某个网站或浏览某个网页应用。在浏览的过程中,他们并不是被动地观看按指定顺序和时长呈现的刺激材料,而是会与呈现的刺激材料进行交互,这样每个被试者的结果都是独一无二的。因此如果要对这些被试者的体验进行对比就会很繁琐,并且多被试的眼动数据自动叠加是一项很有挑战性的工作。
例如,在浏览网页时,一些被试者可能在某个页面的停留时间比其他被试者长,他们可能会跳转到其他页面,多次播放和停止网页内的视频等。如果一个或两个被试者在浏览一个页面时花了很多的时间,那么他们的注视点数量可能会增加,这会对叠加的数据带来影响。页面中还有可能会包含一些动态内容,例如下拉菜单,弹出窗口和flash动画内容,这些都会对数据的自动叠加带来一些挑战。
在进行网页眼动数据采集时,对这些不同的挑战要保持足够的注意并做出相应的分析做好准备。本文将介绍通过Pro Lab软件实现对网页实验项目中多被试者的眼动追踪数据叠加的方法和步骤。我们将对能够自动叠加数据和手动叠加数据的案例进行着重阐述。
1
通过自动网页导航TOI兴趣区间叠加数据
在使用网页元素进行测试时,Pro Lab软件会记录观察窗*区域的测试过程的视频并同时提取所有打开的独立的URL的完整页面屏幕截图。软件还会保存与页面导航时间相关的TOI信息和事件(确定TOI的开始和结束点)在分析过程中,你可以通过这些视频记录来观察被试者的行为并发现可用性问题并找到诠释问题的方法,或可以通过屏幕截图与相应的TOI将眼动追踪数据叠加到每个网页上。例如,将数据叠加到一张热点图上时,Pro Lab软件使用屏幕截图作为数据叠加的背景图像并使用两个TOI事件来确定叠加在热点图上的数据范围。
*观察窗是指被试者在浏览网页时呈现在当前屏幕上的那部分网页。
如果在测试中被试者多次访问同一个网页,那么每次访问都将生成相同的开始和结束事件并作为属于相同的兴趣区间TOI的不同时间片段和屏幕截图被记录下来。默认情况下,当你选择了一个兴趣区间TOI,Pro Lab软件会按所有属于该兴趣区间TOI的时间片段来叠加数据。
图1. 对相同的网页进行多次访问的数据是如何被叠加到相同的网页导航兴趣区间(TOI)的。
接下来,我们将分步骤介绍创建数据叠加可视化结果和根据网页导航兴趣区间TOI提取眼动追踪统计指标的方法。
将数据叠加到热点图上的操作步骤:
1. 点击Visualization按钮,可以在Project Overview界面或从顶部导航栏中的Analyze下拉列表中找到该按钮。
2. 在界面右侧打开工具栏中的Visualization Type和Settings工具,并选择Heat Map。
3. 选择创建热点图所使用的眼动数据过滤器。请参考Pro Lab用户手册附录部分 “Appendix B Gaze Filters’ functions and effects” 进一步了解眼动数据过滤器。
4. 进入Times of Interest工具并选择与要创建热点图的网页相对应的网页导航。为了帮你高效地进行兴趣区间TOI的选择,软件将呈现网页的名称和缩略图。
5.切换到Recordings工具并选择或取消选择要叠加到热点图上的记录。
6. 选择热点图的创建方式- 绝对计数, 相对计数,绝对时间或相对时间。(请参阅Pro Lab 用户手册附录部分“Appendix C Calculating heat maps” 进一步了解热点图的不同创建方式)。
7. 叠加了多个记录的数据的热点图创建ok。
提取眼动追踪统计指标的步骤:
1. 打开AOI选项卡来创建你的AOI兴趣区。
2. 在Media Selection部分选择目标网页图像。
3. 为要分析的元素描绘兴趣区域。
4. 如果你想跨多个兴趣区来叠加数据,也可以创建AOI标签并将每个AOI进行标记(兴趣区组)。
5. 切换到Metrics Export选项卡。
6. 在Settings面板点击Export Format下拉列表选择数据输出的格式。选择Interval based TSV file (default).tsv格式将按照页面的每次访问来切分数据或选择Excel report for the.xlsx格式导出汇总报告。
7. 选择要包含在导出数据文件中的统计指标(可选的统计指标按第2步的选择有所不同)。
8. 选择导出使用的眼动数据过滤器。请参考Pro Lab用户手册附录部分 “Appendix B Gaze Filters’ functions and effects” 进一步了解眼动数据过滤器。
9. 选择记录。选择导出全部记录或按照需要选择相应的记录进行导出。
10. 选择Participant variables可根据被试变量对数据做进一步筛选。
11. 选择网页导航兴趣区间TOI。
12. 选择第1-4步创建的AOI兴趣区和兴趣区标签。
13. 可选择Web Navigation Event types来导出与事件相关的统计指标。
14. 点击Export开始数据导出。
2
使用自定义兴趣区间TOI叠加数据的操作步骤
如果你的研究需要将数据叠加到带有少量或没有动态元素的网页上,你可以使用网页导航兴趣区间TOI和相应的屏幕截图来叠加数据。但如果网页包含较多动态元素,你就会面临三个挑战:
1. 浏览器不支持某些动态内容**
2. 网页截图无法呈现某些网页的动态元素***
3. 在网页访问期间如果用户花了一些时间与动态元素进行交互和观察,那么这期间采集到的眼动数据可能会错误地叠加到网页图像上。
** 例如,Pro Lab内嵌浏览器目前不支持 Flash动画元素。
***唯一的例外是网页的固定元素,Tobii Pro Lab软件能够追踪这些元素并正确叠加数据。固定元素是指网页中与浏览窗口位置相关而不是与网页本身位置相关的元素。当被试者将包含固定元素的网页向下滚动时,这些元素仍停留在网页截图中固定的位置不变,而其他的元素则会相应地移动。这些元素在网页截图中的位置是固定的。任何在这些元素上的眼动数据都将被叠加到屏幕截图中相应元素的位置,无论这些元素真正被看到时处于什么位置。这样可以更真实地展现注视点。
上面列出的挑战也说明了系统生成的网页导航兴趣区间TOI可能无法满足你的研究需求,因为将会有一部分眼动数据无法正确叠加到自动生成的网页截图所无法呈现的元素上,即一部份数据是视觉上无意义的。而这部分数据应该属于被试与动态元素的交互行为。例如,如果被试在网页中打开了一个下拉菜单,那么观察该菜单的视觉模式将会被记录并叠加到网页截图上,但在网页截图上,该菜单是不可见的。其他类型的动态元素也会出现这种情况,例如不会生成独立URL的弹出窗口或跨越屏幕呈现的元素。
如前文所述,在眼动测试数据采集期间,Pro Lab也会捕捉整个浏览环节中观察窗部分的视频。该视频也可以在后期回放记录时被回放出来。该视频其实就是被试者网页浏览行为的屏幕记录,因此你可以在回放中看到不同的动态元素和被试者对这些元素的观察与交互行为。在数据分析期间,你可以使用该视频在时间轴上创建事件作为被试者与这些元素交互的开始和结束标记。创建好这些事件后,就可以进一步通过它们来创建与视频帧相关的自定义兴趣区间TOI。自定义兴趣区间TOI可将与动态内容的交互相关的视觉浏览行为数据进行叠加,而视频的帧图像可作为带有动态内容的网页的数据叠加背景图像。将自定义兴趣区间TOI和帧图像结合,就可以实现叠加了多被试数据的可视化结果生成并创建兴趣区来提取眼动追踪统计指标。
在上一个例子中,当被试者与一个下拉菜单进行交互时,你可能需要标记两个事件,例如,下拉菜单打开和下拉菜单关闭,然后通过这两个事件作为开始点和结束点,结合一帧视频图像来创建自定义兴趣区间TOI。帧图像需要在视频中该下拉菜单处于打开状态时截取。然后重复这个步骤,在其他记录中创建相应的兴趣区间TOI,然后在Visualization工具中选择按自定义兴趣区间TOI来创建热点图等可视化结果。这样,生成的热点图就将展示出叠加了多被试数据的对下拉菜单的视觉观察行为。下面将按步骤介绍基于视频帧的自定义兴趣区间TOI的创建方法。
创建自定义兴趣区间TOI的操作步骤:
1. 打开一条记录
2. 创建一个或两个自定义事件来确定兴趣区间TOI的开始点和结束点,例如,每当用户打开下拉菜单和关闭该菜单。
3. 将鼠标指针移到打开的菜单中视频的一帧,然后点击位于记录的计时器右侧的创建帧图像的图标并选择Create Toi with frame选项。如前文所述,帧与网页截图的功能相同。
4. 在Create custom Time of Interest 窗口中选择在第1步中创建的开始和结束点。
5. 将Media重命名为对分析有意义的描述性名称。
6. 点击OK 创建兴趣区间TOI。
7. 重复第1步和第2步为其他记录定义兴趣区间TOI的开始和结束点。
创建了与帧相关联的自定义兴趣区间TOI后,你就可以像使用网页导航兴趣区间TOI一样使用这些自定义的兴趣区间TOI来生成可视化结果并提取基于多被试的叠加的眼动统计指标了。
这种分析流程的局限性在于网页的动态内容需要适应观察窗。如果被试需要通过滚动操作来与元素进行交互,那么这种方案就不可行,因为你无法将观察行为汇总到一个单独的视频帧上。
3
结语
在网页的眼动测试中叠加多个被试的数据在概念上和技术上都具有挑战性,对如今包含大量动态内容的网页来说更是如此。
从概念上看,由于动态内容使每个被试在一个网页的交互数据都不同,所以很难在几个不同被试之间进行数据对比;而从技术上看,很难有效地捕捉用于创建热点图的眼动数据,因为 内容是不断变化的——尤其是仅当页面的某些部分发生变化。
在研究的准备阶段,你就需要充分考虑到这些可能会面临的挑战并针对每个难点确定可行的分析方案和流程。这样你才能更现实际地预估为数据分析工作投入的时间和资源。
表1.不同的网页动态元素与跨多被试数据叠加的相应流程/功能汇总
网页动态内容
Pro Lab 分析元素
无
网页截图相关联的网页导航兴趣区间TOI
事件自动生成,自动抓取整幅网页图像
可展开的元素与不需要滚动的内容(适应观察窗)
视频帧相关联的自定义兴趣区间TOI
需手动添加事件并从视频中选择背景帧
可展开的元素与需要滚动的内容(不会自适应观察窗)
手动叠加 (请参见用户手册第8.2 章节)
需要通过手动Coding的方式将注视点叠加到视觉编码方案表单或导入的网页图像上
固定元素
网页导航兴趣区间TOI相关联的网页截图
事件自动生成,自动抓取整幅网页图像
生成新URL的弹出元素
网页导航兴趣区间TOI相关联的网页截图
事件自动生成,自动抓取整幅网页图像
不生成新URL的弹出元素
视频帧相关联的自定义兴趣区间TOI
需手动添加事件并从视频中选择背景帧
嵌入式mp4视频内容
暂时无法分析 (浏览器不支持)
在视频记录中不可见
嵌入式Flash动画内容
暂时无法分析 (浏览器不支持)
在视频记录中不可见
-The end-
你可能还想看:
探究人类行为
我们通过领先的眼动追踪解决方案帮助商业和科研专家获得人类行为的真实洞察力。我们的眼动追踪研究产品和服务正在被全球超过2,000家企业和1,500所研究机构所使用。
抓取网页flash视频不存在性能问题,测试了几个浏览器
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-29 15:02
抓取网页flash视频不存在性能问题,测试了几个浏览器:chrome、firefox、safari、uc,不存在时延问题。本质上是浏览器的问题。如果涉及html5的话,可能需要在access-control-allow-origin前加上上传链接,否则该连接不能用。
安卓5.3以上是可以同步的ios只有付费的premium客户端能同步一般情况是一个页面一个页面刷新或者和视频本地连接
速度是可以的,uc有这个功能可以同步.比如把视频上传到百度云连接,然后下载好再同步到我的电脑上.或者你采用加密方式,比如transferwise把视频上传,然后同步到本地.
可以啊,我用了很多google浏览器,目前还是有问题。
html5本身就是不支持上传视频,目前最好的办法是对视频进行加密传输,然后让视频本地缓存再传输到nas,进行上传。
网页版基本不支持上传视频,因为html5大小是不定的,最长只能传2m,以前html5时代视频数据是可以后端存储的。现在不行了。可以考虑用音视频合并,然后直接播放即可。本地已有的视频,先直接做好合并脚本,然后先上传到服务器,然后直接配置过去,就能直接播放。xml配置方法,就是能直接访问视频内容。这个跟ip没关系。
网页上的视频传输主要是通过iframe嵌套传播的,所以用js控制一个iframe的实现了。 查看全部
抓取网页flash视频不存在性能问题,测试了几个浏览器
抓取网页flash视频不存在性能问题,测试了几个浏览器:chrome、firefox、safari、uc,不存在时延问题。本质上是浏览器的问题。如果涉及html5的话,可能需要在access-control-allow-origin前加上上传链接,否则该连接不能用。
安卓5.3以上是可以同步的ios只有付费的premium客户端能同步一般情况是一个页面一个页面刷新或者和视频本地连接
速度是可以的,uc有这个功能可以同步.比如把视频上传到百度云连接,然后下载好再同步到我的电脑上.或者你采用加密方式,比如transferwise把视频上传,然后同步到本地.
可以啊,我用了很多google浏览器,目前还是有问题。
html5本身就是不支持上传视频,目前最好的办法是对视频进行加密传输,然后让视频本地缓存再传输到nas,进行上传。
网页版基本不支持上传视频,因为html5大小是不定的,最长只能传2m,以前html5时代视频数据是可以后端存储的。现在不行了。可以考虑用音视频合并,然后直接播放即可。本地已有的视频,先直接做好合并脚本,然后先上传到服务器,然后直接配置过去,就能直接播放。xml配置方法,就是能直接访问视频内容。这个跟ip没关系。
网页上的视频传输主要是通过iframe嵌套传播的,所以用js控制一个iframe的实现了。
抓取网页flash视频( 具体方法以人人网页面为例讲述Python实现从Web的一个中抓取文档的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-04-09 14:06
具体方法以人人网页面为例讲述Python实现从Web的一个中抓取文档的方法)
Python 实现了一种从网络上抓取文档的方法
更新时间:2014年9月26日09:28:02投稿:shichen2014
本文文章主要介绍python从网页爬取文档的方法。以人人网的爬取为例,说明爬取网页文档的完整方法。有需要的朋友可以参考以下
p>
本文中的示例介绍了Python如何实现从Web上的URL爬取文档,分享给大家,供大家参考。具体方法分析如下:
示例代码如下:
import urllib
doc = urllib.urlopen("http://www.python.org").read()
print doc#直接打印出网页
def reporthook(*a):
print a
#将http://www.renren.com网页保存到renre.html中,
#每读取一个块调用一字reporthook函数
urllib.urlretrieve("http://www.renren.com",'renren.html',reporthook)
#将http://www.renren.com网页保存到renre.html中
urllib.urlretrieve("http://www.renren.com",'renren.html')
程序运行结果如下:
..........................网页内容
(0, 8192, -1)
(1, 8192, -1)
(2, 8192, -1)
其中 urllib.urlopen 返回一个类似文件的对象。
希望本文对您的 Python 编程有所帮助。 查看全部
抓取网页flash视频(
具体方法以人人网页面为例讲述Python实现从Web的一个中抓取文档的方法)
Python 实现了一种从网络上抓取文档的方法
更新时间:2014年9月26日09:28:02投稿:shichen2014
本文文章主要介绍python从网页爬取文档的方法。以人人网的爬取为例,说明爬取网页文档的完整方法。有需要的朋友可以参考以下
p>
本文中的示例介绍了Python如何实现从Web上的URL爬取文档,分享给大家,供大家参考。具体方法分析如下:
示例代码如下:
import urllib
doc = urllib.urlopen("http://www.python.org";).read()
print doc#直接打印出网页
def reporthook(*a):
print a
#将http://www.renren.com网页保存到renre.html中,
#每读取一个块调用一字reporthook函数
urllib.urlretrieve("http://www.renren.com",'renren.html',reporthook)
#将http://www.renren.com网页保存到renre.html中
urllib.urlretrieve("http://www.renren.com",'renren.html')
程序运行结果如下:
..........................网页内容
(0, 8192, -1)
(1, 8192, -1)
(2, 8192, -1)
其中 urllib.urlopen 返回一个类似文件的对象。
希望本文对您的 Python 编程有所帮助。
抓取网页flash视频(我正在尝试获取在我的客户端上播放的Wowza视频流)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-07 07:27
我正在尝试获取在我的客户端上播放的 Wowza 视频流的位图/快照,如下所示:
var bitmapData:BitmapData = new BitmapData(view.videoPlayerComponent.width, view.videoPlayerComponent.height);
bitmapData.draw(view.videoPlayerComponent);
当我这样做时,我收到以下错误消息:SecurityError:错误 #2123:安全沙箱违规:BitmapData.draw::51150/Resources/WRemoteWebCam.swf 无法访问 rtmp://localhost/videochat /smithkl42._default/。没有授予访问权限的策略文本我认为错误来自无法找到相应的 crossdomain.xml 文件。我不太确定它在哪里寻找它,wireshark 嗅探没有结果,所以我尝试在以下每个中放置一个: :1935/crossdomain。 xml :1935/crossdomain.xml ://localhost:51150/crossdomain.xml 我可以成功地从这三个位置检索文件。 (我很确定最后一个没有任何区别,因为它只是托管 .swf 文件的网页所在的 网站 的位置,但机会是......)这些就是它抓住的在每个实例中获取的文件的内容:
它仍然会抛出相同的错误消息。我还按照 Wowza 论坛上的说明在 [install] conf [appname] Application.xml 中打开 StreamVideoSampleAccess,不好玩:
-1
*
*
*
*
*
*
有什么想法吗? 查看全部
抓取网页flash视频(我正在尝试获取在我的客户端上播放的Wowza视频流)
我正在尝试获取在我的客户端上播放的 Wowza 视频流的位图/快照,如下所示:
var bitmapData:BitmapData = new BitmapData(view.videoPlayerComponent.width, view.videoPlayerComponent.height);
bitmapData.draw(view.videoPlayerComponent);
当我这样做时,我收到以下错误消息:SecurityError:错误 #2123:安全沙箱违规:BitmapData.draw::51150/Resources/WRemoteWebCam.swf 无法访问 rtmp://localhost/videochat /smithkl42._default/。没有授予访问权限的策略文本我认为错误来自无法找到相应的 crossdomain.xml 文件。我不太确定它在哪里寻找它,wireshark 嗅探没有结果,所以我尝试在以下每个中放置一个: :1935/crossdomain。 xml :1935/crossdomain.xml ://localhost:51150/crossdomain.xml 我可以成功地从这三个位置检索文件。 (我很确定最后一个没有任何区别,因为它只是托管 .swf 文件的网页所在的 网站 的位置,但机会是......)这些就是它抓住的在每个实例中获取的文件的内容:
它仍然会抛出相同的错误消息。我还按照 Wowza 论坛上的说明在 [install] conf [appname] Application.xml 中打开 StreamVideoSampleAccess,不好玩:
-1
*
*
*
*
*
*
有什么想法吗?
抓取网页flash视频(抓取网页flash视频也用到了html模板中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-04-06 17:01
抓取网页flash视频也用到了webgl知识。楼主没提供清晰完整的网站地址所以暂且仅仅提出一个初步的解决方案:先要获取该网站上的所有flash视频html模板页面。用vs开发工具把视频封装好放到html模板中。页面渲染出来的flash文件就可以通过./img的形式导入js中,从而实现拖拽文件播放。我所理解的一些要点:可以通过通过javascript对img进行写劫持,就可以实现网页任意切换flash影片的方式,从而实现网页播放flash视频。可以通过javascript实现播放动画,从而实现拖拽文件播放。
听说有ie镜像页,百度一下可以找到啊,把搜狗输入法设置成特别模式就可以浏览其他程序有播放器的页面了。
百度搜索一个“javascript调试工具”。没有看到有公开免费的方法,但是有一些开源的。
貌似有thunderjs,
试试交叉渲染算法吧,这个github搜一下应该都有。firefox有相关的方案,chrome貌似也有,不过可能需要chrome7.0以上版本。百度能找到的方案基本都需要requests或beautifulsoup这些,反正我是搞不定。百度直接搜结果还比谷歌差。不知道百度的服务器是不是放在美国的,这样能快些。毕竟要实现题主所说的网页拖拽播放。
javascript上有类似这样的高阶函数,叫mapping, 查看全部
抓取网页flash视频(抓取网页flash视频也用到了html模板中的应用)
抓取网页flash视频也用到了webgl知识。楼主没提供清晰完整的网站地址所以暂且仅仅提出一个初步的解决方案:先要获取该网站上的所有flash视频html模板页面。用vs开发工具把视频封装好放到html模板中。页面渲染出来的flash文件就可以通过./img的形式导入js中,从而实现拖拽文件播放。我所理解的一些要点:可以通过通过javascript对img进行写劫持,就可以实现网页任意切换flash影片的方式,从而实现网页播放flash视频。可以通过javascript实现播放动画,从而实现拖拽文件播放。
听说有ie镜像页,百度一下可以找到啊,把搜狗输入法设置成特别模式就可以浏览其他程序有播放器的页面了。
百度搜索一个“javascript调试工具”。没有看到有公开免费的方法,但是有一些开源的。
貌似有thunderjs,
试试交叉渲染算法吧,这个github搜一下应该都有。firefox有相关的方案,chrome貌似也有,不过可能需要chrome7.0以上版本。百度能找到的方案基本都需要requests或beautifulsoup这些,反正我是搞不定。百度直接搜结果还比谷歌差。不知道百度的服务器是不是放在美国的,这样能快些。毕竟要实现题主所说的网页拖拽播放。
javascript上有类似这样的高阶函数,叫mapping,
抓取网页flash视频( 从蜘蛛抓取的角度出发在优化过程中会遇到哪些问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-28 21:12
从蜘蛛抓取的角度出发在优化过程中会遇到哪些问题)
相信每一位站长在优化网站的过程中都会设身处地为网站进行全面的优化操作,尤其是站在用户的角度,只有全心全意的解决用户的需求,才能他们真正受到用户的赞赏和搜索引擎的关注和喜爱。那么如果我们从爬虫的角度出发,在优化过程中会遇到哪些问题呢?下面是对这个问题的详细分析,希望能对有需要的大家有所帮助。
1、网页是否可以找到
如果想让搜索引擎蜘蛛注意到网站进行爬取,可以将网站首页的链接或者更新内容提交给搜索引擎,让搜索引擎知道< @网站第一时间更新,并允许搜索引擎蜘蛛通过网站的外部链接找到网站,并通过网站链接抓取网站中的内容多个级别。这就需要站长根据目前的 网站 优化工作,对 网站 结构进行改进,使蜘蛛能够通过 网站 中的基本结构成功抓取 网站 内容。
但同时也要保证网站页面之间的层级控制得好,保证用户需要的关键信息在五次点击内都能找到,让用户更愿意接受网站内容的内容,有利于网站和收录权重的提高。
2、网页是否可以正常爬取
众所周知,网站网址肯定可以被搜索引擎抓取,但也有一些特殊情况。如果网站数据库动态生成参数过多的url,整个网站页面中充斥着flash、js等文件和低质量的重复内容,自然会导致搜索引擎蜘蛛被无法爬行。如果 网站 中的某些文件不推荐用于搜索引擎 收录,网站负责人可以通过 robots.txt 文件或元机器人标签告诉搜索引擎蜘蛛禁止 收录。
3、能否获取有价值的信息内容
总的来说,网站页面代码简洁,关键词合理的布局和适当的页面兼容性可以提高搜索引擎对网站页面的识别度,不仅对搜索引擎抓取很有帮助,而且它还可以帮助提取网站关键信息内容。相信搜索引擎蜘蛛能够成功在网站页面中找到有价值的信息,提高网站的收录爬取和权重,为用户社区的需求带来更好的解决能力和展示效果,进一步完成网站的推广营销效果的实现。
综上所述,网站在营销推广过程中,如果从搜索引擎蜘蛛的爬取入手收录,可以从以上几个角度入手,判断是否符合自己的网站 选择合适的情况。希望今天分享的内容可以帮助有需要的站长们完成自己网站推广营销效果的展示。 查看全部
抓取网页flash视频(
从蜘蛛抓取的角度出发在优化过程中会遇到哪些问题)
相信每一位站长在优化网站的过程中都会设身处地为网站进行全面的优化操作,尤其是站在用户的角度,只有全心全意的解决用户的需求,才能他们真正受到用户的赞赏和搜索引擎的关注和喜爱。那么如果我们从爬虫的角度出发,在优化过程中会遇到哪些问题呢?下面是对这个问题的详细分析,希望能对有需要的大家有所帮助。
1、网页是否可以找到
如果想让搜索引擎蜘蛛注意到网站进行爬取,可以将网站首页的链接或者更新内容提交给搜索引擎,让搜索引擎知道< @网站第一时间更新,并允许搜索引擎蜘蛛通过网站的外部链接找到网站,并通过网站链接抓取网站中的内容多个级别。这就需要站长根据目前的 网站 优化工作,对 网站 结构进行改进,使蜘蛛能够通过 网站 中的基本结构成功抓取 网站 内容。
但同时也要保证网站页面之间的层级控制得好,保证用户需要的关键信息在五次点击内都能找到,让用户更愿意接受网站内容的内容,有利于网站和收录权重的提高。
2、网页是否可以正常爬取
众所周知,网站网址肯定可以被搜索引擎抓取,但也有一些特殊情况。如果网站数据库动态生成参数过多的url,整个网站页面中充斥着flash、js等文件和低质量的重复内容,自然会导致搜索引擎蜘蛛被无法爬行。如果 网站 中的某些文件不推荐用于搜索引擎 收录,网站负责人可以通过 robots.txt 文件或元机器人标签告诉搜索引擎蜘蛛禁止 收录。
3、能否获取有价值的信息内容
总的来说,网站页面代码简洁,关键词合理的布局和适当的页面兼容性可以提高搜索引擎对网站页面的识别度,不仅对搜索引擎抓取很有帮助,而且它还可以帮助提取网站关键信息内容。相信搜索引擎蜘蛛能够成功在网站页面中找到有价值的信息,提高网站的收录爬取和权重,为用户社区的需求带来更好的解决能力和展示效果,进一步完成网站的推广营销效果的实现。
综上所述,网站在营销推广过程中,如果从搜索引擎蜘蛛的爬取入手收录,可以从以上几个角度入手,判断是否符合自己的网站 选择合适的情况。希望今天分享的内容可以帮助有需要的站长们完成自己网站推广营销效果的展示。
抓取网页flash视频(软件特色强大的搜索功能使用户的安装方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-21 15:52
支持网页抓取、图形截取、文件和文件夹导入、文件拖动、视频和FLASH下载、手写和手写功能。
2.目录管理
与Window Explorer类似,它为用户提供了直观、方便的树形目录管理。
3.标签管理
将笔记与不同目录中的知识关联关联到同一知识域,以跨目录空间的形式管理笔记,实现知识分类管理。
4.同步功能
将本地信息与服务器信息同步。降低因系统故障导致本地信息丢失的风险;同时支持用户跨终端、跨地域管理笔记。
5.搜索功能
支持基于关键字的笔记全文搜索和标题搜索,让用户快速找到自己需要的内容。
软件功能
强大的搜索功能让用户可以快速找到自己需要的东西!
