
国外网页视频抓取软件
国外网页视频抓取软件(火狐浏览器实用插件一览(附下载地址)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-23 05:14
阿里云>云栖社区>主题地图>H>Firefox网站下载视频
推荐活动:
更多优惠>
当前主题:Firefox网站下载视频添加到采集夹
相关话题:
Firefox网站 下载视频相关博客,查看更多博客
火狐浏览器实用插件
作者:神巧合1871人浏览评论:05年前
User Agent Switcher中间没有横向的,模拟百度等搜索引擎蜘蛛抓取页面FireBug Web开发工具JSONView在浏览器中查看json格式修改Headers修改X-Forwarded-For等请求头xpa
阅读全文
【VIP视频网站项目上线】VIP视频网站项目以及基于Nodejs Express框架的完整代码分享
作者:向山的灯1602人浏览评论:03年前
版权声明:本文为博主原创文章所有,未经博主许可,不得转载。更多学习资料请访问我爱科技论坛::///m0_37981569/article/details/829
阅读全文
【教程转载】火狐浏览器好用插件列表(附插件下载地址)
作者:落雨_2077人浏览评论:011年前
【教程转载】火狐实用插件列表(附插件下载地址) 简单介绍:火狐最大的优点就是安全、快速、稳定。有人抱怨Firefox功能太少,有些网页无法正常浏览。. 没关系,这些都不是问题,因为我们有插件!重要插件:注:安装火狐后可以直接上网
阅读全文
【开源项目】基于Nodejs的Express框架的VIP视频网站项目及源码分享
作者:向山的灯 6162人浏览评论:03年前
先直接看最终效果图:网站首页:play.jpg 播放页面:评论页面:搜索页面:登录页面:注册页面:用户中心:项目名称:VIP视频网站项目开发语言: HTML, CSS (前端), JavaScript, NODEJS (expres) (后端)
阅读全文
最大化与 html5 视频的兼容性
作者:waylau1697人浏览评论:05年前
HTML5 使用 video 元素在网页上呈现视频。但是 HTML5 视频不是最终的解决方案,它不会在所有浏览器中都有效。您知道 HTML5 视频真的可以在线播放吗?您是否担心 HMTL5 视频兼容性?看看这个 文章 建议和解决方案如何最大化 HMTL5
阅读全文
织梦 php 网站 构建
作者:古真月影 2165人浏览评论:08年前
引用: %E7%BB%87%E6%A2%A6 织梦内容管理系统(Dedecms)以简单、实用、开源着称,是最知名的PHP开源源码在中国网站管理系统,也是用户使用最多的PHPcms系统。经过两年多的发展,目前
阅读全文
通过web安全工具Burp套件(二)
作者:apache9153 浏览评论人数:03年前
一、背景作者6月份在Mukenet上录制了视频教程XSS跨站漏洞,以增强Web安全。有很多实际案例需要提及。漏洞挖掘案例分为人工挖掘、工具挖掘、代码审计三部分。, 手工挖矿文章的参考地址是快速找出网站(一)
阅读全文
手动找出网站中可能存在的XSS漏洞
作者:apache1720 浏览评论人数:03年前
一、背景 作者最近在MOOC录制了一套加强Web安全的XSS跨站漏洞视频教程。课程讲的是XSS挖掘方法,所以在录制课程之前需要做很多实际案例。该视频是最近录制的。说完了,准备记录一下这些XSS漏洞的挖掘过程,方便自己和他人。在这篇文章中 文章 将是一个 permea
阅读全文 查看全部
国外网页视频抓取软件(火狐浏览器实用插件一览(附下载地址)(组图))
阿里云>云栖社区>主题地图>H>Firefox网站下载视频

推荐活动:
更多优惠>
当前主题:Firefox网站下载视频添加到采集夹
相关话题:
Firefox网站 下载视频相关博客,查看更多博客
火狐浏览器实用插件

作者:神巧合1871人浏览评论:05年前
User Agent Switcher中间没有横向的,模拟百度等搜索引擎蜘蛛抓取页面FireBug Web开发工具JSONView在浏览器中查看json格式修改Headers修改X-Forwarded-For等请求头xpa
阅读全文
【VIP视频网站项目上线】VIP视频网站项目以及基于Nodejs Express框架的完整代码分享

作者:向山的灯1602人浏览评论:03年前
版权声明:本文为博主原创文章所有,未经博主许可,不得转载。更多学习资料请访问我爱科技论坛::///m0_37981569/article/details/829
阅读全文
【教程转载】火狐浏览器好用插件列表(附插件下载地址)


作者:落雨_2077人浏览评论:011年前
【教程转载】火狐实用插件列表(附插件下载地址) 简单介绍:火狐最大的优点就是安全、快速、稳定。有人抱怨Firefox功能太少,有些网页无法正常浏览。. 没关系,这些都不是问题,因为我们有插件!重要插件:注:安装火狐后可以直接上网
阅读全文
【开源项目】基于Nodejs的Express框架的VIP视频网站项目及源码分享

作者:向山的灯 6162人浏览评论:03年前
先直接看最终效果图:网站首页:play.jpg 播放页面:评论页面:搜索页面:登录页面:注册页面:用户中心:项目名称:VIP视频网站项目开发语言: HTML, CSS (前端), JavaScript, NODEJS (expres) (后端)
阅读全文
最大化与 html5 视频的兼容性


作者:waylau1697人浏览评论:05年前
HTML5 使用 video 元素在网页上呈现视频。但是 HTML5 视频不是最终的解决方案,它不会在所有浏览器中都有效。您知道 HTML5 视频真的可以在线播放吗?您是否担心 HMTL5 视频兼容性?看看这个 文章 建议和解决方案如何最大化 HMTL5
阅读全文
织梦 php 网站 构建

作者:古真月影 2165人浏览评论:08年前
引用: %E7%BB%87%E6%A2%A6 织梦内容管理系统(Dedecms)以简单、实用、开源着称,是最知名的PHP开源源码在中国网站管理系统,也是用户使用最多的PHPcms系统。经过两年多的发展,目前
阅读全文
通过web安全工具Burp套件(二)

作者:apache9153 浏览评论人数:03年前
一、背景作者6月份在Mukenet上录制了视频教程XSS跨站漏洞,以增强Web安全。有很多实际案例需要提及。漏洞挖掘案例分为人工挖掘、工具挖掘、代码审计三部分。, 手工挖矿文章的参考地址是快速找出网站(一)
阅读全文
手动找出网站中可能存在的XSS漏洞

作者:apache1720 浏览评论人数:03年前
一、背景 作者最近在MOOC录制了一套加强Web安全的XSS跨站漏洞视频教程。课程讲的是XSS挖掘方法,所以在录制课程之前需要做很多实际案例。该视频是最近录制的。说完了,准备记录一下这些XSS漏洞的挖掘过程,方便自己和他人。在这篇文章中 文章 将是一个 permea
阅读全文
国外网页视频抓取软件(数码荔枝IDM斩获国内外多项大奖,官网原价79的终生版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-10-22 16:14
InternetDownloadManager(IDM)是一款非常知名的Windows平台下载工具,在国内外获得了很多奖项。与其他同类工具的炫目界面和功能相比,IDM界面无广告,无弹窗,无内置浏览器。专注下载,下载速度提升5倍,真正发挥速度下载优势。
这么好的软件价格自然不便宜,官网价格往往让人望而却步。
现在,我们正在与“数字荔枝”合作开展IDM折扣活动,特价30%起。官网原价79的IDM一年授权现仅需35元,官网原价160终身版现仅需129元!新注册用户可再享5元优惠!
专注下载
作为一款下载工具,IDM在P2P以外的文件下载功能上做到了极致,主要体现在自动链接抓取、静默下载、多线程和多媒体下载等,降低用户运营成本,提升文件下载体验。
自动捕获链接
IDM 可以在使用浏览器下载文件时自动捕获下载链接并添加下载任务。IDM 支持大部分主流浏览器,如 Chrome、Safari、Firefox、Edge、Internet Explorer 等。如果您使用的浏览器不在 IDM 的默认支持中,您也可以在软件设置中进行自定义。
静默下载
大多数人在下载文件时,会习惯性地将文件保存到固定位置,等待下载完成后再进行进一步处理。如果每次下载都需要重复点击“保存对话框”中的按钮,那将是非常多余和低效的。
IDM 的静默下载功能可以自动最小化下载窗口。如果您想在下载过程中修改保存位置或其他选项,可以直接调用托盘中的IDM图标。
多媒体下载
只要打开要下载的音视频的网站页面,IDM就会自动检测在线播放器发送的多媒体请求,并在播放器上显示下载浮动条。用户可以直接下载流媒体网站中的视频,在本地离线观看。
IDM支持MP4/MP3/MOV/AAC等常见音视频格式的检测和下载。在设置窗口中,您还可以指定特定站点显示或隐藏软件的下载浮动栏等自定义操作。
强大的扩展功能
IDM还配备了强大的自动下载功能,通过批量下载、定时下载任务、站点爬取等方式满足用户高层次的下载需求。
安排下载任务
通过设置定时下载任务,用户可以让IDM在指定的时间段内自动启动相应的下载任务,无论下载还是暂停等,都可以通过该功能实现。让家里的电脑在工作时间自动下载你需要的文件,到家就可以立即使用,非常方便。
网站抓取
“网站抓取”功能可以让您在输入链接后直接选择您要下载的网页的指定内容,无需使用通配符,包括图片、音频、视频、文件或收录完整样式的离线文件。IDM 可以做到这一切。您还可以根据自己的需要自定义站点抓取的内容和规则,并保存起来,方便下次调用。
批量下载
只要使用软件默认或自定义通配符,就可以使用IDM下载链接中收录的所有文件,例如网页中的所有图片。类似的形式如下:
一些网站.com/pictures/img*.jpg
使用上述命令,可以在IDM官网下载所有命名为img001.jpg、img002.jpg等命名规则的图片。
支持国外主流网盘
网站 上的很多国外资源文件都会放在他们常用的网盘里。如果直接下载这些文件,速度会很慢,很容易中断。这时候就需要IDM了。可将这些文件从网盘下载成队列进行批量下载,让您独立自定义每个队列的下载时间和下载文件数,灵活提高下载效率。
目前支持的网盘包括RapidShare、FileServe等,您可以访问官网查看所有IDM支持的网盘服务。
可接受的价格
最后,不要错过 IDM 折扣。官网原价79的IDM一年期授权现仅需35元,官网原价160的终身版现仅需129元!新用户注册领券立减5元! 查看全部
国外网页视频抓取软件(数码荔枝IDM斩获国内外多项大奖,官网原价79的终生版)
InternetDownloadManager(IDM)是一款非常知名的Windows平台下载工具,在国内外获得了很多奖项。与其他同类工具的炫目界面和功能相比,IDM界面无广告,无弹窗,无内置浏览器。专注下载,下载速度提升5倍,真正发挥速度下载优势。
 pt-IDM_1800x600@2x-1024x341.png 1024w, pt-IDM_1800x600@2x-300x100.png" rel="nofollow" target="_blank">https://www.rdonly.com/wp-cont ... 0.png 300w, pt-IDM_1800x600@2x-768x256.png" rel="nofollow" target="_blank">https://www.rdonly.com/wp-cont ... 6.png 768w, pt-IDM_1800x600@2x-1536x512.png" rel="nofollow" target="_blank">https://www.rdonly.com/wp-cont ... 2.png 1536w, pt-IDM_1800x600@2x.png" rel="nofollow" target="_blank">https://www.rdonly.com/wp-cont ... x.png 1800w" />
pt-IDM_1800x600@2x-1024x341.png 1024w, pt-IDM_1800x600@2x-300x100.png" rel="nofollow" target="_blank">https://www.rdonly.com/wp-cont ... 0.png 300w, pt-IDM_1800x600@2x-768x256.png" rel="nofollow" target="_blank">https://www.rdonly.com/wp-cont ... 6.png 768w, pt-IDM_1800x600@2x-1536x512.png" rel="nofollow" target="_blank">https://www.rdonly.com/wp-cont ... 2.png 1536w, pt-IDM_1800x600@2x.png" rel="nofollow" target="_blank">https://www.rdonly.com/wp-cont ... x.png 1800w" />这么好的软件价格自然不便宜,官网价格往往让人望而却步。
现在,我们正在与“数字荔枝”合作开展IDM折扣活动,特价30%起。官网原价79的IDM一年授权现仅需35元,官网原价160终身版现仅需129元!新注册用户可再享5元优惠!
专注下载
作为一款下载工具,IDM在P2P以外的文件下载功能上做到了极致,主要体现在自动链接抓取、静默下载、多线程和多媒体下载等,降低用户运营成本,提升文件下载体验。
自动捕获链接
IDM 可以在使用浏览器下载文件时自动捕获下载链接并添加下载任务。IDM 支持大部分主流浏览器,如 Chrome、Safari、Firefox、Edge、Internet Explorer 等。如果您使用的浏览器不在 IDM 的默认支持中,您也可以在软件设置中进行自定义。
 https://www.rdonly.com/wp-cont ... 5.jpg 300w, https://www.rdonly.com/wp-cont ... 7.jpg 768w" />
https://www.rdonly.com/wp-cont ... 5.jpg 300w, https://www.rdonly.com/wp-cont ... 7.jpg 768w" />静默下载
大多数人在下载文件时,会习惯性地将文件保存到固定位置,等待下载完成后再进行进一步处理。如果每次下载都需要重复点击“保存对话框”中的按钮,那将是非常多余和低效的。
IDM 的静默下载功能可以自动最小化下载窗口。如果您想在下载过程中修改保存位置或其他选项,可以直接调用托盘中的IDM图标。
多媒体下载
只要打开要下载的音视频的网站页面,IDM就会自动检测在线播放器发送的多媒体请求,并在播放器上显示下载浮动条。用户可以直接下载流媒体网站中的视频,在本地离线观看。
 https://www.rdonly.com/wp-cont ... 1.png 300w, https://www.rdonly.com/wp-cont ... 3.png 768w" />
https://www.rdonly.com/wp-cont ... 1.png 300w, https://www.rdonly.com/wp-cont ... 3.png 768w" />IDM支持MP4/MP3/MOV/AAC等常见音视频格式的检测和下载。在设置窗口中,您还可以指定特定站点显示或隐藏软件的下载浮动栏等自定义操作。
 https://www.rdonly.com/wp-cont ... 0.jpg 300w, https://www.rdonly.com/wp-cont ... 9.jpg 768w" />
https://www.rdonly.com/wp-cont ... 0.jpg 300w, https://www.rdonly.com/wp-cont ... 9.jpg 768w" />强大的扩展功能
IDM还配备了强大的自动下载功能,通过批量下载、定时下载任务、站点爬取等方式满足用户高层次的下载需求。
安排下载任务
通过设置定时下载任务,用户可以让IDM在指定的时间段内自动启动相应的下载任务,无论下载还是暂停等,都可以通过该功能实现。让家里的电脑在工作时间自动下载你需要的文件,到家就可以立即使用,非常方便。
 https://www.rdonly.com/wp-cont ... 0.jpg 300w, https://www.rdonly.com/wp-cont ... 3.jpg 768w" />
https://www.rdonly.com/wp-cont ... 0.jpg 300w, https://www.rdonly.com/wp-cont ... 3.jpg 768w" />网站抓取
“网站抓取”功能可以让您在输入链接后直接选择您要下载的网页的指定内容,无需使用通配符,包括图片、音频、视频、文件或收录完整样式的离线文件。IDM 可以做到这一切。您还可以根据自己的需要自定义站点抓取的内容和规则,并保存起来,方便下次调用。
 https://www.rdonly.com/wp-cont ... 3.jpg 300w, https://www.rdonly.com/wp-cont ... 1.jpg 768w" />
https://www.rdonly.com/wp-cont ... 3.jpg 300w, https://www.rdonly.com/wp-cont ... 1.jpg 768w" />批量下载
只要使用软件默认或自定义通配符,就可以使用IDM下载链接中收录的所有文件,例如网页中的所有图片。类似的形式如下:
一些网站.com/pictures/img*.jpg
使用上述命令,可以在IDM官网下载所有命名为img001.jpg、img002.jpg等命名规则的图片。
支持国外主流网盘
网站 上的很多国外资源文件都会放在他们常用的网盘里。如果直接下载这些文件,速度会很慢,很容易中断。这时候就需要IDM了。可将这些文件从网盘下载成队列进行批量下载,让您独立自定义每个队列的下载时间和下载文件数,灵活提高下载效率。
目前支持的网盘包括RapidShare、FileServe等,您可以访问官网查看所有IDM支持的网盘服务。
可接受的价格
最后,不要错过 IDM 折扣。官网原价79的IDM一年期授权现仅需35元,官网原价160的终身版现仅需129元!新用户注册领券立减5元!
国外网页视频抓取软件( 我们先用之前推文中介绍的方法尝试寻找其真实链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-14 00:04
我们先用之前推文中介绍的方法尝试寻找其真实链接
)
在之前的推文《一起来挖掘网页的真实链接吧!》中,我们介绍了如何使用谷歌浏览器在网页分页显示且点击时没有变化的情况下找到网页的真实链接但是有时我们也会遇到另一种情况:通过上述方法找到网页的链接后,发现URL中仍然没有可以用来识别不同网页的标识参数(例如page= 1). 别慌,今天小编就带你亲手解决这个问题。
1
我们以新浪财经中代码为00001的港股历史交易数据为例()。首先我们来看一下网页:虽然不是分页显示,但右上角有年度和季度选项。基于此,您可以查看昌河过去不同年份、不同季度的股票交易信息,如下图:
同时我们注意到网页的URL没有参数可以作为识别,所以这里需要再次踏上寻找网页真实链接的旅程~
我们首先尝试使用上一条推文介绍的方法找到真正的链接:在网页空白处右键单击“检查”,单击“网络”,然后按F5刷新,单击中间的第一个链接很多弹出查看它的响应的链接发现它的内容和网页的内容是一致的。是否可以确定它是我们现在正在寻找的网页的真实链接?
不用着急,我们继续右键第一个名为1.html的链接,点击复制→复制链接地址(这个操作可以复制网页的真实链接),结果这显然不是我们需要什么 带有识别参数的网页链接非常尴尬。
2
为什么会出现这样的情况?这主要是因为新浪财经的http请求方式是post。正如我们在上一条推文中提到的,两种最常见的 http 请求方法是 get 和 post。它们的区别在于get请求的数据会附加到URL上。之后URL和传输数据用?分割,参数用&连接,浏览器会生成目标URL,但是post不会。那么现在我们来介绍一下如何实现对http请求方式为post的网页的抓取。
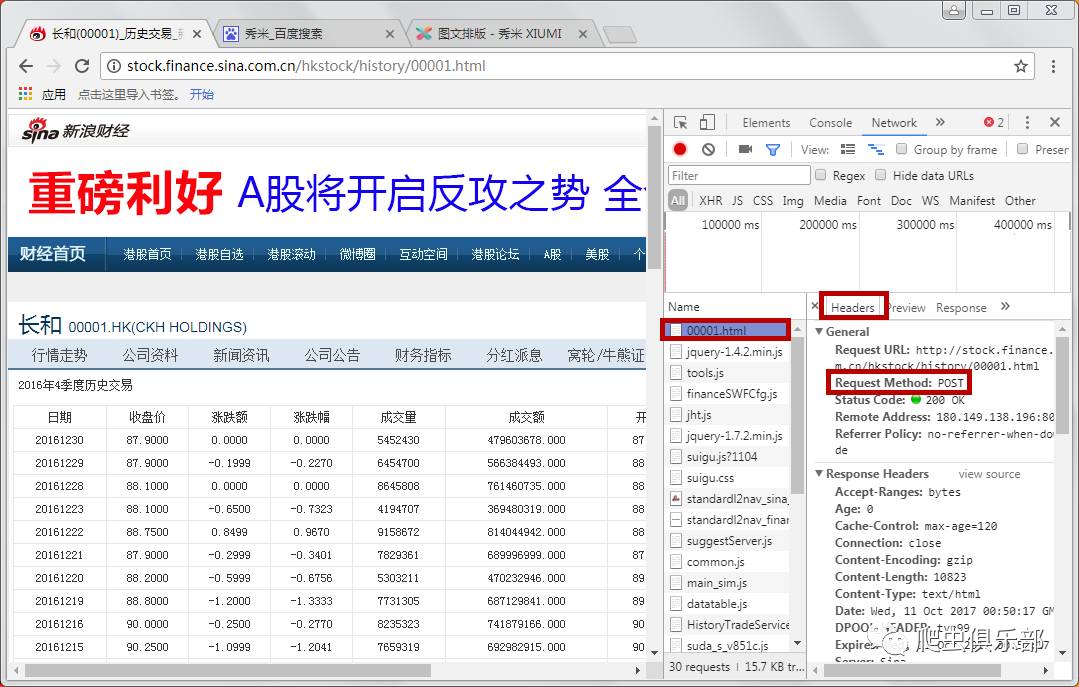
我们首先选择查看港股领头羊和过去一个季度(例如2016年第四季度)的交易数据。一开始我们还是用上面的方法去寻找网页的真实链接。我们可以发现第一个链接的返回信息和网页的内容是匹配的。它的Headers注意到网页的请求方法(Request Method)是POST,如图:
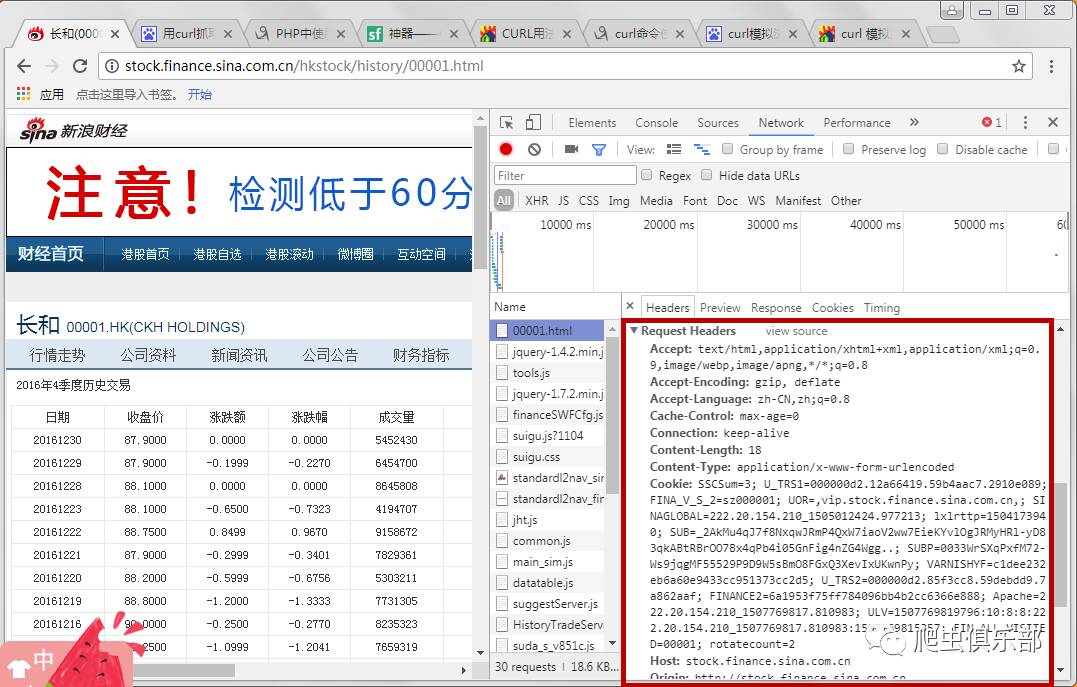
这时候如果继续像之前一样操作,是无法获取到网页的源代码的,需要使用curl来模拟浏览器请求。在这之前,我们先来了解一下网页的请求头,也就是Request Headers,谷歌开发者工具已经为我们准备了这个信息,如下图:
先简单介绍一下请求头中一些headers的含义:
Accept-Encoding:由浏览器发送给服务器,声明浏览器支持的编码类型
Accept-Language:用于告诉服务器浏览器可以支持什么语言
User Agent:中文名称为User Agent,简称UA。它是一个特殊的字符串头,使服务器能够识别操作系统和版本、CPU 类型、客户端使用的浏览器和版本、浏览器渲染引擎、浏览器语言和浏览器插件
Referer:当浏览器向Web服务器发送请求时,通常会带一个Referer,它代表网页的来源,也就是告诉服务器它是从哪个页面链接的。
Cookies:用于记录一些网站登录信息和访问信息等。
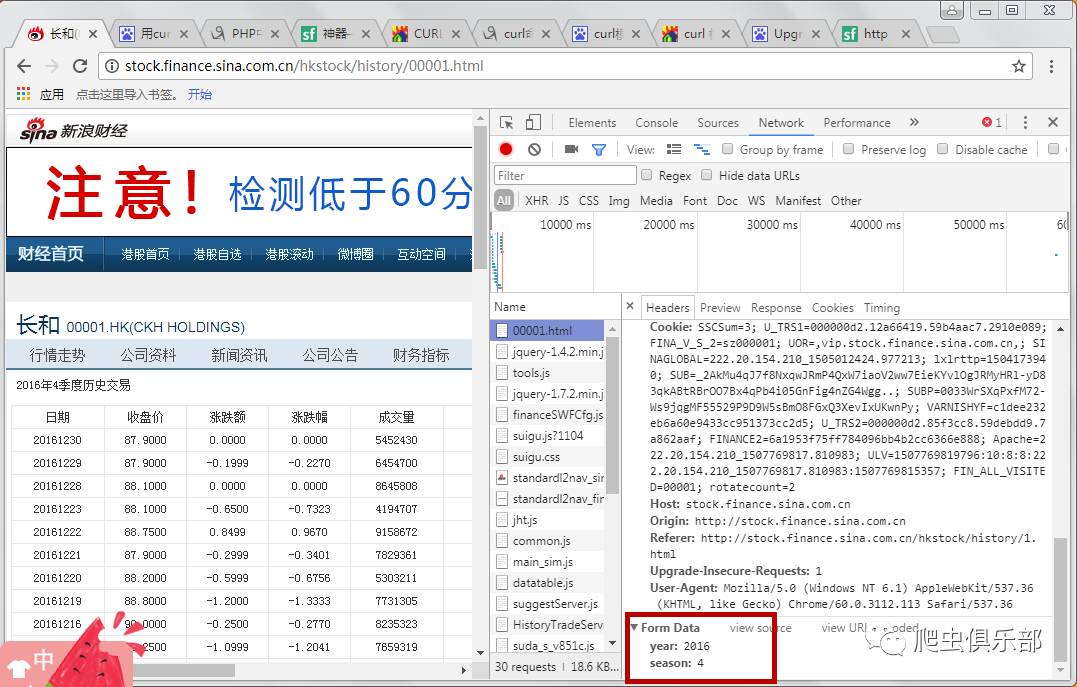
在请求头信息下面,有年份和季节两个参数。这些就是我们最初查询到的2016年第四季度对应的参数,也就是我们需要的识别参数,如下图所示:
3
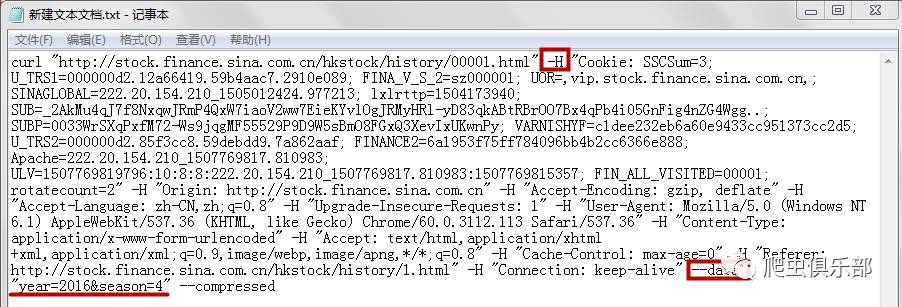
为了使用curl模拟浏览器请求,我们使用-H连接headers,使用--data或者-d指定使用POST传输数据,如下图:
现在你可以在 stata 中使用 curl 来抓取这个网页。我们可以保留如上图所示的所有header,但是如果网页不反爬或者只是做一些基本的反爬,则只保留识别参数。即 year=2016 和 season=4 并与 & 相连。在stata中输入以下命令:
清除
!curl --data "year=2016&season=4" -o sina.txt
shellout sina.txt
-o的作用是将获取到的网页信息下载保存到一个名为sina.txt的文件中,保存的路径为stata的默认保存路径。如下所示:
就这样,港交所总裁和2016年第四季度的历史交易信息就被抓获了。以后可以使用该方法抓取http请求方式为post的网页。不要忘记再次查看捕获。如何获取请求方式为get的网页~
不明白的记得戳下方视频学习哦!
查看全部
国外网页视频抓取软件(
我们先用之前推文中介绍的方法尝试寻找其真实链接
)


