
免费网页采集器
下载PTCMS网站源代码破解版,PT自动小说采集免费源代码
采集交流 • 优采云 发表了文章 • 0 个评论 • 413 次浏览 • 2020-08-09 01:11
PT新颖的聚合程序适用于中小型网站管理员. 基于“相同起源”技术,它可以在不同站点上匹配同一本小说,还可以在不同站点上匹配章节,从不同来源阅读并获得更多更新. 良好的阅读经验.
PT新颖的聚合程序继承了PT产品所依赖的智能,愚蠢和基层的技术特征. 它在30秒内安装完毕,并在3分钟内建成. 该站点可以在很短的时间内建立,并且可以复制并重新安装该程序. 也就是说,您可以快速地批量建立网站,并且登录程序是内置的,并且您可以在登录后的第二天阅读没有广告的广告.
PC和移动终端的访问域名分别设置,可以在后台设置.
自动采集!自动收款!自动采集!
无需挂起软件
<p>程序使用百度xml插件,傻瓜式操作,自动赚钱工具,移动版本,源代码自动判断跳转到移动版本,自动更新和汇总各个网站的新颖数据 查看全部
最新的PTCMS小说聚合程序破解版,PT小说聚合搜索源代码全自动小说采集源代码模板程序.
PT新颖的聚合程序适用于中小型网站管理员. 基于“相同起源”技术,它可以在不同站点上匹配同一本小说,还可以在不同站点上匹配章节,从不同来源阅读并获得更多更新. 良好的阅读经验.
PT新颖的聚合程序继承了PT产品所依赖的智能,愚蠢和基层的技术特征. 它在30秒内安装完毕,并在3分钟内建成. 该站点可以在很短的时间内建立,并且可以复制并重新安装该程序. 也就是说,您可以快速地批量建立网站,并且登录程序是内置的,并且您可以在登录后的第二天阅读没有广告的广告.
PC和移动终端的访问域名分别设置,可以在后台设置.
自动采集!自动收款!自动采集!
无需挂起软件
<p>程序使用百度xml插件,傻瓜式操作,自动赚钱工具,移动版本,源代码自动判断跳转到移动版本,自动更新和汇总各个网站的新颖数据
优采云采集器 v7.4.6.8011下载Web信息采集和Internet辅助的新颖采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-08 21:36
绿色软件基础编辑器测试这是一个可以使您的信息采集非常简单的工具. 优采云改变了传统的互联网数据思考方式. 它使用户越来越容易地在Internet上获取信息. 优采云采集器是任何需要从Artifact网页上获取信息的孩子的必备工具
软件功能
简单的操作,完全可视化的图形操作,不需要专业的IT人员,任何可以使用计算机访问Internet的人都可以轻松掌握它.
云采集
采集任务会自动分发到云中的多个服务器以同时执行,从而提高了采集效率,并可以在短时间内获取数千条信息.
拖放采集过程
模仿人的操作思维方式,可以登录,输入数据,单击链接,按钮等,并且可以针对不同情况采用不同的采集程序.
图像识别
内置可扩展的OCR界面,支持解析图片中的文本,并提取图片中的文本.
定时自动采集
采集任务自动运行,可以根据指定的时间段自动采集,并且还支持每分钟一次的实时采集.
2分钟内快速入门
从入门到精通的内置视频教程,可以在2分钟内使用,并且还提供文档,论坛,qq小组等.
免费使用
它是免费的,免费版本没有功能限制. 您可以立即尝试,立即下载并安装.
功能介绍
简而言之,您可以使用优采云轻松地从任何网页上采集所需的数据,并生成自定义的常规数据格式. 优采云数据采集系统可以执行的操作包括但不限于以下内容:
1. 财务数据,例如季度报告,年度报告,财务报告,包括自动采集最新的每日净资产;
2. 实时监控主要新闻门户,自动更新和上传最新新闻;
3. 监视竞争对手的最新信息,包括商品价格和库存; 查看全部
您也是网站管理员吗?最好手动输入信息以建立网站〜采集到的东西在SEO中很差~~
绿色软件基础编辑器测试这是一个可以使您的信息采集非常简单的工具. 优采云改变了传统的互联网数据思考方式. 它使用户越来越容易地在Internet上获取信息. 优采云采集器是任何需要从Artifact网页上获取信息的孩子的必备工具

软件功能
简单的操作,完全可视化的图形操作,不需要专业的IT人员,任何可以使用计算机访问Internet的人都可以轻松掌握它.
云采集
采集任务会自动分发到云中的多个服务器以同时执行,从而提高了采集效率,并可以在短时间内获取数千条信息.
拖放采集过程
模仿人的操作思维方式,可以登录,输入数据,单击链接,按钮等,并且可以针对不同情况采用不同的采集程序.
图像识别
内置可扩展的OCR界面,支持解析图片中的文本,并提取图片中的文本.
定时自动采集
采集任务自动运行,可以根据指定的时间段自动采集,并且还支持每分钟一次的实时采集.
2分钟内快速入门
从入门到精通的内置视频教程,可以在2分钟内使用,并且还提供文档,论坛,qq小组等.
免费使用
它是免费的,免费版本没有功能限制. 您可以立即尝试,立即下载并安装.

功能介绍
简而言之,您可以使用优采云轻松地从任何网页上采集所需的数据,并生成自定义的常规数据格式. 优采云数据采集系统可以执行的操作包括但不限于以下内容:
1. 财务数据,例如季度报告,年度报告,财务报告,包括自动采集最新的每日净资产;
2. 实时监控主要新闻门户,自动更新和上传最新新闻;
3. 监视竞争对手的最新信息,包括商品价格和库存;
大黄蜂网页采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 522 次浏览 • 2020-08-08 20:04
软件简介
Bumblebee Web Collector是一个完全免费的工具,用于采集,处理和发布网络信息!它可以根据用户设置的规则自动批量采集网页,论坛,博客等的内容,并处理采集的数据并将其保存到数据库或发布到网站. 有需要的朋友可以下载并体验它!
软件功能
支持登录网站采集,提交采集,脚本网页采集,动态网页采集,您可以在几秒钟内下载整个网站页面,支持文本文件存储,支持市场上主流的数据库存储,我们的产品已经精心策划而Design可以节省您的时间和精力.
信息采集技术的应用
网络数据挖掘:
通过从特定网站采集有用的数据,将数据存储为文本文件或数据格式,然后您可以分析,处理和过滤这些数据以获得有价值的数据.
网站内容管理:
您的网站没有信息或内容!怎么做?定期采集新闻,文章和其他信息,然后将此信息发布到您的网站以丰富您的网站内容.
网络信息监视:
通过自动采集,您可以监视论坛和社区网站,掌握整个网络的民意和需求方向,并为您的决策提供有力的支持.
软件说明
大黄蜂网页采集器在每个网页上都有很多信息,包括文本,图片,音乐,视频等. 对于网站管理员,博客作者和其他用户,这些信息数据非常重要,那么如何采集此数据并使用它供您自己使用?大黄蜂采集器派上用场.
软件屏幕截图
相关软件
Zuntian网页采集器: 这是Zuntian网页采集器. 现在市场上充斥着一些付费的网页采集器. 无论其功能是什么,这种免费的绿色免费网页采集器都是很少见的. 上!
Feiying网页采集和爬网系统: 这是Feiying网页采集和爬网系统. 它是市场上独一无二的实用下载商店专业mp3下载软件. 它具有全面的下载功能,涵盖所有下载服务,并且是下载服务的最佳助手. 查看全部
这是Hornet网页采集器,这是一个完全免费的工具,用于采集,处理和发布网络信息!可以根据用户设置的规则自动批量采集网页,论坛,博客等内容,并且可以对采集的数据进行处理并保存到数据库或发布到网站.
软件简介
Bumblebee Web Collector是一个完全免费的工具,用于采集,处理和发布网络信息!它可以根据用户设置的规则自动批量采集网页,论坛,博客等的内容,并处理采集的数据并将其保存到数据库或发布到网站. 有需要的朋友可以下载并体验它!
软件功能
支持登录网站采集,提交采集,脚本网页采集,动态网页采集,您可以在几秒钟内下载整个网站页面,支持文本文件存储,支持市场上主流的数据库存储,我们的产品已经精心策划而Design可以节省您的时间和精力.
信息采集技术的应用
网络数据挖掘:
通过从特定网站采集有用的数据,将数据存储为文本文件或数据格式,然后您可以分析,处理和过滤这些数据以获得有价值的数据.
网站内容管理:
您的网站没有信息或内容!怎么做?定期采集新闻,文章和其他信息,然后将此信息发布到您的网站以丰富您的网站内容.
网络信息监视:
通过自动采集,您可以监视论坛和社区网站,掌握整个网络的民意和需求方向,并为您的决策提供有力的支持.
软件说明
大黄蜂网页采集器在每个网页上都有很多信息,包括文本,图片,音乐,视频等. 对于网站管理员,博客作者和其他用户,这些信息数据非常重要,那么如何采集此数据并使用它供您自己使用?大黄蜂采集器派上用场.
软件屏幕截图

相关软件
Zuntian网页采集器: 这是Zuntian网页采集器. 现在市场上充斥着一些付费的网页采集器. 无论其功能是什么,这种免费的绿色免费网页采集器都是很少见的. 上!
Feiying网页采集和爬网系统: 这是Feiying网页采集和爬网系统. 它是市场上独一无二的实用下载商店专业mp3下载软件. 它具有全面的下载功能,涵盖所有下载服务,并且是下载服务的最佳助手.
[58个相同城市] Web爬虫软件,优采云采集器获得58个相同城市的出租信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 383 次浏览 • 2020-08-08 18:39
我刚刚介绍了老板要求我的朋友绍捷采集有关同一城市58家房地产的信息. 但是实际上,除了传统的复制粘贴之外,实际上还有一个非常简单易用的妙招,那就是使用优采云采集器采集了58个出租信息,今天小蔡将与大家分享这种方法.
[58个相同城市] Web爬虫软件,又才云采集器获得了58个相同城市的租赁信息. Rar
1. 打开58合肥市出租网站
2. 根据URL和源代码制定采集规则
1. 网址设置:
URL测试结果如下:
二,内容获取设置:
1. 捕获之前和之后:
2. 多页设置:
结果如下:
手机号是从手机网站上获得的,可以在源代码中找到.
3. 运行任务的结果如下:
嗯,这是一个简单而实用的操作,不是很方便吗?
优采云采集器不仅可以为您节省整套繁琐而复杂的复制和粘贴过程,还可以使您的工作效率提高一倍,并在老板面前脱颖而出.
如果您想自己租房子,优采云采集器也是一个“租赁产品”,可以节省您一半以上的在线观看时间!
爱情秘诀:
1.58您可以在同一城市采集电话信息吗?
答案: 在同一城市中有两种呼叫方式. 一种是直接在页面上显示电话信息,可以采集该信息.
第二个是您需要扫描代码以查看无法采集的电话信息(不能突破QR码扫描的限制)
2.58使用优采云采集器采集同一城市中的信息有什么局限性?
回答: 如果58个相同的城市长时间采集,则计算机IP将被阻止. 可以设置这种代理IP(可以从第三方平台购买代理IP)
3. 可以通过输入58个相同的城市地址来自动采集云彩吗?
回答: 否,优采云采集器需要为不同的列设置规则,因为每个列都有不同的采集规则,只有与不同列对应的规则才能准确采集
联系我们
客户服务QQ: 800019423
客户服务电话:
购买软件: 查看全部
我刚刚介绍了老板要求我的朋友绍捷采集有关同一城市58家房地产的信息. 但是实际上,除了传统的复制粘贴之外,实际上还有一个非常简单易用的妙招,那就是使用优采云采集器采集了58个出租信息,今天小蔡将与大家分享这种方法.
[58个相同城市] Web爬虫软件,又才云采集器获得了58个相同城市的租赁信息. Rar
1. 打开58合肥市出租网站
2. 根据URL和源代码制定采集规则
1. 网址设置:
URL测试结果如下:
二,内容获取设置:
1. 捕获之前和之后:
2. 多页设置:
结果如下:
手机号是从手机网站上获得的,可以在源代码中找到.
3. 运行任务的结果如下:
嗯,这是一个简单而实用的操作,不是很方便吗?
优采云采集器不仅可以为您节省整套繁琐而复杂的复制和粘贴过程,还可以使您的工作效率提高一倍,并在老板面前脱颖而出.
如果您想自己租房子,优采云采集器也是一个“租赁产品”,可以节省您一半以上的在线观看时间!
爱情秘诀:
1.58您可以在同一城市采集电话信息吗?
答案: 在同一城市中有两种呼叫方式. 一种是直接在页面上显示电话信息,可以采集该信息.
第二个是您需要扫描代码以查看无法采集的电话信息(不能突破QR码扫描的限制)
2.58使用优采云采集器采集同一城市中的信息有什么局限性?
回答: 如果58个相同的城市长时间采集,则计算机IP将被阻止. 可以设置这种代理IP(可以从第三方平台购买代理IP)
3. 可以通过输入58个相同的城市地址来自动采集云彩吗?
回答: 否,优采云采集器需要为不同的列设置规则,因为每个列都有不同的采集规则,只有与不同列对应的规则才能准确采集
联系我们
客户服务QQ: 800019423
客户服务电话:
购买软件:
网页数据采集器下载,最新版本的Teleport Ultra v1.72
采集交流 • 优采云 发表了文章 • 0 个评论 • 745 次浏览 • 2020-08-08 17:47
Teleport Ultra安装教程
1. 首先从小型下载站下载Teleport Ultra v1.72安装程序包,双击将其打开
2,选择安装位置
3. 完成安装并运行软件
4. 进入软件主界面
软件功能
1. 将网站的全部或部分下载到您的计算机上,以便您可以直接从硬盘上浏览网站,其速度要比在线浏览网站快
2,创建精确的副本或网站镜像,完成子目录结构和所有必需的文件
3. 在网站上搜索特定类型和大小的文件
4. 下载已知地址的文件列表
5. 浏览从中央网站链接的每个网站
6. 在网站上搜索关键字
7. 列出网站上的所有页面和文件
软件功能
1. 使用正则表达式指定要收录的收录和排除区域
2,指定用于对具有多个名称的服务器进行爬网的域别名
3. 借用浏览器的cookie缓存,以使您可以使用浏览器执行复杂的身份验证,然后使用Teleport进行爬网
4. 将自定义HTTP标头注入服务器请求
5. 同步离线副本以自动删除旧文件和孤儿
6. 重写未搜索文件的链接时,使用可自定义的消息
7. 使用原创URL和检索日期/时间戳控制HTML标签并注入meta标签
8,可以对HTTPS(安全)服务器进行爬网
常见问题
1. Teleport可以在Windows操作系统上运行吗?
是的,它适用于所有Win32操作系统,包括Windows 95、98,Me,NT,2000,XP,2003,Vista,2008,Windows 7和Windows8. 不适用于Windows 3.1或更早版本.
2. Teleport可以下载ASP,PHP或其他动态生成的网站吗?
是的,Teleport可以处理ASP,PHP,CGI,Cold Fusion和所有其他类型的动态生成的网页. 服务器像其他页面一样,将这些页面作为HTML发送到Teleport,并且Teleport像HTML一样接收和处理它们. Teleport无法从这些页面获取服务器端代码-此信息无法通过Web服务器获得. 但是,它可以像处理其他任何网页一样处理这些类型的网页.
3. Teleport可以处理诸如Javascript或“ onclick”事件之类的事件吗?
是的,从URL版本1.29.1847开始,Teleport可以处理简单的脚本命令,例如window.open(...)和location.href = ...,只要URL参数只是带引号的string即可. 当Teleport出现在诸如onclick事件之类的事件中时,它甚至会处理这些命令. 但是,该程序无法处理更复杂的脚本,例如调用由脚本定义的功能的脚本或打开由计算或连接字符串创建的URL的脚本. 要启用脚本解析,必须在“项目属性”的“探索”页面中将用于处理脚本和事件代码的选项设置为“开”. (默认情况下启用此选项. )
4. 瞬移可以处理“ cookie”吗?
是的,从1.29.1847版本开始,Teleport可以处理cookie. 只要在“项目属性”的“探索”页面上启用了此选项,Teleport就会接受并返回cookie. (默认情况下启用此选项. )
5. 瞬移可以处理Shockwave或Flash小程序吗?
从1.29.1718版本开始,Teleport将加载明确标识为对象参数的Flash或Shockwave电影. 但是,Teleport不会读取Flash或Shockwave小程序(.swf文件)来查找小程序可能链接到的其他文件.
6. Teleport可以处理NTLM身份验证吗?
不简单. NTLM身份验证是Teleport不支持的Microsoft特定身份验证形式. 如果可以控制要复制的Web服务器,则可以对其进行更改以允许基本身份验证,这是Internet上使用的常规身份验证形式. 如果需要,可以将服务器设置为允许Basic和NTLM. 有时Web服务器确实接受基本身份验证,但会误解您的用户名. 您可以尝试使用以下格式之一指定用户名,其中一种可能有效: 用户名/域名,用户名\域名,域/用户名,域\用户名. 最后,另一种解决方案是使用Python NTLM身份验证代理服务器应用程序,该应用程序可在以下位置找到. 安装Python(免费下载),解压缩NTLMAPS zip文件,使用代理服务器详细信息(ip,端口,用户名,域名,密码)配置server.cfg文件. 然后将Teleport配置为使用127.0.0.1作为代理,并使用cfg文件中的LISTEN端口号.
7. 如何将Teleport项目移动到另一个位置或其他硬盘上?
移动项目,移动(或复制)项目文件(.tpp文件)和项目文件夹(与项目名称相同,并且位于相同位置). 只要项目文件及其文件夹位于同一位置,Teleport就会知道如何找到所需的一切.
更新日志
版本1.72
1. 改进了解析器以更好地处理脚本中的字符串
2. 从重写过程中删除已知的问题脚本(jquery,addthis)
3. 更新公司联系信息
版本1.71
1. 改进了解析器,更好地处理了jQuery
2. 修复了HTTPS系统中的错误,该错误会在某些服务器的早期中断连接 查看全部
Teleport Ultra是一个Web数据采集器,您可以将其用作采集器软件. 它的功能非常强大,可以扫描数十万个地址并处理一个项目中的多台服务器,从而可以提高吞吐量,效果非常明显. 有兴趣的用户可以下载并尝试.

Teleport Ultra安装教程
1. 首先从小型下载站下载Teleport Ultra v1.72安装程序包,双击将其打开

2,选择安装位置

3. 完成安装并运行软件

4. 进入软件主界面
软件功能
1. 将网站的全部或部分下载到您的计算机上,以便您可以直接从硬盘上浏览网站,其速度要比在线浏览网站快
2,创建精确的副本或网站镜像,完成子目录结构和所有必需的文件
3. 在网站上搜索特定类型和大小的文件
4. 下载已知地址的文件列表
5. 浏览从中央网站链接的每个网站
6. 在网站上搜索关键字
7. 列出网站上的所有页面和文件
软件功能
1. 使用正则表达式指定要收录的收录和排除区域
2,指定用于对具有多个名称的服务器进行爬网的域别名
3. 借用浏览器的cookie缓存,以使您可以使用浏览器执行复杂的身份验证,然后使用Teleport进行爬网
4. 将自定义HTTP标头注入服务器请求
5. 同步离线副本以自动删除旧文件和孤儿
6. 重写未搜索文件的链接时,使用可自定义的消息
7. 使用原创URL和检索日期/时间戳控制HTML标签并注入meta标签
8,可以对HTTPS(安全)服务器进行爬网
常见问题
1. Teleport可以在Windows操作系统上运行吗?
是的,它适用于所有Win32操作系统,包括Windows 95、98,Me,NT,2000,XP,2003,Vista,2008,Windows 7和Windows8. 不适用于Windows 3.1或更早版本.
2. Teleport可以下载ASP,PHP或其他动态生成的网站吗?
是的,Teleport可以处理ASP,PHP,CGI,Cold Fusion和所有其他类型的动态生成的网页. 服务器像其他页面一样,将这些页面作为HTML发送到Teleport,并且Teleport像HTML一样接收和处理它们. Teleport无法从这些页面获取服务器端代码-此信息无法通过Web服务器获得. 但是,它可以像处理其他任何网页一样处理这些类型的网页.
3. Teleport可以处理诸如Javascript或“ onclick”事件之类的事件吗?
是的,从URL版本1.29.1847开始,Teleport可以处理简单的脚本命令,例如window.open(...)和location.href = ...,只要URL参数只是带引号的string即可. 当Teleport出现在诸如onclick事件之类的事件中时,它甚至会处理这些命令. 但是,该程序无法处理更复杂的脚本,例如调用由脚本定义的功能的脚本或打开由计算或连接字符串创建的URL的脚本. 要启用脚本解析,必须在“项目属性”的“探索”页面中将用于处理脚本和事件代码的选项设置为“开”. (默认情况下启用此选项. )
4. 瞬移可以处理“ cookie”吗?
是的,从1.29.1847版本开始,Teleport可以处理cookie. 只要在“项目属性”的“探索”页面上启用了此选项,Teleport就会接受并返回cookie. (默认情况下启用此选项. )
5. 瞬移可以处理Shockwave或Flash小程序吗?
从1.29.1718版本开始,Teleport将加载明确标识为对象参数的Flash或Shockwave电影. 但是,Teleport不会读取Flash或Shockwave小程序(.swf文件)来查找小程序可能链接到的其他文件.
6. Teleport可以处理NTLM身份验证吗?
不简单. NTLM身份验证是Teleport不支持的Microsoft特定身份验证形式. 如果可以控制要复制的Web服务器,则可以对其进行更改以允许基本身份验证,这是Internet上使用的常规身份验证形式. 如果需要,可以将服务器设置为允许Basic和NTLM. 有时Web服务器确实接受基本身份验证,但会误解您的用户名. 您可以尝试使用以下格式之一指定用户名,其中一种可能有效: 用户名/域名,用户名\域名,域/用户名,域\用户名. 最后,另一种解决方案是使用Python NTLM身份验证代理服务器应用程序,该应用程序可在以下位置找到. 安装Python(免费下载),解压缩NTLMAPS zip文件,使用代理服务器详细信息(ip,端口,用户名,域名,密码)配置server.cfg文件. 然后将Teleport配置为使用127.0.0.1作为代理,并使用cfg文件中的LISTEN端口号.
7. 如何将Teleport项目移动到另一个位置或其他硬盘上?