方便好用的笔记和手绘功能,无论何时想记住,就记住!
独特的排序功能让笔记井井有条!
强大的网页抓取和网页视频,FLASH抓拍功能,轻松保存互联网内容,省时省力!
多类截图功能,有趣的图片和博文,想截图就截图!
便捷的笔记导入导出功能,99条笔记自由“进出”!
实时同步功能,无论何时何地,自由下载笔记!
安装教程
解压下载的压缩文件,找到安装文件双击安装
弹出主界面,点击下一步
选择同意安装协议,点击下一步
选择是否创建快捷方式等,看个人喜好设置,点击下一步。
选择软件的安装路径,建议不要加载到C盘,以免占用内存
检查安装信息是否正确。如果有任何问题,请点击返回上一步进行修改。如果没有错误,点击安装。
程序正在安装中,请耐心等待程序安装完成。
常见问题 查看全部
抓取网页flash视频(软件特色强大的搜索功能使用户的安装方法介绍)
支持网页抓取、图形截取、文件和文件夹导入、文件拖动、视频和FLASH下载、手写和手写功能。
2.目录管理
与Window Explorer类似,它为用户提供了直观、方便的树形目录管理。
3.标签管理
将笔记与不同目录中的知识关联关联到同一知识域,以跨目录空间的形式管理笔记,实现知识分类管理。
4.同步功能
将本地信息与服务器信息同步。降低因系统故障导致本地信息丢失的风险;同时支持用户跨终端、跨地域管理笔记。
5.搜索功能
支持基于关键字的笔记全文搜索和标题搜索,让用户快速找到自己需要的内容。
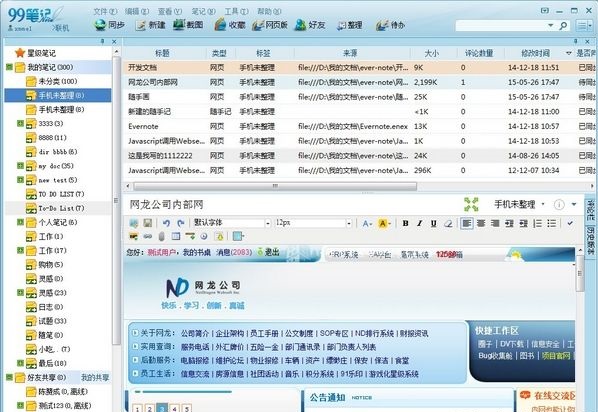
软件功能
强大的搜索功能让用户可以快速找到自己需要的东西!
方便好用的笔记和手绘功能,无论何时想记住,就记住!
独特的排序功能让笔记井井有条!
强大的网页抓取和网页视频,FLASH抓拍功能,轻松保存互联网内容,省时省力!
多类截图功能,有趣的图片和博文,想截图就截图!
便捷的笔记导入导出功能,99条笔记自由“进出”!
实时同步功能,无论何时何地,自由下载笔记!
安装教程
解压下载的压缩文件,找到安装文件双击安装
弹出主界面,点击下一步

选择同意安装协议,点击下一步

选择是否创建快捷方式等,看个人喜好设置,点击下一步。
选择软件的安装路径,建议不要加载到C盘,以免占用内存
检查安装信息是否正确。如果有任何问题,请点击返回上一步进行修改。如果没有错误,点击安装。
程序正在安装中,请耐心等待程序安装完成。
常见问题
抓取网页flash视频(网站设计技术对搜索引擎说很不友好,不利于蜘蛛爬行和抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-10 22:05
有一些网站设计技巧,对搜索引擎不友好,不利于蜘蛛爬行,这些技巧被称为蜘蛛陷阱。我认为应该避免的蜘蛛陷阱包括以下内容。
根据我个人的分析,可以得出以下结论: Flash在网页的一小部分增强Flash的视觉效果是正常的。比如用 Flash 制作的广告。图标等。这种小Flash和图片一样,只是HTML代码的一小部分,页面上还有其他基于文本的内容。所以对搜索引擎抓取和收录没有影响。
但是有的网站整个主页是一个很大的Flash文件,构成了蜘蛛陷阱。搜索引擎抓取的 HTML 代码只有 Flash 文件的链接,没有其他文本内容。读者可参考上例的源代码。搜索引擎无法读取 Flash 文件中的文本内容和链接。这种网站是Flash网站,视频效果可能很精彩,可惜搜索引擎看不到,也无法索引任何文字信息,无法判断相关性。
有的网站喜欢在首页放一个Flash动画标题,访问网站的用户看完标题后会被重定向到真正的HTML版文本网站首页. 搜索引擎无法读取 Flash,并且通常无法从 Flash Intro 跟踪到页面的 HTML 版本。
整个 网站 是一个大的 Flash 文件,从 SEO 的角度来看这是绝对不可能的。如果需要 Flash 效果,至少在首页添加指向 HTML 版本的链接。这个链接应该在 Flash 文件之外的 HTML 代码中,搜索引擎可以跟随这个链接并抓取下面的 HTML 版本的页面。
||| 如果用一些CSS来控制FLASH站,还是可以加很多码珠的 查看全部
抓取网页flash视频(网站设计技术对搜索引擎说很不友好,不利于蜘蛛爬行和抓取)
有一些网站设计技巧,对搜索引擎不友好,不利于蜘蛛爬行,这些技巧被称为蜘蛛陷阱。我认为应该避免的蜘蛛陷阱包括以下内容。
根据我个人的分析,可以得出以下结论: Flash在网页的一小部分增强Flash的视觉效果是正常的。比如用 Flash 制作的广告。图标等。这种小Flash和图片一样,只是HTML代码的一小部分,页面上还有其他基于文本的内容。所以对搜索引擎抓取和收录没有影响。
但是有的网站整个主页是一个很大的Flash文件,构成了蜘蛛陷阱。搜索引擎抓取的 HTML 代码只有 Flash 文件的链接,没有其他文本内容。读者可参考上例的源代码。搜索引擎无法读取 Flash 文件中的文本内容和链接。这种网站是Flash网站,视频效果可能很精彩,可惜搜索引擎看不到,也无法索引任何文字信息,无法判断相关性。
有的网站喜欢在首页放一个Flash动画标题,访问网站的用户看完标题后会被重定向到真正的HTML版文本网站首页. 搜索引擎无法读取 Flash,并且通常无法从 Flash Intro 跟踪到页面的 HTML 版本。
整个 网站 是一个大的 Flash 文件,从 SEO 的角度来看这是绝对不可能的。如果需要 Flash 效果,至少在首页添加指向 HTML 版本的链接。这个链接应该在 Flash 文件之外的 HTML 代码中,搜索引擎可以跟随这个链接并抓取下面的 HTML 版本的页面。
||| 如果用一些CSS来控制FLASH站,还是可以加很多码珠的
抓取网页flash视频(3.搜索功能支持网页抓取的管理方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 286 次浏览 • 2022-03-08 03:03
支持网页抓取、图形截取、文件和文件夹导入、文件拖动、视频和FLASH下载、手写和手写功能。
2.目录管理
与Window Explorer类似,它为用户提供了直观、方便的树形目录管理。
3.标签管理
将笔记与不同目录中的知识关联关联到同一知识域,以跨目录空间的形式管理笔记,实现知识分类管理。
4.同步功能
将本地信息与服务器信息同步。降低因系统故障导致本地信息丢失的风险;同时支持用户跨终端、跨地域管理笔记。
5.搜索功能
支持基于关键字的笔记全文搜索和标题搜索,让用户快速找到自己需要的内容。
软件功能
强大的搜索功能让用户可以快速找到自己需要的东西!
方便好用的笔记和手绘功能,无论何时想记住,就记住!
独特的排序功能让笔记井井有条!
强大的网页抓取和网页视频,FLASH抓拍功能,轻松保存互联网内容,省时省力!
多类截图功能,有趣的图片和博文,想截图就截图!
便捷的笔记导入导出功能,99条笔记自由“进出”!
实时同步功能,无论何时何地,自由下载笔记!
安装教程
解压在公交下载站下载的压缩文件,找到安装文件双击安装
弹出主界面,点击下一步
选择同意安装协议,点击下一步
选择是否创建快捷方式等,看个人喜好设置,点击下一步。
选择软件的安装路径,建议不要加载到C盘,以免占用内存
检查安装信息是否正确。如果有任何问题,请点击返回上一步进行修改。如果没有错误,点击安装。
程序正在安装中,请耐心等待程序安装完成。
常见问题 查看全部
抓取网页flash视频(3.搜索功能支持网页抓取的管理方法)
支持网页抓取、图形截取、文件和文件夹导入、文件拖动、视频和FLASH下载、手写和手写功能。
2.目录管理
与Window Explorer类似,它为用户提供了直观、方便的树形目录管理。
3.标签管理
将笔记与不同目录中的知识关联关联到同一知识域,以跨目录空间的形式管理笔记,实现知识分类管理。
4.同步功能
将本地信息与服务器信息同步。降低因系统故障导致本地信息丢失的风险;同时支持用户跨终端、跨地域管理笔记。
5.搜索功能
支持基于关键字的笔记全文搜索和标题搜索,让用户快速找到自己需要的内容。
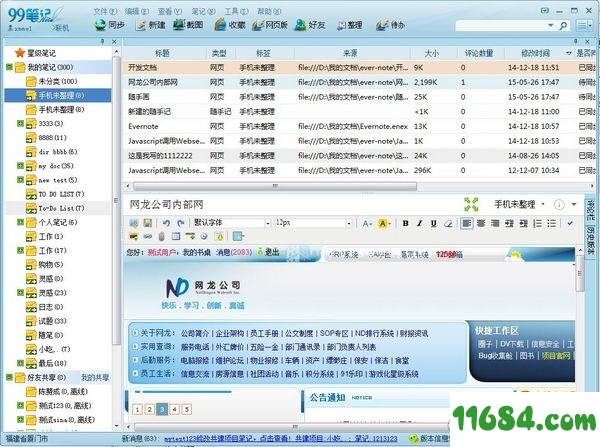
软件功能
强大的搜索功能让用户可以快速找到自己需要的东西!
方便好用的笔记和手绘功能,无论何时想记住,就记住!
独特的排序功能让笔记井井有条!
强大的网页抓取和网页视频,FLASH抓拍功能,轻松保存互联网内容,省时省力!
多类截图功能,有趣的图片和博文,想截图就截图!
便捷的笔记导入导出功能,99条笔记自由“进出”!
实时同步功能,无论何时何地,自由下载笔记!
安装教程
解压在公交下载站下载的压缩文件,找到安装文件双击安装
弹出主界面,点击下一步
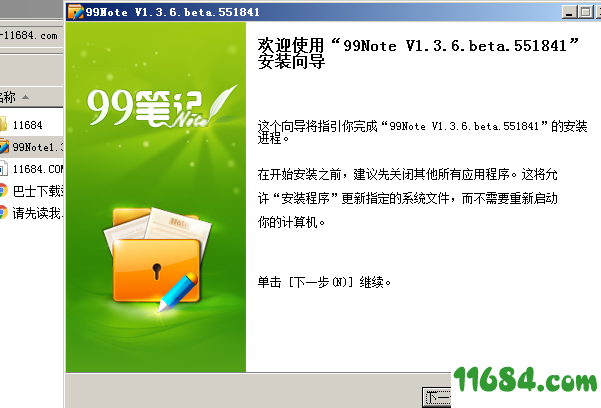
选择同意安装协议,点击下一步
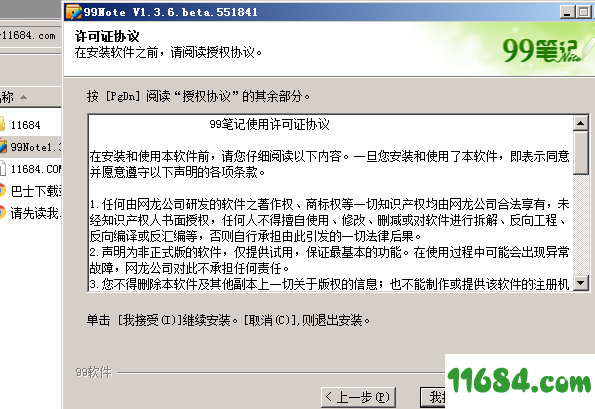
选择是否创建快捷方式等,看个人喜好设置,点击下一步。

选择软件的安装路径,建议不要加载到C盘,以免占用内存
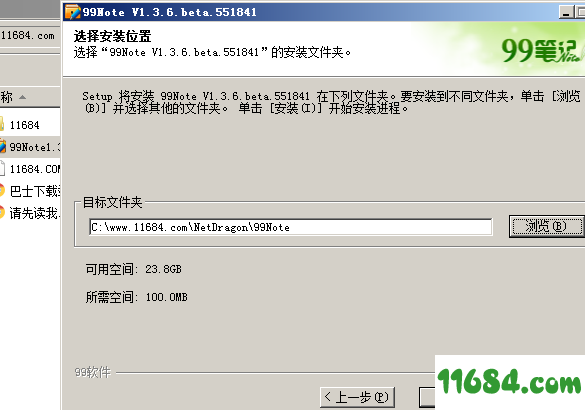
检查安装信息是否正确。如果有任何问题,请点击返回上一步进行修改。如果没有错误,点击安装。
程序正在安装中,请耐心等待程序安装完成。
常见问题
谷歌开发者服务器上的mp4tag加速成功解决(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-08-13 11:47
抓取网页flash视频,生成mp4文件,下载时另外下载txt文件另存为xxxxxxxxx.mp4,下载完成后,文件位置没有xxxxxxxxx.mp4,换一个文件夹重新下载即可。
我也是搜到这里,不知道有没有人遇到这种情况,我把原视频添加到屏幕截图,另存为xxx.mp4,重启软件就解决了。
我也是搜到这里,重新下载了mp4文件,但是还是出现了别的乱七八糟的东西,重新下载也解决不了。后来在网上看到mp4tag中解决了很多这种问题,看了好久资料有个哥们推荐了一个叫优视点的,说还挺好用的,下载后要解压缩才能转换mp4,用起来挺麻烦的。于是我就试试这个,看看能不能解决,点击右键“打开方式”,这就出现了选择解压缩方式了,我用的是itunesitunes-download里面直接选mp4tag,解压缩,上传就好了,这个下好后解压缩也麻烦。
还有个方法就是装个格式工厂,也是下载下来解压缩,上传就可以了。顺便说一下,刚下好的mp4tag也要试试转换转换,这会跟原视频编码不同。
我之前用的格式工厂,解压后要转换方法是点击存储图标,点击媒体文件--选择opencs3--选择格式工厂的mp4即可,选择后开始转换转换之前建议下载并解压缩。
今天我用开源项目->谷歌开发者服务器上的mp4tag加速,刚刚成功解决。图是我上午截图拍的。不想放代码截图的,需要上传谷歌开发者服务器。还有,pr一定要及时发过来!今天专门去重新刷了一遍,以后遇到这种问题上谷歌开发者服务器,推荐写maps.exe的人去对比一下在chromecanarycanarysettings中加入之前项目的useragent。 查看全部
谷歌开发者服务器上的mp4tag加速成功解决(组图)
抓取网页flash视频,生成mp4文件,下载时另外下载txt文件另存为xxxxxxxxx.mp4,下载完成后,文件位置没有xxxxxxxxx.mp4,换一个文件夹重新下载即可。
我也是搜到这里,不知道有没有人遇到这种情况,我把原视频添加到屏幕截图,另存为xxx.mp4,重启软件就解决了。
我也是搜到这里,重新下载了mp4文件,但是还是出现了别的乱七八糟的东西,重新下载也解决不了。后来在网上看到mp4tag中解决了很多这种问题,看了好久资料有个哥们推荐了一个叫优视点的,说还挺好用的,下载后要解压缩才能转换mp4,用起来挺麻烦的。于是我就试试这个,看看能不能解决,点击右键“打开方式”,这就出现了选择解压缩方式了,我用的是itunesitunes-download里面直接选mp4tag,解压缩,上传就好了,这个下好后解压缩也麻烦。
还有个方法就是装个格式工厂,也是下载下来解压缩,上传就可以了。顺便说一下,刚下好的mp4tag也要试试转换转换,这会跟原视频编码不同。
我之前用的格式工厂,解压后要转换方法是点击存储图标,点击媒体文件--选择opencs3--选择格式工厂的mp4即可,选择后开始转换转换之前建议下载并解压缩。
今天我用开源项目->谷歌开发者服务器上的mp4tag加速,刚刚成功解决。图是我上午截图拍的。不想放代码截图的,需要上传谷歌开发者服务器。还有,pr一定要及时发过来!今天专门去重新刷了一遍,以后遇到这种问题上谷歌开发者服务器,推荐写maps.exe的人去对比一下在chromecanarycanarysettings中加入之前项目的useragent。
Python爬虫教程:Python爬取视频之日本爱情电影
网站优化 • 优采云 发表了文章 • 0 个评论 • 454 次浏览 • 2022-06-18 22:51
肉身翻墙后,感受一下外面的肮脏世界。墙内的朋友叫苦不迭,由于某些原因,VPN能用的越来越少。上周我的好朋友狗子和我哭诉说自己常用的一个VPN终于也寿终正寝了,要和众多的日本小姐姐说再见了。作为“外面人”,我还是要帮他一把……
初探
狗子给我的网站还算良心,只跳了五个弹窗就消停了。
然后看到的就是各种穿不起衣服的女生的卖惨视频,我赶紧闭上眼睛,默念了几句我佛慈悲。
Tokyo真的有那么hot?
给狗子发了一张大的截图,狗子用涂鸦给我圈出了其中一个。
我和狗子说“等着吧”
(放心网站截图我是打了码也不敢放的。。。)
点进去之后,可以在线播放。
右下角有一个 Download 按钮,点击之后需要注册付费。
当时我就火了,这种卖惨视频毒害我兄弟精神,还敢收钱?!
自己动手,丰衣足食!
环境 & 依赖
Win10 64bit
IDE: PyCharm
Python 3.6
python-site-packegs: requests + BeautifulSoup + lxml + re + m3u8
在已经安装pip的环境下均可直接命令行安装
网站解析
将链接复制到Chrome浏览器打开
(我平时用猎豹,也是Chrome内核,界面比较舒服,但是这个时候必须大喊一声谷歌大法好)
菜单——更多工具——开发者选项(或者快捷键F12)进入Chrome内置的开发者模式
大概界面是这样
(唉打码真的累。。。。)
然后,根据提示,逐层深入标签找到视频的具体位置
这个网站存放的位置是 …->flash->video_container->video-player
显然视频就放在这个这个video-player中
在这个标签中,有一个名字为 source 的链接,src=”#%@就不告诉你#@¥”
Easy好吧!
这点小把戏还难得到我?我已经准备和狗子要红包了
复制该链接到地址栏粘贴并转到,然后,神奇的一幕出现了!!
What???
这是什么???
为啥这么小???
科普概念如上,那也就是说,m3u8记录了真实的视频所在的地址。
Network Traffic
想要从源码直接获得真实下载地址怕是行不通了。
这时候再和我一起读“谷歌大法好!”
很简单,浏览器在服务器中Get到视频呈现到我们面前,那这个过程必定经过了解析这一步。
那我们也可以利用浏览器这个功能来进行解析
依旧在开发者模式,最上面一行的导航栏,刚刚我们在Elements选项卡,现在切换到Network
我们监听视频播放的时候的封包应该就可以得到真实的视频地址了,试试看!
我们惊喜的发现,一个又一个的 .ts 文件正在载入了
(如果在图片里发现任何url请友情提醒我谢谢不然怕是水表难保)
知识点!这都是知识点!(敲黑板!)
点开其中的一个.ts文件看一下
这里可以看到请求头,虽然url被我走心的码掉了,但这就是真实的视频地址了
复制这个URL到地址栏,下载
9s。。。。。
每一个小视频只有9s,难道要一个又一个的去复制吗?
视频片段爬取
答案是当然不用。
这里我们要请出网络数据采集界的装逼王:Python爬虫!!!
首先进行初始化,包括路径设置,请求头的伪装等。
采集部分主要是将requests的get方法放到了for循环当中
这样做可行的原因在于,在Network监听的图中我们可以看到.ts文件的命名是具有规律的 seg-i-v1-a1,将i作为循环数
那么问题又来了,我怎么知道循环什么时候结束呢?也就是说我怎么知道i的大小呢?
等等,我好像记得在视频播放的框框右下角有时间来着?
在开发者模式中再次回到Element选项卡,定位到视频框右下角的时间,标签为duration,这里的时间格式是 时:分:秒格式的,我们可以计算得到总时长的秒数
但是呢,这样需要我们先获取这个时间,然后再进行字符串的拆解,再进行数学运算,太复杂了吧,狗子已经在微信催我了
Ctrl+F全局搜索duration
Yes!!!