在之前的推文《一起来挖掘网页的真实链接吧!》中,我们介绍了如何使用谷歌浏览器在网页分页显示且点击时没有变化的情况下找到网页的真实链接但是有时我们也会遇到另一种情况:通过上述方法找到网页的链接后,发现URL中仍然没有可以用来识别不同网页的标识参数(例如page= 1). 别慌,今天小编就带你亲手解决这个问题。
1
我们以新浪财经中代码为00001的港股历史交易数据为例()。首先我们来看一下网页:虽然不是分页显示,但右上角有年度和季度选项。基于此,您可以查看昌河过去不同年份、不同季度的股票交易信息,如下图:
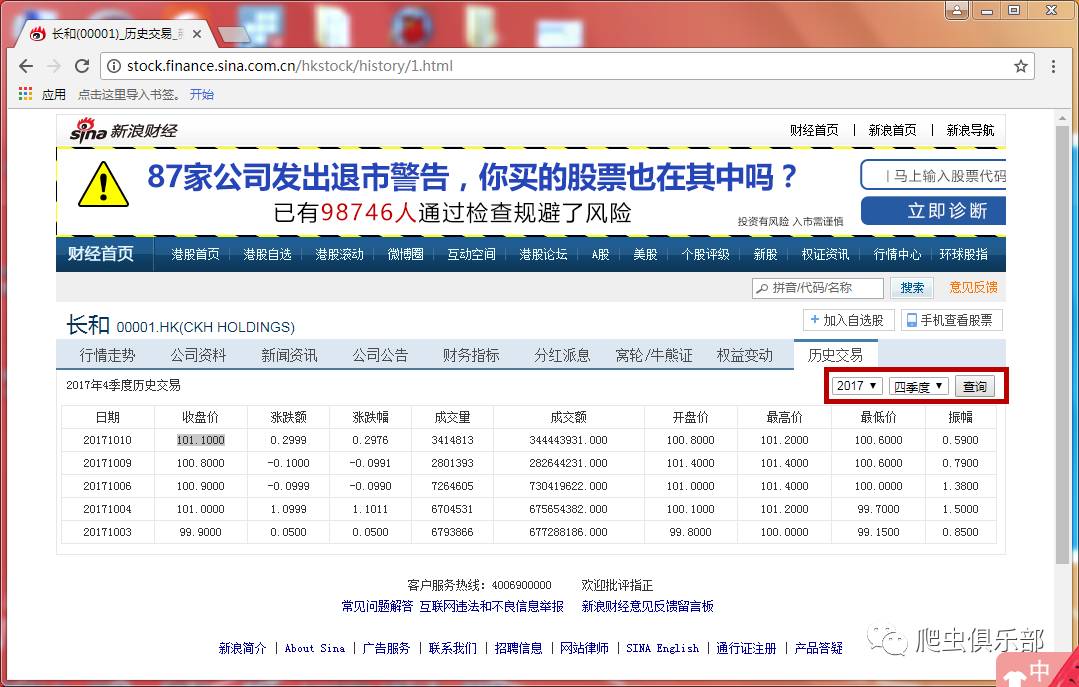
同时我们注意到网页的URL没有参数可以作为识别,所以这里需要再次踏上寻找网页真实链接的旅程~
我们首先尝试使用上一条推文介绍的方法找到真正的链接:在网页空白处右键单击“检查”,单击“网络”,然后按F5刷新,单击中间的第一个链接很多弹出查看它的响应的链接发现它的内容和网页的内容是一致的。是否可以确定它是我们现在正在寻找的网页的真实链接?
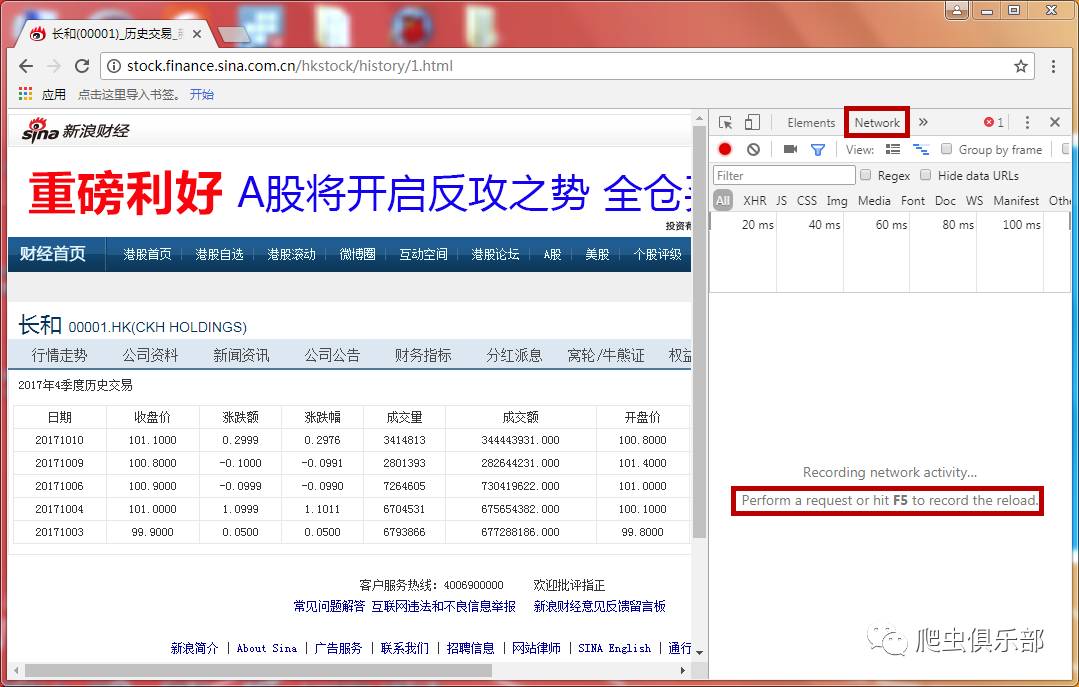
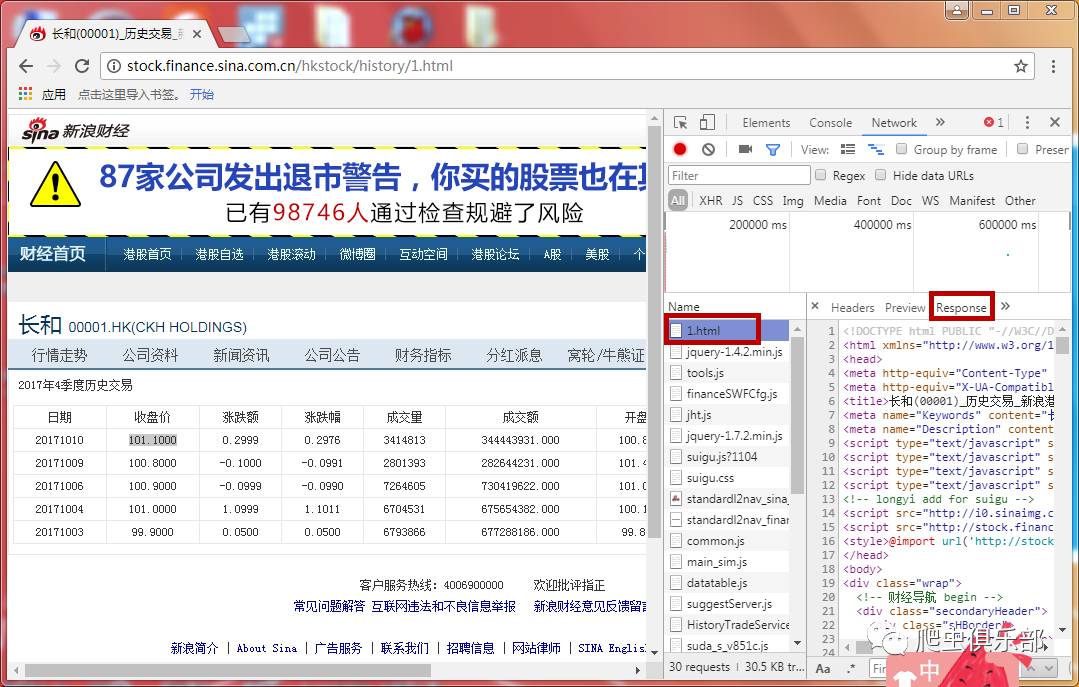
不用着急,我们继续右键第一个名为1.html的链接,点击复制→复制链接地址(这个操作可以复制网页的真实链接),结果这显然不是我们需要什么 带有识别参数的网页链接非常尴尬。
2
为什么会出现这样的情况?这主要是因为新浪财经的http请求方式是post。正如我们在上一条推文中提到的,两种最常见的 http 请求方法是 get 和 post。它们的区别在于get请求的数据会附加到URL上。之后URL和传输数据用?分割,参数用&连接,浏览器会生成目标URL,但是post不会。那么现在我们来介绍一下如何实现对http请求方式为post的网页的抓取。
我们首先选择查看港股领头羊和过去一个季度(例如2016年第四季度)的交易数据。一开始我们还是用上面的方法去寻找网页的真实链接。我们可以发现第一个链接的返回信息和网页的内容是匹配的。它的Headers注意到网页的请求方法(Request Method)是POST,如图:
这时候如果继续像之前一样操作,是无法获取到网页的源代码的,需要使用curl来模拟浏览器请求。在这之前,我们先来了解一下网页的请求头,也就是Request Headers,谷歌开发者工具已经为我们准备了这个信息,如下图:
先简单介绍一下请求头中一些headers的含义:
Accept-Encoding:由浏览器发送给服务器,声明浏览器支持的编码类型
Accept-Language:用于告诉服务器浏览器可以支持什么语言
User Agent:中文名称为User Agent,简称UA。它是一个特殊的字符串头,使服务器能够识别操作系统和版本、CPU 类型、客户端使用的浏览器和版本、浏览器渲染引擎、浏览器语言和浏览器插件
Referer:当浏览器向Web服务器发送请求时,通常会带一个Referer,它代表网页的来源,也就是告诉服务器它是从哪个页面链接的。
Cookies:用于记录一些网站登录信息和访问信息等。
在请求头信息下面,有年份和季节两个参数。这些就是我们最初查询到的2016年第四季度对应的参数,也就是我们需要的识别参数,如下图所示:
3
为了使用curl模拟浏览器请求,我们使用-H连接headers,使用--data或者-d指定使用POST传输数据,如下图:
现在你可以在 stata 中使用 curl 来抓取这个网页。我们可以保留如上图所示的所有header,但是如果网页不反爬或者只是做一些基本的反爬,则只保留识别参数。即 year=2016 和 season=4 并与 & 相连。在stata中输入以下命令:
清除
!curl --data "year=2016&season=4" -o sina.txt
shellout sina.txt
-o的作用是将获取到的网页信息下载保存到一个名为sina.txt的文件中,保存的路径为stata的默认保存路径。如下所示:
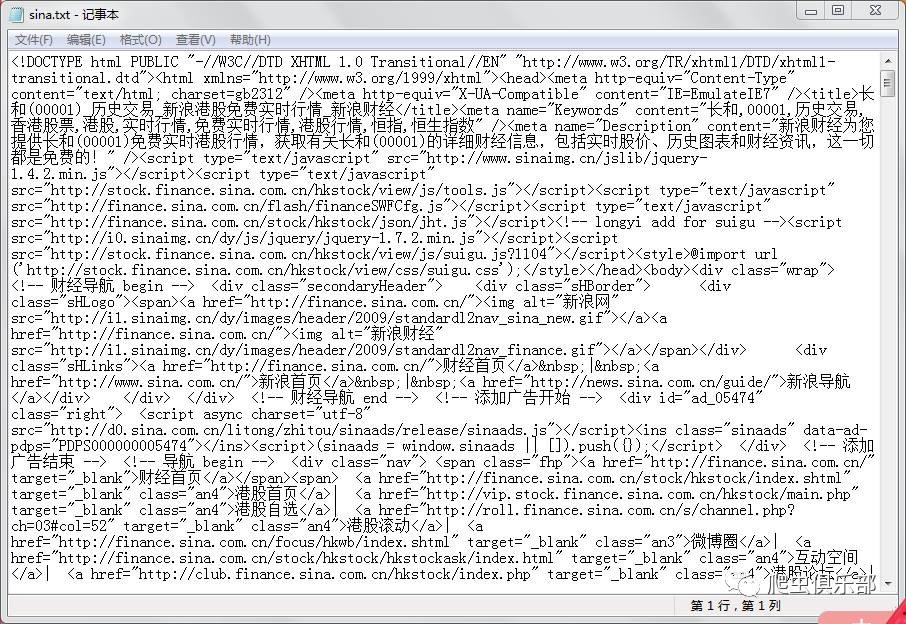
就这样,港交所总裁和2016年第四季度的历史交易信息就被抓获了。以后可以使用该方法抓取http请求方式为post的网页。不要忘记再次查看捕获。如何获取请求方式为get的网页~

