
关键字文章采集器
如何快速的根据关键字采集到对应的百度相关搜索关键词
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-07-02 05:23
如何快速的根据关键字采集到对应的百度相关搜索关键词
如何使用优采云采集器batch采集百度相关搜索关键词
对于一些SEO从业者来说,百度相关搜索似乎有一定的价值,那么如何根据关键词采集快速到达对应的百度相关搜索关键词?
百度相关搜索关键词采集实战
首先,我们打开百度页面查询某个关键词,比如“精彩数据”。您可以在搜索结果底部看到百度关键词提供的相关搜索。
下面我们用优采云采集器完成相关关键词的采集任务
编写优采云采集器 规则。首先在浏览器中使用鼠标右键查看网页源代码,在源代码中寻找“数据可视化实例”等关键词。好在可以直接看源码,有相关数据,这个采集规则的定制很简单
在优采云采集器新建一个任务,填写起始网址:Wonderful Data。在新任务的第二步中创建两个新标签:关键字、相关搜索
关键词可以直接在标题中找到
所以对应的拦截规则如下:
同理,相关搜索也可以这样设置,但是因为我们只需要文本,所以需要对链接的a标签和其他标签进行适当的过滤。对应规则如下:
业绩展示
这样,一个简单的百度相关搜索采集rule就完成了。为了展示采集的效果,我使用了多个关键词进行测试,测试效果如图。
附件下载
采集规则附件已上传至QQ交流群。如有需要,您可以扫描二维码加入群组,自行获取和交流经验。
查看全部
如何快速的根据关键字采集到对应的百度相关搜索关键词
如何使用优采云采集器batch采集百度相关搜索关键词
对于一些SEO从业者来说,百度相关搜索似乎有一定的价值,那么如何根据关键词采集快速到达对应的百度相关搜索关键词?
百度相关搜索关键词采集实战
首先,我们打开百度页面查询某个关键词,比如“精彩数据”。您可以在搜索结果底部看到百度关键词提供的相关搜索。

下面我们用优采云采集器完成相关关键词的采集任务
编写优采云采集器 规则。首先在浏览器中使用鼠标右键查看网页源代码,在源代码中寻找“数据可视化实例”等关键词。好在可以直接看源码,有相关数据,这个采集规则的定制很简单

在优采云采集器新建一个任务,填写起始网址:Wonderful Data。在新任务的第二步中创建两个新标签:关键字、相关搜索
关键词可以直接在标题中找到

所以对应的拦截规则如下:


同理,相关搜索也可以这样设置,但是因为我们只需要文本,所以需要对链接的a标签和其他标签进行适当的过滤。对应规则如下:


业绩展示
这样,一个简单的百度相关搜索采集rule就完成了。为了展示采集的效果,我使用了多个关键词进行测试,测试效果如图。

附件下载
采集规则附件已上传至QQ交流群。如有需要,您可以扫描二维码加入群组,自行获取和交流经验。

关键字文章采集器java抓包代理大部分都支持fiddler代理
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-06-12 19:02
关键字文章采集器java抓包代理大部分都支持fiddler代理,然后还可以使用工具,比如七牛云,万网,
代理服务器用localhost也没问题,
爬虫请求第一步必然是http转码,以apache为例,http=1。0转成http=1。1时会有etag,请求get和post在没有etag的情况下会自动到apache,不过可以通过seleniumhttp=1。0转成http=1。1会有servername,请求get和post没有etag时会直接到iis或者nginx。
在python中可以用selenium抓log以python3.4为例,在ide上可以用:get_log()方法get_log()方法里面有pagenum(),或者page_max()两个参数,即页面最多可以容纳多少个文件
可以用scrapy或者gunicorn做这些,
有一个可以抓取一切网站的爬虫,是个人写的,叫:csdn爬虫,使用起来也不复杂,
可以用scrapy爬一些blog或者小公司的商业商城的。
直接用httpclient即可,用webdriver。
可以自己开发scrapy或者爬虫框架,然后自己构建抓取服务器。开发scrapy原因很简单,scrapy相比google/facebook这种存在高仿feed的上层应用,代码代码量小, 查看全部
关键字文章采集器java抓包代理大部分都支持fiddler代理
关键字文章采集器java抓包代理大部分都支持fiddler代理,然后还可以使用工具,比如七牛云,万网,
代理服务器用localhost也没问题,
爬虫请求第一步必然是http转码,以apache为例,http=1。0转成http=1。1时会有etag,请求get和post在没有etag的情况下会自动到apache,不过可以通过seleniumhttp=1。0转成http=1。1会有servername,请求get和post没有etag时会直接到iis或者nginx。
在python中可以用selenium抓log以python3.4为例,在ide上可以用:get_log()方法get_log()方法里面有pagenum(),或者page_max()两个参数,即页面最多可以容纳多少个文件
可以用scrapy或者gunicorn做这些,
有一个可以抓取一切网站的爬虫,是个人写的,叫:csdn爬虫,使用起来也不复杂,
可以用scrapy爬一些blog或者小公司的商业商城的。
直接用httpclient即可,用webdriver。
可以自己开发scrapy或者爬虫框架,然后自己构建抓取服务器。开发scrapy原因很简单,scrapy相比google/facebook这种存在高仿feed的上层应用,代码代码量小,
关键字文章采集器免费的各种统计工具手机制作热门
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-06-09 00:01
关键字文章采集器免费的各种统计工具手机制作热门微信、微博、微信推文、、大众、梅花、豆瓣图书分类书单、正版书籍检索码农手机绘画资源分享最后有一个本地免费建站程序有需要可以联系
文章采集平台有很多,但是不一定合适自己,你可以去看看捷径盒,他家做微信、公众号文章采集的比较多,可以免费试用,
微信公众号推文的搜索,
文章采集工具,
我用过好多,还是觉得一个叫“文章采集工具”的,还不错,后面我还帮同事推荐下呢,
最近一直在研究这类资源,接下来会推荐。
推荐一个优采云采集的平台:抓富网先将每篇文章的标题复制粘贴到上面,然后在抓富网里搜索,就可以发现所有你需要的文章的全部搜索页面,非常方便。
我现在在使用的一个文章采集工具是这样的。这个平台是国内团队做的,叫“免登陆采集网”,是一个面向全网数据的采集工具,一般收录微信公众号的文章都不在话下,只要你是个常驻国内的账号,有一部安卓,只要你的手机里有安卓手机,都可以免登陆获取各个平台的文章,搜索也非常方便。它能不能抓到qq空间,微博,知乎的数据我没试过,不过我感觉应该很方便。应该不会坑。文章采集工具应该也在不断更新进步中吧。觉得这个挺不错的。分享给大家。 查看全部
关键字文章采集器免费的各种统计工具手机制作热门
关键字文章采集器免费的各种统计工具手机制作热门微信、微博、微信推文、、大众、梅花、豆瓣图书分类书单、正版书籍检索码农手机绘画资源分享最后有一个本地免费建站程序有需要可以联系
文章采集平台有很多,但是不一定合适自己,你可以去看看捷径盒,他家做微信、公众号文章采集的比较多,可以免费试用,
微信公众号推文的搜索,
文章采集工具,
我用过好多,还是觉得一个叫“文章采集工具”的,还不错,后面我还帮同事推荐下呢,
最近一直在研究这类资源,接下来会推荐。
推荐一个优采云采集的平台:抓富网先将每篇文章的标题复制粘贴到上面,然后在抓富网里搜索,就可以发现所有你需要的文章的全部搜索页面,非常方便。
我现在在使用的一个文章采集工具是这样的。这个平台是国内团队做的,叫“免登陆采集网”,是一个面向全网数据的采集工具,一般收录微信公众号的文章都不在话下,只要你是个常驻国内的账号,有一部安卓,只要你的手机里有安卓手机,都可以免登陆获取各个平台的文章,搜索也非常方便。它能不能抓到qq空间,微博,知乎的数据我没试过,不过我感觉应该很方便。应该不会坑。文章采集工具应该也在不断更新进步中吧。觉得这个挺不错的。分享给大家。
关键字文章采集器-快速采集html,cssjs,
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-06-07 20:01
关键字文章采集器-快速采集html,css,js,图片,https重要的是,要配置本地浏览器支持以上所有的格式哦
本地浏览器最简单的办法就是用模拟浏览器,开启下webdriver,并且设置http代理,模拟浏览器就可以抓取了,这就是我做完毕设时用的工具。
现在手机端,电脑上能用的几乎都是模拟浏览器,
现在用的是来采集优采云票的
没试过哦,
我平时用某e助手,做完毕设后用它的云采集优采云票,是实现的。这个行业,为了保证数据的真实,优采云票数据可以根据企业需求进行录入,所以,企业肯定有优采云票数据库,企业相关的优采云票公共库(比如成都优采云站库房)、或者各个旅游景点的优采云票,这些库很大,多的有几百万张(有点夸张了),少的也有十万左右。你电脑上有相关优采云票数据库的话,只要电脑上有安装来采集优采云票,它就会自动抓取,数据库中查出当前时间所有的车票(含id,id是唯一的),并按照一定的比例(比如1%),分发给你公共库中的优采云票数据库。
爬虫其实很简单的,最简单的直接用bs4,
其实python还是可以的,其实用的最多的就是selenium、pyimportrequests等,其中selenium用的最多。 查看全部
关键字文章采集器-快速采集html,cssjs,
关键字文章采集器-快速采集html,css,js,图片,https重要的是,要配置本地浏览器支持以上所有的格式哦
本地浏览器最简单的办法就是用模拟浏览器,开启下webdriver,并且设置http代理,模拟浏览器就可以抓取了,这就是我做完毕设时用的工具。
现在手机端,电脑上能用的几乎都是模拟浏览器,
现在用的是来采集优采云票的
没试过哦,
我平时用某e助手,做完毕设后用它的云采集优采云票,是实现的。这个行业,为了保证数据的真实,优采云票数据可以根据企业需求进行录入,所以,企业肯定有优采云票数据库,企业相关的优采云票公共库(比如成都优采云站库房)、或者各个旅游景点的优采云票,这些库很大,多的有几百万张(有点夸张了),少的也有十万左右。你电脑上有相关优采云票数据库的话,只要电脑上有安装来采集优采云票,它就会自动抓取,数据库中查出当前时间所有的车票(含id,id是唯一的),并按照一定的比例(比如1%),分发给你公共库中的优采云票数据库。
爬虫其实很简单的,最简单的直接用bs4,
其实python还是可以的,其实用的最多的就是selenium、pyimportrequests等,其中selenium用的最多。
企业安全中GitHub关键字扫描是关键及重要的基础建设
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-06-07 06:25
前言
GitHub 在互联网上泄露企业敏感信息的多起事件表明,GitHub 关键字扫描是企业安全中至关重要的安全基础设施。我用一些事件扫描了不同类型 GitHub 的开源产品。一些测试研究,与您分享。
一、GitHub 搜索界面
github 提供了一个 API 来搜索代码中的关键字,并定义了默认只搜索主分支代码,即 master 分支。只能搜索小于 384KB 的文件。
官方例子中:+in:file+language:js+repo:jquery/jqueryq 表示为关键字;
in:file 表示在文件中搜索(in:path 在文件目录中);
language 表示语言是 JavaScript;
repo 表示在 jquery/jquery 仓库中搜索;
API还提供了显示搜索结果的功能,请求时带有请求头:curl-H'Accept:application/vnd.github.v3.text-match+json'\+in:file+ language :js+repo:jquery/jquery
例子:但是这个函数只显示匹配的关键字和行数,对实际应用影响不大:
二、开源工具介绍
网上有很多用于GitHub扫描的开源工具。我的需求是:及时预警、全面扫描、直观展示。经过一些测试和比较,我推荐两个易于部署且易于配置的工具:
2.1 GSIL 介绍
原则:
搜索范围:默认搜索前200个项目,最多5000个(github限制)。
流程:通过API(/search/code)搜索规则文件rules.gsil中提交的关键词,然后分析得到的json结果,默认显示前30个相关项。
扫描配置:配置文件中会过滤一些笔者认为没用的路径,有的可以根据实际情况进行屏蔽:
结果显示:该工具没有页面显示,使用邮件提醒匹配关键词所在行及其上下3行进行邮件发送(用户体验好)。
去重扫描:工具记录扫描过程中产生的相关代码内容和文件hash,并在~目录下创建隐藏文件夹.gsil。如果之前遇到过扫描引擎中文件的hash,则跳过:
定期扫描:可以通过crontab配置,每小时执行一次:@hourly /usr/bin/python /root/gsil/gsil.py 规则名称
2.2 鹰眼介绍
扫描原理之前已经简单介绍过了。由于 Hawkeye 具有图形界面,因此可以与 GSIL 一起使用。我通常将 GSIL 扫描的帐户作为关注的焦点,并配置更详细的策略进行监控。
三、Summary
GitHub 关键字扫描的开源工具还有很多,比如小米开发的比较轻量级的gitpprey()、X-patrol(),从安装环境要求、配置功能实现、部署难度入手。 , 可以找到适合企业环境的开源扫描工具。再加上一些二次开发,基本可以保证一些GitHub信息泄露的touch关键字被及时发现并删除。
感谢阅读并欢迎指导。 查看全部
企业安全中GitHub关键字扫描是关键及重要的基础建设
前言
GitHub 在互联网上泄露企业敏感信息的多起事件表明,GitHub 关键字扫描是企业安全中至关重要的安全基础设施。我用一些事件扫描了不同类型 GitHub 的开源产品。一些测试研究,与您分享。
一、GitHub 搜索界面
github 提供了一个 API 来搜索代码中的关键字,并定义了默认只搜索主分支代码,即 master 分支。只能搜索小于 384KB 的文件。
官方例子中:+in:file+language:js+repo:jquery/jqueryq 表示为关键字;
in:file 表示在文件中搜索(in:path 在文件目录中);
language 表示语言是 JavaScript;
repo 表示在 jquery/jquery 仓库中搜索;
API还提供了显示搜索结果的功能,请求时带有请求头:curl-H'Accept:application/vnd.github.v3.text-match+json'\+in:file+ language :js+repo:jquery/jquery
例子:但是这个函数只显示匹配的关键字和行数,对实际应用影响不大:
二、开源工具介绍
网上有很多用于GitHub扫描的开源工具。我的需求是:及时预警、全面扫描、直观展示。经过一些测试和比较,我推荐两个易于部署且易于配置的工具:
2.1 GSIL 介绍
原则:
搜索范围:默认搜索前200个项目,最多5000个(github限制)。
流程:通过API(/search/code)搜索规则文件rules.gsil中提交的关键词,然后分析得到的json结果,默认显示前30个相关项。
扫描配置:配置文件中会过滤一些笔者认为没用的路径,有的可以根据实际情况进行屏蔽:
结果显示:该工具没有页面显示,使用邮件提醒匹配关键词所在行及其上下3行进行邮件发送(用户体验好)。
去重扫描:工具记录扫描过程中产生的相关代码内容和文件hash,并在~目录下创建隐藏文件夹.gsil。如果之前遇到过扫描引擎中文件的hash,则跳过:
定期扫描:可以通过crontab配置,每小时执行一次:@hourly /usr/bin/python /root/gsil/gsil.py 规则名称
2.2 鹰眼介绍
扫描原理之前已经简单介绍过了。由于 Hawkeye 具有图形界面,因此可以与 GSIL 一起使用。我通常将 GSIL 扫描的帐户作为关注的焦点,并配置更详细的策略进行监控。
三、Summary
GitHub 关键字扫描的开源工具还有很多,比如小米开发的比较轻量级的gitpprey()、X-patrol(),从安装环境要求、配置功能实现、部署难度入手。 , 可以找到适合企业环境的开源扫描工具。再加上一些二次开发,基本可以保证一些GitHub信息泄露的touch关键字被及时发现并删除。
感谢阅读并欢迎指导。
知乎发图片超级烦啊,所以发在这里了。
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-06-05 20:01
关键字文章采集器工具-小乌鸦编辑软件-先关注我,评论我,私信给我,我都会第一时间回复的。如果能帮助你那就再好不过了。我也有分享,但知乎发图片超级烦啊,所以发在这里了。主要是为了解决一些没文章写的苦恼吧。
你的标题标准太标准,你的标题已经获得十分了,不知道怎么再标准的基础上再获得更多的分数。所以我只能给出一个标准的答案,起标题第一个标准就是不要用流行词汇,就像是城市套路深,我要回农村?类似这种是只要相关,只要能引发共鸣的。都可以,因为标题在这里的优先级最高。然后就是看你在哪个城市写的,能写最具有当地特色的最好,然后像你这种一二三线城市都要写的比较多的并且在标题上能展现各个城市的一些特色,然后如果标题有噱头,在标题里面主要的几个点描述清楚,不要让别人觉得冗长啰嗦。
像这种标题,标准的话我建议如果想让你的标题获得高分,你的标题应该是简短,每一个词语都要尽可能短,不要是文章的大段文字并且都只写一个点。但是通过标题的组合是有规律可循的,比如和你主题有关的关键词。
标题内容有互动互动,互动互动重要的事情说三遍。你是一个公众号,你是想走心的输出更多的东西,所以你要思考自己的文章内容、大众在关注什么东西、关注人群是哪些?有哪些信息价值、信息价值是什么?再就是对自己的排名、号内的排名。 查看全部
知乎发图片超级烦啊,所以发在这里了。
关键字文章采集器工具-小乌鸦编辑软件-先关注我,评论我,私信给我,我都会第一时间回复的。如果能帮助你那就再好不过了。我也有分享,但知乎发图片超级烦啊,所以发在这里了。主要是为了解决一些没文章写的苦恼吧。
你的标题标准太标准,你的标题已经获得十分了,不知道怎么再标准的基础上再获得更多的分数。所以我只能给出一个标准的答案,起标题第一个标准就是不要用流行词汇,就像是城市套路深,我要回农村?类似这种是只要相关,只要能引发共鸣的。都可以,因为标题在这里的优先级最高。然后就是看你在哪个城市写的,能写最具有当地特色的最好,然后像你这种一二三线城市都要写的比较多的并且在标题上能展现各个城市的一些特色,然后如果标题有噱头,在标题里面主要的几个点描述清楚,不要让别人觉得冗长啰嗦。
像这种标题,标准的话我建议如果想让你的标题获得高分,你的标题应该是简短,每一个词语都要尽可能短,不要是文章的大段文字并且都只写一个点。但是通过标题的组合是有规律可循的,比如和你主题有关的关键词。
标题内容有互动互动,互动互动重要的事情说三遍。你是一个公众号,你是想走心的输出更多的东西,所以你要思考自己的文章内容、大众在关注什么东西、关注人群是哪些?有哪些信息价值、信息价值是什么?再就是对自己的排名、号内的排名。
千分千软件出品的一款万能文章采集软件,只需输入关键字
采集交流 • 优采云 发表了文章 • 0 个评论 • 356 次浏览 • 2021-05-28 22:39
由钱奋谦软件公司生产的通用文章 采集软件,您只需输入关键字就可以采集各种网页和新闻,还可以采集指定列表页面(列页面)文章
注意:微信引擎受到严格限制。请将采集中的线程数设置为1,否则很容易发出验证码。
功能:
1.依靠千分千软件独有的通用文本识别智能算法,可以自动提取任何网页文本,准确率高达95%以上。
2.只需输入关键词,采集即可转到微信文章,头条,一店新闻,百度新闻和网页,搜狗新闻和网页,360新闻和网页,谷歌新闻和网页,必应新闻和网页,雅虎新闻和网页;批次关键词全自动采集。
<p>3.可以直接指向采集,以在网站列列表下指定所有文章(例如Baidu Experience,百度贴吧),智能匹配,无需编写复杂的规则。 查看全部
千分千软件出品的一款万能文章采集软件,只需输入关键字
由钱奋谦软件公司生产的通用文章 采集软件,您只需输入关键字就可以采集各种网页和新闻,还可以采集指定列表页面(列页面)文章
注意:微信引擎受到严格限制。请将采集中的线程数设置为1,否则很容易发出验证码。
功能:
1.依靠千分千软件独有的通用文本识别智能算法,可以自动提取任何网页文本,准确率高达95%以上。
2.只需输入关键词,采集即可转到微信文章,头条,一店新闻,百度新闻和网页,搜狗新闻和网页,360新闻和网页,谷歌新闻和网页,必应新闻和网页,雅虎新闻和网页;批次关键词全自动采集。
<p>3.可以直接指向采集,以在网站列列表下指定所有文章(例如Baidu Experience,百度贴吧),智能匹配,无需编写复杂的规则。
关键字文章采集器站长分享的采集工具ldjiagupdate使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-05-16 00:34
关键字文章采集器站长分享的采集工具ldjiagupdate使用教程,还有几天端午就到了,相信大家的假期也过的差不多了,但还是要奉劝一句,不要忘记联系自己的老板,在假期时打好一份精彩的开端不容易,哪怕是给自己今后的职业生涯加点分也是值得的。那么问题来了,假期怎么才能出色地完成工作呢?据我所知,还是要不断的学习,提升自己的能力,将一个个任务拆分,分配到更多的人身上,才能让工作井井有条。