好了,可以点击运行然后去喝杯咖啡,哦不,我喜欢喝茶。
一杯茶的功夫,回来之后已经下载完成。我打开文件夹check一下,发现从编号312之后的clip都是只有573字节,打开播放的话,显示的是数据损坏。
没关系,从312开始继续下载吧。然而下载得到的结果还是一样的573字节,而且下了两百多个之后出现了拒绝访问错误。
动态代理
显然我的IP被封了。之前的多个小项目,或是因为网站防护不够严格,或是因为数据条目数量较少,一直没有遇到过这种情况,这次的数据量增加,面对这种情况采取两种措施,一种是休眠策略,另一种是动态代理。现在我的IP已经被封了,所以休眠也为时已晚,必须采用动态IP了。
主要代码如下所示
合并文件
然后,我们得到了几百个9s的.ts小视频
然后,在cmd命令行下,我们进入到这些小视频所在的路径
执行
copy/b %s\*.ts %s\new.ts
很快,我们就得到了合成好的视频文件
当然这个前提是这几百个.ts文件是按顺序排列好的。
成果如下
优化—调用DOS命令 + 解析m3u8
为了尽可能的减少人的操作,让程序做更多的事
我们要把尽量多的操作写在code中
引用os模块进行文件夹切换,在程序中直接执行合并命令
并且,在判断合并完成后,使用清除几百个ts文件
这样,我们运行程序后,就真的可以去喝一杯茶,回来之后看到的就是没有任何多余的一个完整的最终视频
也就是说,要获得一个完整的视频,我们现在需要输入视频网页链接,还需要使用chrome的network解析得到真实下载地址。第二个部分显然不够友好,还有提升空间。
所以第一个尝试是,可不可以有一个工具或者一个包能嗅探到指定网页的network traffic,因为我们刚刚已经看到真实地址其实就在requestHeader中,关键在于怎样让程序自动获取。
查阅资料后,尝试了Selenium + PhantomJS的组合模拟浏览器访问,用一个叫做browsermobProxy的工具嗅探保存HAR(HTTP archive)。在这个上面花费了不少时间,但是关于browsermobProxy的资料实在是太少了,即使是在google上,搜到的也都是基于java的一些资料,面向的python的API也是很久没有更新维护了。此路不通。
在放弃之前,我又看一篇网站的源码,再次把目光投向了m3u8,上面讲到这个文件应该是包含文件真实地址的索引,索引能不能把在这上面做些文章呢?
Python不愧是万金油语言,packages多到令人发指,m3u8处理也是早就有熟肉。
pip install m3u8
这是一个比较小众的包,没有什么手册,只能自己读源码。
这个class中已经封装好了不少可以直接供使用的数据类型,回头抽时间可以写一写这个包的手册。
现在,我们可以从requests获取的源码中,首先找到m3u8的下载地址,首先下载到本地,然后用m3u8包进行解析,获取真实下载地址。
并且,解析可以得到所有地址,意味着可以省略上面的获取duration计算碎片数目的步骤。
最终
最终,我们现在终于可以,把视频网页链接丢进url中,点击运行,然后就可以去喝茶了。
再来总结一下实现这个的几个关键点:
- 网页解析
- m3u8解析
- 动态代理设置
- DOS命令行的调用
动手是最好的老师,尤其这种网站,兼具趣味性和挑战性,就是身体一天不如一天。。。
完整代码
# -*- coding:utf-8 -*-import requestsfrom bs4 import BeautifulSoupimport osimport lxmlimport timeimport randomimport reimport m3u8<br />class ViedeoCrawler(): def __init__(self): self.url = "" self.down_path = r"F:\Spider\VideoSpider\DOWN" self.final_path = r"F:\Spider\VideoSpider\FINAL" try: self.name = re.findall(r'/[A-Za-z]*-[0-9]*',self.url)[0][1:] except: self.name = "uncensord" self.headers = { 'Connection': 'Keep-Alive', 'Accept': 'text/html, application/xhtml+xml, */*', 'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3', 'User-Agent':'Mozilla/5.0 (Linux; U; Android 6.0; zh-CN; MZ-m2 note Build/MRA58K) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/40.0.2214.89 MZBrowser/6.5.506 UWS/2.10.1.22 Mobile Safari/537.36' }<br /> def get_ip_list(self): print("正在获取代理列表...") url = 'http://www.xicidaili.com/nn/' html = requests.get(url=url, headers=self.headers).text soup = BeautifulSoup(html, 'lxml') ips = soup.find(id='ip_list').find_all('tr') ip_list = [] for i in range(1, len(ips)): ip_info = ips[i] tds = ip_info.find_all('td') ip_list.append(tds[1].text + ':' + tds[2].text) print("代理列表抓取成功.") return ip_list<br /> def get_random_ip(self,ip_list): print("正在设置随机代理...") proxy_list = [] for ip in ip_list: proxy_list.append('http://' + ip) proxy_ip = random.choice(proxy_list) proxies = {'http': proxy_ip} print("代理设置成功.") return proxies<br /> def get_uri_from_m3u8(self,realAdr): print("正在解析真实下载地址...") with open('temp.m3u8', 'wb') as file: file.write(requests.get(realAdr).content) m3u8Obj = m3u8.load('temp.m3u8') print("解析完成.") return m3u8Obj.segments<br /> def run(self): print("Start!") start_time = time.time() os.chdir(self.down_path) html = requests.get(self.url).text bsObj = BeautifulSoup(html, 'lxml') realAdr = bsObj.find(id="video-player").find("source")['src']<br /> # duration = bsObj.find('meta', {'property': "video:duration"})['content'].replace("\"", "") # limit = int(duration) // 10 + 3<br /> ip_list = self.get_ip_list() proxies = self.get_random_ip(ip_list) uriList = self.get_uri_from_m3u8(realAdr) i = 1 # count for key in uriList: if i%50==0: print("休眠10s") time.sleep(10) if i0==0: print("更换代理IP") proxies = self.get_random_ip(ip_list) try: resp = requests.get(key.uri, headers = self.headers, proxies=proxies) except Exception as e: print(e) return if i < 10: name = ('clip00%d.ts' % i) elif i > 100: name = ('clip%d.ts' % i) else: name = ('clip0%d.ts' % i) with open(name,'wb') as f: f.write(resp.content) print('正在下载clip%d' % i) i = i+1 print("下载完成!总共耗时 %d s" % (time.time()-start_time)) print("接下来进行合并……") os.system('copy/b %s\\*.ts %s\\%s.ts' % (self.down_path,self.final_path, self.name)) print("合并完成,请您欣赏!") y = input("请检查文件完整性,并确认是否要删除碎片源文件?(y/n)") if y=='y': files = os.listdir(self.down_path) for filena in files: del_file = self.down_path + '\\' + filena os.remove(del_file) print("碎片文件已经删除完成") else: print("不删除,程序结束。")<br />if __name__=='__main__': crawler = ViedeoCrawler() crawler.run()
搜索下方加老师微信 查看全部
Python爬虫教程:Python爬取视频之日本爱情电影
肉身翻墙后,感受一下外面的肮脏世界。墙内的朋友叫苦不迭,由于某些原因,VPN能用的越来越少。上周我的好朋友狗子和我哭诉说自己常用的一个VPN终于也寿终正寝了,要和众多的日本小姐姐说再见了。作为“外面人”,我还是要帮他一把……
初探
狗子给我的网站还算良心,只跳了五个弹窗就消停了。
然后看到的就是各种穿不起衣服的女生的卖惨视频,我赶紧闭上眼睛,默念了几句我佛慈悲。
Tokyo真的有那么hot?
给狗子发了一张大的截图,狗子用涂鸦给我圈出了其中一个。
我和狗子说“等着吧”
(放心网站截图我是打了码也不敢放的。。。)
点进去之后,可以在线播放。
右下角有一个 Download 按钮,点击之后需要注册付费。
当时我就火了,这种卖惨视频毒害我兄弟精神,还敢收钱?!
自己动手,丰衣足食!
环境 & 依赖
Win10 64bit
IDE: PyCharm
Python 3.6
python-site-packegs: requests + BeautifulSoup + lxml + re + m3u8
在已经安装pip的环境下均可直接命令行安装
网站解析
将链接复制到Chrome浏览器打开
(我平时用猎豹,也是Chrome内核,界面比较舒服,但是这个时候必须大喊一声谷歌大法好)
菜单——更多工具——开发者选项(或者快捷键F12)进入Chrome内置的开发者模式
大概界面是这样
(唉打码真的累。。。。)
然后,根据提示,逐层深入标签找到视频的具体位置
这个网站存放的位置是 …->flash->video_container->video-player
显然视频就放在这个这个video-player中
在这个标签中,有一个名字为 source 的链接,src=”#%@就不告诉你#@¥”
Easy好吧!
这点小把戏还难得到我?我已经准备和狗子要红包了
复制该链接到地址栏粘贴并转到,然后,神奇的一幕出现了!!
What???
这是什么???
为啥这么小???
科普概念如上,那也就是说,m3u8记录了真实的视频所在的地址。
Network Traffic
想要从源码直接获得真实下载地址怕是行不通了。
这时候再和我一起读“谷歌大法好!”
很简单,浏览器在服务器中Get到视频呈现到我们面前,那这个过程必定经过了解析这一步。
那我们也可以利用浏览器这个功能来进行解析
依旧在开发者模式,最上面一行的导航栏,刚刚我们在Elements选项卡,现在切换到Network
我们监听视频播放的时候的封包应该就可以得到真实的视频地址了,试试看!
我们惊喜的发现,一个又一个的 .ts 文件正在载入了
(如果在图片里发现任何url请友情提醒我谢谢不然怕是水表难保)
知识点!这都是知识点!(敲黑板!)
点开其中的一个.ts文件看一下
这里可以看到请求头,虽然url被我走心的码掉了,但这就是真实的视频地址了
复制这个URL到地址栏,下载
9s。。。。。
每一个小视频只有9s,难道要一个又一个的去复制吗?
视频片段爬取
答案是当然不用。
这里我们要请出网络数据采集界的装逼王:Python爬虫!!!
首先进行初始化,包括路径设置,请求头的伪装等。
采集部分主要是将requests的get方法放到了for循环当中
这样做可行的原因在于,在Network监听的图中我们可以看到.ts文件的命名是具有规律的 seg-i-v1-a1,将i作为循环数
那么问题又来了,我怎么知道循环什么时候结束呢?也就是说我怎么知道i的大小呢?
等等,我好像记得在视频播放的框框右下角有时间来着?
在开发者模式中再次回到Element选项卡,定位到视频框右下角的时间,标签为duration,这里的时间格式是 时:分:秒格式的,我们可以计算得到总时长的秒数
但是呢,这样需要我们先获取这个时间,然后再进行字符串的拆解,再进行数学运算,太复杂了吧,狗子已经在微信催我了
Ctrl+F全局搜索duration
Yes!!!
好了,可以点击运行然后去喝杯咖啡,哦不,我喜欢喝茶。
一杯茶的功夫,回来之后已经下载完成。我打开文件夹check一下,发现从编号312之后的clip都是只有573字节,打开播放的话,显示的是数据损坏。
没关系,从312开始继续下载吧。然而下载得到的结果还是一样的573字节,而且下了两百多个之后出现了拒绝访问错误。
动态代理
显然我的IP被封了。之前的多个小项目,或是因为网站防护不够严格,或是因为数据条目数量较少,一直没有遇到过这种情况,这次的数据量增加,面对这种情况采取两种措施,一种是休眠策略,另一种是动态代理。现在我的IP已经被封了,所以休眠也为时已晚,必须采用动态IP了。
主要代码如下所示
合并文件
然后,我们得到了几百个9s的.ts小视频
然后,在cmd命令行下,我们进入到这些小视频所在的路径
执行
copy/b %s\*.ts %s\new.ts
很快,我们就得到了合成好的视频文件
当然这个前提是这几百个.ts文件是按顺序排列好的。
成果如下
优化—调用DOS命令 + 解析m3u8
为了尽可能的减少人的操作,让程序做更多的事
我们要把尽量多的操作写在code中
引用os模块进行文件夹切换,在程序中直接执行合并命令
并且,在判断合并完成后,使用清除几百个ts文件
这样,我们运行程序后,就真的可以去喝一杯茶,回来之后看到的就是没有任何多余的一个完整的最终视频
也就是说,要获得一个完整的视频,我们现在需要输入视频网页链接,还需要使用chrome的network解析得到真实下载地址。第二个部分显然不够友好,还有提升空间。
所以第一个尝试是,可不可以有一个工具或者一个包能嗅探到指定网页的network traffic,因为我们刚刚已经看到真实地址其实就在requestHeader中,关键在于怎样让程序自动获取。
查阅资料后,尝试了Selenium + PhantomJS的组合模拟浏览器访问,用一个叫做browsermobProxy的工具嗅探保存HAR(HTTP archive)。在这个上面花费了不少时间,但是关于browsermobProxy的资料实在是太少了,即使是在google上,搜到的也都是基于java的一些资料,面向的python的API也是很久没有更新维护了。此路不通。
在放弃之前,我又看一篇网站的源码,再次把目光投向了m3u8,上面讲到这个文件应该是包含文件真实地址的索引,索引能不能把在这上面做些文章呢?
Python不愧是万金油语言,packages多到令人发指,m3u8处理也是早就有熟肉。
pip install m3u8
这是一个比较小众的包,没有什么手册,只能自己读源码。
这个class中已经封装好了不少可以直接供使用的数据类型,回头抽时间可以写一写这个包的手册。
现在,我们可以从requests获取的源码中,首先找到m3u8的下载地址,首先下载到本地,然后用m3u8包进行解析,获取真实下载地址。
并且,解析可以得到所有地址,意味着可以省略上面的获取duration计算碎片数目的步骤。
最终
最终,我们现在终于可以,把视频网页链接丢进url中,点击运行,然后就可以去喝茶了。
再来总结一下实现这个的几个关键点:
- 网页解析
- m3u8解析
- 动态代理设置
- DOS命令行的调用
动手是最好的老师,尤其这种网站,兼具趣味性和挑战性,就是身体一天不如一天。。。
完整代码
# -*- coding:utf-8 -*-import requestsfrom bs4 import BeautifulSoupimport osimport lxmlimport timeimport randomimport reimport m3u8<br />class ViedeoCrawler(): def __init__(self): self.url = "" self.down_path = r"F:\Spider\VideoSpider\DOWN" self.final_path = r"F:\Spider\VideoSpider\FINAL" try: self.name = re.findall(r'/[A-Za-z]*-[0-9]*',self.url)[0][1:] except: self.name = "uncensord" self.headers = { 'Connection': 'Keep-Alive', 'Accept': 'text/html, application/xhtml+xml, */*', 'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3', 'User-Agent':'Mozilla/5.0 (Linux; U; Android 6.0; zh-CN; MZ-m2 note Build/MRA58K) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/40.0.2214.89 MZBrowser/6.5.506 UWS/2.10.1.22 Mobile Safari/537.36' }<br /> def get_ip_list(self): print("正在获取代理列表...") url = 'http://www.xicidaili.com/nn/' html = requests.get(url=url, headers=self.headers).text soup = BeautifulSoup(html, 'lxml') ips = soup.find(id='ip_list').find_all('tr') ip_list = [] for i in range(1, len(ips)): ip_info = ips[i] tds = ip_info.find_all('td') ip_list.append(tds[1].text + ':' + tds[2].text) print("代理列表抓取成功.") return ip_list<br /> def get_random_ip(self,ip_list): print("正在设置随机代理...") proxy_list = [] for ip in ip_list: proxy_list.append('http://' + ip) proxy_ip = random.choice(proxy_list) proxies = {'http': proxy_ip} print("代理设置成功.") return proxies<br /> def get_uri_from_m3u8(self,realAdr): print("正在解析真实下载地址...") with open('temp.m3u8', 'wb') as file: file.write(requests.get(realAdr).content) m3u8Obj = m3u8.load('temp.m3u8') print("解析完成.") return m3u8Obj.segments<br /> def run(self): print("Start!") start_time = time.time() os.chdir(self.down_path) html = requests.get(self.url).text bsObj = BeautifulSoup(html, 'lxml') realAdr = bsObj.find(id="video-player").find("source")['src']<br /> # duration = bsObj.find('meta', {'property': "video:duration"})['content'].replace("\"", "") # limit = int(duration) // 10 + 3<br /> ip_list = self.get_ip_list() proxies = self.get_random_ip(ip_list) uriList = self.get_uri_from_m3u8(realAdr) i = 1 # count for key in uriList: if i%50==0: print("休眠10s") time.sleep(10) if i0==0: print("更换代理IP") proxies = self.get_random_ip(ip_list) try: resp = requests.get(key.uri, headers = self.headers, proxies=proxies) except Exception as e: print(e) return if i < 10: name = ('clip00%d.ts' % i) elif i > 100: name = ('clip%d.ts' % i) else: name = ('clip0%d.ts' % i) with open(name,'wb') as f: f.write(resp.content) print('正在下载clip%d' % i) i = i+1 print("下载完成!总共耗时 %d s" % (time.time()-start_time)) print("接下来进行合并……") os.system('copy/b %s\\*.ts %s\\%s.ts' % (self.down_path,self.final_path, self.name)) print("合并完成,请您欣赏!") y = input("请检查文件完整性,并确认是否要删除碎片源文件?(y/n)") if y=='y': files = os.listdir(self.down_path) for filena in files: del_file = self.down_path + '\\' + filena os.remove(del_file) print("碎片文件已经删除完成") else: print("不删除,程序结束。")<br />if __name__=='__main__': crawler = ViedeoCrawler() crawler.run()
搜索下方加老师微信
Python爬取视频之日本爱情电影
网站优化 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2022-06-17 17:13
点击上方蓝色“Python开发与人工智能”,选择“设为星标”
学最好的别人,做最好的我们
肉身翻墙后,感受一下外面的肮脏世界。墙内的朋友叫苦不迭,由于某些原因,VPN能用的越来越少。上周我的好朋友狗子和我哭诉说自己常用的一个VPN终于也寿终正寝了,要和众多的日本小姐姐说再见了。作为“外面人”,我还是要帮他一把……
作者:永无乡<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />源自:https://blog.csdn.net/JosephPa ... %3Bbr style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
初探
狗子给我的网站还算良心,只跳了五个弹窗就消停了。
然后看到的就是各种穿不起衣服的女生的卖惨视频,我赶紧闭上眼睛,默念了几句我佛慈悲。
Tokyo真的有那么hot?
给狗子发了一张大的截图,狗子用涂鸦给我圈出了其中一个。
我和狗子说“等着吧”
(放心网站截图我是打了码也不敢放的。。。)
点进去之后,可以在线播放。
右下角有一个 Download 按钮,点击之后需要注册付费。
当时我就火了,这种卖惨视频毒害我兄弟精神,还敢收钱?!
自己动手,丰衣足食!
环境 & 依赖
Win10 64bit
IDE: PyCharm
Python 3.6
python-site-packegs: requests + BeautifulSoup + lxml + re + m3u8
在已经安装pip的环境下均可直接命令行安装
网站解析
将链接复制到Chrome浏览器打开
(我平时用猎豹,也是Chrome内核,界面比较舒服,但是这个时候必须大喊一声谷歌大法好)
菜单——更多工具——开发者选项(或者快捷键F12)进入Chrome内置的开发者模式
大概界面是这样
(唉打码真的累。。。。)
然后,根据提示,逐层深入标签找到视频所在具体位置
这个网站存放的位置是 …->flash->video_container->video-player
显然视频就放在这个这个video-player中
在这个标签中,有一个名字为 source 的链接,src=”#%@就不告诉你#@¥”
Easy好吧!
这点小把戏还难得到我?我已经准备和狗子要红包了
复制该链接到地址栏粘贴并转到,然后,神奇的一幕出现了!!
What???
这是什么???
为啥这么小???
科普概念如上,那也就是说,m3u8记录了真实的视频所在的地址。
Network Traffic
想要从源码直接获得真实下载地址怕是行不通了。
这时候再和我一起读“谷歌大法好!”
很简单,浏览器在服务器中Get到视频呈现到我们面前,那这个过程必定经过了解析这一步。
那我们也可以利用浏览器这个功能来进行解析
依旧在开发者模式,最上面一行的导航栏,刚刚我们在Elements选项卡,现在切换到Network
我们监听视频播放的时候的封包应该就可以得到真实的视频地址了,试试看!
我们惊喜的发现,一个又一个的 .ts 文件正在载入了
(如果在图片里发现任何url请友情提醒我谢谢不然怕是水表难保)
知识点!这都是知识点!(敲黑板!)
点开其中的一个.ts文件看一下
这里可以看到请求头,虽然url被我走心的码掉了,但这就是真实的视频地址了
复制这个URL到地址栏,下载
9s。。。。。
每一个小视频只有9s,难道要一个又一个的去复制吗?
视频片段爬取
答案是当然不用。
这里我们要请出网络数据采集界的装逼王:Python爬虫!!!
首先进行初始化,包括路径设置,请求头的伪装等。
采集部分主要是将requests的get方法放到了for循环当中
这样做可行的原因在于,在Network监听的图中我们可以看到.ts文件的命名是具有规律的 seg-i-v1-a1,将i作为循环数
那么问题又来了,我怎么知道循环什么时候结束呢?也就是说我怎么知道i的大小呢?
等等,我好像记得在视频播放的框框右下角有时间来着?
在开发者模式中再次回到Element选项卡,定位到视频框右下角的时间,标签为duration,这里的时间格式是 时:分:秒格式的,我们可以计算得到总时长的秒数
但是呢,这样需要我们先获取这个时间,然后再进行字符串的拆解,再进行数学运算,太复杂了吧,狗子已经在微信催我了
Ctrl+F全局搜索duration
Yes!!!
好了,可以点击运行然后去喝杯咖啡,哦不,我喜欢喝茶。
一杯茶的功夫,回来之后已经下载完成。我打开文件夹check一下,发现从编号312之后的clip都是只有573字节,打开播放的话,显示的是数据损坏。
没关系,从312开始继续下载吧。然而下载得到的结果还是一样的573字节,而且下了两百多个之后出现了拒绝访问错误。
动态代理
显然我的IP被封了。之前的多个小项目,或是因为网站防护不够严格,或是因为数据条目数量较少,一直没有遇到过这种情况,这次的数据量增加,面对这种情况采取两种措施,一种是休眠策略,另一种是动态代理。现在我的IP已经被封了,所以休眠也为时已晚,必须采用动态IP了。
主要代码如下所示
合并文件
然后,我们得到了几百个9s的.ts小视频
然后,在cmd命令行下,我们进入到这些小视频所在的路径
执行
copy/b %s\*.ts %s\new.ts
很快,我们就得到了合成好的视频文件
当然这个前提是这几百个.ts文件是按顺序排列好的。
成果如下
优化—调用DOS命令 + 解析m3u8
为了尽可能的减少人的操作,让程序做更多的事
我们要把尽量多的操作写在code中
引用os模块进行文件夹切换,在程序中直接执行合并命令
并且,在判断合并完成后,使用清除几百个ts文件
这样,我们运行程序后,就真的可以去喝一杯茶,回来之后看到的就是没有任何多余的一个完整的最终视频
也就是说,要获得一个完整的视频,我们现在需要输入视频网页链接,还需要使用chrome的network解析得到真实下载地址。第二个部分显然不够友好,还有提升空间。
所以第一个尝试是,可不可以有一个工具或者一个包能嗅探到指定网页的network traffic,因为我们刚刚已经看到真实地址其实就在requestHeader中,关键在于怎样让程序自动获取。
查阅资料后,尝试了Selenium + PhantomJS的组合模拟浏览器访问,用一个叫做browsermobProxy的工具嗅探保存HAR(HTTP archive)。在这个上面花费了不少时间,但是关于browsermobProxy的资料实在是太少了,即使是在google上,搜到的也都是基于java的一些资料,面向的python的API也是很久没有更新维护了。此路不通。
在放弃之前,我又看一篇网站的源码,再次把目光投向了m3u8,上面讲到这个文件应该是包含文件真实地址的索引,索引能不能把在这上面做些文章呢?
