
内容采集器
解决方案:网页内容采集器Content Grabber Premium v2.48
采集交流 • 优采云 发表了文章 • 0 个评论 • 424 次浏览 • 2020-08-28 21:13
Content Grabber Premium破解版是一款用于网页抓取和网页自动化的网页内容采集工具,它可以从几乎任何网站提取内容,并以您选择的格式(包括Excel报告,XML,CSV和大多数数据库)将其保存为结构化数据,欢迎有须要的同事前来下载使用。
基本介绍
Content Grabber Premium(网页内容采集器) 一款由国内高手制做的能从网页中抓取内容(视频、图片、文本)并提取成Excel、XML、CSV和大多数数据库的利器,软件基于网页抓取和Web自动化。完全免费提供使用,常用于数据的调查和测量用途。
功能介绍
价格比较门户/移动应用程序
- 数据汇总
- 协作清单(例如,房屋止赎,工作委员会,旅游景点)
- 新闻和内容聚合
- 搜索引擎排名
市场情报和检测
- 有竞争力的价钱
- 零售连锁监控
- 社交媒体和品牌检测
- 金融和市场研究
- 欺诈辨识
- 知识产权保护
- 合规性和风险管理
政府解决方案
- 及时获取世界各地的新闻,活动和意见
- 减少数据搜集和IT成本
- 促进信息共享
- 开源智能(OSINT)
内容集成
- 内容迁移(即CMS / CRM)
- 企业搜索
- 传统的应用程序集成
B2B整合/流程自动化
- 合作伙伴/供应商/客户整合
可扩展性和可靠性
内容抓取器针对的是对网路抓取至关重要的公司,并注重于可扩展性和可靠性。网络收录大量的数据,而且利用多线程,优化的Web浏览器以及许多其他性能调整选项,Content Grabber将比其他任何软件提取的速率更快,更可靠。我们强悍的测试和调试功能可帮助您建立可靠的代理,并且可靠的错误处理和错误恢复将使代理在最困难的情况下运行。
建立数百个网页刮取代理
“内容抓取器”代理编辑器的易用性和可视化方式让其适用于建立数百个网页抓取代理,比使用任何其他软件要快得多。
代理编辑器会手动检查并配置所需的命令。它会手动创建内容和链接列表,处理分页和网页表单,下载或上传文件,并配置您在网页上执行的任何其他操作。同时,您仍然可以自动微调这种命令,因此,“内容抓取器”为您提供了简单性和控制性。
有数百个网路抓取工具,您须要合适的工具来管理这种工具,并且抓取内容不会使您沮丧。您可以查看所有代理的状态和日志,或在一个集中位置运行和安排代理。
分配网刮刮剂免版税
构建免版税的自收录网页抓取代理,可以在没有“内容抓取器”软件的情况下在任何地方运行。独立代理是一个简单的可执行文件,可以随时随地发送或复制,并且拥有丰富的配置选项。您可以自由地销售或附送您的独立代理商,并且可以将促销消息和广告添加到代理商的用户界面。
使用脚本自定义所有内容
脚本是“内容抓取器”的一个组成部份,可以用于须要个别特殊功能的情况,以便完全依照您的须要完成所有操作。使用外置的脚本编辑器,或者借助Content Grabber与Visual Studio的集成,实现更强大的脚本编辑和调试功能。
使用API来建立奇特的解决方案
将Web抓取功能添加到您自己的桌面应用程序中,并免费分发您的应用程序的Content Grabber运行时。使用专用的内容抓取器Web API建立Web应用程序,并按照须要直接从您的网站执行Web抓取代理。
系统要求
在安装“内容抓取器”之前,请确保您符合这种要求。
Windows 7/8/10 / 2008R2 / 2012 / 2012R2
.NET v4.5(将手动安装,如果它仍未安装在您的计算机上)。
安装步骤
1、在本站提供的百度网站中下载该软件,并解压缩后,双击“setup.exe”程序
2、如果笔记本中没有安装Microsoft .NET版本,安装程序会显示下来Microsoft .NET版本4.5许可合同,并会手动为你安装
3、接受许可合同并安装
4、在安装向导中按照提示进行安装 查看全部
网页内容采集器Content Grabber Premium v2.48
Content Grabber Premium破解版是一款用于网页抓取和网页自动化的网页内容采集工具,它可以从几乎任何网站提取内容,并以您选择的格式(包括Excel报告,XML,CSV和大多数数据库)将其保存为结构化数据,欢迎有须要的同事前来下载使用。
基本介绍
Content Grabber Premium(网页内容采集器) 一款由国内高手制做的能从网页中抓取内容(视频、图片、文本)并提取成Excel、XML、CSV和大多数数据库的利器,软件基于网页抓取和Web自动化。完全免费提供使用,常用于数据的调查和测量用途。
功能介绍
价格比较门户/移动应用程序
- 数据汇总
- 协作清单(例如,房屋止赎,工作委员会,旅游景点)
- 新闻和内容聚合
- 搜索引擎排名
市场情报和检测
- 有竞争力的价钱
- 零售连锁监控
- 社交媒体和品牌检测
- 金融和市场研究
- 欺诈辨识
- 知识产权保护
- 合规性和风险管理
政府解决方案
- 及时获取世界各地的新闻,活动和意见
- 减少数据搜集和IT成本
- 促进信息共享
- 开源智能(OSINT)
内容集成
- 内容迁移(即CMS / CRM)
- 企业搜索
- 传统的应用程序集成
B2B整合/流程自动化
- 合作伙伴/供应商/客户整合
可扩展性和可靠性
内容抓取器针对的是对网路抓取至关重要的公司,并注重于可扩展性和可靠性。网络收录大量的数据,而且利用多线程,优化的Web浏览器以及许多其他性能调整选项,Content Grabber将比其他任何软件提取的速率更快,更可靠。我们强悍的测试和调试功能可帮助您建立可靠的代理,并且可靠的错误处理和错误恢复将使代理在最困难的情况下运行。
建立数百个网页刮取代理
“内容抓取器”代理编辑器的易用性和可视化方式让其适用于建立数百个网页抓取代理,比使用任何其他软件要快得多。
代理编辑器会手动检查并配置所需的命令。它会手动创建内容和链接列表,处理分页和网页表单,下载或上传文件,并配置您在网页上执行的任何其他操作。同时,您仍然可以自动微调这种命令,因此,“内容抓取器”为您提供了简单性和控制性。
有数百个网路抓取工具,您须要合适的工具来管理这种工具,并且抓取内容不会使您沮丧。您可以查看所有代理的状态和日志,或在一个集中位置运行和安排代理。
分配网刮刮剂免版税
构建免版税的自收录网页抓取代理,可以在没有“内容抓取器”软件的情况下在任何地方运行。独立代理是一个简单的可执行文件,可以随时随地发送或复制,并且拥有丰富的配置选项。您可以自由地销售或附送您的独立代理商,并且可以将促销消息和广告添加到代理商的用户界面。
使用脚本自定义所有内容
脚本是“内容抓取器”的一个组成部份,可以用于须要个别特殊功能的情况,以便完全依照您的须要完成所有操作。使用外置的脚本编辑器,或者借助Content Grabber与Visual Studio的集成,实现更强大的脚本编辑和调试功能。
使用API来建立奇特的解决方案
将Web抓取功能添加到您自己的桌面应用程序中,并免费分发您的应用程序的Content Grabber运行时。使用专用的内容抓取器Web API建立Web应用程序,并按照须要直接从您的网站执行Web抓取代理。
系统要求
在安装“内容抓取器”之前,请确保您符合这种要求。
Windows 7/8/10 / 2008R2 / 2012 / 2012R2
.NET v4.5(将手动安装,如果它仍未安装在您的计算机上)。
安装步骤
1、在本站提供的百度网站中下载该软件,并解压缩后,双击“setup.exe”程序
2、如果笔记本中没有安装Microsoft .NET版本,安装程序会显示下来Microsoft .NET版本4.5许可合同,并会手动为你安装
3、接受许可合同并安装
4、在安装向导中按照提示进行安装
【网页表格数据采集器】
采集交流 • 优采云 发表了文章 • 0 个评论 • 354 次浏览 • 2020-08-27 14:28
网页表格数据采集器软件支持对一个网站上的连续无限个页面中的同类表格数据的批量采集,支持对一个页面中的指定表格数据的采集,也支持对一个页面中具有共同数据的多个表格数据的采集,采集时可依照网页上类似“下一页”这样的链接的后续页面的无限采集,也可按照网址中的页数采集指定的连续的页面中的表格数据,还可依据你自己指定的网址列表连续批量采集,有没有合并的单元格都可采集,而且还能手动过滤隐藏的干扰码,采集的结果可显示为文本表格,保存成文本,也可保存为EXCEL就能直接读取的CSV格式,能够用EXCEL打开采集后的表格数据了,那么以后的排序、筛选、统计、分析就是轻松的事情了。
网页表格数据采集软件的使用也很简单,如果你熟悉以后,采集表格可以说是一键搞定。
时间就是生命,一寸光阴一寸金,寸金难买寸时光,我们不能将有限的生命浪费在一些重复的、枯燥的工作上,有现成的软件,何不使用软件,不能再迟疑了,需要的就请尽早下载吧!
网页表格数据采集器使用方式
1、首先在地址栏输入待采集的网页地址,如果待采集网页早已在IE类浏览器中打开了,那么软件的网址列表上将手动会加入此地址的,你只要下拉选择一下都会打开了。
2、再点击抓取测试按键,看看网页源码及该网页中所含的表格数目,网页源码在软件下边的文本框中显示,网页中所含的表格数及表头信息在软件左上角列表框中显示。
3、从表格数列表中选择你要抓取的表格,此时表格左上角第一格文字将显示在软件的表格左上角第一格内容输入框中,表格所含数组(列)将显示在软件两侧的中间列表中。
4、再选择你要采集的表格数据的数组(列),如果不选择,网页表格数据采集器将全部采集。
5、选择你是否要抓取表格的表头行,保存时是否显示表格线,如果网页表格中有数组有链接,你可以选择是否收录链接地址,如果有且要采集其链接地址,那么你不能同时选择收录表头行。
6、如果你要采集的表格数据只有一个网页,那么你如今就可直接点击抓取表格抓取了,如果后面不选择收录表格线,表格数据将以CVS格式保存,此格式可用谷歌EXCEL软件直接打开转为EXCEL表格,如果上面选择收录表格线,表格数据将以TXT格式保存,可用记事本软件打开查看,直接具有表格线,也太清晰。
7、如果你要采集的表格数据有连续多个页面,并且你都想将其采集下来,那么,请再设置程序采集下一页及后续页面的形式,可以是按照链接名打开下页,链接名称几乎大部分页面都是“下一页”,你看页面,找到后输入即可,如果网页没有下一页链接,但是网址中收录页数,那么你也可选择按照网址中的页数打开,你可以选择从前到后,如从1页到10页,也可选择从后到前,如从10页到1页,在页数输入框中输入即可,但此时网址中代表页数的位置要用“(*)”代替,否则网页表格数据采集器程序将不认识。
8、再选择是定时采集或等待网页打开并加载结束后立刻采集,定时采集是程序按照一个设定的太小的时间间隔去判定打开的页面中是否有你要的表格,有就采集,而网页加载后采集是只要是要采集的网页早已打开了,程序都会立刻进行采集,两者各有特色,看须要选择。
9、最后,就是你点击一下抓取表格按键,就可以泡杯奶茶逍遥去了!
10、如果是你已然比较熟悉了你要采集的网页的信息,而且要采集指定表格的所有数组,你也可以输入须要的一些信息后,不经过抓取测试等操作,直接点击抓取表格的。
展开 查看全部
【网页表格数据采集器】
网页表格数据采集器软件支持对一个网站上的连续无限个页面中的同类表格数据的批量采集,支持对一个页面中的指定表格数据的采集,也支持对一个页面中具有共同数据的多个表格数据的采集,采集时可依照网页上类似“下一页”这样的链接的后续页面的无限采集,也可按照网址中的页数采集指定的连续的页面中的表格数据,还可依据你自己指定的网址列表连续批量采集,有没有合并的单元格都可采集,而且还能手动过滤隐藏的干扰码,采集的结果可显示为文本表格,保存成文本,也可保存为EXCEL就能直接读取的CSV格式,能够用EXCEL打开采集后的表格数据了,那么以后的排序、筛选、统计、分析就是轻松的事情了。
网页表格数据采集软件的使用也很简单,如果你熟悉以后,采集表格可以说是一键搞定。
时间就是生命,一寸光阴一寸金,寸金难买寸时光,我们不能将有限的生命浪费在一些重复的、枯燥的工作上,有现成的软件,何不使用软件,不能再迟疑了,需要的就请尽早下载吧!
网页表格数据采集器使用方式
1、首先在地址栏输入待采集的网页地址,如果待采集网页早已在IE类浏览器中打开了,那么软件的网址列表上将手动会加入此地址的,你只要下拉选择一下都会打开了。
2、再点击抓取测试按键,看看网页源码及该网页中所含的表格数目,网页源码在软件下边的文本框中显示,网页中所含的表格数及表头信息在软件左上角列表框中显示。
3、从表格数列表中选择你要抓取的表格,此时表格左上角第一格文字将显示在软件的表格左上角第一格内容输入框中,表格所含数组(列)将显示在软件两侧的中间列表中。
4、再选择你要采集的表格数据的数组(列),如果不选择,网页表格数据采集器将全部采集。
5、选择你是否要抓取表格的表头行,保存时是否显示表格线,如果网页表格中有数组有链接,你可以选择是否收录链接地址,如果有且要采集其链接地址,那么你不能同时选择收录表头行。
6、如果你要采集的表格数据只有一个网页,那么你如今就可直接点击抓取表格抓取了,如果后面不选择收录表格线,表格数据将以CVS格式保存,此格式可用谷歌EXCEL软件直接打开转为EXCEL表格,如果上面选择收录表格线,表格数据将以TXT格式保存,可用记事本软件打开查看,直接具有表格线,也太清晰。
7、如果你要采集的表格数据有连续多个页面,并且你都想将其采集下来,那么,请再设置程序采集下一页及后续页面的形式,可以是按照链接名打开下页,链接名称几乎大部分页面都是“下一页”,你看页面,找到后输入即可,如果网页没有下一页链接,但是网址中收录页数,那么你也可选择按照网址中的页数打开,你可以选择从前到后,如从1页到10页,也可选择从后到前,如从10页到1页,在页数输入框中输入即可,但此时网址中代表页数的位置要用“(*)”代替,否则网页表格数据采集器程序将不认识。
8、再选择是定时采集或等待网页打开并加载结束后立刻采集,定时采集是程序按照一个设定的太小的时间间隔去判定打开的页面中是否有你要的表格,有就采集,而网页加载后采集是只要是要采集的网页早已打开了,程序都会立刻进行采集,两者各有特色,看须要选择。
9、最后,就是你点击一下抓取表格按键,就可以泡杯奶茶逍遥去了!
10、如果是你已然比较熟悉了你要采集的网页的信息,而且要采集指定表格的所有数组,你也可以输入须要的一些信息后,不经过抓取测试等操作,直接点击抓取表格的。
展开
Python爬虫实战练习:实现一个简易的网页采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2020-08-27 11:34
前言
本文的文字及图片来源于网路,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:虫萧
PS:如有须要Python学习资料的小伙伴可以加下方的群去找免费管理员发放
可以免费发放源码、项目实战视频、PDF文件等
requests模块
python中封装好的一个基于网路恳求的模块。用来模拟浏览器发恳求。安装:pip install requests
requests模块的编码流程指定url发起恳求获取相应数据持久化存储
# 爬取搜狗首页的页面源码数据
import requests
# 1. 指定url
url = "https://www.sogou.com"
# 2.发送请求 get
response = requests.get(url=url) # get返回值是Response对象
# 获取响应数据,响应数据在Response对象里
page_text = response.text # text返回字符串形式的响应数据
# 4.持久化储存
with open("sogou.html","w",encoding='utf-8') as fp:
fp.write(page_text)
项目:实现一个简易的网页采集器
要求:程序基于搜狗录入任意的关键字之后获取关键字对应的相关的整个页面。
# 1.指定url,需要让url携带的参数动态化
url = "https://www.sogou.com/web"
# 实现参数动态化,不推荐参数的拼接,参数如果太多就相当麻烦。
# requests模块实现了更为简便的方法
ky = input("enter a key")
params = {
'query':ky
}
# 将需要的请求参数对应的字典作用到get方法的params参数中,params参数接受一个字典
response = requests.get(url=url,params=params)
page_text = response.text
with open(f"{ky}.html","w",encoding='utf-8') as fp:
fp.write(page_text)
上述代码执行后:
出现了乱码数据量级不对
# 解决乱码
url = "https://www.sogou.com/web"
ky = input("enter a key")
params = {
'query':ky
}
response = requests.get(url=url,params=params)
# print(response.encoding) 会打印原来response的编码格式
response.encoding = 'utf-8' # 修改响应数据的编码格式
page_text = response.text
with open(f"{ky}.html","w",encoding='utf-8') as fp:
fp.write(page_text)
上述代码执行后:
收到了错误页面(搜狗的反爬机制)
UA检查
反反爬策略:UA伪装 请求头降低User-Agent
打开浏览器恳求搜狗页面,右键点击检测步入Network,点击Headers找到浏览器的User-Agent
注意:任意浏览器的身分标示都可以。
# 反反爬策略:请求头增加User-Agent
url = "https://www.sogou.com/web"
ky = input("enter a key")
params = {
'query':ky
}
# 请求头中增加User-Agent ,注意请求头的数据格式是键值对,且都是字符串。
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
}
response = requests.get(url=url,params=params,headers=headers)
response.encoding = 'utf-8'
page_text = response.text
with open(f"{ky}.html","w",encoding='utf-8') as fp:
fp.write(page_text)
注意:get的参数headers是一个字典,且通配符都是字符串方式 查看全部
Python爬虫实战练习:实现一个简易的网页采集器
前言
本文的文字及图片来源于网路,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:虫萧
PS:如有须要Python学习资料的小伙伴可以加下方的群去找免费管理员发放

可以免费发放源码、项目实战视频、PDF文件等
requests模块
python中封装好的一个基于网路恳求的模块。用来模拟浏览器发恳求。安装:pip install requests
requests模块的编码流程指定url发起恳求获取相应数据持久化存储
# 爬取搜狗首页的页面源码数据
import requests
# 1. 指定url
url = "https://www.sogou.com"
# 2.发送请求 get
response = requests.get(url=url) # get返回值是Response对象
# 获取响应数据,响应数据在Response对象里
page_text = response.text # text返回字符串形式的响应数据
# 4.持久化储存
with open("sogou.html","w",encoding='utf-8') as fp:
fp.write(page_text)

项目:实现一个简易的网页采集器
要求:程序基于搜狗录入任意的关键字之后获取关键字对应的相关的整个页面。
# 1.指定url,需要让url携带的参数动态化
url = "https://www.sogou.com/web"
# 实现参数动态化,不推荐参数的拼接,参数如果太多就相当麻烦。
# requests模块实现了更为简便的方法
ky = input("enter a key")
params = {
'query':ky
}
# 将需要的请求参数对应的字典作用到get方法的params参数中,params参数接受一个字典
response = requests.get(url=url,params=params)
page_text = response.text
with open(f"{ky}.html","w",encoding='utf-8') as fp:
fp.write(page_text)
上述代码执行后:
出现了乱码数据量级不对
# 解决乱码
url = "https://www.sogou.com/web"
ky = input("enter a key")
params = {
'query':ky
}
response = requests.get(url=url,params=params)
# print(response.encoding) 会打印原来response的编码格式
response.encoding = 'utf-8' # 修改响应数据的编码格式
page_text = response.text
with open(f"{ky}.html","w",encoding='utf-8') as fp:
fp.write(page_text)
上述代码执行后:
收到了错误页面(搜狗的反爬机制)
UA检查
反反爬策略:UA伪装 请求头降低User-Agent
打开浏览器恳求搜狗页面,右键点击检测步入Network,点击Headers找到浏览器的User-Agent
注意:任意浏览器的身分标示都可以。
# 反反爬策略:请求头增加User-Agent
url = "https://www.sogou.com/web"
ky = input("enter a key")
params = {
'query':ky
}
# 请求头中增加User-Agent ,注意请求头的数据格式是键值对,且都是字符串。
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
}
response = requests.get(url=url,params=params,headers=headers)
response.encoding = 'utf-8'
page_text = response.text
with open(f"{ky}.html","w",encoding='utf-8') as fp:
fp.write(page_text)
注意:get的参数headers是一个字典,且通配符都是字符串方式
优采云采集器采集网页文本内容的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 331 次浏览 • 2020-08-26 11:53
优采云采集器是一款多功能的网页信息采集工具,这款软件采用的是全新的信息抓取模式,能够帮助用户愈发快速的采集网页中的数据,并且可以对每一个网页模块中的数据进行选择性采集,很多用户在须要采集网页内容的时侯大多都是采集网页的文本内容,介于还有一些用户不知道如何使用这款软件来采集网页文本内容,那么小编就来跟你们分享一下具体的操作方法步骤吧,有须要的同事赶快一起来瞧瞧小编分享的方式,希望这篇教程才能对你们有所帮助。
方法步骤
1.首先第一步我们打开软件以后须要在软件的主界面中输入自己想要采集文本内容的网址,输入网址以后点击开始采集。
2.点击开始采集之后软件会手动辨识出该网址的网页界面,并且用户可以联通键盘在网页中选择要采集的元素位置,点击选择以后在出现的界面中选择采集该元素的文本这个选项。
3.选择点击采集该元素的文本这个选项以后,界面中会出现一个智能提示窗口,提示我们可以保存存开始采集操作,然后我们点击它。
4.点击以后还会步入到采集操作的界面了,等到一会之后软件会返回采集完成的窗口,紧接着我们点击其中的导入数据这个按键。
5.点击导入数据按键以后的下一步是选择我们要导入的形式,小编就以HTML文件为例来跟你们演示,点击选择然后再点击右下角的确定按键。
6.最后点击确定按键以后就来到另存为文件的界面了,然后我们在界面中输入文件须要保存的名称,然后点击保存按键即可。 查看全部
优采云采集器采集网页文本内容的方式
优采云采集器是一款多功能的网页信息采集工具,这款软件采用的是全新的信息抓取模式,能够帮助用户愈发快速的采集网页中的数据,并且可以对每一个网页模块中的数据进行选择性采集,很多用户在须要采集网页内容的时侯大多都是采集网页的文本内容,介于还有一些用户不知道如何使用这款软件来采集网页文本内容,那么小编就来跟你们分享一下具体的操作方法步骤吧,有须要的同事赶快一起来瞧瞧小编分享的方式,希望这篇教程才能对你们有所帮助。

