
分页
Dedecms采集含有分页的普通文章的使用方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 642 次浏览 • 2020-07-24 08:00
单击“保存信息并步入下一步设置”后,便可步入“新增采集节点:第二步设置内容数组获取规则”页面,如(图1)所示,
系统将会手动指定一个“预览网址”,一般是文章列表页的第一篇文章的网址。但是,由于第一篇文章中没有涉及到分页的部份,所以在这里自动修改为第二篇文章的网址:“”,
上图红箭头部份是写下边来设定分页部份的匹配规则。其具体操作步骤为:
打开文章内容页面,在网页上单击右键,在弹出的对话框中单击“查看源文件“。在源代码中,找到分页代码的开始部份和结束部份,如(图2)所示,
经过观察可知,分页代码坐落“
“和”
”之间。因此,在”内容分页导航所在的区域匹配规则“中,应填写”
[内容]
“。对于分页代码的款式,一共有三种可供选择,这里应选择第一种” 全部列举的分页列表”。填写后,如(图3)所示,
对于“固定采集项目”中的“内容摘要、关键字和缩略图“三个部份,系统会用正则进行手动匹配,这里仅需配置过滤内容即可。下面主要介绍怎么获取“文章标题、文章作者、文章来源、发布时间和文章内容”的采集规则,过滤规则仅简单涉及。
首先,打开“预览网址“的页面并单击右键,选择”查看源代码“,找到文章标题” OpenFlow网路是空谈吗?“织梦采集规则中分页,如(图4)所示,
图18-在源代码中的文章标题
这里的文章标题处在””之间,因此这儿应当填写”[内容]”作为文章标题的匹配规则。如果在文章标题中富含相关链接等,可使用过滤规则加以处理,这里无需设置。填写后,如(图5)所示,
图5-文章标题的采集规则
经过查找北京班车租赁企业租车网站的源代码和对比原文的标题部份,可发觉本文没有涉及到作者,所以这儿不用填写,空着即可。
2.1.3 获取文章来源的采集规则
在上图19中,可发觉来源的内容介于“来源:“和“”之间,因此这儿应填写“来源:[内容]”作为文章来源的采集规则。同样,这里也不需要使用过滤规则。填写后,如图6所示,
图6-文章来源的采集规则
再次回到图17,可找到“时间:2011-05-13 11:47”,因此这儿应把“时间:[内容]”作为发布时间的采集规则。同样,这里也不需要使用过滤规则。填写后,如图7所示,
图7-文章发布时间的采集规则
这个部份是编撰采集规则的重点,也是难点。需要非常注意。
具体操作步骤:
(a)在在打开的文章内容页面的源代码中,找到文章内容的开始部份“计算机网路知识的学习”,如图8所示,
图8-文章内容的开始部份
这里应把””作为匹配规则的开始部份,注意到这段代码中包含一段广告代码,需要采用过滤规则把其清除。经观察发觉,这段JS广告代码是坐落“
”和“
”之间的。因此,应在“过滤规则”中填写:“{dede:trim replace=’’}
(.*)
”{/dede:trim}。填写后,如(图9)所示,
图9-开始部份的匹配规则及其过滤规则
(b)找到文章内容的结束部份,因为涉及到分页部份织梦采集规则中分页,所以应当选定分页结束的位置,如图10所示,
图10-文章内容的结束部份
这里应选定“”作为文章内容的结束部份,由于在选定的内容中又包含了一段JS代码,因此应再度使用过滤规则,把其清除。同时,考虑到本页没有涉及到分页,所以在分页代码中的之间是空的。但是,如果页面包含分页的话,也是应当使用过滤规则去掉的。此外,如果所设定的文章内容中,含有图片、链接等不希望被采集到的内容,也应当使用过滤规则一并清除掉。填写完成后,如(图11)所示,
图11-文章内容的匹配规则
到这儿,“新增采集节点:第二步设置内容数组获取规则”,就设置完成了。来看一下整个配置页面,如(图12)所示,
图12-设置后的新增采集节点:第二步设置内容数组获取规则
检查无误后,单击“保存配置并预览”。如果之前设置正确,单击后,将会步入“新增采集节点:测试内容数组设置”页面并见到相应的文章内容。如(图13)和(图14)所示,
图13-新增采集节点:测试内容数组设置
图14-新增采集节点:测试内容数组设置
其中,图中画圈的地方代表的是分页符号。
确定正确无误后,如果单击“仅保存”,系统将会提示“成功保存配置“并返回”采集节点管理“界面;如果单击“保存并开始采集“,将会步入”采集指定节点“界面。否则,请单击“返回上一步进行更改”。 查看全部

单击“保存信息并步入下一步设置”后,便可步入“新增采集节点:第二步设置内容数组获取规则”页面,如(图1)所示,

系统将会手动指定一个“预览网址”,一般是文章列表页的第一篇文章的网址。但是,由于第一篇文章中没有涉及到分页的部份,所以在这里自动修改为第二篇文章的网址:“”,
上图红箭头部份是写下边来设定分页部份的匹配规则。其具体操作步骤为:
打开文章内容页面,在网页上单击右键,在弹出的对话框中单击“查看源文件“。在源代码中,找到分页代码的开始部份和结束部份,如(图2)所示,

经过观察可知,分页代码坐落“
“和”
”之间。因此,在”内容分页导航所在的区域匹配规则“中,应填写”
[内容]
“。对于分页代码的款式,一共有三种可供选择,这里应选择第一种” 全部列举的分页列表”。填写后,如(图3)所示,

对于“固定采集项目”中的“内容摘要、关键字和缩略图“三个部份,系统会用正则进行手动匹配,这里仅需配置过滤内容即可。下面主要介绍怎么获取“文章标题、文章作者、文章来源、发布时间和文章内容”的采集规则,过滤规则仅简单涉及。
首先,打开“预览网址“的页面并单击右键,选择”查看源代码“,找到文章标题” OpenFlow网路是空谈吗?“织梦采集规则中分页,如(图4)所示,

图18-在源代码中的文章标题
这里的文章标题处在””之间,因此这儿应当填写”[内容]”作为文章标题的匹配规则。如果在文章标题中富含相关链接等,可使用过滤规则加以处理,这里无需设置。填写后,如(图5)所示,
图5-文章标题的采集规则
经过查找北京班车租赁企业租车网站的源代码和对比原文的标题部份,可发觉本文没有涉及到作者,所以这儿不用填写,空着即可。
2.1.3 获取文章来源的采集规则
在上图19中,可发觉来源的内容介于“来源:“和“”之间,因此这儿应填写“来源:[内容]”作为文章来源的采集规则。同样,这里也不需要使用过滤规则。填写后,如图6所示,
图6-文章来源的采集规则
再次回到图17,可找到“时间:2011-05-13 11:47”,因此这儿应把“时间:[内容]”作为发布时间的采集规则。同样,这里也不需要使用过滤规则。填写后,如图7所示,
图7-文章发布时间的采集规则
这个部份是编撰采集规则的重点,也是难点。需要非常注意。
具体操作步骤:
(a)在在打开的文章内容页面的源代码中,找到文章内容的开始部份“计算机网路知识的学习”,如图8所示,
图8-文章内容的开始部份
这里应把””作为匹配规则的开始部份,注意到这段代码中包含一段广告代码,需要采用过滤规则把其清除。经观察发觉,这段JS广告代码是坐落“
”和“
”之间的。因此,应在“过滤规则”中填写:“{dede:trim replace=’’}
(.*)
”{/dede:trim}。填写后,如(图9)所示,
图9-开始部份的匹配规则及其过滤规则
(b)找到文章内容的结束部份,因为涉及到分页部份织梦采集规则中分页,所以应当选定分页结束的位置,如图10所示,
图10-文章内容的结束部份
这里应选定“”作为文章内容的结束部份,由于在选定的内容中又包含了一段JS代码,因此应再度使用过滤规则,把其清除。同时,考虑到本页没有涉及到分页,所以在分页代码中的之间是空的。但是,如果页面包含分页的话,也是应当使用过滤规则去掉的。此外,如果所设定的文章内容中,含有图片、链接等不希望被采集到的内容,也应当使用过滤规则一并清除掉。填写完成后,如(图11)所示,
图11-文章内容的匹配规则
到这儿,“新增采集节点:第二步设置内容数组获取规则”,就设置完成了。来看一下整个配置页面,如(图12)所示,
图12-设置后的新增采集节点:第二步设置内容数组获取规则
检查无误后,单击“保存配置并预览”。如果之前设置正确,单击后,将会步入“新增采集节点:测试内容数组设置”页面并见到相应的文章内容。如(图13)和(图14)所示,
图13-新增采集节点:测试内容数组设置
图14-新增采集节点:测试内容数组设置
其中,图中画圈的地方代表的是分页符号。
确定正确无误后,如果单击“仅保存”,系统将会提示“成功保存配置“并返回”采集节点管理“界面;如果单击“保存并开始采集“,将会步入”采集指定节点“界面。否则,请单击“返回上一步进行更改”。
解析织梦v5.3的分页采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 477 次浏览 • 2020-07-23 08:01
还好自己有点基础,弄了三天就基本搞清织梦的操作流程了,申请域名、空间,上传程序。忙得是不亦乐乎,好了,开始采集文章了。好高兴,一下就有了2000多篇文章。高兴的打开来看看,哇,突然吓了一跳织梦采集规则中分页,发现一个文章一看就只有一段没有完整,打开源旧址一看,原来有分页,在网上找了N久,还是没有结果,自己摸索摸索吧,搞了一天一夜几乎没有睡着,我差点都没有信心了,想着就是采集的文章只有一半,别人怎样看啊,都不想做了,也累了,还是好好睡一觉吧。
也许是老天看我太辛苦了吧,刚想睡着,突然我一下睡意全无,我很激动了,我听到了,看到了分页被我采集了。好了,说了这么多,还是开始步入题外话了。直接看图。如果看不懂请打开源网址,查看源文件,和我的教程比较。开始选着左侧的采集,然后打开采集节点管理,添加新节点,选着普通文章。1、文章列表页采集节点名称:自己按照你的网站目录和采集内容结合上去。网址:(*).html 是有规则的网址列表。如果有不规则追加就好了。如果只有一页或几页没有规则就直接写在下边手工指定网址就好了。
文章列表匹配规则。注意要多看几页找出相同的,列表页大体相同,但有些有点小变化,所以要找出几页的共同html代码。
区域开始的html :
建议写上筛选,一般写必须包含,这样确切点:/flashsl
保存步入下一步设置。以看见下边的图为准。
3、分页设置预览网址可以修改。选择有分页的页面来预览,当然最很多预览几页织梦采集规则中分页,主要是和上面一样代码可能有小变化,选着相同的html代码分页匹配规则这儿只要做过一次就不难了。
看我的代码 ,请和源网址,查看源文件对比。 查看全部
还好自己有点基础,弄了三天就基本搞清织梦的操作流程了,申请域名、空间,上传程序。忙得是不亦乐乎,好了,开始采集文章了。好高兴,一下就有了2000多篇文章。高兴的打开来看看,哇,突然吓了一跳织梦采集规则中分页,发现一个文章一看就只有一段没有完整,打开源旧址一看,原来有分页,在网上找了N久,还是没有结果,自己摸索摸索吧,搞了一天一夜几乎没有睡着,我差点都没有信心了,想着就是采集的文章只有一半,别人怎样看啊,都不想做了,也累了,还是好好睡一觉吧。
也许是老天看我太辛苦了吧,刚想睡着,突然我一下睡意全无,我很激动了,我听到了,看到了分页被我采集了。好了,说了这么多,还是开始步入题外话了。直接看图。如果看不懂请打开源网址,查看源文件,和我的教程比较。开始选着左侧的采集,然后打开采集节点管理,添加新节点,选着普通文章。1、文章列表页采集节点名称:自己按照你的网站目录和采集内容结合上去。网址:(*).html 是有规则的网址列表。如果有不规则追加就好了。如果只有一页或几页没有规则就直接写在下边手工指定网址就好了。

