
如何抓取网页数据
如何抓取网页数据(如何用一些有用的数据抓取一个网页数据(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-17 02:13
前不久在LearnML分论坛看到一个帖子。主机在这篇文章中提到他需要为他的机器学习项目抓取网络数据。很多人在回复中给出了自己的方法,主要是学习如何使用BeautifulSoup和Selenium。
我在一些数据科学项目中使用过 BeautifulSoup 和 Selenium。在本文中,我将向您展示如何抓取收录一些有用数据的网页并将其转换为 Pandas 数据结构(DataFrame)。
为什么要转换成数据结构?这是因为大多数机器学习库都可以处理 Pandas 数据结构,并且您只需稍作修改即可编辑您的模型。
首先,我们需要在维基百科上找一张表,转换成数据结构。我抓到的表格显示了维基百科上观看次数最多的运动员数据。
许多任务之一是浏览 HTML 树以获取我们需要的表格。
通过请求和正则表达式库,我们开始使用 BeautifulSoup。
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
复制代码
接下来,我们将从网页中提取 HTML 代码:
website_url = requests.get('https://en.wikipedia.org/wiki/Wikipedia:Multiyear_ranking_of_most_viewed_pages').text
soup = BeautifulSoup(website_url, 'lxml')
print(soup.prettify())
</a>
Disclaimers
Contact Wikipedia
<a>
复制代码
从语料库中采集所有表格,我们有一个很小的表面积可供搜索。
wiki_tables = soup.find_all('table', class_='wikitable')
wiki_tables
复制代码
因为有很多表,所以需要一种过滤它们的方法。
据我们所知,克里斯蒂亚诺·罗纳尔多(Cristiano Ronaldo)(也被称为葡萄牙足球运动员罗纳尔多)有一个锚标记,这在几张表中可能是独一无二的。
使用 Cristiano Ronaldo 文本,我们可以过滤那些由锚点标记的表格。此外,我们还发现了一些收录此锚标记的父元素。
links = []
for table in wiki_tables:
_table = table.find('a', string=re.compile('Cristiano Ronaldo'))
if not _table:
continue
print(_table)
_parent = _table.parent
print(_parent)
links.append(_parent)
Cristiano Ronaldo
Cristiano Ronaldo
Cristiano Ronaldo
Cristiano Ronaldo
Cristiano Ronaldo
Cristiano Ronaldo
复制代码
父元素只显示单元格。
这是一个带有浏览器 Web 开发工具的单元格。
parent_lst = []
for anchor in links:
_ = anchor.find_parents('tbody')
print(_)
parent_lst.append(_)
复制代码
使用 tbody,我们可以返回收录先前锚标记的其他表。
为了进一步过滤,我们可以在下表中搜索不同的标题:
for i in parent_lst:
print(i[0].find('tr'))
tr>
Rank*
Page
Views in millions
Rank
Page
Views in millions
Rank
Page
Sport
Views in millions
复制代码
第三个看起来很像我们需要的表。
接下来,我们开始创建必要的逻辑来提取和清理我们需要的细节。
sports_table = parent_lst[2]
complete_row = []
for i in sports_table:
rows = i.find_all('tr')
print('n--------row--------n')
print(rows)
for row in rows:
cells = row.find_all('td')
print('n-------cells--------n')
print(cells)
if not cells:
continue
rank = cells[0].text.strip('n')
page_name = cells[1].find('a').text
sport = cells[2].find('a').text
views = cells[3].text.strip('n')
print('n-------CLEAN--------n')
print(rank)
print(page_name)
print(sport)
print(views)
complete_row.append([rank, page_name, sport, views])
for i in complete_row:
print(i)
复制代码
分解一下:
sports_table = parent_lst[2]
complete_row = []
复制代码
下面我们从上面的列表中选择第三个元素。这是我们需要的表。
接下来,创建一个空列表来存储每一行的详细信息。遍历这个表时,创建一个循环来遍历表中的每一行,并将其保存到rows变量中。
for i in sports_table:
rows = i.find_all('tr')
print('n--------row--------n')
print(rows)
复制代码
for row in rows:
cells = row.find_all('td')
print('n-------cells--------n')
print(cells)
复制代码
建立一个嵌套循环。遍历上一个循环中保存的每一行。在遍历这些单元格时,我们将每个单元格保存在一个新变量中。
if not cells:
continue
复制代码
这段简短的代码使我们能够在从单元格中提取文本时避免出现空单元格并防止出现错误。
rank = cells[0].text.strip('n')
page_name = cells[1].find('a').text
sport = cells[2].find('a').text
views = cells[3].text.strip('n')
复制代码
在这里,我们将各种单元格清理成纯文本格式。清除的值存储在其列名下的变量中。
print('n-------CLEAN--------n')
print(rank)
print(page_name)
print(sport)
print(views)
complete_row.append([rank, page_name, sport, views])
复制代码
在这里,我们将这些值添加到行列表中。然后输出清洗后的值。
-------cells--------
[13
, Conor McGregor
, Mixed martial arts
, 43
]
-------CLEAN--------
13
Conor McGregor
Mixed martial arts
43
复制代码
将其转换为如下数据结构:
headers = ['Rank', 'Name', 'Sport', 'Views Mil']
df = pd.DataFrame(complete_row, columns=headers)
df
复制代码
现在您可以在机器学习项目中使用 pandas 数据结构。您可以使用您喜欢的库来拟合模型数据。 查看全部
如何抓取网页数据(如何用一些有用的数据抓取一个网页数据(图))
前不久在LearnML分论坛看到一个帖子。主机在这篇文章中提到他需要为他的机器学习项目抓取网络数据。很多人在回复中给出了自己的方法,主要是学习如何使用BeautifulSoup和Selenium。
我在一些数据科学项目中使用过 BeautifulSoup 和 Selenium。在本文中,我将向您展示如何抓取收录一些有用数据的网页并将其转换为 Pandas 数据结构(DataFrame)。
为什么要转换成数据结构?这是因为大多数机器学习库都可以处理 Pandas 数据结构,并且您只需稍作修改即可编辑您的模型。
首先,我们需要在维基百科上找一张表,转换成数据结构。我抓到的表格显示了维基百科上观看次数最多的运动员数据。

许多任务之一是浏览 HTML 树以获取我们需要的表格。

通过请求和正则表达式库,我们开始使用 BeautifulSoup。
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
复制代码
接下来,我们将从网页中提取 HTML 代码:
website_url = requests.get('https://en.wikipedia.org/wiki/Wikipedia:Multiyear_ranking_of_most_viewed_pages').text
soup = BeautifulSoup(website_url, 'lxml')
print(soup.prettify())
</a>
Disclaimers
Contact Wikipedia
<a>
复制代码
从语料库中采集所有表格,我们有一个很小的表面积可供搜索。
wiki_tables = soup.find_all('table', class_='wikitable')
wiki_tables
复制代码
因为有很多表,所以需要一种过滤它们的方法。
据我们所知,克里斯蒂亚诺·罗纳尔多(Cristiano Ronaldo)(也被称为葡萄牙足球运动员罗纳尔多)有一个锚标记,这在几张表中可能是独一无二的。

使用 Cristiano Ronaldo 文本,我们可以过滤那些由锚点标记的表格。此外,我们还发现了一些收录此锚标记的父元素。
links = []
for table in wiki_tables:
_table = table.find('a', string=re.compile('Cristiano Ronaldo'))
if not _table:
continue
print(_table)
_parent = _table.parent
print(_parent)
links.append(_parent)
Cristiano Ronaldo
Cristiano Ronaldo
Cristiano Ronaldo
Cristiano Ronaldo
Cristiano Ronaldo
Cristiano Ronaldo
复制代码
父元素只显示单元格。
这是一个带有浏览器 Web 开发工具的单元格。

parent_lst = []
for anchor in links:
_ = anchor.find_parents('tbody')
print(_)
parent_lst.append(_)
复制代码
使用 tbody,我们可以返回收录先前锚标记的其他表。
为了进一步过滤,我们可以在下表中搜索不同的标题:
for i in parent_lst:
print(i[0].find('tr'))
tr>
Rank*
Page
Views in millions
Rank
Page
Views in millions
Rank
Page
Sport
Views in millions
复制代码
第三个看起来很像我们需要的表。
接下来,我们开始创建必要的逻辑来提取和清理我们需要的细节。
sports_table = parent_lst[2]
complete_row = []
for i in sports_table:
rows = i.find_all('tr')
print('n--------row--------n')
print(rows)
for row in rows:
cells = row.find_all('td')
print('n-------cells--------n')
print(cells)
if not cells:
continue
rank = cells[0].text.strip('n')
page_name = cells[1].find('a').text
sport = cells[2].find('a').text
views = cells[3].text.strip('n')
print('n-------CLEAN--------n')
print(rank)
print(page_name)
print(sport)
print(views)
complete_row.append([rank, page_name, sport, views])
for i in complete_row:
print(i)
复制代码
分解一下:
sports_table = parent_lst[2]
complete_row = []
复制代码
下面我们从上面的列表中选择第三个元素。这是我们需要的表。
接下来,创建一个空列表来存储每一行的详细信息。遍历这个表时,创建一个循环来遍历表中的每一行,并将其保存到rows变量中。
for i in sports_table:
rows = i.find_all('tr')
print('n--------row--------n')
print(rows)
复制代码

for row in rows:
cells = row.find_all('td')
print('n-------cells--------n')
print(cells)
复制代码
建立一个嵌套循环。遍历上一个循环中保存的每一行。在遍历这些单元格时,我们将每个单元格保存在一个新变量中。

if not cells:
continue
复制代码
这段简短的代码使我们能够在从单元格中提取文本时避免出现空单元格并防止出现错误。
rank = cells[0].text.strip('n')
page_name = cells[1].find('a').text
sport = cells[2].find('a').text
views = cells[3].text.strip('n')
复制代码
在这里,我们将各种单元格清理成纯文本格式。清除的值存储在其列名下的变量中。
print('n-------CLEAN--------n')
print(rank)
print(page_name)
print(sport)
print(views)
complete_row.append([rank, page_name, sport, views])
复制代码
在这里,我们将这些值添加到行列表中。然后输出清洗后的值。
-------cells--------
[13
, Conor McGregor
, Mixed martial arts
, 43
]
-------CLEAN--------
13
Conor McGregor
Mixed martial arts
43
复制代码
将其转换为如下数据结构:
headers = ['Rank', 'Name', 'Sport', 'Views Mil']
df = pd.DataFrame(complete_row, columns=headers)
df
复制代码

现在您可以在机器学习项目中使用 pandas 数据结构。您可以使用您喜欢的库来拟合模型数据。
如何抓取网页数据(如何用PowerBI批量爬取网页数据?原创采悟PowerBI星球微信号PowerBIStar功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-11-13 18:18
如何使用PowerBI批量抓取网页数据?
原创 蔡武
PowerBI 星球
PowerBI 星球
微信 PowerBIStar
功能介绍海量干货,助你轻松上手PowerBI
2018-04-01
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,
从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]之后的所有步骤,然后展开数据,删除前面几列的数据。
这样,第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页时,排序后的数据结构与第一页的数据结构相同。采集的数据可以直接使用;它不会在这里排序。没关系,你可以等到采集所有的网页数据整理在一起。
如果要大量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并将第一行的URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,大概10分钟就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试一页采集。如果可以采集,那就用上面的步骤。如果 采集 没有到达,则不再有任何延迟。
现在打开 PowerBI 并尝试抓取您感兴趣的 网站 数据。
Power Query 系列评论:
结束
提高技能,拓宽视野
读
在看
已经同步来看看,写下你的想法
进入“发现”-“看一看”,浏览“好友在看”
去看看
看看入口是封闭的
在“设置”-“通用”-“发现页面管理”中打开“看一看”条目
我懂了
已发送
取消
发送来看看
发送
如何使用PowerBI批量抓取网页数据?
最多 200 个字符,当前字符总数
发送 查看全部
如何抓取网页数据(如何用PowerBI批量爬取网页数据?原创采悟PowerBI星球微信号PowerBIStar功能)
如何使用PowerBI批量抓取网页数据?
原创 蔡武
PowerBI 星球
PowerBI 星球
微信 PowerBIStar
功能介绍海量干货,助你轻松上手PowerBI
2018-04-01

之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,

向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。

从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,

从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]之后的所有步骤,然后展开数据,删除前面几列的数据。

这样,第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页时,排序后的数据结构与第一页的数据结构相同。采集的数据可以直接使用;它不会在这里排序。没关系,你可以等到采集所有的网页数据整理在一起。
如果要大量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>

并将第一行的URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。

输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:

然后调用自定义函数,

在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。

点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,

至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,大概10分钟就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试一页采集。如果可以采集,那就用上面的步骤。如果 采集 没有到达,则不再有任何延迟。
现在打开 PowerBI 并尝试抓取您感兴趣的 网站 数据。
Power Query 系列评论:
结束
提高技能,拓宽视野
读
在看
已经同步来看看,写下你的想法
进入“发现”-“看一看”,浏览“好友在看”

去看看
看看入口是封闭的
在“设置”-“通用”-“发现页面管理”中打开“看一看”条目
我懂了
已发送
取消
发送来看看
发送
如何使用PowerBI批量抓取网页数据?
最多 200 个字符,当前字符总数
发送
如何抓取网页数据(如何抓取网页数据:“google-simplegraphs”在网页源代码的相应部分即可处理结果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-12 12:04
如何抓取网页数据:“google-simplegraphs”在网页源代码的相应部分即可处理结果,方法如下:首先:要读取的文件要存在服务器上(不能用手机上存);然后要设置一个urlurl="-simplegraphs"/sitemap/image/extract_gradient-rfgs.jpg/style/rgba_2_10937f6625031d0af0e0c0b5c03b901274730.jpg"/linkvara=getdata(url);//获取网页文件;//获取该网页的爬虫代码;//获取相应的urlvarq=newspider();//设置爬虫代码//获取文件名;returnq;step1:获取源文件地址、文件名等信息,以及代码的部分内容varli=newpromise(function(resolve,reject){varself=newli();varp=promise.then(function(timestamp){//获取前端代码,用promise作为异步队列if(is.state(timestamp)){resolve(timestamp);}if(is.state(null)){reject("cannotprocessstate");}});//对代码进行校验;p=promise.then(function(err,data){resolve(err);});//发送请求timestamp=p.then(function(){console.log("正在获取数据");});console.log("请求正在接收响应");p.then(function(data){console.log("您已接收文件");});}).catch(function(error){//错误的处理reject(error);});//调用q()方法去获取fundefined属性值//获取首页的爬虫代码self.start(fundefined);step2:用self.stop()方法停止对爬虫代码的处理//其他方法进行上面两个步骤的循环step3:获取到fundefined属性值(当文件的fundefined属性值为”\\”时)存储在内存中(这个内存地址会存在本地的某个目录中),当读取网页时,对对图片上fundefined属性的值进行读取,解析出每个文件的fundefined属性值,获取响应值//此时只获取到数据的一部分p.then(function(data){console.log("请求正在接收响应");reject("由响应接收");});//同时也要收回并将当前的返回值存储到内存中,以便将来的爬虫代码(class="gg-world")及部分代码放到当前目录下。
这样就实现了爬虫的无刷新,但是仅仅获取到前端文件的内容(只是存储并解析响应值)if(is.state(fundefined)){resolve(timestamp);}。 查看全部
如何抓取网页数据(如何抓取网页数据:“google-simplegraphs”在网页源代码的相应部分即可处理结果)
如何抓取网页数据:“google-simplegraphs”在网页源代码的相应部分即可处理结果,方法如下:首先:要读取的文件要存在服务器上(不能用手机上存);然后要设置一个urlurl="-simplegraphs"/sitemap/image/extract_gradient-rfgs.jpg/style/rgba_2_10937f6625031d0af0e0c0b5c03b901274730.jpg"/linkvara=getdata(url);//获取网页文件;//获取该网页的爬虫代码;//获取相应的urlvarq=newspider();//设置爬虫代码//获取文件名;returnq;step1:获取源文件地址、文件名等信息,以及代码的部分内容varli=newpromise(function(resolve,reject){varself=newli();varp=promise.then(function(timestamp){//获取前端代码,用promise作为异步队列if(is.state(timestamp)){resolve(timestamp);}if(is.state(null)){reject("cannotprocessstate");}});//对代码进行校验;p=promise.then(function(err,data){resolve(err);});//发送请求timestamp=p.then(function(){console.log("正在获取数据");});console.log("请求正在接收响应");p.then(function(data){console.log("您已接收文件");});}).catch(function(error){//错误的处理reject(error);});//调用q()方法去获取fundefined属性值//获取首页的爬虫代码self.start(fundefined);step2:用self.stop()方法停止对爬虫代码的处理//其他方法进行上面两个步骤的循环step3:获取到fundefined属性值(当文件的fundefined属性值为”\\”时)存储在内存中(这个内存地址会存在本地的某个目录中),当读取网页时,对对图片上fundefined属性的值进行读取,解析出每个文件的fundefined属性值,获取响应值//此时只获取到数据的一部分p.then(function(data){console.log("请求正在接收响应");reject("由响应接收");});//同时也要收回并将当前的返回值存储到内存中,以便将来的爬虫代码(class="gg-world")及部分代码放到当前目录下。
这样就实现了爬虫的无刷新,但是仅仅获取到前端文件的内容(只是存储并解析响应值)if(is.state(fundefined)){resolve(timestamp);}。
如何抓取网页数据( Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-11 19:03
Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取
)
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍了四个步骤。Python爬虫的基本流程。
第1步
请求尝试
先到b站首页,点击排行榜,复制链接。
https://www.bilibili.com/ranki ... 162.3
启动 Jupyter notebook 并运行以下代码:
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,做了以下三件事: 可以看到返回值为200,说明服务器响应正常,可以继续了。
第2步
解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象。现在我们可以使用 .text 来查看其内容。
可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。
Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的。
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步
提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下图的说明找到。
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第四步
存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' ,否则会出现中文乱码的问题。
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果您熟悉pandas,您可以通过一行代码轻松地将字典转换为DataFrame。
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
结束语
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都遵循以上四个步骤。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜,因为够简单,希望通过这个案例,让大家了解Python爬虫工作的基本流程,最后附上完整代码
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig') 查看全部
如何抓取网页数据(
Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取
)


爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍了四个步骤。Python爬虫的基本流程。
第1步
请求尝试
先到b站首页,点击排行榜,复制链接。
https://www.bilibili.com/ranki ... 162.3
启动 Jupyter notebook 并运行以下代码:
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,做了以下三件事: 可以看到返回值为200,说明服务器响应正常,可以继续了。
第2步
解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象。现在我们可以使用 .text 来查看其内容。

可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。
Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的。
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步
提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下图的说明找到。

可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第四步
存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' ,否则会出现中文乱码的问题。
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果您熟悉pandas,您可以通过一行代码轻松地将字典转换为DataFrame。
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')