方法步骤
1.首先第一步我们打开软件以后须要在软件的主界面中输入自己想要采集文本内容的网址,输入网址以后点击开始采集。

2.点击开始采集之后软件会手动辨识出该网址的网页界面,并且用户可以联通键盘在网页中选择要采集的元素位置,点击选择以后在出现的界面中选择采集该元素的文本这个选项。

3.选择点击采集该元素的文本这个选项以后,界面中会出现一个智能提示窗口,提示我们可以保存存开始采集操作,然后我们点击它。

4.点击以后还会步入到采集操作的界面了,等到一会之后软件会返回采集完成的窗口,紧接着我们点击其中的导入数据这个按键。

5.点击导入数据按键以后的下一步是选择我们要导入的形式,小编就以HTML文件为例来跟你们演示,点击选择然后再点击右下角的确定按键。

6.最后点击确定按键以后就来到另存为文件的界面了,然后我们在界面中输入文件须要保存的名称,然后点击保存按键即可。
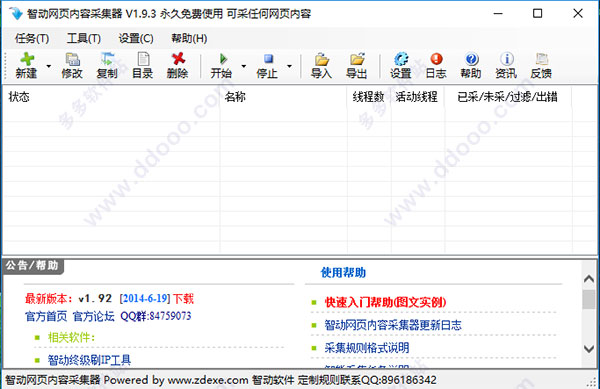
智动网页内容采集器 v1.93官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 290 次浏览 • 2020-08-26 07:22
智动网页内容采集器是由智动软件推出的一款操作简单,功能实用的网页内容手动采集工具。支持采用多任务多线程形式采集任何网页上的任何指定文本内容,支持多级多网页内容混采,并进行你须要的相应过滤和处理,可以用搜索关键词形式采集需要的指定搜索结果,支持智能采集,光输网址就可以采集网页内容,非常便捷,智能,而且永久免费使用,有需求的用户不妨下载体验!
功能特色
1、采用底层HTTP方法采集数据,快速稳定,可建多个任务多线程采同时采集多个网站数据
2、用户可以随便导出导入任务
3、任务可以设置密码,保障您采集任务的细节安全不泄露
4、并具有N页采集暂停/拨号换IP,采集遇特殊标记暂停/拨号换IP等多种破解防采集功能
5、可以直接输入网址采,或JavaScript脚本生成网址,或以关键词搜索方法采集
6、可以用登陆采集方式采集需要登入账号能够查看的网页内容
7、可以无限深入N个栏目采集内容、采链接,支持多级内容分页采集
8、支持多种内容提取模式,可以对采到的内容进行你须要的处理,如消除HTML,图片等等
9、可自编JAVASCRIPT脚本来提取网页内容,轻松实现任意部份内容的采集
10、可按设定的模版保存采到的文本内容
11、可将采到的多个文件按模版保存到同一个文件中
12、可对网页上的多个部份内容分别进行分页内容采集
13、可自设顾客信息模拟百度等搜索引擎对目标网站采集
14、支持智能采集,光输网址就可以采到网页内容
15、本软件永久终生免费使用
更新日志
智动网页内容采集器 1.93更新:
1、去除外置浏览器手动加http前缀,需要自动添加,排除特殊前缀未能打开问题
2、测试时获取的HTML手动消除WINDOWS不辨识无意义字符,解决windows显示时HTML内容不全问题 查看全部
智动网页内容采集器 v1.93官方版
智动网页内容采集器是由智动软件推出的一款操作简单,功能实用的网页内容手动采集工具。支持采用多任务多线程形式采集任何网页上的任何指定文本内容,支持多级多网页内容混采,并进行你须要的相应过滤和处理,可以用搜索关键词形式采集需要的指定搜索结果,支持智能采集,光输网址就可以采集网页内容,非常便捷,智能,而且永久免费使用,有需求的用户不妨下载体验!
功能特色
1、采用底层HTTP方法采集数据,快速稳定,可建多个任务多线程采同时采集多个网站数据
2、用户可以随便导出导入任务
3、任务可以设置密码,保障您采集任务的细节安全不泄露
4、并具有N页采集暂停/拨号换IP,采集遇特殊标记暂停/拨号换IP等多种破解防采集功能
5、可以直接输入网址采,或JavaScript脚本生成网址,或以关键词搜索方法采集
6、可以用登陆采集方式采集需要登入账号能够查看的网页内容
7、可以无限深入N个栏目采集内容、采链接,支持多级内容分页采集
8、支持多种内容提取模式,可以对采到的内容进行你须要的处理,如消除HTML,图片等等
9、可自编JAVASCRIPT脚本来提取网页内容,轻松实现任意部份内容的采集
10、可按设定的模版保存采到的文本内容
11、可将采到的多个文件按模版保存到同一个文件中
12、可对网页上的多个部份内容分别进行分页内容采集
13、可自设顾客信息模拟百度等搜索引擎对目标网站采集
14、支持智能采集,光输网址就可以采到网页内容
15、本软件永久终生免费使用
更新日志
智动网页内容采集器 1.93更新:
1、去除外置浏览器手动加http前缀,需要自动添加,排除特殊前缀未能打开问题
2、测试时获取的HTML手动消除WINDOWS不辨识无意义字符,解决windows显示时HTML内容不全问题
站长怎么能够更好地运用网站内容采集器?
采集交流 • 优采云 发表了文章 • 0 个评论 • 334 次浏览 • 2020-08-26 02:19
我们都晓得,一些网站很喜欢进行分页的方法,来降低PV。然而这样不利之处就是很明显把一个完整的内容进行分割开来,造成用户在阅读方面上的一些障碍。用户不能不去进行点击下一页能够查看到自己想要的内容,反过来想,如果要做到区别原内容网站,就要作出不同于它的排版形式。我们可以把内容整理到一起(在文章不算很长的情况),这样一来,搜索引擎都会太轻松的把整个内容抓取完整,并且用户也不用再去翻页来进行查看。
网站内容分段和小标题的使用
在查看一篇内容的时侯,如果标题太精确,我们可以从标题里面就可以晓得内容大约讲的是哪些?然而,如果作者写的内容过长,就会把整个内容的中心点进行模糊化,这样一来在用户阅读里面就很容易导致抓不住作者真正想要抒发的观念,这时候,对于内容采集器来说,适当的分辨段落和降低相应的小标题,让用户很容易晓得每一段或则是上面作者想要抒发哪些,后面作者都构建哪些观点等。
使用这两种方法,都可以把全篇内容进行合理的分割,在抒发作者观点里面不要发生冲突,尽量在设置小标题前面才能保证作者的原先的思路。
采集内容尽量不要超过一定的时间
其实,在搜索引擎跟人一样,对于新内容搜索引擎也是青睐,并且在最短时间抓取下来,呈现给用户,但是时间一长,内容新鲜度已过,搜索引擎就很难在抓取相同的内容。我们完全可以借助这点,搜索引擎对于一篇新文章的青睐,采集内容的时侯,尽量采集在一天之内的内容。
增加高清晰度的图片
有些采集过来的内容,原网站没有降低图片,我们就可以添加高清晰度的图片。虽然,增加图片对于文章没有多大的影响,但是由于我们是采集的内容,尽量在做采集内容的调整中,保证一定的改动,不要采集过来,不做任何的修饰。增加图片就是要降低对于搜索引擎对于好感度。
我们采集别人的内容,首先在搜索引擎来看,就是属于重复剽窃内,在搜索引擎来说,我们的内容相对于原内容就早已在质量度方面分值增长好多。但是,我们可以通过一些方面进行填补增长的分值,这就须要个人站长在内容体验度和网站体验度里面作出努力。
最后一款通用高效的网站内容采集器一定能为你的工作效率加分,也就有更多的时间去研究收录,最受欢迎的优采云采集器值得您下载试用一番哦~ 查看全部
站长怎么能够更好地运用网站内容采集器?
我们都晓得,一些网站很喜欢进行分页的方法,来降低PV。然而这样不利之处就是很明显把一个完整的内容进行分割开来,造成用户在阅读方面上的一些障碍。用户不能不去进行点击下一页能够查看到自己想要的内容,反过来想,如果要做到区别原内容网站,就要作出不同于它的排版形式。我们可以把内容整理到一起(在文章不算很长的情况),这样一来,搜索引擎都会太轻松的把整个内容抓取完整,并且用户也不用再去翻页来进行查看。
网站内容分段和小标题的使用
在查看一篇内容的时侯,如果标题太精确,我们可以从标题里面就可以晓得内容大约讲的是哪些?然而,如果作者写的内容过长,就会把整个内容的中心点进行模糊化,这样一来在用户阅读里面就很容易导致抓不住作者真正想要抒发的观念,这时候,对于内容采集器来说,适当的分辨段落和降低相应的小标题,让用户很容易晓得每一段或则是上面作者想要抒发哪些,后面作者都构建哪些观点等。
使用这两种方法,都可以把全篇内容进行合理的分割,在抒发作者观点里面不要发生冲突,尽量在设置小标题前面才能保证作者的原先的思路。
采集内容尽量不要超过一定的时间
其实,在搜索引擎跟人一样,对于新内容搜索引擎也是青睐,并且在最短时间抓取下来,呈现给用户,但是时间一长,内容新鲜度已过,搜索引擎就很难在抓取相同的内容。我们完全可以借助这点,搜索引擎对于一篇新文章的青睐,采集内容的时侯,尽量采集在一天之内的内容。
增加高清晰度的图片
有些采集过来的内容,原网站没有降低图片,我们就可以添加高清晰度的图片。虽然,增加图片对于文章没有多大的影响,但是由于我们是采集的内容,尽量在做采集内容的调整中,保证一定的改动,不要采集过来,不做任何的修饰。增加图片就是要降低对于搜索引擎对于好感度。
我们采集别人的内容,首先在搜索引擎来看,就是属于重复剽窃内,在搜索引擎来说,我们的内容相对于原内容就早已在质量度方面分值增长好多。但是,我们可以通过一些方面进行填补增长的分值,这就须要个人站长在内容体验度和网站体验度里面作出努力。
最后一款通用高效的网站内容采集器一定能为你的工作效率加分,也就有更多的时间去研究收录,最受欢迎的优采云采集器值得您下载试用一番哦~
智动网页内容采集器 v1.93
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-08-25 13:39
智动网页内容采集器可用多任务多线程形式采集任何网页上的任何指定文本内容,并进行你须要的相应过滤和处理,可以用搜索关键词形式采集需要的指定搜索结果。
1、采用底层HTTP方法采集数据,快速稳定,可建多个任务多线程采同时采集多个网站数据
2、用户可以随便导出导入任务
3、任务可以设置密码,并具有N页采集暂停,采集遇特殊标记暂停等多种破解防采集功能
4、可以直接输入网址采,或JavaScript脚本生成网址,或以关键词搜索方法采集
5、可以用登陆采集方式采集需要登入账号能够查看的网页内容
6、可以无限深入N个栏目采集内容、采链接
7、支持多种内容提取模式,可以对采到的内容进行你须要的处理,如消除HTML,图片等等
8、可自编JAVASCRIPT脚本来提取网页内容,轻松实现任意部份内容的采集
9、可按设定的模版保存采到的文本内容
10、可将采到的多个文件按模版保存到同一个文件中
11、可对网页上的多个部份内容分别进行分页内容采集
12、可自设顾客信息模拟百度等搜索引擎对目标网站采集
13、本软件永久终生免费使用
智动网页内容采集器 v1.9更新:
软件外置网址更新为
采用全新的智动软件控件UI
增加用户反馈到EMAIL功能
增加将初始化链接直接设置作为最终内容页处理功能
加强内核功能,支持关键词搜索替换POST内的关键词标记
优化采集内核
优化断线拔号算法
优化去重复工具算法
修正拔号显示IP不正确BUG
修正遇出错关键词暂停或拔号时没有重新采集出错页面的BUG
修正限定内容最大值为0时,最小值未能正确保存BUG 查看全部
智动网页内容采集器 v1.93
智动网页内容采集器可用多任务多线程形式采集任何网页上的任何指定文本内容,并进行你须要的相应过滤和处理,可以用搜索关键词形式采集需要的指定搜索结果。
1、采用底层HTTP方法采集数据,快速稳定,可建多个任务多线程采同时采集多个网站数据
2、用户可以随便导出导入任务
3、任务可以设置密码,并具有N页采集暂停,采集遇特殊标记暂停等多种破解防采集功能
4、可以直接输入网址采,或JavaScript脚本生成网址,或以关键词搜索方法采集
5、可以用登陆采集方式采集需要登入账号能够查看的网页内容
6、可以无限深入N个栏目采集内容、采链接
7、支持多种内容提取模式,可以对采到的内容进行你须要的处理,如消除HTML,图片等等
8、可自编JAVASCRIPT脚本来提取网页内容,轻松实现任意部份内容的采集
9、可按设定的模版保存采到的文本内容
10、可将采到的多个文件按模版保存到同一个文件中
11、可对网页上的多个部份内容分别进行分页内容采集
12、可自设顾客信息模拟百度等搜索引擎对目标网站采集
13、本软件永久终生免费使用
智动网页内容采集器 v1.9更新:
软件外置网址更新为
采用全新的智动软件控件UI
增加用户反馈到EMAIL功能
增加将初始化链接直接设置作为最终内容页处理功能
加强内核功能,支持关键词搜索替换POST内的关键词标记
优化采集内核
优化断线拔号算法
优化去重复工具算法
修正拔号显示IP不正确BUG
修正遇出错关键词暂停或拔号时没有重新采集出错页面的BUG
修正限定内容最大值为0时,最小值未能正确保存BUG
尤克地图数据采集软件 V2.1.1 绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-08-24 18:22
电话销售
可以通过直接致电或转让机器人来制造
电话销售服务
短信营销
手机号码可以导入
短信群营销产品特色:1.多图融合:可以选择“高德图”,“百度图”,“腾讯图”,“日图”来搜集最新数据。
2,选择并输入采集条件:可以快速选择或输入多个城市,多个关键词,最全面的数据采集。
3,条件过滤和重复数据删掉:支持多条件过滤,多种算法去加权,准确的数据搜集而无需重复。
4,数据本地储存:数据不会遗失,可以随时导入数据。
5,清除数据:一键消除搜集列表中的数据和本地库中的数据。
6,导出数据:支持多种数据格式导入,Excel,CSV,VCF(可以将VCard文件导出到电话通讯录中),TXT,可以设置每位文件的最大导入数目。
7,在线升级:新版本即将发布后,打开客户端会手动升级到最新版本。
8.使用账户密码登入:它不受计算机限制,可以修改。
软件功能:Yuk _ Map大数据采集软件是一款专业的电子地图集成采集软件,可实时搜集各主要地图官方网站的最新POI数据。采集的数据储存在本地数据库中,可以导入到Excel或一键导出到电话通讯簿。
可以搜集全省所有城市和地区的所有行业数据,并且所搜集的数据十分确切,不会重复。该产品是由许多批发商,电子商务业务推动和微业务推动人员组成的批发商,从而扩大了业务量,并被许多行业的业务人员所选择。 查看全部
尤克地图数据采集软件 V2.1.1 绿色版
电话销售
可以通过直接致电或转让机器人来制造
电话销售服务
短信营销
手机号码可以导入
短信群营销产品特色:1.多图融合:可以选择“高德图”,“百度图”,“腾讯图”,“日图”来搜集最新数据。
2,选择并输入采集条件:可以快速选择或输入多个城市,多个关键词,最全面的数据采集。
3,条件过滤和重复数据删掉:支持多条件过滤,多种算法去加权,准确的数据搜集而无需重复。
4,数据本地储存:数据不会遗失,可以随时导入数据。
5,清除数据:一键消除搜集列表中的数据和本地库中的数据。
6,导出数据:支持多种数据格式导入,Excel,CSV,VCF(可以将VCard文件导出到电话通讯录中),TXT,可以设置每位文件的最大导入数目。
7,在线升级:新版本即将发布后,打开客户端会手动升级到最新版本。
8.使用账户密码登入:它不受计算机限制,可以修改。
软件功能:Yuk _ Map大数据采集软件是一款专业的电子地图集成采集软件,可实时搜集各主要地图官方网站的最新POI数据。采集的数据储存在本地数据库中,可以导入到Excel或一键导出到电话通讯簿。
可以搜集全省所有城市和地区的所有行业数据,并且所搜集的数据十分确切,不会重复。该产品是由许多批发商,电子商务业务推动和微业务推动人员组成的批发商,从而扩大了业务量,并被许多行业的业务人员所选择。
3. 网页采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 256 次浏览 • 2020-08-22 18:00
1.基本入门
网页采集器模拟了浏览器的设计,填入网址,点击刷新,即可获取对应地址的html源码。
左侧的区域,显示了html源码和浏览器视图,可通过tab页切换。右侧配置区域,可对关键字进行搜索,并对面前所有的属性进行管理。
概念解释:
Hawk把网页分成两种类型:
普通文档(One)->单文档模式当你没有为网页采集器添加任何属性时,默认行为是返回只有一个数组Content的单文档,内容为整个页面。可以显式指定为NoTransform来支持这个模式。2. 纯自动模式
由于软件不知道究竟要获取什么内容,因此须要手工给定几个关键字, 让Hawk搜索关键字, 并获取位置。填入搜索字符, 发现才能成功获取XPath, 编写属性名称,点击添加数组,即可添加一个属性。类似地,再填入30535,设置属性名称为“单价”,即可添加另外一个属性。
在搜索属性的文本框中,输入你要获取的关键字,由于关键字在网页中可能出现多次,可连续点击继续搜索,在多个结果间切换,左侧的html源码会对搜索的结果进行高亮。
请注意观察搜索的关键字在网页中的位置,是否符合预期,否则抓取数据可能会有问题。尤其在List模式。如果须要抓取本页面的多块数据,可新建多个网页采集器,分别进行配置。
如果发觉有错误,可点击编辑集合,对属性进行删掉,修改和排序。
你可以类似的将所有要抓取的特点数组添加进去,或是直接点击手气不错,系统会依照目前的属性,推测其他属性。
3. 手气不错
这是Hawk最被人赞誉的功能!在新的Hawk3中,该功能被极大地提高。
3.1 List模式的手气不错
在List模式下,一般来说,输入网址加载页面后,点击手气不错即可,Hawk会手动根据优先级将列表数据抓取下来。
左右切换选择你想要的数据集,之后在下边的属性栏对结果进行微调。
下面的图标可以全选,反选所有属性,点击删掉即可删掉选中的属性,亦可对属性名称进行更改。 点击刷新即可更新结果。
添加一个属性,手气不错能够更准确地进行。添加两个属性,即可选取惟一区域。
3.1 One模式的手气不错
Hawk3新增功能,当网页中收录多达几十种属性时,挨个添加会显得非常繁琐,这在某种商品属性页非常常见。
为了解决这个问题,将关键字加入到搜索属性中,此时不要将其添加到属性列表中,直接点击手气不错即可。
是不是太amazing? 欢迎给作者打赏!
3.2 原理
网页采集器的功能是获取网页中的数据(废话)。通常来说,目标可能是列表(如购物车列表),或是一个页面中的固定数组(如JD某商品的价钱和介绍,在页面中只有一个)。因此须要设置其读取模式。传统的采集器须要编撰正则表达式,但方式过于复杂。
如果认识到html是一棵树,只要找到了承载数据的节点即可,之后用XPath来描述。
手工编撰XPath也很复杂,因此软件可以通过关键字,自动检索XPath,提供关键字,软件都会从树中递归搜索收录该数据的叶子节点。因此关键字最好是在页面中独一无二的。
如上图所示,只要提供“北京”和“42”这两个关键字,就能找到parent节点, 进而获取div[0]和div1这两个列表元素。通过div[0]和div1两个节点的比较,我们能够手动发觉相同的子节点(name,mount)和不同的节点(北京:上海,37:42)。相同的节点会保存为属性名,不同的节点为属性值。但是,不能提供上海和37,此时,公共节点是div[0], 这不是列表。
软件在不提供关键字的情况下,也能通过html文档的特点,去估算最可能是列表父节点(如图中的parent)的节点,但当网页非常复杂时,猜测可能会出错。
本算法原理是原创的,可查看源码或留言交流。
4. 结果检测
工作过程中,可点击提取测试 ,随时查看采集器目前的才能抓取的数据内容。在属性管理器的上方,可以更改采集器的模块名称,这样就便捷数据清洗 模块调用该采集器。
5. 对恳求进行设置
当出现乱码,或者希望自己填入cookie等恳请头时,可在属性对话框点击恳求详情,弹出的对话框中进行设置。有时为了简便,可以将浏览器中的requests恳求头直接拷贝到恳求参数中。
Hawk有一定的网页编码检查功能,但出现乱码时,可以将编码从GB2312设置为UTF8,即可解决大多数乱码问题。
如何调用网页采集器,或实现Post恳求? 参考4.1节:从爬虫转换
6. 具体的事例
以抓取新闻内容为例:页面如下:![image_1at5pff7g7m71jtq1b2o1hlq1dt9.png-76.5kB][8]
你可以在搜索关键字中,搜索【2016年09月21日】,属性填写为时间,搜索【人民日报】,属性为【来源】。
提取正文须要注意,你可以随便填写正文中的一部分关键字,例如【量子隐形传态是一种传递量子】,这样Hawk就检索出了XPath:前面省略/div[1]/p[1]
如果你直接使用这个路径,则抓取的内容只有这一段。为了抓取正文,我们可以将/p[1]部分去除,只获取其父节点。这样能够抓取全文数据(是不是很赞)?
如果你想获取原创正文的html,则在属性列表的对话框里,可以勾选某个属性的【HTML标签】。
此时,点击提取测试,看看是不是获取了所需的数据? 查看全部
3. 网页采集器
1.基本入门
网页采集器模拟了浏览器的设计,填入网址,点击刷新,即可获取对应地址的html源码。
左侧的区域,显示了html源码和浏览器视图,可通过tab页切换。右侧配置区域,可对关键字进行搜索,并对面前所有的属性进行管理。
概念解释:
Hawk把网页分成两种类型:
普通文档(One)->单文档模式当你没有为网页采集器添加任何属性时,默认行为是返回只有一个数组Content的单文档,内容为整个页面。可以显式指定为NoTransform来支持这个模式。2. 纯自动模式
由于软件不知道究竟要获取什么内容,因此须要手工给定几个关键字, 让Hawk搜索关键字, 并获取位置。填入搜索字符, 发现才能成功获取XPath, 编写属性名称,点击添加数组,即可添加一个属性。类似地,再填入30535,设置属性名称为“单价”,即可添加另外一个属性。
在搜索属性的文本框中,输入你要获取的关键字,由于关键字在网页中可能出现多次,可连续点击继续搜索,在多个结果间切换,左侧的html源码会对搜索的结果进行高亮。
请注意观察搜索的关键字在网页中的位置,是否符合预期,否则抓取数据可能会有问题。尤其在List模式。如果须要抓取本页面的多块数据,可新建多个网页采集器,分别进行配置。
如果发觉有错误,可点击编辑集合,对属性进行删掉,修改和排序。
你可以类似的将所有要抓取的特点数组添加进去,或是直接点击手气不错,系统会依照目前的属性,推测其他属性。
3. 手气不错
这是Hawk最被人赞誉的功能!在新的Hawk3中,该功能被极大地提高。
3.1 List模式的手气不错
在List模式下,一般来说,输入网址加载页面后,点击手气不错即可,Hawk会手动根据优先级将列表数据抓取下来。
左右切换选择你想要的数据集,之后在下边的属性栏对结果进行微调。
下面的图标可以全选,反选所有属性,点击删掉即可删掉选中的属性,亦可对属性名称进行更改。 点击刷新即可更新结果。
添加一个属性,手气不错能够更准确地进行。添加两个属性,即可选取惟一区域。
3.1 One模式的手气不错
Hawk3新增功能,当网页中收录多达几十种属性时,挨个添加会显得非常繁琐,这在某种商品属性页非常常见。
为了解决这个问题,将关键字加入到搜索属性中,此时不要将其添加到属性列表中,直接点击手气不错即可。
是不是太amazing? 欢迎给作者打赏!
3.2 原理
网页采集器的功能是获取网页中的数据(废话)。通常来说,目标可能是列表(如购物车列表),或是一个页面中的固定数组(如JD某商品的价钱和介绍,在页面中只有一个)。因此须要设置其读取模式。传统的采集器须要编撰正则表达式,但方式过于复杂。
如果认识到html是一棵树,只要找到了承载数据的节点即可,之后用XPath来描述。
手工编撰XPath也很复杂,因此软件可以通过关键字,自动检索XPath,提供关键字,软件都会从树中递归搜索收录该数据的叶子节点。因此关键字最好是在页面中独一无二的。
如上图所示,只要提供“北京”和“42”这两个关键字,就能找到parent节点, 进而获取div[0]和div1这两个列表元素。通过div[0]和div1两个节点的比较,我们能够手动发觉相同的子节点(name,mount)和不同的节点(北京:上海,37:42)。相同的节点会保存为属性名,不同的节点为属性值。但是,不能提供上海和37,此时,公共节点是div[0], 这不是列表。
软件在不提供关键字的情况下,也能通过html文档的特点,去估算最可能是列表父节点(如图中的parent)的节点,但当网页非常复杂时,猜测可能会出错。
本算法原理是原创的,可查看源码或留言交流。
4. 结果检测
工作过程中,可点击提取测试 ,随时查看采集器目前的才能抓取的数据内容。在属性管理器的上方,可以更改采集器的模块名称,这样就便捷数据清洗 模块调用该采集器。
5. 对恳求进行设置
当出现乱码,或者希望自己填入cookie等恳请头时,可在属性对话框点击恳求详情,弹出的对话框中进行设置。有时为了简便,可以将浏览器中的requests恳求头直接拷贝到恳求参数中。
Hawk有一定的网页编码检查功能,但出现乱码时,可以将编码从GB2312设置为UTF8,即可解决大多数乱码问题。
如何调用网页采集器,或实现Post恳求? 参考4.1节:从爬虫转换
6. 具体的事例
以抓取新闻内容为例:页面如下:![image_1at5pff7g7m71jtq1b2o1hlq1dt9.png-76.5kB][8]
你可以在搜索关键字中,搜索【2016年09月21日】,属性填写为时间,搜索【人民日报】,属性为【来源】。
提取正文须要注意,你可以随便填写正文中的一部分关键字,例如【量子隐形传态是一种传递量子】,这样Hawk就检索出了XPath:前面省略/div[1]/p[1]
如果你直接使用这个路径,则抓取的内容只有这一段。为了抓取正文,我们可以将/p[1]部分去除,只获取其父节点。这样能够抓取全文数据(是不是很赞)?
如果你想获取原创正文的html,则在属性列表的对话框里,可以勾选某个属性的【HTML标签】。
此时,点击提取测试,看看是不是获取了所需的数据?
网页信息搜集器 v1.0绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2020-08-22 09:56
网页信息采集器是一款红色精巧,功能实用的网页信息采集软件。Internet上有着非常庞大的资源信息,各行各业的信息无所不有,网页信息采集器可以很方便的针对某个网站的信息内容进行搜集。如某个峰会的所有注册会员的E-MAIL列表、某个行业网站的企业名录、某个下载网站上所有软件列表等等。操作简单便捷,更容易为普通用户所把握,有需求的用户不妨下载体验!
功能特色
1、执行任务
根据已完善的任务信息保存、提取网页,也可通过“双击”某项任务启动此功能
2、新建、复制、修改、删除任务
新建、复制、修改、删除任务信息
3、默认选项
设置默认工作路径(默认为当前程序目录下的WorkDir文件夹)
设置默认提取测试数 (默认为10)
设置默认文本分隔符 (默认为 *)
4、新建、编辑任务信息
任务名称:在默认的工作文件夹下生成借此命名的文件夹。
登录地址:针对个别须要登陆能够查看其网页内容的网站,填写登入页面地址。在执行任务时,软件会打开此登陆页面使您登陆该网站
序数格式类型网页、非序数格式类型网:
这里的序数格式、非序数格式主要是指提取地址是否仅仅是数字的变化。例如类似于:
① 和 就属于序数格式
② 和 则属于非序数格式
列表地址:在类型为“非序数格式类型网”时,第一页列表的链接地址
提取地址:由实际保存的网页地址共同部份 + * 号组成。
例如要提取:
① 和 则提取地址为 *.html
② 和 则提取地址为 *./*.html 查看全部
网页信息搜集器 v1.0绿色版
网页信息采集器是一款红色精巧,功能实用的网页信息采集软件。Internet上有着非常庞大的资源信息,各行各业的信息无所不有,网页信息采集器可以很方便的针对某个网站的信息内容进行搜集。如某个峰会的所有注册会员的E-MAIL列表、某个行业网站的企业名录、某个下载网站上所有软件列表等等。操作简单便捷,更容易为普通用户所把握,有需求的用户不妨下载体验!

功能特色
1、执行任务
根据已完善的任务信息保存、提取网页,也可通过“双击”某项任务启动此功能

2、新建、复制、修改、删除任务
新建、复制、修改、删除任务信息

3、默认选项
设置默认工作路径(默认为当前程序目录下的WorkDir文件夹)
设置默认提取测试数 (默认为10)
设置默认文本分隔符 (默认为 *)

4、新建、编辑任务信息
任务名称:在默认的工作文件夹下生成借此命名的文件夹。
登录地址:针对个别须要登陆能够查看其网页内容的网站,填写登入页面地址。在执行任务时,软件会打开此登陆页面使您登陆该网站
序数格式类型网页、非序数格式类型网:
这里的序数格式、非序数格式主要是指提取地址是否仅仅是数字的变化。例如类似于:
① 和 就属于序数格式
② 和 则属于非序数格式
列表地址:在类型为“非序数格式类型网”时,第一页列表的链接地址
提取地址:由实际保存的网页地址共同部份 + * 号组成。
例如要提取:
① 和 则提取地址为 *.html
② 和 则提取地址为 *./*.html
【程序发布】www.ucaiyun.com网页内容采集器1.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 290 次浏览 • 2020-08-21 20:17
2005-11-21
写这个采集器的本意本是为自己站添加内容之用,后来经群上面几个好友一再要求,做成了个通用型了,功能虽不说太强悍,现在应当还是能将就着用吧,不怕笑话,今天将它发布。如果疗效还好,我将继续开发下去。
安装环境:
本采集器采用Visual C#编撰,可以在Windows2003下运行,若在Windows2000,Xp下运行请先到谷歌官方下载一个.net framework1.1或更高环境组件:
附:.net framework 1.1下载地址: ... p;displaylang=zh-cn
.net framework 2.0下载地址: ... p;displaylang=zh-cn
功能简介:
1、多系统支持,现已加入对PHPWIND,DISCUZ,DEDECMS2.X和PHPArticle2.01的采集支持,若您的系统现今软件里没加入,请与我们联系,将在上期版本中加入网友要求最多的几套系统。
2、模拟用户登陆,和操作浏览器一样,但程序只处理核心数据,运行速率更快。
3、可以设定是否将远程图片及Flash下载到本地(Flash文件通常较大,建议不下载,程序会将其手动获取到其绝对地址)。
4、多线程,时间间隔设定 可以按照您的机器性能和网速或系统容许的文章发表时间设定
5、较强悍的网址采集功能,配合页面内定义区域采集、手动生成网址及采集二级页面功能基本上可采集到您所要的任何网址集合。
6、内容规则定义有多条内容过滤规则,彻底过滤掉内容里的广告等无用内容。
7、网址集合、内容规则导出、导出功能,方便网友共享采集到的内容。
8、论坛支持Html和UBB发贴两种模式。
最新版下载地址:
论坛讨论:
内容入库功能仍未加入,以后再建立吧。。。
Enjoy it!
2005-11-21 by 优采云
QQ群2:16326410 群3:16126184 今天也在峰会里也加了个版块,欢迎你们加入讨论
觉得好的话就顶一个了~~哈哈 查看全部
【程序发布】www.ucaiyun.com网页内容采集器1.0

2005-11-21
写这个采集器的本意本是为自己站添加内容之用,后来经群上面几个好友一再要求,做成了个通用型了,功能虽不说太强悍,现在应当还是能将就着用吧,不怕笑话,今天将它发布。如果疗效还好,我将继续开发下去。
安装环境:
本采集器采用Visual C#编撰,可以在Windows2003下运行,若在Windows2000,Xp下运行请先到谷歌官方下载一个.net framework1.1或更高环境组件:
附:.net framework 1.1下载地址: ... p;displaylang=zh-cn
.net framework 2.0下载地址: ... p;displaylang=zh-cn
功能简介:
1、多系统支持,现已加入对PHPWIND,DISCUZ,DEDECMS2.X和PHPArticle2.01的采集支持,若您的系统现今软件里没加入,请与我们联系,将在上期版本中加入网友要求最多的几套系统。
2、模拟用户登陆,和操作浏览器一样,但程序只处理核心数据,运行速率更快。
3、可以设定是否将远程图片及Flash下载到本地(Flash文件通常较大,建议不下载,程序会将其手动获取到其绝对地址)。
4、多线程,时间间隔设定 可以按照您的机器性能和网速或系统容许的文章发表时间设定
5、较强悍的网址采集功能,配合页面内定义区域采集、手动生成网址及采集二级页面功能基本上可采集到您所要的任何网址集合。
6、内容规则定义有多条内容过滤规则,彻底过滤掉内容里的广告等无用内容。
7、网址集合、内容规则导出、导出功能,方便网友共享采集到的内容。
8、论坛支持Html和UBB发贴两种模式。
最新版下载地址:
论坛讨论:
内容入库功能仍未加入,以后再建立吧。。。
Enjoy it!
2005-11-21 by 优采云
QQ群2:16326410 群3:16126184 今天也在峰会里也加了个版块,欢迎你们加入讨论
觉得好的话就顶一个了~~哈哈
PHP采集利器之phpQuery的用法解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 631 次浏览 • 2020-08-21 02:22
官方文档地址:
See Gitub:
基础用法:
require_once "/path/to/phpQuery/phpQuery.php";
phpQuery::newDocumentFile('http://www.blogdaren.com');
echo pq("title")->text(); // 获取网页标题
echo pq("input#uid")->val(); // 获取id为uid的input的控件值
上例中第一行引入phpQuery.php文件,
第二行通过newDocumentFile加载一个文件,
第三行通过pq()函数获取title标签的文本内容,
第四行获取id为uid的input控件的值,
上述代码主要做了两件事:即加载文件和读取文件内容。
加载文档:
加载文档主要通过phpQuery::newDocument来进行操作,其作用是促使phpQuery可以在服务器预先读取到指定的文件或文本内容。
主要的方式包括:
phpQuery::newDocument($html, $contentType = null)
phpQuery::newDocumentFile($file, $contentType = null)
phpQuery::newDocumentHTML($html, $charset = "utf-8")
phpQuery::newDocumentXHTML($html, $charset = "utf-8")
phpQuery::newDocumentXML($html, $charset = "utf-8")
phpQuery::newDocumentPHP($html, $contentType = null)
phpQuery::newDocumentFileHTML($file, $charset = "utf-8")
phpQuery::newDocumentFileXHTML($file, $charset = "utf-8")
phpQuery::newDocumentFileXML($file, $charset = "utf-8")
phpQuery::newDocumentFilePHP($file, $contentType)
pq()函数用法:
pq()函数的用法是phpQuery的重点,主要分两部份:即选择器和过滤器
1. 选择器
要了解phpQuery选择器的用法,建议先了解jQuery的句型,最常用的句型包括有:
pq('#id'):即以#号开头的ID选择器,用于选择已知ID的容器所包括的内容
pq('.classname'):即以.开头的class选择器,用于选择class匹配的容器内容
pq('parent > child'):选择指定层次结构的容器内容,如:pq('.main> p')用于选择class=main容器的所有p标签
2. 过滤器
主要包括::first,:last,:not,:even,:odd,:eq(index),:gt(index),:lt(index),:header,:animated等,例如:
pq('p:last'):用于选择最后一个p标签
pq('tr:even'):用于选择表格中碰巧行
phpQuery连贯操作:
pq()函数返回的结果是一个phpQuery对象,可以对返回结果继续进行后续的操作,例如:
pq('a')->attr('href', 'newVal')->removeClass('className')->html('newHtml')->......
详情请查阅jQuery相关资料,用法基本一致,只须要注意 . 与 -> 的区别即可。 查看全部
PHP采集利器之phpQuery的用法解读
官方文档地址:
See Gitub:
基础用法:
require_once "/path/to/phpQuery/phpQuery.php";
phpQuery::newDocumentFile('http://www.blogdaren.com');
echo pq("title")->text(); // 获取网页标题
echo pq("input#uid")->val(); // 获取id为uid的input的控件值
上例中第一行引入phpQuery.php文件,
第二行通过newDocumentFile加载一个文件,
第三行通过pq()函数获取title标签的文本内容,
第四行获取id为uid的input控件的值,
上述代码主要做了两件事:即加载文件和读取文件内容。
加载文档:
加载文档主要通过phpQuery::newDocument来进行操作,其作用是促使phpQuery可以在服务器预先读取到指定的文件或文本内容。
主要的方式包括:
phpQuery::newDocument($html, $contentType = null)
phpQuery::newDocumentFile($file, $contentType = null)
phpQuery::newDocumentHTML($html, $charset = "utf-8")
phpQuery::newDocumentXHTML($html, $charset = "utf-8")
phpQuery::newDocumentXML($html, $charset = "utf-8")
phpQuery::newDocumentPHP($html, $contentType = null)
phpQuery::newDocumentFileHTML($file, $charset = "utf-8")
phpQuery::newDocumentFileXHTML($file, $charset = "utf-8")
phpQuery::newDocumentFileXML($file, $charset = "utf-8")
phpQuery::newDocumentFilePHP($file, $contentType)
pq()函数用法:
pq()函数的用法是phpQuery的重点,主要分两部份:即选择器和过滤器
1. 选择器
要了解phpQuery选择器的用法,建议先了解jQuery的句型,最常用的句型包括有:
pq('#id'):即以#号开头的ID选择器,用于选择已知ID的容器所包括的内容
pq('.classname'):即以.开头的class选择器,用于选择class匹配的容器内容
pq('parent > child'):选择指定层次结构的容器内容,如:pq('.main> p')用于选择class=main容器的所有p标签
2. 过滤器
主要包括::first,:last,:not,:even,:odd,:eq(index),:gt(index),:lt(index),:header,:animated等,例如:
pq('p:last'):用于选择最后一个p标签
pq('tr:even'):用于选择表格中碰巧行
phpQuery连贯操作:
pq()函数返回的结果是一个phpQuery对象,可以对返回结果继续进行后续的操作,例如:
pq('a')->attr('href', 'newVal')->removeClass('className')->html('newHtml')->......
详情请查阅jQuery相关资料,用法基本一致,只须要注意 . 与 -> 的区别即可。
Hawk教程-网页采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 414 次浏览 • 2020-08-20 09:43
[模块和算子]常见问题更新日志作者和捐款列表专题:案例:发布文章:故事:网页采集器
网页采集器主界面
1.快速使用说明
网页采集器 模拟了浏览器的设计,填入网址,点击刷新,即可获取对应地址的html源码。
认识到网页是一棵树(DOM)后,每个XPath对应一个属性,即可从网页上获取单个或多个文档。网页采集器的目的就是更快地通过手工或手动配置找到最优XPath。
1.1.工作模式
使用采集器,首先要根据抓取的目标,选择合适的工作模式:
注意:
1.2.基本操作
在多文档模式下,通常直接点击右上角的手气不错,在弹出的结果下选择所需数据,可配置其名称和XPath。点击确定即可配置完毕。即可手动获取绝大多数网页的目标内容。
[图片上传失败...(image-57cdac-30)]
可手工填入搜索字符,即可在网页上快速定位元素和XPath,可在多个结果间快速切换,找到所需数据后,输入属性名称后手工添加属性。
1.3.高级功能点击【Http恳求详情】,可更改网页编码,代理,cookie和恳求方法等,网页出现乱码可用若希望手动登入,或获取动态页面(ajax)的真实地址,填入搜索字符,点击【自动嗅探】,在弹出的浏览器中翻到对应的关键字,Hawk能够手动捕捉真实恳求超级模式下,Hawk会将源码中的js,html,json都转成html,从而使用手气不错, 更通用但性能较差填写【共享源】,本采集器同步共享源的【Http恳求详情】,避免重复设置cookie代理等。详情页(单文档模式)也可以手气不错(Hawk3新功能),搜索所需数组,不需要添加到属性列表,点击手气不错试试!网页地址也可以是本地文件路径,如D:\target.html, 用其他方式保存网页后,再通过Hawk剖析网页内容
单文档模式下的手气不错
网页采集器 不能单独工作,而是沟通 网页采集器 和数据清洗的桥梁。本质上说, 网页采集器 是针对获取网页而非常订制的数据清洗模块。
2.高级配置介绍2.1.列表根路径
列表根路径是所有属性的XPath公共部份,能简化XPath编撰,提升兼容性。只能在多文档模式下工作。
你可以通过Hawk手动剖析根路径,或自动设置。
2.2.自动规约列表路径
以事例来说明,使用手气不错后,嗅探器会找到列表节点的父节点,以及挂载在父节点上的多个子节点,从而产生一个树形结构
每个节点要抽取下边的属性:
为了能获取父节点下所有的div子节点,因此列表根路径就是/html/div[2]/div[3]/div[4]/div。 注意:父节点Path路径末尾是不带序号的,这样就能获取多个子节点。可以如此理解,列表根路径就是不带结尾数字的父节点路径。
有时候,父节点的xpath是不稳定的,举个反例,北京北京的二手房页面,上海会在列表前面降低一个广告banner,从而真正的父节点都会发生变化,比如向后偏斜了div[1]变成了div[2]。为了应对这些变化,通常的做法是手工更改【列表根路径】
2.3.手动设置根路径
继续举例子,父节点的id为house_list,且在网页中全局惟一,你就可以使用另外一种父节点表示法//*[@id='house_list']/li(写法可以参考其他XPath教程),而子节点表达式不变。这样会使程序显得愈发鲁棒。
3.抓取网页数据
网页采集器需配合数据清洗使用,才能 使用 网页采集器 获取网页数据,拖入的列须要为超链接
3.1.一般的get恳求
一般情况下, 将从爬虫转换推入到对应的URL列中,通过下拉菜单选择要调用的爬虫名称,即可完成所有的配置:
请求配置
本模块是沟通网页采集器和数据清洗的桥梁。本质上说,网页采集器是针对获取网页而非常订制的数据清洗模块。
你须要填写爬虫选择,告诉它要调用那个采集器。注意:
3.2.实现post恳求
web恳求中,有两种主要的恳求类型:post和get。 使用POST能支持传输更多的数据。更多的细节,可以参考http合同的相关文档,网上汗牛充栋,这里就不多说了。
post恳求时,Hawk要给服务器须要传递两个参数:url 和post。一般来说,在执行post恳求时,url是稳定的,post值是动态改变的。
首先要配置调用的网页采集器为post模式(打开网页采集器,Http恳求详情,模式->下拉菜单)。
之后,需要将从爬虫转换拖到要调用的url列上。如果没有url列,可以通过添加新列,生成要访问的url列。
之后,我们要将post数据传递到网页采集器中。你总是可以通过合并多列拼接或各类手段,生成要Post的数据列。之后,可以在从爬虫转换中的post数据中,填写[post列], 而post列就是收录post数据的列名。 注意:
4.手气不错
这是Hawk最被人赞誉的功能!在新的Hawk3中,该功能被极大地提高。
4.1.多文档下的手气不错
一般来说,输入网址加载页面后,点击手气不错即可,Hawk会手动根据优先级将列表数据抓取下来
手气不错配置
[图片上传失败...(image-9f6836-30)]
左右切换选择你想要的数据集,之后在下边的属性栏对结果进行微调。
添加一个属性,手气不错能够更准确地进行。添加两个属性,即可选取惟一区域。
4.2.单文档模式的手气不错
Hawk3新增功能,当网页中收录多达几十种属性时,挨个添加会显得非常繁琐,这在某种商品属性页非常常见。
为了解决这个问题,将关键字加入到搜索字符中,此时不要将其添加到属性列表中,直接点击手气不错即可。
单文档模式下的手气不错
4.3.手动模式
在手气不错不能工作或不符合预期时,需要手工给定几个关键字, 让Hawk搜索关键字, 并获取在网页中所在的位置(XPath)。
填入搜索字符,能够成功获取XPath, 编写属性名称,点击添加,即可添加一个属性。类似地,再填入30535,设置属性名称为“单价”,即可添加另外一个属性。
手动添加属性
在搜索字符的文本框中,输入你要获取的关键字,由于关键字在网页中可能出现多次,可连续点击继续搜索,在多个结果间切换,左侧的html源码会对搜索的结果进行高亮。
请注意观察搜索的关键字在网页中的位置,是否符合预期,否则抓取数据可能会有问题。尤其在 多文档模式。如果须要抓取本页面的多块数据,可新建多个网页采集器,分别进行配置。如果发觉有错误,可点击编辑集合,对属性进行删掉,修改和排序。你可以类似的将所有要抓取的特点数组添加进去,或是直接点击 手气不错 ,系统会依照目前的属性,推测其他属性。5.动态嗅探5.1.什么是动态页面?
动态瀑布流和ajax的页面,通常按需返回html和json.
老式网站在刷新时会返回页面的全部内容,但若只更新部份,即可大大节省带宽。该方法叫ajax,服务端传递xml或则json到浏览器,浏览器的js代码执行,并将数据渲染到页面上。 因此,获取数据的真实url,不一定显示在浏览器地址栏,而是隐藏在js调用中。本质上,javascript发起了新的隐藏http请求来获取数据,只要能模拟之,就能象真实浏览器一样获取所要数据。参考百度百科的介绍
5.2.Hawk手动获取动态恳求
通过浏览器和抓包,可以获取那些隐藏恳求,但须要对HTTP请求的原理比较熟悉,不适合于初学者。
Hawk简化了流程,采用手动嗅探的方法来进行。Hawk成为前端代理,会拦截和剖析所有系统级Http请求,并将收录关键字的恳求筛选下来 (基于fiddler)
当搜索字符时,若没有在当前页面中找到该关键字,Hawk会有提示,“是否启动动态嗅探?”此时Hawk会弹出浏览器并打开所在网页。您可将页面拖到收录关键字的位置,Hawk会手动记录和过滤收录关键字的真实恳求, 检索完毕后,Hawk会手动回弹。
5.3.如果难以手动嗅探?
由于Hawk有拦截功能,会被浏览器觉得不安全,如何解决呢?
Hawk底层的嗅探基于fiddler,因此可通过fiddler生成证书后,导入到chrome解决,方法可参考这篇文档:
按如下方法对采集器进行设置:
网页采集器恳求设置
5.4.注意事项有时直接将url拷贝到Hawk,并使用手气不错时,也能获取到数据。这是因为好多网站对第一页和其他页分别作了不同的处理。第一页内容会跟随整体frame返回回去。但以后页面内容就通过ajax单独返回了。
有时针对第一页做了大量的XPath开发,却最后发觉难以在其他页面使用,多半就是前面提及的问题(一脸懵逼)。因此经验上,建议翻到其他页面上再做恳求。
超级模式能将网页中所有的javascript, json, xml都转换为HTML DOM树,从而实现属性提取和手气不错。
6.超级模式
为了能使动态网页也能使用添加属性和手气不错,Hawk在嗅探后默认会开启超级模式。 超级模式能将网页中所有的javascript, json, xml都转换为HTML DOM树,从而实现属性提取和手气不错。
超级模式极大的简化了动态恳求的处理,但它仍然可能有以下问题:
7.自动登入
很多网站需要登入能够访问其内部内容。而登陆涉及到十分复杂的逻辑,例如须要传递用户名和密码,验证码等,并经过多次的恳求,获取token等一系列流程,连写代码都要写整整一页纸并须要反复调试。考虑到Hawk是通用的数据采集器,其开发成本十分之高。
但本质上说,登录只是获取了cookie,只要以后的恳求加入该cookie,远端服务器就不能分辨其是浏览器还是爬虫。一般传统的爬虫软件,会外置一个浏览器,用户在内部填入用户名密码。软件在内部获取cookie后进行恳求。 但Hawk不准备再搞外置浏览器,那种方法很重,很难与Hawk的流系统兼容。所以,Hawk不玩手动登入了!
我们使用了全新的思路解决该问题。
Hawk的手动登入和动态嗅探所使用的技术是一样的,其本质上还是在底层替换了系统代理,你可以在搜索字符填写在登陆后页面上的任意文本,点击嗅探即可。若该方法难以工作,还可以自动拷贝浏览器上的恳求参数到网页采集器。
其更多的使用细节,可参考动态嗅探章节。
8.设置共享恳求参数的采集器名称
为了抓取一个网站的不同数据,我们须要多个 网页采集器 。但是访问网站需要登入和cookie,难不成每位采集器都要设置对应的恳求参数吗?
采集器的属性对话框中,可以设置共享源,也就是要共享的 网页采集器 的名称。
例如设置为链家采集器,那么本采集器的恳求参数,都会在执行时,动态地从链家采集器中获得。这样就极大地简化了配置过程。
在按键上手动弹出帮助
9.附录:XPath和CSS写法9.1.XPath
关于XPath句型,可参考教程
XPath可以十分灵活,例如:
9.2.CSSSelector
多数情况下,使用XPath才能解决问题,但是CSSSelector更简练,且鲁棒性更强。关于它的介绍,可参考教程
当然,大部分情况不需要这么复杂,只要记住以下几点:
10.手气不错的原理
网页采集器的功能是获取网页中的数据(废话)。通常来说,目标可能是列表(如购物车列表),或是一个页面中的固定数组(如JD某商品的价钱和介绍,在页面中只有一个)。因此须要设置其读取模式。传统的采集器须要编撰正则表达式,但方式过于复杂。
如果认识到html是一棵树,只要找到了承载数据的节点即可,之后用XPath来描述。
手气不错原理
手工编撰XPath也很复杂,因此软件可以通过关键字,自动检索XPath,提供关键字,软件都会从树中递归搜索收录该数据的叶子节点。因此关键字最好是在页面中独一无二的。
如上图所示,只要提供“北京”和“42”这两个关键字,就能找到parent节点, 进而获取div[0]和div[1]这两个列表元素。通过div[0]和div[1]两个节点的比较,我们能够手动发觉相同的子节点(name,mount)和不同的节点(北京:上海,37:42)。相同的节点会保存为属性名,不同的节点为属性值。但是,不能提供上海和37,此时,公共节点是div[0], 这不是列表。
软件在不提供关键字的情况下,也能通过html文档的特点,去估算最可能是列表父节点(如图中的parent)的节点,但当网页非常复杂时,猜测可能会出错。 查看全部
Hawk教程-网页采集器
[模块和算子]常见问题更新日志作者和捐款列表专题:案例:发布文章:故事:网页采集器

