
全网文章采集软件
全网文章采集软件(全网文章采集软件可以做到哦~欢迎联系我哦)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-10-15 05:01
全网文章采集软件可以做到哦~欢迎联系我哦,为你提供最贴心的文章采集软件。vip采集软件vip采集软件是一款集采集、抓取、批量管理、上传下载、文章聚合、分类排序、视频、图片、音乐等为一体的网页分析工具,致力于提高网页网页抓取效率和质量,全网链接采集工具,可以采集搜索引擎内所有站点,并与其他网站整合。数据采集(简单说就是:抓取)完全免费哦,无任何限制。
以1.0版本为例,如果你需要采集阿里巴巴、天猫、美团、、百度、500px、豆瓣、拉勾网、招聘网、58同城、百姓网、天天快报等等网站里的信息。新用户注册一天即可使用,免费使用!。
可以考虑安装个wap助手,安装后你的网站的图片资源都会自动下载下来。毕竟网站上都会存在各种图片的啊,需要的话可以说各种图片都是可以抓取下来的,只要你的网站和爬虫能共存。
现在都用beautifulsoup这个库,甚至rawtext也能搜集。还有rawtext采集库不仅采集采集的比较全,而且还是结构化文本爬虫。内置数据可供下载也可以自己上传图片,真正给了爬虫可以自由采集文本的权力。
还是web爬虫机器人,一键,批量采集,不过网站少些,
我这里有几个:一个是web爬虫机器人一个是免费采集网站工具希望对题主有用。 查看全部
全网文章采集软件(全网文章采集软件可以做到哦~欢迎联系我哦)
全网文章采集软件可以做到哦~欢迎联系我哦,为你提供最贴心的文章采集软件。vip采集软件vip采集软件是一款集采集、抓取、批量管理、上传下载、文章聚合、分类排序、视频、图片、音乐等为一体的网页分析工具,致力于提高网页网页抓取效率和质量,全网链接采集工具,可以采集搜索引擎内所有站点,并与其他网站整合。数据采集(简单说就是:抓取)完全免费哦,无任何限制。
以1.0版本为例,如果你需要采集阿里巴巴、天猫、美团、、百度、500px、豆瓣、拉勾网、招聘网、58同城、百姓网、天天快报等等网站里的信息。新用户注册一天即可使用,免费使用!。
可以考虑安装个wap助手,安装后你的网站的图片资源都会自动下载下来。毕竟网站上都会存在各种图片的啊,需要的话可以说各种图片都是可以抓取下来的,只要你的网站和爬虫能共存。
现在都用beautifulsoup这个库,甚至rawtext也能搜集。还有rawtext采集库不仅采集采集的比较全,而且还是结构化文本爬虫。内置数据可供下载也可以自己上传图片,真正给了爬虫可以自由采集文本的权力。
还是web爬虫机器人,一键,批量采集,不过网站少些,
我这里有几个:一个是web爬虫机器人一个是免费采集网站工具希望对题主有用。
全网文章采集软件(爬取《鱿鱼游戏》豆瓣上的技术栈和工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-10-12 12:28
各位读者好,我是小张~
今天不是国庆节,所以回顾了一部最近很火的韩剧《鱿鱼游戏》。这部剧的整体剧情还是很不错的,值得一看。
作为技术博主,当然不能在这里介绍这部剧的影评。毕竟我这方面不专业,最重要的是写不出来。
本文主要是爬取豆瓣上《鱿鱼游戏》的一些影评,对数据做一些简单的分析,从数据的角度重新审视这部剧。
技术工具
在正文开始之前,先介绍一下本文中用到的技术栈和工具文章。本文所涉及的所有源码数据可通过公众号【小张Python】后台回复关键词211003获取。
本文用到的技术栈和工具如下,可以概括为四个方面:
数据采集
这次数据采集的目标网站是豆瓣,但是我的账号之前被封了,所以只能采集获取200条左右的数据。豆瓣有相应的反爬虫机制。查看超过10页的评论需要用户登录才能进行下一步
至于账号为什么被封,是因为我在学习爬虫的时候不知道在哪里制作【豆瓣模拟登录】代码。当时不知道代码有没有问题。试用后被封,永久封号
图1
这里也给大家提个醒。以后做爬虫的时候,在模拟登录的时候尽量使用一些测试账号,如果不需要自己的账号就不要使用。
这次的数据采集也比较简单,就是改变图2中url上的start参数,使用offset为20的规则作为下一页url的拼接;
图2
获取到请求连接后,使用requests的get请求,然后分析获取到的html数据,就可以得到我们需要的数据;采集 核心代码贴在下面
for offset in range(0,220,20):
url = "https://movie.douban.com/subje ... rt%3D{}&limit=20&status=P&sort=new_score".format(offset)
res = requests.get(url,headers= headers)
# print(res.text)
soup = BeautifulSoup(res.text,'lxml')
time.sleep(2)
for comment_item in soup.select("#comments > .comment-item"):
try:
data_item = []
avatar = comment_item.select(".avatar a img")[0].get("src")
name = comment_item.select(".comment h3 .comment-info a")[0]
rate = comment_item.select(".comment h3 .comment-info span:nth-child(3)")[0]
date = comment_item.select(".comment h3 .comment-info span:nth-child(4)")[0]
comment = comment_item.select(".comment .comment-content span")[0]
# comment_item.get("div img").ge
data_item.append(avatar)
data_item.append(str(name.string).strip("\t"))
data_item.append(str(rate.get("class")[0]).strip("allstar").strip('\t').strip("\n"))
data_item.append(str(date.string).replace('\n','').strip('\t'))
data_item.append(str(comment.string).strip("\t").strip("\n"))
