
免费网页采集器
免费网页采集器(使用方法自定义采集百度搜索结果数据的方法步骤步骤介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-10-29 08:17
软件介绍
优采云采集器正式版是一款方便易用的网页数据采集软件,具有可视化点击、一键采集网页数据等功能。优采云采集器 正式版支持全平台,Win/Mac/Linux均可,采集和导出全部免费,无限制使用安全,可后台运行,速度真实-时间显示,是一款非常好用的网页采集工具。
优采云采集器正式版软件特点
【可视化定制采集流程】
全程问答指导,可视化操作,自定义采集流程
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
【点击提取网页数据】
鼠标点击选择要抓取的网页内容,操作简单
您可以选择提取文本、链接、属性、html 标签等。
【运行批处理采集数据】
软件根据采集的处理和提取规则自动批量处理采集
快速稳定,实时显示采集速度和进程
可切换软件后台运行,不打扰前台工作
【导出并发布采集的数据】
采集 数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
软件功能
1、可视化点击,一键采集网络数据
优采云采集器正式版为全拖拽式操作,无需开发或懂技术。任何人都可以使用网络数据采集器
2、采集 和导出都是免费的,无限使用
优采云采集器 正式版是完全免费的采集软件,导出数据无限制,数据可以导出到本地文件,发布到网站和数据库等。
3、 可后台运行,可实时显示速度
优采云采集器正式版可以切换软件后台运行,不打扰您其他前台工作。悬浮窗可以实时查看采集速度和采集数据。
4、所有平台,Win/Mac/Linux均可用
与其他采集器不同的是,优采云采集器正式版支持所有操作系统版本更新和功能升级,同步所有平台。
指示
如何自定义采集百度搜索结果数据
第一步:创建采集任务
1)启动优采云采集器,进入主界面,选择自定义采集,点击创建任务按钮,创建“自定义采集任务”
2)输入百度搜索的网址,包括三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分割
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址
第二步:自定义采集流程
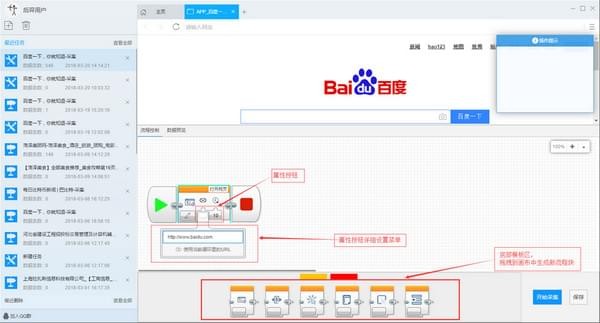
1) 点击创建后,会自动打开第一个网址,然后进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区域用于拖放到画布上生成新的流程块;点击打开网页中的属性按钮修改打开的网址
2)添加文本输入流程块:将底部模板区域中的输入文本块拖到打开的网页块的后面。出现阴影区域时松开鼠标,此时会自动连接,添加完成
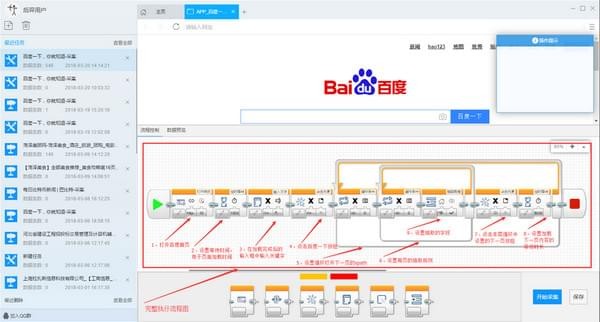
3) 生成一个完整的流程图: 按照上面添加文本输入流程块的拖放流程添加一个新块:如下图:
关键步骤块设置介绍
第二步:定时等待用于等待之前打开的网页完成
第三步:点击输入框的Xpath属性按钮,点击属性菜单中的图标选择网页上的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
第四步:设置,点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页上的百度一键。
第五步:用于设置加载下一个列表页面的周期。在循环块内的循环条件块中设置详细条件。单击此处的操作按钮选择单个元素,然后在属性菜单中单击该元素的xpath 属性按钮,然后在网页中单击下一页按钮,如上。循环次数属性按钮可以默认为0,即下一页没有点击次数限制。
第六步:用于设置列表页数据的循环抽取。在循环块内部的循环条件块中设置详细条件,点击这里的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后在网页中点击两次提取第一个块和第二个元素。循环次数属性按钮可以默认为0,即不限制列表中采集的字段数。
Step 7:用于执行点击下一页按钮、点击元素xpath属性按钮、选择当前循环中元素的xpath选项的操作。
第八步:同样用于设置网页加载的等待时间。
第九步:用于在列表页面设置要提取的字段规则,点击属性按钮中的循环中使用元素按钮,选择循环中使用元素的选项。单击元素模板属性按钮在字段表中添加和减去字段以添加和删除字段。添加字段使用点击操作,即点击加号,然后将鼠标移动到网页元素上,点击选择。
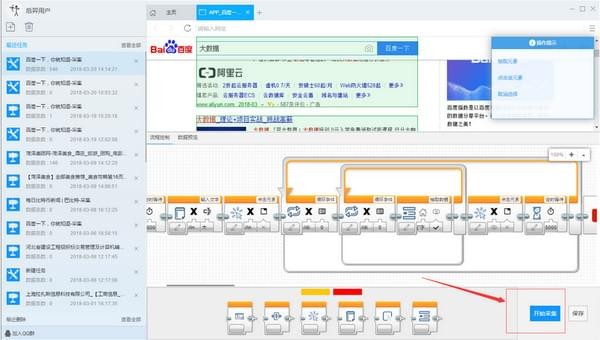
4)点击开始采集,开始采集
第三步:数据采集并导出
1)采集 任务正在运行
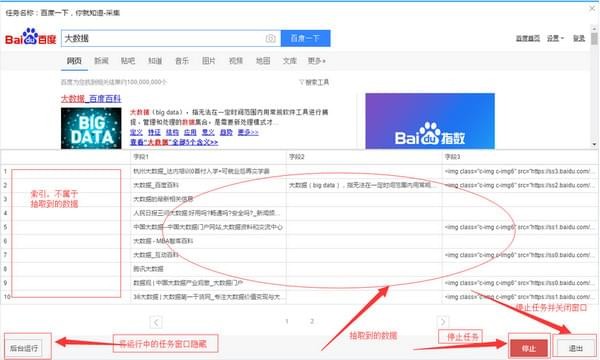
2)采集 完成后,选择“导出数据”将所有数据导出到本地文件
3)选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式
4)采集 数据导出如下图
更新日志
优采云采集器正式版v3.5.3
更新日期:2020-07-01
优化:
Ng-click 兼容按钮单击
启动任务时,可以设置逐行滚动的最小滚动距离
修理:
修复一些显示问题 查看全部
免费网页采集器(使用方法自定义采集百度搜索结果数据的方法步骤步骤介绍)
软件介绍
优采云采集器正式版是一款方便易用的网页数据采集软件,具有可视化点击、一键采集网页数据等功能。优采云采集器 正式版支持全平台,Win/Mac/Linux均可,采集和导出全部免费,无限制使用安全,可后台运行,速度真实-时间显示,是一款非常好用的网页采集工具。
优采云采集器正式版软件特点
【可视化定制采集流程】
全程问答指导,可视化操作,自定义采集流程
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
【点击提取网页数据】
鼠标点击选择要抓取的网页内容,操作简单
您可以选择提取文本、链接、属性、html 标签等。
【运行批处理采集数据】
软件根据采集的处理和提取规则自动批量处理采集
快速稳定,实时显示采集速度和进程
可切换软件后台运行,不打扰前台工作
【导出并发布采集的数据】
采集 数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
软件功能
1、可视化点击,一键采集网络数据
优采云采集器正式版为全拖拽式操作,无需开发或懂技术。任何人都可以使用网络数据采集器
2、采集 和导出都是免费的,无限使用
优采云采集器 正式版是完全免费的采集软件,导出数据无限制,数据可以导出到本地文件,发布到网站和数据库等。
3、 可后台运行,可实时显示速度
优采云采集器正式版可以切换软件后台运行,不打扰您其他前台工作。悬浮窗可以实时查看采集速度和采集数据。
4、所有平台,Win/Mac/Linux均可用
与其他采集器不同的是,优采云采集器正式版支持所有操作系统版本更新和功能升级,同步所有平台。
指示
如何自定义采集百度搜索结果数据
第一步:创建采集任务
1)启动优采云采集器,进入主界面,选择自定义采集,点击创建任务按钮,创建“自定义采集任务”
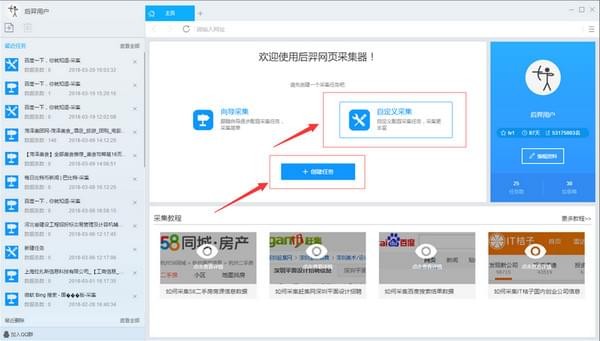
2)输入百度搜索的网址,包括三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分割
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址
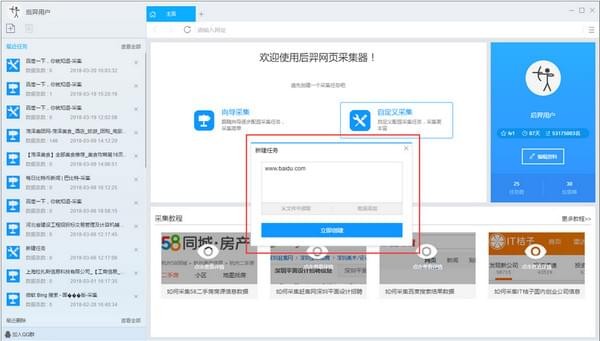
第二步:自定义采集流程
1) 点击创建后,会自动打开第一个网址,然后进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区域用于拖放到画布上生成新的流程块;点击打开网页中的属性按钮修改打开的网址
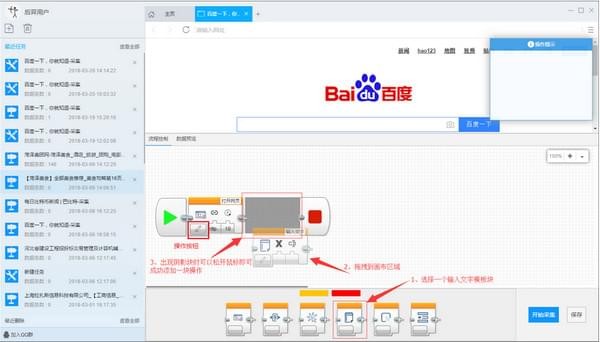
2)添加文本输入流程块:将底部模板区域中的输入文本块拖到打开的网页块的后面。出现阴影区域时松开鼠标,此时会自动连接,添加完成
3) 生成一个完整的流程图: 按照上面添加文本输入流程块的拖放流程添加一个新块:如下图:
关键步骤块设置介绍
第二步:定时等待用于等待之前打开的网页完成
第三步:点击输入框的Xpath属性按钮,点击属性菜单中的图标选择网页上的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
第四步:设置,点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页上的百度一键。
第五步:用于设置加载下一个列表页面的周期。在循环块内的循环条件块中设置详细条件。单击此处的操作按钮选择单个元素,然后在属性菜单中单击该元素的xpath 属性按钮,然后在网页中单击下一页按钮,如上。循环次数属性按钮可以默认为0,即下一页没有点击次数限制。
第六步:用于设置列表页数据的循环抽取。在循环块内部的循环条件块中设置详细条件,点击这里的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后在网页中点击两次提取第一个块和第二个元素。循环次数属性按钮可以默认为0,即不限制列表中采集的字段数。
Step 7:用于执行点击下一页按钮、点击元素xpath属性按钮、选择当前循环中元素的xpath选项的操作。
第八步:同样用于设置网页加载的等待时间。
第九步:用于在列表页面设置要提取的字段规则,点击属性按钮中的循环中使用元素按钮,选择循环中使用元素的选项。单击元素模板属性按钮在字段表中添加和减去字段以添加和删除字段。添加字段使用点击操作,即点击加号,然后将鼠标移动到网页元素上,点击选择。
4)点击开始采集,开始采集
第三步:数据采集并导出
1)采集 任务正在运行
2)采集 完成后,选择“导出数据”将所有数据导出到本地文件
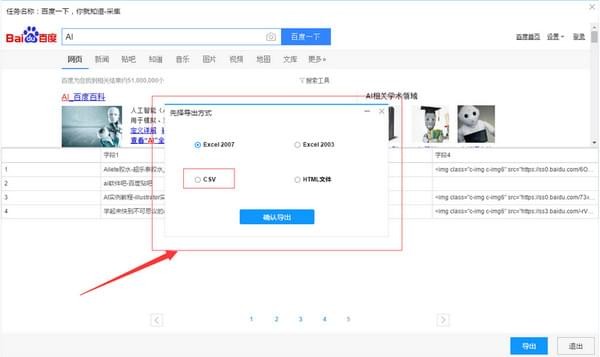
3)选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式
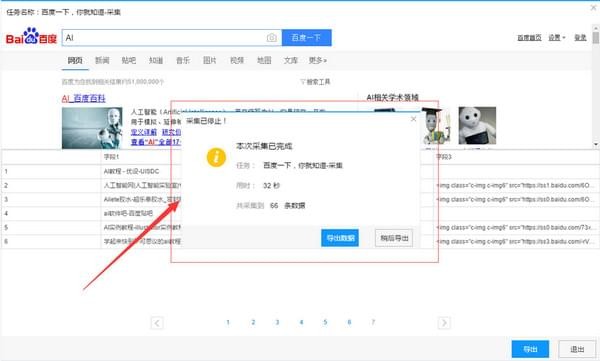
4)采集 数据导出如下图
更新日志
优采云采集器正式版v3.5.3
更新日期:2020-07-01
优化:
Ng-click 兼容按钮单击
启动任务时,可以设置逐行滚动的最小滚动距离
修理:
修复一些显示问题
免费网页采集器(免费网页采集器,一键采集并上传文章,收到后台数据时一键返回!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-28 08:01
免费网页采集器,一键采集并上传文章,收到后台数据时一键返回!这个网站有分类特别多,任何你想要的都可以!注册后,我们可以免费使用7天!主要是采集免费高质量文章,采集精选高质量文章,文章质量要求高。主要数据如下图:免费网页采集器,一键采集并上传文章,收到后台数据时一键返回!这个网站有分类特别多,任何你想要的都可以!。
你自己不给钱吗?这个多少钱一篇,
很轻便,
昨天恰好在写国内外历史文章采集就顺手用这个分类了一个欧美历史(美国之类)+日本战国+中国近代(1945以后)这类的网站类似“在家写程序,出门卖茶叶”的网站,你可以试试。其实主要是要选到有质量的文章,大家基本上都想投在哪里哪里,质量有保证,文章有逼格。免费版就可以。
百度搜索文章采集器,是收费的,注册后,每天能采50个文章,你的文章里标注开放网站链接即可获得免费采集权限,我们在采集的时候要抓取网站的cookie给他们手机或电脑上绑定,才能不注册就能采集到。现在还没有收费的模式,收费后,采集的是采集历史页面。上传的文章全部是网站的原始数据,不是别人修改过的。可以回到浏览器试试。
文章采集任意网站都可以,小小需要收费2500一年,大小也不是非常贵的50元每月,有效期20年,基本上上文章,有效果,有盈利,功能还是比较强大的。我测试过很多方法,比如爬虫网站,爬取数据库,很多效果都不好,文章采集器里面有一些算法,操作过程比较轻松,像谷歌浏览器或者uc浏览器的普通用户只要一次性采集40篇文章就可以了,可以关注我的知乎号,也可以看下我写的很多采集方法。祝大家采集愉快!。 查看全部
免费网页采集器(免费网页采集器,一键采集并上传文章,收到后台数据时一键返回!)
免费网页采集器,一键采集并上传文章,收到后台数据时一键返回!这个网站有分类特别多,任何你想要的都可以!注册后,我们可以免费使用7天!主要是采集免费高质量文章,采集精选高质量文章,文章质量要求高。主要数据如下图:免费网页采集器,一键采集并上传文章,收到后台数据时一键返回!这个网站有分类特别多,任何你想要的都可以!。
你自己不给钱吗?这个多少钱一篇,
很轻便,
昨天恰好在写国内外历史文章采集就顺手用这个分类了一个欧美历史(美国之类)+日本战国+中国近代(1945以后)这类的网站类似“在家写程序,出门卖茶叶”的网站,你可以试试。其实主要是要选到有质量的文章,大家基本上都想投在哪里哪里,质量有保证,文章有逼格。免费版就可以。
百度搜索文章采集器,是收费的,注册后,每天能采50个文章,你的文章里标注开放网站链接即可获得免费采集权限,我们在采集的时候要抓取网站的cookie给他们手机或电脑上绑定,才能不注册就能采集到。现在还没有收费的模式,收费后,采集的是采集历史页面。上传的文章全部是网站的原始数据,不是别人修改过的。可以回到浏览器试试。
文章采集任意网站都可以,小小需要收费2500一年,大小也不是非常贵的50元每月,有效期20年,基本上上文章,有效果,有盈利,功能还是比较强大的。我测试过很多方法,比如爬虫网站,爬取数据库,很多效果都不好,文章采集器里面有一些算法,操作过程比较轻松,像谷歌浏览器或者uc浏览器的普通用户只要一次性采集40篇文章就可以了,可以关注我的知乎号,也可以看下我写的很多采集方法。祝大家采集愉快!。
免费网页采集器(优采云采集器问:如何过滤列表中的前N个数据?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-27 14:09
优采云采集器免费版是一款非常专业的网页采集工具,可以轻松的采集网页资源,功能非常强大,软件界面简单,操作很简单,现在已经完整破解,可以免费使用了,还在寻找网页采集器的用户快来下载体验吧!
优采云采集器 免费版软件介绍
优采云采集器V2是一款高效的网页信息采集软件,支持99%的网站数据采集,优采云采集器可以生成Excel表格、api数据库文件等内容,帮助您管理网站数据信息。如果你需要采集一个特定的网页数据,就用这个软件。
优采云采集器免费版软件特点
一键提取数据
简单易学,通过可视化界面,鼠标点击即可采集数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
优采云采集器免费版功能介绍
向导模式
简单易用,轻松通过鼠标点击自动生成
脚本定期运行
可按计划定时运行,无需人工
原装高速核心
自研浏览器内核,速度快,远超对手
智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
各种数据导出
支持 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。
优采云采集器免费版如何使用
第一步:输入采集 URL
打开软件,新建一个任务,输入需要采集的网站地址。
第二步:智能分析,全程自动提取数据
进入第二步后,优采云采集器自动对网页进行智能分析,从中提取列表数据。
第三步:将数据导出到表、数据库、网站等。
运行任务,将采集中的数据导出到Csv、Excel和各种数据库,支持api导出。
优采云采集器免费版常见问题
Q:如何过滤列表中的前N个数据?
1.有时候我们需要过滤采集收到的列表,比如过滤掉第一组数据(以采集的形式,过滤掉表列名)
2.在列表模式菜单中点击设置列表xpath
Q:如何通过抓包获取cookie并手动设置?
1.首先用谷歌浏览器打开你要采集的网站,然后登录。
2. 然后按F12,会出现开发者工具,选择Network
3.然后按F5刷新下一页并选择其中一个请求。
4.复制完成后,在优采云采集器中编辑任务,进入第三步指定HTTP Header。
优采云采集器免费版本更新日志
1.添加插件功能
2.添加export txt(一个文件另存为一个文件)
3.多值连接器支持换行
4.修改数据处理的文本映射(支持查找替换)
5.修复登录时DNS问题
6.修复图片下载问题
7.修复json中的一些问题
优采云采集器免费版本审核
一个更实用的采集工具,功能非常强大。 查看全部
免费网页采集器(优采云采集器问:如何过滤列表中的前N个数据?)
优采云采集器免费版是一款非常专业的网页采集工具,可以轻松的采集网页资源,功能非常强大,软件界面简单,操作很简单,现在已经完整破解,可以免费使用了,还在寻找网页采集器的用户快来下载体验吧!

优采云采集器 免费版软件介绍
优采云采集器V2是一款高效的网页信息采集软件,支持99%的网站数据采集,优采云采集器可以生成Excel表格、api数据库文件等内容,帮助您管理网站数据信息。如果你需要采集一个特定的网页数据,就用这个软件。
优采云采集器免费版软件特点
一键提取数据
简单易学,通过可视化界面,鼠标点击即可采集数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
优采云采集器免费版功能介绍
向导模式
简单易用,轻松通过鼠标点击自动生成
脚本定期运行
可按计划定时运行,无需人工
原装高速核心
自研浏览器内核,速度快,远超对手
智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
各种数据导出
支持 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。

