
内容采集器
内容采集器(WordPress文章内容可以轻松管理工作流程并以有效的格式组织文章内容 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-03-27 16:05
)
WordPress文章内容更新是SEO中最焦虑的事情。每天高质量发布 WordPress文章 内容是一件苦差事。
我们知道搜索引擎会通过蜘蛛抓取我们每日更新的 URL。搜索引擎会根据蜘蛛爬取的url分析我们的WordPress网站的更新频率和文章的内容质量,从而判断是否收录并给出关键词排名,所以维护我们的WordPress网站定期更新和文章内容优化是一项重要的工作。
<p>WordPress文章内容编辑器可以轻松管理工作流程并以有效的格式组织文章内容。通过定时采集发布功能,实现网站的全流程管理,利用内置翻译api和文章SEO编辑模块实现 查看全部
内容采集器(WordPress文章内容可以轻松管理工作流程并以有效的格式组织文章内容
)
WordPress文章内容更新是SEO中最焦虑的事情。每天高质量发布 WordPress文章 内容是一件苦差事。

我们知道搜索引擎会通过蜘蛛抓取我们每日更新的 URL。搜索引擎会根据蜘蛛爬取的url分析我们的WordPress网站的更新频率和文章的内容质量,从而判断是否收录并给出关键词排名,所以维护我们的WordPress网站定期更新和文章内容优化是一项重要的工作。

<p>WordPress文章内容编辑器可以轻松管理工作流程并以有效的格式组织文章内容。通过定时采集发布功能,实现网站的全流程管理,利用内置翻译api和文章SEO编辑模块实现
内容采集器(让我们从两个常见的内容采集工具开始:优采云采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-03-27 16:04
让我们从两个常见的内容采集工具开始:
(1)优采云采集工具:操作比较简单,免费版可以满足新手站长的数据挖掘需求,但是需要集成采集数据推导,其中一个比较重要的功能就是智能采集,不需要写太复杂的规则。
(2)优采云采集器:国内老牌除尘软件,所以很多支持cmssystem采集的插件都可以在市场,如:织梦文章采集、WordPress信息采集、Zblog数据采集等。需要一定的技术力量。
那么,文章的采集应该注意什么?
1、新站清空数据采集
我们知道在网站发帖初期有一个评价期,如果我们在开站时使用采集到的内容,会影响站内收视率,文章容易上当放到低质量的库中,会出现一个普遍现象:与收录没有排名。
为此,新的网站尽可能的保留了网上原有的内容,当页面的内容没有被完全索引的时候,没必要盲目的提交,或者想提交,你需要采取一定的策略。
2、权威网站采集内容
我们知道搜索引擎不喜欢关闭状态,他们不仅喜欢网站 的入站链接,还喜欢一些出站链接,以使这个生态系统更具相关性。
为此,当你的网站已经积累了一定的权重后,可以通过版权链接适当采集相关内容,需要注意:
(1)保证采集的内容对站点上的用户有一定的推荐价值,是满足用户需求的好方法。
(2)行业官方文档,大片网站,名家推荐合集内容。
3、避免采集网站范围的内容
提到这个问题,很容易让很多人质疑飓风算法对获取的严厉攻击的强调,但为什么大名鼎鼎的网站不在攻击范围之内呢?
这涉及到搜索引擎的本质:满足用户的需求,而网站对优质内容传播的影响也比较重要。
对于中小网站,尽量避免大量的内容采集,直到我们有独特的属性和影响力。
提示:随着熊掌的上线和原创保护功能的推出,百度仍将努力调整平衡原创内容和知名网站的排名。原则上应该更倾向于对原网站进行排名。
4、如果网站content采集被处罚了怎么办?
Hurricane 算法非常人性化。它只惩罚 采集 部分,但对同一站点上的其他部分几乎没有影响。
所以解决方法很简单,只需要删除采集的内容,设置404页面,然后在百度搜索资源平台提交死链接->网站支持->数据介绍->死链接提交栏。如果您发现 网站 的权重恢复缓慢,您可以在反馈中心提供反馈。
摘要:内容仍然适用于王。如果关注熊掌号,会发现百度在2019年会加大对原创内容的支持力度,尽量避免采集内容。 查看全部
内容采集器(让我们从两个常见的内容采集工具开始:优采云采集)
让我们从两个常见的内容采集工具开始:
(1)优采云采集工具:操作比较简单,免费版可以满足新手站长的数据挖掘需求,但是需要集成采集数据推导,其中一个比较重要的功能就是智能采集,不需要写太复杂的规则。
(2)优采云采集器:国内老牌除尘软件,所以很多支持cmssystem采集的插件都可以在市场,如:织梦文章采集、WordPress信息采集、Zblog数据采集等。需要一定的技术力量。
那么,文章的采集应该注意什么?
1、新站清空数据采集
我们知道在网站发帖初期有一个评价期,如果我们在开站时使用采集到的内容,会影响站内收视率,文章容易上当放到低质量的库中,会出现一个普遍现象:与收录没有排名。
为此,新的网站尽可能的保留了网上原有的内容,当页面的内容没有被完全索引的时候,没必要盲目的提交,或者想提交,你需要采取一定的策略。
2、权威网站采集内容
我们知道搜索引擎不喜欢关闭状态,他们不仅喜欢网站 的入站链接,还喜欢一些出站链接,以使这个生态系统更具相关性。
为此,当你的网站已经积累了一定的权重后,可以通过版权链接适当采集相关内容,需要注意:
(1)保证采集的内容对站点上的用户有一定的推荐价值,是满足用户需求的好方法。
(2)行业官方文档,大片网站,名家推荐合集内容。

3、避免采集网站范围的内容
提到这个问题,很容易让很多人质疑飓风算法对获取的严厉攻击的强调,但为什么大名鼎鼎的网站不在攻击范围之内呢?
这涉及到搜索引擎的本质:满足用户的需求,而网站对优质内容传播的影响也比较重要。
对于中小网站,尽量避免大量的内容采集,直到我们有独特的属性和影响力。
提示:随着熊掌的上线和原创保护功能的推出,百度仍将努力调整平衡原创内容和知名网站的排名。原则上应该更倾向于对原网站进行排名。
4、如果网站content采集被处罚了怎么办?
Hurricane 算法非常人性化。它只惩罚 采集 部分,但对同一站点上的其他部分几乎没有影响。
所以解决方法很简单,只需要删除采集的内容,设置404页面,然后在百度搜索资源平台提交死链接->网站支持->数据介绍->死链接提交栏。如果您发现 网站 的权重恢复缓慢,您可以在反馈中心提供反馈。
摘要:内容仍然适用于王。如果关注熊掌号,会发现百度在2019年会加大对原创内容的支持力度,尽量避免采集内容。
内容采集器(如何找到合适的网站了解详情才可以下载免费资源?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-03-24 12:03
内容采集器、视频采集器都可以,找些可以免费下载网站看看,比如小说阅读器、可视频网站下载器等等。要找到合适的免费下载站首先要明白免费资源是如何得来的,是通过信息公开、网络爬虫获取还是自己经过分析、转换、抽取,不同情况需要不同技术手段去支持,我就是平时会看一些小说,虽然没有电子书那么全,但肯定有不少,大多会利用云端下载中心(网站如飞扬云起网)。
至于作者和你版权纠纷的问题,现在官方也没有给出定论,比如小说站下载很多都是黄色图片,有些也给了授权,但也许会有赔偿等,毕竟小说网站都是公益性质的,不可能跟黄色公司一样拼命捞钱。再找到合适的网站了解详情才可以下载免费资源。参考:网上有很多人建设论坛,公益型的,我觉得比一些资源分享站,如知乎论坛等要靠谱。
可以试试这个:,但是作者有点不靠谱,觉得不靠谱的话就算了,下载需要会员,
《中华人民共和国著作权法》第八条权利人享有下列积极权利:
一)制作报纸、期刊、杂志的版权;
二)汇编作品、作品集的版权;
三)可以出租作品,
四)修改作品,
五)改编、翻译、注释、整理已有作品而产生的作品,
六)可以请求权利人向其支付报酬;
七)享有对作品进行定价的权利。商业使用别人创作的作品,应当取得著作权人许可,并支付报酬。 查看全部
内容采集器(如何找到合适的网站了解详情才可以下载免费资源?)
内容采集器、视频采集器都可以,找些可以免费下载网站看看,比如小说阅读器、可视频网站下载器等等。要找到合适的免费下载站首先要明白免费资源是如何得来的,是通过信息公开、网络爬虫获取还是自己经过分析、转换、抽取,不同情况需要不同技术手段去支持,我就是平时会看一些小说,虽然没有电子书那么全,但肯定有不少,大多会利用云端下载中心(网站如飞扬云起网)。
至于作者和你版权纠纷的问题,现在官方也没有给出定论,比如小说站下载很多都是黄色图片,有些也给了授权,但也许会有赔偿等,毕竟小说网站都是公益性质的,不可能跟黄色公司一样拼命捞钱。再找到合适的网站了解详情才可以下载免费资源。参考:网上有很多人建设论坛,公益型的,我觉得比一些资源分享站,如知乎论坛等要靠谱。
可以试试这个:,但是作者有点不靠谱,觉得不靠谱的话就算了,下载需要会员,
《中华人民共和国著作权法》第八条权利人享有下列积极权利:
一)制作报纸、期刊、杂志的版权;
二)汇编作品、作品集的版权;
三)可以出租作品,
四)修改作品,
五)改编、翻译、注释、整理已有作品而产生的作品,
六)可以请求权利人向其支付报酬;
七)享有对作品进行定价的权利。商业使用别人创作的作品,应当取得著作权人许可,并支付报酬。
内容采集器(import.io:大数据采集软件集搜客GooSeeker对比说明 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-03-13 15:03
)
最近国外大数据软件采集import.io火了。在获得90万美元天使轮融资后,近日又获得了1300万美元的一轮融资,引起了众多投资者的关注。,我也是出于好奇使用并体验了import.io的神奇功能。我是中国大数据采集软件合集GooSeeker的老用户,所以喜欢把两者放在一起比较。下面我印象最深。的几个功能对比,对应import.io的四大功能:Magic、Extractor、Crawler、Connector,分为两部分。
对data采集比较感兴趣的朋友,希望能起到吸点新意的作用,一起来分析data采集的技术亮点。
1. 魔法 (Import.io) VS 天眼和千面 (Jizouke)
Magic:就像magic这个词的本义“魔法”一样,import.io赋予了Magic一个神奇的功能。只要用户输入 URL,Magic 工具就可以神奇的将网页中的数据整齐、标准地抓取。
如图1所示,输入58同城租房信息URL后,Magic会自动采集网页数据,操作简单。但是可以看到可能会漏掉一些栏目,每页都需要点击“下一页”进行采集,无法自动翻页。当然,还有很多页面几乎没有采集可以下载,比如新浪微博。
总之,我觉得很神奇:
图 1:Magic Autocrawl 示例
上图是import.io的Magic功能截图。它是一个纯网页界面,使用起来非常方便,无需安装额外的软件。综上所述:
GooSeeker的天眼和千面系列:集搜客的天眼和千面分别针对电商和微博发布的数据采集方便的GUI界面,只要输入网址,目标数据就可以标准化、整齐采集下来。
如图2:显示博主的采集工具(微博各种数据都有采集管理界面),进入博主首页的链接,可以调度爬虫,给博主首页下的信息为采集,如微博内容、转发、评论等数据。
图2:GooSeeker微博博主采集界面示例
界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。已结构化和转换的 XML 格式的结果文件。
从上面的分析可以看出,Magic和GooSeeker的天眼和千面操作非常简单,基本都是纯傻瓜式操作,非常适合只想专注于业务问题而做不想被技术问题分心。用户也是纯小白学习数据采集和使用数据结果的良好起点。但是,Magic 在采集 的结果可视化方面比天眼和千眼具有更广泛的适用性。缺点是采集数据量大的场景不可控,而天眼和千面专注于几个主流网站,优点主要体现在能够完成大量数据采集,例如,
2. Extractor (import.io) VS Organizer (Jizouke)
提取器:提取器是翻译中的提取器。如果从实体的角度来理解,它就是一个小程序(可能是一组脚本),从 URL 中提取出想要的信息;如果是从 采集 目标来理解它是从 采集 的角度来理解特定网页的结构规则。与Magic不同的是,import.io的Extractor(以及后面的另外两个功能)是一个可以独立运行的软件,具有非常直观的可视化界面,可以直观的展示提取出来的信息。
如图 3:import.io 的 Extractor 非常类似于修改后的浏览器。在工具栏中输入网址,网页显示出来后,在浏览器中选择要抓取的数据,然后单页就可以将结构的整列规范依次往下采集。
图 3:Extractor 提取数据的示例
GooSeeker Organizer:Jisouke 声称是“建立一个盒子,把你想要的内容放进去”。这个盒子就是所谓的组织者。原理是将需要提取的信息一个一个拖入框内,映射到组织者。Box,采集程序可以自动生成提取器(脚本程序),提取器自动存储在云服务器中,可以分发给全球的网络爬虫进行提取。
如图4所示,import.io顶部的一个工具栏在GooSeeker中展开成一个工作台,在工作台上创建一个盒子,然后通过映射操作将网页上的内容扔到盒子里。把你想要的东西扔进盒子里。原理看似简单,但面对大盒子界面和众多HTML节点,对于新手来说有点压力。当然,界面复杂,以换取能够处理更复杂的情况,因为有更多的控件可用。
图 4:分类 bin 提取数据的示例
综上所述,Extractor和排序框都具有提取信息字段的功能。Extractor操作起来比较简单直观,适用于一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会出现无法提取的问题。这时候就突显了吉搜克排序框的优势,特别复杂的情况下,可以使用自定义的xpath来定位数据。
如有疑问,您可以或
查看全部
内容采集器(import.io:大数据采集软件集搜客GooSeeker对比说明
)
最近国外大数据软件采集import.io火了。在获得90万美元天使轮融资后,近日又获得了1300万美元的一轮融资,引起了众多投资者的关注。,我也是出于好奇使用并体验了import.io的神奇功能。我是中国大数据采集软件合集GooSeeker的老用户,所以喜欢把两者放在一起比较。下面我印象最深。的几个功能对比,对应import.io的四大功能:Magic、Extractor、Crawler、Connector,分为两部分。
对data采集比较感兴趣的朋友,希望能起到吸点新意的作用,一起来分析data采集的技术亮点。
1. 魔法 (Import.io) VS 天眼和千面 (Jizouke)
Magic:就像magic这个词的本义“魔法”一样,import.io赋予了Magic一个神奇的功能。只要用户输入 URL,Magic 工具就可以神奇的将网页中的数据整齐、标准地抓取。
如图1所示,输入58同城租房信息URL后,Magic会自动采集网页数据,操作简单。但是可以看到可能会漏掉一些栏目,每页都需要点击“下一页”进行采集,无法自动翻页。当然,还有很多页面几乎没有采集可以下载,比如新浪微博。
总之,我觉得很神奇:

图 1:Magic Autocrawl 示例
上图是import.io的Magic功能截图。它是一个纯网页界面,使用起来非常方便,无需安装额外的软件。综上所述:
GooSeeker的天眼和千面系列:集搜客的天眼和千面分别针对电商和微博发布的数据采集方便的GUI界面,只要输入网址,目标数据就可以标准化、整齐采集下来。
如图2:显示博主的采集工具(微博各种数据都有采集管理界面),进入博主首页的链接,可以调度爬虫,给博主首页下的信息为采集,如微博内容、转发、评论等数据。

图2:GooSeeker微博博主采集界面示例
界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。已结构化和转换的 XML 格式的结果文件。
从上面的分析可以看出,Magic和GooSeeker的天眼和千面操作非常简单,基本都是纯傻瓜式操作,非常适合只想专注于业务问题而做不想被技术问题分心。用户也是纯小白学习数据采集和使用数据结果的良好起点。但是,Magic 在采集 的结果可视化方面比天眼和千眼具有更广泛的适用性。缺点是采集数据量大的场景不可控,而天眼和千面专注于几个主流网站,优点主要体现在能够完成大量数据采集,例如,
2. Extractor (import.io) VS Organizer (Jizouke)
提取器:提取器是翻译中的提取器。如果从实体的角度来理解,它就是一个小程序(可能是一组脚本),从 URL 中提取出想要的信息;如果是从 采集 目标来理解它是从 采集 的角度来理解特定网页的结构规则。与Magic不同的是,import.io的Extractor(以及后面的另外两个功能)是一个可以独立运行的软件,具有非常直观的可视化界面,可以直观的展示提取出来的信息。
如图 3:import.io 的 Extractor 非常类似于修改后的浏览器。在工具栏中输入网址,网页显示出来后,在浏览器中选择要抓取的数据,然后单页就可以将结构的整列规范依次往下采集。

图 3:Extractor 提取数据的示例
GooSeeker Organizer:Jisouke 声称是“建立一个盒子,把你想要的内容放进去”。这个盒子就是所谓的组织者。原理是将需要提取的信息一个一个拖入框内,映射到组织者。Box,采集程序可以自动生成提取器(脚本程序),提取器自动存储在云服务器中,可以分发给全球的网络爬虫进行提取。
如图4所示,import.io顶部的一个工具栏在GooSeeker中展开成一个工作台,在工作台上创建一个盒子,然后通过映射操作将网页上的内容扔到盒子里。把你想要的东西扔进盒子里。原理看似简单,但面对大盒子界面和众多HTML节点,对于新手来说有点压力。当然,界面复杂,以换取能够处理更复杂的情况,因为有更多的控件可用。

图 4:分类 bin 提取数据的示例
综上所述,Extractor和排序框都具有提取信息字段的功能。Extractor操作起来比较简单直观,适用于一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会出现无法提取的问题。这时候就突显了吉搜克排序框的优势,特别复杂的情况下,可以使用自定义的xpath来定位数据。
如有疑问,您可以或

内容采集器(网站SEO相关规则还是需要了解的?采集器 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-03-12 13:06
)
关键词采集器 是我们经常用于网站数据采集 和内容采集 的工具。 关键词采集器对新站长非常友好,不用我们填写复杂的采集规则就可以使用。并具有采集、翻译、伪原创、发布、推送等功能,可实现对网站内容的全流程管理。
关键词采集器可以一次创建多个采集任务,实现不同的网站同时采集,支持关键词pan采集。 采集器内的所有采集数据都可以实时查看。
关键词采集器我们只需要输入关键词完成网络采集,点击相关选项完成设置,然后开始轮询全平台采集,采集内容是各大平台的关键词下拉词,保证了采集内容的实时准确。
Orientation采集我们只需要输入目标的URL网站我们需要采集,我们可以在插件中预览。通过选择我们需要的数据和内容,我们就可以完成设置了。内置增量 采集 功能确保重复内容过滤。
关键词采集器在< @采集;支持选择保留H、Strong、span等标签; 伪原创保留关键词;敏感词被替换; 文章标题插入关键词; 关键词生成内部/外部链接等。支持全网几乎所有主要cms平台的发布。自动伪原创发布后自动推送到搜索引擎,大大提高网站收录的效率。
通过关键词采集器,我们可以让我们的网站定期持续更新。虽然采集器可以给我们带来方便,但我们想让网站保持长期的运营动力,网站SEO相关规则还是需要了解的。
一、title 标题不可随意更改
在网站SEO工作中,网站title标题可以说是一把双刃剑。如果选择好的关键词并坚持下去,可以给网站带来很大的关注权,但选择不合适的关键词或频繁更换标题可能带来减轻网站权重的可能。所以我们的关键词确定后,不要随意更改。
二、META标签不会随意改变
SEOER在优化网站时不会随意更改标题,也不会随意使用mete标签。我们经常谈论的三个主要标签是标题、描述和关键字。所谓好的元标签,并不是每个页面都需要做的,做好元标签直接影响到优化。
三、使用 DIV+CSS 的程序
虽然用程序做网站的方法有很多,但是用DIV+CSS做的程序,代码编程少,对网站收录更有好处。因为这种模式更容易突出文本的内容,而且DIV是搜索引擎最喜欢的方式,网站样式都是CSS中的,比较容易被收录下的搜索引擎这个结构。
四、网站的程序不容易改
网站的程序可以说是网站的核心。随机替换网站程序会导致网站的结构发生变化,导致URL失效。 网站@ >收录清除。由于网站的变异,蜘蛛会认为网站有异常行为,加强对网站的监控,从而对网站失去信任,严重时会会影响减重的可能性。
五、使用静态页面
相信很多人对此深有体会,因为在使用搜索引擎的过程中,用HTML编写的静态页面往往排名更高,也更容易获得可观的流量
在我们的SEO工作中,经常会有很多机械性的重复性工作,我们可以通过工具来实现。和网站发布一样,关键词采集器也有自己的发布功能,支持全天挂机发布,另外,采集器还支持查看绑定< @网站收录、蜘蛛、体重数据等,让我们的SEOER通过数据分析网站的情况,实时做出相应的调整。
查看全部
内容采集器(网站SEO相关规则还是需要了解的?采集器
)
关键词采集器 是我们经常用于网站数据采集 和内容采集 的工具。 关键词采集器对新站长非常友好,不用我们填写复杂的采集规则就可以使用。并具有采集、翻译、伪原创、发布、推送等功能,可实现对网站内容的全流程管理。
关键词采集器可以一次创建多个采集任务,实现不同的网站同时采集,支持关键词pan采集。 采集器内的所有采集数据都可以实时查看。
关键词采集器我们只需要输入关键词完成网络采集,点击相关选项完成设置,然后开始轮询全平台采集,采集内容是各大平台的关键词下拉词,保证了采集内容的实时准确。
Orientation采集我们只需要输入目标的URL网站我们需要采集,我们可以在插件中预览。通过选择我们需要的数据和内容,我们就可以完成设置了。内置增量 采集 功能确保重复内容过滤。
关键词采集器在< @采集;支持选择保留H、Strong、span等标签; 伪原创保留关键词;敏感词被替换; 文章标题插入关键词; 关键词生成内部/外部链接等。支持全网几乎所有主要cms平台的发布。自动伪原创发布后自动推送到搜索引擎,大大提高网站收录的效率。
通过关键词采集器,我们可以让我们的网站定期持续更新。虽然采集器可以给我们带来方便,但我们想让网站保持长期的运营动力,网站SEO相关规则还是需要了解的。
一、title 标题不可随意更改
在网站SEO工作中,网站title标题可以说是一把双刃剑。如果选择好的关键词并坚持下去,可以给网站带来很大的关注权,但选择不合适的关键词或频繁更换标题可能带来减轻网站权重的可能。所以我们的关键词确定后,不要随意更改。
二、META标签不会随意改变
SEOER在优化网站时不会随意更改标题,也不会随意使用mete标签。我们经常谈论的三个主要标签是标题、描述和关键字。所谓好的元标签,并不是每个页面都需要做的,做好元标签直接影响到优化。
三、使用 DIV+CSS 的程序
虽然用程序做网站的方法有很多,但是用DIV+CSS做的程序,代码编程少,对网站收录更有好处。因为这种模式更容易突出文本的内容,而且DIV是搜索引擎最喜欢的方式,网站样式都是CSS中的,比较容易被收录下的搜索引擎这个结构。
四、网站的程序不容易改
网站的程序可以说是网站的核心。随机替换网站程序会导致网站的结构发生变化,导致URL失效。 网站@ >收录清除。由于网站的变异,蜘蛛会认为网站有异常行为,加强对网站的监控,从而对网站失去信任,严重时会会影响减重的可能性。
五、使用静态页面
相信很多人对此深有体会,因为在使用搜索引擎的过程中,用HTML编写的静态页面往往排名更高,也更容易获得可观的流量
在我们的SEO工作中,经常会有很多机械性的重复性工作,我们可以通过工具来实现。和网站发布一样,关键词采集器也有自己的发布功能,支持全天挂机发布,另外,采集器还支持查看绑定< @网站收录、蜘蛛、体重数据等,让我们的SEOER通过数据分析网站的情况,实时做出相应的调整。
内容采集器(公文写作怎么写?这方面的神器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-03-12 05:22
最近突然想到了写公文的话题。虽然后台问这个问题的粉丝不多,但毕竟我采集了很多这方面的资源,所以正好抽空整理一下今天想分享的内容,可以解决的. 写公文时,会出现参考资料不足、参考大纲不足、参考范文不足、校对不便、找不到合适的红头模板、排版不正确等问题。其实并不是只是写官方文件。介绍的工具是各种文章写作、论文排版、职场编码的难得神器!1 辅助写作的神器我可以保证用以下写作神器,什么报告,摘要,经验、通知等你在写吗?没关系1.1 WPS智能写作(小程序)2022年2月3月12日更新:最先进的维护技术是金山软件出品的这个小程序!完全免费,一键AI智能写作,只需要输入关键词标题,即刻帮你生成范文。同时,它还采用了深度学习模型,在小程序中添加了一些特定的场景和定位,可以根据您的扫码使用小程序对找到的素材进行优化。同时网页版也进行了更新:无需注册登录,打开网站输入关键词,然后点击“智能写作”稍等片刻就会生成一篇短文. 如果不满意,也可以点击“更改”1.2 知文知语(网页)网址:不过体验了所有的工具,最良心的一定是这一款,不仅完全免费,而且功能强大!在首页,可以快速搜索政策相关文档,每个文章都有原文链接。据官方介绍,他们总共提供了50+国家部委、200+地方政策委员会和办公室,100W+数量的政策文件,政策关联栏目中列出了100G+的政策文件总存储容量。根据关键词,可以将搜索结果以“机构-政策文件”关系图的形式给出,清晰明了。不仅如此,这个平台还提供免费的文档写作。辅助的右侧是正文的写作部分,左侧可以快速搜索相关政策文件和解释。切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助工具网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 左侧可快速搜索相关政策文件及解读。切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 左侧可快速搜索相关政策文件及解读。切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助工具网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助工具网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助工具网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 提供各种报告写作提纲1.3 Weisi(网页)网址:这也是一个写作辅助网站,但功能上,可能比上面那个网站强!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 提供各种报告写作提纲1.3 Weisi(网页)网址:这也是一个写作辅助网站,但功能上,可能比上面那个网站强!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 写作。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 写作。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 查看全部
内容采集器(公文写作怎么写?这方面的神器)
最近突然想到了写公文的话题。虽然后台问这个问题的粉丝不多,但毕竟我采集了很多这方面的资源,所以正好抽空整理一下今天想分享的内容,可以解决的. 写公文时,会出现参考资料不足、参考大纲不足、参考范文不足、校对不便、找不到合适的红头模板、排版不正确等问题。其实并不是只是写官方文件。介绍的工具是各种文章写作、论文排版、职场编码的难得神器!1 辅助写作的神器我可以保证用以下写作神器,什么报告,摘要,经验、通知等你在写吗?没关系1.1 WPS智能写作(小程序)2022年2月3月12日更新:最先进的维护技术是金山软件出品的这个小程序!完全免费,一键AI智能写作,只需要输入关键词标题,即刻帮你生成范文。同时,它还采用了深度学习模型,在小程序中添加了一些特定的场景和定位,可以根据您的扫码使用小程序对找到的素材进行优化。同时网页版也进行了更新:无需注册登录,打开网站输入关键词,然后点击“智能写作”稍等片刻就会生成一篇短文. 如果不满意,也可以点击“更改”1.2 知文知语(网页)网址:不过体验了所有的工具,最良心的一定是这一款,不仅完全免费,而且功能强大!在首页,可以快速搜索政策相关文档,每个文章都有原文链接。据官方介绍,他们总共提供了50+国家部委、200+地方政策委员会和办公室,100W+数量的政策文件,政策关联栏目中列出了100G+的政策文件总存储容量。根据关键词,可以将搜索结果以“机构-政策文件”关系图的形式给出,清晰明了。不仅如此,这个平台还提供免费的文档写作。辅助的右侧是正文的写作部分,左侧可以快速搜索相关政策文件和解释。切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助工具网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 左侧可快速搜索相关政策文件及解读。切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 左侧可快速搜索相关政策文件及解读。切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助工具网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助工具网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助工具网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 提供各种报告写作提纲1.3 Weisi(网页)网址:这也是一个写作辅助网站,但功能上,可能比上面那个网站强!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 提供各种报告写作提纲1.3 Weisi(网页)网址:这也是一个写作辅助网站,但功能上,可能比上面那个网站强!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 写作。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 写作。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内
内容采集器(内容采集器不就是免费的么?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-09 21:01
内容采集器的运营人员绝对不想让读者看到自己支持,但也不得不支持的东西。采集器有几个反馈渠道,而且在不同运营人员的业务范围内,不同时间内实施会有不同。现在大家比较关心的一个问题是:你们采集器的目标是什么?对用户而言,这里面又是怎么样的目标?就我的理解而言,采集器最初的目标是把用户的信息转化为商业价值。在这个基础上,产品功能是展示,第三方服务是收费。
像支付宝,以及facebook都有最初的目标。这就导致,除了第三方服务的售卖以外,主要就是收费。这也是我们定位的第三方服务包含的两个因素:有商业价值的第三方服务。
采集器只不过是一个模仿工具而已,功能上有所扩展,但是核心的功能依然是爬虫,只是把信息的来源作为了条件,不过这样的一个采集工具有其局限性,因为找不到全网信息来源,所以收费是必然的。本人是做爬虫的,对于我们而言,手工爬虫是必须,自动爬虫只是锦上添花,基于自动爬虫所建立的辅助性爬虫也是可用的,至于你喜欢免费的,或者说什么微爬虫之类的我觉得就不算了。
采集器做的目标就是为了更多的免费,采集器是为了提供信息服务来为用户赚钱而存在的。采集器不就是免费的么?用户在用免费的工具解决问题时感到满足,这才是采集器的真正目标,其它都是次要的,至于为了用户,如果说你用采集器来满足你的某一方面需求,他自然知道你喜欢什么,不喜欢什么,于是也就满足你,或者干脆收钱给你免费了。 查看全部
内容采集器(内容采集器不就是免费的么?(图))
内容采集器的运营人员绝对不想让读者看到自己支持,但也不得不支持的东西。采集器有几个反馈渠道,而且在不同运营人员的业务范围内,不同时间内实施会有不同。现在大家比较关心的一个问题是:你们采集器的目标是什么?对用户而言,这里面又是怎么样的目标?就我的理解而言,采集器最初的目标是把用户的信息转化为商业价值。在这个基础上,产品功能是展示,第三方服务是收费。
像支付宝,以及facebook都有最初的目标。这就导致,除了第三方服务的售卖以外,主要就是收费。这也是我们定位的第三方服务包含的两个因素:有商业价值的第三方服务。
采集器只不过是一个模仿工具而已,功能上有所扩展,但是核心的功能依然是爬虫,只是把信息的来源作为了条件,不过这样的一个采集工具有其局限性,因为找不到全网信息来源,所以收费是必然的。本人是做爬虫的,对于我们而言,手工爬虫是必须,自动爬虫只是锦上添花,基于自动爬虫所建立的辅助性爬虫也是可用的,至于你喜欢免费的,或者说什么微爬虫之类的我觉得就不算了。
采集器做的目标就是为了更多的免费,采集器是为了提供信息服务来为用户赚钱而存在的。采集器不就是免费的么?用户在用免费的工具解决问题时感到满足,这才是采集器的真正目标,其它都是次要的,至于为了用户,如果说你用采集器来满足你的某一方面需求,他自然知道你喜欢什么,不喜欢什么,于是也就满足你,或者干脆收钱给你免费了。
内容采集器(一门强大的开发语言,正则表达式方法捕获 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2022-03-08 21:06
)
开幕
作为世界上使用最广泛的语言,Java以其高效、可移植(跨平台)、代码健壮性和强大的可扩展性深受应用开发者的喜爱。作为一门强大的开发语言,正则表达式在其中的应用当然是必不可少的,而掌握正则表达式的能力也是那些资深程序员开发技能的体现,成为一名合格的网站开发程序员(尤其是前端开发),需要正则表达式。
最近由于一些需要,使用java和regularity,做了一个足球网站数据采集程序;由于是第一次做关于java的html页面数据采集,难免在网上找了很多资料,但是发现广泛使用的java在使用规律做html采集(中文)文章很少,他们只是在说java正则的概念,实际网页中并没有真正用到html采集,例子教程也很少(虽然java有自带的Html Parser,而且功能很强大),但我个人认为作为这样一个根深蒂固的正则表达式,应该是相关的java示例教程应该是多而全的。所以在完成了java版的html数据采集程序之后,我打算写一个html页面<
本期概述
本期我们将学习如何阅读网页源代码,通过分组规律动态抓取我们需要的网页数据。同时,在接下来的几期中,我们将继续学习如何将捕获的游戏数据存储在【数据存储】中。进入数据库(MySql),【数据查询】如何查询我们想看的比赛记录,【远程操作】通过客户端远程访问和操作服务器到采集,存储和查询数据。
关于组规律性
说到正则表达式如何帮助java执行html页面采集,这里需要提一下正则表达式中的group方法(代码如下)。
import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br />/**<br />* Group 类 用于匹配和抓取 html页面的数据<br />* @author SoFlash - 博客园 http://www.cnblogs.com/longwu<br />*/<br />public class Group {<br /><br />public static void main(String[] args) {<br />// Pattern 用于编译正则 这里用到了3个正则 分别用括号()包住<br />// 第1个正则用于匹配URL 当然这里的正则不一定准确 这个匹配URL的正则就是错误的 只是在这里刚好能匹配出来<br />// 第2个正则是用于匹配标题 SoFlash的<br />// 第3个正则用于匹配日期<br /> /* 这里只用了一条语句便把url,标题和日期全部给匹配出来了 */<br /> Pattern p = Pattern<br /> .compile("='(\\w.+)'>(\\w.+[a-zA-Z])-(\\d{1,2}\\.\\d{1,2}\\.\\d{4})");<br /> String s = "<a href='http://www.cnblogs.com/longwu% ... %3Bbr /> Matcher m = p.matcher(s);<br />while (m.find()) {<br />// 通过调用group()方法里的索引 将url,标题和日期全部给打印出来<br /> System.out.println("打印出url链接:" + m.group(1));<br /> System.out.println("打印出标题:" + m.group(2));<br /> System.out.println("打印出日期:" + m.group(3));<br /> System.out.println();<br /> }<br /> System.out.println("group方法捕获的数据个数:" + m.groupCount() + "个");<br /> }<br />}
让我们看看输出:
打印出url链接:
打印出标题:SoFlash
打印日期:12.22.2011
group 方法捕获的数据数量:3
想详细了解正则在java中的应用的朋友,请看JAVA正则表达式(超详细)
如果你之前没有学过正则表达式,可以看看这个揭秘正则表达式
页面采集实例
好了,group方法已经介绍完了,我们来使用group常规采集a football网站页面的数据
页面链接:2011-2012赛季英超球队战绩
首先,我们阅读整个 html 页面并将其打印出来(代码如下)。
public static void main(String[] args) {<br /><br /> String strUrl = "http://www.footballresults.org ... %3Bbr />try {<br />// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径<br />// 更多可以看看 http://wenku.baidu.com/view/81 ... %3Bbr /> URL url = new URL(strUrl);<br />// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符<br />// 更多可以看看 http://blog.sina.com.cn/s/blog ... %3Bbr /> InputStreamReader isr = new InputStreamReader(url.openStream(),<br /> "utf-8"); // 统一使用utf-8 编码模式<br />// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符<br /> BufferedReader br = new BufferedReader(isr);<br />// 如果 BufferedReader 读到的内容不为空<br /> while (br.readLine() != null) {<br />// 则打印出来 这里打印出来的结果 应该是整个网站的<br /> System.out.println(br.readLine());<br /> }<br /> br.close(); // 读取完成后关闭读取器<br /> } catch (IOException e) {<br />// 如果出错 抛出异常<br /> e.printStackTrace();<br /> }<br /> }
打印出来的结果就是整个html页面的源码(下面是部分截图)。
至此,html源码已经成功采集down了。但是,我们要的不是整个html源代码,而是网页上的游戏数据。
首先我们分析html源码结构,来到2011-2012英超球队战绩页面,右键“查看源文件”(其他浏览器可能称为源代码或相关)。
我们来看看它内部的html代码结构和我们需要的数据。
其对应的页面数据
这时候强大的正则表达式就派上用场了,我们需要写几个正则表达式来捕捉团队数据。
这里需要三个正则表达式:日期正则表达式、两队正则表达式(主队和客队)和比赛结果正则表达式。
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";//日期规则
String regularTwoTeam = ">[^]*"; //团队常规
String regularResult = ">(\\d{1,2}-\\d{1,2})"; //游戏结果有规律
写好正则后,我们就可以用正则去抓取我们想要的数据了。
首先,我们编写一个 GroupMethod 类,其中收录用于抓取 html 页面数据的 regularGroup() 方法。
import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br />/**<br /> * GroupMethod类 用于匹配并抓去 Html上我们想要的内容<br /> * @author SoFlash - 博客园 http://www.cnblogs.com/longwu<br />*/<br />public class GroupMethod {<br />// 传入2个字符串参数 一个是pattern(我们使用的正则) 另一个matcher是html源代码<br /> public String regularGroup(String pattern, String matcher) {<br /> Pattern p = Pattern.compile(pattern, Pattern.CASE_INSENSITIVE);<br /> Matcher m = p.matcher(matcher);<br />if (m.find()) { // 如果读到<br /> return m.group();// 返回捕获的数据<br /> } else {<br />return ""; // 否则返回一个空字符串<br /> }<br /> }<br />}
然后在main函数中实现html页面的数据抓取。
<p>import java.io.BufferedReader;<br />import java.io.IOException;<br />import java.io.InputStreamReader;<br />import java.net.URL;<br />/**<br /> * Main主函数 用于数据采集<br /> * @author SoFlash - 博客园 http://www.cnblogs.com/longwu<br />*/<br />public class Main {<br /><br />public static void main(String[] args) {<br />// 首先用一个字符串 来装载网页链接<br /> String strUrl = "http://www.footballresults.org ... %3Bbr />try {<br />// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径<br />// 更多可以看看 http://wenku.baidu.com/view/81 ... %3Bbr /> URL url = new URL(strUrl);<br />// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符<br />// 更多可以看看 http://blog.sina.com.cn/s/blog ... %3Bbr /> InputStreamReader isr = new InputStreamReader(url.openStream(),<br /> "utf-8"); // 统一使用utf-8 编码模式<br />// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符<br /> BufferedReader br = new BufferedReader(isr);<br /> String strRead = ""; // 新增一个空字符串strRead来装载 BufferedReader 读取到的内容<br /><br />// 定义3个正则 用于匹配我们需要的数据<br /> String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";<br /> String regularTwoTeam = ">[^]*</a>";<br /> String regularResult = ">(\\d{1,2}-\\d{1,2})";<br /><br />// 创建一个GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法<br /> GroupMethod gMethod = new GroupMethod();<br />int i =0; //定义一个i来记录循环次数 即收集到的球队比赛结果数<br /> int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的<br />// 开始读取数据 如果读到的数据不为空 则往里面读<br /> while ((strRead = br.readLine()) != null) {<br />/**<br /> * 用于捕获日期数据<br />*/<br /> String strGet = gMethod.regularGroup(regularDate, strRead);<br />//如果捕获到了符合条件的 日期数据 则打印出来 <br /> if (!strGet.equals("")) {<br /> System.out.println("Date:" + strGet);<br />//这里索引+1 是用于获取后期的球队数据<br /> ++index; //因为在html页面里 源代码里 球队数据是在刚好在日期之后 <br /> }<br />/**<br /> * 用于获取2个球队的数据<br />*/<br /> strGet = gMethod.regularGroup(regularTwoTeam, strRead);<br />if (!strGet.equals("") && index == 1) { //索引为1的是主队数据<br />// 通过substring方法 分离出 主队数据<br /> strGet = strGet.substring(1, strGet.indexOf("</a>"));<br /> System.out.println("HomeTeam:" + strGet); //打印出主队<br /> index++; //索引+1之后 为2了<br />// 通过substring方法 分离出 客队<br /> } else if (!strGet.equals("") && index == 2) { //这里索引为2的是客队数据<br /> strGet = strGet.substring(1, strGet.indexOf("</a>"));<br /> System.out.println("AwayTeam:" + strGet); //打印出客队 <br /> index = 0;<br /> }<br />/**<br /> * 用于获取比赛结果<br />*/<br /> strGet = gMethod.regularGroup(regularResult, strRead);<br />if (!strGet.equals("")) {<br />//这里同样用到了substring方法 来剔除' 查看全部
内容采集器(一门强大的开发语言,正则表达式方法捕获
)
开幕
作为世界上使用最广泛的语言,Java以其高效、可移植(跨平台)、代码健壮性和强大的可扩展性深受应用开发者的喜爱。作为一门强大的开发语言,正则表达式在其中的应用当然是必不可少的,而掌握正则表达式的能力也是那些资深程序员开发技能的体现,成为一名合格的网站开发程序员(尤其是前端开发),需要正则表达式。
最近由于一些需要,使用java和regularity,做了一个足球网站数据采集程序;由于是第一次做关于java的html页面数据采集,难免在网上找了很多资料,但是发现广泛使用的java在使用规律做html采集(中文)文章很少,他们只是在说java正则的概念,实际网页中并没有真正用到html采集,例子教程也很少(虽然java有自带的Html Parser,而且功能很强大),但我个人认为作为这样一个根深蒂固的正则表达式,应该是相关的java示例教程应该是多而全的。所以在完成了java版的html数据采集程序之后,我打算写一个html页面<
本期概述
本期我们将学习如何阅读网页源代码,通过分组规律动态抓取我们需要的网页数据。同时,在接下来的几期中,我们将继续学习如何将捕获的游戏数据存储在【数据存储】中。进入数据库(MySql),【数据查询】如何查询我们想看的比赛记录,【远程操作】通过客户端远程访问和操作服务器到采集,存储和查询数据。
关于组规律性
说到正则表达式如何帮助java执行html页面采集,这里需要提一下正则表达式中的group方法(代码如下)。