移动项目,移动(或复制)项目文件(.tpp文件)和项目文件夹(与项目名称相同,并且位于相同位置). 只要项目文件及其文件夹位于同一位置,Teleport就会知道如何找到所需的一切.
更新日志
版本1.72
1. 改进了解析器以更好地处理脚本中的字符串
2. 从重写过程中删除已知的问题脚本(jquery,addthis)
3. 更新公司联系信息
版本1.71
1. 改进了解析器,更好地处理了jQuery
2. 修复了HTTPS系统中的错误,该错误会在某些服务器的早期中断连接
Web Information Collector V1.1绿色免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2020-08-08 17:46
功能亮点:
1,执行任务
根据建立的任务信息保存并提取网页. 您也可以通过“双击”任务来启动此功能.
2,创建,复制,修改,删除任务
新建,复制,修改,删除任务信息
3. 默认选项
设置默认工作路径(默认为当前程序目录中的WorkDir文件夹)
设置提取测试的默认数量(默认为10)
设置默认的文本分隔符(默认为*)
4. 创建和编辑任务信息
任务名称: 在默认工作文件夹中生成一个以此名称命名的文件夹.
登录地址: 对于某些需要登录以查看其网页内容的网站,请填写登录页面地址. 执行任务时,软件将打开此登录页面,让您登录网站
常规格式类型网页,非常规格式类型网页:
此处的序数格式和非序数格式主要是指提取的地址是否只是数字更改. 例如,类似:
①并且属于顺序格式
②并且属于非常规格式
列表地址: 当类型为“非常规格式类型net”时,列表第一页的链接地址
提取地址: 由实际保存的网页地址+ *的公共部分组成.
例如,提取:
①然后提取地址为* .html
②然后提取地址为*. / *. html 查看全部
网页信息采集器(网页信息采集助手)是非常有用的网页信息采集器. 如何抓取网页信息?网页信息采集器(网页信息采集助手)可以为用户快速采集信息. 网页信息采集器功能强大且易于使用. 它可以轻松地采集某个网站的信息内容. 它可以根据已建立的任务信息保存和提取网页,也可以通过“双击”任务来启动此功能.
功能亮点:
1,执行任务
根据建立的任务信息保存并提取网页. 您也可以通过“双击”任务来启动此功能.
2,创建,复制,修改,删除任务
新建,复制,修改,删除任务信息
3. 默认选项
设置默认工作路径(默认为当前程序目录中的WorkDir文件夹)
设置提取测试的默认数量(默认为10)
设置默认的文本分隔符(默认为*)
4. 创建和编辑任务信息
任务名称: 在默认工作文件夹中生成一个以此名称命名的文件夹.
登录地址: 对于某些需要登录以查看其网页内容的网站,请填写登录页面地址. 执行任务时,软件将打开此登录页面,让您登录网站
常规格式类型网页,非常规格式类型网页:
此处的序数格式和非序数格式主要是指提取的地址是否只是数字更改. 例如,类似:
①并且属于顺序格式
②并且属于非常规格式
列表地址: 当类型为“非常规格式类型net”时,列表第一页的链接地址
提取地址: 由实际保存的网页地址+ *的公共部分组成.
例如,提取:
①然后提取地址为* .html
②然后提取地址为*. / *. html
SysNucleus WebHarvy(网页数据采集器)V5.2.0.155
采集交流 • 优采云 发表了文章 • 0 个评论 • 362 次浏览 • 2020-08-08 17:45
软件功能
1. SysNucleus WebHarvy允许您分析网页上的数据
2. 它可以显示和分析来自HTML地址的连接数据
3. 可以扩展到下一个网页
4. 您可以指定搜索数据的范围和内容
5. 您可以下载并保存扫描的图像
6. 支持在浏览器上复制链接搜索
7. 支持配置搜索对应的资源项
8,您可以使用项目名称和资源名称查找
9,SysNucleus WebHarvy可以轻松提取数据
10. 提供更高级的多词搜索和多页搜索
软件功能
1. 视觉点和点击界面
WebHarvy是一个可视网页提取工具. 实际上,无需编写任何脚本或代码来提取数据. 使用WebHarvy的内置浏览器浏览网络. 您可以选择单击鼠标提取数据. 很简单!
2. 智能识别模式
自动识别网页中出现的数据模式. 因此,如果您需要从网页上抓取项目列表(名称,地址,电子邮件,价格等),则无需进行任何其他配置. 如果数据重复,WebHarvy将自动对其进行刮擦.
3. 导出捕获的数据
可以保存从网页提取的各种格式的数据. 当前版本的WebHarvy网站抓取工具允许您将抓取的数据导出为XML,CSV,JSON或TSV文件. 您还可以将抓取的数据导出到SQL数据库.
4. 从多个页面中提取
通常,网页在多个页面上显示数据,例如产品目录. WebHarvy可以自动从多个网页爬网和提取数据. 刚刚指出“链接到下一页,WebHarvy网站抓取工具将自动从所有页面抓取数据.
5. 基于关键字的提取
基于关键字的提取使您可以捕获从搜索结果页面输入的关键字的列表数据. 挖掘数据时,将为所有给定的输入关键字自动重复创建的配置. 您可以指定任意数量的输入关键字. 6.通过生成{pass} {filter}服务器提取
要提取匿名信息并防止Web服务器提取Web软件,必须使用{pass} {filter}代理服务器访问目标网站选项. 您可以使用一个代理服务器地址或代理服务器地址列表.
7. 提取分类
WebHarvy网站抓取工具使您可以从链接列表中提取数据,这些链接可指向网站内的相似页面. 这样一来,您就可以使用一种配置来抓取网站中的类别或部分.
8. 使用正则表达式提取
WebHarvy可以在网页的文本或HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分. 这项强大的技术为您提供了更大的灵活性,同时您可以争夺数据. 查看全部
SysNucleus WebHarvy是一个非常易于使用的网页数据采集软件. 它可以帮助用户轻松地从网页中提取数据并将其保存为不同的格式. 它还支持提取各种类型的文件,例如视频和图片.
软件功能
1. SysNucleus WebHarvy允许您分析网页上的数据
2. 它可以显示和分析来自HTML地址的连接数据
3. 可以扩展到下一个网页
4. 您可以指定搜索数据的范围和内容
5. 您可以下载并保存扫描的图像
6. 支持在浏览器上复制链接搜索
7. 支持配置搜索对应的资源项
8,您可以使用项目名称和资源名称查找
9,SysNucleus WebHarvy可以轻松提取数据
10. 提供更高级的多词搜索和多页搜索
软件功能
1. 视觉点和点击界面
WebHarvy是一个可视网页提取工具. 实际上,无需编写任何脚本或代码来提取数据. 使用WebHarvy的内置浏览器浏览网络. 您可以选择单击鼠标提取数据. 很简单!
2. 智能识别模式
自动识别网页中出现的数据模式. 因此,如果您需要从网页上抓取项目列表(名称,地址,电子邮件,价格等),则无需进行任何其他配置. 如果数据重复,WebHarvy将自动对其进行刮擦.
3. 导出捕获的数据
可以保存从网页提取的各种格式的数据. 当前版本的WebHarvy网站抓取工具允许您将抓取的数据导出为XML,CSV,JSON或TSV文件. 您还可以将抓取的数据导出到SQL数据库.
4. 从多个页面中提取
通常,网页在多个页面上显示数据,例如产品目录. WebHarvy可以自动从多个网页爬网和提取数据. 刚刚指出“链接到下一页,WebHarvy网站抓取工具将自动从所有页面抓取数据.
5. 基于关键字的提取
基于关键字的提取使您可以捕获从搜索结果页面输入的关键字的列表数据. 挖掘数据时,将为所有给定的输入关键字自动重复创建的配置. 您可以指定任意数量的输入关键字. 6.通过生成{pass} {filter}服务器提取
要提取匿名信息并防止Web服务器提取Web软件,必须使用{pass} {filter}代理服务器访问目标网站选项. 您可以使用一个代理服务器地址或代理服务器地址列表.
7. 提取分类
WebHarvy网站抓取工具使您可以从链接列表中提取数据,这些链接可指向网站内的相似页面. 这样一来,您就可以使用一种配置来抓取网站中的类别或部分.
8. 使用正则表达式提取
WebHarvy可以在网页的文本或HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分. 这项强大的技术为您提供了更大的灵活性,同时您可以争夺数据.
优采云采集器·网络数据信息挖掘软件(www.ucaiyun.com)v9.6.5免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 389 次浏览 • 2020-08-08 03:10
该程序支持远程下载图片文件,登录网站后采集信息,检测文件的真实地址,支持代理,支持防盗链的采集,支持直接存储采集的数据和手册通过模仿人来释放,以及许多其他功能.
优采云采集器支持从任何类型的网站(例如各种新闻网站,论坛,电子商务网站,求职网站等)采集所需的信息.
同时,它具有强大的网站登录采集,多页和页面采集,网站跨层采集,POST采集,脚本页面采集,动态页面采集和其他高级采集功能.
强大的php和c#插件支持使您可以通过二次开发实现所需的任何更强大的功能.
软件功能
1. 强大的多功能性
无论新闻,论坛,视频,黄页,图片,下载网站如何,只要可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集所需的内容.
2,稳定高效
五年磨一剑,软件不断更新和完善,采集速度快,性能稳定,资源少.
3. 强大的可扩展性和广泛的应用范围
自定义Web发布,自定义主流数据库的保存和发布,自定义本地PHP和.net外部编程接口以处理数据,以便您可以使用这些数据.
基本功能
1. 规则的自定义-通过采集规则的定义,您可以搜索所有网站以采集几乎任何类型的信息.
2. 多任务,多线程,多个信息采集任务可以同时执行,每个任务可以使用多个线程.
3. 您所看到的就是您所得到的-您所看到的就是您在任务采集过程中所得到的,并且在此过程中遍历的链接信息,采集信息和错误信息将及时反映在软件界面中.
4. 数据存储数据在采集时会自动保存到关系数据库中,并且数据结构可以自动调整. 该软件可以根据采集规则自动创建数据库以及其中的表和字段,或者可以由数据库灵活地指导将数据保存到客户现有的数据库结构中.
5. 在断点处继续采集-停止后,可以继续从断点采集信息采集任务. 从那时起,您不必担心采集任务会意外中断.
6. 网站登录-支持采集网站Cookie和可视网站登录,甚至可以采集登录时需要验证码的网站.
7. 计划任务-此功能可让您定期,定量或循环执行采集任务.
8. 采集范围的限制-可以根据采集的深度和网站徽标来限制采集范围.
9. 文件下载-您可以将采集的二进制文件(例如图片,音乐,软件,文档等)下载到本地磁盘或采集结果数据库中.
10. 结果替换-您可以根据规则用定义的内容替换采集的结果.
11. 条件保存-您可以根据特定条件决定要保存和过滤哪些信息.
12. 过滤重复内容-该软件可以根据用户设置和实际情况自动删除重复内容和重复URL.
13. 特殊链接识别-使用此功能可以识别由JavaScript动态生成的链接或其他怪异链接.
14. 数据发布-可以通过自定义界面将采集到的结果数据发布到任何内容管理系统和指定的数据库中. 当前支持的目标发布媒体包括: 数据库(访问,SQL Server,我的SQL,Oracle),静态htm文件.
15. 保留的编程接口-定义多个编程接口,用户可以在事件中使用PHP,C#语言进行编程,扩展采集功能.
功能
1. 支持所有网站编码: 它完美支持所有编码格式的网页的采集,并且该程序还可以自动识别网页编码.
2. 多种发布方式: 支持当前所有主流和非主流CMS,BBS和其他网站程序,并且可以通过系统的发布模块实现采集器和网站程序的完美结合.
3. 全自动: 无人值守的工作. 配置该程序后,该程序将根据您的设置自动运行,而无需人工干预. 查看全部
该软件非常实用〜无论您是否使用过,建议您使用它. 专业而强大的网络数据/信息挖掘软件. 通过灵活的配置,您可以轻松地从Web上获取它. 任何资源,例如文本,图片,文件等.

该程序支持远程下载图片文件,登录网站后采集信息,检测文件的真实地址,支持代理,支持防盗链的采集,支持直接存储采集的数据和手册通过模仿人来释放,以及许多其他功能.
优采云采集器支持从任何类型的网站(例如各种新闻网站,论坛,电子商务网站,求职网站等)采集所需的信息.
同时,它具有强大的网站登录采集,多页和页面采集,网站跨层采集,POST采集,脚本页面采集,动态页面采集和其他高级采集功能.
强大的php和c#插件支持使您可以通过二次开发实现所需的任何更强大的功能.
软件功能
1. 强大的多功能性
无论新闻,论坛,视频,黄页,图片,下载网站如何,只要可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集所需的内容.
2,稳定高效
五年磨一剑,软件不断更新和完善,采集速度快,性能稳定,资源少.
3. 强大的可扩展性和广泛的应用范围
自定义Web发布,自定义主流数据库的保存和发布,自定义本地PHP和.net外部编程接口以处理数据,以便您可以使用这些数据.
基本功能
1. 规则的自定义-通过采集规则的定义,您可以搜索所有网站以采集几乎任何类型的信息.
2. 多任务,多线程,多个信息采集任务可以同时执行,每个任务可以使用多个线程.
3. 您所看到的就是您所得到的-您所看到的就是您在任务采集过程中所得到的,并且在此过程中遍历的链接信息,采集信息和错误信息将及时反映在软件界面中.
4. 数据存储数据在采集时会自动保存到关系数据库中,并且数据结构可以自动调整. 该软件可以根据采集规则自动创建数据库以及其中的表和字段,或者可以由数据库灵活地指导将数据保存到客户现有的数据库结构中.
5. 在断点处继续采集-停止后,可以继续从断点采集信息采集任务. 从那时起,您不必担心采集任务会意外中断.
6. 网站登录-支持采集网站Cookie和可视网站登录,甚至可以采集登录时需要验证码的网站.
7. 计划任务-此功能可让您定期,定量或循环执行采集任务.
8. 采集范围的限制-可以根据采集的深度和网站徽标来限制采集范围.
9. 文件下载-您可以将采集的二进制文件(例如图片,音乐,软件,文档等)下载到本地磁盘或采集结果数据库中.
10. 结果替换-您可以根据规则用定义的内容替换采集的结果.
11. 条件保存-您可以根据特定条件决定要保存和过滤哪些信息.
12. 过滤重复内容-该软件可以根据用户设置和实际情况自动删除重复内容和重复URL.
13. 特殊链接识别-使用此功能可以识别由JavaScript动态生成的链接或其他怪异链接.
14. 数据发布-可以通过自定义界面将采集到的结果数据发布到任何内容管理系统和指定的数据库中. 当前支持的目标发布媒体包括: 数据库(访问,SQL Server,我的SQL,Oracle),静态htm文件.
15. 保留的编程接口-定义多个编程接口,用户可以在事件中使用PHP,C#语言进行编程,扩展采集功能.
功能
1. 支持所有网站编码: 它完美支持所有编码格式的网页的采集,并且该程序还可以自动识别网页编码.
2. 多种发布方式: 支持当前所有主流和非主流CMS,BBS和其他网站程序,并且可以通过系统的发布模块实现采集器和网站程序的完美结合.
3. 全自动: 无人值守的工作. 配置该程序后,该程序将根据您的设置自动运行,而无需人工干预.
优采云采集器v2.4.9.0免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 352 次浏览 • 2020-08-08 00:33
软件功能
一键式数据提取
易于学习,通过可视界面,只需单击鼠标即可捕获数据
快速高效
内置一组高速浏览器内核,再加上HTTP引擎模式,以实现快速数据采集
适用于各种网站
可以采集99%的Internet站点,包括单页应用程序Ajax加载和其他动态站点
功能介绍
向导模式
易于使用,易于通过单击鼠标自动生成
脚本定期运行
可以按计划定期运行,而无需手动
原创高速内核
自主开发的浏览器内核速度很快,远远超出了对手
智能识别
智能识别网页中的列表和表单结构(多选框下拉列表等)
广告屏蔽
自定义广告阻止模块,与AdblockPlus语法兼容,可以添加自定义规则
多个数据导出
支持Txt,Excel,MySQL,SQLServer,SQlite,Access,网站等.
使用方法
第一步: 输入采集网址
打开软件,创建一个新任务,然后输入要采集的网站地址.
第2步: 智能分析,在整个过程中自动提取数据
进入第二步后,优采云采集器会自动智能地分析网页并从中提取列表数据.
第3步: 将数据导出到表格,数据库,网站等
运行任务,将采集的数据导出到Csv,Excel和各种数据库,并支持api导出.
常见问题
问: 如何过滤列表中的前N个数据?
1. 有时我们需要过滤采集到的列表,例如过滤掉第一组数据(采集表时,过滤掉表的列名)
2. 在列表模式菜单中单击,设置列表xpath
问: 如何捕获cookie以获取cookie并进行手动设置?
1. 首先,使用Google Chrome浏览器打开要采集的网站并登录.
2. 然后按F12键,将出现开发人员工具,选择“网络”
3. 然后按F5刷新下一页,然后选择一个请求.
4. 复制完成后,在优采云采集器中编辑任务,然后输入第三步以指定HTTP标头. 查看全部
优采云采集器 V2是高效的Web信息采集软件,支持99%的网站数据采集. 优采云采集器可以生成Excel表,api数据库文件和其他内容,以帮助您管理网站数据信息. 您需要从指定的网页上采集数据,只需使用此软件即可.

软件功能
一键式数据提取
易于学习,通过可视界面,只需单击鼠标即可捕获数据
快速高效
内置一组高速浏览器内核,再加上HTTP引擎模式,以实现快速数据采集
适用于各种网站
可以采集99%的Internet站点,包括单页应用程序Ajax加载和其他动态站点
功能介绍
向导模式
易于使用,易于通过单击鼠标自动生成
脚本定期运行
可以按计划定期运行,而无需手动
原创高速内核
自主开发的浏览器内核速度很快,远远超出了对手
智能识别
智能识别网页中的列表和表单结构(多选框下拉列表等)
广告屏蔽
自定义广告阻止模块,与AdblockPlus语法兼容,可以添加自定义规则
多个数据导出
支持Txt,Excel,MySQL,SQLServer,SQlite,Access,网站等.
使用方法
第一步: 输入采集网址
打开软件,创建一个新任务,然后输入要采集的网站地址.
第2步: 智能分析,在整个过程中自动提取数据
进入第二步后,优采云采集器会自动智能地分析网页并从中提取列表数据.
第3步: 将数据导出到表格,数据库,网站等
运行任务,将采集的数据导出到Csv,Excel和各种数据库,并支持api导出.
常见问题
问: 如何过滤列表中的前N个数据?
1. 有时我们需要过滤采集到的列表,例如过滤掉第一组数据(采集表时,过滤掉表的列名)
2. 在列表模式菜单中单击,设置列表xpath
问: 如何捕获cookie以获取cookie并进行手动设置?
1. 首先,使用Google Chrome浏览器打开要采集的网站并登录.
2. 然后按F12键,将出现开发人员工具,选择“网络”
3. 然后按F5刷新下一页,然后选择一个请求.
4. 复制完成后,在优采云采集器中编辑任务,然后输入第三步以指定HTTP标头.
Sage网站采集器V5.2.3
采集交流 • 优采云 发表了文章 • 0 个评论 • 281 次浏览 • 2020-08-07 23:28
[基本介绍] 1. Sage网站采集器简单易用,它是绿色软件,无需安装,下载并解压缩后即可使用; 2.实用性强,内置网站采集功能; 3.只需输入搜索关键字,您就可以采集成千上万的数据和信息,然后生成一个网站; 4.您可以选择“新闻,文章,电影,视频,图片,关键字”采集选项来采集和定位; 5.用Google生成网站地图. 6.您可以将生成的网站路径,目录名称,文件前缀,后缀名称设置为HI; 7. 12套模板供您选择和匹配,生成的网站不再单一; 8. SEO优化了一些网站管理员将内容插入到Google广告连接参数中; 9.优化了在文章内容中随机插入大量关键词的功能; 10.生成的网站语言代码可以随机设置(简体,繁体,UTF-8); 11.网站广告的采集和生成可以随意设置(耦合,浮动,底端); 12.附加的HtmlJs交换功能,方便网站管理员使用; [软件功能] 1.采集对象不受限制,只要可以连接页面即可(该软件设置了N个多重采集规则);问题: 如果您想采集有关您认为良好的特定网站的信息,请参阅“图腾网站采集软件”. 它可以自定义规则并设置采集蜘蛛. 2.采集对象支持: 文章,图片,Flash,音频和视频等. 3.完善的内容存储解决方案,Sage Collector提供了2种存储方法: 直接数据库指导和模拟提交. 1)直接数据库引导方法支持基于Mysql数据库存储信息的任何内容管理系统; 2)模拟提交方法理论上可以支持任何目标,并且不受目标程序语言和数据库类别的限制;实际使用效果受目标应用程序的影响.
Content Grabber Premium v2.48 Web内容采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 772 次浏览 • 2020-08-07 22:44
基本介绍
Content Grabber Premium(Web Content Grabber Premium)是由外国神灵制成的人工制品,可以从网页中获取内容(视频,图片,文本)并将其提取到Excel,XML,CSV和大多数数据库中. 该软件基于Web爬行和Web自动化. 它是完全免费的,并且经常用于数据调查和测试目的.
功能介绍
价格比较门户/移动应用程序
-数据摘要
-合作列表(例如房屋止赎,工作委员会,旅游景点)
-新闻和内容汇总
-搜索引擎排名
市场情报和监控
-有竞争力的价格
-零售链监控
-社交媒体和品牌监控
-金融与市场研究
-欺诈识别
-知识产权保护
-合规与风险管理
政府解决方案
-及时获取来自世界各地的新闻,事件和意见
-减少数据采集和IT成本
-促进信息共享
-开源情报(OSINT)
内容集成
-内容迁移(即CMS / CRM)
-企业搜索
-传统应用程序集成
B2B集成/流程自动化
-合作伙伴/供应商/客户集成
可扩展性和可靠性
内容采集器针对的是对网络搜寻至关重要的公司,并专注于可伸缩性和可靠性. 该网络收录大量数据,借助多线程,优化的Web浏览器和许多其他性能调整选项,Content Grabber将比任何其他软件更快,更可靠地提取. 我们强大的测试和调试功能可以帮助您构建可靠的代理,可靠的错误处理和错误恢复将使代理在最困难的情况下运行.
建立数百种网页抓取代理
“ Content Crawler”代理编辑器的易用性和可视化使其适合于构建数百个Web爬网代理,比使用任何其他软件要快得多.