不明白的记得戳下方视频学习哦!
国外网页视频抓取软件(Python从入门到进阶共10本电子书今日鸡汤众里寻他千百度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-10-14 00:03
点击上方“Python爬虫与数据挖掘”关注
回复“Books”即可领取从初级到高级共10本Python电子书
这个
日
小鸡
汤
人们上千百度找他。忽然回头一看,人就在那里,昏暗的灯光。
/1 简介/
上一篇其实是昨天发的,只是忘记标为原创。今天继续发布,和下一篇分享,让大家再次看到结局。这个文章主要是实战,实现谷歌人机破解的具体过程。
/2 实施步骤/
1、如果你来了,你就安全了。如果选择2captcha,就得看他们的官网了,如下图。
2、嗯...纯英文,看不懂..怎么办,别着急,我一步步带你分析主要功能。首先,登录您的帐户,如下图所示。
3、 登录后会自动跳转到首页,如下图。
上图中第一个红圈表示还剩多少钱。没钱记得要氪金,不然不能用滴。氪金工艺这里就不多解释了。问题不大。
红色圈出的第二个位置表示这是您唯一的钥匙。您必须在每次请求时携带此密钥,因此请妥善保管
4、进入主题,研究文档。点击红圈,API,通用API都是文档,如下图。
5、恩……什么东西……完全看不懂,别慌,下去
滑动到rates目录,我们知道Google Human Machine是ReCaptcha,但是三个,到底是哪一个,我给大家展示一下。
6、首先点击ReCaptcha(oldmethod),这个是老方法,我不知道,先看看这个,由浅入深,这里为了方便大家直接翻译了手表。
7、你看,其他人也说老方法求解ReCaptcha准确率较低。建议使用新方法,然后我们点击新方法看看。
8、我们找到了。这种验证码属于 ReCaptcha v2。确实和谷歌的人机一样。我们来看看文档是怎么写的。
9、人们说,我们先找到data-sitekey参数,然后提交data-sitekey参数给它,等待15-20s才得到结果。然后找到id=g-recaptcha-response的textarea标签,删除css display:none,在textarea输入框为我们添加字符串,点击submit,就大功告成了。
是不是很简单?我们也试试吧。打开谷歌的示例样式,如下图所示。
10、我们打开开发者工具,搜索data-sitekey,可以看到真的有一个。
11、 让我们分配这个data-sitekey,用代码得到最终的结果。
12、 然后我们找到id=g-recaptcha-response的textarea标签,删除它的display属性。
13、 不过有点不对。
14、看,下图是2captcha的例子。
我们可以看到2captcha是删除显示后,直接显示textarea框,但是我们删除显示后,基本没用了。这个...
15、别着急,大家想到了,我们就滑倒了。
由于我们不能直接显示textarea,就说明我们是隐式ReCaptcha验证码。其实它的原理很简单。
如果你学过一些前端,知道一些js,你可能会认为虽然我看不到这个textarea,但是我们仍然可以通过js改变textarea的数据,只是鼠标不能点击。看第一个红圈的位置。通过这个js,我们可以赋值2captcha得到的值。第二圈js是提交表单。其实只是我们人点击提交而已。它只是帮助我们的js代码。完成。就这样,我们也完成了日常的变化。
/3小试大锤/
1、好吧,我们先手动完成。上面我们已经根据data-sietkey得到了最终的结果。很明显,我们只能通过js来做,所以来试试吧。
通过上面的gif可以看到,我们通过js绕过了点击车辆识别,其他识别真的很方便。
2、但是我们不能每次都通过人来做,但是因为涉及到执行js,所以只能使用selenium,所以我们来看看在selenium上的效果。
看,这样我们就完成了谷歌人机(ReCaptcha)验证码的自动登录。如果你爬到国外XX网站,遇到ReCaptcha,相信对你有帮助。
/4。结论/
本文主要介绍使用第三方平台()破解谷歌人机登录。方法有点曲折,但是效果很好。
欢迎大家尝试在家消磨无聊的时间。本文涉及的代码已经上传到github地址,后台回复“谷歌人机”四个字即可获取代码。
- - - - - - - - - -结尾 - - - - - - - - - - 查看全部
国外网页视频抓取软件(Python从入门到进阶共10本电子书今日鸡汤众里寻他千百度)
点击上方“Python爬虫与数据挖掘”关注
回复“Books”即可领取从初级到高级共10本Python电子书
这个
日
小鸡
汤
人们上千百度找他。忽然回头一看,人就在那里,昏暗的灯光。
/1 简介/
上一篇其实是昨天发的,只是忘记标为原创。今天继续发布,和下一篇分享,让大家再次看到结局。这个文章主要是实战,实现谷歌人机破解的具体过程。
/2 实施步骤/
1、如果你来了,你就安全了。如果选择2captcha,就得看他们的官网了,如下图。
2、嗯...纯英文,看不懂..怎么办,别着急,我一步步带你分析主要功能。首先,登录您的帐户,如下图所示。
3、 登录后会自动跳转到首页,如下图。
上图中第一个红圈表示还剩多少钱。没钱记得要氪金,不然不能用滴。氪金工艺这里就不多解释了。问题不大。
红色圈出的第二个位置表示这是您唯一的钥匙。您必须在每次请求时携带此密钥,因此请妥善保管
4、进入主题,研究文档。点击红圈,API,通用API都是文档,如下图。
5、恩……什么东西……完全看不懂,别慌,下去
滑动到rates目录,我们知道Google Human Machine是ReCaptcha,但是三个,到底是哪一个,我给大家展示一下。
6、首先点击ReCaptcha(oldmethod),这个是老方法,我不知道,先看看这个,由浅入深,这里为了方便大家直接翻译了手表。
7、你看,其他人也说老方法求解ReCaptcha准确率较低。建议使用新方法,然后我们点击新方法看看。
8、我们找到了。这种验证码属于 ReCaptcha v2。确实和谷歌的人机一样。我们来看看文档是怎么写的。
9、人们说,我们先找到data-sitekey参数,然后提交data-sitekey参数给它,等待15-20s才得到结果。然后找到id=g-recaptcha-response的textarea标签,删除css display:none,在textarea输入框为我们添加字符串,点击submit,就大功告成了。
是不是很简单?我们也试试吧。打开谷歌的示例样式,如下图所示。
10、我们打开开发者工具,搜索data-sitekey,可以看到真的有一个。
11、 让我们分配这个data-sitekey,用代码得到最终的结果。
12、 然后我们找到id=g-recaptcha-response的textarea标签,删除它的display属性。
13、 不过有点不对。
14、看,下图是2captcha的例子。
我们可以看到2captcha是删除显示后,直接显示textarea框,但是我们删除显示后,基本没用了。这个...
15、别着急,大家想到了,我们就滑倒了。
由于我们不能直接显示textarea,就说明我们是隐式ReCaptcha验证码。其实它的原理很简单。
如果你学过一些前端,知道一些js,你可能会认为虽然我看不到这个textarea,但是我们仍然可以通过js改变textarea的数据,只是鼠标不能点击。看第一个红圈的位置。通过这个js,我们可以赋值2captcha得到的值。第二圈js是提交表单。其实只是我们人点击提交而已。它只是帮助我们的js代码。完成。就这样,我们也完成了日常的变化。
/3小试大锤/
1、好吧,我们先手动完成。上面我们已经根据data-sietkey得到了最终的结果。很明显,我们只能通过js来做,所以来试试吧。
通过上面的gif可以看到,我们通过js绕过了点击车辆识别,其他识别真的很方便。
2、但是我们不能每次都通过人来做,但是因为涉及到执行js,所以只能使用selenium,所以我们来看看在selenium上的效果。
看,这样我们就完成了谷歌人机(ReCaptcha)验证码的自动登录。如果你爬到国外XX网站,遇到ReCaptcha,相信对你有帮助。
/4。结论/
本文主要介绍使用第三方平台()破解谷歌人机登录。方法有点曲折,但是效果很好。
欢迎大家尝试在家消磨无聊的时间。本文涉及的代码已经上传到github地址,后台回复“谷歌人机”四个字即可获取代码。
- - - - - - - - - -结尾 - - - - - - - - - -
国外网页视频抓取软件(搜索引擎蜘蛛模拟器(国内)Google蜘蛛模拟访问工具(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-13 14:18
搜索引擎蜘蛛蜘蛛模拟器[]
1. 搜索引擎蜘蛛模拟器(国外)
蜘蛛模拟器工具可以模拟搜索引擎的蜘蛛,以搜索引擎的蜘蛛的方式抓取网页上的内容或链接。可以帮助您对网页的内容或链接进行直观的分析。一般来说,你在网页上看到的内容(网页上显示的内容)与搜索引擎蜘蛛(Spider)可以抓取的内容是不同的。也就是说,通过Flash、图片或Javascript等客户端渲染方式显示的内容及其收录的链接是搜索引擎无法抓取的。蜘蛛模拟器的作用也在这里,从搜索引擎的角度爬取和分析你的网页。
搜索引擎蜘蛛模拟器(国产)
2.谷歌蜘蛛模拟访问工具,模拟谷歌蜘蛛访问某个页面,可以让大家检查蜘蛛抓取的页面是否与你用浏览器看到的页面相同,可以用来识别友情链接欺骗。现在很多站长使用一些友情链接欺骗的方法,让自己的网站在搜索引擎中导出链接的次数变少,从而达到提高PR或者权重的效果。这个你可以通过你的浏览器浏览网站,我可以看到我自己的网站,但实际上他们是通过一些代码实现的。当搜索引擎抓取这个页面时,会有很多友情链接不会显示给搜索引擎。这个工具通过模拟谷歌蜘蛛,让大家知道别人的网站是否在友情链接上作弊。
使用方法:输入要查询的页面的URL并提交,显示的结果分别为抓取的文本和链接。
类似工具:蜘蛛模拟器
,您可以选择从Google以外的4个搜索引擎抓取网页:Altavista、Fast、Inktomi、WiseNut,还可以直观地显示抓取到的链接的绝对网址。
参考资料: 查看全部
国外网页视频抓取软件(搜索引擎蜘蛛模拟器(国内)Google蜘蛛模拟访问工具(组图))
搜索引擎蜘蛛蜘蛛模拟器[]
1. 搜索引擎蜘蛛模拟器(国外)
蜘蛛模拟器工具可以模拟搜索引擎的蜘蛛,以搜索引擎的蜘蛛的方式抓取网页上的内容或链接。可以帮助您对网页的内容或链接进行直观的分析。一般来说,你在网页上看到的内容(网页上显示的内容)与搜索引擎蜘蛛(Spider)可以抓取的内容是不同的。也就是说,通过Flash、图片或Javascript等客户端渲染方式显示的内容及其收录的链接是搜索引擎无法抓取的。蜘蛛模拟器的作用也在这里,从搜索引擎的角度爬取和分析你的网页。
搜索引擎蜘蛛模拟器(国产)
2.谷歌蜘蛛模拟访问工具,模拟谷歌蜘蛛访问某个页面,可以让大家检查蜘蛛抓取的页面是否与你用浏览器看到的页面相同,可以用来识别友情链接欺骗。现在很多站长使用一些友情链接欺骗的方法,让自己的网站在搜索引擎中导出链接的次数变少,从而达到提高PR或者权重的效果。这个你可以通过你的浏览器浏览网站,我可以看到我自己的网站,但实际上他们是通过一些代码实现的。当搜索引擎抓取这个页面时,会有很多友情链接不会显示给搜索引擎。这个工具通过模拟谷歌蜘蛛,让大家知道别人的网站是否在友情链接上作弊。
使用方法:输入要查询的页面的URL并提交,显示的结果分别为抓取的文本和链接。
类似工具:蜘蛛模拟器
,您可以选择从Google以外的4个搜索引擎抓取网页:Altavista、Fast、Inktomi、WiseNut,还可以直观地显示抓取到的链接的绝对网址。
参考资料:
国外网页视频抓取软件(国外网页视频抓取软件抓取整理利用webrtc来转换(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-28 23:07
国外网页视频抓取软件抓取整理利用webrtc来转换:flv抓取http抓取抓取整理:webrtc爬虫+正则表达式/python爬虫+pandas整理和分析matlab-matlab介绍和安装使用方法python爬虫+pandas整理和分析matlab-matlab介绍和安装
附一个精华回答整理:量化基础和量化策略研究,量化交易从业者学习必备经典书籍汇总量化交易从业者在外汇投资中,
除了基础,再推荐两本《从零开始学量化》和《深入浅出量化交易》。
推荐过去半年的写的文章,半年以内总结的写成回答,里面总结了我对软件使用和盈利的一些认识。也欢迎参与讨论,点个赞,知乎关注,收藏关注,还可以加交流群,
推荐量化交易书籍
上期软件app
如果去培训机构的话,教材是一方面,最重要的还是在去机构培训时老师对你讲的方法和指导等,市场是残酷的,仅凭一个人自己的独立思考去完成一个交易系统是完全不可能完成的,需要老师和团队的力量去完成交易的辅助完成一个原始交易,软件很重要,但是没有人教,
交易其实有很多种方法,但是盈利的关键就两点:1、开仓2、持仓当然这两点其实不是在同一时刻做到的,因为一般进场要么超买(盘中),要么超卖(盘后)。持仓要么就是之前无交易历史,要么交易历史少。你要做的是如何在一个点位,在多空双方都没有任何实质性利空信息的情况下,得到一个可靠的点位,赚到钱。 查看全部
国外网页视频抓取软件(国外网页视频抓取软件抓取整理利用webrtc来转换(组图))
国外网页视频抓取软件抓取整理利用webrtc来转换:flv抓取http抓取抓取整理:webrtc爬虫+正则表达式/python爬虫+pandas整理和分析matlab-matlab介绍和安装使用方法python爬虫+pandas整理和分析matlab-matlab介绍和安装
附一个精华回答整理:量化基础和量化策略研究,量化交易从业者学习必备经典书籍汇总量化交易从业者在外汇投资中,
除了基础,再推荐两本《从零开始学量化》和《深入浅出量化交易》。
推荐过去半年的写的文章,半年以内总结的写成回答,里面总结了我对软件使用和盈利的一些认识。也欢迎参与讨论,点个赞,知乎关注,收藏关注,还可以加交流群,
推荐量化交易书籍
上期软件app
如果去培训机构的话,教材是一方面,最重要的还是在去机构培训时老师对你讲的方法和指导等,市场是残酷的,仅凭一个人自己的独立思考去完成一个交易系统是完全不可能完成的,需要老师和团队的力量去完成交易的辅助完成一个原始交易,软件很重要,但是没有人教,
交易其实有很多种方法,但是盈利的关键就两点:1、开仓2、持仓当然这两点其实不是在同一时刻做到的,因为一般进场要么超买(盘中),要么超卖(盘后)。持仓要么就是之前无交易历史,要么交易历史少。你要做的是如何在一个点位,在多空双方都没有任何实质性利空信息的情况下,得到一个可靠的点位,赚到钱。
国外网页视频抓取软件(import.io有所获得种子加A轮共计一千多万美金万美金)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-12 09:05
随着提倡个性化的“web2.0”概念的兴起,UGC让我们从一个以下载为主的网络时代,进化到一个下载与上传并存的交互时代。这意味着互联网上的信息量变得更加丰富了,它带来的增加量也是我们难以预料的。面对海量海量的“大数据”,国内外衍生出了经典的网络爬虫工具。 .
首先,让我们把注意力转向国外。熟悉互联网和大数据的朋友一定听说过import.io。种子加A轮融资总额超过1000万美元,国内人士纷纷被吸引。 Import.io的不同之处在于,用户只需要在网站想要抓取数据的地方简单的点击几下,然后就可以根据你的操作计算出你想要抓取的数据,然后创建一个真正的-这些数据的实时连接,那么您只需要选择想要的导出格式,就可以得到一份指定内容的副本和实时更新的数据。
听起来真的很神奇,就像产品名称一样“神奇”。有兴趣的朋友可以体验一下,但需要注意的是import.io更适合一些列表数据,比如微博、店铺页面,这些类型往往不适用,因为它抓取的字段不是全部字段。它是基于特殊的选择性计算,所以用户需要根据自己的需要选择使用。
那么国内最经典的网络爬虫工具,你一定已经想到了。是行业经验最深的优采云采集器。它于 2005 年开发,目前拥有超过 400,000 名免费用户。与 Import.io 不同,优采云采集器 更注重准确性。在去那里之前,它需要用户的明确指示,即采集规则。执行操作,所以可以应用的网页类型更多,甚至整个网络。
因为优采云采集器的工作原理是提取网页结构的源代码,所以只要网页上能看到内容,不管布局如何都可以快速提取。最终捕获的数据可以导入任何目标数据库或导出为所需的格式。在网页爬取的过程中,还可以选择不同的线程来控制优采云采集器采集的速度。一般来说优采云采集器适用于对抓取、速度、完整性有明确要求的用户。
在程序员们惊为天人的高智商的发展下,网络信息和数据的爬行不再让我们感到疯狂。市面上还有很多新兴的或者仿制的网页抓取工具,但真正值得用户称赞的才是最好的,这里就不一一列举了。与国外的import.io相比,中国本土网页抓取工具优采云采集器开发较早,功能上也不逊色。看来国内大数据技术未来的发展值得期待! 查看全部
国外网页视频抓取软件(import.io有所获得种子加A轮共计一千多万美金万美金)
随着提倡个性化的“web2.0”概念的兴起,UGC让我们从一个以下载为主的网络时代,进化到一个下载与上传并存的交互时代。这意味着互联网上的信息量变得更加丰富了,它带来的增加量也是我们难以预料的。面对海量海量的“大数据”,国内外衍生出了经典的网络爬虫工具。 .
首先,让我们把注意力转向国外。熟悉互联网和大数据的朋友一定听说过import.io。种子加A轮融资总额超过1000万美元,国内人士纷纷被吸引。 Import.io的不同之处在于,用户只需要在网站想要抓取数据的地方简单的点击几下,然后就可以根据你的操作计算出你想要抓取的数据,然后创建一个真正的-这些数据的实时连接,那么您只需要选择想要的导出格式,就可以得到一份指定内容的副本和实时更新的数据。
听起来真的很神奇,就像产品名称一样“神奇”。有兴趣的朋友可以体验一下,但需要注意的是import.io更适合一些列表数据,比如微博、店铺页面,这些类型往往不适用,因为它抓取的字段不是全部字段。它是基于特殊的选择性计算,所以用户需要根据自己的需要选择使用。
那么国内最经典的网络爬虫工具,你一定已经想到了。是行业经验最深的优采云采集器。它于 2005 年开发,目前拥有超过 400,000 名免费用户。与 Import.io 不同,优采云采集器 更注重准确性。在去那里之前,它需要用户的明确指示,即采集规则。执行操作,所以可以应用的网页类型更多,甚至整个网络。
因为优采云采集器的工作原理是提取网页结构的源代码,所以只要网页上能看到内容,不管布局如何都可以快速提取。最终捕获的数据可以导入任何目标数据库或导出为所需的格式。在网页爬取的过程中,还可以选择不同的线程来控制优采云采集器采集的速度。一般来说优采云采集器适用于对抓取、速度、完整性有明确要求的用户。
在程序员们惊为天人的高智商的发展下,网络信息和数据的爬行不再让我们感到疯狂。市面上还有很多新兴的或者仿制的网页抓取工具,但真正值得用户称赞的才是最好的,这里就不一一列举了。与国外的import.io相比,中国本土网页抓取工具优采云采集器开发较早,功能上也不逊色。看来国内大数据技术未来的发展值得期待!
国外网页视频抓取软件(VidCoder让小伙伴们可以轻松抓取和转码蓝光视频和DVD)
网站优化 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-09-12 09:02
VidCoder 允许朋友轻松抓取蓝光视频和 DVD 并对其进行转码。作为开源软件,支持批量编码处理,提高您的操作效率。用户还可以为视频添加水印和字幕,创建自己的视频资源库。
软件功能
开源免费视频编辑工具是一款免费开源的视频下载、编辑、字幕上传工具。它可用于 DVD/蓝光视频捕获和转码操作。更重要的是,它可以导入字幕。而对于校队来说,目前支持中文语言包,操作更方便。特别适合视频发布团队编辑视频、添加字母、水印、转换格式等。当我们观看一些没有字幕的视频时,不妨使用这个视频编辑工具自己添加字母。可以设置偏移量,最适合用胶片采集器。
功能介绍
多线程
MP4、MKV 容器
H.264 编码 x264,世界上最好的视频编码器
完全集成的编码方式:一切都在一个过程中,没有庞大的中间临时文件
它还支持mpeg-2,mpeg-4视频
AC3、MP3、AAC Vorbis FLAC和AAC音频编码/AC3 /MP3/DTS/DTS-HD透传
视频的目标比特率、大小或质量
2-pass 编码
Decomb detelecine, de-interlace filter
批量编码
即时预览视频源
创建一个小的编码预览剪辑
暂停和恢复编码
如何使用
更新日志
在主窗口增加了编辑字幕和音轨名称的功能。
增加了从源视频中保存字幕轨道名称的功能。
文件源搜索栏中添加了时间戳,以便于与源进行比较。
更新了“保留文件的创建/修改时间”选项,并保留了“媒体创建”扩展属性。
设置默认输出文件夹的要求已被删除。现在默认选择用户的“视频”文件夹。
标题下拉菜单中小时的前导零已被清除。
改进了编码失败的错误记录。
更新了核心。
修复了视频时长超过 24 小时的格式问题。
修复了 x264 日志信息丢失的问题。
修复编辑队列项后切换到章节范围选择模式开始/结束章节开始空白的问题。
修复了正常应用程序数据文件夹已经存在时Microsoft Store版本的“打开应用程序数据文件夹”命令。
修复了主窗口字幕列表的屏幕阅读器行为。
以上就是小编为大家带来的蓝光视频采集工具(VidCoder)。更多精彩软件请关注IE浏览器Chinese网站! 查看全部
国外网页视频抓取软件(VidCoder让小伙伴们可以轻松抓取和转码蓝光视频和DVD)
VidCoder 允许朋友轻松抓取蓝光视频和 DVD 并对其进行转码。作为开源软件,支持批量编码处理,提高您的操作效率。用户还可以为视频添加水印和字幕,创建自己的视频资源库。
软件功能
开源免费视频编辑工具是一款免费开源的视频下载、编辑、字幕上传工具。它可用于 DVD/蓝光视频捕获和转码操作。更重要的是,它可以导入字幕。而对于校队来说,目前支持中文语言包,操作更方便。特别适合视频发布团队编辑视频、添加字母、水印、转换格式等。当我们观看一些没有字幕的视频时,不妨使用这个视频编辑工具自己添加字母。可以设置偏移量,最适合用胶片采集器。
功能介绍
多线程
MP4、MKV 容器
H.264 编码 x264,世界上最好的视频编码器
完全集成的编码方式:一切都在一个过程中,没有庞大的中间临时文件
它还支持mpeg-2,mpeg-4视频
AC3、MP3、AAC Vorbis FLAC和AAC音频编码/AC3 /MP3/DTS/DTS-HD透传
视频的目标比特率、大小或质量
2-pass 编码
Decomb detelecine, de-interlace filter
批量编码
即时预览视频源
创建一个小的编码预览剪辑
暂停和恢复编码
如何使用
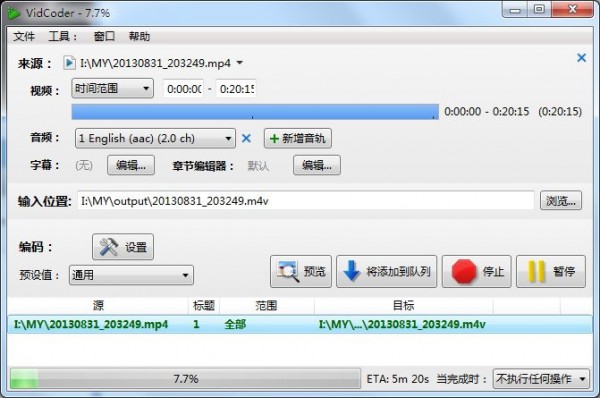
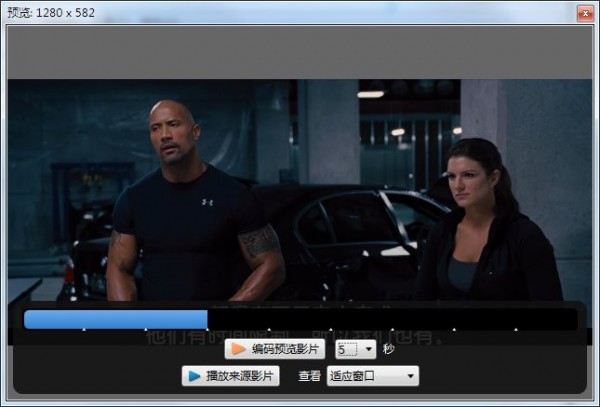
更新日志
在主窗口增加了编辑字幕和音轨名称的功能。
增加了从源视频中保存字幕轨道名称的功能。
文件源搜索栏中添加了时间戳,以便于与源进行比较。
更新了“保留文件的创建/修改时间”选项,并保留了“媒体创建”扩展属性。
设置默认输出文件夹的要求已被删除。现在默认选择用户的“视频”文件夹。
标题下拉菜单中小时的前导零已被清除。
改进了编码失败的错误记录。
更新了核心。
修复了视频时长超过 24 小时的格式问题。
修复了 x264 日志信息丢失的问题。
修复编辑队列项后切换到章节范围选择模式开始/结束章节开始空白的问题。
修复了正常应用程序数据文件夹已经存在时Microsoft Store版本的“打开应用程序数据文件夹”命令。
修复了主窗口字幕列表的屏幕阅读器行为。
以上就是小编为大家带来的蓝光视频采集工具(VidCoder)。更多精彩软件请关注IE浏览器Chinese网站!
国外网页视频抓取软件(25h打造出一款外贸网站挖掘工具,10s提取100客户网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-10 07:01
最后给大家介绍几个主要的功能按钮:1、 上图中的两个按钮用于在谷歌地图/谷歌搜索引擎和两种抓取模式之间切换。这个不用我多说了,自然会点进去。明白了!
下图中的工具,我之前给大家介绍过,这是我做的谷歌搜索提取工具2.0的版本。
2.0 版本主要是帮你在谷歌搜索引擎上直接提取网站和标题信息。可以参考我之前的文章《25h打造外贸网站挖矿工具,10s提取100个客户网站!》,看详细介绍!
今天主要给大家介绍一下我前两天刚拿到的谷歌搜索提取工具3.0的新修订版。与之前的版本相比,新增了googlemaps提取功能,可以帮助您直接提取谷歌地图。公司信息,很多老牌外贸公司对谷歌地图可能并不陌生。在谷歌地图上输入关键词,可以搜索到周边所有的精准买家,是外贸客户发展的常用渠道。
只要通过关键词搜索公司信息页面,直接点击开始爬取按钮就可以开发爬取信息。操作相当简单,不用担心,会自动翻页,直到搜索完成。
另外3.0版本与2.0版本相比,谷歌搜索引擎抓取也进行了调整。不像之前直接输入关键词进行爬取,还需要手动跳转到第二页。这一次,将整个真实网页直接转入工具中,搜索和翻页也完全自动化。完全模拟人工操作,降低验证码弹窗的概率,即使验证码弹出,我们也可以手动填写!
最后给大家介绍几个主要的功能按钮:
1、
上图中的两个按钮用于在谷歌地图/谷歌搜索引擎和两种抓取模式之间切换。关于这一点我不需要多说。点进去就明白了!
2、
翻转搜索是本次更新的一个很好的功能。如果你电脑上的fq工具失败了,你可以试着检查一下这个,然后切换到更流畅的线条。这样,您也可以使用此工具。去谷歌取资料(毕竟大家有空,肯定会慢!)
3、
红框中选中的四个按钮当然不用我过多解释了,照字面意思。全部导出就是将搜索到的数据以excel格式导出到本地电脑。
4、
如果你上传这个选项,我们一般默认不勾选。如果您不是使用F墙工具,而是使用F墙路由器上网,您不妨勾选这个选项试试。 (切记不要随意检查,否则无法加载googe页面)
其他的就不解释了,自己下载体验吧!这些工具是针对个人兴趣和爱好的,可以免费与大家分享。您不必担心是否充电。只要对大家有帮助,我一定会持续优化更新更多功能给大家!
下载链接:
某些计算机下载和安装可能会弹出风险警告。您只需单击“允许”即可放心使用。没必要为你什么年龄生产病毒!
同理,有什么bug或者好的建议都可以在评论区写! 查看全部
国外网页视频抓取软件(25h打造出一款外贸网站挖掘工具,10s提取100客户网站)
最后给大家介绍几个主要的功能按钮:1、 上图中的两个按钮用于在谷歌地图/谷歌搜索引擎和两种抓取模式之间切换。这个不用我多说了,自然会点进去。明白了!
下图中的工具,我之前给大家介绍过,这是我做的谷歌搜索提取工具2.0的版本。

