
关键词采集器
关键词采集器(关键字网址采集器怎么做?租赁CDN防护、人工客服)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-26 15:10
Keyword URL Collector是一款专业的网站关键词采集工具,可以采集收录
关键词的网站,并且可以实现关键词 URL的批量采集,只需要输入关键词的标题、域名、描述可通过百度、搜狗、谷歌等搜索引擎获取,采集
相关网站信息。
软件截图
特征
输入关键词采集
各个搜索引擎的网址、域名、标题、描述等信息,支持百度。搜狗。谷歌。冰。雅虎。360等。每个关键词 600到800个,集合例子,关键词可以附带搜索引擎参数,就像在网页中输入关键词搜索一样,比如百度搜索结果URL必须收录
self- media 等待关键词,然后输入“关键词来自媒体、快手、抖音、小红书、视频号等”。
特征
1. 可自动搜索代理服务器,验证代理服务器,过滤掉国内ip地址,用户无需查找代理服务器;
2. 可以导入外部代理服务器并验证;
3. 可以选择不同的网卡进行优化;
4.本地网卡的mac地址在优化时可以动态修改;
5.每次点击的间隔可以随机设置;
6.每次优化都可以修改机器的显示分辨率;
7. 每次优化都可以修改ie信息;
8.完全模拟人们对怀旧网站的使用习惯,高效的优化算法;
9.符合百度和谷歌的分析习惯;
10.原生编译代码,win2000以上所有平台,包括winxp、win2003、vista等;
11. 多核优化,发送时充分利用机器,没有任何拖延和滞后。
指示
1. 下载完成后,不要运行压缩包中的软件直接使用,先解压;
2.软件同时支持32位和64位运行环境;
3.如果软件无法正常打开,请右键使用管理员模式运行。
你得到的就是你得到的
软件下载
下载仅供技术交流学习讨论使用,请勿用于非法用途!下载后请在24小时内删除!
收取的费用仅用于赞助和支持本站的组织、编辑和维护运营相关费用(服务器租用、CDN保护、人工客服等)!
此部分为付费内容,付费后即可查看
支付30元
有薪酬的?输入手机号码查看 查看全部
关键词采集器(关键字网址采集器怎么做?租赁CDN防护、人工客服)
Keyword URL Collector是一款专业的网站关键词采集工具,可以采集收录
关键词的网站,并且可以实现关键词 URL的批量采集,只需要输入关键词的标题、域名、描述可通过百度、搜狗、谷歌等搜索引擎获取,采集
相关网站信息。
软件截图

特征
输入关键词采集
各个搜索引擎的网址、域名、标题、描述等信息,支持百度。搜狗。谷歌。冰。雅虎。360等。每个关键词 600到800个,集合例子,关键词可以附带搜索引擎参数,就像在网页中输入关键词搜索一样,比如百度搜索结果URL必须收录
self- media 等待关键词,然后输入“关键词来自媒体、快手、抖音、小红书、视频号等”。
特征
1. 可自动搜索代理服务器,验证代理服务器,过滤掉国内ip地址,用户无需查找代理服务器;
2. 可以导入外部代理服务器并验证;
3. 可以选择不同的网卡进行优化;
4.本地网卡的mac地址在优化时可以动态修改;
5.每次点击的间隔可以随机设置;
6.每次优化都可以修改机器的显示分辨率;
7. 每次优化都可以修改ie信息;
8.完全模拟人们对怀旧网站的使用习惯,高效的优化算法;
9.符合百度和谷歌的分析习惯;
10.原生编译代码,win2000以上所有平台,包括winxp、win2003、vista等;
11. 多核优化,发送时充分利用机器,没有任何拖延和滞后。
指示
1. 下载完成后,不要运行压缩包中的软件直接使用,先解压;
2.软件同时支持32位和64位运行环境;
3.如果软件无法正常打开,请右键使用管理员模式运行。
你得到的就是你得到的

软件下载
下载仅供技术交流学习讨论使用,请勿用于非法用途!下载后请在24小时内删除!
收取的费用仅用于赞助和支持本站的组织、编辑和维护运营相关费用(服务器租用、CDN保护、人工客服等)!

此部分为付费内容,付费后即可查看
支付30元
有薪酬的?输入手机号码查看
关键词采集器(这款软件,只需要输入关键字就可以采集各搜索引擎收录信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-12-22 19:29
分享是一切,但价值是关键。相遇不易,请珍惜。
使用本软件,您只需在采集各个搜索引擎收录的网址、域名、标题、描述等信息中输入关键字即可。
优采云·关键词网址采集器
搜索引擎支持:搜狗、谷歌、雅虎、百度、360、必应等。
关键词可以带搜索引擎参数,就像在网页中输入关键词搜索一样,如果百度搜索结果URL必须收录bbs的关键词,则输入“关键词 inurl :bbs。”
Excel导出:
CSV是一个文本表格,Excel可以显示为多列多行数据。只需在保存模板中设置为:
“#URL#”、“#title#”、“#描述#”
此格式为 csv 格式。每个项目用引号括起来,多个项目用逗号隔开,然后保存扩展名,填入csv。
保存模板可以引用的数据:
关于#URL#
采集对象的网站 URL
关于#Title#
网站标题
关于#domain#
取原网址,不要添加/.html、/index.php等,如“xxxxx/1.html”中的“xxxxx com”
关于#顶级域#
顶级域名,不要添加二级和三级域名,如“muge.xxxxx/1.html”中的“xxxxx com”
关于#描述#
页面标题下方的一段描述性文字
部分软件使用问题解答:
1.为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章的文章内页,内页收录关键词的主题,所以可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:
, 保存为htm文件,采集后可以打开文件查看对比。
2.不同批次的关键词采集 为什么有些重复的网址?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内部页面可能收录很多主题,而不同的关键词可能会采集去不同的网站内部页面,当域name是引用的,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中存在重复的URL,可以将它们合并在一起,使用软件去重(优采云·text deduplication scrambler)。
3为什么一段时间后采集不能采集?
可能是采集受搜索引擎限制比较多。一般可以通过更改IP来继续采集(如使用VPN更改IP)。如果不改,只能在搜索引擎解封后继续采集。百度的屏蔽时间一般是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
百度云盘地址:
软件正常上报病毒。不放心的话可以用360沙盒、影子系统、虚拟机等来运行软件~ 查看全部
关键词采集器(这款软件,只需要输入关键字就可以采集各搜索引擎收录信息)
分享是一切,但价值是关键。相遇不易,请珍惜。
使用本软件,您只需在采集各个搜索引擎收录的网址、域名、标题、描述等信息中输入关键字即可。

优采云·关键词网址采集器
搜索引擎支持:搜狗、谷歌、雅虎、百度、360、必应等。
关键词可以带搜索引擎参数,就像在网页中输入关键词搜索一样,如果百度搜索结果URL必须收录bbs的关键词,则输入“关键词 inurl :bbs。”
Excel导出:
CSV是一个文本表格,Excel可以显示为多列多行数据。只需在保存模板中设置为:
“#URL#”、“#title#”、“#描述#”
此格式为 csv 格式。每个项目用引号括起来,多个项目用逗号隔开,然后保存扩展名,填入csv。
保存模板可以引用的数据:
关于#URL#
采集对象的网站 URL
关于#Title#
网站标题
关于#domain#
取原网址,不要添加/.html、/index.php等,如“xxxxx/1.html”中的“xxxxx com”
关于#顶级域#
顶级域名,不要添加二级和三级域名,如“muge.xxxxx/1.html”中的“xxxxx com”
关于#描述#
页面标题下方的一段描述性文字
部分软件使用问题解答:
1.为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章的文章内页,内页收录关键词的主题,所以可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:
, 保存为htm文件,采集后可以打开文件查看对比。
2.不同批次的关键词采集 为什么有些重复的网址?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内部页面可能收录很多主题,而不同的关键词可能会采集去不同的网站内部页面,当域name是引用的,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中存在重复的URL,可以将它们合并在一起,使用软件去重(优采云·text deduplication scrambler)。
3为什么一段时间后采集不能采集?
可能是采集受搜索引擎限制比较多。一般可以通过更改IP来继续采集(如使用VPN更改IP)。如果不改,只能在搜索引擎解封后继续采集。百度的屏蔽时间一般是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
百度云盘地址:
软件正常上报病毒。不放心的话可以用360沙盒、影子系统、虚拟机等来运行软件~
关键词采集器(关键词网址采集器绿色版批次关键词采集结果为什么会引用部分网址重复)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-12-22 18:17
关键词URL采集器 绿色版是一款可以帮助用户按关键词到采集网站的软件。在该软件中,用户可以快速执行Collect指定的关键词网站,以减少其他网页的外观。
总体介绍
输入关键字采集各搜索引擎的网址、域名、标题、描述等信息,支持百度、搜狗、谷歌、必应、雅虎、360等。每个关键词600到800,采集例子,关键词可以带搜索引擎参数,就像在网页中输入关键词搜索一样,比如百度中的搜索结果URL必须收录bbs的关键词,那么输入“关键词 inurl:bbs。”
资料参考
#URL#:采集的原创URL
#Title#:URL对应的页面标题
#Domain#:原创URL的域名部分,如“”中的“”
#顶级域名#:取原网址的顶级域名部分,如“”中的“”
#Description#:页面标题下方的一段描述性文字
常见问题
1.为什么一段时间后不能采集采集?
这可能是采集受搜索引擎限制较多,重启软件继续采集,如果不改,只能在搜索引擎解封后继续采集。百度的屏蔽时间一般是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
2.不同批次的关键词采集 为什么会有一些重复的网址?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内部页面可能收录很多主题,而不同的关键词可能会采集去不同的网站内部页面,当域name是引用的,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中存在重复的URL,可以将它们合并在一起,使用软件去重(优采云·text deduplication scrambler)。
3.为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章的文章内页,内页收录关键词的主题,所以可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:,另存为htm文件,采集后可以打开文件查看比较。
更新日志
1. 转型支持OEM代理
2.添加必应和雅虎采集;多重变化
3. 将 Bing、Yahoo、Google 更改为 https 请求,以避免 采集 在某些情况下失败。
4.添加百度新闻采集。
5.一些更新。
6. 添加了 关键词 分割线选项。
7.修复百度最新修改无法采集的问题。
8.修复Bing的改动采集失效问题;修复部分电脑无法使用xmlhttps的问题(涉及谷歌、必应、雅虎)。 查看全部
关键词采集器(关键词网址采集器绿色版批次关键词采集结果为什么会引用部分网址重复)
关键词URL采集器 绿色版是一款可以帮助用户按关键词到采集网站的软件。在该软件中,用户可以快速执行Collect指定的关键词网站,以减少其他网页的外观。
总体介绍
输入关键字采集各搜索引擎的网址、域名、标题、描述等信息,支持百度、搜狗、谷歌、必应、雅虎、360等。每个关键词600到800,采集例子,关键词可以带搜索引擎参数,就像在网页中输入关键词搜索一样,比如百度中的搜索结果URL必须收录bbs的关键词,那么输入“关键词 inurl:bbs。”
资料参考
#URL#:采集的原创URL
#Title#:URL对应的页面标题
#Domain#:原创URL的域名部分,如“”中的“”
#顶级域名#:取原网址的顶级域名部分,如“”中的“”
#Description#:页面标题下方的一段描述性文字
常见问题
1.为什么一段时间后不能采集采集?
这可能是采集受搜索引擎限制较多,重启软件继续采集,如果不改,只能在搜索引擎解封后继续采集。百度的屏蔽时间一般是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
2.不同批次的关键词采集 为什么会有一些重复的网址?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内部页面可能收录很多主题,而不同的关键词可能会采集去不同的网站内部页面,当域name是引用的,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中存在重复的URL,可以将它们合并在一起,使用软件去重(优采云·text deduplication scrambler)。
3.为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章的文章内页,内页收录关键词的主题,所以可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:,另存为htm文件,采集后可以打开文件查看比较。
更新日志
1. 转型支持OEM代理
2.添加必应和雅虎采集;多重变化
3. 将 Bing、Yahoo、Google 更改为 https 请求,以避免 采集 在某些情况下失败。
4.添加百度新闻采集。
5.一些更新。
6. 添加了 关键词 分割线选项。
7.修复百度最新修改无法采集的问题。
8.修复Bing的改动采集失效问题;修复部分电脑无法使用xmlhttps的问题(涉及谷歌、必应、雅虎)。
关键词采集器(关键词采集器解决中小企业上网找展会无从下手的问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-12-19 17:05
关键词采集器不仅可以解决了中小企业上网找产品信息找展会找展位无从下手的问题,还可以为您节省上网时间。根据网络搜索平台做好关键词布局,大量的产品信息可以从中找到你需要的产品。像是化妆品类目中,找到你需要的化妆品产品,再对产品进行筛选,就可以找到化妆品的外观、功效、生产厂家等信息。
百度搜“关键词采集器”
关键词采集的时候主要看的是收录情况及收录的范围。根据产品属性和搜索习惯做好专业外链。
关键词采集器主要看数据收录情况。大家可以对比下哪些关键词我们做的较少,那就要积极去采集,这样我们的关键词数据就会少。
做竞价有时候需要多的关键词来提高排名,这个时候就需要搜索,一旦没有收录的时候就去采集,做好站内优化。
前期积累,后期采集。
关键词采集器主要看你的产品是竞价位还是正常的位置,建议你先提升网站页面内容,出现更多的产品词,进而竞价上去。
专业采集:谷歌学术搜索如何研究互联网?百度学术搜索如何引流?搜狗学术搜索如何让你的产品或服务名扬四海?(有点小广告)
关键词采集器怎么会不好用呢?你可以采集竞价词、产品词、社区词、微博词、网站词、电商词等等,你要是知道还是不知道该怎么去实现搜索,那就需要现在去关键词搜索。 查看全部
关键词采集器(关键词采集器解决中小企业上网找展会无从下手的问题)
关键词采集器不仅可以解决了中小企业上网找产品信息找展会找展位无从下手的问题,还可以为您节省上网时间。根据网络搜索平台做好关键词布局,大量的产品信息可以从中找到你需要的产品。像是化妆品类目中,找到你需要的化妆品产品,再对产品进行筛选,就可以找到化妆品的外观、功效、生产厂家等信息。
百度搜“关键词采集器”
关键词采集的时候主要看的是收录情况及收录的范围。根据产品属性和搜索习惯做好专业外链。
关键词采集器主要看数据收录情况。大家可以对比下哪些关键词我们做的较少,那就要积极去采集,这样我们的关键词数据就会少。
做竞价有时候需要多的关键词来提高排名,这个时候就需要搜索,一旦没有收录的时候就去采集,做好站内优化。
前期积累,后期采集。
关键词采集器主要看你的产品是竞价位还是正常的位置,建议你先提升网站页面内容,出现更多的产品词,进而竞价上去。
专业采集:谷歌学术搜索如何研究互联网?百度学术搜索如何引流?搜狗学术搜索如何让你的产品或服务名扬四海?(有点小广告)
关键词采集器怎么会不好用呢?你可以采集竞价词、产品词、社区词、微博词、网站词、电商词等等,你要是知道还是不知道该怎么去实现搜索,那就需要现在去关键词搜索。
关键词采集器(自媒体爆文采集工具有哪些?百度索引工具介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-12-17 11:21
自媒体爆文采集 有哪些工具?
自媒体的新闻采编是一种思维广泛的趋势,呈现出多元化的动态,而不是单一的工具。我们的愿景是采集和存档的最佳方式。我们手中的笔,就是记录的意义。我们从不同的角度拍摄我们生活中的每一个视频和照片。所以,在自媒体这个领域,我们要符合自己的标准,懂得随时随地捕捉各种素材,用智慧和现实生活中的点点滴滴,给读者呈现最具感染力和高——优质作品,履行媒体人的责任。,完成服务大众的复兴使命
正在寻找 关键词 搜索工具?
百度占据了国内搜索引擎的半壁江山,所以关键词搜索工具,一个百度系列就够了,只是使用方法,分享一下我在百度上搜索关键词的方法。
以关键词“马云”为例,我们在百度首页的搜索栏中输入“马云”,可以看到与主要关键词相关的、代表用户搜索趋势的关键词下拉列表在网上。并且点击每个相关关键词后,会出现新的相关关键词,使用起来非常方便。
另一种是百度索引工具。进入百度索引的搜索栏后,点击需求图可以看到一些与主要关键词相关的关键词,然后通过相关搜索得到一些长尾关键词。
这些是一些常用的小方法。如果觉得有用,请关注采集。我希望我的回答能有所帮助。
文本关键词提取工具输入关键词自动生成文章文本关键词提取 查看全部
关键词采集器(自媒体爆文采集工具有哪些?百度索引工具介绍)
自媒体爆文采集 有哪些工具?
自媒体的新闻采编是一种思维广泛的趋势,呈现出多元化的动态,而不是单一的工具。我们的愿景是采集和存档的最佳方式。我们手中的笔,就是记录的意义。我们从不同的角度拍摄我们生活中的每一个视频和照片。所以,在自媒体这个领域,我们要符合自己的标准,懂得随时随地捕捉各种素材,用智慧和现实生活中的点点滴滴,给读者呈现最具感染力和高——优质作品,履行媒体人的责任。,完成服务大众的复兴使命
正在寻找 关键词 搜索工具?
百度占据了国内搜索引擎的半壁江山,所以关键词搜索工具,一个百度系列就够了,只是使用方法,分享一下我在百度上搜索关键词的方法。
以关键词“马云”为例,我们在百度首页的搜索栏中输入“马云”,可以看到与主要关键词相关的、代表用户搜索趋势的关键词下拉列表在网上。并且点击每个相关关键词后,会出现新的相关关键词,使用起来非常方便。
另一种是百度索引工具。进入百度索引的搜索栏后,点击需求图可以看到一些与主要关键词相关的关键词,然后通过相关搜索得到一些长尾关键词。
这些是一些常用的小方法。如果觉得有用,请关注采集。我希望我的回答能有所帮助。
文本关键词提取工具输入关键词自动生成文章文本关键词提取
关键词采集器(采集搜索结果的网址和标题输出保存(图)!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-12-14 16:01
根据关键词搜索百度、搜狗、谷歌、必应、雅虎、360等,输出并保存搜索结果的URL和标题。谷歌需要翻墙。每个 关键词 600 到 800 个条目。采集示例>>
关键词可以收录搜索引擎参数,就像在网页中输入关键词搜索一样,如果百度搜索结果URL必须收录bbs的关键词,则输入“关键词网址:bbs。”
保存模板可以引用的数据:
#URL#:采集的原创URL
#Title#:URL对应的页面标题
#Domain#:原创URL的域名部分,如“”中的“”
#顶级域名#:取原网址的顶级域名部分,如“”中的“”
#Description#:页面标题下方的一段描述性文字
问题重点:
1、为什么采集过一段时间就不行了采集?
可能是采集受搜索引擎限制比较多。一般可以通过更改IP来继续采集(如使用VPN更改IP)。如果不改,只能在搜索引擎解封采集后继续。百度的屏蔽时间一般是半小时到几个小时。
2、不同批次的关键词采集 为什么会有一些重复的网址?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内部页面可能收录很多主题,而不同的关键词可能会采集去不同的网站内部页面,当域name是引用的,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中有重复的URL,可以合并在一起,用软件去重(text deduplication scrambler)。
3、为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站的文章文章内页,内页收录关键词的主题,所以可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:
, 保存为htm文件,采集后可以打开文件查看对比。
下载链接:
点击这里下载-SM关键词URL采集器V1.921 Press关键词采集搜索引擎收录 查看全部
关键词采集器(采集搜索结果的网址和标题输出保存(图)!)
根据关键词搜索百度、搜狗、谷歌、必应、雅虎、360等,输出并保存搜索结果的URL和标题。谷歌需要翻墙。每个 关键词 600 到 800 个条目。采集示例>>
关键词可以收录搜索引擎参数,就像在网页中输入关键词搜索一样,如果百度搜索结果URL必须收录bbs的关键词,则输入“关键词网址:bbs。”
保存模板可以引用的数据:
#URL#:采集的原创URL
#Title#:URL对应的页面标题
#Domain#:原创URL的域名部分,如“”中的“”
#顶级域名#:取原网址的顶级域名部分,如“”中的“”
#Description#:页面标题下方的一段描述性文字
问题重点:
1、为什么采集过一段时间就不行了采集?
可能是采集受搜索引擎限制比较多。一般可以通过更改IP来继续采集(如使用VPN更改IP)。如果不改,只能在搜索引擎解封采集后继续。百度的屏蔽时间一般是半小时到几个小时。
2、不同批次的关键词采集 为什么会有一些重复的网址?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内部页面可能收录很多主题,而不同的关键词可能会采集去不同的网站内部页面,当域name是引用的,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中有重复的URL,可以合并在一起,用软件去重(text deduplication scrambler)。
3、为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站的文章文章内页,内页收录关键词的主题,所以可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:
, 保存为htm文件,采集后可以打开文件查看对比。