代理编辑器将自动检测和配置所需的命令. 它会自动创建内容和链接列表,处理分页和Web表单,下载或上传文件,并配置您在网页上执行的任何其他操作. 同时,您始终可以手动微调这些命令,因此“内容抓取器”为您提供了简单性和控制性.
有数百种Web爬网程序,您需要使用正确的工具来管理这些工具,并且爬网内容不会使您失望. 您可以查看所有代理的状态和日志,也可以在集中位置运行和安排代理.
净刮除剂的使用费分配免费
构建免版税,独立的Web爬网代理,该代理可以在没有“内容爬网程序”软件的情况下在任何地方运行. 独立代理是一个简单的可执行文件,可以随时随地发送或复制,并具有丰富的配置选项. 您可以自由出售或赠送独立代理商,也可以在代理商的用户界面中添加促销信息和广告.
使用脚本自定义所有内容
脚本是“内容获取器”不可或缺的一部分,可用于需要某些特殊功能才能完全按照需要完成所有操作的情况. 使用内置脚本编辑器,或使用Content Grabber和Visual Studio的集成来实现更强大的脚本编辑和调试功能.
使用API构建独特的解决方案
将网络抓取功能添加到自己的桌面应用程序中,并免费分发应用程序的Content Grabber运行时. 使用专用的内容采集器Web API来构建Web应用程序,并根据需要直接从您的网站直接执行Web抓取代理.
系统要求
在安装内容采集器之前,请确保您满足这些要求.
Windows 7/8/10 / 2008R2 / 2012 / 2012R2
.NET v4.5(如果您的计算机尚未安装,则将自动安装. )
安装步骤
1. 从该站点提供的百度网站下载该软件,解压后,双击“ setup.exe”程序
2. 如果计算机上未安装Microsoft .NET版本,则安装程序将显示Microsoft .NET 4.5许可协议,并将自动为您安装
3,接受许可协议并安装
4. 按照提示在安装向导中进行安装 查看全部
Content Grabber Premium是用于Web爬网和Web自动化的Web内容采集工具. 它可以按照您选择的格式从几乎任何网站中提取内容(包括Excel报告,XML,CSV和大型大多数数据库),并将其另存为结构化数据,欢迎有需要的朋友下载和使用.
基本介绍
Content Grabber Premium(Web Content Grabber Premium)是由外国神灵制成的人工制品,可以从网页中获取内容(视频,图片,文本)并将其提取到Excel,XML,CSV和大多数数据库中. 该软件基于Web爬行和Web自动化. 它是完全免费的,并且经常用于数据调查和测试目的.
功能介绍
价格比较门户/移动应用程序
-数据摘要
-合作列表(例如房屋止赎,工作委员会,旅游景点)
-新闻和内容汇总
-搜索引擎排名
市场情报和监控
-有竞争力的价格
-零售链监控
-社交媒体和品牌监控
-金融与市场研究
-欺诈识别
-知识产权保护
-合规与风险管理
政府解决方案
-及时获取来自世界各地的新闻,事件和意见
-减少数据采集和IT成本
-促进信息共享
-开源情报(OSINT)
内容集成
-内容迁移(即CMS / CRM)
-企业搜索
-传统应用程序集成
B2B集成/流程自动化
-合作伙伴/供应商/客户集成
可扩展性和可靠性
内容采集器针对的是对网络搜寻至关重要的公司,并专注于可伸缩性和可靠性. 该网络收录大量数据,借助多线程,优化的Web浏览器和许多其他性能调整选项,Content Grabber将比任何其他软件更快,更可靠地提取. 我们强大的测试和调试功能可以帮助您构建可靠的代理,可靠的错误处理和错误恢复将使代理在最困难的情况下运行.
建立数百种网页抓取代理
“ Content Crawler”代理编辑器的易用性和可视化使其适合于构建数百个Web爬网代理,比使用任何其他软件要快得多.
代理编辑器将自动检测和配置所需的命令. 它会自动创建内容和链接列表,处理分页和Web表单,下载或上传文件,并配置您在网页上执行的任何其他操作. 同时,您始终可以手动微调这些命令,因此“内容抓取器”为您提供了简单性和控制性.
有数百种Web爬网程序,您需要使用正确的工具来管理这些工具,并且爬网内容不会使您失望. 您可以查看所有代理的状态和日志,也可以在集中位置运行和安排代理.
净刮除剂的使用费分配免费
构建免版税,独立的Web爬网代理,该代理可以在没有“内容爬网程序”软件的情况下在任何地方运行. 独立代理是一个简单的可执行文件,可以随时随地发送或复制,并具有丰富的配置选项. 您可以自由出售或赠送独立代理商,也可以在代理商的用户界面中添加促销信息和广告.
使用脚本自定义所有内容
脚本是“内容获取器”不可或缺的一部分,可用于需要某些特殊功能才能完全按照需要完成所有操作的情况. 使用内置脚本编辑器,或使用Content Grabber和Visual Studio的集成来实现更强大的脚本编辑和调试功能.
使用API构建独特的解决方案
将网络抓取功能添加到自己的桌面应用程序中,并免费分发应用程序的Content Grabber运行时. 使用专用的内容采集器Web API来构建Web应用程序,并根据需要直接从您的网站直接执行Web抓取代理.
系统要求
在安装内容采集器之前,请确保您满足这些要求.
Windows 7/8/10 / 2008R2 / 2012 / 2012R2
.NET v4.5(如果您的计算机尚未安装,则将自动安装. )
安装步骤
1. 从该站点提供的百度网站下载该软件,解压后,双击“ setup.exe”程序
2. 如果计算机上未安装Microsoft .NET版本,则安装程序将显示Microsoft .NET 4.5许可协议,并将自动为您安装
3,接受许可协议并安装
4. 按照提示在安装向导中进行安装
如何编写优采云采集器的采集规则并采集页面图片中的文本?
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-08-07 22:42
优采云采集器如何采集内容页面的两个内容?: 这需要您的经验. 找到内容2和内容7与其他内容之间的差异,然后基于该差异采集规则. 例如,内容2和内容7在开头和结尾分别带有符号x和y,但是其他内容则没有,那么您可以编辑内容标签的规则以采集从x的开头到y的结尾的内容,以便您可以合并内容2和采集的内容7. 还可以使用正则表达式进行采集,这需要您对正则表达式有一定的了解和要求.
如何使用优采云采集器采集文章标题: 使用免费的Web数据采集器-优采云采集器轻松采集优采云采集器更适合新手网站管理员,只需将其拖放就可以了规则市场上有许多免费的现成规则可以直接下载和使用!
<p>如何使用优采云采集器采集网页图片. 详细的图形教程_: 优采云采集器通过两个步骤采集信息: 1.采集URL. 该步骤还告诉软件需要采集多少个网页,并给出特定的网页地址. 2.采集内容. 在拥有网站之后,您可以转到该网站来采集信息,但是网页上有很多信息,并且软件不知道您要采集什么. 采集内容... 查看全部
如何写优采云采集器的采集规则和采集页上图片中的文字?_: 我不得不说优采云很有用,但我认为它不是很有用. 只需编写这些采集规则. 有很多不清楚的事情要设置. 拿钱买,一开始客服很热情为您解答,一旦您付清钱,就可以购买,写下规则,确定,如果有任何疑问,请致电客服解决,结果已被延迟和延迟...
优采云采集器如何采集内容页面的两个内容?: 这需要您的经验. 找到内容2和内容7与其他内容之间的差异,然后基于该差异采集规则. 例如,内容2和内容7在开头和结尾分别带有符号x和y,但是其他内容则没有,那么您可以编辑内容标签的规则以采集从x的开头到y的结尾的内容,以便您可以合并内容2和采集的内容7. 还可以使用正则表达式进行采集,这需要您对正则表达式有一定的了解和要求.
如何使用优采云采集器采集文章标题: 使用免费的Web数据采集器-优采云采集器轻松采集优采云采集器更适合新手网站管理员,只需将其拖放就可以了规则市场上有许多免费的现成规则可以直接下载和使用!
<p>如何使用优采云采集器采集网页图片. 详细的图形教程_: 优采云采集器通过两个步骤采集信息: 1.采集URL. 该步骤还告诉软件需要采集多少个网页,并给出特定的网页地址. 2.采集内容. 在拥有网站之后,您可以转到该网站来采集信息,但是网页上有很多信息,并且软件不知道您要采集什么. 采集内容...
智能网络内容采集器v1.92
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-08-07 22:17
1. 底层HTTP方法用于快速,稳定地采集数据,并且可以构建多个任务和多个线程来同时从多个网站采集数据
2,用户可以随意导入和导出任务
3. 可以设置该任务的密码,并具有N页采集暂停,遇到特殊标记时采集暂停等多种破解反采集功能
4. 您可以直接输入网址,也可以通过JavaScript脚本生成网址,或通过关键字搜索来采集网址
5. 您可以使用登录采集方法来采集需要登录帐户才能查看的Web内容
6. 在N列中无限深入地采集内容和链接
7. 支持多种内容提取模式,您可以根据需要处理采集的内容,例如清除HTML,图片等.
8. 您可以编译自己的JAVASCRIPT脚本以提取网页的内容,并轻松实现内容的任何部分的采集
9. 可以根据设置的模板保存采集到的文本内容
10. 可以根据模板将多个文件保存到同一文件中
11. 针对网页的多个部分分别进行分页内容采集
12. 可以设置客户信息以模拟百度等搜索引擎采集目标网站的情况
13. 该软件是永久免费的
智能Web内容采集器v1.9更新:
内置软件URL已更新为
使用新的智能软件控件UI
向EMAIL功能添加用户反馈
添加直接将初始链接设置为最终内容页面处理功能的功能
增强内核功能,支持关键字搜索并替换POST中的关键字标签
优化获取核心
优化断开的拨号算法
优化重复数据删除工具的算法
修复了拨号显示IP错误的错误
修复了错误关键字被暂停或拨打时未重新采集错误页面的错误.
修复了受限内容的最大值为0时,最小值无法正确保存的问题. 查看全部
Smart Web Content Collector可以以多任务和多线程的方式采集任何网页上的任何指定文本内容,并执行所需的相应过滤和处理. 它可以通过搜索关键字来采集所需的指定搜索结果.
1. 底层HTTP方法用于快速,稳定地采集数据,并且可以构建多个任务和多个线程来同时从多个网站采集数据
2,用户可以随意导入和导出任务
3. 可以设置该任务的密码,并具有N页采集暂停,遇到特殊标记时采集暂停等多种破解反采集功能
4. 您可以直接输入网址,也可以通过JavaScript脚本生成网址,或通过关键字搜索来采集网址
5. 您可以使用登录采集方法来采集需要登录帐户才能查看的Web内容
6. 在N列中无限深入地采集内容和链接
7. 支持多种内容提取模式,您可以根据需要处理采集的内容,例如清除HTML,图片等.
8. 您可以编译自己的JAVASCRIPT脚本以提取网页的内容,并轻松实现内容的任何部分的采集
9. 可以根据设置的模板保存采集到的文本内容
10. 可以根据模板将多个文件保存到同一文件中
11. 针对网页的多个部分分别进行分页内容采集
12. 可以设置客户信息以模拟百度等搜索引擎采集目标网站的情况
13. 该软件是永久免费的
智能Web内容采集器v1.9更新:
内置软件URL已更新为
使用新的智能软件控件UI
向EMAIL功能添加用户反馈
添加直接将初始链接设置为最终内容页面处理功能的功能
增强内核功能,支持关键字搜索并替换POST中的关键字标签
优化获取核心
优化断开的拨号算法
优化重复数据删除工具的算法
修复了拨号显示IP错误的错误
修复了错误关键字被暂停或拨打时未重新采集错误页面的错误.
修复了受限内容的最大值为0时,最小值无法正确保存的问题.
遵天市网页采集器v1.0.1绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2020-08-07 21:53
此软件通过Internet采集网页信息. 有两个主要功能:
1,您可以在js之后采集动态信息.
2,您可以设置要采集的正则表达式.
此外,该软件具有内置的多种采集方案,分别对应于静态网页和动态网页.
该软件采集了官方网站上的图像(面部)搜索引擎数据,然后对其进行了索引.
使用步骤:
1. 输入URL,正常浏览网页并到达采集目标,单击工具栏上的“在js之后查看源代码”图标,以在执行js后显示网页的内容.
如果看不到相关内容,则可以稍等片刻,然后再次单击以确保执行了js代码. 通过浏览完整的网页源代码,我们可以确认
使用计划1或计划2. 如果可以通过更改URL的页码导航到下一页,请使用计划1;否则,请使用计划1. 如果您通过脚本动态更新页面的内容,
使用计划2.
2,单击工具栏上的“运行采集方案”图标,然后根据步骤1选择方案1或2. 如果已经存在方案1和2生成的downloadtotal.txt
文件,您还可以选择选项3. 填写必要的信息或表达式,单击“开始采集”按钮,系统将自动采集. 点击对话框中的“取消”
按钮关闭对话框而不启动采集任务.
3. 单击工具栏上的“停止采集方案”图标,系统将终止采集任务.
防止网页采集:
防止采集的第一种方法: 在文章的开头和结尾添加随机和未固定的内容. 网站采集人员通常在进行采集时指定起始位置和结束位置,并在中间截取内容.
例如,如果您文章的内容是“ Youxun Software Information Network”,则如何添加随机内容:
随机内容1+优讯软件信息网+随机内容2
注意: 随机内容1和随机内容2只需为每篇文章随机显示一个. 查看全部
现在市场上充斥着一些付费的网页采集器. 不管其功能是什么,如此绿色免费的网页采集器都是免费的!
此软件通过Internet采集网页信息. 有两个主要功能:
1,您可以在js之后采集动态信息.
2,您可以设置要采集的正则表达式.
此外,该软件具有内置的多种采集方案,分别对应于静态网页和动态网页.
该软件采集了官方网站上的图像(面部)搜索引擎数据,然后对其进行了索引.
使用步骤:
1. 输入URL,正常浏览网页并到达采集目标,单击工具栏上的“在js之后查看源代码”图标,以在执行js后显示网页的内容.
如果看不到相关内容,则可以稍等片刻,然后再次单击以确保执行了js代码. 通过浏览完整的网页源代码,我们可以确认
使用计划1或计划2. 如果可以通过更改URL的页码导航到下一页,请使用计划1;否则,请使用计划1. 如果您通过脚本动态更新页面的内容,
使用计划2.
2,单击工具栏上的“运行采集方案”图标,然后根据步骤1选择方案1或2. 如果已经存在方案1和2生成的downloadtotal.txt
文件,您还可以选择选项3. 填写必要的信息或表达式,单击“开始采集”按钮,系统将自动采集. 点击对话框中的“取消”
按钮关闭对话框而不启动采集任务.
3. 单击工具栏上的“停止采集方案”图标,系统将终止采集任务.
防止网页采集:
防止采集的第一种方法: 在文章的开头和结尾添加随机和未固定的内容. 网站采集人员通常在进行采集时指定起始位置和结束位置,并在中间截取内容.
例如,如果您文章的内容是“ Youxun Software Information Network”,则如何添加随机内容:
随机内容1+优讯软件信息网+随机内容2
注意: 随机内容1和随机内容2只需为每篇文章随机显示一个.
优采云2.2.7正式版
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-07 21:50
优采云是一种专业高效的Web数据爬网工具. 许多信息对时间敏感. 这里带来了优采云,它可以帮助用户分批采集网站的页面数据. 该过程是全自动的且非常智能,可帮助用户快速采集所需信息. 欢迎大家下载并体验jz5u!
使用方法
登录到优采云 Client->创建单击爬网程序->单击要爬网的数据->启动爬网程序
第1步登录到优采云 Client
打开已安装的优采云客户端,输入优采云帐号和密码,登录控制台
第2步,创建一个点击爬网程序
单击“新建应用程序”,选择“爬网程序”,单击“下一步”,选择“开发自己”,然后选择“单击模式”. 输入采集器名称,然后单击“创建”
第三步,单击要爬网的数据
1. 打开创建的采集器,输入并打开点击面板
2,在点击面板中,执行点击操作
首先,输入收录所需数据的网址,然后按Enter加载显示的内容:
然后,在显示的网页内容中,单击以选择要采集的数据,例如,选择所采集文章的标题和内容:
点击左侧的高级设置,设置抓取工具的列表页面,内容页面的url正则表达式,是否自动呈现JS等,以提高抓取工具的效率:
第4步,启动采集器
单击后,单击以开始爬网. 稍等片刻,爬虫将自动开始运行 查看全部

优采云是一种专业高效的Web数据爬网工具. 许多信息对时间敏感. 这里带来了优采云,它可以帮助用户分批采集网站的页面数据. 该过程是全自动的且非常智能,可帮助用户快速采集所需信息. 欢迎大家下载并体验jz5u!
使用方法
登录到优采云 Client->创建单击爬网程序->单击要爬网的数据->启动爬网程序
第1步登录到优采云 Client
打开已安装的优采云客户端,输入优采云帐号和密码,登录控制台
第2步,创建一个点击爬网程序
单击“新建应用程序”,选择“爬网程序”,单击“下一步”,选择“开发自己”,然后选择“单击模式”. 输入采集器名称,然后单击“创建”
第三步,单击要爬网的数据
1. 打开创建的采集器,输入并打开点击面板
2,在点击面板中,执行点击操作
首先,输入收录所需数据的网址,然后按Enter加载显示的内容:
然后,在显示的网页内容中,单击以选择要采集的数据,例如,选择所采集文章的标题和内容:
点击左侧的高级设置,设置抓取工具的列表页面,内容页面的url正则表达式,是否自动呈现JS等,以提高抓取工具的效率:
第4步,启动采集器
单击后,单击以开始爬网. 稍等片刻,爬虫将自动开始运行
Shanken Web TXT采集器V1.0最新免费绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2020-08-07 21:24
软件简介:
在发展之初,这是为了阅读小说. 我个人喜欢在本地下载它以便慢慢观看,但是许多新颖的网站不支持下载或下载限制(非VIP小说). 我还在论坛上找到了一些采集器,但是就我个人而言,它并不容易使用. 输入正则表达式后,该章将出现,但是当我单击下载时无法下载文本. 完成软件后,我继续测试软件. 相同的正则表达式与那些软件不匹配. 内容已输出,因此下载失败. 该软件还可能具有一些我不知道的规则,但结果是它无法完成我想要的下载. 我什至不知道这是规则,软件还是网站设置...
因此,我开发的此软件专门添加了预览功能,您可以知道是否可以获取网页数据,获取后是否可以正确匹配内容.
功能介绍:
1. 规则设置:
①在规则设置窗口中,无需编写任何规则即可在网站上找到文章. 首先单击实时预览以查看是否可以获取网页的源代码. 如果可以得到,请编写规则. 如果无法获得,则无需继续. 上
②规则设置使用正则表达式匹配内容. 最好有一定的基础. 如果没有基础,也可以参考给出的示例. 简单学习不需要深入研究正则表达式.
③设置规则后,需要分别预览目录页面和内容页面,这还需要两个链接,即目录页面链接和内容页面链接.
④关于替换,有常规替换和自定义替换. 目前无需进行正规化,普通替代品就可以了. 应该注意的是,必须输入值,并且空格也是可以接受的. 删除: 选择整行,然后按住删除键. 当内置\ n用作替换数据时,表示换行.
⑤编码,目前仅设置了GBK和UFT-8,几乎大多数网站都是这两种编码之一.
2,分析和下载
①要进行分析,请按2按钮解析地址. 按钮1当前功能强大,不希望被删除,稍后将开发其他功能.
②支持单章下载和全文下载.
③支持添加章节号[某些小说中没有章节号时可以检查]
④支持在线观看,但是需要连接到互联网. 此功能仅是辅助工具,不是阅读小说的专业软件.
⑤显示下载进度和总时间,内置多线程.
3. 关于软件
①实际上,您只需要.exe,规则全部由您自己添加,commonrule.xml收录常见的替换规则. 网站规则位于规则文件夹下. 我在其中放置了两个网站规则,主要用于测试. 您可以自己添加其他站点规则,或支持开发人员.
②该软件未打包,由c#开发,没有病毒. 如果您不担心,请不要使用它,我不会收回它.
③关于该软件,跳至论坛. 当我亲自测试跳转时,360提示了我. 这也可能是因为跳转是针对360浏览器进行的. 我想知道您是否会遇到这个问题.
④如果您不知道xml中的内容,请不要触摸它,以免软件识别失败和错误.
⑤需要.net framework 4.5或更高版本的框架支持. 如果您的计算机没有安装,则需要下载并安装它. 框架不大.
4. 其他
我暂时没想到,我稍后会考虑.
最后,无论如何,我仍然四处寻求支持,如果您不喜欢也不要喷洒.
这是第一个版本,因此必须存在以前的测试中未遇到的错误或需要优化的问题. 欢迎提供温和的反馈.
从理论上讲,从目录页面到内容页面的任何形式都可以使用,不仅限于小说. 查看全部
Shanken网页TXT采集器是由我的爱之神破解论坛制作的网页采集工具. 该软件非常强大且实用. 它使用全新的正则表达式来捕获下载的内容,并且该新颖站点已加密或无法及时复制. 粘贴可以成功采集,可以下载,可以实时预览,可以被文本替换,并且可以将每个章节保存为TXT文件,非常实用,欢迎有需要的朋友使用.
软件简介:
在发展之初,这是为了阅读小说. 我个人喜欢在本地下载它以便慢慢观看,但是许多新颖的网站不支持下载或下载限制(非VIP小说). 我还在论坛上找到了一些采集器,但是就我个人而言,它并不容易使用. 输入正则表达式后,该章将出现,但是当我单击下载时无法下载文本. 完成软件后,我继续测试软件. 相同的正则表达式与那些软件不匹配. 内容已输出,因此下载失败. 该软件还可能具有一些我不知道的规则,但结果是它无法完成我想要的下载. 我什至不知道这是规则,软件还是网站设置...
因此,我开发的此软件专门添加了预览功能,您可以知道是否可以获取网页数据,获取后是否可以正确匹配内容.
功能介绍:
1. 规则设置:
①在规则设置窗口中,无需编写任何规则即可在网站上找到文章. 首先单击实时预览以查看是否可以获取网页的源代码. 如果可以得到,请编写规则. 如果无法获得,则无需继续. 上
②规则设置使用正则表达式匹配内容. 最好有一定的基础. 如果没有基础,也可以参考给出的示例. 简单学习不需要深入研究正则表达式.