2.0 版本主要是帮你在谷歌搜索引擎上直接提取网站和标题信息。可以参考我之前的文章《25h打造外贸网站挖矿工具,10s提取100个客户网站!》,看详细介绍!
今天主要给大家介绍一下我前两天刚拿到的谷歌搜索提取工具3.0的新修订版。与之前的版本相比,新增了googlemaps提取功能,可以帮助您直接提取谷歌地图。公司信息,很多老牌外贸公司对谷歌地图可能并不陌生。在谷歌地图上输入关键词,可以搜索到周边所有的精准买家,是外贸客户发展的常用渠道。

只要通过关键词搜索公司信息页面,直接点击开始爬取按钮就可以开发爬取信息。操作相当简单,不用担心,会自动翻页,直到搜索完成。
另外3.0版本与2.0版本相比,谷歌搜索引擎抓取也进行了调整。不像之前直接输入关键词进行爬取,还需要手动跳转到第二页。这一次,将整个真实网页直接转入工具中,搜索和翻页也完全自动化。完全模拟人工操作,降低验证码弹窗的概率,即使验证码弹出,我们也可以手动填写!

最后给大家介绍几个主要的功能按钮:
1、

上图中的两个按钮用于在谷歌地图/谷歌搜索引擎和两种抓取模式之间切换。关于这一点我不需要多说。点进去就明白了!
2、

翻转搜索是本次更新的一个很好的功能。如果你电脑上的fq工具失败了,你可以试着检查一下这个,然后切换到更流畅的线条。这样,您也可以使用此工具。去谷歌取资料(毕竟大家有空,肯定会慢!)
3、

红框中选中的四个按钮当然不用我过多解释了,照字面意思。全部导出就是将搜索到的数据以excel格式导出到本地电脑。
4、

如果你上传这个选项,我们一般默认不勾选。如果您不是使用F墙工具,而是使用F墙路由器上网,您不妨勾选这个选项试试。 (切记不要随意检查,否则无法加载googe页面)
其他的就不解释了,自己下载体验吧!这些工具是针对个人兴趣和爱好的,可以免费与大家分享。您不必担心是否充电。只要对大家有帮助,我一定会持续优化更新更多功能给大家!
下载链接:
某些计算机下载和安装可能会弹出风险警告。您只需单击“允许”即可放心使用。没必要为你什么年龄生产病毒!
同理,有什么bug或者好的建议都可以在评论区写!
国外网页视频抓取软件(基于动态内容抓取JavaScript页面的优势--互联网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-09-10 07:00
指南
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
代理抓取
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
代理抓取
可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
Scrapy
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用 Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。
抢
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
雪貂
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
Diffbot
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。
原文来自: 查看全部
国外网页视频抓取软件(基于动态内容抓取JavaScript页面的优势--互联网)
指南
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
代理抓取
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
 https://www.linuxprobe.com/wp- ... 2.jpg 300w" />
https://www.linuxprobe.com/wp- ... 2.jpg 300w" />代理抓取
可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
 https://www.linuxprobe.com/wp- ... 7.jpg 300w" />
https://www.linuxprobe.com/wp- ... 7.jpg 300w" />Scrapy
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用 Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。
 https://www.linuxprobe.com/wp- ... 1.jpg 300w" />
https://www.linuxprobe.com/wp- ... 1.jpg 300w" />抢
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
雪貂
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
 https://www.linuxprobe.com/wp- ... 1.jpg 300w" />
https://www.linuxprobe.com/wp- ... 1.jpg 300w" />此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
 https://www.linuxprobe.com/wp- ... 4.jpg 300w" />
https://www.linuxprobe.com/wp- ... 4.jpg 300w" />Diffbot
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
 https://www.linuxprobe.com/wp- ... 2.jpg 300w" />
https://www.linuxprobe.com/wp- ... 2.jpg 300w" />PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。
原文来自:
国外网页视频抓取软件(如何利用IDM自带的视频嗅探功能来下载视频完整播放)
网站优化 • 优采云 发表了文章 • 0 个评论 • 606 次浏览 • 2021-09-10 06:10
我在网上看到好的视频,总有一些想下载下来慢慢欣赏,但是现在网站的一些视频越来越难下载了。视频的真实地址被加密隐藏,或者被分割成无数个小片段。如果要完整下载视频,一般的工具真的搞不定~
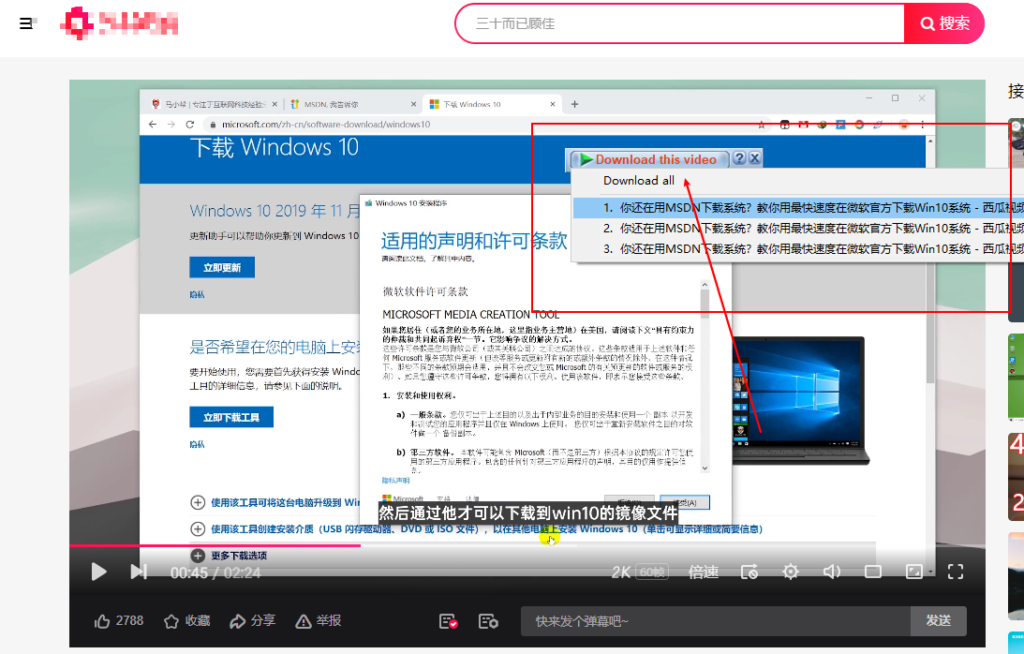
作为多线程下载工具IDM的用户,我之前和大家分享过IDM内置的视频嗅探功能是用来下载视频的。虽然这个方法可以解决很多网站video 下载的问题,但是还是有很多小众的网站video 无法下载。
之前和大家分享过其他网络视频下载工具,但效果总是不尽如人意。苦苦寻找一款优秀的网络视频下载工具后,进入了自己的视野——CoCoCut
这是 Google Chrome 的扩展程序。虽然上架时间不长,但用户量已经突破10000,好评如潮~
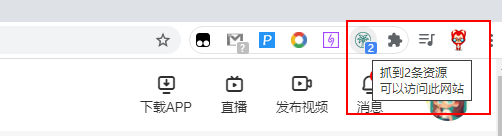
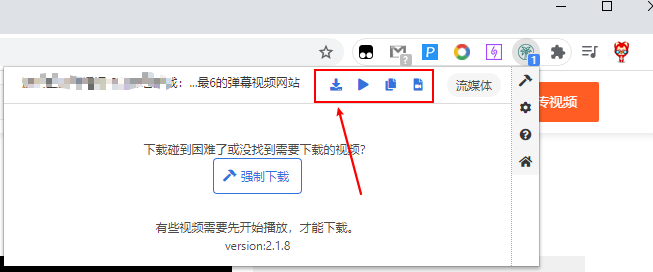
只要你当前访问的网页含有视频、音乐的网页时,CocoCut可以自动发现可供下载的视频、音乐。并且在插件栏显示已经抓取的资源数量。
您只需要点击chrome右上角的CocoCut扩展图标,即可显示可下载的内容。点击下载按钮,进入下载界面,保存并下载完整视频。
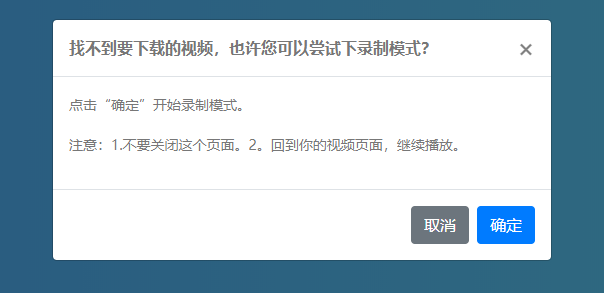
你认为这已经结束了吗?当然不是,如果只是这样的话,那么不推荐这个工具。对于一些非常顽固的网络视频,有时根本无法识别下载地址。那么这个插件还有“强制下载”功能!
这个强制下载功能的原理其实就是录制模式,点击强制下载。然后点击确定按钮开始录制,然后返回视频页面播放视频。
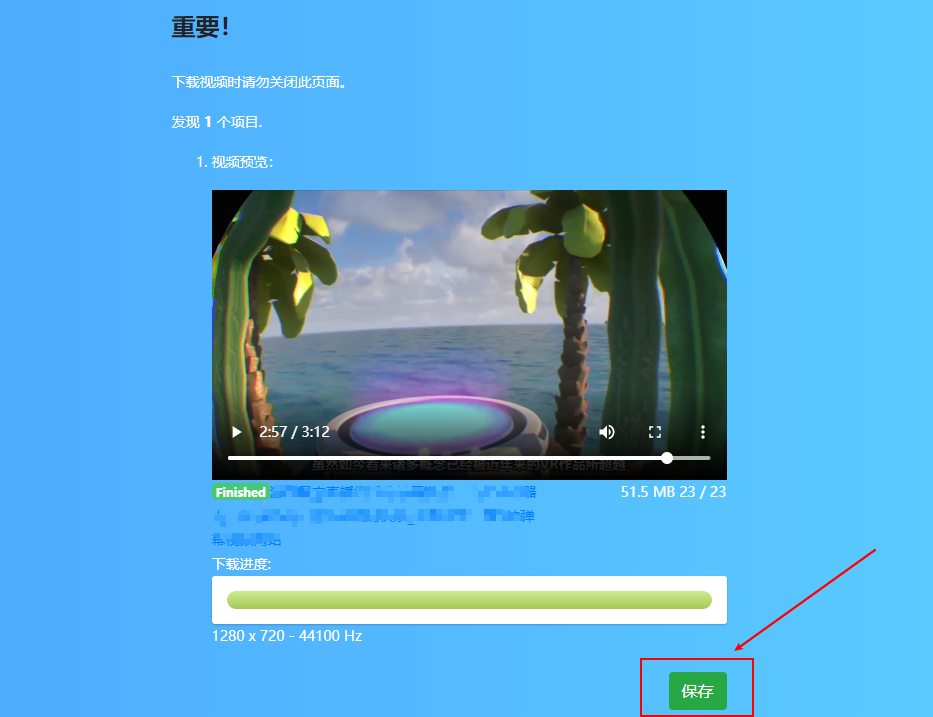
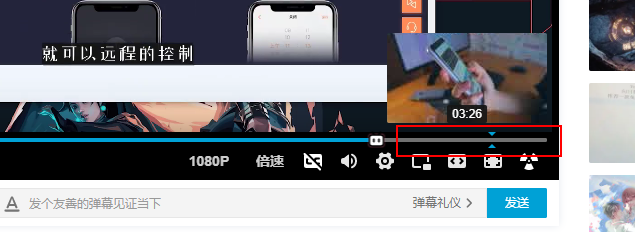
录制视频不会等待视频播放完毕。只要视频已被缓冲,就会被记录下来。可以直接将进度条拖到缓冲条的末尾,加快录制速度。
CocoCut 就其功能而言,已经是一款出色的网络视频下载工具。声称支持 99% 的视频格式并不是吹嘘。 网站的大部分视频都可以用这个工具下载,但还是不够完美。部分视频网站仍会在直接下载或录制模式下进行分段。希望以后能改进或增加合并功能。
下载链接:
本文原创文章。发布者:Bang,如转载请注明出处: 查看全部
国外网页视频抓取软件(如何利用IDM自带的视频嗅探功能来下载视频完整播放)
我在网上看到好的视频,总有一些想下载下来慢慢欣赏,但是现在网站的一些视频越来越难下载了。视频的真实地址被加密隐藏,或者被分割成无数个小片段。如果要完整下载视频,一般的工具真的搞不定~
作为多线程下载工具IDM的用户,我之前和大家分享过IDM内置的视频嗅探功能是用来下载视频的。虽然这个方法可以解决很多网站video 下载的问题,但是还是有很多小众的网站video 无法下载。
之前和大家分享过其他网络视频下载工具,但效果总是不尽如人意。苦苦寻找一款优秀的网络视频下载工具后,进入了自己的视野——CoCoCut