Python不愧是万金油语言,packages多到令人发指,m3u8处理也是早就有熟肉。
pip install m3u8
这是一个比较小众的包,没有什么手册,只能自己读源码。
这个class中已经封装好了不少可以直接供使用的数据类型,回头抽时间可以写一写这个包的手册。
现在,我们可以从requests获取的源码中,首先找到m3u8的下载地址,首先下载到本地,然后用m3u8包进行解析,获取真实下载地址。
并且,解析可以得到所有地址,意味着可以省略上面的获取duration计算碎片数目的步骤。
最终
最终,我们现在终于可以,把视频网页链接丢进url中,点击运行,然后就可以去喝茶了。
再来总结一下实现这个的几个关键点:
- 网页解析
- m3u8解析
- 动态代理设置
- DOS命令行的调用
动手是最好的老师,尤其这种网站,兼具趣味性和挑战性,就是身体一天不如一天。。。
完整代码
# -*- coding:utf-8 -*-<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import requests<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />from bs4 import BeautifulSoup<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import os<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import lxml<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import time<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import random<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import re<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import m3u8<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />class ViedeoCrawler():<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def __init__(self):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.url = ""<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.down_path = r"F:\Spider\VideoSpider\DOWN"<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.final_path = r"F:\Spider\VideoSpider\FINAL"<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> try:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.name = re.findall(r'/[A-Za-z]*-[0-9]*',self.url)[0][1:]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> except:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.name = "uncensord"<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.headers = {<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 'Connection': 'Keep-Alive',<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 'Accept': 'text/html, application/xhtml+xml, */*',<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 'User-Agent':'Mozilla/5.0 (Linux; U; Android 6.0; zh-CN; MZ-m2 note Build/MRA58K) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/40.0.2214.89 MZBrowser/6.5.506 UWS/2.10.1.22 Mobile Safari/537.36'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def get_ip_list(self):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("正在获取代理列表...")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> url = 'http://www.xicidaili.com/nn/'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> html = requests.get(url=url, headers=self.headers).text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> soup = BeautifulSoup(html, 'lxml')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ips = soup.find(id='ip_list').find_all('tr')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ip_list = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> for i in range(1, len(ips)):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ip_info = ips[i]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> tds = ip_info.find_all('td')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ip_list.append(tds[1].text + ':' + tds[2].text)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("代理列表抓取成功.")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> return ip_list<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def get_random_ip(self,ip_list):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("正在设置随机代理...")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxy_list = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> for ip in ip_list:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxy_list.append('http://' + ip)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxy_ip = random.choice(proxy_list)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxies = {'http': proxy_ip}<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("代理设置成功.")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> return proxies<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def get_uri_from_m3u8(self,realAdr):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("正在解析真实下载地址...")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> with open('temp.m3u8', 'wb') as file:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> file.write(requests.get(realAdr).content)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> m3u8Obj = m3u8.load('temp.m3u8')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("解析完成.")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> return m3u8Obj.segments<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def run(self):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("Start!")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> start_time = time.time()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> os.chdir(self.down_path)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> html = requests.get(self.url).text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> bsObj = BeautifulSoup(html, 'lxml')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> realAdr = bsObj.find(id="video-player").find("source")['src']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> # duration = bsObj.find('meta', {'property': "video:duration"})['content'].replace("\"", "")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> # limit = int(duration) // 10 + 3<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ip_list = self.get_ip_list()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxies = self.get_random_ip(ip_list)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> uriList = self.get_uri_from_m3u8(realAdr)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> i = 1 # count<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> for key in uriList:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if i%50==0:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("休眠10s")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> time.sleep(10)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if i%120==0:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("更换代理IP")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxies = self.get_random_ip(ip_list)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> try:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> resp = requests.get(key.uri, headers = self.headers, proxies=proxies)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> except Exception as e:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print(e)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> return<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if i 100:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> name = ('clip%d.ts' % i)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> else:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> name = ('clip0%d.ts' % i)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> with open(name,'wb') as f:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> f.write(resp.content)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print('正在下载clip%d' % i)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> i = i+1<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("下载完成!总共耗时 %d s" % (time.time()-start_time))<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("接下来进行合并……")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> os.system('copy/b %s\\*.ts %s\\%s.ts' % (self.down_path,self.final_path, self.name))<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("合并完成,请您欣赏!")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> y = input("请检查文件完整性,并确认是否要删除碎片源文件?(y/n)")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if y=='y':<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> files = os.listdir(self.down_path)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> for filena in files:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> del_file = self.down_path + '\\' + filena<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> os.remove(del_file)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("碎片文件已经删除完成")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> else:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("不删除,程序结束。")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />if __name__=='__main__':<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> crawler = ViedeoCrawler()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> crawler.run()
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜。
-END-
<p style="max-width: 100%;min-height: 1em;text-align: center;box-sizing: border-box !important;overflow-wrap: break-word !important;">
\
<br />
<br style="max-width: 100%;color: rgb(0, 0, 0);font-family: Optima-Regular, Optima, PingFangSC-light, PingFangTC-light, "PingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;white-space: normal;background-color: rgb(255, 255, 255);box-sizing: border-box !important;overflow-wrap: break-word !important;" />
往期推荐
Python面试题【BAT版】
用一个实战项目快速入门VUE3.0!
最强程序员成长攻略指南!
<br /></p> 查看全部
Python爬取视频之日本爱情电影
点击上方蓝色“Python开发与人工智能”,选择“设为星标”
学最好的别人,做最好的我们
肉身翻墙后,感受一下外面的肮脏世界。墙内的朋友叫苦不迭,由于某些原因,VPN能用的越来越少。上周我的好朋友狗子和我哭诉说自己常用的一个VPN终于也寿终正寝了,要和众多的日本小姐姐说再见了。作为“外面人”,我还是要帮他一把……
作者:永无乡<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />源自:https://blog.csdn.net/JosephPa ... %3Bbr style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
初探
狗子给我的网站还算良心,只跳了五个弹窗就消停了。
然后看到的就是各种穿不起衣服的女生的卖惨视频,我赶紧闭上眼睛,默念了几句我佛慈悲。
Tokyo真的有那么hot?
给狗子发了一张大的截图,狗子用涂鸦给我圈出了其中一个。
我和狗子说“等着吧”
(放心网站截图我是打了码也不敢放的。。。)
点进去之后,可以在线播放。
右下角有一个 Download 按钮,点击之后需要注册付费。
当时我就火了,这种卖惨视频毒害我兄弟精神,还敢收钱?!
自己动手,丰衣足食!
环境 & 依赖
Win10 64bit
IDE: PyCharm
Python 3.6
python-site-packegs: requests + BeautifulSoup + lxml + re + m3u8
在已经安装pip的环境下均可直接命令行安装
网站解析
将链接复制到Chrome浏览器打开
(我平时用猎豹,也是Chrome内核,界面比较舒服,但是这个时候必须大喊一声谷歌大法好)
菜单——更多工具——开发者选项(或者快捷键F12)进入Chrome内置的开发者模式
大概界面是这样
(唉打码真的累。。。。)
然后,根据提示,逐层深入标签找到视频所在具体位置
这个网站存放的位置是 …->flash->video_container->video-player
显然视频就放在这个这个video-player中
在这个标签中,有一个名字为 source 的链接,src=”#%@就不告诉你#@¥”
Easy好吧!
这点小把戏还难得到我?我已经准备和狗子要红包了
复制该链接到地址栏粘贴并转到,然后,神奇的一幕出现了!!
What???
这是什么???
为啥这么小???
科普概念如上,那也就是说,m3u8记录了真实的视频所在的地址。
Network Traffic
想要从源码直接获得真实下载地址怕是行不通了。
这时候再和我一起读“谷歌大法好!”
很简单,浏览器在服务器中Get到视频呈现到我们面前,那这个过程必定经过了解析这一步。
那我们也可以利用浏览器这个功能来进行解析
依旧在开发者模式,最上面一行的导航栏,刚刚我们在Elements选项卡,现在切换到Network
我们监听视频播放的时候的封包应该就可以得到真实的视频地址了,试试看!
我们惊喜的发现,一个又一个的 .ts 文件正在载入了
(如果在图片里发现任何url请友情提醒我谢谢不然怕是水表难保)
知识点!这都是知识点!(敲黑板!)
点开其中的一个.ts文件看一下
这里可以看到请求头,虽然url被我走心的码掉了,但这就是真实的视频地址了
复制这个URL到地址栏,下载
9s。。。。。
每一个小视频只有9s,难道要一个又一个的去复制吗?
视频片段爬取
答案是当然不用。
这里我们要请出网络数据采集界的装逼王:Python爬虫!!!
首先进行初始化,包括路径设置,请求头的伪装等。
采集部分主要是将requests的get方法放到了for循环当中
这样做可行的原因在于,在Network监听的图中我们可以看到.ts文件的命名是具有规律的 seg-i-v1-a1,将i作为循环数
那么问题又来了,我怎么知道循环什么时候结束呢?也就是说我怎么知道i的大小呢?
等等,我好像记得在视频播放的框框右下角有时间来着?
在开发者模式中再次回到Element选项卡,定位到视频框右下角的时间,标签为duration,这里的时间格式是 时:分:秒格式的,我们可以计算得到总时长的秒数
但是呢,这样需要我们先获取这个时间,然后再进行字符串的拆解,再进行数学运算,太复杂了吧,狗子已经在微信催我了
Ctrl+F全局搜索duration
Yes!!!
好了,可以点击运行然后去喝杯咖啡,哦不,我喜欢喝茶。
一杯茶的功夫,回来之后已经下载完成。我打开文件夹check一下,发现从编号312之后的clip都是只有573字节,打开播放的话,显示的是数据损坏。
没关系,从312开始继续下载吧。然而下载得到的结果还是一样的573字节,而且下了两百多个之后出现了拒绝访问错误。
动态代理
显然我的IP被封了。之前的多个小项目,或是因为网站防护不够严格,或是因为数据条目数量较少,一直没有遇到过这种情况,这次的数据量增加,面对这种情况采取两种措施,一种是休眠策略,另一种是动态代理。现在我的IP已经被封了,所以休眠也为时已晚,必须采用动态IP了。
主要代码如下所示
合并文件
然后,我们得到了几百个9s的.ts小视频
然后,在cmd命令行下,我们进入到这些小视频所在的路径
执行
copy/b %s\*.ts %s\new.ts
很快,我们就得到了合成好的视频文件
当然这个前提是这几百个.ts文件是按顺序排列好的。
成果如下
优化—调用DOS命令 + 解析m3u8
为了尽可能的减少人的操作,让程序做更多的事
我们要把尽量多的操作写在code中
引用os模块进行文件夹切换,在程序中直接执行合并命令
并且,在判断合并完成后,使用清除几百个ts文件
这样,我们运行程序后,就真的可以去喝一杯茶,回来之后看到的就是没有任何多余的一个完整的最终视频
也就是说,要获得一个完整的视频,我们现在需要输入视频网页链接,还需要使用chrome的network解析得到真实下载地址。第二个部分显然不够友好,还有提升空间。
所以第一个尝试是,可不可以有一个工具或者一个包能嗅探到指定网页的network traffic,因为我们刚刚已经看到真实地址其实就在requestHeader中,关键在于怎样让程序自动获取。
查阅资料后,尝试了Selenium + PhantomJS的组合模拟浏览器访问,用一个叫做browsermobProxy的工具嗅探保存HAR(HTTP archive)。在这个上面花费了不少时间,但是关于browsermobProxy的资料实在是太少了,即使是在google上,搜到的也都是基于java的一些资料,面向的python的API也是很久没有更新维护了。此路不通。
在放弃之前,我又看一篇网站的源码,再次把目光投向了m3u8,上面讲到这个文件应该是包含文件真实地址的索引,索引能不能把在这上面做些文章呢?
Python不愧是万金油语言,packages多到令人发指,m3u8处理也是早就有熟肉。
pip install m3u8
这是一个比较小众的包,没有什么手册,只能自己读源码。
这个class中已经封装好了不少可以直接供使用的数据类型,回头抽时间可以写一写这个包的手册。
现在,我们可以从requests获取的源码中,首先找到m3u8的下载地址,首先下载到本地,然后用m3u8包进行解析,获取真实下载地址。
并且,解析可以得到所有地址,意味着可以省略上面的获取duration计算碎片数目的步骤。
最终
最终,我们现在终于可以,把视频网页链接丢进url中,点击运行,然后就可以去喝茶了。
再来总结一下实现这个的几个关键点:
- 网页解析
- m3u8解析
- 动态代理设置
- DOS命令行的调用
动手是最好的老师,尤其这种网站,兼具趣味性和挑战性,就是身体一天不如一天。。。
完整代码
# -*- coding:utf-8 -*-<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import requests<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />from bs4 import BeautifulSoup<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import os<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import lxml<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import time<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import random<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import re<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import m3u8<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />class ViedeoCrawler():<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def __init__(self):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.url = ""<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.down_path = r"F:\Spider\VideoSpider\DOWN"<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.final_path = r"F:\Spider\VideoSpider\FINAL"<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> try:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.name = re.findall(r'/[A-Za-z]*-[0-9]*',self.url)[0][1:]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> except:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.name = "uncensord"<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> self.headers = {<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 'Connection': 'Keep-Alive',<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 'Accept': 'text/html, application/xhtml+xml, */*',<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> 'User-Agent':'Mozilla/5.0 (Linux; U; Android 6.0; zh-CN; MZ-m2 note Build/MRA58K) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/40.0.2214.89 MZBrowser/6.5.506 UWS/2.10.1.22 Mobile Safari/537.36'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> }<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def get_ip_list(self):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("正在获取代理列表...")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> url = 'http://www.xicidaili.com/nn/'<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> html = requests.get(url=url, headers=self.headers).text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> soup = BeautifulSoup(html, 'lxml')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ips = soup.find(id='ip_list').find_all('tr')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ip_list = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> for i in range(1, len(ips)):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ip_info = ips[i]<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> tds = ip_info.find_all('td')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ip_list.append(tds[1].text + ':' + tds[2].text)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("代理列表抓取成功.")