文章列表匹配规则。注意要多看几页找出相同的,列表页大体相同,但有些有点小变化,所以要找出几页的共同html代码。
区域开始的html :
建议写上筛选,一般写必须包含,这样确切点:/flashsl

保存步入下一步设置。以看见下边的图为准。

3、分页设置预览网址可以修改。选择有分页的页面来预览,当然最很多预览几页织梦采集规则中分页,主要是和上面一样代码可能有小变化,选着相同的html代码分页匹配规则这儿只要做过一次就不难了。
看我的代码 ,请和源网址,查看源文件对比。
织梦CMS怎么做分页的采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 512 次浏览 • 2020-07-23 08:01
最近想做个技术型的网站,不知道用哪些cms来做,在网上搜索了一大堆,看到织梦的采集功能还不错,我也在想啊,做一个站假如所有的文章都须要站长一个一个的加,那不是要吓死啊,所以就选着了织梦。
还好自己有点基础,弄了三天就基本搞清织梦的操作流程了,申请域名、空间,上传程序。忙得是不亦乐乎,好了,开始采集文章了。好高兴,一下就有了2000多篇文章。高兴的打开来看看,哇,突然吓了一跳,发现一个文章一看就只有一段没有完整,打开源旧址一看,原来有分页,在网上找了N久,还是没有结果,自己摸索摸索吧,搞了一天一夜几乎没有午睡,我差点都没有信心了,想着就是采集的文章只有一半,别人如何看啊,都不想做了,也累了,还是好好睡一觉吧。
也许是老天看我太辛苦了吧,刚想午睡,突然我一下睡意全无,我很激动了,我看见了,看到了分页被我采集了。好了,说了这么多,还是开始步入题外话了。直接看图。如果看不懂请打开源网址,查看源文件,和我的教程比较。开始选着左侧的采集,然后打开采集节点管理,添加新节点,选着普通文章。1、文章列表页采集节点名称:自己按照你的网站目录和采集内容结合上去。网址:(*).html是有规则的网址列表。如果有不规则追加就好了。如果只有一页或几页没有规则就直接写在下边手工指定网址就好了。
文章列表匹配规则。注意要多看几页找出相同的织梦采集规则中分页,列表页大体相同,但有些有点小变化,所以要找出几页的共同html代码。
区域开始的html :
以下为引用的内容:
区域结束的html :
建议写上筛选织梦采集规则中分页,一般写必须包含,这样确切点:/flashsl
保存步入下一步设置。以看见下边的图为准。
3、分页设置预览网址可以修改。选择有分页的页面来预览,当然最很多预览几页,主要是和上面一样代码可能有小变化,选着相同的html代码分页匹配规则这儿只要做过一次就不难了。
看我的代码 ,请和源网址,查看源文件对比。
以下为引用的内容:
[内容]
[内容]为我们须要的内容,这个我想你们都晓得了同理做好文章标题:(标题有两个地方有,当然选简单的个)
[内容]
文章作者:
[内容]
查看全部
最近想做个技术型的网站,不知道用哪些cms来做,在网上搜索了一大堆,看到织梦的采集功能还不错,我也在想啊,做一个站假如所有的文章都须要站长一个一个的加,那不是要吓死啊,所以就选着了织梦。
还好自己有点基础,弄了三天就基本搞清织梦的操作流程了,申请域名、空间,上传程序。忙得是不亦乐乎,好了,开始采集文章了。好高兴,一下就有了2000多篇文章。高兴的打开来看看,哇,突然吓了一跳,发现一个文章一看就只有一段没有完整,打开源旧址一看,原来有分页,在网上找了N久,还是没有结果,自己摸索摸索吧,搞了一天一夜几乎没有午睡,我差点都没有信心了,想着就是采集的文章只有一半,别人如何看啊,都不想做了,也累了,还是好好睡一觉吧。
也许是老天看我太辛苦了吧,刚想午睡,突然我一下睡意全无,我很激动了,我看见了,看到了分页被我采集了。好了,说了这么多,还是开始步入题外话了。直接看图。如果看不懂请打开源网址,查看源文件,和我的教程比较。开始选着左侧的采集,然后打开采集节点管理,添加新节点,选着普通文章。1、文章列表页采集节点名称:自己按照你的网站目录和采集内容结合上去。网址:(*).html是有规则的网址列表。如果有不规则追加就好了。如果只有一页或几页没有规则就直接写在下边手工指定网址就好了。

文章列表匹配规则。注意要多看几页找出相同的织梦采集规则中分页,列表页大体相同,但有些有点小变化,所以要找出几页的共同html代码。
区域开始的html :
以下为引用的内容:
区域结束的html :
建议写上筛选织梦采集规则中分页,一般写必须包含,这样确切点:/flashsl

保存步入下一步设置。以看见下边的图为准。

3、分页设置预览网址可以修改。选择有分页的页面来预览,当然最很多预览几页,主要是和上面一样代码可能有小变化,选着相同的html代码分页匹配规则这儿只要做过一次就不难了。
看我的代码 ,请和源网址,查看源文件对比。
以下为引用的内容:
[内容]
[内容]为我们须要的内容,这个我想你们都晓得了同理做好文章标题:(标题有两个地方有,当然选简单的个)
[内容]
文章作者:

[内容]

帝国cms网站采集内容分页教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 486 次浏览 • 2020-07-22 08:00
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以“中华网内容分页()”为例:
可以看见这条新闻总共有3条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:
可以看见这条新闻总共有20条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:
(2)第2页代码:
从这两幅图片可以见到她们有着相同的“分页区域开始代码”,“分页链接”格式,“分页区域结束代码”,那么就可以确定“分页区域正则”,“分页链接正则”。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
5、为了便捷教程显示,newstext我采集了标题而不是采集内容,预览结果:
注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用“全部列出式”。在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时帝国cms采集分页教程,老是采到第1页帝国cms采集分页教程,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。 查看全部

一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以“中华网内容分页()”为例:

可以看见这条新闻总共有3条分页。
2、查看源代码:

这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
3、取得 分页区域正则([!--smallpageallzz--]):

4、取得 分页链接正则([!--pageallzz--]):

二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:

可以看见这条新闻总共有20条分页。
2、查看源代码:

这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:

(2)第2页代码:

从这两幅图片可以见到她们有着相同的“分页区域开始代码”,“分页链接”格式,“分页区域结束代码”,那么就可以确定“分页区域正则”,“分页链接正则”。
3、取得 分页区域正则([!--smallpageallzz--]):

4、取得 分页链接正则([!--pageallzz--]):

5、为了便捷教程显示,newstext我采集了标题而不是采集内容,预览结果:

注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用“全部列出式”。在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时帝国cms采集分页教程,老是采到第1页帝国cms采集分页教程,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
帝国cms采集图文教程(中)
采集交流 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2020-07-21 08:03
1、 我们以“爱丽网内容分页()”为例: 可以看见这条新闻总共有 20 条分页。 2、 查看源代码: 这一页里不仅早已采集到的第 1 条分页外, 还包括了 第 2, 第 3, 第 4, 第 5, 第 6, 第 7,第 8, 第 20 条分页, 但是第 9 到第 19 条分页并没有列下来, 这时候我们拿用第 1 页和第 2页的代码来进行对比剖析, 来确定分页正则: (1) 第 1 页代码:(2) 第 2 页代码: 从这两幅图片可以见到她们有着相同的“分页区域开始代码”, “分页链接”格式, “分页区域结束代码”,那么就可以确定“分页区域正则”, “分页链接正则”。 3、 取得 分页区域正则([!--smallpageallzz--]): 4、 取得 分页链接正则([!--pageallzz--]):5、 为了便捷教程显示, newstext 我采集了标题而不是采集内容, 预览结果: 注意事项: 第一、 在第一页的页面 HTML 代码里, 内容分页链接全部列下来的情况下我们使用“全部列出式”。 在第一页的页面 HTML 代码里, 内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、 用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页帝国cms采集分页教程, 这时可以借助替换法把它过滤掉(下一讲我们再说)。 第三、 用上下页导航式时, 老是采到第 1 页, 其他页连个影子都没有见过, 这是因为分页区域正则([!--smallpagezz--])截取错误。 第四、 用上下页导航式时, 可以采集到前几页了 , 但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误, 截取范围过大, 导致重复截取前几个分页链接。 好的, 这一讲就到这儿, 下一讲我们主要介绍帝国 cms 采集过滤和替换。 本文由 国外网站大全 原创, 转载请标明出处, 谢谢! 查看全部
1、 我们以“爱丽网内容分页()”为例: 可以看见这条新闻总共有 20 条分页。 2、 查看源代码: 这一页里不仅早已采集到的第 1 条分页外, 还包括了 第 2, 第 3, 第 4, 第 5, 第 6, 第 7,第 8, 第 20 条分页, 但是第 9 到第 19 条分页并没有列下来, 这时候我们拿用第 1 页和第 2页的代码来进行对比剖析, 来确定分页正则: (1) 第 1 页代码:(2) 第 2 页代码: 从这两幅图片可以见到她们有着相同的“分页区域开始代码”, “分页链接”格式, “分页区域结束代码”,那么就可以确定“分页区域正则”, “分页链接正则”。 3、 取得 分页区域正则([!--smallpageallzz--]): 4、 取得 分页链接正则([!--pageallzz--]):5、 为了便捷教程显示, newstext 我采集了标题而不是采集内容, 预览结果: 注意事项: 第一、 在第一页的页面 HTML 代码里, 内容分页链接全部列下来的情况下我们使用“全部列出式”。 在第一页的页面 HTML 代码里, 内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、 用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页帝国cms采集分页教程, 这时可以借助替换法把它过滤掉(下一讲我们再说)。 第三、 用上下页导航式时, 老是采到第 1 页, 其他页连个影子都没有见过, 这是因为分页区域正则([!--smallpagezz--])截取错误。 第四、 用上下页导航式时, 可以采集到前几页了 , 但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误, 截取范围过大, 导致重复截取前几个分页链接。 好的, 这一讲就到这儿, 下一讲我们主要介绍帝国 cms 采集过滤和替换。 本文由 国外网站大全 原创, 转载请标明出处, 谢谢!
SEO站长怎么批量采集文章?优采云采集器操作教程
站长必读 • 优采云 发表了文章 • 0 个评论 • 803 次浏览 • 2020-07-20 08:04
已经很久没有使用优采云采集器了。想起以前做站群SEO那段时间,经常会登录优采云采集器去采集各大相关网站的资讯内容。而且那种时侯采集之风兴起,到处是各类采集站,尤其是小说站、文章站等,动不动就是采集数十万的文章火车头采集文章,网站做到权重4那是轻而易举。虽然如今大部分网站很少采集了,但采集还是无处不在,因为一些所谓的原创站点,文章内容很有可能也是采集之后再进行加工制做而成的。所以把握一种采集技巧对SEO站长而言还是挺有帮助的。下面小编分享的便是优采云采集器使用教程,供菜鸟SEO参考。
优采云采集器网址规则设置
第一步、打开优采云采集器,点击【新建】创建一个新任务,填写一个任务名,设置采集网址规则,分别设置列表页采集规则和列表页所在的文章页规则,分为以下两个步骤。
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的火车头采集文章,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
优采云采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
优采云采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,优采云采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:优采云采集器功能非常强悍,除了采集文章还可以采集视频等,优采云采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。优采云采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。 查看全部

