
原创文章自动采集
让你的文章秒被收录(伪原创方法大全)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2020-08-11 19:33
但是一个网站的原创内容假如做少量还不是很难,可是天天更新无论对于哪一个草根站长来说,都是一件十分困难的事情,特别是一些垂直行业类的网站,由于这方面行业的内容都相对固定,发布原创内容就愈加困难,所以伪原创是一个重要的途径,可是传统的伪原创方式早已无法提高内容质量,进而会使网站沦为垃圾网站,所以从发展的角度上来看,提升伪原创的质量就变得极为关键。
那么怎么能够够有效提高伪原创内容的质量呢?我觉得可以从下边几个方面来着手,能够使伪原创内容和原创内容的质量在伯仲之间。
一,伪原创的合并创新方式。
我们晓得伪原创一般就是在互联网找一些内容,然后更换标题以及将文章的段落搅乱,甚至有的用伪原创工具进行同义词替换,从而引起伪原创内容的可阅读性显得极差,所以我们要抛开这些伪原创方式,可以将相关性的内容进行整合,而且用自己的语言进行重新梳理,并在梳理的过程中,结合相关的内容进行一定的观点创新,就能够使这样的伪原创内容显示出新意来。
在合并相关的内容时,一定要保障首段和尾段都是原创的内容,而且在这两个地方构建你的中心内容,这种中心内容常常可以结合不同的观念的整合,如果作为站长此时才思如泉涌的话,有着自己的独立思想,那么也可以进行撰写,这样才能够有效保障伪原创内容的质量,哪怕此时在文中存在着部份的内容相似度较高,也不会造成百度的讨厌。
二,内容的整合以及科学的采集。
我们晓得互联网上的有些内容和市场上销售的图书内容存在着一定的相关性,但是却不可能一模一样,要不然这种图书都会被冠之以剽窃,所以这种图书的内容我们可以迁往互联网上,并进行稍稍的优化和创新,就能够转化成特别不错的原创内容,而且也具有良好的可读性以及知识性,并成为百度蜘蛛偏爱的内容大餐。
另外就是整合互联网现有的内容,比如制做一些峰会发贴大全,游戏攻略大全等等各类大全性质的内容,这些内容常常都不需要进行原创,只须要在互联网上采集相关的内容,然后针对那些内容进行承袭,就能够产生特别具有参考性的内容,而且这样的内容同样也是百度蜘蛛偏爱的大餐,很有希望成为百度的首页常客。
三、等价交换法
①、文字排序法:如随便拿本站的这篇文章“游戏编辑写伪首创文章的五大方法”如何做等价交换法?经过反义词以及搅乱标题关键词次第来抵达等价交换,你就能改成“游戏编辑五大方法写伪首创文章”,“五大方法协助游戏编辑写伪首创文章”你看标题巧妙改动了,但意义却没变,这就是等价交换法。
②、数字交换法:比方标题:五大伪首创方法,你就能停止恰当的消除几个本人以为不是伪首创方法的,或者降低一些伪首创方法,都还能,至少你才能使搜索引擎起码以为你的标题就标新立异。
③、词语交换法:望文生义就是把成语的相关或则反义词交换一下,这样也才能抵达换汤不换药的疗效。
四、标题组合法
组合法是用前面总结的三个办法或二个办法一齐运用。如在拿站长网一篇文章标题“站长怎么做网站营销分析并制订战略”能够改成“做好网路营销分析需制其献策”其中上面就用了等价交换法和文字修饰法。
五、文字修饰法
标题太精确的时分我们能否经过一定的加工修饰,如降低疑惑,反问,比照,比喻,拟人,和原标题完满分离,到达降低标题的冲击力。如“五大伪首创方法”能够改为“五大伪首创方法有用吗”?
六、标题与内容相关
标题的修正,在于增加搜索引擎中的反复度,而非你更改正后,把原文的意义给改头换面,这样就丧失了伪首创的本意。不论标题怎么停止修正,第一要忠于原文标题的原意;第二要出席更加契合阅读者需求的特点。只要这样,才会抵达伪首创的意想不到的结果。
七、正文内容修正法
①、首段总结法:给本人来写首段,就像序言的作用一样,假如你有精神,就看完整文做个总结,放在首页,假如认为没时间看,那么也很简单:本人编,而且一定要融入本人网站的关键词;
②、文中插入链接锚文本:想必你们都知道锚文本的作用,能够有助于进步相关的关键词排行,也才能他人采集你的材料的时分,把锚文本链接一并采集去,这样就相当于给你降低一条外链:你采集我,我就应用你,很公正的。 每200-300字之间,能够恰当添加2-3个锚文本链接;
③、尾部总结法:对全篇文章做个总结,其实关于搜索引擎优化,不只仅是那些内容,但小的方法上一定要留心,玩搜索引擎就是个细致活,所以不只要会做,更要会考虑,触类旁通才干有快速的进步和进步;
④、新降低图片:大家一定就会知道,一图胜千言的道理。固然,目前大局部搜索引擎还不可以读取图片的内容,但是图片中的alt属性才能停止注释,也会给搜索引擎面目一新的感觉,以为你的内容是新的而收录;
⑤、段落交换法:这个办法就是把内容的次第停止相互的交流,但是,一定要留心不要影响原文的阅读。特别是一个操作办法,千万不能否运用,否则,你懂的。因而,此办法并不迎合一切,逻辑性的文章切忌。
上面的几种伪原创方式才能有效的提高内容的创作速率,同时也就能有效拓展内容的创作空间,不过我们在进行伪原创时,一定要注意内容的可读性,而不是简单的通过软件进行同义词替换,段落搅乱的方式。尽量的在伪原创的同时融入一些自己的观点,这样才会使伪原创内容拥有新的生命,从而为网站质量的提高做出更大的贡献。 查看全部
我们都晓得,百度搜索引擎现今对于网站的内容质量要求显得越来越高,如果一个网站的内容质量太差,哪怕网站的外链特别多,而且高质量的外链也十分多,通常也不会获得很高的排行,因为内容质量太差的网站,其跳出率常常十分高,而这一点也早已成为百度排名算法的重要要素

但是一个网站的原创内容假如做少量还不是很难,可是天天更新无论对于哪一个草根站长来说,都是一件十分困难的事情,特别是一些垂直行业类的网站,由于这方面行业的内容都相对固定,发布原创内容就愈加困难,所以伪原创是一个重要的途径,可是传统的伪原创方式早已无法提高内容质量,进而会使网站沦为垃圾网站,所以从发展的角度上来看,提升伪原创的质量就变得极为关键。
那么怎么能够够有效提高伪原创内容的质量呢?我觉得可以从下边几个方面来着手,能够使伪原创内容和原创内容的质量在伯仲之间。
一,伪原创的合并创新方式。
我们晓得伪原创一般就是在互联网找一些内容,然后更换标题以及将文章的段落搅乱,甚至有的用伪原创工具进行同义词替换,从而引起伪原创内容的可阅读性显得极差,所以我们要抛开这些伪原创方式,可以将相关性的内容进行整合,而且用自己的语言进行重新梳理,并在梳理的过程中,结合相关的内容进行一定的观点创新,就能够使这样的伪原创内容显示出新意来。
在合并相关的内容时,一定要保障首段和尾段都是原创的内容,而且在这两个地方构建你的中心内容,这种中心内容常常可以结合不同的观念的整合,如果作为站长此时才思如泉涌的话,有着自己的独立思想,那么也可以进行撰写,这样才能够有效保障伪原创内容的质量,哪怕此时在文中存在着部份的内容相似度较高,也不会造成百度的讨厌。
二,内容的整合以及科学的采集。
我们晓得互联网上的有些内容和市场上销售的图书内容存在着一定的相关性,但是却不可能一模一样,要不然这种图书都会被冠之以剽窃,所以这种图书的内容我们可以迁往互联网上,并进行稍稍的优化和创新,就能够转化成特别不错的原创内容,而且也具有良好的可读性以及知识性,并成为百度蜘蛛偏爱的内容大餐。
另外就是整合互联网现有的内容,比如制做一些峰会发贴大全,游戏攻略大全等等各类大全性质的内容,这些内容常常都不需要进行原创,只须要在互联网上采集相关的内容,然后针对那些内容进行承袭,就能够产生特别具有参考性的内容,而且这样的内容同样也是百度蜘蛛偏爱的大餐,很有希望成为百度的首页常客。
三、等价交换法
①、文字排序法:如随便拿本站的这篇文章“游戏编辑写伪首创文章的五大方法”如何做等价交换法?经过反义词以及搅乱标题关键词次第来抵达等价交换,你就能改成“游戏编辑五大方法写伪首创文章”,“五大方法协助游戏编辑写伪首创文章”你看标题巧妙改动了,但意义却没变,这就是等价交换法。
②、数字交换法:比方标题:五大伪首创方法,你就能停止恰当的消除几个本人以为不是伪首创方法的,或者降低一些伪首创方法,都还能,至少你才能使搜索引擎起码以为你的标题就标新立异。
③、词语交换法:望文生义就是把成语的相关或则反义词交换一下,这样也才能抵达换汤不换药的疗效。
四、标题组合法
组合法是用前面总结的三个办法或二个办法一齐运用。如在拿站长网一篇文章标题“站长怎么做网站营销分析并制订战略”能够改成“做好网路营销分析需制其献策”其中上面就用了等价交换法和文字修饰法。
五、文字修饰法
标题太精确的时分我们能否经过一定的加工修饰,如降低疑惑,反问,比照,比喻,拟人,和原标题完满分离,到达降低标题的冲击力。如“五大伪首创方法”能够改为“五大伪首创方法有用吗”?
六、标题与内容相关
标题的修正,在于增加搜索引擎中的反复度,而非你更改正后,把原文的意义给改头换面,这样就丧失了伪首创的本意。不论标题怎么停止修正,第一要忠于原文标题的原意;第二要出席更加契合阅读者需求的特点。只要这样,才会抵达伪首创的意想不到的结果。

七、正文内容修正法
①、首段总结法:给本人来写首段,就像序言的作用一样,假如你有精神,就看完整文做个总结,放在首页,假如认为没时间看,那么也很简单:本人编,而且一定要融入本人网站的关键词;
②、文中插入链接锚文本:想必你们都知道锚文本的作用,能够有助于进步相关的关键词排行,也才能他人采集你的材料的时分,把锚文本链接一并采集去,这样就相当于给你降低一条外链:你采集我,我就应用你,很公正的。 每200-300字之间,能够恰当添加2-3个锚文本链接;
③、尾部总结法:对全篇文章做个总结,其实关于搜索引擎优化,不只仅是那些内容,但小的方法上一定要留心,玩搜索引擎就是个细致活,所以不只要会做,更要会考虑,触类旁通才干有快速的进步和进步;
④、新降低图片:大家一定就会知道,一图胜千言的道理。固然,目前大局部搜索引擎还不可以读取图片的内容,但是图片中的alt属性才能停止注释,也会给搜索引擎面目一新的感觉,以为你的内容是新的而收录;
⑤、段落交换法:这个办法就是把内容的次第停止相互的交流,但是,一定要留心不要影响原文的阅读。特别是一个操作办法,千万不能否运用,否则,你懂的。因而,此办法并不迎合一切,逻辑性的文章切忌。
上面的几种伪原创方式才能有效的提高内容的创作速率,同时也就能有效拓展内容的创作空间,不过我们在进行伪原创时,一定要注意内容的可读性,而不是简单的通过软件进行同义词替换,段落搅乱的方式。尽量的在伪原创的同时融入一些自己的观点,这样才会使伪原创内容拥有新的生命,从而为网站质量的提高做出更大的贡献。
【8月25日更新】ET2手动采集For Discuz!
采集交流 • 优采云 发表了文章 • 0 个评论 • 375 次浏览 • 2020-08-11 18:35
一、软件下载
当前版本2.1.2.1(8月25日更新)
二、演示教程
ET2之discuz x1 门户视频演示,含封面手动缩略、文章分页显示
()
ET2之discuz x1 图文使用教程
( )
ET2之discuz x1 BBS 视频演示
( )
三、接口下载
Discuz! X1正式版门户文章-完美支持封面、图片手动缩略,免费插口
下载地址:
(6月10日:增加手动提取第一幅jpg图片做封面缩略图的功能;最新的软件包里外置了门户范例方案,需要的同学请将方案对应采集规则的“文件下载”开启,并开启对应发布规则的“FTP上传”)
Discuz! X1正式版广场BBS+群组讨论市贴子-支持手动回复,完美支持附件 免费插口
下载地址:
(6月9日,增加发布插口可选参数zzhour,用于拟真回帖、回复时间;6月8日,增加可选参数addfeed,用于启用发送动态到佳苑;6月7日,增加发布插口可选参数maxclick,用于设定贴子查看数的最大随机值;5月24日,增加随机生成贴子查看数,增加关于群组的说明)
注:同时使用两个插口的用户,请注意更改插口文件名称,以防止互相覆盖;
用户帮助指南地址:
视频教程地址:
三、本帖更新说明:
8月25日:软件升级到2.1.2.1,增加独立的高速伪原创模块,执行效率为处理1万字内容时1万词条0.4秒,10万词条4秒:
图1:
图2:
8月1日:软件升级;支持DZX1的7月23升级
6月17日:增加DZX1 门户采集视频演示;
6月16日:增加DZX1 BBS采集视频演示;
6月12日: 增加DZX1简易图文使用教程;
6月10日:为便捷菜鸟使用,门户插口降低手动提取第一幅jpg图片做封面缩略图的功能,大家可以不用自己指定哪幅图做封面了;用此功能时发布配置-发布项-文件列表参数名须填etattachs,见图示:
建议不熟悉怎样更改的新同学使用最新软件包里ET自带的DZX1门户范例发布规则;更多详情请看插口说明;
6月9日:BBS插口降低参数zzhour,用于拟真回帖、回复时间,详情请看插口说明;
6月8日:BBS插口降低参数addfeed,可将动态发送到佳苑;原来提供的2.0.9.9.1版,因版本号过长,不易于在线升级,现在早已调整版本号为2.1.0;
6月7日:本日19点发布2.0.9.9.1版修正一个2.0.9.9版中造成List index out of bounds错误的BUG;
6月7日:BBS插口降低可选参数最大随机查看数maxclick;软件已升级到2.0.9.9,现在数据项中重复的文件不会被重复下载了,没有内容的回复项不会被递交回复了,改进了对文件类型的手动辨识,无扩充名或动态的文件网址能更好的下载;
6月5日:软件已升级到2.0.9.8,内置的预设规则调整,给你们更好的参照;
5月28日:2个插口均已升级,增加参数ashowul,支持修改附件目录和远程附件,请须要的同事重新下载软件或单独下载插口,该参数使用方式见插口说明;
5月26日:软件升级到2.0.9.7版,优化HTML图片到UBB图片转换;
5月25日:软件升级到2.0.9.6版,内置的门户范例方案有封面图片下载上传演示,需要的同学请将方案对应采集规则的“文件下载”开启,并开启对应发布规则的“FTP上传”;
5月24日:广场BBS的插口是支持群组讨论县的,因为有些同学不清楚,所以非常说明,大家将FID更改为群组讨论县的FID即可,同时降低随机生成贴子查看数。
5月19日:下午与DZ官方同步发布X1正式版免费插口 查看全部
可独立运行在服务器或本地计算机,不需要打开网站即可24小时无人操作不间断工作,最少的服务器压力和最佳的稳定性,适合长时间沉静运行。
一、软件下载
当前版本2.1.2.1(8月25日更新)
二、演示教程
ET2之discuz x1 门户视频演示,含封面手动缩略、文章分页显示
()
ET2之discuz x1 图文使用教程
( )
ET2之discuz x1 BBS 视频演示
( )
三、接口下载
Discuz! X1正式版门户文章-完美支持封面、图片手动缩略,免费插口
下载地址:
(6月10日:增加手动提取第一幅jpg图片做封面缩略图的功能;最新的软件包里外置了门户范例方案,需要的同学请将方案对应采集规则的“文件下载”开启,并开启对应发布规则的“FTP上传”)
Discuz! X1正式版广场BBS+群组讨论市贴子-支持手动回复,完美支持附件 免费插口
下载地址:
(6月9日,增加发布插口可选参数zzhour,用于拟真回帖、回复时间;6月8日,增加可选参数addfeed,用于启用发送动态到佳苑;6月7日,增加发布插口可选参数maxclick,用于设定贴子查看数的最大随机值;5月24日,增加随机生成贴子查看数,增加关于群组的说明)
注:同时使用两个插口的用户,请注意更改插口文件名称,以防止互相覆盖;
用户帮助指南地址:
视频教程地址:
三、本帖更新说明:
8月25日:软件升级到2.1.2.1,增加独立的高速伪原创模块,执行效率为处理1万字内容时1万词条0.4秒,10万词条4秒:
图1:
图2:
8月1日:软件升级;支持DZX1的7月23升级
6月17日:增加DZX1 门户采集视频演示;
6月16日:增加DZX1 BBS采集视频演示;
6月12日: 增加DZX1简易图文使用教程;
6月10日:为便捷菜鸟使用,门户插口降低手动提取第一幅jpg图片做封面缩略图的功能,大家可以不用自己指定哪幅图做封面了;用此功能时发布配置-发布项-文件列表参数名须填etattachs,见图示:
建议不熟悉怎样更改的新同学使用最新软件包里ET自带的DZX1门户范例发布规则;更多详情请看插口说明;
6月9日:BBS插口降低参数zzhour,用于拟真回帖、回复时间,详情请看插口说明;
6月8日:BBS插口降低参数addfeed,可将动态发送到佳苑;原来提供的2.0.9.9.1版,因版本号过长,不易于在线升级,现在早已调整版本号为2.1.0;
6月7日:本日19点发布2.0.9.9.1版修正一个2.0.9.9版中造成List index out of bounds错误的BUG;
6月7日:BBS插口降低可选参数最大随机查看数maxclick;软件已升级到2.0.9.9,现在数据项中重复的文件不会被重复下载了,没有内容的回复项不会被递交回复了,改进了对文件类型的手动辨识,无扩充名或动态的文件网址能更好的下载;
6月5日:软件已升级到2.0.9.8,内置的预设规则调整,给你们更好的参照;
5月28日:2个插口均已升级,增加参数ashowul,支持修改附件目录和远程附件,请须要的同事重新下载软件或单独下载插口,该参数使用方式见插口说明;
5月26日:软件升级到2.0.9.7版,优化HTML图片到UBB图片转换;
5月25日:软件升级到2.0.9.6版,内置的门户范例方案有封面图片下载上传演示,需要的同学请将方案对应采集规则的“文件下载”开启,并开启对应发布规则的“FTP上传”;
5月24日:广场BBS的插口是支持群组讨论县的,因为有些同学不清楚,所以非常说明,大家将FID更改为群组讨论县的FID即可,同时降低随机生成贴子查看数。
5月19日:下午与DZ官方同步发布X1正式版免费插口
基于Python3.6爬虫 采集知网文献
采集交流 • 优采云 发表了文章 • 0 个评论 • 330 次浏览 • 2020-08-11 03:29
知网搜索结果:
远见搜索结果:
仔细观察会发觉,该网站是post恳求,重点是带参数恳求。打开远见,搜索你想要的,按f2,查看参数里的表单数据。像我要采的是卷积神经网络,文章类型刊物,这里替换成你的参数就ok了。
formdata = {'Type': 1,
'Order': 1,
'Islegal': 'false',
'ArticleType': 1,
'Theme': '卷积神经网络',
'searchType': 'MulityTermsSearch',
'ParamIsNullOrEmpty': 'true',
'Page': i}
下面直接上代码:
# encoding='utf-8'
import json
import time
import random
from lxml import etree
import requests
import codecs
class CNKI(object):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'}
cookies = {
'Cookie': 'Ecp_ClientId=4181108101501154830; cnkiUserKey=ec1ef785-3872-fac6-cad3-402229207945; UM_distinctid=166f12b44b1654-05e4c1a8d86edc-b79183d-1fa400-166f12b44b2ac8; KEYWORD=%E5%8D%B7%E7%A7%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%24%E5%8D%B7%E7%A7%AF%20%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C; Ecp_IpLoginFail=1811121.119.135.10; amid=73b0014b-8b61-4e24-a333-8774cb4dd8bd; SID=110105; CNZZDATA1257838113=579682214-1541655561-http%253A%252F%252Fsearch.cnki.net%252F%7C1542070177'}
param = {
'Accept': 'text/html, */*; q=0.01',
'Accept - Encoding': 'gzip, deflate',
'Accept - Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep - alive',
'Content - Type': 'application / x - www - form - urlencoded;charset = UTF - 8',
'Host': 'yuanjian.cnki.net',
'Origin': 'http: // yuanjian.cnki.net',
'Referer': 'http: // yuanjian.cnki.net / Search / Result',
'X - Requested - With': 'XMLHttpRequest'}
def content(self):
li = []
for j in range(274, 275):
for i in range(j, j + 1):
url = 'http://yuanjian.cnki.net/Search/Result'
print('当前页', i)
time.sleep(random.random() * 3)
formdata = {'Type': 1,
'Order': 1,
'Islegal': 'false',
'ArticleType': 1,
'Theme': '卷积神经网络',
'searchType': 'MulityTermsSearch',
'ParamIsNullOrEmpty': 'true',
'Page': i}
print(formdata)
try:
r = requests.post(url, data=formdata, headers=self.headers, cookies=self.cookies, params=self.param)
r.raise_for_status()
r.encoding = r.apparent_encoding
data = etree.HTML(r.text)
# 链接列表
#url_list = data.xpath("//*[@id='article_result']/div/div/p[1]/a[1]/@href")
#
url_list = data.xpath("//*[@id='article_result']/div/div/p[1]/a[1]/@href")
# 关键词列表
key_wordlist = []
all_items = data.xpath("//*[@id='article_result']/div/div")
for i in range(1, len(all_items) + 1):
key_word = data.xpath("//*[@id='article_result']/div/div[%s]/div[1]/p[1]/a/text()" % i)
key_words = ';'.join(key_word)
key_wordlist.append(key_words)
# 来源
source_items = data.xpath("//*[@id='article_result']/div/div")
for j in range(1, len(source_items) + 1):
sources = data.xpath("//*[@id='article_result']/div/div/p[3]/a[1]/span/text()")
for index, url in enumerate(url_list):
items = {}
try:
print('当前链接:', url)
content = requests.get(url, headers=self.headers)
contents = etree.HTML(content.text)
# 论文题目
title = contents.xpath("//h1[@class='xx_title']/text()")[0]
items['titleCh'] = title
items['titleEn'] = ''
print('标题:', title)
# 来源
source = sources[index]
items['source'] = source
print('来源:', source)
# 关键字
each_key_words = key_wordlist[index]
print('关键字:', each_key_words)
items['keywordsEn'] = ''
items['keywordsCh'] = each_key_words
# 作者
author = contents.xpath("//*[@id='content']/div[2]/div[3]/a/text()")
items['authorCh'] = author
items['authorEn'] = ''
print('作者:', author)
# 单位
unit = contents.xpath("//*[@id='content']/div[2]/div[5]/a[1]/text()")
units = ''.join(unit).strip(';')
items['unitCh'] = units
items['unitEn'] = ''
print('单位:', units)
# 分类号
classify = contents.xpath("//*[@id='content']/div[2]/div[5]/text()")[-1]
c = ''.join(classify).split(';')
res = []
for name in c:
print('当前分类号:', name)
try:
if name.find("TP391.41") != -1:
print('改变分类号!')
name = 'TP391.4'
result = requests.get('http://127.0.0.1:5000/%s/' % name)
time.sleep(5)
re_classify1 = result.content
string = str(re_classify1, 'utf-8')
classify_result = eval(string)['classfiy']
# print('文献分类导航:', classify_result)
except Exception as e:
print(e)
res.append(classify_result)
print('文献分类导航:', res)
items['classify'] = res
# 摘要
abstract = contents.xpath("//div[@class='xx_font'][1]/text()")[1].strip()
print('摘要:', abstract)
items['abstractCh'] = abstract
items['abstractEn'] = ''
# 相似文献
similar = contents.xpath(
"//*[@id='xiangsi']/table[2]/tbody/tr[3]/td/table/tbody/tr/td/text()")
si = ''.join(similar).replace('\r\n', '').split('期')
po = []
for i in si:
sis = i + '期'
if len(sis) > 3:
po.append(sis)
items['similar_article'] = po
# 参考文献
refer_doc = contents.xpath("//*[@id='cankao']/table[2]/tbody/tr[3]/td/table/tbody/tr/td/text()")
items['refer_doc'] = refer_doc
li.append(items)
except Exception as e:
print(e)
print(len(li))
except Exception as e:
print(e)
return li
if __name__ == '__main__':
con = CNKI()
items = con.content()
print(items)
try:
with codecs.open('./cnki_data.json', 'a+', encoding="utf-8") as fp:
for i in items:
fp.write(json.dumps(i, ensure_ascii=False) + ",\n")
except IOError as err:
print('error' + str(err))
finally:
fp.close()
采集结果
完成! 查看全部
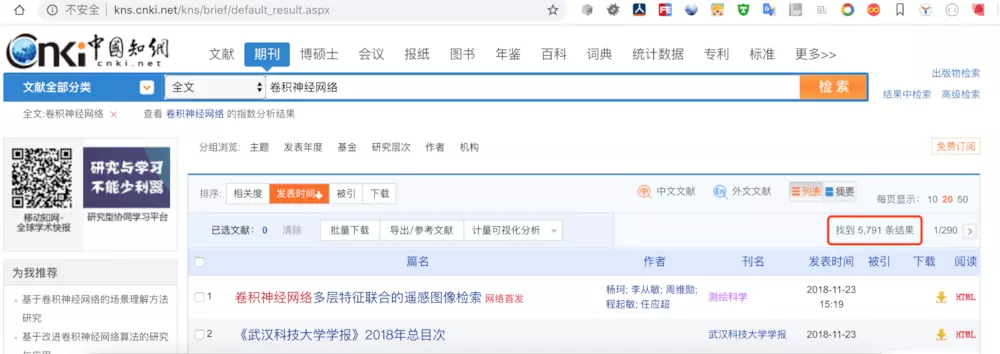
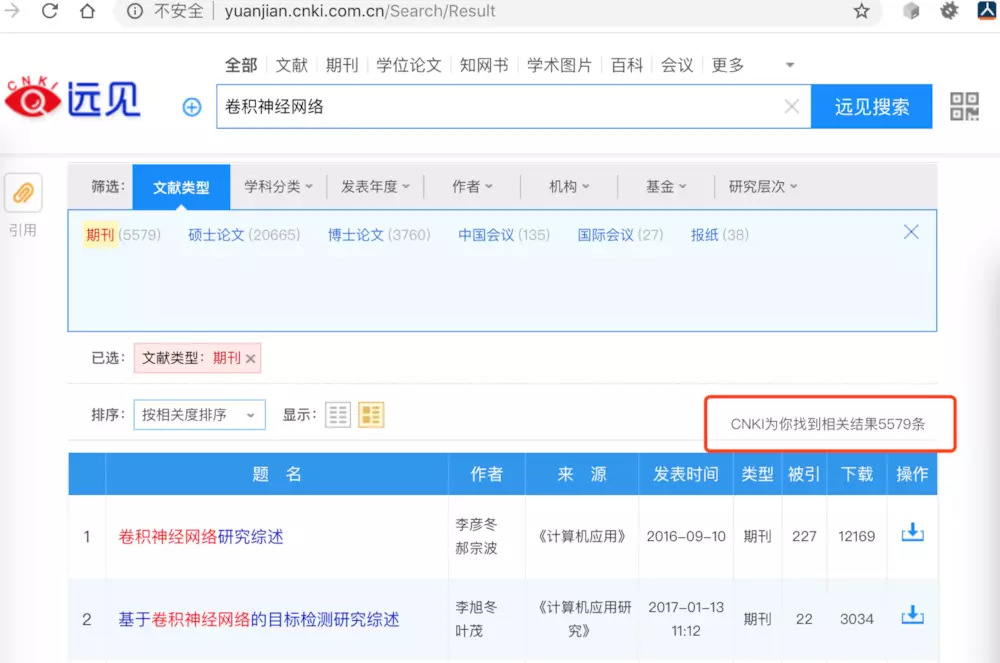
最近因公司需求采集知网数据(标题、来源、关键字、作者、单位、分类号、摘要、相似文献这种数组),由于知网防爬很强,内容页链接加密,尝试了pyspider、scrapy、selenium,都未能步入内容页,直接跳转到知网首页。于是只得采用知网的一个插口进行采集:链接: link,以下是两个网站关于“卷积神经网络”的刊物数据量相比如下图所示:
知网搜索结果:
远见搜索结果:
仔细观察会发觉,该网站是post恳求,重点是带参数恳求。打开远见,搜索你想要的,按f2,查看参数里的表单数据。像我要采的是卷积神经网络,文章类型刊物,这里替换成你的参数就ok了。
formdata = {'Type': 1,
'Order': 1,
'Islegal': 'false',
'ArticleType': 1,
'Theme': '卷积神经网络',
'searchType': 'MulityTermsSearch',
'ParamIsNullOrEmpty': 'true',
'Page': i}
下面直接上代码:
# encoding='utf-8'
import json
import time
import random
from lxml import etree
import requests
import codecs
class CNKI(object):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'}
cookies = {
'Cookie': 'Ecp_ClientId=4181108101501154830; cnkiUserKey=ec1ef785-3872-fac6-cad3-402229207945; UM_distinctid=166f12b44b1654-05e4c1a8d86edc-b79183d-1fa400-166f12b44b2ac8; KEYWORD=%E5%8D%B7%E7%A7%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%24%E5%8D%B7%E7%A7%AF%20%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C; Ecp_IpLoginFail=1811121.119.135.10; amid=73b0014b-8b61-4e24-a333-8774cb4dd8bd; SID=110105; CNZZDATA1257838113=579682214-1541655561-http%253A%252F%252Fsearch.cnki.net%252F%7C1542070177'}
param = {
'Accept': 'text/html, */*; q=0.01',
'Accept - Encoding': 'gzip, deflate',
'Accept - Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep - alive',
'Content - Type': 'application / x - www - form - urlencoded;charset = UTF - 8',
'Host': 'yuanjian.cnki.net',
'Origin': 'http: // yuanjian.cnki.net',
'Referer': 'http: // yuanjian.cnki.net / Search / Result',
'X - Requested - With': 'XMLHttpRequest'}
def content(self):
li = []
for j in range(274, 275):
for i in range(j, j + 1):
url = 'http://yuanjian.cnki.net/Search/Result'
print('当前页', i)
time.sleep(random.random() * 3)
formdata = {'Type': 1,
'Order': 1,
'Islegal': 'false',
'ArticleType': 1,
'Theme': '卷积神经网络',
'searchType': 'MulityTermsSearch',
'ParamIsNullOrEmpty': 'true',
'Page': i}
print(formdata)
try:
r = requests.post(url, data=formdata, headers=self.headers, cookies=self.cookies, params=self.param)
r.raise_for_status()
r.encoding = r.apparent_encoding
data = etree.HTML(r.text)
# 链接列表
#url_list = data.xpath("//*[@id='article_result']/div/div/p[1]/a[1]/@href")
#
url_list = data.xpath("//*[@id='article_result']/div/div/p[1]/a[1]/@href")
# 关键词列表
key_wordlist = []
all_items = data.xpath("//*[@id='article_result']/div/div")
for i in range(1, len(all_items) + 1):
key_word = data.xpath("//*[@id='article_result']/div/div[%s]/div[1]/p[1]/a/text()" % i)
key_words = ';'.join(key_word)
key_wordlist.append(key_words)
# 来源
source_items = data.xpath("//*[@id='article_result']/div/div")
for j in range(1, len(source_items) + 1):
sources = data.xpath("//*[@id='article_result']/div/div/p[3]/a[1]/span/text()")
for index, url in enumerate(url_list):
items = {}
try:
print('当前链接:', url)
content = requests.get(url, headers=self.headers)
contents = etree.HTML(content.text)
# 论文题目
title = contents.xpath("//h1[@class='xx_title']/text()")[0]
items['titleCh'] = title
items['titleEn'] = ''
print('标题:', title)
# 来源
source = sources[index]
items['source'] = source
print('来源:', source)
# 关键字
each_key_words = key_wordlist[index]
print('关键字:', each_key_words)
items['keywordsEn'] = ''
items['keywordsCh'] = each_key_words
# 作者
author = contents.xpath("//*[@id='content']/div[2]/div[3]/a/text()")
items['authorCh'] = author
items['authorEn'] = ''
print('作者:', author)
# 单位
unit = contents.xpath("//*[@id='content']/div[2]/div[5]/a[1]/text()")
units = ''.join(unit).strip(';')
items['unitCh'] = units
items['unitEn'] = ''
print('单位:', units)
# 分类号
classify = contents.xpath("//*[@id='content']/div[2]/div[5]/text()")[-1]
c = ''.join(classify).split(';')
res = []
for name in c:
print('当前分类号:', name)
try:
if name.find("TP391.41") != -1:
print('改变分类号!')
name = 'TP391.4'
result = requests.get('http://127.0.0.1:5000/%s/' % name)
time.sleep(5)
re_classify1 = result.content
string = str(re_classify1, 'utf-8')
classify_result = eval(string)['classfiy']
# print('文献分类导航:', classify_result)
except Exception as e:
print(e)
res.append(classify_result)
print('文献分类导航:', res)
items['classify'] = res
# 摘要
abstract = contents.xpath("//div[@class='xx_font'][1]/text()")[1].strip()
print('摘要:', abstract)
items['abstractCh'] = abstract
items['abstractEn'] = ''
# 相似文献
similar = contents.xpath(
"//*[@id='xiangsi']/table[2]/tbody/tr[3]/td/table/tbody/tr/td/text()")
si = ''.join(similar).replace('\r\n', '').split('期')
po = []
for i in si:
sis = i + '期'
if len(sis) > 3:
po.append(sis)
items['similar_article'] = po
# 参考文献
refer_doc = contents.xpath("//*[@id='cankao']/table[2]/tbody/tr[3]/td/table/tbody/tr/td/text()")
items['refer_doc'] = refer_doc
li.append(items)
except Exception as e:
print(e)
print(len(li))
except Exception as e:
print(e)
return li
if __name__ == '__main__':
con = CNKI()
items = con.content()
print(items)
try:
with codecs.open('./cnki_data.json', 'a+', encoding="utf-8") as fp:
for i in items:
fp.write(json.dumps(i, ensure_ascii=False) + ",\n")
except IOError as err:
print('error' + str(err))
finally:
fp.close()
采集结果