结束语
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都遵循以上四个步骤。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜,因为够简单,希望通过这个案例,让大家了解Python爬虫工作的基本流程,最后附上完整代码
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
如何抓取网页数据(3.百度spider介绍5.只需两步,正确识别百度蜘蛛)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-11 19:01
最近一直在看SEO相关的资料。我比较好奇的是百度蜘蛛是如何抓取网站的内容的?我在网上搜了一下,找到了从百度搜索学院文章复制过来的那些文章:
1.搜索引擎爬虫系统概述(一)
2.搜索引擎爬虫系统概述(二)
3.搜索引擎检索系统概述
4.百度蜘蛛介绍
5.如何识别百度蜘蛛
6.只需两步即可正确识别百度蜘蛛
网上看到最多的一句话是:百度蜘蛛一、爬取、二、存储、三、预处理、四、索引、五、排名。这种描述问题不大,但也无济于事。我只想知道百度蜘蛛是怎么来我的网站爬取内容的,爬取的顺序,爬取的频率?
一、网络蜘蛛怎么会来我的网站;
网上也有很多关于这个问题的讨论。总结就是:1、指向你的网站外链;2、到站长平台提交网站的url;3、sitemap文件并链接到网站的首页。关于第一点和第二点,网上有很多相关的说明和实践指南,这里不再赘述。我想谈谈我对第三点的理解。首先,我必须为我的站点创建一个站点地图文件,并且这个文件必须放在网站的根目录下。必须可以在没有权限控制的情况下正常访问。. 具体的文档创建请参考各个搜索引擎的指南(如:百度站点地图文档)。还要注意此文件的 URL 和更新率。
https://www.onekbit.com/adminUserAction/toIndex.do
2018-12-23
weekly
1.0
https://www.onekbit.com/FrontP ... s.jsp
2018-12-23
weekly
0.8
https://www.onekbit.com/ViewBlog/toBlogIndex.do
2018-12-23
hourly
1.0
https://www.onekbit.com/ViewBl ... 00027
2018-12-23
hourly
1.0
这里有几个代表性的 URL 来展示。我的初始 URL 很长,收录很多参数。当我把它放在xml文件中时它会报告错误。后面都会优化成这个简单的连接。继续写更多实用价值原创文章,每天频繁更新这个文件。
关于这个文件的更新,大家需要多注意观察你在网站上的百度访问日志:
123.125.71.38 - - [23/Dec/2018:21:18:36 +0800] "GET /Sitemap.xml HTTP/1.1" 304 3673
这是我网站上百度蜘蛛的一行访问日志。请注意,其中的 304 代码表示: 304 未修改 — 文档未按预期进行修改。如果你每天得到的是304,那么对于蜘蛛来说,你没有任何信息可以得到它。自然,它的爬行速度会越来越低,最后也不会来。所以一定要定时定量更新网站原创,让蜘蛛每次都能把信息抢回来,让蜘蛛经常来。最后一点是网站内部链接必须向各个方向延伸,这样蜘蛛才能获得更多的链接给你网站回来。
二、网络蜘蛛在网站上爬行的顺序
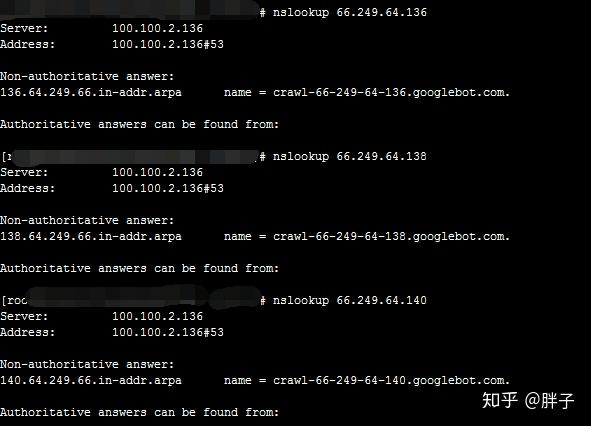
网站 目录中网络蜘蛛访问的第一个文件应该是robots.txt。一般情况下,应该根据这个文件是否存在而定。如果不是,则表示可以爬取整个网站。, 爬取取决于文件中的具体限制,这是正常搜索引擎的规则。至于访问robots.txt后应该访问第二个是首页还是sitemap文件,这个在网上有点争议,但是我倾向于认为第二个访问sitemap文件,我用我的< @网站 蜘蛛访问日志的最后一段。证明给我看:
66.249.64.136 - - [22/Dec/2018:04:10:05 +0800] "GET /robots.txt HTTP/1.1" 404 793
66.249.64.140 - - [22/Dec/2018:04:10:06 +0800] "GET /Sitemap.xml HTTP/1.1" 200 3253
66.249.64.136 - - [22/Dec/2018:04:10:38 +0800] "GET /ViewBlog/blog/BID20181204100011 HTTP/1.1" 200 4331
66.249.64.136 - - [22/Dec/2018:04:10:48 +0800] "GET /ViewBlog/blog/BID20181210100016 HTTP/1.1" 200 4258
66.249.64.138 - - [22/Dec/2018:04:11:02 +0800] "GET /ViewBlog/blog/BID20181213100019 HTTP/1.1" 200 3696
66.249.64.138 - - [22/Dec/2018:04:11:39 +0800] "GET /ViewBlog/blog/BID20181207100014 HTTP/1.1" 200 3595
66.249.64.140 - - [22/Dec/2018:04:12:02 +0800] "GET /ViewBlog/blog/BID20181203100010 HTTP/1.1" 200 26710
66.249.64.138 - - [22/Dec/2018:04:15:14 +0800] "GET /adminUserAction/toIndex.do HTTP/1.1" 200 32040
我用的是nslookup 66.249.64.136的IP:
nslookup 命令结果
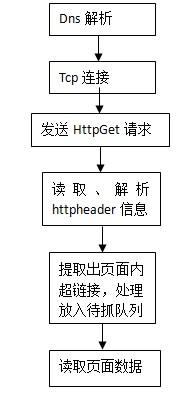
从日志来看,首先访问的是robots.txt文件,其次是sitemap文件,修改后的URL添加到sitemap中,第四个好像是首页。从蜘蛛的IP来看,我猜是一种专门用来获取网页链接的,另一种是专门用来抓取网页内容的。百度站长里面有一张图,描述了百度蜘蛛的工作流程:
这也可以看出获取url后读取内容。
三、 网络蜘蛛对 网站 的抓取频率
其实,与网络蜘蛛爬取网站的频率有关的因素上面已经说了。感觉最重要的是定期定量更新网站上原创的内容,并提供网站话题相关信息的质量,其次是在导入链接方面做更多的工作.
本文章由onekbit自定义支付导航供稿,原文链接: 查看全部
如何抓取网页数据(3.百度spider介绍5.只需两步,正确识别百度蜘蛛)
最近一直在看SEO相关的资料。我比较好奇的是百度蜘蛛是如何抓取网站的内容的?我在网上搜了一下,找到了从百度搜索学院文章复制过来的那些文章:
1.搜索引擎爬虫系统概述(一)
2.搜索引擎爬虫系统概述(二)
3.搜索引擎检索系统概述
4.百度蜘蛛介绍
5.如何识别百度蜘蛛
6.只需两步即可正确识别百度蜘蛛
网上看到最多的一句话是:百度蜘蛛一、爬取、二、存储、三、预处理、四、索引、五、排名。这种描述问题不大,但也无济于事。我只想知道百度蜘蛛是怎么来我的网站爬取内容的,爬取的顺序,爬取的频率?
一、网络蜘蛛怎么会来我的网站;
网上也有很多关于这个问题的讨论。总结就是:1、指向你的网站外链;2、到站长平台提交网站的url;3、sitemap文件并链接到网站的首页。关于第一点和第二点,网上有很多相关的说明和实践指南,这里不再赘述。我想谈谈我对第三点的理解。首先,我必须为我的站点创建一个站点地图文件,并且这个文件必须放在网站的根目录下。必须可以在没有权限控制的情况下正常访问。. 具体的文档创建请参考各个搜索引擎的指南(如:百度站点地图文档)。还要注意此文件的 URL 和更新率。
https://www.onekbit.com/adminUserAction/toIndex.do
2018-12-23
weekly
1.0
https://www.onekbit.com/FrontP ... s.jsp
2018-12-23
weekly
0.8
https://www.onekbit.com/ViewBlog/toBlogIndex.do
2018-12-23
hourly
1.0
https://www.onekbit.com/ViewBl ... 00027
2018-12-23
hourly
1.0
这里有几个代表性的 URL 来展示。我的初始 URL 很长,收录很多参数。当我把它放在xml文件中时它会报告错误。后面都会优化成这个简单的连接。继续写更多实用价值原创文章,每天频繁更新这个文件。
关于这个文件的更新,大家需要多注意观察你在网站上的百度访问日志:
123.125.71.38 - - [23/Dec/2018:21:18:36 +0800] "GET /Sitemap.xml HTTP/1.1" 304 3673
这是我网站上百度蜘蛛的一行访问日志。请注意,其中的 304 代码表示: 304 未修改 — 文档未按预期进行修改。如果你每天得到的是304,那么对于蜘蛛来说,你没有任何信息可以得到它。自然,它的爬行速度会越来越低,最后也不会来。所以一定要定时定量更新网站原创,让蜘蛛每次都能把信息抢回来,让蜘蛛经常来。最后一点是网站内部链接必须向各个方向延伸,这样蜘蛛才能获得更多的链接给你网站回来。
二、网络蜘蛛在网站上爬行的顺序
网站 目录中网络蜘蛛访问的第一个文件应该是robots.txt。一般情况下,应该根据这个文件是否存在而定。如果不是,则表示可以爬取整个网站。, 爬取取决于文件中的具体限制,这是正常搜索引擎的规则。至于访问robots.txt后应该访问第二个是首页还是sitemap文件,这个在网上有点争议,但是我倾向于认为第二个访问sitemap文件,我用我的< @网站 蜘蛛访问日志的最后一段。证明给我看:
66.249.64.136 - - [22/Dec/2018:04:10:05 +0800] "GET /robots.txt HTTP/1.1" 404 793
66.249.64.140 - - [22/Dec/2018:04:10:06 +0800] "GET /Sitemap.xml HTTP/1.1" 200 3253
66.249.64.136 - - [22/Dec/2018:04:10:38 +0800] "GET /ViewBlog/blog/BID20181204100011 HTTP/1.1" 200 4331
66.249.64.136 - - [22/Dec/2018:04:10:48 +0800] "GET /ViewBlog/blog/BID20181210100016 HTTP/1.1" 200 4258
66.249.64.138 - - [22/Dec/2018:04:11:02 +0800] "GET /ViewBlog/blog/BID20181213100019 HTTP/1.1" 200 3696
66.249.64.138 - - [22/Dec/2018:04:11:39 +0800] "GET /ViewBlog/blog/BID20181207100014 HTTP/1.1" 200 3595
66.249.64.140 - - [22/Dec/2018:04:12:02 +0800] "GET /ViewBlog/blog/BID20181203100010 HTTP/1.1" 200 26710
66.249.64.138 - - [22/Dec/2018:04:15:14 +0800] "GET /adminUserAction/toIndex.do HTTP/1.1" 200 32040
我用的是nslookup 66.249.64.136的IP:
nslookup 命令结果
从日志来看,首先访问的是robots.txt文件,其次是sitemap文件,修改后的URL添加到sitemap中,第四个好像是首页。从蜘蛛的IP来看,我猜是一种专门用来获取网页链接的,另一种是专门用来抓取网页内容的。百度站长里面有一张图,描述了百度蜘蛛的工作流程:
这也可以看出获取url后读取内容。
三、 网络蜘蛛对 网站 的抓取频率
其实,与网络蜘蛛爬取网站的频率有关的因素上面已经说了。感觉最重要的是定期定量更新网站上原创的内容,并提供网站话题相关信息的质量,其次是在导入链接方面做更多的工作.
本文章由onekbit自定义支付导航供稿,原文链接:
如何抓取网页数据(本例如何从网站下载数据中提供日常更新数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-31 14:08
有时出于某种目的,我们可能需要从某些网站 获取一些数据。如果网站提供了下载选项,那么我们可以直接从网站下载。当然,有些网站可能只提供每日更新,但是如果没有提供下载选项,我们就得另辟蹊径了。
如果你只是想突然从某个网站获取数据,即使没有可用的下载,也只需复制粘贴即可。如果需要大量的数据,复制粘贴太费时,或者需要从某个网站中获取一些数据,那么就得考虑(code)do(substitute)方法(code )。
由于本人是气象学家,本例将以怀俄明大学提供的探测数据下载为例,谈谈如何从某个网站下载数据。
打开网站后,我们会看到一些选择区域、日期和站点的选项。
绘图类型提供了许多选项
但在这里我们只下载探测数据并选择默认选项 Text:List。而我们通常需要的是国内的探空数据,所以在Region项中选择东南亚。
在站点字段中输入 58238。如果您知道站点编号,则可以直接输入。如果不知道,可以直接在地图上点击站点编号。
然后按回车查看测深数据页面
因为我们只选了一次,所以探探信息只有一次。而且,从网页上给出的数据可以看出,给出的信息非常清晰,基本上只有测深数据和一些计算出来的指标。
在测深数据页面右击查看页面源码:
可以看出,我们可以使用的信息是H2、PRE、H3标签对应的信息,PRE标签对应的是sounding data、site信息和sounding index信息。
获取网页地址,然后就可以直接从网页下载数据了。
使用的库:BeautifulSoup4、requests
import requests
from bs4 import BeautifulSoup
url = 'http://weather.uwyo.edu/cgi-bi ... 27%3B
# 使用requests 获取网页数据,然后用 BeautifulSoup 解析网页
data = BeautifulSoup(requests.request('get', url).text, 'lxml')
# 打印 站点信息
print(data.h2.string)
# 打印探空数据
print(data.pre.get_text())
# 保存探空数据到文件
uppair = open(r'F:\uppair.txt', 'w')
print(data.pre.get_text(), file = uppair)
# 一定要关闭
uppair.close()
于是下载了测深数据
-----------------------------------------------------------------------------
PRES HGHT TEMP DWPT RELH MIXR DRCT SKNT THTA THTE THTV
hPa m C C % g/kg deg knot K K K
-----------------------------------------------------------------------------
1000.0 7 26.0 22.7 82 17.72 115 6 299.1 351.1 302.3
925.0 720 21.4 18.4 83 14.62 150 16 301.2 344.4 303.8
850.0 1449 17.4 11.4 68 10.05 130 17 304.4 334.7 306.2
700.0 3084 9.2 -1.8 46 4.81 100 19 312.6 328.1 313.6
500.0 5790 -4.9 -12.9 53 2.85 280 17 327.0 336.9 327.6
400.0 7510 -16.5 -21.0 68 1.80 280 39 333.5 340.0 333.8
300.0 9600 -32.7 -43.7 33 0.27 260 62 339.2 340.3 339.2
250.0 10870 -40.3 -56.3 16 0.07 250 85 346.0 346.4 346.0
220.0 11724 -46.3 -61.7 16 0.04 245 91 349.7 349.9 349.7
200.0 12360 -50.7 -65.7 15 0.03 250 89 352.3 352.5 352.3
150.0 14180 -62.3 250 78 362.6 362.6
118.0 15633 -70.3 270 64 373.6 373.6
100.0 16620 -68.9 270 47 394.4 394.4
70.0 18750 -64.7 305 10 445.6 445.6
50.0 20820 -58.3 105 10 505.7 505.7
30.0 24060 -53.7 80 21 597.6 597.6
20.0 26700 -48.9 90 33 685.7 685.7
你认为代码现在结束了吗?如果每次都手动确定网页的网址,复制和粘贴有什么区别?为了以后节省很多时间,我们来看看网页网址的特点:
http://weather.uwyo.edu/cgi-bi ... 58238
URL中有region、TYPE、YEAR、MONTH、STNM,天的选择由FROM和TO控制。对应每个选项在选择网页时选择地区、日期、站点等信息。
东南亚的region值是seasia,北美的region值是naconf,但是在下载数据的时候,真正控制选择的探测数据的是站点和日期信息。区域信息并不重要。
因此,以后选择下载探测数据时,只需根据需要修改URL即可。例如,获取2017.6.20 8:00到2017.6.22 8:00的探测数据,URL应为:
http://weather.uwyo.edu/cgi-bi ... 58238
注:探测时间为UTC时间。同时注意region值是naconf,也可以得到正确的测深数据。2000对应的时间是日和小时,前两位对应的是天,后两位对应的是小时。
细心的你可能已经发现,上面打印PRE标签信息的时候,打印的是sounding信息,但是打印的时候没有指定index。这就是问题所在:如果有多个信息对应同一个标签,默认获取第一条信息。要获取所有信息,您可以使用 ing_all 方法。
print(data.find_all('pre')[1].string)
Station identifier: ZSNJ
Station number: 58238
Observation time: 170621/1200
Station latitude: 32.00
Station longitude: 118.80
Station elevation: 7.0
Showalter index: 4.27
Lifted index: -1.30
LIFT computed using virtual temperature: -1.80
SWEAT index: 276.75
K index: 22.70
Cross totals index: 16.30
Vertical totals index: 22.30
Totals totals index: 38.60
Convective Available Potential Energy: 637.33
CAPE using virtual temperature: 813.63
Convective Inhibition: -22.85
CINS using virtual temperature: -10.14
Equilibrum Level: 243.86
Equilibrum Level using virtual temperature: 243.14
Level of Free Convection: 829.33
LFCT using virtual temperature: 884.16
Bulk Richardson Number: 1946.17
Bulk Richardson Number using CAPV: 2484.53
Temp [K] of the Lifted Condensation Level: 293.58
Pres [hPa] of the Lifted Condensation Level: 928.82
Mean mixed layer potential temperature: 299.87
Mean mixed layer mixing ratio: 16.61
1000 hPa to 500 hPa thickness: 5783.00
Precipitable water [mm] for entire sounding: 44.52
如果要在获取台站信息和探测索引信息后获取相应的数值信息,则必须使用正则表达式。
使用的库:re
<p>import re
# 获取对流有效位能值
cape = re.findall('(? 查看全部
如何抓取网页数据(本例如何从网站下载数据中提供日常更新数据?)
有时出于某种目的,我们可能需要从某些网站 获取一些数据。如果网站提供了下载选项,那么我们可以直接从网站下载。当然,有些网站可能只提供每日更新,但是如果没有提供下载选项,我们就得另辟蹊径了。
如果你只是想突然从某个网站获取数据,即使没有可用的下载,也只需复制粘贴即可。如果需要大量的数据,复制粘贴太费时,或者需要从某个网站中获取一些数据,那么就得考虑(code)do(substitute)方法(code )。
由于本人是气象学家,本例将以怀俄明大学提供的探测数据下载为例,谈谈如何从某个网站下载数据。
打开网站后,我们会看到一些选择区域、日期和站点的选项。
绘图类型提供了许多选项
但在这里我们只下载探测数据并选择默认选项 Text:List。而我们通常需要的是国内的探空数据,所以在Region项中选择东南亚。
在站点字段中输入 58238。如果您知道站点编号,则可以直接输入。如果不知道,可以直接在地图上点击站点编号。
然后按回车查看测深数据页面
因为我们只选了一次,所以探探信息只有一次。而且,从网页上给出的数据可以看出,给出的信息非常清晰,基本上只有测深数据和一些计算出来的指标。
在测深数据页面右击查看页面源码:
可以看出,我们可以使用的信息是H2、PRE、H3标签对应的信息,PRE标签对应的是sounding data、site信息和sounding index信息。
获取网页地址,然后就可以直接从网页下载数据了。
使用的库:BeautifulSoup4、requests
import requests
from bs4 import BeautifulSoup
url = 'http://weather.uwyo.edu/cgi-bi ... 27%3B
# 使用requests 获取网页数据,然后用 BeautifulSoup 解析网页
data = BeautifulSoup(requests.request('get', url).text, 'lxml')
# 打印 站点信息
print(data.h2.string)
# 打印探空数据
print(data.pre.get_text())
# 保存探空数据到文件
uppair = open(r'F:\uppair.txt', 'w')
print(data.pre.get_text(), file = uppair)
# 一定要关闭
uppair.close()
于是下载了测深数据
-----------------------------------------------------------------------------
PRES HGHT TEMP DWPT RELH MIXR DRCT SKNT THTA THTE THTV
hPa m C C % g/kg deg knot K K K
-----------------------------------------------------------------------------
1000.0 7 26.0 22.7 82 17.72 115 6 299.1 351.1 302.3
925.0 720 21.4 18.4 83 14.62 150 16 301.2 344.4 303.8
850.0 1449 17.4 11.4 68 10.05 130 17 304.4 334.7 306.2
700.0 3084 9.2 -1.8 46 4.81 100 19 312.6 328.1 313.6
500.0 5790 -4.9 -12.9 53 2.85 280 17 327.0 336.9 327.6
400.0 7510 -16.5 -21.0 68 1.80 280 39 333.5 340.0 333.8
300.0 9600 -32.7 -43.7 33 0.27 260 62 339.2 340.3 339.2
250.0 10870 -40.3 -56.3 16 0.07 250 85 346.0 346.4 346.0
220.0 11724 -46.3 -61.7 16 0.04 245 91 349.7 349.9 349.7
200.0 12360 -50.7 -65.7 15 0.03 250 89 352.3 352.5 352.3
150.0 14180 -62.3 250 78 362.6 362.6
118.0 15633 -70.3 270 64 373.6 373.6
100.0 16620 -68.9 270 47 394.4 394.4
70.0 18750 -64.7 305 10 445.6 445.6
50.0 20820 -58.3 105 10 505.7 505.7
30.0 24060 -53.7 80 21 597.6 597.6
20.0 26700 -48.9 90 33 685.7 685.7
你认为代码现在结束了吗?如果每次都手动确定网页的网址,复制和粘贴有什么区别?为了以后节省很多时间,我们来看看网页网址的特点:
http://weather.uwyo.edu/cgi-bi ... 58238
URL中有region、TYPE、YEAR、MONTH、STNM,天的选择由FROM和TO控制。对应每个选项在选择网页时选择地区、日期、站点等信息。
东南亚的region值是seasia,北美的region值是naconf,但是在下载数据的时候,真正控制选择的探测数据的是站点和日期信息。区域信息并不重要。
因此,以后选择下载探测数据时,只需根据需要修改URL即可。例如,获取2017.6.20 8:00到2017.6.22 8:00的探测数据,URL应为:
http://weather.uwyo.edu/cgi-bi ... 58238
注:探测时间为UTC时间。同时注意region值是naconf,也可以得到正确的测深数据。2000对应的时间是日和小时,前两位对应的是天,后两位对应的是小时。
细心的你可能已经发现,上面打印PRE标签信息的时候,打印的是sounding信息,但是打印的时候没有指定index。这就是问题所在:如果有多个信息对应同一个标签,默认获取第一条信息。要获取所有信息,您可以使用 ing_all 方法。
print(data.find_all('pre')[1].string)
Station identifier: ZSNJ
Station number: 58238
Observation time: 170621/1200
Station latitude: 32.00
Station longitude: 118.80
Station elevation: 7.0
Showalter index: 4.27
Lifted index: -1.30
LIFT computed using virtual temperature: -1.80
SWEAT index: 276.75
K index: 22.70
Cross totals index: 16.30
Vertical totals index: 22.30
Totals totals index: 38.60
Convective Available Potential Energy: 637.33
CAPE using virtual temperature: 813.63
Convective Inhibition: -22.85
CINS using virtual temperature: -10.14
Equilibrum Level: 243.86
Equilibrum Level using virtual temperature: 243.14
Level of Free Convection: 829.33
LFCT using virtual temperature: 884.16
Bulk Richardson Number: 1946.17
Bulk Richardson Number using CAPV: 2484.53
Temp [K] of the Lifted Condensation Level: 293.58
Pres [hPa] of the Lifted Condensation Level: 928.82
Mean mixed layer potential temperature: 299.87
Mean mixed layer mixing ratio: 16.61
1000 hPa to 500 hPa thickness: 5783.00
Precipitable water [mm] for entire sounding: 44.52
如果要在获取台站信息和探测索引信息后获取相应的数值信息,则必须使用正则表达式。
使用的库:re
<p>import re
# 获取对流有效位能值
cape = re.findall('(?
如何抓取网页数据(TheCode:我最近开始使用selenium和scrapy进行网页抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-29 20:12
情况:
我最近开始使用 selenium 和 scrapy 进行网页抓取。我在一个项目中工作。我有一个收录 42,000 个邮政编码的 csv 文件。我的工作是获取邮政编码并输入 网站 输入邮政编码。并获取所有结果。
问题:
这里的问题是,在执行此操作时,我必须不断单击“加载更多”按钮,直到显示所有结果,只有完成后才能采集数据。
这可能不是什么大问题,但是每个邮政编码需要 2 分钟,而我有 42,000 个邮政编码。
编码:
import scrapy
from numpy.lib.npyio import load
from selenium import webdriver
from selenium.common.exceptions import ElementClickInterceptedException, ElementNotInteractableException, ElementNotSelectableException, NoSuchElementException, StaleElementReferenceException
from selenium.webdriver.common.keys import Keys
from items import CareCreditItem
from datetime import datetime
import os
from scrapy.crawler import CrawlerProcess
global pin_code
pin_code = input("enter pin code")
class CareCredit1Spider(scrapy.Spider):
name = 'care_credit_1'
start_urls = ['https://www.carecredit.com/doctor-locator/results/Any-Profession/Any-Specialty//?Sort=D&Radius=75&Page=1']
def start_requests(self):
directory = os.getcwd()
options = webdriver.ChromeOptions()
options.headless = True
options.add_experimental_option("excludeSwitches", ["enable-logging"])
path = (directory+r"\\Chromedriver.exe")
driver = webdriver.Chrome(path,options=options)
#URL of the website
url = "https://www.carecredit.com/doc ... ot%3B +pin_code + "/?Sort=D&Radius=75&Page=1"
driver.maximize_window()
#opening link in the browser
driver.get(url)
driver.implicitly_wait(200)
try:
cookies = driver.find_element_by_xpath('//*[@id="onetrust-accept-btn-handler"]')
cookies.click()
except:
pass
i = 0
loadMoreButtonExists = True
while loadMoreButtonExists:
try:
load_more = driver.find_element_by_xpath('//*[@id="next-page"]')
load_more.click()
driver.implicitly_wait(30)
except ElementNotInteractableException:
loadMoreButtonExists = False
except ElementClickInterceptedException:
pass
except StaleElementReferenceException:
pass
except NoSuchElementException:
loadMoreButtonExists = False
try:
previous_page = driver.find_element_by_xpath('//*[@id="previous-page"]')
previous_page.click()
except:
pass
name = driver.find_elements_by_class_name('dl-result-item')
r = 1
temp_list=[]
j = 0
for element in name:
link = element.find_element_by_tag_name('a')
c = link.get_property('href')
yield scrapy.Request(c)
def parse(self, response):
item = CareCreditItem()
item['Practise_name'] = response.css('h1 ::text').get()
item['address'] = response.css('.google-maps-external ::text').get()
item['phone_no'] = response.css('.dl-detail-phone ::text').get()
yield item
now = datetime.now()
dt_string = now.strftime("%d/%m/%Y")
dt = now.strftime("%H-%M-%S")
file_name = dt_string+"_"+dt+"zip-code"+pin_code+".csv"
process = CrawlerProcess(settings={
'FEED_URI' : file_name,
'FEED_FORMAT':'csv'
})
process.crawl(CareCredit1Spider)
process.start()
print("CSV File is Ready")
项目.py
import scrapy
class CareCreditItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Practise_name = scrapy.Field()
address = scrapy.Field()
phone_no = scrapy.Field()
问题:
基本上我的问题很简单。有没有办法优化这段代码以使其执行得更快?或者,还有什么其他可能的方法可以在不花费很长时间的情况下处理这些数据? 查看全部
如何抓取网页数据(TheCode:我最近开始使用selenium和scrapy进行网页抓取)
情况:
我最近开始使用 selenium 和 scrapy 进行网页抓取。我在一个项目中工作。我有一个收录 42,000 个邮政编码的 csv 文件。我的工作是获取邮政编码并输入 网站 输入邮政编码。并获取所有结果。
问题:
这里的问题是,在执行此操作时,我必须不断单击“加载更多”按钮,直到显示所有结果,只有完成后才能采集数据。
这可能不是什么大问题,但是每个邮政编码需要 2 分钟,而我有 42,000 个邮政编码。
编码:
import scrapy
from numpy.lib.npyio import load
from selenium import webdriver
from selenium.common.exceptions import ElementClickInterceptedException, ElementNotInteractableException, ElementNotSelectableException, NoSuchElementException, StaleElementReferenceException
from selenium.webdriver.common.keys import Keys
from items import CareCreditItem
from datetime import datetime
import os
from scrapy.crawler import CrawlerProcess
global pin_code
pin_code = input("enter pin code")
class CareCredit1Spider(scrapy.Spider):
name = 'care_credit_1'
start_urls = ['https://www.carecredit.com/doctor-locator/results/Any-Profession/Any-Specialty//?Sort=D&Radius=75&Page=1']
def start_requests(self):
directory = os.getcwd()
options = webdriver.ChromeOptions()
options.headless = True
options.add_experimental_option("excludeSwitches", ["enable-logging"])
path = (directory+r"\\Chromedriver.exe")
driver = webdriver.Chrome(path,options=options)
#URL of the website
url = "https://www.carecredit.com/doc ... ot%3B +pin_code + "/?Sort=D&Radius=75&Page=1"
driver.maximize_window()
#opening link in the browser
driver.get(url)
driver.implicitly_wait(200)
try:
cookies = driver.find_element_by_xpath('//*[@id="onetrust-accept-btn-handler"]')
cookies.click()
except:
pass
i = 0
loadMoreButtonExists = True
while loadMoreButtonExists:
try:
load_more = driver.find_element_by_xpath('//*[@id="next-page"]')
load_more.click()
driver.implicitly_wait(30)
except ElementNotInteractableException:
loadMoreButtonExists = False
except ElementClickInterceptedException:
pass
except StaleElementReferenceException:
pass
except NoSuchElementException:
loadMoreButtonExists = False
try:
previous_page = driver.find_element_by_xpath('//*[@id="previous-page"]')
previous_page.click()
except:
pass
name = driver.find_elements_by_class_name('dl-result-item')
r = 1
temp_list=[]
j = 0
for element in name:
link = element.find_element_by_tag_name('a')
c = link.get_property('href')
yield scrapy.Request(c)
def parse(self, response):
item = CareCreditItem()
item['Practise_name'] = response.css('h1 ::text').get()
item['address'] = response.css('.google-maps-external ::text').get()
item['phone_no'] = response.css('.dl-detail-phone ::text').get()
yield item
now = datetime.now()
dt_string = now.strftime("%d/%m/%Y")
dt = now.strftime("%H-%M-%S")
file_name = dt_string+"_"+dt+"zip-code"+pin_code+".csv"
process = CrawlerProcess(settings={
'FEED_URI' : file_name,
'FEED_FORMAT':'csv'
})
process.crawl(CareCredit1Spider)
process.start()
print("CSV File is Ready")
项目.py
import scrapy
class CareCreditItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Practise_name = scrapy.Field()
address = scrapy.Field()
phone_no = scrapy.Field()
问题:
基本上我的问题很简单。有没有办法优化这段代码以使其执行得更快?或者,还有什么其他可能的方法可以在不花费很长时间的情况下处理这些数据?
如何抓取网页数据(ESPN中获取棒球运动员公共网站下载数据的过程-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-28 09:12
网页抓取是从公共网站 下载数据的过程。例如,您可以从 ESPN 获取棒球运动员的统计数据,并构建一个模型,根据他们的球员统计数据和获胜率来预测球队获胜的机会。以下是网络抓取的一些用例。
监控竞争对手的价格以进行价格匹配(竞争定价)。
从各种 网站 采集统计信息以创建仪表板,例如 COVID-19 仪表板。
监控金融论坛和 Twitter 以计算特定资产的情绪。
我将演示的一个用例是抓取 网站 来发布招聘信息。假设您正在寻找工作,但您被列表的数量所淹没。您可以设置一个流程来实际每天抓取。然后你可以编写一个脚本来自动应用于满足特定条件的帖子。
免责声明:网络抓取确实违反了他们的使用条款。本文仅用于教育目的。在抓取 网站 之前,请务必阅读他们的服务条款并遵循他们的 robots.txt 指南。
数据仓库注意事项
我们的蜘蛛每天都会抓取给定搜索查询可用的所有页面,因此我们想要存储大量重复项。如果帖子持续多天,那么我们将在帖子发布的每一天都有一份副本。为了容忍重复,我们将设计一个管道来捕获所有内容,然后过滤数据以创建可用于分析的标准化数据模型。
首先会从网页中解析出数据,然后放入半结构化的数据结构中,比如JSON。从这里开始,数据结构将存储在对象存储中(例如 S3、GS)。对象存储是捕获数据的有用起点。它便宜、可扩展,并且可以通过我们的数据模型灵活更改。一旦数据进入我们的对象存储,网络爬虫的工作就完成了,数据也被捕获了。
下一步是将数据非规范化为更有用的数据以供分析。如前所述,数据收录重复项。我会选择使用 SQL 数据库,因为它具有强大的分析查询功能。它还允许我区分不同的实体,例如公司、职位发布和地点。首先,所有帖子都会进入事实表(大型只写表),带有时间戳,显示帖子何时被抓取以及何时插入到表中。从这里,我们可以将数据非规范化为代表当前活动版本的有状态表。
您可以编写合并语句来更新和插入表示实时发布的表中的发布。从这里我们还想删除已删除或过期的帖子。现在我们有了一个标准化的表,或者换句话说,所有的重复项都被删除了。
设置项目
对于这个项目,我将使用 Scrapy,因为它带有有用的特性和抽象,可以节省你的时间和精力。例如,scrapy 可以轻松地将结构化数据推送到 S3 或 GCS 等对象存储。这是通过将您的凭据以及存储桶名称和路径添加到由 scrapy 生成的配置文件来完成的。目的是为了长期存储并在我们每次运行刮刀时生成一个不可变的副本。由于 S3 是无限的对象存储,因此是长期存储的理想场所,并且可以轻松地随任何项目进行扩展。
为了突出更多特性,scrapy 使用了 Twisted 框架来处理异步 web 请求。这意味着程序可以在等待网站服务器响应请求的同时完成它的工作,而不是因为空闲等待而浪费时间。Scrapy 有一个活跃的社区,因此您可以寻求帮助并查看其他项目的示例。它还提供了一些更高级的选项,例如在具有 Redis 和用户代理欺骗的集群中运行,但这些不在本教程的范围内。
让我们从在 python 中创建一个虚拟环境并安装依赖项开始。然后初始化一个空白项目,我们将在其中安装我们的网络爬虫。请务必在项目的顶级目录中执行此代码。
python3 -m venv venv
源 ./venv/bin/activate
pip install scrapy lxml BeautifulSoup4 jupyterlab pandas
scrapy startproject 工作
cd 工作/工作/
确实是scrapy genspider
解析网页的代码将被放置在蜘蛛/目录中的文件中。蜘蛛是网络爬虫的抽象。它生成 HTTP 请求并解析返回的页面。有一个单独的抽象用于处理和存储称为 ItemPipeline 的信息。这种抽象分离允许解耦、灵活性和水平扩展。比如,你可以在不修改蜘蛛代码内部逻辑的情况下,将蜘蛛的结果发送到多个地方。一个好的做法是将结果作为文件保存在对象存储中进行长期存储,并将其保存在数据库中进行重复数据删除和临时查询。
开发环境
您可以将网络抓取视为对他人工作的逆向工程。有许多工具可以使 Web 开发更易于组装和管理,例如使用可重用模板或 ES6 模块。这些允许 Web 开发人员在多个地方重用相同的代码,目标是将简单的部分组合成更复杂的部分。当您抓取网站 时,您所拥有的只是实际的网页,我们无法访问用于构建页面的组件。因此,我们必须向后工作以使用我们可以使用的任何技术来获得我们想要的东西。
任何网络抓取项目的第一步都是在网络浏览器中打开要抓取的页面,然后使用“检查元素”在您选择的浏览器中探索 DOM。使用浏览器中的开发者工具,您可以探索 DOM 的结构或页面的骨架。现在您可以随意打开页面,使用开发者工具进行探索。在整个过程中,我们将使用浏览器以可视化和交互的方式快速浏览dom。
我喜欢使用带有 iPython 的 scrapy shell 来为我的网页抓取开发解析代码。交互性允许快速反馈循环,允许大量试验和错误。scrapy shell 带您进入已实例化的所有帮助程序和便利函数的 scrapy 上下文。这些相同的对象在运行时可供蜘蛛使用。它还使您可以访问 iPython 的所有功能。您可以使用以下代码来启动您的 shell。
scrapy shell',-MA-jobs.html'
这里最重要的对象是响应。这收录从 Web 服务器到我们的 HTTP GET 请求的 HTTP 响应。它收录页面的 HTML,以及与 HTTP 响应相关的标头和其他信息。基本的反馈循环是使用浏览器识别我们要解析的内容,然后在终端中测试解析代码。
起始网址
如果您查看上面的链接,您可能会注意到该 URL 收录我们的搜索查询。这是在 HTTP GET 请求中传递参数的方式(此示例未使用标准化格式)。我们可以使用此信息以编程方式尝试不同的搜索查询。
在 url 中,在字母 q 之后,我们看到了与位置对应的查询。字母 l 之后是位置。假设在我们的用例中,我们要搜索多个位置和位置。例如,医疗助理也称为患者护理助理。
在scrapy中,我们可以使用我们蜘蛛的几个URL作为抓取的起点。我们可以向它传递与多个位置和位置相对应的 URL 以获得此行为。在这个例子中,我使用 product 函数生成位置和位置的每个组合,然后我将它传递给蜘蛛作为我们的起点。
从 itertools 导入产品
job_titles = [“医疗助理”、“病人护理技术员”、“病人护理助理”]
状态 = [“MA”]
城市 = [“波士顿”、“剑桥”、“萨默维尔”、“多切斯特”]
网址 = []
对于产品(job_titles,states,城市)中的(job_title,state,city):
urls.append(f"{'-'.join(job_title.split())}-l-{city},-{state}-jobs.html")
类确实蜘蛛(scrapy.Spider):
名称 = "确实"
allowed_domains = [""]
start_urls = urls
也许您已经注意到,在相邻城市中搜索相同的位置会产生重叠的结果。换句话说,在剑桥和波士顿搜索相同的标题将返回重复项。任何数据项目的主要挑战是重复数据删除。我们可以使用的一种策略是拥有像 redis 这样的应用程序缓存。我们的程序可以根据职位、公司名称、地点和发布日期组成的自然主键检查列表是否已解析。我们甚至可以在服务器生成的 DOM 中查找唯一 ID。为简单起见,一旦所有内容都保存到我们的对象存储中,我们将在最后进行重复数据删除。
解析页面
我将使用 Python 库 BeautifulSoup4 来解析 HTML,因为这是我最熟悉的库。默认情况下,scrapy 带有 CSS 选择器和 XPath 选择器,它们都是针对 DOM 编写查询的强大方法。在本教程中,您需要将 Beautiful Soup 导入我们的 shell,然后将 HTML 解析为一个 BeautifulSoup 对象。我喜欢 BeautifulSoup,因为 find API 非常简单。
从 bs4 导入 BeautifulSoup
汤 = BeautifulSoup(response.text, features="lxml")
请注意,当他们重命名 CSS 类时,此解析代码将被破坏。如果您发现这些示例不起作用,请尝试修复它们以适应今天的 网站 结构和命名方法。
首先,我们需要找到一种方法来解析给定页面上所有作业的列表。我们想找到一种方法来捕获每个列表的顶部节点。一旦我们有了每个列表的父节点,我们就可以迭代如何解析每个列表的属性。目前,每个列表都有一个顶级锚元素 (),class="tapItem"。我们可以使用 CSS 类来选择代表单个列表的所有这些节点。
listings = soup.find_all("a", {"class": "tapItem"})
在本教程中,我们将定位属性职位、雇主、地点和职位描述。前三个属性可以在搜索结果页面上找到,职位描述需要点击职位描述页面上的链接。从这个页面上可用的属性开始,我们可以使用 CSS 类在每个父节点中定位列表的不同属性。
在列表中列出:
job_title = listing.find("h2", {"class": "jobTitle"}).get_text().strip()
summary = listing.find("div", {"class": "job-snippet"}).get_text().strip() # 去除换行符
company = listing.find("span", {"class": "companyName"}).get_text().strip()
location = listing.find("div", {"class": "companyLocation"}).get_text().strip()
我通过在检查元素 devtools 中找到帖子然后在 iPython 中迭代代码来编写这段代码。在每种情况下,我发现通过 HTML 元素和 CSS 类进行选择就足以获得我需要的信息。
现在我们需要检索位于单独页面上的职位描述。为此,我们将发送另一个 HTTP 请求,以使用我们在搜索结果页面上找到的链接检索收录职位描述的页面。我们通过将在锚标记的 href 中找到的相对路径与在我们的响应对象中找到的搜索结果页面的 URL 相结合来获得链接 url。然后我们会要求scrapy使用异步事件循环来调度请求。
我们会将职位描述(jd)与我们在此页面上找到的信息结合起来,因此我们会将解析后的属性传递给回调函数,以便它们都可以存储在同一个项目中。Scrapy 需要使用 yield 语句,因为该函数是由异步调度器执行的。parse_jd 回调函数将返回一个表示职位发布的字典。
发布 = {“job_title”:job_title,“summary”:摘要,“company”:公司,“location”:location}
jd_page = listing.get("href")
如果 jd_page 不是 None:
yield response.follow(jd_page, callback=self.parse_jd, cb_kwargs=posting)
现在剩下要做的就是解析工作描述并生成要采集的项目。幸运的是,职位描述有一个唯一的 ID。这是选择特定元素的最简单方法。我们想要保存职位描述的 URL,因为如果我们最终申请,我们将需要找到申请按钮的链接。
def parse_jd(self, response, **posting):
汤 = BeautifulSoup(response.text, features="lxml")
jd = soup.find("div", {"id": "jobDescriptionText"}).get_text()
url = response.url
post.update({"job_description": jd, "url": url})
收益过帐
解析通常是编写蜘蛛程序最具挑战性和最耗时的阶段。网站 会随着时间的推移而变化,所以需要在断掉的时候修改代码。添加验证步骤以检查无字符串或空字符串然后引发错误会很有用。这样,当代码不再起作用时,您会收到通知。这应该只对关键路径信息进行,因为丢失的信息可能很常见。
最后一步是告诉我们的爬虫去搜索结果的下一页。我们希望爬虫检索当前可用的每个帖子,而不仅仅是第一页上的结果。当下一页按钮不再可用时,我们就会知道我们已经完成了。
next_page = soup.find("a", {"aria-label": "Next"}).get("href")
如果 next_page 不是 None:
next_page = response.urljoin(next_page)
产生scrapy.Request(next_page,回调=self.parse)
有了这些简单的指令集,我们现在有了一个相当强大的过程来提取所有重要的细节。跟随下一页上的链接的能力意味着爬虫将抓取所有可用的结果,而无需任何额外的编码。现在我们已经完成了蜘蛛的准备工作,我们可以继续研究结果。
保存结果
现在解析器已经写好了,我们可以开始使用一些scrapy特性了。我们可以选择使用 ItemPipline 将每个 Item 发送到文件对象存储或数据库。我们可以利用具有高写入吞吐量的高可用分布式数据库(例如DynamoDB、Cassandra)并在表运行时将项目插入表中。
对于这个项目,我将使用内置提要选项从命令行创建一个摘录。我会选择 JSON 行,因为 JSON 编码器将正确转义换行符和引号,作为编组到 JSON 的过程的一部分。与 CSV 相比,这可以为您节省一些将来的麻烦,其中额外的换行符或引号可能会导致解析错误和头痛。当架构不是静态的并且每个项目可能收录的属性不同时,半结构化格式也很有用。
有一种方法可以在配置文件中指定提要,但我将向您展示如何从命令行执行此操作。我们将创建一个 JSON Lines 文件,其中收录捕获到本地文件系统的所有数据。从那里我们可以开始与结果交互以提取价值。
确实爬行抓取 -o jobs.jl
这将需要一些时间来运行,具体取决于您配置的位置和位置的数量。所有 网站 都有某种形式的速率限制。可以通过 CDN 或负载均衡器/反向代理(如 Cloudflare)实现速率限制。速率限制可防止拒绝服务 (DoS) 攻击关闭 Web 服务器。Scrapy 将执行指数退避,直到得到 200 响应代码,这意味着它会在每次失败后等待更长时间,直到请求成功。
分析结果
现在我们有一个收录所有帖子的文件,我们可以开始分析。执行分析的一种方法是使用 Jupyter 笔记本。Jupyter Notebook 可用于探索性数据分析和非线性规划。当我们为发现和分析编码时,我们不知道最终状态是什么样的。我们在写代码的时候,需要改变事物的顺序,做出重大的改变,这就是为什么它被称为非线性规划。Jupyter 使这种编程风格更容易。
Jupyter notebooks 通过使用单元格和 iPython 促进了这种类型的开发。通过使用 iPython 作为后端,它允许您在 REPL 环境中工作。REPL 允许您快速查看执行代码的输出并在创建对象后保留它们。第二部分是可以移动、剪切、复制和删除的单元格。单元格可以轻松更改执行顺序和更改对象的范围。我发现笔记本是我分析结果的好地方。
综上所述
下一步是聚合和规范化数据,分析它,然后创建某种用户界面来访问它。例如,您可以有一个网站,网站 显示所有已爬取的网站 根据自定义条件进行排序和过滤。您可以使用关键字检测来确定提供您最感兴趣的机会的列表的优先级。
用scrapy写spider可以让你通过第一步,解析网页中的数据并保存。这是任何依赖网络爬行数据的数据管道中的第一个组件。一旦您捕获了数据,您就可以开始为您希望的任何应用程序从中提取价值。
您可以从本教程下载收录所有代码的 python 文件。 查看全部
如何抓取网页数据(ESPN中获取棒球运动员公共网站下载数据的过程-乐题库)
网页抓取是从公共网站 下载数据的过程。例如,您可以从 ESPN 获取棒球运动员的统计数据,并构建一个模型,根据他们的球员统计数据和获胜率来预测球队获胜的机会。以下是网络抓取的一些用例。
监控竞争对手的价格以进行价格匹配(竞争定价)。
从各种 网站 采集统计信息以创建仪表板,例如 COVID-19 仪表板。
监控金融论坛和 Twitter 以计算特定资产的情绪。
我将演示的一个用例是抓取 网站 来发布招聘信息。假设您正在寻找工作,但您被列表的数量所淹没。您可以设置一个流程来实际每天抓取。然后你可以编写一个脚本来自动应用于满足特定条件的帖子。
免责声明:网络抓取确实违反了他们的使用条款。本文仅用于教育目的。在抓取 网站 之前,请务必阅读他们的服务条款并遵循他们的 robots.txt 指南。
数据仓库注意事项
我们的蜘蛛每天都会抓取给定搜索查询可用的所有页面,因此我们想要存储大量重复项。如果帖子持续多天,那么我们将在帖子发布的每一天都有一份副本。为了容忍重复,我们将设计一个管道来捕获所有内容,然后过滤数据以创建可用于分析的标准化数据模型。
首先会从网页中解析出数据,然后放入半结构化的数据结构中,比如JSON。从这里开始,数据结构将存储在对象存储中(例如 S3、GS)。对象存储是捕获数据的有用起点。它便宜、可扩展,并且可以通过我们的数据模型灵活更改。一旦数据进入我们的对象存储,网络爬虫的工作就完成了,数据也被捕获了。
下一步是将数据非规范化为更有用的数据以供分析。如前所述,数据收录重复项。我会选择使用 SQL 数据库,因为它具有强大的分析查询功能。它还允许我区分不同的实体,例如公司、职位发布和地点。首先,所有帖子都会进入事实表(大型只写表),带有时间戳,显示帖子何时被抓取以及何时插入到表中。从这里,我们可以将数据非规范化为代表当前活动版本的有状态表。
您可以编写合并语句来更新和插入表示实时发布的表中的发布。从这里我们还想删除已删除或过期的帖子。现在我们有了一个标准化的表,或者换句话说,所有的重复项都被删除了。
设置项目
对于这个项目,我将使用 Scrapy,因为它带有有用的特性和抽象,可以节省你的时间和精力。例如,scrapy 可以轻松地将结构化数据推送到 S3 或 GCS 等对象存储。这是通过将您的凭据以及存储桶名称和路径添加到由 scrapy 生成的配置文件来完成的。目的是为了长期存储并在我们每次运行刮刀时生成一个不可变的副本。由于 S3 是无限的对象存储,因此是长期存储的理想场所,并且可以轻松地随任何项目进行扩展。
为了突出更多特性,scrapy 使用了 Twisted 框架来处理异步 web 请求。这意味着程序可以在等待网站服务器响应请求的同时完成它的工作,而不是因为空闲等待而浪费时间。Scrapy 有一个活跃的社区,因此您可以寻求帮助并查看其他项目的示例。它还提供了一些更高级的选项,例如在具有 Redis 和用户代理欺骗的集群中运行,但这些不在本教程的范围内。
让我们从在 python 中创建一个虚拟环境并安装依赖项开始。然后初始化一个空白项目,我们将在其中安装我们的网络爬虫。请务必在项目的顶级目录中执行此代码。
python3 -m venv venv
源 ./venv/bin/activate
pip install scrapy lxml BeautifulSoup4 jupyterlab pandas
scrapy startproject 工作
cd 工作/工作/
确实是scrapy genspider
解析网页的代码将被放置在蜘蛛/目录中的文件中。蜘蛛是网络爬虫的抽象。它生成 HTTP 请求并解析返回的页面。有一个单独的抽象用于处理和存储称为 ItemPipeline 的信息。这种抽象分离允许解耦、灵活性和水平扩展。比如,你可以在不修改蜘蛛代码内部逻辑的情况下,将蜘蛛的结果发送到多个地方。一个好的做法是将结果作为文件保存在对象存储中进行长期存储,并将其保存在数据库中进行重复数据删除和临时查询。
开发环境
您可以将网络抓取视为对他人工作的逆向工程。有许多工具可以使 Web 开发更易于组装和管理,例如使用可重用模板或 ES6 模块。这些允许 Web 开发人员在多个地方重用相同的代码,目标是将简单的部分组合成更复杂的部分。当您抓取网站 时,您所拥有的只是实际的网页,我们无法访问用于构建页面的组件。因此,我们必须向后工作以使用我们可以使用的任何技术来获得我们想要的东西。
任何网络抓取项目的第一步都是在网络浏览器中打开要抓取的页面,然后使用“检查元素”在您选择的浏览器中探索 DOM。使用浏览器中的开发者工具,您可以探索 DOM 的结构或页面的骨架。现在您可以随意打开页面,使用开发者工具进行探索。在整个过程中,我们将使用浏览器以可视化和交互的方式快速浏览dom。
我喜欢使用带有 iPython 的 scrapy shell 来为我的网页抓取开发解析代码。交互性允许快速反馈循环,允许大量试验和错误。scrapy shell 带您进入已实例化的所有帮助程序和便利函数的 scrapy 上下文。这些相同的对象在运行时可供蜘蛛使用。它还使您可以访问 iPython 的所有功能。您可以使用以下代码来启动您的 shell。
scrapy shell',-MA-jobs.html'
这里最重要的对象是响应。这收录从 Web 服务器到我们的 HTTP GET 请求的 HTTP 响应。它收录页面的 HTML,以及与 HTTP 响应相关的标头和其他信息。基本的反馈循环是使用浏览器识别我们要解析的内容,然后在终端中测试解析代码。
起始网址
如果您查看上面的链接,您可能会注意到该 URL 收录我们的搜索查询。这是在 HTTP GET 请求中传递参数的方式(此示例未使用标准化格式)。我们可以使用此信息以编程方式尝试不同的搜索查询。
在 url 中,在字母 q 之后,我们看到了与位置对应的查询。字母 l 之后是位置。假设在我们的用例中,我们要搜索多个位置和位置。例如,医疗助理也称为患者护理助理。
在scrapy中,我们可以使用我们蜘蛛的几个URL作为抓取的起点。我们可以向它传递与多个位置和位置相对应的 URL 以获得此行为。在这个例子中,我使用 product 函数生成位置和位置的每个组合,然后我将它传递给蜘蛛作为我们的起点。
从 itertools 导入产品
job_titles = [“医疗助理”、“病人护理技术员”、“病人护理助理”]
状态 = [“MA”]
城市 = [“波士顿”、“剑桥”、“萨默维尔”、“多切斯特”]
网址 = []
对于产品(job_titles,states,城市)中的(job_title,state,city):
urls.append(f"{'-'.join(job_title.split())}-l-{city},-{state}-jobs.html")
类确实蜘蛛(scrapy.Spider):
名称 = "确实"
allowed_domains = [""]
start_urls = urls
也许您已经注意到,在相邻城市中搜索相同的位置会产生重叠的结果。换句话说,在剑桥和波士顿搜索相同的标题将返回重复项。任何数据项目的主要挑战是重复数据删除。我们可以使用的一种策略是拥有像 redis 这样的应用程序缓存。我们的程序可以根据职位、公司名称、地点和发布日期组成的自然主键检查列表是否已解析。我们甚至可以在服务器生成的 DOM 中查找唯一 ID。为简单起见,一旦所有内容都保存到我们的对象存储中,我们将在最后进行重复数据删除。
解析页面
我将使用 Python 库 BeautifulSoup4 来解析 HTML,因为这是我最熟悉的库。默认情况下,scrapy 带有 CSS 选择器和 XPath 选择器,它们都是针对 DOM 编写查询的强大方法。在本教程中,您需要将 Beautiful Soup 导入我们的 shell,然后将 HTML 解析为一个 BeautifulSoup 对象。我喜欢 BeautifulSoup,因为 find API 非常简单。
从 bs4 导入 BeautifulSoup
汤 = BeautifulSoup(response.text, features="lxml")
请注意,当他们重命名 CSS 类时,此解析代码将被破坏。如果您发现这些示例不起作用,请尝试修复它们以适应今天的 网站 结构和命名方法。
首先,我们需要找到一种方法来解析给定页面上所有作业的列表。我们想找到一种方法来捕获每个列表的顶部节点。一旦我们有了每个列表的父节点,我们就可以迭代如何解析每个列表的属性。目前,每个列表都有一个顶级锚元素 (),class="tapItem"。我们可以使用 CSS 类来选择代表单个列表的所有这些节点。
listings = soup.find_all("a", {"class": "tapItem"})
在本教程中,我们将定位属性职位、雇主、地点和职位描述。前三个属性可以在搜索结果页面上找到,职位描述需要点击职位描述页面上的链接。从这个页面上可用的属性开始,我们可以使用 CSS 类在每个父节点中定位列表的不同属性。
在列表中列出:
job_title = listing.find("h2", {"class": "jobTitle"}).get_text().strip()
summary = listing.find("div", {"class": "job-snippet"}).get_text().strip() # 去除换行符
company = listing.find("span", {"class": "companyName"}).get_text().strip()
location = listing.find("div", {"class": "companyLocation"}).get_text().strip()
我通过在检查元素 devtools 中找到帖子然后在 iPython 中迭代代码来编写这段代码。在每种情况下,我发现通过 HTML 元素和 CSS 类进行选择就足以获得我需要的信息。
现在我们需要检索位于单独页面上的职位描述。为此,我们将发送另一个 HTTP 请求,以使用我们在搜索结果页面上找到的链接检索收录职位描述的页面。我们通过将在锚标记的 href 中找到的相对路径与在我们的响应对象中找到的搜索结果页面的 URL 相结合来获得链接 url。然后我们会要求scrapy使用异步事件循环来调度请求。
我们会将职位描述(jd)与我们在此页面上找到的信息结合起来,因此我们会将解析后的属性传递给回调函数,以便它们都可以存储在同一个项目中。Scrapy 需要使用 yield 语句,因为该函数是由异步调度器执行的。parse_jd 回调函数将返回一个表示职位发布的字典。
发布 = {“job_title”:job_title,“summary”:摘要,“company”:公司,“location”:location}
jd_page = listing.get("href")
如果 jd_page 不是 None:
yield response.follow(jd_page, callback=self.parse_jd, cb_kwargs=posting)
现在剩下要做的就是解析工作描述并生成要采集的项目。幸运的是,职位描述有一个唯一的 ID。这是选择特定元素的最简单方法。我们想要保存职位描述的 URL,因为如果我们最终申请,我们将需要找到申请按钮的链接。
def parse_jd(self, response, **posting):
汤 = BeautifulSoup(response.text, features="lxml")
jd = soup.find("div", {"id": "jobDescriptionText"}).get_text()
url = response.url
post.update({"job_description": jd, "url": url})
收益过帐
解析通常是编写蜘蛛程序最具挑战性和最耗时的阶段。网站 会随着时间的推移而变化,所以需要在断掉的时候修改代码。添加验证步骤以检查无字符串或空字符串然后引发错误会很有用。这样,当代码不再起作用时,您会收到通知。这应该只对关键路径信息进行,因为丢失的信息可能很常见。
最后一步是告诉我们的爬虫去搜索结果的下一页。我们希望爬虫检索当前可用的每个帖子,而不仅仅是第一页上的结果。当下一页按钮不再可用时,我们就会知道我们已经完成了。
next_page = soup.find("a", {"aria-label": "Next"}).get("href")
如果 next_page 不是 None:
next_page = response.urljoin(next_page)
产生scrapy.Request(next_page,回调=self.parse)
有了这些简单的指令集,我们现在有了一个相当强大的过程来提取所有重要的细节。跟随下一页上的链接的能力意味着爬虫将抓取所有可用的结果,而无需任何额外的编码。现在我们已经完成了蜘蛛的准备工作,我们可以继续研究结果。
保存结果
现在解析器已经写好了,我们可以开始使用一些scrapy特性了。我们可以选择使用 ItemPipline 将每个 Item 发送到文件对象存储或数据库。我们可以利用具有高写入吞吐量的高可用分布式数据库(例如DynamoDB、Cassandra)并在表运行时将项目插入表中。
对于这个项目,我将使用内置提要选项从命令行创建一个摘录。我会选择 JSON 行,因为 JSON 编码器将正确转义换行符和引号,作为编组到 JSON 的过程的一部分。与 CSV 相比,这可以为您节省一些将来的麻烦,其中额外的换行符或引号可能会导致解析错误和头痛。当架构不是静态的并且每个项目可能收录的属性不同时,半结构化格式也很有用。
有一种方法可以在配置文件中指定提要,但我将向您展示如何从命令行执行此操作。我们将创建一个 JSON Lines 文件,其中收录捕获到本地文件系统的所有数据。从那里我们可以开始与结果交互以提取价值。
确实爬行抓取 -o jobs.jl
这将需要一些时间来运行,具体取决于您配置的位置和位置的数量。所有 网站 都有某种形式的速率限制。可以通过 CDN 或负载均衡器/反向代理(如 Cloudflare)实现速率限制。速率限制可防止拒绝服务 (DoS) 攻击关闭 Web 服务器。Scrapy 将执行指数退避,直到得到 200 响应代码,这意味着它会在每次失败后等待更长时间,直到请求成功。
分析结果
现在我们有一个收录所有帖子的文件,我们可以开始分析。执行分析的一种方法是使用 Jupyter 笔记本。Jupyter Notebook 可用于探索性数据分析和非线性规划。当我们为发现和分析编码时,我们不知道最终状态是什么样的。我们在写代码的时候,需要改变事物的顺序,做出重大的改变,这就是为什么它被称为非线性规划。Jupyter 使这种编程风格更容易。
Jupyter notebooks 通过使用单元格和 iPython 促进了这种类型的开发。通过使用 iPython 作为后端,它允许您在 REPL 环境中工作。REPL 允许您快速查看执行代码的输出并在创建对象后保留它们。第二部分是可以移动、剪切、复制和删除的单元格。单元格可以轻松更改执行顺序和更改对象的范围。我发现笔记本是我分析结果的好地方。
综上所述
下一步是聚合和规范化数据,分析它,然后创建某种用户界面来访问它。例如,您可以有一个网站,网站 显示所有已爬取的网站 根据自定义条件进行排序和过滤。您可以使用关键字检测来确定提供您最感兴趣的机会的列表的优先级。
用scrapy写spider可以让你通过第一步,解析网页中的数据并保存。这是任何依赖网络爬行数据的数据管道中的第一个组件。一旦您捕获了数据,您就可以开始为您希望的任何应用程序从中提取价值。
您可以从本教程下载收录所有代码的 python 文件。
如何抓取网页数据( Scrapy爬虫框架中meta参数的使用示例演示(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-28 05:08
Scrapy爬虫框架中meta参数的使用示例演示(上))
上一阶段我们实现了通过Scrapy爬取特定网页的具体信息,Scrapy爬虫框架中元参数的使用demo(上),以及Scrapy爬虫中元参数的使用demo框架(下),但是没有实现所有页面的顺序提取。首先我们梳理一下爬行的思路。大体思路是:当获取到第一页的URL后,再将第二页的URL发送给Scrapy,这样Scrapy就会自动下载该网页的信息,然后通过第二页的URL继续获取第三页的网址。由于每个页面的网页结构是相同的,这样反复迭代就可以实现对整个网页的信息提取。具体的实现过程会通过Scrapy框架来实现。具体教程如下。
/执行/
1、首先,URL不再是特定文章的URL,而是所有文章列表的URL,如下图,把链接放在start_urls中,如下图如下图所示。
2、接下来我们需要修改parse()函数,在这个函数中我们需要实现两件事。
首先是获取某个页面上文章的所有URL,并解析得到每个文章中的具体网页内容。二是获取下一个网页的URL,交给Scrapy处理。下载完成后交给parse()函数进行下载。
有了之前的 Xpath 和 CSS 选择器的基础知识,获取一个网页链接的 URL 就变得相对简单了。
3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个网址,而文章的列表存在于id中="在标签“存档”下,然后我们将像剥洋葱一样获得我们想要的URL链接。
4、点击下拉三角,不难发现文章详情页的链接并没有隐藏很深,如下图圆圈所示。
5、根据标签,我们搜索图片并添加选择器工具获取URL,就像搜索某些东西一样。在cmd中输入以下命令进入shell调试窗口,事半功倍。再说一遍,这个网址是所有文章的网址,而不是某个文章的网址。如果不这样做,调试很长时间后将没有结果。
6、根据第四步对网页结构的分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。推荐朋友们在提取网页信息的时候可以经常使用,非常方便。
至此,第一页文章列表的所有URL都已获取。提取URL后,如何交给Scrapy下载?下载完成后,如何调用自己定义的解析函数? 查看全部
如何抓取网页数据(
Scrapy爬虫框架中meta参数的使用示例演示(上))