已经很久没有使用优采云采集器了。想起以前做站群SEO那段时间,经常会登录优采云采集器去采集各大相关网站的资讯内容。而且那种时侯采集之风兴起,到处是各类采集站,尤其是小说站、文章站等,动不动就是采集数十万的文章火车头采集文章,网站做到权重4那是轻而易举。虽然如今大部分网站很少采集了,但采集还是无处不在,因为一些所谓的原创站点,文章内容很有可能也是采集之后再进行加工制做而成的。所以把握一种采集技巧对SEO站长而言还是挺有帮助的。下面小编分享的便是优采云采集器使用教程,供菜鸟SEO参考。

优采云采集器网址规则设置
第一步、打开优采云采集器,点击【新建】创建一个新任务,填写一个任务名,设置采集网址规则,分别设置列表页采集规则和列表页所在的文章页规则,分为以下两个步骤。
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。

采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的火车头采集文章,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
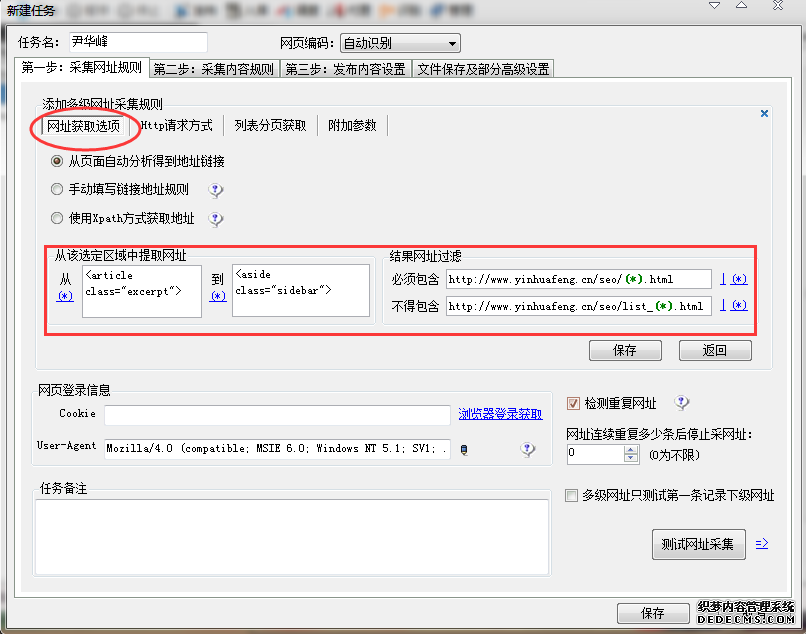
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
优采云采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。

步骤a:双击【标题】标签,一般网页的标题是标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。

优采云采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,优采云采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。

结语:优采云采集器功能非常强悍,除了采集文章还可以采集视频等,优采云采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。优采云采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。
优采云采集器如何采集内容页的分页
采集交流 • 优采云 发表了文章 • 0 个评论 • 495 次浏览 • 2020-06-29 08:02
记得在之前的教程早已教会了你们怎样采集列表的分页,那么下边我们继续将,我们领到列表的url如何去采集文章内容页。相信你们在平常浏览网页的时侯,特别是在打开新闻网站,看新闻
记得在之前的教程早已教会了你们怎样采集列表的分页,那么下边我们继续将,我们领到列表的url如何去采集文章内容页。
相信你们在平常浏览网页的时侯,特别是在打开新闻网站,看新闻的时侯。经常听到文章内页上面还有分页,还要一个一个的去点击,这样就能把全篇文章看完。
首先,这种做法我个人而言是厌恶的。接着,他们这样做的目的,只要值为了降低pv,提高一些百度联盟或则哪些推广的广告而已,为了广告费。都说做网站,主要还是为了钱嘛,这点无可厚非。
但是,他们这样的做,我们在采集数据的时侯,就碰到了如何去采集内容页分页的问题了。
好的,那么接下来火车采集器 分页,我就来告诉你们,怎么用优采云采集器去采集文章内容页上面的分页。
前面的采集网址,就一笔带过了。不明白的小伙伴,可以瞧瞧后面的优采云采集前面采集列表页的教程。
第一步:我们在编撰抓取内容的规则时,记得勾选右上方的【该标签在分页中匹配】。
如图:
第二步:我们在采集内容页把分页获取规则填上,这里是要抓取你的分页的。也可以在标签循环处理的选项下边,填上分页内容链接代码。
如图:
第三步:测试,我们编撰的采集分页的规则正不正确。
如图:
通过前面的几个步骤火车采集器 分页,是不是太轻松的就把内容页的分页内容,采集下来了。感觉不错就试试吧。
×作者:高蒙
地址: 查看全部

记得在之前的教程早已教会了你们怎样采集列表的分页,那么下边我们继续将,我们领到列表的url如何去采集文章内容页。相信你们在平常浏览网页的时侯,特别是在打开新闻网站,看新闻
记得在之前的教程早已教会了你们怎样采集列表的分页,那么下边我们继续将,我们领到列表的url如何去采集文章内容页。
相信你们在平常浏览网页的时侯,特别是在打开新闻网站,看新闻的时侯。经常听到文章内页上面还有分页,还要一个一个的去点击,这样就能把全篇文章看完。
首先,这种做法我个人而言是厌恶的。接着,他们这样做的目的,只要值为了降低pv,提高一些百度联盟或则哪些推广的广告而已,为了广告费。都说做网站,主要还是为了钱嘛,这点无可厚非。
但是,他们这样的做,我们在采集数据的时侯,就碰到了如何去采集内容页分页的问题了。
好的,那么接下来火车采集器 分页,我就来告诉你们,怎么用优采云采集器去采集文章内容页上面的分页。
前面的采集网址,就一笔带过了。不明白的小伙伴,可以瞧瞧后面的优采云采集前面采集列表页的教程。
第一步:我们在编撰抓取内容的规则时,记得勾选右上方的【该标签在分页中匹配】。
如图:

第二步:我们在采集内容页把分页获取规则填上,这里是要抓取你的分页的。也可以在标签循环处理的选项下边,填上分页内容链接代码。
如图:


第三步:测试,我们编撰的采集分页的规则正不正确。
如图:

通过前面的几个步骤火车采集器 分页,是不是太轻松的就把内容页的分页内容,采集下来了。感觉不错就试试吧。
×作者:高蒙
地址:
文章采集器抓取列表分页示例
采集交流 • 优采云 发表了文章 • 0 个评论 • 464 次浏览 • 2020-06-25 08:00
对于设置列表分页,通过右图的起始网址——批量网址来设置是最常见也是最常用的。
现在我们用另外一种获取分页的办法,即通过列表上下页无限分页采集获取功能来自动获取分页。使用这个功能,起始页就只须要把首页地址添加进去就可以了火车采集器 分页,如下图:
然后步入[高级模式]——分页设置,设置区域开始字符串、区域结束字符串、地址式样、分页地址等数组。
我们以为例,先查看下第一页分页源代码的情况,如下图:
继续查看下第二页分页源代码的情况如下:
分析得出:当前页都是在<div>后的<strong></strong>这个代码前面紧接着一个<a href="">就是下一页地址。 也就是说我们是要通过当前页获取下一页,这样一级一级的向上获取,直至把所有分页获取到。 所以,区域开始字符串为:<div>(*)</strong> 区域结束字符串为:</a>(*)</div>
地址式样按照截取区域的格式来写:<a href="[参数]">,效果如下:
另外上图 “4” 是表示获取4页的意思,默认为“0”表示不限,将采集所有分页。这样就可以用列车采集器获取到我们须要的上下页列表分页了火车采集器 分页,用列车采集器抓取内容页上下页模式也是可以参考这些操作的,更多使用教程可以访问官网进行学习。 查看全部
在使用文章采集器采集文章的过程中,我们常常须要对分页进行抓取,比如列表分页或内容分页,这里我们就以列表分页为例,为你们讲解一下列车采集器是怎么操作分页的。
对于设置列表分页,通过右图的起始网址——批量网址来设置是最常见也是最常用的。
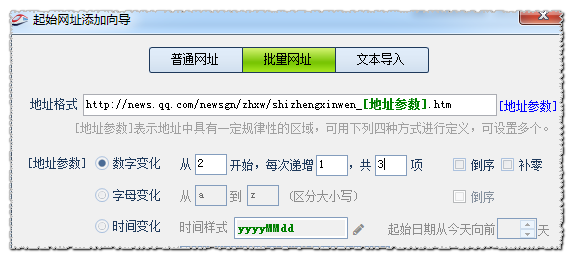
现在我们用另外一种获取分页的办法,即通过列表上下页无限分页采集获取功能来自动获取分页。使用这个功能,起始页就只须要把首页地址添加进去就可以了火车采集器 分页,如下图:

然后步入[高级模式]——分页设置,设置区域开始字符串、区域结束字符串、地址式样、分页地址等数组。
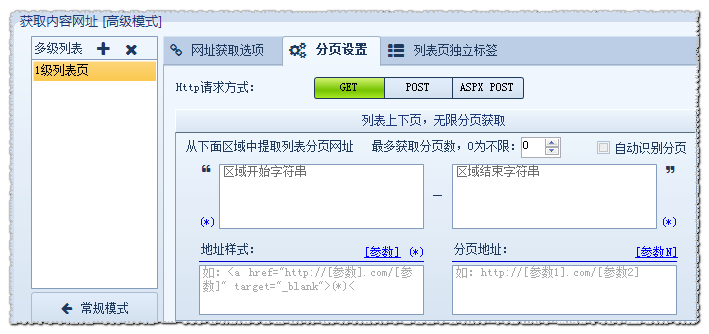
我们以为例,先查看下第一页分页源代码的情况,如下图:

继续查看下第二页分页源代码的情况如下:

分析得出:当前页都是在<div>后的<strong></strong>这个代码前面紧接着一个<a href="">就是下一页地址。 也就是说我们是要通过当前页获取下一页,这样一级一级的向上获取,直至把所有分页获取到。 所以,区域开始字符串为:<div>(*)</strong> 区域结束字符串为:</a>(*)</div>