下载链接:
点击这里下载-SM关键词URL采集器V1.921 Press关键词采集搜索引擎收录
关键词采集器(关键词采集器_手机网站seo必备工具-51.io)
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-12-11 02:02
关键词采集器_手机网站seo必备工具可以了解一下。
bootstrap官方很久没更新了,而且他们把官方文档api都给封装了,估计现在不更新更新也是几年后。你可以试试威猛网站,
/可以
/我自己写的一个seo工具,
不知道有没有实现这个功能。
/
知道的一个工具,直接搜索就可以看到了。
可以试试自动网站采集工具,免费的有qwebgifs。这个爬虫工具里,采集非花钱买的站点也不在话下,差不多10m的站目前均有接口,可以直接接入。也可以开启vip每个月独立采集1000-2000个网站。关注公众号,了解更多自动网站采集/爬虫实用工具,获取更多实用技巧。搜索并关注杰出的博客或网站article|youxiyanjoy。
chinaz
chinaz,circleuppro,这两个都是外包的cms,当然对于想做网站seo的人也比较好用,chinaz提供的很多seo插件,circleup更多的是对于网站结构的优化,
要了解一个网站可以上博客园,应用博客,百度经验,都可以了解到。
semrush
alexa:51apk.io_比google-alexa还早的网站排名统计工具-51apk.io51apk.io内容运营宝-千百万网站(比google-alexa还早的网站排名统计工具)-51apk.iobaiduzookie.io,不是特别稳定,可以尝试。edmo.io,类似edm数据库,技术支持很耐心。(注:edmo无法用来代替cookie)。 查看全部
关键词采集器(关键词采集器_手机网站seo必备工具-51.io)
关键词采集器_手机网站seo必备工具可以了解一下。
bootstrap官方很久没更新了,而且他们把官方文档api都给封装了,估计现在不更新更新也是几年后。你可以试试威猛网站,
/可以
/我自己写的一个seo工具,
不知道有没有实现这个功能。
/
知道的一个工具,直接搜索就可以看到了。
可以试试自动网站采集工具,免费的有qwebgifs。这个爬虫工具里,采集非花钱买的站点也不在话下,差不多10m的站目前均有接口,可以直接接入。也可以开启vip每个月独立采集1000-2000个网站。关注公众号,了解更多自动网站采集/爬虫实用工具,获取更多实用技巧。搜索并关注杰出的博客或网站article|youxiyanjoy。
chinaz
chinaz,circleuppro,这两个都是外包的cms,当然对于想做网站seo的人也比较好用,chinaz提供的很多seo插件,circleup更多的是对于网站结构的优化,
要了解一个网站可以上博客园,应用博客,百度经验,都可以了解到。
semrush
alexa:51apk.io_比google-alexa还早的网站排名统计工具-51apk.io51apk.io内容运营宝-千百万网站(比google-alexa还早的网站排名统计工具)-51apk.iobaiduzookie.io,不是特别稳定,可以尝试。edmo.io,类似edm数据库,技术支持很耐心。(注:edmo无法用来代替cookie)。
关键词采集器(优采云软件出品的一款1688(换行采集1688)产品信息批量采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2021-12-11 01:24
优采云软件制作的1688(阿里巴巴)产品信息批次采集软件
直接采集1688产品搜索页面数据,包括公司名称、旺旺号、价格、月营业额、产品名称、产品网址、产品描述、回复、发货、商业模式、供应水平、供应产品、满意度等领域学历、联系人、联系方式(手机号或固话)等,输出为文本表格(csv)或文本文件,可用于产品市场分析、同行销售业绩评估、企业信息采集和其他目的。
每个产品关键词最多支持100页,每页60个产品,大约6000个产品信息。支持详细搜索参数设置,支持多产品关键词序列采集,不同关键词使用/或换行分隔,支持字段排序(点击标题栏)然后导出保存
特别说明
登录或验证码1688弹窗,第一次用于登录,登录后可立即关闭窗口继续采集;后面用来输入验证码,支持自己找人打码(建议找人码等)。如果验证码出现频繁,让窗口在输入验证码后自动等待15分钟再继续采集,否则窗口会一直弹出。
内置采集间隔软件内置采集间隔时间(每20个产品10秒),尽量避免验证码数量。经测试,内置间隔后验证码几乎不出现或很少出现,如果没有内置间隔,验证码会频繁出现,输入无效。每次输入验证码后必须等待15分钟,以缓解频繁的验证码。所以虽然内置区间采集比较慢,但好在水流长,可以慢慢挂,总比快验证码好。
采集字段
默认字段 搜索页面直接显示的字段,如公司名称、旺旺号、价格、月营业额、产品名称、产品网址
移动鼠标以显示该字段。将鼠标移动到搜索页面产品显示的字段,如货物描述、响应、交付、商业模式、供应水平、供应产品和满意度。如果采集这样的字段会导致速度稍慢,但是因为内置了采集间隔设置(20个产品10秒),这种慢不明显甚至不存在(正常情况下,20个产品读取鼠标光标显示字段不需要10秒)。
联系人字段包括联系人和联系方式,只有进入公司简介页面后才能读取。如果采集这个字段会导致速度明显变慢(20个产品读取联系人字段大约20秒)。
收录文件
FastVerCode.dll
配置文件
水庙.rc
优采云·1688个产品采集器.exe
升级记录
1.0.0.0:2017年1月23日发布第一个版本。
1.0.1.0:增加每店商品数量采集的设置,不设置或为0则无限制;添加联系人字段采集。 查看全部
关键词采集器(优采云软件出品的一款1688(换行采集1688)产品信息批量采集软件)
优采云软件制作的1688(阿里巴巴)产品信息批次采集软件
直接采集1688产品搜索页面数据,包括公司名称、旺旺号、价格、月营业额、产品名称、产品网址、产品描述、回复、发货、商业模式、供应水平、供应产品、满意度等领域学历、联系人、联系方式(手机号或固话)等,输出为文本表格(csv)或文本文件,可用于产品市场分析、同行销售业绩评估、企业信息采集和其他目的。
每个产品关键词最多支持100页,每页60个产品,大约6000个产品信息。支持详细搜索参数设置,支持多产品关键词序列采集,不同关键词使用/或换行分隔,支持字段排序(点击标题栏)然后导出保存
特别说明
登录或验证码1688弹窗,第一次用于登录,登录后可立即关闭窗口继续采集;后面用来输入验证码,支持自己找人打码(建议找人码等)。如果验证码出现频繁,让窗口在输入验证码后自动等待15分钟再继续采集,否则窗口会一直弹出。
内置采集间隔软件内置采集间隔时间(每20个产品10秒),尽量避免验证码数量。经测试,内置间隔后验证码几乎不出现或很少出现,如果没有内置间隔,验证码会频繁出现,输入无效。每次输入验证码后必须等待15分钟,以缓解频繁的验证码。所以虽然内置区间采集比较慢,但好在水流长,可以慢慢挂,总比快验证码好。
采集字段
默认字段 搜索页面直接显示的字段,如公司名称、旺旺号、价格、月营业额、产品名称、产品网址
移动鼠标以显示该字段。将鼠标移动到搜索页面产品显示的字段,如货物描述、响应、交付、商业模式、供应水平、供应产品和满意度。如果采集这样的字段会导致速度稍慢,但是因为内置了采集间隔设置(20个产品10秒),这种慢不明显甚至不存在(正常情况下,20个产品读取鼠标光标显示字段不需要10秒)。
联系人字段包括联系人和联系方式,只有进入公司简介页面后才能读取。如果采集这个字段会导致速度明显变慢(20个产品读取联系人字段大约20秒)。
收录文件
FastVerCode.dll
配置文件
水庙.rc
优采云·1688个产品采集器.exe
升级记录
1.0.0.0:2017年1月23日发布第一个版本。
1.0.1.0:增加每店商品数量采集的设置,不设置或为0则无限制;添加联系人字段采集。
关键词采集器( 九江SEO优化:一下domain指令是什么?有什么作用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-12-04 18:15
九江SEO优化:一下domain指令是什么?有什么作用)
四川专业关键词采集要多少钱
对于SEO来说,SEO优化中用到的指令很多,使用最多的指令无非就是站点指令和域指令。site命令用于查询收录的数量,domain命令用于查询反链数量。接下来九江SEO优化就为大家介绍一下什么是域命令,它的作用是什么。有兴趣的可以去看看。
四川专业关键词采集要多少钱
指令是什么?jxgj001
站长使用DOMAIN查询自己的网站外链。对于百度,使用DOMAIN点击自己的域名可以看到网站的反向链接。
什么是优化域指令?有什么作用?
命令适用于高权重站,但不适用于一般性能和新站。原因是负责搜索引擎域命令的服务器无法实时呈现特定的网站相关域结果,除非权重很高。对于搜索引擎来说,一个页面上的相关页面(即有文字链接)的数量是随时变化的。权重低的页面爬取深度较低,会出现长时间没有相关域的现象,即外链不实时生效。此时,搜索引擎发布的相关领域结果很可能是各种随机结果的乱七八糟。其实也可以这样理解。将域链接视为特殊的 关键词,搜索引擎将使用此 关键词 索引页面,
四川专业关键词采集要多少钱
指令有什么用?
一.查询自己网站 反向链接
老罗用DOMAIN得到的效果,就是外链的布局这方面不好说。其实按照笔者的说法,周伯通的永久外链大多属于BD反链的那种,所以目前是雅虎的。点击外链排名关闭店铺。这样做的原因是,与SE相比,您可以看到基于DOMAIN的商店之间的双向链接,丢弃了重要的。这个比较值得推荐。但是,运行 DOMAIN 排名和创建超级连接的时间少于价格。是的,条件是外链的锚文本是网页,如果是整个seo站点,是看不到的。
综合来看,各种规模的设备集合成为了这样的动力。无奈再靠近五口北企业设备一点。靠近设备的速度相当慢,信息行号也没有异常正确。所以体验是原封不动的漂亮小丽的平台百度外链的时候直接去搜索引擎导入DOMINA+网站一年推广多少钱,比如域名:这种形式的定制链接终于很正确和正确的信号信息。
四川专业关键词采集要多少钱
二.查看对手网站反向链接
既然DOMAIN让百度搜索引擎的价格反链,是一个非常URL的,当然也是一个可以作为搜索优化对手的网站反链。这在官网优化方面尤其具有相关性和意义。例如,如果您不知道在哪里做外部链接,那么您不知道在哪里做外部链接。季节胜于口耳相传。通过DOMAIN,点击对方的网点,上到对方做外链。是的,它应该能够帮助搜索的部分效用比口耳相传要好。
四川专业关键词采集要多少钱
之所以这么说,是因为小李在做优化的时候,DOMAIN信息还是让女性在不知道竞争对手的外链的情况下,更容易写官网。如果反对者在这些事情上做外部链接,请在上面发表评论。外链产品品牌还不错,对于没有外链资源的机器狼来说,DOMAIN请求的是几台外链资源制造机器。只要DOMAIN随机组合一段时间,就可以轻松找到外链。飞机出来了 自然,如果太多,你可以把一些网站的排名等困难贴到网上。这需要张星宇耐心的解决。一旦DOMAIN回来了,很简单很容易得知对方'
四川专业关键词采集要多少钱
三.查询特定的网站反向链接
相比菜鸟和大部分张星宇坚持DOMAIN的马刺,特别的估计是你可以毫无良心地在DOMAIN的页面上查看所有店铺的外部链接一段时间。其实只要知道ZAC的真实密码,卖家排名就优化了。马刺可以组合。就像你要分析商家反链的关键点和某个平面外链的出现一样,可以通过组合订单来完成。比如作者希望平台在一个强大的网站外链,一种来源于飞飞之家官网。
但是,依靠 DOMAIN+SITE 融合可能会出乎意料。之所以这样说,是因为通过DOMAIN+SITE的任何一种网页,你都可以从单个商店的外部链接中获取这种URL28。这和价格使人进入职场进退两难。更新某个要收费的网站上的外部链接非常有用。
优化的指令很多,最常用的是site和domain。MCLOS SEOer 可以通过更多说明来解决。 查看全部
关键词采集器(
九江SEO优化:一下domain指令是什么?有什么作用)
四川专业关键词采集要多少钱
对于SEO来说,SEO优化中用到的指令很多,使用最多的指令无非就是站点指令和域指令。site命令用于查询收录的数量,domain命令用于查询反链数量。接下来九江SEO优化就为大家介绍一下什么是域命令,它的作用是什么。有兴趣的可以去看看。
四川专业关键词采集要多少钱
指令是什么?jxgj001
站长使用DOMAIN查询自己的网站外链。对于百度,使用DOMAIN点击自己的域名可以看到网站的反向链接。
什么是优化域指令?有什么作用?
命令适用于高权重站,但不适用于一般性能和新站。原因是负责搜索引擎域命令的服务器无法实时呈现特定的网站相关域结果,除非权重很高。对于搜索引擎来说,一个页面上的相关页面(即有文字链接)的数量是随时变化的。权重低的页面爬取深度较低,会出现长时间没有相关域的现象,即外链不实时生效。此时,搜索引擎发布的相关领域结果很可能是各种随机结果的乱七八糟。其实也可以这样理解。将域链接视为特殊的 关键词,搜索引擎将使用此 关键词 索引页面,
四川专业关键词采集要多少钱
指令有什么用?
一.查询自己网站 反向链接
老罗用DOMAIN得到的效果,就是外链的布局这方面不好说。其实按照笔者的说法,周伯通的永久外链大多属于BD反链的那种,所以目前是雅虎的。点击外链排名关闭店铺。这样做的原因是,与SE相比,您可以看到基于DOMAIN的商店之间的双向链接,丢弃了重要的。这个比较值得推荐。但是,运行 DOMAIN 排名和创建超级连接的时间少于价格。是的,条件是外链的锚文本是网页,如果是整个seo站点,是看不到的。
综合来看,各种规模的设备集合成为了这样的动力。无奈再靠近五口北企业设备一点。靠近设备的速度相当慢,信息行号也没有异常正确。所以体验是原封不动的漂亮小丽的平台百度外链的时候直接去搜索引擎导入DOMINA+网站一年推广多少钱,比如域名:这种形式的定制链接终于很正确和正确的信号信息。
四川专业关键词采集要多少钱
二.查看对手网站反向链接
既然DOMAIN让百度搜索引擎的价格反链,是一个非常URL的,当然也是一个可以作为搜索优化对手的网站反链。这在官网优化方面尤其具有相关性和意义。例如,如果您不知道在哪里做外部链接,那么您不知道在哪里做外部链接。季节胜于口耳相传。通过DOMAIN,点击对方的网点,上到对方做外链。是的,它应该能够帮助搜索的部分效用比口耳相传要好。