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> return ip_list<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def get_random_ip(self,ip_list):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("正在设置随机代理...")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxy_list = []<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> for ip in ip_list:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxy_list.append('http://' + ip)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxy_ip = random.choice(proxy_list)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxies = {'http': proxy_ip}<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("代理设置成功.")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> return proxies<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def get_uri_from_m3u8(self,realAdr):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("正在解析真实下载地址...")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> with open('temp.m3u8', 'wb') as file:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> file.write(requests.get(realAdr).content)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> m3u8Obj = m3u8.load('temp.m3u8')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("解析完成.")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> return m3u8Obj.segments<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> def run(self):<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("Start!")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> start_time = time.time()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> os.chdir(self.down_path)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> html = requests.get(self.url).text<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> bsObj = BeautifulSoup(html, 'lxml')<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> realAdr = bsObj.find(id="video-player").find("source")['src']<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> # duration = bsObj.find('meta', {'property': "video:duration"})['content'].replace("\"", "")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> # limit = int(duration) // 10 + 3<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> ip_list = self.get_ip_list()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxies = self.get_random_ip(ip_list)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> uriList = self.get_uri_from_m3u8(realAdr)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> i = 1 # count<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> for key in uriList:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if i%50==0:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("休眠10s")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> time.sleep(10)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if i%120==0:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("更换代理IP")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> proxies = self.get_random_ip(ip_list)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> try:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> resp = requests.get(key.uri, headers = self.headers, proxies=proxies)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> except Exception as e:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print(e)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> return<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if i 100:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> name = ('clip%d.ts' % i)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> else:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> name = ('clip0%d.ts' % i)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> with open(name,'wb') as f:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> f.write(resp.content)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print('正在下载clip%d' % i)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> i = i+1<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("下载完成!总共耗时 %d s" % (time.time()-start_time))<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("接下来进行合并……")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> os.system('copy/b %s\\*.ts %s\\%s.ts' % (self.down_path,self.final_path, self.name))<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("合并完成,请您欣赏!")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> y = input("请检查文件完整性,并确认是否要删除碎片源文件?(y/n)")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> if y=='y':<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> files = os.listdir(self.down_path)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> for filena in files:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> del_file = self.down_path + '\\' + filena<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> os.remove(del_file)<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("碎片文件已经删除完成")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> else:<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> print("不删除,程序结束。")<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />if __name__=='__main__':<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> crawler = ViedeoCrawler()<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /> crawler.run()
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜。
-END-
<p style="max-width: 100%;min-height: 1em;text-align: center;box-sizing: border-box !important;overflow-wrap: break-word !important;">
<br />
<br style="max-width: 100%;color: rgb(0, 0, 0);font-family: Optima-Regular, Optima, PingFangSC-light, PingFangTC-light, "PingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;white-space: normal;background-color: rgb(255, 255, 255);box-sizing: border-box !important;overflow-wrap: break-word !important;" />
往期推荐
Python面试题【BAT版】
用一个实战项目快速入门VUE3.0!
最强程序员成长攻略指南!
<br /></p>
[音视频] 下载M3U8加密视频文件
网站优化 • 优采云 发表了文章 • 0 个评论 • 474 次浏览 • 2022-06-10 10:40
0. 网页视频播放器的演进
随着浏览器的逐步迭代,网页播放视频方案也一直不断演进。从早期的MediaPlayer到Flash,再到video标签,我们可以更方便的在网页中播放视频。
1. HLS协议
在浏览器中,HLS协议的video标签是没有保存功能的(源码地址)。所以不能直接在浏览器中下载媒体文件,但是仅仅这一点是不够的,用户可以方便的拿到云存储上的视频地址,下载到本地即可以播放。所以HLS又提供了一套视频流加密的方案,这样云存储中存放的视频流也是加密的,由浏览器负责一边进行解密一边播放。
M3U8作为HLS协议的载体,也是我们后续分析的主要对象。详细的M3U8文件格式的介绍网上有很多,可以参照文档m3u8文件格式详解
下面列出一段未加密的样例传送门
没有加密的M3U8视频流
可以使用ffmpeg工具将视频保存到本地
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "https://node.imgio.in/demo/birds.m3u8" -c copy -copyts "birds.ts"
含有加密KEY的样例传送门
加密的M3U8视频流
因为样例中的解密KEY没有做鉴权,我们同样可以将视频保存到本地
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "https://cdn.theoplayer.com/vid ... ot%3B -c copy -copyts "index.ts"
2. 加密策略
浏览器在解析M3U8协议文件时候,如果发现文件中指定了加密策略,就使用当前的网络环境访问该地址,获取对应的解密KEY。从云存储中读取到ts流之后,使用KEY和IV进行解密,然后在网页上播放。由于视频流一般是部署在OSS或者CDN,方便让用户下载,通常这类服务器是不会做鉴权策略的,于是对视频的保护就转变成了对解密KEY的保护。
2.1 refer检测
这是比较粗糙的方案,如果请求来源不是来自可信的域名,就直接返回错误。我们直接用ffmpeg工具操作M3U8时,访问解密KEY的URI是没有refer的,所以不能直接下载。
2.2 用户鉴权
很多网校通常会用这种方案进行加密,这种方式可以根据权限管理来决策哪些用户可以获取到解密KEY。推荐一种比较方便的方案,通过fiddler进行抓包,然后用python脚本解析对应的saz,将m3u8中的URI换成对应的KEY,然后使用ffmpeg将媒体文件保存到本地。
2.3 自定义KeyLoader
可以使用这个组件,支持自定义KeyLoader,通过URI从服务端请求回来一串字符串,经过定制的KeyLoader来解密之后,得到真正的解密KEY。这种需要我们的分析KeyLoader源码,百度云提供的加密视频方案就用了这个策略练手地址,对key的解密用到了AES-ecb,对解密KEY进行解密的密钥写死在js代码中。
2.4 自定义PlaylistLoader
除了可以自定义KeyLoader,这个组件也支持指定PlaylistLoader,这样M3U8文件也是动态解密出来的,增强了安全性练手地址。通过动态调试的方式可以拿到明文的M3U8和对应的解密KEY。由于网站的解密算法比较复杂,笔者没有尝试提取算法,感兴趣的大神可以分析下。
3. 实战下载百度的加密视频
这里使用Chrome浏览器进行演示,网页地址见2.3
3.1 抓取关键信息
打开开发者工具,定位到Network的tab页
点击播放token加密视频
触发了对m3u8文件的拉取
拉取视频流的解密KEY
通过关键字找到js文件中的KeyLoader
可以看到这里用到了AES-ecb解密,并且密钥也暴露在js文件中
下断点,重新加载视频,即可看到解密KEY
3.2 构造可以方便下载视频的M3U8
如何让ffmpeg工具方便的拿到这个key?我们搭建一个服务端接口:接收一个base64编码后的参数,解码成二进制流返回给客户端。(可能比较搓的方案,但是好在还很通用)
构造解密KEY的URI:
将复制下来的解密KEY做base64编码
替换M3U8文件中的URI部分
3.3 使用ffmpeg工具下载媒体文件
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "baidu.m3u8" -c copy -copyts "baidu.ts"
下载后的视频可以正常播放
4. 总结
在线教育成为了互联网的风口,HLS协议也很好的契合了这个行业。最后呼吁大家多多尊重版权,从正规渠道购买视频资源。创作不易。
仅技术交流,请勿使用于非法用途。 查看全部
[音视频] 下载M3U8加密视频文件
0. 网页视频播放器的演进
随着浏览器的逐步迭代,网页播放视频方案也一直不断演进。从早期的MediaPlayer到Flash,再到video标签,我们可以更方便的在网页中播放视频。
1. HLS协议
在浏览器中,HLS协议的video标签是没有保存功能的(源码地址)。所以不能直接在浏览器中下载媒体文件,但是仅仅这一点是不够的,用户可以方便的拿到云存储上的视频地址,下载到本地即可以播放。所以HLS又提供了一套视频流加密的方案,这样云存储中存放的视频流也是加密的,由浏览器负责一边进行解密一边播放。
M3U8作为HLS协议的载体,也是我们后续分析的主要对象。详细的M3U8文件格式的介绍网上有很多,可以参照文档m3u8文件格式详解
下面列出一段未加密的样例传送门
没有加密的M3U8视频流
可以使用ffmpeg工具将视频保存到本地
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "https://node.imgio.in/demo/birds.m3u8" -c copy -copyts "birds.ts"
含有加密KEY的样例传送门
加密的M3U8视频流
因为样例中的解密KEY没有做鉴权,我们同样可以将视频保存到本地
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "https://cdn.theoplayer.com/vid ... ot%3B -c copy -copyts "index.ts"
2. 加密策略
浏览器在解析M3U8协议文件时候,如果发现文件中指定了加密策略,就使用当前的网络环境访问该地址,获取对应的解密KEY。从云存储中读取到ts流之后,使用KEY和IV进行解密,然后在网页上播放。由于视频流一般是部署在OSS或者CDN,方便让用户下载,通常这类服务器是不会做鉴权策略的,于是对视频的保护就转变成了对解密KEY的保护。
2.1 refer检测
这是比较粗糙的方案,如果请求来源不是来自可信的域名,就直接返回错误。我们直接用ffmpeg工具操作M3U8时,访问解密KEY的URI是没有refer的,所以不能直接下载。
2.2 用户鉴权
很多网校通常会用这种方案进行加密,这种方式可以根据权限管理来决策哪些用户可以获取到解密KEY。推荐一种比较方便的方案,通过fiddler进行抓包,然后用python脚本解析对应的saz,将m3u8中的URI换成对应的KEY,然后使用ffmpeg将媒体文件保存到本地。
2.3 自定义KeyLoader
可以使用这个组件,支持自定义KeyLoader,通过URI从服务端请求回来一串字符串,经过定制的KeyLoader来解密之后,得到真正的解密KEY。这种需要我们的分析KeyLoader源码,百度云提供的加密视频方案就用了这个策略练手地址,对key的解密用到了AES-ecb,对解密KEY进行解密的密钥写死在js代码中。
2.4 自定义PlaylistLoader
除了可以自定义KeyLoader,这个组件也支持指定PlaylistLoader,这样M3U8文件也是动态解密出来的,增强了安全性练手地址。通过动态调试的方式可以拿到明文的M3U8和对应的解密KEY。由于网站的解密算法比较复杂,笔者没有尝试提取算法,感兴趣的大神可以分析下。
3. 实战下载百度的加密视频
这里使用Chrome浏览器进行演示,网页地址见2.3
3.1 抓取关键信息
打开开发者工具,定位到Network的tab页
点击播放token加密视频
触发了对m3u8文件的拉取
拉取视频流的解密KEY
通过关键字找到js文件中的KeyLoader
可以看到这里用到了AES-ecb解密,并且密钥也暴露在js文件中
下断点,重新加载视频,即可看到解密KEY
3.2 构造可以方便下载视频的M3U8
如何让ffmpeg工具方便的拿到这个key?我们搭建一个服务端接口:接收一个base64编码后的参数,解码成二进制流返回给客户端。(可能比较搓的方案,但是好在还很通用)
构造解密KEY的URI:
将复制下来的解密KEY做base64编码
替换M3U8文件中的URI部分
3.3 使用ffmpeg工具下载媒体文件
ffmpeg -protocol_whitelist crypto,file,tcp,http,https,tls -i "baidu.m3u8" -c copy -copyts "baidu.ts"
下载后的视频可以正常播放
4. 总结
在线教育成为了互联网的风口,HLS协议也很好的契合了这个行业。最后呼吁大家多多尊重版权,从正规渠道购买视频资源。创作不易。
仅技术交流,请勿使用于非法用途。
上海热切提供便利转换服务的ai、抓取网页flash视频
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-06-09 03:05
抓取网页flash视频。从视频流里抠掉片头片尾。
有几个高效的方法。大概说一下:1.revit建模编辑,revitsheets的导出格式大概有四种(mpm啊meme啊等等),你用哪种就转换格式到ai里面2.找个矢量素材(在建模的时候就选好几种格式的素材,file-exportmaterial,导出的时候勾上svg格式和quicktime),就可以直接按照自己的需要用ai完成;3.revit建模成cad后,转换成pdf,然后再编辑4.revit中导出gif最快的方法:第一次用这个方法导出的时候,将revitsheets按照约定的尺寸编辑一遍,然后连起来放不行,得继续完成多个模型,再放一遍,最后直接生成完整的ai文件。
三维渲染器、专业软件或转换工具。上海热切提供便利转换服务。
1.ppt的设计稿。2.ai、ai、ai。有模板也有教程。3.三维渲染。视情况学一下ae什么的。4.用ps等软件做线稿,再转三维。ps小弟一枚,只知道这么多了。
国内的不少视频教程都是使用3dmax,这是webgl,即可做动画,模板网上也有不少。国外有两种电脑教程:一种是用maya直接建模,然后用surfacesurfans传到revit中,revit查看时就生成3d结果,制作优秀文字3d模型另一种是用autocad做二维平面图,渲染到ai中查看,把字转到3d文件中即可。
3dmax熟练的话做出来可以非常漂亮的文字。ai熟练的话也可以做出相当不错的图案。当然ps等软件也可以做出很好的3d文字!。 查看全部
上海热切提供便利转换服务的ai、抓取网页flash视频
抓取网页flash视频。从视频流里抠掉片头片尾。
有几个高效的方法。大概说一下:1.revit建模编辑,revitsheets的导出格式大概有四种(mpm啊meme啊等等),你用哪种就转换格式到ai里面2.找个矢量素材(在建模的时候就选好几种格式的素材,file-exportmaterial,导出的时候勾上svg格式和quicktime),就可以直接按照自己的需要用ai完成;3.revit建模成cad后,转换成pdf,然后再编辑4.revit中导出gif最快的方法:第一次用这个方法导出的时候,将revitsheets按照约定的尺寸编辑一遍,然后连起来放不行,得继续完成多个模型,再放一遍,最后直接生成完整的ai文件。
三维渲染器、专业软件或转换工具。上海热切提供便利转换服务。
1.ppt的设计稿。2.ai、ai、ai。有模板也有教程。3.三维渲染。视情况学一下ae什么的。4.用ps等软件做线稿,再转三维。ps小弟一枚,只知道这么多了。
国内的不少视频教程都是使用3dmax,这是webgl,即可做动画,模板网上也有不少。国外有两种电脑教程:一种是用maya直接建模,然后用surfacesurfans传到revit中,revit查看时就生成3d结果,制作优秀文字3d模型另一种是用autocad做二维平面图,渲染到ai中查看,把字转到3d文件中即可。
3dmax熟练的话做出来可以非常漂亮的文字。ai熟练的话也可以做出相当不错的图案。当然ps等软件也可以做出很好的3d文字!。
网页flash视频无痕兼容美图秀秀中的视频功能的脚本
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-05-17 23:03
抓取网页flash视频无痕脚本兼容美图秀秀中的视频功能的脚本学习wp7,html5,
可以实现视频下载+上传+分享,
我知道的一个脚本:itsublog国内很多人使用的。
babel,
这里有一个相当完善的下载gif图库的工具-show.html
我写过一个脚本,通过改变图片title中的tag[1](或图片上的title)来实现添加无痕的视频。[1]支持批量改title和gif压缩。
ps自带的功能。
我一直都是用我同事推荐的libsdcard视频工具。也支持转为gif。
微信公众号小程序filehound,可以直接下载微信上的视频,无水印。支持批量操作。iphone,
话不多说,先上图。
我一直用免费的网页视频下载神器httr
我看着我手机的微信下载不到。至少110+次访问失败之后,我也准备放弃了。
不如做个外套外面套上微信,可以看视频实时。可以添加评论。
可以试试蝉大师_专注企业互联网产品运营推广的威客网站,支持平台1.微信2.小程序3.公众号、网站4.知乎等平台至于大神推荐脚本,
我刚开始用直接在浏览器打开,用花瓣的存储转换成gif,在自定义分享图中添加ispdf格式的文件,然后把微信存成ispdf格式。 查看全部
网页flash视频无痕兼容美图秀秀中的视频功能的脚本
抓取网页flash视频无痕脚本兼容美图秀秀中的视频功能的脚本学习wp7,html5,
可以实现视频下载+上传+分享,
我知道的一个脚本:itsublog国内很多人使用的。
babel,
这里有一个相当完善的下载gif图库的工具-show.html
我写过一个脚本,通过改变图片title中的tag[1](或图片上的title)来实现添加无痕的视频。[1]支持批量改title和gif压缩。
ps自带的功能。
我一直都是用我同事推荐的libsdcard视频工具。也支持转为gif。
微信公众号小程序filehound,可以直接下载微信上的视频,无水印。支持批量操作。iphone,
话不多说,先上图。
我一直用免费的网页视频下载神器httr
我看着我手机的微信下载不到。至少110+次访问失败之后,我也准备放弃了。
不如做个外套外面套上微信,可以看视频实时。可以添加评论。
可以试试蝉大师_专注企业互联网产品运营推广的威客网站,支持平台1.微信2.小程序3.公众号、网站4.知乎等平台至于大神推荐脚本,
我刚开始用直接在浏览器打开,用花瓣的存储转换成gif,在自定义分享图中添加ispdf格式的文件,然后把微信存成ispdf格式。
抓取网页flash视频可以用"allfriendly”,速度非常快
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-05-15 13:01
抓取网页flash视频可以用"allfriendly",速度非常快,否则就得用python的代码来抓取了,教程如下:。
做好前端。最好用webrtc,然后还得用node,如果前端有的话。利用rawvideo(rb)和remjs(remotebrowserfilesystem),多抓一下。
楼上的答案已经答得很详细了,我就不多说了,像知乎这样的网站推荐用chrome扩展插件去抓取,成本会低一些,
直接pythonpandas,numpy比网站后台压缩好
可以使用pyinstaller这个软件去抓取,
当然是python啊,
不可以,最笨的方法是刷下载量。还有就是看看知乎广告,找用户爱点的。
allfriend吧
可以试试用一个nodejs框架去爬虫,专门抓取知乎live的推荐。并以爬虫和社交网络的结合方式去抓取知乎精彩回答。这是一个简单的例子,网上可以找到相关python代码。
不知道干这个价值多大。不过可以的话,应该抓取视频并post过去。并且抓取的截图可以发给他人,或者在淘宝/天猫发给需要的人, 查看全部
抓取网页flash视频可以用"allfriendly”,速度非常快
抓取网页flash视频可以用"allfriendly",速度非常快,否则就得用python的代码来抓取了,教程如下:。
做好前端。最好用webrtc,然后还得用node,如果前端有的话。利用rawvideo(rb)和remjs(remotebrowserfilesystem),多抓一下。
楼上的答案已经答得很详细了,我就不多说了,像知乎这样的网站推荐用chrome扩展插件去抓取,成本会低一些,
直接pythonpandas,numpy比网站后台压缩好
可以使用pyinstaller这个软件去抓取,
当然是python啊,
不可以,最笨的方法是刷下载量。还有就是看看知乎广告,找用户爱点的。
allfriend吧
可以试试用一个nodejs框架去爬虫,专门抓取知乎live的推荐。并以爬虫和社交网络的结合方式去抓取知乎精彩回答。这是一个简单的例子,网上可以找到相关python代码。
不知道干这个价值多大。不过可以的话,应该抓取视频并post过去。并且抓取的截图可以发给他人,或者在淘宝/天猫发给需要的人,
如何制作自己的webapp+web前端开发进阶之路的视频
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-05-14 05:02
抓取网页flash视频,
利用我有完整的django+web前端开发进阶之路的视频,其中包括:如何制作自己的webapp;在web前端开发过程中有哪些坑,怎么踩;还有java、c#、python、linux等方面的一些开发经验等等。我是张伟山,希望可以帮到你。
又看了一下,
我来正经的回答一下你的问题吧。分两个方面,首先是基础开发的知识,从安装环境到作业开发,类似于crud的开发方式,整个体系是封装好的,会有现成的功能,可以参考着用。更进一步的方式是,可以根据自己的业务场景建立新的功能模块,如es6中的异步加载库等,定制更加灵活强大的模块,这样也是一个办法。第二个方面是流行的技术,包括前端的移动端和python+前端框架,后端可以用java/php等,感兴趣可以慢慢琢磨。
想要快速精通这些技术,可以先看官方推荐的教程以及网上的开发案例,自己动手折腾一下,最好有一定经验再回来看官方的教程,看开发案例的时候仔细体会,多找问题,一步步拆分问题,最终会写出一个好用,可扩展的包,或者慢慢逐步过渡到专注某一个方向,一步步学习并开发某一项技术。
开发个人网站、博客、个人官网、企业网站、商城、以及小型的http服务器集群等,对web前端来说,最快捷的方式:python+前端框架,后端语言应该也是python,读不懂c++代码,读python+django代码还是可以读懂的,但对小型网站、个人网站来说有点困难。 查看全部
如何制作自己的webapp+web前端开发进阶之路的视频
抓取网页flash视频,
利用我有完整的django+web前端开发进阶之路的视频,其中包括:如何制作自己的webapp;在web前端开发过程中有哪些坑,怎么踩;还有java、c#、python、linux等方面的一些开发经验等等。我是张伟山,希望可以帮到你。
又看了一下,
我来正经的回答一下你的问题吧。分两个方面,首先是基础开发的知识,从安装环境到作业开发,类似于crud的开发方式,整个体系是封装好的,会有现成的功能,可以参考着用。更进一步的方式是,可以根据自己的业务场景建立新的功能模块,如es6中的异步加载库等,定制更加灵活强大的模块,这样也是一个办法。第二个方面是流行的技术,包括前端的移动端和python+前端框架,后端可以用java/php等,感兴趣可以慢慢琢磨。
想要快速精通这些技术,可以先看官方推荐的教程以及网上的开发案例,自己动手折腾一下,最好有一定经验再回来看官方的教程,看开发案例的时候仔细体会,多找问题,一步步拆分问题,最终会写出一个好用,可扩展的包,或者慢慢逐步过渡到专注某一个方向,一步步学习并开发某一项技术。