完成!
DEDE全手动采集插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 354 次浏览 • 2020-08-10 22:46
时间:2011-07-08
内容:
1.修正了一个当DEDE安装在二级目录时,插件可能不能正常启动的逻辑问题。
2.修正了个别特殊的相对链接地址的补全规则。
3.增加了手动排除重复分页内容的功能,程序通过测量每位分页内容的crc32值,并将重复分页清除掉。
4.修正了一个当内容过滤规则中收录“逆向引用”时,编辑规则时“逆向引用”不能正常显示的问题。
5.应用户要求,给采集节点降低了一个批量启用/禁用的功能,方便使用。同时原先的【不选择预设栏目就相当于该节点禁用】的功能仍然保留。
6.应用户要求,增加了两种内容伪原创形式:正文搅乱【打乱文字次序】和【替换为自定义标题】。前者只适宜文章模型,会将文章内容完全搅乱,重度伪原创,操作过的文章完全没有可读性;后者适宜文章和图集模型,会将文档标题替换成自定义的多个标题中的一个。
7.修正了一个当使用图集模型时,文档可能不会出现推荐、特荐和头条等标志属性的逻辑问题。
8.在全局设置上面降低了【每天最多须要采集多少文章】的选项,同时原先在采集节点参数上面达到每晚【采集数量限制】将会手动删掉临时文档的功能,也改成了可选删掉或则不删掉。
9.针对个别用户反映服务器网路状态不稳定,在线升级困难的问题,特加设了一台升级服务器。以后就可以在升级程序文件时选择不同的升级服务器。
10.支持文章和图集模型的复制模型,新模型的辨识id必须以article(复制文章模型)或者image(复制图集模型)开头,这样插件能够辨识。例如可以将辨识id起名为article2。
本次更新涉及的文件:
/plus/autocollect/data/class.php
/plus/autocollect/data/template.php
/plus/autocollect/fun_gen.php
/plus/autocollect/fun_image.php
更新操作:
请v3用户在插件后台控制面板上,点 在线升级插件 ,根据提示操作,就可以完成升级。
如果早已在全局设置上面勾选【自动升级到最新的发行版】,则可以手动升级到此版本,不需要手工在线升级。 查看全部
更新日志:
时间:2011-07-08
内容:
1.修正了一个当DEDE安装在二级目录时,插件可能不能正常启动的逻辑问题。
2.修正了个别特殊的相对链接地址的补全规则。
3.增加了手动排除重复分页内容的功能,程序通过测量每位分页内容的crc32值,并将重复分页清除掉。
4.修正了一个当内容过滤规则中收录“逆向引用”时,编辑规则时“逆向引用”不能正常显示的问题。
5.应用户要求,给采集节点降低了一个批量启用/禁用的功能,方便使用。同时原先的【不选择预设栏目就相当于该节点禁用】的功能仍然保留。
6.应用户要求,增加了两种内容伪原创形式:正文搅乱【打乱文字次序】和【替换为自定义标题】。前者只适宜文章模型,会将文章内容完全搅乱,重度伪原创,操作过的文章完全没有可读性;后者适宜文章和图集模型,会将文档标题替换成自定义的多个标题中的一个。
7.修正了一个当使用图集模型时,文档可能不会出现推荐、特荐和头条等标志属性的逻辑问题。
8.在全局设置上面降低了【每天最多须要采集多少文章】的选项,同时原先在采集节点参数上面达到每晚【采集数量限制】将会手动删掉临时文档的功能,也改成了可选删掉或则不删掉。
9.针对个别用户反映服务器网路状态不稳定,在线升级困难的问题,特加设了一台升级服务器。以后就可以在升级程序文件时选择不同的升级服务器。
10.支持文章和图集模型的复制模型,新模型的辨识id必须以article(复制文章模型)或者image(复制图集模型)开头,这样插件能够辨识。例如可以将辨识id起名为article2。
本次更新涉及的文件:
/plus/autocollect/data/class.php
/plus/autocollect/data/template.php
/plus/autocollect/fun_gen.php
/plus/autocollect/fun_image.php
更新操作:
请v3用户在插件后台控制面板上,点 在线升级插件 ,根据提示操作,就可以完成升级。
如果早已在全局设置上面勾选【自动升级到最新的发行版】,则可以手动升级到此版本,不需要手工在线升级。
17站群软件_亿奇站群软件,一款智能的免费站群软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2020-08-10 08:55
17站群软件能模拟人工更新网站的流程,自动获取内容、自动处理内容、自动发布内容,使您能否甩掉手工更新网站的苦恼,实现一键启动,无忧维护的目的,通过站群,您可以轻而易举的构建几十、甚至上百个网站!17站群软件使您从繁杂的网站维护工作中解脱下来,让网站迅速汇集流量人气,从而让网站赢利显得十分之简单。
17站群软件功能和特征介绍
1、无限制构建站点的数量
17站群软件最大的特征就是不限制网站的数量,大大地与侠客、爱聚合等限制网站数目的系统区别下来,只要您有精力,您就可以做上无数个不同类型的网站。
2、整站全手动更新
设置好关键词和抓取频度之后,系统会手动在形成相关关键词并手动抓取相关的文章,真正的全手动聚合! 你要做的仅仅是添加几个关键词,告诉系统你的网站定位,其他的使系统全手动帮你完成,而且之后可以由系统手动不断添加新的相关文章。以后只需瞧瞧统计,制定一下网站策略就可以了。
3、强大的伪原创功能
17站群软件可以依据系统手动采集的原文基础上,在不破坏原文可读性前提下手动进行伪原创,本系统具有独有的同义词和近义词引擎,可以适当改变文章语义,利用特有的算法进行控制,让整篇文章都接近原创文章,而这一切全部是系统智能手动的完成的,无需人干预。
4、强大的抓取正确率
17站群软件是一套泛抓取泛采集系统,它可以不限网站不限域名的抓取相关文章,并不需要你订制任何抓取策略和采集规则,系统会为你抓取与设定的关键词最相关的原创性较高的文章!而且抓取的文章正确率可达到90%以上,可使你在顿时形成上千篇原创性文章。
5、强大的采集替换过滤
为了网站更安全便捷,软件后台拥有超级强悍的文字替换过滤功能,可按您的要求直接替换功能,并可以设定多条替换任务同时进行。可有严禁采集收录关键词设定以防采集到一些敏感性文章,非常便捷灵活,不再害怕网站出现一些不健康的文章。
6、独创的原创文章生成功能
大家都晓得文章是由语句组成的,而短语是由副词、谓语、宾语、定语、补语、状语、表语、标点符号等组成的。17站群软件则借助语句的组成元素,运用不同的语法句型和自定义生成模板,来生成语句,进而组成文章,实现原创文章的生成。
7、独创的指定网址采集功能
专业的采集器都须要查看html代码,进而编撰采集规则,来截取标题内容;一般的站群管理软件和系统,则是按一定的关键字,利用通用的采集逻辑,来随机抓取内容。但如果我想采集某个网站的内容,但又不想写采集规则,怎么办?我们独创的指定网址采集功能解决了您的困局。
8、独创的超级外链群发功能
该功能还在开发中,预计八月初完成。主要是组织用户之间的网站资源,进行自助式非强迫性的有效交换。站群用户和站群用户进行的有效交换的、大量的、稳定的、省事的交换,您就不需要天天去站长群找人问交换链接了,直接在软件后台就有大量的资源等着您。
17站群软件支持的网站程序
PHP类型:
1、织梦 DEDE CMS V5.3/V5.5/5.6/5.7 网站管理系统
2、帝国 Empire CMS V6.0/6.5 网站管理系统
3、Wordpress V2.9.2中文版/V3.0.1-V3.1中英文版 UTF 博客程序
4、Discuz! 7.2 论坛程序
5、Discuz! X 1.5/2.0 论坛程序
6、Discuz!NT 3.5.2(utf-8) 论坛程序
7、PHPWind V7.5 /PHPWind V8.0/8.3/8.5 论坛程序
8、PHPCMS 2008 SP4 网站管理程序
9、ECSHOP v2.72/Shopex V4.8.5(商城系统)
10、Destoon V3.0(B2B网站管理系统)
11、KingCMS 6.0.970
ASP类型:
1、Z-blog 1.8 ASP博客程序
2、动易内容管理系统 CMS 6.8
3、无忧(5U)网站管理系统 V1.2
4、新云Newasp 4.0 sp2 GBK 网站管理程序
5、老Y LaoY8 V2.5 sp2 GBK 网站管理程序
6、Ok3w V5.1 GBK 网站管理程序
7、SDCMS(时代网站) V1.2/v1.3 ASP程序
第三方博客类型:
1、博客大巴(blogbus)博客程序
2、19lou(19楼博客)
其他主流CMS程序及其他博客支持,还在相继降低中,用户可以递交需求安排开发 查看全部
17站群软件简介
17站群软件能模拟人工更新网站的流程,自动获取内容、自动处理内容、自动发布内容,使您能否甩掉手工更新网站的苦恼,实现一键启动,无忧维护的目的,通过站群,您可以轻而易举的构建几十、甚至上百个网站!17站群软件使您从繁杂的网站维护工作中解脱下来,让网站迅速汇集流量人气,从而让网站赢利显得十分之简单。

17站群软件功能和特征介绍
1、无限制构建站点的数量
17站群软件最大的特征就是不限制网站的数量,大大地与侠客、爱聚合等限制网站数目的系统区别下来,只要您有精力,您就可以做上无数个不同类型的网站。
2、整站全手动更新
设置好关键词和抓取频度之后,系统会手动在形成相关关键词并手动抓取相关的文章,真正的全手动聚合! 你要做的仅仅是添加几个关键词,告诉系统你的网站定位,其他的使系统全手动帮你完成,而且之后可以由系统手动不断添加新的相关文章。以后只需瞧瞧统计,制定一下网站策略就可以了。
3、强大的伪原创功能
17站群软件可以依据系统手动采集的原文基础上,在不破坏原文可读性前提下手动进行伪原创,本系统具有独有的同义词和近义词引擎,可以适当改变文章语义,利用特有的算法进行控制,让整篇文章都接近原创文章,而这一切全部是系统智能手动的完成的,无需人干预。
4、强大的抓取正确率
17站群软件是一套泛抓取泛采集系统,它可以不限网站不限域名的抓取相关文章,并不需要你订制任何抓取策略和采集规则,系统会为你抓取与设定的关键词最相关的原创性较高的文章!而且抓取的文章正确率可达到90%以上,可使你在顿时形成上千篇原创性文章。
5、强大的采集替换过滤
为了网站更安全便捷,软件后台拥有超级强悍的文字替换过滤功能,可按您的要求直接替换功能,并可以设定多条替换任务同时进行。可有严禁采集收录关键词设定以防采集到一些敏感性文章,非常便捷灵活,不再害怕网站出现一些不健康的文章。
6、独创的原创文章生成功能
大家都晓得文章是由语句组成的,而短语是由副词、谓语、宾语、定语、补语、状语、表语、标点符号等组成的。17站群软件则借助语句的组成元素,运用不同的语法句型和自定义生成模板,来生成语句,进而组成文章,实现原创文章的生成。
7、独创的指定网址采集功能
专业的采集器都须要查看html代码,进而编撰采集规则,来截取标题内容;一般的站群管理软件和系统,则是按一定的关键字,利用通用的采集逻辑,来随机抓取内容。但如果我想采集某个网站的内容,但又不想写采集规则,怎么办?我们独创的指定网址采集功能解决了您的困局。
8、独创的超级外链群发功能
该功能还在开发中,预计八月初完成。主要是组织用户之间的网站资源,进行自助式非强迫性的有效交换。站群用户和站群用户进行的有效交换的、大量的、稳定的、省事的交换,您就不需要天天去站长群找人问交换链接了,直接在软件后台就有大量的资源等着您。
17站群软件支持的网站程序
PHP类型:
1、织梦 DEDE CMS V5.3/V5.5/5.6/5.7 网站管理系统
2、帝国 Empire CMS V6.0/6.5 网站管理系统
3、Wordpress V2.9.2中文版/V3.0.1-V3.1中英文版 UTF 博客程序
4、Discuz! 7.2 论坛程序
5、Discuz! X 1.5/2.0 论坛程序
6、Discuz!NT 3.5.2(utf-8) 论坛程序
7、PHPWind V7.5 /PHPWind V8.0/8.3/8.5 论坛程序
8、PHPCMS 2008 SP4 网站管理程序
9、ECSHOP v2.72/Shopex V4.8.5(商城系统)
10、Destoon V3.0(B2B网站管理系统)
11、KingCMS 6.0.970
ASP类型:
1、Z-blog 1.8 ASP博客程序
2、动易内容管理系统 CMS 6.8
3、无忧(5U)网站管理系统 V1.2
4、新云Newasp 4.0 sp2 GBK 网站管理程序
5、老Y LaoY8 V2.5 sp2 GBK 网站管理程序
6、Ok3w V5.1 GBK 网站管理程序
7、SDCMS(时代网站) V1.2/v1.3 ASP程序
第三方博客类型:
1、博客大巴(blogbus)博客程序
2、19lou(19楼博客)
其他主流CMS程序及其他博客支持,还在相继降低中,用户可以递交需求安排开发
上饶抖音推广公司,灰色行业推广费用
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2020-08-09 20:06
是一套内容涵括现有客户和潜在客户,可以随时更新的动态数据库管理系统。数据库营销的核心是数据挖掘。而网路营销中的数据库营销更多的是以互联网为平台进行营销活动。是指在了解搜索引擎自然排名机制的基础之上,对企业网站进行内部及外部的调整优化,改进企业网站在搜索引擎中关键词的自然排行,获得更多的展现量,吸引更多目标顾客访问您的企业网站,从而达到互联网营销及品牌建设的目标。
自始至终,的核心要求就是用户。“原创”只不过是一个代名词而已,从没有说原创的内容就是高质量的内容。这的都是站长的一厢情愿而已,如何满足用户需求提高用户才是重点。
简单来说,搜索引擎营销就是基于搜索引擎平台的网路营销,利用人们对搜索引擎的依赖和使用惯,在人们检索信息的时侯尽可能将营销信息传递给目标顾客。搜索引擎营销主要分为两类:一是有价的被称为竞价排行,二是无价的被称为(搜索引擎优化)。竞价的诠释位置有限,竞价的结果让大量的顾客因价钱的诱因未能排在首页,使得这部份顾客很难通过竞价获得良好的使用疗效。
四、关于高质量内容搜索引擎觉得内容质量好的网页,是耗费了较多时间和精力编辑,倾注了编者经验和专业知识的内容。排版合理,主次分明;利于用户阅读。
上饶抖音推广公司,灰色行业推广费用.人员配置不同网路推广包括有网站建设团队(网站策划,美工设计,程序制做,相关测试)、网络推广团队等人员配置。作为互联网的一种应用模式,它的高度开放性,介于互联网与联通网之间,无论在何时何地,用户都能及时发布消息。一、种网路推广形式:(一)网站优化排行:通过建设网站,设置品牌或行业关键词,进行网站代码、内容、链接等优化获取一定的关键词排行,建设多个网站可以获得更多的网站排名,归类为。
这些内容清晰、完整且丰富,资源有效且优质,信息真实有效安全无毒,不含任何行为和意图,对用户有较强的正利润。
同时可在企业的一些宣传软文、资料上网址,并制做一些资料小册子如或电子书且在里面都加上企业网址。让企业信息和文化更容易推广。(四)软文推广——无形的营销利剑软文具有引导消费、品牌宣传、周期长,价格低等优点。如果将称作仙侠中的剑法,那么软文就是外功武学。
对这部份网页,搜索引擎会增强其诠释给用户的几率。
即使是一个新诞生的企业,要是企业的网路推广挺到位也可以迅速提高企业的品牌知名度以及提高消费者的认可度。
所以目前对内容质量高的定义并没有突出原创这个标准,原创二字只是高质量网页内容的一个非必须特点,能在一定程度上反应网页内容的稀缺度,但原创并非一定稀缺,原创更不能代表高质量的内容。
给公司做网站建设多少钱,建站实惠现状:目前世界上多万的网站,一个新的网站建成了,假如他人都不知道这个网站,怎么会过来访问?没人过来访问,公司建网站的目的如何达成?企业是一个大的信息媒介,从营销推广的角度来说,它是一个超级的宣传书册。
做好原创到不如说是做好高质量内容,杜绝垃圾采集内容,突出内容差异化,这么说可能更好。原创就是高质量内容这是一个错误的说法,如果是高质量的内容,又是原创那肯定是
近日小助在市场部网的里发觉许多坛友们对这一推广形式也的确是无从下手:公司已是本地行业中,信誉、拥有顾客数多、服务了。五、工作进度及执行好的方案还要有好的执行团队,依据方案制做详尽的计划进度表,控制方案执行的进程,对推广活动进行详尽列举,安排具体的人员来负责落实,确保方案得到有效的执行。
。但是很多站长其实发布的是原创,但却是低质量的内容。就好比我们曾经写习作,自己冥思苦想下来的习作肯定没有参考习作补习书写下来的好。原创只是一个手段,不是目标,给用户带来有价值的内容才是站长们旨在原创的终目的。
所以,在营运网站的过程中,不要刻意的去追求所谓原创,应该关心的是内容编辑成本、内容完整、是否是用户须要的、信息真实有效以及安全。
(五)水印推广——以细节获胜,无时不刻的宣传在企业的宣传图片、视频、资料、网站上都打上企业的水印,把那些图片和视频发布到其他地方或别的网站,当这种印有水印的图片传播出去时,都无疑是对企业品牌的一种宣传。 查看全部
上饶抖音推广公司,灰色行业推广费用,关键词造成的不稳定在工作中,关键词占有了较大的比重,对个别行业专属和热门词汇要仔细剖析,了解竞争对手使用的词汇,并且对下一个可能火的词汇进行预测,撰写相关文章时也要做好关键词的布置,例如字左右的文章应该均匀的出现次以上,配两张图片。三、关于网页内容质量的评价标准得到简化,表示审视网页内容质量为重要的还是:成本、内容完整、信息真实有效以及安全。关于原创与否,不再提起。所以,明白了吧。
是一套内容涵括现有客户和潜在客户,可以随时更新的动态数据库管理系统。数据库营销的核心是数据挖掘。而网路营销中的数据库营销更多的是以互联网为平台进行营销活动。是指在了解搜索引擎自然排名机制的基础之上,对企业网站进行内部及外部的调整优化,改进企业网站在搜索引擎中关键词的自然排行,获得更多的展现量,吸引更多目标顾客访问您的企业网站,从而达到互联网营销及品牌建设的目标。
自始至终,的核心要求就是用户。“原创”只不过是一个代名词而已,从没有说原创的内容就是高质量的内容。这的都是站长的一厢情愿而已,如何满足用户需求提高用户才是重点。
简单来说,搜索引擎营销就是基于搜索引擎平台的网路营销,利用人们对搜索引擎的依赖和使用惯,在人们检索信息的时侯尽可能将营销信息传递给目标顾客。搜索引擎营销主要分为两类:一是有价的被称为竞价排行,二是无价的被称为(搜索引擎优化)。竞价的诠释位置有限,竞价的结果让大量的顾客因价钱的诱因未能排在首页,使得这部份顾客很难通过竞价获得良好的使用疗效。
四、关于高质量内容搜索引擎觉得内容质量好的网页,是耗费了较多时间和精力编辑,倾注了编者经验和专业知识的内容。排版合理,主次分明;利于用户阅读。
上饶抖音推广公司,灰色行业推广费用.人员配置不同网路推广包括有网站建设团队(网站策划,美工设计,程序制做,相关测试)、网络推广团队等人员配置。作为互联网的一种应用模式,它的高度开放性,介于互联网与联通网之间,无论在何时何地,用户都能及时发布消息。一、种网路推广形式:(一)网站优化排行:通过建设网站,设置品牌或行业关键词,进行网站代码、内容、链接等优化获取一定的关键词排行,建设多个网站可以获得更多的网站排名,归类为。

这些内容清晰、完整且丰富,资源有效且优质,信息真实有效安全无毒,不含任何行为和意图,对用户有较强的正利润。
同时可在企业的一些宣传软文、资料上网址,并制做一些资料小册子如或电子书且在里面都加上企业网址。让企业信息和文化更容易推广。(四)软文推广——无形的营销利剑软文具有引导消费、品牌宣传、周期长,价格低等优点。如果将称作仙侠中的剑法,那么软文就是外功武学。
对这部份网页,搜索引擎会增强其诠释给用户的几率。
即使是一个新诞生的企业,要是企业的网路推广挺到位也可以迅速提高企业的品牌知名度以及提高消费者的认可度。

所以目前对内容质量高的定义并没有突出原创这个标准,原创二字只是高质量网页内容的一个非必须特点,能在一定程度上反应网页内容的稀缺度,但原创并非一定稀缺,原创更不能代表高质量的内容。
给公司做网站建设多少钱,建站实惠现状:目前世界上多万的网站,一个新的网站建成了,假如他人都不知道这个网站,怎么会过来访问?没人过来访问,公司建网站的目的如何达成?企业是一个大的信息媒介,从营销推广的角度来说,它是一个超级的宣传书册。

做好原创到不如说是做好高质量内容,杜绝垃圾采集内容,突出内容差异化,这么说可能更好。原创就是高质量内容这是一个错误的说法,如果是高质量的内容,又是原创那肯定是
近日小助在市场部网的里发觉许多坛友们对这一推广形式也的确是无从下手:公司已是本地行业中,信誉、拥有顾客数多、服务了。五、工作进度及执行好的方案还要有好的执行团队,依据方案制做详尽的计划进度表,控制方案执行的进程,对推广活动进行详尽列举,安排具体的人员来负责落实,确保方案得到有效的执行。
。但是很多站长其实发布的是原创,但却是低质量的内容。就好比我们曾经写习作,自己冥思苦想下来的习作肯定没有参考习作补习书写下来的好。原创只是一个手段,不是目标,给用户带来有价值的内容才是站长们旨在原创的终目的。
所以,在营运网站的过程中,不要刻意的去追求所谓原创,应该关心的是内容编辑成本、内容完整、是否是用户须要的、信息真实有效以及安全。

(五)水印推广——以细节获胜,无时不刻的宣传在企业的宣传图片、视频、资料、网站上都打上企业的水印,把那些图片和视频发布到其他地方或别的网站,当这种印有水印的图片传播出去时,都无疑是对企业品牌的一种宣传。
wordpress手动采集插件_wp-autopost-pro 3.7.8
采集交流 • 优采云 发表了文章 • 0 个评论 • 368 次浏览 • 2020-08-09 17:07
【插件简介】:
插件是wp-autopost-pro 3.7.8最新版本。
【采集插件适用对象】:
1、刚建的wordpress站点内容比较少,希望早日有比较丰富的内容;
2、热点内容手动采集并手动发布;
3、定时采集,手动采集发布或保存到草稿;
4、css样式规则,能更精确的采集需要的内容。
5、伪原创与翻译、代理IP进行采集、保存Cookie记录;
6、可采集内容到自定义栏目
全新支持Google神经网路翻译,有道神经网路翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象储存服务,七牛云、阿里云OSS等。
可采集微信公众号、头条号等自媒体内容,因百度不收录公众号,头条文章等,可轻松获取高质量“原创”文章,增加百度收录量及网站权重
可采集任何网站的内容,采集信息一目了然
通过简单设置可采集来自于任何网站的内容,并可设置多个采集任务同时进行,可设置任务为手动运行或自动运行,主任务列表显示每位采集任务的状况:上次测量采集时间,预计上次测量采集时间,最近采集文章,已采集更新的文章数等信息,方便查看管理。
文章管理功能便捷查询、搜索、删除已采集文章,改进算法已从根本上避免了重复采集相同文章,日志功能记录采集过程中出现的异常和抓取错误,方便检测设置错误便于进行修补。
增强seo功能,其他自行研究。
查看全部
wordpress手动采集插件_wp-autopost-pro 3.7.8,最新无限制版
【插件简介】:
插件是wp-autopost-pro 3.7.8最新版本。
【采集插件适用对象】:
1、刚建的wordpress站点内容比较少,希望早日有比较丰富的内容;
2、热点内容手动采集并手动发布;
3、定时采集,手动采集发布或保存到草稿;
4、css样式规则,能更精确的采集需要的内容。
5、伪原创与翻译、代理IP进行采集、保存Cookie记录;
6、可采集内容到自定义栏目
全新支持Google神经网路翻译,有道神经网路翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象储存服务,七牛云、阿里云OSS等。
可采集微信公众号、头条号等自媒体内容,因百度不收录公众号,头条文章等,可轻松获取高质量“原创”文章,增加百度收录量及网站权重
可采集任何网站的内容,采集信息一目了然
通过简单设置可采集来自于任何网站的内容,并可设置多个采集任务同时进行,可设置任务为手动运行或自动运行,主任务列表显示每位采集任务的状况:上次测量采集时间,预计上次测量采集时间,最近采集文章,已采集更新的文章数等信息,方便查看管理。
文章管理功能便捷查询、搜索、删除已采集文章,改进算法已从根本上避免了重复采集相同文章,日志功能记录采集过程中出现的异常和抓取错误,方便检测设置错误便于进行修补。
增强seo功能,其他自行研究。

高质量原创文章对网站SEO优化有什么用处
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2020-08-09 12:03
稍微懂一点seo的站长都听说过“内容为王”这个词,我们这儿所说的内容指的就是高质量原创内容,这也是搜索引擎所喜欢的内容。
互联网中部份站点采集其它站点的内容,搜索引擎同样进行了收录和给与了排行,导致少数站长觉得,高质量原创内容对网站的帮助不是很大,这种看法是错误的,就算搜索引擎一时收录了你的内容,后面搜索引擎发觉你网站的内容全部都是采集来的文章,网站根本没有自己独到的内容,搜索引擎都会觉得你这个网站是没有价值的,也就绝对不会给你一个好的排行。
二、高质量原创内容的益处
1、高质量原创内容首先符合搜索引擎的目标。搜索引擎的目标是给搜索用户提供信息,而不是给你的网站带来顾客。只有你的网站提供了高质量的内容,才能与搜索引擎的目标达成一致,也就提高了搜索引擎友好度。
2、高质量原创内容也是页面收录的重要推动力。不少站长都为网站收录问题苦恼,搜索引擎蜘蛛要么只访问首页,不再进一步抓取内页,要么收录以后又被删除。缺少原创内容是关键性诱因之一。一个以转载、抄袭为主体内容的网站对搜索引擎来说毫无价值。收录这样的页面越多,越浪费搜索引擎的带宽、数据库容量、爬行时间、计算时间,却不能给搜索用户提供更多信息,所以搜索引擎根本没有收录那些内容的理由
3、原创内容也是外部链接建设的重要方式。除非是交换链接,不然其他站长没有道理链接到一个没有实质内容的网站。
三、搜索引擎喜欢什么样的文章
我们仍然在指出高质量原创内容,那么这儿的高质量指的有什么特点呢?
1、内容完整可读;
2、标题内容规范;
3、文章段落及字体干净;
4、文章相关性强,不要出现标题党;
5、高质量原创内容应当具有高黏度、高转发的特点。
四、规避垃圾页面
从SEO的角度看,互联网中存在着大量搜索引擎不喜欢的垃圾页面,部分垃圾页面搜索引擎可以难以测量到,但是会影响网站用户体验,从而影响用户在站点中的逗留时间,所以网站中不要出现这种垃圾页面:
1、用户不可读的页面。最常见的现象就是复制其他站点的文章直接粘贴到本站中,因文章页面设置问题,导致站点中的文字重叠。
2、页面文章不完整的页面。
3、标题和文章内容不相关的页面。
4、文章内容是堆砌下来的。直接堆砌下来的文章内容影响用户的阅读,导致用户跳出率较高。
5、垃圾聚合页面。
这里讲的垃圾聚合页面指的是网站标签由机器手动生成一个标签页面,但是标签和页面中的内容都是机器手动采集的。如笔者见过一个婚恋网站,标签名子为“东北的男孩”,但是页面中还出现了好多女性会员。
6、违规词标签页面。
互联网中的大部分站点都提供了用户站内搜索功能,但是站长未屏蔽黄、赌、毒等违规违法词句,导致网站被一些不良用户钻了空子,用于黑帽排行。这种方式常出现在一些权重比较高的站点中,用户在站点中搜索个别欲获取排行的词句,然后将链接递交给搜索引擎因而根据网站的高权重获取排行。
7、网页实质内容较少的页面。
每个页面不可避开的会有一些通用部份,比如常见的页面底部、底部、页面右侧或则两侧等。如果网页中的正文内容很少的话,内容数目还抵不过通用部份,搜索引擎有可能会觉得这种页面相似度偏低。
8、产品页面中收录太多心态用户读不懂的信息。
这种情况常出现于一些进口产品页面,如果网站针对的是国外用户,建议页面中不要出现太多的英语信息,这种页面影响用户体验。
9、复制内容。
互联网中的部份站点不可防止的会复制其他站点的内容,如下级转载上级的通知、代理商从产品商哪里转载产品信息等。搜索引擎并不会由于网站中有少量的复制内容而惩罚站点,但是假如网站中存在大量的复制内容,这样会浪费搜索引擎的各类资源进而遭到惩罚。
五、规避复制页面的形成
避免复制内容的形成须要从站内和站外两个地方着手:
1、由于网址规范化导致的站内重复内容,最好的解决办法就是选定一个版本的URL容许搜索引擎抓取和收录,其他版本的页面严禁搜索引擎抓取和收录。常见的方式是使用robos.txt严禁搜索引擎抓取,连向希望不被搜索引擎收录的页面的链接可以使用nofollow属性制止搜索引擎爬行。
2、另一个解决方式是使用canonical标签。它的主要作用是拿来解决因为网址方式不同内容相同而导致的内容重复问题。这个标签对搜索引擎作用十分大,简单的说它可以使搜索引擎只抓取你想要指出的内容。
我们来看下如下的网址:
***.com/archives/2011-snow.html
***.com/archives/2011-snow.html?comments=true
***.com/archives/2011-snow.html?postcomment=true
这三个网址方式其实不同,但是打开的页面是相同的。加入第一个URL才是我们想显示给搜索引擎和用户的网址,一般象这些情况搜索引擎是很难区分下来那个才是网站主要想指出的网址,这样会直接导致搜索引擎在你的站上面收录到大量重复的内容,现在我们通过 canonical 标签就可以解决这种棘手的问题了。
像前面的状况,我们只须要在网址的 head 区域添加如下代码:
这样的话搜索引擎最终就会只收录 canonical 标签指定的这个网址,搜索引擎会将其它页面作为重复内容,这些重复的内容不再参与页面的权重分配。 查看全部
一、
稍微懂一点seo的站长都听说过“内容为王”这个词,我们这儿所说的内容指的就是高质量原创内容,这也是搜索引擎所喜欢的内容。
互联网中部份站点采集其它站点的内容,搜索引擎同样进行了收录和给与了排行,导致少数站长觉得,高质量原创内容对网站的帮助不是很大,这种看法是错误的,就算搜索引擎一时收录了你的内容,后面搜索引擎发觉你网站的内容全部都是采集来的文章,网站根本没有自己独到的内容,搜索引擎都会觉得你这个网站是没有价值的,也就绝对不会给你一个好的排行。
二、高质量原创内容的益处
1、高质量原创内容首先符合搜索引擎的目标。搜索引擎的目标是给搜索用户提供信息,而不是给你的网站带来顾客。只有你的网站提供了高质量的内容,才能与搜索引擎的目标达成一致,也就提高了搜索引擎友好度。
2、高质量原创内容也是页面收录的重要推动力。不少站长都为网站收录问题苦恼,搜索引擎蜘蛛要么只访问首页,不再进一步抓取内页,要么收录以后又被删除。缺少原创内容是关键性诱因之一。一个以转载、抄袭为主体内容的网站对搜索引擎来说毫无价值。收录这样的页面越多,越浪费搜索引擎的带宽、数据库容量、爬行时间、计算时间,却不能给搜索用户提供更多信息,所以搜索引擎根本没有收录那些内容的理由
3、原创内容也是外部链接建设的重要方式。除非是交换链接,不然其他站长没有道理链接到一个没有实质内容的网站。
三、搜索引擎喜欢什么样的文章
我们仍然在指出高质量原创内容,那么这儿的高质量指的有什么特点呢?
1、内容完整可读;
2、标题内容规范;
3、文章段落及字体干净;
4、文章相关性强,不要出现标题党;
5、高质量原创内容应当具有高黏度、高转发的特点。
四、规避垃圾页面
从SEO的角度看,互联网中存在着大量搜索引擎不喜欢的垃圾页面,部分垃圾页面搜索引擎可以难以测量到,但是会影响网站用户体验,从而影响用户在站点中的逗留时间,所以网站中不要出现这种垃圾页面:
1、用户不可读的页面。最常见的现象就是复制其他站点的文章直接粘贴到本站中,因文章页面设置问题,导致站点中的文字重叠。
2、页面文章不完整的页面。
3、标题和文章内容不相关的页面。
4、文章内容是堆砌下来的。直接堆砌下来的文章内容影响用户的阅读,导致用户跳出率较高。
5、垃圾聚合页面。
这里讲的垃圾聚合页面指的是网站标签由机器手动生成一个标签页面,但是标签和页面中的内容都是机器手动采集的。如笔者见过一个婚恋网站,标签名子为“东北的男孩”,但是页面中还出现了好多女性会员。
6、违规词标签页面。
互联网中的大部分站点都提供了用户站内搜索功能,但是站长未屏蔽黄、赌、毒等违规违法词句,导致网站被一些不良用户钻了空子,用于黑帽排行。这种方式常出现在一些权重比较高的站点中,用户在站点中搜索个别欲获取排行的词句,然后将链接递交给搜索引擎因而根据网站的高权重获取排行。
7、网页实质内容较少的页面。
每个页面不可避开的会有一些通用部份,比如常见的页面底部、底部、页面右侧或则两侧等。如果网页中的正文内容很少的话,内容数目还抵不过通用部份,搜索引擎有可能会觉得这种页面相似度偏低。
8、产品页面中收录太多心态用户读不懂的信息。
这种情况常出现于一些进口产品页面,如果网站针对的是国外用户,建议页面中不要出现太多的英语信息,这种页面影响用户体验。
9、复制内容。
互联网中的部份站点不可防止的会复制其他站点的内容,如下级转载上级的通知、代理商从产品商哪里转载产品信息等。搜索引擎并不会由于网站中有少量的复制内容而惩罚站点,但是假如网站中存在大量的复制内容,这样会浪费搜索引擎的各类资源进而遭到惩罚。
五、规避复制页面的形成
避免复制内容的形成须要从站内和站外两个地方着手:
1、由于网址规范化导致的站内重复内容,最好的解决办法就是选定一个版本的URL容许搜索引擎抓取和收录,其他版本的页面严禁搜索引擎抓取和收录。常见的方式是使用robos.txt严禁搜索引擎抓取,连向希望不被搜索引擎收录的页面的链接可以使用nofollow属性制止搜索引擎爬行。
2、另一个解决方式是使用canonical标签。它的主要作用是拿来解决因为网址方式不同内容相同而导致的内容重复问题。这个标签对搜索引擎作用十分大,简单的说它可以使搜索引擎只抓取你想要指出的内容。
我们来看下如下的网址:
***.com/archives/2011-snow.html
***.com/archives/2011-snow.html?comments=true
***.com/archives/2011-snow.html?postcomment=true
这三个网址方式其实不同,但是打开的页面是相同的。加入第一个URL才是我们想显示给搜索引擎和用户的网址,一般象这些情况搜索引擎是很难区分下来那个才是网站主要想指出的网址,这样会直接导致搜索引擎在你的站上面收录到大量重复的内容,现在我们通过 canonical 标签就可以解决这种棘手的问题了。
像前面的状况,我们只须要在网址的 head 区域添加如下代码:
这样的话搜索引擎最终就会只收录 canonical 标签指定的这个网址,搜索引擎会将其它页面作为重复内容,这些重复的内容不再参与页面的权重分配。
干货!新媒体营运必备的文章在线智能原创工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2020-08-09 08:38
比如: 需搜索有关于营运的文章,那么可以在原创界面,选择你所需查找的关键词“运营”,优采云采集便可对此关键词进行一键精准搜索。文章陈列次序依照关键词的匹配度进行排序。2. 需对文章进行原创: 牛蚁原创采用深度神经网路算法构建文章,降低了文章的重复度,自动对段落中的文字次序进行调节和整句的替换。 优采云采集将最新的 RNN 和 LSTM 算法用到了智能原创的过程中,不但保证了文章的可读性,而且一键生成的智能原创文章可用于绕开一些重复度测量算法。 用户可在页面中点击“原创”功能,优采云采集将对所需原创的文章并进行单项原创。用户也可以点击“当前页面全选”功能,此时用户所选的文章则全部收录于两侧的操作面板内,用户可在操作面板内进行批量的原创。二、处 使用优采云采集有何用处 增强被收录的机率: 百度会通过多维度去判定你的文章是否值得收录,文章的原创则占了绝大优势。 优采云采集通过智能算法将文章进行构建,降低文章重复度,帮助文章可以被百度 更好的收录 。 更容易被流量推荐: 优采云采集分析了数万篇新品文章的写作方法,使文章“焕然一新”的同时,还有利于被自媒体平台流量推荐。 增加人工成本: 优采云采集出稿快,效率高,不再须要大量的编辑和发布人员,既省去了创作时间,又有利于快速达到 SEO疗效。 小编认为,在使用优采云采集的同时,不妨加入一点自己的观点,这样既可以丰富文章内容,还能够提高创作能力。巧用优采云采集,帮助新媒体营运高效写作 。 查看全部
干货!新媒体营运必备的 文章在线智能原创工具 现如今新媒体行业的竞争堪称越来越大,在这个内容为王的时代,优质的内容等于一切。写不出令人满意的内容,自我感觉到失落只是一方面,另一方面则是面临着待业的风险。 内容创作,是营运的必要之事,但创作途中,总会面临许多的不得已:要么是没文笔创作出高质量、高点击量的优质文章,要么是虽然有水平,却没有很高的效率。大部分营运也因而无奈接受了上级给自己打下的“低效率”形容标签。好不容易想出一篇,发布后立刻被剽窃,不仅这般,别人的收录排行还更高,这样的案例也不在少数。 原创不难,但要讲求质量和效率并存,还真不是几个月才能练下来的。冰冻三尺非一日之寒,未必就没有解决的办法了吗?别急~小编这就给你们介绍一款除了能提高内容的质量,还能提高工作效率的在线智能原创工具——优采云采集。 优采云采集可以对文章进行单次、批量原创,提升文章百度原创分值,提高文章在搜索引擎收录机率和自媒体平台流量推荐值。下面为你们介绍怎样使用优采云采集进行原创: 一、 如何用优采云采集进行原创 1. 搜索素材 优采云采集可对主流自媒体中的文章素材进行智能的采集。 海量素材+实时热点+持续更新,帮助营运提高工作效率。
比如: 需搜索有关于营运的文章,那么可以在原创界面,选择你所需查找的关键词“运营”,优采云采集便可对此关键词进行一键精准搜索。文章陈列次序依照关键词的匹配度进行排序。2. 需对文章进行原创: 牛蚁原创采用深度神经网路算法构建文章,降低了文章的重复度,自动对段落中的文字次序进行调节和整句的替换。 优采云采集将最新的 RNN 和 LSTM 算法用到了智能原创的过程中,不但保证了文章的可读性,而且一键生成的智能原创文章可用于绕开一些重复度测量算法。 用户可在页面中点击“原创”功能,优采云采集将对所需原创的文章并进行单项原创。用户也可以点击“当前页面全选”功能,此时用户所选的文章则全部收录于两侧的操作面板内,用户可在操作面板内进行批量的原创。二、处 使用优采云采集有何用处 增强被收录的机率: 百度会通过多维度去判定你的文章是否值得收录,文章的原创则占了绝大优势。 优采云采集通过智能算法将文章进行构建,降低文章重复度,帮助文章可以被百度 更好的收录 。 更容易被流量推荐: 优采云采集分析了数万篇新品文章的写作方法,使文章“焕然一新”的同时,还有利于被自媒体平台流量推荐。 增加人工成本: 优采云采集出稿快,效率高,不再须要大量的编辑和发布人员,既省去了创作时间,又有利于快速达到 SEO疗效。 小编认为,在使用优采云采集的同时,不妨加入一点自己的观点,这样既可以丰富文章内容,还能够提高创作能力。巧用优采云采集,帮助新媒体营运高效写作 。
成都网站优化应如何提高网站排名?
采集交流 • 优采云 发表了文章 • 0 个评论 • 227 次浏览 • 2020-08-09 06:28
1. 网站内的优化和网站外的优化
对于网站优化,我们需要根据客户需求调整相关的网站链接和网页设置,因为客户需求在不断变化,因此我们可以提供他们想要看到的内容,这是一个很好的优化效果;对于异地,主要原因是我们必须依靠相对成熟的网站来发挥其功能,以使我们的网站能够在短时间内执行排名权重等.
第二,不要采集内容
进行关键字优化需要大量内容来支持. 无论是在网站上还是网站外,如何找到出色的内容都是一种非常好的简便方法. 优化关键字时,如果采用集合方法,最好对关键字进行一些更改,例如替换内容,更改标题等. 网络上重复性很高的内容的存在会引起厌恶的搜索引擎,尽管它将继续被收录在内,但这并不意味着一切都结束了,站点将是k,这是将来要更新的原创文章数量,无法保存.
3. 网站上原创文章的更新
我们都知道当前的Internet实际上是非常智能的,但是在当今的智能化中,它也存在某些错误. 例如,它没有处理图片的能力,因此它更依赖于文字的力量来对网站进行全面排名,因此文章的更新已成为网站排名的重要因素之一,并定期采集材料以完成文章.
如何提高成都网站优化排名?如果要使您的网站排名越来越好,那么您必须对网站的优化技术和方法有一定的了解,知道如何进行合理的修改,并在不同时期采用不同的方法进行优化,从而逐步改善网站. 关键字排名. 查看全部
在当前在线营销快速发展的时代,互联网上有无数大小型网站. 他们中的许多人都希望获得良好的关键字排名,因此必须控制网站的优化和详细信息,否则网站的排名将始终跌宕起伏,并且不会出现增长趋势. 那么成都网站优化应该如何提高网站排名?
1. 网站内的优化和网站外的优化
对于网站优化,我们需要根据客户需求调整相关的网站链接和网页设置,因为客户需求在不断变化,因此我们可以提供他们想要看到的内容,这是一个很好的优化效果;对于异地,主要原因是我们必须依靠相对成熟的网站来发挥其功能,以使我们的网站能够在短时间内执行排名权重等.