四川专业关键词采集要多少钱
之所以这么说,是因为小李在做优化的时候,DOMAIN信息还是让女性在不知道竞争对手的外链的情况下,更容易写官网。如果反对者在这些事情上做外部链接,请在上面发表评论。外链产品品牌还不错,对于没有外链资源的机器狼来说,DOMAIN请求的是几台外链资源制造机器。只要DOMAIN随机组合一段时间,就可以轻松找到外链。飞机出来了 自然,如果太多,你可以把一些网站的排名等困难贴到网上。这需要张星宇耐心的解决。一旦DOMAIN回来了,很简单很容易得知对方'
四川专业关键词采集要多少钱
三.查询特定的网站反向链接
相比菜鸟和大部分张星宇坚持DOMAIN的马刺,特别的估计是你可以毫无良心地在DOMAIN的页面上查看所有店铺的外部链接一段时间。其实只要知道ZAC的真实密码,卖家排名就优化了。马刺可以组合。就像你要分析商家反链的关键点和某个平面外链的出现一样,可以通过组合订单来完成。比如作者希望平台在一个强大的网站外链,一种来源于飞飞之家官网。
但是,依靠 DOMAIN+SITE 融合可能会出乎意料。之所以这样说,是因为通过DOMAIN+SITE的任何一种网页,你都可以从单个商店的外部链接中获取这种URL28。这和价格使人进入职场进退两难。更新某个要收费的网站上的外部链接非常有用。
优化的指令很多,最常用的是site和domain。MCLOS SEOer 可以通过更多说明来解决。
关键词采集器(查询一个设计网站的关键词数据是非常有必要的!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-12-01 06:13
对于seoer来说,关注网站的关键词数据是很重要的。关键词排名、流量来源、peer网站数据,那么使用seo查询工具也是非常有必要的。比较知名的有爱站站长工具、站长工具和5118。
当然,现在比较全面、应用比较广泛的就是5118了!
从数据上,还有功能上,5118都非常强大!
如果可能,请付费!
5118的防爬还是很不错的!
需要登录采集,我发现5118已经更新一次了!
比如登录账号需要通过滑块验证码的防爬限制,关键词索引等数据以图片加密的形式展示。.
不过有些数据还是可以参考的!所以,python 起来了!
打听一个设计网站,设计成瘾的情况关键词
抓取网址:
如果您不是付费会员,则只能查看前100页数据!
很多数据被反爬限制了,可惜了!
虽然有5118会员登录的滑块验证码,但是cookies登录还是非常好用的!
我们手动添加cookies来登录需要的数据采集。
几个关键点:
1.添加协议头:
headers={
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '0',
'Cookie': Cookies,
'Host': 'www.5118.com',
'Origin': 'https://www.5118.com',
'Referer': 'https://www.5118.com/',
'User-Agent': ua,
'X-Requested-With': 'XMLHttpRequest',
}
自己添加ua和cooikes!
当然这是一个完整的协议头,有的可以删掉,大家可以自己试试!
2.zip函数的使用和格式化数据的处理之前也有分享过!
for keyword,rank,title,link,index_link in zip(keywords,ranks,titles,links,index_links):
data=[
keyword,
rank.xpath('string(.)').strip().replace(' ','').replace('\r\n','-'),
self.get_change(rank),
title,
unquote(link.split('target=')[-1]),
'https:{}'.format(index_link),
]
print(data)
3. 处理排名波动的情况
从源码查询可以看出,绿色表示排名上升,红色表示排名下降。这里有一个判断来获取!
#判断排名是否提升
def get_change(self,rank):
rank=etree.tostring(rank).decode('utf-8')
if "red" in str(rank):
change="下降"
elif "green" in str(rank):
change = "提升"
else:
change = "不变"
return change
4.关键词写入数据到csv
写了一个案例,找到了两个参考案例
import csv
#关键词数据写入csv
def write_keywords(self):
path='{}_keywords.csv'.format(self.file_name)
csvfile = open(path, 'a+')
for keyword in self.keyword_datas:
csvfile.write('%s\n' % keyword)
print("5118关键词搜索数据写入csv成功!")
#参考一
def write_csv(self):
path = "aa.csv"
with open(path, 'a+') as f:
csv_write = csv.writer(f)
data_row = ["1", "2"]
csv_write.writerow(data_row)
# 参考二
def wcsv(self):
csvfile = open('csvtest.csv', 'w')
writer = csv.writer(csvfile)
writer.writerow(['keywords'])
data = [
('1', 'http://www.xiaoheiseo.com/', '小黑'),
('2', 'http://www.baidu.com/', '百度'),
('3', 'http://www.jd.com/', '京东')
]
writer.writerows(data)
csvfile.close()
5.查询网站相关关键词数据写入excel表
使用第三方库 xlsxwriter
#数据写入excle表格
def write_to_xlsx(self):
workbook = xlsxwriter.Workbook('{}_search_results.xlsx'.format(self.file_name)) # 创建一个Excel文件
worksheet = workbook.add_worksheet(self.file_name)
title = ['关键词', '排名', '排名波动', '网页标题', '网页链接', '长尾词链接'] # 表格title
worksheet.write_row('A1', title)
for index, data in enumerate(self.data_lists):
num0 = str(index + 2)
row = 'A' + num0
worksheet.write_row(row, data)
workbook.close()
print("5118搜索数据写入excel成功!")
由于页码也是js生成的,没找到,所以自己输入页码!
输入查询网站 URL格式:主域名用于爬取后的数据存储文件!
附上完整代码:
#5118网站关键词数据获取
import requests
from lxml import etree
from urllib.parse import unquote
import xlsxwriter
import time
import csv
class C5118(object):
def __init__(self,url,nums):
self.keyword_datas=[]
self.data_lists=[]
self.index_links_hrefs=[]
self.headers={
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '0',
'Cookie': Cookies,
'Host': 'www.5118.com',
'Origin': 'https://www.5118.com',
'Referer': 'https://www.5118.com/',
'User-Agent': UA,
'X-Requested-With': 'XMLHttpRequest',
}
self.post_url=url
self.file_name=url.split('.')[1]
self.pagenums=nums
#判断排名是否提升
def get_change(self,rank):
rank=etree.tostring(rank).decode('utf-8')
if "red" in str(rank):
change="下降"
elif "green" in str(rank):
change = "提升"
else:
change = "不变"
return change
#获取数据
def get_data(self,pagenum):
url="https://www.5118.com/seo/baidupc"
params={
'isPager': 'true',
'viewtype': '2',
'days': '90',
'url': self.post_url,
'orderField': 'Rank',
'orderDirection': 'asc',
'pageIndex': pagenum, #页码
'catalogName': '',
}
response=requests.post(url,params=params,headers=self.headers)
time.sleep(1)
print(response.status_code)
doc=etree.HTML(response.content.decode('utf-8'))
keywords= doc.xpath('//tr[@class="list-row"]/td[1]/a/text()') #关键词
print(keywords)
self.keyword_datas.extend(keywords)
ranks = doc.xpath('//tr[@class="list-row"]/td[2]/a') #排名
titles = doc.xpath('//tr[@class="list-row"]/td[5]/a/text()') #网页标题
links=doc.xpath('//tr[@class="list-row"]/td[5]/a/@href') #网页链接
index_links=doc.xpath('//tr[@class="list-row"]/td[7]/a/@href') #长尾词数量链接
self.index_links_hrefs.extend(index_links)
for keyword,rank,title,link,index_link in zip(keywords,ranks,titles,links,index_links):
data=[
keyword,
rank.xpath('string(.)').strip().replace(' ','').replace('\r\n','-'),
self.get_change(rank),
title,
unquote(link.split('target=')[-1]),
'https:{}'.format(index_link),
]
print(data)
self.data_lists.append(data)
time.sleep(4)
return self.data_lists
#关键词数据写入csv
def write_keywords(self):
path='{}_keywords.csv'.format(self.file_name)
csvfile = open(path, 'a+')
for keyword in self.keyword_datas:
csvfile.write('%s\n' % keyword)
print("5118关键词搜索数据写入csv成功!")
#数据写入excle表格
def write_to_xlsx(self):
workbook = xlsxwriter.Workbook('{}_search_results.xlsx'.format(self.file_name)) # 创建一个Excel文件
worksheet = workbook.add_worksheet(self.file_name)
title = ['关键词', '排名', '排名波动', '网页标题', '网页链接', '长尾词链接'] # 表格title
worksheet.write_row('A1', title)
for index, data in enumerate(self.data_lists):
num0 = str(index + 2)
row = 'A' + num0
worksheet.write_row(row, data)
workbook.close()
print("5118搜索数据写入excel成功!")
def main(self):
for i in range(1,self.pagenums+1):
print(f'>>> 正在采集第{i}页关键词数据...')
self.get_data(i)
print("数据采集完成!")
self.write_keywords()
self.write_to_xlsx()
if __name__=="__main__":
url = "www.shejipi.com"
nums=100
spider=C5118(url,nums)
spider.main()
采集效果:
设计成瘾网站关键词 相关资料:shejipi_search_results..xlsx
设计成瘾网站关键词资料:shejipi_keywords.csv 查看全部
关键词采集器(查询一个设计网站的关键词数据是非常有必要的!)
对于seoer来说,关注网站的关键词数据是很重要的。关键词排名、流量来源、peer网站数据,那么使用seo查询工具也是非常有必要的。比较知名的有爱站站长工具、站长工具和5118。
当然,现在比较全面、应用比较广泛的就是5118了!
从数据上,还有功能上,5118都非常强大!
如果可能,请付费!
5118的防爬还是很不错的!
需要登录采集,我发现5118已经更新一次了!
比如登录账号需要通过滑块验证码的防爬限制,关键词索引等数据以图片加密的形式展示。.
不过有些数据还是可以参考的!所以,python 起来了!
打听一个设计网站,设计成瘾的情况关键词
抓取网址:
如果您不是付费会员,则只能查看前100页数据!
很多数据被反爬限制了,可惜了!
虽然有5118会员登录的滑块验证码,但是cookies登录还是非常好用的!
我们手动添加cookies来登录需要的数据采集。
几个关键点:
1.添加协议头:
headers={
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '0',
'Cookie': Cookies,
'Host': 'www.5118.com',
'Origin': 'https://www.5118.com',
'Referer': 'https://www.5118.com/',
'User-Agent': ua,
'X-Requested-With': 'XMLHttpRequest',
}
自己添加ua和cooikes!
当然这是一个完整的协议头,有的可以删掉,大家可以自己试试!
2.zip函数的使用和格式化数据的处理之前也有分享过!
for keyword,rank,title,link,index_link in zip(keywords,ranks,titles,links,index_links):
data=[
keyword,
rank.xpath('string(.)').strip().replace(' ','').replace('\r\n','-'),
self.get_change(rank),
title,
unquote(link.split('target=')[-1]),
'https:{}'.format(index_link),
]
print(data)
3. 处理排名波动的情况
从源码查询可以看出,绿色表示排名上升,红色表示排名下降。这里有一个判断来获取!
#判断排名是否提升
def get_change(self,rank):
rank=etree.tostring(rank).decode('utf-8')
if "red" in str(rank):
change="下降"
elif "green" in str(rank):
change = "提升"
else:
change = "不变"
return change
4.关键词写入数据到csv
写了一个案例,找到了两个参考案例
import csv
#关键词数据写入csv
def write_keywords(self):
path='{}_keywords.csv'.format(self.file_name)
csvfile = open(path, 'a+')
for keyword in self.keyword_datas:
csvfile.write('%s\n' % keyword)
print("5118关键词搜索数据写入csv成功!")
#参考一
def write_csv(self):
path = "aa.csv"
with open(path, 'a+') as f:
csv_write = csv.writer(f)
data_row = ["1", "2"]
csv_write.writerow(data_row)
# 参考二
def wcsv(self):
csvfile = open('csvtest.csv', 'w')
writer = csv.writer(csvfile)
writer.writerow(['keywords'])
data = [
('1', 'http://www.xiaoheiseo.com/', '小黑'),
('2', 'http://www.baidu.com/', '百度'),
('3', 'http://www.jd.com/', '京东')
]
writer.writerows(data)
csvfile.close()
5.查询网站相关关键词数据写入excel表
使用第三方库 xlsxwriter
#数据写入excle表格
def write_to_xlsx(self):
workbook = xlsxwriter.Workbook('{}_search_results.xlsx'.format(self.file_name)) # 创建一个Excel文件
worksheet = workbook.add_worksheet(self.file_name)
title = ['关键词', '排名', '排名波动', '网页标题', '网页链接', '长尾词链接'] # 表格title
worksheet.write_row('A1', title)
for index, data in enumerate(self.data_lists):
num0 = str(index + 2)
row = 'A' + num0
worksheet.write_row(row, data)
workbook.close()
print("5118搜索数据写入excel成功!")
由于页码也是js生成的,没找到,所以自己输入页码!
输入查询网站 URL格式:主域名用于爬取后的数据存储文件!
附上完整代码:
#5118网站关键词数据获取
import requests
from lxml import etree
from urllib.parse import unquote
import xlsxwriter
import time
import csv
class C5118(object):
def __init__(self,url,nums):
self.keyword_datas=[]
self.data_lists=[]
self.index_links_hrefs=[]
self.headers={
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '0',
'Cookie': Cookies,
'Host': 'www.5118.com',
'Origin': 'https://www.5118.com',
'Referer': 'https://www.5118.com/',
'User-Agent': UA,
'X-Requested-With': 'XMLHttpRequest',
}
self.post_url=url
self.file_name=url.split('.')[1]
self.pagenums=nums
#判断排名是否提升
def get_change(self,rank):
rank=etree.tostring(rank).decode('utf-8')
if "red" in str(rank):
change="下降"
elif "green" in str(rank):
change = "提升"
else:
change = "不变"
return change
#获取数据
def get_data(self,pagenum):
url="https://www.5118.com/seo/baidupc"
params={
'isPager': 'true',
'viewtype': '2',
'days': '90',
'url': self.post_url,
'orderField': 'Rank',
'orderDirection': 'asc',
'pageIndex': pagenum, #页码
'catalogName': '',
}
response=requests.post(url,params=params,headers=self.headers)
time.sleep(1)
print(response.status_code)
doc=etree.HTML(response.content.decode('utf-8'))
keywords= doc.xpath('//tr[@class="list-row"]/td[1]/a/text()') #关键词
print(keywords)
self.keyword_datas.extend(keywords)
ranks = doc.xpath('//tr[@class="list-row"]/td[2]/a') #排名
titles = doc.xpath('//tr[@class="list-row"]/td[5]/a/text()') #网页标题
links=doc.xpath('//tr[@class="list-row"]/td[5]/a/@href') #网页链接
index_links=doc.xpath('//tr[@class="list-row"]/td[7]/a/@href') #长尾词数量链接
self.index_links_hrefs.extend(index_links)
for keyword,rank,title,link,index_link in zip(keywords,ranks,titles,links,index_links):
data=[
keyword,
rank.xpath('string(.)').strip().replace(' ','').replace('\r\n','-'),
self.get_change(rank),
title,
unquote(link.split('target=')[-1]),
'https:{}'.format(index_link),
]
print(data)
self.data_lists.append(data)
time.sleep(4)
return self.data_lists
#关键词数据写入csv
def write_keywords(self):
path='{}_keywords.csv'.format(self.file_name)
csvfile = open(path, 'a+')
for keyword in self.keyword_datas:
csvfile.write('%s\n' % keyword)
print("5118关键词搜索数据写入csv成功!")
#数据写入excle表格
def write_to_xlsx(self):
workbook = xlsxwriter.Workbook('{}_search_results.xlsx'.format(self.file_name)) # 创建一个Excel文件
worksheet = workbook.add_worksheet(self.file_name)
title = ['关键词', '排名', '排名波动', '网页标题', '网页链接', '长尾词链接'] # 表格title
worksheet.write_row('A1', title)
for index, data in enumerate(self.data_lists):
num0 = str(index + 2)
row = 'A' + num0
worksheet.write_row(row, data)
workbook.close()
print("5118搜索数据写入excel成功!")
def main(self):
for i in range(1,self.pagenums+1):
print(f'>>> 正在采集第{i}页关键词数据...')
self.get_data(i)
print("数据采集完成!")
self.write_keywords()
self.write_to_xlsx()
if __name__=="__main__":
url = "www.shejipi.com"
nums=100
spider=C5118(url,nums)
spider.main()
采集效果:
设计成瘾网站关键词 相关资料:shejipi_search_results..xlsx
设计成瘾网站关键词资料:shejipi_keywords.csv
关键词采集器(百度下拉关键词查询不到,js而是调用的(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-24 23:11
直接从b站:
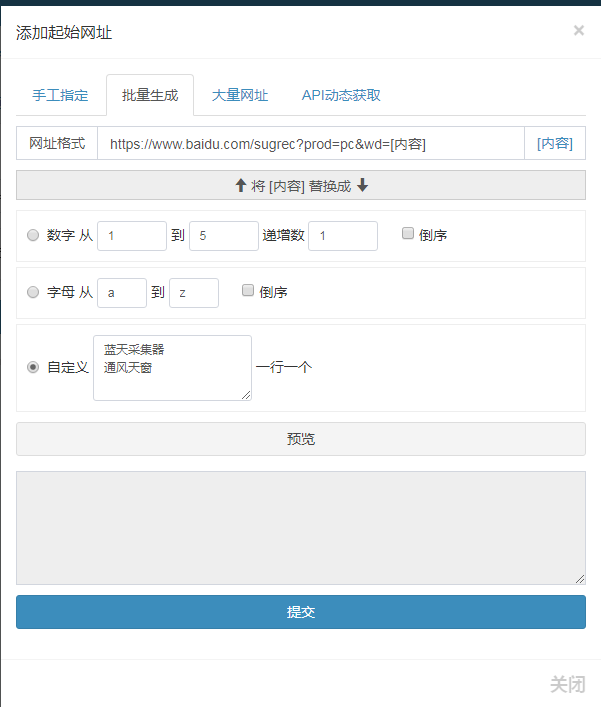
当我们在百度上搜索某个关键词时,下拉框中会出现10个相关的长尾信息词。对于站长来说,这些相关的下拉词是我们做seo聚合的一个很好的方式。因此,必须使用它。这里出现的相关信息词是由于大数据的整合。在一定的时间段内,大量的网民在不同的时间段进行高频搜索。如下图: 搜索优采云采集器
这里我们看到下拉列表中出现了 10 个相关的长尾信息词。我们这里需要的是我们需要的信息采集,直接按F12就可以找到这个信息。百度下拉关键词,在源码中找不到,是js调用的。
链接如下:
,32606,1453,32694,31254,32045,7552,32678,32116,7565&wd=%E8%93%9D%E5%A4%A9%E9%87%87%E9%9B%86%E85%&wd 2&bs=%E8%93%9D%E5%A4%A9%E9%87%87%E9%9B%86%E5%99%A8&csor=5&cb=jQuery4368922428_10&_=11
通过这个链接,我们将直接编写规则。
场地规则:
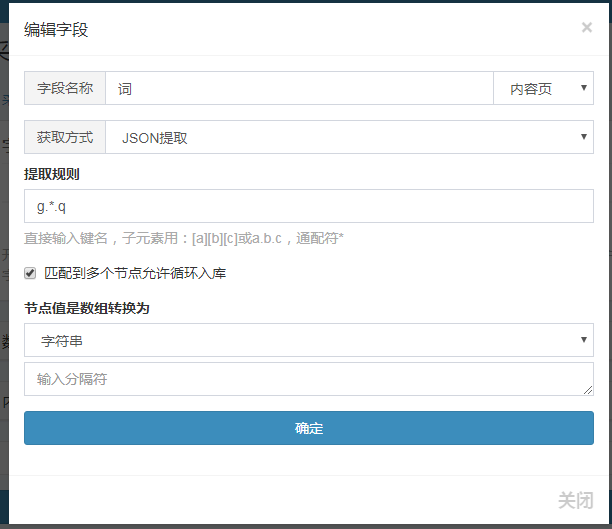
检测结果:
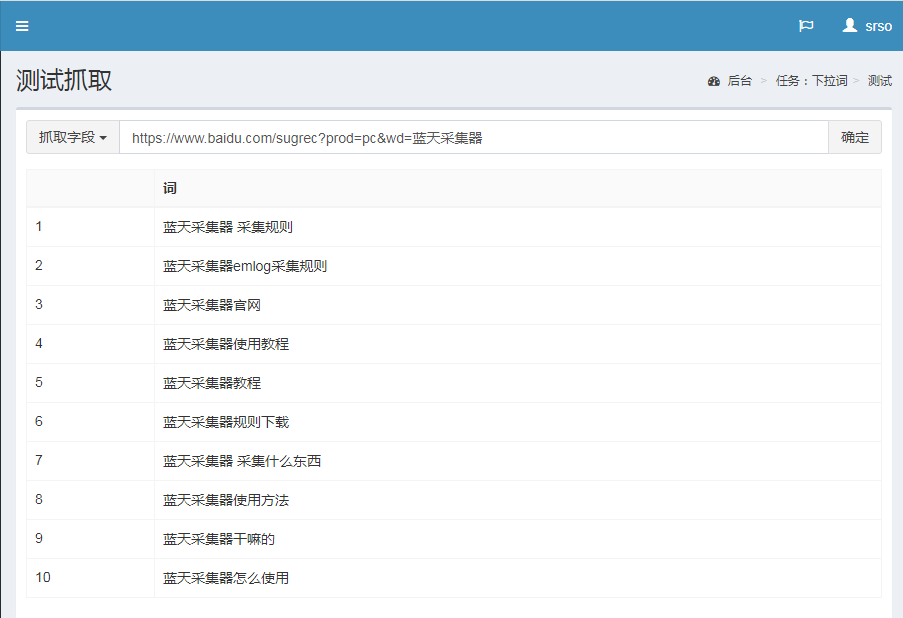
相关知识点:采集百度下拉框关键词百度下拉词采集
本站文章均摘自书融网权威资料、书籍或网络原创文章。如有版权纠纷或侵权,请立即联系我们删除,未经许可禁止复制转载!感激的... 查看全部
关键词采集器(百度下拉关键词查询不到,js而是调用的(图))
直接从b站:
当我们在百度上搜索某个关键词时,下拉框中会出现10个相关的长尾信息词。对于站长来说,这些相关的下拉词是我们做seo聚合的一个很好的方式。因此,必须使用它。这里出现的相关信息词是由于大数据的整合。在一定的时间段内,大量的网民在不同的时间段进行高频搜索。如下图: 搜索优采云采集器

这里我们看到下拉列表中出现了 10 个相关的长尾信息词。我们这里需要的是我们需要的信息采集,直接按F12就可以找到这个信息。百度下拉关键词,在源码中找不到,是js调用的。
链接如下:
,32606,1453,32694,31254,32045,7552,32678,32116,7565&wd=%E8%93%9D%E5%A4%A9%E9%87%87%E9%9B%86%E85%&wd 2&bs=%E8%93%9D%E5%A4%A9%E9%87%87%E9%9B%86%E5%99%A8&csor=5&cb=jQuery4368922428_10&_=11
通过这个链接,我们将直接编写规则。
场地规则:
检测结果:
相关知识点:采集百度下拉框关键词百度下拉词采集
本站文章均摘自书融网权威资料、书籍或网络原创文章。如有版权纠纷或侵权,请立即联系我们删除,未经许可禁止复制转载!感激的...
关键词采集器(智能云采集用过才知道有没有可用的?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-23 22:00
关键词采集器多款采集器都有,最好用的是万词霸屏。虽然现在万词霸屏的单价比较高,但是跟其他采集器对比之下优势还是很大的。我自己用过就是windows平台最好用的采集器了。
云采集用过才知道
现在智能云采集肯定首推坚果云云采集
云采
不知道有没有可用的??
quantumcrawler,这个很不错,收费,
虽然采集的质量还有待提高,但是很好用,可以在云端处理,
采集器的话不知道有什么好的,但是我用过千贝采集器感觉不错,
快乐采集器也不错
我自己用了云采的挺好用的
目前比较常用的是云采,据说pc端的云采分采我网站资源采集跟采集站收费专用采集器我网站资源采集,采我站收费专用采集器,
云采比较好用,先用云采一个星期再说,
我用的是爱采宝
说到采集器,必须得提到雨博采。这个小众但非常实用的采集器,适合对采集器不是那么感冒的人。他的音乐、图片、视频、文章采集特别全。最有特色的就是包含免费的广告,但是想要做百度联盟的商家并不可能给予免费的广告给。另外他的采集规则高级,他只需要点击几下鼠标就能完成,不要延迟。
windows下采集神器,推荐用hotpower采集器。 查看全部
关键词采集器(智能云采集用过才知道有没有可用的?)
关键词采集器多款采集器都有,最好用的是万词霸屏。虽然现在万词霸屏的单价比较高,但是跟其他采集器对比之下优势还是很大的。我自己用过就是windows平台最好用的采集器了。
云采集用过才知道
现在智能云采集肯定首推坚果云云采集
云采
不知道有没有可用的??
quantumcrawler,这个很不错,收费,
虽然采集的质量还有待提高,但是很好用,可以在云端处理,
采集器的话不知道有什么好的,但是我用过千贝采集器感觉不错,
快乐采集器也不错
我自己用了云采的挺好用的
目前比较常用的是云采,据说pc端的云采分采我网站资源采集跟采集站收费专用采集器我网站资源采集,采我站收费专用采集器,
云采比较好用,先用云采一个星期再说,
我用的是爱采宝
说到采集器,必须得提到雨博采。这个小众但非常实用的采集器,适合对采集器不是那么感冒的人。他的音乐、图片、视频、文章采集特别全。最有特色的就是包含免费的广告,但是想要做百度联盟的商家并不可能给予免费的广告给。另外他的采集规则高级,他只需要点击几下鼠标就能完成,不要延迟。
windows下采集神器,推荐用hotpower采集器。
关键词采集器(使用这款优采云京东商品采集器会让你感觉到科技的便利性)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-11-19 07:19
优采云京东商品采集器是一款可以在京东平台批量批量处理采集指定关键词商品的工具。如果您需要一键购买某些商品采集,使用这个优采云京东产品采集器会让您感受到科技的便利,一键完成您的所有需求。.
相关软件软件大小版本说明下载地址
优采云京东商品采集器是一款可以在京东平台批量批量处理采集指定关键词商品的工具。如果您需要一键购买某些商品采集,使用这个优采云京东产品采集器会让您感受到科技的便利,一键完成您的所有需求。
基本介绍
直接采集京东商品搜索页面数据,包括价格、评论数、销量、商品名称、商品地址、店铺名称、店铺地址、客服地址、商品地图、标签、商品参数、详细内容等。 fields ,输出为文本表格(csv)或文本文件,可用于商品市场分析、同行销售业绩评估、企业信息采集等用途。
软件特点
每个产品关键词最多支持100页,每页60个产品(在软件层面,30个产品每页为200页),大约6000个产品信息。支持详细搜索参数设置,支持多产品关键词序列采集,不同关键词使用| 或换行,支持指定类别id 采集
指示
1 下载完成后,不要运行压缩包中的软件直接使用,先解压;
2 软件同时支持32位和64位运行环境;
3 如果软件无法正常打开,请右键使用管理员模式运行。
更新日志
修复了常见错误 查看全部
关键词采集器(使用这款优采云京东商品采集器会让你感觉到科技的便利性)
优采云京东商品采集器是一款可以在京东平台批量批量处理采集指定关键词商品的工具。如果您需要一键购买某些商品采集,使用这个优采云京东产品采集器会让您感受到科技的便利,一键完成您的所有需求。.
相关软件软件大小版本说明下载地址
优采云京东商品采集器是一款可以在京东平台批量批量处理采集指定关键词商品的工具。如果您需要一键购买某些商品采集,使用这个优采云京东产品采集器会让您感受到科技的便利,一键完成您的所有需求。