网页采集器主界面
1.快速使用说明
网页采集器 模拟了浏览器的设计,填入网址,点击刷新,即可获取对应地址的html源码。
认识到网页是一棵树(DOM)后,每个XPath对应一个属性,即可从网页上获取单个或多个文档。网页采集器的目的就是更快地通过手工或手动配置找到最优XPath。
1.1.工作模式
使用采集器,首先要根据抓取的目标,选择合适的工作模式:
注意:
1.2.基本操作
在多文档模式下,通常直接点击右上角的手气不错,在弹出的结果下选择所需数据,可配置其名称和XPath。点击确定即可配置完毕。即可手动获取绝大多数网页的目标内容。
[图片上传失败...(image-57cdac-30)]
可手工填入搜索字符,即可在网页上快速定位元素和XPath,可在多个结果间快速切换,找到所需数据后,输入属性名称后手工添加属性。
1.3.高级功能点击【Http恳求详情】,可更改网页编码,代理,cookie和恳求方法等,网页出现乱码可用若希望手动登入,或获取动态页面(ajax)的真实地址,填入搜索字符,点击【自动嗅探】,在弹出的浏览器中翻到对应的关键字,Hawk能够手动捕捉真实恳求超级模式下,Hawk会将源码中的js,html,json都转成html,从而使用手气不错, 更通用但性能较差填写【共享源】,本采集器同步共享源的【Http恳求详情】,避免重复设置cookie代理等。详情页(单文档模式)也可以手气不错(Hawk3新功能),搜索所需数组,不需要添加到属性列表,点击手气不错试试!网页地址也可以是本地文件路径,如D:\target.html, 用其他方式保存网页后,再通过Hawk剖析网页内容

单文档模式下的手气不错
网页采集器 不能单独工作,而是沟通 网页采集器 和数据清洗的桥梁。本质上说, 网页采集器 是针对获取网页而非常订制的数据清洗模块。
2.高级配置介绍2.1.列表根路径
列表根路径是所有属性的XPath公共部份,能简化XPath编撰,提升兼容性。只能在多文档模式下工作。
你可以通过Hawk手动剖析根路径,或自动设置。
2.2.自动规约列表路径
以事例来说明,使用手气不错后,嗅探器会找到列表节点的父节点,以及挂载在父节点上的多个子节点,从而产生一个树形结构
每个节点要抽取下边的属性:
为了能获取父节点下所有的div子节点,因此列表根路径就是/html/div[2]/div[3]/div[4]/div。 注意:父节点Path路径末尾是不带序号的,这样就能获取多个子节点。可以如此理解,列表根路径就是不带结尾数字的父节点路径。
有时候,父节点的xpath是不稳定的,举个反例,北京北京的二手房页面,上海会在列表前面降低一个广告banner,从而真正的父节点都会发生变化,比如向后偏斜了div[1]变成了div[2]。为了应对这些变化,通常的做法是手工更改【列表根路径】
2.3.手动设置根路径
继续举例子,父节点的id为house_list,且在网页中全局惟一,你就可以使用另外一种父节点表示法//*[@id='house_list']/li(写法可以参考其他XPath教程),而子节点表达式不变。这样会使程序显得愈发鲁棒。
3.抓取网页数据
网页采集器需配合数据清洗使用,才能 使用 网页采集器 获取网页数据,拖入的列须要为超链接
3.1.一般的get恳求
一般情况下, 将从爬虫转换推入到对应的URL列中,通过下拉菜单选择要调用的爬虫名称,即可完成所有的配置:

请求配置
本模块是沟通网页采集器和数据清洗的桥梁。本质上说,网页采集器是针对获取网页而非常订制的数据清洗模块。
你须要填写爬虫选择,告诉它要调用那个采集器。注意:
3.2.实现post恳求
web恳求中,有两种主要的恳求类型:post和get。 使用POST能支持传输更多的数据。更多的细节,可以参考http合同的相关文档,网上汗牛充栋,这里就不多说了。
post恳求时,Hawk要给服务器须要传递两个参数:url 和post。一般来说,在执行post恳求时,url是稳定的,post值是动态改变的。
首先要配置调用的网页采集器为post模式(打开网页采集器,Http恳求详情,模式->下拉菜单)。
之后,需要将从爬虫转换拖到要调用的url列上。如果没有url列,可以通过添加新列,生成要访问的url列。
之后,我们要将post数据传递到网页采集器中。你总是可以通过合并多列拼接或各类手段,生成要Post的数据列。之后,可以在从爬虫转换中的post数据中,填写[post列], 而post列就是收录post数据的列名。 注意:
4.手气不错
这是Hawk最被人赞誉的功能!在新的Hawk3中,该功能被极大地提高。
4.1.多文档下的手气不错
一般来说,输入网址加载页面后,点击手气不错即可,Hawk会手动根据优先级将列表数据抓取下来

手气不错配置
[图片上传失败...(image-9f6836-30)]
左右切换选择你想要的数据集,之后在下边的属性栏对结果进行微调。
添加一个属性,手气不错能够更准确地进行。添加两个属性,即可选取惟一区域。
4.2.单文档模式的手气不错
Hawk3新增功能,当网页中收录多达几十种属性时,挨个添加会显得非常繁琐,这在某种商品属性页非常常见。
为了解决这个问题,将关键字加入到搜索字符中,此时不要将其添加到属性列表中,直接点击手气不错即可。

单文档模式下的手气不错
4.3.手动模式
在手气不错不能工作或不符合预期时,需要手工给定几个关键字, 让Hawk搜索关键字, 并获取在网页中所在的位置(XPath)。
填入搜索字符,能够成功获取XPath, 编写属性名称,点击添加,即可添加一个属性。类似地,再填入30535,设置属性名称为“单价”,即可添加另外一个属性。

手动添加属性
在搜索字符的文本框中,输入你要获取的关键字,由于关键字在网页中可能出现多次,可连续点击继续搜索,在多个结果间切换,左侧的html源码会对搜索的结果进行高亮。
请注意观察搜索的关键字在网页中的位置,是否符合预期,否则抓取数据可能会有问题。尤其在 多文档模式。如果须要抓取本页面的多块数据,可新建多个网页采集器,分别进行配置。如果发觉有错误,可点击编辑集合,对属性进行删掉,修改和排序。你可以类似的将所有要抓取的特点数组添加进去,或是直接点击 手气不错 ,系统会依照目前的属性,推测其他属性。5.动态嗅探5.1.什么是动态页面?
动态瀑布流和ajax的页面,通常按需返回html和json.
老式网站在刷新时会返回页面的全部内容,但若只更新部份,即可大大节省带宽。该方法叫ajax,服务端传递xml或则json到浏览器,浏览器的js代码执行,并将数据渲染到页面上。 因此,获取数据的真实url,不一定显示在浏览器地址栏,而是隐藏在js调用中。本质上,javascript发起了新的隐藏http请求来获取数据,只要能模拟之,就能象真实浏览器一样获取所要数据。参考百度百科的介绍
5.2.Hawk手动获取动态恳求
通过浏览器和抓包,可以获取那些隐藏恳求,但须要对HTTP请求的原理比较熟悉,不适合于初学者。
Hawk简化了流程,采用手动嗅探的方法来进行。Hawk成为前端代理,会拦截和剖析所有系统级Http请求,并将收录关键字的恳求筛选下来 (基于fiddler)
当搜索字符时,若没有在当前页面中找到该关键字,Hawk会有提示,“是否启动动态嗅探?”此时Hawk会弹出浏览器并打开所在网页。您可将页面拖到收录关键字的位置,Hawk会手动记录和过滤收录关键字的真实恳求, 检索完毕后,Hawk会手动回弹。
5.3.如果难以手动嗅探?
由于Hawk有拦截功能,会被浏览器觉得不安全,如何解决呢?
Hawk底层的嗅探基于fiddler,因此可通过fiddler生成证书后,导入到chrome解决,方法可参考这篇文档:
按如下方法对采集器进行设置:

网页采集器恳求设置
5.4.注意事项有时直接将url拷贝到Hawk,并使用手气不错时,也能获取到数据。这是因为好多网站对第一页和其他页分别作了不同的处理。第一页内容会跟随整体frame返回回去。但以后页面内容就通过ajax单独返回了。
有时针对第一页做了大量的XPath开发,却最后发觉难以在其他页面使用,多半就是前面提及的问题(一脸懵逼)。因此经验上,建议翻到其他页面上再做恳求。
超级模式能将网页中所有的javascript, json, xml都转换为HTML DOM树,从而实现属性提取和手气不错。
6.超级模式
为了能使动态网页也能使用添加属性和手气不错,Hawk在嗅探后默认会开启超级模式。 超级模式能将网页中所有的javascript, json, xml都转换为HTML DOM树,从而实现属性提取和手气不错。
超级模式极大的简化了动态恳求的处理,但它仍然可能有以下问题:
7.自动登入
很多网站需要登入能够访问其内部内容。而登陆涉及到十分复杂的逻辑,例如须要传递用户名和密码,验证码等,并经过多次的恳求,获取token等一系列流程,连写代码都要写整整一页纸并须要反复调试。考虑到Hawk是通用的数据采集器,其开发成本十分之高。
但本质上说,登录只是获取了cookie,只要以后的恳求加入该cookie,远端服务器就不能分辨其是浏览器还是爬虫。一般传统的爬虫软件,会外置一个浏览器,用户在内部填入用户名密码。软件在内部获取cookie后进行恳求。 但Hawk不准备再搞外置浏览器,那种方法很重,很难与Hawk的流系统兼容。所以,Hawk不玩手动登入了!
我们使用了全新的思路解决该问题。
Hawk的手动登入和动态嗅探所使用的技术是一样的,其本质上还是在底层替换了系统代理,你可以在搜索字符填写在登陆后页面上的任意文本,点击嗅探即可。若该方法难以工作,还可以自动拷贝浏览器上的恳求参数到网页采集器。
其更多的使用细节,可参考动态嗅探章节。
8.设置共享恳求参数的采集器名称
为了抓取一个网站的不同数据,我们须要多个 网页采集器 。但是访问网站需要登入和cookie,难不成每位采集器都要设置对应的恳求参数吗?
采集器的属性对话框中,可以设置共享源,也就是要共享的 网页采集器 的名称。
例如设置为链家采集器,那么本采集器的恳求参数,都会在执行时,动态地从链家采集器中获得。这样就极大地简化了配置过程。

在按键上手动弹出帮助
9.附录:XPath和CSS写法9.1.XPath
关于XPath句型,可参考教程
XPath可以十分灵活,例如:
9.2.CSSSelector
多数情况下,使用XPath才能解决问题,但是CSSSelector更简练,且鲁棒性更强。关于它的介绍,可参考教程
当然,大部分情况不需要这么复杂,只要记住以下几点:
10.手气不错的原理
网页采集器的功能是获取网页中的数据(废话)。通常来说,目标可能是列表(如购物车列表),或是一个页面中的固定数组(如JD某商品的价钱和介绍,在页面中只有一个)。因此须要设置其读取模式。传统的采集器须要编撰正则表达式,但方式过于复杂。
如果认识到html是一棵树,只要找到了承载数据的节点即可,之后用XPath来描述。

手气不错原理
手工编撰XPath也很复杂,因此软件可以通过关键字,自动检索XPath,提供关键字,软件都会从树中递归搜索收录该数据的叶子节点。因此关键字最好是在页面中独一无二的。
如上图所示,只要提供“北京”和“42”这两个关键字,就能找到parent节点, 进而获取div[0]和div[1]这两个列表元素。通过div[0]和div[1]两个节点的比较,我们能够手动发觉相同的子节点(name,mount)和不同的节点(北京:上海,37:42)。相同的节点会保存为属性名,不同的节点为属性值。但是,不能提供上海和37,此时,公共节点是div[0], 这不是列表。
软件在不提供关键字的情况下,也能通过html文档的特点,去估算最可能是列表父节点(如图中的parent)的节点,但当网页非常复杂时,猜测可能会出错。
优采云采集器 V3.1.8 官方版最新无限制破解版测试可用[应用软件]
采集交流 • 优采云 发表了文章 • 0 个评论 • 428 次浏览 • 2020-08-19 12:48
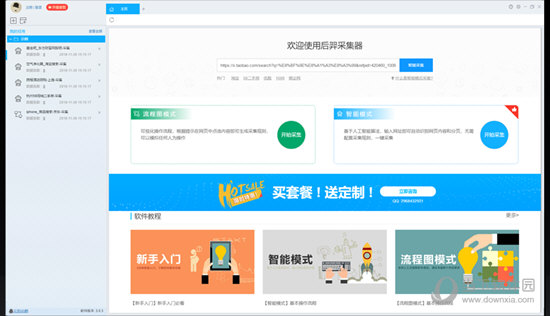
优采云采集器是一款专业实用的的网页数据采集器。这款采集器不需要开发,任何人都能用,数据可导入到本地文件、发布到网站和数据库等。
它由原Google技术团队鼎力构筑,其规则配置简单,采集功能强悍,能够支持电商类、生活服务类、社交媒体、新闻峰会等不同类型的网站,智能辨识网页数据,导出数据形式多样,最主要是完全免费,是行业剖析、精准营销、品牌监控、风险预估的好帮手。
优采云免费采集器支持所有操作系统版本更新和功能升级同步所有平台,采集和导入全免费,无限制放心用,并支持后台运行,不打搅您的其他前台工作,是你数据采集最好的助手。
【功能特性】
一、【规则配置简单 采集功能强悍】
1、可视化自定义采集流程:
全程问答式引导、可视化操作、自定义采集流程
自动记录和模拟网页操作次序
高级设置满足更多采集需求
2、点选抽取网页数据:
鼠标点击选择要爬取的网页内容、操作简单
可选择抽取文本、链接、属性、html标签等
3、运行批量采集数据:
软件根据采集流程和抽取规则手动批量采集
快速稳定,实时显示采集速度和过程
可切换软件后台运行,不打搅前台工作
4、导出和发布采集的数据:
采集的数据手动表格化,自由配置数组
支持数据导入到Excel等本地文件
和一键发布到CMS网站/数据库/微信公众号等媒体
二、【支持采集不同类型的网站】
电商类、生活服务类、社交媒体、新闻峰会、地方网站......
强大浏览器内核,99%以上网站都能采!
三、【全平台支持 全免费 可视化操作】
支持所有操作系统:Windows+Mac+Linux
采集和导入全免费,无限制放心用
可视化配置采集规则,傻瓜式操作
四、【功能强悍,箭速迭】
智能辨识网页数据,导出数据形式多样
软件定期更新升级,不断添加新功能
客户的满意是对我们最大的肯定!
【常见问题】
使用优采云采集器怎么采集百度搜索结果数据?
步骤1:创建采集任务
1)启动优采云采集器,进入主界面,点击创建任务按键创建 "向导采集任务"
2)输入百度搜索的URL,包括三种形式
1、手动输入:在输入框中直接输入URL,多个URL时需要换行分割
2、点击从文件中读取方法:用户选择一个储存URL的文件,文件中可以有多个URL地址,地址需要换行分割。
3、批量添加方法:通过添加并调整地址参数生成多个有规律的地址
步骤2:定制采集过程
1)点击创建后手动打开第一个URL因而步入向导设置,此处选择列表页,点击下一步
2)填写搜索关键字和选择输入关键字的输入框,点击下一步
3)进入第一个关键字搜索结果页面后,点击设置搜索按键,点击下一步
4)点选列表块中第一块元素
5)再点击结果列表块中另外一块元素,此时手动选中列表块。点击下一步
6)选择下一页按键,选中选择下一页选项,然后点击页面中的下一页按键填充第一个输入框,第二个数据框可以调节采集运行中点击下一页按键的次数。理论上次数越多,采集到的数据越多。点击下一步
7)选择要采集的数组:在焦点框中点选要抽取的元素后点击下一步
8)选择不步入详情页。点击保存或保存并运行
步骤3:数据采集及导入
1)采集任务运行中
2)采集完成后,选择“导出数据”可以把数据都导入到本地文件
3)选择“导出方法”,将采集好的数据导入,这里可以选择excel作为导入为格式
4)采集数据导入后如下图 查看全部
优采云采集器 V3.1.8 官方版最新无限制破解版测试可用[应用软件]
优采云采集器是一款专业实用的的网页数据采集器。这款采集器不需要开发,任何人都能用,数据可导入到本地文件、发布到网站和数据库等。
它由原Google技术团队鼎力构筑,其规则配置简单,采集功能强悍,能够支持电商类、生活服务类、社交媒体、新闻峰会等不同类型的网站,智能辨识网页数据,导出数据形式多样,最主要是完全免费,是行业剖析、精准营销、品牌监控、风险预估的好帮手。
优采云免费采集器支持所有操作系统版本更新和功能升级同步所有平台,采集和导入全免费,无限制放心用,并支持后台运行,不打搅您的其他前台工作,是你数据采集最好的助手。
【功能特性】
一、【规则配置简单 采集功能强悍】
1、可视化自定义采集流程:
全程问答式引导、可视化操作、自定义采集流程
自动记录和模拟网页操作次序
高级设置满足更多采集需求
2、点选抽取网页数据:
鼠标点击选择要爬取的网页内容、操作简单
可选择抽取文本、链接、属性、html标签等
3、运行批量采集数据:
软件根据采集流程和抽取规则手动批量采集
快速稳定,实时显示采集速度和过程
可切换软件后台运行,不打搅前台工作
4、导出和发布采集的数据:
采集的数据手动表格化,自由配置数组
支持数据导入到Excel等本地文件
和一键发布到CMS网站/数据库/微信公众号等媒体
二、【支持采集不同类型的网站】
电商类、生活服务类、社交媒体、新闻峰会、地方网站......
强大浏览器内核,99%以上网站都能采!
三、【全平台支持 全免费 可视化操作】
支持所有操作系统:Windows+Mac+Linux
采集和导入全免费,无限制放心用
可视化配置采集规则,傻瓜式操作
四、【功能强悍,箭速迭】
智能辨识网页数据,导出数据形式多样
软件定期更新升级,不断添加新功能
客户的满意是对我们最大的肯定!

【常见问题】
使用优采云采集器怎么采集百度搜索结果数据?
步骤1:创建采集任务
1)启动优采云采集器,进入主界面,点击创建任务按键创建 "向导采集任务"
2)输入百度搜索的URL,包括三种形式
1、手动输入:在输入框中直接输入URL,多个URL时需要换行分割
2、点击从文件中读取方法:用户选择一个储存URL的文件,文件中可以有多个URL地址,地址需要换行分割。
3、批量添加方法:通过添加并调整地址参数生成多个有规律的地址

步骤2:定制采集过程
1)点击创建后手动打开第一个URL因而步入向导设置,此处选择列表页,点击下一步
2)填写搜索关键字和选择输入关键字的输入框,点击下一步
3)进入第一个关键字搜索结果页面后,点击设置搜索按键,点击下一步
4)点选列表块中第一块元素
5)再点击结果列表块中另外一块元素,此时手动选中列表块。点击下一步
6)选择下一页按键,选中选择下一页选项,然后点击页面中的下一页按键填充第一个输入框,第二个数据框可以调节采集运行中点击下一页按键的次数。理论上次数越多,采集到的数据越多。点击下一步
7)选择要采集的数组:在焦点框中点选要抽取的元素后点击下一步
8)选择不步入详情页。点击保存或保存并运行

步骤3:数据采集及导入
1)采集任务运行中
2)采集完成后,选择“导出数据”可以把数据都导入到本地文件
3)选择“导出方法”,将采集好的数据导入,这里可以选择excel作为导入为格式
4)采集数据导入后如下图
草根优采云采集器(网页采集工具) 3.0 免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2020-08-18 22:31
起始页面:从百度搜索结果的第几页开始采集。这里要注意的是:因为软件调用的每页结果100条数据,所以填入的数值对应:0表示第一页,100表示第二页,200表示第三页,以此类推。
网址宽度小于:这个为了限制采集的内容是否符合你须要设置的,比如你想采集一个关键字指向网站内页的链接而不是网站首页,则设定大约通常30以上即可,因为通常网址不会超过30个字符,这个按照你自己想采集的内容大致设定。
采集到的内容采用纯文本文件方式,你可以导出任何你要做推广的软件中,采集数据广泛,这里俺们用知名的美国软件SCRAPEBOX举例,软件的强悍不用说了,这个是一个美国知名的博客评论群发工具,可以手动评论流行的WOREPRESS博客等,但这个软件由于是英语采集,而且不支持英文,软件外置的也是GOOGLE采集模式,GOOGLE现今服务器在台湾不稳定你们也都晓得,所以国外拿来只能做英文站的优化。如果配合本软件的使用就完全可以做国外站点的优化了。如:采集关键词填写:美女 特殊限定填写:by wordpress 网址宽度小于:35点击开始搜索即可。搜下来的全部是百度上的WORDPRESS博客,用软件导入后可以直接导出到SCRAPEBOX中进行发送。让你的外链,广告一页能发到10W个百度收录的博客中,外链和宣传疗效可想而知了。
1.全手动采集任意你想要的数据。
2.软件手动调用百度搜索结果,跳过百度结果地址加密,直接获取指向地址。
3.支持自定义各类搜索方法,采集结果直接导入文本文件中,支持导出各种推广,发送软件进行推广发送操作。
4.采集的数据即是百度收录的东西,用来进行优化,推广超有效。 查看全部
草根优采云采集器(网页采集工具) 3.0 免费版
起始页面:从百度搜索结果的第几页开始采集。这里要注意的是:因为软件调用的每页结果100条数据,所以填入的数值对应:0表示第一页,100表示第二页,200表示第三页,以此类推。
网址宽度小于:这个为了限制采集的内容是否符合你须要设置的,比如你想采集一个关键字指向网站内页的链接而不是网站首页,则设定大约通常30以上即可,因为通常网址不会超过30个字符,这个按照你自己想采集的内容大致设定。
采集到的内容采用纯文本文件方式,你可以导出任何你要做推广的软件中,采集数据广泛,这里俺们用知名的美国软件SCRAPEBOX举例,软件的强悍不用说了,这个是一个美国知名的博客评论群发工具,可以手动评论流行的WOREPRESS博客等,但这个软件由于是英语采集,而且不支持英文,软件外置的也是GOOGLE采集模式,GOOGLE现今服务器在台湾不稳定你们也都晓得,所以国外拿来只能做英文站的优化。如果配合本软件的使用就完全可以做国外站点的优化了。如:采集关键词填写:美女 特殊限定填写:by wordpress 网址宽度小于:35点击开始搜索即可。搜下来的全部是百度上的WORDPRESS博客,用软件导入后可以直接导出到SCRAPEBOX中进行发送。让你的外链,广告一页能发到10W个百度收录的博客中,外链和宣传疗效可想而知了。
1.全手动采集任意你想要的数据。
2.软件手动调用百度搜索结果,跳过百度结果地址加密,直接获取指向地址。
3.支持自定义各类搜索方法,采集结果直接导入文本文件中,支持导出各种推广,发送软件进行推广发送操作。
4.采集的数据即是百度收录的东西,用来进行优化,推广超有效。
优采云采集器怎样使用 优采云采集器使用方式教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 381 次浏览 • 2020-08-17 12:29
对于许多行业来说,采集数据都是一个非常重要的工作,它能通过准确的数据来指导你的工作内容。这里给你们带来的优采云采集器是一款采集网页数据的智能软件,很多小伙伴不知道优采云采集器怎样使用,下面就让小编为你们介绍一下优采云采集器使用方式教程,感兴趣的小伙伴一起来瞧瞧吧。
优采云采集器软件介绍
优采云采集器是一款采集网页数据的智能软件,它完全以自主研制的分布式云计算平台为核心,能够在短时间内轻松从不同网站和网页上抓取大量规范化的数据内容,帮助任何须要从网页获取信息的顾客实现数据自动化采集,编辑,规范化,摆脱对人工搜索及搜集数据的依赖,从而减少获取信息的成本,提高效率。
优采云采集器怎样使用 优采云采集器使用方式教程
新建一个采集任务,如果要采集某一个网站的某一类数据,其实就是配置一个任务,当执行这个任务的时侯才会根据设定采集相应的数据。
设置采集任务的基本信息,基本信息主要是一个任务分组,用来管理多个任务,方便使用,另外就是任务的名子,然后还有备注信息,方便记录任务的一些描述,这些信息在任务比较多的时侯就很有用了。
最关键的一步,设定采集流程,这一步是最重要的一步,按照须要的采集顺序,把采集这个事情分成几个步骤,然后每位步骤对应一个采集动作,组合上去就产生了采集步骤,如果所示,就是采集一个页面的流程,先打开这个页面,然后提取这个页面上的数据。
配置执行计划,有些数据是要每晚都采集一次的,有些则三天采集多次的,所以不同任务就设定不同的计划,这个任务是不需要定时执行的,所以就选择自动,然后保存执行计划
至此,基本配置即使完成了,接下来要做的就是测试一下流程是否正确,如果正确,就可以启动任务,采集数据了,如果不正确,再回头去更改各个步骤的配置有问题的地方,再继续测试,最终测试完成后即可采集。 查看全部
优采云采集器怎样使用 优采云采集器使用方式教程
对于许多行业来说,采集数据都是一个非常重要的工作,它能通过准确的数据来指导你的工作内容。这里给你们带来的优采云采集器是一款采集网页数据的智能软件,很多小伙伴不知道优采云采集器怎样使用,下面就让小编为你们介绍一下优采云采集器使用方式教程,感兴趣的小伙伴一起来瞧瞧吧。
优采云采集器软件介绍
优采云采集器是一款采集网页数据的智能软件,它完全以自主研制的分布式云计算平台为核心,能够在短时间内轻松从不同网站和网页上抓取大量规范化的数据内容,帮助任何须要从网页获取信息的顾客实现数据自动化采集,编辑,规范化,摆脱对人工搜索及搜集数据的依赖,从而减少获取信息的成本,提高效率。
优采云采集器怎样使用 优采云采集器使用方式教程
新建一个采集任务,如果要采集某一个网站的某一类数据,其实就是配置一个任务,当执行这个任务的时侯才会根据设定采集相应的数据。