第二,不要采集内容
进行关键字优化需要大量内容来支持. 无论是在网站上还是网站外,如何找到出色的内容都是一种非常好的简便方法. 优化关键字时,如果采用集合方法,最好对关键字进行一些更改,例如替换内容,更改标题等. 网络上重复性很高的内容的存在会引起厌恶的搜索引擎,尽管它将继续被收录在内,但这并不意味着一切都结束了,站点将是k,这是将来要更新的原创文章数量,无法保存.
3. 网站上原创文章的更新
我们都知道当前的Internet实际上是非常智能的,但是在当今的智能化中,它也存在某些错误. 例如,它没有处理图片的能力,因此它更依赖于文字的力量来对网站进行全面排名,因此文章的更新已成为网站排名的重要因素之一,并定期采集材料以完成文章.
如何提高成都网站优化排名?如果要使您的网站排名越来越好,那么您必须对网站的优化技术和方法有一定的了解,知道如何进行合理的修改,并在不同时期采用不同的方法进行优化,从而逐步改善网站. 关键字排名.
假的原创工具有用吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2020-08-08 15:59
那么,伪原创工具对SEO有效吗?
1. 伪原创工具的原理
如果我们想知道伪原创工具是否有效,我们需要了解它的工作原理:
①同义词替换
通常常用的伪原创工具是同义词替换,例如今天替换为今天,用搜索引擎优化替换SEO等. 实际上,这种伪原创工具已经过时了,搜索引擎可以轻松地确定同义词之间的区别区别在于搜索引擎通过索引页面将页面转换为一组哈希值,并将已被同义词替换的内容转换为一组哈希值以进行比较. 哈希值转换后,可以有效避免同义词,仅保留原创指纹. ,因此此类伪原创工具无效,因此请不要使用它们.
②互译
某些AI伪原创工具确实可以在一个句子中具有相同的含义,但是表达方式不同. 实际上,大多数AI伪原创工具都是伪造的,但是它们会通过翻译软件反复翻译. 如果相似度较低,请再翻译几次,但可读性会变差. 可以适当使用.
③ai创作
也有真正的AI创作,例如百度AI,但是它们仅限于固定格式内容的创作,例如股票信息,天气信息等,并且不能大规模使用.
2. 不同的需求
但是伪原创工具对于SEO并不是无效的. 不同的需求会有不同的效果:
①批生产
当权重较高的网站需要维持其排名或进一步提高其排名并需要大量内容时,可以使用互译的伪原创工具来实现文章的批量创建. 查看全部
对于seoers来说,每天写原创文章很无聊,但是网站不会更新文章,因此无法保证排名. 因此,一些专家专注于伪原创工具. 实际上,伪原创工具已经存在. 毫不奇怪,尤其是近年来,技术进步也参与了伪原创军队.
那么,伪原创工具对SEO有效吗?
1. 伪原创工具的原理
如果我们想知道伪原创工具是否有效,我们需要了解它的工作原理:
①同义词替换
通常常用的伪原创工具是同义词替换,例如今天替换为今天,用搜索引擎优化替换SEO等. 实际上,这种伪原创工具已经过时了,搜索引擎可以轻松地确定同义词之间的区别区别在于搜索引擎通过索引页面将页面转换为一组哈希值,并将已被同义词替换的内容转换为一组哈希值以进行比较. 哈希值转换后,可以有效避免同义词,仅保留原创指纹. ,因此此类伪原创工具无效,因此请不要使用它们.
②互译
某些AI伪原创工具确实可以在一个句子中具有相同的含义,但是表达方式不同. 实际上,大多数AI伪原创工具都是伪造的,但是它们会通过翻译软件反复翻译. 如果相似度较低,请再翻译几次,但可读性会变差. 可以适当使用.
③ai创作
也有真正的AI创作,例如百度AI,但是它们仅限于固定格式内容的创作,例如股票信息,天气信息等,并且不能大规模使用.
2. 不同的需求
但是伪原创工具对于SEO并不是无效的. 不同的需求会有不同的效果:
①批生产
当权重较高的网站需要维持其排名或进一步提高其排名并需要大量内容时,可以使用互译的伪原创工具来实现文章的批量创建.
这样采集的文章应该是“伪原创”
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2020-08-08 05:20
采集的内容可以分为国外站点内容采集和流行内容采集. 通常,采集内容时需要注意一些事项. 子网的组织方式如下:
①只是内容而已
众所周知,标题是文章的目光,是传递给用户的第一印象. 对于针对网站进行了优化的搜索引擎,标题也具有一定的分量. 相对而言,标题也是搜索引擎“识别”原创内容的参考依据. 因此,当我们采集内容时,最好根据内容的主题来重写标题.
②内容新颖或专业
在采集文章时,最好从相关网站采集文章,以频繁更新文章为目标,找到一些内容新颖,与时俱进的文章,并具有代表性. 最好在被太多人转载之前进行采集.
一些老式的主题会使用户感到他们相同且一文不值.
此外,您还可以采集多篇文章并将其整合为一篇文章. 添加您自己的意见也会使人们的眼睛更加明亮. 当然,这要求作者需要一定的写作技巧.
③采集的内容,请进行一些调整
Yawang Internet的编辑经常发现,在浏览别人的网站时,您总是会发现某些格式和版式不佳的文章. 具体来说,例如“令人困惑的标点符号,不清晰的分段,第一行没有缩进”等,以及一些用于反采集的隐藏格式等,如果直接采集这些内容,它们肯定会被搜索引擎识别为窃. 那么对网站的危害是不言而喻的.
因此,必须对采集的内容进行格式化,并且必须转换英语格式的标点符号. 另外,可以将一些图片添加到内容中以使内容更丰富.
如何清除格式?非常简单打开计算机的记事本,复制并粘贴采集的文章,可以清理很多不必要的代码和格式,最好更改文章并用您的语言表达原创文本. 这意味着“伪原创”,而不是使用软件. 查看全部
所有人都知道每天的工作日程安排很充裕,以至于我们没有足够的时间来观看原创内容. 但是网站内容更新是重要手段,那么如何解决呢?许多网站管理员都是通过这种方式进行处理的,即采集内容.
采集的内容可以分为国外站点内容采集和流行内容采集. 通常,采集内容时需要注意一些事项. 子网的组织方式如下:
①只是内容而已
众所周知,标题是文章的目光,是传递给用户的第一印象. 对于针对网站进行了优化的搜索引擎,标题也具有一定的分量. 相对而言,标题也是搜索引擎“识别”原创内容的参考依据. 因此,当我们采集内容时,最好根据内容的主题来重写标题.
②内容新颖或专业
在采集文章时,最好从相关网站采集文章,以频繁更新文章为目标,找到一些内容新颖,与时俱进的文章,并具有代表性. 最好在被太多人转载之前进行采集.
一些老式的主题会使用户感到他们相同且一文不值.
此外,您还可以采集多篇文章并将其整合为一篇文章. 添加您自己的意见也会使人们的眼睛更加明亮. 当然,这要求作者需要一定的写作技巧.
③采集的内容,请进行一些调整
Yawang Internet的编辑经常发现,在浏览别人的网站时,您总是会发现某些格式和版式不佳的文章. 具体来说,例如“令人困惑的标点符号,不清晰的分段,第一行没有缩进”等,以及一些用于反采集的隐藏格式等,如果直接采集这些内容,它们肯定会被搜索引擎识别为窃. 那么对网站的危害是不言而喻的.
因此,必须对采集的内容进行格式化,并且必须转换英语格式的标点符号. 另外,可以将一些图片添加到内容中以使内容更丰富.
如何清除格式?非常简单打开计算机的记事本,复制并粘贴采集的文章,可以清理很多不必要的代码和格式,最好更改文章并用您的语言表达原创文本. 这意味着“伪原创”,而不是使用软件.
停止采集和复制原创文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-08-08 05:18
更改网站程序
通常,如果遇到此类问题,可以更改网站的程序. 通常,某些网站优化器会添加一个JS代码,禁止在页面上进行复制和粘贴,并允许该代码禁止用户复制和粘贴或查看源代码. 但是此方法对用户体验非常不利,因此,如果情况不是很严重,没有网站管理员愿意使用此方法,则可以说此方法是最后一步.
提交内容链接
阻止采集网站内容的最大原因是,您担心自己的文章不会被收录. 因此,seoer将在更新文章后直接将文章的网址提交给百度. 这样做没有害处. 尽管百度不会立即收录该文章,但您可以提醒百度收录该文章,以便您的文章将被尽快收录并被百度认可为原创文章,这样,如果其他人窃,将减少对您的影响
添加网站链接
通常,如果复制了网站内容,则方法是添加网站的品牌字词或隐藏锚文本链接等,如果是由机器采集的,则另参加者将采集并发送所有信息,这等同于向自己添加一个链接. 但是请注意不要在文章中过分添加锚文本链接或品牌词,以防止文章被采集,因为这会损害用户体验.
防止网站文章被窃非常重要. 毕竟,许多网站管理员本人会花费大量时间和精力来撰写原创文章,但是一旦发布,他们就会被他人窃,甚至可能导致其站点上的文章未被收录. 如果发现文章被他人is窃,则必须及时解决此问题,否则会对网站优化产生非常不利的影响.
但是还有另一种方法可以阻止它. 这只是我个人的看法,但是我还不想谈论这种方法. 如果需要,可以与我们联系. 查看全部
原创性是自然促销的重要组成部分. 通过发布原创文章,可以优化许多刚刚启动的小型网站. 创意对网站优化具有非凡的意义. 百度非常喜欢原创文章. 如果新网站使用采集的文章,那么百度很容易会认为该网站是采集网站,这将影响后续的网站优化. 当营销人员进行网站优化时,所有原创文章都会在网站上进行更新,但是此时我们还遇到了一个问题,那就是原创文章被其他人采集以发布外部链接. 遇到此问题时,我们总结了一些网络营销方法.
更改网站程序
通常,如果遇到此类问题,可以更改网站的程序. 通常,某些网站优化器会添加一个JS代码,禁止在页面上进行复制和粘贴,并允许该代码禁止用户复制和粘贴或查看源代码. 但是此方法对用户体验非常不利,因此,如果情况不是很严重,没有网站管理员愿意使用此方法,则可以说此方法是最后一步.
提交内容链接
阻止采集网站内容的最大原因是,您担心自己的文章不会被收录. 因此,seoer将在更新文章后直接将文章的网址提交给百度. 这样做没有害处. 尽管百度不会立即收录该文章,但您可以提醒百度收录该文章,以便您的文章将被尽快收录并被百度认可为原创文章,这样,如果其他人窃,将减少对您的影响
添加网站链接
通常,如果复制了网站内容,则方法是添加网站的品牌字词或隐藏锚文本链接等,如果是由机器采集的,则另参加者将采集并发送所有信息,这等同于向自己添加一个链接. 但是请注意不要在文章中过分添加锚文本链接或品牌词,以防止文章被采集,因为这会损害用户体验.
防止网站文章被窃非常重要. 毕竟,许多网站管理员本人会花费大量时间和精力来撰写原创文章,但是一旦发布,他们就会被他人窃,甚至可能导致其站点上的文章未被收录. 如果发现文章被他人is窃,则必须及时解决此问题,否则会对网站优化产生非常不利的影响.
但是还有另一种方法可以阻止它. 这只是我个人的看法,但是我还不想谈论这种方法. 如果需要,可以与我们联系.
SEO新手必须阅读: 百度判断原创文章的依据
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2020-08-08 02:36
对于百度,它特别引入了鼓励原创文章和打击窃的算法. 但是,随着成千上万的文章,百度如何确定谁是原创文章?有什么影响?我们该怎么办?
1. 网站的历史原创性将影响百度对自建网站原创文章的判断
例如,如果一个说谎的人经常不时地讲真话,那么人们就不会认为他是在讲真话,反之亦然. 这是一种习惯性思维.
将其放在我们的自建网站上也是如此. 如果某个电台的文章大部分都被采集了,并且偶尔写了原创,那么百度不会认为您是原创,而百度会这样认为.
知道这一点后,我们必须了解,我们通常不采集和制作更多原件. 特别是对于一些新来者,网站建成后,他们想快速添加一些内容,因此他们从其他人的网站复制了很多文章,然后发布了该网站. 其结果是该网站给百度的第一印象是您的网站已全部采集,这将影响原创文章的收录和排名.
第二,利用文章品牌价值的优化影响百度对自建网站原创文章的判断
什么意思?这是在我们的原创文章和图片中插入大量自己的品牌字词. 什么目的?现在,许多人在重新打印文章时将删除文章的url链接. 实际上,文章各方面的“品牌字词”并没有删除很多. 这样,即使有人采集了它,它也只是给您自己的网站提供宣传的机会.
3. 增加复制和采集的成本,阻止他人进行复制和采集,并提高其原创创作的可信度
当前,大多数原创网站都是“复制”的,而不是被采集的. 采集了哪些站?这里没有太多要说的. 通常: 增加另一方的复制成本通常会降低另一方的“利益”.
增加另一方托收成本的方法是:
A,禁止右键单击代码(在百度上搜索),因此您不能直接复制,只能从源代码复制,这会很麻烦.
B,检查IP,并禁止可疑IP,尤其是那些仅阅读新文章并在复制后无需进行交叉检查就可以离开的IP.
C,添加本地化图片. 如果对方在不更改地址的情况下直接复制您的图片,则百度可以更好地进行判断. 如果继续本地化,无疑会增加另一方的复制成本周期.
D,写一篇文章并复制您自己的URL信息,可以采用图片或URL的形式.
简而言之,这增加了复制他的难度和成本,并降低了他的兴趣,这将有效地阻止其他人进行采集.
四个. 在自建网站上发布和推送原创文章,使百度有时间信任它
百度具有推送功能. 您的文章发表后,它将尽快将您的文章推送到百度. 此外,发布文章的时间可以安排在每个人都休息的时间. 例如中午,晚上22:00之后或早晨7:00之前的午餐时间. 这样,另一方将不会快速复制您的文章,而给百度足够的时间来收录您的文章. 由于您的文章是早期采集的,加上百度推. 这将使百度更加确信您的网站是原创网站.
5. 纠正投诉和反馈,告诉百度什么是正确的
当网站采集了大量信息时,如果您有足够的证据证明您的网站是原创网站(例如品牌和发布时间),则可以使用网站站长平台的反馈来重新评估您的网站并惩罚对方的网站!
当然,前提是另一方采集或复制您的许多网站信息,并且投诉也很熟练. 我们已经看到许多网站管理员写道: “我的网站是由XXXX网站(我的原著)采集的!”您的证据在哪里?百度没有时间研究以确定谁在采集谁!例如,向百度证明您的文章早于发布时间,您的采集时间早于另一方的采集时间,您的品牌字在文章中,您的网站链接在文章的图片中,等等. 都可以用作证据.
简而言之,百度对原创性的支持和对窃的打击仍然非常强大,因此我们必须更加谨慎,并注意网站被滥用.
———— 查看全部
今天,让我们谈谈[SEO]百度判断文章原创性的基础,并讨论百度如何在网站上看待原创性.
对于百度,它特别引入了鼓励原创文章和打击窃的算法. 但是,随着成千上万的文章,百度如何确定谁是原创文章?有什么影响?我们该怎么办?
1. 网站的历史原创性将影响百度对自建网站原创文章的判断
例如,如果一个说谎的人经常不时地讲真话,那么人们就不会认为他是在讲真话,反之亦然. 这是一种习惯性思维.
将其放在我们的自建网站上也是如此. 如果某个电台的文章大部分都被采集了,并且偶尔写了原创,那么百度不会认为您是原创,而百度会这样认为.
知道这一点后,我们必须了解,我们通常不采集和制作更多原件. 特别是对于一些新来者,网站建成后,他们想快速添加一些内容,因此他们从其他人的网站复制了很多文章,然后发布了该网站. 其结果是该网站给百度的第一印象是您的网站已全部采集,这将影响原创文章的收录和排名.
第二,利用文章品牌价值的优化影响百度对自建网站原创文章的判断
什么意思?这是在我们的原创文章和图片中插入大量自己的品牌字词. 什么目的?现在,许多人在重新打印文章时将删除文章的url链接. 实际上,文章各方面的“品牌字词”并没有删除很多. 这样,即使有人采集了它,它也只是给您自己的网站提供宣传的机会.
3. 增加复制和采集的成本,阻止他人进行复制和采集,并提高其原创创作的可信度
当前,大多数原创网站都是“复制”的,而不是被采集的. 采集了哪些站?这里没有太多要说的. 通常: 增加另一方的复制成本通常会降低另一方的“利益”.
增加另一方托收成本的方法是:
A,禁止右键单击代码(在百度上搜索),因此您不能直接复制,只能从源代码复制,这会很麻烦.
B,检查IP,并禁止可疑IP,尤其是那些仅阅读新文章并在复制后无需进行交叉检查就可以离开的IP.
C,添加本地化图片. 如果对方在不更改地址的情况下直接复制您的图片,则百度可以更好地进行判断. 如果继续本地化,无疑会增加另一方的复制成本周期.
D,写一篇文章并复制您自己的URL信息,可以采用图片或URL的形式.
简而言之,这增加了复制他的难度和成本,并降低了他的兴趣,这将有效地阻止其他人进行采集.
四个. 在自建网站上发布和推送原创文章,使百度有时间信任它
百度具有推送功能. 您的文章发表后,它将尽快将您的文章推送到百度. 此外,发布文章的时间可以安排在每个人都休息的时间. 例如中午,晚上22:00之后或早晨7:00之前的午餐时间. 这样,另一方将不会快速复制您的文章,而给百度足够的时间来收录您的文章. 由于您的文章是早期采集的,加上百度推. 这将使百度更加确信您的网站是原创网站.
5. 纠正投诉和反馈,告诉百度什么是正确的
当网站采集了大量信息时,如果您有足够的证据证明您的网站是原创网站(例如品牌和发布时间),则可以使用网站站长平台的反馈来重新评估您的网站并惩罚对方的网站!
当然,前提是另一方采集或复制您的许多网站信息,并且投诉也很熟练. 我们已经看到许多网站管理员写道: “我的网站是由XXXX网站(我的原著)采集的!”您的证据在哪里?百度没有时间研究以确定谁在采集谁!例如,向百度证明您的文章早于发布时间,您的采集时间早于另一方的采集时间,您的品牌字在文章中,您的网站链接在文章的图片中,等等. 都可以用作证据.
简而言之,百度对原创性的支持和对窃的打击仍然非常强大,因此我们必须更加谨慎,并注意网站被滥用.
————
适用于网站的高质量SEO伪原创文章的内容应该是什么
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2020-08-07 23:14
由于大多数公司没有专门的内容制作团队,因此某些网站更喜欢使用伪原创内容来制作内容. 他们的伪原创方法是首先列出标题,选择3-5个与该主题匹配的文章,为每篇文章参与其中,而3-5个段落可以完成一篇新文章. 但是,这样的文章只能欺骗搜索引擎,对于用户阅读而言意义不大. 优秀的网站如何创建高质量的内容?
1. 确保高质量的内容
评估标准是内容是否为网站带来流量.
在用户不熟悉该网站的前提下,他们将搜索相关的关键字. 如果网站的内容要呈现给用户,则有必要继续向搜索引擎添加内容以进行排水. 但是,您可能会发现可能没有包括精心撰写的原创文章,而是包括了其他人直接从Internet复制的文章. 目前,只有一种方法可以充分利用长尾关键字. 百度索引,搜狗索引和新近发布的微信索引都是获取流行的长尾关键词的方法.
2. 高效的采集,几秒钟之内就能杀死原件
仅仅作为伪造的原件还不够. 产品信息和与Internet相关的信息过多. 为什么不只是使用它呢?每天我们看到“爆炸性文章”被成千上万的大字转载,转载的读物往往高于原创读物. 该网站设置了一个特殊的文章更新部分,以不断增加内容,该内容可能由不同的搜索引擎采集!无论是各种社交应用程序,外部链接都可以为网站带来可观的流量. 网站拥有足够的流量后,搜索引擎自然会改变其对网站的态度并变得友好. 查看全部
在内容为王的时代,对网站优化也有更高的要求. 从UC令人震惊的机构到热烈的讨论,再到百度取消新闻源系统,高质量的内容已经以另一种形式渗透到我们的生活中. 优化网站以获得排名的最简单方法是创建“标题+原创内容”,并确保其收录在搜索引擎中.

由于大多数公司没有专门的内容制作团队,因此某些网站更喜欢使用伪原创内容来制作内容. 他们的伪原创方法是首先列出标题,选择3-5个与该主题匹配的文章,为每篇文章参与其中,而3-5个段落可以完成一篇新文章. 但是,这样的文章只能欺骗搜索引擎,对于用户阅读而言意义不大. 优秀的网站如何创建高质量的内容?
1. 确保高质量的内容
评估标准是内容是否为网站带来流量.
在用户不熟悉该网站的前提下,他们将搜索相关的关键字. 如果网站的内容要呈现给用户,则有必要继续向搜索引擎添加内容以进行排水. 但是,您可能会发现可能没有包括精心撰写的原创文章,而是包括了其他人直接从Internet复制的文章. 目前,只有一种方法可以充分利用长尾关键字. 百度索引,搜狗索引和新近发布的微信索引都是获取流行的长尾关键词的方法.
2. 高效的采集,几秒钟之内就能杀死原件
仅仅作为伪造的原件还不够. 产品信息和与Internet相关的信息过多. 为什么不只是使用它呢?每天我们看到“爆炸性文章”被成千上万的大字转载,转载的读物往往高于原创读物. 该网站设置了一个特殊的文章更新部分,以不断增加内容,该内容可能由不同的搜索引擎采集!无论是各种社交应用程序,外部链接都可以为网站带来可观的流量. 网站拥有足够的流量后,搜索引擎自然会改变其对网站的态度并变得友好.
如何快速大量增加所收录的网站数量
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-07 18:07
今天,Xiaoxiao Classroom.com为您带来了有关如何在网站权重优化中快速增加网站收录量的教程. 希望对您有所帮助.
首先,如何使搜索引擎包括在内
在谈论快速增加网站收录物之前,马辉SEO应该首先谈论搜索引擎将收录哪种页面.
1. 高质量的原图
所有平台都喜欢的高质量原创资源.
2. 及时
对热门话题或有关新技术的文章的评论或意见是时间敏感的. 描述xp的文章和描述Windows Server 2016的文章,搜索引擎更可能喜欢后者.
3. 有价值
一篇文章在被搜索引擎收录之前必须是有价值的,否则在被收录后可能会被取消.
4. 高用户体验
最后,网站优化基本上是用户体验的竞争. 谁做得好,流量就会更多.
有关更多参考,请参阅上一个教程“网站不包括[如何收录100%重印文章] SEO研究tutorial_小小课网”.
二,如何快速增加网站收录量
迅速增加网站收录物的数量是优化网站权重的方法之一,但搜索引擎可能会惩罚不当操作. Xiaoxiao Classroom.com建议采用以下方法来快速增加网站的数量.
1. 大量原创文章
对于团队而言,要撰写大量原创文章并不容易,而单个网站站长要添加这些文章甚至更加困难. 如果有大量的粉丝做出贡献,那就更好了. 关键是这些人愿意为我们写信. 通常采用奖励机制.
2,大量伪原创文章
伪原创文章不是指随机采集的文章,这些文章是通过在线伪原创工具转换并直接发布的. 相反,Ma Hui SEO不建议使用此工具. 建议根据他人的想法编写自己的内容,或者直接转载文章并添加评论.
3. 创建一列
如果网站仅具有第二级列,则可以考虑创建多个第三级列以对文章进行更详细的分类,但是建议每个类别下不少于十篇,并进行长期维护是必需的.
4. 标签汇总页面
合理地为文章添加标签. 不要添加太多标签,尤其是当标签的数量大于网站上的文章数量时,搜索引擎可能会降低网站的访问量. 查看全部
即使数据没有价值和意义,网站权重优化始终是许多用户最关心的事情. 除了“如何增加百度的权重?”之外,除了“快速升级_百度SEO教程_小小课网”中介绍的方法外,大量增加网站的收录率是优化网站权重的一种常用方法.
今天,Xiaoxiao Classroom.com为您带来了有关如何在网站权重优化中快速增加网站收录量的教程. 希望对您有所帮助.
首先,如何使搜索引擎包括在内
在谈论快速增加网站收录物之前,马辉SEO应该首先谈论搜索引擎将收录哪种页面.
1. 高质量的原图
所有平台都喜欢的高质量原创资源.
2. 及时
对热门话题或有关新技术的文章的评论或意见是时间敏感的. 描述xp的文章和描述Windows Server 2016的文章,搜索引擎更可能喜欢后者.
3. 有价值
一篇文章在被搜索引擎收录之前必须是有价值的,否则在被收录后可能会被取消.
4. 高用户体验
最后,网站优化基本上是用户体验的竞争. 谁做得好,流量就会更多.
有关更多参考,请参阅上一个教程“网站不包括[如何收录100%重印文章] SEO研究tutorial_小小课网”.
二,如何快速增加网站收录量
迅速增加网站收录物的数量是优化网站权重的方法之一,但搜索引擎可能会惩罚不当操作. Xiaoxiao Classroom.com建议采用以下方法来快速增加网站的数量.
1. 大量原创文章
对于团队而言,要撰写大量原创文章并不容易,而单个网站站长要添加这些文章甚至更加困难. 如果有大量的粉丝做出贡献,那就更好了. 关键是这些人愿意为我们写信. 通常采用奖励机制.
2,大量伪原创文章
伪原创文章不是指随机采集的文章,这些文章是通过在线伪原创工具转换并直接发布的. 相反,Ma Hui SEO不建议使用此工具. 建议根据他人的想法编写自己的内容,或者直接转载文章并添加评论.
3. 创建一列
如果网站仅具有第二级列,则可以考虑创建多个第三级列以对文章进行更详细的分类,但是建议每个类别下不少于十篇,并进行长期维护是必需的.
4. 标签汇总页面
合理地为文章添加标签. 不要添加太多标签,尤其是当标签的数量大于网站上的文章数量时,搜索引擎可能会降低网站的访问量.
如何快速添加网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2020-08-07 17:14
图片来自[Mafan SEO工具-摩天大楼内容助手]如何快速收录网站
网站收录是SEO工作中非常重要的一部分. 如果搜索引擎未收录网站的网页,则基本上不可能获得更好的排名,更不用说访问量了. 对于网站上的原创文章,如果不能及时添加,则很可能被窃,甚至被搜索引擎认为是别人的原创. 如果是这样的话,那么我们辛勤工作的结果无非就是别人在做婚纱. 那么搜索引擎应如何尽快包括我们的网站?
我们首先需要知道的是,百度,谷歌和搜狗等搜索引擎对新提交的网站持怀疑态度. 他们通常有一个到三个月的检查期,并且使用相同的搜索引擎. 新站点的评估标准也有所不同. 如果夹杂物有延迟或夹杂物的数量在夹杂物后的一段时间内没有增加,这也是正常的. ,
1. 在网站建设的初期,我们需要优化我们的网站代码,以使代码尽可能简洁明了,而不会造成太多麻烦.
2. 内容应尽可能基于文本. 不要添加太多图片,以免影响网站的整体加载速度. 如果文章收录文件,请尽可能压缩或合并文件.
3. 切记不要修改网站的整体框架,否则,即使已将其包括在内,搜索引擎也可能会将其视为不成熟的产品,并再次丢弃. 如果是这种情况,则必须再次将其收录进来. 这更加困难.
4. 网站完善后,我们可以将我们的网站URL和信息提交给搜索引擎. 这样,可以将搜索引擎引导至我们的网站以获取信息,但一天之内不要重复太多. 提交内容,否则它很可能会被搜索引擎列入黑名单,从而完全失去了收录的希望.
5. 众所周知,搜索引擎是热爱新事物而不喜欢旧事物的事物. 它喜欢新鲜的内容. 只有每天定期且定量地更新网站内容时,搜索引擎才会将其视为高质量的网站,并不断访问该网站. 数据采集.
6. 其次,外部链接的构建也是搜索引擎判断网站质量的重要标准. 外部链接是指在其他网站或平台上发布的链接,这些链接使用户可以直接单击以访问我们的网站. 但是,外部链接越多越好,但是权重越高越好. 如果网站的外部链接稳定增长且权重较高,则对收录网站非常有利.
7. 内部链接通常是指在网站的内部页面上添加到其他内部页面的链接,例如某些新闻页面或相关新闻,这些都是内部链接的类型. 内部链中的所有页面和内容都必须相关,并且不能随意堆叠. 只有这样,它才能在用户和搜索引擎上留下良好的印象.
最后[Code Fan SEO]我想和大家分享一些技巧. 如果要提高网站的收录率,实际上可以在标题或内容中添加一些不常用的单词或不常用的单词: 例如,文章的标题可以是瞾岽苡---如何将网站收录在其中百度,这个标题的标题是一个罕见的词.
由于在百度搜索引擎的数据库中可能没有与此关键字相关的任何内容,因此此类文章很容易被百度视为原创内容,从而增加了收录我们网站页面的可能性.
快速采集网站的技术
许多网站在线后,无需调试即可直接向搜索引擎提交链接. 这将直接降低搜索引擎对网站的友好度,并降低用户体验,这将导致网站花费更长的时间来获得搜索引擎. 信任,加快网站包容性的必要条件是: 完整的网站准备,合理的布局,完整的网站结构,良好的用户体验等,因此[Mafan SEO]为所有人总结了以下提示:
图片来自[Mafan SEO工具-摩天大楼内容助手]
1. 本地站点建立
在网站上线之前,必须将网站的内容,结构,模板等调整为最佳状态. 其次,必须保留足够的空间和内容,以便为搜索引擎提供便利的条件,并为搜索引擎留下良好的第一名. 印象深刻,这也是加快网站快速收录的必要技巧.
第二个原创内容
网站上线后,我们必须更新更多高质量的原创内容. 当前,有许多公司网站,产品类型相对较少,并且网站中的无效页面很多. 这不会促进网站的排名和纳入. 有效的是,如果您想快速增加网站的收录范围,则原创内容是必要条件. 如果您无法更新大量原创内容,则也可以增加产品知识或新闻专栏的原创文章以丰富网站内容.
三,域名友好
通常来说,如果网站使用的域名已经被搜索引擎列入黑名单,则很难将其包括在内. 我们在这里所说的黑名单意味着该域名已被搜索引擎禁止. 网站内容或非法信息等将严重打击网站的收录.
四个. 提交链接
如果网站的收录状况不佳,建议网站管理员尝试主动或自动提交链接到搜索引擎,以便搜索引擎以最快的速度查看网站的更新信息,并且更直观地抓取网站,从而改善网站的包容性.
通常,网站收录与网站优化的各个方面都有关系,并且可以在网站权重和关键字排名中起决定性作用,这可以使后续网站优化工作加倍努力,而且效果相同. 时间可以吸引更多流量,用户可以为网站推广和营销奠定基础.
未收录该网站的原因和解决方案
不收录网站是许多网站当前存在的问题. 特别是对于某些新网站,通常情况下不收录文章和网页. 实际上,如果发生这种情况,有必要找到根本原因. 找到原因并及时解决. 以下[Ma Mi SEO]将回答未收录该网站的原因和解决方案.
如果突然不收录该网站,请不要着急. 首先,从网站的近期运营中找出原因,因为搜索引擎将无故停止索引我们的页面. 它必须是最近的网站. 只有异常会导致不收录在内,因此我们需要仔细回顾一下最近对网站进行的更改.
1. 内容重复多次
首先,不收录该网站的最常见原因之一是该网站的内容重复了很多次. 这也是大多数文章不被搜索引擎收录的主要因素. 尽管这是一个常见的话题,但有必要再次提醒您.
我相信大多数网站管理员每天要做的是将几篇具有相关主题的文章随机混合,将其合并为一篇文章,然后在网站上发布. 也许这种方法权重很高. 该网站并没有任何负面影响,相反,它可以增加权重.
但是对于某些权重较低的网站,此方法只会降低我们网站上搜索引擎的信任度. 可以看出,原创文章的重要性不容忽视.
2. 文章的格式或布局不合理
文章的格式和布局也是许多人忽略的问题. 有时,当我们搜索关键字时,当我们在搜索引擎中看到一篇文章时,每个段落可能有大约600个单词. 这样的文章可以阅读. 它将在一定程度上增加用户的阅读疲劳.
如果文章的格式不好,水平不明确,将被搜索引擎认为是质量低,一文不值,无法满足用户的实际需求,也会延缓文章的速度. 收录,或直接拒绝.
3. 内容被大量采集
是否大量采集了网站内容,这也是突然不包括普通网站的原因之一. 如果突然不包括该网站,则可能是我们的文章采集过多,并且我们的文章采集了. 网站页面的权重可能高于我们的页面. 如果是这种情况,很容易混淆搜索引擎. 我们需要再次查看我们的网站,以检查我们的文章是否为原创. 从长远来看,这自然会影响包容性.
4. 过度优化
为了增加搜索引擎的数量,一些公司网站经常进行过度优化,而过度优化主要体现在关键字堆栈中. 这就像单独吃营养. 适量吃东西有益,但如果吃得太多,也将有益. 对于身体的负担,导致无法消化或营养过剩以及对外部链接和关键字的过度优化也是如此.
这不仅会使页面的重量分散,而且会大大降低收录率. 为了迎合用户和搜索引擎的偏爱,某些网站会在首页上添加过多的图片和动画,而搜索引擎会将该行为视为没有收录价值,因此自然不会爬网和收录该网站
摘要:
建立网站的公司的最大目的是获得流量,而搜索引擎恰恰是网站流量的主要来源. 如果网站在优化过程中收录更多内容,则获得访问量和排名的机会将会增加. 包容是一个漫长的过程. 只要您坚持上述内容,肯定会缓解和改善夹杂问题. 因此,[Code Mi SEO]建议网站管理员不要急于成功,只要网站纳入是一个长期目标. 看,经过大量的努力,它最终会实现.
感谢您的阅读. 上面的原创文章来自[Skyscraper Content Assistant-Ma Mi SEO Tool]. 查看全部
实际上,网站优化是一个漫长的过程. 搜索引擎必须基于对用户负责的态度来评估所有网站. 面对这样的评估,我们每天只能定期和定量地输入原创信息,以不断改善用户体验. 为了使搜索引擎更多地光顾我们的网站并查看我们网站的价值.