基本介绍
直接采集京东商品搜索页面数据,包括价格、评论数、销量、商品名称、商品地址、店铺名称、店铺地址、客服地址、商品地图、标签、商品参数、详细内容等。 fields ,输出为文本表格(csv)或文本文件,可用于商品市场分析、同行销售业绩评估、企业信息采集等用途。
软件特点
每个产品关键词最多支持100页,每页60个产品(在软件层面,30个产品每页为200页),大约6000个产品信息。支持详细搜索参数设置,支持多产品关键词序列采集,不同关键词使用| 或换行,支持指定类别id 采集
指示
1 下载完成后,不要运行压缩包中的软件直接使用,先解压;
2 软件同时支持32位和64位运行环境;
3 如果软件无法正常打开,请右键使用管理员模式运行。
更新日志
修复了常见错误
关键词采集器(悟空QQ群采集器可以导出群号及群详细信息的通知)
采集交流 • 优采云 发表了文章 • 0 个评论 • 386 次浏览 • 2021-11-17 00:03
在我们的生活中,QQ群的使用随处可见。现在,我们每个人的QQ里都会有几个QQ群,都是为了方便大家的联系,有什么消息可以直接发到群里,不用一一通知。悟空QQ群采集器悟空QQ群采集器是一款简单易用的QQ群号批量采集工具。用户可以通过QQ群相关关键字设置,快速提取出符合条件的QQ群号。并且该软件支持过滤重复和导出所有成员,是QQ营销人员的有力武器。 一、软件功能介绍1. 可以指定单个或多个关键词到采集,可以根据指定的群成员数量推导出群号。 2.采集可以按人数、活动或腾讯默认的采集进行排序。 3.可以指定某个区域采集,也可以设置扫描各个区域。 4.多线程、全自动、快速采集。 5.可以检索组名、介绍以及标签是否收录关键词。 6.可以导出组号和组详细信息,并自动将采集的结果保存到软件目录文件夹中。 7. 可以过滤添加群和公众群的方式,直接添加群、付费群、证书群等,导出群主QQ。 二、软件界面展示软件由于腾讯的限制,每个关键词大概可以有采集500-1000个QQ群。建议精炼关键词采集!比如你想采集股票相关的,可以用长尾关键词比如股票交易所,股票分析,股票投资! 采集 如果有更多,则需要更改IP。更多信息请点击悟空营销软件官网了解 查看全部
关键词采集器(悟空QQ群采集器可以导出群号及群详细信息的通知)
在我们的生活中,QQ群的使用随处可见。现在,我们每个人的QQ里都会有几个QQ群,都是为了方便大家的联系,有什么消息可以直接发到群里,不用一一通知。悟空QQ群采集器悟空QQ群采集器是一款简单易用的QQ群号批量采集工具。用户可以通过QQ群相关关键字设置,快速提取出符合条件的QQ群号。并且该软件支持过滤重复和导出所有成员,是QQ营销人员的有力武器。 一、软件功能介绍1. 可以指定单个或多个关键词到采集,可以根据指定的群成员数量推导出群号。 2.采集可以按人数、活动或腾讯默认的采集进行排序。 3.可以指定某个区域采集,也可以设置扫描各个区域。 4.多线程、全自动、快速采集。 5.可以检索组名、介绍以及标签是否收录关键词。 6.可以导出组号和组详细信息,并自动将采集的结果保存到软件目录文件夹中。 7. 可以过滤添加群和公众群的方式,直接添加群、付费群、证书群等,导出群主QQ。 二、软件界面展示软件由于腾讯的限制,每个关键词大概可以有采集500-1000个QQ群。建议精炼关键词采集!比如你想采集股票相关的,可以用长尾关键词比如股票交易所,股票分析,股票投资! 采集 如果有更多,则需要更改IP。更多信息请点击悟空营销软件官网了解
关键词采集器(搜索引擎优化是最为愈来愈复杂的一项任务,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-15 13:19
站群和采集器的区别 搜索引擎优化是最关键的任务。同时,随着搜索引擎不断改变自己的排名算法规则,算法的每一次变化都可能导致一些排名靠前的网站一夜之间失名,失去排名的直接后果就是失去排名网站 @网站固有的大量流量。所以每一次搜索引擎算法的变化,都会在网站之间引起很大的骚动和焦虑。可以说,搜索引擎优化已经成为一项越来越复杂的任务。搜索引擎优化一、内部优化(1)META标签优化:很容易上到搜索引擎,只要关键词的使用达到一定的密度,在搜索引擎上会很容易安排 值得一提的是,搜索引擎 InfoSeek 是每天第一次更新。你早上8点提交网站,下午你就收录,第二天就会出现在搜索中。因为更新快,投稿容易收录,一大批站主开始改变方式,频繁登录不同的网站。垃圾邮件一词出现在英文中,用来描述网站所有者不负责任地制造垃圾。百度(Baidu)是一家以搜索引擎服务为主的互联网公司,由李彦宏、徐勇于2000年1月1日在北京中关村创立。中国南宋时期:公众为他搜索了千百度,描述了诗人对理想的执着追求。公司业务范围涵盖搜索、人工智能、云计算、大数据等,是中国互联网公司的三大巨头之一。2005年8月5日,在美国纳斯达克成功上市,成为首家进入纳斯达克成分股的中国公司。站群 和 采集器 的区别 成功在美国纳斯达克上市,成为首家进入纳斯达克成分股的中国公司。站群 和 采集器 的区别 成功在美国纳斯达克上市,成为首家进入纳斯达克成分股的中国公司。站群 和 采集器 的区别
<p>站群 和 采集器 的区别还没有出现在搜索引擎中。那是因为搜索引擎还没有启动收录。每个搜索引擎都允许用户提交没有收录 的站点。这个项目通常需要3-5天。SEO基于长期探索和观察获得的技术和经验,利用搜索引擎准入规则网站、网站、网站布局、 查看全部
关键词采集器(搜索引擎优化是最为愈来愈复杂的一项任务,你知道吗?)
站群和采集器的区别 搜索引擎优化是最关键的任务。同时,随着搜索引擎不断改变自己的排名算法规则,算法的每一次变化都可能导致一些排名靠前的网站一夜之间失名,失去排名的直接后果就是失去排名网站 @网站固有的大量流量。所以每一次搜索引擎算法的变化,都会在网站之间引起很大的骚动和焦虑。可以说,搜索引擎优化已经成为一项越来越复杂的任务。搜索引擎优化一、内部优化(1)META标签优化:很容易上到搜索引擎,只要关键词的使用达到一定的密度,在搜索引擎上会很容易安排 值得一提的是,搜索引擎 InfoSeek 是每天第一次更新。你早上8点提交网站,下午你就收录,第二天就会出现在搜索中。因为更新快,投稿容易收录,一大批站主开始改变方式,频繁登录不同的网站。垃圾邮件一词出现在英文中,用来描述网站所有者不负责任地制造垃圾。百度(Baidu)是一家以搜索引擎服务为主的互联网公司,由李彦宏、徐勇于2000年1月1日在北京中关村创立。中国南宋时期:公众为他搜索了千百度,描述了诗人对理想的执着追求。公司业务范围涵盖搜索、人工智能、云计算、大数据等,是中国互联网公司的三大巨头之一。2005年8月5日,在美国纳斯达克成功上市,成为首家进入纳斯达克成分股的中国公司。站群 和 采集器 的区别 成功在美国纳斯达克上市,成为首家进入纳斯达克成分股的中国公司。站群 和 采集器 的区别 成功在美国纳斯达克上市,成为首家进入纳斯达克成分股的中国公司。站群 和 采集器 的区别

<p>站群 和 采集器 的区别还没有出现在搜索引擎中。那是因为搜索引擎还没有启动收录。每个搜索引擎都允许用户提交没有收录 的站点。这个项目通常需要3-5天。SEO基于长期探索和观察获得的技术和经验,利用搜索引擎准入规则网站、网站、网站布局、
关键词采集器(阿里鱼采集器教程采过去了,怎么做好?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-11-15 13:09
关键词采集器:【阿里云】【网页版】本来是要在上面找一下网页的,被一篇从阿里里采集的教程采过去了,哈哈。应该是分析好了需要采的关键词,其实可以先放那里,真不错,想起来在更新,毕竟那篇教程还是不错的。文章里写的很详细,大家一起上车。可以拿走一个g2000+钱做投资,大家一起采集,毕竟三级联动返利的钱好赚,哈哈!如果需要成为达人才能返利的,可以私聊。速度是线上最快的采集器,速度快,稳定!。
有,我在实验室用的就是,不过要钱,
有,
不行的
可以分享给你下面的三个软件,楼主要用就用吧1。阿里鱼采集器是一款专业的手机端电商交易平台分析软件,只需要把所要采集的网站,输入到软件里面,然后进行采集,然后就可以进行分析了2。找我免费送0。1元,楼主要采集的话我会分享给你下面的三个软件,线上我用的都是软件啦3。爱采购是一款采集热门网站的软件,里面分的是一些首页的链接,楼主要是想做类的站可以下载对应的版本。
有需要联系我
一直都有买东西返现金的活动,不限金额,但要求必须是专业采集的商家,要有资质,没有资质店铺是不可以卖东西返现金的,比如我有时候去看到一些商品,有的款式不错,便宜,但是有的专业机构做的,没有牌子,但是有点名气,很多人就去购买,买了以后的返现金越来越多,因为他们采集的次数越来越多,所以有的款式经常不在别人家看到,价格还便宜。
这样的款式卖家返现比较大,但是下家想买他的东西时发现找不到,就很郁闷,就去找专业机构拿货就便宜又稳定,有些机构专业做大量的高品质的货,而的那些商家作假比较厉害,通过这些机构拿货,不用担心是假货,因为产品设计制作都是专业的,而且都有专业的程序和,根本不用担心,所以我自己有工厂想找合作的,就找这些有技术专业的供货商。分享给大家,如果你想找阿里下单的也可以联系我,我每次回答大家都很热情。 查看全部
关键词采集器(阿里鱼采集器教程采过去了,怎么做好?)
关键词采集器:【阿里云】【网页版】本来是要在上面找一下网页的,被一篇从阿里里采集的教程采过去了,哈哈。应该是分析好了需要采的关键词,其实可以先放那里,真不错,想起来在更新,毕竟那篇教程还是不错的。文章里写的很详细,大家一起上车。可以拿走一个g2000+钱做投资,大家一起采集,毕竟三级联动返利的钱好赚,哈哈!如果需要成为达人才能返利的,可以私聊。速度是线上最快的采集器,速度快,稳定!。
有,我在实验室用的就是,不过要钱,
有,
不行的
可以分享给你下面的三个软件,楼主要用就用吧1。阿里鱼采集器是一款专业的手机端电商交易平台分析软件,只需要把所要采集的网站,输入到软件里面,然后进行采集,然后就可以进行分析了2。找我免费送0。1元,楼主要采集的话我会分享给你下面的三个软件,线上我用的都是软件啦3。爱采购是一款采集热门网站的软件,里面分的是一些首页的链接,楼主要是想做类的站可以下载对应的版本。
有需要联系我
一直都有买东西返现金的活动,不限金额,但要求必须是专业采集的商家,要有资质,没有资质店铺是不可以卖东西返现金的,比如我有时候去看到一些商品,有的款式不错,便宜,但是有的专业机构做的,没有牌子,但是有点名气,很多人就去购买,买了以后的返现金越来越多,因为他们采集的次数越来越多,所以有的款式经常不在别人家看到,价格还便宜。
这样的款式卖家返现比较大,但是下家想买他的东西时发现找不到,就很郁闷,就去找专业机构拿货就便宜又稳定,有些机构专业做大量的高品质的货,而的那些商家作假比较厉害,通过这些机构拿货,不用担心是假货,因为产品设计制作都是专业的,而且都有专业的程序和,根本不用担心,所以我自己有工厂想找合作的,就找这些有技术专业的供货商。分享给大家,如果你想找阿里下单的也可以联系我,我每次回答大家都很热情。
关键词采集器(优采云关键词网址采集器的功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-11-13 12:20
优采云关键词URL采集器是一个可以根据特定的关键词快速搜索百度、360、搜狗、谷歌和采集的URL,它还可以将搜索结果的 URL 和标题保存到计算机。
关键词URL采集器的作用是帮助用户挖掘长尾词、采集外部链接、采集例子等,可以分析竞争。
【数据参考说明】
#URL#:采集的原创URL
#Title#:URL对应的页面标题
#Domain#:原创URL的域名部分,如“”中的“”
#顶级域名#:取原网址的顶级域名部分,如“”中的“”
#Description#:页面标题下方的一段描述性文字
【常见问题】
为什么我在采集一段时间后不能采集?
可能是采集受搜索引擎限制较多,重启软件继续采集,如果不改,只能在搜索引擎解封后继续采集。百度的屏蔽时间一般是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
为什么关键词采集的不同批次的结果中有一些重复的URL?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内页可能收录很多主题,不同的关键词可能会采集到网站的不同内页,当域名引用,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中有重复的URL,可以合并在一起,用软件去重(优采云·text deduplication scrambler)。
为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章的文章内页,内页收录关键词的主题,所以可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:,另存为htm文件,采集后可以打开文件查看比较。
【更新内容】
1. 转型支持OEM代理
2.添加必应和雅虎采集;多重变化
3. 将 Bing、Yahoo、Google 更改为 https 请求,以避免 采集 在某些情况下失败。
4.添加百度新闻采集。
5.一些更新。
6. 添加了 关键词 分割线选项。
7.修复百度最新修改无法采集的问题。
8.修复Bing修改失败的问题采集; 修复部分电脑无法使用xmlhttps的问题(涉及谷歌、必应、雅虎)。 查看全部
关键词采集器(优采云关键词网址采集器的功能)
优采云关键词URL采集器是一个可以根据特定的关键词快速搜索百度、360、搜狗、谷歌和采集的URL,它还可以将搜索结果的 URL 和标题保存到计算机。
关键词URL采集器的作用是帮助用户挖掘长尾词、采集外部链接、采集例子等,可以分析竞争。
【数据参考说明】
#URL#:采集的原创URL
#Title#:URL对应的页面标题
#Domain#:原创URL的域名部分,如“”中的“”
#顶级域名#:取原网址的顶级域名部分,如“”中的“”
#Description#:页面标题下方的一段描述性文字
【常见问题】
为什么我在采集一段时间后不能采集?
可能是采集受搜索引擎限制较多,重启软件继续采集,如果不改,只能在搜索引擎解封后继续采集。百度的屏蔽时间一般是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
为什么关键词采集的不同批次的结果中有一些重复的URL?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内页可能收录很多主题,不同的关键词可能会采集到网站的不同内页,当域名引用,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中有重复的URL,可以合并在一起,用软件去重(优采云·text deduplication scrambler)。
为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章的文章内页,内页收录关键词的主题,所以可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:,另存为htm文件,采集后可以打开文件查看比较。
【更新内容】
1. 转型支持OEM代理
2.添加必应和雅虎采集;多重变化
3. 将 Bing、Yahoo、Google 更改为 https 请求,以避免 采集 在某些情况下失败。
4.添加百度新闻采集。
5.一些更新。
6. 添加了 关键词 分割线选项。
7.修复百度最新修改无法采集的问题。
8.修复Bing修改失败的问题采集; 修复部分电脑无法使用xmlhttps的问题(涉及谷歌、必应、雅虎)。
关键词采集器(输入关键字采集各搜索引擎的网址、域名、标题、描述等信息支持)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-12 01:11
输入关键字采集各搜索引擎的网址、域名、标题、描述等信息
支持百度、搜狗、谷歌、必应、雅虎、360等每个关键词600到800,采集示例
关键词可以收录搜索引擎参数,就像在网页上输入关键词搜索一样,
如果百度搜索结果网址必须收录bbs的关键词,则输入“关键词 inurl:bbs”。
保存模板可以引用的数据:
#URL#采集 的原创 URL
# Title# URL对应的页面标题
#Domain#原创URL的域名部分,如“”中的“”
#Top domain# 取原创URL的顶级域部分,如“”
#描述#页面标题下方的一段描述性文字
Excel导出:
CSV是一个文本表格,Excel可以显示为多列多行数据。只需在保存模板中设置为:
“#URL#”、“#title#”、“#描述#”
此格式为 csv 格式。用引号将每一项括起来,多个项之间用逗号隔开,然后保存扩展名并填写csv。
问题重点:
1.为什么一段时间后不能采集采集?
可能是采集受搜索引擎限制比较多。一般可以通过更改IP来继续采集(如使用VPN更改IP)。如果不改,只能在搜索引擎解封后继续。采集。百度的屏蔽时间通常是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
2.不同批次的关键词采集 为什么结果中有一些重复的网址?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内页可能收录很多主题,而不同的关键词可能会采集去到网站的不同内页,当域name是引用的,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中有重复的URL,可以合并在一起,用软件去重(优采云·text deduplication scrambler)。
3.为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章的文章内页,内页收录关键词主题,可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:
, 保存为htm文件,采集后可以打开文件查看对比。
您不是VIP会员,您无权下载此资源。VIP会员 查看全部
关键词采集器(输入关键字采集各搜索引擎的网址、域名、标题、描述等信息支持)
输入关键字采集各搜索引擎的网址、域名、标题、描述等信息
支持百度、搜狗、谷歌、必应、雅虎、360等每个关键词600到800,采集示例
关键词可以收录搜索引擎参数,就像在网页上输入关键词搜索一样,
如果百度搜索结果网址必须收录bbs的关键词,则输入“关键词 inurl:bbs”。
保存模板可以引用的数据:
#URL#采集 的原创 URL
# Title# URL对应的页面标题
#Domain#原创URL的域名部分,如“”中的“”
#Top domain# 取原创URL的顶级域部分,如“”
#描述#页面标题下方的一段描述性文字
Excel导出:
CSV是一个文本表格,Excel可以显示为多列多行数据。只需在保存模板中设置为:
“#URL#”、“#title#”、“#描述#”
此格式为 csv 格式。用引号将每一项括起来,多个项之间用逗号隔开,然后保存扩展名并填写csv。
问题重点:
1.为什么一段时间后不能采集采集?
可能是采集受搜索引擎限制比较多。一般可以通过更改IP来继续采集(如使用VPN更改IP)。如果不改,只能在搜索引擎解封后继续。采集。百度的屏蔽时间通常是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
2.不同批次的关键词采集 为什么结果中有一些重复的网址?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内页可能收录很多主题,而不同的关键词可能会采集去到网站的不同内页,当域name是引用的,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中有重复的URL,可以合并在一起,用软件去重(优采云·text deduplication scrambler)。
3.为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章的文章内页,内页收录关键词主题,可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:
, 保存为htm文件,采集后可以打开文件查看对比。


您不是VIP会员,您无权下载此资源。VIP会员
关键词采集器(创佳软件园频道小编推荐优采云爱站数据采集器软件下载和使用介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-11-11 10:08
创佳软件园应用软件频道小编推荐优采云爱站data采集器软件下载和使用介绍分享给大家,也许优采云爱站data采集器@ >免费版下载的存在,为您提供了不一样的应用软件选择!快来下载吧
优采云爱站数据采集器 软件介绍
优采云爱站Data采集器是数据检索和采集的专用工具。您可以批量查询并将数据保存在本地文件中(导出到模板、共享和粘贴)。操作简单,轻松采集爱站数据!
优采云爱站数据采集器软件功能介绍
搜索权重查询
用于搜索和获取爱站搜索排名的数据可以保存在一个csv文件中(可以通过Excel选择)。优采云网络数据采集终端可以在百度上搜索关键词的所有网站排名数据。效果如何?一个典型的例子就是搜索这些网站中权重高、关键词排名网站的关键词,利用原理,综合多方面的选择,成为一个道士?创建一个 网站?做营销推广?请随意扩展!注:访客或普通VIP会员仅具有搜索部分排名数据的管理权限。可以自行申请注册,拨打爱立信高级级别,然后在程序流程中设置快速登录,搜索所有排名数据!优采云网数据< @采集 终端的实际操作非常简单。只需输入网站域名(部分域名以“|”分隔),即可搜索网站的百度收录关键词、总流量、排名网站 domain name 等内容,然后导出为Csv文件,Excel办公软件可以打开选择。
关键词分析
用于查找和获取爱括号中的关键词的数据可以存储在文本文件中。关键词分析就是输入所有关键词,比如瘦身。你可以找到很多相关的词,包括减肥,这些词在网络搜索结果中排名非常好。注:访客或普通VIP会员只能搜索管理机构发现的关键词部分,可自行申请注册,并致电爱站高级管理人员。然后,他们可以在程序流程中设置快速登录,这样他们就可以搜索并获取他们找到的所有关键词目录!其实操作比较简单。只需输入关键词(每行一个)即可快速找到关键词的关键词目录。
优采云爱站数据采集器 更新内容:
优采云爱站数据采集器v3.8.1.0更新内容
部分页面已更改;
优化的步伐从未停止!
改进和优化错误;
创佳软件园编辑推荐
除了优采云爱站data采集器非常方便之外,软件园的编辑可以满足您对软件的需求!此外,小编还推荐在线美术字体生成器等相关软件下载使用。如果喜欢,希望大家来下载! 查看全部
关键词采集器(创佳软件园频道小编推荐优采云爱站数据采集器软件下载和使用介绍)
创佳软件园应用软件频道小编推荐优采云爱站data采集器软件下载和使用介绍分享给大家,也许优采云爱站data采集器@ >免费版下载的存在,为您提供了不一样的应用软件选择!快来下载吧
优采云爱站数据采集器 软件介绍
优采云爱站Data采集器是数据检索和采集的专用工具。您可以批量查询并将数据保存在本地文件中(导出到模板、共享和粘贴)。操作简单,轻松采集爱站数据!
优采云爱站数据采集器软件功能介绍
搜索权重查询
用于搜索和获取爱站搜索排名的数据可以保存在一个csv文件中(可以通过Excel选择)。优采云网络数据采集终端可以在百度上搜索关键词的所有网站排名数据。效果如何?一个典型的例子就是搜索这些网站中权重高、关键词排名网站的关键词,利用原理,综合多方面的选择,成为一个道士?创建一个 网站?做营销推广?请随意扩展!注:访客或普通VIP会员仅具有搜索部分排名数据的管理权限。可以自行申请注册,拨打爱立信高级级别,然后在程序流程中设置快速登录,搜索所有排名数据!优采云网数据< @采集 终端的实际操作非常简单。只需输入网站域名(部分域名以“|”分隔),即可搜索网站的百度收录关键词、总流量、排名网站 domain name 等内容,然后导出为Csv文件,Excel办公软件可以打开选择。
关键词分析
用于查找和获取爱括号中的关键词的数据可以存储在文本文件中。关键词分析就是输入所有关键词,比如瘦身。你可以找到很多相关的词,包括减肥,这些词在网络搜索结果中排名非常好。注:访客或普通VIP会员只能搜索管理机构发现的关键词部分,可自行申请注册,并致电爱站高级管理人员。然后,他们可以在程序流程中设置快速登录,这样他们就可以搜索并获取他们找到的所有关键词目录!其实操作比较简单。只需输入关键词(每行一个)即可快速找到关键词的关键词目录。
优采云爱站数据采集器 更新内容:
优采云爱站数据采集器v3.8.1.0更新内容
部分页面已更改;
优化的步伐从未停止!
改进和优化错误;
创佳软件园编辑推荐
除了优采云爱站data采集器非常方便之外,软件园的编辑可以满足您对软件的需求!此外,小编还推荐在线美术字体生成器等相关软件下载使用。如果喜欢,希望大家来下载!
关键词采集器(迷你爬虫是一简单小巧的SEO抓取工具,它的作用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-11-09 13:09
迷你爬虫是一款简单小巧的SEO爬虫工具。它的作用是模拟搜索引擎抓取网页的标题、关键词、描述等信息。可以用于采集自己的网站,也可以用于采集竞争对手的网站,这样你就可以知道他们的头衔,关键词是怎样的写出来,从中学习。需要的SEOER可以下载迷你爬虫使用。
它是一款超小型快速的SEO工具,为seo行业合作伙伴快速抓取自己的网站关键词、标题、描述等内容提供简单、快速、强大的支持。通过分析抓取的内容来改进 URL。提高网站的排名。
特征
自动输入连续的 URL
获取浏览器的输入历史,可以快速找到已经输入的网址。无需记住一长串无意义的 URL。
通过输入通配符,可以快速输入一系列网址,大大降低人工输入的效率。
如果自动生成的URL需要更正,可以右键删除修改对应的URL。
灵活的人爬规则
默认提供三个常用的内容:标题、关键词和网页描述。供seo专业的同学快速上手,直接使用。快速完成老板账号的内容。
通过自定义XPath,你可以任意设置你的爬取内容,也可以设置无限制的规则。
指示
1、 安装运行,在网址输入要爬取的网页的网址,此时网址会自动添加到网址列表中,输入标题、关键词、描述在规则列表中,然后单击开始。
2、 爬取后,Cheng 会自动打开一个 Excel 表格,其中收录您输入的 URL 地址以及您输入的标题、关键词 和描述。
文件信息
文件大小:2014208 字节
MD5:FF86958701C899A7379BA612E0ABF2DE
SHA1:FE9F24ACC57D5FB6A3653D0C18850F23DE37D9E8
CRC32:5B3E0727
官方 网站:
相关搜索:SEO爬虫 查看全部
关键词采集器(迷你爬虫是一简单小巧的SEO抓取工具,它的作用)
迷你爬虫是一款简单小巧的SEO爬虫工具。它的作用是模拟搜索引擎抓取网页的标题、关键词、描述等信息。可以用于采集自己的网站,也可以用于采集竞争对手的网站,这样你就可以知道他们的头衔,关键词是怎样的写出来,从中学习。需要的SEOER可以下载迷你爬虫使用。