data_json ={
'avatar':avatar,
'name': str(name.string).strip("\t"),
'rate': str(rate.get("class")[0]).strip("allstar").strip('\t').strip("\n"),
'date' : str(date.string).replace('\n','').replace('\t','').strip(' '),
'comment': str(comment.string).strip("\t").strip("\n")
}
if not (collection.find_one({'avatar':avatar})):
print("data _json is {}".format(data_json))
collection.insert_one(data_json)
f.write('\t'.join(data_item))
f.write("\n")
except Exception as e:
print(e)
continue
抓取豆瓣的时候需要记得添加cookie和User-Agent,否则不会有数据为空。
为了方便后面数据的可视化和提取,本文使用Mongodb作为数据存储。有211条数据。采集的主要数据字段为头像、姓名、评分、日期、评论,分别代表用户头像、用户名、明星。成绩、日期、评论;结果如图3所示;
图 3
关于Python如何使用MongoDB,可以参考旧新闻[]
数据可视化
可视化部分之前计划用Python+Pyecharts来实现,但是Python图表中的交互效果不是很好。只需使用原生的 Echarts + Vue 组合即可实现。而且,在这种情况下,将所有图表放在一个网页上更方便。
首先是对评论时间和评论数量进行图表预览。根据数据,评论时间分布为散点图。看用户评论的主要时间分布。
图 4
图4中圆点的大小和颜色代表了当天的评论数,评论数也可以反映当天剧的热度。
据了解,《鱿鱼游戏》的影评从9月17日开始上涨,20日见顶,21日回落;评论数量在21日和29日之间来回波动,差别不大;
至少要到国庆节,10月1日,猜测可能一方面是国庆假期大家都出去玩了,另一方面,随着时间的推移,这部剧的热度也有所下降。
为了了解大家对《鱿鱼游戏》的评价,我根据这200条节目的【评分星级】数据绘制了饼图,最终效果如图5所示。
图 5
老实说,图 5 的结果让我有点吃惊。至少对我来说,这部剧的质量是相当高的。画之前我觉得应该是【五颗星】的比例最大,其次是【四颗星】,然后是【三星】;
现在【三星】和【五星】的比例正好相反。可能是这部剧的剧情残酷,会引起不适,所以高分占的比例不高;
为了方便,我最后把上面两个图表放在一个网页上,效果如图6和图7两种不同的布局
垂直布局
图 6
横向布局
图 7 词云可视化
这次采集的数据信息有限,可以分析的数据维度并不多。对数据图表的分析到此基本结束。以下是采集收到的评论的几张词云图
图 8
从图8中可以看出,人性不是现实中常用的口头语,而是影评中出现频率最高的词,而这个词确实契合了电视剧《鱿鱼游戏》的主题,从第一集开始到结尾他们都在分析人性,赌徒的“贪婪和赌瘾”,贵宾的“弱肉强食”
图9
与之前的词云图相比,图9突出了相对更多的信息。比如韩国,人物、刺激、剧情、赌博启示、题材等都和剧情有关。除了这几条信息,李政宰、孔刘、李秉宪等几位主演也都被提到了
最后,我用采集到达的用户头像制作了两个图片墙作为文章的结尾
图10
图11
图10、图11 照片墙的轮廓使用了剧中两个角色的截图,一个是123木人,一个是男一玩游戏二的截图:
关于照片墙的制作方法请参考旧闻:
概括
本文涉及的所有源码和信息获取方式:关注微信公众号:【小张Python】,后台回复关键词211003,即可获取,
好了,这就是本文文章的全部内容。这篇文章分析的东西不多。主要介绍Python在数据采集和可视化方面的一些应用。
如果内容对你有帮助,希望给文章点个赞鼓励一下。当然,也欢迎读者朋友们把文章分享给更多的人!
最后,感谢大家的阅读,下期再见~ 查看全部
全网文章采集软件(爬取《鱿鱼游戏》豆瓣上的技术栈和工具)
各位读者好,我是小张~
今天不是国庆节,所以回顾了一部最近很火的韩剧《鱿鱼游戏》。这部剧的整体剧情还是很不错的,值得一看。
作为技术博主,当然不能在这里介绍这部剧的影评。毕竟我这方面不专业,最重要的是写不出来。
本文主要是爬取豆瓣上《鱿鱼游戏》的一些影评,对数据做一些简单的分析,从数据的角度重新审视这部剧。
技术工具
在正文开始之前,先介绍一下本文中用到的技术栈和工具文章。本文所涉及的所有源码数据可通过公众号【小张Python】后台回复关键词211003获取。
本文用到的技术栈和工具如下,可以概括为四个方面:
数据采集
这次数据采集的目标网站是豆瓣,但是我的账号之前被封了,所以只能采集获取200条左右的数据。豆瓣有相应的反爬虫机制。查看超过10页的评论需要用户登录才能进行下一步
至于账号为什么被封,是因为我在学习爬虫的时候不知道在哪里制作【豆瓣模拟登录】代码。当时不知道代码有没有问题。试用后被封,永久封号
图1
这里也给大家提个醒。以后做爬虫的时候,在模拟登录的时候尽量使用一些测试账号,如果不需要自己的账号就不要使用。
这次的数据采集也比较简单,就是改变图2中url上的start参数,使用offset为20的规则作为下一页url的拼接;

图2
获取到请求连接后,使用requests的get请求,然后分析获取到的html数据,就可以得到我们需要的数据;采集 核心代码贴在下面
for offset in range(0,220,20):
url = "https://movie.douban.com/subje ... rt%3D{}&limit=20&status=P&sort=new_score".format(offset)
res = requests.get(url,headers= headers)
# print(res.text)
soup = BeautifulSoup(res.text,'lxml')
time.sleep(2)
for comment_item in soup.select("#comments > .comment-item"):
try:
data_item = []
avatar = comment_item.select(".avatar a img")[0].get("src")
name = comment_item.select(".comment h3 .comment-info a")[0]