地址式样按照截取区域的格式来写:<a href="[参数]">,效果如下:
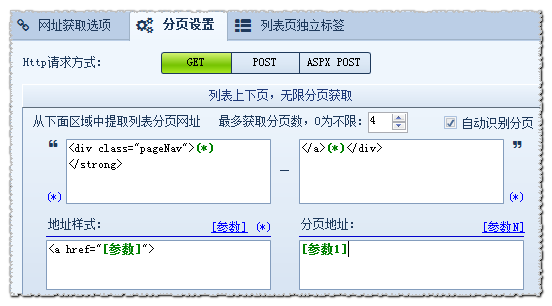
另外上图 “4” 是表示获取4页的意思,默认为“0”表示不限,将采集所有分页。这样就可以用列车采集器获取到我们须要的上下页列表分页了火车采集器 分页,用列车采集器抓取内容页上下页模式也是可以参考这些操作的,更多使用教程可以访问官网进行学习。
【优采云v7采集教程】分页列表详尽信息采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 473 次浏览 • 2020-06-24 08:00
在下边界面中更改数组名称,修改完成以后,点击“确定”保存优采云·云采集服务平台 分页列表详尽信息采集-图 6步骤 6 点击“保存并启动”,再再弹出的对话框中选择“启动本地采集”。系 统会在本地开启一个采集任务并采集数据, 接下来选择导入数据,这里以选择导 出 excel2007 为例,然后点击确定. 之后选择文件储存路径,再点保存即可优采云·云采集服务平台 分页列表详尽信息采集-图 7下边是数据示例优采云·云采集服务平台 分页列表详尽信息采集-图 8相关采集教程:黄页 88 数据采集 赶集急聘信息采集 大众点评评价采集优采云——70 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景八爪鱼采集器 分页,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。优采云·云采集服务平台 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机八爪鱼采集器 分页,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
优采云·云采集服务平台 【优采云采集教程】分页列表详尽信息采集方法好多网站有会这些模式, 多个列表页面,点击列表中的一行链接会打开一个详尽 信息页面, 本文给你们演示怎么采集分页列表详情页面里的信息。目的是使你们 了解如何创建循环翻页并能正常采集网页详情的数据信息。本文教程里提到的示例网站地址为: 步骤 1 登陆优采云 7.0 采集器→点击新建任务→自定义采集, 进入到任务配置页 面: 然后输入网址→保存网址, 系统会步入到流程设计页面并手动打开上面输入的网 址。优采云·云采集服务平台 分页列表详尽信息采集-图 1 我们须要循环点击右图浏览器中影片名称,再提取子页面中的数据信息,所以我们 需要先做一个翻页循环再做一个循环点击影片名称提取数据的列表。 步骤 2 点击右图浏览器页面中的“下一页”按钮,在弹出的对话框中选择“循 环点击下一页”;优采云·云采集服务平台 分页列表详尽信息采集-图 2下面对影片名称创建循环点击 步骤 3 鼠标点击右图中第一个影片名称“教父:第二部”,在弹出的操作提示 中选择“选中全部”选项, 然后选择“循环点击每位链接”选项优采云·云采集服务平台 分页列表详尽信息采集-图 3优采云·云采集服务平台 分页列表详尽信息采集-图 4接下来页面就手动跳转到详情页面中去了,我们再做提取数据 步骤 4 点击要提取的标题在弹出的提示框中选择“采集该元素的文本”,然后 同样的方法选择点击浏览器中的其他数组,再选择“采集该元素的文本”优采云·云采集服务平台 分页列表详尽信息采集-图 5步骤 5这样提取完毕以后我们可以点一下流程按键,然后更改数组名称。
在下边界面中更改数组名称,修改完成以后,点击“确定”保存优采云·云采集服务平台 分页列表详尽信息采集-图 6步骤 6 点击“保存并启动”,再再弹出的对话框中选择“启动本地采集”。系 统会在本地开启一个采集任务并采集数据, 接下来选择导入数据,这里以选择导 出 excel2007 为例,然后点击确定. 之后选择文件储存路径,再点保存即可优采云·云采集服务平台 分页列表详尽信息采集-图 7下边是数据示例优采云·云采集服务平台 分页列表详尽信息采集-图 8相关采集教程:黄页 88 数据采集 赶集急聘信息采集 大众点评评价采集优采云——70 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景八爪鱼采集器 分页,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。优采云·云采集服务平台 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机八爪鱼采集器 分页,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
火车头文章采集规则分享? - 搜外问答
采集交流 • 优采云 发表了文章 • 0 个评论 • 492 次浏览 • 2020-05-19 08:03
第一步、打开火车头采集器,点击【新建】创建一个新任务,填写一个任务名,设置采集网址规则,分别设置列表页采集规则和列表页所在的文章页规则,分为以下两个步骤。
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此火车采集器 规则,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是<title>标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,</article>为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可火车采集器 规则,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。火车头采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。 查看全部

第一步、打开火车头采集器,点击【新建】创建一个新任务,填写一个任务名,设置采集网址规则,分别设置列表页采集规则和列表页所在的文章页规则,分为以下两个步骤。
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此火车采集器 规则,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是<title>标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,</article>为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可火车采集器 规则,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。火车头采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。
火车头采集器采集文章操作教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 907 次浏览 • 2020-04-27 11:03
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接火车头采集教程,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试火车头采集教程,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是<title>标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,</article>为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的采集工具。但请在版权范围内采集。 查看全部
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接火车头采集教程,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试火车头采集教程,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是<title>标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,</article>为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的采集工具。但请在版权范围内采集。
火车头采集教程你把握多少
采集交流 • 优采云 发表了文章 • 0 个评论 • 734 次浏览 • 2020-04-24 11:04
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置火车头采集教程,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是title标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整火车头采集教程,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。火车头采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。 查看全部
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。

采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。

多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置火车头采集教程,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。

步骤a:双击【标题】标签,一般网页的标题是title标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。

火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。

注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。

结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整火车头采集教程,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。火车头采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。
【腾讯新闻】使用文章采集软件快速提取网页文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 478 次浏览 • 2020-04-22 11:03
1、添加起始网址:按照给出的网址打开腾讯新闻,发现新闻页面是以列表分页的方式诠释的,那么首先就要把列表页的地址作为起始网址先添加到列车采集器中。
这里我们以添加6页为例,我们可以点开这6个分页的网址一条条的添加到采集器中。但是假如我们要添加的网址好多,几百或上千条,那么一条条的进行添加就过分冗长,所以我们可以试着找出网址之间的变化规律,进行批量添加。
我们分别打开第一页、第二页……观察其网址变化,可以发觉不仅第一页之外,后面的分页网址都是以“_数字”递增的规律变化的,如下:
那么我们首先将不符合规律的第一页网址“”添加到起始网址的列表中如下:
第一页添加好了,那么前面的列表分页我们选择向导添加——批量网址添加文章自动采集软件,用一个通用的格式手动产生所须要的网址,网址中的变量就可以用地址参数来取代,地址参数的规律须要我们设置一下,上述规律就是从2开始,以1为递增量,共计5项。填写完成后列车采集器V9手动生成预览如下图,点击确定后起始网址(这里就是列表页网址)就添加好了。
2、获取内容页网址:通过观察新闻页面可以发觉列表分页的下一级就是内容页,那么内容页 网址就是一级网址(列表页为0级网址),这里我们使用最简单的“自动获取地址链接”的方法,通过剖析列表页面的源代码,可以找出新闻内容页地址所在的市 域文章自动采集软件,其开始字符为:“<div class="mod newslist">”,结束字符为:“</div>”。填写然后列车采集器会在这个区域内手动辨识地址链接,我们点击网址采集测试就 可以看见我们设置的规则采集到列表页和内容页网址是否正确和完整。
第二步、内容采集规则 查看全部

1、添加起始网址:按照给出的网址打开腾讯新闻,发现新闻页面是以列表分页的方式诠释的,那么首先就要把列表页的地址作为起始网址先添加到列车采集器中。
这里我们以添加6页为例,我们可以点开这6个分页的网址一条条的添加到采集器中。但是假如我们要添加的网址好多,几百或上千条,那么一条条的进行添加就过分冗长,所以我们可以试着找出网址之间的变化规律,进行批量添加。
我们分别打开第一页、第二页……观察其网址变化,可以发觉不仅第一页之外,后面的分页网址都是以“_数字”递增的规律变化的,如下:
那么我们首先将不符合规律的第一页网址“”添加到起始网址的列表中如下:
第一页添加好了,那么前面的列表分页我们选择向导添加——批量网址添加文章自动采集软件,用一个通用的格式手动产生所须要的网址,网址中的变量就可以用地址参数来取代,地址参数的规律须要我们设置一下,上述规律就是从2开始,以1为递增量,共计5项。填写完成后列车采集器V9手动生成预览如下图,点击确定后起始网址(这里就是列表页网址)就添加好了。
2、获取内容页网址:通过观察新闻页面可以发觉列表分页的下一级就是内容页,那么内容页 网址就是一级网址(列表页为0级网址),这里我们使用最简单的“自动获取地址链接”的方法,通过剖析列表页面的源代码,可以找出新闻内容页地址所在的市 域文章自动采集软件,其开始字符为:“<div class="mod newslist">”,结束字符为:“</div>”。填写然后列车采集器会在这个区域内手动辨识地址链接,我们点击网址采集测试就 可以看见我们设置的规则采集到列表页和内容页网址是否正确和完整。
第二步、内容采集规则
火车头采集:快速采集网页文章教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 508 次浏览 • 2020-04-18 11:00
1、添加起始网址:按照给出的网址打开腾讯新闻,发现新闻页面是以列表分页的方式诠释的,那么首先就要把列表页的地址作为起始网址先添加到列车采集器中。
这里我们以添加6页为例,我们可以点开这6个分页的网址一条条的添加到采集器中。但是假如我们要添加的网址好多火车头文章采集,几百或上千条,那么一条条的进行添加就过分冗长,所以我们可以试着找出网址之间的变化规律火车头文章采集,进行批量添加。
我们分别打开第一页、第二页……观察其网址变化采集器,可以发觉不仅第一页之外,后面的分页网址都是以“_数字”递增的规律变化的,如下:
那么我们首先将不符合规律的第一页网址“”添加到起始网址的列表中如下:
第一页添加好了,那么前面的列表分页我们选择向导添加——批量网址添加,用一个通用的格式手动产生所须要的网址,网址中的变量就可以用地址参数来取代,地址参数的规律须要我们设置一下,上述规律就是从2开始,以1为递增量,共计5项。填写完成后列车采集器V9手动生成预览如下图,点击确定后起始网址(这里就是列表页网址)就添加好了。
2、获取内容页网址:通过观察新闻页面可以发觉列表分页的下一级就是内容页,那么内容页网址就是一级网址(列表页为0级网址),这里我们使用最简单的“自动获取地址链接”的方法,通过剖析列表页面的源代码,可以找出新闻内容页地址所在的区域,其开始字符为:“<div class="mod newslist">”,结束字符为:“</div>”。填写以后列车采集器会在这个区域内手动辨识地址链接,我们点击网址采集测试就可以看见我们设置的规则采集到列表页和内容页网址是否正确和完整。 查看全部

1、添加起始网址:按照给出的网址打开腾讯新闻,发现新闻页面是以列表分页的方式诠释的,那么首先就要把列表页的地址作为起始网址先添加到列车采集器中。
这里我们以添加6页为例,我们可以点开这6个分页的网址一条条的添加到采集器中。但是假如我们要添加的网址好多火车头文章采集,几百或上千条,那么一条条的进行添加就过分冗长,所以我们可以试着找出网址之间的变化规律火车头文章采集,进行批量添加。
我们分别打开第一页、第二页……观察其网址变化采集器,可以发觉不仅第一页之外,后面的分页网址都是以“_数字”递增的规律变化的,如下:
那么我们首先将不符合规律的第一页网址“”添加到起始网址的列表中如下:
第一页添加好了,那么前面的列表分页我们选择向导添加——批量网址添加,用一个通用的格式手动产生所须要的网址,网址中的变量就可以用地址参数来取代,地址参数的规律须要我们设置一下,上述规律就是从2开始,以1为递增量,共计5项。填写完成后列车采集器V9手动生成预览如下图,点击确定后起始网址(这里就是列表页网址)就添加好了。
2、获取内容页网址:通过观察新闻页面可以发觉列表分页的下一级就是内容页,那么内容页网址就是一级网址(列表页为0级网址),这里我们使用最简单的“自动获取地址链接”的方法,通过剖析列表页面的源代码,可以找出新闻内容页地址所在的区域,其开始字符为:“<div class="mod newslist">”,结束字符为:“</div>”。填写以后列车采集器会在这个区域内手动辨识地址链接,我们点击网址采集测试就可以看见我们设置的规则采集到列表页和内容页网址是否正确和完整。
SEO站长怎么批量采集文章?火车头采集器操作教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 513 次浏览 • 2020-04-17 11:06
第一步、打开火车头采集器,点击【新建】创建一个新任务,填写一个任务名,设置采集网址规则,分别设置列表页采集规则和列表页所在的文章页规则,分为以下两个步骤。
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列火车头采集文章,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是<title>标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的火车头采集文章,通常的表现形式是article标签为起始,</article>为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。火车头采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。 查看全部
第一步、打开火车头采集器,点击【新建】创建一个新任务,填写一个任务名,设置采集网址规则,分别设置列表页采集规则和列表页所在的文章页规则,分为以下两个步骤。
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。