图片来自[Mafan SEO工具-摩天大楼内容助手]如何快速收录网站
网站收录是SEO工作中非常重要的一部分. 如果搜索引擎未收录网站的网页,则基本上不可能获得更好的排名,更不用说访问量了. 对于网站上的原创文章,如果不能及时添加,则很可能被窃,甚至被搜索引擎认为是别人的原创. 如果是这样的话,那么我们辛勤工作的结果无非就是别人在做婚纱. 那么搜索引擎应如何尽快包括我们的网站?
我们首先需要知道的是,百度,谷歌和搜狗等搜索引擎对新提交的网站持怀疑态度. 他们通常有一个到三个月的检查期,并且使用相同的搜索引擎. 新站点的评估标准也有所不同. 如果夹杂物有延迟或夹杂物的数量在夹杂物后的一段时间内没有增加,这也是正常的. ,
1. 在网站建设的初期,我们需要优化我们的网站代码,以使代码尽可能简洁明了,而不会造成太多麻烦.
2. 内容应尽可能基于文本. 不要添加太多图片,以免影响网站的整体加载速度. 如果文章收录文件,请尽可能压缩或合并文件.
3. 切记不要修改网站的整体框架,否则,即使已将其包括在内,搜索引擎也可能会将其视为不成熟的产品,并再次丢弃. 如果是这种情况,则必须再次将其收录进来. 这更加困难.
4. 网站完善后,我们可以将我们的网站URL和信息提交给搜索引擎. 这样,可以将搜索引擎引导至我们的网站以获取信息,但一天之内不要重复太多. 提交内容,否则它很可能会被搜索引擎列入黑名单,从而完全失去了收录的希望.
5. 众所周知,搜索引擎是热爱新事物而不喜欢旧事物的事物. 它喜欢新鲜的内容. 只有每天定期且定量地更新网站内容时,搜索引擎才会将其视为高质量的网站,并不断访问该网站. 数据采集.
6. 其次,外部链接的构建也是搜索引擎判断网站质量的重要标准. 外部链接是指在其他网站或平台上发布的链接,这些链接使用户可以直接单击以访问我们的网站. 但是,外部链接越多越好,但是权重越高越好. 如果网站的外部链接稳定增长且权重较高,则对收录网站非常有利.
7. 内部链接通常是指在网站的内部页面上添加到其他内部页面的链接,例如某些新闻页面或相关新闻,这些都是内部链接的类型. 内部链中的所有页面和内容都必须相关,并且不能随意堆叠. 只有这样,它才能在用户和搜索引擎上留下良好的印象.
最后[Code Fan SEO]我想和大家分享一些技巧. 如果要提高网站的收录率,实际上可以在标题或内容中添加一些不常用的单词或不常用的单词: 例如,文章的标题可以是瞾岽苡---如何将网站收录在其中百度,这个标题的标题是一个罕见的词.
由于在百度搜索引擎的数据库中可能没有与此关键字相关的任何内容,因此此类文章很容易被百度视为原创内容,从而增加了收录我们网站页面的可能性.
快速采集网站的技术
许多网站在线后,无需调试即可直接向搜索引擎提交链接. 这将直接降低搜索引擎对网站的友好度,并降低用户体验,这将导致网站花费更长的时间来获得搜索引擎. 信任,加快网站包容性的必要条件是: 完整的网站准备,合理的布局,完整的网站结构,良好的用户体验等,因此[Mafan SEO]为所有人总结了以下提示:

图片来自[Mafan SEO工具-摩天大楼内容助手]
1. 本地站点建立
在网站上线之前,必须将网站的内容,结构,模板等调整为最佳状态. 其次,必须保留足够的空间和内容,以便为搜索引擎提供便利的条件,并为搜索引擎留下良好的第一名. 印象深刻,这也是加快网站快速收录的必要技巧.
第二个原创内容
网站上线后,我们必须更新更多高质量的原创内容. 当前,有许多公司网站,产品类型相对较少,并且网站中的无效页面很多. 这不会促进网站的排名和纳入. 有效的是,如果您想快速增加网站的收录范围,则原创内容是必要条件. 如果您无法更新大量原创内容,则也可以增加产品知识或新闻专栏的原创文章以丰富网站内容.
三,域名友好
通常来说,如果网站使用的域名已经被搜索引擎列入黑名单,则很难将其包括在内. 我们在这里所说的黑名单意味着该域名已被搜索引擎禁止. 网站内容或非法信息等将严重打击网站的收录.
四个. 提交链接
如果网站的收录状况不佳,建议网站管理员尝试主动或自动提交链接到搜索引擎,以便搜索引擎以最快的速度查看网站的更新信息,并且更直观地抓取网站,从而改善网站的包容性.
通常,网站收录与网站优化的各个方面都有关系,并且可以在网站权重和关键字排名中起决定性作用,这可以使后续网站优化工作加倍努力,而且效果相同. 时间可以吸引更多流量,用户可以为网站推广和营销奠定基础.
未收录该网站的原因和解决方案
不收录网站是许多网站当前存在的问题. 特别是对于某些新网站,通常情况下不收录文章和网页. 实际上,如果发生这种情况,有必要找到根本原因. 找到原因并及时解决. 以下[Ma Mi SEO]将回答未收录该网站的原因和解决方案.
如果突然不收录该网站,请不要着急. 首先,从网站的近期运营中找出原因,因为搜索引擎将无故停止索引我们的页面. 它必须是最近的网站. 只有异常会导致不收录在内,因此我们需要仔细回顾一下最近对网站进行的更改.
1. 内容重复多次
首先,不收录该网站的最常见原因之一是该网站的内容重复了很多次. 这也是大多数文章不被搜索引擎收录的主要因素. 尽管这是一个常见的话题,但有必要再次提醒您.
我相信大多数网站管理员每天要做的是将几篇具有相关主题的文章随机混合,将其合并为一篇文章,然后在网站上发布. 也许这种方法权重很高. 该网站并没有任何负面影响,相反,它可以增加权重.
但是对于某些权重较低的网站,此方法只会降低我们网站上搜索引擎的信任度. 可以看出,原创文章的重要性不容忽视.
2. 文章的格式或布局不合理
文章的格式和布局也是许多人忽略的问题. 有时,当我们搜索关键字时,当我们在搜索引擎中看到一篇文章时,每个段落可能有大约600个单词. 这样的文章可以阅读. 它将在一定程度上增加用户的阅读疲劳.
如果文章的格式不好,水平不明确,将被搜索引擎认为是质量低,一文不值,无法满足用户的实际需求,也会延缓文章的速度. 收录,或直接拒绝.
3. 内容被大量采集
是否大量采集了网站内容,这也是突然不包括普通网站的原因之一. 如果突然不包括该网站,则可能是我们的文章采集过多,并且我们的文章采集了. 网站页面的权重可能高于我们的页面. 如果是这种情况,很容易混淆搜索引擎. 我们需要再次查看我们的网站,以检查我们的文章是否为原创. 从长远来看,这自然会影响包容性.
4. 过度优化
为了增加搜索引擎的数量,一些公司网站经常进行过度优化,而过度优化主要体现在关键字堆栈中. 这就像单独吃营养. 适量吃东西有益,但如果吃得太多,也将有益. 对于身体的负担,导致无法消化或营养过剩以及对外部链接和关键字的过度优化也是如此.
这不仅会使页面的重量分散,而且会大大降低收录率. 为了迎合用户和搜索引擎的偏爱,某些网站会在首页上添加过多的图片和动画,而搜索引擎会将该行为视为没有收录价值,因此自然不会爬网和收录该网站
摘要:
建立网站的公司的最大目的是获得流量,而搜索引擎恰恰是网站流量的主要来源. 如果网站在优化过程中收录更多内容,则获得访问量和排名的机会将会增加. 包容是一个漫长的过程. 只要您坚持上述内容,肯定会缓解和改善夹杂问题. 因此,[Code Mi SEO]建议网站管理员不要急于成功,只要网站纳入是一个长期目标. 看,经过大量的努力,它最终会实现.
感谢您的阅读. 上面的原创文章来自[Skyscraper Content Assistant-Ma Mi SEO Tool].
百度如何判断原创文章?
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2020-08-07 16:07
1.1馆藏泛滥
百度的一项调查显示,从传统媒体报纸到娱乐网站的花边新闻,从游戏指南到产品评论,甚至是大学图书馆,超过80%的新闻和信息都是手动复制或通过机器采集的还请注意,所有站点都在进行机器采集. 可以说,高质量的原创内容是一块小米,周围是广阔的采集海洋. 通过搜索引擎在海中搜索小米既困难又具有挑战性.
1.2改善搜索用户体验
数字化降低了传播成本,工具化降低了采集成本,并且机器采集的行为使内容源混乱,并降低了内容质量. 在采集过程中,无意或有意出现了诸如内容不完整和不完整,格式混乱或出现其他垃圾等问题,这些问题严重影响了搜索结果和用户体验的质量. 搜索引擎重视原创性的根本原因是为了改善用户体验. 这里提到的原创性是高质量的原创内容.
1.3鼓励原创作者和文章
重新发布和采集,转移了高质量原创网站的访问量,并且不再具有原创作者的名字,这将直接影响高质量原创网站管理员和作者的收入. 从长远来看,它将影响原创创作者的积极性,不利于创新,也不利于新的高质量内容的生产. 鼓励高质量的原创性,鼓励创新,并为原创站点和作者提供合理的访问量,从而促进Internet内容的繁荣,应该是搜索引擎的一项重要任务.
第二,采集非常狡猾,很难识别原创图片
2.1采集伪装成原件并篡改关键信息
当前,大量网站在分批采集原创内容之后,会使用手动或机器方法篡改关键信息,例如作者,发布时间和来源,并假装为原创内容. 这种冒充原创物的东西需要由搜索引擎识别并进行相应调整.
2.2内容生成器,制作伪原创
使用自动文章生成器之类的工具来“创建”文章,然后安装醒目的标题,现在的成本非常低,而且必须是原创的. 但是,原创性必须具有社会共识的价值,并且不能将任何不合理的垃圾视为有价值和高质量的原创内容. 尽管内容是唯一的,但它没有社会共识的价值. 搜索引擎需要识别和打击这种伪原创信息.
2.3不同的网页,难以提取结构化信息
不同的站点具有相对较大的结构差异,并且html标签的含义和分布也不同. 因此,提取诸如标题,作者和时间之类的关键信息的难度也相对较大. 在目前的中国互联网规模下,这并不容易. 这部分将需要搜索引擎和网站管理员的配合才能更平稳地运行. 如果网站站长将更清晰的结构告知搜索引擎网页布局,将使搜索引擎能够有效地提取原创信息和相关信息.
3. 百度如何识别原创性?
3.1建立原创的项目团队来进行长期战斗
面对挑战,为了改善搜索引擎的用户体验,为了获得高质量的原创原创网站的利益,并促进中国互联网的发展,我们选择了大量人组成一个原创的项目团队: 技术,产品,运营,法律事务等等,这不是一个临时组织,不是一个两个月和两个月的项目,我们已经准备好进行旷日持久的战斗.
3.2原创识别“起源”算法
Internet上有数百亿个网页,从中发现原创内容可以说是大海捞针. 我们的原创识别系统是在百度大数据的云计算平台上开发的,可以快速实现所有中文Internet页面的重复聚合和链接点关系分析.
首先,根据内容的相似性采集馆藏和原创作品,并将相似的网页聚集在一起,作为一组原创作品的候选者;
第二,对于原创候选集,原创网页是根据作者,发布时间,链接方向,用户评论,作者和站点的历史原创性以及转发路径等数百种因素来标识和判断的;
最后,使用价值分析系统确定原创内容的价值,然后适当地指导最终排名.
目前,通过我们的实验和真实的在线数据,“起源”算法取得了一些进展,并解决了新闻,信息等领域的大多数问题. 当然,在其他领域,还有更多原创问题等待“来源”解决,我们决心走.
3.3 Original Spark项目
我们一直致力于调整原创内容的识别和排序算法,但是在当前的Internet环境中,快速识别原创内容和解决原创问题确实面临着巨大的挑战. 计算数据的规模巨大,我们面临的采集方法是无穷无尽的. 网站构建方法和模板,复杂的内容提取和其他问题存在巨大差异. 这些因素将影响原创算法的识别,甚至导致判断错误. 这时,百度和网站管理员必须共同维护互联网的生态环境. 网站站长推荐原创内容,搜索引擎经过一定判断后会优先处理原创内容,共同促进生态的改善并鼓励原创性. 这是“原创Spark项目”,旨在快速解决当前面临的严重问题. 此外,网站站长对原创内容的推荐将应用于“起源”算法,这将有助于百度找到该算法的缺陷,进行持续改进,并使用更智能的识别算法自动识别原创内容.
目前,原创Spark项目也已取得初步成果. 在百度搜索结果中,一些关键原创新闻站点的原创内容的第一阶段已被赋予原创标签,作者显示等,并且还实现了排名和访问量. 合理促销.
最后,创意是生态问题,需要长期改进. 我们将继续投资并与网站管理员合作,以促进互联网生态的进步;创意是一个环境问题,需要每个人维护. 网站管理员应制作更多原创作品,并推荐更多原创作品,百度将继续努力改善排名算法,鼓励原创内容,并为原创作者和原创网站提供合理的排名和流量. 查看全部
1. 搜索引擎为什么要重视原创性?
1.1馆藏泛滥
百度的一项调查显示,从传统媒体报纸到娱乐网站的花边新闻,从游戏指南到产品评论,甚至是大学图书馆,超过80%的新闻和信息都是手动复制或通过机器采集的还请注意,所有站点都在进行机器采集. 可以说,高质量的原创内容是一块小米,周围是广阔的采集海洋. 通过搜索引擎在海中搜索小米既困难又具有挑战性.
1.2改善搜索用户体验
数字化降低了传播成本,工具化降低了采集成本,并且机器采集的行为使内容源混乱,并降低了内容质量. 在采集过程中,无意或有意出现了诸如内容不完整和不完整,格式混乱或出现其他垃圾等问题,这些问题严重影响了搜索结果和用户体验的质量. 搜索引擎重视原创性的根本原因是为了改善用户体验. 这里提到的原创性是高质量的原创内容.
1.3鼓励原创作者和文章
重新发布和采集,转移了高质量原创网站的访问量,并且不再具有原创作者的名字,这将直接影响高质量原创网站管理员和作者的收入. 从长远来看,它将影响原创创作者的积极性,不利于创新,也不利于新的高质量内容的生产. 鼓励高质量的原创性,鼓励创新,并为原创站点和作者提供合理的访问量,从而促进Internet内容的繁荣,应该是搜索引擎的一项重要任务.

第二,采集非常狡猾,很难识别原创图片
2.1采集伪装成原件并篡改关键信息
当前,大量网站在分批采集原创内容之后,会使用手动或机器方法篡改关键信息,例如作者,发布时间和来源,并假装为原创内容. 这种冒充原创物的东西需要由搜索引擎识别并进行相应调整.
2.2内容生成器,制作伪原创
使用自动文章生成器之类的工具来“创建”文章,然后安装醒目的标题,现在的成本非常低,而且必须是原创的. 但是,原创性必须具有社会共识的价值,并且不能将任何不合理的垃圾视为有价值和高质量的原创内容. 尽管内容是唯一的,但它没有社会共识的价值. 搜索引擎需要识别和打击这种伪原创信息.
2.3不同的网页,难以提取结构化信息
不同的站点具有相对较大的结构差异,并且html标签的含义和分布也不同. 因此,提取诸如标题,作者和时间之类的关键信息的难度也相对较大. 在目前的中国互联网规模下,这并不容易. 这部分将需要搜索引擎和网站管理员的配合才能更平稳地运行. 如果网站站长将更清晰的结构告知搜索引擎网页布局,将使搜索引擎能够有效地提取原创信息和相关信息.
3. 百度如何识别原创性?
3.1建立原创的项目团队来进行长期战斗
面对挑战,为了改善搜索引擎的用户体验,为了获得高质量的原创原创网站的利益,并促进中国互联网的发展,我们选择了大量人组成一个原创的项目团队: 技术,产品,运营,法律事务等等,这不是一个临时组织,不是一个两个月和两个月的项目,我们已经准备好进行旷日持久的战斗.
3.2原创识别“起源”算法
Internet上有数百亿个网页,从中发现原创内容可以说是大海捞针. 我们的原创识别系统是在百度大数据的云计算平台上开发的,可以快速实现所有中文Internet页面的重复聚合和链接点关系分析.
首先,根据内容的相似性采集馆藏和原创作品,并将相似的网页聚集在一起,作为一组原创作品的候选者;
第二,对于原创候选集,原创网页是根据作者,发布时间,链接方向,用户评论,作者和站点的历史原创性以及转发路径等数百种因素来标识和判断的;
最后,使用价值分析系统确定原创内容的价值,然后适当地指导最终排名.
目前,通过我们的实验和真实的在线数据,“起源”算法取得了一些进展,并解决了新闻,信息等领域的大多数问题. 当然,在其他领域,还有更多原创问题等待“来源”解决,我们决心走.
3.3 Original Spark项目
我们一直致力于调整原创内容的识别和排序算法,但是在当前的Internet环境中,快速识别原创内容和解决原创问题确实面临着巨大的挑战. 计算数据的规模巨大,我们面临的采集方法是无穷无尽的. 网站构建方法和模板,复杂的内容提取和其他问题存在巨大差异. 这些因素将影响原创算法的识别,甚至导致判断错误. 这时,百度和网站管理员必须共同维护互联网的生态环境. 网站站长推荐原创内容,搜索引擎经过一定判断后会优先处理原创内容,共同促进生态的改善并鼓励原创性. 这是“原创Spark项目”,旨在快速解决当前面临的严重问题. 此外,网站站长对原创内容的推荐将应用于“起源”算法,这将有助于百度找到该算法的缺陷,进行持续改进,并使用更智能的识别算法自动识别原创内容.
目前,原创Spark项目也已取得初步成果. 在百度搜索结果中,一些关键原创新闻站点的原创内容的第一阶段已被赋予原创标签,作者显示等,并且还实现了排名和访问量. 合理促销.
最后,创意是生态问题,需要长期改进. 我们将继续投资并与网站管理员合作,以促进互联网生态的进步;创意是一个环境问题,需要每个人维护. 网站管理员应制作更多原创作品,并推荐更多原创作品,百度将继续努力改善排名算法,鼓励原创内容,并为原创作者和原创网站提供合理的排名和流量.
[原创和免费]微信公众号文章检索方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2020-08-07 12:07
参考文章
AnyProxy代理批量采集
如何实现: anyproxy + js
如何实现: anyproxy + java + webmagic
FiddlerCore
实现方法: 数据包捕获工具Fiddler4
通过捕获和分析多个帐户,我们可以确定:
步骤:
1. 编写按键向导脚本,并自动单击电话上的“公众号文章列表”页面,即“查看历史新闻”;
2,使用提琴手代理劫持手机访问权,并将URL转发到用PHP编写的本地网页;
3,将php网页上收到的URL备份到数据库中;
4,使用python从数据库中获取URL,然后执行正常的爬网.
在抓取过程中发现问题:
如果您只想抓取文章的内容,似乎没有访问频率的限制,但是如果您想获取阅读次数和喜欢的次数,经过一定的频率后,返回值将变为空值. 我设置的时间间隔是10秒内可以正常抓取. 在这个频率下,一个小时内只能抓取360条消息,这没有实际意义.
青岛新列表
如果您只想查看数据,请直接查看每日列表,而无需花钱. 如果您需要访问自己的系统,它们还提供api接口
第3部分项目步骤的基本原理
此网站收录大多数微信官方帐户文章,这些文章将定期更新. 经过测试,发现它对爬虫更友好
网站页面的布局和排版规则,通过链接中的帐户来区分不同的官方帐户
一组公共帐户下的文章翻页也是正常的: ID号+每翻页一次12
Portal-Copy.png
所以这个想法可能是一样的
与环境相关的软件包获取页面
def get_one_page(url):
#需要加一个请求头部,不然会被网站封禁
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status #若不为200,则引发HTTPError错误
response.encoding = response.apparent_encoding
return response.text
except:
return "产生异常"
请注意,目标采集器网站必须添加标头,否则它将直接拒绝访问
常规解析html
def parse_one_page(html):
pattern = re.compile('.*?.*?<a class="question_link" href="(.*?)".*?_blank"(.*?)/a.*?"timestamp".*?">(.*?)', re.S)
items = re.findall(pattern, html)
return items
自动跳转页面
def main(offset, i):
url = 'http://chuansong.me/account/' + str(offset) + '?start=' + str(12*i)
print(url)
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
html = get_one_page(url)
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
删除标题中的非法字符
由于Windows下有file命令,因此无法使用某些字符,因此我们需要使用常规消除符
itle = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
转换html
使用pandas的read_csv函数读取抓取的csv文件,并在“链接”,“标题”,“日期”之间循环
def html_to_pdf(offset):
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
path = get_path(offset)
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe' #安装wkhtmltopdf的位置
config = pdfkit.configuration(wkhtmltopdf = path_wk)
if path == "" :
print("尚未抓取该公众号")
else:
info = get_url_info(offset)
for indexs in info.index:
url = info.loc[indexs]['链接']
title = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
date = info.loc[indexs]['日期']
wait = round(random.uniform(4,5),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
print(url)
with eventlet.Timeout(4,False):
pdfkit.from_url(url, get_path(offset)+'\\'+ date+'_'+title+'.pdf', configuration=config)
print('转换成功!')
结果显示抓取结果
结果1-copy.png
已抓取的几个正式帐户存储在文件夹中
结果2-copy.png
文件夹目录下的内容
结果3-copy.png
已抓取CSV内容格式
生成的PDF结果
结果4-copy.png
遇到的问题,问题1
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
info = info.strip('\"')
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
解决方案
字符串中首尾带有“”,使用上文中的#注释部分的各种方法都不好使,
最后的解决办法是:
在写入字符串的代码出,加上.strip('\'\"'),以去掉‘和”
with open(path, 'a', encoding='utf-8') as f: #追加存储形式,content是字典形式
f.write(str(json.dumps(content, ensure_ascii=False).strip('\'\"') + '\n'))
f.close()
问题2
调用wkhtmltopdf.exe将html转成pdf报错
调用代码
``` python
path_wk = 'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
```
错误消息
OSError: No wkhtmltopdf executable found: "D:\Program Files\wkhtmltopdin\wkhtmltopdf.exe"
If this file exists please check that this process can read it. Otherwise please install wkhtmltopdf - https://github.com/JazzCore/py ... topdf
解决方案
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
或者
path_wk = 'D:\\Program Files\\wkhtmltopdf\\bin\\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
原因 查看全部
python爬行
参考文章
AnyProxy代理批量采集
如何实现: anyproxy + js
如何实现: anyproxy + java + webmagic
FiddlerCore
实现方法: 数据包捕获工具Fiddler4
通过捕获和分析多个帐户,我们可以确定:
步骤:
1. 编写按键向导脚本,并自动单击电话上的“公众号文章列表”页面,即“查看历史新闻”;
2,使用提琴手代理劫持手机访问权,并将URL转发到用PHP编写的本地网页;
3,将php网页上收到的URL备份到数据库中;
4,使用python从数据库中获取URL,然后执行正常的爬网.
在抓取过程中发现问题:
如果您只想抓取文章的内容,似乎没有访问频率的限制,但是如果您想获取阅读次数和喜欢的次数,经过一定的频率后,返回值将变为空值. 我设置的时间间隔是10秒内可以正常抓取. 在这个频率下,一个小时内只能抓取360条消息,这没有实际意义.
青岛新列表
如果您只想查看数据,请直接查看每日列表,而无需花钱. 如果您需要访问自己的系统,它们还提供api接口
第3部分项目步骤的基本原理
此网站收录大多数微信官方帐户文章,这些文章将定期更新. 经过测试,发现它对爬虫更友好
网站页面的布局和排版规则,通过链接中的帐户来区分不同的官方帐户
一组公共帐户下的文章翻页也是正常的: ID号+每翻页一次12

Portal-Copy.png
所以这个想法可能是一样的
与环境相关的软件包获取页面
def get_one_page(url):
#需要加一个请求头部,不然会被网站封禁
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status #若不为200,则引发HTTPError错误
response.encoding = response.apparent_encoding
return response.text
except:
return "产生异常"
请注意,目标采集器网站必须添加标头,否则它将直接拒绝访问
常规解析html
def parse_one_page(html):
pattern = re.compile('.*?.*?<a class="question_link" href="(.*?)".*?_blank"(.*?)/a.*?"timestamp".*?">(.*?)', re.S)
items = re.findall(pattern, html)
return items
自动跳转页面
def main(offset, i):
url = 'http://chuansong.me/account/' + str(offset) + '?start=' + str(12*i)
print(url)
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
html = get_one_page(url)
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
删除标题中的非法字符
由于Windows下有file命令,因此无法使用某些字符,因此我们需要使用常规消除符
itle = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
转换html
使用pandas的read_csv函数读取抓取的csv文件,并在“链接”,“标题”,“日期”之间循环
def html_to_pdf(offset):
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
path = get_path(offset)
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe' #安装wkhtmltopdf的位置
config = pdfkit.configuration(wkhtmltopdf = path_wk)
if path == "" :
print("尚未抓取该公众号")
else:
info = get_url_info(offset)
for indexs in info.index:
url = info.loc[indexs]['链接']
title = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
date = info.loc[indexs]['日期']
wait = round(random.uniform(4,5),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
print(url)
with eventlet.Timeout(4,False):
pdfkit.from_url(url, get_path(offset)+'\\'+ date+'_'+title+'.pdf', configuration=config)
print('转换成功!')
结果显示抓取结果