rate = comment_item.select(".comment h3 .comment-info span:nth-child(3)")[0]
date = comment_item.select(".comment h3 .comment-info span:nth-child(4)")[0]
comment = comment_item.select(".comment .comment-content span")[0]
# comment_item.get("div img").ge
data_item.append(avatar)
data_item.append(str(name.string).strip("\t"))
data_item.append(str(rate.get("class")[0]).strip("allstar").strip('\t').strip("\n"))
data_item.append(str(date.string).replace('\n','').strip('\t'))
data_item.append(str(comment.string).strip("\t").strip("\n"))
data_json ={
'avatar':avatar,
'name': str(name.string).strip("\t"),
'rate': str(rate.get("class")[0]).strip("allstar").strip('\t').strip("\n"),
'date' : str(date.string).replace('\n','').replace('\t','').strip(' '),
'comment': str(comment.string).strip("\t").strip("\n")
}
if not (collection.find_one({'avatar':avatar})):
print("data _json is {}".format(data_json))
collection.insert_one(data_json)
f.write('\t'.join(data_item))
f.write("\n")
except Exception as e:
print(e)
continue
抓取豆瓣的时候需要记得添加cookie和User-Agent,否则不会有数据为空。
为了方便后面数据的可视化和提取,本文使用Mongodb作为数据存储。有211条数据。采集的主要数据字段为头像、姓名、评分、日期、评论,分别代表用户头像、用户名、明星。成绩、日期、评论;结果如图3所示;
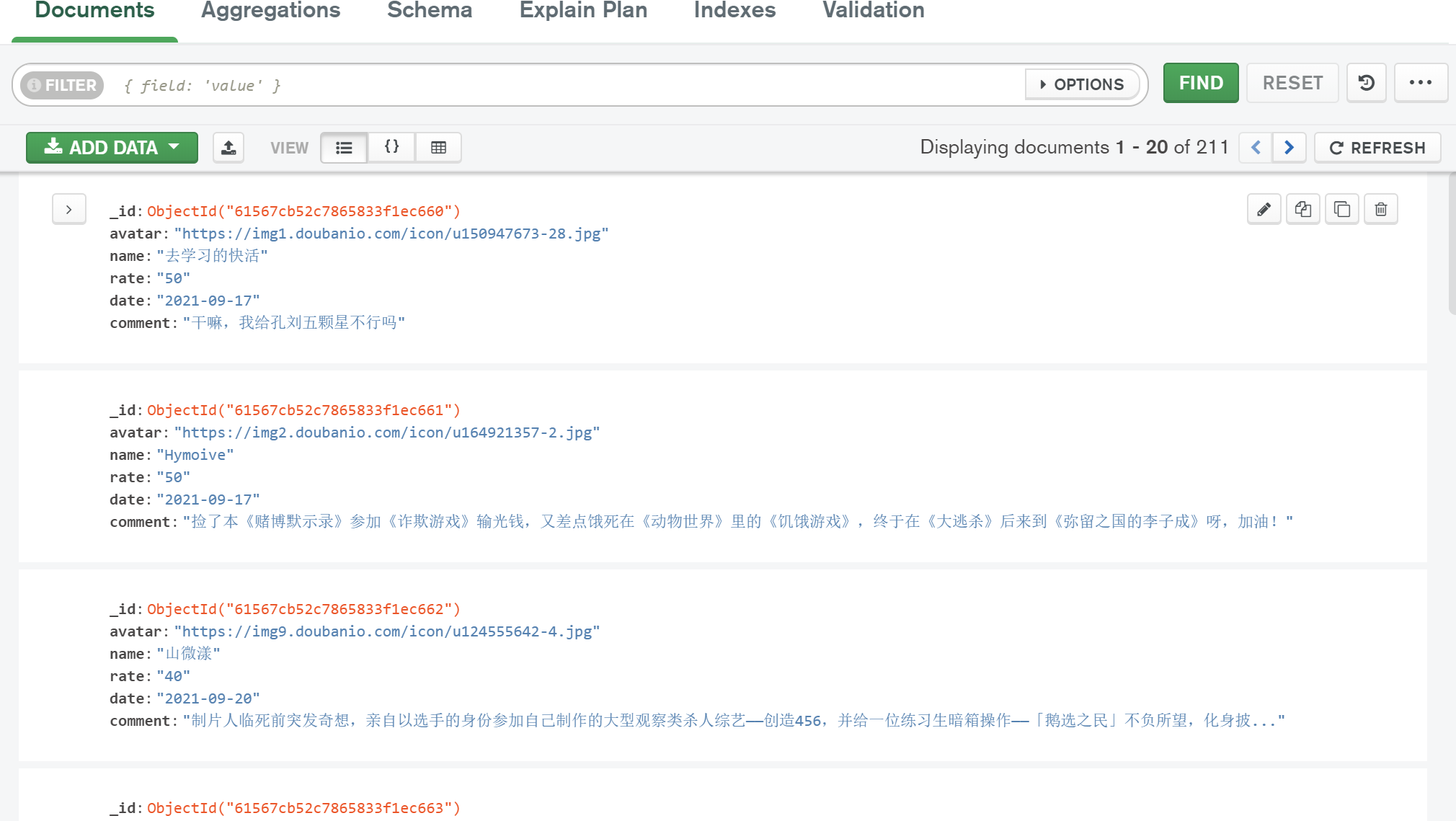
图 3
关于Python如何使用MongoDB,可以参考旧新闻[]
数据可视化
可视化部分之前计划用Python+Pyecharts来实现,但是Python图表中的交互效果不是很好。只需使用原生的 Echarts + Vue 组合即可实现。而且,在这种情况下,将所有图表放在一个网页上更方便。
首先是对评论时间和评论数量进行图表预览。根据数据,评论时间分布为散点图。看用户评论的主要时间分布。
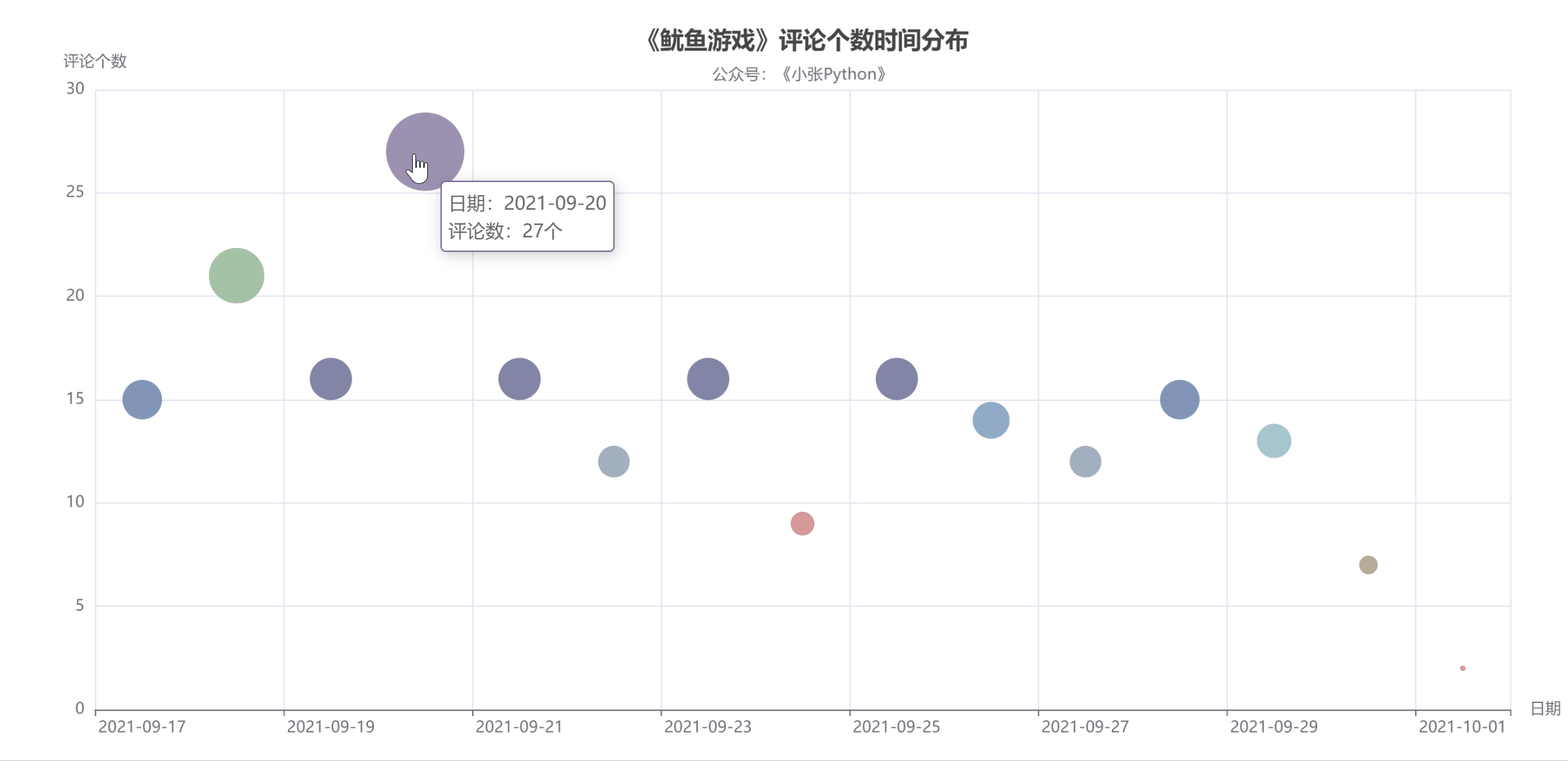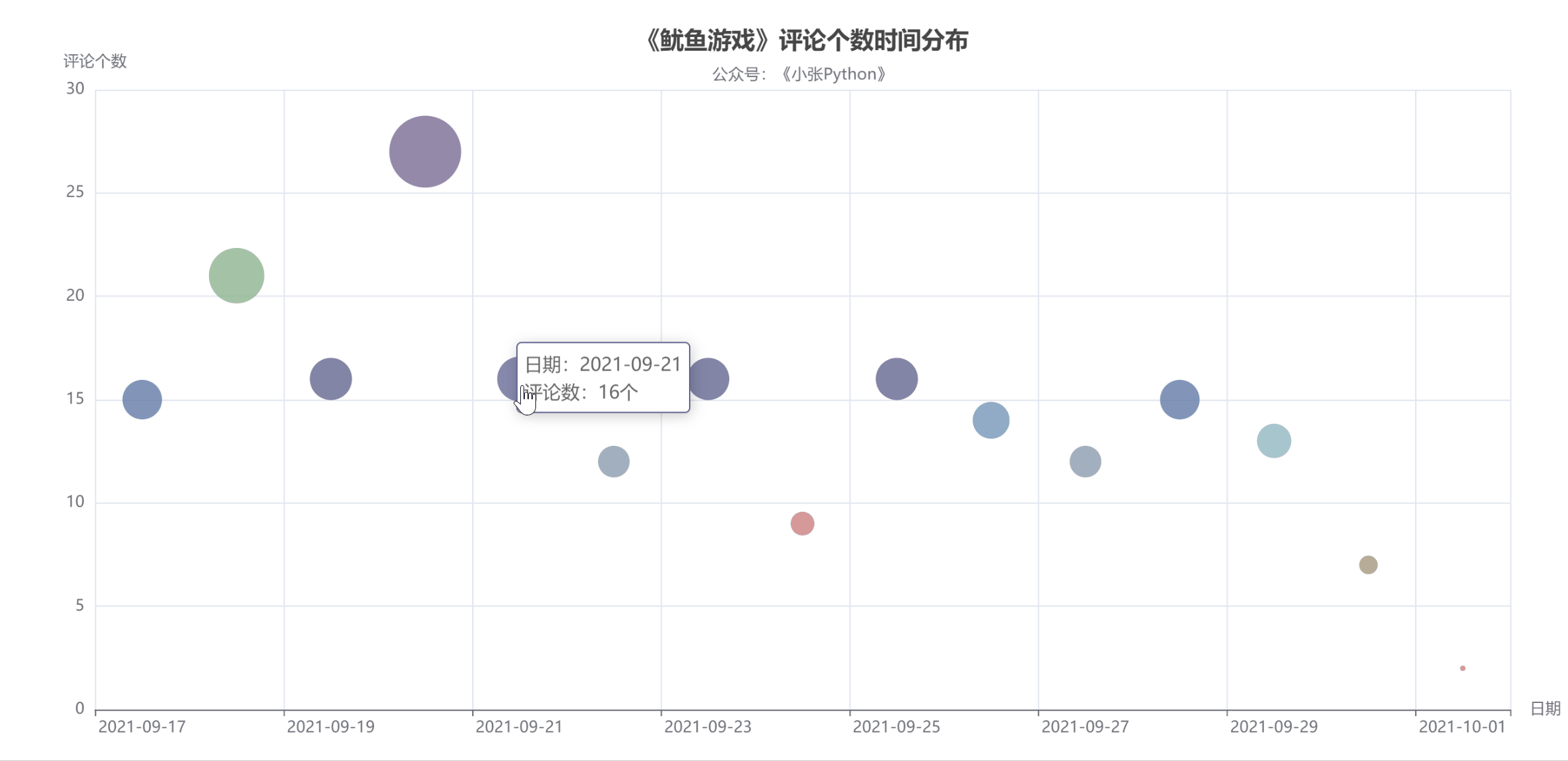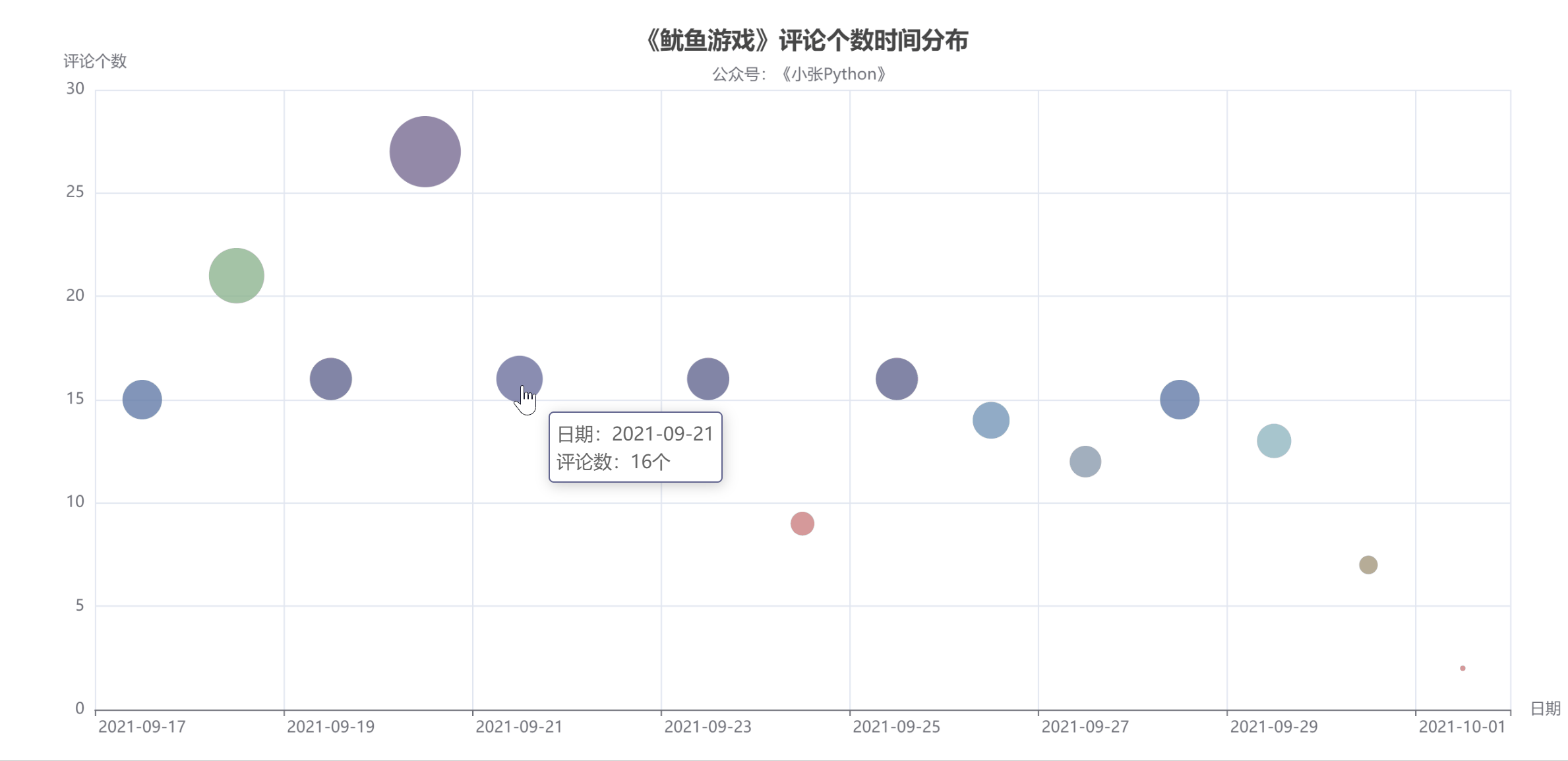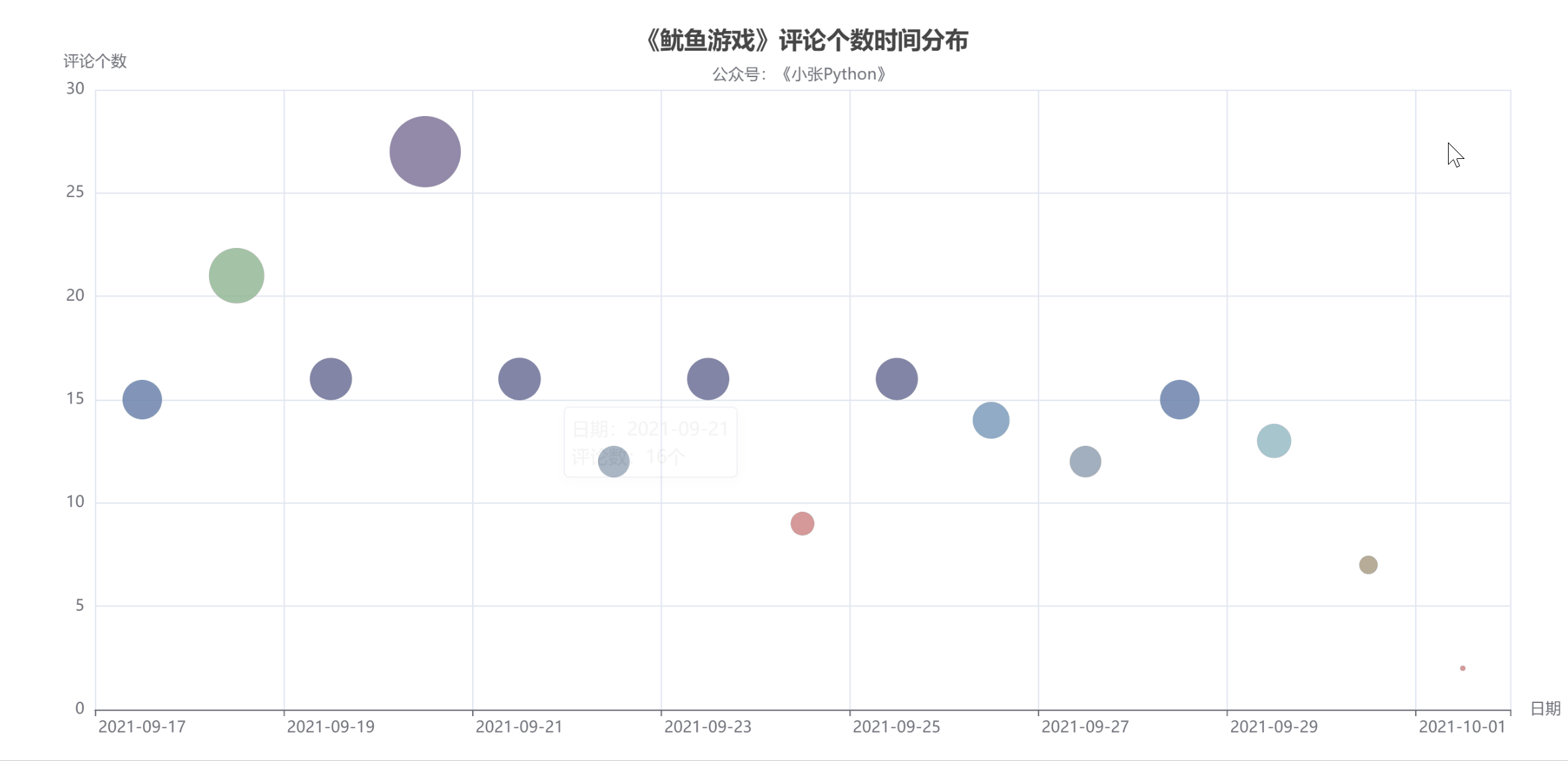
图 4
图4中圆点的大小和颜色代表了当天的评论数,评论数也可以反映当天剧的热度。
据了解,《鱿鱼游戏》的影评从9月17日开始上涨,20日见顶,21日回落;评论数量在21日和29日之间来回波动,差别不大;
至少要到国庆节,10月1日,猜测可能一方面是国庆假期大家都出去玩了,另一方面,随着时间的推移,这部剧的热度也有所下降。
为了了解大家对《鱿鱼游戏》的评价,我根据这200条节目的【评分星级】数据绘制了饼图,最终效果如图5所示。
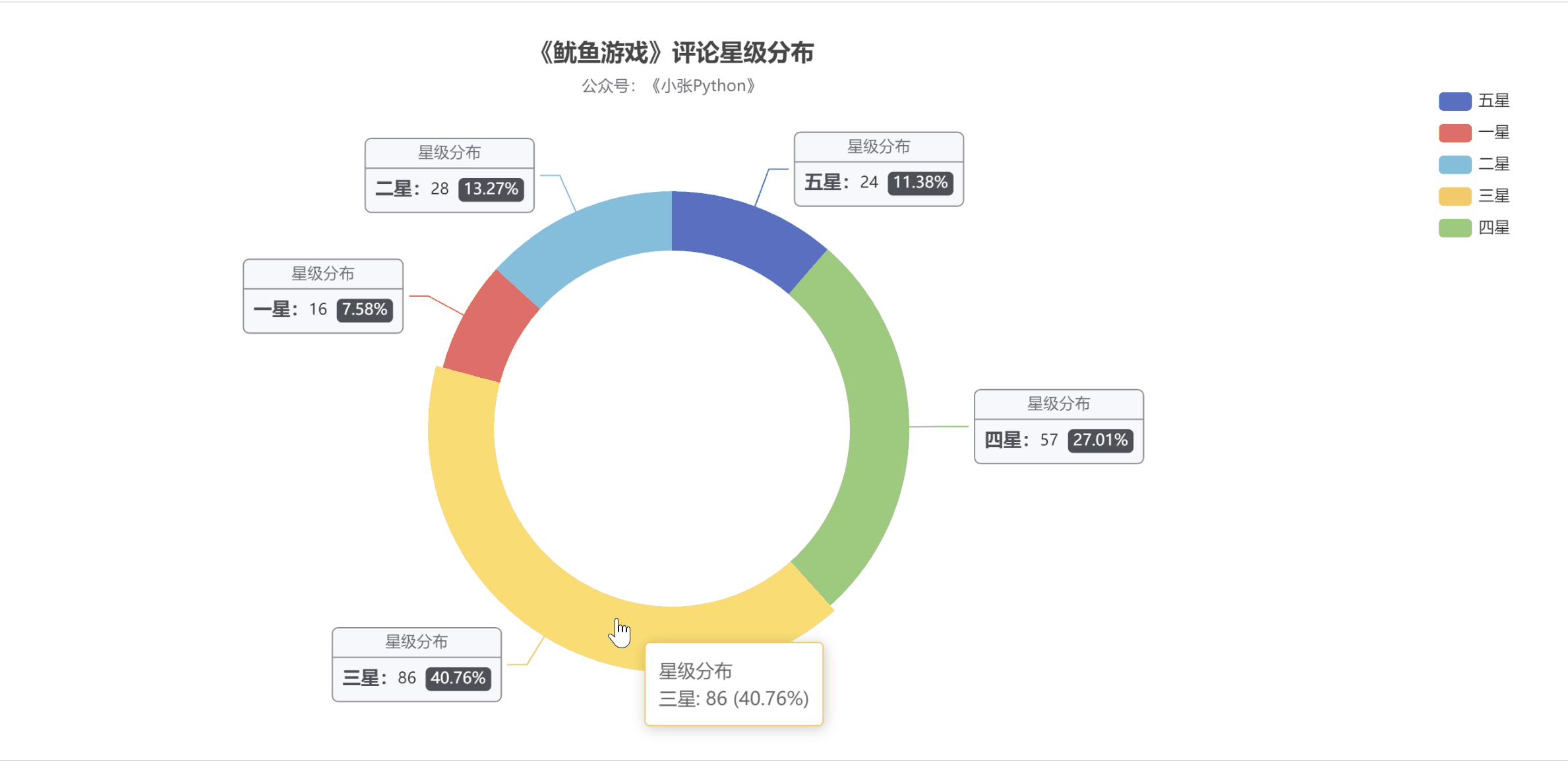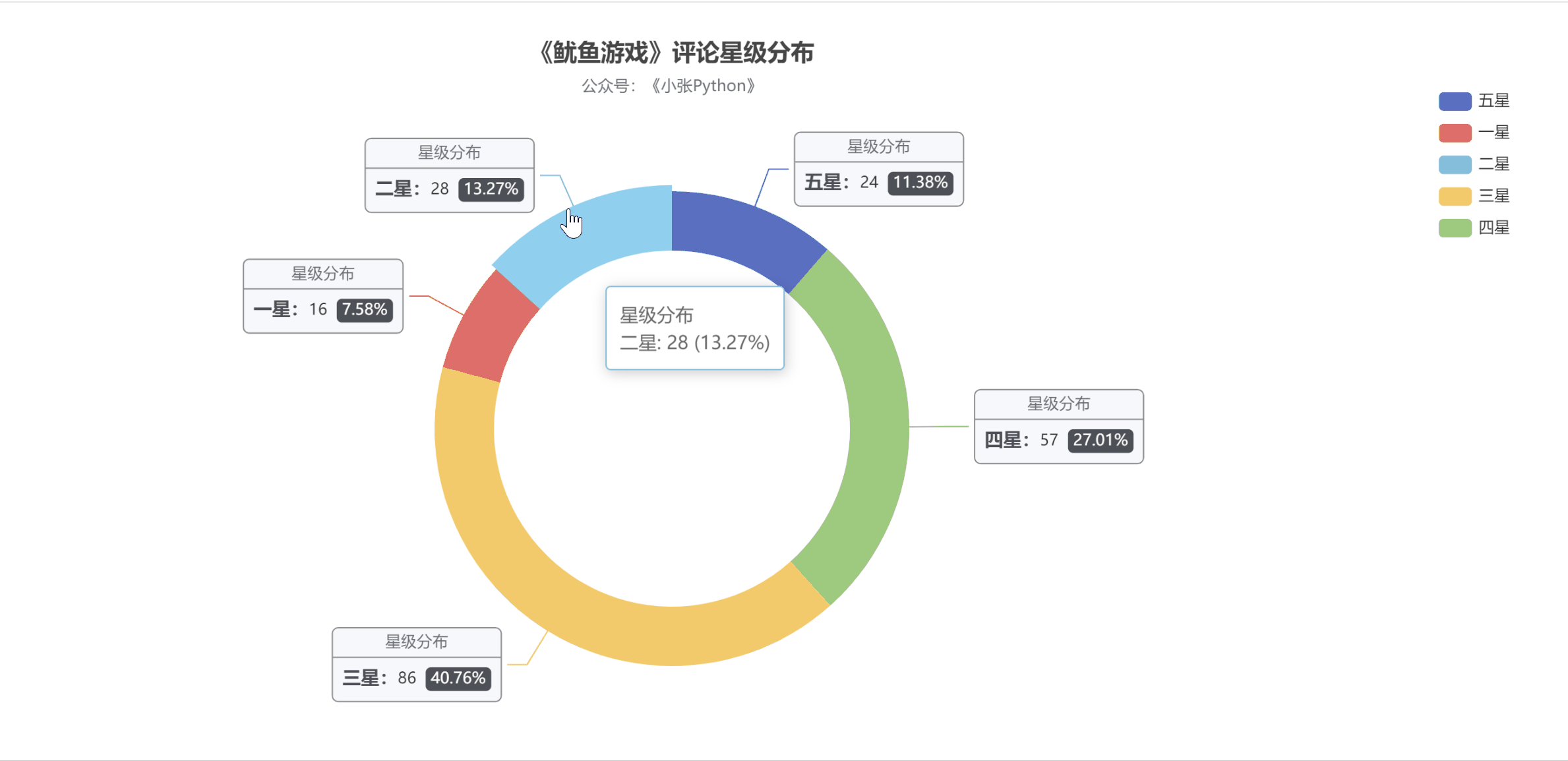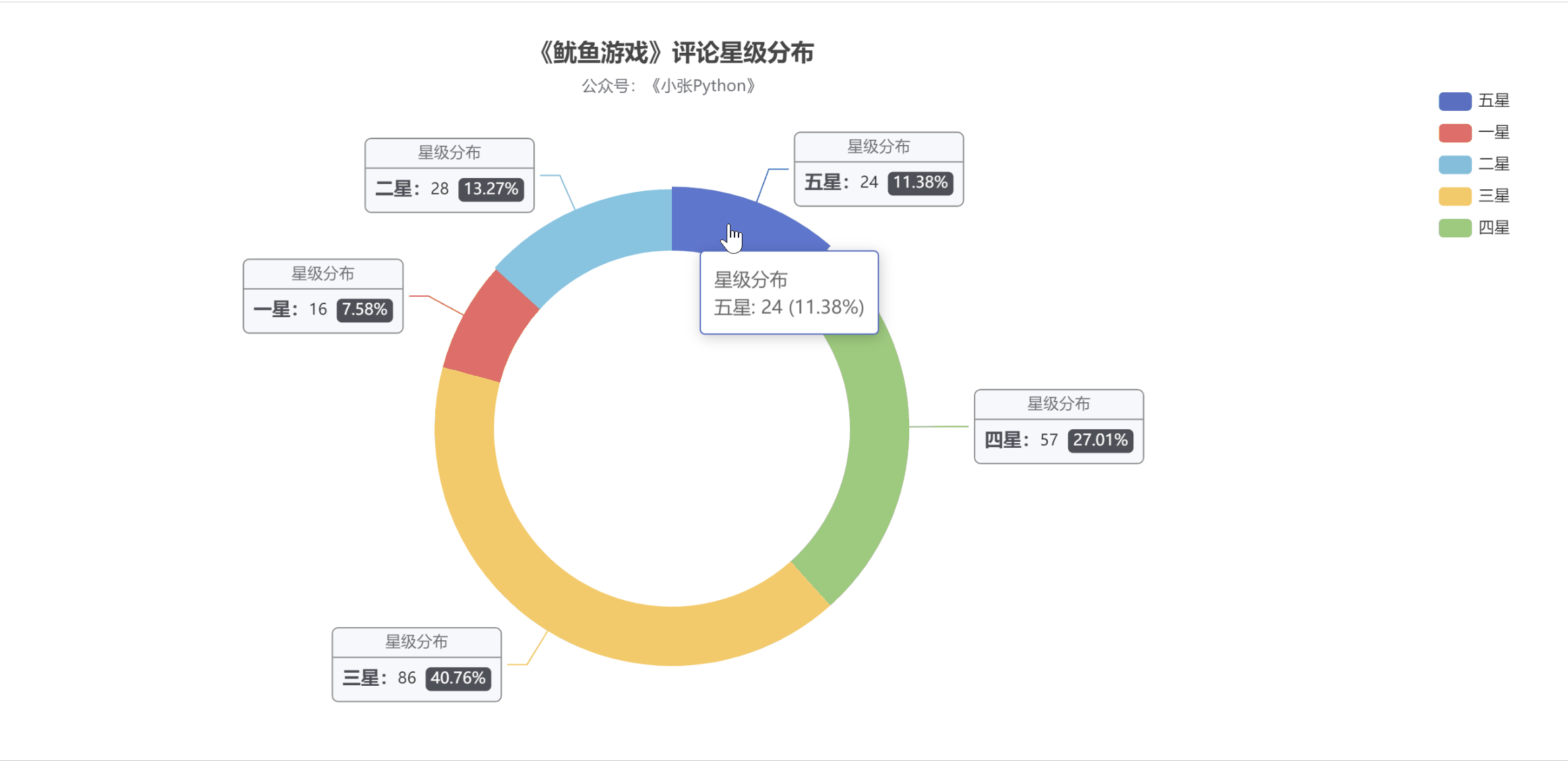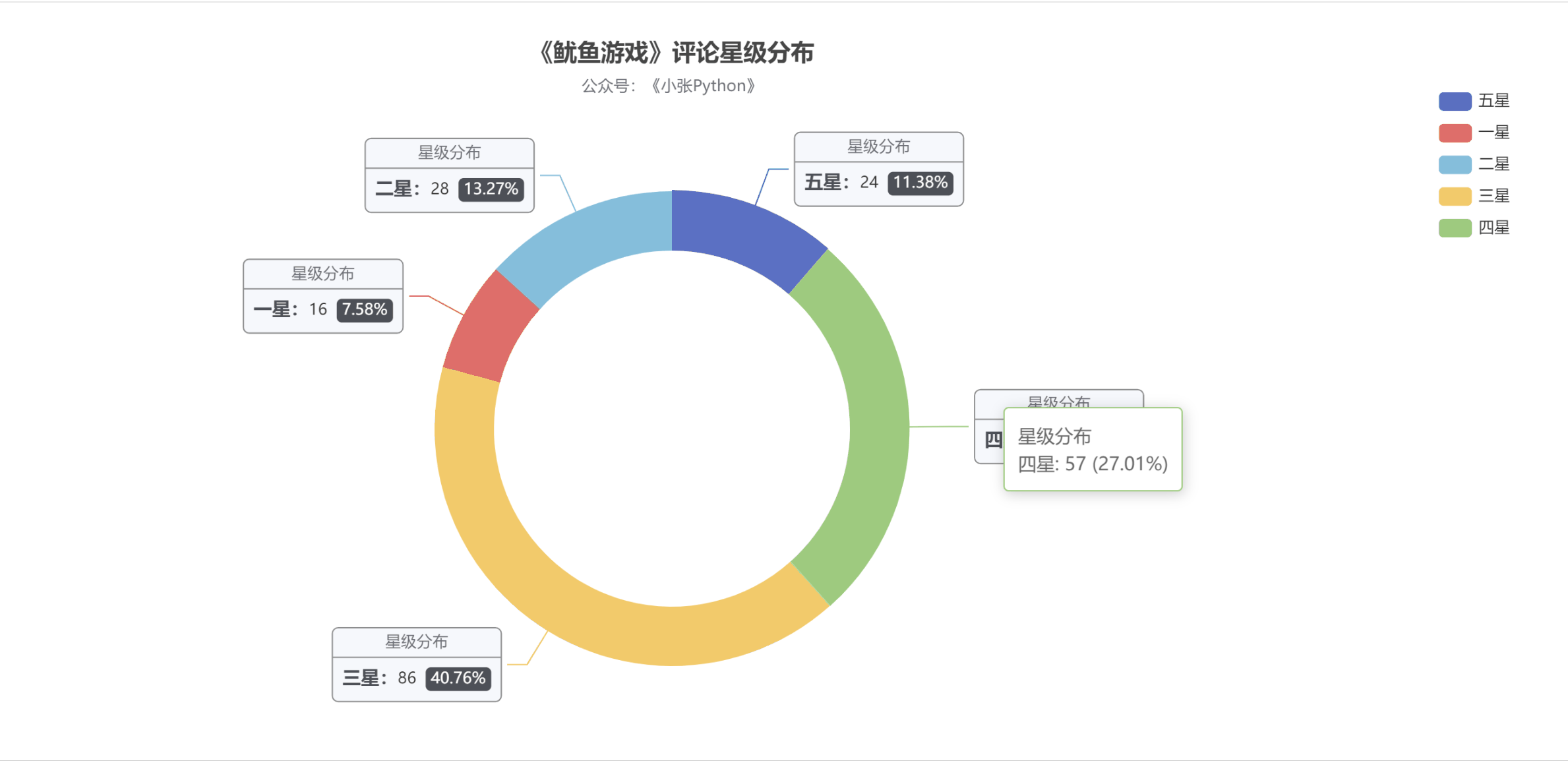
图 5
老实说,图 5 的结果让我有点吃惊。至少对我来说,这部剧的质量是相当高的。画之前我觉得应该是【五颗星】的比例最大,其次是【四颗星】,然后是【三星】;
现在【三星】和【五星】的比例正好相反。可能是这部剧的剧情残酷,会引起不适,所以高分占的比例不高;
为了方便,我最后把上面两个图表放在一个网页上,效果如图6和图7两种不同的布局
垂直布局

图 6
横向布局
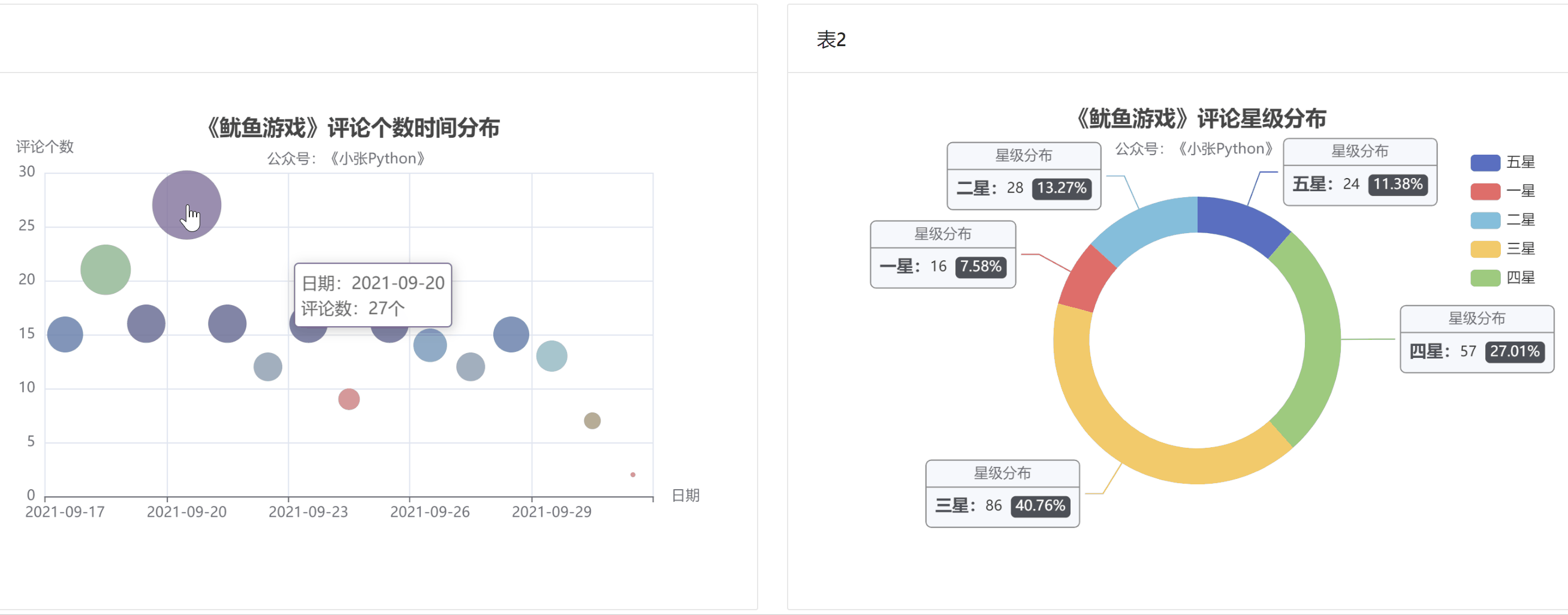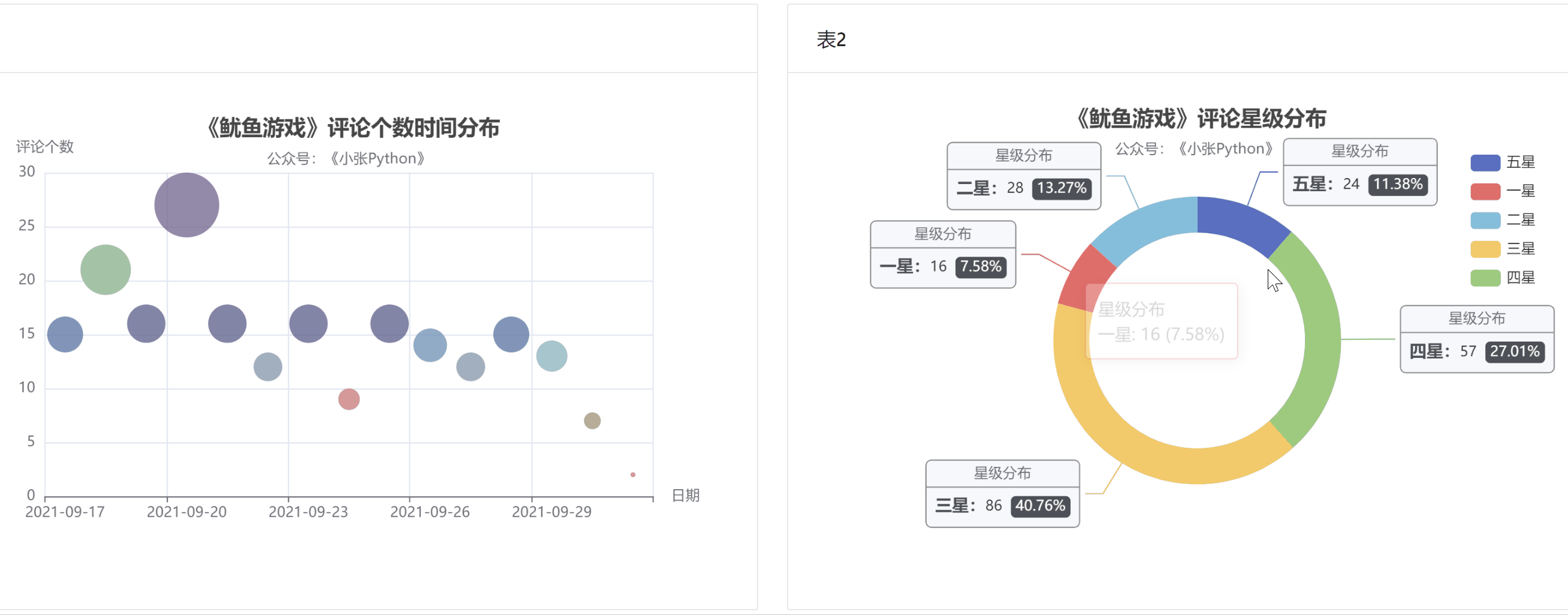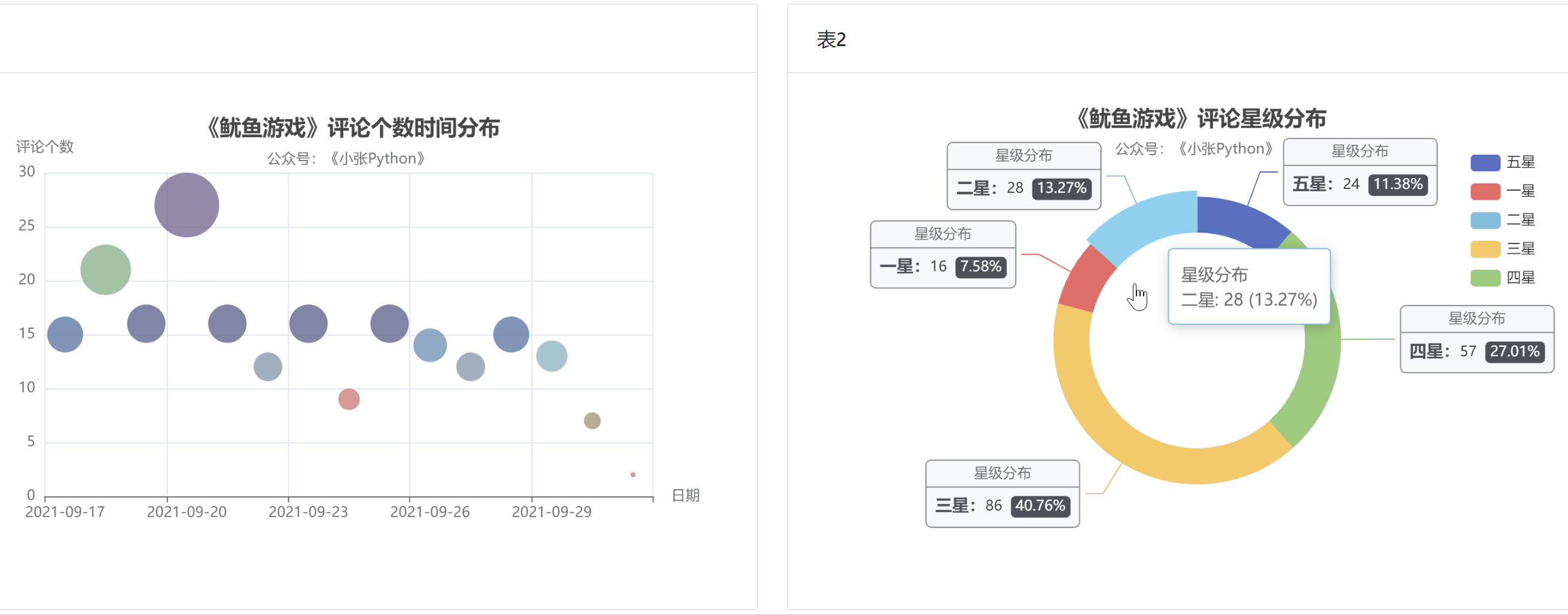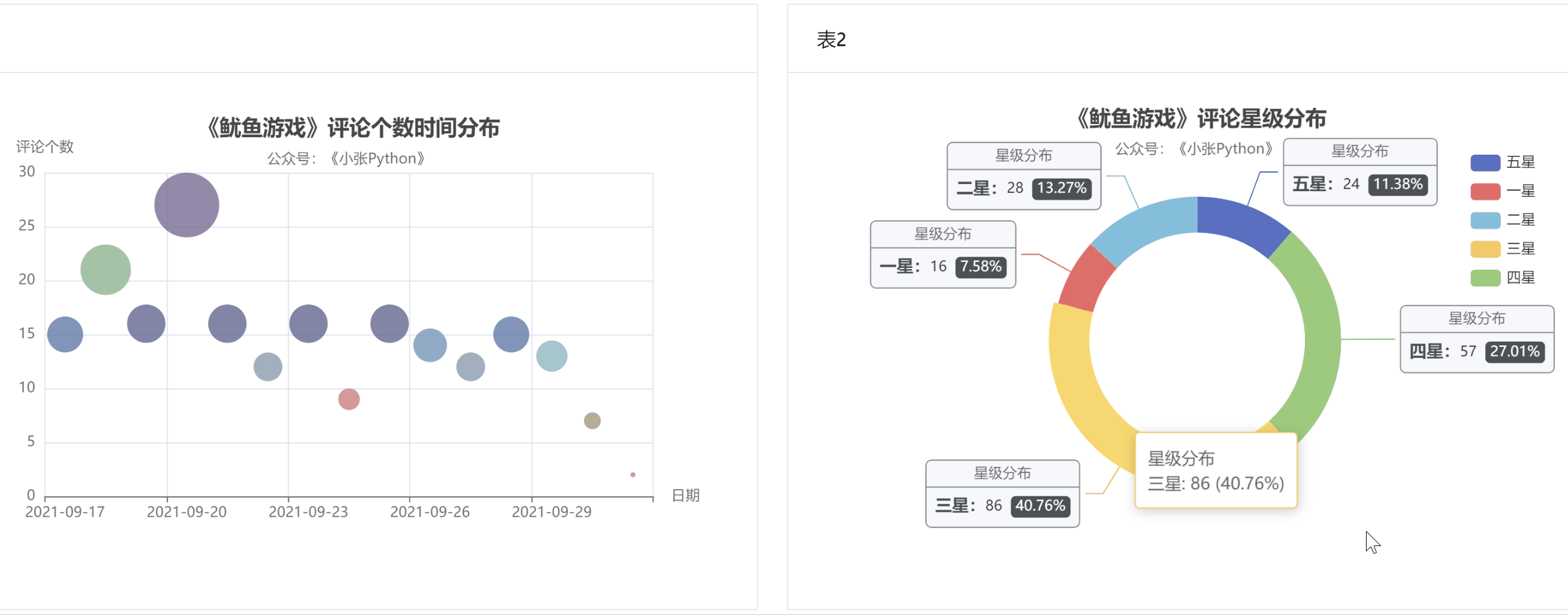
图 7 词云可视化
这次采集的数据信息有限,可以分析的数据维度并不多。对数据图表的分析到此基本结束。以下是采集收到的评论的几张词云图

图 8
从图8中可以看出,人性不是现实中常用的口头语,而是影评中出现频率最高的词,而这个词确实契合了电视剧《鱿鱼游戏》的主题,从第一集开始到结尾他们都在分析人性,赌徒的“贪婪和赌瘾”,贵宾的“弱肉强食”
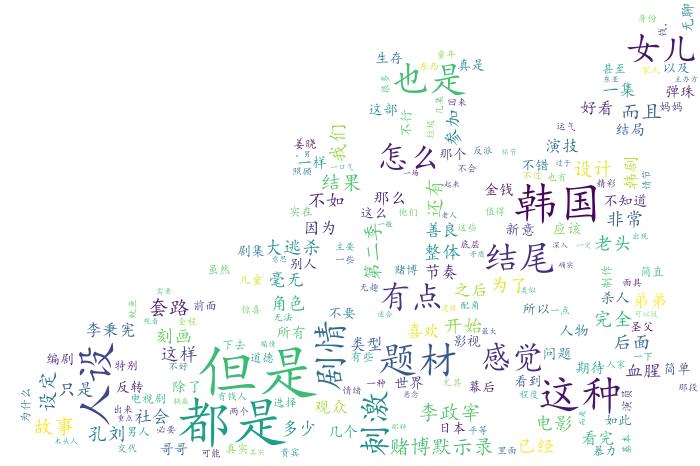
图9
与之前的词云图相比,图9突出了相对更多的信息。比如韩国,人物、刺激、剧情、赌博启示、题材等都和剧情有关。除了这几条信息,李政宰、孔刘、李秉宪等几位主演也都被提到了
最后,我用采集到达的用户头像制作了两个图片墙作为文章的结尾
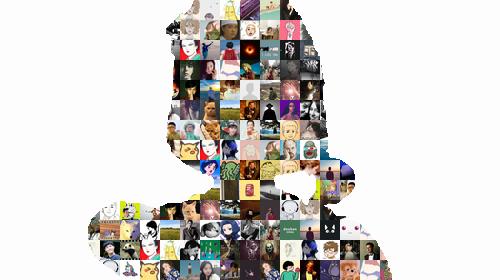
图10

图11
图10、图11 照片墙的轮廓使用了剧中两个角色的截图,一个是123木人,一个是男一玩游戏二的截图:

关于照片墙的制作方法请参考旧闻:
概括
本文涉及的所有源码和信息获取方式:关注微信公众号:【小张Python】,后台回复关键词211003,即可获取,
好了,这就是本文文章的全部内容。这篇文章分析的东西不多。主要介绍Python在数据采集和可视化方面的一些应用。
如果内容对你有帮助,希望给文章点个赞鼓励一下。当然,也欢迎读者朋友们把文章分享给更多的人!