采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列火车头采集文章,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。

多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。

步骤a:双击【标题】标签,一般网页的标题是<title>标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的火车头采集文章,通常的表现形式是article标签为起始,</article>为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。

火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。

结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。火车头采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。
Dedecms采集含有分页的普通文章的使用方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 642 次浏览 • 2020-07-24 08:00
单击“保存信息并步入下一步设置”后,便可步入“新增采集节点:第二步设置内容数组获取规则”页面,如(图1)所示,
系统将会手动指定一个“预览网址”,一般是文章列表页的第一篇文章的网址。但是,由于第一篇文章中没有涉及到分页的部份,所以在这里自动修改为第二篇文章的网址:“”,
上图红箭头部份是写下边来设定分页部份的匹配规则。其具体操作步骤为:
打开文章内容页面,在网页上单击右键,在弹出的对话框中单击“查看源文件“。在源代码中,找到分页代码的开始部份和结束部份,如(图2)所示,
经过观察可知,分页代码坐落“
“和”
”之间。因此,在”内容分页导航所在的区域匹配规则“中,应填写”
[内容]
“。对于分页代码的款式,一共有三种可供选择,这里应选择第一种” 全部列举的分页列表”。填写后,如(图3)所示,
对于“固定采集项目”中的“内容摘要、关键字和缩略图“三个部份,系统会用正则进行手动匹配,这里仅需配置过滤内容即可。下面主要介绍怎么获取“文章标题、文章作者、文章来源、发布时间和文章内容”的采集规则,过滤规则仅简单涉及。
首先,打开“预览网址“的页面并单击右键,选择”查看源代码“,找到文章标题” OpenFlow网路是空谈吗?“织梦采集规则中分页,如(图4)所示,
图18-在源代码中的文章标题
这里的文章标题处在””之间,因此这儿应当填写”[内容]”作为文章标题的匹配规则。如果在文章标题中富含相关链接等,可使用过滤规则加以处理,这里无需设置。填写后,如(图5)所示,
图5-文章标题的采集规则
经过查找北京班车租赁企业租车网站的源代码和对比原文的标题部份,可发觉本文没有涉及到作者,所以这儿不用填写,空着即可。
2.1.3 获取文章来源的采集规则
在上图19中,可发觉来源的内容介于“来源:“和“”之间,因此这儿应填写“来源:[内容]”作为文章来源的采集规则。同样,这里也不需要使用过滤规则。填写后,如图6所示,
图6-文章来源的采集规则
再次回到图17,可找到“时间:2011-05-13 11:47”,因此这儿应把“时间:[内容]”作为发布时间的采集规则。同样,这里也不需要使用过滤规则。填写后,如图7所示,
图7-文章发布时间的采集规则
这个部份是编撰采集规则的重点,也是难点。需要非常注意。
具体操作步骤:
(a)在在打开的文章内容页面的源代码中,找到文章内容的开始部份“计算机网路知识的学习”,如图8所示,
图8-文章内容的开始部份
这里应把””作为匹配规则的开始部份,注意到这段代码中包含一段广告代码,需要采用过滤规则把其清除。经观察发觉,这段JS广告代码是坐落“
”和“
”之间的。因此,应在“过滤规则”中填写:“{dede:trim replace=’’}
(.*)
”{/dede:trim}。填写后,如(图9)所示,
图9-开始部份的匹配规则及其过滤规则
(b)找到文章内容的结束部份,因为涉及到分页部份织梦采集规则中分页,所以应当选定分页结束的位置,如图10所示,
图10-文章内容的结束部份
这里应选定“”作为文章内容的结束部份,由于在选定的内容中又包含了一段JS代码,因此应再度使用过滤规则,把其清除。同时,考虑到本页没有涉及到分页,所以在分页代码中的之间是空的。但是,如果页面包含分页的话,也是应当使用过滤规则去掉的。此外,如果所设定的文章内容中,含有图片、链接等不希望被采集到的内容,也应当使用过滤规则一并清除掉。填写完成后,如(图11)所示,
图11-文章内容的匹配规则
到这儿,“新增采集节点:第二步设置内容数组获取规则”,就设置完成了。来看一下整个配置页面,如(图12)所示,
图12-设置后的新增采集节点:第二步设置内容数组获取规则
检查无误后,单击“保存配置并预览”。如果之前设置正确,单击后,将会步入“新增采集节点:测试内容数组设置”页面并见到相应的文章内容。如(图13)和(图14)所示,
图13-新增采集节点:测试内容数组设置
图14-新增采集节点:测试内容数组设置
其中,图中画圈的地方代表的是分页符号。
确定正确无误后,如果单击“仅保存”,系统将会提示“成功保存配置“并返回”采集节点管理“界面;如果单击“保存并开始采集“,将会步入”采集指定节点“界面。否则,请单击“返回上一步进行更改”。 查看全部
单击“保存信息并步入下一步设置”后,便可步入“新增采集节点:第二步设置内容数组获取规则”页面,如(图1)所示,
系统将会手动指定一个“预览网址”,一般是文章列表页的第一篇文章的网址。但是,由于第一篇文章中没有涉及到分页的部份,所以在这里自动修改为第二篇文章的网址:“”,
上图红箭头部份是写下边来设定分页部份的匹配规则。其具体操作步骤为:
打开文章内容页面,在网页上单击右键,在弹出的对话框中单击“查看源文件“。在源代码中,找到分页代码的开始部份和结束部份,如(图2)所示,
经过观察可知,分页代码坐落“
“和”
”之间。因此,在”内容分页导航所在的区域匹配规则“中,应填写”
[内容]
“。对于分页代码的款式,一共有三种可供选择,这里应选择第一种” 全部列举的分页列表”。填写后,如(图3)所示,
对于“固定采集项目”中的“内容摘要、关键字和缩略图“三个部份,系统会用正则进行手动匹配,这里仅需配置过滤内容即可。下面主要介绍怎么获取“文章标题、文章作者、文章来源、发布时间和文章内容”的采集规则,过滤规则仅简单涉及。
首先,打开“预览网址“的页面并单击右键,选择”查看源代码“,找到文章标题” OpenFlow网路是空谈吗?“织梦采集规则中分页,如(图4)所示,
图18-在源代码中的文章标题
这里的文章标题处在””之间,因此这儿应当填写”[内容]”作为文章标题的匹配规则。如果在文章标题中富含相关链接等,可使用过滤规则加以处理,这里无需设置。填写后,如(图5)所示,
图5-文章标题的采集规则
经过查找北京班车租赁企业租车网站的源代码和对比原文的标题部份,可发觉本文没有涉及到作者,所以这儿不用填写,空着即可。
2.1.3 获取文章来源的采集规则
在上图19中,可发觉来源的内容介于“来源:“和“”之间,因此这儿应填写“来源:[内容]”作为文章来源的采集规则。同样,这里也不需要使用过滤规则。填写后,如图6所示,
图6-文章来源的采集规则
再次回到图17,可找到“时间:2011-05-13 11:47”,因此这儿应把“时间:[内容]”作为发布时间的采集规则。同样,这里也不需要使用过滤规则。填写后,如图7所示,
图7-文章发布时间的采集规则
这个部份是编撰采集规则的重点,也是难点。需要非常注意。
具体操作步骤:
(a)在在打开的文章内容页面的源代码中,找到文章内容的开始部份“计算机网路知识的学习”,如图8所示,
图8-文章内容的开始部份
这里应把””作为匹配规则的开始部份,注意到这段代码中包含一段广告代码,需要采用过滤规则把其清除。经观察发觉,这段JS广告代码是坐落“
”和“
”之间的。因此,应在“过滤规则”中填写:“{dede:trim replace=’’}
(.*)
”{/dede:trim}。填写后,如(图9)所示,
图9-开始部份的匹配规则及其过滤规则
(b)找到文章内容的结束部份,因为涉及到分页部份织梦采集规则中分页,所以应当选定分页结束的位置,如图10所示,
图10-文章内容的结束部份
这里应选定“”作为文章内容的结束部份,由于在选定的内容中又包含了一段JS代码,因此应再度使用过滤规则,把其清除。同时,考虑到本页没有涉及到分页,所以在分页代码中的之间是空的。但是,如果页面包含分页的话,也是应当使用过滤规则去掉的。此外,如果所设定的文章内容中,含有图片、链接等不希望被采集到的内容,也应当使用过滤规则一并清除掉。填写完成后,如(图11)所示,
图11-文章内容的匹配规则
到这儿,“新增采集节点:第二步设置内容数组获取规则”,就设置完成了。来看一下整个配置页面,如(图12)所示,
图12-设置后的新增采集节点:第二步设置内容数组获取规则
检查无误后,单击“保存配置并预览”。如果之前设置正确,单击后,将会步入“新增采集节点:测试内容数组设置”页面并见到相应的文章内容。如(图13)和(图14)所示,
图13-新增采集节点:测试内容数组设置
图14-新增采集节点:测试内容数组设置
其中,图中画圈的地方代表的是分页符号。
确定正确无误后,如果单击“仅保存”,系统将会提示“成功保存配置“并返回”采集节点管理“界面;如果单击“保存并开始采集“,将会步入”采集指定节点“界面。否则,请单击“返回上一步进行更改”。
解析织梦v5.3的分页采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 477 次浏览 • 2020-07-23 08:01
还好自己有点基础,弄了三天就基本搞清织梦的操作流程了,申请域名、空间,上传程序。忙得是不亦乐乎,好了,开始采集文章了。好高兴,一下就有了2000多篇文章。高兴的打开来看看,哇,突然吓了一跳织梦采集规则中分页,发现一个文章一看就只有一段没有完整,打开源旧址一看,原来有分页,在网上找了N久,还是没有结果,自己摸索摸索吧,搞了一天一夜几乎没有睡着,我差点都没有信心了,想着就是采集的文章只有一半,别人怎样看啊,都不想做了,也累了,还是好好睡一觉吧。
也许是老天看我太辛苦了吧,刚想睡着,突然我一下睡意全无,我很激动了,我听到了,看到了分页被我采集了。好了,说了这么多,还是开始步入题外话了。直接看图。如果看不懂请打开源网址,查看源文件,和我的教程比较。开始选着左侧的采集,然后打开采集节点管理,添加新节点,选着普通文章。1、文章列表页采集节点名称:自己按照你的网站目录和采集内容结合上去。网址:(*).html 是有规则的网址列表。如果有不规则追加就好了。如果只有一页或几页没有规则就直接写在下边手工指定网址就好了。
文章列表匹配规则。注意要多看几页找出相同的,列表页大体相同,但有些有点小变化,所以要找出几页的共同html代码。
区域开始的html :
建议写上筛选,一般写必须包含,这样确切点:/flashsl
保存步入下一步设置。以看见下边的图为准。
3、分页设置预览网址可以修改。选择有分页的页面来预览,当然最很多预览几页织梦采集规则中分页,主要是和上面一样代码可能有小变化,选着相同的html代码分页匹配规则这儿只要做过一次就不难了。
看我的代码 ,请和源网址,查看源文件对比。 查看全部
还好自己有点基础,弄了三天就基本搞清织梦的操作流程了,申请域名、空间,上传程序。忙得是不亦乐乎,好了,开始采集文章了。好高兴,一下就有了2000多篇文章。高兴的打开来看看,哇,突然吓了一跳织梦采集规则中分页,发现一个文章一看就只有一段没有完整,打开源旧址一看,原来有分页,在网上找了N久,还是没有结果,自己摸索摸索吧,搞了一天一夜几乎没有睡着,我差点都没有信心了,想着就是采集的文章只有一半,别人怎样看啊,都不想做了,也累了,还是好好睡一觉吧。
也许是老天看我太辛苦了吧,刚想睡着,突然我一下睡意全无,我很激动了,我听到了,看到了分页被我采集了。好了,说了这么多,还是开始步入题外话了。直接看图。如果看不懂请打开源网址,查看源文件,和我的教程比较。开始选着左侧的采集,然后打开采集节点管理,添加新节点,选着普通文章。1、文章列表页采集节点名称:自己按照你的网站目录和采集内容结合上去。网址:(*).html 是有规则的网址列表。如果有不规则追加就好了。如果只有一页或几页没有规则就直接写在下边手工指定网址就好了。
文章列表匹配规则。注意要多看几页找出相同的,列表页大体相同,但有些有点小变化,所以要找出几页的共同html代码。
区域开始的html :
建议写上筛选,一般写必须包含,这样确切点:/flashsl
保存步入下一步设置。以看见下边的图为准。
3、分页设置预览网址可以修改。选择有分页的页面来预览,当然最很多预览几页织梦采集规则中分页,主要是和上面一样代码可能有小变化,选着相同的html代码分页匹配规则这儿只要做过一次就不难了。
看我的代码 ,请和源网址,查看源文件对比。
织梦CMS怎么做分页的采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 512 次浏览 • 2020-07-23 08:01
最近想做个技术型的网站,不知道用哪些cms来做,在网上搜索了一大堆,看到织梦的采集功能还不错,我也在想啊,做一个站假如所有的文章都须要站长一个一个的加,那不是要吓死啊,所以就选着了织梦。