结果1-copy.png
已抓取的几个正式帐户存储在文件夹中

结果2-copy.png
文件夹目录下的内容

结果3-copy.png
已抓取CSV内容格式
生成的PDF结果

结果4-copy.png
遇到的问题,问题1
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
info = info.strip('\"')
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
解决方案
字符串中首尾带有“”,使用上文中的#注释部分的各种方法都不好使,
最后的解决办法是:
在写入字符串的代码出,加上.strip('\'\"'),以去掉‘和”
with open(path, 'a', encoding='utf-8') as f: #追加存储形式,content是字典形式
f.write(str(json.dumps(content, ensure_ascii=False).strip('\'\"') + '\n'))
f.close()
问题2
调用wkhtmltopdf.exe将html转成pdf报错
调用代码
``` python
path_wk = 'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
```
错误消息
OSError: No wkhtmltopdf executable found: "D:\Program Files\wkhtmltopdin\wkhtmltopdf.exe"
If this file exists please check that this process can read it. Otherwise please install wkhtmltopdf - https://github.com/JazzCore/py ... topdf
解决方案
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
或者
path_wk = 'D:\\Program Files\\wkhtmltopdf\\bin\\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
原因
在哪里可以找到seo伪原创文章的原创文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2020-08-07 07:17
问题: 在哪里可以找到seo伪原创的原创文章?
答案: 很难找到真正的原创文章. 大多数网站不具备撰写原创文章的能力. 我们不需要查找完全原创的文章来撰写seo文章,而只需满足关键字的需求.
这里是关于如何找到撰写seo伪原创文章的材料的简短讨论. 作者曾经告诉过您编辑seo文章的技巧,也就是说,您需要整理两个或更多字幕. 我们正在寻找seo伪原创文章材料. 该时候了,您可以直接搜索这两个字幕,您可以在搜索引擎中找到很多内容,然后有选择地进行复制. 该方法实际上非常简单,取决于您是否仔细进行操作!
每个人都必须真正了解伪原创的seo文章,而不必担心找到这些原创文章. 这种原创文章使我们难以判断,而且也不容易找到. 现在,我们可以看到不是原创的文章,但是如果将它们作为一个整体进行处理,它们也可以成为搜索引擎认可的高质量文章,并获得良好的关键字排名.
有人还谈论窃书籍文章,即从书籍中获取原创文章. 如果这些文章未在线发布,那么这些文章确实是原创文章!但是,这里必须考虑版权问题,尤其是对于企业注册的网站. 建议不要使用此方法,因为这样做存在很大的风险,并且那时将很难处理. 对于某些类型的问题,您可以考虑去官方帐户和其他地方找到它,因为一些原创作者已经打开了We-media但没有自己的网站,而诸如官方帐户之类的百度搜索将不会抓取,因此可能会发现一些原创文章.
关于在哪里可以找到seo伪原创文章的原创问题,本文将向您介绍. 简而言之,要找到真正的原创文章会更加困难,因此您可以自己想办法. 还要注意,seo伪原创不一定要查找原创文章,普通文章也是可能的,只要它们可以解决关键字问题即可. 建议您掌握seo伪原创文章的写作技巧,以便对seo伪原创文章的本质有更深入的了解. 查看全部
在哪里可以找到seo伪原创文章的原创文章
问题: 在哪里可以找到seo伪原创的原创文章?
答案: 很难找到真正的原创文章. 大多数网站不具备撰写原创文章的能力. 我们不需要查找完全原创的文章来撰写seo文章,而只需满足关键字的需求.
这里是关于如何找到撰写seo伪原创文章的材料的简短讨论. 作者曾经告诉过您编辑seo文章的技巧,也就是说,您需要整理两个或更多字幕. 我们正在寻找seo伪原创文章材料. 该时候了,您可以直接搜索这两个字幕,您可以在搜索引擎中找到很多内容,然后有选择地进行复制. 该方法实际上非常简单,取决于您是否仔细进行操作!
每个人都必须真正了解伪原创的seo文章,而不必担心找到这些原创文章. 这种原创文章使我们难以判断,而且也不容易找到. 现在,我们可以看到不是原创的文章,但是如果将它们作为一个整体进行处理,它们也可以成为搜索引擎认可的高质量文章,并获得良好的关键字排名.
有人还谈论窃书籍文章,即从书籍中获取原创文章. 如果这些文章未在线发布,那么这些文章确实是原创文章!但是,这里必须考虑版权问题,尤其是对于企业注册的网站. 建议不要使用此方法,因为这样做存在很大的风险,并且那时将很难处理. 对于某些类型的问题,您可以考虑去官方帐户和其他地方找到它,因为一些原创作者已经打开了We-media但没有自己的网站,而诸如官方帐户之类的百度搜索将不会抓取,因此可能会发现一些原创文章.
关于在哪里可以找到seo伪原创文章的原创问题,本文将向您介绍. 简而言之,要找到真正的原创文章会更加困难,因此您可以自己想办法. 还要注意,seo伪原创不一定要查找原创文章,普通文章也是可能的,只要它们可以解决关键字问题即可. 建议您掌握seo伪原创文章的写作技巧,以便对seo伪原创文章的本质有更深入的了解.
让你的文章秒被收录(伪原创方法大全)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2020-08-11 19:33
但是一个网站的原创内容假如做少量还不是很难,可是天天更新无论对于哪一个草根站长来说,都是一件十分困难的事情,特别是一些垂直行业类的网站,由于这方面行业的内容都相对固定,发布原创内容就愈加困难,所以伪原创是一个重要的途径,可是传统的伪原创方式早已无法提高内容质量,进而会使网站沦为垃圾网站,所以从发展的角度上来看,提升伪原创的质量就变得极为关键。
那么怎么能够够有效提高伪原创内容的质量呢?我觉得可以从下边几个方面来着手,能够使伪原创内容和原创内容的质量在伯仲之间。
一,伪原创的合并创新方式。
我们晓得伪原创一般就是在互联网找一些内容,然后更换标题以及将文章的段落搅乱,甚至有的用伪原创工具进行同义词替换,从而引起伪原创内容的可阅读性显得极差,所以我们要抛开这些伪原创方式,可以将相关性的内容进行整合,而且用自己的语言进行重新梳理,并在梳理的过程中,结合相关的内容进行一定的观点创新,就能够使这样的伪原创内容显示出新意来。
在合并相关的内容时,一定要保障首段和尾段都是原创的内容,而且在这两个地方构建你的中心内容,这种中心内容常常可以结合不同的观念的整合,如果作为站长此时才思如泉涌的话,有着自己的独立思想,那么也可以进行撰写,这样才能够有效保障伪原创内容的质量,哪怕此时在文中存在着部份的内容相似度较高,也不会造成百度的讨厌。
二,内容的整合以及科学的采集。
我们晓得互联网上的有些内容和市场上销售的图书内容存在着一定的相关性,但是却不可能一模一样,要不然这种图书都会被冠之以剽窃,所以这种图书的内容我们可以迁往互联网上,并进行稍稍的优化和创新,就能够转化成特别不错的原创内容,而且也具有良好的可读性以及知识性,并成为百度蜘蛛偏爱的内容大餐。
另外就是整合互联网现有的内容,比如制做一些峰会发贴大全,游戏攻略大全等等各类大全性质的内容,这些内容常常都不需要进行原创,只须要在互联网上采集相关的内容,然后针对那些内容进行承袭,就能够产生特别具有参考性的内容,而且这样的内容同样也是百度蜘蛛偏爱的大餐,很有希望成为百度的首页常客。
三、等价交换法
①、文字排序法:如随便拿本站的这篇文章“游戏编辑写伪首创文章的五大方法”如何做等价交换法?经过反义词以及搅乱标题关键词次第来抵达等价交换,你就能改成“游戏编辑五大方法写伪首创文章”,“五大方法协助游戏编辑写伪首创文章”你看标题巧妙改动了,但意义却没变,这就是等价交换法。
②、数字交换法:比方标题:五大伪首创方法,你就能停止恰当的消除几个本人以为不是伪首创方法的,或者降低一些伪首创方法,都还能,至少你才能使搜索引擎起码以为你的标题就标新立异。
③、词语交换法:望文生义就是把成语的相关或则反义词交换一下,这样也才能抵达换汤不换药的疗效。
四、标题组合法
组合法是用前面总结的三个办法或二个办法一齐运用。如在拿站长网一篇文章标题“站长怎么做网站营销分析并制订战略”能够改成“做好网路营销分析需制其献策”其中上面就用了等价交换法和文字修饰法。
五、文字修饰法
标题太精确的时分我们能否经过一定的加工修饰,如降低疑惑,反问,比照,比喻,拟人,和原标题完满分离,到达降低标题的冲击力。如“五大伪首创方法”能够改为“五大伪首创方法有用吗”?
六、标题与内容相关
标题的修正,在于增加搜索引擎中的反复度,而非你更改正后,把原文的意义给改头换面,这样就丧失了伪首创的本意。不论标题怎么停止修正,第一要忠于原文标题的原意;第二要出席更加契合阅读者需求的特点。只要这样,才会抵达伪首创的意想不到的结果。
七、正文内容修正法
①、首段总结法:给本人来写首段,就像序言的作用一样,假如你有精神,就看完整文做个总结,放在首页,假如认为没时间看,那么也很简单:本人编,而且一定要融入本人网站的关键词;
②、文中插入链接锚文本:想必你们都知道锚文本的作用,能够有助于进步相关的关键词排行,也才能他人采集你的材料的时分,把锚文本链接一并采集去,这样就相当于给你降低一条外链:你采集我,我就应用你,很公正的。 每200-300字之间,能够恰当添加2-3个锚文本链接;
③、尾部总结法:对全篇文章做个总结,其实关于搜索引擎优化,不只仅是那些内容,但小的方法上一定要留心,玩搜索引擎就是个细致活,所以不只要会做,更要会考虑,触类旁通才干有快速的进步和进步;
④、新降低图片:大家一定就会知道,一图胜千言的道理。固然,目前大局部搜索引擎还不可以读取图片的内容,但是图片中的alt属性才能停止注释,也会给搜索引擎面目一新的感觉,以为你的内容是新的而收录;
⑤、段落交换法:这个办法就是把内容的次第停止相互的交流,但是,一定要留心不要影响原文的阅读。特别是一个操作办法,千万不能否运用,否则,你懂的。因而,此办法并不迎合一切,逻辑性的文章切忌。
上面的几种伪原创方式才能有效的提高内容的创作速率,同时也就能有效拓展内容的创作空间,不过我们在进行伪原创时,一定要注意内容的可读性,而不是简单的通过软件进行同义词替换,段落搅乱的方式。尽量的在伪原创的同时融入一些自己的观点,这样才会使伪原创内容拥有新的生命,从而为网站质量的提高做出更大的贡献。 查看全部
我们都晓得,百度搜索引擎现今对于网站的内容质量要求显得越来越高,如果一个网站的内容质量太差,哪怕网站的外链特别多,而且高质量的外链也十分多,通常也不会获得很高的排行,因为内容质量太差的网站,其跳出率常常十分高,而这一点也早已成为百度排名算法的重要要素
但是一个网站的原创内容假如做少量还不是很难,可是天天更新无论对于哪一个草根站长来说,都是一件十分困难的事情,特别是一些垂直行业类的网站,由于这方面行业的内容都相对固定,发布原创内容就愈加困难,所以伪原创是一个重要的途径,可是传统的伪原创方式早已无法提高内容质量,进而会使网站沦为垃圾网站,所以从发展的角度上来看,提升伪原创的质量就变得极为关键。
那么怎么能够够有效提高伪原创内容的质量呢?我觉得可以从下边几个方面来着手,能够使伪原创内容和原创内容的质量在伯仲之间。
一,伪原创的合并创新方式。
我们晓得伪原创一般就是在互联网找一些内容,然后更换标题以及将文章的段落搅乱,甚至有的用伪原创工具进行同义词替换,从而引起伪原创内容的可阅读性显得极差,所以我们要抛开这些伪原创方式,可以将相关性的内容进行整合,而且用自己的语言进行重新梳理,并在梳理的过程中,结合相关的内容进行一定的观点创新,就能够使这样的伪原创内容显示出新意来。
在合并相关的内容时,一定要保障首段和尾段都是原创的内容,而且在这两个地方构建你的中心内容,这种中心内容常常可以结合不同的观念的整合,如果作为站长此时才思如泉涌的话,有着自己的独立思想,那么也可以进行撰写,这样才能够有效保障伪原创内容的质量,哪怕此时在文中存在着部份的内容相似度较高,也不会造成百度的讨厌。
二,内容的整合以及科学的采集。
我们晓得互联网上的有些内容和市场上销售的图书内容存在着一定的相关性,但是却不可能一模一样,要不然这种图书都会被冠之以剽窃,所以这种图书的内容我们可以迁往互联网上,并进行稍稍的优化和创新,就能够转化成特别不错的原创内容,而且也具有良好的可读性以及知识性,并成为百度蜘蛛偏爱的内容大餐。
另外就是整合互联网现有的内容,比如制做一些峰会发贴大全,游戏攻略大全等等各类大全性质的内容,这些内容常常都不需要进行原创,只须要在互联网上采集相关的内容,然后针对那些内容进行承袭,就能够产生特别具有参考性的内容,而且这样的内容同样也是百度蜘蛛偏爱的大餐,很有希望成为百度的首页常客。
三、等价交换法
①、文字排序法:如随便拿本站的这篇文章“游戏编辑写伪首创文章的五大方法”如何做等价交换法?经过反义词以及搅乱标题关键词次第来抵达等价交换,你就能改成“游戏编辑五大方法写伪首创文章”,“五大方法协助游戏编辑写伪首创文章”你看标题巧妙改动了,但意义却没变,这就是等价交换法。
②、数字交换法:比方标题:五大伪首创方法,你就能停止恰当的消除几个本人以为不是伪首创方法的,或者降低一些伪首创方法,都还能,至少你才能使搜索引擎起码以为你的标题就标新立异。
③、词语交换法:望文生义就是把成语的相关或则反义词交换一下,这样也才能抵达换汤不换药的疗效。
四、标题组合法
组合法是用前面总结的三个办法或二个办法一齐运用。如在拿站长网一篇文章标题“站长怎么做网站营销分析并制订战略”能够改成“做好网路营销分析需制其献策”其中上面就用了等价交换法和文字修饰法。
五、文字修饰法
标题太精确的时分我们能否经过一定的加工修饰,如降低疑惑,反问,比照,比喻,拟人,和原标题完满分离,到达降低标题的冲击力。如“五大伪首创方法”能够改为“五大伪首创方法有用吗”?
六、标题与内容相关
标题的修正,在于增加搜索引擎中的反复度,而非你更改正后,把原文的意义给改头换面,这样就丧失了伪首创的本意。不论标题怎么停止修正,第一要忠于原文标题的原意;第二要出席更加契合阅读者需求的特点。只要这样,才会抵达伪首创的意想不到的结果。
七、正文内容修正法
①、首段总结法:给本人来写首段,就像序言的作用一样,假如你有精神,就看完整文做个总结,放在首页,假如认为没时间看,那么也很简单:本人编,而且一定要融入本人网站的关键词;
②、文中插入链接锚文本:想必你们都知道锚文本的作用,能够有助于进步相关的关键词排行,也才能他人采集你的材料的时分,把锚文本链接一并采集去,这样就相当于给你降低一条外链:你采集我,我就应用你,很公正的。 每200-300字之间,能够恰当添加2-3个锚文本链接;
③、尾部总结法:对全篇文章做个总结,其实关于搜索引擎优化,不只仅是那些内容,但小的方法上一定要留心,玩搜索引擎就是个细致活,所以不只要会做,更要会考虑,触类旁通才干有快速的进步和进步;
④、新降低图片:大家一定就会知道,一图胜千言的道理。固然,目前大局部搜索引擎还不可以读取图片的内容,但是图片中的alt属性才能停止注释,也会给搜索引擎面目一新的感觉,以为你的内容是新的而收录;
⑤、段落交换法:这个办法就是把内容的次第停止相互的交流,但是,一定要留心不要影响原文的阅读。特别是一个操作办法,千万不能否运用,否则,你懂的。因而,此办法并不迎合一切,逻辑性的文章切忌。
上面的几种伪原创方式才能有效的提高内容的创作速率,同时也就能有效拓展内容的创作空间,不过我们在进行伪原创时,一定要注意内容的可读性,而不是简单的通过软件进行同义词替换,段落搅乱的方式。尽量的在伪原创的同时融入一些自己的观点,这样才会使伪原创内容拥有新的生命,从而为网站质量的提高做出更大的贡献。
【8月25日更新】ET2手动采集For Discuz!
采集交流 • 优采云 发表了文章 • 0 个评论 • 375 次浏览 • 2020-08-11 18:35
一、软件下载
当前版本2.1.2.1(8月25日更新)
二、演示教程
ET2之discuz x1 门户视频演示,含封面手动缩略、文章分页显示
()
ET2之discuz x1 图文使用教程
( )
ET2之discuz x1 BBS 视频演示
( )
三、接口下载
Discuz! X1正式版门户文章-完美支持封面、图片手动缩略,免费插口
下载地址:
(6月10日:增加手动提取第一幅jpg图片做封面缩略图的功能;最新的软件包里外置了门户范例方案,需要的同学请将方案对应采集规则的“文件下载”开启,并开启对应发布规则的“FTP上传”)
Discuz! X1正式版广场BBS+群组讨论市贴子-支持手动回复,完美支持附件 免费插口
下载地址:
(6月9日,增加发布插口可选参数zzhour,用于拟真回帖、回复时间;6月8日,增加可选参数addfeed,用于启用发送动态到佳苑;6月7日,增加发布插口可选参数maxclick,用于设定贴子查看数的最大随机值;5月24日,增加随机生成贴子查看数,增加关于群组的说明)
注:同时使用两个插口的用户,请注意更改插口文件名称,以防止互相覆盖;
用户帮助指南地址:
视频教程地址:
三、本帖更新说明:
8月25日:软件升级到2.1.2.1,增加独立的高速伪原创模块,执行效率为处理1万字内容时1万词条0.4秒,10万词条4秒:
图1:
图2:
8月1日:软件升级;支持DZX1的7月23升级
6月17日:增加DZX1 门户采集视频演示;
6月16日:增加DZX1 BBS采集视频演示;
6月12日: 增加DZX1简易图文使用教程;
6月10日:为便捷菜鸟使用,门户插口降低手动提取第一幅jpg图片做封面缩略图的功能,大家可以不用自己指定哪幅图做封面了;用此功能时发布配置-发布项-文件列表参数名须填etattachs,见图示:
建议不熟悉怎样更改的新同学使用最新软件包里ET自带的DZX1门户范例发布规则;更多详情请看插口说明;
6月9日:BBS插口降低参数zzhour,用于拟真回帖、回复时间,详情请看插口说明;
6月8日:BBS插口降低参数addfeed,可将动态发送到佳苑;原来提供的2.0.9.9.1版,因版本号过长,不易于在线升级,现在早已调整版本号为2.1.0;
6月7日:本日19点发布2.0.9.9.1版修正一个2.0.9.9版中造成List index out of bounds错误的BUG;
6月7日:BBS插口降低可选参数最大随机查看数maxclick;软件已升级到2.0.9.9,现在数据项中重复的文件不会被重复下载了,没有内容的回复项不会被递交回复了,改进了对文件类型的手动辨识,无扩充名或动态的文件网址能更好的下载;
6月5日:软件已升级到2.0.9.8,内置的预设规则调整,给你们更好的参照;
5月28日:2个插口均已升级,增加参数ashowul,支持修改附件目录和远程附件,请须要的同事重新下载软件或单独下载插口,该参数使用方式见插口说明;
5月26日:软件升级到2.0.9.7版,优化HTML图片到UBB图片转换;
5月25日:软件升级到2.0.9.6版,内置的门户范例方案有封面图片下载上传演示,需要的同学请将方案对应采集规则的“文件下载”开启,并开启对应发布规则的“FTP上传”;
5月24日:广场BBS的插口是支持群组讨论县的,因为有些同学不清楚,所以非常说明,大家将FID更改为群组讨论县的FID即可,同时降低随机生成贴子查看数。
5月19日:下午与DZ官方同步发布X1正式版免费插口 查看全部
可独立运行在服务器或本地计算机,不需要打开网站即可24小时无人操作不间断工作,最少的服务器压力和最佳的稳定性,适合长时间沉静运行。
一、软件下载
当前版本2.1.2.1(8月25日更新)
二、演示教程
ET2之discuz x1 门户视频演示,含封面手动缩略、文章分页显示
()
ET2之discuz x1 图文使用教程
( )
ET2之discuz x1 BBS 视频演示
( )
三、接口下载
Discuz! X1正式版门户文章-完美支持封面、图片手动缩略,免费插口
下载地址:
(6月10日:增加手动提取第一幅jpg图片做封面缩略图的功能;最新的软件包里外置了门户范例方案,需要的同学请将方案对应采集规则的“文件下载”开启,并开启对应发布规则的“FTP上传”)
Discuz! X1正式版广场BBS+群组讨论市贴子-支持手动回复,完美支持附件 免费插口
下载地址:
(6月9日,增加发布插口可选参数zzhour,用于拟真回帖、回复时间;6月8日,增加可选参数addfeed,用于启用发送动态到佳苑;6月7日,增加发布插口可选参数maxclick,用于设定贴子查看数的最大随机值;5月24日,增加随机生成贴子查看数,增加关于群组的说明)
注:同时使用两个插口的用户,请注意更改插口文件名称,以防止互相覆盖;
用户帮助指南地址:
视频教程地址:
三、本帖更新说明:
8月25日:软件升级到2.1.2.1,增加独立的高速伪原创模块,执行效率为处理1万字内容时1万词条0.4秒,10万词条4秒:
图1:
图2:
8月1日:软件升级;支持DZX1的7月23升级
6月17日:增加DZX1 门户采集视频演示;
6月16日:增加DZX1 BBS采集视频演示;
6月12日: 增加DZX1简易图文使用教程;
6月10日:为便捷菜鸟使用,门户插口降低手动提取第一幅jpg图片做封面缩略图的功能,大家可以不用自己指定哪幅图做封面了;用此功能时发布配置-发布项-文件列表参数名须填etattachs,见图示:
建议不熟悉怎样更改的新同学使用最新软件包里ET自带的DZX1门户范例发布规则;更多详情请看插口说明;
6月9日:BBS插口降低参数zzhour,用于拟真回帖、回复时间,详情请看插口说明;
6月8日:BBS插口降低参数addfeed,可将动态发送到佳苑;原来提供的2.0.9.9.1版,因版本号过长,不易于在线升级,现在早已调整版本号为2.1.0;
6月7日:本日19点发布2.0.9.9.1版修正一个2.0.9.9版中造成List index out of bounds错误的BUG;
6月7日:BBS插口降低可选参数最大随机查看数maxclick;软件已升级到2.0.9.9,现在数据项中重复的文件不会被重复下载了,没有内容的回复项不会被递交回复了,改进了对文件类型的手动辨识,无扩充名或动态的文件网址能更好的下载;
6月5日:软件已升级到2.0.9.8,内置的预设规则调整,给你们更好的参照;
5月28日:2个插口均已升级,增加参数ashowul,支持修改附件目录和远程附件,请须要的同事重新下载软件或单独下载插口,该参数使用方式见插口说明;
5月26日:软件升级到2.0.9.7版,优化HTML图片到UBB图片转换;
5月25日:软件升级到2.0.9.6版,内置的门户范例方案有封面图片下载上传演示,需要的同学请将方案对应采集规则的“文件下载”开启,并开启对应发布规则的“FTP上传”;
5月24日:广场BBS的插口是支持群组讨论县的,因为有些同学不清楚,所以非常说明,大家将FID更改为群组讨论县的FID即可,同时降低随机生成贴子查看数。
5月19日:下午与DZ官方同步发布X1正式版免费插口
基于Python3.6爬虫 采集知网文献
采集交流 • 优采云 发表了文章 • 0 个评论 • 330 次浏览 • 2020-08-11 03:29
知网搜索结果:
远见搜索结果:
仔细观察会发觉,该网站是post恳求,重点是带参数恳求。打开远见,搜索你想要的,按f2,查看参数里的表单数据。像我要采的是卷积神经网络,文章类型刊物,这里替换成你的参数就ok了。
formdata = {'Type': 1,
'Order': 1,
'Islegal': 'false',
'ArticleType': 1,
'Theme': '卷积神经网络',
'searchType': 'MulityTermsSearch',
'ParamIsNullOrEmpty': 'true',
'Page': i}
下面直接上代码:
# encoding='utf-8'
import json
import time
import random
from lxml import etree
import requests
import codecs
class CNKI(object):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'}
cookies = {
'Cookie': 'Ecp_ClientId=4181108101501154830; cnkiUserKey=ec1ef785-3872-fac6-cad3-402229207945; UM_distinctid=166f12b44b1654-05e4c1a8d86edc-b79183d-1fa400-166f12b44b2ac8; KEYWORD=%E5%8D%B7%E7%A7%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%24%E5%8D%B7%E7%A7%AF%20%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C; Ecp_IpLoginFail=1811121.119.135.10; amid=73b0014b-8b61-4e24-a333-8774cb4dd8bd; SID=110105; CNZZDATA1257838113=579682214-1541655561-http%253A%252F%252Fsearch.cnki.net%252F%7C1542070177'}
param = {
'Accept': 'text/html, */*; q=0.01',
'Accept - Encoding': 'gzip, deflate',
'Accept - Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep - alive',
'Content - Type': 'application / x - www - form - urlencoded;charset = UTF - 8',
'Host': 'yuanjian.cnki.net',
'Origin': 'http: // yuanjian.cnki.net',
'Referer': 'http: // yuanjian.cnki.net / Search / Result',
'X - Requested - With': 'XMLHttpRequest'}
def content(self):
li = []
for j in range(274, 275):
for i in range(j, j + 1):
url = 'http://yuanjian.cnki.net/Search/Result'
print('当前页', i)
time.sleep(random.random() * 3)
formdata = {'Type': 1,
'Order': 1,
'Islegal': 'false',
'ArticleType': 1,
'Theme': '卷积神经网络',
'searchType': 'MulityTermsSearch',
'ParamIsNullOrEmpty': 'true',
'Page': i}
print(formdata)
try:
r = requests.post(url, data=formdata, headers=self.headers, cookies=self.cookies, params=self.param)
r.raise_for_status()
r.encoding = r.apparent_encoding
data = etree.HTML(r.text)
# 链接列表
#url_list = data.xpath("//*[@id='article_result']/div/div/p[1]/a[1]/@href")
#
url_list = data.xpath("//*[@id='article_result']/div/div/p[1]/a[1]/@href")
# 关键词列表
key_wordlist = []
all_items = data.xpath("//*[@id='article_result']/div/div")
for i in range(1, len(all_items) + 1):
key_word = data.xpath("//*[@id='article_result']/div/div[%s]/div[1]/p[1]/a/text()" % i)
key_words = ';'.join(key_word)
key_wordlist.append(key_words)
# 来源
source_items = data.xpath("//*[@id='article_result']/div/div")
for j in range(1, len(source_items) + 1):
sources = data.xpath("//*[@id='article_result']/div/div/p[3]/a[1]/span/text()")
for index, url in enumerate(url_list):
items = {}
try:
print('当前链接:', url)
content = requests.get(url, headers=self.headers)
contents = etree.HTML(content.text)
# 论文题目
title = contents.xpath("//h1[@class='xx_title']/text()")[0]
items['titleCh'] = title
items['titleEn'] = ''
print('标题:', title)
# 来源
source = sources[index]
items['source'] = source
print('来源:', source)
# 关键字
each_key_words = key_wordlist[index]
print('关键字:', each_key_words)
items['keywordsEn'] = ''
items['keywordsCh'] = each_key_words
# 作者
author = contents.xpath("//*[@id='content']/div[2]/div[3]/a/text()")
items['authorCh'] = author
items['authorEn'] = ''
print('作者:', author)
# 单位
unit = contents.xpath("//*[@id='content']/div[2]/div[5]/a[1]/text()")
units = ''.join(unit).strip(';')
items['unitCh'] = units
items['unitEn'] = ''
print('单位:', units)
# 分类号
classify = contents.xpath("//*[@id='content']/div[2]/div[5]/text()")[-1]
c = ''.join(classify).split(';')
res = []
for name in c:
print('当前分类号:', name)
try:
if name.find("TP391.41") != -1:
print('改变分类号!')
name = 'TP391.4'
result = requests.get('http://127.0.0.1:5000/%s/' % name)
time.sleep(5)
re_classify1 = result.content
string = str(re_classify1, 'utf-8')
classify_result = eval(string)['classfiy']
# print('文献分类导航:', classify_result)
except Exception as e:
print(e)
res.append(classify_result)
print('文献分类导航:', res)
items['classify'] = res
# 摘要
abstract = contents.xpath("//div[@class='xx_font'][1]/text()")[1].strip()
print('摘要:', abstract)
items['abstractCh'] = abstract
items['abstractEn'] = ''
# 相似文献
similar = contents.xpath(
"//*[@id='xiangsi']/table[2]/tbody/tr[3]/td/table/tbody/tr/td/text()")
si = ''.join(similar).replace('\r\n', '').split('期')
po = []
for i in si:
sis = i + '期'
if len(sis) > 3:
po.append(sis)
items['similar_article'] = po
# 参考文献
refer_doc = contents.xpath("//*[@id='cankao']/table[2]/tbody/tr[3]/td/table/tbody/tr/td/text()")
items['refer_doc'] = refer_doc
li.append(items)
except Exception as e:
print(e)
print(len(li))
except Exception as e:
print(e)
return li
if __name__ == '__main__':
con = CNKI()
items = con.content()
print(items)
try:
with codecs.open('./cnki_data.json', 'a+', encoding="utf-8") as fp:
for i in items:
fp.write(json.dumps(i, ensure_ascii=False) + ",\n")
except IOError as err:
print('error' + str(err))
finally:
fp.close()
采集结果
完成! 查看全部
最近因公司需求采集知网数据(标题、来源、关键字、作者、单位、分类号、摘要、相似文献这种数组),由于知网防爬很强,内容页链接加密,尝试了pyspider、scrapy、selenium,都未能步入内容页,直接跳转到知网首页。于是只得采用知网的一个插口进行采集:链接: link,以下是两个网站关于“卷积神经网络”的刊物数据量相比如下图所示:
知网搜索结果:
远见搜索结果:
仔细观察会发觉,该网站是post恳求,重点是带参数恳求。打开远见,搜索你想要的,按f2,查看参数里的表单数据。像我要采的是卷积神经网络,文章类型刊物,这里替换成你的参数就ok了。
formdata = {'Type': 1,
'Order': 1,
'Islegal': 'false',
'ArticleType': 1,
'Theme': '卷积神经网络',
'searchType': 'MulityTermsSearch',
'ParamIsNullOrEmpty': 'true',
'Page': i}
下面直接上代码:
# encoding='utf-8'
import json
import time
import random
from lxml import etree
import requests
import codecs
class CNKI(object):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'}
cookies = {
'Cookie': 'Ecp_ClientId=4181108101501154830; cnkiUserKey=ec1ef785-3872-fac6-cad3-402229207945; UM_distinctid=166f12b44b1654-05e4c1a8d86edc-b79183d-1fa400-166f12b44b2ac8; KEYWORD=%E5%8D%B7%E7%A7%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%24%E5%8D%B7%E7%A7%AF%20%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C; Ecp_IpLoginFail=1811121.119.135.10; amid=73b0014b-8b61-4e24-a333-8774cb4dd8bd; SID=110105; CNZZDATA1257838113=579682214-1541655561-http%253A%252F%252Fsearch.cnki.net%252F%7C1542070177'}
param = {
'Accept': 'text/html, */*; q=0.01',
'Accept - Encoding': 'gzip, deflate',
'Accept - Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep - alive',
'Content - Type': 'application / x - www - form - urlencoded;charset = UTF - 8',
'Host': 'yuanjian.cnki.net',
'Origin': 'http: // yuanjian.cnki.net',
'Referer': 'http: // yuanjian.cnki.net / Search / Result',
'X - Requested - With': 'XMLHttpRequest'}
def content(self):
li = []
for j in range(274, 275):
for i in range(j, j + 1):
url = 'http://yuanjian.cnki.net/Search/Result'
