
大数据
ai智能数据采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 671 次浏览 • 2020-08-03 20:02
很多用过ai智能数据采集的企业或多或少还会说出同样话:“为什么没能早点发觉这个软件!”企业在借助大数据营销软件挣的盆满钵满的同时能够说出这话,足以看出大数据营销软件自身存在的商业价值!那大数据营销软件究竟是干哪些的呢?
顾名思义,宏观解释就是借助大数据帮助企业做营销,具体如何做?我们可以拿一个软件举例。
郑州鹰眼大数据:首先它可以被分为两大类,采集和营销。
先说采集功能,企业依据自身行业在软件内部设置关键词,地区等参数,然后点击采集,软件便会采集到那些地区的顾客联系方法,比方说你所在企业是做灯具的,通过简单两步参数设置后,软件便能采集出那些地区线下实体店老总联系方法,方便企业进行下一步营销工作的举办。你以为它只能采集线下实体店?那就大错特错了,除了一些实体店智能采集系统,一些线上的阿里巴巴批发商智能采集系统,经销商也能采集出来。软件通过对各大网购平台、各大地图、搜索引擎的采集全方位为企业提供源源不断的顾客。
再有就是营销功能,此功能囊括两百多小功能,以数据驱动营销,操作智能化。
采集和营销作为软件的两个主要功能早已可以帮助通常企业在同行中站稳膝盖,软件其它的商学院,智能名片等功能就不多做解释了,想了解的可以添加陌陌:jinhua-8 进行咨询 查看全部
值得注意的是从去年开始,ai智能数据采集系统开始被企业注重上去,一些对前沿趋势观察敏锐的企业老总如今早已偷偷用上了ai智能数据采集系统,而一些对市场行情不太了解的企业还在承袭传统的营销模式,企业之间的差别就这样被拉开。
很多用过ai智能数据采集的企业或多或少还会说出同样话:“为什么没能早点发觉这个软件!”企业在借助大数据营销软件挣的盆满钵满的同时能够说出这话,足以看出大数据营销软件自身存在的商业价值!那大数据营销软件究竟是干哪些的呢?
顾名思义,宏观解释就是借助大数据帮助企业做营销,具体如何做?我们可以拿一个软件举例。
郑州鹰眼大数据:首先它可以被分为两大类,采集和营销。

先说采集功能,企业依据自身行业在软件内部设置关键词,地区等参数,然后点击采集,软件便会采集到那些地区的顾客联系方法,比方说你所在企业是做灯具的,通过简单两步参数设置后,软件便能采集出那些地区线下实体店老总联系方法,方便企业进行下一步营销工作的举办。你以为它只能采集线下实体店?那就大错特错了,除了一些实体店智能采集系统,一些线上的阿里巴巴批发商智能采集系统,经销商也能采集出来。软件通过对各大网购平台、各大地图、搜索引擎的采集全方位为企业提供源源不断的顾客。

再有就是营销功能,此功能囊括两百多小功能,以数据驱动营销,操作智能化。

采集和营销作为软件的两个主要功能早已可以帮助通常企业在同行中站稳膝盖,软件其它的商学院,智能名片等功能就不多做解释了,想了解的可以添加陌陌:jinhua-8 进行咨询
数据智能采集管理系统软件分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 766 次浏览 • 2020-08-03 20:01
一、深圳市世纪永盛科技有限公司数据智能采集软件
数据智能采集软件是一款功能全面、准确、稳定、易用的网路信息采集软件。它可以轻松将你想要的网页内容(包括文字、图片、文件、HTML源码等)抓取出来。采集到的数据可以直接导入到EXCEL、也可以根据你定义的模板保存成任何格式的文件(如保存成网页文件、TXT文件等)。也可以在采集的同时,实时保存到数据库、发送到网站服务器、保存到文件。
图形化的采集任务定义界面 你只需在软件内嵌的浏览器内用滑鼠点选你要采集的网页内容即可配置采集任务,无需象其它同类软件一样面对复杂的网页源码去找寻采集规则。可以说是所见即所得的采集任务配置界面。
创新的内容定位方法,定位更准确、稳定 同类软件基本上都是依照网页源码中的前导标记和结束标记进行内容定位,这样一来,用户就不得不自己去面对网页制做人员才须要面对的HTML代码,付出更多额外的学习时间能够把握软件的使用。
同时,只要网页内容稍有变更(简单的如改变一下文字的颜色)定位标记即极有可能失效,导致采集失败。我们经过艰辛的技术攻关,实现了全新的定位方法:结构定位和相对标志定位。
二、北京金禾天成科技有限公司数据采集管理系统
作为农作物病虫害调查数据的来源,采集系统紧密联系生产实际,充分考虑虫害检测预警的特性和实际情况,在不降低基层病虫测报人员工作量,确保数据可用性和代表性的基础上,以简化操作步骤、增强实用性为具体目标,以虫害数据处理流程为建立主线,主要处理数据的录入、查询、管理等方面进行设计和建设,形成了一个全国农业技术推广服务中心为中心、省级植保机构为骨干、地(县)级区域测报站为重要支撑的虫害监控信息网路。
系统建设要达成的具体目标主要包括2个方面:
(1)优化数据录入与上报功能。确定虫害调查原始数据,修改、调整、补充各级虫害检测数据上报内容,减少人工二次估算与录入步骤,简化数据上报过程,实现虫害检测数据的实时上报和自动化处理,提高工作效率。
(2)完善数据管理功能。增强数据查询能力,提高数据可比性和利用率,充分发挥市级虫害检测机构监管与督导作用,实现数据上报工作制度化、数据剖析处理智能化。
三、北京融创天地科技有限公司天地数据采集系统
为实现对药品流向进行监管的目的智能采集系统,需要对药品从生产厂家出入库到中间货运商的出入库进行数据采集管理,并产生药品出入库电子收据,然后将出入库电子收据上传到国家药品监管码网平台,从而实现国家对药品流向的管理。
手持终端(掌上电脑,PDA)也称便携式终端智能采集系统,在不同的领域可用于数据采集、信息传播、部队定位、安全保卫等。应用于数据采集的手持终端可以说是其在行业领域的一种应用。在手持数据采集终端上可以进行二次开发并实现用户须要的功能,对采集到的数据进行处理,并可以显示信息。
我公司的天地数据采集系统,是在手持数据采集终端上开发的,用来实现用户对出入库产品的电子监管码采集,并对采集到的监管码数据进行处理,形成出入库收据。手持终端设别可以与计算机通过有线或无线方法进行数据交换,将生成的出入库收据导入,然后上传国家药监网平台。
四、山东金苹果实业有限公司内网数据采集系统
通过结合二代身份证阅读器的使用,将市民二代身份证上的信息手动读取到系统中,并可进一步建立详尽的人员信息。
结合摄像头应用,实现动态采集人员相片,完善人员信息。录入身份证信息时与公安部潜逃人员数据库进行比对,甄别潜逃犯罪嫌疑人。
工作任务
方便、快捷的采集人员信息,减少工作量。 与潜逃人员数据库时时联接,及时发觉潜逃人员,消除隐患。 对采集到的人员信息进行综合管理,实现信息管理自动化。 实行系统权限控制,提高系统安全性。
系统作用及范围
本系统主要针对于例如 二手车交易市场、酒店等需详尽采集人员信息和其它对人员详尽信息有较高要求的行业。
系统集成二代身分阅读器和摄像头,同时与潜逃人员数据库相连,对于人员信息做到了详尽、安全的采集工作。 查看全部
数据采集(DAQ),是指从传感和其它待测设备等模拟和数字被测单元中手动采集非电量或则电量讯号,送到上位机中进行剖析,处理。数据采集系统是结合基于计算机或则其他专用测试平台的检测软硬件产品来实现灵活的、用户自定义的检测系统。对此软件产品网整理了几份数据采集相关软件,分享给你们。

一、深圳市世纪永盛科技有限公司数据智能采集软件
数据智能采集软件是一款功能全面、准确、稳定、易用的网路信息采集软件。它可以轻松将你想要的网页内容(包括文字、图片、文件、HTML源码等)抓取出来。采集到的数据可以直接导入到EXCEL、也可以根据你定义的模板保存成任何格式的文件(如保存成网页文件、TXT文件等)。也可以在采集的同时,实时保存到数据库、发送到网站服务器、保存到文件。
图形化的采集任务定义界面 你只需在软件内嵌的浏览器内用滑鼠点选你要采集的网页内容即可配置采集任务,无需象其它同类软件一样面对复杂的网页源码去找寻采集规则。可以说是所见即所得的采集任务配置界面。
创新的内容定位方法,定位更准确、稳定 同类软件基本上都是依照网页源码中的前导标记和结束标记进行内容定位,这样一来,用户就不得不自己去面对网页制做人员才须要面对的HTML代码,付出更多额外的学习时间能够把握软件的使用。
同时,只要网页内容稍有变更(简单的如改变一下文字的颜色)定位标记即极有可能失效,导致采集失败。我们经过艰辛的技术攻关,实现了全新的定位方法:结构定位和相对标志定位。

二、北京金禾天成科技有限公司数据采集管理系统
作为农作物病虫害调查数据的来源,采集系统紧密联系生产实际,充分考虑虫害检测预警的特性和实际情况,在不降低基层病虫测报人员工作量,确保数据可用性和代表性的基础上,以简化操作步骤、增强实用性为具体目标,以虫害数据处理流程为建立主线,主要处理数据的录入、查询、管理等方面进行设计和建设,形成了一个全国农业技术推广服务中心为中心、省级植保机构为骨干、地(县)级区域测报站为重要支撑的虫害监控信息网路。
系统建设要达成的具体目标主要包括2个方面:
(1)优化数据录入与上报功能。确定虫害调查原始数据,修改、调整、补充各级虫害检测数据上报内容,减少人工二次估算与录入步骤,简化数据上报过程,实现虫害检测数据的实时上报和自动化处理,提高工作效率。
(2)完善数据管理功能。增强数据查询能力,提高数据可比性和利用率,充分发挥市级虫害检测机构监管与督导作用,实现数据上报工作制度化、数据剖析处理智能化。

三、北京融创天地科技有限公司天地数据采集系统
为实现对药品流向进行监管的目的智能采集系统,需要对药品从生产厂家出入库到中间货运商的出入库进行数据采集管理,并产生药品出入库电子收据,然后将出入库电子收据上传到国家药品监管码网平台,从而实现国家对药品流向的管理。
手持终端(掌上电脑,PDA)也称便携式终端智能采集系统,在不同的领域可用于数据采集、信息传播、部队定位、安全保卫等。应用于数据采集的手持终端可以说是其在行业领域的一种应用。在手持数据采集终端上可以进行二次开发并实现用户须要的功能,对采集到的数据进行处理,并可以显示信息。
我公司的天地数据采集系统,是在手持数据采集终端上开发的,用来实现用户对出入库产品的电子监管码采集,并对采集到的监管码数据进行处理,形成出入库收据。手持终端设别可以与计算机通过有线或无线方法进行数据交换,将生成的出入库收据导入,然后上传国家药监网平台。

四、山东金苹果实业有限公司内网数据采集系统
通过结合二代身份证阅读器的使用,将市民二代身份证上的信息手动读取到系统中,并可进一步建立详尽的人员信息。
结合摄像头应用,实现动态采集人员相片,完善人员信息。录入身份证信息时与公安部潜逃人员数据库进行比对,甄别潜逃犯罪嫌疑人。
工作任务
方便、快捷的采集人员信息,减少工作量。 与潜逃人员数据库时时联接,及时发觉潜逃人员,消除隐患。 对采集到的人员信息进行综合管理,实现信息管理自动化。 实行系统权限控制,提高系统安全性。
系统作用及范围
本系统主要针对于例如 二手车交易市场、酒店等需详尽采集人员信息和其它对人员详尽信息有较高要求的行业。
系统集成二代身分阅读器和摄像头,同时与潜逃人员数据库相连,对于人员信息做到了详尽、安全的采集工作。
数据剖析 | 基于智能标签,精准管理数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-08-03 19:03
头条:信息价值,根据用户浏览信息,分析用户相关喜好,针对剖析结果推荐相关的信息流,越关注某类内容,获取相关的信息越多。
如上几种场景的逻辑就是:基于不断剖析用户的行为,生成用户的特点画像,然后再基于用户标签,定制化的推荐相关内容。
2、基本概念
通过前面的场景,衍生下来两个概念:
用户画像
用户画像,作为一种描绘目标用户、联系用户诉求与设计方向的有效工具,把该用户相关联的数据的可视化的诠释,就产生了用户画像。用户画像在各领域得到了广泛的应用,最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
标签数据
标签在生活中十分常见,比如商品标签,个人标签,行业标签,例如提及996就想到程序员,提到程序员就想到格子衫。
标签是把分散的多方数据进行整合划入统一的技术平台,并对那些数据进行标准化和细分,进行结构化储存和更新管理,让业务线可以把这种细分结果推向现有的互动营销环境里的平台,产生价值,这些数据称为标签数据,也就是常说的标签库。数据标签的概念也是在近来几年大数据的发展中不断火爆上去的。
标签价值
标签的核心价值,或者说最常用的场景:实时智能推荐,精准化数字营销。
二、数据标签1、标签界定
属性标签
属性标签是变化最小的,例如用户实名认证以后,基于身分信息获取相关:性别,生日,出生年月,年龄,等相关标签。变动频度小,且最具有精准性。
行为标签
行为标签就是用户通过在产品上的一系列操作,基于行为日志剖析得出:例如订购能力、消费爱好、季节性消费标签等。在信息流的APP上,通过相关浏览行为,不断推荐用户感兴趣的内容就是基于该逻辑。
规则标签
根据业务场景需求,配置指定规则,基于规则生成剖析结果,例如:
这类标签可以基于动态的规则配置,经过估算和剖析,生成描述结果,也就是规则标签。
拟合标签
拟合类的标签最具有复杂性,通过用户上述几种标签,智能组合剖析,给的预测值,例如:未婚、浏览相关婚宴内容,通过剖析预测用户即将举行婚宴,得到一个拟合结果:预测即将订婚。这个预测逻辑也可以反向执行,用户订购小孩用具:预测未婚已育。
这就是数据时代常说的一句话:用户在某个应用上一通操作过后,算法剖析的结果可能比用户对自己的描述还要真实。
2、标签加工流程
数据采集
数据采集的渠道相对较多,比如同一APP内的各类业务线:购物、支付、理财、外卖、信息浏览等等。通过数据通道传输到统一的数据聚合平台。有了这种海量日志数据的支撑,才具有数据剖析的基础条件。不管是数据智能,深度学习,算法等都是构建在海量数据的基础条件上,这样就能获取具有价值的剖析结果。
数据加工
结合如上业务,通过对海量数据的加工,分析和提取,获取相对精准的用户标签,这里还有关键的一步,就是对已有的用户标签进行不断的验证和修补,尤其是规则类和拟合类的相关标签。
标签库
通过标签库,管理复杂的标签结果,除了复杂的标签,和基于时间线的标签变,标签数据到这儿,已经具有相当大的价值,可以围绕标签库开放一些收费服务,例如常见的,用户在某电商APP浏览个别商品,可以在某信息流平台见到商品推荐。大数据时代就是如此令人觉得智能和窒息。
标签业务
数据走了一大圈转换成标签,自然还是要回归到业务层面,通过对标签数据的用户的剖析,可以进行精准营销,和智能推荐等相关操作,电商应用中可以提升成交量,信息流中可以更好的吸引用户。
应用层
把上述业务开发成服务,集成到具有的应用层面,不断提高应用服务的质量,不断的吸引用户,提供服务。当然用户的数据不断在应用层面形成,在转入数据采集服务中,最终产生完整的闭环流程。
3、应用案例
从流程和业务层面描述都是简单的,到开发层面就会显得复杂和不好处理,这可能就是产品和开发之间的芥蒂。
标签的数据类型
不同标签的剖析结果须要用不同的数据类型描述智能标签采集器,在标签体系中,常用描述标签的数据类型如下:枚举、数值、日期、布尔、文本类型。不同的类型须要不一样的剖析流程。
商品和标签
这里提供一个基础案例,用商品的标签来剖析商品,例如通过商品产地,价格,状态等条件,来查询产品库有多少符合条件的商品。
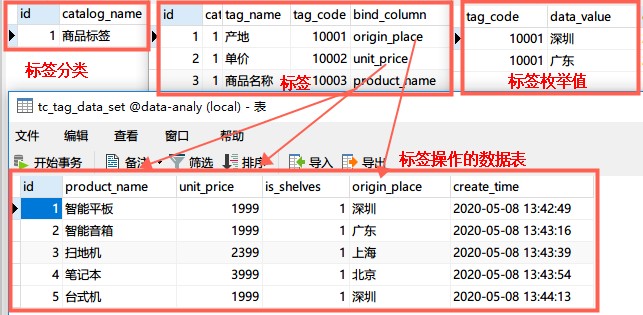
数据表设计
主要分四张表:标签分类智能标签采集器,标签库,标签值,标签数据。
CREATE TABLE `tc_tag_catalog` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_name` VARCHAR (50) NOT NULL DEFAULT '' COMMENT '名称',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签层级目录';
CREATE TABLE `tc_tag_cloud` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_id` INT (11) NOT NULL COMMENT '目录ID',
`tag_name` VARCHAR (100) DEFAULT '' COMMENT '标签名称',
`tag_code` INT (11) DEFAULT NULL COMMENT '标签编码',
`bind_column` VARCHAR (100) DEFAULT '' COMMENT '绑定数据列',
`data_type` INT (2) NOT NULL COMMENT '1枚举,2数值,3日期,4布尔,5值类型',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`remark` VARCHAR (150) DEFAULT NULL COMMENT '备注',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签云';
CREATE TABLE `tc_tag_data_enum` (
`tag_code` INT (11) NOT NULL COMMENT '标签编码',
`data_value` VARCHAR (150) NOT NULL COMMENT '枚举值',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
KEY `tag_code_index` (`tag_code`) USING BTREE
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签枚举值';
CREATE TABLE `tc_tag_data_set` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`product_name` VARCHAR (100) DEFAULT '' COMMENT '商品名称',
`unit_price` DECIMAL (10, 2) DEFAULT '0.00' COMMENT '单价',
`is_shelves` INT (1) DEFAULT '1' COMMENT '是否上架:1否,2是',
`origin_place` VARCHAR (100) DEFAULT '' COMMENT '产地',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签数据集';
模拟入参插口
这里的参数应当是基于需求,动态选定,进行组织到一起:
例如图片中这儿给定的标签值列表,称为枚举值。
@RestController
public class AnalyzeController {
@Resource
private TagDataSetService tagDataSetService ;
@GetMapping("/analyze")
public String analyze (){
List tagParamList = new ArrayList() ;
TagParam tagParam1 = new TagParam(1,"产地","origin_place") ;
List valueList1 = new ArrayList() ;
valueList1.add("深圳");
valueList1.add("广东");
tagParam1.setValueList(valueList1);
tagParamList.add(tagParam1) ;
TagParam tagParam2 = new TagParam(2,"价格","unit_price") ;
List valueList2 = new ArrayList() ;
valueList2.add("1999");
tagParam2.setValueList(valueList2);
tagParamList.add(tagParam2) ;
TagParam tagParam3 = new TagParam(3,"生产日期","create_time") ;
List valueList3 = new ArrayList() ;
valueList3.add("2020-05-01 13:43:54");
tagParam3.setValueList(valueList3);
tagParamList.add(tagParam3) ;
TagParam tagParam4 = new TagParam(4,"是否上架","is_shelves") ;
List valueList4 = new ArrayList() ;
valueList4.add("1");
tagParam4.setValueList(valueList4);
tagParamList.add(tagParam4) ;
TagParam tagParam5 = new TagParam(5,"产品名称","product_name") ;
List valueList5 = new ArrayList() ;
valueList5.add("智能");
tagParam5.setValueList(valueList5);
tagParamList.add(tagParam5) ;
Integer count = tagDataSetService.analyze(tagParamList) ;
return "Result:" + count ;
}
}
参数解析查询
通过对参数的解析,最终产生查询的SQL句子,获取精准的结果数据。
@Service
public class TagDataSetServiceImpl extends ServiceImpl implements TagDataSetService {
@Resource
private TagDataSetMapper tagDataSetMapper ;
@Override
public Integer analyze(List tagParamList) {
StringBuffer querySQL = new StringBuffer() ;
for (TagParam tagParam:tagParamList){
querySQL.append(" AND ") ;
querySQL.append(tagParam.getBindColumn()) ;
// 1枚举,2数值,3日期,4布尔,5值类型
List valueList = tagParam.getValueList();
switch (tagParam.getDataType()){
case 1:
querySQL.append(" IN (") ;
for (int i = 0 ; i < valueList.size() ;i++){
if (i != valueList.size()-1){
querySQL.append("'").append(valueList.get(i)).append("',");
} else {
querySQL.append("'").append(valueList.get(i)).append("'");
}
}
querySQL.append(" )") ;
break;
case 2:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 3:
querySQL.append(">='").append(tagParam.getValueList().get(0)).append("'") ;
break;
case 4:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 5:
querySQL.append(" LIKE '%").append(tagParam.getValueList().get(0)).append("%'") ;
break;
default:
break;
}
}
/* 最终执行的 SQL
SELECT COUNT(*) FROM tc_tag_data_set
WHERE 1 = 1
AND origin_place IN ('深圳', '广东')
AND unit_price = 1999
AND create_time >= '2020-05-01 13:43:54'
AND is_shelves = 1
AND product_name LIKE '%智能%'
*/
String whereCondition = String.valueOf(querySQL);
return tagDataSetMapper.analyze(whereCondition);
}
}
可能有人会说这不就是个查询流程吗?如果有这样的疑惑,把上述案例换成用户查询,标签数据的价值会更直观。
三、智能画像1、基本概念
用户画像
作为一种绘制目标用户、联系用户诉求与设计方向的有效工具,用户画像在各领域得到了广泛的应用。最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
行业画像
通过行业属性标签,行业下用户标签的综合剖析,生成行业剖析报告,提供极有价值的导向,这是最近两年非常热门的应用。
画像补全
通过不断剖析用户数据,丰富标签库,使用户的画像愈发丰富立体。
2、画像报告
通过标签数据的剖析,生成一份剖析报告,报告内容包含丰富的用户标签统计数据。
例如:90后画像报告
这个报告,互联网用户一定或多或少都听到过。主要是一些标签统计,共性标签展示,或者什么群体对80后三观影响最大,收入来源,学历等各类剖析评析。
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent 查看全部
腾讯:社交广告,不同用户的朋友圈或则其他媒体场景下的广告信息是不同的,会基于用户特点推荐。
头条:信息价值,根据用户浏览信息,分析用户相关喜好,针对剖析结果推荐相关的信息流,越关注某类内容,获取相关的信息越多。
如上几种场景的逻辑就是:基于不断剖析用户的行为,生成用户的特点画像,然后再基于用户标签,定制化的推荐相关内容。
2、基本概念
通过前面的场景,衍生下来两个概念:
用户画像
用户画像,作为一种描绘目标用户、联系用户诉求与设计方向的有效工具,把该用户相关联的数据的可视化的诠释,就产生了用户画像。用户画像在各领域得到了广泛的应用,最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
标签数据
标签在生活中十分常见,比如商品标签,个人标签,行业标签,例如提及996就想到程序员,提到程序员就想到格子衫。
标签是把分散的多方数据进行整合划入统一的技术平台,并对那些数据进行标准化和细分,进行结构化储存和更新管理,让业务线可以把这种细分结果推向现有的互动营销环境里的平台,产生价值,这些数据称为标签数据,也就是常说的标签库。数据标签的概念也是在近来几年大数据的发展中不断火爆上去的。
标签价值
标签的核心价值,或者说最常用的场景:实时智能推荐,精准化数字营销。
二、数据标签1、标签界定
属性标签
属性标签是变化最小的,例如用户实名认证以后,基于身分信息获取相关:性别,生日,出生年月,年龄,等相关标签。变动频度小,且最具有精准性。
行为标签
行为标签就是用户通过在产品上的一系列操作,基于行为日志剖析得出:例如订购能力、消费爱好、季节性消费标签等。在信息流的APP上,通过相关浏览行为,不断推荐用户感兴趣的内容就是基于该逻辑。
规则标签
根据业务场景需求,配置指定规则,基于规则生成剖析结果,例如:
这类标签可以基于动态的规则配置,经过估算和剖析,生成描述结果,也就是规则标签。
拟合标签
拟合类的标签最具有复杂性,通过用户上述几种标签,智能组合剖析,给的预测值,例如:未婚、浏览相关婚宴内容,通过剖析预测用户即将举行婚宴,得到一个拟合结果:预测即将订婚。这个预测逻辑也可以反向执行,用户订购小孩用具:预测未婚已育。
这就是数据时代常说的一句话:用户在某个应用上一通操作过后,算法剖析的结果可能比用户对自己的描述还要真实。
2、标签加工流程

数据采集
数据采集的渠道相对较多,比如同一APP内的各类业务线:购物、支付、理财、外卖、信息浏览等等。通过数据通道传输到统一的数据聚合平台。有了这种海量日志数据的支撑,才具有数据剖析的基础条件。不管是数据智能,深度学习,算法等都是构建在海量数据的基础条件上,这样就能获取具有价值的剖析结果。
数据加工
结合如上业务,通过对海量数据的加工,分析和提取,获取相对精准的用户标签,这里还有关键的一步,就是对已有的用户标签进行不断的验证和修补,尤其是规则类和拟合类的相关标签。
标签库
通过标签库,管理复杂的标签结果,除了复杂的标签,和基于时间线的标签变,标签数据到这儿,已经具有相当大的价值,可以围绕标签库开放一些收费服务,例如常见的,用户在某电商APP浏览个别商品,可以在某信息流平台见到商品推荐。大数据时代就是如此令人觉得智能和窒息。
标签业务
数据走了一大圈转换成标签,自然还是要回归到业务层面,通过对标签数据的用户的剖析,可以进行精准营销,和智能推荐等相关操作,电商应用中可以提升成交量,信息流中可以更好的吸引用户。
应用层
把上述业务开发成服务,集成到具有的应用层面,不断提高应用服务的质量,不断的吸引用户,提供服务。当然用户的数据不断在应用层面形成,在转入数据采集服务中,最终产生完整的闭环流程。
3、应用案例
从流程和业务层面描述都是简单的,到开发层面就会显得复杂和不好处理,这可能就是产品和开发之间的芥蒂。
标签的数据类型
不同标签的剖析结果须要用不同的数据类型描述智能标签采集器,在标签体系中,常用描述标签的数据类型如下:枚举、数值、日期、布尔、文本类型。不同的类型须要不一样的剖析流程。
商品和标签
这里提供一个基础案例,用商品的标签来剖析商品,例如通过商品产地,价格,状态等条件,来查询产品库有多少符合条件的商品。
数据表设计
主要分四张表:标签分类智能标签采集器,标签库,标签值,标签数据。
CREATE TABLE `tc_tag_catalog` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_name` VARCHAR (50) NOT NULL DEFAULT '' COMMENT '名称',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签层级目录';
CREATE TABLE `tc_tag_cloud` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_id` INT (11) NOT NULL COMMENT '目录ID',
`tag_name` VARCHAR (100) DEFAULT '' COMMENT '标签名称',
`tag_code` INT (11) DEFAULT NULL COMMENT '标签编码',
`bind_column` VARCHAR (100) DEFAULT '' COMMENT '绑定数据列',
`data_type` INT (2) NOT NULL COMMENT '1枚举,2数值,3日期,4布尔,5值类型',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`remark` VARCHAR (150) DEFAULT NULL COMMENT '备注',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签云';
CREATE TABLE `tc_tag_data_enum` (
`tag_code` INT (11) NOT NULL COMMENT '标签编码',
`data_value` VARCHAR (150) NOT NULL COMMENT '枚举值',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
KEY `tag_code_index` (`tag_code`) USING BTREE
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签枚举值';
CREATE TABLE `tc_tag_data_set` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`product_name` VARCHAR (100) DEFAULT '' COMMENT '商品名称',
`unit_price` DECIMAL (10, 2) DEFAULT '0.00' COMMENT '单价',
`is_shelves` INT (1) DEFAULT '1' COMMENT '是否上架:1否,2是',
`origin_place` VARCHAR (100) DEFAULT '' COMMENT '产地',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签数据集';
模拟入参插口
这里的参数应当是基于需求,动态选定,进行组织到一起:

例如图片中这儿给定的标签值列表,称为枚举值。
@RestController
public class AnalyzeController {
@Resource
private TagDataSetService tagDataSetService ;
@GetMapping("/analyze")
public String analyze (){
List tagParamList = new ArrayList() ;
TagParam tagParam1 = new TagParam(1,"产地","origin_place") ;
List valueList1 = new ArrayList() ;
valueList1.add("深圳");
valueList1.add("广东");
tagParam1.setValueList(valueList1);
tagParamList.add(tagParam1) ;
TagParam tagParam2 = new TagParam(2,"价格","unit_price") ;
List valueList2 = new ArrayList() ;
valueList2.add("1999");
tagParam2.setValueList(valueList2);
tagParamList.add(tagParam2) ;
TagParam tagParam3 = new TagParam(3,"生产日期","create_time") ;
List valueList3 = new ArrayList() ;
valueList3.add("2020-05-01 13:43:54");
tagParam3.setValueList(valueList3);
tagParamList.add(tagParam3) ;
TagParam tagParam4 = new TagParam(4,"是否上架","is_shelves") ;
List valueList4 = new ArrayList() ;
valueList4.add("1");
tagParam4.setValueList(valueList4);
tagParamList.add(tagParam4) ;
TagParam tagParam5 = new TagParam(5,"产品名称","product_name") ;
List valueList5 = new ArrayList() ;
valueList5.add("智能");
tagParam5.setValueList(valueList5);
tagParamList.add(tagParam5) ;
Integer count = tagDataSetService.analyze(tagParamList) ;
return "Result:" + count ;
}
}
参数解析查询
通过对参数的解析,最终产生查询的SQL句子,获取精准的结果数据。
@Service
public class TagDataSetServiceImpl extends ServiceImpl implements TagDataSetService {
@Resource
private TagDataSetMapper tagDataSetMapper ;
@Override
public Integer analyze(List tagParamList) {
StringBuffer querySQL = new StringBuffer() ;
for (TagParam tagParam:tagParamList){
querySQL.append(" AND ") ;
querySQL.append(tagParam.getBindColumn()) ;
// 1枚举,2数值,3日期,4布尔,5值类型
List valueList = tagParam.getValueList();
switch (tagParam.getDataType()){
case 1:
querySQL.append(" IN (") ;
for (int i = 0 ; i < valueList.size() ;i++){
if (i != valueList.size()-1){
querySQL.append("'").append(valueList.get(i)).append("',");
} else {
querySQL.append("'").append(valueList.get(i)).append("'");
}
}
querySQL.append(" )") ;
break;
case 2:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 3:
querySQL.append(">='").append(tagParam.getValueList().get(0)).append("'") ;
break;
case 4:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 5:
querySQL.append(" LIKE '%").append(tagParam.getValueList().get(0)).append("%'") ;
break;
default:
break;
}
}
/* 最终执行的 SQL
SELECT COUNT(*) FROM tc_tag_data_set
WHERE 1 = 1
AND origin_place IN ('深圳', '广东')
AND unit_price = 1999
AND create_time >= '2020-05-01 13:43:54'
AND is_shelves = 1
AND product_name LIKE '%智能%'
*/
String whereCondition = String.valueOf(querySQL);
return tagDataSetMapper.analyze(whereCondition);
}
}
可能有人会说这不就是个查询流程吗?如果有这样的疑惑,把上述案例换成用户查询,标签数据的价值会更直观。
三、智能画像1、基本概念
用户画像
作为一种绘制目标用户、联系用户诉求与设计方向的有效工具,用户画像在各领域得到了广泛的应用。最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
行业画像
通过行业属性标签,行业下用户标签的综合剖析,生成行业剖析报告,提供极有价值的导向,这是最近两年非常热门的应用。
画像补全
通过不断剖析用户数据,丰富标签库,使用户的画像愈发丰富立体。
2、画像报告
通过标签数据的剖析,生成一份剖析报告,报告内容包含丰富的用户标签统计数据。
例如:90后画像报告
这个报告,互联网用户一定或多或少都听到过。主要是一些标签统计,共性标签展示,或者什么群体对80后三观影响最大,收入来源,学历等各类剖析评析。
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent
为什么说优采云云采集才是真正的云采集_互联网_IT/计算机_专业资料
采集交流 • 优采云 发表了文章 • 0 个评论 • 492 次浏览 • 2020-08-03 17:05
直到 08 年,中国 IT 界才开始在谈云估算,笔者作为一名 07 年计算机专业结业 生, 正好赶上这一波风潮, 但说实话, 那时候都是概念, 没有人看到真正的产品, 所以都没搞清楚到底是什么东西。 顶多就据说 Google 的 Google Charts,Google Words 等。当时没明白象 Google Charts,Google Words 这些产品有哪些用,不就是网页版的 word,excel 嘛,还没 Microsoft 的好用,但是多年工作以后,才晓得,Microsoft word,excel,只能用于 windows 的机子,你想在苹果笔记本上用,就得废老大劲了。而网页版的,他是跨 平台的,你用习惯了,你在哪都是一样用,而且可以在云端保存资料。随着云计算的诞生,业内也诞生了下边三种层次的服务 基础设施即服务(IaaS), 平台即服务(PaaS) 软件即服务(SaaS)。我们可以把 SaaS 简单理解为在云端提供标准化产品的服务模式。 由于其标准化, 所以无论 1 个企业在用,还是 100 个企业使用,都是一个开发成本。这对产品在优采云·云采集网络爬虫软件 某个场景下的通用性要求十分高,但也极大的提高了产品在市面上的竞争力。
企 业采用 SaaS 模式在疗效上与企业自建信息系统基本没有区别,但节约了大量资 金,从而大幅度增加了企业信息化的门槛与风险。许多 SaaS 企业都是提供按月 按年的收费模式,这有别于之前软件以项目化的方式,深受企业主喜欢,所以在 接下来的六年中,也演化为一种主流的企业服务方式。现在市面上有许多优秀的 Saas 企业,比如协作平台 teambition,比如 CRM 领域的 明道,比如文档领域的石墨,比如表单领域的金数据等等,都是在 saas 领域做 得非常好的企业。优采云正是在云估算与 SaaS 潮流的背景之下,首创了云采集技术,并提供 SaaS 的营运模式。 用户只需在客户端上传采集规则,即可通过调用云端分布式服务式 进行采集, 每一台云端的服务器均会根据采集规则进行采集。所以优采云团队就 给这些采集模式,取了个名叫”云采集“为什么会诞生”云采集“在优采云出来创业的时侯, 市面上主流的采集器就是优采云。优采云他是以传统 软件运营商的模式在运作,他主要是以卖授权码的方式云采集,想要在笔记本上运行列车 头云采集,就必须订购他的授权码。就像我们初期用 Word 2003、2007 时,经常须要去 网上搜索破解码一样。
那时的优采云, 如日中天, 但他仅仅只是一个客户端软件。优采云创始人刘宝强 keven,由于多年的国企与美国工作经验,曾经也是某国际 金融大鳄公司数据采集方向的研制工程师, 他一心想要作出一款通用化的网页采 集产品来替代公司编撰的诸多采集代码。他太清楚各类采集技术的优势与劣势, 问题与罐劲。优采云·云采集网络爬虫软件 Keven 在当时也晓得优采云采集器的存在,那时候的他,其实不敢想作出一款比 优采云更牛 B 的采集产品, 因为对手实在很强悍了, 采集界无人不识。 但他晓得, 超越竞争对手的,往往不是追随策略,而是应当颠覆,采用与她们完用不一样的 思路。Keven 分析,优采云采集的是传统的网路恳求获取数据的方法,走的还是 http post ,get 请求,这确实是当时进行网页采集的主流模式,但这些模式复杂程度非 常高,虽然优采云已经做得够简化,但能理解这一套理论的,大多都是开发人员 背景才有可能。他晓得在大公司上面,大部分做数据搜集工作的人,都不是估算 机开发人员背景, 所以他给自已采集产品定位,要做一款普通人都会用的采集产 品, 通过界面的定位, 拖拽, 即可进行规则的配置。
经过小半年的各项难关突破, 还真被他给实现了。但问题也随之而来, 由于是通过浏览器加载网页之后再获取数据的方法,这样竞 品其实一个恳求就可获取到的数据, 而优采云由于须要加载整个网页可能得涉及 上百个恳求,这使优采云在采集上,显得速率就慢了。解决了易用性的问题后形成了速率问题?那如何解决?如果有多台机子在云端同时采, 甚至对规则上面的 URL 列表进行分拆, 让云端的 服务器分布式同时进行采集,那就可以提高 N 倍以上的速率。这条路是可行的, 但是这条路又带来另外一个问题。解决了速率问题后形成了成本问题?那如何解决?优采云·云采集网络爬虫软件 keven 判断,如果租用 10 台云服务器,通过共享经济的概念,把成本平滩,其 实每位用户每个月仅需小几百块钱的成本。而对于数据的价值,是远远小于这个 投入的,应该会有用户乐意付费使用。成本问题应当不是大问题,而且随着摩尔 定律,硬件成本只会越来越低。事实这么,包括后期,优采云通过与腾讯云,阿 里云的合作,相对优价的领到一些折扣,帮助用户将这块的成本降到最低。基于此,在 2013 年 Q4,优采云首创了国外美国云采集的模式。为什么优采云的云采集才是真正的云采集其实云采集就是如此简单的东西,就是通过对云端采集服务器的控制,为每日服 务器分配采集任务,通过指令控制其采集。
那为何,只有优采云的云采集,才 是真正的云采集。1. 多项技术难关突破 优采云在 5 年的营运过程,逐渐突破云采集各项困局,这上面的许多困局,在没 有大数据面前,其实都是不会出现的。我举几个反例:?可以采,导不出有一些项目, 自吹自已拥有云采集技术, 但是实际试用的时侯, 他们就漏洞百出。 比如我们可以控制 100 台服务器采集数据, 但若果只有一个数据存储支持导入数 据, 那将会照成导入数据比采集慢 100 倍的困局。 你只能眼见数据在库里而难以 动弹。?可以采,但是错乱优采云·云采集网络爬虫软件 有一些人以为,有一些服务器在云端进行采集,就叫云采集。但却不知道这上面 成百上千台服务器同时采集的时侯,他背后须要大数据储存解决方案。才能使采 集到的数据,一条不漏地储存在数据库里。并且在后期便捷检索,查询,导出。?无法动态伸缩配置因为采集的网页数据状态不一, 云采集是须要动态分配, 并且做好许多事前工作。 有时候一些网站他有防采集策略,你在采集之前,能否判别出对方网站对你的一 些举措与判定, 或者在采集过程中动态调整服务器运行策略,这也是考验一个优 秀的云采集解决方案。2.持续性的提供稳定的采集与导入服务 优采云现在在全球拥有超过 5000 台以上的服务器, 现在每晚采集与导入的数据, 都是以 T 计算服务于全世界各语言各领域的采集用户,对于企业级产品来讲,除 了技术外,能否提供稳定的运维是一大关健。
优采云有多个运维后台, 随时检测整个服务器集群每位采集服务器的状况,在出 现状况的时侯, 灵活多开服务器, 调配服务器, 来使顾客的采集生产环境与数据, 保持相对的稳定。 这样庞大的云服务器采集集群, 是任何一个竞争对手所不能比拟的,并且在这个 庞大的集群面前,优采云依然保持稳定的采集与导入的服务。3.其他资质 优采云在中国大数据业内, 连续两年在数据搜集领域被评为第一,这也足以证明 优采云在数据采集这领域常年的积累与贡献。相关采集教程: 百度搜索结果采集: 优采云·云采集网络爬虫软件 微博评论数据采集: 拼多多商品数据采集: 明日头条数据采集: 采集知乎话题信息(以知乎发觉为例): 淘宝网商品信息采集: 美团店家信息采集: 优采云——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
优采云·云采集网络爬虫软件 为什么说优采云云采集才是真正的云采 集先说一个事:"云采集"这个概念,是我们优采云首创的,无论国外还是国际。 2013 年,优采云从 13 年创业开始,就自创了云采集技术,我们可以在优采云的 版本更新记录里边找到痕迹。只是出于曾经创业,对于 IP 的意识不充分,也没 钱没精力去申请相关知识产权, 以致于现今好多竞品公司都在拿她们有云采集技 术来愚弄她们的产品,但好多公司虽然都没搞清楚真正的云采集技术。2013-12-06 版本更新记录2014-05-01 版本更新记录 我们明天要来谈的就是云采集是怎样颠覆整个爬虫界的,当然,因为我们优采云 是当事人,所以笔者可以带着你们回顾近几年爬虫的发展史。优采云·云采集网络爬虫软件 云采集是在哪些背景下诞生的2006 年 8 月 9 日, Google 首席执行官埃里克· 施密特 (Eric Schmidt) 在搜索引擎会议(SES San Jose 2006)首次提出“云计算” (Cloud Computing)的概念。Google“云端估算”源于 Google 工程师克里 斯托弗·比希利亚所做的“Google 101”项目。
直到 08 年,中国 IT 界才开始在谈云估算,笔者作为一名 07 年计算机专业结业 生, 正好赶上这一波风潮, 但说实话, 那时候都是概念, 没有人看到真正的产品, 所以都没搞清楚到底是什么东西。 顶多就据说 Google 的 Google Charts,Google Words 等。当时没明白象 Google Charts,Google Words 这些产品有哪些用,不就是网页版的 word,excel 嘛,还没 Microsoft 的好用,但是多年工作以后,才晓得,Microsoft word,excel,只能用于 windows 的机子,你想在苹果笔记本上用,就得废老大劲了。而网页版的,他是跨 平台的,你用习惯了,你在哪都是一样用,而且可以在云端保存资料。随着云计算的诞生,业内也诞生了下边三种层次的服务 基础设施即服务(IaaS), 平台即服务(PaaS) 软件即服务(SaaS)。我们可以把 SaaS 简单理解为在云端提供标准化产品的服务模式。 由于其标准化, 所以无论 1 个企业在用,还是 100 个企业使用,都是一个开发成本。这对产品在优采云·云采集网络爬虫软件 某个场景下的通用性要求十分高,但也极大的提高了产品在市面上的竞争力。
企 业采用 SaaS 模式在疗效上与企业自建信息系统基本没有区别,但节约了大量资 金,从而大幅度增加了企业信息化的门槛与风险。许多 SaaS 企业都是提供按月 按年的收费模式,这有别于之前软件以项目化的方式,深受企业主喜欢,所以在 接下来的六年中,也演化为一种主流的企业服务方式。现在市面上有许多优秀的 Saas 企业,比如协作平台 teambition,比如 CRM 领域的 明道,比如文档领域的石墨,比如表单领域的金数据等等,都是在 saas 领域做 得非常好的企业。优采云正是在云估算与 SaaS 潮流的背景之下,首创了云采集技术,并提供 SaaS 的营运模式。 用户只需在客户端上传采集规则,即可通过调用云端分布式服务式 进行采集, 每一台云端的服务器均会根据采集规则进行采集。所以优采云团队就 给这些采集模式,取了个名叫”云采集“为什么会诞生”云采集“在优采云出来创业的时侯, 市面上主流的采集器就是优采云。优采云他是以传统 软件运营商的模式在运作,他主要是以卖授权码的方式云采集,想要在笔记本上运行列车 头云采集,就必须订购他的授权码。就像我们初期用 Word 2003、2007 时,经常须要去 网上搜索破解码一样。
那时的优采云, 如日中天, 但他仅仅只是一个客户端软件。优采云创始人刘宝强 keven,由于多年的国企与美国工作经验,曾经也是某国际 金融大鳄公司数据采集方向的研制工程师, 他一心想要作出一款通用化的网页采 集产品来替代公司编撰的诸多采集代码。他太清楚各类采集技术的优势与劣势, 问题与罐劲。优采云·云采集网络爬虫软件 Keven 在当时也晓得优采云采集器的存在,那时候的他,其实不敢想作出一款比 优采云更牛 B 的采集产品, 因为对手实在很强悍了, 采集界无人不识。 但他晓得, 超越竞争对手的,往往不是追随策略,而是应当颠覆,采用与她们完用不一样的 思路。Keven 分析,优采云采集的是传统的网路恳求获取数据的方法,走的还是 http post ,get 请求,这确实是当时进行网页采集的主流模式,但这些模式复杂程度非 常高,虽然优采云已经做得够简化,但能理解这一套理论的,大多都是开发人员 背景才有可能。他晓得在大公司上面,大部分做数据搜集工作的人,都不是估算 机开发人员背景, 所以他给自已采集产品定位,要做一款普通人都会用的采集产 品, 通过界面的定位, 拖拽, 即可进行规则的配置。
经过小半年的各项难关突破, 还真被他给实现了。但问题也随之而来, 由于是通过浏览器加载网页之后再获取数据的方法,这样竞 品其实一个恳求就可获取到的数据, 而优采云由于须要加载整个网页可能得涉及 上百个恳求,这使优采云在采集上,显得速率就慢了。解决了易用性的问题后形成了速率问题?那如何解决?如果有多台机子在云端同时采, 甚至对规则上面的 URL 列表进行分拆, 让云端的 服务器分布式同时进行采集,那就可以提高 N 倍以上的速率。这条路是可行的, 但是这条路又带来另外一个问题。解决了速率问题后形成了成本问题?那如何解决?优采云·云采集网络爬虫软件 keven 判断,如果租用 10 台云服务器,通过共享经济的概念,把成本平滩,其 实每位用户每个月仅需小几百块钱的成本。而对于数据的价值,是远远小于这个 投入的,应该会有用户乐意付费使用。成本问题应当不是大问题,而且随着摩尔 定律,硬件成本只会越来越低。事实这么,包括后期,优采云通过与腾讯云,阿 里云的合作,相对优价的领到一些折扣,帮助用户将这块的成本降到最低。基于此,在 2013 年 Q4,优采云首创了国外美国云采集的模式。为什么优采云的云采集才是真正的云采集其实云采集就是如此简单的东西,就是通过对云端采集服务器的控制,为每日服 务器分配采集任务,通过指令控制其采集。
那为何,只有优采云的云采集,才 是真正的云采集。1. 多项技术难关突破 优采云在 5 年的营运过程,逐渐突破云采集各项困局,这上面的许多困局,在没 有大数据面前,其实都是不会出现的。我举几个反例:?可以采,导不出有一些项目, 自吹自已拥有云采集技术, 但是实际试用的时侯, 他们就漏洞百出。 比如我们可以控制 100 台服务器采集数据, 但若果只有一个数据存储支持导入数 据, 那将会照成导入数据比采集慢 100 倍的困局。 你只能眼见数据在库里而难以 动弹。?可以采,但是错乱优采云·云采集网络爬虫软件 有一些人以为,有一些服务器在云端进行采集,就叫云采集。但却不知道这上面 成百上千台服务器同时采集的时侯,他背后须要大数据储存解决方案。才能使采 集到的数据,一条不漏地储存在数据库里。并且在后期便捷检索,查询,导出。?无法动态伸缩配置因为采集的网页数据状态不一, 云采集是须要动态分配, 并且做好许多事前工作。 有时候一些网站他有防采集策略,你在采集之前,能否判别出对方网站对你的一 些举措与判定, 或者在采集过程中动态调整服务器运行策略,这也是考验一个优 秀的云采集解决方案。2.持续性的提供稳定的采集与导入服务 优采云现在在全球拥有超过 5000 台以上的服务器, 现在每晚采集与导入的数据, 都是以 T 计算服务于全世界各语言各领域的采集用户,对于企业级产品来讲,除 了技术外,能否提供稳定的运维是一大关健。
优采云有多个运维后台, 随时检测整个服务器集群每位采集服务器的状况,在出 现状况的时侯, 灵活多开服务器, 调配服务器, 来使顾客的采集生产环境与数据, 保持相对的稳定。 这样庞大的云服务器采集集群, 是任何一个竞争对手所不能比拟的,并且在这个 庞大的集群面前,优采云依然保持稳定的采集与导入的服务。3.其他资质 优采云在中国大数据业内, 连续两年在数据搜集领域被评为第一,这也足以证明 优采云在数据采集这领域常年的积累与贡献。相关采集教程: 百度搜索结果采集: 优采云·云采集网络爬虫软件 微博评论数据采集: 拼多多商品数据采集: 明日头条数据采集: 采集知乎话题信息(以知乎发觉为例): 淘宝网商品信息采集: 美团店家信息采集: 优采云——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
使用最多的自媒体平台文章采集工具有什么
采集交流 • 优采云 发表了文章 • 0 个评论 • 436 次浏览 • 2020-08-03 15:03
那么追热点热搜,首先就须要到各大媒体平台里面搜集热点,包括360热点、微博热点、百度搜索风云榜等等。光到各大平台里面找寻搜集剖析这种热点就须要耗费大量的时间精力。花费大量时间效率慢还不是最重要的,最难过的是耗费了大量的时间精力一旦判定失误追错了热点,导致一切辛苦都枉费。
那么这是就在想,有没有一款自媒体爆文采集工具可以使我们耗费最短的时间,用最高的效率搜集采集分析每晚的实时热点热搜数据呢?
使用最多的自媒体平台文章采集工具有什么
自媒体文章采集平台的强悍功能
智能采集,拓途数据提供多种网页采集策略与配套资源,帮助整个采集过程实现数据的完整性与稳定性。拓途数据的工作人员告诉你,全网适用,眼见即可采,不管是文字图片,还是帖吧峰会,支持所有业务渠道的爬虫,满足各类采集需求,海量模板,内置数百个网站数据源,全面覆盖多个行业,只需简单设置,就可快速确切获取数据。简单易用网站文章采集平台,无需再学爬虫编程技术,简单三步就可以轻松抓取网页数据,支持多种格式一键导入,快速导出数据库。稳定高效,分布式云集服务器和多用户协作管理平台的支撑,可灵活调度任务,顺利爬取海量数据。
通过以上文章,各位是不是对自媒体平台文章采集工具有了更多的了解,灵活使用拓途数据提供的自媒体平台文章采集工具可以确切跟踪实事动向,准确剖析数据,节约时间网站文章采集平台,提高效率,节省成本。
更多资讯知识点可持续关注,后续还有自媒咖爆文采集平台,自媒体文章采集平台,公众号 查询,公众号转载他人的原创文章,公众号历史文章等知识点。 查看全部
做自媒体营运难免不了的事情就是追热点热搜,其主要诱因还是热点内容可以获得特别不错的流量阅读。
那么追热点热搜,首先就须要到各大媒体平台里面搜集热点,包括360热点、微博热点、百度搜索风云榜等等。光到各大平台里面找寻搜集剖析这种热点就须要耗费大量的时间精力。花费大量时间效率慢还不是最重要的,最难过的是耗费了大量的时间精力一旦判定失误追错了热点,导致一切辛苦都枉费。
那么这是就在想,有没有一款自媒体爆文采集工具可以使我们耗费最短的时间,用最高的效率搜集采集分析每晚的实时热点热搜数据呢?
使用最多的自媒体平台文章采集工具有什么
自媒体文章采集平台的强悍功能
智能采集,拓途数据提供多种网页采集策略与配套资源,帮助整个采集过程实现数据的完整性与稳定性。拓途数据的工作人员告诉你,全网适用,眼见即可采,不管是文字图片,还是帖吧峰会,支持所有业务渠道的爬虫,满足各类采集需求,海量模板,内置数百个网站数据源,全面覆盖多个行业,只需简单设置,就可快速确切获取数据。简单易用网站文章采集平台,无需再学爬虫编程技术,简单三步就可以轻松抓取网页数据,支持多种格式一键导入,快速导出数据库。稳定高效,分布式云集服务器和多用户协作管理平台的支撑,可灵活调度任务,顺利爬取海量数据。
通过以上文章,各位是不是对自媒体平台文章采集工具有了更多的了解,灵活使用拓途数据提供的自媒体平台文章采集工具可以确切跟踪实事动向,准确剖析数据,节约时间网站文章采集平台,提高效率,节省成本。
更多资讯知识点可持续关注,后续还有自媒咖爆文采集平台,自媒体文章采集平台,公众号 查询,公众号转载他人的原创文章,公众号历史文章等知识点。
大数据采集工具,除了Flume,还有哪些工具?
采集交流 • 优采云 发表了文章 • 0 个评论 • 743 次浏览 • 2020-08-03 09:04
大数据平台与数据采集
任何完整的大数据平台,一般包括以下的几个过程:
数据采集-->数据储存-->数据处理-->数据凸显(可视化,报表和监控)
其中,数据采集是所有数据系统必不可少的采集工具,随着大数据越来越被注重,数据采集的挑战也变的尤为突出。这其中包括:
我们明天就来瞧瞧当前可用的六款数据采集的产品,重点关注它们是怎么做到高可靠,高性能和高扩充。
1、Apache Flume
官网:
Flume 是Apache旗下的一款开源、高可靠、高扩充、容易管理、支持顾客扩充的数据采集系统。 Flume使用JRuby来建立,所以依赖Java运行环境。
Flume最初是由Cloudera的工程师设计用于合并日志数据的系统,后来逐步发展用于处理流数据风波。
Flume设计成一个分布式的管线构架,可以看作在数据源和目的地之间有一个Agent的网路,支持数据路由。
每一个agent都由Source,Channel和Sink组成。
Source
Source负责接收输入数据,并将数据写入管线。Flume的Source支持HTTP,JMS,RPC,NetCat,Exec,Spooling Directory。其中Spooling支持监视一个目录或则文件,解析其中新生成的风波。
Channel
Channel 存储,缓存从source到Sink的中间数据。可使用不同的配置来做Channel,例如显存,文件,JDBC等。使用显存性能高但不持久,有可能丢数据。使用文件更可靠,但性能不如显存。
Sink
Sink负责从管线中读出数据并发给下一个Agent或则最终的目的地。Sink支持的不同目的地种类包括:HDFS,HBASE,Solr,ElasticSearch,File,Logger或则其它的Flume Agent。
Flume在source和sink端都使用了transaction机制保证在数据传输中没有数据遗失。
Source上的数据可以复制到不同的通道上。每一个Channel也可以联接不同数目的Sink。这样联接不同配置的Agent就可以组成一个复杂的数据搜集网路。通过对agent的配置,可以组成一个路由复杂的数据传输网路。
配置如上图所示的agent结构,Flume支持设置sink的Failover和Load Balance,这样就可以保证虽然有一个agent失效的情况下,整个系统仍能正常搜集数据。
Flume中传输的内容定义为风波(Event),事件由Headers(包含元数据,Meta Data)和Payload组成。
Flume提供SDK,可以支持用户订制开发:
Flume客户端负责在风波形成的源头把风波发送给Flume的Agent。客户端一般和形成数据源的应用在同一个进程空间。常见的Flume 客户端有Avro,log4J,syslog和HTTP Post。另外ExecSource支持指定一个本地进程的输出作为Flume的输入。当然很有可能,以上的那些客户端都不能满足需求,用户可以订制的客户端,和已有的FLume的Source进行通讯,或者订制实现一种新的Source类型。
同时,用户可以使用Flume的SDK订制Source和Sink。似乎不支持订制的Channel。
2、Fluentd
官网:
Fluentd是另一个开源的数据搜集框架。Fluentd使用C/Ruby开发,使用JSON文件来统一日志数据。它的可拔插构架,支持各类不同种类和格式的数据源和数据输出。最后它也同时提供了高可靠和挺好的扩展性。Treasure Data, Inc 对该产品提供支持和维护。
Fluentd的布署和Flume十分相像:
Fluentd的构架设计和Flume如出一辙:
Fluentd的Input/Buffer/Output特别类似于Flume的Source/Channel/Sink。
Input
Input负责接收数据或则主动抓取数据。支持syslog,http,file tail等。
Buffer
Buffer负责数据获取的性能和可靠性,也有文件或显存等不同类型的Buffer可以配置。
Output
Output负责输出数据到目的地比如文件,AWS S3或则其它的Fluentd。
Fluentd的配置十分便捷,如下图:
Fluentd的技术栈如下图:
FLuentd和其插件都是由Ruby开发,MessgaePack提供了JSON的序列化和异步的并行通信RPC机制。
Cool.io是基于libev的风波驱动框架。
FLuentd的扩展性非常好,客户可以自己订制(Ruby)Input/Buffer/Output。
Fluentd从各方面看都太象Flume,区别是使用Ruby开发,Footprint会小一些,但是也带来了跨平台的问题,并不能支持Windows平台。另外采用JSON统一数据/日志格式是它的另一个特性。相对去Flumed,配置也相对简单一些。
3、Logstash
Logstash是知名的开源数据栈ELK (ElasticSearch, Logstash, Kibana)中的那种L。
Logstash用JRuby开发,所有运行时依赖JVM。
Logstash的布署构架如下图,当然这只是一种布署的选项。
一个典型的Logstash的配置如下,包括了Input,filter的Output的设置。
几乎在大部分的情况下ELK作为一个栈是被同时使用的。所有当你的数据系统使用ElasticSearch的情况下,logstash是首选。
4、Chukwa
官网:
Apache Chukwa是apache旗下另一个开源的数据搜集平台,它远没有其他几个有名。Chukwa基于Hadoop的HDFS和Map Reduce来建立(显而易见,它用Java来实现),提供扩展性和可靠性。Chukwa同时提供对数据的展示,分析和监视。很奇怪的是它的上一次 github的更新事7年前。可见该项目应当早已不活跃了。
Chukwa的布署构架如下:
Chukwa的主要单元有:Agent,Collector,DataSink,ArchiveBuilder,Demux等等,看上去相当复杂。由于该项目早已不活跃,我们就不细看了。
5、Scribe
代码托管:
Scribe是Facebook开发的数据(日志)收集系统。已经多年不维护,同样的,就不多说了。
6、Splunk Forwarder
官网:
以上的所有系统都是开源的。在商业化的大数据平台产品中,Splunk提供完整的数据采金,数据储存,数据剖析和处理,以及数据凸显的能力。
Splunk是一个分布式的机器数据平台,主要有三个角色:
Search Head负责数据的搜索和处理,提供搜索时的信息抽取。Indexer负责数据的储存和索引Forwarder,负责数据的搜集,清洗,变形,并发献给Indexer
Splunk外置了对Syslog,TCP/UDP,Spooling的支持,同时采集工具,用户可以通过开发 Input和Modular Input的方法来获取特定的数据。在Splunk提供的软件库房里有好多成熟的数据采集应用,例如AWS,数据库(DBConnect)等等,可以便捷的从云或则是数据库中获取数据步入Splunk的数据平台做剖析。
这里要注意的是,Search Head和Indexer都支持Cluster的配置,也就是高可用,高扩充的,但是Splunk现今还没有针对Farwarder的Cluster的功能。也就是说假如有一台Farwarder的机器出了故障,数据搜集也会急剧中断,并不能把正在运行的数据采集任务Failover到其它的 Farwarder上。
总结
我们简单讨论了几种流行的数据搜集平台,它们大都提供高可靠和高扩充的数据搜集。大多平台都具象出了输入,输出和中间的缓冲的构架。利用分布式的网路联接,大多数平台都能实现一定程度的扩展性和高可靠性。
其中Flume,Fluentd是两个被使用较多的产品。如果你用ElasticSearch,Logstash其实是首选,因为ELK栈提供了挺好的集成。Chukwa和Scribe因为项目的不活跃,不推荐使用。
Splunk作为一个优秀的商业产品,它的数据采集还存在一定的限制,相信Splunk很快会开发出更好的数据搜集的解决方案。 查看全部
随着大数据越来越被注重,数据采集的挑战变的尤为突出。今天为你们介绍几款数据采集平台:
大数据平台与数据采集
任何完整的大数据平台,一般包括以下的几个过程:
数据采集-->数据储存-->数据处理-->数据凸显(可视化,报表和监控)
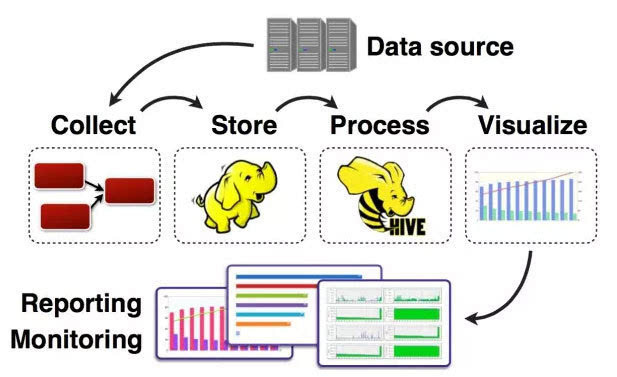
其中,数据采集是所有数据系统必不可少的采集工具,随着大数据越来越被注重,数据采集的挑战也变的尤为突出。这其中包括:
我们明天就来瞧瞧当前可用的六款数据采集的产品,重点关注它们是怎么做到高可靠,高性能和高扩充。
1、Apache Flume
官网:
Flume 是Apache旗下的一款开源、高可靠、高扩充、容易管理、支持顾客扩充的数据采集系统。 Flume使用JRuby来建立,所以依赖Java运行环境。
Flume最初是由Cloudera的工程师设计用于合并日志数据的系统,后来逐步发展用于处理流数据风波。