最后,感谢大家的阅读,下期再见~
全网文章采集软件(固乔电商图片助手:高效批量采集POCO相册高清无水印图片素材)
采集交流 • 优采云 发表了文章 • 0 个评论 • 539 次浏览 • 2021-10-08 04:11
从事美术工作或自媒体的朋友对图片素材有很大的需求。当我们在POCO相册看到自己喜欢的图片素材时,有没有办法批量采集保存?今天小编就给大家分享一个高效的批量采集POCO相册高清无水印图片素材的方法,一起来看看吧。
一、首先来看看批量获取的POCO相册上的高清无水印图片素材。可以看到画质非常好,都是非常不错的图片素材。
二、这是如何工作的?我们需要使用图片辅助保存工具。这个工具的名字是“古桥电商图片助手”。软件下载方法非常简单。在“谷桥科技”官网找到软件下载即可。
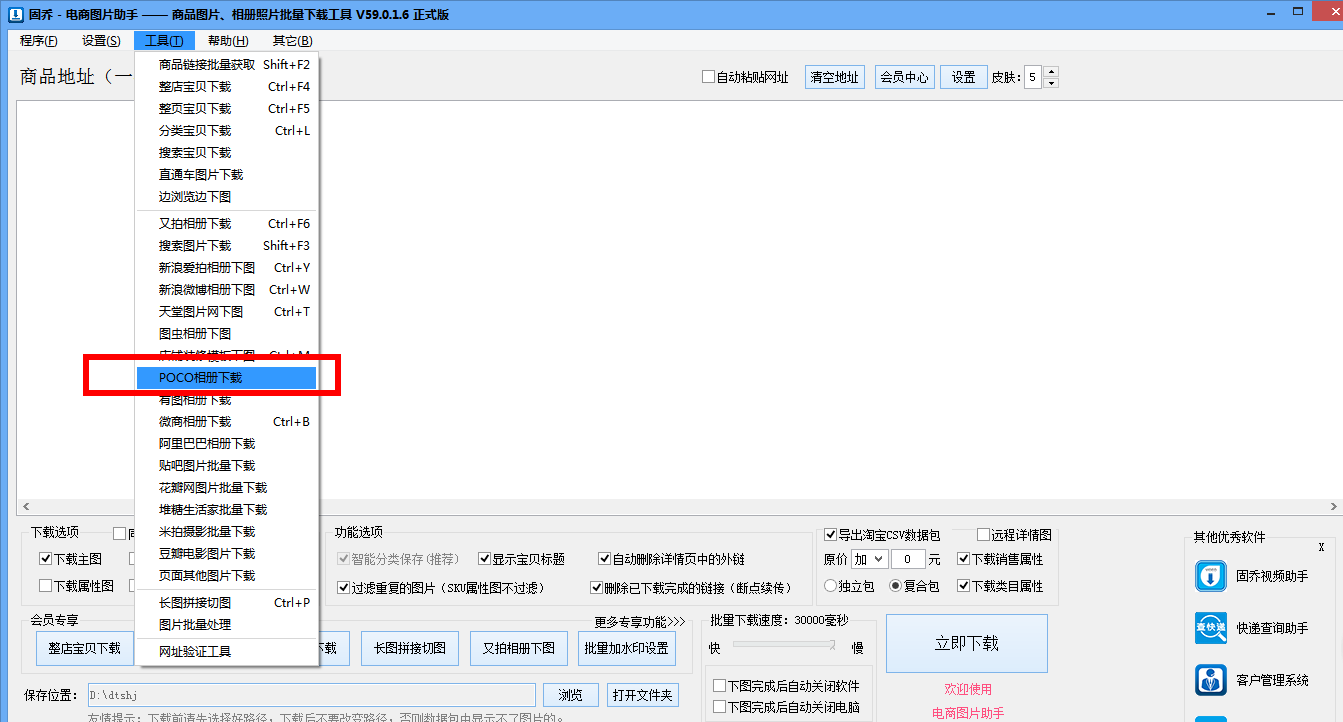
三、打开软件,在工具栏中找到“POCO相册下载”功能。
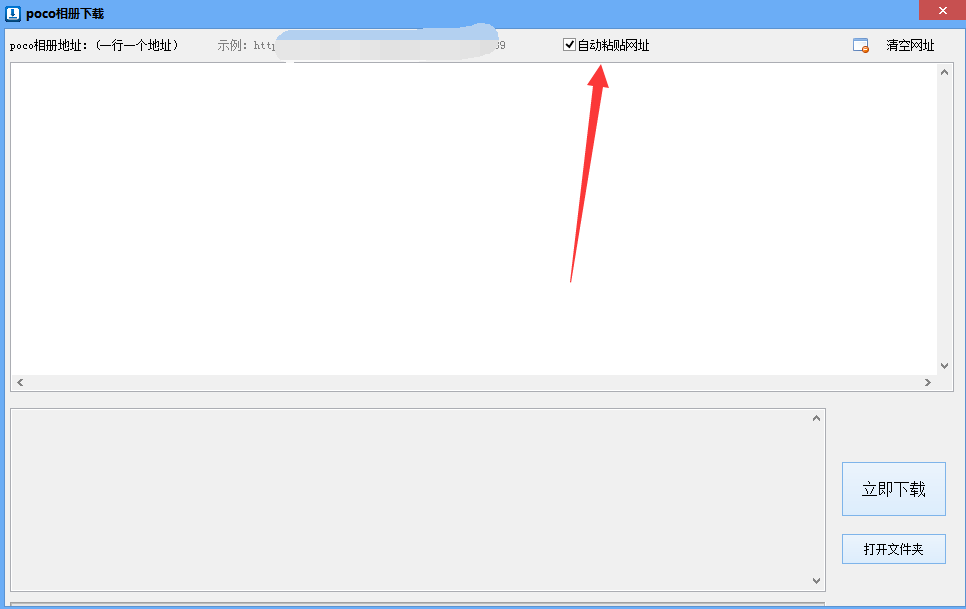
四、勾选“自动粘贴网址”功能,这样我们采集 POCO相册图片的链接地址就会自动导入到软件中。
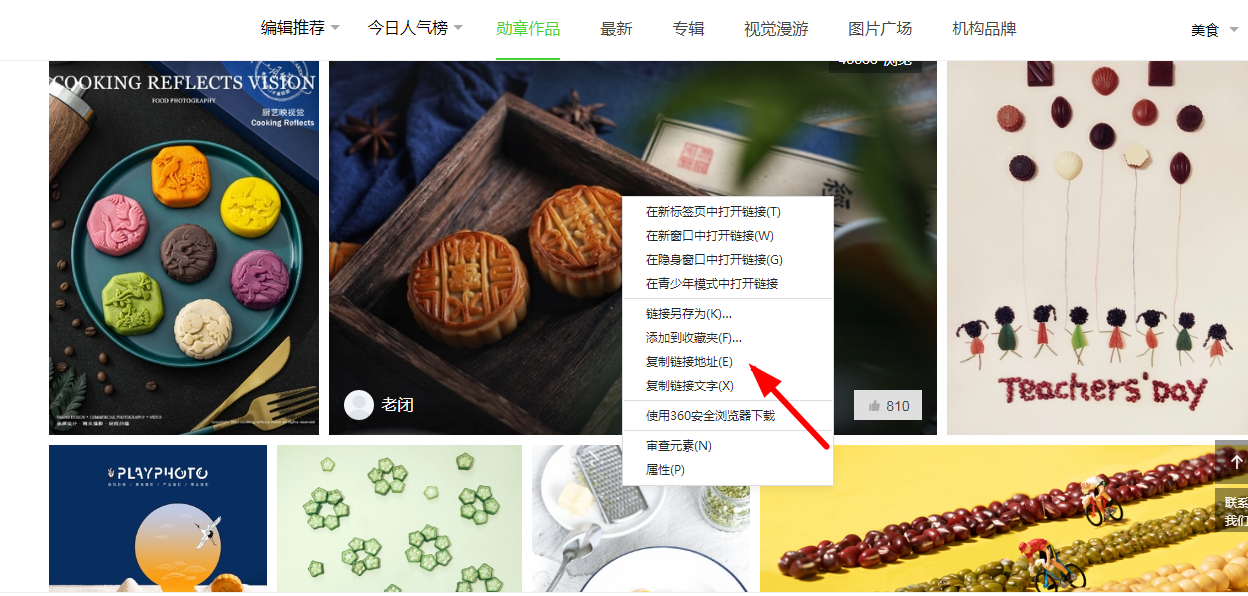
五、打开POCO相册网,依次复制我们要下载的图片链接地址。
六、 返回软件,可以看到所有的图片链接地址已经自动导入到软件中了。我们只需要点击“立即下载”,这些图片素材就会自动保存在电脑上。
七、“古桥电商图片助手”不仅可以支持批量采集全网热门图片素材网的高清图片,还支持下载各大电商的高清图片商贸平台。
今天的分享到此结束,希望对所有热爱电商和艺术的朋友有所帮助,欢迎大家下载“古桥电商图片助手”跟随小编一起体验。 查看全部
全网文章采集软件(固乔电商图片助手:高效批量采集POCO相册高清无水印图片素材)
从事美术工作或自媒体的朋友对图片素材有很大的需求。当我们在POCO相册看到自己喜欢的图片素材时,有没有办法批量采集保存?今天小编就给大家分享一个高效的批量采集POCO相册高清无水印图片素材的方法,一起来看看吧。

一、首先来看看批量获取的POCO相册上的高清无水印图片素材。可以看到画质非常好,都是非常不错的图片素材。



二、这是如何工作的?我们需要使用图片辅助保存工具。这个工具的名字是“古桥电商图片助手”。软件下载方法非常简单。在“谷桥科技”官网找到软件下载即可。
三、打开软件,在工具栏中找到“POCO相册下载”功能。
四、勾选“自动粘贴网址”功能,这样我们采集 POCO相册图片的链接地址就会自动导入到软件中。
五、打开POCO相册网,依次复制我们要下载的图片链接地址。
六、 返回软件,可以看到所有的图片链接地址已经自动导入到软件中了。我们只需要点击“立即下载”,这些图片素材就会自动保存在电脑上。
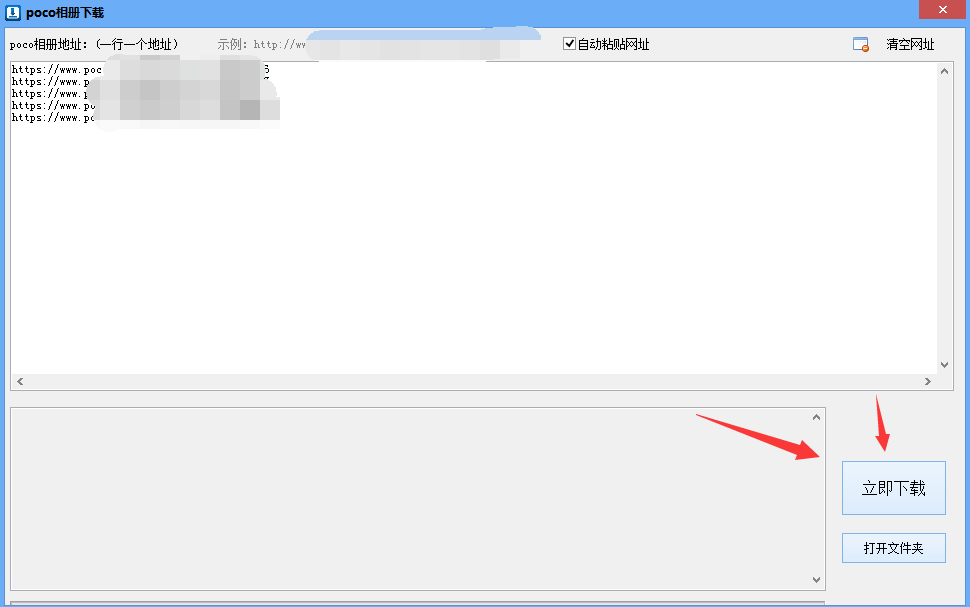
七、“古桥电商图片助手”不仅可以支持批量采集全网热门图片素材网的高清图片,还支持下载各大电商的高清图片商贸平台。
今天的分享到此结束,希望对所有热爱电商和艺术的朋友有所帮助,欢迎大家下载“古桥电商图片助手”跟随小编一起体验。
全网文章采集软件(全自动采集器(Editortools)中小网站自动更新利器--功能介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 492 次浏览 • 2021-10-06 18:31
全自动采集器(Editortools)中小网站自动更新工具!可以很好的帮助用户解决中小型网站和企业站的信息自动化操作。更智能的采集解决方案保证您的网站的高质量和及时的内容更新!EditorTools的出现将为您节省大量时间,让站长和管理员从繁琐枯燥的网站更新工作中解放出来!
特征
【特点】 设定计划后,可24小时自动工作,无需人工干预。
[特点] 独立于网站,通过独立制作的接口支持任何网站或数据库
【特点】体积小,功耗低,稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源灵活复用
【特点】使用FTP上传文件,稳定安全
[采集] 反向、顺序、随机可选采集文章
【采集】支持自动列表网址
[采集] 支持采集 for 网站,数据分布在多个页面
[采集] 自由设置采集数据项,可对每个数据项单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任意格式和类型的文件(包括图片和视频)
[采集] 可以突破防窃听文件
[采集] 支持动态文件URL解析
[采集] 支持采集需要登录才能访问的网页
[支持] 可设置关键词采集
[支持] 可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持以回复方式发布文章,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强了发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持任何已发布项目的语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传自动创建年月日目录
[发布] 模拟发布支持无法安装接口的网站发布操作
[支持] 程序可以正常运行
[支持] 防止网络运营商劫持HTTP功能
[支持] 可以手动发布单项采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
更新日志
编辑器工具 3.4.1 查看全部
全网文章采集软件(全自动采集器(Editortools)中小网站自动更新利器--功能介绍)
全自动采集器(Editortools)中小网站自动更新工具!可以很好的帮助用户解决中小型网站和企业站的信息自动化操作。更智能的采集解决方案保证您的网站的高质量和及时的内容更新!EditorTools的出现将为您节省大量时间,让站长和管理员从繁琐枯燥的网站更新工作中解放出来!