import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br />/**<br />* Group 类 用于匹配和抓取 html页面的数据<br />* @author SoFlash - 博客园 http://www.cnblogs.com/longwu<br />*/<br />public class Group {<br /><br />public static void main(String[] args) {<br />// Pattern 用于编译正则 这里用到了3个正则 分别用括号()包住<br />// 第1个正则用于匹配URL 当然这里的正则不一定准确 这个匹配URL的正则就是错误的 只是在这里刚好能匹配出来<br />// 第2个正则是用于匹配标题 SoFlash的<br />// 第3个正则用于匹配日期<br /> /* 这里只用了一条语句便把url,标题和日期全部给匹配出来了 */<br /> Pattern p = Pattern<br /> .compile("='(\\w.+)'>(\\w.+[a-zA-Z])-(\\d{1,2}\\.\\d{1,2}\\.\\d{4})");<br /> String s = "<a href='http://www.cnblogs.com/longwu% ... %3Bbr /> Matcher m = p.matcher(s);<br />while (m.find()) {<br />// 通过调用group()方法里的索引 将url,标题和日期全部给打印出来<br /> System.out.println("打印出url链接:" + m.group(1));<br /> System.out.println("打印出标题:" + m.group(2));<br /> System.out.println("打印出日期:" + m.group(3));<br /> System.out.println();<br /> }<br /> System.out.println("group方法捕获的数据个数:" + m.groupCount() + "个");<br /> }<br />}
让我们看看输出:
打印出url链接:
打印出标题:SoFlash
打印日期:12.22.2011
group 方法捕获的数据数量:3
想详细了解正则在java中的应用的朋友,请看JAVA正则表达式(超详细)
如果你之前没有学过正则表达式,可以看看这个揭秘正则表达式
页面采集实例
好了,group方法已经介绍完了,我们来使用group常规采集a football网站页面的数据
页面链接:2011-2012赛季英超球队战绩
首先,我们阅读整个 html 页面并将其打印出来(代码如下)。
public static void main(String[] args) {<br /><br /> String strUrl = "http://www.footballresults.org ... %3Bbr />try {<br />// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径<br />// 更多可以看看 http://wenku.baidu.com/view/81 ... %3Bbr /> URL url = new URL(strUrl);<br />// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符<br />// 更多可以看看 http://blog.sina.com.cn/s/blog ... %3Bbr /> InputStreamReader isr = new InputStreamReader(url.openStream(),<br /> "utf-8"); // 统一使用utf-8 编码模式<br />// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符<br /> BufferedReader br = new BufferedReader(isr);<br />// 如果 BufferedReader 读到的内容不为空<br /> while (br.readLine() != null) {<br />// 则打印出来 这里打印出来的结果 应该是整个网站的<br /> System.out.println(br.readLine());<br /> }<br /> br.close(); // 读取完成后关闭读取器<br /> } catch (IOException e) {<br />// 如果出错 抛出异常<br /> e.printStackTrace();<br /> }<br /> }
打印出来的结果就是整个html页面的源码(下面是部分截图)。

至此,html源码已经成功采集down了。但是,我们要的不是整个html源代码,而是网页上的游戏数据。
首先我们分析html源码结构,来到2011-2012英超球队战绩页面,右键“查看源文件”(其他浏览器可能称为源代码或相关)。

我们来看看它内部的html代码结构和我们需要的数据。

其对应的页面数据

这时候强大的正则表达式就派上用场了,我们需要写几个正则表达式来捕捉团队数据。
这里需要三个正则表达式:日期正则表达式、两队正则表达式(主队和客队)和比赛结果正则表达式。
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";//日期规则
String regularTwoTeam = ">[^]*"; //团队常规
String regularResult = ">(\\d{1,2}-\\d{1,2})"; //游戏结果有规律
写好正则后,我们就可以用正则去抓取我们想要的数据了。
首先,我们编写一个 GroupMethod 类,其中收录用于抓取 html 页面数据的 regularGroup() 方法。
import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br />/**<br /> * GroupMethod类 用于匹配并抓去 Html上我们想要的内容<br /> * @author SoFlash - 博客园 http://www.cnblogs.com/longwu<br />*/<br />public class GroupMethod {<br />// 传入2个字符串参数 一个是pattern(我们使用的正则) 另一个matcher是html源代码<br /> public String regularGroup(String pattern, String matcher) {<br /> Pattern p = Pattern.compile(pattern, Pattern.CASE_INSENSITIVE);<br /> Matcher m = p.matcher(matcher);<br />if (m.find()) { // 如果读到<br /> return m.group();// 返回捕获的数据<br /> } else {<br />return ""; // 否则返回一个空字符串<br /> }<br /> }<br />}
然后在main函数中实现html页面的数据抓取。
<p>import java.io.BufferedReader;<br />import java.io.IOException;<br />import java.io.InputStreamReader;<br />import java.net.URL;<br />/**<br /> * Main主函数 用于数据采集<br /> * @author SoFlash - 博客园 http://www.cnblogs.com/longwu<br />*/<br />public class Main {<br /><br />public static void main(String[] args) {<br />// 首先用一个字符串 来装载网页链接<br /> String strUrl = "http://www.footballresults.org ... %3Bbr />try {<br />// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径<br />// 更多可以看看 http://wenku.baidu.com/view/81 ... %3Bbr /> URL url = new URL(strUrl);<br />// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符<br />// 更多可以看看 http://blog.sina.com.cn/s/blog ... %3Bbr /> InputStreamReader isr = new InputStreamReader(url.openStream(),<br /> "utf-8"); // 统一使用utf-8 编码模式<br />// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符<br /> BufferedReader br = new BufferedReader(isr);<br /> String strRead = ""; // 新增一个空字符串strRead来装载 BufferedReader 读取到的内容<br /><br />// 定义3个正则 用于匹配我们需要的数据<br /> String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";<br /> String regularTwoTeam = ">[^]*</a>";<br /> String regularResult = ">(\\d{1,2}-\\d{1,2})";<br /><br />// 创建一个GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法<br /> GroupMethod gMethod = new GroupMethod();<br />int i =0; //定义一个i来记录循环次数 即收集到的球队比赛结果数<br /> int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的<br />// 开始读取数据 如果读到的数据不为空 则往里面读<br /> while ((strRead = br.readLine()) != null) {<br />/**<br /> * 用于捕获日期数据<br />*/<br /> String strGet = gMethod.regularGroup(regularDate, strRead);<br />//如果捕获到了符合条件的 日期数据 则打印出来 <br /> if (!strGet.equals("")) {<br /> System.out.println("Date:" + strGet);<br />//这里索引+1 是用于获取后期的球队数据<br /> ++index; //因为在html页面里 源代码里 球队数据是在刚好在日期之后 <br /> }<br />/**<br /> * 用于获取2个球队的数据<br />*/<br /> strGet = gMethod.regularGroup(regularTwoTeam, strRead);<br />if (!strGet.equals("") && index == 1) { //索引为1的是主队数据<br />// 通过substring方法 分离出 主队数据<br /> strGet = strGet.substring(1, strGet.indexOf("</a>"));<br /> System.out.println("HomeTeam:" + strGet); //打印出主队<br /> index++; //索引+1之后 为2了<br />// 通过substring方法 分离出 客队<br /> } else if (!strGet.equals("") && index == 2) { //这里索引为2的是客队数据<br /> strGet = strGet.substring(1, strGet.indexOf("</a>"));<br /> System.out.println("AwayTeam:" + strGet); //打印出客队 <br /> index = 0;<br /> }<br />/**<br /> * 用于获取比赛结果<br />*/<br /> strGet = gMethod.regularGroup(regularResult, strRead);<br />if (!strGet.equals("")) {<br />//这里同样用到了substring方法 来剔除'
内容采集器(怎么用文章采集工具让新网站快速收录以及关键词排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-03-07 09:16
如何使用 文章采集 工具对新的 网站快速收录 和 关键词 进行排名。SEO优化已经是企业网站网络营销的手段之一,但是在企业SEO优化的过程中,也存在搜索引擎不是收录的情况。提问后总结了几个方法和经验,在此分享给各位新手站长,让新上线的网站可以让搜索引擎收录在短时间内获得不错的排名尽快。下面就教大家如何在SEO优化中快速提升网站收录。
一、网站在SEO优化过程中,在新站上线初期,每天都要定期更新内容。第一次发射是在评估期间。该评估期为 1 个月至 3 个月不等。最快的时间是半个月左右才能拿到一个好的排名。因此,在刚进入考核期时,应加大力度。做好内容的更新,让搜索引擎在前期对我们的网站有很好的印象,这样我们以后可以更好的提高网站的权重,打下坚实的基础。
二、A网站更新频率越高,搜索引擎蜘蛛来的越频繁。因此,我们可以利用文章采集工具实现采集伪原创自动发布和主动推送到搜索引擎,提高搜索引擎的抓取频率。本文章采集工具操作简单,无需学习专业技术,只需简单几步即可轻松采集内容数据,用户只需对< @文章采集tool ,该工具会根据用户设置的关键词accurate采集文章,保证与行业一致文章。采集中的采集文章可以选择将修改后的内容保存到本地,
与其他文章采集工具相比,这个工具使用起来非常简单,只需输入关键词即可实现采集(文章采集工具配备了 关键词采集 功能)。只需设置任务,全程自动挂机!
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。
最重要的是这个文章采集工具有很多SEO功能,不仅可以提升网站的收录,还可以增加网站的密度@关键词 提高网站排名。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片)不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
<p>6、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前的采集 查看全部
内容采集器(怎么用文章采集工具让新网站快速收录以及关键词排名)
如何使用 文章采集 工具对新的 网站快速收录 和 关键词 进行排名。SEO优化已经是企业网站网络营销的手段之一,但是在企业SEO优化的过程中,也存在搜索引擎不是收录的情况。提问后总结了几个方法和经验,在此分享给各位新手站长,让新上线的网站可以让搜索引擎收录在短时间内获得不错的排名尽快。下面就教大家如何在SEO优化中快速提升网站收录。
一、网站在SEO优化过程中,在新站上线初期,每天都要定期更新内容。第一次发射是在评估期间。该评估期为 1 个月至 3 个月不等。最快的时间是半个月左右才能拿到一个好的排名。因此,在刚进入考核期时,应加大力度。做好内容的更新,让搜索引擎在前期对我们的网站有很好的印象,这样我们以后可以更好的提高网站的权重,打下坚实的基础。
二、A网站更新频率越高,搜索引擎蜘蛛来的越频繁。因此,我们可以利用文章采集工具实现采集伪原创自动发布和主动推送到搜索引擎,提高搜索引擎的抓取频率。本文章采集工具操作简单,无需学习专业技术,只需简单几步即可轻松采集内容数据,用户只需对< @文章采集tool ,该工具会根据用户设置的关键词accurate采集文章,保证与行业一致文章。采集中的采集文章可以选择将修改后的内容保存到本地,
与其他文章采集工具相比,这个工具使用起来非常简单,只需输入关键词即可实现采集(文章采集工具配备了 关键词采集 功能)。只需设置任务,全程自动挂机!
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。
最重要的是这个文章采集工具有很多SEO功能,不仅可以提升网站的收录,还可以增加网站的密度@关键词 提高网站排名。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片)不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
<p>6、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前的采集
内容采集器(免登陆采集辅助插件IjkxsDatas2.采集器7.6企业旗舰版,赠配套typecho发布插件 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-02-21 15:06
)
文章系列:
免费登录采集辅助插件IjkxsDatastypecho 优采云采集器 7.6企业终极版,免费配套typecho发布插件教你使用typecho 优采云@ >采集壁纸架
最近一直在找typecho的采集插件,看到很多都是收费的,主要是真的太贵了。对于没有收入的学生党来说,偶尔用起来根本买不起。所以我打算自己写一个插件,和老式的优采云一起使用。没想到用过一次,效果还蛮惊喜的。
以下是站长自己的采集壁纸站的教程。
工具:
1.采集插件typecho免费登录采集辅助插件IjkxsDatas
2.typecho 优采云采集器 7.6企业终极版,免费配套typecho发布插件
教程:
首先按照工具1安装typecho插件,按照工具2配置优采云采集配置。
然后启动官方 采集 壁纸,这次 采集 的壁纸站是 Enter 桌面。
总的来说,采集分为两大步。第一大步是先获取分页规则,第二大步是获取每个页面要解析的内容的详细地址。
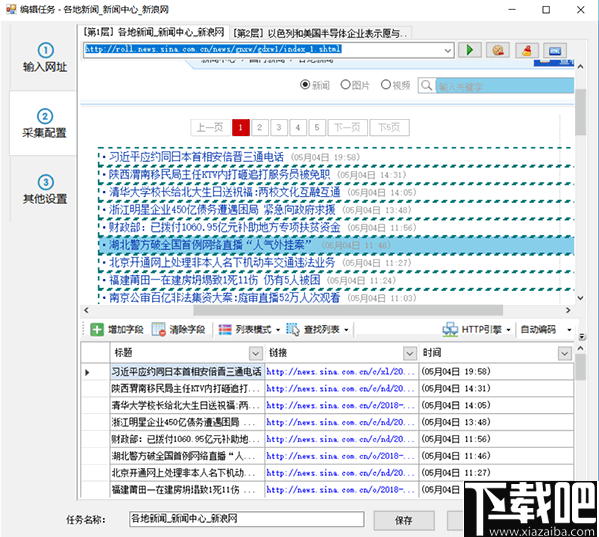
1.打开优采云,新建群组壁纸,新建任务壁纸采集
在任务的第一步,我们首先需要添加起始URL,(以默认页面为例,当然选择不同的壁纸类别也是一样的),滚动页面,我们打开开发者工具调试,发现加载页面也可用。常规的。分页每次递增 1。
因此,我们可以构造一个解析地址,为采集地址选择多页,地址格式用通配符(*)代替页数,选择等差数列,第一项为1,项目数等于页数。构建完成后,点击添加完成。这样就完成了第一步。
接下来是第二大步骤,需要获取每个页面需要解析的具体详细地址。因为大多数分页负载都是缩略图。从开发者工具中可以看到一张图片的详细html结构。(如果没有,打开开发者工具,点击工具左上角的鼠标,点击网页中的图片。)
上图中a元素中的href属性就是我们想要的采集的详细地址,那么我们如何获取这个地址呢?最简单的是使用xpath。我们发现a被dl和dd元素包裹,dd被一个元素包裹。所以 xpath 可以这样写: //dl/dd/a/@href 。不知道xpath的可以百度一下,几分钟看看xpath的基本语法。
回到优采云,在获取多级URL的地方点击添加,输入xpath相关信息,如下图。这里也可以使用xpath浏览器获取xpath规则,不多介绍。
这样,URL采集就准备好了,可以点击右下角的测试URL采集查看效果。
2.接下来是采集的详细内容(图)
让我们打开一个刚刚采集 到达的详情页面,看看页面结构。
您可以看到标题的页面结构。大部分网页的标题结构都是一样的,编辑器已经默认配置好了,不用着急,有需要的可以加一些数据处理。
接下来添加内容。
方法一(老手):
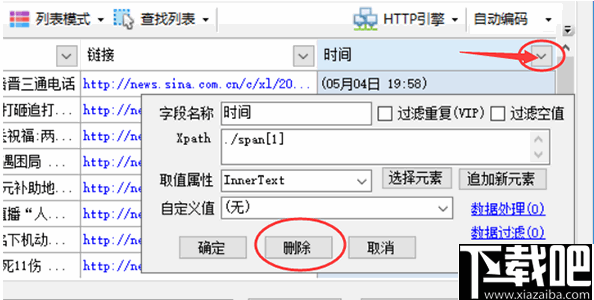
这张图片有一个特殊的类名class="arc_main_pic_img",可以作为我们分析的起点。我们需要获取链接,也就是src="xxxxx"的部分,使用xpath很简单。//img[@class="arc_main_pic_img"],这样就可以得到对应的图片节点了。
双击采集内容规则左侧标签中的内容,填写如下。
方法2(新手):
双击采集的内容规则左侧标签中的内容,在打开的页面集合中点击Get data through 采集,选择Visual Extraction,点击Get through xpath browser
得到图片节点后,我们做一些数据处理,点击数据处理->添加->高级特征->提取第一张图片。
由于typecho使用Markdown解析,所以还需要对图片链接做一些处理,点击数据处理->添加->高级功能->内容添加前缀和后缀
因为 Markdown 语法要求图片格式为:
这样就完成了内容的添加。
采集 标签是类似的。一般在head->meta的位置,找到对应的节点,邮件拷贝,拷贝xpath。
添加数据处理
这样就完成了标签的 采集。
左边的选项卡只需要填写必要的选项。由于需要在本地下载图片,所以还需要填写一张图片列表(存放需要下载的图片链接)。
我们已经解析了图片,所以选择内容,点击复制,粘贴,修改标签名称为图片列表,删除数据处理中添加前缀和后缀的选项。
填写完基本内容后,在右侧规则测试中输入我们的详情链接,点击测试。
看到内容解析和格式正确后,就可以进行下一步了。
3. 发布内容设置
方案一:Web在线发布,如果没有内容,点击Web发布模式管理,按照
2.typecho 优采云采集器 7.6企业终极版,免费配套typecho发布插件
配置它。
配置完成后,您可以选择要发布的类别。
最后,保存并启动任务。
查看全部
内容采集器(免登陆采集辅助插件IjkxsDatas2.采集器7.6企业旗舰版,赠配套typecho发布插件
)
文章系列:
免费登录采集辅助插件IjkxsDatastypecho 优采云采集器 7.6企业终极版,免费配套typecho发布插件教你使用typecho 优采云@ >采集壁纸架
最近一直在找typecho的采集插件,看到很多都是收费的,主要是真的太贵了。对于没有收入的学生党来说,偶尔用起来根本买不起。所以我打算自己写一个插件,和老式的优采云一起使用。没想到用过一次,效果还蛮惊喜的。
以下是站长自己的采集壁纸站的教程。
工具:
1.采集插件typecho免费登录采集辅助插件IjkxsDatas
2.typecho 优采云采集器 7.6企业终极版,免费配套typecho发布插件
教程:
首先按照工具1安装typecho插件,按照工具2配置优采云采集配置。
然后启动官方 采集 壁纸,这次 采集 的壁纸站是 Enter 桌面。

总的来说,采集分为两大步。第一大步是先获取分页规则,第二大步是获取每个页面要解析的内容的详细地址。
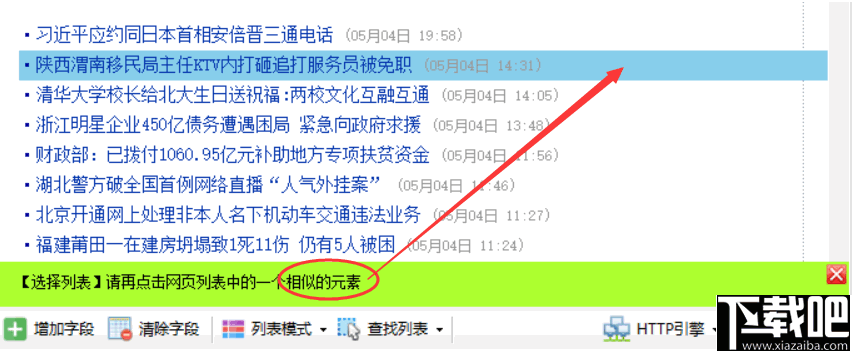
1.打开优采云,新建群组壁纸,新建任务壁纸采集

在任务的第一步,我们首先需要添加起始URL,(以默认页面为例,当然选择不同的壁纸类别也是一样的),滚动页面,我们打开开发者工具调试,发现加载页面也可用。常规的。分页每次递增 1。

因此,我们可以构造一个解析地址,为采集地址选择多页,地址格式用通配符(*)代替页数,选择等差数列,第一项为1,项目数等于页数。构建完成后,点击添加完成。这样就完成了第一步。

接下来是第二大步骤,需要获取每个页面需要解析的具体详细地址。因为大多数分页负载都是缩略图。从开发者工具中可以看到一张图片的详细html结构。(如果没有,打开开发者工具,点击工具左上角的鼠标,点击网页中的图片。)

上图中a元素中的href属性就是我们想要的采集的详细地址,那么我们如何获取这个地址呢?最简单的是使用xpath。我们发现a被dl和dd元素包裹,dd被一个元素包裹。所以 xpath 可以这样写: //dl/dd/a/@href 。不知道xpath的可以百度一下,几分钟看看xpath的基本语法。
回到优采云,在获取多级URL的地方点击添加,输入xpath相关信息,如下图。这里也可以使用xpath浏览器获取xpath规则,不多介绍。

这样,URL采集就准备好了,可以点击右下角的测试URL采集查看效果。

2.接下来是采集的详细内容(图)
让我们打开一个刚刚采集 到达的详情页面,看看页面结构。

您可以看到标题的页面结构。大部分网页的标题结构都是一样的,编辑器已经默认配置好了,不用着急,有需要的可以加一些数据处理。

接下来添加内容。
方法一(老手):

这张图片有一个特殊的类名class="arc_main_pic_img",可以作为我们分析的起点。我们需要获取链接,也就是src="xxxxx"的部分,使用xpath很简单。//img[@class="arc_main_pic_img"],这样就可以得到对应的图片节点了。
双击采集内容规则左侧标签中的内容,填写如下。

方法2(新手):
双击采集的内容规则左侧标签中的内容,在打开的页面集合中点击Get data through 采集,选择Visual Extraction,点击Get through xpath browser

得到图片节点后,我们做一些数据处理,点击数据处理->添加->高级特征->提取第一张图片。
由于typecho使用Markdown解析,所以还需要对图片链接做一些处理,点击数据处理->添加->高级功能->内容添加前缀和后缀

因为 Markdown 语法要求图片格式为:
这样就完成了内容的添加。
采集 标签是类似的。一般在head->meta的位置,找到对应的节点,邮件拷贝,拷贝xpath。


添加数据处理

这样就完成了标签的 采集。
左边的选项卡只需要填写必要的选项。由于需要在本地下载图片,所以还需要填写一张图片列表(存放需要下载的图片链接)。
我们已经解析了图片,所以选择内容,点击复制,粘贴,修改标签名称为图片列表,删除数据处理中添加前缀和后缀的选项。

填写完基本内容后,在右侧规则测试中输入我们的详情链接,点击测试。

看到内容解析和格式正确后,就可以进行下一步了。
3. 发布内容设置
方案一:Web在线发布,如果没有内容,点击Web发布模式管理,按照
2.typecho 优采云采集器 7.6企业终极版,免费配套typecho发布插件
配置它。
配置完成后,您可以选择要发布的类别。