上一阶段我们实现了通过Scrapy爬取特定网页的具体信息,Scrapy爬虫框架中元参数的使用demo(上),以及Scrapy爬虫中元参数的使用demo框架(下),但是没有实现所有页面的顺序提取。首先我们梳理一下爬行的思路。大体思路是:当获取到第一页的URL后,再将第二页的URL发送给Scrapy,这样Scrapy就会自动下载该网页的信息,然后通过第二页的URL继续获取第三页的网址。由于每个页面的网页结构是相同的,这样反复迭代就可以实现对整个网页的信息提取。具体的实现过程会通过Scrapy框架来实现。具体教程如下。
/执行/
1、首先,URL不再是特定文章的URL,而是所有文章列表的URL,如下图,把链接放在start_urls中,如下图如下图所示。

2、接下来我们需要修改parse()函数,在这个函数中我们需要实现两件事。
首先是获取某个页面上文章的所有URL,并解析得到每个文章中的具体网页内容。二是获取下一个网页的URL,交给Scrapy处理。下载完成后交给parse()函数进行下载。
有了之前的 Xpath 和 CSS 选择器的基础知识,获取一个网页链接的 URL 就变得相对简单了。

3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个网址,而文章的列表存在于id中="在标签“存档”下,然后我们将像剥洋葱一样获得我们想要的URL链接。

4、点击下拉三角,不难发现文章详情页的链接并没有隐藏很深,如下图圆圈所示。

5、根据标签,我们搜索图片并添加选择器工具获取URL,就像搜索某些东西一样。在cmd中输入以下命令进入shell调试窗口,事半功倍。再说一遍,这个网址是所有文章的网址,而不是某个文章的网址。如果不这样做,调试很长时间后将没有结果。

6、根据第四步对网页结构的分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。推荐朋友们在提取网页信息的时候可以经常使用,非常方便。

至此,第一页文章列表的所有URL都已获取。提取URL后,如何交给Scrapy下载?下载完成后,如何调用自己定义的解析函数?
如何抓取网页数据(使用selenium爬取动态网页信息Pythonselenium自动控制 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-27 11:05
)
使用selenium抓取动态网页信息
Python selenium自动控制浏览器抓取网页的数据,包括按钮点击、页面跳转、搜索框输入、页面值数据存储、mongodb自动id识别等。
首先介绍一下Python selenium——一种用于控制浏览器对网页操作的自动化测试工具。将它与爬虫中的 BeautifulSoup 结合起来是无缝的。除了国外一些不正常的验证网页,图片验证码我有自己的破解码。图片验证码源代码成功率为85%。
使用 conda butler 安装:
在cmd命令行输入“conda install selenium”进行安装
您还需要安装 Google Chrome Drive 或 Firefox 浏览器插件
设置环境变量
通过硒访问百度
from selenium import webdriver
#打开一个浏览器
browser = webdriver.Chrome()
#准备一个网址
url = 'http://www.baidu.com'
browser.get(url)
#获取元素
login = browser.find_elements_by_class_name('lb')[0]
print(login)
获取网易云音乐
from selenium import webdriver
#打开浏览器
brower = webdriver.Chrome()
url='https://music.163.com/#/discover/toplist'
brower.get(url)
#寻找logo文字
#logo = brower.find_elements_by_class_name('logo')[0]
#print(logo.text)
#一般情况下动态加载的内容都可以找到
#有一种情况就没有
#就是网页内存在网页框架iframe
#需要切换网页的层级
#语法:brower.switch_to.frame(iframe的id或者你提前获取这个对象,放入此处)
#方法一:id
#brower.switch_to.frame('g_iframe')
#方法二:name
#brower.switch_to.frame('contentFrame')
#方法三:提前用变量存iframe
iframe = brower.find_element_by_id('g_iframe')
brower.switch_to.frame(iframe)
#寻找大容器
toplist = brower.find_element_by_id('toplist')
#寻找tbody 通过标签名
tbody = toplist.find_elements_by_tag_name('tbody')[0]
#寻找所有tr
trs = tbody.find_elements_by_tag_name('tr')
dataList = []
for each in trs:
#排名
rank = each.find_elements_by_tag_name('td')[0].find_elements_by_class_name('num')[0].text
musicName = each.find_elements_by_tag_name('td')[1].find_elements_by_class_name('txt')[0].\
find_element_by_tag_name('b').get_attribute('title')
#print(musicName)
singer = each.find_elements_by_tag_name('td')[3].find_elements_by_class_name('text')[0].\
get_attribute('title')
#print(singer)
dataList.append([rank,musicName,singer])
#print(dataList)
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
ws.title = '云音乐飙升榜'
ws.append(['排名','歌名','歌手'])
for data in dataList:
ws.append(data)
wb.save("云音乐飙升榜.xlsx") 查看全部
如何抓取网页数据(使用selenium爬取动态网页信息Pythonselenium自动控制
)
使用selenium抓取动态网页信息
Python selenium自动控制浏览器抓取网页的数据,包括按钮点击、页面跳转、搜索框输入、页面值数据存储、mongodb自动id识别等。
首先介绍一下Python selenium——一种用于控制浏览器对网页操作的自动化测试工具。将它与爬虫中的 BeautifulSoup 结合起来是无缝的。除了国外一些不正常的验证网页,图片验证码我有自己的破解码。图片验证码源代码成功率为85%。
使用 conda butler 安装:
在cmd命令行输入“conda install selenium”进行安装
您还需要安装 Google Chrome Drive 或 Firefox 浏览器插件
设置环境变量
通过硒访问百度
from selenium import webdriver
#打开一个浏览器
browser = webdriver.Chrome()
#准备一个网址
url = 'http://www.baidu.com'
browser.get(url)
#获取元素
login = browser.find_elements_by_class_name('lb')[0]
print(login)
获取网易云音乐
from selenium import webdriver
#打开浏览器
brower = webdriver.Chrome()
url='https://music.163.com/#/discover/toplist'
brower.get(url)
#寻找logo文字
#logo = brower.find_elements_by_class_name('logo')[0]
#print(logo.text)
#一般情况下动态加载的内容都可以找到
#有一种情况就没有
#就是网页内存在网页框架iframe
#需要切换网页的层级
#语法:brower.switch_to.frame(iframe的id或者你提前获取这个对象,放入此处)
#方法一:id
#brower.switch_to.frame('g_iframe')
#方法二:name
#brower.switch_to.frame('contentFrame')
#方法三:提前用变量存iframe
iframe = brower.find_element_by_id('g_iframe')
brower.switch_to.frame(iframe)
#寻找大容器
toplist = brower.find_element_by_id('toplist')
#寻找tbody 通过标签名
tbody = toplist.find_elements_by_tag_name('tbody')[0]
#寻找所有tr
trs = tbody.find_elements_by_tag_name('tr')
dataList = []
for each in trs:
#排名
rank = each.find_elements_by_tag_name('td')[0].find_elements_by_class_name('num')[0].text
musicName = each.find_elements_by_tag_name('td')[1].find_elements_by_class_name('txt')[0].\
find_element_by_tag_name('b').get_attribute('title')
#print(musicName)
singer = each.find_elements_by_tag_name('td')[3].find_elements_by_class_name('text')[0].\
get_attribute('title')
#print(singer)
dataList.append([rank,musicName,singer])
#print(dataList)
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
ws.title = '云音乐飙升榜'
ws.append(['排名','歌名','歌手'])
for data in dataList:
ws.append(data)
wb.save("云音乐飙升榜.xlsx")
如何抓取网页数据( Python学习笔记之抓取某只基金历史净值数据案例,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-27 05:08
Python学习笔记之抓取某只基金历史净值数据案例,)
Python学习笔记中抓取某基金历史净值数据的实际案例
更新时间:2019-06-03 10:42:04 作者:学习笔记666
本文章主要介绍Python学习笔记中某基金的历史净值数据捕获案例,分析Python基于selenium库的数据捕获以及mysql交互相关的实现技巧结合具体例子。朋友们可以参考一下
本文以Python抓取某基金历史净值数据为例。分享给大家,供大家参考,如下:
1、接下来,我们需要手动抓取html(这部分知识我们之前已经学过,所以现在重温一下)
# coding: utf-8
from selenium.webdriver.support.ui import WebDriverWait
from selenium import webdriver
from bs4 import BeautifulSoup
from threading import Thread,Lock
import os
import csv
# 下面是利用 selenium 抓取html页面的代码
# 初始化函数
def initSpider():
driver = webdriver.PhantomJS(executable_path=r"你phantomjs可执行文件的绝对路径")
driver.get("http://fund.eastmoney.com/f10/ ... 6quot;) # 要抓取的网页地址
# 找到"下一页"按钮,就可以得到它前面的一个label,就是总页数
getPage_text = driver.find_element_by_id("pagebar").find_element_by_xpath(
"div[@class='pagebtns']/label[text()='下一页']/preceding-sibling::label[1]").get_attribute("innerHTML")
# 得到总共有多少页
total_page = int("".join(filter(str.isdigit, getPage_text)))
# 返回
return (driver,total_page)
# 获取html内容
def getData(myrange,driver,lock):
for x in myrange:
# 锁住
lock.acquire()
tonum = driver.find_element_by_id("pagebar").find_element_by_xpath(
"div[@class='pagebtns']/input[@class='pnum']") # 得到 页码文本框
jumpbtn = driver.find_element_by_id("pagebar").find_element_by_xpath(
"div[@class='pagebtns']/input[@class='pgo']") # 跳转到按钮
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpbtn.click() # 点击按钮
# ץȡ
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pagebar").find_element_by_xpath("div[@class='pagebtns']/label[@value={0} and @class='cur']".format(x)) != None)
# 保存到项目中
with open("../htmls/details/{0}.txt".format(x), 'wb') as f:
f.write(driver.find_element_by_id("jztable").get_attribute("innerHTML").encode('utf-8'))
f.close()
# 解锁
lock.release()
# 开始抓取函数
def beginSpider():
# 初始化爬虫
(driver, total_page) = initSpider()
# 创建锁
lock = Lock()
r = range(1, int(total_page)+1)
step = 10
range_list = [r[x:x + step] for x in range(0, len(r), step)] #把页码分段
thread_list = []
for r in range_list:
t = Thread(target=getData, args=(r,driver,lock))
thread_list.append(t)
t.start()
for t in thread_list:
t.join() # 这一步是需要的,等待线程全部执行完成
print("抓取完成")
# #################上面代码就完成了 抓取远程网站html内容并保存到项目中的 过程
需要解释一下这3个函数:
initSpider 函数初始化 selenium webdriver 对象,首先获取我们需要爬取的页面总数。
getData 函数有 3 个参数。对于 myrange,我们仍然需要分段捕获。之前我们学习了太多进程捕获,这里我们多线程捕获; lock参数用于锁定线程,防止线程冲突; driver就是我们在initSpider函数中初始化的webdriver对象。
在 getData 函数中,我们循环 myrange 并将捕获的 html 内容保存在项目目录中。
开始Spider函数,我们在这个函数中对总页数进行分段,并创建一个线程,调用getData。
所以最后一次执行:
beginSpider()
开始抓取该基金的“历史净资产详细信息”。共有 31 页。
2、根据我们学到的python和mysql交互的知识,我们也可以将这些数据写入数据表中。
这里就不赘述了,给出基金的详细表结构:
CREATE TABLE `fund_detail` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`fcode` varchar(10) NOT NULL DEFAULT '' COMMENT '基金代码',
`fdate` datetime DEFAULT NULL COMMENT '基金日期',
`NAV` decimal(10,4) DEFAULT NULL COMMENT '单位净值',
`ACCNAV` decimal(10,4) DEFAULT NULL COMMENT '累计净值',
`DGR` varchar(20) DEFAULT NULL COMMENT '日增长率',
`pstate` varchar(20) DEFAULT NULL COMMENT '申购状态',
`rstate` varchar(20) DEFAULT NULL COMMENT '赎回状态',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='基金详细数据表';
更多Python相关内容请参考本站专题:《Python Socket编程技巧总结》、《Python正则表达式使用总结》、《Python数据结构与算法教程》、《Python函数使用技巧》总结》、《Python字符串操作技巧总结》、《Python入门及进阶经典教程》、《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。 查看全部
如何抓取网页数据(
Python学习笔记之抓取某只基金历史净值数据案例,)
Python学习笔记中抓取某基金历史净值数据的实际案例
更新时间:2019-06-03 10:42:04 作者:学习笔记666
本文章主要介绍Python学习笔记中某基金的历史净值数据捕获案例,分析Python基于selenium库的数据捕获以及mysql交互相关的实现技巧结合具体例子。朋友们可以参考一下
本文以Python抓取某基金历史净值数据为例。分享给大家,供大家参考,如下:

1、接下来,我们需要手动抓取html(这部分知识我们之前已经学过,所以现在重温一下)
# coding: utf-8
from selenium.webdriver.support.ui import WebDriverWait
from selenium import webdriver
from bs4 import BeautifulSoup
from threading import Thread,Lock
import os
import csv
# 下面是利用 selenium 抓取html页面的代码
# 初始化函数
def initSpider():
driver = webdriver.PhantomJS(executable_path=r"你phantomjs可执行文件的绝对路径")
driver.get("http://fund.eastmoney.com/f10/ ... 6quot;) # 要抓取的网页地址
# 找到"下一页"按钮,就可以得到它前面的一个label,就是总页数
getPage_text = driver.find_element_by_id("pagebar").find_element_by_xpath(
"div[@class='pagebtns']/label[text()='下一页']/preceding-sibling::label[1]").get_attribute("innerHTML")
# 得到总共有多少页
total_page = int("".join(filter(str.isdigit, getPage_text)))
# 返回
return (driver,total_page)
# 获取html内容
def getData(myrange,driver,lock):
for x in myrange:
# 锁住
lock.acquire()
tonum = driver.find_element_by_id("pagebar").find_element_by_xpath(
"div[@class='pagebtns']/input[@class='pnum']") # 得到 页码文本框
jumpbtn = driver.find_element_by_id("pagebar").find_element_by_xpath(
"div[@class='pagebtns']/input[@class='pgo']") # 跳转到按钮
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpbtn.click() # 点击按钮
# ץȡ
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pagebar").find_element_by_xpath("div[@class='pagebtns']/label[@value={0} and @class='cur']".format(x)) != None)
# 保存到项目中
with open("../htmls/details/{0}.txt".format(x), 'wb') as f:
f.write(driver.find_element_by_id("jztable").get_attribute("innerHTML").encode('utf-8'))
f.close()
# 解锁
lock.release()
# 开始抓取函数
def beginSpider():
# 初始化爬虫
(driver, total_page) = initSpider()
# 创建锁
lock = Lock()
r = range(1, int(total_page)+1)
step = 10
range_list = [r[x:x + step] for x in range(0, len(r), step)] #把页码分段
thread_list = []
for r in range_list:
t = Thread(target=getData, args=(r,driver,lock))
thread_list.append(t)
t.start()
for t in thread_list:
t.join() # 这一步是需要的,等待线程全部执行完成
print("抓取完成")
# #################上面代码就完成了 抓取远程网站html内容并保存到项目中的 过程
需要解释一下这3个函数:
initSpider 函数初始化 selenium webdriver 对象,首先获取我们需要爬取的页面总数。
getData 函数有 3 个参数。对于 myrange,我们仍然需要分段捕获。之前我们学习了太多进程捕获,这里我们多线程捕获; lock参数用于锁定线程,防止线程冲突; driver就是我们在initSpider函数中初始化的webdriver对象。
在 getData 函数中,我们循环 myrange 并将捕获的 html 内容保存在项目目录中。
开始Spider函数,我们在这个函数中对总页数进行分段,并创建一个线程,调用getData。
所以最后一次执行:
beginSpider()
开始抓取该基金的“历史净资产详细信息”。共有 31 页。

2、根据我们学到的python和mysql交互的知识,我们也可以将这些数据写入数据表中。
这里就不赘述了,给出基金的详细表结构:
CREATE TABLE `fund_detail` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`fcode` varchar(10) NOT NULL DEFAULT '' COMMENT '基金代码',
`fdate` datetime DEFAULT NULL COMMENT '基金日期',
`NAV` decimal(10,4) DEFAULT NULL COMMENT '单位净值',
`ACCNAV` decimal(10,4) DEFAULT NULL COMMENT '累计净值',
`DGR` varchar(20) DEFAULT NULL COMMENT '日增长率',
`pstate` varchar(20) DEFAULT NULL COMMENT '申购状态',
`rstate` varchar(20) DEFAULT NULL COMMENT '赎回状态',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='基金详细数据表';
更多Python相关内容请参考本站专题:《Python Socket编程技巧总结》、《Python正则表达式使用总结》、《Python数据结构与算法教程》、《Python函数使用技巧》总结》、《Python字符串操作技巧总结》、《Python入门及进阶经典教程》、《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
如何抓取网页数据(如何抓取网页数据、数据处理、网页性能优化..)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-26 17:02
如何抓取网页数据、数据处理、网页性能优化..上一节中我们学习了python如何从互联网上的静态文件中获取数据,本节继续从url形式抓取数据。本节主要是提供一种抓取网页数据的方法,同时方便后续的抓取项目。第一步,构建分析网页,拿到md5和html的关系。我们用excel中的file函数进行数据抓取。excel中的函数图第二步,在网页上查找到我们需要的所有数据。
excel中的函数如下图所示第三步,对数据进行处理。在本节中,我们拿到html之后先将其变成数组格式。数组形式的数据我们可以拿到总的数据量。在本节中我们只需要抓取每个id获取到的信息。excel中的函数图在网页数据抓取中我们需要使用到的工具就是我们常用的抓包工具。在网页上获取数据就是我们常用的抓包。抓包的方法、工具都有很多,以后有机会将会再次介绍。
网络抓包抓包是什么?抓包,就是抓取网络包,即在网络中发起一个包。在抓包中我们会使用到urllib2,urllib是python中比较好用的urllib。urllib2.encoding是python的一个包,可以处理网络包,urllib2.urlencode是python的一个方法,也是python处理网络包的一个方法。
本次我们只需要抓取一个包。在本地抓包就是在windows下使用ultraiso工具,mac下使用netstat工具。抓包工具的使用方法在下一篇中再详细介绍。网络包怎么获取?我们先来看一下我们在本地抓包的网址(网页抓包方法的其中一种)。以本地为例子,我们本地访问.com后面的网址就是一个url。在windows下:打开浏览器,在浏览器地址栏中输入c:\users\用户名\appdata\local\temp\lxi_pages\baidu\https,返回的页面地址为网页链接,以下是所获取的html代码。
在mac下:打开浏览器,在地址栏中输入,然后回车在python中查找、解析和解析html怎么抓包?每次抓包我们都要浏览网页并输入ip地址,在此,我们可以使用浏览器和浏览器地址栏来查找我们需要的所有数据。http请求我们拿到数据之后还需要解析数据,这个步骤比较简单,我们可以在网上搜索或者自己写一个。下一篇,我们将介绍一种比较酷的方法。
性能优化urllib2是python中比较有用的包,在解析网页和抓取数据,由于urllib2包本身代码比较复杂,对于抓取数据来说代码量太大。因此,我们也可以使用beautifulsoup库进行数据解析。beautifulsoup提供了常用的元素解析方法,可以实现更快的开发。上图为beautifulsoup解析效果示意图:beautifulsoup解析效果示意图构建数据源,在上一节中, 查看全部
如何抓取网页数据(如何抓取网页数据、数据处理、网页性能优化..)
如何抓取网页数据、数据处理、网页性能优化..上一节中我们学习了python如何从互联网上的静态文件中获取数据,本节继续从url形式抓取数据。本节主要是提供一种抓取网页数据的方法,同时方便后续的抓取项目。第一步,构建分析网页,拿到md5和html的关系。我们用excel中的file函数进行数据抓取。excel中的函数图第二步,在网页上查找到我们需要的所有数据。
excel中的函数如下图所示第三步,对数据进行处理。在本节中,我们拿到html之后先将其变成数组格式。数组形式的数据我们可以拿到总的数据量。在本节中我们只需要抓取每个id获取到的信息。excel中的函数图在网页数据抓取中我们需要使用到的工具就是我们常用的抓包工具。在网页上获取数据就是我们常用的抓包。抓包的方法、工具都有很多,以后有机会将会再次介绍。
网络抓包抓包是什么?抓包,就是抓取网络包,即在网络中发起一个包。在抓包中我们会使用到urllib2,urllib是python中比较好用的urllib。urllib2.encoding是python的一个包,可以处理网络包,urllib2.urlencode是python的一个方法,也是python处理网络包的一个方法。
本次我们只需要抓取一个包。在本地抓包就是在windows下使用ultraiso工具,mac下使用netstat工具。抓包工具的使用方法在下一篇中再详细介绍。网络包怎么获取?我们先来看一下我们在本地抓包的网址(网页抓包方法的其中一种)。以本地为例子,我们本地访问.com后面的网址就是一个url。在windows下:打开浏览器,在浏览器地址栏中输入c:\users\用户名\appdata\local\temp\lxi_pages\baidu\https,返回的页面地址为网页链接,以下是所获取的html代码。
在mac下:打开浏览器,在地址栏中输入,然后回车在python中查找、解析和解析html怎么抓包?每次抓包我们都要浏览网页并输入ip地址,在此,我们可以使用浏览器和浏览器地址栏来查找我们需要的所有数据。http请求我们拿到数据之后还需要解析数据,这个步骤比较简单,我们可以在网上搜索或者自己写一个。下一篇,我们将介绍一种比较酷的方法。
性能优化urllib2是python中比较有用的包,在解析网页和抓取数据,由于urllib2包本身代码比较复杂,对于抓取数据来说代码量太大。因此,我们也可以使用beautifulsoup库进行数据解析。beautifulsoup提供了常用的元素解析方法,可以实现更快的开发。上图为beautifulsoup解析效果示意图:beautifulsoup解析效果示意图构建数据源,在上一节中,
如何抓取网页数据(如何抓取网页数据?常用的几种:用浏览器自带的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-25 14:01
如何抓取网页数据?常用的几种:用浏览器自带的方法。用chrome浏览器自带的工具。用ajax技术的工具,使用flash插件,有点像现在流行的adobeflash。用api封装的方法。用一些抓包工具。如何判断网页数据是否抓取成功?如何才能判断网页数据抓取成功呢?先来个直观的,两种方法判断网页数据抓取成功方法a:尝试发送http请求,看响应结果是否成功。
如果成功则说明数据抓取成功方法b:使用formdataurlapi这个接口,这个接口提供验证json对象数据的方法,如果可以响应成功则说明数据抓取成功使用浏览器自带的方法;这个方法比较快,但是要管理网站地址,比较麻烦,不适合小公司小网站的抓取;其他方法,参考h5在线教程对应h5页面,判断是否抓取成功:看body里是否包含标签,如果包含,那么成功抓取,否则不成功,没有抓取到本地数据。
抓取数据分两步:爬虫和数据分析:数据分析可能更偏重于技术上的,爬虫主要关注的是分析和用户操作一般常用的数据抓取工具有requests、scrapy、beautifulsoup、selenium等。以上是常用的工具,如果想写爬虫完成具体的分析,
数据抓取按照功能可以分为网页抓取和非网页抓取,其中网页抓取又可以分为中文数据抓取和中文数据抓取。
一、网页抓取中文数据抓取可以说是最基础,应用最多的抓取方式。最近两年scrapy项目又火了一把,目前很多爬虫工程师都会用scrapy+requests+crawlspider来完成抓取工作。爬虫分为单机爬虫,网站爬虫,分布式爬虫,自动化爬虫,还有一些数据分析抓取。单机爬虫基本上就是自己电脑的爬虫,这是最为基础的一种爬虫,没有之一。中文数据抓取可以用codesheep的api来完成。
1、首先注册一个账号,登录一个第三方。第三方里面有很多网站,基本上所有的中文网站都可以爬取。
2、注册好了,后面就好办了,直接点进去就可以抓取。缺点:不是每个网站都提供api。有些根本就没有api。优点:简单,基本上所有的网站都提供api,没有提供api的,基本上没有任何价值。
3、后面如果有效果我会过来更新。
二、其他数据抓取
1、英文数据抓取这个涉及到爬虫的问题,和中文数据抓取没有太大的关系。但是还是要分享一下,很多人在爬虫的时候无法爬取好数据,然后反复的想办法绕过api。很多人没有打开谷歌浏览器的api开发者工具,去抓取来自于谷歌的数据。有些数据可能也会有,但是大部分数据都是谷歌没有提供api的。
2、日语数据抓取用日语爬取的人不少,但是应该没有人打开日语数据抓取工具抓取, 查看全部
如何抓取网页数据(如何抓取网页数据?常用的几种:用浏览器自带的方法)
如何抓取网页数据?常用的几种:用浏览器自带的方法。用chrome浏览器自带的工具。用ajax技术的工具,使用flash插件,有点像现在流行的adobeflash。用api封装的方法。用一些抓包工具。如何判断网页数据是否抓取成功?如何才能判断网页数据抓取成功呢?先来个直观的,两种方法判断网页数据抓取成功方法a:尝试发送http请求,看响应结果是否成功。
如果成功则说明数据抓取成功方法b:使用formdataurlapi这个接口,这个接口提供验证json对象数据的方法,如果可以响应成功则说明数据抓取成功使用浏览器自带的方法;这个方法比较快,但是要管理网站地址,比较麻烦,不适合小公司小网站的抓取;其他方法,参考h5在线教程对应h5页面,判断是否抓取成功:看body里是否包含标签,如果包含,那么成功抓取,否则不成功,没有抓取到本地数据。
抓取数据分两步:爬虫和数据分析:数据分析可能更偏重于技术上的,爬虫主要关注的是分析和用户操作一般常用的数据抓取工具有requests、scrapy、beautifulsoup、selenium等。以上是常用的工具,如果想写爬虫完成具体的分析,
数据抓取按照功能可以分为网页抓取和非网页抓取,其中网页抓取又可以分为中文数据抓取和中文数据抓取。
一、网页抓取中文数据抓取可以说是最基础,应用最多的抓取方式。最近两年scrapy项目又火了一把,目前很多爬虫工程师都会用scrapy+requests+crawlspider来完成抓取工作。爬虫分为单机爬虫,网站爬虫,分布式爬虫,自动化爬虫,还有一些数据分析抓取。单机爬虫基本上就是自己电脑的爬虫,这是最为基础的一种爬虫,没有之一。中文数据抓取可以用codesheep的api来完成。
1、首先注册一个账号,登录一个第三方。第三方里面有很多网站,基本上所有的中文网站都可以爬取。
2、注册好了,后面就好办了,直接点进去就可以抓取。缺点:不是每个网站都提供api。有些根本就没有api。优点:简单,基本上所有的网站都提供api,没有提供api的,基本上没有任何价值。
3、后面如果有效果我会过来更新。
二、其他数据抓取
1、英文数据抓取这个涉及到爬虫的问题,和中文数据抓取没有太大的关系。但是还是要分享一下,很多人在爬虫的时候无法爬取好数据,然后反复的想办法绕过api。很多人没有打开谷歌浏览器的api开发者工具,去抓取来自于谷歌的数据。有些数据可能也会有,但是大部分数据都是谷歌没有提供api的。
2、日语数据抓取用日语爬取的人不少,但是应该没有人打开日语数据抓取工具抓取,
如何抓取网页数据( 前端工程师如何进行网页爬虫?如何做好网页解析?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-10-22 09:04
前端工程师如何进行网页爬虫?如何做好网页解析?)
如何采集网站数据(如何快速抓取网页数据)
无论是数据分析、数据建模甚至数据挖掘,我们都必须在执行这些高级任务之前进行数据处理。数据是数据工作的基础。没有数据,挖掘毫无意义。俗话说,巧妇难为无米之炊,接下来说说爬虫。
爬虫是采集外部数据的重要途径。常用于竞争分析,也有商家将爬虫用于自己的业务。例如,搜索引擎是最高的爬虫应用程序。当然,爬虫也不能肆无忌惮。如果他们不小心,他们可能会成为面向监狱的编程。
一、什么是爬虫?
爬虫爬取一般是针对特定的网站或App,通过爬虫脚本或程序获取指定页面上的数据采集。意思是通过编程向Web服务器请求数据(HTML形式),然后解析HTML,提取出你想要的数据。
一般来说,爬虫需要掌握一门编程语言。了解HTML、Web服务器、数据库等,建议从python入手快速上手,有很多第三方库可以快速轻松的抓取网页。
二、如何抓取网页
1、 网页分析先
按F12调出网页调试界面,在Element标签下可以看到对应的HTML代码,这些其实就是网页的代码,网页通过hmtl等源代码显示,加载渲染为每个人都看到了。,就像你穿着衣服和化妆(手动搞笑)。
我们可以定位网页元素。左上角有个小按钮,点击它,在网页上找到你要定位的地方,这里可以直接定位到源码,如下图:
我们可以修改源代码看看,把定位到的源代码【python】改成【我是帅哥】,嘿嘿,网页上会发生不同的变化。以上主要是为了科普。这主要是前端工程师的领域。大家看到的地方都是前端的辛苦,后端工程师都在冰山之下。
有点跑题了,回到正题,网页已经解析完毕,你要爬取的元素内容就可以定位了。下一步是打包和编写爬虫脚本。基本网页上能看到的一切都可以爬取,所见即所得。
2、程序如何访问网页
您可以单击网络按钮,通过在浏览器搜索输入框中输入 关键词 来查看我们经历了什么。所涉及的专业内容可能过于复杂。你可能会觉得我输入了一个关键词,网页返回了很多内容。其实就是本地客户端向服务端发送get请求,服务端解析内容。, 经过 TCP 三次握手、四次挥手、网络安全、加密等,最后内容安全返回到你本地客户端,你是不是觉得头开始有点大了,这样我们就可以开心上网冲浪,工程师真不容易~~
了解这些内容有助于我们了解爬虫机制。简单的说,就是一个模拟人登录网页、请求访问、查找返回的网页内容并下载数据的程序。刚才讲了网页网络的内容。常见的请求包括 get 和 post。GET 请求在 URL 上公开请求参数,而 POST 请求参数放在请求正文中。POST 请求方法还会对密码参数进行加密。,所以相对来说比较安全。
程序应该模拟请求头(Request Header)进行访问。除了在发起http请求时提交一些参数之外,我们还定义了一些请求头信息,比如Accept、Host、cookie、User-Agent等,主要是将爬虫程序伪装成一个正式的请求来获取情报内容。
爬虫有点像间谍。它深入到地方,提取我们想要的信息。我不知道在这里做什么,skr~~~
3、接收请求返回的信息
r = requests.get('https://httpbin.org/get')
r.status_code
//返回200r.headers
{
'content-encoding': 'gzip',
'transfer-encoding': 'chunked',
'connection': 'close',
'server': 'nginx/1.0.4',
'x-runtime': '148ms',
'etag': '"e1ca502697e5c9317743dc078f67693f"',
'content-type': 'application/json'
}import requests
r = requests.get('https://api.github.com/events')
r.json()
// 以上操作可以算是最基本的爬虫了,返回内容如下:
[{u'repository': {u'open_issues': 0, u'url': 'https://github.com/...
可以通过解析返回的json字符串得到你想要的数据,恭喜~
三、python自动化爬虫实战
接下来,我们来看看豆瓣电影排行榜的真实爬虫:
#!/usr/bin/env python3# -*- coding: utf-8 -*-"""
Created on Wed Jul 31 15:52:53 2019
@author: kaluosi
"""import requestsimport reimport codecsfrom bs4 import BeautifulSoupfrom openpyxl import Workbookimport pandas as pd
wb = Workbook()
dest_filename = '电影.xlsx'ws1 = wb.active
ws1.title = "电影top250"DOWNLOAD_URL = 'http://movie.douban.com/top250/'def download_page(url):
"""获取url地址页面内容"""
headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}
data = requests.get(url, headers=headers).content return datadef get_li(doc):
soup = BeautifulSoup(doc, 'html.parser')
ol = soup.find('ol', class_='grid_view')
name = [] # 名字
star_con = [] # 评价人数
score = [] # 评分
info_list = [] # 短评
for i in ol.find_all('li'):
detail = i.find('div', attrs={'class': 'hd'})
movie_name = detail.find('span', attrs={'class': 'title'}).get_text() # 电影名字
level_star = i.find('span', attrs={'class': 'rating_num'}).get_text() # 评分
star = i.find('div', attrs={'class': 'star'})
star_num = star.find(text=re.compile('评价')) # 评价
info = i.find('span', attrs={'class': 'inq'}) # 短评
if info: # 判断是否有短评
info_list.append(info.get_text()) else:
info_list.append('无')
score.append(level_star)
name.append(movie_name)
star_con.append(star_num)
page = soup.find('span', attrs={'class': 'next'}).find('a') # 获取下一页
if page: return name, star_con, score, info_list, DOWNLOAD_URL + page['href'] return name, star_con, score, info_list, Nonedef main():
url = DOWNLOAD_URL
name = []
star_con = []
score = []
info = [] while url:
doc = download_page(url)
movie, star, level_num, info_list, url = get_li(doc)
name = name + movie
star_con = star_con + star
score = score + level_num
info = info + info_list #pandas处理数据
c = {'电影名称':name , '评论人数':star_con , '电影评分':score , '评论':info}
data = pd.DataFrame(c)
data.to_excel('豆瓣影评.xlsx')if __name__ == '__main__':
main()
写在最后
最后,这次文章的爬虫仅限于交流和学习。
版权声明:转载本文是为了传达更多信息。如来源标注有误或侵犯您的合法权益,请持权属证明与本站联系,我们将及时更正、删除。感谢您的支持和理解。 查看全部
如何抓取网页数据(
前端工程师如何进行网页爬虫?如何做好网页解析?)
如何采集网站数据(如何快速抓取网页数据)
无论是数据分析、数据建模甚至数据挖掘,我们都必须在执行这些高级任务之前进行数据处理。数据是数据工作的基础。没有数据,挖掘毫无意义。俗话说,巧妇难为无米之炊,接下来说说爬虫。
爬虫是采集外部数据的重要途径。常用于竞争分析,也有商家将爬虫用于自己的业务。例如,搜索引擎是最高的爬虫应用程序。当然,爬虫也不能肆无忌惮。如果他们不小心,他们可能会成为面向监狱的编程。
一、什么是爬虫?
爬虫爬取一般是针对特定的网站或App,通过爬虫脚本或程序获取指定页面上的数据采集。意思是通过编程向Web服务器请求数据(HTML形式),然后解析HTML,提取出你想要的数据。

一般来说,爬虫需要掌握一门编程语言。了解HTML、Web服务器、数据库等,建议从python入手快速上手,有很多第三方库可以快速轻松的抓取网页。
二、如何抓取网页
1、 网页分析先

按F12调出网页调试界面,在Element标签下可以看到对应的HTML代码,这些其实就是网页的代码,网页通过hmtl等源代码显示,加载渲染为每个人都看到了。,就像你穿着衣服和化妆(手动搞笑)。
我们可以定位网页元素。左上角有个小按钮,点击它,在网页上找到你要定位的地方,这里可以直接定位到源码,如下图:

我们可以修改源代码看看,把定位到的源代码【python】改成【我是帅哥】,嘿嘿,网页上会发生不同的变化。以上主要是为了科普。这主要是前端工程师的领域。大家看到的地方都是前端的辛苦,后端工程师都在冰山之下。

有点跑题了,回到正题,网页已经解析完毕,你要爬取的元素内容就可以定位了。下一步是打包和编写爬虫脚本。基本网页上能看到的一切都可以爬取,所见即所得。
2、程序如何访问网页

您可以单击网络按钮,通过在浏览器搜索输入框中输入 关键词 来查看我们经历了什么。所涉及的专业内容可能过于复杂。你可能会觉得我输入了一个关键词,网页返回了很多内容。其实就是本地客户端向服务端发送get请求,服务端解析内容。, 经过 TCP 三次握手、四次挥手、网络安全、加密等,最后内容安全返回到你本地客户端,你是不是觉得头开始有点大了,这样我们就可以开心上网冲浪,工程师真不容易~~
了解这些内容有助于我们了解爬虫机制。简单的说,就是一个模拟人登录网页、请求访问、查找返回的网页内容并下载数据的程序。刚才讲了网页网络的内容。常见的请求包括 get 和 post。GET 请求在 URL 上公开请求参数,而 POST 请求参数放在请求正文中。POST 请求方法还会对密码参数进行加密。,所以相对来说比较安全。
程序应该模拟请求头(Request Header)进行访问。除了在发起http请求时提交一些参数之外,我们还定义了一些请求头信息,比如Accept、Host、cookie、User-Agent等,主要是将爬虫程序伪装成一个正式的请求来获取情报内容。

爬虫有点像间谍。它深入到地方,提取我们想要的信息。我不知道在这里做什么,skr~~~
3、接收请求返回的信息
r = requests.get('https://httpbin.org/get')
r.status_code
//返回200r.headers
{
'content-encoding': 'gzip',
'transfer-encoding': 'chunked',
'connection': 'close',
'server': 'nginx/1.0.4',
'x-runtime': '148ms',
'etag': '"e1ca502697e5c9317743dc078f67693f"',
'content-type': 'application/json'
}import requests
r = requests.get('https://api.github.com/events')
r.json()
// 以上操作可以算是最基本的爬虫了,返回内容如下:
[{u'repository': {u'open_issues': 0, u'url': 'https://github.com/...
可以通过解析返回的json字符串得到你想要的数据,恭喜~
三、python自动化爬虫实战
接下来,我们来看看豆瓣电影排行榜的真实爬虫:
#!/usr/bin/env python3# -*- coding: utf-8 -*-"""
Created on Wed Jul 31 15:52:53 2019
@author: kaluosi
"""import requestsimport reimport codecsfrom bs4 import BeautifulSoupfrom openpyxl import Workbookimport pandas as pd
wb = Workbook()
dest_filename = '电影.xlsx'ws1 = wb.active
ws1.title = "电影top250"DOWNLOAD_URL = 'http://movie.douban.com/top250/'def download_page(url):
"""获取url地址页面内容"""
headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}
data = requests.get(url, headers=headers).content return datadef get_li(doc):
soup = BeautifulSoup(doc, 'html.parser')
ol = soup.find('ol', class_='grid_view')
name = [] # 名字
star_con = [] # 评价人数
score = [] # 评分
info_list = [] # 短评
for i in ol.find_all('li'):
detail = i.find('div', attrs={'class': 'hd'})
movie_name = detail.find('span', attrs={'class': 'title'}).get_text() # 电影名字
level_star = i.find('span', attrs={'class': 'rating_num'}).get_text() # 评分
star = i.find('div', attrs={'class': 'star'})
star_num = star.find(text=re.compile('评价')) # 评价
info = i.find('span', attrs={'class': 'inq'}) # 短评
if info: # 判断是否有短评
info_list.append(info.get_text()) else:
info_list.append('无')
score.append(level_star)
name.append(movie_name)
star_con.append(star_num)
page = soup.find('span', attrs={'class': 'next'}).find('a') # 获取下一页
if page: return name, star_con, score, info_list, DOWNLOAD_URL + page['href'] return name, star_con, score, info_list, Nonedef main():
url = DOWNLOAD_URL
name = []
star_con = []
score = []
info = [] while url:
doc = download_page(url)
movie, star, level_num, info_list, url = get_li(doc)
name = name + movie
star_con = star_con + star
score = score + level_num
info = info + info_list #pandas处理数据
c = {'电影名称':name , '评论人数':star_con , '电影评分':score , '评论':info}
data = pd.DataFrame(c)
data.to_excel('豆瓣影评.xlsx')if __name__ == '__main__':
main()
写在最后
最后,这次文章的爬虫仅限于交流和学习。
版权声明:转载本文是为了传达更多信息。如来源标注有误或侵犯您的合法权益,请持权属证明与本站联系,我们将及时更正、删除。感谢您的支持和理解。
如何抓取网页数据(网站数据抓取网站目前对爬虫开放了、get和request3种数据提取方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-22 08:05
如何抓取网页数据,即如何从一个网页一个人的头像中,提取所需要的数据。如果从准确率较高的模板,提取所需要的对应数据,相对来说会复杂很多。下面我们就来逐一阐述网站数据抓取网站目前对爬虫开放了post、get和request3种数据提取方式1.post方式网站举例:/#/meta/trailer/a-my-world.html【1】-my-world.html【2】-my-world.html【3】-args.json#easy-to-post【4】-get方式网站举例:url-generates-a-google-file.php【1】-websites-get-websites.html【2】-websites-get-the-google-chrome-websites-generator.html【3】-easy-to-get/url-talking.html举例分析:【1】:第一部分,首先请求defpost(url)函数,其返回的url是个http请求的报文,但是我们却希望获取一个cookie。
【2】:ifurl=='':method='post'method='multipart/form-data'#...对应详情参见官方文档-websites-get-websites.html#loaded/image.jpg#loaded/text(3。
5)===-websites-get-the-google-chrome-websites-generator.html#loaded/image.jpg#loaded/text(3
5)===form-data['requestid']="choice"choice="0"#下载官方的第四节习题>>>form-data['specification']="image-extraction。jpg"#下载官方的第五节习题>>>form-data['useragent']="mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/60。3061。132safari/537。36"#官方文档分析第一篇的习题>>>form-data['draft_id']="5s"#官方文档分析第二篇的习题>>>form-data['response_access_token']="crypto"#官方文档分析第三篇的习题>>>form-data['request_type']="get"#官方文档分析第五篇的习题>>>form-data['username']="jack"#官方文档分析第六篇的习题>>>form-data['password']="what"#官方文档分析第七篇的习题>>>。 查看全部
如何抓取网页数据(网站数据抓取网站目前对爬虫开放了、get和request3种数据提取方式)
如何抓取网页数据,即如何从一个网页一个人的头像中,提取所需要的数据。如果从准确率较高的模板,提取所需要的对应数据,相对来说会复杂很多。下面我们就来逐一阐述网站数据抓取网站目前对爬虫开放了post、get和request3种数据提取方式1.post方式网站举例:/#/meta/trailer/a-my-world.html【1】-my-world.html【2】-my-world.html【3】-args.json#easy-to-post【4】-get方式网站举例:url-generates-a-google-file.php【1】-websites-get-websites.html【2】-websites-get-the-google-chrome-websites-generator.html【3】-easy-to-get/url-talking.html举例分析:【1】:第一部分,首先请求defpost(url)函数,其返回的url是个http请求的报文,但是我们却希望获取一个cookie。
【2】:ifurl=='':method='post'method='multipart/form-data'#...对应详情参见官方文档-websites-get-websites.html#loaded/image.jpg#loaded/text(3。
5)===-websites-get-the-google-chrome-websites-generator.html#loaded/image.jpg#loaded/text(3
5)===form-data['requestid']="choice"choice="0"#下载官方的第四节习题>>>form-data['specification']="image-extraction。jpg"#下载官方的第五节习题>>>form-data['useragent']="mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/60。3061。132safari/537。36"#官方文档分析第一篇的习题>>>form-data['draft_id']="5s"#官方文档分析第二篇的习题>>>form-data['response_access_token']="crypto"#官方文档分析第三篇的习题>>>form-data['request_type']="get"#官方文档分析第五篇的习题>>>form-data['username']="jack"#官方文档分析第六篇的习题>>>form-data['password']="what"#官方文档分析第七篇的习题>>>。
如何抓取网页数据(如何在爬网时避免检测网络抓取(图)阻塞)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-22 07:11
爬行时如何避免检测
网络抓取是指从 Internet 上的各个站点采集和提取信息以供个人使用。通过抓取,您可以从其他站点采集有价值的数据,以帮助您改进网页。例如,您可以从竞争对手的网站 采集定价和折扣数据以改善您的业务网站。您获得的数据还可以帮助您了解产品的哪些功能需要改进、标准价格设置和提供的折扣百分比以及其他可以为您提供竞争优势的数据。
由于网络抓取对您的在线业务的成功至关重要,因此您必须尽职尽责地进行,以免在此过程中被阻止。顾名思义,网络抓取涉及非常快速地采集大量数据。因此,这个过程会对爬取到的网站的性能产生负面影响。出于这个原因,网络管理员密切关注可能的爬虫。尽管大多数网站可能没有适当的反爬虫机制,但其他网站已经提出了防止爬虫的巧妙方法。
网络抓取代理如何帮助您进行数据挖掘
阻塞是网络爬虫可能发生的最令人失望的事情之一。幸运的是,有几种聪明的方法可以避免这种情况。即使您被特定网站列入黑名单,也有办法绕过限制并采集急需的数据。虽然渗透受限网站需要大量细致的工作,但如果使用优质的网页抓取代理是可以做到的。这里有一些最聪明的爬行代理选项,可以轻松获取您感兴趣的数据。
共享代理
顾名思义,共享代理允许多个用户同时使用它。它们是伪装身份的绝佳工具,适用于匿名网络抓取。如果您没有足够的现金来确保您拥有私人或专职代理,那么共享代理是最合适的。它们比我们将在此处讨论的其他选项相对便宜。但是,它们并不太复杂,因此不能保证您的安全。
尽管如此,共享代理可以执行绕过网络过滤器、隐藏您的身份和伪装您的地理位置的主要作用。它们也适用于网络爬虫,可以适应机器人的使用。共享代理可能不是您的最佳选择,但您可以最大限度地提高其安全性和性能。您所需要的只是一个可靠的网络抓取代理提供商,为您提供正确的 IP。
私人代理
与共享代理不同,私有代理一次只为一个用户提供服务。私人代理永远不会允许两个用户同时连接到 Internet。由于其出色的安全特性和完美的匿名性,它们是最受企业欢迎的IP代理。例如,大多数旅行票价聚合公司依靠私人代理从航空公司网站 采集基本数据,而不管任何 IP 限制。
私人代理是从竞争对手那里获取有关定价、折扣和新兴趋势的有价值信息的重要工具。私人代理也是创建和运营多个个人和商业社交媒体账户的最佳选择。确保您保持较低的频率,这样您就可以确保在最严格的网络抓取限制中幸存下来。
数据中心代理
数据中心代理有两种主要类型:安全套接字代理 (SOCKS) 和超文本传输协议代理 (HTTP)。在隐藏身份和地理位置时,两者都是流行的网络抓取解决方案。与前面提到的其他选项不同,数据中心代理完全独立于您的 Internet 连接和 ISP。代理独立于 Internet 连接,因此无需链接到特定位置即可使用。
基本上,数据中心代理是由互联网服务提供商以外的另一家公司提供的 IP 地址。每次您通过数据中心代理访问 Internet 时,网络都会识别数据中心代理的凭据,而不是您的实际身份。没有关于您的网络活动的可追踪信息。
住宅代理
住宅代理和数据中心代理的区别在于,它们连接到无法禁止的真实住宅地址。因此,住宅代理有效地隐藏了您的 IP 地址并从网络采集重要数据。住宅代理的主要优点是不受限制。它们也是完全合法的,允许每分钟发送更多请求。另一方面,它们比其他代理更昂贵且更难获得。
网络抓取并不违法。获取有价值的数据很重要,这可以将您的业务提升到一个新的水平。但是,您需要注意它的处理方式和采集的数据类型。为了充分利用网页抓取的优势,请确保您找到可靠的网页抓取代理提供商,为您提供适合您业务需求的优质代理! 查看全部
如何抓取网页数据(如何在爬网时避免检测网络抓取(图)阻塞)
爬行时如何避免检测
网络抓取是指从 Internet 上的各个站点采集和提取信息以供个人使用。通过抓取,您可以从其他站点采集有价值的数据,以帮助您改进网页。例如,您可以从竞争对手的网站 采集定价和折扣数据以改善您的业务网站。您获得的数据还可以帮助您了解产品的哪些功能需要改进、标准价格设置和提供的折扣百分比以及其他可以为您提供竞争优势的数据。