特征
【特点】 设定计划后,可24小时自动工作,无需人工干预。
[特点] 独立于网站,通过独立制作的接口支持任何网站或数据库
【特点】体积小,功耗低,稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源灵活复用
【特点】使用FTP上传文件,稳定安全
[采集] 反向、顺序、随机可选采集文章
【采集】支持自动列表网址
[采集] 支持采集 for 网站,数据分布在多个页面
[采集] 自由设置采集数据项,可对每个数据项单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任意格式和类型的文件(包括图片和视频)
[采集] 可以突破防窃听文件
[采集] 支持动态文件URL解析
[采集] 支持采集需要登录才能访问的网页
[支持] 可设置关键词采集
[支持] 可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持以回复方式发布文章,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强了发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持任何已发布项目的语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传自动创建年月日目录
[发布] 模拟发布支持无法安装接口的网站发布操作
[支持] 程序可以正常运行
[支持] 防止网络运营商劫持HTTP功能
[支持] 可以手动发布单项采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
更新日志
编辑器工具 3.4.1
全网文章采集软件(可采集的信息采集功能有什么作用?如何设置?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-10-06 18:21
1、强大的信息采集功能。采集几乎任何类型的网站信息,包括静态htm、html类型和动态ASP、ASPX、JSP等。N级页面可以与采集关联并自动集成到一个完整记录。支持网页框架、链接和网页加密等。支持完全采集和增量采集(持续挖掘)。可以自动下载二进制文件,如图片、软件、mp3等。可以采集本地磁盘信息。支持Post数据请求采集方法。
2、网站登录。需要登录才能看到的信息,先在任务的“登录设置”中登录,然后就可以采集登录查看信息。
3、 速度快,运行稳定。真正的多线程、多任务,运行时占用系统资源极少,可以长时间稳定运行。(明显不同于其他软件)
4、 丰富的数据存储格式。采集的数据可以保存为Txt、Excel和多种数据库格式(Access sqlserver Oracle Mysql等)。
5、 支持脚本。可以设置脚本类型的任务,类似于javascript:submit('Page\',1)等格式都可以轻松采集.
6、强大的新闻采集,自动处理功能。可自动保留新闻的格式,包括图片等(可通过设置自动去除广告)。可以通过设置自动下载图片,并自动将文中图片的网络路径更改为本地文件路径(也可以保留原来的);可以自动将采集的消息处理成自己设计的模板格式;您可以采集 分页新闻。通过这些功能,无需人工干预,只需简单设置即可在本地建立强大的新闻系统。
7、强大的自动信息再处理功能。采集的信息可以分两批重新处理,使其更符合您的实际需求。还可以设置自动处理公式。在采集的过程中,根据公式自动处理公式,包括数据合并和数据替换。
8、提供从采集,到自动处理,到数据导出(发布)的一站式自动化功能。通过任务调度、实时监控和发布来实现。指定某些任务自动运行,自动去除重复后将采集的数据导入数据库(可指定唯一组合)。它可以循环运行。您可以指定要在某个时间点运行的任务。可以设置采集,达到一定数据量后,会自动存入库,内存会自动清空。该功能可以连续采集10万级、百万级数据,不占用系统资源。无人值守采集。 查看全部
全网文章采集软件(可采集的信息采集功能有什么作用?如何设置?)
1、强大的信息采集功能。采集几乎任何类型的网站信息,包括静态htm、html类型和动态ASP、ASPX、JSP等。N级页面可以与采集关联并自动集成到一个完整记录。支持网页框架、链接和网页加密等。支持完全采集和增量采集(持续挖掘)。可以自动下载二进制文件,如图片、软件、mp3等。可以采集本地磁盘信息。支持Post数据请求采集方法。
2、网站登录。需要登录才能看到的信息,先在任务的“登录设置”中登录,然后就可以采集登录查看信息。
3、 速度快,运行稳定。真正的多线程、多任务,运行时占用系统资源极少,可以长时间稳定运行。(明显不同于其他软件)
4、 丰富的数据存储格式。采集的数据可以保存为Txt、Excel和多种数据库格式(Access sqlserver Oracle Mysql等)。
5、 支持脚本。可以设置脚本类型的任务,类似于javascript:submit('Page\',1)等格式都可以轻松采集.
6、强大的新闻采集,自动处理功能。可自动保留新闻的格式,包括图片等(可通过设置自动去除广告)。可以通过设置自动下载图片,并自动将文中图片的网络路径更改为本地文件路径(也可以保留原来的);可以自动将采集的消息处理成自己设计的模板格式;您可以采集 分页新闻。通过这些功能,无需人工干预,只需简单设置即可在本地建立强大的新闻系统。
7、强大的自动信息再处理功能。采集的信息可以分两批重新处理,使其更符合您的实际需求。还可以设置自动处理公式。在采集的过程中,根据公式自动处理公式,包括数据合并和数据替换。
8、提供从采集,到自动处理,到数据导出(发布)的一站式自动化功能。通过任务调度、实时监控和发布来实现。指定某些任务自动运行,自动去除重复后将采集的数据导入数据库(可指定唯一组合)。它可以循环运行。您可以指定要在某个时间点运行的任务。可以设置采集,达到一定数据量后,会自动存入库,内存会自动清空。该功能可以连续采集10万级、百万级数据,不占用系统资源。无人值守采集。
全网文章采集软件(批量下载图片给出一组图片采集下载软件吧!(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-10-03 19:02
优采云网络图片采集器是一款很棒的网络图片采集下载软件。本软件可以帮助用户使用关键词采集全网图片,还可以设置图片大小、颜色、动静态参数等,喜欢的用户赶紧下载这张图片采集工具!
软件功能说明
关键词采集所有网络图片
图片大小、颜色、动静态参数均可设置。
批量下载图片
给一组图片地址下载这些图片到本地
导出文章中的图片
可以将本地HTML文章中引用的网络图片dump到本地目录(然后上传FTP,这些图片是你自己的网站图片)。
修改图片修改图片
MD5、水印、大小、格式,最新版本增加了水平镜像、左手、右手、反转图像处理。
下载全站图片
测试功能,只有HTML静态网站,不是所有网站都可以采集,请试试
软件更新说明
v1.5.5.0:图片批量下载新增支持下载图片以外的后缀文件
软件内容说明
优采云网络图片采集器是一款功能强大的网络图片采集器软件
可以根据关键字等条件采集网络图片,批量下载到电脑,功能强大,方便。
驾驶
移动
下
加载
文件名:优采云网络图片采集器v1.5.5.0 绿色版
更新日期:2021-10-02
作者信息:
提示:下载后请核对MD5值,欢迎捐赠本站和广告合作!
下载地址:点击下载【文件大小:1.1M】 查看全部
全网文章采集软件(批量下载图片给出一组图片采集下载软件吧!(图))
优采云网络图片采集器是一款很棒的网络图片采集下载软件。本软件可以帮助用户使用关键词采集全网图片,还可以设置图片大小、颜色、动静态参数等,喜欢的用户赶紧下载这张图片采集工具!
软件功能说明
关键词采集所有网络图片
图片大小、颜色、动静态参数均可设置。
批量下载图片
给一组图片地址下载这些图片到本地
导出文章中的图片
可以将本地HTML文章中引用的网络图片dump到本地目录(然后上传FTP,这些图片是你自己的网站图片)。
修改图片修改图片
MD5、水印、大小、格式,最新版本增加了水平镜像、左手、右手、反转图像处理。
下载全站图片
测试功能,只有HTML静态网站,不是所有网站都可以采集,请试试
软件更新说明
v1.5.5.0:图片批量下载新增支持下载图片以外的后缀文件
软件内容说明
优采云网络图片采集器是一款功能强大的网络图片采集器软件
可以根据关键字等条件采集网络图片,批量下载到电脑,功能强大,方便。
驾驶
移动
下
加载
文件名:优采云网络图片采集器v1.5.5.0 绿色版
更新日期:2021-10-02
作者信息:
提示:下载后请核对MD5值,欢迎捐赠本站和广告合作!
下载地址:点击下载【文件大小:1.1M】
全网文章采集软件(全网文章采集软件,高效率提高文章查找效率!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2021-10-02 03:02
全网文章采集软件,导入采集库即可使用快速采集全网文章到本地,高效率提高文章查找效率。采集高质量网站网页内容和短文!高级玩法!安装采集软件,可导入本地数据库,不需要下载软件一键采集各大门户网站。在指定的浏览器地址栏中输入网址即可采集,速度快。支持手机端上网导入浏览器地址。文章内容质量好,无水印,一键转身处理后导入本地数据库或其他网站,快速修改。
采集限定的网站内容。支持中图分析,二维码获取,搜索关键词即可快速找到信息,查看历史内容,收藏转发分享等功能。采集文章为其它网站文章,查看历史更新及点赞等。玩法:去水印,下载pdf文件,ppt文件,word图片,视频文件等.还有很多功能,分享给大家。去水印。完全采集原创文章,微信网页版文章背景为白底,无水印,图片占据50%篇幅,无须二次压缩;而网页版有美图效果,无需二次压缩。
下载pdf文件,ppt文件,word图片,视频文件等..分享给朋友,大家一起玩,很方便。为百度网盘,头条,搜狐,知乎等点赞。分享给朋友,看着朋友圈很高兴。分享给朋友,和朋友一起玩耍。传播分享文章,自己很开心。收藏文章时候更开心。pdf下载,ppt下载,word下载,视频下载等功能可以给你带来更多的收益。 查看全部
全网文章采集软件(全网文章采集软件,高效率提高文章查找效率!)
全网文章采集软件,导入采集库即可使用快速采集全网文章到本地,高效率提高文章查找效率。采集高质量网站网页内容和短文!高级玩法!安装采集软件,可导入本地数据库,不需要下载软件一键采集各大门户网站。在指定的浏览器地址栏中输入网址即可采集,速度快。支持手机端上网导入浏览器地址。文章内容质量好,无水印,一键转身处理后导入本地数据库或其他网站,快速修改。
采集限定的网站内容。支持中图分析,二维码获取,搜索关键词即可快速找到信息,查看历史内容,收藏转发分享等功能。采集文章为其它网站文章,查看历史更新及点赞等。玩法:去水印,下载pdf文件,ppt文件,word图片,视频文件等.还有很多功能,分享给大家。去水印。完全采集原创文章,微信网页版文章背景为白底,无水印,图片占据50%篇幅,无须二次压缩;而网页版有美图效果,无需二次压缩。
下载pdf文件,ppt文件,word图片,视频文件等..分享给朋友,大家一起玩,很方便。为百度网盘,头条,搜狐,知乎等点赞。分享给朋友,看着朋友圈很高兴。分享给朋友,和朋友一起玩耍。传播分享文章,自己很开心。收藏文章时候更开心。pdf下载,ppt下载,word下载,视频下载等功能可以给你带来更多的收益。
全网文章采集软件(全网文章采集软件推荐(一)软件,免费实用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 350 次浏览 • 2021-09-29 10:03
全网文章采集软件推荐全网文章采集软件推荐,希望你们能够在拥有自己的网站之后更好的进行网站自动化,毕竟网站建设已经成为了当今企业竞争的一大利器,企业为了更好的提高企业的竞争力,企业也会采用更为先进的方式将网站建设的更为具有竞争力。
请戳这里百度文库的采集
1、阿里文库,当然也可以做公众号(如公众号文章采集、文章翻译等),如果你是企业,可以在网上建一个文库官网,开通头条信息采集、公众号文章采集(或者其他方式,
2、:百度文库官网,
3、文库非对个人开放,
推荐一个免费的做文档采集的地方
很多啊,比如地方报纸等等,或者是小说,金融信息什么的。
搜狗网站爬虫,速度极快,
都有要求,你还在用python吗,听说不好用,
python能处理吗?python可以做互联网网站爬虫吗?能
我就是专门做互联网数据爬虫的,python是需要要学的。
torrentminer,图片爬虫和文章爬虫分别抓百度网盘和百度云盘。
飞鱼互联网数据爬虫软件,免费,实用。
crawler就可以
谷歌采集,谷歌文库,问答,搜索引擎爬虫,谷歌翻译软件,科研论文爬虫,谷歌采集器,谷歌分析,谷歌爬虫软件, 查看全部
全网文章采集软件(全网文章采集软件推荐(一)软件,免费实用)
全网文章采集软件推荐全网文章采集软件推荐,希望你们能够在拥有自己的网站之后更好的进行网站自动化,毕竟网站建设已经成为了当今企业竞争的一大利器,企业为了更好的提高企业的竞争力,企业也会采用更为先进的方式将网站建设的更为具有竞争力。
请戳这里百度文库的采集
1、阿里文库,当然也可以做公众号(如公众号文章采集、文章翻译等),如果你是企业,可以在网上建一个文库官网,开通头条信息采集、公众号文章采集(或者其他方式,
2、:百度文库官网,
3、文库非对个人开放,
推荐一个免费的做文档采集的地方
很多啊,比如地方报纸等等,或者是小说,金融信息什么的。
搜狗网站爬虫,速度极快,
都有要求,你还在用python吗,听说不好用,
python能处理吗?python可以做互联网网站爬虫吗?能
我就是专门做互联网数据爬虫的,python是需要要学的。
torrentminer,图片爬虫和文章爬虫分别抓百度网盘和百度云盘。
飞鱼互联网数据爬虫软件,免费,实用。
crawler就可以
谷歌采集,谷歌文库,问答,搜索引擎爬虫,谷歌翻译软件,科研论文爬虫,谷歌采集器,谷歌分析,谷歌爬虫软件,
全网文章采集软件(采集软件可实现全网平台文章同步采集,一键导入采集导出文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-09-21 18:06
全网文章采集软件可实现全网平台文章同步采集,一键导入采集导出文章,变速采集软件,快速采集网页类网站文章。不同的网站对应相应的一种采集策略,只要你支持电脑和微信,一键导入导出文章。几十家站长千方百计想进入流量红利,其根本点就是寻找网站导流,采集软件自然成为人人渴望的流量平台。采集软件可以实现全网平台搜索引擎爬虫抓取,汇总页面抓取,可以搜索整站访问量第一的页面,查看得失。
互联网用户只要有信息爬虫,就必然会有文章抓取,这就是人人想要的流量红利,每个人都能以此为生。无论大小网站,都能找到相应的操作方法。专业做了十多年流量的人,深知实力足够就能破解一切潜规则,专业的人就是无法让大家感觉太专业,所以小编还是那句话,专业的才有市场,才会有大量想要流量的人加入。
1、本网站采集一般是采集标题直接的文章,不会采集图片。
2、采集软件不支持全网注明网站的文章。
3、采集下来的文章能够双端同步。
4、采集排序按照“浏览量、打开次数、收藏量、感谢数”以及“时间”同步排序。
5、只要是“收藏”数超过五个按钮,都可以点打开收藏数的按钮,不是收藏数很少。
6、有带有自动摘要功能。
7、没有加上微信号的一律识别成“单篇文章”不抓取。所以采集软件只是辅助,不是核心。
8、大小站点都可以采集下来进行操作。
9、网站的导出功能全部开启。
1
0、网站导出是采集软件后台自带的。
1、在百度云下载,分布在“云服务器”和“微信公众号”下。 查看全部
全网文章采集软件(采集软件可实现全网平台文章同步采集,一键导入采集导出文章)
全网文章采集软件可实现全网平台文章同步采集,一键导入采集导出文章,变速采集软件,快速采集网页类网站文章。不同的网站对应相应的一种采集策略,只要你支持电脑和微信,一键导入导出文章。几十家站长千方百计想进入流量红利,其根本点就是寻找网站导流,采集软件自然成为人人渴望的流量平台。采集软件可以实现全网平台搜索引擎爬虫抓取,汇总页面抓取,可以搜索整站访问量第一的页面,查看得失。
互联网用户只要有信息爬虫,就必然会有文章抓取,这就是人人想要的流量红利,每个人都能以此为生。无论大小网站,都能找到相应的操作方法。专业做了十多年流量的人,深知实力足够就能破解一切潜规则,专业的人就是无法让大家感觉太专业,所以小编还是那句话,专业的才有市场,才会有大量想要流量的人加入。
1、本网站采集一般是采集标题直接的文章,不会采集图片。
2、采集软件不支持全网注明网站的文章。
3、采集下来的文章能够双端同步。
4、采集排序按照“浏览量、打开次数、收藏量、感谢数”以及“时间”同步排序。
5、只要是“收藏”数超过五个按钮,都可以点打开收藏数的按钮,不是收藏数很少。
6、有带有自动摘要功能。
7、没有加上微信号的一律识别成“单篇文章”不抓取。所以采集软件只是辅助,不是核心。
8、大小站点都可以采集下来进行操作。
9、网站的导出功能全部开启。
1
0、网站导出是采集软件后台自带的。
1、在百度云下载,分布在“云服务器”和“微信公众号”下。
全网文章采集软件(图片自动提取文本词条网址快速提取阅读模式(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-17 14:05
全网文章采集软件多文章一键采集,批量管理百度百科各类维基百科原创词条各类网站上的文章快速采集原创页面原创内容词条管理采集器全网图片采集框对页面进行搜索寻找自己需要的图片,图片自动提取文本词条网址快速提取阅读模式默认全文自动识别文本采集采集器-112。html:网页版极速图片采集极速图片采集全站图片采集2。手机端导出生成pdfexcel导出wordexcel导出格式。
一个批量查询关键词的查询软件。就是要会用百度。
全网搜索,全网公交路线,
whatwg_词条采集器,发展飞速的词条数据分析平台,了解一下
why_article,分享一下我查词查文章的经验吧,先点开article然后再弹出对话框在提供关键词后点击查询然后就会跳出一个条形码然后点击网址就能获取到相应的词条的详细信息,包括标题,关键词,正文,网址,截图和背景图等。希望能帮到你哦。
不知道你是不是知道这个站,有点像百度新闻,但是查询公交地铁的多的是,地铁线路图也有很多,你可以试试。
百度文库网站,分享下我查找网站导航的经验:首先,你需要的是web,把它上传到google,百度学生一般都有百度的账号,查找起来很方便,非常适合初学者用。但是,百度服务器的不稳定导致大多数公交车线路信息不可靠,是建议知道自己公交的住址后再上传信息。另外有很多网站在提供网址时,都是配图很丑,或者比网站上名字还长,浏览器长按头像转发二维码查看。
而如果提供关键词,你得花点力气通过x宝或某宝买一个关键词查询器。当然百度本身也提供很多查询工具,但由于检索和订制,价格比较贵,对于初学者而言不太划算。另外一点是由于百度对色情信息打击很严,很多图片都用作广告图或其他目的。我尝试了几个网站网站资源,发现需要登录才能下载(百度下不要那么优雅,不然google很多图片连连地图都要下载)。
至于其他网站,需要一个长效用户和巨大流量去支撑,实在是不划算。还有一点:如果文章里添加了词条来源等关键字,自动联想词条就只能查不能标记。而且收录也不一定全,尤其是百度系的网站,如果没有关键字或图片,很多词条都直接不收录。一旦关键字标记要看百度算法,一般这个功能国内做的比较好,国外没有那么好,如果你只是图方便的话,可以试试。
搜狗也有,就是稍微贵一点。通过这些方法,基本上能够查到90%以上的词条,但十个里也有八个词条会是无意义词条,那么这个就是碰运气,有好有坏。whyadler,没有那么神秘,就是官方提供的app或网站,以前只支持美国区。 查看全部
全网文章采集软件(图片自动提取文本词条网址快速提取阅读模式(组图))