还好自己有点基础,弄了三天就基本搞清织梦的操作流程了,申请域名、空间,上传程序。忙得是不亦乐乎,好了,开始采集文章了。好高兴,一下就有了2000多篇文章。高兴的打开来看看,哇,突然吓了一跳,发现一个文章一看就只有一段没有完整,打开源旧址一看,原来有分页,在网上找了N久,还是没有结果,自己摸索摸索吧,搞了一天一夜几乎没有午睡,我差点都没有信心了,想着就是采集的文章只有一半,别人如何看啊,都不想做了,也累了,还是好好睡一觉吧。
也许是老天看我太辛苦了吧,刚想午睡,突然我一下睡意全无,我很激动了,我看见了,看到了分页被我采集了。好了,说了这么多,还是开始步入题外话了。直接看图。如果看不懂请打开源网址,查看源文件,和我的教程比较。开始选着左侧的采集,然后打开采集节点管理,添加新节点,选着普通文章。1、文章列表页采集节点名称:自己按照你的网站目录和采集内容结合上去。网址:(*).html是有规则的网址列表。如果有不规则追加就好了。如果只有一页或几页没有规则就直接写在下边手工指定网址就好了。
文章列表匹配规则。注意要多看几页找出相同的织梦采集规则中分页,列表页大体相同,但有些有点小变化,所以要找出几页的共同html代码。
区域开始的html :
以下为引用的内容:
区域结束的html :
建议写上筛选织梦采集规则中分页,一般写必须包含,这样确切点:/flashsl
保存步入下一步设置。以看见下边的图为准。
3、分页设置预览网址可以修改。选择有分页的页面来预览,当然最很多预览几页,主要是和上面一样代码可能有小变化,选着相同的html代码分页匹配规则这儿只要做过一次就不难了。
看我的代码 ,请和源网址,查看源文件对比。
以下为引用的内容:
[内容]
[内容]为我们须要的内容,这个我想你们都晓得了同理做好文章标题:(标题有两个地方有,当然选简单的个)
[内容]
文章作者:
[内容]
查看全部
最近想做个技术型的网站,不知道用哪些cms来做,在网上搜索了一大堆,看到织梦的采集功能还不错,我也在想啊,做一个站假如所有的文章都须要站长一个一个的加,那不是要吓死啊,所以就选着了织梦。
还好自己有点基础,弄了三天就基本搞清织梦的操作流程了,申请域名、空间,上传程序。忙得是不亦乐乎,好了,开始采集文章了。好高兴,一下就有了2000多篇文章。高兴的打开来看看,哇,突然吓了一跳,发现一个文章一看就只有一段没有完整,打开源旧址一看,原来有分页,在网上找了N久,还是没有结果,自己摸索摸索吧,搞了一天一夜几乎没有午睡,我差点都没有信心了,想着就是采集的文章只有一半,别人如何看啊,都不想做了,也累了,还是好好睡一觉吧。
也许是老天看我太辛苦了吧,刚想午睡,突然我一下睡意全无,我很激动了,我看见了,看到了分页被我采集了。好了,说了这么多,还是开始步入题外话了。直接看图。如果看不懂请打开源网址,查看源文件,和我的教程比较。开始选着左侧的采集,然后打开采集节点管理,添加新节点,选着普通文章。1、文章列表页采集节点名称:自己按照你的网站目录和采集内容结合上去。网址:(*).html是有规则的网址列表。如果有不规则追加就好了。如果只有一页或几页没有规则就直接写在下边手工指定网址就好了。
文章列表匹配规则。注意要多看几页找出相同的织梦采集规则中分页,列表页大体相同,但有些有点小变化,所以要找出几页的共同html代码。
区域开始的html :
以下为引用的内容:
区域结束的html :
建议写上筛选织梦采集规则中分页,一般写必须包含,这样确切点:/flashsl
保存步入下一步设置。以看见下边的图为准。
3、分页设置预览网址可以修改。选择有分页的页面来预览,当然最很多预览几页,主要是和上面一样代码可能有小变化,选着相同的html代码分页匹配规则这儿只要做过一次就不难了。
看我的代码 ,请和源网址,查看源文件对比。
以下为引用的内容:
[内容]
[内容]为我们须要的内容,这个我想你们都晓得了同理做好文章标题:(标题有两个地方有,当然选简单的个)
[内容]
文章作者:
[内容]
帝国cms网站采集内容分页教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 486 次浏览 • 2020-07-22 08:00
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以“中华网内容分页()”为例:
可以看见这条新闻总共有3条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:
可以看见这条新闻总共有20条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:
(2)第2页代码:
从这两幅图片可以见到她们有着相同的“分页区域开始代码”,“分页链接”格式,“分页区域结束代码”,那么就可以确定“分页区域正则”,“分页链接正则”。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
5、为了便捷教程显示,newstext我采集了标题而不是采集内容,预览结果:
注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用“全部列出式”。在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时帝国cms采集分页教程,老是采到第1页帝国cms采集分页教程,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。 查看全部
一、全部列出式
全部列表式只需看第一页的页面HTML代码,这一页的所有分页链接都列下来了。
1、我们以“中华网内容分页()”为例:
可以看见这条新闻总共有3条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2条和第3条分页,所有的分页都列下来了。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
二、上下页导航式
上下页导航式是分页采集的难点,他须要所有页面都符合分页正则才行,在不熟悉的情况下,我们可以用第1页和第2页的代码来进行对比剖析之后确定分页正则。
1、我们以下网站的内容分页为例:
可以看见这条新闻总共有20条分页。
2、查看源代码:
这一页里不仅早已采集到的第1条分页外,还包括了第2,第3,第4,第5,第6,第7,第8,第20条分页,但是第9到第19条分页并没有列下来,这时候我们拿用第1页和第2页的代码来进行对比剖析,来确定分页正则:
(1)第1页代码:
(2)第2页代码:
从这两幅图片可以见到她们有着相同的“分页区域开始代码”,“分页链接”格式,“分页区域结束代码”,那么就可以确定“分页区域正则”,“分页链接正则”。
3、取得 分页区域正则([!--smallpageallzz--]):
4、取得 分页链接正则([!--pageallzz--]):
5、为了便捷教程显示,newstext我采集了标题而不是采集内容,预览结果:
注意事项:
第一、在第一页的页面HTML代码里,内容分页链接全部列下来的情况下我们使用“全部列出式”。在第一页的页面HTML代码里,内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页,这时可以借助替换法把它过滤掉(下一讲我们再说)。
第三、用上下页导航式时帝国cms采集分页教程,老是采到第1页帝国cms采集分页教程,其他页连个影子都没有见过,这是因为分页区域正则([!--smallpagezz--])截取错误。
第四、用上下页导航式时,可以采集到前几页了,但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误,截取范围过大,导致重复截取前几个分页链接。
帝国cms采集图文教程(中)
采集交流 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2020-07-21 08:03
1、 我们以“爱丽网内容分页()”为例: 可以看见这条新闻总共有 20 条分页。 2、 查看源代码: 这一页里不仅早已采集到的第 1 条分页外, 还包括了 第 2, 第 3, 第 4, 第 5, 第 6, 第 7,第 8, 第 20 条分页, 但是第 9 到第 19 条分页并没有列下来, 这时候我们拿用第 1 页和第 2页的代码来进行对比剖析, 来确定分页正则: (1) 第 1 页代码:(2) 第 2 页代码: 从这两幅图片可以见到她们有着相同的“分页区域开始代码”, “分页链接”格式, “分页区域结束代码”,那么就可以确定“分页区域正则”, “分页链接正则”。 3、 取得 分页区域正则([!--smallpageallzz--]): 4、 取得 分页链接正则([!--pageallzz--]):5、 为了便捷教程显示, newstext 我采集了标题而不是采集内容, 预览结果: 注意事项: 第一、 在第一页的页面 HTML 代码里, 内容分页链接全部列下来的情况下我们使用“全部列出式”。 在第一页的页面 HTML 代码里, 内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、 用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页帝国cms采集分页教程, 这时可以借助替换法把它过滤掉(下一讲我们再说)。 第三、 用上下页导航式时, 老是采到第 1 页, 其他页连个影子都没有见过, 这是因为分页区域正则([!--smallpagezz--])截取错误。 第四、 用上下页导航式时, 可以采集到前几页了 , 但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误, 截取范围过大, 导致重复截取前几个分页链接。 好的, 这一讲就到这儿, 下一讲我们主要介绍帝国 cms 采集过滤和替换。 本文由 国外网站大全 原创, 转载请标明出处, 谢谢! 查看全部
1、 我们以“爱丽网内容分页()”为例: 可以看见这条新闻总共有 20 条分页。 2、 查看源代码: 这一页里不仅早已采集到的第 1 条分页外, 还包括了 第 2, 第 3, 第 4, 第 5, 第 6, 第 7,第 8, 第 20 条分页, 但是第 9 到第 19 条分页并没有列下来, 这时候我们拿用第 1 页和第 2页的代码来进行对比剖析, 来确定分页正则: (1) 第 1 页代码:(2) 第 2 页代码: 从这两幅图片可以见到她们有着相同的“分页区域开始代码”, “分页链接”格式, “分页区域结束代码”,那么就可以确定“分页区域正则”, “分页链接正则”。 3、 取得 分页区域正则([!--smallpageallzz--]): 4、 取得 分页链接正则([!--pageallzz--]):5、 为了便捷教程显示, newstext 我采集了标题而不是采集内容, 预览结果: 注意事项: 第一、 在第一页的页面 HTML 代码里, 内容分页链接全部列下来的情况下我们使用“全部列出式”。 在第一页的页面 HTML 代码里, 内容分页链接没有全部列下来的情况下我们使用“上下页导航式”。
第二、 用全部列举式时,采集规则正确并且莫名其妙的出现重复的分页帝国cms采集分页教程, 这时可以借助替换法把它过滤掉(下一讲我们再说)。 第三、 用上下页导航式时, 老是采到第 1 页, 其他页连个影子都没有见过, 这是因为分页区域正则([!--smallpagezz--])截取错误。 第四、 用上下页导航式时, 可以采集到前几页了 , 但是接下来这前几页全部重复循环究竟,这也是由于分页区域正则([!--smallpagezz--])截取错误, 截取范围过大, 导致重复截取前几个分页链接。 好的, 这一讲就到这儿, 下一讲我们主要介绍帝国 cms 采集过滤和替换。 本文由 国外网站大全 原创, 转载请标明出处, 谢谢!
SEO站长怎么批量采集文章?优采云采集器操作教程
站长必读 • 优采云 发表了文章 • 0 个评论 • 803 次浏览 • 2020-07-20 08:04
已经很久没有使用优采云采集器了。想起以前做站群SEO那段时间,经常会登录优采云采集器去采集各大相关网站的资讯内容。而且那种时侯采集之风兴起,到处是各类采集站,尤其是小说站、文章站等,动不动就是采集数十万的文章火车头采集文章,网站做到权重4那是轻而易举。虽然如今大部分网站很少采集了,但采集还是无处不在,因为一些所谓的原创站点,文章内容很有可能也是采集之后再进行加工制做而成的。所以把握一种采集技巧对SEO站长而言还是挺有帮助的。下面小编分享的便是优采云采集器使用教程,供菜鸟SEO参考。
优采云采集器网址规则设置
第一步、打开优采云采集器,点击【新建】创建一个新任务,填写一个任务名,设置采集网址规则,分别设置列表页采集规则和列表页所在的文章页规则,分为以下两个步骤。
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的火车头采集文章,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
优采云采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