Flume设计成一个分布式的管线构架,可以看作在数据源和目的地之间有一个Agent的网路,支持数据路由。

每一个agent都由Source,Channel和Sink组成。
Source
Source负责接收输入数据,并将数据写入管线。Flume的Source支持HTTP,JMS,RPC,NetCat,Exec,Spooling Directory。其中Spooling支持监视一个目录或则文件,解析其中新生成的风波。
Channel
Channel 存储,缓存从source到Sink的中间数据。可使用不同的配置来做Channel,例如显存,文件,JDBC等。使用显存性能高但不持久,有可能丢数据。使用文件更可靠,但性能不如显存。
Sink
Sink负责从管线中读出数据并发给下一个Agent或则最终的目的地。Sink支持的不同目的地种类包括:HDFS,HBASE,Solr,ElasticSearch,File,Logger或则其它的Flume Agent。
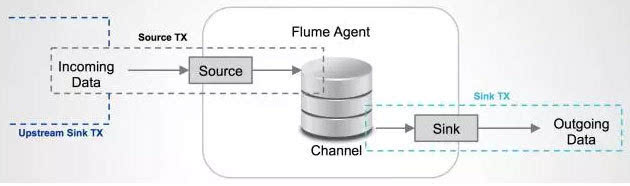
Flume在source和sink端都使用了transaction机制保证在数据传输中没有数据遗失。
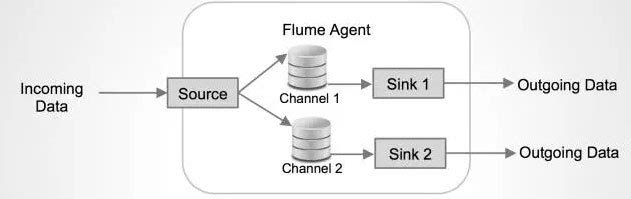
Source上的数据可以复制到不同的通道上。每一个Channel也可以联接不同数目的Sink。这样联接不同配置的Agent就可以组成一个复杂的数据搜集网路。通过对agent的配置,可以组成一个路由复杂的数据传输网路。
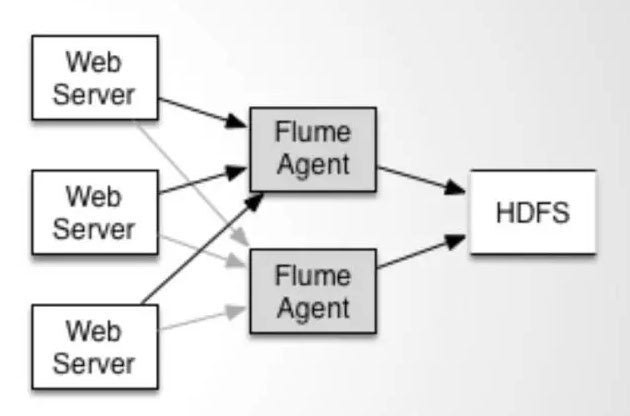
配置如上图所示的agent结构,Flume支持设置sink的Failover和Load Balance,这样就可以保证虽然有一个agent失效的情况下,整个系统仍能正常搜集数据。

Flume中传输的内容定义为风波(Event),事件由Headers(包含元数据,Meta Data)和Payload组成。
Flume提供SDK,可以支持用户订制开发:
Flume客户端负责在风波形成的源头把风波发送给Flume的Agent。客户端一般和形成数据源的应用在同一个进程空间。常见的Flume 客户端有Avro,log4J,syslog和HTTP Post。另外ExecSource支持指定一个本地进程的输出作为Flume的输入。当然很有可能,以上的那些客户端都不能满足需求,用户可以订制的客户端,和已有的FLume的Source进行通讯,或者订制实现一种新的Source类型。
同时,用户可以使用Flume的SDK订制Source和Sink。似乎不支持订制的Channel。
2、Fluentd
官网:
Fluentd是另一个开源的数据搜集框架。Fluentd使用C/Ruby开发,使用JSON文件来统一日志数据。它的可拔插构架,支持各类不同种类和格式的数据源和数据输出。最后它也同时提供了高可靠和挺好的扩展性。Treasure Data, Inc 对该产品提供支持和维护。
Fluentd的布署和Flume十分相像:
Fluentd的构架设计和Flume如出一辙:
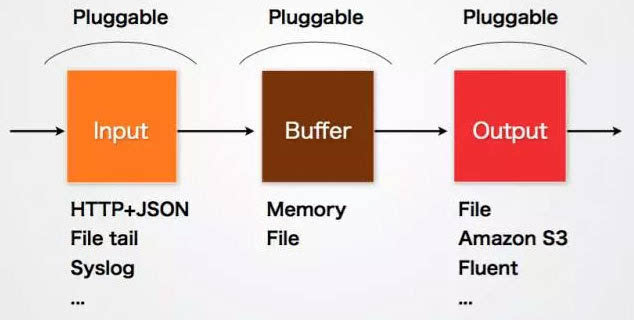
Fluentd的Input/Buffer/Output特别类似于Flume的Source/Channel/Sink。
Input
Input负责接收数据或则主动抓取数据。支持syslog,http,file tail等。
Buffer
Buffer负责数据获取的性能和可靠性,也有文件或显存等不同类型的Buffer可以配置。
Output
Output负责输出数据到目的地比如文件,AWS S3或则其它的Fluentd。
Fluentd的配置十分便捷,如下图:
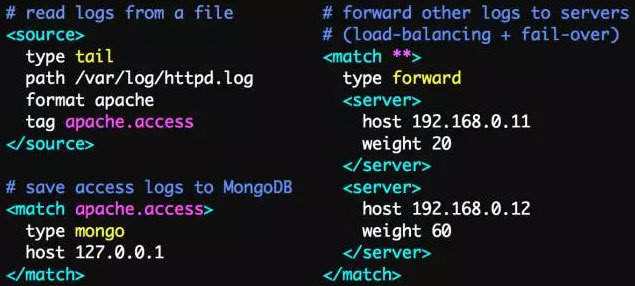
Fluentd的技术栈如下图:
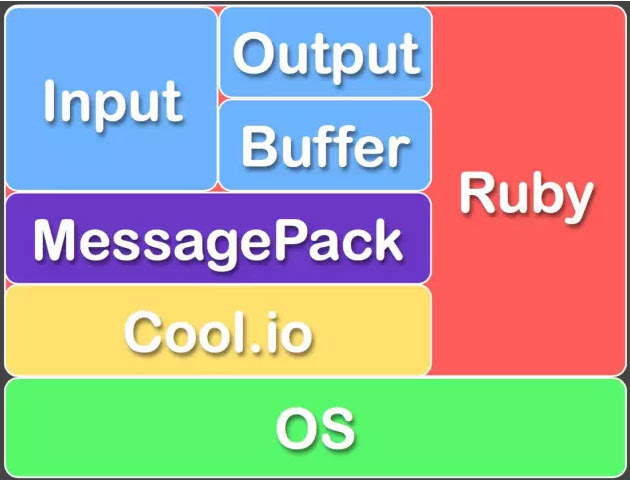
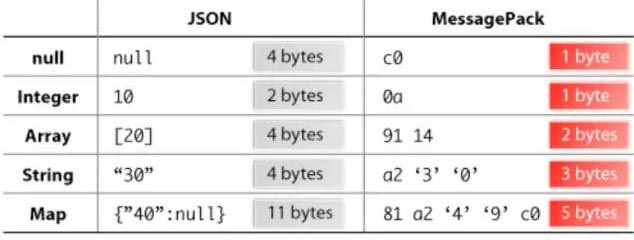
FLuentd和其插件都是由Ruby开发,MessgaePack提供了JSON的序列化和异步的并行通信RPC机制。
Cool.io是基于libev的风波驱动框架。
FLuentd的扩展性非常好,客户可以自己订制(Ruby)Input/Buffer/Output。
Fluentd从各方面看都太象Flume,区别是使用Ruby开发,Footprint会小一些,但是也带来了跨平台的问题,并不能支持Windows平台。另外采用JSON统一数据/日志格式是它的另一个特性。相对去Flumed,配置也相对简单一些。
3、Logstash
Logstash是知名的开源数据栈ELK (ElasticSearch, Logstash, Kibana)中的那种L。
Logstash用JRuby开发,所有运行时依赖JVM。
Logstash的布署构架如下图,当然这只是一种布署的选项。
一个典型的Logstash的配置如下,包括了Input,filter的Output的设置。

几乎在大部分的情况下ELK作为一个栈是被同时使用的。所有当你的数据系统使用ElasticSearch的情况下,logstash是首选。
4、Chukwa
官网:
Apache Chukwa是apache旗下另一个开源的数据搜集平台,它远没有其他几个有名。Chukwa基于Hadoop的HDFS和Map Reduce来建立(显而易见,它用Java来实现),提供扩展性和可靠性。Chukwa同时提供对数据的展示,分析和监视。很奇怪的是它的上一次 github的更新事7年前。可见该项目应当早已不活跃了。
Chukwa的布署构架如下:

Chukwa的主要单元有:Agent,Collector,DataSink,ArchiveBuilder,Demux等等,看上去相当复杂。由于该项目早已不活跃,我们就不细看了。
5、Scribe
代码托管:
Scribe是Facebook开发的数据(日志)收集系统。已经多年不维护,同样的,就不多说了。
6、Splunk Forwarder
官网:
以上的所有系统都是开源的。在商业化的大数据平台产品中,Splunk提供完整的数据采金,数据储存,数据剖析和处理,以及数据凸显的能力。
Splunk是一个分布式的机器数据平台,主要有三个角色:
Search Head负责数据的搜索和处理,提供搜索时的信息抽取。Indexer负责数据的储存和索引Forwarder,负责数据的搜集,清洗,变形,并发献给Indexer
Splunk外置了对Syslog,TCP/UDP,Spooling的支持,同时采集工具,用户可以通过开发 Input和Modular Input的方法来获取特定的数据。在Splunk提供的软件库房里有好多成熟的数据采集应用,例如AWS,数据库(DBConnect)等等,可以便捷的从云或则是数据库中获取数据步入Splunk的数据平台做剖析。
这里要注意的是,Search Head和Indexer都支持Cluster的配置,也就是高可用,高扩充的,但是Splunk现今还没有针对Farwarder的Cluster的功能。也就是说假如有一台Farwarder的机器出了故障,数据搜集也会急剧中断,并不能把正在运行的数据采集任务Failover到其它的 Farwarder上。
总结
我们简单讨论了几种流行的数据搜集平台,它们大都提供高可靠和高扩充的数据搜集。大多平台都具象出了输入,输出和中间的缓冲的构架。利用分布式的网路联接,大多数平台都能实现一定程度的扩展性和高可靠性。
其中Flume,Fluentd是两个被使用较多的产品。如果你用ElasticSearch,Logstash其实是首选,因为ELK栈提供了挺好的集成。Chukwa和Scribe因为项目的不活跃,不推荐使用。
Splunk作为一个优秀的商业产品,它的数据采集还存在一定的限制,相信Splunk很快会开发出更好的数据搜集的解决方案。
【虾哥SEO】常见SEO数据剖析的重要性以及方法!
采集交流 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2020-07-07 08:02
6、核心关键词排名
7、内页长尾关键词排行数目
。。。。。。。
我们先来点评一下seo快速排名软件 虾哥,为什么往年的SEO数据剖析,不能做到从数据驱动SEO。我们逐字剖析一下往年做条目。
1、在其他诱因不变的情况下,PR或则百度权重高,流量一定高吗?很显然不是,而且还只是首页的PR值或则百度权重,对于任意一个网站来说,首页的流量仅仅是一小部份,对于超级大站来说,首页的流量所占比列小到可以忽视。(由于基数大,小比列的数据也比好多网站可观了)。首页PR(百度权重)数据完全没必要剖析。
2、Alexa的数据还有一定的参考性,但是对国外网站来说,几乎可以无视,除了搞IT的,基本没人会装。Alexa统计的流量是所有流量,并非单纯的SEO流量,所以对SEO没很大关系,不过Alexa的数据获取比较容易,就作为一个参考吧。
3、site收录准不准先不说,问题是site下来的数据有哪些意义呢?如果一个网站有1个亿的页面,site下来100万,是好还是坏?一个网站有1万个页面,site下来是1万,是好还是坏?因此,除了site的数据,你起码得晓得这个网站有多少页面量,否则site的数据毫无意义;一切收录量还是以百度站长工具当中的索引量为准。
4、首页快照,网页有更新了,爬虫可能拍个照,快照时间更新一下。更多时侯你页面动都没动。你指望快照变化对你SEO有哪些影响呢?而且和首页PR(百度权重)同理,首页只是一个页面而已,没这么特殊。
5、外链数目,外链为王,外链数目肯定是重要的。外链真的是越多越好吗?有的查询网站很明显排行第1的比排行第10的外链少得多的多。其实外链的整体质量很难评判,反正你也统计不全,何必要用这个数目作为一个结果,如果相关外链多,则排行都会提升,这不是我说的,是Google、百度说的。所以我们统计排行这个直接诱因就好了,而且百度和微软对于外链的过滤机制成熟,低质量的外链发太多反倒影响网站排名。
6、说到排行,要谈谈核心关键词的排行与网站整体排行的问题。相信诸位SEO站长手头都有自己的网站,看看流量报告吧,那些核心关键词能带来的流量占所有流量的比列是多少?但是通常做SEO优化的时侯,大家都习惯于把资源集中在几个核心词上,而大量的关键词流量,都属于没人要的,随便分配一些资源过去,流量就上来了。只看核心词的排行做SEO,属于“捡了芝麻,丢了西瓜”。“两手都要抓,两手都要硬”,平均分配资源,才能利润最大化。
从以上几个数据可以看出,过往的SEO数据剖析,分析的数据大都是不靠谱、不确切的。自然对SEO没哪些影响,而且从那些数据中,也很难发觉核心问题。SEO数据剖析seo快速排名软件 虾哥,往往就成了一个“噱头”,花了大量时间精力,却连一点疗效和指导也没有。
那么怎么做SEO的数据剖析?先推荐一些前人的智慧(曾庆平SEO:大家可以在百度搜索一下以下文章)
1、前阿里巴巴SEO国平:
详解光年SEO日志剖析系统2.0
网页加载速率是怎样影响SEO疗效的
2、天极网SEO废魅族:
百度收录抽检
任重而道远--IT垂直类门户搜索引擎关键词排行对比
虽然有些文章很老,但是到现今也太有指导性作用。先不借用谁的理论,我们从事实出发,好好回想一下用户是怎样通过搜索引擎来到我们网站的。
1、用户在搜索框中输入一个关键词。
2、用户在搜索结果页面中阅读大量结果。
3、用户点击步入某个他满意的结果。
虾姐SEOSEO数据剖析
---------> 查看全部
5、外链数目
6、核心关键词排名
7、内页长尾关键词排行数目
。。。。。。。

我们先来点评一下seo快速排名软件 虾哥,为什么往年的SEO数据剖析,不能做到从数据驱动SEO。我们逐字剖析一下往年做条目。
1、在其他诱因不变的情况下,PR或则百度权重高,流量一定高吗?很显然不是,而且还只是首页的PR值或则百度权重,对于任意一个网站来说,首页的流量仅仅是一小部份,对于超级大站来说,首页的流量所占比列小到可以忽视。(由于基数大,小比列的数据也比好多网站可观了)。首页PR(百度权重)数据完全没必要剖析。
2、Alexa的数据还有一定的参考性,但是对国外网站来说,几乎可以无视,除了搞IT的,基本没人会装。Alexa统计的流量是所有流量,并非单纯的SEO流量,所以对SEO没很大关系,不过Alexa的数据获取比较容易,就作为一个参考吧。
3、site收录准不准先不说,问题是site下来的数据有哪些意义呢?如果一个网站有1个亿的页面,site下来100万,是好还是坏?一个网站有1万个页面,site下来是1万,是好还是坏?因此,除了site的数据,你起码得晓得这个网站有多少页面量,否则site的数据毫无意义;一切收录量还是以百度站长工具当中的索引量为准。
4、首页快照,网页有更新了,爬虫可能拍个照,快照时间更新一下。更多时侯你页面动都没动。你指望快照变化对你SEO有哪些影响呢?而且和首页PR(百度权重)同理,首页只是一个页面而已,没这么特殊。
5、外链数目,外链为王,外链数目肯定是重要的。外链真的是越多越好吗?有的查询网站很明显排行第1的比排行第10的外链少得多的多。其实外链的整体质量很难评判,反正你也统计不全,何必要用这个数目作为一个结果,如果相关外链多,则排行都会提升,这不是我说的,是Google、百度说的。所以我们统计排行这个直接诱因就好了,而且百度和微软对于外链的过滤机制成熟,低质量的外链发太多反倒影响网站排名。
6、说到排行,要谈谈核心关键词的排行与网站整体排行的问题。相信诸位SEO站长手头都有自己的网站,看看流量报告吧,那些核心关键词能带来的流量占所有流量的比列是多少?但是通常做SEO优化的时侯,大家都习惯于把资源集中在几个核心词上,而大量的关键词流量,都属于没人要的,随便分配一些资源过去,流量就上来了。只看核心词的排行做SEO,属于“捡了芝麻,丢了西瓜”。“两手都要抓,两手都要硬”,平均分配资源,才能利润最大化。
从以上几个数据可以看出,过往的SEO数据剖析,分析的数据大都是不靠谱、不确切的。自然对SEO没哪些影响,而且从那些数据中,也很难发觉核心问题。SEO数据剖析seo快速排名软件 虾哥,往往就成了一个“噱头”,花了大量时间精力,却连一点疗效和指导也没有。
那么怎么做SEO的数据剖析?先推荐一些前人的智慧(曾庆平SEO:大家可以在百度搜索一下以下文章)
1、前阿里巴巴SEO国平:
详解光年SEO日志剖析系统2.0
网页加载速率是怎样影响SEO疗效的
2、天极网SEO废魅族:
百度收录抽检
任重而道远--IT垂直类门户搜索引擎关键词排行对比
虽然有些文章很老,但是到现今也太有指导性作用。先不借用谁的理论,我们从事实出发,好好回想一下用户是怎样通过搜索引擎来到我们网站的。
1、用户在搜索框中输入一个关键词。
2、用户在搜索结果页面中阅读大量结果。
3、用户点击步入某个他满意的结果。
虾姐SEOSEO数据剖析
--------->
写爬虫,用哪些编程语言好,python好吗
采集交流 • 优采云 发表了文章 • 0 个评论 • 423 次浏览 • 2020-06-23 08:01
之前换了份工作,不再是单纯的Web开发了,要学习的东西真的很多的。入职的第1天,就让我入手写个爬虫,只是这个爬虫没有采集几个亿数据量的业务场景。
于是,整理了下需求,简单的设计了下方案就草草开始了。小B是我学院时侯的同事,那天这哥们约我喝水,想看下能够顺带介绍几个姑娘。酒过三巡,不胜酒力,于是便聊起了近来的工作。
当他知晓我居然在写爬虫,便起了同情之心,觉得我怀才不遇。仿佛写爬虫是件太低级太low的技术活。在他那家公司,招进来的实习生就多多少少会点爬虫,什么nodejs、golang,哪个不是爬虫的好手。没想到我结业多年,竟然沦落到做实习生的工作,可悲可泣。
接着建议我转入Java阵营,如果到他公司去,多多少少也能混个主任的职位。搞得自己只能一番苦笑。
不知道从何时起,程序员的世界流行起了鄙视链这玩意。什么写C语言的厌恶写C++,写C++的厌恶写Java的,最后鄙视链最高端是PHP。具体是如何的关系,就不再揣测了。
写爬虫,用哪些编程语言好,python好吗
然而,纵观整个行业,都说Python火。具体有多火,看培训机构的广告就晓得了。在16年之前,Python还是1个若不见经传的词组,之后各家培训机构铺天盖地的广告,什么大数据、自动化运维全都跟Python扯上了关系。毕业学生工资更是达到了50-100W,还老是招不到人。
更有意思的是,学Python最容易上手的过程就是写爬虫。什么Scrapy、Pysider是必学,HTML、Javascript是重点,外带几个豆瓣、花瓣网的实战案例,让你一下子才能解决企业的刚需。
这样说来,难怪连实习生也能跟你抢饭碗了,技术发展的很快,各种框架构建的结果是释放人力,降低成本。
据我了解,Python的优势集中于数据剖析、信息安全那些领域。你可能听说过Hadoop、Spark、Tensorflow这种高大上的名词,但是对于数据取证、DLL注入等内容可能从无听闻。举个简单的事例,在数据取证中,由于犯罪人员不配合检测机关的工作,通过数据取证技术我们可以进行一些信息的提取,从而辅助否认其犯罪记录,如获取系统密码、浏览器中帐号及密码。
听起来觉得很高大上的,但是假如我跟你说其过程就是对sqlite3文件数据库查询一下SQL,不知道你会不会认为上述取证的事例顿时很low的。但是,当你不留神把陌陌消息的图片删除想寻回的时侯,或许你能在Python中找到对应的方案,而其他的语言还真没发觉有合适的。
于是,我开导他说,搞完这波爬虫骚操作,下一次就是数据剖析了,你看不有前进了一步?
还数据剖析,你似乎想的很远的。小B打断了我的话,你认为人家会使你搞数据剖析,没有数据何来的剖析。况且,没有哪家公司会笨到把所有数据都曝露在互联网上。你能看到的只是那冰山的一角。即使你想深入进去,没有分布式技术支撑和几十个亿的数据业务,你简历上也不会有亮点。
然后,又聊到他公司近日招了个大数据的开发,薪资比他还要高出一大截,但是技术却不咋地。我从小B的话里听出了一丝揶揄了。于是,又教唆我不要再搞哪些爬虫了,还是搞Spark才有未来。既不用害怕大深夜服务挂了,又不用害怕完不成采集数量。完全是实打实的数据,何乐而不为呢?
这话听得我都有点动心了,没有攀比就没有伤害。但是一想到Java是加班加点工作,我还是打消了这个念头。
我不知道该说些哪些,只是认为时间过得太慢,是种熬煎。于是只能扯开了话题,免得喝顿饭都艰难。
结语
技术没有low不low,没有烂的技术,只有不会用的人。重要的是人家能给你多少钱,你能弄成如何的结果。
这年头会有多少公司乐意给实习生税后1W+的起薪,而这一切都只是份养活自己的技能而已,别把面子很当回事。
写爬虫,用哪些编程语言好,python好吗,其实编程的路上只在于擅长,没有所谓的行不行,如果不擅长,就是给您好用的编程语言也没有疗效,如果想要学编程,那就关注IT培训网网络爬虫用什么语言写,让我们一起走入编程的世界! 查看全部
用Python写爬虫就太low?你赞成嘛?为何不建议使用python写爬虫呢网络爬虫用什么语言写,是有哪些诱因吗,难道用python写爬虫不好吗?
之前换了份工作,不再是单纯的Web开发了,要学习的东西真的很多的。入职的第1天,就让我入手写个爬虫,只是这个爬虫没有采集几个亿数据量的业务场景。
于是,整理了下需求,简单的设计了下方案就草草开始了。小B是我学院时侯的同事,那天这哥们约我喝水,想看下能够顺带介绍几个姑娘。酒过三巡,不胜酒力,于是便聊起了近来的工作。
当他知晓我居然在写爬虫,便起了同情之心,觉得我怀才不遇。仿佛写爬虫是件太低级太low的技术活。在他那家公司,招进来的实习生就多多少少会点爬虫,什么nodejs、golang,哪个不是爬虫的好手。没想到我结业多年,竟然沦落到做实习生的工作,可悲可泣。
接着建议我转入Java阵营,如果到他公司去,多多少少也能混个主任的职位。搞得自己只能一番苦笑。
不知道从何时起,程序员的世界流行起了鄙视链这玩意。什么写C语言的厌恶写C++,写C++的厌恶写Java的,最后鄙视链最高端是PHP。具体是如何的关系,就不再揣测了。

写爬虫,用哪些编程语言好,python好吗
然而,纵观整个行业,都说Python火。具体有多火,看培训机构的广告就晓得了。在16年之前,Python还是1个若不见经传的词组,之后各家培训机构铺天盖地的广告,什么大数据、自动化运维全都跟Python扯上了关系。毕业学生工资更是达到了50-100W,还老是招不到人。
更有意思的是,学Python最容易上手的过程就是写爬虫。什么Scrapy、Pysider是必学,HTML、Javascript是重点,外带几个豆瓣、花瓣网的实战案例,让你一下子才能解决企业的刚需。
这样说来,难怪连实习生也能跟你抢饭碗了,技术发展的很快,各种框架构建的结果是释放人力,降低成本。
据我了解,Python的优势集中于数据剖析、信息安全那些领域。你可能听说过Hadoop、Spark、Tensorflow这种高大上的名词,但是对于数据取证、DLL注入等内容可能从无听闻。举个简单的事例,在数据取证中,由于犯罪人员不配合检测机关的工作,通过数据取证技术我们可以进行一些信息的提取,从而辅助否认其犯罪记录,如获取系统密码、浏览器中帐号及密码。
听起来觉得很高大上的,但是假如我跟你说其过程就是对sqlite3文件数据库查询一下SQL,不知道你会不会认为上述取证的事例顿时很low的。但是,当你不留神把陌陌消息的图片删除想寻回的时侯,或许你能在Python中找到对应的方案,而其他的语言还真没发觉有合适的。
于是,我开导他说,搞完这波爬虫骚操作,下一次就是数据剖析了,你看不有前进了一步?
还数据剖析,你似乎想的很远的。小B打断了我的话,你认为人家会使你搞数据剖析,没有数据何来的剖析。况且,没有哪家公司会笨到把所有数据都曝露在互联网上。你能看到的只是那冰山的一角。即使你想深入进去,没有分布式技术支撑和几十个亿的数据业务,你简历上也不会有亮点。
然后,又聊到他公司近日招了个大数据的开发,薪资比他还要高出一大截,但是技术却不咋地。我从小B的话里听出了一丝揶揄了。于是,又教唆我不要再搞哪些爬虫了,还是搞Spark才有未来。既不用害怕大深夜服务挂了,又不用害怕完不成采集数量。完全是实打实的数据,何乐而不为呢?
这话听得我都有点动心了,没有攀比就没有伤害。但是一想到Java是加班加点工作,我还是打消了这个念头。
我不知道该说些哪些,只是认为时间过得太慢,是种熬煎。于是只能扯开了话题,免得喝顿饭都艰难。
结语
技术没有low不low,没有烂的技术,只有不会用的人。重要的是人家能给你多少钱,你能弄成如何的结果。
这年头会有多少公司乐意给实习生税后1W+的起薪,而这一切都只是份养活自己的技能而已,别把面子很当回事。
写爬虫,用哪些编程语言好,python好吗,其实编程的路上只在于擅长,没有所谓的行不行,如果不擅长,就是给您好用的编程语言也没有疗效,如果想要学编程,那就关注IT培训网网络爬虫用什么语言写,让我们一起走入编程的世界!
网页数据抓取三步走
采集交流 • 优采云 发表了文章 • 0 个评论 • 384 次浏览 • 2020-06-20 08:01
当我们有了抓取目标后,第一步就是剖析。首先是剖析页面的特性火车采集器v9的怎么用,网页通常包括静态页面、伪静态页面以及动态页面。静态网页URL以.htm、.html、.shtml等常见方式为后缀,动态页面则是以.asp、.jsp、.php、.perl、.cgi等方式为后缀,并且在动态网页网址中有一个标志性的符号——“?”。相对来说静态页面采集比较容易一些,比如一些新闻页面,功能比较简单;而象峰会就属于动态页面,它的后台服务器会手动更新,这样的页面采集时涉及到的功能就多一些,相对比较复杂。
其次是剖析数据,我们须要的数据是怎样诠释的,是否有列表分页、内容分页或是多页?需要的数据是图片还是文本还是其他文件?
最后须要剖析的是源代码,根据我们须要采集到的数据,依次找出它们的源代码及相关规律,方便后续在采集工具中得以彰显。
第二步:获取
这里须要用到精典的抓取工具列车采集器V9,火车采集器获取数据的原理就是基于WEB结构的源代码提取,因此在第一步中剖析源代码是极其重要的。我们在列车采集器V9中对每一项须要的数据设置获取规则,将它提取下来。在列车采集器中,可以自动获取,也支持部份类型的数据手动辨识提取。分析正确的前提下火车采集器v9的怎么用,获取数据十分方便。
第三步:处理
获取到的数据假如可以直接用这么就无需进行这一步,如果还须要使数据愈加符合要求,就须要使用列车采集器V9强悍的处理功能了。比如标签过滤;敏感词,近义词替换/排除;数据转换;补全单网址;智能提取图片、邮箱,电话号码等智能化的处理体系,必要的话还可以开发插件进行处理。
按照上述的这三个步骤,网页数据抓取虽然并不难,除了强化对软件操作的熟悉度之外,我们还须要提升自身的剖析能力和网页相关的技术知识,那么网页数据抓取将愈加得心应手。 查看全部
当我们有了抓取目标后,第一步就是剖析。首先是剖析页面的特性火车采集器v9的怎么用,网页通常包括静态页面、伪静态页面以及动态页面。静态网页URL以.htm、.html、.shtml等常见方式为后缀,动态页面则是以.asp、.jsp、.php、.perl、.cgi等方式为后缀,并且在动态网页网址中有一个标志性的符号——“?”。相对来说静态页面采集比较容易一些,比如一些新闻页面,功能比较简单;而象峰会就属于动态页面,它的后台服务器会手动更新,这样的页面采集时涉及到的功能就多一些,相对比较复杂。
其次是剖析数据,我们须要的数据是怎样诠释的,是否有列表分页、内容分页或是多页?需要的数据是图片还是文本还是其他文件?
最后须要剖析的是源代码,根据我们须要采集到的数据,依次找出它们的源代码及相关规律,方便后续在采集工具中得以彰显。
第二步:获取
这里须要用到精典的抓取工具列车采集器V9,火车采集器获取数据的原理就是基于WEB结构的源代码提取,因此在第一步中剖析源代码是极其重要的。我们在列车采集器V9中对每一项须要的数据设置获取规则,将它提取下来。在列车采集器中,可以自动获取,也支持部份类型的数据手动辨识提取。分析正确的前提下火车采集器v9的怎么用,获取数据十分方便。
第三步:处理
获取到的数据假如可以直接用这么就无需进行这一步,如果还须要使数据愈加符合要求,就须要使用列车采集器V9强悍的处理功能了。比如标签过滤;敏感词,近义词替换/排除;数据转换;补全单网址;智能提取图片、邮箱,电话号码等智能化的处理体系,必要的话还可以开发插件进行处理。
按照上述的这三个步骤,网页数据抓取虽然并不难,除了强化对软件操作的熟悉度之外,我们还须要提升自身的剖析能力和网页相关的技术知识,那么网页数据抓取将愈加得心应手。
什么是爬虫技术?
采集交流 • 优采云 发表了文章 • 0 个评论 • 273 次浏览 • 2020-06-17 08:00
有一个说法是,互联网上50%的流量都是爬虫创造的。这个说法似乎夸张了点,但也彰显出了爬虫的无处不在。爬虫之所以无处不在,是因为爬虫可以为互联网企业带来利润。
爬虫技术的现况
语言
理论上来说,任何支持网路通讯的语言都是可以写爬虫的,爬虫本身其实语言关系不大,但是,总有相对顺手、简单的。目前来说,大多数爬虫是用后台脚本类语言写的,其中python无疑是用的最多最广的,并且也诞生了好多优秀的库和框架,如scrapy、BeautifulSoup 、pyquery、Mechanize等。但是一般来说,搜索引擎的爬虫对爬虫的效率要求更高,会选用c++、java、go(适合高并发)。
运行环境
爬虫本身不分辨究竟是运行在windows还是Linux,又或是OSX,但从业务角度讲爬虫技术用什么语言,我们把运行在服务端(后台)的,称之为后台爬虫。而如今,几乎所有的爬虫都是后台爬虫。
爬虫的作用
1、爬虫爬出top1000和top10000数据,范围减小,然后根据情况选定细分产品信息等进行开发。
2、通过爬虫数据,跟踪产品情况,用来作出快速反应。
3、利用爬虫信息,抓取产品信息库类目变动情况。
未来,人工智能将会颠覆所有的商业应用。而人工智能的基础在于大数据,大数据的基础核心是数据采集,数据采集的主力是爬虫技术,因此,爬虫技术作为大数据最基层的应用,其重要性毋庸置疑。 查看全部
在一大堆技术术语里,最为被普通人所熟知的大约就是“爬虫”了。其实爬虫这个名子就早已非常好地表现出了这项技术的作用——像密密麻麻的蚊子一样分布在网路上爬虫技术用什么语言,爬行至每一个角落获取数据;也一定程度上抒发了人们对这项技术的情感倾向——虫子其实无害,但总是不受欢迎的。
有一个说法是,互联网上50%的流量都是爬虫创造的。这个说法似乎夸张了点,但也彰显出了爬虫的无处不在。爬虫之所以无处不在,是因为爬虫可以为互联网企业带来利润。
爬虫技术的现况
语言
理论上来说,任何支持网路通讯的语言都是可以写爬虫的,爬虫本身其实语言关系不大,但是,总有相对顺手、简单的。目前来说,大多数爬虫是用后台脚本类语言写的,其中python无疑是用的最多最广的,并且也诞生了好多优秀的库和框架,如scrapy、BeautifulSoup 、pyquery、Mechanize等。但是一般来说,搜索引擎的爬虫对爬虫的效率要求更高,会选用c++、java、go(适合高并发)。
运行环境
爬虫本身不分辨究竟是运行在windows还是Linux,又或是OSX,但从业务角度讲爬虫技术用什么语言,我们把运行在服务端(后台)的,称之为后台爬虫。而如今,几乎所有的爬虫都是后台爬虫。
爬虫的作用
1、爬虫爬出top1000和top10000数据,范围减小,然后根据情况选定细分产品信息等进行开发。
2、通过爬虫数据,跟踪产品情况,用来作出快速反应。
3、利用爬虫信息,抓取产品信息库类目变动情况。
未来,人工智能将会颠覆所有的商业应用。而人工智能的基础在于大数据,大数据的基础核心是数据采集,数据采集的主力是爬虫技术,因此,爬虫技术作为大数据最基层的应用,其重要性毋庸置疑。
分析百度最近一个月的SEO数据风向标
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2020-06-15 08:01
图一:最近一周的SEO数据风向标
图二:上一周的SEO数据风向标
上图可以显著看出本周五百度更新幅度最大,这就是普遍被觉得的周日、周五排行更新,不过最新几个月百度也不喜欢根据常理出牌了,对比下上周的SEO数据风 向标你们可以发觉上周的各项数据基本是平稳的,不过这个现象可以正常理解,主要是因为上周是10.1春节期间,百度也得休假吧,好不容易的周末,百度也应 该人性化点,让站长们过个评价的暑假。我们最害怕的K站风波一直都在上演,仔细看下图表不能发觉明天的K站比列高达:0.84%,这意味着1000个网站 中有84个将被K,今天的K站比列是本周中最大的。经历过周六的大更新后,很多站收录都降低了,增加的比列是45.17%。
以上是笔者对SEO数据风向标的简单剖析,可以肯定的是K站仍然在继续,笔者的几个顾客网站收录都在降低,百度现今的算法是每周清除掉一些垃圾页面,比如 一个权重不错的企业站,注册域名时间是几年的,但之前因为无专业人员管理,一般这样的企业站在公司都是随意找人管理的,于是复制了太多的行业新闻,这样的 企业站收录会持续增长,即便是更新后很快收录了,也会在一二周内被消除掉。企业站更新不需要过分频繁,保持规律就行,最重要的是内容质量,这就要去我们去 撰写产品软文,但这确实是目前摆在我们面前最头痛的事情,企业站各行各业都有,产品软文很难写,所以未来企业站也须要有专业的编辑或则软文写手。
图三:最近一个月的K站数据
再来剖析下最近一个月的K站比列,为了便捷查看,我把其他几个网站数据指标隐藏了。从2012年9月14日至2012年10月9日,差不到就是一个月的数 据,可以看见几个最高点的波峰,居然都是星期六,真是站长们的红色星期六,为什么百度新算法要在星期六下狠手呢?个人猜想:星期六是百度一周大更新后的第 一天(或者是第二天),经过新算法的一周的测验基本早已确定了什么站点该被K,也就是算法在进一步的查证,那些显著的垃圾站活不到周末,剩余出来的被装入 黑名单的站点,这次最终被确定了,误加入黑名单的站点被生擒,剩下的全部搞死。
SEO数据风向标基本可以剖析出算法大致的方向,不过要想剖析自己的同行业的网站,还得平时统计一下这些竞争对手网站,做好表格,了解下他人站点基本情 况,比如:更新频度、外链降低频度,站内内容等,通过这种数据才能帮助你更好的找到自己网站的不足,更利于做好优化和监控。对于新人们数据剖析是个难点,不过也不用害怕分析百度seo,平常多观察,做好数据统计,不懂就多问问前辈们,今天就聊这么多。调整好自己的态度,不 要由于K站一蹶不振! 本文由 zwz轴承() 原创撰写 ,转载保留链接! 查看全部
SEO数据风向标你们都不会陌生,通过剖析SEO数据风向标可以挺好的了解近来百度算法的大致动态,SEO数据剖析必须构建在大量数据 统计的基础上,因此几个站点不能说明哪些问题,若通过几个站点剖析数据似乎是不科学的,做科学的SEO数据剖析是我们这种SEO人员必须学习的分析百度seo,笔者觉得 现在许多SEO新人们都不太喜欢去剖析数据,盲目的反复执行不能做好SEO,从6月份开始百度就让我们没法淡定了。下面是笔者对最近一个月、最近一周、上 一周的SEO数据风向标截图,从那些数据我们可以剖析百度新算法的实际疗效:
图一:最近一周的SEO数据风向标
图二:上一周的SEO数据风向标
上图可以显著看出本周五百度更新幅度最大,这就是普遍被觉得的周日、周五排行更新,不过最新几个月百度也不喜欢根据常理出牌了,对比下上周的SEO数据风 向标你们可以发觉上周的各项数据基本是平稳的,不过这个现象可以正常理解,主要是因为上周是10.1春节期间,百度也得休假吧,好不容易的周末,百度也应 该人性化点,让站长们过个评价的暑假。我们最害怕的K站风波一直都在上演,仔细看下图表不能发觉明天的K站比列高达:0.84%,这意味着1000个网站 中有84个将被K,今天的K站比列是本周中最大的。经历过周六的大更新后,很多站收录都降低了,增加的比列是45.17%。
以上是笔者对SEO数据风向标的简单剖析,可以肯定的是K站仍然在继续,笔者的几个顾客网站收录都在降低,百度现今的算法是每周清除掉一些垃圾页面,比如 一个权重不错的企业站,注册域名时间是几年的,但之前因为无专业人员管理,一般这样的企业站在公司都是随意找人管理的,于是复制了太多的行业新闻,这样的 企业站收录会持续增长,即便是更新后很快收录了,也会在一二周内被消除掉。企业站更新不需要过分频繁,保持规律就行,最重要的是内容质量,这就要去我们去 撰写产品软文,但这确实是目前摆在我们面前最头痛的事情,企业站各行各业都有,产品软文很难写,所以未来企业站也须要有专业的编辑或则软文写手。
图三:最近一个月的K站数据
再来剖析下最近一个月的K站比列,为了便捷查看,我把其他几个网站数据指标隐藏了。从2012年9月14日至2012年10月9日,差不到就是一个月的数 据,可以看见几个最高点的波峰,居然都是星期六,真是站长们的红色星期六,为什么百度新算法要在星期六下狠手呢?个人猜想:星期六是百度一周大更新后的第 一天(或者是第二天),经过新算法的一周的测验基本早已确定了什么站点该被K,也就是算法在进一步的查证,那些显著的垃圾站活不到周末,剩余出来的被装入 黑名单的站点,这次最终被确定了,误加入黑名单的站点被生擒,剩下的全部搞死。
SEO数据风向标基本可以剖析出算法大致的方向,不过要想剖析自己的同行业的网站,还得平时统计一下这些竞争对手网站,做好表格,了解下他人站点基本情 况,比如:更新频度、外链降低频度,站内内容等,通过这种数据才能帮助你更好的找到自己网站的不足,更利于做好优化和监控。对于新人们数据剖析是个难点,不过也不用害怕分析百度seo,平常多观察,做好数据统计,不懂就多问问前辈们,今天就聊这么多。调整好自己的态度,不 要由于K站一蹶不振! 本文由 zwz轴承() 原创撰写 ,转载保留链接!
【苹果IP代理】 8大高效的Python爬虫框架,你用过几个?
采集交流 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2020-06-09 08:01
4.Portia Portia 是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面爬虫代理软件爬虫代理软件,Portia 将创建一个蜘蛛来从类似的页面提取数据。5.Newspaper Newspaper 可以拿来提取新闻、文章和内容剖析。使用多线 程,支持 10 多种语言等。 6.Beautiful Soup Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据 的 Python 库.它还能通过你喜欢的转换器实现惯用的文档导航, 查找,修改文档的方法.Beautiful Soup 会帮你节约数小时甚至数天 的工作时间。 7.Grab Grab 是一个用于建立 Web 刮板的 Python 框架。借助 Grab, 您可以建立各类复杂的网页抓取工具,从简单的 5 行脚本到处理 数百万个网页的复杂异步网站抓取工具。Grab 提供一个 API 用于 执行网路恳求和处理接收到的内容,例如与 HTML 文档的 DOM 树进行交互。 8.Cola Cola 是一个分布式的爬虫框架,对于用户来说,只需编撰几 个特定的函数,而无需关注分布式运行的细节。任务会手动分配 到多台机器上,整个过程对用户是透明的。 查看全部
【苹果 IP 代理】8 大高效的 Python 爬虫框架,你用过几个? 【苹果 IP 代理】大数据时代下,数据采集推动着数据剖析, 数据剖析加快发展。但是在这个过程中会出现好多问题。拿最简 单最基础的爬虫采集数据为例,过程中还会面临,IP 被封,爬取 受限、违法操作等多种问题,所以在爬取数据之前,一定要了解 好预爬网站是否涉及违规操作,找到合适的代理 IP 访问网站等 一系列问题。今天我们就来讲讲这些高效的爬虫框架。 1.Scrapy Scrapy 是一个为了爬取网站数据,提取结构性数据而编撰的 应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数 据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商 品信息之类的数据。 2.PySpider pyspider 是一个用 python 实现的功能强悍的网路爬虫系统, 能在浏览器界面上进行脚本的编撰,功能的调度和爬取结果的实 时查看,后端使用常用的数据库进行爬取结果的储存,还能定时 设置任务与任务优先级等。 3.Crawley Crawley 可以高速爬取对应网站的内容,支持关系和非关系 数据库,数据可以导入为 JSON、XML 等。
4.Portia Portia 是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面爬虫代理软件爬虫代理软件,Portia 将创建一个蜘蛛来从类似的页面提取数据。5.Newspaper Newspaper 可以拿来提取新闻、文章和内容剖析。使用多线 程,支持 10 多种语言等。 6.Beautiful Soup Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据 的 Python 库.它还能通过你喜欢的转换器实现惯用的文档导航, 查找,修改文档的方法.Beautiful Soup 会帮你节约数小时甚至数天 的工作时间。 7.Grab Grab 是一个用于建立 Web 刮板的 Python 框架。借助 Grab, 您可以建立各类复杂的网页抓取工具,从简单的 5 行脚本到处理 数百万个网页的复杂异步网站抓取工具。Grab 提供一个 API 用于 执行网路恳求和处理接收到的内容,例如与 HTML 文档的 DOM 树进行交互。 8.Cola Cola 是一个分布式的爬虫框架,对于用户来说,只需编撰几 个特定的函数,而无需关注分布式运行的细节。任务会手动分配 到多台机器上,整个过程对用户是透明的。
大数据采集之网路爬虫的基本流程及抓取策略
采集交流 • 优采云 发表了文章 • 0 个评论 • 536 次浏览 • 2020-06-08 08:01
本篇教程阐述了大数据采集之网路爬虫的基本流程及抓取策略,希望阅读本篇文章以后你们有所收获,帮助你们对相关内容的理解愈发深入。
大数据时代下,数据采集推动着数据剖析,数据剖析促进发展。但是在这个过程中会出现好多问题。拿最简单最基础的爬虫采集数据为例,过程中还会面临,IP被封,爬取受限、违法操作等多种问题,所以在爬去数据之前,一定要了解好预爬网站是否涉及违规操作,找到合适的代理IP访问网站等一系列问题。
掌握爬虫技术也成为现今技术流的营销推广人员必须把握的。爬虫入门,这些知识你必须了解。
一、网络爬虫的基本工作流程如下:
1.首先选定一部分悉心选购的种子URL;
2.将这种URL倒入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL倒入待抓取URL队列,从而步入下一个循环。
二、抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面,后抓取那个页面。而决定那些URL排列次序的方式,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.PartialPageRank策略
PartialPageRank算法借鉴了PageRank算法的思想:对于早已下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每位页面的PageRank值,计算完以后,将待抓取URL队列中的URL根据PageRank值的大小排列,并根据该次序抓取页面。
如果每次抓取一个页面,就重新估算PageRank值,一种折中方案是:每抓取K个页面后,重新估算一次PageRank值。但是此类情况都会有一个问题:对于早已下载出来的页面中剖析出的链接,也就是我们之前谈到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给那些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总大数据网络爬虫原理,这样就产生了该未知页面的PageRank值,从而参与排序。
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发觉的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。
3.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因而称作大站优先策略。
4.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。
在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那种也的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。
5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P以后,将P的现金平摊给所有从P中剖析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面根据现金数进行排序。
6.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路然后再转到下一个起始页,继续跟踪链接。
三、从爬虫的角度对互联网进行界定
对应的,可以将互联网的所有页面分为五个部份:
1.已下载未过期网页
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就早已过期了。
3.待下载网页:也就是待抓取URL队列中的这些页面
4.可知网页:还没有抓取出来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或则待抓取URL对应页面进行剖析获取到的URL,认为是可知网页。
5.还有一部分网页,爬虫是难以直接抓取下载的。称为不可知网页。
太阳软件,一个好用的互联网推广换IP工具大数据网络爬虫原理,海量IP,一键切换,提升权重,必不可少! 查看全部