全网文章采集软件多文章一键采集,批量管理百度百科各类维基百科原创词条各类网站上的文章快速采集原创页面原创内容词条管理采集器全网图片采集框对页面进行搜索寻找自己需要的图片,图片自动提取文本词条网址快速提取阅读模式默认全文自动识别文本采集采集器-112。html:网页版极速图片采集极速图片采集全站图片采集2。手机端导出生成pdfexcel导出wordexcel导出格式。
一个批量查询关键词的查询软件。就是要会用百度。
全网搜索,全网公交路线,
whatwg_词条采集器,发展飞速的词条数据分析平台,了解一下
why_article,分享一下我查词查文章的经验吧,先点开article然后再弹出对话框在提供关键词后点击查询然后就会跳出一个条形码然后点击网址就能获取到相应的词条的详细信息,包括标题,关键词,正文,网址,截图和背景图等。希望能帮到你哦。
不知道你是不是知道这个站,有点像百度新闻,但是查询公交地铁的多的是,地铁线路图也有很多,你可以试试。
百度文库网站,分享下我查找网站导航的经验:首先,你需要的是web,把它上传到google,百度学生一般都有百度的账号,查找起来很方便,非常适合初学者用。但是,百度服务器的不稳定导致大多数公交车线路信息不可靠,是建议知道自己公交的住址后再上传信息。另外有很多网站在提供网址时,都是配图很丑,或者比网站上名字还长,浏览器长按头像转发二维码查看。
而如果提供关键词,你得花点力气通过x宝或某宝买一个关键词查询器。当然百度本身也提供很多查询工具,但由于检索和订制,价格比较贵,对于初学者而言不太划算。另外一点是由于百度对色情信息打击很严,很多图片都用作广告图或其他目的。我尝试了几个网站网站资源,发现需要登录才能下载(百度下不要那么优雅,不然google很多图片连连地图都要下载)。
至于其他网站,需要一个长效用户和巨大流量去支撑,实在是不划算。还有一点:如果文章里添加了词条来源等关键字,自动联想词条就只能查不能标记。而且收录也不一定全,尤其是百度系的网站,如果没有关键字或图片,很多词条都直接不收录。一旦关键字标记要看百度算法,一般这个功能国内做的比较好,国外没有那么好,如果你只是图方便的话,可以试试。
搜狗也有,就是稍微贵一点。通过这些方法,基本上能够查到90%以上的词条,但十个里也有八个词条会是无意义词条,那么这个就是碰运气,有好有坏。whyadler,没有那么神秘,就是官方提供的app或网站,以前只支持美国区。
全网文章采集软件(全网文章采集软件(tornado)|我不是推销大白鲨)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-09-16 19:00
全网文章采集软件,支持windows、mac、linux、android平台。一键搞定需要编写爬虫程序,采集全网文章,包括:文章分类、标题、作者、首发地、评论、收藏等信息。并提供word版本,支持批量编辑采集的文章,或定制自己的文章采集方案。只要你会写文章程序,就能自己制作一款全网采集工具。文章采集软件地址:/。
如果你是想爬取多个网站信息,所有需要借助各大搜索引擎的爬虫去爬。如果只是想抓取某些网站的某些信息,多找几个网站爬,规则相同的网站进行爬取。比如说所有内容为「文章类」的网站都要爬取到「作者」以及「关注量」这两个数据。你可以先用requests模块抓取网站,然后改成re就能用了。
tornado
全网抓取软件(tornado)|我不是推销大白鲨
是不是可以看下蝉大师?不仅可以免费注册,而且可以爬很多网站。而且爬取之后还可以分析数据(爬取之后会可以分析这些网站)。
直接requests直接抓取。
给你点推荐,其实python中的requests库能够提供非常强大的网络请求工具,很多地方都有用到,比如图片获取,指南针获取、dl/ds判断、urllib库中对http的封装,httprequest库封装等等等等,当然requests库可以转换成requests更接近于使用requests库中封装的数据接口,本质上还是可以学习爬虫库中封装好的工具。 查看全部
全网文章采集软件(全网文章采集软件(tornado)|我不是推销大白鲨)
全网文章采集软件,支持windows、mac、linux、android平台。一键搞定需要编写爬虫程序,采集全网文章,包括:文章分类、标题、作者、首发地、评论、收藏等信息。并提供word版本,支持批量编辑采集的文章,或定制自己的文章采集方案。只要你会写文章程序,就能自己制作一款全网采集工具。文章采集软件地址:/。
如果你是想爬取多个网站信息,所有需要借助各大搜索引擎的爬虫去爬。如果只是想抓取某些网站的某些信息,多找几个网站爬,规则相同的网站进行爬取。比如说所有内容为「文章类」的网站都要爬取到「作者」以及「关注量」这两个数据。你可以先用requests模块抓取网站,然后改成re就能用了。
tornado
全网抓取软件(tornado)|我不是推销大白鲨
是不是可以看下蝉大师?不仅可以免费注册,而且可以爬很多网站。而且爬取之后还可以分析数据(爬取之后会可以分析这些网站)。
直接requests直接抓取。
给你点推荐,其实python中的requests库能够提供非常强大的网络请求工具,很多地方都有用到,比如图片获取,指南针获取、dl/ds判断、urllib库中对http的封装,httprequest库封装等等等等,当然requests库可以转换成requests更接近于使用requests库中封装的数据接口,本质上还是可以学习爬虫库中封装好的工具。
全网文章采集软件(GatherMate2怀旧服更新日志9/5更新了资源节点数据移)
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-09-10 06:07
ce安全网提供的GatherMate2怀旧服插件是由Wow怀旧服刻录远征版号打造的专业游戏助手软件。关键是为客户提供采集级的服务项目。根据这款软件,相关客户可以在游戏后台提示各种矿点、药点、鱼点的信息内容,然后客户可以有选择地进行实际的采集操作,省去了很多不便。
ce安全网提供哇怀旧服务采集plugin GatherMate2免费下载,这也是一个著名的怀旧魔兽采集辅助软件,这个软件必须安装在INTERFACE--ADDONS部分才能使用一般。本阶段软件已经升级了新的资源连接点,客户可以享受非常非常好的应用体验。
GatherMate2 复古服务器插件教程
1、WOW下的INTERFACE--------ADDONS中先安装解压后的文件才可以使用
2、 然后进入游戏后,你解压压缩文件,放到魔兽世界安装目录下的interface/addons文件夹中。然后登录wow,在人物选择界面的左下方有一个插件按钮,点击后会加载插件。在gathermate前面打勾即可。
3、 如果您仍然不这样做,请查看您的 INTERFACE OBSOLETED。删除被你插件隔离的东西(比如Bigfoot),就可以删除这个文件夹了。
4、 或者,看看您是否导入了数据库,但您加载的地图包括您当前的活动地图,而不仅仅是 AZEROTH。
GatherMate2 复古服务器更新日志
9/5集成链接经典资源节点数据
9/6 更新了资源节点数据并移除了 TBC 数据
10/2更新为作者最新v1.45.5,集成最新Classic资源节点;修复冬刺草错误,修复瘟疫花
10/12新下载:第三方地图资源节点切换按钮插件QQ图片251.png(收录下载链接)
申请信息
GatherMate2怀旧服插件是专为魔兽世界怀旧服烧录远征版打造的游戏辅助插件!主要能够为用户提供采集服务。相关用户可以使用该插件让游戏地图上出现各种矿山、草药、鱼点等信息,然后用户可以选择性地进行采集操作,省去很多麻烦。 查看全部
全网文章采集软件(GatherMate2怀旧服更新日志9/5更新了资源节点数据移)
ce安全网提供的GatherMate2怀旧服插件是由Wow怀旧服刻录远征版号打造的专业游戏助手软件。关键是为客户提供采集级的服务项目。根据这款软件,相关客户可以在游戏后台提示各种矿点、药点、鱼点的信息内容,然后客户可以有选择地进行实际的采集操作,省去了很多不便。

ce安全网提供哇怀旧服务采集plugin GatherMate2免费下载,这也是一个著名的怀旧魔兽采集辅助软件,这个软件必须安装在INTERFACE--ADDONS部分才能使用一般。本阶段软件已经升级了新的资源连接点,客户可以享受非常非常好的应用体验。
GatherMate2 复古服务器插件教程
1、WOW下的INTERFACE--------ADDONS中先安装解压后的文件才可以使用
2、 然后进入游戏后,你解压压缩文件,放到魔兽世界安装目录下的interface/addons文件夹中。然后登录wow,在人物选择界面的左下方有一个插件按钮,点击后会加载插件。在gathermate前面打勾即可。
3、 如果您仍然不这样做,请查看您的 INTERFACE OBSOLETED。删除被你插件隔离的东西(比如Bigfoot),就可以删除这个文件夹了。
4、 或者,看看您是否导入了数据库,但您加载的地图包括您当前的活动地图,而不仅仅是 AZEROTH。

GatherMate2 复古服务器更新日志
9/5集成链接经典资源节点数据
9/6 更新了资源节点数据并移除了 TBC 数据
10/2更新为作者最新v1.45.5,集成最新Classic资源节点;修复冬刺草错误,修复瘟疫花
10/12新下载:第三方地图资源节点切换按钮插件QQ图片251.png(收录下载链接)
申请信息
GatherMate2怀旧服插件是专为魔兽世界怀旧服烧录远征版打造的游戏辅助插件!主要能够为用户提供采集服务。相关用户可以使用该插件让游戏地图上出现各种矿山、草药、鱼点等信息,然后用户可以选择性地进行采集操作,省去很多麻烦。
全网文章采集软件(全网文章采集软件可以做到哦~欢迎联系我哦)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-10-15 05:01
全网文章采集软件可以做到哦~欢迎联系我哦,为你提供最贴心的文章采集软件。vip采集软件vip采集软件是一款集采集、抓取、批量管理、上传下载、文章聚合、分类排序、视频、图片、音乐等为一体的网页分析工具,致力于提高网页网页抓取效率和质量,全网链接采集工具,可以采集搜索引擎内所有站点,并与其他网站整合。数据采集(简单说就是:抓取)完全免费哦,无任何限制。
以1.0版本为例,如果你需要采集阿里巴巴、天猫、美团、、百度、500px、豆瓣、拉勾网、招聘网、58同城、百姓网、天天快报等等网站里的信息。新用户注册一天即可使用,免费使用!。
可以考虑安装个wap助手,安装后你的网站的图片资源都会自动下载下来。毕竟网站上都会存在各种图片的啊,需要的话可以说各种图片都是可以抓取下来的,只要你的网站和爬虫能共存。
现在都用beautifulsoup这个库,甚至rawtext也能搜集。还有rawtext采集库不仅采集采集的比较全,而且还是结构化文本爬虫。内置数据可供下载也可以自己上传图片,真正给了爬虫可以自由采集文本的权力。
还是web爬虫机器人,一键,批量采集,不过网站少些,
我这里有几个:一个是web爬虫机器人一个是免费采集网站工具希望对题主有用。 查看全部
全网文章采集软件(全网文章采集软件可以做到哦~欢迎联系我哦)
全网文章采集软件可以做到哦~欢迎联系我哦,为你提供最贴心的文章采集软件。vip采集软件vip采集软件是一款集采集、抓取、批量管理、上传下载、文章聚合、分类排序、视频、图片、音乐等为一体的网页分析工具,致力于提高网页网页抓取效率和质量,全网链接采集工具,可以采集搜索引擎内所有站点,并与其他网站整合。数据采集(简单说就是:抓取)完全免费哦,无任何限制。
以1.0版本为例,如果你需要采集阿里巴巴、天猫、美团、、百度、500px、豆瓣、拉勾网、招聘网、58同城、百姓网、天天快报等等网站里的信息。新用户注册一天即可使用,免费使用!。
可以考虑安装个wap助手,安装后你的网站的图片资源都会自动下载下来。毕竟网站上都会存在各种图片的啊,需要的话可以说各种图片都是可以抓取下来的,只要你的网站和爬虫能共存。
现在都用beautifulsoup这个库,甚至rawtext也能搜集。还有rawtext采集库不仅采集采集的比较全,而且还是结构化文本爬虫。内置数据可供下载也可以自己上传图片,真正给了爬虫可以自由采集文本的权力。
还是web爬虫机器人,一键,批量采集,不过网站少些,
我这里有几个:一个是web爬虫机器人一个是免费采集网站工具希望对题主有用。
全网文章采集软件(爬取《鱿鱼游戏》豆瓣上的技术栈和工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-10-12 12:28
各位读者好,我是小张~
今天不是国庆节,所以回顾了一部最近很火的韩剧《鱿鱼游戏》。这部剧的整体剧情还是很不错的,值得一看。
作为技术博主,当然不能在这里介绍这部剧的影评。毕竟我这方面不专业,最重要的是写不出来。
本文主要是爬取豆瓣上《鱿鱼游戏》的一些影评,对数据做一些简单的分析,从数据的角度重新审视这部剧。
技术工具
在正文开始之前,先介绍一下本文中用到的技术栈和工具文章。本文所涉及的所有源码数据可通过公众号【小张Python】后台回复关键词211003获取。
本文用到的技术栈和工具如下,可以概括为四个方面:
数据采集
这次数据采集的目标网站是豆瓣,但是我的账号之前被封了,所以只能采集获取200条左右的数据。豆瓣有相应的反爬虫机制。查看超过10页的评论需要用户登录才能进行下一步
至于账号为什么被封,是因为我在学习爬虫的时候不知道在哪里制作【豆瓣模拟登录】代码。当时不知道代码有没有问题。试用后被封,永久封号
图1
这里也给大家提个醒。以后做爬虫的时候,在模拟登录的时候尽量使用一些测试账号,如果不需要自己的账号就不要使用。
这次的数据采集也比较简单,就是改变图2中url上的start参数,使用offset为20的规则作为下一页url的拼接;
图2
获取到请求连接后,使用requests的get请求,然后分析获取到的html数据,就可以得到我们需要的数据;采集 核心代码贴在下面
for offset in range(0,220,20):
url = "https://movie.douban.com/subje ... rt%3D{}&limit=20&status=P&sort=new_score".format(offset)
res = requests.get(url,headers= headers)
# print(res.text)
soup = BeautifulSoup(res.text,'lxml')
time.sleep(2)
for comment_item in soup.select("#comments > .comment-item"):
try:
data_item = []
avatar = comment_item.select(".avatar a img")[0].get("src")
name = comment_item.select(".comment h3 .comment-info a")[0]
rate = comment_item.select(".comment h3 .comment-info span:nth-child(3)")[0]
date = comment_item.select(".comment h3 .comment-info span:nth-child(4)")[0]
comment = comment_item.select(".comment .comment-content span")[0]
# comment_item.get("div img").ge
data_item.append(avatar)
data_item.append(str(name.string).strip("\t"))
data_item.append(str(rate.get("class")[0]).strip("allstar").strip('\t').strip("\n"))
data_item.append(str(date.string).replace('\n','').strip('\t'))
data_item.append(str(comment.string).strip("\t").strip("\n"))
data_json ={
'avatar':avatar,
'name': str(name.string).strip("\t"),
'rate': str(rate.get("class")[0]).strip("allstar").strip('\t').strip("\n"),
'date' : str(date.string).replace('\n','').replace('\t','').strip(' '),
'comment': str(comment.string).strip("\t").strip("\n")
}
if not (collection.find_one({'avatar':avatar})):
print("data _json is {}".format(data_json))
collection.insert_one(data_json)
f.write('\t'.join(data_item))
f.write("\n")
except Exception as e:
print(e)
continue
抓取豆瓣的时候需要记得添加cookie和User-Agent,否则不会有数据为空。
为了方便后面数据的可视化和提取,本文使用Mongodb作为数据存储。有211条数据。采集的主要数据字段为头像、姓名、评分、日期、评论,分别代表用户头像、用户名、明星。成绩、日期、评论;结果如图3所示;
图 3
关于Python如何使用MongoDB,可以参考旧新闻[]
数据可视化
可视化部分之前计划用Python+Pyecharts来实现,但是Python图表中的交互效果不是很好。只需使用原生的 Echarts + Vue 组合即可实现。而且,在这种情况下,将所有图表放在一个网页上更方便。
首先是对评论时间和评论数量进行图表预览。根据数据,评论时间分布为散点图。看用户评论的主要时间分布。
图 4
图4中圆点的大小和颜色代表了当天的评论数,评论数也可以反映当天剧的热度。
据了解,《鱿鱼游戏》的影评从9月17日开始上涨,20日见顶,21日回落;评论数量在21日和29日之间来回波动,差别不大;
至少要到国庆节,10月1日,猜测可能一方面是国庆假期大家都出去玩了,另一方面,随着时间的推移,这部剧的热度也有所下降。
为了了解大家对《鱿鱼游戏》的评价,我根据这200条节目的【评分星级】数据绘制了饼图,最终效果如图5所示。
图 5
老实说,图 5 的结果让我有点吃惊。至少对我来说,这部剧的质量是相当高的。画之前我觉得应该是【五颗星】的比例最大,其次是【四颗星】,然后是【三星】;
现在【三星】和【五星】的比例正好相反。可能是这部剧的剧情残酷,会引起不适,所以高分占的比例不高;
为了方便,我最后把上面两个图表放在一个网页上,效果如图6和图7两种不同的布局
垂直布局
图 6
横向布局
图 7 词云可视化
这次采集的数据信息有限,可以分析的数据维度并不多。对数据图表的分析到此基本结束。以下是采集收到的评论的几张词云图
图 8
从图8中可以看出,人性不是现实中常用的口头语,而是影评中出现频率最高的词,而这个词确实契合了电视剧《鱿鱼游戏》的主题,从第一集开始到结尾他们都在分析人性,赌徒的“贪婪和赌瘾”,贵宾的“弱肉强食”
图9
与之前的词云图相比,图9突出了相对更多的信息。比如韩国,人物、刺激、剧情、赌博启示、题材等都和剧情有关。除了这几条信息,李政宰、孔刘、李秉宪等几位主演也都被提到了
最后,我用采集到达的用户头像制作了两个图片墙作为文章的结尾
图10
图11
图10、图11 照片墙的轮廓使用了剧中两个角色的截图,一个是123木人,一个是男一玩游戏二的截图:
关于照片墙的制作方法请参考旧闻:
概括
本文涉及的所有源码和信息获取方式:关注微信公众号:【小张Python】,后台回复关键词211003,即可获取,
好了,这就是本文文章的全部内容。这篇文章分析的东西不多。主要介绍Python在数据采集和可视化方面的一些应用。
如果内容对你有帮助,希望给文章点个赞鼓励一下。当然,也欢迎读者朋友们把文章分享给更多的人!