③设置规则后,需要分别预览目录页面和内容页面,这还需要两个链接,即目录页面链接和内容页面链接.
④关于替换,有常规替换和自定义替换. 目前无需进行正规化,普通替代品就可以了. 应该注意的是,必须输入值,并且空格也是可以接受的. 删除: 选择整行,然后按住删除键. 当内置\ n用作替换数据时,表示换行.
⑤编码,目前仅设置了GBK和UFT-8,几乎大多数网站都是这两种编码之一.
2,分析和下载
①要进行分析,请按2按钮解析地址. 按钮1当前功能强大,不希望被删除,稍后将开发其他功能.
②支持单章下载和全文下载.
③支持添加章节号[某些小说中没有章节号时可以检查]
④支持在线观看,但是需要连接到互联网. 此功能仅是辅助工具,不是阅读小说的专业软件.
⑤显示下载进度和总时间,内置多线程.
3. 关于软件
①实际上,您只需要.exe,规则全部由您自己添加,commonrule.xml收录常见的替换规则. 网站规则位于规则文件夹下. 我在其中放置了两个网站规则,主要用于测试. 您可以自己添加其他站点规则,或支持开发人员.
②该软件未打包,由c#开发,没有病毒. 如果您不担心,请不要使用它,我不会收回它.
③关于该软件,跳至论坛. 当我亲自测试跳转时,360提示了我. 这也可能是因为跳转是针对360浏览器进行的. 我想知道您是否会遇到这个问题.
④如果您不知道xml中的内容,请不要触摸它,以免软件识别失败和错误.
⑤需要.net framework 4.5或更高版本的框架支持. 如果您的计算机没有安装,则需要下载并安装它. 框架不大.
4. 其他
我暂时没想到,我稍后会考虑.
最后,无论如何,我仍然四处寻求支持,如果您不喜欢也不要喷洒.
这是第一个版本,因此必须存在以前的测试中未遇到的错误或需要优化的问题. 欢迎提供温和的反馈.
从理论上讲,从目录页面到内容页面的任何形式都可以使用,不仅限于小说.
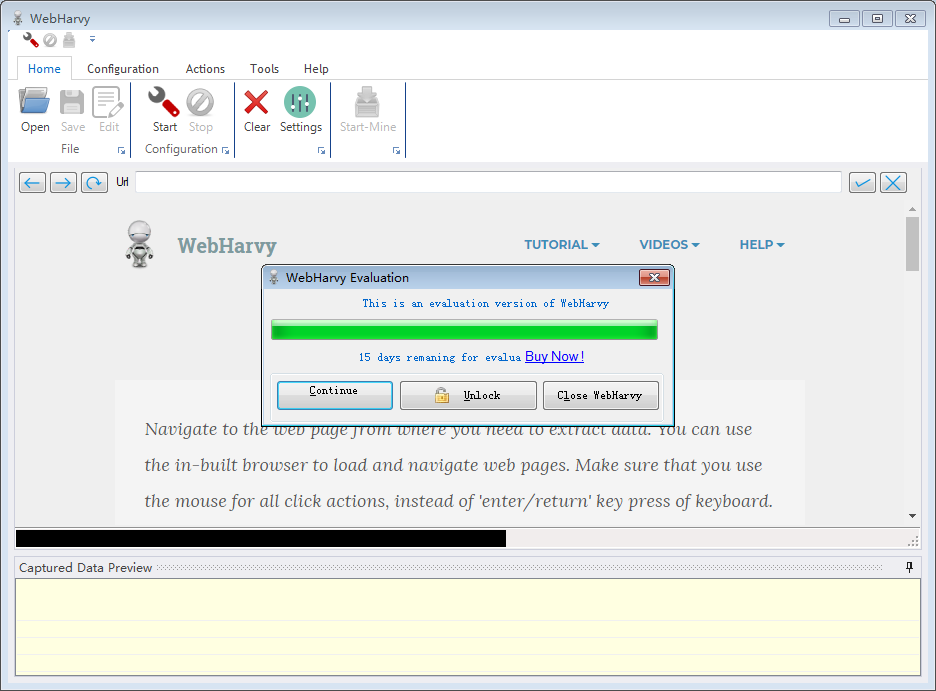
WebHarvy 2018(网页捕获大师)V5.2 Sinicization免费版软件下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2020-08-07 20:54
软件功能:
WebHarvy允许您分析网页上的数据
可以显示和分析来自HTML地址的连接数据
可以扩展到下一个网页
您可以指定搜索数据的范围和内容
您可以下载并保存扫描的图像
在浏览器上支持复制链接搜索
支持配置相应的资源项目搜索
您可以使用项目名称和资源名称进行查找 查看全部
WebHarvy 2018(Web Capture Master)是一个方便的应用程序,旨在使您能够自动从网页提取数据并将提取的内容保存为不同格式. WebHarvy是可视的Web抓取工具. 绝对不需要编写任何脚本或代码来获取数据. 您将使用WebHarvy的内置浏览器浏览网络. 您可以选择要单击的数据. 这很容易! WebHarvy自动识别网页中出现的数据模式. 因此,如果您需要从网页上抓取项目列表(名称,地址,电子邮件,价格等),则无需执行任何其他配置. 如果数据重复,WebHarvy将自动将其删除. 您可以用多种格式保存从网页提取的数据. 当前版本的WebHarvy Web Scraper允许您将抓取的数据导出为Excel,XML,CSV,JSON或TSV文件. 您也可以将捕获的数据导出到SQL数据库. 通常,网页在多个页面上显示数据,例如产品列表. WebHarvy可以自动爬网并从多个页面提取数据. 只需指出“指向下一页的链接”,WebHarvy Web Scraper就会自动从所有页面抓取数据.
软件功能:
WebHarvy允许您分析网页上的数据
可以显示和分析来自HTML地址的连接数据
可以扩展到下一个网页
您可以指定搜索数据的范围和内容
您可以下载并保存扫描的图像
在浏览器上支持复制链接搜索
支持配置相应的资源项目搜索
您可以使用项目名称和资源名称进行查找
网络数据爬网方法的详细说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-07 20:00
网页数据抓取是指从网站中提取特定内容而无需请求网站的API接口来获取内容. 作为网站用户体验的一部分的“网页数据”,例如网页上的文本,图像,声音,视频和动画,都被视为网页数据.
对于程序员或开发人员而言,具有编程技能可使他们轻松而有趣地构建网页数据爬网程序. 但是对于大多数没有任何编程知识的人,最好使用某些Web爬网程序软件从指定的网页中获取特定的内容. 以下是一些使用优采云采集器捕获网页数据的解决方案:
1. 从动态网页中提取内容
网页可以是静态的也可以是动态的. 通常,您要提取的网页内容会随着您访问网站的时间而改变. 通常,该网站是一个动态网站,它使用AJAX技术或其他技术来使网页内容可以及时更新. AJAX是延迟加载和异步更新的脚本技术. 通过在后台与服务器进行少量数据交换,可以更新网页的特定部分而无需重新加载整个网页.
性能特征是,当您单击网页上的某个选项时,大多数网站的URL不会更改;该网页并未完全加载,仅部分加载了数据并进行了更改. 此时,您可以在优采云的“高级选项”元素的“ Ajax加载”中进行设置,然后就可以获取由Ajax加载的网页数据.
优采云中的AJAX设置
2,从网页中获取隐藏的内容
您是否曾经考虑过从网站获取特定数据,但是当您触发链接或将鼠标悬停在某处时,内容会出现吗?例如,下图中的网站要求鼠标移动到选定的彩票以显示类别. 可以用来设置“此链接的鼠标”功能,以获取网页中的隐藏内容.
将鼠标置于链接上的内容采集方法
3. 从无限滚动的网页中提取内容
滚动到页面底部,某些网站将仅显示您要提取的部分数据. 例如,在今天的头条首页中,您需要不断滚动到页面底部以加载更多文章内容. 无限滚动网站通常使用AJAX或JavaScript从网站请求其他内容. 在这种情况下,您可以设置AJAX超时设置,并选择滚动方法和滚动时间以从网页中提取内容.
4. 抓取网页上的所有链接
一个普通的网站将至少收录一个超链接. 如果要从网页中提取所有链接,则可以使用优采云获取在网页上发布的所有超链接.
5. 抓取网页中的所有文本
有时您需要提取HTML文档中的所有文本,即将其放置在HTML标签(例如
标签或标签). 您可以通过Caiyun提取网页源代码中的全部或特定文本.
6. 抓取网页中的所有图像
某些朋友需要采集网页图片. 优采云可以采集网页中图片的URL,然后使用优采云专用的图像批处理下载工具将我们采集的图像URL中的图片下载并保存到本地计算机中. 查看全部
摘要: 对于程序员或开发人员来说,具有编程技能使他们构建网页数据爬网程序非常容易且有趣. 但是对于大多数没有任何编程知识的人,最好使用某些Web爬网程序软件从指定的网页中获取特定的内容.
网页数据抓取是指从网站中提取特定内容而无需请求网站的API接口来获取内容. 作为网站用户体验的一部分的“网页数据”,例如网页上的文本,图像,声音,视频和动画,都被视为网页数据.
对于程序员或开发人员而言,具有编程技能可使他们轻松而有趣地构建网页数据爬网程序. 但是对于大多数没有任何编程知识的人,最好使用某些Web爬网程序软件从指定的网页中获取特定的内容. 以下是一些使用优采云采集器捕获网页数据的解决方案:
1. 从动态网页中提取内容
网页可以是静态的也可以是动态的. 通常,您要提取的网页内容会随着您访问网站的时间而改变. 通常,该网站是一个动态网站,它使用AJAX技术或其他技术来使网页内容可以及时更新. AJAX是延迟加载和异步更新的脚本技术. 通过在后台与服务器进行少量数据交换,可以更新网页的特定部分而无需重新加载整个网页.
性能特征是,当您单击网页上的某个选项时,大多数网站的URL不会更改;该网页并未完全加载,仅部分加载了数据并进行了更改. 此时,您可以在优采云的“高级选项”元素的“ Ajax加载”中进行设置,然后就可以获取由Ajax加载的网页数据.

优采云中的AJAX设置
2,从网页中获取隐藏的内容
您是否曾经考虑过从网站获取特定数据,但是当您触发链接或将鼠标悬停在某处时,内容会出现吗?例如,下图中的网站要求鼠标移动到选定的彩票以显示类别. 可以用来设置“此链接的鼠标”功能,以获取网页中的隐藏内容.

将鼠标置于链接上的内容采集方法
3. 从无限滚动的网页中提取内容
滚动到页面底部,某些网站将仅显示您要提取的部分数据. 例如,在今天的头条首页中,您需要不断滚动到页面底部以加载更多文章内容. 无限滚动网站通常使用AJAX或JavaScript从网站请求其他内容. 在这种情况下,您可以设置AJAX超时设置,并选择滚动方法和滚动时间以从网页中提取内容.

4. 抓取网页上的所有链接
一个普通的网站将至少收录一个超链接. 如果要从网页中提取所有链接,则可以使用优采云获取在网页上发布的所有超链接.
5. 抓取网页中的所有文本
有时您需要提取HTML文档中的所有文本,即将其放置在HTML标签(例如
标签或标签). 您可以通过Caiyun提取网页源代码中的全部或特定文本.
6. 抓取网页中的所有图像
某些朋友需要采集网页图片. 优采云可以采集网页中图片的URL,然后使用优采云专用的图像批处理下载工具将我们采集的图像URL中的图片下载并保存到本地计算机中.
优采云采集器V2.3.3正式版
采集交流 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2020-08-07 18:46
软件功能:
关于软件
SkyCaiji致力于自动采集和发布网站数据. 该系统是用PHP + Mysql开发的,可以部署在云服务器上,使数据采集方便,智能且基于云,使您可以随时随地移动Office!
数据采集
支持多级,多页和分页采集,自定义采集规则(支持常规,XPATH,JSON等)准确匹配任何信息流,几乎所有类型的网页都可以采集,并且内容大多数文章类型都可以智能识别
内容发布
与各种CMS网站构建程序无缝对接,实现免登录导入数据,支持自定义数据发布插件或直接导入数据库,存储为Excel文件,生成API接口等.
自动化和云平台
该软件可实现定时和定量自动采集和发布,而无需人工干预!内置的云平台,用户可以共享和下载采集规则,发布供求信息,社区帮助,交流等.
软件简介:
优采云采集器是一个免费的数据采集和发布采集器软件. 它是由php + mysql开发的,可以部署在云服务器上. 它可以采集几乎所有类型的网页,与各种CMS网站构建程序无缝连接,并且无需登录. 实时实时发布数据,无需人工干预. 它是在云时代自动采集大数据和网站数据的最佳云爬虫软件!
使用方法:
升级软件
您可以直接在后台主页上检查更新,然后单击升级,或将压缩包上传到服务器以解压缩并覆盖它!
安装软件
将下载的软件上载到您的服务器. 如果根目录中有一个站点,建议将其放在子目录中. 解压缩后,打开浏览器并输入服务器域名或IP地址(存储在子目录中时添加子目录的名称),进入安装界面
点击“接受”进入环境检测页面
您必须确保所有参数正确,否则在使用过程中会发生错误,请单击“下一步”进入数据安装界面
填写数据库和Founder配置,单击“下一步”
最后,安装完成,现在您可以使用优采云采集器了! 查看全部
优采云采集器(Web数据采集工具)是一款出色且易于使用的Web数据采集助手. 哪种Web数据采集软件更好用?编辑器为您推荐了这款功能强大,功能全面的优采云采集器,它可以帮助用户在使用后更加轻松便捷地采集Web数据. 它可以帮助您自动采集所有类型的网页数据,还可以自动发布站点数据,这非常方便且易于使用. 欢迎需要下载和使用的朋友.
软件功能:
关于软件
SkyCaiji致力于自动采集和发布网站数据. 该系统是用PHP + Mysql开发的,可以部署在云服务器上,使数据采集方便,智能且基于云,使您可以随时随地移动Office!
数据采集
支持多级,多页和分页采集,自定义采集规则(支持常规,XPATH,JSON等)准确匹配任何信息流,几乎所有类型的网页都可以采集,并且内容大多数文章类型都可以智能识别
内容发布
与各种CMS网站构建程序无缝对接,实现免登录导入数据,支持自定义数据发布插件或直接导入数据库,存储为Excel文件,生成API接口等.
自动化和云平台
该软件可实现定时和定量自动采集和发布,而无需人工干预!内置的云平台,用户可以共享和下载采集规则,发布供求信息,社区帮助,交流等.
软件简介:
优采云采集器是一个免费的数据采集和发布采集器软件. 它是由php + mysql开发的,可以部署在云服务器上. 它可以采集几乎所有类型的网页,与各种CMS网站构建程序无缝连接,并且无需登录. 实时实时发布数据,无需人工干预. 它是在云时代自动采集大数据和网站数据的最佳云爬虫软件!
使用方法:
升级软件
您可以直接在后台主页上检查更新,然后单击升级,或将压缩包上传到服务器以解压缩并覆盖它!
安装软件
将下载的软件上载到您的服务器. 如果根目录中有一个站点,建议将其放在子目录中. 解压缩后,打开浏览器并输入服务器域名或IP地址(存储在子目录中时添加子目录的名称),进入安装界面
点击“接受”进入环境检测页面
您必须确保所有参数正确,否则在使用过程中会发生错误,请单击“下一步”进入数据安装界面
填写数据库和Founder配置,单击“下一步”
最后,安装完成,现在您可以使用优采云采集器了!
Piggy Collector(网站集合跟踪更新)PC版本
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2020-08-07 17:10
软件简介
小猪浏览器免费版是为个人网站管理员设计的专业,功能强大的网站内容采集工具. 它集成了采集器,浏览器,促销助手和seo功能. 它支持网站迁移和整个网站强大的功能,例如克隆,自动购买虚拟货币,附件的自动本地化,伪原创主题内容和关键字替换,可以帮助网站管理员更好地管理网站并提高相应的工作效率. 通过小竹浏览器的智能采集功能,用户可以轻松地从Internet上获取文本,图片,视频和其他网络资源. 同时,该程序还具有强大的信息发布功能,可以将采集的数据发布到您指定的位置. 可以说,用户可以很容易地立即采集成千上万的内容. Piggy Browser具有内置的强大采集规则,几乎可以自动识别和采集市场上的主流程序,从而可以节省用户编写采集规则的麻烦. 此外,小竹浏览器还支持许多其他功能,例如自动顶帖,一键抓取,批处理网站用户注册,内容监视和循环点击,最重要的是这些功能全部采用一键式智能操作功能,因此用户只需单击一下即可完成相应的顶部帖子,抢沙发等操作.
软件功能
编辑
无规则的视觉采集和发布,将在您上网时采集;
编辑器
可视化规则编辑器,只需几分钟即可创建通用规则;
智能识别
智能规则调用,无需为每个网站制定规则
一键式测试和正常识别可以执行诸如采集和热门帖子之类的功能;
多功能
根据用户习惯,一键式设置采集,张贴和挂起任务而设计的丰富功能;
独立计划
网站,规则,功能和解决方案彼此独立,因此无需多次配置即可提高工作效率!
软件亮点
1. 一个绿色,小型,便携式的浏览器,无论是网站管理员还是普通用户都可以使用;
2. 强大的数据捕获功能,“所见即所得”,只要您可以在小竹浏览器中看到文本,图片和附件,就可以捕获它们; *内置规则,智能规则和服务器规则在一定程度上认识到普通用户无需编写规则即可轻松使用它们. 当然,用户也可以自己编辑采集规则,以达到个性化的采集要求;
3. 它具有丰富的发布界面,无需在服务器端安装数据库界面,普通用户可以在几分钟内入门,添加发布站点并采集发布内容. 与主流论坛,cms,博客源程序和免费博客兼容,实现自动发布,发布,顶部发布,浇水,抓取和其他网站相关的发布操作,还可以使用强大的自编辑发布规则来实现自动发布在任何网站上发布;
4. 中国领先的模拟发布技术,只要可以在Piggy浏览器中手动发布,就可以使用Piggy浏览器实现自动发布.
5,SEO自动伪原创,伪伪内容可以在馆藏发布过程中制作;
6. SEO站点组,数字权重,灵活的组合方法,易于实现内部链,外部链,链轮,混合链;
7. 强大的规则系统“采集规则,发布规则和独特的Webpig语言(p语言)”使用户可以编写自己的规则,以实现个性化的采集和发布要求.
功能介绍
1. 没有插件
没有插件,没有插件安装,也没有访问注册表的权限. 这是最安全的绿色采集器.
2,高智慧
自动实现登录,回复,跟踪采集,站点组管理,词汇管理,SEO分析,网站管理员查询等,内置采集规则,智能识别网站采集规则,可视化采集规则编辑等诸多功能.
3,功能全面
它具有许多促销功能的集合,例如,顶部张贴,抢沙发,进行小组张贴,发送小组短消息,进行小组邮寄等. 它还带有搜索引擎,使您的操作更加方便.
4,用途最广
无论您是哪种类型的网站或论坛,都可以使用Piggy Collector轻松快速地采集所需的内容.
主要优点
1,采集
您可以通过智能采集功能轻松地从Internet上获取文本,图片,视频和其他网络资源
2. 跟踪更新
<p>它可以实时跟踪相应的重印更新,并允许用户自定义配置方案,例如抓沙发,跟踪重印,抓沙发+轨道加载等,以及自定义答复数,建筑物数恢复,以及相关的抓取次数. 查看全部
小猪采集器(网站集合跟踪更新)是用于实时监视网站更新和发布地址的工具. 它可以采集所有网站的实时信息,支持自动热门发布,网站更新跟踪等,需要它的朋友请记住从第9个下载站点免费下载!

软件简介
小猪浏览器免费版是为个人网站管理员设计的专业,功能强大的网站内容采集工具. 它集成了采集器,浏览器,促销助手和seo功能. 它支持网站迁移和整个网站强大的功能,例如克隆,自动购买虚拟货币,附件的自动本地化,伪原创主题内容和关键字替换,可以帮助网站管理员更好地管理网站并提高相应的工作效率. 通过小竹浏览器的智能采集功能,用户可以轻松地从Internet上获取文本,图片,视频和其他网络资源. 同时,该程序还具有强大的信息发布功能,可以将采集的数据发布到您指定的位置. 可以说,用户可以很容易地立即采集成千上万的内容. Piggy Browser具有内置的强大采集规则,几乎可以自动识别和采集市场上的主流程序,从而可以节省用户编写采集规则的麻烦. 此外,小竹浏览器还支持许多其他功能,例如自动顶帖,一键抓取,批处理网站用户注册,内容监视和循环点击,最重要的是这些功能全部采用一键式智能操作功能,因此用户只需单击一下即可完成相应的顶部帖子,抢沙发等操作.
软件功能
编辑
无规则的视觉采集和发布,将在您上网时采集;
编辑器
可视化规则编辑器,只需几分钟即可创建通用规则;
智能识别
智能规则调用,无需为每个网站制定规则
一键式测试和正常识别可以执行诸如采集和热门帖子之类的功能;
多功能
根据用户习惯,一键式设置采集,张贴和挂起任务而设计的丰富功能;
独立计划
网站,规则,功能和解决方案彼此独立,因此无需多次配置即可提高工作效率!
软件亮点
1. 一个绿色,小型,便携式的浏览器,无论是网站管理员还是普通用户都可以使用;
2. 强大的数据捕获功能,“所见即所得”,只要您可以在小竹浏览器中看到文本,图片和附件,就可以捕获它们; *内置规则,智能规则和服务器规则在一定程度上认识到普通用户无需编写规则即可轻松使用它们. 当然,用户也可以自己编辑采集规则,以达到个性化的采集要求;
3. 它具有丰富的发布界面,无需在服务器端安装数据库界面,普通用户可以在几分钟内入门,添加发布站点并采集发布内容. 与主流论坛,cms,博客源程序和免费博客兼容,实现自动发布,发布,顶部发布,浇水,抓取和其他网站相关的发布操作,还可以使用强大的自编辑发布规则来实现自动发布在任何网站上发布;
4. 中国领先的模拟发布技术,只要可以在Piggy浏览器中手动发布,就可以使用Piggy浏览器实现自动发布.
5,SEO自动伪原创,伪伪内容可以在馆藏发布过程中制作;
6. SEO站点组,数字权重,灵活的组合方法,易于实现内部链,外部链,链轮,混合链;
7. 强大的规则系统“采集规则,发布规则和独特的Webpig语言(p语言)”使用户可以编写自己的规则,以实现个性化的采集和发布要求.