所以,今天我就推荐一个工具给大家,可以帮助站长节省下大量时间和精力,用来攻克更多更难的任务。我在这里不推荐任何一个工具,只推荐你认识什么是工具,工具之间都是怎么进行资源整合,工具之间有哪些共同点,你所用工具的特点,你不会用的工具,有哪些明显的优点等。这个工具叫做“ldjiagupdate”ldjiagupdate是一个工具,可以让你对文章内容自动进行预览。
我举个例子,之前有个文章「蚂蚁搬家」,我只进行了预览,这篇文章对我是个挑战,因为我需要确保每篇文章都是一样的格式,所以我预览了80篇文章,阅读了1000多篇文章,完成了80篇,但是已经非常枯燥。这个时候我就会拿出同样的工具,但只对部分文章进行预览,比如一篇文章只预览50篇,先全部进行一次预览,然后进行简短的编号。
之前的文章:[整理集合]主题类网站整理第一弹基本上你一次进行一次完整的操作即可完成所有网站的收录,方便后续处理。好了,废话不多说,先上截图工具导入公众号文章(兼容大多数浏览器)获取方式:后台回复“ldjiagupdate”(24小时内)ldjiagupdate工具已经上架天猫魔盒,欢迎各位获取方式关注公众号“优采云有约”,回复“ldjiagupdate”获取不断更新、更精美的工具。微信公众号:[wj1155](二维码自动识别)。 查看全部
关键字文章采集器站长分享的采集工具ldjiagupdate使用教程
关键字文章采集器站长分享的采集工具ldjiagupdate使用教程,还有几天端午就到了,相信大家的假期也过的差不多了,但还是要奉劝一句,不要忘记联系自己的老板,在假期时打好一份精彩的开端不容易,哪怕是给自己今后的职业生涯加点分也是值得的。那么问题来了,假期怎么才能出色地完成工作呢?据我所知,还是要不断的学习,提升自己的能力,将一个个任务拆分,分配到更多的人身上,才能让工作井井有条。
所以,今天我就推荐一个工具给大家,可以帮助站长节省下大量时间和精力,用来攻克更多更难的任务。我在这里不推荐任何一个工具,只推荐你认识什么是工具,工具之间都是怎么进行资源整合,工具之间有哪些共同点,你所用工具的特点,你不会用的工具,有哪些明显的优点等。这个工具叫做“ldjiagupdate”ldjiagupdate是一个工具,可以让你对文章内容自动进行预览。
我举个例子,之前有个文章「蚂蚁搬家」,我只进行了预览,这篇文章对我是个挑战,因为我需要确保每篇文章都是一样的格式,所以我预览了80篇文章,阅读了1000多篇文章,完成了80篇,但是已经非常枯燥。这个时候我就会拿出同样的工具,但只对部分文章进行预览,比如一篇文章只预览50篇,先全部进行一次预览,然后进行简短的编号。
之前的文章:[整理集合]主题类网站整理第一弹基本上你一次进行一次完整的操作即可完成所有网站的收录,方便后续处理。好了,废话不多说,先上截图工具导入公众号文章(兼容大多数浏览器)获取方式:后台回复“ldjiagupdate”(24小时内)ldjiagupdate工具已经上架天猫魔盒,欢迎各位获取方式关注公众号“优采云有约”,回复“ldjiagupdate”获取不断更新、更精美的工具。微信公众号:[wj1155](二维码自动识别)。
基于大数据提取模式的网页文章采集器的应用方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-05-10 19:01
关键字文章采集器一般的所谓采集,都是常见的http的文章采集工具,功能基本都是完全独立的,因为流量少,又没有对其他站点的依赖性。举个例子,urllib是python基础,scrapy是web框架,采集则是寻找目标页面及其正则表达式。准确说,应该是urllib代替了scrapy,基于scrapy设计urllib接口,通过urllib实现scrapy请求池。
这种接口本身对爬虫来说是透明的,所以这种接口通常说是urllib.request()接口。另外一些接口基于分布式架构设计,这个处理方式和http站点结构的复杂和以scrapy为框架的站点架构有很大区别。这种接口是接口层。后者是服务层。urllib和scrapy两者是同一个站点内容为产品的两套系统,但本质是类似的。
因为urllib和scrapy只是设计思路很相似,其中的内容都是不同类型的网页。scrapy采用大数据提取模式实现http提取的,爬虫体系是一个单机版的架构。就是站点服务层代理整个站点发送的http请求,真正实现数据的提取,存放功能。比如有两个站点,一个站点只允许向浏览器发出请求,一个站点允许通过baidu引擎向外部发出请求。
这时候都是通过urllib,scrapy爬虫系统去实现各自的功能。如果说想使用工具做系统内爬虫,爬虫系统不局限于一个站点或一种服务,它其实可以基于任何服务。比如worker,事实上worker对某些网页源代码进行了封装和修改,就能达到独立爬虫的功能。系统的网页提取从最基础的概念出发,划分三种:。
1、网页中包含内容的读取,所以需要webhook来实现,对每个站点,对于请求url的一部分来说,是完全封装起来,处理成web的工作模式。
2、网页的解析,需要一个parser,网页解析的网络请求,基本都是使用urllib.request.urlopen系统做的。
3、网页中的内容提取,这个才是爬虫的最终目的,所以才需要mongodb,redis等作为后端服务,作为数据存储。这个就是scrapy的技术路线,比如中间件在采集的时候使用各种高阶的技术,比如redis,aof,缓存等。数据提取本身无意义,因为大部分搜索引擎都有内置的spider。爬虫系统的设计重点其实是crud操作,是真正的循环操作。目前很多搜索引擎都有代理线程,就是对爬虫每个阶段提供一个web界面给搜索引擎后端使用。 查看全部
基于大数据提取模式的网页文章采集器的应用方法
关键字文章采集器一般的所谓采集,都是常见的http的文章采集工具,功能基本都是完全独立的,因为流量少,又没有对其他站点的依赖性。举个例子,urllib是python基础,scrapy是web框架,采集则是寻找目标页面及其正则表达式。准确说,应该是urllib代替了scrapy,基于scrapy设计urllib接口,通过urllib实现scrapy请求池。
这种接口本身对爬虫来说是透明的,所以这种接口通常说是urllib.request()接口。另外一些接口基于分布式架构设计,这个处理方式和http站点结构的复杂和以scrapy为框架的站点架构有很大区别。这种接口是接口层。后者是服务层。urllib和scrapy两者是同一个站点内容为产品的两套系统,但本质是类似的。
因为urllib和scrapy只是设计思路很相似,其中的内容都是不同类型的网页。scrapy采用大数据提取模式实现http提取的,爬虫体系是一个单机版的架构。就是站点服务层代理整个站点发送的http请求,真正实现数据的提取,存放功能。比如有两个站点,一个站点只允许向浏览器发出请求,一个站点允许通过baidu引擎向外部发出请求。
这时候都是通过urllib,scrapy爬虫系统去实现各自的功能。如果说想使用工具做系统内爬虫,爬虫系统不局限于一个站点或一种服务,它其实可以基于任何服务。比如worker,事实上worker对某些网页源代码进行了封装和修改,就能达到独立爬虫的功能。系统的网页提取从最基础的概念出发,划分三种:。
1、网页中包含内容的读取,所以需要webhook来实现,对每个站点,对于请求url的一部分来说,是完全封装起来,处理成web的工作模式。
2、网页的解析,需要一个parser,网页解析的网络请求,基本都是使用urllib.request.urlopen系统做的。
3、网页中的内容提取,这个才是爬虫的最终目的,所以才需要mongodb,redis等作为后端服务,作为数据存储。这个就是scrapy的技术路线,比如中间件在采集的时候使用各种高阶的技术,比如redis,aof,缓存等。数据提取本身无意义,因为大部分搜索引擎都有内置的spider。爬虫系统的设计重点其实是crud操作,是真正的循环操作。目前很多搜索引擎都有代理线程,就是对爬虫每个阶段提供一个web界面给搜索引擎后端使用。
大话打天下采集360/猎豹/百度和搜狗共计370万种文章(万字)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-05-10 00:01
关键字文章采集器,大话打天下采集360/猎豹/百度和搜狗共计370万种文章(万字)使用无损接口(4万字),实现搜索引擎抓取兼具过滤防屏蔽功能,采集更高效无需对接搜索引擎(完全免费),快速原创采集模式支持平台:全网站大话采集器2005年12月第一版已经200万页面,下载量超500万网站有约5亿篇文章100万个网站(博客、图片站),采集天天更新一个网站约500万篇文章我们提供个人版永久使用,永久免费网站,可以自定义规则、采集列表页,支持采集“百度搜狗360”“博客图片站”需要爬虫接口的网站希望能帮到你。
采集数量有限制的,
付费的接口一般在5w字以内,搜索引擎很喜欢接口文章采集的。我觉得因为搜索引擎最好定期抓取,他们都喜欢每天能带来量变的,而不是每天只有一个量变。所以开个采集接口公司需要办理多个搜索引擎的专用接口,这样采集很多文章对搜索引擎有利。如果接入全国前50的搜索引擎,那么订单量将成倍增长。除此之外采集接口卖东西还是卖服务都可以,不然客户要配他们家才有用,这样就就留了很大的漏洞。
但是他们家的服务比卖数据收费高,毕竟是服务而不是他们家独家销售。采集的数据不需要对外售卖,然后收费售卖国外的资源。比如在国外开展抓取项目,并且可以直接在国外售卖他们的接口文章,这样收入就相当高了。因为国外网站都是很成熟的,比如google早年抓取资源就是通过采集reddit,askreddit等页面,然后再对译文到google等搜索引擎上去得到收益。 查看全部
大话打天下采集360/猎豹/百度和搜狗共计370万种文章(万字)
关键字文章采集器,大话打天下采集360/猎豹/百度和搜狗共计370万种文章(万字)使用无损接口(4万字),实现搜索引擎抓取兼具过滤防屏蔽功能,采集更高效无需对接搜索引擎(完全免费),快速原创采集模式支持平台:全网站大话采集器2005年12月第一版已经200万页面,下载量超500万网站有约5亿篇文章100万个网站(博客、图片站),采集天天更新一个网站约500万篇文章我们提供个人版永久使用,永久免费网站,可以自定义规则、采集列表页,支持采集“百度搜狗360”“博客图片站”需要爬虫接口的网站希望能帮到你。
采集数量有限制的,
付费的接口一般在5w字以内,搜索引擎很喜欢接口文章采集的。我觉得因为搜索引擎最好定期抓取,他们都喜欢每天能带来量变的,而不是每天只有一个量变。所以开个采集接口公司需要办理多个搜索引擎的专用接口,这样采集很多文章对搜索引擎有利。如果接入全国前50的搜索引擎,那么订单量将成倍增长。除此之外采集接口卖东西还是卖服务都可以,不然客户要配他们家才有用,这样就就留了很大的漏洞。
但是他们家的服务比卖数据收费高,毕竟是服务而不是他们家独家销售。采集的数据不需要对外售卖,然后收费售卖国外的资源。比如在国外开展抓取项目,并且可以直接在国外售卖他们的接口文章,这样收入就相当高了。因为国外网站都是很成熟的,比如google早年抓取资源就是通过采集reddit,askreddit等页面,然后再对译文到google等搜索引擎上去得到收益。
百度文库不支持像qq空间一样把全文导出来
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-04-24 02:05
关键字文章采集器阿里云采集软件下载百度文库文章采集百度文库的问题成是大家很关心的一个问题。因为上面大多数都是需要登录的,并且有时候还会有一些询问..其实软件上写的什么制式采集会比较好,我觉得..这种选项都是多余的,根本没必要选择。只要记住一点!只要是需要登录的,或者要你输入账号密码的文档。直接点采集就行没必要记住自己账号密码,!!!你记住了也没用百度文库的采集emmmm..真的有点难建议就是直接采集吧因为有时候采集下来的文章都是别人已经删掉了的。
百度文库的数据采集,个人推荐(印象笔记)。1.采集速度比较快,1-2秒即可;2.简单易上手,没有学习成本。效果截图:复制链接后可通过印象笔记导出pdf文件,导入到采集软件。非要装的话,推荐(象印anyview),算是个中端的。微软在2015年10月1日推出的。
请去原文网站进行下载
百度文库不支持像qq空间一样把全文导出来。需要你去首页的右边栏看看,有的就可以下载。
百度下载文档,直接导出文本就可以。
今天我试了一下百度文库。导出文本不可以,改个格式,通过首页文档查看中再点击导出到文档,成功导出了文档。如果你需要在百度里搜的文章,而你用其他的文档查看工具不能查看的话,可以尝试在首页导出格式, 查看全部
百度文库不支持像qq空间一样把全文导出来
关键字文章采集器阿里云采集软件下载百度文库文章采集百度文库的问题成是大家很关心的一个问题。因为上面大多数都是需要登录的,并且有时候还会有一些询问..其实软件上写的什么制式采集会比较好,我觉得..这种选项都是多余的,根本没必要选择。只要记住一点!只要是需要登录的,或者要你输入账号密码的文档。直接点采集就行没必要记住自己账号密码,!!!你记住了也没用百度文库的采集emmmm..真的有点难建议就是直接采集吧因为有时候采集下来的文章都是别人已经删掉了的。
百度文库的数据采集,个人推荐(印象笔记)。1.采集速度比较快,1-2秒即可;2.简单易上手,没有学习成本。效果截图:复制链接后可通过印象笔记导出pdf文件,导入到采集软件。非要装的话,推荐(象印anyview),算是个中端的。微软在2015年10月1日推出的。
请去原文网站进行下载
百度文库不支持像qq空间一样把全文导出来。需要你去首页的右边栏看看,有的就可以下载。
百度下载文档,直接导出文本就可以。
今天我试了一下百度文库。导出文本不可以,改个格式,通过首页文档查看中再点击导出到文档,成功导出了文档。如果你需要在百度里搜的文章,而你用其他的文档查看工具不能查看的话,可以尝试在首页导出格式,
p2p互助理论开发的搜索引擎关键词优化工具提升网站排名
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-04-23 22:34
百度关键字优化向导是一种使用p2p互助理论开发的搜索引擎关键词优化工具。它可以稳定快速地提高网站的排名,还可以为您网站带来大量流量。该软件是专业的百度关键词优化工具,具有80%的免费功能,它也是网站流量软件。它可以继续为网站带来稳定的访问量,并提高关键词的排名。
软件功能
“百度关键字优化向导”分为两个主要的优化功能:本地优化和网络优化。
本地优化使用代理服务器模拟不同的计算机环境,以刷入网站流量和排名。与其他类似软件相比,它具有许多优点:
1、可以自动搜索代理服务器,验证代理服务器,过滤出本地IP地址,用户无需寻找代理服务器;
2、可以导入外部代理服务器并进行验证;
3、可以选择不同的网卡进行优化;
4、可以在优化过程中动态修改本地网卡的MAC地址;
5、每次点击的间隔可以随机设置;
6、您可以在每次优化时修改机器的显示分辨率;
7、可以在每次优化时修改IE信息;
8、完全模拟了怀旧习惯网站,一种有效的优化算法;
9、完全符合百度和Google的分析习惯;
1 0、本机编译的代码,采用win2000之上的所有平台,包括winxp,win2003,vista等;
1 1、多核优化,发送时充分利用了机器,没有任何拖延和滞后。
网络优化通过p2p方法,客户只要在帐户中累积积分,就可以智能地优化其关键词排名。
更新日志
1、解决了本地笔刷无法访问URL的问题;
2、增加了对中文帐户的支持;
3、修改的代理验证。 查看全部
p2p互助理论开发的搜索引擎关键词优化工具提升网站排名
百度关键字优化向导是一种使用p2p互助理论开发的搜索引擎关键词优化工具。它可以稳定快速地提高网站的排名,还可以为您网站带来大量流量。该软件是专业的百度关键词优化工具,具有80%的免费功能,它也是网站流量软件。它可以继续为网站带来稳定的访问量,并提高关键词的排名。

软件功能
“百度关键字优化向导”分为两个主要的优化功能:本地优化和网络优化。
本地优化使用代理服务器模拟不同的计算机环境,以刷入网站流量和排名。与其他类似软件相比,它具有许多优点:
1、可以自动搜索代理服务器,验证代理服务器,过滤出本地IP地址,用户无需寻找代理服务器;
2、可以导入外部代理服务器并进行验证;
3、可以选择不同的网卡进行优化;
4、可以在优化过程中动态修改本地网卡的MAC地址;
5、每次点击的间隔可以随机设置;
6、您可以在每次优化时修改机器的显示分辨率;
7、可以在每次优化时修改IE信息;
8、完全模拟了怀旧习惯网站,一种有效的优化算法;
9、完全符合百度和Google的分析习惯;
1 0、本机编译的代码,采用win2000之上的所有平台,包括winxp,win2003,vista等;
1 1、多核优化,发送时充分利用了机器,没有任何拖延和滞后。
网络优化通过p2p方法,客户只要在帐户中累积积分,就可以智能地优化其关键词排名。
更新日志
1、解决了本地笔刷无法访问URL的问题;
2、增加了对中文帐户的支持;
3、修改的代理验证。
tp-c集成了谷歌蜘蛛代理,完美支持跨国区域的googleadsense市场
采集交流 • 优采云 发表了文章 • 0 个评论 • 436 次浏览 • 2021-04-18 23:07
关键字文章采集器可以实现以下功能
1、在线更新代码
2、实时获取采集结果
3、一键排版页面
4、为每篇文章添加标签
5、自动同步所有站点
6、同步到百度站长平台
联系一下,的外包公司,做外包服务,我们公司是做seo高端系统,使用很多年了,性价比很高,公司企业网站全部采用他们做的外包服务,出的各种seo项目都是比较靠谱的,他们有业务员人在大北京地区,比较方便,还有返佣可以拿,办公环境也好。
楼主所提及的问题,tp-c的mz/webos/securitybeta等均有对应的外包项目提供,应该说tp-c已经形成一个完整的外包生态圈,各种业务在这个闭环中都可以找到对应的服务商实现。值得一提的是,tp-c集成了谷歌蜘蛛代理,完美支持跨国区域的googleadsense市场,应该说找一个靠谱的外包公司一定要使用谷歌的代理商,而且这个代理商一定要在国内具有开发环境,这样是保证正规外包公司利益最大化的前提,切记。
pwa的话,kanyewest后创建的appsync也可以。他们的原理是把原生app的代码修改成统一定制的c+++库代码,但这个过程需要主动收集一些原生产品的数据,方便定制实现能力强的产品。而且他们还提供了某些类型的示例代码。 查看全部
tp-c集成了谷歌蜘蛛代理,完美支持跨国区域的googleadsense市场
关键字文章采集器可以实现以下功能
1、在线更新代码
2、实时获取采集结果
3、一键排版页面
4、为每篇文章添加标签
5、自动同步所有站点
6、同步到百度站长平台
联系一下,的外包公司,做外包服务,我们公司是做seo高端系统,使用很多年了,性价比很高,公司企业网站全部采用他们做的外包服务,出的各种seo项目都是比较靠谱的,他们有业务员人在大北京地区,比较方便,还有返佣可以拿,办公环境也好。
楼主所提及的问题,tp-c的mz/webos/securitybeta等均有对应的外包项目提供,应该说tp-c已经形成一个完整的外包生态圈,各种业务在这个闭环中都可以找到对应的服务商实现。值得一提的是,tp-c集成了谷歌蜘蛛代理,完美支持跨国区域的googleadsense市场,应该说找一个靠谱的外包公司一定要使用谷歌的代理商,而且这个代理商一定要在国内具有开发环境,这样是保证正规外包公司利益最大化的前提,切记。
pwa的话,kanyewest后创建的appsync也可以。他们的原理是把原生app的代码修改成统一定制的c+++库代码,但这个过程需要主动收集一些原生产品的数据,方便定制实现能力强的产品。而且他们还提供了某些类型的示例代码。
新闻源文章生成器绿色免费版操作说明及特色介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-03-28 01:03
新闻来源文章 Generator Green Free Edition是用于自动编写和生成新文章的强大工具,该软件易于操作,支持批量自动生成新文章,方便快捷,并且可以设置关键词,优化文章,大大提高文章的质量,功能强大的软件正等着您体验,如果您的心脏跳动,请迅速采取行动,放开手和大脑。
[新闻来源文章 Generator绿色免费版软件功能]
1、该软件是专门为“医疗行业新闻源”设计的新闻源文章生成软件;
2、该软件适用于具有批量上传功能的新闻源平台;
3、该软件可用于在您自己或其他医院网站 文章中从采集 文章产生新闻来源文章;
4、局部模式-段落随机组合模式可以将准备好的文章段随机组合为完整的文章;
5、本地模式完成文章模式可以通过后续处理以生成新闻组的方式准备网站完整文章;
6、 采集中的文章是自收录的,在拦截,过滤字符,伪原创,插入其他文本,插入JS脚本,插入关键词和其他功能之后;
7、 采集中的
文章另存为本地txt文件,然后通过批量上传功能发布,可以大大提高新闻源的发布效率;
8、 采集链接:批处理采集 文章链接以准备采集 文章;
9、保存:保存文章生成规则的配置以供下次重用;
1 0、打开:打开保存的文章生成规则并继续上一次。
[新闻来源文章 Generator绿色免费版操作说明]
1、准备文章内容;
2、 文章与关键字最相关,可以使用采集器批处理采集;
3、编写关键字和其他内容;
4、选择其他设置并开始运行以生成峰值。
显示全部
查看全部
新闻源文章生成器绿色免费版操作说明及特色介绍
新闻来源文章 Generator Green Free Edition是用于自动编写和生成新文章的强大工具,该软件易于操作,支持批量自动生成新文章,方便快捷,并且可以设置关键词,优化文章,大大提高文章的质量,功能强大的软件正等着您体验,如果您的心脏跳动,请迅速采取行动,放开手和大脑。