最后,感谢大家的阅读,下期再见~ 查看全部
全网文章采集软件(爬取《鱿鱼游戏》豆瓣上的技术栈和工具)
各位读者好,我是小张~
今天不是国庆节,所以回顾了一部最近很火的韩剧《鱿鱼游戏》。这部剧的整体剧情还是很不错的,值得一看。
作为技术博主,当然不能在这里介绍这部剧的影评。毕竟我这方面不专业,最重要的是写不出来。
本文主要是爬取豆瓣上《鱿鱼游戏》的一些影评,对数据做一些简单的分析,从数据的角度重新审视这部剧。
技术工具
在正文开始之前,先介绍一下本文中用到的技术栈和工具文章。本文所涉及的所有源码数据可通过公众号【小张Python】后台回复关键词211003获取。
本文用到的技术栈和工具如下,可以概括为四个方面:
数据采集
这次数据采集的目标网站是豆瓣,但是我的账号之前被封了,所以只能采集获取200条左右的数据。豆瓣有相应的反爬虫机制。查看超过10页的评论需要用户登录才能进行下一步
至于账号为什么被封,是因为我在学习爬虫的时候不知道在哪里制作【豆瓣模拟登录】代码。当时不知道代码有没有问题。试用后被封,永久封号
图1
这里也给大家提个醒。以后做爬虫的时候,在模拟登录的时候尽量使用一些测试账号,如果不需要自己的账号就不要使用。
这次的数据采集也比较简单,就是改变图2中url上的start参数,使用offset为20的规则作为下一页url的拼接;
图2
获取到请求连接后,使用requests的get请求,然后分析获取到的html数据,就可以得到我们需要的数据;采集 核心代码贴在下面
for offset in range(0,220,20):
url = "https://movie.douban.com/subje ... rt%3D{}&limit=20&status=P&sort=new_score".format(offset)
res = requests.get(url,headers= headers)
# print(res.text)
soup = BeautifulSoup(res.text,'lxml')
time.sleep(2)
for comment_item in soup.select("#comments > .comment-item"):
try:
data_item = []
avatar = comment_item.select(".avatar a img")[0].get("src")
name = comment_item.select(".comment h3 .comment-info a")[0]
rate = comment_item.select(".comment h3 .comment-info span:nth-child(3)")[0]
date = comment_item.select(".comment h3 .comment-info span:nth-child(4)")[0]
comment = comment_item.select(".comment .comment-content span")[0]
# comment_item.get("div img").ge
data_item.append(avatar)
data_item.append(str(name.string).strip("\t"))
data_item.append(str(rate.get("class")[0]).strip("allstar").strip('\t').strip("\n"))
data_item.append(str(date.string).replace('\n','').strip('\t'))
data_item.append(str(comment.string).strip("\t").strip("\n"))
data_json ={
'avatar':avatar,
'name': str(name.string).strip("\t"),
'rate': str(rate.get("class")[0]).strip("allstar").strip('\t').strip("\n"),
'date' : str(date.string).replace('\n','').replace('\t','').strip(' '),
'comment': str(comment.string).strip("\t").strip("\n")
}
if not (collection.find_one({'avatar':avatar})):
print("data _json is {}".format(data_json))
collection.insert_one(data_json)
f.write('\t'.join(data_item))
f.write("\n")
except Exception as e:
print(e)
continue
抓取豆瓣的时候需要记得添加cookie和User-Agent,否则不会有数据为空。
为了方便后面数据的可视化和提取,本文使用Mongodb作为数据存储。有211条数据。采集的主要数据字段为头像、姓名、评分、日期、评论,分别代表用户头像、用户名、明星。成绩、日期、评论;结果如图3所示;
图 3
关于Python如何使用MongoDB,可以参考旧新闻[]
数据可视化
可视化部分之前计划用Python+Pyecharts来实现,但是Python图表中的交互效果不是很好。只需使用原生的 Echarts + Vue 组合即可实现。而且,在这种情况下,将所有图表放在一个网页上更方便。
首先是对评论时间和评论数量进行图表预览。根据数据,评论时间分布为散点图。看用户评论的主要时间分布。
图 4
图4中圆点的大小和颜色代表了当天的评论数,评论数也可以反映当天剧的热度。
据了解,《鱿鱼游戏》的影评从9月17日开始上涨,20日见顶,21日回落;评论数量在21日和29日之间来回波动,差别不大;
至少要到国庆节,10月1日,猜测可能一方面是国庆假期大家都出去玩了,另一方面,随着时间的推移,这部剧的热度也有所下降。
为了了解大家对《鱿鱼游戏》的评价,我根据这200条节目的【评分星级】数据绘制了饼图,最终效果如图5所示。
图 5
老实说,图 5 的结果让我有点吃惊。至少对我来说,这部剧的质量是相当高的。画之前我觉得应该是【五颗星】的比例最大,其次是【四颗星】,然后是【三星】;
现在【三星】和【五星】的比例正好相反。可能是这部剧的剧情残酷,会引起不适,所以高分占的比例不高;
为了方便,我最后把上面两个图表放在一个网页上,效果如图6和图7两种不同的布局
垂直布局
图 6
横向布局
图 7 词云可视化
这次采集的数据信息有限,可以分析的数据维度并不多。对数据图表的分析到此基本结束。以下是采集收到的评论的几张词云图
图 8
从图8中可以看出,人性不是现实中常用的口头语,而是影评中出现频率最高的词,而这个词确实契合了电视剧《鱿鱼游戏》的主题,从第一集开始到结尾他们都在分析人性,赌徒的“贪婪和赌瘾”,贵宾的“弱肉强食”
图9
与之前的词云图相比,图9突出了相对更多的信息。比如韩国,人物、刺激、剧情、赌博启示、题材等都和剧情有关。除了这几条信息,李政宰、孔刘、李秉宪等几位主演也都被提到了
最后,我用采集到达的用户头像制作了两个图片墙作为文章的结尾
图10
图11
图10、图11 照片墙的轮廓使用了剧中两个角色的截图,一个是123木人,一个是男一玩游戏二的截图:
关于照片墙的制作方法请参考旧闻:
概括
本文涉及的所有源码和信息获取方式:关注微信公众号:【小张Python】,后台回复关键词211003,即可获取,
好了,这就是本文文章的全部内容。这篇文章分析的东西不多。主要介绍Python在数据采集和可视化方面的一些应用。
如果内容对你有帮助,希望给文章点个赞鼓励一下。当然,也欢迎读者朋友们把文章分享给更多的人!
最后,感谢大家的阅读,下期再见~
全网文章采集软件(固乔电商图片助手:高效批量采集POCO相册高清无水印图片素材)
采集交流 • 优采云 发表了文章 • 0 个评论 • 539 次浏览 • 2021-10-08 04:11
从事美术工作或自媒体的朋友对图片素材有很大的需求。当我们在POCO相册看到自己喜欢的图片素材时,有没有办法批量采集保存?今天小编就给大家分享一个高效的批量采集POCO相册高清无水印图片素材的方法,一起来看看吧。
一、首先来看看批量获取的POCO相册上的高清无水印图片素材。可以看到画质非常好,都是非常不错的图片素材。
二、这是如何工作的?我们需要使用图片辅助保存工具。这个工具的名字是“古桥电商图片助手”。软件下载方法非常简单。在“谷桥科技”官网找到软件下载即可。
三、打开软件,在工具栏中找到“POCO相册下载”功能。
四、勾选“自动粘贴网址”功能,这样我们采集 POCO相册图片的链接地址就会自动导入到软件中。
五、打开POCO相册网,依次复制我们要下载的图片链接地址。
六、 返回软件,可以看到所有的图片链接地址已经自动导入到软件中了。我们只需要点击“立即下载”,这些图片素材就会自动保存在电脑上。
七、“古桥电商图片助手”不仅可以支持批量采集全网热门图片素材网的高清图片,还支持下载各大电商的高清图片商贸平台。
今天的分享到此结束,希望对所有热爱电商和艺术的朋友有所帮助,欢迎大家下载“古桥电商图片助手”跟随小编一起体验。 查看全部
全网文章采集软件(固乔电商图片助手:高效批量采集POCO相册高清无水印图片素材)
从事美术工作或自媒体的朋友对图片素材有很大的需求。当我们在POCO相册看到自己喜欢的图片素材时,有没有办法批量采集保存?今天小编就给大家分享一个高效的批量采集POCO相册高清无水印图片素材的方法,一起来看看吧。
一、首先来看看批量获取的POCO相册上的高清无水印图片素材。可以看到画质非常好,都是非常不错的图片素材。
二、这是如何工作的?我们需要使用图片辅助保存工具。这个工具的名字是“古桥电商图片助手”。软件下载方法非常简单。在“谷桥科技”官网找到软件下载即可。
三、打开软件,在工具栏中找到“POCO相册下载”功能。
四、勾选“自动粘贴网址”功能,这样我们采集 POCO相册图片的链接地址就会自动导入到软件中。
五、打开POCO相册网,依次复制我们要下载的图片链接地址。
六、 返回软件,可以看到所有的图片链接地址已经自动导入到软件中了。我们只需要点击“立即下载”,这些图片素材就会自动保存在电脑上。
七、“古桥电商图片助手”不仅可以支持批量采集全网热门图片素材网的高清图片,还支持下载各大电商的高清图片商贸平台。
今天的分享到此结束,希望对所有热爱电商和艺术的朋友有所帮助,欢迎大家下载“古桥电商图片助手”跟随小编一起体验。
全网文章采集软件(全自动采集器(Editortools)中小网站自动更新利器--功能介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 492 次浏览 • 2021-10-06 18:31
全自动采集器(Editortools)中小网站自动更新工具!可以很好的帮助用户解决中小型网站和企业站的信息自动化操作。更智能的采集解决方案保证您的网站的高质量和及时的内容更新!EditorTools的出现将为您节省大量时间,让站长和管理员从繁琐枯燥的网站更新工作中解放出来!
特征
【特点】 设定计划后,可24小时自动工作,无需人工干预。
[特点] 独立于网站,通过独立制作的接口支持任何网站或数据库
【特点】体积小,功耗低,稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源灵活复用
【特点】使用FTP上传文件,稳定安全
[采集] 反向、顺序、随机可选采集文章
【采集】支持自动列表网址
[采集] 支持采集 for 网站,数据分布在多个页面
[采集] 自由设置采集数据项,可对每个数据项单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任意格式和类型的文件(包括图片和视频)
[采集] 可以突破防窃听文件
[采集] 支持动态文件URL解析
[采集] 支持采集需要登录才能访问的网页
[支持] 可设置关键词采集
[支持] 可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持以回复方式发布文章,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强了发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持任何已发布项目的语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传自动创建年月日目录
[发布] 模拟发布支持无法安装接口的网站发布操作
[支持] 程序可以正常运行
[支持] 防止网络运营商劫持HTTP功能
[支持] 可以手动发布单项采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
更新日志
编辑器工具 3.4.1 查看全部
全网文章采集软件(全自动采集器(Editortools)中小网站自动更新利器--功能介绍)
全自动采集器(Editortools)中小网站自动更新工具!可以很好的帮助用户解决中小型网站和企业站的信息自动化操作。更智能的采集解决方案保证您的网站的高质量和及时的内容更新!EditorTools的出现将为您节省大量时间,让站长和管理员从繁琐枯燥的网站更新工作中解放出来!
特征
【特点】 设定计划后,可24小时自动工作,无需人工干预。
[特点] 独立于网站,通过独立制作的接口支持任何网站或数据库
【特点】体积小,功耗低,稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源灵活复用
【特点】使用FTP上传文件,稳定安全
[采集] 反向、顺序、随机可选采集文章
【采集】支持自动列表网址
[采集] 支持采集 for 网站,数据分布在多个页面
[采集] 自由设置采集数据项,可对每个数据项单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任意格式和类型的文件(包括图片和视频)
[采集] 可以突破防窃听文件
[采集] 支持动态文件URL解析
[采集] 支持采集需要登录才能访问的网页
[支持] 可设置关键词采集
[支持] 可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持以回复方式发布文章,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强了发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持任何已发布项目的语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传自动创建年月日目录
[发布] 模拟发布支持无法安装接口的网站发布操作
[支持] 程序可以正常运行
[支持] 防止网络运营商劫持HTTP功能
[支持] 可以手动发布单项采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
更新日志
编辑器工具 3.4.1
全网文章采集软件(可采集的信息采集功能有什么作用?如何设置?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-10-06 18:21
1、强大的信息采集功能。采集几乎任何类型的网站信息,包括静态htm、html类型和动态ASP、ASPX、JSP等。N级页面可以与采集关联并自动集成到一个完整记录。支持网页框架、链接和网页加密等。支持完全采集和增量采集(持续挖掘)。可以自动下载二进制文件,如图片、软件、mp3等。可以采集本地磁盘信息。支持Post数据请求采集方法。
2、网站登录。需要登录才能看到的信息,先在任务的“登录设置”中登录,然后就可以采集登录查看信息。
3、 速度快,运行稳定。真正的多线程、多任务,运行时占用系统资源极少,可以长时间稳定运行。(明显不同于其他软件)
4、 丰富的数据存储格式。采集的数据可以保存为Txt、Excel和多种数据库格式(Access sqlserver Oracle Mysql等)。
5、 支持脚本。可以设置脚本类型的任务,类似于javascript:submit('Page\',1)等格式都可以轻松采集.
6、强大的新闻采集,自动处理功能。可自动保留新闻的格式,包括图片等(可通过设置自动去除广告)。可以通过设置自动下载图片,并自动将文中图片的网络路径更改为本地文件路径(也可以保留原来的);可以自动将采集的消息处理成自己设计的模板格式;您可以采集 分页新闻。通过这些功能,无需人工干预,只需简单设置即可在本地建立强大的新闻系统。
7、强大的自动信息再处理功能。采集的信息可以分两批重新处理,使其更符合您的实际需求。还可以设置自动处理公式。在采集的过程中,根据公式自动处理公式,包括数据合并和数据替换。
8、提供从采集,到自动处理,到数据导出(发布)的一站式自动化功能。通过任务调度、实时监控和发布来实现。指定某些任务自动运行,自动去除重复后将采集的数据导入数据库(可指定唯一组合)。它可以循环运行。您可以指定要在某个时间点运行的任务。可以设置采集,达到一定数据量后,会自动存入库,内存会自动清空。该功能可以连续采集10万级、百万级数据,不占用系统资源。无人值守采集。 查看全部
全网文章采集软件(可采集的信息采集功能有什么作用?如何设置?)
1、强大的信息采集功能。采集几乎任何类型的网站信息,包括静态htm、html类型和动态ASP、ASPX、JSP等。N级页面可以与采集关联并自动集成到一个完整记录。支持网页框架、链接和网页加密等。支持完全采集和增量采集(持续挖掘)。可以自动下载二进制文件,如图片、软件、mp3等。可以采集本地磁盘信息。支持Post数据请求采集方法。
2、网站登录。需要登录才能看到的信息,先在任务的“登录设置”中登录,然后就可以采集登录查看信息。
3、 速度快,运行稳定。真正的多线程、多任务,运行时占用系统资源极少,可以长时间稳定运行。(明显不同于其他软件)
4、 丰富的数据存储格式。采集的数据可以保存为Txt、Excel和多种数据库格式(Access sqlserver Oracle Mysql等)。
5、 支持脚本。可以设置脚本类型的任务,类似于javascript:submit('Page\',1)等格式都可以轻松采集.
6、强大的新闻采集,自动处理功能。可自动保留新闻的格式,包括图片等(可通过设置自动去除广告)。可以通过设置自动下载图片,并自动将文中图片的网络路径更改为本地文件路径(也可以保留原来的);可以自动将采集的消息处理成自己设计的模板格式;您可以采集 分页新闻。通过这些功能,无需人工干预,只需简单设置即可在本地建立强大的新闻系统。
7、强大的自动信息再处理功能。采集的信息可以分两批重新处理,使其更符合您的实际需求。还可以设置自动处理公式。在采集的过程中,根据公式自动处理公式,包括数据合并和数据替换。
8、提供从采集,到自动处理,到数据导出(发布)的一站式自动化功能。通过任务调度、实时监控和发布来实现。指定某些任务自动运行,自动去除重复后将采集的数据导入数据库(可指定唯一组合)。它可以循环运行。您可以指定要在某个时间点运行的任务。可以设置采集,达到一定数据量后,会自动存入库,内存会自动清空。该功能可以连续采集10万级、百万级数据,不占用系统资源。无人值守采集。
全网文章采集软件(批量下载图片给出一组图片采集下载软件吧!(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-10-03 19:02
优采云网络图片采集器是一款很棒的网络图片采集下载软件。本软件可以帮助用户使用关键词采集全网图片,还可以设置图片大小、颜色、动静态参数等,喜欢的用户赶紧下载这张图片采集工具!
软件功能说明
关键词采集所有网络图片
图片大小、颜色、动静态参数均可设置。
批量下载图片
给一组图片地址下载这些图片到本地
导出文章中的图片
可以将本地HTML文章中引用的网络图片dump到本地目录(然后上传FTP,这些图片是你自己的网站图片)。
修改图片修改图片
MD5、水印、大小、格式,最新版本增加了水平镜像、左手、右手、反转图像处理。
下载全站图片
测试功能,只有HTML静态网站,不是所有网站都可以采集,请试试
软件更新说明
v1.5.5.0:图片批量下载新增支持下载图片以外的后缀文件
软件内容说明
优采云网络图片采集器是一款功能强大的网络图片采集器软件
可以根据关键字等条件采集网络图片,批量下载到电脑,功能强大,方便。
驾驶
移动
下
加载
文件名:优采云网络图片采集器v1.5.5.0 绿色版
更新日期:2021-10-02
作者信息:
提示:下载后请核对MD5值,欢迎捐赠本站和广告合作!
下载地址:点击下载【文件大小:1.1M】 查看全部
全网文章采集软件(批量下载图片给出一组图片采集下载软件吧!(图))
优采云网络图片采集器是一款很棒的网络图片采集下载软件。本软件可以帮助用户使用关键词采集全网图片,还可以设置图片大小、颜色、动静态参数等,喜欢的用户赶紧下载这张图片采集工具!
软件功能说明
关键词采集所有网络图片
图片大小、颜色、动静态参数均可设置。
批量下载图片
给一组图片地址下载这些图片到本地
导出文章中的图片
可以将本地HTML文章中引用的网络图片dump到本地目录(然后上传FTP,这些图片是你自己的网站图片)。
修改图片修改图片
MD5、水印、大小、格式,最新版本增加了水平镜像、左手、右手、反转图像处理。
下载全站图片
测试功能,只有HTML静态网站,不是所有网站都可以采集,请试试
软件更新说明
v1.5.5.0:图片批量下载新增支持下载图片以外的后缀文件
软件内容说明
优采云网络图片采集器是一款功能强大的网络图片采集器软件
可以根据关键字等条件采集网络图片,批量下载到电脑,功能强大,方便。
驾驶
移动
下
加载
文件名:优采云网络图片采集器v1.5.5.0 绿色版
更新日期:2021-10-02
作者信息:
提示:下载后请核对MD5值,欢迎捐赠本站和广告合作!
下载地址:点击下载【文件大小:1.1M】
全网文章采集软件(全网文章采集软件,高效率提高文章查找效率!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2021-10-02 03:02
全网文章采集软件,导入采集库即可使用快速采集全网文章到本地,高效率提高文章查找效率。采集高质量网站网页内容和短文!高级玩法!安装采集软件,可导入本地数据库,不需要下载软件一键采集各大门户网站。在指定的浏览器地址栏中输入网址即可采集,速度快。支持手机端上网导入浏览器地址。文章内容质量好,无水印,一键转身处理后导入本地数据库或其他网站,快速修改。
采集限定的网站内容。支持中图分析,二维码获取,搜索关键词即可快速找到信息,查看历史内容,收藏转发分享等功能。采集文章为其它网站文章,查看历史更新及点赞等。玩法:去水印,下载pdf文件,ppt文件,word图片,视频文件等.还有很多功能,分享给大家。去水印。完全采集原创文章,微信网页版文章背景为白底,无水印,图片占据50%篇幅,无须二次压缩;而网页版有美图效果,无需二次压缩。
下载pdf文件,ppt文件,word图片,视频文件等..分享给朋友,大家一起玩,很方便。为百度网盘,头条,搜狐,知乎等点赞。分享给朋友,看着朋友圈很高兴。分享给朋友,和朋友一起玩耍。传播分享文章,自己很开心。收藏文章时候更开心。pdf下载,ppt下载,word下载,视频下载等功能可以给你带来更多的收益。 查看全部
全网文章采集软件(全网文章采集软件,高效率提高文章查找效率!)