开发个人网站、博客、个人官网、企业网站、商城、以及小型的http服务器集群等,对web前端来说,最快捷的方式:python+前端框架,后端语言应该也是python,读不懂c++代码,读python+django代码还是可以读懂的,但对小型网站、个人网站来说有点困难。
知乎的分享模块对于地址的处理是个孤岛(下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-05-14 02:02
抓取网页flash视频地址直接发送给微信分享功能要求:正常浏览器、ie浏览器支持,微信客户端需要支持视频播放性能要求:耗流量高的浏览器无法正常分享;分享到网页、微信朋友圈中不会显示;如果地址在你的本地播放(包括本地播放和网页分享),那么默认分享到本地的html5网页浏览器;分享到微信,微信客户端会抓取本地的html5分享到自己的浏览器。
对于现在的浏览器,分享一个html5视频,其实真的非常难(不考虑用户安装css浏览器插件的问题)。连其他编程语言的视频编码标准都无法解决,更不要说别的浏览器解码这种技术问题了。所以我推测知乎的分享模块对于地址的处理是个孤岛(a,b,c这三个页面的地址),从这个地址走地址可以反向流回去一个页面地址,再从这个页面反向流回去我没听说过(个人理解),就算可以,那我觉得也不是能够通过分享模块收到这个链接的方式来实现的方案一:看使用什么浏览器能反向,如果这些浏览器不支持这种方案就只能麻烦点,把地址用url编码去掉也可以,再用cookie对下数据,或者换个数据模式,再用ua来个上行转发之类的方案二:如果选用https的地址编码,要考虑地址被https识别的问题,好在我知道现在还是有的,根据这个ssl和一些前端协议就可以处理。 查看全部
知乎的分享模块对于地址的处理是个孤岛(下)
抓取网页flash视频地址直接发送给微信分享功能要求:正常浏览器、ie浏览器支持,微信客户端需要支持视频播放性能要求:耗流量高的浏览器无法正常分享;分享到网页、微信朋友圈中不会显示;如果地址在你的本地播放(包括本地播放和网页分享),那么默认分享到本地的html5网页浏览器;分享到微信,微信客户端会抓取本地的html5分享到自己的浏览器。
对于现在的浏览器,分享一个html5视频,其实真的非常难(不考虑用户安装css浏览器插件的问题)。连其他编程语言的视频编码标准都无法解决,更不要说别的浏览器解码这种技术问题了。所以我推测知乎的分享模块对于地址的处理是个孤岛(a,b,c这三个页面的地址),从这个地址走地址可以反向流回去一个页面地址,再从这个页面反向流回去我没听说过(个人理解),就算可以,那我觉得也不是能够通过分享模块收到这个链接的方式来实现的方案一:看使用什么浏览器能反向,如果这些浏览器不支持这种方案就只能麻烦点,把地址用url编码去掉也可以,再用cookie对下数据,或者换个数据模式,再用ua来个上行转发之类的方案二:如果选用https的地址编码,要考虑地址被https识别的问题,好在我知道现在还是有的,根据这个ssl和一些前端协议就可以处理。
抓取网页flash视频做作品试试?不是外包的话
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-05-12 03:01
抓取网页flash视频做作品试试?
不是外包的话可以试试看对方做个app出来可以达到这个功能
推荐一个免费爬虫工具,我目前正在使用,对国内各大网站进行抓取。适合小白。网站爬虫工具,支持requests+beautifulsoup+pyquery+jqueryextractor+lxml+jsonp2抓取网页内容中文can_use_editable_text_with_requests&app=zh_cn_us。
1.获取学校招聘信息公司给地方教育局每年都报送很多招聘信息,并不是所有的都是人才市场上可以买到的,每年老师们都可以从学校很多招聘信息里扒几块出来做数据分析。2.涉及地区招聘信息获取一般地区的高校周边都会有不少实体店,能从这些店里很快买到自己需要的信息。3.招聘经历公司自己建了一个会员账号,可以通过学校的系统直接查到录取人员的经历。
一般会在每个学生毕业时会发起一次选人,比如某学生高考成绩在哪里可以查到,然后根据这些信息自己制作简历。
看数据量,如果只是给孩子填志愿的数据。1.出租车信息,做乘车网站,比如滴滴打车。现在乘车网站那么多,你输入日期和时间就能直接出租车的信息。2.餐饮信息,饭店。大家去买饭的话,对食物的图片信息非常在意,如果你发布个坐标信息,简直棒呆。 查看全部
抓取网页flash视频做作品试试?不是外包的话
抓取网页flash视频做作品试试?
不是外包的话可以试试看对方做个app出来可以达到这个功能
推荐一个免费爬虫工具,我目前正在使用,对国内各大网站进行抓取。适合小白。网站爬虫工具,支持requests+beautifulsoup+pyquery+jqueryextractor+lxml+jsonp2抓取网页内容中文can_use_editable_text_with_requests&app=zh_cn_us。
1.获取学校招聘信息公司给地方教育局每年都报送很多招聘信息,并不是所有的都是人才市场上可以买到的,每年老师们都可以从学校很多招聘信息里扒几块出来做数据分析。2.涉及地区招聘信息获取一般地区的高校周边都会有不少实体店,能从这些店里很快买到自己需要的信息。3.招聘经历公司自己建了一个会员账号,可以通过学校的系统直接查到录取人员的经历。
一般会在每个学生毕业时会发起一次选人,比如某学生高考成绩在哪里可以查到,然后根据这些信息自己制作简历。
看数据量,如果只是给孩子填志愿的数据。1.出租车信息,做乘车网站,比如滴滴打车。现在乘车网站那么多,你输入日期和时间就能直接出租车的信息。2.餐饮信息,饭店。大家去买饭的话,对食物的图片信息非常在意,如果你发布个坐标信息,简直棒呆。
了解搜索引擎来进行SEO
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-05-07 09:29
搜索引擎的工作的过程非常复杂,而简单的讲搜索引擎的工过程大体可以分成三个阶段。爬行和抓取:搜索引擎蜘蛛通过跟踪链接访问页面,获取页面HTML代码存入数据库。预处理:搜索赢球对抓取来的页面数据文字进行文字提取、中文分词、索引等处理,以备排名程序调用。排名:用户输入关键字后,排名调用索引库数据,计算相关性,然后按一定格式生成搜索结果页面。
爬行和抓取
爬行和抓取是搜索引擎工作的第一步,完成数据收集任务。
蜘蛛
搜索引擎用来爬行和访问页面的程序被称为蜘蛛(spider),也称为机器人(bot)。
蜘蛛代理名称:
百度蜘蛛:Baiduspider+(+) ·
雅虎中国蜘蛛:Mozilla/5.0 (compatible; Yahoo! Slurp China; ) ·
英文雅虎蜘蛛:Mozilla/5.0 (compatible; Yahoo! Slurp/3.0; )
Google 蜘蛛:Mozilla/5.0 (compatible; Googlebot/2.1; +) ·
微软 Bing 蜘蛛:msnbot/1.1 (+)·
搜狗蜘蛛: Sogou+web+robot+(+#07) ·
搜搜蜘蛛:Sosospider+(+) ·
有道蜘蛛:Mozilla/5.0 (compatible; YodaoBot/1.0; ; )
跟踪链接
为了抓取网上尽量多的页面,搜索引擎蜘蛛会跟踪页面上的链接,从一个页面爬到下一个页面,就好像蜘蛛在蜘蛛网上爬行那样,这也就是搜索引擎蜘蛛这个名称的由来。最简单的爬行遍历策略分为两种,一是深度优先,二是广度优先。
深度优先搜索
深度优先搜索就是在搜索树的每一层始终先只扩展一个子节点,不断地向纵深前进直到不能再前进(到达叶子节点或受到深度限制)时,才从当前节点返回到上一级节点,沿另一方向又继续前进。这种方法的搜索树是从树根开始一枝一枝逐渐形成的。
深度优先搜索亦称为纵向搜索。由于一个有解的问题树可能含有无穷分枝,深度优先搜索如果误入无穷分枝(即深度无限),则不可能找到目标节点。所以,深度优先搜索策略是不完备的。另外,应用此策略得到的解不一定是最佳解(最短路径)。
广度优先搜索
在深度优先搜索算法中,是深度越大的结点越先得到扩展。如果在搜索中把算法改为按结点的层次进行搜索, 本层的结点没有搜索处理完时,不能对下层结点进行处理,即深度越小的结点越先得到扩展,也就是说先产生 的结点先得以扩展处理,这种搜索算法称为广度优先搜索法。
在深度优先搜索算法中,是深度越大的结点越先得到扩展。如果在搜索中把算法改为按结点的层次进行搜索, 本层的结点没有搜索处理完时,不能对下层结点进行处理,即深度越小的结点越先得到扩展,也就是说先产生 的结点先得以扩展处理,这种搜索算法称为广度优先搜索法。
吸引蜘蛛
哪些页面被认为比较重要呢?有几方面影响因素:
· 网站和页面权重。质量高、资格老的网站被认为权重比较高,这种网站上的页面被爬行的深度也会比较高,所以会有更多内页被收录。
· 页面更新度。蜘蛛每次爬行都会把页面数据存储起来。如果第二次爬行发现页面与第一次收录的完全一样,说明页面没有更新,蜘蛛也就没有必要经常抓取。如果页面内容经常更新,蜘蛛就会更加频繁地访问这种页面,页面上出现的新链接,也自然会被蜘蛛更快跟踪,抓取新页面。
· 导入链接。无论是外部链接还是同一个网站的内部链接,要被蜘蛛抓取就必须有导入链接进入页面,否则蜘蛛根本没有机会知道页面的存在。高质量的导入链接也经常使页面上的导出链接被爬行深度增加。一般来说网站上权重最高的是首页,大部分外部链接是指向首页,蜘蛛访问最频繁的也是首页。离首页点击距离越近,页面权重越高,被蜘蛛爬行的机会也越大。
地址库
为了避免重复爬行和抓取网址,搜索引擎会建立一个地址库,记录已经被发现还没有抓取的页面,以及已经被抓取的页面。地址库中的uRL有几个来源:
(1)人工录入的种子网站。
(2)蜘蛛抓取页面后,从HTML中解析出新的链接uRL,与地址库中的数据进行对比,如果是地址库中没有的网址,就存入待访问地址库。
(3)站长通过搜索引擎网页提交表格提交进来的网址。
蜘蛛按重要性从待访问地址库中提取uRL,访问并抓取页面,然后把这个uRL从待访问地址库中删除,放进已访问地址库中。
大部分主流搜索引擎都提供一个表格,让站长提交网址。不过这些提交来的网址都只是存入地址库而已,是否收录还要看页面重要性如何。搜索引擎所收录的绝大部分页面是蜘蛛自己跟踪链接得到的。可以说提交页面基本t是毫无用处的,搜索引擎更喜欢自己沿着链接发现新页面。
文件存储搜索引擎蜘蛛抓取的数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML是完全一样的。每个uRI,都有一个独特的文件编号。
爬行时的复制内容检测
检测并删除复制内容通常是在下面介绍的预处理过程中进行的,但现在的蜘蛛在爬行和抓取文件时也会进行定程度的复制内容检测。遇到权重很低的网站上大量转载或抄袭内容时,很可能不再继续爬行。这也就是有的站长在日志文件中发现了蜘蛛,但页面从来没有被真正收录过的原因。
预处理
在一些SEO材料中,“预处理”也被简称为“索引”,因为索引是预处理最主要的步骤。
搜索引擎蜘蛛抓取的原始页面,并不能直接用于查询排名处理。搜索引擎数据库中的页面数都在数万亿级别以上,用户输入搜索词后,靠排名程序实时对这么多页面分析相关性,计算量太大,不可能在一两秒内返回排名结果。因此抓取来的页面必须经过预处理,为最后的查询排名做好准备。
和爬行抓取一样,预处理也是在后台提前完成的,用户搜索时感觉不到这个过程。
1.提取文字
现在的搜索引擎还是以文字内容为基础。蜘蛛抓取到的页面中的HTML代码,除了用户在浏览器上可以看到的可见文字外,还包含了大量的HTML格式标签、 JavaScript程序等无法用于排名的内容。搜索引擎预处理首先要做的就是从HTML文件中去除标签、程序,提取出可以用于排名处理的网页面文字内 容。
今天愚人节哈
除去HTML代码后,剩下的用于排名的文字只是这一行:
今天愚人节哈
除了可见文字,搜索引擎也会提取出一些特殊的包含文字信息的代码,如Meta标签中的文字、图片替代文字、Flash文件的替代文字、链接锚文字等。
2.中文分词
分词是中文搜索引擎特有的步骤。搜索引擎存储和处理页面及用户搜索都是以词为基础的。英文等语言单词与单词之间有空格分隔,搜索引擎索引程序可以直接把句子 划分为单词的集合。而中文词与词之间没有任何分隔符,一个句子中的所有字和词都是连在一起的。搜索引擎必须首先分辨哪几个字组成一个词,哪些字本身就是一 个词。比如“减肥方法”将被分词为“减肥”和“方法”两个词。
中文分词方法基本上有两种,一种是基于词典匹配,另一种是基于统计。
基于词典匹配的方法是指,将待分析的一段汉字与一个事先造好的词典中的词条进行匹配,在待分析汉字串中扫描到词典中已有的词条则匹配成功,或者说切分出一个单词。
按照扫描方向,基于词典的匹配法可以分为正向匹配和逆向匹配。按照匹配长度优先级的不同,又可以分为最大匹配和最小匹配。将扫描方向和长度优先混合,又可以产生正向最大匹配、逆向最大匹配等不同方法。
词典匹配方法计算简单,其准确度在很大程度上取决于词典的完整性和更新情况。
基于统计的分词方法指的是分析大量文字样本,计算出字与字相邻出现的统计概率,几个字相邻出现越多,就越可能形成一个单词。基于统计的方法的优势是对新出现的词反应更快速,也有利于消除歧义。
基于词典匹配和基于统计的分词方法各有优劣,实际使用中的分词系统都是混合使用两种方法的,快速高效,又能识别生词、新词,消除歧义。
中文分词的准确性往往影响搜索引擎排名的相关性。比如在百度搜索“搜索引擎优化”,从快照中可以看到,百度把“搜索引擎优化”这六个字当成一个词。
而在Google搜索同样的词,快照显示Google将其分切为“搜索引擎”和“优化”两个词。显然百度切分得更为合理,搜索引擎优化是一个完整的概念。Google分词时倾向于更为细碎。
这种分词上的不同很可能是一些关键词排名在不同搜索引擎有不同表现的原因之一。比如百度更喜欢将搜索词完整匹配地出现在页面上,也就是说搜索“够戏博客” 时,这四个字连续完整出现更容易在百度获得好的排名。Google就与此不同,不太要求完整匹配。一些页面出现“够戏”和“博客”两个词,但不必完整匹配 地出现,“够戏”出现在前面,“博客”出现在页面的其他地方,这样的页面在Google搜索“够戏博客”时,也可以获得不错的排名。
搜索引擎对页面的分词取决于词库的规模、准确性和分词算法的好坏,而不是取决于页面本身如何,所以SEO人员对分词所能做的很少。唯一能做的是在页面上用某种形 式提示搜索引擎,某几个字应该被当做一个词处理,尤其是可能产生歧义的时候,比如在页面标题、h1标签及黑体中出现关键词。如果页面是关于“和服”的内 容,那么可以把“和服”这两个字特意标为黑体。如果页面是关于“化妆和服装”,可以把“服装”两个字标为黑体。这样,搜索引擎对页面进行分析时就知道标为 黑体的应该是一个词。
3.去停止词
无论是英文还是中文,页面内容中都会有一些出现频率很 高,却对内容没有任何影响的词,如“的”、“地”、“得”之类的助词,“啊”、“哈”、“呀”之类的感叹词,“从而”、“以”、“却”之类的副词或介词。 这些词被称为停止词,因为它们对页面的主要意思没什么影响。英文中的常见停止词有the,a,an,to,of等。
搜索引擎在索引页面之前会去掉这些停止词,使索引数据主题更为突出,减少无谓的计算量。
4.消除噪声
绝 大部分页面上还有一部分内容对页面主题也没有什么贡献,比如版权声明文字、导航条、广告等。以常见的博客导航为例,几乎每个博客页面上都会出现文章分类、 历史存档等导航内容,但是这些页面本身与“分类”、“历史”这些词都没有任何关系。用户搜索“历史”、“分类”这些关键词时仅仅因为页面上有这些词出现而 返回博客帖子是毫无意义的,完全不相关。所以这些区块都属于噪声,对页面主题只能起到分散作用。
搜索引擎需要识别并消除这些噪声,排名时不使用噪声内容。消噪的基本方法是根据HTML标签对页面分块,区分出页头、导航、正文、页脚、广告等区域,在网站上大量重复出现的区块往往属于噪声。对页面进行消噪后,剩下的才是页面主体内容。
5.去重
搜索引擎还需要对页面进行去重处理。
同 一篇文章经常会重复出现在不同网站及同一个网站的不同网址上,搜索引擎并不喜欢这种重复性的内容。用户搜索时,如果在前两页看到的都是来自不同网站的同一 篇文章,用户体验就太差了,虽然都是内容相关的。搜索引擎希望只返回相同文章中的一篇,所以在进行索引前还需要识别和删除重复内容,这个过程就称为“去 重”。
去重的基本方法是对页面特征关键词计算指纹,也就是说从页面主体内容中选取最有代表性的一部分关键词(经常是出现频率最高的关键 词),然后计算这些关键词的数字指纹。这里的关键词选取是在分词、去停止词、消噪之后。实验表明,通常选取10个特征关键词就可以达到比较高的计算准确 性,再选取更多词对去重准确性提高的贡献也就不大了。
典型的指纹计算方法如MD5算法(信息摘要算法第五版)。这类指纹算法的特点是,输入(特征关键词)有任何微小的变化,都会导致计算出的指纹有很大差距。
了 解了搜索引擎的去重算法,SEO人员就应该知道简单地增加“的”、“地”、“得”、调换段落顺序这种所谓伪原创,并不能逃过搜索引擎的去重算法,因为这样 的操作无法改变文章的特征关键词。而且搜索引擎的去重算法很可能不止于页面级别,而是进行到段落级别,混合不同文章、交叉调换段落顺序也不能使转载和抄袭 变成原创。
6.正向索引
正向索引也可以简称为索引。
经过文字提取、分词、 消噪、去重后,搜索引擎得到的就是独特的、能反映页面主体内容的、以词为单位的内容。接下来搜索引擎索引程序就可以提取关键词,按照分词程序划分好的词, 把页面转换为一个关键词组成的集合,同时记录每一个关键词在页面上的出现频率、出现次数、格式(如出现在标题标签、黑体、H标签、锚文字等)、位置(如页 面第一段文字等)。这样,每一个页面都可以记录为一串关键词集合,其中每个关键词的词频、格式、位置等权重信息也都记录在案。
搜索引擎索引程序将页面及关键词形成词表结构存储进索引库。简化的索引词表形式如表2-1所示。
每个文件都对应一个文件ID,文件内容被表示为一串关键词的集合。实际上在搜索引擎索引库中,关键词也已经转换为关键词ID.这样的数据结构就称为正向索引。
7.倒排索引
正向索引还不能直接用于排名。假设用户搜索关键词2,如果只存在正向索引,排名程序需要扫描所有索引库中的文件,找出包含关键词2的文件,再进行相关性计算。这样的计算量无法满足实时返回排名结果的要求。
所以搜索引擎会将正向索引数据库重新构造为倒排索引,把文件对应到关键词的映射转换为关键词到文件的映射,如表2-2所示。
在倒排索引中关键词是主键,每个关键词都对应着一系列文件,这些文件中都出现了这个关键词。这样当用户搜索某个关键词时,排序程序在倒排索引中定位到这个关键词,就可以马上找出所有包含这个关键词的文件。
8.链接关系计算
链接关系计算也是预处理中很重要的一部分。现在所有的主流搜索引擎排名因素中都包含网页之间的链接流动信息。搜索引擎在抓取页面内容后,必须事前计算出:页 面上有哪些链接指向哪些其他页面,每个页面有哪些导入链接,链接使用了什么锚文字,这些复杂的链接指向关系形成了网站和页面的链接权重。
Google PR值就是这种链接关系的最主要体现之一。其他搜索引擎也都进行类似计算,虽然它们并不称为PR.
由于页面和链接数量巨大,网上的链接关系又时时处在更新中,因此链接关系及PR的计算要耗费很长时间。关于PR和链接分析,后面还有专门的章节介绍。
9.特殊文件处理
除 了HTML文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如PDF、Word、WPS、XLS、PPT、TXT文件等。我们在搜索结果 中也经常会看到这些文件类型。但目前的搜索引擎还不能处理图片、视频、Flash这类非文字内容,也不能执行脚本和程序。
虽然搜索引擎在识别图片及从Flash中提取文字内容方面有些进步,不过距离直接靠读取图片、视频、Flash内容返回结果的目标还很远。对图片、视频内容的排名还往往是依据与之相关的文字内容,详细情况可以参考后面的整合搜索部分。
排名
经过搜索引擎蜘蛛抓取的界面,搜索引擎程序 计算得到倒排索引后,收索引擎就准备好可以随时处理用户搜索了。用户在搜索框填入关键字后,排名程序调用索引库数据,计算排名显示给客户,排名过程是与客户直接互动的。 查看全部
了解搜索引擎来进行SEO
搜索引擎的工作的过程非常复杂,而简单的讲搜索引擎的工过程大体可以分成三个阶段。爬行和抓取:搜索引擎蜘蛛通过跟踪链接访问页面,获取页面HTML代码存入数据库。预处理:搜索赢球对抓取来的页面数据文字进行文字提取、中文分词、索引等处理,以备排名程序调用。排名:用户输入关键字后,排名调用索引库数据,计算相关性,然后按一定格式生成搜索结果页面。
爬行和抓取
爬行和抓取是搜索引擎工作的第一步,完成数据收集任务。
蜘蛛
搜索引擎用来爬行和访问页面的程序被称为蜘蛛(spider),也称为机器人(bot)。
蜘蛛代理名称:
百度蜘蛛:Baiduspider+(+) ·
雅虎中国蜘蛛:Mozilla/5.0 (compatible; Yahoo! Slurp China; ) ·
英文雅虎蜘蛛:Mozilla/5.0 (compatible; Yahoo! Slurp/3.0; )
Google 蜘蛛:Mozilla/5.0 (compatible; Googlebot/2.1; +) ·
微软 Bing 蜘蛛:msnbot/1.1 (+)·
搜狗蜘蛛: Sogou+web+robot+(+#07) ·
搜搜蜘蛛:Sosospider+(+) ·
有道蜘蛛:Mozilla/5.0 (compatible; YodaoBot/1.0; ; )
跟踪链接
为了抓取网上尽量多的页面,搜索引擎蜘蛛会跟踪页面上的链接,从一个页面爬到下一个页面,就好像蜘蛛在蜘蛛网上爬行那样,这也就是搜索引擎蜘蛛这个名称的由来。最简单的爬行遍历策略分为两种,一是深度优先,二是广度优先。
深度优先搜索
深度优先搜索就是在搜索树的每一层始终先只扩展一个子节点,不断地向纵深前进直到不能再前进(到达叶子节点或受到深度限制)时,才从当前节点返回到上一级节点,沿另一方向又继续前进。这种方法的搜索树是从树根开始一枝一枝逐渐形成的。
深度优先搜索亦称为纵向搜索。由于一个有解的问题树可能含有无穷分枝,深度优先搜索如果误入无穷分枝(即深度无限),则不可能找到目标节点。所以,深度优先搜索策略是不完备的。另外,应用此策略得到的解不一定是最佳解(最短路径)。
广度优先搜索
在深度优先搜索算法中,是深度越大的结点越先得到扩展。如果在搜索中把算法改为按结点的层次进行搜索, 本层的结点没有搜索处理完时,不能对下层结点进行处理,即深度越小的结点越先得到扩展,也就是说先产生 的结点先得以扩展处理,这种搜索算法称为广度优先搜索法。
在深度优先搜索算法中,是深度越大的结点越先得到扩展。如果在搜索中把算法改为按结点的层次进行搜索, 本层的结点没有搜索处理完时,不能对下层结点进行处理,即深度越小的结点越先得到扩展,也就是说先产生 的结点先得以扩展处理,这种搜索算法称为广度优先搜索法。
吸引蜘蛛
哪些页面被认为比较重要呢?有几方面影响因素:
· 网站和页面权重。质量高、资格老的网站被认为权重比较高,这种网站上的页面被爬行的深度也会比较高,所以会有更多内页被收录。
· 页面更新度。蜘蛛每次爬行都会把页面数据存储起来。如果第二次爬行发现页面与第一次收录的完全一样,说明页面没有更新,蜘蛛也就没有必要经常抓取。如果页面内容经常更新,蜘蛛就会更加频繁地访问这种页面,页面上出现的新链接,也自然会被蜘蛛更快跟踪,抓取新页面。
· 导入链接。无论是外部链接还是同一个网站的内部链接,要被蜘蛛抓取就必须有导入链接进入页面,否则蜘蛛根本没有机会知道页面的存在。高质量的导入链接也经常使页面上的导出链接被爬行深度增加。一般来说网站上权重最高的是首页,大部分外部链接是指向首页,蜘蛛访问最频繁的也是首页。离首页点击距离越近,页面权重越高,被蜘蛛爬行的机会也越大。
地址库
为了避免重复爬行和抓取网址,搜索引擎会建立一个地址库,记录已经被发现还没有抓取的页面,以及已经被抓取的页面。地址库中的uRL有几个来源:
(1)人工录入的种子网站。
(2)蜘蛛抓取页面后,从HTML中解析出新的链接uRL,与地址库中的数据进行对比,如果是地址库中没有的网址,就存入待访问地址库。
(3)站长通过搜索引擎网页提交表格提交进来的网址。
蜘蛛按重要性从待访问地址库中提取uRL,访问并抓取页面,然后把这个uRL从待访问地址库中删除,放进已访问地址库中。
大部分主流搜索引擎都提供一个表格,让站长提交网址。不过这些提交来的网址都只是存入地址库而已,是否收录还要看页面重要性如何。搜索引擎所收录的绝大部分页面是蜘蛛自己跟踪链接得到的。可以说提交页面基本t是毫无用处的,搜索引擎更喜欢自己沿着链接发现新页面。
文件存储搜索引擎蜘蛛抓取的数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML是完全一样的。每个uRI,都有一个独特的文件编号。
爬行时的复制内容检测
检测并删除复制内容通常是在下面介绍的预处理过程中进行的,但现在的蜘蛛在爬行和抓取文件时也会进行定程度的复制内容检测。遇到权重很低的网站上大量转载或抄袭内容时,很可能不再继续爬行。这也就是有的站长在日志文件中发现了蜘蛛,但页面从来没有被真正收录过的原因。
预处理
在一些SEO材料中,“预处理”也被简称为“索引”,因为索引是预处理最主要的步骤。
搜索引擎蜘蛛抓取的原始页面,并不能直接用于查询排名处理。搜索引擎数据库中的页面数都在数万亿级别以上,用户输入搜索词后,靠排名程序实时对这么多页面分析相关性,计算量太大,不可能在一两秒内返回排名结果。因此抓取来的页面必须经过预处理,为最后的查询排名做好准备。
和爬行抓取一样,预处理也是在后台提前完成的,用户搜索时感觉不到这个过程。
1.提取文字
现在的搜索引擎还是以文字内容为基础。蜘蛛抓取到的页面中的HTML代码,除了用户在浏览器上可以看到的可见文字外,还包含了大量的HTML格式标签、 JavaScript程序等无法用于排名的内容。搜索引擎预处理首先要做的就是从HTML文件中去除标签、程序,提取出可以用于排名处理的网页面文字内 容。
今天愚人节哈
除去HTML代码后,剩下的用于排名的文字只是这一行:
今天愚人节哈
除了可见文字,搜索引擎也会提取出一些特殊的包含文字信息的代码,如Meta标签中的文字、图片替代文字、Flash文件的替代文字、链接锚文字等。
2.中文分词
分词是中文搜索引擎特有的步骤。搜索引擎存储和处理页面及用户搜索都是以词为基础的。英文等语言单词与单词之间有空格分隔,搜索引擎索引程序可以直接把句子 划分为单词的集合。而中文词与词之间没有任何分隔符,一个句子中的所有字和词都是连在一起的。搜索引擎必须首先分辨哪几个字组成一个词,哪些字本身就是一 个词。比如“减肥方法”将被分词为“减肥”和“方法”两个词。
中文分词方法基本上有两种,一种是基于词典匹配,另一种是基于统计。
基于词典匹配的方法是指,将待分析的一段汉字与一个事先造好的词典中的词条进行匹配,在待分析汉字串中扫描到词典中已有的词条则匹配成功,或者说切分出一个单词。
按照扫描方向,基于词典的匹配法可以分为正向匹配和逆向匹配。按照匹配长度优先级的不同,又可以分为最大匹配和最小匹配。将扫描方向和长度优先混合,又可以产生正向最大匹配、逆向最大匹配等不同方法。
词典匹配方法计算简单,其准确度在很大程度上取决于词典的完整性和更新情况。
基于统计的分词方法指的是分析大量文字样本,计算出字与字相邻出现的统计概率,几个字相邻出现越多,就越可能形成一个单词。基于统计的方法的优势是对新出现的词反应更快速,也有利于消除歧义。
基于词典匹配和基于统计的分词方法各有优劣,实际使用中的分词系统都是混合使用两种方法的,快速高效,又能识别生词、新词,消除歧义。
中文分词的准确性往往影响搜索引擎排名的相关性。比如在百度搜索“搜索引擎优化”,从快照中可以看到,百度把“搜索引擎优化”这六个字当成一个词。
而在Google搜索同样的词,快照显示Google将其分切为“搜索引擎”和“优化”两个词。显然百度切分得更为合理,搜索引擎优化是一个完整的概念。Google分词时倾向于更为细碎。
这种分词上的不同很可能是一些关键词排名在不同搜索引擎有不同表现的原因之一。比如百度更喜欢将搜索词完整匹配地出现在页面上,也就是说搜索“够戏博客” 时,这四个字连续完整出现更容易在百度获得好的排名。Google就与此不同,不太要求完整匹配。一些页面出现“够戏”和“博客”两个词,但不必完整匹配 地出现,“够戏”出现在前面,“博客”出现在页面的其他地方,这样的页面在Google搜索“够戏博客”时,也可以获得不错的排名。
搜索引擎对页面的分词取决于词库的规模、准确性和分词算法的好坏,而不是取决于页面本身如何,所以SEO人员对分词所能做的很少。唯一能做的是在页面上用某种形 式提示搜索引擎,某几个字应该被当做一个词处理,尤其是可能产生歧义的时候,比如在页面标题、h1标签及黑体中出现关键词。如果页面是关于“和服”的内 容,那么可以把“和服”这两个字特意标为黑体。如果页面是关于“化妆和服装”,可以把“服装”两个字标为黑体。这样,搜索引擎对页面进行分析时就知道标为 黑体的应该是一个词。
3.去停止词
无论是英文还是中文,页面内容中都会有一些出现频率很 高,却对内容没有任何影响的词,如“的”、“地”、“得”之类的助词,“啊”、“哈”、“呀”之类的感叹词,“从而”、“以”、“却”之类的副词或介词。 这些词被称为停止词,因为它们对页面的主要意思没什么影响。英文中的常见停止词有the,a,an,to,of等。
搜索引擎在索引页面之前会去掉这些停止词,使索引数据主题更为突出,减少无谓的计算量。
4.消除噪声
绝 大部分页面上还有一部分内容对页面主题也没有什么贡献,比如版权声明文字、导航条、广告等。以常见的博客导航为例,几乎每个博客页面上都会出现文章分类、 历史存档等导航内容,但是这些页面本身与“分类”、“历史”这些词都没有任何关系。用户搜索“历史”、“分类”这些关键词时仅仅因为页面上有这些词出现而 返回博客帖子是毫无意义的,完全不相关。所以这些区块都属于噪声,对页面主题只能起到分散作用。
搜索引擎需要识别并消除这些噪声,排名时不使用噪声内容。消噪的基本方法是根据HTML标签对页面分块,区分出页头、导航、正文、页脚、广告等区域,在网站上大量重复出现的区块往往属于噪声。对页面进行消噪后,剩下的才是页面主体内容。
5.去重
搜索引擎还需要对页面进行去重处理。
同 一篇文章经常会重复出现在不同网站及同一个网站的不同网址上,搜索引擎并不喜欢这种重复性的内容。用户搜索时,如果在前两页看到的都是来自不同网站的同一 篇文章,用户体验就太差了,虽然都是内容相关的。搜索引擎希望只返回相同文章中的一篇,所以在进行索引前还需要识别和删除重复内容,这个过程就称为“去 重”。
去重的基本方法是对页面特征关键词计算指纹,也就是说从页面主体内容中选取最有代表性的一部分关键词(经常是出现频率最高的关键 词),然后计算这些关键词的数字指纹。这里的关键词选取是在分词、去停止词、消噪之后。实验表明,通常选取10个特征关键词就可以达到比较高的计算准确 性,再选取更多词对去重准确性提高的贡献也就不大了。
典型的指纹计算方法如MD5算法(信息摘要算法第五版)。这类指纹算法的特点是,输入(特征关键词)有任何微小的变化,都会导致计算出的指纹有很大差距。
了 解了搜索引擎的去重算法,SEO人员就应该知道简单地增加“的”、“地”、“得”、调换段落顺序这种所谓伪原创,并不能逃过搜索引擎的去重算法,因为这样 的操作无法改变文章的特征关键词。而且搜索引擎的去重算法很可能不止于页面级别,而是进行到段落级别,混合不同文章、交叉调换段落顺序也不能使转载和抄袭 变成原创。
6.正向索引
正向索引也可以简称为索引。
经过文字提取、分词、 消噪、去重后,搜索引擎得到的就是独特的、能反映页面主体内容的、以词为单位的内容。接下来搜索引擎索引程序就可以提取关键词,按照分词程序划分好的词, 把页面转换为一个关键词组成的集合,同时记录每一个关键词在页面上的出现频率、出现次数、格式(如出现在标题标签、黑体、H标签、锚文字等)、位置(如页 面第一段文字等)。这样,每一个页面都可以记录为一串关键词集合,其中每个关键词的词频、格式、位置等权重信息也都记录在案。
搜索引擎索引程序将页面及关键词形成词表结构存储进索引库。简化的索引词表形式如表2-1所示。
每个文件都对应一个文件ID,文件内容被表示为一串关键词的集合。实际上在搜索引擎索引库中,关键词也已经转换为关键词ID.这样的数据结构就称为正向索引。
7.倒排索引
正向索引还不能直接用于排名。假设用户搜索关键词2,如果只存在正向索引,排名程序需要扫描所有索引库中的文件,找出包含关键词2的文件,再进行相关性计算。这样的计算量无法满足实时返回排名结果的要求。
所以搜索引擎会将正向索引数据库重新构造为倒排索引,把文件对应到关键词的映射转换为关键词到文件的映射,如表2-2所示。
在倒排索引中关键词是主键,每个关键词都对应着一系列文件,这些文件中都出现了这个关键词。这样当用户搜索某个关键词时,排序程序在倒排索引中定位到这个关键词,就可以马上找出所有包含这个关键词的文件。
8.链接关系计算
链接关系计算也是预处理中很重要的一部分。现在所有的主流搜索引擎排名因素中都包含网页之间的链接流动信息。搜索引擎在抓取页面内容后,必须事前计算出:页 面上有哪些链接指向哪些其他页面,每个页面有哪些导入链接,链接使用了什么锚文字,这些复杂的链接指向关系形成了网站和页面的链接权重。
Google PR值就是这种链接关系的最主要体现之一。其他搜索引擎也都进行类似计算,虽然它们并不称为PR.
由于页面和链接数量巨大,网上的链接关系又时时处在更新中,因此链接关系及PR的计算要耗费很长时间。关于PR和链接分析,后面还有专门的章节介绍。
9.特殊文件处理
除 了HTML文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如PDF、Word、WPS、XLS、PPT、TXT文件等。我们在搜索结果 中也经常会看到这些文件类型。但目前的搜索引擎还不能处理图片、视频、Flash这类非文字内容,也不能执行脚本和程序。
虽然搜索引擎在识别图片及从Flash中提取文字内容方面有些进步,不过距离直接靠读取图片、视频、Flash内容返回结果的目标还很远。对图片、视频内容的排名还往往是依据与之相关的文字内容,详细情况可以参考后面的整合搜索部分。
排名
经过搜索引擎蜘蛛抓取的界面,搜索引擎程序 计算得到倒排索引后,收索引擎就准备好可以随时处理用户搜索了。用户在搜索框填入关键字后,排名程序调用索引库数据,计算排名显示给客户,排名过程是与客户直接互动的。
如何在网页测试中叠加多个被试的眼动追踪数据?