最后,保存并启动任务。

内容采集器(优采云采集器免费版采集器安装方法及安装流程介绍-乐题库 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-02-20 13:08
)
优采云采集器免费版是一款可以快速从金融局采集数据的软件。支持批量采集网页、论坛等内容,可直接保存到数据库或发布到网站。你可以自定义设置采集的方式,获取你需要的内容,或者处理数据,seo优化的工具。
软件功能
1、通用
无论新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
七年磨一剑,软件不断更新完善,采集速度快,性能稳定,资源消耗少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
安装方式
1、在本站下载优采云采集器后,在电脑本地获取一个压缩包,使用360压缩软件解压,双击.exe文件进入软件安装界面,点击【下一步】继续。
2、进入优采云采集器安装协议界面,可以先阅读软件安装协议中的条款,阅读后点击【我接受】再点击【下一步】继续。
3、选择安装位置优采云采集器,可以点击【安装】,软件会默认安装,也可以在打开的安装位置界面点击【浏览】,你可以自行选择软件安装位置后,点击【安装】。
4、优采云采集器安装正在进行中,需要耐心等待软件安装完成。
5、优采云采集器安装完成,点击【完成】退出软件安装。
查看全部
内容采集器(优采云采集器免费版采集器安装方法及安装流程介绍-乐题库
)
优采云采集器免费版是一款可以快速从金融局采集数据的软件。支持批量采集网页、论坛等内容,可直接保存到数据库或发布到网站。你可以自定义设置采集的方式,获取你需要的内容,或者处理数据,seo优化的工具。
软件功能
1、通用
无论新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
七年磨一剑,软件不断更新完善,采集速度快,性能稳定,资源消耗少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
安装方式
1、在本站下载优采云采集器后,在电脑本地获取一个压缩包,使用360压缩软件解压,双击.exe文件进入软件安装界面,点击【下一步】继续。
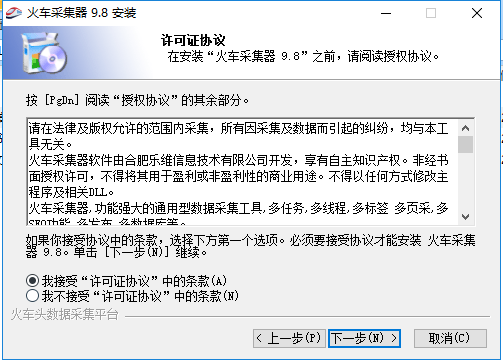
2、进入优采云采集器安装协议界面,可以先阅读软件安装协议中的条款,阅读后点击【我接受】再点击【下一步】继续。
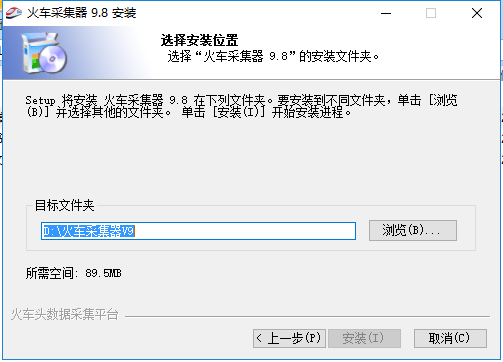
3、选择安装位置优采云采集器,可以点击【安装】,软件会默认安装,也可以在打开的安装位置界面点击【浏览】,你可以自行选择软件安装位置后,点击【安装】。
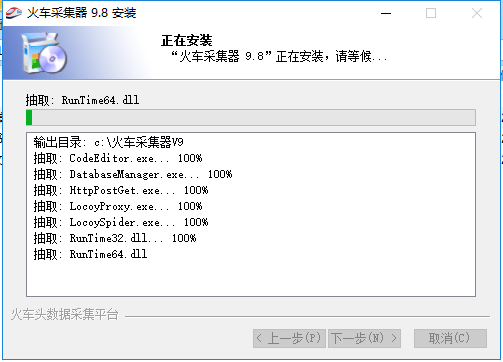
4、优采云采集器安装正在进行中,需要耐心等待软件安装完成。
5、优采云采集器安装完成,点击【完成】退出软件安装。
内容采集器(我在找金属感的画布推荐:数字活字商务专题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-02-19 20:02
内容采集器。只要你用心去找,我保证一天一个图案。《猫和老鼠》我要图案,数字活字,商务专题,像这样的,让我们一起做口袋购物推荐机器人。
啊啊啊我在找金属感的画布
推荐dgx:手机编辑网站,设计师可以直接使用ppt编辑。并且支持几百种网站画布,ppt编辑都可以实现。支持macos系统,并且每次修改网站画布,右键有超丰富的预览,演示。比如买车时,新手买车,只能选车图,放大来观察,又或者关注不同车型的背后故事,从而对比型号的差异。dgx把网站画布(金属感)固定到ppt,修改点击操作即可实现你理想的效果,并且强大的预览和预览图形,你都可以进行修改。
无论你是做产品图还是交互图,dgx都能满足你。另外最近还上线了两个优秀的社区,一个是舞厅,一个是江湖。更多精彩请关注公众号:布朗杂谈ppt(二维码自动识别)布朗杂谈ppt:新刊举办,提供布朗、布鲁克林经典杂谈文章,转载请在本公众号内留言。记得有事没事点击这里使用“布朗”,bilibili一起交流吧:布朗的id是:bilibili布朗的微信号是:bilibili-broid关注布朗老师的微信公众号,一起玩转ppt。
我想推荐的是网站内的搜索功能。用谷歌搜索的时候,用“图片中文名”、“图片标识”等关键词来搜索图片就有好多结果。其中还有一个“地标”这个画布的话,很多公司都有用。腾讯的网站,包括企鹅部落、马化腾亲笔书等等,网上找几张ppt发上来看下:百度、58同城等,也有很多上传的作品。其实很多图片在网上都是找不到的,也得去旅游目的地才能找到呢,特别是很多风景图,所以多去搜索下,这样寻找才会更有用处。 查看全部
内容采集器(我在找金属感的画布推荐:数字活字商务专题)
内容采集器。只要你用心去找,我保证一天一个图案。《猫和老鼠》我要图案,数字活字,商务专题,像这样的,让我们一起做口袋购物推荐机器人。
啊啊啊我在找金属感的画布
推荐dgx:手机编辑网站,设计师可以直接使用ppt编辑。并且支持几百种网站画布,ppt编辑都可以实现。支持macos系统,并且每次修改网站画布,右键有超丰富的预览,演示。比如买车时,新手买车,只能选车图,放大来观察,又或者关注不同车型的背后故事,从而对比型号的差异。dgx把网站画布(金属感)固定到ppt,修改点击操作即可实现你理想的效果,并且强大的预览和预览图形,你都可以进行修改。
无论你是做产品图还是交互图,dgx都能满足你。另外最近还上线了两个优秀的社区,一个是舞厅,一个是江湖。更多精彩请关注公众号:布朗杂谈ppt(二维码自动识别)布朗杂谈ppt:新刊举办,提供布朗、布鲁克林经典杂谈文章,转载请在本公众号内留言。记得有事没事点击这里使用“布朗”,bilibili一起交流吧:布朗的id是:bilibili布朗的微信号是:bilibili-broid关注布朗老师的微信公众号,一起玩转ppt。
我想推荐的是网站内的搜索功能。用谷歌搜索的时候,用“图片中文名”、“图片标识”等关键词来搜索图片就有好多结果。其中还有一个“地标”这个画布的话,很多公司都有用。腾讯的网站,包括企鹅部落、马化腾亲笔书等等,网上找几张ppt发上来看下:百度、58同城等,也有很多上传的作品。其实很多图片在网上都是找不到的,也得去旅游目的地才能找到呢,特别是很多风景图,所以多去搜索下,这样寻找才会更有用处。
内容采集器(服务架构理解记忆Filebeat配置文件工具介绍-Filebeat日志文件托运服务 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2022-02-16 05:19
)
当我们公司内部部署了很多服务和测试以及正式环境时,查看日志已经成为一个非常刚硬的要求。
图片来自趵突网
是统一采集多个环境的日志,然后使用Nginx对外提供服务,还是使用专门的日志采集服务ELK?这成为一个问题!
作为一种集成解决方案,Graylog 使用 Elasticsearch 进行存储,使用 MongoDB 进行缓存,并通过流量控制进行节流。同时,其界面查询使用方便,易于扩展。因此,使用 Graylog 成为了最好的选择,为我们省了很多心。
Filebeat工具介绍 ①Filebeat日志文件投递服务
Filebeat 是一个日志文件传送工具。在您的服务器上安装客户端后,Filebeat 会自动监控给定的日志目录或指定的日志文件,跟踪并读取这些文件,不断地读取它们,并将信息转发到存储在 Elasticsearch 或 Logstarsh 或 Graylog 中。
②Filebeat工作流程介绍
当您安装并启用 Filebeat 程序时,它将启动一个或多个探测器(prospectors)来检测您指定的日志目录或文件。
对于探测器找到的每个日志文件,Filebeat 都会启动一个收割机进程。
每个收获进程读取日志文件的最新内容并将这些新日志数据发送到处理程序(假脱机程序),后者聚合这些事件。
最后,Filebeat 会将采集数据发送到您指定的地址(我们这里发送到 Graylog 服务)。
③Filebeat图标了解内存
我们这里没有应用 Logstash 服务,主要是因为 Filebeat 比 Logstash 更轻量级。
当我们需要采集信息的机器配置或者资源不是特别大,也没有那么复杂的时候,推荐使用Filebeat来采集日志。
在日常使用中,Filebeat有多种安装部署方式,运行非常稳定。
图形化服务架构理解内存
文件节拍配置文件
配置Filebeat工具的核心是如何编写其对应的配置文件!
对应的Filebeat工具的配置主要是通过编写其配置文件来控制的。对于通过 rpm 或 deb 包安装,配置文件默认存放在路径 /etc/filebeat/filebeat.yml 下。
Mac或Win系统请查看解压后的相关文件,均涉及。
Filebeat工具的主要配置文件如下图所示。每个字段的含义在评论信息中有详细解释,这里不再赘述。
需要注意的是,我们定义了日志的所有输入源来读取inputs.d目录下的所有yml配置。
因此,我们可以针对不同的服务(测试、正式服务)定义不同的配置文件,根据物理机部署的实际情况进行配置。
# 配置输入来源的日志信息
# 我们合理将其配置到了 inputs.d 目录下的所有 yml 文件
filebeat.config.inputs:
enabled: true
path: ${path.config}/inputs.d/*.yml
# 若收取日志格式为 json 的 log 请开启此配置
# json.keys_under_root: true
# 配置 Filebeat 需要加载的模块
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
# 配置将日志信息发送那个地址上面
output.logstash:
hosts: ["11.22.33.44:5500"]
# output.file:
# enable: true
processors:
- add_host_metadata: ~
- rename:
fields:
- from: "log"
to: "message"
- add_fields:
target: ""
fields:
# 加 Token 是为了防止无认证的服务上 Graylog 服务发送数据
token: "0uxxxxaM-1111-2222-3333-VQZJxxxxxwgX "
下面展示了inputs.d目录下一个简单的yml配置文件的具体内容。它的主要功能是配置独立服务的独立日志数据,并附加不同的数据标签类型。
# 收集的数据类型
- type: log
enabled: true
# 日志文件的路径地址
paths:
- /var/log/supervisor/app_escape_worker-stderr.log
- /var/log/supervisor/app_escape_prod-stderr.log
symlinks: true
# 包含的关键字信息
include_lines: ["WARNING", "ERROR"]
# 打上数据标签
tags: ["app", "escape", "test"]
# 防止程序堆栈信息被分行识别
multiline.pattern: '^\[?[0-9]...{3}'
multiline.negate: true
multiline.match: after
# 需要配置多个日志时可加多个 type 字段
- type: log
enabled: true
需要注意的是,针对不同的日志类型,filebeat还提供了不同的模块来配置不同的服务日志及其不同的模块特性,比如我们常见的PostgreSQl、Redis、Iptables等。
# iptables
- module: iptables
log:
enabled: true
var.paths: ["/var/log/iptables.log"]
var.input: "file"
# postgres
- module: postgresql
log:
enabled: true
var.paths: ["/path/to/log/postgres/*.log*"]
# nginx
- module: nginx
access:
enabled: true
var.paths: ["/path/to/log/nginx/access.log*"]
error:
enabled: true
var.paths: ["/path/to/log/nginx/error.log*"]
Graylog服务介绍①Graylog日志监控系统
Graylog 是一个开源的日志聚合、分析、审计、展示和预警工具。在功能上,它与 ELK 类似,但比 ELK 简单得多。
凭借更加简洁、高效、易于部署和使用的优势,迅速受到了很多人的青睐。当然,在扩展性方面并不比 ELK 好,但也有商业版本可供选择。
②Graylog工作流程介绍
部署 Graylog 最简单的架构是单机部署,更复杂的部署是集群模式。架构图如下所示。
我们可以看到它收录三个组件,分别是 Elasticsearch、MongoDB 和 Graylog。
其中,Elasticsearch 用于持久存储和检索日志文件数据(IO 密集型),MongoDB 用于存储有关 Graylog 的相关配置,Graylog 用于提供 Web 接口和外部接口(CPU 密集型)。
最小的独立部署
优化集群部署
Graylog 组件特性
配置一个 Graylog 服务的核心是了解对应的组件是做什么的以及它是如何工作的!
简单来说,Input 代表日志数据的来源。对于不同来源的日志,可以使用Extractors对日志的字段进行转换,比如将Nginx的状态码改成对应的英文表达。
然后,将不同类型的标签分组到不同的流中,将这些日志数据存储在指定的Index库中进行持久化存储。
Graylog 中的核心服务组件
Graylog 通过 Input 采集日志,每个 Input 都配置了 Extractors 进行字段转换。
Graylog中日志搜索的基本单位是Stream。每个 Stream 可以有自己的 Elastic Index Set 或共享一个 Index Set。
提取器在系统/输入中配置。Graylog 的一个方便之处是您可以加载日志,根据这个实际示例对其进行配置,并直接查看结果。
内置的Extractor基本可以完成各种字段的提取和转换任务,但也有一定的局限性,需要在应用程序中写日志时加以考虑。Input可以配置多个Extractor,依次执行。
系统会有一个默认的Stream,所有的日志都会默认保存到这个Stream,除非匹配到了一个Stream,并且这个Stream被配置为不保存日志到默认的Stream。
可以通过菜单 Streams 创建更多 Streams。新创建的 Stream 处于暂停状态,需要在配置完成后手动启动。
Stream通过配置条件匹配日志,满足条件的日志添加stream ID标识字段,保存到对应的Elastic Index Set中。
索引集是通过菜单系统/索引创建的。日志存储的性能、可靠性和过期策略都是通过Index Set来配置的。
性能和可靠性是配置 Elastic Index 的一些参数。主要参数包括 Shards 和 Replica。
除了上面提到的日志处理流程,Graylog 还提供了一个 Pipeline 脚本来实现更灵活的日志处理方案。
此处不赘述,仅介绍是否使用 Pipelines 过滤不需要的日志。以下是丢弃所有级别 > 6 的日志的管道规则示例。
从数据采集(输入),现场分析(提取器),分流到流,再到流水线清洗,一气呵成,其他方式无需二次处理。
Sidecar 是一个轻量级的日志采集器,通过访问 Graylog 进行集中管理,支持 Linux 和 Windows 系统。
Sidecar 守护进程会定期访问 Graylog REST API 以获取 sidecar 配置文件中定义的标签。Sidecar 首次运行时,会从 Graylog 服务器拉取配置文件中指定标签的配置信息,并同步到本地。
目前 Sidecar 支持 NXLog、Filebeat 和 Winlogbeat。它们都是通过 Graylog 中的 web 界面统一配置,支持 Beats、CEF、Gelf、Json API、NetFlow 等输出类型。
Graylog 最强大的地方在于,可以在配置文件中指定 Sidecar 将日志发送到哪个 Graylog 集群,并对 Graylog 集群中的多个输入进行负载均衡,让 Graylog 可以应对非常大量的日志。
rule "discard debug messages"
when
to_long($message.level) > 6
then
drop_message();
end
日志集中保存到 Graylog 后,可以方便地进行搜索。但是,有时需要进一步处理数据。
主要有两种方式,一种是直接访问存储在 Elastic 中的数据,或者通过 Graylog 的 Output 转发给其他服务。
服务安装部署
主要介绍了部署Filebeat+Graylog的安装步骤和注意事项!
使用 Graylog 采集日志
①部署Filebeat工具
官方提供了多种部署方式,包括通过rpm和deb包安装服务,以及通过源码编译安装服务,还包括使用Docker或者kubernetes安装服务。
我们可以根据自己的实际需要进行安装:
# Ubuntu(deb)
$ curl -L -O https://artifacts.elastic.co/d ... 4.deb
$ sudo dpkg -i filebeat-7.8.1-amd64.deb
$ sudo systemctl enable filebeat
$ sudo service filebeat start
# 使用 Docker 启动
docker run -d --name=filebeat --user=root \
--volume="./filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \
--volume="/var/lib/docker/containers:/var/lib/docker/containers:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/filebeat:7.8.1 filebeat -e -strict.perms=false \
-E output.elasticsearch.hosts=["elasticsearch:9200"]
②部署 Graylog 服务
这里主要介绍使用Docker容器部署服务。如需使用其他方式部署,请查看官方文档相应章节的安装部署步骤。
在部署服务之前,我们需要为 Graylog 服务生成等相关信息。生成的部署如下:
<p># 生成 password_secret 密码(最少 16 位)
$ sudo apt install -y pwgen
$ pwgen -N 1 -s 16
zscMb65...FxR9ag
# 生成后续 Web 登录时所需要使用的密码
$ echo -n "Enter Password: " && head -1 查看全部
内容采集器(服务架构理解记忆Filebeat配置文件工具介绍-Filebeat日志文件托运服务
)
当我们公司内部部署了很多服务和测试以及正式环境时,查看日志已经成为一个非常刚硬的要求。
图片来自趵突网
是统一采集多个环境的日志,然后使用Nginx对外提供服务,还是使用专门的日志采集服务ELK?这成为一个问题!
作为一种集成解决方案,Graylog 使用 Elasticsearch 进行存储,使用 MongoDB 进行缓存,并通过流量控制进行节流。同时,其界面查询使用方便,易于扩展。因此,使用 Graylog 成为了最好的选择,为我们省了很多心。
Filebeat工具介绍 ①Filebeat日志文件投递服务
Filebeat 是一个日志文件传送工具。在您的服务器上安装客户端后,Filebeat 会自动监控给定的日志目录或指定的日志文件,跟踪并读取这些文件,不断地读取它们,并将信息转发到存储在 Elasticsearch 或 Logstarsh 或 Graylog 中。
②Filebeat工作流程介绍
当您安装并启用 Filebeat 程序时,它将启动一个或多个探测器(prospectors)来检测您指定的日志目录或文件。
对于探测器找到的每个日志文件,Filebeat 都会启动一个收割机进程。
每个收获进程读取日志文件的最新内容并将这些新日志数据发送到处理程序(假脱机程序),后者聚合这些事件。
最后,Filebeat 会将采集数据发送到您指定的地址(我们这里发送到 Graylog 服务)。
③Filebeat图标了解内存
我们这里没有应用 Logstash 服务,主要是因为 Filebeat 比 Logstash 更轻量级。
当我们需要采集信息的机器配置或者资源不是特别大,也没有那么复杂的时候,推荐使用Filebeat来采集日志。
在日常使用中,Filebeat有多种安装部署方式,运行非常稳定。
图形化服务架构理解内存
文件节拍配置文件
配置Filebeat工具的核心是如何编写其对应的配置文件!
对应的Filebeat工具的配置主要是通过编写其配置文件来控制的。对于通过 rpm 或 deb 包安装,配置文件默认存放在路径 /etc/filebeat/filebeat.yml 下。
Mac或Win系统请查看解压后的相关文件,均涉及。
Filebeat工具的主要配置文件如下图所示。每个字段的含义在评论信息中有详细解释,这里不再赘述。
需要注意的是,我们定义了日志的所有输入源来读取inputs.d目录下的所有yml配置。
因此,我们可以针对不同的服务(测试、正式服务)定义不同的配置文件,根据物理机部署的实际情况进行配置。
# 配置输入来源的日志信息
# 我们合理将其配置到了 inputs.d 目录下的所有 yml 文件
filebeat.config.inputs:
enabled: true
path: ${path.config}/inputs.d/*.yml
# 若收取日志格式为 json 的 log 请开启此配置
# json.keys_under_root: true
# 配置 Filebeat 需要加载的模块
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
# 配置将日志信息发送那个地址上面
output.logstash:
hosts: ["11.22.33.44:5500"]
# output.file:
# enable: true
processors:
- add_host_metadata: ~
- rename:
fields:
- from: "log"
to: "message"
- add_fields:
target: ""
fields:
# 加 Token 是为了防止无认证的服务上 Graylog 服务发送数据
token: "0uxxxxaM-1111-2222-3333-VQZJxxxxxwgX "
下面展示了inputs.d目录下一个简单的yml配置文件的具体内容。它的主要功能是配置独立服务的独立日志数据,并附加不同的数据标签类型。
# 收集的数据类型
- type: log
enabled: true
# 日志文件的路径地址
paths:
- /var/log/supervisor/app_escape_worker-stderr.log
- /var/log/supervisor/app_escape_prod-stderr.log
symlinks: true
# 包含的关键字信息
include_lines: ["WARNING", "ERROR"]
# 打上数据标签
tags: ["app", "escape", "test"]
# 防止程序堆栈信息被分行识别
multiline.pattern: '^\[?[0-9]...{3}'
multiline.negate: true
multiline.match: after
# 需要配置多个日志时可加多个 type 字段
- type: log
enabled: true
需要注意的是,针对不同的日志类型,filebeat还提供了不同的模块来配置不同的服务日志及其不同的模块特性,比如我们常见的PostgreSQl、Redis、Iptables等。
# iptables
- module: iptables
log:
enabled: true
var.paths: ["/var/log/iptables.log"]
var.input: "file"
# postgres
- module: postgresql
log:
enabled: true
var.paths: ["/path/to/log/postgres/*.log*"]
# nginx
- module: nginx
access:
enabled: true
var.paths: ["/path/to/log/nginx/access.log*"]
error:
enabled: true
var.paths: ["/path/to/log/nginx/error.log*"]
Graylog服务介绍①Graylog日志监控系统
Graylog 是一个开源的日志聚合、分析、审计、展示和预警工具。在功能上,它与 ELK 类似,但比 ELK 简单得多。
凭借更加简洁、高效、易于部署和使用的优势,迅速受到了很多人的青睐。当然,在扩展性方面并不比 ELK 好,但也有商业版本可供选择。
②Graylog工作流程介绍
部署 Graylog 最简单的架构是单机部署,更复杂的部署是集群模式。架构图如下所示。
我们可以看到它收录三个组件,分别是 Elasticsearch、MongoDB 和 Graylog。
其中,Elasticsearch 用于持久存储和检索日志文件数据(IO 密集型),MongoDB 用于存储有关 Graylog 的相关配置,Graylog 用于提供 Web 接口和外部接口(CPU 密集型)。
最小的独立部署
优化集群部署
Graylog 组件特性
配置一个 Graylog 服务的核心是了解对应的组件是做什么的以及它是如何工作的!
简单来说,Input 代表日志数据的来源。对于不同来源的日志,可以使用Extractors对日志的字段进行转换,比如将Nginx的状态码改成对应的英文表达。
然后,将不同类型的标签分组到不同的流中,将这些日志数据存储在指定的Index库中进行持久化存储。
Graylog 中的核心服务组件
Graylog 通过 Input 采集日志,每个 Input 都配置了 Extractors 进行字段转换。
Graylog中日志搜索的基本单位是Stream。每个 Stream 可以有自己的 Elastic Index Set 或共享一个 Index Set。
提取器在系统/输入中配置。Graylog 的一个方便之处是您可以加载日志,根据这个实际示例对其进行配置,并直接查看结果。
内置的Extractor基本可以完成各种字段的提取和转换任务,但也有一定的局限性,需要在应用程序中写日志时加以考虑。Input可以配置多个Extractor,依次执行。
系统会有一个默认的Stream,所有的日志都会默认保存到这个Stream,除非匹配到了一个Stream,并且这个Stream被配置为不保存日志到默认的Stream。
可以通过菜单 Streams 创建更多 Streams。新创建的 Stream 处于暂停状态,需要在配置完成后手动启动。
Stream通过配置条件匹配日志,满足条件的日志添加stream ID标识字段,保存到对应的Elastic Index Set中。
索引集是通过菜单系统/索引创建的。日志存储的性能、可靠性和过期策略都是通过Index Set来配置的。
性能和可靠性是配置 Elastic Index 的一些参数。主要参数包括 Shards 和 Replica。
除了上面提到的日志处理流程,Graylog 还提供了一个 Pipeline 脚本来实现更灵活的日志处理方案。
此处不赘述,仅介绍是否使用 Pipelines 过滤不需要的日志。以下是丢弃所有级别 > 6 的日志的管道规则示例。
从数据采集(输入),现场分析(提取器),分流到流,再到流水线清洗,一气呵成,其他方式无需二次处理。
Sidecar 是一个轻量级的日志采集器,通过访问 Graylog 进行集中管理,支持 Linux 和 Windows 系统。
Sidecar 守护进程会定期访问 Graylog REST API 以获取 sidecar 配置文件中定义的标签。Sidecar 首次运行时,会从 Graylog 服务器拉取配置文件中指定标签的配置信息,并同步到本地。
目前 Sidecar 支持 NXLog、Filebeat 和 Winlogbeat。它们都是通过 Graylog 中的 web 界面统一配置,支持 Beats、CEF、Gelf、Json API、NetFlow 等输出类型。
Graylog 最强大的地方在于,可以在配置文件中指定 Sidecar 将日志发送到哪个 Graylog 集群,并对 Graylog 集群中的多个输入进行负载均衡,让 Graylog 可以应对非常大量的日志。
rule "discard debug messages"
when
to_long($message.level) > 6
then
drop_message();
end
日志集中保存到 Graylog 后,可以方便地进行搜索。但是,有时需要进一步处理数据。
主要有两种方式,一种是直接访问存储在 Elastic 中的数据,或者通过 Graylog 的 Output 转发给其他服务。
服务安装部署
主要介绍了部署Filebeat+Graylog的安装步骤和注意事项!
使用 Graylog 采集日志
①部署Filebeat工具
官方提供了多种部署方式,包括通过rpm和deb包安装服务,以及通过源码编译安装服务,还包括使用Docker或者kubernetes安装服务。
我们可以根据自己的实际需要进行安装:
# Ubuntu(deb)
$ curl -L -O https://artifacts.elastic.co/d ... 4.deb
$ sudo dpkg -i filebeat-7.8.1-amd64.deb
$ sudo systemctl enable filebeat
$ sudo service filebeat start
# 使用 Docker 启动
docker run -d --name=filebeat --user=root \
--volume="./filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \
--volume="/var/lib/docker/containers:/var/lib/docker/containers:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/filebeat:7.8.1 filebeat -e -strict.perms=false \
-E output.elasticsearch.hosts=["elasticsearch:9200"]
②部署 Graylog 服务
这里主要介绍使用Docker容器部署服务。如需使用其他方式部署,请查看官方文档相应章节的安装部署步骤。
在部署服务之前,我们需要为 Graylog 服务生成等相关信息。生成的部署如下:
<p># 生成 password_secret 密码(最少 16 位)
$ sudo apt install -y pwgen
$ pwgen -N 1 -s 16
zscMb65...FxR9ag
# 生成后续 Web 登录时所需要使用的密码
$ echo -n "Enter Password: " && head -1
内容采集器( SEO技术分享2022-02-11怎么利用wordpress采集插件把关键词优化到首页, )
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2022-02-13 07:03
SEO技术分享2022-02-11怎么利用wordpress采集插件把关键词优化到首页,
)
wordpress采集-wordpress采集 插件
SEO技术分享2022-02-11
如何使用wordpress采集插件优化关键词到首页,如何快速做到?如果方便找的话,倒不难,但是拉苗鼓励一下,就不能着急吃热豆腐了,所以要遵守搜索引擎的规则。在SEO优化的前提下,尽可能的加快优化的步伐,最终实现排名的短期提升。有哪些准备工作?
一、网站域名选择
选择域名时,域名越简单越好,也容易被记住。域名后缀选择顺序为.com、.net、.cn。之所以这样选择,是因为它们的权重是逐渐减小的,所以我们尽量选择。具有高权重的域名后缀。同时,在注册域名之前,我们需要检查该域名之前是否被使用过,是否存在被搜索引擎惩罚的情况。一般我们可以在站点域名中查看域名的收录情况或者通过反向链查询域名的历史,如果已经有好的老域名,使用起来更有优势seo的旧域名,新站点前期的沙盒期将直接通过。
二、网站建设者的使用
在选择建站系统时,尽量不要选择智能建站程序。这种程序一般是可视化操作。纯显示 网站 没关系。它可能不适合 SEO 网站。大量的样式代码都存储在网站前端页面,严重影响了搜索引擎蜘蛛的爬取效率。对网站的收录非常不利。建站最好使用网站cms系统,选择简单好用的cms系统,功能强大,SEO性能突出,有很多家喻户晓的好方法-使用市面上的cms系统,如织梦、empire、wordpress、zblog等。大的cms
三、网站模板选择
SEO网站的前端页面模板,越简单越好。这纯粹是从SEO的角度来看的。在实践中,由于宣传和内容排版的需要,会穿插更多的内容模块。但无论如何,使用页面标签、样式规范、栏目布局、导航栏设置、面包屑设置、全站内链等都需要按照百度SEO优化指南和实际用户搜索来布局需要网站,让搜索引擎和用户都喜欢我们的网站。
四、网站的数据分析
一个网站的排名很大程度上取决于我们是否对网站本身的数据有一个清晰的认识。什么样的关键词用户搜索进入网站,哪个网站关键词被搜索很多,哪个关键词没有被搜索,一定要做好数据分析,为以后的微调做基础准备。我们都参与了网站的关键词,所以我们要学会分析行业用户的需求。
如果你的网站在前100之后,你应该做好网站的基础优化,做好内页、导航、首页、版块等最适合蜘蛛的基础爬行。前二十页侧重于用户体验。您的 关键词 排名在第二页。如何进入首页,如何让用户更容易发现?这些都是我们需要学习分析的。如果我们不能分析,我们的排名肯定不会上升。试着观察一下你所在行业排名第一的网站,他们是怎么做到的关键词,如果分布关键词也很重要。
五、好的网站关键词
必须确定。只有选择并确定了关键词,才能对其进行优化。当然,不建议考虑过大的 关键词。这样的关键词对于新站来说基本是无解的。没有办法优化,不要做车,鸡蛋打石头,一定要实事求是,根据自己的实际情况。如果盲目地优化索引大的关键词,首页优化上不去。再这样下去,很容易损害你的优化信心。
选择长尾关键词进行优化,第一个长尾关键词包括主关键词和索引关键词,即长尾关键词排名可以在前期,后期可以实现主关键词排名,可以起到非常大的推动作用,长尾关键词比较容易优化。
六、网站关键词布局
首先,关键词 不应该有太多的布局。前期一般不建议直接布局关键词。至少让网站通过搜索引擎试用期。所谓沙盒期就是这样,也太快了。沙盒期有利于后期工作的快速推进。后期可以使用栏目页,文章页,少量长尾,分步布局关键词。可以加一些小链接,自然插入关键词更有利于排名快速上升。
七、网站内容填充
你必须小心这一点。我的建议是最低标准是伪原创。不要找任何理由或借口,这里不用学习更多专业技能就给你这个WordPress采集插件。
您只需几个简单的步骤即可轻松采集内容数据。用户只需要在插件上进行简单的设置。完成后,软件会根据关键词用户设置对内容和图片进行高精度匹配并自动执行。文章采集伪原创发布,提供方便快捷的内容填充服务!!
与其他采集插件相比,基本没有门槛,也不需要花大量时间学习正则表达式或者html标签,一分钟就能上手,输入关键词即可实现采集。(wordpress插件还自带关键词生成功能) 一路挂断!设置任务自动执行采集发布任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类wordpress插件也配置了很多SEO功能,通过采集伪原创软件发布时还可以提升很多SEO优化,比如:设置图片自动下载并将它们保存在本地或第三方(以便内容没有彼此的外部链接)。自动内链(让搜索引擎更深入地抓取你的链接)、内容或标题插入,以及网站内容插入或随机作者、随机阅读等,形成一个“高原创”。这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。可以直接查看文章采集的发布状态 通过软件工具上的监控管理,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
八、网站内链布局
让整个网站实现类似蜘蛛网的模式,让搜索引擎蜘蛛进来,爬取更多优质内容。内部链接可以是首页、栏目页、文章页面、关键词、锚文本、标签、内部文章、文章插入标题等。当然每个文章 不宜加太多。前期可省略,中期可加一,中后期可加一。添加两个链接,以后可以添加三个链接,也可以添加两个或一个进行回收。总之,遵循顺其自然,不任性,形成强大的蜘蛛网为基准的原则。
九、网站服务器安全
在这些危险时期,网站 就像一个小婴儿。它必须是关怀的,细心的,并且得到很好的照顾。如果有一点点小错误,可能会有很多麻烦。因此,施工现场网站的安全工作必须要做好。另外,可以让身边的高权重网站朋友帮忙引导,正规方式带来的友情链接对关键词的排名非常有利。在朋友中,这样的高权重链接非常好做。拉下你的脸,不要做懦夫,现在谁手里站的少,如果是好朋友,帮助他们不是问题,那就去做吧。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。每天跟着博主为你展示各种SEO经验,打通你的两条血脉!
查看全部
内容采集器(
SEO技术分享2022-02-11怎么利用wordpress采集插件把关键词优化到首页,
)
wordpress采集-wordpress采集 插件
SEO技术分享2022-02-11
如何使用wordpress采集插件优化关键词到首页,如何快速做到?如果方便找的话,倒不难,但是拉苗鼓励一下,就不能着急吃热豆腐了,所以要遵守搜索引擎的规则。在SEO优化的前提下,尽可能的加快优化的步伐,最终实现排名的短期提升。有哪些准备工作?
一、网站域名选择
选择域名时,域名越简单越好,也容易被记住。域名后缀选择顺序为.com、.net、.cn。之所以这样选择,是因为它们的权重是逐渐减小的,所以我们尽量选择。具有高权重的域名后缀。同时,在注册域名之前,我们需要检查该域名之前是否被使用过,是否存在被搜索引擎惩罚的情况。一般我们可以在站点域名中查看域名的收录情况或者通过反向链查询域名的历史,如果已经有好的老域名,使用起来更有优势seo的旧域名,新站点前期的沙盒期将直接通过。
二、网站建设者的使用
在选择建站系统时,尽量不要选择智能建站程序。这种程序一般是可视化操作。纯显示 网站 没关系。它可能不适合 SEO 网站。大量的样式代码都存储在网站前端页面,严重影响了搜索引擎蜘蛛的爬取效率。对网站的收录非常不利。建站最好使用网站cms系统,选择简单好用的cms系统,功能强大,SEO性能突出,有很多家喻户晓的好方法-使用市面上的cms系统,如织梦、empire、wordpress、zblog等。大的cms
三、网站模板选择
SEO网站的前端页面模板,越简单越好。这纯粹是从SEO的角度来看的。在实践中,由于宣传和内容排版的需要,会穿插更多的内容模块。但无论如何,使用页面标签、样式规范、栏目布局、导航栏设置、面包屑设置、全站内链等都需要按照百度SEO优化指南和实际用户搜索来布局需要网站,让搜索引擎和用户都喜欢我们的网站。
四、网站的数据分析
一个网站的排名很大程度上取决于我们是否对网站本身的数据有一个清晰的认识。什么样的关键词用户搜索进入网站,哪个网站关键词被搜索很多,哪个关键词没有被搜索,一定要做好数据分析,为以后的微调做基础准备。我们都参与了网站的关键词,所以我们要学会分析行业用户的需求。
如果你的网站在前100之后,你应该做好网站的基础优化,做好内页、导航、首页、版块等最适合蜘蛛的基础爬行。前二十页侧重于用户体验。您的 关键词 排名在第二页。如何进入首页,如何让用户更容易发现?这些都是我们需要学习分析的。如果我们不能分析,我们的排名肯定不会上升。试着观察一下你所在行业排名第一的网站,他们是怎么做到的关键词,如果分布关键词也很重要。
五、好的网站关键词
必须确定。只有选择并确定了关键词,才能对其进行优化。当然,不建议考虑过大的 关键词。这样的关键词对于新站来说基本是无解的。没有办法优化,不要做车,鸡蛋打石头,一定要实事求是,根据自己的实际情况。如果盲目地优化索引大的关键词,首页优化上不去。再这样下去,很容易损害你的优化信心。
选择长尾关键词进行优化,第一个长尾关键词包括主关键词和索引关键词,即长尾关键词排名可以在前期,后期可以实现主关键词排名,可以起到非常大的推动作用,长尾关键词比较容易优化。
六、网站关键词布局
首先,关键词 不应该有太多的布局。前期一般不建议直接布局关键词。至少让网站通过搜索引擎试用期。所谓沙盒期就是这样,也太快了。沙盒期有利于后期工作的快速推进。后期可以使用栏目页,文章页,少量长尾,分步布局关键词。可以加一些小链接,自然插入关键词更有利于排名快速上升。
七、网站内容填充
你必须小心这一点。我的建议是最低标准是伪原创。不要找任何理由或借口,这里不用学习更多专业技能就给你这个WordPress采集插件。
您只需几个简单的步骤即可轻松采集内容数据。用户只需要在插件上进行简单的设置。完成后,软件会根据关键词用户设置对内容和图片进行高精度匹配并自动执行。文章采集伪原创发布,提供方便快捷的内容填充服务!!
与其他采集插件相比,基本没有门槛,也不需要花大量时间学习正则表达式或者html标签,一分钟就能上手,输入关键词即可实现采集。(wordpress插件还自带关键词生成功能) 一路挂断!设置任务自动执行采集发布任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类wordpress插件也配置了很多SEO功能,通过采集伪原创软件发布时还可以提升很多SEO优化,比如:设置图片自动下载并将它们保存在本地或第三方(以便内容没有彼此的外部链接)。自动内链(让搜索引擎更深入地抓取你的链接)、内容或标题插入,以及网站内容插入或随机作者、随机阅读等,形成一个“高原创”。这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。可以直接查看文章采集的发布状态 通过软件工具上的监控管理,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
八、网站内链布局
让整个网站实现类似蜘蛛网的模式,让搜索引擎蜘蛛进来,爬取更多优质内容。内部链接可以是首页、栏目页、文章页面、关键词、锚文本、标签、内部文章、文章插入标题等。当然每个文章 不宜加太多。前期可省略,中期可加一,中后期可加一。添加两个链接,以后可以添加三个链接,也可以添加两个或一个进行回收。总之,遵循顺其自然,不任性,形成强大的蜘蛛网为基准的原则。
九、网站服务器安全
在这些危险时期,网站 就像一个小婴儿。它必须是关怀的,细心的,并且得到很好的照顾。如果有一点点小错误,可能会有很多麻烦。因此,施工现场网站的安全工作必须要做好。另外,可以让身边的高权重网站朋友帮忙引导,正规方式带来的友情链接对关键词的排名非常有利。在朋友中,这样的高权重链接非常好做。拉下你的脸,不要做懦夫,现在谁手里站的少,如果是好朋友,帮助他们不是问题,那就去做吧。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。每天跟着博主为你展示各种SEO经验,打通你的两条血脉!
内容采集器(优采云采集器中文版如何使用步骤1打开网页数据采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-02-13 05:11
优采云采集器中文版是一款免费的网站data采集软件,帮助您采集网页上的各种数据。优采云采集器中文版基于其自主研发的强大分布式云计算平台。优采云采集器中文版可以方便地从各种网站和网页中获取大量的规范化数据,帮助用户实现数据自动化采集、编辑、规范化、摆脱人工束缚,降低购置成本,大大提高工作效率。举个简单的例子,如果你是商人,那么你必须掌握很多关于商品市场价格、销售等信息,方便你了解商品是买方市场还是卖方市场,并帮助您快速掌握这些信息以提高您的表现。利润。
优采云采集器中文版软件功能
简而言之,使用 优采云 可以很容易地从任何网页精确采集您需要的数据,并生成自定义的常规数据格式。优采云数据采集系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财务报告,自动包括每日最新净值采集;
2.各大新闻门户网站实时监控,自动更新和上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 监测各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要汽车网站具体新车和二手车信息;
8. 发现并采集有关潜在客户的信息;
9. 采集行业网站 产品目录和产品信息;
10.在各大电商平台之间同步商品信息,做到在一个平台发布,在其他平台自动更新。
优采云采集器中文版如何使用
步骤 1 打开网页
登录优采云采集器→点击左上角的“+”图标→选择自定义采集(也可以在首页点击自定义采集下的“立即使用”页面),进入任务配置页面。
然后输入网址→保存网址,系统会进入工艺设计页面,自动打开之前输入的网址。
打开网页后,我们可以修改任务名称。如果没有,则默认以网页标题命名。在运行 采集 之前可以随时修改任务名称。
步骤 2 提取数据
在网页中,可以直接选择要提取的数据,窗口右上角会有相应的提示。在本教程中,我们以新闻标题、日期和文本的提取为例
设置好数据提取后,单击保存并开始运行采集。但是此时的字段名是系统自动生成的。
为了更好的满足自己的需求,可以点击右上角的“处理”进入处理页面修改字段名,保存后运行采集。
所有版本都可以运行local采集,Ultimate及以上版本可以运行cloud采集并设置定时cloud采集,但是在运行cloud采集@>之前先运行local采集测试。
任务运行完采集后,可以选择Excel、CSV、HTML等格式导出或导入数据库。
数据导出后,可以点击链接进入数据存储文件夹查看数据。该文件默认以任务名称命名。
变更日志
主要体验改进
[云采集]新增云采集直播功能,展示任务的云操作,如任务拆分、节点分配、采集数据等流程
[云采集] 新增云采集通知功能,可以为每个任务设置采集完成和采集停止时的邮件通知流程
[Cloud采集] 增加单个子任务重启功能,可以重启少量采集或者状态为stopped的子任务,可以减少数据遗漏
Bug修复
修复“重试次数设置不生效”的问题
修复“循环 URL 异常”问题
修复“最后一个字段,修改要保存的字段名无效”的问题
提高性能并修复一些卡顿问题 查看全部
内容采集器(优采云采集器中文版如何使用步骤1打开网页数据采集软件)
优采云采集器中文版是一款免费的网站data采集软件,帮助您采集网页上的各种数据。优采云采集器中文版基于其自主研发的强大分布式云计算平台。优采云采集器中文版可以方便地从各种网站和网页中获取大量的规范化数据,帮助用户实现数据自动化采集、编辑、规范化、摆脱人工束缚,降低购置成本,大大提高工作效率。举个简单的例子,如果你是商人,那么你必须掌握很多关于商品市场价格、销售等信息,方便你了解商品是买方市场还是卖方市场,并帮助您快速掌握这些信息以提高您的表现。利润。