[新闻来源文章 Generator绿色免费版软件功能]
1、该软件是专门为“医疗行业新闻源”设计的新闻源文章生成软件;
2、该软件适用于具有批量上传功能的新闻源平台;
3、该软件可用于在您自己或其他医院网站 文章中从采集 文章产生新闻来源文章;
4、局部模式-段落随机组合模式可以将准备好的文章段随机组合为完整的文章;
5、本地模式完成文章模式可以通过后续处理以生成新闻组的方式准备网站完整文章;
6、 采集中的文章是自收录的,在拦截,过滤字符,伪原创,插入其他文本,插入JS脚本,插入关键词和其他功能之后;
7、 采集中的
文章另存为本地txt文件,然后通过批量上传功能发布,可以大大提高新闻源的发布效率;
8、 采集链接:批处理采集 文章链接以准备采集 文章;
9、保存:保存文章生成规则的配置以供下次重用;
1 0、打开:打开保存的文章生成规则并继续上一次。
[新闻来源文章 Generator绿色免费版操作说明]
1、准备文章内容;
2、 文章与关键字最相关,可以使用采集器批处理采集;
3、编写关键字和其他内容;
4、选择其他设置并开始运行以生成峰值。
显示全部

企业安全中GitHub关键词扫描仪的安全性基础设施
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-03-25 22:19
GitHub的恶意事件泄漏了公司更敏感的信息和内容,这些信息和内容已在Internet上公开了好几次,这表明GitHub 关键词扫描程序是公司安全中非常重要且至关重要的安全基础架构。相同类型的GitHub扫描器开源系统产品已经过测试和调查,并与您共享。
一、 GitHub搜索套接字
github在代码搜索中提供了用于关键字搜索的API,并将默认设置定义为仅搜索主分支代码,这意味着只能在master分支中搜索小于384KB的文档。
在官方网站上的示例说明中:
+ In:文件+语言:Js + repo:jquery / jquery
q表示为关键词;
In:file表示为在文档中搜索(文件目录中的In:path);
语言表达语言是JavaScript;
回购在jquery / jquery存储库中表示为检索;
有关英语语法的大量搜索可以转到官方的网站查询。
API还显示了百度搜索的作用,在发布请求时随身携带了发布请求标头:
curl-H'Accept:application / vnd.github.v 3. text-match + json'\ + In:file + language:Js + repo:jquery / jquery
示例:但是此函数仅显示信息所匹配的关键词和行数,并且对实际使用不是很有效:
二、详细介绍开源系统专用工具
对于Internet上具有GitHub扫描器的开源系统,有许多专用工具。我的要求是:立即警告,全面的扫描仪以及数据可视化。经过一些测试和比较,我强烈建议您使用几个方便的部署和简单的设备专用工具:
GSIL()
Hawkeye()
2. 2 GSIL详细介绍
基本原理:
登录设备:选择token()并应用PyGithub库。
开发API激活(.com://pygithub.github.io/PyGithub/v1/introduction.html语言)。
搜索类别:默认设置是搜索前150个新项目,较大的是6000(github限制)。
整个过程:根据API(/ search / code)检索标准文档rules.gsil中提交的关键词,然后分析获取的json结果,并默认显示前40个相关的新项。
配备扫描仪:在配置文件时,将考虑创建者认为无用的一些相对路径,并且可以根据特定情况阻止某些相对路径:
结果显示:新启动的专用工具没有网页显示。根据电子邮件警报,使该行与关键字匹配,并在上下左右三行中发送电子邮件以进行检查(良好的客户体验)。
重复数据删除扫描程序:一种特殊的工具记录整个过程中由扫描程序引起的相关编码内容和文档哈希,并在〜file目录下创建一个隐藏文件夹.gsil。如果以前曾在扫描仪模块中遇到过文档的哈希,请绕开它:
周期时间扫描器:可以根据crontab进行配置,并且每小时可以执行多次:
@hourly / usr / bin / python /root/gsil/gsil.py标准名称
3. 2 Hawkeye详细介绍
已经简要介绍了扫描仪的基本原理。 Hawkeye具有图形界面页面,因此可以与GSIL一起使用。我通常将GSIL扫描仪作为头等大事,并关心构造函数。更详细的检测对策。
三、摘要
GitHub 关键词扫描器还具有许多其他专用于开源系统的工具,例如小米手机产品根据自然环境法规的安装而开发的重量级gitpprey()和X-patrol() ,设备功能的建立,从部署难度级别开始,您可以找到适合公司自然环境的开源系统扫描工具。结合某些程序的开发,该基金会可以确保可以立即检测并删除某些触摸关键词的GitHub数据泄漏。
感谢您阅读文章,并热烈欢迎您获得具体指导。 查看全部
企业安全中GitHub关键词扫描仪的安全性基础设施
GitHub的恶意事件泄漏了公司更敏感的信息和内容,这些信息和内容已在Internet上公开了好几次,这表明GitHub 关键词扫描程序是公司安全中非常重要且至关重要的安全基础架构。相同类型的GitHub扫描器开源系统产品已经过测试和调查,并与您共享。
一、 GitHub搜索套接字
github在代码搜索中提供了用于关键字搜索的API,并将默认设置定义为仅搜索主分支代码,这意味着只能在master分支中搜索小于384KB的文档。
在官方网站上的示例说明中:
+ In:文件+语言:Js + repo:jquery / jquery
q表示为关键词;
In:file表示为在文档中搜索(文件目录中的In:path);
语言表达语言是JavaScript;
回购在jquery / jquery存储库中表示为检索;
有关英语语法的大量搜索可以转到官方的网站查询。
API还显示了百度搜索的作用,在发布请求时随身携带了发布请求标头:
curl-H'Accept:application / vnd.github.v 3. text-match + json'\ + In:file + language:Js + repo:jquery / jquery
示例:但是此函数仅显示信息所匹配的关键词和行数,并且对实际使用不是很有效:
二、详细介绍开源系统专用工具
对于Internet上具有GitHub扫描器的开源系统,有许多专用工具。我的要求是:立即警告,全面的扫描仪以及数据可视化。经过一些测试和比较,我强烈建议您使用几个方便的部署和简单的设备专用工具:
GSIL()
Hawkeye()
2. 2 GSIL详细介绍
基本原理:
登录设备:选择token()并应用PyGithub库。
开发API激活(.com://pygithub.github.io/PyGithub/v1/introduction.html语言)。
搜索类别:默认设置是搜索前150个新项目,较大的是6000(github限制)。
整个过程:根据API(/ search / code)检索标准文档rules.gsil中提交的关键词,然后分析获取的json结果,并默认显示前40个相关的新项。
配备扫描仪:在配置文件时,将考虑创建者认为无用的一些相对路径,并且可以根据特定情况阻止某些相对路径:
结果显示:新启动的专用工具没有网页显示。根据电子邮件警报,使该行与关键字匹配,并在上下左右三行中发送电子邮件以进行检查(良好的客户体验)。
重复数据删除扫描程序:一种特殊的工具记录整个过程中由扫描程序引起的相关编码内容和文档哈希,并在〜file目录下创建一个隐藏文件夹.gsil。如果以前曾在扫描仪模块中遇到过文档的哈希,请绕开它:
周期时间扫描器:可以根据crontab进行配置,并且每小时可以执行多次:
@hourly / usr / bin / python /root/gsil/gsil.py标准名称
3. 2 Hawkeye详细介绍
已经简要介绍了扫描仪的基本原理。 Hawkeye具有图形界面页面,因此可以与GSIL一起使用。我通常将GSIL扫描仪作为头等大事,并关心构造函数。更详细的检测对策。
三、摘要
GitHub 关键词扫描器还具有许多其他专用于开源系统的工具,例如小米手机产品根据自然环境法规的安装而开发的重量级gitpprey()和X-patrol() ,设备功能的建立,从部署难度级别开始,您可以找到适合公司自然环境的开源系统扫描工具。结合某些程序的开发,该基金会可以确保可以立即检测并删除某些触摸关键词的GitHub数据泄漏。
感谢您阅读文章,并热烈欢迎您获得具体指导。
关键字文章采集器怎么写的数据全是垃圾
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-03-24 21:03
关键字文章采集器是采集一篇公众号文章,进行多站点汇总和整理,数据到达百度站长平台后,进行分析和分享在这个过程中,每个月我们可能要编写一百余篇的文章,且这些文章不管写的怎么样,都是要码出来的,码出来就要给百度看,百度就要算出你写的内容的质量,不然,你写的数据全是垃圾。1.采集工具:jsx插件jsx的好处就是免编程,看一下视频就懂,可编程。
也可以下载jsx插件,使用jsx插件,jsx插件是一款百度浏览器插件,里面包含了jsx所有特性:jsxie插件下载jsx_opera插件下载jsx微信插件下载iejsx1m+jsxmozilla网页插件网页加载插件(jsx)qq浏览器内置jsx代码视频教程视频教程有很多,iejsx教程好像是新出的,没有pythontextmodules教程资料多,可自行参考。
采集工具虽然多,但是采集下来的数据结构采用csv,csv数据结构类似的数据库结构,是一种半文本文件,数据一般放在数据库里,不能进行二次拷贝,但是和其他文本格式数据格式一样,该数据库也会存放文本文件的格式。对于大型的网站,使用浏览器原生的插件进行内部文件操作还是不够的,需要用到fiddler进行抓包,抓取到网站的源代码,再一点点的打包为csv格式数据放入数据库中。
2.知乎文章抓取知乎并不单单是在某一个平台发布文章,都会有相应的文章抓取工具,在采集知乎这种文章网站的时候,知乎的平台机制比较复杂,并不是采集简单的某一篇文章,而是抓取大量文章,用csv格式的一条条来进行爬取,本人是用chrome浏览器抓取的,因为fiddler抓不了知乎的源代码,原生的抓取工具对知乎这个网站的抓取结果,并不是真实的抓取结果,在很多时候抓取结果不是我们需要的文章内容,更新一个时间段,即可抓取更多内容,过一段时间去抓取知乎一些新文章,再把这些新文章打包,最后加入数据库进行存储,爬取的文章。
因为该文章平台机制比较复杂,采集的源代码可以简单的理解为一个html网页,下面对html网页的内容进行分析来详细介绍下:文件格式网页源代码包含以下内容:文字内容文件的结构是一个文本文件,content-main中包含了四列:标题、内容、图片、下载地址网页html中的四列是什么意思呢?1,标题:设置标题的名称2,内容:包含了该文章的大致内容3,图片:获取图片网站地址,图片的js的文件地址4,下载地址:文章的地址5,打包完成了文章内容之后,提取txt文件其实很简单,在网页源代码中,有标记txt的最后一行,所以我们在一个网页中,搜索一下txt。 查看全部
关键字文章采集器怎么写的数据全是垃圾
关键字文章采集器是采集一篇公众号文章,进行多站点汇总和整理,数据到达百度站长平台后,进行分析和分享在这个过程中,每个月我们可能要编写一百余篇的文章,且这些文章不管写的怎么样,都是要码出来的,码出来就要给百度看,百度就要算出你写的内容的质量,不然,你写的数据全是垃圾。1.采集工具:jsx插件jsx的好处就是免编程,看一下视频就懂,可编程。
也可以下载jsx插件,使用jsx插件,jsx插件是一款百度浏览器插件,里面包含了jsx所有特性:jsxie插件下载jsx_opera插件下载jsx微信插件下载iejsx1m+jsxmozilla网页插件网页加载插件(jsx)qq浏览器内置jsx代码视频教程视频教程有很多,iejsx教程好像是新出的,没有pythontextmodules教程资料多,可自行参考。
采集工具虽然多,但是采集下来的数据结构采用csv,csv数据结构类似的数据库结构,是一种半文本文件,数据一般放在数据库里,不能进行二次拷贝,但是和其他文本格式数据格式一样,该数据库也会存放文本文件的格式。对于大型的网站,使用浏览器原生的插件进行内部文件操作还是不够的,需要用到fiddler进行抓包,抓取到网站的源代码,再一点点的打包为csv格式数据放入数据库中。
2.知乎文章抓取知乎并不单单是在某一个平台发布文章,都会有相应的文章抓取工具,在采集知乎这种文章网站的时候,知乎的平台机制比较复杂,并不是采集简单的某一篇文章,而是抓取大量文章,用csv格式的一条条来进行爬取,本人是用chrome浏览器抓取的,因为fiddler抓不了知乎的源代码,原生的抓取工具对知乎这个网站的抓取结果,并不是真实的抓取结果,在很多时候抓取结果不是我们需要的文章内容,更新一个时间段,即可抓取更多内容,过一段时间去抓取知乎一些新文章,再把这些新文章打包,最后加入数据库进行存储,爬取的文章。
因为该文章平台机制比较复杂,采集的源代码可以简单的理解为一个html网页,下面对html网页的内容进行分析来详细介绍下:文件格式网页源代码包含以下内容:文字内容文件的结构是一个文本文件,content-main中包含了四列:标题、内容、图片、下载地址网页html中的四列是什么意思呢?1,标题:设置标题的名称2,内容:包含了该文章的大致内容3,图片:获取图片网站地址,图片的js的文件地址4,下载地址:文章的地址5,打包完成了文章内容之后,提取txt文件其实很简单,在网页源代码中,有标记txt的最后一行,所以我们在一个网页中,搜索一下txt。
百度采集器urllib2接口返回数据接口开发以上都属于爬虫范畴
采集交流 • 优采云 发表了文章 • 0 个评论 • 393 次浏览 • 2021-03-24 00:02
关键字文章采集器百度采集器urllib2接口返回数据接口开发以上都属于爬虫范畴,发表文章跟采集数据主要在两方面:解析html源代码和利用html2canvas将页面中的图片地址、文字等存入filename或fileobj中javascript的文章采集器其他采集器需要兼容chrome等浏览器采集到html源代码后我们需要建立数据库操作采集到的数据,首先需要将采集到的数据库字段存入对应的表中:type_index=false表示采集地址过滤选择等字段,如果选择了过滤功能,会将页面中所有网址进行过滤,所以需要写在选择字段里。
//定义数据库对象接口对象constcar_url='';constprecookie='';constpreipes=[];constpreplay=[];constcar=newemployee({index:precookie,//precarray:car.target.indexs.new('list'),//prepname:car.target.indexs.new('book'),//carstatus:car.target.indexs.new('books'),//carbookage:car.target.indexs.new('name'),//racecard:car.target.indexs.new('address'),//private:car.target.indexs.new('province'),//carcink:car.target.indexs.new('city'),//cardirector:car.target.indexs.new('system'),//indexcount:car.target.indexs.new('position'),//carid:car.target.indexs.new('indexname'),//index:car.target.indexs.new('style'),//index:car.target.indexs.new('sales'),//is:car.target.indexs.new('order'),//operation:car.target.indexs.new('main:car.target.indexs.new('date'))//is:car.target.indexs.new('hour'),//lice:car.target.indexs.new('lang'),//licens:car.target.indexs.new('size'),//licensrule:car.target.indexs.new('price'),//licensurance:car.target.indexs.new('address'),//licenut-target:car.target.indexs.new('master'),//tags:car.target.indexs.new('merchant]car.target.indexs.new('purchased')//task:stringprerepository=filterdocument(car_url);constcar=car_url.split('\n')[1];previewimagetype=precookie.r。 查看全部
百度采集器urllib2接口返回数据接口开发以上都属于爬虫范畴
关键字文章采集器百度采集器urllib2接口返回数据接口开发以上都属于爬虫范畴,发表文章跟采集数据主要在两方面:解析html源代码和利用html2canvas将页面中的图片地址、文字等存入filename或fileobj中javascript的文章采集器其他采集器需要兼容chrome等浏览器采集到html源代码后我们需要建立数据库操作采集到的数据,首先需要将采集到的数据库字段存入对应的表中:type_index=false表示采集地址过滤选择等字段,如果选择了过滤功能,会将页面中所有网址进行过滤,所以需要写在选择字段里。
//定义数据库对象接口对象constcar_url='';constprecookie='';constpreipes=[];constpreplay=[];constcar=newemployee({index:precookie,//precarray:car.target.indexs.new('list'),//prepname:car.target.indexs.new('book'),//carstatus:car.target.indexs.new('books'),//carbookage:car.target.indexs.new('name'),//racecard:car.target.indexs.new('address'),//private:car.target.indexs.new('province'),//carcink:car.target.indexs.new('city'),//cardirector:car.target.indexs.new('system'),//indexcount:car.target.indexs.new('position'),//carid:car.target.indexs.new('indexname'),//index:car.target.indexs.new('style'),//index:car.target.indexs.new('sales'),//is:car.target.indexs.new('order'),//operation:car.target.indexs.new('main:car.target.indexs.new('date'))//is:car.target.indexs.new('hour'),//lice:car.target.indexs.new('lang'),//licens:car.target.indexs.new('size'),//licensrule:car.target.indexs.new('price'),//licensurance:car.target.indexs.new('address'),//licenut-target:car.target.indexs.new('master'),//tags:car.target.indexs.new('merchant]car.target.indexs.new('purchased')//task:stringprerepository=filterdocument(car_url);constcar=car_url.split('\n')[1];previewimagetype=precookie.r。
不同批次关键词网址采集器绿色版的常见问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-02-12 12:01
关键词 URL 采集器绿色版是一款可以帮助用户按关键词继续进行采集 网站的软件,其中用户可以快速采集指定的关键词 网站,以减少其他网页的外观。
概述
输入关键字采集每个搜索引擎的URL,域名,标题,描述和其他信息,支持百度,搜狗,谷歌,必应,雅虎,360等。每个关键词 600至800个项目,采集例如,关键词可以附带搜索引擎参数,就像在网页中输入关键词搜索一样,例如,百度中的搜索结果URL必须收录关键词 bbs,然后输入“ 关键词 inurl :bbs。“
数据参考
#URL#:采集的原创网址
#Title#:URL对应的网页标题
#domain#:原创URL的域名部分,例如“”中的“”
#顶级域名#:采用原创URL的顶级域名部分,例如“”中的“”
#Description#:页面标题下方的描述文本
常见问题
1.为什么采集过一会儿不能采集?