优采云采集器免费版如何使用
第一步:输入采集 URL
打开软件,新建一个任务,输入需要采集的网站地址。
第二步:智能分析,全程自动提取数据
进入第二步后,优采云采集器自动对网页进行智能分析,从中提取列表数据。
第三步:将数据导出到表、数据库、网站等。
运行任务,将采集中的数据导出到Csv、Excel和各种数据库,支持api导出。
优采云采集器免费版常见问题
Q:如何过滤列表中的前N个数据?
1.有时候我们需要过滤采集收到的列表,比如过滤掉第一组数据(以采集的形式,过滤掉表列名)
2.在列表模式菜单中点击设置列表xpath
Q:如何通过抓包获取cookie并手动设置?
1.首先用谷歌浏览器打开你要采集的网站,然后登录。
2. 然后按F12,会出现开发者工具,选择Network
3.然后按F5刷新下一页并选择其中一个请求。
4.复制完成后,在优采云采集器中编辑任务,进入第三步指定HTTP Header。
优采云采集器免费版本更新日志
1.添加插件功能
2.添加export txt(一个文件另存为一个文件)
3.多值连接器支持换行
4.修改数据处理的文本映射(支持查找替换)
5.修复登录时DNS问题
6.修复图片下载问题
7.修复json中的一些问题
优采云采集器免费版本审核
一个更实用的采集工具,功能非常强大。
免费网页采集器(五大免费网站数据采集器性能对比(优采云,优采云采集))
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-26 14:00
五张免费网站数据采集器性能对比(优采云、海纳、ET、三人、优采云采集)在当前站长圈,对比有很多流行的采集工具,但总结起来,只有几个比较著名的免费工具:优采云、海纳、ET、三星、优采云。下面我们对这几个采集工具做一个简单的对比。1.优采云 基本上大家都知道,所以先说几句。优采云应该是国产采集软件最成功的例子之一。用户数包括付费用户数应该是最多的功能:简单,强大,快速,支持网站最丰富,支持丰富的扩展优点:功能比较齐全,采集比较快,主要针对cms,短时间内可以采集很多,过滤替换都不错,比较详细;许多人编写接口、规则和发布模块。接口比较齐全。其中有一个叫陈元的人,开发了目前PHP类cms的几乎所有接口;支持的扩展非常易于使用。如果你是个技术娴熟的站长,你可以用PHP或C#来开发任何功能扩展,真是令人难忘;附件采集功能完善。技术:该技术以论坛为主,帮助文件多,上手容易。有付费版和免费版。缺点:功能较多,软件越来越大,内存和CPU资源较多,资源回收控制不好@>,功能比较齐全。第一的,不知道三星和优采云是什么关系,但是接口和功能都出同一个模型。特点:针对各大论坛,动,动,快,准确率高优点:还是针对论坛,技术适合开论坛:收费技术,免费带广告缺点:超级复杂,上手难,支持cms@ > 比较差3.ET工具特点:无人值守,稳定,资源占用最低,基本上可以称得上是安静的优点:无人值守,自动更新,适合长站,用户群主要集中在长-term站潜水站长。软件一目了然,必备的功能也很齐全。关键是该软件是免费的。我听说采集 增加了中英文翻译功能。技术:论坛支持,软件本身免费,但也提供收费服务。帮助文件少,不易上手缺点:一般支持论坛和cms4.海纳特点:海量,关键词抓取,可以预览采集的内容,不需要写规则的优点:海量,可以抢到很多关键词文章,好像很适合网站的话题,尤其是文章和博客技术:没有论坛 查看全部
免费网页采集器(五大免费网站数据采集器性能对比(优采云,优采云采集))
五张免费网站数据采集器性能对比(优采云、海纳、ET、三人、优采云采集)在当前站长圈,对比有很多流行的采集工具,但总结起来,只有几个比较著名的免费工具:优采云、海纳、ET、三星、优采云。下面我们对这几个采集工具做一个简单的对比。1.优采云 基本上大家都知道,所以先说几句。优采云应该是国产采集软件最成功的例子之一。用户数包括付费用户数应该是最多的功能:简单,强大,快速,支持网站最丰富,支持丰富的扩展优点:功能比较齐全,采集比较快,主要针对cms,短时间内可以采集很多,过滤替换都不错,比较详细;许多人编写接口、规则和发布模块。接口比较齐全。其中有一个叫陈元的人,开发了目前PHP类cms的几乎所有接口;支持的扩展非常易于使用。如果你是个技术娴熟的站长,你可以用PHP或C#来开发任何功能扩展,真是令人难忘;附件采集功能完善。技术:该技术以论坛为主,帮助文件多,上手容易。有付费版和免费版。缺点:功能较多,软件越来越大,内存和CPU资源较多,资源回收控制不好@>,功能比较齐全。第一的,不知道三星和优采云是什么关系,但是接口和功能都出同一个模型。特点:针对各大论坛,动,动,快,准确率高优点:还是针对论坛,技术适合开论坛:收费技术,免费带广告缺点:超级复杂,上手难,支持cms@ > 比较差3.ET工具特点:无人值守,稳定,资源占用最低,基本上可以称得上是安静的优点:无人值守,自动更新,适合长站,用户群主要集中在长-term站潜水站长。软件一目了然,必备的功能也很齐全。关键是该软件是免费的。我听说采集 增加了中英文翻译功能。技术:论坛支持,软件本身免费,但也提供收费服务。帮助文件少,不易上手缺点:一般支持论坛和cms4.海纳特点:海量,关键词抓取,可以预览采集的内容,不需要写规则的优点:海量,可以抢到很多关键词文章,好像很适合网站的话题,尤其是文章和博客技术:没有论坛
免费网页采集器(免费的网页采集器不管他功能怎么样,是免费就很难得了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-10-24 04:12
现在市场上充斥着一些付费网页采集器,这样一个绿色免费的网页采集器不管它的功能是什么,免费的都是非常罕见的!
本软件使用互联网,采集网页信息。有两个主要特点:
1.可以在js后采集动态信息。
2、可以设置采集的正则表达式。
此外,本软件内置多种采集解决方案,分别对应静态网页和动态网页。
官网的图片(人脸)搜索引擎数据都是用这个软件索引的采集。
使用步骤:
1、输入网址,正常浏览网页,达到采集的目标,点击工具栏上的“查看js后查看源代码”图标,会显示执行js后的网页内容。
如果没有看到相关内容,可以稍等片刻,再次点击,确保js代码执行完毕。通过浏览完整的网页源代码,我们可以确定
使用方案1或方案2。如果可以通过更改URL的页码导航到下一页,则使用方案1;如果页面内容通过脚本动态更新,
然后使用选项 2。
2、点击工具栏上的“运行采集方案”图标,根据步骤1选择方案1或2。如果已经有方案1和方案2生成的downloadtotal.txt
文件,也可以选择选项3。填写必要的信息或表达式,点击“开始采集”按钮,系统会自动采集。在对话框中点击“取消”
按钮,对话框将关闭而不启动采集任务。
3、点击工具栏上的“停止采集解决方案”图标,系统将终止采集任务。
防止网页采集:
防止采集 第一种方法:在文章的开头和结尾添加随机不固定的内容。当网站采集在采集时,通常指定开始位置和结束位置,截取中间的内容。
比如你的文章内容是“优讯软件信息网”,如何添加随机内容:
随机内容1+优讯软件信息网+随机内容2
注意:随机内容1和随机内容2每个文章只需要随机显示一个。 查看全部
免费网页采集器(免费的网页采集器不管他功能怎么样,是免费就很难得了)
现在市场上充斥着一些付费网页采集器,这样一个绿色免费的网页采集器不管它的功能是什么,免费的都是非常罕见的!
本软件使用互联网,采集网页信息。有两个主要特点:
1.可以在js后采集动态信息。
2、可以设置采集的正则表达式。
此外,本软件内置多种采集解决方案,分别对应静态网页和动态网页。
官网的图片(人脸)搜索引擎数据都是用这个软件索引的采集。
使用步骤:
1、输入网址,正常浏览网页,达到采集的目标,点击工具栏上的“查看js后查看源代码”图标,会显示执行js后的网页内容。
如果没有看到相关内容,可以稍等片刻,再次点击,确保js代码执行完毕。通过浏览完整的网页源代码,我们可以确定
使用方案1或方案2。如果可以通过更改URL的页码导航到下一页,则使用方案1;如果页面内容通过脚本动态更新,
然后使用选项 2。
2、点击工具栏上的“运行采集方案”图标,根据步骤1选择方案1或2。如果已经有方案1和方案2生成的downloadtotal.txt
文件,也可以选择选项3。填写必要的信息或表达式,点击“开始采集”按钮,系统会自动采集。在对话框中点击“取消”
按钮,对话框将关闭而不启动采集任务。
3、点击工具栏上的“停止采集解决方案”图标,系统将终止采集任务。
防止网页采集:
防止采集 第一种方法:在文章的开头和结尾添加随机不固定的内容。当网站采集在采集时,通常指定开始位置和结束位置,截取中间的内容。
比如你的文章内容是“优讯软件信息网”,如何添加随机内容:
随机内容1+优讯软件信息网+随机内容2
注意:随机内容1和随机内容2每个文章只需要随机显示一个。
免费网页采集器(淘气哥素材网»所有源码都100%无错或无bug)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-10-23 03:10
5、采集 测试:这是任何其他类似的采集 软件都无法比拟的。程序支持直接查看采集结果和测试发布。
6、 管理便捷:使用站点+任务模式管理采集节点,任务支持批量操作,更轻松的数据管理。
限制软件
优采云采集器
下载说明:
1. 本站的资源都是白菜价卖的,同样的东西,我们不卖几百块,我们不卖几十块,甚至几块钱,一个永久会员可以下载100%全站源码,所以无论是否单独购买,会员和会员均不提供相关技术服务。2. 如果源代码下载地址无效,请联系站长QQ补发。3.本站所有资源仅用于学习和研究。请在24小时内删除下载的资源。请勿将其用于商业用途,否则由此引起的本站与发布者的法律纠纷及连带责任概不承担。除原创标记的资源外,所有资源均来自网络。版权属于原作者或本站特刊原创的作者。如侵犯您的权益,请联系本站删除!4. 本站提供的所有可下载的本站资源(软件等)均保证不做任何负面改动(不包括修复bug、改进功能等积极优化或二次开发);但本网站不能保证资源的准确性和安全性 用户下载后的自由裁量权和完整性,我们以交流和学习为目的,并非所有源代码都是100%无错或无bug;同时,本站用户必须明白,【淘气兄弟素材网】提供的可下载软件等不拥有任何权利(本站作者除外原创 和特殊合同原创),其版权属于资源的合法所有者。5. 请仔细阅读以上内容,购买即表示您同意以上内容。
淘气哥素材网»优采云采集器进入限制版优采云采集器无需登录V8.4进入限制版 查看全部
免费网页采集器(淘气哥素材网»所有源码都100%无错或无bug)
5、采集 测试:这是任何其他类似的采集 软件都无法比拟的。程序支持直接查看采集结果和测试发布。
6、 管理便捷:使用站点+任务模式管理采集节点,任务支持批量操作,更轻松的数据管理。
限制软件
优采云采集器
下载说明:
1. 本站的资源都是白菜价卖的,同样的东西,我们不卖几百块,我们不卖几十块,甚至几块钱,一个永久会员可以下载100%全站源码,所以无论是否单独购买,会员和会员均不提供相关技术服务。2. 如果源代码下载地址无效,请联系站长QQ补发。3.本站所有资源仅用于学习和研究。请在24小时内删除下载的资源。请勿将其用于商业用途,否则由此引起的本站与发布者的法律纠纷及连带责任概不承担。除原创标记的资源外,所有资源均来自网络。版权属于原作者或本站特刊原创的作者。如侵犯您的权益,请联系本站删除!4. 本站提供的所有可下载的本站资源(软件等)均保证不做任何负面改动(不包括修复bug、改进功能等积极优化或二次开发);但本网站不能保证资源的准确性和安全性 用户下载后的自由裁量权和完整性,我们以交流和学习为目的,并非所有源代码都是100%无错或无bug;同时,本站用户必须明白,【淘气兄弟素材网】提供的可下载软件等不拥有任何权利(本站作者除外原创 和特殊合同原创),其版权属于资源的合法所有者。5. 请仔细阅读以上内容,购买即表示您同意以上内容。
淘气哥素材网»优采云采集器进入限制版优采云采集器无需登录V8.4进入限制版
免费网页采集器(政府网站网页在线归档的首要环节,就是利用相关工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-10-23 03:09
网页采集作为政府网站网页在线存档的主要环节,就是利用相关工具,按照既定的频率和方法,及时筛选出值得保存的政府网页内容。网页采集的步骤是确定采集的对象,政府网页采集中存储的信息是域中带有""的政府网站名称,以保证政府网页的采集。@采集质量要求对目标网站进行评价,选择信息规模大、信息原创、更新频繁的政府网站作为采集的目标。确定目标政府网站到采集后,对应的采集
完整性采集和选择性采集是目前比较常用的网络资源采集方法。他们有自己的优点和缺点。为了弥补自身的不足,可以实现两种采集@。>方法优势互补,采用混合采集方法,综合两者的优点,同时完成所选政府所有网页的完整性网站,同时通过人工干预对网页内容进行一定程度的筛选,对具有证据价值、历史价值、研究价值的重要网页进行选择性、频繁的采集深度挖掘,兼顾政府网页< @采集 面对广度,
采集和网页的抓取需要依赖相应的网络爬虫工具来实现。目前,网页归档的爬虫工具有很多。其中常用的有Heritrix和HTTrack,利用这些工具可以完成针对性的匹配。目标政府网站网页自动批量在线采集。 查看全部
免费网页采集器(政府网站网页在线归档的首要环节,就是利用相关工具)
网页采集作为政府网站网页在线存档的主要环节,就是利用相关工具,按照既定的频率和方法,及时筛选出值得保存的政府网页内容。网页采集的步骤是确定采集的对象,政府网页采集中存储的信息是域中带有""的政府网站名称,以保证政府网页的采集。@采集质量要求对目标网站进行评价,选择信息规模大、信息原创、更新频繁的政府网站作为采集的目标。确定目标政府网站到采集后,对应的采集
完整性采集和选择性采集是目前比较常用的网络资源采集方法。他们有自己的优点和缺点。为了弥补自身的不足,可以实现两种采集@。>方法优势互补,采用混合采集方法,综合两者的优点,同时完成所选政府所有网页的完整性网站,同时通过人工干预对网页内容进行一定程度的筛选,对具有证据价值、历史价值、研究价值的重要网页进行选择性、频繁的采集深度挖掘,兼顾政府网页< @采集 面对广度,
采集和网页的抓取需要依赖相应的网络爬虫工具来实现。目前,网页归档的爬虫工具有很多。其中常用的有Heritrix和HTTrack,利用这些工具可以完成针对性的匹配。目标政府网站网页自动批量在线采集。
免费网页采集器(列车采集器安卓版升级日志-上海怡健医学())
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-21 17:18
机车头采集器v9 安卓版可免费下载。机车头采集器安卓版是一款功能齐全、使用方便的数据网络信息内容发现手机软件。机车头采集器安卓版是海量采集网页、社区论坛等的专用工具,即时存入数据库查询或发布到网站。它们可以按照客户设定的标准使用。自动采集原创网页,获取格式网页中需要的内容,现在的发展趋势是做seo优化的专用工具,也能解决信息!
火车采集器安卓版特点:
1、实用性强
无论是新闻报道、社区论坛、视频、企业黄页、照片、免费下载地址,您都可以根据电脑浏览器可以看到的结构化内容和具体的匹配标准,采集得到您所需要的. 内容。
2、稳定高效
七年磨一剑,手机软件不断创新发展,采集速度更快,功能稳定,占用资源更少。
3、可扩展性强,应用领域广泛
自定义web发布,自定义流行数据库系统的存储和发布,自定义本地PHP和.net外部编程socket解决数据信息,让数据信息人人可用。
火车采集器 升级日志:
1、全新升级的页面,更强大的用户界面和客户体验。
2、新架构,新内核,使用9年的.NET2.0架构升级到.NET4.0架构。
3、 适合在新的win10系统下运行。
4、 为辅助服务器代理添加了 Socks 代理。
5、改进采集的步骤,大大提高采集的上架率和备货率。
6、 在日常任务运行过程中可以改变线程数等主要参数,实时调整运行率。
7、适用的SSH(SFTP文件)提交。
8、内容获取增加了JSON获取方式,使得获取JSON数据信息更加容易。
9、 增加C#源码类型软件,可同时编写插件源码,立即生效。
10、软件崩溃,适合存放未完成的工作进度。
11、 将日常任务操作合并成一个统一的页面,加上“实时数据”查询和“任务明细”统计分析。
12、 列表页,分页查询,多个需要一流功能的自定义header。
13、 批量修改日常任务标准关键点的主要参数,批量修改Web发布设备。
14、开始和结束网址大型网址的详细地址格式可以添加多个详细地址主参数,自定义列表的主参数适用。
1 5、的标签数据来自更精致,可设置为从默认页面获取、分页查询、多源代码、URL详细地址、返回头数据。
16、 识别数据处理方式增加了统计分析识别数组的长度和质量替换的效果。
17、 改变了原先获取无限极列表页面URL的方式,无限极装备更轻松。 查看全部
免费网页采集器(列车采集器安卓版升级日志-上海怡健医学())
机车头采集器v9 安卓版可免费下载。机车头采集器安卓版是一款功能齐全、使用方便的数据网络信息内容发现手机软件。机车头采集器安卓版是海量采集网页、社区论坛等的专用工具,即时存入数据库查询或发布到网站。它们可以按照客户设定的标准使用。自动采集原创网页,获取格式网页中需要的内容,现在的发展趋势是做seo优化的专用工具,也能解决信息!
火车采集器安卓版特点:
1、实用性强
无论是新闻报道、社区论坛、视频、企业黄页、照片、免费下载地址,您都可以根据电脑浏览器可以看到的结构化内容和具体的匹配标准,采集得到您所需要的. 内容。
2、稳定高效
七年磨一剑,手机软件不断创新发展,采集速度更快,功能稳定,占用资源更少。
3、可扩展性强,应用领域广泛
自定义web发布,自定义流行数据库系统的存储和发布,自定义本地PHP和.net外部编程socket解决数据信息,让数据信息人人可用。
火车采集器 升级日志:
1、全新升级的页面,更强大的用户界面和客户体验。
2、新架构,新内核,使用9年的.NET2.0架构升级到.NET4.0架构。
3、 适合在新的win10系统下运行。
4、 为辅助服务器代理添加了 Socks 代理。
5、改进采集的步骤,大大提高采集的上架率和备货率。
6、 在日常任务运行过程中可以改变线程数等主要参数,实时调整运行率。
7、适用的SSH(SFTP文件)提交。
8、内容获取增加了JSON获取方式,使得获取JSON数据信息更加容易。
9、 增加C#源码类型软件,可同时编写插件源码,立即生效。
10、软件崩溃,适合存放未完成的工作进度。
11、 将日常任务操作合并成一个统一的页面,加上“实时数据”查询和“任务明细”统计分析。
12、 列表页,分页查询,多个需要一流功能的自定义header。
13、 批量修改日常任务标准关键点的主要参数,批量修改Web发布设备。
14、开始和结束网址大型网址的详细地址格式可以添加多个详细地址主参数,自定义列表的主参数适用。
1 5、的标签数据来自更精致,可设置为从默认页面获取、分页查询、多源代码、URL详细地址、返回头数据。
16、 识别数据处理方式增加了统计分析识别数组的长度和质量替换的效果。
17、 改变了原先获取无限极列表页面URL的方式,无限极装备更轻松。
免费网页采集器(免费网页采集器要想免费的,支持动态抓取断点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-10-18 14:03
免费网页采集器要想免费的,支持动态,抓取,断点,前景翻页。全屏的。支持上传本地txt或者json文件.然后把文件推送到云端,云端,云端抓取文件后生成一个网页链接,你只需要下载这个网页链接就可以免费加入。
可以百度搜一下,可以抓取电脑上的网页,看一下链接,然后抓取下来就可以在各种网站上,包括百度这样的搜索引擎直接下载并使用。
目前百度提供的内置的免费网页采集软件虽然功能齐全,只需要用简单的抓包分析就可以抓取有限的数据,但这并不足以满足用户的需求,并且限制很多。内置的免费网页采集软件要想收费,常用的是将网页中的所有txt或json文件推送到后台服务器。而如果想要直接一次编写网页代码,从而获取需要的数据,那就需要前后端分离,那么百度的人为的框架框架采用前端代码来获取数据,这就导致了网页采集器只能抓取指定范围的数据,并且是以文本格式存储的。
尤其对于敏感的数据获取没有好的解决方案。而今天给大家介绍的可以抓取网页中的音频和视频,并且自动传输到服务器,便捷性和安全性,全面性大大提高。实现手机与电脑无线传输数据方法很简单,通过人工的复制粘贴工作量很大,既不能自动抓取所有文件格式,又不能高效的传输,为了解决这些问题,我们研发出一款简单的工具。这款工具就是使用python语言编写的内置免费网页采集器,可以用于免费采集任何网页内容,并且能自动生成下载链接,还支持使用链接插件进行进一步的封装。
工具名称:python自动抓取工具官网地址:python免费网页采集器介绍工具简介:可抓取网页中的所有txt文件,以文本格式存储;也支持下载音频和视频,并且支持保存本地。特点方便快捷:一行代码也可以对wordpress、freebase等需要代码的网站进行代码采集;目前只支持wordpress平台;提供网页预览;支持预览网页源代码;支持抓取过滤元素;扩展灵活:插件可以在python语言中编写。
用户操作步骤如下:1.使用python代码,编写网页数据抓取程序。2.打开百度浏览器中的微云,并且从百度直接下载程序,并且需要高速下载。3.将采集好的数据存储到服务器。 查看全部
免费网页采集器(免费网页采集器要想免费的,支持动态抓取断点)
免费网页采集器要想免费的,支持动态,抓取,断点,前景翻页。全屏的。支持上传本地txt或者json文件.然后把文件推送到云端,云端,云端抓取文件后生成一个网页链接,你只需要下载这个网页链接就可以免费加入。
可以百度搜一下,可以抓取电脑上的网页,看一下链接,然后抓取下来就可以在各种网站上,包括百度这样的搜索引擎直接下载并使用。
目前百度提供的内置的免费网页采集软件虽然功能齐全,只需要用简单的抓包分析就可以抓取有限的数据,但这并不足以满足用户的需求,并且限制很多。内置的免费网页采集软件要想收费,常用的是将网页中的所有txt或json文件推送到后台服务器。而如果想要直接一次编写网页代码,从而获取需要的数据,那就需要前后端分离,那么百度的人为的框架框架采用前端代码来获取数据,这就导致了网页采集器只能抓取指定范围的数据,并且是以文本格式存储的。
尤其对于敏感的数据获取没有好的解决方案。而今天给大家介绍的可以抓取网页中的音频和视频,并且自动传输到服务器,便捷性和安全性,全面性大大提高。实现手机与电脑无线传输数据方法很简单,通过人工的复制粘贴工作量很大,既不能自动抓取所有文件格式,又不能高效的传输,为了解决这些问题,我们研发出一款简单的工具。这款工具就是使用python语言编写的内置免费网页采集器,可以用于免费采集任何网页内容,并且能自动生成下载链接,还支持使用链接插件进行进一步的封装。
工具名称:python自动抓取工具官网地址:python免费网页采集器介绍工具简介:可抓取网页中的所有txt文件,以文本格式存储;也支持下载音频和视频,并且支持保存本地。特点方便快捷:一行代码也可以对wordpress、freebase等需要代码的网站进行代码采集;目前只支持wordpress平台;提供网页预览;支持预览网页源代码;支持抓取过滤元素;扩展灵活:插件可以在python语言中编写。
用户操作步骤如下:1.使用python代码,编写网页数据抓取程序。2.打开百度浏览器中的微云,并且从百度直接下载程序,并且需要高速下载。3.将采集好的数据存储到服务器。
免费网页采集器(永恒之城网站数据采集器软件安装视频,一键ssl加密)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-15 22:04
免费网页采集器推荐:网页抓取推荐使用“永恒之城网站数据采集器”软件。永恒之城网站数据采集器所有版本均是免费在线使用,最新的版本最低标准免费使用1个月。不用安装,直接浏览器操作。windows操作系统的,安装好软件后,打开网址,选择目标网站采集下载所需数据源,点击下载所需数据文件即可。移动操作系统的,可以选择目标网站安装好软件,手机app浏览器访问网站,选择任意目标网站采集下载,并同步保存到自己的网盘,通过电脑网页版操作,即可实现数据统计等功能。
永恒之城网站数据采集器所有版本都有,标准版是最低标准免费使用1个月。永恒之城网站数据采集器支持网站一键ssl加密抓取,自动补全网址,一键验证抓取的网址是正确无误的。永恒之城网站数据采集器软件安装视频,永恒之城网站数据采集器的安装,请参考以下的方法:文章采集安装教程安装前准备工作安装过程中常见问题解决方法ssl加密全过程演示数据源/网址清洗网站安装完成,需要进行dns解析,方法和fiddler相同,可用fiddler扩展程序实现,同时支持https://。
分析出数据源/网址为,结果页无法通过解析抓取。原因为:cookie记录造成。故需要手动清洗获取;代码中%abbeditor_url%/%div2%8a%7d=%?解析到的数据为“%b12%db%e8%9c%a8%ab%b12%8a%f2%bf%3f%5c%50%e2%9d%b5%3f2%3f2%3f2%3f%2345%c8%e9%a2%94%e6%9d%8b%b8%e6%83%88%e4%b4%a8%e8%8d%a3%e7%af%94%e8%ad%91/2”cookie已被列入黑名单。
清洗代码其中%e8%9c%a8%ab%e4%b4%a8%e8%8d%a3%e7%af%94%e8%ad%91%e4%b8%a8%e8%90%9f%3f%24%7d为数据源网址的cookie代码,必须清洗干净才可以采集数据。清洗完成后,自动获取js代码及css文件的代码,保证我们能够采集到正确的数据;一键验证https.验证成功后,会显示完成抓取成功,即采集成功。
使用永恒之城网站数据采集器进行数据采集时需要输入“验证码”,安全验证正确后,方可采集正确的数据。请设置为如下长度:一个验证码是998位(字符)的数字。永恒之城网站数据采集器安全验证,如果验证码输入错误,数据无法被抓取,所以建议大家一定要设置“验证码采集”。分析出数据源/网址为。 查看全部
免费网页采集器(永恒之城网站数据采集器软件安装视频,一键ssl加密)
免费网页采集器推荐:网页抓取推荐使用“永恒之城网站数据采集器”软件。永恒之城网站数据采集器所有版本均是免费在线使用,最新的版本最低标准免费使用1个月。不用安装,直接浏览器操作。windows操作系统的,安装好软件后,打开网址,选择目标网站采集下载所需数据源,点击下载所需数据文件即可。移动操作系统的,可以选择目标网站安装好软件,手机app浏览器访问网站,选择任意目标网站采集下载,并同步保存到自己的网盘,通过电脑网页版操作,即可实现数据统计等功能。
永恒之城网站数据采集器所有版本都有,标准版是最低标准免费使用1个月。永恒之城网站数据采集器支持网站一键ssl加密抓取,自动补全网址,一键验证抓取的网址是正确无误的。永恒之城网站数据采集器软件安装视频,永恒之城网站数据采集器的安装,请参考以下的方法:文章采集安装教程安装前准备工作安装过程中常见问题解决方法ssl加密全过程演示数据源/网址清洗网站安装完成,需要进行dns解析,方法和fiddler相同,可用fiddler扩展程序实现,同时支持https://。
分析出数据源/网址为,结果页无法通过解析抓取。原因为:cookie记录造成。故需要手动清洗获取;代码中%abbeditor_url%/%div2%8a%7d=%?解析到的数据为“%b12%db%e8%9c%a8%ab%b12%8a%f2%bf%3f%5c%50%e2%9d%b5%3f2%3f2%3f2%3f%2345%c8%e9%a2%94%e6%9d%8b%b8%e6%83%88%e4%b4%a8%e8%8d%a3%e7%af%94%e8%ad%91/2”cookie已被列入黑名单。
清洗代码其中%e8%9c%a8%ab%e4%b4%a8%e8%8d%a3%e7%af%94%e8%ad%91%e4%b8%a8%e8%90%9f%3f%24%7d为数据源网址的cookie代码,必须清洗干净才可以采集数据。清洗完成后,自动获取js代码及css文件的代码,保证我们能够采集到正确的数据;一键验证https.验证成功后,会显示完成抓取成功,即采集成功。
使用永恒之城网站数据采集器进行数据采集时需要输入“验证码”,安全验证正确后,方可采集正确的数据。请设置为如下长度:一个验证码是998位(字符)的数字。永恒之城网站数据采集器安全验证,如果验证码输入错误,数据无法被抓取,所以建议大家一定要设置“验证码采集”。分析出数据源/网址为。
免费网页采集器(优采云采集器的网络数据收集工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 487 次浏览 • 2021-10-14 22:16
优采云采集器是一款绿色、免费的网络信息采集工具。采集网页信息请使用优采云采集器。本软件是优采云软件开发的网络数据采集工具。它旨在帮助用户快速、准确、有效地采集网络信息。该软件不仅可以为用户提供采集方式的选择和设置,还可以自动帮助用户过滤和采集重复的URL信息。与其他网络信息采集软件相比,该软件的优点是集内容采集和信息发布于一体,体积小,操作简单,支持批量上传数据到当前各种主流程序。如果需要,请下载此软件以获取经验。
软件特点:
使用任务管理功能,方便用户管理网页采集
本机型支持用户手册信息采集方式
帮助用户自动过滤重复网址和非法网站
可支持自定义过滤规则,需要采集信息URL
用户可以从列表中获取信息并将其添加到内容页面
支持从内容页面派生的多级页面爬取,快速完成信息爬取
软件支持用户本地化图片或附件
软件可支持多任务、多线程同时采集网页信息
软件可支持将采集到的内容发布到开源程序中
采集内容选择功能,支持使用网页文字前后截取或正则表达式提取
使用说明:
1.下载软件资源包,解压打开,然后点击.exe文件启动软件
2.启动软件后,在如图所示的登录窗口中,输入用户名和密码登录软件
3.在如图所示的操作窗口中,输入需要采集信息的网页地址
4.在如图所示的列表URL集合设置窗口中,或者自定义一个单独列表的每一行的基本参数
5.在如图所示的操作界面中,设置列表中的每组参数都是通过页面全面定制的
6. 在如图所示的多页提取管理器的设置窗口中,自定义提取的名称并选择父页面
7.在如图所示的字段设置窗口中,点击选择通用采集方式,自定义通用内容
8. 在如图所示的操作窗口中,点击水印和缩略图,为采集的网页信息添加文字水印
9. 在软件的操作界面,打开过滤功能,选择过滤条件
软件功能:
使用本软件采集网页信息
用户无需进行重复的软件安装操作
它的体积非常小,用户携带非常方便
软件完全免费,可为用户提供网络信息采集功能
不需要用户购买软件或注册软件
支持用户自定义设置发布页面、内容页面、发布时间间隔
软件的界面设计非常新颖美观
支持软件官方主页获取同类软件
支持添加QQ与软件设计师互动 查看全部
免费网页采集器(优采云采集器的网络数据收集工具)
优采云采集器是一款绿色、免费的网络信息采集工具。采集网页信息请使用优采云采集器。本软件是优采云软件开发的网络数据采集工具。它旨在帮助用户快速、准确、有效地采集网络信息。该软件不仅可以为用户提供采集方式的选择和设置,还可以自动帮助用户过滤和采集重复的URL信息。与其他网络信息采集软件相比,该软件的优点是集内容采集和信息发布于一体,体积小,操作简单,支持批量上传数据到当前各种主流程序。如果需要,请下载此软件以获取经验。
软件特点:
使用任务管理功能,方便用户管理网页采集
本机型支持用户手册信息采集方式
帮助用户自动过滤重复网址和非法网站
可支持自定义过滤规则,需要采集信息URL
用户可以从列表中获取信息并将其添加到内容页面
支持从内容页面派生的多级页面爬取,快速完成信息爬取
软件支持用户本地化图片或附件
软件可支持多任务、多线程同时采集网页信息
软件可支持将采集到的内容发布到开源程序中
采集内容选择功能,支持使用网页文字前后截取或正则表达式提取
使用说明:
1.下载软件资源包,解压打开,然后点击.exe文件启动软件
2.启动软件后,在如图所示的登录窗口中,输入用户名和密码登录软件
3.在如图所示的操作窗口中,输入需要采集信息的网页地址
4.在如图所示的列表URL集合设置窗口中,或者自定义一个单独列表的每一行的基本参数
5.在如图所示的操作界面中,设置列表中的每组参数都是通过页面全面定制的
6. 在如图所示的多页提取管理器的设置窗口中,自定义提取的名称并选择父页面