由于网络抓取对您的在线业务的成功至关重要,因此您必须尽职尽责地进行,以免在此过程中被阻止。顾名思义,网络抓取涉及非常快速地采集大量数据。因此,这个过程会对爬取到的网站的性能产生负面影响。出于这个原因,网络管理员密切关注可能的爬虫。尽管大多数网站可能没有适当的反爬虫机制,但其他网站已经提出了防止爬虫的巧妙方法。
网络抓取代理如何帮助您进行数据挖掘
阻塞是网络爬虫可能发生的最令人失望的事情之一。幸运的是,有几种聪明的方法可以避免这种情况。即使您被特定网站列入黑名单,也有办法绕过限制并采集急需的数据。虽然渗透受限网站需要大量细致的工作,但如果使用优质的网页抓取代理是可以做到的。这里有一些最聪明的爬行代理选项,可以轻松获取您感兴趣的数据。
共享代理
顾名思义,共享代理允许多个用户同时使用它。它们是伪装身份的绝佳工具,适用于匿名网络抓取。如果您没有足够的现金来确保您拥有私人或专职代理,那么共享代理是最合适的。它们比我们将在此处讨论的其他选项相对便宜。但是,它们并不太复杂,因此不能保证您的安全。
尽管如此,共享代理可以执行绕过网络过滤器、隐藏您的身份和伪装您的地理位置的主要作用。它们也适用于网络爬虫,可以适应机器人的使用。共享代理可能不是您的最佳选择,但您可以最大限度地提高其安全性和性能。您所需要的只是一个可靠的网络抓取代理提供商,为您提供正确的 IP。
私人代理
与共享代理不同,私有代理一次只为一个用户提供服务。私人代理永远不会允许两个用户同时连接到 Internet。由于其出色的安全特性和完美的匿名性,它们是最受企业欢迎的IP代理。例如,大多数旅行票价聚合公司依靠私人代理从航空公司网站 采集基本数据,而不管任何 IP 限制。
私人代理是从竞争对手那里获取有关定价、折扣和新兴趋势的有价值信息的重要工具。私人代理也是创建和运营多个个人和商业社交媒体账户的最佳选择。确保您保持较低的频率,这样您就可以确保在最严格的网络抓取限制中幸存下来。
数据中心代理
数据中心代理有两种主要类型:安全套接字代理 (SOCKS) 和超文本传输协议代理 (HTTP)。在隐藏身份和地理位置时,两者都是流行的网络抓取解决方案。与前面提到的其他选项不同,数据中心代理完全独立于您的 Internet 连接和 ISP。代理独立于 Internet 连接,因此无需链接到特定位置即可使用。
基本上,数据中心代理是由互联网服务提供商以外的另一家公司提供的 IP 地址。每次您通过数据中心代理访问 Internet 时,网络都会识别数据中心代理的凭据,而不是您的实际身份。没有关于您的网络活动的可追踪信息。
住宅代理
住宅代理和数据中心代理的区别在于,它们连接到无法禁止的真实住宅地址。因此,住宅代理有效地隐藏了您的 IP 地址并从网络采集重要数据。住宅代理的主要优点是不受限制。它们也是完全合法的,允许每分钟发送更多请求。另一方面,它们比其他代理更昂贵且更难获得。
网络抓取并不违法。获取有价值的数据很重要,这可以将您的业务提升到一个新的水平。但是,您需要注意它的处理方式和采集的数据类型。为了充分利用网页抓取的优势,请确保您找到可靠的网页抓取代理提供商,为您提供适合您业务需求的优质代理!
如何抓取网页数据( 如何用PowerBI批量采集多个网页的数据?(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2021-10-18 04:12
如何用PowerBI批量采集多个网页的数据?(二))
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,
从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页时,排序后的数据结构与第一页的数据结构相同。采集的数据可以直接使用;这里不做排序也没关系,可以等到采集所有网页数据排序在一起。
如果要大量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并将第一行的URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取网站数据之前,先尝试采集一页,如果可以采集,则使用上面的步骤,如果采集不行当它到达时,不再有任何延迟。
现在打开 PowerBI 并尝试抓取您感兴趣的 网站 数据。
Power Query 系列评论:
结束
提高技能,拓宽视野 查看全部
如何抓取网页数据(
如何用PowerBI批量采集多个网页的数据?(二))
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,
从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页时,排序后的数据结构与第一页的数据结构相同。采集的数据可以直接使用;这里不做排序也没关系,可以等到采集所有网页数据排序在一起。
如果要大量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并将第一行的URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取网站数据之前,先尝试采集一页,如果可以采集,则使用上面的步骤,如果采集不行当它到达时,不再有任何延迟。
现在打开 PowerBI 并尝试抓取您感兴趣的 网站 数据。
Power Query 系列评论:
结束
提高技能,拓宽视野
如何抓取网页数据(如何使用Beautifulsoup构建一个简单的PythonWebScraper库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-15 17:26
美汤
BeautifulSoup 是一个解析库,用于解析 HTML 和 XML 文件。它将 Web 文档转换为解析树,以便您可以以 Python 的方式遍历和操作它。使用 BeautiSoup,您可以解析 HTML 中可用的任何所需数据。重要的是要知道 BeautifulSoup 没有自己的解析器,它位于其他解析器(例如 lxml 甚至 html)之上。
在解析网络数据时,BeautifulSoup 是最受欢迎的选择。它很容易学习和掌握。使用 BeautifulSoup 解析网页时,即使页面的 HTML 乱七八糟,也不会遇到问题。
就像讨论的其他库一样,您可以通过 pip 安装它。在命令提示符中输入以下命令。
pip install beautifulsoup4
以下代码可以抓取尼日利亚的 LGA 列表并将其打印到控制台。BeautifulSoup 没有下载网页的功能,所以我们将使用 Python Requests 库。
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/ ... ot%3B
page_content = requests.get(url).text
soup = BeautifulSoup(page_content, "html.parser")
table = soup.find("table", {"class": "wikitable"})
lga_trs = table.find_all("tr")[1:]
for i in lga_trs:
tds = i.find_all("td")
td1 = tds[0].find("a")
td2 = tds[1].find("a")
l_name = td1.contents[0]
l_url = td1["href"]
l_state = td2["title"]
l_state_url = td2["href"]
print([l_name,l_url, l_state, l_state_url])
阅读更多,如何使用 Beautifulsoup 构建一个简单的 Python Web Scraper
xml文件
从库的名字就可以知道它和XML有关。其实它是一个解析器——它确实是一个解析器,不像BeautifulSoup,它是作为解析器顶部的一个解析库。除了 XML 文件,lxml 还可以用于解析 HTML 文件。您可能想知道 lxml 是 BeautifulSoup 用来将 Web 文档转换为要解析的树的解析器之一。
LXML 解析速度非常快。然而,它很难学习和掌握。大多数网页抓取工具不会单独使用它,而是将其用作 BeautifulSoup 使用的解析器。因此,实际上不需要代码示例,因为您不会单独使用它。
从这个库的名字可以看出,它与XML有关。实际上,它是一个解析器——一个真正的解析器,不像 BeautifulSoup 坐在解析器之上,充当解析库。除了 XML 文件,lxml 还可以用于解析 HTML 文件。lxml 是 BeautifulSoup 使用的解析器之一,用于将网页文档转换为要解析的树。
解析时,Lxml 非常快。然而,它很难学习和掌握。大多数网络爬虫不会单独使用它,而是将其用作 BeautifulSoup 使用的解析器。因此,实际上不需要代码示例,因为您不会单独使用它。
Lxml 可以在 Pypi 存储库中使用,因此您可以使用 pip 命令来安装它。下面是安装 lxml 的命令。
pip install lxml
Python网络爬虫框架
与仅用于一个功能的库不同,该框架是一个完整的工具,收录了开发网络爬虫所需的大量功能,包括发送HTTP请求和解析请求的功能。
刮痧
Scrapy 是最受欢迎且可以说是最好的 Web 抓取框架,它作为开源工具公开可用。它是由 Scrapinghub 创建的,目前仍处于广泛的管理之下。
Scrapy是一个完整的框架,负责发送请求,解析下载页面所需的数据。Scrapy 是多线程的,是所有 Python 框架和库中最快的。它使复杂的网络爬行变得容易。但是,一个相关的问题是它无法渲染和执行 JavaScript,因此它需要使用 Selenium 或 Splash。
Scrapy 在 Pypi 上可用,因此您可以使用 pip 命令安装它。以下是在命令提示符/终端上运行以下载和安装 Scrapy 的命令。
pip install scrapy
如前所述,Scrapy 是一个完整的框架,没有简单的学习曲线。对于代码示例,您需要编写大量代码,并且在上述情况下无法像这样工作。如需了解 Scrapy 代码示例,请访问 Scrapy网站 官方教程页面。
阅读更多:Scrapy Vs Beautifulsoup Vs Selenium Web 抓取
蜘蛛
Pyspider 是另一个为 Python 程序员开发的网页抓取框架,用于开发网页抓取工具。Pyspider 是一个强大的网络爬虫框架,可用于为现代网络创建网络抓取工具。与 Scrapy 无法自行渲染 JavaScript 的情况不同,Pyspider 擅长做这项工作。但是,Scrapy 在可靠性和成熟度方面远远领先于 Pyspider。支持分布式架构,支持Python 2和Python 3。支持海量数据库系统,拥有强大的WebUI监控爬虫/爬虫性能。要运行它,它必须在服务器上。
Pyspider 是另一个为 Python 程序员编写的网页抓取框架,用于开发网页抓取工具。Pyspider 是一个强大的网络爬虫框架,您可以使用它为现代网络创建网络爬虫。与 Scrapy 本身不呈现 JavaScript 的情况不同,Pyspider 在这方面做得很好。但是,Scrapy 在可靠性和成熟度方面远远领先于 Pyspider。支持分布式架构,提供对Python 2和Python 3的支持,支持大量的数据库系统,自带强大的WebUI监控性能。
您可以使用下面的 pip 命令安装 Pyspider。
pip install pyspider
以下代码是 Pyspider 在其文档页面上提供的示例代码。它抓取 Scrapy 主页上的链接。
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {}
@every(minutes=24 * 60)
def on_start(self):
self.crawl("https://scrapy.org/", callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a][href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
def detail_page(self, response):
return {"url": response.url, "title": response.doc('title').text()
如前所述,Pyspider 运行在服务器上。您的计算机是一台服务器,它将从本地主机上侦听以运行它。
pyspider
命令和访问:5000/
有关的:
综上所述
当谈到 Python 编程语言中用于网页抓取的工具、库和框架的数量时,您需要了解很多。但是,您无法全部学习。如果你正在开发一个不需要复杂架构的简单scraper,那么你可以使用request和BeautifulSoup——如果网站使用大量javascript,你也可以添加Selenium。硒甚至可以单独使用。但是,当你想开发一个复杂的网络爬虫或爬虫时,你可以使用 Scrapy 框架。
这个 文章 有用吗?
点击星标以对其进行评分!
提交评分
平均评分 0 / 5. 投票数:0
至今没有投票!成为第一个评论此 文章 的人。
相关文章 查看全部
如何抓取网页数据(如何使用Beautifulsoup构建一个简单的PythonWebScraper库)
美汤
BeautifulSoup 是一个解析库,用于解析 HTML 和 XML 文件。它将 Web 文档转换为解析树,以便您可以以 Python 的方式遍历和操作它。使用 BeautiSoup,您可以解析 HTML 中可用的任何所需数据。重要的是要知道 BeautifulSoup 没有自己的解析器,它位于其他解析器(例如 lxml 甚至 html)之上。
在解析网络数据时,BeautifulSoup 是最受欢迎的选择。它很容易学习和掌握。使用 BeautifulSoup 解析网页时,即使页面的 HTML 乱七八糟,也不会遇到问题。
就像讨论的其他库一样,您可以通过 pip 安装它。在命令提示符中输入以下命令。
pip install beautifulsoup4
以下代码可以抓取尼日利亚的 LGA 列表并将其打印到控制台。BeautifulSoup 没有下载网页的功能,所以我们将使用 Python Requests 库。
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/ ... ot%3B
page_content = requests.get(url).text
soup = BeautifulSoup(page_content, "html.parser")
table = soup.find("table", {"class": "wikitable"})
lga_trs = table.find_all("tr")[1:]
for i in lga_trs:
tds = i.find_all("td")
td1 = tds[0].find("a")
td2 = tds[1].find("a")
l_name = td1.contents[0]
l_url = td1["href"]
l_state = td2["title"]
l_state_url = td2["href"]
print([l_name,l_url, l_state, l_state_url])
阅读更多,如何使用 Beautifulsoup 构建一个简单的 Python Web Scraper
xml文件
从库的名字就可以知道它和XML有关。其实它是一个解析器——它确实是一个解析器,不像BeautifulSoup,它是作为解析器顶部的一个解析库。除了 XML 文件,lxml 还可以用于解析 HTML 文件。您可能想知道 lxml 是 BeautifulSoup 用来将 Web 文档转换为要解析的树的解析器之一。
LXML 解析速度非常快。然而,它很难学习和掌握。大多数网页抓取工具不会单独使用它,而是将其用作 BeautifulSoup 使用的解析器。因此,实际上不需要代码示例,因为您不会单独使用它。
从这个库的名字可以看出,它与XML有关。实际上,它是一个解析器——一个真正的解析器,不像 BeautifulSoup 坐在解析器之上,充当解析库。除了 XML 文件,lxml 还可以用于解析 HTML 文件。lxml 是 BeautifulSoup 使用的解析器之一,用于将网页文档转换为要解析的树。
解析时,Lxml 非常快。然而,它很难学习和掌握。大多数网络爬虫不会单独使用它,而是将其用作 BeautifulSoup 使用的解析器。因此,实际上不需要代码示例,因为您不会单独使用它。
Lxml 可以在 Pypi 存储库中使用,因此您可以使用 pip 命令来安装它。下面是安装 lxml 的命令。
pip install lxml
Python网络爬虫框架
与仅用于一个功能的库不同,该框架是一个完整的工具,收录了开发网络爬虫所需的大量功能,包括发送HTTP请求和解析请求的功能。
刮痧
Scrapy 是最受欢迎且可以说是最好的 Web 抓取框架,它作为开源工具公开可用。它是由 Scrapinghub 创建的,目前仍处于广泛的管理之下。
Scrapy是一个完整的框架,负责发送请求,解析下载页面所需的数据。Scrapy 是多线程的,是所有 Python 框架和库中最快的。它使复杂的网络爬行变得容易。但是,一个相关的问题是它无法渲染和执行 JavaScript,因此它需要使用 Selenium 或 Splash。
Scrapy 在 Pypi 上可用,因此您可以使用 pip 命令安装它。以下是在命令提示符/终端上运行以下载和安装 Scrapy 的命令。
pip install scrapy
如前所述,Scrapy 是一个完整的框架,没有简单的学习曲线。对于代码示例,您需要编写大量代码,并且在上述情况下无法像这样工作。如需了解 Scrapy 代码示例,请访问 Scrapy网站 官方教程页面。
阅读更多:Scrapy Vs Beautifulsoup Vs Selenium Web 抓取
蜘蛛
Pyspider 是另一个为 Python 程序员开发的网页抓取框架,用于开发网页抓取工具。Pyspider 是一个强大的网络爬虫框架,可用于为现代网络创建网络抓取工具。与 Scrapy 无法自行渲染 JavaScript 的情况不同,Pyspider 擅长做这项工作。但是,Scrapy 在可靠性和成熟度方面远远领先于 Pyspider。支持分布式架构,支持Python 2和Python 3。支持海量数据库系统,拥有强大的WebUI监控爬虫/爬虫性能。要运行它,它必须在服务器上。
Pyspider 是另一个为 Python 程序员编写的网页抓取框架,用于开发网页抓取工具。Pyspider 是一个强大的网络爬虫框架,您可以使用它为现代网络创建网络爬虫。与 Scrapy 本身不呈现 JavaScript 的情况不同,Pyspider 在这方面做得很好。但是,Scrapy 在可靠性和成熟度方面远远领先于 Pyspider。支持分布式架构,提供对Python 2和Python 3的支持,支持大量的数据库系统,自带强大的WebUI监控性能。
您可以使用下面的 pip 命令安装 Pyspider。
pip install pyspider
以下代码是 Pyspider 在其文档页面上提供的示例代码。它抓取 Scrapy 主页上的链接。
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {}
@every(minutes=24 * 60)
def on_start(self):
self.crawl("https://scrapy.org/", callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a][href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
def detail_page(self, response):
return {"url": response.url, "title": response.doc('title').text()
如前所述,Pyspider 运行在服务器上。您的计算机是一台服务器,它将从本地主机上侦听以运行它。
pyspider
命令和访问:5000/
有关的:
综上所述
当谈到 Python 编程语言中用于网页抓取的工具、库和框架的数量时,您需要了解很多。但是,您无法全部学习。如果你正在开发一个不需要复杂架构的简单scraper,那么你可以使用request和BeautifulSoup——如果网站使用大量javascript,你也可以添加Selenium。硒甚至可以单独使用。但是,当你想开发一个复杂的网络爬虫或爬虫时,你可以使用 Scrapy 框架。
这个 文章 有用吗?
点击星标以对其进行评分!
提交评分
平均评分 0 / 5. 投票数:0
至今没有投票!成为第一个评论此 文章 的人。
相关文章
如何抓取网页数据(如何抓取网页数据,一直是不少朋友们提出的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-15 05:04
如何抓取网页数据,一直是不少朋友们提出的问题。当问到具体操作时,无人能够细说;但是如果谈到数据结构以及转换时,不少朋友则面露尴尬,并寻求更多的方法。一切的问题,源于数据字段组织结构的混乱,难以转换,难以抽象。很多朋友看到这里,可能已经忘记想要问的问题了,首先打开你手机浏览器的应用商店,找到你想要的网页,不要犹豫,直接点击打开。
点击刷新之后你会看到,所有提供免费下载的应用产品,右上角都有个蓝色的关注按钮,点击关注按钮,打开该应用的客户端,并找到数据抓取方面,然后勾选数据存放的目录,并点击下一步。当打开浏览器,打开你要进行数据抓取的网页时,你会发现很多网页,在右上角都有大大的关注按钮,点击按钮,打开搜索功能,然后在搜索框中输入“数据抓取”这个关键词,然后勾选爬虫方面的抓取功能,并点击下一步。
如果你的应用是通过浏览器直接下载到手机的浏览器的浏览器应用商店中,那么你将会得到:网页设置信息:对于同一个标题同一个栏目,左侧中间位置一般为两个相似的标题,上下左右的栏目则不同;同一个标题下的不同页面,也不相同。爬虫设置:不同页面关注按钮,如果想要抓取同一个网页,一般需要点击上面那个按钮,如果想要抓取某个特定页面,一般需要点击下面那个按钮。
按提示操作,完成后,你会看到下图所示:一部分页面的设置信息点击具体页面后,进入分析页面,这里需要在分析页面时将页面放大,然后对分析后的信息进行分析,要用到页面相似度检测工具,在应用商店中,这个工具叫做aloha。对网页进行分析操作,会在分析结果中实现对分析页面中不同页面之间页面元素的信息检测,如果在得到相似度检测结果后,你对确定检测框中实际是否存在相同的相似页面,这个时候你在在检测框中如果有相同标题下的一个元素,那么这个元素为你所需要的网页。
因此,当遇到类似这样的需求时,首先在你浏览器中打开你想要抓取的网页,找到并确定需要的信息,然后在应用商店中找到aloha,并确定,是否使用该工具。下面是我使用aloha进行抓取相似页面时的数据分析结果:【页面元素】相似页面展示相似页面显示(1)【页面内容】相似页面展示(2)在我确定页面元素之后,再结合页面内容信息,选择你要进行数据抓取的页面。
接下来到了关键时刻,在找到页面元素之后,接下来需要寻找页面间是否存在相同的页面,如果存在相同页面,那么继续往下。在找到页面元素之后,到刚才看到的页面间元素展示,在这里你能够清楚找到“访问”这个标识按钮,因此对“访问”这个按钮进行解析, 查看全部
如何抓取网页数据(如何抓取网页数据,一直是不少朋友们提出的问题)
如何抓取网页数据,一直是不少朋友们提出的问题。当问到具体操作时,无人能够细说;但是如果谈到数据结构以及转换时,不少朋友则面露尴尬,并寻求更多的方法。一切的问题,源于数据字段组织结构的混乱,难以转换,难以抽象。很多朋友看到这里,可能已经忘记想要问的问题了,首先打开你手机浏览器的应用商店,找到你想要的网页,不要犹豫,直接点击打开。
点击刷新之后你会看到,所有提供免费下载的应用产品,右上角都有个蓝色的关注按钮,点击关注按钮,打开该应用的客户端,并找到数据抓取方面,然后勾选数据存放的目录,并点击下一步。当打开浏览器,打开你要进行数据抓取的网页时,你会发现很多网页,在右上角都有大大的关注按钮,点击按钮,打开搜索功能,然后在搜索框中输入“数据抓取”这个关键词,然后勾选爬虫方面的抓取功能,并点击下一步。
如果你的应用是通过浏览器直接下载到手机的浏览器的浏览器应用商店中,那么你将会得到:网页设置信息:对于同一个标题同一个栏目,左侧中间位置一般为两个相似的标题,上下左右的栏目则不同;同一个标题下的不同页面,也不相同。爬虫设置:不同页面关注按钮,如果想要抓取同一个网页,一般需要点击上面那个按钮,如果想要抓取某个特定页面,一般需要点击下面那个按钮。
按提示操作,完成后,你会看到下图所示:一部分页面的设置信息点击具体页面后,进入分析页面,这里需要在分析页面时将页面放大,然后对分析后的信息进行分析,要用到页面相似度检测工具,在应用商店中,这个工具叫做aloha。对网页进行分析操作,会在分析结果中实现对分析页面中不同页面之间页面元素的信息检测,如果在得到相似度检测结果后,你对确定检测框中实际是否存在相同的相似页面,这个时候你在在检测框中如果有相同标题下的一个元素,那么这个元素为你所需要的网页。
因此,当遇到类似这样的需求时,首先在你浏览器中打开你想要抓取的网页,找到并确定需要的信息,然后在应用商店中找到aloha,并确定,是否使用该工具。下面是我使用aloha进行抓取相似页面时的数据分析结果:【页面元素】相似页面展示相似页面显示(1)【页面内容】相似页面展示(2)在我确定页面元素之后,再结合页面内容信息,选择你要进行数据抓取的页面。
接下来到了关键时刻,在找到页面元素之后,接下来需要寻找页面间是否存在相同的页面,如果存在相同页面,那么继续往下。在找到页面元素之后,到刚才看到的页面间元素展示,在这里你能够清楚找到“访问”这个标识按钮,因此对“访问”这个按钮进行解析,
如何抓取网页数据(如何抓取网页数据?显然不是直接获取网页中的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-14 20:00
如何抓取网页数据?显然不是直接获取网页中的数据,而是通过分析html源代码的格式,对数据进行解析!为了更好的理解html文档中的格式特点,先来看下我的博客案例。
一、案例描述对于html页面,如果想解析网页的源代码,需要通过:修改源代码头部的解析规则代码,主要包括标签。
(这句是xhtml标签后面的自定义标签,
0);//在第一次访问有效;setinterval(xs,100
0);//在第一次访问有效;文件修改了附加代码之后,
1)//获取网页的源代码语句:type:text/javascriptdataurl://网页的源代码shortcode:"short"shortcode:";"shortcode:";"
2)//解析网页源代码语句:dataurl:"/";shortcode:";";shortcode:";"
3)//通过shortcode获取网页源代码语句:any:falseany:falsefalse:trueany:false
4)//通过shortcode获取网页源代码语句:all:falseall:falsefalse:trueall:false
5)//通过shortcode获取网页源代码语句:a:alla:alltext:text;string:string
6)//通过js获取网页源代码语句:options.type:textoptions.dataurl:"/"options.options:anyvalue:undefineddataurl://解析html源代码
二、思路分析本博客案例是学习网页爬虫的学员使用thinkphp做的爬虫案例,thinkphp是php框架,mvc模式,public,它是以“控制器”“定义public属性”来配置一个public方法,可以在局部范围内使用。这次我们把它代码拆分为public、model、waitgroup三个函数,每个函数使用javascript实现或使用ajax技术获取网页源代码,并保存在deferres时间周期内(因为waitgroup函数过时所以javascript不支持);再通过html解析一步步获取网页源代码。
1、thinkphp项目搭建
2、thinkphp解析网页源代码
3、自定义javascript属性
4、html解析
三、操作案例创建一个deferresert数据实例初始化model实例selectabledata实例用户画像toast专题更多面试解析:知识的罗网 查看全部
如何抓取网页数据(如何抓取网页数据?显然不是直接获取网页中的数据)
如何抓取网页数据?显然不是直接获取网页中的数据,而是通过分析html源代码的格式,对数据进行解析!为了更好的理解html文档中的格式特点,先来看下我的博客案例。
一、案例描述对于html页面,如果想解析网页的源代码,需要通过:修改源代码头部的解析规则代码,主要包括标签。
(这句是xhtml标签后面的自定义标签,
0);//在第一次访问有效;setinterval(xs,100
0);//在第一次访问有效;文件修改了附加代码之后,
1)//获取网页的源代码语句:type:text/javascriptdataurl://网页的源代码shortcode:"short"shortcode:";"shortcode:";"
2)//解析网页源代码语句:dataurl:"/";shortcode:";";shortcode:";"
3)//通过shortcode获取网页源代码语句:any:falseany:falsefalse:trueany:false
4)//通过shortcode获取网页源代码语句:all:falseall:falsefalse:trueall:false
5)//通过shortcode获取网页源代码语句:a:alla:alltext:text;string:string
6)//通过js获取网页源代码语句:options.type:textoptions.dataurl:"/"options.options:anyvalue:undefineddataurl://解析html源代码
二、思路分析本博客案例是学习网页爬虫的学员使用thinkphp做的爬虫案例,thinkphp是php框架,mvc模式,public,它是以“控制器”“定义public属性”来配置一个public方法,可以在局部范围内使用。这次我们把它代码拆分为public、model、waitgroup三个函数,每个函数使用javascript实现或使用ajax技术获取网页源代码,并保存在deferres时间周期内(因为waitgroup函数过时所以javascript不支持);再通过html解析一步步获取网页源代码。
1、thinkphp项目搭建
2、thinkphp解析网页源代码
3、自定义javascript属性
4、html解析
三、操作案例创建一个deferresert数据实例初始化model实例selectabledata实例用户画像toast专题更多面试解析:知识的罗网
如何抓取网页数据(如何用一些有用的数据抓取一个网页数据(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-17 02:13
前不久在LearnML分论坛看到一个帖子。主机在这篇文章中提到他需要为他的机器学习项目抓取网络数据。很多人在回复中给出了自己的方法,主要是学习如何使用BeautifulSoup和Selenium。
我在一些数据科学项目中使用过 BeautifulSoup 和 Selenium。在本文中,我将向您展示如何抓取收录一些有用数据的网页并将其转换为 Pandas 数据结构(DataFrame)。
为什么要转换成数据结构?这是因为大多数机器学习库都可以处理 Pandas 数据结构,并且您只需稍作修改即可编辑您的模型。
首先,我们需要在维基百科上找一张表,转换成数据结构。我抓到的表格显示了维基百科上观看次数最多的运动员数据。
许多任务之一是浏览 HTML 树以获取我们需要的表格。
通过请求和正则表达式库,我们开始使用 BeautifulSoup。
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
复制代码
接下来,我们将从网页中提取 HTML 代码:
website_url = requests.get('https://en.wikipedia.org/wiki/Wikipedia:Multiyear_ranking_of_most_viewed_pages').text
soup = BeautifulSoup(website_url, 'lxml')
print(soup.prettify())
</a>
Disclaimers
Contact Wikipedia
<a>
复制代码
从语料库中采集所有表格,我们有一个很小的表面积可供搜索。
wiki_tables = soup.find_all('table', class_='wikitable')
wiki_tables
复制代码
因为有很多表,所以需要一种过滤它们的方法。
据我们所知,克里斯蒂亚诺·罗纳尔多(Cristiano Ronaldo)(也被称为葡萄牙足球运动员罗纳尔多)有一个锚标记,这在几张表中可能是独一无二的。
使用 Cristiano Ronaldo 文本,我们可以过滤那些由锚点标记的表格。此外,我们还发现了一些收录此锚标记的父元素。
links = []
for table in wiki_tables:
_table = table.find('a', string=re.compile('Cristiano Ronaldo'))
if not _table:
continue
print(_table)
_parent = _table.parent
print(_parent)
links.append(_parent)
Cristiano Ronaldo
Cristiano Ronaldo
Cristiano Ronaldo
Cristiano Ronaldo
Cristiano Ronaldo
Cristiano Ronaldo
复制代码
父元素只显示单元格。
这是一个带有浏览器 Web 开发工具的单元格。
parent_lst = []
for anchor in links:
_ = anchor.find_parents('tbody')
print(_)
parent_lst.append(_)
复制代码
使用 tbody,我们可以返回收录先前锚标记的其他表。
为了进一步过滤,我们可以在下表中搜索不同的标题:
for i in parent_lst:
print(i[0].find('tr'))
tr>
Rank*
Page
Views in millions
Rank
Page
Views in millions
Rank
Page
Sport
Views in millions
复制代码
第三个看起来很像我们需要的表。
接下来,我们开始创建必要的逻辑来提取和清理我们需要的细节。
sports_table = parent_lst[2]
complete_row = []
for i in sports_table:
rows = i.find_all('tr')
print('n--------row--------n')
print(rows)
for row in rows:
cells = row.find_all('td')
print('n-------cells--------n')
print(cells)
if not cells:
continue
rank = cells[0].text.strip('n')
page_name = cells[1].find('a').text
sport = cells[2].find('a').text
views = cells[3].text.strip('n')
print('n-------CLEAN--------n')
print(rank)
print(page_name)
print(sport)
print(views)
complete_row.append([rank, page_name, sport, views])
for i in complete_row:
print(i)
复制代码
分解一下:
sports_table = parent_lst[2]
complete_row = []
复制代码
下面我们从上面的列表中选择第三个元素。这是我们需要的表。
接下来,创建一个空列表来存储每一行的详细信息。遍历这个表时,创建一个循环来遍历表中的每一行,并将其保存到rows变量中。
for i in sports_table:
rows = i.find_all('tr')
print('n--------row--------n')
print(rows)
复制代码
for row in rows:
cells = row.find_all('td')
print('n-------cells--------n')
print(cells)
复制代码
建立一个嵌套循环。遍历上一个循环中保存的每一行。在遍历这些单元格时,我们将每个单元格保存在一个新变量中。
if not cells:
continue
复制代码
这段简短的代码使我们能够在从单元格中提取文本时避免出现空单元格并防止出现错误。
rank = cells[0].text.strip('n')
page_name = cells[1].find('a').text
sport = cells[2].find('a').text
views = cells[3].text.strip('n')
复制代码
在这里,我们将各种单元格清理成纯文本格式。清除的值存储在其列名下的变量中。
print('n-------CLEAN--------n')
print(rank)
print(page_name)
print(sport)
print(views)
complete_row.append([rank, page_name, sport, views])
复制代码
在这里,我们将这些值添加到行列表中。然后输出清洗后的值。
-------cells--------
[13
, Conor McGregor
, Mixed martial arts
, 43
]
-------CLEAN--------
13
Conor McGregor
Mixed martial arts
43
复制代码
将其转换为如下数据结构:
headers = ['Rank', 'Name', 'Sport', 'Views Mil']
df = pd.DataFrame(complete_row, columns=headers)
df
复制代码
现在您可以在机器学习项目中使用 pandas 数据结构。您可以使用您喜欢的库来拟合模型数据。 查看全部
如何抓取网页数据(如何用一些有用的数据抓取一个网页数据(图))
前不久在LearnML分论坛看到一个帖子。主机在这篇文章中提到他需要为他的机器学习项目抓取网络数据。很多人在回复中给出了自己的方法,主要是学习如何使用BeautifulSoup和Selenium。
我在一些数据科学项目中使用过 BeautifulSoup 和 Selenium。在本文中,我将向您展示如何抓取收录一些有用数据的网页并将其转换为 Pandas 数据结构(DataFrame)。
为什么要转换成数据结构?这是因为大多数机器学习库都可以处理 Pandas 数据结构,并且您只需稍作修改即可编辑您的模型。
首先,我们需要在维基百科上找一张表,转换成数据结构。我抓到的表格显示了维基百科上观看次数最多的运动员数据。
许多任务之一是浏览 HTML 树以获取我们需要的表格。
通过请求和正则表达式库,我们开始使用 BeautifulSoup。
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
复制代码
接下来,我们将从网页中提取 HTML 代码:
website_url = requests.get('https://en.wikipedia.org/wiki/Wikipedia:Multiyear_ranking_of_most_viewed_pages').text
soup = BeautifulSoup(website_url, 'lxml')
print(soup.prettify())
</a>
Disclaimers
Contact Wikipedia
<a>
复制代码
从语料库中采集所有表格,我们有一个很小的表面积可供搜索。
wiki_tables = soup.find_all('table', class_='wikitable')
wiki_tables
复制代码
因为有很多表,所以需要一种过滤它们的方法。
据我们所知,克里斯蒂亚诺·罗纳尔多(Cristiano Ronaldo)(也被称为葡萄牙足球运动员罗纳尔多)有一个锚标记,这在几张表中可能是独一无二的。
使用 Cristiano Ronaldo 文本,我们可以过滤那些由锚点标记的表格。此外,我们还发现了一些收录此锚标记的父元素。
links = []
for table in wiki_tables:
_table = table.find('a', string=re.compile('Cristiano Ronaldo'))
if not _table:
continue
print(_table)
_parent = _table.parent
print(_parent)
links.append(_parent)
Cristiano Ronaldo
Cristiano Ronaldo
Cristiano Ronaldo
Cristiano Ronaldo
Cristiano Ronaldo
Cristiano Ronaldo
复制代码
父元素只显示单元格。
这是一个带有浏览器 Web 开发工具的单元格。
parent_lst = []
for anchor in links:
_ = anchor.find_parents('tbody')
print(_)
parent_lst.append(_)
复制代码
使用 tbody,我们可以返回收录先前锚标记的其他表。
为了进一步过滤,我们可以在下表中搜索不同的标题:
for i in parent_lst:
print(i[0].find('tr'))
tr>
Rank*
Page
Views in millions
Rank
Page
Views in millions
Rank
Page
Sport
Views in millions
复制代码
第三个看起来很像我们需要的表。
接下来,我们开始创建必要的逻辑来提取和清理我们需要的细节。
sports_table = parent_lst[2]
complete_row = []
for i in sports_table:
rows = i.find_all('tr')
print('n--------row--------n')
print(rows)
for row in rows:
cells = row.find_all('td')
print('n-------cells--------n')
print(cells)
if not cells:
continue
rank = cells[0].text.strip('n')
page_name = cells[1].find('a').text
sport = cells[2].find('a').text
views = cells[3].text.strip('n')
print('n-------CLEAN--------n')
print(rank)
print(page_name)
print(sport)
print(views)
complete_row.append([rank, page_name, sport, views])
for i in complete_row:
print(i)
复制代码
分解一下:
sports_table = parent_lst[2]
complete_row = []
复制代码
下面我们从上面的列表中选择第三个元素。这是我们需要的表。
接下来,创建一个空列表来存储每一行的详细信息。遍历这个表时,创建一个循环来遍历表中的每一行,并将其保存到rows变量中。
for i in sports_table:
rows = i.find_all('tr')
print('n--------row--------n')
print(rows)
复制代码
for row in rows:
cells = row.find_all('td')
print('n-------cells--------n')
print(cells)
复制代码
建立一个嵌套循环。遍历上一个循环中保存的每一行。在遍历这些单元格时,我们将每个单元格保存在一个新变量中。
if not cells:
continue
复制代码
这段简短的代码使我们能够在从单元格中提取文本时避免出现空单元格并防止出现错误。
rank = cells[0].text.strip('n')
page_name = cells[1].find('a').text
sport = cells[2].find('a').text
views = cells[3].text.strip('n')
复制代码
在这里,我们将各种单元格清理成纯文本格式。清除的值存储在其列名下的变量中。
print('n-------CLEAN--------n')
print(rank)
print(page_name)
print(sport)
print(views)
complete_row.append([rank, page_name, sport, views])
复制代码
在这里,我们将这些值添加到行列表中。然后输出清洗后的值。
-------cells--------
[13
, Conor McGregor
, Mixed martial arts
, 43
]
-------CLEAN--------
13
Conor McGregor
Mixed martial arts
43
复制代码
将其转换为如下数据结构:
headers = ['Rank', 'Name', 'Sport', 'Views Mil']
df = pd.DataFrame(complete_row, columns=headers)
df
复制代码
现在您可以在机器学习项目中使用 pandas 数据结构。您可以使用您喜欢的库来拟合模型数据。
如何抓取网页数据(如何用PowerBI批量爬取网页数据?原创采悟PowerBI星球微信号PowerBIStar功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-11-13 18:18
如何使用PowerBI批量抓取网页数据?
原创 蔡武
PowerBI 星球
PowerBI 星球
微信 PowerBIStar
功能介绍海量干货,助你轻松上手PowerBI
2018-04-01
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,
从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]之后的所有步骤,然后展开数据,删除前面几列的数据。
这样,第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页时,排序后的数据结构与第一页的数据结构相同。采集的数据可以直接使用;它不会在这里排序。没关系,你可以等到采集所有的网页数据整理在一起。
如果要大量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并将第一行的URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,大概10分钟就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试一页采集。如果可以采集,那就用上面的步骤。如果 采集 没有到达,则不再有任何延迟。
现在打开 PowerBI 并尝试抓取您感兴趣的 网站 数据。
Power Query 系列评论:
结束
提高技能,拓宽视野
读
在看
已经同步来看看,写下你的想法
进入“发现”-“看一看”,浏览“好友在看”
去看看
看看入口是封闭的
在“设置”-“通用”-“发现页面管理”中打开“看一看”条目
我懂了
已发送
取消
发送来看看
发送
如何使用PowerBI批量抓取网页数据?
最多 200 个字符,当前字符总数
发送 查看全部
如何抓取网页数据(如何用PowerBI批量爬取网页数据?原创采悟PowerBI星球微信号PowerBIStar功能)
如何使用PowerBI批量抓取网页数据?
原创 蔡武
PowerBI 星球
PowerBI 星球
微信 PowerBIStar
功能介绍海量干货,助你轻松上手PowerBI
2018-04-01
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,
从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]之后的所有步骤,然后展开数据,删除前面几列的数据。
这样,第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页时,排序后的数据结构与第一页的数据结构相同。采集的数据可以直接使用;它不会在这里排序。没关系,你可以等到采集所有的网页数据整理在一起。
如果要大量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并将第一行的URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,大概10分钟就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试一页采集。如果可以采集,那就用上面的步骤。如果 采集 没有到达,则不再有任何延迟。
现在打开 PowerBI 并尝试抓取您感兴趣的 网站 数据。
Power Query 系列评论:
结束
提高技能,拓宽视野
读
在看
已经同步来看看,写下你的想法
进入“发现”-“看一看”,浏览“好友在看”
去看看
看看入口是封闭的
在“设置”-“通用”-“发现页面管理”中打开“看一看”条目
我懂了
已发送
取消
发送来看看
发送
如何使用PowerBI批量抓取网页数据?
最多 200 个字符,当前字符总数
发送
如何抓取网页数据(如何抓取网页数据:“google-simplegraphs”在网页源代码的相应部分即可处理结果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-12 12:04
如何抓取网页数据:“google-simplegraphs”在网页源代码的相应部分即可处理结果,方法如下:首先:要读取的文件要存在服务器上(不能用手机上存);然后要设置一个urlurl="-simplegraphs"/sitemap/image/extract_gradient-rfgs.jpg/style/rgba_2_10937f6625031d0af0e0c0b5c03b901274730.jpg"/linkvara=getdata(url);//获取网页文件;//获取该网页的爬虫代码;//获取相应的urlvarq=newspider();//设置爬虫代码//获取文件名;returnq;step1:获取源文件地址、文件名等信息,以及代码的部分内容varli=newpromise(function(resolve,reject){varself=newli();varp=promise.then(function(timestamp){//获取前端代码,用promise作为异步队列if(is.state(timestamp)){resolve(timestamp);}if(is.state(null)){reject("cannotprocessstate");}});//对代码进行校验;p=promise.then(function(err,data){resolve(err);});//发送请求timestamp=p.then(function(){console.log("正在获取数据");});console.log("请求正在接收响应");p.then(function(data){console.log("您已接收文件");});}).catch(function(error){//错误的处理reject(error);});//调用q()方法去获取fundefined属性值//获取首页的爬虫代码self.start(fundefined);step2:用self.stop()方法停止对爬虫代码的处理//其他方法进行上面两个步骤的循环step3:获取到fundefined属性值(当文件的fundefined属性值为”\\”时)存储在内存中(这个内存地址会存在本地的某个目录中),当读取网页时,对对图片上fundefined属性的值进行读取,解析出每个文件的fundefined属性值,获取响应值//此时只获取到数据的一部分p.then(function(data){console.log("请求正在接收响应");reject("由响应接收");});//同时也要收回并将当前的返回值存储到内存中,以便将来的爬虫代码(class="gg-world")及部分代码放到当前目录下。
这样就实现了爬虫的无刷新,但是仅仅获取到前端文件的内容(只是存储并解析响应值)if(is.state(fundefined)){resolve(timestamp);}。 查看全部
如何抓取网页数据(如何抓取网页数据:“google-simplegraphs”在网页源代码的相应部分即可处理结果)
如何抓取网页数据:“google-simplegraphs”在网页源代码的相应部分即可处理结果,方法如下:首先:要读取的文件要存在服务器上(不能用手机上存);然后要设置一个urlurl="-simplegraphs"/sitemap/image/extract_gradient-rfgs.jpg/style/rgba_2_10937f6625031d0af0e0c0b5c03b901274730.jpg"/linkvara=getdata(url);//获取网页文件;//获取该网页的爬虫代码;//获取相应的urlvarq=newspider();//设置爬虫代码//获取文件名;returnq;step1:获取源文件地址、文件名等信息,以及代码的部分内容varli=newpromise(function(resolve,reject){varself=newli();varp=promise.then(function(timestamp){//获取前端代码,用promise作为异步队列if(is.state(timestamp)){resolve(timestamp);}if(is.state(null)){reject("cannotprocessstate");}});//对代码进行校验;p=promise.then(function(err,data){resolve(err);});//发送请求timestamp=p.then(function(){console.log("正在获取数据");});console.log("请求正在接收响应");p.then(function(data){console.log("您已接收文件");});}).catch(function(error){//错误的处理reject(error);});//调用q()方法去获取fundefined属性值//获取首页的爬虫代码self.start(fundefined);step2:用self.stop()方法停止对爬虫代码的处理//其他方法进行上面两个步骤的循环step3:获取到fundefined属性值(当文件的fundefined属性值为”\\”时)存储在内存中(这个内存地址会存在本地的某个目录中),当读取网页时,对对图片上fundefined属性的值进行读取,解析出每个文件的fundefined属性值,获取响应值//此时只获取到数据的一部分p.then(function(data){console.log("请求正在接收响应");reject("由响应接收");});//同时也要收回并将当前的返回值存储到内存中,以便将来的爬虫代码(class="gg-world")及部分代码放到当前目录下。
这样就实现了爬虫的无刷新,但是仅仅获取到前端文件的内容(只是存储并解析响应值)if(is.state(fundefined)){resolve(timestamp);}。
如何抓取网页数据( Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-11 19:03
Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取
)
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍了四个步骤。Python爬虫的基本流程。
第1步
请求尝试
先到b站首页,点击排行榜,复制链接。
https://www.bilibili.com/ranki ... 162.3
启动 Jupyter notebook 并运行以下代码:
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,做了以下三件事: 可以看到返回值为200,说明服务器响应正常,可以继续了。
第2步
解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象。现在我们可以使用 .text 来查看其内容。
可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。
Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的。
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步
提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下图的说明找到。
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第四步
存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' ,否则会出现中文乱码的问题。
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果您熟悉pandas,您可以通过一行代码轻松地将字典转换为DataFrame。