本篇教程阐述了大数据采集之网路爬虫的基本流程及抓取策略,希望阅读本篇文章以后你们有所收获,帮助你们对相关内容的理解愈发深入。
大数据时代下,数据采集推动着数据剖析,数据剖析促进发展。但是在这个过程中会出现好多问题。拿最简单最基础的爬虫采集数据为例,过程中还会面临,IP被封,爬取受限、违法操作等多种问题,所以在爬去数据之前,一定要了解好预爬网站是否涉及违规操作,找到合适的代理IP访问网站等一系列问题。
掌握爬虫技术也成为现今技术流的营销推广人员必须把握的。爬虫入门,这些知识你必须了解。
一、网络爬虫的基本工作流程如下:
1.首先选定一部分悉心选购的种子URL;
2.将这种URL倒入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL倒入待抓取URL队列,从而步入下一个循环。
二、抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面,后抓取那个页面。而决定那些URL排列次序的方式,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.PartialPageRank策略
PartialPageRank算法借鉴了PageRank算法的思想:对于早已下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每位页面的PageRank值,计算完以后,将待抓取URL队列中的URL根据PageRank值的大小排列,并根据该次序抓取页面。
如果每次抓取一个页面,就重新估算PageRank值,一种折中方案是:每抓取K个页面后,重新估算一次PageRank值。但是此类情况都会有一个问题:对于早已下载出来的页面中剖析出的链接,也就是我们之前谈到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给那些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总大数据网络爬虫原理,这样就产生了该未知页面的PageRank值,从而参与排序。
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发觉的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。
3.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因而称作大站优先策略。
4.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。
在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那种也的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。
5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P以后,将P的现金平摊给所有从P中剖析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面根据现金数进行排序。
6.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路然后再转到下一个起始页,继续跟踪链接。
三、从爬虫的角度对互联网进行界定
对应的,可以将互联网的所有页面分为五个部份:
1.已下载未过期网页
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就早已过期了。
3.待下载网页:也就是待抓取URL队列中的这些页面
4.可知网页:还没有抓取出来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或则待抓取URL对应页面进行剖析获取到的URL,认为是可知网页。
5.还有一部分网页,爬虫是难以直接抓取下载的。称为不可知网页。
太阳软件,一个好用的互联网推广换IP工具大数据网络爬虫原理,海量IP,一键切换,提升权重,必不可少!
PHP用户数据爬取
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-06-02 08:02
广告
云服务器1核2G首年95年,助力轻松上云!还有千元代金卷免费领,开团成功最高免费续费40个月!
代码托管地址: https:github.comhectorhuzhihuspider 这次抓取了110万的用户数据,数据剖析结果如下:? 开发前的打算安装linux系统(ubuntu14.04),在vmware虚拟机下安装一个ubuntu; 安装php5.6或以上版本; 安装mysql5.5或以上版本; 安装curl、pcntl扩充。 使用php的curl扩充抓取页面数据php的curl扩充是php支持...
但经验其实是经验,数据才是最靠谱的,通过剖析数据,可以评估一个队员的价值(当然,球员的各方面的表现(特征),都会有一个权重,最终评判权重*特征值之和最高者的神锋机率胜算大些)。 那么,如何获取那些数据呢? 写段简单的爬取数据的代码就是最好的获取工具。 本文以2014年的巴西世界杯球队为基础进行实践操作...
一、引言 在实际工作中,难免会遇见从网页爬取数据信息的需求,如:从谷歌官网上爬取最新发布的系统版本。 很明显这是个网页爬虫的工作,所谓网页爬虫,就是须要模拟浏览器,向网路服务器发送恳求便于将网路资源从网络流中读取下来,保存到本地,并对这种信息做些简单提取,将我们要的信息分离提取下来。 在做网页...
经过我的测试,我这一个学期以来的消费记录在这个网页上只有50多页,所以爬虫须要爬取的数据量太小,处理上去是完全没有压力的,直接一次性得到所有的结果以后保存文件就行了。 至于爬虫程序的语言选择,我也没哪些好说的,目前我也就对php比较熟悉一些,所以接下来的程序我也是用php完成的。 首先确定我应当怎样模拟...
如果你是有经验的开发者,完全可以跳过第一章步入第二章的学习了。 这个项目主要围绕两大核心点展开: 1. php爬虫 2. 代理ip 咱们先讲讲哪些是爬虫,简单来讲,爬虫就是一个侦测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按键,查查数据,或者把听到的信息背回去。 就像一只蟑螂在一幢楼里不知疲惫地爬...
通过抓取并剖析在线社交网站的数据,研究者可以迅速地掌握人类社交网路行为背后所隐藏的规律、机制乃至一般性的法则。 然而在线社交网络数据的获取方式...这个网站的网路链接为:http:members.lovingfromadistance.comforum.php,我们首先写一个叫screen_login的函数。 其核心是定义个浏览器对象br = mechanize...
每分钟执行一次爬取全省新型脑炎疫情实时动态并写入到指定的.php文件functionupdate() { (async () =&gt; { const browser = await puppeteer.launch({args: ...fscnpm i -g cron具体操作:用puppeteer爬取:puppeteer本质上是一个chrome浏览器,网页很难分清这是人类用户还是爬虫,我们可以用它来加载动态网页...
爬取微博的 id weibologin(username, password, cookie_path).login() withopen({}{}.csv.format(comment_path, id), mode=w, encoding=utf-8-sig...或者在文件中读取cookie数据到程序 self.session.cookies =cookielib.lwpcookiejar(filename=self.cookie_path) self.index_url = http:weibo.comlogin...
python爬虫突破限制,爬取vip视频主要介绍了python爬虫项目实例代码,文中通过示例代码介绍的十分详尽,对你们的学习或则工作具有一定的参考学习价值,需要的同学可以参考下? 其他也不多说什么直接附上源码? 只要学会爬虫技术,想爬取哪些资源基本都可以做到,当然python不止爬虫技术还有web开发,大数据,人工智能等! ...
但是使用java访问的时侯爬取的html里却没有该mp3的文件地址,那么这肯定是在该页面的位置使用了js来加载mp3,那么刷新下网页,看网页加载了什么东西,加载的东西有点多,着重看一下js、php的恳求,主要是看上面有没有mp3的地址,分析细节就不用说了。? 最终我在列表的https:wwwapi.kugou.comyyindex.php? r=playgetd...
总结上去就三部,首先获取登陆界面的验证码并储存cookie,然后通过cookie来模拟登录,最后步入教务系统取想要的东西。 现在我们须要去留心的内容,各个恳求的联接、header、和发送的数据2. 查看恳求首先我们查看首页,我们发觉登陆并不在首页上,需要点击用户登陆后才算步入了登陆界面。 然后我们查看登陆界面的恳求...
就是如此一个简单的功能,类似好多的云盘搜索类网站,我这个采集和搜索程序都是php实现的,全文和动词搜索部份使用到了开源软件xunsearch。 真实上线案例:搜碟子-网盘影片资源站上一篇( 网盘搜索引擎-采集爬取百度网盘分享文件实现云盘搜索中我重点介绍了如何去获取一大批的百度网盘用户,这一篇介绍如何获得指定...
当然, 并不是所有数据都适宜? 在学习爬虫的过程中, 遇到过不少坑. 今天这个坑可能之后你也会碰到, 随着爬取数据量的降低,以及爬取的网站数据字段的变化, 以往在爬虫入门时使用的方式局限性可能会飙升. 怎么个骤降法? intro 引例在爬虫入门的时侯,我们爬取豆瓣影片top250那些数据量并不是很大的网页时(仅估算文本数据...
- 利用爬虫获取舆情数据 -? 爬取的某急聘网站职位信息例如你可以批量爬取社交平台的数据资源,可以爬取网站的交易数据,爬取急聘网站的职位信息等,可以用于个性化的剖析研究。 总之,爬虫是十分强悍的,甚至有人说天下没有不能爬的网站,因而爬取数据也成为了好多极客的乐趣。 开发出高效的爬虫工具可以帮助我们...
请先阅读“中国年轻人正率领国家迈向危机”php 网络爬虫 抓取数据php 网络爬虫 抓取数据,这锅背是不背? 一文,以对“手把手教你完成一个数据科学小项目”系列有个全局性的了解。 上一篇文章(1)数据爬取里我讲解了怎样用爬虫爬取新浪财经《中国年轻人正率领国家迈向危机》一文的评论数据,其中涉及的抓包过程是挺通用的,大家假如想爬取其他网站,也会是类似...
在领英心知肚明的情况下(领英甚至还派出过代表出席过hiq的晚会),hiq这样做了两年,但是在领英开发了一个与 skill mapper 非常类似的产品以后,领英立即变了脸,其向 hiq 发出了 勒令停止侵权函 ,威胁道假如 hiq 不停止搜集其用户数据的话,就将其控告。 不仅这么,领英还采取了技术举措,阻断了hiq的数据爬取,hi...
什么是大数据和人工智能,分享2019年我用python爬虫技术做企业大数据的那些事儿由于仍然从事php+python+ai大数据深度挖掘的技术研制,当前互联网早已从it时代发展到data时代,人工智能+大数据是当前互联网技术领域的两大趋势,记得在2010-2016年从事过电商的技术研制,当时电商时代缔造了好多创业人,很多有看法的...
- 利用爬虫获取舆情数据 -? 爬取的某急聘网站职位信息例如你可以批量爬取社交平台的数据资源,可以爬取网站的交易数据,爬取急聘网站的职位信息等,可以用于个性化的剖析研究。 总之,爬虫是十分强悍的,甚至有人说天下没有不能爬的网站,因而爬取数据也成为了好多极客的乐趣。 开发出高效的爬虫工具可以帮助我们...
usrbinenv python# -*- coding:utf-8 -*-import urllibfrom urllib import requestimport jsonimportrandomimport reimport urllib.errodef hq_html(hq_url):hq_html()封装的爬虫函数,自动启用了用户代理和ip代理 接收一个参数url,要爬取页面的url,返回html源码 def yh_dl():#创建用户代理池 yhdl = thisua = ...
pandas 是使数据剖析工作显得愈发简单的中级数据结构,我们可以用 pandas 保存爬取的数据。 最后通过pandas再写入到xls或则mysql等数据库中。 requests...上一节中我们讲了怎样对用户画像建模,而建模之前我们都要进行数据采集。 数据采集是数据挖掘的基础,没有数据,挖掘也没有意义。 很多时侯,我们拥有多少... 查看全部


广告
云服务器1核2G首年95年,助力轻松上云!还有千元代金卷免费领,开团成功最高免费续费40个月!

代码托管地址: https:github.comhectorhuzhihuspider 这次抓取了110万的用户数据,数据剖析结果如下:? 开发前的打算安装linux系统(ubuntu14.04),在vmware虚拟机下安装一个ubuntu; 安装php5.6或以上版本; 安装mysql5.5或以上版本; 安装curl、pcntl扩充。 使用php的curl扩充抓取页面数据php的curl扩充是php支持...
但经验其实是经验,数据才是最靠谱的,通过剖析数据,可以评估一个队员的价值(当然,球员的各方面的表现(特征),都会有一个权重,最终评判权重*特征值之和最高者的神锋机率胜算大些)。 那么,如何获取那些数据呢? 写段简单的爬取数据的代码就是最好的获取工具。 本文以2014年的巴西世界杯球队为基础进行实践操作...

一、引言 在实际工作中,难免会遇见从网页爬取数据信息的需求,如:从谷歌官网上爬取最新发布的系统版本。 很明显这是个网页爬虫的工作,所谓网页爬虫,就是须要模拟浏览器,向网路服务器发送恳求便于将网路资源从网络流中读取下来,保存到本地,并对这种信息做些简单提取,将我们要的信息分离提取下来。 在做网页...
经过我的测试,我这一个学期以来的消费记录在这个网页上只有50多页,所以爬虫须要爬取的数据量太小,处理上去是完全没有压力的,直接一次性得到所有的结果以后保存文件就行了。 至于爬虫程序的语言选择,我也没哪些好说的,目前我也就对php比较熟悉一些,所以接下来的程序我也是用php完成的。 首先确定我应当怎样模拟...
如果你是有经验的开发者,完全可以跳过第一章步入第二章的学习了。 这个项目主要围绕两大核心点展开: 1. php爬虫 2. 代理ip 咱们先讲讲哪些是爬虫,简单来讲,爬虫就是一个侦测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按键,查查数据,或者把听到的信息背回去。 就像一只蟑螂在一幢楼里不知疲惫地爬...

通过抓取并剖析在线社交网站的数据,研究者可以迅速地掌握人类社交网路行为背后所隐藏的规律、机制乃至一般性的法则。 然而在线社交网络数据的获取方式...这个网站的网路链接为:http:members.lovingfromadistance.comforum.php,我们首先写一个叫screen_login的函数。 其核心是定义个浏览器对象br = mechanize...

每分钟执行一次爬取全省新型脑炎疫情实时动态并写入到指定的.php文件functionupdate() { (async () =&gt; { const browser = await puppeteer.launch({args: ...fscnpm i -g cron具体操作:用puppeteer爬取:puppeteer本质上是一个chrome浏览器,网页很难分清这是人类用户还是爬虫,我们可以用它来加载动态网页...

爬取微博的 id weibologin(username, password, cookie_path).login() withopen({}{}.csv.format(comment_path, id), mode=w, encoding=utf-8-sig...或者在文件中读取cookie数据到程序 self.session.cookies =cookielib.lwpcookiejar(filename=self.cookie_path) self.index_url = http:weibo.comlogin...
python爬虫突破限制,爬取vip视频主要介绍了python爬虫项目实例代码,文中通过示例代码介绍的十分详尽,对你们的学习或则工作具有一定的参考学习价值,需要的同学可以参考下? 其他也不多说什么直接附上源码? 只要学会爬虫技术,想爬取哪些资源基本都可以做到,当然python不止爬虫技术还有web开发,大数据,人工智能等! ...

但是使用java访问的时侯爬取的html里却没有该mp3的文件地址,那么这肯定是在该页面的位置使用了js来加载mp3,那么刷新下网页,看网页加载了什么东西,加载的东西有点多,着重看一下js、php的恳求,主要是看上面有没有mp3的地址,分析细节就不用说了。? 最终我在列表的https:wwwapi.kugou.comyyindex.php? r=playgetd...

总结上去就三部,首先获取登陆界面的验证码并储存cookie,然后通过cookie来模拟登录,最后步入教务系统取想要的东西。 现在我们须要去留心的内容,各个恳求的联接、header、和发送的数据2. 查看恳求首先我们查看首页,我们发觉登陆并不在首页上,需要点击用户登陆后才算步入了登陆界面。 然后我们查看登陆界面的恳求...
就是如此一个简单的功能,类似好多的云盘搜索类网站,我这个采集和搜索程序都是php实现的,全文和动词搜索部份使用到了开源软件xunsearch。 真实上线案例:搜碟子-网盘影片资源站上一篇( 网盘搜索引擎-采集爬取百度网盘分享文件实现云盘搜索中我重点介绍了如何去获取一大批的百度网盘用户,这一篇介绍如何获得指定...

当然, 并不是所有数据都适宜? 在学习爬虫的过程中, 遇到过不少坑. 今天这个坑可能之后你也会碰到, 随着爬取数据量的降低,以及爬取的网站数据字段的变化, 以往在爬虫入门时使用的方式局限性可能会飙升. 怎么个骤降法? intro 引例在爬虫入门的时侯,我们爬取豆瓣影片top250那些数据量并不是很大的网页时(仅估算文本数据...

- 利用爬虫获取舆情数据 -? 爬取的某急聘网站职位信息例如你可以批量爬取社交平台的数据资源,可以爬取网站的交易数据,爬取急聘网站的职位信息等,可以用于个性化的剖析研究。 总之,爬虫是十分强悍的,甚至有人说天下没有不能爬的网站,因而爬取数据也成为了好多极客的乐趣。 开发出高效的爬虫工具可以帮助我们...

请先阅读“中国年轻人正率领国家迈向危机”php 网络爬虫 抓取数据php 网络爬虫 抓取数据,这锅背是不背? 一文,以对“手把手教你完成一个数据科学小项目”系列有个全局性的了解。 上一篇文章(1)数据爬取里我讲解了怎样用爬虫爬取新浪财经《中国年轻人正率领国家迈向危机》一文的评论数据,其中涉及的抓包过程是挺通用的,大家假如想爬取其他网站,也会是类似...

在领英心知肚明的情况下(领英甚至还派出过代表出席过hiq的晚会),hiq这样做了两年,但是在领英开发了一个与 skill mapper 非常类似的产品以后,领英立即变了脸,其向 hiq 发出了 勒令停止侵权函 ,威胁道假如 hiq 不停止搜集其用户数据的话,就将其控告。 不仅这么,领英还采取了技术举措,阻断了hiq的数据爬取,hi...

什么是大数据和人工智能,分享2019年我用python爬虫技术做企业大数据的那些事儿由于仍然从事php+python+ai大数据深度挖掘的技术研制,当前互联网早已从it时代发展到data时代,人工智能+大数据是当前互联网技术领域的两大趋势,记得在2010-2016年从事过电商的技术研制,当时电商时代缔造了好多创业人,很多有看法的...

- 利用爬虫获取舆情数据 -? 爬取的某急聘网站职位信息例如你可以批量爬取社交平台的数据资源,可以爬取网站的交易数据,爬取急聘网站的职位信息等,可以用于个性化的剖析研究。 总之,爬虫是十分强悍的,甚至有人说天下没有不能爬的网站,因而爬取数据也成为了好多极客的乐趣。 开发出高效的爬虫工具可以帮助我们...
usrbinenv python# -*- coding:utf-8 -*-import urllibfrom urllib import requestimport jsonimportrandomimport reimport urllib.errodef hq_html(hq_url):hq_html()封装的爬虫函数,自动启用了用户代理和ip代理 接收一个参数url,要爬取页面的url,返回html源码 def yh_dl():#创建用户代理池 yhdl = thisua = ...

pandas 是使数据剖析工作显得愈发简单的中级数据结构,我们可以用 pandas 保存爬取的数据。 最后通过pandas再写入到xls或则mysql等数据库中。 requests...上一节中我们讲了怎样对用户画像建模,而建模之前我们都要进行数据采集。 数据采集是数据挖掘的基础,没有数据,挖掘也没有意义。 很多时侯,我们拥有多少...
大数据环境下基于python的网路爬虫技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 273 次浏览 • 2020-05-26 08:03
它让你才能专注于解决问题而不是去搞明白语言本身。(2)使用便捷,不需要笨重的 IDE,Python 只须要一个 sublime text 或者是一个文本编辑器,就可以进行大部分中小型应用的开发了。(3)功能强悍的爬虫框架 ScraPy,Scrapy 是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。(4)强大的网路支持库以及 html 解析器,利用网路支持库 requests,编写较少的代码,就可以下载网页。利用网页解析库 BeautifulSoup,可以便捷的解析网页各个标签,再结合正则表达式,方便的抓取网页中的内容。(5)十分擅长做文本处理字符串处理:python 包含了常用的文本处理函数,支持正则表达式,可以便捷的处理文本内容。 ■ 1.3 爬虫的工作原理网络爬虫是一个手动获取网页的程序,它为搜索引擎从互联网上下载网页,是搜索引擎的重要组成。从功能上来讲,爬虫通常分为数据采集,处理,储存三个部份。爬虫的工作原理,爬虫通常从一个或则多个初始 URL 开始,下载网页内容,然后通过搜索或是内容匹配手段(比如正则表达式),获取网页中感兴趣的内容,同时不断从当前页面提取新的 URL,根据网页抓取策略,按一定的次序倒入待抓取 URL 队列中,整个过程循环执行,一直到满足系统相应的停止条件,然后对那些被抓取的数据进行清洗,整理,并构建索引,存入数据库或文件中,最后按照查询须要,从数据库或文件中提取相应的数据,以文本或图表的形式显示下来。
■ 1.4 网页抓取策略在网路爬虫系统中,待抓取 URL 队列是很重要的一部分,待抓取 URL 队列中的 URL 以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面大数据网络爬虫原理,后抓取那个页面。而决定那些 URL 排列次序的方式,叫做抓取策略。网页的抓取策略可以分为深度优先、广度优先和最佳优先三种:(1)广度优先搜索策略,其主要思想是,由根节点开始,首先遍历当前层次的搜索,然后才进行下一层的搜索,依次类推逐层的搜索。这种策略多用在主题爬虫上,因为越是与初始 URL 距离逾的网页,其具有的主题相关性越大。(2)深度优先搜索策略,这种策略的主要思想是,从根节点出发找出叶子节点,以此类推。在一个网页中,选择一个超链接,被链接的网页将执行深度优先搜索,形成单独的一条搜索链,当没有其他超链接时,搜索结束。(3)最佳优先搜索策略,该策略通过估算 URL 描述文本与目标网页的相似度,或者与主题的相关性,根据所设定的阀值选出有效 URL 进行抓取。 ■ 1.5 网络爬虫模块按照网路爬虫的工作原理,设计了一个通用的爬虫框架结构,其结构图如图 1 所示。大数据环境下基于 python 的网路爬虫技术作者/谢克武,重庆工商大学派斯学院软件工程学院摘要:随着互联网的发展壮大,网络数据呈爆炸式下降,传统搜索引擎早已不能满足人们对所需求数据的获取的需求,作为搜索引擎的抓取数据的重要组成部份,网络爬虫的作用非常重要,本文首先介绍了在大数据环境下网络爬虫的重要性,接着介绍了网络爬虫的概念,工作原理,工作流程,网页爬行策略,python在编撰爬虫领域的优势,最后设计了一个通用网路爬虫的框架,介绍了框架中模块的互相协作完成数据抓取的过程。
关键词:网络爬虫;python;数据采集;大数据 | 45软件开发图 1网路爬虫的基本工作流程如下:(1)首先选定一部分悉心选购的种子 URL;(2)将这种 URL 放入待抓取 URL 队列;(3)从待抓取 URL 队列中取出待抓取在 URL,将URL 对应的网页下载出来,将下载出来的网页传给数据解析模块,再将这种 URL 放进已抓取 URL 队列。(4)分析下载模块传过来的网页数据,通过正则抒发,提取出感兴趣的数据,将数据传送给数据清洗模块,然后再解析其中的其他 URL,并且将 URL 传给 URL 调度模块。(5)URL 调度模块接收到数据解析模块传递过来的URL 数 据, 首 先 将 这 些 URL 数 据 和 已 抓 取 URL 队 列 比较,如果是早已抓取的 URL,就遗弃掉,如果是未抓取的URL,就按照系统的搜索策略,将 URL 放入待抓取 URL 队列。(6)整个系统在 3-5 步中循环,直到待抓取 URL 队列里所有的 URL 已经完全抓取,或者系统主动停止爬取,循环结束。(7)整理清洗数据,将数据以规范的格式存入数据库。(8)根据使用者偏好,将爬取结果从数据库中读出,以文字,图形的方法展示给使用者。
2. 系统模块整个系统主要有六个模块,爬虫主控模块,网页下载模块,网页解析模块,URL 调度模块,数据清洗模块,数据显示模块。这几个模块之间互相协作,共同完成网路数据抓取的功能。(1)主控模块,主要是完成一些初始化工作,生成种子 URL, 并将这种 URL 放入待爬取 URL 队列,启动网页下载器下载网页,然后解析网页,提取须要的数据和URL地址,进入工作循环,控制各个模块工作流程,协调各个模块之间的工作(2)网页下载模块,主要功能就是下载网页,但其中有几种情况,对于可以匿名访问的网页,可以直接下载,对于须要身分验证的,就须要模拟用户登录后再进行下载,对于须要数字签名或数字证书就能访问的网站,就须要获取相应证书,加载到程序中,通过验证以后才会下载网页。网络上数据丰富,对于不同的数据,需要不同的下载形式。数据下载完成后大数据网络爬虫原理,将下载的网页数据传递给网页解析模块,将URL 地址装入已爬取 URL 队列。(3)网页解析模块,它的主要功能是从网页中提取满足要求的信息传递给数据清洗模块,提取 URL 地址传递给URL 调度模块,另外,它还通过正则表达式匹配的方法或直接搜索的方法,来提取满足特定要求的数据,将这种数据传递给数据清洗模块。
(4)URL 调度模块,接收网页解析模块传递来的 URL地址,然后将这种 URL 地址和已爬取 URL 队列中的 URL 地址比较,如果 URL 存在于已爬取 URL 队列中,就遗弃这种URL 地址,如果不存在于已爬取 URL 队列中,就按系统采取的网页抓取策略,将 URL 放入待爬取 URL 地址相应的位置。(5)数据清洗模块,接收网页解析模块传送来的数据,网页解析模块提取的数据,一般是比较零乱或款式不规范的数据,这就须要对那些数据进行清洗,整理,将那些数据整理为满足一定格式的数据,然后将这种数据存入数据库中。(6)数据显示模块,根据用户需求,统计数据库中的数据,将统计结果以文本或则图文的形式显示下来,也可以将统计结果存入不同的格式的文件将中(如 word 文档,pdf 文档,或者 excel 文档),永久保存。3. 结束语如今早已步入大数据时代,社会各行各业都对数据有需求,对于一些现成的数据,可以通过网路免费获取或则订购,对于一下非现成的数据,就要求编撰特定的网路爬虫,自己在网路起来搜索,分析,转换为自己须要的数据,网络爬虫就满足了这个需求,而 python 简单易学,拥有现成的爬虫框架,强大的网路支持库,文本处理库,可以快速的实现满足特定功能的网路爬虫。
参考文献* [1]于成龙, 于洪波. 网络爬虫技术研究[J]. 东莞理工学院学报, 2011, 18(3):25-29.* [2]李俊丽. 基于Linux的python多线程爬虫程序设计[J]. 计算机与数字工程 , 2015, 43(5):861-863.* [3]周中华, 张惠然, 谢江. 基于Python的新浪微博数据爬虫[J]. 计算机应用 , 2014, 34(11):3131-3134. 查看全部
44 | 电子制做 2017 年 5月软件开发序言大数据背景下,各行各业都须要数据支持,如何在广袤的数据中获取自己感兴趣的数据,在数据搜索方面,现在的搜索引擎似乎比刚开始有了很大的进步,但对于一些特殊数据搜索或复杂搜索,还不能挺好的完成,利用搜索引擎的数据不能满足需求,网络安全,产品督查,都须要数据支持,而网路上没有现成的数据,需要自己自动去搜索、分析、提炼,格式化为满足需求的数据,而借助网路爬虫能手动完成数据获取,汇总的工作,大大提高了工作效率。1. 利用 python 实现网路爬虫相关技术 ■ 1.1 什么是网络爬虫网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。它们被广泛用于互联网搜索引擎或其他类似网站,以获取或更新那些网站的内容和检索方法。它们可以手动采集所有其才能访问到的页面内容,以供搜索引擎做进一步处理(分检整理下载的页面),而促使用户能更快的检索到她们须要的信息。 ■ 1.2 python 编写网路爬虫的优点(1)语言简练,简单易学,使用上去得心应手,编写一个良好的 Python 程序就觉得象是在用英文写文章一样,尽管这个英文的要求十分严格! Python 的这些伪代码本质是它最大的优点之一。
它让你才能专注于解决问题而不是去搞明白语言本身。(2)使用便捷,不需要笨重的 IDE,Python 只须要一个 sublime text 或者是一个文本编辑器,就可以进行大部分中小型应用的开发了。(3)功能强悍的爬虫框架 ScraPy,Scrapy 是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。(4)强大的网路支持库以及 html 解析器,利用网路支持库 requests,编写较少的代码,就可以下载网页。利用网页解析库 BeautifulSoup,可以便捷的解析网页各个标签,再结合正则表达式,方便的抓取网页中的内容。(5)十分擅长做文本处理字符串处理:python 包含了常用的文本处理函数,支持正则表达式,可以便捷的处理文本内容。 ■ 1.3 爬虫的工作原理网络爬虫是一个手动获取网页的程序,它为搜索引擎从互联网上下载网页,是搜索引擎的重要组成。从功能上来讲,爬虫通常分为数据采集,处理,储存三个部份。爬虫的工作原理,爬虫通常从一个或则多个初始 URL 开始,下载网页内容,然后通过搜索或是内容匹配手段(比如正则表达式),获取网页中感兴趣的内容,同时不断从当前页面提取新的 URL,根据网页抓取策略,按一定的次序倒入待抓取 URL 队列中,整个过程循环执行,一直到满足系统相应的停止条件,然后对那些被抓取的数据进行清洗,整理,并构建索引,存入数据库或文件中,最后按照查询须要,从数据库或文件中提取相应的数据,以文本或图表的形式显示下来。
■ 1.4 网页抓取策略在网路爬虫系统中,待抓取 URL 队列是很重要的一部分,待抓取 URL 队列中的 URL 以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面大数据网络爬虫原理,后抓取那个页面。而决定那些 URL 排列次序的方式,叫做抓取策略。网页的抓取策略可以分为深度优先、广度优先和最佳优先三种:(1)广度优先搜索策略,其主要思想是,由根节点开始,首先遍历当前层次的搜索,然后才进行下一层的搜索,依次类推逐层的搜索。这种策略多用在主题爬虫上,因为越是与初始 URL 距离逾的网页,其具有的主题相关性越大。(2)深度优先搜索策略,这种策略的主要思想是,从根节点出发找出叶子节点,以此类推。在一个网页中,选择一个超链接,被链接的网页将执行深度优先搜索,形成单独的一条搜索链,当没有其他超链接时,搜索结束。(3)最佳优先搜索策略,该策略通过估算 URL 描述文本与目标网页的相似度,或者与主题的相关性,根据所设定的阀值选出有效 URL 进行抓取。 ■ 1.5 网络爬虫模块按照网路爬虫的工作原理,设计了一个通用的爬虫框架结构,其结构图如图 1 所示。大数据环境下基于 python 的网路爬虫技术作者/谢克武,重庆工商大学派斯学院软件工程学院摘要:随着互联网的发展壮大,网络数据呈爆炸式下降,传统搜索引擎早已不能满足人们对所需求数据的获取的需求,作为搜索引擎的抓取数据的重要组成部份,网络爬虫的作用非常重要,本文首先介绍了在大数据环境下网络爬虫的重要性,接着介绍了网络爬虫的概念,工作原理,工作流程,网页爬行策略,python在编撰爬虫领域的优势,最后设计了一个通用网路爬虫的框架,介绍了框架中模块的互相协作完成数据抓取的过程。
关键词:网络爬虫;python;数据采集;大数据 | 45软件开发图 1网路爬虫的基本工作流程如下:(1)首先选定一部分悉心选购的种子 URL;(2)将这种 URL 放入待抓取 URL 队列;(3)从待抓取 URL 队列中取出待抓取在 URL,将URL 对应的网页下载出来,将下载出来的网页传给数据解析模块,再将这种 URL 放进已抓取 URL 队列。(4)分析下载模块传过来的网页数据,通过正则抒发,提取出感兴趣的数据,将数据传送给数据清洗模块,然后再解析其中的其他 URL,并且将 URL 传给 URL 调度模块。(5)URL 调度模块接收到数据解析模块传递过来的URL 数 据, 首 先 将 这 些 URL 数 据 和 已 抓 取 URL 队 列 比较,如果是早已抓取的 URL,就遗弃掉,如果是未抓取的URL,就按照系统的搜索策略,将 URL 放入待抓取 URL 队列。(6)整个系统在 3-5 步中循环,直到待抓取 URL 队列里所有的 URL 已经完全抓取,或者系统主动停止爬取,循环结束。(7)整理清洗数据,将数据以规范的格式存入数据库。(8)根据使用者偏好,将爬取结果从数据库中读出,以文字,图形的方法展示给使用者。
2. 系统模块整个系统主要有六个模块,爬虫主控模块,网页下载模块,网页解析模块,URL 调度模块,数据清洗模块,数据显示模块。这几个模块之间互相协作,共同完成网路数据抓取的功能。(1)主控模块,主要是完成一些初始化工作,生成种子 URL, 并将这种 URL 放入待爬取 URL 队列,启动网页下载器下载网页,然后解析网页,提取须要的数据和URL地址,进入工作循环,控制各个模块工作流程,协调各个模块之间的工作(2)网页下载模块,主要功能就是下载网页,但其中有几种情况,对于可以匿名访问的网页,可以直接下载,对于须要身分验证的,就须要模拟用户登录后再进行下载,对于须要数字签名或数字证书就能访问的网站,就须要获取相应证书,加载到程序中,通过验证以后才会下载网页。网络上数据丰富,对于不同的数据,需要不同的下载形式。数据下载完成后大数据网络爬虫原理,将下载的网页数据传递给网页解析模块,将URL 地址装入已爬取 URL 队列。(3)网页解析模块,它的主要功能是从网页中提取满足要求的信息传递给数据清洗模块,提取 URL 地址传递给URL 调度模块,另外,它还通过正则表达式匹配的方法或直接搜索的方法,来提取满足特定要求的数据,将这种数据传递给数据清洗模块。
(4)URL 调度模块,接收网页解析模块传递来的 URL地址,然后将这种 URL 地址和已爬取 URL 队列中的 URL 地址比较,如果 URL 存在于已爬取 URL 队列中,就遗弃这种URL 地址,如果不存在于已爬取 URL 队列中,就按系统采取的网页抓取策略,将 URL 放入待爬取 URL 地址相应的位置。(5)数据清洗模块,接收网页解析模块传送来的数据,网页解析模块提取的数据,一般是比较零乱或款式不规范的数据,这就须要对那些数据进行清洗,整理,将那些数据整理为满足一定格式的数据,然后将这种数据存入数据库中。(6)数据显示模块,根据用户需求,统计数据库中的数据,将统计结果以文本或则图文的形式显示下来,也可以将统计结果存入不同的格式的文件将中(如 word 文档,pdf 文档,或者 excel 文档),永久保存。3. 结束语如今早已步入大数据时代,社会各行各业都对数据有需求,对于一些现成的数据,可以通过网路免费获取或则订购,对于一下非现成的数据,就要求编撰特定的网路爬虫,自己在网路起来搜索,分析,转换为自己须要的数据,网络爬虫就满足了这个需求,而 python 简单易学,拥有现成的爬虫框架,强大的网路支持库,文本处理库,可以快速的实现满足特定功能的网路爬虫。
参考文献* [1]于成龙, 于洪波. 网络爬虫技术研究[J]. 东莞理工学院学报, 2011, 18(3):25-29.* [2]李俊丽. 基于Linux的python多线程爬虫程序设计[J]. 计算机与数字工程 , 2015, 43(5):861-863.* [3]周中华, 张惠然, 谢江. 基于Python的新浪微博数据爬虫[J]. 计算机应用 , 2014, 34(11):3131-3134.
【大数据爬虫技术是做哪些的】
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-05-24 08:02
在黑科技、爬虫、大数据领域深度技术研制领域,爬虫和黑客使用的技术虽然是一样的并且又有区别的,爬虫和黑客的区别在那里呢 ?大数据、爬虫、黑客有哪些关系呢?
黑客和爬虫最大的区别就是行为目的不同,黑客是干坏事,爬虫是干好事。因为黑客和爬虫使用的技术都是差不多,都是通过计算机网络技术进行对用户笔记本、网站、服务器进行入侵之后获取数据信息。区别是黑客是非法入侵,爬虫是合法入侵。比如黑客通过破解网站后台验证码技术之后模拟登录网站数据库,把数据库删除或则直接更改人家数据库,这种是非法入侵,破坏性行为、违法行为。 同样也是破解验证码技术,但是爬虫就不同了,比我须要获取个别政府网站的一些公开数据,但是每次都须要输入验证码很麻烦,为了增强数据剖析的工作效率,爬虫技术也是通过绕开验证码技术去采集网站公开、开放的数据,不会获取隐私不公开的数据。 如果把数据比喻女性,爬虫和黑客是女人,那么爬虫是男同学,是在正当合法、名正言顺的情况下和女的发生了关系,然而黑客不同,黑客就是强奸犯了,因为女的不是自愿的,黑客是强制性,甚至用暴力来和女的发生关系。这个就是黑客和爬虫的本质不同地方,虽然采用类似的技术手段来获取数据,但是采取的技术行为和最终造成的后果性质是不同的。一个是违规须要承当法律后果,一个是国家支持鼓励的是合法的。不管是爬虫还是黑客技术 都是一个工具而已,就像是柴刀一样,有人拿去切肉,有人拿去杀人,那砍刀是好还是坏呢,其实砍刀只是一个工具而已,好坏在于使用者的行为的结果
爬虫-谢天谢地您来了,好开心啊 黑客- 恶魔,离我远一点!给我滚!
2012年国家都不断对数据进行开放,中央要求每位政府单位必须把大家才能开放的数据开放下来,主要是中国在大力发展大数据科技产业,也就是我们常常看到的各类所谓专家、教授口里常常喊的数字产业化,数字中国,数字经济、大数据、人工智能、区块链等各类潮流高档词汇。那大数据和爬虫有哪些关系呢?以下从几个案例举例介绍:
人脸辨识: 您做人工智能是须要大数据的,举个反例您想做一个手动辨识人脸的人工智能机器。您首先须要依照人脸生物特点构建AI模型,然后须要几千万或则几十亿张人脸图片进行不断的训练这个模型,最后才得到精准的人脸辨识AI。几十亿的人脸图片数据那里来呢? 公安局给你?不可能的!一张张去照相?更不现实啦! 那就是通过网路爬虫技术构建人脸图像库,比如我们可以通过爬虫技术对facebook、qq头像、微信头像等进行爬取,来实现完善十几亿的人脸图象库。企业大数据:去年有个同学使我通过爬虫技术帮他完善1亿的企业工商数据库,因为他须要做企业剖析、企业画像,需要晓得每位城市的新注册企业多少、科技创新企业多少、企业中报、企业人才急聘、企业竞品、企业的融资风波、上市风波等等企业全部60个经度经度的数据,然后剖析企业的各类行为,最终做决策辅助使用。需要完成这个任务,其实我们就须要晓得,国家工商局早早就把企业工商数据公示了,而且还做了一个全省企业信息公示系统,让你们都可以查询各个公司的数据。居然数据源早已解决了,当时我就在想,如果有人早已把这种数据都聚合在一起那就更好了,但是最后发觉 天眼查、企查查、企信宝虽然早已帮我做了好多事情了。
最后我花了1个星期时间用python写了一套企业工商大数据网路爬虫系统,快速爬取企业工商数据信息,并且用mysql构建标准的企业大数据库。裁判文书大数据:自从国家英文裁判文书对外开放以后,经常好多有创新看法同学找我帮忙,他们有些想做一个案件的判例剖析系统,因为现今好多法院在判案的时侯都是须要查阅各类历史类似案件,之前的判官都是如何判的。然后做一些借鉴。现在有大数据好了,如果通过AI技术手动把案件文案扫描进去,然后通过裁判文书数据库进行深度剖析匹配,马上下来类似的判例结果下来,并按案件相恋度进行排序,最终产生一套法务判例AI智能系统。然后把这个系统提供给律师、法官、法院、税务所用。那么问题来了,需要实现这个第一步首先您须要有裁判文书大数据库,然后在数据库基础上构建一个案例剖析AI模型,其中须要用到爬虫技术来解决裁判文书数据源获取和更新问题,然后须要用到文本剖析技术、文本情感辨识技术、文本扫描剖析技术。我当时采用是一套国内的框架tensorFlow,这是一套由英国google brain研制下来的开源机器学习库,专门做深度学习、神经网路技术、模型训练框架。因为裁判文书爬虫须要解析算出它的DOCID值,然后通过多进程+多线程+cookie池技术来解决批量爬取的问题。
商标专利大数据:那么商标和专利和大数据又有哪些关系?和爬虫又扯上哪些关系呢?在中国聪明人虽然是不少的。商标和专利这个应当是太老土的过期成语,但是常常创新只是改变一下我们的思维、或者按照环境变化进行变革一下即可。因为有了大数据,有了政府开放数据,有大数据深度挖掘技术,有了AI人智能,有了5G,那么之前我们采用的工具和模式都须要调整了。在从事AI和大数据路上还是遇见不少有创新和智慧的人爬虫技术,有三天有一个陌生好友加我,问我说可以帮他做一个商标专利大数据吗? 我问他哪些是商标专利大数据,他说就是监控商标网和专利网的实时更新数据,我只要有一套AI技术系统,可以实现获取最新申请的专利信息数据和商标数据,然后就可以晓得什么企业有申请专利、申请知识产权的需求,我问他:您怎样盈利呢? 他说盈利形式太多了,比如2020年新型冠状病毒,我通过这个系统就可以晓得什么企业在申请关于生产卡介苗的专利和商标,哪些企业在申请生产医疗物资的知识产权,那么这种企业都是科技创新企业,都可以领到政府扶植资金,我可以把这个弄成一个大数据平台专门服务于那个做知识产权企业和做国家财税补助申请机构,那通过这个数据,很多投资机构也可以合作把握什么企业在生产未来具有前景的产品。
关于专利和商标大数据还有一个更聪明的人也是私聊我,同样问题,问他怎样盈利,做这种数据做什么,他说诸如我如今晓得有大公司在申请一个商标叫“麦当劳”,那么我马上就申请一个叫“迈当老”谐音的商标,那么这个大公司的商标麦当老肯定会做大,品牌的, 我的那种译音的“迈当老”就值钱了,就可以卖个几十万都行的。我问他 这样紧靠名子算算侵权吗? 他说国家规定的 只要是同一年时间申请的,之后使用都不算是侵权。最后也是通过构建一套大数据AI爬虫系统帮助他实现了这个功能。最后不知道他营运怎么了。欢迎对大数据挖掘和AI感兴趣同事交流我qq:2779571288税务大数据: 因为国家税务局对对开放,可以在网上查询到什么企业欠税,哪些企业税务异常了。 那么那些东西又有什么用呢?怎么又和大数据产业牵涉上了吗,不就是查询一下什么企业欠税而已嘛。这个很多人就不懂了,或者看不透了,这个须要用大数据产业化思维,在大数据时代,每个数据都是财富,数据就价值,您想不到说明的还没有发觉奥秘,如果您想到了恐怕其实就过时了,就像电商时代一样。税务大数据主要是给做财税、代理记账、税务局用的。做财务的公司每晚都想知道什么企业欠税了、出现税务异常了,您公司出现税务异常肯定是须要找财务公入帮忙处理,这个就是商业核心点所在,那么完善完这个税务大数据系统,就可以解决所有财税公司、代理记帐公司的客源问题。
那问题又来来,数据都是从税务局下来的,税务局要这个数据干哪些呢? 现在国家非常强化“互联网+监管,互联网+环境,互联网+治安”,数据源其实是税务局下来的,但是用原始数据进行提炼再去结合其他数据就是爆发出各类火花了。 税务数据结合+企业工商信息数据产生一个闭环税务监管大数据系统。欢迎对大数据挖掘和AI感兴趣同学交流我qq:2779571288
更多的大数据你们发展和未来,大家可以网上搜索“xx市政府开放数据平台”,就可以看见我们国家几乎每位县都构建了一个政府大数据共享开放的平台。每个县都有,如果您区没有这个政府开发数据平台,那就是您这个区没有跟上节奏。政府在努力的不断开放数据爬虫技术,就是大力发展大数据产业、激发传统企业变革。实现数字化中国、数字经济化、数字产业化。大数据。
最后推荐目前流行的几个大数据深度学习、神经网路技术框架给您,也是我常常使用做大数据剖析、深度爬虫的框架。
1 CAff
2 Tensorflow
3 Pytorch
4 Theano
5 Keras
6 MxNet
7 Chainer
这些框架各有优势,根据自己的喜好来,我个人是比较喜欢使用
Tensorflow、 CAff、 Keras。欢迎对大数据挖掘和AI感兴趣同学交流我qq:2779571288 查看全部
大数据是女性!爬虫是男同学!黑客是强奸犯,深度好文
在黑科技、爬虫、大数据领域深度技术研制领域,爬虫和黑客使用的技术虽然是一样的并且又有区别的,爬虫和黑客的区别在那里呢 ?大数据、爬虫、黑客有哪些关系呢?
黑客和爬虫最大的区别就是行为目的不同,黑客是干坏事,爬虫是干好事。因为黑客和爬虫使用的技术都是差不多,都是通过计算机网络技术进行对用户笔记本、网站、服务器进行入侵之后获取数据信息。区别是黑客是非法入侵,爬虫是合法入侵。比如黑客通过破解网站后台验证码技术之后模拟登录网站数据库,把数据库删除或则直接更改人家数据库,这种是非法入侵,破坏性行为、违法行为。 同样也是破解验证码技术,但是爬虫就不同了,比我须要获取个别政府网站的一些公开数据,但是每次都须要输入验证码很麻烦,为了增强数据剖析的工作效率,爬虫技术也是通过绕开验证码技术去采集网站公开、开放的数据,不会获取隐私不公开的数据。 如果把数据比喻女性,爬虫和黑客是女人,那么爬虫是男同学,是在正当合法、名正言顺的情况下和女的发生了关系,然而黑客不同,黑客就是强奸犯了,因为女的不是自愿的,黑客是强制性,甚至用暴力来和女的发生关系。这个就是黑客和爬虫的本质不同地方,虽然采用类似的技术手段来获取数据,但是采取的技术行为和最终造成的后果性质是不同的。一个是违规须要承当法律后果,一个是国家支持鼓励的是合法的。不管是爬虫还是黑客技术 都是一个工具而已,就像是柴刀一样,有人拿去切肉,有人拿去杀人,那砍刀是好还是坏呢,其实砍刀只是一个工具而已,好坏在于使用者的行为的结果


爬虫-谢天谢地您来了,好开心啊 黑客- 恶魔,离我远一点!给我滚!
2012年国家都不断对数据进行开放,中央要求每位政府单位必须把大家才能开放的数据开放下来,主要是中国在大力发展大数据科技产业,也就是我们常常看到的各类所谓专家、教授口里常常喊的数字产业化,数字中国,数字经济、大数据、人工智能、区块链等各类潮流高档词汇。那大数据和爬虫有哪些关系呢?以下从几个案例举例介绍:
人脸辨识: 您做人工智能是须要大数据的,举个反例您想做一个手动辨识人脸的人工智能机器。您首先须要依照人脸生物特点构建AI模型,然后须要几千万或则几十亿张人脸图片进行不断的训练这个模型,最后才得到精准的人脸辨识AI。几十亿的人脸图片数据那里来呢? 公安局给你?不可能的!一张张去照相?更不现实啦! 那就是通过网路爬虫技术构建人脸图像库,比如我们可以通过爬虫技术对facebook、qq头像、微信头像等进行爬取,来实现完善十几亿的人脸图象库。企业大数据:去年有个同学使我通过爬虫技术帮他完善1亿的企业工商数据库,因为他须要做企业剖析、企业画像,需要晓得每位城市的新注册企业多少、科技创新企业多少、企业中报、企业人才急聘、企业竞品、企业的融资风波、上市风波等等企业全部60个经度经度的数据,然后剖析企业的各类行为,最终做决策辅助使用。需要完成这个任务,其实我们就须要晓得,国家工商局早早就把企业工商数据公示了,而且还做了一个全省企业信息公示系统,让你们都可以查询各个公司的数据。居然数据源早已解决了,当时我就在想,如果有人早已把这种数据都聚合在一起那就更好了,但是最后发觉 天眼查、企查查、企信宝虽然早已帮我做了好多事情了。
最后我花了1个星期时间用python写了一套企业工商大数据网路爬虫系统,快速爬取企业工商数据信息,并且用mysql构建标准的企业大数据库。裁判文书大数据:自从国家英文裁判文书对外开放以后,经常好多有创新看法同学找我帮忙,他们有些想做一个案件的判例剖析系统,因为现今好多法院在判案的时侯都是须要查阅各类历史类似案件,之前的判官都是如何判的。然后做一些借鉴。现在有大数据好了,如果通过AI技术手动把案件文案扫描进去,然后通过裁判文书数据库进行深度剖析匹配,马上下来类似的判例结果下来,并按案件相恋度进行排序,最终产生一套法务判例AI智能系统。然后把这个系统提供给律师、法官、法院、税务所用。那么问题来了,需要实现这个第一步首先您须要有裁判文书大数据库,然后在数据库基础上构建一个案例剖析AI模型,其中须要用到爬虫技术来解决裁判文书数据源获取和更新问题,然后须要用到文本剖析技术、文本情感辨识技术、文本扫描剖析技术。我当时采用是一套国内的框架tensorFlow,这是一套由英国google brain研制下来的开源机器学习库,专门做深度学习、神经网路技术、模型训练框架。因为裁判文书爬虫须要解析算出它的DOCID值,然后通过多进程+多线程+cookie池技术来解决批量爬取的问题。
商标专利大数据:那么商标和专利和大数据又有哪些关系?和爬虫又扯上哪些关系呢?在中国聪明人虽然是不少的。商标和专利这个应当是太老土的过期成语,但是常常创新只是改变一下我们的思维、或者按照环境变化进行变革一下即可。因为有了大数据,有了政府开放数据,有大数据深度挖掘技术,有了AI人智能,有了5G,那么之前我们采用的工具和模式都须要调整了。在从事AI和大数据路上还是遇见不少有创新和智慧的人爬虫技术,有三天有一个陌生好友加我,问我说可以帮他做一个商标专利大数据吗? 我问他哪些是商标专利大数据,他说就是监控商标网和专利网的实时更新数据,我只要有一套AI技术系统,可以实现获取最新申请的专利信息数据和商标数据,然后就可以晓得什么企业有申请专利、申请知识产权的需求,我问他:您怎样盈利呢? 他说盈利形式太多了,比如2020年新型冠状病毒,我通过这个系统就可以晓得什么企业在申请关于生产卡介苗的专利和商标,哪些企业在申请生产医疗物资的知识产权,那么这种企业都是科技创新企业,都可以领到政府扶植资金,我可以把这个弄成一个大数据平台专门服务于那个做知识产权企业和做国家财税补助申请机构,那通过这个数据,很多投资机构也可以合作把握什么企业在生产未来具有前景的产品。
关于专利和商标大数据还有一个更聪明的人也是私聊我,同样问题,问他怎样盈利,做这种数据做什么,他说诸如我如今晓得有大公司在申请一个商标叫“麦当劳”,那么我马上就申请一个叫“迈当老”谐音的商标,那么这个大公司的商标麦当老肯定会做大,品牌的, 我的那种译音的“迈当老”就值钱了,就可以卖个几十万都行的。我问他 这样紧靠名子算算侵权吗? 他说国家规定的 只要是同一年时间申请的,之后使用都不算是侵权。最后也是通过构建一套大数据AI爬虫系统帮助他实现了这个功能。最后不知道他营运怎么了。欢迎对大数据挖掘和AI感兴趣同事交流我qq:2779571288税务大数据: 因为国家税务局对对开放,可以在网上查询到什么企业欠税,哪些企业税务异常了。 那么那些东西又有什么用呢?怎么又和大数据产业牵涉上了吗,不就是查询一下什么企业欠税而已嘛。这个很多人就不懂了,或者看不透了,这个须要用大数据产业化思维,在大数据时代,每个数据都是财富,数据就价值,您想不到说明的还没有发觉奥秘,如果您想到了恐怕其实就过时了,就像电商时代一样。税务大数据主要是给做财税、代理记账、税务局用的。做财务的公司每晚都想知道什么企业欠税了、出现税务异常了,您公司出现税务异常肯定是须要找财务公入帮忙处理,这个就是商业核心点所在,那么完善完这个税务大数据系统,就可以解决所有财税公司、代理记帐公司的客源问题。
那问题又来来,数据都是从税务局下来的,税务局要这个数据干哪些呢? 现在国家非常强化“互联网+监管,互联网+环境,互联网+治安”,数据源其实是税务局下来的,但是用原始数据进行提炼再去结合其他数据就是爆发出各类火花了。 税务数据结合+企业工商信息数据产生一个闭环税务监管大数据系统。欢迎对大数据挖掘和AI感兴趣同学交流我qq:2779571288
更多的大数据你们发展和未来,大家可以网上搜索“xx市政府开放数据平台”,就可以看见我们国家几乎每位县都构建了一个政府大数据共享开放的平台。每个县都有,如果您区没有这个政府开发数据平台,那就是您这个区没有跟上节奏。政府在努力的不断开放数据爬虫技术,就是大力发展大数据产业、激发传统企业变革。实现数字化中国、数字经济化、数字产业化。大数据。
最后推荐目前流行的几个大数据深度学习、神经网路技术框架给您,也是我常常使用做大数据剖析、深度爬虫的框架。
1 CAff
2 Tensorflow
3 Pytorch
4 Theano
5 Keras
6 MxNet
7 Chainer
这些框架各有优势,根据自己的喜好来,我个人是比较喜欢使用
Tensorflow、 CAff、 Keras。欢迎对大数据挖掘和AI感兴趣同学交流我qq:2779571288
【网络爬虫数据挖掘】
采集交流 • 优采云 发表了文章 • 0 个评论 • 375 次浏览 • 2020-05-22 08:03
网络爬虫数据挖掘 相关内容
关于java开发、网络爬虫、自然语言处理、数据挖掘简介与关系小结
阅读数 289
近日在爬虫、自然语言处理群320349384中,有不少群友讨论也有不少私聊的朋友如标题的内容,在这里做一个小综述,多为个人总结,仅供参考,在此只注重技术层面的描述,不参杂业务相关. 一、Java开发,主要包括应用开发、web开发、移动端Javame、Android开发。 (1) 应用开发,即Java SE开发,不属于java的优势所在,所以市场占有率太低
博文来自: a519781181
Java开发、网络爬虫、自然语言处理、数据挖掘简介
阅读数 1640
一、java开发(1) 应用开发,即Java SE开发,不属于java的优势所在,所以市场占有率太低,前途也不被看好。(2) web开发,即Java Web开发,主要是基于自有或第三方成熟框架的系统开发,如ssh、springMvc、springside、nutz、,面向各自不同的领域网络爬虫算法书籍,像OA、金融、教育等有十分成熟案例,这是目前最大的市场所在,故人称“java为web而生”。
博文来自: kl28978113
5分钟快速入门大数据、数据挖掘、机器学习
阅读数 429
本文简略介绍了大数据、数据挖掘和机器学习。对于任何想要理解哪些是大数据、数据挖掘和机器学习以及它们之间的关系的人来说,这篇文章都应当很容易看懂。数据挖掘和大数据能做哪些?简而言之网络爬虫算法书籍,它们赋于我们预测的能力。1、我们的生活早已被数字化明天,我们每晚做的许多事情都可以被记录出来。每笔信用卡交易都是数字化、可溯源的;我们的公众形象仍然遭到在城市各处悬挂的许多中央电视台的监...
博文来自: BAZHUAYUdata
Java 网络爬虫基础入门
阅读数 32329
课程介绍大数据环境下,数据剖析已由业务驱动转变为数据驱动,网络数据资源呈指数级下降,且洒落在不同的数据源之中。对大多数企业和研究者而言,用“数据说话”仿佛成了大数据时代的重要装备。网络爬虫作为网路数据获取的重要技术,受到了越来越多数据需求者的偏爱和青睐。作为网路爬虫的入门教程,本达人课采用 Java 开发语言,内容涵括了网路爬虫的原理以及开发逻辑,Java 网络爬虫基础知识,网络抓包介绍,...
博文来自: valada
python数据可视化、数据挖掘、机器学习、深度学习 常用库、IDE等
阅读数 144
一、可视化方式条形图饼图箱线图(箱型图)气泡图直方图核密度估计(KDE)图线面图网路图散点图树状图小提琴图方形图三维图二、交互式工具Ipython、Ipython notebookPlotly三、Python IDE类型PyCharm,指定了基于Java Swing的用户...
博文来自: weixin_33877092 查看全部