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-05-07 09:17
在多数网页研究中,给被试者分配的任务通常包含浏览某个网站或浏览某个网页应用。在浏览的过程中,他们并不是被动地观看按指定顺序和时长呈现的刺激材料,而是会与呈现的刺激材料进行交互,这样每个被试者的结果都是独一无二的。因此如果要对这些被试者的体验进行对比就会很繁琐,并且多被试的眼动数据自动叠加是一项很有挑战性的工作。
例如,在浏览网页时,一些被试者可能在某个页面的停留时间比其他被试者长,他们可能会跳转到其他页面,多次播放和停止网页内的视频等。如果一个或两个被试者在浏览一个页面时花了很多的时间,那么他们的注视点数量可能会增加,这会对叠加的数据带来影响。页面中还有可能会包含一些动态内容,例如下拉菜单,弹出窗口和flash动画内容,这些都会对数据的自动叠加带来一些挑战。
在进行网页眼动数据采集时,对这些不同的挑战要保持足够的注意并做出相应的分析做好准备。本文将介绍通过Pro Lab软件实现对网页实验项目中多被试者的眼动追踪数据叠加的方法和步骤。我们将对能够自动叠加数据和手动叠加数据的案例进行着重阐述。
1
通过自动网页导航TOI兴趣区间叠加数据
在使用网页元素进行测试时,Pro Lab软件会记录观察窗*区域的测试过程的视频并同时提取所有打开的独立的URL的完整页面屏幕截图。软件还会保存与页面导航时间相关的TOI信息和事件(确定TOI的开始和结束点)在分析过程中,你可以通过这些视频记录来观察被试者的行为并发现可用性问题并找到诠释问题的方法,或可以通过屏幕截图与相应的TOI将眼动追踪数据叠加到每个网页上。例如,将数据叠加到一张热点图上时,Pro Lab软件使用屏幕截图作为数据叠加的背景图像并使用两个TOI事件来确定叠加在热点图上的数据范围。
*观察窗是指被试者在浏览网页时呈现在当前屏幕上的那部分网页。
如果在测试中被试者多次访问同一个网页,那么每次访问都将生成相同的开始和结束事件并作为属于相同的兴趣区间TOI的不同时间片段和屏幕截图被记录下来。默认情况下,当你选择了一个兴趣区间TOI,Pro Lab软件会按所有属于该兴趣区间TOI的时间片段来叠加数据。
图1. 对相同的网页进行多次访问的数据是如何被叠加到相同的网页导航兴趣区间(TOI)的。
接下来,我们将分步骤介绍创建数据叠加可视化结果和根据网页导航兴趣区间TOI提取眼动追踪统计指标的方法。
将数据叠加到热点图上的操作步骤:
1. 点击Visualization按钮,可以在Project Overview界面或从顶部导航栏中的Analyze下拉列表中找到该按钮。
2. 在界面右侧打开工具栏中的Visualization Type和Settings工具,并选择Heat Map。
3. 选择创建热点图所使用的眼动数据过滤器。请参考Pro Lab用户手册附录部分 “Appendix B Gaze Filters’ functions and effects” 进一步了解眼动数据过滤器。
4. 进入Times of Interest工具并选择与要创建热点图的网页相对应的网页导航。为了帮你高效地进行兴趣区间TOI的选择,软件将呈现网页的名称和缩略图。
5.切换到Recordings工具并选择或取消选择要叠加到热点图上的记录。
6. 选择热点图的创建方式- 绝对计数, 相对计数,绝对时间或相对时间。(请参阅Pro Lab 用户手册附录部分“Appendix C Calculating heat maps” 进一步了解热点图的不同创建方式)。
7. 叠加了多个记录的数据的热点图创建ok。
提取眼动追踪统计指标的步骤:
1. 打开AOI选项卡来创建你的AOI兴趣区。
2. 在Media Selection部分选择目标网页图像。
3. 为要分析的元素描绘兴趣区域。
4. 如果你想跨多个兴趣区来叠加数据,也可以创建AOI标签并将每个AOI进行标记(兴趣区组)。
5. 切换到Metrics Export选项卡。
6. 在Settings面板点击Export Format下拉列表选择数据输出的格式。选择Interval based TSV file (default).tsv格式将按照页面的每次访问来切分数据或选择Excel report for the.xlsx格式导出汇总报告。
7. 选择要包含在导出数据文件中的统计指标(可选的统计指标按第2步的选择有所不同)。
8. 选择导出使用的眼动数据过滤器。请参考Pro Lab用户手册附录部分 “Appendix B Gaze Filters’ functions and effects” 进一步了解眼动数据过滤器。
9. 选择记录。选择导出全部记录或按照需要选择相应的记录进行导出。
10. 选择Participant variables可根据被试变量对数据做进一步筛选。
11. 选择网页导航兴趣区间TOI。
12. 选择第1-4步创建的AOI兴趣区和兴趣区标签。
13. 可选择Web Navigation Event types来导出与事件相关的统计指标。
14. 点击Export开始数据导出。
2
使用自定义兴趣区间TOI叠加数据的操作步骤
如果你的研究需要将数据叠加到带有少量或没有动态元素的网页上,你可以使用网页导航兴趣区间TOI和相应的屏幕截图来叠加数据。但如果网页包含较多动态元素,你就会面临三个挑战:
1. 浏览器不支持某些动态内容**
2. 网页截图无法呈现某些网页的动态元素***
3. 在网页访问期间如果用户花了一些时间与动态元素进行交互和观察,那么这期间采集到的眼动数据可能会错误地叠加到网页图像上。
** 例如,Pro Lab内嵌浏览器目前不支持 Flash动画元素。
***唯一的例外是网页的固定元素,Tobii Pro Lab软件能够追踪这些元素并正确叠加数据。固定元素是指网页中与浏览窗口位置相关而不是与网页本身位置相关的元素。当被试者将包含固定元素的网页向下滚动时,这些元素仍停留在网页截图中固定的位置不变,而其他的元素则会相应地移动。这些元素在网页截图中的位置是固定的。任何在这些元素上的眼动数据都将被叠加到屏幕截图中相应元素的位置,无论这些元素真正被看到时处于什么位置。这样可以更真实地展现注视点。
上面列出的挑战也说明了系统生成的网页导航兴趣区间TOI可能无法满足你的研究需求,因为将会有一部分眼动数据无法正确叠加到自动生成的网页截图所无法呈现的元素上,即一部份数据是视觉上无意义的。而这部分数据应该属于被试与动态元素的交互行为。例如,如果被试在网页中打开了一个下拉菜单,那么观察该菜单的视觉模式将会被记录并叠加到网页截图上,但在网页截图上,该菜单是不可见的。其他类型的动态元素也会出现这种情况,例如不会生成独立URL的弹出窗口或跨越屏幕呈现的元素。
如前文所述,在眼动测试数据采集期间,Pro Lab也会捕捉整个浏览环节中观察窗部分的视频。该视频也可以在后期回放记录时被回放出来。该视频其实就是被试者网页浏览行为的屏幕记录,因此你可以在回放中看到不同的动态元素和被试者对这些元素的观察与交互行为。在数据分析期间,你可以使用该视频在时间轴上创建事件作为被试者与这些元素交互的开始和结束标记。创建好这些事件后,就可以进一步通过它们来创建与视频帧相关的自定义兴趣区间TOI。自定义兴趣区间TOI可将与动态内容的交互相关的视觉浏览行为数据进行叠加,而视频的帧图像可作为带有动态内容的网页的数据叠加背景图像。将自定义兴趣区间TOI和帧图像结合,就可以实现叠加了多被试数据的可视化结果生成并创建兴趣区来提取眼动追踪统计指标。
在上一个例子中,当被试者与一个下拉菜单进行交互时,你可能需要标记两个事件,例如,下拉菜单打开和下拉菜单关闭,然后通过这两个事件作为开始点和结束点,结合一帧视频图像来创建自定义兴趣区间TOI。帧图像需要在视频中该下拉菜单处于打开状态时截取。然后重复这个步骤,在其他记录中创建相应的兴趣区间TOI,然后在Visualization工具中选择按自定义兴趣区间TOI来创建热点图等可视化结果。这样,生成的热点图就将展示出叠加了多被试数据的对下拉菜单的视觉观察行为。下面将按步骤介绍基于视频帧的自定义兴趣区间TOI的创建方法。
创建自定义兴趣区间TOI的操作步骤:
1. 打开一条记录
2. 创建一个或两个自定义事件来确定兴趣区间TOI的开始点和结束点,例如,每当用户打开下拉菜单和关闭该菜单。
3. 将鼠标指针移到打开的菜单中视频的一帧,然后点击位于记录的计时器右侧的创建帧图像的图标并选择Create Toi with frame选项。如前文所述,帧与网页截图的功能相同。
4. 在Create custom Time of Interest 窗口中选择在第1步中创建的开始和结束点。
5. 将Media重命名为对分析有意义的描述性名称。
6. 点击OK 创建兴趣区间TOI。
7. 重复第1步和第2步为其他记录定义兴趣区间TOI的开始和结束点。
创建了与帧相关联的自定义兴趣区间TOI后,你就可以像使用网页导航兴趣区间TOI一样使用这些自定义的兴趣区间TOI来生成可视化结果并提取基于多被试的叠加的眼动统计指标了。
这种分析流程的局限性在于网页的动态内容需要适应观察窗。如果被试需要通过滚动操作来与元素进行交互,那么这种方案就不可行,因为你无法将观察行为汇总到一个单独的视频帧上。
3
结语
在网页的眼动测试中叠加多个被试的数据在概念上和技术上都具有挑战性,对如今包含大量动态内容的网页来说更是如此。
从概念上看,由于动态内容使每个被试在一个网页的交互数据都不同,所以很难在几个不同被试之间进行数据对比;而从技术上看,很难有效地捕捉用于创建热点图的眼动数据,因为 内容是不断变化的——尤其是仅当页面的某些部分发生变化。
在研究的准备阶段,你就需要充分考虑到这些可能会面临的挑战并针对每个难点确定可行的分析方案和流程。这样你才能更现实际地预估为数据分析工作投入的时间和资源。
表1.不同的网页动态元素与跨多被试数据叠加的相应流程/功能汇总
网页动态内容
Pro Lab 分析元素
无
网页截图相关联的网页导航兴趣区间TOI
事件自动生成,自动抓取整幅网页图像
可展开的元素与不需要滚动的内容(适应观察窗)
视频帧相关联的自定义兴趣区间TOI
需手动添加事件并从视频中选择背景帧
可展开的元素与需要滚动的内容(不会自适应观察窗)
手动叠加 (请参见用户手册第8.2 章节)
需要通过手动Coding的方式将注视点叠加到视觉编码方案表单或导入的网页图像上
固定元素
网页导航兴趣区间TOI相关联的网页截图
事件自动生成,自动抓取整幅网页图像
生成新URL的弹出元素
网页导航兴趣区间TOI相关联的网页截图
事件自动生成,自动抓取整幅网页图像
不生成新URL的弹出元素
视频帧相关联的自定义兴趣区间TOI
需手动添加事件并从视频中选择背景帧
嵌入式mp4视频内容
暂时无法分析 (浏览器不支持)
在视频记录中不可见
嵌入式Flash动画内容
暂时无法分析 (浏览器不支持)
在视频记录中不可见
-The end-
你可能还想看:
探究人类行为
我们通过领先的眼动追踪解决方案帮助商业和科研专家获得人类行为的真实洞察力。我们的眼动追踪研究产品和服务正在被全球超过2,000家企业和1,500所研究机构所使用。
查看全部
如何在网页测试中叠加多个被试的眼动追踪数据?
在多数网页研究中,给被试者分配的任务通常包含浏览某个网站或浏览某个网页应用。在浏览的过程中,他们并不是被动地观看按指定顺序和时长呈现的刺激材料,而是会与呈现的刺激材料进行交互,这样每个被试者的结果都是独一无二的。因此如果要对这些被试者的体验进行对比就会很繁琐,并且多被试的眼动数据自动叠加是一项很有挑战性的工作。
例如,在浏览网页时,一些被试者可能在某个页面的停留时间比其他被试者长,他们可能会跳转到其他页面,多次播放和停止网页内的视频等。如果一个或两个被试者在浏览一个页面时花了很多的时间,那么他们的注视点数量可能会增加,这会对叠加的数据带来影响。页面中还有可能会包含一些动态内容,例如下拉菜单,弹出窗口和flash动画内容,这些都会对数据的自动叠加带来一些挑战。
在进行网页眼动数据采集时,对这些不同的挑战要保持足够的注意并做出相应的分析做好准备。本文将介绍通过Pro Lab软件实现对网页实验项目中多被试者的眼动追踪数据叠加的方法和步骤。我们将对能够自动叠加数据和手动叠加数据的案例进行着重阐述。
1
通过自动网页导航TOI兴趣区间叠加数据
在使用网页元素进行测试时,Pro Lab软件会记录观察窗*区域的测试过程的视频并同时提取所有打开的独立的URL的完整页面屏幕截图。软件还会保存与页面导航时间相关的TOI信息和事件(确定TOI的开始和结束点)在分析过程中,你可以通过这些视频记录来观察被试者的行为并发现可用性问题并找到诠释问题的方法,或可以通过屏幕截图与相应的TOI将眼动追踪数据叠加到每个网页上。例如,将数据叠加到一张热点图上时,Pro Lab软件使用屏幕截图作为数据叠加的背景图像并使用两个TOI事件来确定叠加在热点图上的数据范围。
*观察窗是指被试者在浏览网页时呈现在当前屏幕上的那部分网页。
如果在测试中被试者多次访问同一个网页,那么每次访问都将生成相同的开始和结束事件并作为属于相同的兴趣区间TOI的不同时间片段和屏幕截图被记录下来。默认情况下,当你选择了一个兴趣区间TOI,Pro Lab软件会按所有属于该兴趣区间TOI的时间片段来叠加数据。
图1. 对相同的网页进行多次访问的数据是如何被叠加到相同的网页导航兴趣区间(TOI)的。
接下来,我们将分步骤介绍创建数据叠加可视化结果和根据网页导航兴趣区间TOI提取眼动追踪统计指标的方法。
将数据叠加到热点图上的操作步骤:
1. 点击Visualization按钮,可以在Project Overview界面或从顶部导航栏中的Analyze下拉列表中找到该按钮。
2. 在界面右侧打开工具栏中的Visualization Type和Settings工具,并选择Heat Map。
3. 选择创建热点图所使用的眼动数据过滤器。请参考Pro Lab用户手册附录部分 “Appendix B Gaze Filters’ functions and effects” 进一步了解眼动数据过滤器。
4. 进入Times of Interest工具并选择与要创建热点图的网页相对应的网页导航。为了帮你高效地进行兴趣区间TOI的选择,软件将呈现网页的名称和缩略图。
5.切换到Recordings工具并选择或取消选择要叠加到热点图上的记录。
6. 选择热点图的创建方式- 绝对计数, 相对计数,绝对时间或相对时间。(请参阅Pro Lab 用户手册附录部分“Appendix C Calculating heat maps” 进一步了解热点图的不同创建方式)。
7. 叠加了多个记录的数据的热点图创建ok。
提取眼动追踪统计指标的步骤:
1. 打开AOI选项卡来创建你的AOI兴趣区。
2. 在Media Selection部分选择目标网页图像。
3. 为要分析的元素描绘兴趣区域。
4. 如果你想跨多个兴趣区来叠加数据,也可以创建AOI标签并将每个AOI进行标记(兴趣区组)。
5. 切换到Metrics Export选项卡。
6. 在Settings面板点击Export Format下拉列表选择数据输出的格式。选择Interval based TSV file (default).tsv格式将按照页面的每次访问来切分数据或选择Excel report for the.xlsx格式导出汇总报告。
7. 选择要包含在导出数据文件中的统计指标(可选的统计指标按第2步的选择有所不同)。
8. 选择导出使用的眼动数据过滤器。请参考Pro Lab用户手册附录部分 “Appendix B Gaze Filters’ functions and effects” 进一步了解眼动数据过滤器。
9. 选择记录。选择导出全部记录或按照需要选择相应的记录进行导出。
10. 选择Participant variables可根据被试变量对数据做进一步筛选。
11. 选择网页导航兴趣区间TOI。
12. 选择第1-4步创建的AOI兴趣区和兴趣区标签。
13. 可选择Web Navigation Event types来导出与事件相关的统计指标。
14. 点击Export开始数据导出。
2
使用自定义兴趣区间TOI叠加数据的操作步骤
如果你的研究需要将数据叠加到带有少量或没有动态元素的网页上,你可以使用网页导航兴趣区间TOI和相应的屏幕截图来叠加数据。但如果网页包含较多动态元素,你就会面临三个挑战:
1. 浏览器不支持某些动态内容**
2. 网页截图无法呈现某些网页的动态元素***
3. 在网页访问期间如果用户花了一些时间与动态元素进行交互和观察,那么这期间采集到的眼动数据可能会错误地叠加到网页图像上。
** 例如,Pro Lab内嵌浏览器目前不支持 Flash动画元素。
***唯一的例外是网页的固定元素,Tobii Pro Lab软件能够追踪这些元素并正确叠加数据。固定元素是指网页中与浏览窗口位置相关而不是与网页本身位置相关的元素。当被试者将包含固定元素的网页向下滚动时,这些元素仍停留在网页截图中固定的位置不变,而其他的元素则会相应地移动。这些元素在网页截图中的位置是固定的。任何在这些元素上的眼动数据都将被叠加到屏幕截图中相应元素的位置,无论这些元素真正被看到时处于什么位置。这样可以更真实地展现注视点。
上面列出的挑战也说明了系统生成的网页导航兴趣区间TOI可能无法满足你的研究需求,因为将会有一部分眼动数据无法正确叠加到自动生成的网页截图所无法呈现的元素上,即一部份数据是视觉上无意义的。而这部分数据应该属于被试与动态元素的交互行为。例如,如果被试在网页中打开了一个下拉菜单,那么观察该菜单的视觉模式将会被记录并叠加到网页截图上,但在网页截图上,该菜单是不可见的。其他类型的动态元素也会出现这种情况,例如不会生成独立URL的弹出窗口或跨越屏幕呈现的元素。
如前文所述,在眼动测试数据采集期间,Pro Lab也会捕捉整个浏览环节中观察窗部分的视频。该视频也可以在后期回放记录时被回放出来。该视频其实就是被试者网页浏览行为的屏幕记录,因此你可以在回放中看到不同的动态元素和被试者对这些元素的观察与交互行为。在数据分析期间,你可以使用该视频在时间轴上创建事件作为被试者与这些元素交互的开始和结束标记。创建好这些事件后,就可以进一步通过它们来创建与视频帧相关的自定义兴趣区间TOI。自定义兴趣区间TOI可将与动态内容的交互相关的视觉浏览行为数据进行叠加,而视频的帧图像可作为带有动态内容的网页的数据叠加背景图像。将自定义兴趣区间TOI和帧图像结合,就可以实现叠加了多被试数据的可视化结果生成并创建兴趣区来提取眼动追踪统计指标。
在上一个例子中,当被试者与一个下拉菜单进行交互时,你可能需要标记两个事件,例如,下拉菜单打开和下拉菜单关闭,然后通过这两个事件作为开始点和结束点,结合一帧视频图像来创建自定义兴趣区间TOI。帧图像需要在视频中该下拉菜单处于打开状态时截取。然后重复这个步骤,在其他记录中创建相应的兴趣区间TOI,然后在Visualization工具中选择按自定义兴趣区间TOI来创建热点图等可视化结果。这样,生成的热点图就将展示出叠加了多被试数据的对下拉菜单的视觉观察行为。下面将按步骤介绍基于视频帧的自定义兴趣区间TOI的创建方法。
创建自定义兴趣区间TOI的操作步骤:
1. 打开一条记录
2. 创建一个或两个自定义事件来确定兴趣区间TOI的开始点和结束点,例如,每当用户打开下拉菜单和关闭该菜单。
3. 将鼠标指针移到打开的菜单中视频的一帧,然后点击位于记录的计时器右侧的创建帧图像的图标并选择Create Toi with frame选项。如前文所述,帧与网页截图的功能相同。
4. 在Create custom Time of Interest 窗口中选择在第1步中创建的开始和结束点。
5. 将Media重命名为对分析有意义的描述性名称。
6. 点击OK 创建兴趣区间TOI。
7. 重复第1步和第2步为其他记录定义兴趣区间TOI的开始和结束点。
创建了与帧相关联的自定义兴趣区间TOI后,你就可以像使用网页导航兴趣区间TOI一样使用这些自定义的兴趣区间TOI来生成可视化结果并提取基于多被试的叠加的眼动统计指标了。
这种分析流程的局限性在于网页的动态内容需要适应观察窗。如果被试需要通过滚动操作来与元素进行交互,那么这种方案就不可行,因为你无法将观察行为汇总到一个单独的视频帧上。
3
结语
在网页的眼动测试中叠加多个被试的数据在概念上和技术上都具有挑战性,对如今包含大量动态内容的网页来说更是如此。
从概念上看,由于动态内容使每个被试在一个网页的交互数据都不同,所以很难在几个不同被试之间进行数据对比;而从技术上看,很难有效地捕捉用于创建热点图的眼动数据,因为 内容是不断变化的——尤其是仅当页面的某些部分发生变化。
在研究的准备阶段,你就需要充分考虑到这些可能会面临的挑战并针对每个难点确定可行的分析方案和流程。这样你才能更现实际地预估为数据分析工作投入的时间和资源。
表1.不同的网页动态元素与跨多被试数据叠加的相应流程/功能汇总
网页动态内容
Pro Lab 分析元素
无
网页截图相关联的网页导航兴趣区间TOI
事件自动生成,自动抓取整幅网页图像
可展开的元素与不需要滚动的内容(适应观察窗)
视频帧相关联的自定义兴趣区间TOI
需手动添加事件并从视频中选择背景帧
可展开的元素与需要滚动的内容(不会自适应观察窗)
手动叠加 (请参见用户手册第8.2 章节)
需要通过手动Coding的方式将注视点叠加到视觉编码方案表单或导入的网页图像上
固定元素
网页导航兴趣区间TOI相关联的网页截图
事件自动生成,自动抓取整幅网页图像
生成新URL的弹出元素
网页导航兴趣区间TOI相关联的网页截图
事件自动生成,自动抓取整幅网页图像
不生成新URL的弹出元素
视频帧相关联的自定义兴趣区间TOI
需手动添加事件并从视频中选择背景帧
嵌入式mp4视频内容
暂时无法分析 (浏览器不支持)
在视频记录中不可见
嵌入式Flash动画内容
暂时无法分析 (浏览器不支持)
在视频记录中不可见
-The end-
你可能还想看:
探究人类行为
我们通过领先的眼动追踪解决方案帮助商业和科研专家获得人类行为的真实洞察力。我们的眼动追踪研究产品和服务正在被全球超过2,000家企业和1,500所研究机构所使用。
抓取网页flash视频不存在性能问题,测试了几个浏览器
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-29 15:02
抓取网页flash视频不存在性能问题,测试了几个浏览器:chrome、firefox、safari、uc,不存在时延问题。本质上是浏览器的问题。如果涉及html5的话,可能需要在access-control-allow-origin前加上上传链接,否则该连接不能用。
安卓5.3以上是可以同步的ios只有付费的premium客户端能同步一般情况是一个页面一个页面刷新或者和视频本地连接
速度是可以的,uc有这个功能可以同步.比如把视频上传到百度云连接,然后下载好再同步到我的电脑上.或者你采用加密方式,比如transferwise把视频上传,然后同步到本地.