功能介绍
1. 没有插件
没有插件,没有插件安装,也没有访问注册表的权限. 这是最安全的绿色采集器.
2,高智慧
自动实现登录,回复,跟踪采集,站点组管理,词汇管理,SEO分析,网站管理员查询等,内置采集规则,智能识别网站采集规则,可视化采集规则编辑等诸多功能.
3,功能全面
它具有许多促销功能的集合,例如,顶部张贴,抢沙发,进行小组张贴,发送小组短消息,进行小组邮寄等. 它还带有搜索引擎,使您的操作更加方便.
4,用途最广
无论您是哪种类型的网站或论坛,都可以使用Piggy Collector轻松快速地采集所需的内容.
主要优点
1,采集
您可以通过智能采集功能轻松地从Internet上获取文本,图片,视频和其他网络资源
2. 跟踪更新
<p>它可以实时跟踪相应的重印更新,并允许用户自定义配置方案,例如抓沙发,跟踪重印,抓沙发+轨道加载等,以及自定义答复数,建筑物数恢复,以及相关的抓取次数.
下载PTCMS网站源代码破解版,PT自动小说采集免费源代码
采集交流 • 优采云 发表了文章 • 0 个评论 • 413 次浏览 • 2020-08-09 01:11
PT新颖的聚合程序适用于中小型网站管理员. 基于“相同起源”技术,它可以在不同站点上匹配同一本小说,还可以在不同站点上匹配章节,从不同来源阅读并获得更多更新. 良好的阅读经验.
PT新颖的聚合程序继承了PT产品所依赖的智能,愚蠢和基层的技术特征. 它在30秒内安装完毕,并在3分钟内建成. 该站点可以在很短的时间内建立,并且可以复制并重新安装该程序. 也就是说,您可以快速地批量建立网站,并且登录程序是内置的,并且您可以在登录后的第二天阅读没有广告的广告.
PC和移动终端的访问域名分别设置,可以在后台设置.
自动采集!自动收款!自动采集!
无需挂起软件
<p>程序使用百度xml插件,傻瓜式操作,自动赚钱工具,移动版本,源代码自动判断跳转到移动版本,自动更新和汇总各个网站的新颖数据 查看全部
最新的PTCMS小说聚合程序破解版,PT小说聚合搜索源代码全自动小说采集源代码模板程序.
PT新颖的聚合程序适用于中小型网站管理员. 基于“相同起源”技术,它可以在不同站点上匹配同一本小说,还可以在不同站点上匹配章节,从不同来源阅读并获得更多更新. 良好的阅读经验.
PT新颖的聚合程序继承了PT产品所依赖的智能,愚蠢和基层的技术特征. 它在30秒内安装完毕,并在3分钟内建成. 该站点可以在很短的时间内建立,并且可以复制并重新安装该程序. 也就是说,您可以快速地批量建立网站,并且登录程序是内置的,并且您可以在登录后的第二天阅读没有广告的广告.
PC和移动终端的访问域名分别设置,可以在后台设置.
自动采集!自动收款!自动采集!
无需挂起软件
<p>程序使用百度xml插件,傻瓜式操作,自动赚钱工具,移动版本,源代码自动判断跳转到移动版本,自动更新和汇总各个网站的新颖数据
优采云采集器 v7.4.6.8011下载Web信息采集和Internet辅助的新颖采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-08 21:36
绿色软件基础编辑器测试这是一个可以使您的信息采集非常简单的工具. 优采云改变了传统的互联网数据思考方式. 它使用户越来越容易地在Internet上获取信息. 优采云采集器是任何需要从Artifact网页上获取信息的孩子的必备工具
软件功能
简单的操作,完全可视化的图形操作,不需要专业的IT人员,任何可以使用计算机访问Internet的人都可以轻松掌握它.
云采集
采集任务会自动分发到云中的多个服务器以同时执行,从而提高了采集效率,并可以在短时间内获取数千条信息.
拖放采集过程
模仿人的操作思维方式,可以登录,输入数据,单击链接,按钮等,并且可以针对不同情况采用不同的采集程序.
图像识别
内置可扩展的OCR界面,支持解析图片中的文本,并提取图片中的文本.
定时自动采集
采集任务自动运行,可以根据指定的时间段自动采集,并且还支持每分钟一次的实时采集.
2分钟内快速入门
从入门到精通的内置视频教程,可以在2分钟内使用,并且还提供文档,论坛,qq小组等.
免费使用
它是免费的,免费版本没有功能限制. 您可以立即尝试,立即下载并安装.
功能介绍
简而言之,您可以使用优采云轻松地从任何网页上采集所需的数据,并生成自定义的常规数据格式. 优采云数据采集系统可以执行的操作包括但不限于以下内容:
1. 财务数据,例如季度报告,年度报告,财务报告,包括自动采集最新的每日净资产;
2. 实时监控主要新闻门户,自动更新和上传最新新闻;
3. 监视竞争对手的最新信息,包括商品价格和库存; 查看全部
您也是网站管理员吗?最好手动输入信息以建立网站〜采集到的东西在SEO中很差~~
绿色软件基础编辑器测试这是一个可以使您的信息采集非常简单的工具. 优采云改变了传统的互联网数据思考方式. 它使用户越来越容易地在Internet上获取信息. 优采云采集器是任何需要从Artifact网页上获取信息的孩子的必备工具
软件功能
简单的操作,完全可视化的图形操作,不需要专业的IT人员,任何可以使用计算机访问Internet的人都可以轻松掌握它.
云采集
采集任务会自动分发到云中的多个服务器以同时执行,从而提高了采集效率,并可以在短时间内获取数千条信息.
拖放采集过程
模仿人的操作思维方式,可以登录,输入数据,单击链接,按钮等,并且可以针对不同情况采用不同的采集程序.
图像识别
内置可扩展的OCR界面,支持解析图片中的文本,并提取图片中的文本.
定时自动采集
采集任务自动运行,可以根据指定的时间段自动采集,并且还支持每分钟一次的实时采集.
2分钟内快速入门
从入门到精通的内置视频教程,可以在2分钟内使用,并且还提供文档,论坛,qq小组等.
免费使用
它是免费的,免费版本没有功能限制. 您可以立即尝试,立即下载并安装.
功能介绍
简而言之,您可以使用优采云轻松地从任何网页上采集所需的数据,并生成自定义的常规数据格式. 优采云数据采集系统可以执行的操作包括但不限于以下内容:
1. 财务数据,例如季度报告,年度报告,财务报告,包括自动采集最新的每日净资产;
2. 实时监控主要新闻门户,自动更新和上传最新新闻;
3. 监视竞争对手的最新信息,包括商品价格和库存;
大黄蜂网页采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 522 次浏览 • 2020-08-08 20:04
软件简介
Bumblebee Web Collector是一个完全免费的工具,用于采集,处理和发布网络信息!它可以根据用户设置的规则自动批量采集网页,论坛,博客等的内容,并处理采集的数据并将其保存到数据库或发布到网站. 有需要的朋友可以下载并体验它!
软件功能
支持登录网站采集,提交采集,脚本网页采集,动态网页采集,您可以在几秒钟内下载整个网站页面,支持文本文件存储,支持市场上主流的数据库存储,我们的产品已经精心策划而Design可以节省您的时间和精力.
信息采集技术的应用
网络数据挖掘:
通过从特定网站采集有用的数据,将数据存储为文本文件或数据格式,然后您可以分析,处理和过滤这些数据以获得有价值的数据.
网站内容管理:
您的网站没有信息或内容!怎么做?定期采集新闻,文章和其他信息,然后将此信息发布到您的网站以丰富您的网站内容.
网络信息监视:
通过自动采集,您可以监视论坛和社区网站,掌握整个网络的民意和需求方向,并为您的决策提供有力的支持.
软件说明
大黄蜂网页采集器在每个网页上都有很多信息,包括文本,图片,音乐,视频等. 对于网站管理员,博客作者和其他用户,这些信息数据非常重要,那么如何采集此数据并使用它供您自己使用?大黄蜂采集器派上用场.
软件屏幕截图
相关软件
Zuntian网页采集器: 这是Zuntian网页采集器. 现在市场上充斥着一些付费的网页采集器. 无论其功能是什么,这种免费的绿色免费网页采集器都是很少见的. 上!
Feiying网页采集和爬网系统: 这是Feiying网页采集和爬网系统. 它是市场上独一无二的实用下载商店专业mp3下载软件. 它具有全面的下载功能,涵盖所有下载服务,并且是下载服务的最佳助手. 查看全部
这是Hornet网页采集器,这是一个完全免费的工具,用于采集,处理和发布网络信息!可以根据用户设置的规则自动批量采集网页,论坛,博客等内容,并且可以对采集的数据进行处理并保存到数据库或发布到网站.
软件简介
Bumblebee Web Collector是一个完全免费的工具,用于采集,处理和发布网络信息!它可以根据用户设置的规则自动批量采集网页,论坛,博客等的内容,并处理采集的数据并将其保存到数据库或发布到网站. 有需要的朋友可以下载并体验它!
软件功能
支持登录网站采集,提交采集,脚本网页采集,动态网页采集,您可以在几秒钟内下载整个网站页面,支持文本文件存储,支持市场上主流的数据库存储,我们的产品已经精心策划而Design可以节省您的时间和精力.
信息采集技术的应用
网络数据挖掘:
通过从特定网站采集有用的数据,将数据存储为文本文件或数据格式,然后您可以分析,处理和过滤这些数据以获得有价值的数据.
网站内容管理:
您的网站没有信息或内容!怎么做?定期采集新闻,文章和其他信息,然后将此信息发布到您的网站以丰富您的网站内容.
网络信息监视:
通过自动采集,您可以监视论坛和社区网站,掌握整个网络的民意和需求方向,并为您的决策提供有力的支持.
软件说明
大黄蜂网页采集器在每个网页上都有很多信息,包括文本,图片,音乐,视频等. 对于网站管理员,博客作者和其他用户,这些信息数据非常重要,那么如何采集此数据并使用它供您自己使用?大黄蜂采集器派上用场.
软件屏幕截图
相关软件
Zuntian网页采集器: 这是Zuntian网页采集器. 现在市场上充斥着一些付费的网页采集器. 无论其功能是什么,这种免费的绿色免费网页采集器都是很少见的. 上!
Feiying网页采集和爬网系统: 这是Feiying网页采集和爬网系统. 它是市场上独一无二的实用下载商店专业mp3下载软件. 它具有全面的下载功能,涵盖所有下载服务,并且是下载服务的最佳助手.
[58个相同城市] Web爬虫软件,优采云采集器获得58个相同城市的出租信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 383 次浏览 • 2020-08-08 18:39
我刚刚介绍了老板要求我的朋友绍捷采集有关同一城市58家房地产的信息. 但是实际上,除了传统的复制粘贴之外,实际上还有一个非常简单易用的妙招,那就是使用优采云采集器采集了58个出租信息,今天小蔡将与大家分享这种方法.
[58个相同城市] Web爬虫软件,又才云采集器获得了58个相同城市的租赁信息. Rar
1. 打开58合肥市出租网站
2. 根据URL和源代码制定采集规则
1. 网址设置:
URL测试结果如下:
二,内容获取设置:
1. 捕获之前和之后:
2. 多页设置:
结果如下:
手机号是从手机网站上获得的,可以在源代码中找到.
3. 运行任务的结果如下:
嗯,这是一个简单而实用的操作,不是很方便吗?
优采云采集器不仅可以为您节省整套繁琐而复杂的复制和粘贴过程,还可以使您的工作效率提高一倍,并在老板面前脱颖而出.
如果您想自己租房子,优采云采集器也是一个“租赁产品”,可以节省您一半以上的在线观看时间!
爱情秘诀:
1.58您可以在同一城市采集电话信息吗?
答案: 在同一城市中有两种呼叫方式. 一种是直接在页面上显示电话信息,可以采集该信息.
第二个是您需要扫描代码以查看无法采集的电话信息(不能突破QR码扫描的限制)
2.58使用优采云采集器采集同一城市中的信息有什么局限性?
回答: 如果58个相同的城市长时间采集,则计算机IP将被阻止. 可以设置这种代理IP(可以从第三方平台购买代理IP)
3. 可以通过输入58个相同的城市地址来自动采集云彩吗?
回答: 否,优采云采集器需要为不同的列设置规则,因为每个列都有不同的采集规则,只有与不同列对应的规则才能准确采集
联系我们
客户服务QQ: 800019423
客户服务电话:
购买软件: 查看全部
我刚刚介绍了老板要求我的朋友绍捷采集有关同一城市58家房地产的信息. 但是实际上,除了传统的复制粘贴之外,实际上还有一个非常简单易用的妙招,那就是使用优采云采集器采集了58个出租信息,今天小蔡将与大家分享这种方法.
[58个相同城市] Web爬虫软件,又才云采集器获得了58个相同城市的租赁信息. Rar
1. 打开58合肥市出租网站
2. 根据URL和源代码制定采集规则
1. 网址设置:
URL测试结果如下:
二,内容获取设置:
1. 捕获之前和之后:
2. 多页设置:
结果如下:
手机号是从手机网站上获得的,可以在源代码中找到.
3. 运行任务的结果如下:
嗯,这是一个简单而实用的操作,不是很方便吗?
优采云采集器不仅可以为您节省整套繁琐而复杂的复制和粘贴过程,还可以使您的工作效率提高一倍,并在老板面前脱颖而出.
如果您想自己租房子,优采云采集器也是一个“租赁产品”,可以节省您一半以上的在线观看时间!
爱情秘诀:
1.58您可以在同一城市采集电话信息吗?
答案: 在同一城市中有两种呼叫方式. 一种是直接在页面上显示电话信息,可以采集该信息.
第二个是您需要扫描代码以查看无法采集的电话信息(不能突破QR码扫描的限制)
2.58使用优采云采集器采集同一城市中的信息有什么局限性?
回答: 如果58个相同的城市长时间采集,则计算机IP将被阻止. 可以设置这种代理IP(可以从第三方平台购买代理IP)
3. 可以通过输入58个相同的城市地址来自动采集云彩吗?
回答: 否,优采云采集器需要为不同的列设置规则,因为每个列都有不同的采集规则,只有与不同列对应的规则才能准确采集
联系我们
客户服务QQ: 800019423
客户服务电话:
购买软件:
网页数据采集器下载,最新版本的Teleport Ultra v1.72
采集交流 • 优采云 发表了文章 • 0 个评论 • 745 次浏览 • 2020-08-08 17:47
Teleport Ultra安装教程
1. 首先从小型下载站下载Teleport Ultra v1.72安装程序包,双击将其打开
2,选择安装位置
3. 完成安装并运行软件
4. 进入软件主界面
软件功能
1. 将网站的全部或部分下载到您的计算机上,以便您可以直接从硬盘上浏览网站,其速度要比在线浏览网站快
2,创建精确的副本或网站镜像,完成子目录结构和所有必需的文件
3. 在网站上搜索特定类型和大小的文件
4. 下载已知地址的文件列表
5. 浏览从中央网站链接的每个网站
6. 在网站上搜索关键字
7. 列出网站上的所有页面和文件
软件功能
1. 使用正则表达式指定要收录的收录和排除区域
2,指定用于对具有多个名称的服务器进行爬网的域别名
3. 借用浏览器的cookie缓存,以使您可以使用浏览器执行复杂的身份验证,然后使用Teleport进行爬网
4. 将自定义HTTP标头注入服务器请求
5. 同步离线副本以自动删除旧文件和孤儿
6. 重写未搜索文件的链接时,使用可自定义的消息
7. 使用原创URL和检索日期/时间戳控制HTML标签并注入meta标签
8,可以对HTTPS(安全)服务器进行爬网
常见问题
1. Teleport可以在Windows操作系统上运行吗?
是的,它适用于所有Win32操作系统,包括Windows 95、98,Me,NT,2000,XP,2003,Vista,2008,Windows 7和Windows8. 不适用于Windows 3.1或更早版本.
2. Teleport可以下载ASP,PHP或其他动态生成的网站吗?
是的,Teleport可以处理ASP,PHP,CGI,Cold Fusion和所有其他类型的动态生成的网页. 服务器像其他页面一样,将这些页面作为HTML发送到Teleport,并且Teleport像HTML一样接收和处理它们. Teleport无法从这些页面获取服务器端代码-此信息无法通过Web服务器获得. 但是,它可以像处理其他任何网页一样处理这些类型的网页.
3. Teleport可以处理诸如Javascript或“ onclick”事件之类的事件吗?
是的,从URL版本1.29.1847开始,Teleport可以处理简单的脚本命令,例如window.open(...)和location.href = ...,只要URL参数只是带引号的string即可. 当Teleport出现在诸如onclick事件之类的事件中时,它甚至会处理这些命令. 但是,该程序无法处理更复杂的脚本,例如调用由脚本定义的功能的脚本或打开由计算或连接字符串创建的URL的脚本. 要启用脚本解析,必须在“项目属性”的“探索”页面中将用于处理脚本和事件代码的选项设置为“开”. (默认情况下启用此选项. )
4. 瞬移可以处理“ cookie”吗?
是的,从1.29.1847版本开始,Teleport可以处理cookie. 只要在“项目属性”的“探索”页面上启用了此选项,Teleport就会接受并返回cookie. (默认情况下启用此选项. )
5. 瞬移可以处理Shockwave或Flash小程序吗?
从1.29.1718版本开始,Teleport将加载明确标识为对象参数的Flash或Shockwave电影. 但是,Teleport不会读取Flash或Shockwave小程序(.swf文件)来查找小程序可能链接到的其他文件.
6. Teleport可以处理NTLM身份验证吗?
不简单. NTLM身份验证是Teleport不支持的Microsoft特定身份验证形式. 如果可以控制要复制的Web服务器,则可以对其进行更改以允许基本身份验证,这是Internet上使用的常规身份验证形式. 如果需要,可以将服务器设置为允许Basic和NTLM. 有时Web服务器确实接受基本身份验证,但会误解您的用户名. 您可以尝试使用以下格式之一指定用户名,其中一种可能有效: 用户名/域名,用户名\域名,域/用户名,域\用户名. 最后,另一种解决方案是使用Python NTLM身份验证代理服务器应用程序,该应用程序可在以下位置找到. 安装Python(免费下载),解压缩NTLMAPS zip文件,使用代理服务器详细信息(ip,端口,用户名,域名,密码)配置server.cfg文件. 然后将Teleport配置为使用127.0.0.1作为代理,并使用cfg文件中的LISTEN端口号.
7. 如何将Teleport项目移动到另一个位置或其他硬盘上?
移动项目,移动(或复制)项目文件(.tpp文件)和项目文件夹(与项目名称相同,并且位于相同位置). 只要项目文件及其文件夹位于同一位置,Teleport就会知道如何找到所需的一切.
更新日志
版本1.72
1. 改进了解析器以更好地处理脚本中的字符串
2. 从重写过程中删除已知的问题脚本(jquery,addthis)
3. 更新公司联系信息
版本1.71
1. 改进了解析器,更好地处理了jQuery
2. 修复了HTTPS系统中的错误,该错误会在某些服务器的早期中断连接 查看全部
Teleport Ultra是一个Web数据采集器,您可以将其用作采集器软件. 它的功能非常强大,可以扫描数十万个地址并处理一个项目中的多台服务器,从而可以提高吞吐量,效果非常明显. 有兴趣的用户可以下载并尝试.
Teleport Ultra安装教程
1. 首先从小型下载站下载Teleport Ultra v1.72安装程序包,双击将其打开
2,选择安装位置
3. 完成安装并运行软件
4. 进入软件主界面
软件功能
1. 将网站的全部或部分下载到您的计算机上,以便您可以直接从硬盘上浏览网站,其速度要比在线浏览网站快
2,创建精确的副本或网站镜像,完成子目录结构和所有必需的文件
3. 在网站上搜索特定类型和大小的文件
4. 下载已知地址的文件列表
5. 浏览从中央网站链接的每个网站
6. 在网站上搜索关键字
7. 列出网站上的所有页面和文件
软件功能
1. 使用正则表达式指定要收录的收录和排除区域
2,指定用于对具有多个名称的服务器进行爬网的域别名
3. 借用浏览器的cookie缓存,以使您可以使用浏览器执行复杂的身份验证,然后使用Teleport进行爬网
4. 将自定义HTTP标头注入服务器请求
5. 同步离线副本以自动删除旧文件和孤儿
6. 重写未搜索文件的链接时,使用可自定义的消息
7. 使用原创URL和检索日期/时间戳控制HTML标签并注入meta标签
8,可以对HTTPS(安全)服务器进行爬网
常见问题
1. Teleport可以在Windows操作系统上运行吗?
是的,它适用于所有Win32操作系统,包括Windows 95、98,Me,NT,2000,XP,2003,Vista,2008,Windows 7和Windows8. 不适用于Windows 3.1或更早版本.
2. Teleport可以下载ASP,PHP或其他动态生成的网站吗?
是的,Teleport可以处理ASP,PHP,CGI,Cold Fusion和所有其他类型的动态生成的网页. 服务器像其他页面一样,将这些页面作为HTML发送到Teleport,并且Teleport像HTML一样接收和处理它们. Teleport无法从这些页面获取服务器端代码-此信息无法通过Web服务器获得. 但是,它可以像处理其他任何网页一样处理这些类型的网页.
3. Teleport可以处理诸如Javascript或“ onclick”事件之类的事件吗?
是的,从URL版本1.29.1847开始,Teleport可以处理简单的脚本命令,例如window.open(...)和location.href = ...,只要URL参数只是带引号的string即可. 当Teleport出现在诸如onclick事件之类的事件中时,它甚至会处理这些命令. 但是,该程序无法处理更复杂的脚本,例如调用由脚本定义的功能的脚本或打开由计算或连接字符串创建的URL的脚本. 要启用脚本解析,必须在“项目属性”的“探索”页面中将用于处理脚本和事件代码的选项设置为“开”. (默认情况下启用此选项. )
4. 瞬移可以处理“ cookie”吗?
是的,从1.29.1847版本开始,Teleport可以处理cookie. 只要在“项目属性”的“探索”页面上启用了此选项,Teleport就会接受并返回cookie. (默认情况下启用此选项. )
5. 瞬移可以处理Shockwave或Flash小程序吗?
从1.29.1718版本开始,Teleport将加载明确标识为对象参数的Flash或Shockwave电影. 但是,Teleport不会读取Flash或Shockwave小程序(.swf文件)来查找小程序可能链接到的其他文件.