优采云采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,优采云采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:优采云采集器功能非常强悍,除了采集文章还可以采集视频等,优采云采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。优采云采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。 查看全部
已经很久没有使用优采云采集器了。想起以前做站群SEO那段时间,经常会登录优采云采集器去采集各大相关网站的资讯内容。而且那种时侯采集之风兴起,到处是各类采集站,尤其是小说站、文章站等,动不动就是采集数十万的文章火车头采集文章,网站做到权重4那是轻而易举。虽然如今大部分网站很少采集了,但采集还是无处不在,因为一些所谓的原创站点,文章内容很有可能也是采集之后再进行加工制做而成的。所以把握一种采集技巧对SEO站长而言还是挺有帮助的。下面小编分享的便是优采云采集器使用教程,供菜鸟SEO参考。
优采云采集器网址规则设置
第一步、打开优采云采集器,点击【新建】创建一个新任务,填写一个任务名,设置采集网址规则,分别设置列表页采集规则和列表页所在的文章页规则,分为以下两个步骤。
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的火车头采集文章,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
优采云采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
优采云采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,优采云采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:优采云采集器功能非常强悍,除了采集文章还可以采集视频等,优采云采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。优采云采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。
优采云采集器如何采集内容页的分页
采集交流 • 优采云 发表了文章 • 0 个评论 • 495 次浏览 • 2020-06-29 08:02
记得在之前的教程早已教会了你们怎样采集列表的分页,那么下边我们继续将,我们领到列表的url如何去采集文章内容页。相信你们在平常浏览网页的时侯,特别是在打开新闻网站,看新闻
记得在之前的教程早已教会了你们怎样采集列表的分页,那么下边我们继续将,我们领到列表的url如何去采集文章内容页。
相信你们在平常浏览网页的时侯,特别是在打开新闻网站,看新闻的时侯。经常听到文章内页上面还有分页,还要一个一个的去点击,这样就能把全篇文章看完。
首先,这种做法我个人而言是厌恶的。接着,他们这样做的目的,只要值为了降低pv,提高一些百度联盟或则哪些推广的广告而已,为了广告费。都说做网站,主要还是为了钱嘛,这点无可厚非。
但是,他们这样的做,我们在采集数据的时侯,就碰到了如何去采集内容页分页的问题了。
好的,那么接下来火车采集器 分页,我就来告诉你们,怎么用优采云采集器去采集文章内容页上面的分页。
前面的采集网址,就一笔带过了。不明白的小伙伴,可以瞧瞧后面的优采云采集前面采集列表页的教程。
第一步:我们在编撰抓取内容的规则时,记得勾选右上方的【该标签在分页中匹配】。
如图:
第二步:我们在采集内容页把分页获取规则填上,这里是要抓取你的分页的。也可以在标签循环处理的选项下边,填上分页内容链接代码。
如图:
第三步:测试,我们编撰的采集分页的规则正不正确。
如图:
通过前面的几个步骤火车采集器 分页,是不是太轻松的就把内容页的分页内容,采集下来了。感觉不错就试试吧。
×作者:高蒙
地址: 查看全部
记得在之前的教程早已教会了你们怎样采集列表的分页,那么下边我们继续将,我们领到列表的url如何去采集文章内容页。相信你们在平常浏览网页的时侯,特别是在打开新闻网站,看新闻
记得在之前的教程早已教会了你们怎样采集列表的分页,那么下边我们继续将,我们领到列表的url如何去采集文章内容页。
相信你们在平常浏览网页的时侯,特别是在打开新闻网站,看新闻的时侯。经常听到文章内页上面还有分页,还要一个一个的去点击,这样就能把全篇文章看完。
首先,这种做法我个人而言是厌恶的。接着,他们这样做的目的,只要值为了降低pv,提高一些百度联盟或则哪些推广的广告而已,为了广告费。都说做网站,主要还是为了钱嘛,这点无可厚非。
但是,他们这样的做,我们在采集数据的时侯,就碰到了如何去采集内容页分页的问题了。
好的,那么接下来火车采集器 分页,我就来告诉你们,怎么用优采云采集器去采集文章内容页上面的分页。
前面的采集网址,就一笔带过了。不明白的小伙伴,可以瞧瞧后面的优采云采集前面采集列表页的教程。
第一步:我们在编撰抓取内容的规则时,记得勾选右上方的【该标签在分页中匹配】。
如图:
第二步:我们在采集内容页把分页获取规则填上,这里是要抓取你的分页的。也可以在标签循环处理的选项下边,填上分页内容链接代码。
如图:
第三步:测试,我们编撰的采集分页的规则正不正确。
如图:
通过前面的几个步骤火车采集器 分页,是不是太轻松的就把内容页的分页内容,采集下来了。感觉不错就试试吧。
×作者:高蒙
地址:
文章采集器抓取列表分页示例
采集交流 • 优采云 发表了文章 • 0 个评论 • 464 次浏览 • 2020-06-25 08:00
对于设置列表分页,通过右图的起始网址——批量网址来设置是最常见也是最常用的。
现在我们用另外一种获取分页的办法,即通过列表上下页无限分页采集获取功能来自动获取分页。使用这个功能,起始页就只须要把首页地址添加进去就可以了火车采集器 分页,如下图:
然后步入[高级模式]——分页设置,设置区域开始字符串、区域结束字符串、地址式样、分页地址等数组。
我们以为例,先查看下第一页分页源代码的情况,如下图:
继续查看下第二页分页源代码的情况如下:
分析得出:当前页都是在<div>后的<strong></strong>这个代码前面紧接着一个<a href="">就是下一页地址。 也就是说我们是要通过当前页获取下一页,这样一级一级的向上获取,直至把所有分页获取到。 所以,区域开始字符串为:<div>(*)</strong> 区域结束字符串为:</a>(*)</div>
地址式样按照截取区域的格式来写:<a href="[参数]">,效果如下:
另外上图 “4” 是表示获取4页的意思,默认为“0”表示不限,将采集所有分页。这样就可以用列车采集器获取到我们须要的上下页列表分页了火车采集器 分页,用列车采集器抓取内容页上下页模式也是可以参考这些操作的,更多使用教程可以访问官网进行学习。 查看全部
在使用文章采集器采集文章的过程中,我们常常须要对分页进行抓取,比如列表分页或内容分页,这里我们就以列表分页为例,为你们讲解一下列车采集器是怎么操作分页的。
对于设置列表分页,通过右图的起始网址——批量网址来设置是最常见也是最常用的。
现在我们用另外一种获取分页的办法,即通过列表上下页无限分页采集获取功能来自动获取分页。使用这个功能,起始页就只须要把首页地址添加进去就可以了火车采集器 分页,如下图:
然后步入[高级模式]——分页设置,设置区域开始字符串、区域结束字符串、地址式样、分页地址等数组。
我们以为例,先查看下第一页分页源代码的情况,如下图:
继续查看下第二页分页源代码的情况如下:
分析得出:当前页都是在<div>后的<strong></strong>这个代码前面紧接着一个<a href="">就是下一页地址。 也就是说我们是要通过当前页获取下一页,这样一级一级的向上获取,直至把所有分页获取到。 所以,区域开始字符串为:<div>(*)</strong> 区域结束字符串为:</a>(*)</div>
地址式样按照截取区域的格式来写:<a href="[参数]">,效果如下:
另外上图 “4” 是表示获取4页的意思,默认为“0”表示不限,将采集所有分页。这样就可以用列车采集器获取到我们须要的上下页列表分页了火车采集器 分页,用列车采集器抓取内容页上下页模式也是可以参考这些操作的,更多使用教程可以访问官网进行学习。
【优采云v7采集教程】分页列表详尽信息采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 473 次浏览 • 2020-06-24 08:00
在下边界面中更改数组名称,修改完成以后,点击“确定”保存优采云·云采集服务平台 分页列表详尽信息采集-图 6步骤 6 点击“保存并启动”,再再弹出的对话框中选择“启动本地采集”。系 统会在本地开启一个采集任务并采集数据, 接下来选择导入数据,这里以选择导 出 excel2007 为例,然后点击确定. 之后选择文件储存路径,再点保存即可优采云·云采集服务平台 分页列表详尽信息采集-图 7下边是数据示例优采云·云采集服务平台 分页列表详尽信息采集-图 8相关采集教程:黄页 88 数据采集 赶集急聘信息采集 大众点评评价采集优采云——70 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景八爪鱼采集器 分页,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。优采云·云采集服务平台 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机八爪鱼采集器 分页,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
优采云·云采集服务平台 【优采云采集教程】分页列表详尽信息采集方法好多网站有会这些模式, 多个列表页面,点击列表中的一行链接会打开一个详尽 信息页面, 本文给你们演示怎么采集分页列表详情页面里的信息。目的是使你们 了解如何创建循环翻页并能正常采集网页详情的数据信息。本文教程里提到的示例网站地址为: 步骤 1 登陆优采云 7.0 采集器→点击新建任务→自定义采集, 进入到任务配置页 面: 然后输入网址→保存网址, 系统会步入到流程设计页面并手动打开上面输入的网 址。优采云·云采集服务平台 分页列表详尽信息采集-图 1 我们须要循环点击右图浏览器中影片名称,再提取子页面中的数据信息,所以我们 需要先做一个翻页循环再做一个循环点击影片名称提取数据的列表。 步骤 2 点击右图浏览器页面中的“下一页”按钮,在弹出的对话框中选择“循 环点击下一页”;优采云·云采集服务平台 分页列表详尽信息采集-图 2下面对影片名称创建循环点击 步骤 3 鼠标点击右图中第一个影片名称“教父:第二部”,在弹出的操作提示 中选择“选中全部”选项, 然后选择“循环点击每位链接”选项优采云·云采集服务平台 分页列表详尽信息采集-图 3优采云·云采集服务平台 分页列表详尽信息采集-图 4接下来页面就手动跳转到详情页面中去了,我们再做提取数据 步骤 4 点击要提取的标题在弹出的提示框中选择“采集该元素的文本”,然后 同样的方法选择点击浏览器中的其他数组,再选择“采集该元素的文本”优采云·云采集服务平台 分页列表详尽信息采集-图 5步骤 5这样提取完毕以后我们可以点一下流程按键,然后更改数组名称。
在下边界面中更改数组名称,修改完成以后,点击“确定”保存优采云·云采集服务平台 分页列表详尽信息采集-图 6步骤 6 点击“保存并启动”,再再弹出的对话框中选择“启动本地采集”。系 统会在本地开启一个采集任务并采集数据, 接下来选择导入数据,这里以选择导 出 excel2007 为例,然后点击确定. 之后选择文件储存路径,再点保存即可优采云·云采集服务平台 分页列表详尽信息采集-图 7下边是数据示例优采云·云采集服务平台 分页列表详尽信息采集-图 8相关采集教程:黄页 88 数据采集 赶集急聘信息采集 大众点评评价采集优采云——70 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景八爪鱼采集器 分页,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。优采云·云采集服务平台 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机八爪鱼采集器 分页,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
火车头文章采集规则分享? - 搜外问答
采集交流 • 优采云 发表了文章 • 0 个评论 • 492 次浏览 • 2020-05-19 08:03
第一步、打开火车头采集器,点击【新建】创建一个新任务,填写一个任务名,设置采集网址规则,分别设置列表页采集规则和列表页所在的文章页规则,分为以下两个步骤。
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此火车采集器 规则,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是<title>标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,</article>为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可火车采集器 规则,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。火车头采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。 查看全部