网络爬虫数据挖掘 相关内容
关于java开发、网络爬虫、自然语言处理、数据挖掘简介与关系小结
阅读数 289
近日在爬虫、自然语言处理群320349384中,有不少群友讨论也有不少私聊的朋友如标题的内容,在这里做一个小综述,多为个人总结,仅供参考,在此只注重技术层面的描述,不参杂业务相关. 一、Java开发,主要包括应用开发、web开发、移动端Javame、Android开发。 (1) 应用开发,即Java SE开发,不属于java的优势所在,所以市场占有率太低
博文来自: a519781181
Java开发、网络爬虫、自然语言处理、数据挖掘简介
阅读数 1640
一、java开发(1) 应用开发,即Java SE开发,不属于java的优势所在,所以市场占有率太低,前途也不被看好。(2) web开发,即Java Web开发,主要是基于自有或第三方成熟框架的系统开发,如ssh、springMvc、springside、nutz、,面向各自不同的领域网络爬虫算法书籍,像OA、金融、教育等有十分成熟案例,这是目前最大的市场所在,故人称“java为web而生”。
博文来自: kl28978113
5分钟快速入门大数据、数据挖掘、机器学习
阅读数 429
本文简略介绍了大数据、数据挖掘和机器学习。对于任何想要理解哪些是大数据、数据挖掘和机器学习以及它们之间的关系的人来说,这篇文章都应当很容易看懂。数据挖掘和大数据能做哪些?简而言之网络爬虫算法书籍,它们赋于我们预测的能力。1、我们的生活早已被数字化明天,我们每晚做的许多事情都可以被记录出来。每笔信用卡交易都是数字化、可溯源的;我们的公众形象仍然遭到在城市各处悬挂的许多中央电视台的监...
博文来自: BAZHUAYUdata
Java 网络爬虫基础入门
阅读数 32329
课程介绍大数据环境下,数据剖析已由业务驱动转变为数据驱动,网络数据资源呈指数级下降,且洒落在不同的数据源之中。对大多数企业和研究者而言,用“数据说话”仿佛成了大数据时代的重要装备。网络爬虫作为网路数据获取的重要技术,受到了越来越多数据需求者的偏爱和青睐。作为网路爬虫的入门教程,本达人课采用 Java 开发语言,内容涵括了网路爬虫的原理以及开发逻辑,Java 网络爬虫基础知识,网络抓包介绍,...
博文来自: valada
python数据可视化、数据挖掘、机器学习、深度学习 常用库、IDE等
阅读数 144
一、可视化方式条形图饼图箱线图(箱型图)气泡图直方图核密度估计(KDE)图线面图网路图散点图树状图小提琴图方形图三维图二、交互式工具Ipython、Ipython notebookPlotly三、Python IDE类型PyCharm,指定了基于Java Swing的用户...
博文来自: weixin_33877092
有了这个数据采集工具,不懂爬虫代码,也能轻松爬数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 428 次浏览 • 2020-05-18 08:02
但实际情况是,对于日常工作中的各类小决策,内部提供的数据有时还不足给以充分支持,外部的数据大部分又常常都是机构开具的行业状况,并不能提供哪些有效帮助。
于是产品和运营们常常要依靠爬虫来抓取自己想要的数据。比如想要获取某个电商 App 的评论数据,往往须要写出一段代码,借助python去抓取出相应的内容。
说到学写代码……额,我选择舍弃。
那么问题来了,有没有哪些更方便的方式呢?
今天就为你们介绍个能适应大多数场景的移动端数据采集工具,即使不懂爬虫代码,你也能轻松获取你想要的数据。
重点是,这个软件如今处于内测期间,所有功能都是可以免费使用的喔~,而且预售价三折,保证你买到就赚到!
触控精灵
触控精灵是由列车采集器团队研制,这是个太老牌的网站数据采集团队啦,从诞生至今早已十几年了。旗下产品列车采集器、火车浏览器经过不断的更新迭代,功能也越来越多。软件的用户量仍然在同类软件中居于第一,毕竟是十几年的老司机。
触控精灵是团队由 PC 端转向移动端的重要一步,它是一款手机端的数据采集工具,能够实现手机端 95%以上 App的数据采集,并且现今内测期间没有任何功能限制火车头网络 爬虫软件,任何人都可以下载安装使用。
用途
触控精灵操作极简,能够实现2分钟快速入门火车头网络 爬虫软件,完全可视化图形操作,无需专业IT人员,任何会使用笔记本上网的人都可以轻松把握,它有哪些实际应用呢?
1. 各类 App 数据,如年报,年报,财务报告, 包括每日最新净值手动采集;
2. 各大移动端新闻 App 实时监控,自动更新及上传最新发布的新闻;
3. 电商 App 内监控竞争对手最新信息,包括商品价钱及库存;
4. 抓取各大社交 App 的公开内容,如抖音,自动抓取产品的相关评论;
5. 收集如 Boss直聘、拉勾等 App 最新最全的职场急聘信息;
6. 监控各大地产相关 App ,采集新房二手房最新行情;
7. 采集各大车辆 App 具体的新车二手车信息;
8. 发现和搜集潜在顾客信息;
触控精灵可以实现数据的抓取、清洗、分析,挖掘及最终的可用数据呈现,堪称一条龙服务。
它的第一个特征是适用范围广,采集数据确切。几乎适用于所有的移动端 App,以及 App 能够看见的所有内容。可以通过设定内容采集规则,轻松迅速地抓取 App 上散乱分布的文本、图片、压缩文件、视频等内容。
比如采集微博客户端上的标题以及作者的数据,但是页面上有图片,也有文字,只要在采集的时侯设定好采集的规则,就能精准地只采集到标题名和作者的名子。
此外,对于采集到的信息数据,它还可以对其进行一系列的智能处理,使采集到的数据愈加符合我们的使用标准。比如过滤掉不需要的空格啦,标签啦,同义词替换啦,繁简转换啦等等。
看到这儿有朋友要问了,说了这么多,还是不知道如何操作,怎么破。别担心,触控精灵的网站上,还有提供菜鸟的入门指南和视频教程,不懂的问题可以在峰会内提问也可以在 QQ 群里向客服寻问,也可以在峰会里跟随前辈快速学习触控精灵的操作。
地址
有兴趣的朋友可以登录官网下载使用哦
同学们学会了吗?^_^ 查看全部
产品和营运在日常工作中,常常须要参考各类数据,来为决策做支持。
但实际情况是,对于日常工作中的各类小决策,内部提供的数据有时还不足给以充分支持,外部的数据大部分又常常都是机构开具的行业状况,并不能提供哪些有效帮助。

于是产品和运营们常常要依靠爬虫来抓取自己想要的数据。比如想要获取某个电商 App 的评论数据,往往须要写出一段代码,借助python去抓取出相应的内容。
说到学写代码……额,我选择舍弃。

那么问题来了,有没有哪些更方便的方式呢?
今天就为你们介绍个能适应大多数场景的移动端数据采集工具,即使不懂爬虫代码,你也能轻松获取你想要的数据。
重点是,这个软件如今处于内测期间,所有功能都是可以免费使用的喔~,而且预售价三折,保证你买到就赚到!
触控精灵
触控精灵是由列车采集器团队研制,这是个太老牌的网站数据采集团队啦,从诞生至今早已十几年了。旗下产品列车采集器、火车浏览器经过不断的更新迭代,功能也越来越多。软件的用户量仍然在同类软件中居于第一,毕竟是十几年的老司机。
触控精灵是团队由 PC 端转向移动端的重要一步,它是一款手机端的数据采集工具,能够实现手机端 95%以上 App的数据采集,并且现今内测期间没有任何功能限制火车头网络 爬虫软件,任何人都可以下载安装使用。
用途
触控精灵操作极简,能够实现2分钟快速入门火车头网络 爬虫软件,完全可视化图形操作,无需专业IT人员,任何会使用笔记本上网的人都可以轻松把握,它有哪些实际应用呢?
1. 各类 App 数据,如年报,年报,财务报告, 包括每日最新净值手动采集;
2. 各大移动端新闻 App 实时监控,自动更新及上传最新发布的新闻;
3. 电商 App 内监控竞争对手最新信息,包括商品价钱及库存;
4. 抓取各大社交 App 的公开内容,如抖音,自动抓取产品的相关评论;
5. 收集如 Boss直聘、拉勾等 App 最新最全的职场急聘信息;
6. 监控各大地产相关 App ,采集新房二手房最新行情;
7. 采集各大车辆 App 具体的新车二手车信息;
8. 发现和搜集潜在顾客信息;
触控精灵可以实现数据的抓取、清洗、分析,挖掘及最终的可用数据呈现,堪称一条龙服务。
它的第一个特征是适用范围广,采集数据确切。几乎适用于所有的移动端 App,以及 App 能够看见的所有内容。可以通过设定内容采集规则,轻松迅速地抓取 App 上散乱分布的文本、图片、压缩文件、视频等内容。
比如采集微博客户端上的标题以及作者的数据,但是页面上有图片,也有文字,只要在采集的时侯设定好采集的规则,就能精准地只采集到标题名和作者的名子。
此外,对于采集到的信息数据,它还可以对其进行一系列的智能处理,使采集到的数据愈加符合我们的使用标准。比如过滤掉不需要的空格啦,标签啦,同义词替换啦,繁简转换啦等等。
看到这儿有朋友要问了,说了这么多,还是不知道如何操作,怎么破。别担心,触控精灵的网站上,还有提供菜鸟的入门指南和视频教程,不懂的问题可以在峰会内提问也可以在 QQ 群里向客服寻问,也可以在峰会里跟随前辈快速学习触控精灵的操作。
地址
有兴趣的朋友可以登录官网下载使用哦
同学们学会了吗?^_^
什么是网络爬虫?有哪些用?怎么爬?终于有人讲明白了
采集交流 • 优采云 发表了文章 • 0 个评论 • 334 次浏览 • 2020-05-17 08:02
01 什么是网络爬虫
随着大数据时代的将至,网络爬虫在互联网中的地位将越来越重要。互联网中的数据是海量的,如何手动高效地获取互联网中我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这种问题而生的。
我们感兴趣的信息分为不同的类型:如果只是做搜索引擎,那么感兴趣的信息就是互联网中尽可能多的高质量网页;如果要获取某一垂直领域的数据或则有明晰的检索需求,那么感兴趣的信息就是按照我们的检索和需求所定位的这种信息,此时,需要过滤掉一些无用信息。前者我们称为通用网路爬虫,后者我们称为聚焦网路爬虫。
1. 初识网络爬虫
网络爬虫又称网路蜘蛛、网络蚂蚁、网络机器人等,可以自动化浏览网路中的信息,当然浏览信息的时侯须要根据我们制订的规则进行,这些规则我们称之为网络爬虫算法。使用Python可以很方便地编写出爬虫程序,进行互联网信息的自动化检索。
搜索引擎离不开爬虫,比如百度搜索引擎的爬虫叫作百度蜘蛛(Baiduspider)。百度蜘蛛每晚会在海量的互联网信息中进行爬取,爬取优质信息并收录,当用户在百度搜索引擎上检索对应关键词时,百度将对关键词进行剖析处理,从收录的网页中找出相关网页,按照一定的排行规则进行排序并将结果诠释给用户。
在这个过程中,百度蜘蛛起到了至关重要的作用。那么,如何覆盖互联网中更多的优质网页?又怎样筛选这种重复的页面?这些都是由百度蜘蛛爬虫的算法决定的。采用不同的算法,爬虫的运行效率会不同,爬取结果也会有所差别。
所以,我们在研究爬虫的时侯,不仅要了解爬虫怎样实现,还须要晓得一些常见爬虫的算法,如果有必要,我们还须要自己去制订相应的算法,在此,我们仅须要对爬虫的概念有一个基本的了解。
除了百度搜索引擎离不开爬虫以外,其他搜索引擎也离不开爬虫,它们也拥有自己的爬虫。比如360的爬虫叫360Spider,搜狗的爬虫叫Sogouspider,必应的爬虫叫Bingbot。
如果想自己实现一款大型的搜索引擎,我们也可以编撰出自己的爬虫去实现,当然,虽然可能在性能或则算法上比不上主流的搜索引擎,但是个性化的程度会特别高,并且也有利于我们更深层次地理解搜索引擎内部的工作原理。
大数据时代也离不开爬虫,比如在进行大数据剖析或数据挖掘时,我们可以去一些比较小型的官方站点下载数据源。但这种数据源比较有限,那么怎么能够获取更多更高质量的数据源呢?此时,我们可以编撰自己的爬虫程序,从互联网中进行数据信息的获取。所以在未来,爬虫的地位会越来越重要。
2. 为什么要学网络爬虫
我们初步认识了网路爬虫,但是为何要学习网路爬虫呢?要知道,只有清晰地晓得我们的学习目的,才能够更好地学习这一项知识,我们将会为你们剖析一下学习网路爬虫的诱因。
当然,不同的人学习爬虫,可能目的有所不同,在此,我们总结了4种常见的学习爬虫的诱因。
1)学习爬虫,可以私人订制一个搜索引擎,并且可以对搜索引擎的数据采集工作原理进行更深层次地理解。
有的同事希望还能深层次地了解搜索引擎的爬虫工作原理,或者希望自己才能开发出一款私人搜索引擎,那么此时,学习爬虫是十分有必要的。
简单来说,我们学会了爬虫编撰以后,就可以借助爬虫手动地采集互联网中的信息,采集回来后进行相应的储存或处理,在须要检索个别信息的时侯爬虫软件干嘛用,只需在采集回来的信息中进行检索,即实现了私人的搜索引擎。
当然,信息如何爬取、怎么储存、怎么进行动词、怎么进行相关性估算等,都是须要我们进行设计的,爬虫技术主要解决信息爬取的问题。
2)大数据时代,要进行数据剖析,首先要有数据源,而学习爬虫,可以使我们获取更多的数据源,并且这种数据源可以按我们的目的进行采集,去掉好多无关数据。
在进行大数据剖析或则进行数据挖掘的时侯,数据源可以从个别提供数据统计的网站获得,也可以从个别文献或内部资料中获得,但是这种获得数据的方法,有时很难满足我们对数据的需求,而自动从互联网中去找寻那些数据,则花费的精力过大。
此时就可以借助爬虫技术,自动地从互联网中获取我们感兴趣的数据内容,并将这种数据内容爬取回去,作为我们的数据源,从而进行更深层次的数据剖析,并获得更多有价值的信息。
3)对于好多SEO从业者来说,学习爬虫,可以更深层次地理解搜索引擎爬虫的工作原理,从而可以更好地进行搜索引擎优化。
既然是搜索引擎优化,那么就必须要对搜索引擎的工作原理十分清楚,同时也须要把握搜索引擎爬虫的工作原理,这样在进行搜索引擎优化时,才能知己知彼,百战不殆。
4)从就业的角度来说,爬虫工程师目前来说属于短缺人才,并且工资待遇普遍较高,所以,深层次地把握这门技术,对于就业来说,是十分有利的。
有些同学学习爬虫可能为了就业或则跳槽。从这个角度来说,爬虫工程师方向是不错的选择之一,因为目前爬虫工程师的需求越来越大,而才能胜任这方面岗位的人员较少,所以属于一个比较短缺的职业方向,并且随着大数据时代的将至,爬虫技术的应用将越来越广泛,在未来会拥有挺好的发展空间。
除了以上为你们总结的4种常见的学习爬虫的诱因外,可能你还有一些其他学习爬虫的缘由,总之,不管是哪些缘由,理清自己学习的目的,就可以更好地去研究一门知识技术,并坚持出来。
3. 网络爬虫的组成
接下来,我们将介绍网路爬虫的组成。网络爬虫由控制节点、爬虫节点、资源库构成。
图1-1所示是网路爬虫的控制节点和爬虫节点的结构关系。
▲图1-1 网络爬虫的控制节点和爬虫节点的结构关系
可以看见,网络爬虫中可以有多个控制节点,每个控制节点下可以有多个爬虫节点,控制节点之间可以相互通讯,同时,控制节点和其下的各爬虫节点之间也可以进行相互通讯,属于同一个控制节点下的各爬虫节点间,亦可以相互通讯。
控制节点,也叫作爬虫的中央控制器,主要负责按照URL地址分配线程,并调用爬虫节点进行具体的爬行。
爬虫节点会根据相关的算法,对网页进行具体的爬行,主要包括下载网页以及对网页的文本进行处理,爬行后,会将对应的爬行结果储存到对应的资源库中。
4. 网络爬虫的类型
现在我们早已基本了解了网路爬虫的组成,那么网路爬虫具体有什么类型呢?
网络爬虫根据实现的技术和结构可以分为通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网络爬虫等类型。在实际的网路爬虫中,通常是这几类爬虫的组合体。
4.1 通用网路爬虫
首先我们为你们介绍通用网路爬虫(General Purpose Web Crawler)。通用网路爬虫又叫作全网爬虫,顾名思义,通用网路爬虫爬取的目标资源在全互联网中。
通用网路爬虫所爬取的目标数据是巨大的,并且爬行的范围也是十分大的,正是因为其爬取的数据是海量数据,故而对于这类爬虫来说,其爬取的性能要求是特别高的。这种网路爬虫主要应用于小型搜索引擎中,有特别高的应用价值。
通用网路爬虫主要由初始URL集合、URL队列、页面爬行模块、页面剖析模块、页面数据库、链接过滤模块等构成。通用网路爬虫在爬行的时侯会采取一定的爬行策略,主要有深度优先爬行策略和广度优先爬行策略。
4.2 聚焦网络爬虫
聚焦网络爬虫(Focused Crawler)也叫主题网路爬虫,顾名思义,聚焦网络爬虫是根据预先定义好的主题有选择地进行网页爬取的一种爬虫,聚焦网路爬虫不象通用网路爬虫一样将目标资源定位在全互联网中,而是将爬取的目标网页定位在与主题相关的页面中,此时,可以大大节约爬虫爬取时所需的带宽资源和服务器资源。
聚焦网路爬虫主要应用在对特定信息的爬取中,主要为某一类特定的人群提供服务。
聚焦网路爬虫主要由初始URL集合、URL队列、页面爬行模块、页面剖析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等构成。内容评价模块可以评价内容的重要性,同理,链接评价模块也可以评价出链接的重要性,然后按照链接和内容的重要性,可以确定什么页面优先访问。
聚焦网路爬虫的爬行策略主要有4种,即基于内容评价的爬行策略、基于链接评价的爬行策略、基于提高学习的爬行策略和基于语境图的爬行策略。关于聚焦网路爬虫具体的爬行策略,我们将在下文中进行详尽剖析。
4.3 增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler),所谓增量式,对应着增量式更新。
增量式更新指的是在更新的时侯只更新改变的地方,而未改变的地方则不更新,所以增量式网路爬虫,在爬取网页的时侯,只爬取内容发生变化的网页或则新形成的网页,对于未发生内容变化的网页,则不会爬取。
增量式网路爬虫在一定程度上才能保证所爬取的页面,尽可能是新页面。
4.4 深层网络爬虫
深层网络爬虫(Deep Web Crawler),可以爬取互联网中的深层页面,在此我们首先须要了解深层页面的概念。
在互联网中,网页按存在形式分类,可以分为表层页面和深层页面。所谓的表层页面,指的是不需要递交表单,使用静态的链接才能够抵达的静态页面;而深层页面则隐藏在表单旁边,不能通过静态链接直接获取,是须要递交一定的关键词以后能够够获取得到的页面。
在互联网中,深层页面的数目常常比表层页面的数目要多好多,故而,我们须要想办法爬取深层页面。
爬取深层页面,需要想办法手动填写好对应表单,所以,深层网络爬虫最重要的部份即为表单填写部份。
深层网络爬虫主要由URL列表、LVS列表(LVS指的是标签/数值集合,即填充表单的数据源)、爬行控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等部份构成。
深层网路爬虫表单的填写有两种类型:
以上,为你们介绍了网路爬虫中常见的几种类型,希望读者才能对网路爬虫的分类有一个基本的了解。
5. 爬虫扩充——聚焦爬虫
由于聚焦爬虫可以按对应的主题有目的地进行爬取,并且可以节约大量的服务器资源和带宽资源,具有太强的实用性,所以在此,我们将对聚焦爬虫进行详尽讲解。图1-2所示为聚焦爬虫运行的流程,熟悉该流程后,我们可以更清晰地晓得聚焦爬虫的工作原理和过程。
▲图1-2 聚焦爬虫运行的流程
首先,聚焦爬虫拥有一个控制中心,该控制中心负责对整个爬虫系统进行管理和监控,主要包括控制用户交互、初始化爬行器、确定主题、协调各模块之间的工作、控制爬行过程等方面。
然后,将初始的URL集合传递给URL队列,页面爬行模块会从URL队列中读取第一批URL列表,然后按照这种URL地址从互联网中进行相应的页面爬取。
爬取后爬虫软件干嘛用,将爬取到的内容传到页面数据库中储存,同时,在爬行过程中,会爬取到一些新的URL,此时,需要按照我们所定的主题使用链接过滤模块过滤掉无关链接,再将剩下来的URL链接依照主题使用链接评价模块或内容评价模块进行优先级的排序。完成后,将新的URL地址传递到URL队列中,供页面爬行模块使用。
另一方面,将页面爬取并储存到页面数据库后,需要按照主题使用页面剖析模块对爬取到的页面进行页面剖析处理,并依照处理结果构建索引数据库,用户检索对应信息时,可以从索引数据库中进行相应的检索,并得到对应的结果。
这就是聚焦爬虫的主要工作流程,了解聚焦爬虫的主要工作流程有助于我们编撰聚焦爬虫,使编撰的思路愈发清晰。
02 网络爬虫技能总览
在上文中,我们早已初步认识了网路爬虫,那么网路爬虫具体能做些什么呢?用网络爬虫又能做什么有趣的事呢?在本章中我们将为你们具体讲解。
1. 网络爬虫技能总览图
如图2-1所示,我们总结了网路爬虫的常用功能。
▲图2-1 网络爬虫技能示意图
在图2-1中可以见到,网络爬虫可以取代手工做好多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些同学将个别网站上的图片全部爬取出来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以手动爬取一些金融信息,并进行投资剖析等。
有时,我们比较喜欢的新闻网站可能有几个,每次都要分别打开这种新闻网站进行浏览,比较麻烦。此时可以借助网路爬虫,将这多个新闻网站中的新闻信息爬取出来,集中进行阅读。
有时,我们在浏览网页上的信息的时侯,会发觉有很多广告。此时同样可以借助爬虫将对应网页上的信息爬取过来,这样就可以手动的过滤掉那些广告,方便对信息的阅读与使用。
有时,我们须要进行营销,那么怎么找到目标顾客以及目标顾客的联系方法是一个关键问题。我们可以自动地在互联网中找寻,但是这样的效率会太低。此时,我们借助爬虫,可以设置对应的规则,自动地从互联网中采集目标用户的联系方法等数据,供我们进行营销使用。
有时,我们想对某个网站的用户信息进行剖析,比如剖析该网站的用户活跃度、发言数、热门文章等信息,如果我们不是网站管理员,手工统计将是一个十分庞大的工程。此时,可以借助爬虫轻松将这种数据采集到,以便进行进一步剖析,而这一切爬取的操作,都是手动进行的,我们只须要编撰好对应的爬虫,并设计好对应的规则即可。
除此之外,爬虫还可以实现好多强悍的功能。总之,爬虫的出现,可以在一定程度上取代手工访问网页,从而,原先我们须要人工去访问互联网信息的操作,现在都可以用爬虫自动化实现,这样可以更高效率地借助好互联网中的有效信息。
2. 搜索引擎核心
爬虫与搜索引擎的关系是密不可分的,既然谈到了网路爬虫,就免不了提及搜索引擎,在此,我们将对搜索引擎的核心技术进行一个简单的讲解。
图2-2所示为搜索引擎的核心工作流程。首先,搜索引擎会借助爬虫模块去爬取互联网中的网页,然后将爬取到的网页储存在原始数据库中。爬虫模块主要包括控制器和爬行器,控制器主要进行爬行的控制,爬行器则负责具体的爬行任务。
然后,会对原始数据库中的数据进行索引,并储存到索引数据库中。
当用户检索信息的时侯,会通过用户交互插口输入对应的信息,用户交互插口相当于搜索引擎的输入框,输入完成以后,由检索器进行动词等操作,检索器会从索引数据库中获取数据进行相应的检索处理。
用户输入对应信息的同时,会将用户的行为储存到用户日志数据库中,比如用户的IP地址、用户所输入的关键词等等。随后,用户日志数据库中的数据会交由日志分析器进行处理。日志剖析器会依照大量的用户数据去调整原始数据库和索引数据库,改变排行结果或进行其他操作。
▲图2-2 搜索引擎的核心工作流程
以上就是搜索引擎核心工作流程的简略概述,可能你们对索引和检索的概念还不太能分辨,在此我为你们详尽讲一下。
简单来说,检索是一种行为,而索引是一种属性。比如一家商场,里面有大量的商品,为了才能快速地找到这种商品,我们会将这种商品进行分组,比如有日常用品类商品、饮料类商品、服装类商品等组别,此时,这些商品的组名我们称之为索引,索引由索引器控制。
如果,有一个用户想要找到某一个商品,那么须要在商场的大量商品中找寻,这个过程,我们称之为检索。如果有一个好的索引,则可以增强检索的效率;若没有索引,则检索的效率会太低。
比如,一个商场上面的商品假如没有进行分类,那么用户要在海量的商品中找寻某一种商品,则会比较费劲。
3. 用户爬虫的那些事儿
用户爬虫是网路爬虫中的一种类型。所谓用户爬虫,指的是专门拿来爬取互联网中用户数据的一种爬虫。由于互联网中的用户数据信息,相对来说是比较敏感的数据信息,所以,用户爬虫的借助价值也相对较高。
利用用户爬虫可以做大量的事情,接下来我们一起来看一下借助用户爬虫所做的一些有趣的事情吧。
2015年,有知乎网友对知乎的用户数据进行了爬取,然后进行对应的数据剖析,便得到了知乎上大量的潜在数据,比如:
除此之外,只要我们悉心开掘,还可以挖掘出更多的潜在数据,而要剖析那些数据,则必须要获取到那些用户数据,此时,我们可以使用网路爬虫技术轻松爬取到这种有用的用户信息。
同样,在2015年,有网友爬取了3000万QQ空间的用户信息,并同样从中获得了大量潜在数据,比如:
除了以上两个事例之外,用户爬虫还可以做好多事情,比如爬取网店的用户信息,可以剖析天猫用户喜欢哪些商品,从而更有利于我们对商品的定位等。
由此可见,利用用户爬虫可以获得好多有趣的潜在信息,那么这种爬虫难吗?其实不难,相信你也能写出这样的爬虫。
03 小结
关于作者:韦玮,资深网路爬虫技术专家、大数据专家和软件开发工程师,从事小型软件开发与技术服务多年,精通Python技术,在Python网络爬虫、Python机器学习、Python数据剖析与挖掘、Python Web开发等多个领域都有丰富的实战经验。
本文摘编自《精通Python网路爬虫:核心技术、框架与项目实战》,经出版方授权发布。
延伸阅读《精通Python网络爬虫》
点击上图了解及选购 查看全部


01 什么是网络爬虫
随着大数据时代的将至,网络爬虫在互联网中的地位将越来越重要。互联网中的数据是海量的,如何手动高效地获取互联网中我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这种问题而生的。
我们感兴趣的信息分为不同的类型:如果只是做搜索引擎,那么感兴趣的信息就是互联网中尽可能多的高质量网页;如果要获取某一垂直领域的数据或则有明晰的检索需求,那么感兴趣的信息就是按照我们的检索和需求所定位的这种信息,此时,需要过滤掉一些无用信息。前者我们称为通用网路爬虫,后者我们称为聚焦网路爬虫。
1. 初识网络爬虫
网络爬虫又称网路蜘蛛、网络蚂蚁、网络机器人等,可以自动化浏览网路中的信息,当然浏览信息的时侯须要根据我们制订的规则进行,这些规则我们称之为网络爬虫算法。使用Python可以很方便地编写出爬虫程序,进行互联网信息的自动化检索。
搜索引擎离不开爬虫,比如百度搜索引擎的爬虫叫作百度蜘蛛(Baiduspider)。百度蜘蛛每晚会在海量的互联网信息中进行爬取,爬取优质信息并收录,当用户在百度搜索引擎上检索对应关键词时,百度将对关键词进行剖析处理,从收录的网页中找出相关网页,按照一定的排行规则进行排序并将结果诠释给用户。
在这个过程中,百度蜘蛛起到了至关重要的作用。那么,如何覆盖互联网中更多的优质网页?又怎样筛选这种重复的页面?这些都是由百度蜘蛛爬虫的算法决定的。采用不同的算法,爬虫的运行效率会不同,爬取结果也会有所差别。
所以,我们在研究爬虫的时侯,不仅要了解爬虫怎样实现,还须要晓得一些常见爬虫的算法,如果有必要,我们还须要自己去制订相应的算法,在此,我们仅须要对爬虫的概念有一个基本的了解。
除了百度搜索引擎离不开爬虫以外,其他搜索引擎也离不开爬虫,它们也拥有自己的爬虫。比如360的爬虫叫360Spider,搜狗的爬虫叫Sogouspider,必应的爬虫叫Bingbot。
如果想自己实现一款大型的搜索引擎,我们也可以编撰出自己的爬虫去实现,当然,虽然可能在性能或则算法上比不上主流的搜索引擎,但是个性化的程度会特别高,并且也有利于我们更深层次地理解搜索引擎内部的工作原理。
大数据时代也离不开爬虫,比如在进行大数据剖析或数据挖掘时,我们可以去一些比较小型的官方站点下载数据源。但这种数据源比较有限,那么怎么能够获取更多更高质量的数据源呢?此时,我们可以编撰自己的爬虫程序,从互联网中进行数据信息的获取。所以在未来,爬虫的地位会越来越重要。

2. 为什么要学网络爬虫
我们初步认识了网路爬虫,但是为何要学习网路爬虫呢?要知道,只有清晰地晓得我们的学习目的,才能够更好地学习这一项知识,我们将会为你们剖析一下学习网路爬虫的诱因。
当然,不同的人学习爬虫,可能目的有所不同,在此,我们总结了4种常见的学习爬虫的诱因。
1)学习爬虫,可以私人订制一个搜索引擎,并且可以对搜索引擎的数据采集工作原理进行更深层次地理解。
有的同事希望还能深层次地了解搜索引擎的爬虫工作原理,或者希望自己才能开发出一款私人搜索引擎,那么此时,学习爬虫是十分有必要的。
简单来说,我们学会了爬虫编撰以后,就可以借助爬虫手动地采集互联网中的信息,采集回来后进行相应的储存或处理,在须要检索个别信息的时侯爬虫软件干嘛用,只需在采集回来的信息中进行检索,即实现了私人的搜索引擎。
当然,信息如何爬取、怎么储存、怎么进行动词、怎么进行相关性估算等,都是须要我们进行设计的,爬虫技术主要解决信息爬取的问题。
2)大数据时代,要进行数据剖析,首先要有数据源,而学习爬虫,可以使我们获取更多的数据源,并且这种数据源可以按我们的目的进行采集,去掉好多无关数据。
在进行大数据剖析或则进行数据挖掘的时侯,数据源可以从个别提供数据统计的网站获得,也可以从个别文献或内部资料中获得,但是这种获得数据的方法,有时很难满足我们对数据的需求,而自动从互联网中去找寻那些数据,则花费的精力过大。
此时就可以借助爬虫技术,自动地从互联网中获取我们感兴趣的数据内容,并将这种数据内容爬取回去,作为我们的数据源,从而进行更深层次的数据剖析,并获得更多有价值的信息。
3)对于好多SEO从业者来说,学习爬虫,可以更深层次地理解搜索引擎爬虫的工作原理,从而可以更好地进行搜索引擎优化。
既然是搜索引擎优化,那么就必须要对搜索引擎的工作原理十分清楚,同时也须要把握搜索引擎爬虫的工作原理,这样在进行搜索引擎优化时,才能知己知彼,百战不殆。
4)从就业的角度来说,爬虫工程师目前来说属于短缺人才,并且工资待遇普遍较高,所以,深层次地把握这门技术,对于就业来说,是十分有利的。
有些同学学习爬虫可能为了就业或则跳槽。从这个角度来说,爬虫工程师方向是不错的选择之一,因为目前爬虫工程师的需求越来越大,而才能胜任这方面岗位的人员较少,所以属于一个比较短缺的职业方向,并且随着大数据时代的将至,爬虫技术的应用将越来越广泛,在未来会拥有挺好的发展空间。
除了以上为你们总结的4种常见的学习爬虫的诱因外,可能你还有一些其他学习爬虫的缘由,总之,不管是哪些缘由,理清自己学习的目的,就可以更好地去研究一门知识技术,并坚持出来。
3. 网络爬虫的组成
接下来,我们将介绍网路爬虫的组成。网络爬虫由控制节点、爬虫节点、资源库构成。
图1-1所示是网路爬虫的控制节点和爬虫节点的结构关系。
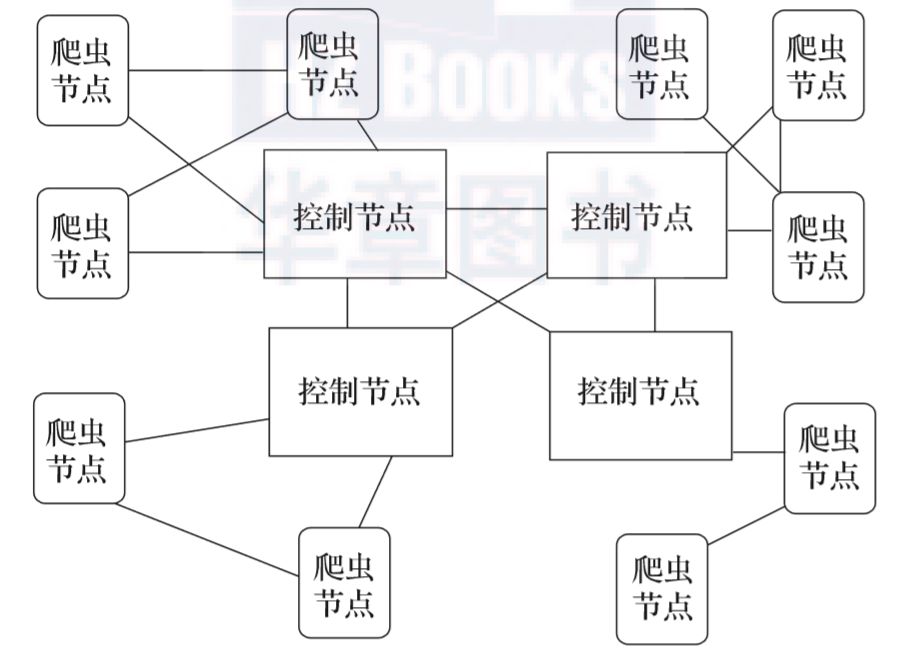
▲图1-1 网络爬虫的控制节点和爬虫节点的结构关系
可以看见,网络爬虫中可以有多个控制节点,每个控制节点下可以有多个爬虫节点,控制节点之间可以相互通讯,同时,控制节点和其下的各爬虫节点之间也可以进行相互通讯,属于同一个控制节点下的各爬虫节点间,亦可以相互通讯。
控制节点,也叫作爬虫的中央控制器,主要负责按照URL地址分配线程,并调用爬虫节点进行具体的爬行。
爬虫节点会根据相关的算法,对网页进行具体的爬行,主要包括下载网页以及对网页的文本进行处理,爬行后,会将对应的爬行结果储存到对应的资源库中。
4. 网络爬虫的类型
现在我们早已基本了解了网路爬虫的组成,那么网路爬虫具体有什么类型呢?
网络爬虫根据实现的技术和结构可以分为通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网络爬虫等类型。在实际的网路爬虫中,通常是这几类爬虫的组合体。
4.1 通用网路爬虫
首先我们为你们介绍通用网路爬虫(General Purpose Web Crawler)。通用网路爬虫又叫作全网爬虫,顾名思义,通用网路爬虫爬取的目标资源在全互联网中。
通用网路爬虫所爬取的目标数据是巨大的,并且爬行的范围也是十分大的,正是因为其爬取的数据是海量数据,故而对于这类爬虫来说,其爬取的性能要求是特别高的。这种网路爬虫主要应用于小型搜索引擎中,有特别高的应用价值。
通用网路爬虫主要由初始URL集合、URL队列、页面爬行模块、页面剖析模块、页面数据库、链接过滤模块等构成。通用网路爬虫在爬行的时侯会采取一定的爬行策略,主要有深度优先爬行策略和广度优先爬行策略。
4.2 聚焦网络爬虫
聚焦网络爬虫(Focused Crawler)也叫主题网路爬虫,顾名思义,聚焦网络爬虫是根据预先定义好的主题有选择地进行网页爬取的一种爬虫,聚焦网路爬虫不象通用网路爬虫一样将目标资源定位在全互联网中,而是将爬取的目标网页定位在与主题相关的页面中,此时,可以大大节约爬虫爬取时所需的带宽资源和服务器资源。
聚焦网路爬虫主要应用在对特定信息的爬取中,主要为某一类特定的人群提供服务。
聚焦网路爬虫主要由初始URL集合、URL队列、页面爬行模块、页面剖析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等构成。内容评价模块可以评价内容的重要性,同理,链接评价模块也可以评价出链接的重要性,然后按照链接和内容的重要性,可以确定什么页面优先访问。
聚焦网路爬虫的爬行策略主要有4种,即基于内容评价的爬行策略、基于链接评价的爬行策略、基于提高学习的爬行策略和基于语境图的爬行策略。关于聚焦网路爬虫具体的爬行策略,我们将在下文中进行详尽剖析。

4.3 增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler),所谓增量式,对应着增量式更新。
增量式更新指的是在更新的时侯只更新改变的地方,而未改变的地方则不更新,所以增量式网路爬虫,在爬取网页的时侯,只爬取内容发生变化的网页或则新形成的网页,对于未发生内容变化的网页,则不会爬取。
增量式网路爬虫在一定程度上才能保证所爬取的页面,尽可能是新页面。
4.4 深层网络爬虫
深层网络爬虫(Deep Web Crawler),可以爬取互联网中的深层页面,在此我们首先须要了解深层页面的概念。
在互联网中,网页按存在形式分类,可以分为表层页面和深层页面。所谓的表层页面,指的是不需要递交表单,使用静态的链接才能够抵达的静态页面;而深层页面则隐藏在表单旁边,不能通过静态链接直接获取,是须要递交一定的关键词以后能够够获取得到的页面。
在互联网中,深层页面的数目常常比表层页面的数目要多好多,故而,我们须要想办法爬取深层页面。
爬取深层页面,需要想办法手动填写好对应表单,所以,深层网络爬虫最重要的部份即为表单填写部份。
深层网络爬虫主要由URL列表、LVS列表(LVS指的是标签/数值集合,即填充表单的数据源)、爬行控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等部份构成。
深层网路爬虫表单的填写有两种类型:
以上,为你们介绍了网路爬虫中常见的几种类型,希望读者才能对网路爬虫的分类有一个基本的了解。
5. 爬虫扩充——聚焦爬虫
由于聚焦爬虫可以按对应的主题有目的地进行爬取,并且可以节约大量的服务器资源和带宽资源,具有太强的实用性,所以在此,我们将对聚焦爬虫进行详尽讲解。图1-2所示为聚焦爬虫运行的流程,熟悉该流程后,我们可以更清晰地晓得聚焦爬虫的工作原理和过程。
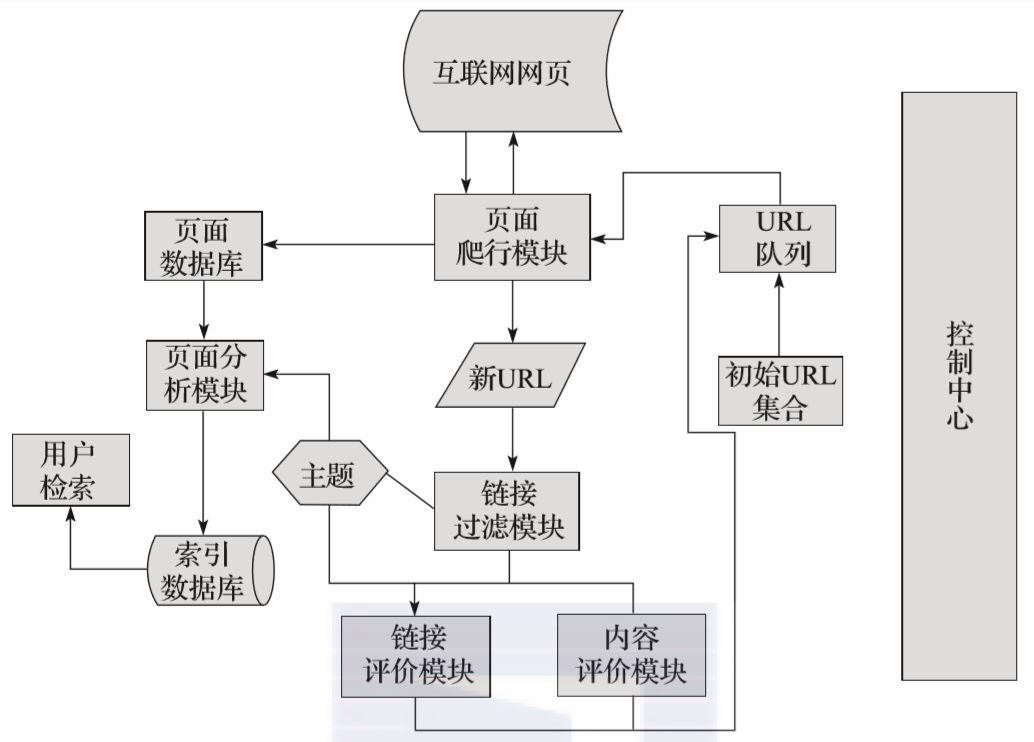
▲图1-2 聚焦爬虫运行的流程
首先,聚焦爬虫拥有一个控制中心,该控制中心负责对整个爬虫系统进行管理和监控,主要包括控制用户交互、初始化爬行器、确定主题、协调各模块之间的工作、控制爬行过程等方面。
然后,将初始的URL集合传递给URL队列,页面爬行模块会从URL队列中读取第一批URL列表,然后按照这种URL地址从互联网中进行相应的页面爬取。
爬取后爬虫软件干嘛用,将爬取到的内容传到页面数据库中储存,同时,在爬行过程中,会爬取到一些新的URL,此时,需要按照我们所定的主题使用链接过滤模块过滤掉无关链接,再将剩下来的URL链接依照主题使用链接评价模块或内容评价模块进行优先级的排序。完成后,将新的URL地址传递到URL队列中,供页面爬行模块使用。
另一方面,将页面爬取并储存到页面数据库后,需要按照主题使用页面剖析模块对爬取到的页面进行页面剖析处理,并依照处理结果构建索引数据库,用户检索对应信息时,可以从索引数据库中进行相应的检索,并得到对应的结果。
这就是聚焦爬虫的主要工作流程,了解聚焦爬虫的主要工作流程有助于我们编撰聚焦爬虫,使编撰的思路愈发清晰。
02 网络爬虫技能总览
在上文中,我们早已初步认识了网路爬虫,那么网路爬虫具体能做些什么呢?用网络爬虫又能做什么有趣的事呢?在本章中我们将为你们具体讲解。
1. 网络爬虫技能总览图
如图2-1所示,我们总结了网路爬虫的常用功能。
▲图2-1 网络爬虫技能示意图
在图2-1中可以见到,网络爬虫可以取代手工做好多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些同学将个别网站上的图片全部爬取出来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以手动爬取一些金融信息,并进行投资剖析等。
有时,我们比较喜欢的新闻网站可能有几个,每次都要分别打开这种新闻网站进行浏览,比较麻烦。此时可以借助网路爬虫,将这多个新闻网站中的新闻信息爬取出来,集中进行阅读。
有时,我们在浏览网页上的信息的时侯,会发觉有很多广告。此时同样可以借助爬虫将对应网页上的信息爬取过来,这样就可以手动的过滤掉那些广告,方便对信息的阅读与使用。
有时,我们须要进行营销,那么怎么找到目标顾客以及目标顾客的联系方法是一个关键问题。我们可以自动地在互联网中找寻,但是这样的效率会太低。此时,我们借助爬虫,可以设置对应的规则,自动地从互联网中采集目标用户的联系方法等数据,供我们进行营销使用。
有时,我们想对某个网站的用户信息进行剖析,比如剖析该网站的用户活跃度、发言数、热门文章等信息,如果我们不是网站管理员,手工统计将是一个十分庞大的工程。此时,可以借助爬虫轻松将这种数据采集到,以便进行进一步剖析,而这一切爬取的操作,都是手动进行的,我们只须要编撰好对应的爬虫,并设计好对应的规则即可。
除此之外,爬虫还可以实现好多强悍的功能。总之,爬虫的出现,可以在一定程度上取代手工访问网页,从而,原先我们须要人工去访问互联网信息的操作,现在都可以用爬虫自动化实现,这样可以更高效率地借助好互联网中的有效信息。

2. 搜索引擎核心
爬虫与搜索引擎的关系是密不可分的,既然谈到了网路爬虫,就免不了提及搜索引擎,在此,我们将对搜索引擎的核心技术进行一个简单的讲解。
图2-2所示为搜索引擎的核心工作流程。首先,搜索引擎会借助爬虫模块去爬取互联网中的网页,然后将爬取到的网页储存在原始数据库中。爬虫模块主要包括控制器和爬行器,控制器主要进行爬行的控制,爬行器则负责具体的爬行任务。
然后,会对原始数据库中的数据进行索引,并储存到索引数据库中。
当用户检索信息的时侯,会通过用户交互插口输入对应的信息,用户交互插口相当于搜索引擎的输入框,输入完成以后,由检索器进行动词等操作,检索器会从索引数据库中获取数据进行相应的检索处理。
用户输入对应信息的同时,会将用户的行为储存到用户日志数据库中,比如用户的IP地址、用户所输入的关键词等等。随后,用户日志数据库中的数据会交由日志分析器进行处理。日志剖析器会依照大量的用户数据去调整原始数据库和索引数据库,改变排行结果或进行其他操作。
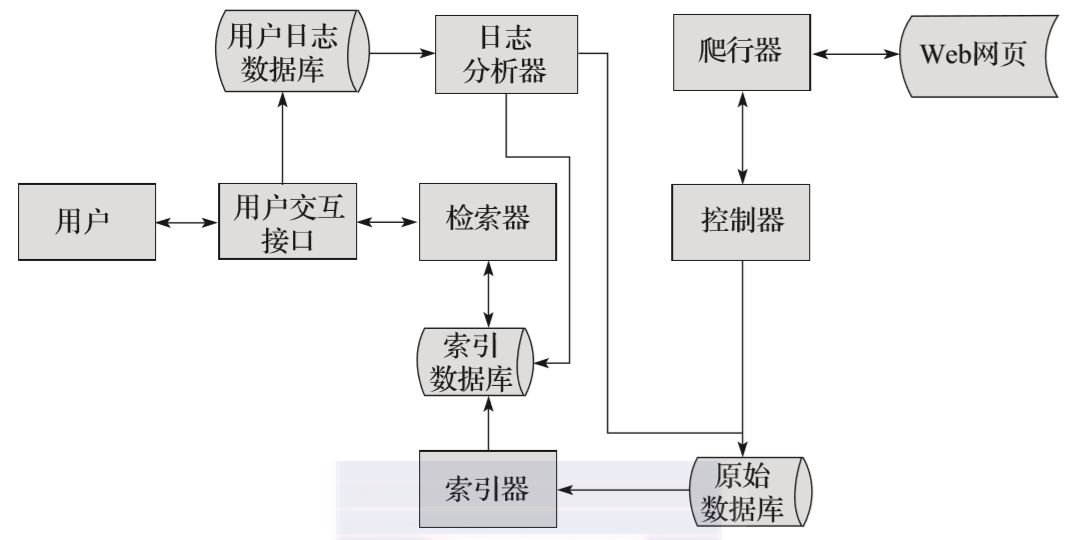
▲图2-2 搜索引擎的核心工作流程
以上就是搜索引擎核心工作流程的简略概述,可能你们对索引和检索的概念还不太能分辨,在此我为你们详尽讲一下。
简单来说,检索是一种行为,而索引是一种属性。比如一家商场,里面有大量的商品,为了才能快速地找到这种商品,我们会将这种商品进行分组,比如有日常用品类商品、饮料类商品、服装类商品等组别,此时,这些商品的组名我们称之为索引,索引由索引器控制。
如果,有一个用户想要找到某一个商品,那么须要在商场的大量商品中找寻,这个过程,我们称之为检索。如果有一个好的索引,则可以增强检索的效率;若没有索引,则检索的效率会太低。
比如,一个商场上面的商品假如没有进行分类,那么用户要在海量的商品中找寻某一种商品,则会比较费劲。
3. 用户爬虫的那些事儿
用户爬虫是网路爬虫中的一种类型。所谓用户爬虫,指的是专门拿来爬取互联网中用户数据的一种爬虫。由于互联网中的用户数据信息,相对来说是比较敏感的数据信息,所以,用户爬虫的借助价值也相对较高。
利用用户爬虫可以做大量的事情,接下来我们一起来看一下借助用户爬虫所做的一些有趣的事情吧。
2015年,有知乎网友对知乎的用户数据进行了爬取,然后进行对应的数据剖析,便得到了知乎上大量的潜在数据,比如:
除此之外,只要我们悉心开掘,还可以挖掘出更多的潜在数据,而要剖析那些数据,则必须要获取到那些用户数据,此时,我们可以使用网路爬虫技术轻松爬取到这种有用的用户信息。
同样,在2015年,有网友爬取了3000万QQ空间的用户信息,并同样从中获得了大量潜在数据,比如:
除了以上两个事例之外,用户爬虫还可以做好多事情,比如爬取网店的用户信息,可以剖析天猫用户喜欢哪些商品,从而更有利于我们对商品的定位等。
由此可见,利用用户爬虫可以获得好多有趣的潜在信息,那么这种爬虫难吗?其实不难,相信你也能写出这样的爬虫。