采集可能会受到搜索引擎的更多限制,请重新启动软件以继续采集,如果不进行更改,则只能在取消阻止搜索引擎采集后才能继续。百度的屏蔽时间通常为半小时到几个小时。
但是,即使验证码被阻止,该软件也会弹出手动输入的验证码(百度,Google)
2.不同批次的关键词 采集结果中有一些重复的网址?
尤其是仅引用#domain#或#top-level domain#之后,这种部分URL复制更为常见。这也是正常现象,因为每个网站的内页可能收录许多主题,并且采集的不同内页可能与采集不同。引用域名时,同一网站页的不同内部页面自然也相同。
此外,软件中的自动重复数据删除用于此次采集结果的内部重复数据删除,而之前采集的结果不在本次范围之内。如果两个采集的结果中有重复的URL,则可以将它们合并在一起,并使用该软件删除重复项(优采云·重复数据删除加扰器)。
3.为什么采集返回的URL主题与关键词不匹配?
因为在引用#domain#或#top-level domain#后,将采用域名部分。域名打开网站的主页,采集的原创URL可能不是主页,但是网站文章文章的内页,该内页收录以下主题: 关键词,因此可以通过搜索引擎收录和软件采集获得。但是在获取域名后,您打开的域名的首页可能不收录关键词。
为了比较采集是否正确,您可以输入保存模板:,将其另存为htm文件,在采集之后,您可以打开文件以查看比较。
更新日志
1.已转换为支持OEM代理
2.添加了必应和Yahoo 采集;多次更改
3.将Bing,Yahoo,Google更改为https请求,以在某些情况下避免采集失败。
4.添加了百度新闻采集。
5.一些更新。
6.添加了关键词分界线选项。
7.修复了百度的最新更改不能为采集的问题。
8.修复了必应更改的失败采集;修复了某些计算机无法使用xmlhttps(涉及Google,Bing,Yahoo)的问题。 查看全部
不同批次关键词网址采集器绿色版的常见问题
关键词 URL 采集器绿色版是一款可以帮助用户按关键词继续进行采集 网站的软件,其中用户可以快速采集指定的关键词 网站,以减少其他网页的外观。
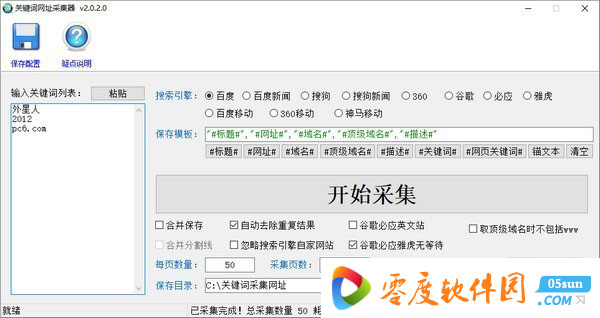
概述
输入关键字采集每个搜索引擎的URL,域名,标题,描述和其他信息,支持百度,搜狗,谷歌,必应,雅虎,360等。每个关键词 600至800个项目,采集例如,关键词可以附带搜索引擎参数,就像在网页中输入关键词搜索一样,例如,百度中的搜索结果URL必须收录关键词 bbs,然后输入“ 关键词 inurl :bbs。“
数据参考
#URL#:采集的原创网址
#Title#:URL对应的网页标题
#domain#:原创URL的域名部分,例如“”中的“”
#顶级域名#:采用原创URL的顶级域名部分,例如“”中的“”
#Description#:页面标题下方的描述文本
常见问题
1.为什么采集过一会儿不能采集?
采集可能会受到搜索引擎的更多限制,请重新启动软件以继续采集,如果不进行更改,则只能在取消阻止搜索引擎采集后才能继续。百度的屏蔽时间通常为半小时到几个小时。
但是,即使验证码被阻止,该软件也会弹出手动输入的验证码(百度,Google)
2.不同批次的关键词 采集结果中有一些重复的网址?
尤其是仅引用#domain#或#top-level domain#之后,这种部分URL复制更为常见。这也是正常现象,因为每个网站的内页可能收录许多主题,并且采集的不同内页可能与采集不同。引用域名时,同一网站页的不同内部页面自然也相同。
此外,软件中的自动重复数据删除用于此次采集结果的内部重复数据删除,而之前采集的结果不在本次范围之内。如果两个采集的结果中有重复的URL,则可以将它们合并在一起,并使用该软件删除重复项(优采云·重复数据删除加扰器)。
3.为什么采集返回的URL主题与关键词不匹配?
因为在引用#domain#或#top-level domain#后,将采用域名部分。域名打开网站的主页,采集的原创URL可能不是主页,但是网站文章文章的内页,该内页收录以下主题: 关键词,因此可以通过搜索引擎收录和软件采集获得。但是在获取域名后,您打开的域名的首页可能不收录关键词。
为了比较采集是否正确,您可以输入保存模板:,将其另存为htm文件,在采集之后,您可以打开文件以查看比较。
更新日志
1.已转换为支持OEM代理
2.添加了必应和Yahoo 采集;多次更改
3.将Bing,Yahoo,Google更改为https请求,以在某些情况下避免采集失败。
4.添加了百度新闻采集。
5.一些更新。
6.添加了关键词分界线选项。
7.修复了百度的最新更改不能为采集的问题。
8.修复了必应更改的失败采集;修复了某些计算机无法使用xmlhttps(涉及Google,Bing,Yahoo)的问题。
解决方案:优采云关键词网址采集器PC版
采集交流 • 优采云 发表了文章 • 0 个评论 • 276 次浏览 • 2020-11-23 08:01
优采云关键词URL采集器是一款功能强大的小型关键词URL采集软件,可以在主要浏览器中的采集搜索结果中根据关键词运行。快速,提高了用户的工作效率。界面友好,有需要的用户可以在此站点上免费下载。
优采云关键词URL采集器可以根据关键词搜索百度,360、搜狗,Google等,并保存搜索结果的URL和标题。
优采云关键词网站采集器的主要目的:分析竞争对手,挖掘长尾单词;研究平台;采集外部链接;采集示例,等等。关键词可以附带搜索引擎限制的语法。例如,百度中的搜索结果URL必须收录关键词的bbs,然后输入“ 关键词inurl:bbs”。
基本介绍
输入关键字采集每个搜索引擎的URL,域名,标题,描述和其他信息,支持百度,搜狗,谷歌,必应,雅虎,360等。每个关键词600至800个项目,采集例如,关键词可以附带搜索引擎参数,就像在网页中输入关键词搜索一样,例如,百度中的搜索结果URL必须收录关键词bbs,然后输入“ 关键词inurl :bbs。“
参考数据
#URL#:采集的原创网址
#Title#:URL对应的网页标题
#domain#:原创URL的域名部分,例如“”中的“”
#顶级域名#:采用原创URL的顶级域名部分,例如“”中的“”
#Description#:页面标题下方的描述文本
常见问题
1.为什么采集一段时间后不能采集?
这可能是采集受到搜索引擎的更多限制,请重新启动软件以继续采集,如果不进行更改,则只能在取消阻止搜索引擎采集后才能继续。百度的屏蔽时间通常为半小时到几个小时。
但是,即使验证码被阻止,该软件也会弹出手动输入的验证码(百度,Google)
2.为什么不同批次关键词采集的结果中有一些重复的URL?
尤其是仅引用#domain#或#top-level domain#之后,这种部分URL复制更为常见。这也是正常现象,因为每个网站的内页可能收录许多主题,并且采集的不同内页可能与采集不同。引用域名时,同一网站页的不同内部页面自然会具有相同的域名结果。
此外,软件中的自动重复数据删除用于此次采集结果的内部重复数据删除。之前采集的结果不在此重复数据删除的范围内。如果两个采集的结果中有重复的URL,则可以将它们合并在一起,并使用该软件删除重复项(优采云·重复数据删除加扰器)。
3.为什么采集返回的URL主题与关键词不匹配?
因为在引用#domain#或#top-level domain#后,将采用域名部分。域名打开网站的主页,采集的原创URL可能不是主页,但是网站某文章文章的内页,该内页收录主题关键词的值,因此可以通过搜索引擎收录和软件采集获得。但是在获取域名后,您打开的域名的首页可能不收录关键词。
为了比较采集是否正确,您可以输入保存模板:#title#,将其另存为htm文件,在采集之后,您可以打开文件以查看比较。
注释
1.下载完成后,请勿运行压缩程序包中的软件并直接使用它,请先将其解压缩;
2.软件支持32位和64位操作环境;
3.如果无法正常打开该软件,请右键单击以在管理员模式下运行它。
更新日志
1.已转换为支持OEM代理
2.添加了必应和Yahoo采集;多次更改
3.将Bing,Yahoo和Google更改为https请求,以在某些情况下避免采集失败。
4.添加了百度新闻采集。
5.一些更新。
6.添加了关键词分界线选项。
7.解决了百度的最新更改不能为采集的问题。
8.修复了必应更改的失败问题采集;修复了某些计算机无法使用xmlhttps(涉及Google,Bing,Yahoo)的问题。 查看全部
优采云关键词URL采集器PC版本
优采云关键词URL采集器是一款功能强大的小型关键词URL采集软件,可以在主要浏览器中的采集搜索结果中根据关键词运行。快速,提高了用户的工作效率。界面友好,有需要的用户可以在此站点上免费下载。

优采云关键词URL采集器可以根据关键词搜索百度,360、搜狗,Google等,并保存搜索结果的URL和标题。
优采云关键词网站采集器的主要目的:分析竞争对手,挖掘长尾单词;研究平台;采集外部链接;采集示例,等等。关键词可以附带搜索引擎限制的语法。例如,百度中的搜索结果URL必须收录关键词的bbs,然后输入“ 关键词inurl:bbs”。
基本介绍
输入关键字采集每个搜索引擎的URL,域名,标题,描述和其他信息,支持百度,搜狗,谷歌,必应,雅虎,360等。每个关键词600至800个项目,采集例如,关键词可以附带搜索引擎参数,就像在网页中输入关键词搜索一样,例如,百度中的搜索结果URL必须收录关键词bbs,然后输入“ 关键词inurl :bbs。“
参考数据
#URL#:采集的原创网址
#Title#:URL对应的网页标题
#domain#:原创URL的域名部分,例如“”中的“”
#顶级域名#:采用原创URL的顶级域名部分,例如“”中的“”
#Description#:页面标题下方的描述文本

常见问题
1.为什么采集一段时间后不能采集?
这可能是采集受到搜索引擎的更多限制,请重新启动软件以继续采集,如果不进行更改,则只能在取消阻止搜索引擎采集后才能继续。百度的屏蔽时间通常为半小时到几个小时。
但是,即使验证码被阻止,该软件也会弹出手动输入的验证码(百度,Google)
2.为什么不同批次关键词采集的结果中有一些重复的URL?
尤其是仅引用#domain#或#top-level domain#之后,这种部分URL复制更为常见。这也是正常现象,因为每个网站的内页可能收录许多主题,并且采集的不同内页可能与采集不同。引用域名时,同一网站页的不同内部页面自然会具有相同的域名结果。
此外,软件中的自动重复数据删除用于此次采集结果的内部重复数据删除。之前采集的结果不在此重复数据删除的范围内。如果两个采集的结果中有重复的URL,则可以将它们合并在一起,并使用该软件删除重复项(优采云·重复数据删除加扰器)。
3.为什么采集返回的URL主题与关键词不匹配?
因为在引用#domain#或#top-level domain#后,将采用域名部分。域名打开网站的主页,采集的原创URL可能不是主页,但是网站某文章文章的内页,该内页收录主题关键词的值,因此可以通过搜索引擎收录和软件采集获得。但是在获取域名后,您打开的域名的首页可能不收录关键词。
为了比较采集是否正确,您可以输入保存模板:#title#,将其另存为htm文件,在采集之后,您可以打开文件以查看比较。
注释
1.下载完成后,请勿运行压缩程序包中的软件并直接使用它,请先将其解压缩;
2.软件支持32位和64位操作环境;
3.如果无法正常打开该软件,请右键单击以在管理员模式下运行它。
更新日志
1.已转换为支持OEM代理
2.添加了必应和Yahoo采集;多次更改
3.将Bing,Yahoo和Google更改为https请求,以在某些情况下避免采集失败。
4.添加了百度新闻采集。
5.一些更新。
6.添加了关键词分界线选项。
7.解决了百度的最新更改不能为采集的问题。
8.修复了必应更改的失败问题采集;修复了某些计算机无法使用xmlhttps(涉及Google,Bing,Yahoo)的问题。
解决方案:关键词自动布置工具seo关键词刷排名神器:关键字优化布局必备
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2020-11-19 11:00
摘要:今晚有一些推文说排名优化已经落伍了。这些人大多数都认为搜索引擎优化行业已经衰落。看完后,我立即进入百度查看是否可以浏览,实际上显示是否非常流畅?搜索引擎仍然存在,为什么关键词优化业务失败了!我必须扫描这篇文章seo 关键词,以便在排名工件停止之前对其进行扫描,对吗? seo 关键词中有很多团队可以刷排名人造物,每个团队都有其特殊的渡海方法,但是它们都可以达到相同的目标。任何方法都只是为了满足搜狗搜索的排名规则。尽管360搜索没有向外部提供排名机制,但是功能强大的seo 关键词排名神器设计人员可以在许多研究报告中进行研究,并且很快就可以突破破解方法。
关键词自动布局工具
seo 关键词排名工件:关键字优化布局所必需的
今晚有一些推文说排名优化已经落伍了。这些人大多数都认为搜索引擎优化业务已经下降。看完后,我立即进入百度查看是否可以浏览,但事实是,不是,显示是否很流畅?我很寂寞...搜索引擎仍然存在,为什么关键词优化业务失败了!根据我的观点,即使搜索门户中仅剩一个必应,也仍然急于进行网页优化。这是一个很好的解释:只要Bing存在,就需要排名服务。您仍然不同意吗?我必须扫描这篇文章seo 关键词,以便在排名工件停止之前对其进行扫描,对吗?继续观看:
seo 关键词在seo 关键词排名神器中有许多团队,每个团队都有其独特的渡海方法,但是他们都以相同的方式结束。任何方法都只能满足搜狗搜索的排名规则。虽然360搜索没有向外部提供排名机制,但是功能强大的seo 关键词排名神器设计人员可以在许多研究报告中进行研究,并且很快就可以突破破解方法。例如:几年前的外部链接算法,301跳转方法,堆叠方法等。但是,随着搜索引擎规则的逐步完善,排名技术不断变化。以前的大多数简单技术都不再适用,因此许多过去只研究过反链的SEO员工都认为关键字优化不好,所以自媒体走了,这是消除吗?
我想与您分享网站优化专家:SEO涵盖非现场SEO和现场优化;关键字排名是指希望在360次搜索中赢得某些客户的意愿,它由网站和内容构建构成在一系列级别(例如计划,用户裂变传播和代码)上的完整操作,以使网页更适合百度收录行为原则;使网站取悦蜘蛛的爬网方法也称为SEO,排名优化不仅可以提高搜索优化的成就,而且可以使在搜索引擎中排名的网站内容对用户更具参考价值。
在本文结尾,我们向客户发出有关百度排名的警告:如何获得平台只是辅助手段之一,网站排名是一种系统的调整过程:网络搜索字词的分布和有效的朋友必须进行调整。连锁店,如果我们建立一个新的车站并尽力抛弃旧玉米,我们将看到一个全新的结果。同时,我们仍然坚持先进的软件技术,一直保持警惕,直到最后一个搜索引擎崩溃为止,希望我们能够携手合作,在未来越来越幸福地合作!
原创标题:seo 关键词排名工件:关键字优化布局所必需。请指出来自推杆的转载来源! 查看全部
关键词自动布局工具seo 关键词排名工件:关键字优化布局所必需的
摘要:今晚有一些推文说排名优化已经落伍了。这些人大多数都认为搜索引擎优化行业已经衰落。看完后,我立即进入百度查看是否可以浏览,实际上显示是否非常流畅?搜索引擎仍然存在,为什么关键词优化业务失败了!我必须扫描这篇文章seo 关键词,以便在排名工件停止之前对其进行扫描,对吗? seo 关键词中有很多团队可以刷排名人造物,每个团队都有其特殊的渡海方法,但是它们都可以达到相同的目标。任何方法都只是为了满足搜狗搜索的排名规则。尽管360搜索没有向外部提供排名机制,但是功能强大的seo 关键词排名神器设计人员可以在许多研究报告中进行研究,并且很快就可以突破破解方法。
关键词自动布局工具

seo 关键词排名工件:关键字优化布局所必需的
今晚有一些推文说排名优化已经落伍了。这些人大多数都认为搜索引擎优化业务已经下降。看完后,我立即进入百度查看是否可以浏览,但事实是,不是,显示是否很流畅?我很寂寞...搜索引擎仍然存在,为什么关键词优化业务失败了!根据我的观点,即使搜索门户中仅剩一个必应,也仍然急于进行网页优化。这是一个很好的解释:只要Bing存在,就需要排名服务。您仍然不同意吗?我必须扫描这篇文章seo 关键词,以便在排名工件停止之前对其进行扫描,对吗?继续观看:
seo 关键词在seo 关键词排名神器中有许多团队,每个团队都有其独特的渡海方法,但是他们都以相同的方式结束。任何方法都只能满足搜狗搜索的排名规则。虽然360搜索没有向外部提供排名机制,但是功能强大的seo 关键词排名神器设计人员可以在许多研究报告中进行研究,并且很快就可以突破破解方法。例如:几年前的外部链接算法,301跳转方法,堆叠方法等。但是,随着搜索引擎规则的逐步完善,排名技术不断变化。以前的大多数简单技术都不再适用,因此许多过去只研究过反链的SEO员工都认为关键字优化不好,所以自媒体走了,这是消除吗?
我想与您分享网站优化专家:SEO涵盖非现场SEO和现场优化;关键字排名是指希望在360次搜索中赢得某些客户的意愿,它由网站和内容构建构成在一系列级别(例如计划,用户裂变传播和代码)上的完整操作,以使网页更适合百度收录行为原则;使网站取悦蜘蛛的爬网方法也称为SEO,排名优化不仅可以提高搜索优化的成就,而且可以使在搜索引擎中排名的网站内容对用户更具参考价值。
在本文结尾,我们向客户发出有关百度排名的警告:如何获得平台只是辅助手段之一,网站排名是一种系统的调整过程:网络搜索字词的分布和有效的朋友必须进行调整。连锁店,如果我们建立一个新的车站并尽力抛弃旧玉米,我们将看到一个全新的结果。同时,我们仍然坚持先进的软件技术,一直保持警惕,直到最后一个搜索引擎崩溃为止,希望我们能够携手合作,在未来越来越幸福地合作!