6. Teleport可以处理NTLM身份验证吗?
不简单. NTLM身份验证是Teleport不支持的Microsoft特定身份验证形式. 如果可以控制要复制的Web服务器,则可以对其进行更改以允许基本身份验证,这是Internet上使用的常规身份验证形式. 如果需要,可以将服务器设置为允许Basic和NTLM. 有时Web服务器确实接受基本身份验证,但会误解您的用户名. 您可以尝试使用以下格式之一指定用户名,其中一种可能有效: 用户名/域名,用户名\域名,域/用户名,域\用户名. 最后,另一种解决方案是使用Python NTLM身份验证代理服务器应用程序,该应用程序可在以下位置找到. 安装Python(免费下载),解压缩NTLMAPS zip文件,使用代理服务器详细信息(ip,端口,用户名,域名,密码)配置server.cfg文件. 然后将Teleport配置为使用127.0.0.1作为代理,并使用cfg文件中的LISTEN端口号.
7. 如何将Teleport项目移动到另一个位置或其他硬盘上?
移动项目,移动(或复制)项目文件(.tpp文件)和项目文件夹(与项目名称相同,并且位于相同位置). 只要项目文件及其文件夹位于同一位置,Teleport就会知道如何找到所需的一切.
更新日志
版本1.72
1. 改进了解析器以更好地处理脚本中的字符串
2. 从重写过程中删除已知的问题脚本(jquery,addthis)
3. 更新公司联系信息
版本1.71
1. 改进了解析器,更好地处理了jQuery
2. 修复了HTTPS系统中的错误,该错误会在某些服务器的早期中断连接
Web Information Collector V1.1绿色免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2020-08-08 17:46
功能亮点:
1,执行任务
根据建立的任务信息保存并提取网页. 您也可以通过“双击”任务来启动此功能.
2,创建,复制,修改,删除任务
新建,复制,修改,删除任务信息
3. 默认选项
设置默认工作路径(默认为当前程序目录中的WorkDir文件夹)
设置提取测试的默认数量(默认为10)
设置默认的文本分隔符(默认为*)
4. 创建和编辑任务信息
任务名称: 在默认工作文件夹中生成一个以此名称命名的文件夹.
登录地址: 对于某些需要登录以查看其网页内容的网站,请填写登录页面地址. 执行任务时,软件将打开此登录页面,让您登录网站
常规格式类型网页,非常规格式类型网页:
此处的序数格式和非序数格式主要是指提取的地址是否只是数字更改. 例如,类似:
①并且属于顺序格式
②并且属于非常规格式
列表地址: 当类型为“非常规格式类型net”时,列表第一页的链接地址
提取地址: 由实际保存的网页地址+ *的公共部分组成.
例如,提取:
①然后提取地址为* .html
②然后提取地址为*. / *. html 查看全部
网页信息采集器(网页信息采集助手)是非常有用的网页信息采集器. 如何抓取网页信息?网页信息采集器(网页信息采集助手)可以为用户快速采集信息. 网页信息采集器功能强大且易于使用. 它可以轻松地采集某个网站的信息内容. 它可以根据已建立的任务信息保存和提取网页,也可以通过“双击”任务来启动此功能.
功能亮点:
1,执行任务
根据建立的任务信息保存并提取网页. 您也可以通过“双击”任务来启动此功能.
2,创建,复制,修改,删除任务
新建,复制,修改,删除任务信息
3. 默认选项
设置默认工作路径(默认为当前程序目录中的WorkDir文件夹)
设置提取测试的默认数量(默认为10)
设置默认的文本分隔符(默认为*)
4. 创建和编辑任务信息
任务名称: 在默认工作文件夹中生成一个以此名称命名的文件夹.
登录地址: 对于某些需要登录以查看其网页内容的网站,请填写登录页面地址. 执行任务时,软件将打开此登录页面,让您登录网站
常规格式类型网页,非常规格式类型网页:
此处的序数格式和非序数格式主要是指提取的地址是否只是数字更改. 例如,类似:
①并且属于顺序格式
②并且属于非常规格式
列表地址: 当类型为“非常规格式类型net”时,列表第一页的链接地址
提取地址: 由实际保存的网页地址+ *的公共部分组成.
例如,提取:
①然后提取地址为* .html
②然后提取地址为*. / *. html
SysNucleus WebHarvy(网页数据采集器)V5.2.0.155
采集交流 • 优采云 发表了文章 • 0 个评论 • 362 次浏览 • 2020-08-08 17:45
软件功能
1. SysNucleus WebHarvy允许您分析网页上的数据
2. 它可以显示和分析来自HTML地址的连接数据
3. 可以扩展到下一个网页
4. 您可以指定搜索数据的范围和内容
5. 您可以下载并保存扫描的图像
6. 支持在浏览器上复制链接搜索
7. 支持配置搜索对应的资源项
8,您可以使用项目名称和资源名称查找
9,SysNucleus WebHarvy可以轻松提取数据
10. 提供更高级的多词搜索和多页搜索
软件功能
1. 视觉点和点击界面
WebHarvy是一个可视网页提取工具. 实际上,无需编写任何脚本或代码来提取数据. 使用WebHarvy的内置浏览器浏览网络. 您可以选择单击鼠标提取数据. 很简单!
2. 智能识别模式
自动识别网页中出现的数据模式. 因此,如果您需要从网页上抓取项目列表(名称,地址,电子邮件,价格等),则无需进行任何其他配置. 如果数据重复,WebHarvy将自动对其进行刮擦.
3. 导出捕获的数据
可以保存从网页提取的各种格式的数据. 当前版本的WebHarvy网站抓取工具允许您将抓取的数据导出为XML,CSV,JSON或TSV文件. 您还可以将抓取的数据导出到SQL数据库.
4. 从多个页面中提取
通常,网页在多个页面上显示数据,例如产品目录. WebHarvy可以自动从多个网页爬网和提取数据. 刚刚指出“链接到下一页,WebHarvy网站抓取工具将自动从所有页面抓取数据.
5. 基于关键字的提取
基于关键字的提取使您可以捕获从搜索结果页面输入的关键字的列表数据. 挖掘数据时,将为所有给定的输入关键字自动重复创建的配置. 您可以指定任意数量的输入关键字. 6.通过生成{pass} {filter}服务器提取
要提取匿名信息并防止Web服务器提取Web软件,必须使用{pass} {filter}代理服务器访问目标网站选项. 您可以使用一个代理服务器地址或代理服务器地址列表.
7. 提取分类
WebHarvy网站抓取工具使您可以从链接列表中提取数据,这些链接可指向网站内的相似页面. 这样一来,您就可以使用一种配置来抓取网站中的类别或部分.
8. 使用正则表达式提取
WebHarvy可以在网页的文本或HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分. 这项强大的技术为您提供了更大的灵活性,同时您可以争夺数据. 查看全部
SysNucleus WebHarvy是一个非常易于使用的网页数据采集软件. 它可以帮助用户轻松地从网页中提取数据并将其保存为不同的格式. 它还支持提取各种类型的文件,例如视频和图片.
软件功能
1. SysNucleus WebHarvy允许您分析网页上的数据
2. 它可以显示和分析来自HTML地址的连接数据
3. 可以扩展到下一个网页
4. 您可以指定搜索数据的范围和内容
5. 您可以下载并保存扫描的图像
6. 支持在浏览器上复制链接搜索
7. 支持配置搜索对应的资源项
8,您可以使用项目名称和资源名称查找
9,SysNucleus WebHarvy可以轻松提取数据
10. 提供更高级的多词搜索和多页搜索
软件功能
1. 视觉点和点击界面
WebHarvy是一个可视网页提取工具. 实际上,无需编写任何脚本或代码来提取数据. 使用WebHarvy的内置浏览器浏览网络. 您可以选择单击鼠标提取数据. 很简单!
2. 智能识别模式
自动识别网页中出现的数据模式. 因此,如果您需要从网页上抓取项目列表(名称,地址,电子邮件,价格等),则无需进行任何其他配置. 如果数据重复,WebHarvy将自动对其进行刮擦.
3. 导出捕获的数据
可以保存从网页提取的各种格式的数据. 当前版本的WebHarvy网站抓取工具允许您将抓取的数据导出为XML,CSV,JSON或TSV文件. 您还可以将抓取的数据导出到SQL数据库.
4. 从多个页面中提取
通常,网页在多个页面上显示数据,例如产品目录. WebHarvy可以自动从多个网页爬网和提取数据. 刚刚指出“链接到下一页,WebHarvy网站抓取工具将自动从所有页面抓取数据.
5. 基于关键字的提取
基于关键字的提取使您可以捕获从搜索结果页面输入的关键字的列表数据. 挖掘数据时,将为所有给定的输入关键字自动重复创建的配置. 您可以指定任意数量的输入关键字. 6.通过生成{pass} {filter}服务器提取
要提取匿名信息并防止Web服务器提取Web软件,必须使用{pass} {filter}代理服务器访问目标网站选项. 您可以使用一个代理服务器地址或代理服务器地址列表.
7. 提取分类
WebHarvy网站抓取工具使您可以从链接列表中提取数据,这些链接可指向网站内的相似页面. 这样一来,您就可以使用一种配置来抓取网站中的类别或部分.
8. 使用正则表达式提取
WebHarvy可以在网页的文本或HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分. 这项强大的技术为您提供了更大的灵活性,同时您可以争夺数据.
优采云采集器·网络数据信息挖掘软件(www.ucaiyun.com)v9.6.5免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 389 次浏览 • 2020-08-08 03:10
该程序支持远程下载图片文件,登录网站后采集信息,检测文件的真实地址,支持代理,支持防盗链的采集,支持直接存储采集的数据和手册通过模仿人来释放,以及许多其他功能.
优采云采集器支持从任何类型的网站(例如各种新闻网站,论坛,电子商务网站,求职网站等)采集所需的信息.
同时,它具有强大的网站登录采集,多页和页面采集,网站跨层采集,POST采集,脚本页面采集,动态页面采集和其他高级采集功能.
强大的php和c#插件支持使您可以通过二次开发实现所需的任何更强大的功能.
软件功能
1. 强大的多功能性
无论新闻,论坛,视频,黄页,图片,下载网站如何,只要可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集所需的内容.
2,稳定高效
五年磨一剑,软件不断更新和完善,采集速度快,性能稳定,资源少.
3. 强大的可扩展性和广泛的应用范围
自定义Web发布,自定义主流数据库的保存和发布,自定义本地PHP和.net外部编程接口以处理数据,以便您可以使用这些数据.
基本功能
1. 规则的自定义-通过采集规则的定义,您可以搜索所有网站以采集几乎任何类型的信息.
2. 多任务,多线程,多个信息采集任务可以同时执行,每个任务可以使用多个线程.
3. 您所看到的就是您所得到的-您所看到的就是您在任务采集过程中所得到的,并且在此过程中遍历的链接信息,采集信息和错误信息将及时反映在软件界面中.
4. 数据存储数据在采集时会自动保存到关系数据库中,并且数据结构可以自动调整. 该软件可以根据采集规则自动创建数据库以及其中的表和字段,或者可以由数据库灵活地指导将数据保存到客户现有的数据库结构中.
5. 在断点处继续采集-停止后,可以继续从断点采集信息采集任务. 从那时起,您不必担心采集任务会意外中断.
6. 网站登录-支持采集网站Cookie和可视网站登录,甚至可以采集登录时需要验证码的网站.
7. 计划任务-此功能可让您定期,定量或循环执行采集任务.
8. 采集范围的限制-可以根据采集的深度和网站徽标来限制采集范围.
9. 文件下载-您可以将采集的二进制文件(例如图片,音乐,软件,文档等)下载到本地磁盘或采集结果数据库中.
10. 结果替换-您可以根据规则用定义的内容替换采集的结果.
11. 条件保存-您可以根据特定条件决定要保存和过滤哪些信息.
12. 过滤重复内容-该软件可以根据用户设置和实际情况自动删除重复内容和重复URL.
13. 特殊链接识别-使用此功能可以识别由JavaScript动态生成的链接或其他怪异链接.
14. 数据发布-可以通过自定义界面将采集到的结果数据发布到任何内容管理系统和指定的数据库中. 当前支持的目标发布媒体包括: 数据库(访问,SQL Server,我的SQL,Oracle),静态htm文件.
15. 保留的编程接口-定义多个编程接口,用户可以在事件中使用PHP,C#语言进行编程,扩展采集功能.
功能
1. 支持所有网站编码: 它完美支持所有编码格式的网页的采集,并且该程序还可以自动识别网页编码.
2. 多种发布方式: 支持当前所有主流和非主流CMS,BBS和其他网站程序,并且可以通过系统的发布模块实现采集器和网站程序的完美结合.
3. 全自动: 无人值守的工作. 配置该程序后,该程序将根据您的设置自动运行,而无需人工干预. 查看全部
该软件非常实用〜无论您是否使用过,建议您使用它. 专业而强大的网络数据/信息挖掘软件. 通过灵活的配置,您可以轻松地从Web上获取它. 任何资源,例如文本,图片,文件等.
该程序支持远程下载图片文件,登录网站后采集信息,检测文件的真实地址,支持代理,支持防盗链的采集,支持直接存储采集的数据和手册通过模仿人来释放,以及许多其他功能.
优采云采集器支持从任何类型的网站(例如各种新闻网站,论坛,电子商务网站,求职网站等)采集所需的信息.
同时,它具有强大的网站登录采集,多页和页面采集,网站跨层采集,POST采集,脚本页面采集,动态页面采集和其他高级采集功能.
强大的php和c#插件支持使您可以通过二次开发实现所需的任何更强大的功能.
软件功能
1. 强大的多功能性
无论新闻,论坛,视频,黄页,图片,下载网站如何,只要可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集所需的内容.
2,稳定高效
五年磨一剑,软件不断更新和完善,采集速度快,性能稳定,资源少.
3. 强大的可扩展性和广泛的应用范围
自定义Web发布,自定义主流数据库的保存和发布,自定义本地PHP和.net外部编程接口以处理数据,以便您可以使用这些数据.
基本功能
1. 规则的自定义-通过采集规则的定义,您可以搜索所有网站以采集几乎任何类型的信息.
2. 多任务,多线程,多个信息采集任务可以同时执行,每个任务可以使用多个线程.
3. 您所看到的就是您所得到的-您所看到的就是您在任务采集过程中所得到的,并且在此过程中遍历的链接信息,采集信息和错误信息将及时反映在软件界面中.
4. 数据存储数据在采集时会自动保存到关系数据库中,并且数据结构可以自动调整. 该软件可以根据采集规则自动创建数据库以及其中的表和字段,或者可以由数据库灵活地指导将数据保存到客户现有的数据库结构中.
5. 在断点处继续采集-停止后,可以继续从断点采集信息采集任务. 从那时起,您不必担心采集任务会意外中断.
6. 网站登录-支持采集网站Cookie和可视网站登录,甚至可以采集登录时需要验证码的网站.
7. 计划任务-此功能可让您定期,定量或循环执行采集任务.
8. 采集范围的限制-可以根据采集的深度和网站徽标来限制采集范围.
9. 文件下载-您可以将采集的二进制文件(例如图片,音乐,软件,文档等)下载到本地磁盘或采集结果数据库中.
10. 结果替换-您可以根据规则用定义的内容替换采集的结果.
11. 条件保存-您可以根据特定条件决定要保存和过滤哪些信息.
12. 过滤重复内容-该软件可以根据用户设置和实际情况自动删除重复内容和重复URL.
13. 特殊链接识别-使用此功能可以识别由JavaScript动态生成的链接或其他怪异链接.
14. 数据发布-可以通过自定义界面将采集到的结果数据发布到任何内容管理系统和指定的数据库中. 当前支持的目标发布媒体包括: 数据库(访问,SQL Server,我的SQL,Oracle),静态htm文件.
15. 保留的编程接口-定义多个编程接口,用户可以在事件中使用PHP,C#语言进行编程,扩展采集功能.
功能
1. 支持所有网站编码: 它完美支持所有编码格式的网页的采集,并且该程序还可以自动识别网页编码.
2. 多种发布方式: 支持当前所有主流和非主流CMS,BBS和其他网站程序,并且可以通过系统的发布模块实现采集器和网站程序的完美结合.
3. 全自动: 无人值守的工作. 配置该程序后,该程序将根据您的设置自动运行,而无需人工干预.
优采云采集器v2.4.9.0免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 352 次浏览 • 2020-08-08 00:33
软件功能
一键式数据提取
易于学习,通过可视界面,只需单击鼠标即可捕获数据
快速高效
内置一组高速浏览器内核,再加上HTTP引擎模式,以实现快速数据采集
适用于各种网站
可以采集99%的Internet站点,包括单页应用程序Ajax加载和其他动态站点
功能介绍
向导模式
易于使用,易于通过单击鼠标自动生成
脚本定期运行
可以按计划定期运行,而无需手动
原创高速内核
自主开发的浏览器内核速度很快,远远超出了对手
智能识别
智能识别网页中的列表和表单结构(多选框下拉列表等)
广告屏蔽
自定义广告阻止模块,与AdblockPlus语法兼容,可以添加自定义规则
多个数据导出
支持Txt,Excel,MySQL,SQLServer,SQlite,Access,网站等.
使用方法
第一步: 输入采集网址
打开软件,创建一个新任务,然后输入要采集的网站地址.
第2步: 智能分析,在整个过程中自动提取数据
进入第二步后,优采云采集器会自动智能地分析网页并从中提取列表数据.
第3步: 将数据导出到表格,数据库,网站等
运行任务,将采集的数据导出到Csv,Excel和各种数据库,并支持api导出.
常见问题
问: 如何过滤列表中的前N个数据?
1. 有时我们需要过滤采集到的列表,例如过滤掉第一组数据(采集表时,过滤掉表的列名)
2. 在列表模式菜单中单击,设置列表xpath
问: 如何捕获cookie以获取cookie并进行手动设置?
1. 首先,使用Google Chrome浏览器打开要采集的网站并登录.
2. 然后按F12键,将出现开发人员工具,选择“网络”
3. 然后按F5刷新下一页,然后选择一个请求.
4. 复制完成后,在优采云采集器中编辑任务,然后输入第三步以指定HTTP标头. 查看全部
优采云采集器 V2是高效的Web信息采集软件,支持99%的网站数据采集. 优采云采集器可以生成Excel表,api数据库文件和其他内容,以帮助您管理网站数据信息. 您需要从指定的网页上采集数据,只需使用此软件即可.
软件功能
一键式数据提取
易于学习,通过可视界面,只需单击鼠标即可捕获数据
快速高效
内置一组高速浏览器内核,再加上HTTP引擎模式,以实现快速数据采集
适用于各种网站
可以采集99%的Internet站点,包括单页应用程序Ajax加载和其他动态站点
功能介绍
向导模式
易于使用,易于通过单击鼠标自动生成
脚本定期运行
可以按计划定期运行,而无需手动
原创高速内核
自主开发的浏览器内核速度很快,远远超出了对手
智能识别
智能识别网页中的列表和表单结构(多选框下拉列表等)
广告屏蔽
自定义广告阻止模块,与AdblockPlus语法兼容,可以添加自定义规则
多个数据导出
支持Txt,Excel,MySQL,SQLServer,SQlite,Access,网站等.
使用方法
第一步: 输入采集网址
打开软件,创建一个新任务,然后输入要采集的网站地址.
第2步: 智能分析,在整个过程中自动提取数据
进入第二步后,优采云采集器会自动智能地分析网页并从中提取列表数据.
第3步: 将数据导出到表格,数据库,网站等
运行任务,将采集的数据导出到Csv,Excel和各种数据库,并支持api导出.
常见问题
问: 如何过滤列表中的前N个数据?
1. 有时我们需要过滤采集到的列表,例如过滤掉第一组数据(采集表时,过滤掉表的列名)
2. 在列表模式菜单中单击,设置列表xpath
问: 如何捕获cookie以获取cookie并进行手动设置?
1. 首先,使用Google Chrome浏览器打开要采集的网站并登录.
2. 然后按F12键,将出现开发人员工具,选择“网络”
3. 然后按F5刷新下一页,然后选择一个请求.
4. 复制完成后,在优采云采集器中编辑任务,然后输入第三步以指定HTTP标头.
Sage网站采集器V5.2.3
采集交流 • 优采云 发表了文章 • 0 个评论 • 281 次浏览 • 2020-08-07 23:28
[基本介绍] 1. Sage网站采集器简单易用,它是绿色软件,无需安装,下载并解压缩后即可使用; 2.实用性强,内置网站采集功能; 3.只需输入搜索关键字,您就可以采集成千上万的数据和信息,然后生成一个网站; 4.您可以选择“新闻,文章,电影,视频,图片,关键字”采集选项来采集和定位; 5.用Google生成网站地图. 6.您可以将生成的网站路径,目录名称,文件前缀,后缀名称设置为HI; 7. 12套模板供您选择和匹配,生成的网站不再单一; 8. SEO优化了一些网站管理员将内容插入到Google广告连接参数中; 9.优化了在文章内容中随机插入大量关键词的功能; 10.生成的网站语言代码可以随机设置(简体,繁体,UTF-8); 11.网站广告的采集和生成可以随意设置(耦合,浮动,底端); 12.附加的HtmlJs交换功能,方便网站管理员使用; [软件功能] 1.采集对象不受限制,只要可以连接页面即可(该软件设置了N个多重采集规则);问题: 如果您想采集有关您认为良好的特定网站的信息,请参阅“图腾网站采集软件”. 它可以自定义规则并设置采集蜘蛛. 2.采集对象支持: 文章,图片,Flash,音频和视频等. 3.完善的内容存储解决方案,Sage Collector提供了2种存储方法: 直接数据库指导和模拟提交. 1)直接数据库引导方法支持基于Mysql数据库存储信息的任何内容管理系统; 2)模拟提交方法理论上可以支持任何目标,并且不受目标程序语言和数据库类别的限制;实际使用效果受目标应用程序的影响.
Content Grabber Premium v2.48 Web内容采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 772 次浏览 • 2020-08-07 22:44
基本介绍
Content Grabber Premium(Web Content Grabber Premium)是由外国神灵制成的人工制品,可以从网页中获取内容(视频,图片,文本)并将其提取到Excel,XML,CSV和大多数数据库中. 该软件基于Web爬行和Web自动化. 它是完全免费的,并且经常用于数据调查和测试目的.