第一步、打开火车头采集器,点击【新建】创建一个新任务,填写一个任务名,设置采集网址规则,分别设置列表页采集规则和列表页所在的文章页规则,分为以下两个步骤。
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此火车采集器 规则,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是<title>标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,</article>为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可火车采集器 规则,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。火车头采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。
火车头采集器采集文章操作教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 907 次浏览 • 2020-04-27 11:03
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接火车头采集教程,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试火车头采集教程,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是<title>标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,</article>为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的采集工具。但请在版权范围内采集。 查看全部
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接火车头采集教程,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试火车头采集教程,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是<title>标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,</article>为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的采集工具。但请在版权范围内采集。
火车头采集教程你把握多少
采集交流 • 优采云 发表了文章 • 0 个评论 • 734 次浏览 • 2020-04-24 11:04
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置火车头采集教程,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是title标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整火车头采集教程,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。火车头采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。 查看全部
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置火车头采集教程,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是title标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整火车头采集教程,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。火车头采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。
【腾讯新闻】使用文章采集软件快速提取网页文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 478 次浏览 • 2020-04-22 11:03
1、添加起始网址:按照给出的网址打开腾讯新闻,发现新闻页面是以列表分页的方式诠释的,那么首先就要把列表页的地址作为起始网址先添加到列车采集器中。
这里我们以添加6页为例,我们可以点开这6个分页的网址一条条的添加到采集器中。但是假如我们要添加的网址好多,几百或上千条,那么一条条的进行添加就过分冗长,所以我们可以试着找出网址之间的变化规律,进行批量添加。
我们分别打开第一页、第二页……观察其网址变化,可以发觉不仅第一页之外,后面的分页网址都是以“_数字”递增的规律变化的,如下:
那么我们首先将不符合规律的第一页网址“”添加到起始网址的列表中如下:
第一页添加好了,那么前面的列表分页我们选择向导添加——批量网址添加文章自动采集软件,用一个通用的格式手动产生所须要的网址,网址中的变量就可以用地址参数来取代,地址参数的规律须要我们设置一下,上述规律就是从2开始,以1为递增量,共计5项。填写完成后列车采集器V9手动生成预览如下图,点击确定后起始网址(这里就是列表页网址)就添加好了。
2、获取内容页网址:通过观察新闻页面可以发觉列表分页的下一级就是内容页,那么内容页 网址就是一级网址(列表页为0级网址),这里我们使用最简单的“自动获取地址链接”的方法,通过剖析列表页面的源代码,可以找出新闻内容页地址所在的市 域文章自动采集软件,其开始字符为:“<div class="mod newslist">”,结束字符为:“</div>”。填写然后列车采集器会在这个区域内手动辨识地址链接,我们点击网址采集测试就 可以看见我们设置的规则采集到列表页和内容页网址是否正确和完整。
第二步、内容采集规则 查看全部
1、添加起始网址:按照给出的网址打开腾讯新闻,发现新闻页面是以列表分页的方式诠释的,那么首先就要把列表页的地址作为起始网址先添加到列车采集器中。
这里我们以添加6页为例,我们可以点开这6个分页的网址一条条的添加到采集器中。但是假如我们要添加的网址好多,几百或上千条,那么一条条的进行添加就过分冗长,所以我们可以试着找出网址之间的变化规律,进行批量添加。
我们分别打开第一页、第二页……观察其网址变化,可以发觉不仅第一页之外,后面的分页网址都是以“_数字”递增的规律变化的,如下:
那么我们首先将不符合规律的第一页网址“”添加到起始网址的列表中如下:
第一页添加好了,那么前面的列表分页我们选择向导添加——批量网址添加文章自动采集软件,用一个通用的格式手动产生所须要的网址,网址中的变量就可以用地址参数来取代,地址参数的规律须要我们设置一下,上述规律就是从2开始,以1为递增量,共计5项。填写完成后列车采集器V9手动生成预览如下图,点击确定后起始网址(这里就是列表页网址)就添加好了。
2、获取内容页网址:通过观察新闻页面可以发觉列表分页的下一级就是内容页,那么内容页 网址就是一级网址(列表页为0级网址),这里我们使用最简单的“自动获取地址链接”的方法,通过剖析列表页面的源代码,可以找出新闻内容页地址所在的市 域文章自动采集软件,其开始字符为:“<div class="mod newslist">”,结束字符为:“</div>”。填写然后列车采集器会在这个区域内手动辨识地址链接,我们点击网址采集测试就 可以看见我们设置的规则采集到列表页和内容页网址是否正确和完整。
第二步、内容采集规则
火车头采集:快速采集网页文章教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 508 次浏览 • 2020-04-18 11:00
1、添加起始网址:按照给出的网址打开腾讯新闻,发现新闻页面是以列表分页的方式诠释的,那么首先就要把列表页的地址作为起始网址先添加到列车采集器中。
这里我们以添加6页为例,我们可以点开这6个分页的网址一条条的添加到采集器中。但是假如我们要添加的网址好多火车头文章采集,几百或上千条,那么一条条的进行添加就过分冗长,所以我们可以试着找出网址之间的变化规律火车头文章采集,进行批量添加。
我们分别打开第一页、第二页……观察其网址变化采集器,可以发觉不仅第一页之外,后面的分页网址都是以“_数字”递增的规律变化的,如下:
那么我们首先将不符合规律的第一页网址“”添加到起始网址的列表中如下:
第一页添加好了,那么前面的列表分页我们选择向导添加——批量网址添加,用一个通用的格式手动产生所须要的网址,网址中的变量就可以用地址参数来取代,地址参数的规律须要我们设置一下,上述规律就是从2开始,以1为递增量,共计5项。填写完成后列车采集器V9手动生成预览如下图,点击确定后起始网址(这里就是列表页网址)就添加好了。
2、获取内容页网址:通过观察新闻页面可以发觉列表分页的下一级就是内容页,那么内容页网址就是一级网址(列表页为0级网址),这里我们使用最简单的“自动获取地址链接”的方法,通过剖析列表页面的源代码,可以找出新闻内容页地址所在的区域,其开始字符为:“<div class="mod newslist">”,结束字符为:“</div>”。填写以后列车采集器会在这个区域内手动辨识地址链接,我们点击网址采集测试就可以看见我们设置的规则采集到列表页和内容页网址是否正确和完整。 查看全部
1、添加起始网址:按照给出的网址打开腾讯新闻,发现新闻页面是以列表分页的方式诠释的,那么首先就要把列表页的地址作为起始网址先添加到列车采集器中。
这里我们以添加6页为例,我们可以点开这6个分页的网址一条条的添加到采集器中。但是假如我们要添加的网址好多火车头文章采集,几百或上千条,那么一条条的进行添加就过分冗长,所以我们可以试着找出网址之间的变化规律火车头文章采集,进行批量添加。
我们分别打开第一页、第二页……观察其网址变化采集器,可以发觉不仅第一页之外,后面的分页网址都是以“_数字”递增的规律变化的,如下:
那么我们首先将不符合规律的第一页网址“”添加到起始网址的列表中如下:
第一页添加好了,那么前面的列表分页我们选择向导添加——批量网址添加,用一个通用的格式手动产生所须要的网址,网址中的变量就可以用地址参数来取代,地址参数的规律须要我们设置一下,上述规律就是从2开始,以1为递增量,共计5项。填写完成后列车采集器V9手动生成预览如下图,点击确定后起始网址(这里就是列表页网址)就添加好了。
2、获取内容页网址:通过观察新闻页面可以发觉列表分页的下一级就是内容页,那么内容页网址就是一级网址(列表页为0级网址),这里我们使用最简单的“自动获取地址链接”的方法,通过剖析列表页面的源代码,可以找出新闻内容页地址所在的区域,其开始字符为:“<div class="mod newslist">”,结束字符为:“</div>”。填写以后列车采集器会在这个区域内手动辨识地址链接,我们点击网址采集测试就可以看见我们设置的规则采集到列表页和内容页网址是否正确和完整。
SEO站长怎么批量采集文章?火车头采集器操作教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 513 次浏览 • 2020-04-17 11:06
第一步、打开火车头采集器,点击【新建】创建一个新任务,填写一个任务名,设置采集网址规则,分别设置列表页采集规则和列表页所在的文章页规则,分为以下两个步骤。
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列火车头采集文章,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是<title>标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的火车头采集文章,通常的表现形式是article标签为起始,</article>为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。火车头采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。 查看全部
第一步、打开火车头采集器,点击【新建】创建一个新任务,填写一个任务名,设置采集网址规则,分别设置列表页采集规则和列表页所在的文章页规则,分为以下两个步骤。
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列火车头采集文章,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是<title>标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的火车头采集文章,通常的表现形式是article标签为起始,</article>为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。火车头采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。