设置采集任务的基本信息,基本信息主要是一个任务分组,用来管理多个任务,方便使用,另外就是任务的名子,然后还有备注信息,方便记录任务的一些描述,这些信息在任务比较多的时侯就很有用了。

最关键的一步,设定采集流程,这一步是最重要的一步,按照须要的采集顺序,把采集这个事情分成几个步骤,然后每位步骤对应一个采集动作,组合上去就产生了采集步骤,如果所示,就是采集一个页面的流程,先打开这个页面,然后提取这个页面上的数据。

配置执行计划,有些数据是要每晚都采集一次的,有些则三天采集多次的,所以不同任务就设定不同的计划,这个任务是不需要定时执行的,所以就选择自动,然后保存执行计划

至此,基本配置即使完成了,接下来要做的就是测试一下流程是否正确,如果正确,就可以启动任务,采集数据了,如果不正确,再回头去更改各个步骤的配置有问题的地方,再继续测试,最终测试完成后即可采集。
SysNucleus WebHarvy(网页数据采集器)V6.0.1
采集交流 • 优采云 发表了文章 • 0 个评论 • 368 次浏览 • 2020-08-14 02:43
功能
智能辨识模式
WebHarvy手动辨识网页中出现的数据模式。所以,如果你须要从一个网页刮项目(姓名,地址,电子邮件,价格等)的列表,你不需要做任何额外的配置。如果数据重复,WebHarvy会手动刮。
导出捕获的数据
可以保存从各类格式的网页中提取的数据。 WebHarvy网站刮板的当前版本容许你导入的刮数据作为XML,CSV,JSON或TSV文件。您还可以刮下数据导入到一个SQL数据库。
从多个页面提取
通常网页显示数据,如在多个页面中的产品目录。 WebHarvy可以手动抓取并从多个网页中提取数据。只是强调了“链接到下一页'和WebHarvy网站刮板将手动刮从所有页面的数据。
直观化的操作界面
WebHarvy是一个可视化的网页提取工具。其实完全没有必要编撰任何脚本或代码拿来提取数据。使用webharvy的外置浏览器浏览网页。您可以选择用滑鼠点击来提取数据。它是这么容易!
基于关键字的提取
基于关键字的提取可使您捕捉从搜索结果页面输入关键字的列表数据。您创建的配置将被手动重复所有给定输入关键字,而挖掘的数据。可以指定任意数目的输入关键字
提取分类
WebHarvy网站刮板容许您从一个链接列表,从而造成一个网站内的相像页面抽取数据。这让您可以使用一个单一的配置刮网站内的类别或小节。
使用正则表达式提取
WebHarvy可以应用正则表达式(正则表达式)在文本或网页的HTML源代码,并提取去匹配的部份。这种强悍的技术为您提供了更多的灵活性,同时拼抢的数据。
WebHarvy是一个视觉网路刮板。绝对不需要编撰任何脚本或代码来抓取数据。您将使用WebHarvy的外置浏览器浏览网页。您可以选择要点击的数据。这很容易!
WebHarvy手动辨识网页中发生的数据模式。因此,如果您须要从网页上刮取项目列表(名称,地址,电子邮件,价格等),则无需执行任何其他配置。如果数据重复,WebHarvy会手动删掉它。
您可以以多种格式保存从网页中提取的数据。WebHarvy Web Scraper的当前版本容许您将抓取的数据导入为Excel,XML,CSV,JSON或TSV文件。您也可以将抓取的数据导入到SQL数据库。
通常,网页在多个页面上显示产品列表等数据。WebHarvy可以手动抓取并从多个页面提取数据。只需强调“链接到下一页”,WebHarvy Web Scraper都会手动从所有页面中抓取数据。 查看全部
SysNucleus WebHarvy(网页数据采集器)是还能帮助用户从网页中提取数据的工具。旨在让您可以手动从网页中提取数据,并保存在不同的格式提取内容。输入网址即可打开,默认使用内部浏览器,支持扩充剖析,可以手动获取类似链接的列表,软件界面直观操作简单。
功能
智能辨识模式
WebHarvy手动辨识网页中出现的数据模式。所以,如果你须要从一个网页刮项目(姓名,地址,电子邮件,价格等)的列表,你不需要做任何额外的配置。如果数据重复,WebHarvy会手动刮。
导出捕获的数据
可以保存从各类格式的网页中提取的数据。 WebHarvy网站刮板的当前版本容许你导入的刮数据作为XML,CSV,JSON或TSV文件。您还可以刮下数据导入到一个SQL数据库。
从多个页面提取
通常网页显示数据,如在多个页面中的产品目录。 WebHarvy可以手动抓取并从多个网页中提取数据。只是强调了“链接到下一页'和WebHarvy网站刮板将手动刮从所有页面的数据。
直观化的操作界面
WebHarvy是一个可视化的网页提取工具。其实完全没有必要编撰任何脚本或代码拿来提取数据。使用webharvy的外置浏览器浏览网页。您可以选择用滑鼠点击来提取数据。它是这么容易!
基于关键字的提取
基于关键字的提取可使您捕捉从搜索结果页面输入关键字的列表数据。您创建的配置将被手动重复所有给定输入关键字,而挖掘的数据。可以指定任意数目的输入关键字
提取分类
WebHarvy网站刮板容许您从一个链接列表,从而造成一个网站内的相像页面抽取数据。这让您可以使用一个单一的配置刮网站内的类别或小节。
使用正则表达式提取
WebHarvy可以应用正则表达式(正则表达式)在文本或网页的HTML源代码,并提取去匹配的部份。这种强悍的技术为您提供了更多的灵活性,同时拼抢的数据。
WebHarvy是一个视觉网路刮板。绝对不需要编撰任何脚本或代码来抓取数据。您将使用WebHarvy的外置浏览器浏览网页。您可以选择要点击的数据。这很容易!
WebHarvy手动辨识网页中发生的数据模式。因此,如果您须要从网页上刮取项目列表(名称,地址,电子邮件,价格等),则无需执行任何其他配置。如果数据重复,WebHarvy会手动删掉它。
您可以以多种格式保存从网页中提取的数据。WebHarvy Web Scraper的当前版本容许您将抓取的数据导入为Excel,XML,CSV,JSON或TSV文件。您也可以将抓取的数据导入到SQL数据库。
通常,网页在多个页面上显示产品列表等数据。WebHarvy可以手动抓取并从多个页面提取数据。只需强调“链接到下一页”,WebHarvy Web Scraper都会手动从所有页面中抓取数据。
抓取网页数据工具怎么单独进行发布操作
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2020-08-14 02:16
其实这个需求也是很容易实现的,大家可以根据以下步骤来进行:
1、首先是新建一个任务,这步操作会形成一个任务数据库,然后将自己已有的数据导出到这个数据库中。当然,这个任务你须要设置发布步骤,否则难以实现发布。
2、在任务数据库中,将已采设置为true或1,mysql,sqlserver是1。
3、开始运行任务,在优采云采集器最新版V9上面不需要勾选采集,在其他版本中不需要勾选采网址和采内容,只勾选发内容即可。
有的用户反映说,抓取网页数据工具优采云采集器会重复发布文章,也就是说发布到网站后,下一次运行时又接着发布,导致网站上内容重复。对于这个问题,我们须要从以下两点着手考虑:
1、采集器是否采集了多篇一样的文章内容? 可以通过,右击规则——本地编辑数据来查看采集的数据。
2、采集器发布的时侯,是否提示了发布成功? 如果您发布的时侯提示的是 “发布未知” 或者“发布失败” ,而实际上您的内容确实是早已成功发布到您的网站了。那么这个状态下,采集器不会把内容标记为已发状态,下次发布的时侯,还是会作为新内容去发布的。所以就会出现部份用户听到的重复发布的问题。
针对里面的问题,解决方案如下:
1、如果是发布的内容有的显示成功,有的显示未知,那么考虑调整下发布时间间隔,间隔设置长一些,然后再运行发布试试,关于怎么设置线程可参考官网教程。
2、如果里面方式一直解决不了问题,那么可以考虑强制解决办法,在文件保存及部份中级设置的右下角发布结束后,勾选标记所有记录为已发,这样每次发布无论发布结果怎样提示,都会把这条记录标示为早已发布。
抓取网页数据工具优采云采集器V9对于采集、处理、发布均能进行高效的操作,学会灵活运用才能为我们的日常工作和学习带来极大的便利。 查看全部
抓取网页数据工具优采云采集器V9是市场中功能最全面的采集软件,具备数据采集、处理和发布功能,能够轻松应对网站更新维护、内容群发等需求。采集完发布你们一定还会操作了,但是假如你早已有了一批数据,不需要再进行采集,只须要发布该如何通过优采云采集器来实现呢?
其实这个需求也是很容易实现的,大家可以根据以下步骤来进行:
1、首先是新建一个任务,这步操作会形成一个任务数据库,然后将自己已有的数据导出到这个数据库中。当然,这个任务你须要设置发布步骤,否则难以实现发布。
2、在任务数据库中,将已采设置为true或1,mysql,sqlserver是1。
3、开始运行任务,在优采云采集器最新版V9上面不需要勾选采集,在其他版本中不需要勾选采网址和采内容,只勾选发内容即可。
有的用户反映说,抓取网页数据工具优采云采集器会重复发布文章,也就是说发布到网站后,下一次运行时又接着发布,导致网站上内容重复。对于这个问题,我们须要从以下两点着手考虑:
1、采集器是否采集了多篇一样的文章内容? 可以通过,右击规则——本地编辑数据来查看采集的数据。
2、采集器发布的时侯,是否提示了发布成功? 如果您发布的时侯提示的是 “发布未知” 或者“发布失败” ,而实际上您的内容确实是早已成功发布到您的网站了。那么这个状态下,采集器不会把内容标记为已发状态,下次发布的时侯,还是会作为新内容去发布的。所以就会出现部份用户听到的重复发布的问题。
针对里面的问题,解决方案如下:
1、如果是发布的内容有的显示成功,有的显示未知,那么考虑调整下发布时间间隔,间隔设置长一些,然后再运行发布试试,关于怎么设置线程可参考官网教程。
2、如果里面方式一直解决不了问题,那么可以考虑强制解决办法,在文件保存及部份中级设置的右下角发布结束后,勾选标记所有记录为已发,这样每次发布无论发布结果怎样提示,都会把这条记录标示为早已发布。
抓取网页数据工具优采云采集器V9对于采集、处理、发布均能进行高效的操作,学会灵活运用才能为我们的日常工作和学习带来极大的便利。
豆瓣读书书籍信息采集方法
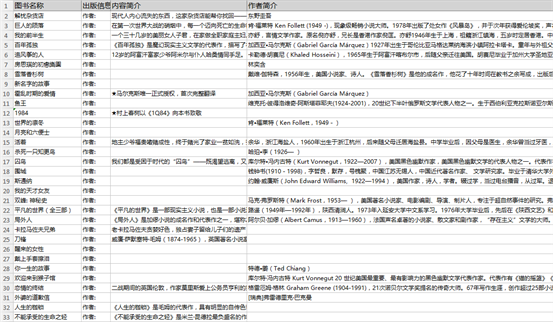
采集交流 • 优采云 发表了文章 • 0 个评论 • 700 次浏览 • 2020-08-13 10:54
采集网站:
%E5%B0%8F%E8%AF%B4?start=0&type=T
使用功能点:
l分页列表及详尽信息提取
/tutorial/fylbxq7.aspx?t=1
lXpath
/tutorialdetail-1/xpath1.html
豆瓣读书:豆瓣读书为豆瓣网的一个子栏目。豆瓣读书自2005年上线,已成为国外信息最全、用户数目最大且最为活跃的读书网站。我们专注于为用户提供全面且精细化的读书服务,同时不断探求新的产品模式。到2012年豆瓣读书每个月有超过800万的来访用户,过亿的访问次数。。
豆瓣读书采集数据说明:本文进行了豆瓣读书-书籍详尽信息的采集,本文首先进去豆瓣读书分类列表页,然后循环点击每一条图书信息,进入图书详情页采集具体详尽信息 。本文仅以“豆瓣读书采集”为例。大家在实操过程中,可依照自身需求,更换豆瓣的其他内容进行数据采集。
豆瓣读书采集字段详尽说明:图书名称,图书作者,图书定价,图书价钱,图书出版年,图书作者简介。
步骤1:创建采集任务
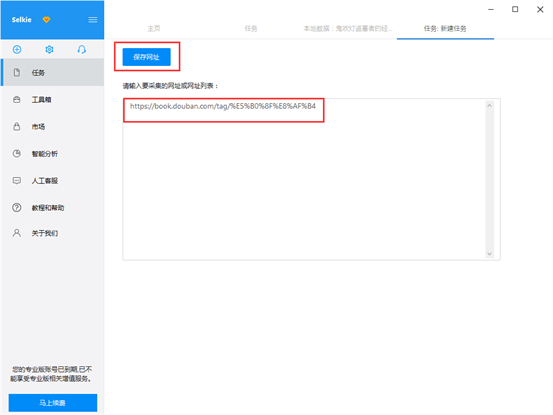
1)进入主界面,选择“自定义模式”
2)将要采集的网址URL,复制粘贴到网址输入框中,点击“保存网址”
步骤2:创建翻页循环
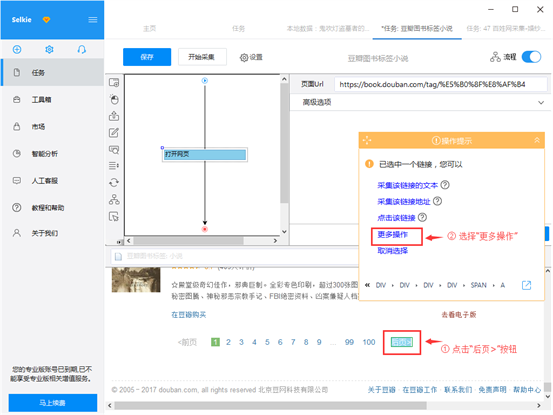
1)在页面右上角,打开“流程”,以突显出“流程设计器”和“定制当前操作”两个蓝筹股。将页面下拉到顶部,点击“后页>”按钮,在两侧的操作提示框中,选择“更多操作”
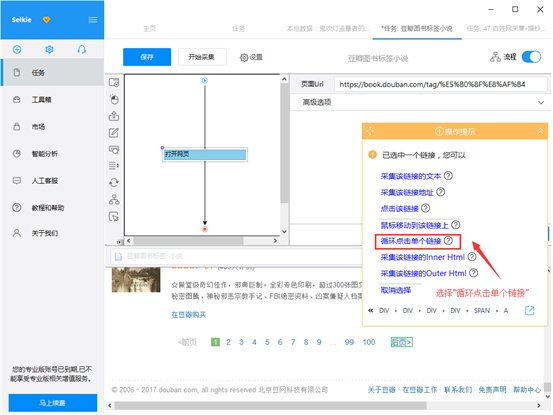
2)选择“循环点击单个链接”
步骤3:创建列表循环
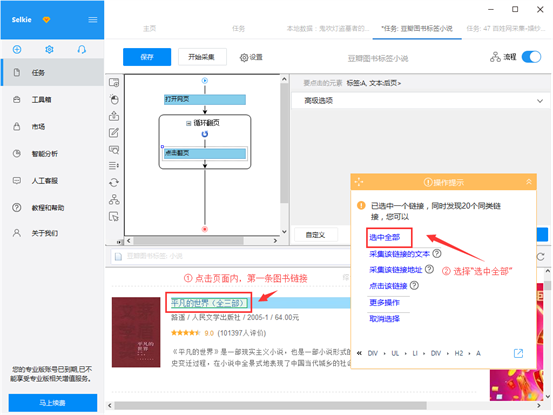
1)移动滑鼠,选中页面里的第一个图书链接。选中后,系统会手动辨识页面里的其他相像链接。在左侧操作提示框中,选择“选中全部”
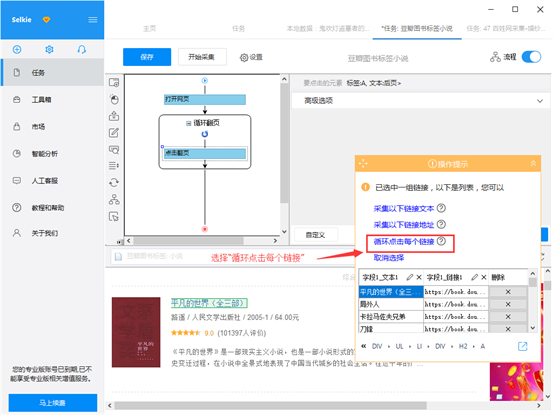
2)选择“循环点击每位链接”,以创建一个列表循环
步骤4:提取图书信息
1)在创建列表循环后,系统会手动点击第一个图书链接,进入图书详尽信息页。
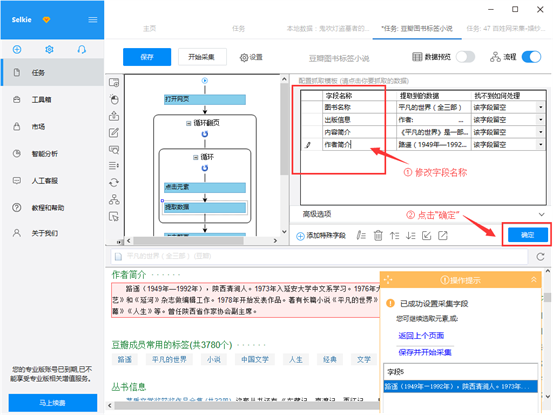
点击须要的数组信息,在两侧的操作提示框中,选择“采集该元素的文本”。我们在这里,采集了图书名称、图书出版信息、内容简介、作者简介
2)字段信息选择完成后,选中相应的数组,可以进行数组的自定义命名,修改完成后,点击“确定”。完成后,点击左上角的“保存并启动”,启动采集任务
3)选择“启动本地采集”
4)采集完成后,会跳出提示,选择“导出数据”。选择“合适的导入方法”,将采集好的数据导入。这里我们选择excel作为导入为格式,数据导入后如下图
步骤5:修改Xpath
通过上述导入的数据我们可以发觉,部分图书的“内容简介”、“作者简介”没有采集下来(如:《解忧杂货店》图书详情页的“内容简介”采集下来了,但是《雪落香杉树》图书详情页的“内容简介”并未采集下来)。这是因为,每个图书详情页的网页情况有所不同,系统手动生成的Xpath,不能完全正确定位到每位图书详情页的“内容简介”和“作者简介”。以下将以“内容简介”这个数组为例,具体讲解xpath的更改。“作者简介”字段更改同理,在此文中不做多讲。
1)选中“提取元素”步骤,点击“内容简介”字段,再点击如图所示的按键
2)选择“自定义定位元素形式”
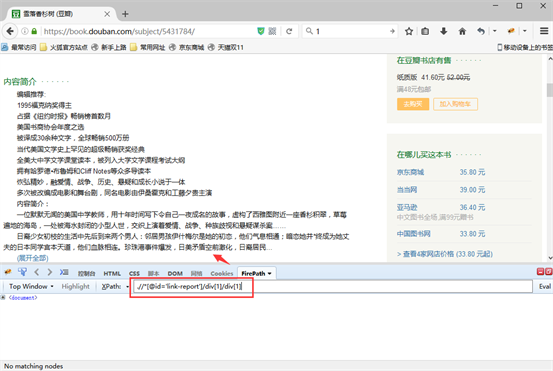
3)将优采云系统手动生成的这条Xpath:
//DIV[@id='link-report']/DIV[1]/DIV[1]/P[1],复制粘贴到火狐浏览器中进行测量
4)将优采云系统手动生成的此条Xpath,删减为
//DIV[@id='link-report']/DIV[1]/DIV[1](P[1]代表内容简介里的第一段,删掉即可定位到整个内容简介段落)。我们发觉:通过此条Xpath:
//DIV[@id='link-report']/DIV[1]/DIV[1],在《解忧杂货店》图书详情页,可以定位到“内容简介”字段,但是在《雪落香杉树》图书详情页,不能定位到“内容简介”字段
《解忧杂货店》图书详情页:可定位到“内容简介”字段
《雪落香杉树》图书详情页:不能定位到“内容简介”字段
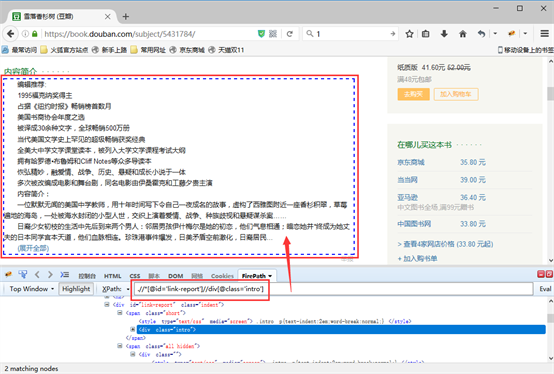
5)观察网页源码发觉,图书详情页“内容简介”字段,都具有相同的class属性,通过class属性,我们可写出一条才能定位所有图书详情页“内容简介”字段的Xpath:.//*[@id='link-report']//div[@class='intro']。在火狐浏览器中检测发觉,通过此条Xpath,确实能都定位到所有图书详情页的“内容简介”字段
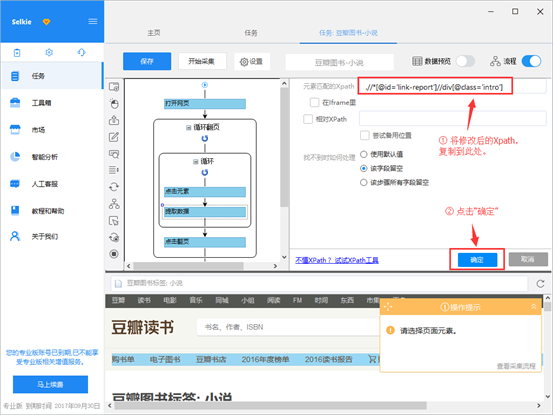
6)将新写的此条Xpath:.//*[@id='link-report']//div[@class='intro'],复制粘贴到优采云中的相应位置,并点击“确定”
7)重新“启动本地采集”并导入数据。可以看见,所有图书详情页的“内容简介”字段均被抓取出来
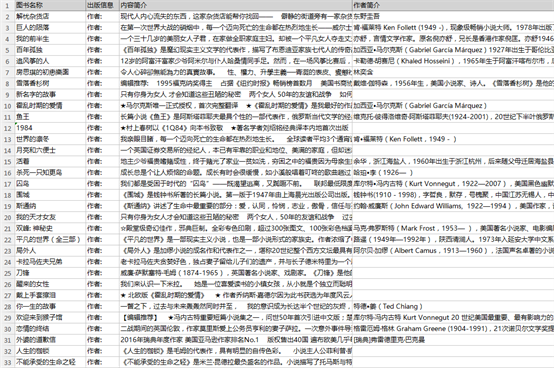
注意:“作者简介”字段更改同理,需要更改Xpath,在此文中不做多讲。 查看全部
本文介绍使用优采云采集器v7采集豆瓣读书详尽信息。
采集网站:
%E5%B0%8F%E8%AF%B4?start=0&type=T
使用功能点:
l分页列表及详尽信息提取
/tutorial/fylbxq7.aspx?t=1
lXpath
/tutorialdetail-1/xpath1.html
豆瓣读书:豆瓣读书为豆瓣网的一个子栏目。豆瓣读书自2005年上线,已成为国外信息最全、用户数目最大且最为活跃的读书网站。我们专注于为用户提供全面且精细化的读书服务,同时不断探求新的产品模式。到2012年豆瓣读书每个月有超过800万的来访用户,过亿的访问次数。。
豆瓣读书采集数据说明:本文进行了豆瓣读书-书籍详尽信息的采集,本文首先进去豆瓣读书分类列表页,然后循环点击每一条图书信息,进入图书详情页采集具体详尽信息 。本文仅以“豆瓣读书采集”为例。大家在实操过程中,可依照自身需求,更换豆瓣的其他内容进行数据采集。
豆瓣读书采集字段详尽说明:图书名称,图书作者,图书定价,图书价钱,图书出版年,图书作者简介。
步骤1:创建采集任务
1)进入主界面,选择“自定义模式”
2)将要采集的网址URL,复制粘贴到网址输入框中,点击“保存网址”
步骤2:创建翻页循环
1)在页面右上角,打开“流程”,以突显出“流程设计器”和“定制当前操作”两个蓝筹股。将页面下拉到顶部,点击“后页>”按钮,在两侧的操作提示框中,选择“更多操作”
2)选择“循环点击单个链接”
步骤3:创建列表循环
1)移动滑鼠,选中页面里的第一个图书链接。选中后,系统会手动辨识页面里的其他相像链接。在左侧操作提示框中,选择“选中全部”
2)选择“循环点击每位链接”,以创建一个列表循环
步骤4:提取图书信息
1)在创建列表循环后,系统会手动点击第一个图书链接,进入图书详尽信息页。
点击须要的数组信息,在两侧的操作提示框中,选择“采集该元素的文本”。我们在这里,采集了图书名称、图书出版信息、内容简介、作者简介
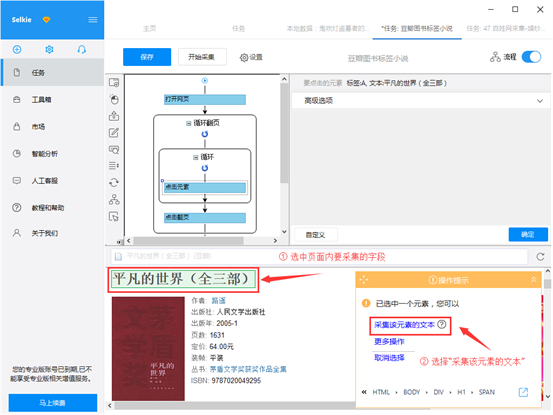
2)字段信息选择完成后,选中相应的数组,可以进行数组的自定义命名,修改完成后,点击“确定”。完成后,点击左上角的“保存并启动”,启动采集任务
3)选择“启动本地采集”
4)采集完成后,会跳出提示,选择“导出数据”。选择“合适的导入方法”,将采集好的数据导入。这里我们选择excel作为导入为格式,数据导入后如下图
步骤5:修改Xpath
通过上述导入的数据我们可以发觉,部分图书的“内容简介”、“作者简介”没有采集下来(如:《解忧杂货店》图书详情页的“内容简介”采集下来了,但是《雪落香杉树》图书详情页的“内容简介”并未采集下来)。这是因为,每个图书详情页的网页情况有所不同,系统手动生成的Xpath,不能完全正确定位到每位图书详情页的“内容简介”和“作者简介”。以下将以“内容简介”这个数组为例,具体讲解xpath的更改。“作者简介”字段更改同理,在此文中不做多讲。
1)选中“提取元素”步骤,点击“内容简介”字段,再点击如图所示的按键
2)选择“自定义定位元素形式”
3)将优采云系统手动生成的这条Xpath:
//DIV[@id='link-report']/DIV[1]/DIV[1]/P[1],复制粘贴到火狐浏览器中进行测量
4)将优采云系统手动生成的此条Xpath,删减为
//DIV[@id='link-report']/DIV[1]/DIV[1](P[1]代表内容简介里的第一段,删掉即可定位到整个内容简介段落)。我们发觉:通过此条Xpath:
//DIV[@id='link-report']/DIV[1]/DIV[1],在《解忧杂货店》图书详情页,可以定位到“内容简介”字段,但是在《雪落香杉树》图书详情页,不能定位到“内容简介”字段
《解忧杂货店》图书详情页:可定位到“内容简介”字段
《雪落香杉树》图书详情页:不能定位到“内容简介”字段
5)观察网页源码发觉,图书详情页“内容简介”字段,都具有相同的class属性,通过class属性,我们可写出一条才能定位所有图书详情页“内容简介”字段的Xpath:.//*[@id='link-report']//div[@class='intro']。在火狐浏览器中检测发觉,通过此条Xpath,确实能都定位到所有图书详情页的“内容简介”字段
6)将新写的此条Xpath:.//*[@id='link-report']//div[@class='intro'],复制粘贴到优采云中的相应位置,并点击“确定”
7)重新“启动本地采集”并导入数据。可以看见,所有图书详情页的“内容简介”字段均被抓取出来
注意:“作者简介”字段更改同理,需要更改Xpath,在此文中不做多讲。
网页数据采集到底是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 411 次浏览 • 2020-08-13 04:23
什么是网页数据采集
上网去搜索网页数据采集这几个字,出来的网页不少,可是看来看去,还没有一篇完整全面的说明,其实,网页数据采集是一个古老而又常新的话题,如果要下个定义,可以这么说:网页数据采集就是从网页上获取数据,一般来说是指通过软件或则工具从大量的公开可见的网页上精准的获取某一类信息,并且整理成规整的数据。
从前面这个定义来看,有几个关键的点,如果这几个点没有搞明白,就会有很多误会和困扰,在列出关键点之前,我们先瞧瞧几种常见的错误的理解:
错误观点1:网页数据采集就是“偷他人网站后台数据”。
经常有人找我所谓“拿站”,说白了就是想把他人网站数据非常是后台数据库,包括帐号等等全部“拿过来”,他们能够告诉我“要用点黑客手段”,这种是一种十分常见的错误理解。
错误观点2:网页数据采集就是“仿站”,或者“抄站”
还有人觉得,采集就是用工具把一个网站全部“复制出来”,然后仿照一个类似的“山寨版”。
错误观点3:网页数据采集就是转载,复制新闻贴子
甚至有些早已做过太长时间网页采集工作的人,或依照自己的经验把网页数据采集等同为复制转载新闻资讯贴子等。
正确观点:
其实以上几个观点都不正确,第一个,网页数据采集的目标是公开的网页,别人网站后台是“私有数据”,凡是没有经过授权,以所谓任何“黑客手段”盗取的后台数据都属于违法行为,我跟专业律师聊过这一点。第二个,网页数据采集本身是数据获取的过程,指的是从公开网页中获取数据,并不涉及拿数据来做什么,“仿站”其实是一种违背互联网精神,不尊重知识产权的行为,并且在一定程度上违规,如果对此有兴趣,可以查阅相关法律文件,对此我也有过深入研究,这种行为可能违规,因为构成不正当竞争,感兴趣的朋友可以去深入了解一下“京东严禁一淘”等知名案例,在日本,很多年前早已有一宗十分典型的这种案件开审。第三个,网页数据采集确实可以实现自动化转载新闻贴子等,但是这只是网页数据采集非常特别小的一个应用,不能把他等同于网页数据采集,而且这些方法也不应当成为倡导的借助网页数据采集的主要用途,再加上很多人,转载复制不说,还采取除去版权信息,掐头去尾,关键词替换,等等所谓的“伪原创”措施,想要误导搜索引擎,制造重复垃圾内容,这除了损害了被采集器的权益,还使想要搜索一些有用信息的人,淹没在成百上千条重复搜索结果中,我就常常十分苦恼,翻了10页,都是同样的一篇垃圾内容,各个网站都有。这最大的害处是破坏了互联网的良性发展气氛,大家都恶意复制垃圾内容制制造重复垃圾,最终坏了一锅汤,到头来被K站,自食恶果。
好了,说了这么多,正确的理解主要由以下几个关键点:
采集的目标和源头是公开的网页。采集一般是通过工具来完成。采集的结果是规整的数据。采集应该在法律和互联网规范的约束下进行,应该尊重知识产权。最后,这除了是我的理解,更是我始终倡导的网页采集的和游戏规则:就是把采集作为获取原创素材的方法,当获取到大量的原创素材以后,应该对数据进行自己原创性的独立的处理,处理的推论或则输出应当是自有知识产权的原创性内容,并且在必要的时侯保留对原创采集网页的版权引用,注明参考出处。
结论
讲了这么多,其实只是阐述了哪些是网页数据采集这个简单的概念,希望你们能共同支持和提倡互联网原创内容,积极维护网页数据采集的良好气氛,共同创造一个更好的互联网佳苑。
这次讨论网页数据采集是准备写一系列的原创文章,对网页数据采集这一话题做全面深入的阐述,欢迎诸位一起阐述,互相学习。
讨论请加群:网页数据采集,群号:254764602,加群暗号:网页数据采集 查看全部
摘要:上网去搜索网页数据采集这几个字,出来的网页不少,可是看来看去,还没有一篇完整全面的说明,其实,网页数据采集是一个古老而又常新的话题,如果要下个定义,可以这么说:网页数据采集就是从网页上获取数据,一般来说是指通过软件或则工具从大量的公开可见的网页上精准的获取某一类信息,并且整理成规整的数据。
什么是网页数据采集
上网去搜索网页数据采集这几个字,出来的网页不少,可是看来看去,还没有一篇完整全面的说明,其实,网页数据采集是一个古老而又常新的话题,如果要下个定义,可以这么说:网页数据采集就是从网页上获取数据,一般来说是指通过软件或则工具从大量的公开可见的网页上精准的获取某一类信息,并且整理成规整的数据。
从前面这个定义来看,有几个关键的点,如果这几个点没有搞明白,就会有很多误会和困扰,在列出关键点之前,我们先瞧瞧几种常见的错误的理解:
错误观点1:网页数据采集就是“偷他人网站后台数据”。
经常有人找我所谓“拿站”,说白了就是想把他人网站数据非常是后台数据库,包括帐号等等全部“拿过来”,他们能够告诉我“要用点黑客手段”,这种是一种十分常见的错误理解。
错误观点2:网页数据采集就是“仿站”,或者“抄站”
还有人觉得,采集就是用工具把一个网站全部“复制出来”,然后仿照一个类似的“山寨版”。
错误观点3:网页数据采集就是转载,复制新闻贴子
甚至有些早已做过太长时间网页采集工作的人,或依照自己的经验把网页数据采集等同为复制转载新闻资讯贴子等。
正确观点:
其实以上几个观点都不正确,第一个,网页数据采集的目标是公开的网页,别人网站后台是“私有数据”,凡是没有经过授权,以所谓任何“黑客手段”盗取的后台数据都属于违法行为,我跟专业律师聊过这一点。第二个,网页数据采集本身是数据获取的过程,指的是从公开网页中获取数据,并不涉及拿数据来做什么,“仿站”其实是一种违背互联网精神,不尊重知识产权的行为,并且在一定程度上违规,如果对此有兴趣,可以查阅相关法律文件,对此我也有过深入研究,这种行为可能违规,因为构成不正当竞争,感兴趣的朋友可以去深入了解一下“京东严禁一淘”等知名案例,在日本,很多年前早已有一宗十分典型的这种案件开审。第三个,网页数据采集确实可以实现自动化转载新闻贴子等,但是这只是网页数据采集非常特别小的一个应用,不能把他等同于网页数据采集,而且这些方法也不应当成为倡导的借助网页数据采集的主要用途,再加上很多人,转载复制不说,还采取除去版权信息,掐头去尾,关键词替换,等等所谓的“伪原创”措施,想要误导搜索引擎,制造重复垃圾内容,这除了损害了被采集器的权益,还使想要搜索一些有用信息的人,淹没在成百上千条重复搜索结果中,我就常常十分苦恼,翻了10页,都是同样的一篇垃圾内容,各个网站都有。这最大的害处是破坏了互联网的良性发展气氛,大家都恶意复制垃圾内容制制造重复垃圾,最终坏了一锅汤,到头来被K站,自食恶果。
好了,说了这么多,正确的理解主要由以下几个关键点:
采集的目标和源头是公开的网页。采集一般是通过工具来完成。采集的结果是规整的数据。采集应该在法律和互联网规范的约束下进行,应该尊重知识产权。最后,这除了是我的理解,更是我始终倡导的网页采集的和游戏规则:就是把采集作为获取原创素材的方法,当获取到大量的原创素材以后,应该对数据进行自己原创性的独立的处理,处理的推论或则输出应当是自有知识产权的原创性内容,并且在必要的时侯保留对原创采集网页的版权引用,注明参考出处。
结论
讲了这么多,其实只是阐述了哪些是网页数据采集这个简单的概念,希望你们能共同支持和提倡互联网原创内容,积极维护网页数据采集的良好气氛,共同创造一个更好的互联网佳苑。
这次讨论网页数据采集是准备写一系列的原创文章,对网页数据采集这一话题做全面深入的阐述,欢迎诸位一起阐述,互相学习。
讨论请加群:网页数据采集,群号:254764602,加群暗号:网页数据采集
解决方案:网页内容采集器Content Grabber Premium v2.48
采集交流 • 优采云 发表了文章 • 0 个评论 • 424 次浏览 • 2020-08-28 21:13
Content Grabber Premium破解版是一款用于网页抓取和网页自动化的网页内容采集工具,它可以从几乎任何网站提取内容,并以您选择的格式(包括Excel报告,XML,CSV和大多数数据库)将其保存为结构化数据,欢迎有须要的同事前来下载使用。
基本介绍
Content Grabber Premium(网页内容采集器) 一款由国内高手制做的能从网页中抓取内容(视频、图片、文本)并提取成Excel、XML、CSV和大多数数据库的利器,软件基于网页抓取和Web自动化。完全免费提供使用,常用于数据的调查和测量用途。
功能介绍
价格比较门户/移动应用程序
- 数据汇总
- 协作清单(例如,房屋止赎,工作委员会,旅游景点)
- 新闻和内容聚合
- 搜索引擎排名
市场情报和检测
- 有竞争力的价钱
- 零售连锁监控
- 社交媒体和品牌检测
- 金融和市场研究
- 欺诈辨识
- 知识产权保护
- 合规性和风险管理
政府解决方案
- 及时获取世界各地的新闻,活动和意见
- 减少数据搜集和IT成本
- 促进信息共享
- 开源智能(OSINT)
内容集成
- 内容迁移(即CMS / CRM)
- 企业搜索
- 传统的应用程序集成
B2B整合/流程自动化
- 合作伙伴/供应商/客户整合
可扩展性和可靠性
内容抓取器针对的是对网路抓取至关重要的公司,并注重于可扩展性和可靠性。网络收录大量的数据,而且利用多线程,优化的Web浏览器以及许多其他性能调整选项,Content Grabber将比其他任何软件提取的速率更快,更可靠。我们强悍的测试和调试功能可帮助您建立可靠的代理,并且可靠的错误处理和错误恢复将使代理在最困难的情况下运行。
建立数百个网页刮取代理
“内容抓取器”代理编辑器的易用性和可视化方式让其适用于建立数百个网页抓取代理,比使用任何其他软件要快得多。
代理编辑器会手动检查并配置所需的命令。它会手动创建内容和链接列表,处理分页和网页表单,下载或上传文件,并配置您在网页上执行的任何其他操作。同时,您仍然可以自动微调这种命令,因此,“内容抓取器”为您提供了简单性和控制性。
有数百个网路抓取工具,您须要合适的工具来管理这种工具,并且抓取内容不会使您沮丧。您可以查看所有代理的状态和日志,或在一个集中位置运行和安排代理。
分配网刮刮剂免版税
构建免版税的自收录网页抓取代理,可以在没有“内容抓取器”软件的情况下在任何地方运行。独立代理是一个简单的可执行文件,可以随时随地发送或复制,并且拥有丰富的配置选项。您可以自由地销售或附送您的独立代理商,并且可以将促销消息和广告添加到代理商的用户界面。
使用脚本自定义所有内容
脚本是“内容抓取器”的一个组成部份,可以用于须要个别特殊功能的情况,以便完全依照您的须要完成所有操作。使用外置的脚本编辑器,或者借助Content Grabber与Visual Studio的集成,实现更强大的脚本编辑和调试功能。
使用API来建立奇特的解决方案
将Web抓取功能添加到您自己的桌面应用程序中,并免费分发您的应用程序的Content Grabber运行时。使用专用的内容抓取器Web API建立Web应用程序,并按照须要直接从您的网站执行Web抓取代理。
系统要求
在安装“内容抓取器”之前,请确保您符合这种要求。
Windows 7/8/10 / 2008R2 / 2012 / 2012R2
.NET v4.5(将手动安装,如果它仍未安装在您的计算机上)。
安装步骤