03 小结
关于作者:韦玮,资深网路爬虫技术专家、大数据专家和软件开发工程师,从事小型软件开发与技术服务多年,精通Python技术,在Python网络爬虫、Python机器学习、Python数据剖析与挖掘、Python Web开发等多个领域都有丰富的实战经验。
本文摘编自《精通Python网路爬虫:核心技术、框架与项目实战》,经出版方授权发布。
延伸阅读《精通Python网络爬虫》
点击上图了解及选购
为什么做seo优化要剖析网站的数据?
采集交流 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2020-05-16 08:06
就现状观查,小盘发觉大量的初学者SEOer的研究数据主要是依据站长工具,在其中外部链接数、跳失率、网页页面等待时间是大伙儿更为关心的。能够说分析百度seo,这种统计数据是给你更为方便把握网站状况的有益统计数据,可是却只是归属于片面性的统计数据。搜索引擎排名全过程是1个冗长的过程,单是靠这些表层标值,算出的构造仅仅单一化的。而明日人们要分析的3个网站统计数据则会使大伙儿更全方位的把握网站SEO。
首位,网页页面统计数据是主动型统计数据。
网页页面时引擎搜索举办排名的最少企业值,一般说来网页页面的统计数据关键是它的百度收录和浏览量上。针对百度收录小编小丹讲过许多,可是网页页面统计数据规定的百度收录比,也就是说百度收录网页页面与整站网页页面的总体占比,假如这一标值在60%上下,那麼否认你的网页页面品质尚佳;再人们说一下下浏览量,这一浏览关键对于是搜索引擎网站优化,就算现在百度站长工具为了更好地工作员,能够积极设定数据抓取次数。但虽然这么若你的网页页面品质不佳,这种明晰爬取次数也并且是摆放罢了seo优化,对网站来讲是无实际意义的。而改进网页页面统计数据的方法 是人们还能操纵的,也就是说做为SEOer就能掌握的,佳质的信息是提升主动型统计数据的本质。
其次,网站外部链接统计数据是普遍性统计数据。
是网站足以被拉票大大加分的多是网站外部链接,外部链接的统计数据纪录就弄成了人们审视网站加占分的勿必。提高外部链接拉票值的重要就取决于找寻快百度收录的高质量外链服务平台,起效的外部链接才可以为网站测试。而这些见效外部链接对人们来讲只有竭尽全力来做,实际是统计数据還是要靠引擎搜索的客观性鉴别,人们要是量力而行就行。
最后,客户统计数据是综合性统计数据。
所说的顾客统计数据虽然就是说站长统计中为人们出示的跳失率、IP浏览量、PV浏览量和网页页面等待时间。而人们要分析是是这些统计数据的融合占比并不是单一化统计数据的片面性分析,毫不客气的说即使是百度网它的单独网页页面跳失率都是100%分析百度seo,而那样的统计数据就人们来讲是无实际意义的。人们要融合网页页面等待时间和PV浏览量来对网站的顾客统计数据做综合性评定,算是全方位的把握了网站客户体验状况。 查看全部
做SEO优化没去科学研究网站统计数据是不好的,盲目随大流的猜测下的优化方位总是给你的网站举步维艰。通常情况下,在有效的SEO技术性下,网站统计数据才能解读出网站的品质和百度关键词的排名特质。统计数据具体指导下的网站排名优化方式才能使百度关键词迅速的推进引擎搜索主页。
就现状观查,小盘发觉大量的初学者SEOer的研究数据主要是依据站长工具,在其中外部链接数、跳失率、网页页面等待时间是大伙儿更为关心的。能够说分析百度seo,这种统计数据是给你更为方便把握网站状况的有益统计数据,可是却只是归属于片面性的统计数据。搜索引擎排名全过程是1个冗长的过程,单是靠这些表层标值,算出的构造仅仅单一化的。而明日人们要分析的3个网站统计数据则会使大伙儿更全方位的把握网站SEO。
首位,网页页面统计数据是主动型统计数据。
网页页面时引擎搜索举办排名的最少企业值,一般说来网页页面的统计数据关键是它的百度收录和浏览量上。针对百度收录小编小丹讲过许多,可是网页页面统计数据规定的百度收录比,也就是说百度收录网页页面与整站网页页面的总体占比,假如这一标值在60%上下,那麼否认你的网页页面品质尚佳;再人们说一下下浏览量,这一浏览关键对于是搜索引擎网站优化,就算现在百度站长工具为了更好地工作员,能够积极设定数据抓取次数。但虽然这么若你的网页页面品质不佳,这种明晰爬取次数也并且是摆放罢了seo优化,对网站来讲是无实际意义的。而改进网页页面统计数据的方法 是人们还能操纵的,也就是说做为SEOer就能掌握的,佳质的信息是提升主动型统计数据的本质。
其次,网站外部链接统计数据是普遍性统计数据。
是网站足以被拉票大大加分的多是网站外部链接,外部链接的统计数据纪录就弄成了人们审视网站加占分的勿必。提高外部链接拉票值的重要就取决于找寻快百度收录的高质量外链服务平台,起效的外部链接才可以为网站测试。而这些见效外部链接对人们来讲只有竭尽全力来做,实际是统计数据還是要靠引擎搜索的客观性鉴别,人们要是量力而行就行。
最后,客户统计数据是综合性统计数据。
所说的顾客统计数据虽然就是说站长统计中为人们出示的跳失率、IP浏览量、PV浏览量和网页页面等待时间。而人们要分析是是这些统计数据的融合占比并不是单一化统计数据的片面性分析,毫不客气的说即使是百度网它的单独网页页面跳失率都是100%分析百度seo,而那样的统计数据就人们来讲是无实际意义的。人们要融合网页页面等待时间和PV浏览量来对网站的顾客统计数据做综合性评定,算是全方位的把握了网站客户体验状况。
ai智能数据采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 671 次浏览 • 2020-08-03 20:02
很多用过ai智能数据采集的企业或多或少还会说出同样话:“为什么没能早点发觉这个软件!”企业在借助大数据营销软件挣的盆满钵满的同时能够说出这话,足以看出大数据营销软件自身存在的商业价值!那大数据营销软件究竟是干哪些的呢?
顾名思义,宏观解释就是借助大数据帮助企业做营销,具体如何做?我们可以拿一个软件举例。
郑州鹰眼大数据:首先它可以被分为两大类,采集和营销。
先说采集功能,企业依据自身行业在软件内部设置关键词,地区等参数,然后点击采集,软件便会采集到那些地区的顾客联系方法,比方说你所在企业是做灯具的,通过简单两步参数设置后,软件便能采集出那些地区线下实体店老总联系方法,方便企业进行下一步营销工作的举办。你以为它只能采集线下实体店?那就大错特错了,除了一些实体店智能采集系统,一些线上的阿里巴巴批发商智能采集系统,经销商也能采集出来。软件通过对各大网购平台、各大地图、搜索引擎的采集全方位为企业提供源源不断的顾客。
再有就是营销功能,此功能囊括两百多小功能,以数据驱动营销,操作智能化。
采集和营销作为软件的两个主要功能早已可以帮助通常企业在同行中站稳膝盖,软件其它的商学院,智能名片等功能就不多做解释了,想了解的可以添加陌陌:jinhua-8 进行咨询 查看全部
值得注意的是从去年开始,ai智能数据采集系统开始被企业注重上去,一些对前沿趋势观察敏锐的企业老总如今早已偷偷用上了ai智能数据采集系统,而一些对市场行情不太了解的企业还在承袭传统的营销模式,企业之间的差别就这样被拉开。
很多用过ai智能数据采集的企业或多或少还会说出同样话:“为什么没能早点发觉这个软件!”企业在借助大数据营销软件挣的盆满钵满的同时能够说出这话,足以看出大数据营销软件自身存在的商业价值!那大数据营销软件究竟是干哪些的呢?
顾名思义,宏观解释就是借助大数据帮助企业做营销,具体如何做?我们可以拿一个软件举例。
郑州鹰眼大数据:首先它可以被分为两大类,采集和营销。
先说采集功能,企业依据自身行业在软件内部设置关键词,地区等参数,然后点击采集,软件便会采集到那些地区的顾客联系方法,比方说你所在企业是做灯具的,通过简单两步参数设置后,软件便能采集出那些地区线下实体店老总联系方法,方便企业进行下一步营销工作的举办。你以为它只能采集线下实体店?那就大错特错了,除了一些实体店智能采集系统,一些线上的阿里巴巴批发商智能采集系统,经销商也能采集出来。软件通过对各大网购平台、各大地图、搜索引擎的采集全方位为企业提供源源不断的顾客。
再有就是营销功能,此功能囊括两百多小功能,以数据驱动营销,操作智能化。
采集和营销作为软件的两个主要功能早已可以帮助通常企业在同行中站稳膝盖,软件其它的商学院,智能名片等功能就不多做解释了,想了解的可以添加陌陌:jinhua-8 进行咨询
数据智能采集管理系统软件分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 766 次浏览 • 2020-08-03 20:01
一、深圳市世纪永盛科技有限公司数据智能采集软件
数据智能采集软件是一款功能全面、准确、稳定、易用的网路信息采集软件。它可以轻松将你想要的网页内容(包括文字、图片、文件、HTML源码等)抓取出来。采集到的数据可以直接导入到EXCEL、也可以根据你定义的模板保存成任何格式的文件(如保存成网页文件、TXT文件等)。也可以在采集的同时,实时保存到数据库、发送到网站服务器、保存到文件。
图形化的采集任务定义界面 你只需在软件内嵌的浏览器内用滑鼠点选你要采集的网页内容即可配置采集任务,无需象其它同类软件一样面对复杂的网页源码去找寻采集规则。可以说是所见即所得的采集任务配置界面。
创新的内容定位方法,定位更准确、稳定 同类软件基本上都是依照网页源码中的前导标记和结束标记进行内容定位,这样一来,用户就不得不自己去面对网页制做人员才须要面对的HTML代码,付出更多额外的学习时间能够把握软件的使用。
同时,只要网页内容稍有变更(简单的如改变一下文字的颜色)定位标记即极有可能失效,导致采集失败。我们经过艰辛的技术攻关,实现了全新的定位方法:结构定位和相对标志定位。
二、北京金禾天成科技有限公司数据采集管理系统
作为农作物病虫害调查数据的来源,采集系统紧密联系生产实际,充分考虑虫害检测预警的特性和实际情况,在不降低基层病虫测报人员工作量,确保数据可用性和代表性的基础上,以简化操作步骤、增强实用性为具体目标,以虫害数据处理流程为建立主线,主要处理数据的录入、查询、管理等方面进行设计和建设,形成了一个全国农业技术推广服务中心为中心、省级植保机构为骨干、地(县)级区域测报站为重要支撑的虫害监控信息网路。
系统建设要达成的具体目标主要包括2个方面:
(1)优化数据录入与上报功能。确定虫害调查原始数据,修改、调整、补充各级虫害检测数据上报内容,减少人工二次估算与录入步骤,简化数据上报过程,实现虫害检测数据的实时上报和自动化处理,提高工作效率。
(2)完善数据管理功能。增强数据查询能力,提高数据可比性和利用率,充分发挥市级虫害检测机构监管与督导作用,实现数据上报工作制度化、数据剖析处理智能化。
三、北京融创天地科技有限公司天地数据采集系统
为实现对药品流向进行监管的目的智能采集系统,需要对药品从生产厂家出入库到中间货运商的出入库进行数据采集管理,并产生药品出入库电子收据,然后将出入库电子收据上传到国家药品监管码网平台,从而实现国家对药品流向的管理。
手持终端(掌上电脑,PDA)也称便携式终端智能采集系统,在不同的领域可用于数据采集、信息传播、部队定位、安全保卫等。应用于数据采集的手持终端可以说是其在行业领域的一种应用。在手持数据采集终端上可以进行二次开发并实现用户须要的功能,对采集到的数据进行处理,并可以显示信息。
我公司的天地数据采集系统,是在手持数据采集终端上开发的,用来实现用户对出入库产品的电子监管码采集,并对采集到的监管码数据进行处理,形成出入库收据。手持终端设别可以与计算机通过有线或无线方法进行数据交换,将生成的出入库收据导入,然后上传国家药监网平台。
四、山东金苹果实业有限公司内网数据采集系统
通过结合二代身份证阅读器的使用,将市民二代身份证上的信息手动读取到系统中,并可进一步建立详尽的人员信息。
结合摄像头应用,实现动态采集人员相片,完善人员信息。录入身份证信息时与公安部潜逃人员数据库进行比对,甄别潜逃犯罪嫌疑人。
工作任务
方便、快捷的采集人员信息,减少工作量。 与潜逃人员数据库时时联接,及时发觉潜逃人员,消除隐患。 对采集到的人员信息进行综合管理,实现信息管理自动化。 实行系统权限控制,提高系统安全性。
系统作用及范围
本系统主要针对于例如 二手车交易市场、酒店等需详尽采集人员信息和其它对人员详尽信息有较高要求的行业。
系统集成二代身分阅读器和摄像头,同时与潜逃人员数据库相连,对于人员信息做到了详尽、安全的采集工作。 查看全部
数据采集(DAQ),是指从传感和其它待测设备等模拟和数字被测单元中手动采集非电量或则电量讯号,送到上位机中进行剖析,处理。数据采集系统是结合基于计算机或则其他专用测试平台的检测软硬件产品来实现灵活的、用户自定义的检测系统。对此软件产品网整理了几份数据采集相关软件,分享给你们。
一、深圳市世纪永盛科技有限公司数据智能采集软件
数据智能采集软件是一款功能全面、准确、稳定、易用的网路信息采集软件。它可以轻松将你想要的网页内容(包括文字、图片、文件、HTML源码等)抓取出来。采集到的数据可以直接导入到EXCEL、也可以根据你定义的模板保存成任何格式的文件(如保存成网页文件、TXT文件等)。也可以在采集的同时,实时保存到数据库、发送到网站服务器、保存到文件。
图形化的采集任务定义界面 你只需在软件内嵌的浏览器内用滑鼠点选你要采集的网页内容即可配置采集任务,无需象其它同类软件一样面对复杂的网页源码去找寻采集规则。可以说是所见即所得的采集任务配置界面。
创新的内容定位方法,定位更准确、稳定 同类软件基本上都是依照网页源码中的前导标记和结束标记进行内容定位,这样一来,用户就不得不自己去面对网页制做人员才须要面对的HTML代码,付出更多额外的学习时间能够把握软件的使用。
同时,只要网页内容稍有变更(简单的如改变一下文字的颜色)定位标记即极有可能失效,导致采集失败。我们经过艰辛的技术攻关,实现了全新的定位方法:结构定位和相对标志定位。
二、北京金禾天成科技有限公司数据采集管理系统
作为农作物病虫害调查数据的来源,采集系统紧密联系生产实际,充分考虑虫害检测预警的特性和实际情况,在不降低基层病虫测报人员工作量,确保数据可用性和代表性的基础上,以简化操作步骤、增强实用性为具体目标,以虫害数据处理流程为建立主线,主要处理数据的录入、查询、管理等方面进行设计和建设,形成了一个全国农业技术推广服务中心为中心、省级植保机构为骨干、地(县)级区域测报站为重要支撑的虫害监控信息网路。
系统建设要达成的具体目标主要包括2个方面:
(1)优化数据录入与上报功能。确定虫害调查原始数据,修改、调整、补充各级虫害检测数据上报内容,减少人工二次估算与录入步骤,简化数据上报过程,实现虫害检测数据的实时上报和自动化处理,提高工作效率。
(2)完善数据管理功能。增强数据查询能力,提高数据可比性和利用率,充分发挥市级虫害检测机构监管与督导作用,实现数据上报工作制度化、数据剖析处理智能化。
三、北京融创天地科技有限公司天地数据采集系统
为实现对药品流向进行监管的目的智能采集系统,需要对药品从生产厂家出入库到中间货运商的出入库进行数据采集管理,并产生药品出入库电子收据,然后将出入库电子收据上传到国家药品监管码网平台,从而实现国家对药品流向的管理。
手持终端(掌上电脑,PDA)也称便携式终端智能采集系统,在不同的领域可用于数据采集、信息传播、部队定位、安全保卫等。应用于数据采集的手持终端可以说是其在行业领域的一种应用。在手持数据采集终端上可以进行二次开发并实现用户须要的功能,对采集到的数据进行处理,并可以显示信息。
我公司的天地数据采集系统,是在手持数据采集终端上开发的,用来实现用户对出入库产品的电子监管码采集,并对采集到的监管码数据进行处理,形成出入库收据。手持终端设别可以与计算机通过有线或无线方法进行数据交换,将生成的出入库收据导入,然后上传国家药监网平台。
四、山东金苹果实业有限公司内网数据采集系统
通过结合二代身份证阅读器的使用,将市民二代身份证上的信息手动读取到系统中,并可进一步建立详尽的人员信息。
结合摄像头应用,实现动态采集人员相片,完善人员信息。录入身份证信息时与公安部潜逃人员数据库进行比对,甄别潜逃犯罪嫌疑人。
工作任务
方便、快捷的采集人员信息,减少工作量。 与潜逃人员数据库时时联接,及时发觉潜逃人员,消除隐患。 对采集到的人员信息进行综合管理,实现信息管理自动化。 实行系统权限控制,提高系统安全性。
系统作用及范围
本系统主要针对于例如 二手车交易市场、酒店等需详尽采集人员信息和其它对人员详尽信息有较高要求的行业。
系统集成二代身分阅读器和摄像头,同时与潜逃人员数据库相连,对于人员信息做到了详尽、安全的采集工作。
数据剖析 | 基于智能标签,精准管理数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-08-03 19:03
头条:信息价值,根据用户浏览信息,分析用户相关喜好,针对剖析结果推荐相关的信息流,越关注某类内容,获取相关的信息越多。
如上几种场景的逻辑就是:基于不断剖析用户的行为,生成用户的特点画像,然后再基于用户标签,定制化的推荐相关内容。
2、基本概念
通过前面的场景,衍生下来两个概念:
用户画像
用户画像,作为一种描绘目标用户、联系用户诉求与设计方向的有效工具,把该用户相关联的数据的可视化的诠释,就产生了用户画像。用户画像在各领域得到了广泛的应用,最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
标签数据
标签在生活中十分常见,比如商品标签,个人标签,行业标签,例如提及996就想到程序员,提到程序员就想到格子衫。
标签是把分散的多方数据进行整合划入统一的技术平台,并对那些数据进行标准化和细分,进行结构化储存和更新管理,让业务线可以把这种细分结果推向现有的互动营销环境里的平台,产生价值,这些数据称为标签数据,也就是常说的标签库。数据标签的概念也是在近来几年大数据的发展中不断火爆上去的。
标签价值
标签的核心价值,或者说最常用的场景:实时智能推荐,精准化数字营销。
二、数据标签1、标签界定
属性标签
属性标签是变化最小的,例如用户实名认证以后,基于身分信息获取相关:性别,生日,出生年月,年龄,等相关标签。变动频度小,且最具有精准性。
行为标签
行为标签就是用户通过在产品上的一系列操作,基于行为日志剖析得出:例如订购能力、消费爱好、季节性消费标签等。在信息流的APP上,通过相关浏览行为,不断推荐用户感兴趣的内容就是基于该逻辑。
规则标签
根据业务场景需求,配置指定规则,基于规则生成剖析结果,例如:
这类标签可以基于动态的规则配置,经过估算和剖析,生成描述结果,也就是规则标签。
拟合标签
拟合类的标签最具有复杂性,通过用户上述几种标签,智能组合剖析,给的预测值,例如:未婚、浏览相关婚宴内容,通过剖析预测用户即将举行婚宴,得到一个拟合结果:预测即将订婚。这个预测逻辑也可以反向执行,用户订购小孩用具:预测未婚已育。
这就是数据时代常说的一句话:用户在某个应用上一通操作过后,算法剖析的结果可能比用户对自己的描述还要真实。
2、标签加工流程
数据采集
数据采集的渠道相对较多,比如同一APP内的各类业务线:购物、支付、理财、外卖、信息浏览等等。通过数据通道传输到统一的数据聚合平台。有了这种海量日志数据的支撑,才具有数据剖析的基础条件。不管是数据智能,深度学习,算法等都是构建在海量数据的基础条件上,这样就能获取具有价值的剖析结果。
数据加工
结合如上业务,通过对海量数据的加工,分析和提取,获取相对精准的用户标签,这里还有关键的一步,就是对已有的用户标签进行不断的验证和修补,尤其是规则类和拟合类的相关标签。
标签库
通过标签库,管理复杂的标签结果,除了复杂的标签,和基于时间线的标签变,标签数据到这儿,已经具有相当大的价值,可以围绕标签库开放一些收费服务,例如常见的,用户在某电商APP浏览个别商品,可以在某信息流平台见到商品推荐。大数据时代就是如此令人觉得智能和窒息。
标签业务
数据走了一大圈转换成标签,自然还是要回归到业务层面,通过对标签数据的用户的剖析,可以进行精准营销,和智能推荐等相关操作,电商应用中可以提升成交量,信息流中可以更好的吸引用户。
应用层
把上述业务开发成服务,集成到具有的应用层面,不断提高应用服务的质量,不断的吸引用户,提供服务。当然用户的数据不断在应用层面形成,在转入数据采集服务中,最终产生完整的闭环流程。
3、应用案例
从流程和业务层面描述都是简单的,到开发层面就会显得复杂和不好处理,这可能就是产品和开发之间的芥蒂。
标签的数据类型
不同标签的剖析结果须要用不同的数据类型描述智能标签采集器,在标签体系中,常用描述标签的数据类型如下:枚举、数值、日期、布尔、文本类型。不同的类型须要不一样的剖析流程。
商品和标签
这里提供一个基础案例,用商品的标签来剖析商品,例如通过商品产地,价格,状态等条件,来查询产品库有多少符合条件的商品。
数据表设计
主要分四张表:标签分类智能标签采集器,标签库,标签值,标签数据。
CREATE TABLE `tc_tag_catalog` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_name` VARCHAR (50) NOT NULL DEFAULT '' COMMENT '名称',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签层级目录';
CREATE TABLE `tc_tag_cloud` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_id` INT (11) NOT NULL COMMENT '目录ID',
`tag_name` VARCHAR (100) DEFAULT '' COMMENT '标签名称',
`tag_code` INT (11) DEFAULT NULL COMMENT '标签编码',
`bind_column` VARCHAR (100) DEFAULT '' COMMENT '绑定数据列',
`data_type` INT (2) NOT NULL COMMENT '1枚举,2数值,3日期,4布尔,5值类型',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`remark` VARCHAR (150) DEFAULT NULL COMMENT '备注',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签云';
CREATE TABLE `tc_tag_data_enum` (
`tag_code` INT (11) NOT NULL COMMENT '标签编码',
`data_value` VARCHAR (150) NOT NULL COMMENT '枚举值',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
KEY `tag_code_index` (`tag_code`) USING BTREE
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签枚举值';
CREATE TABLE `tc_tag_data_set` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`product_name` VARCHAR (100) DEFAULT '' COMMENT '商品名称',
`unit_price` DECIMAL (10, 2) DEFAULT '0.00' COMMENT '单价',
`is_shelves` INT (1) DEFAULT '1' COMMENT '是否上架:1否,2是',
`origin_place` VARCHAR (100) DEFAULT '' COMMENT '产地',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签数据集';
模拟入参插口
这里的参数应当是基于需求,动态选定,进行组织到一起:
例如图片中这儿给定的标签值列表,称为枚举值。
@RestController
public class AnalyzeController {
@Resource
private TagDataSetService tagDataSetService ;
@GetMapping("/analyze")
public String analyze (){
List tagParamList = new ArrayList() ;
TagParam tagParam1 = new TagParam(1,"产地","origin_place") ;
List valueList1 = new ArrayList() ;
valueList1.add("深圳");
valueList1.add("广东");
tagParam1.setValueList(valueList1);
tagParamList.add(tagParam1) ;
TagParam tagParam2 = new TagParam(2,"价格","unit_price") ;
List valueList2 = new ArrayList() ;
valueList2.add("1999");
tagParam2.setValueList(valueList2);
tagParamList.add(tagParam2) ;
TagParam tagParam3 = new TagParam(3,"生产日期","create_time") ;
List valueList3 = new ArrayList() ;
valueList3.add("2020-05-01 13:43:54");
tagParam3.setValueList(valueList3);
tagParamList.add(tagParam3) ;
TagParam tagParam4 = new TagParam(4,"是否上架","is_shelves") ;
List valueList4 = new ArrayList() ;
valueList4.add("1");
tagParam4.setValueList(valueList4);
tagParamList.add(tagParam4) ;
TagParam tagParam5 = new TagParam(5,"产品名称","product_name") ;
List valueList5 = new ArrayList() ;
valueList5.add("智能");
tagParam5.setValueList(valueList5);
tagParamList.add(tagParam5) ;
Integer count = tagDataSetService.analyze(tagParamList) ;
return "Result:" + count ;
}
}
参数解析查询
通过对参数的解析,最终产生查询的SQL句子,获取精准的结果数据。
@Service
public class TagDataSetServiceImpl extends ServiceImpl implements TagDataSetService {
@Resource
private TagDataSetMapper tagDataSetMapper ;
@Override
public Integer analyze(List tagParamList) {
StringBuffer querySQL = new StringBuffer() ;
for (TagParam tagParam:tagParamList){
querySQL.append(" AND ") ;
querySQL.append(tagParam.getBindColumn()) ;
// 1枚举,2数值,3日期,4布尔,5值类型
List valueList = tagParam.getValueList();
switch (tagParam.getDataType()){
case 1:
querySQL.append(" IN (") ;
for (int i = 0 ; i < valueList.size() ;i++){
if (i != valueList.size()-1){
querySQL.append("'").append(valueList.get(i)).append("',");
} else {
querySQL.append("'").append(valueList.get(i)).append("'");
}
}
querySQL.append(" )") ;
break;
case 2:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 3:
querySQL.append(">='").append(tagParam.getValueList().get(0)).append("'") ;
break;
case 4:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 5:
querySQL.append(" LIKE '%").append(tagParam.getValueList().get(0)).append("%'") ;
break;
default:
break;
}
}
/* 最终执行的 SQL
SELECT COUNT(*) FROM tc_tag_data_set
WHERE 1 = 1
AND origin_place IN ('深圳', '广东')
AND unit_price = 1999
AND create_time >= '2020-05-01 13:43:54'
AND is_shelves = 1
AND product_name LIKE '%智能%'
*/
String whereCondition = String.valueOf(querySQL);
return tagDataSetMapper.analyze(whereCondition);
}
}
可能有人会说这不就是个查询流程吗?如果有这样的疑惑,把上述案例换成用户查询,标签数据的价值会更直观。
三、智能画像1、基本概念
用户画像
作为一种绘制目标用户、联系用户诉求与设计方向的有效工具,用户画像在各领域得到了广泛的应用。最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
行业画像
通过行业属性标签,行业下用户标签的综合剖析,生成行业剖析报告,提供极有价值的导向,这是最近两年非常热门的应用。
画像补全
通过不断剖析用户数据,丰富标签库,使用户的画像愈发丰富立体。
2、画像报告
通过标签数据的剖析,生成一份剖析报告,报告内容包含丰富的用户标签统计数据。
例如:90后画像报告
这个报告,互联网用户一定或多或少都听到过。主要是一些标签统计,共性标签展示,或者什么群体对80后三观影响最大,收入来源,学历等各类剖析评析。
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent 查看全部
腾讯:社交广告,不同用户的朋友圈或则其他媒体场景下的广告信息是不同的,会基于用户特点推荐。
头条:信息价值,根据用户浏览信息,分析用户相关喜好,针对剖析结果推荐相关的信息流,越关注某类内容,获取相关的信息越多。
如上几种场景的逻辑就是:基于不断剖析用户的行为,生成用户的特点画像,然后再基于用户标签,定制化的推荐相关内容。
2、基本概念
通过前面的场景,衍生下来两个概念:
用户画像
用户画像,作为一种描绘目标用户、联系用户诉求与设计方向的有效工具,把该用户相关联的数据的可视化的诠释,就产生了用户画像。用户画像在各领域得到了广泛的应用,最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
标签数据
标签在生活中十分常见,比如商品标签,个人标签,行业标签,例如提及996就想到程序员,提到程序员就想到格子衫。
标签是把分散的多方数据进行整合划入统一的技术平台,并对那些数据进行标准化和细分,进行结构化储存和更新管理,让业务线可以把这种细分结果推向现有的互动营销环境里的平台,产生价值,这些数据称为标签数据,也就是常说的标签库。数据标签的概念也是在近来几年大数据的发展中不断火爆上去的。
标签价值
标签的核心价值,或者说最常用的场景:实时智能推荐,精准化数字营销。
二、数据标签1、标签界定
属性标签
属性标签是变化最小的,例如用户实名认证以后,基于身分信息获取相关:性别,生日,出生年月,年龄,等相关标签。变动频度小,且最具有精准性。
行为标签
行为标签就是用户通过在产品上的一系列操作,基于行为日志剖析得出:例如订购能力、消费爱好、季节性消费标签等。在信息流的APP上,通过相关浏览行为,不断推荐用户感兴趣的内容就是基于该逻辑。
规则标签
根据业务场景需求,配置指定规则,基于规则生成剖析结果,例如:
这类标签可以基于动态的规则配置,经过估算和剖析,生成描述结果,也就是规则标签。
拟合标签
拟合类的标签最具有复杂性,通过用户上述几种标签,智能组合剖析,给的预测值,例如:未婚、浏览相关婚宴内容,通过剖析预测用户即将举行婚宴,得到一个拟合结果:预测即将订婚。这个预测逻辑也可以反向执行,用户订购小孩用具:预测未婚已育。
这就是数据时代常说的一句话:用户在某个应用上一通操作过后,算法剖析的结果可能比用户对自己的描述还要真实。
2、标签加工流程
数据采集
数据采集的渠道相对较多,比如同一APP内的各类业务线:购物、支付、理财、外卖、信息浏览等等。通过数据通道传输到统一的数据聚合平台。有了这种海量日志数据的支撑,才具有数据剖析的基础条件。不管是数据智能,深度学习,算法等都是构建在海量数据的基础条件上,这样就能获取具有价值的剖析结果。
数据加工
结合如上业务,通过对海量数据的加工,分析和提取,获取相对精准的用户标签,这里还有关键的一步,就是对已有的用户标签进行不断的验证和修补,尤其是规则类和拟合类的相关标签。
标签库
通过标签库,管理复杂的标签结果,除了复杂的标签,和基于时间线的标签变,标签数据到这儿,已经具有相当大的价值,可以围绕标签库开放一些收费服务,例如常见的,用户在某电商APP浏览个别商品,可以在某信息流平台见到商品推荐。大数据时代就是如此令人觉得智能和窒息。
标签业务
数据走了一大圈转换成标签,自然还是要回归到业务层面,通过对标签数据的用户的剖析,可以进行精准营销,和智能推荐等相关操作,电商应用中可以提升成交量,信息流中可以更好的吸引用户。
应用层
把上述业务开发成服务,集成到具有的应用层面,不断提高应用服务的质量,不断的吸引用户,提供服务。当然用户的数据不断在应用层面形成,在转入数据采集服务中,最终产生完整的闭环流程。
3、应用案例
从流程和业务层面描述都是简单的,到开发层面就会显得复杂和不好处理,这可能就是产品和开发之间的芥蒂。
标签的数据类型
不同标签的剖析结果须要用不同的数据类型描述智能标签采集器,在标签体系中,常用描述标签的数据类型如下:枚举、数值、日期、布尔、文本类型。不同的类型须要不一样的剖析流程。
商品和标签
这里提供一个基础案例,用商品的标签来剖析商品,例如通过商品产地,价格,状态等条件,来查询产品库有多少符合条件的商品。
数据表设计
主要分四张表:标签分类智能标签采集器,标签库,标签值,标签数据。
CREATE TABLE `tc_tag_catalog` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_name` VARCHAR (50) NOT NULL DEFAULT '' COMMENT '名称',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签层级目录';
CREATE TABLE `tc_tag_cloud` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_id` INT (11) NOT NULL COMMENT '目录ID',
`tag_name` VARCHAR (100) DEFAULT '' COMMENT '标签名称',
`tag_code` INT (11) DEFAULT NULL COMMENT '标签编码',
`bind_column` VARCHAR (100) DEFAULT '' COMMENT '绑定数据列',
`data_type` INT (2) NOT NULL COMMENT '1枚举,2数值,3日期,4布尔,5值类型',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`remark` VARCHAR (150) DEFAULT NULL COMMENT '备注',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签云';
CREATE TABLE `tc_tag_data_enum` (
`tag_code` INT (11) NOT NULL COMMENT '标签编码',
`data_value` VARCHAR (150) NOT NULL COMMENT '枚举值',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
KEY `tag_code_index` (`tag_code`) USING BTREE
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签枚举值';
CREATE TABLE `tc_tag_data_set` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`product_name` VARCHAR (100) DEFAULT '' COMMENT '商品名称',
`unit_price` DECIMAL (10, 2) DEFAULT '0.00' COMMENT '单价',
`is_shelves` INT (1) DEFAULT '1' COMMENT '是否上架:1否,2是',
`origin_place` VARCHAR (100) DEFAULT '' COMMENT '产地',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签数据集';
模拟入参插口
这里的参数应当是基于需求,动态选定,进行组织到一起:
例如图片中这儿给定的标签值列表,称为枚举值。
@RestController
public class AnalyzeController {
@Resource
private TagDataSetService tagDataSetService ;
@GetMapping("/analyze")
public String analyze (){
List tagParamList = new ArrayList() ;
TagParam tagParam1 = new TagParam(1,"产地","origin_place") ;
List valueList1 = new ArrayList() ;
valueList1.add("深圳");
valueList1.add("广东");
tagParam1.setValueList(valueList1);
tagParamList.add(tagParam1) ;
TagParam tagParam2 = new TagParam(2,"价格","unit_price") ;
List valueList2 = new ArrayList() ;
valueList2.add("1999");
tagParam2.setValueList(valueList2);
tagParamList.add(tagParam2) ;
TagParam tagParam3 = new TagParam(3,"生产日期","create_time") ;
List valueList3 = new ArrayList() ;
valueList3.add("2020-05-01 13:43:54");
tagParam3.setValueList(valueList3);
tagParamList.add(tagParam3) ;
TagParam tagParam4 = new TagParam(4,"是否上架","is_shelves") ;
List valueList4 = new ArrayList() ;
valueList4.add("1");
tagParam4.setValueList(valueList4);
tagParamList.add(tagParam4) ;
TagParam tagParam5 = new TagParam(5,"产品名称","product_name") ;
List valueList5 = new ArrayList() ;
valueList5.add("智能");
tagParam5.setValueList(valueList5);
tagParamList.add(tagParam5) ;
Integer count = tagDataSetService.analyze(tagParamList) ;
return "Result:" + count ;
}
}
参数解析查询
通过对参数的解析,最终产生查询的SQL句子,获取精准的结果数据。
@Service
public class TagDataSetServiceImpl extends ServiceImpl implements TagDataSetService {
@Resource
private TagDataSetMapper tagDataSetMapper ;
@Override
public Integer analyze(List tagParamList) {
StringBuffer querySQL = new StringBuffer() ;
for (TagParam tagParam:tagParamList){
querySQL.append(" AND ") ;
querySQL.append(tagParam.getBindColumn()) ;
// 1枚举,2数值,3日期,4布尔,5值类型
List valueList = tagParam.getValueList();
switch (tagParam.getDataType()){
case 1:
querySQL.append(" IN (") ;
for (int i = 0 ; i < valueList.size() ;i++){
if (i != valueList.size()-1){
querySQL.append("'").append(valueList.get(i)).append("',");
} else {
querySQL.append("'").append(valueList.get(i)).append("'");
}
}
querySQL.append(" )") ;
break;
case 2:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 3:
querySQL.append(">='").append(tagParam.getValueList().get(0)).append("'") ;
break;
case 4:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 5:
querySQL.append(" LIKE '%").append(tagParam.getValueList().get(0)).append("%'") ;
break;
default:
break;
}
}
/* 最终执行的 SQL
SELECT COUNT(*) FROM tc_tag_data_set
WHERE 1 = 1
AND origin_place IN ('深圳', '广东')
AND unit_price = 1999
AND create_time >= '2020-05-01 13:43:54'
AND is_shelves = 1
AND product_name LIKE '%智能%'
*/
String whereCondition = String.valueOf(querySQL);
return tagDataSetMapper.analyze(whereCondition);
}
}
可能有人会说这不就是个查询流程吗?如果有这样的疑惑,把上述案例换成用户查询,标签数据的价值会更直观。
三、智能画像1、基本概念
用户画像
作为一种绘制目标用户、联系用户诉求与设计方向的有效工具,用户画像在各领域得到了广泛的应用。最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
行业画像
通过行业属性标签,行业下用户标签的综合剖析,生成行业剖析报告,提供极有价值的导向,这是最近两年非常热门的应用。
画像补全
通过不断剖析用户数据,丰富标签库,使用户的画像愈发丰富立体。
2、画像报告
通过标签数据的剖析,生成一份剖析报告,报告内容包含丰富的用户标签统计数据。
例如:90后画像报告
这个报告,互联网用户一定或多或少都听到过。主要是一些标签统计,共性标签展示,或者什么群体对80后三观影响最大,收入来源,学历等各类剖析评析。
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent
为什么说优采云云采集才是真正的云采集_互联网_IT/计算机_专业资料
采集交流 • 优采云 发表了文章 • 0 个评论 • 492 次浏览 • 2020-08-03 17:05
直到 08 年,中国 IT 界才开始在谈云估算,笔者作为一名 07 年计算机专业结业 生, 正好赶上这一波风潮, 但说实话, 那时候都是概念, 没有人看到真正的产品, 所以都没搞清楚到底是什么东西。 顶多就据说 Google 的 Google Charts,Google Words 等。当时没明白象 Google Charts,Google Words 这些产品有哪些用,不就是网页版的 word,excel 嘛,还没 Microsoft 的好用,但是多年工作以后,才晓得,Microsoft word,excel,只能用于 windows 的机子,你想在苹果笔记本上用,就得废老大劲了。而网页版的,他是跨 平台的,你用习惯了,你在哪都是一样用,而且可以在云端保存资料。随着云计算的诞生,业内也诞生了下边三种层次的服务 基础设施即服务(IaaS), 平台即服务(PaaS) 软件即服务(SaaS)。我们可以把 SaaS 简单理解为在云端提供标准化产品的服务模式。 由于其标准化, 所以无论 1 个企业在用,还是 100 个企业使用,都是一个开发成本。这对产品在优采云·云采集网络爬虫软件 某个场景下的通用性要求十分高,但也极大的提高了产品在市面上的竞争力。
企 业采用 SaaS 模式在疗效上与企业自建信息系统基本没有区别,但节约了大量资 金,从而大幅度增加了企业信息化的门槛与风险。许多 SaaS 企业都是提供按月 按年的收费模式,这有别于之前软件以项目化的方式,深受企业主喜欢,所以在 接下来的六年中,也演化为一种主流的企业服务方式。现在市面上有许多优秀的 Saas 企业,比如协作平台 teambition,比如 CRM 领域的 明道,比如文档领域的石墨,比如表单领域的金数据等等,都是在 saas 领域做 得非常好的企业。优采云正是在云估算与 SaaS 潮流的背景之下,首创了云采集技术,并提供 SaaS 的营运模式。 用户只需在客户端上传采集规则,即可通过调用云端分布式服务式 进行采集, 每一台云端的服务器均会根据采集规则进行采集。所以优采云团队就 给这些采集模式,取了个名叫”云采集“为什么会诞生”云采集“在优采云出来创业的时侯, 市面上主流的采集器就是优采云。优采云他是以传统 软件运营商的模式在运作,他主要是以卖授权码的方式云采集,想要在笔记本上运行列车 头云采集,就必须订购他的授权码。就像我们初期用 Word 2003、2007 时,经常须要去 网上搜索破解码一样。
那时的优采云, 如日中天, 但他仅仅只是一个客户端软件。优采云创始人刘宝强 keven,由于多年的国企与美国工作经验,曾经也是某国际 金融大鳄公司数据采集方向的研制工程师, 他一心想要作出一款通用化的网页采 集产品来替代公司编撰的诸多采集代码。他太清楚各类采集技术的优势与劣势, 问题与罐劲。优采云·云采集网络爬虫软件 Keven 在当时也晓得优采云采集器的存在,那时候的他,其实不敢想作出一款比 优采云更牛 B 的采集产品, 因为对手实在很强悍了, 采集界无人不识。 但他晓得, 超越竞争对手的,往往不是追随策略,而是应当颠覆,采用与她们完用不一样的 思路。Keven 分析,优采云采集的是传统的网路恳求获取数据的方法,走的还是 http post ,get 请求,这确实是当时进行网页采集的主流模式,但这些模式复杂程度非 常高,虽然优采云已经做得够简化,但能理解这一套理论的,大多都是开发人员 背景才有可能。他晓得在大公司上面,大部分做数据搜集工作的人,都不是估算 机开发人员背景, 所以他给自已采集产品定位,要做一款普通人都会用的采集产 品, 通过界面的定位, 拖拽, 即可进行规则的配置。
经过小半年的各项难关突破, 还真被他给实现了。但问题也随之而来, 由于是通过浏览器加载网页之后再获取数据的方法,这样竞 品其实一个恳求就可获取到的数据, 而优采云由于须要加载整个网页可能得涉及 上百个恳求,这使优采云在采集上,显得速率就慢了。解决了易用性的问题后形成了速率问题?那如何解决?如果有多台机子在云端同时采, 甚至对规则上面的 URL 列表进行分拆, 让云端的 服务器分布式同时进行采集,那就可以提高 N 倍以上的速率。这条路是可行的, 但是这条路又带来另外一个问题。解决了速率问题后形成了成本问题?那如何解决?优采云·云采集网络爬虫软件 keven 判断,如果租用 10 台云服务器,通过共享经济的概念,把成本平滩,其 实每位用户每个月仅需小几百块钱的成本。而对于数据的价值,是远远小于这个 投入的,应该会有用户乐意付费使用。成本问题应当不是大问题,而且随着摩尔 定律,硬件成本只会越来越低。事实这么,包括后期,优采云通过与腾讯云,阿 里云的合作,相对优价的领到一些折扣,帮助用户将这块的成本降到最低。基于此,在 2013 年 Q4,优采云首创了国外美国云采集的模式。为什么优采云的云采集才是真正的云采集其实云采集就是如此简单的东西,就是通过对云端采集服务器的控制,为每日服 务器分配采集任务,通过指令控制其采集。
那为何,只有优采云的云采集,才 是真正的云采集。1. 多项技术难关突破 优采云在 5 年的营运过程,逐渐突破云采集各项困局,这上面的许多困局,在没 有大数据面前,其实都是不会出现的。我举几个反例:?可以采,导不出有一些项目, 自吹自已拥有云采集技术, 但是实际试用的时侯, 他们就漏洞百出。 比如我们可以控制 100 台服务器采集数据, 但若果只有一个数据存储支持导入数 据, 那将会照成导入数据比采集慢 100 倍的困局。 你只能眼见数据在库里而难以 动弹。?可以采,但是错乱优采云·云采集网络爬虫软件 有一些人以为,有一些服务器在云端进行采集,就叫云采集。但却不知道这上面 成百上千台服务器同时采集的时侯,他背后须要大数据储存解决方案。才能使采 集到的数据,一条不漏地储存在数据库里。并且在后期便捷检索,查询,导出。?无法动态伸缩配置因为采集的网页数据状态不一, 云采集是须要动态分配, 并且做好许多事前工作。 有时候一些网站他有防采集策略,你在采集之前,能否判别出对方网站对你的一 些举措与判定, 或者在采集过程中动态调整服务器运行策略,这也是考验一个优 秀的云采集解决方案。2.持续性的提供稳定的采集与导入服务 优采云现在在全球拥有超过 5000 台以上的服务器, 现在每晚采集与导入的数据, 都是以 T 计算服务于全世界各语言各领域的采集用户,对于企业级产品来讲,除 了技术外,能否提供稳定的运维是一大关健。
优采云有多个运维后台, 随时检测整个服务器集群每位采集服务器的状况,在出 现状况的时侯, 灵活多开服务器, 调配服务器, 来使顾客的采集生产环境与数据, 保持相对的稳定。 这样庞大的云服务器采集集群, 是任何一个竞争对手所不能比拟的,并且在这个 庞大的集群面前,优采云依然保持稳定的采集与导入的服务。3.其他资质 优采云在中国大数据业内, 连续两年在数据搜集领域被评为第一,这也足以证明 优采云在数据采集这领域常年的积累与贡献。相关采集教程: 百度搜索结果采集: 优采云·云采集网络爬虫软件 微博评论数据采集: 拼多多商品数据采集: 明日头条数据采集: 采集知乎话题信息(以知乎发觉为例): 淘宝网商品信息采集: 美团店家信息采集: 优采云——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
优采云·云采集网络爬虫软件 为什么说优采云云采集才是真正的云采 集先说一个事:"云采集"这个概念,是我们优采云首创的,无论国外还是国际。 2013 年,优采云从 13 年创业开始,就自创了云采集技术,我们可以在优采云的 版本更新记录里边找到痕迹。只是出于曾经创业,对于 IP 的意识不充分,也没 钱没精力去申请相关知识产权, 以致于现今好多竞品公司都在拿她们有云采集技 术来愚弄她们的产品,但好多公司虽然都没搞清楚真正的云采集技术。2013-12-06 版本更新记录2014-05-01 版本更新记录 我们明天要来谈的就是云采集是怎样颠覆整个爬虫界的,当然,因为我们优采云 是当事人,所以笔者可以带着你们回顾近几年爬虫的发展史。优采云·云采集网络爬虫软件 云采集是在哪些背景下诞生的2006 年 8 月 9 日, Google 首席执行官埃里克· 施密特 (Eric Schmidt) 在搜索引擎会议(SES San Jose 2006)首次提出“云计算” (Cloud Computing)的概念。Google“云端估算”源于 Google 工程师克里 斯托弗·比希利亚所做的“Google 101”项目。
直到 08 年,中国 IT 界才开始在谈云估算,笔者作为一名 07 年计算机专业结业 生, 正好赶上这一波风潮, 但说实话, 那时候都是概念, 没有人看到真正的产品, 所以都没搞清楚到底是什么东西。 顶多就据说 Google 的 Google Charts,Google Words 等。当时没明白象 Google Charts,Google Words 这些产品有哪些用,不就是网页版的 word,excel 嘛,还没 Microsoft 的好用,但是多年工作以后,才晓得,Microsoft word,excel,只能用于 windows 的机子,你想在苹果笔记本上用,就得废老大劲了。而网页版的,他是跨 平台的,你用习惯了,你在哪都是一样用,而且可以在云端保存资料。随着云计算的诞生,业内也诞生了下边三种层次的服务 基础设施即服务(IaaS), 平台即服务(PaaS) 软件即服务(SaaS)。我们可以把 SaaS 简单理解为在云端提供标准化产品的服务模式。 由于其标准化, 所以无论 1 个企业在用,还是 100 个企业使用,都是一个开发成本。这对产品在优采云·云采集网络爬虫软件 某个场景下的通用性要求十分高,但也极大的提高了产品在市面上的竞争力。