这是 Google Chrome 的扩展程序。虽然上架时间不长,但用户量已经突破10000,好评如潮~
只要你当前访问的网页含有视频、音乐的网页时,CocoCut可以自动发现可供下载的视频、音乐。并且在插件栏显示已经抓取的资源数量。
您只需要点击chrome右上角的CocoCut扩展图标,即可显示可下载的内容。点击下载按钮,进入下载界面,保存并下载完整视频。
你认为这已经结束了吗?当然不是,如果只是这样的话,那么不推荐这个工具。对于一些非常顽固的网络视频,有时根本无法识别下载地址。那么这个插件还有“强制下载”功能!

这个强制下载功能的原理其实就是录制模式,点击强制下载。然后点击确定按钮开始录制,然后返回视频页面播放视频。
录制视频不会等待视频播放完毕。只要视频已被缓冲,就会被记录下来。可以直接将进度条拖到缓冲条的末尾,加快录制速度。
CocoCut 就其功能而言,已经是一款出色的网络视频下载工具。声称支持 99% 的视频格式并不是吹嘘。 网站的大部分视频都可以用这个工具下载,但还是不够完美。部分视频网站仍会在直接下载或录制模式下进行分段。希望以后能改进或增加合并功能。

下载链接:
本文原创文章。发布者:Bang,如转载请注明出处:
国外网页视频抓取软件(两款实用的图片批量抓取——ExtremePictureFinderPicture )
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-10 04:11
)
今天介绍两款实用的图片批量抓取下载工具-ExtremePictureFinder直装破解版+Bulk.Image.Downloader.5.64.0.直装破解版替换破解中的文件安装后。
1、Extreme Picture Finder(官方主页)。它是一个强大的批量图像下载器。从任何网站 快速自动下载所有图像。但不仅是图像!它允许您下载音乐、视频或任何其他文件——只需输入网站 地址,选择您要下载的文件和文件的保存位置,剩下的交给 Extreme Picture Finder。您可以立即在内置图像查看器中查看下载的文件。
该程序可以配置为从受密码保护的网站、论坛主题甚至社交网络下载图像。使用高级设置,您可以让 Extreme Picture Finder 跳过网站 的某些部分,例如整个文件夹或单个页面,以加快下载过程。不知道从哪里开始下载? Extreme Picture Finder 提供了一个内置的在线项目数据库,其中收录数千个按类别分类的网站 地址:桌面壁纸、汽车、女孩、自然等等。
顾名思义,该程序的另一个重要功能是内置图片查找器。只要您输入一个关键字,程序就会为您查找并下载数千张图片。它具有不同的搜索模式,允许您更改与下载过程的交互级别。您可以让程序只查找和下载缩略图,然后在几秒钟内看到数百张图片向您飞来——这是最快的搜索模式。
然后您可以选择要手动下载的全尺寸图像。当然,您可以让 Extreme Picture Finder 自动查找、下载和保存缩略图和全尺寸图像,或者只是查找、下载和保存全尺寸图像。此外,该程序还可以保存在与原创全尺寸图像相同的页面上找到的所有图像相关图像。
特点:
-自动下载您从网站 中选择的图片、音乐、视频或任何其他文件
-来自 TGP 和受密码保护的 网站
下载-下载 URL 列表(fusker 链接)
-内置网络图片查找器
-最多可同时下载 30 次-您“立即拥有您的文件,速度非常快
-内置数据库和数千个网站地址
-内置图片浏览器的缩略图和幻灯片放映方式
-用户友好的界面被翻译成多种语言
实际测试截图。图片来自网络,仅供测试和展示。请不要在意这些细节。
下载链接:
密码:52pj
2、Bulk.Image.Downloader(官方主页) 这个不如第一个强大,但是也很实用。最重要的是安装后有新手指南。
功能:
图片托管支持-BID 可用于几乎所有流行的图片托管网站,例如 flickr、imagevenue、imagefap、imageshack、imagebam 等。
Social网站-BID 支持从 Facebook、myspace 和 Twitter 等相关主机网站下载相册图片,
全尺寸图像-BID 使用高级启发式评分方法来定位全尺寸图像。这意味着 BID 无需用户配置即可在大多数画廊上自动运行。
批量下载 - 通过集成的队列管理器从大量的库 URL 列表中自动下载。
Web 浏览器集成-BID 与 IE、Opera、FireFox 和 Chrome 集成。只需在浏览器窗口中右键单击并选择“使用 BID 打开当前页面”
Web 论坛支持-BID 可扫描多页论坛主题并快速提取所有图片链接。
多页图库下载-BID 可以立即检测和下载最流行的多页网络图库。
受密码保护的网站- 如果网站 要求,BID 将提示输入用户名和密码。
视频下载-不仅用于图片-BID 还支持来自直接链接的视频文件(.avi、.wmv、.mpeg、.mov、.flv、.mp4 等)
下载VIDEO-内嵌图片-BID除了可以查找和下载全尺寸图片,如镜像所示,还可以在页面下载内嵌图片
图像序列化的图像文件名(fusker)-BID 支持序列化图像下载的“范围内”URL。
图像验证-BID 检查每个图像以确保其已正确下载。无效图片将自动重试。
Resume download-BID 将从断开连接点恢复下载。
多线程下载-BID一次最多可下载50张图片。快速下载这些图库!
重定向分析——一些网站在重定向到imagehost之前使用图像重定向“服务”如imagecash、urlcash等来展示广告。 BID 将自动解析这些类型的链接。
取消文件名-BID会从可能干扰文件名的图片主机(如imagevenue、imagefap)取回正确的文件名。
生成文件名-可以选择自己创建顺序文件名,供镜像主机打乱文件名,
将图库导出为 HTML 或 BB 代码 - 快速生成适合粘贴到网络论坛的图库代码。
实际测试截图。图片来自网络,仅供测试和展示使用。请不要在意这些细节。
下载链接:
密码:52pj
我喜欢整理一些国内外实用的工具。有兴趣的朋友可以关注一波,有能力者多给我奖励。谢谢!
查看全部
国外网页视频抓取软件(两款实用的图片批量抓取——ExtremePictureFinderPicture
)
今天介绍两款实用的图片批量抓取下载工具-ExtremePictureFinder直装破解版+Bulk.Image.Downloader.5.64.0.直装破解版替换破解中的文件安装后。
1、Extreme Picture Finder(官方主页)。它是一个强大的批量图像下载器。从任何网站 快速自动下载所有图像。但不仅是图像!它允许您下载音乐、视频或任何其他文件——只需输入网站 地址,选择您要下载的文件和文件的保存位置,剩下的交给 Extreme Picture Finder。您可以立即在内置图像查看器中查看下载的文件。
该程序可以配置为从受密码保护的网站、论坛主题甚至社交网络下载图像。使用高级设置,您可以让 Extreme Picture Finder 跳过网站 的某些部分,例如整个文件夹或单个页面,以加快下载过程。不知道从哪里开始下载? Extreme Picture Finder 提供了一个内置的在线项目数据库,其中收录数千个按类别分类的网站 地址:桌面壁纸、汽车、女孩、自然等等。
顾名思义,该程序的另一个重要功能是内置图片查找器。只要您输入一个关键字,程序就会为您查找并下载数千张图片。它具有不同的搜索模式,允许您更改与下载过程的交互级别。您可以让程序只查找和下载缩略图,然后在几秒钟内看到数百张图片向您飞来——这是最快的搜索模式。
然后您可以选择要手动下载的全尺寸图像。当然,您可以让 Extreme Picture Finder 自动查找、下载和保存缩略图和全尺寸图像,或者只是查找、下载和保存全尺寸图像。此外,该程序还可以保存在与原创全尺寸图像相同的页面上找到的所有图像相关图像。
特点:
-自动下载您从网站 中选择的图片、音乐、视频或任何其他文件
-来自 TGP 和受密码保护的 网站
下载-下载 URL 列表(fusker 链接)
-内置网络图片查找器
-最多可同时下载 30 次-您“立即拥有您的文件,速度非常快
-内置数据库和数千个网站地址
-内置图片浏览器的缩略图和幻灯片放映方式
-用户友好的界面被翻译成多种语言
实际测试截图。图片来自网络,仅供测试和展示。请不要在意这些细节。

下载链接:
密码:52pj
2、Bulk.Image.Downloader(官方主页) 这个不如第一个强大,但是也很实用。最重要的是安装后有新手指南。
功能:
图片托管支持-BID 可用于几乎所有流行的图片托管网站,例如 flickr、imagevenue、imagefap、imageshack、imagebam 等。
Social网站-BID 支持从 Facebook、myspace 和 Twitter 等相关主机网站下载相册图片,
全尺寸图像-BID 使用高级启发式评分方法来定位全尺寸图像。这意味着 BID 无需用户配置即可在大多数画廊上自动运行。
批量下载 - 通过集成的队列管理器从大量的库 URL 列表中自动下载。
Web 浏览器集成-BID 与 IE、Opera、FireFox 和 Chrome 集成。只需在浏览器窗口中右键单击并选择“使用 BID 打开当前页面”
Web 论坛支持-BID 可扫描多页论坛主题并快速提取所有图片链接。
多页图库下载-BID 可以立即检测和下载最流行的多页网络图库。
受密码保护的网站- 如果网站 要求,BID 将提示输入用户名和密码。
视频下载-不仅用于图片-BID 还支持来自直接链接的视频文件(.avi、.wmv、.mpeg、.mov、.flv、.mp4 等)
下载VIDEO-内嵌图片-BID除了可以查找和下载全尺寸图片,如镜像所示,还可以在页面下载内嵌图片
图像序列化的图像文件名(fusker)-BID 支持序列化图像下载的“范围内”URL。
图像验证-BID 检查每个图像以确保其已正确下载。无效图片将自动重试。
Resume download-BID 将从断开连接点恢复下载。
多线程下载-BID一次最多可下载50张图片。快速下载这些图库!
重定向分析——一些网站在重定向到imagehost之前使用图像重定向“服务”如imagecash、urlcash等来展示广告。 BID 将自动解析这些类型的链接。
取消文件名-BID会从可能干扰文件名的图片主机(如imagevenue、imagefap)取回正确的文件名。
生成文件名-可以选择自己创建顺序文件名,供镜像主机打乱文件名,
将图库导出为 HTML 或 BB 代码 - 快速生成适合粘贴到网络论坛的图库代码。
实际测试截图。图片来自网络,仅供测试和展示使用。请不要在意这些细节。

下载链接:
密码:52pj
我喜欢整理一些国内外实用的工具。有兴趣的朋友可以关注一波,有能力者多给我奖励。谢谢!