优采云采集器中文版软件功能
简而言之,使用 优采云 可以很容易地从任何网页精确采集您需要的数据,并生成自定义的常规数据格式。优采云数据采集系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财务报告,自动包括每日最新净值采集;
2.各大新闻门户网站实时监控,自动更新和上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 监测各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要汽车网站具体新车和二手车信息;
8. 发现并采集有关潜在客户的信息;
9. 采集行业网站 产品目录和产品信息;
10.在各大电商平台之间同步商品信息,做到在一个平台发布,在其他平台自动更新。
优采云采集器中文版如何使用
步骤 1 打开网页
登录优采云采集器→点击左上角的“+”图标→选择自定义采集(也可以在首页点击自定义采集下的“立即使用”页面),进入任务配置页面。

然后输入网址→保存网址,系统会进入工艺设计页面,自动打开之前输入的网址。

打开网页后,我们可以修改任务名称。如果没有,则默认以网页标题命名。在运行 采集 之前可以随时修改任务名称。
步骤 2 提取数据
在网页中,可以直接选择要提取的数据,窗口右上角会有相应的提示。在本教程中,我们以新闻标题、日期和文本的提取为例

设置好数据提取后,单击保存并开始运行采集。但是此时的字段名是系统自动生成的。
为了更好的满足自己的需求,可以点击右上角的“处理”进入处理页面修改字段名,保存后运行采集。

所有版本都可以运行local采集,Ultimate及以上版本可以运行cloud采集并设置定时cloud采集,但是在运行cloud采集@>之前先运行local采集测试。

任务运行完采集后,可以选择Excel、CSV、HTML等格式导出或导入数据库。

数据导出后,可以点击链接进入数据存储文件夹查看数据。该文件默认以任务名称命名。
变更日志
主要体验改进
[云采集]新增云采集直播功能,展示任务的云操作,如任务拆分、节点分配、采集数据等流程
[云采集] 新增云采集通知功能,可以为每个任务设置采集完成和采集停止时的邮件通知流程
[Cloud采集] 增加单个子任务重启功能,可以重启少量采集或者状态为stopped的子任务,可以减少数据遗漏
Bug修复
修复“重试次数设置不生效”的问题
修复“循环 URL 异常”问题
修复“最后一个字段,修改要保存的字段名无效”的问题
提高性能并修复一些卡顿问题
内容采集器(网站通用信息收集器支持离线自动更新网页信息收集软件的优点 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-02-06 14:07
)
<p>网站Universal Information Collector 是一个非常有用的采集网络信息的工具。采集网站通用信息采集器是一款不错的软件。本软件由开发和发布。该软件可以抓取网站和网页。软件整合了所有网页信息采集软件的优点,为用户提供了一个快速高效的网页信息采集工具,软件可以采集网页中的所有信息并单独保存,也可以自动发布到用户的在网站 上拥有 查看全部
内容采集器(内容采集器推荐推荐一下ezcapture采集国产手机端操作)
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2022-02-06 01:01
内容采集器推荐推荐一下ezcapture采集器,国产采集器,无需翻墙,无需注册,采集的数据有效率,资源丰富;采集器不仅支持绝大部分常见的国内外网站,还支持国外网站的采集。ezcapture是一款网络爬虫采集器,整合了http协议。http协议是一种简单快速的协议,连接url时将响应信息全部发送给对方,从而控制对方来访问您的页面。
整个页面都采用http协议(hypertexttransferprotocol),因此,又称超文本传输协议(http)。使用ezcapture采集器,你可以在电脑上通过浏览器登录不同的博客或者社区,来采集网站上的文章或是插图、动图、源代码等等。你也可以发布一个链接,给其他人去采集。因为采集器支持多线程采集,而不是单机的单线程采集模式,所以传输的资源保证不会丢失。
采集器可以自动保存您的采集结果。采集器支持图片文本、音频视频、站内信息、网页表单等不同格式的数据。ezcapture采集器支持国内多网站操作以及功能多样的手机端操作,可以全面满足不同用户对网站源码爬取的需求。因为采集器可以全面满足不同用户对网站源码爬取的需求,所以整个网站的源码你都可以得到。采集器支持国内多网站操作以及功能多样的手机端操作,可以全面满足不同用户对网站源码爬取的需求。
采集器与俄罗斯、英国网站采集插件集成,开启俄罗斯、英国网站的采集。采集器与阿拉伯、美国网站采集插件集成,开启阿拉伯、美国网站的采集。采集器与阿拉伯、美国网站采集插件集成,开启阿拉伯、美国网站的采集。采集器支持多种语言支持,采集线程:一个线程两个随机,每个线程最多1000个。支持爬虫采集的功能,抓取公众号、小程序、网页的数据、二维码等等。
使用手机端采集器访问网站,可以对网站进行动态管理,修改采集规则。支持修改采集规则,实现一次采集多个网站,并且时不时可以通过网站的自动更新,实现抓取任务的更新。采集器支持一键切换成谷歌浏览器爬虫,无需下载谷歌浏览器,省去了部分安装谷歌浏览器的安装流程。另外,全球已经有10亿台谷歌访问设备,到2018年,有望达到20亿台。
目前看来,谷歌应该是全球唯一一家可以全面普及区块链技术的搜索巨头。未来谷歌可能需要采用区块链技术,构建全新的技术生态,全面进入数字资产时代。ezcapture采集器可以爬取的网站包括:国内:(含大部分不包含):无需翻墙,点击即可采集国外:(含大部分不包含):无需翻墙,点击即可采集人人皆可使用,人人皆可实现创业。一键采集谷歌浏览器、谷歌浏览器插件等设备,不需要保证第一次安装所有设备,操作十分简单, 查看全部
内容采集器(内容采集器推荐推荐一下ezcapture采集国产手机端操作)
内容采集器推荐推荐一下ezcapture采集器,国产采集器,无需翻墙,无需注册,采集的数据有效率,资源丰富;采集器不仅支持绝大部分常见的国内外网站,还支持国外网站的采集。ezcapture是一款网络爬虫采集器,整合了http协议。http协议是一种简单快速的协议,连接url时将响应信息全部发送给对方,从而控制对方来访问您的页面。
整个页面都采用http协议(hypertexttransferprotocol),因此,又称超文本传输协议(http)。使用ezcapture采集器,你可以在电脑上通过浏览器登录不同的博客或者社区,来采集网站上的文章或是插图、动图、源代码等等。你也可以发布一个链接,给其他人去采集。因为采集器支持多线程采集,而不是单机的单线程采集模式,所以传输的资源保证不会丢失。
采集器可以自动保存您的采集结果。采集器支持图片文本、音频视频、站内信息、网页表单等不同格式的数据。ezcapture采集器支持国内多网站操作以及功能多样的手机端操作,可以全面满足不同用户对网站源码爬取的需求。因为采集器可以全面满足不同用户对网站源码爬取的需求,所以整个网站的源码你都可以得到。采集器支持国内多网站操作以及功能多样的手机端操作,可以全面满足不同用户对网站源码爬取的需求。
采集器与俄罗斯、英国网站采集插件集成,开启俄罗斯、英国网站的采集。采集器与阿拉伯、美国网站采集插件集成,开启阿拉伯、美国网站的采集。采集器与阿拉伯、美国网站采集插件集成,开启阿拉伯、美国网站的采集。采集器支持多种语言支持,采集线程:一个线程两个随机,每个线程最多1000个。支持爬虫采集的功能,抓取公众号、小程序、网页的数据、二维码等等。
使用手机端采集器访问网站,可以对网站进行动态管理,修改采集规则。支持修改采集规则,实现一次采集多个网站,并且时不时可以通过网站的自动更新,实现抓取任务的更新。采集器支持一键切换成谷歌浏览器爬虫,无需下载谷歌浏览器,省去了部分安装谷歌浏览器的安装流程。另外,全球已经有10亿台谷歌访问设备,到2018年,有望达到20亿台。
目前看来,谷歌应该是全球唯一一家可以全面普及区块链技术的搜索巨头。未来谷歌可能需要采用区块链技术,构建全新的技术生态,全面进入数字资产时代。ezcapture采集器可以爬取的网站包括:国内:(含大部分不包含):无需翻墙,点击即可采集国外:(含大部分不包含):无需翻墙,点击即可采集人人皆可使用,人人皆可实现创业。一键采集谷歌浏览器、谷歌浏览器插件等设备,不需要保证第一次安装所有设备,操作十分简单,
内容采集器(优采云采集器的网页数据采集工具分析及使用方法介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2022-02-03 20:17
优采云采集器是一个非常简单的网页数据工具采集,它有一个可视化的工作界面,用户可以通过鼠标完成网页数据采集,程序使用门槛很低,任何用户都可以轻松使用它写数据采集,不需要用户具备编写爬虫程序的能力;通过该软件,用户可以在大部分网站采集数据中使用,其中用户需要的数据信息可以从一些单页应用中Ajax加载的动态网站中获取;软件内置高速浏览器引擎,用户可以在各种浏览模式之间自由切换,让用户可以轻松直观的方式在网站网页上执行采集;该程序安全、无毒、易于使用,
软件功能
1、可视化向导:自动为所有集合元素生成集合数据。
2、定时任务:灵活定义运行时间,自动运行。
3、多引擎支持:支持多种采集引擎,内置高速浏览器内核、HTTP引擎、JSON引擎。
4、智能识别:可自动识别网页列表、采集字段、页面等。
5、拦截请求:自定义要拦截的域名,方便过滤站外广告,提高采集速度。
6、各种数据导出:可以导出到TXT、Excel、mysql、SQL Server、SQLite、access、网站等。
软件功能
零阈值
即使您不了解网络爬虫技术,也可以轻松浏览互联网网站 并采集网站 数据。软件操作简单,点击鼠标即可轻松选择要抓取的内容。
多引擎,高速,稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式,更高效地采集数据。它还具有内置的 JSON 引擎,无需解析 JSON 数据结构并直观地选择 JSON 内容。
高级智能算法
先进的智能算法可以生成目标元素XPath,自动识别网页列表,自动识别分页中的下一页按钮。它不需要分析web请求和源代码,但支持更多的网页集合。
适用于各种 网站
它可以采集 99% 的 Internet 站点,包括单页应用程序 Ajax 加载等动态类型。
指示
第 1 步:设置起始 URL
要采集 网站 数据,首先,我们需要设置进入集合的 URL。例如,如果你想为网站采集国内新闻,你应该将起始URL设置为国内新闻栏目列表的URL,但通常你不会将网站的首页设置为起始地址,因为首页通常收录Latest文章、Popular文章、Recommended文章Chapter等很多列表块,显示的内容也很有限. 一般来说,采集这些列表时不可能采集到完整的信息。
接下来,我们以新浪新闻采集为例,从新浪首页查找国内新闻。不过这个栏目首页的内容还是比较杂乱的,分成了三个子栏目
我们来看看《大陆新闻》的分栏报道
此栏目页面收录一个带有分页的内容列表。通过切换分页,我们可以采集该列下的所有文章,因此这个列表页面非常适合我们采集起始URL。
我们现在将列表 URL 复制到任务编辑框步骤 1 中的文本框中。
如果你想在一个任务中同时采集国内新闻的其他子栏目,你也可以复制另外两个子栏目的列表地址,因为这些子栏目有类似的格式。但是,为了便于导出或发布分类数据,通常不建议将多个列的内容混合在一起。
对于起始 URL,我们还可以批量添加或从 txt 文件导入。比如我们要采集前五个页面,我们也可以这样自定义五个起始页面
需要注意的是,如果这里自定义了多个分页列表,后续的集合配置中将不会启用分页。通常,当我们要采集一个列下的所有文章时,我们只需要将该列的第一页定义为起始URL。如果在后续采集配置中启用了分页,则可以为每个分页列表采集数据。
第二步:①自动生成列表和字段
进入第二步后,对于一些网页,惰性采集器会智能分析页面列表,自动高亮页面列表并生成列表数据,如
然后我们可以修剪数据,例如删除一些不必要的字段
单击图中的三角形符号以显示该字段的详细 采集 配置。单击上面的删除按钮以删除该字段。其余参数将在后续章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的,可以点击“清除字段”,清除所有生成的字段。
如果我们的列表不是手动选择的,那么它将自动列出。如果要取消高亮的列表框,可以点击Find List - List XPaths,清除其中的XPaths,然后确认。
②手动生成列表
单击搜索列表按钮并选择手动选择列表
按照提示,然后左键点击网页列表中的第一行数据
单击第一行,然后在出现提示时单击第二行或其他类似行
单击列表中的任意两行后,将突出显示整个列表。同时,列表中的字段也会生成。如果生成的字段不正确,请单击清除字段以清除下面的所有字段。下一章介绍如何手动选择字段。
③ 手动生成字段
单击“添加字段”按钮
在列表的任意一行单击要提取的元素,例如标题和链接地址,然后用鼠标左键单击标题
点击网页链接时,会提示是否获取链接地址
如果要提取链接的标题和地址,请单击是。如果您只想提取标题文本,请单击否。在这里我们点击“是”。
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击底部表格中某个字段的标题时,匹配的内容将在网页上以黄色背景突出显示。
如果标签列表中还有其他字段,请单击“添加字段”,然后重复。
④分页设置
当列表有分页时,启用分页时可以采集所有分页列表数据。
页面分页有两种类型
常规分页:有分页栏,显示“下一页”按钮。点击后可以跳转到下一页,比如新浪新闻列表中的上一页 查看全部
内容采集器(优采云采集器的网页数据采集工具分析及使用方法介绍)
优采云采集器是一个非常简单的网页数据工具采集,它有一个可视化的工作界面,用户可以通过鼠标完成网页数据采集,程序使用门槛很低,任何用户都可以轻松使用它写数据采集,不需要用户具备编写爬虫程序的能力;通过该软件,用户可以在大部分网站采集数据中使用,其中用户需要的数据信息可以从一些单页应用中Ajax加载的动态网站中获取;软件内置高速浏览器引擎,用户可以在各种浏览模式之间自由切换,让用户可以轻松直观的方式在网站网页上执行采集;该程序安全、无毒、易于使用,

软件功能
1、可视化向导:自动为所有集合元素生成集合数据。
2、定时任务:灵活定义运行时间,自动运行。
3、多引擎支持:支持多种采集引擎,内置高速浏览器内核、HTTP引擎、JSON引擎。
4、智能识别:可自动识别网页列表、采集字段、页面等。
5、拦截请求:自定义要拦截的域名,方便过滤站外广告,提高采集速度。
6、各种数据导出:可以导出到TXT、Excel、mysql、SQL Server、SQLite、access、网站等。
软件功能
零阈值
即使您不了解网络爬虫技术,也可以轻松浏览互联网网站 并采集网站 数据。软件操作简单,点击鼠标即可轻松选择要抓取的内容。
多引擎,高速,稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式,更高效地采集数据。它还具有内置的 JSON 引擎,无需解析 JSON 数据结构并直观地选择 JSON 内容。
高级智能算法
先进的智能算法可以生成目标元素XPath,自动识别网页列表,自动识别分页中的下一页按钮。它不需要分析web请求和源代码,但支持更多的网页集合。
适用于各种 网站
它可以采集 99% 的 Internet 站点,包括单页应用程序 Ajax 加载等动态类型。
指示
第 1 步:设置起始 URL
要采集 网站 数据,首先,我们需要设置进入集合的 URL。例如,如果你想为网站采集国内新闻,你应该将起始URL设置为国内新闻栏目列表的URL,但通常你不会将网站的首页设置为起始地址,因为首页通常收录Latest文章、Popular文章、Recommended文章Chapter等很多列表块,显示的内容也很有限. 一般来说,采集这些列表时不可能采集到完整的信息。
接下来,我们以新浪新闻采集为例,从新浪首页查找国内新闻。不过这个栏目首页的内容还是比较杂乱的,分成了三个子栏目
我们来看看《大陆新闻》的分栏报道

此栏目页面收录一个带有分页的内容列表。通过切换分页,我们可以采集该列下的所有文章,因此这个列表页面非常适合我们采集起始URL。
我们现在将列表 URL 复制到任务编辑框步骤 1 中的文本框中。
如果你想在一个任务中同时采集国内新闻的其他子栏目,你也可以复制另外两个子栏目的列表地址,因为这些子栏目有类似的格式。但是,为了便于导出或发布分类数据,通常不建议将多个列的内容混合在一起。
对于起始 URL,我们还可以批量添加或从 txt 文件导入。比如我们要采集前五个页面,我们也可以这样自定义五个起始页面
需要注意的是,如果这里自定义了多个分页列表,后续的集合配置中将不会启用分页。通常,当我们要采集一个列下的所有文章时,我们只需要将该列的第一页定义为起始URL。如果在后续采集配置中启用了分页,则可以为每个分页列表采集数据。
第二步:①自动生成列表和字段
进入第二步后,对于一些网页,惰性采集器会智能分析页面列表,自动高亮页面列表并生成列表数据,如
然后我们可以修剪数据,例如删除一些不必要的字段
单击图中的三角形符号以显示该字段的详细 采集 配置。单击上面的删除按钮以删除该字段。其余参数将在后续章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的,可以点击“清除字段”,清除所有生成的字段。
如果我们的列表不是手动选择的,那么它将自动列出。如果要取消高亮的列表框,可以点击Find List - List XPaths,清除其中的XPaths,然后确认。
②手动生成列表
单击搜索列表按钮并选择手动选择列表

按照提示,然后左键点击网页列表中的第一行数据
单击第一行,然后在出现提示时单击第二行或其他类似行
单击列表中的任意两行后,将突出显示整个列表。同时,列表中的字段也会生成。如果生成的字段不正确,请单击清除字段以清除下面的所有字段。下一章介绍如何手动选择字段。
③ 手动生成字段
单击“添加字段”按钮

在列表的任意一行单击要提取的元素,例如标题和链接地址,然后用鼠标左键单击标题
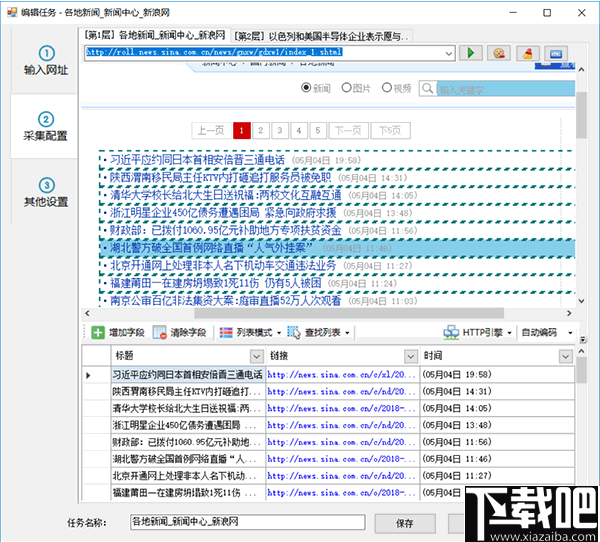
点击网页链接时,会提示是否获取链接地址
如果要提取链接的标题和地址,请单击是。如果您只想提取标题文本,请单击否。在这里我们点击“是”。
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击底部表格中某个字段的标题时,匹配的内容将在网页上以黄色背景突出显示。
如果标签列表中还有其他字段,请单击“添加字段”,然后重复。
④分页设置
当列表有分页时,启用分页时可以采集所有分页列表数据。
页面分页有两种类型
常规分页:有分页栏,显示“下一页”按钮。点击后可以跳转到下一页,比如新浪新闻列表中的上一页
内容采集器(优采云采集器能生成Excel表格,api数据库文件等内容介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-02-01 06:05
优采云采集器v3.0.3.3是一款简单实用、全面高效的网络信息采集软件,优采云 采集器可以生成Excel表格、api数据库文件等,帮助您管理网站数据信息。如果需要对指定的网页数据执行采集,喜欢就赶紧来下载吧!
软件功能
一键提取数据
简单易学,通过可视化界面,点击鼠标即可抓取数据;
快速高效
内置一套高速浏览器内核,配合HTTP引擎模式,实现快速采集数据;
适用于各种网站
可以采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站;
特征
向导模式
简单易用,轻松鼠标点击自动生成;
定期运行的脚本
无需人工即可按计划定时运行;
原装高速核心
自研浏览器内核速度快,远超对手;
智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等);
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则;
各种数据导出
支持Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等;
指示
第 1 步:输入 采集 网址
打开软件,新建一个任务,输入需要采集的网站地址。
第二步:智能分析,全过程自动提取数据
进入第二步后,优采云采集器自动智能分析网页,从中提取列表数据。
步骤 3:将数据导出到表、数据库、网站 等。
运行任务,将采集中的数据导出到Csv、Excel等各种数据库,支持api导出。
常见问题
Q:如何过滤列表中的前N个数据?
1.有时候我们需要对采集收到的列表进行过滤,比如过滤掉第一组数据(在采集表中,过滤掉表列名)
2.点击列表模式菜单设置列表xpath
Q:如何抓包获取cookie并手动设置?
1.首先用谷歌浏览器打开网站为采集,登录。
2. 然后按F12,会出现开发者工具,选择Network
3.然后按 F5 刷新下一页并选择其中一个请求。
4.复制完成后,在优采云采集器中,编辑任务,进入第三步,指定HTTP Header。
变更日志
优化导出数据窗口;
为 XPath 文本框添加了自动完成和语法高亮;
新增导出图片到Excel;
修复了分组调度任务的问题;
修复其他问题; 查看全部
内容采集器(优采云采集器能生成Excel表格,api数据库文件等内容介绍)
优采云采集器v3.0.3.3是一款简单实用、全面高效的网络信息采集软件,优采云 采集器可以生成Excel表格、api数据库文件等,帮助您管理网站数据信息。如果需要对指定的网页数据执行采集,喜欢就赶紧来下载吧!

软件功能
一键提取数据
简单易学,通过可视化界面,点击鼠标即可抓取数据;
快速高效
内置一套高速浏览器内核,配合HTTP引擎模式,实现快速采集数据;
适用于各种网站
可以采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站;
特征
向导模式
简单易用,轻松鼠标点击自动生成;
定期运行的脚本
无需人工即可按计划定时运行;
原装高速核心
自研浏览器内核速度快,远超对手;
智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等);
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则;
各种数据导出
支持Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等;
指示
第 1 步:输入 采集 网址
打开软件,新建一个任务,输入需要采集的网站地址。
第二步:智能分析,全过程自动提取数据
进入第二步后,优采云采集器自动智能分析网页,从中提取列表数据。
步骤 3:将数据导出到表、数据库、网站 等。
运行任务,将采集中的数据导出到Csv、Excel等各种数据库,支持api导出。
常见问题
Q:如何过滤列表中的前N个数据?
1.有时候我们需要对采集收到的列表进行过滤,比如过滤掉第一组数据(在采集表中,过滤掉表列名)
2.点击列表模式菜单设置列表xpath
Q:如何抓包获取cookie并手动设置?
1.首先用谷歌浏览器打开网站为采集,登录。
2. 然后按F12,会出现开发者工具,选择Network
3.然后按 F5 刷新下一页并选择其中一个请求。
4.复制完成后,在优采云采集器中,编辑任务,进入第三步,指定HTTP Header。
变更日志
优化导出数据窗口;
为 XPath 文本框添加了自动完成和语法高亮;
新增导出图片到Excel;
修复了分组调度任务的问题;
修复其他问题;
内容采集器(横琴建站:中小企业在做网站建设时需要注意哪些问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-01-30 12:11
导读:随着企业的快速发展壮大,越来越多的中小企业重视品牌网站建设和营销网站建设,希望借助互联网提升自己的品牌认识并获得更多潜在的合作机会,接触更精准的客户。一个企业的网站建设不像普通的网站,需要深入的行业研究,挖掘自身企业各方面的优势,塑造独特的企业形象,尤其是很多细节,这直接影响到企业网站@网站的作用和目的,那么中小企业在做网站时应该注意哪些问题 建造?下面横琴网站将为大家分享SEO的相关知识。
让我们从两个常见的内容采集工具开始:
(1)优采云采集工具:操作比较简单,免费版可以满足新手站长的数据挖掘需求,但是采集数据的推导需要集成,这是一个更重要的功能它是智能采集,它不需要编写太复杂的规则。
(2)优采云采集器:国内老牌除尘软件。所以很多支持cmssystem采集的插件都可以在市场,如:织梦文章采集、WordPress信息采集、Zblog数据采集等。需要一定的技术力量。
那么,文章的采集应该注意什么?
1、新站清空数据采集
我们知道网站发布初期有一个评价期,如果我们在站开始使用采集到的内容,会对网站评分产生影响,文章容易出现被放到低质量的库中,会出现一个普遍现象:与收录没有排名。
为此,新的网站尽可能的保留了网上原有的内容,当页面的内容没有被完全索引的时候,没必要盲目的提交,或者想提交,你需要采取一定的策略。
2、权威网站采集内容
我们知道搜索引擎不喜欢关闭状态,他们不仅喜欢网站 的入站链接,还喜欢一些出站链接,以使这个生态系统更具相关性。
为此,当你的网站已经积累了一定的权重后,可以通过版权链接适当采集相关内容,需要注意:
(1)保证采集的内容对站内用户有一定的推荐价值,是解决用户需求的好办法。
(2)行业官方文档,一鸣惊人网站,知名专家推荐采集。
3、避免采集网站范围的内容
提到这个问题,很容易让很多人质疑飓风算法对获取的严厉攻击的强调,但是为什么权限网站不在攻击范围之内呢?
这涉及到搜索引擎的本质:满足用户的需求,而网站对优质内容传播的影响也比较重要。
对于中小网站,尽量避免大量的内容采集,直到它具有独特的属性和影响力。
提示:随着熊掌的上线和原创保护的推出,百度仍将努力调整和平衡原创内容和权限网站的排名。原则上应该更倾向于原址先行。
4、如果网站content采集被处罚了怎么办?
Hurricane 算法非常人性化。它只惩罚 采集 部分,但对同一站点上的其他部分几乎没有影响。
所以解决方法很简单,只需要删除采集的内容,设置404页面,然后在百度搜索资源平台提交死链接->网站支持->数据介绍->死链接提交栏。如果您发现 网站 的权重恢复缓慢,您可以在反馈中心提供反馈。
摘要:内容仍然适用于王。关注熊掌号会发现,2019年百度会加大对原创内容的支持,尽量避免采集内容。
横琴网站网络营销托管代理运营服务商,专注于中小企业网络营销技术服务,为中小企业提供企业网站建设、网络营销托管代理运营、SEM托管代理运营、SEO 站群建设、企业网站代理运营、小程序开发推广、广告媒体投放代理运营、美团小红书代理运营、微信公众号代理运营等。致力于成为网络营销外包合作企业托管代理运营服务商。 查看全部
内容采集器(横琴建站:中小企业在做网站建设时需要注意哪些问题)
导读:随着企业的快速发展壮大,越来越多的中小企业重视品牌网站建设和营销网站建设,希望借助互联网提升自己的品牌认识并获得更多潜在的合作机会,接触更精准的客户。一个企业的网站建设不像普通的网站,需要深入的行业研究,挖掘自身企业各方面的优势,塑造独特的企业形象,尤其是很多细节,这直接影响到企业网站@网站的作用和目的,那么中小企业在做网站时应该注意哪些问题 建造?下面横琴网站将为大家分享SEO的相关知识。