原创标题:seo 关键词排名工件:关键字优化布局所必需。请指出来自推杆的转载来源!
如何快速的根据关键字采集到对应的百度相关搜索关键词
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-07-02 05:23
如何快速的根据关键字采集到对应的百度相关搜索关键词
如何使用优采云采集器batch采集百度相关搜索关键词
对于一些SEO从业者来说,百度相关搜索似乎有一定的价值,那么如何根据关键词采集快速到达对应的百度相关搜索关键词?
百度相关搜索关键词采集实战
首先,我们打开百度页面查询某个关键词,比如“精彩数据”。您可以在搜索结果底部看到百度关键词提供的相关搜索。
下面我们用优采云采集器完成相关关键词的采集任务
编写优采云采集器 规则。首先在浏览器中使用鼠标右键查看网页源代码,在源代码中寻找“数据可视化实例”等关键词。好在可以直接看源码,有相关数据,这个采集规则的定制很简单
在优采云采集器新建一个任务,填写起始网址:Wonderful Data。在新任务的第二步中创建两个新标签:关键字、相关搜索
关键词可以直接在标题中找到
所以对应的拦截规则如下:
同理,相关搜索也可以这样设置,但是因为我们只需要文本,所以需要对链接的a标签和其他标签进行适当的过滤。对应规则如下:
业绩展示
这样,一个简单的百度相关搜索采集rule就完成了。为了展示采集的效果,我使用了多个关键词进行测试,测试效果如图。
附件下载
采集规则附件已上传至QQ交流群。如有需要,您可以扫描二维码加入群组,自行获取和交流经验。
查看全部
如何快速的根据关键字采集到对应的百度相关搜索关键词
如何使用优采云采集器batch采集百度相关搜索关键词
对于一些SEO从业者来说,百度相关搜索似乎有一定的价值,那么如何根据关键词采集快速到达对应的百度相关搜索关键词?
百度相关搜索关键词采集实战
首先,我们打开百度页面查询某个关键词,比如“精彩数据”。您可以在搜索结果底部看到百度关键词提供的相关搜索。
下面我们用优采云采集器完成相关关键词的采集任务
编写优采云采集器 规则。首先在浏览器中使用鼠标右键查看网页源代码,在源代码中寻找“数据可视化实例”等关键词。好在可以直接看源码,有相关数据,这个采集规则的定制很简单
在优采云采集器新建一个任务,填写起始网址:Wonderful Data。在新任务的第二步中创建两个新标签:关键字、相关搜索
关键词可以直接在标题中找到
所以对应的拦截规则如下:
同理,相关搜索也可以这样设置,但是因为我们只需要文本,所以需要对链接的a标签和其他标签进行适当的过滤。对应规则如下:
业绩展示
这样,一个简单的百度相关搜索采集rule就完成了。为了展示采集的效果,我使用了多个关键词进行测试,测试效果如图。
附件下载
采集规则附件已上传至QQ交流群。如有需要,您可以扫描二维码加入群组,自行获取和交流经验。
关键字文章采集器java抓包代理大部分都支持fiddler代理
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-06-12 19:02
关键字文章采集器java抓包代理大部分都支持fiddler代理,然后还可以使用工具,比如七牛云,万网,
代理服务器用localhost也没问题,
爬虫请求第一步必然是http转码,以apache为例,http=1。0转成http=1。1时会有etag,请求get和post在没有etag的情况下会自动到apache,不过可以通过seleniumhttp=1。0转成http=1。1会有servername,请求get和post没有etag时会直接到iis或者nginx。
在python中可以用selenium抓log以python3.4为例,在ide上可以用:get_log()方法get_log()方法里面有pagenum(),或者page_max()两个参数,即页面最多可以容纳多少个文件
可以用scrapy或者gunicorn做这些,
有一个可以抓取一切网站的爬虫,是个人写的,叫:csdn爬虫,使用起来也不复杂,
可以用scrapy爬一些blog或者小公司的商业商城的。
直接用httpclient即可,用webdriver。
可以自己开发scrapy或者爬虫框架,然后自己构建抓取服务器。开发scrapy原因很简单,scrapy相比google/facebook这种存在高仿feed的上层应用,代码代码量小, 查看全部
关键字文章采集器java抓包代理大部分都支持fiddler代理
关键字文章采集器java抓包代理大部分都支持fiddler代理,然后还可以使用工具,比如七牛云,万网,
代理服务器用localhost也没问题,
爬虫请求第一步必然是http转码,以apache为例,http=1。0转成http=1。1时会有etag,请求get和post在没有etag的情况下会自动到apache,不过可以通过seleniumhttp=1。0转成http=1。1会有servername,请求get和post没有etag时会直接到iis或者nginx。
在python中可以用selenium抓log以python3.4为例,在ide上可以用:get_log()方法get_log()方法里面有pagenum(),或者page_max()两个参数,即页面最多可以容纳多少个文件
可以用scrapy或者gunicorn做这些,
有一个可以抓取一切网站的爬虫,是个人写的,叫:csdn爬虫,使用起来也不复杂,
可以用scrapy爬一些blog或者小公司的商业商城的。
直接用httpclient即可,用webdriver。
可以自己开发scrapy或者爬虫框架,然后自己构建抓取服务器。开发scrapy原因很简单,scrapy相比google/facebook这种存在高仿feed的上层应用,代码代码量小,
关键字文章采集器免费的各种统计工具手机制作热门
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-06-09 00:01
关键字文章采集器免费的各种统计工具手机制作热门微信、微博、微信推文、、大众、梅花、豆瓣图书分类书单、正版书籍检索码农手机绘画资源分享最后有一个本地免费建站程序有需要可以联系
文章采集平台有很多,但是不一定合适自己,你可以去看看捷径盒,他家做微信、公众号文章采集的比较多,可以免费试用,
微信公众号推文的搜索,
文章采集工具,
我用过好多,还是觉得一个叫“文章采集工具”的,还不错,后面我还帮同事推荐下呢,
最近一直在研究这类资源,接下来会推荐。
推荐一个优采云采集的平台:抓富网先将每篇文章的标题复制粘贴到上面,然后在抓富网里搜索,就可以发现所有你需要的文章的全部搜索页面,非常方便。
我现在在使用的一个文章采集工具是这样的。这个平台是国内团队做的,叫“免登陆采集网”,是一个面向全网数据的采集工具,一般收录微信公众号的文章都不在话下,只要你是个常驻国内的账号,有一部安卓,只要你的手机里有安卓手机,都可以免登陆获取各个平台的文章,搜索也非常方便。它能不能抓到qq空间,微博,知乎的数据我没试过,不过我感觉应该很方便。应该不会坑。文章采集工具应该也在不断更新进步中吧。觉得这个挺不错的。分享给大家。 查看全部
关键字文章采集器免费的各种统计工具手机制作热门
关键字文章采集器免费的各种统计工具手机制作热门微信、微博、微信推文、、大众、梅花、豆瓣图书分类书单、正版书籍检索码农手机绘画资源分享最后有一个本地免费建站程序有需要可以联系
文章采集平台有很多,但是不一定合适自己,你可以去看看捷径盒,他家做微信、公众号文章采集的比较多,可以免费试用,
微信公众号推文的搜索,
文章采集工具,
我用过好多,还是觉得一个叫“文章采集工具”的,还不错,后面我还帮同事推荐下呢,
最近一直在研究这类资源,接下来会推荐。
推荐一个优采云采集的平台:抓富网先将每篇文章的标题复制粘贴到上面,然后在抓富网里搜索,就可以发现所有你需要的文章的全部搜索页面,非常方便。
我现在在使用的一个文章采集工具是这样的。这个平台是国内团队做的,叫“免登陆采集网”,是一个面向全网数据的采集工具,一般收录微信公众号的文章都不在话下,只要你是个常驻国内的账号,有一部安卓,只要你的手机里有安卓手机,都可以免登陆获取各个平台的文章,搜索也非常方便。它能不能抓到qq空间,微博,知乎的数据我没试过,不过我感觉应该很方便。应该不会坑。文章采集工具应该也在不断更新进步中吧。觉得这个挺不错的。分享给大家。
关键字文章采集器-快速采集html,cssjs,
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-06-07 20:01
关键字文章采集器-快速采集html,css,js,图片,https重要的是,要配置本地浏览器支持以上所有的格式哦
本地浏览器最简单的办法就是用模拟浏览器,开启下webdriver,并且设置http代理,模拟浏览器就可以抓取了,这就是我做完毕设时用的工具。
现在手机端,电脑上能用的几乎都是模拟浏览器,
现在用的是来采集优采云票的
没试过哦,
我平时用某e助手,做完毕设后用它的云采集优采云票,是实现的。这个行业,为了保证数据的真实,优采云票数据可以根据企业需求进行录入,所以,企业肯定有优采云票数据库,企业相关的优采云票公共库(比如成都优采云站库房)、或者各个旅游景点的优采云票,这些库很大,多的有几百万张(有点夸张了),少的也有十万左右。你电脑上有相关优采云票数据库的话,只要电脑上有安装来采集优采云票,它就会自动抓取,数据库中查出当前时间所有的车票(含id,id是唯一的),并按照一定的比例(比如1%),分发给你公共库中的优采云票数据库。
爬虫其实很简单的,最简单的直接用bs4,
其实python还是可以的,其实用的最多的就是selenium、pyimportrequests等,其中selenium用的最多。 查看全部
关键字文章采集器-快速采集html,cssjs,
关键字文章采集器-快速采集html,css,js,图片,https重要的是,要配置本地浏览器支持以上所有的格式哦
本地浏览器最简单的办法就是用模拟浏览器,开启下webdriver,并且设置http代理,模拟浏览器就可以抓取了,这就是我做完毕设时用的工具。
现在手机端,电脑上能用的几乎都是模拟浏览器,
现在用的是来采集优采云票的
没试过哦,
我平时用某e助手,做完毕设后用它的云采集优采云票,是实现的。这个行业,为了保证数据的真实,优采云票数据可以根据企业需求进行录入,所以,企业肯定有优采云票数据库,企业相关的优采云票公共库(比如成都优采云站库房)、或者各个旅游景点的优采云票,这些库很大,多的有几百万张(有点夸张了),少的也有十万左右。你电脑上有相关优采云票数据库的话,只要电脑上有安装来采集优采云票,它就会自动抓取,数据库中查出当前时间所有的车票(含id,id是唯一的),并按照一定的比例(比如1%),分发给你公共库中的优采云票数据库。
爬虫其实很简单的,最简单的直接用bs4,
其实python还是可以的,其实用的最多的就是selenium、pyimportrequests等,其中selenium用的最多。
企业安全中GitHub关键字扫描是关键及重要的基础建设
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-06-07 06:25
前言
GitHub 在互联网上泄露企业敏感信息的多起事件表明,GitHub 关键字扫描是企业安全中至关重要的安全基础设施。我用一些事件扫描了不同类型 GitHub 的开源产品。一些测试研究,与您分享。
一、GitHub 搜索界面
github 提供了一个 API 来搜索代码中的关键字,并定义了默认只搜索主分支代码,即 master 分支。只能搜索小于 384KB 的文件。
官方例子中:+in:file+language:js+repo:jquery/jqueryq 表示为关键字;
in:file 表示在文件中搜索(in:path 在文件目录中);
language 表示语言是 JavaScript;
repo 表示在 jquery/jquery 仓库中搜索;
API还提供了显示搜索结果的功能,请求时带有请求头:curl-H'Accept:application/vnd.github.v3.text-match+json'\+in:file+ language :js+repo:jquery/jquery
例子:但是这个函数只显示匹配的关键字和行数,对实际应用影响不大:
二、开源工具介绍
网上有很多用于GitHub扫描的开源工具。我的需求是:及时预警、全面扫描、直观展示。经过一些测试和比较,我推荐两个易于部署且易于配置的工具:
2.1 GSIL 介绍
原则:
搜索范围:默认搜索前200个项目,最多5000个(github限制)。
流程:通过API(/search/code)搜索规则文件rules.gsil中提交的关键词,然后分析得到的json结果,默认显示前30个相关项。
扫描配置:配置文件中会过滤一些笔者认为没用的路径,有的可以根据实际情况进行屏蔽:
结果显示:该工具没有页面显示,使用邮件提醒匹配关键词所在行及其上下3行进行邮件发送(用户体验好)。
去重扫描:工具记录扫描过程中产生的相关代码内容和文件hash,并在~目录下创建隐藏文件夹.gsil。如果之前遇到过扫描引擎中文件的hash,则跳过:
定期扫描:可以通过crontab配置,每小时执行一次:@hourly /usr/bin/python /root/gsil/gsil.py 规则名称
2.2 鹰眼介绍
扫描原理之前已经简单介绍过了。由于 Hawkeye 具有图形界面,因此可以与 GSIL 一起使用。我通常将 GSIL 扫描的帐户作为关注的焦点,并配置更详细的策略进行监控。
三、Summary
GitHub 关键字扫描的开源工具还有很多,比如小米开发的比较轻量级的gitpprey()、X-patrol(),从安装环境要求、配置功能实现、部署难度入手。 , 可以找到适合企业环境的开源扫描工具。再加上一些二次开发,基本可以保证一些GitHub信息泄露的touch关键字被及时发现并删除。
感谢阅读并欢迎指导。 查看全部
企业安全中GitHub关键字扫描是关键及重要的基础建设
前言
GitHub 在互联网上泄露企业敏感信息的多起事件表明,GitHub 关键字扫描是企业安全中至关重要的安全基础设施。我用一些事件扫描了不同类型 GitHub 的开源产品。一些测试研究,与您分享。
一、GitHub 搜索界面
github 提供了一个 API 来搜索代码中的关键字,并定义了默认只搜索主分支代码,即 master 分支。只能搜索小于 384KB 的文件。
官方例子中:+in:file+language:js+repo:jquery/jqueryq 表示为关键字;
in:file 表示在文件中搜索(in:path 在文件目录中);
language 表示语言是 JavaScript;
repo 表示在 jquery/jquery 仓库中搜索;
API还提供了显示搜索结果的功能,请求时带有请求头:curl-H'Accept:application/vnd.github.v3.text-match+json'\+in:file+ language :js+repo:jquery/jquery
例子:但是这个函数只显示匹配的关键字和行数,对实际应用影响不大:
二、开源工具介绍
网上有很多用于GitHub扫描的开源工具。我的需求是:及时预警、全面扫描、直观展示。经过一些测试和比较,我推荐两个易于部署且易于配置的工具:
2.1 GSIL 介绍
原则:
搜索范围:默认搜索前200个项目,最多5000个(github限制)。
流程:通过API(/search/code)搜索规则文件rules.gsil中提交的关键词,然后分析得到的json结果,默认显示前30个相关项。
扫描配置:配置文件中会过滤一些笔者认为没用的路径,有的可以根据实际情况进行屏蔽:
结果显示:该工具没有页面显示,使用邮件提醒匹配关键词所在行及其上下3行进行邮件发送(用户体验好)。
去重扫描:工具记录扫描过程中产生的相关代码内容和文件hash,并在~目录下创建隐藏文件夹.gsil。如果之前遇到过扫描引擎中文件的hash,则跳过:
定期扫描:可以通过crontab配置,每小时执行一次:@hourly /usr/bin/python /root/gsil/gsil.py 规则名称
2.2 鹰眼介绍
扫描原理之前已经简单介绍过了。由于 Hawkeye 具有图形界面,因此可以与 GSIL 一起使用。我通常将 GSIL 扫描的帐户作为关注的焦点,并配置更详细的策略进行监控。
三、Summary
GitHub 关键字扫描的开源工具还有很多,比如小米开发的比较轻量级的gitpprey()、X-patrol(),从安装环境要求、配置功能实现、部署难度入手。 , 可以找到适合企业环境的开源扫描工具。再加上一些二次开发,基本可以保证一些GitHub信息泄露的touch关键字被及时发现并删除。
感谢阅读并欢迎指导。
知乎发图片超级烦啊,所以发在这里了。
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-06-05 20:01
关键字文章采集器工具-小乌鸦编辑软件-先关注我,评论我,私信给我,我都会第一时间回复的。如果能帮助你那就再好不过了。我也有分享,但知乎发图片超级烦啊,所以发在这里了。主要是为了解决一些没文章写的苦恼吧。
你的标题标准太标准,你的标题已经获得十分了,不知道怎么再标准的基础上再获得更多的分数。所以我只能给出一个标准的答案,起标题第一个标准就是不要用流行词汇,就像是城市套路深,我要回农村?类似这种是只要相关,只要能引发共鸣的。都可以,因为标题在这里的优先级最高。然后就是看你在哪个城市写的,能写最具有当地特色的最好,然后像你这种一二三线城市都要写的比较多的并且在标题上能展现各个城市的一些特色,然后如果标题有噱头,在标题里面主要的几个点描述清楚,不要让别人觉得冗长啰嗦。
像这种标题,标准的话我建议如果想让你的标题获得高分,你的标题应该是简短,每一个词语都要尽可能短,不要是文章的大段文字并且都只写一个点。但是通过标题的组合是有规律可循的,比如和你主题有关的关键词。
标题内容有互动互动,互动互动重要的事情说三遍。你是一个公众号,你是想走心的输出更多的东西,所以你要思考自己的文章内容、大众在关注什么东西、关注人群是哪些?有哪些信息价值、信息价值是什么?再就是对自己的排名、号内的排名。 查看全部
知乎发图片超级烦啊,所以发在这里了。
关键字文章采集器工具-小乌鸦编辑软件-先关注我,评论我,私信给我,我都会第一时间回复的。如果能帮助你那就再好不过了。我也有分享,但知乎发图片超级烦啊,所以发在这里了。主要是为了解决一些没文章写的苦恼吧。
你的标题标准太标准,你的标题已经获得十分了,不知道怎么再标准的基础上再获得更多的分数。所以我只能给出一个标准的答案,起标题第一个标准就是不要用流行词汇,就像是城市套路深,我要回农村?类似这种是只要相关,只要能引发共鸣的。都可以,因为标题在这里的优先级最高。然后就是看你在哪个城市写的,能写最具有当地特色的最好,然后像你这种一二三线城市都要写的比较多的并且在标题上能展现各个城市的一些特色,然后如果标题有噱头,在标题里面主要的几个点描述清楚,不要让别人觉得冗长啰嗦。
像这种标题,标准的话我建议如果想让你的标题获得高分,你的标题应该是简短,每一个词语都要尽可能短,不要是文章的大段文字并且都只写一个点。但是通过标题的组合是有规律可循的,比如和你主题有关的关键词。
标题内容有互动互动,互动互动重要的事情说三遍。你是一个公众号,你是想走心的输出更多的东西,所以你要思考自己的文章内容、大众在关注什么东西、关注人群是哪些?有哪些信息价值、信息价值是什么?再就是对自己的排名、号内的排名。
千分千软件出品的一款万能文章采集软件,只需输入关键字
采集交流 • 优采云 发表了文章 • 0 个评论 • 356 次浏览 • 2021-05-28 22:39
由钱奋谦软件公司生产的通用文章 采集软件,您只需输入关键字就可以采集各种网页和新闻,还可以采集指定列表页面(列页面)文章
注意:微信引擎受到严格限制。请将采集中的线程数设置为1,否则很容易发出验证码。
功能:
1.依靠千分千软件独有的通用文本识别智能算法,可以自动提取任何网页文本,准确率高达95%以上。
2.只需输入关键词,采集即可转到微信文章,头条,一店新闻,百度新闻和网页,搜狗新闻和网页,360新闻和网页,谷歌新闻和网页,必应新闻和网页,雅虎新闻和网页;批次关键词全自动采集。
<p>3.可以直接指向采集,以在网站列列表下指定所有文章(例如Baidu Experience,百度贴吧),智能匹配,无需编写复杂的规则。 查看全部
千分千软件出品的一款万能文章采集软件,只需输入关键字
由钱奋谦软件公司生产的通用文章 采集软件,您只需输入关键字就可以采集各种网页和新闻,还可以采集指定列表页面(列页面)文章
注意:微信引擎受到严格限制。请将采集中的线程数设置为1,否则很容易发出验证码。
功能:
1.依靠千分千软件独有的通用文本识别智能算法,可以自动提取任何网页文本,准确率高达95%以上。
2.只需输入关键词,采集即可转到微信文章,头条,一店新闻,百度新闻和网页,搜狗新闻和网页,360新闻和网页,谷歌新闻和网页,必应新闻和网页,雅虎新闻和网页;批次关键词全自动采集。
<p>3.可以直接指向采集,以在网站列列表下指定所有文章(例如Baidu Experience,百度贴吧),智能匹配,无需编写复杂的规则。
关键字文章采集器站长分享的采集工具ldjiagupdate使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-05-16 00:34
关键字文章采集器站长分享的采集工具ldjiagupdate使用教程,还有几天端午就到了,相信大家的假期也过的差不多了,但还是要奉劝一句,不要忘记联系自己的老板,在假期时打好一份精彩的开端不容易,哪怕是给自己今后的职业生涯加点分也是值得的。那么问题来了,假期怎么才能出色地完成工作呢?据我所知,还是要不断的学习,提升自己的能力,将一个个任务拆分,分配到更多的人身上,才能让工作井井有条。