它是一款超小型快速的SEO工具,为seo行业合作伙伴快速抓取自己的网站关键词、标题、描述等内容提供简单、快速、强大的支持。通过分析抓取的内容来改进 URL。提高网站的排名。
特征
自动输入连续的 URL
获取浏览器的输入历史,可以快速找到已经输入的网址。无需记住一长串无意义的 URL。
通过输入通配符,可以快速输入一系列网址,大大降低人工输入的效率。
如果自动生成的URL需要更正,可以右键删除修改对应的URL。


灵活的人爬规则
默认提供三个常用的内容:标题、关键词和网页描述。供seo专业的同学快速上手,直接使用。快速完成老板账号的内容。
通过自定义XPath,你可以任意设置你的爬取内容,也可以设置无限制的规则。

指示
1、 安装运行,在网址输入要爬取的网页的网址,此时网址会自动添加到网址列表中,输入标题、关键词、描述在规则列表中,然后单击开始。

2、 爬取后,Cheng 会自动打开一个 Excel 表格,其中收录您输入的 URL 地址以及您输入的标题、关键词 和描述。

文件信息
文件大小:2014208 字节
MD5:FF86958701C899A7379BA612E0ABF2DE
SHA1:FE9F24ACC57D5FB6A3653D0C18850F23DE37D9E8
CRC32:5B3E0727
官方 网站:
相关搜索:SEO爬虫
关键词采集器(关键字网址采集器怎么做?租赁CDN防护、人工客服)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-26 15:10
Keyword URL Collector是一款专业的网站关键词采集工具,可以采集收录
关键词的网站,并且可以实现关键词 URL的批量采集,只需要输入关键词的标题、域名、描述可通过百度、搜狗、谷歌等搜索引擎获取,采集
相关网站信息。
软件截图
特征
输入关键词采集
各个搜索引擎的网址、域名、标题、描述等信息,支持百度。搜狗。谷歌。冰。雅虎。360等。每个关键词 600到800个,集合例子,关键词可以附带搜索引擎参数,就像在网页中输入关键词搜索一样,比如百度搜索结果URL必须收录
self- media 等待关键词,然后输入“关键词来自媒体、快手、抖音、小红书、视频号等”。
特征
1. 可自动搜索代理服务器,验证代理服务器,过滤掉国内ip地址,用户无需查找代理服务器;
2. 可以导入外部代理服务器并验证;
3. 可以选择不同的网卡进行优化;
4.本地网卡的mac地址在优化时可以动态修改;
5.每次点击的间隔可以随机设置;
6.每次优化都可以修改机器的显示分辨率;
7. 每次优化都可以修改ie信息;
8.完全模拟人们对怀旧网站的使用习惯,高效的优化算法;
9.符合百度和谷歌的分析习惯;
10.原生编译代码,win2000以上所有平台,包括winxp、win2003、vista等;
11. 多核优化,发送时充分利用机器,没有任何拖延和滞后。
指示
1. 下载完成后,不要运行压缩包中的软件直接使用,先解压;
2.软件同时支持32位和64位运行环境;
3.如果软件无法正常打开,请右键使用管理员模式运行。
你得到的就是你得到的
软件下载
下载仅供技术交流学习讨论使用,请勿用于非法用途!下载后请在24小时内删除!
收取的费用仅用于赞助和支持本站的组织、编辑和维护运营相关费用(服务器租用、CDN保护、人工客服等)!
此部分为付费内容,付费后即可查看
支付30元
有薪酬的?输入手机号码查看 查看全部
关键词采集器(关键字网址采集器怎么做?租赁CDN防护、人工客服)
Keyword URL Collector是一款专业的网站关键词采集工具,可以采集收录
关键词的网站,并且可以实现关键词 URL的批量采集,只需要输入关键词的标题、域名、描述可通过百度、搜狗、谷歌等搜索引擎获取,采集
相关网站信息。
软件截图
特征
输入关键词采集
各个搜索引擎的网址、域名、标题、描述等信息,支持百度。搜狗。谷歌。冰。雅虎。360等。每个关键词 600到800个,集合例子,关键词可以附带搜索引擎参数,就像在网页中输入关键词搜索一样,比如百度搜索结果URL必须收录
self- media 等待关键词,然后输入“关键词来自媒体、快手、抖音、小红书、视频号等”。
特征
1. 可自动搜索代理服务器,验证代理服务器,过滤掉国内ip地址,用户无需查找代理服务器;
2. 可以导入外部代理服务器并验证;
3. 可以选择不同的网卡进行优化;
4.本地网卡的mac地址在优化时可以动态修改;
5.每次点击的间隔可以随机设置;
6.每次优化都可以修改机器的显示分辨率;
7. 每次优化都可以修改ie信息;
8.完全模拟人们对怀旧网站的使用习惯,高效的优化算法;
9.符合百度和谷歌的分析习惯;
10.原生编译代码,win2000以上所有平台,包括winxp、win2003、vista等;
11. 多核优化,发送时充分利用机器,没有任何拖延和滞后。
指示
1. 下载完成后,不要运行压缩包中的软件直接使用,先解压;
2.软件同时支持32位和64位运行环境;
3.如果软件无法正常打开,请右键使用管理员模式运行。
你得到的就是你得到的
软件下载
下载仅供技术交流学习讨论使用,请勿用于非法用途!下载后请在24小时内删除!
收取的费用仅用于赞助和支持本站的组织、编辑和维护运营相关费用(服务器租用、CDN保护、人工客服等)!
此部分为付费内容,付费后即可查看
支付30元
有薪酬的?输入手机号码查看
关键词采集器(这款软件,只需要输入关键字就可以采集各搜索引擎收录信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-12-22 19:29
分享是一切,但价值是关键。相遇不易,请珍惜。
使用本软件,您只需在采集各个搜索引擎收录的网址、域名、标题、描述等信息中输入关键字即可。
优采云·关键词网址采集器
搜索引擎支持:搜狗、谷歌、雅虎、百度、360、必应等。
关键词可以带搜索引擎参数,就像在网页中输入关键词搜索一样,如果百度搜索结果URL必须收录bbs的关键词,则输入“关键词 inurl :bbs。”
Excel导出:
CSV是一个文本表格,Excel可以显示为多列多行数据。只需在保存模板中设置为:
“#URL#”、“#title#”、“#描述#”
此格式为 csv 格式。每个项目用引号括起来,多个项目用逗号隔开,然后保存扩展名,填入csv。
保存模板可以引用的数据:
关于#URL#
采集对象的网站 URL
关于#Title#
网站标题
关于#domain#
取原网址,不要添加/.html、/index.php等,如“xxxxx/1.html”中的“xxxxx com”
关于#顶级域#
顶级域名,不要添加二级和三级域名,如“muge.xxxxx/1.html”中的“xxxxx com”
关于#描述#
页面标题下方的一段描述性文字
部分软件使用问题解答:
1.为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章的文章内页,内页收录关键词的主题,所以可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:
, 保存为htm文件,采集后可以打开文件查看对比。
2.不同批次的关键词采集 为什么有些重复的网址?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内部页面可能收录很多主题,而不同的关键词可能会采集去不同的网站内部页面,当域name是引用的,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中存在重复的URL,可以将它们合并在一起,使用软件去重(优采云·text deduplication scrambler)。
3为什么一段时间后采集不能采集?
可能是采集受搜索引擎限制比较多。一般可以通过更改IP来继续采集(如使用VPN更改IP)。如果不改,只能在搜索引擎解封后继续采集。百度的屏蔽时间一般是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
百度云盘地址:
软件正常上报病毒。不放心的话可以用360沙盒、影子系统、虚拟机等来运行软件~ 查看全部
关键词采集器(这款软件,只需要输入关键字就可以采集各搜索引擎收录信息)
分享是一切,但价值是关键。相遇不易,请珍惜。
使用本软件,您只需在采集各个搜索引擎收录的网址、域名、标题、描述等信息中输入关键字即可。
优采云·关键词网址采集器
搜索引擎支持:搜狗、谷歌、雅虎、百度、360、必应等。
关键词可以带搜索引擎参数,就像在网页中输入关键词搜索一样,如果百度搜索结果URL必须收录bbs的关键词,则输入“关键词 inurl :bbs。”
Excel导出:
CSV是一个文本表格,Excel可以显示为多列多行数据。只需在保存模板中设置为:
“#URL#”、“#title#”、“#描述#”
此格式为 csv 格式。每个项目用引号括起来,多个项目用逗号隔开,然后保存扩展名,填入csv。
保存模板可以引用的数据:
关于#URL#
采集对象的网站 URL
关于#Title#
网站标题
关于#domain#
取原网址,不要添加/.html、/index.php等,如“xxxxx/1.html”中的“xxxxx com”
关于#顶级域#
顶级域名,不要添加二级和三级域名,如“muge.xxxxx/1.html”中的“xxxxx com”
关于#描述#
页面标题下方的一段描述性文字
部分软件使用问题解答:
1.为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章的文章内页,内页收录关键词的主题,所以可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:
, 保存为htm文件,采集后可以打开文件查看对比。
2.不同批次的关键词采集 为什么有些重复的网址?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内部页面可能收录很多主题,而不同的关键词可能会采集去不同的网站内部页面,当域name是引用的,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中存在重复的URL,可以将它们合并在一起,使用软件去重(优采云·text deduplication scrambler)。
3为什么一段时间后采集不能采集?
可能是采集受搜索引擎限制比较多。一般可以通过更改IP来继续采集(如使用VPN更改IP)。如果不改,只能在搜索引擎解封后继续采集。百度的屏蔽时间一般是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
百度云盘地址:
软件正常上报病毒。不放心的话可以用360沙盒、影子系统、虚拟机等来运行软件~
关键词采集器(关键词网址采集器绿色版批次关键词采集结果为什么会引用部分网址重复)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-12-22 18:17
关键词URL采集器 绿色版是一款可以帮助用户按关键词到采集网站的软件。在该软件中,用户可以快速执行Collect指定的关键词网站,以减少其他网页的外观。
总体介绍
输入关键字采集各搜索引擎的网址、域名、标题、描述等信息,支持百度、搜狗、谷歌、必应、雅虎、360等。每个关键词600到800,采集例子,关键词可以带搜索引擎参数,就像在网页中输入关键词搜索一样,比如百度中的搜索结果URL必须收录bbs的关键词,那么输入“关键词 inurl:bbs。”
资料参考
#URL#:采集的原创URL
#Title#:URL对应的页面标题
#Domain#:原创URL的域名部分,如“”中的“”
#顶级域名#:取原网址的顶级域名部分,如“”中的“”
#Description#:页面标题下方的一段描述性文字
常见问题
1.为什么一段时间后不能采集采集?
这可能是采集受搜索引擎限制较多,重启软件继续采集,如果不改,只能在搜索引擎解封后继续采集。百度的屏蔽时间一般是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
2.不同批次的关键词采集 为什么会有一些重复的网址?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内部页面可能收录很多主题,而不同的关键词可能会采集去不同的网站内部页面,当域name是引用的,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中存在重复的URL,可以将它们合并在一起,使用软件去重(优采云·text deduplication scrambler)。
3.为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章的文章内页,内页收录关键词的主题,所以可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:,另存为htm文件,采集后可以打开文件查看比较。
更新日志
1. 转型支持OEM代理
2.添加必应和雅虎采集;多重变化
3. 将 Bing、Yahoo、Google 更改为 https 请求,以避免 采集 在某些情况下失败。
4.添加百度新闻采集。
5.一些更新。
6. 添加了 关键词 分割线选项。
7.修复百度最新修改无法采集的问题。
8.修复Bing的改动采集失效问题;修复部分电脑无法使用xmlhttps的问题(涉及谷歌、必应、雅虎)。 查看全部
关键词采集器(关键词网址采集器绿色版批次关键词采集结果为什么会引用部分网址重复)
关键词URL采集器 绿色版是一款可以帮助用户按关键词到采集网站的软件。在该软件中,用户可以快速执行Collect指定的关键词网站,以减少其他网页的外观。
总体介绍
输入关键字采集各搜索引擎的网址、域名、标题、描述等信息,支持百度、搜狗、谷歌、必应、雅虎、360等。每个关键词600到800,采集例子,关键词可以带搜索引擎参数,就像在网页中输入关键词搜索一样,比如百度中的搜索结果URL必须收录bbs的关键词,那么输入“关键词 inurl:bbs。”
资料参考
#URL#:采集的原创URL
#Title#:URL对应的页面标题
#Domain#:原创URL的域名部分,如“”中的“”
#顶级域名#:取原网址的顶级域名部分,如“”中的“”
#Description#:页面标题下方的一段描述性文字
常见问题
1.为什么一段时间后不能采集采集?
这可能是采集受搜索引擎限制较多,重启软件继续采集,如果不改,只能在搜索引擎解封后继续采集。百度的屏蔽时间一般是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
2.不同批次的关键词采集 为什么会有一些重复的网址?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内部页面可能收录很多主题,而不同的关键词可能会采集去不同的网站内部页面,当域name是引用的,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中存在重复的URL,可以将它们合并在一起,使用软件去重(优采云·text deduplication scrambler)。
3.为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章的文章内页,内页收录关键词的主题,所以可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:,另存为htm文件,采集后可以打开文件查看比较。
更新日志
1. 转型支持OEM代理
2.添加必应和雅虎采集;多重变化
3. 将 Bing、Yahoo、Google 更改为 https 请求,以避免 采集 在某些情况下失败。
4.添加百度新闻采集。
5.一些更新。
6. 添加了 关键词 分割线选项。
7.修复百度最新修改无法采集的问题。
8.修复Bing的改动采集失效问题;修复部分电脑无法使用xmlhttps的问题(涉及谷歌、必应、雅虎)。
关键词采集器(关键词采集器解决中小企业上网找展会无从下手的问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-12-19 17:05
关键词采集器不仅可以解决了中小企业上网找产品信息找展会找展位无从下手的问题,还可以为您节省上网时间。根据网络搜索平台做好关键词布局,大量的产品信息可以从中找到你需要的产品。像是化妆品类目中,找到你需要的化妆品产品,再对产品进行筛选,就可以找到化妆品的外观、功效、生产厂家等信息。
百度搜“关键词采集器”
关键词采集的时候主要看的是收录情况及收录的范围。根据产品属性和搜索习惯做好专业外链。
关键词采集器主要看数据收录情况。大家可以对比下哪些关键词我们做的较少,那就要积极去采集,这样我们的关键词数据就会少。
做竞价有时候需要多的关键词来提高排名,这个时候就需要搜索,一旦没有收录的时候就去采集,做好站内优化。
前期积累,后期采集。
关键词采集器主要看你的产品是竞价位还是正常的位置,建议你先提升网站页面内容,出现更多的产品词,进而竞价上去。
专业采集:谷歌学术搜索如何研究互联网?百度学术搜索如何引流?搜狗学术搜索如何让你的产品或服务名扬四海?(有点小广告)
关键词采集器怎么会不好用呢?你可以采集竞价词、产品词、社区词、微博词、网站词、电商词等等,你要是知道还是不知道该怎么去实现搜索,那就需要现在去关键词搜索。 查看全部
关键词采集器(关键词采集器解决中小企业上网找展会无从下手的问题)
关键词采集器不仅可以解决了中小企业上网找产品信息找展会找展位无从下手的问题,还可以为您节省上网时间。根据网络搜索平台做好关键词布局,大量的产品信息可以从中找到你需要的产品。像是化妆品类目中,找到你需要的化妆品产品,再对产品进行筛选,就可以找到化妆品的外观、功效、生产厂家等信息。
百度搜“关键词采集器”
关键词采集的时候主要看的是收录情况及收录的范围。根据产品属性和搜索习惯做好专业外链。
关键词采集器主要看数据收录情况。大家可以对比下哪些关键词我们做的较少,那就要积极去采集,这样我们的关键词数据就会少。
做竞价有时候需要多的关键词来提高排名,这个时候就需要搜索,一旦没有收录的时候就去采集,做好站内优化。
前期积累,后期采集。
关键词采集器主要看你的产品是竞价位还是正常的位置,建议你先提升网站页面内容,出现更多的产品词,进而竞价上去。
专业采集:谷歌学术搜索如何研究互联网?百度学术搜索如何引流?搜狗学术搜索如何让你的产品或服务名扬四海?(有点小广告)
关键词采集器怎么会不好用呢?你可以采集竞价词、产品词、社区词、微博词、网站词、电商词等等,你要是知道还是不知道该怎么去实现搜索,那就需要现在去关键词搜索。
关键词采集器(自媒体爆文采集工具有哪些?百度索引工具介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-12-17 11:21
自媒体爆文采集 有哪些工具?
自媒体的新闻采编是一种思维广泛的趋势,呈现出多元化的动态,而不是单一的工具。我们的愿景是采集和存档的最佳方式。我们手中的笔,就是记录的意义。我们从不同的角度拍摄我们生活中的每一个视频和照片。所以,在自媒体这个领域,我们要符合自己的标准,懂得随时随地捕捉各种素材,用智慧和现实生活中的点点滴滴,给读者呈现最具感染力和高——优质作品,履行媒体人的责任。,完成服务大众的复兴使命
正在寻找 关键词 搜索工具?
百度占据了国内搜索引擎的半壁江山,所以关键词搜索工具,一个百度系列就够了,只是使用方法,分享一下我在百度上搜索关键词的方法。
以关键词“马云”为例,我们在百度首页的搜索栏中输入“马云”,可以看到与主要关键词相关的、代表用户搜索趋势的关键词下拉列表在网上。并且点击每个相关关键词后,会出现新的相关关键词,使用起来非常方便。
另一种是百度索引工具。进入百度索引的搜索栏后,点击需求图可以看到一些与主要关键词相关的关键词,然后通过相关搜索得到一些长尾关键词。
这些是一些常用的小方法。如果觉得有用,请关注采集。我希望我的回答能有所帮助。
文本关键词提取工具输入关键词自动生成文章文本关键词提取 查看全部
关键词采集器(自媒体爆文采集工具有哪些?百度索引工具介绍)
自媒体爆文采集 有哪些工具?
自媒体的新闻采编是一种思维广泛的趋势,呈现出多元化的动态,而不是单一的工具。我们的愿景是采集和存档的最佳方式。我们手中的笔,就是记录的意义。我们从不同的角度拍摄我们生活中的每一个视频和照片。所以,在自媒体这个领域,我们要符合自己的标准,懂得随时随地捕捉各种素材,用智慧和现实生活中的点点滴滴,给读者呈现最具感染力和高——优质作品,履行媒体人的责任。,完成服务大众的复兴使命
正在寻找 关键词 搜索工具?
百度占据了国内搜索引擎的半壁江山,所以关键词搜索工具,一个百度系列就够了,只是使用方法,分享一下我在百度上搜索关键词的方法。
以关键词“马云”为例,我们在百度首页的搜索栏中输入“马云”,可以看到与主要关键词相关的、代表用户搜索趋势的关键词下拉列表在网上。并且点击每个相关关键词后,会出现新的相关关键词,使用起来非常方便。
另一种是百度索引工具。进入百度索引的搜索栏后,点击需求图可以看到一些与主要关键词相关的关键词,然后通过相关搜索得到一些长尾关键词。
这些是一些常用的小方法。如果觉得有用,请关注采集。我希望我的回答能有所帮助。
文本关键词提取工具输入关键词自动生成文章文本关键词提取
关键词采集器(采集搜索结果的网址和标题输出保存(图)!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-12-14 16:01
根据关键词搜索百度、搜狗、谷歌、必应、雅虎、360等,输出并保存搜索结果的URL和标题。谷歌需要翻墙。每个 关键词 600 到 800 个条目。采集示例>>
关键词可以收录搜索引擎参数,就像在网页中输入关键词搜索一样,如果百度搜索结果URL必须收录bbs的关键词,则输入“关键词网址:bbs。”
保存模板可以引用的数据:
#URL#:采集的原创URL
#Title#:URL对应的页面标题
#Domain#:原创URL的域名部分,如“”中的“”
#顶级域名#:取原网址的顶级域名部分,如“”中的“”
#Description#:页面标题下方的一段描述性文字
问题重点:
1、为什么采集过一段时间就不行了采集?
可能是采集受搜索引擎限制比较多。一般可以通过更改IP来继续采集(如使用VPN更改IP)。如果不改,只能在搜索引擎解封采集后继续。百度的屏蔽时间一般是半小时到几个小时。
2、不同批次的关键词采集 为什么会有一些重复的网址?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内部页面可能收录很多主题,而不同的关键词可能会采集去不同的网站内部页面,当域name是引用的,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中有重复的URL,可以合并在一起,用软件去重(text deduplication scrambler)。
3、为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站的文章文章内页,内页收录关键词的主题,所以可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:
, 保存为htm文件,采集后可以打开文件查看对比。
下载链接:
点击这里下载-SM关键词URL采集器V1.921 Press关键词采集搜索引擎收录 查看全部
关键词采集器(采集搜索结果的网址和标题输出保存(图)!)
根据关键词搜索百度、搜狗、谷歌、必应、雅虎、360等,输出并保存搜索结果的URL和标题。谷歌需要翻墙。每个 关键词 600 到 800 个条目。采集示例>>
关键词可以收录搜索引擎参数,就像在网页中输入关键词搜索一样,如果百度搜索结果URL必须收录bbs的关键词,则输入“关键词网址:bbs。”
保存模板可以引用的数据:
#URL#:采集的原创URL
#Title#:URL对应的页面标题
#Domain#:原创URL的域名部分,如“”中的“”
#顶级域名#:取原网址的顶级域名部分,如“”中的“”
#Description#:页面标题下方的一段描述性文字
问题重点:
1、为什么采集过一段时间就不行了采集?
可能是采集受搜索引擎限制比较多。一般可以通过更改IP来继续采集(如使用VPN更改IP)。如果不改,只能在搜索引擎解封采集后继续。百度的屏蔽时间一般是半小时到几个小时。
2、不同批次的关键词采集 为什么会有一些重复的网址?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内部页面可能收录很多主题,而不同的关键词可能会采集去不同的网站内部页面,当域name是引用的,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中有重复的URL,可以合并在一起,用软件去重(text deduplication scrambler)。
3、为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站的文章文章内页,内页收录关键词的主题,所以可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:
, 保存为htm文件,采集后可以打开文件查看对比。
下载链接:
点击这里下载-SM关键词URL采集器V1.921 Press关键词采集搜索引擎收录
关键词采集器(关键词采集器_手机网站seo必备工具-51.io)