全网文章采集软件,导入采集库即可使用快速采集全网文章到本地,高效率提高文章查找效率。采集高质量网站网页内容和短文!高级玩法!安装采集软件,可导入本地数据库,不需要下载软件一键采集各大门户网站。在指定的浏览器地址栏中输入网址即可采集,速度快。支持手机端上网导入浏览器地址。文章内容质量好,无水印,一键转身处理后导入本地数据库或其他网站,快速修改。
采集限定的网站内容。支持中图分析,二维码获取,搜索关键词即可快速找到信息,查看历史内容,收藏转发分享等功能。采集文章为其它网站文章,查看历史更新及点赞等。玩法:去水印,下载pdf文件,ppt文件,word图片,视频文件等.还有很多功能,分享给大家。去水印。完全采集原创文章,微信网页版文章背景为白底,无水印,图片占据50%篇幅,无须二次压缩;而网页版有美图效果,无需二次压缩。
下载pdf文件,ppt文件,word图片,视频文件等..分享给朋友,大家一起玩,很方便。为百度网盘,头条,搜狐,知乎等点赞。分享给朋友,看着朋友圈很高兴。分享给朋友,和朋友一起玩耍。传播分享文章,自己很开心。收藏文章时候更开心。pdf下载,ppt下载,word下载,视频下载等功能可以给你带来更多的收益。
全网文章采集软件(全网文章采集软件推荐(一)软件,免费实用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 350 次浏览 • 2021-09-29 10:03
全网文章采集软件推荐全网文章采集软件推荐,希望你们能够在拥有自己的网站之后更好的进行网站自动化,毕竟网站建设已经成为了当今企业竞争的一大利器,企业为了更好的提高企业的竞争力,企业也会采用更为先进的方式将网站建设的更为具有竞争力。
请戳这里百度文库的采集
1、阿里文库,当然也可以做公众号(如公众号文章采集、文章翻译等),如果你是企业,可以在网上建一个文库官网,开通头条信息采集、公众号文章采集(或者其他方式,
2、:百度文库官网,
3、文库非对个人开放,
推荐一个免费的做文档采集的地方
很多啊,比如地方报纸等等,或者是小说,金融信息什么的。
搜狗网站爬虫,速度极快,
都有要求,你还在用python吗,听说不好用,
python能处理吗?python可以做互联网网站爬虫吗?能
我就是专门做互联网数据爬虫的,python是需要要学的。
torrentminer,图片爬虫和文章爬虫分别抓百度网盘和百度云盘。
飞鱼互联网数据爬虫软件,免费,实用。
crawler就可以
谷歌采集,谷歌文库,问答,搜索引擎爬虫,谷歌翻译软件,科研论文爬虫,谷歌采集器,谷歌分析,谷歌爬虫软件, 查看全部
全网文章采集软件(全网文章采集软件推荐(一)软件,免费实用)
全网文章采集软件推荐全网文章采集软件推荐,希望你们能够在拥有自己的网站之后更好的进行网站自动化,毕竟网站建设已经成为了当今企业竞争的一大利器,企业为了更好的提高企业的竞争力,企业也会采用更为先进的方式将网站建设的更为具有竞争力。
请戳这里百度文库的采集
1、阿里文库,当然也可以做公众号(如公众号文章采集、文章翻译等),如果你是企业,可以在网上建一个文库官网,开通头条信息采集、公众号文章采集(或者其他方式,
2、:百度文库官网,
3、文库非对个人开放,
推荐一个免费的做文档采集的地方
很多啊,比如地方报纸等等,或者是小说,金融信息什么的。
搜狗网站爬虫,速度极快,
都有要求,你还在用python吗,听说不好用,
python能处理吗?python可以做互联网网站爬虫吗?能
我就是专门做互联网数据爬虫的,python是需要要学的。
torrentminer,图片爬虫和文章爬虫分别抓百度网盘和百度云盘。
飞鱼互联网数据爬虫软件,免费,实用。
crawler就可以
谷歌采集,谷歌文库,问答,搜索引擎爬虫,谷歌翻译软件,科研论文爬虫,谷歌采集器,谷歌分析,谷歌爬虫软件,
全网文章采集软件(采集软件可实现全网平台文章同步采集,一键导入采集导出文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-09-21 18:06
全网文章采集软件可实现全网平台文章同步采集,一键导入采集导出文章,变速采集软件,快速采集网页类网站文章。不同的网站对应相应的一种采集策略,只要你支持电脑和微信,一键导入导出文章。几十家站长千方百计想进入流量红利,其根本点就是寻找网站导流,采集软件自然成为人人渴望的流量平台。采集软件可以实现全网平台搜索引擎爬虫抓取,汇总页面抓取,可以搜索整站访问量第一的页面,查看得失。
互联网用户只要有信息爬虫,就必然会有文章抓取,这就是人人想要的流量红利,每个人都能以此为生。无论大小网站,都能找到相应的操作方法。专业做了十多年流量的人,深知实力足够就能破解一切潜规则,专业的人就是无法让大家感觉太专业,所以小编还是那句话,专业的才有市场,才会有大量想要流量的人加入。
1、本网站采集一般是采集标题直接的文章,不会采集图片。
2、采集软件不支持全网注明网站的文章。
3、采集下来的文章能够双端同步。
4、采集排序按照“浏览量、打开次数、收藏量、感谢数”以及“时间”同步排序。
5、只要是“收藏”数超过五个按钮,都可以点打开收藏数的按钮,不是收藏数很少。
6、有带有自动摘要功能。
7、没有加上微信号的一律识别成“单篇文章”不抓取。所以采集软件只是辅助,不是核心。
8、大小站点都可以采集下来进行操作。
9、网站的导出功能全部开启。
1
0、网站导出是采集软件后台自带的。
1、在百度云下载,分布在“云服务器”和“微信公众号”下。 查看全部
全网文章采集软件(采集软件可实现全网平台文章同步采集,一键导入采集导出文章)
全网文章采集软件可实现全网平台文章同步采集,一键导入采集导出文章,变速采集软件,快速采集网页类网站文章。不同的网站对应相应的一种采集策略,只要你支持电脑和微信,一键导入导出文章。几十家站长千方百计想进入流量红利,其根本点就是寻找网站导流,采集软件自然成为人人渴望的流量平台。采集软件可以实现全网平台搜索引擎爬虫抓取,汇总页面抓取,可以搜索整站访问量第一的页面,查看得失。
互联网用户只要有信息爬虫,就必然会有文章抓取,这就是人人想要的流量红利,每个人都能以此为生。无论大小网站,都能找到相应的操作方法。专业做了十多年流量的人,深知实力足够就能破解一切潜规则,专业的人就是无法让大家感觉太专业,所以小编还是那句话,专业的才有市场,才会有大量想要流量的人加入。
1、本网站采集一般是采集标题直接的文章,不会采集图片。
2、采集软件不支持全网注明网站的文章。
3、采集下来的文章能够双端同步。
4、采集排序按照“浏览量、打开次数、收藏量、感谢数”以及“时间”同步排序。
5、只要是“收藏”数超过五个按钮,都可以点打开收藏数的按钮,不是收藏数很少。
6、有带有自动摘要功能。
7、没有加上微信号的一律识别成“单篇文章”不抓取。所以采集软件只是辅助,不是核心。
8、大小站点都可以采集下来进行操作。
9、网站的导出功能全部开启。
1
0、网站导出是采集软件后台自带的。
1、在百度云下载,分布在“云服务器”和“微信公众号”下。
全网文章采集软件(图片自动提取文本词条网址快速提取阅读模式(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-17 14:05
全网文章采集软件多文章一键采集,批量管理百度百科各类维基百科原创词条各类网站上的文章快速采集原创页面原创内容词条管理采集器全网图片采集框对页面进行搜索寻找自己需要的图片,图片自动提取文本词条网址快速提取阅读模式默认全文自动识别文本采集采集器-112。html:网页版极速图片采集极速图片采集全站图片采集2。手机端导出生成pdfexcel导出wordexcel导出格式。
一个批量查询关键词的查询软件。就是要会用百度。
全网搜索,全网公交路线,
whatwg_词条采集器,发展飞速的词条数据分析平台,了解一下
why_article,分享一下我查词查文章的经验吧,先点开article然后再弹出对话框在提供关键词后点击查询然后就会跳出一个条形码然后点击网址就能获取到相应的词条的详细信息,包括标题,关键词,正文,网址,截图和背景图等。希望能帮到你哦。
不知道你是不是知道这个站,有点像百度新闻,但是查询公交地铁的多的是,地铁线路图也有很多,你可以试试。
百度文库网站,分享下我查找网站导航的经验:首先,你需要的是web,把它上传到google,百度学生一般都有百度的账号,查找起来很方便,非常适合初学者用。但是,百度服务器的不稳定导致大多数公交车线路信息不可靠,是建议知道自己公交的住址后再上传信息。另外有很多网站在提供网址时,都是配图很丑,或者比网站上名字还长,浏览器长按头像转发二维码查看。
而如果提供关键词,你得花点力气通过x宝或某宝买一个关键词查询器。当然百度本身也提供很多查询工具,但由于检索和订制,价格比较贵,对于初学者而言不太划算。另外一点是由于百度对色情信息打击很严,很多图片都用作广告图或其他目的。我尝试了几个网站网站资源,发现需要登录才能下载(百度下不要那么优雅,不然google很多图片连连地图都要下载)。
至于其他网站,需要一个长效用户和巨大流量去支撑,实在是不划算。还有一点:如果文章里添加了词条来源等关键字,自动联想词条就只能查不能标记。而且收录也不一定全,尤其是百度系的网站,如果没有关键字或图片,很多词条都直接不收录。一旦关键字标记要看百度算法,一般这个功能国内做的比较好,国外没有那么好,如果你只是图方便的话,可以试试。
搜狗也有,就是稍微贵一点。通过这些方法,基本上能够查到90%以上的词条,但十个里也有八个词条会是无意义词条,那么这个就是碰运气,有好有坏。whyadler,没有那么神秘,就是官方提供的app或网站,以前只支持美国区。 查看全部
全网文章采集软件(图片自动提取文本词条网址快速提取阅读模式(组图))
全网文章采集软件多文章一键采集,批量管理百度百科各类维基百科原创词条各类网站上的文章快速采集原创页面原创内容词条管理采集器全网图片采集框对页面进行搜索寻找自己需要的图片,图片自动提取文本词条网址快速提取阅读模式默认全文自动识别文本采集采集器-112。html:网页版极速图片采集极速图片采集全站图片采集2。手机端导出生成pdfexcel导出wordexcel导出格式。
一个批量查询关键词的查询软件。就是要会用百度。
全网搜索,全网公交路线,
whatwg_词条采集器,发展飞速的词条数据分析平台,了解一下
why_article,分享一下我查词查文章的经验吧,先点开article然后再弹出对话框在提供关键词后点击查询然后就会跳出一个条形码然后点击网址就能获取到相应的词条的详细信息,包括标题,关键词,正文,网址,截图和背景图等。希望能帮到你哦。
不知道你是不是知道这个站,有点像百度新闻,但是查询公交地铁的多的是,地铁线路图也有很多,你可以试试。
百度文库网站,分享下我查找网站导航的经验:首先,你需要的是web,把它上传到google,百度学生一般都有百度的账号,查找起来很方便,非常适合初学者用。但是,百度服务器的不稳定导致大多数公交车线路信息不可靠,是建议知道自己公交的住址后再上传信息。另外有很多网站在提供网址时,都是配图很丑,或者比网站上名字还长,浏览器长按头像转发二维码查看。
而如果提供关键词,你得花点力气通过x宝或某宝买一个关键词查询器。当然百度本身也提供很多查询工具,但由于检索和订制,价格比较贵,对于初学者而言不太划算。另外一点是由于百度对色情信息打击很严,很多图片都用作广告图或其他目的。我尝试了几个网站网站资源,发现需要登录才能下载(百度下不要那么优雅,不然google很多图片连连地图都要下载)。
至于其他网站,需要一个长效用户和巨大流量去支撑,实在是不划算。还有一点:如果文章里添加了词条来源等关键字,自动联想词条就只能查不能标记。而且收录也不一定全,尤其是百度系的网站,如果没有关键字或图片,很多词条都直接不收录。一旦关键字标记要看百度算法,一般这个功能国内做的比较好,国外没有那么好,如果你只是图方便的话,可以试试。
搜狗也有,就是稍微贵一点。通过这些方法,基本上能够查到90%以上的词条,但十个里也有八个词条会是无意义词条,那么这个就是碰运气,有好有坏。whyadler,没有那么神秘,就是官方提供的app或网站,以前只支持美国区。
全网文章采集软件(全网文章采集软件(tornado)|我不是推销大白鲨)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-09-16 19:00
全网文章采集软件,支持windows、mac、linux、android平台。一键搞定需要编写爬虫程序,采集全网文章,包括:文章分类、标题、作者、首发地、评论、收藏等信息。并提供word版本,支持批量编辑采集的文章,或定制自己的文章采集方案。只要你会写文章程序,就能自己制作一款全网采集工具。文章采集软件地址:/。
如果你是想爬取多个网站信息,所有需要借助各大搜索引擎的爬虫去爬。如果只是想抓取某些网站的某些信息,多找几个网站爬,规则相同的网站进行爬取。比如说所有内容为「文章类」的网站都要爬取到「作者」以及「关注量」这两个数据。你可以先用requests模块抓取网站,然后改成re就能用了。
tornado
全网抓取软件(tornado)|我不是推销大白鲨
是不是可以看下蝉大师?不仅可以免费注册,而且可以爬很多网站。而且爬取之后还可以分析数据(爬取之后会可以分析这些网站)。
直接requests直接抓取。
给你点推荐,其实python中的requests库能够提供非常强大的网络请求工具,很多地方都有用到,比如图片获取,指南针获取、dl/ds判断、urllib库中对http的封装,httprequest库封装等等等等,当然requests库可以转换成requests更接近于使用requests库中封装的数据接口,本质上还是可以学习爬虫库中封装好的工具。 查看全部
全网文章采集软件(全网文章采集软件(tornado)|我不是推销大白鲨)
全网文章采集软件,支持windows、mac、linux、android平台。一键搞定需要编写爬虫程序,采集全网文章,包括:文章分类、标题、作者、首发地、评论、收藏等信息。并提供word版本,支持批量编辑采集的文章,或定制自己的文章采集方案。只要你会写文章程序,就能自己制作一款全网采集工具。文章采集软件地址:/。
如果你是想爬取多个网站信息,所有需要借助各大搜索引擎的爬虫去爬。如果只是想抓取某些网站的某些信息,多找几个网站爬,规则相同的网站进行爬取。比如说所有内容为「文章类」的网站都要爬取到「作者」以及「关注量」这两个数据。你可以先用requests模块抓取网站,然后改成re就能用了。
tornado
全网抓取软件(tornado)|我不是推销大白鲨
是不是可以看下蝉大师?不仅可以免费注册,而且可以爬很多网站。而且爬取之后还可以分析数据(爬取之后会可以分析这些网站)。
直接requests直接抓取。
给你点推荐,其实python中的requests库能够提供非常强大的网络请求工具,很多地方都有用到,比如图片获取,指南针获取、dl/ds判断、urllib库中对http的封装,httprequest库封装等等等等,当然requests库可以转换成requests更接近于使用requests库中封装的数据接口,本质上还是可以学习爬虫库中封装好的工具。
全网文章采集软件(GatherMate2怀旧服更新日志9/5更新了资源节点数据移)
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-09-10 06:07
ce安全网提供的GatherMate2怀旧服插件是由Wow怀旧服刻录远征版号打造的专业游戏助手软件。关键是为客户提供采集级的服务项目。根据这款软件,相关客户可以在游戏后台提示各种矿点、药点、鱼点的信息内容,然后客户可以有选择地进行实际的采集操作,省去了很多不便。
ce安全网提供哇怀旧服务采集plugin GatherMate2免费下载,这也是一个著名的怀旧魔兽采集辅助软件,这个软件必须安装在INTERFACE--ADDONS部分才能使用一般。本阶段软件已经升级了新的资源连接点,客户可以享受非常非常好的应用体验。
GatherMate2 复古服务器插件教程
1、WOW下的INTERFACE--------ADDONS中先安装解压后的文件才可以使用
2、 然后进入游戏后,你解压压缩文件,放到魔兽世界安装目录下的interface/addons文件夹中。然后登录wow,在人物选择界面的左下方有一个插件按钮,点击后会加载插件。在gathermate前面打勾即可。
3、 如果您仍然不这样做,请查看您的 INTERFACE OBSOLETED。删除被你插件隔离的东西(比如Bigfoot),就可以删除这个文件夹了。
4、 或者,看看您是否导入了数据库,但您加载的地图包括您当前的活动地图,而不仅仅是 AZEROTH。
GatherMate2 复古服务器更新日志
9/5集成链接经典资源节点数据
9/6 更新了资源节点数据并移除了 TBC 数据
10/2更新为作者最新v1.45.5,集成最新Classic资源节点;修复冬刺草错误,修复瘟疫花
10/12新下载:第三方地图资源节点切换按钮插件QQ图片251.png(收录下载链接)
申请信息
GatherMate2怀旧服插件是专为魔兽世界怀旧服烧录远征版打造的游戏辅助插件!主要能够为用户提供采集服务。相关用户可以使用该插件让游戏地图上出现各种矿山、草药、鱼点等信息,然后用户可以选择性地进行采集操作,省去很多麻烦。 查看全部
全网文章采集软件(GatherMate2怀旧服更新日志9/5更新了资源节点数据移)
ce安全网提供的GatherMate2怀旧服插件是由Wow怀旧服刻录远征版号打造的专业游戏助手软件。关键是为客户提供采集级的服务项目。根据这款软件,相关客户可以在游戏后台提示各种矿点、药点、鱼点的信息内容,然后客户可以有选择地进行实际的采集操作,省去了很多不便。
ce安全网提供哇怀旧服务采集plugin GatherMate2免费下载,这也是一个著名的怀旧魔兽采集辅助软件,这个软件必须安装在INTERFACE--ADDONS部分才能使用一般。本阶段软件已经升级了新的资源连接点,客户可以享受非常非常好的应用体验。
GatherMate2 复古服务器插件教程
1、WOW下的INTERFACE--------ADDONS中先安装解压后的文件才可以使用
2、 然后进入游戏后,你解压压缩文件,放到魔兽世界安装目录下的interface/addons文件夹中。然后登录wow,在人物选择界面的左下方有一个插件按钮,点击后会加载插件。在gathermate前面打勾即可。
3、 如果您仍然不这样做,请查看您的 INTERFACE OBSOLETED。删除被你插件隔离的东西(比如Bigfoot),就可以删除这个文件夹了。
4、 或者,看看您是否导入了数据库,但您加载的地图包括您当前的活动地图,而不仅仅是 AZEROTH。
GatherMate2 复古服务器更新日志
9/5集成链接经典资源节点数据
9/6 更新了资源节点数据并移除了 TBC 数据
10/2更新为作者最新v1.45.5,集成最新Classic资源节点;修复冬刺草错误,修复瘟疫花
10/12新下载:第三方地图资源节点切换按钮插件QQ图片251.png(收录下载链接)
申请信息
GatherMate2怀旧服插件是专为魔兽世界怀旧服烧录远征版打造的游戏辅助插件!主要能够为用户提供采集服务。相关用户可以使用该插件让游戏地图上出现各种矿山、草药、鱼点等信息,然后用户可以选择性地进行采集操作,省去很多麻烦。