1、在本站提供的百度网站中下载该软件,并解压缩后,双击“setup.exe”程序
2、如果笔记本中没有安装Microsoft .NET版本,安装程序会显示下来Microsoft .NET版本4.5许可合同,并会手动为你安装
3、接受许可合同并安装
4、在安装向导中按照提示进行安装 查看全部
网页内容采集器Content Grabber Premium v2.48
Content Grabber Premium破解版是一款用于网页抓取和网页自动化的网页内容采集工具,它可以从几乎任何网站提取内容,并以您选择的格式(包括Excel报告,XML,CSV和大多数数据库)将其保存为结构化数据,欢迎有须要的同事前来下载使用。
基本介绍
Content Grabber Premium(网页内容采集器) 一款由国内高手制做的能从网页中抓取内容(视频、图片、文本)并提取成Excel、XML、CSV和大多数数据库的利器,软件基于网页抓取和Web自动化。完全免费提供使用,常用于数据的调查和测量用途。
功能介绍
价格比较门户/移动应用程序
- 数据汇总
- 协作清单(例如,房屋止赎,工作委员会,旅游景点)
- 新闻和内容聚合
- 搜索引擎排名
市场情报和检测
- 有竞争力的价钱
- 零售连锁监控
- 社交媒体和品牌检测
- 金融和市场研究
- 欺诈辨识
- 知识产权保护
- 合规性和风险管理
政府解决方案
- 及时获取世界各地的新闻,活动和意见
- 减少数据搜集和IT成本
- 促进信息共享
- 开源智能(OSINT)
内容集成
- 内容迁移(即CMS / CRM)
- 企业搜索
- 传统的应用程序集成
B2B整合/流程自动化
- 合作伙伴/供应商/客户整合
可扩展性和可靠性
内容抓取器针对的是对网路抓取至关重要的公司,并注重于可扩展性和可靠性。网络收录大量的数据,而且利用多线程,优化的Web浏览器以及许多其他性能调整选项,Content Grabber将比其他任何软件提取的速率更快,更可靠。我们强悍的测试和调试功能可帮助您建立可靠的代理,并且可靠的错误处理和错误恢复将使代理在最困难的情况下运行。
建立数百个网页刮取代理
“内容抓取器”代理编辑器的易用性和可视化方式让其适用于建立数百个网页抓取代理,比使用任何其他软件要快得多。
代理编辑器会手动检查并配置所需的命令。它会手动创建内容和链接列表,处理分页和网页表单,下载或上传文件,并配置您在网页上执行的任何其他操作。同时,您仍然可以自动微调这种命令,因此,“内容抓取器”为您提供了简单性和控制性。
有数百个网路抓取工具,您须要合适的工具来管理这种工具,并且抓取内容不会使您沮丧。您可以查看所有代理的状态和日志,或在一个集中位置运行和安排代理。
分配网刮刮剂免版税
构建免版税的自收录网页抓取代理,可以在没有“内容抓取器”软件的情况下在任何地方运行。独立代理是一个简单的可执行文件,可以随时随地发送或复制,并且拥有丰富的配置选项。您可以自由地销售或附送您的独立代理商,并且可以将促销消息和广告添加到代理商的用户界面。
使用脚本自定义所有内容
脚本是“内容抓取器”的一个组成部份,可以用于须要个别特殊功能的情况,以便完全依照您的须要完成所有操作。使用外置的脚本编辑器,或者借助Content Grabber与Visual Studio的集成,实现更强大的脚本编辑和调试功能。
使用API来建立奇特的解决方案
将Web抓取功能添加到您自己的桌面应用程序中,并免费分发您的应用程序的Content Grabber运行时。使用专用的内容抓取器Web API建立Web应用程序,并按照须要直接从您的网站执行Web抓取代理。
系统要求
在安装“内容抓取器”之前,请确保您符合这种要求。
Windows 7/8/10 / 2008R2 / 2012 / 2012R2
.NET v4.5(将手动安装,如果它仍未安装在您的计算机上)。
安装步骤
1、在本站提供的百度网站中下载该软件,并解压缩后,双击“setup.exe”程序
2、如果笔记本中没有安装Microsoft .NET版本,安装程序会显示下来Microsoft .NET版本4.5许可合同,并会手动为你安装
3、接受许可合同并安装
4、在安装向导中按照提示进行安装
【网页表格数据采集器】
采集交流 • 优采云 发表了文章 • 0 个评论 • 354 次浏览 • 2020-08-27 14:28
网页表格数据采集器软件支持对一个网站上的连续无限个页面中的同类表格数据的批量采集,支持对一个页面中的指定表格数据的采集,也支持对一个页面中具有共同数据的多个表格数据的采集,采集时可依照网页上类似“下一页”这样的链接的后续页面的无限采集,也可按照网址中的页数采集指定的连续的页面中的表格数据,还可依据你自己指定的网址列表连续批量采集,有没有合并的单元格都可采集,而且还能手动过滤隐藏的干扰码,采集的结果可显示为文本表格,保存成文本,也可保存为EXCEL就能直接读取的CSV格式,能够用EXCEL打开采集后的表格数据了,那么以后的排序、筛选、统计、分析就是轻松的事情了。
网页表格数据采集软件的使用也很简单,如果你熟悉以后,采集表格可以说是一键搞定。
时间就是生命,一寸光阴一寸金,寸金难买寸时光,我们不能将有限的生命浪费在一些重复的、枯燥的工作上,有现成的软件,何不使用软件,不能再迟疑了,需要的就请尽早下载吧!
网页表格数据采集器使用方式
1、首先在地址栏输入待采集的网页地址,如果待采集网页早已在IE类浏览器中打开了,那么软件的网址列表上将手动会加入此地址的,你只要下拉选择一下都会打开了。
2、再点击抓取测试按键,看看网页源码及该网页中所含的表格数目,网页源码在软件下边的文本框中显示,网页中所含的表格数及表头信息在软件左上角列表框中显示。
3、从表格数列表中选择你要抓取的表格,此时表格左上角第一格文字将显示在软件的表格左上角第一格内容输入框中,表格所含数组(列)将显示在软件两侧的中间列表中。
4、再选择你要采集的表格数据的数组(列),如果不选择,网页表格数据采集器将全部采集。
5、选择你是否要抓取表格的表头行,保存时是否显示表格线,如果网页表格中有数组有链接,你可以选择是否收录链接地址,如果有且要采集其链接地址,那么你不能同时选择收录表头行。
6、如果你要采集的表格数据只有一个网页,那么你如今就可直接点击抓取表格抓取了,如果后面不选择收录表格线,表格数据将以CVS格式保存,此格式可用谷歌EXCEL软件直接打开转为EXCEL表格,如果上面选择收录表格线,表格数据将以TXT格式保存,可用记事本软件打开查看,直接具有表格线,也太清晰。
7、如果你要采集的表格数据有连续多个页面,并且你都想将其采集下来,那么,请再设置程序采集下一页及后续页面的形式,可以是按照链接名打开下页,链接名称几乎大部分页面都是“下一页”,你看页面,找到后输入即可,如果网页没有下一页链接,但是网址中收录页数,那么你也可选择按照网址中的页数打开,你可以选择从前到后,如从1页到10页,也可选择从后到前,如从10页到1页,在页数输入框中输入即可,但此时网址中代表页数的位置要用“(*)”代替,否则网页表格数据采集器程序将不认识。
8、再选择是定时采集或等待网页打开并加载结束后立刻采集,定时采集是程序按照一个设定的太小的时间间隔去判定打开的页面中是否有你要的表格,有就采集,而网页加载后采集是只要是要采集的网页早已打开了,程序都会立刻进行采集,两者各有特色,看须要选择。
9、最后,就是你点击一下抓取表格按键,就可以泡杯奶茶逍遥去了!
10、如果是你已然比较熟悉了你要采集的网页的信息,而且要采集指定表格的所有数组,你也可以输入须要的一些信息后,不经过抓取测试等操作,直接点击抓取表格的。
展开 查看全部
【网页表格数据采集器】
网页表格数据采集器软件支持对一个网站上的连续无限个页面中的同类表格数据的批量采集,支持对一个页面中的指定表格数据的采集,也支持对一个页面中具有共同数据的多个表格数据的采集,采集时可依照网页上类似“下一页”这样的链接的后续页面的无限采集,也可按照网址中的页数采集指定的连续的页面中的表格数据,还可依据你自己指定的网址列表连续批量采集,有没有合并的单元格都可采集,而且还能手动过滤隐藏的干扰码,采集的结果可显示为文本表格,保存成文本,也可保存为EXCEL就能直接读取的CSV格式,能够用EXCEL打开采集后的表格数据了,那么以后的排序、筛选、统计、分析就是轻松的事情了。
网页表格数据采集软件的使用也很简单,如果你熟悉以后,采集表格可以说是一键搞定。
时间就是生命,一寸光阴一寸金,寸金难买寸时光,我们不能将有限的生命浪费在一些重复的、枯燥的工作上,有现成的软件,何不使用软件,不能再迟疑了,需要的就请尽早下载吧!
网页表格数据采集器使用方式
1、首先在地址栏输入待采集的网页地址,如果待采集网页早已在IE类浏览器中打开了,那么软件的网址列表上将手动会加入此地址的,你只要下拉选择一下都会打开了。
2、再点击抓取测试按键,看看网页源码及该网页中所含的表格数目,网页源码在软件下边的文本框中显示,网页中所含的表格数及表头信息在软件左上角列表框中显示。
3、从表格数列表中选择你要抓取的表格,此时表格左上角第一格文字将显示在软件的表格左上角第一格内容输入框中,表格所含数组(列)将显示在软件两侧的中间列表中。
4、再选择你要采集的表格数据的数组(列),如果不选择,网页表格数据采集器将全部采集。
5、选择你是否要抓取表格的表头行,保存时是否显示表格线,如果网页表格中有数组有链接,你可以选择是否收录链接地址,如果有且要采集其链接地址,那么你不能同时选择收录表头行。
6、如果你要采集的表格数据只有一个网页,那么你如今就可直接点击抓取表格抓取了,如果后面不选择收录表格线,表格数据将以CVS格式保存,此格式可用谷歌EXCEL软件直接打开转为EXCEL表格,如果上面选择收录表格线,表格数据将以TXT格式保存,可用记事本软件打开查看,直接具有表格线,也太清晰。
7、如果你要采集的表格数据有连续多个页面,并且你都想将其采集下来,那么,请再设置程序采集下一页及后续页面的形式,可以是按照链接名打开下页,链接名称几乎大部分页面都是“下一页”,你看页面,找到后输入即可,如果网页没有下一页链接,但是网址中收录页数,那么你也可选择按照网址中的页数打开,你可以选择从前到后,如从1页到10页,也可选择从后到前,如从10页到1页,在页数输入框中输入即可,但此时网址中代表页数的位置要用“(*)”代替,否则网页表格数据采集器程序将不认识。
8、再选择是定时采集或等待网页打开并加载结束后立刻采集,定时采集是程序按照一个设定的太小的时间间隔去判定打开的页面中是否有你要的表格,有就采集,而网页加载后采集是只要是要采集的网页早已打开了,程序都会立刻进行采集,两者各有特色,看须要选择。
9、最后,就是你点击一下抓取表格按键,就可以泡杯奶茶逍遥去了!
10、如果是你已然比较熟悉了你要采集的网页的信息,而且要采集指定表格的所有数组,你也可以输入须要的一些信息后,不经过抓取测试等操作,直接点击抓取表格的。
展开
Python爬虫实战练习:实现一个简易的网页采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2020-08-27 11:34
前言
本文的文字及图片来源于网路,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:虫萧
PS:如有须要Python学习资料的小伙伴可以加下方的群去找免费管理员发放
可以免费发放源码、项目实战视频、PDF文件等
requests模块
python中封装好的一个基于网路恳求的模块。用来模拟浏览器发恳求。安装:pip install requests
requests模块的编码流程指定url发起恳求获取相应数据持久化存储
# 爬取搜狗首页的页面源码数据
import requests
# 1. 指定url
url = "https://www.sogou.com"
# 2.发送请求 get
response = requests.get(url=url) # get返回值是Response对象
# 获取响应数据,响应数据在Response对象里
page_text = response.text # text返回字符串形式的响应数据
# 4.持久化储存
with open("sogou.html","w",encoding='utf-8') as fp:
fp.write(page_text)
项目:实现一个简易的网页采集器
要求:程序基于搜狗录入任意的关键字之后获取关键字对应的相关的整个页面。
# 1.指定url,需要让url携带的参数动态化
url = "https://www.sogou.com/web"
# 实现参数动态化,不推荐参数的拼接,参数如果太多就相当麻烦。
# requests模块实现了更为简便的方法
ky = input("enter a key")
params = {
'query':ky
}
# 将需要的请求参数对应的字典作用到get方法的params参数中,params参数接受一个字典
response = requests.get(url=url,params=params)
page_text = response.text
with open(f"{ky}.html","w",encoding='utf-8') as fp:
fp.write(page_text)
上述代码执行后:
出现了乱码数据量级不对
# 解决乱码
url = "https://www.sogou.com/web"
ky = input("enter a key")
params = {
'query':ky
}
response = requests.get(url=url,params=params)
# print(response.encoding) 会打印原来response的编码格式
response.encoding = 'utf-8' # 修改响应数据的编码格式
page_text = response.text
with open(f"{ky}.html","w",encoding='utf-8') as fp:
fp.write(page_text)
上述代码执行后:
收到了错误页面(搜狗的反爬机制)
UA检查
反反爬策略:UA伪装 请求头降低User-Agent
打开浏览器恳求搜狗页面,右键点击检测步入Network,点击Headers找到浏览器的User-Agent
注意:任意浏览器的身分标示都可以。
# 反反爬策略:请求头增加User-Agent
url = "https://www.sogou.com/web"
ky = input("enter a key")
params = {
'query':ky
}
# 请求头中增加User-Agent ,注意请求头的数据格式是键值对,且都是字符串。
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
}
response = requests.get(url=url,params=params,headers=headers)
response.encoding = 'utf-8'
page_text = response.text
with open(f"{ky}.html","w",encoding='utf-8') as fp:
fp.write(page_text)
注意:get的参数headers是一个字典,且通配符都是字符串方式 查看全部
Python爬虫实战练习:实现一个简易的网页采集器
前言
本文的文字及图片来源于网路,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:虫萧
PS:如有须要Python学习资料的小伙伴可以加下方的群去找免费管理员发放
可以免费发放源码、项目实战视频、PDF文件等
requests模块
python中封装好的一个基于网路恳求的模块。用来模拟浏览器发恳求。安装:pip install requests
requests模块的编码流程指定url发起恳求获取相应数据持久化存储
# 爬取搜狗首页的页面源码数据
import requests
# 1. 指定url
url = "https://www.sogou.com"
# 2.发送请求 get
response = requests.get(url=url) # get返回值是Response对象
# 获取响应数据,响应数据在Response对象里
page_text = response.text # text返回字符串形式的响应数据
# 4.持久化储存
with open("sogou.html","w",encoding='utf-8') as fp:
fp.write(page_text)
项目:实现一个简易的网页采集器
要求:程序基于搜狗录入任意的关键字之后获取关键字对应的相关的整个页面。
# 1.指定url,需要让url携带的参数动态化
url = "https://www.sogou.com/web"
# 实现参数动态化,不推荐参数的拼接,参数如果太多就相当麻烦。
# requests模块实现了更为简便的方法
ky = input("enter a key")
params = {
'query':ky
}
# 将需要的请求参数对应的字典作用到get方法的params参数中,params参数接受一个字典
response = requests.get(url=url,params=params)
page_text = response.text
with open(f"{ky}.html","w",encoding='utf-8') as fp:
fp.write(page_text)
上述代码执行后:
出现了乱码数据量级不对
# 解决乱码
url = "https://www.sogou.com/web"
ky = input("enter a key")
params = {
'query':ky
}
response = requests.get(url=url,params=params)
# print(response.encoding) 会打印原来response的编码格式
response.encoding = 'utf-8' # 修改响应数据的编码格式
page_text = response.text
with open(f"{ky}.html","w",encoding='utf-8') as fp:
fp.write(page_text)
上述代码执行后:
收到了错误页面(搜狗的反爬机制)
UA检查
反反爬策略:UA伪装 请求头降低User-Agent
打开浏览器恳求搜狗页面,右键点击检测步入Network,点击Headers找到浏览器的User-Agent
注意:任意浏览器的身分标示都可以。
# 反反爬策略:请求头增加User-Agent
url = "https://www.sogou.com/web"
ky = input("enter a key")
params = {
'query':ky
}
# 请求头中增加User-Agent ,注意请求头的数据格式是键值对,且都是字符串。
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
}
response = requests.get(url=url,params=params,headers=headers)
response.encoding = 'utf-8'
page_text = response.text
with open(f"{ky}.html","w",encoding='utf-8') as fp:
fp.write(page_text)
注意:get的参数headers是一个字典,且通配符都是字符串方式
优采云采集器采集网页文本内容的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 331 次浏览 • 2020-08-26 11:53
优采云采集器是一款多功能的网页信息采集工具,这款软件采用的是全新的信息抓取模式,能够帮助用户愈发快速的采集网页中的数据,并且可以对每一个网页模块中的数据进行选择性采集,很多用户在须要采集网页内容的时侯大多都是采集网页的文本内容,介于还有一些用户不知道如何使用这款软件来采集网页文本内容,那么小编就来跟你们分享一下具体的操作方法步骤吧,有须要的同事赶快一起来瞧瞧小编分享的方式,希望这篇教程才能对你们有所帮助。
方法步骤
1.首先第一步我们打开软件以后须要在软件的主界面中输入自己想要采集文本内容的网址,输入网址以后点击开始采集。
2.点击开始采集之后软件会手动辨识出该网址的网页界面,并且用户可以联通键盘在网页中选择要采集的元素位置,点击选择以后在出现的界面中选择采集该元素的文本这个选项。
3.选择点击采集该元素的文本这个选项以后,界面中会出现一个智能提示窗口,提示我们可以保存存开始采集操作,然后我们点击它。
4.点击以后还会步入到采集操作的界面了,等到一会之后软件会返回采集完成的窗口,紧接着我们点击其中的导入数据这个按键。
5.点击导入数据按键以后的下一步是选择我们要导入的形式,小编就以HTML文件为例来跟你们演示,点击选择然后再点击右下角的确定按键。
6.最后点击确定按键以后就来到另存为文件的界面了,然后我们在界面中输入文件须要保存的名称,然后点击保存按键即可。 查看全部
优采云采集器采集网页文本内容的方式
优采云采集器是一款多功能的网页信息采集工具,这款软件采用的是全新的信息抓取模式,能够帮助用户愈发快速的采集网页中的数据,并且可以对每一个网页模块中的数据进行选择性采集,很多用户在须要采集网页内容的时侯大多都是采集网页的文本内容,介于还有一些用户不知道如何使用这款软件来采集网页文本内容,那么小编就来跟你们分享一下具体的操作方法步骤吧,有须要的同事赶快一起来瞧瞧小编分享的方式,希望这篇教程才能对你们有所帮助。
方法步骤
1.首先第一步我们打开软件以后须要在软件的主界面中输入自己想要采集文本内容的网址,输入网址以后点击开始采集。
2.点击开始采集之后软件会手动辨识出该网址的网页界面,并且用户可以联通键盘在网页中选择要采集的元素位置,点击选择以后在出现的界面中选择采集该元素的文本这个选项。
3.选择点击采集该元素的文本这个选项以后,界面中会出现一个智能提示窗口,提示我们可以保存存开始采集操作,然后我们点击它。
4.点击以后还会步入到采集操作的界面了,等到一会之后软件会返回采集完成的窗口,紧接着我们点击其中的导入数据这个按键。
5.点击导入数据按键以后的下一步是选择我们要导入的形式,小编就以HTML文件为例来跟你们演示,点击选择然后再点击右下角的确定按键。
6.最后点击确定按键以后就来到另存为文件的界面了,然后我们在界面中输入文件须要保存的名称,然后点击保存按键即可。
智动网页内容采集器 v1.93官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 290 次浏览 • 2020-08-26 07:22
智动网页内容采集器是由智动软件推出的一款操作简单,功能实用的网页内容手动采集工具。支持采用多任务多线程形式采集任何网页上的任何指定文本内容,支持多级多网页内容混采,并进行你须要的相应过滤和处理,可以用搜索关键词形式采集需要的指定搜索结果,支持智能采集,光输网址就可以采集网页内容,非常便捷,智能,而且永久免费使用,有需求的用户不妨下载体验!
功能特色
1、采用底层HTTP方法采集数据,快速稳定,可建多个任务多线程采同时采集多个网站数据
2、用户可以随便导出导入任务
3、任务可以设置密码,保障您采集任务的细节安全不泄露
4、并具有N页采集暂停/拨号换IP,采集遇特殊标记暂停/拨号换IP等多种破解防采集功能
5、可以直接输入网址采,或JavaScript脚本生成网址,或以关键词搜索方法采集
6、可以用登陆采集方式采集需要登入账号能够查看的网页内容
7、可以无限深入N个栏目采集内容、采链接,支持多级内容分页采集
8、支持多种内容提取模式,可以对采到的内容进行你须要的处理,如消除HTML,图片等等
9、可自编JAVASCRIPT脚本来提取网页内容,轻松实现任意部份内容的采集
10、可按设定的模版保存采到的文本内容
11、可将采到的多个文件按模版保存到同一个文件中
12、可对网页上的多个部份内容分别进行分页内容采集
13、可自设顾客信息模拟百度等搜索引擎对目标网站采集
14、支持智能采集,光输网址就可以采到网页内容
15、本软件永久终生免费使用
更新日志
智动网页内容采集器 1.93更新:
1、去除外置浏览器手动加http前缀,需要自动添加,排除特殊前缀未能打开问题
2、测试时获取的HTML手动消除WINDOWS不辨识无意义字符,解决windows显示时HTML内容不全问题 查看全部
智动网页内容采集器 v1.93官方版
智动网页内容采集器是由智动软件推出的一款操作简单,功能实用的网页内容手动采集工具。支持采用多任务多线程形式采集任何网页上的任何指定文本内容,支持多级多网页内容混采,并进行你须要的相应过滤和处理,可以用搜索关键词形式采集需要的指定搜索结果,支持智能采集,光输网址就可以采集网页内容,非常便捷,智能,而且永久免费使用,有需求的用户不妨下载体验!
功能特色
1、采用底层HTTP方法采集数据,快速稳定,可建多个任务多线程采同时采集多个网站数据
2、用户可以随便导出导入任务
3、任务可以设置密码,保障您采集任务的细节安全不泄露
4、并具有N页采集暂停/拨号换IP,采集遇特殊标记暂停/拨号换IP等多种破解防采集功能
5、可以直接输入网址采,或JavaScript脚本生成网址,或以关键词搜索方法采集
6、可以用登陆采集方式采集需要登入账号能够查看的网页内容
7、可以无限深入N个栏目采集内容、采链接,支持多级内容分页采集
8、支持多种内容提取模式,可以对采到的内容进行你须要的处理,如消除HTML,图片等等
9、可自编JAVASCRIPT脚本来提取网页内容,轻松实现任意部份内容的采集
10、可按设定的模版保存采到的文本内容
11、可将采到的多个文件按模版保存到同一个文件中
12、可对网页上的多个部份内容分别进行分页内容采集
13、可自设顾客信息模拟百度等搜索引擎对目标网站采集
14、支持智能采集,光输网址就可以采到网页内容
15、本软件永久终生免费使用
更新日志
智动网页内容采集器 1.93更新:
1、去除外置浏览器手动加http前缀,需要自动添加,排除特殊前缀未能打开问题
2、测试时获取的HTML手动消除WINDOWS不辨识无意义字符,解决windows显示时HTML内容不全问题
站长怎么能够更好地运用网站内容采集器?
采集交流 • 优采云 发表了文章 • 0 个评论 • 334 次浏览 • 2020-08-26 02:19
我们都晓得,一些网站很喜欢进行分页的方法,来降低PV。然而这样不利之处就是很明显把一个完整的内容进行分割开来,造成用户在阅读方面上的一些障碍。用户不能不去进行点击下一页能够查看到自己想要的内容,反过来想,如果要做到区别原内容网站,就要作出不同于它的排版形式。我们可以把内容整理到一起(在文章不算很长的情况),这样一来,搜索引擎都会太轻松的把整个内容抓取完整,并且用户也不用再去翻页来进行查看。
网站内容分段和小标题的使用
在查看一篇内容的时侯,如果标题太精确,我们可以从标题里面就可以晓得内容大约讲的是哪些?然而,如果作者写的内容过长,就会把整个内容的中心点进行模糊化,这样一来在用户阅读里面就很容易导致抓不住作者真正想要抒发的观念,这时候,对于内容采集器来说,适当的分辨段落和降低相应的小标题,让用户很容易晓得每一段或则是上面作者想要抒发哪些,后面作者都构建哪些观点等。
使用这两种方法,都可以把全篇内容进行合理的分割,在抒发作者观点里面不要发生冲突,尽量在设置小标题前面才能保证作者的原先的思路。
采集内容尽量不要超过一定的时间
其实,在搜索引擎跟人一样,对于新内容搜索引擎也是青睐,并且在最短时间抓取下来,呈现给用户,但是时间一长,内容新鲜度已过,搜索引擎就很难在抓取相同的内容。我们完全可以借助这点,搜索引擎对于一篇新文章的青睐,采集内容的时侯,尽量采集在一天之内的内容。
增加高清晰度的图片
有些采集过来的内容,原网站没有降低图片,我们就可以添加高清晰度的图片。虽然,增加图片对于文章没有多大的影响,但是由于我们是采集的内容,尽量在做采集内容的调整中,保证一定的改动,不要采集过来,不做任何的修饰。增加图片就是要降低对于搜索引擎对于好感度。
我们采集别人的内容,首先在搜索引擎来看,就是属于重复剽窃内,在搜索引擎来说,我们的内容相对于原内容就早已在质量度方面分值增长好多。但是,我们可以通过一些方面进行填补增长的分值,这就须要个人站长在内容体验度和网站体验度里面作出努力。
最后一款通用高效的网站内容采集器一定能为你的工作效率加分,也就有更多的时间去研究收录,最受欢迎的优采云采集器值得您下载试用一番哦~ 查看全部
站长怎么能够更好地运用网站内容采集器?
我们都晓得,一些网站很喜欢进行分页的方法,来降低PV。然而这样不利之处就是很明显把一个完整的内容进行分割开来,造成用户在阅读方面上的一些障碍。用户不能不去进行点击下一页能够查看到自己想要的内容,反过来想,如果要做到区别原内容网站,就要作出不同于它的排版形式。我们可以把内容整理到一起(在文章不算很长的情况),这样一来,搜索引擎都会太轻松的把整个内容抓取完整,并且用户也不用再去翻页来进行查看。
网站内容分段和小标题的使用
在查看一篇内容的时侯,如果标题太精确,我们可以从标题里面就可以晓得内容大约讲的是哪些?然而,如果作者写的内容过长,就会把整个内容的中心点进行模糊化,这样一来在用户阅读里面就很容易导致抓不住作者真正想要抒发的观念,这时候,对于内容采集器来说,适当的分辨段落和降低相应的小标题,让用户很容易晓得每一段或则是上面作者想要抒发哪些,后面作者都构建哪些观点等。
使用这两种方法,都可以把全篇内容进行合理的分割,在抒发作者观点里面不要发生冲突,尽量在设置小标题前面才能保证作者的原先的思路。
采集内容尽量不要超过一定的时间
其实,在搜索引擎跟人一样,对于新内容搜索引擎也是青睐,并且在最短时间抓取下来,呈现给用户,但是时间一长,内容新鲜度已过,搜索引擎就很难在抓取相同的内容。我们完全可以借助这点,搜索引擎对于一篇新文章的青睐,采集内容的时侯,尽量采集在一天之内的内容。
增加高清晰度的图片
有些采集过来的内容,原网站没有降低图片,我们就可以添加高清晰度的图片。虽然,增加图片对于文章没有多大的影响,但是由于我们是采集的内容,尽量在做采集内容的调整中,保证一定的改动,不要采集过来,不做任何的修饰。增加图片就是要降低对于搜索引擎对于好感度。
我们采集别人的内容,首先在搜索引擎来看,就是属于重复剽窃内,在搜索引擎来说,我们的内容相对于原内容就早已在质量度方面分值增长好多。但是,我们可以通过一些方面进行填补增长的分值,这就须要个人站长在内容体验度和网站体验度里面作出努力。
最后一款通用高效的网站内容采集器一定能为你的工作效率加分,也就有更多的时间去研究收录,最受欢迎的优采云采集器值得您下载试用一番哦~
智动网页内容采集器 v1.93
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-08-25 13:39
智动网页内容采集器可用多任务多线程形式采集任何网页上的任何指定文本内容,并进行你须要的相应过滤和处理,可以用搜索关键词形式采集需要的指定搜索结果。
1、采用底层HTTP方法采集数据,快速稳定,可建多个任务多线程采同时采集多个网站数据
2、用户可以随便导出导入任务