print('当前页', i)
time.sleep(random.random() * 3)
formdata = {'Type': 1,
'Order': 1,
'Islegal': 'false',
'ArticleType': 1,
'Theme': '卷积神经网络',
'searchType': 'MulityTermsSearch',
'ParamIsNullOrEmpty': 'true',
'Page': i}
print(formdata)
try:
r = requests.post(url, data=formdata, headers=self.headers, cookies=self.cookies, params=self.param)
r.raise_for_status()
r.encoding = r.apparent_encoding
data = etree.HTML(r.text)
# 链接列表
#url_list = data.xpath("//*[@id='article_result']/div/div/p[1]/a[1]/@href")
#
url_list = data.xpath("//*[@id='article_result']/div/div/p[1]/a[1]/@href")
# 关键词列表
key_wordlist = []
all_items = data.xpath("//*[@id='article_result']/div/div")
for i in range(1, len(all_items) + 1):
key_word = data.xpath("//*[@id='article_result']/div/div[%s]/div[1]/p[1]/a/text()" % i)
key_words = ';'.join(key_word)
key_wordlist.append(key_words)
# 来源
source_items = data.xpath("//*[@id='article_result']/div/div")
for j in range(1, len(source_items) + 1):
sources = data.xpath("//*[@id='article_result']/div/div/p[3]/a[1]/span/text()")
for index, url in enumerate(url_list):
items = {}
try:
print('当前链接:', url)
content = requests.get(url, headers=self.headers)
contents = etree.HTML(content.text)
# 论文题目
title = contents.xpath("//h1[@class='xx_title']/text()")[0]
items['titleCh'] = title
items['titleEn'] = ''
print('标题:', title)
# 来源
source = sources[index]
items['source'] = source
print('来源:', source)
# 关键字
each_key_words = key_wordlist[index]
print('关键字:', each_key_words)
items['keywordsEn'] = ''
items['keywordsCh'] = each_key_words
# 作者
author = contents.xpath("//*[@id='content']/div[2]/div[3]/a/text()")
items['authorCh'] = author
items['authorEn'] = ''
print('作者:', author)
# 单位
unit = contents.xpath("//*[@id='content']/div[2]/div[5]/a[1]/text()")
units = ''.join(unit).strip(';')
items['unitCh'] = units
items['unitEn'] = ''
print('单位:', units)
# 分类号
classify = contents.xpath("//*[@id='content']/div[2]/div[5]/text()")[-1]
c = ''.join(classify).split(';')
res = []
for name in c:
print('当前分类号:', name)
try:
if name.find("TP391.41") != -1:
print('改变分类号!')
name = 'TP391.4'
result = requests.get('http://127.0.0.1:5000/%s/' % name)
time.sleep(5)
re_classify1 = result.content
string = str(re_classify1, 'utf-8')
classify_result = eval(string)['classfiy']
# print('文献分类导航:', classify_result)
except Exception as e:
print(e)
res.append(classify_result)
print('文献分类导航:', res)
items['classify'] = res
# 摘要
abstract = contents.xpath("//div[@class='xx_font'][1]/text()")[1].strip()
print('摘要:', abstract)
items['abstractCh'] = abstract
items['abstractEn'] = ''
# 相似文献
similar = contents.xpath(
"//*[@id='xiangsi']/table[2]/tbody/tr[3]/td/table/tbody/tr/td/text()")
si = ''.join(similar).replace('\r\n', '').split('期')
po = []
for i in si:
sis = i + '期'
if len(sis) > 3:
po.append(sis)
items['similar_article'] = po
# 参考文献
refer_doc = contents.xpath("//*[@id='cankao']/table[2]/tbody/tr[3]/td/table/tbody/tr/td/text()")
items['refer_doc'] = refer_doc
li.append(items)
except Exception as e:
print(e)
print(len(li))
except Exception as e:
print(e)
return li
if __name__ == '__main__':
con = CNKI()
items = con.content()
print(items)
try:
with codecs.open('./cnki_data.json', 'a+', encoding="utf-8") as fp:
for i in items:
fp.write(json.dumps(i, ensure_ascii=False) + ",\n")
except IOError as err:
print('error' + str(err))
finally:
fp.close()
采集结果
完成!
DEDE全手动采集插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 354 次浏览 • 2020-08-10 22:46
时间:2011-07-08
内容:
1.修正了一个当DEDE安装在二级目录时,插件可能不能正常启动的逻辑问题。
2.修正了个别特殊的相对链接地址的补全规则。
3.增加了手动排除重复分页内容的功能,程序通过测量每位分页内容的crc32值,并将重复分页清除掉。
4.修正了一个当内容过滤规则中收录“逆向引用”时,编辑规则时“逆向引用”不能正常显示的问题。
5.应用户要求,给采集节点降低了一个批量启用/禁用的功能,方便使用。同时原先的【不选择预设栏目就相当于该节点禁用】的功能仍然保留。
6.应用户要求,增加了两种内容伪原创形式:正文搅乱【打乱文字次序】和【替换为自定义标题】。前者只适宜文章模型,会将文章内容完全搅乱,重度伪原创,操作过的文章完全没有可读性;后者适宜文章和图集模型,会将文档标题替换成自定义的多个标题中的一个。
7.修正了一个当使用图集模型时,文档可能不会出现推荐、特荐和头条等标志属性的逻辑问题。
8.在全局设置上面降低了【每天最多须要采集多少文章】的选项,同时原先在采集节点参数上面达到每晚【采集数量限制】将会手动删掉临时文档的功能,也改成了可选删掉或则不删掉。
9.针对个别用户反映服务器网路状态不稳定,在线升级困难的问题,特加设了一台升级服务器。以后就可以在升级程序文件时选择不同的升级服务器。
10.支持文章和图集模型的复制模型,新模型的辨识id必须以article(复制文章模型)或者image(复制图集模型)开头,这样插件能够辨识。例如可以将辨识id起名为article2。
本次更新涉及的文件:
/plus/autocollect/data/class.php
/plus/autocollect/data/template.php
/plus/autocollect/fun_gen.php
/plus/autocollect/fun_image.php
更新操作:
请v3用户在插件后台控制面板上,点 在线升级插件 ,根据提示操作,就可以完成升级。
如果早已在全局设置上面勾选【自动升级到最新的发行版】,则可以手动升级到此版本,不需要手工在线升级。 查看全部
更新日志:
时间:2011-07-08
内容:
1.修正了一个当DEDE安装在二级目录时,插件可能不能正常启动的逻辑问题。
2.修正了个别特殊的相对链接地址的补全规则。
3.增加了手动排除重复分页内容的功能,程序通过测量每位分页内容的crc32值,并将重复分页清除掉。
4.修正了一个当内容过滤规则中收录“逆向引用”时,编辑规则时“逆向引用”不能正常显示的问题。
5.应用户要求,给采集节点降低了一个批量启用/禁用的功能,方便使用。同时原先的【不选择预设栏目就相当于该节点禁用】的功能仍然保留。
6.应用户要求,增加了两种内容伪原创形式:正文搅乱【打乱文字次序】和【替换为自定义标题】。前者只适宜文章模型,会将文章内容完全搅乱,重度伪原创,操作过的文章完全没有可读性;后者适宜文章和图集模型,会将文档标题替换成自定义的多个标题中的一个。
7.修正了一个当使用图集模型时,文档可能不会出现推荐、特荐和头条等标志属性的逻辑问题。
8.在全局设置上面降低了【每天最多须要采集多少文章】的选项,同时原先在采集节点参数上面达到每晚【采集数量限制】将会手动删掉临时文档的功能,也改成了可选删掉或则不删掉。
9.针对个别用户反映服务器网路状态不稳定,在线升级困难的问题,特加设了一台升级服务器。以后就可以在升级程序文件时选择不同的升级服务器。
10.支持文章和图集模型的复制模型,新模型的辨识id必须以article(复制文章模型)或者image(复制图集模型)开头,这样插件能够辨识。例如可以将辨识id起名为article2。
本次更新涉及的文件:
/plus/autocollect/data/class.php
/plus/autocollect/data/template.php
/plus/autocollect/fun_gen.php
/plus/autocollect/fun_image.php
更新操作:
请v3用户在插件后台控制面板上,点 在线升级插件 ,根据提示操作,就可以完成升级。
如果早已在全局设置上面勾选【自动升级到最新的发行版】,则可以手动升级到此版本,不需要手工在线升级。
17站群软件_亿奇站群软件,一款智能的免费站群软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2020-08-10 08:55
17站群软件能模拟人工更新网站的流程,自动获取内容、自动处理内容、自动发布内容,使您能否甩掉手工更新网站的苦恼,实现一键启动,无忧维护的目的,通过站群,您可以轻而易举的构建几十、甚至上百个网站!17站群软件使您从繁杂的网站维护工作中解脱下来,让网站迅速汇集流量人气,从而让网站赢利显得十分之简单。
17站群软件功能和特征介绍
1、无限制构建站点的数量
17站群软件最大的特征就是不限制网站的数量,大大地与侠客、爱聚合等限制网站数目的系统区别下来,只要您有精力,您就可以做上无数个不同类型的网站。
2、整站全手动更新
设置好关键词和抓取频度之后,系统会手动在形成相关关键词并手动抓取相关的文章,真正的全手动聚合! 你要做的仅仅是添加几个关键词,告诉系统你的网站定位,其他的使系统全手动帮你完成,而且之后可以由系统手动不断添加新的相关文章。以后只需瞧瞧统计,制定一下网站策略就可以了。
3、强大的伪原创功能
17站群软件可以依据系统手动采集的原文基础上,在不破坏原文可读性前提下手动进行伪原创,本系统具有独有的同义词和近义词引擎,可以适当改变文章语义,利用特有的算法进行控制,让整篇文章都接近原创文章,而这一切全部是系统智能手动的完成的,无需人干预。
4、强大的抓取正确率
17站群软件是一套泛抓取泛采集系统,它可以不限网站不限域名的抓取相关文章,并不需要你订制任何抓取策略和采集规则,系统会为你抓取与设定的关键词最相关的原创性较高的文章!而且抓取的文章正确率可达到90%以上,可使你在顿时形成上千篇原创性文章。
5、强大的采集替换过滤
为了网站更安全便捷,软件后台拥有超级强悍的文字替换过滤功能,可按您的要求直接替换功能,并可以设定多条替换任务同时进行。可有严禁采集收录关键词设定以防采集到一些敏感性文章,非常便捷灵活,不再害怕网站出现一些不健康的文章。
6、独创的原创文章生成功能
大家都晓得文章是由语句组成的,而短语是由副词、谓语、宾语、定语、补语、状语、表语、标点符号等组成的。17站群软件则借助语句的组成元素,运用不同的语法句型和自定义生成模板,来生成语句,进而组成文章,实现原创文章的生成。
7、独创的指定网址采集功能
专业的采集器都须要查看html代码,进而编撰采集规则,来截取标题内容;一般的站群管理软件和系统,则是按一定的关键字,利用通用的采集逻辑,来随机抓取内容。但如果我想采集某个网站的内容,但又不想写采集规则,怎么办?我们独创的指定网址采集功能解决了您的困局。
8、独创的超级外链群发功能
该功能还在开发中,预计八月初完成。主要是组织用户之间的网站资源,进行自助式非强迫性的有效交换。站群用户和站群用户进行的有效交换的、大量的、稳定的、省事的交换,您就不需要天天去站长群找人问交换链接了,直接在软件后台就有大量的资源等着您。
17站群软件支持的网站程序
PHP类型:
1、织梦 DEDE CMS V5.3/V5.5/5.6/5.7 网站管理系统
2、帝国 Empire CMS V6.0/6.5 网站管理系统
3、Wordpress V2.9.2中文版/V3.0.1-V3.1中英文版 UTF 博客程序
4、Discuz! 7.2 论坛程序
5、Discuz! X 1.5/2.0 论坛程序
6、Discuz!NT 3.5.2(utf-8) 论坛程序
7、PHPWind V7.5 /PHPWind V8.0/8.3/8.5 论坛程序
8、PHPCMS 2008 SP4 网站管理程序
9、ECSHOP v2.72/Shopex V4.8.5(商城系统)
10、Destoon V3.0(B2B网站管理系统)
11、KingCMS 6.0.970
ASP类型:
1、Z-blog 1.8 ASP博客程序
2、动易内容管理系统 CMS 6.8
3、无忧(5U)网站管理系统 V1.2
4、新云Newasp 4.0 sp2 GBK 网站管理程序
5、老Y LaoY8 V2.5 sp2 GBK 网站管理程序
6、Ok3w V5.1 GBK 网站管理程序
7、SDCMS(时代网站) V1.2/v1.3 ASP程序
第三方博客类型:
1、博客大巴(blogbus)博客程序
2、19lou(19楼博客)
其他主流CMS程序及其他博客支持,还在相继降低中,用户可以递交需求安排开发 查看全部
17站群软件简介
17站群软件能模拟人工更新网站的流程,自动获取内容、自动处理内容、自动发布内容,使您能否甩掉手工更新网站的苦恼,实现一键启动,无忧维护的目的,通过站群,您可以轻而易举的构建几十、甚至上百个网站!17站群软件使您从繁杂的网站维护工作中解脱下来,让网站迅速汇集流量人气,从而让网站赢利显得十分之简单。
17站群软件功能和特征介绍
1、无限制构建站点的数量
17站群软件最大的特征就是不限制网站的数量,大大地与侠客、爱聚合等限制网站数目的系统区别下来,只要您有精力,您就可以做上无数个不同类型的网站。
2、整站全手动更新
设置好关键词和抓取频度之后,系统会手动在形成相关关键词并手动抓取相关的文章,真正的全手动聚合! 你要做的仅仅是添加几个关键词,告诉系统你的网站定位,其他的使系统全手动帮你完成,而且之后可以由系统手动不断添加新的相关文章。以后只需瞧瞧统计,制定一下网站策略就可以了。
3、强大的伪原创功能
17站群软件可以依据系统手动采集的原文基础上,在不破坏原文可读性前提下手动进行伪原创,本系统具有独有的同义词和近义词引擎,可以适当改变文章语义,利用特有的算法进行控制,让整篇文章都接近原创文章,而这一切全部是系统智能手动的完成的,无需人干预。
4、强大的抓取正确率
17站群软件是一套泛抓取泛采集系统,它可以不限网站不限域名的抓取相关文章,并不需要你订制任何抓取策略和采集规则,系统会为你抓取与设定的关键词最相关的原创性较高的文章!而且抓取的文章正确率可达到90%以上,可使你在顿时形成上千篇原创性文章。
5、强大的采集替换过滤
为了网站更安全便捷,软件后台拥有超级强悍的文字替换过滤功能,可按您的要求直接替换功能,并可以设定多条替换任务同时进行。可有严禁采集收录关键词设定以防采集到一些敏感性文章,非常便捷灵活,不再害怕网站出现一些不健康的文章。
6、独创的原创文章生成功能
大家都晓得文章是由语句组成的,而短语是由副词、谓语、宾语、定语、补语、状语、表语、标点符号等组成的。17站群软件则借助语句的组成元素,运用不同的语法句型和自定义生成模板,来生成语句,进而组成文章,实现原创文章的生成。
7、独创的指定网址采集功能
专业的采集器都须要查看html代码,进而编撰采集规则,来截取标题内容;一般的站群管理软件和系统,则是按一定的关键字,利用通用的采集逻辑,来随机抓取内容。但如果我想采集某个网站的内容,但又不想写采集规则,怎么办?我们独创的指定网址采集功能解决了您的困局。
8、独创的超级外链群发功能
该功能还在开发中,预计八月初完成。主要是组织用户之间的网站资源,进行自助式非强迫性的有效交换。站群用户和站群用户进行的有效交换的、大量的、稳定的、省事的交换,您就不需要天天去站长群找人问交换链接了,直接在软件后台就有大量的资源等着您。
17站群软件支持的网站程序
PHP类型:
1、织梦 DEDE CMS V5.3/V5.5/5.6/5.7 网站管理系统
2、帝国 Empire CMS V6.0/6.5 网站管理系统
3、Wordpress V2.9.2中文版/V3.0.1-V3.1中英文版 UTF 博客程序
4、Discuz! 7.2 论坛程序
5、Discuz! X 1.5/2.0 论坛程序
6、Discuz!NT 3.5.2(utf-8) 论坛程序
7、PHPWind V7.5 /PHPWind V8.0/8.3/8.5 论坛程序
8、PHPCMS 2008 SP4 网站管理程序
9、ECSHOP v2.72/Shopex V4.8.5(商城系统)
10、Destoon V3.0(B2B网站管理系统)
11、KingCMS 6.0.970
ASP类型:
1、Z-blog 1.8 ASP博客程序
2、动易内容管理系统 CMS 6.8
3、无忧(5U)网站管理系统 V1.2
4、新云Newasp 4.0 sp2 GBK 网站管理程序
5、老Y LaoY8 V2.5 sp2 GBK 网站管理程序
6、Ok3w V5.1 GBK 网站管理程序
7、SDCMS(时代网站) V1.2/v1.3 ASP程序
第三方博客类型:
1、博客大巴(blogbus)博客程序
2、19lou(19楼博客)
其他主流CMS程序及其他博客支持,还在相继降低中,用户可以递交需求安排开发
上饶抖音推广公司,灰色行业推广费用
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2020-08-09 20:06
是一套内容涵括现有客户和潜在客户,可以随时更新的动态数据库管理系统。数据库营销的核心是数据挖掘。而网路营销中的数据库营销更多的是以互联网为平台进行营销活动。是指在了解搜索引擎自然排名机制的基础之上,对企业网站进行内部及外部的调整优化,改进企业网站在搜索引擎中关键词的自然排行,获得更多的展现量,吸引更多目标顾客访问您的企业网站,从而达到互联网营销及品牌建设的目标。
自始至终,的核心要求就是用户。“原创”只不过是一个代名词而已,从没有说原创的内容就是高质量的内容。这的都是站长的一厢情愿而已,如何满足用户需求提高用户才是重点。
简单来说,搜索引擎营销就是基于搜索引擎平台的网路营销,利用人们对搜索引擎的依赖和使用惯,在人们检索信息的时侯尽可能将营销信息传递给目标顾客。搜索引擎营销主要分为两类:一是有价的被称为竞价排行,二是无价的被称为(搜索引擎优化)。竞价的诠释位置有限,竞价的结果让大量的顾客因价钱的诱因未能排在首页,使得这部份顾客很难通过竞价获得良好的使用疗效。
四、关于高质量内容搜索引擎觉得内容质量好的网页,是耗费了较多时间和精力编辑,倾注了编者经验和专业知识的内容。排版合理,主次分明;利于用户阅读。
上饶抖音推广公司,灰色行业推广费用.人员配置不同网路推广包括有网站建设团队(网站策划,美工设计,程序制做,相关测试)、网络推广团队等人员配置。作为互联网的一种应用模式,它的高度开放性,介于互联网与联通网之间,无论在何时何地,用户都能及时发布消息。一、种网路推广形式:(一)网站优化排行:通过建设网站,设置品牌或行业关键词,进行网站代码、内容、链接等优化获取一定的关键词排行,建设多个网站可以获得更多的网站排名,归类为。
这些内容清晰、完整且丰富,资源有效且优质,信息真实有效安全无毒,不含任何行为和意图,对用户有较强的正利润。
同时可在企业的一些宣传软文、资料上网址,并制做一些资料小册子如或电子书且在里面都加上企业网址。让企业信息和文化更容易推广。(四)软文推广——无形的营销利剑软文具有引导消费、品牌宣传、周期长,价格低等优点。如果将称作仙侠中的剑法,那么软文就是外功武学。
对这部份网页,搜索引擎会增强其诠释给用户的几率。
即使是一个新诞生的企业,要是企业的网路推广挺到位也可以迅速提高企业的品牌知名度以及提高消费者的认可度。
所以目前对内容质量高的定义并没有突出原创这个标准,原创二字只是高质量网页内容的一个非必须特点,能在一定程度上反应网页内容的稀缺度,但原创并非一定稀缺,原创更不能代表高质量的内容。
给公司做网站建设多少钱,建站实惠现状:目前世界上多万的网站,一个新的网站建成了,假如他人都不知道这个网站,怎么会过来访问?没人过来访问,公司建网站的目的如何达成?企业是一个大的信息媒介,从营销推广的角度来说,它是一个超级的宣传书册。
做好原创到不如说是做好高质量内容,杜绝垃圾采集内容,突出内容差异化,这么说可能更好。原创就是高质量内容这是一个错误的说法,如果是高质量的内容,又是原创那肯定是
近日小助在市场部网的里发觉许多坛友们对这一推广形式也的确是无从下手:公司已是本地行业中,信誉、拥有顾客数多、服务了。五、工作进度及执行好的方案还要有好的执行团队,依据方案制做详尽的计划进度表,控制方案执行的进程,对推广活动进行详尽列举,安排具体的人员来负责落实,确保方案得到有效的执行。
。但是很多站长其实发布的是原创,但却是低质量的内容。就好比我们曾经写习作,自己冥思苦想下来的习作肯定没有参考习作补习书写下来的好。原创只是一个手段,不是目标,给用户带来有价值的内容才是站长们旨在原创的终目的。
所以,在营运网站的过程中,不要刻意的去追求所谓原创,应该关心的是内容编辑成本、内容完整、是否是用户须要的、信息真实有效以及安全。
(五)水印推广——以细节获胜,无时不刻的宣传在企业的宣传图片、视频、资料、网站上都打上企业的水印,把那些图片和视频发布到其他地方或别的网站,当这种印有水印的图片传播出去时,都无疑是对企业品牌的一种宣传。 查看全部
上饶抖音推广公司,灰色行业推广费用,关键词造成的不稳定在工作中,关键词占有了较大的比重,对个别行业专属和热门词汇要仔细剖析,了解竞争对手使用的词汇,并且对下一个可能火的词汇进行预测,撰写相关文章时也要做好关键词的布置,例如字左右的文章应该均匀的出现次以上,配两张图片。三、关于网页内容质量的评价标准得到简化,表示审视网页内容质量为重要的还是:成本、内容完整、信息真实有效以及安全。关于原创与否,不再提起。所以,明白了吧。
是一套内容涵括现有客户和潜在客户,可以随时更新的动态数据库管理系统。数据库营销的核心是数据挖掘。而网路营销中的数据库营销更多的是以互联网为平台进行营销活动。是指在了解搜索引擎自然排名机制的基础之上,对企业网站进行内部及外部的调整优化,改进企业网站在搜索引擎中关键词的自然排行,获得更多的展现量,吸引更多目标顾客访问您的企业网站,从而达到互联网营销及品牌建设的目标。
自始至终,的核心要求就是用户。“原创”只不过是一个代名词而已,从没有说原创的内容就是高质量的内容。这的都是站长的一厢情愿而已,如何满足用户需求提高用户才是重点。
简单来说,搜索引擎营销就是基于搜索引擎平台的网路营销,利用人们对搜索引擎的依赖和使用惯,在人们检索信息的时侯尽可能将营销信息传递给目标顾客。搜索引擎营销主要分为两类:一是有价的被称为竞价排行,二是无价的被称为(搜索引擎优化)。竞价的诠释位置有限,竞价的结果让大量的顾客因价钱的诱因未能排在首页,使得这部份顾客很难通过竞价获得良好的使用疗效。
四、关于高质量内容搜索引擎觉得内容质量好的网页,是耗费了较多时间和精力编辑,倾注了编者经验和专业知识的内容。排版合理,主次分明;利于用户阅读。
上饶抖音推广公司,灰色行业推广费用.人员配置不同网路推广包括有网站建设团队(网站策划,美工设计,程序制做,相关测试)、网络推广团队等人员配置。作为互联网的一种应用模式,它的高度开放性,介于互联网与联通网之间,无论在何时何地,用户都能及时发布消息。一、种网路推广形式:(一)网站优化排行:通过建设网站,设置品牌或行业关键词,进行网站代码、内容、链接等优化获取一定的关键词排行,建设多个网站可以获得更多的网站排名,归类为。
这些内容清晰、完整且丰富,资源有效且优质,信息真实有效安全无毒,不含任何行为和意图,对用户有较强的正利润。
同时可在企业的一些宣传软文、资料上网址,并制做一些资料小册子如或电子书且在里面都加上企业网址。让企业信息和文化更容易推广。(四)软文推广——无形的营销利剑软文具有引导消费、品牌宣传、周期长,价格低等优点。如果将称作仙侠中的剑法,那么软文就是外功武学。
对这部份网页,搜索引擎会增强其诠释给用户的几率。
即使是一个新诞生的企业,要是企业的网路推广挺到位也可以迅速提高企业的品牌知名度以及提高消费者的认可度。
所以目前对内容质量高的定义并没有突出原创这个标准,原创二字只是高质量网页内容的一个非必须特点,能在一定程度上反应网页内容的稀缺度,但原创并非一定稀缺,原创更不能代表高质量的内容。
给公司做网站建设多少钱,建站实惠现状:目前世界上多万的网站,一个新的网站建成了,假如他人都不知道这个网站,怎么会过来访问?没人过来访问,公司建网站的目的如何达成?企业是一个大的信息媒介,从营销推广的角度来说,它是一个超级的宣传书册。
做好原创到不如说是做好高质量内容,杜绝垃圾采集内容,突出内容差异化,这么说可能更好。原创就是高质量内容这是一个错误的说法,如果是高质量的内容,又是原创那肯定是
近日小助在市场部网的里发觉许多坛友们对这一推广形式也的确是无从下手:公司已是本地行业中,信誉、拥有顾客数多、服务了。五、工作进度及执行好的方案还要有好的执行团队,依据方案制做详尽的计划进度表,控制方案执行的进程,对推广活动进行详尽列举,安排具体的人员来负责落实,确保方案得到有效的执行。
。但是很多站长其实发布的是原创,但却是低质量的内容。就好比我们曾经写习作,自己冥思苦想下来的习作肯定没有参考习作补习书写下来的好。原创只是一个手段,不是目标,给用户带来有价值的内容才是站长们旨在原创的终目的。
所以,在营运网站的过程中,不要刻意的去追求所谓原创,应该关心的是内容编辑成本、内容完整、是否是用户须要的、信息真实有效以及安全。
(五)水印推广——以细节获胜,无时不刻的宣传在企业的宣传图片、视频、资料、网站上都打上企业的水印,把那些图片和视频发布到其他地方或别的网站,当这种印有水印的图片传播出去时,都无疑是对企业品牌的一种宣传。
wordpress手动采集插件_wp-autopost-pro 3.7.8
采集交流 • 优采云 发表了文章 • 0 个评论 • 368 次浏览 • 2020-08-09 17:07
【插件简介】:
插件是wp-autopost-pro 3.7.8最新版本。
【采集插件适用对象】:
1、刚建的wordpress站点内容比较少,希望早日有比较丰富的内容;
2、热点内容手动采集并手动发布;
3、定时采集,手动采集发布或保存到草稿;
4、css样式规则,能更精确的采集需要的内容。
5、伪原创与翻译、代理IP进行采集、保存Cookie记录;
6、可采集内容到自定义栏目
全新支持Google神经网路翻译,有道神经网路翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象储存服务,七牛云、阿里云OSS等。
可采集微信公众号、头条号等自媒体内容,因百度不收录公众号,头条文章等,可轻松获取高质量“原创”文章,增加百度收录量及网站权重
可采集任何网站的内容,采集信息一目了然
通过简单设置可采集来自于任何网站的内容,并可设置多个采集任务同时进行,可设置任务为手动运行或自动运行,主任务列表显示每位采集任务的状况:上次测量采集时间,预计上次测量采集时间,最近采集文章,已采集更新的文章数等信息,方便查看管理。
文章管理功能便捷查询、搜索、删除已采集文章,改进算法已从根本上避免了重复采集相同文章,日志功能记录采集过程中出现的异常和抓取错误,方便检测设置错误便于进行修补。
增强seo功能,其他自行研究。
查看全部
wordpress手动采集插件_wp-autopost-pro 3.7.8,最新无限制版
【插件简介】:
插件是wp-autopost-pro 3.7.8最新版本。
【采集插件适用对象】:
1、刚建的wordpress站点内容比较少,希望早日有比较丰富的内容;
2、热点内容手动采集并手动发布;
3、定时采集,手动采集发布或保存到草稿;
4、css样式规则,能更精确的采集需要的内容。
5、伪原创与翻译、代理IP进行采集、保存Cookie记录;
6、可采集内容到自定义栏目
全新支持Google神经网路翻译,有道神经网路翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象储存服务,七牛云、阿里云OSS等。
可采集微信公众号、头条号等自媒体内容,因百度不收录公众号,头条文章等,可轻松获取高质量“原创”文章,增加百度收录量及网站权重
可采集任何网站的内容,采集信息一目了然
通过简单设置可采集来自于任何网站的内容,并可设置多个采集任务同时进行,可设置任务为手动运行或自动运行,主任务列表显示每位采集任务的状况:上次测量采集时间,预计上次测量采集时间,最近采集文章,已采集更新的文章数等信息,方便查看管理。
文章管理功能便捷查询、搜索、删除已采集文章,改进算法已从根本上避免了重复采集相同文章,日志功能记录采集过程中出现的异常和抓取错误,方便检测设置错误便于进行修补。
增强seo功能,其他自行研究。
高质量原创文章对网站SEO优化有什么用处
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2020-08-09 12:03
稍微懂一点seo的站长都听说过“内容为王”这个词,我们这儿所说的内容指的就是高质量原创内容,这也是搜索引擎所喜欢的内容。
互联网中部份站点采集其它站点的内容,搜索引擎同样进行了收录和给与了排行,导致少数站长觉得,高质量原创内容对网站的帮助不是很大,这种看法是错误的,就算搜索引擎一时收录了你的内容,后面搜索引擎发觉你网站的内容全部都是采集来的文章,网站根本没有自己独到的内容,搜索引擎都会觉得你这个网站是没有价值的,也就绝对不会给你一个好的排行。
二、高质量原创内容的益处
1、高质量原创内容首先符合搜索引擎的目标。搜索引擎的目标是给搜索用户提供信息,而不是给你的网站带来顾客。只有你的网站提供了高质量的内容,才能与搜索引擎的目标达成一致,也就提高了搜索引擎友好度。
2、高质量原创内容也是页面收录的重要推动力。不少站长都为网站收录问题苦恼,搜索引擎蜘蛛要么只访问首页,不再进一步抓取内页,要么收录以后又被删除。缺少原创内容是关键性诱因之一。一个以转载、抄袭为主体内容的网站对搜索引擎来说毫无价值。收录这样的页面越多,越浪费搜索引擎的带宽、数据库容量、爬行时间、计算时间,却不能给搜索用户提供更多信息,所以搜索引擎根本没有收录那些内容的理由
3、原创内容也是外部链接建设的重要方式。除非是交换链接,不然其他站长没有道理链接到一个没有实质内容的网站。
三、搜索引擎喜欢什么样的文章
我们仍然在指出高质量原创内容,那么这儿的高质量指的有什么特点呢?
1、内容完整可读;
2、标题内容规范;
3、文章段落及字体干净;
4、文章相关性强,不要出现标题党;
5、高质量原创内容应当具有高黏度、高转发的特点。
四、规避垃圾页面
从SEO的角度看,互联网中存在着大量搜索引擎不喜欢的垃圾页面,部分垃圾页面搜索引擎可以难以测量到,但是会影响网站用户体验,从而影响用户在站点中的逗留时间,所以网站中不要出现这种垃圾页面:
1、用户不可读的页面。最常见的现象就是复制其他站点的文章直接粘贴到本站中,因文章页面设置问题,导致站点中的文字重叠。
2、页面文章不完整的页面。
3、标题和文章内容不相关的页面。
4、文章内容是堆砌下来的。直接堆砌下来的文章内容影响用户的阅读,导致用户跳出率较高。
5、垃圾聚合页面。
这里讲的垃圾聚合页面指的是网站标签由机器手动生成一个标签页面,但是标签和页面中的内容都是机器手动采集的。如笔者见过一个婚恋网站,标签名子为“东北的男孩”,但是页面中还出现了好多女性会员。
6、违规词标签页面。
互联网中的大部分站点都提供了用户站内搜索功能,但是站长未屏蔽黄、赌、毒等违规违法词句,导致网站被一些不良用户钻了空子,用于黑帽排行。这种方式常出现在一些权重比较高的站点中,用户在站点中搜索个别欲获取排行的词句,然后将链接递交给搜索引擎因而根据网站的高权重获取排行。
7、网页实质内容较少的页面。
每个页面不可避开的会有一些通用部份,比如常见的页面底部、底部、页面右侧或则两侧等。如果网页中的正文内容很少的话,内容数目还抵不过通用部份,搜索引擎有可能会觉得这种页面相似度偏低。
8、产品页面中收录太多心态用户读不懂的信息。
这种情况常出现于一些进口产品页面,如果网站针对的是国外用户,建议页面中不要出现太多的英语信息,这种页面影响用户体验。
9、复制内容。
互联网中的部份站点不可防止的会复制其他站点的内容,如下级转载上级的通知、代理商从产品商哪里转载产品信息等。搜索引擎并不会由于网站中有少量的复制内容而惩罚站点,但是假如网站中存在大量的复制内容,这样会浪费搜索引擎的各类资源进而遭到惩罚。
五、规避复制页面的形成
避免复制内容的形成须要从站内和站外两个地方着手:
1、由于网址规范化导致的站内重复内容,最好的解决办法就是选定一个版本的URL容许搜索引擎抓取和收录,其他版本的页面严禁搜索引擎抓取和收录。常见的方式是使用robos.txt严禁搜索引擎抓取,连向希望不被搜索引擎收录的页面的链接可以使用nofollow属性制止搜索引擎爬行。
2、另一个解决方式是使用canonical标签。它的主要作用是拿来解决因为网址方式不同内容相同而导致的内容重复问题。这个标签对搜索引擎作用十分大,简单的说它可以使搜索引擎只抓取你想要指出的内容。
我们来看下如下的网址:
***.com/archives/2011-snow.html
***.com/archives/2011-snow.html?comments=true
***.com/archives/2011-snow.html?postcomment=true
这三个网址方式其实不同,但是打开的页面是相同的。加入第一个URL才是我们想显示给搜索引擎和用户的网址,一般象这些情况搜索引擎是很难区分下来那个才是网站主要想指出的网址,这样会直接导致搜索引擎在你的站上面收录到大量重复的内容,现在我们通过 canonical 标签就可以解决这种棘手的问题了。
像前面的状况,我们只须要在网址的 head 区域添加如下代码:
这样的话搜索引擎最终就会只收录 canonical 标签指定的这个网址,搜索引擎会将其它页面作为重复内容,这些重复的内容不再参与页面的权重分配。 查看全部
一、
稍微懂一点seo的站长都听说过“内容为王”这个词,我们这儿所说的内容指的就是高质量原创内容,这也是搜索引擎所喜欢的内容。
互联网中部份站点采集其它站点的内容,搜索引擎同样进行了收录和给与了排行,导致少数站长觉得,高质量原创内容对网站的帮助不是很大,这种看法是错误的,就算搜索引擎一时收录了你的内容,后面搜索引擎发觉你网站的内容全部都是采集来的文章,网站根本没有自己独到的内容,搜索引擎都会觉得你这个网站是没有价值的,也就绝对不会给你一个好的排行。
二、高质量原创内容的益处
1、高质量原创内容首先符合搜索引擎的目标。搜索引擎的目标是给搜索用户提供信息,而不是给你的网站带来顾客。只有你的网站提供了高质量的内容,才能与搜索引擎的目标达成一致,也就提高了搜索引擎友好度。
2、高质量原创内容也是页面收录的重要推动力。不少站长都为网站收录问题苦恼,搜索引擎蜘蛛要么只访问首页,不再进一步抓取内页,要么收录以后又被删除。缺少原创内容是关键性诱因之一。一个以转载、抄袭为主体内容的网站对搜索引擎来说毫无价值。收录这样的页面越多,越浪费搜索引擎的带宽、数据库容量、爬行时间、计算时间,却不能给搜索用户提供更多信息,所以搜索引擎根本没有收录那些内容的理由
3、原创内容也是外部链接建设的重要方式。除非是交换链接,不然其他站长没有道理链接到一个没有实质内容的网站。
三、搜索引擎喜欢什么样的文章
我们仍然在指出高质量原创内容,那么这儿的高质量指的有什么特点呢?
1、内容完整可读;
2、标题内容规范;