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-12-11 02:02
关键词采集器_手机网站seo必备工具可以了解一下。
bootstrap官方很久没更新了,而且他们把官方文档api都给封装了,估计现在不更新更新也是几年后。你可以试试威猛网站,
/可以
/我自己写的一个seo工具,
不知道有没有实现这个功能。
/
知道的一个工具,直接搜索就可以看到了。
可以试试自动网站采集工具,免费的有qwebgifs。这个爬虫工具里,采集非花钱买的站点也不在话下,差不多10m的站目前均有接口,可以直接接入。也可以开启vip每个月独立采集1000-2000个网站。关注公众号,了解更多自动网站采集/爬虫实用工具,获取更多实用技巧。搜索并关注杰出的博客或网站article|youxiyanjoy。
chinaz
chinaz,circleuppro,这两个都是外包的cms,当然对于想做网站seo的人也比较好用,chinaz提供的很多seo插件,circleup更多的是对于网站结构的优化,
要了解一个网站可以上博客园,应用博客,百度经验,都可以了解到。
semrush
alexa:51apk.io_比google-alexa还早的网站排名统计工具-51apk.io51apk.io内容运营宝-千百万网站(比google-alexa还早的网站排名统计工具)-51apk.iobaiduzookie.io,不是特别稳定,可以尝试。edmo.io,类似edm数据库,技术支持很耐心。(注:edmo无法用来代替cookie)。 查看全部
关键词采集器(关键词采集器_手机网站seo必备工具-51.io)
关键词采集器_手机网站seo必备工具可以了解一下。
bootstrap官方很久没更新了,而且他们把官方文档api都给封装了,估计现在不更新更新也是几年后。你可以试试威猛网站,
/可以
/我自己写的一个seo工具,
不知道有没有实现这个功能。
/
知道的一个工具,直接搜索就可以看到了。
可以试试自动网站采集工具,免费的有qwebgifs。这个爬虫工具里,采集非花钱买的站点也不在话下,差不多10m的站目前均有接口,可以直接接入。也可以开启vip每个月独立采集1000-2000个网站。关注公众号,了解更多自动网站采集/爬虫实用工具,获取更多实用技巧。搜索并关注杰出的博客或网站article|youxiyanjoy。
chinaz
chinaz,circleuppro,这两个都是外包的cms,当然对于想做网站seo的人也比较好用,chinaz提供的很多seo插件,circleup更多的是对于网站结构的优化,
要了解一个网站可以上博客园,应用博客,百度经验,都可以了解到。
semrush
alexa:51apk.io_比google-alexa还早的网站排名统计工具-51apk.io51apk.io内容运营宝-千百万网站(比google-alexa还早的网站排名统计工具)-51apk.iobaiduzookie.io,不是特别稳定,可以尝试。edmo.io,类似edm数据库,技术支持很耐心。(注:edmo无法用来代替cookie)。
关键词采集器(优采云软件出品的一款1688(换行采集1688)产品信息批量采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2021-12-11 01:24
优采云软件制作的1688(阿里巴巴)产品信息批次采集软件
直接采集1688产品搜索页面数据,包括公司名称、旺旺号、价格、月营业额、产品名称、产品网址、产品描述、回复、发货、商业模式、供应水平、供应产品、满意度等领域学历、联系人、联系方式(手机号或固话)等,输出为文本表格(csv)或文本文件,可用于产品市场分析、同行销售业绩评估、企业信息采集和其他目的。
每个产品关键词最多支持100页,每页60个产品,大约6000个产品信息。支持详细搜索参数设置,支持多产品关键词序列采集,不同关键词使用/或换行分隔,支持字段排序(点击标题栏)然后导出保存
特别说明
登录或验证码1688弹窗,第一次用于登录,登录后可立即关闭窗口继续采集;后面用来输入验证码,支持自己找人打码(建议找人码等)。如果验证码出现频繁,让窗口在输入验证码后自动等待15分钟再继续采集,否则窗口会一直弹出。
内置采集间隔软件内置采集间隔时间(每20个产品10秒),尽量避免验证码数量。经测试,内置间隔后验证码几乎不出现或很少出现,如果没有内置间隔,验证码会频繁出现,输入无效。每次输入验证码后必须等待15分钟,以缓解频繁的验证码。所以虽然内置区间采集比较慢,但好在水流长,可以慢慢挂,总比快验证码好。
采集字段
默认字段 搜索页面直接显示的字段,如公司名称、旺旺号、价格、月营业额、产品名称、产品网址
移动鼠标以显示该字段。将鼠标移动到搜索页面产品显示的字段,如货物描述、响应、交付、商业模式、供应水平、供应产品和满意度。如果采集这样的字段会导致速度稍慢,但是因为内置了采集间隔设置(20个产品10秒),这种慢不明显甚至不存在(正常情况下,20个产品读取鼠标光标显示字段不需要10秒)。
联系人字段包括联系人和联系方式,只有进入公司简介页面后才能读取。如果采集这个字段会导致速度明显变慢(20个产品读取联系人字段大约20秒)。
收录文件
FastVerCode.dll
配置文件
水庙.rc
优采云·1688个产品采集器.exe
升级记录
1.0.0.0:2017年1月23日发布第一个版本。
1.0.1.0:增加每店商品数量采集的设置,不设置或为0则无限制;添加联系人字段采集。 查看全部
关键词采集器(优采云软件出品的一款1688(换行采集1688)产品信息批量采集软件)
优采云软件制作的1688(阿里巴巴)产品信息批次采集软件
直接采集1688产品搜索页面数据,包括公司名称、旺旺号、价格、月营业额、产品名称、产品网址、产品描述、回复、发货、商业模式、供应水平、供应产品、满意度等领域学历、联系人、联系方式(手机号或固话)等,输出为文本表格(csv)或文本文件,可用于产品市场分析、同行销售业绩评估、企业信息采集和其他目的。
每个产品关键词最多支持100页,每页60个产品,大约6000个产品信息。支持详细搜索参数设置,支持多产品关键词序列采集,不同关键词使用/或换行分隔,支持字段排序(点击标题栏)然后导出保存
特别说明
登录或验证码1688弹窗,第一次用于登录,登录后可立即关闭窗口继续采集;后面用来输入验证码,支持自己找人打码(建议找人码等)。如果验证码出现频繁,让窗口在输入验证码后自动等待15分钟再继续采集,否则窗口会一直弹出。
内置采集间隔软件内置采集间隔时间(每20个产品10秒),尽量避免验证码数量。经测试,内置间隔后验证码几乎不出现或很少出现,如果没有内置间隔,验证码会频繁出现,输入无效。每次输入验证码后必须等待15分钟,以缓解频繁的验证码。所以虽然内置区间采集比较慢,但好在水流长,可以慢慢挂,总比快验证码好。
采集字段
默认字段 搜索页面直接显示的字段,如公司名称、旺旺号、价格、月营业额、产品名称、产品网址
移动鼠标以显示该字段。将鼠标移动到搜索页面产品显示的字段,如货物描述、响应、交付、商业模式、供应水平、供应产品和满意度。如果采集这样的字段会导致速度稍慢,但是因为内置了采集间隔设置(20个产品10秒),这种慢不明显甚至不存在(正常情况下,20个产品读取鼠标光标显示字段不需要10秒)。
联系人字段包括联系人和联系方式,只有进入公司简介页面后才能读取。如果采集这个字段会导致速度明显变慢(20个产品读取联系人字段大约20秒)。
收录文件
FastVerCode.dll
配置文件
水庙.rc
优采云·1688个产品采集器.exe
升级记录
1.0.0.0:2017年1月23日发布第一个版本。
1.0.1.0:增加每店商品数量采集的设置,不设置或为0则无限制;添加联系人字段采集。
关键词采集器( 九江SEO优化:一下domain指令是什么?有什么作用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-12-04 18:15
九江SEO优化:一下domain指令是什么?有什么作用)
四川专业关键词采集要多少钱
对于SEO来说,SEO优化中用到的指令很多,使用最多的指令无非就是站点指令和域指令。site命令用于查询收录的数量,domain命令用于查询反链数量。接下来九江SEO优化就为大家介绍一下什么是域命令,它的作用是什么。有兴趣的可以去看看。
四川专业关键词采集要多少钱
指令是什么?jxgj001
站长使用DOMAIN查询自己的网站外链。对于百度,使用DOMAIN点击自己的域名可以看到网站的反向链接。
什么是优化域指令?有什么作用?
命令适用于高权重站,但不适用于一般性能和新站。原因是负责搜索引擎域命令的服务器无法实时呈现特定的网站相关域结果,除非权重很高。对于搜索引擎来说,一个页面上的相关页面(即有文字链接)的数量是随时变化的。权重低的页面爬取深度较低,会出现长时间没有相关域的现象,即外链不实时生效。此时,搜索引擎发布的相关领域结果很可能是各种随机结果的乱七八糟。其实也可以这样理解。将域链接视为特殊的 关键词,搜索引擎将使用此 关键词 索引页面,
四川专业关键词采集要多少钱
指令有什么用?
一.查询自己网站 反向链接
老罗用DOMAIN得到的效果,就是外链的布局这方面不好说。其实按照笔者的说法,周伯通的永久外链大多属于BD反链的那种,所以目前是雅虎的。点击外链排名关闭店铺。这样做的原因是,与SE相比,您可以看到基于DOMAIN的商店之间的双向链接,丢弃了重要的。这个比较值得推荐。但是,运行 DOMAIN 排名和创建超级连接的时间少于价格。是的,条件是外链的锚文本是网页,如果是整个seo站点,是看不到的。
综合来看,各种规模的设备集合成为了这样的动力。无奈再靠近五口北企业设备一点。靠近设备的速度相当慢,信息行号也没有异常正确。所以体验是原封不动的漂亮小丽的平台百度外链的时候直接去搜索引擎导入DOMINA+网站一年推广多少钱,比如域名:这种形式的定制链接终于很正确和正确的信号信息。
四川专业关键词采集要多少钱
二.查看对手网站反向链接
既然DOMAIN让百度搜索引擎的价格反链,是一个非常URL的,当然也是一个可以作为搜索优化对手的网站反链。这在官网优化方面尤其具有相关性和意义。例如,如果您不知道在哪里做外部链接,那么您不知道在哪里做外部链接。季节胜于口耳相传。通过DOMAIN,点击对方的网点,上到对方做外链。是的,它应该能够帮助搜索的部分效用比口耳相传要好。
四川专业关键词采集要多少钱
之所以这么说,是因为小李在做优化的时候,DOMAIN信息还是让女性在不知道竞争对手的外链的情况下,更容易写官网。如果反对者在这些事情上做外部链接,请在上面发表评论。外链产品品牌还不错,对于没有外链资源的机器狼来说,DOMAIN请求的是几台外链资源制造机器。只要DOMAIN随机组合一段时间,就可以轻松找到外链。飞机出来了 自然,如果太多,你可以把一些网站的排名等困难贴到网上。这需要张星宇耐心的解决。一旦DOMAIN回来了,很简单很容易得知对方'
四川专业关键词采集要多少钱
三.查询特定的网站反向链接
相比菜鸟和大部分张星宇坚持DOMAIN的马刺,特别的估计是你可以毫无良心地在DOMAIN的页面上查看所有店铺的外部链接一段时间。其实只要知道ZAC的真实密码,卖家排名就优化了。马刺可以组合。就像你要分析商家反链的关键点和某个平面外链的出现一样,可以通过组合订单来完成。比如作者希望平台在一个强大的网站外链,一种来源于飞飞之家官网。
但是,依靠 DOMAIN+SITE 融合可能会出乎意料。之所以这样说,是因为通过DOMAIN+SITE的任何一种网页,你都可以从单个商店的外部链接中获取这种URL28。这和价格使人进入职场进退两难。更新某个要收费的网站上的外部链接非常有用。
优化的指令很多,最常用的是site和domain。MCLOS SEOer 可以通过更多说明来解决。 查看全部
关键词采集器(
九江SEO优化:一下domain指令是什么?有什么作用)
四川专业关键词采集要多少钱
对于SEO来说,SEO优化中用到的指令很多,使用最多的指令无非就是站点指令和域指令。site命令用于查询收录的数量,domain命令用于查询反链数量。接下来九江SEO优化就为大家介绍一下什么是域命令,它的作用是什么。有兴趣的可以去看看。
四川专业关键词采集要多少钱
指令是什么?jxgj001
站长使用DOMAIN查询自己的网站外链。对于百度,使用DOMAIN点击自己的域名可以看到网站的反向链接。
什么是优化域指令?有什么作用?
命令适用于高权重站,但不适用于一般性能和新站。原因是负责搜索引擎域命令的服务器无法实时呈现特定的网站相关域结果,除非权重很高。对于搜索引擎来说,一个页面上的相关页面(即有文字链接)的数量是随时变化的。权重低的页面爬取深度较低,会出现长时间没有相关域的现象,即外链不实时生效。此时,搜索引擎发布的相关领域结果很可能是各种随机结果的乱七八糟。其实也可以这样理解。将域链接视为特殊的 关键词,搜索引擎将使用此 关键词 索引页面,
四川专业关键词采集要多少钱
指令有什么用?
一.查询自己网站 反向链接
老罗用DOMAIN得到的效果,就是外链的布局这方面不好说。其实按照笔者的说法,周伯通的永久外链大多属于BD反链的那种,所以目前是雅虎的。点击外链排名关闭店铺。这样做的原因是,与SE相比,您可以看到基于DOMAIN的商店之间的双向链接,丢弃了重要的。这个比较值得推荐。但是,运行 DOMAIN 排名和创建超级连接的时间少于价格。是的,条件是外链的锚文本是网页,如果是整个seo站点,是看不到的。
综合来看,各种规模的设备集合成为了这样的动力。无奈再靠近五口北企业设备一点。靠近设备的速度相当慢,信息行号也没有异常正确。所以体验是原封不动的漂亮小丽的平台百度外链的时候直接去搜索引擎导入DOMINA+网站一年推广多少钱,比如域名:这种形式的定制链接终于很正确和正确的信号信息。
四川专业关键词采集要多少钱
二.查看对手网站反向链接
既然DOMAIN让百度搜索引擎的价格反链,是一个非常URL的,当然也是一个可以作为搜索优化对手的网站反链。这在官网优化方面尤其具有相关性和意义。例如,如果您不知道在哪里做外部链接,那么您不知道在哪里做外部链接。季节胜于口耳相传。通过DOMAIN,点击对方的网点,上到对方做外链。是的,它应该能够帮助搜索的部分效用比口耳相传要好。
四川专业关键词采集要多少钱
之所以这么说,是因为小李在做优化的时候,DOMAIN信息还是让女性在不知道竞争对手的外链的情况下,更容易写官网。如果反对者在这些事情上做外部链接,请在上面发表评论。外链产品品牌还不错,对于没有外链资源的机器狼来说,DOMAIN请求的是几台外链资源制造机器。只要DOMAIN随机组合一段时间,就可以轻松找到外链。飞机出来了 自然,如果太多,你可以把一些网站的排名等困难贴到网上。这需要张星宇耐心的解决。一旦DOMAIN回来了,很简单很容易得知对方'
四川专业关键词采集要多少钱
三.查询特定的网站反向链接
相比菜鸟和大部分张星宇坚持DOMAIN的马刺,特别的估计是你可以毫无良心地在DOMAIN的页面上查看所有店铺的外部链接一段时间。其实只要知道ZAC的真实密码,卖家排名就优化了。马刺可以组合。就像你要分析商家反链的关键点和某个平面外链的出现一样,可以通过组合订单来完成。比如作者希望平台在一个强大的网站外链,一种来源于飞飞之家官网。
但是,依靠 DOMAIN+SITE 融合可能会出乎意料。之所以这样说,是因为通过DOMAIN+SITE的任何一种网页,你都可以从单个商店的外部链接中获取这种URL28。这和价格使人进入职场进退两难。更新某个要收费的网站上的外部链接非常有用。
优化的指令很多,最常用的是site和domain。MCLOS SEOer 可以通过更多说明来解决。
关键词采集器(查询一个设计网站的关键词数据是非常有必要的!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-12-01 06:13
对于seoer来说,关注网站的关键词数据是很重要的。关键词排名、流量来源、peer网站数据,那么使用seo查询工具也是非常有必要的。比较知名的有爱站站长工具、站长工具和5118。
当然,现在比较全面、应用比较广泛的就是5118了!
从数据上,还有功能上,5118都非常强大!
如果可能,请付费!
5118的防爬还是很不错的!
需要登录采集,我发现5118已经更新一次了!
比如登录账号需要通过滑块验证码的防爬限制,关键词索引等数据以图片加密的形式展示。.
不过有些数据还是可以参考的!所以,python 起来了!
打听一个设计网站,设计成瘾的情况关键词
抓取网址:
如果您不是付费会员,则只能查看前100页数据!
很多数据被反爬限制了,可惜了!
虽然有5118会员登录的滑块验证码,但是cookies登录还是非常好用的!
我们手动添加cookies来登录需要的数据采集。
几个关键点:
1.添加协议头:
headers={
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '0',
'Cookie': Cookies,
'Host': 'www.5118.com',
'Origin': 'https://www.5118.com',
'Referer': 'https://www.5118.com/',
'User-Agent': ua,
'X-Requested-With': 'XMLHttpRequest',
}
自己添加ua和cooikes!
当然这是一个完整的协议头,有的可以删掉,大家可以自己试试!
2.zip函数的使用和格式化数据的处理之前也有分享过!
for keyword,rank,title,link,index_link in zip(keywords,ranks,titles,links,index_links):
data=[
keyword,
rank.xpath('string(.)').strip().replace(' ','').replace('\r\n','-'),
self.get_change(rank),
title,
unquote(link.split('target=')[-1]),
'https:{}'.format(index_link),
]
print(data)
3. 处理排名波动的情况
从源码查询可以看出,绿色表示排名上升,红色表示排名下降。这里有一个判断来获取!
#判断排名是否提升
def get_change(self,rank):
rank=etree.tostring(rank).decode('utf-8')
if "red" in str(rank):
change="下降"
elif "green" in str(rank):
change = "提升"
else:
change = "不变"
return change
4.关键词写入数据到csv
写了一个案例,找到了两个参考案例
import csv
#关键词数据写入csv
def write_keywords(self):
path='{}_keywords.csv'.format(self.file_name)
csvfile = open(path, 'a+')
for keyword in self.keyword_datas:
csvfile.write('%s\n' % keyword)
print("5118关键词搜索数据写入csv成功!")
#参考一
def write_csv(self):
path = "aa.csv"
with open(path, 'a+') as f:
csv_write = csv.writer(f)
data_row = ["1", "2"]
csv_write.writerow(data_row)
# 参考二
def wcsv(self):
csvfile = open('csvtest.csv', 'w')
writer = csv.writer(csvfile)
writer.writerow(['keywords'])
data = [
('1', 'http://www.xiaoheiseo.com/', '小黑'),
('2', 'http://www.baidu.com/', '百度'),
('3', 'http://www.jd.com/', '京东')
]
writer.writerows(data)
csvfile.close()
5.查询网站相关关键词数据写入excel表
使用第三方库 xlsxwriter
#数据写入excle表格
def write_to_xlsx(self):
workbook = xlsxwriter.Workbook('{}_search_results.xlsx'.format(self.file_name)) # 创建一个Excel文件
worksheet = workbook.add_worksheet(self.file_name)
title = ['关键词', '排名', '排名波动', '网页标题', '网页链接', '长尾词链接'] # 表格title
worksheet.write_row('A1', title)
for index, data in enumerate(self.data_lists):
num0 = str(index + 2)
row = 'A' + num0
worksheet.write_row(row, data)
workbook.close()
print("5118搜索数据写入excel成功!")
由于页码也是js生成的,没找到,所以自己输入页码!
输入查询网站 URL格式:主域名用于爬取后的数据存储文件!
附上完整代码:
#5118网站关键词数据获取
import requests
from lxml import etree
from urllib.parse import unquote
import xlsxwriter
import time
import csv
class C5118(object):
def __init__(self,url,nums):
self.keyword_datas=[]
self.data_lists=[]
self.index_links_hrefs=[]
self.headers={
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '0',
'Cookie': Cookies,
'Host': 'www.5118.com',
'Origin': 'https://www.5118.com',
'Referer': 'https://www.5118.com/',
'User-Agent': UA,
'X-Requested-With': 'XMLHttpRequest',
}
self.post_url=url
self.file_name=url.split('.')[1]
self.pagenums=nums
#判断排名是否提升
def get_change(self,rank):
rank=etree.tostring(rank).decode('utf-8')
if "red" in str(rank):
change="下降"
elif "green" in str(rank):
change = "提升"
else:
change = "不变"
return change
#获取数据
def get_data(self,pagenum):
url="https://www.5118.com/seo/baidupc"
params={
'isPager': 'true',
'viewtype': '2',
'days': '90',
'url': self.post_url,
'orderField': 'Rank',
'orderDirection': 'asc',
'pageIndex': pagenum, #页码
'catalogName': '',
}
response=requests.post(url,params=params,headers=self.headers)
time.sleep(1)
print(response.status_code)
doc=etree.HTML(response.content.decode('utf-8'))
keywords= doc.xpath('//tr[@class="list-row"]/td[1]/a/text()') #关键词
print(keywords)
self.keyword_datas.extend(keywords)
ranks = doc.xpath('//tr[@class="list-row"]/td[2]/a') #排名
titles = doc.xpath('//tr[@class="list-row"]/td[5]/a/text()') #网页标题
links=doc.xpath('//tr[@class="list-row"]/td[5]/a/@href') #网页链接
index_links=doc.xpath('//tr[@class="list-row"]/td[7]/a/@href') #长尾词数量链接
self.index_links_hrefs.extend(index_links)
for keyword,rank,title,link,index_link in zip(keywords,ranks,titles,links,index_links):
data=[
keyword,
rank.xpath('string(.)').strip().replace(' ','').replace('\r\n','-'),
self.get_change(rank),
title,
unquote(link.split('target=')[-1]),