功能介绍
价格比较门户/移动应用程序
-数据摘要
-合作列表(例如房屋止赎,工作委员会,旅游景点)
-新闻和内容汇总
-搜索引擎排名
市场情报和监控
-有竞争力的价格
-零售链监控
-社交媒体和品牌监控
-金融与市场研究
-欺诈识别
-知识产权保护
-合规与风险管理
政府解决方案
-及时获取来自世界各地的新闻,事件和意见
-减少数据采集和IT成本
-促进信息共享
-开源情报(OSINT)
内容集成
-内容迁移(即CMS / CRM)
-企业搜索
-传统应用程序集成
B2B集成/流程自动化
-合作伙伴/供应商/客户集成
可扩展性和可靠性
内容采集器针对的是对网络搜寻至关重要的公司,并专注于可伸缩性和可靠性. 该网络收录大量数据,借助多线程,优化的Web浏览器和许多其他性能调整选项,Content Grabber将比任何其他软件更快,更可靠地提取. 我们强大的测试和调试功能可以帮助您构建可靠的代理,可靠的错误处理和错误恢复将使代理在最困难的情况下运行.
建立数百种网页抓取代理
“ Content Crawler”代理编辑器的易用性和可视化使其适合于构建数百个Web爬网代理,比使用任何其他软件要快得多.
代理编辑器将自动检测和配置所需的命令. 它会自动创建内容和链接列表,处理分页和Web表单,下载或上传文件,并配置您在网页上执行的任何其他操作. 同时,您始终可以手动微调这些命令,因此“内容抓取器”为您提供了简单性和控制性.
有数百种Web爬网程序,您需要使用正确的工具来管理这些工具,并且爬网内容不会使您失望. 您可以查看所有代理的状态和日志,也可以在集中位置运行和安排代理.
净刮除剂的使用费分配免费
构建免版税,独立的Web爬网代理,该代理可以在没有“内容爬网程序”软件的情况下在任何地方运行. 独立代理是一个简单的可执行文件,可以随时随地发送或复制,并具有丰富的配置选项. 您可以自由出售或赠送独立代理商,也可以在代理商的用户界面中添加促销信息和广告.
使用脚本自定义所有内容
脚本是“内容获取器”不可或缺的一部分,可用于需要某些特殊功能才能完全按照需要完成所有操作的情况. 使用内置脚本编辑器,或使用Content Grabber和Visual Studio的集成来实现更强大的脚本编辑和调试功能.
使用API构建独特的解决方案
将网络抓取功能添加到自己的桌面应用程序中,并免费分发应用程序的Content Grabber运行时. 使用专用的内容采集器Web API来构建Web应用程序,并根据需要直接从您的网站直接执行Web抓取代理.
系统要求
在安装内容采集器之前,请确保您满足这些要求.
Windows 7/8/10 / 2008R2 / 2012 / 2012R2
.NET v4.5(如果您的计算机尚未安装,则将自动安装. )
安装步骤
1. 从该站点提供的百度网站下载该软件,解压后,双击“ setup.exe”程序
2. 如果计算机上未安装Microsoft .NET版本,则安装程序将显示Microsoft .NET 4.5许可协议,并将自动为您安装
3,接受许可协议并安装
4. 按照提示在安装向导中进行安装 查看全部
Content Grabber Premium是用于Web爬网和Web自动化的Web内容采集工具. 它可以按照您选择的格式从几乎任何网站中提取内容(包括Excel报告,XML,CSV和大型大多数数据库),并将其另存为结构化数据,欢迎有需要的朋友下载和使用.
基本介绍
Content Grabber Premium(Web Content Grabber Premium)是由外国神灵制成的人工制品,可以从网页中获取内容(视频,图片,文本)并将其提取到Excel,XML,CSV和大多数数据库中. 该软件基于Web爬行和Web自动化. 它是完全免费的,并且经常用于数据调查和测试目的.
功能介绍
价格比较门户/移动应用程序
-数据摘要
-合作列表(例如房屋止赎,工作委员会,旅游景点)
-新闻和内容汇总
-搜索引擎排名
市场情报和监控
-有竞争力的价格
-零售链监控
-社交媒体和品牌监控
-金融与市场研究
-欺诈识别
-知识产权保护
-合规与风险管理
政府解决方案
-及时获取来自世界各地的新闻,事件和意见
-减少数据采集和IT成本
-促进信息共享
-开源情报(OSINT)
内容集成
-内容迁移(即CMS / CRM)
-企业搜索
-传统应用程序集成
B2B集成/流程自动化
-合作伙伴/供应商/客户集成
可扩展性和可靠性
内容采集器针对的是对网络搜寻至关重要的公司,并专注于可伸缩性和可靠性. 该网络收录大量数据,借助多线程,优化的Web浏览器和许多其他性能调整选项,Content Grabber将比任何其他软件更快,更可靠地提取. 我们强大的测试和调试功能可以帮助您构建可靠的代理,可靠的错误处理和错误恢复将使代理在最困难的情况下运行.
建立数百种网页抓取代理
“ Content Crawler”代理编辑器的易用性和可视化使其适合于构建数百个Web爬网代理,比使用任何其他软件要快得多.
代理编辑器将自动检测和配置所需的命令. 它会自动创建内容和链接列表,处理分页和Web表单,下载或上传文件,并配置您在网页上执行的任何其他操作. 同时,您始终可以手动微调这些命令,因此“内容抓取器”为您提供了简单性和控制性.
有数百种Web爬网程序,您需要使用正确的工具来管理这些工具,并且爬网内容不会使您失望. 您可以查看所有代理的状态和日志,也可以在集中位置运行和安排代理.
净刮除剂的使用费分配免费
构建免版税,独立的Web爬网代理,该代理可以在没有“内容爬网程序”软件的情况下在任何地方运行. 独立代理是一个简单的可执行文件,可以随时随地发送或复制,并具有丰富的配置选项. 您可以自由出售或赠送独立代理商,也可以在代理商的用户界面中添加促销信息和广告.
使用脚本自定义所有内容
脚本是“内容获取器”不可或缺的一部分,可用于需要某些特殊功能才能完全按照需要完成所有操作的情况. 使用内置脚本编辑器,或使用Content Grabber和Visual Studio的集成来实现更强大的脚本编辑和调试功能.
使用API构建独特的解决方案
将网络抓取功能添加到自己的桌面应用程序中,并免费分发应用程序的Content Grabber运行时. 使用专用的内容采集器Web API来构建Web应用程序,并根据需要直接从您的网站直接执行Web抓取代理.
系统要求
在安装内容采集器之前,请确保您满足这些要求.
Windows 7/8/10 / 2008R2 / 2012 / 2012R2
.NET v4.5(如果您的计算机尚未安装,则将自动安装. )
安装步骤
1. 从该站点提供的百度网站下载该软件,解压后,双击“ setup.exe”程序
2. 如果计算机上未安装Microsoft .NET版本,则安装程序将显示Microsoft .NET 4.5许可协议,并将自动为您安装
3,接受许可协议并安装
4. 按照提示在安装向导中进行安装
如何编写优采云采集器的采集规则并采集页面图片中的文本?
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-08-07 22:42
优采云采集器如何采集内容页面的两个内容?: 这需要您的经验. 找到内容2和内容7与其他内容之间的差异,然后基于该差异采集规则. 例如,内容2和内容7在开头和结尾分别带有符号x和y,但是其他内容则没有,那么您可以编辑内容标签的规则以采集从x的开头到y的结尾的内容,以便您可以合并内容2和采集的内容7. 还可以使用正则表达式进行采集,这需要您对正则表达式有一定的了解和要求.
如何使用优采云采集器采集文章标题: 使用免费的Web数据采集器-优采云采集器轻松采集优采云采集器更适合新手网站管理员,只需将其拖放就可以了规则市场上有许多免费的现成规则可以直接下载和使用!
<p>如何使用优采云采集器采集网页图片. 详细的图形教程_: 优采云采集器通过两个步骤采集信息: 1.采集URL. 该步骤还告诉软件需要采集多少个网页,并给出特定的网页地址. 2.采集内容. 在拥有网站之后,您可以转到该网站来采集信息,但是网页上有很多信息,并且软件不知道您要采集什么. 采集内容... 查看全部
如何写优采云采集器的采集规则和采集页上图片中的文字?_: 我不得不说优采云很有用,但我认为它不是很有用. 只需编写这些采集规则. 有很多不清楚的事情要设置. 拿钱买,一开始客服很热情为您解答,一旦您付清钱,就可以购买,写下规则,确定,如果有任何疑问,请致电客服解决,结果已被延迟和延迟...
优采云采集器如何采集内容页面的两个内容?: 这需要您的经验. 找到内容2和内容7与其他内容之间的差异,然后基于该差异采集规则. 例如,内容2和内容7在开头和结尾分别带有符号x和y,但是其他内容则没有,那么您可以编辑内容标签的规则以采集从x的开头到y的结尾的内容,以便您可以合并内容2和采集的内容7. 还可以使用正则表达式进行采集,这需要您对正则表达式有一定的了解和要求.
如何使用优采云采集器采集文章标题: 使用免费的Web数据采集器-优采云采集器轻松采集优采云采集器更适合新手网站管理员,只需将其拖放就可以了规则市场上有许多免费的现成规则可以直接下载和使用!
<p>如何使用优采云采集器采集网页图片. 详细的图形教程_: 优采云采集器通过两个步骤采集信息: 1.采集URL. 该步骤还告诉软件需要采集多少个网页,并给出特定的网页地址. 2.采集内容. 在拥有网站之后,您可以转到该网站来采集信息,但是网页上有很多信息,并且软件不知道您要采集什么. 采集内容...
智能网络内容采集器v1.92
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-08-07 22:17
1. 底层HTTP方法用于快速,稳定地采集数据,并且可以构建多个任务和多个线程来同时从多个网站采集数据
2,用户可以随意导入和导出任务
3. 可以设置该任务的密码,并具有N页采集暂停,遇到特殊标记时采集暂停等多种破解反采集功能
4. 您可以直接输入网址,也可以通过JavaScript脚本生成网址,或通过关键字搜索来采集网址
5. 您可以使用登录采集方法来采集需要登录帐户才能查看的Web内容
6. 在N列中无限深入地采集内容和链接
7. 支持多种内容提取模式,您可以根据需要处理采集的内容,例如清除HTML,图片等.
8. 您可以编译自己的JAVASCRIPT脚本以提取网页的内容,并轻松实现内容的任何部分的采集
9. 可以根据设置的模板保存采集到的文本内容
10. 可以根据模板将多个文件保存到同一文件中
11. 针对网页的多个部分分别进行分页内容采集
12. 可以设置客户信息以模拟百度等搜索引擎采集目标网站的情况
13. 该软件是永久免费的
智能Web内容采集器v1.9更新:
内置软件URL已更新为
使用新的智能软件控件UI
向EMAIL功能添加用户反馈
添加直接将初始链接设置为最终内容页面处理功能的功能
增强内核功能,支持关键字搜索并替换POST中的关键字标签
优化获取核心
优化断开的拨号算法
优化重复数据删除工具的算法
修复了拨号显示IP错误的错误
修复了错误关键字被暂停或拨打时未重新采集错误页面的错误.
修复了受限内容的最大值为0时,最小值无法正确保存的问题. 查看全部
Smart Web Content Collector可以以多任务和多线程的方式采集任何网页上的任何指定文本内容,并执行所需的相应过滤和处理. 它可以通过搜索关键字来采集所需的指定搜索结果.
1. 底层HTTP方法用于快速,稳定地采集数据,并且可以构建多个任务和多个线程来同时从多个网站采集数据
2,用户可以随意导入和导出任务
3. 可以设置该任务的密码,并具有N页采集暂停,遇到特殊标记时采集暂停等多种破解反采集功能
4. 您可以直接输入网址,也可以通过JavaScript脚本生成网址,或通过关键字搜索来采集网址
5. 您可以使用登录采集方法来采集需要登录帐户才能查看的Web内容
6. 在N列中无限深入地采集内容和链接
7. 支持多种内容提取模式,您可以根据需要处理采集的内容,例如清除HTML,图片等.
8. 您可以编译自己的JAVASCRIPT脚本以提取网页的内容,并轻松实现内容的任何部分的采集
9. 可以根据设置的模板保存采集到的文本内容
10. 可以根据模板将多个文件保存到同一文件中
11. 针对网页的多个部分分别进行分页内容采集
12. 可以设置客户信息以模拟百度等搜索引擎采集目标网站的情况
13. 该软件是永久免费的
智能Web内容采集器v1.9更新:
内置软件URL已更新为
使用新的智能软件控件UI
向EMAIL功能添加用户反馈
添加直接将初始链接设置为最终内容页面处理功能的功能
增强内核功能,支持关键字搜索并替换POST中的关键字标签
优化获取核心
优化断开的拨号算法
优化重复数据删除工具的算法
修复了拨号显示IP错误的错误
修复了错误关键字被暂停或拨打时未重新采集错误页面的错误.
修复了受限内容的最大值为0时,最小值无法正确保存的问题.
遵天市网页采集器v1.0.1绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2020-08-07 21:53
此软件通过Internet采集网页信息. 有两个主要功能:
1,您可以在js之后采集动态信息.
2,您可以设置要采集的正则表达式.
此外,该软件具有内置的多种采集方案,分别对应于静态网页和动态网页.
该软件采集了官方网站上的图像(面部)搜索引擎数据,然后对其进行了索引.
使用步骤:
1. 输入URL,正常浏览网页并到达采集目标,单击工具栏上的“在js之后查看源代码”图标,以在执行js后显示网页的内容.
如果看不到相关内容,则可以稍等片刻,然后再次单击以确保执行了js代码. 通过浏览完整的网页源代码,我们可以确认
使用计划1或计划2. 如果可以通过更改URL的页码导航到下一页,请使用计划1;否则,请使用计划1. 如果您通过脚本动态更新页面的内容,
使用计划2.
2,单击工具栏上的“运行采集方案”图标,然后根据步骤1选择方案1或2. 如果已经存在方案1和2生成的downloadtotal.txt
文件,您还可以选择选项3. 填写必要的信息或表达式,单击“开始采集”按钮,系统将自动采集. 点击对话框中的“取消”
按钮关闭对话框而不启动采集任务.
3. 单击工具栏上的“停止采集方案”图标,系统将终止采集任务.
防止网页采集:
防止采集的第一种方法: 在文章的开头和结尾添加随机和未固定的内容. 网站采集人员通常在进行采集时指定起始位置和结束位置,并在中间截取内容.
例如,如果您文章的内容是“ Youxun Software Information Network”,则如何添加随机内容:
随机内容1+优讯软件信息网+随机内容2
注意: 随机内容1和随机内容2只需为每篇文章随机显示一个. 查看全部
现在市场上充斥着一些付费的网页采集器. 不管其功能是什么,如此绿色免费的网页采集器都是免费的!
此软件通过Internet采集网页信息. 有两个主要功能:
1,您可以在js之后采集动态信息.
2,您可以设置要采集的正则表达式.
此外,该软件具有内置的多种采集方案,分别对应于静态网页和动态网页.
该软件采集了官方网站上的图像(面部)搜索引擎数据,然后对其进行了索引.
使用步骤:
1. 输入URL,正常浏览网页并到达采集目标,单击工具栏上的“在js之后查看源代码”图标,以在执行js后显示网页的内容.
如果看不到相关内容,则可以稍等片刻,然后再次单击以确保执行了js代码. 通过浏览完整的网页源代码,我们可以确认
使用计划1或计划2. 如果可以通过更改URL的页码导航到下一页,请使用计划1;否则,请使用计划1. 如果您通过脚本动态更新页面的内容,
使用计划2.
2,单击工具栏上的“运行采集方案”图标,然后根据步骤1选择方案1或2. 如果已经存在方案1和2生成的downloadtotal.txt
文件,您还可以选择选项3. 填写必要的信息或表达式,单击“开始采集”按钮,系统将自动采集. 点击对话框中的“取消”
按钮关闭对话框而不启动采集任务.
3. 单击工具栏上的“停止采集方案”图标,系统将终止采集任务.
防止网页采集:
防止采集的第一种方法: 在文章的开头和结尾添加随机和未固定的内容. 网站采集人员通常在进行采集时指定起始位置和结束位置,并在中间截取内容.
例如,如果您文章的内容是“ Youxun Software Information Network”,则如何添加随机内容:
随机内容1+优讯软件信息网+随机内容2
注意: 随机内容1和随机内容2只需为每篇文章随机显示一个.
优采云2.2.7正式版
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-07 21:50
优采云是一种专业高效的Web数据爬网工具. 许多信息对时间敏感. 这里带来了优采云,它可以帮助用户分批采集网站的页面数据. 该过程是全自动的且非常智能,可帮助用户快速采集所需信息. 欢迎大家下载并体验jz5u!
使用方法
登录到优采云 Client->创建单击爬网程序->单击要爬网的数据->启动爬网程序
第1步登录到优采云 Client
打开已安装的优采云客户端,输入优采云帐号和密码,登录控制台
第2步,创建一个点击爬网程序
单击“新建应用程序”,选择“爬网程序”,单击“下一步”,选择“开发自己”,然后选择“单击模式”. 输入采集器名称,然后单击“创建”
第三步,单击要爬网的数据
1. 打开创建的采集器,输入并打开点击面板
2,在点击面板中,执行点击操作
首先,输入收录所需数据的网址,然后按Enter加载显示的内容:
然后,在显示的网页内容中,单击以选择要采集的数据,例如,选择所采集文章的标题和内容:
点击左侧的高级设置,设置抓取工具的列表页面,内容页面的url正则表达式,是否自动呈现JS等,以提高抓取工具的效率:
第4步,启动采集器
单击后,单击以开始爬网. 稍等片刻,爬虫将自动开始运行 查看全部
优采云是一种专业高效的Web数据爬网工具. 许多信息对时间敏感. 这里带来了优采云,它可以帮助用户分批采集网站的页面数据. 该过程是全自动的且非常智能,可帮助用户快速采集所需信息. 欢迎大家下载并体验jz5u!
使用方法
登录到优采云 Client->创建单击爬网程序->单击要爬网的数据->启动爬网程序
第1步登录到优采云 Client
打开已安装的优采云客户端,输入优采云帐号和密码,登录控制台
第2步,创建一个点击爬网程序
单击“新建应用程序”,选择“爬网程序”,单击“下一步”,选择“开发自己”,然后选择“单击模式”. 输入采集器名称,然后单击“创建”
第三步,单击要爬网的数据
1. 打开创建的采集器,输入并打开点击面板
2,在点击面板中,执行点击操作
首先,输入收录所需数据的网址,然后按Enter加载显示的内容:
然后,在显示的网页内容中,单击以选择要采集的数据,例如,选择所采集文章的标题和内容:
点击左侧的高级设置,设置抓取工具的列表页面,内容页面的url正则表达式,是否自动呈现JS等,以提高抓取工具的效率:
第4步,启动采集器
单击后,单击以开始爬网. 稍等片刻,爬虫将自动开始运行
Shanken Web TXT采集器V1.0最新免费绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2020-08-07 21:24
软件简介:
在发展之初,这是为了阅读小说. 我个人喜欢在本地下载它以便慢慢观看,但是许多新颖的网站不支持下载或下载限制(非VIP小说). 我还在论坛上找到了一些采集器,但是就我个人而言,它并不容易使用. 输入正则表达式后,该章将出现,但是当我单击下载时无法下载文本. 完成软件后,我继续测试软件. 相同的正则表达式与那些软件不匹配. 内容已输出,因此下载失败. 该软件还可能具有一些我不知道的规则,但结果是它无法完成我想要的下载. 我什至不知道这是规则,软件还是网站设置...
因此,我开发的此软件专门添加了预览功能,您可以知道是否可以获取网页数据,获取后是否可以正确匹配内容.
功能介绍:
1. 规则设置:
①在规则设置窗口中,无需编写任何规则即可在网站上找到文章. 首先单击实时预览以查看是否可以获取网页的源代码. 如果可以得到,请编写规则. 如果无法获得,则无需继续. 上
②规则设置使用正则表达式匹配内容. 最好有一定的基础. 如果没有基础,也可以参考给出的示例. 简单学习不需要深入研究正则表达式.
③设置规则后,需要分别预览目录页面和内容页面,这还需要两个链接,即目录页面链接和内容页面链接.
④关于替换,有常规替换和自定义替换. 目前无需进行正规化,普通替代品就可以了. 应该注意的是,必须输入值,并且空格也是可以接受的. 删除: 选择整行,然后按住删除键. 当内置\ n用作替换数据时,表示换行.
⑤编码,目前仅设置了GBK和UFT-8,几乎大多数网站都是这两种编码之一.
2,分析和下载
①要进行分析,请按2按钮解析地址. 按钮1当前功能强大,不希望被删除,稍后将开发其他功能.
②支持单章下载和全文下载.
③支持添加章节号[某些小说中没有章节号时可以检查]
④支持在线观看,但是需要连接到互联网. 此功能仅是辅助工具,不是阅读小说的专业软件.
⑤显示下载进度和总时间,内置多线程.
3. 关于软件
①实际上,您只需要.exe,规则全部由您自己添加,commonrule.xml收录常见的替换规则. 网站规则位于规则文件夹下. 我在其中放置了两个网站规则,主要用于测试. 您可以自己添加其他站点规则,或支持开发人员.
②该软件未打包,由c#开发,没有病毒. 如果您不担心,请不要使用它,我不会收回它.
③关于该软件,跳至论坛. 当我亲自测试跳转时,360提示了我. 这也可能是因为跳转是针对360浏览器进行的. 我想知道您是否会遇到这个问题.
④如果您不知道xml中的内容,请不要触摸它,以免软件识别失败和错误.
⑤需要.net framework 4.5或更高版本的框架支持. 如果您的计算机没有安装,则需要下载并安装它. 框架不大.
4. 其他
我暂时没想到,我稍后会考虑.
最后,无论如何,我仍然四处寻求支持,如果您不喜欢也不要喷洒.
这是第一个版本,因此必须存在以前的测试中未遇到的错误或需要优化的问题. 欢迎提供温和的反馈.
从理论上讲,从目录页面到内容页面的任何形式都可以使用,不仅限于小说. 查看全部
Shanken网页TXT采集器是由我的爱之神破解论坛制作的网页采集工具. 该软件非常强大且实用. 它使用全新的正则表达式来捕获下载的内容,并且该新颖站点已加密或无法及时复制. 粘贴可以成功采集,可以下载,可以实时预览,可以被文本替换,并且可以将每个章节保存为TXT文件,非常实用,欢迎有需要的朋友使用.