可以啊,我用了很多google浏览器,目前还是有问题。
html5本身就是不支持上传视频,目前最好的办法是对视频进行加密传输,然后让视频本地缓存再传输到nas,进行上传。
网页版基本不支持上传视频,因为html5大小是不定的,最长只能传2m,以前html5时代视频数据是可以后端存储的。现在不行了。可以考虑用音视频合并,然后直接播放即可。本地已有的视频,先直接做好合并脚本,然后先上传到服务器,然后直接配置过去,就能直接播放。xml配置方法,就是能直接访问视频内容。这个跟ip没关系。
网页上的视频传输主要是通过iframe嵌套传播的,所以用js控制一个iframe的实现了。 查看全部
抓取网页flash视频不存在性能问题,测试了几个浏览器
抓取网页flash视频不存在性能问题,测试了几个浏览器:chrome、firefox、safari、uc,不存在时延问题。本质上是浏览器的问题。如果涉及html5的话,可能需要在access-control-allow-origin前加上上传链接,否则该连接不能用。
安卓5.3以上是可以同步的ios只有付费的premium客户端能同步一般情况是一个页面一个页面刷新或者和视频本地连接
速度是可以的,uc有这个功能可以同步.比如把视频上传到百度云连接,然后下载好再同步到我的电脑上.或者你采用加密方式,比如transferwise把视频上传,然后同步到本地.
可以啊,我用了很多google浏览器,目前还是有问题。
html5本身就是不支持上传视频,目前最好的办法是对视频进行加密传输,然后让视频本地缓存再传输到nas,进行上传。
网页版基本不支持上传视频,因为html5大小是不定的,最长只能传2m,以前html5时代视频数据是可以后端存储的。现在不行了。可以考虑用音视频合并,然后直接播放即可。本地已有的视频,先直接做好合并脚本,然后先上传到服务器,然后直接配置过去,就能直接播放。xml配置方法,就是能直接访问视频内容。这个跟ip没关系。
网页上的视频传输主要是通过iframe嵌套传播的,所以用js控制一个iframe的实现了。
抓取网页flash视频( 具体方法以人人网页面为例讲述Python实现从Web的一个中抓取文档的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-04-09 14:06
具体方法以人人网页面为例讲述Python实现从Web的一个中抓取文档的方法)
Python 实现了一种从网络上抓取文档的方法
更新时间:2014年9月26日09:28:02投稿:shichen2014
本文文章主要介绍python从网页爬取文档的方法。以人人网的爬取为例,说明爬取网页文档的完整方法。有需要的朋友可以参考以下
p>
本文中的示例介绍了Python如何实现从Web上的URL爬取文档,分享给大家,供大家参考。具体方法分析如下:
示例代码如下:
import urllib
doc = urllib.urlopen("http://www.python.org").read()
print doc#直接打印出网页
def reporthook(*a):
print a
#将http://www.renren.com网页保存到renre.html中,
#每读取一个块调用一字reporthook函数
urllib.urlretrieve("http://www.renren.com",'renren.html',reporthook)
#将http://www.renren.com网页保存到renre.html中
urllib.urlretrieve("http://www.renren.com",'renren.html')
程序运行结果如下:
..........................网页内容
(0, 8192, -1)
(1, 8192, -1)
(2, 8192, -1)
其中 urllib.urlopen 返回一个类似文件的对象。
希望本文对您的 Python 编程有所帮助。 查看全部
抓取网页flash视频(
具体方法以人人网页面为例讲述Python实现从Web的一个中抓取文档的方法)
Python 实现了一种从网络上抓取文档的方法
更新时间:2014年9月26日09:28:02投稿:shichen2014
本文文章主要介绍python从网页爬取文档的方法。以人人网的爬取为例,说明爬取网页文档的完整方法。有需要的朋友可以参考以下
p>
本文中的示例介绍了Python如何实现从Web上的URL爬取文档,分享给大家,供大家参考。具体方法分析如下:
示例代码如下:
import urllib
doc = urllib.urlopen("http://www.python.org";).read()
print doc#直接打印出网页
def reporthook(*a):
print a
#将http://www.renren.com网页保存到renre.html中,
#每读取一个块调用一字reporthook函数
urllib.urlretrieve("http://www.renren.com",'renren.html',reporthook)
#将http://www.renren.com网页保存到renre.html中
urllib.urlretrieve("http://www.renren.com",'renren.html')
程序运行结果如下:
..........................网页内容
(0, 8192, -1)
(1, 8192, -1)
(2, 8192, -1)
其中 urllib.urlopen 返回一个类似文件的对象。
希望本文对您的 Python 编程有所帮助。
抓取网页flash视频(我正在尝试获取在我的客户端上播放的Wowza视频流)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-07 07:27
我正在尝试获取在我的客户端上播放的 Wowza 视频流的位图/快照,如下所示:
var bitmapData:BitmapData = new BitmapData(view.videoPlayerComponent.width, view.videoPlayerComponent.height);
bitmapData.draw(view.videoPlayerComponent);
当我这样做时,我收到以下错误消息:SecurityError:错误 #2123:安全沙箱违规:BitmapData.draw::51150/Resources/WRemoteWebCam.swf 无法访问 rtmp://localhost/videochat /smithkl42._default/。没有授予访问权限的策略文本我认为错误来自无法找到相应的 crossdomain.xml 文件。我不太确定它在哪里寻找它,wireshark 嗅探没有结果,所以我尝试在以下每个中放置一个: :1935/crossdomain。 xml :1935/crossdomain.xml ://localhost:51150/crossdomain.xml 我可以成功地从这三个位置检索文件。 (我很确定最后一个没有任何区别,因为它只是托管 .swf 文件的网页所在的 网站 的位置,但机会是......)这些就是它抓住的在每个实例中获取的文件的内容:
它仍然会抛出相同的错误消息。我还按照 Wowza 论坛上的说明在 [install] conf [appname] Application.xml 中打开 StreamVideoSampleAccess,不好玩:
-1
*
*
*
*
*
*
有什么想法吗? 查看全部
抓取网页flash视频(我正在尝试获取在我的客户端上播放的Wowza视频流)
我正在尝试获取在我的客户端上播放的 Wowza 视频流的位图/快照,如下所示:
var bitmapData:BitmapData = new BitmapData(view.videoPlayerComponent.width, view.videoPlayerComponent.height);
bitmapData.draw(view.videoPlayerComponent);
当我这样做时,我收到以下错误消息:SecurityError:错误 #2123:安全沙箱违规:BitmapData.draw::51150/Resources/WRemoteWebCam.swf 无法访问 rtmp://localhost/videochat /smithkl42._default/。没有授予访问权限的策略文本我认为错误来自无法找到相应的 crossdomain.xml 文件。我不太确定它在哪里寻找它,wireshark 嗅探没有结果,所以我尝试在以下每个中放置一个: :1935/crossdomain。 xml :1935/crossdomain.xml ://localhost:51150/crossdomain.xml 我可以成功地从这三个位置检索文件。 (我很确定最后一个没有任何区别,因为它只是托管 .swf 文件的网页所在的 网站 的位置,但机会是......)这些就是它抓住的在每个实例中获取的文件的内容:
它仍然会抛出相同的错误消息。我还按照 Wowza 论坛上的说明在 [install] conf [appname] Application.xml 中打开 StreamVideoSampleAccess,不好玩:
-1
*
*
*
*
*
*
有什么想法吗?
抓取网页flash视频(抓取网页flash视频也用到了html模板中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-04-06 17:01
抓取网页flash视频也用到了webgl知识。楼主没提供清晰完整的网站地址所以暂且仅仅提出一个初步的解决方案:先要获取该网站上的所有flash视频html模板页面。用vs开发工具把视频封装好放到html模板中。页面渲染出来的flash文件就可以通过./img的形式导入js中,从而实现拖拽文件播放。我所理解的一些要点:可以通过通过javascript对img进行写劫持,就可以实现网页任意切换flash影片的方式,从而实现网页播放flash视频。可以通过javascript实现播放动画,从而实现拖拽文件播放。
听说有ie镜像页,百度一下可以找到啊,把搜狗输入法设置成特别模式就可以浏览其他程序有播放器的页面了。
百度搜索一个“javascript调试工具”。没有看到有公开免费的方法,但是有一些开源的。
貌似有thunderjs,
试试交叉渲染算法吧,这个github搜一下应该都有。firefox有相关的方案,chrome貌似也有,不过可能需要chrome7.0以上版本。百度能找到的方案基本都需要requests或beautifulsoup这些,反正我是搞不定。百度直接搜结果还比谷歌差。不知道百度的服务器是不是放在美国的,这样能快些。毕竟要实现题主所说的网页拖拽播放。
javascript上有类似这样的高阶函数,叫mapping, 查看全部
抓取网页flash视频(抓取网页flash视频也用到了html模板中的应用)
抓取网页flash视频也用到了webgl知识。楼主没提供清晰完整的网站地址所以暂且仅仅提出一个初步的解决方案:先要获取该网站上的所有flash视频html模板页面。用vs开发工具把视频封装好放到html模板中。页面渲染出来的flash文件就可以通过./img的形式导入js中,从而实现拖拽文件播放。我所理解的一些要点:可以通过通过javascript对img进行写劫持,就可以实现网页任意切换flash影片的方式,从而实现网页播放flash视频。可以通过javascript实现播放动画,从而实现拖拽文件播放。
听说有ie镜像页,百度一下可以找到啊,把搜狗输入法设置成特别模式就可以浏览其他程序有播放器的页面了。
百度搜索一个“javascript调试工具”。没有看到有公开免费的方法,但是有一些开源的。
貌似有thunderjs,
试试交叉渲染算法吧,这个github搜一下应该都有。firefox有相关的方案,chrome貌似也有,不过可能需要chrome7.0以上版本。百度能找到的方案基本都需要requests或beautifulsoup这些,反正我是搞不定。百度直接搜结果还比谷歌差。不知道百度的服务器是不是放在美国的,这样能快些。毕竟要实现题主所说的网页拖拽播放。
javascript上有类似这样的高阶函数,叫mapping,
抓取网页flash视频( 从蜘蛛抓取的角度出发在优化过程中会遇到哪些问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-28 21:12
从蜘蛛抓取的角度出发在优化过程中会遇到哪些问题)
相信每一位站长在优化网站的过程中都会设身处地为网站进行全面的优化操作,尤其是站在用户的角度,只有全心全意的解决用户的需求,才能他们真正受到用户的赞赏和搜索引擎的关注和喜爱。那么如果我们从爬虫的角度出发,在优化过程中会遇到哪些问题呢?下面是对这个问题的详细分析,希望能对有需要的大家有所帮助。
1、网页是否可以找到
如果想让搜索引擎蜘蛛注意到网站进行爬取,可以将网站首页的链接或者更新内容提交给搜索引擎,让搜索引擎知道< @网站第一时间更新,并允许搜索引擎蜘蛛通过网站的外部链接找到网站,并通过网站链接抓取网站中的内容多个级别。这就需要站长根据目前的 网站 优化工作,对 网站 结构进行改进,使蜘蛛能够通过 网站 中的基本结构成功抓取 网站 内容。
但同时也要保证网站页面之间的层级控制得好,保证用户需要的关键信息在五次点击内都能找到,让用户更愿意接受网站内容的内容,有利于网站和收录权重的提高。
2、网页是否可以正常爬取
众所周知,网站网址肯定可以被搜索引擎抓取,但也有一些特殊情况。如果网站数据库动态生成参数过多的url,整个网站页面中充斥着flash、js等文件和低质量的重复内容,自然会导致搜索引擎蜘蛛被无法爬行。如果 网站 中的某些文件不推荐用于搜索引擎 收录,网站负责人可以通过 robots.txt 文件或元机器人标签告诉搜索引擎蜘蛛禁止 收录。
3、能否获取有价值的信息内容
总的来说,网站页面代码简洁,关键词合理的布局和适当的页面兼容性可以提高搜索引擎对网站页面的识别度,不仅对搜索引擎抓取很有帮助,而且它还可以帮助提取网站关键信息内容。相信搜索引擎蜘蛛能够成功在网站页面中找到有价值的信息,提高网站的收录爬取和权重,为用户社区的需求带来更好的解决能力和展示效果,进一步完成网站的推广营销效果的实现。
综上所述,网站在营销推广过程中,如果从搜索引擎蜘蛛的爬取入手收录,可以从以上几个角度入手,判断是否符合自己的网站 选择合适的情况。希望今天分享的内容可以帮助有需要的站长们完成自己网站推广营销效果的展示。 查看全部
抓取网页flash视频(
从蜘蛛抓取的角度出发在优化过程中会遇到哪些问题)
相信每一位站长在优化网站的过程中都会设身处地为网站进行全面的优化操作,尤其是站在用户的角度,只有全心全意的解决用户的需求,才能他们真正受到用户的赞赏和搜索引擎的关注和喜爱。那么如果我们从爬虫的角度出发,在优化过程中会遇到哪些问题呢?下面是对这个问题的详细分析,希望能对有需要的大家有所帮助。
1、网页是否可以找到
如果想让搜索引擎蜘蛛注意到网站进行爬取,可以将网站首页的链接或者更新内容提交给搜索引擎,让搜索引擎知道< @网站第一时间更新,并允许搜索引擎蜘蛛通过网站的外部链接找到网站,并通过网站链接抓取网站中的内容多个级别。这就需要站长根据目前的 网站 优化工作,对 网站 结构进行改进,使蜘蛛能够通过 网站 中的基本结构成功抓取 网站 内容。
但同时也要保证网站页面之间的层级控制得好,保证用户需要的关键信息在五次点击内都能找到,让用户更愿意接受网站内容的内容,有利于网站和收录权重的提高。
2、网页是否可以正常爬取
众所周知,网站网址肯定可以被搜索引擎抓取,但也有一些特殊情况。如果网站数据库动态生成参数过多的url,整个网站页面中充斥着flash、js等文件和低质量的重复内容,自然会导致搜索引擎蜘蛛被无法爬行。如果 网站 中的某些文件不推荐用于搜索引擎 收录,网站负责人可以通过 robots.txt 文件或元机器人标签告诉搜索引擎蜘蛛禁止 收录。
3、能否获取有价值的信息内容
总的来说,网站页面代码简洁,关键词合理的布局和适当的页面兼容性可以提高搜索引擎对网站页面的识别度,不仅对搜索引擎抓取很有帮助,而且它还可以帮助提取网站关键信息内容。相信搜索引擎蜘蛛能够成功在网站页面中找到有价值的信息,提高网站的收录爬取和权重,为用户社区的需求带来更好的解决能力和展示效果,进一步完成网站的推广营销效果的实现。
综上所述,网站在营销推广过程中,如果从搜索引擎蜘蛛的爬取入手收录,可以从以上几个角度入手,判断是否符合自己的网站 选择合适的情况。希望今天分享的内容可以帮助有需要的站长们完成自己网站推广营销效果的展示。
抓取网页flash视频(软件特色强大的搜索功能使用户的安装方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-21 15:52
支持网页抓取、图形截取、文件和文件夹导入、文件拖动、视频和FLASH下载、手写和手写功能。
2.目录管理
与Window Explorer类似,它为用户提供了直观、方便的树形目录管理。
3.标签管理
将笔记与不同目录中的知识关联关联到同一知识域,以跨目录空间的形式管理笔记,实现知识分类管理。
4.同步功能
将本地信息与服务器信息同步。降低因系统故障导致本地信息丢失的风险;同时支持用户跨终端、跨地域管理笔记。
5.搜索功能
支持基于关键字的笔记全文搜索和标题搜索,让用户快速找到自己需要的内容。
软件功能
强大的搜索功能让用户可以快速找到自己需要的东西!
方便好用的笔记和手绘功能,无论何时想记住,就记住!
独特的排序功能让笔记井井有条!
强大的网页抓取和网页视频,FLASH抓拍功能,轻松保存互联网内容,省时省力!
多类截图功能,有趣的图片和博文,想截图就截图!
便捷的笔记导入导出功能,99条笔记自由“进出”!
实时同步功能,无论何时何地,自由下载笔记!
安装教程
解压下载的压缩文件,找到安装文件双击安装
弹出主界面,点击下一步
选择同意安装协议,点击下一步
选择是否创建快捷方式等,看个人喜好设置,点击下一步。
选择软件的安装路径,建议不要加载到C盘,以免占用内存
检查安装信息是否正确。如果有任何问题,请点击返回上一步进行修改。如果没有错误,点击安装。
程序正在安装中,请耐心等待程序安装完成。
常见问题 查看全部
抓取网页flash视频(软件特色强大的搜索功能使用户的安装方法介绍)
支持网页抓取、图形截取、文件和文件夹导入、文件拖动、视频和FLASH下载、手写和手写功能。
2.目录管理
与Window Explorer类似,它为用户提供了直观、方便的树形目录管理。
3.标签管理
将笔记与不同目录中的知识关联关联到同一知识域,以跨目录空间的形式管理笔记,实现知识分类管理。
4.同步功能
将本地信息与服务器信息同步。降低因系统故障导致本地信息丢失的风险;同时支持用户跨终端、跨地域管理笔记。
5.搜索功能
支持基于关键字的笔记全文搜索和标题搜索,让用户快速找到自己需要的内容。
软件功能
强大的搜索功能让用户可以快速找到自己需要的东西!
方便好用的笔记和手绘功能,无论何时想记住,就记住!
独特的排序功能让笔记井井有条!
强大的网页抓取和网页视频,FLASH抓拍功能,轻松保存互联网内容,省时省力!
多类截图功能,有趣的图片和博文,想截图就截图!
便捷的笔记导入导出功能,99条笔记自由“进出”!
实时同步功能,无论何时何地,自由下载笔记!
安装教程
解压下载的压缩文件,找到安装文件双击安装
弹出主界面,点击下一步
选择同意安装协议,点击下一步
选择是否创建快捷方式等,看个人喜好设置,点击下一步。
选择软件的安装路径,建议不要加载到C盘,以免占用内存
检查安装信息是否正确。如果有任何问题,请点击返回上一步进行修改。如果没有错误,点击安装。
程序正在安装中,请耐心等待程序安装完成。
常见问题
抓取网页flash视频(网站设计技术对搜索引擎说很不友好,不利于蜘蛛爬行和抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-10 22:05
有一些网站设计技巧,对搜索引擎不友好,不利于蜘蛛爬行,这些技巧被称为蜘蛛陷阱。我认为应该避免的蜘蛛陷阱包括以下内容。
根据我个人的分析,可以得出以下结论: Flash在网页的一小部分增强Flash的视觉效果是正常的。比如用 Flash 制作的广告。图标等。这种小Flash和图片一样,只是HTML代码的一小部分,页面上还有其他基于文本的内容。所以对搜索引擎抓取和收录没有影响。
但是有的网站整个主页是一个很大的Flash文件,构成了蜘蛛陷阱。搜索引擎抓取的 HTML 代码只有 Flash 文件的链接,没有其他文本内容。读者可参考上例的源代码。搜索引擎无法读取 Flash 文件中的文本内容和链接。这种网站是Flash网站,视频效果可能很精彩,可惜搜索引擎看不到,也无法索引任何文字信息,无法判断相关性。
有的网站喜欢在首页放一个Flash动画标题,访问网站的用户看完标题后会被重定向到真正的HTML版文本网站首页. 搜索引擎无法读取 Flash,并且通常无法从 Flash Intro 跟踪到页面的 HTML 版本。
整个 网站 是一个大的 Flash 文件,从 SEO 的角度来看这是绝对不可能的。如果需要 Flash 效果,至少在首页添加指向 HTML 版本的链接。这个链接应该在 Flash 文件之外的 HTML 代码中,搜索引擎可以跟随这个链接并抓取下面的 HTML 版本的页面。
||| 如果用一些CSS来控制FLASH站,还是可以加很多码珠的 查看全部
抓取网页flash视频(网站设计技术对搜索引擎说很不友好,不利于蜘蛛爬行和抓取)
有一些网站设计技巧,对搜索引擎不友好,不利于蜘蛛爬行,这些技巧被称为蜘蛛陷阱。我认为应该避免的蜘蛛陷阱包括以下内容。
根据我个人的分析,可以得出以下结论: Flash在网页的一小部分增强Flash的视觉效果是正常的。比如用 Flash 制作的广告。图标等。这种小Flash和图片一样,只是HTML代码的一小部分,页面上还有其他基于文本的内容。所以对搜索引擎抓取和收录没有影响。
但是有的网站整个主页是一个很大的Flash文件,构成了蜘蛛陷阱。搜索引擎抓取的 HTML 代码只有 Flash 文件的链接,没有其他文本内容。读者可参考上例的源代码。搜索引擎无法读取 Flash 文件中的文本内容和链接。这种网站是Flash网站,视频效果可能很精彩,可惜搜索引擎看不到,也无法索引任何文字信息,无法判断相关性。
有的网站喜欢在首页放一个Flash动画标题,访问网站的用户看完标题后会被重定向到真正的HTML版文本网站首页. 搜索引擎无法读取 Flash,并且通常无法从 Flash Intro 跟踪到页面的 HTML 版本。
整个 网站 是一个大的 Flash 文件,从 SEO 的角度来看这是绝对不可能的。如果需要 Flash 效果,至少在首页添加指向 HTML 版本的链接。这个链接应该在 Flash 文件之外的 HTML 代码中,搜索引擎可以跟随这个链接并抓取下面的 HTML 版本的页面。
||| 如果用一些CSS来控制FLASH站,还是可以加很多码珠的
抓取网页flash视频(3.搜索功能支持网页抓取的管理方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 286 次浏览 • 2022-03-08 03:03
支持网页抓取、图形截取、文件和文件夹导入、文件拖动、视频和FLASH下载、手写和手写功能。
2.目录管理
与Window Explorer类似,它为用户提供了直观、方便的树形目录管理。
3.标签管理
将笔记与不同目录中的知识关联关联到同一知识域,以跨目录空间的形式管理笔记,实现知识分类管理。
4.同步功能
将本地信息与服务器信息同步。降低因系统故障导致本地信息丢失的风险;同时支持用户跨终端、跨地域管理笔记。
5.搜索功能
支持基于关键字的笔记全文搜索和标题搜索,让用户快速找到自己需要的内容。
软件功能
强大的搜索功能让用户可以快速找到自己需要的东西!
方便好用的笔记和手绘功能,无论何时想记住,就记住!
独特的排序功能让笔记井井有条!
强大的网页抓取和网页视频,FLASH抓拍功能,轻松保存互联网内容,省时省力!
多类截图功能,有趣的图片和博文,想截图就截图!
便捷的笔记导入导出功能,99条笔记自由“进出”!
实时同步功能,无论何时何地,自由下载笔记!
安装教程
解压在公交下载站下载的压缩文件,找到安装文件双击安装
弹出主界面,点击下一步
选择同意安装协议,点击下一步
选择是否创建快捷方式等,看个人喜好设置,点击下一步。
选择软件的安装路径,建议不要加载到C盘,以免占用内存
检查安装信息是否正确。如果有任何问题,请点击返回上一步进行修改。如果没有错误,点击安装。
程序正在安装中,请耐心等待程序安装完成。
常见问题 查看全部
抓取网页flash视频(3.搜索功能支持网页抓取的管理方法)
支持网页抓取、图形截取、文件和文件夹导入、文件拖动、视频和FLASH下载、手写和手写功能。
2.目录管理
与Window Explorer类似,它为用户提供了直观、方便的树形目录管理。
3.标签管理
将笔记与不同目录中的知识关联关联到同一知识域,以跨目录空间的形式管理笔记,实现知识分类管理。
4.同步功能
将本地信息与服务器信息同步。降低因系统故障导致本地信息丢失的风险;同时支持用户跨终端、跨地域管理笔记。
5.搜索功能
支持基于关键字的笔记全文搜索和标题搜索,让用户快速找到自己需要的内容。
软件功能
强大的搜索功能让用户可以快速找到自己需要的东西!
方便好用的笔记和手绘功能,无论何时想记住,就记住!
独特的排序功能让笔记井井有条!
强大的网页抓取和网页视频,FLASH抓拍功能,轻松保存互联网内容,省时省力!
多类截图功能,有趣的图片和博文,想截图就截图!
便捷的笔记导入导出功能,99条笔记自由“进出”!
实时同步功能,无论何时何地,自由下载笔记!
安装教程
解压在公交下载站下载的压缩文件,找到安装文件双击安装
弹出主界面,点击下一步
选择同意安装协议,点击下一步
选择是否创建快捷方式等,看个人喜好设置,点击下一步。
选择软件的安装路径,建议不要加载到C盘,以免占用内存
检查安装信息是否正确。如果有任何问题,请点击返回上一步进行修改。如果没有错误,点击安装。
程序正在安装中,请耐心等待程序安装完成。
常见问题