3、任务可以设置密码,并具有N页采集暂停,采集遇特殊标记暂停等多种破解防采集功能
4、可以直接输入网址采,或JavaScript脚本生成网址,或以关键词搜索方法采集
5、可以用登陆采集方式采集需要登入账号能够查看的网页内容
6、可以无限深入N个栏目采集内容、采链接
7、支持多种内容提取模式,可以对采到的内容进行你须要的处理,如消除HTML,图片等等
8、可自编JAVASCRIPT脚本来提取网页内容,轻松实现任意部份内容的采集
9、可按设定的模版保存采到的文本内容
10、可将采到的多个文件按模版保存到同一个文件中
11、可对网页上的多个部份内容分别进行分页内容采集
12、可自设顾客信息模拟百度等搜索引擎对目标网站采集
13、本软件永久终生免费使用
智动网页内容采集器 v1.9更新:
软件外置网址更新为
采用全新的智动软件控件UI
增加用户反馈到EMAIL功能
增加将初始化链接直接设置作为最终内容页处理功能
加强内核功能,支持关键词搜索替换POST内的关键词标记
优化采集内核
优化断线拔号算法
优化去重复工具算法
修正拔号显示IP不正确BUG
修正遇出错关键词暂停或拔号时没有重新采集出错页面的BUG
修正限定内容最大值为0时,最小值未能正确保存BUG 查看全部
智动网页内容采集器 v1.93
智动网页内容采集器可用多任务多线程形式采集任何网页上的任何指定文本内容,并进行你须要的相应过滤和处理,可以用搜索关键词形式采集需要的指定搜索结果。
1、采用底层HTTP方法采集数据,快速稳定,可建多个任务多线程采同时采集多个网站数据
2、用户可以随便导出导入任务
3、任务可以设置密码,并具有N页采集暂停,采集遇特殊标记暂停等多种破解防采集功能
4、可以直接输入网址采,或JavaScript脚本生成网址,或以关键词搜索方法采集
5、可以用登陆采集方式采集需要登入账号能够查看的网页内容
6、可以无限深入N个栏目采集内容、采链接
7、支持多种内容提取模式,可以对采到的内容进行你须要的处理,如消除HTML,图片等等
8、可自编JAVASCRIPT脚本来提取网页内容,轻松实现任意部份内容的采集
9、可按设定的模版保存采到的文本内容
10、可将采到的多个文件按模版保存到同一个文件中
11、可对网页上的多个部份内容分别进行分页内容采集
12、可自设顾客信息模拟百度等搜索引擎对目标网站采集
13、本软件永久终生免费使用
智动网页内容采集器 v1.9更新:
软件外置网址更新为
采用全新的智动软件控件UI
增加用户反馈到EMAIL功能
增加将初始化链接直接设置作为最终内容页处理功能
加强内核功能,支持关键词搜索替换POST内的关键词标记
优化采集内核
优化断线拔号算法
优化去重复工具算法
修正拔号显示IP不正确BUG
修正遇出错关键词暂停或拔号时没有重新采集出错页面的BUG
修正限定内容最大值为0时,最小值未能正确保存BUG
尤克地图数据采集软件 V2.1.1 绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-08-24 18:22
电话销售
可以通过直接致电或转让机器人来制造
电话销售服务
短信营销
手机号码可以导入
短信群营销产品特色:1.多图融合:可以选择“高德图”,“百度图”,“腾讯图”,“日图”来搜集最新数据。
2,选择并输入采集条件:可以快速选择或输入多个城市,多个关键词,最全面的数据采集。
3,条件过滤和重复数据删掉:支持多条件过滤,多种算法去加权,准确的数据搜集而无需重复。
4,数据本地储存:数据不会遗失,可以随时导入数据。
5,清除数据:一键消除搜集列表中的数据和本地库中的数据。
6,导出数据:支持多种数据格式导入,Excel,CSV,VCF(可以将VCard文件导出到电话通讯录中),TXT,可以设置每位文件的最大导入数目。
7,在线升级:新版本即将发布后,打开客户端会手动升级到最新版本。
8.使用账户密码登入:它不受计算机限制,可以修改。
软件功能:Yuk _ Map大数据采集软件是一款专业的电子地图集成采集软件,可实时搜集各主要地图官方网站的最新POI数据。采集的数据储存在本地数据库中,可以导入到Excel或一键导出到电话通讯簿。
可以搜集全省所有城市和地区的所有行业数据,并且所搜集的数据十分确切,不会重复。该产品是由许多批发商,电子商务业务推动和微业务推动人员组成的批发商,从而扩大了业务量,并被许多行业的业务人员所选择。 查看全部
尤克地图数据采集软件 V2.1.1 绿色版
电话销售
可以通过直接致电或转让机器人来制造
电话销售服务
短信营销
手机号码可以导入
短信群营销产品特色:1.多图融合:可以选择“高德图”,“百度图”,“腾讯图”,“日图”来搜集最新数据。
2,选择并输入采集条件:可以快速选择或输入多个城市,多个关键词,最全面的数据采集。
3,条件过滤和重复数据删掉:支持多条件过滤,多种算法去加权,准确的数据搜集而无需重复。
4,数据本地储存:数据不会遗失,可以随时导入数据。
5,清除数据:一键消除搜集列表中的数据和本地库中的数据。
6,导出数据:支持多种数据格式导入,Excel,CSV,VCF(可以将VCard文件导出到电话通讯录中),TXT,可以设置每位文件的最大导入数目。
7,在线升级:新版本即将发布后,打开客户端会手动升级到最新版本。
8.使用账户密码登入:它不受计算机限制,可以修改。
软件功能:Yuk _ Map大数据采集软件是一款专业的电子地图集成采集软件,可实时搜集各主要地图官方网站的最新POI数据。采集的数据储存在本地数据库中,可以导入到Excel或一键导出到电话通讯簿。
可以搜集全省所有城市和地区的所有行业数据,并且所搜集的数据十分确切,不会重复。该产品是由许多批发商,电子商务业务推动和微业务推动人员组成的批发商,从而扩大了业务量,并被许多行业的业务人员所选择。
3. 网页采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 256 次浏览 • 2020-08-22 18:00
1.基本入门
网页采集器模拟了浏览器的设计,填入网址,点击刷新,即可获取对应地址的html源码。
左侧的区域,显示了html源码和浏览器视图,可通过tab页切换。右侧配置区域,可对关键字进行搜索,并对面前所有的属性进行管理。
概念解释:
Hawk把网页分成两种类型:
普通文档(One)->单文档模式当你没有为网页采集器添加任何属性时,默认行为是返回只有一个数组Content的单文档,内容为整个页面。可以显式指定为NoTransform来支持这个模式。2. 纯自动模式
由于软件不知道究竟要获取什么内容,因此须要手工给定几个关键字, 让Hawk搜索关键字, 并获取位置。填入搜索字符, 发现才能成功获取XPath, 编写属性名称,点击添加数组,即可添加一个属性。类似地,再填入30535,设置属性名称为“单价”,即可添加另外一个属性。
在搜索属性的文本框中,输入你要获取的关键字,由于关键字在网页中可能出现多次,可连续点击继续搜索,在多个结果间切换,左侧的html源码会对搜索的结果进行高亮。
请注意观察搜索的关键字在网页中的位置,是否符合预期,否则抓取数据可能会有问题。尤其在List模式。如果须要抓取本页面的多块数据,可新建多个网页采集器,分别进行配置。
如果发觉有错误,可点击编辑集合,对属性进行删掉,修改和排序。
你可以类似的将所有要抓取的特点数组添加进去,或是直接点击手气不错,系统会依照目前的属性,推测其他属性。
3. 手气不错
这是Hawk最被人赞誉的功能!在新的Hawk3中,该功能被极大地提高。
3.1 List模式的手气不错
在List模式下,一般来说,输入网址加载页面后,点击手气不错即可,Hawk会手动根据优先级将列表数据抓取下来。
左右切换选择你想要的数据集,之后在下边的属性栏对结果进行微调。
下面的图标可以全选,反选所有属性,点击删掉即可删掉选中的属性,亦可对属性名称进行更改。 点击刷新即可更新结果。
添加一个属性,手气不错能够更准确地进行。添加两个属性,即可选取惟一区域。
3.1 One模式的手气不错
Hawk3新增功能,当网页中收录多达几十种属性时,挨个添加会显得非常繁琐,这在某种商品属性页非常常见。
为了解决这个问题,将关键字加入到搜索属性中,此时不要将其添加到属性列表中,直接点击手气不错即可。
是不是太amazing? 欢迎给作者打赏!
3.2 原理
网页采集器的功能是获取网页中的数据(废话)。通常来说,目标可能是列表(如购物车列表),或是一个页面中的固定数组(如JD某商品的价钱和介绍,在页面中只有一个)。因此须要设置其读取模式。传统的采集器须要编撰正则表达式,但方式过于复杂。
如果认识到html是一棵树,只要找到了承载数据的节点即可,之后用XPath来描述。
手工编撰XPath也很复杂,因此软件可以通过关键字,自动检索XPath,提供关键字,软件都会从树中递归搜索收录该数据的叶子节点。因此关键字最好是在页面中独一无二的。
如上图所示,只要提供“北京”和“42”这两个关键字,就能找到parent节点, 进而获取div[0]和div1这两个列表元素。通过div[0]和div1两个节点的比较,我们能够手动发觉相同的子节点(name,mount)和不同的节点(北京:上海,37:42)。相同的节点会保存为属性名,不同的节点为属性值。但是,不能提供上海和37,此时,公共节点是div[0], 这不是列表。
软件在不提供关键字的情况下,也能通过html文档的特点,去估算最可能是列表父节点(如图中的parent)的节点,但当网页非常复杂时,猜测可能会出错。
本算法原理是原创的,可查看源码或留言交流。
4. 结果检测
工作过程中,可点击提取测试 ,随时查看采集器目前的才能抓取的数据内容。在属性管理器的上方,可以更改采集器的模块名称,这样就便捷数据清洗 模块调用该采集器。
5. 对恳求进行设置
当出现乱码,或者希望自己填入cookie等恳请头时,可在属性对话框点击恳求详情,弹出的对话框中进行设置。有时为了简便,可以将浏览器中的requests恳求头直接拷贝到恳求参数中。
Hawk有一定的网页编码检查功能,但出现乱码时,可以将编码从GB2312设置为UTF8,即可解决大多数乱码问题。
如何调用网页采集器,或实现Post恳求? 参考4.1节:从爬虫转换
6. 具体的事例
以抓取新闻内容为例:页面如下:![image_1at5pff7g7m71jtq1b2o1hlq1dt9.png-76.5kB][8]
你可以在搜索关键字中,搜索【2016年09月21日】,属性填写为时间,搜索【人民日报】,属性为【来源】。
提取正文须要注意,你可以随便填写正文中的一部分关键字,例如【量子隐形传态是一种传递量子】,这样Hawk就检索出了XPath:前面省略/div[1]/p[1]
如果你直接使用这个路径,则抓取的内容只有这一段。为了抓取正文,我们可以将/p[1]部分去除,只获取其父节点。这样能够抓取全文数据(是不是很赞)?
如果你想获取原创正文的html,则在属性列表的对话框里,可以勾选某个属性的【HTML标签】。
此时,点击提取测试,看看是不是获取了所需的数据? 查看全部
3. 网页采集器
1.基本入门
网页采集器模拟了浏览器的设计,填入网址,点击刷新,即可获取对应地址的html源码。
左侧的区域,显示了html源码和浏览器视图,可通过tab页切换。右侧配置区域,可对关键字进行搜索,并对面前所有的属性进行管理。
概念解释:
Hawk把网页分成两种类型:
普通文档(One)->单文档模式当你没有为网页采集器添加任何属性时,默认行为是返回只有一个数组Content的单文档,内容为整个页面。可以显式指定为NoTransform来支持这个模式。2. 纯自动模式
由于软件不知道究竟要获取什么内容,因此须要手工给定几个关键字, 让Hawk搜索关键字, 并获取位置。填入搜索字符, 发现才能成功获取XPath, 编写属性名称,点击添加数组,即可添加一个属性。类似地,再填入30535,设置属性名称为“单价”,即可添加另外一个属性。
在搜索属性的文本框中,输入你要获取的关键字,由于关键字在网页中可能出现多次,可连续点击继续搜索,在多个结果间切换,左侧的html源码会对搜索的结果进行高亮。
请注意观察搜索的关键字在网页中的位置,是否符合预期,否则抓取数据可能会有问题。尤其在List模式。如果须要抓取本页面的多块数据,可新建多个网页采集器,分别进行配置。
如果发觉有错误,可点击编辑集合,对属性进行删掉,修改和排序。
你可以类似的将所有要抓取的特点数组添加进去,或是直接点击手气不错,系统会依照目前的属性,推测其他属性。
3. 手气不错
这是Hawk最被人赞誉的功能!在新的Hawk3中,该功能被极大地提高。
3.1 List模式的手气不错
在List模式下,一般来说,输入网址加载页面后,点击手气不错即可,Hawk会手动根据优先级将列表数据抓取下来。
左右切换选择你想要的数据集,之后在下边的属性栏对结果进行微调。
下面的图标可以全选,反选所有属性,点击删掉即可删掉选中的属性,亦可对属性名称进行更改。 点击刷新即可更新结果。
添加一个属性,手气不错能够更准确地进行。添加两个属性,即可选取惟一区域。
3.1 One模式的手气不错
Hawk3新增功能,当网页中收录多达几十种属性时,挨个添加会显得非常繁琐,这在某种商品属性页非常常见。
为了解决这个问题,将关键字加入到搜索属性中,此时不要将其添加到属性列表中,直接点击手气不错即可。
是不是太amazing? 欢迎给作者打赏!
3.2 原理
网页采集器的功能是获取网页中的数据(废话)。通常来说,目标可能是列表(如购物车列表),或是一个页面中的固定数组(如JD某商品的价钱和介绍,在页面中只有一个)。因此须要设置其读取模式。传统的采集器须要编撰正则表达式,但方式过于复杂。
如果认识到html是一棵树,只要找到了承载数据的节点即可,之后用XPath来描述。
手工编撰XPath也很复杂,因此软件可以通过关键字,自动检索XPath,提供关键字,软件都会从树中递归搜索收录该数据的叶子节点。因此关键字最好是在页面中独一无二的。
如上图所示,只要提供“北京”和“42”这两个关键字,就能找到parent节点, 进而获取div[0]和div1这两个列表元素。通过div[0]和div1两个节点的比较,我们能够手动发觉相同的子节点(name,mount)和不同的节点(北京:上海,37:42)。相同的节点会保存为属性名,不同的节点为属性值。但是,不能提供上海和37,此时,公共节点是div[0], 这不是列表。
软件在不提供关键字的情况下,也能通过html文档的特点,去估算最可能是列表父节点(如图中的parent)的节点,但当网页非常复杂时,猜测可能会出错。
本算法原理是原创的,可查看源码或留言交流。
4. 结果检测
工作过程中,可点击提取测试 ,随时查看采集器目前的才能抓取的数据内容。在属性管理器的上方,可以更改采集器的模块名称,这样就便捷数据清洗 模块调用该采集器。
5. 对恳求进行设置
当出现乱码,或者希望自己填入cookie等恳请头时,可在属性对话框点击恳求详情,弹出的对话框中进行设置。有时为了简便,可以将浏览器中的requests恳求头直接拷贝到恳求参数中。
Hawk有一定的网页编码检查功能,但出现乱码时,可以将编码从GB2312设置为UTF8,即可解决大多数乱码问题。
如何调用网页采集器,或实现Post恳求? 参考4.1节:从爬虫转换
6. 具体的事例
以抓取新闻内容为例:页面如下:![image_1at5pff7g7m71jtq1b2o1hlq1dt9.png-76.5kB][8]
你可以在搜索关键字中,搜索【2016年09月21日】,属性填写为时间,搜索【人民日报】,属性为【来源】。
提取正文须要注意,你可以随便填写正文中的一部分关键字,例如【量子隐形传态是一种传递量子】,这样Hawk就检索出了XPath:前面省略/div[1]/p[1]
如果你直接使用这个路径,则抓取的内容只有这一段。为了抓取正文,我们可以将/p[1]部分去除,只获取其父节点。这样能够抓取全文数据(是不是很赞)?
如果你想获取原创正文的html,则在属性列表的对话框里,可以勾选某个属性的【HTML标签】。
此时,点击提取测试,看看是不是获取了所需的数据?
网页信息搜集器 v1.0绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2020-08-22 09:56
网页信息采集器是一款红色精巧,功能实用的网页信息采集软件。Internet上有着非常庞大的资源信息,各行各业的信息无所不有,网页信息采集器可以很方便的针对某个网站的信息内容进行搜集。如某个峰会的所有注册会员的E-MAIL列表、某个行业网站的企业名录、某个下载网站上所有软件列表等等。操作简单便捷,更容易为普通用户所把握,有需求的用户不妨下载体验!
功能特色
1、执行任务
根据已完善的任务信息保存、提取网页,也可通过“双击”某项任务启动此功能
2、新建、复制、修改、删除任务
新建、复制、修改、删除任务信息
3、默认选项
设置默认工作路径(默认为当前程序目录下的WorkDir文件夹)
设置默认提取测试数 (默认为10)
设置默认文本分隔符 (默认为 *)
4、新建、编辑任务信息
任务名称:在默认的工作文件夹下生成借此命名的文件夹。
登录地址:针对个别须要登陆能够查看其网页内容的网站,填写登入页面地址。在执行任务时,软件会打开此登陆页面使您登陆该网站
序数格式类型网页、非序数格式类型网:
这里的序数格式、非序数格式主要是指提取地址是否仅仅是数字的变化。例如类似于:
① 和 就属于序数格式
② 和 则属于非序数格式
列表地址:在类型为“非序数格式类型网”时,第一页列表的链接地址
提取地址:由实际保存的网页地址共同部份 + * 号组成。
例如要提取:
① 和 则提取地址为 *.html
② 和 则提取地址为 *./*.html 查看全部
网页信息搜集器 v1.0绿色版
网页信息采集器是一款红色精巧,功能实用的网页信息采集软件。Internet上有着非常庞大的资源信息,各行各业的信息无所不有,网页信息采集器可以很方便的针对某个网站的信息内容进行搜集。如某个峰会的所有注册会员的E-MAIL列表、某个行业网站的企业名录、某个下载网站上所有软件列表等等。操作简单便捷,更容易为普通用户所把握,有需求的用户不妨下载体验!
功能特色
1、执行任务
根据已完善的任务信息保存、提取网页,也可通过“双击”某项任务启动此功能
2、新建、复制、修改、删除任务
新建、复制、修改、删除任务信息
3、默认选项
设置默认工作路径(默认为当前程序目录下的WorkDir文件夹)
设置默认提取测试数 (默认为10)
设置默认文本分隔符 (默认为 *)
4、新建、编辑任务信息
任务名称:在默认的工作文件夹下生成借此命名的文件夹。
登录地址:针对个别须要登陆能够查看其网页内容的网站,填写登入页面地址。在执行任务时,软件会打开此登陆页面使您登陆该网站
序数格式类型网页、非序数格式类型网:
这里的序数格式、非序数格式主要是指提取地址是否仅仅是数字的变化。例如类似于:
① 和 就属于序数格式
② 和 则属于非序数格式
列表地址:在类型为“非序数格式类型网”时,第一页列表的链接地址
提取地址:由实际保存的网页地址共同部份 + * 号组成。
例如要提取:
① 和 则提取地址为 *.html
② 和 则提取地址为 *./*.html
【程序发布】www.ucaiyun.com网页内容采集器1.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 290 次浏览 • 2020-08-21 20:17
2005-11-21
写这个采集器的本意本是为自己站添加内容之用,后来经群上面几个好友一再要求,做成了个通用型了,功能虽不说太强悍,现在应当还是能将就着用吧,不怕笑话,今天将它发布。如果疗效还好,我将继续开发下去。
安装环境:
本采集器采用Visual C#编撰,可以在Windows2003下运行,若在Windows2000,Xp下运行请先到谷歌官方下载一个.net framework1.1或更高环境组件:
附:.net framework 1.1下载地址: ... p;displaylang=zh-cn
.net framework 2.0下载地址: ... p;displaylang=zh-cn
功能简介:
1、多系统支持,现已加入对PHPWIND,DISCUZ,DEDECMS2.X和PHPArticle2.01的采集支持,若您的系统现今软件里没加入,请与我们联系,将在上期版本中加入网友要求最多的几套系统。
2、模拟用户登陆,和操作浏览器一样,但程序只处理核心数据,运行速率更快。
3、可以设定是否将远程图片及Flash下载到本地(Flash文件通常较大,建议不下载,程序会将其手动获取到其绝对地址)。
4、多线程,时间间隔设定 可以按照您的机器性能和网速或系统容许的文章发表时间设定
5、较强悍的网址采集功能,配合页面内定义区域采集、手动生成网址及采集二级页面功能基本上可采集到您所要的任何网址集合。
6、内容规则定义有多条内容过滤规则,彻底过滤掉内容里的广告等无用内容。
7、网址集合、内容规则导出、导出功能,方便网友共享采集到的内容。
8、论坛支持Html和UBB发贴两种模式。
最新版下载地址:
论坛讨论:
内容入库功能仍未加入,以后再建立吧。。。
Enjoy it!
2005-11-21 by 优采云
QQ群2:16326410 群3:16126184 今天也在峰会里也加了个版块,欢迎你们加入讨论
觉得好的话就顶一个了~~哈哈 查看全部
【程序发布】www.ucaiyun.com网页内容采集器1.0
2005-11-21
写这个采集器的本意本是为自己站添加内容之用,后来经群上面几个好友一再要求,做成了个通用型了,功能虽不说太强悍,现在应当还是能将就着用吧,不怕笑话,今天将它发布。如果疗效还好,我将继续开发下去。
安装环境:
本采集器采用Visual C#编撰,可以在Windows2003下运行,若在Windows2000,Xp下运行请先到谷歌官方下载一个.net framework1.1或更高环境组件:
附:.net framework 1.1下载地址: ... p;displaylang=zh-cn
.net framework 2.0下载地址: ... p;displaylang=zh-cn
功能简介:
1、多系统支持,现已加入对PHPWIND,DISCUZ,DEDECMS2.X和PHPArticle2.01的采集支持,若您的系统现今软件里没加入,请与我们联系,将在上期版本中加入网友要求最多的几套系统。
2、模拟用户登陆,和操作浏览器一样,但程序只处理核心数据,运行速率更快。
3、可以设定是否将远程图片及Flash下载到本地(Flash文件通常较大,建议不下载,程序会将其手动获取到其绝对地址)。
4、多线程,时间间隔设定 可以按照您的机器性能和网速或系统容许的文章发表时间设定
5、较强悍的网址采集功能,配合页面内定义区域采集、手动生成网址及采集二级页面功能基本上可采集到您所要的任何网址集合。
6、内容规则定义有多条内容过滤规则,彻底过滤掉内容里的广告等无用内容。
7、网址集合、内容规则导出、导出功能,方便网友共享采集到的内容。
8、论坛支持Html和UBB发贴两种模式。
最新版下载地址:
论坛讨论:
内容入库功能仍未加入,以后再建立吧。。。
Enjoy it!
2005-11-21 by 优采云
QQ群2:16326410 群3:16126184 今天也在峰会里也加了个版块,欢迎你们加入讨论
觉得好的话就顶一个了~~哈哈
PHP采集利器之phpQuery的用法解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 631 次浏览 • 2020-08-21 02:22
官方文档地址:
See Gitub:
基础用法:
require_once "/path/to/phpQuery/phpQuery.php";
phpQuery::newDocumentFile('http://www.blogdaren.com');
echo pq("title")->text(); // 获取网页标题
echo pq("input#uid")->val(); // 获取id为uid的input的控件值
上例中第一行引入phpQuery.php文件,
第二行通过newDocumentFile加载一个文件,
第三行通过pq()函数获取title标签的文本内容,
第四行获取id为uid的input控件的值,
上述代码主要做了两件事:即加载文件和读取文件内容。
加载文档:
加载文档主要通过phpQuery::newDocument来进行操作,其作用是促使phpQuery可以在服务器预先读取到指定的文件或文本内容。
主要的方式包括:
phpQuery::newDocument($html, $contentType = null)
phpQuery::newDocumentFile($file, $contentType = null)
phpQuery::newDocumentHTML($html, $charset = "utf-8")
phpQuery::newDocumentXHTML($html, $charset = "utf-8")
phpQuery::newDocumentXML($html, $charset = "utf-8")
phpQuery::newDocumentPHP($html, $contentType = null)
phpQuery::newDocumentFileHTML($file, $charset = "utf-8")
phpQuery::newDocumentFileXHTML($file, $charset = "utf-8")
phpQuery::newDocumentFileXML($file, $charset = "utf-8")
phpQuery::newDocumentFilePHP($file, $contentType)
pq()函数用法:
pq()函数的用法是phpQuery的重点,主要分两部份:即选择器和过滤器
1. 选择器
要了解phpQuery选择器的用法,建议先了解jQuery的句型,最常用的句型包括有:
pq('#id'):即以#号开头的ID选择器,用于选择已知ID的容器所包括的内容
pq('.classname'):即以.开头的class选择器,用于选择class匹配的容器内容
pq('parent > child'):选择指定层次结构的容器内容,如:pq('.main> p')用于选择class=main容器的所有p标签
2. 过滤器
主要包括::first,:last,:not,:even,:odd,:eq(index),:gt(index),:lt(index),:header,:animated等,例如:
pq('p:last'):用于选择最后一个p标签
pq('tr:even'):用于选择表格中碰巧行
phpQuery连贯操作:
pq()函数返回的结果是一个phpQuery对象,可以对返回结果继续进行后续的操作,例如:
pq('a')->attr('href', 'newVal')->removeClass('className')->html('newHtml')->......
详情请查阅jQuery相关资料,用法基本一致,只须要注意 . 与 -> 的区别即可。 查看全部
PHP采集利器之phpQuery的用法解读
官方文档地址:
See Gitub:
基础用法:
require_once "/path/to/phpQuery/phpQuery.php";
phpQuery::newDocumentFile('http://www.blogdaren.com');
echo pq("title")->text(); // 获取网页标题
echo pq("input#uid")->val(); // 获取id为uid的input的控件值
上例中第一行引入phpQuery.php文件,
第二行通过newDocumentFile加载一个文件,
第三行通过pq()函数获取title标签的文本内容,
第四行获取id为uid的input控件的值,
上述代码主要做了两件事:即加载文件和读取文件内容。
加载文档:
加载文档主要通过phpQuery::newDocument来进行操作,其作用是促使phpQuery可以在服务器预先读取到指定的文件或文本内容。
主要的方式包括:
phpQuery::newDocument($html, $contentType = null)
phpQuery::newDocumentFile($file, $contentType = null)
phpQuery::newDocumentHTML($html, $charset = "utf-8")
phpQuery::newDocumentXHTML($html, $charset = "utf-8")
phpQuery::newDocumentXML($html, $charset = "utf-8")
phpQuery::newDocumentPHP($html, $contentType = null)
phpQuery::newDocumentFileHTML($file, $charset = "utf-8")
phpQuery::newDocumentFileXHTML($file, $charset = "utf-8")
phpQuery::newDocumentFileXML($file, $charset = "utf-8")
phpQuery::newDocumentFilePHP($file, $contentType)
pq()函数用法:
pq()函数的用法是phpQuery的重点,主要分两部份:即选择器和过滤器
1. 选择器
要了解phpQuery选择器的用法,建议先了解jQuery的句型,最常用的句型包括有:
pq('#id'):即以#号开头的ID选择器,用于选择已知ID的容器所包括的内容
pq('.classname'):即以.开头的class选择器,用于选择class匹配的容器内容
pq('parent > child'):选择指定层次结构的容器内容,如:pq('.main> p')用于选择class=main容器的所有p标签
2. 过滤器
主要包括::first,:last,:not,:even,:odd,:eq(index),:gt(index),:lt(index),:header,:animated等,例如:
pq('p:last'):用于选择最后一个p标签
pq('tr:even'):用于选择表格中碰巧行
phpQuery连贯操作:
pq()函数返回的结果是一个phpQuery对象,可以对返回结果继续进行后续的操作,例如:
pq('a')->attr('href', 'newVal')->removeClass('className')->html('newHtml')->......
详情请查阅jQuery相关资料,用法基本一致,只须要注意 . 与 -> 的区别即可。
Hawk教程-网页采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 414 次浏览 • 2020-08-20 09:43
[模块和算子]常见问题更新日志作者和捐款列表专题:案例:发布文章:故事:网页采集器
网页采集器主界面
1.快速使用说明
网页采集器 模拟了浏览器的设计,填入网址,点击刷新,即可获取对应地址的html源码。
认识到网页是一棵树(DOM)后,每个XPath对应一个属性,即可从网页上获取单个或多个文档。网页采集器的目的就是更快地通过手工或手动配置找到最优XPath。