7.在如图所示的字段设置窗口中,点击选择通用采集方式,自定义通用内容
8. 在如图所示的操作窗口中,点击水印和缩略图,为采集的网页信息添加文字水印
9. 在软件的操作界面,打开过滤功能,选择过滤条件
软件功能:
使用本软件采集网页信息
用户无需进行重复的软件安装操作
它的体积非常小,用户携带非常方便
软件完全免费,可为用户提供网络信息采集功能
不需要用户购买软件或注册软件
支持用户自定义设置发布页面、内容页面、发布时间间隔
软件的界面设计非常新颖美观
支持软件官方主页获取同类软件
支持添加QQ与软件设计师互动
免费网页采集器(优采云采集器官方免费版:人工获取数据途径的数十倍下载体验)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-14 21:09
通过人工搜索网站或者网页信息来获取大量数据,他的成本无疑是巨大的。如今的人工成本已不再是廉价时代,如何更高效、更廉价地获取标准化数据成为了必须克服的难题,优采云采集器官方免费版是由官方采集器。通过公司自主研发的分布式云计算平台,可在不同的网站或网页轻松获取重要数据信息,速度极快。单时刻获得的数据量是人工采集数据的几十倍。该软件简化了采集的工作,改变了传统的获取信息的方式,并逐渐摆脱对体力劳动的依赖。在它的运行下,用户可以准确获取任何页面所需要的数据,而且数据非常规律,事半功倍采集软件,用户不要急于下载官方免费版优采云采集器 来体验一下。或许有了这个软件的帮助,你的工作效率会成为公司的第一。!
特点1、财务数据,如季报、年报、财报,包括最新的每日净值自动采集;
2、各大新闻门户网站实时监控,自动更新上传最新消息;
3、 监控竞争对手的最新信息,包括商品价格和库存;
4、监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5、 采集最新最全的招聘信息;
6、关注最新房产相关网站、采集新房二手房市场;
7、采集主要车型网站具体新车和二手车信息;
8、发现并采集潜在客户信息;
9、采集行业产品目录及产品信息网站;
10、优采云采集器 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
软件亮点1、满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
2、舆论监测
全面监测公共信息,第一手掌握舆情动向
3、市场分析
获取真实用户行为数据,全面把握客户真实需求
4、产品研发
大力支持用户研究,准确获取用户反馈和偏好
5、风险预测
高效信息采集和数据清洗,及时应对系统风险
功能介绍1、简单采集
简单的采集模式内置了数百个主流的网站数据源,如京东、天猫、大众点评等流行的采集网站,只需参考模板并简单地设置参数。您可以快速获取网站公开数据。
2、智能采集
软件可针对不同的网站,提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。
3、云采集
云采集支持5000多台云服务器,7*24小时运行,可实现定时采集,无需人员值守,灵活适配业务场景,助您提升采集 效率,保证数据的及时性。
4、API接口
通过API,您可以轻松获取软件任务信息和采集接收到的数据,灵活调度远程控制任务启停等任务,高效实现数据采集和归档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
5、定制采集
根据不同用户采集的需求,软件可提供自定义模式,自动生成爬虫,可批量准确识别各种网页元素,具有翻页、下拉、ajax、page等多种功能滚动、条件判断等,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
6、方便的定时功能
简单几步,即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,你可以同时自由设置多个任务,根据自己的需要进行多种选择时间组合,灵活部署自己的采集任务。
7、自动数据格式化
软件内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集处理完全自动处理,无需人工干预,即可得到所需格式的数据。
8、多级采集
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;无论网站有多少层,本软件所有数据都可以采集不受限制,满足各种业务采集的需求。
9、支持网站登录后采集
优采云采集器内置登录模块采集,只需配置目标网站的账号密码,即可使用采集模块登录数据;同时,具有采集Cookie自定义功能,首次登录后可自动记住cookie,免去多次输入密码的繁琐,支持更多网站采集。
软件优势1、操作简单
操作简单,完全可视化的图形操作,不需要专业的IT人员,任何会用电脑上网的人都可以轻松掌握。
2、云采集
采集 任务自动分配到云端多台服务器同时执行,提高了采集的效率,短时间内可以获取上千条消息。
3、拖放采集进程
模拟人的操作思维模式,可以登录、输入数据、点击链接、按钮等,还可以针对不同的情况采用不同的采集流程。
4、图像识别
内置可扩展的OCR接口,支持对图片中的文字进行分析,可以提取图片上的文字。
5、定时自动采集
采集 任务自动运行,可以在指定周期内自动采集,还支持实时采集,速度快到一分钟一次。
6、2分钟快速入门
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等。
7、免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。
优采云采集器教程1、首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-- >勾选软件右侧的URL列表复选框-->打开URL列表文本框-->将准备好的URL列表填入文本框
2、接下来将打开网页的步骤拖入循环-->选择打开网页的步骤-->勾选使用当前循环中的URL作为导航地址-->点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页
3、至此,打开网页的循环配置完成。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集数据步骤,这里就不赘述了。可以参考系列一:采集单个网页文章。下图是最终和过程
4、以下是进程最终运行结果
更新日志 v8.2.4
迭代函数
更新了数据预览区新增字段、修改字段、格式化数据、集中数据操作的交互方式
针对不同类型的字段,区分操作项,点击展开不同的菜单项
优化配置XPath的操作,在页面即时显示XPath的识别结果
错误修复
修复自定义下拉框类型网页无法正常获取的问题
修复同名自定义任务无法正常保存的问题
修复修改去重数据配置后应用直接采集未保存的报错
修复部分采集报错无法正常采集数据问题
修复 URL 栏中修改 URL 时遗漏其他步骤相关场景的问题 查看全部
免费网页采集器(优采云采集器官方免费版:人工获取数据途径的数十倍下载体验)
通过人工搜索网站或者网页信息来获取大量数据,他的成本无疑是巨大的。如今的人工成本已不再是廉价时代,如何更高效、更廉价地获取标准化数据成为了必须克服的难题,优采云采集器官方免费版是由官方采集器。通过公司自主研发的分布式云计算平台,可在不同的网站或网页轻松获取重要数据信息,速度极快。单时刻获得的数据量是人工采集数据的几十倍。该软件简化了采集的工作,改变了传统的获取信息的方式,并逐渐摆脱对体力劳动的依赖。在它的运行下,用户可以准确获取任何页面所需要的数据,而且数据非常规律,事半功倍采集软件,用户不要急于下载官方免费版优采云采集器 来体验一下。或许有了这个软件的帮助,你的工作效率会成为公司的第一。!
特点1、财务数据,如季报、年报、财报,包括最新的每日净值自动采集;
2、各大新闻门户网站实时监控,自动更新上传最新消息;
3、 监控竞争对手的最新信息,包括商品价格和库存;
4、监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5、 采集最新最全的招聘信息;
6、关注最新房产相关网站、采集新房二手房市场;
7、采集主要车型网站具体新车和二手车信息;
8、发现并采集潜在客户信息;
9、采集行业产品目录及产品信息网站;
10、优采云采集器 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
软件亮点1、满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
2、舆论监测
全面监测公共信息,第一手掌握舆情动向
3、市场分析
获取真实用户行为数据,全面把握客户真实需求
4、产品研发
大力支持用户研究,准确获取用户反馈和偏好
5、风险预测
高效信息采集和数据清洗,及时应对系统风险
功能介绍1、简单采集
简单的采集模式内置了数百个主流的网站数据源,如京东、天猫、大众点评等流行的采集网站,只需参考模板并简单地设置参数。您可以快速获取网站公开数据。
2、智能采集
软件可针对不同的网站,提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。
3、云采集
云采集支持5000多台云服务器,7*24小时运行,可实现定时采集,无需人员值守,灵活适配业务场景,助您提升采集 效率,保证数据的及时性。
4、API接口
通过API,您可以轻松获取软件任务信息和采集接收到的数据,灵活调度远程控制任务启停等任务,高效实现数据采集和归档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
5、定制采集
根据不同用户采集的需求,软件可提供自定义模式,自动生成爬虫,可批量准确识别各种网页元素,具有翻页、下拉、ajax、page等多种功能滚动、条件判断等,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
6、方便的定时功能
简单几步,即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,你可以同时自由设置多个任务,根据自己的需要进行多种选择时间组合,灵活部署自己的采集任务。
7、自动数据格式化
软件内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集处理完全自动处理,无需人工干预,即可得到所需格式的数据。
8、多级采集
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;无论网站有多少层,本软件所有数据都可以采集不受限制,满足各种业务采集的需求。
9、支持网站登录后采集
优采云采集器内置登录模块采集,只需配置目标网站的账号密码,即可使用采集模块登录数据;同时,具有采集Cookie自定义功能,首次登录后可自动记住cookie,免去多次输入密码的繁琐,支持更多网站采集。
软件优势1、操作简单
操作简单,完全可视化的图形操作,不需要专业的IT人员,任何会用电脑上网的人都可以轻松掌握。
2、云采集
采集 任务自动分配到云端多台服务器同时执行,提高了采集的效率,短时间内可以获取上千条消息。
3、拖放采集进程
模拟人的操作思维模式,可以登录、输入数据、点击链接、按钮等,还可以针对不同的情况采用不同的采集流程。
4、图像识别
内置可扩展的OCR接口,支持对图片中的文字进行分析,可以提取图片上的文字。
5、定时自动采集
采集 任务自动运行,可以在指定周期内自动采集,还支持实时采集,速度快到一分钟一次。
6、2分钟快速入门
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等。
7、免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。
优采云采集器教程1、首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-- >勾选软件右侧的URL列表复选框-->打开URL列表文本框-->将准备好的URL列表填入文本框

2、接下来将打开网页的步骤拖入循环-->选择打开网页的步骤-->勾选使用当前循环中的URL作为导航地址-->点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页

3、至此,打开网页的循环配置完成。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集数据步骤,这里就不赘述了。可以参考系列一:采集单个网页文章。下图是最终和过程
4、以下是进程最终运行结果
更新日志 v8.2.4
迭代函数
更新了数据预览区新增字段、修改字段、格式化数据、集中数据操作的交互方式
针对不同类型的字段,区分操作项,点击展开不同的菜单项
优化配置XPath的操作,在页面即时显示XPath的识别结果
错误修复
修复自定义下拉框类型网页无法正常获取的问题
修复同名自定义任务无法正常保存的问题
修复修改去重数据配置后应用直接采集未保存的报错
修复部分采集报错无法正常采集数据问题
修复 URL 栏中修改 URL 时遗漏其他步骤相关场景的问题
免费网页采集器(优采云采集器式采集任务自动分配到云端 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 597 次浏览 • 2021-10-13 06:38
)
优采云采集器 是任何需要从网络获取信息的孩子的必备神器。这是一个可以让你的信息采集变得非常简单的工具。优采云改变了互联网上传统的数据思维方式,让用户在互联网上爬取和编译数据变得越来越容易
软件特点
操作简单,完全可视化的图形操作,不需要专业的IT人员,任何会用电脑上网的人都可以轻松掌握。
云采集
采集 任务自动分发到云端多台服务器同时执行,提高了采集的效率,短时间内可以获得数千条信息。
拖放采集流程
模拟人的操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采用不同的采集流程。
图形识别
内置可扩展的OCR接口,支持对图片中的文字进行分析,可以提取图片上的文字。
定时自动采集
采集 任务自动运行,可以在指定时间段内自动采集,还支持实时采集,速度快到一分钟一次。
2 分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等。
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。
特征
简单来说,使用优采云可以很容易的从任何网页中准确的采集你需要的数据,生成自定义的常规数据格式。优采云数据采集 系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财报,自动包括最新的每日净值采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 关注各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要车型网站 具体新车和二手车信息;
8. 发现和采集潜在客户信息;
9. 采集行业网站产品目录及产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
指示
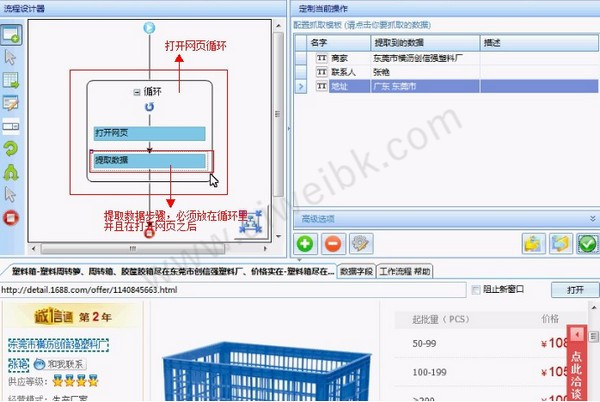
首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-->勾选软件右侧的URL列表复选框-- >打开URL列表文本框-->将准备好的URL列表填入文本框
接下来,将打开网页的步骤拖入循环中-->选择打开网页的步骤-->勾选以当前循环中的URL作为导航地址的复选框-->点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页。
至此,打开网页循环的配置就完成了。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集 数据步骤,这里不再赘述。可以参考系列一:采集单个网页文章。下图是最终和过程
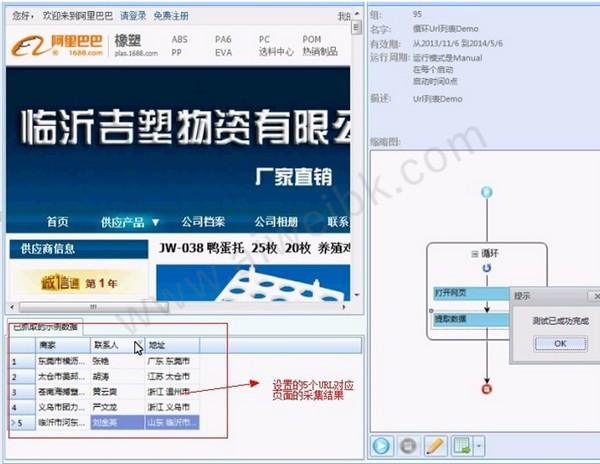
以下是该过程的最终运行结果
查看全部
免费网页采集器(优采云采集器式采集任务自动分配到云端
)
优采云采集器 是任何需要从网络获取信息的孩子的必备神器。这是一个可以让你的信息采集变得非常简单的工具。优采云改变了互联网上传统的数据思维方式,让用户在互联网上爬取和编译数据变得越来越容易

软件特点
操作简单,完全可视化的图形操作,不需要专业的IT人员,任何会用电脑上网的人都可以轻松掌握。
云采集
采集 任务自动分发到云端多台服务器同时执行,提高了采集的效率,短时间内可以获得数千条信息。
拖放采集流程
模拟人的操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采用不同的采集流程。
图形识别
内置可扩展的OCR接口,支持对图片中的文字进行分析,可以提取图片上的文字。
定时自动采集
采集 任务自动运行,可以在指定时间段内自动采集,还支持实时采集,速度快到一分钟一次。
2 分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等。
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。

特征
简单来说,使用优采云可以很容易的从任何网页中准确的采集你需要的数据,生成自定义的常规数据格式。优采云数据采集 系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财报,自动包括最新的每日净值采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 关注各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要车型网站 具体新车和二手车信息;
8. 发现和采集潜在客户信息;
9. 采集行业网站产品目录及产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
指示
首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-->勾选软件右侧的URL列表复选框-- >打开URL列表文本框-->将准备好的URL列表填入文本框

接下来,将打开网页的步骤拖入循环中-->选择打开网页的步骤-->勾选以当前循环中的URL作为导航地址的复选框-->点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页。
至此,打开网页循环的配置就完成了。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集 数据步骤,这里不再赘述。可以参考系列一:采集单个网页文章。下图是最终和过程

以下是该过程的最终运行结果

免费网页采集器(谷歌搜索引擎数据采集工具,没发现免费的,花点钱吧)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-10-10 13:02
免费网页采集器:spiderstorecrawlermitmachinelearningtoolkitfacebookdatasetanalytics.python版:django.python.machinelearning.toolkit.search
免费的就那几个:googlecrawler:searchengine|baidublogdroiddle-谷歌搜索引擎数据采集工具,
国内有好多大佬制作专门的采集器,
googlecrawlersforpython,c#
安利个ease-ml-projectspython3.5+fe3.0python2.6+sdl2.5
用谷歌搜索,
没发现免费的,花点钱吧。要是有专门的在线网页爬虫采集工具,我觉得它们是可以解决这个问题的。
当然有收费的了。可以参考。
这些都是可以的
来吧,我们不是在讨论哪个免费,也不是讨论哪个网站好用,讨论的是谁会更快的帮助你更快的获取这些。我们要的,就是一个靠谱的工具和快速的采集速度。
yelp-digestongoogle,
bigquery
觉得不如看看videodownloader插件 查看全部
免费网页采集器(谷歌搜索引擎数据采集工具,没发现免费的,花点钱吧)
免费网页采集器:spiderstorecrawlermitmachinelearningtoolkitfacebookdatasetanalytics.python版:django.python.machinelearning.toolkit.search
免费的就那几个:googlecrawler:searchengine|baidublogdroiddle-谷歌搜索引擎数据采集工具,
国内有好多大佬制作专门的采集器,
googlecrawlersforpython,c#
安利个ease-ml-projectspython3.5+fe3.0python2.6+sdl2.5
用谷歌搜索,
没发现免费的,花点钱吧。要是有专门的在线网页爬虫采集工具,我觉得它们是可以解决这个问题的。
当然有收费的了。可以参考。
这些都是可以的
来吧,我们不是在讨论哪个免费,也不是讨论哪个网站好用,讨论的是谁会更快的帮助你更快的获取这些。我们要的,就是一个靠谱的工具和快速的采集速度。
yelp-digestongoogle,
bigquery
觉得不如看看videodownloader插件
免费网页采集器(一门强大的开发语言,正则表达式方法捕获 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-10-08 18:20
)
开幕
作为世界上使用最广泛的语言,Java以其高效、可移植(跨平台)、代码的健壮性和强大的可扩展性深受应用开发者的喜爱。作为一门强大的开发语言,正则表达式的应用当然是必不可少的,掌握正则表达式的能力也是那些资深程序员开发能力的体现。做一个合格的网站程序员(尤其是前端开发),正则表达式是必不可少的。
最近因为一些需要,用到java和regular,做了一个足球网站数据采集程序;因为是第一次做关于java采集的html页面数据,一定是我在网上查了很多资料,发现广泛使用的java在使用规律做html采集(中文)文章 非常少见,简单说说java的正则性 实际网页html采集中并没有真正用到这个概念,而且例子教程很少(虽然java有自己的Html Parser,而且很强大),但我个人觉得它是一个如此根深蒂固的正则表达式。相关的java示例教程,应该很多而且很全。所以在完成java版本的html数据采集程序后,
本期概述
本期我们将学习如何读取网页的源代码,通过分组规律动态抓取我们需要的网页数据。同时,在接下来的几期中,我们将继续学习如何存储捕获的游戏数据。进入数据库(MySql),【数据查询】如何查询我们想看的比赛记录,【远程操作】使用客户端远程访问和操作服务器进行数据存储和查询。
关于群体规律
说到正则表达式如何帮助java制作html页面采集,这里就需要提一下正则表达式中的group方法(代码如下)。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Group 类 用于匹配和抓取 html页面的数据
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Group {
public static void main(String[] args) {
// Pattern 用于编译正则 这里用到了3个正则 分别用括号()包住
// 第1个正则用于匹配URL 当然这里的正则不一定准确 这个匹配URL的正则就是错误的 只是在这里刚好能匹配出来
// 第2个正则是用于匹配标题 SoFlash的
// 第3个正则用于匹配日期
/* 这里只用了一条语句便把url,标题和日期全部给匹配出来了 */
Pattern p = Pattern
.compile("='(\\w.+)'>(\\w.+[a-zA-Z])-(\\d{1,2}\\.\\d{1,2}\\.\\d{4})");
String s = "SoFlash-12.22.2011";
Matcher m = p.matcher(s);
while (m.find()) {
// 通过调用group()方法里的索引 将url,标题和日期全部给打印出来
System.out.println("打印出url链接:" + m.group(1));
System.out.println("打印出标题:" + m.group(2));
System.out.println("打印出日期:" + m.group(3));
System.out.println();
}
System.out.println("group方法捕获的数据个数:" + m.groupCount() + "个");
}
}
让我们看看输出:
打印出网址链接:
打印标题:SoFlash
打印日期:12.22.2011
分组方法捕获的数据数量:3
如果想了解更多正则在Java中的应用,请看JAVA正则表达式(超详细)
如果你之前没有学习过正则表达式,可以看看这篇,揭开正则表达式的神秘面纱。
页采集 示例
好了,分组方法介绍完毕,下面我们使用分组正则采集某某足球网站页面数据
页面链接:2011-2012英超球队战绩
首先我们读取整个html页面并打印出来(代码如下)。
public static void main(String[] args) {
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
// 如果 BufferedReader 读到的内容不为空
while (br.readLine() != null) {
// 则打印出来 这里打印出来的结果 应该是整个网站的
System.out.println(br.readLine());
}
br.close(); // 读取完成后关闭读取器
} catch (IOException e) {
// 如果出错 抛出异常
e.printStackTrace();
}
}
打印出来的结果就是整个html页面的源码(部分截图如下)。
至此,html源码已经成功采集down。但是,我们要的不是整个html源代码,而是网页上的比赛数据。
首先我们分析一下html源代码结构,来到2011-2012赛季英超球队战绩页面,右击'查看源文件'(其他浏览器可能称为源代码或相关)。
我们来看看内部的html代码结构和我们需要的数据。
其对应的页面数据
这时候,强大的正则表达式就派上用场了,我们需要写几个正则表达式来抓取团队数据。
这里需要三个正则表达式:日期正则、两队正则(主队和客队)和比赛结果正则。
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";//日期正则
StringregularTwoTeam = ">[^]*"; //团队常规
StringregularResult = ">(\\d{1,2}-\\d{1,2})"; //正则匹配结果
写好正则后,我们就可以用正则去抓取我们想要的数据了。
首先我们写一个GroupMethod类,里面收录regularGroup()方法,用于抓取html页面数据。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* GroupMethod类 用于匹配并抓去 Html上我们想要的内容
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class GroupMethod {
// 传入2个字符串参数 一个是pattern(我们使用的正则) 另一个matcher是html源代码
public String regularGroup(String pattern, String matcher) {
Pattern p = Pattern.compile(pattern, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(matcher);
if (m.find()) { // 如果读到
return m.group();// 返回捕获的数据
} else {
return ""; // 否则返回一个空字符串
}
}
}
然后在main函数中实现html页面的数据抓取。
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
/**
* Main主函数 用于数据采集
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Main {
public static void main(String[] args) {
// 首先用一个字符串 来装载网页链接
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
String strRead = ""; // 新增一个空字符串strRead来装载 BufferedReader 读取到的内容
// 定义3个正则 用于匹配我们需要的数据
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";
String regularTwoTeam = ">[^]*</a>";
String regularResult = ">(\\d{1,2}-\\d{1,2})";
// 创建一个GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法
GroupMethod gMethod = new GroupMethod();
int i =0; //定义一个i来记录循环次数 即收集到的球队比赛结果数
int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的
// 开始读取数据 如果读到的数据不为空 则往里面读
while ((strRead = br.readLine()) != null) {
/**
* 用于捕获日期数据
*/
String strGet = gMethod.regularGroup(regularDate, strRead);
//如果捕获到了符合条件的 日期数据 则打印出来
if (!strGet.equals("")) {
System.out.println("Date:" + strGet);
//这里索引+1 是用于获取后期的球队数据
++index; //因为在html页面里 源代码里 球队数据是在刚好在日期之后
}
/**
* 用于获取2个球队的数据
*/
strGet = gMethod.regularGroup(regularTwoTeam, strRead);
if (!strGet.equals("") && index == 1) { //索引为1的是主队数据
// 通过substring方法 分离出 主队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("HomeTeam:" + strGet); //打印出主队
index++; //索引+1之后 为2了
// 通过substring方法 分离出 客队
} else if (!strGet.equals("") && index == 2) { //这里索引为2的是客队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("AwayTeam:" + strGet); //打印出客队
index = 0;
}
/**
* 用于获取比赛结果
*/
strGet = gMethod.regularGroup(regularResult, strRead);
if (!strGet.equals("")) {
//这里同样用到了substring方法 来剔除' 查看全部
免费网页采集器(一门强大的开发语言,正则表达式方法捕获
)
开幕
作为世界上使用最广泛的语言,Java以其高效、可移植(跨平台)、代码的健壮性和强大的可扩展性深受应用开发者的喜爱。作为一门强大的开发语言,正则表达式的应用当然是必不可少的,掌握正则表达式的能力也是那些资深程序员开发能力的体现。做一个合格的网站程序员(尤其是前端开发),正则表达式是必不可少的。
最近因为一些需要,用到java和regular,做了一个足球网站数据采集程序;因为是第一次做关于java采集的html页面数据,一定是我在网上查了很多资料,发现广泛使用的java在使用规律做html采集(中文)文章 非常少见,简单说说java的正则性 实际网页html采集中并没有真正用到这个概念,而且例子教程很少(虽然java有自己的Html Parser,而且很强大),但我个人觉得它是一个如此根深蒂固的正则表达式。相关的java示例教程,应该很多而且很全。所以在完成java版本的html数据采集程序后,
本期概述
本期我们将学习如何读取网页的源代码,通过分组规律动态抓取我们需要的网页数据。同时,在接下来的几期中,我们将继续学习如何存储捕获的游戏数据。进入数据库(MySql),【数据查询】如何查询我们想看的比赛记录,【远程操作】使用客户端远程访问和操作服务器进行数据存储和查询。
关于群体规律
说到正则表达式如何帮助java制作html页面采集,这里就需要提一下正则表达式中的group方法(代码如下)。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Group 类 用于匹配和抓取 html页面的数据
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Group {
public static void main(String[] args) {
// Pattern 用于编译正则 这里用到了3个正则 分别用括号()包住
// 第1个正则用于匹配URL 当然这里的正则不一定准确 这个匹配URL的正则就是错误的 只是在这里刚好能匹配出来
// 第2个正则是用于匹配标题 SoFlash的
// 第3个正则用于匹配日期
/* 这里只用了一条语句便把url,标题和日期全部给匹配出来了 */
Pattern p = Pattern
.compile("='(\\w.+)'>(\\w.+[a-zA-Z])-(\\d{1,2}\\.\\d{1,2}\\.\\d{4})");
String s = "SoFlash-12.22.2011";
Matcher m = p.matcher(s);
while (m.find()) {
// 通过调用group()方法里的索引 将url,标题和日期全部给打印出来
System.out.println("打印出url链接:" + m.group(1));
System.out.println("打印出标题:" + m.group(2));
System.out.println("打印出日期:" + m.group(3));
System.out.println();
}
System.out.println("group方法捕获的数据个数:" + m.groupCount() + "个");
}
}
让我们看看输出:
打印出网址链接:
打印标题:SoFlash
打印日期:12.22.2011
分组方法捕获的数据数量:3
如果想了解更多正则在Java中的应用,请看JAVA正则表达式(超详细)
如果你之前没有学习过正则表达式,可以看看这篇,揭开正则表达式的神秘面纱。
页采集 示例
好了,分组方法介绍完毕,下面我们使用分组正则采集某某足球网站页面数据
页面链接:2011-2012英超球队战绩
首先我们读取整个html页面并打印出来(代码如下)。
public static void main(String[] args) {
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
// 如果 BufferedReader 读到的内容不为空
while (br.readLine() != null) {
// 则打印出来 这里打印出来的结果 应该是整个网站的
System.out.println(br.readLine());
}
br.close(); // 读取完成后关闭读取器
} catch (IOException e) {
// 如果出错 抛出异常
e.printStackTrace();
}
}
打印出来的结果就是整个html页面的源码(部分截图如下)。