所以,今天我就推荐一个工具给大家,可以帮助站长节省下大量时间和精力,用来攻克更多更难的任务。我在这里不推荐任何一个工具,只推荐你认识什么是工具,工具之间都是怎么进行资源整合,工具之间有哪些共同点,你所用工具的特点,你不会用的工具,有哪些明显的优点等。这个工具叫做“ldjiagupdate”ldjiagupdate是一个工具,可以让你对文章内容自动进行预览。
我举个例子,之前有个文章「蚂蚁搬家」,我只进行了预览,这篇文章对我是个挑战,因为我需要确保每篇文章都是一样的格式,所以我预览了80篇文章,阅读了1000多篇文章,完成了80篇,但是已经非常枯燥。这个时候我就会拿出同样的工具,但只对部分文章进行预览,比如一篇文章只预览50篇,先全部进行一次预览,然后进行简短的编号。
之前的文章:[整理集合]主题类网站整理第一弹基本上你一次进行一次完整的操作即可完成所有网站的收录,方便后续处理。好了,废话不多说,先上截图工具导入公众号文章(兼容大多数浏览器)获取方式:后台回复“ldjiagupdate”(24小时内)ldjiagupdate工具已经上架天猫魔盒,欢迎各位获取方式关注公众号“优采云有约”,回复“ldjiagupdate”获取不断更新、更精美的工具。微信公众号:[wj1155](二维码自动识别)。 查看全部
关键字文章采集器站长分享的采集工具ldjiagupdate使用教程
关键字文章采集器站长分享的采集工具ldjiagupdate使用教程,还有几天端午就到了,相信大家的假期也过的差不多了,但还是要奉劝一句,不要忘记联系自己的老板,在假期时打好一份精彩的开端不容易,哪怕是给自己今后的职业生涯加点分也是值得的。那么问题来了,假期怎么才能出色地完成工作呢?据我所知,还是要不断的学习,提升自己的能力,将一个个任务拆分,分配到更多的人身上,才能让工作井井有条。
所以,今天我就推荐一个工具给大家,可以帮助站长节省下大量时间和精力,用来攻克更多更难的任务。我在这里不推荐任何一个工具,只推荐你认识什么是工具,工具之间都是怎么进行资源整合,工具之间有哪些共同点,你所用工具的特点,你不会用的工具,有哪些明显的优点等。这个工具叫做“ldjiagupdate”ldjiagupdate是一个工具,可以让你对文章内容自动进行预览。
我举个例子,之前有个文章「蚂蚁搬家」,我只进行了预览,这篇文章对我是个挑战,因为我需要确保每篇文章都是一样的格式,所以我预览了80篇文章,阅读了1000多篇文章,完成了80篇,但是已经非常枯燥。这个时候我就会拿出同样的工具,但只对部分文章进行预览,比如一篇文章只预览50篇,先全部进行一次预览,然后进行简短的编号。
之前的文章:[整理集合]主题类网站整理第一弹基本上你一次进行一次完整的操作即可完成所有网站的收录,方便后续处理。好了,废话不多说,先上截图工具导入公众号文章(兼容大多数浏览器)获取方式:后台回复“ldjiagupdate”(24小时内)ldjiagupdate工具已经上架天猫魔盒,欢迎各位获取方式关注公众号“优采云有约”,回复“ldjiagupdate”获取不断更新、更精美的工具。微信公众号:[wj1155](二维码自动识别)。
基于大数据提取模式的网页文章采集器的应用方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-05-10 19:01
关键字文章采集器一般的所谓采集,都是常见的http的文章采集工具,功能基本都是完全独立的,因为流量少,又没有对其他站点的依赖性。举个例子,urllib是python基础,scrapy是web框架,采集则是寻找目标页面及其正则表达式。准确说,应该是urllib代替了scrapy,基于scrapy设计urllib接口,通过urllib实现scrapy请求池。
这种接口本身对爬虫来说是透明的,所以这种接口通常说是urllib.request()接口。另外一些接口基于分布式架构设计,这个处理方式和http站点结构的复杂和以scrapy为框架的站点架构有很大区别。这种接口是接口层。后者是服务层。urllib和scrapy两者是同一个站点内容为产品的两套系统,但本质是类似的。
因为urllib和scrapy只是设计思路很相似,其中的内容都是不同类型的网页。scrapy采用大数据提取模式实现http提取的,爬虫体系是一个单机版的架构。就是站点服务层代理整个站点发送的http请求,真正实现数据的提取,存放功能。比如有两个站点,一个站点只允许向浏览器发出请求,一个站点允许通过baidu引擎向外部发出请求。
这时候都是通过urllib,scrapy爬虫系统去实现各自的功能。如果说想使用工具做系统内爬虫,爬虫系统不局限于一个站点或一种服务,它其实可以基于任何服务。比如worker,事实上worker对某些网页源代码进行了封装和修改,就能达到独立爬虫的功能。系统的网页提取从最基础的概念出发,划分三种:。
1、网页中包含内容的读取,所以需要webhook来实现,对每个站点,对于请求url的一部分来说,是完全封装起来,处理成web的工作模式。
2、网页的解析,需要一个parser,网页解析的网络请求,基本都是使用urllib.request.urlopen系统做的。
3、网页中的内容提取,这个才是爬虫的最终目的,所以才需要mongodb,redis等作为后端服务,作为数据存储。这个就是scrapy的技术路线,比如中间件在采集的时候使用各种高阶的技术,比如redis,aof,缓存等。数据提取本身无意义,因为大部分搜索引擎都有内置的spider。爬虫系统的设计重点其实是crud操作,是真正的循环操作。目前很多搜索引擎都有代理线程,就是对爬虫每个阶段提供一个web界面给搜索引擎后端使用。 查看全部
基于大数据提取模式的网页文章采集器的应用方法
关键字文章采集器一般的所谓采集,都是常见的http的文章采集工具,功能基本都是完全独立的,因为流量少,又没有对其他站点的依赖性。举个例子,urllib是python基础,scrapy是web框架,采集则是寻找目标页面及其正则表达式。准确说,应该是urllib代替了scrapy,基于scrapy设计urllib接口,通过urllib实现scrapy请求池。
这种接口本身对爬虫来说是透明的,所以这种接口通常说是urllib.request()接口。另外一些接口基于分布式架构设计,这个处理方式和http站点结构的复杂和以scrapy为框架的站点架构有很大区别。这种接口是接口层。后者是服务层。urllib和scrapy两者是同一个站点内容为产品的两套系统,但本质是类似的。
因为urllib和scrapy只是设计思路很相似,其中的内容都是不同类型的网页。scrapy采用大数据提取模式实现http提取的,爬虫体系是一个单机版的架构。就是站点服务层代理整个站点发送的http请求,真正实现数据的提取,存放功能。比如有两个站点,一个站点只允许向浏览器发出请求,一个站点允许通过baidu引擎向外部发出请求。
这时候都是通过urllib,scrapy爬虫系统去实现各自的功能。如果说想使用工具做系统内爬虫,爬虫系统不局限于一个站点或一种服务,它其实可以基于任何服务。比如worker,事实上worker对某些网页源代码进行了封装和修改,就能达到独立爬虫的功能。系统的网页提取从最基础的概念出发,划分三种:。
1、网页中包含内容的读取,所以需要webhook来实现,对每个站点,对于请求url的一部分来说,是完全封装起来,处理成web的工作模式。
2、网页的解析,需要一个parser,网页解析的网络请求,基本都是使用urllib.request.urlopen系统做的。
3、网页中的内容提取,这个才是爬虫的最终目的,所以才需要mongodb,redis等作为后端服务,作为数据存储。这个就是scrapy的技术路线,比如中间件在采集的时候使用各种高阶的技术,比如redis,aof,缓存等。数据提取本身无意义,因为大部分搜索引擎都有内置的spider。爬虫系统的设计重点其实是crud操作,是真正的循环操作。目前很多搜索引擎都有代理线程,就是对爬虫每个阶段提供一个web界面给搜索引擎后端使用。
大话打天下采集360/猎豹/百度和搜狗共计370万种文章(万字)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-05-10 00:01
关键字文章采集器,大话打天下采集360/猎豹/百度和搜狗共计370万种文章(万字)使用无损接口(4万字),实现搜索引擎抓取兼具过滤防屏蔽功能,采集更高效无需对接搜索引擎(完全免费),快速原创采集模式支持平台:全网站大话采集器2005年12月第一版已经200万页面,下载量超500万网站有约5亿篇文章100万个网站(博客、图片站),采集天天更新一个网站约500万篇文章我们提供个人版永久使用,永久免费网站,可以自定义规则、采集列表页,支持采集“百度搜狗360”“博客图片站”需要爬虫接口的网站希望能帮到你。
采集数量有限制的,
付费的接口一般在5w字以内,搜索引擎很喜欢接口文章采集的。我觉得因为搜索引擎最好定期抓取,他们都喜欢每天能带来量变的,而不是每天只有一个量变。所以开个采集接口公司需要办理多个搜索引擎的专用接口,这样采集很多文章对搜索引擎有利。如果接入全国前50的搜索引擎,那么订单量将成倍增长。除此之外采集接口卖东西还是卖服务都可以,不然客户要配他们家才有用,这样就就留了很大的漏洞。
但是他们家的服务比卖数据收费高,毕竟是服务而不是他们家独家销售。采集的数据不需要对外售卖,然后收费售卖国外的资源。比如在国外开展抓取项目,并且可以直接在国外售卖他们的接口文章,这样收入就相当高了。因为国外网站都是很成熟的,比如google早年抓取资源就是通过采集reddit,askreddit等页面,然后再对译文到google等搜索引擎上去得到收益。 查看全部
大话打天下采集360/猎豹/百度和搜狗共计370万种文章(万字)
关键字文章采集器,大话打天下采集360/猎豹/百度和搜狗共计370万种文章(万字)使用无损接口(4万字),实现搜索引擎抓取兼具过滤防屏蔽功能,采集更高效无需对接搜索引擎(完全免费),快速原创采集模式支持平台:全网站大话采集器2005年12月第一版已经200万页面,下载量超500万网站有约5亿篇文章100万个网站(博客、图片站),采集天天更新一个网站约500万篇文章我们提供个人版永久使用,永久免费网站,可以自定义规则、采集列表页,支持采集“百度搜狗360”“博客图片站”需要爬虫接口的网站希望能帮到你。
采集数量有限制的,
付费的接口一般在5w字以内,搜索引擎很喜欢接口文章采集的。我觉得因为搜索引擎最好定期抓取,他们都喜欢每天能带来量变的,而不是每天只有一个量变。所以开个采集接口公司需要办理多个搜索引擎的专用接口,这样采集很多文章对搜索引擎有利。如果接入全国前50的搜索引擎,那么订单量将成倍增长。除此之外采集接口卖东西还是卖服务都可以,不然客户要配他们家才有用,这样就就留了很大的漏洞。
但是他们家的服务比卖数据收费高,毕竟是服务而不是他们家独家销售。采集的数据不需要对外售卖,然后收费售卖国外的资源。比如在国外开展抓取项目,并且可以直接在国外售卖他们的接口文章,这样收入就相当高了。因为国外网站都是很成熟的,比如google早年抓取资源就是通过采集reddit,askreddit等页面,然后再对译文到google等搜索引擎上去得到收益。
百度文库不支持像qq空间一样把全文导出来
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-04-24 02:05
关键字文章采集器阿里云采集软件下载百度文库文章采集百度文库的问题成是大家很关心的一个问题。因为上面大多数都是需要登录的,并且有时候还会有一些询问..其实软件上写的什么制式采集会比较好,我觉得..这种选项都是多余的,根本没必要选择。只要记住一点!只要是需要登录的,或者要你输入账号密码的文档。直接点采集就行没必要记住自己账号密码,!!!你记住了也没用百度文库的采集emmmm..真的有点难建议就是直接采集吧因为有时候采集下来的文章都是别人已经删掉了的。
百度文库的数据采集,个人推荐(印象笔记)。1.采集速度比较快,1-2秒即可;2.简单易上手,没有学习成本。效果截图:复制链接后可通过印象笔记导出pdf文件,导入到采集软件。非要装的话,推荐(象印anyview),算是个中端的。微软在2015年10月1日推出的。
请去原文网站进行下载
百度文库不支持像qq空间一样把全文导出来。需要你去首页的右边栏看看,有的就可以下载。
百度下载文档,直接导出文本就可以。
今天我试了一下百度文库。导出文本不可以,改个格式,通过首页文档查看中再点击导出到文档,成功导出了文档。如果你需要在百度里搜的文章,而你用其他的文档查看工具不能查看的话,可以尝试在首页导出格式, 查看全部
百度文库不支持像qq空间一样把全文导出来
关键字文章采集器阿里云采集软件下载百度文库文章采集百度文库的问题成是大家很关心的一个问题。因为上面大多数都是需要登录的,并且有时候还会有一些询问..其实软件上写的什么制式采集会比较好,我觉得..这种选项都是多余的,根本没必要选择。只要记住一点!只要是需要登录的,或者要你输入账号密码的文档。直接点采集就行没必要记住自己账号密码,!!!你记住了也没用百度文库的采集emmmm..真的有点难建议就是直接采集吧因为有时候采集下来的文章都是别人已经删掉了的。
百度文库的数据采集,个人推荐(印象笔记)。1.采集速度比较快,1-2秒即可;2.简单易上手,没有学习成本。效果截图:复制链接后可通过印象笔记导出pdf文件,导入到采集软件。非要装的话,推荐(象印anyview),算是个中端的。微软在2015年10月1日推出的。
请去原文网站进行下载
百度文库不支持像qq空间一样把全文导出来。需要你去首页的右边栏看看,有的就可以下载。
百度下载文档,直接导出文本就可以。
今天我试了一下百度文库。导出文本不可以,改个格式,通过首页文档查看中再点击导出到文档,成功导出了文档。如果你需要在百度里搜的文章,而你用其他的文档查看工具不能查看的话,可以尝试在首页导出格式,
p2p互助理论开发的搜索引擎关键词优化工具提升网站排名
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-04-23 22:34
百度关键字优化向导是一种使用p2p互助理论开发的搜索引擎关键词优化工具。它可以稳定快速地提高网站的排名,还可以为您网站带来大量流量。该软件是专业的百度关键词优化工具,具有80%的免费功能,它也是网站流量软件。它可以继续为网站带来稳定的访问量,并提高关键词的排名。
软件功能
“百度关键字优化向导”分为两个主要的优化功能:本地优化和网络优化。
本地优化使用代理服务器模拟不同的计算机环境,以刷入网站流量和排名。与其他类似软件相比,它具有许多优点:
1、可以自动搜索代理服务器,验证代理服务器,过滤出本地IP地址,用户无需寻找代理服务器;
2、可以导入外部代理服务器并进行验证;
3、可以选择不同的网卡进行优化;
4、可以在优化过程中动态修改本地网卡的MAC地址;
5、每次点击的间隔可以随机设置;
6、您可以在每次优化时修改机器的显示分辨率;
7、可以在每次优化时修改IE信息;
8、完全模拟了怀旧习惯网站,一种有效的优化算法;
9、完全符合百度和Google的分析习惯;
1 0、本机编译的代码,采用win2000之上的所有平台,包括winxp,win2003,vista等;
1 1、多核优化,发送时充分利用了机器,没有任何拖延和滞后。
网络优化通过p2p方法,客户只要在帐户中累积积分,就可以智能地优化其关键词排名。
更新日志
1、解决了本地笔刷无法访问URL的问题;
2、增加了对中文帐户的支持;
3、修改的代理验证。 查看全部
p2p互助理论开发的搜索引擎关键词优化工具提升网站排名
百度关键字优化向导是一种使用p2p互助理论开发的搜索引擎关键词优化工具。它可以稳定快速地提高网站的排名,还可以为您网站带来大量流量。该软件是专业的百度关键词优化工具,具有80%的免费功能,它也是网站流量软件。它可以继续为网站带来稳定的访问量,并提高关键词的排名。
软件功能
“百度关键字优化向导”分为两个主要的优化功能:本地优化和网络优化。
本地优化使用代理服务器模拟不同的计算机环境,以刷入网站流量和排名。与其他类似软件相比,它具有许多优点:
1、可以自动搜索代理服务器,验证代理服务器,过滤出本地IP地址,用户无需寻找代理服务器;
2、可以导入外部代理服务器并进行验证;
3、可以选择不同的网卡进行优化;
4、可以在优化过程中动态修改本地网卡的MAC地址;
5、每次点击的间隔可以随机设置;
6、您可以在每次优化时修改机器的显示分辨率;
7、可以在每次优化时修改IE信息;
8、完全模拟了怀旧习惯网站,一种有效的优化算法;
9、完全符合百度和Google的分析习惯;
1 0、本机编译的代码,采用win2000之上的所有平台,包括winxp,win2003,vista等;
1 1、多核优化,发送时充分利用了机器,没有任何拖延和滞后。
网络优化通过p2p方法,客户只要在帐户中累积积分,就可以智能地优化其关键词排名。
更新日志
1、解决了本地笔刷无法访问URL的问题;
2、增加了对中文帐户的支持;
3、修改的代理验证。
tp-c集成了谷歌蜘蛛代理,完美支持跨国区域的googleadsense市场
采集交流 • 优采云 发表了文章 • 0 个评论 • 436 次浏览 • 2021-04-18 23:07
关键字文章采集器可以实现以下功能
1、在线更新代码
2、实时获取采集结果
3、一键排版页面
4、为每篇文章添加标签
5、自动同步所有站点
6、同步到百度站长平台
联系一下,的外包公司,做外包服务,我们公司是做seo高端系统,使用很多年了,性价比很高,公司企业网站全部采用他们做的外包服务,出的各种seo项目都是比较靠谱的,他们有业务员人在大北京地区,比较方便,还有返佣可以拿,办公环境也好。
楼主所提及的问题,tp-c的mz/webos/securitybeta等均有对应的外包项目提供,应该说tp-c已经形成一个完整的外包生态圈,各种业务在这个闭环中都可以找到对应的服务商实现。值得一提的是,tp-c集成了谷歌蜘蛛代理,完美支持跨国区域的googleadsense市场,应该说找一个靠谱的外包公司一定要使用谷歌的代理商,而且这个代理商一定要在国内具有开发环境,这样是保证正规外包公司利益最大化的前提,切记。
pwa的话,kanyewest后创建的appsync也可以。他们的原理是把原生app的代码修改成统一定制的c+++库代码,但这个过程需要主动收集一些原生产品的数据,方便定制实现能力强的产品。而且他们还提供了某些类型的示例代码。 查看全部
tp-c集成了谷歌蜘蛛代理,完美支持跨国区域的googleadsense市场
关键字文章采集器可以实现以下功能
1、在线更新代码
2、实时获取采集结果
3、一键排版页面
4、为每篇文章添加标签
5、自动同步所有站点
6、同步到百度站长平台
联系一下,的外包公司,做外包服务,我们公司是做seo高端系统,使用很多年了,性价比很高,公司企业网站全部采用他们做的外包服务,出的各种seo项目都是比较靠谱的,他们有业务员人在大北京地区,比较方便,还有返佣可以拿,办公环境也好。
楼主所提及的问题,tp-c的mz/webos/securitybeta等均有对应的外包项目提供,应该说tp-c已经形成一个完整的外包生态圈,各种业务在这个闭环中都可以找到对应的服务商实现。值得一提的是,tp-c集成了谷歌蜘蛛代理,完美支持跨国区域的googleadsense市场,应该说找一个靠谱的外包公司一定要使用谷歌的代理商,而且这个代理商一定要在国内具有开发环境,这样是保证正规外包公司利益最大化的前提,切记。
pwa的话,kanyewest后创建的appsync也可以。他们的原理是把原生app的代码修改成统一定制的c+++库代码,但这个过程需要主动收集一些原生产品的数据,方便定制实现能力强的产品。而且他们还提供了某些类型的示例代码。
新闻源文章生成器绿色免费版操作说明及特色介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-03-28 01:03
新闻来源文章 Generator Green Free Edition是用于自动编写和生成新文章的强大工具,该软件易于操作,支持批量自动生成新文章,方便快捷,并且可以设置关键词,优化文章,大大提高文章的质量,功能强大的软件正等着您体验,如果您的心脏跳动,请迅速采取行动,放开手和大脑。
[新闻来源文章 Generator绿色免费版软件功能]
1、该软件是专门为“医疗行业新闻源”设计的新闻源文章生成软件;
2、该软件适用于具有批量上传功能的新闻源平台;
3、该软件可用于在您自己或其他医院网站 文章中从采集 文章产生新闻来源文章;
4、局部模式-段落随机组合模式可以将准备好的文章段随机组合为完整的文章;
5、本地模式完成文章模式可以通过后续处理以生成新闻组的方式准备网站完整文章;
6、 采集中的文章是自收录的,在拦截,过滤字符,伪原创,插入其他文本,插入JS脚本,插入关键词和其他功能之后;
7、 采集中的
文章另存为本地txt文件,然后通过批量上传功能发布,可以大大提高新闻源的发布效率;
8、 采集链接:批处理采集 文章链接以准备采集 文章;
9、保存:保存文章生成规则的配置以供下次重用;
1 0、打开:打开保存的文章生成规则并继续上一次。
[新闻来源文章 Generator绿色免费版操作说明]
1、准备文章内容;
2、 文章与关键字最相关,可以使用采集器批处理采集;
3、编写关键字和其他内容;
4、选择其他设置并开始运行以生成峰值。
显示全部
查看全部
新闻源文章生成器绿色免费版操作说明及特色介绍
新闻来源文章 Generator Green Free Edition是用于自动编写和生成新文章的强大工具,该软件易于操作,支持批量自动生成新文章,方便快捷,并且可以设置关键词,优化文章,大大提高文章的质量,功能强大的软件正等着您体验,如果您的心脏跳动,请迅速采取行动,放开手和大脑。