软件简介:
在发展之初,这是为了阅读小说. 我个人喜欢在本地下载它以便慢慢观看,但是许多新颖的网站不支持下载或下载限制(非VIP小说). 我还在论坛上找到了一些采集器,但是就我个人而言,它并不容易使用. 输入正则表达式后,该章将出现,但是当我单击下载时无法下载文本. 完成软件后,我继续测试软件. 相同的正则表达式与那些软件不匹配. 内容已输出,因此下载失败. 该软件还可能具有一些我不知道的规则,但结果是它无法完成我想要的下载. 我什至不知道这是规则,软件还是网站设置...
因此,我开发的此软件专门添加了预览功能,您可以知道是否可以获取网页数据,获取后是否可以正确匹配内容.
功能介绍:
1. 规则设置:
①在规则设置窗口中,无需编写任何规则即可在网站上找到文章. 首先单击实时预览以查看是否可以获取网页的源代码. 如果可以得到,请编写规则. 如果无法获得,则无需继续. 上
②规则设置使用正则表达式匹配内容. 最好有一定的基础. 如果没有基础,也可以参考给出的示例. 简单学习不需要深入研究正则表达式.
③设置规则后,需要分别预览目录页面和内容页面,这还需要两个链接,即目录页面链接和内容页面链接.
④关于替换,有常规替换和自定义替换. 目前无需进行正规化,普通替代品就可以了. 应该注意的是,必须输入值,并且空格也是可以接受的. 删除: 选择整行,然后按住删除键. 当内置\ n用作替换数据时,表示换行.
⑤编码,目前仅设置了GBK和UFT-8,几乎大多数网站都是这两种编码之一.
2,分析和下载
①要进行分析,请按2按钮解析地址. 按钮1当前功能强大,不希望被删除,稍后将开发其他功能.
②支持单章下载和全文下载.
③支持添加章节号[某些小说中没有章节号时可以检查]
④支持在线观看,但是需要连接到互联网. 此功能仅是辅助工具,不是阅读小说的专业软件.
⑤显示下载进度和总时间,内置多线程.
3. 关于软件
①实际上,您只需要.exe,规则全部由您自己添加,commonrule.xml收录常见的替换规则. 网站规则位于规则文件夹下. 我在其中放置了两个网站规则,主要用于测试. 您可以自己添加其他站点规则,或支持开发人员.
②该软件未打包,由c#开发,没有病毒. 如果您不担心,请不要使用它,我不会收回它.
③关于该软件,跳至论坛. 当我亲自测试跳转时,360提示了我. 这也可能是因为跳转是针对360浏览器进行的. 我想知道您是否会遇到这个问题.
④如果您不知道xml中的内容,请不要触摸它,以免软件识别失败和错误.
⑤需要.net framework 4.5或更高版本的框架支持. 如果您的计算机没有安装,则需要下载并安装它. 框架不大.
4. 其他
我暂时没想到,我稍后会考虑.
最后,无论如何,我仍然四处寻求支持,如果您不喜欢也不要喷洒.
这是第一个版本,因此必须存在以前的测试中未遇到的错误或需要优化的问题. 欢迎提供温和的反馈.
从理论上讲,从目录页面到内容页面的任何形式都可以使用,不仅限于小说.
WebHarvy 2018(网页捕获大师)V5.2 Sinicization免费版软件下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2020-08-07 20:54
软件功能:
WebHarvy允许您分析网页上的数据
可以显示和分析来自HTML地址的连接数据
可以扩展到下一个网页
您可以指定搜索数据的范围和内容
您可以下载并保存扫描的图像
在浏览器上支持复制链接搜索
支持配置相应的资源项目搜索
您可以使用项目名称和资源名称进行查找 查看全部
WebHarvy 2018(Web Capture Master)是一个方便的应用程序,旨在使您能够自动从网页提取数据并将提取的内容保存为不同格式. WebHarvy是可视的Web抓取工具. 绝对不需要编写任何脚本或代码来获取数据. 您将使用WebHarvy的内置浏览器浏览网络. 您可以选择要单击的数据. 这很容易! WebHarvy自动识别网页中出现的数据模式. 因此,如果您需要从网页上抓取项目列表(名称,地址,电子邮件,价格等),则无需执行任何其他配置. 如果数据重复,WebHarvy将自动将其删除. 您可以用多种格式保存从网页提取的数据. 当前版本的WebHarvy Web Scraper允许您将抓取的数据导出为Excel,XML,CSV,JSON或TSV文件. 您也可以将捕获的数据导出到SQL数据库. 通常,网页在多个页面上显示数据,例如产品列表. WebHarvy可以自动爬网并从多个页面提取数据. 只需指出“指向下一页的链接”,WebHarvy Web Scraper就会自动从所有页面抓取数据.
软件功能:
WebHarvy允许您分析网页上的数据
可以显示和分析来自HTML地址的连接数据
可以扩展到下一个网页
您可以指定搜索数据的范围和内容
您可以下载并保存扫描的图像
在浏览器上支持复制链接搜索
支持配置相应的资源项目搜索
您可以使用项目名称和资源名称进行查找
网络数据爬网方法的详细说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-07 20:00
网页数据抓取是指从网站中提取特定内容而无需请求网站的API接口来获取内容. 作为网站用户体验的一部分的“网页数据”,例如网页上的文本,图像,声音,视频和动画,都被视为网页数据.
对于程序员或开发人员而言,具有编程技能可使他们轻松而有趣地构建网页数据爬网程序. 但是对于大多数没有任何编程知识的人,最好使用某些Web爬网程序软件从指定的网页中获取特定的内容. 以下是一些使用优采云采集器捕获网页数据的解决方案:
1. 从动态网页中提取内容
网页可以是静态的也可以是动态的. 通常,您要提取的网页内容会随着您访问网站的时间而改变. 通常,该网站是一个动态网站,它使用AJAX技术或其他技术来使网页内容可以及时更新. AJAX是延迟加载和异步更新的脚本技术. 通过在后台与服务器进行少量数据交换,可以更新网页的特定部分而无需重新加载整个网页.
性能特征是,当您单击网页上的某个选项时,大多数网站的URL不会更改;该网页并未完全加载,仅部分加载了数据并进行了更改. 此时,您可以在优采云的“高级选项”元素的“ Ajax加载”中进行设置,然后就可以获取由Ajax加载的网页数据.
优采云中的AJAX设置
2,从网页中获取隐藏的内容
您是否曾经考虑过从网站获取特定数据,但是当您触发链接或将鼠标悬停在某处时,内容会出现吗?例如,下图中的网站要求鼠标移动到选定的彩票以显示类别. 可以用来设置“此链接的鼠标”功能,以获取网页中的隐藏内容.
将鼠标置于链接上的内容采集方法
3. 从无限滚动的网页中提取内容
滚动到页面底部,某些网站将仅显示您要提取的部分数据. 例如,在今天的头条首页中,您需要不断滚动到页面底部以加载更多文章内容. 无限滚动网站通常使用AJAX或JavaScript从网站请求其他内容. 在这种情况下,您可以设置AJAX超时设置,并选择滚动方法和滚动时间以从网页中提取内容.
4. 抓取网页上的所有链接
一个普通的网站将至少收录一个超链接. 如果要从网页中提取所有链接,则可以使用优采云获取在网页上发布的所有超链接.
5. 抓取网页中的所有文本
有时您需要提取HTML文档中的所有文本,即将其放置在HTML标签(例如
标签或标签). 您可以通过Caiyun提取网页源代码中的全部或特定文本.
6. 抓取网页中的所有图像
某些朋友需要采集网页图片. 优采云可以采集网页中图片的URL,然后使用优采云专用的图像批处理下载工具将我们采集的图像URL中的图片下载并保存到本地计算机中. 查看全部
摘要: 对于程序员或开发人员来说,具有编程技能使他们构建网页数据爬网程序非常容易且有趣. 但是对于大多数没有任何编程知识的人,最好使用某些Web爬网程序软件从指定的网页中获取特定的内容.
网页数据抓取是指从网站中提取特定内容而无需请求网站的API接口来获取内容. 作为网站用户体验的一部分的“网页数据”,例如网页上的文本,图像,声音,视频和动画,都被视为网页数据.
对于程序员或开发人员而言,具有编程技能可使他们轻松而有趣地构建网页数据爬网程序. 但是对于大多数没有任何编程知识的人,最好使用某些Web爬网程序软件从指定的网页中获取特定的内容. 以下是一些使用优采云采集器捕获网页数据的解决方案:
1. 从动态网页中提取内容
网页可以是静态的也可以是动态的. 通常,您要提取的网页内容会随着您访问网站的时间而改变. 通常,该网站是一个动态网站,它使用AJAX技术或其他技术来使网页内容可以及时更新. AJAX是延迟加载和异步更新的脚本技术. 通过在后台与服务器进行少量数据交换,可以更新网页的特定部分而无需重新加载整个网页.
性能特征是,当您单击网页上的某个选项时,大多数网站的URL不会更改;该网页并未完全加载,仅部分加载了数据并进行了更改. 此时,您可以在优采云的“高级选项”元素的“ Ajax加载”中进行设置,然后就可以获取由Ajax加载的网页数据.
优采云中的AJAX设置
2,从网页中获取隐藏的内容
您是否曾经考虑过从网站获取特定数据,但是当您触发链接或将鼠标悬停在某处时,内容会出现吗?例如,下图中的网站要求鼠标移动到选定的彩票以显示类别. 可以用来设置“此链接的鼠标”功能,以获取网页中的隐藏内容.
将鼠标置于链接上的内容采集方法
3. 从无限滚动的网页中提取内容
滚动到页面底部,某些网站将仅显示您要提取的部分数据. 例如,在今天的头条首页中,您需要不断滚动到页面底部以加载更多文章内容. 无限滚动网站通常使用AJAX或JavaScript从网站请求其他内容. 在这种情况下,您可以设置AJAX超时设置,并选择滚动方法和滚动时间以从网页中提取内容.
4. 抓取网页上的所有链接
一个普通的网站将至少收录一个超链接. 如果要从网页中提取所有链接,则可以使用优采云获取在网页上发布的所有超链接.
5. 抓取网页中的所有文本
有时您需要提取HTML文档中的所有文本,即将其放置在HTML标签(例如
标签或标签). 您可以通过Caiyun提取网页源代码中的全部或特定文本.
6. 抓取网页中的所有图像
某些朋友需要采集网页图片. 优采云可以采集网页中图片的URL,然后使用优采云专用的图像批处理下载工具将我们采集的图像URL中的图片下载并保存到本地计算机中.
优采云采集器V2.3.3正式版
采集交流 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2020-08-07 18:46
软件功能:
关于软件
SkyCaiji致力于自动采集和发布网站数据. 该系统是用PHP + Mysql开发的,可以部署在云服务器上,使数据采集方便,智能且基于云,使您可以随时随地移动Office!
数据采集
支持多级,多页和分页采集,自定义采集规则(支持常规,XPATH,JSON等)准确匹配任何信息流,几乎所有类型的网页都可以采集,并且内容大多数文章类型都可以智能识别
内容发布
与各种CMS网站构建程序无缝对接,实现免登录导入数据,支持自定义数据发布插件或直接导入数据库,存储为Excel文件,生成API接口等.
自动化和云平台
该软件可实现定时和定量自动采集和发布,而无需人工干预!内置的云平台,用户可以共享和下载采集规则,发布供求信息,社区帮助,交流等.
软件简介:
优采云采集器是一个免费的数据采集和发布采集器软件. 它是由php + mysql开发的,可以部署在云服务器上. 它可以采集几乎所有类型的网页,与各种CMS网站构建程序无缝连接,并且无需登录. 实时实时发布数据,无需人工干预. 它是在云时代自动采集大数据和网站数据的最佳云爬虫软件!
使用方法:
升级软件
您可以直接在后台主页上检查更新,然后单击升级,或将压缩包上传到服务器以解压缩并覆盖它!
安装软件
将下载的软件上载到您的服务器. 如果根目录中有一个站点,建议将其放在子目录中. 解压缩后,打开浏览器并输入服务器域名或IP地址(存储在子目录中时添加子目录的名称),进入安装界面
点击“接受”进入环境检测页面
您必须确保所有参数正确,否则在使用过程中会发生错误,请单击“下一步”进入数据安装界面
填写数据库和Founder配置,单击“下一步”
最后,安装完成,现在您可以使用优采云采集器了! 查看全部
优采云采集器(Web数据采集工具)是一款出色且易于使用的Web数据采集助手. 哪种Web数据采集软件更好用?编辑器为您推荐了这款功能强大,功能全面的优采云采集器,它可以帮助用户在使用后更加轻松便捷地采集Web数据. 它可以帮助您自动采集所有类型的网页数据,还可以自动发布站点数据,这非常方便且易于使用. 欢迎需要下载和使用的朋友.
软件功能:
关于软件
SkyCaiji致力于自动采集和发布网站数据. 该系统是用PHP + Mysql开发的,可以部署在云服务器上,使数据采集方便,智能且基于云,使您可以随时随地移动Office!
数据采集
支持多级,多页和分页采集,自定义采集规则(支持常规,XPATH,JSON等)准确匹配任何信息流,几乎所有类型的网页都可以采集,并且内容大多数文章类型都可以智能识别
内容发布
与各种CMS网站构建程序无缝对接,实现免登录导入数据,支持自定义数据发布插件或直接导入数据库,存储为Excel文件,生成API接口等.
自动化和云平台
该软件可实现定时和定量自动采集和发布,而无需人工干预!内置的云平台,用户可以共享和下载采集规则,发布供求信息,社区帮助,交流等.
软件简介:
优采云采集器是一个免费的数据采集和发布采集器软件. 它是由php + mysql开发的,可以部署在云服务器上. 它可以采集几乎所有类型的网页,与各种CMS网站构建程序无缝连接,并且无需登录. 实时实时发布数据,无需人工干预. 它是在云时代自动采集大数据和网站数据的最佳云爬虫软件!
使用方法:
升级软件
您可以直接在后台主页上检查更新,然后单击升级,或将压缩包上传到服务器以解压缩并覆盖它!
安装软件
将下载的软件上载到您的服务器. 如果根目录中有一个站点,建议将其放在子目录中. 解压缩后,打开浏览器并输入服务器域名或IP地址(存储在子目录中时添加子目录的名称),进入安装界面
点击“接受”进入环境检测页面
您必须确保所有参数正确,否则在使用过程中会发生错误,请单击“下一步”进入数据安装界面
填写数据库和Founder配置,单击“下一步”
最后,安装完成,现在您可以使用优采云采集器了!
Piggy Collector(网站集合跟踪更新)PC版本
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2020-08-07 17:10
软件简介
小猪浏览器免费版是为个人网站管理员设计的专业,功能强大的网站内容采集工具. 它集成了采集器,浏览器,促销助手和seo功能. 它支持网站迁移和整个网站强大的功能,例如克隆,自动购买虚拟货币,附件的自动本地化,伪原创主题内容和关键字替换,可以帮助网站管理员更好地管理网站并提高相应的工作效率. 通过小竹浏览器的智能采集功能,用户可以轻松地从Internet上获取文本,图片,视频和其他网络资源. 同时,该程序还具有强大的信息发布功能,可以将采集的数据发布到您指定的位置. 可以说,用户可以很容易地立即采集成千上万的内容. Piggy Browser具有内置的强大采集规则,几乎可以自动识别和采集市场上的主流程序,从而可以节省用户编写采集规则的麻烦. 此外,小竹浏览器还支持许多其他功能,例如自动顶帖,一键抓取,批处理网站用户注册,内容监视和循环点击,最重要的是这些功能全部采用一键式智能操作功能,因此用户只需单击一下即可完成相应的顶部帖子,抢沙发等操作.
软件功能
编辑
无规则的视觉采集和发布,将在您上网时采集;
编辑器
可视化规则编辑器,只需几分钟即可创建通用规则;
智能识别
智能规则调用,无需为每个网站制定规则
一键式测试和正常识别可以执行诸如采集和热门帖子之类的功能;
多功能
根据用户习惯,一键式设置采集,张贴和挂起任务而设计的丰富功能;
独立计划
网站,规则,功能和解决方案彼此独立,因此无需多次配置即可提高工作效率!
软件亮点
1. 一个绿色,小型,便携式的浏览器,无论是网站管理员还是普通用户都可以使用;
2. 强大的数据捕获功能,“所见即所得”,只要您可以在小竹浏览器中看到文本,图片和附件,就可以捕获它们; *内置规则,智能规则和服务器规则在一定程度上认识到普通用户无需编写规则即可轻松使用它们. 当然,用户也可以自己编辑采集规则,以达到个性化的采集要求;
3. 它具有丰富的发布界面,无需在服务器端安装数据库界面,普通用户可以在几分钟内入门,添加发布站点并采集发布内容. 与主流论坛,cms,博客源程序和免费博客兼容,实现自动发布,发布,顶部发布,浇水,抓取和其他网站相关的发布操作,还可以使用强大的自编辑发布规则来实现自动发布在任何网站上发布;
4. 中国领先的模拟发布技术,只要可以在Piggy浏览器中手动发布,就可以使用Piggy浏览器实现自动发布.
5,SEO自动伪原创,伪伪内容可以在馆藏发布过程中制作;
6. SEO站点组,数字权重,灵活的组合方法,易于实现内部链,外部链,链轮,混合链;
7. 强大的规则系统“采集规则,发布规则和独特的Webpig语言(p语言)”使用户可以编写自己的规则,以实现个性化的采集和发布要求.
功能介绍
1. 没有插件
没有插件,没有插件安装,也没有访问注册表的权限. 这是最安全的绿色采集器.
2,高智慧
自动实现登录,回复,跟踪采集,站点组管理,词汇管理,SEO分析,网站管理员查询等,内置采集规则,智能识别网站采集规则,可视化采集规则编辑等诸多功能.
3,功能全面
它具有许多促销功能的集合,例如,顶部张贴,抢沙发,进行小组张贴,发送小组短消息,进行小组邮寄等. 它还带有搜索引擎,使您的操作更加方便.
4,用途最广
无论您是哪种类型的网站或论坛,都可以使用Piggy Collector轻松快速地采集所需的内容.
主要优点
1,采集
您可以通过智能采集功能轻松地从Internet上获取文本,图片,视频和其他网络资源
2. 跟踪更新
<p>它可以实时跟踪相应的重印更新,并允许用户自定义配置方案,例如抓沙发,跟踪重印,抓沙发+轨道加载等,以及自定义答复数,建筑物数恢复,以及相关的抓取次数. 查看全部
小猪采集器(网站集合跟踪更新)是用于实时监视网站更新和发布地址的工具. 它可以采集所有网站的实时信息,支持自动热门发布,网站更新跟踪等,需要它的朋友请记住从第9个下载站点免费下载!
软件简介
小猪浏览器免费版是为个人网站管理员设计的专业,功能强大的网站内容采集工具. 它集成了采集器,浏览器,促销助手和seo功能. 它支持网站迁移和整个网站强大的功能,例如克隆,自动购买虚拟货币,附件的自动本地化,伪原创主题内容和关键字替换,可以帮助网站管理员更好地管理网站并提高相应的工作效率. 通过小竹浏览器的智能采集功能,用户可以轻松地从Internet上获取文本,图片,视频和其他网络资源. 同时,该程序还具有强大的信息发布功能,可以将采集的数据发布到您指定的位置. 可以说,用户可以很容易地立即采集成千上万的内容. Piggy Browser具有内置的强大采集规则,几乎可以自动识别和采集市场上的主流程序,从而可以节省用户编写采集规则的麻烦. 此外,小竹浏览器还支持许多其他功能,例如自动顶帖,一键抓取,批处理网站用户注册,内容监视和循环点击,最重要的是这些功能全部采用一键式智能操作功能,因此用户只需单击一下即可完成相应的顶部帖子,抢沙发等操作.
软件功能
编辑
无规则的视觉采集和发布,将在您上网时采集;
编辑器
可视化规则编辑器,只需几分钟即可创建通用规则;
智能识别
智能规则调用,无需为每个网站制定规则
一键式测试和正常识别可以执行诸如采集和热门帖子之类的功能;
多功能
根据用户习惯,一键式设置采集,张贴和挂起任务而设计的丰富功能;
独立计划
网站,规则,功能和解决方案彼此独立,因此无需多次配置即可提高工作效率!
软件亮点
1. 一个绿色,小型,便携式的浏览器,无论是网站管理员还是普通用户都可以使用;
2. 强大的数据捕获功能,“所见即所得”,只要您可以在小竹浏览器中看到文本,图片和附件,就可以捕获它们; *内置规则,智能规则和服务器规则在一定程度上认识到普通用户无需编写规则即可轻松使用它们. 当然,用户也可以自己编辑采集规则,以达到个性化的采集要求;
3. 它具有丰富的发布界面,无需在服务器端安装数据库界面,普通用户可以在几分钟内入门,添加发布站点并采集发布内容. 与主流论坛,cms,博客源程序和免费博客兼容,实现自动发布,发布,顶部发布,浇水,抓取和其他网站相关的发布操作,还可以使用强大的自编辑发布规则来实现自动发布在任何网站上发布;
4. 中国领先的模拟发布技术,只要可以在Piggy浏览器中手动发布,就可以使用Piggy浏览器实现自动发布.
5,SEO自动伪原创,伪伪内容可以在馆藏发布过程中制作;
6. SEO站点组,数字权重,灵活的组合方法,易于实现内部链,外部链,链轮,混合链;
7. 强大的规则系统“采集规则,发布规则和独特的Webpig语言(p语言)”使用户可以编写自己的规则,以实现个性化的采集和发布要求.
功能介绍
1. 没有插件
没有插件,没有插件安装,也没有访问注册表的权限. 这是最安全的绿色采集器.
2,高智慧
自动实现登录,回复,跟踪采集,站点组管理,词汇管理,SEO分析,网站管理员查询等,内置采集规则,智能识别网站采集规则,可视化采集规则编辑等诸多功能.
3,功能全面
它具有许多促销功能的集合,例如,顶部张贴,抢沙发,进行小组张贴,发送小组短消息,进行小组邮寄等. 它还带有搜索引擎,使您的操作更加方便.
4,用途最广
无论您是哪种类型的网站或论坛,都可以使用Piggy Collector轻松快速地采集所需的内容.
主要优点
1,采集
您可以通过智能采集功能轻松地从Internet上获取文本,图片,视频和其他网络资源
2. 跟踪更新
<p>它可以实时跟踪相应的重印更新,并允许用户自定义配置方案,例如抓沙发,跟踪重印,抓沙发+轨道加载等,以及自定义答复数,建筑物数恢复,以及相关的抓取次数.