让我们从两个常见的内容采集工具开始:
(1)优采云采集工具:操作比较简单,免费版可以满足新手站长的数据挖掘需求,但是采集数据的推导需要集成,这是一个更重要的功能它是智能采集,它不需要编写太复杂的规则。
(2)优采云采集器:国内老牌除尘软件。所以很多支持cmssystem采集的插件都可以在市场,如:织梦文章采集、WordPress信息采集、Zblog数据采集等。需要一定的技术力量。
那么,文章的采集应该注意什么?
1、新站清空数据采集
我们知道网站发布初期有一个评价期,如果我们在站开始使用采集到的内容,会对网站评分产生影响,文章容易出现被放到低质量的库中,会出现一个普遍现象:与收录没有排名。
为此,新的网站尽可能的保留了网上原有的内容,当页面的内容没有被完全索引的时候,没必要盲目的提交,或者想提交,你需要采取一定的策略。
2、权威网站采集内容
我们知道搜索引擎不喜欢关闭状态,他们不仅喜欢网站 的入站链接,还喜欢一些出站链接,以使这个生态系统更具相关性。
为此,当你的网站已经积累了一定的权重后,可以通过版权链接适当采集相关内容,需要注意:
(1)保证采集的内容对站内用户有一定的推荐价值,是解决用户需求的好办法。
(2)行业官方文档,一鸣惊人网站,知名专家推荐采集。
3、避免采集网站范围的内容
提到这个问题,很容易让很多人质疑飓风算法对获取的严厉攻击的强调,但是为什么权限网站不在攻击范围之内呢?
这涉及到搜索引擎的本质:满足用户的需求,而网站对优质内容传播的影响也比较重要。
对于中小网站,尽量避免大量的内容采集,直到它具有独特的属性和影响力。
提示:随着熊掌的上线和原创保护的推出,百度仍将努力调整和平衡原创内容和权限网站的排名。原则上应该更倾向于原址先行。
4、如果网站content采集被处罚了怎么办?
Hurricane 算法非常人性化。它只惩罚 采集 部分,但对同一站点上的其他部分几乎没有影响。
所以解决方法很简单,只需要删除采集的内容,设置404页面,然后在百度搜索资源平台提交死链接->网站支持->数据介绍->死链接提交栏。如果您发现 网站 的权重恢复缓慢,您可以在反馈中心提供反馈。
摘要:内容仍然适用于王。关注熊掌号会发现,2019年百度会加大对原创内容的支持,尽量避免采集内容。
横琴网站网络营销托管代理运营服务商,专注于中小企业网络营销技术服务,为中小企业提供企业网站建设、网络营销托管代理运营、SEM托管代理运营、SEO 站群建设、企业网站代理运营、小程序开发推广、广告媒体投放代理运营、美团小红书代理运营、微信公众号代理运营等。致力于成为网络营销外包合作企业托管代理运营服务商。
内容采集器(WordPress文章内容可以轻松管理工作流程并以有效的格式组织文章内容 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-03-27 16:05
)
WordPress文章内容更新是SEO中最焦虑的事情。每天高质量发布 WordPress文章 内容是一件苦差事。
我们知道搜索引擎会通过蜘蛛抓取我们每日更新的 URL。搜索引擎会根据蜘蛛爬取的url分析我们的WordPress网站的更新频率和文章的内容质量,从而判断是否收录并给出关键词排名,所以维护我们的WordPress网站定期更新和文章内容优化是一项重要的工作。
<p>WordPress文章内容编辑器可以轻松管理工作流程并以有效的格式组织文章内容。通过定时采集发布功能,实现网站的全流程管理,利用内置翻译api和文章SEO编辑模块实现 查看全部
内容采集器(WordPress文章内容可以轻松管理工作流程并以有效的格式组织文章内容
)
WordPress文章内容更新是SEO中最焦虑的事情。每天高质量发布 WordPress文章 内容是一件苦差事。
我们知道搜索引擎会通过蜘蛛抓取我们每日更新的 URL。搜索引擎会根据蜘蛛爬取的url分析我们的WordPress网站的更新频率和文章的内容质量,从而判断是否收录并给出关键词排名,所以维护我们的WordPress网站定期更新和文章内容优化是一项重要的工作。
<p>WordPress文章内容编辑器可以轻松管理工作流程并以有效的格式组织文章内容。通过定时采集发布功能,实现网站的全流程管理,利用内置翻译api和文章SEO编辑模块实现
内容采集器(让我们从两个常见的内容采集工具开始:优采云采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-03-27 16:04
让我们从两个常见的内容采集工具开始:
(1)优采云采集工具:操作比较简单,免费版可以满足新手站长的数据挖掘需求,但是需要集成采集数据推导,其中一个比较重要的功能就是智能采集,不需要写太复杂的规则。
(2)优采云采集器:国内老牌除尘软件,所以很多支持cmssystem采集的插件都可以在市场,如:织梦文章采集、WordPress信息采集、Zblog数据采集等。需要一定的技术力量。
那么,文章的采集应该注意什么?
1、新站清空数据采集
我们知道在网站发帖初期有一个评价期,如果我们在开站时使用采集到的内容,会影响站内收视率,文章容易上当放到低质量的库中,会出现一个普遍现象:与收录没有排名。
为此,新的网站尽可能的保留了网上原有的内容,当页面的内容没有被完全索引的时候,没必要盲目的提交,或者想提交,你需要采取一定的策略。
2、权威网站采集内容
我们知道搜索引擎不喜欢关闭状态,他们不仅喜欢网站 的入站链接,还喜欢一些出站链接,以使这个生态系统更具相关性。
为此,当你的网站已经积累了一定的权重后,可以通过版权链接适当采集相关内容,需要注意:
(1)保证采集的内容对站点上的用户有一定的推荐价值,是满足用户需求的好方法。
(2)行业官方文档,大片网站,名家推荐合集内容。
3、避免采集网站范围的内容
提到这个问题,很容易让很多人质疑飓风算法对获取的严厉攻击的强调,但为什么大名鼎鼎的网站不在攻击范围之内呢?
这涉及到搜索引擎的本质:满足用户的需求,而网站对优质内容传播的影响也比较重要。
对于中小网站,尽量避免大量的内容采集,直到我们有独特的属性和影响力。
提示:随着熊掌的上线和原创保护功能的推出,百度仍将努力调整平衡原创内容和知名网站的排名。原则上应该更倾向于对原网站进行排名。
4、如果网站content采集被处罚了怎么办?
Hurricane 算法非常人性化。它只惩罚 采集 部分,但对同一站点上的其他部分几乎没有影响。
所以解决方法很简单,只需要删除采集的内容,设置404页面,然后在百度搜索资源平台提交死链接->网站支持->数据介绍->死链接提交栏。如果您发现 网站 的权重恢复缓慢,您可以在反馈中心提供反馈。
摘要:内容仍然适用于王。如果关注熊掌号,会发现百度在2019年会加大对原创内容的支持力度,尽量避免采集内容。 查看全部
内容采集器(让我们从两个常见的内容采集工具开始:优采云采集)
让我们从两个常见的内容采集工具开始:
(1)优采云采集工具:操作比较简单,免费版可以满足新手站长的数据挖掘需求,但是需要集成采集数据推导,其中一个比较重要的功能就是智能采集,不需要写太复杂的规则。
(2)优采云采集器:国内老牌除尘软件,所以很多支持cmssystem采集的插件都可以在市场,如:织梦文章采集、WordPress信息采集、Zblog数据采集等。需要一定的技术力量。
那么,文章的采集应该注意什么?
1、新站清空数据采集
我们知道在网站发帖初期有一个评价期,如果我们在开站时使用采集到的内容,会影响站内收视率,文章容易上当放到低质量的库中,会出现一个普遍现象:与收录没有排名。
为此,新的网站尽可能的保留了网上原有的内容,当页面的内容没有被完全索引的时候,没必要盲目的提交,或者想提交,你需要采取一定的策略。
2、权威网站采集内容
我们知道搜索引擎不喜欢关闭状态,他们不仅喜欢网站 的入站链接,还喜欢一些出站链接,以使这个生态系统更具相关性。
为此,当你的网站已经积累了一定的权重后,可以通过版权链接适当采集相关内容,需要注意:
(1)保证采集的内容对站点上的用户有一定的推荐价值,是满足用户需求的好方法。
(2)行业官方文档,大片网站,名家推荐合集内容。
3、避免采集网站范围的内容
提到这个问题,很容易让很多人质疑飓风算法对获取的严厉攻击的强调,但为什么大名鼎鼎的网站不在攻击范围之内呢?
这涉及到搜索引擎的本质:满足用户的需求,而网站对优质内容传播的影响也比较重要。
对于中小网站,尽量避免大量的内容采集,直到我们有独特的属性和影响力。
提示:随着熊掌的上线和原创保护功能的推出,百度仍将努力调整平衡原创内容和知名网站的排名。原则上应该更倾向于对原网站进行排名。
4、如果网站content采集被处罚了怎么办?
Hurricane 算法非常人性化。它只惩罚 采集 部分,但对同一站点上的其他部分几乎没有影响。
所以解决方法很简单,只需要删除采集的内容,设置404页面,然后在百度搜索资源平台提交死链接->网站支持->数据介绍->死链接提交栏。如果您发现 网站 的权重恢复缓慢,您可以在反馈中心提供反馈。
摘要:内容仍然适用于王。如果关注熊掌号,会发现百度在2019年会加大对原创内容的支持力度,尽量避免采集内容。
内容采集器(如何找到合适的网站了解详情才可以下载免费资源?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-03-24 12:03
内容采集器、视频采集器都可以,找些可以免费下载网站看看,比如小说阅读器、可视频网站下载器等等。要找到合适的免费下载站首先要明白免费资源是如何得来的,是通过信息公开、网络爬虫获取还是自己经过分析、转换、抽取,不同情况需要不同技术手段去支持,我就是平时会看一些小说,虽然没有电子书那么全,但肯定有不少,大多会利用云端下载中心(网站如飞扬云起网)。
至于作者和你版权纠纷的问题,现在官方也没有给出定论,比如小说站下载很多都是黄色图片,有些也给了授权,但也许会有赔偿等,毕竟小说网站都是公益性质的,不可能跟黄色公司一样拼命捞钱。再找到合适的网站了解详情才可以下载免费资源。参考:网上有很多人建设论坛,公益型的,我觉得比一些资源分享站,如知乎论坛等要靠谱。
可以试试这个:,但是作者有点不靠谱,觉得不靠谱的话就算了,下载需要会员,
《中华人民共和国著作权法》第八条权利人享有下列积极权利:
一)制作报纸、期刊、杂志的版权;
二)汇编作品、作品集的版权;
三)可以出租作品,
四)修改作品,
五)改编、翻译、注释、整理已有作品而产生的作品,
六)可以请求权利人向其支付报酬;
七)享有对作品进行定价的权利。商业使用别人创作的作品,应当取得著作权人许可,并支付报酬。 查看全部
内容采集器(如何找到合适的网站了解详情才可以下载免费资源?)
内容采集器、视频采集器都可以,找些可以免费下载网站看看,比如小说阅读器、可视频网站下载器等等。要找到合适的免费下载站首先要明白免费资源是如何得来的,是通过信息公开、网络爬虫获取还是自己经过分析、转换、抽取,不同情况需要不同技术手段去支持,我就是平时会看一些小说,虽然没有电子书那么全,但肯定有不少,大多会利用云端下载中心(网站如飞扬云起网)。
至于作者和你版权纠纷的问题,现在官方也没有给出定论,比如小说站下载很多都是黄色图片,有些也给了授权,但也许会有赔偿等,毕竟小说网站都是公益性质的,不可能跟黄色公司一样拼命捞钱。再找到合适的网站了解详情才可以下载免费资源。参考:网上有很多人建设论坛,公益型的,我觉得比一些资源分享站,如知乎论坛等要靠谱。
可以试试这个:,但是作者有点不靠谱,觉得不靠谱的话就算了,下载需要会员,
《中华人民共和国著作权法》第八条权利人享有下列积极权利:
一)制作报纸、期刊、杂志的版权;
二)汇编作品、作品集的版权;
三)可以出租作品,
四)修改作品,
五)改编、翻译、注释、整理已有作品而产生的作品,
六)可以请求权利人向其支付报酬;
七)享有对作品进行定价的权利。商业使用别人创作的作品,应当取得著作权人许可,并支付报酬。
内容采集器(import.io:大数据采集软件集搜客GooSeeker对比说明 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-03-13 15:03
)
最近国外大数据软件采集import.io火了。在获得90万美元天使轮融资后,近日又获得了1300万美元的一轮融资,引起了众多投资者的关注。,我也是出于好奇使用并体验了import.io的神奇功能。我是中国大数据采集软件合集GooSeeker的老用户,所以喜欢把两者放在一起比较。下面我印象最深。的几个功能对比,对应import.io的四大功能:Magic、Extractor、Crawler、Connector,分为两部分。
对data采集比较感兴趣的朋友,希望能起到吸点新意的作用,一起来分析data采集的技术亮点。
1. 魔法 (Import.io) VS 天眼和千面 (Jizouke)
Magic:就像magic这个词的本义“魔法”一样,import.io赋予了Magic一个神奇的功能。只要用户输入 URL,Magic 工具就可以神奇的将网页中的数据整齐、标准地抓取。
如图1所示,输入58同城租房信息URL后,Magic会自动采集网页数据,操作简单。但是可以看到可能会漏掉一些栏目,每页都需要点击“下一页”进行采集,无法自动翻页。当然,还有很多页面几乎没有采集可以下载,比如新浪微博。
总之,我觉得很神奇:
图 1:Magic Autocrawl 示例
上图是import.io的Magic功能截图。它是一个纯网页界面,使用起来非常方便,无需安装额外的软件。综上所述:
GooSeeker的天眼和千面系列:集搜客的天眼和千面分别针对电商和微博发布的数据采集方便的GUI界面,只要输入网址,目标数据就可以标准化、整齐采集下来。
如图2:显示博主的采集工具(微博各种数据都有采集管理界面),进入博主首页的链接,可以调度爬虫,给博主首页下的信息为采集,如微博内容、转发、评论等数据。
图2:GooSeeker微博博主采集界面示例
界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。已结构化和转换的 XML 格式的结果文件。
从上面的分析可以看出,Magic和GooSeeker的天眼和千面操作非常简单,基本都是纯傻瓜式操作,非常适合只想专注于业务问题而做不想被技术问题分心。用户也是纯小白学习数据采集和使用数据结果的良好起点。但是,Magic 在采集 的结果可视化方面比天眼和千眼具有更广泛的适用性。缺点是采集数据量大的场景不可控,而天眼和千面专注于几个主流网站,优点主要体现在能够完成大量数据采集,例如,
2. Extractor (import.io) VS Organizer (Jizouke)
提取器:提取器是翻译中的提取器。如果从实体的角度来理解,它就是一个小程序(可能是一组脚本),从 URL 中提取出想要的信息;如果是从 采集 目标来理解它是从 采集 的角度来理解特定网页的结构规则。与Magic不同的是,import.io的Extractor(以及后面的另外两个功能)是一个可以独立运行的软件,具有非常直观的可视化界面,可以直观的展示提取出来的信息。
如图 3:import.io 的 Extractor 非常类似于修改后的浏览器。在工具栏中输入网址,网页显示出来后,在浏览器中选择要抓取的数据,然后单页就可以将结构的整列规范依次往下采集。
图 3:Extractor 提取数据的示例
GooSeeker Organizer:Jisouke 声称是“建立一个盒子,把你想要的内容放进去”。这个盒子就是所谓的组织者。原理是将需要提取的信息一个一个拖入框内,映射到组织者。Box,采集程序可以自动生成提取器(脚本程序),提取器自动存储在云服务器中,可以分发给全球的网络爬虫进行提取。
如图4所示,import.io顶部的一个工具栏在GooSeeker中展开成一个工作台,在工作台上创建一个盒子,然后通过映射操作将网页上的内容扔到盒子里。把你想要的东西扔进盒子里。原理看似简单,但面对大盒子界面和众多HTML节点,对于新手来说有点压力。当然,界面复杂,以换取能够处理更复杂的情况,因为有更多的控件可用。
图 4:分类 bin 提取数据的示例
综上所述,Extractor和排序框都具有提取信息字段的功能。Extractor操作起来比较简单直观,适用于一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会出现无法提取的问题。这时候就突显了吉搜克排序框的优势,特别复杂的情况下,可以使用自定义的xpath来定位数据。
如有疑问,您可以或
查看全部
内容采集器(import.io:大数据采集软件集搜客GooSeeker对比说明
)
最近国外大数据软件采集import.io火了。在获得90万美元天使轮融资后,近日又获得了1300万美元的一轮融资,引起了众多投资者的关注。,我也是出于好奇使用并体验了import.io的神奇功能。我是中国大数据采集软件合集GooSeeker的老用户,所以喜欢把两者放在一起比较。下面我印象最深。的几个功能对比,对应import.io的四大功能:Magic、Extractor、Crawler、Connector,分为两部分。
对data采集比较感兴趣的朋友,希望能起到吸点新意的作用,一起来分析data采集的技术亮点。
1. 魔法 (Import.io) VS 天眼和千面 (Jizouke)
Magic:就像magic这个词的本义“魔法”一样,import.io赋予了Magic一个神奇的功能。只要用户输入 URL,Magic 工具就可以神奇的将网页中的数据整齐、标准地抓取。
如图1所示,输入58同城租房信息URL后,Magic会自动采集网页数据,操作简单。但是可以看到可能会漏掉一些栏目,每页都需要点击“下一页”进行采集,无法自动翻页。当然,还有很多页面几乎没有采集可以下载,比如新浪微博。
总之,我觉得很神奇:
图 1:Magic Autocrawl 示例
上图是import.io的Magic功能截图。它是一个纯网页界面,使用起来非常方便,无需安装额外的软件。综上所述:
GooSeeker的天眼和千面系列:集搜客的天眼和千面分别针对电商和微博发布的数据采集方便的GUI界面,只要输入网址,目标数据就可以标准化、整齐采集下来。
如图2:显示博主的采集工具(微博各种数据都有采集管理界面),进入博主首页的链接,可以调度爬虫,给博主首页下的信息为采集,如微博内容、转发、评论等数据。
图2:GooSeeker微博博主采集界面示例
界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。已结构化和转换的 XML 格式的结果文件。
从上面的分析可以看出,Magic和GooSeeker的天眼和千面操作非常简单,基本都是纯傻瓜式操作,非常适合只想专注于业务问题而做不想被技术问题分心。用户也是纯小白学习数据采集和使用数据结果的良好起点。但是,Magic 在采集 的结果可视化方面比天眼和千眼具有更广泛的适用性。缺点是采集数据量大的场景不可控,而天眼和千面专注于几个主流网站,优点主要体现在能够完成大量数据采集,例如,
2. Extractor (import.io) VS Organizer (Jizouke)
提取器:提取器是翻译中的提取器。如果从实体的角度来理解,它就是一个小程序(可能是一组脚本),从 URL 中提取出想要的信息;如果是从 采集 目标来理解它是从 采集 的角度来理解特定网页的结构规则。与Magic不同的是,import.io的Extractor(以及后面的另外两个功能)是一个可以独立运行的软件,具有非常直观的可视化界面,可以直观的展示提取出来的信息。
如图 3:import.io 的 Extractor 非常类似于修改后的浏览器。在工具栏中输入网址,网页显示出来后,在浏览器中选择要抓取的数据,然后单页就可以将结构的整列规范依次往下采集。
图 3:Extractor 提取数据的示例
GooSeeker Organizer:Jisouke 声称是“建立一个盒子,把你想要的内容放进去”。这个盒子就是所谓的组织者。原理是将需要提取的信息一个一个拖入框内,映射到组织者。Box,采集程序可以自动生成提取器(脚本程序),提取器自动存储在云服务器中,可以分发给全球的网络爬虫进行提取。
如图4所示,import.io顶部的一个工具栏在GooSeeker中展开成一个工作台,在工作台上创建一个盒子,然后通过映射操作将网页上的内容扔到盒子里。把你想要的东西扔进盒子里。原理看似简单,但面对大盒子界面和众多HTML节点,对于新手来说有点压力。当然,界面复杂,以换取能够处理更复杂的情况,因为有更多的控件可用。
图 4:分类 bin 提取数据的示例
综上所述,Extractor和排序框都具有提取信息字段的功能。Extractor操作起来比较简单直观,适用于一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会出现无法提取的问题。这时候就突显了吉搜克排序框的优势,特别复杂的情况下,可以使用自定义的xpath来定位数据。
如有疑问,您可以或
内容采集器(网站SEO相关规则还是需要了解的?采集器 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-03-12 13:06
)
关键词采集器 是我们经常用于网站数据采集 和内容采集 的工具。 关键词采集器对新站长非常友好,不用我们填写复杂的采集规则就可以使用。并具有采集、翻译、伪原创、发布、推送等功能,可实现对网站内容的全流程管理。
关键词采集器可以一次创建多个采集任务,实现不同的网站同时采集,支持关键词pan采集。 采集器内的所有采集数据都可以实时查看。
关键词采集器我们只需要输入关键词完成网络采集,点击相关选项完成设置,然后开始轮询全平台采集,采集内容是各大平台的关键词下拉词,保证了采集内容的实时准确。
Orientation采集我们只需要输入目标的URL网站我们需要采集,我们可以在插件中预览。通过选择我们需要的数据和内容,我们就可以完成设置了。内置增量 采集 功能确保重复内容过滤。
关键词采集器在< @采集;支持选择保留H、Strong、span等标签; 伪原创保留关键词;敏感词被替换; 文章标题插入关键词; 关键词生成内部/外部链接等。支持全网几乎所有主要cms平台的发布。自动伪原创发布后自动推送到搜索引擎,大大提高网站收录的效率。
通过关键词采集器,我们可以让我们的网站定期持续更新。虽然采集器可以给我们带来方便,但我们想让网站保持长期的运营动力,网站SEO相关规则还是需要了解的。
一、title 标题不可随意更改
在网站SEO工作中,网站title标题可以说是一把双刃剑。如果选择好的关键词并坚持下去,可以给网站带来很大的关注权,但选择不合适的关键词或频繁更换标题可能带来减轻网站权重的可能。所以我们的关键词确定后,不要随意更改。
二、META标签不会随意改变
SEOER在优化网站时不会随意更改标题,也不会随意使用mete标签。我们经常谈论的三个主要标签是标题、描述和关键字。所谓好的元标签,并不是每个页面都需要做的,做好元标签直接影响到优化。
三、使用 DIV+CSS 的程序
虽然用程序做网站的方法有很多,但是用DIV+CSS做的程序,代码编程少,对网站收录更有好处。因为这种模式更容易突出文本的内容,而且DIV是搜索引擎最喜欢的方式,网站样式都是CSS中的,比较容易被收录下的搜索引擎这个结构。
四、网站的程序不容易改
网站的程序可以说是网站的核心。随机替换网站程序会导致网站的结构发生变化,导致URL失效。 网站@ >收录清除。由于网站的变异,蜘蛛会认为网站有异常行为,加强对网站的监控,从而对网站失去信任,严重时会会影响减重的可能性。
五、使用静态页面
相信很多人对此深有体会,因为在使用搜索引擎的过程中,用HTML编写的静态页面往往排名更高,也更容易获得可观的流量
在我们的SEO工作中,经常会有很多机械性的重复性工作,我们可以通过工具来实现。和网站发布一样,关键词采集器也有自己的发布功能,支持全天挂机发布,另外,采集器还支持查看绑定< @网站收录、蜘蛛、体重数据等,让我们的SEOER通过数据分析网站的情况,实时做出相应的调整。
查看全部
内容采集器(网站SEO相关规则还是需要了解的?采集器
)
关键词采集器 是我们经常用于网站数据采集 和内容采集 的工具。 关键词采集器对新站长非常友好,不用我们填写复杂的采集规则就可以使用。并具有采集、翻译、伪原创、发布、推送等功能,可实现对网站内容的全流程管理。
关键词采集器可以一次创建多个采集任务,实现不同的网站同时采集,支持关键词pan采集。 采集器内的所有采集数据都可以实时查看。
关键词采集器我们只需要输入关键词完成网络采集,点击相关选项完成设置,然后开始轮询全平台采集,采集内容是各大平台的关键词下拉词,保证了采集内容的实时准确。
Orientation采集我们只需要输入目标的URL网站我们需要采集,我们可以在插件中预览。通过选择我们需要的数据和内容,我们就可以完成设置了。内置增量 采集 功能确保重复内容过滤。
关键词采集器在< @采集;支持选择保留H、Strong、span等标签; 伪原创保留关键词;敏感词被替换; 文章标题插入关键词; 关键词生成内部/外部链接等。支持全网几乎所有主要cms平台的发布。自动伪原创发布后自动推送到搜索引擎,大大提高网站收录的效率。
通过关键词采集器,我们可以让我们的网站定期持续更新。虽然采集器可以给我们带来方便,但我们想让网站保持长期的运营动力,网站SEO相关规则还是需要了解的。
一、title 标题不可随意更改
在网站SEO工作中,网站title标题可以说是一把双刃剑。如果选择好的关键词并坚持下去,可以给网站带来很大的关注权,但选择不合适的关键词或频繁更换标题可能带来减轻网站权重的可能。所以我们的关键词确定后,不要随意更改。
二、META标签不会随意改变
SEOER在优化网站时不会随意更改标题,也不会随意使用mete标签。我们经常谈论的三个主要标签是标题、描述和关键字。所谓好的元标签,并不是每个页面都需要做的,做好元标签直接影响到优化。
三、使用 DIV+CSS 的程序
虽然用程序做网站的方法有很多,但是用DIV+CSS做的程序,代码编程少,对网站收录更有好处。因为这种模式更容易突出文本的内容,而且DIV是搜索引擎最喜欢的方式,网站样式都是CSS中的,比较容易被收录下的搜索引擎这个结构。
四、网站的程序不容易改
网站的程序可以说是网站的核心。随机替换网站程序会导致网站的结构发生变化,导致URL失效。 网站@ >收录清除。由于网站的变异,蜘蛛会认为网站有异常行为,加强对网站的监控,从而对网站失去信任,严重时会会影响减重的可能性。
五、使用静态页面
相信很多人对此深有体会,因为在使用搜索引擎的过程中,用HTML编写的静态页面往往排名更高,也更容易获得可观的流量
在我们的SEO工作中,经常会有很多机械性的重复性工作,我们可以通过工具来实现。和网站发布一样,关键词采集器也有自己的发布功能,支持全天挂机发布,另外,采集器还支持查看绑定< @网站收录、蜘蛛、体重数据等,让我们的SEOER通过数据分析网站的情况,实时做出相应的调整。
内容采集器(公文写作怎么写?这方面的神器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-03-12 05:22
最近突然想到了写公文的话题。虽然后台问这个问题的粉丝不多,但毕竟我采集了很多这方面的资源,所以正好抽空整理一下今天想分享的内容,可以解决的. 写公文时,会出现参考资料不足、参考大纲不足、参考范文不足、校对不便、找不到合适的红头模板、排版不正确等问题。其实并不是只是写官方文件。介绍的工具是各种文章写作、论文排版、职场编码的难得神器!1 辅助写作的神器我可以保证用以下写作神器,什么报告,摘要,经验、通知等你在写吗?没关系1.1 WPS智能写作(小程序)2022年2月3月12日更新:最先进的维护技术是金山软件出品的这个小程序!完全免费,一键AI智能写作,只需要输入关键词标题,即刻帮你生成范文。同时,它还采用了深度学习模型,在小程序中添加了一些特定的场景和定位,可以根据您的扫码使用小程序对找到的素材进行优化。同时网页版也进行了更新:无需注册登录,打开网站输入关键词,然后点击“智能写作”稍等片刻就会生成一篇短文. 如果不满意,也可以点击“更改”1.2 知文知语(网页)网址:不过体验了所有的工具,最良心的一定是这一款,不仅完全免费,而且功能强大!在首页,可以快速搜索政策相关文档,每个文章都有原文链接。据官方介绍,他们总共提供了50+国家部委、200+地方政策委员会和办公室,100W+数量的政策文件,政策关联栏目中列出了100G+的政策文件总存储容量。根据关键词,可以将搜索结果以“机构-政策文件”关系图的形式给出,清晰明了。不仅如此,这个平台还提供免费的文档写作。辅助的右侧是正文的写作部分,左侧可以快速搜索相关政策文件和解释。切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助工具网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 左侧可快速搜索相关政策文件及解读。切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 左侧可快速搜索相关政策文件及解读。切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助工具网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助工具网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助工具网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 提供各种报告写作提纲1.3 Weisi(网页)网址:这也是一个写作辅助网站,但功能上,可能比上面那个网站强!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 提供各种报告写作提纲1.3 Weisi(网页)网址:这也是一个写作辅助网站,但功能上,可能比上面那个网站强!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 写作。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 写作。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 查看全部
内容采集器(公文写作怎么写?这方面的神器)
最近突然想到了写公文的话题。虽然后台问这个问题的粉丝不多,但毕竟我采集了很多这方面的资源,所以正好抽空整理一下今天想分享的内容,可以解决的. 写公文时,会出现参考资料不足、参考大纲不足、参考范文不足、校对不便、找不到合适的红头模板、排版不正确等问题。其实并不是只是写官方文件。介绍的工具是各种文章写作、论文排版、职场编码的难得神器!1 辅助写作的神器我可以保证用以下写作神器,什么报告,摘要,经验、通知等你在写吗?没关系1.1 WPS智能写作(小程序)2022年2月3月12日更新:最先进的维护技术是金山软件出品的这个小程序!完全免费,一键AI智能写作,只需要输入关键词标题,即刻帮你生成范文。同时,它还采用了深度学习模型,在小程序中添加了一些特定的场景和定位,可以根据您的扫码使用小程序对找到的素材进行优化。同时网页版也进行了更新:无需注册登录,打开网站输入关键词,然后点击“智能写作”稍等片刻就会生成一篇短文. 如果不满意,也可以点击“更改”1.2 知文知语(网页)网址:不过体验了所有的工具,最良心的一定是这一款,不仅完全免费,而且功能强大!在首页,可以快速搜索政策相关文档,每个文章都有原文链接。据官方介绍,他们总共提供了50+国家部委、200+地方政策委员会和办公室,100W+数量的政策文件,政策关联栏目中列出了100G+的政策文件总存储容量。根据关键词,可以将搜索结果以“机构-政策文件”关系图的形式给出,清晰明了。不仅如此,这个平台还提供免费的文档写作。辅助的右侧是正文的写作部分,左侧可以快速搜索相关政策文件和解释。切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助工具网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 左侧可快速搜索相关政策文件及解读。切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 左侧可快速搜索相关政策文件及解读。切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助工具网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助工具网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 切换到写作素材栏,输入一个关键词,可以快速搜索公文写作中的常用词句。写作提纲栏,提供了各种报告写作提纲1.3微丝(网页)网址:这也是写作辅助工具网站,但功能上,可能比上面那个要强网站!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 提供各种报告写作提纲1.3 Weisi(网页)网址:这也是一个写作辅助网站,但功能上,可能比上面那个网站强!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 提供各种报告写作提纲1.3 Weisi(网页)网址:这也是一个写作辅助网站,但功能上,可能比上面那个网站强!▲在写作和查询的同时,还可以随时在右侧查询相关词、古诗词、名言,对于一般的文章写作也很有帮助。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 写作。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内 写作。更重要的是,可以快速搜索相关公文资料,查询相关规划,政策内
内容采集器(内容采集器不就是免费的么?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-09 21:01
内容采集器的运营人员绝对不想让读者看到自己支持,但也不得不支持的东西。采集器有几个反馈渠道,而且在不同运营人员的业务范围内,不同时间内实施会有不同。现在大家比较关心的一个问题是:你们采集器的目标是什么?对用户而言,这里面又是怎么样的目标?就我的理解而言,采集器最初的目标是把用户的信息转化为商业价值。在这个基础上,产品功能是展示,第三方服务是收费。
像支付宝,以及facebook都有最初的目标。这就导致,除了第三方服务的售卖以外,主要就是收费。这也是我们定位的第三方服务包含的两个因素:有商业价值的第三方服务。
采集器只不过是一个模仿工具而已,功能上有所扩展,但是核心的功能依然是爬虫,只是把信息的来源作为了条件,不过这样的一个采集工具有其局限性,因为找不到全网信息来源,所以收费是必然的。本人是做爬虫的,对于我们而言,手工爬虫是必须,自动爬虫只是锦上添花,基于自动爬虫所建立的辅助性爬虫也是可用的,至于你喜欢免费的,或者说什么微爬虫之类的我觉得就不算了。
采集器做的目标就是为了更多的免费,采集器是为了提供信息服务来为用户赚钱而存在的。采集器不就是免费的么?用户在用免费的工具解决问题时感到满足,这才是采集器的真正目标,其它都是次要的,至于为了用户,如果说你用采集器来满足你的某一方面需求,他自然知道你喜欢什么,不喜欢什么,于是也就满足你,或者干脆收钱给你免费了。 查看全部
内容采集器(内容采集器不就是免费的么?(图))
内容采集器的运营人员绝对不想让读者看到自己支持,但也不得不支持的东西。采集器有几个反馈渠道,而且在不同运营人员的业务范围内,不同时间内实施会有不同。现在大家比较关心的一个问题是:你们采集器的目标是什么?对用户而言,这里面又是怎么样的目标?就我的理解而言,采集器最初的目标是把用户的信息转化为商业价值。在这个基础上,产品功能是展示,第三方服务是收费。
像支付宝,以及facebook都有最初的目标。这就导致,除了第三方服务的售卖以外,主要就是收费。这也是我们定位的第三方服务包含的两个因素:有商业价值的第三方服务。
采集器只不过是一个模仿工具而已,功能上有所扩展,但是核心的功能依然是爬虫,只是把信息的来源作为了条件,不过这样的一个采集工具有其局限性,因为找不到全网信息来源,所以收费是必然的。本人是做爬虫的,对于我们而言,手工爬虫是必须,自动爬虫只是锦上添花,基于自动爬虫所建立的辅助性爬虫也是可用的,至于你喜欢免费的,或者说什么微爬虫之类的我觉得就不算了。
采集器做的目标就是为了更多的免费,采集器是为了提供信息服务来为用户赚钱而存在的。采集器不就是免费的么?用户在用免费的工具解决问题时感到满足,这才是采集器的真正目标,其它都是次要的,至于为了用户,如果说你用采集器来满足你的某一方面需求,他自然知道你喜欢什么,不喜欢什么,于是也就满足你,或者干脆收钱给你免费了。
内容采集器(一门强大的开发语言,正则表达式方法捕获 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2022-03-08 21:06
)
开幕
作为世界上使用最广泛的语言,Java以其高效、可移植(跨平台)、代码健壮性和强大的可扩展性深受应用开发者的喜爱。作为一门强大的开发语言,正则表达式在其中的应用当然是必不可少的,而掌握正则表达式的能力也是那些资深程序员开发技能的体现,成为一名合格的网站开发程序员(尤其是前端开发),需要正则表达式。
最近由于一些需要,使用java和regularity,做了一个足球网站数据采集程序;由于是第一次做关于java的html页面数据采集,难免在网上找了很多资料,但是发现广泛使用的java在使用规律做html采集(中文)文章很少,他们只是在说java正则的概念,实际网页中并没有真正用到html采集,例子教程也很少(虽然java有自带的Html Parser,而且功能很强大),但我个人认为作为这样一个根深蒂固的正则表达式,应该是相关的java示例教程应该是多而全的。所以在完成了java版的html数据采集程序之后,我打算写一个html页面<
本期概述
本期我们将学习如何阅读网页源代码,通过分组规律动态抓取我们需要的网页数据。同时,在接下来的几期中,我们将继续学习如何将捕获的游戏数据存储在【数据存储】中。进入数据库(MySql),【数据查询】如何查询我们想看的比赛记录,【远程操作】通过客户端远程访问和操作服务器到采集,存储和查询数据。
关于组规律性
说到正则表达式如何帮助java执行html页面采集,这里需要提一下正则表达式中的group方法(代码如下)。