至此,html源码已经成功采集down。但是,我们要的不是整个html源代码,而是网页上的比赛数据。
首先我们分析一下html源代码结构,来到2011-2012赛季英超球队战绩页面,右击'查看源文件'(其他浏览器可能称为源代码或相关)。

我们来看看内部的html代码结构和我们需要的数据。

其对应的页面数据

这时候,强大的正则表达式就派上用场了,我们需要写几个正则表达式来抓取团队数据。
这里需要三个正则表达式:日期正则、两队正则(主队和客队)和比赛结果正则。
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";//日期正则
StringregularTwoTeam = ">[^]*"; //团队常规
StringregularResult = ">(\\d{1,2}-\\d{1,2})"; //正则匹配结果
写好正则后,我们就可以用正则去抓取我们想要的数据了。
首先我们写一个GroupMethod类,里面收录regularGroup()方法,用于抓取html页面数据。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* GroupMethod类 用于匹配并抓去 Html上我们想要的内容
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class GroupMethod {
// 传入2个字符串参数 一个是pattern(我们使用的正则) 另一个matcher是html源代码
public String regularGroup(String pattern, String matcher) {
Pattern p = Pattern.compile(pattern, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(matcher);
if (m.find()) { // 如果读到
return m.group();// 返回捕获的数据
} else {
return ""; // 否则返回一个空字符串
}
}
}
然后在main函数中实现html页面的数据抓取。
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
/**
* Main主函数 用于数据采集
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Main {
public static void main(String[] args) {
// 首先用一个字符串 来装载网页链接
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
String strRead = ""; // 新增一个空字符串strRead来装载 BufferedReader 读取到的内容
// 定义3个正则 用于匹配我们需要的数据
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";
String regularTwoTeam = ">[^]*</a>";
String regularResult = ">(\\d{1,2}-\\d{1,2})";
// 创建一个GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法
GroupMethod gMethod = new GroupMethod();
int i =0; //定义一个i来记录循环次数 即收集到的球队比赛结果数
int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的
// 开始读取数据 如果读到的数据不为空 则往里面读
while ((strRead = br.readLine()) != null) {
/**
* 用于捕获日期数据
*/
String strGet = gMethod.regularGroup(regularDate, strRead);
//如果捕获到了符合条件的 日期数据 则打印出来
if (!strGet.equals("")) {
System.out.println("Date:" + strGet);
//这里索引+1 是用于获取后期的球队数据
++index; //因为在html页面里 源代码里 球队数据是在刚好在日期之后
}
/**
* 用于获取2个球队的数据
*/
strGet = gMethod.regularGroup(regularTwoTeam, strRead);
if (!strGet.equals("") && index == 1) { //索引为1的是主队数据
// 通过substring方法 分离出 主队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("HomeTeam:" + strGet); //打印出主队
index++; //索引+1之后 为2了
// 通过substring方法 分离出 客队
} else if (!strGet.equals("") && index == 2) { //这里索引为2的是客队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("AwayTeam:" + strGet); //打印出客队
index = 0;
}
/**
* 用于获取比赛结果
*/
strGet = gMethod.regularGroup(regularResult, strRead);
if (!strGet.equals("")) {
//这里同样用到了substring方法 来剔除'
免费网页采集器(利用爬虫技术能做到哪些很酷很有趣很有用的事情?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-10-08 01:44
随着Scrapy等框架的流行,用编程语言编写爬虫已经成为一种时尚,看来网上的每个人都对爬虫有所了解。
大神用爬虫将学校所有重要的在线服务整合成一套JSON API,然后开发成App;
爬上知乎 12万用户的头像,把长得像的头像放在一起方便浏览:然后我采集了朋友的点击量,预测这就是你(一般)最喜欢的人长什么样子。;
有网友写了一个爬虫,按照标签对所有豆瓣图书进行爬取,根据已有的标签对豆瓣图书进行排序检索,并按分数从高到低排序。
......
这些有趣的故事都来自于知乎上的一个热门话题:爬虫技术可以做哪些酷、有趣、有用的事情?
每个人都可以爬
在互联网的早期,编写爬行动物是一项技术任务。在更大的方向上,爬行动物技术是搜索引擎不可或缺的一部分。
随着互联网技术的发展,编写爬虫的门槛一再下降。有些编程语言甚至直接提供了爬虫框架,比如Python Scrapy框架,可以让爬虫进入“常人之家”。
我们发现写爬虫是一件很酷的事情,但即便如此,学习爬虫还是有一定的技术门槛。
目前主流的爬虫方式是使用Python编程。Python 无疑是强大的,但初学者学习 Python 仍然需要一两个月的时间。
有没有一些更简单的方法来抓取数据?答案是肯定的。
一些可视化爬虫工具使用策略来爬取特定数据。虽然他们自己写爬虫并不准确,但是学习成本要低很多。这里有一些可视化爬虫工具。
家用工具
01 微软Excel
首先教大家一个用Excel爬取数据的方法。下面是Microsoft Excel 2013的版本,开始动手教学吧~
(1)新建一个Excel,打开,如下图
(2)点击“数据”——“来自网站”
(3)在弹出的对话框中输入目标网址,这里以全国实时空气质量网站为例,点击Go,然后导入
选择导入位置并确认
(4)结果如下图,怎么样,是不是很棒?
(5)如果要实时更新数据,可以在“数据”-“全部更新”-“连接属性”中设置,输入更新频率即可。
02 优采云
一款可视化免编程网页采集软件,可以快速从不同的网站中提取标准化数据,帮助用户实现数据自动化采集,编辑标准化,降低工作成本。
简易模式采集步骤
是一款采集 适合新手尝试的软件。云功能强大。当然,爬虫的老手也可以开发它的高级功能。
03 优采云
优采云 是一款互联网数据采集、处理、分析、挖掘软件。采集功能齐全,不限于网页和内容,可以任意文件格式下载,称为采集99%页面。
软件定位更专业、更精准。用户需要有基本的HTML基础,能够理解网页的源代码和结构。不过软件提供了相应的教程,新手也可以学习使用。
04 采集客户
一款简单易用的网页信息抓取软件,能够抓取网页文字、图表、超链接等网页元素。
操作比较简单,适合新手用户,功能方面没有太多特色,后续支付需求比较多。
网址:
05 优采云云爬虫
一种新型的云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量标准化的网络数据。
类似于爬虫系统框架,具体的采集也需要用户自己编写爬虫,需要有代码基础。
06 优采云采集器
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取、分论坛采集器、cms采集器 和博客采集器 三种类型。
专注于论坛和博客的文字内容爬取,全网数据的采集通用性不高。
国外工具
01 谷歌表格
使用Google Sheet抓取数据前,必须保证三点:使用Chrome浏览器,有Google账号,电脑翻墙。满足这三个条件,我们现在就开始吧~
(1)打开谷歌表格网站:/sheets/about/
(2)首页点击“Go to Google Sheets”,然后登录自己的账号,可以看到如下界面,然后点击“+”新建表单
新创建的表如下:
(3)打开要爬取的目标网站,全国实时空气质量网站pm25.in/rank,目标上的表结构网站@ > 如下图所示
(4)返回Google表格页面,使用function=IMPORTHTML(URL, query, index),“URL”为要抓取的数据的目标网站,输入“list”或“在“查询”表中,这个取决于数据的具体结构类型,“索引”用阿拉伯数字填充,从1开始,对应网站中定义的哪个表或列表
对于我们要爬取的网站,我们在Google sheet的A1单元格中输入function=IMPORTHTML("pm25.in/rank","table",1),然后按回车我可以稍后抓取数据
(5)将爬取的表单保存到本地
是不是感觉超级简单?
02 你得到
这是一个程序员基于python 3开发的项目,已经在github上开源,支持64个网站,包括优酷、土豆、爱奇艺、B站、酷狗音乐、虾米……反正你可以想其中网站 拥有一切!
还有一个黑科技,即使不在列表中,当你输入链接时,程序会猜测你要下载什么,然后为你下载。
当然you-get需要安装在python3环境下。用pip安装好后,在终端输入“你得到的+你要下载的资源的链接”,就可以等待资源的采集了。
这里有一个中文说明,按照说明中的步骤操作即可。
03 import.io
Import.io是一个基于网页的网页数据采集平台,用户无需编写代码,点击即可生成提取器。与国内大多数采集软件相比,Import.io更加智能,能够匹配并生成相似元素列表,用户只需一键输入URL即可获得采集数据。
Import.io的智能开发采集简单,但对于一些复杂的网页结构处理能力较弱。
04章鱼解析
Octoparse是优采云的海外版本。采集 页面设计简洁友好,完全可视化,适合新手用户。
运行并获取数据
Octoparse 功能齐全,价格合理,可以应用于复杂的网络结构。如果你想在不破墙的情况下使用亚马逊、Facebook、Twitter 等平台,Octoparse 是一个选择。
网址:
05 可视化网络撕裂者
Visual Web Ripper 是一种支持各种功能的自动化 Web 抓取工具。
适用于一些高级且采集难度较大的网页结构,需要有较强编程能力的用户。
网址:
06 内容抓取器
Content Grabber 是最强大的网络抓取工具之一。它更适合具有高级编程技能的人,并提供许多强大的脚本编辑和调试接口。允许用户编写正则表达式而不是使用内置工具。
Content Grabber网页适用性强,功能强大。它没有完全为用户提供基本功能。它适合具有高级编程技能的人。
网址:
07 莫曾达
Mozenda是一款基于云的数据采集软件,为用户提供了包括数据云存储在内的诸多实用功能。
适合有基本爬虫经验的人。
网址: 查看全部
免费网页采集器(利用爬虫技术能做到哪些很酷很有趣很有用的事情?)
随着Scrapy等框架的流行,用编程语言编写爬虫已经成为一种时尚,看来网上的每个人都对爬虫有所了解。
大神用爬虫将学校所有重要的在线服务整合成一套JSON API,然后开发成App;
爬上知乎 12万用户的头像,把长得像的头像放在一起方便浏览:然后我采集了朋友的点击量,预测这就是你(一般)最喜欢的人长什么样子。;
有网友写了一个爬虫,按照标签对所有豆瓣图书进行爬取,根据已有的标签对豆瓣图书进行排序检索,并按分数从高到低排序。
......
这些有趣的故事都来自于知乎上的一个热门话题:爬虫技术可以做哪些酷、有趣、有用的事情?
每个人都可以爬
在互联网的早期,编写爬行动物是一项技术任务。在更大的方向上,爬行动物技术是搜索引擎不可或缺的一部分。
随着互联网技术的发展,编写爬虫的门槛一再下降。有些编程语言甚至直接提供了爬虫框架,比如Python Scrapy框架,可以让爬虫进入“常人之家”。
我们发现写爬虫是一件很酷的事情,但即便如此,学习爬虫还是有一定的技术门槛。
目前主流的爬虫方式是使用Python编程。Python 无疑是强大的,但初学者学习 Python 仍然需要一两个月的时间。
有没有一些更简单的方法来抓取数据?答案是肯定的。
一些可视化爬虫工具使用策略来爬取特定数据。虽然他们自己写爬虫并不准确,但是学习成本要低很多。这里有一些可视化爬虫工具。
家用工具
01 微软Excel
首先教大家一个用Excel爬取数据的方法。下面是Microsoft Excel 2013的版本,开始动手教学吧~
(1)新建一个Excel,打开,如下图
(2)点击“数据”——“来自网站”
(3)在弹出的对话框中输入目标网址,这里以全国实时空气质量网站为例,点击Go,然后导入
选择导入位置并确认
(4)结果如下图,怎么样,是不是很棒?
(5)如果要实时更新数据,可以在“数据”-“全部更新”-“连接属性”中设置,输入更新频率即可。
02 优采云
一款可视化免编程网页采集软件,可以快速从不同的网站中提取标准化数据,帮助用户实现数据自动化采集,编辑标准化,降低工作成本。
简易模式采集步骤
是一款采集 适合新手尝试的软件。云功能强大。当然,爬虫的老手也可以开发它的高级功能。
03 优采云
优采云 是一款互联网数据采集、处理、分析、挖掘软件。采集功能齐全,不限于网页和内容,可以任意文件格式下载,称为采集99%页面。
软件定位更专业、更精准。用户需要有基本的HTML基础,能够理解网页的源代码和结构。不过软件提供了相应的教程,新手也可以学习使用。
04 采集客户
一款简单易用的网页信息抓取软件,能够抓取网页文字、图表、超链接等网页元素。
操作比较简单,适合新手用户,功能方面没有太多特色,后续支付需求比较多。
网址:
05 优采云云爬虫
一种新型的云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量标准化的网络数据。
类似于爬虫系统框架,具体的采集也需要用户自己编写爬虫,需要有代码基础。
06 优采云采集器
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取、分论坛采集器、cms采集器 和博客采集器 三种类型。
专注于论坛和博客的文字内容爬取,全网数据的采集通用性不高。
国外工具
01 谷歌表格
使用Google Sheet抓取数据前,必须保证三点:使用Chrome浏览器,有Google账号,电脑翻墙。满足这三个条件,我们现在就开始吧~
(1)打开谷歌表格网站:/sheets/about/
(2)首页点击“Go to Google Sheets”,然后登录自己的账号,可以看到如下界面,然后点击“+”新建表单
新创建的表如下:
(3)打开要爬取的目标网站,全国实时空气质量网站pm25.in/rank,目标上的表结构网站@ > 如下图所示
(4)返回Google表格页面,使用function=IMPORTHTML(URL, query, index),“URL”为要抓取的数据的目标网站,输入“list”或“在“查询”表中,这个取决于数据的具体结构类型,“索引”用阿拉伯数字填充,从1开始,对应网站中定义的哪个表或列表
对于我们要爬取的网站,我们在Google sheet的A1单元格中输入function=IMPORTHTML("pm25.in/rank","table",1),然后按回车我可以稍后抓取数据
(5)将爬取的表单保存到本地
是不是感觉超级简单?
02 你得到
这是一个程序员基于python 3开发的项目,已经在github上开源,支持64个网站,包括优酷、土豆、爱奇艺、B站、酷狗音乐、虾米……反正你可以想其中网站 拥有一切!
还有一个黑科技,即使不在列表中,当你输入链接时,程序会猜测你要下载什么,然后为你下载。
当然you-get需要安装在python3环境下。用pip安装好后,在终端输入“你得到的+你要下载的资源的链接”,就可以等待资源的采集了。
这里有一个中文说明,按照说明中的步骤操作即可。
03 import.io
Import.io是一个基于网页的网页数据采集平台,用户无需编写代码,点击即可生成提取器。与国内大多数采集软件相比,Import.io更加智能,能够匹配并生成相似元素列表,用户只需一键输入URL即可获得采集数据。
Import.io的智能开发采集简单,但对于一些复杂的网页结构处理能力较弱。
04章鱼解析
Octoparse是优采云的海外版本。采集 页面设计简洁友好,完全可视化,适合新手用户。
运行并获取数据
Octoparse 功能齐全,价格合理,可以应用于复杂的网络结构。如果你想在不破墙的情况下使用亚马逊、Facebook、Twitter 等平台,Octoparse 是一个选择。
网址:
05 可视化网络撕裂者
Visual Web Ripper 是一种支持各种功能的自动化 Web 抓取工具。
适用于一些高级且采集难度较大的网页结构,需要有较强编程能力的用户。
网址:
06 内容抓取器
Content Grabber 是最强大的网络抓取工具之一。它更适合具有高级编程技能的人,并提供许多强大的脚本编辑和调试接口。允许用户编写正则表达式而不是使用内置工具。
Content Grabber网页适用性强,功能强大。它没有完全为用户提供基本功能。它适合具有高级编程技能的人。
网址:
07 莫曾达
Mozenda是一款基于云的数据采集软件,为用户提供了包括数据云存储在内的诸多实用功能。
适合有基本爬虫经验的人。
网址:
免费网页采集器(网页表格数据采集助手使用方法:1.格式保存方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-06 08:18
<p>网页表单数据采集助手是一款绿色、免费的网页表单数据采集软件。软件功能强大,可以采集单页规则和不规则表格,并自动连续采集指定网站的表格,并指定 查看全部
免费网页采集器(网页表格数据采集助手使用方法:1.格式保存方法)
<p>网页表单数据采集助手是一款绿色、免费的网页表单数据采集软件。软件功能强大,可以采集单页规则和不规则表格,并自动连续采集指定网站的表格,并指定
免费网页采集器(优采云问:如何过滤列表中的前N个数据?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-02 11:23
优采云采集器V2是一款高效的网页信息采集软件,支持99%的网站数据采集,优采云采集器可以生成Excel表格、api数据库文件等内容,帮助您管理网站数据信息。如果你需要采集一个指定的网页数据,就用这个软件。
软件特点
一键提取数据
简单易学,通过可视化界面,鼠标点击即可采集数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
特征
向导模式
简单易用,轻松通过鼠标点击自动生成
脚本定期运行
可按计划定时运行,无需人工
原装高速核心
自主研发的浏览器内核速度快,远超对手
智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
各种数据导出
支持 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。
指示
第一步:输入采集 URL
打开软件,新建一个任务,输入需要采集的网站地址。
第二步:智能分析,全程自动提取数据
进入第二步后,优采云采集器自动对网页进行智能分析,从中提取列表数据。
第三步:将数据导出到表、数据库、网站等。
运行任务,将采集中的数据导出到Csv、Excel及各种数据库,支持api导出。
常见问题
Q:如何过滤列表中的前N个数据?
1.有时候我们需要过滤采集收到的列表,比如过滤掉第一组数据(以采集的形式,过滤掉表列名)
2.在列表模式菜单中点击设置列表xpath
Q:如何通过抓包获取cookie并手动设置?
1.首先用谷歌浏览器打开你要采集的网站,然后登录。
2. 然后按F12,会出现开发者工具,选择Network
3.然后按F5刷新下一页并选择其中一个请求。
4.复制完成后,在优采云采集器中编辑任务,进入第三步指定HTTP Header。
更新日志
1.添加插件功能
2.添加export txt(一个文件另存为一个文件)
3.多值连接器支持换行
4.修改数据处理的文本映射(支持查找替换)
5.修复登录时DNS问题
6.修复图片下载问题
7.修复json中的一些问题 查看全部
免费网页采集器(优采云问:如何过滤列表中的前N个数据?)
优采云采集器V2是一款高效的网页信息采集软件,支持99%的网站数据采集,优采云采集器可以生成Excel表格、api数据库文件等内容,帮助您管理网站数据信息。如果你需要采集一个指定的网页数据,就用这个软件。

软件特点
一键提取数据
简单易学,通过可视化界面,鼠标点击即可采集数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
特征
向导模式
简单易用,轻松通过鼠标点击自动生成
脚本定期运行
可按计划定时运行,无需人工
原装高速核心
自主研发的浏览器内核速度快,远超对手
智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
各种数据导出
支持 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。
指示
第一步:输入采集 URL
打开软件,新建一个任务,输入需要采集的网站地址。
第二步:智能分析,全程自动提取数据
进入第二步后,优采云采集器自动对网页进行智能分析,从中提取列表数据。
第三步:将数据导出到表、数据库、网站等。
运行任务,将采集中的数据导出到Csv、Excel及各种数据库,支持api导出。
常见问题
Q:如何过滤列表中的前N个数据?
1.有时候我们需要过滤采集收到的列表,比如过滤掉第一组数据(以采集的形式,过滤掉表列名)
2.在列表模式菜单中点击设置列表xpath
Q:如何通过抓包获取cookie并手动设置?
1.首先用谷歌浏览器打开你要采集的网站,然后登录。
2. 然后按F12,会出现开发者工具,选择Network
3.然后按F5刷新下一页并选择其中一个请求。
4.复制完成后,在优采云采集器中编辑任务,进入第三步指定HTTP Header。
更新日志
1.添加插件功能
2.添加export txt(一个文件另存为一个文件)
3.多值连接器支持换行
4.修改数据处理的文本映射(支持查找替换)
5.修复登录时DNS问题
6.修复图片下载问题
7.修复json中的一些问题
免费网页采集器(免费网页采集器可以采集、天猫、京东等网站的一键免费在线的网页并按需要自动生成)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-30 10:22
免费网页采集器可以采集、天猫、京东等网站的一键免费在线的网页并按需要自动生成网页代码上传到后台本软件有四大功能
1、实时定位各类网站
2、采集速度快
3、自动格式化网页
4、实时上传新代码注意:需要安装到电脑里面。
一、上网采集各类网站一键免费在线抓取各类网站免费自动抓取各种大中小网站任何页面所有页面文字(视频,图片,站内信)自动采集不花钱采集任何大中小网站页面任何页面内容(高清图片,插图,ppt,html)无需任何代码技术和技术,你可以操作手机、电脑、电视或盒子电脑上直接采集(指定浏览器内录制或模拟电脑可在电脑)电脑采集电脑内输入网址"-8jnjdewcmb4ljvzibjy/"电脑浏览器网址右键另存,在浏览器里面直接点击网址"-8jnjdewcmb4ljvzibjy/"。
二、自动格式化网页及代码采集任何网站的基本数据,如url、cookie、账号、密码、账号app等信息获取后自动格式化html代码,文字、图片及音视频等格式化。格式化格式化后可通过电脑“浏览器”进行格式化,成为通用网页,未经格式化的网页代码在采集时会造成额外的工作量。
三、实时上传新代码添加网站新代码(如:高清电影、网页图片、插图、音频、视频、html、链接等)上传时可添加网站链接或自己定义网址
四、如何使用
1、首先点击软件右上角的"编辑"在编辑页面输入我们想要采集的网站名称,然后点击"开始采集"点击"保存"你的网站源代码。如果没有报错,会出现这样的提示:无法获取我们需要的信息:要获取的网站网址、html代码编码等内容。
2、如果上传成功,软件会自动创建采集目录如下图,采集目录以第一个"邮件"为例。
3、接下来的采集过程我们就可以点击采集目录,
4、获取网页源码后点击右下角的"提交",然后会弹出"已采集成功"提示框。当我们点击"提交"按钮的时候软件会自动保存保存在这个网站源码的目录中。
5、另外,我们可以将这个网站代码保存为本地电子文档,例如,我们保存为"txt文档"。 查看全部
免费网页采集器(免费网页采集器可以采集、天猫、京东等网站的一键免费在线的网页并按需要自动生成)
免费网页采集器可以采集、天猫、京东等网站的一键免费在线的网页并按需要自动生成网页代码上传到后台本软件有四大功能
1、实时定位各类网站
2、采集速度快
3、自动格式化网页
4、实时上传新代码注意:需要安装到电脑里面。
一、上网采集各类网站一键免费在线抓取各类网站免费自动抓取各种大中小网站任何页面所有页面文字(视频,图片,站内信)自动采集不花钱采集任何大中小网站页面任何页面内容(高清图片,插图,ppt,html)无需任何代码技术和技术,你可以操作手机、电脑、电视或盒子电脑上直接采集(指定浏览器内录制或模拟电脑可在电脑)电脑采集电脑内输入网址"-8jnjdewcmb4ljvzibjy/"电脑浏览器网址右键另存,在浏览器里面直接点击网址"-8jnjdewcmb4ljvzibjy/"。
二、自动格式化网页及代码采集任何网站的基本数据,如url、cookie、账号、密码、账号app等信息获取后自动格式化html代码,文字、图片及音视频等格式化。格式化格式化后可通过电脑“浏览器”进行格式化,成为通用网页,未经格式化的网页代码在采集时会造成额外的工作量。
三、实时上传新代码添加网站新代码(如:高清电影、网页图片、插图、音频、视频、html、链接等)上传时可添加网站链接或自己定义网址
四、如何使用
1、首先点击软件右上角的"编辑"在编辑页面输入我们想要采集的网站名称,然后点击"开始采集"点击"保存"你的网站源代码。如果没有报错,会出现这样的提示:无法获取我们需要的信息:要获取的网站网址、html代码编码等内容。
2、如果上传成功,软件会自动创建采集目录如下图,采集目录以第一个"邮件"为例。
3、接下来的采集过程我们就可以点击采集目录,
4、获取网页源码后点击右下角的"提交",然后会弹出"已采集成功"提示框。当我们点击"提交"按钮的时候软件会自动保存保存在这个网站源码的目录中。
5、另外,我们可以将这个网站代码保存为本地电子文档,例如,我们保存为"txt文档"。
免费网页采集器(优采云采集器软件特色介绍及解决方法步骤介绍-苏州安嘉 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-09-27 22:06
)
优采云采集器是一款专业的网页数据采集软件,可以一键使用采集网页数据功能,任何人都可以使用,可视化,无需开发,无需导出数据限制,支持后台操作,速度实时显示,非常方便。优采云采集器软件特点
1、运行批处理采集数据
软件根据采集的处理和提取规则自动对采集进行批量处理;
快速稳定,实时显示采集速度和进程;
软件可切换后台运行,不打扰前台工作。
2、导出发布采集的数据
采集 数据自动制表,字段可自由配置;
支持数据导出到Excel等本地文件;
并一键发布到cms网站/database/微信公众号等媒体。
优采云采集器 使用说明
如何自定义采集百度搜索结果数据
第一步:创建采集任务
1)启动优采云采集器,进入主界面,选择自定义采集,点击创建任务按钮,创建“自定义采集任务”
2)输入百度搜索的网址,三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分隔。
2、 点击读取文件:用户选择一个文件来存储 URL。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址。
第二步:自定义采集流程
1) 点击创建后,会自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区域用于拖放到画布上生成新的流程块;点击打开网页中的属性按钮,修改打开的网址。
2)添加文本输入流程块:将底部模板区域中的输入文本块拖到打开的网页块的后面。出现阴影区域时,松开鼠标,此时会自动连接,添加完成。
3) 生成一个完整的流程图: 按照上面添加输入文本流程块的拖放流程添加一个新块:如下图所示:
关键步骤块设置介绍
第二步:定时等待用于等待之前打开的网页完成。
第三步:点击输入框的Xpath属性按钮,点击属性菜单中的图标选择网页上的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
第四步:设置,点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页上的百度按钮确定。
第五步:用于设置加载下一个列表页面的周期。在循环块内的循环条件块中设置详细条件。单击此处的操作按钮选择单个元素,然后在属性菜单中单击该元素的xpath 属性按钮,然后在网页中单击下一页按钮,如上。循环次数属性按钮可以默认为0,即下一页没有点击次数限制。
第六步:用于设置列表页数据的循环抽取。在循环块内部的循环条件块中设置详细条件,点击这里的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后在网页中点击两次即可提取第一个块和第二个元素。循环次数属性按钮可以默认为0,即不限制列表中采集的字段数。
Step 7:用于执行点击下一页按钮、点击元素xpath属性按钮、选择当前循环中元素的xpath选项的操作。
第八步:同样用于设置网页加载的等待时间。
第九步:用于在列表页面设置要提取的字段规则,点击属性按钮中的循环中使用元素按钮,选择循环中使用元素的选项。单击元素模板属性按钮在字段表中添加和减去字段以添加和删除字段。添加字段使用点击操作,即点击加号,然后将鼠标移动到网页元素上,点击选择。
4)点击开始采集,开始采集
第三步:数据采集并导出
1)采集 任务正在运行
2)采集 完成后,选择Export Data,将所有数据导出到本地文件。
3)选择导出方式,导出采集的好数据。在这里您可以选择excel作为导出格式。
界面预览:
查看全部
免费网页采集器(优采云采集器软件特色介绍及解决方法步骤介绍-苏州安嘉
)
优采云采集器是一款专业的网页数据采集软件,可以一键使用采集网页数据功能,任何人都可以使用,可视化,无需开发,无需导出数据限制,支持后台操作,速度实时显示,非常方便。优采云采集器软件特点
1、运行批处理采集数据
软件根据采集的处理和提取规则自动对采集进行批量处理;
快速稳定,实时显示采集速度和进程;
软件可切换后台运行,不打扰前台工作。
2、导出发布采集的数据
采集 数据自动制表,字段可自由配置;
支持数据导出到Excel等本地文件;
并一键发布到cms网站/database/微信公众号等媒体。
优采云采集器 使用说明
如何自定义采集百度搜索结果数据
第一步:创建采集任务
1)启动优采云采集器,进入主界面,选择自定义采集,点击创建任务按钮,创建“自定义采集任务”
2)输入百度搜索的网址,三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分隔。
2、 点击读取文件:用户选择一个文件来存储 URL。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址。
第二步:自定义采集流程
1) 点击创建后,会自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区域用于拖放到画布上生成新的流程块;点击打开网页中的属性按钮,修改打开的网址。
2)添加文本输入流程块:将底部模板区域中的输入文本块拖到打开的网页块的后面。出现阴影区域时,松开鼠标,此时会自动连接,添加完成。
3) 生成一个完整的流程图: 按照上面添加输入文本流程块的拖放流程添加一个新块:如下图所示:

关键步骤块设置介绍
第二步:定时等待用于等待之前打开的网页完成。
第三步:点击输入框的Xpath属性按钮,点击属性菜单中的图标选择网页上的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
第四步:设置,点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页上的百度按钮确定。
第五步:用于设置加载下一个列表页面的周期。在循环块内的循环条件块中设置详细条件。单击此处的操作按钮选择单个元素,然后在属性菜单中单击该元素的xpath 属性按钮,然后在网页中单击下一页按钮,如上。循环次数属性按钮可以默认为0,即下一页没有点击次数限制。
第六步:用于设置列表页数据的循环抽取。在循环块内部的循环条件块中设置详细条件,点击这里的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后在网页中点击两次即可提取第一个块和第二个元素。循环次数属性按钮可以默认为0,即不限制列表中采集的字段数。
Step 7:用于执行点击下一页按钮、点击元素xpath属性按钮、选择当前循环中元素的xpath选项的操作。
第八步:同样用于设置网页加载的等待时间。
第九步:用于在列表页面设置要提取的字段规则,点击属性按钮中的循环中使用元素按钮,选择循环中使用元素的选项。单击元素模板属性按钮在字段表中添加和减去字段以添加和删除字段。添加字段使用点击操作,即点击加号,然后将鼠标移动到网页元素上,点击选择。
4)点击开始采集,开始采集

第三步:数据采集并导出
1)采集 任务正在运行

2)采集 完成后,选择Export Data,将所有数据导出到本地文件。
3)选择导出方式,导出采集的好数据。在这里您可以选择excel作为导出格式。
界面预览:

免费网页采集器(使用方法自定义采集百度搜索结果数据的方法步骤步骤介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-10-29 08:17
软件介绍
优采云采集器正式版是一款方便易用的网页数据采集软件,具有可视化点击、一键采集网页数据等功能。优采云采集器 正式版支持全平台,Win/Mac/Linux均可,采集和导出全部免费,无限制使用安全,可后台运行,速度真实-时间显示,是一款非常好用的网页采集工具。
优采云采集器正式版软件特点
【可视化定制采集流程】
全程问答指导,可视化操作,自定义采集流程
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
【点击提取网页数据】
鼠标点击选择要抓取的网页内容,操作简单
您可以选择提取文本、链接、属性、html 标签等。
【运行批处理采集数据】
软件根据采集的处理和提取规则自动批量处理采集
快速稳定,实时显示采集速度和进程
可切换软件后台运行,不打扰前台工作
【导出并发布采集的数据】
采集 数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
软件功能
1、可视化点击,一键采集网络数据
优采云采集器正式版为全拖拽式操作,无需开发或懂技术。任何人都可以使用网络数据采集器
2、采集 和导出都是免费的,无限使用
优采云采集器 正式版是完全免费的采集软件,导出数据无限制,数据可以导出到本地文件,发布到网站和数据库等。
3、 可后台运行,可实时显示速度
优采云采集器正式版可以切换软件后台运行,不打扰您其他前台工作。悬浮窗可以实时查看采集速度和采集数据。
4、所有平台,Win/Mac/Linux均可用
与其他采集器不同的是,优采云采集器正式版支持所有操作系统版本更新和功能升级,同步所有平台。
指示
如何自定义采集百度搜索结果数据
第一步:创建采集任务
1)启动优采云采集器,进入主界面,选择自定义采集,点击创建任务按钮,创建“自定义采集任务”
2)输入百度搜索的网址,包括三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分割
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址
第二步:自定义采集流程
1) 点击创建后,会自动打开第一个网址,然后进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区域用于拖放到画布上生成新的流程块;点击打开网页中的属性按钮修改打开的网址
2)添加文本输入流程块:将底部模板区域中的输入文本块拖到打开的网页块的后面。出现阴影区域时松开鼠标,此时会自动连接,添加完成
3) 生成一个完整的流程图: 按照上面添加文本输入流程块的拖放流程添加一个新块:如下图:
关键步骤块设置介绍
第二步:定时等待用于等待之前打开的网页完成
第三步:点击输入框的Xpath属性按钮,点击属性菜单中的图标选择网页上的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
第四步:设置,点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页上的百度一键。
第五步:用于设置加载下一个列表页面的周期。在循环块内的循环条件块中设置详细条件。单击此处的操作按钮选择单个元素,然后在属性菜单中单击该元素的xpath 属性按钮,然后在网页中单击下一页按钮,如上。循环次数属性按钮可以默认为0,即下一页没有点击次数限制。
第六步:用于设置列表页数据的循环抽取。在循环块内部的循环条件块中设置详细条件,点击这里的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后在网页中点击两次提取第一个块和第二个元素。循环次数属性按钮可以默认为0,即不限制列表中采集的字段数。
Step 7:用于执行点击下一页按钮、点击元素xpath属性按钮、选择当前循环中元素的xpath选项的操作。
第八步:同样用于设置网页加载的等待时间。
第九步:用于在列表页面设置要提取的字段规则,点击属性按钮中的循环中使用元素按钮,选择循环中使用元素的选项。单击元素模板属性按钮在字段表中添加和减去字段以添加和删除字段。添加字段使用点击操作,即点击加号,然后将鼠标移动到网页元素上,点击选择。
4)点击开始采集,开始采集
第三步:数据采集并导出
1)采集 任务正在运行
2)采集 完成后,选择“导出数据”将所有数据导出到本地文件
3)选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式
4)采集 数据导出如下图
更新日志
优采云采集器正式版v3.5.3
更新日期:2020-07-01
优化:
Ng-click 兼容按钮单击
启动任务时,可以设置逐行滚动的最小滚动距离
修理:
修复一些显示问题 查看全部
免费网页采集器(使用方法自定义采集百度搜索结果数据的方法步骤步骤介绍)
软件介绍
优采云采集器正式版是一款方便易用的网页数据采集软件,具有可视化点击、一键采集网页数据等功能。优采云采集器 正式版支持全平台,Win/Mac/Linux均可,采集和导出全部免费,无限制使用安全,可后台运行,速度真实-时间显示,是一款非常好用的网页采集工具。
优采云采集器正式版软件特点
【可视化定制采集流程】
全程问答指导,可视化操作,自定义采集流程
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
【点击提取网页数据】
鼠标点击选择要抓取的网页内容,操作简单
您可以选择提取文本、链接、属性、html 标签等。
【运行批处理采集数据】
软件根据采集的处理和提取规则自动批量处理采集
快速稳定,实时显示采集速度和进程
可切换软件后台运行,不打扰前台工作
【导出并发布采集的数据】
采集 数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
软件功能
1、可视化点击,一键采集网络数据
优采云采集器正式版为全拖拽式操作,无需开发或懂技术。任何人都可以使用网络数据采集器
2、采集 和导出都是免费的,无限使用
优采云采集器 正式版是完全免费的采集软件,导出数据无限制,数据可以导出到本地文件,发布到网站和数据库等。
3、 可后台运行,可实时显示速度
优采云采集器正式版可以切换软件后台运行,不打扰您其他前台工作。悬浮窗可以实时查看采集速度和采集数据。
4、所有平台,Win/Mac/Linux均可用
与其他采集器不同的是,优采云采集器正式版支持所有操作系统版本更新和功能升级,同步所有平台。
指示
如何自定义采集百度搜索结果数据
第一步:创建采集任务
1)启动优采云采集器,进入主界面,选择自定义采集,点击创建任务按钮,创建“自定义采集任务”
2)输入百度搜索的网址,包括三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分割
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址
第二步:自定义采集流程
1) 点击创建后,会自动打开第一个网址,然后进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区域用于拖放到画布上生成新的流程块;点击打开网页中的属性按钮修改打开的网址
2)添加文本输入流程块:将底部模板区域中的输入文本块拖到打开的网页块的后面。出现阴影区域时松开鼠标,此时会自动连接,添加完成
3) 生成一个完整的流程图: 按照上面添加文本输入流程块的拖放流程添加一个新块:如下图:
关键步骤块设置介绍
第二步:定时等待用于等待之前打开的网页完成
第三步:点击输入框的Xpath属性按钮,点击属性菜单中的图标选择网页上的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
第四步:设置,点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页上的百度一键。
第五步:用于设置加载下一个列表页面的周期。在循环块内的循环条件块中设置详细条件。单击此处的操作按钮选择单个元素,然后在属性菜单中单击该元素的xpath 属性按钮,然后在网页中单击下一页按钮,如上。循环次数属性按钮可以默认为0,即下一页没有点击次数限制。
第六步:用于设置列表页数据的循环抽取。在循环块内部的循环条件块中设置详细条件,点击这里的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后在网页中点击两次提取第一个块和第二个元素。循环次数属性按钮可以默认为0,即不限制列表中采集的字段数。
Step 7:用于执行点击下一页按钮、点击元素xpath属性按钮、选择当前循环中元素的xpath选项的操作。
第八步:同样用于设置网页加载的等待时间。
第九步:用于在列表页面设置要提取的字段规则,点击属性按钮中的循环中使用元素按钮,选择循环中使用元素的选项。单击元素模板属性按钮在字段表中添加和减去字段以添加和删除字段。添加字段使用点击操作,即点击加号,然后将鼠标移动到网页元素上,点击选择。
4)点击开始采集,开始采集
第三步:数据采集并导出
1)采集 任务正在运行
2)采集 完成后,选择“导出数据”将所有数据导出到本地文件
3)选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式
4)采集 数据导出如下图
更新日志
优采云采集器正式版v3.5.3
更新日期:2020-07-01
优化:
Ng-click 兼容按钮单击
启动任务时,可以设置逐行滚动的最小滚动距离
修理:
修复一些显示问题
免费网页采集器(免费网页采集器,一键采集并上传文章,收到后台数据时一键返回!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-28 08:01
免费网页采集器,一键采集并上传文章,收到后台数据时一键返回!这个网站有分类特别多,任何你想要的都可以!注册后,我们可以免费使用7天!主要是采集免费高质量文章,采集精选高质量文章,文章质量要求高。主要数据如下图:免费网页采集器,一键采集并上传文章,收到后台数据时一键返回!这个网站有分类特别多,任何你想要的都可以!。
你自己不给钱吗?这个多少钱一篇,
很轻便,
昨天恰好在写国内外历史文章采集就顺手用这个分类了一个欧美历史(美国之类)+日本战国+中国近代(1945以后)这类的网站类似“在家写程序,出门卖茶叶”的网站,你可以试试。其实主要是要选到有质量的文章,大家基本上都想投在哪里哪里,质量有保证,文章有逼格。免费版就可以。
百度搜索文章采集器,是收费的,注册后,每天能采50个文章,你的文章里标注开放网站链接即可获得免费采集权限,我们在采集的时候要抓取网站的cookie给他们手机或电脑上绑定,才能不注册就能采集到。现在还没有收费的模式,收费后,采集的是采集历史页面。上传的文章全部是网站的原始数据,不是别人修改过的。可以回到浏览器试试。
文章采集任意网站都可以,小小需要收费2500一年,大小也不是非常贵的50元每月,有效期20年,基本上上文章,有效果,有盈利,功能还是比较强大的。我测试过很多方法,比如爬虫网站,爬取数据库,很多效果都不好,文章采集器里面有一些算法,操作过程比较轻松,像谷歌浏览器或者uc浏览器的普通用户只要一次性采集40篇文章就可以了,可以关注我的知乎号,也可以看下我写的很多采集方法。祝大家采集愉快!。 查看全部
免费网页采集器(免费网页采集器,一键采集并上传文章,收到后台数据时一键返回!)
免费网页采集器,一键采集并上传文章,收到后台数据时一键返回!这个网站有分类特别多,任何你想要的都可以!注册后,我们可以免费使用7天!主要是采集免费高质量文章,采集精选高质量文章,文章质量要求高。主要数据如下图:免费网页采集器,一键采集并上传文章,收到后台数据时一键返回!这个网站有分类特别多,任何你想要的都可以!。
你自己不给钱吗?这个多少钱一篇,
很轻便,
昨天恰好在写国内外历史文章采集就顺手用这个分类了一个欧美历史(美国之类)+日本战国+中国近代(1945以后)这类的网站类似“在家写程序,出门卖茶叶”的网站,你可以试试。其实主要是要选到有质量的文章,大家基本上都想投在哪里哪里,质量有保证,文章有逼格。免费版就可以。
百度搜索文章采集器,是收费的,注册后,每天能采50个文章,你的文章里标注开放网站链接即可获得免费采集权限,我们在采集的时候要抓取网站的cookie给他们手机或电脑上绑定,才能不注册就能采集到。现在还没有收费的模式,收费后,采集的是采集历史页面。上传的文章全部是网站的原始数据,不是别人修改过的。可以回到浏览器试试。
文章采集任意网站都可以,小小需要收费2500一年,大小也不是非常贵的50元每月,有效期20年,基本上上文章,有效果,有盈利,功能还是比较强大的。我测试过很多方法,比如爬虫网站,爬取数据库,很多效果都不好,文章采集器里面有一些算法,操作过程比较轻松,像谷歌浏览器或者uc浏览器的普通用户只要一次性采集40篇文章就可以了,可以关注我的知乎号,也可以看下我写的很多采集方法。祝大家采集愉快!。
免费网页采集器(优采云采集器问:如何过滤列表中的前N个数据?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-27 14:09
优采云采集器免费版是一款非常专业的网页采集工具,可以轻松的采集网页资源,功能非常强大,软件界面简单,操作很简单,现在已经完整破解,可以免费使用了,还在寻找网页采集器的用户快来下载体验吧!
优采云采集器 免费版软件介绍
优采云采集器V2是一款高效的网页信息采集软件,支持99%的网站数据采集,优采云采集器可以生成Excel表格、api数据库文件等内容,帮助您管理网站数据信息。如果你需要采集一个特定的网页数据,就用这个软件。
优采云采集器免费版软件特点
一键提取数据
简单易学,通过可视化界面,鼠标点击即可采集数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
优采云采集器免费版功能介绍
向导模式
简单易用,轻松通过鼠标点击自动生成
脚本定期运行
可按计划定时运行,无需人工
原装高速核心
自研浏览器内核,速度快,远超对手
智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
各种数据导出
支持 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。
优采云采集器免费版如何使用
第一步:输入采集 URL
打开软件,新建一个任务,输入需要采集的网站地址。
第二步:智能分析,全程自动提取数据
进入第二步后,优采云采集器自动对网页进行智能分析,从中提取列表数据。
第三步:将数据导出到表、数据库、网站等。
运行任务,将采集中的数据导出到Csv、Excel和各种数据库,支持api导出。
优采云采集器免费版常见问题
Q:如何过滤列表中的前N个数据?
1.有时候我们需要过滤采集收到的列表,比如过滤掉第一组数据(以采集的形式,过滤掉表列名)
2.在列表模式菜单中点击设置列表xpath
Q:如何通过抓包获取cookie并手动设置?
1.首先用谷歌浏览器打开你要采集的网站,然后登录。
2. 然后按F12,会出现开发者工具,选择Network
3.然后按F5刷新下一页并选择其中一个请求。
4.复制完成后,在优采云采集器中编辑任务,进入第三步指定HTTP Header。
优采云采集器免费版本更新日志
1.添加插件功能
2.添加export txt(一个文件另存为一个文件)
3.多值连接器支持换行
4.修改数据处理的文本映射(支持查找替换)
5.修复登录时DNS问题
6.修复图片下载问题
7.修复json中的一些问题
优采云采集器免费版本审核
一个更实用的采集工具,功能非常强大。 查看全部
免费网页采集器(优采云采集器问:如何过滤列表中的前N个数据?)
优采云采集器免费版是一款非常专业的网页采集工具,可以轻松的采集网页资源,功能非常强大,软件界面简单,操作很简单,现在已经完整破解,可以免费使用了,还在寻找网页采集器的用户快来下载体验吧!
优采云采集器 免费版软件介绍
优采云采集器V2是一款高效的网页信息采集软件,支持99%的网站数据采集,优采云采集器可以生成Excel表格、api数据库文件等内容,帮助您管理网站数据信息。如果你需要采集一个特定的网页数据,就用这个软件。
优采云采集器免费版软件特点
一键提取数据
简单易学,通过可视化界面,鼠标点击即可采集数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
优采云采集器免费版功能介绍
向导模式
简单易用,轻松通过鼠标点击自动生成
脚本定期运行
可按计划定时运行,无需人工
原装高速核心
自研浏览器内核,速度快,远超对手
智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
各种数据导出
支持 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。
优采云采集器免费版如何使用
第一步:输入采集 URL
打开软件,新建一个任务,输入需要采集的网站地址。
第二步:智能分析,全程自动提取数据
进入第二步后,优采云采集器自动对网页进行智能分析,从中提取列表数据。
第三步:将数据导出到表、数据库、网站等。
运行任务,将采集中的数据导出到Csv、Excel和各种数据库,支持api导出。
优采云采集器免费版常见问题
Q:如何过滤列表中的前N个数据?
1.有时候我们需要过滤采集收到的列表,比如过滤掉第一组数据(以采集的形式,过滤掉表列名)
2.在列表模式菜单中点击设置列表xpath
Q:如何通过抓包获取cookie并手动设置?
1.首先用谷歌浏览器打开你要采集的网站,然后登录。
2. 然后按F12,会出现开发者工具,选择Network
3.然后按F5刷新下一页并选择其中一个请求。
4.复制完成后,在优采云采集器中编辑任务,进入第三步指定HTTP Header。
优采云采集器免费版本更新日志
1.添加插件功能
2.添加export txt(一个文件另存为一个文件)
3.多值连接器支持换行
4.修改数据处理的文本映射(支持查找替换)
5.修复登录时DNS问题
6.修复图片下载问题
7.修复json中的一些问题
优采云采集器免费版本审核
一个更实用的采集工具,功能非常强大。
免费网页采集器(五大免费网站数据采集器性能对比(优采云,优采云采集))
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-26 14:00
五张免费网站数据采集器性能对比(优采云、海纳、ET、三人、优采云采集)在当前站长圈,对比有很多流行的采集工具,但总结起来,只有几个比较著名的免费工具:优采云、海纳、ET、三星、优采云。下面我们对这几个采集工具做一个简单的对比。1.优采云 基本上大家都知道,所以先说几句。优采云应该是国产采集软件最成功的例子之一。用户数包括付费用户数应该是最多的功能:简单,强大,快速,支持网站最丰富,支持丰富的扩展优点:功能比较齐全,采集比较快,主要针对cms,短时间内可以采集很多,过滤替换都不错,比较详细;许多人编写接口、规则和发布模块。接口比较齐全。其中有一个叫陈元的人,开发了目前PHP类cms的几乎所有接口;支持的扩展非常易于使用。如果你是个技术娴熟的站长,你可以用PHP或C#来开发任何功能扩展,真是令人难忘;附件采集功能完善。技术:该技术以论坛为主,帮助文件多,上手容易。有付费版和免费版。缺点:功能较多,软件越来越大,内存和CPU资源较多,资源回收控制不好@>,功能比较齐全。第一的,不知道三星和优采云是什么关系,但是接口和功能都出同一个模型。特点:针对各大论坛,动,动,快,准确率高优点:还是针对论坛,技术适合开论坛:收费技术,免费带广告缺点:超级复杂,上手难,支持cms@ > 比较差3.ET工具特点:无人值守,稳定,资源占用最低,基本上可以称得上是安静的优点:无人值守,自动更新,适合长站,用户群主要集中在长-term站潜水站长。软件一目了然,必备的功能也很齐全。关键是该软件是免费的。我听说采集 增加了中英文翻译功能。技术:论坛支持,软件本身免费,但也提供收费服务。帮助文件少,不易上手缺点:一般支持论坛和cms4.海纳特点:海量,关键词抓取,可以预览采集的内容,不需要写规则的优点:海量,可以抢到很多关键词文章,好像很适合网站的话题,尤其是文章和博客技术:没有论坛 查看全部
免费网页采集器(五大免费网站数据采集器性能对比(优采云,优采云采集))
五张免费网站数据采集器性能对比(优采云、海纳、ET、三人、优采云采集)在当前站长圈,对比有很多流行的采集工具,但总结起来,只有几个比较著名的免费工具:优采云、海纳、ET、三星、优采云。下面我们对这几个采集工具做一个简单的对比。1.优采云 基本上大家都知道,所以先说几句。优采云应该是国产采集软件最成功的例子之一。用户数包括付费用户数应该是最多的功能:简单,强大,快速,支持网站最丰富,支持丰富的扩展优点:功能比较齐全,采集比较快,主要针对cms,短时间内可以采集很多,过滤替换都不错,比较详细;许多人编写接口、规则和发布模块。接口比较齐全。其中有一个叫陈元的人,开发了目前PHP类cms的几乎所有接口;支持的扩展非常易于使用。如果你是个技术娴熟的站长,你可以用PHP或C#来开发任何功能扩展,真是令人难忘;附件采集功能完善。技术:该技术以论坛为主,帮助文件多,上手容易。有付费版和免费版。缺点:功能较多,软件越来越大,内存和CPU资源较多,资源回收控制不好@>,功能比较齐全。第一的,不知道三星和优采云是什么关系,但是接口和功能都出同一个模型。特点:针对各大论坛,动,动,快,准确率高优点:还是针对论坛,技术适合开论坛:收费技术,免费带广告缺点:超级复杂,上手难,支持cms@ > 比较差3.ET工具特点:无人值守,稳定,资源占用最低,基本上可以称得上是安静的优点:无人值守,自动更新,适合长站,用户群主要集中在长-term站潜水站长。软件一目了然,必备的功能也很齐全。关键是该软件是免费的。我听说采集 增加了中英文翻译功能。技术:论坛支持,软件本身免费,但也提供收费服务。帮助文件少,不易上手缺点:一般支持论坛和cms4.海纳特点:海量,关键词抓取,可以预览采集的内容,不需要写规则的优点:海量,可以抢到很多关键词文章,好像很适合网站的话题,尤其是文章和博客技术:没有论坛
免费网页采集器(免费的网页采集器不管他功能怎么样,是免费就很难得了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-10-24 04:12
现在市场上充斥着一些付费网页采集器,这样一个绿色免费的网页采集器不管它的功能是什么,免费的都是非常罕见的!
本软件使用互联网,采集网页信息。有两个主要特点:
1.可以在js后采集动态信息。
2、可以设置采集的正则表达式。
此外,本软件内置多种采集解决方案,分别对应静态网页和动态网页。
官网的图片(人脸)搜索引擎数据都是用这个软件索引的采集。
使用步骤:
1、输入网址,正常浏览网页,达到采集的目标,点击工具栏上的“查看js后查看源代码”图标,会显示执行js后的网页内容。
如果没有看到相关内容,可以稍等片刻,再次点击,确保js代码执行完毕。通过浏览完整的网页源代码,我们可以确定
使用方案1或方案2。如果可以通过更改URL的页码导航到下一页,则使用方案1;如果页面内容通过脚本动态更新,
然后使用选项 2。
2、点击工具栏上的“运行采集方案”图标,根据步骤1选择方案1或2。如果已经有方案1和方案2生成的downloadtotal.txt
文件,也可以选择选项3。填写必要的信息或表达式,点击“开始采集”按钮,系统会自动采集。在对话框中点击“取消”
按钮,对话框将关闭而不启动采集任务。
3、点击工具栏上的“停止采集解决方案”图标,系统将终止采集任务。
防止网页采集:
防止采集 第一种方法:在文章的开头和结尾添加随机不固定的内容。当网站采集在采集时,通常指定开始位置和结束位置,截取中间的内容。
比如你的文章内容是“优讯软件信息网”,如何添加随机内容:
随机内容1+优讯软件信息网+随机内容2
注意:随机内容1和随机内容2每个文章只需要随机显示一个。 查看全部
免费网页采集器(免费的网页采集器不管他功能怎么样,是免费就很难得了)
现在市场上充斥着一些付费网页采集器,这样一个绿色免费的网页采集器不管它的功能是什么,免费的都是非常罕见的!
本软件使用互联网,采集网页信息。有两个主要特点:
1.可以在js后采集动态信息。
2、可以设置采集的正则表达式。
此外,本软件内置多种采集解决方案,分别对应静态网页和动态网页。
官网的图片(人脸)搜索引擎数据都是用这个软件索引的采集。
使用步骤:
1、输入网址,正常浏览网页,达到采集的目标,点击工具栏上的“查看js后查看源代码”图标,会显示执行js后的网页内容。
如果没有看到相关内容,可以稍等片刻,再次点击,确保js代码执行完毕。通过浏览完整的网页源代码,我们可以确定
使用方案1或方案2。如果可以通过更改URL的页码导航到下一页,则使用方案1;如果页面内容通过脚本动态更新,
然后使用选项 2。
2、点击工具栏上的“运行采集方案”图标,根据步骤1选择方案1或2。如果已经有方案1和方案2生成的downloadtotal.txt
文件,也可以选择选项3。填写必要的信息或表达式,点击“开始采集”按钮,系统会自动采集。在对话框中点击“取消”
按钮,对话框将关闭而不启动采集任务。
3、点击工具栏上的“停止采集解决方案”图标,系统将终止采集任务。
防止网页采集:
防止采集 第一种方法:在文章的开头和结尾添加随机不固定的内容。当网站采集在采集时,通常指定开始位置和结束位置,截取中间的内容。
比如你的文章内容是“优讯软件信息网”,如何添加随机内容:
随机内容1+优讯软件信息网+随机内容2
注意:随机内容1和随机内容2每个文章只需要随机显示一个。
免费网页采集器(淘气哥素材网»所有源码都100%无错或无bug)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-10-23 03:10
5、采集 测试:这是任何其他类似的采集 软件都无法比拟的。程序支持直接查看采集结果和测试发布。
6、 管理便捷:使用站点+任务模式管理采集节点,任务支持批量操作,更轻松的数据管理。
限制软件
优采云采集器
下载说明:
1. 本站的资源都是白菜价卖的,同样的东西,我们不卖几百块,我们不卖几十块,甚至几块钱,一个永久会员可以下载100%全站源码,所以无论是否单独购买,会员和会员均不提供相关技术服务。2. 如果源代码下载地址无效,请联系站长QQ补发。3.本站所有资源仅用于学习和研究。请在24小时内删除下载的资源。请勿将其用于商业用途,否则由此引起的本站与发布者的法律纠纷及连带责任概不承担。除原创标记的资源外,所有资源均来自网络。版权属于原作者或本站特刊原创的作者。如侵犯您的权益,请联系本站删除!4. 本站提供的所有可下载的本站资源(软件等)均保证不做任何负面改动(不包括修复bug、改进功能等积极优化或二次开发);但本网站不能保证资源的准确性和安全性 用户下载后的自由裁量权和完整性,我们以交流和学习为目的,并非所有源代码都是100%无错或无bug;同时,本站用户必须明白,【淘气兄弟素材网】提供的可下载软件等不拥有任何权利(本站作者除外原创 和特殊合同原创),其版权属于资源的合法所有者。5. 请仔细阅读以上内容,购买即表示您同意以上内容。
淘气哥素材网»优采云采集器进入限制版优采云采集器无需登录V8.4进入限制版 查看全部
免费网页采集器(淘气哥素材网»所有源码都100%无错或无bug)
5、采集 测试:这是任何其他类似的采集 软件都无法比拟的。程序支持直接查看采集结果和测试发布。
6、 管理便捷:使用站点+任务模式管理采集节点,任务支持批量操作,更轻松的数据管理。
限制软件
优采云采集器
下载说明:
1. 本站的资源都是白菜价卖的,同样的东西,我们不卖几百块,我们不卖几十块,甚至几块钱,一个永久会员可以下载100%全站源码,所以无论是否单独购买,会员和会员均不提供相关技术服务。2. 如果源代码下载地址无效,请联系站长QQ补发。3.本站所有资源仅用于学习和研究。请在24小时内删除下载的资源。请勿将其用于商业用途,否则由此引起的本站与发布者的法律纠纷及连带责任概不承担。除原创标记的资源外,所有资源均来自网络。版权属于原作者或本站特刊原创的作者。如侵犯您的权益,请联系本站删除!4. 本站提供的所有可下载的本站资源(软件等)均保证不做任何负面改动(不包括修复bug、改进功能等积极优化或二次开发);但本网站不能保证资源的准确性和安全性 用户下载后的自由裁量权和完整性,我们以交流和学习为目的,并非所有源代码都是100%无错或无bug;同时,本站用户必须明白,【淘气兄弟素材网】提供的可下载软件等不拥有任何权利(本站作者除外原创 和特殊合同原创),其版权属于资源的合法所有者。5. 请仔细阅读以上内容,购买即表示您同意以上内容。
淘气哥素材网»优采云采集器进入限制版优采云采集器无需登录V8.4进入限制版
免费网页采集器(政府网站网页在线归档的首要环节,就是利用相关工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-10-23 03:09
网页采集作为政府网站网页在线存档的主要环节,就是利用相关工具,按照既定的频率和方法,及时筛选出值得保存的政府网页内容。网页采集的步骤是确定采集的对象,政府网页采集中存储的信息是域中带有""的政府网站名称,以保证政府网页的采集。@采集质量要求对目标网站进行评价,选择信息规模大、信息原创、更新频繁的政府网站作为采集的目标。确定目标政府网站到采集后,对应的采集
完整性采集和选择性采集是目前比较常用的网络资源采集方法。他们有自己的优点和缺点。为了弥补自身的不足,可以实现两种采集@。>方法优势互补,采用混合采集方法,综合两者的优点,同时完成所选政府所有网页的完整性网站,同时通过人工干预对网页内容进行一定程度的筛选,对具有证据价值、历史价值、研究价值的重要网页进行选择性、频繁的采集深度挖掘,兼顾政府网页< @采集 面对广度,
采集和网页的抓取需要依赖相应的网络爬虫工具来实现。目前,网页归档的爬虫工具有很多。其中常用的有Heritrix和HTTrack,利用这些工具可以完成针对性的匹配。目标政府网站网页自动批量在线采集。 查看全部
免费网页采集器(政府网站网页在线归档的首要环节,就是利用相关工具)
网页采集作为政府网站网页在线存档的主要环节,就是利用相关工具,按照既定的频率和方法,及时筛选出值得保存的政府网页内容。网页采集的步骤是确定采集的对象,政府网页采集中存储的信息是域中带有""的政府网站名称,以保证政府网页的采集。@采集质量要求对目标网站进行评价,选择信息规模大、信息原创、更新频繁的政府网站作为采集的目标。确定目标政府网站到采集后,对应的采集
完整性采集和选择性采集是目前比较常用的网络资源采集方法。他们有自己的优点和缺点。为了弥补自身的不足,可以实现两种采集@。>方法优势互补,采用混合采集方法,综合两者的优点,同时完成所选政府所有网页的完整性网站,同时通过人工干预对网页内容进行一定程度的筛选,对具有证据价值、历史价值、研究价值的重要网页进行选择性、频繁的采集深度挖掘,兼顾政府网页< @采集 面对广度,
采集和网页的抓取需要依赖相应的网络爬虫工具来实现。目前,网页归档的爬虫工具有很多。其中常用的有Heritrix和HTTrack,利用这些工具可以完成针对性的匹配。目标政府网站网页自动批量在线采集。
免费网页采集器(列车采集器安卓版升级日志-上海怡健医学())
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-21 17:18
机车头采集器v9 安卓版可免费下载。机车头采集器安卓版是一款功能齐全、使用方便的数据网络信息内容发现手机软件。机车头采集器安卓版是海量采集网页、社区论坛等的专用工具,即时存入数据库查询或发布到网站。它们可以按照客户设定的标准使用。自动采集原创网页,获取格式网页中需要的内容,现在的发展趋势是做seo优化的专用工具,也能解决信息!
火车采集器安卓版特点:
1、实用性强
无论是新闻报道、社区论坛、视频、企业黄页、照片、免费下载地址,您都可以根据电脑浏览器可以看到的结构化内容和具体的匹配标准,采集得到您所需要的. 内容。
2、稳定高效
七年磨一剑,手机软件不断创新发展,采集速度更快,功能稳定,占用资源更少。
3、可扩展性强,应用领域广泛
自定义web发布,自定义流行数据库系统的存储和发布,自定义本地PHP和.net外部编程socket解决数据信息,让数据信息人人可用。
火车采集器 升级日志:
1、全新升级的页面,更强大的用户界面和客户体验。
2、新架构,新内核,使用9年的.NET2.0架构升级到.NET4.0架构。
3、 适合在新的win10系统下运行。
4、 为辅助服务器代理添加了 Socks 代理。
5、改进采集的步骤,大大提高采集的上架率和备货率。
6、 在日常任务运行过程中可以改变线程数等主要参数,实时调整运行率。
7、适用的SSH(SFTP文件)提交。
8、内容获取增加了JSON获取方式,使得获取JSON数据信息更加容易。
9、 增加C#源码类型软件,可同时编写插件源码,立即生效。
10、软件崩溃,适合存放未完成的工作进度。
11、 将日常任务操作合并成一个统一的页面,加上“实时数据”查询和“任务明细”统计分析。
12、 列表页,分页查询,多个需要一流功能的自定义header。
13、 批量修改日常任务标准关键点的主要参数,批量修改Web发布设备。
14、开始和结束网址大型网址的详细地址格式可以添加多个详细地址主参数,自定义列表的主参数适用。
1 5、的标签数据来自更精致,可设置为从默认页面获取、分页查询、多源代码、URL详细地址、返回头数据。
16、 识别数据处理方式增加了统计分析识别数组的长度和质量替换的效果。
17、 改变了原先获取无限极列表页面URL的方式,无限极装备更轻松。 查看全部
免费网页采集器(列车采集器安卓版升级日志-上海怡健医学())
机车头采集器v9 安卓版可免费下载。机车头采集器安卓版是一款功能齐全、使用方便的数据网络信息内容发现手机软件。机车头采集器安卓版是海量采集网页、社区论坛等的专用工具,即时存入数据库查询或发布到网站。它们可以按照客户设定的标准使用。自动采集原创网页,获取格式网页中需要的内容,现在的发展趋势是做seo优化的专用工具,也能解决信息!
火车采集器安卓版特点:
1、实用性强
无论是新闻报道、社区论坛、视频、企业黄页、照片、免费下载地址,您都可以根据电脑浏览器可以看到的结构化内容和具体的匹配标准,采集得到您所需要的. 内容。
2、稳定高效
七年磨一剑,手机软件不断创新发展,采集速度更快,功能稳定,占用资源更少。
3、可扩展性强,应用领域广泛
自定义web发布,自定义流行数据库系统的存储和发布,自定义本地PHP和.net外部编程socket解决数据信息,让数据信息人人可用。
火车采集器 升级日志:
1、全新升级的页面,更强大的用户界面和客户体验。
2、新架构,新内核,使用9年的.NET2.0架构升级到.NET4.0架构。
3、 适合在新的win10系统下运行。
4、 为辅助服务器代理添加了 Socks 代理。
5、改进采集的步骤,大大提高采集的上架率和备货率。
6、 在日常任务运行过程中可以改变线程数等主要参数,实时调整运行率。
7、适用的SSH(SFTP文件)提交。
8、内容获取增加了JSON获取方式,使得获取JSON数据信息更加容易。
9、 增加C#源码类型软件,可同时编写插件源码,立即生效。
10、软件崩溃,适合存放未完成的工作进度。
11、 将日常任务操作合并成一个统一的页面,加上“实时数据”查询和“任务明细”统计分析。
12、 列表页,分页查询,多个需要一流功能的自定义header。
13、 批量修改日常任务标准关键点的主要参数,批量修改Web发布设备。
14、开始和结束网址大型网址的详细地址格式可以添加多个详细地址主参数,自定义列表的主参数适用。
1 5、的标签数据来自更精致,可设置为从默认页面获取、分页查询、多源代码、URL详细地址、返回头数据。
16、 识别数据处理方式增加了统计分析识别数组的长度和质量替换的效果。
17、 改变了原先获取无限极列表页面URL的方式,无限极装备更轻松。
免费网页采集器(免费网页采集器要想免费的,支持动态抓取断点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-10-18 14:03
免费网页采集器要想免费的,支持动态,抓取,断点,前景翻页。全屏的。支持上传本地txt或者json文件.然后把文件推送到云端,云端,云端抓取文件后生成一个网页链接,你只需要下载这个网页链接就可以免费加入。
可以百度搜一下,可以抓取电脑上的网页,看一下链接,然后抓取下来就可以在各种网站上,包括百度这样的搜索引擎直接下载并使用。
目前百度提供的内置的免费网页采集软件虽然功能齐全,只需要用简单的抓包分析就可以抓取有限的数据,但这并不足以满足用户的需求,并且限制很多。内置的免费网页采集软件要想收费,常用的是将网页中的所有txt或json文件推送到后台服务器。而如果想要直接一次编写网页代码,从而获取需要的数据,那就需要前后端分离,那么百度的人为的框架框架采用前端代码来获取数据,这就导致了网页采集器只能抓取指定范围的数据,并且是以文本格式存储的。
尤其对于敏感的数据获取没有好的解决方案。而今天给大家介绍的可以抓取网页中的音频和视频,并且自动传输到服务器,便捷性和安全性,全面性大大提高。实现手机与电脑无线传输数据方法很简单,通过人工的复制粘贴工作量很大,既不能自动抓取所有文件格式,又不能高效的传输,为了解决这些问题,我们研发出一款简单的工具。这款工具就是使用python语言编写的内置免费网页采集器,可以用于免费采集任何网页内容,并且能自动生成下载链接,还支持使用链接插件进行进一步的封装。
工具名称:python自动抓取工具官网地址:python免费网页采集器介绍工具简介:可抓取网页中的所有txt文件,以文本格式存储;也支持下载音频和视频,并且支持保存本地。特点方便快捷:一行代码也可以对wordpress、freebase等需要代码的网站进行代码采集;目前只支持wordpress平台;提供网页预览;支持预览网页源代码;支持抓取过滤元素;扩展灵活:插件可以在python语言中编写。
用户操作步骤如下:1.使用python代码,编写网页数据抓取程序。2.打开百度浏览器中的微云,并且从百度直接下载程序,并且需要高速下载。3.将采集好的数据存储到服务器。 查看全部