国外网页视频抓取软件(火狐浏览器实用插件一览(附下载地址)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-23 05:14
阿里云>云栖社区>主题地图>H>Firefox网站下载视频
推荐活动:
更多优惠>
当前主题:Firefox网站下载视频添加到采集夹
相关话题:
Firefox网站 下载视频相关博客,查看更多博客
火狐浏览器实用插件
作者:神巧合1871人浏览评论:05年前
User Agent Switcher中间没有横向的,模拟百度等搜索引擎蜘蛛抓取页面FireBug Web开发工具JSONView在浏览器中查看json格式修改Headers修改X-Forwarded-For等请求头xpa
阅读全文
【VIP视频网站项目上线】VIP视频网站项目以及基于Nodejs Express框架的完整代码分享
作者:向山的灯1602人浏览评论:03年前
版权声明:本文为博主原创文章所有,未经博主许可,不得转载。更多学习资料请访问我爱科技论坛::///m0_37981569/article/details/829
阅读全文
【教程转载】火狐浏览器好用插件列表(附插件下载地址)
作者:落雨_2077人浏览评论:011年前
【教程转载】火狐实用插件列表(附插件下载地址) 简单介绍:火狐最大的优点就是安全、快速、稳定。有人抱怨Firefox功能太少,有些网页无法正常浏览。. 没关系,这些都不是问题,因为我们有插件!重要插件:注:安装火狐后可以直接上网
阅读全文
【开源项目】基于Nodejs的Express框架的VIP视频网站项目及源码分享
作者:向山的灯 6162人浏览评论:03年前
先直接看最终效果图:网站首页:play.jpg 播放页面:评论页面:搜索页面:登录页面:注册页面:用户中心:项目名称:VIP视频网站项目开发语言: HTML, CSS (前端), JavaScript, NODEJS (expres) (后端)
阅读全文
最大化与 html5 视频的兼容性
作者:waylau1697人浏览评论:05年前
HTML5 使用 video 元素在网页上呈现视频。但是 HTML5 视频不是最终的解决方案,它不会在所有浏览器中都有效。您知道 HTML5 视频真的可以在线播放吗?您是否担心 HMTL5 视频兼容性?看看这个 文章 建议和解决方案如何最大化 HMTL5
阅读全文
织梦 php 网站 构建
作者:古真月影 2165人浏览评论:08年前
引用: %E7%BB%87%E6%A2%A6 织梦内容管理系统(Dedecms)以简单、实用、开源着称,是最知名的PHP开源源码在中国网站管理系统,也是用户使用最多的PHPcms系统。经过两年多的发展,目前
阅读全文
通过web安全工具Burp套件(二)
作者:apache9153 浏览评论人数:03年前
一、背景作者6月份在Mukenet上录制了视频教程XSS跨站漏洞,以增强Web安全。有很多实际案例需要提及。漏洞挖掘案例分为人工挖掘、工具挖掘、代码审计三部分。, 手工挖矿文章的参考地址是快速找出网站(一)
阅读全文
手动找出网站中可能存在的XSS漏洞
作者:apache1720 浏览评论人数:03年前
一、背景 作者最近在MOOC录制了一套加强Web安全的XSS跨站漏洞视频教程。课程讲的是XSS挖掘方法,所以在录制课程之前需要做很多实际案例。该视频是最近录制的。说完了,准备记录一下这些XSS漏洞的挖掘过程,方便自己和他人。在这篇文章中 文章 将是一个 permea
阅读全文 查看全部
国外网页视频抓取软件(火狐浏览器实用插件一览(附下载地址)(组图))
阿里云>云栖社区>主题地图>H>Firefox网站下载视频
推荐活动:
更多优惠>
当前主题:Firefox网站下载视频添加到采集夹
相关话题:
Firefox网站 下载视频相关博客,查看更多博客
火狐浏览器实用插件
作者:神巧合1871人浏览评论:05年前
User Agent Switcher中间没有横向的,模拟百度等搜索引擎蜘蛛抓取页面FireBug Web开发工具JSONView在浏览器中查看json格式修改Headers修改X-Forwarded-For等请求头xpa
阅读全文
【VIP视频网站项目上线】VIP视频网站项目以及基于Nodejs Express框架的完整代码分享
作者:向山的灯1602人浏览评论:03年前
版权声明:本文为博主原创文章所有,未经博主许可,不得转载。更多学习资料请访问我爱科技论坛::///m0_37981569/article/details/829
阅读全文
【教程转载】火狐浏览器好用插件列表(附插件下载地址)
作者:落雨_2077人浏览评论:011年前
【教程转载】火狐实用插件列表(附插件下载地址) 简单介绍:火狐最大的优点就是安全、快速、稳定。有人抱怨Firefox功能太少,有些网页无法正常浏览。. 没关系,这些都不是问题,因为我们有插件!重要插件:注:安装火狐后可以直接上网
阅读全文
【开源项目】基于Nodejs的Express框架的VIP视频网站项目及源码分享
作者:向山的灯 6162人浏览评论:03年前
先直接看最终效果图:网站首页:play.jpg 播放页面:评论页面:搜索页面:登录页面:注册页面:用户中心:项目名称:VIP视频网站项目开发语言: HTML, CSS (前端), JavaScript, NODEJS (expres) (后端)
阅读全文
最大化与 html5 视频的兼容性
作者:waylau1697人浏览评论:05年前
HTML5 使用 video 元素在网页上呈现视频。但是 HTML5 视频不是最终的解决方案,它不会在所有浏览器中都有效。您知道 HTML5 视频真的可以在线播放吗?您是否担心 HMTL5 视频兼容性?看看这个 文章 建议和解决方案如何最大化 HMTL5
阅读全文
织梦 php 网站 构建
作者:古真月影 2165人浏览评论:08年前
引用: %E7%BB%87%E6%A2%A6 织梦内容管理系统(Dedecms)以简单、实用、开源着称,是最知名的PHP开源源码在中国网站管理系统,也是用户使用最多的PHPcms系统。经过两年多的发展,目前
阅读全文
通过web安全工具Burp套件(二)
作者:apache9153 浏览评论人数:03年前
一、背景作者6月份在Mukenet上录制了视频教程XSS跨站漏洞,以增强Web安全。有很多实际案例需要提及。漏洞挖掘案例分为人工挖掘、工具挖掘、代码审计三部分。, 手工挖矿文章的参考地址是快速找出网站(一)
阅读全文
手动找出网站中可能存在的XSS漏洞
作者:apache1720 浏览评论人数:03年前
一、背景 作者最近在MOOC录制了一套加强Web安全的XSS跨站漏洞视频教程。课程讲的是XSS挖掘方法,所以在录制课程之前需要做很多实际案例。该视频是最近录制的。说完了,准备记录一下这些XSS漏洞的挖掘过程,方便自己和他人。在这篇文章中 文章 将是一个 permea
阅读全文
国外网页视频抓取软件(数码荔枝IDM斩获国内外多项大奖,官网原价79的终生版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-10-22 16:14
InternetDownloadManager(IDM)是一款非常知名的Windows平台下载工具,在国内外获得了很多奖项。与其他同类工具的炫目界面和功能相比,IDM界面无广告,无弹窗,无内置浏览器。专注下载,下载速度提升5倍,真正发挥速度下载优势。
这么好的软件价格自然不便宜,官网价格往往让人望而却步。
现在,我们正在与“数字荔枝”合作开展IDM折扣活动,特价30%起。官网原价79的IDM一年授权现仅需35元,官网原价160终身版现仅需129元!新注册用户可再享5元优惠!
专注下载
作为一款下载工具,IDM在P2P以外的文件下载功能上做到了极致,主要体现在自动链接抓取、静默下载、多线程和多媒体下载等,降低用户运营成本,提升文件下载体验。
自动捕获链接
IDM 可以在使用浏览器下载文件时自动捕获下载链接并添加下载任务。IDM 支持大部分主流浏览器,如 Chrome、Safari、Firefox、Edge、Internet Explorer 等。如果您使用的浏览器不在 IDM 的默认支持中,您也可以在软件设置中进行自定义。
静默下载
大多数人在下载文件时,会习惯性地将文件保存到固定位置,等待下载完成后再进行进一步处理。如果每次下载都需要重复点击“保存对话框”中的按钮,那将是非常多余和低效的。
IDM 的静默下载功能可以自动最小化下载窗口。如果您想在下载过程中修改保存位置或其他选项,可以直接调用托盘中的IDM图标。
多媒体下载
只要打开要下载的音视频的网站页面,IDM就会自动检测在线播放器发送的多媒体请求,并在播放器上显示下载浮动条。用户可以直接下载流媒体网站中的视频,在本地离线观看。
IDM支持MP4/MP3/MOV/AAC等常见音视频格式的检测和下载。在设置窗口中,您还可以指定特定站点显示或隐藏软件的下载浮动栏等自定义操作。
强大的扩展功能
IDM还配备了强大的自动下载功能,通过批量下载、定时下载任务、站点爬取等方式满足用户高层次的下载需求。
安排下载任务
通过设置定时下载任务,用户可以让IDM在指定的时间段内自动启动相应的下载任务,无论下载还是暂停等,都可以通过该功能实现。让家里的电脑在工作时间自动下载你需要的文件,到家就可以立即使用,非常方便。
网站抓取
“网站抓取”功能可以让您在输入链接后直接选择您要下载的网页的指定内容,无需使用通配符,包括图片、音频、视频、文件或收录完整样式的离线文件。IDM 可以做到这一切。您还可以根据自己的需要自定义站点抓取的内容和规则,并保存起来,方便下次调用。
批量下载
只要使用软件默认或自定义通配符,就可以使用IDM下载链接中收录的所有文件,例如网页中的所有图片。类似的形式如下:
一些网站.com/pictures/img*.jpg
使用上述命令,可以在IDM官网下载所有命名为img001.jpg、img002.jpg等命名规则的图片。
支持国外主流网盘
网站 上的很多国外资源文件都会放在他们常用的网盘里。如果直接下载这些文件,速度会很慢,很容易中断。这时候就需要IDM了。可将这些文件从网盘下载成队列进行批量下载,让您独立自定义每个队列的下载时间和下载文件数,灵活提高下载效率。
目前支持的网盘包括RapidShare、FileServe等,您可以访问官网查看所有IDM支持的网盘服务。
可接受的价格
最后,不要错过 IDM 折扣。官网原价79的IDM一年期授权现仅需35元,官网原价160的终身版现仅需129元!新用户注册领券立减5元! 查看全部
国外网页视频抓取软件(数码荔枝IDM斩获国内外多项大奖,官网原价79的终生版)
InternetDownloadManager(IDM)是一款非常知名的Windows平台下载工具,在国内外获得了很多奖项。与其他同类工具的炫目界面和功能相比,IDM界面无广告,无弹窗,无内置浏览器。专注下载,下载速度提升5倍,真正发挥速度下载优势。
pt-IDM_1800x600@2x-1024x341.png 1024w, pt-IDM_1800x600@2x-300x100.png" rel="nofollow" target="_blank">https://www.rdonly.com/wp-cont ... 0.png 300w, pt-IDM_1800x600@2x-768x256.png" rel="nofollow" target="_blank">https://www.rdonly.com/wp-cont ... 6.png 768w, pt-IDM_1800x600@2x-1536x512.png" rel="nofollow" target="_blank">https://www.rdonly.com/wp-cont ... 2.png 1536w, pt-IDM_1800x600@2x.png" rel="nofollow" target="_blank">https://www.rdonly.com/wp-cont ... x.png 1800w" />这么好的软件价格自然不便宜,官网价格往往让人望而却步。
现在,我们正在与“数字荔枝”合作开展IDM折扣活动,特价30%起。官网原价79的IDM一年授权现仅需35元,官网原价160终身版现仅需129元!新注册用户可再享5元优惠!
专注下载
作为一款下载工具,IDM在P2P以外的文件下载功能上做到了极致,主要体现在自动链接抓取、静默下载、多线程和多媒体下载等,降低用户运营成本,提升文件下载体验。
自动捕获链接
IDM 可以在使用浏览器下载文件时自动捕获下载链接并添加下载任务。IDM 支持大部分主流浏览器,如 Chrome、Safari、Firefox、Edge、Internet Explorer 等。如果您使用的浏览器不在 IDM 的默认支持中,您也可以在软件设置中进行自定义。
https://www.rdonly.com/wp-cont ... 5.jpg 300w, https://www.rdonly.com/wp-cont ... 7.jpg 768w" />静默下载
大多数人在下载文件时,会习惯性地将文件保存到固定位置,等待下载完成后再进行进一步处理。如果每次下载都需要重复点击“保存对话框”中的按钮,那将是非常多余和低效的。
IDM 的静默下载功能可以自动最小化下载窗口。如果您想在下载过程中修改保存位置或其他选项,可以直接调用托盘中的IDM图标。
多媒体下载
只要打开要下载的音视频的网站页面,IDM就会自动检测在线播放器发送的多媒体请求,并在播放器上显示下载浮动条。用户可以直接下载流媒体网站中的视频,在本地离线观看。
https://www.rdonly.com/wp-cont ... 1.png 300w, https://www.rdonly.com/wp-cont ... 3.png 768w" />IDM支持MP4/MP3/MOV/AAC等常见音视频格式的检测和下载。在设置窗口中,您还可以指定特定站点显示或隐藏软件的下载浮动栏等自定义操作。
https://www.rdonly.com/wp-cont ... 0.jpg 300w, https://www.rdonly.com/wp-cont ... 9.jpg 768w" />强大的扩展功能
IDM还配备了强大的自动下载功能,通过批量下载、定时下载任务、站点爬取等方式满足用户高层次的下载需求。
安排下载任务
通过设置定时下载任务,用户可以让IDM在指定的时间段内自动启动相应的下载任务,无论下载还是暂停等,都可以通过该功能实现。让家里的电脑在工作时间自动下载你需要的文件,到家就可以立即使用,非常方便。
https://www.rdonly.com/wp-cont ... 0.jpg 300w, https://www.rdonly.com/wp-cont ... 3.jpg 768w" />网站抓取
“网站抓取”功能可以让您在输入链接后直接选择您要下载的网页的指定内容,无需使用通配符,包括图片、音频、视频、文件或收录完整样式的离线文件。IDM 可以做到这一切。您还可以根据自己的需要自定义站点抓取的内容和规则,并保存起来,方便下次调用。
https://www.rdonly.com/wp-cont ... 3.jpg 300w, https://www.rdonly.com/wp-cont ... 1.jpg 768w" />批量下载
只要使用软件默认或自定义通配符,就可以使用IDM下载链接中收录的所有文件,例如网页中的所有图片。类似的形式如下:
一些网站.com/pictures/img*.jpg
使用上述命令,可以在IDM官网下载所有命名为img001.jpg、img002.jpg等命名规则的图片。
支持国外主流网盘
网站 上的很多国外资源文件都会放在他们常用的网盘里。如果直接下载这些文件,速度会很慢,很容易中断。这时候就需要IDM了。可将这些文件从网盘下载成队列进行批量下载,让您独立自定义每个队列的下载时间和下载文件数,灵活提高下载效率。
目前支持的网盘包括RapidShare、FileServe等,您可以访问官网查看所有IDM支持的网盘服务。
可接受的价格
最后,不要错过 IDM 折扣。官网原价79的IDM一年期授权现仅需35元,官网原价160的终身版现仅需129元!新用户注册领券立减5元!
国外网页视频抓取软件( 我们先用之前推文中介绍的方法尝试寻找其真实链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-14 00:04
我们先用之前推文中介绍的方法尝试寻找其真实链接
)
在之前的推文《一起来挖掘网页的真实链接吧!》中,我们介绍了如何使用谷歌浏览器在网页分页显示且点击时没有变化的情况下找到网页的真实链接但是有时我们也会遇到另一种情况:通过上述方法找到网页的链接后,发现URL中仍然没有可以用来识别不同网页的标识参数(例如page= 1). 别慌,今天小编就带你亲手解决这个问题。
1
我们以新浪财经中代码为00001的港股历史交易数据为例()。首先我们来看一下网页:虽然不是分页显示,但右上角有年度和季度选项。基于此,您可以查看昌河过去不同年份、不同季度的股票交易信息,如下图:
同时我们注意到网页的URL没有参数可以作为识别,所以这里需要再次踏上寻找网页真实链接的旅程~
我们首先尝试使用上一条推文介绍的方法找到真正的链接:在网页空白处右键单击“检查”,单击“网络”,然后按F5刷新,单击中间的第一个链接很多弹出查看它的响应的链接发现它的内容和网页的内容是一致的。是否可以确定它是我们现在正在寻找的网页的真实链接?
不用着急,我们继续右键第一个名为1.html的链接,点击复制→复制链接地址(这个操作可以复制网页的真实链接),结果这显然不是我们需要什么 带有识别参数的网页链接非常尴尬。
2
为什么会出现这样的情况?这主要是因为新浪财经的http请求方式是post。正如我们在上一条推文中提到的,两种最常见的 http 请求方法是 get 和 post。它们的区别在于get请求的数据会附加到URL上。之后URL和传输数据用?分割,参数用&连接,浏览器会生成目标URL,但是post不会。那么现在我们来介绍一下如何实现对http请求方式为post的网页的抓取。
我们首先选择查看港股领头羊和过去一个季度(例如2016年第四季度)的交易数据。一开始我们还是用上面的方法去寻找网页的真实链接。我们可以发现第一个链接的返回信息和网页的内容是匹配的。它的Headers注意到网页的请求方法(Request Method)是POST,如图:
这时候如果继续像之前一样操作,是无法获取到网页的源代码的,需要使用curl来模拟浏览器请求。在这之前,我们先来了解一下网页的请求头,也就是Request Headers,谷歌开发者工具已经为我们准备了这个信息,如下图:
先简单介绍一下请求头中一些headers的含义:
Accept-Encoding:由浏览器发送给服务器,声明浏览器支持的编码类型
Accept-Language:用于告诉服务器浏览器可以支持什么语言
User Agent:中文名称为User Agent,简称UA。它是一个特殊的字符串头,使服务器能够识别操作系统和版本、CPU 类型、客户端使用的浏览器和版本、浏览器渲染引擎、浏览器语言和浏览器插件
Referer:当浏览器向Web服务器发送请求时,通常会带一个Referer,它代表网页的来源,也就是告诉服务器它是从哪个页面链接的。
Cookies:用于记录一些网站登录信息和访问信息等。
在请求头信息下面,有年份和季节两个参数。这些就是我们最初查询到的2016年第四季度对应的参数,也就是我们需要的识别参数,如下图所示:
3
为了使用curl模拟浏览器请求,我们使用-H连接headers,使用--data或者-d指定使用POST传输数据,如下图:
现在你可以在 stata 中使用 curl 来抓取这个网页。我们可以保留如上图所示的所有header,但是如果网页不反爬或者只是做一些基本的反爬,则只保留识别参数。即 year=2016 和 season=4 并与 & 相连。在stata中输入以下命令:
清除
!curl --data "year=2016&season=4" -o sina.txt
shellout sina.txt
-o的作用是将获取到的网页信息下载保存到一个名为sina.txt的文件中,保存的路径为stata的默认保存路径。如下所示:
就这样,港交所总裁和2016年第四季度的历史交易信息就被抓获了。以后可以使用该方法抓取http请求方式为post的网页。不要忘记再次查看捕获。如何获取请求方式为get的网页~
不明白的记得戳下方视频学习哦!
查看全部
国外网页视频抓取软件(
我们先用之前推文中介绍的方法尝试寻找其真实链接
)
在之前的推文《一起来挖掘网页的真实链接吧!》中,我们介绍了如何使用谷歌浏览器在网页分页显示且点击时没有变化的情况下找到网页的真实链接但是有时我们也会遇到另一种情况:通过上述方法找到网页的链接后,发现URL中仍然没有可以用来识别不同网页的标识参数(例如page= 1). 别慌,今天小编就带你亲手解决这个问题。
1
我们以新浪财经中代码为00001的港股历史交易数据为例()。首先我们来看一下网页:虽然不是分页显示,但右上角有年度和季度选项。基于此,您可以查看昌河过去不同年份、不同季度的股票交易信息,如下图:
同时我们注意到网页的URL没有参数可以作为识别,所以这里需要再次踏上寻找网页真实链接的旅程~
我们首先尝试使用上一条推文介绍的方法找到真正的链接:在网页空白处右键单击“检查”,单击“网络”,然后按F5刷新,单击中间的第一个链接很多弹出查看它的响应的链接发现它的内容和网页的内容是一致的。是否可以确定它是我们现在正在寻找的网页的真实链接?
不用着急,我们继续右键第一个名为1.html的链接,点击复制→复制链接地址(这个操作可以复制网页的真实链接),结果这显然不是我们需要什么 带有识别参数的网页链接非常尴尬。
2
为什么会出现这样的情况?这主要是因为新浪财经的http请求方式是post。正如我们在上一条推文中提到的,两种最常见的 http 请求方法是 get 和 post。它们的区别在于get请求的数据会附加到URL上。之后URL和传输数据用?分割,参数用&连接,浏览器会生成目标URL,但是post不会。那么现在我们来介绍一下如何实现对http请求方式为post的网页的抓取。
我们首先选择查看港股领头羊和过去一个季度(例如2016年第四季度)的交易数据。一开始我们还是用上面的方法去寻找网页的真实链接。我们可以发现第一个链接的返回信息和网页的内容是匹配的。它的Headers注意到网页的请求方法(Request Method)是POST,如图:
这时候如果继续像之前一样操作,是无法获取到网页的源代码的,需要使用curl来模拟浏览器请求。在这之前,我们先来了解一下网页的请求头,也就是Request Headers,谷歌开发者工具已经为我们准备了这个信息,如下图:
先简单介绍一下请求头中一些headers的含义:
Accept-Encoding:由浏览器发送给服务器,声明浏览器支持的编码类型
Accept-Language:用于告诉服务器浏览器可以支持什么语言
User Agent:中文名称为User Agent,简称UA。它是一个特殊的字符串头,使服务器能够识别操作系统和版本、CPU 类型、客户端使用的浏览器和版本、浏览器渲染引擎、浏览器语言和浏览器插件
Referer:当浏览器向Web服务器发送请求时,通常会带一个Referer,它代表网页的来源,也就是告诉服务器它是从哪个页面链接的。
Cookies:用于记录一些网站登录信息和访问信息等。
在请求头信息下面,有年份和季节两个参数。这些就是我们最初查询到的2016年第四季度对应的参数,也就是我们需要的识别参数,如下图所示:
3
为了使用curl模拟浏览器请求,我们使用-H连接headers,使用--data或者-d指定使用POST传输数据,如下图:
现在你可以在 stata 中使用 curl 来抓取这个网页。我们可以保留如上图所示的所有header,但是如果网页不反爬或者只是做一些基本的反爬,则只保留识别参数。即 year=2016 和 season=4 并与 & 相连。在stata中输入以下命令:
清除
!curl --data "year=2016&season=4" -o sina.txt
shellout sina.txt
-o的作用是将获取到的网页信息下载保存到一个名为sina.txt的文件中,保存的路径为stata的默认保存路径。如下所示:
就这样,港交所总裁和2016年第四季度的历史交易信息就被抓获了。以后可以使用该方法抓取http请求方式为post的网页。不要忘记再次查看捕获。如何获取请求方式为get的网页~
不明白的记得戳下方视频学习哦!
国外网页视频抓取软件(Python从入门到进阶共10本电子书今日鸡汤众里寻他千百度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-10-14 00:03
点击上方“Python爬虫与数据挖掘”关注
回复“Books”即可领取从初级到高级共10本Python电子书
这个
日
小鸡
汤
人们上千百度找他。忽然回头一看,人就在那里,昏暗的灯光。
/1 简介/
上一篇其实是昨天发的,只是忘记标为原创。今天继续发布,和下一篇分享,让大家再次看到结局。这个文章主要是实战,实现谷歌人机破解的具体过程。
/2 实施步骤/
1、如果你来了,你就安全了。如果选择2captcha,就得看他们的官网了,如下图。
2、嗯...纯英文,看不懂..怎么办,别着急,我一步步带你分析主要功能。首先,登录您的帐户,如下图所示。
3、 登录后会自动跳转到首页,如下图。
上图中第一个红圈表示还剩多少钱。没钱记得要氪金,不然不能用滴。氪金工艺这里就不多解释了。问题不大。
红色圈出的第二个位置表示这是您唯一的钥匙。您必须在每次请求时携带此密钥,因此请妥善保管
4、进入主题,研究文档。点击红圈,API,通用API都是文档,如下图。
5、恩……什么东西……完全看不懂,别慌,下去
滑动到rates目录,我们知道Google Human Machine是ReCaptcha,但是三个,到底是哪一个,我给大家展示一下。
6、首先点击ReCaptcha(oldmethod),这个是老方法,我不知道,先看看这个,由浅入深,这里为了方便大家直接翻译了手表。
7、你看,其他人也说老方法求解ReCaptcha准确率较低。建议使用新方法,然后我们点击新方法看看。
8、我们找到了。这种验证码属于 ReCaptcha v2。确实和谷歌的人机一样。我们来看看文档是怎么写的。
9、人们说,我们先找到data-sitekey参数,然后提交data-sitekey参数给它,等待15-20s才得到结果。然后找到id=g-recaptcha-response的textarea标签,删除css display:none,在textarea输入框为我们添加字符串,点击submit,就大功告成了。
是不是很简单?我们也试试吧。打开谷歌的示例样式,如下图所示。
10、我们打开开发者工具,搜索data-sitekey,可以看到真的有一个。
11、 让我们分配这个data-sitekey,用代码得到最终的结果。
12、 然后我们找到id=g-recaptcha-response的textarea标签,删除它的display属性。
13、 不过有点不对。
14、看,下图是2captcha的例子。
我们可以看到2captcha是删除显示后,直接显示textarea框,但是我们删除显示后,基本没用了。这个...
15、别着急,大家想到了,我们就滑倒了。
由于我们不能直接显示textarea,就说明我们是隐式ReCaptcha验证码。其实它的原理很简单。
如果你学过一些前端,知道一些js,你可能会认为虽然我看不到这个textarea,但是我们仍然可以通过js改变textarea的数据,只是鼠标不能点击。看第一个红圈的位置。通过这个js,我们可以赋值2captcha得到的值。第二圈js是提交表单。其实只是我们人点击提交而已。它只是帮助我们的js代码。完成。就这样,我们也完成了日常的变化。
/3小试大锤/
1、好吧,我们先手动完成。上面我们已经根据data-sietkey得到了最终的结果。很明显,我们只能通过js来做,所以来试试吧。
通过上面的gif可以看到,我们通过js绕过了点击车辆识别,其他识别真的很方便。
2、但是我们不能每次都通过人来做,但是因为涉及到执行js,所以只能使用selenium,所以我们来看看在selenium上的效果。
看,这样我们就完成了谷歌人机(ReCaptcha)验证码的自动登录。如果你爬到国外XX网站,遇到ReCaptcha,相信对你有帮助。
/4。结论/
本文主要介绍使用第三方平台()破解谷歌人机登录。方法有点曲折,但是效果很好。
欢迎大家尝试在家消磨无聊的时间。本文涉及的代码已经上传到github地址,后台回复“谷歌人机”四个字即可获取代码。
- - - - - - - - - -结尾 - - - - - - - - - - 查看全部
国外网页视频抓取软件(Python从入门到进阶共10本电子书今日鸡汤众里寻他千百度)
点击上方“Python爬虫与数据挖掘”关注
回复“Books”即可领取从初级到高级共10本Python电子书
这个
日
小鸡
汤
人们上千百度找他。忽然回头一看,人就在那里,昏暗的灯光。
/1 简介/
上一篇其实是昨天发的,只是忘记标为原创。今天继续发布,和下一篇分享,让大家再次看到结局。这个文章主要是实战,实现谷歌人机破解的具体过程。
/2 实施步骤/
1、如果你来了,你就安全了。如果选择2captcha,就得看他们的官网了,如下图。
2、嗯...纯英文,看不懂..怎么办,别着急,我一步步带你分析主要功能。首先,登录您的帐户,如下图所示。
3、 登录后会自动跳转到首页,如下图。
上图中第一个红圈表示还剩多少钱。没钱记得要氪金,不然不能用滴。氪金工艺这里就不多解释了。问题不大。
红色圈出的第二个位置表示这是您唯一的钥匙。您必须在每次请求时携带此密钥,因此请妥善保管
4、进入主题,研究文档。点击红圈,API,通用API都是文档,如下图。
5、恩……什么东西……完全看不懂,别慌,下去
滑动到rates目录,我们知道Google Human Machine是ReCaptcha,但是三个,到底是哪一个,我给大家展示一下。
6、首先点击ReCaptcha(oldmethod),这个是老方法,我不知道,先看看这个,由浅入深,这里为了方便大家直接翻译了手表。
7、你看,其他人也说老方法求解ReCaptcha准确率较低。建议使用新方法,然后我们点击新方法看看。
8、我们找到了。这种验证码属于 ReCaptcha v2。确实和谷歌的人机一样。我们来看看文档是怎么写的。
9、人们说,我们先找到data-sitekey参数,然后提交data-sitekey参数给它,等待15-20s才得到结果。然后找到id=g-recaptcha-response的textarea标签,删除css display:none,在textarea输入框为我们添加字符串,点击submit,就大功告成了。
是不是很简单?我们也试试吧。打开谷歌的示例样式,如下图所示。
10、我们打开开发者工具,搜索data-sitekey,可以看到真的有一个。
11、 让我们分配这个data-sitekey,用代码得到最终的结果。
12、 然后我们找到id=g-recaptcha-response的textarea标签,删除它的display属性。
13、 不过有点不对。
14、看,下图是2captcha的例子。
我们可以看到2captcha是删除显示后,直接显示textarea框,但是我们删除显示后,基本没用了。这个...
15、别着急,大家想到了,我们就滑倒了。
由于我们不能直接显示textarea,就说明我们是隐式ReCaptcha验证码。其实它的原理很简单。
如果你学过一些前端,知道一些js,你可能会认为虽然我看不到这个textarea,但是我们仍然可以通过js改变textarea的数据,只是鼠标不能点击。看第一个红圈的位置。通过这个js,我们可以赋值2captcha得到的值。第二圈js是提交表单。其实只是我们人点击提交而已。它只是帮助我们的js代码。完成。就这样,我们也完成了日常的变化。
/3小试大锤/
1、好吧,我们先手动完成。上面我们已经根据data-sietkey得到了最终的结果。很明显,我们只能通过js来做,所以来试试吧。
通过上面的gif可以看到,我们通过js绕过了点击车辆识别,其他识别真的很方便。
2、但是我们不能每次都通过人来做,但是因为涉及到执行js,所以只能使用selenium,所以我们来看看在selenium上的效果。
看,这样我们就完成了谷歌人机(ReCaptcha)验证码的自动登录。如果你爬到国外XX网站,遇到ReCaptcha,相信对你有帮助。
/4。结论/
本文主要介绍使用第三方平台()破解谷歌人机登录。方法有点曲折,但是效果很好。
欢迎大家尝试在家消磨无聊的时间。本文涉及的代码已经上传到github地址,后台回复“谷歌人机”四个字即可获取代码。
- - - - - - - - - -结尾 - - - - - - - - - -
国外网页视频抓取软件(搜索引擎蜘蛛模拟器(国内)Google蜘蛛模拟访问工具(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-13 14:18
搜索引擎蜘蛛蜘蛛模拟器[]
1. 搜索引擎蜘蛛模拟器(国外)
蜘蛛模拟器工具可以模拟搜索引擎的蜘蛛,以搜索引擎的蜘蛛的方式抓取网页上的内容或链接。可以帮助您对网页的内容或链接进行直观的分析。一般来说,你在网页上看到的内容(网页上显示的内容)与搜索引擎蜘蛛(Spider)可以抓取的内容是不同的。也就是说,通过Flash、图片或Javascript等客户端渲染方式显示的内容及其收录的链接是搜索引擎无法抓取的。蜘蛛模拟器的作用也在这里,从搜索引擎的角度爬取和分析你的网页。
搜索引擎蜘蛛模拟器(国产)
2.谷歌蜘蛛模拟访问工具,模拟谷歌蜘蛛访问某个页面,可以让大家检查蜘蛛抓取的页面是否与你用浏览器看到的页面相同,可以用来识别友情链接欺骗。现在很多站长使用一些友情链接欺骗的方法,让自己的网站在搜索引擎中导出链接的次数变少,从而达到提高PR或者权重的效果。这个你可以通过你的浏览器浏览网站,我可以看到我自己的网站,但实际上他们是通过一些代码实现的。当搜索引擎抓取这个页面时,会有很多友情链接不会显示给搜索引擎。这个工具通过模拟谷歌蜘蛛,让大家知道别人的网站是否在友情链接上作弊。
使用方法:输入要查询的页面的URL并提交,显示的结果分别为抓取的文本和链接。
类似工具:蜘蛛模拟器
,您可以选择从Google以外的4个搜索引擎抓取网页:Altavista、Fast、Inktomi、WiseNut,还可以直观地显示抓取到的链接的绝对网址。
参考资料: 查看全部
国外网页视频抓取软件(搜索引擎蜘蛛模拟器(国内)Google蜘蛛模拟访问工具(组图))
搜索引擎蜘蛛蜘蛛模拟器[]
1. 搜索引擎蜘蛛模拟器(国外)
蜘蛛模拟器工具可以模拟搜索引擎的蜘蛛,以搜索引擎的蜘蛛的方式抓取网页上的内容或链接。可以帮助您对网页的内容或链接进行直观的分析。一般来说,你在网页上看到的内容(网页上显示的内容)与搜索引擎蜘蛛(Spider)可以抓取的内容是不同的。也就是说,通过Flash、图片或Javascript等客户端渲染方式显示的内容及其收录的链接是搜索引擎无法抓取的。蜘蛛模拟器的作用也在这里,从搜索引擎的角度爬取和分析你的网页。
搜索引擎蜘蛛模拟器(国产)
2.谷歌蜘蛛模拟访问工具,模拟谷歌蜘蛛访问某个页面,可以让大家检查蜘蛛抓取的页面是否与你用浏览器看到的页面相同,可以用来识别友情链接欺骗。现在很多站长使用一些友情链接欺骗的方法,让自己的网站在搜索引擎中导出链接的次数变少,从而达到提高PR或者权重的效果。这个你可以通过你的浏览器浏览网站,我可以看到我自己的网站,但实际上他们是通过一些代码实现的。当搜索引擎抓取这个页面时,会有很多友情链接不会显示给搜索引擎。这个工具通过模拟谷歌蜘蛛,让大家知道别人的网站是否在友情链接上作弊。
使用方法:输入要查询的页面的URL并提交,显示的结果分别为抓取的文本和链接。
类似工具:蜘蛛模拟器
,您可以选择从Google以外的4个搜索引擎抓取网页:Altavista、Fast、Inktomi、WiseNut,还可以直观地显示抓取到的链接的绝对网址。
参考资料:
国外网页视频抓取软件(国外网页视频抓取软件抓取整理利用webrtc来转换(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-28 23:07
国外网页视频抓取软件抓取整理利用webrtc来转换:flv抓取http抓取抓取整理:webrtc爬虫+正则表达式/python爬虫+pandas整理和分析matlab-matlab介绍和安装使用方法python爬虫+pandas整理和分析matlab-matlab介绍和安装
附一个精华回答整理:量化基础和量化策略研究,量化交易从业者学习必备经典书籍汇总量化交易从业者在外汇投资中,
除了基础,再推荐两本《从零开始学量化》和《深入浅出量化交易》。
推荐过去半年的写的文章,半年以内总结的写成回答,里面总结了我对软件使用和盈利的一些认识。也欢迎参与讨论,点个赞,知乎关注,收藏关注,还可以加交流群,
推荐量化交易书籍
上期软件app
如果去培训机构的话,教材是一方面,最重要的还是在去机构培训时老师对你讲的方法和指导等,市场是残酷的,仅凭一个人自己的独立思考去完成一个交易系统是完全不可能完成的,需要老师和团队的力量去完成交易的辅助完成一个原始交易,软件很重要,但是没有人教,
交易其实有很多种方法,但是盈利的关键就两点:1、开仓2、持仓当然这两点其实不是在同一时刻做到的,因为一般进场要么超买(盘中),要么超卖(盘后)。持仓要么就是之前无交易历史,要么交易历史少。你要做的是如何在一个点位,在多空双方都没有任何实质性利空信息的情况下,得到一个可靠的点位,赚到钱。 查看全部
国外网页视频抓取软件(国外网页视频抓取软件抓取整理利用webrtc来转换(组图))
国外网页视频抓取软件抓取整理利用webrtc来转换:flv抓取http抓取抓取整理:webrtc爬虫+正则表达式/python爬虫+pandas整理和分析matlab-matlab介绍和安装使用方法python爬虫+pandas整理和分析matlab-matlab介绍和安装
附一个精华回答整理:量化基础和量化策略研究,量化交易从业者学习必备经典书籍汇总量化交易从业者在外汇投资中,
除了基础,再推荐两本《从零开始学量化》和《深入浅出量化交易》。
推荐过去半年的写的文章,半年以内总结的写成回答,里面总结了我对软件使用和盈利的一些认识。也欢迎参与讨论,点个赞,知乎关注,收藏关注,还可以加交流群,
推荐量化交易书籍
上期软件app
如果去培训机构的话,教材是一方面,最重要的还是在去机构培训时老师对你讲的方法和指导等,市场是残酷的,仅凭一个人自己的独立思考去完成一个交易系统是完全不可能完成的,需要老师和团队的力量去完成交易的辅助完成一个原始交易,软件很重要,但是没有人教,
交易其实有很多种方法,但是盈利的关键就两点:1、开仓2、持仓当然这两点其实不是在同一时刻做到的,因为一般进场要么超买(盘中),要么超卖(盘后)。持仓要么就是之前无交易历史,要么交易历史少。你要做的是如何在一个点位,在多空双方都没有任何实质性利空信息的情况下,得到一个可靠的点位,赚到钱。
国外网页视频抓取软件(import.io有所获得种子加A轮共计一千多万美金万美金)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-12 09:05
随着提倡个性化的“web2.0”概念的兴起,UGC让我们从一个以下载为主的网络时代,进化到一个下载与上传并存的交互时代。这意味着互联网上的信息量变得更加丰富了,它带来的增加量也是我们难以预料的。面对海量海量的“大数据”,国内外衍生出了经典的网络爬虫工具。 .
首先,让我们把注意力转向国外。熟悉互联网和大数据的朋友一定听说过import.io。种子加A轮融资总额超过1000万美元,国内人士纷纷被吸引。 Import.io的不同之处在于,用户只需要在网站想要抓取数据的地方简单的点击几下,然后就可以根据你的操作计算出你想要抓取的数据,然后创建一个真正的-这些数据的实时连接,那么您只需要选择想要的导出格式,就可以得到一份指定内容的副本和实时更新的数据。
听起来真的很神奇,就像产品名称一样“神奇”。有兴趣的朋友可以体验一下,但需要注意的是import.io更适合一些列表数据,比如微博、店铺页面,这些类型往往不适用,因为它抓取的字段不是全部字段。它是基于特殊的选择性计算,所以用户需要根据自己的需要选择使用。
那么国内最经典的网络爬虫工具,你一定已经想到了。是行业经验最深的优采云采集器。它于 2005 年开发,目前拥有超过 400,000 名免费用户。与 Import.io 不同,优采云采集器 更注重准确性。在去那里之前,它需要用户的明确指示,即采集规则。执行操作,所以可以应用的网页类型更多,甚至整个网络。
因为优采云采集器的工作原理是提取网页结构的源代码,所以只要网页上能看到内容,不管布局如何都可以快速提取。最终捕获的数据可以导入任何目标数据库或导出为所需的格式。在网页爬取的过程中,还可以选择不同的线程来控制优采云采集器采集的速度。一般来说优采云采集器适用于对抓取、速度、完整性有明确要求的用户。
在程序员们惊为天人的高智商的发展下,网络信息和数据的爬行不再让我们感到疯狂。市面上还有很多新兴的或者仿制的网页抓取工具,但真正值得用户称赞的才是最好的,这里就不一一列举了。与国外的import.io相比,中国本土网页抓取工具优采云采集器开发较早,功能上也不逊色。看来国内大数据技术未来的发展值得期待! 查看全部
国外网页视频抓取软件(import.io有所获得种子加A轮共计一千多万美金万美金)
随着提倡个性化的“web2.0”概念的兴起,UGC让我们从一个以下载为主的网络时代,进化到一个下载与上传并存的交互时代。这意味着互联网上的信息量变得更加丰富了,它带来的增加量也是我们难以预料的。面对海量海量的“大数据”,国内外衍生出了经典的网络爬虫工具。 .
首先,让我们把注意力转向国外。熟悉互联网和大数据的朋友一定听说过import.io。种子加A轮融资总额超过1000万美元,国内人士纷纷被吸引。 Import.io的不同之处在于,用户只需要在网站想要抓取数据的地方简单的点击几下,然后就可以根据你的操作计算出你想要抓取的数据,然后创建一个真正的-这些数据的实时连接,那么您只需要选择想要的导出格式,就可以得到一份指定内容的副本和实时更新的数据。
听起来真的很神奇,就像产品名称一样“神奇”。有兴趣的朋友可以体验一下,但需要注意的是import.io更适合一些列表数据,比如微博、店铺页面,这些类型往往不适用,因为它抓取的字段不是全部字段。它是基于特殊的选择性计算,所以用户需要根据自己的需要选择使用。
那么国内最经典的网络爬虫工具,你一定已经想到了。是行业经验最深的优采云采集器。它于 2005 年开发,目前拥有超过 400,000 名免费用户。与 Import.io 不同,优采云采集器 更注重准确性。在去那里之前,它需要用户的明确指示,即采集规则。执行操作,所以可以应用的网页类型更多,甚至整个网络。
因为优采云采集器的工作原理是提取网页结构的源代码,所以只要网页上能看到内容,不管布局如何都可以快速提取。最终捕获的数据可以导入任何目标数据库或导出为所需的格式。在网页爬取的过程中,还可以选择不同的线程来控制优采云采集器采集的速度。一般来说优采云采集器适用于对抓取、速度、完整性有明确要求的用户。
在程序员们惊为天人的高智商的发展下,网络信息和数据的爬行不再让我们感到疯狂。市面上还有很多新兴的或者仿制的网页抓取工具,但真正值得用户称赞的才是最好的,这里就不一一列举了。与国外的import.io相比,中国本土网页抓取工具优采云采集器开发较早,功能上也不逊色。看来国内大数据技术未来的发展值得期待!
国外网页视频抓取软件(VidCoder让小伙伴们可以轻松抓取和转码蓝光视频和DVD)
网站优化 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-09-12 09:02
VidCoder 允许朋友轻松抓取蓝光视频和 DVD 并对其进行转码。作为开源软件,支持批量编码处理,提高您的操作效率。用户还可以为视频添加水印和字幕,创建自己的视频资源库。
软件功能
开源免费视频编辑工具是一款免费开源的视频下载、编辑、字幕上传工具。它可用于 DVD/蓝光视频捕获和转码操作。更重要的是,它可以导入字幕。而对于校队来说,目前支持中文语言包,操作更方便。特别适合视频发布团队编辑视频、添加字母、水印、转换格式等。当我们观看一些没有字幕的视频时,不妨使用这个视频编辑工具自己添加字母。可以设置偏移量,最适合用胶片采集器。
功能介绍
多线程
MP4、MKV 容器
H.264 编码 x264,世界上最好的视频编码器
完全集成的编码方式:一切都在一个过程中,没有庞大的中间临时文件
它还支持mpeg-2,mpeg-4视频
AC3、MP3、AAC Vorbis FLAC和AAC音频编码/AC3 /MP3/DTS/DTS-HD透传
视频的目标比特率、大小或质量
2-pass 编码
Decomb detelecine, de-interlace filter
批量编码
即时预览视频源
创建一个小的编码预览剪辑
暂停和恢复编码
如何使用
更新日志
在主窗口增加了编辑字幕和音轨名称的功能。
增加了从源视频中保存字幕轨道名称的功能。
文件源搜索栏中添加了时间戳,以便于与源进行比较。
更新了“保留文件的创建/修改时间”选项,并保留了“媒体创建”扩展属性。
设置默认输出文件夹的要求已被删除。现在默认选择用户的“视频”文件夹。
标题下拉菜单中小时的前导零已被清除。
改进了编码失败的错误记录。
更新了核心。
修复了视频时长超过 24 小时的格式问题。
修复了 x264 日志信息丢失的问题。
修复编辑队列项后切换到章节范围选择模式开始/结束章节开始空白的问题。
修复了正常应用程序数据文件夹已经存在时Microsoft Store版本的“打开应用程序数据文件夹”命令。
修复了主窗口字幕列表的屏幕阅读器行为。
以上就是小编为大家带来的蓝光视频采集工具(VidCoder)。更多精彩软件请关注IE浏览器Chinese网站! 查看全部
国外网页视频抓取软件(VidCoder让小伙伴们可以轻松抓取和转码蓝光视频和DVD)
VidCoder 允许朋友轻松抓取蓝光视频和 DVD 并对其进行转码。作为开源软件,支持批量编码处理,提高您的操作效率。用户还可以为视频添加水印和字幕,创建自己的视频资源库。
软件功能
开源免费视频编辑工具是一款免费开源的视频下载、编辑、字幕上传工具。它可用于 DVD/蓝光视频捕获和转码操作。更重要的是,它可以导入字幕。而对于校队来说,目前支持中文语言包,操作更方便。特别适合视频发布团队编辑视频、添加字母、水印、转换格式等。当我们观看一些没有字幕的视频时,不妨使用这个视频编辑工具自己添加字母。可以设置偏移量,最适合用胶片采集器。
功能介绍
多线程
MP4、MKV 容器
H.264 编码 x264,世界上最好的视频编码器
完全集成的编码方式:一切都在一个过程中,没有庞大的中间临时文件
它还支持mpeg-2,mpeg-4视频