3、文章段落及字体干净;
4、文章相关性强,不要出现标题党;
5、高质量原创内容应当具有高黏度、高转发的特点。
四、规避垃圾页面
从SEO的角度看,互联网中存在着大量搜索引擎不喜欢的垃圾页面,部分垃圾页面搜索引擎可以难以测量到,但是会影响网站用户体验,从而影响用户在站点中的逗留时间,所以网站中不要出现这种垃圾页面:
1、用户不可读的页面。最常见的现象就是复制其他站点的文章直接粘贴到本站中,因文章页面设置问题,导致站点中的文字重叠。
2、页面文章不完整的页面。
3、标题和文章内容不相关的页面。
4、文章内容是堆砌下来的。直接堆砌下来的文章内容影响用户的阅读,导致用户跳出率较高。
5、垃圾聚合页面。
这里讲的垃圾聚合页面指的是网站标签由机器手动生成一个标签页面,但是标签和页面中的内容都是机器手动采集的。如笔者见过一个婚恋网站,标签名子为“东北的男孩”,但是页面中还出现了好多女性会员。
6、违规词标签页面。
互联网中的大部分站点都提供了用户站内搜索功能,但是站长未屏蔽黄、赌、毒等违规违法词句,导致网站被一些不良用户钻了空子,用于黑帽排行。这种方式常出现在一些权重比较高的站点中,用户在站点中搜索个别欲获取排行的词句,然后将链接递交给搜索引擎因而根据网站的高权重获取排行。
7、网页实质内容较少的页面。
每个页面不可避开的会有一些通用部份,比如常见的页面底部、底部、页面右侧或则两侧等。如果网页中的正文内容很少的话,内容数目还抵不过通用部份,搜索引擎有可能会觉得这种页面相似度偏低。
8、产品页面中收录太多心态用户读不懂的信息。
这种情况常出现于一些进口产品页面,如果网站针对的是国外用户,建议页面中不要出现太多的英语信息,这种页面影响用户体验。
9、复制内容。
互联网中的部份站点不可防止的会复制其他站点的内容,如下级转载上级的通知、代理商从产品商哪里转载产品信息等。搜索引擎并不会由于网站中有少量的复制内容而惩罚站点,但是假如网站中存在大量的复制内容,这样会浪费搜索引擎的各类资源进而遭到惩罚。
五、规避复制页面的形成
避免复制内容的形成须要从站内和站外两个地方着手:
1、由于网址规范化导致的站内重复内容,最好的解决办法就是选定一个版本的URL容许搜索引擎抓取和收录,其他版本的页面严禁搜索引擎抓取和收录。常见的方式是使用robos.txt严禁搜索引擎抓取,连向希望不被搜索引擎收录的页面的链接可以使用nofollow属性制止搜索引擎爬行。
2、另一个解决方式是使用canonical标签。它的主要作用是拿来解决因为网址方式不同内容相同而导致的内容重复问题。这个标签对搜索引擎作用十分大,简单的说它可以使搜索引擎只抓取你想要指出的内容。
我们来看下如下的网址:
***.com/archives/2011-snow.html
***.com/archives/2011-snow.html?comments=true
***.com/archives/2011-snow.html?postcomment=true
这三个网址方式其实不同,但是打开的页面是相同的。加入第一个URL才是我们想显示给搜索引擎和用户的网址,一般象这些情况搜索引擎是很难区分下来那个才是网站主要想指出的网址,这样会直接导致搜索引擎在你的站上面收录到大量重复的内容,现在我们通过 canonical 标签就可以解决这种棘手的问题了。
像前面的状况,我们只须要在网址的 head 区域添加如下代码:
这样的话搜索引擎最终就会只收录 canonical 标签指定的这个网址,搜索引擎会将其它页面作为重复内容,这些重复的内容不再参与页面的权重分配。
干货!新媒体营运必备的文章在线智能原创工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2020-08-09 08:38
比如: 需搜索有关于营运的文章,那么可以在原创界面,选择你所需查找的关键词“运营”,优采云采集便可对此关键词进行一键精准搜索。文章陈列次序依照关键词的匹配度进行排序。2. 需对文章进行原创: 牛蚁原创采用深度神经网路算法构建文章,降低了文章的重复度,自动对段落中的文字次序进行调节和整句的替换。 优采云采集将最新的 RNN 和 LSTM 算法用到了智能原创的过程中,不但保证了文章的可读性,而且一键生成的智能原创文章可用于绕开一些重复度测量算法。 用户可在页面中点击“原创”功能,优采云采集将对所需原创的文章并进行单项原创。用户也可以点击“当前页面全选”功能,此时用户所选的文章则全部收录于两侧的操作面板内,用户可在操作面板内进行批量的原创。二、处 使用优采云采集有何用处 增强被收录的机率: 百度会通过多维度去判定你的文章是否值得收录,文章的原创则占了绝大优势。 优采云采集通过智能算法将文章进行构建,降低文章重复度,帮助文章可以被百度 更好的收录 。 更容易被流量推荐: 优采云采集分析了数万篇新品文章的写作方法,使文章“焕然一新”的同时,还有利于被自媒体平台流量推荐。 增加人工成本: 优采云采集出稿快,效率高,不再须要大量的编辑和发布人员,既省去了创作时间,又有利于快速达到 SEO疗效。 小编认为,在使用优采云采集的同时,不妨加入一点自己的观点,这样既可以丰富文章内容,还能够提高创作能力。巧用优采云采集,帮助新媒体营运高效写作 。 查看全部
干货!新媒体营运必备的 文章在线智能原创工具 现如今新媒体行业的竞争堪称越来越大,在这个内容为王的时代,优质的内容等于一切。写不出令人满意的内容,自我感觉到失落只是一方面,另一方面则是面临着待业的风险。 内容创作,是营运的必要之事,但创作途中,总会面临许多的不得已:要么是没文笔创作出高质量、高点击量的优质文章,要么是虽然有水平,却没有很高的效率。大部分营运也因而无奈接受了上级给自己打下的“低效率”形容标签。好不容易想出一篇,发布后立刻被剽窃,不仅这般,别人的收录排行还更高,这样的案例也不在少数。 原创不难,但要讲求质量和效率并存,还真不是几个月才能练下来的。冰冻三尺非一日之寒,未必就没有解决的办法了吗?别急~小编这就给你们介绍一款除了能提高内容的质量,还能提高工作效率的在线智能原创工具——优采云采集。 优采云采集可以对文章进行单次、批量原创,提升文章百度原创分值,提高文章在搜索引擎收录机率和自媒体平台流量推荐值。下面为你们介绍怎样使用优采云采集进行原创: 一、 如何用优采云采集进行原创 1. 搜索素材 优采云采集可对主流自媒体中的文章素材进行智能的采集。 海量素材+实时热点+持续更新,帮助营运提高工作效率。
比如: 需搜索有关于营运的文章,那么可以在原创界面,选择你所需查找的关键词“运营”,优采云采集便可对此关键词进行一键精准搜索。文章陈列次序依照关键词的匹配度进行排序。2. 需对文章进行原创: 牛蚁原创采用深度神经网路算法构建文章,降低了文章的重复度,自动对段落中的文字次序进行调节和整句的替换。 优采云采集将最新的 RNN 和 LSTM 算法用到了智能原创的过程中,不但保证了文章的可读性,而且一键生成的智能原创文章可用于绕开一些重复度测量算法。 用户可在页面中点击“原创”功能,优采云采集将对所需原创的文章并进行单项原创。用户也可以点击“当前页面全选”功能,此时用户所选的文章则全部收录于两侧的操作面板内,用户可在操作面板内进行批量的原创。二、处 使用优采云采集有何用处 增强被收录的机率: 百度会通过多维度去判定你的文章是否值得收录,文章的原创则占了绝大优势。 优采云采集通过智能算法将文章进行构建,降低文章重复度,帮助文章可以被百度 更好的收录 。 更容易被流量推荐: 优采云采集分析了数万篇新品文章的写作方法,使文章“焕然一新”的同时,还有利于被自媒体平台流量推荐。 增加人工成本: 优采云采集出稿快,效率高,不再须要大量的编辑和发布人员,既省去了创作时间,又有利于快速达到 SEO疗效。 小编认为,在使用优采云采集的同时,不妨加入一点自己的观点,这样既可以丰富文章内容,还能够提高创作能力。巧用优采云采集,帮助新媒体营运高效写作 。
成都网站优化应如何提高网站排名?
采集交流 • 优采云 发表了文章 • 0 个评论 • 227 次浏览 • 2020-08-09 06:28
1. 网站内的优化和网站外的优化
对于网站优化,我们需要根据客户需求调整相关的网站链接和网页设置,因为客户需求在不断变化,因此我们可以提供他们想要看到的内容,这是一个很好的优化效果;对于异地,主要原因是我们必须依靠相对成熟的网站来发挥其功能,以使我们的网站能够在短时间内执行排名权重等.
第二,不要采集内容
进行关键字优化需要大量内容来支持. 无论是在网站上还是网站外,如何找到出色的内容都是一种非常好的简便方法. 优化关键字时,如果采用集合方法,最好对关键字进行一些更改,例如替换内容,更改标题等. 网络上重复性很高的内容的存在会引起厌恶的搜索引擎,尽管它将继续被收录在内,但这并不意味着一切都结束了,站点将是k,这是将来要更新的原创文章数量,无法保存.
3. 网站上原创文章的更新
我们都知道当前的Internet实际上是非常智能的,但是在当今的智能化中,它也存在某些错误. 例如,它没有处理图片的能力,因此它更依赖于文字的力量来对网站进行全面排名,因此文章的更新已成为网站排名的重要因素之一,并定期采集材料以完成文章.
如何提高成都网站优化排名?如果要使您的网站排名越来越好,那么您必须对网站的优化技术和方法有一定的了解,知道如何进行合理的修改,并在不同时期采用不同的方法进行优化,从而逐步改善网站. 关键字排名. 查看全部
在当前在线营销快速发展的时代,互联网上有无数大小型网站. 他们中的许多人都希望获得良好的关键字排名,因此必须控制网站的优化和详细信息,否则网站的排名将始终跌宕起伏,并且不会出现增长趋势. 那么成都网站优化应该如何提高网站排名?
1. 网站内的优化和网站外的优化
对于网站优化,我们需要根据客户需求调整相关的网站链接和网页设置,因为客户需求在不断变化,因此我们可以提供他们想要看到的内容,这是一个很好的优化效果;对于异地,主要原因是我们必须依靠相对成熟的网站来发挥其功能,以使我们的网站能够在短时间内执行排名权重等.
第二,不要采集内容
进行关键字优化需要大量内容来支持. 无论是在网站上还是网站外,如何找到出色的内容都是一种非常好的简便方法. 优化关键字时,如果采用集合方法,最好对关键字进行一些更改,例如替换内容,更改标题等. 网络上重复性很高的内容的存在会引起厌恶的搜索引擎,尽管它将继续被收录在内,但这并不意味着一切都结束了,站点将是k,这是将来要更新的原创文章数量,无法保存.
3. 网站上原创文章的更新
我们都知道当前的Internet实际上是非常智能的,但是在当今的智能化中,它也存在某些错误. 例如,它没有处理图片的能力,因此它更依赖于文字的力量来对网站进行全面排名,因此文章的更新已成为网站排名的重要因素之一,并定期采集材料以完成文章.
如何提高成都网站优化排名?如果要使您的网站排名越来越好,那么您必须对网站的优化技术和方法有一定的了解,知道如何进行合理的修改,并在不同时期采用不同的方法进行优化,从而逐步改善网站. 关键字排名.
假的原创工具有用吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2020-08-08 15:59
那么,伪原创工具对SEO有效吗?
1. 伪原创工具的原理
如果我们想知道伪原创工具是否有效,我们需要了解它的工作原理:
①同义词替换
通常常用的伪原创工具是同义词替换,例如今天替换为今天,用搜索引擎优化替换SEO等. 实际上,这种伪原创工具已经过时了,搜索引擎可以轻松地确定同义词之间的区别区别在于搜索引擎通过索引页面将页面转换为一组哈希值,并将已被同义词替换的内容转换为一组哈希值以进行比较. 哈希值转换后,可以有效避免同义词,仅保留原创指纹. ,因此此类伪原创工具无效,因此请不要使用它们.
②互译
某些AI伪原创工具确实可以在一个句子中具有相同的含义,但是表达方式不同. 实际上,大多数AI伪原创工具都是伪造的,但是它们会通过翻译软件反复翻译. 如果相似度较低,请再翻译几次,但可读性会变差. 可以适当使用.
③ai创作
也有真正的AI创作,例如百度AI,但是它们仅限于固定格式内容的创作,例如股票信息,天气信息等,并且不能大规模使用.
2. 不同的需求
但是伪原创工具对于SEO并不是无效的. 不同的需求会有不同的效果:
①批生产
当权重较高的网站需要维持其排名或进一步提高其排名并需要大量内容时,可以使用互译的伪原创工具来实现文章的批量创建. 查看全部
对于seoers来说,每天写原创文章很无聊,但是网站不会更新文章,因此无法保证排名. 因此,一些专家专注于伪原创工具. 实际上,伪原创工具已经存在. 毫不奇怪,尤其是近年来,技术进步也参与了伪原创军队.
那么,伪原创工具对SEO有效吗?
1. 伪原创工具的原理
如果我们想知道伪原创工具是否有效,我们需要了解它的工作原理:
①同义词替换
通常常用的伪原创工具是同义词替换,例如今天替换为今天,用搜索引擎优化替换SEO等. 实际上,这种伪原创工具已经过时了,搜索引擎可以轻松地确定同义词之间的区别区别在于搜索引擎通过索引页面将页面转换为一组哈希值,并将已被同义词替换的内容转换为一组哈希值以进行比较. 哈希值转换后,可以有效避免同义词,仅保留原创指纹. ,因此此类伪原创工具无效,因此请不要使用它们.
②互译
某些AI伪原创工具确实可以在一个句子中具有相同的含义,但是表达方式不同. 实际上,大多数AI伪原创工具都是伪造的,但是它们会通过翻译软件反复翻译. 如果相似度较低,请再翻译几次,但可读性会变差. 可以适当使用.
③ai创作
也有真正的AI创作,例如百度AI,但是它们仅限于固定格式内容的创作,例如股票信息,天气信息等,并且不能大规模使用.
2. 不同的需求
但是伪原创工具对于SEO并不是无效的. 不同的需求会有不同的效果:
①批生产
当权重较高的网站需要维持其排名或进一步提高其排名并需要大量内容时,可以使用互译的伪原创工具来实现文章的批量创建.
这样采集的文章应该是“伪原创”
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2020-08-08 05:20
采集的内容可以分为国外站点内容采集和流行内容采集. 通常,采集内容时需要注意一些事项. 子网的组织方式如下:
①只是内容而已
众所周知,标题是文章的目光,是传递给用户的第一印象. 对于针对网站进行了优化的搜索引擎,标题也具有一定的分量. 相对而言,标题也是搜索引擎“识别”原创内容的参考依据. 因此,当我们采集内容时,最好根据内容的主题来重写标题.
②内容新颖或专业
在采集文章时,最好从相关网站采集文章,以频繁更新文章为目标,找到一些内容新颖,与时俱进的文章,并具有代表性. 最好在被太多人转载之前进行采集.
一些老式的主题会使用户感到他们相同且一文不值.
此外,您还可以采集多篇文章并将其整合为一篇文章. 添加您自己的意见也会使人们的眼睛更加明亮. 当然,这要求作者需要一定的写作技巧.
③采集的内容,请进行一些调整
Yawang Internet的编辑经常发现,在浏览别人的网站时,您总是会发现某些格式和版式不佳的文章. 具体来说,例如“令人困惑的标点符号,不清晰的分段,第一行没有缩进”等,以及一些用于反采集的隐藏格式等,如果直接采集这些内容,它们肯定会被搜索引擎识别为窃. 那么对网站的危害是不言而喻的.
因此,必须对采集的内容进行格式化,并且必须转换英语格式的标点符号. 另外,可以将一些图片添加到内容中以使内容更丰富.
如何清除格式?非常简单打开计算机的记事本,复制并粘贴采集的文章,可以清理很多不必要的代码和格式,最好更改文章并用您的语言表达原创文本. 这意味着“伪原创”,而不是使用软件. 查看全部
所有人都知道每天的工作日程安排很充裕,以至于我们没有足够的时间来观看原创内容. 但是网站内容更新是重要手段,那么如何解决呢?许多网站管理员都是通过这种方式进行处理的,即采集内容.
采集的内容可以分为国外站点内容采集和流行内容采集. 通常,采集内容时需要注意一些事项. 子网的组织方式如下:
①只是内容而已
众所周知,标题是文章的目光,是传递给用户的第一印象. 对于针对网站进行了优化的搜索引擎,标题也具有一定的分量. 相对而言,标题也是搜索引擎“识别”原创内容的参考依据. 因此,当我们采集内容时,最好根据内容的主题来重写标题.
②内容新颖或专业
在采集文章时,最好从相关网站采集文章,以频繁更新文章为目标,找到一些内容新颖,与时俱进的文章,并具有代表性. 最好在被太多人转载之前进行采集.
一些老式的主题会使用户感到他们相同且一文不值.
此外,您还可以采集多篇文章并将其整合为一篇文章. 添加您自己的意见也会使人们的眼睛更加明亮. 当然,这要求作者需要一定的写作技巧.
③采集的内容,请进行一些调整
Yawang Internet的编辑经常发现,在浏览别人的网站时,您总是会发现某些格式和版式不佳的文章. 具体来说,例如“令人困惑的标点符号,不清晰的分段,第一行没有缩进”等,以及一些用于反采集的隐藏格式等,如果直接采集这些内容,它们肯定会被搜索引擎识别为窃. 那么对网站的危害是不言而喻的.
因此,必须对采集的内容进行格式化,并且必须转换英语格式的标点符号. 另外,可以将一些图片添加到内容中以使内容更丰富.
如何清除格式?非常简单打开计算机的记事本,复制并粘贴采集的文章,可以清理很多不必要的代码和格式,最好更改文章并用您的语言表达原创文本. 这意味着“伪原创”,而不是使用软件.
停止采集和复制原创文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-08-08 05:18
更改网站程序
通常,如果遇到此类问题,可以更改网站的程序. 通常,某些网站优化器会添加一个JS代码,禁止在页面上进行复制和粘贴,并允许该代码禁止用户复制和粘贴或查看源代码. 但是此方法对用户体验非常不利,因此,如果情况不是很严重,没有网站管理员愿意使用此方法,则可以说此方法是最后一步.
提交内容链接
阻止采集网站内容的最大原因是,您担心自己的文章不会被收录. 因此,seoer将在更新文章后直接将文章的网址提交给百度. 这样做没有害处. 尽管百度不会立即收录该文章,但您可以提醒百度收录该文章,以便您的文章将被尽快收录并被百度认可为原创文章,这样,如果其他人窃,将减少对您的影响
添加网站链接
通常,如果复制了网站内容,则方法是添加网站的品牌字词或隐藏锚文本链接等,如果是由机器采集的,则另参加者将采集并发送所有信息,这等同于向自己添加一个链接. 但是请注意不要在文章中过分添加锚文本链接或品牌词,以防止文章被采集,因为这会损害用户体验.
防止网站文章被窃非常重要. 毕竟,许多网站管理员本人会花费大量时间和精力来撰写原创文章,但是一旦发布,他们就会被他人窃,甚至可能导致其站点上的文章未被收录. 如果发现文章被他人is窃,则必须及时解决此问题,否则会对网站优化产生非常不利的影响.
但是还有另一种方法可以阻止它. 这只是我个人的看法,但是我还不想谈论这种方法. 如果需要,可以与我们联系. 查看全部
原创性是自然促销的重要组成部分. 通过发布原创文章,可以优化许多刚刚启动的小型网站. 创意对网站优化具有非凡的意义. 百度非常喜欢原创文章. 如果新网站使用采集的文章,那么百度很容易会认为该网站是采集网站,这将影响后续的网站优化. 当营销人员进行网站优化时,所有原创文章都会在网站上进行更新,但是此时我们还遇到了一个问题,那就是原创文章被其他人采集以发布外部链接. 遇到此问题时,我们总结了一些网络营销方法.
更改网站程序
通常,如果遇到此类问题,可以更改网站的程序. 通常,某些网站优化器会添加一个JS代码,禁止在页面上进行复制和粘贴,并允许该代码禁止用户复制和粘贴或查看源代码. 但是此方法对用户体验非常不利,因此,如果情况不是很严重,没有网站管理员愿意使用此方法,则可以说此方法是最后一步.
提交内容链接
阻止采集网站内容的最大原因是,您担心自己的文章不会被收录. 因此,seoer将在更新文章后直接将文章的网址提交给百度. 这样做没有害处. 尽管百度不会立即收录该文章,但您可以提醒百度收录该文章,以便您的文章将被尽快收录并被百度认可为原创文章,这样,如果其他人窃,将减少对您的影响
添加网站链接
通常,如果复制了网站内容,则方法是添加网站的品牌字词或隐藏锚文本链接等,如果是由机器采集的,则另参加者将采集并发送所有信息,这等同于向自己添加一个链接. 但是请注意不要在文章中过分添加锚文本链接或品牌词,以防止文章被采集,因为这会损害用户体验.
防止网站文章被窃非常重要. 毕竟,许多网站管理员本人会花费大量时间和精力来撰写原创文章,但是一旦发布,他们就会被他人窃,甚至可能导致其站点上的文章未被收录. 如果发现文章被他人is窃,则必须及时解决此问题,否则会对网站优化产生非常不利的影响.
但是还有另一种方法可以阻止它. 这只是我个人的看法,但是我还不想谈论这种方法. 如果需要,可以与我们联系.
SEO新手必须阅读: 百度判断原创文章的依据
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2020-08-08 02:36
对于百度,它特别引入了鼓励原创文章和打击窃的算法. 但是,随着成千上万的文章,百度如何确定谁是原创文章?有什么影响?我们该怎么办?
1. 网站的历史原创性将影响百度对自建网站原创文章的判断
例如,如果一个说谎的人经常不时地讲真话,那么人们就不会认为他是在讲真话,反之亦然. 这是一种习惯性思维.
将其放在我们的自建网站上也是如此. 如果某个电台的文章大部分都被采集了,并且偶尔写了原创,那么百度不会认为您是原创,而百度会这样认为.
知道这一点后,我们必须了解,我们通常不采集和制作更多原件. 特别是对于一些新来者,网站建成后,他们想快速添加一些内容,因此他们从其他人的网站复制了很多文章,然后发布了该网站. 其结果是该网站给百度的第一印象是您的网站已全部采集,这将影响原创文章的收录和排名.
第二,利用文章品牌价值的优化影响百度对自建网站原创文章的判断
什么意思?这是在我们的原创文章和图片中插入大量自己的品牌字词. 什么目的?现在,许多人在重新打印文章时将删除文章的url链接. 实际上,文章各方面的“品牌字词”并没有删除很多. 这样,即使有人采集了它,它也只是给您自己的网站提供宣传的机会.
3. 增加复制和采集的成本,阻止他人进行复制和采集,并提高其原创创作的可信度
当前,大多数原创网站都是“复制”的,而不是被采集的. 采集了哪些站?这里没有太多要说的. 通常: 增加另一方的复制成本通常会降低另一方的“利益”.
增加另一方托收成本的方法是:
A,禁止右键单击代码(在百度上搜索),因此您不能直接复制,只能从源代码复制,这会很麻烦.
B,检查IP,并禁止可疑IP,尤其是那些仅阅读新文章并在复制后无需进行交叉检查就可以离开的IP.
C,添加本地化图片. 如果对方在不更改地址的情况下直接复制您的图片,则百度可以更好地进行判断. 如果继续本地化,无疑会增加另一方的复制成本周期.
D,写一篇文章并复制您自己的URL信息,可以采用图片或URL的形式.
简而言之,这增加了复制他的难度和成本,并降低了他的兴趣,这将有效地阻止其他人进行采集.
四个. 在自建网站上发布和推送原创文章,使百度有时间信任它
百度具有推送功能. 您的文章发表后,它将尽快将您的文章推送到百度. 此外,发布文章的时间可以安排在每个人都休息的时间. 例如中午,晚上22:00之后或早晨7:00之前的午餐时间. 这样,另一方将不会快速复制您的文章,而给百度足够的时间来收录您的文章. 由于您的文章是早期采集的,加上百度推. 这将使百度更加确信您的网站是原创网站.
5. 纠正投诉和反馈,告诉百度什么是正确的
当网站采集了大量信息时,如果您有足够的证据证明您的网站是原创网站(例如品牌和发布时间),则可以使用网站站长平台的反馈来重新评估您的网站并惩罚对方的网站!
当然,前提是另一方采集或复制您的许多网站信息,并且投诉也很熟练. 我们已经看到许多网站管理员写道: “我的网站是由XXXX网站(我的原著)采集的!”您的证据在哪里?百度没有时间研究以确定谁在采集谁!例如,向百度证明您的文章早于发布时间,您的采集时间早于另一方的采集时间,您的品牌字在文章中,您的网站链接在文章的图片中,等等. 都可以用作证据.
简而言之,百度对原创性的支持和对窃的打击仍然非常强大,因此我们必须更加谨慎,并注意网站被滥用.
———— 查看全部
今天,让我们谈谈[SEO]百度判断文章原创性的基础,并讨论百度如何在网站上看待原创性.
对于百度,它特别引入了鼓励原创文章和打击窃的算法. 但是,随着成千上万的文章,百度如何确定谁是原创文章?有什么影响?我们该怎么办?
1. 网站的历史原创性将影响百度对自建网站原创文章的判断
例如,如果一个说谎的人经常不时地讲真话,那么人们就不会认为他是在讲真话,反之亦然. 这是一种习惯性思维.
将其放在我们的自建网站上也是如此. 如果某个电台的文章大部分都被采集了,并且偶尔写了原创,那么百度不会认为您是原创,而百度会这样认为.
知道这一点后,我们必须了解,我们通常不采集和制作更多原件. 特别是对于一些新来者,网站建成后,他们想快速添加一些内容,因此他们从其他人的网站复制了很多文章,然后发布了该网站. 其结果是该网站给百度的第一印象是您的网站已全部采集,这将影响原创文章的收录和排名.
第二,利用文章品牌价值的优化影响百度对自建网站原创文章的判断
什么意思?这是在我们的原创文章和图片中插入大量自己的品牌字词. 什么目的?现在,许多人在重新打印文章时将删除文章的url链接. 实际上,文章各方面的“品牌字词”并没有删除很多. 这样,即使有人采集了它,它也只是给您自己的网站提供宣传的机会.
3. 增加复制和采集的成本,阻止他人进行复制和采集,并提高其原创创作的可信度
当前,大多数原创网站都是“复制”的,而不是被采集的. 采集了哪些站?这里没有太多要说的. 通常: 增加另一方的复制成本通常会降低另一方的“利益”.
增加另一方托收成本的方法是:
A,禁止右键单击代码(在百度上搜索),因此您不能直接复制,只能从源代码复制,这会很麻烦.
B,检查IP,并禁止可疑IP,尤其是那些仅阅读新文章并在复制后无需进行交叉检查就可以离开的IP.
C,添加本地化图片. 如果对方在不更改地址的情况下直接复制您的图片,则百度可以更好地进行判断. 如果继续本地化,无疑会增加另一方的复制成本周期.
D,写一篇文章并复制您自己的URL信息,可以采用图片或URL的形式.
简而言之,这增加了复制他的难度和成本,并降低了他的兴趣,这将有效地阻止其他人进行采集.
四个. 在自建网站上发布和推送原创文章,使百度有时间信任它
百度具有推送功能. 您的文章发表后,它将尽快将您的文章推送到百度. 此外,发布文章的时间可以安排在每个人都休息的时间. 例如中午,晚上22:00之后或早晨7:00之前的午餐时间. 这样,另一方将不会快速复制您的文章,而给百度足够的时间来收录您的文章. 由于您的文章是早期采集的,加上百度推. 这将使百度更加确信您的网站是原创网站.
5. 纠正投诉和反馈,告诉百度什么是正确的
当网站采集了大量信息时,如果您有足够的证据证明您的网站是原创网站(例如品牌和发布时间),则可以使用网站站长平台的反馈来重新评估您的网站并惩罚对方的网站!
当然,前提是另一方采集或复制您的许多网站信息,并且投诉也很熟练. 我们已经看到许多网站管理员写道: “我的网站是由XXXX网站(我的原著)采集的!”您的证据在哪里?百度没有时间研究以确定谁在采集谁!例如,向百度证明您的文章早于发布时间,您的采集时间早于另一方的采集时间,您的品牌字在文章中,您的网站链接在文章的图片中,等等. 都可以用作证据.
简而言之,百度对原创性的支持和对窃的打击仍然非常强大,因此我们必须更加谨慎,并注意网站被滥用.
————
适用于网站的高质量SEO伪原创文章的内容应该是什么
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2020-08-07 23:14
由于大多数公司没有专门的内容制作团队,因此某些网站更喜欢使用伪原创内容来制作内容. 他们的伪原创方法是首先列出标题,选择3-5个与该主题匹配的文章,为每篇文章参与其中,而3-5个段落可以完成一篇新文章. 但是,这样的文章只能欺骗搜索引擎,对于用户阅读而言意义不大. 优秀的网站如何创建高质量的内容?
1. 确保高质量的内容
评估标准是内容是否为网站带来流量.
在用户不熟悉该网站的前提下,他们将搜索相关的关键字. 如果网站的内容要呈现给用户,则有必要继续向搜索引擎添加内容以进行排水. 但是,您可能会发现可能没有包括精心撰写的原创文章,而是包括了其他人直接从Internet复制的文章. 目前,只有一种方法可以充分利用长尾关键字. 百度索引,搜狗索引和新近发布的微信索引都是获取流行的长尾关键词的方法.
2. 高效的采集,几秒钟之内就能杀死原件
仅仅作为伪造的原件还不够. 产品信息和与Internet相关的信息过多. 为什么不只是使用它呢?每天我们看到“爆炸性文章”被成千上万的大字转载,转载的读物往往高于原创读物. 该网站设置了一个特殊的文章更新部分,以不断增加内容,该内容可能由不同的搜索引擎采集!无论是各种社交应用程序,外部链接都可以为网站带来可观的流量. 网站拥有足够的流量后,搜索引擎自然会改变其对网站的态度并变得友好. 查看全部
在内容为王的时代,对网站优化也有更高的要求. 从UC令人震惊的机构到热烈的讨论,再到百度取消新闻源系统,高质量的内容已经以另一种形式渗透到我们的生活中. 优化网站以获得排名的最简单方法是创建“标题+原创内容”,并确保其收录在搜索引擎中.
由于大多数公司没有专门的内容制作团队,因此某些网站更喜欢使用伪原创内容来制作内容. 他们的伪原创方法是首先列出标题,选择3-5个与该主题匹配的文章,为每篇文章参与其中,而3-5个段落可以完成一篇新文章. 但是,这样的文章只能欺骗搜索引擎,对于用户阅读而言意义不大. 优秀的网站如何创建高质量的内容?
1. 确保高质量的内容
评估标准是内容是否为网站带来流量.
在用户不熟悉该网站的前提下,他们将搜索相关的关键字. 如果网站的内容要呈现给用户,则有必要继续向搜索引擎添加内容以进行排水. 但是,您可能会发现可能没有包括精心撰写的原创文章,而是包括了其他人直接从Internet复制的文章. 目前,只有一种方法可以充分利用长尾关键字. 百度索引,搜狗索引和新近发布的微信索引都是获取流行的长尾关键词的方法.
2. 高效的采集,几秒钟之内就能杀死原件
仅仅作为伪造的原件还不够. 产品信息和与Internet相关的信息过多. 为什么不只是使用它呢?每天我们看到“爆炸性文章”被成千上万的大字转载,转载的读物往往高于原创读物. 该网站设置了一个特殊的文章更新部分,以不断增加内容,该内容可能由不同的搜索引擎采集!无论是各种社交应用程序,外部链接都可以为网站带来可观的流量. 网站拥有足够的流量后,搜索引擎自然会改变其对网站的态度并变得友好.
如何快速大量增加所收录的网站数量
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-07 18:07
今天,Xiaoxiao Classroom.com为您带来了有关如何在网站权重优化中快速增加网站收录量的教程. 希望对您有所帮助.
首先,如何使搜索引擎包括在内
在谈论快速增加网站收录物之前,马辉SEO应该首先谈论搜索引擎将收录哪种页面.
1. 高质量的原图
所有平台都喜欢的高质量原创资源.
2. 及时
对热门话题或有关新技术的文章的评论或意见是时间敏感的. 描述xp的文章和描述Windows Server 2016的文章,搜索引擎更可能喜欢后者.
3. 有价值
一篇文章在被搜索引擎收录之前必须是有价值的,否则在被收录后可能会被取消.
4. 高用户体验
最后,网站优化基本上是用户体验的竞争. 谁做得好,流量就会更多.
有关更多参考,请参阅上一个教程“网站不包括[如何收录100%重印文章] SEO研究tutorial_小小课网”.
二,如何快速增加网站收录量
迅速增加网站收录物的数量是优化网站权重的方法之一,但搜索引擎可能会惩罚不当操作. Xiaoxiao Classroom.com建议采用以下方法来快速增加网站的数量.
1. 大量原创文章
对于团队而言,要撰写大量原创文章并不容易,而单个网站站长要添加这些文章甚至更加困难. 如果有大量的粉丝做出贡献,那就更好了. 关键是这些人愿意为我们写信. 通常采用奖励机制.
2,大量伪原创文章
伪原创文章不是指随机采集的文章,这些文章是通过在线伪原创工具转换并直接发布的. 相反,Ma Hui SEO不建议使用此工具. 建议根据他人的想法编写自己的内容,或者直接转载文章并添加评论.
3. 创建一列
如果网站仅具有第二级列,则可以考虑创建多个第三级列以对文章进行更详细的分类,但是建议每个类别下不少于十篇,并进行长期维护是必需的.
4. 标签汇总页面
合理地为文章添加标签. 不要添加太多标签,尤其是当标签的数量大于网站上的文章数量时,搜索引擎可能会降低网站的访问量. 查看全部
即使数据没有价值和意义,网站权重优化始终是许多用户最关心的事情. 除了“如何增加百度的权重?”之外,除了“快速升级_百度SEO教程_小小课网”中介绍的方法外,大量增加网站的收录率是优化网站权重的一种常用方法.
今天,Xiaoxiao Classroom.com为您带来了有关如何在网站权重优化中快速增加网站收录量的教程. 希望对您有所帮助.
首先,如何使搜索引擎包括在内
在谈论快速增加网站收录物之前,马辉SEO应该首先谈论搜索引擎将收录哪种页面.
1. 高质量的原图
所有平台都喜欢的高质量原创资源.
2. 及时
对热门话题或有关新技术的文章的评论或意见是时间敏感的. 描述xp的文章和描述Windows Server 2016的文章,搜索引擎更可能喜欢后者.
3. 有价值
一篇文章在被搜索引擎收录之前必须是有价值的,否则在被收录后可能会被取消.
4. 高用户体验
最后,网站优化基本上是用户体验的竞争. 谁做得好,流量就会更多.
有关更多参考,请参阅上一个教程“网站不包括[如何收录100%重印文章] SEO研究tutorial_小小课网”.
二,如何快速增加网站收录量
迅速增加网站收录物的数量是优化网站权重的方法之一,但搜索引擎可能会惩罚不当操作. Xiaoxiao Classroom.com建议采用以下方法来快速增加网站的数量.
1. 大量原创文章
对于团队而言,要撰写大量原创文章并不容易,而单个网站站长要添加这些文章甚至更加困难. 如果有大量的粉丝做出贡献,那就更好了. 关键是这些人愿意为我们写信. 通常采用奖励机制.
2,大量伪原创文章
伪原创文章不是指随机采集的文章,这些文章是通过在线伪原创工具转换并直接发布的. 相反,Ma Hui SEO不建议使用此工具. 建议根据他人的想法编写自己的内容,或者直接转载文章并添加评论.
3. 创建一列
如果网站仅具有第二级列,则可以考虑创建多个第三级列以对文章进行更详细的分类,但是建议每个类别下不少于十篇,并进行长期维护是必需的.
4. 标签汇总页面
合理地为文章添加标签. 不要添加太多标签,尤其是当标签的数量大于网站上的文章数量时,搜索引擎可能会降低网站的访问量.
如何快速添加网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2020-08-07 17:14
图片来自[Mafan SEO工具-摩天大楼内容助手]如何快速收录网站
网站收录是SEO工作中非常重要的一部分. 如果搜索引擎未收录网站的网页,则基本上不可能获得更好的排名,更不用说访问量了. 对于网站上的原创文章,如果不能及时添加,则很可能被窃,甚至被搜索引擎认为是别人的原创. 如果是这样的话,那么我们辛勤工作的结果无非就是别人在做婚纱. 那么搜索引擎应如何尽快包括我们的网站?
我们首先需要知道的是,百度,谷歌和搜狗等搜索引擎对新提交的网站持怀疑态度. 他们通常有一个到三个月的检查期,并且使用相同的搜索引擎. 新站点的评估标准也有所不同. 如果夹杂物有延迟或夹杂物的数量在夹杂物后的一段时间内没有增加,这也是正常的. ,
1. 在网站建设的初期,我们需要优化我们的网站代码,以使代码尽可能简洁明了,而不会造成太多麻烦.
2. 内容应尽可能基于文本. 不要添加太多图片,以免影响网站的整体加载速度. 如果文章收录文件,请尽可能压缩或合并文件.
3. 切记不要修改网站的整体框架,否则,即使已将其包括在内,搜索引擎也可能会将其视为不成熟的产品,并再次丢弃. 如果是这种情况,则必须再次将其收录进来. 这更加困难.
4. 网站完善后,我们可以将我们的网站URL和信息提交给搜索引擎. 这样,可以将搜索引擎引导至我们的网站以获取信息,但一天之内不要重复太多. 提交内容,否则它很可能会被搜索引擎列入黑名单,从而完全失去了收录的希望.
5. 众所周知,搜索引擎是热爱新事物而不喜欢旧事物的事物. 它喜欢新鲜的内容. 只有每天定期且定量地更新网站内容时,搜索引擎才会将其视为高质量的网站,并不断访问该网站. 数据采集.
6. 其次,外部链接的构建也是搜索引擎判断网站质量的重要标准. 外部链接是指在其他网站或平台上发布的链接,这些链接使用户可以直接单击以访问我们的网站. 但是,外部链接越多越好,但是权重越高越好. 如果网站的外部链接稳定增长且权重较高,则对收录网站非常有利.
7. 内部链接通常是指在网站的内部页面上添加到其他内部页面的链接,例如某些新闻页面或相关新闻,这些都是内部链接的类型. 内部链中的所有页面和内容都必须相关,并且不能随意堆叠. 只有这样,它才能在用户和搜索引擎上留下良好的印象.
最后[Code Fan SEO]我想和大家分享一些技巧. 如果要提高网站的收录率,实际上可以在标题或内容中添加一些不常用的单词或不常用的单词: 例如,文章的标题可以是瞾岽苡---如何将网站收录在其中百度,这个标题的标题是一个罕见的词.
由于在百度搜索引擎的数据库中可能没有与此关键字相关的任何内容,因此此类文章很容易被百度视为原创内容,从而增加了收录我们网站页面的可能性.
快速采集网站的技术
许多网站在线后,无需调试即可直接向搜索引擎提交链接. 这将直接降低搜索引擎对网站的友好度,并降低用户体验,这将导致网站花费更长的时间来获得搜索引擎. 信任,加快网站包容性的必要条件是: 完整的网站准备,合理的布局,完整的网站结构,良好的用户体验等,因此[Mafan SEO]为所有人总结了以下提示:
图片来自[Mafan SEO工具-摩天大楼内容助手]
1. 本地站点建立
在网站上线之前,必须将网站的内容,结构,模板等调整为最佳状态. 其次,必须保留足够的空间和内容,以便为搜索引擎提供便利的条件,并为搜索引擎留下良好的第一名. 印象深刻,这也是加快网站快速收录的必要技巧.
第二个原创内容
网站上线后,我们必须更新更多高质量的原创内容. 当前,有许多公司网站,产品类型相对较少,并且网站中的无效页面很多. 这不会促进网站的排名和纳入. 有效的是,如果您想快速增加网站的收录范围,则原创内容是必要条件. 如果您无法更新大量原创内容,则也可以增加产品知识或新闻专栏的原创文章以丰富网站内容.
三,域名友好
通常来说,如果网站使用的域名已经被搜索引擎列入黑名单,则很难将其包括在内. 我们在这里所说的黑名单意味着该域名已被搜索引擎禁止. 网站内容或非法信息等将严重打击网站的收录.
四个. 提交链接
如果网站的收录状况不佳,建议网站管理员尝试主动或自动提交链接到搜索引擎,以便搜索引擎以最快的速度查看网站的更新信息,并且更直观地抓取网站,从而改善网站的包容性.