import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br />/**<br />* Group 类 用于匹配和抓取 html页面的数据<br />* @author SoFlash - 博客园 http://www.cnblogs.com/longwu<br />*/<br />public class Group {<br /><br />public static void main(String[] args) {<br />// Pattern 用于编译正则 这里用到了3个正则 分别用括号()包住<br />// 第1个正则用于匹配URL 当然这里的正则不一定准确 这个匹配URL的正则就是错误的 只是在这里刚好能匹配出来<br />// 第2个正则是用于匹配标题 SoFlash的<br />// 第3个正则用于匹配日期<br /> /* 这里只用了一条语句便把url,标题和日期全部给匹配出来了 */<br /> Pattern p = Pattern<br /> .compile("='(\\w.+)'>(\\w.+[a-zA-Z])-(\\d{1,2}\\.\\d{1,2}\\.\\d{4})");<br /> String s = "<a href='http://www.cnblogs.com/longwu% ... %3Bbr /> Matcher m = p.matcher(s);<br />while (m.find()) {<br />// 通过调用group()方法里的索引 将url,标题和日期全部给打印出来<br /> System.out.println("打印出url链接:" + m.group(1));<br /> System.out.println("打印出标题:" + m.group(2));<br /> System.out.println("打印出日期:" + m.group(3));<br /> System.out.println();<br /> }<br /> System.out.println("group方法捕获的数据个数:" + m.groupCount() + "个");<br /> }<br />}
让我们看看输出:
打印出url链接:
打印出标题:SoFlash
打印日期:12.22.2011
group 方法捕获的数据数量:3
想详细了解正则在java中的应用的朋友,请看JAVA正则表达式(超详细)
如果你之前没有学过正则表达式,可以看看这个揭秘正则表达式
页面采集实例
好了,group方法已经介绍完了,我们来使用group常规采集a football网站页面的数据
页面链接:2011-2012赛季英超球队战绩
首先,我们阅读整个 html 页面并将其打印出来(代码如下)。
public static void main(String[] args) {<br /><br /> String strUrl = "http://www.footballresults.org ... %3Bbr />try {<br />// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径<br />// 更多可以看看 http://wenku.baidu.com/view/81 ... %3Bbr /> URL url = new URL(strUrl);<br />// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符<br />// 更多可以看看 http://blog.sina.com.cn/s/blog ... %3Bbr /> InputStreamReader isr = new InputStreamReader(url.openStream(),<br /> "utf-8"); // 统一使用utf-8 编码模式<br />// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符<br /> BufferedReader br = new BufferedReader(isr);<br />// 如果 BufferedReader 读到的内容不为空<br /> while (br.readLine() != null) {<br />// 则打印出来 这里打印出来的结果 应该是整个网站的<br /> System.out.println(br.readLine());<br /> }<br /> br.close(); // 读取完成后关闭读取器<br /> } catch (IOException e) {<br />// 如果出错 抛出异常<br /> e.printStackTrace();<br /> }<br /> }
打印出来的结果就是整个html页面的源码(下面是部分截图)。
至此,html源码已经成功采集down了。但是,我们要的不是整个html源代码,而是网页上的游戏数据。
首先我们分析html源码结构,来到2011-2012英超球队战绩页面,右键“查看源文件”(其他浏览器可能称为源代码或相关)。
我们来看看它内部的html代码结构和我们需要的数据。
其对应的页面数据
这时候强大的正则表达式就派上用场了,我们需要写几个正则表达式来捕捉团队数据。
这里需要三个正则表达式:日期正则表达式、两队正则表达式(主队和客队)和比赛结果正则表达式。
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";//日期规则
String regularTwoTeam = ">[^]*"; //团队常规
String regularResult = ">(\\d{1,2}-\\d{1,2})"; //游戏结果有规律
写好正则后,我们就可以用正则去抓取我们想要的数据了。
首先,我们编写一个 GroupMethod 类,其中收录用于抓取 html 页面数据的 regularGroup() 方法。
import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br />/**<br /> * GroupMethod类 用于匹配并抓去 Html上我们想要的内容<br /> * @author SoFlash - 博客园 http://www.cnblogs.com/longwu<br />*/<br />public class GroupMethod {<br />// 传入2个字符串参数 一个是pattern(我们使用的正则) 另一个matcher是html源代码<br /> public String regularGroup(String pattern, String matcher) {<br /> Pattern p = Pattern.compile(pattern, Pattern.CASE_INSENSITIVE);<br /> Matcher m = p.matcher(matcher);<br />if (m.find()) { // 如果读到<br /> return m.group();// 返回捕获的数据<br /> } else {<br />return ""; // 否则返回一个空字符串<br /> }<br /> }<br />}
然后在main函数中实现html页面的数据抓取。
<p>import java.io.BufferedReader;<br />import java.io.IOException;<br />import java.io.InputStreamReader;<br />import java.net.URL;<br />/**<br /> * Main主函数 用于数据采集<br /> * @author SoFlash - 博客园 http://www.cnblogs.com/longwu<br />*/<br />public class Main {<br /><br />public static void main(String[] args) {<br />// 首先用一个字符串 来装载网页链接<br /> String strUrl = "http://www.footballresults.org ... %3Bbr />try {<br />// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径<br />// 更多可以看看 http://wenku.baidu.com/view/81 ... %3Bbr /> URL url = new URL(strUrl);<br />// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符<br />// 更多可以看看 http://blog.sina.com.cn/s/blog ... %3Bbr /> InputStreamReader isr = new InputStreamReader(url.openStream(),<br /> "utf-8"); // 统一使用utf-8 编码模式<br />// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符<br /> BufferedReader br = new BufferedReader(isr);<br /> String strRead = ""; // 新增一个空字符串strRead来装载 BufferedReader 读取到的内容<br /><br />// 定义3个正则 用于匹配我们需要的数据<br /> String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";<br /> String regularTwoTeam = ">[^]*</a>";<br /> String regularResult = ">(\\d{1,2}-\\d{1,2})";<br /><br />// 创建一个GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法<br /> GroupMethod gMethod = new GroupMethod();<br />int i =0; //定义一个i来记录循环次数 即收集到的球队比赛结果数<br /> int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的<br />// 开始读取数据 如果读到的数据不为空 则往里面读<br /> while ((strRead = br.readLine()) != null) {<br />/**<br /> * 用于捕获日期数据<br />*/<br /> String strGet = gMethod.regularGroup(regularDate, strRead);<br />//如果捕获到了符合条件的 日期数据 则打印出来 <br /> if (!strGet.equals("")) {<br /> System.out.println("Date:" + strGet);<br />//这里索引+1 是用于获取后期的球队数据<br /> ++index; //因为在html页面里 源代码里 球队数据是在刚好在日期之后 <br /> }<br />/**<br /> * 用于获取2个球队的数据<br />*/<br /> strGet = gMethod.regularGroup(regularTwoTeam, strRead);<br />if (!strGet.equals("") && index == 1) { //索引为1的是主队数据<br />// 通过substring方法 分离出 主队数据<br /> strGet = strGet.substring(1, strGet.indexOf("</a>"));<br /> System.out.println("HomeTeam:" + strGet); //打印出主队<br /> index++; //索引+1之后 为2了<br />// 通过substring方法 分离出 客队<br /> } else if (!strGet.equals("") && index == 2) { //这里索引为2的是客队数据<br /> strGet = strGet.substring(1, strGet.indexOf("</a>"));<br /> System.out.println("AwayTeam:" + strGet); //打印出客队 <br /> index = 0;<br /> }<br />/**<br /> * 用于获取比赛结果<br />*/<br /> strGet = gMethod.regularGroup(regularResult, strRead);<br />if (!strGet.equals("")) {<br />//这里同样用到了substring方法 来剔除' 查看全部
内容采集器(一门强大的开发语言,正则表达式方法捕获
)
开幕
作为世界上使用最广泛的语言,Java以其高效、可移植(跨平台)、代码健壮性和强大的可扩展性深受应用开发者的喜爱。作为一门强大的开发语言,正则表达式在其中的应用当然是必不可少的,而掌握正则表达式的能力也是那些资深程序员开发技能的体现,成为一名合格的网站开发程序员(尤其是前端开发),需要正则表达式。
最近由于一些需要,使用java和regularity,做了一个足球网站数据采集程序;由于是第一次做关于java的html页面数据采集,难免在网上找了很多资料,但是发现广泛使用的java在使用规律做html采集(中文)文章很少,他们只是在说java正则的概念,实际网页中并没有真正用到html采集,例子教程也很少(虽然java有自带的Html Parser,而且功能很强大),但我个人认为作为这样一个根深蒂固的正则表达式,应该是相关的java示例教程应该是多而全的。所以在完成了java版的html数据采集程序之后,我打算写一个html页面<
本期概述
本期我们将学习如何阅读网页源代码,通过分组规律动态抓取我们需要的网页数据。同时,在接下来的几期中,我们将继续学习如何将捕获的游戏数据存储在【数据存储】中。进入数据库(MySql),【数据查询】如何查询我们想看的比赛记录,【远程操作】通过客户端远程访问和操作服务器到采集,存储和查询数据。
关于组规律性
说到正则表达式如何帮助java执行html页面采集,这里需要提一下正则表达式中的group方法(代码如下)。
import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br />/**<br />* Group 类 用于匹配和抓取 html页面的数据<br />* @author SoFlash - 博客园 http://www.cnblogs.com/longwu<br />*/<br />public class Group {<br /><br />public static void main(String[] args) {<br />// Pattern 用于编译正则 这里用到了3个正则 分别用括号()包住<br />// 第1个正则用于匹配URL 当然这里的正则不一定准确 这个匹配URL的正则就是错误的 只是在这里刚好能匹配出来<br />// 第2个正则是用于匹配标题 SoFlash的<br />// 第3个正则用于匹配日期<br /> /* 这里只用了一条语句便把url,标题和日期全部给匹配出来了 */<br /> Pattern p = Pattern<br /> .compile("='(\\w.+)'>(\\w.+[a-zA-Z])-(\\d{1,2}\\.\\d{1,2}\\.\\d{4})");<br /> String s = "<a href='http://www.cnblogs.com/longwu% ... %3Bbr /> Matcher m = p.matcher(s);<br />while (m.find()) {<br />// 通过调用group()方法里的索引 将url,标题和日期全部给打印出来<br /> System.out.println("打印出url链接:" + m.group(1));<br /> System.out.println("打印出标题:" + m.group(2));<br /> System.out.println("打印出日期:" + m.group(3));<br /> System.out.println();<br /> }<br /> System.out.println("group方法捕获的数据个数:" + m.groupCount() + "个");<br /> }<br />}
让我们看看输出:
打印出url链接:
打印出标题:SoFlash
打印日期:12.22.2011
group 方法捕获的数据数量:3
想详细了解正则在java中的应用的朋友,请看JAVA正则表达式(超详细)
如果你之前没有学过正则表达式,可以看看这个揭秘正则表达式
页面采集实例
好了,group方法已经介绍完了,我们来使用group常规采集a football网站页面的数据
页面链接:2011-2012赛季英超球队战绩
首先,我们阅读整个 html 页面并将其打印出来(代码如下)。
public static void main(String[] args) {<br /><br /> String strUrl = "http://www.footballresults.org ... %3Bbr />try {<br />// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径<br />// 更多可以看看 http://wenku.baidu.com/view/81 ... %3Bbr /> URL url = new URL(strUrl);<br />// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符<br />// 更多可以看看 http://blog.sina.com.cn/s/blog ... %3Bbr /> InputStreamReader isr = new InputStreamReader(url.openStream(),<br /> "utf-8"); // 统一使用utf-8 编码模式<br />// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符<br /> BufferedReader br = new BufferedReader(isr);<br />// 如果 BufferedReader 读到的内容不为空<br /> while (br.readLine() != null) {<br />// 则打印出来 这里打印出来的结果 应该是整个网站的<br /> System.out.println(br.readLine());<br /> }<br /> br.close(); // 读取完成后关闭读取器<br /> } catch (IOException e) {<br />// 如果出错 抛出异常<br /> e.printStackTrace();<br /> }<br /> }
打印出来的结果就是整个html页面的源码(下面是部分截图)。
至此,html源码已经成功采集down了。但是,我们要的不是整个html源代码,而是网页上的游戏数据。
首先我们分析html源码结构,来到2011-2012英超球队战绩页面,右键“查看源文件”(其他浏览器可能称为源代码或相关)。
我们来看看它内部的html代码结构和我们需要的数据。
其对应的页面数据
这时候强大的正则表达式就派上用场了,我们需要写几个正则表达式来捕捉团队数据。
这里需要三个正则表达式:日期正则表达式、两队正则表达式(主队和客队)和比赛结果正则表达式。
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";//日期规则
String regularTwoTeam = ">[^]*"; //团队常规
String regularResult = ">(\\d{1,2}-\\d{1,2})"; //游戏结果有规律
写好正则后,我们就可以用正则去抓取我们想要的数据了。
首先,我们编写一个 GroupMethod 类,其中收录用于抓取 html 页面数据的 regularGroup() 方法。
import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br />/**<br /> * GroupMethod类 用于匹配并抓去 Html上我们想要的内容<br /> * @author SoFlash - 博客园 http://www.cnblogs.com/longwu<br />*/<br />public class GroupMethod {<br />// 传入2个字符串参数 一个是pattern(我们使用的正则) 另一个matcher是html源代码<br /> public String regularGroup(String pattern, String matcher) {<br /> Pattern p = Pattern.compile(pattern, Pattern.CASE_INSENSITIVE);<br /> Matcher m = p.matcher(matcher);<br />if (m.find()) { // 如果读到<br /> return m.group();// 返回捕获的数据<br /> } else {<br />return ""; // 否则返回一个空字符串<br /> }<br /> }<br />}
然后在main函数中实现html页面的数据抓取。
<p>import java.io.BufferedReader;<br />import java.io.IOException;<br />import java.io.InputStreamReader;<br />import java.net.URL;<br />/**<br /> * Main主函数 用于数据采集<br /> * @author SoFlash - 博客园 http://www.cnblogs.com/longwu<br />*/<br />public class Main {<br /><br />public static void main(String[] args) {<br />// 首先用一个字符串 来装载网页链接<br /> String strUrl = "http://www.footballresults.org ... %3Bbr />try {<br />// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径<br />// 更多可以看看 http://wenku.baidu.com/view/81 ... %3Bbr /> URL url = new URL(strUrl);<br />// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符<br />// 更多可以看看 http://blog.sina.com.cn/s/blog ... %3Bbr /> InputStreamReader isr = new InputStreamReader(url.openStream(),<br /> "utf-8"); // 统一使用utf-8 编码模式<br />// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符<br /> BufferedReader br = new BufferedReader(isr);<br /> String strRead = ""; // 新增一个空字符串strRead来装载 BufferedReader 读取到的内容<br /><br />// 定义3个正则 用于匹配我们需要的数据<br /> String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";<br /> String regularTwoTeam = ">[^]*</a>";<br /> String regularResult = ">(\\d{1,2}-\\d{1,2})";<br /><br />// 创建一个GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法<br /> GroupMethod gMethod = new GroupMethod();<br />int i =0; //定义一个i来记录循环次数 即收集到的球队比赛结果数<br /> int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的<br />// 开始读取数据 如果读到的数据不为空 则往里面读<br /> while ((strRead = br.readLine()) != null) {<br />/**<br /> * 用于捕获日期数据<br />*/<br /> String strGet = gMethod.regularGroup(regularDate, strRead);<br />//如果捕获到了符合条件的 日期数据 则打印出来 <br /> if (!strGet.equals("")) {<br /> System.out.println("Date:" + strGet);<br />//这里索引+1 是用于获取后期的球队数据<br /> ++index; //因为在html页面里 源代码里 球队数据是在刚好在日期之后 <br /> }<br />/**<br /> * 用于获取2个球队的数据<br />*/<br /> strGet = gMethod.regularGroup(regularTwoTeam, strRead);<br />if (!strGet.equals("") && index == 1) { //索引为1的是主队数据<br />// 通过substring方法 分离出 主队数据<br /> strGet = strGet.substring(1, strGet.indexOf("</a>"));<br /> System.out.println("HomeTeam:" + strGet); //打印出主队<br /> index++; //索引+1之后 为2了<br />// 通过substring方法 分离出 客队<br /> } else if (!strGet.equals("") && index == 2) { //这里索引为2的是客队数据<br /> strGet = strGet.substring(1, strGet.indexOf("</a>"));<br /> System.out.println("AwayTeam:" + strGet); //打印出客队 <br /> index = 0;<br /> }<br />/**<br /> * 用于获取比赛结果<br />*/<br /> strGet = gMethod.regularGroup(regularResult, strRead);<br />if (!strGet.equals("")) {<br />//这里同样用到了substring方法 来剔除'
内容采集器(怎么用文章采集工具让新网站快速收录以及关键词排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-03-07 09:16
如何使用 文章采集 工具对新的 网站快速收录 和 关键词 进行排名。SEO优化已经是企业网站网络营销的手段之一,但是在企业SEO优化的过程中,也存在搜索引擎不是收录的情况。提问后总结了几个方法和经验,在此分享给各位新手站长,让新上线的网站可以让搜索引擎收录在短时间内获得不错的排名尽快。下面就教大家如何在SEO优化中快速提升网站收录。
一、网站在SEO优化过程中,在新站上线初期,每天都要定期更新内容。第一次发射是在评估期间。该评估期为 1 个月至 3 个月不等。最快的时间是半个月左右才能拿到一个好的排名。因此,在刚进入考核期时,应加大力度。做好内容的更新,让搜索引擎在前期对我们的网站有很好的印象,这样我们以后可以更好的提高网站的权重,打下坚实的基础。
二、A网站更新频率越高,搜索引擎蜘蛛来的越频繁。因此,我们可以利用文章采集工具实现采集伪原创自动发布和主动推送到搜索引擎,提高搜索引擎的抓取频率。本文章采集工具操作简单,无需学习专业技术,只需简单几步即可轻松采集内容数据,用户只需对< @文章采集tool ,该工具会根据用户设置的关键词accurate采集文章,保证与行业一致文章。采集中的采集文章可以选择将修改后的内容保存到本地,
与其他文章采集工具相比,这个工具使用起来非常简单,只需输入关键词即可实现采集(文章采集工具配备了 关键词采集 功能)。只需设置任务,全程自动挂机!
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。
最重要的是这个文章采集工具有很多SEO功能,不仅可以提升网站的收录,还可以增加网站的密度@关键词 提高网站排名。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片)不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
<p>6、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前的采集 查看全部
内容采集器(怎么用文章采集工具让新网站快速收录以及关键词排名)
如何使用 文章采集 工具对新的 网站快速收录 和 关键词 进行排名。SEO优化已经是企业网站网络营销的手段之一,但是在企业SEO优化的过程中,也存在搜索引擎不是收录的情况。提问后总结了几个方法和经验,在此分享给各位新手站长,让新上线的网站可以让搜索引擎收录在短时间内获得不错的排名尽快。下面就教大家如何在SEO优化中快速提升网站收录。
一、网站在SEO优化过程中,在新站上线初期,每天都要定期更新内容。第一次发射是在评估期间。该评估期为 1 个月至 3 个月不等。最快的时间是半个月左右才能拿到一个好的排名。因此,在刚进入考核期时,应加大力度。做好内容的更新,让搜索引擎在前期对我们的网站有很好的印象,这样我们以后可以更好的提高网站的权重,打下坚实的基础。
二、A网站更新频率越高,搜索引擎蜘蛛来的越频繁。因此,我们可以利用文章采集工具实现采集伪原创自动发布和主动推送到搜索引擎,提高搜索引擎的抓取频率。本文章采集工具操作简单,无需学习专业技术,只需简单几步即可轻松采集内容数据,用户只需对< @文章采集tool ,该工具会根据用户设置的关键词accurate采集文章,保证与行业一致文章。采集中的采集文章可以选择将修改后的内容保存到本地,
与其他文章采集工具相比,这个工具使用起来非常简单,只需输入关键词即可实现采集(文章采集工具配备了 关键词采集 功能)。只需设置任务,全程自动挂机!
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。
最重要的是这个文章采集工具有很多SEO功能,不仅可以提升网站的收录,还可以增加网站的密度@关键词 提高网站排名。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片)不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
<p>6、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前的采集
内容采集器(免登陆采集辅助插件IjkxsDatas2.采集器7.6企业旗舰版,赠配套typecho发布插件 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-02-21 15:06
)
文章系列:
免费登录采集辅助插件IjkxsDatastypecho 优采云采集器 7.6企业终极版,免费配套typecho发布插件教你使用typecho 优采云@ >采集壁纸架
最近一直在找typecho的采集插件,看到很多都是收费的,主要是真的太贵了。对于没有收入的学生党来说,偶尔用起来根本买不起。所以我打算自己写一个插件,和老式的优采云一起使用。没想到用过一次,效果还蛮惊喜的。
以下是站长自己的采集壁纸站的教程。
工具:
1.采集插件typecho免费登录采集辅助插件IjkxsDatas
2.typecho 优采云采集器 7.6企业终极版,免费配套typecho发布插件
教程:
首先按照工具1安装typecho插件,按照工具2配置优采云采集配置。
然后启动官方 采集 壁纸,这次 采集 的壁纸站是 Enter 桌面。
总的来说,采集分为两大步。第一大步是先获取分页规则,第二大步是获取每个页面要解析的内容的详细地址。
1.打开优采云,新建群组壁纸,新建任务壁纸采集
在任务的第一步,我们首先需要添加起始URL,(以默认页面为例,当然选择不同的壁纸类别也是一样的),滚动页面,我们打开开发者工具调试,发现加载页面也可用。常规的。分页每次递增 1。
因此,我们可以构造一个解析地址,为采集地址选择多页,地址格式用通配符(*)代替页数,选择等差数列,第一项为1,项目数等于页数。构建完成后,点击添加完成。这样就完成了第一步。
接下来是第二大步骤,需要获取每个页面需要解析的具体详细地址。因为大多数分页负载都是缩略图。从开发者工具中可以看到一张图片的详细html结构。(如果没有,打开开发者工具,点击工具左上角的鼠标,点击网页中的图片。)
上图中a元素中的href属性就是我们想要的采集的详细地址,那么我们如何获取这个地址呢?最简单的是使用xpath。我们发现a被dl和dd元素包裹,dd被一个元素包裹。所以 xpath 可以这样写: //dl/dd/a/@href 。不知道xpath的可以百度一下,几分钟看看xpath的基本语法。
回到优采云,在获取多级URL的地方点击添加,输入xpath相关信息,如下图。这里也可以使用xpath浏览器获取xpath规则,不多介绍。
这样,URL采集就准备好了,可以点击右下角的测试URL采集查看效果。
2.接下来是采集的详细内容(图)
让我们打开一个刚刚采集 到达的详情页面,看看页面结构。
您可以看到标题的页面结构。大部分网页的标题结构都是一样的,编辑器已经默认配置好了,不用着急,有需要的可以加一些数据处理。
接下来添加内容。
方法一(老手):
这张图片有一个特殊的类名class="arc_main_pic_img",可以作为我们分析的起点。我们需要获取链接,也就是src="xxxxx"的部分,使用xpath很简单。//img[@class="arc_main_pic_img"],这样就可以得到对应的图片节点了。
双击采集内容规则左侧标签中的内容,填写如下。
方法2(新手):
双击采集的内容规则左侧标签中的内容,在打开的页面集合中点击Get data through 采集,选择Visual Extraction,点击Get through xpath browser
得到图片节点后,我们做一些数据处理,点击数据处理->添加->高级特征->提取第一张图片。
由于typecho使用Markdown解析,所以还需要对图片链接做一些处理,点击数据处理->添加->高级功能->内容添加前缀和后缀
因为 Markdown 语法要求图片格式为:
这样就完成了内容的添加。
采集 标签是类似的。一般在head->meta的位置,找到对应的节点,邮件拷贝,拷贝xpath。
添加数据处理
这样就完成了标签的 采集。
左边的选项卡只需要填写必要的选项。由于需要在本地下载图片,所以还需要填写一张图片列表(存放需要下载的图片链接)。
我们已经解析了图片,所以选择内容,点击复制,粘贴,修改标签名称为图片列表,删除数据处理中添加前缀和后缀的选项。
填写完基本内容后,在右侧规则测试中输入我们的详情链接,点击测试。
看到内容解析和格式正确后,就可以进行下一步了。
3. 发布内容设置
方案一:Web在线发布,如果没有内容,点击Web发布模式管理,按照
2.typecho 优采云采集器 7.6企业终极版,免费配套typecho发布插件
配置它。
配置完成后,您可以选择要发布的类别。
最后,保存并启动任务。
查看全部
内容采集器(免登陆采集辅助插件IjkxsDatas2.采集器7.6企业旗舰版,赠配套typecho发布插件
)
文章系列:
免费登录采集辅助插件IjkxsDatastypecho 优采云采集器 7.6企业终极版,免费配套typecho发布插件教你使用typecho 优采云@ >采集壁纸架
最近一直在找typecho的采集插件,看到很多都是收费的,主要是真的太贵了。对于没有收入的学生党来说,偶尔用起来根本买不起。所以我打算自己写一个插件,和老式的优采云一起使用。没想到用过一次,效果还蛮惊喜的。
以下是站长自己的采集壁纸站的教程。
工具:
1.采集插件typecho免费登录采集辅助插件IjkxsDatas
2.typecho 优采云采集器 7.6企业终极版,免费配套typecho发布插件
教程:
首先按照工具1安装typecho插件,按照工具2配置优采云采集配置。
然后启动官方 采集 壁纸,这次 采集 的壁纸站是 Enter 桌面。
总的来说,采集分为两大步。第一大步是先获取分页规则,第二大步是获取每个页面要解析的内容的详细地址。
1.打开优采云,新建群组壁纸,新建任务壁纸采集
在任务的第一步,我们首先需要添加起始URL,(以默认页面为例,当然选择不同的壁纸类别也是一样的),滚动页面,我们打开开发者工具调试,发现加载页面也可用。常规的。分页每次递增 1。
因此,我们可以构造一个解析地址,为采集地址选择多页,地址格式用通配符(*)代替页数,选择等差数列,第一项为1,项目数等于页数。构建完成后,点击添加完成。这样就完成了第一步。
接下来是第二大步骤,需要获取每个页面需要解析的具体详细地址。因为大多数分页负载都是缩略图。从开发者工具中可以看到一张图片的详细html结构。(如果没有,打开开发者工具,点击工具左上角的鼠标,点击网页中的图片。)
上图中a元素中的href属性就是我们想要的采集的详细地址,那么我们如何获取这个地址呢?最简单的是使用xpath。我们发现a被dl和dd元素包裹,dd被一个元素包裹。所以 xpath 可以这样写: //dl/dd/a/@href 。不知道xpath的可以百度一下,几分钟看看xpath的基本语法。
回到优采云,在获取多级URL的地方点击添加,输入xpath相关信息,如下图。这里也可以使用xpath浏览器获取xpath规则,不多介绍。
这样,URL采集就准备好了,可以点击右下角的测试URL采集查看效果。
2.接下来是采集的详细内容(图)
让我们打开一个刚刚采集 到达的详情页面,看看页面结构。
您可以看到标题的页面结构。大部分网页的标题结构都是一样的,编辑器已经默认配置好了,不用着急,有需要的可以加一些数据处理。
接下来添加内容。
方法一(老手):
这张图片有一个特殊的类名class="arc_main_pic_img",可以作为我们分析的起点。我们需要获取链接,也就是src="xxxxx"的部分,使用xpath很简单。//img[@class="arc_main_pic_img"],这样就可以得到对应的图片节点了。
双击采集内容规则左侧标签中的内容,填写如下。
方法2(新手):
双击采集的内容规则左侧标签中的内容,在打开的页面集合中点击Get data through 采集,选择Visual Extraction,点击Get through xpath browser
得到图片节点后,我们做一些数据处理,点击数据处理->添加->高级特征->提取第一张图片。