AC3、MP3、AAC Vorbis FLAC和AAC音频编码/AC3 /MP3/DTS/DTS-HD透传
视频的目标比特率、大小或质量
2-pass 编码
Decomb detelecine, de-interlace filter
批量编码
即时预览视频源
创建一个小的编码预览剪辑
暂停和恢复编码
如何使用
更新日志
在主窗口增加了编辑字幕和音轨名称的功能。
增加了从源视频中保存字幕轨道名称的功能。
文件源搜索栏中添加了时间戳,以便于与源进行比较。
更新了“保留文件的创建/修改时间”选项,并保留了“媒体创建”扩展属性。
设置默认输出文件夹的要求已被删除。现在默认选择用户的“视频”文件夹。
标题下拉菜单中小时的前导零已被清除。
改进了编码失败的错误记录。
更新了核心。
修复了视频时长超过 24 小时的格式问题。
修复了 x264 日志信息丢失的问题。
修复编辑队列项后切换到章节范围选择模式开始/结束章节开始空白的问题。
修复了正常应用程序数据文件夹已经存在时Microsoft Store版本的“打开应用程序数据文件夹”命令。
修复了主窗口字幕列表的屏幕阅读器行为。
以上就是小编为大家带来的蓝光视频采集工具(VidCoder)。更多精彩软件请关注IE浏览器Chinese网站!
国外网页视频抓取软件(25h打造出一款外贸网站挖掘工具,10s提取100客户网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-10 07:01
最后给大家介绍几个主要的功能按钮:1、 上图中的两个按钮用于在谷歌地图/谷歌搜索引擎和两种抓取模式之间切换。这个不用我多说了,自然会点进去。明白了!
下图中的工具,我之前给大家介绍过,这是我做的谷歌搜索提取工具2.0的版本。
2.0 版本主要是帮你在谷歌搜索引擎上直接提取网站和标题信息。可以参考我之前的文章《25h打造外贸网站挖矿工具,10s提取100个客户网站!》,看详细介绍!
今天主要给大家介绍一下我前两天刚拿到的谷歌搜索提取工具3.0的新修订版。与之前的版本相比,新增了googlemaps提取功能,可以帮助您直接提取谷歌地图。公司信息,很多老牌外贸公司对谷歌地图可能并不陌生。在谷歌地图上输入关键词,可以搜索到周边所有的精准买家,是外贸客户发展的常用渠道。
只要通过关键词搜索公司信息页面,直接点击开始爬取按钮就可以开发爬取信息。操作相当简单,不用担心,会自动翻页,直到搜索完成。
另外3.0版本与2.0版本相比,谷歌搜索引擎抓取也进行了调整。不像之前直接输入关键词进行爬取,还需要手动跳转到第二页。这一次,将整个真实网页直接转入工具中,搜索和翻页也完全自动化。完全模拟人工操作,降低验证码弹窗的概率,即使验证码弹出,我们也可以手动填写!
最后给大家介绍几个主要的功能按钮:
1、
上图中的两个按钮用于在谷歌地图/谷歌搜索引擎和两种抓取模式之间切换。关于这一点我不需要多说。点进去就明白了!
2、
翻转搜索是本次更新的一个很好的功能。如果你电脑上的fq工具失败了,你可以试着检查一下这个,然后切换到更流畅的线条。这样,您也可以使用此工具。去谷歌取资料(毕竟大家有空,肯定会慢!)
3、
红框中选中的四个按钮当然不用我过多解释了,照字面意思。全部导出就是将搜索到的数据以excel格式导出到本地电脑。
4、
如果你上传这个选项,我们一般默认不勾选。如果您不是使用F墙工具,而是使用F墙路由器上网,您不妨勾选这个选项试试。 (切记不要随意检查,否则无法加载googe页面)
其他的就不解释了,自己下载体验吧!这些工具是针对个人兴趣和爱好的,可以免费与大家分享。您不必担心是否充电。只要对大家有帮助,我一定会持续优化更新更多功能给大家!
下载链接:
某些计算机下载和安装可能会弹出风险警告。您只需单击“允许”即可放心使用。没必要为你什么年龄生产病毒!
同理,有什么bug或者好的建议都可以在评论区写! 查看全部
国外网页视频抓取软件(25h打造出一款外贸网站挖掘工具,10s提取100客户网站)
最后给大家介绍几个主要的功能按钮:1、 上图中的两个按钮用于在谷歌地图/谷歌搜索引擎和两种抓取模式之间切换。这个不用我多说了,自然会点进去。明白了!
下图中的工具,我之前给大家介绍过,这是我做的谷歌搜索提取工具2.0的版本。
2.0 版本主要是帮你在谷歌搜索引擎上直接提取网站和标题信息。可以参考我之前的文章《25h打造外贸网站挖矿工具,10s提取100个客户网站!》,看详细介绍!
今天主要给大家介绍一下我前两天刚拿到的谷歌搜索提取工具3.0的新修订版。与之前的版本相比,新增了googlemaps提取功能,可以帮助您直接提取谷歌地图。公司信息,很多老牌外贸公司对谷歌地图可能并不陌生。在谷歌地图上输入关键词,可以搜索到周边所有的精准买家,是外贸客户发展的常用渠道。
只要通过关键词搜索公司信息页面,直接点击开始爬取按钮就可以开发爬取信息。操作相当简单,不用担心,会自动翻页,直到搜索完成。
另外3.0版本与2.0版本相比,谷歌搜索引擎抓取也进行了调整。不像之前直接输入关键词进行爬取,还需要手动跳转到第二页。这一次,将整个真实网页直接转入工具中,搜索和翻页也完全自动化。完全模拟人工操作,降低验证码弹窗的概率,即使验证码弹出,我们也可以手动填写!
最后给大家介绍几个主要的功能按钮:
1、
上图中的两个按钮用于在谷歌地图/谷歌搜索引擎和两种抓取模式之间切换。关于这一点我不需要多说。点进去就明白了!
2、
翻转搜索是本次更新的一个很好的功能。如果你电脑上的fq工具失败了,你可以试着检查一下这个,然后切换到更流畅的线条。这样,您也可以使用此工具。去谷歌取资料(毕竟大家有空,肯定会慢!)
3、
红框中选中的四个按钮当然不用我过多解释了,照字面意思。全部导出就是将搜索到的数据以excel格式导出到本地电脑。
4、
如果你上传这个选项,我们一般默认不勾选。如果您不是使用F墙工具,而是使用F墙路由器上网,您不妨勾选这个选项试试。 (切记不要随意检查,否则无法加载googe页面)
其他的就不解释了,自己下载体验吧!这些工具是针对个人兴趣和爱好的,可以免费与大家分享。您不必担心是否充电。只要对大家有帮助,我一定会持续优化更新更多功能给大家!
下载链接:
某些计算机下载和安装可能会弹出风险警告。您只需单击“允许”即可放心使用。没必要为你什么年龄生产病毒!
同理,有什么bug或者好的建议都可以在评论区写!
国外网页视频抓取软件(基于动态内容抓取JavaScript页面的优势--互联网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-09-10 07:00
指南
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
代理抓取
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
代理抓取
可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
Scrapy
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用 Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。
抢
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
雪貂
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
Diffbot
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。
原文来自: 查看全部
国外网页视频抓取软件(基于动态内容抓取JavaScript页面的优势--互联网)
指南
互联网上不断涌现新的信息、新的设计模式和大量的c。将这些数据组织到一个独特的库中并不容易。但是,有很多出色的网络抓取工具可用。
代理抓取
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
https://www.linuxprobe.com/wp- ... 2.jpg 300w" />代理抓取
可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
https://www.linuxprobe.com/wp- ... 7.jpg 300w" />Scrapy
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl***集成。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)变得轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。使用 Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。
https://www.linuxprobe.com/wp- ... 1.jpg 300w" />抢
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
雪貂
Ferret 是一种相当新的网络抓取,在开源社区中获得了相当大的吸引力。 Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
https://www.linuxprobe.com/wp- ... 1.jpg 300w" />此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
https://www.linuxprobe.com/wp- ... 4.jpg 300w" />Diffbot
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
https://www.linuxprobe.com/wp- ... 2.jpg 300w" />PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。
原文来自:
国外网页视频抓取软件(如何利用IDM自带的视频嗅探功能来下载视频完整播放)
网站优化 • 优采云 发表了文章 • 0 个评论 • 606 次浏览 • 2021-09-10 06:10
我在网上看到好的视频,总有一些想下载下来慢慢欣赏,但是现在网站的一些视频越来越难下载了。视频的真实地址被加密隐藏,或者被分割成无数个小片段。如果要完整下载视频,一般的工具真的搞不定~
作为多线程下载工具IDM的用户,我之前和大家分享过IDM内置的视频嗅探功能是用来下载视频的。虽然这个方法可以解决很多网站video 下载的问题,但是还是有很多小众的网站video 无法下载。
之前和大家分享过其他网络视频下载工具,但效果总是不尽如人意。苦苦寻找一款优秀的网络视频下载工具后,进入了自己的视野——CoCoCut
这是 Google Chrome 的扩展程序。虽然上架时间不长,但用户量已经突破10000,好评如潮~
只要你当前访问的网页含有视频、音乐的网页时,CocoCut可以自动发现可供下载的视频、音乐。并且在插件栏显示已经抓取的资源数量。
您只需要点击chrome右上角的CocoCut扩展图标,即可显示可下载的内容。点击下载按钮,进入下载界面,保存并下载完整视频。
你认为这已经结束了吗?当然不是,如果只是这样的话,那么不推荐这个工具。对于一些非常顽固的网络视频,有时根本无法识别下载地址。那么这个插件还有“强制下载”功能!
这个强制下载功能的原理其实就是录制模式,点击强制下载。然后点击确定按钮开始录制,然后返回视频页面播放视频。
录制视频不会等待视频播放完毕。只要视频已被缓冲,就会被记录下来。可以直接将进度条拖到缓冲条的末尾,加快录制速度。
CocoCut 就其功能而言,已经是一款出色的网络视频下载工具。声称支持 99% 的视频格式并不是吹嘘。 网站的大部分视频都可以用这个工具下载,但还是不够完美。部分视频网站仍会在直接下载或录制模式下进行分段。希望以后能改进或增加合并功能。
下载链接:
本文原创文章。发布者:Bang,如转载请注明出处: 查看全部
国外网页视频抓取软件(如何利用IDM自带的视频嗅探功能来下载视频完整播放)
我在网上看到好的视频,总有一些想下载下来慢慢欣赏,但是现在网站的一些视频越来越难下载了。视频的真实地址被加密隐藏,或者被分割成无数个小片段。如果要完整下载视频,一般的工具真的搞不定~
作为多线程下载工具IDM的用户,我之前和大家分享过IDM内置的视频嗅探功能是用来下载视频的。虽然这个方法可以解决很多网站video 下载的问题,但是还是有很多小众的网站video 无法下载。
之前和大家分享过其他网络视频下载工具,但效果总是不尽如人意。苦苦寻找一款优秀的网络视频下载工具后,进入了自己的视野——CoCoCut
这是 Google Chrome 的扩展程序。虽然上架时间不长,但用户量已经突破10000,好评如潮~
只要你当前访问的网页含有视频、音乐的网页时,CocoCut可以自动发现可供下载的视频、音乐。并且在插件栏显示已经抓取的资源数量。
您只需要点击chrome右上角的CocoCut扩展图标,即可显示可下载的内容。点击下载按钮,进入下载界面,保存并下载完整视频。
你认为这已经结束了吗?当然不是,如果只是这样的话,那么不推荐这个工具。对于一些非常顽固的网络视频,有时根本无法识别下载地址。那么这个插件还有“强制下载”功能!
这个强制下载功能的原理其实就是录制模式,点击强制下载。然后点击确定按钮开始录制,然后返回视频页面播放视频。
录制视频不会等待视频播放完毕。只要视频已被缓冲,就会被记录下来。可以直接将进度条拖到缓冲条的末尾,加快录制速度。
CocoCut 就其功能而言,已经是一款出色的网络视频下载工具。声称支持 99% 的视频格式并不是吹嘘。 网站的大部分视频都可以用这个工具下载,但还是不够完美。部分视频网站仍会在直接下载或录制模式下进行分段。希望以后能改进或增加合并功能。
下载链接:
本文原创文章。发布者:Bang,如转载请注明出处:
国外网页视频抓取软件(两款实用的图片批量抓取——ExtremePictureFinderPicture )
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-10 04:11
)
今天介绍两款实用的图片批量抓取下载工具-ExtremePictureFinder直装破解版+Bulk.Image.Downloader.5.64.0.直装破解版替换破解中的文件安装后。
1、Extreme Picture Finder(官方主页)。它是一个强大的批量图像下载器。从任何网站 快速自动下载所有图像。但不仅是图像!它允许您下载音乐、视频或任何其他文件——只需输入网站 地址,选择您要下载的文件和文件的保存位置,剩下的交给 Extreme Picture Finder。您可以立即在内置图像查看器中查看下载的文件。
该程序可以配置为从受密码保护的网站、论坛主题甚至社交网络下载图像。使用高级设置,您可以让 Extreme Picture Finder 跳过网站 的某些部分,例如整个文件夹或单个页面,以加快下载过程。不知道从哪里开始下载? Extreme Picture Finder 提供了一个内置的在线项目数据库,其中收录数千个按类别分类的网站 地址:桌面壁纸、汽车、女孩、自然等等。
顾名思义,该程序的另一个重要功能是内置图片查找器。只要您输入一个关键字,程序就会为您查找并下载数千张图片。它具有不同的搜索模式,允许您更改与下载过程的交互级别。您可以让程序只查找和下载缩略图,然后在几秒钟内看到数百张图片向您飞来——这是最快的搜索模式。
然后您可以选择要手动下载的全尺寸图像。当然,您可以让 Extreme Picture Finder 自动查找、下载和保存缩略图和全尺寸图像,或者只是查找、下载和保存全尺寸图像。此外,该程序还可以保存在与原创全尺寸图像相同的页面上找到的所有图像相关图像。
特点:
-自动下载您从网站 中选择的图片、音乐、视频或任何其他文件
-来自 TGP 和受密码保护的 网站
下载-下载 URL 列表(fusker 链接)
-内置网络图片查找器
-最多可同时下载 30 次-您“立即拥有您的文件,速度非常快
-内置数据库和数千个网站地址
-内置图片浏览器的缩略图和幻灯片放映方式
-用户友好的界面被翻译成多种语言
实际测试截图。图片来自网络,仅供测试和展示。请不要在意这些细节。
下载链接:
密码:52pj
2、Bulk.Image.Downloader(官方主页) 这个不如第一个强大,但是也很实用。最重要的是安装后有新手指南。
功能:
图片托管支持-BID 可用于几乎所有流行的图片托管网站,例如 flickr、imagevenue、imagefap、imageshack、imagebam 等。
Social网站-BID 支持从 Facebook、myspace 和 Twitter 等相关主机网站下载相册图片,
全尺寸图像-BID 使用高级启发式评分方法来定位全尺寸图像。这意味着 BID 无需用户配置即可在大多数画廊上自动运行。
批量下载 - 通过集成的队列管理器从大量的库 URL 列表中自动下载。
Web 浏览器集成-BID 与 IE、Opera、FireFox 和 Chrome 集成。只需在浏览器窗口中右键单击并选择“使用 BID 打开当前页面”
Web 论坛支持-BID 可扫描多页论坛主题并快速提取所有图片链接。
多页图库下载-BID 可以立即检测和下载最流行的多页网络图库。
受密码保护的网站- 如果网站 要求,BID 将提示输入用户名和密码。
视频下载-不仅用于图片-BID 还支持来自直接链接的视频文件(.avi、.wmv、.mpeg、.mov、.flv、.mp4 等)
下载VIDEO-内嵌图片-BID除了可以查找和下载全尺寸图片,如镜像所示,还可以在页面下载内嵌图片
图像序列化的图像文件名(fusker)-BID 支持序列化图像下载的“范围内”URL。
图像验证-BID 检查每个图像以确保其已正确下载。无效图片将自动重试。
Resume download-BID 将从断开连接点恢复下载。
多线程下载-BID一次最多可下载50张图片。快速下载这些图库!
重定向分析——一些网站在重定向到imagehost之前使用图像重定向“服务”如imagecash、urlcash等来展示广告。 BID 将自动解析这些类型的链接。
取消文件名-BID会从可能干扰文件名的图片主机(如imagevenue、imagefap)取回正确的文件名。
生成文件名-可以选择自己创建顺序文件名,供镜像主机打乱文件名,
将图库导出为 HTML 或 BB 代码 - 快速生成适合粘贴到网络论坛的图库代码。
实际测试截图。图片来自网络,仅供测试和展示使用。请不要在意这些细节。
下载链接:
密码:52pj
我喜欢整理一些国内外实用的工具。有兴趣的朋友可以关注一波,有能力者多给我奖励。谢谢!
查看全部
国外网页视频抓取软件(两款实用的图片批量抓取——ExtremePictureFinderPicture
)
今天介绍两款实用的图片批量抓取下载工具-ExtremePictureFinder直装破解版+Bulk.Image.Downloader.5.64.0.直装破解版替换破解中的文件安装后。
1、Extreme Picture Finder(官方主页)。它是一个强大的批量图像下载器。从任何网站 快速自动下载所有图像。但不仅是图像!它允许您下载音乐、视频或任何其他文件——只需输入网站 地址,选择您要下载的文件和文件的保存位置,剩下的交给 Extreme Picture Finder。您可以立即在内置图像查看器中查看下载的文件。
该程序可以配置为从受密码保护的网站、论坛主题甚至社交网络下载图像。使用高级设置,您可以让 Extreme Picture Finder 跳过网站 的某些部分,例如整个文件夹或单个页面,以加快下载过程。不知道从哪里开始下载? Extreme Picture Finder 提供了一个内置的在线项目数据库,其中收录数千个按类别分类的网站 地址:桌面壁纸、汽车、女孩、自然等等。
顾名思义,该程序的另一个重要功能是内置图片查找器。只要您输入一个关键字,程序就会为您查找并下载数千张图片。它具有不同的搜索模式,允许您更改与下载过程的交互级别。您可以让程序只查找和下载缩略图,然后在几秒钟内看到数百张图片向您飞来——这是最快的搜索模式。
然后您可以选择要手动下载的全尺寸图像。当然,您可以让 Extreme Picture Finder 自动查找、下载和保存缩略图和全尺寸图像,或者只是查找、下载和保存全尺寸图像。此外,该程序还可以保存在与原创全尺寸图像相同的页面上找到的所有图像相关图像。
特点:
-自动下载您从网站 中选择的图片、音乐、视频或任何其他文件
-来自 TGP 和受密码保护的 网站
下载-下载 URL 列表(fusker 链接)
-内置网络图片查找器
-最多可同时下载 30 次-您“立即拥有您的文件,速度非常快
-内置数据库和数千个网站地址
-内置图片浏览器的缩略图和幻灯片放映方式
-用户友好的界面被翻译成多种语言
实际测试截图。图片来自网络,仅供测试和展示。请不要在意这些细节。
下载链接:
密码:52pj
2、Bulk.Image.Downloader(官方主页) 这个不如第一个强大,但是也很实用。最重要的是安装后有新手指南。
功能:
图片托管支持-BID 可用于几乎所有流行的图片托管网站,例如 flickr、imagevenue、imagefap、imageshack、imagebam 等。
Social网站-BID 支持从 Facebook、myspace 和 Twitter 等相关主机网站下载相册图片,
全尺寸图像-BID 使用高级启发式评分方法来定位全尺寸图像。这意味着 BID 无需用户配置即可在大多数画廊上自动运行。
批量下载 - 通过集成的队列管理器从大量的库 URL 列表中自动下载。
Web 浏览器集成-BID 与 IE、Opera、FireFox 和 Chrome 集成。只需在浏览器窗口中右键单击并选择“使用 BID 打开当前页面”
Web 论坛支持-BID 可扫描多页论坛主题并快速提取所有图片链接。
多页图库下载-BID 可以立即检测和下载最流行的多页网络图库。
受密码保护的网站- 如果网站 要求,BID 将提示输入用户名和密码。
视频下载-不仅用于图片-BID 还支持来自直接链接的视频文件(.avi、.wmv、.mpeg、.mov、.flv、.mp4 等)
下载VIDEO-内嵌图片-BID除了可以查找和下载全尺寸图片,如镜像所示,还可以在页面下载内嵌图片
图像序列化的图像文件名(fusker)-BID 支持序列化图像下载的“范围内”URL。
图像验证-BID 检查每个图像以确保其已正确下载。无效图片将自动重试。
Resume download-BID 将从断开连接点恢复下载。
多线程下载-BID一次最多可下载50张图片。快速下载这些图库!
重定向分析——一些网站在重定向到imagehost之前使用图像重定向“服务”如imagecash、urlcash等来展示广告。 BID 将自动解析这些类型的链接。
取消文件名-BID会从可能干扰文件名的图片主机(如imagevenue、imagefap)取回正确的文件名。
生成文件名-可以选择自己创建顺序文件名,供镜像主机打乱文件名,
将图库导出为 HTML 或 BB 代码 - 快速生成适合粘贴到网络论坛的图库代码。
实际测试截图。图片来自网络,仅供测试和展示使用。请不要在意这些细节。
下载链接:
密码:52pj
我喜欢整理一些国内外实用的工具。有兴趣的朋友可以关注一波,有能力者多给我奖励。谢谢!