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
结束语
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都遵循以上四个步骤。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜,因为够简单,希望通过这个案例,让大家了解Python爬虫工作的基本流程,最后附上完整代码
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig') 查看全部
如何抓取网页数据(
Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取
)
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍了四个步骤。Python爬虫的基本流程。
第1步
请求尝试
先到b站首页,点击排行榜,复制链接。
https://www.bilibili.com/ranki ... 162.3
启动 Jupyter notebook 并运行以下代码:
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,做了以下三件事: 可以看到返回值为200,说明服务器响应正常,可以继续了。
第2步
解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象。现在我们可以使用 .text 来查看其内容。
可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。
Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的。
from bs4 import BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.text
print(title)
# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步
提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下图的说明找到。
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第四步
存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' ,否则会出现中文乱码的问题。
import csv
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果您熟悉pandas,您可以通过一行代码轻松地将字典转换为DataFrame。
import pandas as pd
keys = all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
结束语
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都遵循以上四个步骤。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜,因为够简单,希望通过这个案例,让大家了解Python爬虫工作的基本流程,最后附上完整代码
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = []
products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip()
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({
"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})
keys = all_products[0].keys()
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
如何抓取网页数据(3.百度spider介绍5.只需两步,正确识别百度蜘蛛)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-11 19:01
最近一直在看SEO相关的资料。我比较好奇的是百度蜘蛛是如何抓取网站的内容的?我在网上搜了一下,找到了从百度搜索学院文章复制过来的那些文章:
1.搜索引擎爬虫系统概述(一)
2.搜索引擎爬虫系统概述(二)
3.搜索引擎检索系统概述
4.百度蜘蛛介绍
5.如何识别百度蜘蛛
6.只需两步即可正确识别百度蜘蛛
网上看到最多的一句话是:百度蜘蛛一、爬取、二、存储、三、预处理、四、索引、五、排名。这种描述问题不大,但也无济于事。我只想知道百度蜘蛛是怎么来我的网站爬取内容的,爬取的顺序,爬取的频率?
一、网络蜘蛛怎么会来我的网站;
网上也有很多关于这个问题的讨论。总结就是:1、指向你的网站外链;2、到站长平台提交网站的url;3、sitemap文件并链接到网站的首页。关于第一点和第二点,网上有很多相关的说明和实践指南,这里不再赘述。我想谈谈我对第三点的理解。首先,我必须为我的站点创建一个站点地图文件,并且这个文件必须放在网站的根目录下。必须可以在没有权限控制的情况下正常访问。. 具体的文档创建请参考各个搜索引擎的指南(如:百度站点地图文档)。还要注意此文件的 URL 和更新率。
https://www.onekbit.com/adminUserAction/toIndex.do
2018-12-23
weekly
1.0
https://www.onekbit.com/FrontP ... s.jsp
2018-12-23
weekly
0.8
https://www.onekbit.com/ViewBlog/toBlogIndex.do
2018-12-23
hourly
1.0
https://www.onekbit.com/ViewBl ... 00027
2018-12-23
hourly
1.0
这里有几个代表性的 URL 来展示。我的初始 URL 很长,收录很多参数。当我把它放在xml文件中时它会报告错误。后面都会优化成这个简单的连接。继续写更多实用价值原创文章,每天频繁更新这个文件。
关于这个文件的更新,大家需要多注意观察你在网站上的百度访问日志:
123.125.71.38 - - [23/Dec/2018:21:18:36 +0800] "GET /Sitemap.xml HTTP/1.1" 304 3673
这是我网站上百度蜘蛛的一行访问日志。请注意,其中的 304 代码表示: 304 未修改 — 文档未按预期进行修改。如果你每天得到的是304,那么对于蜘蛛来说,你没有任何信息可以得到它。自然,它的爬行速度会越来越低,最后也不会来。所以一定要定时定量更新网站原创,让蜘蛛每次都能把信息抢回来,让蜘蛛经常来。最后一点是网站内部链接必须向各个方向延伸,这样蜘蛛才能获得更多的链接给你网站回来。
二、网络蜘蛛在网站上爬行的顺序
网站 目录中网络蜘蛛访问的第一个文件应该是robots.txt。一般情况下,应该根据这个文件是否存在而定。如果不是,则表示可以爬取整个网站。, 爬取取决于文件中的具体限制,这是正常搜索引擎的规则。至于访问robots.txt后应该访问第二个是首页还是sitemap文件,这个在网上有点争议,但是我倾向于认为第二个访问sitemap文件,我用我的< @网站 蜘蛛访问日志的最后一段。证明给我看:
66.249.64.136 - - [22/Dec/2018:04:10:05 +0800] "GET /robots.txt HTTP/1.1" 404 793
66.249.64.140 - - [22/Dec/2018:04:10:06 +0800] "GET /Sitemap.xml HTTP/1.1" 200 3253
66.249.64.136 - - [22/Dec/2018:04:10:38 +0800] "GET /ViewBlog/blog/BID20181204100011 HTTP/1.1" 200 4331
66.249.64.136 - - [22/Dec/2018:04:10:48 +0800] "GET /ViewBlog/blog/BID20181210100016 HTTP/1.1" 200 4258
66.249.64.138 - - [22/Dec/2018:04:11:02 +0800] "GET /ViewBlog/blog/BID20181213100019 HTTP/1.1" 200 3696
66.249.64.138 - - [22/Dec/2018:04:11:39 +0800] "GET /ViewBlog/blog/BID20181207100014 HTTP/1.1" 200 3595
66.249.64.140 - - [22/Dec/2018:04:12:02 +0800] "GET /ViewBlog/blog/BID20181203100010 HTTP/1.1" 200 26710
66.249.64.138 - - [22/Dec/2018:04:15:14 +0800] "GET /adminUserAction/toIndex.do HTTP/1.1" 200 32040
我用的是nslookup 66.249.64.136的IP:
nslookup 命令结果
从日志来看,首先访问的是robots.txt文件,其次是sitemap文件,修改后的URL添加到sitemap中,第四个好像是首页。从蜘蛛的IP来看,我猜是一种专门用来获取网页链接的,另一种是专门用来抓取网页内容的。百度站长里面有一张图,描述了百度蜘蛛的工作流程:
这也可以看出获取url后读取内容。
三、 网络蜘蛛对 网站 的抓取频率
其实,与网络蜘蛛爬取网站的频率有关的因素上面已经说了。感觉最重要的是定期定量更新网站上原创的内容,并提供网站话题相关信息的质量,其次是在导入链接方面做更多的工作.
本文章由onekbit自定义支付导航供稿,原文链接: 查看全部
如何抓取网页数据(3.百度spider介绍5.只需两步,正确识别百度蜘蛛)
最近一直在看SEO相关的资料。我比较好奇的是百度蜘蛛是如何抓取网站的内容的?我在网上搜了一下,找到了从百度搜索学院文章复制过来的那些文章:
1.搜索引擎爬虫系统概述(一)
2.搜索引擎爬虫系统概述(二)
3.搜索引擎检索系统概述
4.百度蜘蛛介绍
5.如何识别百度蜘蛛
6.只需两步即可正确识别百度蜘蛛
网上看到最多的一句话是:百度蜘蛛一、爬取、二、存储、三、预处理、四、索引、五、排名。这种描述问题不大,但也无济于事。我只想知道百度蜘蛛是怎么来我的网站爬取内容的,爬取的顺序,爬取的频率?
一、网络蜘蛛怎么会来我的网站;
网上也有很多关于这个问题的讨论。总结就是:1、指向你的网站外链;2、到站长平台提交网站的url;3、sitemap文件并链接到网站的首页。关于第一点和第二点,网上有很多相关的说明和实践指南,这里不再赘述。我想谈谈我对第三点的理解。首先,我必须为我的站点创建一个站点地图文件,并且这个文件必须放在网站的根目录下。必须可以在没有权限控制的情况下正常访问。. 具体的文档创建请参考各个搜索引擎的指南(如:百度站点地图文档)。还要注意此文件的 URL 和更新率。
https://www.onekbit.com/adminUserAction/toIndex.do
2018-12-23
weekly
1.0
https://www.onekbit.com/FrontP ... s.jsp
2018-12-23
weekly
0.8
https://www.onekbit.com/ViewBlog/toBlogIndex.do
2018-12-23
hourly
1.0
https://www.onekbit.com/ViewBl ... 00027
2018-12-23
hourly
1.0
这里有几个代表性的 URL 来展示。我的初始 URL 很长,收录很多参数。当我把它放在xml文件中时它会报告错误。后面都会优化成这个简单的连接。继续写更多实用价值原创文章,每天频繁更新这个文件。
关于这个文件的更新,大家需要多注意观察你在网站上的百度访问日志:
123.125.71.38 - - [23/Dec/2018:21:18:36 +0800] "GET /Sitemap.xml HTTP/1.1" 304 3673
这是我网站上百度蜘蛛的一行访问日志。请注意,其中的 304 代码表示: 304 未修改 — 文档未按预期进行修改。如果你每天得到的是304,那么对于蜘蛛来说,你没有任何信息可以得到它。自然,它的爬行速度会越来越低,最后也不会来。所以一定要定时定量更新网站原创,让蜘蛛每次都能把信息抢回来,让蜘蛛经常来。最后一点是网站内部链接必须向各个方向延伸,这样蜘蛛才能获得更多的链接给你网站回来。
二、网络蜘蛛在网站上爬行的顺序
网站 目录中网络蜘蛛访问的第一个文件应该是robots.txt。一般情况下,应该根据这个文件是否存在而定。如果不是,则表示可以爬取整个网站。, 爬取取决于文件中的具体限制,这是正常搜索引擎的规则。至于访问robots.txt后应该访问第二个是首页还是sitemap文件,这个在网上有点争议,但是我倾向于认为第二个访问sitemap文件,我用我的< @网站 蜘蛛访问日志的最后一段。证明给我看:
66.249.64.136 - - [22/Dec/2018:04:10:05 +0800] "GET /robots.txt HTTP/1.1" 404 793
66.249.64.140 - - [22/Dec/2018:04:10:06 +0800] "GET /Sitemap.xml HTTP/1.1" 200 3253
66.249.64.136 - - [22/Dec/2018:04:10:38 +0800] "GET /ViewBlog/blog/BID20181204100011 HTTP/1.1" 200 4331
66.249.64.136 - - [22/Dec/2018:04:10:48 +0800] "GET /ViewBlog/blog/BID20181210100016 HTTP/1.1" 200 4258
66.249.64.138 - - [22/Dec/2018:04:11:02 +0800] "GET /ViewBlog/blog/BID20181213100019 HTTP/1.1" 200 3696
66.249.64.138 - - [22/Dec/2018:04:11:39 +0800] "GET /ViewBlog/blog/BID20181207100014 HTTP/1.1" 200 3595
66.249.64.140 - - [22/Dec/2018:04:12:02 +0800] "GET /ViewBlog/blog/BID20181203100010 HTTP/1.1" 200 26710
66.249.64.138 - - [22/Dec/2018:04:15:14 +0800] "GET /adminUserAction/toIndex.do HTTP/1.1" 200 32040
我用的是nslookup 66.249.64.136的IP:
nslookup 命令结果
从日志来看,首先访问的是robots.txt文件,其次是sitemap文件,修改后的URL添加到sitemap中,第四个好像是首页。从蜘蛛的IP来看,我猜是一种专门用来获取网页链接的,另一种是专门用来抓取网页内容的。百度站长里面有一张图,描述了百度蜘蛛的工作流程:
这也可以看出获取url后读取内容。
三、 网络蜘蛛对 网站 的抓取频率
其实,与网络蜘蛛爬取网站的频率有关的因素上面已经说了。感觉最重要的是定期定量更新网站上原创的内容,并提供网站话题相关信息的质量,其次是在导入链接方面做更多的工作.
本文章由onekbit自定义支付导航供稿,原文链接:
如何抓取网页数据(本例如何从网站下载数据中提供日常更新数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-31 14:08
有时出于某种目的,我们可能需要从某些网站 获取一些数据。如果网站提供了下载选项,那么我们可以直接从网站下载。当然,有些网站可能只提供每日更新,但是如果没有提供下载选项,我们就得另辟蹊径了。
如果你只是想突然从某个网站获取数据,即使没有可用的下载,也只需复制粘贴即可。如果需要大量的数据,复制粘贴太费时,或者需要从某个网站中获取一些数据,那么就得考虑(code)do(substitute)方法(code )。
由于本人是气象学家,本例将以怀俄明大学提供的探测数据下载为例,谈谈如何从某个网站下载数据。
打开网站后,我们会看到一些选择区域、日期和站点的选项。
绘图类型提供了许多选项
但在这里我们只下载探测数据并选择默认选项 Text:List。而我们通常需要的是国内的探空数据,所以在Region项中选择东南亚。
在站点字段中输入 58238。如果您知道站点编号,则可以直接输入。如果不知道,可以直接在地图上点击站点编号。
然后按回车查看测深数据页面
因为我们只选了一次,所以探探信息只有一次。而且,从网页上给出的数据可以看出,给出的信息非常清晰,基本上只有测深数据和一些计算出来的指标。
在测深数据页面右击查看页面源码:
可以看出,我们可以使用的信息是H2、PRE、H3标签对应的信息,PRE标签对应的是sounding data、site信息和sounding index信息。
获取网页地址,然后就可以直接从网页下载数据了。
使用的库:BeautifulSoup4、requests
import requests
from bs4 import BeautifulSoup
url = 'http://weather.uwyo.edu/cgi-bi ... 27%3B
# 使用requests 获取网页数据,然后用 BeautifulSoup 解析网页
data = BeautifulSoup(requests.request('get', url).text, 'lxml')
# 打印 站点信息
print(data.h2.string)
# 打印探空数据
print(data.pre.get_text())
# 保存探空数据到文件
uppair = open(r'F:\uppair.txt', 'w')
print(data.pre.get_text(), file = uppair)
# 一定要关闭
uppair.close()
于是下载了测深数据
-----------------------------------------------------------------------------
PRES HGHT TEMP DWPT RELH MIXR DRCT SKNT THTA THTE THTV
hPa m C C % g/kg deg knot K K K
-----------------------------------------------------------------------------
1000.0 7 26.0 22.7 82 17.72 115 6 299.1 351.1 302.3
925.0 720 21.4 18.4 83 14.62 150 16 301.2 344.4 303.8
850.0 1449 17.4 11.4 68 10.05 130 17 304.4 334.7 306.2
700.0 3084 9.2 -1.8 46 4.81 100 19 312.6 328.1 313.6
500.0 5790 -4.9 -12.9 53 2.85 280 17 327.0 336.9 327.6
400.0 7510 -16.5 -21.0 68 1.80 280 39 333.5 340.0 333.8
300.0 9600 -32.7 -43.7 33 0.27 260 62 339.2 340.3 339.2
250.0 10870 -40.3 -56.3 16 0.07 250 85 346.0 346.4 346.0
220.0 11724 -46.3 -61.7 16 0.04 245 91 349.7 349.9 349.7
200.0 12360 -50.7 -65.7 15 0.03 250 89 352.3 352.5 352.3
150.0 14180 -62.3 250 78 362.6 362.6
118.0 15633 -70.3 270 64 373.6 373.6
100.0 16620 -68.9 270 47 394.4 394.4
70.0 18750 -64.7 305 10 445.6 445.6
50.0 20820 -58.3 105 10 505.7 505.7
30.0 24060 -53.7 80 21 597.6 597.6
20.0 26700 -48.9 90 33 685.7 685.7
你认为代码现在结束了吗?如果每次都手动确定网页的网址,复制和粘贴有什么区别?为了以后节省很多时间,我们来看看网页网址的特点:
http://weather.uwyo.edu/cgi-bi ... 58238
URL中有region、TYPE、YEAR、MONTH、STNM,天的选择由FROM和TO控制。对应每个选项在选择网页时选择地区、日期、站点等信息。
东南亚的region值是seasia,北美的region值是naconf,但是在下载数据的时候,真正控制选择的探测数据的是站点和日期信息。区域信息并不重要。
因此,以后选择下载探测数据时,只需根据需要修改URL即可。例如,获取2017.6.20 8:00到2017.6.22 8:00的探测数据,URL应为:
http://weather.uwyo.edu/cgi-bi ... 58238
注:探测时间为UTC时间。同时注意region值是naconf,也可以得到正确的测深数据。2000对应的时间是日和小时,前两位对应的是天,后两位对应的是小时。
细心的你可能已经发现,上面打印PRE标签信息的时候,打印的是sounding信息,但是打印的时候没有指定index。这就是问题所在:如果有多个信息对应同一个标签,默认获取第一条信息。要获取所有信息,您可以使用 ing_all 方法。
print(data.find_all('pre')[1].string)
Station identifier: ZSNJ
Station number: 58238
Observation time: 170621/1200
Station latitude: 32.00
Station longitude: 118.80
Station elevation: 7.0
Showalter index: 4.27
Lifted index: -1.30
LIFT computed using virtual temperature: -1.80
SWEAT index: 276.75
K index: 22.70
Cross totals index: 16.30
Vertical totals index: 22.30
Totals totals index: 38.60
Convective Available Potential Energy: 637.33
CAPE using virtual temperature: 813.63
Convective Inhibition: -22.85
CINS using virtual temperature: -10.14
Equilibrum Level: 243.86
Equilibrum Level using virtual temperature: 243.14
Level of Free Convection: 829.33
LFCT using virtual temperature: 884.16
Bulk Richardson Number: 1946.17
Bulk Richardson Number using CAPV: 2484.53
Temp [K] of the Lifted Condensation Level: 293.58
Pres [hPa] of the Lifted Condensation Level: 928.82
Mean mixed layer potential temperature: 299.87
Mean mixed layer mixing ratio: 16.61
1000 hPa to 500 hPa thickness: 5783.00
Precipitable water [mm] for entire sounding: 44.52
如果要在获取台站信息和探测索引信息后获取相应的数值信息,则必须使用正则表达式。
使用的库:re
<p>import re
# 获取对流有效位能值
cape = re.findall('(? 查看全部
如何抓取网页数据(本例如何从网站下载数据中提供日常更新数据?)
有时出于某种目的,我们可能需要从某些网站 获取一些数据。如果网站提供了下载选项,那么我们可以直接从网站下载。当然,有些网站可能只提供每日更新,但是如果没有提供下载选项,我们就得另辟蹊径了。
如果你只是想突然从某个网站获取数据,即使没有可用的下载,也只需复制粘贴即可。如果需要大量的数据,复制粘贴太费时,或者需要从某个网站中获取一些数据,那么就得考虑(code)do(substitute)方法(code )。
由于本人是气象学家,本例将以怀俄明大学提供的探测数据下载为例,谈谈如何从某个网站下载数据。
打开网站后,我们会看到一些选择区域、日期和站点的选项。
绘图类型提供了许多选项
但在这里我们只下载探测数据并选择默认选项 Text:List。而我们通常需要的是国内的探空数据,所以在Region项中选择东南亚。
在站点字段中输入 58238。如果您知道站点编号,则可以直接输入。如果不知道,可以直接在地图上点击站点编号。
然后按回车查看测深数据页面
因为我们只选了一次,所以探探信息只有一次。而且,从网页上给出的数据可以看出,给出的信息非常清晰,基本上只有测深数据和一些计算出来的指标。
在测深数据页面右击查看页面源码:
可以看出,我们可以使用的信息是H2、PRE、H3标签对应的信息,PRE标签对应的是sounding data、site信息和sounding index信息。
获取网页地址,然后就可以直接从网页下载数据了。
使用的库:BeautifulSoup4、requests
import requests
from bs4 import BeautifulSoup
url = 'http://weather.uwyo.edu/cgi-bi ... 27%3B
# 使用requests 获取网页数据,然后用 BeautifulSoup 解析网页
data = BeautifulSoup(requests.request('get', url).text, 'lxml')
# 打印 站点信息
print(data.h2.string)
# 打印探空数据
print(data.pre.get_text())
# 保存探空数据到文件
uppair = open(r'F:\uppair.txt', 'w')
print(data.pre.get_text(), file = uppair)
# 一定要关闭
uppair.close()
于是下载了测深数据
-----------------------------------------------------------------------------
PRES HGHT TEMP DWPT RELH MIXR DRCT SKNT THTA THTE THTV
hPa m C C % g/kg deg knot K K K
-----------------------------------------------------------------------------
1000.0 7 26.0 22.7 82 17.72 115 6 299.1 351.1 302.3
925.0 720 21.4 18.4 83 14.62 150 16 301.2 344.4 303.8
850.0 1449 17.4 11.4 68 10.05 130 17 304.4 334.7 306.2
700.0 3084 9.2 -1.8 46 4.81 100 19 312.6 328.1 313.6
500.0 5790 -4.9 -12.9 53 2.85 280 17 327.0 336.9 327.6
400.0 7510 -16.5 -21.0 68 1.80 280 39 333.5 340.0 333.8
300.0 9600 -32.7 -43.7 33 0.27 260 62 339.2 340.3 339.2
250.0 10870 -40.3 -56.3 16 0.07 250 85 346.0 346.4 346.0
220.0 11724 -46.3 -61.7 16 0.04 245 91 349.7 349.9 349.7
200.0 12360 -50.7 -65.7 15 0.03 250 89 352.3 352.5 352.3
150.0 14180 -62.3 250 78 362.6 362.6
118.0 15633 -70.3 270 64 373.6 373.6
100.0 16620 -68.9 270 47 394.4 394.4
70.0 18750 -64.7 305 10 445.6 445.6
50.0 20820 -58.3 105 10 505.7 505.7
30.0 24060 -53.7 80 21 597.6 597.6
20.0 26700 -48.9 90 33 685.7 685.7
你认为代码现在结束了吗?如果每次都手动确定网页的网址,复制和粘贴有什么区别?为了以后节省很多时间,我们来看看网页网址的特点:
http://weather.uwyo.edu/cgi-bi ... 58238
URL中有region、TYPE、YEAR、MONTH、STNM,天的选择由FROM和TO控制。对应每个选项在选择网页时选择地区、日期、站点等信息。
东南亚的region值是seasia,北美的region值是naconf,但是在下载数据的时候,真正控制选择的探测数据的是站点和日期信息。区域信息并不重要。
因此,以后选择下载探测数据时,只需根据需要修改URL即可。例如,获取2017.6.20 8:00到2017.6.22 8:00的探测数据,URL应为:
http://weather.uwyo.edu/cgi-bi ... 58238
注:探测时间为UTC时间。同时注意region值是naconf,也可以得到正确的测深数据。2000对应的时间是日和小时,前两位对应的是天,后两位对应的是小时。
细心的你可能已经发现,上面打印PRE标签信息的时候,打印的是sounding信息,但是打印的时候没有指定index。这就是问题所在:如果有多个信息对应同一个标签,默认获取第一条信息。要获取所有信息,您可以使用 ing_all 方法。
print(data.find_all('pre')[1].string)
Station identifier: ZSNJ
Station number: 58238
Observation time: 170621/1200
Station latitude: 32.00
Station longitude: 118.80
Station elevation: 7.0
Showalter index: 4.27
Lifted index: -1.30
LIFT computed using virtual temperature: -1.80
SWEAT index: 276.75
K index: 22.70
Cross totals index: 16.30
Vertical totals index: 22.30
Totals totals index: 38.60
Convective Available Potential Energy: 637.33
CAPE using virtual temperature: 813.63
Convective Inhibition: -22.85
CINS using virtual temperature: -10.14
Equilibrum Level: 243.86
Equilibrum Level using virtual temperature: 243.14
Level of Free Convection: 829.33
LFCT using virtual temperature: 884.16
Bulk Richardson Number: 1946.17
Bulk Richardson Number using CAPV: 2484.53
Temp [K] of the Lifted Condensation Level: 293.58
Pres [hPa] of the Lifted Condensation Level: 928.82
Mean mixed layer potential temperature: 299.87
Mean mixed layer mixing ratio: 16.61
1000 hPa to 500 hPa thickness: 5783.00
Precipitable water [mm] for entire sounding: 44.52
如果要在获取台站信息和探测索引信息后获取相应的数值信息,则必须使用正则表达式。
使用的库:re
<p>import re
# 获取对流有效位能值
cape = re.findall('(?
如何抓取网页数据(TheCode:我最近开始使用selenium和scrapy进行网页抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-29 20:12
情况:
我最近开始使用 selenium 和 scrapy 进行网页抓取。我在一个项目中工作。我有一个收录 42,000 个邮政编码的 csv 文件。我的工作是获取邮政编码并输入 网站 输入邮政编码。并获取所有结果。
问题:
这里的问题是,在执行此操作时,我必须不断单击“加载更多”按钮,直到显示所有结果,只有完成后才能采集数据。
这可能不是什么大问题,但是每个邮政编码需要 2 分钟,而我有 42,000 个邮政编码。
编码:
import scrapy
from numpy.lib.npyio import load
from selenium import webdriver
from selenium.common.exceptions import ElementClickInterceptedException, ElementNotInteractableException, ElementNotSelectableException, NoSuchElementException, StaleElementReferenceException
from selenium.webdriver.common.keys import Keys
from items import CareCreditItem
from datetime import datetime
import os
from scrapy.crawler import CrawlerProcess
global pin_code
pin_code = input("enter pin code")
class CareCredit1Spider(scrapy.Spider):
name = 'care_credit_1'
start_urls = ['https://www.carecredit.com/doctor-locator/results/Any-Profession/Any-Specialty//?Sort=D&Radius=75&Page=1']
def start_requests(self):
directory = os.getcwd()
options = webdriver.ChromeOptions()
options.headless = True
options.add_experimental_option("excludeSwitches", ["enable-logging"])
path = (directory+r"\\Chromedriver.exe")
driver = webdriver.Chrome(path,options=options)
#URL of the website
url = "https://www.carecredit.com/doc ... ot%3B +pin_code + "/?Sort=D&Radius=75&Page=1"
driver.maximize_window()
#opening link in the browser
driver.get(url)
driver.implicitly_wait(200)
try:
cookies = driver.find_element_by_xpath('//*[@id="onetrust-accept-btn-handler"]')
cookies.click()
except:
pass
i = 0
loadMoreButtonExists = True
while loadMoreButtonExists:
try:
load_more = driver.find_element_by_xpath('//*[@id="next-page"]')
load_more.click()
driver.implicitly_wait(30)
except ElementNotInteractableException:
loadMoreButtonExists = False
except ElementClickInterceptedException:
pass
except StaleElementReferenceException:
pass
except NoSuchElementException:
loadMoreButtonExists = False
try:
previous_page = driver.find_element_by_xpath('//*[@id="previous-page"]')
previous_page.click()
except:
pass
name = driver.find_elements_by_class_name('dl-result-item')
r = 1
temp_list=[]
j = 0
for element in name:
link = element.find_element_by_tag_name('a')
c = link.get_property('href')
yield scrapy.Request(c)
def parse(self, response):
item = CareCreditItem()
item['Practise_name'] = response.css('h1 ::text').get()
item['address'] = response.css('.google-maps-external ::text').get()
item['phone_no'] = response.css('.dl-detail-phone ::text').get()
yield item
now = datetime.now()
dt_string = now.strftime("%d/%m/%Y")
dt = now.strftime("%H-%M-%S")
file_name = dt_string+"_"+dt+"zip-code"+pin_code+".csv"
process = CrawlerProcess(settings={
'FEED_URI' : file_name,
'FEED_FORMAT':'csv'
})
process.crawl(CareCredit1Spider)
process.start()
print("CSV File is Ready")
项目.py
import scrapy
class CareCreditItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Practise_name = scrapy.Field()
address = scrapy.Field()
phone_no = scrapy.Field()
问题:
基本上我的问题很简单。有没有办法优化这段代码以使其执行得更快?或者,还有什么其他可能的方法可以在不花费很长时间的情况下处理这些数据? 查看全部
如何抓取网页数据(TheCode:我最近开始使用selenium和scrapy进行网页抓取)
情况:
我最近开始使用 selenium 和 scrapy 进行网页抓取。我在一个项目中工作。我有一个收录 42,000 个邮政编码的 csv 文件。我的工作是获取邮政编码并输入 网站 输入邮政编码。并获取所有结果。
问题:
这里的问题是,在执行此操作时,我必须不断单击“加载更多”按钮,直到显示所有结果,只有完成后才能采集数据。
这可能不是什么大问题,但是每个邮政编码需要 2 分钟,而我有 42,000 个邮政编码。
编码:
import scrapy
from numpy.lib.npyio import load
from selenium import webdriver
from selenium.common.exceptions import ElementClickInterceptedException, ElementNotInteractableException, ElementNotSelectableException, NoSuchElementException, StaleElementReferenceException
from selenium.webdriver.common.keys import Keys
from items import CareCreditItem
from datetime import datetime
import os
from scrapy.crawler import CrawlerProcess
global pin_code
pin_code = input("enter pin code")
class CareCredit1Spider(scrapy.Spider):
name = 'care_credit_1'
start_urls = ['https://www.carecredit.com/doctor-locator/results/Any-Profession/Any-Specialty//?Sort=D&Radius=75&Page=1']
def start_requests(self):
directory = os.getcwd()
options = webdriver.ChromeOptions()
options.headless = True
options.add_experimental_option("excludeSwitches", ["enable-logging"])
path = (directory+r"\\Chromedriver.exe")
driver = webdriver.Chrome(path,options=options)
#URL of the website
url = "https://www.carecredit.com/doc ... ot%3B +pin_code + "/?Sort=D&Radius=75&Page=1"
driver.maximize_window()
#opening link in the browser
driver.get(url)
driver.implicitly_wait(200)
try:
cookies = driver.find_element_by_xpath('//*[@id="onetrust-accept-btn-handler"]')
cookies.click()
except:
pass
i = 0
loadMoreButtonExists = True
while loadMoreButtonExists:
try:
load_more = driver.find_element_by_xpath('//*[@id="next-page"]')
load_more.click()
driver.implicitly_wait(30)
except ElementNotInteractableException:
loadMoreButtonExists = False
except ElementClickInterceptedException:
pass
except StaleElementReferenceException:
pass
except NoSuchElementException:
loadMoreButtonExists = False
try:
previous_page = driver.find_element_by_xpath('//*[@id="previous-page"]')
previous_page.click()
except:
pass
name = driver.find_elements_by_class_name('dl-result-item')
r = 1
temp_list=[]
j = 0
for element in name:
link = element.find_element_by_tag_name('a')
c = link.get_property('href')
yield scrapy.Request(c)
def parse(self, response):
item = CareCreditItem()
item['Practise_name'] = response.css('h1 ::text').get()
item['address'] = response.css('.google-maps-external ::text').get()
item['phone_no'] = response.css('.dl-detail-phone ::text').get()
yield item
now = datetime.now()
dt_string = now.strftime("%d/%m/%Y")
dt = now.strftime("%H-%M-%S")
file_name = dt_string+"_"+dt+"zip-code"+pin_code+".csv"
process = CrawlerProcess(settings={
'FEED_URI' : file_name,
'FEED_FORMAT':'csv'
})
process.crawl(CareCredit1Spider)
process.start()
print("CSV File is Ready")
项目.py
import scrapy
class CareCreditItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Practise_name = scrapy.Field()
address = scrapy.Field()
phone_no = scrapy.Field()
问题:
基本上我的问题很简单。有没有办法优化这段代码以使其执行得更快?或者,还有什么其他可能的方法可以在不花费很长时间的情况下处理这些数据?
如何抓取网页数据(ESPN中获取棒球运动员公共网站下载数据的过程-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-28 09:12
网页抓取是从公共网站 下载数据的过程。例如,您可以从 ESPN 获取棒球运动员的统计数据,并构建一个模型,根据他们的球员统计数据和获胜率来预测球队获胜的机会。以下是网络抓取的一些用例。
监控竞争对手的价格以进行价格匹配(竞争定价)。
从各种 网站 采集统计信息以创建仪表板,例如 COVID-19 仪表板。
监控金融论坛和 Twitter 以计算特定资产的情绪。
我将演示的一个用例是抓取 网站 来发布招聘信息。假设您正在寻找工作,但您被列表的数量所淹没。您可以设置一个流程来实际每天抓取。然后你可以编写一个脚本来自动应用于满足特定条件的帖子。
免责声明:网络抓取确实违反了他们的使用条款。本文仅用于教育目的。在抓取 网站 之前,请务必阅读他们的服务条款并遵循他们的 robots.txt 指南。
数据仓库注意事项
我们的蜘蛛每天都会抓取给定搜索查询可用的所有页面,因此我们想要存储大量重复项。如果帖子持续多天,那么我们将在帖子发布的每一天都有一份副本。为了容忍重复,我们将设计一个管道来捕获所有内容,然后过滤数据以创建可用于分析的标准化数据模型。
首先会从网页中解析出数据,然后放入半结构化的数据结构中,比如JSON。从这里开始,数据结构将存储在对象存储中(例如 S3、GS)。对象存储是捕获数据的有用起点。它便宜、可扩展,并且可以通过我们的数据模型灵活更改。一旦数据进入我们的对象存储,网络爬虫的工作就完成了,数据也被捕获了。
下一步是将数据非规范化为更有用的数据以供分析。如前所述,数据收录重复项。我会选择使用 SQL 数据库,因为它具有强大的分析查询功能。它还允许我区分不同的实体,例如公司、职位发布和地点。首先,所有帖子都会进入事实表(大型只写表),带有时间戳,显示帖子何时被抓取以及何时插入到表中。从这里,我们可以将数据非规范化为代表当前活动版本的有状态表。
您可以编写合并语句来更新和插入表示实时发布的表中的发布。从这里我们还想删除已删除或过期的帖子。现在我们有了一个标准化的表,或者换句话说,所有的重复项都被删除了。
设置项目
对于这个项目,我将使用 Scrapy,因为它带有有用的特性和抽象,可以节省你的时间和精力。例如,scrapy 可以轻松地将结构化数据推送到 S3 或 GCS 等对象存储。这是通过将您的凭据以及存储桶名称和路径添加到由 scrapy 生成的配置文件来完成的。目的是为了长期存储并在我们每次运行刮刀时生成一个不可变的副本。由于 S3 是无限的对象存储,因此是长期存储的理想场所,并且可以轻松地随任何项目进行扩展。
为了突出更多特性,scrapy 使用了 Twisted 框架来处理异步 web 请求。这意味着程序可以在等待网站服务器响应请求的同时完成它的工作,而不是因为空闲等待而浪费时间。Scrapy 有一个活跃的社区,因此您可以寻求帮助并查看其他项目的示例。它还提供了一些更高级的选项,例如在具有 Redis 和用户代理欺骗的集群中运行,但这些不在本教程的范围内。
让我们从在 python 中创建一个虚拟环境并安装依赖项开始。然后初始化一个空白项目,我们将在其中安装我们的网络爬虫。请务必在项目的顶级目录中执行此代码。
python3 -m venv venv
源 ./venv/bin/activate
pip install scrapy lxml BeautifulSoup4 jupyterlab pandas
scrapy startproject 工作
cd 工作/工作/
确实是scrapy genspider
解析网页的代码将被放置在蜘蛛/目录中的文件中。蜘蛛是网络爬虫的抽象。它生成 HTTP 请求并解析返回的页面。有一个单独的抽象用于处理和存储称为 ItemPipeline 的信息。这种抽象分离允许解耦、灵活性和水平扩展。比如,你可以在不修改蜘蛛代码内部逻辑的情况下,将蜘蛛的结果发送到多个地方。一个好的做法是将结果作为文件保存在对象存储中进行长期存储,并将其保存在数据库中进行重复数据删除和临时查询。
开发环境
您可以将网络抓取视为对他人工作的逆向工程。有许多工具可以使 Web 开发更易于组装和管理,例如使用可重用模板或 ES6 模块。这些允许 Web 开发人员在多个地方重用相同的代码,目标是将简单的部分组合成更复杂的部分。当您抓取网站 时,您所拥有的只是实际的网页,我们无法访问用于构建页面的组件。因此,我们必须向后工作以使用我们可以使用的任何技术来获得我们想要的东西。
任何网络抓取项目的第一步都是在网络浏览器中打开要抓取的页面,然后使用“检查元素”在您选择的浏览器中探索 DOM。使用浏览器中的开发者工具,您可以探索 DOM 的结构或页面的骨架。现在您可以随意打开页面,使用开发者工具进行探索。在整个过程中,我们将使用浏览器以可视化和交互的方式快速浏览dom。
我喜欢使用带有 iPython 的 scrapy shell 来为我的网页抓取开发解析代码。交互性允许快速反馈循环,允许大量试验和错误。scrapy shell 带您进入已实例化的所有帮助程序和便利函数的 scrapy 上下文。这些相同的对象在运行时可供蜘蛛使用。它还使您可以访问 iPython 的所有功能。您可以使用以下代码来启动您的 shell。
scrapy shell',-MA-jobs.html'
这里最重要的对象是响应。这收录从 Web 服务器到我们的 HTTP GET 请求的 HTTP 响应。它收录页面的 HTML,以及与 HTTP 响应相关的标头和其他信息。基本的反馈循环是使用浏览器识别我们要解析的内容,然后在终端中测试解析代码。
起始网址
如果您查看上面的链接,您可能会注意到该 URL 收录我们的搜索查询。这是在 HTTP GET 请求中传递参数的方式(此示例未使用标准化格式)。我们可以使用此信息以编程方式尝试不同的搜索查询。
在 url 中,在字母 q 之后,我们看到了与位置对应的查询。字母 l 之后是位置。假设在我们的用例中,我们要搜索多个位置和位置。例如,医疗助理也称为患者护理助理。
在scrapy中,我们可以使用我们蜘蛛的几个URL作为抓取的起点。我们可以向它传递与多个位置和位置相对应的 URL 以获得此行为。在这个例子中,我使用 product 函数生成位置和位置的每个组合,然后我将它传递给蜘蛛作为我们的起点。
从 itertools 导入产品
job_titles = [“医疗助理”、“病人护理技术员”、“病人护理助理”]
状态 = [“MA”]
城市 = [“波士顿”、“剑桥”、“萨默维尔”、“多切斯特”]
网址 = []
对于产品(job_titles,states,城市)中的(job_title,state,city):
urls.append(f"{'-'.join(job_title.split())}-l-{city},-{state}-jobs.html")
类确实蜘蛛(scrapy.Spider):
名称 = "确实"
allowed_domains = [""]
start_urls = urls
也许您已经注意到,在相邻城市中搜索相同的位置会产生重叠的结果。换句话说,在剑桥和波士顿搜索相同的标题将返回重复项。任何数据项目的主要挑战是重复数据删除。我们可以使用的一种策略是拥有像 redis 这样的应用程序缓存。我们的程序可以根据职位、公司名称、地点和发布日期组成的自然主键检查列表是否已解析。我们甚至可以在服务器生成的 DOM 中查找唯一 ID。为简单起见,一旦所有内容都保存到我们的对象存储中,我们将在最后进行重复数据删除。
解析页面
我将使用 Python 库 BeautifulSoup4 来解析 HTML,因为这是我最熟悉的库。默认情况下,scrapy 带有 CSS 选择器和 XPath 选择器,它们都是针对 DOM 编写查询的强大方法。在本教程中,您需要将 Beautiful Soup 导入我们的 shell,然后将 HTML 解析为一个 BeautifulSoup 对象。我喜欢 BeautifulSoup,因为 find API 非常简单。
从 bs4 导入 BeautifulSoup
汤 = BeautifulSoup(response.text, features="lxml")
请注意,当他们重命名 CSS 类时,此解析代码将被破坏。如果您发现这些示例不起作用,请尝试修复它们以适应今天的 网站 结构和命名方法。
首先,我们需要找到一种方法来解析给定页面上所有作业的列表。我们想找到一种方法来捕获每个列表的顶部节点。一旦我们有了每个列表的父节点,我们就可以迭代如何解析每个列表的属性。目前,每个列表都有一个顶级锚元素 (),class="tapItem"。我们可以使用 CSS 类来选择代表单个列表的所有这些节点。
listings = soup.find_all("a", {"class": "tapItem"})
在本教程中,我们将定位属性职位、雇主、地点和职位描述。前三个属性可以在搜索结果页面上找到,职位描述需要点击职位描述页面上的链接。从这个页面上可用的属性开始,我们可以使用 CSS 类在每个父节点中定位列表的不同属性。
在列表中列出:
job_title = listing.find("h2", {"class": "jobTitle"}).get_text().strip()
summary = listing.find("div", {"class": "job-snippet"}).get_text().strip() # 去除换行符
company = listing.find("span", {"class": "companyName"}).get_text().strip()
location = listing.find("div", {"class": "companyLocation"}).get_text().strip()
我通过在检查元素 devtools 中找到帖子然后在 iPython 中迭代代码来编写这段代码。在每种情况下,我发现通过 HTML 元素和 CSS 类进行选择就足以获得我需要的信息。
现在我们需要检索位于单独页面上的职位描述。为此,我们将发送另一个 HTTP 请求,以使用我们在搜索结果页面上找到的链接检索收录职位描述的页面。我们通过将在锚标记的 href 中找到的相对路径与在我们的响应对象中找到的搜索结果页面的 URL 相结合来获得链接 url。然后我们会要求scrapy使用异步事件循环来调度请求。
我们会将职位描述(jd)与我们在此页面上找到的信息结合起来,因此我们会将解析后的属性传递给回调函数,以便它们都可以存储在同一个项目中。Scrapy 需要使用 yield 语句,因为该函数是由异步调度器执行的。parse_jd 回调函数将返回一个表示职位发布的字典。
发布 = {“job_title”:job_title,“summary”:摘要,“company”:公司,“location”:location}
jd_page = listing.get("href")
如果 jd_page 不是 None:
yield response.follow(jd_page, callback=self.parse_jd, cb_kwargs=posting)
现在剩下要做的就是解析工作描述并生成要采集的项目。幸运的是,职位描述有一个唯一的 ID。这是选择特定元素的最简单方法。我们想要保存职位描述的 URL,因为如果我们最终申请,我们将需要找到申请按钮的链接。