通常,网站收录与网站优化的各个方面都有关系,并且可以在网站权重和关键字排名中起决定性作用,这可以使后续网站优化工作加倍努力,而且效果相同. 时间可以吸引更多流量,用户可以为网站推广和营销奠定基础.
未收录该网站的原因和解决方案
不收录网站是许多网站当前存在的问题. 特别是对于某些新网站,通常情况下不收录文章和网页. 实际上,如果发生这种情况,有必要找到根本原因. 找到原因并及时解决. 以下[Ma Mi SEO]将回答未收录该网站的原因和解决方案.
如果突然不收录该网站,请不要着急. 首先,从网站的近期运营中找出原因,因为搜索引擎将无故停止索引我们的页面. 它必须是最近的网站. 只有异常会导致不收录在内,因此我们需要仔细回顾一下最近对网站进行的更改.
1. 内容重复多次
首先,不收录该网站的最常见原因之一是该网站的内容重复了很多次. 这也是大多数文章不被搜索引擎收录的主要因素. 尽管这是一个常见的话题,但有必要再次提醒您.
我相信大多数网站管理员每天要做的是将几篇具有相关主题的文章随机混合,将其合并为一篇文章,然后在网站上发布. 也许这种方法权重很高. 该网站并没有任何负面影响,相反,它可以增加权重.
但是对于某些权重较低的网站,此方法只会降低我们网站上搜索引擎的信任度. 可以看出,原创文章的重要性不容忽视.
2. 文章的格式或布局不合理
文章的格式和布局也是许多人忽略的问题. 有时,当我们搜索关键字时,当我们在搜索引擎中看到一篇文章时,每个段落可能有大约600个单词. 这样的文章可以阅读. 它将在一定程度上增加用户的阅读疲劳.
如果文章的格式不好,水平不明确,将被搜索引擎认为是质量低,一文不值,无法满足用户的实际需求,也会延缓文章的速度. 收录,或直接拒绝.
3. 内容被大量采集
是否大量采集了网站内容,这也是突然不包括普通网站的原因之一. 如果突然不包括该网站,则可能是我们的文章采集过多,并且我们的文章采集了. 网站页面的权重可能高于我们的页面. 如果是这种情况,很容易混淆搜索引擎. 我们需要再次查看我们的网站,以检查我们的文章是否为原创. 从长远来看,这自然会影响包容性.
4. 过度优化
为了增加搜索引擎的数量,一些公司网站经常进行过度优化,而过度优化主要体现在关键字堆栈中. 这就像单独吃营养. 适量吃东西有益,但如果吃得太多,也将有益. 对于身体的负担,导致无法消化或营养过剩以及对外部链接和关键字的过度优化也是如此.
这不仅会使页面的重量分散,而且会大大降低收录率. 为了迎合用户和搜索引擎的偏爱,某些网站会在首页上添加过多的图片和动画,而搜索引擎会将该行为视为没有收录价值,因此自然不会爬网和收录该网站
摘要:
建立网站的公司的最大目的是获得流量,而搜索引擎恰恰是网站流量的主要来源. 如果网站在优化过程中收录更多内容,则获得访问量和排名的机会将会增加. 包容是一个漫长的过程. 只要您坚持上述内容,肯定会缓解和改善夹杂问题. 因此,[Code Mi SEO]建议网站管理员不要急于成功,只要网站纳入是一个长期目标. 看,经过大量的努力,它最终会实现.
感谢您的阅读. 上面的原创文章来自[Skyscraper Content Assistant-Ma Mi SEO Tool]. 查看全部
实际上,网站优化是一个漫长的过程. 搜索引擎必须基于对用户负责的态度来评估所有网站. 面对这样的评估,我们每天只能定期和定量地输入原创信息,以不断改善用户体验. 为了使搜索引擎更多地光顾我们的网站并查看我们网站的价值.
图片来自[Mafan SEO工具-摩天大楼内容助手]如何快速收录网站
网站收录是SEO工作中非常重要的一部分. 如果搜索引擎未收录网站的网页,则基本上不可能获得更好的排名,更不用说访问量了. 对于网站上的原创文章,如果不能及时添加,则很可能被窃,甚至被搜索引擎认为是别人的原创. 如果是这样的话,那么我们辛勤工作的结果无非就是别人在做婚纱. 那么搜索引擎应如何尽快包括我们的网站?
我们首先需要知道的是,百度,谷歌和搜狗等搜索引擎对新提交的网站持怀疑态度. 他们通常有一个到三个月的检查期,并且使用相同的搜索引擎. 新站点的评估标准也有所不同. 如果夹杂物有延迟或夹杂物的数量在夹杂物后的一段时间内没有增加,这也是正常的. ,
1. 在网站建设的初期,我们需要优化我们的网站代码,以使代码尽可能简洁明了,而不会造成太多麻烦.
2. 内容应尽可能基于文本. 不要添加太多图片,以免影响网站的整体加载速度. 如果文章收录文件,请尽可能压缩或合并文件.
3. 切记不要修改网站的整体框架,否则,即使已将其包括在内,搜索引擎也可能会将其视为不成熟的产品,并再次丢弃. 如果是这种情况,则必须再次将其收录进来. 这更加困难.
4. 网站完善后,我们可以将我们的网站URL和信息提交给搜索引擎. 这样,可以将搜索引擎引导至我们的网站以获取信息,但一天之内不要重复太多. 提交内容,否则它很可能会被搜索引擎列入黑名单,从而完全失去了收录的希望.
5. 众所周知,搜索引擎是热爱新事物而不喜欢旧事物的事物. 它喜欢新鲜的内容. 只有每天定期且定量地更新网站内容时,搜索引擎才会将其视为高质量的网站,并不断访问该网站. 数据采集.
6. 其次,外部链接的构建也是搜索引擎判断网站质量的重要标准. 外部链接是指在其他网站或平台上发布的链接,这些链接使用户可以直接单击以访问我们的网站. 但是,外部链接越多越好,但是权重越高越好. 如果网站的外部链接稳定增长且权重较高,则对收录网站非常有利.
7. 内部链接通常是指在网站的内部页面上添加到其他内部页面的链接,例如某些新闻页面或相关新闻,这些都是内部链接的类型. 内部链中的所有页面和内容都必须相关,并且不能随意堆叠. 只有这样,它才能在用户和搜索引擎上留下良好的印象.
最后[Code Fan SEO]我想和大家分享一些技巧. 如果要提高网站的收录率,实际上可以在标题或内容中添加一些不常用的单词或不常用的单词: 例如,文章的标题可以是瞾岽苡---如何将网站收录在其中百度,这个标题的标题是一个罕见的词.
由于在百度搜索引擎的数据库中可能没有与此关键字相关的任何内容,因此此类文章很容易被百度视为原创内容,从而增加了收录我们网站页面的可能性.
快速采集网站的技术
许多网站在线后,无需调试即可直接向搜索引擎提交链接. 这将直接降低搜索引擎对网站的友好度,并降低用户体验,这将导致网站花费更长的时间来获得搜索引擎. 信任,加快网站包容性的必要条件是: 完整的网站准备,合理的布局,完整的网站结构,良好的用户体验等,因此[Mafan SEO]为所有人总结了以下提示:
图片来自[Mafan SEO工具-摩天大楼内容助手]
1. 本地站点建立
在网站上线之前,必须将网站的内容,结构,模板等调整为最佳状态. 其次,必须保留足够的空间和内容,以便为搜索引擎提供便利的条件,并为搜索引擎留下良好的第一名. 印象深刻,这也是加快网站快速收录的必要技巧.
第二个原创内容
网站上线后,我们必须更新更多高质量的原创内容. 当前,有许多公司网站,产品类型相对较少,并且网站中的无效页面很多. 这不会促进网站的排名和纳入. 有效的是,如果您想快速增加网站的收录范围,则原创内容是必要条件. 如果您无法更新大量原创内容,则也可以增加产品知识或新闻专栏的原创文章以丰富网站内容.
三,域名友好
通常来说,如果网站使用的域名已经被搜索引擎列入黑名单,则很难将其包括在内. 我们在这里所说的黑名单意味着该域名已被搜索引擎禁止. 网站内容或非法信息等将严重打击网站的收录.
四个. 提交链接
如果网站的收录状况不佳,建议网站管理员尝试主动或自动提交链接到搜索引擎,以便搜索引擎以最快的速度查看网站的更新信息,并且更直观地抓取网站,从而改善网站的包容性.
通常,网站收录与网站优化的各个方面都有关系,并且可以在网站权重和关键字排名中起决定性作用,这可以使后续网站优化工作加倍努力,而且效果相同. 时间可以吸引更多流量,用户可以为网站推广和营销奠定基础.
未收录该网站的原因和解决方案
不收录网站是许多网站当前存在的问题. 特别是对于某些新网站,通常情况下不收录文章和网页. 实际上,如果发生这种情况,有必要找到根本原因. 找到原因并及时解决. 以下[Ma Mi SEO]将回答未收录该网站的原因和解决方案.
如果突然不收录该网站,请不要着急. 首先,从网站的近期运营中找出原因,因为搜索引擎将无故停止索引我们的页面. 它必须是最近的网站. 只有异常会导致不收录在内,因此我们需要仔细回顾一下最近对网站进行的更改.
1. 内容重复多次
首先,不收录该网站的最常见原因之一是该网站的内容重复了很多次. 这也是大多数文章不被搜索引擎收录的主要因素. 尽管这是一个常见的话题,但有必要再次提醒您.
我相信大多数网站管理员每天要做的是将几篇具有相关主题的文章随机混合,将其合并为一篇文章,然后在网站上发布. 也许这种方法权重很高. 该网站并没有任何负面影响,相反,它可以增加权重.
但是对于某些权重较低的网站,此方法只会降低我们网站上搜索引擎的信任度. 可以看出,原创文章的重要性不容忽视.
2. 文章的格式或布局不合理
文章的格式和布局也是许多人忽略的问题. 有时,当我们搜索关键字时,当我们在搜索引擎中看到一篇文章时,每个段落可能有大约600个单词. 这样的文章可以阅读. 它将在一定程度上增加用户的阅读疲劳.
如果文章的格式不好,水平不明确,将被搜索引擎认为是质量低,一文不值,无法满足用户的实际需求,也会延缓文章的速度. 收录,或直接拒绝.
3. 内容被大量采集
是否大量采集了网站内容,这也是突然不包括普通网站的原因之一. 如果突然不包括该网站,则可能是我们的文章采集过多,并且我们的文章采集了. 网站页面的权重可能高于我们的页面. 如果是这种情况,很容易混淆搜索引擎. 我们需要再次查看我们的网站,以检查我们的文章是否为原创. 从长远来看,这自然会影响包容性.
4. 过度优化
为了增加搜索引擎的数量,一些公司网站经常进行过度优化,而过度优化主要体现在关键字堆栈中. 这就像单独吃营养. 适量吃东西有益,但如果吃得太多,也将有益. 对于身体的负担,导致无法消化或营养过剩以及对外部链接和关键字的过度优化也是如此.
这不仅会使页面的重量分散,而且会大大降低收录率. 为了迎合用户和搜索引擎的偏爱,某些网站会在首页上添加过多的图片和动画,而搜索引擎会将该行为视为没有收录价值,因此自然不会爬网和收录该网站
摘要:
建立网站的公司的最大目的是获得流量,而搜索引擎恰恰是网站流量的主要来源. 如果网站在优化过程中收录更多内容,则获得访问量和排名的机会将会增加. 包容是一个漫长的过程. 只要您坚持上述内容,肯定会缓解和改善夹杂问题. 因此,[Code Mi SEO]建议网站管理员不要急于成功,只要网站纳入是一个长期目标. 看,经过大量的努力,它最终会实现.
感谢您的阅读. 上面的原创文章来自[Skyscraper Content Assistant-Ma Mi SEO Tool].
百度如何判断原创文章?
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2020-08-07 16:07
1.1馆藏泛滥
百度的一项调查显示,从传统媒体报纸到娱乐网站的花边新闻,从游戏指南到产品评论,甚至是大学图书馆,超过80%的新闻和信息都是手动复制或通过机器采集的还请注意,所有站点都在进行机器采集. 可以说,高质量的原创内容是一块小米,周围是广阔的采集海洋. 通过搜索引擎在海中搜索小米既困难又具有挑战性.
1.2改善搜索用户体验
数字化降低了传播成本,工具化降低了采集成本,并且机器采集的行为使内容源混乱,并降低了内容质量. 在采集过程中,无意或有意出现了诸如内容不完整和不完整,格式混乱或出现其他垃圾等问题,这些问题严重影响了搜索结果和用户体验的质量. 搜索引擎重视原创性的根本原因是为了改善用户体验. 这里提到的原创性是高质量的原创内容.
1.3鼓励原创作者和文章
重新发布和采集,转移了高质量原创网站的访问量,并且不再具有原创作者的名字,这将直接影响高质量原创网站管理员和作者的收入. 从长远来看,它将影响原创创作者的积极性,不利于创新,也不利于新的高质量内容的生产. 鼓励高质量的原创性,鼓励创新,并为原创站点和作者提供合理的访问量,从而促进Internet内容的繁荣,应该是搜索引擎的一项重要任务.
第二,采集非常狡猾,很难识别原创图片
2.1采集伪装成原件并篡改关键信息
当前,大量网站在分批采集原创内容之后,会使用手动或机器方法篡改关键信息,例如作者,发布时间和来源,并假装为原创内容. 这种冒充原创物的东西需要由搜索引擎识别并进行相应调整.
2.2内容生成器,制作伪原创
使用自动文章生成器之类的工具来“创建”文章,然后安装醒目的标题,现在的成本非常低,而且必须是原创的. 但是,原创性必须具有社会共识的价值,并且不能将任何不合理的垃圾视为有价值和高质量的原创内容. 尽管内容是唯一的,但它没有社会共识的价值. 搜索引擎需要识别和打击这种伪原创信息.
2.3不同的网页,难以提取结构化信息
不同的站点具有相对较大的结构差异,并且html标签的含义和分布也不同. 因此,提取诸如标题,作者和时间之类的关键信息的难度也相对较大. 在目前的中国互联网规模下,这并不容易. 这部分将需要搜索引擎和网站管理员的配合才能更平稳地运行. 如果网站站长将更清晰的结构告知搜索引擎网页布局,将使搜索引擎能够有效地提取原创信息和相关信息.
3. 百度如何识别原创性?
3.1建立原创的项目团队来进行长期战斗
面对挑战,为了改善搜索引擎的用户体验,为了获得高质量的原创原创网站的利益,并促进中国互联网的发展,我们选择了大量人组成一个原创的项目团队: 技术,产品,运营,法律事务等等,这不是一个临时组织,不是一个两个月和两个月的项目,我们已经准备好进行旷日持久的战斗.
3.2原创识别“起源”算法
Internet上有数百亿个网页,从中发现原创内容可以说是大海捞针. 我们的原创识别系统是在百度大数据的云计算平台上开发的,可以快速实现所有中文Internet页面的重复聚合和链接点关系分析.
首先,根据内容的相似性采集馆藏和原创作品,并将相似的网页聚集在一起,作为一组原创作品的候选者;
第二,对于原创候选集,原创网页是根据作者,发布时间,链接方向,用户评论,作者和站点的历史原创性以及转发路径等数百种因素来标识和判断的;
最后,使用价值分析系统确定原创内容的价值,然后适当地指导最终排名.
目前,通过我们的实验和真实的在线数据,“起源”算法取得了一些进展,并解决了新闻,信息等领域的大多数问题. 当然,在其他领域,还有更多原创问题等待“来源”解决,我们决心走.
3.3 Original Spark项目
我们一直致力于调整原创内容的识别和排序算法,但是在当前的Internet环境中,快速识别原创内容和解决原创问题确实面临着巨大的挑战. 计算数据的规模巨大,我们面临的采集方法是无穷无尽的. 网站构建方法和模板,复杂的内容提取和其他问题存在巨大差异. 这些因素将影响原创算法的识别,甚至导致判断错误. 这时,百度和网站管理员必须共同维护互联网的生态环境. 网站站长推荐原创内容,搜索引擎经过一定判断后会优先处理原创内容,共同促进生态的改善并鼓励原创性. 这是“原创Spark项目”,旨在快速解决当前面临的严重问题. 此外,网站站长对原创内容的推荐将应用于“起源”算法,这将有助于百度找到该算法的缺陷,进行持续改进,并使用更智能的识别算法自动识别原创内容.
目前,原创Spark项目也已取得初步成果. 在百度搜索结果中,一些关键原创新闻站点的原创内容的第一阶段已被赋予原创标签,作者显示等,并且还实现了排名和访问量. 合理促销.
最后,创意是生态问题,需要长期改进. 我们将继续投资并与网站管理员合作,以促进互联网生态的进步;创意是一个环境问题,需要每个人维护. 网站管理员应制作更多原创作品,并推荐更多原创作品,百度将继续努力改善排名算法,鼓励原创内容,并为原创作者和原创网站提供合理的排名和流量. 查看全部
1. 搜索引擎为什么要重视原创性?
1.1馆藏泛滥
百度的一项调查显示,从传统媒体报纸到娱乐网站的花边新闻,从游戏指南到产品评论,甚至是大学图书馆,超过80%的新闻和信息都是手动复制或通过机器采集的还请注意,所有站点都在进行机器采集. 可以说,高质量的原创内容是一块小米,周围是广阔的采集海洋. 通过搜索引擎在海中搜索小米既困难又具有挑战性.
1.2改善搜索用户体验
数字化降低了传播成本,工具化降低了采集成本,并且机器采集的行为使内容源混乱,并降低了内容质量. 在采集过程中,无意或有意出现了诸如内容不完整和不完整,格式混乱或出现其他垃圾等问题,这些问题严重影响了搜索结果和用户体验的质量. 搜索引擎重视原创性的根本原因是为了改善用户体验. 这里提到的原创性是高质量的原创内容.
1.3鼓励原创作者和文章
重新发布和采集,转移了高质量原创网站的访问量,并且不再具有原创作者的名字,这将直接影响高质量原创网站管理员和作者的收入. 从长远来看,它将影响原创创作者的积极性,不利于创新,也不利于新的高质量内容的生产. 鼓励高质量的原创性,鼓励创新,并为原创站点和作者提供合理的访问量,从而促进Internet内容的繁荣,应该是搜索引擎的一项重要任务.
第二,采集非常狡猾,很难识别原创图片
2.1采集伪装成原件并篡改关键信息
当前,大量网站在分批采集原创内容之后,会使用手动或机器方法篡改关键信息,例如作者,发布时间和来源,并假装为原创内容. 这种冒充原创物的东西需要由搜索引擎识别并进行相应调整.
2.2内容生成器,制作伪原创
使用自动文章生成器之类的工具来“创建”文章,然后安装醒目的标题,现在的成本非常低,而且必须是原创的. 但是,原创性必须具有社会共识的价值,并且不能将任何不合理的垃圾视为有价值和高质量的原创内容. 尽管内容是唯一的,但它没有社会共识的价值. 搜索引擎需要识别和打击这种伪原创信息.
2.3不同的网页,难以提取结构化信息
不同的站点具有相对较大的结构差异,并且html标签的含义和分布也不同. 因此,提取诸如标题,作者和时间之类的关键信息的难度也相对较大. 在目前的中国互联网规模下,这并不容易. 这部分将需要搜索引擎和网站管理员的配合才能更平稳地运行. 如果网站站长将更清晰的结构告知搜索引擎网页布局,将使搜索引擎能够有效地提取原创信息和相关信息.
3. 百度如何识别原创性?
3.1建立原创的项目团队来进行长期战斗
面对挑战,为了改善搜索引擎的用户体验,为了获得高质量的原创原创网站的利益,并促进中国互联网的发展,我们选择了大量人组成一个原创的项目团队: 技术,产品,运营,法律事务等等,这不是一个临时组织,不是一个两个月和两个月的项目,我们已经准备好进行旷日持久的战斗.
3.2原创识别“起源”算法
Internet上有数百亿个网页,从中发现原创内容可以说是大海捞针. 我们的原创识别系统是在百度大数据的云计算平台上开发的,可以快速实现所有中文Internet页面的重复聚合和链接点关系分析.
首先,根据内容的相似性采集馆藏和原创作品,并将相似的网页聚集在一起,作为一组原创作品的候选者;
第二,对于原创候选集,原创网页是根据作者,发布时间,链接方向,用户评论,作者和站点的历史原创性以及转发路径等数百种因素来标识和判断的;
最后,使用价值分析系统确定原创内容的价值,然后适当地指导最终排名.
目前,通过我们的实验和真实的在线数据,“起源”算法取得了一些进展,并解决了新闻,信息等领域的大多数问题. 当然,在其他领域,还有更多原创问题等待“来源”解决,我们决心走.
3.3 Original Spark项目
我们一直致力于调整原创内容的识别和排序算法,但是在当前的Internet环境中,快速识别原创内容和解决原创问题确实面临着巨大的挑战. 计算数据的规模巨大,我们面临的采集方法是无穷无尽的. 网站构建方法和模板,复杂的内容提取和其他问题存在巨大差异. 这些因素将影响原创算法的识别,甚至导致判断错误. 这时,百度和网站管理员必须共同维护互联网的生态环境. 网站站长推荐原创内容,搜索引擎经过一定判断后会优先处理原创内容,共同促进生态的改善并鼓励原创性. 这是“原创Spark项目”,旨在快速解决当前面临的严重问题. 此外,网站站长对原创内容的推荐将应用于“起源”算法,这将有助于百度找到该算法的缺陷,进行持续改进,并使用更智能的识别算法自动识别原创内容.
目前,原创Spark项目也已取得初步成果. 在百度搜索结果中,一些关键原创新闻站点的原创内容的第一阶段已被赋予原创标签,作者显示等,并且还实现了排名和访问量. 合理促销.
最后,创意是生态问题,需要长期改进. 我们将继续投资并与网站管理员合作,以促进互联网生态的进步;创意是一个环境问题,需要每个人维护. 网站管理员应制作更多原创作品,并推荐更多原创作品,百度将继续努力改善排名算法,鼓励原创内容,并为原创作者和原创网站提供合理的排名和流量.
[原创和免费]微信公众号文章检索方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2020-08-07 12:07
参考文章
AnyProxy代理批量采集
如何实现: anyproxy + js
如何实现: anyproxy + java + webmagic
FiddlerCore
实现方法: 数据包捕获工具Fiddler4
通过捕获和分析多个帐户,我们可以确定:
步骤:
1. 编写按键向导脚本,并自动单击电话上的“公众号文章列表”页面,即“查看历史新闻”;
2,使用提琴手代理劫持手机访问权,并将URL转发到用PHP编写的本地网页;
3,将php网页上收到的URL备份到数据库中;
4,使用python从数据库中获取URL,然后执行正常的爬网.
在抓取过程中发现问题:
如果您只想抓取文章的内容,似乎没有访问频率的限制,但是如果您想获取阅读次数和喜欢的次数,经过一定的频率后,返回值将变为空值. 我设置的时间间隔是10秒内可以正常抓取. 在这个频率下,一个小时内只能抓取360条消息,这没有实际意义.
青岛新列表
如果您只想查看数据,请直接查看每日列表,而无需花钱. 如果您需要访问自己的系统,它们还提供api接口
第3部分项目步骤的基本原理
此网站收录大多数微信官方帐户文章,这些文章将定期更新. 经过测试,发现它对爬虫更友好
网站页面的布局和排版规则,通过链接中的帐户来区分不同的官方帐户
一组公共帐户下的文章翻页也是正常的: ID号+每翻页一次12
Portal-Copy.png
所以这个想法可能是一样的
与环境相关的软件包获取页面
def get_one_page(url):
#需要加一个请求头部,不然会被网站封禁
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status #若不为200,则引发HTTPError错误
response.encoding = response.apparent_encoding
return response.text
except:
return "产生异常"
请注意,目标采集器网站必须添加标头,否则它将直接拒绝访问
常规解析html
def parse_one_page(html):
pattern = re.compile('.*?.*?<a class="question_link" href="(.*?)".*?_blank"(.*?)/a.*?"timestamp".*?">(.*?)', re.S)
items = re.findall(pattern, html)
return items
自动跳转页面
def main(offset, i):
url = 'http://chuansong.me/account/' + str(offset) + '?start=' + str(12*i)
print(url)
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
html = get_one_page(url)
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
删除标题中的非法字符
由于Windows下有file命令,因此无法使用某些字符,因此我们需要使用常规消除符
itle = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
转换html
使用pandas的read_csv函数读取抓取的csv文件,并在“链接”,“标题”,“日期”之间循环
def html_to_pdf(offset):
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
path = get_path(offset)
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe' #安装wkhtmltopdf的位置
config = pdfkit.configuration(wkhtmltopdf = path_wk)
if path == "" :
print("尚未抓取该公众号")
else:
info = get_url_info(offset)
for indexs in info.index:
url = info.loc[indexs]['链接']
title = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
date = info.loc[indexs]['日期']
wait = round(random.uniform(4,5),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
print(url)
with eventlet.Timeout(4,False):
pdfkit.from_url(url, get_path(offset)+'\\'+ date+'_'+title+'.pdf', configuration=config)
print('转换成功!')
结果显示抓取结果
结果1-copy.png
已抓取的几个正式帐户存储在文件夹中
结果2-copy.png
文件夹目录下的内容
结果3-copy.png
已抓取CSV内容格式
生成的PDF结果
结果4-copy.png
遇到的问题,问题1
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
info = info.strip('\"')
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
解决方案
字符串中首尾带有“”,使用上文中的#注释部分的各种方法都不好使,
最后的解决办法是:
在写入字符串的代码出,加上.strip('\'\"'),以去掉‘和”
with open(path, 'a', encoding='utf-8') as f: #追加存储形式,content是字典形式
f.write(str(json.dumps(content, ensure_ascii=False).strip('\'\"') + '\n'))
f.close()
问题2
调用wkhtmltopdf.exe将html转成pdf报错
调用代码
``` python
path_wk = 'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
```
错误消息
OSError: No wkhtmltopdf executable found: "D:\Program Files\wkhtmltopdin\wkhtmltopdf.exe"
If this file exists please check that this process can read it. Otherwise please install wkhtmltopdf - https://github.com/JazzCore/py ... topdf
解决方案
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
或者
path_wk = 'D:\\Program Files\\wkhtmltopdf\\bin\\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
原因 查看全部
python爬行
参考文章
AnyProxy代理批量采集
如何实现: anyproxy + js
如何实现: anyproxy + java + webmagic
FiddlerCore
实现方法: 数据包捕获工具Fiddler4
通过捕获和分析多个帐户,我们可以确定:
步骤:
1. 编写按键向导脚本,并自动单击电话上的“公众号文章列表”页面,即“查看历史新闻”;
2,使用提琴手代理劫持手机访问权,并将URL转发到用PHP编写的本地网页;
3,将php网页上收到的URL备份到数据库中;
4,使用python从数据库中获取URL,然后执行正常的爬网.
在抓取过程中发现问题:
如果您只想抓取文章的内容,似乎没有访问频率的限制,但是如果您想获取阅读次数和喜欢的次数,经过一定的频率后,返回值将变为空值. 我设置的时间间隔是10秒内可以正常抓取. 在这个频率下,一个小时内只能抓取360条消息,这没有实际意义.
青岛新列表
如果您只想查看数据,请直接查看每日列表,而无需花钱. 如果您需要访问自己的系统,它们还提供api接口
第3部分项目步骤的基本原理
此网站收录大多数微信官方帐户文章,这些文章将定期更新. 经过测试,发现它对爬虫更友好
网站页面的布局和排版规则,通过链接中的帐户来区分不同的官方帐户
一组公共帐户下的文章翻页也是正常的: ID号+每翻页一次12
Portal-Copy.png
所以这个想法可能是一样的
与环境相关的软件包获取页面
def get_one_page(url):
#需要加一个请求头部,不然会被网站封禁
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status #若不为200,则引发HTTPError错误
response.encoding = response.apparent_encoding
return response.text
except:
return "产生异常"
请注意,目标采集器网站必须添加标头,否则它将直接拒绝访问
常规解析html
def parse_one_page(html):
pattern = re.compile('.*?.*?<a class="question_link" href="(.*?)".*?_blank"(.*?)/a.*?"timestamp".*?">(.*?)', re.S)
items = re.findall(pattern, html)
return items
自动跳转页面
def main(offset, i):
url = 'http://chuansong.me/account/' + str(offset) + '?start=' + str(12*i)
print(url)
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
html = get_one_page(url)
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
删除标题中的非法字符
由于Windows下有file命令,因此无法使用某些字符,因此我们需要使用常规消除符
itle = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
转换html
使用pandas的read_csv函数读取抓取的csv文件,并在“链接”,“标题”,“日期”之间循环
def html_to_pdf(offset):
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
path = get_path(offset)
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe' #安装wkhtmltopdf的位置
config = pdfkit.configuration(wkhtmltopdf = path_wk)
if path == "" :
print("尚未抓取该公众号")
else:
info = get_url_info(offset)
for indexs in info.index:
url = info.loc[indexs]['链接']
title = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
date = info.loc[indexs]['日期']
wait = round(random.uniform(4,5),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
print(url)
with eventlet.Timeout(4,False):
pdfkit.from_url(url, get_path(offset)+'\\'+ date+'_'+title+'.pdf', configuration=config)
print('转换成功!')
结果显示抓取结果
结果1-copy.png
已抓取的几个正式帐户存储在文件夹中
结果2-copy.png
文件夹目录下的内容
结果3-copy.png
已抓取CSV内容格式
生成的PDF结果
结果4-copy.png
遇到的问题,问题1
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
info = info.strip('\"')
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
解决方案
字符串中首尾带有“”,使用上文中的#注释部分的各种方法都不好使,
最后的解决办法是:
在写入字符串的代码出,加上.strip('\'\"'),以去掉‘和”
with open(path, 'a', encoding='utf-8') as f: #追加存储形式,content是字典形式
f.write(str(json.dumps(content, ensure_ascii=False).strip('\'\"') + '\n'))
f.close()
问题2
调用wkhtmltopdf.exe将html转成pdf报错
调用代码
``` python
path_wk = 'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
```
错误消息
OSError: No wkhtmltopdf executable found: "D:\Program Files\wkhtmltopdin\wkhtmltopdf.exe"
If this file exists please check that this process can read it. Otherwise please install wkhtmltopdf - https://github.com/JazzCore/py ... topdf
解决方案
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
或者
path_wk = 'D:\\Program Files\\wkhtmltopdf\\bin\\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
原因
在哪里可以找到seo伪原创文章的原创文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2020-08-07 07:17
问题: 在哪里可以找到seo伪原创的原创文章?
答案: 很难找到真正的原创文章. 大多数网站不具备撰写原创文章的能力. 我们不需要查找完全原创的文章来撰写seo文章,而只需满足关键字的需求.
这里是关于如何找到撰写seo伪原创文章的材料的简短讨论. 作者曾经告诉过您编辑seo文章的技巧,也就是说,您需要整理两个或更多字幕. 我们正在寻找seo伪原创文章材料. 该时候了,您可以直接搜索这两个字幕,您可以在搜索引擎中找到很多内容,然后有选择地进行复制. 该方法实际上非常简单,取决于您是否仔细进行操作!
每个人都必须真正了解伪原创的seo文章,而不必担心找到这些原创文章. 这种原创文章使我们难以判断,而且也不容易找到. 现在,我们可以看到不是原创的文章,但是如果将它们作为一个整体进行处理,它们也可以成为搜索引擎认可的高质量文章,并获得良好的关键字排名.
有人还谈论窃书籍文章,即从书籍中获取原创文章. 如果这些文章未在线发布,那么这些文章确实是原创文章!但是,这里必须考虑版权问题,尤其是对于企业注册的网站. 建议不要使用此方法,因为这样做存在很大的风险,并且那时将很难处理. 对于某些类型的问题,您可以考虑去官方帐户和其他地方找到它,因为一些原创作者已经打开了We-media但没有自己的网站,而诸如官方帐户之类的百度搜索将不会抓取,因此可能会发现一些原创文章.
关于在哪里可以找到seo伪原创文章的原创问题,本文将向您介绍. 简而言之,要找到真正的原创文章会更加困难,因此您可以自己想办法. 还要注意,seo伪原创不一定要查找原创文章,普通文章也是可能的,只要它们可以解决关键字问题即可. 建议您掌握seo伪原创文章的写作技巧,以便对seo伪原创文章的本质有更深入的了解. 查看全部
在哪里可以找到seo伪原创文章的原创文章
问题: 在哪里可以找到seo伪原创的原创文章?
答案: 很难找到真正的原创文章. 大多数网站不具备撰写原创文章的能力. 我们不需要查找完全原创的文章来撰写seo文章,而只需满足关键字的需求.
这里是关于如何找到撰写seo伪原创文章的材料的简短讨论. 作者曾经告诉过您编辑seo文章的技巧,也就是说,您需要整理两个或更多字幕. 我们正在寻找seo伪原创文章材料. 该时候了,您可以直接搜索这两个字幕,您可以在搜索引擎中找到很多内容,然后有选择地进行复制. 该方法实际上非常简单,取决于您是否仔细进行操作!
每个人都必须真正了解伪原创的seo文章,而不必担心找到这些原创文章. 这种原创文章使我们难以判断,而且也不容易找到. 现在,我们可以看到不是原创的文章,但是如果将它们作为一个整体进行处理,它们也可以成为搜索引擎认可的高质量文章,并获得良好的关键字排名.
有人还谈论窃书籍文章,即从书籍中获取原创文章. 如果这些文章未在线发布,那么这些文章确实是原创文章!但是,这里必须考虑版权问题,尤其是对于企业注册的网站. 建议不要使用此方法,因为这样做存在很大的风险,并且那时将很难处理. 对于某些类型的问题,您可以考虑去官方帐户和其他地方找到它,因为一些原创作者已经打开了We-media但没有自己的网站,而诸如官方帐户之类的百度搜索将不会抓取,因此可能会发现一些原创文章.
关于在哪里可以找到seo伪原创文章的原创问题,本文将向您介绍. 简而言之,要找到真正的原创文章会更加困难,因此您可以自己想办法. 还要注意,seo伪原创不一定要查找原创文章,普通文章也是可能的,只要它们可以解决关键字问题即可. 建议您掌握seo伪原创文章的写作技巧,以便对seo伪原创文章的本质有更深入的了解.