免费网页采集器(免费网页采集器要想免费的,支持动态抓取断点)
免费网页采集器要想免费的,支持动态,抓取,断点,前景翻页。全屏的。支持上传本地txt或者json文件.然后把文件推送到云端,云端,云端抓取文件后生成一个网页链接,你只需要下载这个网页链接就可以免费加入。
可以百度搜一下,可以抓取电脑上的网页,看一下链接,然后抓取下来就可以在各种网站上,包括百度这样的搜索引擎直接下载并使用。
目前百度提供的内置的免费网页采集软件虽然功能齐全,只需要用简单的抓包分析就可以抓取有限的数据,但这并不足以满足用户的需求,并且限制很多。内置的免费网页采集软件要想收费,常用的是将网页中的所有txt或json文件推送到后台服务器。而如果想要直接一次编写网页代码,从而获取需要的数据,那就需要前后端分离,那么百度的人为的框架框架采用前端代码来获取数据,这就导致了网页采集器只能抓取指定范围的数据,并且是以文本格式存储的。
尤其对于敏感的数据获取没有好的解决方案。而今天给大家介绍的可以抓取网页中的音频和视频,并且自动传输到服务器,便捷性和安全性,全面性大大提高。实现手机与电脑无线传输数据方法很简单,通过人工的复制粘贴工作量很大,既不能自动抓取所有文件格式,又不能高效的传输,为了解决这些问题,我们研发出一款简单的工具。这款工具就是使用python语言编写的内置免费网页采集器,可以用于免费采集任何网页内容,并且能自动生成下载链接,还支持使用链接插件进行进一步的封装。
工具名称:python自动抓取工具官网地址:python免费网页采集器介绍工具简介:可抓取网页中的所有txt文件,以文本格式存储;也支持下载音频和视频,并且支持保存本地。特点方便快捷:一行代码也可以对wordpress、freebase等需要代码的网站进行代码采集;目前只支持wordpress平台;提供网页预览;支持预览网页源代码;支持抓取过滤元素;扩展灵活:插件可以在python语言中编写。
用户操作步骤如下:1.使用python代码,编写网页数据抓取程序。2.打开百度浏览器中的微云,并且从百度直接下载程序,并且需要高速下载。3.将采集好的数据存储到服务器。
免费网页采集器(永恒之城网站数据采集器软件安装视频,一键ssl加密)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-15 22:04
免费网页采集器推荐:网页抓取推荐使用“永恒之城网站数据采集器”软件。永恒之城网站数据采集器所有版本均是免费在线使用,最新的版本最低标准免费使用1个月。不用安装,直接浏览器操作。windows操作系统的,安装好软件后,打开网址,选择目标网站采集下载所需数据源,点击下载所需数据文件即可。移动操作系统的,可以选择目标网站安装好软件,手机app浏览器访问网站,选择任意目标网站采集下载,并同步保存到自己的网盘,通过电脑网页版操作,即可实现数据统计等功能。
永恒之城网站数据采集器所有版本都有,标准版是最低标准免费使用1个月。永恒之城网站数据采集器支持网站一键ssl加密抓取,自动补全网址,一键验证抓取的网址是正确无误的。永恒之城网站数据采集器软件安装视频,永恒之城网站数据采集器的安装,请参考以下的方法:文章采集安装教程安装前准备工作安装过程中常见问题解决方法ssl加密全过程演示数据源/网址清洗网站安装完成,需要进行dns解析,方法和fiddler相同,可用fiddler扩展程序实现,同时支持https://。
分析出数据源/网址为,结果页无法通过解析抓取。原因为:cookie记录造成。故需要手动清洗获取;代码中%abbeditor_url%/%div2%8a%7d=%?解析到的数据为“%b12%db%e8%9c%a8%ab%b12%8a%f2%bf%3f%5c%50%e2%9d%b5%3f2%3f2%3f2%3f%2345%c8%e9%a2%94%e6%9d%8b%b8%e6%83%88%e4%b4%a8%e8%8d%a3%e7%af%94%e8%ad%91/2”cookie已被列入黑名单。
清洗代码其中%e8%9c%a8%ab%e4%b4%a8%e8%8d%a3%e7%af%94%e8%ad%91%e4%b8%a8%e8%90%9f%3f%24%7d为数据源网址的cookie代码,必须清洗干净才可以采集数据。清洗完成后,自动获取js代码及css文件的代码,保证我们能够采集到正确的数据;一键验证https.验证成功后,会显示完成抓取成功,即采集成功。
使用永恒之城网站数据采集器进行数据采集时需要输入“验证码”,安全验证正确后,方可采集正确的数据。请设置为如下长度:一个验证码是998位(字符)的数字。永恒之城网站数据采集器安全验证,如果验证码输入错误,数据无法被抓取,所以建议大家一定要设置“验证码采集”。分析出数据源/网址为。 查看全部
免费网页采集器(永恒之城网站数据采集器软件安装视频,一键ssl加密)
免费网页采集器推荐:网页抓取推荐使用“永恒之城网站数据采集器”软件。永恒之城网站数据采集器所有版本均是免费在线使用,最新的版本最低标准免费使用1个月。不用安装,直接浏览器操作。windows操作系统的,安装好软件后,打开网址,选择目标网站采集下载所需数据源,点击下载所需数据文件即可。移动操作系统的,可以选择目标网站安装好软件,手机app浏览器访问网站,选择任意目标网站采集下载,并同步保存到自己的网盘,通过电脑网页版操作,即可实现数据统计等功能。
永恒之城网站数据采集器所有版本都有,标准版是最低标准免费使用1个月。永恒之城网站数据采集器支持网站一键ssl加密抓取,自动补全网址,一键验证抓取的网址是正确无误的。永恒之城网站数据采集器软件安装视频,永恒之城网站数据采集器的安装,请参考以下的方法:文章采集安装教程安装前准备工作安装过程中常见问题解决方法ssl加密全过程演示数据源/网址清洗网站安装完成,需要进行dns解析,方法和fiddler相同,可用fiddler扩展程序实现,同时支持https://。
分析出数据源/网址为,结果页无法通过解析抓取。原因为:cookie记录造成。故需要手动清洗获取;代码中%abbeditor_url%/%div2%8a%7d=%?解析到的数据为“%b12%db%e8%9c%a8%ab%b12%8a%f2%bf%3f%5c%50%e2%9d%b5%3f2%3f2%3f2%3f%2345%c8%e9%a2%94%e6%9d%8b%b8%e6%83%88%e4%b4%a8%e8%8d%a3%e7%af%94%e8%ad%91/2”cookie已被列入黑名单。
清洗代码其中%e8%9c%a8%ab%e4%b4%a8%e8%8d%a3%e7%af%94%e8%ad%91%e4%b8%a8%e8%90%9f%3f%24%7d为数据源网址的cookie代码,必须清洗干净才可以采集数据。清洗完成后,自动获取js代码及css文件的代码,保证我们能够采集到正确的数据;一键验证https.验证成功后,会显示完成抓取成功,即采集成功。
使用永恒之城网站数据采集器进行数据采集时需要输入“验证码”,安全验证正确后,方可采集正确的数据。请设置为如下长度:一个验证码是998位(字符)的数字。永恒之城网站数据采集器安全验证,如果验证码输入错误,数据无法被抓取,所以建议大家一定要设置“验证码采集”。分析出数据源/网址为。
免费网页采集器(优采云采集器的网络数据收集工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 487 次浏览 • 2021-10-14 22:16
优采云采集器是一款绿色、免费的网络信息采集工具。采集网页信息请使用优采云采集器。本软件是优采云软件开发的网络数据采集工具。它旨在帮助用户快速、准确、有效地采集网络信息。该软件不仅可以为用户提供采集方式的选择和设置,还可以自动帮助用户过滤和采集重复的URL信息。与其他网络信息采集软件相比,该软件的优点是集内容采集和信息发布于一体,体积小,操作简单,支持批量上传数据到当前各种主流程序。如果需要,请下载此软件以获取经验。
软件特点:
使用任务管理功能,方便用户管理网页采集
本机型支持用户手册信息采集方式
帮助用户自动过滤重复网址和非法网站
可支持自定义过滤规则,需要采集信息URL
用户可以从列表中获取信息并将其添加到内容页面
支持从内容页面派生的多级页面爬取,快速完成信息爬取
软件支持用户本地化图片或附件
软件可支持多任务、多线程同时采集网页信息
软件可支持将采集到的内容发布到开源程序中
采集内容选择功能,支持使用网页文字前后截取或正则表达式提取
使用说明:
1.下载软件资源包,解压打开,然后点击.exe文件启动软件
2.启动软件后,在如图所示的登录窗口中,输入用户名和密码登录软件
3.在如图所示的操作窗口中,输入需要采集信息的网页地址
4.在如图所示的列表URL集合设置窗口中,或者自定义一个单独列表的每一行的基本参数
5.在如图所示的操作界面中,设置列表中的每组参数都是通过页面全面定制的
6. 在如图所示的多页提取管理器的设置窗口中,自定义提取的名称并选择父页面
7.在如图所示的字段设置窗口中,点击选择通用采集方式,自定义通用内容
8. 在如图所示的操作窗口中,点击水印和缩略图,为采集的网页信息添加文字水印
9. 在软件的操作界面,打开过滤功能,选择过滤条件
软件功能:
使用本软件采集网页信息
用户无需进行重复的软件安装操作
它的体积非常小,用户携带非常方便
软件完全免费,可为用户提供网络信息采集功能
不需要用户购买软件或注册软件
支持用户自定义设置发布页面、内容页面、发布时间间隔
软件的界面设计非常新颖美观
支持软件官方主页获取同类软件
支持添加QQ与软件设计师互动 查看全部
免费网页采集器(优采云采集器的网络数据收集工具)
优采云采集器是一款绿色、免费的网络信息采集工具。采集网页信息请使用优采云采集器。本软件是优采云软件开发的网络数据采集工具。它旨在帮助用户快速、准确、有效地采集网络信息。该软件不仅可以为用户提供采集方式的选择和设置,还可以自动帮助用户过滤和采集重复的URL信息。与其他网络信息采集软件相比,该软件的优点是集内容采集和信息发布于一体,体积小,操作简单,支持批量上传数据到当前各种主流程序。如果需要,请下载此软件以获取经验。
软件特点:
使用任务管理功能,方便用户管理网页采集
本机型支持用户手册信息采集方式
帮助用户自动过滤重复网址和非法网站
可支持自定义过滤规则,需要采集信息URL
用户可以从列表中获取信息并将其添加到内容页面
支持从内容页面派生的多级页面爬取,快速完成信息爬取
软件支持用户本地化图片或附件
软件可支持多任务、多线程同时采集网页信息
软件可支持将采集到的内容发布到开源程序中
采集内容选择功能,支持使用网页文字前后截取或正则表达式提取
使用说明:
1.下载软件资源包,解压打开,然后点击.exe文件启动软件
2.启动软件后,在如图所示的登录窗口中,输入用户名和密码登录软件
3.在如图所示的操作窗口中,输入需要采集信息的网页地址
4.在如图所示的列表URL集合设置窗口中,或者自定义一个单独列表的每一行的基本参数
5.在如图所示的操作界面中,设置列表中的每组参数都是通过页面全面定制的
6. 在如图所示的多页提取管理器的设置窗口中,自定义提取的名称并选择父页面
7.在如图所示的字段设置窗口中,点击选择通用采集方式,自定义通用内容
8. 在如图所示的操作窗口中,点击水印和缩略图,为采集的网页信息添加文字水印
9. 在软件的操作界面,打开过滤功能,选择过滤条件
软件功能:
使用本软件采集网页信息
用户无需进行重复的软件安装操作
它的体积非常小,用户携带非常方便
软件完全免费,可为用户提供网络信息采集功能
不需要用户购买软件或注册软件
支持用户自定义设置发布页面、内容页面、发布时间间隔
软件的界面设计非常新颖美观
支持软件官方主页获取同类软件
支持添加QQ与软件设计师互动
免费网页采集器(优采云采集器官方免费版:人工获取数据途径的数十倍下载体验)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-14 21:09
通过人工搜索网站或者网页信息来获取大量数据,他的成本无疑是巨大的。如今的人工成本已不再是廉价时代,如何更高效、更廉价地获取标准化数据成为了必须克服的难题,优采云采集器官方免费版是由官方采集器。通过公司自主研发的分布式云计算平台,可在不同的网站或网页轻松获取重要数据信息,速度极快。单时刻获得的数据量是人工采集数据的几十倍。该软件简化了采集的工作,改变了传统的获取信息的方式,并逐渐摆脱对体力劳动的依赖。在它的运行下,用户可以准确获取任何页面所需要的数据,而且数据非常规律,事半功倍采集软件,用户不要急于下载官方免费版优采云采集器 来体验一下。或许有了这个软件的帮助,你的工作效率会成为公司的第一。!
特点1、财务数据,如季报、年报、财报,包括最新的每日净值自动采集;
2、各大新闻门户网站实时监控,自动更新上传最新消息;
3、 监控竞争对手的最新信息,包括商品价格和库存;
4、监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5、 采集最新最全的招聘信息;
6、关注最新房产相关网站、采集新房二手房市场;
7、采集主要车型网站具体新车和二手车信息;
8、发现并采集潜在客户信息;
9、采集行业产品目录及产品信息网站;
10、优采云采集器 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
软件亮点1、满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
2、舆论监测
全面监测公共信息,第一手掌握舆情动向
3、市场分析
获取真实用户行为数据,全面把握客户真实需求
4、产品研发
大力支持用户研究,准确获取用户反馈和偏好
5、风险预测
高效信息采集和数据清洗,及时应对系统风险
功能介绍1、简单采集
简单的采集模式内置了数百个主流的网站数据源,如京东、天猫、大众点评等流行的采集网站,只需参考模板并简单地设置参数。您可以快速获取网站公开数据。
2、智能采集
软件可针对不同的网站,提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。
3、云采集
云采集支持5000多台云服务器,7*24小时运行,可实现定时采集,无需人员值守,灵活适配业务场景,助您提升采集 效率,保证数据的及时性。
4、API接口
通过API,您可以轻松获取软件任务信息和采集接收到的数据,灵活调度远程控制任务启停等任务,高效实现数据采集和归档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
5、定制采集
根据不同用户采集的需求,软件可提供自定义模式,自动生成爬虫,可批量准确识别各种网页元素,具有翻页、下拉、ajax、page等多种功能滚动、条件判断等,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
6、方便的定时功能
简单几步,即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,你可以同时自由设置多个任务,根据自己的需要进行多种选择时间组合,灵活部署自己的采集任务。
7、自动数据格式化
软件内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集处理完全自动处理,无需人工干预,即可得到所需格式的数据。
8、多级采集
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;无论网站有多少层,本软件所有数据都可以采集不受限制,满足各种业务采集的需求。
9、支持网站登录后采集
优采云采集器内置登录模块采集,只需配置目标网站的账号密码,即可使用采集模块登录数据;同时,具有采集Cookie自定义功能,首次登录后可自动记住cookie,免去多次输入密码的繁琐,支持更多网站采集。
软件优势1、操作简单
操作简单,完全可视化的图形操作,不需要专业的IT人员,任何会用电脑上网的人都可以轻松掌握。
2、云采集
采集 任务自动分配到云端多台服务器同时执行,提高了采集的效率,短时间内可以获取上千条消息。
3、拖放采集进程
模拟人的操作思维模式,可以登录、输入数据、点击链接、按钮等,还可以针对不同的情况采用不同的采集流程。
4、图像识别
内置可扩展的OCR接口,支持对图片中的文字进行分析,可以提取图片上的文字。
5、定时自动采集
采集 任务自动运行,可以在指定周期内自动采集,还支持实时采集,速度快到一分钟一次。
6、2分钟快速入门
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等。
7、免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。
优采云采集器教程1、首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-- >勾选软件右侧的URL列表复选框-->打开URL列表文本框-->将准备好的URL列表填入文本框
2、接下来将打开网页的步骤拖入循环-->选择打开网页的步骤-->勾选使用当前循环中的URL作为导航地址-->点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页
3、至此,打开网页的循环配置完成。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集数据步骤,这里就不赘述了。可以参考系列一:采集单个网页文章。下图是最终和过程
4、以下是进程最终运行结果
更新日志 v8.2.4
迭代函数
更新了数据预览区新增字段、修改字段、格式化数据、集中数据操作的交互方式
针对不同类型的字段,区分操作项,点击展开不同的菜单项
优化配置XPath的操作,在页面即时显示XPath的识别结果
错误修复
修复自定义下拉框类型网页无法正常获取的问题
修复同名自定义任务无法正常保存的问题
修复修改去重数据配置后应用直接采集未保存的报错
修复部分采集报错无法正常采集数据问题
修复 URL 栏中修改 URL 时遗漏其他步骤相关场景的问题 查看全部
免费网页采集器(优采云采集器官方免费版:人工获取数据途径的数十倍下载体验)
通过人工搜索网站或者网页信息来获取大量数据,他的成本无疑是巨大的。如今的人工成本已不再是廉价时代,如何更高效、更廉价地获取标准化数据成为了必须克服的难题,优采云采集器官方免费版是由官方采集器。通过公司自主研发的分布式云计算平台,可在不同的网站或网页轻松获取重要数据信息,速度极快。单时刻获得的数据量是人工采集数据的几十倍。该软件简化了采集的工作,改变了传统的获取信息的方式,并逐渐摆脱对体力劳动的依赖。在它的运行下,用户可以准确获取任何页面所需要的数据,而且数据非常规律,事半功倍采集软件,用户不要急于下载官方免费版优采云采集器 来体验一下。或许有了这个软件的帮助,你的工作效率会成为公司的第一。!
特点1、财务数据,如季报、年报、财报,包括最新的每日净值自动采集;
2、各大新闻门户网站实时监控,自动更新上传最新消息;
3、 监控竞争对手的最新信息,包括商品价格和库存;
4、监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5、 采集最新最全的招聘信息;
6、关注最新房产相关网站、采集新房二手房市场;
7、采集主要车型网站具体新车和二手车信息;
8、发现并采集潜在客户信息;
9、采集行业产品目录及产品信息网站;
10、优采云采集器 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
软件亮点1、满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
2、舆论监测
全面监测公共信息,第一手掌握舆情动向
3、市场分析
获取真实用户行为数据,全面把握客户真实需求
4、产品研发
大力支持用户研究,准确获取用户反馈和偏好
5、风险预测
高效信息采集和数据清洗,及时应对系统风险
功能介绍1、简单采集
简单的采集模式内置了数百个主流的网站数据源,如京东、天猫、大众点评等流行的采集网站,只需参考模板并简单地设置参数。您可以快速获取网站公开数据。
2、智能采集
软件可针对不同的网站,提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。
3、云采集
云采集支持5000多台云服务器,7*24小时运行,可实现定时采集,无需人员值守,灵活适配业务场景,助您提升采集 效率,保证数据的及时性。
4、API接口
通过API,您可以轻松获取软件任务信息和采集接收到的数据,灵活调度远程控制任务启停等任务,高效实现数据采集和归档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
5、定制采集
根据不同用户采集的需求,软件可提供自定义模式,自动生成爬虫,可批量准确识别各种网页元素,具有翻页、下拉、ajax、page等多种功能滚动、条件判断等,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
6、方便的定时功能
简单几步,即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,你可以同时自由设置多个任务,根据自己的需要进行多种选择时间组合,灵活部署自己的采集任务。
7、自动数据格式化
软件内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集处理完全自动处理,无需人工干预,即可得到所需格式的数据。
8、多级采集
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;无论网站有多少层,本软件所有数据都可以采集不受限制,满足各种业务采集的需求。
9、支持网站登录后采集
优采云采集器内置登录模块采集,只需配置目标网站的账号密码,即可使用采集模块登录数据;同时,具有采集Cookie自定义功能,首次登录后可自动记住cookie,免去多次输入密码的繁琐,支持更多网站采集。
软件优势1、操作简单
操作简单,完全可视化的图形操作,不需要专业的IT人员,任何会用电脑上网的人都可以轻松掌握。
2、云采集
采集 任务自动分配到云端多台服务器同时执行,提高了采集的效率,短时间内可以获取上千条消息。
3、拖放采集进程
模拟人的操作思维模式,可以登录、输入数据、点击链接、按钮等,还可以针对不同的情况采用不同的采集流程。
4、图像识别
内置可扩展的OCR接口,支持对图片中的文字进行分析,可以提取图片上的文字。
5、定时自动采集
采集 任务自动运行,可以在指定周期内自动采集,还支持实时采集,速度快到一分钟一次。
6、2分钟快速入门
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等。
7、免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。
优采云采集器教程1、首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-- >勾选软件右侧的URL列表复选框-->打开URL列表文本框-->将准备好的URL列表填入文本框
2、接下来将打开网页的步骤拖入循环-->选择打开网页的步骤-->勾选使用当前循环中的URL作为导航地址-->点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页
3、至此,打开网页的循环配置完成。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集数据步骤,这里就不赘述了。可以参考系列一:采集单个网页文章。下图是最终和过程
4、以下是进程最终运行结果
更新日志 v8.2.4
迭代函数
更新了数据预览区新增字段、修改字段、格式化数据、集中数据操作的交互方式
针对不同类型的字段,区分操作项,点击展开不同的菜单项
优化配置XPath的操作,在页面即时显示XPath的识别结果
错误修复
修复自定义下拉框类型网页无法正常获取的问题
修复同名自定义任务无法正常保存的问题
修复修改去重数据配置后应用直接采集未保存的报错
修复部分采集报错无法正常采集数据问题
修复 URL 栏中修改 URL 时遗漏其他步骤相关场景的问题
免费网页采集器(优采云采集器式采集任务自动分配到云端 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 597 次浏览 • 2021-10-13 06:38
)
优采云采集器 是任何需要从网络获取信息的孩子的必备神器。这是一个可以让你的信息采集变得非常简单的工具。优采云改变了互联网上传统的数据思维方式,让用户在互联网上爬取和编译数据变得越来越容易
软件特点
操作简单,完全可视化的图形操作,不需要专业的IT人员,任何会用电脑上网的人都可以轻松掌握。
云采集
采集 任务自动分发到云端多台服务器同时执行,提高了采集的效率,短时间内可以获得数千条信息。
拖放采集流程
模拟人的操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采用不同的采集流程。
图形识别
内置可扩展的OCR接口,支持对图片中的文字进行分析,可以提取图片上的文字。
定时自动采集
采集 任务自动运行,可以在指定时间段内自动采集,还支持实时采集,速度快到一分钟一次。
2 分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等。
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。
特征
简单来说,使用优采云可以很容易的从任何网页中准确的采集你需要的数据,生成自定义的常规数据格式。优采云数据采集 系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财报,自动包括最新的每日净值采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 关注各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要车型网站 具体新车和二手车信息;
8. 发现和采集潜在客户信息;
9. 采集行业网站产品目录及产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
指示
首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-->勾选软件右侧的URL列表复选框-- >打开URL列表文本框-->将准备好的URL列表填入文本框
接下来,将打开网页的步骤拖入循环中-->选择打开网页的步骤-->勾选以当前循环中的URL作为导航地址的复选框-->点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页。
至此,打开网页循环的配置就完成了。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集 数据步骤,这里不再赘述。可以参考系列一:采集单个网页文章。下图是最终和过程
以下是该过程的最终运行结果
查看全部
免费网页采集器(优采云采集器式采集任务自动分配到云端
)
优采云采集器 是任何需要从网络获取信息的孩子的必备神器。这是一个可以让你的信息采集变得非常简单的工具。优采云改变了互联网上传统的数据思维方式,让用户在互联网上爬取和编译数据变得越来越容易
软件特点
操作简单,完全可视化的图形操作,不需要专业的IT人员,任何会用电脑上网的人都可以轻松掌握。
云采集
采集 任务自动分发到云端多台服务器同时执行,提高了采集的效率,短时间内可以获得数千条信息。
拖放采集流程
模拟人的操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采用不同的采集流程。
图形识别
内置可扩展的OCR接口,支持对图片中的文字进行分析,可以提取图片上的文字。
定时自动采集
采集 任务自动运行,可以在指定时间段内自动采集,还支持实时采集,速度快到一分钟一次。
2 分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等。
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。
特征
简单来说,使用优采云可以很容易的从任何网页中准确的采集你需要的数据,生成自定义的常规数据格式。优采云数据采集 系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财报,自动包括最新的每日净值采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 关注各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要车型网站 具体新车和二手车信息;
8. 发现和采集潜在客户信息;
9. 采集行业网站产品目录及产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
指示
首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-->勾选软件右侧的URL列表复选框-- >打开URL列表文本框-->将准备好的URL列表填入文本框
接下来,将打开网页的步骤拖入循环中-->选择打开网页的步骤-->勾选以当前循环中的URL作为导航地址的复选框-->点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页。
至此,打开网页循环的配置就完成了。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集 数据步骤,这里不再赘述。可以参考系列一:采集单个网页文章。下图是最终和过程
以下是该过程的最终运行结果
免费网页采集器(谷歌搜索引擎数据采集工具,没发现免费的,花点钱吧)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-10-10 13:02
免费网页采集器:spiderstorecrawlermitmachinelearningtoolkitfacebookdatasetanalytics.python版:django.python.machinelearning.toolkit.search
免费的就那几个:googlecrawler:searchengine|baidublogdroiddle-谷歌搜索引擎数据采集工具,
国内有好多大佬制作专门的采集器,
googlecrawlersforpython,c#
安利个ease-ml-projectspython3.5+fe3.0python2.6+sdl2.5
用谷歌搜索,
没发现免费的,花点钱吧。要是有专门的在线网页爬虫采集工具,我觉得它们是可以解决这个问题的。
当然有收费的了。可以参考。
这些都是可以的
来吧,我们不是在讨论哪个免费,也不是讨论哪个网站好用,讨论的是谁会更快的帮助你更快的获取这些。我们要的,就是一个靠谱的工具和快速的采集速度。
yelp-digestongoogle,
bigquery
觉得不如看看videodownloader插件 查看全部
免费网页采集器(谷歌搜索引擎数据采集工具,没发现免费的,花点钱吧)
免费网页采集器:spiderstorecrawlermitmachinelearningtoolkitfacebookdatasetanalytics.python版:django.python.machinelearning.toolkit.search
免费的就那几个:googlecrawler:searchengine|baidublogdroiddle-谷歌搜索引擎数据采集工具,
国内有好多大佬制作专门的采集器,
googlecrawlersforpython,c#
安利个ease-ml-projectspython3.5+fe3.0python2.6+sdl2.5
用谷歌搜索,
没发现免费的,花点钱吧。要是有专门的在线网页爬虫采集工具,我觉得它们是可以解决这个问题的。
当然有收费的了。可以参考。
这些都是可以的
来吧,我们不是在讨论哪个免费,也不是讨论哪个网站好用,讨论的是谁会更快的帮助你更快的获取这些。我们要的,就是一个靠谱的工具和快速的采集速度。
yelp-digestongoogle,
bigquery
觉得不如看看videodownloader插件
免费网页采集器(一门强大的开发语言,正则表达式方法捕获 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-10-08 18:20
)
开幕
作为世界上使用最广泛的语言,Java以其高效、可移植(跨平台)、代码的健壮性和强大的可扩展性深受应用开发者的喜爱。作为一门强大的开发语言,正则表达式的应用当然是必不可少的,掌握正则表达式的能力也是那些资深程序员开发能力的体现。做一个合格的网站程序员(尤其是前端开发),正则表达式是必不可少的。
最近因为一些需要,用到java和regular,做了一个足球网站数据采集程序;因为是第一次做关于java采集的html页面数据,一定是我在网上查了很多资料,发现广泛使用的java在使用规律做html采集(中文)文章 非常少见,简单说说java的正则性 实际网页html采集中并没有真正用到这个概念,而且例子教程很少(虽然java有自己的Html Parser,而且很强大),但我个人觉得它是一个如此根深蒂固的正则表达式。相关的java示例教程,应该很多而且很全。所以在完成java版本的html数据采集程序后,
本期概述
本期我们将学习如何读取网页的源代码,通过分组规律动态抓取我们需要的网页数据。同时,在接下来的几期中,我们将继续学习如何存储捕获的游戏数据。进入数据库(MySql),【数据查询】如何查询我们想看的比赛记录,【远程操作】使用客户端远程访问和操作服务器进行数据存储和查询。
关于群体规律
说到正则表达式如何帮助java制作html页面采集,这里就需要提一下正则表达式中的group方法(代码如下)。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Group 类 用于匹配和抓取 html页面的数据
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Group {
public static void main(String[] args) {
// Pattern 用于编译正则 这里用到了3个正则 分别用括号()包住
// 第1个正则用于匹配URL 当然这里的正则不一定准确 这个匹配URL的正则就是错误的 只是在这里刚好能匹配出来
// 第2个正则是用于匹配标题 SoFlash的
// 第3个正则用于匹配日期
/* 这里只用了一条语句便把url,标题和日期全部给匹配出来了 */
Pattern p = Pattern
.compile("='(\\w.+)'>(\\w.+[a-zA-Z])-(\\d{1,2}\\.\\d{1,2}\\.\\d{4})");
String s = "SoFlash-12.22.2011";
Matcher m = p.matcher(s);
while (m.find()) {
// 通过调用group()方法里的索引 将url,标题和日期全部给打印出来
System.out.println("打印出url链接:" + m.group(1));
System.out.println("打印出标题:" + m.group(2));
System.out.println("打印出日期:" + m.group(3));
System.out.println();
}
System.out.println("group方法捕获的数据个数:" + m.groupCount() + "个");
}
}
让我们看看输出:
打印出网址链接:
打印标题:SoFlash
打印日期:12.22.2011
分组方法捕获的数据数量:3
如果想了解更多正则在Java中的应用,请看JAVA正则表达式(超详细)
如果你之前没有学习过正则表达式,可以看看这篇,揭开正则表达式的神秘面纱。
页采集 示例
好了,分组方法介绍完毕,下面我们使用分组正则采集某某足球网站页面数据
页面链接:2011-2012英超球队战绩
首先我们读取整个html页面并打印出来(代码如下)。
public static void main(String[] args) {
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
// 如果 BufferedReader 读到的内容不为空
while (br.readLine() != null) {
// 则打印出来 这里打印出来的结果 应该是整个网站的
System.out.println(br.readLine());
}
br.close(); // 读取完成后关闭读取器
} catch (IOException e) {
// 如果出错 抛出异常
e.printStackTrace();
}
}
打印出来的结果就是整个html页面的源码(部分截图如下)。
至此,html源码已经成功采集down。但是,我们要的不是整个html源代码,而是网页上的比赛数据。
首先我们分析一下html源代码结构,来到2011-2012赛季英超球队战绩页面,右击'查看源文件'(其他浏览器可能称为源代码或相关)。
我们来看看内部的html代码结构和我们需要的数据。
其对应的页面数据
这时候,强大的正则表达式就派上用场了,我们需要写几个正则表达式来抓取团队数据。
这里需要三个正则表达式:日期正则、两队正则(主队和客队)和比赛结果正则。
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";//日期正则
StringregularTwoTeam = ">[^]*"; //团队常规
StringregularResult = ">(\\d{1,2}-\\d{1,2})"; //正则匹配结果
写好正则后,我们就可以用正则去抓取我们想要的数据了。