def parse_jd(self, response, **posting):
汤 = BeautifulSoup(response.text, features="lxml")
jd = soup.find("div", {"id": "jobDescriptionText"}).get_text()
url = response.url
post.update({"job_description": jd, "url": url})
收益过帐
解析通常是编写蜘蛛程序最具挑战性和最耗时的阶段。网站 会随着时间的推移而变化,所以需要在断掉的时候修改代码。添加验证步骤以检查无字符串或空字符串然后引发错误会很有用。这样,当代码不再起作用时,您会收到通知。这应该只对关键路径信息进行,因为丢失的信息可能很常见。
最后一步是告诉我们的爬虫去搜索结果的下一页。我们希望爬虫检索当前可用的每个帖子,而不仅仅是第一页上的结果。当下一页按钮不再可用时,我们就会知道我们已经完成了。
next_page = soup.find("a", {"aria-label": "Next"}).get("href")
如果 next_page 不是 None:
next_page = response.urljoin(next_page)
产生scrapy.Request(next_page,回调=self.parse)
有了这些简单的指令集,我们现在有了一个相当强大的过程来提取所有重要的细节。跟随下一页上的链接的能力意味着爬虫将抓取所有可用的结果,而无需任何额外的编码。现在我们已经完成了蜘蛛的准备工作,我们可以继续研究结果。
保存结果
现在解析器已经写好了,我们可以开始使用一些scrapy特性了。我们可以选择使用 ItemPipline 将每个 Item 发送到文件对象存储或数据库。我们可以利用具有高写入吞吐量的高可用分布式数据库(例如DynamoDB、Cassandra)并在表运行时将项目插入表中。
对于这个项目,我将使用内置提要选项从命令行创建一个摘录。我会选择 JSON 行,因为 JSON 编码器将正确转义换行符和引号,作为编组到 JSON 的过程的一部分。与 CSV 相比,这可以为您节省一些将来的麻烦,其中额外的换行符或引号可能会导致解析错误和头痛。当架构不是静态的并且每个项目可能收录的属性不同时,半结构化格式也很有用。
有一种方法可以在配置文件中指定提要,但我将向您展示如何从命令行执行此操作。我们将创建一个 JSON Lines 文件,其中收录捕获到本地文件系统的所有数据。从那里我们可以开始与结果交互以提取价值。
确实爬行抓取 -o jobs.jl
这将需要一些时间来运行,具体取决于您配置的位置和位置的数量。所有 网站 都有某种形式的速率限制。可以通过 CDN 或负载均衡器/反向代理(如 Cloudflare)实现速率限制。速率限制可防止拒绝服务 (DoS) 攻击关闭 Web 服务器。Scrapy 将执行指数退避,直到得到 200 响应代码,这意味着它会在每次失败后等待更长时间,直到请求成功。
分析结果
现在我们有一个收录所有帖子的文件,我们可以开始分析。执行分析的一种方法是使用 Jupyter 笔记本。Jupyter Notebook 可用于探索性数据分析和非线性规划。当我们为发现和分析编码时,我们不知道最终状态是什么样的。我们在写代码的时候,需要改变事物的顺序,做出重大的改变,这就是为什么它被称为非线性规划。Jupyter 使这种编程风格更容易。
Jupyter notebooks 通过使用单元格和 iPython 促进了这种类型的开发。通过使用 iPython 作为后端,它允许您在 REPL 环境中工作。REPL 允许您快速查看执行代码的输出并在创建对象后保留它们。第二部分是可以移动、剪切、复制和删除的单元格。单元格可以轻松更改执行顺序和更改对象的范围。我发现笔记本是我分析结果的好地方。
综上所述
下一步是聚合和规范化数据,分析它,然后创建某种用户界面来访问它。例如,您可以有一个网站,网站 显示所有已爬取的网站 根据自定义条件进行排序和过滤。您可以使用关键字检测来确定提供您最感兴趣的机会的列表的优先级。
用scrapy写spider可以让你通过第一步,解析网页中的数据并保存。这是任何依赖网络爬行数据的数据管道中的第一个组件。一旦您捕获了数据,您就可以开始为您希望的任何应用程序从中提取价值。
您可以从本教程下载收录所有代码的 python 文件。 查看全部
如何抓取网页数据(ESPN中获取棒球运动员公共网站下载数据的过程-乐题库)
网页抓取是从公共网站 下载数据的过程。例如,您可以从 ESPN 获取棒球运动员的统计数据,并构建一个模型,根据他们的球员统计数据和获胜率来预测球队获胜的机会。以下是网络抓取的一些用例。
监控竞争对手的价格以进行价格匹配(竞争定价)。
从各种 网站 采集统计信息以创建仪表板,例如 COVID-19 仪表板。
监控金融论坛和 Twitter 以计算特定资产的情绪。
我将演示的一个用例是抓取 网站 来发布招聘信息。假设您正在寻找工作,但您被列表的数量所淹没。您可以设置一个流程来实际每天抓取。然后你可以编写一个脚本来自动应用于满足特定条件的帖子。
免责声明:网络抓取确实违反了他们的使用条款。本文仅用于教育目的。在抓取 网站 之前,请务必阅读他们的服务条款并遵循他们的 robots.txt 指南。
数据仓库注意事项
我们的蜘蛛每天都会抓取给定搜索查询可用的所有页面,因此我们想要存储大量重复项。如果帖子持续多天,那么我们将在帖子发布的每一天都有一份副本。为了容忍重复,我们将设计一个管道来捕获所有内容,然后过滤数据以创建可用于分析的标准化数据模型。
首先会从网页中解析出数据,然后放入半结构化的数据结构中,比如JSON。从这里开始,数据结构将存储在对象存储中(例如 S3、GS)。对象存储是捕获数据的有用起点。它便宜、可扩展,并且可以通过我们的数据模型灵活更改。一旦数据进入我们的对象存储,网络爬虫的工作就完成了,数据也被捕获了。
下一步是将数据非规范化为更有用的数据以供分析。如前所述,数据收录重复项。我会选择使用 SQL 数据库,因为它具有强大的分析查询功能。它还允许我区分不同的实体,例如公司、职位发布和地点。首先,所有帖子都会进入事实表(大型只写表),带有时间戳,显示帖子何时被抓取以及何时插入到表中。从这里,我们可以将数据非规范化为代表当前活动版本的有状态表。
您可以编写合并语句来更新和插入表示实时发布的表中的发布。从这里我们还想删除已删除或过期的帖子。现在我们有了一个标准化的表,或者换句话说,所有的重复项都被删除了。
设置项目
对于这个项目,我将使用 Scrapy,因为它带有有用的特性和抽象,可以节省你的时间和精力。例如,scrapy 可以轻松地将结构化数据推送到 S3 或 GCS 等对象存储。这是通过将您的凭据以及存储桶名称和路径添加到由 scrapy 生成的配置文件来完成的。目的是为了长期存储并在我们每次运行刮刀时生成一个不可变的副本。由于 S3 是无限的对象存储,因此是长期存储的理想场所,并且可以轻松地随任何项目进行扩展。
为了突出更多特性,scrapy 使用了 Twisted 框架来处理异步 web 请求。这意味着程序可以在等待网站服务器响应请求的同时完成它的工作,而不是因为空闲等待而浪费时间。Scrapy 有一个活跃的社区,因此您可以寻求帮助并查看其他项目的示例。它还提供了一些更高级的选项,例如在具有 Redis 和用户代理欺骗的集群中运行,但这些不在本教程的范围内。
让我们从在 python 中创建一个虚拟环境并安装依赖项开始。然后初始化一个空白项目,我们将在其中安装我们的网络爬虫。请务必在项目的顶级目录中执行此代码。
python3 -m venv venv
源 ./venv/bin/activate
pip install scrapy lxml BeautifulSoup4 jupyterlab pandas
scrapy startproject 工作
cd 工作/工作/
确实是scrapy genspider
解析网页的代码将被放置在蜘蛛/目录中的文件中。蜘蛛是网络爬虫的抽象。它生成 HTTP 请求并解析返回的页面。有一个单独的抽象用于处理和存储称为 ItemPipeline 的信息。这种抽象分离允许解耦、灵活性和水平扩展。比如,你可以在不修改蜘蛛代码内部逻辑的情况下,将蜘蛛的结果发送到多个地方。一个好的做法是将结果作为文件保存在对象存储中进行长期存储,并将其保存在数据库中进行重复数据删除和临时查询。
开发环境
您可以将网络抓取视为对他人工作的逆向工程。有许多工具可以使 Web 开发更易于组装和管理,例如使用可重用模板或 ES6 模块。这些允许 Web 开发人员在多个地方重用相同的代码,目标是将简单的部分组合成更复杂的部分。当您抓取网站 时,您所拥有的只是实际的网页,我们无法访问用于构建页面的组件。因此,我们必须向后工作以使用我们可以使用的任何技术来获得我们想要的东西。
任何网络抓取项目的第一步都是在网络浏览器中打开要抓取的页面,然后使用“检查元素”在您选择的浏览器中探索 DOM。使用浏览器中的开发者工具,您可以探索 DOM 的结构或页面的骨架。现在您可以随意打开页面,使用开发者工具进行探索。在整个过程中,我们将使用浏览器以可视化和交互的方式快速浏览dom。
我喜欢使用带有 iPython 的 scrapy shell 来为我的网页抓取开发解析代码。交互性允许快速反馈循环,允许大量试验和错误。scrapy shell 带您进入已实例化的所有帮助程序和便利函数的 scrapy 上下文。这些相同的对象在运行时可供蜘蛛使用。它还使您可以访问 iPython 的所有功能。您可以使用以下代码来启动您的 shell。
scrapy shell',-MA-jobs.html'
这里最重要的对象是响应。这收录从 Web 服务器到我们的 HTTP GET 请求的 HTTP 响应。它收录页面的 HTML,以及与 HTTP 响应相关的标头和其他信息。基本的反馈循环是使用浏览器识别我们要解析的内容,然后在终端中测试解析代码。
起始网址
如果您查看上面的链接,您可能会注意到该 URL 收录我们的搜索查询。这是在 HTTP GET 请求中传递参数的方式(此示例未使用标准化格式)。我们可以使用此信息以编程方式尝试不同的搜索查询。
在 url 中,在字母 q 之后,我们看到了与位置对应的查询。字母 l 之后是位置。假设在我们的用例中,我们要搜索多个位置和位置。例如,医疗助理也称为患者护理助理。
在scrapy中,我们可以使用我们蜘蛛的几个URL作为抓取的起点。我们可以向它传递与多个位置和位置相对应的 URL 以获得此行为。在这个例子中,我使用 product 函数生成位置和位置的每个组合,然后我将它传递给蜘蛛作为我们的起点。
从 itertools 导入产品
job_titles = [“医疗助理”、“病人护理技术员”、“病人护理助理”]
状态 = [“MA”]
城市 = [“波士顿”、“剑桥”、“萨默维尔”、“多切斯特”]
网址 = []
对于产品(job_titles,states,城市)中的(job_title,state,city):
urls.append(f"{'-'.join(job_title.split())}-l-{city},-{state}-jobs.html")
类确实蜘蛛(scrapy.Spider):
名称 = "确实"
allowed_domains = [""]
start_urls = urls
也许您已经注意到,在相邻城市中搜索相同的位置会产生重叠的结果。换句话说,在剑桥和波士顿搜索相同的标题将返回重复项。任何数据项目的主要挑战是重复数据删除。我们可以使用的一种策略是拥有像 redis 这样的应用程序缓存。我们的程序可以根据职位、公司名称、地点和发布日期组成的自然主键检查列表是否已解析。我们甚至可以在服务器生成的 DOM 中查找唯一 ID。为简单起见,一旦所有内容都保存到我们的对象存储中,我们将在最后进行重复数据删除。
解析页面
我将使用 Python 库 BeautifulSoup4 来解析 HTML,因为这是我最熟悉的库。默认情况下,scrapy 带有 CSS 选择器和 XPath 选择器,它们都是针对 DOM 编写查询的强大方法。在本教程中,您需要将 Beautiful Soup 导入我们的 shell,然后将 HTML 解析为一个 BeautifulSoup 对象。我喜欢 BeautifulSoup,因为 find API 非常简单。
从 bs4 导入 BeautifulSoup
汤 = BeautifulSoup(response.text, features="lxml")
请注意,当他们重命名 CSS 类时,此解析代码将被破坏。如果您发现这些示例不起作用,请尝试修复它们以适应今天的 网站 结构和命名方法。
首先,我们需要找到一种方法来解析给定页面上所有作业的列表。我们想找到一种方法来捕获每个列表的顶部节点。一旦我们有了每个列表的父节点,我们就可以迭代如何解析每个列表的属性。目前,每个列表都有一个顶级锚元素 (),class="tapItem"。我们可以使用 CSS 类来选择代表单个列表的所有这些节点。
listings = soup.find_all("a", {"class": "tapItem"})
在本教程中,我们将定位属性职位、雇主、地点和职位描述。前三个属性可以在搜索结果页面上找到,职位描述需要点击职位描述页面上的链接。从这个页面上可用的属性开始,我们可以使用 CSS 类在每个父节点中定位列表的不同属性。
在列表中列出:
job_title = listing.find("h2", {"class": "jobTitle"}).get_text().strip()
summary = listing.find("div", {"class": "job-snippet"}).get_text().strip() # 去除换行符
company = listing.find("span", {"class": "companyName"}).get_text().strip()
location = listing.find("div", {"class": "companyLocation"}).get_text().strip()
我通过在检查元素 devtools 中找到帖子然后在 iPython 中迭代代码来编写这段代码。在每种情况下,我发现通过 HTML 元素和 CSS 类进行选择就足以获得我需要的信息。
现在我们需要检索位于单独页面上的职位描述。为此,我们将发送另一个 HTTP 请求,以使用我们在搜索结果页面上找到的链接检索收录职位描述的页面。我们通过将在锚标记的 href 中找到的相对路径与在我们的响应对象中找到的搜索结果页面的 URL 相结合来获得链接 url。然后我们会要求scrapy使用异步事件循环来调度请求。
我们会将职位描述(jd)与我们在此页面上找到的信息结合起来,因此我们会将解析后的属性传递给回调函数,以便它们都可以存储在同一个项目中。Scrapy 需要使用 yield 语句,因为该函数是由异步调度器执行的。parse_jd 回调函数将返回一个表示职位发布的字典。
发布 = {“job_title”:job_title,“summary”:摘要,“company”:公司,“location”:location}
jd_page = listing.get("href")
如果 jd_page 不是 None:
yield response.follow(jd_page, callback=self.parse_jd, cb_kwargs=posting)
现在剩下要做的就是解析工作描述并生成要采集的项目。幸运的是,职位描述有一个唯一的 ID。这是选择特定元素的最简单方法。我们想要保存职位描述的 URL,因为如果我们最终申请,我们将需要找到申请按钮的链接。
def parse_jd(self, response, **posting):
汤 = BeautifulSoup(response.text, features="lxml")
jd = soup.find("div", {"id": "jobDescriptionText"}).get_text()
url = response.url
post.update({"job_description": jd, "url": url})
收益过帐
解析通常是编写蜘蛛程序最具挑战性和最耗时的阶段。网站 会随着时间的推移而变化,所以需要在断掉的时候修改代码。添加验证步骤以检查无字符串或空字符串然后引发错误会很有用。这样,当代码不再起作用时,您会收到通知。这应该只对关键路径信息进行,因为丢失的信息可能很常见。
最后一步是告诉我们的爬虫去搜索结果的下一页。我们希望爬虫检索当前可用的每个帖子,而不仅仅是第一页上的结果。当下一页按钮不再可用时,我们就会知道我们已经完成了。
next_page = soup.find("a", {"aria-label": "Next"}).get("href")
如果 next_page 不是 None:
next_page = response.urljoin(next_page)
产生scrapy.Request(next_page,回调=self.parse)
有了这些简单的指令集,我们现在有了一个相当强大的过程来提取所有重要的细节。跟随下一页上的链接的能力意味着爬虫将抓取所有可用的结果,而无需任何额外的编码。现在我们已经完成了蜘蛛的准备工作,我们可以继续研究结果。
保存结果
现在解析器已经写好了,我们可以开始使用一些scrapy特性了。我们可以选择使用 ItemPipline 将每个 Item 发送到文件对象存储或数据库。我们可以利用具有高写入吞吐量的高可用分布式数据库(例如DynamoDB、Cassandra)并在表运行时将项目插入表中。
对于这个项目,我将使用内置提要选项从命令行创建一个摘录。我会选择 JSON 行,因为 JSON 编码器将正确转义换行符和引号,作为编组到 JSON 的过程的一部分。与 CSV 相比,这可以为您节省一些将来的麻烦,其中额外的换行符或引号可能会导致解析错误和头痛。当架构不是静态的并且每个项目可能收录的属性不同时,半结构化格式也很有用。
有一种方法可以在配置文件中指定提要,但我将向您展示如何从命令行执行此操作。我们将创建一个 JSON Lines 文件,其中收录捕获到本地文件系统的所有数据。从那里我们可以开始与结果交互以提取价值。
确实爬行抓取 -o jobs.jl
这将需要一些时间来运行,具体取决于您配置的位置和位置的数量。所有 网站 都有某种形式的速率限制。可以通过 CDN 或负载均衡器/反向代理(如 Cloudflare)实现速率限制。速率限制可防止拒绝服务 (DoS) 攻击关闭 Web 服务器。Scrapy 将执行指数退避,直到得到 200 响应代码,这意味着它会在每次失败后等待更长时间,直到请求成功。
分析结果
现在我们有一个收录所有帖子的文件,我们可以开始分析。执行分析的一种方法是使用 Jupyter 笔记本。Jupyter Notebook 可用于探索性数据分析和非线性规划。当我们为发现和分析编码时,我们不知道最终状态是什么样的。我们在写代码的时候,需要改变事物的顺序,做出重大的改变,这就是为什么它被称为非线性规划。Jupyter 使这种编程风格更容易。
Jupyter notebooks 通过使用单元格和 iPython 促进了这种类型的开发。通过使用 iPython 作为后端,它允许您在 REPL 环境中工作。REPL 允许您快速查看执行代码的输出并在创建对象后保留它们。第二部分是可以移动、剪切、复制和删除的单元格。单元格可以轻松更改执行顺序和更改对象的范围。我发现笔记本是我分析结果的好地方。
综上所述
下一步是聚合和规范化数据,分析它,然后创建某种用户界面来访问它。例如,您可以有一个网站,网站 显示所有已爬取的网站 根据自定义条件进行排序和过滤。您可以使用关键字检测来确定提供您最感兴趣的机会的列表的优先级。
用scrapy写spider可以让你通过第一步,解析网页中的数据并保存。这是任何依赖网络爬行数据的数据管道中的第一个组件。一旦您捕获了数据,您就可以开始为您希望的任何应用程序从中提取价值。
您可以从本教程下载收录所有代码的 python 文件。
如何抓取网页数据( Scrapy爬虫框架中meta参数的使用示例演示(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-28 05:08
Scrapy爬虫框架中meta参数的使用示例演示(上))
上一阶段我们实现了通过Scrapy爬取特定网页的具体信息,Scrapy爬虫框架中元参数的使用demo(上),以及Scrapy爬虫中元参数的使用demo框架(下),但是没有实现所有页面的顺序提取。首先我们梳理一下爬行的思路。大体思路是:当获取到第一页的URL后,再将第二页的URL发送给Scrapy,这样Scrapy就会自动下载该网页的信息,然后通过第二页的URL继续获取第三页的网址。由于每个页面的网页结构是相同的,这样反复迭代就可以实现对整个网页的信息提取。具体的实现过程会通过Scrapy框架来实现。具体教程如下。
/执行/
1、首先,URL不再是特定文章的URL,而是所有文章列表的URL,如下图,把链接放在start_urls中,如下图如下图所示。
2、接下来我们需要修改parse()函数,在这个函数中我们需要实现两件事。
首先是获取某个页面上文章的所有URL,并解析得到每个文章中的具体网页内容。二是获取下一个网页的URL,交给Scrapy处理。下载完成后交给parse()函数进行下载。
有了之前的 Xpath 和 CSS 选择器的基础知识,获取一个网页链接的 URL 就变得相对简单了。
3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个网址,而文章的列表存在于id中="在标签“存档”下,然后我们将像剥洋葱一样获得我们想要的URL链接。
4、点击下拉三角,不难发现文章详情页的链接并没有隐藏很深,如下图圆圈所示。
5、根据标签,我们搜索图片并添加选择器工具获取URL,就像搜索某些东西一样。在cmd中输入以下命令进入shell调试窗口,事半功倍。再说一遍,这个网址是所有文章的网址,而不是某个文章的网址。如果不这样做,调试很长时间后将没有结果。
6、根据第四步对网页结构的分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。推荐朋友们在提取网页信息的时候可以经常使用,非常方便。
至此,第一页文章列表的所有URL都已获取。提取URL后,如何交给Scrapy下载?下载完成后,如何调用自己定义的解析函数? 查看全部
如何抓取网页数据(
Scrapy爬虫框架中meta参数的使用示例演示(上))
上一阶段我们实现了通过Scrapy爬取特定网页的具体信息,Scrapy爬虫框架中元参数的使用demo(上),以及Scrapy爬虫中元参数的使用demo框架(下),但是没有实现所有页面的顺序提取。首先我们梳理一下爬行的思路。大体思路是:当获取到第一页的URL后,再将第二页的URL发送给Scrapy,这样Scrapy就会自动下载该网页的信息,然后通过第二页的URL继续获取第三页的网址。由于每个页面的网页结构是相同的,这样反复迭代就可以实现对整个网页的信息提取。具体的实现过程会通过Scrapy框架来实现。具体教程如下。
/执行/
1、首先,URL不再是特定文章的URL,而是所有文章列表的URL,如下图,把链接放在start_urls中,如下图如下图所示。
2、接下来我们需要修改parse()函数,在这个函数中我们需要实现两件事。
首先是获取某个页面上文章的所有URL,并解析得到每个文章中的具体网页内容。二是获取下一个网页的URL,交给Scrapy处理。下载完成后交给parse()函数进行下载。
有了之前的 Xpath 和 CSS 选择器的基础知识,获取一个网页链接的 URL 就变得相对简单了。
3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个网址,而文章的列表存在于id中="在标签“存档”下,然后我们将像剥洋葱一样获得我们想要的URL链接。
4、点击下拉三角,不难发现文章详情页的链接并没有隐藏很深,如下图圆圈所示。
5、根据标签,我们搜索图片并添加选择器工具获取URL,就像搜索某些东西一样。在cmd中输入以下命令进入shell调试窗口,事半功倍。再说一遍,这个网址是所有文章的网址,而不是某个文章的网址。如果不这样做,调试很长时间后将没有结果。
6、根据第四步对网页结构的分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。推荐朋友们在提取网页信息的时候可以经常使用,非常方便。
至此,第一页文章列表的所有URL都已获取。提取URL后,如何交给Scrapy下载?下载完成后,如何调用自己定义的解析函数?
如何抓取网页数据(使用selenium爬取动态网页信息Pythonselenium自动控制 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-27 11:05
)
使用selenium抓取动态网页信息
Python selenium自动控制浏览器抓取网页的数据,包括按钮点击、页面跳转、搜索框输入、页面值数据存储、mongodb自动id识别等。
首先介绍一下Python selenium——一种用于控制浏览器对网页操作的自动化测试工具。将它与爬虫中的 BeautifulSoup 结合起来是无缝的。除了国外一些不正常的验证网页,图片验证码我有自己的破解码。图片验证码源代码成功率为85%。
使用 conda butler 安装:
在cmd命令行输入“conda install selenium”进行安装
您还需要安装 Google Chrome Drive 或 Firefox 浏览器插件
设置环境变量
通过硒访问百度
from selenium import webdriver
#打开一个浏览器
browser = webdriver.Chrome()
#准备一个网址
url = 'http://www.baidu.com'
browser.get(url)
#获取元素
login = browser.find_elements_by_class_name('lb')[0]
print(login)
获取网易云音乐
from selenium import webdriver
#打开浏览器
brower = webdriver.Chrome()
url='https://music.163.com/#/discover/toplist'
brower.get(url)
#寻找logo文字
#logo = brower.find_elements_by_class_name('logo')[0]
#print(logo.text)
#一般情况下动态加载的内容都可以找到
#有一种情况就没有
#就是网页内存在网页框架iframe
#需要切换网页的层级
#语法:brower.switch_to.frame(iframe的id或者你提前获取这个对象,放入此处)
#方法一:id
#brower.switch_to.frame('g_iframe')
#方法二:name
#brower.switch_to.frame('contentFrame')
#方法三:提前用变量存iframe
iframe = brower.find_element_by_id('g_iframe')
brower.switch_to.frame(iframe)
#寻找大容器
toplist = brower.find_element_by_id('toplist')
#寻找tbody 通过标签名
tbody = toplist.find_elements_by_tag_name('tbody')[0]
#寻找所有tr
trs = tbody.find_elements_by_tag_name('tr')
dataList = []
for each in trs:
#排名
rank = each.find_elements_by_tag_name('td')[0].find_elements_by_class_name('num')[0].text
musicName = each.find_elements_by_tag_name('td')[1].find_elements_by_class_name('txt')[0].\
find_element_by_tag_name('b').get_attribute('title')
#print(musicName)
singer = each.find_elements_by_tag_name('td')[3].find_elements_by_class_name('text')[0].\
get_attribute('title')
#print(singer)
dataList.append([rank,musicName,singer])
#print(dataList)
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
ws.title = '云音乐飙升榜'
ws.append(['排名','歌名','歌手'])
for data in dataList:
ws.append(data)
wb.save("云音乐飙升榜.xlsx") 查看全部
如何抓取网页数据(使用selenium爬取动态网页信息Pythonselenium自动控制
)
使用selenium抓取动态网页信息
Python selenium自动控制浏览器抓取网页的数据,包括按钮点击、页面跳转、搜索框输入、页面值数据存储、mongodb自动id识别等。
首先介绍一下Python selenium——一种用于控制浏览器对网页操作的自动化测试工具。将它与爬虫中的 BeautifulSoup 结合起来是无缝的。除了国外一些不正常的验证网页,图片验证码我有自己的破解码。图片验证码源代码成功率为85%。
使用 conda butler 安装:
在cmd命令行输入“conda install selenium”进行安装
您还需要安装 Google Chrome Drive 或 Firefox 浏览器插件
设置环境变量
通过硒访问百度
from selenium import webdriver
#打开一个浏览器
browser = webdriver.Chrome()
#准备一个网址
url = 'http://www.baidu.com'
browser.get(url)
#获取元素
login = browser.find_elements_by_class_name('lb')[0]
print(login)
获取网易云音乐
from selenium import webdriver
#打开浏览器
brower = webdriver.Chrome()
url='https://music.163.com/#/discover/toplist'
brower.get(url)
#寻找logo文字
#logo = brower.find_elements_by_class_name('logo')[0]
#print(logo.text)
#一般情况下动态加载的内容都可以找到
#有一种情况就没有
#就是网页内存在网页框架iframe
#需要切换网页的层级
#语法:brower.switch_to.frame(iframe的id或者你提前获取这个对象,放入此处)
#方法一:id
#brower.switch_to.frame('g_iframe')
#方法二:name
#brower.switch_to.frame('contentFrame')
#方法三:提前用变量存iframe
iframe = brower.find_element_by_id('g_iframe')
brower.switch_to.frame(iframe)
#寻找大容器
toplist = brower.find_element_by_id('toplist')
#寻找tbody 通过标签名
tbody = toplist.find_elements_by_tag_name('tbody')[0]
#寻找所有tr
trs = tbody.find_elements_by_tag_name('tr')
dataList = []
for each in trs:
#排名
rank = each.find_elements_by_tag_name('td')[0].find_elements_by_class_name('num')[0].text
musicName = each.find_elements_by_tag_name('td')[1].find_elements_by_class_name('txt')[0].\
find_element_by_tag_name('b').get_attribute('title')
#print(musicName)
singer = each.find_elements_by_tag_name('td')[3].find_elements_by_class_name('text')[0].\
get_attribute('title')
#print(singer)
dataList.append([rank,musicName,singer])
#print(dataList)
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
ws.title = '云音乐飙升榜'
ws.append(['排名','歌名','歌手'])
for data in dataList:
ws.append(data)
wb.save("云音乐飙升榜.xlsx")
如何抓取网页数据( Python学习笔记之抓取某只基金历史净值数据案例,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-27 05:08
Python学习笔记之抓取某只基金历史净值数据案例,)
Python学习笔记中抓取某基金历史净值数据的实际案例
更新时间:2019-06-03 10:42:04 作者:学习笔记666
本文章主要介绍Python学习笔记中某基金的历史净值数据捕获案例,分析Python基于selenium库的数据捕获以及mysql交互相关的实现技巧结合具体例子。朋友们可以参考一下
本文以Python抓取某基金历史净值数据为例。分享给大家,供大家参考,如下:
1、接下来,我们需要手动抓取html(这部分知识我们之前已经学过,所以现在重温一下)
# coding: utf-8
from selenium.webdriver.support.ui import WebDriverWait
from selenium import webdriver
from bs4 import BeautifulSoup
from threading import Thread,Lock
import os
import csv
# 下面是利用 selenium 抓取html页面的代码
# 初始化函数
def initSpider():
driver = webdriver.PhantomJS(executable_path=r"你phantomjs可执行文件的绝对路径")
driver.get("http://fund.eastmoney.com/f10/ ... 6quot;) # 要抓取的网页地址
# 找到"下一页"按钮,就可以得到它前面的一个label,就是总页数
getPage_text = driver.find_element_by_id("pagebar").find_element_by_xpath(
"div[@class='pagebtns']/label[text()='下一页']/preceding-sibling::label[1]").get_attribute("innerHTML")
# 得到总共有多少页
total_page = int("".join(filter(str.isdigit, getPage_text)))
# 返回
return (driver,total_page)
# 获取html内容
def getData(myrange,driver,lock):
for x in myrange:
# 锁住
lock.acquire()
tonum = driver.find_element_by_id("pagebar").find_element_by_xpath(
"div[@class='pagebtns']/input[@class='pnum']") # 得到 页码文本框
jumpbtn = driver.find_element_by_id("pagebar").find_element_by_xpath(
"div[@class='pagebtns']/input[@class='pgo']") # 跳转到按钮
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpbtn.click() # 点击按钮
# ץȡ
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pagebar").find_element_by_xpath("div[@class='pagebtns']/label[@value={0} and @class='cur']".format(x)) != None)
# 保存到项目中
with open("../htmls/details/{0}.txt".format(x), 'wb') as f:
f.write(driver.find_element_by_id("jztable").get_attribute("innerHTML").encode('utf-8'))
f.close()
# 解锁
lock.release()
# 开始抓取函数
def beginSpider():
# 初始化爬虫
(driver, total_page) = initSpider()
# 创建锁
lock = Lock()
r = range(1, int(total_page)+1)
step = 10
range_list = [r[x:x + step] for x in range(0, len(r), step)] #把页码分段
thread_list = []
for r in range_list:
t = Thread(target=getData, args=(r,driver,lock))
thread_list.append(t)
t.start()
for t in thread_list:
t.join() # 这一步是需要的,等待线程全部执行完成
print("抓取完成")
# #################上面代码就完成了 抓取远程网站html内容并保存到项目中的 过程
需要解释一下这3个函数:
initSpider 函数初始化 selenium webdriver 对象,首先获取我们需要爬取的页面总数。
getData 函数有 3 个参数。对于 myrange,我们仍然需要分段捕获。之前我们学习了太多进程捕获,这里我们多线程捕获; lock参数用于锁定线程,防止线程冲突; driver就是我们在initSpider函数中初始化的webdriver对象。
在 getData 函数中,我们循环 myrange 并将捕获的 html 内容保存在项目目录中。
开始Spider函数,我们在这个函数中对总页数进行分段,并创建一个线程,调用getData。
所以最后一次执行:
beginSpider()
开始抓取该基金的“历史净资产详细信息”。共有 31 页。
2、根据我们学到的python和mysql交互的知识,我们也可以将这些数据写入数据表中。
这里就不赘述了,给出基金的详细表结构:
CREATE TABLE `fund_detail` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`fcode` varchar(10) NOT NULL DEFAULT '' COMMENT '基金代码',
`fdate` datetime DEFAULT NULL COMMENT '基金日期',
`NAV` decimal(10,4) DEFAULT NULL COMMENT '单位净值',
`ACCNAV` decimal(10,4) DEFAULT NULL COMMENT '累计净值',
`DGR` varchar(20) DEFAULT NULL COMMENT '日增长率',
`pstate` varchar(20) DEFAULT NULL COMMENT '申购状态',
`rstate` varchar(20) DEFAULT NULL COMMENT '赎回状态',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='基金详细数据表';
更多Python相关内容请参考本站专题:《Python Socket编程技巧总结》、《Python正则表达式使用总结》、《Python数据结构与算法教程》、《Python函数使用技巧》总结》、《Python字符串操作技巧总结》、《Python入门及进阶经典教程》、《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。 查看全部
如何抓取网页数据(
Python学习笔记之抓取某只基金历史净值数据案例,)
Python学习笔记中抓取某基金历史净值数据的实际案例
更新时间:2019-06-03 10:42:04 作者:学习笔记666
本文章主要介绍Python学习笔记中某基金的历史净值数据捕获案例,分析Python基于selenium库的数据捕获以及mysql交互相关的实现技巧结合具体例子。朋友们可以参考一下
本文以Python抓取某基金历史净值数据为例。分享给大家,供大家参考,如下:
1、接下来,我们需要手动抓取html(这部分知识我们之前已经学过,所以现在重温一下)
# coding: utf-8
from selenium.webdriver.support.ui import WebDriverWait
from selenium import webdriver
from bs4 import BeautifulSoup
from threading import Thread,Lock
import os
import csv
# 下面是利用 selenium 抓取html页面的代码
# 初始化函数
def initSpider():
driver = webdriver.PhantomJS(executable_path=r"你phantomjs可执行文件的绝对路径")
driver.get("http://fund.eastmoney.com/f10/ ... 6quot;) # 要抓取的网页地址
# 找到"下一页"按钮,就可以得到它前面的一个label,就是总页数
getPage_text = driver.find_element_by_id("pagebar").find_element_by_xpath(
"div[@class='pagebtns']/label[text()='下一页']/preceding-sibling::label[1]").get_attribute("innerHTML")
# 得到总共有多少页
total_page = int("".join(filter(str.isdigit, getPage_text)))
# 返回
return (driver,total_page)
# 获取html内容
def getData(myrange,driver,lock):
for x in myrange:
# 锁住
lock.acquire()
tonum = driver.find_element_by_id("pagebar").find_element_by_xpath(
"div[@class='pagebtns']/input[@class='pnum']") # 得到 页码文本框
jumpbtn = driver.find_element_by_id("pagebar").find_element_by_xpath(
"div[@class='pagebtns']/input[@class='pgo']") # 跳转到按钮
tonum.clear() # 第x页 输入框
tonum.send_keys(str(x)) # 去第x页
jumpbtn.click() # 点击按钮
# ץȡ
WebDriverWait(driver, 20).until(lambda driver: driver.find_element_by_id("pagebar").find_element_by_xpath("div[@class='pagebtns']/label[@value={0} and @class='cur']".format(x)) != None)
# 保存到项目中
with open("../htmls/details/{0}.txt".format(x), 'wb') as f:
f.write(driver.find_element_by_id("jztable").get_attribute("innerHTML").encode('utf-8'))
f.close()
# 解锁
lock.release()
# 开始抓取函数
def beginSpider():
# 初始化爬虫
(driver, total_page) = initSpider()
# 创建锁
lock = Lock()
r = range(1, int(total_page)+1)
step = 10
range_list = [r[x:x + step] for x in range(0, len(r), step)] #把页码分段
thread_list = []
for r in range_list:
t = Thread(target=getData, args=(r,driver,lock))
thread_list.append(t)
t.start()
for t in thread_list:
t.join() # 这一步是需要的,等待线程全部执行完成
print("抓取完成")
# #################上面代码就完成了 抓取远程网站html内容并保存到项目中的 过程
需要解释一下这3个函数:
initSpider 函数初始化 selenium webdriver 对象,首先获取我们需要爬取的页面总数。
getData 函数有 3 个参数。对于 myrange,我们仍然需要分段捕获。之前我们学习了太多进程捕获,这里我们多线程捕获; lock参数用于锁定线程,防止线程冲突; driver就是我们在initSpider函数中初始化的webdriver对象。
在 getData 函数中,我们循环 myrange 并将捕获的 html 内容保存在项目目录中。
开始Spider函数,我们在这个函数中对总页数进行分段,并创建一个线程,调用getData。
所以最后一次执行:
beginSpider()
开始抓取该基金的“历史净资产详细信息”。共有 31 页。
2、根据我们学到的python和mysql交互的知识,我们也可以将这些数据写入数据表中。
这里就不赘述了,给出基金的详细表结构:
CREATE TABLE `fund_detail` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`fcode` varchar(10) NOT NULL DEFAULT '' COMMENT '基金代码',
`fdate` datetime DEFAULT NULL COMMENT '基金日期',
`NAV` decimal(10,4) DEFAULT NULL COMMENT '单位净值',
`ACCNAV` decimal(10,4) DEFAULT NULL COMMENT '累计净值',
`DGR` varchar(20) DEFAULT NULL COMMENT '日增长率',
`pstate` varchar(20) DEFAULT NULL COMMENT '申购状态',
`rstate` varchar(20) DEFAULT NULL COMMENT '赎回状态',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='基金详细数据表';
更多Python相关内容请参考本站专题:《Python Socket编程技巧总结》、《Python正则表达式使用总结》、《Python数据结构与算法教程》、《Python函数使用技巧》总结》、《Python字符串操作技巧总结》、《Python入门及进阶经典教程》、《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
如何抓取网页数据(如何抓取网页数据、数据处理、网页性能优化..)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-26 17:02
如何抓取网页数据、数据处理、网页性能优化..上一节中我们学习了python如何从互联网上的静态文件中获取数据,本节继续从url形式抓取数据。本节主要是提供一种抓取网页数据的方法,同时方便后续的抓取项目。第一步,构建分析网页,拿到md5和html的关系。我们用excel中的file函数进行数据抓取。excel中的函数图第二步,在网页上查找到我们需要的所有数据。
excel中的函数如下图所示第三步,对数据进行处理。在本节中,我们拿到html之后先将其变成数组格式。数组形式的数据我们可以拿到总的数据量。在本节中我们只需要抓取每个id获取到的信息。excel中的函数图在网页数据抓取中我们需要使用到的工具就是我们常用的抓包工具。在网页上获取数据就是我们常用的抓包。抓包的方法、工具都有很多,以后有机会将会再次介绍。
网络抓包抓包是什么?抓包,就是抓取网络包,即在网络中发起一个包。在抓包中我们会使用到urllib2,urllib是python中比较好用的urllib。urllib2.encoding是python的一个包,可以处理网络包,urllib2.urlencode是python的一个方法,也是python处理网络包的一个方法。
本次我们只需要抓取一个包。在本地抓包就是在windows下使用ultraiso工具,mac下使用netstat工具。抓包工具的使用方法在下一篇中再详细介绍。网络包怎么获取?我们先来看一下我们在本地抓包的网址(网页抓包方法的其中一种)。以本地为例子,我们本地访问.com后面的网址就是一个url。在windows下:打开浏览器,在浏览器地址栏中输入c:\users\用户名\appdata\local\temp\lxi_pages\baidu\https,返回的页面地址为网页链接,以下是所获取的html代码。
在mac下:打开浏览器,在地址栏中输入,然后回车在python中查找、解析和解析html怎么抓包?每次抓包我们都要浏览网页并输入ip地址,在此,我们可以使用浏览器和浏览器地址栏来查找我们需要的所有数据。http请求我们拿到数据之后还需要解析数据,这个步骤比较简单,我们可以在网上搜索或者自己写一个。下一篇,我们将介绍一种比较酷的方法。
性能优化urllib2是python中比较有用的包,在解析网页和抓取数据,由于urllib2包本身代码比较复杂,对于抓取数据来说代码量太大。因此,我们也可以使用beautifulsoup库进行数据解析。beautifulsoup提供了常用的元素解析方法,可以实现更快的开发。上图为beautifulsoup解析效果示意图:beautifulsoup解析效果示意图构建数据源,在上一节中, 查看全部
如何抓取网页数据(如何抓取网页数据、数据处理、网页性能优化..)
如何抓取网页数据、数据处理、网页性能优化..上一节中我们学习了python如何从互联网上的静态文件中获取数据,本节继续从url形式抓取数据。本节主要是提供一种抓取网页数据的方法,同时方便后续的抓取项目。第一步,构建分析网页,拿到md5和html的关系。我们用excel中的file函数进行数据抓取。excel中的函数图第二步,在网页上查找到我们需要的所有数据。
excel中的函数如下图所示第三步,对数据进行处理。在本节中,我们拿到html之后先将其变成数组格式。数组形式的数据我们可以拿到总的数据量。在本节中我们只需要抓取每个id获取到的信息。excel中的函数图在网页数据抓取中我们需要使用到的工具就是我们常用的抓包工具。在网页上获取数据就是我们常用的抓包。抓包的方法、工具都有很多,以后有机会将会再次介绍。
网络抓包抓包是什么?抓包,就是抓取网络包,即在网络中发起一个包。在抓包中我们会使用到urllib2,urllib是python中比较好用的urllib。urllib2.encoding是python的一个包,可以处理网络包,urllib2.urlencode是python的一个方法,也是python处理网络包的一个方法。
本次我们只需要抓取一个包。在本地抓包就是在windows下使用ultraiso工具,mac下使用netstat工具。抓包工具的使用方法在下一篇中再详细介绍。网络包怎么获取?我们先来看一下我们在本地抓包的网址(网页抓包方法的其中一种)。以本地为例子,我们本地访问.com后面的网址就是一个url。在windows下:打开浏览器,在浏览器地址栏中输入c:\users\用户名\appdata\local\temp\lxi_pages\baidu\https,返回的页面地址为网页链接,以下是所获取的html代码。
在mac下:打开浏览器,在地址栏中输入,然后回车在python中查找、解析和解析html怎么抓包?每次抓包我们都要浏览网页并输入ip地址,在此,我们可以使用浏览器和浏览器地址栏来查找我们需要的所有数据。http请求我们拿到数据之后还需要解析数据,这个步骤比较简单,我们可以在网上搜索或者自己写一个。下一篇,我们将介绍一种比较酷的方法。
性能优化urllib2是python中比较有用的包,在解析网页和抓取数据,由于urllib2包本身代码比较复杂,对于抓取数据来说代码量太大。因此,我们也可以使用beautifulsoup库进行数据解析。beautifulsoup提供了常用的元素解析方法,可以实现更快的开发。上图为beautifulsoup解析效果示意图:beautifulsoup解析效果示意图构建数据源,在上一节中,
如何抓取网页数据(如何抓取网页数据?常用的几种:用浏览器自带的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-25 14:01
如何抓取网页数据?常用的几种:用浏览器自带的方法。用chrome浏览器自带的工具。用ajax技术的工具,使用flash插件,有点像现在流行的adobeflash。用api封装的方法。用一些抓包工具。如何判断网页数据是否抓取成功?如何才能判断网页数据抓取成功呢?先来个直观的,两种方法判断网页数据抓取成功方法a:尝试发送http请求,看响应结果是否成功。
如果成功则说明数据抓取成功方法b:使用formdataurlapi这个接口,这个接口提供验证json对象数据的方法,如果可以响应成功则说明数据抓取成功使用浏览器自带的方法;这个方法比较快,但是要管理网站地址,比较麻烦,不适合小公司小网站的抓取;其他方法,参考h5在线教程对应h5页面,判断是否抓取成功:看body里是否包含标签,如果包含,那么成功抓取,否则不成功,没有抓取到本地数据。
抓取数据分两步:爬虫和数据分析:数据分析可能更偏重于技术上的,爬虫主要关注的是分析和用户操作一般常用的数据抓取工具有requests、scrapy、beautifulsoup、selenium等。以上是常用的工具,如果想写爬虫完成具体的分析,
数据抓取按照功能可以分为网页抓取和非网页抓取,其中网页抓取又可以分为中文数据抓取和中文数据抓取。
一、网页抓取中文数据抓取可以说是最基础,应用最多的抓取方式。最近两年scrapy项目又火了一把,目前很多爬虫工程师都会用scrapy+requests+crawlspider来完成抓取工作。爬虫分为单机爬虫,网站爬虫,分布式爬虫,自动化爬虫,还有一些数据分析抓取。单机爬虫基本上就是自己电脑的爬虫,这是最为基础的一种爬虫,没有之一。中文数据抓取可以用codesheep的api来完成。
1、首先注册一个账号,登录一个第三方。第三方里面有很多网站,基本上所有的中文网站都可以爬取。
2、注册好了,后面就好办了,直接点进去就可以抓取。缺点:不是每个网站都提供api。有些根本就没有api。优点:简单,基本上所有的网站都提供api,没有提供api的,基本上没有任何价值。
3、后面如果有效果我会过来更新。
二、其他数据抓取
1、英文数据抓取这个涉及到爬虫的问题,和中文数据抓取没有太大的关系。但是还是要分享一下,很多人在爬虫的时候无法爬取好数据,然后反复的想办法绕过api。很多人没有打开谷歌浏览器的api开发者工具,去抓取来自于谷歌的数据。有些数据可能也会有,但是大部分数据都是谷歌没有提供api的。
2、日语数据抓取用日语爬取的人不少,但是应该没有人打开日语数据抓取工具抓取, 查看全部
如何抓取网页数据(如何抓取网页数据?常用的几种:用浏览器自带的方法)
如何抓取网页数据?常用的几种:用浏览器自带的方法。用chrome浏览器自带的工具。用ajax技术的工具,使用flash插件,有点像现在流行的adobeflash。用api封装的方法。用一些抓包工具。如何判断网页数据是否抓取成功?如何才能判断网页数据抓取成功呢?先来个直观的,两种方法判断网页数据抓取成功方法a:尝试发送http请求,看响应结果是否成功。
如果成功则说明数据抓取成功方法b:使用formdataurlapi这个接口,这个接口提供验证json对象数据的方法,如果可以响应成功则说明数据抓取成功使用浏览器自带的方法;这个方法比较快,但是要管理网站地址,比较麻烦,不适合小公司小网站的抓取;其他方法,参考h5在线教程对应h5页面,判断是否抓取成功:看body里是否包含标签,如果包含,那么成功抓取,否则不成功,没有抓取到本地数据。
抓取数据分两步:爬虫和数据分析:数据分析可能更偏重于技术上的,爬虫主要关注的是分析和用户操作一般常用的数据抓取工具有requests、scrapy、beautifulsoup、selenium等。以上是常用的工具,如果想写爬虫完成具体的分析,
数据抓取按照功能可以分为网页抓取和非网页抓取,其中网页抓取又可以分为中文数据抓取和中文数据抓取。
一、网页抓取中文数据抓取可以说是最基础,应用最多的抓取方式。最近两年scrapy项目又火了一把,目前很多爬虫工程师都会用scrapy+requests+crawlspider来完成抓取工作。爬虫分为单机爬虫,网站爬虫,分布式爬虫,自动化爬虫,还有一些数据分析抓取。单机爬虫基本上就是自己电脑的爬虫,这是最为基础的一种爬虫,没有之一。中文数据抓取可以用codesheep的api来完成。
1、首先注册一个账号,登录一个第三方。第三方里面有很多网站,基本上所有的中文网站都可以爬取。