1.1.工作模式
使用采集器,首先要根据抓取的目标,选择合适的工作模式:
注意:
1.2.基本操作
在多文档模式下,通常直接点击右上角的手气不错,在弹出的结果下选择所需数据,可配置其名称和XPath。点击确定即可配置完毕。即可手动获取绝大多数网页的目标内容。
[图片上传失败...(image-57cdac-30)]
可手工填入搜索字符,即可在网页上快速定位元素和XPath,可在多个结果间快速切换,找到所需数据后,输入属性名称后手工添加属性。
1.3.高级功能点击【Http恳求详情】,可更改网页编码,代理,cookie和恳求方法等,网页出现乱码可用若希望手动登入,或获取动态页面(ajax)的真实地址,填入搜索字符,点击【自动嗅探】,在弹出的浏览器中翻到对应的关键字,Hawk能够手动捕捉真实恳求超级模式下,Hawk会将源码中的js,html,json都转成html,从而使用手气不错, 更通用但性能较差填写【共享源】,本采集器同步共享源的【Http恳求详情】,避免重复设置cookie代理等。详情页(单文档模式)也可以手气不错(Hawk3新功能),搜索所需数组,不需要添加到属性列表,点击手气不错试试!网页地址也可以是本地文件路径,如D:\target.html, 用其他方式保存网页后,再通过Hawk剖析网页内容
单文档模式下的手气不错
网页采集器 不能单独工作,而是沟通 网页采集器 和数据清洗的桥梁。本质上说, 网页采集器 是针对获取网页而非常订制的数据清洗模块。
2.高级配置介绍2.1.列表根路径
列表根路径是所有属性的XPath公共部份,能简化XPath编撰,提升兼容性。只能在多文档模式下工作。
你可以通过Hawk手动剖析根路径,或自动设置。
2.2.自动规约列表路径
以事例来说明,使用手气不错后,嗅探器会找到列表节点的父节点,以及挂载在父节点上的多个子节点,从而产生一个树形结构
每个节点要抽取下边的属性:
为了能获取父节点下所有的div子节点,因此列表根路径就是/html/div[2]/div[3]/div[4]/div。 注意:父节点Path路径末尾是不带序号的,这样就能获取多个子节点。可以如此理解,列表根路径就是不带结尾数字的父节点路径。
有时候,父节点的xpath是不稳定的,举个反例,北京北京的二手房页面,上海会在列表前面降低一个广告banner,从而真正的父节点都会发生变化,比如向后偏斜了div[1]变成了div[2]。为了应对这些变化,通常的做法是手工更改【列表根路径】
2.3.手动设置根路径
继续举例子,父节点的id为house_list,且在网页中全局惟一,你就可以使用另外一种父节点表示法//*[@id='house_list']/li(写法可以参考其他XPath教程),而子节点表达式不变。这样会使程序显得愈发鲁棒。
3.抓取网页数据
网页采集器需配合数据清洗使用,才能 使用 网页采集器 获取网页数据,拖入的列须要为超链接
3.1.一般的get恳求
一般情况下, 将从爬虫转换推入到对应的URL列中,通过下拉菜单选择要调用的爬虫名称,即可完成所有的配置:
请求配置
本模块是沟通网页采集器和数据清洗的桥梁。本质上说,网页采集器是针对获取网页而非常订制的数据清洗模块。
你须要填写爬虫选择,告诉它要调用那个采集器。注意:
3.2.实现post恳求
web恳求中,有两种主要的恳求类型:post和get。 使用POST能支持传输更多的数据。更多的细节,可以参考http合同的相关文档,网上汗牛充栋,这里就不多说了。
post恳求时,Hawk要给服务器须要传递两个参数:url 和post。一般来说,在执行post恳求时,url是稳定的,post值是动态改变的。
首先要配置调用的网页采集器为post模式(打开网页采集器,Http恳求详情,模式->下拉菜单)。
之后,需要将从爬虫转换拖到要调用的url列上。如果没有url列,可以通过添加新列,生成要访问的url列。
之后,我们要将post数据传递到网页采集器中。你总是可以通过合并多列拼接或各类手段,生成要Post的数据列。之后,可以在从爬虫转换中的post数据中,填写[post列], 而post列就是收录post数据的列名。 注意:
4.手气不错
这是Hawk最被人赞誉的功能!在新的Hawk3中,该功能被极大地提高。
4.1.多文档下的手气不错
一般来说,输入网址加载页面后,点击手气不错即可,Hawk会手动根据优先级将列表数据抓取下来
手气不错配置
[图片上传失败...(image-9f6836-30)]
左右切换选择你想要的数据集,之后在下边的属性栏对结果进行微调。
添加一个属性,手气不错能够更准确地进行。添加两个属性,即可选取惟一区域。
4.2.单文档模式的手气不错
Hawk3新增功能,当网页中收录多达几十种属性时,挨个添加会显得非常繁琐,这在某种商品属性页非常常见。
为了解决这个问题,将关键字加入到搜索字符中,此时不要将其添加到属性列表中,直接点击手气不错即可。
单文档模式下的手气不错
4.3.手动模式
在手气不错不能工作或不符合预期时,需要手工给定几个关键字, 让Hawk搜索关键字, 并获取在网页中所在的位置(XPath)。
填入搜索字符,能够成功获取XPath, 编写属性名称,点击添加,即可添加一个属性。类似地,再填入30535,设置属性名称为“单价”,即可添加另外一个属性。
手动添加属性
在搜索字符的文本框中,输入你要获取的关键字,由于关键字在网页中可能出现多次,可连续点击继续搜索,在多个结果间切换,左侧的html源码会对搜索的结果进行高亮。
请注意观察搜索的关键字在网页中的位置,是否符合预期,否则抓取数据可能会有问题。尤其在 多文档模式。如果须要抓取本页面的多块数据,可新建多个网页采集器,分别进行配置。如果发觉有错误,可点击编辑集合,对属性进行删掉,修改和排序。你可以类似的将所有要抓取的特点数组添加进去,或是直接点击 手气不错 ,系统会依照目前的属性,推测其他属性。5.动态嗅探5.1.什么是动态页面?
动态瀑布流和ajax的页面,通常按需返回html和json.
老式网站在刷新时会返回页面的全部内容,但若只更新部份,即可大大节省带宽。该方法叫ajax,服务端传递xml或则json到浏览器,浏览器的js代码执行,并将数据渲染到页面上。 因此,获取数据的真实url,不一定显示在浏览器地址栏,而是隐藏在js调用中。本质上,javascript发起了新的隐藏http请求来获取数据,只要能模拟之,就能象真实浏览器一样获取所要数据。参考百度百科的介绍
5.2.Hawk手动获取动态恳求
通过浏览器和抓包,可以获取那些隐藏恳求,但须要对HTTP请求的原理比较熟悉,不适合于初学者。
Hawk简化了流程,采用手动嗅探的方法来进行。Hawk成为前端代理,会拦截和剖析所有系统级Http请求,并将收录关键字的恳求筛选下来 (基于fiddler)
当搜索字符时,若没有在当前页面中找到该关键字,Hawk会有提示,“是否启动动态嗅探?”此时Hawk会弹出浏览器并打开所在网页。您可将页面拖到收录关键字的位置,Hawk会手动记录和过滤收录关键字的真实恳求, 检索完毕后,Hawk会手动回弹。
5.3.如果难以手动嗅探?
由于Hawk有拦截功能,会被浏览器觉得不安全,如何解决呢?
Hawk底层的嗅探基于fiddler,因此可通过fiddler生成证书后,导入到chrome解决,方法可参考这篇文档:
按如下方法对采集器进行设置:
网页采集器恳求设置
5.4.注意事项有时直接将url拷贝到Hawk,并使用手气不错时,也能获取到数据。这是因为好多网站对第一页和其他页分别作了不同的处理。第一页内容会跟随整体frame返回回去。但以后页面内容就通过ajax单独返回了。
有时针对第一页做了大量的XPath开发,却最后发觉难以在其他页面使用,多半就是前面提及的问题(一脸懵逼)。因此经验上,建议翻到其他页面上再做恳求。
超级模式能将网页中所有的javascript, json, xml都转换为HTML DOM树,从而实现属性提取和手气不错。
6.超级模式
为了能使动态网页也能使用添加属性和手气不错,Hawk在嗅探后默认会开启超级模式。 超级模式能将网页中所有的javascript, json, xml都转换为HTML DOM树,从而实现属性提取和手气不错。
超级模式极大的简化了动态恳求的处理,但它仍然可能有以下问题:
7.自动登入
很多网站需要登入能够访问其内部内容。而登陆涉及到十分复杂的逻辑,例如须要传递用户名和密码,验证码等,并经过多次的恳求,获取token等一系列流程,连写代码都要写整整一页纸并须要反复调试。考虑到Hawk是通用的数据采集器,其开发成本十分之高。
但本质上说,登录只是获取了cookie,只要以后的恳求加入该cookie,远端服务器就不能分辨其是浏览器还是爬虫。一般传统的爬虫软件,会外置一个浏览器,用户在内部填入用户名密码。软件在内部获取cookie后进行恳求。 但Hawk不准备再搞外置浏览器,那种方法很重,很难与Hawk的流系统兼容。所以,Hawk不玩手动登入了!
我们使用了全新的思路解决该问题。
Hawk的手动登入和动态嗅探所使用的技术是一样的,其本质上还是在底层替换了系统代理,你可以在搜索字符填写在登陆后页面上的任意文本,点击嗅探即可。若该方法难以工作,还可以自动拷贝浏览器上的恳求参数到网页采集器。
其更多的使用细节,可参考动态嗅探章节。
8.设置共享恳求参数的采集器名称
为了抓取一个网站的不同数据,我们须要多个 网页采集器 。但是访问网站需要登入和cookie,难不成每位采集器都要设置对应的恳求参数吗?
采集器的属性对话框中,可以设置共享源,也就是要共享的 网页采集器 的名称。
例如设置为链家采集器,那么本采集器的恳求参数,都会在执行时,动态地从链家采集器中获得。这样就极大地简化了配置过程。
在按键上手动弹出帮助
9.附录:XPath和CSS写法9.1.XPath
关于XPath句型,可参考教程
XPath可以十分灵活,例如:
9.2.CSSSelector
多数情况下,使用XPath才能解决问题,但是CSSSelector更简练,且鲁棒性更强。关于它的介绍,可参考教程
当然,大部分情况不需要这么复杂,只要记住以下几点:
10.手气不错的原理
网页采集器的功能是获取网页中的数据(废话)。通常来说,目标可能是列表(如购物车列表),或是一个页面中的固定数组(如JD某商品的价钱和介绍,在页面中只有一个)。因此须要设置其读取模式。传统的采集器须要编撰正则表达式,但方式过于复杂。
如果认识到html是一棵树,只要找到了承载数据的节点即可,之后用XPath来描述。
手气不错原理
手工编撰XPath也很复杂,因此软件可以通过关键字,自动检索XPath,提供关键字,软件都会从树中递归搜索收录该数据的叶子节点。因此关键字最好是在页面中独一无二的。
如上图所示,只要提供“北京”和“42”这两个关键字,就能找到parent节点, 进而获取div[0]和div[1]这两个列表元素。通过div[0]和div[1]两个节点的比较,我们能够手动发觉相同的子节点(name,mount)和不同的节点(北京:上海,37:42)。相同的节点会保存为属性名,不同的节点为属性值。但是,不能提供上海和37,此时,公共节点是div[0], 这不是列表。
软件在不提供关键字的情况下,也能通过html文档的特点,去估算最可能是列表父节点(如图中的parent)的节点,但当网页非常复杂时,猜测可能会出错。 查看全部
Hawk教程-网页采集器
[模块和算子]常见问题更新日志作者和捐款列表专题:案例:发布文章:故事:网页采集器
网页采集器主界面
1.快速使用说明
网页采集器 模拟了浏览器的设计,填入网址,点击刷新,即可获取对应地址的html源码。
认识到网页是一棵树(DOM)后,每个XPath对应一个属性,即可从网页上获取单个或多个文档。网页采集器的目的就是更快地通过手工或手动配置找到最优XPath。
1.1.工作模式
使用采集器,首先要根据抓取的目标,选择合适的工作模式:
注意:
1.2.基本操作
在多文档模式下,通常直接点击右上角的手气不错,在弹出的结果下选择所需数据,可配置其名称和XPath。点击确定即可配置完毕。即可手动获取绝大多数网页的目标内容。
[图片上传失败...(image-57cdac-30)]
可手工填入搜索字符,即可在网页上快速定位元素和XPath,可在多个结果间快速切换,找到所需数据后,输入属性名称后手工添加属性。
1.3.高级功能点击【Http恳求详情】,可更改网页编码,代理,cookie和恳求方法等,网页出现乱码可用若希望手动登入,或获取动态页面(ajax)的真实地址,填入搜索字符,点击【自动嗅探】,在弹出的浏览器中翻到对应的关键字,Hawk能够手动捕捉真实恳求超级模式下,Hawk会将源码中的js,html,json都转成html,从而使用手气不错, 更通用但性能较差填写【共享源】,本采集器同步共享源的【Http恳求详情】,避免重复设置cookie代理等。详情页(单文档模式)也可以手气不错(Hawk3新功能),搜索所需数组,不需要添加到属性列表,点击手气不错试试!网页地址也可以是本地文件路径,如D:\target.html, 用其他方式保存网页后,再通过Hawk剖析网页内容
单文档模式下的手气不错
网页采集器 不能单独工作,而是沟通 网页采集器 和数据清洗的桥梁。本质上说, 网页采集器 是针对获取网页而非常订制的数据清洗模块。
2.高级配置介绍2.1.列表根路径
列表根路径是所有属性的XPath公共部份,能简化XPath编撰,提升兼容性。只能在多文档模式下工作。
你可以通过Hawk手动剖析根路径,或自动设置。
2.2.自动规约列表路径
以事例来说明,使用手气不错后,嗅探器会找到列表节点的父节点,以及挂载在父节点上的多个子节点,从而产生一个树形结构
每个节点要抽取下边的属性:
为了能获取父节点下所有的div子节点,因此列表根路径就是/html/div[2]/div[3]/div[4]/div。 注意:父节点Path路径末尾是不带序号的,这样就能获取多个子节点。可以如此理解,列表根路径就是不带结尾数字的父节点路径。
有时候,父节点的xpath是不稳定的,举个反例,北京北京的二手房页面,上海会在列表前面降低一个广告banner,从而真正的父节点都会发生变化,比如向后偏斜了div[1]变成了div[2]。为了应对这些变化,通常的做法是手工更改【列表根路径】
2.3.手动设置根路径
继续举例子,父节点的id为house_list,且在网页中全局惟一,你就可以使用另外一种父节点表示法//*[@id='house_list']/li(写法可以参考其他XPath教程),而子节点表达式不变。这样会使程序显得愈发鲁棒。
3.抓取网页数据
网页采集器需配合数据清洗使用,才能 使用 网页采集器 获取网页数据,拖入的列须要为超链接
3.1.一般的get恳求
一般情况下, 将从爬虫转换推入到对应的URL列中,通过下拉菜单选择要调用的爬虫名称,即可完成所有的配置:
请求配置
本模块是沟通网页采集器和数据清洗的桥梁。本质上说,网页采集器是针对获取网页而非常订制的数据清洗模块。
你须要填写爬虫选择,告诉它要调用那个采集器。注意:
3.2.实现post恳求
web恳求中,有两种主要的恳求类型:post和get。 使用POST能支持传输更多的数据。更多的细节,可以参考http合同的相关文档,网上汗牛充栋,这里就不多说了。
post恳求时,Hawk要给服务器须要传递两个参数:url 和post。一般来说,在执行post恳求时,url是稳定的,post值是动态改变的。
首先要配置调用的网页采集器为post模式(打开网页采集器,Http恳求详情,模式->下拉菜单)。
之后,需要将从爬虫转换拖到要调用的url列上。如果没有url列,可以通过添加新列,生成要访问的url列。
之后,我们要将post数据传递到网页采集器中。你总是可以通过合并多列拼接或各类手段,生成要Post的数据列。之后,可以在从爬虫转换中的post数据中,填写[post列], 而post列就是收录post数据的列名。 注意:
4.手气不错
这是Hawk最被人赞誉的功能!在新的Hawk3中,该功能被极大地提高。
4.1.多文档下的手气不错
一般来说,输入网址加载页面后,点击手气不错即可,Hawk会手动根据优先级将列表数据抓取下来
手气不错配置
[图片上传失败...(image-9f6836-30)]
左右切换选择你想要的数据集,之后在下边的属性栏对结果进行微调。
添加一个属性,手气不错能够更准确地进行。添加两个属性,即可选取惟一区域。
4.2.单文档模式的手气不错
Hawk3新增功能,当网页中收录多达几十种属性时,挨个添加会显得非常繁琐,这在某种商品属性页非常常见。
为了解决这个问题,将关键字加入到搜索字符中,此时不要将其添加到属性列表中,直接点击手气不错即可。
单文档模式下的手气不错
4.3.手动模式
在手气不错不能工作或不符合预期时,需要手工给定几个关键字, 让Hawk搜索关键字, 并获取在网页中所在的位置(XPath)。
填入搜索字符,能够成功获取XPath, 编写属性名称,点击添加,即可添加一个属性。类似地,再填入30535,设置属性名称为“单价”,即可添加另外一个属性。
手动添加属性
在搜索字符的文本框中,输入你要获取的关键字,由于关键字在网页中可能出现多次,可连续点击继续搜索,在多个结果间切换,左侧的html源码会对搜索的结果进行高亮。
请注意观察搜索的关键字在网页中的位置,是否符合预期,否则抓取数据可能会有问题。尤其在 多文档模式。如果须要抓取本页面的多块数据,可新建多个网页采集器,分别进行配置。如果发觉有错误,可点击编辑集合,对属性进行删掉,修改和排序。你可以类似的将所有要抓取的特点数组添加进去,或是直接点击 手气不错 ,系统会依照目前的属性,推测其他属性。5.动态嗅探5.1.什么是动态页面?
动态瀑布流和ajax的页面,通常按需返回html和json.
老式网站在刷新时会返回页面的全部内容,但若只更新部份,即可大大节省带宽。该方法叫ajax,服务端传递xml或则json到浏览器,浏览器的js代码执行,并将数据渲染到页面上。 因此,获取数据的真实url,不一定显示在浏览器地址栏,而是隐藏在js调用中。本质上,javascript发起了新的隐藏http请求来获取数据,只要能模拟之,就能象真实浏览器一样获取所要数据。参考百度百科的介绍
5.2.Hawk手动获取动态恳求
通过浏览器和抓包,可以获取那些隐藏恳求,但须要对HTTP请求的原理比较熟悉,不适合于初学者。
Hawk简化了流程,采用手动嗅探的方法来进行。Hawk成为前端代理,会拦截和剖析所有系统级Http请求,并将收录关键字的恳求筛选下来 (基于fiddler)
当搜索字符时,若没有在当前页面中找到该关键字,Hawk会有提示,“是否启动动态嗅探?”此时Hawk会弹出浏览器并打开所在网页。您可将页面拖到收录关键字的位置,Hawk会手动记录和过滤收录关键字的真实恳求, 检索完毕后,Hawk会手动回弹。
5.3.如果难以手动嗅探?
由于Hawk有拦截功能,会被浏览器觉得不安全,如何解决呢?
Hawk底层的嗅探基于fiddler,因此可通过fiddler生成证书后,导入到chrome解决,方法可参考这篇文档:
按如下方法对采集器进行设置:
网页采集器恳求设置
5.4.注意事项有时直接将url拷贝到Hawk,并使用手气不错时,也能获取到数据。这是因为好多网站对第一页和其他页分别作了不同的处理。第一页内容会跟随整体frame返回回去。但以后页面内容就通过ajax单独返回了。
有时针对第一页做了大量的XPath开发,却最后发觉难以在其他页面使用,多半就是前面提及的问题(一脸懵逼)。因此经验上,建议翻到其他页面上再做恳求。
超级模式能将网页中所有的javascript, json, xml都转换为HTML DOM树,从而实现属性提取和手气不错。
6.超级模式
为了能使动态网页也能使用添加属性和手气不错,Hawk在嗅探后默认会开启超级模式。 超级模式能将网页中所有的javascript, json, xml都转换为HTML DOM树,从而实现属性提取和手气不错。
超级模式极大的简化了动态恳求的处理,但它仍然可能有以下问题:
7.自动登入
很多网站需要登入能够访问其内部内容。而登陆涉及到十分复杂的逻辑,例如须要传递用户名和密码,验证码等,并经过多次的恳求,获取token等一系列流程,连写代码都要写整整一页纸并须要反复调试。考虑到Hawk是通用的数据采集器,其开发成本十分之高。
但本质上说,登录只是获取了cookie,只要以后的恳求加入该cookie,远端服务器就不能分辨其是浏览器还是爬虫。一般传统的爬虫软件,会外置一个浏览器,用户在内部填入用户名密码。软件在内部获取cookie后进行恳求。 但Hawk不准备再搞外置浏览器,那种方法很重,很难与Hawk的流系统兼容。所以,Hawk不玩手动登入了!
我们使用了全新的思路解决该问题。
Hawk的手动登入和动态嗅探所使用的技术是一样的,其本质上还是在底层替换了系统代理,你可以在搜索字符填写在登陆后页面上的任意文本,点击嗅探即可。若该方法难以工作,还可以自动拷贝浏览器上的恳求参数到网页采集器。
其更多的使用细节,可参考动态嗅探章节。
8.设置共享恳求参数的采集器名称
为了抓取一个网站的不同数据,我们须要多个 网页采集器 。但是访问网站需要登入和cookie,难不成每位采集器都要设置对应的恳求参数吗?
采集器的属性对话框中,可以设置共享源,也就是要共享的 网页采集器 的名称。
例如设置为链家采集器,那么本采集器的恳求参数,都会在执行时,动态地从链家采集器中获得。这样就极大地简化了配置过程。
在按键上手动弹出帮助
9.附录:XPath和CSS写法9.1.XPath
关于XPath句型,可参考教程
XPath可以十分灵活,例如:
9.2.CSSSelector
多数情况下,使用XPath才能解决问题,但是CSSSelector更简练,且鲁棒性更强。关于它的介绍,可参考教程
当然,大部分情况不需要这么复杂,只要记住以下几点:
10.手气不错的原理
网页采集器的功能是获取网页中的数据(废话)。通常来说,目标可能是列表(如购物车列表),或是一个页面中的固定数组(如JD某商品的价钱和介绍,在页面中只有一个)。因此须要设置其读取模式。传统的采集器须要编撰正则表达式,但方式过于复杂。
如果认识到html是一棵树,只要找到了承载数据的节点即可,之后用XPath来描述。
手气不错原理
手工编撰XPath也很复杂,因此软件可以通过关键字,自动检索XPath,提供关键字,软件都会从树中递归搜索收录该数据的叶子节点。因此关键字最好是在页面中独一无二的。
如上图所示,只要提供“北京”和“42”这两个关键字,就能找到parent节点, 进而获取div[0]和div[1]这两个列表元素。通过div[0]和div[1]两个节点的比较,我们能够手动发觉相同的子节点(name,mount)和不同的节点(北京:上海,37:42)。相同的节点会保存为属性名,不同的节点为属性值。但是,不能提供上海和37,此时,公共节点是div[0], 这不是列表。
软件在不提供关键字的情况下,也能通过html文档的特点,去估算最可能是列表父节点(如图中的parent)的节点,但当网页非常复杂时,猜测可能会出错。
优采云采集器 V3.1.8 官方版最新无限制破解版测试可用[应用软件]
采集交流 • 优采云 发表了文章 • 0 个评论 • 428 次浏览 • 2020-08-19 12:48
优采云采集器是一款专业实用的的网页数据采集器。这款采集器不需要开发,任何人都能用,数据可导入到本地文件、发布到网站和数据库等。
它由原Google技术团队鼎力构筑,其规则配置简单,采集功能强悍,能够支持电商类、生活服务类、社交媒体、新闻峰会等不同类型的网站,智能辨识网页数据,导出数据形式多样,最主要是完全免费,是行业剖析、精准营销、品牌监控、风险预估的好帮手。
优采云免费采集器支持所有操作系统版本更新和功能升级同步所有平台,采集和导入全免费,无限制放心用,并支持后台运行,不打搅您的其他前台工作,是你数据采集最好的助手。
【功能特性】
一、【规则配置简单 采集功能强悍】
1、可视化自定义采集流程:
全程问答式引导、可视化操作、自定义采集流程
自动记录和模拟网页操作次序
高级设置满足更多采集需求
2、点选抽取网页数据:
鼠标点击选择要爬取的网页内容、操作简单
可选择抽取文本、链接、属性、html标签等
3、运行批量采集数据:
软件根据采集流程和抽取规则手动批量采集
快速稳定,实时显示采集速度和过程
可切换软件后台运行,不打搅前台工作
4、导出和发布采集的数据:
采集的数据手动表格化,自由配置数组
支持数据导入到Excel等本地文件
和一键发布到CMS网站/数据库/微信公众号等媒体
二、【支持采集不同类型的网站】
电商类、生活服务类、社交媒体、新闻峰会、地方网站......
强大浏览器内核,99%以上网站都能采!
三、【全平台支持 全免费 可视化操作】
支持所有操作系统:Windows+Mac+Linux
采集和导入全免费,无限制放心用
可视化配置采集规则,傻瓜式操作
四、【功能强悍,箭速迭】
智能辨识网页数据,导出数据形式多样
软件定期更新升级,不断添加新功能
客户的满意是对我们最大的肯定!
【常见问题】
使用优采云采集器怎么采集百度搜索结果数据?
步骤1:创建采集任务
1)启动优采云采集器,进入主界面,点击创建任务按键创建 "向导采集任务"
2)输入百度搜索的URL,包括三种形式
1、手动输入:在输入框中直接输入URL,多个URL时需要换行分割
2、点击从文件中读取方法:用户选择一个储存URL的文件,文件中可以有多个URL地址,地址需要换行分割。
3、批量添加方法:通过添加并调整地址参数生成多个有规律的地址
步骤2:定制采集过程
1)点击创建后手动打开第一个URL因而步入向导设置,此处选择列表页,点击下一步
2)填写搜索关键字和选择输入关键字的输入框,点击下一步
3)进入第一个关键字搜索结果页面后,点击设置搜索按键,点击下一步
4)点选列表块中第一块元素
5)再点击结果列表块中另外一块元素,此时手动选中列表块。点击下一步
6)选择下一页按键,选中选择下一页选项,然后点击页面中的下一页按键填充第一个输入框,第二个数据框可以调节采集运行中点击下一页按键的次数。理论上次数越多,采集到的数据越多。点击下一步
7)选择要采集的数组:在焦点框中点选要抽取的元素后点击下一步
8)选择不步入详情页。点击保存或保存并运行
步骤3:数据采集及导入
1)采集任务运行中
2)采集完成后,选择“导出数据”可以把数据都导入到本地文件
3)选择“导出方法”,将采集好的数据导入,这里可以选择excel作为导入为格式
4)采集数据导入后如下图 查看全部
优采云采集器 V3.1.8 官方版最新无限制破解版测试可用[应用软件]
优采云采集器是一款专业实用的的网页数据采集器。这款采集器不需要开发,任何人都能用,数据可导入到本地文件、发布到网站和数据库等。
它由原Google技术团队鼎力构筑,其规则配置简单,采集功能强悍,能够支持电商类、生活服务类、社交媒体、新闻峰会等不同类型的网站,智能辨识网页数据,导出数据形式多样,最主要是完全免费,是行业剖析、精准营销、品牌监控、风险预估的好帮手。
优采云免费采集器支持所有操作系统版本更新和功能升级同步所有平台,采集和导入全免费,无限制放心用,并支持后台运行,不打搅您的其他前台工作,是你数据采集最好的助手。
【功能特性】
一、【规则配置简单 采集功能强悍】
1、可视化自定义采集流程:
全程问答式引导、可视化操作、自定义采集流程
自动记录和模拟网页操作次序
高级设置满足更多采集需求
2、点选抽取网页数据:
鼠标点击选择要爬取的网页内容、操作简单
可选择抽取文本、链接、属性、html标签等
3、运行批量采集数据:
软件根据采集流程和抽取规则手动批量采集
快速稳定,实时显示采集速度和过程
可切换软件后台运行,不打搅前台工作
4、导出和发布采集的数据:
采集的数据手动表格化,自由配置数组
支持数据导入到Excel等本地文件
和一键发布到CMS网站/数据库/微信公众号等媒体
二、【支持采集不同类型的网站】
电商类、生活服务类、社交媒体、新闻峰会、地方网站......
强大浏览器内核,99%以上网站都能采!
三、【全平台支持 全免费 可视化操作】
支持所有操作系统:Windows+Mac+Linux
采集和导入全免费,无限制放心用
可视化配置采集规则,傻瓜式操作
四、【功能强悍,箭速迭】
智能辨识网页数据,导出数据形式多样
软件定期更新升级,不断添加新功能
客户的满意是对我们最大的肯定!
【常见问题】
使用优采云采集器怎么采集百度搜索结果数据?
步骤1:创建采集任务
1)启动优采云采集器,进入主界面,点击创建任务按键创建 "向导采集任务"
2)输入百度搜索的URL,包括三种形式
1、手动输入:在输入框中直接输入URL,多个URL时需要换行分割
2、点击从文件中读取方法:用户选择一个储存URL的文件,文件中可以有多个URL地址,地址需要换行分割。
3、批量添加方法:通过添加并调整地址参数生成多个有规律的地址
步骤2:定制采集过程
1)点击创建后手动打开第一个URL因而步入向导设置,此处选择列表页,点击下一步
2)填写搜索关键字和选择输入关键字的输入框,点击下一步
3)进入第一个关键字搜索结果页面后,点击设置搜索按键,点击下一步
4)点选列表块中第一块元素
5)再点击结果列表块中另外一块元素,此时手动选中列表块。点击下一步
6)选择下一页按键,选中选择下一页选项,然后点击页面中的下一页按键填充第一个输入框,第二个数据框可以调节采集运行中点击下一页按键的次数。理论上次数越多,采集到的数据越多。点击下一步
7)选择要采集的数组:在焦点框中点选要抽取的元素后点击下一步
8)选择不步入详情页。点击保存或保存并运行
步骤3:数据采集及导入
1)采集任务运行中
2)采集完成后,选择“导出数据”可以把数据都导入到本地文件
3)选择“导出方法”,将采集好的数据导入,这里可以选择excel作为导入为格式
4)采集数据导入后如下图
草根优采云采集器(网页采集工具) 3.0 免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2020-08-18 22:31
起始页面:从百度搜索结果的第几页开始采集。这里要注意的是:因为软件调用的每页结果100条数据,所以填入的数值对应:0表示第一页,100表示第二页,200表示第三页,以此类推。
网址宽度小于:这个为了限制采集的内容是否符合你须要设置的,比如你想采集一个关键字指向网站内页的链接而不是网站首页,则设定大约通常30以上即可,因为通常网址不会超过30个字符,这个按照你自己想采集的内容大致设定。
采集到的内容采用纯文本文件方式,你可以导出任何你要做推广的软件中,采集数据广泛,这里俺们用知名的美国软件SCRAPEBOX举例,软件的强悍不用说了,这个是一个美国知名的博客评论群发工具,可以手动评论流行的WOREPRESS博客等,但这个软件由于是英语采集,而且不支持英文,软件外置的也是GOOGLE采集模式,GOOGLE现今服务器在台湾不稳定你们也都晓得,所以国外拿来只能做英文站的优化。如果配合本软件的使用就完全可以做国外站点的优化了。如:采集关键词填写:美女 特殊限定填写:by wordpress 网址宽度小于:35点击开始搜索即可。搜下来的全部是百度上的WORDPRESS博客,用软件导入后可以直接导出到SCRAPEBOX中进行发送。让你的外链,广告一页能发到10W个百度收录的博客中,外链和宣传疗效可想而知了。
1.全手动采集任意你想要的数据。
2.软件手动调用百度搜索结果,跳过百度结果地址加密,直接获取指向地址。
3.支持自定义各类搜索方法,采集结果直接导入文本文件中,支持导出各种推广,发送软件进行推广发送操作。