[新闻来源文章 Generator绿色免费版软件功能]
1、该软件是专门为“医疗行业新闻源”设计的新闻源文章生成软件;
2、该软件适用于具有批量上传功能的新闻源平台;
3、该软件可用于在您自己或其他医院网站 文章中从采集 文章产生新闻来源文章;
4、局部模式-段落随机组合模式可以将准备好的文章段随机组合为完整的文章;
5、本地模式完成文章模式可以通过后续处理以生成新闻组的方式准备网站完整文章;
6、 采集中的文章是自收录的,在拦截,过滤字符,伪原创,插入其他文本,插入JS脚本,插入关键词和其他功能之后;
7、 采集中的
文章另存为本地txt文件,然后通过批量上传功能发布,可以大大提高新闻源的发布效率;
8、 采集链接:批处理采集 文章链接以准备采集 文章;
9、保存:保存文章生成规则的配置以供下次重用;
1 0、打开:打开保存的文章生成规则并继续上一次。
[新闻来源文章 Generator绿色免费版操作说明]
1、准备文章内容;
2、 文章与关键字最相关,可以使用采集器批处理采集;
3、编写关键字和其他内容;
4、选择其他设置并开始运行以生成峰值。
显示全部
企业安全中GitHub关键词扫描仪的安全性基础设施
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-03-25 22:19
GitHub的恶意事件泄漏了公司更敏感的信息和内容,这些信息和内容已在Internet上公开了好几次,这表明GitHub 关键词扫描程序是公司安全中非常重要且至关重要的安全基础架构。相同类型的GitHub扫描器开源系统产品已经过测试和调查,并与您共享。
一、 GitHub搜索套接字
github在代码搜索中提供了用于关键字搜索的API,并将默认设置定义为仅搜索主分支代码,这意味着只能在master分支中搜索小于384KB的文档。
在官方网站上的示例说明中:
+ In:文件+语言:Js + repo:jquery / jquery
q表示为关键词;
In:file表示为在文档中搜索(文件目录中的In:path);
语言表达语言是JavaScript;
回购在jquery / jquery存储库中表示为检索;
有关英语语法的大量搜索可以转到官方的网站查询。
API还显示了百度搜索的作用,在发布请求时随身携带了发布请求标头:
curl-H'Accept:application / vnd.github.v 3. text-match + json'\ + In:file + language:Js + repo:jquery / jquery
示例:但是此函数仅显示信息所匹配的关键词和行数,并且对实际使用不是很有效:
二、详细介绍开源系统专用工具
对于Internet上具有GitHub扫描器的开源系统,有许多专用工具。我的要求是:立即警告,全面的扫描仪以及数据可视化。经过一些测试和比较,我强烈建议您使用几个方便的部署和简单的设备专用工具:
GSIL()
Hawkeye()
2. 2 GSIL详细介绍
基本原理:
登录设备:选择token()并应用PyGithub库。
开发API激活(.com://pygithub.github.io/PyGithub/v1/introduction.html语言)。
搜索类别:默认设置是搜索前150个新项目,较大的是6000(github限制)。
整个过程:根据API(/ search / code)检索标准文档rules.gsil中提交的关键词,然后分析获取的json结果,并默认显示前40个相关的新项。
配备扫描仪:在配置文件时,将考虑创建者认为无用的一些相对路径,并且可以根据特定情况阻止某些相对路径:
结果显示:新启动的专用工具没有网页显示。根据电子邮件警报,使该行与关键字匹配,并在上下左右三行中发送电子邮件以进行检查(良好的客户体验)。
重复数据删除扫描程序:一种特殊的工具记录整个过程中由扫描程序引起的相关编码内容和文档哈希,并在〜file目录下创建一个隐藏文件夹.gsil。如果以前曾在扫描仪模块中遇到过文档的哈希,请绕开它:
周期时间扫描器:可以根据crontab进行配置,并且每小时可以执行多次:
@hourly / usr / bin / python /root/gsil/gsil.py标准名称
3. 2 Hawkeye详细介绍
已经简要介绍了扫描仪的基本原理。 Hawkeye具有图形界面页面,因此可以与GSIL一起使用。我通常将GSIL扫描仪作为头等大事,并关心构造函数。更详细的检测对策。
三、摘要
GitHub 关键词扫描器还具有许多其他专用于开源系统的工具,例如小米手机产品根据自然环境法规的安装而开发的重量级gitpprey()和X-patrol() ,设备功能的建立,从部署难度级别开始,您可以找到适合公司自然环境的开源系统扫描工具。结合某些程序的开发,该基金会可以确保可以立即检测并删除某些触摸关键词的GitHub数据泄漏。
感谢您阅读文章,并热烈欢迎您获得具体指导。 查看全部
企业安全中GitHub关键词扫描仪的安全性基础设施
GitHub的恶意事件泄漏了公司更敏感的信息和内容,这些信息和内容已在Internet上公开了好几次,这表明GitHub 关键词扫描程序是公司安全中非常重要且至关重要的安全基础架构。相同类型的GitHub扫描器开源系统产品已经过测试和调查,并与您共享。
一、 GitHub搜索套接字
github在代码搜索中提供了用于关键字搜索的API,并将默认设置定义为仅搜索主分支代码,这意味着只能在master分支中搜索小于384KB的文档。
在官方网站上的示例说明中:
+ In:文件+语言:Js + repo:jquery / jquery
q表示为关键词;
In:file表示为在文档中搜索(文件目录中的In:path);
语言表达语言是JavaScript;
回购在jquery / jquery存储库中表示为检索;
有关英语语法的大量搜索可以转到官方的网站查询。
API还显示了百度搜索的作用,在发布请求时随身携带了发布请求标头:
curl-H'Accept:application / vnd.github.v 3. text-match + json'\ + In:file + language:Js + repo:jquery / jquery
示例:但是此函数仅显示信息所匹配的关键词和行数,并且对实际使用不是很有效:
二、详细介绍开源系统专用工具
对于Internet上具有GitHub扫描器的开源系统,有许多专用工具。我的要求是:立即警告,全面的扫描仪以及数据可视化。经过一些测试和比较,我强烈建议您使用几个方便的部署和简单的设备专用工具:
GSIL()
Hawkeye()
2. 2 GSIL详细介绍
基本原理:
登录设备:选择token()并应用PyGithub库。
开发API激活(.com://pygithub.github.io/PyGithub/v1/introduction.html语言)。
搜索类别:默认设置是搜索前150个新项目,较大的是6000(github限制)。
整个过程:根据API(/ search / code)检索标准文档rules.gsil中提交的关键词,然后分析获取的json结果,并默认显示前40个相关的新项。
配备扫描仪:在配置文件时,将考虑创建者认为无用的一些相对路径,并且可以根据特定情况阻止某些相对路径:
结果显示:新启动的专用工具没有网页显示。根据电子邮件警报,使该行与关键字匹配,并在上下左右三行中发送电子邮件以进行检查(良好的客户体验)。
重复数据删除扫描程序:一种特殊的工具记录整个过程中由扫描程序引起的相关编码内容和文档哈希,并在〜file目录下创建一个隐藏文件夹.gsil。如果以前曾在扫描仪模块中遇到过文档的哈希,请绕开它:
周期时间扫描器:可以根据crontab进行配置,并且每小时可以执行多次:
@hourly / usr / bin / python /root/gsil/gsil.py标准名称
3. 2 Hawkeye详细介绍
已经简要介绍了扫描仪的基本原理。 Hawkeye具有图形界面页面,因此可以与GSIL一起使用。我通常将GSIL扫描仪作为头等大事,并关心构造函数。更详细的检测对策。
三、摘要
GitHub 关键词扫描器还具有许多其他专用于开源系统的工具,例如小米手机产品根据自然环境法规的安装而开发的重量级gitpprey()和X-patrol() ,设备功能的建立,从部署难度级别开始,您可以找到适合公司自然环境的开源系统扫描工具。结合某些程序的开发,该基金会可以确保可以立即检测并删除某些触摸关键词的GitHub数据泄漏。
感谢您阅读文章,并热烈欢迎您获得具体指导。
关键字文章采集器怎么写的数据全是垃圾
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-03-24 21:03
关键字文章采集器是采集一篇公众号文章,进行多站点汇总和整理,数据到达百度站长平台后,进行分析和分享在这个过程中,每个月我们可能要编写一百余篇的文章,且这些文章不管写的怎么样,都是要码出来的,码出来就要给百度看,百度就要算出你写的内容的质量,不然,你写的数据全是垃圾。1.采集工具:jsx插件jsx的好处就是免编程,看一下视频就懂,可编程。
也可以下载jsx插件,使用jsx插件,jsx插件是一款百度浏览器插件,里面包含了jsx所有特性:jsxie插件下载jsx_opera插件下载jsx微信插件下载iejsx1m+jsxmozilla网页插件网页加载插件(jsx)qq浏览器内置jsx代码视频教程视频教程有很多,iejsx教程好像是新出的,没有pythontextmodules教程资料多,可自行参考。
采集工具虽然多,但是采集下来的数据结构采用csv,csv数据结构类似的数据库结构,是一种半文本文件,数据一般放在数据库里,不能进行二次拷贝,但是和其他文本格式数据格式一样,该数据库也会存放文本文件的格式。对于大型的网站,使用浏览器原生的插件进行内部文件操作还是不够的,需要用到fiddler进行抓包,抓取到网站的源代码,再一点点的打包为csv格式数据放入数据库中。
2.知乎文章抓取知乎并不单单是在某一个平台发布文章,都会有相应的文章抓取工具,在采集知乎这种文章网站的时候,知乎的平台机制比较复杂,并不是采集简单的某一篇文章,而是抓取大量文章,用csv格式的一条条来进行爬取,本人是用chrome浏览器抓取的,因为fiddler抓不了知乎的源代码,原生的抓取工具对知乎这个网站的抓取结果,并不是真实的抓取结果,在很多时候抓取结果不是我们需要的文章内容,更新一个时间段,即可抓取更多内容,过一段时间去抓取知乎一些新文章,再把这些新文章打包,最后加入数据库进行存储,爬取的文章。
因为该文章平台机制比较复杂,采集的源代码可以简单的理解为一个html网页,下面对html网页的内容进行分析来详细介绍下:文件格式网页源代码包含以下内容:文字内容文件的结构是一个文本文件,content-main中包含了四列:标题、内容、图片、下载地址网页html中的四列是什么意思呢?1,标题:设置标题的名称2,内容:包含了该文章的大致内容3,图片:获取图片网站地址,图片的js的文件地址4,下载地址:文章的地址5,打包完成了文章内容之后,提取txt文件其实很简单,在网页源代码中,有标记txt的最后一行,所以我们在一个网页中,搜索一下txt。 查看全部
关键字文章采集器怎么写的数据全是垃圾
关键字文章采集器是采集一篇公众号文章,进行多站点汇总和整理,数据到达百度站长平台后,进行分析和分享在这个过程中,每个月我们可能要编写一百余篇的文章,且这些文章不管写的怎么样,都是要码出来的,码出来就要给百度看,百度就要算出你写的内容的质量,不然,你写的数据全是垃圾。1.采集工具:jsx插件jsx的好处就是免编程,看一下视频就懂,可编程。
也可以下载jsx插件,使用jsx插件,jsx插件是一款百度浏览器插件,里面包含了jsx所有特性:jsxie插件下载jsx_opera插件下载jsx微信插件下载iejsx1m+jsxmozilla网页插件网页加载插件(jsx)qq浏览器内置jsx代码视频教程视频教程有很多,iejsx教程好像是新出的,没有pythontextmodules教程资料多,可自行参考。
采集工具虽然多,但是采集下来的数据结构采用csv,csv数据结构类似的数据库结构,是一种半文本文件,数据一般放在数据库里,不能进行二次拷贝,但是和其他文本格式数据格式一样,该数据库也会存放文本文件的格式。对于大型的网站,使用浏览器原生的插件进行内部文件操作还是不够的,需要用到fiddler进行抓包,抓取到网站的源代码,再一点点的打包为csv格式数据放入数据库中。
2.知乎文章抓取知乎并不单单是在某一个平台发布文章,都会有相应的文章抓取工具,在采集知乎这种文章网站的时候,知乎的平台机制比较复杂,并不是采集简单的某一篇文章,而是抓取大量文章,用csv格式的一条条来进行爬取,本人是用chrome浏览器抓取的,因为fiddler抓不了知乎的源代码,原生的抓取工具对知乎这个网站的抓取结果,并不是真实的抓取结果,在很多时候抓取结果不是我们需要的文章内容,更新一个时间段,即可抓取更多内容,过一段时间去抓取知乎一些新文章,再把这些新文章打包,最后加入数据库进行存储,爬取的文章。
因为该文章平台机制比较复杂,采集的源代码可以简单的理解为一个html网页,下面对html网页的内容进行分析来详细介绍下:文件格式网页源代码包含以下内容:文字内容文件的结构是一个文本文件,content-main中包含了四列:标题、内容、图片、下载地址网页html中的四列是什么意思呢?1,标题:设置标题的名称2,内容:包含了该文章的大致内容3,图片:获取图片网站地址,图片的js的文件地址4,下载地址:文章的地址5,打包完成了文章内容之后,提取txt文件其实很简单,在网页源代码中,有标记txt的最后一行,所以我们在一个网页中,搜索一下txt。
百度采集器urllib2接口返回数据接口开发以上都属于爬虫范畴
采集交流 • 优采云 发表了文章 • 0 个评论 • 393 次浏览 • 2021-03-24 00:02
关键字文章采集器百度采集器urllib2接口返回数据接口开发以上都属于爬虫范畴,发表文章跟采集数据主要在两方面:解析html源代码和利用html2canvas将页面中的图片地址、文字等存入filename或fileobj中javascript的文章采集器其他采集器需要兼容chrome等浏览器采集到html源代码后我们需要建立数据库操作采集到的数据,首先需要将采集到的数据库字段存入对应的表中:type_index=false表示采集地址过滤选择等字段,如果选择了过滤功能,会将页面中所有网址进行过滤,所以需要写在选择字段里。
//定义数据库对象接口对象constcar_url='';constprecookie='';constpreipes=[];constpreplay=[];constcar=newemployee({index:precookie,//precarray:car.target.indexs.new('list'),//prepname:car.target.indexs.new('book'),//carstatus:car.target.indexs.new('books'),//carbookage:car.target.indexs.new('name'),//racecard:car.target.indexs.new('address'),//private:car.target.indexs.new('province'),//carcink:car.target.indexs.new('city'),//cardirector:car.target.indexs.new('system'),//indexcount:car.target.indexs.new('position'),//carid:car.target.indexs.new('indexname'),//index:car.target.indexs.new('style'),//index:car.target.indexs.new('sales'),//is:car.target.indexs.new('order'),//operation:car.target.indexs.new('main:car.target.indexs.new('date'))//is:car.target.indexs.new('hour'),//lice:car.target.indexs.new('lang'),//licens:car.target.indexs.new('size'),//licensrule:car.target.indexs.new('price'),//licensurance:car.target.indexs.new('address'),//licenut-target:car.target.indexs.new('master'),//tags:car.target.indexs.new('merchant]car.target.indexs.new('purchased')//task:stringprerepository=filterdocument(car_url);constcar=car_url.split('\n')[1];previewimagetype=precookie.r。 查看全部
百度采集器urllib2接口返回数据接口开发以上都属于爬虫范畴
关键字文章采集器百度采集器urllib2接口返回数据接口开发以上都属于爬虫范畴,发表文章跟采集数据主要在两方面:解析html源代码和利用html2canvas将页面中的图片地址、文字等存入filename或fileobj中javascript的文章采集器其他采集器需要兼容chrome等浏览器采集到html源代码后我们需要建立数据库操作采集到的数据,首先需要将采集到的数据库字段存入对应的表中:type_index=false表示采集地址过滤选择等字段,如果选择了过滤功能,会将页面中所有网址进行过滤,所以需要写在选择字段里。
//定义数据库对象接口对象constcar_url='';constprecookie='';constpreipes=[];constpreplay=[];constcar=newemployee({index:precookie,//precarray:car.target.indexs.new('list'),//prepname:car.target.indexs.new('book'),//carstatus:car.target.indexs.new('books'),//carbookage:car.target.indexs.new('name'),//racecard:car.target.indexs.new('address'),//private:car.target.indexs.new('province'),//carcink:car.target.indexs.new('city'),//cardirector:car.target.indexs.new('system'),//indexcount:car.target.indexs.new('position'),//carid:car.target.indexs.new('indexname'),//index:car.target.indexs.new('style'),//index:car.target.indexs.new('sales'),//is:car.target.indexs.new('order'),//operation:car.target.indexs.new('main:car.target.indexs.new('date'))//is:car.target.indexs.new('hour'),//lice:car.target.indexs.new('lang'),//licens:car.target.indexs.new('size'),//licensrule:car.target.indexs.new('price'),//licensurance:car.target.indexs.new('address'),//licenut-target:car.target.indexs.new('master'),//tags:car.target.indexs.new('merchant]car.target.indexs.new('purchased')//task:stringprerepository=filterdocument(car_url);constcar=car_url.split('\n')[1];previewimagetype=precookie.r。
不同批次关键词网址采集器绿色版的常见问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-02-12 12:01
关键词 URL 采集器绿色版是一款可以帮助用户按关键词继续进行采集 网站的软件,其中用户可以快速采集指定的关键词 网站,以减少其他网页的外观。
概述
输入关键字采集每个搜索引擎的URL,域名,标题,描述和其他信息,支持百度,搜狗,谷歌,必应,雅虎,360等。每个关键词 600至800个项目,采集例如,关键词可以附带搜索引擎参数,就像在网页中输入关键词搜索一样,例如,百度中的搜索结果URL必须收录关键词 bbs,然后输入“ 关键词 inurl :bbs。“
数据参考
#URL#:采集的原创网址
#Title#:URL对应的网页标题
#domain#:原创URL的域名部分,例如“”中的“”
#顶级域名#:采用原创URL的顶级域名部分,例如“”中的“”
#Description#:页面标题下方的描述文本
常见问题
1.为什么采集过一会儿不能采集?