企 业采用 SaaS 模式在疗效上与企业自建信息系统基本没有区别,但节约了大量资 金,从而大幅度增加了企业信息化的门槛与风险。许多 SaaS 企业都是提供按月 按年的收费模式,这有别于之前软件以项目化的方式,深受企业主喜欢,所以在 接下来的六年中,也演化为一种主流的企业服务方式。现在市面上有许多优秀的 Saas 企业,比如协作平台 teambition,比如 CRM 领域的 明道,比如文档领域的石墨,比如表单领域的金数据等等,都是在 saas 领域做 得非常好的企业。优采云正是在云估算与 SaaS 潮流的背景之下,首创了云采集技术,并提供 SaaS 的营运模式。 用户只需在客户端上传采集规则,即可通过调用云端分布式服务式 进行采集, 每一台云端的服务器均会根据采集规则进行采集。所以优采云团队就 给这些采集模式,取了个名叫”云采集“为什么会诞生”云采集“在优采云出来创业的时侯, 市面上主流的采集器就是优采云。优采云他是以传统 软件运营商的模式在运作,他主要是以卖授权码的方式云采集,想要在笔记本上运行列车 头云采集,就必须订购他的授权码。就像我们初期用 Word 2003、2007 时,经常须要去 网上搜索破解码一样。
那时的优采云, 如日中天, 但他仅仅只是一个客户端软件。优采云创始人刘宝强 keven,由于多年的国企与美国工作经验,曾经也是某国际 金融大鳄公司数据采集方向的研制工程师, 他一心想要作出一款通用化的网页采 集产品来替代公司编撰的诸多采集代码。他太清楚各类采集技术的优势与劣势, 问题与罐劲。优采云·云采集网络爬虫软件 Keven 在当时也晓得优采云采集器的存在,那时候的他,其实不敢想作出一款比 优采云更牛 B 的采集产品, 因为对手实在很强悍了, 采集界无人不识。 但他晓得, 超越竞争对手的,往往不是追随策略,而是应当颠覆,采用与她们完用不一样的 思路。Keven 分析,优采云采集的是传统的网路恳求获取数据的方法,走的还是 http post ,get 请求,这确实是当时进行网页采集的主流模式,但这些模式复杂程度非 常高,虽然优采云已经做得够简化,但能理解这一套理论的,大多都是开发人员 背景才有可能。他晓得在大公司上面,大部分做数据搜集工作的人,都不是估算 机开发人员背景, 所以他给自已采集产品定位,要做一款普通人都会用的采集产 品, 通过界面的定位, 拖拽, 即可进行规则的配置。
经过小半年的各项难关突破, 还真被他给实现了。但问题也随之而来, 由于是通过浏览器加载网页之后再获取数据的方法,这样竞 品其实一个恳求就可获取到的数据, 而优采云由于须要加载整个网页可能得涉及 上百个恳求,这使优采云在采集上,显得速率就慢了。解决了易用性的问题后形成了速率问题?那如何解决?如果有多台机子在云端同时采, 甚至对规则上面的 URL 列表进行分拆, 让云端的 服务器分布式同时进行采集,那就可以提高 N 倍以上的速率。这条路是可行的, 但是这条路又带来另外一个问题。解决了速率问题后形成了成本问题?那如何解决?优采云·云采集网络爬虫软件 keven 判断,如果租用 10 台云服务器,通过共享经济的概念,把成本平滩,其 实每位用户每个月仅需小几百块钱的成本。而对于数据的价值,是远远小于这个 投入的,应该会有用户乐意付费使用。成本问题应当不是大问题,而且随着摩尔 定律,硬件成本只会越来越低。事实这么,包括后期,优采云通过与腾讯云,阿 里云的合作,相对优价的领到一些折扣,帮助用户将这块的成本降到最低。基于此,在 2013 年 Q4,优采云首创了国外美国云采集的模式。为什么优采云的云采集才是真正的云采集其实云采集就是如此简单的东西,就是通过对云端采集服务器的控制,为每日服 务器分配采集任务,通过指令控制其采集。
那为何,只有优采云的云采集,才 是真正的云采集。1. 多项技术难关突破 优采云在 5 年的营运过程,逐渐突破云采集各项困局,这上面的许多困局,在没 有大数据面前,其实都是不会出现的。我举几个反例:?可以采,导不出有一些项目, 自吹自已拥有云采集技术, 但是实际试用的时侯, 他们就漏洞百出。 比如我们可以控制 100 台服务器采集数据, 但若果只有一个数据存储支持导入数 据, 那将会照成导入数据比采集慢 100 倍的困局。 你只能眼见数据在库里而难以 动弹。?可以采,但是错乱优采云·云采集网络爬虫软件 有一些人以为,有一些服务器在云端进行采集,就叫云采集。但却不知道这上面 成百上千台服务器同时采集的时侯,他背后须要大数据储存解决方案。才能使采 集到的数据,一条不漏地储存在数据库里。并且在后期便捷检索,查询,导出。?无法动态伸缩配置因为采集的网页数据状态不一, 云采集是须要动态分配, 并且做好许多事前工作。 有时候一些网站他有防采集策略,你在采集之前,能否判别出对方网站对你的一 些举措与判定, 或者在采集过程中动态调整服务器运行策略,这也是考验一个优 秀的云采集解决方案。2.持续性的提供稳定的采集与导入服务 优采云现在在全球拥有超过 5000 台以上的服务器, 现在每晚采集与导入的数据, 都是以 T 计算服务于全世界各语言各领域的采集用户,对于企业级产品来讲,除 了技术外,能否提供稳定的运维是一大关健。
优采云有多个运维后台, 随时检测整个服务器集群每位采集服务器的状况,在出 现状况的时侯, 灵活多开服务器, 调配服务器, 来使顾客的采集生产环境与数据, 保持相对的稳定。 这样庞大的云服务器采集集群, 是任何一个竞争对手所不能比拟的,并且在这个 庞大的集群面前,优采云依然保持稳定的采集与导入的服务。3.其他资质 优采云在中国大数据业内, 连续两年在数据搜集领域被评为第一,这也足以证明 优采云在数据采集这领域常年的积累与贡献。相关采集教程: 百度搜索结果采集: 优采云·云采集网络爬虫软件 微博评论数据采集: 拼多多商品数据采集: 明日头条数据采集: 采集知乎话题信息(以知乎发觉为例): 淘宝网商品信息采集: 美团店家信息采集: 优采云——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
使用最多的自媒体平台文章采集工具有什么
采集交流 • 优采云 发表了文章 • 0 个评论 • 436 次浏览 • 2020-08-03 15:03
那么追热点热搜,首先就须要到各大媒体平台里面搜集热点,包括360热点、微博热点、百度搜索风云榜等等。光到各大平台里面找寻搜集剖析这种热点就须要耗费大量的时间精力。花费大量时间效率慢还不是最重要的,最难过的是耗费了大量的时间精力一旦判定失误追错了热点,导致一切辛苦都枉费。
那么这是就在想,有没有一款自媒体爆文采集工具可以使我们耗费最短的时间,用最高的效率搜集采集分析每晚的实时热点热搜数据呢?
使用最多的自媒体平台文章采集工具有什么
自媒体文章采集平台的强悍功能
智能采集,拓途数据提供多种网页采集策略与配套资源,帮助整个采集过程实现数据的完整性与稳定性。拓途数据的工作人员告诉你,全网适用,眼见即可采,不管是文字图片,还是帖吧峰会,支持所有业务渠道的爬虫,满足各类采集需求,海量模板,内置数百个网站数据源,全面覆盖多个行业,只需简单设置,就可快速确切获取数据。简单易用网站文章采集平台,无需再学爬虫编程技术,简单三步就可以轻松抓取网页数据,支持多种格式一键导入,快速导出数据库。稳定高效,分布式云集服务器和多用户协作管理平台的支撑,可灵活调度任务,顺利爬取海量数据。
通过以上文章,各位是不是对自媒体平台文章采集工具有了更多的了解,灵活使用拓途数据提供的自媒体平台文章采集工具可以确切跟踪实事动向,准确剖析数据,节约时间网站文章采集平台,提高效率,节省成本。
更多资讯知识点可持续关注,后续还有自媒咖爆文采集平台,自媒体文章采集平台,公众号 查询,公众号转载他人的原创文章,公众号历史文章等知识点。 查看全部
做自媒体营运难免不了的事情就是追热点热搜,其主要诱因还是热点内容可以获得特别不错的流量阅读。
那么追热点热搜,首先就须要到各大媒体平台里面搜集热点,包括360热点、微博热点、百度搜索风云榜等等。光到各大平台里面找寻搜集剖析这种热点就须要耗费大量的时间精力。花费大量时间效率慢还不是最重要的,最难过的是耗费了大量的时间精力一旦判定失误追错了热点,导致一切辛苦都枉费。
那么这是就在想,有没有一款自媒体爆文采集工具可以使我们耗费最短的时间,用最高的效率搜集采集分析每晚的实时热点热搜数据呢?
使用最多的自媒体平台文章采集工具有什么
自媒体文章采集平台的强悍功能
智能采集,拓途数据提供多种网页采集策略与配套资源,帮助整个采集过程实现数据的完整性与稳定性。拓途数据的工作人员告诉你,全网适用,眼见即可采,不管是文字图片,还是帖吧峰会,支持所有业务渠道的爬虫,满足各类采集需求,海量模板,内置数百个网站数据源,全面覆盖多个行业,只需简单设置,就可快速确切获取数据。简单易用网站文章采集平台,无需再学爬虫编程技术,简单三步就可以轻松抓取网页数据,支持多种格式一键导入,快速导出数据库。稳定高效,分布式云集服务器和多用户协作管理平台的支撑,可灵活调度任务,顺利爬取海量数据。
通过以上文章,各位是不是对自媒体平台文章采集工具有了更多的了解,灵活使用拓途数据提供的自媒体平台文章采集工具可以确切跟踪实事动向,准确剖析数据,节约时间网站文章采集平台,提高效率,节省成本。
更多资讯知识点可持续关注,后续还有自媒咖爆文采集平台,自媒体文章采集平台,公众号 查询,公众号转载他人的原创文章,公众号历史文章等知识点。
大数据采集工具,除了Flume,还有哪些工具?
采集交流 • 优采云 发表了文章 • 0 个评论 • 743 次浏览 • 2020-08-03 09:04
大数据平台与数据采集
任何完整的大数据平台,一般包括以下的几个过程:
数据采集-->数据储存-->数据处理-->数据凸显(可视化,报表和监控)
其中,数据采集是所有数据系统必不可少的采集工具,随着大数据越来越被注重,数据采集的挑战也变的尤为突出。这其中包括:
我们明天就来瞧瞧当前可用的六款数据采集的产品,重点关注它们是怎么做到高可靠,高性能和高扩充。
1、Apache Flume
官网:
Flume 是Apache旗下的一款开源、高可靠、高扩充、容易管理、支持顾客扩充的数据采集系统。 Flume使用JRuby来建立,所以依赖Java运行环境。
Flume最初是由Cloudera的工程师设计用于合并日志数据的系统,后来逐步发展用于处理流数据风波。
Flume设计成一个分布式的管线构架,可以看作在数据源和目的地之间有一个Agent的网路,支持数据路由。
每一个agent都由Source,Channel和Sink组成。
Source
Source负责接收输入数据,并将数据写入管线。Flume的Source支持HTTP,JMS,RPC,NetCat,Exec,Spooling Directory。其中Spooling支持监视一个目录或则文件,解析其中新生成的风波。
Channel
Channel 存储,缓存从source到Sink的中间数据。可使用不同的配置来做Channel,例如显存,文件,JDBC等。使用显存性能高但不持久,有可能丢数据。使用文件更可靠,但性能不如显存。
Sink
Sink负责从管线中读出数据并发给下一个Agent或则最终的目的地。Sink支持的不同目的地种类包括:HDFS,HBASE,Solr,ElasticSearch,File,Logger或则其它的Flume Agent。
Flume在source和sink端都使用了transaction机制保证在数据传输中没有数据遗失。
Source上的数据可以复制到不同的通道上。每一个Channel也可以联接不同数目的Sink。这样联接不同配置的Agent就可以组成一个复杂的数据搜集网路。通过对agent的配置,可以组成一个路由复杂的数据传输网路。
配置如上图所示的agent结构,Flume支持设置sink的Failover和Load Balance,这样就可以保证虽然有一个agent失效的情况下,整个系统仍能正常搜集数据。
Flume中传输的内容定义为风波(Event),事件由Headers(包含元数据,Meta Data)和Payload组成。
Flume提供SDK,可以支持用户订制开发:
Flume客户端负责在风波形成的源头把风波发送给Flume的Agent。客户端一般和形成数据源的应用在同一个进程空间。常见的Flume 客户端有Avro,log4J,syslog和HTTP Post。另外ExecSource支持指定一个本地进程的输出作为Flume的输入。当然很有可能,以上的那些客户端都不能满足需求,用户可以订制的客户端,和已有的FLume的Source进行通讯,或者订制实现一种新的Source类型。
同时,用户可以使用Flume的SDK订制Source和Sink。似乎不支持订制的Channel。
2、Fluentd
官网:
Fluentd是另一个开源的数据搜集框架。Fluentd使用C/Ruby开发,使用JSON文件来统一日志数据。它的可拔插构架,支持各类不同种类和格式的数据源和数据输出。最后它也同时提供了高可靠和挺好的扩展性。Treasure Data, Inc 对该产品提供支持和维护。
Fluentd的布署和Flume十分相像:
Fluentd的构架设计和Flume如出一辙:
Fluentd的Input/Buffer/Output特别类似于Flume的Source/Channel/Sink。
Input
Input负责接收数据或则主动抓取数据。支持syslog,http,file tail等。
Buffer
Buffer负责数据获取的性能和可靠性,也有文件或显存等不同类型的Buffer可以配置。
Output
Output负责输出数据到目的地比如文件,AWS S3或则其它的Fluentd。
Fluentd的配置十分便捷,如下图:
Fluentd的技术栈如下图:
FLuentd和其插件都是由Ruby开发,MessgaePack提供了JSON的序列化和异步的并行通信RPC机制。
Cool.io是基于libev的风波驱动框架。
FLuentd的扩展性非常好,客户可以自己订制(Ruby)Input/Buffer/Output。
Fluentd从各方面看都太象Flume,区别是使用Ruby开发,Footprint会小一些,但是也带来了跨平台的问题,并不能支持Windows平台。另外采用JSON统一数据/日志格式是它的另一个特性。相对去Flumed,配置也相对简单一些。
3、Logstash
Logstash是知名的开源数据栈ELK (ElasticSearch, Logstash, Kibana)中的那种L。
Logstash用JRuby开发,所有运行时依赖JVM。
Logstash的布署构架如下图,当然这只是一种布署的选项。
一个典型的Logstash的配置如下,包括了Input,filter的Output的设置。
几乎在大部分的情况下ELK作为一个栈是被同时使用的。所有当你的数据系统使用ElasticSearch的情况下,logstash是首选。
4、Chukwa
官网:
Apache Chukwa是apache旗下另一个开源的数据搜集平台,它远没有其他几个有名。Chukwa基于Hadoop的HDFS和Map Reduce来建立(显而易见,它用Java来实现),提供扩展性和可靠性。Chukwa同时提供对数据的展示,分析和监视。很奇怪的是它的上一次 github的更新事7年前。可见该项目应当早已不活跃了。
Chukwa的布署构架如下:
Chukwa的主要单元有:Agent,Collector,DataSink,ArchiveBuilder,Demux等等,看上去相当复杂。由于该项目早已不活跃,我们就不细看了。
5、Scribe
代码托管:
Scribe是Facebook开发的数据(日志)收集系统。已经多年不维护,同样的,就不多说了。
6、Splunk Forwarder
官网:
以上的所有系统都是开源的。在商业化的大数据平台产品中,Splunk提供完整的数据采金,数据储存,数据剖析和处理,以及数据凸显的能力。
Splunk是一个分布式的机器数据平台,主要有三个角色:
Search Head负责数据的搜索和处理,提供搜索时的信息抽取。Indexer负责数据的储存和索引Forwarder,负责数据的搜集,清洗,变形,并发献给Indexer
Splunk外置了对Syslog,TCP/UDP,Spooling的支持,同时采集工具,用户可以通过开发 Input和Modular Input的方法来获取特定的数据。在Splunk提供的软件库房里有好多成熟的数据采集应用,例如AWS,数据库(DBConnect)等等,可以便捷的从云或则是数据库中获取数据步入Splunk的数据平台做剖析。
这里要注意的是,Search Head和Indexer都支持Cluster的配置,也就是高可用,高扩充的,但是Splunk现今还没有针对Farwarder的Cluster的功能。也就是说假如有一台Farwarder的机器出了故障,数据搜集也会急剧中断,并不能把正在运行的数据采集任务Failover到其它的 Farwarder上。
总结
我们简单讨论了几种流行的数据搜集平台,它们大都提供高可靠和高扩充的数据搜集。大多平台都具象出了输入,输出和中间的缓冲的构架。利用分布式的网路联接,大多数平台都能实现一定程度的扩展性和高可靠性。
其中Flume,Fluentd是两个被使用较多的产品。如果你用ElasticSearch,Logstash其实是首选,因为ELK栈提供了挺好的集成。Chukwa和Scribe因为项目的不活跃,不推荐使用。
Splunk作为一个优秀的商业产品,它的数据采集还存在一定的限制,相信Splunk很快会开发出更好的数据搜集的解决方案。 查看全部
随着大数据越来越被注重,数据采集的挑战变的尤为突出。今天为你们介绍几款数据采集平台:
大数据平台与数据采集
任何完整的大数据平台,一般包括以下的几个过程:
数据采集-->数据储存-->数据处理-->数据凸显(可视化,报表和监控)
其中,数据采集是所有数据系统必不可少的采集工具,随着大数据越来越被注重,数据采集的挑战也变的尤为突出。这其中包括:
我们明天就来瞧瞧当前可用的六款数据采集的产品,重点关注它们是怎么做到高可靠,高性能和高扩充。
1、Apache Flume
官网:
Flume 是Apache旗下的一款开源、高可靠、高扩充、容易管理、支持顾客扩充的数据采集系统。 Flume使用JRuby来建立,所以依赖Java运行环境。
Flume最初是由Cloudera的工程师设计用于合并日志数据的系统,后来逐步发展用于处理流数据风波。
Flume设计成一个分布式的管线构架,可以看作在数据源和目的地之间有一个Agent的网路,支持数据路由。
每一个agent都由Source,Channel和Sink组成。
Source
Source负责接收输入数据,并将数据写入管线。Flume的Source支持HTTP,JMS,RPC,NetCat,Exec,Spooling Directory。其中Spooling支持监视一个目录或则文件,解析其中新生成的风波。
Channel
Channel 存储,缓存从source到Sink的中间数据。可使用不同的配置来做Channel,例如显存,文件,JDBC等。使用显存性能高但不持久,有可能丢数据。使用文件更可靠,但性能不如显存。
Sink
Sink负责从管线中读出数据并发给下一个Agent或则最终的目的地。Sink支持的不同目的地种类包括:HDFS,HBASE,Solr,ElasticSearch,File,Logger或则其它的Flume Agent。
Flume在source和sink端都使用了transaction机制保证在数据传输中没有数据遗失。
Source上的数据可以复制到不同的通道上。每一个Channel也可以联接不同数目的Sink。这样联接不同配置的Agent就可以组成一个复杂的数据搜集网路。通过对agent的配置,可以组成一个路由复杂的数据传输网路。
配置如上图所示的agent结构,Flume支持设置sink的Failover和Load Balance,这样就可以保证虽然有一个agent失效的情况下,整个系统仍能正常搜集数据。
Flume中传输的内容定义为风波(Event),事件由Headers(包含元数据,Meta Data)和Payload组成。
Flume提供SDK,可以支持用户订制开发:
Flume客户端负责在风波形成的源头把风波发送给Flume的Agent。客户端一般和形成数据源的应用在同一个进程空间。常见的Flume 客户端有Avro,log4J,syslog和HTTP Post。另外ExecSource支持指定一个本地进程的输出作为Flume的输入。当然很有可能,以上的那些客户端都不能满足需求,用户可以订制的客户端,和已有的FLume的Source进行通讯,或者订制实现一种新的Source类型。
同时,用户可以使用Flume的SDK订制Source和Sink。似乎不支持订制的Channel。
2、Fluentd
官网:
Fluentd是另一个开源的数据搜集框架。Fluentd使用C/Ruby开发,使用JSON文件来统一日志数据。它的可拔插构架,支持各类不同种类和格式的数据源和数据输出。最后它也同时提供了高可靠和挺好的扩展性。Treasure Data, Inc 对该产品提供支持和维护。
Fluentd的布署和Flume十分相像:
Fluentd的构架设计和Flume如出一辙:
Fluentd的Input/Buffer/Output特别类似于Flume的Source/Channel/Sink。
Input
Input负责接收数据或则主动抓取数据。支持syslog,http,file tail等。
Buffer
Buffer负责数据获取的性能和可靠性,也有文件或显存等不同类型的Buffer可以配置。
Output
Output负责输出数据到目的地比如文件,AWS S3或则其它的Fluentd。
Fluentd的配置十分便捷,如下图:
Fluentd的技术栈如下图:
FLuentd和其插件都是由Ruby开发,MessgaePack提供了JSON的序列化和异步的并行通信RPC机制。
Cool.io是基于libev的风波驱动框架。
FLuentd的扩展性非常好,客户可以自己订制(Ruby)Input/Buffer/Output。
Fluentd从各方面看都太象Flume,区别是使用Ruby开发,Footprint会小一些,但是也带来了跨平台的问题,并不能支持Windows平台。另外采用JSON统一数据/日志格式是它的另一个特性。相对去Flumed,配置也相对简单一些。
3、Logstash
Logstash是知名的开源数据栈ELK (ElasticSearch, Logstash, Kibana)中的那种L。
Logstash用JRuby开发,所有运行时依赖JVM。
Logstash的布署构架如下图,当然这只是一种布署的选项。
一个典型的Logstash的配置如下,包括了Input,filter的Output的设置。
几乎在大部分的情况下ELK作为一个栈是被同时使用的。所有当你的数据系统使用ElasticSearch的情况下,logstash是首选。
4、Chukwa
官网:
Apache Chukwa是apache旗下另一个开源的数据搜集平台,它远没有其他几个有名。Chukwa基于Hadoop的HDFS和Map Reduce来建立(显而易见,它用Java来实现),提供扩展性和可靠性。Chukwa同时提供对数据的展示,分析和监视。很奇怪的是它的上一次 github的更新事7年前。可见该项目应当早已不活跃了。
Chukwa的布署构架如下:
Chukwa的主要单元有:Agent,Collector,DataSink,ArchiveBuilder,Demux等等,看上去相当复杂。由于该项目早已不活跃,我们就不细看了。
5、Scribe
代码托管:
Scribe是Facebook开发的数据(日志)收集系统。已经多年不维护,同样的,就不多说了。
6、Splunk Forwarder
官网:
以上的所有系统都是开源的。在商业化的大数据平台产品中,Splunk提供完整的数据采金,数据储存,数据剖析和处理,以及数据凸显的能力。
Splunk是一个分布式的机器数据平台,主要有三个角色:
Search Head负责数据的搜索和处理,提供搜索时的信息抽取。Indexer负责数据的储存和索引Forwarder,负责数据的搜集,清洗,变形,并发献给Indexer
Splunk外置了对Syslog,TCP/UDP,Spooling的支持,同时采集工具,用户可以通过开发 Input和Modular Input的方法来获取特定的数据。在Splunk提供的软件库房里有好多成熟的数据采集应用,例如AWS,数据库(DBConnect)等等,可以便捷的从云或则是数据库中获取数据步入Splunk的数据平台做剖析。
这里要注意的是,Search Head和Indexer都支持Cluster的配置,也就是高可用,高扩充的,但是Splunk现今还没有针对Farwarder的Cluster的功能。也就是说假如有一台Farwarder的机器出了故障,数据搜集也会急剧中断,并不能把正在运行的数据采集任务Failover到其它的 Farwarder上。
总结
我们简单讨论了几种流行的数据搜集平台,它们大都提供高可靠和高扩充的数据搜集。大多平台都具象出了输入,输出和中间的缓冲的构架。利用分布式的网路联接,大多数平台都能实现一定程度的扩展性和高可靠性。
其中Flume,Fluentd是两个被使用较多的产品。如果你用ElasticSearch,Logstash其实是首选,因为ELK栈提供了挺好的集成。Chukwa和Scribe因为项目的不活跃,不推荐使用。
Splunk作为一个优秀的商业产品,它的数据采集还存在一定的限制,相信Splunk很快会开发出更好的数据搜集的解决方案。
【虾哥SEO】常见SEO数据剖析的重要性以及方法!
采集交流 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2020-07-07 08:02
6、核心关键词排名
7、内页长尾关键词排行数目
。。。。。。。
我们先来点评一下seo快速排名软件 虾哥,为什么往年的SEO数据剖析,不能做到从数据驱动SEO。我们逐字剖析一下往年做条目。
1、在其他诱因不变的情况下,PR或则百度权重高,流量一定高吗?很显然不是,而且还只是首页的PR值或则百度权重,对于任意一个网站来说,首页的流量仅仅是一小部份,对于超级大站来说,首页的流量所占比列小到可以忽视。(由于基数大,小比列的数据也比好多网站可观了)。首页PR(百度权重)数据完全没必要剖析。
2、Alexa的数据还有一定的参考性,但是对国外网站来说,几乎可以无视,除了搞IT的,基本没人会装。Alexa统计的流量是所有流量,并非单纯的SEO流量,所以对SEO没很大关系,不过Alexa的数据获取比较容易,就作为一个参考吧。
3、site收录准不准先不说,问题是site下来的数据有哪些意义呢?如果一个网站有1个亿的页面,site下来100万,是好还是坏?一个网站有1万个页面,site下来是1万,是好还是坏?因此,除了site的数据,你起码得晓得这个网站有多少页面量,否则site的数据毫无意义;一切收录量还是以百度站长工具当中的索引量为准。
4、首页快照,网页有更新了,爬虫可能拍个照,快照时间更新一下。更多时侯你页面动都没动。你指望快照变化对你SEO有哪些影响呢?而且和首页PR(百度权重)同理,首页只是一个页面而已,没这么特殊。
5、外链数目,外链为王,外链数目肯定是重要的。外链真的是越多越好吗?有的查询网站很明显排行第1的比排行第10的外链少得多的多。其实外链的整体质量很难评判,反正你也统计不全,何必要用这个数目作为一个结果,如果相关外链多,则排行都会提升,这不是我说的,是Google、百度说的。所以我们统计排行这个直接诱因就好了,而且百度和微软对于外链的过滤机制成熟,低质量的外链发太多反倒影响网站排名。
6、说到排行,要谈谈核心关键词的排行与网站整体排行的问题。相信诸位SEO站长手头都有自己的网站,看看流量报告吧,那些核心关键词能带来的流量占所有流量的比列是多少?但是通常做SEO优化的时侯,大家都习惯于把资源集中在几个核心词上,而大量的关键词流量,都属于没人要的,随便分配一些资源过去,流量就上来了。只看核心词的排行做SEO,属于“捡了芝麻,丢了西瓜”。“两手都要抓,两手都要硬”,平均分配资源,才能利润最大化。
从以上几个数据可以看出,过往的SEO数据剖析,分析的数据大都是不靠谱、不确切的。自然对SEO没哪些影响,而且从那些数据中,也很难发觉核心问题。SEO数据剖析seo快速排名软件 虾哥,往往就成了一个“噱头”,花了大量时间精力,却连一点疗效和指导也没有。
那么怎么做SEO的数据剖析?先推荐一些前人的智慧(曾庆平SEO:大家可以在百度搜索一下以下文章)
1、前阿里巴巴SEO国平:
详解光年SEO日志剖析系统2.0
网页加载速率是怎样影响SEO疗效的
2、天极网SEO废魅族:
百度收录抽检
任重而道远--IT垂直类门户搜索引擎关键词排行对比
虽然有些文章很老,但是到现今也太有指导性作用。先不借用谁的理论,我们从事实出发,好好回想一下用户是怎样通过搜索引擎来到我们网站的。
1、用户在搜索框中输入一个关键词。
2、用户在搜索结果页面中阅读大量结果。
3、用户点击步入某个他满意的结果。
虾姐SEOSEO数据剖析
---------> 查看全部
5、外链数目
6、核心关键词排名
7、内页长尾关键词排行数目
。。。。。。。
我们先来点评一下seo快速排名软件 虾哥,为什么往年的SEO数据剖析,不能做到从数据驱动SEO。我们逐字剖析一下往年做条目。
1、在其他诱因不变的情况下,PR或则百度权重高,流量一定高吗?很显然不是,而且还只是首页的PR值或则百度权重,对于任意一个网站来说,首页的流量仅仅是一小部份,对于超级大站来说,首页的流量所占比列小到可以忽视。(由于基数大,小比列的数据也比好多网站可观了)。首页PR(百度权重)数据完全没必要剖析。
2、Alexa的数据还有一定的参考性,但是对国外网站来说,几乎可以无视,除了搞IT的,基本没人会装。Alexa统计的流量是所有流量,并非单纯的SEO流量,所以对SEO没很大关系,不过Alexa的数据获取比较容易,就作为一个参考吧。
3、site收录准不准先不说,问题是site下来的数据有哪些意义呢?如果一个网站有1个亿的页面,site下来100万,是好还是坏?一个网站有1万个页面,site下来是1万,是好还是坏?因此,除了site的数据,你起码得晓得这个网站有多少页面量,否则site的数据毫无意义;一切收录量还是以百度站长工具当中的索引量为准。
4、首页快照,网页有更新了,爬虫可能拍个照,快照时间更新一下。更多时侯你页面动都没动。你指望快照变化对你SEO有哪些影响呢?而且和首页PR(百度权重)同理,首页只是一个页面而已,没这么特殊。
5、外链数目,外链为王,外链数目肯定是重要的。外链真的是越多越好吗?有的查询网站很明显排行第1的比排行第10的外链少得多的多。其实外链的整体质量很难评判,反正你也统计不全,何必要用这个数目作为一个结果,如果相关外链多,则排行都会提升,这不是我说的,是Google、百度说的。所以我们统计排行这个直接诱因就好了,而且百度和微软对于外链的过滤机制成熟,低质量的外链发太多反倒影响网站排名。
6、说到排行,要谈谈核心关键词的排行与网站整体排行的问题。相信诸位SEO站长手头都有自己的网站,看看流量报告吧,那些核心关键词能带来的流量占所有流量的比列是多少?但是通常做SEO优化的时侯,大家都习惯于把资源集中在几个核心词上,而大量的关键词流量,都属于没人要的,随便分配一些资源过去,流量就上来了。只看核心词的排行做SEO,属于“捡了芝麻,丢了西瓜”。“两手都要抓,两手都要硬”,平均分配资源,才能利润最大化。
从以上几个数据可以看出,过往的SEO数据剖析,分析的数据大都是不靠谱、不确切的。自然对SEO没哪些影响,而且从那些数据中,也很难发觉核心问题。SEO数据剖析seo快速排名软件 虾哥,往往就成了一个“噱头”,花了大量时间精力,却连一点疗效和指导也没有。
那么怎么做SEO的数据剖析?先推荐一些前人的智慧(曾庆平SEO:大家可以在百度搜索一下以下文章)
1、前阿里巴巴SEO国平:
详解光年SEO日志剖析系统2.0
网页加载速率是怎样影响SEO疗效的
2、天极网SEO废魅族:
百度收录抽检
任重而道远--IT垂直类门户搜索引擎关键词排行对比
虽然有些文章很老,但是到现今也太有指导性作用。先不借用谁的理论,我们从事实出发,好好回想一下用户是怎样通过搜索引擎来到我们网站的。
1、用户在搜索框中输入一个关键词。
2、用户在搜索结果页面中阅读大量结果。
3、用户点击步入某个他满意的结果。
虾姐SEOSEO数据剖析
--------->
写爬虫,用哪些编程语言好,python好吗
采集交流 • 优采云 发表了文章 • 0 个评论 • 423 次浏览 • 2020-06-23 08:01
之前换了份工作,不再是单纯的Web开发了,要学习的东西真的很多的。入职的第1天,就让我入手写个爬虫,只是这个爬虫没有采集几个亿数据量的业务场景。
于是,整理了下需求,简单的设计了下方案就草草开始了。小B是我学院时侯的同事,那天这哥们约我喝水,想看下能够顺带介绍几个姑娘。酒过三巡,不胜酒力,于是便聊起了近来的工作。
当他知晓我居然在写爬虫,便起了同情之心,觉得我怀才不遇。仿佛写爬虫是件太低级太low的技术活。在他那家公司,招进来的实习生就多多少少会点爬虫,什么nodejs、golang,哪个不是爬虫的好手。没想到我结业多年,竟然沦落到做实习生的工作,可悲可泣。
接着建议我转入Java阵营,如果到他公司去,多多少少也能混个主任的职位。搞得自己只能一番苦笑。
不知道从何时起,程序员的世界流行起了鄙视链这玩意。什么写C语言的厌恶写C++,写C++的厌恶写Java的,最后鄙视链最高端是PHP。具体是如何的关系,就不再揣测了。
写爬虫,用哪些编程语言好,python好吗
然而,纵观整个行业,都说Python火。具体有多火,看培训机构的广告就晓得了。在16年之前,Python还是1个若不见经传的词组,之后各家培训机构铺天盖地的广告,什么大数据、自动化运维全都跟Python扯上了关系。毕业学生工资更是达到了50-100W,还老是招不到人。
更有意思的是,学Python最容易上手的过程就是写爬虫。什么Scrapy、Pysider是必学,HTML、Javascript是重点,外带几个豆瓣、花瓣网的实战案例,让你一下子才能解决企业的刚需。
这样说来,难怪连实习生也能跟你抢饭碗了,技术发展的很快,各种框架构建的结果是释放人力,降低成本。
据我了解,Python的优势集中于数据剖析、信息安全那些领域。你可能听说过Hadoop、Spark、Tensorflow这种高大上的名词,但是对于数据取证、DLL注入等内容可能从无听闻。举个简单的事例,在数据取证中,由于犯罪人员不配合检测机关的工作,通过数据取证技术我们可以进行一些信息的提取,从而辅助否认其犯罪记录,如获取系统密码、浏览器中帐号及密码。
听起来觉得很高大上的,但是假如我跟你说其过程就是对sqlite3文件数据库查询一下SQL,不知道你会不会认为上述取证的事例顿时很low的。但是,当你不留神把陌陌消息的图片删除想寻回的时侯,或许你能在Python中找到对应的方案,而其他的语言还真没发觉有合适的。
于是,我开导他说,搞完这波爬虫骚操作,下一次就是数据剖析了,你看不有前进了一步?
还数据剖析,你似乎想的很远的。小B打断了我的话,你认为人家会使你搞数据剖析,没有数据何来的剖析。况且,没有哪家公司会笨到把所有数据都曝露在互联网上。你能看到的只是那冰山的一角。即使你想深入进去,没有分布式技术支撑和几十个亿的数据业务,你简历上也不会有亮点。
然后,又聊到他公司近日招了个大数据的开发,薪资比他还要高出一大截,但是技术却不咋地。我从小B的话里听出了一丝揶揄了。于是,又教唆我不要再搞哪些爬虫了,还是搞Spark才有未来。既不用害怕大深夜服务挂了,又不用害怕完不成采集数量。完全是实打实的数据,何乐而不为呢?
这话听得我都有点动心了,没有攀比就没有伤害。但是一想到Java是加班加点工作,我还是打消了这个念头。
我不知道该说些哪些,只是认为时间过得太慢,是种熬煎。于是只能扯开了话题,免得喝顿饭都艰难。
结语
技术没有low不low,没有烂的技术,只有不会用的人。重要的是人家能给你多少钱,你能弄成如何的结果。
这年头会有多少公司乐意给实习生税后1W+的起薪,而这一切都只是份养活自己的技能而已,别把面子很当回事。
写爬虫,用哪些编程语言好,python好吗,其实编程的路上只在于擅长,没有所谓的行不行,如果不擅长,就是给您好用的编程语言也没有疗效,如果想要学编程,那就关注IT培训网网络爬虫用什么语言写,让我们一起走入编程的世界! 查看全部
用Python写爬虫就太low?你赞成嘛?为何不建议使用python写爬虫呢网络爬虫用什么语言写,是有哪些诱因吗,难道用python写爬虫不好吗?
之前换了份工作,不再是单纯的Web开发了,要学习的东西真的很多的。入职的第1天,就让我入手写个爬虫,只是这个爬虫没有采集几个亿数据量的业务场景。
于是,整理了下需求,简单的设计了下方案就草草开始了。小B是我学院时侯的同事,那天这哥们约我喝水,想看下能够顺带介绍几个姑娘。酒过三巡,不胜酒力,于是便聊起了近来的工作。
当他知晓我居然在写爬虫,便起了同情之心,觉得我怀才不遇。仿佛写爬虫是件太低级太low的技术活。在他那家公司,招进来的实习生就多多少少会点爬虫,什么nodejs、golang,哪个不是爬虫的好手。没想到我结业多年,竟然沦落到做实习生的工作,可悲可泣。
接着建议我转入Java阵营,如果到他公司去,多多少少也能混个主任的职位。搞得自己只能一番苦笑。
不知道从何时起,程序员的世界流行起了鄙视链这玩意。什么写C语言的厌恶写C++,写C++的厌恶写Java的,最后鄙视链最高端是PHP。具体是如何的关系,就不再揣测了。
写爬虫,用哪些编程语言好,python好吗
然而,纵观整个行业,都说Python火。具体有多火,看培训机构的广告就晓得了。在16年之前,Python还是1个若不见经传的词组,之后各家培训机构铺天盖地的广告,什么大数据、自动化运维全都跟Python扯上了关系。毕业学生工资更是达到了50-100W,还老是招不到人。
更有意思的是,学Python最容易上手的过程就是写爬虫。什么Scrapy、Pysider是必学,HTML、Javascript是重点,外带几个豆瓣、花瓣网的实战案例,让你一下子才能解决企业的刚需。
这样说来,难怪连实习生也能跟你抢饭碗了,技术发展的很快,各种框架构建的结果是释放人力,降低成本。
据我了解,Python的优势集中于数据剖析、信息安全那些领域。你可能听说过Hadoop、Spark、Tensorflow这种高大上的名词,但是对于数据取证、DLL注入等内容可能从无听闻。举个简单的事例,在数据取证中,由于犯罪人员不配合检测机关的工作,通过数据取证技术我们可以进行一些信息的提取,从而辅助否认其犯罪记录,如获取系统密码、浏览器中帐号及密码。
听起来觉得很高大上的,但是假如我跟你说其过程就是对sqlite3文件数据库查询一下SQL,不知道你会不会认为上述取证的事例顿时很low的。但是,当你不留神把陌陌消息的图片删除想寻回的时侯,或许你能在Python中找到对应的方案,而其他的语言还真没发觉有合适的。
于是,我开导他说,搞完这波爬虫骚操作,下一次就是数据剖析了,你看不有前进了一步?
还数据剖析,你似乎想的很远的。小B打断了我的话,你认为人家会使你搞数据剖析,没有数据何来的剖析。况且,没有哪家公司会笨到把所有数据都曝露在互联网上。你能看到的只是那冰山的一角。即使你想深入进去,没有分布式技术支撑和几十个亿的数据业务,你简历上也不会有亮点。
然后,又聊到他公司近日招了个大数据的开发,薪资比他还要高出一大截,但是技术却不咋地。我从小B的话里听出了一丝揶揄了。于是,又教唆我不要再搞哪些爬虫了,还是搞Spark才有未来。既不用害怕大深夜服务挂了,又不用害怕完不成采集数量。完全是实打实的数据,何乐而不为呢?
这话听得我都有点动心了,没有攀比就没有伤害。但是一想到Java是加班加点工作,我还是打消了这个念头。
我不知道该说些哪些,只是认为时间过得太慢,是种熬煎。于是只能扯开了话题,免得喝顿饭都艰难。
结语
技术没有low不low,没有烂的技术,只有不会用的人。重要的是人家能给你多少钱,你能弄成如何的结果。
这年头会有多少公司乐意给实习生税后1W+的起薪,而这一切都只是份养活自己的技能而已,别把面子很当回事。
写爬虫,用哪些编程语言好,python好吗,其实编程的路上只在于擅长,没有所谓的行不行,如果不擅长,就是给您好用的编程语言也没有疗效,如果想要学编程,那就关注IT培训网网络爬虫用什么语言写,让我们一起走入编程的世界!
网页数据抓取三步走
采集交流 • 优采云 发表了文章 • 0 个评论 • 384 次浏览 • 2020-06-20 08:01
当我们有了抓取目标后,第一步就是剖析。首先是剖析页面的特性火车采集器v9的怎么用,网页通常包括静态页面、伪静态页面以及动态页面。静态网页URL以.htm、.html、.shtml等常见方式为后缀,动态页面则是以.asp、.jsp、.php、.perl、.cgi等方式为后缀,并且在动态网页网址中有一个标志性的符号——“?”。相对来说静态页面采集比较容易一些,比如一些新闻页面,功能比较简单;而象峰会就属于动态页面,它的后台服务器会手动更新,这样的页面采集时涉及到的功能就多一些,相对比较复杂。
其次是剖析数据,我们须要的数据是怎样诠释的,是否有列表分页、内容分页或是多页?需要的数据是图片还是文本还是其他文件?
最后须要剖析的是源代码,根据我们须要采集到的数据,依次找出它们的源代码及相关规律,方便后续在采集工具中得以彰显。
第二步:获取
这里须要用到精典的抓取工具列车采集器V9,火车采集器获取数据的原理就是基于WEB结构的源代码提取,因此在第一步中剖析源代码是极其重要的。我们在列车采集器V9中对每一项须要的数据设置获取规则,将它提取下来。在列车采集器中,可以自动获取,也支持部份类型的数据手动辨识提取。分析正确的前提下火车采集器v9的怎么用,获取数据十分方便。
第三步:处理
获取到的数据假如可以直接用这么就无需进行这一步,如果还须要使数据愈加符合要求,就须要使用列车采集器V9强悍的处理功能了。比如标签过滤;敏感词,近义词替换/排除;数据转换;补全单网址;智能提取图片、邮箱,电话号码等智能化的处理体系,必要的话还可以开发插件进行处理。
按照上述的这三个步骤,网页数据抓取虽然并不难,除了强化对软件操作的熟悉度之外,我们还须要提升自身的剖析能力和网页相关的技术知识,那么网页数据抓取将愈加得心应手。 查看全部
当我们有了抓取目标后,第一步就是剖析。首先是剖析页面的特性火车采集器v9的怎么用,网页通常包括静态页面、伪静态页面以及动态页面。静态网页URL以.htm、.html、.shtml等常见方式为后缀,动态页面则是以.asp、.jsp、.php、.perl、.cgi等方式为后缀,并且在动态网页网址中有一个标志性的符号——“?”。相对来说静态页面采集比较容易一些,比如一些新闻页面,功能比较简单;而象峰会就属于动态页面,它的后台服务器会手动更新,这样的页面采集时涉及到的功能就多一些,相对比较复杂。
其次是剖析数据,我们须要的数据是怎样诠释的,是否有列表分页、内容分页或是多页?需要的数据是图片还是文本还是其他文件?
最后须要剖析的是源代码,根据我们须要采集到的数据,依次找出它们的源代码及相关规律,方便后续在采集工具中得以彰显。
第二步:获取
这里须要用到精典的抓取工具列车采集器V9,火车采集器获取数据的原理就是基于WEB结构的源代码提取,因此在第一步中剖析源代码是极其重要的。我们在列车采集器V9中对每一项须要的数据设置获取规则,将它提取下来。在列车采集器中,可以自动获取,也支持部份类型的数据手动辨识提取。分析正确的前提下火车采集器v9的怎么用,获取数据十分方便。
第三步:处理
获取到的数据假如可以直接用这么就无需进行这一步,如果还须要使数据愈加符合要求,就须要使用列车采集器V9强悍的处理功能了。比如标签过滤;敏感词,近义词替换/排除;数据转换;补全单网址;智能提取图片、邮箱,电话号码等智能化的处理体系,必要的话还可以开发插件进行处理。
按照上述的这三个步骤,网页数据抓取虽然并不难,除了强化对软件操作的熟悉度之外,我们还须要提升自身的剖析能力和网页相关的技术知识,那么网页数据抓取将愈加得心应手。
什么是爬虫技术?
采集交流 • 优采云 发表了文章 • 0 个评论 • 273 次浏览 • 2020-06-17 08:00
有一个说法是,互联网上50%的流量都是爬虫创造的。这个说法似乎夸张了点,但也彰显出了爬虫的无处不在。爬虫之所以无处不在,是因为爬虫可以为互联网企业带来利润。
爬虫技术的现况
语言
理论上来说,任何支持网路通讯的语言都是可以写爬虫的,爬虫本身其实语言关系不大,但是,总有相对顺手、简单的。目前来说,大多数爬虫是用后台脚本类语言写的,其中python无疑是用的最多最广的,并且也诞生了好多优秀的库和框架,如scrapy、BeautifulSoup 、pyquery、Mechanize等。但是一般来说,搜索引擎的爬虫对爬虫的效率要求更高,会选用c++、java、go(适合高并发)。
运行环境
爬虫本身不分辨究竟是运行在windows还是Linux,又或是OSX,但从业务角度讲爬虫技术用什么语言,我们把运行在服务端(后台)的,称之为后台爬虫。而如今,几乎所有的爬虫都是后台爬虫。
爬虫的作用
1、爬虫爬出top1000和top10000数据,范围减小,然后根据情况选定细分产品信息等进行开发。
2、通过爬虫数据,跟踪产品情况,用来作出快速反应。
3、利用爬虫信息,抓取产品信息库类目变动情况。
未来,人工智能将会颠覆所有的商业应用。而人工智能的基础在于大数据,大数据的基础核心是数据采集,数据采集的主力是爬虫技术,因此,爬虫技术作为大数据最基层的应用,其重要性毋庸置疑。 查看全部
在一大堆技术术语里,最为被普通人所熟知的大约就是“爬虫”了。其实爬虫这个名子就早已非常好地表现出了这项技术的作用——像密密麻麻的蚊子一样分布在网路上爬虫技术用什么语言,爬行至每一个角落获取数据;也一定程度上抒发了人们对这项技术的情感倾向——虫子其实无害,但总是不受欢迎的。
有一个说法是,互联网上50%的流量都是爬虫创造的。这个说法似乎夸张了点,但也彰显出了爬虫的无处不在。爬虫之所以无处不在,是因为爬虫可以为互联网企业带来利润。
爬虫技术的现况
语言
理论上来说,任何支持网路通讯的语言都是可以写爬虫的,爬虫本身其实语言关系不大,但是,总有相对顺手、简单的。目前来说,大多数爬虫是用后台脚本类语言写的,其中python无疑是用的最多最广的,并且也诞生了好多优秀的库和框架,如scrapy、BeautifulSoup 、pyquery、Mechanize等。但是一般来说,搜索引擎的爬虫对爬虫的效率要求更高,会选用c++、java、go(适合高并发)。
运行环境
爬虫本身不分辨究竟是运行在windows还是Linux,又或是OSX,但从业务角度讲爬虫技术用什么语言,我们把运行在服务端(后台)的,称之为后台爬虫。而如今,几乎所有的爬虫都是后台爬虫。
爬虫的作用
1、爬虫爬出top1000和top10000数据,范围减小,然后根据情况选定细分产品信息等进行开发。
2、通过爬虫数据,跟踪产品情况,用来作出快速反应。
3、利用爬虫信息,抓取产品信息库类目变动情况。
未来,人工智能将会颠覆所有的商业应用。而人工智能的基础在于大数据,大数据的基础核心是数据采集,数据采集的主力是爬虫技术,因此,爬虫技术作为大数据最基层的应用,其重要性毋庸置疑。
分析百度最近一个月的SEO数据风向标
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2020-06-15 08:01
图一:最近一周的SEO数据风向标
图二:上一周的SEO数据风向标
上图可以显著看出本周五百度更新幅度最大,这就是普遍被觉得的周日、周五排行更新,不过最新几个月百度也不喜欢根据常理出牌了,对比下上周的SEO数据风 向标你们可以发觉上周的各项数据基本是平稳的,不过这个现象可以正常理解,主要是因为上周是10.1春节期间,百度也得休假吧,好不容易的周末,百度也应 该人性化点,让站长们过个评价的暑假。我们最害怕的K站风波一直都在上演,仔细看下图表不能发觉明天的K站比列高达:0.84%,这意味着1000个网站 中有84个将被K,今天的K站比列是本周中最大的。经历过周六的大更新后,很多站收录都降低了,增加的比列是45.17%。
以上是笔者对SEO数据风向标的简单剖析,可以肯定的是K站仍然在继续,笔者的几个顾客网站收录都在降低,百度现今的算法是每周清除掉一些垃圾页面,比如 一个权重不错的企业站,注册域名时间是几年的,但之前因为无专业人员管理,一般这样的企业站在公司都是随意找人管理的,于是复制了太多的行业新闻,这样的 企业站收录会持续增长,即便是更新后很快收录了,也会在一二周内被消除掉。企业站更新不需要过分频繁,保持规律就行,最重要的是内容质量,这就要去我们去 撰写产品软文,但这确实是目前摆在我们面前最头痛的事情,企业站各行各业都有,产品软文很难写,所以未来企业站也须要有专业的编辑或则软文写手。
图三:最近一个月的K站数据
再来剖析下最近一个月的K站比列,为了便捷查看,我把其他几个网站数据指标隐藏了。从2012年9月14日至2012年10月9日,差不到就是一个月的数 据,可以看见几个最高点的波峰,居然都是星期六,真是站长们的红色星期六,为什么百度新算法要在星期六下狠手呢?个人猜想:星期六是百度一周大更新后的第 一天(或者是第二天),经过新算法的一周的测验基本早已确定了什么站点该被K,也就是算法在进一步的查证,那些显著的垃圾站活不到周末,剩余出来的被装入 黑名单的站点,这次最终被确定了,误加入黑名单的站点被生擒,剩下的全部搞死。
SEO数据风向标基本可以剖析出算法大致的方向,不过要想剖析自己的同行业的网站,还得平时统计一下这些竞争对手网站,做好表格,了解下他人站点基本情 况,比如:更新频度、外链降低频度,站内内容等,通过这种数据才能帮助你更好的找到自己网站的不足,更利于做好优化和监控。对于新人们数据剖析是个难点,不过也不用害怕分析百度seo,平常多观察,做好数据统计,不懂就多问问前辈们,今天就聊这么多。调整好自己的态度,不 要由于K站一蹶不振! 本文由 zwz轴承() 原创撰写 ,转载保留链接! 查看全部
SEO数据风向标你们都不会陌生,通过剖析SEO数据风向标可以挺好的了解近来百度算法的大致动态,SEO数据剖析必须构建在大量数据 统计的基础上,因此几个站点不能说明哪些问题,若通过几个站点剖析数据似乎是不科学的,做科学的SEO数据剖析是我们这种SEO人员必须学习的分析百度seo,笔者觉得 现在许多SEO新人们都不太喜欢去剖析数据,盲目的反复执行不能做好SEO,从6月份开始百度就让我们没法淡定了。下面是笔者对最近一个月、最近一周、上 一周的SEO数据风向标截图,从那些数据我们可以剖析百度新算法的实际疗效:
图一:最近一周的SEO数据风向标
图二:上一周的SEO数据风向标
上图可以显著看出本周五百度更新幅度最大,这就是普遍被觉得的周日、周五排行更新,不过最新几个月百度也不喜欢根据常理出牌了,对比下上周的SEO数据风 向标你们可以发觉上周的各项数据基本是平稳的,不过这个现象可以正常理解,主要是因为上周是10.1春节期间,百度也得休假吧,好不容易的周末,百度也应 该人性化点,让站长们过个评价的暑假。我们最害怕的K站风波一直都在上演,仔细看下图表不能发觉明天的K站比列高达:0.84%,这意味着1000个网站 中有84个将被K,今天的K站比列是本周中最大的。经历过周六的大更新后,很多站收录都降低了,增加的比列是45.17%。
以上是笔者对SEO数据风向标的简单剖析,可以肯定的是K站仍然在继续,笔者的几个顾客网站收录都在降低,百度现今的算法是每周清除掉一些垃圾页面,比如 一个权重不错的企业站,注册域名时间是几年的,但之前因为无专业人员管理,一般这样的企业站在公司都是随意找人管理的,于是复制了太多的行业新闻,这样的 企业站收录会持续增长,即便是更新后很快收录了,也会在一二周内被消除掉。企业站更新不需要过分频繁,保持规律就行,最重要的是内容质量,这就要去我们去 撰写产品软文,但这确实是目前摆在我们面前最头痛的事情,企业站各行各业都有,产品软文很难写,所以未来企业站也须要有专业的编辑或则软文写手。
图三:最近一个月的K站数据
再来剖析下最近一个月的K站比列,为了便捷查看,我把其他几个网站数据指标隐藏了。从2012年9月14日至2012年10月9日,差不到就是一个月的数 据,可以看见几个最高点的波峰,居然都是星期六,真是站长们的红色星期六,为什么百度新算法要在星期六下狠手呢?个人猜想:星期六是百度一周大更新后的第 一天(或者是第二天),经过新算法的一周的测验基本早已确定了什么站点该被K,也就是算法在进一步的查证,那些显著的垃圾站活不到周末,剩余出来的被装入 黑名单的站点,这次最终被确定了,误加入黑名单的站点被生擒,剩下的全部搞死。
SEO数据风向标基本可以剖析出算法大致的方向,不过要想剖析自己的同行业的网站,还得平时统计一下这些竞争对手网站,做好表格,了解下他人站点基本情 况,比如:更新频度、外链降低频度,站内内容等,通过这种数据才能帮助你更好的找到自己网站的不足,更利于做好优化和监控。对于新人们数据剖析是个难点,不过也不用害怕分析百度seo,平常多观察,做好数据统计,不懂就多问问前辈们,今天就聊这么多。调整好自己的态度,不 要由于K站一蹶不振! 本文由 zwz轴承() 原创撰写 ,转载保留链接!
【苹果IP代理】 8大高效的Python爬虫框架,你用过几个?
采集交流 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2020-06-09 08:01
4.Portia Portia 是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面爬虫代理软件爬虫代理软件,Portia 将创建一个蜘蛛来从类似的页面提取数据。5.Newspaper Newspaper 可以拿来提取新闻、文章和内容剖析。使用多线 程,支持 10 多种语言等。 6.Beautiful Soup Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据 的 Python 库.它还能通过你喜欢的转换器实现惯用的文档导航, 查找,修改文档的方法.Beautiful Soup 会帮你节约数小时甚至数天 的工作时间。 7.Grab Grab 是一个用于建立 Web 刮板的 Python 框架。借助 Grab, 您可以建立各类复杂的网页抓取工具,从简单的 5 行脚本到处理 数百万个网页的复杂异步网站抓取工具。Grab 提供一个 API 用于 执行网路恳求和处理接收到的内容,例如与 HTML 文档的 DOM 树进行交互。 8.Cola Cola 是一个分布式的爬虫框架,对于用户来说,只需编撰几 个特定的函数,而无需关注分布式运行的细节。任务会手动分配 到多台机器上,整个过程对用户是透明的。 查看全部