4.采集的数据即是百度收录的东西,用来进行优化,推广超有效。 查看全部
草根优采云采集器(网页采集工具) 3.0 免费版
起始页面:从百度搜索结果的第几页开始采集。这里要注意的是:因为软件调用的每页结果100条数据,所以填入的数值对应:0表示第一页,100表示第二页,200表示第三页,以此类推。
网址宽度小于:这个为了限制采集的内容是否符合你须要设置的,比如你想采集一个关键字指向网站内页的链接而不是网站首页,则设定大约通常30以上即可,因为通常网址不会超过30个字符,这个按照你自己想采集的内容大致设定。
采集到的内容采用纯文本文件方式,你可以导出任何你要做推广的软件中,采集数据广泛,这里俺们用知名的美国软件SCRAPEBOX举例,软件的强悍不用说了,这个是一个美国知名的博客评论群发工具,可以手动评论流行的WOREPRESS博客等,但这个软件由于是英语采集,而且不支持英文,软件外置的也是GOOGLE采集模式,GOOGLE现今服务器在台湾不稳定你们也都晓得,所以国外拿来只能做英文站的优化。如果配合本软件的使用就完全可以做国外站点的优化了。如:采集关键词填写:美女 特殊限定填写:by wordpress 网址宽度小于:35点击开始搜索即可。搜下来的全部是百度上的WORDPRESS博客,用软件导入后可以直接导出到SCRAPEBOX中进行发送。让你的外链,广告一页能发到10W个百度收录的博客中,外链和宣传疗效可想而知了。
1.全手动采集任意你想要的数据。
2.软件手动调用百度搜索结果,跳过百度结果地址加密,直接获取指向地址。
3.支持自定义各类搜索方法,采集结果直接导入文本文件中,支持导出各种推广,发送软件进行推广发送操作。
4.采集的数据即是百度收录的东西,用来进行优化,推广超有效。
优采云采集器怎样使用 优采云采集器使用方式教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 381 次浏览 • 2020-08-17 12:29
对于许多行业来说,采集数据都是一个非常重要的工作,它能通过准确的数据来指导你的工作内容。这里给你们带来的优采云采集器是一款采集网页数据的智能软件,很多小伙伴不知道优采云采集器怎样使用,下面就让小编为你们介绍一下优采云采集器使用方式教程,感兴趣的小伙伴一起来瞧瞧吧。
优采云采集器软件介绍
优采云采集器是一款采集网页数据的智能软件,它完全以自主研制的分布式云计算平台为核心,能够在短时间内轻松从不同网站和网页上抓取大量规范化的数据内容,帮助任何须要从网页获取信息的顾客实现数据自动化采集,编辑,规范化,摆脱对人工搜索及搜集数据的依赖,从而减少获取信息的成本,提高效率。
优采云采集器怎样使用 优采云采集器使用方式教程
新建一个采集任务,如果要采集某一个网站的某一类数据,其实就是配置一个任务,当执行这个任务的时侯才会根据设定采集相应的数据。
设置采集任务的基本信息,基本信息主要是一个任务分组,用来管理多个任务,方便使用,另外就是任务的名子,然后还有备注信息,方便记录任务的一些描述,这些信息在任务比较多的时侯就很有用了。
最关键的一步,设定采集流程,这一步是最重要的一步,按照须要的采集顺序,把采集这个事情分成几个步骤,然后每位步骤对应一个采集动作,组合上去就产生了采集步骤,如果所示,就是采集一个页面的流程,先打开这个页面,然后提取这个页面上的数据。
配置执行计划,有些数据是要每晚都采集一次的,有些则三天采集多次的,所以不同任务就设定不同的计划,这个任务是不需要定时执行的,所以就选择自动,然后保存执行计划
至此,基本配置即使完成了,接下来要做的就是测试一下流程是否正确,如果正确,就可以启动任务,采集数据了,如果不正确,再回头去更改各个步骤的配置有问题的地方,再继续测试,最终测试完成后即可采集。 查看全部
优采云采集器怎样使用 优采云采集器使用方式教程
对于许多行业来说,采集数据都是一个非常重要的工作,它能通过准确的数据来指导你的工作内容。这里给你们带来的优采云采集器是一款采集网页数据的智能软件,很多小伙伴不知道优采云采集器怎样使用,下面就让小编为你们介绍一下优采云采集器使用方式教程,感兴趣的小伙伴一起来瞧瞧吧。
优采云采集器软件介绍
优采云采集器是一款采集网页数据的智能软件,它完全以自主研制的分布式云计算平台为核心,能够在短时间内轻松从不同网站和网页上抓取大量规范化的数据内容,帮助任何须要从网页获取信息的顾客实现数据自动化采集,编辑,规范化,摆脱对人工搜索及搜集数据的依赖,从而减少获取信息的成本,提高效率。
优采云采集器怎样使用 优采云采集器使用方式教程
新建一个采集任务,如果要采集某一个网站的某一类数据,其实就是配置一个任务,当执行这个任务的时侯才会根据设定采集相应的数据。
设置采集任务的基本信息,基本信息主要是一个任务分组,用来管理多个任务,方便使用,另外就是任务的名子,然后还有备注信息,方便记录任务的一些描述,这些信息在任务比较多的时侯就很有用了。
最关键的一步,设定采集流程,这一步是最重要的一步,按照须要的采集顺序,把采集这个事情分成几个步骤,然后每位步骤对应一个采集动作,组合上去就产生了采集步骤,如果所示,就是采集一个页面的流程,先打开这个页面,然后提取这个页面上的数据。
配置执行计划,有些数据是要每晚都采集一次的,有些则三天采集多次的,所以不同任务就设定不同的计划,这个任务是不需要定时执行的,所以就选择自动,然后保存执行计划
至此,基本配置即使完成了,接下来要做的就是测试一下流程是否正确,如果正确,就可以启动任务,采集数据了,如果不正确,再回头去更改各个步骤的配置有问题的地方,再继续测试,最终测试完成后即可采集。
SysNucleus WebHarvy(网页数据采集器)V6.0.1
采集交流 • 优采云 发表了文章 • 0 个评论 • 368 次浏览 • 2020-08-14 02:43
功能
智能辨识模式
WebHarvy手动辨识网页中出现的数据模式。所以,如果你须要从一个网页刮项目(姓名,地址,电子邮件,价格等)的列表,你不需要做任何额外的配置。如果数据重复,WebHarvy会手动刮。
导出捕获的数据
可以保存从各类格式的网页中提取的数据。 WebHarvy网站刮板的当前版本容许你导入的刮数据作为XML,CSV,JSON或TSV文件。您还可以刮下数据导入到一个SQL数据库。
从多个页面提取
通常网页显示数据,如在多个页面中的产品目录。 WebHarvy可以手动抓取并从多个网页中提取数据。只是强调了“链接到下一页'和WebHarvy网站刮板将手动刮从所有页面的数据。
直观化的操作界面
WebHarvy是一个可视化的网页提取工具。其实完全没有必要编撰任何脚本或代码拿来提取数据。使用webharvy的外置浏览器浏览网页。您可以选择用滑鼠点击来提取数据。它是这么容易!
基于关键字的提取
基于关键字的提取可使您捕捉从搜索结果页面输入关键字的列表数据。您创建的配置将被手动重复所有给定输入关键字,而挖掘的数据。可以指定任意数目的输入关键字
提取分类
WebHarvy网站刮板容许您从一个链接列表,从而造成一个网站内的相像页面抽取数据。这让您可以使用一个单一的配置刮网站内的类别或小节。
使用正则表达式提取
WebHarvy可以应用正则表达式(正则表达式)在文本或网页的HTML源代码,并提取去匹配的部份。这种强悍的技术为您提供了更多的灵活性,同时拼抢的数据。
WebHarvy是一个视觉网路刮板。绝对不需要编撰任何脚本或代码来抓取数据。您将使用WebHarvy的外置浏览器浏览网页。您可以选择要点击的数据。这很容易!
WebHarvy手动辨识网页中发生的数据模式。因此,如果您须要从网页上刮取项目列表(名称,地址,电子邮件,价格等),则无需执行任何其他配置。如果数据重复,WebHarvy会手动删掉它。
您可以以多种格式保存从网页中提取的数据。WebHarvy Web Scraper的当前版本容许您将抓取的数据导入为Excel,XML,CSV,JSON或TSV文件。您也可以将抓取的数据导入到SQL数据库。
通常,网页在多个页面上显示产品列表等数据。WebHarvy可以手动抓取并从多个页面提取数据。只需强调“链接到下一页”,WebHarvy Web Scraper都会手动从所有页面中抓取数据。 查看全部
SysNucleus WebHarvy(网页数据采集器)是还能帮助用户从网页中提取数据的工具。旨在让您可以手动从网页中提取数据,并保存在不同的格式提取内容。输入网址即可打开,默认使用内部浏览器,支持扩充剖析,可以手动获取类似链接的列表,软件界面直观操作简单。
功能
智能辨识模式
WebHarvy手动辨识网页中出现的数据模式。所以,如果你须要从一个网页刮项目(姓名,地址,电子邮件,价格等)的列表,你不需要做任何额外的配置。如果数据重复,WebHarvy会手动刮。
导出捕获的数据
可以保存从各类格式的网页中提取的数据。 WebHarvy网站刮板的当前版本容许你导入的刮数据作为XML,CSV,JSON或TSV文件。您还可以刮下数据导入到一个SQL数据库。
从多个页面提取
通常网页显示数据,如在多个页面中的产品目录。 WebHarvy可以手动抓取并从多个网页中提取数据。只是强调了“链接到下一页'和WebHarvy网站刮板将手动刮从所有页面的数据。
直观化的操作界面
WebHarvy是一个可视化的网页提取工具。其实完全没有必要编撰任何脚本或代码拿来提取数据。使用webharvy的外置浏览器浏览网页。您可以选择用滑鼠点击来提取数据。它是这么容易!
基于关键字的提取
基于关键字的提取可使您捕捉从搜索结果页面输入关键字的列表数据。您创建的配置将被手动重复所有给定输入关键字,而挖掘的数据。可以指定任意数目的输入关键字
提取分类
WebHarvy网站刮板容许您从一个链接列表,从而造成一个网站内的相像页面抽取数据。这让您可以使用一个单一的配置刮网站内的类别或小节。
使用正则表达式提取
WebHarvy可以应用正则表达式(正则表达式)在文本或网页的HTML源代码,并提取去匹配的部份。这种强悍的技术为您提供了更多的灵活性,同时拼抢的数据。
WebHarvy是一个视觉网路刮板。绝对不需要编撰任何脚本或代码来抓取数据。您将使用WebHarvy的外置浏览器浏览网页。您可以选择要点击的数据。这很容易!
WebHarvy手动辨识网页中发生的数据模式。因此,如果您须要从网页上刮取项目列表(名称,地址,电子邮件,价格等),则无需执行任何其他配置。如果数据重复,WebHarvy会手动删掉它。
您可以以多种格式保存从网页中提取的数据。WebHarvy Web Scraper的当前版本容许您将抓取的数据导入为Excel,XML,CSV,JSON或TSV文件。您也可以将抓取的数据导入到SQL数据库。
通常,网页在多个页面上显示产品列表等数据。WebHarvy可以手动抓取并从多个页面提取数据。只需强调“链接到下一页”,WebHarvy Web Scraper都会手动从所有页面中抓取数据。
抓取网页数据工具怎么单独进行发布操作
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2020-08-14 02:16
其实这个需求也是很容易实现的,大家可以根据以下步骤来进行:
1、首先是新建一个任务,这步操作会形成一个任务数据库,然后将自己已有的数据导出到这个数据库中。当然,这个任务你须要设置发布步骤,否则难以实现发布。
2、在任务数据库中,将已采设置为true或1,mysql,sqlserver是1。
3、开始运行任务,在优采云采集器最新版V9上面不需要勾选采集,在其他版本中不需要勾选采网址和采内容,只勾选发内容即可。
有的用户反映说,抓取网页数据工具优采云采集器会重复发布文章,也就是说发布到网站后,下一次运行时又接着发布,导致网站上内容重复。对于这个问题,我们须要从以下两点着手考虑:
1、采集器是否采集了多篇一样的文章内容? 可以通过,右击规则——本地编辑数据来查看采集的数据。
2、采集器发布的时侯,是否提示了发布成功? 如果您发布的时侯提示的是 “发布未知” 或者“发布失败” ,而实际上您的内容确实是早已成功发布到您的网站了。那么这个状态下,采集器不会把内容标记为已发状态,下次发布的时侯,还是会作为新内容去发布的。所以就会出现部份用户听到的重复发布的问题。
针对里面的问题,解决方案如下:
1、如果是发布的内容有的显示成功,有的显示未知,那么考虑调整下发布时间间隔,间隔设置长一些,然后再运行发布试试,关于怎么设置线程可参考官网教程。
2、如果里面方式一直解决不了问题,那么可以考虑强制解决办法,在文件保存及部份中级设置的右下角发布结束后,勾选标记所有记录为已发,这样每次发布无论发布结果怎样提示,都会把这条记录标示为早已发布。
抓取网页数据工具优采云采集器V9对于采集、处理、发布均能进行高效的操作,学会灵活运用才能为我们的日常工作和学习带来极大的便利。 查看全部
抓取网页数据工具优采云采集器V9是市场中功能最全面的采集软件,具备数据采集、处理和发布功能,能够轻松应对网站更新维护、内容群发等需求。采集完发布你们一定还会操作了,但是假如你早已有了一批数据,不需要再进行采集,只须要发布该如何通过优采云采集器来实现呢?
其实这个需求也是很容易实现的,大家可以根据以下步骤来进行:
1、首先是新建一个任务,这步操作会形成一个任务数据库,然后将自己已有的数据导出到这个数据库中。当然,这个任务你须要设置发布步骤,否则难以实现发布。
2、在任务数据库中,将已采设置为true或1,mysql,sqlserver是1。
3、开始运行任务,在优采云采集器最新版V9上面不需要勾选采集,在其他版本中不需要勾选采网址和采内容,只勾选发内容即可。
有的用户反映说,抓取网页数据工具优采云采集器会重复发布文章,也就是说发布到网站后,下一次运行时又接着发布,导致网站上内容重复。对于这个问题,我们须要从以下两点着手考虑:
1、采集器是否采集了多篇一样的文章内容? 可以通过,右击规则——本地编辑数据来查看采集的数据。
2、采集器发布的时侯,是否提示了发布成功? 如果您发布的时侯提示的是 “发布未知” 或者“发布失败” ,而实际上您的内容确实是早已成功发布到您的网站了。那么这个状态下,采集器不会把内容标记为已发状态,下次发布的时侯,还是会作为新内容去发布的。所以就会出现部份用户听到的重复发布的问题。
针对里面的问题,解决方案如下:
1、如果是发布的内容有的显示成功,有的显示未知,那么考虑调整下发布时间间隔,间隔设置长一些,然后再运行发布试试,关于怎么设置线程可参考官网教程。
2、如果里面方式一直解决不了问题,那么可以考虑强制解决办法,在文件保存及部份中级设置的右下角发布结束后,勾选标记所有记录为已发,这样每次发布无论发布结果怎样提示,都会把这条记录标示为早已发布。
抓取网页数据工具优采云采集器V9对于采集、处理、发布均能进行高效的操作,学会灵活运用才能为我们的日常工作和学习带来极大的便利。
豆瓣读书书籍信息采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 700 次浏览 • 2020-08-13 10:54
采集网站:
%E5%B0%8F%E8%AF%B4?start=0&type=T
使用功能点:
l分页列表及详尽信息提取
/tutorial/fylbxq7.aspx?t=1
lXpath
/tutorialdetail-1/xpath1.html
豆瓣读书:豆瓣读书为豆瓣网的一个子栏目。豆瓣读书自2005年上线,已成为国外信息最全、用户数目最大且最为活跃的读书网站。我们专注于为用户提供全面且精细化的读书服务,同时不断探求新的产品模式。到2012年豆瓣读书每个月有超过800万的来访用户,过亿的访问次数。。
豆瓣读书采集数据说明:本文进行了豆瓣读书-书籍详尽信息的采集,本文首先进去豆瓣读书分类列表页,然后循环点击每一条图书信息,进入图书详情页采集具体详尽信息 。本文仅以“豆瓣读书采集”为例。大家在实操过程中,可依照自身需求,更换豆瓣的其他内容进行数据采集。
豆瓣读书采集字段详尽说明:图书名称,图书作者,图书定价,图书价钱,图书出版年,图书作者简介。
步骤1:创建采集任务
1)进入主界面,选择“自定义模式”
2)将要采集的网址URL,复制粘贴到网址输入框中,点击“保存网址”
步骤2:创建翻页循环
1)在页面右上角,打开“流程”,以突显出“流程设计器”和“定制当前操作”两个蓝筹股。将页面下拉到顶部,点击“后页>”按钮,在两侧的操作提示框中,选择“更多操作”
2)选择“循环点击单个链接”
步骤3:创建列表循环
1)移动滑鼠,选中页面里的第一个图书链接。选中后,系统会手动辨识页面里的其他相像链接。在左侧操作提示框中,选择“选中全部”
2)选择“循环点击每位链接”,以创建一个列表循环
步骤4:提取图书信息
1)在创建列表循环后,系统会手动点击第一个图书链接,进入图书详尽信息页。
点击须要的数组信息,在两侧的操作提示框中,选择“采集该元素的文本”。我们在这里,采集了图书名称、图书出版信息、内容简介、作者简介
2)字段信息选择完成后,选中相应的数组,可以进行数组的自定义命名,修改完成后,点击“确定”。完成后,点击左上角的“保存并启动”,启动采集任务
3)选择“启动本地采集”
4)采集完成后,会跳出提示,选择“导出数据”。选择“合适的导入方法”,将采集好的数据导入。这里我们选择excel作为导入为格式,数据导入后如下图
步骤5:修改Xpath
通过上述导入的数据我们可以发觉,部分图书的“内容简介”、“作者简介”没有采集下来(如:《解忧杂货店》图书详情页的“内容简介”采集下来了,但是《雪落香杉树》图书详情页的“内容简介”并未采集下来)。这是因为,每个图书详情页的网页情况有所不同,系统手动生成的Xpath,不能完全正确定位到每位图书详情页的“内容简介”和“作者简介”。以下将以“内容简介”这个数组为例,具体讲解xpath的更改。“作者简介”字段更改同理,在此文中不做多讲。
1)选中“提取元素”步骤,点击“内容简介”字段,再点击如图所示的按键
2)选择“自定义定位元素形式”
3)将优采云系统手动生成的这条Xpath:
//DIV[@id='link-report']/DIV[1]/DIV[1]/P[1],复制粘贴到火狐浏览器中进行测量
4)将优采云系统手动生成的此条Xpath,删减为
//DIV[@id='link-report']/DIV[1]/DIV[1](P[1]代表内容简介里的第一段,删掉即可定位到整个内容简介段落)。我们发觉:通过此条Xpath:
//DIV[@id='link-report']/DIV[1]/DIV[1],在《解忧杂货店》图书详情页,可以定位到“内容简介”字段,但是在《雪落香杉树》图书详情页,不能定位到“内容简介”字段
《解忧杂货店》图书详情页:可定位到“内容简介”字段
《雪落香杉树》图书详情页:不能定位到“内容简介”字段
5)观察网页源码发觉,图书详情页“内容简介”字段,都具有相同的class属性,通过class属性,我们可写出一条才能定位所有图书详情页“内容简介”字段的Xpath:.//*[@id='link-report']//div[@class='intro']。在火狐浏览器中检测发觉,通过此条Xpath,确实能都定位到所有图书详情页的“内容简介”字段
6)将新写的此条Xpath:.//*[@id='link-report']//div[@class='intro'],复制粘贴到优采云中的相应位置,并点击“确定”
7)重新“启动本地采集”并导入数据。可以看见,所有图书详情页的“内容简介”字段均被抓取出来
注意:“作者简介”字段更改同理,需要更改Xpath,在此文中不做多讲。 查看全部
本文介绍使用优采云采集器v7采集豆瓣读书详尽信息。
采集网站:
%E5%B0%8F%E8%AF%B4?start=0&type=T
使用功能点:
l分页列表及详尽信息提取
/tutorial/fylbxq7.aspx?t=1
lXpath
/tutorialdetail-1/xpath1.html
豆瓣读书:豆瓣读书为豆瓣网的一个子栏目。豆瓣读书自2005年上线,已成为国外信息最全、用户数目最大且最为活跃的读书网站。我们专注于为用户提供全面且精细化的读书服务,同时不断探求新的产品模式。到2012年豆瓣读书每个月有超过800万的来访用户,过亿的访问次数。。
豆瓣读书采集数据说明:本文进行了豆瓣读书-书籍详尽信息的采集,本文首先进去豆瓣读书分类列表页,然后循环点击每一条图书信息,进入图书详情页采集具体详尽信息 。本文仅以“豆瓣读书采集”为例。大家在实操过程中,可依照自身需求,更换豆瓣的其他内容进行数据采集。
豆瓣读书采集字段详尽说明:图书名称,图书作者,图书定价,图书价钱,图书出版年,图书作者简介。
步骤1:创建采集任务
1)进入主界面,选择“自定义模式”
2)将要采集的网址URL,复制粘贴到网址输入框中,点击“保存网址”
步骤2:创建翻页循环
1)在页面右上角,打开“流程”,以突显出“流程设计器”和“定制当前操作”两个蓝筹股。将页面下拉到顶部,点击“后页>”按钮,在两侧的操作提示框中,选择“更多操作”
2)选择“循环点击单个链接”
步骤3:创建列表循环
1)移动滑鼠,选中页面里的第一个图书链接。选中后,系统会手动辨识页面里的其他相像链接。在左侧操作提示框中,选择“选中全部”
2)选择“循环点击每位链接”,以创建一个列表循环
步骤4:提取图书信息
1)在创建列表循环后,系统会手动点击第一个图书链接,进入图书详尽信息页。
点击须要的数组信息,在两侧的操作提示框中,选择“采集该元素的文本”。我们在这里,采集了图书名称、图书出版信息、内容简介、作者简介
2)字段信息选择完成后,选中相应的数组,可以进行数组的自定义命名,修改完成后,点击“确定”。完成后,点击左上角的“保存并启动”,启动采集任务
3)选择“启动本地采集”
4)采集完成后,会跳出提示,选择“导出数据”。选择“合适的导入方法”,将采集好的数据导入。这里我们选择excel作为导入为格式,数据导入后如下图
步骤5:修改Xpath
通过上述导入的数据我们可以发觉,部分图书的“内容简介”、“作者简介”没有采集下来(如:《解忧杂货店》图书详情页的“内容简介”采集下来了,但是《雪落香杉树》图书详情页的“内容简介”并未采集下来)。这是因为,每个图书详情页的网页情况有所不同,系统手动生成的Xpath,不能完全正确定位到每位图书详情页的“内容简介”和“作者简介”。以下将以“内容简介”这个数组为例,具体讲解xpath的更改。“作者简介”字段更改同理,在此文中不做多讲。
1)选中“提取元素”步骤,点击“内容简介”字段,再点击如图所示的按键
2)选择“自定义定位元素形式”
3)将优采云系统手动生成的这条Xpath:
//DIV[@id='link-report']/DIV[1]/DIV[1]/P[1],复制粘贴到火狐浏览器中进行测量
4)将优采云系统手动生成的此条Xpath,删减为
//DIV[@id='link-report']/DIV[1]/DIV[1](P[1]代表内容简介里的第一段,删掉即可定位到整个内容简介段落)。我们发觉:通过此条Xpath:
//DIV[@id='link-report']/DIV[1]/DIV[1],在《解忧杂货店》图书详情页,可以定位到“内容简介”字段,但是在《雪落香杉树》图书详情页,不能定位到“内容简介”字段
《解忧杂货店》图书详情页:可定位到“内容简介”字段
《雪落香杉树》图书详情页:不能定位到“内容简介”字段
5)观察网页源码发觉,图书详情页“内容简介”字段,都具有相同的class属性,通过class属性,我们可写出一条才能定位所有图书详情页“内容简介”字段的Xpath:.//*[@id='link-report']//div[@class='intro']。在火狐浏览器中检测发觉,通过此条Xpath,确实能都定位到所有图书详情页的“内容简介”字段
6)将新写的此条Xpath:.//*[@id='link-report']//div[@class='intro'],复制粘贴到优采云中的相应位置,并点击“确定”
7)重新“启动本地采集”并导入数据。可以看见,所有图书详情页的“内容简介”字段均被抓取出来
注意:“作者简介”字段更改同理,需要更改Xpath,在此文中不做多讲。
网页数据采集到底是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 411 次浏览 • 2020-08-13 04:23
什么是网页数据采集
上网去搜索网页数据采集这几个字,出来的网页不少,可是看来看去,还没有一篇完整全面的说明,其实,网页数据采集是一个古老而又常新的话题,如果要下个定义,可以这么说:网页数据采集就是从网页上获取数据,一般来说是指通过软件或则工具从大量的公开可见的网页上精准的获取某一类信息,并且整理成规整的数据。
从前面这个定义来看,有几个关键的点,如果这几个点没有搞明白,就会有很多误会和困扰,在列出关键点之前,我们先瞧瞧几种常见的错误的理解:
错误观点1:网页数据采集就是“偷他人网站后台数据”。
经常有人找我所谓“拿站”,说白了就是想把他人网站数据非常是后台数据库,包括帐号等等全部“拿过来”,他们能够告诉我“要用点黑客手段”,这种是一种十分常见的错误理解。
错误观点2:网页数据采集就是“仿站”,或者“抄站”
还有人觉得,采集就是用工具把一个网站全部“复制出来”,然后仿照一个类似的“山寨版”。
错误观点3:网页数据采集就是转载,复制新闻贴子
甚至有些早已做过太长时间网页采集工作的人,或依照自己的经验把网页数据采集等同为复制转载新闻资讯贴子等。
正确观点:
其实以上几个观点都不正确,第一个,网页数据采集的目标是公开的网页,别人网站后台是“私有数据”,凡是没有经过授权,以所谓任何“黑客手段”盗取的后台数据都属于违法行为,我跟专业律师聊过这一点。第二个,网页数据采集本身是数据获取的过程,指的是从公开网页中获取数据,并不涉及拿数据来做什么,“仿站”其实是一种违背互联网精神,不尊重知识产权的行为,并且在一定程度上违规,如果对此有兴趣,可以查阅相关法律文件,对此我也有过深入研究,这种行为可能违规,因为构成不正当竞争,感兴趣的朋友可以去深入了解一下“京东严禁一淘”等知名案例,在日本,很多年前早已有一宗十分典型的这种案件开审。第三个,网页数据采集确实可以实现自动化转载新闻贴子等,但是这只是网页数据采集非常特别小的一个应用,不能把他等同于网页数据采集,而且这些方法也不应当成为倡导的借助网页数据采集的主要用途,再加上很多人,转载复制不说,还采取除去版权信息,掐头去尾,关键词替换,等等所谓的“伪原创”措施,想要误导搜索引擎,制造重复垃圾内容,这除了损害了被采集器的权益,还使想要搜索一些有用信息的人,淹没在成百上千条重复搜索结果中,我就常常十分苦恼,翻了10页,都是同样的一篇垃圾内容,各个网站都有。这最大的害处是破坏了互联网的良性发展气氛,大家都恶意复制垃圾内容制制造重复垃圾,最终坏了一锅汤,到头来被K站,自食恶果。
好了,说了这么多,正确的理解主要由以下几个关键点:
采集的目标和源头是公开的网页。采集一般是通过工具来完成。采集的结果是规整的数据。采集应该在法律和互联网规范的约束下进行,应该尊重知识产权。最后,这除了是我的理解,更是我始终倡导的网页采集的和游戏规则:就是把采集作为获取原创素材的方法,当获取到大量的原创素材以后,应该对数据进行自己原创性的独立的处理,处理的推论或则输出应当是自有知识产权的原创性内容,并且在必要的时侯保留对原创采集网页的版权引用,注明参考出处。
结论
讲了这么多,其实只是阐述了哪些是网页数据采集这个简单的概念,希望你们能共同支持和提倡互联网原创内容,积极维护网页数据采集的良好气氛,共同创造一个更好的互联网佳苑。
这次讨论网页数据采集是准备写一系列的原创文章,对网页数据采集这一话题做全面深入的阐述,欢迎诸位一起阐述,互相学习。
讨论请加群:网页数据采集,群号:254764602,加群暗号:网页数据采集 查看全部
摘要:上网去搜索网页数据采集这几个字,出来的网页不少,可是看来看去,还没有一篇完整全面的说明,其实,网页数据采集是一个古老而又常新的话题,如果要下个定义,可以这么说:网页数据采集就是从网页上获取数据,一般来说是指通过软件或则工具从大量的公开可见的网页上精准的获取某一类信息,并且整理成规整的数据。
什么是网页数据采集
上网去搜索网页数据采集这几个字,出来的网页不少,可是看来看去,还没有一篇完整全面的说明,其实,网页数据采集是一个古老而又常新的话题,如果要下个定义,可以这么说:网页数据采集就是从网页上获取数据,一般来说是指通过软件或则工具从大量的公开可见的网页上精准的获取某一类信息,并且整理成规整的数据。
从前面这个定义来看,有几个关键的点,如果这几个点没有搞明白,就会有很多误会和困扰,在列出关键点之前,我们先瞧瞧几种常见的错误的理解:
错误观点1:网页数据采集就是“偷他人网站后台数据”。
经常有人找我所谓“拿站”,说白了就是想把他人网站数据非常是后台数据库,包括帐号等等全部“拿过来”,他们能够告诉我“要用点黑客手段”,这种是一种十分常见的错误理解。
错误观点2:网页数据采集就是“仿站”,或者“抄站”
还有人觉得,采集就是用工具把一个网站全部“复制出来”,然后仿照一个类似的“山寨版”。
错误观点3:网页数据采集就是转载,复制新闻贴子
甚至有些早已做过太长时间网页采集工作的人,或依照自己的经验把网页数据采集等同为复制转载新闻资讯贴子等。
正确观点:
其实以上几个观点都不正确,第一个,网页数据采集的目标是公开的网页,别人网站后台是“私有数据”,凡是没有经过授权,以所谓任何“黑客手段”盗取的后台数据都属于违法行为,我跟专业律师聊过这一点。第二个,网页数据采集本身是数据获取的过程,指的是从公开网页中获取数据,并不涉及拿数据来做什么,“仿站”其实是一种违背互联网精神,不尊重知识产权的行为,并且在一定程度上违规,如果对此有兴趣,可以查阅相关法律文件,对此我也有过深入研究,这种行为可能违规,因为构成不正当竞争,感兴趣的朋友可以去深入了解一下“京东严禁一淘”等知名案例,在日本,很多年前早已有一宗十分典型的这种案件开审。第三个,网页数据采集确实可以实现自动化转载新闻贴子等,但是这只是网页数据采集非常特别小的一个应用,不能把他等同于网页数据采集,而且这些方法也不应当成为倡导的借助网页数据采集的主要用途,再加上很多人,转载复制不说,还采取除去版权信息,掐头去尾,关键词替换,等等所谓的“伪原创”措施,想要误导搜索引擎,制造重复垃圾内容,这除了损害了被采集器的权益,还使想要搜索一些有用信息的人,淹没在成百上千条重复搜索结果中,我就常常十分苦恼,翻了10页,都是同样的一篇垃圾内容,各个网站都有。这最大的害处是破坏了互联网的良性发展气氛,大家都恶意复制垃圾内容制制造重复垃圾,最终坏了一锅汤,到头来被K站,自食恶果。
好了,说了这么多,正确的理解主要由以下几个关键点:
采集的目标和源头是公开的网页。采集一般是通过工具来完成。采集的结果是规整的数据。采集应该在法律和互联网规范的约束下进行,应该尊重知识产权。最后,这除了是我的理解,更是我始终倡导的网页采集的和游戏规则:就是把采集作为获取原创素材的方法,当获取到大量的原创素材以后,应该对数据进行自己原创性的独立的处理,处理的推论或则输出应当是自有知识产权的原创性内容,并且在必要的时侯保留对原创采集网页的版权引用,注明参考出处。
结论
讲了这么多,其实只是阐述了哪些是网页数据采集这个简单的概念,希望你们能共同支持和提倡互联网原创内容,积极维护网页数据采集的良好气氛,共同创造一个更好的互联网佳苑。
这次讨论网页数据采集是准备写一系列的原创文章,对网页数据采集这一话题做全面深入的阐述,欢迎诸位一起阐述,互相学习。
讨论请加群:网页数据采集,群号:254764602,加群暗号:网页数据采集