2、注册好了,后面就好办了,直接点进去就可以抓取。缺点:不是每个网站都提供api。有些根本就没有api。优点:简单,基本上所有的网站都提供api,没有提供api的,基本上没有任何价值。
3、后面如果有效果我会过来更新。
二、其他数据抓取
1、英文数据抓取这个涉及到爬虫的问题,和中文数据抓取没有太大的关系。但是还是要分享一下,很多人在爬虫的时候无法爬取好数据,然后反复的想办法绕过api。很多人没有打开谷歌浏览器的api开发者工具,去抓取来自于谷歌的数据。有些数据可能也会有,但是大部分数据都是谷歌没有提供api的。
2、日语数据抓取用日语爬取的人不少,但是应该没有人打开日语数据抓取工具抓取,
如何抓取网页数据( 前端工程师如何进行网页爬虫?如何做好网页解析?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-10-22 09:04
前端工程师如何进行网页爬虫?如何做好网页解析?)
如何采集网站数据(如何快速抓取网页数据)
无论是数据分析、数据建模甚至数据挖掘,我们都必须在执行这些高级任务之前进行数据处理。数据是数据工作的基础。没有数据,挖掘毫无意义。俗话说,巧妇难为无米之炊,接下来说说爬虫。
爬虫是采集外部数据的重要途径。常用于竞争分析,也有商家将爬虫用于自己的业务。例如,搜索引擎是最高的爬虫应用程序。当然,爬虫也不能肆无忌惮。如果他们不小心,他们可能会成为面向监狱的编程。
一、什么是爬虫?
爬虫爬取一般是针对特定的网站或App,通过爬虫脚本或程序获取指定页面上的数据采集。意思是通过编程向Web服务器请求数据(HTML形式),然后解析HTML,提取出你想要的数据。
一般来说,爬虫需要掌握一门编程语言。了解HTML、Web服务器、数据库等,建议从python入手快速上手,有很多第三方库可以快速轻松的抓取网页。
二、如何抓取网页
1、 网页分析先
按F12调出网页调试界面,在Element标签下可以看到对应的HTML代码,这些其实就是网页的代码,网页通过hmtl等源代码显示,加载渲染为每个人都看到了。,就像你穿着衣服和化妆(手动搞笑)。
我们可以定位网页元素。左上角有个小按钮,点击它,在网页上找到你要定位的地方,这里可以直接定位到源码,如下图:
我们可以修改源代码看看,把定位到的源代码【python】改成【我是帅哥】,嘿嘿,网页上会发生不同的变化。以上主要是为了科普。这主要是前端工程师的领域。大家看到的地方都是前端的辛苦,后端工程师都在冰山之下。
有点跑题了,回到正题,网页已经解析完毕,你要爬取的元素内容就可以定位了。下一步是打包和编写爬虫脚本。基本网页上能看到的一切都可以爬取,所见即所得。
2、程序如何访问网页
您可以单击网络按钮,通过在浏览器搜索输入框中输入 关键词 来查看我们经历了什么。所涉及的专业内容可能过于复杂。你可能会觉得我输入了一个关键词,网页返回了很多内容。其实就是本地客户端向服务端发送get请求,服务端解析内容。, 经过 TCP 三次握手、四次挥手、网络安全、加密等,最后内容安全返回到你本地客户端,你是不是觉得头开始有点大了,这样我们就可以开心上网冲浪,工程师真不容易~~
了解这些内容有助于我们了解爬虫机制。简单的说,就是一个模拟人登录网页、请求访问、查找返回的网页内容并下载数据的程序。刚才讲了网页网络的内容。常见的请求包括 get 和 post。GET 请求在 URL 上公开请求参数,而 POST 请求参数放在请求正文中。POST 请求方法还会对密码参数进行加密。,所以相对来说比较安全。
程序应该模拟请求头(Request Header)进行访问。除了在发起http请求时提交一些参数之外,我们还定义了一些请求头信息,比如Accept、Host、cookie、User-Agent等,主要是将爬虫程序伪装成一个正式的请求来获取情报内容。
爬虫有点像间谍。它深入到地方,提取我们想要的信息。我不知道在这里做什么,skr~~~
3、接收请求返回的信息
r = requests.get('https://httpbin.org/get')
r.status_code
//返回200r.headers
{
'content-encoding': 'gzip',
'transfer-encoding': 'chunked',
'connection': 'close',
'server': 'nginx/1.0.4',
'x-runtime': '148ms',
'etag': '"e1ca502697e5c9317743dc078f67693f"',
'content-type': 'application/json'
}import requests
r = requests.get('https://api.github.com/events')
r.json()
// 以上操作可以算是最基本的爬虫了,返回内容如下:
[{u'repository': {u'open_issues': 0, u'url': 'https://github.com/...
可以通过解析返回的json字符串得到你想要的数据,恭喜~
三、python自动化爬虫实战
接下来,我们来看看豆瓣电影排行榜的真实爬虫:
#!/usr/bin/env python3# -*- coding: utf-8 -*-"""
Created on Wed Jul 31 15:52:53 2019
@author: kaluosi
"""import requestsimport reimport codecsfrom bs4 import BeautifulSoupfrom openpyxl import Workbookimport pandas as pd
wb = Workbook()
dest_filename = '电影.xlsx'ws1 = wb.active
ws1.title = "电影top250"DOWNLOAD_URL = 'http://movie.douban.com/top250/'def download_page(url):
"""获取url地址页面内容"""
headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}
data = requests.get(url, headers=headers).content return datadef get_li(doc):
soup = BeautifulSoup(doc, 'html.parser')
ol = soup.find('ol', class_='grid_view')
name = [] # 名字
star_con = [] # 评价人数
score = [] # 评分
info_list = [] # 短评
for i in ol.find_all('li'):
detail = i.find('div', attrs={'class': 'hd'})
movie_name = detail.find('span', attrs={'class': 'title'}).get_text() # 电影名字
level_star = i.find('span', attrs={'class': 'rating_num'}).get_text() # 评分
star = i.find('div', attrs={'class': 'star'})
star_num = star.find(text=re.compile('评价')) # 评价
info = i.find('span', attrs={'class': 'inq'}) # 短评
if info: # 判断是否有短评
info_list.append(info.get_text()) else:
info_list.append('无')
score.append(level_star)
name.append(movie_name)
star_con.append(star_num)
page = soup.find('span', attrs={'class': 'next'}).find('a') # 获取下一页
if page: return name, star_con, score, info_list, DOWNLOAD_URL + page['href'] return name, star_con, score, info_list, Nonedef main():
url = DOWNLOAD_URL
name = []
star_con = []
score = []
info = [] while url:
doc = download_page(url)
movie, star, level_num, info_list, url = get_li(doc)
name = name + movie
star_con = star_con + star
score = score + level_num
info = info + info_list #pandas处理数据
c = {'电影名称':name , '评论人数':star_con , '电影评分':score , '评论':info}
data = pd.DataFrame(c)
data.to_excel('豆瓣影评.xlsx')if __name__ == '__main__':
main()
写在最后
最后,这次文章的爬虫仅限于交流和学习。
版权声明:转载本文是为了传达更多信息。如来源标注有误或侵犯您的合法权益,请持权属证明与本站联系,我们将及时更正、删除。感谢您的支持和理解。 查看全部
如何抓取网页数据(
前端工程师如何进行网页爬虫?如何做好网页解析?)
如何采集网站数据(如何快速抓取网页数据)
无论是数据分析、数据建模甚至数据挖掘,我们都必须在执行这些高级任务之前进行数据处理。数据是数据工作的基础。没有数据,挖掘毫无意义。俗话说,巧妇难为无米之炊,接下来说说爬虫。
爬虫是采集外部数据的重要途径。常用于竞争分析,也有商家将爬虫用于自己的业务。例如,搜索引擎是最高的爬虫应用程序。当然,爬虫也不能肆无忌惮。如果他们不小心,他们可能会成为面向监狱的编程。
一、什么是爬虫?
爬虫爬取一般是针对特定的网站或App,通过爬虫脚本或程序获取指定页面上的数据采集。意思是通过编程向Web服务器请求数据(HTML形式),然后解析HTML,提取出你想要的数据。
一般来说,爬虫需要掌握一门编程语言。了解HTML、Web服务器、数据库等,建议从python入手快速上手,有很多第三方库可以快速轻松的抓取网页。
二、如何抓取网页
1、 网页分析先
按F12调出网页调试界面,在Element标签下可以看到对应的HTML代码,这些其实就是网页的代码,网页通过hmtl等源代码显示,加载渲染为每个人都看到了。,就像你穿着衣服和化妆(手动搞笑)。
我们可以定位网页元素。左上角有个小按钮,点击它,在网页上找到你要定位的地方,这里可以直接定位到源码,如下图:
我们可以修改源代码看看,把定位到的源代码【python】改成【我是帅哥】,嘿嘿,网页上会发生不同的变化。以上主要是为了科普。这主要是前端工程师的领域。大家看到的地方都是前端的辛苦,后端工程师都在冰山之下。
有点跑题了,回到正题,网页已经解析完毕,你要爬取的元素内容就可以定位了。下一步是打包和编写爬虫脚本。基本网页上能看到的一切都可以爬取,所见即所得。
2、程序如何访问网页
您可以单击网络按钮,通过在浏览器搜索输入框中输入 关键词 来查看我们经历了什么。所涉及的专业内容可能过于复杂。你可能会觉得我输入了一个关键词,网页返回了很多内容。其实就是本地客户端向服务端发送get请求,服务端解析内容。, 经过 TCP 三次握手、四次挥手、网络安全、加密等,最后内容安全返回到你本地客户端,你是不是觉得头开始有点大了,这样我们就可以开心上网冲浪,工程师真不容易~~
了解这些内容有助于我们了解爬虫机制。简单的说,就是一个模拟人登录网页、请求访问、查找返回的网页内容并下载数据的程序。刚才讲了网页网络的内容。常见的请求包括 get 和 post。GET 请求在 URL 上公开请求参数,而 POST 请求参数放在请求正文中。POST 请求方法还会对密码参数进行加密。,所以相对来说比较安全。
程序应该模拟请求头(Request Header)进行访问。除了在发起http请求时提交一些参数之外,我们还定义了一些请求头信息,比如Accept、Host、cookie、User-Agent等,主要是将爬虫程序伪装成一个正式的请求来获取情报内容。
爬虫有点像间谍。它深入到地方,提取我们想要的信息。我不知道在这里做什么,skr~~~
3、接收请求返回的信息
r = requests.get('https://httpbin.org/get')
r.status_code
//返回200r.headers
{
'content-encoding': 'gzip',
'transfer-encoding': 'chunked',
'connection': 'close',
'server': 'nginx/1.0.4',
'x-runtime': '148ms',
'etag': '"e1ca502697e5c9317743dc078f67693f"',
'content-type': 'application/json'
}import requests
r = requests.get('https://api.github.com/events')
r.json()
// 以上操作可以算是最基本的爬虫了,返回内容如下:
[{u'repository': {u'open_issues': 0, u'url': 'https://github.com/...
可以通过解析返回的json字符串得到你想要的数据,恭喜~
三、python自动化爬虫实战
接下来,我们来看看豆瓣电影排行榜的真实爬虫:
#!/usr/bin/env python3# -*- coding: utf-8 -*-"""
Created on Wed Jul 31 15:52:53 2019
@author: kaluosi
"""import requestsimport reimport codecsfrom bs4 import BeautifulSoupfrom openpyxl import Workbookimport pandas as pd
wb = Workbook()
dest_filename = '电影.xlsx'ws1 = wb.active
ws1.title = "电影top250"DOWNLOAD_URL = 'http://movie.douban.com/top250/'def download_page(url):
"""获取url地址页面内容"""
headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}
data = requests.get(url, headers=headers).content return datadef get_li(doc):
soup = BeautifulSoup(doc, 'html.parser')
ol = soup.find('ol', class_='grid_view')
name = [] # 名字
star_con = [] # 评价人数
score = [] # 评分
info_list = [] # 短评
for i in ol.find_all('li'):
detail = i.find('div', attrs={'class': 'hd'})
movie_name = detail.find('span', attrs={'class': 'title'}).get_text() # 电影名字
level_star = i.find('span', attrs={'class': 'rating_num'}).get_text() # 评分
star = i.find('div', attrs={'class': 'star'})
star_num = star.find(text=re.compile('评价')) # 评价
info = i.find('span', attrs={'class': 'inq'}) # 短评
if info: # 判断是否有短评
info_list.append(info.get_text()) else:
info_list.append('无')
score.append(level_star)
name.append(movie_name)
star_con.append(star_num)
page = soup.find('span', attrs={'class': 'next'}).find('a') # 获取下一页
if page: return name, star_con, score, info_list, DOWNLOAD_URL + page['href'] return name, star_con, score, info_list, Nonedef main():
url = DOWNLOAD_URL
name = []
star_con = []
score = []
info = [] while url:
doc = download_page(url)
movie, star, level_num, info_list, url = get_li(doc)
name = name + movie
star_con = star_con + star
score = score + level_num
info = info + info_list #pandas处理数据
c = {'电影名称':name , '评论人数':star_con , '电影评分':score , '评论':info}
data = pd.DataFrame(c)
data.to_excel('豆瓣影评.xlsx')if __name__ == '__main__':
main()
写在最后
最后,这次文章的爬虫仅限于交流和学习。
版权声明:转载本文是为了传达更多信息。如来源标注有误或侵犯您的合法权益,请持权属证明与本站联系,我们将及时更正、删除。感谢您的支持和理解。
如何抓取网页数据(网站数据抓取网站目前对爬虫开放了、get和request3种数据提取方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-22 08:05
如何抓取网页数据,即如何从一个网页一个人的头像中,提取所需要的数据。如果从准确率较高的模板,提取所需要的对应数据,相对来说会复杂很多。下面我们就来逐一阐述网站数据抓取网站目前对爬虫开放了post、get和request3种数据提取方式1.post方式网站举例:/#/meta/trailer/a-my-world.html【1】-my-world.html【2】-my-world.html【3】-args.json#easy-to-post【4】-get方式网站举例:url-generates-a-google-file.php【1】-websites-get-websites.html【2】-websites-get-the-google-chrome-websites-generator.html【3】-easy-to-get/url-talking.html举例分析:【1】:第一部分,首先请求defpost(url)函数,其返回的url是个http请求的报文,但是我们却希望获取一个cookie。
【2】:ifurl=='':method='post'method='multipart/form-data'#...对应详情参见官方文档-websites-get-websites.html#loaded/image.jpg#loaded/text(3。
5)===-websites-get-the-google-chrome-websites-generator.html#loaded/image.jpg#loaded/text(3
5)===form-data['requestid']="choice"choice="0"#下载官方的第四节习题>>>form-data['specification']="image-extraction。jpg"#下载官方的第五节习题>>>form-data['useragent']="mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/60。3061。132safari/537。36"#官方文档分析第一篇的习题>>>form-data['draft_id']="5s"#官方文档分析第二篇的习题>>>form-data['response_access_token']="crypto"#官方文档分析第三篇的习题>>>form-data['request_type']="get"#官方文档分析第五篇的习题>>>form-data['username']="jack"#官方文档分析第六篇的习题>>>form-data['password']="what"#官方文档分析第七篇的习题>>>。 查看全部
如何抓取网页数据(网站数据抓取网站目前对爬虫开放了、get和request3种数据提取方式)
如何抓取网页数据,即如何从一个网页一个人的头像中,提取所需要的数据。如果从准确率较高的模板,提取所需要的对应数据,相对来说会复杂很多。下面我们就来逐一阐述网站数据抓取网站目前对爬虫开放了post、get和request3种数据提取方式1.post方式网站举例:/#/meta/trailer/a-my-world.html【1】-my-world.html【2】-my-world.html【3】-args.json#easy-to-post【4】-get方式网站举例:url-generates-a-google-file.php【1】-websites-get-websites.html【2】-websites-get-the-google-chrome-websites-generator.html【3】-easy-to-get/url-talking.html举例分析:【1】:第一部分,首先请求defpost(url)函数,其返回的url是个http请求的报文,但是我们却希望获取一个cookie。
【2】:ifurl=='':method='post'method='multipart/form-data'#...对应详情参见官方文档-websites-get-websites.html#loaded/image.jpg#loaded/text(3。
5)===-websites-get-the-google-chrome-websites-generator.html#loaded/image.jpg#loaded/text(3
5)===form-data['requestid']="choice"choice="0"#下载官方的第四节习题>>>form-data['specification']="image-extraction。jpg"#下载官方的第五节习题>>>form-data['useragent']="mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/60。3061。132safari/537。36"#官方文档分析第一篇的习题>>>form-data['draft_id']="5s"#官方文档分析第二篇的习题>>>form-data['response_access_token']="crypto"#官方文档分析第三篇的习题>>>form-data['request_type']="get"#官方文档分析第五篇的习题>>>form-data['username']="jack"#官方文档分析第六篇的习题>>>form-data['password']="what"#官方文档分析第七篇的习题>>>。
如何抓取网页数据(如何在爬网时避免检测网络抓取(图)阻塞)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-22 07:11
爬行时如何避免检测
网络抓取是指从 Internet 上的各个站点采集和提取信息以供个人使用。通过抓取,您可以从其他站点采集有价值的数据,以帮助您改进网页。例如,您可以从竞争对手的网站 采集定价和折扣数据以改善您的业务网站。您获得的数据还可以帮助您了解产品的哪些功能需要改进、标准价格设置和提供的折扣百分比以及其他可以为您提供竞争优势的数据。
由于网络抓取对您的在线业务的成功至关重要,因此您必须尽职尽责地进行,以免在此过程中被阻止。顾名思义,网络抓取涉及非常快速地采集大量数据。因此,这个过程会对爬取到的网站的性能产生负面影响。出于这个原因,网络管理员密切关注可能的爬虫。尽管大多数网站可能没有适当的反爬虫机制,但其他网站已经提出了防止爬虫的巧妙方法。
网络抓取代理如何帮助您进行数据挖掘
阻塞是网络爬虫可能发生的最令人失望的事情之一。幸运的是,有几种聪明的方法可以避免这种情况。即使您被特定网站列入黑名单,也有办法绕过限制并采集急需的数据。虽然渗透受限网站需要大量细致的工作,但如果使用优质的网页抓取代理是可以做到的。这里有一些最聪明的爬行代理选项,可以轻松获取您感兴趣的数据。
共享代理
顾名思义,共享代理允许多个用户同时使用它。它们是伪装身份的绝佳工具,适用于匿名网络抓取。如果您没有足够的现金来确保您拥有私人或专职代理,那么共享代理是最合适的。它们比我们将在此处讨论的其他选项相对便宜。但是,它们并不太复杂,因此不能保证您的安全。
尽管如此,共享代理可以执行绕过网络过滤器、隐藏您的身份和伪装您的地理位置的主要作用。它们也适用于网络爬虫,可以适应机器人的使用。共享代理可能不是您的最佳选择,但您可以最大限度地提高其安全性和性能。您所需要的只是一个可靠的网络抓取代理提供商,为您提供正确的 IP。
私人代理
与共享代理不同,私有代理一次只为一个用户提供服务。私人代理永远不会允许两个用户同时连接到 Internet。由于其出色的安全特性和完美的匿名性,它们是最受企业欢迎的IP代理。例如,大多数旅行票价聚合公司依靠私人代理从航空公司网站 采集基本数据,而不管任何 IP 限制。
私人代理是从竞争对手那里获取有关定价、折扣和新兴趋势的有价值信息的重要工具。私人代理也是创建和运营多个个人和商业社交媒体账户的最佳选择。确保您保持较低的频率,这样您就可以确保在最严格的网络抓取限制中幸存下来。
数据中心代理
数据中心代理有两种主要类型:安全套接字代理 (SOCKS) 和超文本传输协议代理 (HTTP)。在隐藏身份和地理位置时,两者都是流行的网络抓取解决方案。与前面提到的其他选项不同,数据中心代理完全独立于您的 Internet 连接和 ISP。代理独立于 Internet 连接,因此无需链接到特定位置即可使用。
基本上,数据中心代理是由互联网服务提供商以外的另一家公司提供的 IP 地址。每次您通过数据中心代理访问 Internet 时,网络都会识别数据中心代理的凭据,而不是您的实际身份。没有关于您的网络活动的可追踪信息。
住宅代理
住宅代理和数据中心代理的区别在于,它们连接到无法禁止的真实住宅地址。因此,住宅代理有效地隐藏了您的 IP 地址并从网络采集重要数据。住宅代理的主要优点是不受限制。它们也是完全合法的,允许每分钟发送更多请求。另一方面,它们比其他代理更昂贵且更难获得。
网络抓取并不违法。获取有价值的数据很重要,这可以将您的业务提升到一个新的水平。但是,您需要注意它的处理方式和采集的数据类型。为了充分利用网页抓取的优势,请确保您找到可靠的网页抓取代理提供商,为您提供适合您业务需求的优质代理! 查看全部
如何抓取网页数据(如何在爬网时避免检测网络抓取(图)阻塞)
爬行时如何避免检测
网络抓取是指从 Internet 上的各个站点采集和提取信息以供个人使用。通过抓取,您可以从其他站点采集有价值的数据,以帮助您改进网页。例如,您可以从竞争对手的网站 采集定价和折扣数据以改善您的业务网站。您获得的数据还可以帮助您了解产品的哪些功能需要改进、标准价格设置和提供的折扣百分比以及其他可以为您提供竞争优势的数据。
由于网络抓取对您的在线业务的成功至关重要,因此您必须尽职尽责地进行,以免在此过程中被阻止。顾名思义,网络抓取涉及非常快速地采集大量数据。因此,这个过程会对爬取到的网站的性能产生负面影响。出于这个原因,网络管理员密切关注可能的爬虫。尽管大多数网站可能没有适当的反爬虫机制,但其他网站已经提出了防止爬虫的巧妙方法。
网络抓取代理如何帮助您进行数据挖掘
阻塞是网络爬虫可能发生的最令人失望的事情之一。幸运的是,有几种聪明的方法可以避免这种情况。即使您被特定网站列入黑名单,也有办法绕过限制并采集急需的数据。虽然渗透受限网站需要大量细致的工作,但如果使用优质的网页抓取代理是可以做到的。这里有一些最聪明的爬行代理选项,可以轻松获取您感兴趣的数据。
共享代理
顾名思义,共享代理允许多个用户同时使用它。它们是伪装身份的绝佳工具,适用于匿名网络抓取。如果您没有足够的现金来确保您拥有私人或专职代理,那么共享代理是最合适的。它们比我们将在此处讨论的其他选项相对便宜。但是,它们并不太复杂,因此不能保证您的安全。
尽管如此,共享代理可以执行绕过网络过滤器、隐藏您的身份和伪装您的地理位置的主要作用。它们也适用于网络爬虫,可以适应机器人的使用。共享代理可能不是您的最佳选择,但您可以最大限度地提高其安全性和性能。您所需要的只是一个可靠的网络抓取代理提供商,为您提供正确的 IP。
私人代理
与共享代理不同,私有代理一次只为一个用户提供服务。私人代理永远不会允许两个用户同时连接到 Internet。由于其出色的安全特性和完美的匿名性,它们是最受企业欢迎的IP代理。例如,大多数旅行票价聚合公司依靠私人代理从航空公司网站 采集基本数据,而不管任何 IP 限制。
私人代理是从竞争对手那里获取有关定价、折扣和新兴趋势的有价值信息的重要工具。私人代理也是创建和运营多个个人和商业社交媒体账户的最佳选择。确保您保持较低的频率,这样您就可以确保在最严格的网络抓取限制中幸存下来。
数据中心代理
数据中心代理有两种主要类型:安全套接字代理 (SOCKS) 和超文本传输协议代理 (HTTP)。在隐藏身份和地理位置时,两者都是流行的网络抓取解决方案。与前面提到的其他选项不同,数据中心代理完全独立于您的 Internet 连接和 ISP。代理独立于 Internet 连接,因此无需链接到特定位置即可使用。
基本上,数据中心代理是由互联网服务提供商以外的另一家公司提供的 IP 地址。每次您通过数据中心代理访问 Internet 时,网络都会识别数据中心代理的凭据,而不是您的实际身份。没有关于您的网络活动的可追踪信息。
住宅代理
住宅代理和数据中心代理的区别在于,它们连接到无法禁止的真实住宅地址。因此,住宅代理有效地隐藏了您的 IP 地址并从网络采集重要数据。住宅代理的主要优点是不受限制。它们也是完全合法的,允许每分钟发送更多请求。另一方面,它们比其他代理更昂贵且更难获得。
网络抓取并不违法。获取有价值的数据很重要,这可以将您的业务提升到一个新的水平。但是,您需要注意它的处理方式和采集的数据类型。为了充分利用网页抓取的优势,请确保您找到可靠的网页抓取代理提供商,为您提供适合您业务需求的优质代理!
如何抓取网页数据( 如何用PowerBI批量采集多个网页的数据?(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2021-10-18 04:12
如何用PowerBI批量采集多个网页的数据?(二))
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,
从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页时,排序后的数据结构与第一页的数据结构相同。采集的数据可以直接使用;这里不做排序也没关系,可以等到采集所有网页数据排序在一起。
如果要大量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并将第一行的URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取网站数据之前,先尝试采集一页,如果可以采集,则使用上面的步骤,如果采集不行当它到达时,不再有任何延迟。
现在打开 PowerBI 并尝试抓取您感兴趣的 网站 数据。
Power Query 系列评论:
结束
提高技能,拓宽视野 查看全部
如何抓取网页数据(
如何用PowerBI批量采集多个网页的数据?(二))
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,
从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页时,排序后的数据结构与第一页的数据结构相同。采集的数据可以直接使用;这里不做排序也没关系,可以等到采集所有网页数据排序在一起。
如果要大量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并将第一行的URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取网站数据之前,先尝试采集一页,如果可以采集,则使用上面的步骤,如果采集不行当它到达时,不再有任何延迟。
现在打开 PowerBI 并尝试抓取您感兴趣的 网站 数据。
Power Query 系列评论:
结束
提高技能,拓宽视野
如何抓取网页数据(如何使用Beautifulsoup构建一个简单的PythonWebScraper库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-15 17:26
美汤
BeautifulSoup 是一个解析库,用于解析 HTML 和 XML 文件。它将 Web 文档转换为解析树,以便您可以以 Python 的方式遍历和操作它。使用 BeautiSoup,您可以解析 HTML 中可用的任何所需数据。重要的是要知道 BeautifulSoup 没有自己的解析器,它位于其他解析器(例如 lxml 甚至 html)之上。
在解析网络数据时,BeautifulSoup 是最受欢迎的选择。它很容易学习和掌握。使用 BeautifulSoup 解析网页时,即使页面的 HTML 乱七八糟,也不会遇到问题。
就像讨论的其他库一样,您可以通过 pip 安装它。在命令提示符中输入以下命令。
pip install beautifulsoup4
以下代码可以抓取尼日利亚的 LGA 列表并将其打印到控制台。BeautifulSoup 没有下载网页的功能,所以我们将使用 Python Requests 库。
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/ ... ot%3B
page_content = requests.get(url).text
soup = BeautifulSoup(page_content, "html.parser")
table = soup.find("table", {"class": "wikitable"})
lga_trs = table.find_all("tr")[1:]
for i in lga_trs:
tds = i.find_all("td")
td1 = tds[0].find("a")
td2 = tds[1].find("a")
l_name = td1.contents[0]
l_url = td1["href"]
l_state = td2["title"]
l_state_url = td2["href"]
print([l_name,l_url, l_state, l_state_url])
阅读更多,如何使用 Beautifulsoup 构建一个简单的 Python Web Scraper
xml文件
从库的名字就可以知道它和XML有关。其实它是一个解析器——它确实是一个解析器,不像BeautifulSoup,它是作为解析器顶部的一个解析库。除了 XML 文件,lxml 还可以用于解析 HTML 文件。您可能想知道 lxml 是 BeautifulSoup 用来将 Web 文档转换为要解析的树的解析器之一。
LXML 解析速度非常快。然而,它很难学习和掌握。大多数网页抓取工具不会单独使用它,而是将其用作 BeautifulSoup 使用的解析器。因此,实际上不需要代码示例,因为您不会单独使用它。
从这个库的名字可以看出,它与XML有关。实际上,它是一个解析器——一个真正的解析器,不像 BeautifulSoup 坐在解析器之上,充当解析库。除了 XML 文件,lxml 还可以用于解析 HTML 文件。lxml 是 BeautifulSoup 使用的解析器之一,用于将网页文档转换为要解析的树。
解析时,Lxml 非常快。然而,它很难学习和掌握。大多数网络爬虫不会单独使用它,而是将其用作 BeautifulSoup 使用的解析器。因此,实际上不需要代码示例,因为您不会单独使用它。
Lxml 可以在 Pypi 存储库中使用,因此您可以使用 pip 命令来安装它。下面是安装 lxml 的命令。
pip install lxml
Python网络爬虫框架
与仅用于一个功能的库不同,该框架是一个完整的工具,收录了开发网络爬虫所需的大量功能,包括发送HTTP请求和解析请求的功能。
刮痧
Scrapy 是最受欢迎且可以说是最好的 Web 抓取框架,它作为开源工具公开可用。它是由 Scrapinghub 创建的,目前仍处于广泛的管理之下。
Scrapy是一个完整的框架,负责发送请求,解析下载页面所需的数据。Scrapy 是多线程的,是所有 Python 框架和库中最快的。它使复杂的网络爬行变得容易。但是,一个相关的问题是它无法渲染和执行 JavaScript,因此它需要使用 Selenium 或 Splash。
Scrapy 在 Pypi 上可用,因此您可以使用 pip 命令安装它。以下是在命令提示符/终端上运行以下载和安装 Scrapy 的命令。
pip install scrapy
如前所述,Scrapy 是一个完整的框架,没有简单的学习曲线。对于代码示例,您需要编写大量代码,并且在上述情况下无法像这样工作。如需了解 Scrapy 代码示例,请访问 Scrapy网站 官方教程页面。
阅读更多:Scrapy Vs Beautifulsoup Vs Selenium Web 抓取
蜘蛛
Pyspider 是另一个为 Python 程序员开发的网页抓取框架,用于开发网页抓取工具。Pyspider 是一个强大的网络爬虫框架,可用于为现代网络创建网络抓取工具。与 Scrapy 无法自行渲染 JavaScript 的情况不同,Pyspider 擅长做这项工作。但是,Scrapy 在可靠性和成熟度方面远远领先于 Pyspider。支持分布式架构,支持Python 2和Python 3。支持海量数据库系统,拥有强大的WebUI监控爬虫/爬虫性能。要运行它,它必须在服务器上。
Pyspider 是另一个为 Python 程序员编写的网页抓取框架,用于开发网页抓取工具。Pyspider 是一个强大的网络爬虫框架,您可以使用它为现代网络创建网络爬虫。与 Scrapy 本身不呈现 JavaScript 的情况不同,Pyspider 在这方面做得很好。但是,Scrapy 在可靠性和成熟度方面远远领先于 Pyspider。支持分布式架构,提供对Python 2和Python 3的支持,支持大量的数据库系统,自带强大的WebUI监控性能。
您可以使用下面的 pip 命令安装 Pyspider。
pip install pyspider
以下代码是 Pyspider 在其文档页面上提供的示例代码。它抓取 Scrapy 主页上的链接。
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {}
@every(minutes=24 * 60)
def on_start(self):
self.crawl("https://scrapy.org/", callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a][href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
def detail_page(self, response):
return {"url": response.url, "title": response.doc('title').text()
如前所述,Pyspider 运行在服务器上。您的计算机是一台服务器,它将从本地主机上侦听以运行它。
pyspider
命令和访问:5000/
有关的:
综上所述
当谈到 Python 编程语言中用于网页抓取的工具、库和框架的数量时,您需要了解很多。但是,您无法全部学习。如果你正在开发一个不需要复杂架构的简单scraper,那么你可以使用request和BeautifulSoup——如果网站使用大量javascript,你也可以添加Selenium。硒甚至可以单独使用。但是,当你想开发一个复杂的网络爬虫或爬虫时,你可以使用 Scrapy 框架。
这个 文章 有用吗?
点击星标以对其进行评分!
提交评分
平均评分 0 / 5. 投票数:0
至今没有投票!成为第一个评论此 文章 的人。
相关文章 查看全部
如何抓取网页数据(如何使用Beautifulsoup构建一个简单的PythonWebScraper库)
美汤
BeautifulSoup 是一个解析库,用于解析 HTML 和 XML 文件。它将 Web 文档转换为解析树,以便您可以以 Python 的方式遍历和操作它。使用 BeautiSoup,您可以解析 HTML 中可用的任何所需数据。重要的是要知道 BeautifulSoup 没有自己的解析器,它位于其他解析器(例如 lxml 甚至 html)之上。
在解析网络数据时,BeautifulSoup 是最受欢迎的选择。它很容易学习和掌握。使用 BeautifulSoup 解析网页时,即使页面的 HTML 乱七八糟,也不会遇到问题。
就像讨论的其他库一样,您可以通过 pip 安装它。在命令提示符中输入以下命令。
pip install beautifulsoup4
以下代码可以抓取尼日利亚的 LGA 列表并将其打印到控制台。BeautifulSoup 没有下载网页的功能,所以我们将使用 Python Requests 库。
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/ ... ot%3B
page_content = requests.get(url).text
soup = BeautifulSoup(page_content, "html.parser")
table = soup.find("table", {"class": "wikitable"})
lga_trs = table.find_all("tr")[1:]
for i in lga_trs:
tds = i.find_all("td")
td1 = tds[0].find("a")
td2 = tds[1].find("a")
l_name = td1.contents[0]
l_url = td1["href"]
l_state = td2["title"]
l_state_url = td2["href"]
print([l_name,l_url, l_state, l_state_url])
阅读更多,如何使用 Beautifulsoup 构建一个简单的 Python Web Scraper
xml文件
从库的名字就可以知道它和XML有关。其实它是一个解析器——它确实是一个解析器,不像BeautifulSoup,它是作为解析器顶部的一个解析库。除了 XML 文件,lxml 还可以用于解析 HTML 文件。您可能想知道 lxml 是 BeautifulSoup 用来将 Web 文档转换为要解析的树的解析器之一。
LXML 解析速度非常快。然而,它很难学习和掌握。大多数网页抓取工具不会单独使用它,而是将其用作 BeautifulSoup 使用的解析器。因此,实际上不需要代码示例,因为您不会单独使用它。
从这个库的名字可以看出,它与XML有关。实际上,它是一个解析器——一个真正的解析器,不像 BeautifulSoup 坐在解析器之上,充当解析库。除了 XML 文件,lxml 还可以用于解析 HTML 文件。lxml 是 BeautifulSoup 使用的解析器之一,用于将网页文档转换为要解析的树。
解析时,Lxml 非常快。然而,它很难学习和掌握。大多数网络爬虫不会单独使用它,而是将其用作 BeautifulSoup 使用的解析器。因此,实际上不需要代码示例,因为您不会单独使用它。
Lxml 可以在 Pypi 存储库中使用,因此您可以使用 pip 命令来安装它。下面是安装 lxml 的命令。
pip install lxml
Python网络爬虫框架
与仅用于一个功能的库不同,该框架是一个完整的工具,收录了开发网络爬虫所需的大量功能,包括发送HTTP请求和解析请求的功能。
刮痧
Scrapy 是最受欢迎且可以说是最好的 Web 抓取框架,它作为开源工具公开可用。它是由 Scrapinghub 创建的,目前仍处于广泛的管理之下。
Scrapy是一个完整的框架,负责发送请求,解析下载页面所需的数据。Scrapy 是多线程的,是所有 Python 框架和库中最快的。它使复杂的网络爬行变得容易。但是,一个相关的问题是它无法渲染和执行 JavaScript,因此它需要使用 Selenium 或 Splash。
Scrapy 在 Pypi 上可用,因此您可以使用 pip 命令安装它。以下是在命令提示符/终端上运行以下载和安装 Scrapy 的命令。
pip install scrapy
如前所述,Scrapy 是一个完整的框架,没有简单的学习曲线。对于代码示例,您需要编写大量代码,并且在上述情况下无法像这样工作。如需了解 Scrapy 代码示例,请访问 Scrapy网站 官方教程页面。
阅读更多:Scrapy Vs Beautifulsoup Vs Selenium Web 抓取
蜘蛛
Pyspider 是另一个为 Python 程序员开发的网页抓取框架,用于开发网页抓取工具。Pyspider 是一个强大的网络爬虫框架,可用于为现代网络创建网络抓取工具。与 Scrapy 无法自行渲染 JavaScript 的情况不同,Pyspider 擅长做这项工作。但是,Scrapy 在可靠性和成熟度方面远远领先于 Pyspider。支持分布式架构,支持Python 2和Python 3。支持海量数据库系统,拥有强大的WebUI监控爬虫/爬虫性能。要运行它,它必须在服务器上。
Pyspider 是另一个为 Python 程序员编写的网页抓取框架,用于开发网页抓取工具。Pyspider 是一个强大的网络爬虫框架,您可以使用它为现代网络创建网络爬虫。与 Scrapy 本身不呈现 JavaScript 的情况不同,Pyspider 在这方面做得很好。但是,Scrapy 在可靠性和成熟度方面远远领先于 Pyspider。支持分布式架构,提供对Python 2和Python 3的支持,支持大量的数据库系统,自带强大的WebUI监控性能。
您可以使用下面的 pip 命令安装 Pyspider。
pip install pyspider
以下代码是 Pyspider 在其文档页面上提供的示例代码。它抓取 Scrapy 主页上的链接。
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {}
@every(minutes=24 * 60)
def on_start(self):
self.crawl("https://scrapy.org/", callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a][href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
def detail_page(self, response):
return {"url": response.url, "title": response.doc('title').text()
如前所述,Pyspider 运行在服务器上。您的计算机是一台服务器,它将从本地主机上侦听以运行它。
pyspider
命令和访问:5000/
有关的:
综上所述
当谈到 Python 编程语言中用于网页抓取的工具、库和框架的数量时,您需要了解很多。但是,您无法全部学习。如果你正在开发一个不需要复杂架构的简单scraper,那么你可以使用request和BeautifulSoup——如果网站使用大量javascript,你也可以添加Selenium。硒甚至可以单独使用。但是,当你想开发一个复杂的网络爬虫或爬虫时,你可以使用 Scrapy 框架。
这个 文章 有用吗?
点击星标以对其进行评分!
提交评分
平均评分 0 / 5. 投票数:0
至今没有投票!成为第一个评论此 文章 的人。
相关文章
如何抓取网页数据(如何抓取网页数据,一直是不少朋友们提出的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-15 05:04
如何抓取网页数据,一直是不少朋友们提出的问题。当问到具体操作时,无人能够细说;但是如果谈到数据结构以及转换时,不少朋友则面露尴尬,并寻求更多的方法。一切的问题,源于数据字段组织结构的混乱,难以转换,难以抽象。很多朋友看到这里,可能已经忘记想要问的问题了,首先打开你手机浏览器的应用商店,找到你想要的网页,不要犹豫,直接点击打开。
点击刷新之后你会看到,所有提供免费下载的应用产品,右上角都有个蓝色的关注按钮,点击关注按钮,打开该应用的客户端,并找到数据抓取方面,然后勾选数据存放的目录,并点击下一步。当打开浏览器,打开你要进行数据抓取的网页时,你会发现很多网页,在右上角都有大大的关注按钮,点击按钮,打开搜索功能,然后在搜索框中输入“数据抓取”这个关键词,然后勾选爬虫方面的抓取功能,并点击下一步。
如果你的应用是通过浏览器直接下载到手机的浏览器的浏览器应用商店中,那么你将会得到:网页设置信息:对于同一个标题同一个栏目,左侧中间位置一般为两个相似的标题,上下左右的栏目则不同;同一个标题下的不同页面,也不相同。爬虫设置:不同页面关注按钮,如果想要抓取同一个网页,一般需要点击上面那个按钮,如果想要抓取某个特定页面,一般需要点击下面那个按钮。
按提示操作,完成后,你会看到下图所示:一部分页面的设置信息点击具体页面后,进入分析页面,这里需要在分析页面时将页面放大,然后对分析后的信息进行分析,要用到页面相似度检测工具,在应用商店中,这个工具叫做aloha。对网页进行分析操作,会在分析结果中实现对分析页面中不同页面之间页面元素的信息检测,如果在得到相似度检测结果后,你对确定检测框中实际是否存在相同的相似页面,这个时候你在在检测框中如果有相同标题下的一个元素,那么这个元素为你所需要的网页。
因此,当遇到类似这样的需求时,首先在你浏览器中打开你想要抓取的网页,找到并确定需要的信息,然后在应用商店中找到aloha,并确定,是否使用该工具。下面是我使用aloha进行抓取相似页面时的数据分析结果:【页面元素】相似页面展示相似页面显示(1)【页面内容】相似页面展示(2)在我确定页面元素之后,再结合页面内容信息,选择你要进行数据抓取的页面。
接下来到了关键时刻,在找到页面元素之后,接下来需要寻找页面间是否存在相同的页面,如果存在相同页面,那么继续往下。在找到页面元素之后,到刚才看到的页面间元素展示,在这里你能够清楚找到“访问”这个标识按钮,因此对“访问”这个按钮进行解析, 查看全部
如何抓取网页数据(如何抓取网页数据,一直是不少朋友们提出的问题)
如何抓取网页数据,一直是不少朋友们提出的问题。当问到具体操作时,无人能够细说;但是如果谈到数据结构以及转换时,不少朋友则面露尴尬,并寻求更多的方法。一切的问题,源于数据字段组织结构的混乱,难以转换,难以抽象。很多朋友看到这里,可能已经忘记想要问的问题了,首先打开你手机浏览器的应用商店,找到你想要的网页,不要犹豫,直接点击打开。
点击刷新之后你会看到,所有提供免费下载的应用产品,右上角都有个蓝色的关注按钮,点击关注按钮,打开该应用的客户端,并找到数据抓取方面,然后勾选数据存放的目录,并点击下一步。当打开浏览器,打开你要进行数据抓取的网页时,你会发现很多网页,在右上角都有大大的关注按钮,点击按钮,打开搜索功能,然后在搜索框中输入“数据抓取”这个关键词,然后勾选爬虫方面的抓取功能,并点击下一步。
如果你的应用是通过浏览器直接下载到手机的浏览器的浏览器应用商店中,那么你将会得到:网页设置信息:对于同一个标题同一个栏目,左侧中间位置一般为两个相似的标题,上下左右的栏目则不同;同一个标题下的不同页面,也不相同。爬虫设置:不同页面关注按钮,如果想要抓取同一个网页,一般需要点击上面那个按钮,如果想要抓取某个特定页面,一般需要点击下面那个按钮。
按提示操作,完成后,你会看到下图所示:一部分页面的设置信息点击具体页面后,进入分析页面,这里需要在分析页面时将页面放大,然后对分析后的信息进行分析,要用到页面相似度检测工具,在应用商店中,这个工具叫做aloha。对网页进行分析操作,会在分析结果中实现对分析页面中不同页面之间页面元素的信息检测,如果在得到相似度检测结果后,你对确定检测框中实际是否存在相同的相似页面,这个时候你在在检测框中如果有相同标题下的一个元素,那么这个元素为你所需要的网页。
因此,当遇到类似这样的需求时,首先在你浏览器中打开你想要抓取的网页,找到并确定需要的信息,然后在应用商店中找到aloha,并确定,是否使用该工具。下面是我使用aloha进行抓取相似页面时的数据分析结果:【页面元素】相似页面展示相似页面显示(1)【页面内容】相似页面展示(2)在我确定页面元素之后,再结合页面内容信息,选择你要进行数据抓取的页面。
接下来到了关键时刻,在找到页面元素之后,接下来需要寻找页面间是否存在相同的页面,如果存在相同页面,那么继续往下。在找到页面元素之后,到刚才看到的页面间元素展示,在这里你能够清楚找到“访问”这个标识按钮,因此对“访问”这个按钮进行解析,
如何抓取网页数据(如何抓取网页数据?显然不是直接获取网页中的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-14 20:00
如何抓取网页数据?显然不是直接获取网页中的数据,而是通过分析html源代码的格式,对数据进行解析!为了更好的理解html文档中的格式特点,先来看下我的博客案例。
一、案例描述对于html页面,如果想解析网页的源代码,需要通过:修改源代码头部的解析规则代码,主要包括标签。
(这句是xhtml标签后面的自定义标签,
0);//在第一次访问有效;setinterval(xs,100
0);//在第一次访问有效;文件修改了附加代码之后,
1)//获取网页的源代码语句:type:text/javascriptdataurl://网页的源代码shortcode:"short"shortcode:";"shortcode:";"
2)//解析网页源代码语句:dataurl:"/";shortcode:";";shortcode:";"
3)//通过shortcode获取网页源代码语句:any:falseany:falsefalse:trueany:false
4)//通过shortcode获取网页源代码语句:all:falseall:falsefalse:trueall:false
5)//通过shortcode获取网页源代码语句:a:alla:alltext:text;string:string
6)//通过js获取网页源代码语句:options.type:textoptions.dataurl:"/"options.options:anyvalue:undefineddataurl://解析html源代码
二、思路分析本博客案例是学习网页爬虫的学员使用thinkphp做的爬虫案例,thinkphp是php框架,mvc模式,public,它是以“控制器”“定义public属性”来配置一个public方法,可以在局部范围内使用。这次我们把它代码拆分为public、model、waitgroup三个函数,每个函数使用javascript实现或使用ajax技术获取网页源代码,并保存在deferres时间周期内(因为waitgroup函数过时所以javascript不支持);再通过html解析一步步获取网页源代码。
1、thinkphp项目搭建
2、thinkphp解析网页源代码
3、自定义javascript属性
4、html解析
三、操作案例创建一个deferresert数据实例初始化model实例selectabledata实例用户画像toast专题更多面试解析:知识的罗网 查看全部
如何抓取网页数据(如何抓取网页数据?显然不是直接获取网页中的数据)
如何抓取网页数据?显然不是直接获取网页中的数据,而是通过分析html源代码的格式,对数据进行解析!为了更好的理解html文档中的格式特点,先来看下我的博客案例。
一、案例描述对于html页面,如果想解析网页的源代码,需要通过:修改源代码头部的解析规则代码,主要包括标签。
(这句是xhtml标签后面的自定义标签,
0);//在第一次访问有效;setinterval(xs,100
0);//在第一次访问有效;文件修改了附加代码之后,
1)//获取网页的源代码语句:type:text/javascriptdataurl://网页的源代码shortcode:"short"shortcode:";"shortcode:";"
2)//解析网页源代码语句:dataurl:"/";shortcode:";";shortcode:";"
3)//通过shortcode获取网页源代码语句:any:falseany:falsefalse:trueany:false
4)//通过shortcode获取网页源代码语句:all:falseall:falsefalse:trueall:false
5)//通过shortcode获取网页源代码语句:a:alla:alltext:text;string:string
6)//通过js获取网页源代码语句:options.type:textoptions.dataurl:"/"options.options:anyvalue:undefineddataurl://解析html源代码
二、思路分析本博客案例是学习网页爬虫的学员使用thinkphp做的爬虫案例,thinkphp是php框架,mvc模式,public,它是以“控制器”“定义public属性”来配置一个public方法,可以在局部范围内使用。这次我们把它代码拆分为public、model、waitgroup三个函数,每个函数使用javascript实现或使用ajax技术获取网页源代码,并保存在deferres时间周期内(因为waitgroup函数过时所以javascript不支持);再通过html解析一步步获取网页源代码。
1、thinkphp项目搭建
2、thinkphp解析网页源代码
3、自定义javascript属性
4、html解析
三、操作案例创建一个deferresert数据实例初始化model实例selectabledata实例用户画像toast专题更多面试解析:知识的罗网