'https:{}'.format(index_link),
]
print(data)
self.data_lists.append(data)
time.sleep(4)
return self.data_lists
#关键词数据写入csv
def write_keywords(self):
path='{}_keywords.csv'.format(self.file_name)
csvfile = open(path, 'a+')
for keyword in self.keyword_datas:
csvfile.write('%s\n' % keyword)
print("5118关键词搜索数据写入csv成功!")
#数据写入excle表格
def write_to_xlsx(self):
workbook = xlsxwriter.Workbook('{}_search_results.xlsx'.format(self.file_name)) # 创建一个Excel文件
worksheet = workbook.add_worksheet(self.file_name)
title = ['关键词', '排名', '排名波动', '网页标题', '网页链接', '长尾词链接'] # 表格title
worksheet.write_row('A1', title)
for index, data in enumerate(self.data_lists):
num0 = str(index + 2)
row = 'A' + num0
worksheet.write_row(row, data)
workbook.close()
print("5118搜索数据写入excel成功!")
def main(self):
for i in range(1,self.pagenums+1):
print(f'>>> 正在采集第{i}页关键词数据...')
self.get_data(i)
print("数据采集完成!")
self.write_keywords()
self.write_to_xlsx()
if __name__=="__main__":
url = "www.shejipi.com"
nums=100
spider=C5118(url,nums)
spider.main()
采集效果:
设计成瘾网站关键词 相关资料:shejipi_search_results..xlsx
设计成瘾网站关键词资料:shejipi_keywords.csv 查看全部
关键词采集器(查询一个设计网站的关键词数据是非常有必要的!)
对于seoer来说,关注网站的关键词数据是很重要的。关键词排名、流量来源、peer网站数据,那么使用seo查询工具也是非常有必要的。比较知名的有爱站站长工具、站长工具和5118。
当然,现在比较全面、应用比较广泛的就是5118了!
从数据上,还有功能上,5118都非常强大!
如果可能,请付费!
5118的防爬还是很不错的!
需要登录采集,我发现5118已经更新一次了!
比如登录账号需要通过滑块验证码的防爬限制,关键词索引等数据以图片加密的形式展示。.
不过有些数据还是可以参考的!所以,python 起来了!
打听一个设计网站,设计成瘾的情况关键词
抓取网址:
如果您不是付费会员,则只能查看前100页数据!
很多数据被反爬限制了,可惜了!
虽然有5118会员登录的滑块验证码,但是cookies登录还是非常好用的!
我们手动添加cookies来登录需要的数据采集。
几个关键点:
1.添加协议头:
headers={
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '0',
'Cookie': Cookies,
'Host': 'www.5118.com',
'Origin': 'https://www.5118.com',
'Referer': 'https://www.5118.com/',
'User-Agent': ua,
'X-Requested-With': 'XMLHttpRequest',
}
自己添加ua和cooikes!
当然这是一个完整的协议头,有的可以删掉,大家可以自己试试!
2.zip函数的使用和格式化数据的处理之前也有分享过!
for keyword,rank,title,link,index_link in zip(keywords,ranks,titles,links,index_links):
data=[
keyword,
rank.xpath('string(.)').strip().replace(' ','').replace('\r\n','-'),
self.get_change(rank),
title,
unquote(link.split('target=')[-1]),
'https:{}'.format(index_link),
]
print(data)
3. 处理排名波动的情况
从源码查询可以看出,绿色表示排名上升,红色表示排名下降。这里有一个判断来获取!
#判断排名是否提升
def get_change(self,rank):
rank=etree.tostring(rank).decode('utf-8')
if "red" in str(rank):
change="下降"
elif "green" in str(rank):
change = "提升"
else:
change = "不变"
return change
4.关键词写入数据到csv
写了一个案例,找到了两个参考案例
import csv
#关键词数据写入csv
def write_keywords(self):
path='{}_keywords.csv'.format(self.file_name)
csvfile = open(path, 'a+')
for keyword in self.keyword_datas:
csvfile.write('%s\n' % keyword)
print("5118关键词搜索数据写入csv成功!")
#参考一
def write_csv(self):
path = "aa.csv"
with open(path, 'a+') as f:
csv_write = csv.writer(f)
data_row = ["1", "2"]
csv_write.writerow(data_row)
# 参考二
def wcsv(self):
csvfile = open('csvtest.csv', 'w')
writer = csv.writer(csvfile)
writer.writerow(['keywords'])
data = [
('1', 'http://www.xiaoheiseo.com/', '小黑'),
('2', 'http://www.baidu.com/', '百度'),
('3', 'http://www.jd.com/', '京东')
]
writer.writerows(data)
csvfile.close()
5.查询网站相关关键词数据写入excel表
使用第三方库 xlsxwriter
#数据写入excle表格
def write_to_xlsx(self):
workbook = xlsxwriter.Workbook('{}_search_results.xlsx'.format(self.file_name)) # 创建一个Excel文件
worksheet = workbook.add_worksheet(self.file_name)
title = ['关键词', '排名', '排名波动', '网页标题', '网页链接', '长尾词链接'] # 表格title
worksheet.write_row('A1', title)
for index, data in enumerate(self.data_lists):
num0 = str(index + 2)
row = 'A' + num0
worksheet.write_row(row, data)
workbook.close()
print("5118搜索数据写入excel成功!")
由于页码也是js生成的,没找到,所以自己输入页码!
输入查询网站 URL格式:主域名用于爬取后的数据存储文件!
附上完整代码:
#5118网站关键词数据获取
import requests
from lxml import etree
from urllib.parse import unquote
import xlsxwriter
import time
import csv
class C5118(object):
def __init__(self,url,nums):
self.keyword_datas=[]
self.data_lists=[]
self.index_links_hrefs=[]
self.headers={
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '0',
'Cookie': Cookies,
'Host': 'www.5118.com',
'Origin': 'https://www.5118.com',
'Referer': 'https://www.5118.com/',
'User-Agent': UA,
'X-Requested-With': 'XMLHttpRequest',
}
self.post_url=url
self.file_name=url.split('.')[1]
self.pagenums=nums
#判断排名是否提升
def get_change(self,rank):
rank=etree.tostring(rank).decode('utf-8')
if "red" in str(rank):
change="下降"
elif "green" in str(rank):
change = "提升"
else:
change = "不变"
return change
#获取数据
def get_data(self,pagenum):
url="https://www.5118.com/seo/baidupc"
params={
'isPager': 'true',
'viewtype': '2',
'days': '90',
'url': self.post_url,
'orderField': 'Rank',
'orderDirection': 'asc',
'pageIndex': pagenum, #页码
'catalogName': '',
}
response=requests.post(url,params=params,headers=self.headers)
time.sleep(1)
print(response.status_code)
doc=etree.HTML(response.content.decode('utf-8'))
keywords= doc.xpath('//tr[@class="list-row"]/td[1]/a/text()') #关键词
print(keywords)
self.keyword_datas.extend(keywords)
ranks = doc.xpath('//tr[@class="list-row"]/td[2]/a') #排名
titles = doc.xpath('//tr[@class="list-row"]/td[5]/a/text()') #网页标题
links=doc.xpath('//tr[@class="list-row"]/td[5]/a/@href') #网页链接
index_links=doc.xpath('//tr[@class="list-row"]/td[7]/a/@href') #长尾词数量链接
self.index_links_hrefs.extend(index_links)
for keyword,rank,title,link,index_link in zip(keywords,ranks,titles,links,index_links):
data=[
keyword,
rank.xpath('string(.)').strip().replace(' ','').replace('\r\n','-'),
self.get_change(rank),
title,
unquote(link.split('target=')[-1]),
'https:{}'.format(index_link),
]
print(data)
self.data_lists.append(data)
time.sleep(4)
return self.data_lists
#关键词数据写入csv
def write_keywords(self):
path='{}_keywords.csv'.format(self.file_name)
csvfile = open(path, 'a+')
for keyword in self.keyword_datas:
csvfile.write('%s\n' % keyword)
print("5118关键词搜索数据写入csv成功!")
#数据写入excle表格
def write_to_xlsx(self):
workbook = xlsxwriter.Workbook('{}_search_results.xlsx'.format(self.file_name)) # 创建一个Excel文件
worksheet = workbook.add_worksheet(self.file_name)
title = ['关键词', '排名', '排名波动', '网页标题', '网页链接', '长尾词链接'] # 表格title
worksheet.write_row('A1', title)
for index, data in enumerate(self.data_lists):
num0 = str(index + 2)
row = 'A' + num0
worksheet.write_row(row, data)
workbook.close()
print("5118搜索数据写入excel成功!")
def main(self):
for i in range(1,self.pagenums+1):
print(f'>>> 正在采集第{i}页关键词数据...')
self.get_data(i)
print("数据采集完成!")
self.write_keywords()
self.write_to_xlsx()
if __name__=="__main__":
url = "www.shejipi.com"
nums=100
spider=C5118(url,nums)
spider.main()
采集效果:
设计成瘾网站关键词 相关资料:shejipi_search_results..xlsx
设计成瘾网站关键词资料:shejipi_keywords.csv
关键词采集器(百度下拉关键词查询不到,js而是调用的(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-24 23:11
直接从b站:
当我们在百度上搜索某个关键词时,下拉框中会出现10个相关的长尾信息词。对于站长来说,这些相关的下拉词是我们做seo聚合的一个很好的方式。因此,必须使用它。这里出现的相关信息词是由于大数据的整合。在一定的时间段内,大量的网民在不同的时间段进行高频搜索。如下图: 搜索优采云采集器
这里我们看到下拉列表中出现了 10 个相关的长尾信息词。我们这里需要的是我们需要的信息采集,直接按F12就可以找到这个信息。百度下拉关键词,在源码中找不到,是js调用的。
链接如下:
,32606,1453,32694,31254,32045,7552,32678,32116,7565&wd=%E8%93%9D%E5%A4%A9%E9%87%87%E9%9B%86%E85%&wd 2&bs=%E8%93%9D%E5%A4%A9%E9%87%87%E9%9B%86%E5%99%A8&csor=5&cb=jQuery4368922428_10&_=11
通过这个链接,我们将直接编写规则。
场地规则:
检测结果:
相关知识点:采集百度下拉框关键词百度下拉词采集
本站文章均摘自书融网权威资料、书籍或网络原创文章。如有版权纠纷或侵权,请立即联系我们删除,未经许可禁止复制转载!感激的... 查看全部
关键词采集器(百度下拉关键词查询不到,js而是调用的(图))
直接从b站:
当我们在百度上搜索某个关键词时,下拉框中会出现10个相关的长尾信息词。对于站长来说,这些相关的下拉词是我们做seo聚合的一个很好的方式。因此,必须使用它。这里出现的相关信息词是由于大数据的整合。在一定的时间段内,大量的网民在不同的时间段进行高频搜索。如下图: 搜索优采云采集器
这里我们看到下拉列表中出现了 10 个相关的长尾信息词。我们这里需要的是我们需要的信息采集,直接按F12就可以找到这个信息。百度下拉关键词,在源码中找不到,是js调用的。
链接如下:
,32606,1453,32694,31254,32045,7552,32678,32116,7565&wd=%E8%93%9D%E5%A4%A9%E9%87%87%E9%9B%86%E85%&wd 2&bs=%E8%93%9D%E5%A4%A9%E9%87%87%E9%9B%86%E5%99%A8&csor=5&cb=jQuery4368922428_10&_=11
通过这个链接,我们将直接编写规则。
场地规则:
检测结果:
相关知识点:采集百度下拉框关键词百度下拉词采集
本站文章均摘自书融网权威资料、书籍或网络原创文章。如有版权纠纷或侵权,请立即联系我们删除,未经许可禁止复制转载!感激的...
关键词采集器(智能云采集用过才知道有没有可用的?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-23 22:00
关键词采集器多款采集器都有,最好用的是万词霸屏。虽然现在万词霸屏的单价比较高,但是跟其他采集器对比之下优势还是很大的。我自己用过就是windows平台最好用的采集器了。
云采集用过才知道
现在智能云采集肯定首推坚果云云采集
云采
不知道有没有可用的??
quantumcrawler,这个很不错,收费,
虽然采集的质量还有待提高,但是很好用,可以在云端处理,
采集器的话不知道有什么好的,但是我用过千贝采集器感觉不错,
快乐采集器也不错
我自己用了云采的挺好用的
目前比较常用的是云采,据说pc端的云采分采我网站资源采集跟采集站收费专用采集器我网站资源采集,采我站收费专用采集器,
云采比较好用,先用云采一个星期再说,
我用的是爱采宝
说到采集器,必须得提到雨博采。这个小众但非常实用的采集器,适合对采集器不是那么感冒的人。他的音乐、图片、视频、文章采集特别全。最有特色的就是包含免费的广告,但是想要做百度联盟的商家并不可能给予免费的广告给。另外他的采集规则高级,他只需要点击几下鼠标就能完成,不要延迟。
windows下采集神器,推荐用hotpower采集器。 查看全部
关键词采集器(智能云采集用过才知道有没有可用的?)
关键词采集器多款采集器都有,最好用的是万词霸屏。虽然现在万词霸屏的单价比较高,但是跟其他采集器对比之下优势还是很大的。我自己用过就是windows平台最好用的采集器了。
云采集用过才知道
现在智能云采集肯定首推坚果云云采集
云采
不知道有没有可用的??
quantumcrawler,这个很不错,收费,
虽然采集的质量还有待提高,但是很好用,可以在云端处理,
采集器的话不知道有什么好的,但是我用过千贝采集器感觉不错,
快乐采集器也不错
我自己用了云采的挺好用的
目前比较常用的是云采,据说pc端的云采分采我网站资源采集跟采集站收费专用采集器我网站资源采集,采我站收费专用采集器,
云采比较好用,先用云采一个星期再说,
我用的是爱采宝
说到采集器,必须得提到雨博采。这个小众但非常实用的采集器,适合对采集器不是那么感冒的人。他的音乐、图片、视频、文章采集特别全。最有特色的就是包含免费的广告,但是想要做百度联盟的商家并不可能给予免费的广告给。另外他的采集规则高级,他只需要点击几下鼠标就能完成,不要延迟。
windows下采集神器,推荐用hotpower采集器。
关键词采集器(使用这款优采云京东商品采集器会让你感觉到科技的便利性)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-11-19 07:19
优采云京东商品采集器是一款可以在京东平台批量批量处理采集指定关键词商品的工具。如果您需要一键购买某些商品采集,使用这个优采云京东产品采集器会让您感受到科技的便利,一键完成您的所有需求。.
相关软件软件大小版本说明下载地址
优采云京东商品采集器是一款可以在京东平台批量批量处理采集指定关键词商品的工具。如果您需要一键购买某些商品采集,使用这个优采云京东产品采集器会让您感受到科技的便利,一键完成您的所有需求。
基本介绍
直接采集京东商品搜索页面数据,包括价格、评论数、销量、商品名称、商品地址、店铺名称、店铺地址、客服地址、商品地图、标签、商品参数、详细内容等。 fields ,输出为文本表格(csv)或文本文件,可用于商品市场分析、同行销售业绩评估、企业信息采集等用途。
软件特点
每个产品关键词最多支持100页,每页60个产品(在软件层面,30个产品每页为200页),大约6000个产品信息。支持详细搜索参数设置,支持多产品关键词序列采集,不同关键词使用| 或换行,支持指定类别id 采集
指示
1 下载完成后,不要运行压缩包中的软件直接使用,先解压;
2 软件同时支持32位和64位运行环境;
3 如果软件无法正常打开,请右键使用管理员模式运行。
更新日志
修复了常见错误 查看全部
关键词采集器(使用这款优采云京东商品采集器会让你感觉到科技的便利性)
优采云京东商品采集器是一款可以在京东平台批量批量处理采集指定关键词商品的工具。如果您需要一键购买某些商品采集,使用这个优采云京东产品采集器会让您感受到科技的便利,一键完成您的所有需求。.
相关软件软件大小版本说明下载地址
优采云京东商品采集器是一款可以在京东平台批量批量处理采集指定关键词商品的工具。如果您需要一键购买某些商品采集,使用这个优采云京东产品采集器会让您感受到科技的便利,一键完成您的所有需求。
基本介绍
直接采集京东商品搜索页面数据,包括价格、评论数、销量、商品名称、商品地址、店铺名称、店铺地址、客服地址、商品地图、标签、商品参数、详细内容等。 fields ,输出为文本表格(csv)或文本文件,可用于商品市场分析、同行销售业绩评估、企业信息采集等用途。
软件特点
每个产品关键词最多支持100页,每页60个产品(在软件层面,30个产品每页为200页),大约6000个产品信息。支持详细搜索参数设置,支持多产品关键词序列采集,不同关键词使用| 或换行,支持指定类别id 采集
指示
1 下载完成后,不要运行压缩包中的软件直接使用,先解压;
2 软件同时支持32位和64位运行环境;
3 如果软件无法正常打开,请右键使用管理员模式运行。
更新日志
修复了常见错误
关键词采集器(悟空QQ群采集器可以导出群号及群详细信息的通知)
采集交流 • 优采云 发表了文章 • 0 个评论 • 386 次浏览 • 2021-11-17 00:03
在我们的生活中,QQ群的使用随处可见。现在,我们每个人的QQ里都会有几个QQ群,都是为了方便大家的联系,有什么消息可以直接发到群里,不用一一通知。悟空QQ群采集器悟空QQ群采集器是一款简单易用的QQ群号批量采集工具。用户可以通过QQ群相关关键字设置,快速提取出符合条件的QQ群号。并且该软件支持过滤重复和导出所有成员,是QQ营销人员的有力武器。 一、软件功能介绍1. 可以指定单个或多个关键词到采集,可以根据指定的群成员数量推导出群号。 2.采集可以按人数、活动或腾讯默认的采集进行排序。 3.可以指定某个区域采集,也可以设置扫描各个区域。 4.多线程、全自动、快速采集。 5.可以检索组名、介绍以及标签是否收录关键词。 6.可以导出组号和组详细信息,并自动将采集的结果保存到软件目录文件夹中。 7. 可以过滤添加群和公众群的方式,直接添加群、付费群、证书群等,导出群主QQ。 二、软件界面展示软件由于腾讯的限制,每个关键词大概可以有采集500-1000个QQ群。建议精炼关键词采集!比如你想采集股票相关的,可以用长尾关键词比如股票交易所,股票分析,股票投资! 采集 如果有更多,则需要更改IP。更多信息请点击悟空营销软件官网了解 查看全部
关键词采集器(悟空QQ群采集器可以导出群号及群详细信息的通知)
在我们的生活中,QQ群的使用随处可见。现在,我们每个人的QQ里都会有几个QQ群,都是为了方便大家的联系,有什么消息可以直接发到群里,不用一一通知。悟空QQ群采集器悟空QQ群采集器是一款简单易用的QQ群号批量采集工具。用户可以通过QQ群相关关键字设置,快速提取出符合条件的QQ群号。并且该软件支持过滤重复和导出所有成员,是QQ营销人员的有力武器。 一、软件功能介绍1. 可以指定单个或多个关键词到采集,可以根据指定的群成员数量推导出群号。 2.采集可以按人数、活动或腾讯默认的采集进行排序。 3.可以指定某个区域采集,也可以设置扫描各个区域。 4.多线程、全自动、快速采集。 5.可以检索组名、介绍以及标签是否收录关键词。 6.可以导出组号和组详细信息,并自动将采集的结果保存到软件目录文件夹中。 7. 可以过滤添加群和公众群的方式,直接添加群、付费群、证书群等,导出群主QQ。 二、软件界面展示软件由于腾讯的限制,每个关键词大概可以有采集500-1000个QQ群。建议精炼关键词采集!比如你想采集股票相关的,可以用长尾关键词比如股票交易所,股票分析,股票投资! 采集 如果有更多,则需要更改IP。更多信息请点击悟空营销软件官网了解