由于typecho使用Markdown解析,所以还需要对图片链接做一些处理,点击数据处理->添加->高级功能->内容添加前缀和后缀
因为 Markdown 语法要求图片格式为:
这样就完成了内容的添加。
采集 标签是类似的。一般在head->meta的位置,找到对应的节点,邮件拷贝,拷贝xpath。
添加数据处理
这样就完成了标签的 采集。
左边的选项卡只需要填写必要的选项。由于需要在本地下载图片,所以还需要填写一张图片列表(存放需要下载的图片链接)。
我们已经解析了图片,所以选择内容,点击复制,粘贴,修改标签名称为图片列表,删除数据处理中添加前缀和后缀的选项。
填写完基本内容后,在右侧规则测试中输入我们的详情链接,点击测试。
看到内容解析和格式正确后,就可以进行下一步了。
3. 发布内容设置
方案一:Web在线发布,如果没有内容,点击Web发布模式管理,按照
2.typecho 优采云采集器 7.6企业终极版,免费配套typecho发布插件
配置它。
配置完成后,您可以选择要发布的类别。
最后,保存并启动任务。
内容采集器(优采云采集器免费版采集器安装方法及安装流程介绍-乐题库 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-02-20 13:08
)
优采云采集器免费版是一款可以快速从金融局采集数据的软件。支持批量采集网页、论坛等内容,可直接保存到数据库或发布到网站。你可以自定义设置采集的方式,获取你需要的内容,或者处理数据,seo优化的工具。
软件功能
1、通用
无论新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
七年磨一剑,软件不断更新完善,采集速度快,性能稳定,资源消耗少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
安装方式
1、在本站下载优采云采集器后,在电脑本地获取一个压缩包,使用360压缩软件解压,双击.exe文件进入软件安装界面,点击【下一步】继续。
2、进入优采云采集器安装协议界面,可以先阅读软件安装协议中的条款,阅读后点击【我接受】再点击【下一步】继续。
3、选择安装位置优采云采集器,可以点击【安装】,软件会默认安装,也可以在打开的安装位置界面点击【浏览】,你可以自行选择软件安装位置后,点击【安装】。
4、优采云采集器安装正在进行中,需要耐心等待软件安装完成。
5、优采云采集器安装完成,点击【完成】退出软件安装。
查看全部
内容采集器(优采云采集器免费版采集器安装方法及安装流程介绍-乐题库
)
优采云采集器免费版是一款可以快速从金融局采集数据的软件。支持批量采集网页、论坛等内容,可直接保存到数据库或发布到网站。你可以自定义设置采集的方式,获取你需要的内容,或者处理数据,seo优化的工具。
软件功能
1、通用
无论新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
七年磨一剑,软件不断更新完善,采集速度快,性能稳定,资源消耗少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
安装方式
1、在本站下载优采云采集器后,在电脑本地获取一个压缩包,使用360压缩软件解压,双击.exe文件进入软件安装界面,点击【下一步】继续。
2、进入优采云采集器安装协议界面,可以先阅读软件安装协议中的条款,阅读后点击【我接受】再点击【下一步】继续。
3、选择安装位置优采云采集器,可以点击【安装】,软件会默认安装,也可以在打开的安装位置界面点击【浏览】,你可以自行选择软件安装位置后,点击【安装】。
4、优采云采集器安装正在进行中,需要耐心等待软件安装完成。
5、优采云采集器安装完成,点击【完成】退出软件安装。
内容采集器(我在找金属感的画布推荐:数字活字商务专题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-02-19 20:02
内容采集器。只要你用心去找,我保证一天一个图案。《猫和老鼠》我要图案,数字活字,商务专题,像这样的,让我们一起做口袋购物推荐机器人。
啊啊啊我在找金属感的画布
推荐dgx:手机编辑网站,设计师可以直接使用ppt编辑。并且支持几百种网站画布,ppt编辑都可以实现。支持macos系统,并且每次修改网站画布,右键有超丰富的预览,演示。比如买车时,新手买车,只能选车图,放大来观察,又或者关注不同车型的背后故事,从而对比型号的差异。dgx把网站画布(金属感)固定到ppt,修改点击操作即可实现你理想的效果,并且强大的预览和预览图形,你都可以进行修改。
无论你是做产品图还是交互图,dgx都能满足你。另外最近还上线了两个优秀的社区,一个是舞厅,一个是江湖。更多精彩请关注公众号:布朗杂谈ppt(二维码自动识别)布朗杂谈ppt:新刊举办,提供布朗、布鲁克林经典杂谈文章,转载请在本公众号内留言。记得有事没事点击这里使用“布朗”,bilibili一起交流吧:布朗的id是:bilibili布朗的微信号是:bilibili-broid关注布朗老师的微信公众号,一起玩转ppt。
我想推荐的是网站内的搜索功能。用谷歌搜索的时候,用“图片中文名”、“图片标识”等关键词来搜索图片就有好多结果。其中还有一个“地标”这个画布的话,很多公司都有用。腾讯的网站,包括企鹅部落、马化腾亲笔书等等,网上找几张ppt发上来看下:百度、58同城等,也有很多上传的作品。其实很多图片在网上都是找不到的,也得去旅游目的地才能找到呢,特别是很多风景图,所以多去搜索下,这样寻找才会更有用处。 查看全部
内容采集器(我在找金属感的画布推荐:数字活字商务专题)
内容采集器。只要你用心去找,我保证一天一个图案。《猫和老鼠》我要图案,数字活字,商务专题,像这样的,让我们一起做口袋购物推荐机器人。
啊啊啊我在找金属感的画布
推荐dgx:手机编辑网站,设计师可以直接使用ppt编辑。并且支持几百种网站画布,ppt编辑都可以实现。支持macos系统,并且每次修改网站画布,右键有超丰富的预览,演示。比如买车时,新手买车,只能选车图,放大来观察,又或者关注不同车型的背后故事,从而对比型号的差异。dgx把网站画布(金属感)固定到ppt,修改点击操作即可实现你理想的效果,并且强大的预览和预览图形,你都可以进行修改。
无论你是做产品图还是交互图,dgx都能满足你。另外最近还上线了两个优秀的社区,一个是舞厅,一个是江湖。更多精彩请关注公众号:布朗杂谈ppt(二维码自动识别)布朗杂谈ppt:新刊举办,提供布朗、布鲁克林经典杂谈文章,转载请在本公众号内留言。记得有事没事点击这里使用“布朗”,bilibili一起交流吧:布朗的id是:bilibili布朗的微信号是:bilibili-broid关注布朗老师的微信公众号,一起玩转ppt。
我想推荐的是网站内的搜索功能。用谷歌搜索的时候,用“图片中文名”、“图片标识”等关键词来搜索图片就有好多结果。其中还有一个“地标”这个画布的话,很多公司都有用。腾讯的网站,包括企鹅部落、马化腾亲笔书等等,网上找几张ppt发上来看下:百度、58同城等,也有很多上传的作品。其实很多图片在网上都是找不到的,也得去旅游目的地才能找到呢,特别是很多风景图,所以多去搜索下,这样寻找才会更有用处。
内容采集器(服务架构理解记忆Filebeat配置文件工具介绍-Filebeat日志文件托运服务 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2022-02-16 05:19
)
当我们公司内部部署了很多服务和测试以及正式环境时,查看日志已经成为一个非常刚硬的要求。
图片来自趵突网
是统一采集多个环境的日志,然后使用Nginx对外提供服务,还是使用专门的日志采集服务ELK?这成为一个问题!
作为一种集成解决方案,Graylog 使用 Elasticsearch 进行存储,使用 MongoDB 进行缓存,并通过流量控制进行节流。同时,其界面查询使用方便,易于扩展。因此,使用 Graylog 成为了最好的选择,为我们省了很多心。
Filebeat工具介绍 ①Filebeat日志文件投递服务
Filebeat 是一个日志文件传送工具。在您的服务器上安装客户端后,Filebeat 会自动监控给定的日志目录或指定的日志文件,跟踪并读取这些文件,不断地读取它们,并将信息转发到存储在 Elasticsearch 或 Logstarsh 或 Graylog 中。
②Filebeat工作流程介绍
当您安装并启用 Filebeat 程序时,它将启动一个或多个探测器(prospectors)来检测您指定的日志目录或文件。
对于探测器找到的每个日志文件,Filebeat 都会启动一个收割机进程。
每个收获进程读取日志文件的最新内容并将这些新日志数据发送到处理程序(假脱机程序),后者聚合这些事件。
最后,Filebeat 会将采集数据发送到您指定的地址(我们这里发送到 Graylog 服务)。
③Filebeat图标了解内存
我们这里没有应用 Logstash 服务,主要是因为 Filebeat 比 Logstash 更轻量级。
当我们需要采集信息的机器配置或者资源不是特别大,也没有那么复杂的时候,推荐使用Filebeat来采集日志。
在日常使用中,Filebeat有多种安装部署方式,运行非常稳定。
图形化服务架构理解内存
文件节拍配置文件
配置Filebeat工具的核心是如何编写其对应的配置文件!
对应的Filebeat工具的配置主要是通过编写其配置文件来控制的。对于通过 rpm 或 deb 包安装,配置文件默认存放在路径 /etc/filebeat/filebeat.yml 下。
Mac或Win系统请查看解压后的相关文件,均涉及。
Filebeat工具的主要配置文件如下图所示。每个字段的含义在评论信息中有详细解释,这里不再赘述。
需要注意的是,我们定义了日志的所有输入源来读取inputs.d目录下的所有yml配置。
因此,我们可以针对不同的服务(测试、正式服务)定义不同的配置文件,根据物理机部署的实际情况进行配置。
# 配置输入来源的日志信息
# 我们合理将其配置到了 inputs.d 目录下的所有 yml 文件
filebeat.config.inputs:
enabled: true
path: ${path.config}/inputs.d/*.yml
# 若收取日志格式为 json 的 log 请开启此配置
# json.keys_under_root: true
# 配置 Filebeat 需要加载的模块
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
# 配置将日志信息发送那个地址上面
output.logstash:
hosts: ["11.22.33.44:5500"]
# output.file:
# enable: true
processors:
- add_host_metadata: ~
- rename:
fields:
- from: "log"
to: "message"
- add_fields:
target: ""
fields:
# 加 Token 是为了防止无认证的服务上 Graylog 服务发送数据
token: "0uxxxxaM-1111-2222-3333-VQZJxxxxxwgX "
下面展示了inputs.d目录下一个简单的yml配置文件的具体内容。它的主要功能是配置独立服务的独立日志数据,并附加不同的数据标签类型。
# 收集的数据类型
- type: log
enabled: true
# 日志文件的路径地址
paths:
- /var/log/supervisor/app_escape_worker-stderr.log
- /var/log/supervisor/app_escape_prod-stderr.log
symlinks: true
# 包含的关键字信息
include_lines: ["WARNING", "ERROR"]
# 打上数据标签
tags: ["app", "escape", "test"]
# 防止程序堆栈信息被分行识别
multiline.pattern: '^\[?[0-9]...{3}'
multiline.negate: true
multiline.match: after
# 需要配置多个日志时可加多个 type 字段
- type: log
enabled: true
需要注意的是,针对不同的日志类型,filebeat还提供了不同的模块来配置不同的服务日志及其不同的模块特性,比如我们常见的PostgreSQl、Redis、Iptables等。
# iptables
- module: iptables
log:
enabled: true
var.paths: ["/var/log/iptables.log"]
var.input: "file"
# postgres
- module: postgresql
log:
enabled: true
var.paths: ["/path/to/log/postgres/*.log*"]
# nginx
- module: nginx
access:
enabled: true
var.paths: ["/path/to/log/nginx/access.log*"]
error:
enabled: true
var.paths: ["/path/to/log/nginx/error.log*"]
Graylog服务介绍①Graylog日志监控系统
Graylog 是一个开源的日志聚合、分析、审计、展示和预警工具。在功能上,它与 ELK 类似,但比 ELK 简单得多。
凭借更加简洁、高效、易于部署和使用的优势,迅速受到了很多人的青睐。当然,在扩展性方面并不比 ELK 好,但也有商业版本可供选择。
②Graylog工作流程介绍
部署 Graylog 最简单的架构是单机部署,更复杂的部署是集群模式。架构图如下所示。
我们可以看到它收录三个组件,分别是 Elasticsearch、MongoDB 和 Graylog。
其中,Elasticsearch 用于持久存储和检索日志文件数据(IO 密集型),MongoDB 用于存储有关 Graylog 的相关配置,Graylog 用于提供 Web 接口和外部接口(CPU 密集型)。
最小的独立部署
优化集群部署
Graylog 组件特性
配置一个 Graylog 服务的核心是了解对应的组件是做什么的以及它是如何工作的!
简单来说,Input 代表日志数据的来源。对于不同来源的日志,可以使用Extractors对日志的字段进行转换,比如将Nginx的状态码改成对应的英文表达。
然后,将不同类型的标签分组到不同的流中,将这些日志数据存储在指定的Index库中进行持久化存储。
Graylog 中的核心服务组件
Graylog 通过 Input 采集日志,每个 Input 都配置了 Extractors 进行字段转换。
Graylog中日志搜索的基本单位是Stream。每个 Stream 可以有自己的 Elastic Index Set 或共享一个 Index Set。
提取器在系统/输入中配置。Graylog 的一个方便之处是您可以加载日志,根据这个实际示例对其进行配置,并直接查看结果。
内置的Extractor基本可以完成各种字段的提取和转换任务,但也有一定的局限性,需要在应用程序中写日志时加以考虑。Input可以配置多个Extractor,依次执行。
系统会有一个默认的Stream,所有的日志都会默认保存到这个Stream,除非匹配到了一个Stream,并且这个Stream被配置为不保存日志到默认的Stream。
可以通过菜单 Streams 创建更多 Streams。新创建的 Stream 处于暂停状态,需要在配置完成后手动启动。
Stream通过配置条件匹配日志,满足条件的日志添加stream ID标识字段,保存到对应的Elastic Index Set中。
索引集是通过菜单系统/索引创建的。日志存储的性能、可靠性和过期策略都是通过Index Set来配置的。
性能和可靠性是配置 Elastic Index 的一些参数。主要参数包括 Shards 和 Replica。
除了上面提到的日志处理流程,Graylog 还提供了一个 Pipeline 脚本来实现更灵活的日志处理方案。
此处不赘述,仅介绍是否使用 Pipelines 过滤不需要的日志。以下是丢弃所有级别 > 6 的日志的管道规则示例。
从数据采集(输入),现场分析(提取器),分流到流,再到流水线清洗,一气呵成,其他方式无需二次处理。
Sidecar 是一个轻量级的日志采集器,通过访问 Graylog 进行集中管理,支持 Linux 和 Windows 系统。
Sidecar 守护进程会定期访问 Graylog REST API 以获取 sidecar 配置文件中定义的标签。Sidecar 首次运行时,会从 Graylog 服务器拉取配置文件中指定标签的配置信息,并同步到本地。
目前 Sidecar 支持 NXLog、Filebeat 和 Winlogbeat。它们都是通过 Graylog 中的 web 界面统一配置,支持 Beats、CEF、Gelf、Json API、NetFlow 等输出类型。
Graylog 最强大的地方在于,可以在配置文件中指定 Sidecar 将日志发送到哪个 Graylog 集群,并对 Graylog 集群中的多个输入进行负载均衡,让 Graylog 可以应对非常大量的日志。
rule "discard debug messages"
when
to_long($message.level) > 6
then
drop_message();
end
日志集中保存到 Graylog 后,可以方便地进行搜索。但是,有时需要进一步处理数据。
主要有两种方式,一种是直接访问存储在 Elastic 中的数据,或者通过 Graylog 的 Output 转发给其他服务。
服务安装部署
主要介绍了部署Filebeat+Graylog的安装步骤和注意事项!
使用 Graylog 采集日志
①部署Filebeat工具
官方提供了多种部署方式,包括通过rpm和deb包安装服务,以及通过源码编译安装服务,还包括使用Docker或者kubernetes安装服务。
我们可以根据自己的实际需要进行安装:
# Ubuntu(deb)
$ curl -L -O https://artifacts.elastic.co/d ... 4.deb
$ sudo dpkg -i filebeat-7.8.1-amd64.deb
$ sudo systemctl enable filebeat
$ sudo service filebeat start
# 使用 Docker 启动
docker run -d --name=filebeat --user=root \
--volume="./filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \
--volume="/var/lib/docker/containers:/var/lib/docker/containers:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/filebeat:7.8.1 filebeat -e -strict.perms=false \
-E output.elasticsearch.hosts=["elasticsearch:9200"]
②部署 Graylog 服务
这里主要介绍使用Docker容器部署服务。如需使用其他方式部署,请查看官方文档相应章节的安装部署步骤。
在部署服务之前,我们需要为 Graylog 服务生成等相关信息。生成的部署如下:
<p># 生成 password_secret 密码(最少 16 位)
$ sudo apt install -y pwgen
$ pwgen -N 1 -s 16
zscMb65...FxR9ag
# 生成后续 Web 登录时所需要使用的密码
$ echo -n "Enter Password: " && head -1 查看全部
内容采集器(服务架构理解记忆Filebeat配置文件工具介绍-Filebeat日志文件托运服务
)
当我们公司内部部署了很多服务和测试以及正式环境时,查看日志已经成为一个非常刚硬的要求。
图片来自趵突网
是统一采集多个环境的日志,然后使用Nginx对外提供服务,还是使用专门的日志采集服务ELK?这成为一个问题!
作为一种集成解决方案,Graylog 使用 Elasticsearch 进行存储,使用 MongoDB 进行缓存,并通过流量控制进行节流。同时,其界面查询使用方便,易于扩展。因此,使用 Graylog 成为了最好的选择,为我们省了很多心。
Filebeat工具介绍 ①Filebeat日志文件投递服务
Filebeat 是一个日志文件传送工具。在您的服务器上安装客户端后,Filebeat 会自动监控给定的日志目录或指定的日志文件,跟踪并读取这些文件,不断地读取它们,并将信息转发到存储在 Elasticsearch 或 Logstarsh 或 Graylog 中。
②Filebeat工作流程介绍
当您安装并启用 Filebeat 程序时,它将启动一个或多个探测器(prospectors)来检测您指定的日志目录或文件。
对于探测器找到的每个日志文件,Filebeat 都会启动一个收割机进程。
每个收获进程读取日志文件的最新内容并将这些新日志数据发送到处理程序(假脱机程序),后者聚合这些事件。
最后,Filebeat 会将采集数据发送到您指定的地址(我们这里发送到 Graylog 服务)。
③Filebeat图标了解内存
我们这里没有应用 Logstash 服务,主要是因为 Filebeat 比 Logstash 更轻量级。
当我们需要采集信息的机器配置或者资源不是特别大,也没有那么复杂的时候,推荐使用Filebeat来采集日志。
在日常使用中,Filebeat有多种安装部署方式,运行非常稳定。
图形化服务架构理解内存
文件节拍配置文件
配置Filebeat工具的核心是如何编写其对应的配置文件!
对应的Filebeat工具的配置主要是通过编写其配置文件来控制的。对于通过 rpm 或 deb 包安装,配置文件默认存放在路径 /etc/filebeat/filebeat.yml 下。
Mac或Win系统请查看解压后的相关文件,均涉及。
Filebeat工具的主要配置文件如下图所示。每个字段的含义在评论信息中有详细解释,这里不再赘述。
需要注意的是,我们定义了日志的所有输入源来读取inputs.d目录下的所有yml配置。
因此,我们可以针对不同的服务(测试、正式服务)定义不同的配置文件,根据物理机部署的实际情况进行配置。
# 配置输入来源的日志信息
# 我们合理将其配置到了 inputs.d 目录下的所有 yml 文件
filebeat.config.inputs:
enabled: true
path: ${path.config}/inputs.d/*.yml
# 若收取日志格式为 json 的 log 请开启此配置
# json.keys_under_root: true
# 配置 Filebeat 需要加载的模块
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
# 配置将日志信息发送那个地址上面
output.logstash:
hosts: ["11.22.33.44:5500"]
# output.file:
# enable: true
processors:
- add_host_metadata: ~
- rename:
fields:
- from: "log"
to: "message"
- add_fields:
target: ""
fields:
# 加 Token 是为了防止无认证的服务上 Graylog 服务发送数据
token: "0uxxxxaM-1111-2222-3333-VQZJxxxxxwgX "
下面展示了inputs.d目录下一个简单的yml配置文件的具体内容。它的主要功能是配置独立服务的独立日志数据,并附加不同的数据标签类型。
# 收集的数据类型
- type: log
enabled: true
# 日志文件的路径地址
paths:
- /var/log/supervisor/app_escape_worker-stderr.log
- /var/log/supervisor/app_escape_prod-stderr.log
symlinks: true
# 包含的关键字信息
include_lines: ["WARNING", "ERROR"]
# 打上数据标签
tags: ["app", "escape", "test"]
# 防止程序堆栈信息被分行识别
multiline.pattern: '^\[?[0-9]...{3}'
multiline.negate: true
multiline.match: after
# 需要配置多个日志时可加多个 type 字段
- type: log
enabled: true
需要注意的是,针对不同的日志类型,filebeat还提供了不同的模块来配置不同的服务日志及其不同的模块特性,比如我们常见的PostgreSQl、Redis、Iptables等。
# iptables
- module: iptables
log:
enabled: true
var.paths: ["/var/log/iptables.log"]
var.input: "file"
# postgres
- module: postgresql
log:
enabled: true
var.paths: ["/path/to/log/postgres/*.log*"]
# nginx
- module: nginx
access:
enabled: true
var.paths: ["/path/to/log/nginx/access.log*"]
error:
enabled: true
var.paths: ["/path/to/log/nginx/error.log*"]
Graylog服务介绍①Graylog日志监控系统
Graylog 是一个开源的日志聚合、分析、审计、展示和预警工具。在功能上,它与 ELK 类似,但比 ELK 简单得多。
凭借更加简洁、高效、易于部署和使用的优势,迅速受到了很多人的青睐。当然,在扩展性方面并不比 ELK 好,但也有商业版本可供选择。
②Graylog工作流程介绍
部署 Graylog 最简单的架构是单机部署,更复杂的部署是集群模式。架构图如下所示。
我们可以看到它收录三个组件,分别是 Elasticsearch、MongoDB 和 Graylog。
其中,Elasticsearch 用于持久存储和检索日志文件数据(IO 密集型),MongoDB 用于存储有关 Graylog 的相关配置,Graylog 用于提供 Web 接口和外部接口(CPU 密集型)。
最小的独立部署
优化集群部署
Graylog 组件特性
配置一个 Graylog 服务的核心是了解对应的组件是做什么的以及它是如何工作的!
简单来说,Input 代表日志数据的来源。对于不同来源的日志,可以使用Extractors对日志的字段进行转换,比如将Nginx的状态码改成对应的英文表达。
然后,将不同类型的标签分组到不同的流中,将这些日志数据存储在指定的Index库中进行持久化存储。
Graylog 中的核心服务组件
Graylog 通过 Input 采集日志,每个 Input 都配置了 Extractors 进行字段转换。
Graylog中日志搜索的基本单位是Stream。每个 Stream 可以有自己的 Elastic Index Set 或共享一个 Index Set。
提取器在系统/输入中配置。Graylog 的一个方便之处是您可以加载日志,根据这个实际示例对其进行配置,并直接查看结果。
内置的Extractor基本可以完成各种字段的提取和转换任务,但也有一定的局限性,需要在应用程序中写日志时加以考虑。Input可以配置多个Extractor,依次执行。
系统会有一个默认的Stream,所有的日志都会默认保存到这个Stream,除非匹配到了一个Stream,并且这个Stream被配置为不保存日志到默认的Stream。
可以通过菜单 Streams 创建更多 Streams。新创建的 Stream 处于暂停状态,需要在配置完成后手动启动。
Stream通过配置条件匹配日志,满足条件的日志添加stream ID标识字段,保存到对应的Elastic Index Set中。
索引集是通过菜单系统/索引创建的。日志存储的性能、可靠性和过期策略都是通过Index Set来配置的。
性能和可靠性是配置 Elastic Index 的一些参数。主要参数包括 Shards 和 Replica。
除了上面提到的日志处理流程,Graylog 还提供了一个 Pipeline 脚本来实现更灵活的日志处理方案。
此处不赘述,仅介绍是否使用 Pipelines 过滤不需要的日志。以下是丢弃所有级别 > 6 的日志的管道规则示例。
从数据采集(输入),现场分析(提取器),分流到流,再到流水线清洗,一气呵成,其他方式无需二次处理。
Sidecar 是一个轻量级的日志采集器,通过访问 Graylog 进行集中管理,支持 Linux 和 Windows 系统。
Sidecar 守护进程会定期访问 Graylog REST API 以获取 sidecar 配置文件中定义的标签。Sidecar 首次运行时,会从 Graylog 服务器拉取配置文件中指定标签的配置信息,并同步到本地。
目前 Sidecar 支持 NXLog、Filebeat 和 Winlogbeat。它们都是通过 Graylog 中的 web 界面统一配置,支持 Beats、CEF、Gelf、Json API、NetFlow 等输出类型。
Graylog 最强大的地方在于,可以在配置文件中指定 Sidecar 将日志发送到哪个 Graylog 集群,并对 Graylog 集群中的多个输入进行负载均衡,让 Graylog 可以应对非常大量的日志。
rule "discard debug messages"
when
to_long($message.level) > 6
then
drop_message();
end
日志集中保存到 Graylog 后,可以方便地进行搜索。但是,有时需要进一步处理数据。
主要有两种方式,一种是直接访问存储在 Elastic 中的数据,或者通过 Graylog 的 Output 转发给其他服务。
服务安装部署
主要介绍了部署Filebeat+Graylog的安装步骤和注意事项!
使用 Graylog 采集日志
①部署Filebeat工具
官方提供了多种部署方式,包括通过rpm和deb包安装服务,以及通过源码编译安装服务,还包括使用Docker或者kubernetes安装服务。
我们可以根据自己的实际需要进行安装:
# Ubuntu(deb)
$ curl -L -O https://artifacts.elastic.co/d ... 4.deb
$ sudo dpkg -i filebeat-7.8.1-amd64.deb
$ sudo systemctl enable filebeat
$ sudo service filebeat start
# 使用 Docker 启动
docker run -d --name=filebeat --user=root \
--volume="./filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \
--volume="/var/lib/docker/containers:/var/lib/docker/containers:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/filebeat:7.8.1 filebeat -e -strict.perms=false \
-E output.elasticsearch.hosts=["elasticsearch:9200"]
②部署 Graylog 服务
这里主要介绍使用Docker容器部署服务。如需使用其他方式部署,请查看官方文档相应章节的安装部署步骤。
在部署服务之前,我们需要为 Graylog 服务生成等相关信息。生成的部署如下:
<p># 生成 password_secret 密码(最少 16 位)
$ sudo apt install -y pwgen
$ pwgen -N 1 -s 16
zscMb65...FxR9ag
# 生成后续 Web 登录时所需要使用的密码
$ echo -n "Enter Password: " && head -1
内容采集器( SEO技术分享2022-02-11怎么利用wordpress采集插件把关键词优化到首页, )
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2022-02-13 07:03
SEO技术分享2022-02-11怎么利用wordpress采集插件把关键词优化到首页,
)
wordpress采集-wordpress采集 插件
SEO技术分享2022-02-11
如何使用wordpress采集插件优化关键词到首页,如何快速做到?如果方便找的话,倒不难,但是拉苗鼓励一下,就不能着急吃热豆腐了,所以要遵守搜索引擎的规则。在SEO优化的前提下,尽可能的加快优化的步伐,最终实现排名的短期提升。有哪些准备工作?
一、网站域名选择
选择域名时,域名越简单越好,也容易被记住。域名后缀选择顺序为.com、.net、.cn。之所以这样选择,是因为它们的权重是逐渐减小的,所以我们尽量选择。具有高权重的域名后缀。同时,在注册域名之前,我们需要检查该域名之前是否被使用过,是否存在被搜索引擎惩罚的情况。一般我们可以在站点域名中查看域名的收录情况或者通过反向链查询域名的历史,如果已经有好的老域名,使用起来更有优势seo的旧域名,新站点前期的沙盒期将直接通过。
二、网站建设者的使用
在选择建站系统时,尽量不要选择智能建站程序。这种程序一般是可视化操作。纯显示 网站 没关系。它可能不适合 SEO 网站。大量的样式代码都存储在网站前端页面,严重影响了搜索引擎蜘蛛的爬取效率。对网站的收录非常不利。建站最好使用网站cms系统,选择简单好用的cms系统,功能强大,SEO性能突出,有很多家喻户晓的好方法-使用市面上的cms系统,如织梦、empire、wordpress、zblog等。大的cms
三、网站模板选择
SEO网站的前端页面模板,越简单越好。这纯粹是从SEO的角度来看的。在实践中,由于宣传和内容排版的需要,会穿插更多的内容模块。但无论如何,使用页面标签、样式规范、栏目布局、导航栏设置、面包屑设置、全站内链等都需要按照百度SEO优化指南和实际用户搜索来布局需要网站,让搜索引擎和用户都喜欢我们的网站。
四、网站的数据分析
一个网站的排名很大程度上取决于我们是否对网站本身的数据有一个清晰的认识。什么样的关键词用户搜索进入网站,哪个网站关键词被搜索很多,哪个关键词没有被搜索,一定要做好数据分析,为以后的微调做基础准备。我们都参与了网站的关键词,所以我们要学会分析行业用户的需求。
如果你的网站在前100之后,你应该做好网站的基础优化,做好内页、导航、首页、版块等最适合蜘蛛的基础爬行。前二十页侧重于用户体验。您的 关键词 排名在第二页。如何进入首页,如何让用户更容易发现?这些都是我们需要学习分析的。如果我们不能分析,我们的排名肯定不会上升。试着观察一下你所在行业排名第一的网站,他们是怎么做到的关键词,如果分布关键词也很重要。
五、好的网站关键词
必须确定。只有选择并确定了关键词,才能对其进行优化。当然,不建议考虑过大的 关键词。这样的关键词对于新站来说基本是无解的。没有办法优化,不要做车,鸡蛋打石头,一定要实事求是,根据自己的实际情况。如果盲目地优化索引大的关键词,首页优化上不去。再这样下去,很容易损害你的优化信心。
选择长尾关键词进行优化,第一个长尾关键词包括主关键词和索引关键词,即长尾关键词排名可以在前期,后期可以实现主关键词排名,可以起到非常大的推动作用,长尾关键词比较容易优化。
六、网站关键词布局
首先,关键词 不应该有太多的布局。前期一般不建议直接布局关键词。至少让网站通过搜索引擎试用期。所谓沙盒期就是这样,也太快了。沙盒期有利于后期工作的快速推进。后期可以使用栏目页,文章页,少量长尾,分步布局关键词。可以加一些小链接,自然插入关键词更有利于排名快速上升。
七、网站内容填充
你必须小心这一点。我的建议是最低标准是伪原创。不要找任何理由或借口,这里不用学习更多专业技能就给你这个WordPress采集插件。
您只需几个简单的步骤即可轻松采集内容数据。用户只需要在插件上进行简单的设置。完成后,软件会根据关键词用户设置对内容和图片进行高精度匹配并自动执行。文章采集伪原创发布,提供方便快捷的内容填充服务!!
与其他采集插件相比,基本没有门槛,也不需要花大量时间学习正则表达式或者html标签,一分钟就能上手,输入关键词即可实现采集。(wordpress插件还自带关键词生成功能) 一路挂断!设置任务自动执行采集发布任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类wordpress插件也配置了很多SEO功能,通过采集伪原创软件发布时还可以提升很多SEO优化,比如:设置图片自动下载并将它们保存在本地或第三方(以便内容没有彼此的外部链接)。自动内链(让搜索引擎更深入地抓取你的链接)、内容或标题插入,以及网站内容插入或随机作者、随机阅读等,形成一个“高原创”。这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。可以直接查看文章采集的发布状态 通过软件工具上的监控管理,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
八、网站内链布局
让整个网站实现类似蜘蛛网的模式,让搜索引擎蜘蛛进来,爬取更多优质内容。内部链接可以是首页、栏目页、文章页面、关键词、锚文本、标签、内部文章、文章插入标题等。当然每个文章 不宜加太多。前期可省略,中期可加一,中后期可加一。添加两个链接,以后可以添加三个链接,也可以添加两个或一个进行回收。总之,遵循顺其自然,不任性,形成强大的蜘蛛网为基准的原则。
九、网站服务器安全
在这些危险时期,网站 就像一个小婴儿。它必须是关怀的,细心的,并且得到很好的照顾。如果有一点点小错误,可能会有很多麻烦。因此,施工现场网站的安全工作必须要做好。另外,可以让身边的高权重网站朋友帮忙引导,正规方式带来的友情链接对关键词的排名非常有利。在朋友中,这样的高权重链接非常好做。拉下你的脸,不要做懦夫,现在谁手里站的少,如果是好朋友,帮助他们不是问题,那就去做吧。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。每天跟着博主为你展示各种SEO经验,打通你的两条血脉!
查看全部
内容采集器(
SEO技术分享2022-02-11怎么利用wordpress采集插件把关键词优化到首页,
)
wordpress采集-wordpress采集 插件
SEO技术分享2022-02-11
如何使用wordpress采集插件优化关键词到首页,如何快速做到?如果方便找的话,倒不难,但是拉苗鼓励一下,就不能着急吃热豆腐了,所以要遵守搜索引擎的规则。在SEO优化的前提下,尽可能的加快优化的步伐,最终实现排名的短期提升。有哪些准备工作?