【苹果 IP 代理】8 大高效的 Python 爬虫框架,你用过几个? 【苹果 IP 代理】大数据时代下,数据采集推动着数据剖析, 数据剖析加快发展。但是在这个过程中会出现好多问题。拿最简 单最基础的爬虫采集数据为例,过程中还会面临,IP 被封,爬取 受限、违法操作等多种问题,所以在爬取数据之前,一定要了解 好预爬网站是否涉及违规操作,找到合适的代理 IP 访问网站等 一系列问题。今天我们就来讲讲这些高效的爬虫框架。 1.Scrapy Scrapy 是一个为了爬取网站数据,提取结构性数据而编撰的 应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数 据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商 品信息之类的数据。 2.PySpider pyspider 是一个用 python 实现的功能强悍的网路爬虫系统, 能在浏览器界面上进行脚本的编撰,功能的调度和爬取结果的实 时查看,后端使用常用的数据库进行爬取结果的储存,还能定时 设置任务与任务优先级等。 3.Crawley Crawley 可以高速爬取对应网站的内容,支持关系和非关系 数据库,数据可以导入为 JSON、XML 等。
4.Portia Portia 是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面爬虫代理软件爬虫代理软件,Portia 将创建一个蜘蛛来从类似的页面提取数据。5.Newspaper Newspaper 可以拿来提取新闻、文章和内容剖析。使用多线 程,支持 10 多种语言等。 6.Beautiful Soup Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据 的 Python 库.它还能通过你喜欢的转换器实现惯用的文档导航, 查找,修改文档的方法.Beautiful Soup 会帮你节约数小时甚至数天 的工作时间。 7.Grab Grab 是一个用于建立 Web 刮板的 Python 框架。借助 Grab, 您可以建立各类复杂的网页抓取工具,从简单的 5 行脚本到处理 数百万个网页的复杂异步网站抓取工具。Grab 提供一个 API 用于 执行网路恳求和处理接收到的内容,例如与 HTML 文档的 DOM 树进行交互。 8.Cola Cola 是一个分布式的爬虫框架,对于用户来说,只需编撰几 个特定的函数,而无需关注分布式运行的细节。任务会手动分配 到多台机器上,整个过程对用户是透明的。
大数据采集之网路爬虫的基本流程及抓取策略
采集交流 • 优采云 发表了文章 • 0 个评论 • 536 次浏览 • 2020-06-08 08:01
本篇教程阐述了大数据采集之网路爬虫的基本流程及抓取策略,希望阅读本篇文章以后你们有所收获,帮助你们对相关内容的理解愈发深入。
大数据时代下,数据采集推动着数据剖析,数据剖析促进发展。但是在这个过程中会出现好多问题。拿最简单最基础的爬虫采集数据为例,过程中还会面临,IP被封,爬取受限、违法操作等多种问题,所以在爬去数据之前,一定要了解好预爬网站是否涉及违规操作,找到合适的代理IP访问网站等一系列问题。
掌握爬虫技术也成为现今技术流的营销推广人员必须把握的。爬虫入门,这些知识你必须了解。
一、网络爬虫的基本工作流程如下:
1.首先选定一部分悉心选购的种子URL;
2.将这种URL倒入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL倒入待抓取URL队列,从而步入下一个循环。
二、抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面,后抓取那个页面。而决定那些URL排列次序的方式,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.PartialPageRank策略
PartialPageRank算法借鉴了PageRank算法的思想:对于早已下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每位页面的PageRank值,计算完以后,将待抓取URL队列中的URL根据PageRank值的大小排列,并根据该次序抓取页面。
如果每次抓取一个页面,就重新估算PageRank值,一种折中方案是:每抓取K个页面后,重新估算一次PageRank值。但是此类情况都会有一个问题:对于早已下载出来的页面中剖析出的链接,也就是我们之前谈到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给那些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总大数据网络爬虫原理,这样就产生了该未知页面的PageRank值,从而参与排序。
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发觉的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。
3.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因而称作大站优先策略。
4.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。
在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那种也的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。
5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P以后,将P的现金平摊给所有从P中剖析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面根据现金数进行排序。
6.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路然后再转到下一个起始页,继续跟踪链接。
三、从爬虫的角度对互联网进行界定
对应的,可以将互联网的所有页面分为五个部份:
1.已下载未过期网页
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就早已过期了。
3.待下载网页:也就是待抓取URL队列中的这些页面
4.可知网页:还没有抓取出来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或则待抓取URL对应页面进行剖析获取到的URL,认为是可知网页。
5.还有一部分网页,爬虫是难以直接抓取下载的。称为不可知网页。
太阳软件,一个好用的互联网推广换IP工具大数据网络爬虫原理,海量IP,一键切换,提升权重,必不可少! 查看全部
本篇教程阐述了大数据采集之网路爬虫的基本流程及抓取策略,希望阅读本篇文章以后你们有所收获,帮助你们对相关内容的理解愈发深入。
大数据时代下,数据采集推动着数据剖析,数据剖析促进发展。但是在这个过程中会出现好多问题。拿最简单最基础的爬虫采集数据为例,过程中还会面临,IP被封,爬取受限、违法操作等多种问题,所以在爬去数据之前,一定要了解好预爬网站是否涉及违规操作,找到合适的代理IP访问网站等一系列问题。
掌握爬虫技术也成为现今技术流的营销推广人员必须把握的。爬虫入门,这些知识你必须了解。
一、网络爬虫的基本工作流程如下:
1.首先选定一部分悉心选购的种子URL;
2.将这种URL倒入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL倒入待抓取URL队列,从而步入下一个循环。
二、抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面,后抓取那个页面。而决定那些URL排列次序的方式,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.PartialPageRank策略
PartialPageRank算法借鉴了PageRank算法的思想:对于早已下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每位页面的PageRank值,计算完以后,将待抓取URL队列中的URL根据PageRank值的大小排列,并根据该次序抓取页面。
如果每次抓取一个页面,就重新估算PageRank值,一种折中方案是:每抓取K个页面后,重新估算一次PageRank值。但是此类情况都会有一个问题:对于早已下载出来的页面中剖析出的链接,也就是我们之前谈到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给那些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总大数据网络爬虫原理,这样就产生了该未知页面的PageRank值,从而参与排序。
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发觉的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。
3.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因而称作大站优先策略。
4.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。
在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那种也的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。
5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P以后,将P的现金平摊给所有从P中剖析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面根据现金数进行排序。
6.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路然后再转到下一个起始页,继续跟踪链接。
三、从爬虫的角度对互联网进行界定
对应的,可以将互联网的所有页面分为五个部份:
1.已下载未过期网页
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就早已过期了。
3.待下载网页:也就是待抓取URL队列中的这些页面
4.可知网页:还没有抓取出来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或则待抓取URL对应页面进行剖析获取到的URL,认为是可知网页。
5.还有一部分网页,爬虫是难以直接抓取下载的。称为不可知网页。
太阳软件,一个好用的互联网推广换IP工具大数据网络爬虫原理,海量IP,一键切换,提升权重,必不可少!
PHP用户数据爬取
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-06-02 08:02
广告
云服务器1核2G首年95年,助力轻松上云!还有千元代金卷免费领,开团成功最高免费续费40个月!
代码托管地址: https:github.comhectorhuzhihuspider 这次抓取了110万的用户数据,数据剖析结果如下:? 开发前的打算安装linux系统(ubuntu14.04),在vmware虚拟机下安装一个ubuntu; 安装php5.6或以上版本; 安装mysql5.5或以上版本; 安装curl、pcntl扩充。 使用php的curl扩充抓取页面数据php的curl扩充是php支持...
但经验其实是经验,数据才是最靠谱的,通过剖析数据,可以评估一个队员的价值(当然,球员的各方面的表现(特征),都会有一个权重,最终评判权重*特征值之和最高者的神锋机率胜算大些)。 那么,如何获取那些数据呢? 写段简单的爬取数据的代码就是最好的获取工具。 本文以2014年的巴西世界杯球队为基础进行实践操作...
一、引言 在实际工作中,难免会遇见从网页爬取数据信息的需求,如:从谷歌官网上爬取最新发布的系统版本。 很明显这是个网页爬虫的工作,所谓网页爬虫,就是须要模拟浏览器,向网路服务器发送恳求便于将网路资源从网络流中读取下来,保存到本地,并对这种信息做些简单提取,将我们要的信息分离提取下来。 在做网页...
经过我的测试,我这一个学期以来的消费记录在这个网页上只有50多页,所以爬虫须要爬取的数据量太小,处理上去是完全没有压力的,直接一次性得到所有的结果以后保存文件就行了。 至于爬虫程序的语言选择,我也没哪些好说的,目前我也就对php比较熟悉一些,所以接下来的程序我也是用php完成的。 首先确定我应当怎样模拟...
如果你是有经验的开发者,完全可以跳过第一章步入第二章的学习了。 这个项目主要围绕两大核心点展开: 1. php爬虫 2. 代理ip 咱们先讲讲哪些是爬虫,简单来讲,爬虫就是一个侦测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按键,查查数据,或者把听到的信息背回去。 就像一只蟑螂在一幢楼里不知疲惫地爬...
通过抓取并剖析在线社交网站的数据,研究者可以迅速地掌握人类社交网路行为背后所隐藏的规律、机制乃至一般性的法则。 然而在线社交网络数据的获取方式...这个网站的网路链接为:http:members.lovingfromadistance.comforum.php,我们首先写一个叫screen_login的函数。 其核心是定义个浏览器对象br = mechanize...
每分钟执行一次爬取全省新型脑炎疫情实时动态并写入到指定的.php文件functionupdate() { (async () =&gt; { const browser = await puppeteer.launch({args: ...fscnpm i -g cron具体操作:用puppeteer爬取:puppeteer本质上是一个chrome浏览器,网页很难分清这是人类用户还是爬虫,我们可以用它来加载动态网页...
爬取微博的 id weibologin(username, password, cookie_path).login() withopen({}{}.csv.format(comment_path, id), mode=w, encoding=utf-8-sig...或者在文件中读取cookie数据到程序 self.session.cookies =cookielib.lwpcookiejar(filename=self.cookie_path) self.index_url = http:weibo.comlogin...
python爬虫突破限制,爬取vip视频主要介绍了python爬虫项目实例代码,文中通过示例代码介绍的十分详尽,对你们的学习或则工作具有一定的参考学习价值,需要的同学可以参考下? 其他也不多说什么直接附上源码? 只要学会爬虫技术,想爬取哪些资源基本都可以做到,当然python不止爬虫技术还有web开发,大数据,人工智能等! ...
但是使用java访问的时侯爬取的html里却没有该mp3的文件地址,那么这肯定是在该页面的位置使用了js来加载mp3,那么刷新下网页,看网页加载了什么东西,加载的东西有点多,着重看一下js、php的恳求,主要是看上面有没有mp3的地址,分析细节就不用说了。? 最终我在列表的https:wwwapi.kugou.comyyindex.php? r=playgetd...
总结上去就三部,首先获取登陆界面的验证码并储存cookie,然后通过cookie来模拟登录,最后步入教务系统取想要的东西。 现在我们须要去留心的内容,各个恳求的联接、header、和发送的数据2. 查看恳求首先我们查看首页,我们发觉登陆并不在首页上,需要点击用户登陆后才算步入了登陆界面。 然后我们查看登陆界面的恳求...
就是如此一个简单的功能,类似好多的云盘搜索类网站,我这个采集和搜索程序都是php实现的,全文和动词搜索部份使用到了开源软件xunsearch。 真实上线案例:搜碟子-网盘影片资源站上一篇( 网盘搜索引擎-采集爬取百度网盘分享文件实现云盘搜索中我重点介绍了如何去获取一大批的百度网盘用户,这一篇介绍如何获得指定...
当然, 并不是所有数据都适宜? 在学习爬虫的过程中, 遇到过不少坑. 今天这个坑可能之后你也会碰到, 随着爬取数据量的降低,以及爬取的网站数据字段的变化, 以往在爬虫入门时使用的方式局限性可能会飙升. 怎么个骤降法? intro 引例在爬虫入门的时侯,我们爬取豆瓣影片top250那些数据量并不是很大的网页时(仅估算文本数据...
- 利用爬虫获取舆情数据 -? 爬取的某急聘网站职位信息例如你可以批量爬取社交平台的数据资源,可以爬取网站的交易数据,爬取急聘网站的职位信息等,可以用于个性化的剖析研究。 总之,爬虫是十分强悍的,甚至有人说天下没有不能爬的网站,因而爬取数据也成为了好多极客的乐趣。 开发出高效的爬虫工具可以帮助我们...
请先阅读“中国年轻人正率领国家迈向危机”php 网络爬虫 抓取数据php 网络爬虫 抓取数据,这锅背是不背? 一文,以对“手把手教你完成一个数据科学小项目”系列有个全局性的了解。 上一篇文章(1)数据爬取里我讲解了怎样用爬虫爬取新浪财经《中国年轻人正率领国家迈向危机》一文的评论数据,其中涉及的抓包过程是挺通用的,大家假如想爬取其他网站,也会是类似...
在领英心知肚明的情况下(领英甚至还派出过代表出席过hiq的晚会),hiq这样做了两年,但是在领英开发了一个与 skill mapper 非常类似的产品以后,领英立即变了脸,其向 hiq 发出了 勒令停止侵权函 ,威胁道假如 hiq 不停止搜集其用户数据的话,就将其控告。 不仅这么,领英还采取了技术举措,阻断了hiq的数据爬取,hi...
什么是大数据和人工智能,分享2019年我用python爬虫技术做企业大数据的那些事儿由于仍然从事php+python+ai大数据深度挖掘的技术研制,当前互联网早已从it时代发展到data时代,人工智能+大数据是当前互联网技术领域的两大趋势,记得在2010-2016年从事过电商的技术研制,当时电商时代缔造了好多创业人,很多有看法的...
- 利用爬虫获取舆情数据 -? 爬取的某急聘网站职位信息例如你可以批量爬取社交平台的数据资源,可以爬取网站的交易数据,爬取急聘网站的职位信息等,可以用于个性化的剖析研究。 总之,爬虫是十分强悍的,甚至有人说天下没有不能爬的网站,因而爬取数据也成为了好多极客的乐趣。 开发出高效的爬虫工具可以帮助我们...
usrbinenv python# -*- coding:utf-8 -*-import urllibfrom urllib import requestimport jsonimportrandomimport reimport urllib.errodef hq_html(hq_url):hq_html()封装的爬虫函数,自动启用了用户代理和ip代理 接收一个参数url,要爬取页面的url,返回html源码 def yh_dl():#创建用户代理池 yhdl = thisua = ...
pandas 是使数据剖析工作显得愈发简单的中级数据结构,我们可以用 pandas 保存爬取的数据。 最后通过pandas再写入到xls或则mysql等数据库中。 requests...上一节中我们讲了怎样对用户画像建模,而建模之前我们都要进行数据采集。 数据采集是数据挖掘的基础,没有数据,挖掘也没有意义。 很多时侯,我们拥有多少... 查看全部
广告
云服务器1核2G首年95年,助力轻松上云!还有千元代金卷免费领,开团成功最高免费续费40个月!
代码托管地址: https:github.comhectorhuzhihuspider 这次抓取了110万的用户数据,数据剖析结果如下:? 开发前的打算安装linux系统(ubuntu14.04),在vmware虚拟机下安装一个ubuntu; 安装php5.6或以上版本; 安装mysql5.5或以上版本; 安装curl、pcntl扩充。 使用php的curl扩充抓取页面数据php的curl扩充是php支持...
但经验其实是经验,数据才是最靠谱的,通过剖析数据,可以评估一个队员的价值(当然,球员的各方面的表现(特征),都会有一个权重,最终评判权重*特征值之和最高者的神锋机率胜算大些)。 那么,如何获取那些数据呢? 写段简单的爬取数据的代码就是最好的获取工具。 本文以2014年的巴西世界杯球队为基础进行实践操作...
一、引言 在实际工作中,难免会遇见从网页爬取数据信息的需求,如:从谷歌官网上爬取最新发布的系统版本。 很明显这是个网页爬虫的工作,所谓网页爬虫,就是须要模拟浏览器,向网路服务器发送恳求便于将网路资源从网络流中读取下来,保存到本地,并对这种信息做些简单提取,将我们要的信息分离提取下来。 在做网页...
经过我的测试,我这一个学期以来的消费记录在这个网页上只有50多页,所以爬虫须要爬取的数据量太小,处理上去是完全没有压力的,直接一次性得到所有的结果以后保存文件就行了。 至于爬虫程序的语言选择,我也没哪些好说的,目前我也就对php比较熟悉一些,所以接下来的程序我也是用php完成的。 首先确定我应当怎样模拟...
如果你是有经验的开发者,完全可以跳过第一章步入第二章的学习了。 这个项目主要围绕两大核心点展开: 1. php爬虫 2. 代理ip 咱们先讲讲哪些是爬虫,简单来讲,爬虫就是一个侦测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按键,查查数据,或者把听到的信息背回去。 就像一只蟑螂在一幢楼里不知疲惫地爬...
通过抓取并剖析在线社交网站的数据,研究者可以迅速地掌握人类社交网路行为背后所隐藏的规律、机制乃至一般性的法则。 然而在线社交网络数据的获取方式...这个网站的网路链接为:http:members.lovingfromadistance.comforum.php,我们首先写一个叫screen_login的函数。 其核心是定义个浏览器对象br = mechanize...
每分钟执行一次爬取全省新型脑炎疫情实时动态并写入到指定的.php文件functionupdate() { (async () =&gt; { const browser = await puppeteer.launch({args: ...fscnpm i -g cron具体操作:用puppeteer爬取:puppeteer本质上是一个chrome浏览器,网页很难分清这是人类用户还是爬虫,我们可以用它来加载动态网页...
爬取微博的 id weibologin(username, password, cookie_path).login() withopen({}{}.csv.format(comment_path, id), mode=w, encoding=utf-8-sig...或者在文件中读取cookie数据到程序 self.session.cookies =cookielib.lwpcookiejar(filename=self.cookie_path) self.index_url = http:weibo.comlogin...
python爬虫突破限制,爬取vip视频主要介绍了python爬虫项目实例代码,文中通过示例代码介绍的十分详尽,对你们的学习或则工作具有一定的参考学习价值,需要的同学可以参考下? 其他也不多说什么直接附上源码? 只要学会爬虫技术,想爬取哪些资源基本都可以做到,当然python不止爬虫技术还有web开发,大数据,人工智能等! ...
但是使用java访问的时侯爬取的html里却没有该mp3的文件地址,那么这肯定是在该页面的位置使用了js来加载mp3,那么刷新下网页,看网页加载了什么东西,加载的东西有点多,着重看一下js、php的恳求,主要是看上面有没有mp3的地址,分析细节就不用说了。? 最终我在列表的https:wwwapi.kugou.comyyindex.php? r=playgetd...
总结上去就三部,首先获取登陆界面的验证码并储存cookie,然后通过cookie来模拟登录,最后步入教务系统取想要的东西。 现在我们须要去留心的内容,各个恳求的联接、header、和发送的数据2. 查看恳求首先我们查看首页,我们发觉登陆并不在首页上,需要点击用户登陆后才算步入了登陆界面。 然后我们查看登陆界面的恳求...
就是如此一个简单的功能,类似好多的云盘搜索类网站,我这个采集和搜索程序都是php实现的,全文和动词搜索部份使用到了开源软件xunsearch。 真实上线案例:搜碟子-网盘影片资源站上一篇( 网盘搜索引擎-采集爬取百度网盘分享文件实现云盘搜索中我重点介绍了如何去获取一大批的百度网盘用户,这一篇介绍如何获得指定...
当然, 并不是所有数据都适宜? 在学习爬虫的过程中, 遇到过不少坑. 今天这个坑可能之后你也会碰到, 随着爬取数据量的降低,以及爬取的网站数据字段的变化, 以往在爬虫入门时使用的方式局限性可能会飙升. 怎么个骤降法? intro 引例在爬虫入门的时侯,我们爬取豆瓣影片top250那些数据量并不是很大的网页时(仅估算文本数据...
- 利用爬虫获取舆情数据 -? 爬取的某急聘网站职位信息例如你可以批量爬取社交平台的数据资源,可以爬取网站的交易数据,爬取急聘网站的职位信息等,可以用于个性化的剖析研究。 总之,爬虫是十分强悍的,甚至有人说天下没有不能爬的网站,因而爬取数据也成为了好多极客的乐趣。 开发出高效的爬虫工具可以帮助我们...
请先阅读“中国年轻人正率领国家迈向危机”php 网络爬虫 抓取数据php 网络爬虫 抓取数据,这锅背是不背? 一文,以对“手把手教你完成一个数据科学小项目”系列有个全局性的了解。 上一篇文章(1)数据爬取里我讲解了怎样用爬虫爬取新浪财经《中国年轻人正率领国家迈向危机》一文的评论数据,其中涉及的抓包过程是挺通用的,大家假如想爬取其他网站,也会是类似...
在领英心知肚明的情况下(领英甚至还派出过代表出席过hiq的晚会),hiq这样做了两年,但是在领英开发了一个与 skill mapper 非常类似的产品以后,领英立即变了脸,其向 hiq 发出了 勒令停止侵权函 ,威胁道假如 hiq 不停止搜集其用户数据的话,就将其控告。 不仅这么,领英还采取了技术举措,阻断了hiq的数据爬取,hi...
什么是大数据和人工智能,分享2019年我用python爬虫技术做企业大数据的那些事儿由于仍然从事php+python+ai大数据深度挖掘的技术研制,当前互联网早已从it时代发展到data时代,人工智能+大数据是当前互联网技术领域的两大趋势,记得在2010-2016年从事过电商的技术研制,当时电商时代缔造了好多创业人,很多有看法的...
- 利用爬虫获取舆情数据 -? 爬取的某急聘网站职位信息例如你可以批量爬取社交平台的数据资源,可以爬取网站的交易数据,爬取急聘网站的职位信息等,可以用于个性化的剖析研究。 总之,爬虫是十分强悍的,甚至有人说天下没有不能爬的网站,因而爬取数据也成为了好多极客的乐趣。 开发出高效的爬虫工具可以帮助我们...
usrbinenv python# -*- coding:utf-8 -*-import urllibfrom urllib import requestimport jsonimportrandomimport reimport urllib.errodef hq_html(hq_url):hq_html()封装的爬虫函数,自动启用了用户代理和ip代理 接收一个参数url,要爬取页面的url,返回html源码 def yh_dl():#创建用户代理池 yhdl = thisua = ...
pandas 是使数据剖析工作显得愈发简单的中级数据结构,我们可以用 pandas 保存爬取的数据。 最后通过pandas再写入到xls或则mysql等数据库中。 requests...上一节中我们讲了怎样对用户画像建模,而建模之前我们都要进行数据采集。 数据采集是数据挖掘的基础,没有数据,挖掘也没有意义。 很多时侯,我们拥有多少...
大数据环境下基于python的网路爬虫技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 273 次浏览 • 2020-05-26 08:03
它让你才能专注于解决问题而不是去搞明白语言本身。(2)使用便捷,不需要笨重的 IDE,Python 只须要一个 sublime text 或者是一个文本编辑器,就可以进行大部分中小型应用的开发了。(3)功能强悍的爬虫框架 ScraPy,Scrapy 是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。(4)强大的网路支持库以及 html 解析器,利用网路支持库 requests,编写较少的代码,就可以下载网页。利用网页解析库 BeautifulSoup,可以便捷的解析网页各个标签,再结合正则表达式,方便的抓取网页中的内容。(5)十分擅长做文本处理字符串处理:python 包含了常用的文本处理函数,支持正则表达式,可以便捷的处理文本内容。 ■ 1.3 爬虫的工作原理网络爬虫是一个手动获取网页的程序,它为搜索引擎从互联网上下载网页,是搜索引擎的重要组成。从功能上来讲,爬虫通常分为数据采集,处理,储存三个部份。爬虫的工作原理,爬虫通常从一个或则多个初始 URL 开始,下载网页内容,然后通过搜索或是内容匹配手段(比如正则表达式),获取网页中感兴趣的内容,同时不断从当前页面提取新的 URL,根据网页抓取策略,按一定的次序倒入待抓取 URL 队列中,整个过程循环执行,一直到满足系统相应的停止条件,然后对那些被抓取的数据进行清洗,整理,并构建索引,存入数据库或文件中,最后按照查询须要,从数据库或文件中提取相应的数据,以文本或图表的形式显示下来。
■ 1.4 网页抓取策略在网路爬虫系统中,待抓取 URL 队列是很重要的一部分,待抓取 URL 队列中的 URL 以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面大数据网络爬虫原理,后抓取那个页面。而决定那些 URL 排列次序的方式,叫做抓取策略。网页的抓取策略可以分为深度优先、广度优先和最佳优先三种:(1)广度优先搜索策略,其主要思想是,由根节点开始,首先遍历当前层次的搜索,然后才进行下一层的搜索,依次类推逐层的搜索。这种策略多用在主题爬虫上,因为越是与初始 URL 距离逾的网页,其具有的主题相关性越大。(2)深度优先搜索策略,这种策略的主要思想是,从根节点出发找出叶子节点,以此类推。在一个网页中,选择一个超链接,被链接的网页将执行深度优先搜索,形成单独的一条搜索链,当没有其他超链接时,搜索结束。(3)最佳优先搜索策略,该策略通过估算 URL 描述文本与目标网页的相似度,或者与主题的相关性,根据所设定的阀值选出有效 URL 进行抓取。 ■ 1.5 网络爬虫模块按照网路爬虫的工作原理,设计了一个通用的爬虫框架结构,其结构图如图 1 所示。大数据环境下基于 python 的网路爬虫技术作者/谢克武,重庆工商大学派斯学院软件工程学院摘要:随着互联网的发展壮大,网络数据呈爆炸式下降,传统搜索引擎早已不能满足人们对所需求数据的获取的需求,作为搜索引擎的抓取数据的重要组成部份,网络爬虫的作用非常重要,本文首先介绍了在大数据环境下网络爬虫的重要性,接着介绍了网络爬虫的概念,工作原理,工作流程,网页爬行策略,python在编撰爬虫领域的优势,最后设计了一个通用网路爬虫的框架,介绍了框架中模块的互相协作完成数据抓取的过程。
关键词:网络爬虫;python;数据采集;大数据 | 45软件开发图 1网路爬虫的基本工作流程如下:(1)首先选定一部分悉心选购的种子 URL;(2)将这种 URL 放入待抓取 URL 队列;(3)从待抓取 URL 队列中取出待抓取在 URL,将URL 对应的网页下载出来,将下载出来的网页传给数据解析模块,再将这种 URL 放进已抓取 URL 队列。(4)分析下载模块传过来的网页数据,通过正则抒发,提取出感兴趣的数据,将数据传送给数据清洗模块,然后再解析其中的其他 URL,并且将 URL 传给 URL 调度模块。(5)URL 调度模块接收到数据解析模块传递过来的URL 数 据, 首 先 将 这 些 URL 数 据 和 已 抓 取 URL 队 列 比较,如果是早已抓取的 URL,就遗弃掉,如果是未抓取的URL,就按照系统的搜索策略,将 URL 放入待抓取 URL 队列。(6)整个系统在 3-5 步中循环,直到待抓取 URL 队列里所有的 URL 已经完全抓取,或者系统主动停止爬取,循环结束。(7)整理清洗数据,将数据以规范的格式存入数据库。(8)根据使用者偏好,将爬取结果从数据库中读出,以文字,图形的方法展示给使用者。
2. 系统模块整个系统主要有六个模块,爬虫主控模块,网页下载模块,网页解析模块,URL 调度模块,数据清洗模块,数据显示模块。这几个模块之间互相协作,共同完成网路数据抓取的功能。(1)主控模块,主要是完成一些初始化工作,生成种子 URL, 并将这种 URL 放入待爬取 URL 队列,启动网页下载器下载网页,然后解析网页,提取须要的数据和URL地址,进入工作循环,控制各个模块工作流程,协调各个模块之间的工作(2)网页下载模块,主要功能就是下载网页,但其中有几种情况,对于可以匿名访问的网页,可以直接下载,对于须要身分验证的,就须要模拟用户登录后再进行下载,对于须要数字签名或数字证书就能访问的网站,就须要获取相应证书,加载到程序中,通过验证以后才会下载网页。网络上数据丰富,对于不同的数据,需要不同的下载形式。数据下载完成后大数据网络爬虫原理,将下载的网页数据传递给网页解析模块,将URL 地址装入已爬取 URL 队列。(3)网页解析模块,它的主要功能是从网页中提取满足要求的信息传递给数据清洗模块,提取 URL 地址传递给URL 调度模块,另外,它还通过正则表达式匹配的方法或直接搜索的方法,来提取满足特定要求的数据,将这种数据传递给数据清洗模块。
(4)URL 调度模块,接收网页解析模块传递来的 URL地址,然后将这种 URL 地址和已爬取 URL 队列中的 URL 地址比较,如果 URL 存在于已爬取 URL 队列中,就遗弃这种URL 地址,如果不存在于已爬取 URL 队列中,就按系统采取的网页抓取策略,将 URL 放入待爬取 URL 地址相应的位置。(5)数据清洗模块,接收网页解析模块传送来的数据,网页解析模块提取的数据,一般是比较零乱或款式不规范的数据,这就须要对那些数据进行清洗,整理,将那些数据整理为满足一定格式的数据,然后将这种数据存入数据库中。(6)数据显示模块,根据用户需求,统计数据库中的数据,将统计结果以文本或则图文的形式显示下来,也可以将统计结果存入不同的格式的文件将中(如 word 文档,pdf 文档,或者 excel 文档),永久保存。3. 结束语如今早已步入大数据时代,社会各行各业都对数据有需求,对于一些现成的数据,可以通过网路免费获取或则订购,对于一下非现成的数据,就要求编撰特定的网路爬虫,自己在网路起来搜索,分析,转换为自己须要的数据,网络爬虫就满足了这个需求,而 python 简单易学,拥有现成的爬虫框架,强大的网路支持库,文本处理库,可以快速的实现满足特定功能的网路爬虫。
参考文献* [1]于成龙, 于洪波. 网络爬虫技术研究[J]. 东莞理工学院学报, 2011, 18(3):25-29.* [2]李俊丽. 基于Linux的python多线程爬虫程序设计[J]. 计算机与数字工程 , 2015, 43(5):861-863.* [3]周中华, 张惠然, 谢江. 基于Python的新浪微博数据爬虫[J]. 计算机应用 , 2014, 34(11):3131-3134. 查看全部
44 | 电子制做 2017 年 5月软件开发序言大数据背景下,各行各业都须要数据支持,如何在广袤的数据中获取自己感兴趣的数据,在数据搜索方面,现在的搜索引擎似乎比刚开始有了很大的进步,但对于一些特殊数据搜索或复杂搜索,还不能挺好的完成,利用搜索引擎的数据不能满足需求,网络安全,产品督查,都须要数据支持,而网路上没有现成的数据,需要自己自动去搜索、分析、提炼,格式化为满足需求的数据,而借助网路爬虫能手动完成数据获取,汇总的工作,大大提高了工作效率。1. 利用 python 实现网路爬虫相关技术 ■ 1.1 什么是网络爬虫网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。它们被广泛用于互联网搜索引擎或其他类似网站,以获取或更新那些网站的内容和检索方法。它们可以手动采集所有其才能访问到的页面内容,以供搜索引擎做进一步处理(分检整理下载的页面),而促使用户能更快的检索到她们须要的信息。 ■ 1.2 python 编写网路爬虫的优点(1)语言简练,简单易学,使用上去得心应手,编写一个良好的 Python 程序就觉得象是在用英文写文章一样,尽管这个英文的要求十分严格! Python 的这些伪代码本质是它最大的优点之一。
它让你才能专注于解决问题而不是去搞明白语言本身。(2)使用便捷,不需要笨重的 IDE,Python 只须要一个 sublime text 或者是一个文本编辑器,就可以进行大部分中小型应用的开发了。(3)功能强悍的爬虫框架 ScraPy,Scrapy 是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。(4)强大的网路支持库以及 html 解析器,利用网路支持库 requests,编写较少的代码,就可以下载网页。利用网页解析库 BeautifulSoup,可以便捷的解析网页各个标签,再结合正则表达式,方便的抓取网页中的内容。(5)十分擅长做文本处理字符串处理:python 包含了常用的文本处理函数,支持正则表达式,可以便捷的处理文本内容。 ■ 1.3 爬虫的工作原理网络爬虫是一个手动获取网页的程序,它为搜索引擎从互联网上下载网页,是搜索引擎的重要组成。从功能上来讲,爬虫通常分为数据采集,处理,储存三个部份。爬虫的工作原理,爬虫通常从一个或则多个初始 URL 开始,下载网页内容,然后通过搜索或是内容匹配手段(比如正则表达式),获取网页中感兴趣的内容,同时不断从当前页面提取新的 URL,根据网页抓取策略,按一定的次序倒入待抓取 URL 队列中,整个过程循环执行,一直到满足系统相应的停止条件,然后对那些被抓取的数据进行清洗,整理,并构建索引,存入数据库或文件中,最后按照查询须要,从数据库或文件中提取相应的数据,以文本或图表的形式显示下来。
■ 1.4 网页抓取策略在网路爬虫系统中,待抓取 URL 队列是很重要的一部分,待抓取 URL 队列中的 URL 以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面大数据网络爬虫原理,后抓取那个页面。而决定那些 URL 排列次序的方式,叫做抓取策略。网页的抓取策略可以分为深度优先、广度优先和最佳优先三种:(1)广度优先搜索策略,其主要思想是,由根节点开始,首先遍历当前层次的搜索,然后才进行下一层的搜索,依次类推逐层的搜索。这种策略多用在主题爬虫上,因为越是与初始 URL 距离逾的网页,其具有的主题相关性越大。(2)深度优先搜索策略,这种策略的主要思想是,从根节点出发找出叶子节点,以此类推。在一个网页中,选择一个超链接,被链接的网页将执行深度优先搜索,形成单独的一条搜索链,当没有其他超链接时,搜索结束。(3)最佳优先搜索策略,该策略通过估算 URL 描述文本与目标网页的相似度,或者与主题的相关性,根据所设定的阀值选出有效 URL 进行抓取。 ■ 1.5 网络爬虫模块按照网路爬虫的工作原理,设计了一个通用的爬虫框架结构,其结构图如图 1 所示。大数据环境下基于 python 的网路爬虫技术作者/谢克武,重庆工商大学派斯学院软件工程学院摘要:随着互联网的发展壮大,网络数据呈爆炸式下降,传统搜索引擎早已不能满足人们对所需求数据的获取的需求,作为搜索引擎的抓取数据的重要组成部份,网络爬虫的作用非常重要,本文首先介绍了在大数据环境下网络爬虫的重要性,接着介绍了网络爬虫的概念,工作原理,工作流程,网页爬行策略,python在编撰爬虫领域的优势,最后设计了一个通用网路爬虫的框架,介绍了框架中模块的互相协作完成数据抓取的过程。
关键词:网络爬虫;python;数据采集;大数据 | 45软件开发图 1网路爬虫的基本工作流程如下:(1)首先选定一部分悉心选购的种子 URL;(2)将这种 URL 放入待抓取 URL 队列;(3)从待抓取 URL 队列中取出待抓取在 URL,将URL 对应的网页下载出来,将下载出来的网页传给数据解析模块,再将这种 URL 放进已抓取 URL 队列。(4)分析下载模块传过来的网页数据,通过正则抒发,提取出感兴趣的数据,将数据传送给数据清洗模块,然后再解析其中的其他 URL,并且将 URL 传给 URL 调度模块。(5)URL 调度模块接收到数据解析模块传递过来的URL 数 据, 首 先 将 这 些 URL 数 据 和 已 抓 取 URL 队 列 比较,如果是早已抓取的 URL,就遗弃掉,如果是未抓取的URL,就按照系统的搜索策略,将 URL 放入待抓取 URL 队列。(6)整个系统在 3-5 步中循环,直到待抓取 URL 队列里所有的 URL 已经完全抓取,或者系统主动停止爬取,循环结束。(7)整理清洗数据,将数据以规范的格式存入数据库。(8)根据使用者偏好,将爬取结果从数据库中读出,以文字,图形的方法展示给使用者。
2. 系统模块整个系统主要有六个模块,爬虫主控模块,网页下载模块,网页解析模块,URL 调度模块,数据清洗模块,数据显示模块。这几个模块之间互相协作,共同完成网路数据抓取的功能。(1)主控模块,主要是完成一些初始化工作,生成种子 URL, 并将这种 URL 放入待爬取 URL 队列,启动网页下载器下载网页,然后解析网页,提取须要的数据和URL地址,进入工作循环,控制各个模块工作流程,协调各个模块之间的工作(2)网页下载模块,主要功能就是下载网页,但其中有几种情况,对于可以匿名访问的网页,可以直接下载,对于须要身分验证的,就须要模拟用户登录后再进行下载,对于须要数字签名或数字证书就能访问的网站,就须要获取相应证书,加载到程序中,通过验证以后才会下载网页。网络上数据丰富,对于不同的数据,需要不同的下载形式。数据下载完成后大数据网络爬虫原理,将下载的网页数据传递给网页解析模块,将URL 地址装入已爬取 URL 队列。(3)网页解析模块,它的主要功能是从网页中提取满足要求的信息传递给数据清洗模块,提取 URL 地址传递给URL 调度模块,另外,它还通过正则表达式匹配的方法或直接搜索的方法,来提取满足特定要求的数据,将这种数据传递给数据清洗模块。
(4)URL 调度模块,接收网页解析模块传递来的 URL地址,然后将这种 URL 地址和已爬取 URL 队列中的 URL 地址比较,如果 URL 存在于已爬取 URL 队列中,就遗弃这种URL 地址,如果不存在于已爬取 URL 队列中,就按系统采取的网页抓取策略,将 URL 放入待爬取 URL 地址相应的位置。(5)数据清洗模块,接收网页解析模块传送来的数据,网页解析模块提取的数据,一般是比较零乱或款式不规范的数据,这就须要对那些数据进行清洗,整理,将那些数据整理为满足一定格式的数据,然后将这种数据存入数据库中。(6)数据显示模块,根据用户需求,统计数据库中的数据,将统计结果以文本或则图文的形式显示下来,也可以将统计结果存入不同的格式的文件将中(如 word 文档,pdf 文档,或者 excel 文档),永久保存。3. 结束语如今早已步入大数据时代,社会各行各业都对数据有需求,对于一些现成的数据,可以通过网路免费获取或则订购,对于一下非现成的数据,就要求编撰特定的网路爬虫,自己在网路起来搜索,分析,转换为自己须要的数据,网络爬虫就满足了这个需求,而 python 简单易学,拥有现成的爬虫框架,强大的网路支持库,文本处理库,可以快速的实现满足特定功能的网路爬虫。
参考文献* [1]于成龙, 于洪波. 网络爬虫技术研究[J]. 东莞理工学院学报, 2011, 18(3):25-29.* [2]李俊丽. 基于Linux的python多线程爬虫程序设计[J]. 计算机与数字工程 , 2015, 43(5):861-863.* [3]周中华, 张惠然, 谢江. 基于Python的新浪微博数据爬虫[J]. 计算机应用 , 2014, 34(11):3131-3134.
【大数据爬虫技术是做哪些的】
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-05-24 08:02
在黑科技、爬虫、大数据领域深度技术研制领域,爬虫和黑客使用的技术虽然是一样的并且又有区别的,爬虫和黑客的区别在那里呢 ?大数据、爬虫、黑客有哪些关系呢?
黑客和爬虫最大的区别就是行为目的不同,黑客是干坏事,爬虫是干好事。因为黑客和爬虫使用的技术都是差不多,都是通过计算机网络技术进行对用户笔记本、网站、服务器进行入侵之后获取数据信息。区别是黑客是非法入侵,爬虫是合法入侵。比如黑客通过破解网站后台验证码技术之后模拟登录网站数据库,把数据库删除或则直接更改人家数据库,这种是非法入侵,破坏性行为、违法行为。 同样也是破解验证码技术,但是爬虫就不同了,比我须要获取个别政府网站的一些公开数据,但是每次都须要输入验证码很麻烦,为了增强数据剖析的工作效率,爬虫技术也是通过绕开验证码技术去采集网站公开、开放的数据,不会获取隐私不公开的数据。 如果把数据比喻女性,爬虫和黑客是女人,那么爬虫是男同学,是在正当合法、名正言顺的情况下和女的发生了关系,然而黑客不同,黑客就是强奸犯了,因为女的不是自愿的,黑客是强制性,甚至用暴力来和女的发生关系。这个就是黑客和爬虫的本质不同地方,虽然采用类似的技术手段来获取数据,但是采取的技术行为和最终造成的后果性质是不同的。一个是违规须要承当法律后果,一个是国家支持鼓励的是合法的。不管是爬虫还是黑客技术 都是一个工具而已,就像是柴刀一样,有人拿去切肉,有人拿去杀人,那砍刀是好还是坏呢,其实砍刀只是一个工具而已,好坏在于使用者的行为的结果
爬虫-谢天谢地您来了,好开心啊 黑客- 恶魔,离我远一点!给我滚!
2012年国家都不断对数据进行开放,中央要求每位政府单位必须把大家才能开放的数据开放下来,主要是中国在大力发展大数据科技产业,也就是我们常常看到的各类所谓专家、教授口里常常喊的数字产业化,数字中国,数字经济、大数据、人工智能、区块链等各类潮流高档词汇。那大数据和爬虫有哪些关系呢?以下从几个案例举例介绍:
人脸辨识: 您做人工智能是须要大数据的,举个反例您想做一个手动辨识人脸的人工智能机器。您首先须要依照人脸生物特点构建AI模型,然后须要几千万或则几十亿张人脸图片进行不断的训练这个模型,最后才得到精准的人脸辨识AI。几十亿的人脸图片数据那里来呢? 公安局给你?不可能的!一张张去照相?更不现实啦! 那就是通过网路爬虫技术构建人脸图像库,比如我们可以通过爬虫技术对facebook、qq头像、微信头像等进行爬取,来实现完善十几亿的人脸图象库。企业大数据:去年有个同学使我通过爬虫技术帮他完善1亿的企业工商数据库,因为他须要做企业剖析、企业画像,需要晓得每位城市的新注册企业多少、科技创新企业多少、企业中报、企业人才急聘、企业竞品、企业的融资风波、上市风波等等企业全部60个经度经度的数据,然后剖析企业的各类行为,最终做决策辅助使用。需要完成这个任务,其实我们就须要晓得,国家工商局早早就把企业工商数据公示了,而且还做了一个全省企业信息公示系统,让你们都可以查询各个公司的数据。居然数据源早已解决了,当时我就在想,如果有人早已把这种数据都聚合在一起那就更好了,但是最后发觉 天眼查、企查查、企信宝虽然早已帮我做了好多事情了。
最后我花了1个星期时间用python写了一套企业工商大数据网路爬虫系统,快速爬取企业工商数据信息,并且用mysql构建标准的企业大数据库。裁判文书大数据:自从国家英文裁判文书对外开放以后,经常好多有创新看法同学找我帮忙,他们有些想做一个案件的判例剖析系统,因为现今好多法院在判案的时侯都是须要查阅各类历史类似案件,之前的判官都是如何判的。然后做一些借鉴。现在有大数据好了,如果通过AI技术手动把案件文案扫描进去,然后通过裁判文书数据库进行深度剖析匹配,马上下来类似的判例结果下来,并按案件相恋度进行排序,最终产生一套法务判例AI智能系统。然后把这个系统提供给律师、法官、法院、税务所用。那么问题来了,需要实现这个第一步首先您须要有裁判文书大数据库,然后在数据库基础上构建一个案例剖析AI模型,其中须要用到爬虫技术来解决裁判文书数据源获取和更新问题,然后须要用到文本剖析技术、文本情感辨识技术、文本扫描剖析技术。我当时采用是一套国内的框架tensorFlow,这是一套由英国google brain研制下来的开源机器学习库,专门做深度学习、神经网路技术、模型训练框架。因为裁判文书爬虫须要解析算出它的DOCID值,然后通过多进程+多线程+cookie池技术来解决批量爬取的问题。
商标专利大数据:那么商标和专利和大数据又有哪些关系?和爬虫又扯上哪些关系呢?在中国聪明人虽然是不少的。商标和专利这个应当是太老土的过期成语,但是常常创新只是改变一下我们的思维、或者按照环境变化进行变革一下即可。因为有了大数据,有了政府开放数据,有大数据深度挖掘技术,有了AI人智能,有了5G,那么之前我们采用的工具和模式都须要调整了。在从事AI和大数据路上还是遇见不少有创新和智慧的人爬虫技术,有三天有一个陌生好友加我,问我说可以帮他做一个商标专利大数据吗? 我问他哪些是商标专利大数据,他说就是监控商标网和专利网的实时更新数据,我只要有一套AI技术系统,可以实现获取最新申请的专利信息数据和商标数据,然后就可以晓得什么企业有申请专利、申请知识产权的需求,我问他:您怎样盈利呢? 他说盈利形式太多了,比如2020年新型冠状病毒,我通过这个系统就可以晓得什么企业在申请关于生产卡介苗的专利和商标,哪些企业在申请生产医疗物资的知识产权,那么这种企业都是科技创新企业,都可以领到政府扶植资金,我可以把这个弄成一个大数据平台专门服务于那个做知识产权企业和做国家财税补助申请机构,那通过这个数据,很多投资机构也可以合作把握什么企业在生产未来具有前景的产品。
关于专利和商标大数据还有一个更聪明的人也是私聊我,同样问题,问他怎样盈利,做这种数据做什么,他说诸如我如今晓得有大公司在申请一个商标叫“麦当劳”,那么我马上就申请一个叫“迈当老”谐音的商标,那么这个大公司的商标麦当老肯定会做大,品牌的, 我的那种译音的“迈当老”就值钱了,就可以卖个几十万都行的。我问他 这样紧靠名子算算侵权吗? 他说国家规定的 只要是同一年时间申请的,之后使用都不算是侵权。最后也是通过构建一套大数据AI爬虫系统帮助他实现了这个功能。最后不知道他营运怎么了。欢迎对大数据挖掘和AI感兴趣同事交流我qq:2779571288税务大数据: 因为国家税务局对对开放,可以在网上查询到什么企业欠税,哪些企业税务异常了。 那么那些东西又有什么用呢?怎么又和大数据产业牵涉上了吗,不就是查询一下什么企业欠税而已嘛。这个很多人就不懂了,或者看不透了,这个须要用大数据产业化思维,在大数据时代,每个数据都是财富,数据就价值,您想不到说明的还没有发觉奥秘,如果您想到了恐怕其实就过时了,就像电商时代一样。税务大数据主要是给做财税、代理记账、税务局用的。做财务的公司每晚都想知道什么企业欠税了、出现税务异常了,您公司出现税务异常肯定是须要找财务公入帮忙处理,这个就是商业核心点所在,那么完善完这个税务大数据系统,就可以解决所有财税公司、代理记帐公司的客源问题。
那问题又来来,数据都是从税务局下来的,税务局要这个数据干哪些呢? 现在国家非常强化“互联网+监管,互联网+环境,互联网+治安”,数据源其实是税务局下来的,但是用原始数据进行提炼再去结合其他数据就是爆发出各类火花了。 税务数据结合+企业工商信息数据产生一个闭环税务监管大数据系统。欢迎对大数据挖掘和AI感兴趣同学交流我qq:2779571288
更多的大数据你们发展和未来,大家可以网上搜索“xx市政府开放数据平台”,就可以看见我们国家几乎每位县都构建了一个政府大数据共享开放的平台。每个县都有,如果您区没有这个政府开发数据平台,那就是您这个区没有跟上节奏。政府在努力的不断开放数据爬虫技术,就是大力发展大数据产业、激发传统企业变革。实现数字化中国、数字经济化、数字产业化。大数据。
最后推荐目前流行的几个大数据深度学习、神经网路技术框架给您,也是我常常使用做大数据剖析、深度爬虫的框架。
1 CAff
2 Tensorflow
3 Pytorch
4 Theano
5 Keras
6 MxNet
7 Chainer
这些框架各有优势,根据自己的喜好来,我个人是比较喜欢使用
Tensorflow、 CAff、 Keras。欢迎对大数据挖掘和AI感兴趣同学交流我qq:2779571288 查看全部
大数据是女性!爬虫是男同学!黑客是强奸犯,深度好文
在黑科技、爬虫、大数据领域深度技术研制领域,爬虫和黑客使用的技术虽然是一样的并且又有区别的,爬虫和黑客的区别在那里呢 ?大数据、爬虫、黑客有哪些关系呢?
黑客和爬虫最大的区别就是行为目的不同,黑客是干坏事,爬虫是干好事。因为黑客和爬虫使用的技术都是差不多,都是通过计算机网络技术进行对用户笔记本、网站、服务器进行入侵之后获取数据信息。区别是黑客是非法入侵,爬虫是合法入侵。比如黑客通过破解网站后台验证码技术之后模拟登录网站数据库,把数据库删除或则直接更改人家数据库,这种是非法入侵,破坏性行为、违法行为。 同样也是破解验证码技术,但是爬虫就不同了,比我须要获取个别政府网站的一些公开数据,但是每次都须要输入验证码很麻烦,为了增强数据剖析的工作效率,爬虫技术也是通过绕开验证码技术去采集网站公开、开放的数据,不会获取隐私不公开的数据。 如果把数据比喻女性,爬虫和黑客是女人,那么爬虫是男同学,是在正当合法、名正言顺的情况下和女的发生了关系,然而黑客不同,黑客就是强奸犯了,因为女的不是自愿的,黑客是强制性,甚至用暴力来和女的发生关系。这个就是黑客和爬虫的本质不同地方,虽然采用类似的技术手段来获取数据,但是采取的技术行为和最终造成的后果性质是不同的。一个是违规须要承当法律后果,一个是国家支持鼓励的是合法的。不管是爬虫还是黑客技术 都是一个工具而已,就像是柴刀一样,有人拿去切肉,有人拿去杀人,那砍刀是好还是坏呢,其实砍刀只是一个工具而已,好坏在于使用者的行为的结果
爬虫-谢天谢地您来了,好开心啊 黑客- 恶魔,离我远一点!给我滚!
2012年国家都不断对数据进行开放,中央要求每位政府单位必须把大家才能开放的数据开放下来,主要是中国在大力发展大数据科技产业,也就是我们常常看到的各类所谓专家、教授口里常常喊的数字产业化,数字中国,数字经济、大数据、人工智能、区块链等各类潮流高档词汇。那大数据和爬虫有哪些关系呢?以下从几个案例举例介绍:
人脸辨识: 您做人工智能是须要大数据的,举个反例您想做一个手动辨识人脸的人工智能机器。您首先须要依照人脸生物特点构建AI模型,然后须要几千万或则几十亿张人脸图片进行不断的训练这个模型,最后才得到精准的人脸辨识AI。几十亿的人脸图片数据那里来呢? 公安局给你?不可能的!一张张去照相?更不现实啦! 那就是通过网路爬虫技术构建人脸图像库,比如我们可以通过爬虫技术对facebook、qq头像、微信头像等进行爬取,来实现完善十几亿的人脸图象库。企业大数据:去年有个同学使我通过爬虫技术帮他完善1亿的企业工商数据库,因为他须要做企业剖析、企业画像,需要晓得每位城市的新注册企业多少、科技创新企业多少、企业中报、企业人才急聘、企业竞品、企业的融资风波、上市风波等等企业全部60个经度经度的数据,然后剖析企业的各类行为,最终做决策辅助使用。需要完成这个任务,其实我们就须要晓得,国家工商局早早就把企业工商数据公示了,而且还做了一个全省企业信息公示系统,让你们都可以查询各个公司的数据。居然数据源早已解决了,当时我就在想,如果有人早已把这种数据都聚合在一起那就更好了,但是最后发觉 天眼查、企查查、企信宝虽然早已帮我做了好多事情了。
最后我花了1个星期时间用python写了一套企业工商大数据网路爬虫系统,快速爬取企业工商数据信息,并且用mysql构建标准的企业大数据库。裁判文书大数据:自从国家英文裁判文书对外开放以后,经常好多有创新看法同学找我帮忙,他们有些想做一个案件的判例剖析系统,因为现今好多法院在判案的时侯都是须要查阅各类历史类似案件,之前的判官都是如何判的。然后做一些借鉴。现在有大数据好了,如果通过AI技术手动把案件文案扫描进去,然后通过裁判文书数据库进行深度剖析匹配,马上下来类似的判例结果下来,并按案件相恋度进行排序,最终产生一套法务判例AI智能系统。然后把这个系统提供给律师、法官、法院、税务所用。那么问题来了,需要实现这个第一步首先您须要有裁判文书大数据库,然后在数据库基础上构建一个案例剖析AI模型,其中须要用到爬虫技术来解决裁判文书数据源获取和更新问题,然后须要用到文本剖析技术、文本情感辨识技术、文本扫描剖析技术。我当时采用是一套国内的框架tensorFlow,这是一套由英国google brain研制下来的开源机器学习库,专门做深度学习、神经网路技术、模型训练框架。因为裁判文书爬虫须要解析算出它的DOCID值,然后通过多进程+多线程+cookie池技术来解决批量爬取的问题。
商标专利大数据:那么商标和专利和大数据又有哪些关系?和爬虫又扯上哪些关系呢?在中国聪明人虽然是不少的。商标和专利这个应当是太老土的过期成语,但是常常创新只是改变一下我们的思维、或者按照环境变化进行变革一下即可。因为有了大数据,有了政府开放数据,有大数据深度挖掘技术,有了AI人智能,有了5G,那么之前我们采用的工具和模式都须要调整了。在从事AI和大数据路上还是遇见不少有创新和智慧的人爬虫技术,有三天有一个陌生好友加我,问我说可以帮他做一个商标专利大数据吗? 我问他哪些是商标专利大数据,他说就是监控商标网和专利网的实时更新数据,我只要有一套AI技术系统,可以实现获取最新申请的专利信息数据和商标数据,然后就可以晓得什么企业有申请专利、申请知识产权的需求,我问他:您怎样盈利呢? 他说盈利形式太多了,比如2020年新型冠状病毒,我通过这个系统就可以晓得什么企业在申请关于生产卡介苗的专利和商标,哪些企业在申请生产医疗物资的知识产权,那么这种企业都是科技创新企业,都可以领到政府扶植资金,我可以把这个弄成一个大数据平台专门服务于那个做知识产权企业和做国家财税补助申请机构,那通过这个数据,很多投资机构也可以合作把握什么企业在生产未来具有前景的产品。
关于专利和商标大数据还有一个更聪明的人也是私聊我,同样问题,问他怎样盈利,做这种数据做什么,他说诸如我如今晓得有大公司在申请一个商标叫“麦当劳”,那么我马上就申请一个叫“迈当老”谐音的商标,那么这个大公司的商标麦当老肯定会做大,品牌的, 我的那种译音的“迈当老”就值钱了,就可以卖个几十万都行的。我问他 这样紧靠名子算算侵权吗? 他说国家规定的 只要是同一年时间申请的,之后使用都不算是侵权。最后也是通过构建一套大数据AI爬虫系统帮助他实现了这个功能。最后不知道他营运怎么了。欢迎对大数据挖掘和AI感兴趣同事交流我qq:2779571288税务大数据: 因为国家税务局对对开放,可以在网上查询到什么企业欠税,哪些企业税务异常了。 那么那些东西又有什么用呢?怎么又和大数据产业牵涉上了吗,不就是查询一下什么企业欠税而已嘛。这个很多人就不懂了,或者看不透了,这个须要用大数据产业化思维,在大数据时代,每个数据都是财富,数据就价值,您想不到说明的还没有发觉奥秘,如果您想到了恐怕其实就过时了,就像电商时代一样。税务大数据主要是给做财税、代理记账、税务局用的。做财务的公司每晚都想知道什么企业欠税了、出现税务异常了,您公司出现税务异常肯定是须要找财务公入帮忙处理,这个就是商业核心点所在,那么完善完这个税务大数据系统,就可以解决所有财税公司、代理记帐公司的客源问题。
那问题又来来,数据都是从税务局下来的,税务局要这个数据干哪些呢? 现在国家非常强化“互联网+监管,互联网+环境,互联网+治安”,数据源其实是税务局下来的,但是用原始数据进行提炼再去结合其他数据就是爆发出各类火花了。 税务数据结合+企业工商信息数据产生一个闭环税务监管大数据系统。欢迎对大数据挖掘和AI感兴趣同学交流我qq:2779571288
更多的大数据你们发展和未来,大家可以网上搜索“xx市政府开放数据平台”,就可以看见我们国家几乎每位县都构建了一个政府大数据共享开放的平台。每个县都有,如果您区没有这个政府开发数据平台,那就是您这个区没有跟上节奏。政府在努力的不断开放数据爬虫技术,就是大力发展大数据产业、激发传统企业变革。实现数字化中国、数字经济化、数字产业化。大数据。
最后推荐目前流行的几个大数据深度学习、神经网路技术框架给您,也是我常常使用做大数据剖析、深度爬虫的框架。
1 CAff
2 Tensorflow
3 Pytorch
4 Theano
5 Keras
6 MxNet
7 Chainer
这些框架各有优势,根据自己的喜好来,我个人是比较喜欢使用
Tensorflow、 CAff、 Keras。欢迎对大数据挖掘和AI感兴趣同学交流我qq:2779571288
【网络爬虫数据挖掘】
采集交流 • 优采云 发表了文章 • 0 个评论 • 375 次浏览 • 2020-05-22 08:03
网络爬虫数据挖掘 相关内容
关于java开发、网络爬虫、自然语言处理、数据挖掘简介与关系小结
阅读数 289
近日在爬虫、自然语言处理群320349384中,有不少群友讨论也有不少私聊的朋友如标题的内容,在这里做一个小综述,多为个人总结,仅供参考,在此只注重技术层面的描述,不参杂业务相关. 一、Java开发,主要包括应用开发、web开发、移动端Javame、Android开发。 (1) 应用开发,即Java SE开发,不属于java的优势所在,所以市场占有率太低
博文来自: a519781181
Java开发、网络爬虫、自然语言处理、数据挖掘简介
阅读数 1640
一、java开发(1) 应用开发,即Java SE开发,不属于java的优势所在,所以市场占有率太低,前途也不被看好。(2) web开发,即Java Web开发,主要是基于自有或第三方成熟框架的系统开发,如ssh、springMvc、springside、nutz、,面向各自不同的领域网络爬虫算法书籍,像OA、金融、教育等有十分成熟案例,这是目前最大的市场所在,故人称“java为web而生”。
博文来自: kl28978113
5分钟快速入门大数据、数据挖掘、机器学习
阅读数 429
本文简略介绍了大数据、数据挖掘和机器学习。对于任何想要理解哪些是大数据、数据挖掘和机器学习以及它们之间的关系的人来说,这篇文章都应当很容易看懂。数据挖掘和大数据能做哪些?简而言之网络爬虫算法书籍,它们赋于我们预测的能力。1、我们的生活早已被数字化明天,我们每晚做的许多事情都可以被记录出来。每笔信用卡交易都是数字化、可溯源的;我们的公众形象仍然遭到在城市各处悬挂的许多中央电视台的监...
博文来自: BAZHUAYUdata
Java 网络爬虫基础入门
阅读数 32329
课程介绍大数据环境下,数据剖析已由业务驱动转变为数据驱动,网络数据资源呈指数级下降,且洒落在不同的数据源之中。对大多数企业和研究者而言,用“数据说话”仿佛成了大数据时代的重要装备。网络爬虫作为网路数据获取的重要技术,受到了越来越多数据需求者的偏爱和青睐。作为网路爬虫的入门教程,本达人课采用 Java 开发语言,内容涵括了网路爬虫的原理以及开发逻辑,Java 网络爬虫基础知识,网络抓包介绍,...
博文来自: valada
python数据可视化、数据挖掘、机器学习、深度学习 常用库、IDE等
阅读数 144
一、可视化方式条形图饼图箱线图(箱型图)气泡图直方图核密度估计(KDE)图线面图网路图散点图树状图小提琴图方形图三维图二、交互式工具Ipython、Ipython notebookPlotly三、Python IDE类型PyCharm,指定了基于Java Swing的用户...
博文来自: weixin_33877092 查看全部
网络爬虫数据挖掘 相关内容
关于java开发、网络爬虫、自然语言处理、数据挖掘简介与关系小结
阅读数 289
近日在爬虫、自然语言处理群320349384中,有不少群友讨论也有不少私聊的朋友如标题的内容,在这里做一个小综述,多为个人总结,仅供参考,在此只注重技术层面的描述,不参杂业务相关. 一、Java开发,主要包括应用开发、web开发、移动端Javame、Android开发。 (1) 应用开发,即Java SE开发,不属于java的优势所在,所以市场占有率太低
博文来自: a519781181
Java开发、网络爬虫、自然语言处理、数据挖掘简介
阅读数 1640
一、java开发(1) 应用开发,即Java SE开发,不属于java的优势所在,所以市场占有率太低,前途也不被看好。(2) web开发,即Java Web开发,主要是基于自有或第三方成熟框架的系统开发,如ssh、springMvc、springside、nutz、,面向各自不同的领域网络爬虫算法书籍,像OA、金融、教育等有十分成熟案例,这是目前最大的市场所在,故人称“java为web而生”。
博文来自: kl28978113
5分钟快速入门大数据、数据挖掘、机器学习
阅读数 429
本文简略介绍了大数据、数据挖掘和机器学习。对于任何想要理解哪些是大数据、数据挖掘和机器学习以及它们之间的关系的人来说,这篇文章都应当很容易看懂。数据挖掘和大数据能做哪些?简而言之网络爬虫算法书籍,它们赋于我们预测的能力。1、我们的生活早已被数字化明天,我们每晚做的许多事情都可以被记录出来。每笔信用卡交易都是数字化、可溯源的;我们的公众形象仍然遭到在城市各处悬挂的许多中央电视台的监...
博文来自: BAZHUAYUdata
Java 网络爬虫基础入门
阅读数 32329
课程介绍大数据环境下,数据剖析已由业务驱动转变为数据驱动,网络数据资源呈指数级下降,且洒落在不同的数据源之中。对大多数企业和研究者而言,用“数据说话”仿佛成了大数据时代的重要装备。网络爬虫作为网路数据获取的重要技术,受到了越来越多数据需求者的偏爱和青睐。作为网路爬虫的入门教程,本达人课采用 Java 开发语言,内容涵括了网路爬虫的原理以及开发逻辑,Java 网络爬虫基础知识,网络抓包介绍,...
博文来自: valada
python数据可视化、数据挖掘、机器学习、深度学习 常用库、IDE等
阅读数 144
一、可视化方式条形图饼图箱线图(箱型图)气泡图直方图核密度估计(KDE)图线面图网路图散点图树状图小提琴图方形图三维图二、交互式工具Ipython、Ipython notebookPlotly三、Python IDE类型PyCharm,指定了基于Java Swing的用户...
博文来自: weixin_33877092
有了这个数据采集工具,不懂爬虫代码,也能轻松爬数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 428 次浏览 • 2020-05-18 08:02
但实际情况是,对于日常工作中的各类小决策,内部提供的数据有时还不足给以充分支持,外部的数据大部分又常常都是机构开具的行业状况,并不能提供哪些有效帮助。
于是产品和运营们常常要依靠爬虫来抓取自己想要的数据。比如想要获取某个电商 App 的评论数据,往往须要写出一段代码,借助python去抓取出相应的内容。
说到学写代码……额,我选择舍弃。
那么问题来了,有没有哪些更方便的方式呢?
今天就为你们介绍个能适应大多数场景的移动端数据采集工具,即使不懂爬虫代码,你也能轻松获取你想要的数据。
重点是,这个软件如今处于内测期间,所有功能都是可以免费使用的喔~,而且预售价三折,保证你买到就赚到!
触控精灵
触控精灵是由列车采集器团队研制,这是个太老牌的网站数据采集团队啦,从诞生至今早已十几年了。旗下产品列车采集器、火车浏览器经过不断的更新迭代,功能也越来越多。软件的用户量仍然在同类软件中居于第一,毕竟是十几年的老司机。
触控精灵是团队由 PC 端转向移动端的重要一步,它是一款手机端的数据采集工具,能够实现手机端 95%以上 App的数据采集,并且现今内测期间没有任何功能限制火车头网络 爬虫软件,任何人都可以下载安装使用。
用途
触控精灵操作极简,能够实现2分钟快速入门火车头网络 爬虫软件,完全可视化图形操作,无需专业IT人员,任何会使用笔记本上网的人都可以轻松把握,它有哪些实际应用呢?
1. 各类 App 数据,如年报,年报,财务报告, 包括每日最新净值手动采集;
2. 各大移动端新闻 App 实时监控,自动更新及上传最新发布的新闻;
3. 电商 App 内监控竞争对手最新信息,包括商品价钱及库存;
4. 抓取各大社交 App 的公开内容,如抖音,自动抓取产品的相关评论;
5. 收集如 Boss直聘、拉勾等 App 最新最全的职场急聘信息;
6. 监控各大地产相关 App ,采集新房二手房最新行情;
7. 采集各大车辆 App 具体的新车二手车信息;
8. 发现和搜集潜在顾客信息;
触控精灵可以实现数据的抓取、清洗、分析,挖掘及最终的可用数据呈现,堪称一条龙服务。
它的第一个特征是适用范围广,采集数据确切。几乎适用于所有的移动端 App,以及 App 能够看见的所有内容。可以通过设定内容采集规则,轻松迅速地抓取 App 上散乱分布的文本、图片、压缩文件、视频等内容。
比如采集微博客户端上的标题以及作者的数据,但是页面上有图片,也有文字,只要在采集的时侯设定好采集的规则,就能精准地只采集到标题名和作者的名子。
此外,对于采集到的信息数据,它还可以对其进行一系列的智能处理,使采集到的数据愈加符合我们的使用标准。比如过滤掉不需要的空格啦,标签啦,同义词替换啦,繁简转换啦等等。
看到这儿有朋友要问了,说了这么多,还是不知道如何操作,怎么破。别担心,触控精灵的网站上,还有提供菜鸟的入门指南和视频教程,不懂的问题可以在峰会内提问也可以在 QQ 群里向客服寻问,也可以在峰会里跟随前辈快速学习触控精灵的操作。
地址
有兴趣的朋友可以登录官网下载使用哦
同学们学会了吗?^_^ 查看全部
产品和营运在日常工作中,常常须要参考各类数据,来为决策做支持。
但实际情况是,对于日常工作中的各类小决策,内部提供的数据有时还不足给以充分支持,外部的数据大部分又常常都是机构开具的行业状况,并不能提供哪些有效帮助。
于是产品和运营们常常要依靠爬虫来抓取自己想要的数据。比如想要获取某个电商 App 的评论数据,往往须要写出一段代码,借助python去抓取出相应的内容。
说到学写代码……额,我选择舍弃。
那么问题来了,有没有哪些更方便的方式呢?
今天就为你们介绍个能适应大多数场景的移动端数据采集工具,即使不懂爬虫代码,你也能轻松获取你想要的数据。
重点是,这个软件如今处于内测期间,所有功能都是可以免费使用的喔~,而且预售价三折,保证你买到就赚到!
触控精灵
触控精灵是由列车采集器团队研制,这是个太老牌的网站数据采集团队啦,从诞生至今早已十几年了。旗下产品列车采集器、火车浏览器经过不断的更新迭代,功能也越来越多。软件的用户量仍然在同类软件中居于第一,毕竟是十几年的老司机。
触控精灵是团队由 PC 端转向移动端的重要一步,它是一款手机端的数据采集工具,能够实现手机端 95%以上 App的数据采集,并且现今内测期间没有任何功能限制火车头网络 爬虫软件,任何人都可以下载安装使用。
用途
触控精灵操作极简,能够实现2分钟快速入门火车头网络 爬虫软件,完全可视化图形操作,无需专业IT人员,任何会使用笔记本上网的人都可以轻松把握,它有哪些实际应用呢?
1. 各类 App 数据,如年报,年报,财务报告, 包括每日最新净值手动采集;
2. 各大移动端新闻 App 实时监控,自动更新及上传最新发布的新闻;
3. 电商 App 内监控竞争对手最新信息,包括商品价钱及库存;
4. 抓取各大社交 App 的公开内容,如抖音,自动抓取产品的相关评论;
5. 收集如 Boss直聘、拉勾等 App 最新最全的职场急聘信息;
6. 监控各大地产相关 App ,采集新房二手房最新行情;
7. 采集各大车辆 App 具体的新车二手车信息;
8. 发现和搜集潜在顾客信息;
触控精灵可以实现数据的抓取、清洗、分析,挖掘及最终的可用数据呈现,堪称一条龙服务。
它的第一个特征是适用范围广,采集数据确切。几乎适用于所有的移动端 App,以及 App 能够看见的所有内容。可以通过设定内容采集规则,轻松迅速地抓取 App 上散乱分布的文本、图片、压缩文件、视频等内容。
比如采集微博客户端上的标题以及作者的数据,但是页面上有图片,也有文字,只要在采集的时侯设定好采集的规则,就能精准地只采集到标题名和作者的名子。
此外,对于采集到的信息数据,它还可以对其进行一系列的智能处理,使采集到的数据愈加符合我们的使用标准。比如过滤掉不需要的空格啦,标签啦,同义词替换啦,繁简转换啦等等。
看到这儿有朋友要问了,说了这么多,还是不知道如何操作,怎么破。别担心,触控精灵的网站上,还有提供菜鸟的入门指南和视频教程,不懂的问题可以在峰会内提问也可以在 QQ 群里向客服寻问,也可以在峰会里跟随前辈快速学习触控精灵的操作。
地址
有兴趣的朋友可以登录官网下载使用哦
同学们学会了吗?^_^
什么是网络爬虫?有哪些用?怎么爬?终于有人讲明白了
采集交流 • 优采云 发表了文章 • 0 个评论 • 334 次浏览 • 2020-05-17 08:02
01 什么是网络爬虫
随着大数据时代的将至,网络爬虫在互联网中的地位将越来越重要。互联网中的数据是海量的,如何手动高效地获取互联网中我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这种问题而生的。
我们感兴趣的信息分为不同的类型:如果只是做搜索引擎,那么感兴趣的信息就是互联网中尽可能多的高质量网页;如果要获取某一垂直领域的数据或则有明晰的检索需求,那么感兴趣的信息就是按照我们的检索和需求所定位的这种信息,此时,需要过滤掉一些无用信息。前者我们称为通用网路爬虫,后者我们称为聚焦网路爬虫。
1. 初识网络爬虫
网络爬虫又称网路蜘蛛、网络蚂蚁、网络机器人等,可以自动化浏览网路中的信息,当然浏览信息的时侯须要根据我们制订的规则进行,这些规则我们称之为网络爬虫算法。使用Python可以很方便地编写出爬虫程序,进行互联网信息的自动化检索。
搜索引擎离不开爬虫,比如百度搜索引擎的爬虫叫作百度蜘蛛(Baiduspider)。百度蜘蛛每晚会在海量的互联网信息中进行爬取,爬取优质信息并收录,当用户在百度搜索引擎上检索对应关键词时,百度将对关键词进行剖析处理,从收录的网页中找出相关网页,按照一定的排行规则进行排序并将结果诠释给用户。
在这个过程中,百度蜘蛛起到了至关重要的作用。那么,如何覆盖互联网中更多的优质网页?又怎样筛选这种重复的页面?这些都是由百度蜘蛛爬虫的算法决定的。采用不同的算法,爬虫的运行效率会不同,爬取结果也会有所差别。
所以,我们在研究爬虫的时侯,不仅要了解爬虫怎样实现,还须要晓得一些常见爬虫的算法,如果有必要,我们还须要自己去制订相应的算法,在此,我们仅须要对爬虫的概念有一个基本的了解。
除了百度搜索引擎离不开爬虫以外,其他搜索引擎也离不开爬虫,它们也拥有自己的爬虫。比如360的爬虫叫360Spider,搜狗的爬虫叫Sogouspider,必应的爬虫叫Bingbot。
如果想自己实现一款大型的搜索引擎,我们也可以编撰出自己的爬虫去实现,当然,虽然可能在性能或则算法上比不上主流的搜索引擎,但是个性化的程度会特别高,并且也有利于我们更深层次地理解搜索引擎内部的工作原理。
大数据时代也离不开爬虫,比如在进行大数据剖析或数据挖掘时,我们可以去一些比较小型的官方站点下载数据源。但这种数据源比较有限,那么怎么能够获取更多更高质量的数据源呢?此时,我们可以编撰自己的爬虫程序,从互联网中进行数据信息的获取。所以在未来,爬虫的地位会越来越重要。
2. 为什么要学网络爬虫
我们初步认识了网路爬虫,但是为何要学习网路爬虫呢?要知道,只有清晰地晓得我们的学习目的,才能够更好地学习这一项知识,我们将会为你们剖析一下学习网路爬虫的诱因。
当然,不同的人学习爬虫,可能目的有所不同,在此,我们总结了4种常见的学习爬虫的诱因。
1)学习爬虫,可以私人订制一个搜索引擎,并且可以对搜索引擎的数据采集工作原理进行更深层次地理解。
有的同事希望还能深层次地了解搜索引擎的爬虫工作原理,或者希望自己才能开发出一款私人搜索引擎,那么此时,学习爬虫是十分有必要的。
简单来说,我们学会了爬虫编撰以后,就可以借助爬虫手动地采集互联网中的信息,采集回来后进行相应的储存或处理,在须要检索个别信息的时侯爬虫软件干嘛用,只需在采集回来的信息中进行检索,即实现了私人的搜索引擎。
当然,信息如何爬取、怎么储存、怎么进行动词、怎么进行相关性估算等,都是须要我们进行设计的,爬虫技术主要解决信息爬取的问题。
2)大数据时代,要进行数据剖析,首先要有数据源,而学习爬虫,可以使我们获取更多的数据源,并且这种数据源可以按我们的目的进行采集,去掉好多无关数据。
在进行大数据剖析或则进行数据挖掘的时侯,数据源可以从个别提供数据统计的网站获得,也可以从个别文献或内部资料中获得,但是这种获得数据的方法,有时很难满足我们对数据的需求,而自动从互联网中去找寻那些数据,则花费的精力过大。
此时就可以借助爬虫技术,自动地从互联网中获取我们感兴趣的数据内容,并将这种数据内容爬取回去,作为我们的数据源,从而进行更深层次的数据剖析,并获得更多有价值的信息。
3)对于好多SEO从业者来说,学习爬虫,可以更深层次地理解搜索引擎爬虫的工作原理,从而可以更好地进行搜索引擎优化。
既然是搜索引擎优化,那么就必须要对搜索引擎的工作原理十分清楚,同时也须要把握搜索引擎爬虫的工作原理,这样在进行搜索引擎优化时,才能知己知彼,百战不殆。
4)从就业的角度来说,爬虫工程师目前来说属于短缺人才,并且工资待遇普遍较高,所以,深层次地把握这门技术,对于就业来说,是十分有利的。
有些同学学习爬虫可能为了就业或则跳槽。从这个角度来说,爬虫工程师方向是不错的选择之一,因为目前爬虫工程师的需求越来越大,而才能胜任这方面岗位的人员较少,所以属于一个比较短缺的职业方向,并且随着大数据时代的将至,爬虫技术的应用将越来越广泛,在未来会拥有挺好的发展空间。
除了以上为你们总结的4种常见的学习爬虫的诱因外,可能你还有一些其他学习爬虫的缘由,总之,不管是哪些缘由,理清自己学习的目的,就可以更好地去研究一门知识技术,并坚持出来。
3. 网络爬虫的组成
接下来,我们将介绍网路爬虫的组成。网络爬虫由控制节点、爬虫节点、资源库构成。
图1-1所示是网路爬虫的控制节点和爬虫节点的结构关系。
▲图1-1 网络爬虫的控制节点和爬虫节点的结构关系
可以看见,网络爬虫中可以有多个控制节点,每个控制节点下可以有多个爬虫节点,控制节点之间可以相互通讯,同时,控制节点和其下的各爬虫节点之间也可以进行相互通讯,属于同一个控制节点下的各爬虫节点间,亦可以相互通讯。
控制节点,也叫作爬虫的中央控制器,主要负责按照URL地址分配线程,并调用爬虫节点进行具体的爬行。
爬虫节点会根据相关的算法,对网页进行具体的爬行,主要包括下载网页以及对网页的文本进行处理,爬行后,会将对应的爬行结果储存到对应的资源库中。
4. 网络爬虫的类型
现在我们早已基本了解了网路爬虫的组成,那么网路爬虫具体有什么类型呢?
网络爬虫根据实现的技术和结构可以分为通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网络爬虫等类型。在实际的网路爬虫中,通常是这几类爬虫的组合体。
4.1 通用网路爬虫
首先我们为你们介绍通用网路爬虫(General Purpose Web Crawler)。通用网路爬虫又叫作全网爬虫,顾名思义,通用网路爬虫爬取的目标资源在全互联网中。
通用网路爬虫所爬取的目标数据是巨大的,并且爬行的范围也是十分大的,正是因为其爬取的数据是海量数据,故而对于这类爬虫来说,其爬取的性能要求是特别高的。这种网路爬虫主要应用于小型搜索引擎中,有特别高的应用价值。
通用网路爬虫主要由初始URL集合、URL队列、页面爬行模块、页面剖析模块、页面数据库、链接过滤模块等构成。通用网路爬虫在爬行的时侯会采取一定的爬行策略,主要有深度优先爬行策略和广度优先爬行策略。
4.2 聚焦网络爬虫
聚焦网络爬虫(Focused Crawler)也叫主题网路爬虫,顾名思义,聚焦网络爬虫是根据预先定义好的主题有选择地进行网页爬取的一种爬虫,聚焦网路爬虫不象通用网路爬虫一样将目标资源定位在全互联网中,而是将爬取的目标网页定位在与主题相关的页面中,此时,可以大大节约爬虫爬取时所需的带宽资源和服务器资源。
聚焦网路爬虫主要应用在对特定信息的爬取中,主要为某一类特定的人群提供服务。
聚焦网路爬虫主要由初始URL集合、URL队列、页面爬行模块、页面剖析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等构成。内容评价模块可以评价内容的重要性,同理,链接评价模块也可以评价出链接的重要性,然后按照链接和内容的重要性,可以确定什么页面优先访问。
聚焦网路爬虫的爬行策略主要有4种,即基于内容评价的爬行策略、基于链接评价的爬行策略、基于提高学习的爬行策略和基于语境图的爬行策略。关于聚焦网路爬虫具体的爬行策略,我们将在下文中进行详尽剖析。
4.3 增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler),所谓增量式,对应着增量式更新。
增量式更新指的是在更新的时侯只更新改变的地方,而未改变的地方则不更新,所以增量式网路爬虫,在爬取网页的时侯,只爬取内容发生变化的网页或则新形成的网页,对于未发生内容变化的网页,则不会爬取。
增量式网路爬虫在一定程度上才能保证所爬取的页面,尽可能是新页面。
4.4 深层网络爬虫
深层网络爬虫(Deep Web Crawler),可以爬取互联网中的深层页面,在此我们首先须要了解深层页面的概念。
在互联网中,网页按存在形式分类,可以分为表层页面和深层页面。所谓的表层页面,指的是不需要递交表单,使用静态的链接才能够抵达的静态页面;而深层页面则隐藏在表单旁边,不能通过静态链接直接获取,是须要递交一定的关键词以后能够够获取得到的页面。
在互联网中,深层页面的数目常常比表层页面的数目要多好多,故而,我们须要想办法爬取深层页面。
爬取深层页面,需要想办法手动填写好对应表单,所以,深层网络爬虫最重要的部份即为表单填写部份。
深层网络爬虫主要由URL列表、LVS列表(LVS指的是标签/数值集合,即填充表单的数据源)、爬行控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等部份构成。
深层网路爬虫表单的填写有两种类型:
以上,为你们介绍了网路爬虫中常见的几种类型,希望读者才能对网路爬虫的分类有一个基本的了解。
5. 爬虫扩充——聚焦爬虫
由于聚焦爬虫可以按对应的主题有目的地进行爬取,并且可以节约大量的服务器资源和带宽资源,具有太强的实用性,所以在此,我们将对聚焦爬虫进行详尽讲解。图1-2所示为聚焦爬虫运行的流程,熟悉该流程后,我们可以更清晰地晓得聚焦爬虫的工作原理和过程。
▲图1-2 聚焦爬虫运行的流程
首先,聚焦爬虫拥有一个控制中心,该控制中心负责对整个爬虫系统进行管理和监控,主要包括控制用户交互、初始化爬行器、确定主题、协调各模块之间的工作、控制爬行过程等方面。
然后,将初始的URL集合传递给URL队列,页面爬行模块会从URL队列中读取第一批URL列表,然后按照这种URL地址从互联网中进行相应的页面爬取。
爬取后爬虫软件干嘛用,将爬取到的内容传到页面数据库中储存,同时,在爬行过程中,会爬取到一些新的URL,此时,需要按照我们所定的主题使用链接过滤模块过滤掉无关链接,再将剩下来的URL链接依照主题使用链接评价模块或内容评价模块进行优先级的排序。完成后,将新的URL地址传递到URL队列中,供页面爬行模块使用。
另一方面,将页面爬取并储存到页面数据库后,需要按照主题使用页面剖析模块对爬取到的页面进行页面剖析处理,并依照处理结果构建索引数据库,用户检索对应信息时,可以从索引数据库中进行相应的检索,并得到对应的结果。
这就是聚焦爬虫的主要工作流程,了解聚焦爬虫的主要工作流程有助于我们编撰聚焦爬虫,使编撰的思路愈发清晰。
02 网络爬虫技能总览
在上文中,我们早已初步认识了网路爬虫,那么网路爬虫具体能做些什么呢?用网络爬虫又能做什么有趣的事呢?在本章中我们将为你们具体讲解。
1. 网络爬虫技能总览图
如图2-1所示,我们总结了网路爬虫的常用功能。
▲图2-1 网络爬虫技能示意图
在图2-1中可以见到,网络爬虫可以取代手工做好多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些同学将个别网站上的图片全部爬取出来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以手动爬取一些金融信息,并进行投资剖析等。
有时,我们比较喜欢的新闻网站可能有几个,每次都要分别打开这种新闻网站进行浏览,比较麻烦。此时可以借助网路爬虫,将这多个新闻网站中的新闻信息爬取出来,集中进行阅读。
有时,我们在浏览网页上的信息的时侯,会发觉有很多广告。此时同样可以借助爬虫将对应网页上的信息爬取过来,这样就可以手动的过滤掉那些广告,方便对信息的阅读与使用。
有时,我们须要进行营销,那么怎么找到目标顾客以及目标顾客的联系方法是一个关键问题。我们可以自动地在互联网中找寻,但是这样的效率会太低。此时,我们借助爬虫,可以设置对应的规则,自动地从互联网中采集目标用户的联系方法等数据,供我们进行营销使用。
有时,我们想对某个网站的用户信息进行剖析,比如剖析该网站的用户活跃度、发言数、热门文章等信息,如果我们不是网站管理员,手工统计将是一个十分庞大的工程。此时,可以借助爬虫轻松将这种数据采集到,以便进行进一步剖析,而这一切爬取的操作,都是手动进行的,我们只须要编撰好对应的爬虫,并设计好对应的规则即可。
除此之外,爬虫还可以实现好多强悍的功能。总之,爬虫的出现,可以在一定程度上取代手工访问网页,从而,原先我们须要人工去访问互联网信息的操作,现在都可以用爬虫自动化实现,这样可以更高效率地借助好互联网中的有效信息。
2. 搜索引擎核心
爬虫与搜索引擎的关系是密不可分的,既然谈到了网路爬虫,就免不了提及搜索引擎,在此,我们将对搜索引擎的核心技术进行一个简单的讲解。
图2-2所示为搜索引擎的核心工作流程。首先,搜索引擎会借助爬虫模块去爬取互联网中的网页,然后将爬取到的网页储存在原始数据库中。爬虫模块主要包括控制器和爬行器,控制器主要进行爬行的控制,爬行器则负责具体的爬行任务。
然后,会对原始数据库中的数据进行索引,并储存到索引数据库中。
当用户检索信息的时侯,会通过用户交互插口输入对应的信息,用户交互插口相当于搜索引擎的输入框,输入完成以后,由检索器进行动词等操作,检索器会从索引数据库中获取数据进行相应的检索处理。
用户输入对应信息的同时,会将用户的行为储存到用户日志数据库中,比如用户的IP地址、用户所输入的关键词等等。随后,用户日志数据库中的数据会交由日志分析器进行处理。日志剖析器会依照大量的用户数据去调整原始数据库和索引数据库,改变排行结果或进行其他操作。
▲图2-2 搜索引擎的核心工作流程
以上就是搜索引擎核心工作流程的简略概述,可能你们对索引和检索的概念还不太能分辨,在此我为你们详尽讲一下。
简单来说,检索是一种行为,而索引是一种属性。比如一家商场,里面有大量的商品,为了才能快速地找到这种商品,我们会将这种商品进行分组,比如有日常用品类商品、饮料类商品、服装类商品等组别,此时,这些商品的组名我们称之为索引,索引由索引器控制。
如果,有一个用户想要找到某一个商品,那么须要在商场的大量商品中找寻,这个过程,我们称之为检索。如果有一个好的索引,则可以增强检索的效率;若没有索引,则检索的效率会太低。
比如,一个商场上面的商品假如没有进行分类,那么用户要在海量的商品中找寻某一种商品,则会比较费劲。
3. 用户爬虫的那些事儿
用户爬虫是网路爬虫中的一种类型。所谓用户爬虫,指的是专门拿来爬取互联网中用户数据的一种爬虫。由于互联网中的用户数据信息,相对来说是比较敏感的数据信息,所以,用户爬虫的借助价值也相对较高。
利用用户爬虫可以做大量的事情,接下来我们一起来看一下借助用户爬虫所做的一些有趣的事情吧。
2015年,有知乎网友对知乎的用户数据进行了爬取,然后进行对应的数据剖析,便得到了知乎上大量的潜在数据,比如:
除此之外,只要我们悉心开掘,还可以挖掘出更多的潜在数据,而要剖析那些数据,则必须要获取到那些用户数据,此时,我们可以使用网路爬虫技术轻松爬取到这种有用的用户信息。
同样,在2015年,有网友爬取了3000万QQ空间的用户信息,并同样从中获得了大量潜在数据,比如:
除了以上两个事例之外,用户爬虫还可以做好多事情,比如爬取网店的用户信息,可以剖析天猫用户喜欢哪些商品,从而更有利于我们对商品的定位等。
由此可见,利用用户爬虫可以获得好多有趣的潜在信息,那么这种爬虫难吗?其实不难,相信你也能写出这样的爬虫。
03 小结
关于作者:韦玮,资深网路爬虫技术专家、大数据专家和软件开发工程师,从事小型软件开发与技术服务多年,精通Python技术,在Python网络爬虫、Python机器学习、Python数据剖析与挖掘、Python Web开发等多个领域都有丰富的实战经验。
本文摘编自《精通Python网路爬虫:核心技术、框架与项目实战》,经出版方授权发布。
延伸阅读《精通Python网络爬虫》
点击上图了解及选购 查看全部
01 什么是网络爬虫
随着大数据时代的将至,网络爬虫在互联网中的地位将越来越重要。互联网中的数据是海量的,如何手动高效地获取互联网中我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这种问题而生的。
我们感兴趣的信息分为不同的类型:如果只是做搜索引擎,那么感兴趣的信息就是互联网中尽可能多的高质量网页;如果要获取某一垂直领域的数据或则有明晰的检索需求,那么感兴趣的信息就是按照我们的检索和需求所定位的这种信息,此时,需要过滤掉一些无用信息。前者我们称为通用网路爬虫,后者我们称为聚焦网路爬虫。
1. 初识网络爬虫
网络爬虫又称网路蜘蛛、网络蚂蚁、网络机器人等,可以自动化浏览网路中的信息,当然浏览信息的时侯须要根据我们制订的规则进行,这些规则我们称之为网络爬虫算法。使用Python可以很方便地编写出爬虫程序,进行互联网信息的自动化检索。
搜索引擎离不开爬虫,比如百度搜索引擎的爬虫叫作百度蜘蛛(Baiduspider)。百度蜘蛛每晚会在海量的互联网信息中进行爬取,爬取优质信息并收录,当用户在百度搜索引擎上检索对应关键词时,百度将对关键词进行剖析处理,从收录的网页中找出相关网页,按照一定的排行规则进行排序并将结果诠释给用户。
在这个过程中,百度蜘蛛起到了至关重要的作用。那么,如何覆盖互联网中更多的优质网页?又怎样筛选这种重复的页面?这些都是由百度蜘蛛爬虫的算法决定的。采用不同的算法,爬虫的运行效率会不同,爬取结果也会有所差别。
所以,我们在研究爬虫的时侯,不仅要了解爬虫怎样实现,还须要晓得一些常见爬虫的算法,如果有必要,我们还须要自己去制订相应的算法,在此,我们仅须要对爬虫的概念有一个基本的了解。
除了百度搜索引擎离不开爬虫以外,其他搜索引擎也离不开爬虫,它们也拥有自己的爬虫。比如360的爬虫叫360Spider,搜狗的爬虫叫Sogouspider,必应的爬虫叫Bingbot。
如果想自己实现一款大型的搜索引擎,我们也可以编撰出自己的爬虫去实现,当然,虽然可能在性能或则算法上比不上主流的搜索引擎,但是个性化的程度会特别高,并且也有利于我们更深层次地理解搜索引擎内部的工作原理。
大数据时代也离不开爬虫,比如在进行大数据剖析或数据挖掘时,我们可以去一些比较小型的官方站点下载数据源。但这种数据源比较有限,那么怎么能够获取更多更高质量的数据源呢?此时,我们可以编撰自己的爬虫程序,从互联网中进行数据信息的获取。所以在未来,爬虫的地位会越来越重要。
2. 为什么要学网络爬虫
我们初步认识了网路爬虫,但是为何要学习网路爬虫呢?要知道,只有清晰地晓得我们的学习目的,才能够更好地学习这一项知识,我们将会为你们剖析一下学习网路爬虫的诱因。
当然,不同的人学习爬虫,可能目的有所不同,在此,我们总结了4种常见的学习爬虫的诱因。
1)学习爬虫,可以私人订制一个搜索引擎,并且可以对搜索引擎的数据采集工作原理进行更深层次地理解。
有的同事希望还能深层次地了解搜索引擎的爬虫工作原理,或者希望自己才能开发出一款私人搜索引擎,那么此时,学习爬虫是十分有必要的。
简单来说,我们学会了爬虫编撰以后,就可以借助爬虫手动地采集互联网中的信息,采集回来后进行相应的储存或处理,在须要检索个别信息的时侯爬虫软件干嘛用,只需在采集回来的信息中进行检索,即实现了私人的搜索引擎。
当然,信息如何爬取、怎么储存、怎么进行动词、怎么进行相关性估算等,都是须要我们进行设计的,爬虫技术主要解决信息爬取的问题。
2)大数据时代,要进行数据剖析,首先要有数据源,而学习爬虫,可以使我们获取更多的数据源,并且这种数据源可以按我们的目的进行采集,去掉好多无关数据。
在进行大数据剖析或则进行数据挖掘的时侯,数据源可以从个别提供数据统计的网站获得,也可以从个别文献或内部资料中获得,但是这种获得数据的方法,有时很难满足我们对数据的需求,而自动从互联网中去找寻那些数据,则花费的精力过大。
此时就可以借助爬虫技术,自动地从互联网中获取我们感兴趣的数据内容,并将这种数据内容爬取回去,作为我们的数据源,从而进行更深层次的数据剖析,并获得更多有价值的信息。
3)对于好多SEO从业者来说,学习爬虫,可以更深层次地理解搜索引擎爬虫的工作原理,从而可以更好地进行搜索引擎优化。
既然是搜索引擎优化,那么就必须要对搜索引擎的工作原理十分清楚,同时也须要把握搜索引擎爬虫的工作原理,这样在进行搜索引擎优化时,才能知己知彼,百战不殆。
4)从就业的角度来说,爬虫工程师目前来说属于短缺人才,并且工资待遇普遍较高,所以,深层次地把握这门技术,对于就业来说,是十分有利的。
有些同学学习爬虫可能为了就业或则跳槽。从这个角度来说,爬虫工程师方向是不错的选择之一,因为目前爬虫工程师的需求越来越大,而才能胜任这方面岗位的人员较少,所以属于一个比较短缺的职业方向,并且随着大数据时代的将至,爬虫技术的应用将越来越广泛,在未来会拥有挺好的发展空间。
除了以上为你们总结的4种常见的学习爬虫的诱因外,可能你还有一些其他学习爬虫的缘由,总之,不管是哪些缘由,理清自己学习的目的,就可以更好地去研究一门知识技术,并坚持出来。
3. 网络爬虫的组成
接下来,我们将介绍网路爬虫的组成。网络爬虫由控制节点、爬虫节点、资源库构成。
图1-1所示是网路爬虫的控制节点和爬虫节点的结构关系。
▲图1-1 网络爬虫的控制节点和爬虫节点的结构关系
可以看见,网络爬虫中可以有多个控制节点,每个控制节点下可以有多个爬虫节点,控制节点之间可以相互通讯,同时,控制节点和其下的各爬虫节点之间也可以进行相互通讯,属于同一个控制节点下的各爬虫节点间,亦可以相互通讯。
控制节点,也叫作爬虫的中央控制器,主要负责按照URL地址分配线程,并调用爬虫节点进行具体的爬行。
爬虫节点会根据相关的算法,对网页进行具体的爬行,主要包括下载网页以及对网页的文本进行处理,爬行后,会将对应的爬行结果储存到对应的资源库中。
4. 网络爬虫的类型
现在我们早已基本了解了网路爬虫的组成,那么网路爬虫具体有什么类型呢?
网络爬虫根据实现的技术和结构可以分为通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网络爬虫等类型。在实际的网路爬虫中,通常是这几类爬虫的组合体。
4.1 通用网路爬虫
首先我们为你们介绍通用网路爬虫(General Purpose Web Crawler)。通用网路爬虫又叫作全网爬虫,顾名思义,通用网路爬虫爬取的目标资源在全互联网中。
通用网路爬虫所爬取的目标数据是巨大的,并且爬行的范围也是十分大的,正是因为其爬取的数据是海量数据,故而对于这类爬虫来说,其爬取的性能要求是特别高的。这种网路爬虫主要应用于小型搜索引擎中,有特别高的应用价值。
通用网路爬虫主要由初始URL集合、URL队列、页面爬行模块、页面剖析模块、页面数据库、链接过滤模块等构成。通用网路爬虫在爬行的时侯会采取一定的爬行策略,主要有深度优先爬行策略和广度优先爬行策略。
4.2 聚焦网络爬虫
聚焦网络爬虫(Focused Crawler)也叫主题网路爬虫,顾名思义,聚焦网络爬虫是根据预先定义好的主题有选择地进行网页爬取的一种爬虫,聚焦网路爬虫不象通用网路爬虫一样将目标资源定位在全互联网中,而是将爬取的目标网页定位在与主题相关的页面中,此时,可以大大节约爬虫爬取时所需的带宽资源和服务器资源。
聚焦网路爬虫主要应用在对特定信息的爬取中,主要为某一类特定的人群提供服务。
聚焦网路爬虫主要由初始URL集合、URL队列、页面爬行模块、页面剖析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等构成。内容评价模块可以评价内容的重要性,同理,链接评价模块也可以评价出链接的重要性,然后按照链接和内容的重要性,可以确定什么页面优先访问。
聚焦网路爬虫的爬行策略主要有4种,即基于内容评价的爬行策略、基于链接评价的爬行策略、基于提高学习的爬行策略和基于语境图的爬行策略。关于聚焦网路爬虫具体的爬行策略,我们将在下文中进行详尽剖析。
4.3 增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler),所谓增量式,对应着增量式更新。
增量式更新指的是在更新的时侯只更新改变的地方,而未改变的地方则不更新,所以增量式网路爬虫,在爬取网页的时侯,只爬取内容发生变化的网页或则新形成的网页,对于未发生内容变化的网页,则不会爬取。
增量式网路爬虫在一定程度上才能保证所爬取的页面,尽可能是新页面。
4.4 深层网络爬虫
深层网络爬虫(Deep Web Crawler),可以爬取互联网中的深层页面,在此我们首先须要了解深层页面的概念。
在互联网中,网页按存在形式分类,可以分为表层页面和深层页面。所谓的表层页面,指的是不需要递交表单,使用静态的链接才能够抵达的静态页面;而深层页面则隐藏在表单旁边,不能通过静态链接直接获取,是须要递交一定的关键词以后能够够获取得到的页面。
在互联网中,深层页面的数目常常比表层页面的数目要多好多,故而,我们须要想办法爬取深层页面。
爬取深层页面,需要想办法手动填写好对应表单,所以,深层网络爬虫最重要的部份即为表单填写部份。
深层网络爬虫主要由URL列表、LVS列表(LVS指的是标签/数值集合,即填充表单的数据源)、爬行控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等部份构成。
深层网路爬虫表单的填写有两种类型:
以上,为你们介绍了网路爬虫中常见的几种类型,希望读者才能对网路爬虫的分类有一个基本的了解。
5. 爬虫扩充——聚焦爬虫
由于聚焦爬虫可以按对应的主题有目的地进行爬取,并且可以节约大量的服务器资源和带宽资源,具有太强的实用性,所以在此,我们将对聚焦爬虫进行详尽讲解。图1-2所示为聚焦爬虫运行的流程,熟悉该流程后,我们可以更清晰地晓得聚焦爬虫的工作原理和过程。
▲图1-2 聚焦爬虫运行的流程
首先,聚焦爬虫拥有一个控制中心,该控制中心负责对整个爬虫系统进行管理和监控,主要包括控制用户交互、初始化爬行器、确定主题、协调各模块之间的工作、控制爬行过程等方面。
然后,将初始的URL集合传递给URL队列,页面爬行模块会从URL队列中读取第一批URL列表,然后按照这种URL地址从互联网中进行相应的页面爬取。
爬取后爬虫软件干嘛用,将爬取到的内容传到页面数据库中储存,同时,在爬行过程中,会爬取到一些新的URL,此时,需要按照我们所定的主题使用链接过滤模块过滤掉无关链接,再将剩下来的URL链接依照主题使用链接评价模块或内容评价模块进行优先级的排序。完成后,将新的URL地址传递到URL队列中,供页面爬行模块使用。
另一方面,将页面爬取并储存到页面数据库后,需要按照主题使用页面剖析模块对爬取到的页面进行页面剖析处理,并依照处理结果构建索引数据库,用户检索对应信息时,可以从索引数据库中进行相应的检索,并得到对应的结果。
这就是聚焦爬虫的主要工作流程,了解聚焦爬虫的主要工作流程有助于我们编撰聚焦爬虫,使编撰的思路愈发清晰。
02 网络爬虫技能总览
在上文中,我们早已初步认识了网路爬虫,那么网路爬虫具体能做些什么呢?用网络爬虫又能做什么有趣的事呢?在本章中我们将为你们具体讲解。
1. 网络爬虫技能总览图
如图2-1所示,我们总结了网路爬虫的常用功能。
▲图2-1 网络爬虫技能示意图
在图2-1中可以见到,网络爬虫可以取代手工做好多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些同学将个别网站上的图片全部爬取出来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以手动爬取一些金融信息,并进行投资剖析等。
有时,我们比较喜欢的新闻网站可能有几个,每次都要分别打开这种新闻网站进行浏览,比较麻烦。此时可以借助网路爬虫,将这多个新闻网站中的新闻信息爬取出来,集中进行阅读。
有时,我们在浏览网页上的信息的时侯,会发觉有很多广告。此时同样可以借助爬虫将对应网页上的信息爬取过来,这样就可以手动的过滤掉那些广告,方便对信息的阅读与使用。
有时,我们须要进行营销,那么怎么找到目标顾客以及目标顾客的联系方法是一个关键问题。我们可以自动地在互联网中找寻,但是这样的效率会太低。此时,我们借助爬虫,可以设置对应的规则,自动地从互联网中采集目标用户的联系方法等数据,供我们进行营销使用。
有时,我们想对某个网站的用户信息进行剖析,比如剖析该网站的用户活跃度、发言数、热门文章等信息,如果我们不是网站管理员,手工统计将是一个十分庞大的工程。此时,可以借助爬虫轻松将这种数据采集到,以便进行进一步剖析,而这一切爬取的操作,都是手动进行的,我们只须要编撰好对应的爬虫,并设计好对应的规则即可。
除此之外,爬虫还可以实现好多强悍的功能。总之,爬虫的出现,可以在一定程度上取代手工访问网页,从而,原先我们须要人工去访问互联网信息的操作,现在都可以用爬虫自动化实现,这样可以更高效率地借助好互联网中的有效信息。
2. 搜索引擎核心
爬虫与搜索引擎的关系是密不可分的,既然谈到了网路爬虫,就免不了提及搜索引擎,在此,我们将对搜索引擎的核心技术进行一个简单的讲解。
图2-2所示为搜索引擎的核心工作流程。首先,搜索引擎会借助爬虫模块去爬取互联网中的网页,然后将爬取到的网页储存在原始数据库中。爬虫模块主要包括控制器和爬行器,控制器主要进行爬行的控制,爬行器则负责具体的爬行任务。
然后,会对原始数据库中的数据进行索引,并储存到索引数据库中。
当用户检索信息的时侯,会通过用户交互插口输入对应的信息,用户交互插口相当于搜索引擎的输入框,输入完成以后,由检索器进行动词等操作,检索器会从索引数据库中获取数据进行相应的检索处理。
用户输入对应信息的同时,会将用户的行为储存到用户日志数据库中,比如用户的IP地址、用户所输入的关键词等等。随后,用户日志数据库中的数据会交由日志分析器进行处理。日志剖析器会依照大量的用户数据去调整原始数据库和索引数据库,改变排行结果或进行其他操作。
▲图2-2 搜索引擎的核心工作流程
以上就是搜索引擎核心工作流程的简略概述,可能你们对索引和检索的概念还不太能分辨,在此我为你们详尽讲一下。
简单来说,检索是一种行为,而索引是一种属性。比如一家商场,里面有大量的商品,为了才能快速地找到这种商品,我们会将这种商品进行分组,比如有日常用品类商品、饮料类商品、服装类商品等组别,此时,这些商品的组名我们称之为索引,索引由索引器控制。
如果,有一个用户想要找到某一个商品,那么须要在商场的大量商品中找寻,这个过程,我们称之为检索。如果有一个好的索引,则可以增强检索的效率;若没有索引,则检索的效率会太低。
比如,一个商场上面的商品假如没有进行分类,那么用户要在海量的商品中找寻某一种商品,则会比较费劲。
3. 用户爬虫的那些事儿
用户爬虫是网路爬虫中的一种类型。所谓用户爬虫,指的是专门拿来爬取互联网中用户数据的一种爬虫。由于互联网中的用户数据信息,相对来说是比较敏感的数据信息,所以,用户爬虫的借助价值也相对较高。
利用用户爬虫可以做大量的事情,接下来我们一起来看一下借助用户爬虫所做的一些有趣的事情吧。
2015年,有知乎网友对知乎的用户数据进行了爬取,然后进行对应的数据剖析,便得到了知乎上大量的潜在数据,比如:
除此之外,只要我们悉心开掘,还可以挖掘出更多的潜在数据,而要剖析那些数据,则必须要获取到那些用户数据,此时,我们可以使用网路爬虫技术轻松爬取到这种有用的用户信息。
同样,在2015年,有网友爬取了3000万QQ空间的用户信息,并同样从中获得了大量潜在数据,比如:
除了以上两个事例之外,用户爬虫还可以做好多事情,比如爬取网店的用户信息,可以剖析天猫用户喜欢哪些商品,从而更有利于我们对商品的定位等。
由此可见,利用用户爬虫可以获得好多有趣的潜在信息,那么这种爬虫难吗?其实不难,相信你也能写出这样的爬虫。
03 小结
关于作者:韦玮,资深网路爬虫技术专家、大数据专家和软件开发工程师,从事小型软件开发与技术服务多年,精通Python技术,在Python网络爬虫、Python机器学习、Python数据剖析与挖掘、Python Web开发等多个领域都有丰富的实战经验。
本文摘编自《精通Python网路爬虫:核心技术、框架与项目实战》,经出版方授权发布。
延伸阅读《精通Python网络爬虫》
点击上图了解及选购
为什么做seo优化要剖析网站的数据?
采集交流 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2020-05-16 08:06
就现状观查,小盘发觉大量的初学者SEOer的研究数据主要是依据站长工具,在其中外部链接数、跳失率、网页页面等待时间是大伙儿更为关心的。能够说分析百度seo,这种统计数据是给你更为方便把握网站状况的有益统计数据,可是却只是归属于片面性的统计数据。搜索引擎排名全过程是1个冗长的过程,单是靠这些表层标值,算出的构造仅仅单一化的。而明日人们要分析的3个网站统计数据则会使大伙儿更全方位的把握网站SEO。
首位,网页页面统计数据是主动型统计数据。
网页页面时引擎搜索举办排名的最少企业值,一般说来网页页面的统计数据关键是它的百度收录和浏览量上。针对百度收录小编小丹讲过许多,可是网页页面统计数据规定的百度收录比,也就是说百度收录网页页面与整站网页页面的总体占比,假如这一标值在60%上下,那麼否认你的网页页面品质尚佳;再人们说一下下浏览量,这一浏览关键对于是搜索引擎网站优化,就算现在百度站长工具为了更好地工作员,能够积极设定数据抓取次数。但虽然这么若你的网页页面品质不佳,这种明晰爬取次数也并且是摆放罢了seo优化,对网站来讲是无实际意义的。而改进网页页面统计数据的方法 是人们还能操纵的,也就是说做为SEOer就能掌握的,佳质的信息是提升主动型统计数据的本质。
其次,网站外部链接统计数据是普遍性统计数据。
是网站足以被拉票大大加分的多是网站外部链接,外部链接的统计数据纪录就弄成了人们审视网站加占分的勿必。提高外部链接拉票值的重要就取决于找寻快百度收录的高质量外链服务平台,起效的外部链接才可以为网站测试。而这些见效外部链接对人们来讲只有竭尽全力来做,实际是统计数据還是要靠引擎搜索的客观性鉴别,人们要是量力而行就行。
最后,客户统计数据是综合性统计数据。
所说的顾客统计数据虽然就是说站长统计中为人们出示的跳失率、IP浏览量、PV浏览量和网页页面等待时间。而人们要分析是是这些统计数据的融合占比并不是单一化统计数据的片面性分析,毫不客气的说即使是百度网它的单独网页页面跳失率都是100%分析百度seo,而那样的统计数据就人们来讲是无实际意义的。人们要融合网页页面等待时间和PV浏览量来对网站的顾客统计数据做综合性评定,算是全方位的把握了网站客户体验状况。 查看全部
做SEO优化没去科学研究网站统计数据是不好的,盲目随大流的猜测下的优化方位总是给你的网站举步维艰。通常情况下,在有效的SEO技术性下,网站统计数据才能解读出网站的品质和百度关键词的排名特质。统计数据具体指导下的网站排名优化方式才能使百度关键词迅速的推进引擎搜索主页。
就现状观查,小盘发觉大量的初学者SEOer的研究数据主要是依据站长工具,在其中外部链接数、跳失率、网页页面等待时间是大伙儿更为关心的。能够说分析百度seo,这种统计数据是给你更为方便把握网站状况的有益统计数据,可是却只是归属于片面性的统计数据。搜索引擎排名全过程是1个冗长的过程,单是靠这些表层标值,算出的构造仅仅单一化的。而明日人们要分析的3个网站统计数据则会使大伙儿更全方位的把握网站SEO。
首位,网页页面统计数据是主动型统计数据。
网页页面时引擎搜索举办排名的最少企业值,一般说来网页页面的统计数据关键是它的百度收录和浏览量上。针对百度收录小编小丹讲过许多,可是网页页面统计数据规定的百度收录比,也就是说百度收录网页页面与整站网页页面的总体占比,假如这一标值在60%上下,那麼否认你的网页页面品质尚佳;再人们说一下下浏览量,这一浏览关键对于是搜索引擎网站优化,就算现在百度站长工具为了更好地工作员,能够积极设定数据抓取次数。但虽然这么若你的网页页面品质不佳,这种明晰爬取次数也并且是摆放罢了seo优化,对网站来讲是无实际意义的。而改进网页页面统计数据的方法 是人们还能操纵的,也就是说做为SEOer就能掌握的,佳质的信息是提升主动型统计数据的本质。
其次,网站外部链接统计数据是普遍性统计数据。
是网站足以被拉票大大加分的多是网站外部链接,外部链接的统计数据纪录就弄成了人们审视网站加占分的勿必。提高外部链接拉票值的重要就取决于找寻快百度收录的高质量外链服务平台,起效的外部链接才可以为网站测试。而这些见效外部链接对人们来讲只有竭尽全力来做,实际是统计数据還是要靠引擎搜索的客观性鉴别,人们要是量力而行就行。
最后,客户统计数据是综合性统计数据。
所说的顾客统计数据虽然就是说站长统计中为人们出示的跳失率、IP浏览量、PV浏览量和网页页面等待时间。而人们要分析是是这些统计数据的融合占比并不是单一化统计数据的片面性分析,毫不客气的说即使是百度网它的单独网页页面跳失率都是100%分析百度seo,而那样的统计数据就人们来讲是无实际意义的。人们要融合网页页面等待时间和PV浏览量来对网站的顾客统计数据做综合性评定,算是全方位的把握了网站客户体验状况。