关键词采集器(搜索引擎优化是最为愈来愈复杂的一项任务,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-15 13:19
站群和采集器的区别 搜索引擎优化是最关键的任务。同时,随着搜索引擎不断改变自己的排名算法规则,算法的每一次变化都可能导致一些排名靠前的网站一夜之间失名,失去排名的直接后果就是失去排名网站 @网站固有的大量流量。所以每一次搜索引擎算法的变化,都会在网站之间引起很大的骚动和焦虑。可以说,搜索引擎优化已经成为一项越来越复杂的任务。搜索引擎优化一、内部优化(1)META标签优化:很容易上到搜索引擎,只要关键词的使用达到一定的密度,在搜索引擎上会很容易安排 值得一提的是,搜索引擎 InfoSeek 是每天第一次更新。你早上8点提交网站,下午你就收录,第二天就会出现在搜索中。因为更新快,投稿容易收录,一大批站主开始改变方式,频繁登录不同的网站。垃圾邮件一词出现在英文中,用来描述网站所有者不负责任地制造垃圾。百度(Baidu)是一家以搜索引擎服务为主的互联网公司,由李彦宏、徐勇于2000年1月1日在北京中关村创立。中国南宋时期:公众为他搜索了千百度,描述了诗人对理想的执着追求。公司业务范围涵盖搜索、人工智能、云计算、大数据等,是中国互联网公司的三大巨头之一。2005年8月5日,在美国纳斯达克成功上市,成为首家进入纳斯达克成分股的中国公司。站群 和 采集器 的区别 成功在美国纳斯达克上市,成为首家进入纳斯达克成分股的中国公司。站群 和 采集器 的区别 成功在美国纳斯达克上市,成为首家进入纳斯达克成分股的中国公司。站群 和 采集器 的区别
<p>站群 和 采集器 的区别还没有出现在搜索引擎中。那是因为搜索引擎还没有启动收录。每个搜索引擎都允许用户提交没有收录 的站点。这个项目通常需要3-5天。SEO基于长期探索和观察获得的技术和经验,利用搜索引擎准入规则网站、网站、网站布局、 查看全部
关键词采集器(搜索引擎优化是最为愈来愈复杂的一项任务,你知道吗?)
站群和采集器的区别 搜索引擎优化是最关键的任务。同时,随着搜索引擎不断改变自己的排名算法规则,算法的每一次变化都可能导致一些排名靠前的网站一夜之间失名,失去排名的直接后果就是失去排名网站 @网站固有的大量流量。所以每一次搜索引擎算法的变化,都会在网站之间引起很大的骚动和焦虑。可以说,搜索引擎优化已经成为一项越来越复杂的任务。搜索引擎优化一、内部优化(1)META标签优化:很容易上到搜索引擎,只要关键词的使用达到一定的密度,在搜索引擎上会很容易安排 值得一提的是,搜索引擎 InfoSeek 是每天第一次更新。你早上8点提交网站,下午你就收录,第二天就会出现在搜索中。因为更新快,投稿容易收录,一大批站主开始改变方式,频繁登录不同的网站。垃圾邮件一词出现在英文中,用来描述网站所有者不负责任地制造垃圾。百度(Baidu)是一家以搜索引擎服务为主的互联网公司,由李彦宏、徐勇于2000年1月1日在北京中关村创立。中国南宋时期:公众为他搜索了千百度,描述了诗人对理想的执着追求。公司业务范围涵盖搜索、人工智能、云计算、大数据等,是中国互联网公司的三大巨头之一。2005年8月5日,在美国纳斯达克成功上市,成为首家进入纳斯达克成分股的中国公司。站群 和 采集器 的区别 成功在美国纳斯达克上市,成为首家进入纳斯达克成分股的中国公司。站群 和 采集器 的区别 成功在美国纳斯达克上市,成为首家进入纳斯达克成分股的中国公司。站群 和 采集器 的区别
<p>站群 和 采集器 的区别还没有出现在搜索引擎中。那是因为搜索引擎还没有启动收录。每个搜索引擎都允许用户提交没有收录 的站点。这个项目通常需要3-5天。SEO基于长期探索和观察获得的技术和经验,利用搜索引擎准入规则网站、网站、网站布局、
关键词采集器(阿里鱼采集器教程采过去了,怎么做好?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-11-15 13:09
关键词采集器:【阿里云】【网页版】本来是要在上面找一下网页的,被一篇从阿里里采集的教程采过去了,哈哈。应该是分析好了需要采的关键词,其实可以先放那里,真不错,想起来在更新,毕竟那篇教程还是不错的。文章里写的很详细,大家一起上车。可以拿走一个g2000+钱做投资,大家一起采集,毕竟三级联动返利的钱好赚,哈哈!如果需要成为达人才能返利的,可以私聊。速度是线上最快的采集器,速度快,稳定!。
有,我在实验室用的就是,不过要钱,
有,
不行的
可以分享给你下面的三个软件,楼主要用就用吧1。阿里鱼采集器是一款专业的手机端电商交易平台分析软件,只需要把所要采集的网站,输入到软件里面,然后进行采集,然后就可以进行分析了2。找我免费送0。1元,楼主要采集的话我会分享给你下面的三个软件,线上我用的都是软件啦3。爱采购是一款采集热门网站的软件,里面分的是一些首页的链接,楼主要是想做类的站可以下载对应的版本。
有需要联系我
一直都有买东西返现金的活动,不限金额,但要求必须是专业采集的商家,要有资质,没有资质店铺是不可以卖东西返现金的,比如我有时候去看到一些商品,有的款式不错,便宜,但是有的专业机构做的,没有牌子,但是有点名气,很多人就去购买,买了以后的返现金越来越多,因为他们采集的次数越来越多,所以有的款式经常不在别人家看到,价格还便宜。
这样的款式卖家返现比较大,但是下家想买他的东西时发现找不到,就很郁闷,就去找专业机构拿货就便宜又稳定,有些机构专业做大量的高品质的货,而的那些商家作假比较厉害,通过这些机构拿货,不用担心是假货,因为产品设计制作都是专业的,而且都有专业的程序和,根本不用担心,所以我自己有工厂想找合作的,就找这些有技术专业的供货商。分享给大家,如果你想找阿里下单的也可以联系我,我每次回答大家都很热情。 查看全部
关键词采集器(阿里鱼采集器教程采过去了,怎么做好?)
关键词采集器:【阿里云】【网页版】本来是要在上面找一下网页的,被一篇从阿里里采集的教程采过去了,哈哈。应该是分析好了需要采的关键词,其实可以先放那里,真不错,想起来在更新,毕竟那篇教程还是不错的。文章里写的很详细,大家一起上车。可以拿走一个g2000+钱做投资,大家一起采集,毕竟三级联动返利的钱好赚,哈哈!如果需要成为达人才能返利的,可以私聊。速度是线上最快的采集器,速度快,稳定!。
有,我在实验室用的就是,不过要钱,
有,
不行的
可以分享给你下面的三个软件,楼主要用就用吧1。阿里鱼采集器是一款专业的手机端电商交易平台分析软件,只需要把所要采集的网站,输入到软件里面,然后进行采集,然后就可以进行分析了2。找我免费送0。1元,楼主要采集的话我会分享给你下面的三个软件,线上我用的都是软件啦3。爱采购是一款采集热门网站的软件,里面分的是一些首页的链接,楼主要是想做类的站可以下载对应的版本。
有需要联系我
一直都有买东西返现金的活动,不限金额,但要求必须是专业采集的商家,要有资质,没有资质店铺是不可以卖东西返现金的,比如我有时候去看到一些商品,有的款式不错,便宜,但是有的专业机构做的,没有牌子,但是有点名气,很多人就去购买,买了以后的返现金越来越多,因为他们采集的次数越来越多,所以有的款式经常不在别人家看到,价格还便宜。
这样的款式卖家返现比较大,但是下家想买他的东西时发现找不到,就很郁闷,就去找专业机构拿货就便宜又稳定,有些机构专业做大量的高品质的货,而的那些商家作假比较厉害,通过这些机构拿货,不用担心是假货,因为产品设计制作都是专业的,而且都有专业的程序和,根本不用担心,所以我自己有工厂想找合作的,就找这些有技术专业的供货商。分享给大家,如果你想找阿里下单的也可以联系我,我每次回答大家都很热情。
关键词采集器(优采云关键词网址采集器的功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-11-13 12:20
优采云关键词URL采集器是一个可以根据特定的关键词快速搜索百度、360、搜狗、谷歌和采集的URL,它还可以将搜索结果的 URL 和标题保存到计算机。
关键词URL采集器的作用是帮助用户挖掘长尾词、采集外部链接、采集例子等,可以分析竞争。
【数据参考说明】
#URL#:采集的原创URL
#Title#:URL对应的页面标题
#Domain#:原创URL的域名部分,如“”中的“”
#顶级域名#:取原网址的顶级域名部分,如“”中的“”
#Description#:页面标题下方的一段描述性文字
【常见问题】
为什么我在采集一段时间后不能采集?
可能是采集受搜索引擎限制较多,重启软件继续采集,如果不改,只能在搜索引擎解封后继续采集。百度的屏蔽时间一般是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
为什么关键词采集的不同批次的结果中有一些重复的URL?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内页可能收录很多主题,不同的关键词可能会采集到网站的不同内页,当域名引用,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中有重复的URL,可以合并在一起,用软件去重(优采云·text deduplication scrambler)。
为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章的文章内页,内页收录关键词的主题,所以可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:,另存为htm文件,采集后可以打开文件查看比较。
【更新内容】
1. 转型支持OEM代理
2.添加必应和雅虎采集;多重变化
3. 将 Bing、Yahoo、Google 更改为 https 请求,以避免 采集 在某些情况下失败。
4.添加百度新闻采集。
5.一些更新。
6. 添加了 关键词 分割线选项。
7.修复百度最新修改无法采集的问题。
8.修复Bing修改失败的问题采集; 修复部分电脑无法使用xmlhttps的问题(涉及谷歌、必应、雅虎)。 查看全部
关键词采集器(优采云关键词网址采集器的功能)
优采云关键词URL采集器是一个可以根据特定的关键词快速搜索百度、360、搜狗、谷歌和采集的URL,它还可以将搜索结果的 URL 和标题保存到计算机。
关键词URL采集器的作用是帮助用户挖掘长尾词、采集外部链接、采集例子等,可以分析竞争。
【数据参考说明】
#URL#:采集的原创URL
#Title#:URL对应的页面标题
#Domain#:原创URL的域名部分,如“”中的“”
#顶级域名#:取原网址的顶级域名部分,如“”中的“”
#Description#:页面标题下方的一段描述性文字
【常见问题】
为什么我在采集一段时间后不能采集?
可能是采集受搜索引擎限制较多,重启软件继续采集,如果不改,只能在搜索引擎解封后继续采集。百度的屏蔽时间一般是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
为什么关键词采集的不同批次的结果中有一些重复的URL?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内页可能收录很多主题,不同的关键词可能会采集到网站的不同内页,当域名引用,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中有重复的URL,可以合并在一起,用软件去重(优采云·text deduplication scrambler)。
为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章的文章内页,内页收录关键词的主题,所以可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:,另存为htm文件,采集后可以打开文件查看比较。
【更新内容】
1. 转型支持OEM代理
2.添加必应和雅虎采集;多重变化
3. 将 Bing、Yahoo、Google 更改为 https 请求,以避免 采集 在某些情况下失败。
4.添加百度新闻采集。
5.一些更新。
6. 添加了 关键词 分割线选项。
7.修复百度最新修改无法采集的问题。
8.修复Bing修改失败的问题采集; 修复部分电脑无法使用xmlhttps的问题(涉及谷歌、必应、雅虎)。
关键词采集器(输入关键字采集各搜索引擎的网址、域名、标题、描述等信息支持)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-12 01:11
输入关键字采集各搜索引擎的网址、域名、标题、描述等信息
支持百度、搜狗、谷歌、必应、雅虎、360等每个关键词600到800,采集示例
关键词可以收录搜索引擎参数,就像在网页上输入关键词搜索一样,
如果百度搜索结果网址必须收录bbs的关键词,则输入“关键词 inurl:bbs”。
保存模板可以引用的数据:
#URL#采集 的原创 URL
# Title# URL对应的页面标题
#Domain#原创URL的域名部分,如“”中的“”
#Top domain# 取原创URL的顶级域部分,如“”
#描述#页面标题下方的一段描述性文字
Excel导出:
CSV是一个文本表格,Excel可以显示为多列多行数据。只需在保存模板中设置为:
“#URL#”、“#title#”、“#描述#”
此格式为 csv 格式。用引号将每一项括起来,多个项之间用逗号隔开,然后保存扩展名并填写csv。
问题重点:
1.为什么一段时间后不能采集采集?
可能是采集受搜索引擎限制比较多。一般可以通过更改IP来继续采集(如使用VPN更改IP)。如果不改,只能在搜索引擎解封后继续。采集。百度的屏蔽时间通常是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
2.不同批次的关键词采集 为什么结果中有一些重复的网址?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内页可能收录很多主题,而不同的关键词可能会采集去到网站的不同内页,当域name是引用的,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中有重复的URL,可以合并在一起,用软件去重(优采云·text deduplication scrambler)。
3.为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章的文章内页,内页收录关键词主题,可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:
, 保存为htm文件,采集后可以打开文件查看对比。
您不是VIP会员,您无权下载此资源。VIP会员 查看全部
关键词采集器(输入关键字采集各搜索引擎的网址、域名、标题、描述等信息支持)
输入关键字采集各搜索引擎的网址、域名、标题、描述等信息
支持百度、搜狗、谷歌、必应、雅虎、360等每个关键词600到800,采集示例
关键词可以收录搜索引擎参数,就像在网页上输入关键词搜索一样,
如果百度搜索结果网址必须收录bbs的关键词,则输入“关键词 inurl:bbs”。
保存模板可以引用的数据:
#URL#采集 的原创 URL
# Title# URL对应的页面标题
#Domain#原创URL的域名部分,如“”中的“”
#Top domain# 取原创URL的顶级域部分,如“”
#描述#页面标题下方的一段描述性文字
Excel导出:
CSV是一个文本表格,Excel可以显示为多列多行数据。只需在保存模板中设置为:
“#URL#”、“#title#”、“#描述#”
此格式为 csv 格式。用引号将每一项括起来,多个项之间用逗号隔开,然后保存扩展名并填写csv。
问题重点:
1.为什么一段时间后不能采集采集?
可能是采集受搜索引擎限制比较多。一般可以通过更改IP来继续采集(如使用VPN更改IP)。如果不改,只能在搜索引擎解封后继续。采集。百度的屏蔽时间通常是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
2.不同批次的关键词采集 为什么结果中有一些重复的网址?
尤其是只引用#domain#或#top-level domain#后,这种部分URL重复的情况更为常见。这也是正常的,因为网站的每个内页可能收录很多主题,而不同的关键词可能会采集去到网站的不同内页,当域name是引用的,同一个网站的不同内页的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。采集 之前的结果不在此重复数据删除的范围内。如果两个采集的结果中有重复的URL,可以合并在一起,用软件去重(优采云·text deduplication scrambler)。
3.为什么采集返回的URL主题与关键词不匹配?
这是因为在引用#domain# 或#top-level domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章的文章内页,内页收录关键词主题,可以通过搜索引擎收录和软件采集获取。但是获取域名后,您打开的域名首页可能不收录关键词。
为了比较采集是否正确,可以在保存模板中输入:
, 保存为htm文件,采集后可以打开文件查看对比。
您不是VIP会员,您无权下载此资源。VIP会员
关键词采集器(创佳软件园频道小编推荐优采云爱站数据采集器软件下载和使用介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-11-11 10:08
创佳软件园应用软件频道小编推荐优采云爱站data采集器软件下载和使用介绍分享给大家,也许优采云爱站data采集器@ >免费版下载的存在,为您提供了不一样的应用软件选择!快来下载吧
优采云爱站数据采集器 软件介绍
优采云爱站Data采集器是数据检索和采集的专用工具。您可以批量查询并将数据保存在本地文件中(导出到模板、共享和粘贴)。操作简单,轻松采集爱站数据!
优采云爱站数据采集器软件功能介绍
搜索权重查询
用于搜索和获取爱站搜索排名的数据可以保存在一个csv文件中(可以通过Excel选择)。优采云网络数据采集终端可以在百度上搜索关键词的所有网站排名数据。效果如何?一个典型的例子就是搜索这些网站中权重高、关键词排名网站的关键词,利用原理,综合多方面的选择,成为一个道士?创建一个 网站?做营销推广?请随意扩展!注:访客或普通VIP会员仅具有搜索部分排名数据的管理权限。可以自行申请注册,拨打爱立信高级级别,然后在程序流程中设置快速登录,搜索所有排名数据!优采云网数据< @采集 终端的实际操作非常简单。只需输入网站域名(部分域名以“|”分隔),即可搜索网站的百度收录关键词、总流量、排名网站 domain name 等内容,然后导出为Csv文件,Excel办公软件可以打开选择。
关键词分析
用于查找和获取爱括号中的关键词的数据可以存储在文本文件中。关键词分析就是输入所有关键词,比如瘦身。你可以找到很多相关的词,包括减肥,这些词在网络搜索结果中排名非常好。注:访客或普通VIP会员只能搜索管理机构发现的关键词部分,可自行申请注册,并致电爱站高级管理人员。然后,他们可以在程序流程中设置快速登录,这样他们就可以搜索并获取他们找到的所有关键词目录!其实操作比较简单。只需输入关键词(每行一个)即可快速找到关键词的关键词目录。
优采云爱站数据采集器 更新内容:
优采云爱站数据采集器v3.8.1.0更新内容
部分页面已更改;
优化的步伐从未停止!
改进和优化错误;
创佳软件园编辑推荐
除了优采云爱站data采集器非常方便之外,软件园的编辑可以满足您对软件的需求!此外,小编还推荐在线美术字体生成器等相关软件下载使用。如果喜欢,希望大家来下载! 查看全部
关键词采集器(创佳软件园频道小编推荐优采云爱站数据采集器软件下载和使用介绍)
创佳软件园应用软件频道小编推荐优采云爱站data采集器软件下载和使用介绍分享给大家,也许优采云爱站data采集器@ >免费版下载的存在,为您提供了不一样的应用软件选择!快来下载吧
优采云爱站数据采集器 软件介绍
优采云爱站Data采集器是数据检索和采集的专用工具。您可以批量查询并将数据保存在本地文件中(导出到模板、共享和粘贴)。操作简单,轻松采集爱站数据!
优采云爱站数据采集器软件功能介绍
搜索权重查询
用于搜索和获取爱站搜索排名的数据可以保存在一个csv文件中(可以通过Excel选择)。优采云网络数据采集终端可以在百度上搜索关键词的所有网站排名数据。效果如何?一个典型的例子就是搜索这些网站中权重高、关键词排名网站的关键词,利用原理,综合多方面的选择,成为一个道士?创建一个 网站?做营销推广?请随意扩展!注:访客或普通VIP会员仅具有搜索部分排名数据的管理权限。可以自行申请注册,拨打爱立信高级级别,然后在程序流程中设置快速登录,搜索所有排名数据!优采云网数据< @采集 终端的实际操作非常简单。只需输入网站域名(部分域名以“|”分隔),即可搜索网站的百度收录关键词、总流量、排名网站 domain name 等内容,然后导出为Csv文件,Excel办公软件可以打开选择。
关键词分析
用于查找和获取爱括号中的关键词的数据可以存储在文本文件中。关键词分析就是输入所有关键词,比如瘦身。你可以找到很多相关的词,包括减肥,这些词在网络搜索结果中排名非常好。注:访客或普通VIP会员只能搜索管理机构发现的关键词部分,可自行申请注册,并致电爱站高级管理人员。然后,他们可以在程序流程中设置快速登录,这样他们就可以搜索并获取他们找到的所有关键词目录!其实操作比较简单。只需输入关键词(每行一个)即可快速找到关键词的关键词目录。
优采云爱站数据采集器 更新内容:
优采云爱站数据采集器v3.8.1.0更新内容
部分页面已更改;
优化的步伐从未停止!
改进和优化错误;
创佳软件园编辑推荐
除了优采云爱站data采集器非常方便之外,软件园的编辑可以满足您对软件的需求!此外,小编还推荐在线美术字体生成器等相关软件下载使用。如果喜欢,希望大家来下载!
关键词采集器(迷你爬虫是一简单小巧的SEO抓取工具,它的作用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-11-09 13:09
迷你爬虫是一款简单小巧的SEO爬虫工具。它的作用是模拟搜索引擎抓取网页的标题、关键词、描述等信息。可以用于采集自己的网站,也可以用于采集竞争对手的网站,这样你就可以知道他们的头衔,关键词是怎样的写出来,从中学习。需要的SEOER可以下载迷你爬虫使用。
它是一款超小型快速的SEO工具,为seo行业合作伙伴快速抓取自己的网站关键词、标题、描述等内容提供简单、快速、强大的支持。通过分析抓取的内容来改进 URL。提高网站的排名。
特征
自动输入连续的 URL
获取浏览器的输入历史,可以快速找到已经输入的网址。无需记住一长串无意义的 URL。
通过输入通配符,可以快速输入一系列网址,大大降低人工输入的效率。
如果自动生成的URL需要更正,可以右键删除修改对应的URL。
灵活的人爬规则
默认提供三个常用的内容:标题、关键词和网页描述。供seo专业的同学快速上手,直接使用。快速完成老板账号的内容。
通过自定义XPath,你可以任意设置你的爬取内容,也可以设置无限制的规则。
指示
1、 安装运行,在网址输入要爬取的网页的网址,此时网址会自动添加到网址列表中,输入标题、关键词、描述在规则列表中,然后单击开始。
2、 爬取后,Cheng 会自动打开一个 Excel 表格,其中收录您输入的 URL 地址以及您输入的标题、关键词 和描述。
文件信息
文件大小:2014208 字节
MD5:FF86958701C899A7379BA612E0ABF2DE
SHA1:FE9F24ACC57D5FB6A3653D0C18850F23DE37D9E8
CRC32:5B3E0727
官方 网站:
相关搜索:SEO爬虫 查看全部
关键词采集器(迷你爬虫是一简单小巧的SEO抓取工具,它的作用)
迷你爬虫是一款简单小巧的SEO爬虫工具。它的作用是模拟搜索引擎抓取网页的标题、关键词、描述等信息。可以用于采集自己的网站,也可以用于采集竞争对手的网站,这样你就可以知道他们的头衔,关键词是怎样的写出来,从中学习。需要的SEOER可以下载迷你爬虫使用。
它是一款超小型快速的SEO工具,为seo行业合作伙伴快速抓取自己的网站关键词、标题、描述等内容提供简单、快速、强大的支持。通过分析抓取的内容来改进 URL。提高网站的排名。
特征
自动输入连续的 URL
获取浏览器的输入历史,可以快速找到已经输入的网址。无需记住一长串无意义的 URL。
通过输入通配符,可以快速输入一系列网址,大大降低人工输入的效率。
如果自动生成的URL需要更正,可以右键删除修改对应的URL。
灵活的人爬规则
默认提供三个常用的内容:标题、关键词和网页描述。供seo专业的同学快速上手,直接使用。快速完成老板账号的内容。
通过自定义XPath,你可以任意设置你的爬取内容,也可以设置无限制的规则。
指示
1、 安装运行,在网址输入要爬取的网页的网址,此时网址会自动添加到网址列表中,输入标题、关键词、描述在规则列表中,然后单击开始。
2、 爬取后,Cheng 会自动打开一个 Excel 表格,其中收录您输入的 URL 地址以及您输入的标题、关键词 和描述。
文件信息
文件大小:2014208 字节
MD5:FF86958701C899A7379BA612E0ABF2DE
SHA1:FE9F24ACC57D5FB6A3653D0C18850F23DE37D9E8
CRC32:5B3E0727
官方 网站:
相关搜索:SEO爬虫