一、网站域名选择
选择域名时,域名越简单越好,也容易被记住。域名后缀选择顺序为.com、.net、.cn。之所以这样选择,是因为它们的权重是逐渐减小的,所以我们尽量选择。具有高权重的域名后缀。同时,在注册域名之前,我们需要检查该域名之前是否被使用过,是否存在被搜索引擎惩罚的情况。一般我们可以在站点域名中查看域名的收录情况或者通过反向链查询域名的历史,如果已经有好的老域名,使用起来更有优势seo的旧域名,新站点前期的沙盒期将直接通过。
二、网站建设者的使用
在选择建站系统时,尽量不要选择智能建站程序。这种程序一般是可视化操作。纯显示 网站 没关系。它可能不适合 SEO 网站。大量的样式代码都存储在网站前端页面,严重影响了搜索引擎蜘蛛的爬取效率。对网站的收录非常不利。建站最好使用网站cms系统,选择简单好用的cms系统,功能强大,SEO性能突出,有很多家喻户晓的好方法-使用市面上的cms系统,如织梦、empire、wordpress、zblog等。大的cms
三、网站模板选择
SEO网站的前端页面模板,越简单越好。这纯粹是从SEO的角度来看的。在实践中,由于宣传和内容排版的需要,会穿插更多的内容模块。但无论如何,使用页面标签、样式规范、栏目布局、导航栏设置、面包屑设置、全站内链等都需要按照百度SEO优化指南和实际用户搜索来布局需要网站,让搜索引擎和用户都喜欢我们的网站。
四、网站的数据分析
一个网站的排名很大程度上取决于我们是否对网站本身的数据有一个清晰的认识。什么样的关键词用户搜索进入网站,哪个网站关键词被搜索很多,哪个关键词没有被搜索,一定要做好数据分析,为以后的微调做基础准备。我们都参与了网站的关键词,所以我们要学会分析行业用户的需求。
如果你的网站在前100之后,你应该做好网站的基础优化,做好内页、导航、首页、版块等最适合蜘蛛的基础爬行。前二十页侧重于用户体验。您的 关键词 排名在第二页。如何进入首页,如何让用户更容易发现?这些都是我们需要学习分析的。如果我们不能分析,我们的排名肯定不会上升。试着观察一下你所在行业排名第一的网站,他们是怎么做到的关键词,如果分布关键词也很重要。
五、好的网站关键词
必须确定。只有选择并确定了关键词,才能对其进行优化。当然,不建议考虑过大的 关键词。这样的关键词对于新站来说基本是无解的。没有办法优化,不要做车,鸡蛋打石头,一定要实事求是,根据自己的实际情况。如果盲目地优化索引大的关键词,首页优化上不去。再这样下去,很容易损害你的优化信心。
选择长尾关键词进行优化,第一个长尾关键词包括主关键词和索引关键词,即长尾关键词排名可以在前期,后期可以实现主关键词排名,可以起到非常大的推动作用,长尾关键词比较容易优化。
六、网站关键词布局
首先,关键词 不应该有太多的布局。前期一般不建议直接布局关键词。至少让网站通过搜索引擎试用期。所谓沙盒期就是这样,也太快了。沙盒期有利于后期工作的快速推进。后期可以使用栏目页,文章页,少量长尾,分步布局关键词。可以加一些小链接,自然插入关键词更有利于排名快速上升。
七、网站内容填充
你必须小心这一点。我的建议是最低标准是伪原创。不要找任何理由或借口,这里不用学习更多专业技能就给你这个WordPress采集插件。
您只需几个简单的步骤即可轻松采集内容数据。用户只需要在插件上进行简单的设置。完成后,软件会根据关键词用户设置对内容和图片进行高精度匹配并自动执行。文章采集伪原创发布,提供方便快捷的内容填充服务!!
与其他采集插件相比,基本没有门槛,也不需要花大量时间学习正则表达式或者html标签,一分钟就能上手,输入关键词即可实现采集。(wordpress插件还自带关键词生成功能) 一路挂断!设置任务自动执行采集发布任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类wordpress插件也配置了很多SEO功能,通过采集伪原创软件发布时还可以提升很多SEO优化,比如:设置图片自动下载并将它们保存在本地或第三方(以便内容没有彼此的外部链接)。自动内链(让搜索引擎更深入地抓取你的链接)、内容或标题插入,以及网站内容插入或随机作者、随机阅读等,形成一个“高原创”。这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。可以直接查看文章采集的发布状态 通过软件工具上的监控管理,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
八、网站内链布局
让整个网站实现类似蜘蛛网的模式,让搜索引擎蜘蛛进来,爬取更多优质内容。内部链接可以是首页、栏目页、文章页面、关键词、锚文本、标签、内部文章、文章插入标题等。当然每个文章 不宜加太多。前期可省略,中期可加一,中后期可加一。添加两个链接,以后可以添加三个链接,也可以添加两个或一个进行回收。总之,遵循顺其自然,不任性,形成强大的蜘蛛网为基准的原则。
九、网站服务器安全
在这些危险时期,网站 就像一个小婴儿。它必须是关怀的,细心的,并且得到很好的照顾。如果有一点点小错误,可能会有很多麻烦。因此,施工现场网站的安全工作必须要做好。另外,可以让身边的高权重网站朋友帮忙引导,正规方式带来的友情链接对关键词的排名非常有利。在朋友中,这样的高权重链接非常好做。拉下你的脸,不要做懦夫,现在谁手里站的少,如果是好朋友,帮助他们不是问题,那就去做吧。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。每天跟着博主为你展示各种SEO经验,打通你的两条血脉!
内容采集器(优采云采集器中文版如何使用步骤1打开网页数据采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-02-13 05:11
优采云采集器中文版是一款免费的网站data采集软件,帮助您采集网页上的各种数据。优采云采集器中文版基于其自主研发的强大分布式云计算平台。优采云采集器中文版可以方便地从各种网站和网页中获取大量的规范化数据,帮助用户实现数据自动化采集、编辑、规范化、摆脱人工束缚,降低购置成本,大大提高工作效率。举个简单的例子,如果你是商人,那么你必须掌握很多关于商品市场价格、销售等信息,方便你了解商品是买方市场还是卖方市场,并帮助您快速掌握这些信息以提高您的表现。利润。
优采云采集器中文版软件功能
简而言之,使用 优采云 可以很容易地从任何网页精确采集您需要的数据,并生成自定义的常规数据格式。优采云数据采集系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财务报告,自动包括每日最新净值采集;
2.各大新闻门户网站实时监控,自动更新和上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 监测各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要汽车网站具体新车和二手车信息;
8. 发现并采集有关潜在客户的信息;
9. 采集行业网站 产品目录和产品信息;
10.在各大电商平台之间同步商品信息,做到在一个平台发布,在其他平台自动更新。
优采云采集器中文版如何使用
步骤 1 打开网页
登录优采云采集器→点击左上角的“+”图标→选择自定义采集(也可以在首页点击自定义采集下的“立即使用”页面),进入任务配置页面。
然后输入网址→保存网址,系统会进入工艺设计页面,自动打开之前输入的网址。
打开网页后,我们可以修改任务名称。如果没有,则默认以网页标题命名。在运行 采集 之前可以随时修改任务名称。
步骤 2 提取数据
在网页中,可以直接选择要提取的数据,窗口右上角会有相应的提示。在本教程中,我们以新闻标题、日期和文本的提取为例
设置好数据提取后,单击保存并开始运行采集。但是此时的字段名是系统自动生成的。
为了更好的满足自己的需求,可以点击右上角的“处理”进入处理页面修改字段名,保存后运行采集。
所有版本都可以运行local采集,Ultimate及以上版本可以运行cloud采集并设置定时cloud采集,但是在运行cloud采集@>之前先运行local采集测试。
任务运行完采集后,可以选择Excel、CSV、HTML等格式导出或导入数据库。
数据导出后,可以点击链接进入数据存储文件夹查看数据。该文件默认以任务名称命名。
变更日志
主要体验改进
[云采集]新增云采集直播功能,展示任务的云操作,如任务拆分、节点分配、采集数据等流程
[云采集] 新增云采集通知功能,可以为每个任务设置采集完成和采集停止时的邮件通知流程
[Cloud采集] 增加单个子任务重启功能,可以重启少量采集或者状态为stopped的子任务,可以减少数据遗漏
Bug修复
修复“重试次数设置不生效”的问题
修复“循环 URL 异常”问题
修复“最后一个字段,修改要保存的字段名无效”的问题
提高性能并修复一些卡顿问题 查看全部
内容采集器(优采云采集器中文版如何使用步骤1打开网页数据采集软件)
优采云采集器中文版是一款免费的网站data采集软件,帮助您采集网页上的各种数据。优采云采集器中文版基于其自主研发的强大分布式云计算平台。优采云采集器中文版可以方便地从各种网站和网页中获取大量的规范化数据,帮助用户实现数据自动化采集、编辑、规范化、摆脱人工束缚,降低购置成本,大大提高工作效率。举个简单的例子,如果你是商人,那么你必须掌握很多关于商品市场价格、销售等信息,方便你了解商品是买方市场还是卖方市场,并帮助您快速掌握这些信息以提高您的表现。利润。
优采云采集器中文版软件功能
简而言之,使用 优采云 可以很容易地从任何网页精确采集您需要的数据,并生成自定义的常规数据格式。优采云数据采集系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财务报告,自动包括每日最新净值采集;
2.各大新闻门户网站实时监控,自动更新和上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 监测各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要汽车网站具体新车和二手车信息;
8. 发现并采集有关潜在客户的信息;
9. 采集行业网站 产品目录和产品信息;
10.在各大电商平台之间同步商品信息,做到在一个平台发布,在其他平台自动更新。
优采云采集器中文版如何使用
步骤 1 打开网页
登录优采云采集器→点击左上角的“+”图标→选择自定义采集(也可以在首页点击自定义采集下的“立即使用”页面),进入任务配置页面。
然后输入网址→保存网址,系统会进入工艺设计页面,自动打开之前输入的网址。
打开网页后,我们可以修改任务名称。如果没有,则默认以网页标题命名。在运行 采集 之前可以随时修改任务名称。
步骤 2 提取数据
在网页中,可以直接选择要提取的数据,窗口右上角会有相应的提示。在本教程中,我们以新闻标题、日期和文本的提取为例
设置好数据提取后,单击保存并开始运行采集。但是此时的字段名是系统自动生成的。
为了更好的满足自己的需求,可以点击右上角的“处理”进入处理页面修改字段名,保存后运行采集。
所有版本都可以运行local采集,Ultimate及以上版本可以运行cloud采集并设置定时cloud采集,但是在运行cloud采集@>之前先运行local采集测试。
任务运行完采集后,可以选择Excel、CSV、HTML等格式导出或导入数据库。
数据导出后,可以点击链接进入数据存储文件夹查看数据。该文件默认以任务名称命名。
变更日志
主要体验改进
[云采集]新增云采集直播功能,展示任务的云操作,如任务拆分、节点分配、采集数据等流程
[云采集] 新增云采集通知功能,可以为每个任务设置采集完成和采集停止时的邮件通知流程
[Cloud采集] 增加单个子任务重启功能,可以重启少量采集或者状态为stopped的子任务,可以减少数据遗漏
Bug修复
修复“重试次数设置不生效”的问题
修复“循环 URL 异常”问题
修复“最后一个字段,修改要保存的字段名无效”的问题
提高性能并修复一些卡顿问题
内容采集器(网站通用信息收集器支持离线自动更新网页信息收集软件的优点 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-02-06 14:07
)
<p>网站Universal Information Collector 是一个非常有用的采集网络信息的工具。采集网站通用信息采集器是一款不错的软件。本软件由开发和发布。该软件可以抓取网站和网页。软件整合了所有网页信息采集软件的优点,为用户提供了一个快速高效的网页信息采集工具,软件可以采集网页中的所有信息并单独保存,也可以自动发布到用户的在网站 上拥有 查看全部
内容采集器(内容采集器推荐推荐一下ezcapture采集国产手机端操作)
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2022-02-06 01:01
内容采集器推荐推荐一下ezcapture采集器,国产采集器,无需翻墙,无需注册,采集的数据有效率,资源丰富;采集器不仅支持绝大部分常见的国内外网站,还支持国外网站的采集。ezcapture是一款网络爬虫采集器,整合了http协议。http协议是一种简单快速的协议,连接url时将响应信息全部发送给对方,从而控制对方来访问您的页面。
整个页面都采用http协议(hypertexttransferprotocol),因此,又称超文本传输协议(http)。使用ezcapture采集器,你可以在电脑上通过浏览器登录不同的博客或者社区,来采集网站上的文章或是插图、动图、源代码等等。你也可以发布一个链接,给其他人去采集。因为采集器支持多线程采集,而不是单机的单线程采集模式,所以传输的资源保证不会丢失。
采集器可以自动保存您的采集结果。采集器支持图片文本、音频视频、站内信息、网页表单等不同格式的数据。ezcapture采集器支持国内多网站操作以及功能多样的手机端操作,可以全面满足不同用户对网站源码爬取的需求。因为采集器可以全面满足不同用户对网站源码爬取的需求,所以整个网站的源码你都可以得到。采集器支持国内多网站操作以及功能多样的手机端操作,可以全面满足不同用户对网站源码爬取的需求。
采集器与俄罗斯、英国网站采集插件集成,开启俄罗斯、英国网站的采集。采集器与阿拉伯、美国网站采集插件集成,开启阿拉伯、美国网站的采集。采集器与阿拉伯、美国网站采集插件集成,开启阿拉伯、美国网站的采集。采集器支持多种语言支持,采集线程:一个线程两个随机,每个线程最多1000个。支持爬虫采集的功能,抓取公众号、小程序、网页的数据、二维码等等。
使用手机端采集器访问网站,可以对网站进行动态管理,修改采集规则。支持修改采集规则,实现一次采集多个网站,并且时不时可以通过网站的自动更新,实现抓取任务的更新。采集器支持一键切换成谷歌浏览器爬虫,无需下载谷歌浏览器,省去了部分安装谷歌浏览器的安装流程。另外,全球已经有10亿台谷歌访问设备,到2018年,有望达到20亿台。
目前看来,谷歌应该是全球唯一一家可以全面普及区块链技术的搜索巨头。未来谷歌可能需要采用区块链技术,构建全新的技术生态,全面进入数字资产时代。ezcapture采集器可以爬取的网站包括:国内:(含大部分不包含):无需翻墙,点击即可采集国外:(含大部分不包含):无需翻墙,点击即可采集人人皆可使用,人人皆可实现创业。一键采集谷歌浏览器、谷歌浏览器插件等设备,不需要保证第一次安装所有设备,操作十分简单, 查看全部
内容采集器(内容采集器推荐推荐一下ezcapture采集国产手机端操作)
内容采集器推荐推荐一下ezcapture采集器,国产采集器,无需翻墙,无需注册,采集的数据有效率,资源丰富;采集器不仅支持绝大部分常见的国内外网站,还支持国外网站的采集。ezcapture是一款网络爬虫采集器,整合了http协议。http协议是一种简单快速的协议,连接url时将响应信息全部发送给对方,从而控制对方来访问您的页面。
整个页面都采用http协议(hypertexttransferprotocol),因此,又称超文本传输协议(http)。使用ezcapture采集器,你可以在电脑上通过浏览器登录不同的博客或者社区,来采集网站上的文章或是插图、动图、源代码等等。你也可以发布一个链接,给其他人去采集。因为采集器支持多线程采集,而不是单机的单线程采集模式,所以传输的资源保证不会丢失。
采集器可以自动保存您的采集结果。采集器支持图片文本、音频视频、站内信息、网页表单等不同格式的数据。ezcapture采集器支持国内多网站操作以及功能多样的手机端操作,可以全面满足不同用户对网站源码爬取的需求。因为采集器可以全面满足不同用户对网站源码爬取的需求,所以整个网站的源码你都可以得到。采集器支持国内多网站操作以及功能多样的手机端操作,可以全面满足不同用户对网站源码爬取的需求。
采集器与俄罗斯、英国网站采集插件集成,开启俄罗斯、英国网站的采集。采集器与阿拉伯、美国网站采集插件集成,开启阿拉伯、美国网站的采集。采集器与阿拉伯、美国网站采集插件集成,开启阿拉伯、美国网站的采集。采集器支持多种语言支持,采集线程:一个线程两个随机,每个线程最多1000个。支持爬虫采集的功能,抓取公众号、小程序、网页的数据、二维码等等。
使用手机端采集器访问网站,可以对网站进行动态管理,修改采集规则。支持修改采集规则,实现一次采集多个网站,并且时不时可以通过网站的自动更新,实现抓取任务的更新。采集器支持一键切换成谷歌浏览器爬虫,无需下载谷歌浏览器,省去了部分安装谷歌浏览器的安装流程。另外,全球已经有10亿台谷歌访问设备,到2018年,有望达到20亿台。
目前看来,谷歌应该是全球唯一一家可以全面普及区块链技术的搜索巨头。未来谷歌可能需要采用区块链技术,构建全新的技术生态,全面进入数字资产时代。ezcapture采集器可以爬取的网站包括:国内:(含大部分不包含):无需翻墙,点击即可采集国外:(含大部分不包含):无需翻墙,点击即可采集人人皆可使用,人人皆可实现创业。一键采集谷歌浏览器、谷歌浏览器插件等设备,不需要保证第一次安装所有设备,操作十分简单,
内容采集器(优采云采集器的网页数据采集工具分析及使用方法介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2022-02-03 20:17
优采云采集器是一个非常简单的网页数据工具采集,它有一个可视化的工作界面,用户可以通过鼠标完成网页数据采集,程序使用门槛很低,任何用户都可以轻松使用它写数据采集,不需要用户具备编写爬虫程序的能力;通过该软件,用户可以在大部分网站采集数据中使用,其中用户需要的数据信息可以从一些单页应用中Ajax加载的动态网站中获取;软件内置高速浏览器引擎,用户可以在各种浏览模式之间自由切换,让用户可以轻松直观的方式在网站网页上执行采集;该程序安全、无毒、易于使用,
软件功能
1、可视化向导:自动为所有集合元素生成集合数据。
2、定时任务:灵活定义运行时间,自动运行。
3、多引擎支持:支持多种采集引擎,内置高速浏览器内核、HTTP引擎、JSON引擎。
4、智能识别:可自动识别网页列表、采集字段、页面等。
5、拦截请求:自定义要拦截的域名,方便过滤站外广告,提高采集速度。
6、各种数据导出:可以导出到TXT、Excel、mysql、SQL Server、SQLite、access、网站等。
软件功能
零阈值
即使您不了解网络爬虫技术,也可以轻松浏览互联网网站 并采集网站 数据。软件操作简单,点击鼠标即可轻松选择要抓取的内容。
多引擎,高速,稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式,更高效地采集数据。它还具有内置的 JSON 引擎,无需解析 JSON 数据结构并直观地选择 JSON 内容。
高级智能算法
先进的智能算法可以生成目标元素XPath,自动识别网页列表,自动识别分页中的下一页按钮。它不需要分析web请求和源代码,但支持更多的网页集合。
适用于各种 网站
它可以采集 99% 的 Internet 站点,包括单页应用程序 Ajax 加载等动态类型。
指示
第 1 步:设置起始 URL
要采集 网站 数据,首先,我们需要设置进入集合的 URL。例如,如果你想为网站采集国内新闻,你应该将起始URL设置为国内新闻栏目列表的URL,但通常你不会将网站的首页设置为起始地址,因为首页通常收录Latest文章、Popular文章、Recommended文章Chapter等很多列表块,显示的内容也很有限. 一般来说,采集这些列表时不可能采集到完整的信息。
接下来,我们以新浪新闻采集为例,从新浪首页查找国内新闻。不过这个栏目首页的内容还是比较杂乱的,分成了三个子栏目
我们来看看《大陆新闻》的分栏报道
此栏目页面收录一个带有分页的内容列表。通过切换分页,我们可以采集该列下的所有文章,因此这个列表页面非常适合我们采集起始URL。
我们现在将列表 URL 复制到任务编辑框步骤 1 中的文本框中。
如果你想在一个任务中同时采集国内新闻的其他子栏目,你也可以复制另外两个子栏目的列表地址,因为这些子栏目有类似的格式。但是,为了便于导出或发布分类数据,通常不建议将多个列的内容混合在一起。
对于起始 URL,我们还可以批量添加或从 txt 文件导入。比如我们要采集前五个页面,我们也可以这样自定义五个起始页面
需要注意的是,如果这里自定义了多个分页列表,后续的集合配置中将不会启用分页。通常,当我们要采集一个列下的所有文章时,我们只需要将该列的第一页定义为起始URL。如果在后续采集配置中启用了分页,则可以为每个分页列表采集数据。
第二步:①自动生成列表和字段
进入第二步后,对于一些网页,惰性采集器会智能分析页面列表,自动高亮页面列表并生成列表数据,如
然后我们可以修剪数据,例如删除一些不必要的字段
单击图中的三角形符号以显示该字段的详细 采集 配置。单击上面的删除按钮以删除该字段。其余参数将在后续章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的,可以点击“清除字段”,清除所有生成的字段。
如果我们的列表不是手动选择的,那么它将自动列出。如果要取消高亮的列表框,可以点击Find List - List XPaths,清除其中的XPaths,然后确认。
②手动生成列表
单击搜索列表按钮并选择手动选择列表
按照提示,然后左键点击网页列表中的第一行数据
单击第一行,然后在出现提示时单击第二行或其他类似行
单击列表中的任意两行后,将突出显示整个列表。同时,列表中的字段也会生成。如果生成的字段不正确,请单击清除字段以清除下面的所有字段。下一章介绍如何手动选择字段。
③ 手动生成字段
单击“添加字段”按钮
在列表的任意一行单击要提取的元素,例如标题和链接地址,然后用鼠标左键单击标题
点击网页链接时,会提示是否获取链接地址
如果要提取链接的标题和地址,请单击是。如果您只想提取标题文本,请单击否。在这里我们点击“是”。
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击底部表格中某个字段的标题时,匹配的内容将在网页上以黄色背景突出显示。
如果标签列表中还有其他字段,请单击“添加字段”,然后重复。
④分页设置
当列表有分页时,启用分页时可以采集所有分页列表数据。
页面分页有两种类型
常规分页:有分页栏,显示“下一页”按钮。点击后可以跳转到下一页,比如新浪新闻列表中的上一页 查看全部
内容采集器(优采云采集器的网页数据采集工具分析及使用方法介绍)
优采云采集器是一个非常简单的网页数据工具采集,它有一个可视化的工作界面,用户可以通过鼠标完成网页数据采集,程序使用门槛很低,任何用户都可以轻松使用它写数据采集,不需要用户具备编写爬虫程序的能力;通过该软件,用户可以在大部分网站采集数据中使用,其中用户需要的数据信息可以从一些单页应用中Ajax加载的动态网站中获取;软件内置高速浏览器引擎,用户可以在各种浏览模式之间自由切换,让用户可以轻松直观的方式在网站网页上执行采集;该程序安全、无毒、易于使用,
软件功能
1、可视化向导:自动为所有集合元素生成集合数据。
2、定时任务:灵活定义运行时间,自动运行。
3、多引擎支持:支持多种采集引擎,内置高速浏览器内核、HTTP引擎、JSON引擎。
4、智能识别:可自动识别网页列表、采集字段、页面等。
5、拦截请求:自定义要拦截的域名,方便过滤站外广告,提高采集速度。
6、各种数据导出:可以导出到TXT、Excel、mysql、SQL Server、SQLite、access、网站等。
软件功能
零阈值
即使您不了解网络爬虫技术,也可以轻松浏览互联网网站 并采集网站 数据。软件操作简单,点击鼠标即可轻松选择要抓取的内容。
多引擎,高速,稳定
内置高速浏览器引擎,还可以切换到HTTP引擎模式,更高效地采集数据。它还具有内置的 JSON 引擎,无需解析 JSON 数据结构并直观地选择 JSON 内容。
高级智能算法
先进的智能算法可以生成目标元素XPath,自动识别网页列表,自动识别分页中的下一页按钮。它不需要分析web请求和源代码,但支持更多的网页集合。
适用于各种 网站
它可以采集 99% 的 Internet 站点,包括单页应用程序 Ajax 加载等动态类型。
指示
第 1 步:设置起始 URL
要采集 网站 数据,首先,我们需要设置进入集合的 URL。例如,如果你想为网站采集国内新闻,你应该将起始URL设置为国内新闻栏目列表的URL,但通常你不会将网站的首页设置为起始地址,因为首页通常收录Latest文章、Popular文章、Recommended文章Chapter等很多列表块,显示的内容也很有限. 一般来说,采集这些列表时不可能采集到完整的信息。
接下来,我们以新浪新闻采集为例,从新浪首页查找国内新闻。不过这个栏目首页的内容还是比较杂乱的,分成了三个子栏目
我们来看看《大陆新闻》的分栏报道
此栏目页面收录一个带有分页的内容列表。通过切换分页,我们可以采集该列下的所有文章,因此这个列表页面非常适合我们采集起始URL。
我们现在将列表 URL 复制到任务编辑框步骤 1 中的文本框中。
如果你想在一个任务中同时采集国内新闻的其他子栏目,你也可以复制另外两个子栏目的列表地址,因为这些子栏目有类似的格式。但是,为了便于导出或发布分类数据,通常不建议将多个列的内容混合在一起。
对于起始 URL,我们还可以批量添加或从 txt 文件导入。比如我们要采集前五个页面,我们也可以这样自定义五个起始页面
需要注意的是,如果这里自定义了多个分页列表,后续的集合配置中将不会启用分页。通常,当我们要采集一个列下的所有文章时,我们只需要将该列的第一页定义为起始URL。如果在后续采集配置中启用了分页,则可以为每个分页列表采集数据。
第二步:①自动生成列表和字段
进入第二步后,对于一些网页,惰性采集器会智能分析页面列表,自动高亮页面列表并生成列表数据,如
然后我们可以修剪数据,例如删除一些不必要的字段
单击图中的三角形符号以显示该字段的详细 采集 配置。单击上面的删除按钮以删除该字段。其余参数将在后续章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的,可以点击“清除字段”,清除所有生成的字段。
如果我们的列表不是手动选择的,那么它将自动列出。如果要取消高亮的列表框,可以点击Find List - List XPaths,清除其中的XPaths,然后确认。
②手动生成列表
单击搜索列表按钮并选择手动选择列表
按照提示,然后左键点击网页列表中的第一行数据
单击第一行,然后在出现提示时单击第二行或其他类似行
单击列表中的任意两行后,将突出显示整个列表。同时,列表中的字段也会生成。如果生成的字段不正确,请单击清除字段以清除下面的所有字段。下一章介绍如何手动选择字段。
③ 手动生成字段
单击“添加字段”按钮
在列表的任意一行单击要提取的元素,例如标题和链接地址,然后用鼠标左键单击标题
点击网页链接时,会提示是否获取链接地址
如果要提取链接的标题和地址,请单击是。如果您只想提取标题文本,请单击否。在这里我们点击“是”。
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您单击底部表格中某个字段的标题时,匹配的内容将在网页上以黄色背景突出显示。
如果标签列表中还有其他字段,请单击“添加字段”,然后重复。
④分页设置
当列表有分页时,启用分页时可以采集所有分页列表数据。
页面分页有两种类型
常规分页:有分页栏,显示“下一页”按钮。点击后可以跳转到下一页,比如新浪新闻列表中的上一页
内容采集器(优采云采集器能生成Excel表格,api数据库文件等内容介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-02-01 06:05
优采云采集器v3.0.3.3是一款简单实用、全面高效的网络信息采集软件,优采云 采集器可以生成Excel表格、api数据库文件等,帮助您管理网站数据信息。如果需要对指定的网页数据执行采集,喜欢就赶紧来下载吧!
软件功能
一键提取数据
简单易学,通过可视化界面,点击鼠标即可抓取数据;
快速高效
内置一套高速浏览器内核,配合HTTP引擎模式,实现快速采集数据;
适用于各种网站
可以采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站;
特征
向导模式
简单易用,轻松鼠标点击自动生成;
定期运行的脚本
无需人工即可按计划定时运行;
原装高速核心
自研浏览器内核速度快,远超对手;
智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等);
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则;
各种数据导出
支持Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等;
指示
第 1 步:输入 采集 网址
打开软件,新建一个任务,输入需要采集的网站地址。
第二步:智能分析,全过程自动提取数据
进入第二步后,优采云采集器自动智能分析网页,从中提取列表数据。
步骤 3:将数据导出到表、数据库、网站 等。
运行任务,将采集中的数据导出到Csv、Excel等各种数据库,支持api导出。
常见问题
Q:如何过滤列表中的前N个数据?
1.有时候我们需要对采集收到的列表进行过滤,比如过滤掉第一组数据(在采集表中,过滤掉表列名)
2.点击列表模式菜单设置列表xpath
Q:如何抓包获取cookie并手动设置?
1.首先用谷歌浏览器打开网站为采集,登录。
2. 然后按F12,会出现开发者工具,选择Network
3.然后按 F5 刷新下一页并选择其中一个请求。
4.复制完成后,在优采云采集器中,编辑任务,进入第三步,指定HTTP Header。
变更日志
优化导出数据窗口;
为 XPath 文本框添加了自动完成和语法高亮;
新增导出图片到Excel;
修复了分组调度任务的问题;
修复其他问题; 查看全部
内容采集器(优采云采集器能生成Excel表格,api数据库文件等内容介绍)
优采云采集器v3.0.3.3是一款简单实用、全面高效的网络信息采集软件,优采云 采集器可以生成Excel表格、api数据库文件等,帮助您管理网站数据信息。如果需要对指定的网页数据执行采集,喜欢就赶紧来下载吧!
软件功能
一键提取数据
简单易学,通过可视化界面,点击鼠标即可抓取数据;
快速高效
内置一套高速浏览器内核,配合HTTP引擎模式,实现快速采集数据;
适用于各种网站
可以采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站;
特征
向导模式
简单易用,轻松鼠标点击自动生成;
定期运行的脚本
无需人工即可按计划定时运行;
原装高速核心
自研浏览器内核速度快,远超对手;
智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等);
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则;
各种数据导出
支持Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等;
指示
第 1 步:输入 采集 网址
打开软件,新建一个任务,输入需要采集的网站地址。
第二步:智能分析,全过程自动提取数据
进入第二步后,优采云采集器自动智能分析网页,从中提取列表数据。
步骤 3:将数据导出到表、数据库、网站 等。
运行任务,将采集中的数据导出到Csv、Excel等各种数据库,支持api导出。
常见问题
Q:如何过滤列表中的前N个数据?
1.有时候我们需要对采集收到的列表进行过滤,比如过滤掉第一组数据(在采集表中,过滤掉表列名)
2.点击列表模式菜单设置列表xpath
Q:如何抓包获取cookie并手动设置?
1.首先用谷歌浏览器打开网站为采集,登录。
2. 然后按F12,会出现开发者工具,选择Network
3.然后按 F5 刷新下一页并选择其中一个请求。
4.复制完成后,在优采云采集器中,编辑任务,进入第三步,指定HTTP Header。
变更日志
优化导出数据窗口;
为 XPath 文本框添加了自动完成和语法高亮;
新增导出图片到Excel;
修复了分组调度任务的问题;
修复其他问题;
内容采集器(横琴建站:中小企业在做网站建设时需要注意哪些问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-01-30 12:11
导读:随着企业的快速发展壮大,越来越多的中小企业重视品牌网站建设和营销网站建设,希望借助互联网提升自己的品牌认识并获得更多潜在的合作机会,接触更精准的客户。一个企业的网站建设不像普通的网站,需要深入的行业研究,挖掘自身企业各方面的优势,塑造独特的企业形象,尤其是很多细节,这直接影响到企业网站@网站的作用和目的,那么中小企业在做网站时应该注意哪些问题 建造?下面横琴网站将为大家分享SEO的相关知识。
让我们从两个常见的内容采集工具开始:
(1)优采云采集工具:操作比较简单,免费版可以满足新手站长的数据挖掘需求,但是采集数据的推导需要集成,这是一个更重要的功能它是智能采集,它不需要编写太复杂的规则。
(2)优采云采集器:国内老牌除尘软件。所以很多支持cmssystem采集的插件都可以在市场,如:织梦文章采集、WordPress信息采集、Zblog数据采集等。需要一定的技术力量。
那么,文章的采集应该注意什么?
1、新站清空数据采集
我们知道网站发布初期有一个评价期,如果我们在站开始使用采集到的内容,会对网站评分产生影响,文章容易出现被放到低质量的库中,会出现一个普遍现象:与收录没有排名。
为此,新的网站尽可能的保留了网上原有的内容,当页面的内容没有被完全索引的时候,没必要盲目的提交,或者想提交,你需要采取一定的策略。
2、权威网站采集内容
我们知道搜索引擎不喜欢关闭状态,他们不仅喜欢网站 的入站链接,还喜欢一些出站链接,以使这个生态系统更具相关性。
为此,当你的网站已经积累了一定的权重后,可以通过版权链接适当采集相关内容,需要注意:
(1)保证采集的内容对站内用户有一定的推荐价值,是解决用户需求的好办法。
(2)行业官方文档,一鸣惊人网站,知名专家推荐采集。
3、避免采集网站范围的内容
提到这个问题,很容易让很多人质疑飓风算法对获取的严厉攻击的强调,但是为什么权限网站不在攻击范围之内呢?
这涉及到搜索引擎的本质:满足用户的需求,而网站对优质内容传播的影响也比较重要。
对于中小网站,尽量避免大量的内容采集,直到它具有独特的属性和影响力。
提示:随着熊掌的上线和原创保护的推出,百度仍将努力调整和平衡原创内容和权限网站的排名。原则上应该更倾向于原址先行。
4、如果网站content采集被处罚了怎么办?
Hurricane 算法非常人性化。它只惩罚 采集 部分,但对同一站点上的其他部分几乎没有影响。
所以解决方法很简单,只需要删除采集的内容,设置404页面,然后在百度搜索资源平台提交死链接->网站支持->数据介绍->死链接提交栏。如果您发现 网站 的权重恢复缓慢,您可以在反馈中心提供反馈。
摘要:内容仍然适用于王。关注熊掌号会发现,2019年百度会加大对原创内容的支持,尽量避免采集内容。
横琴网站网络营销托管代理运营服务商,专注于中小企业网络营销技术服务,为中小企业提供企业网站建设、网络营销托管代理运营、SEM托管代理运营、SEO 站群建设、企业网站代理运营、小程序开发推广、广告媒体投放代理运营、美团小红书代理运营、微信公众号代理运营等。致力于成为网络营销外包合作企业托管代理运营服务商。 查看全部
内容采集器(横琴建站:中小企业在做网站建设时需要注意哪些问题)
导读:随着企业的快速发展壮大,越来越多的中小企业重视品牌网站建设和营销网站建设,希望借助互联网提升自己的品牌认识并获得更多潜在的合作机会,接触更精准的客户。一个企业的网站建设不像普通的网站,需要深入的行业研究,挖掘自身企业各方面的优势,塑造独特的企业形象,尤其是很多细节,这直接影响到企业网站@网站的作用和目的,那么中小企业在做网站时应该注意哪些问题 建造?下面横琴网站将为大家分享SEO的相关知识。
让我们从两个常见的内容采集工具开始:
(1)优采云采集工具:操作比较简单,免费版可以满足新手站长的数据挖掘需求,但是采集数据的推导需要集成,这是一个更重要的功能它是智能采集,它不需要编写太复杂的规则。
(2)优采云采集器:国内老牌除尘软件。所以很多支持cmssystem采集的插件都可以在市场,如:织梦文章采集、WordPress信息采集、Zblog数据采集等。需要一定的技术力量。
那么,文章的采集应该注意什么?
1、新站清空数据采集
我们知道网站发布初期有一个评价期,如果我们在站开始使用采集到的内容,会对网站评分产生影响,文章容易出现被放到低质量的库中,会出现一个普遍现象:与收录没有排名。
为此,新的网站尽可能的保留了网上原有的内容,当页面的内容没有被完全索引的时候,没必要盲目的提交,或者想提交,你需要采取一定的策略。
2、权威网站采集内容
我们知道搜索引擎不喜欢关闭状态,他们不仅喜欢网站 的入站链接,还喜欢一些出站链接,以使这个生态系统更具相关性。
为此,当你的网站已经积累了一定的权重后,可以通过版权链接适当采集相关内容,需要注意:
(1)保证采集的内容对站内用户有一定的推荐价值,是解决用户需求的好办法。
(2)行业官方文档,一鸣惊人网站,知名专家推荐采集。
3、避免采集网站范围的内容
提到这个问题,很容易让很多人质疑飓风算法对获取的严厉攻击的强调,但是为什么权限网站不在攻击范围之内呢?
这涉及到搜索引擎的本质:满足用户的需求,而网站对优质内容传播的影响也比较重要。
对于中小网站,尽量避免大量的内容采集,直到它具有独特的属性和影响力。
提示:随着熊掌的上线和原创保护的推出,百度仍将努力调整和平衡原创内容和权限网站的排名。原则上应该更倾向于原址先行。
4、如果网站content采集被处罚了怎么办?
Hurricane 算法非常人性化。它只惩罚 采集 部分,但对同一站点上的其他部分几乎没有影响。
所以解决方法很简单,只需要删除采集的内容,设置404页面,然后在百度搜索资源平台提交死链接->网站支持->数据介绍->死链接提交栏。如果您发现 网站 的权重恢复缓慢,您可以在反馈中心提供反馈。
摘要:内容仍然适用于王。关注熊掌号会发现,2019年百度会加大对原创内容的支持,尽量避免采集内容。
横琴网站网络营销托管代理运营服务商,专注于中小企业网络营销技术服务,为中小企业提供企业网站建设、网络营销托管代理运营、SEM托管代理运营、SEO 站群建设、企业网站代理运营、小程序开发推广、广告媒体投放代理运营、美团小红书代理运营、微信公众号代理运营等。致力于成为网络营销外包合作企业托管代理运营服务商。