采集可能会受到搜索引擎的更多限制,请重新启动软件以继续采集,如果不进行更改,则只能在取消阻止搜索引擎采集后才能继续。百度的屏蔽时间通常为半小时到几个小时。
但是,即使验证码被阻止,该软件也会弹出手动输入的验证码(百度,Google)
2.不同批次的关键词 采集结果中有一些重复的网址?
尤其是仅引用#domain#或#top-level domain#之后,这种部分URL复制更为常见。这也是正常现象,因为每个网站的内页可能收录许多主题,并且采集的不同内页可能与采集不同。引用域名时,同一网站页的不同内部页面自然也相同。
此外,软件中的自动重复数据删除用于此次采集结果的内部重复数据删除,而之前采集的结果不在本次范围之内。如果两个采集的结果中有重复的URL,则可以将它们合并在一起,并使用该软件删除重复项(优采云·重复数据删除加扰器)。
3.为什么采集返回的URL主题与关键词不匹配?
因为在引用#domain#或#top-level domain#后,将采用域名部分。域名打开网站的主页,采集的原创URL可能不是主页,但是网站文章文章的内页,该内页收录以下主题: 关键词,因此可以通过搜索引擎收录和软件采集获得。但是在获取域名后,您打开的域名的首页可能不收录关键词。
为了比较采集是否正确,您可以输入保存模板:,将其另存为htm文件,在采集之后,您可以打开文件以查看比较。
更新日志
1.已转换为支持OEM代理
2.添加了必应和Yahoo 采集;多次更改
3.将Bing,Yahoo,Google更改为https请求,以在某些情况下避免采集失败。
4.添加了百度新闻采集。
5.一些更新。
6.添加了关键词分界线选项。
7.修复了百度的最新更改不能为采集的问题。
8.修复了必应更改的失败采集;修复了某些计算机无法使用xmlhttps(涉及Google,Bing,Yahoo)的问题。 查看全部
不同批次关键词网址采集器绿色版的常见问题
关键词 URL 采集器绿色版是一款可以帮助用户按关键词继续进行采集 网站的软件,其中用户可以快速采集指定的关键词 网站,以减少其他网页的外观。
概述
输入关键字采集每个搜索引擎的URL,域名,标题,描述和其他信息,支持百度,搜狗,谷歌,必应,雅虎,360等。每个关键词 600至800个项目,采集例如,关键词可以附带搜索引擎参数,就像在网页中输入关键词搜索一样,例如,百度中的搜索结果URL必须收录关键词 bbs,然后输入“ 关键词 inurl :bbs。“
数据参考
#URL#:采集的原创网址
#Title#:URL对应的网页标题
#domain#:原创URL的域名部分,例如“”中的“”
#顶级域名#:采用原创URL的顶级域名部分,例如“”中的“”
#Description#:页面标题下方的描述文本
常见问题
1.为什么采集过一会儿不能采集?
采集可能会受到搜索引擎的更多限制,请重新启动软件以继续采集,如果不进行更改,则只能在取消阻止搜索引擎采集后才能继续。百度的屏蔽时间通常为半小时到几个小时。
但是,即使验证码被阻止,该软件也会弹出手动输入的验证码(百度,Google)
2.不同批次的关键词 采集结果中有一些重复的网址?
尤其是仅引用#domain#或#top-level domain#之后,这种部分URL复制更为常见。这也是正常现象,因为每个网站的内页可能收录许多主题,并且采集的不同内页可能与采集不同。引用域名时,同一网站页的不同内部页面自然也相同。
此外,软件中的自动重复数据删除用于此次采集结果的内部重复数据删除,而之前采集的结果不在本次范围之内。如果两个采集的结果中有重复的URL,则可以将它们合并在一起,并使用该软件删除重复项(优采云·重复数据删除加扰器)。
3.为什么采集返回的URL主题与关键词不匹配?
因为在引用#domain#或#top-level domain#后,将采用域名部分。域名打开网站的主页,采集的原创URL可能不是主页,但是网站文章文章的内页,该内页收录以下主题: 关键词,因此可以通过搜索引擎收录和软件采集获得。但是在获取域名后,您打开的域名的首页可能不收录关键词。
为了比较采集是否正确,您可以输入保存模板:,将其另存为htm文件,在采集之后,您可以打开文件以查看比较。
更新日志
1.已转换为支持OEM代理
2.添加了必应和Yahoo 采集;多次更改
3.将Bing,Yahoo,Google更改为https请求,以在某些情况下避免采集失败。
4.添加了百度新闻采集。
5.一些更新。
6.添加了关键词分界线选项。
7.修复了百度的最新更改不能为采集的问题。
8.修复了必应更改的失败采集;修复了某些计算机无法使用xmlhttps(涉及Google,Bing,Yahoo)的问题。
解决方案:优采云关键词网址采集器PC版
采集交流 • 优采云 发表了文章 • 0 个评论 • 276 次浏览 • 2020-11-23 08:01
优采云关键词URL采集器是一款功能强大的小型关键词URL采集软件,可以在主要浏览器中的采集搜索结果中根据关键词运行。快速,提高了用户的工作效率。界面友好,有需要的用户可以在此站点上免费下载。
优采云关键词URL采集器可以根据关键词搜索百度,360、搜狗,Google等,并保存搜索结果的URL和标题。
优采云关键词网站采集器的主要目的:分析竞争对手,挖掘长尾单词;研究平台;采集外部链接;采集示例,等等。关键词可以附带搜索引擎限制的语法。例如,百度中的搜索结果URL必须收录关键词的bbs,然后输入“ 关键词inurl:bbs”。
基本介绍
输入关键字采集每个搜索引擎的URL,域名,标题,描述和其他信息,支持百度,搜狗,谷歌,必应,雅虎,360等。每个关键词600至800个项目,采集例如,关键词可以附带搜索引擎参数,就像在网页中输入关键词搜索一样,例如,百度中的搜索结果URL必须收录关键词bbs,然后输入“ 关键词inurl :bbs。“
参考数据
#URL#:采集的原创网址
#Title#:URL对应的网页标题
#domain#:原创URL的域名部分,例如“”中的“”
#顶级域名#:采用原创URL的顶级域名部分,例如“”中的“”
#Description#:页面标题下方的描述文本
常见问题
1.为什么采集一段时间后不能采集?
这可能是采集受到搜索引擎的更多限制,请重新启动软件以继续采集,如果不进行更改,则只能在取消阻止搜索引擎采集后才能继续。百度的屏蔽时间通常为半小时到几个小时。
但是,即使验证码被阻止,该软件也会弹出手动输入的验证码(百度,Google)
2.为什么不同批次关键词采集的结果中有一些重复的URL?
尤其是仅引用#domain#或#top-level domain#之后,这种部分URL复制更为常见。这也是正常现象,因为每个网站的内页可能收录许多主题,并且采集的不同内页可能与采集不同。引用域名时,同一网站页的不同内部页面自然会具有相同的域名结果。
此外,软件中的自动重复数据删除用于此次采集结果的内部重复数据删除。之前采集的结果不在此重复数据删除的范围内。如果两个采集的结果中有重复的URL,则可以将它们合并在一起,并使用该软件删除重复项(优采云·重复数据删除加扰器)。
3.为什么采集返回的URL主题与关键词不匹配?
因为在引用#domain#或#top-level domain#后,将采用域名部分。域名打开网站的主页,采集的原创URL可能不是主页,但是网站某文章文章的内页,该内页收录主题关键词的值,因此可以通过搜索引擎收录和软件采集获得。但是在获取域名后,您打开的域名的首页可能不收录关键词。
为了比较采集是否正确,您可以输入保存模板:#title#,将其另存为htm文件,在采集之后,您可以打开文件以查看比较。
注释
1.下载完成后,请勿运行压缩程序包中的软件并直接使用它,请先将其解压缩;
2.软件支持32位和64位操作环境;
3.如果无法正常打开该软件,请右键单击以在管理员模式下运行它。
更新日志
1.已转换为支持OEM代理
2.添加了必应和Yahoo采集;多次更改
3.将Bing,Yahoo和Google更改为https请求,以在某些情况下避免采集失败。
4.添加了百度新闻采集。
5.一些更新。
6.添加了关键词分界线选项。
7.解决了百度的最新更改不能为采集的问题。
8.修复了必应更改的失败问题采集;修复了某些计算机无法使用xmlhttps(涉及Google,Bing,Yahoo)的问题。 查看全部
优采云关键词URL采集器PC版本
优采云关键词URL采集器是一款功能强大的小型关键词URL采集软件,可以在主要浏览器中的采集搜索结果中根据关键词运行。快速,提高了用户的工作效率。界面友好,有需要的用户可以在此站点上免费下载。
优采云关键词URL采集器可以根据关键词搜索百度,360、搜狗,Google等,并保存搜索结果的URL和标题。
优采云关键词网站采集器的主要目的:分析竞争对手,挖掘长尾单词;研究平台;采集外部链接;采集示例,等等。关键词可以附带搜索引擎限制的语法。例如,百度中的搜索结果URL必须收录关键词的bbs,然后输入“ 关键词inurl:bbs”。
基本介绍
输入关键字采集每个搜索引擎的URL,域名,标题,描述和其他信息,支持百度,搜狗,谷歌,必应,雅虎,360等。每个关键词600至800个项目,采集例如,关键词可以附带搜索引擎参数,就像在网页中输入关键词搜索一样,例如,百度中的搜索结果URL必须收录关键词bbs,然后输入“ 关键词inurl :bbs。“
参考数据
#URL#:采集的原创网址
#Title#:URL对应的网页标题
#domain#:原创URL的域名部分,例如“”中的“”
#顶级域名#:采用原创URL的顶级域名部分,例如“”中的“”
#Description#:页面标题下方的描述文本
常见问题
1.为什么采集一段时间后不能采集?
这可能是采集受到搜索引擎的更多限制,请重新启动软件以继续采集,如果不进行更改,则只能在取消阻止搜索引擎采集后才能继续。百度的屏蔽时间通常为半小时到几个小时。
但是,即使验证码被阻止,该软件也会弹出手动输入的验证码(百度,Google)
2.为什么不同批次关键词采集的结果中有一些重复的URL?
尤其是仅引用#domain#或#top-level domain#之后,这种部分URL复制更为常见。这也是正常现象,因为每个网站的内页可能收录许多主题,并且采集的不同内页可能与采集不同。引用域名时,同一网站页的不同内部页面自然会具有相同的域名结果。
此外,软件中的自动重复数据删除用于此次采集结果的内部重复数据删除。之前采集的结果不在此重复数据删除的范围内。如果两个采集的结果中有重复的URL,则可以将它们合并在一起,并使用该软件删除重复项(优采云·重复数据删除加扰器)。
3.为什么采集返回的URL主题与关键词不匹配?
因为在引用#domain#或#top-level domain#后,将采用域名部分。域名打开网站的主页,采集的原创URL可能不是主页,但是网站某文章文章的内页,该内页收录主题关键词的值,因此可以通过搜索引擎收录和软件采集获得。但是在获取域名后,您打开的域名的首页可能不收录关键词。
为了比较采集是否正确,您可以输入保存模板:#title#,将其另存为htm文件,在采集之后,您可以打开文件以查看比较。
注释
1.下载完成后,请勿运行压缩程序包中的软件并直接使用它,请先将其解压缩;
2.软件支持32位和64位操作环境;
3.如果无法正常打开该软件,请右键单击以在管理员模式下运行它。
更新日志
1.已转换为支持OEM代理
2.添加了必应和Yahoo采集;多次更改
3.将Bing,Yahoo和Google更改为https请求,以在某些情况下避免采集失败。
4.添加了百度新闻采集。
5.一些更新。
6.添加了关键词分界线选项。
7.解决了百度的最新更改不能为采集的问题。
8.修复了必应更改的失败问题采集;修复了某些计算机无法使用xmlhttps(涉及Google,Bing,Yahoo)的问题。
解决方案:关键词自动布置工具seo关键词刷排名神器:关键字优化布局必备
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2020-11-19 11:00
摘要:今晚有一些推文说排名优化已经落伍了。这些人大多数都认为搜索引擎优化行业已经衰落。看完后,我立即进入百度查看是否可以浏览,实际上显示是否非常流畅?搜索引擎仍然存在,为什么关键词优化业务失败了!我必须扫描这篇文章seo 关键词,以便在排名工件停止之前对其进行扫描,对吗? seo 关键词中有很多团队可以刷排名人造物,每个团队都有其特殊的渡海方法,但是它们都可以达到相同的目标。任何方法都只是为了满足搜狗搜索的排名规则。尽管360搜索没有向外部提供排名机制,但是功能强大的seo 关键词排名神器设计人员可以在许多研究报告中进行研究,并且很快就可以突破破解方法。
关键词自动布局工具
seo 关键词排名工件:关键字优化布局所必需的
今晚有一些推文说排名优化已经落伍了。这些人大多数都认为搜索引擎优化业务已经下降。看完后,我立即进入百度查看是否可以浏览,但事实是,不是,显示是否很流畅?我很寂寞...搜索引擎仍然存在,为什么关键词优化业务失败了!根据我的观点,即使搜索门户中仅剩一个必应,也仍然急于进行网页优化。这是一个很好的解释:只要Bing存在,就需要排名服务。您仍然不同意吗?我必须扫描这篇文章seo 关键词,以便在排名工件停止之前对其进行扫描,对吗?继续观看:
seo 关键词在seo 关键词排名神器中有许多团队,每个团队都有其独特的渡海方法,但是他们都以相同的方式结束。任何方法都只能满足搜狗搜索的排名规则。虽然360搜索没有向外部提供排名机制,但是功能强大的seo 关键词排名神器设计人员可以在许多研究报告中进行研究,并且很快就可以突破破解方法。例如:几年前的外部链接算法,301跳转方法,堆叠方法等。但是,随着搜索引擎规则的逐步完善,排名技术不断变化。以前的大多数简单技术都不再适用,因此许多过去只研究过反链的SEO员工都认为关键字优化不好,所以自媒体走了,这是消除吗?
我想与您分享网站优化专家:SEO涵盖非现场SEO和现场优化;关键字排名是指希望在360次搜索中赢得某些客户的意愿,它由网站和内容构建构成在一系列级别(例如计划,用户裂变传播和代码)上的完整操作,以使网页更适合百度收录行为原则;使网站取悦蜘蛛的爬网方法也称为SEO,排名优化不仅可以提高搜索优化的成就,而且可以使在搜索引擎中排名的网站内容对用户更具参考价值。
在本文结尾,我们向客户发出有关百度排名的警告:如何获得平台只是辅助手段之一,网站排名是一种系统的调整过程:网络搜索字词的分布和有效的朋友必须进行调整。连锁店,如果我们建立一个新的车站并尽力抛弃旧玉米,我们将看到一个全新的结果。同时,我们仍然坚持先进的软件技术,一直保持警惕,直到最后一个搜索引擎崩溃为止,希望我们能够携手合作,在未来越来越幸福地合作!
原创标题:seo 关键词排名工件:关键字优化布局所必需。请指出来自推杆的转载来源! 查看全部
关键词自动布局工具seo 关键词排名工件:关键字优化布局所必需的
摘要:今晚有一些推文说排名优化已经落伍了。这些人大多数都认为搜索引擎优化行业已经衰落。看完后,我立即进入百度查看是否可以浏览,实际上显示是否非常流畅?搜索引擎仍然存在,为什么关键词优化业务失败了!我必须扫描这篇文章seo 关键词,以便在排名工件停止之前对其进行扫描,对吗? seo 关键词中有很多团队可以刷排名人造物,每个团队都有其特殊的渡海方法,但是它们都可以达到相同的目标。任何方法都只是为了满足搜狗搜索的排名规则。尽管360搜索没有向外部提供排名机制,但是功能强大的seo 关键词排名神器设计人员可以在许多研究报告中进行研究,并且很快就可以突破破解方法。
关键词自动布局工具
seo 关键词排名工件:关键字优化布局所必需的
今晚有一些推文说排名优化已经落伍了。这些人大多数都认为搜索引擎优化业务已经下降。看完后,我立即进入百度查看是否可以浏览,但事实是,不是,显示是否很流畅?我很寂寞...搜索引擎仍然存在,为什么关键词优化业务失败了!根据我的观点,即使搜索门户中仅剩一个必应,也仍然急于进行网页优化。这是一个很好的解释:只要Bing存在,就需要排名服务。您仍然不同意吗?我必须扫描这篇文章seo 关键词,以便在排名工件停止之前对其进行扫描,对吗?继续观看:
seo 关键词在seo 关键词排名神器中有许多团队,每个团队都有其独特的渡海方法,但是他们都以相同的方式结束。任何方法都只能满足搜狗搜索的排名规则。虽然360搜索没有向外部提供排名机制,但是功能强大的seo 关键词排名神器设计人员可以在许多研究报告中进行研究,并且很快就可以突破破解方法。例如:几年前的外部链接算法,301跳转方法,堆叠方法等。但是,随着搜索引擎规则的逐步完善,排名技术不断变化。以前的大多数简单技术都不再适用,因此许多过去只研究过反链的SEO员工都认为关键字优化不好,所以自媒体走了,这是消除吗?
我想与您分享网站优化专家:SEO涵盖非现场SEO和现场优化;关键字排名是指希望在360次搜索中赢得某些客户的意愿,它由网站和内容构建构成在一系列级别(例如计划,用户裂变传播和代码)上的完整操作,以使网页更适合百度收录行为原则;使网站取悦蜘蛛的爬网方法也称为SEO,排名优化不仅可以提高搜索优化的成就,而且可以使在搜索引擎中排名的网站内容对用户更具参考价值。
在本文结尾,我们向客户发出有关百度排名的警告:如何获得平台只是辅助手段之一,网站排名是一种系统的调整过程:网络搜索字词的分布和有效的朋友必须进行调整。连锁店,如果我们建立一个新的车站并尽力抛弃旧玉米,我们将看到一个全新的结果。同时,我们仍然坚持先进的软件技术,一直保持警惕,直到最后一个搜索引擎崩溃为止,希望我们能够携手合作,在未来越来越幸福地合作!
原创标题:seo 关键词排名工件:关键字优化布局所必需。请指出来自推杆的转载来源!