首先我们写一个GroupMethod类,里面收录regularGroup()方法,用于抓取html页面数据。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* GroupMethod类 用于匹配并抓去 Html上我们想要的内容
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class GroupMethod {
// 传入2个字符串参数 一个是pattern(我们使用的正则) 另一个matcher是html源代码
public String regularGroup(String pattern, String matcher) {
Pattern p = Pattern.compile(pattern, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(matcher);
if (m.find()) { // 如果读到
return m.group();// 返回捕获的数据
} else {
return ""; // 否则返回一个空字符串
}
}
}
然后在main函数中实现html页面的数据抓取。
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
/**
* Main主函数 用于数据采集
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Main {
public static void main(String[] args) {
// 首先用一个字符串 来装载网页链接
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
String strRead = ""; // 新增一个空字符串strRead来装载 BufferedReader 读取到的内容
// 定义3个正则 用于匹配我们需要的数据
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";
String regularTwoTeam = ">[^]*</a>";
String regularResult = ">(\\d{1,2}-\\d{1,2})";
// 创建一个GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法
GroupMethod gMethod = new GroupMethod();
int i =0; //定义一个i来记录循环次数 即收集到的球队比赛结果数
int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的
// 开始读取数据 如果读到的数据不为空 则往里面读
while ((strRead = br.readLine()) != null) {
/**
* 用于捕获日期数据
*/
String strGet = gMethod.regularGroup(regularDate, strRead);
//如果捕获到了符合条件的 日期数据 则打印出来
if (!strGet.equals("")) {
System.out.println("Date:" + strGet);
//这里索引+1 是用于获取后期的球队数据
++index; //因为在html页面里 源代码里 球队数据是在刚好在日期之后
}
/**
* 用于获取2个球队的数据
*/
strGet = gMethod.regularGroup(regularTwoTeam, strRead);
if (!strGet.equals("") && index == 1) { //索引为1的是主队数据
// 通过substring方法 分离出 主队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("HomeTeam:" + strGet); //打印出主队
index++; //索引+1之后 为2了
// 通过substring方法 分离出 客队
} else if (!strGet.equals("") && index == 2) { //这里索引为2的是客队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("AwayTeam:" + strGet); //打印出客队
index = 0;
}
/**
* 用于获取比赛结果
*/
strGet = gMethod.regularGroup(regularResult, strRead);
if (!strGet.equals("")) {
//这里同样用到了substring方法 来剔除' 查看全部
免费网页采集器(一门强大的开发语言,正则表达式方法捕获
)
开幕
作为世界上使用最广泛的语言,Java以其高效、可移植(跨平台)、代码的健壮性和强大的可扩展性深受应用开发者的喜爱。作为一门强大的开发语言,正则表达式的应用当然是必不可少的,掌握正则表达式的能力也是那些资深程序员开发能力的体现。做一个合格的网站程序员(尤其是前端开发),正则表达式是必不可少的。
最近因为一些需要,用到java和regular,做了一个足球网站数据采集程序;因为是第一次做关于java采集的html页面数据,一定是我在网上查了很多资料,发现广泛使用的java在使用规律做html采集(中文)文章 非常少见,简单说说java的正则性 实际网页html采集中并没有真正用到这个概念,而且例子教程很少(虽然java有自己的Html Parser,而且很强大),但我个人觉得它是一个如此根深蒂固的正则表达式。相关的java示例教程,应该很多而且很全。所以在完成java版本的html数据采集程序后,
本期概述
本期我们将学习如何读取网页的源代码,通过分组规律动态抓取我们需要的网页数据。同时,在接下来的几期中,我们将继续学习如何存储捕获的游戏数据。进入数据库(MySql),【数据查询】如何查询我们想看的比赛记录,【远程操作】使用客户端远程访问和操作服务器进行数据存储和查询。
关于群体规律
说到正则表达式如何帮助java制作html页面采集,这里就需要提一下正则表达式中的group方法(代码如下)。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Group 类 用于匹配和抓取 html页面的数据
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Group {
public static void main(String[] args) {
// Pattern 用于编译正则 这里用到了3个正则 分别用括号()包住
// 第1个正则用于匹配URL 当然这里的正则不一定准确 这个匹配URL的正则就是错误的 只是在这里刚好能匹配出来
// 第2个正则是用于匹配标题 SoFlash的
// 第3个正则用于匹配日期
/* 这里只用了一条语句便把url,标题和日期全部给匹配出来了 */
Pattern p = Pattern
.compile("='(\\w.+)'>(\\w.+[a-zA-Z])-(\\d{1,2}\\.\\d{1,2}\\.\\d{4})");
String s = "SoFlash-12.22.2011";
Matcher m = p.matcher(s);
while (m.find()) {
// 通过调用group()方法里的索引 将url,标题和日期全部给打印出来
System.out.println("打印出url链接:" + m.group(1));
System.out.println("打印出标题:" + m.group(2));
System.out.println("打印出日期:" + m.group(3));
System.out.println();
}
System.out.println("group方法捕获的数据个数:" + m.groupCount() + "个");
}
}
让我们看看输出:
打印出网址链接:
打印标题:SoFlash
打印日期:12.22.2011
分组方法捕获的数据数量:3
如果想了解更多正则在Java中的应用,请看JAVA正则表达式(超详细)
如果你之前没有学习过正则表达式,可以看看这篇,揭开正则表达式的神秘面纱。
页采集 示例
好了,分组方法介绍完毕,下面我们使用分组正则采集某某足球网站页面数据
页面链接:2011-2012英超球队战绩
首先我们读取整个html页面并打印出来(代码如下)。
public static void main(String[] args) {
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
// 如果 BufferedReader 读到的内容不为空
while (br.readLine() != null) {
// 则打印出来 这里打印出来的结果 应该是整个网站的
System.out.println(br.readLine());
}
br.close(); // 读取完成后关闭读取器
} catch (IOException e) {
// 如果出错 抛出异常
e.printStackTrace();
}
}
打印出来的结果就是整个html页面的源码(部分截图如下)。
至此,html源码已经成功采集down。但是,我们要的不是整个html源代码,而是网页上的比赛数据。
首先我们分析一下html源代码结构,来到2011-2012赛季英超球队战绩页面,右击'查看源文件'(其他浏览器可能称为源代码或相关)。
我们来看看内部的html代码结构和我们需要的数据。
其对应的页面数据
这时候,强大的正则表达式就派上用场了,我们需要写几个正则表达式来抓取团队数据。
这里需要三个正则表达式:日期正则、两队正则(主队和客队)和比赛结果正则。
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";//日期正则
StringregularTwoTeam = ">[^]*"; //团队常规
StringregularResult = ">(\\d{1,2}-\\d{1,2})"; //正则匹配结果
写好正则后,我们就可以用正则去抓取我们想要的数据了。
首先我们写一个GroupMethod类,里面收录regularGroup()方法,用于抓取html页面数据。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* GroupMethod类 用于匹配并抓去 Html上我们想要的内容
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class GroupMethod {
// 传入2个字符串参数 一个是pattern(我们使用的正则) 另一个matcher是html源代码
public String regularGroup(String pattern, String matcher) {
Pattern p = Pattern.compile(pattern, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(matcher);
if (m.find()) { // 如果读到
return m.group();// 返回捕获的数据
} else {
return ""; // 否则返回一个空字符串
}
}
}
然后在main函数中实现html页面的数据抓取。
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
/**
* Main主函数 用于数据采集
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Main {
public static void main(String[] args) {
// 首先用一个字符串 来装载网页链接
String strUrl = "http://www.footballresults.org ... 3B%3B
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
String strRead = ""; // 新增一个空字符串strRead来装载 BufferedReader 读取到的内容
// 定义3个正则 用于匹配我们需要的数据
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";
String regularTwoTeam = ">[^]*</a>";
String regularResult = ">(\\d{1,2}-\\d{1,2})";
// 创建一个GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法
GroupMethod gMethod = new GroupMethod();
int i =0; //定义一个i来记录循环次数 即收集到的球队比赛结果数
int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的
// 开始读取数据 如果读到的数据不为空 则往里面读
while ((strRead = br.readLine()) != null) {
/**
* 用于捕获日期数据
*/
String strGet = gMethod.regularGroup(regularDate, strRead);
//如果捕获到了符合条件的 日期数据 则打印出来
if (!strGet.equals("")) {
System.out.println("Date:" + strGet);
//这里索引+1 是用于获取后期的球队数据
++index; //因为在html页面里 源代码里 球队数据是在刚好在日期之后
}
/**
* 用于获取2个球队的数据
*/
strGet = gMethod.regularGroup(regularTwoTeam, strRead);
if (!strGet.equals("") && index == 1) { //索引为1的是主队数据
// 通过substring方法 分离出 主队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("HomeTeam:" + strGet); //打印出主队
index++; //索引+1之后 为2了
// 通过substring方法 分离出 客队
} else if (!strGet.equals("") && index == 2) { //这里索引为2的是客队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
System.out.println("AwayTeam:" + strGet); //打印出客队
index = 0;
}
/**
* 用于获取比赛结果
*/
strGet = gMethod.regularGroup(regularResult, strRead);
if (!strGet.equals("")) {
//这里同样用到了substring方法 来剔除'
免费网页采集器(利用爬虫技术能做到哪些很酷很有趣很有用的事情?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-10-08 01:44
随着Scrapy等框架的流行,用编程语言编写爬虫已经成为一种时尚,看来网上的每个人都对爬虫有所了解。
大神用爬虫将学校所有重要的在线服务整合成一套JSON API,然后开发成App;
爬上知乎 12万用户的头像,把长得像的头像放在一起方便浏览:然后我采集了朋友的点击量,预测这就是你(一般)最喜欢的人长什么样子。;
有网友写了一个爬虫,按照标签对所有豆瓣图书进行爬取,根据已有的标签对豆瓣图书进行排序检索,并按分数从高到低排序。
......
这些有趣的故事都来自于知乎上的一个热门话题:爬虫技术可以做哪些酷、有趣、有用的事情?
每个人都可以爬
在互联网的早期,编写爬行动物是一项技术任务。在更大的方向上,爬行动物技术是搜索引擎不可或缺的一部分。
随着互联网技术的发展,编写爬虫的门槛一再下降。有些编程语言甚至直接提供了爬虫框架,比如Python Scrapy框架,可以让爬虫进入“常人之家”。
我们发现写爬虫是一件很酷的事情,但即便如此,学习爬虫还是有一定的技术门槛。
目前主流的爬虫方式是使用Python编程。Python 无疑是强大的,但初学者学习 Python 仍然需要一两个月的时间。
有没有一些更简单的方法来抓取数据?答案是肯定的。
一些可视化爬虫工具使用策略来爬取特定数据。虽然他们自己写爬虫并不准确,但是学习成本要低很多。这里有一些可视化爬虫工具。
家用工具
01 微软Excel
首先教大家一个用Excel爬取数据的方法。下面是Microsoft Excel 2013的版本,开始动手教学吧~
(1)新建一个Excel,打开,如下图
(2)点击“数据”——“来自网站”
(3)在弹出的对话框中输入目标网址,这里以全国实时空气质量网站为例,点击Go,然后导入
选择导入位置并确认
(4)结果如下图,怎么样,是不是很棒?
(5)如果要实时更新数据,可以在“数据”-“全部更新”-“连接属性”中设置,输入更新频率即可。
02 优采云
一款可视化免编程网页采集软件,可以快速从不同的网站中提取标准化数据,帮助用户实现数据自动化采集,编辑标准化,降低工作成本。
简易模式采集步骤
是一款采集 适合新手尝试的软件。云功能强大。当然,爬虫的老手也可以开发它的高级功能。
03 优采云
优采云 是一款互联网数据采集、处理、分析、挖掘软件。采集功能齐全,不限于网页和内容,可以任意文件格式下载,称为采集99%页面。
软件定位更专业、更精准。用户需要有基本的HTML基础,能够理解网页的源代码和结构。不过软件提供了相应的教程,新手也可以学习使用。
04 采集客户
一款简单易用的网页信息抓取软件,能够抓取网页文字、图表、超链接等网页元素。
操作比较简单,适合新手用户,功能方面没有太多特色,后续支付需求比较多。
网址:
05 优采云云爬虫
一种新型的云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量标准化的网络数据。
类似于爬虫系统框架,具体的采集也需要用户自己编写爬虫,需要有代码基础。
06 优采云采集器
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取、分论坛采集器、cms采集器 和博客采集器 三种类型。
专注于论坛和博客的文字内容爬取,全网数据的采集通用性不高。
国外工具
01 谷歌表格
使用Google Sheet抓取数据前,必须保证三点:使用Chrome浏览器,有Google账号,电脑翻墙。满足这三个条件,我们现在就开始吧~
(1)打开谷歌表格网站:/sheets/about/
(2)首页点击“Go to Google Sheets”,然后登录自己的账号,可以看到如下界面,然后点击“+”新建表单
新创建的表如下:
(3)打开要爬取的目标网站,全国实时空气质量网站pm25.in/rank,目标上的表结构网站@ > 如下图所示
(4)返回Google表格页面,使用function=IMPORTHTML(URL, query, index),“URL”为要抓取的数据的目标网站,输入“list”或“在“查询”表中,这个取决于数据的具体结构类型,“索引”用阿拉伯数字填充,从1开始,对应网站中定义的哪个表或列表
对于我们要爬取的网站,我们在Google sheet的A1单元格中输入function=IMPORTHTML("pm25.in/rank","table",1),然后按回车我可以稍后抓取数据
(5)将爬取的表单保存到本地
是不是感觉超级简单?
02 你得到
这是一个程序员基于python 3开发的项目,已经在github上开源,支持64个网站,包括优酷、土豆、爱奇艺、B站、酷狗音乐、虾米……反正你可以想其中网站 拥有一切!
还有一个黑科技,即使不在列表中,当你输入链接时,程序会猜测你要下载什么,然后为你下载。
当然you-get需要安装在python3环境下。用pip安装好后,在终端输入“你得到的+你要下载的资源的链接”,就可以等待资源的采集了。
这里有一个中文说明,按照说明中的步骤操作即可。
03 import.io
Import.io是一个基于网页的网页数据采集平台,用户无需编写代码,点击即可生成提取器。与国内大多数采集软件相比,Import.io更加智能,能够匹配并生成相似元素列表,用户只需一键输入URL即可获得采集数据。
Import.io的智能开发采集简单,但对于一些复杂的网页结构处理能力较弱。
04章鱼解析
Octoparse是优采云的海外版本。采集 页面设计简洁友好,完全可视化,适合新手用户。
运行并获取数据
Octoparse 功能齐全,价格合理,可以应用于复杂的网络结构。如果你想在不破墙的情况下使用亚马逊、Facebook、Twitter 等平台,Octoparse 是一个选择。
网址:
05 可视化网络撕裂者
Visual Web Ripper 是一种支持各种功能的自动化 Web 抓取工具。
适用于一些高级且采集难度较大的网页结构,需要有较强编程能力的用户。
网址:
06 内容抓取器
Content Grabber 是最强大的网络抓取工具之一。它更适合具有高级编程技能的人,并提供许多强大的脚本编辑和调试接口。允许用户编写正则表达式而不是使用内置工具。
Content Grabber网页适用性强,功能强大。它没有完全为用户提供基本功能。它适合具有高级编程技能的人。
网址:
07 莫曾达
Mozenda是一款基于云的数据采集软件,为用户提供了包括数据云存储在内的诸多实用功能。
适合有基本爬虫经验的人。
网址: 查看全部
免费网页采集器(利用爬虫技术能做到哪些很酷很有趣很有用的事情?)
随着Scrapy等框架的流行,用编程语言编写爬虫已经成为一种时尚,看来网上的每个人都对爬虫有所了解。
大神用爬虫将学校所有重要的在线服务整合成一套JSON API,然后开发成App;
爬上知乎 12万用户的头像,把长得像的头像放在一起方便浏览:然后我采集了朋友的点击量,预测这就是你(一般)最喜欢的人长什么样子。;
有网友写了一个爬虫,按照标签对所有豆瓣图书进行爬取,根据已有的标签对豆瓣图书进行排序检索,并按分数从高到低排序。
......
这些有趣的故事都来自于知乎上的一个热门话题:爬虫技术可以做哪些酷、有趣、有用的事情?
每个人都可以爬
在互联网的早期,编写爬行动物是一项技术任务。在更大的方向上,爬行动物技术是搜索引擎不可或缺的一部分。
随着互联网技术的发展,编写爬虫的门槛一再下降。有些编程语言甚至直接提供了爬虫框架,比如Python Scrapy框架,可以让爬虫进入“常人之家”。
我们发现写爬虫是一件很酷的事情,但即便如此,学习爬虫还是有一定的技术门槛。
目前主流的爬虫方式是使用Python编程。Python 无疑是强大的,但初学者学习 Python 仍然需要一两个月的时间。
有没有一些更简单的方法来抓取数据?答案是肯定的。
一些可视化爬虫工具使用策略来爬取特定数据。虽然他们自己写爬虫并不准确,但是学习成本要低很多。这里有一些可视化爬虫工具。
家用工具
01 微软Excel
首先教大家一个用Excel爬取数据的方法。下面是Microsoft Excel 2013的版本,开始动手教学吧~
(1)新建一个Excel,打开,如下图
(2)点击“数据”——“来自网站”
(3)在弹出的对话框中输入目标网址,这里以全国实时空气质量网站为例,点击Go,然后导入
选择导入位置并确认
(4)结果如下图,怎么样,是不是很棒?
(5)如果要实时更新数据,可以在“数据”-“全部更新”-“连接属性”中设置,输入更新频率即可。
02 优采云
一款可视化免编程网页采集软件,可以快速从不同的网站中提取标准化数据,帮助用户实现数据自动化采集,编辑标准化,降低工作成本。
简易模式采集步骤
是一款采集 适合新手尝试的软件。云功能强大。当然,爬虫的老手也可以开发它的高级功能。
03 优采云
优采云 是一款互联网数据采集、处理、分析、挖掘软件。采集功能齐全,不限于网页和内容,可以任意文件格式下载,称为采集99%页面。
软件定位更专业、更精准。用户需要有基本的HTML基础,能够理解网页的源代码和结构。不过软件提供了相应的教程,新手也可以学习使用。
04 采集客户
一款简单易用的网页信息抓取软件,能够抓取网页文字、图表、超链接等网页元素。
操作比较简单,适合新手用户,功能方面没有太多特色,后续支付需求比较多。
网址:
05 优采云云爬虫
一种新型的云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量标准化的网络数据。
类似于爬虫系统框架,具体的采集也需要用户自己编写爬虫,需要有代码基础。
06 优采云采集器
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取、分论坛采集器、cms采集器 和博客采集器 三种类型。
专注于论坛和博客的文字内容爬取,全网数据的采集通用性不高。
国外工具
01 谷歌表格
使用Google Sheet抓取数据前,必须保证三点:使用Chrome浏览器,有Google账号,电脑翻墙。满足这三个条件,我们现在就开始吧~
(1)打开谷歌表格网站:/sheets/about/
(2)首页点击“Go to Google Sheets”,然后登录自己的账号,可以看到如下界面,然后点击“+”新建表单
新创建的表如下:
(3)打开要爬取的目标网站,全国实时空气质量网站pm25.in/rank,目标上的表结构网站@ > 如下图所示
(4)返回Google表格页面,使用function=IMPORTHTML(URL, query, index),“URL”为要抓取的数据的目标网站,输入“list”或“在“查询”表中,这个取决于数据的具体结构类型,“索引”用阿拉伯数字填充,从1开始,对应网站中定义的哪个表或列表
对于我们要爬取的网站,我们在Google sheet的A1单元格中输入function=IMPORTHTML("pm25.in/rank","table",1),然后按回车我可以稍后抓取数据
(5)将爬取的表单保存到本地
是不是感觉超级简单?
02 你得到
这是一个程序员基于python 3开发的项目,已经在github上开源,支持64个网站,包括优酷、土豆、爱奇艺、B站、酷狗音乐、虾米……反正你可以想其中网站 拥有一切!
还有一个黑科技,即使不在列表中,当你输入链接时,程序会猜测你要下载什么,然后为你下载。
当然you-get需要安装在python3环境下。用pip安装好后,在终端输入“你得到的+你要下载的资源的链接”,就可以等待资源的采集了。
这里有一个中文说明,按照说明中的步骤操作即可。
03 import.io
Import.io是一个基于网页的网页数据采集平台,用户无需编写代码,点击即可生成提取器。与国内大多数采集软件相比,Import.io更加智能,能够匹配并生成相似元素列表,用户只需一键输入URL即可获得采集数据。
Import.io的智能开发采集简单,但对于一些复杂的网页结构处理能力较弱。
04章鱼解析
Octoparse是优采云的海外版本。采集 页面设计简洁友好,完全可视化,适合新手用户。
运行并获取数据
Octoparse 功能齐全,价格合理,可以应用于复杂的网络结构。如果你想在不破墙的情况下使用亚马逊、Facebook、Twitter 等平台,Octoparse 是一个选择。
网址:
05 可视化网络撕裂者
Visual Web Ripper 是一种支持各种功能的自动化 Web 抓取工具。
适用于一些高级且采集难度较大的网页结构,需要有较强编程能力的用户。
网址:
06 内容抓取器
Content Grabber 是最强大的网络抓取工具之一。它更适合具有高级编程技能的人,并提供许多强大的脚本编辑和调试接口。允许用户编写正则表达式而不是使用内置工具。
Content Grabber网页适用性强,功能强大。它没有完全为用户提供基本功能。它适合具有高级编程技能的人。
网址:
07 莫曾达
Mozenda是一款基于云的数据采集软件,为用户提供了包括数据云存储在内的诸多实用功能。
适合有基本爬虫经验的人。
网址:
免费网页采集器(网页表格数据采集助手使用方法:1.格式保存方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-06 08:18
<p>网页表单数据采集助手是一款绿色、免费的网页表单数据采集软件。软件功能强大,可以采集单页规则和不规则表格,并自动连续采集指定网站的表格,并指定 查看全部
免费网页采集器(网页表格数据采集助手使用方法:1.格式保存方法)
<p>网页表单数据采集助手是一款绿色、免费的网页表单数据采集软件。软件功能强大,可以采集单页规则和不规则表格,并自动连续采集指定网站的表格,并指定
免费网页采集器(优采云问:如何过滤列表中的前N个数据?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-02 11:23
优采云采集器V2是一款高效的网页信息采集软件,支持99%的网站数据采集,优采云采集器可以生成Excel表格、api数据库文件等内容,帮助您管理网站数据信息。如果你需要采集一个指定的网页数据,就用这个软件。
软件特点
一键提取数据
简单易学,通过可视化界面,鼠标点击即可采集数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
特征
向导模式
简单易用,轻松通过鼠标点击自动生成
脚本定期运行
可按计划定时运行,无需人工
原装高速核心
自主研发的浏览器内核速度快,远超对手
智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
各种数据导出
支持 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。
指示
第一步:输入采集 URL
打开软件,新建一个任务,输入需要采集的网站地址。
第二步:智能分析,全程自动提取数据
进入第二步后,优采云采集器自动对网页进行智能分析,从中提取列表数据。
第三步:将数据导出到表、数据库、网站等。
运行任务,将采集中的数据导出到Csv、Excel及各种数据库,支持api导出。
常见问题
Q:如何过滤列表中的前N个数据?
1.有时候我们需要过滤采集收到的列表,比如过滤掉第一组数据(以采集的形式,过滤掉表列名)
2.在列表模式菜单中点击设置列表xpath
Q:如何通过抓包获取cookie并手动设置?
1.首先用谷歌浏览器打开你要采集的网站,然后登录。
2. 然后按F12,会出现开发者工具,选择Network
3.然后按F5刷新下一页并选择其中一个请求。
4.复制完成后,在优采云采集器中编辑任务,进入第三步指定HTTP Header。
更新日志
1.添加插件功能
2.添加export txt(一个文件另存为一个文件)
3.多值连接器支持换行
4.修改数据处理的文本映射(支持查找替换)
5.修复登录时DNS问题
6.修复图片下载问题
7.修复json中的一些问题 查看全部
免费网页采集器(优采云问:如何过滤列表中的前N个数据?)
优采云采集器V2是一款高效的网页信息采集软件,支持99%的网站数据采集,优采云采集器可以生成Excel表格、api数据库文件等内容,帮助您管理网站数据信息。如果你需要采集一个指定的网页数据,就用这个软件。
软件特点
一键提取数据
简单易学,通过可视化界面,鼠标点击即可采集数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据
适用于各种网站
能够采集99%的互联网网站,包括单页应用Ajax加载等动态类型网站
特征
向导模式
简单易用,轻松通过鼠标点击自动生成
脚本定期运行
可按计划定时运行,无需人工
原装高速核心
自主研发的浏览器内核速度快,远超对手
智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
各种数据导出
支持 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等。
指示
第一步:输入采集 URL
打开软件,新建一个任务,输入需要采集的网站地址。
第二步:智能分析,全程自动提取数据
进入第二步后,优采云采集器自动对网页进行智能分析,从中提取列表数据。
第三步:将数据导出到表、数据库、网站等。
运行任务,将采集中的数据导出到Csv、Excel及各种数据库,支持api导出。
常见问题
Q:如何过滤列表中的前N个数据?
1.有时候我们需要过滤采集收到的列表,比如过滤掉第一组数据(以采集的形式,过滤掉表列名)
2.在列表模式菜单中点击设置列表xpath
Q:如何通过抓包获取cookie并手动设置?
1.首先用谷歌浏览器打开你要采集的网站,然后登录。
2. 然后按F12,会出现开发者工具,选择Network
3.然后按F5刷新下一页并选择其中一个请求。
4.复制完成后,在优采云采集器中编辑任务,进入第三步指定HTTP Header。
更新日志
1.添加插件功能
2.添加export txt(一个文件另存为一个文件)
3.多值连接器支持换行
4.修改数据处理的文本映射(支持查找替换)
5.修复登录时DNS问题
6.修复图片下载问题
7.修复json中的一些问题
免费网页采集器(免费网页采集器可以采集、天猫、京东等网站的一键免费在线的网页并按需要自动生成)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-30 10:22
免费网页采集器可以采集、天猫、京东等网站的一键免费在线的网页并按需要自动生成网页代码上传到后台本软件有四大功能
1、实时定位各类网站
2、采集速度快
3、自动格式化网页
4、实时上传新代码注意:需要安装到电脑里面。
一、上网采集各类网站一键免费在线抓取各类网站免费自动抓取各种大中小网站任何页面所有页面文字(视频,图片,站内信)自动采集不花钱采集任何大中小网站页面任何页面内容(高清图片,插图,ppt,html)无需任何代码技术和技术,你可以操作手机、电脑、电视或盒子电脑上直接采集(指定浏览器内录制或模拟电脑可在电脑)电脑采集电脑内输入网址"-8jnjdewcmb4ljvzibjy/"电脑浏览器网址右键另存,在浏览器里面直接点击网址"-8jnjdewcmb4ljvzibjy/"。
二、自动格式化网页及代码采集任何网站的基本数据,如url、cookie、账号、密码、账号app等信息获取后自动格式化html代码,文字、图片及音视频等格式化。格式化格式化后可通过电脑“浏览器”进行格式化,成为通用网页,未经格式化的网页代码在采集时会造成额外的工作量。
三、实时上传新代码添加网站新代码(如:高清电影、网页图片、插图、音频、视频、html、链接等)上传时可添加网站链接或自己定义网址
四、如何使用
1、首先点击软件右上角的"编辑"在编辑页面输入我们想要采集的网站名称,然后点击"开始采集"点击"保存"你的网站源代码。如果没有报错,会出现这样的提示:无法获取我们需要的信息:要获取的网站网址、html代码编码等内容。
2、如果上传成功,软件会自动创建采集目录如下图,采集目录以第一个"邮件"为例。
3、接下来的采集过程我们就可以点击采集目录,
4、获取网页源码后点击右下角的"提交",然后会弹出"已采集成功"提示框。当我们点击"提交"按钮的时候软件会自动保存保存在这个网站源码的目录中。
5、另外,我们可以将这个网站代码保存为本地电子文档,例如,我们保存为"txt文档"。 查看全部
免费网页采集器(免费网页采集器可以采集、天猫、京东等网站的一键免费在线的网页并按需要自动生成)
免费网页采集器可以采集、天猫、京东等网站的一键免费在线的网页并按需要自动生成网页代码上传到后台本软件有四大功能
1、实时定位各类网站
2、采集速度快
3、自动格式化网页
4、实时上传新代码注意:需要安装到电脑里面。
一、上网采集各类网站一键免费在线抓取各类网站免费自动抓取各种大中小网站任何页面所有页面文字(视频,图片,站内信)自动采集不花钱采集任何大中小网站页面任何页面内容(高清图片,插图,ppt,html)无需任何代码技术和技术,你可以操作手机、电脑、电视或盒子电脑上直接采集(指定浏览器内录制或模拟电脑可在电脑)电脑采集电脑内输入网址"-8jnjdewcmb4ljvzibjy/"电脑浏览器网址右键另存,在浏览器里面直接点击网址"-8jnjdewcmb4ljvzibjy/"。
二、自动格式化网页及代码采集任何网站的基本数据,如url、cookie、账号、密码、账号app等信息获取后自动格式化html代码,文字、图片及音视频等格式化。格式化格式化后可通过电脑“浏览器”进行格式化,成为通用网页,未经格式化的网页代码在采集时会造成额外的工作量。
三、实时上传新代码添加网站新代码(如:高清电影、网页图片、插图、音频、视频、html、链接等)上传时可添加网站链接或自己定义网址
四、如何使用
1、首先点击软件右上角的"编辑"在编辑页面输入我们想要采集的网站名称,然后点击"开始采集"点击"保存"你的网站源代码。如果没有报错,会出现这样的提示:无法获取我们需要的信息:要获取的网站网址、html代码编码等内容。
2、如果上传成功,软件会自动创建采集目录如下图,采集目录以第一个"邮件"为例。
3、接下来的采集过程我们就可以点击采集目录,
4、获取网页源码后点击右下角的"提交",然后会弹出"已采集成功"提示框。当我们点击"提交"按钮的时候软件会自动保存保存在这个网站源码的目录中。
5、另外,我们可以将这个网站代码保存为本地电子文档,例如,我们保存为"txt文档"。
免费网页采集器(优采云采集器软件特色介绍及解决方法步骤介绍-苏州安嘉 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-09-27 22:06
)
优采云采集器是一款专业的网页数据采集软件,可以一键使用采集网页数据功能,任何人都可以使用,可视化,无需开发,无需导出数据限制,支持后台操作,速度实时显示,非常方便。优采云采集器软件特点
1、运行批处理采集数据
软件根据采集的处理和提取规则自动对采集进行批量处理;
快速稳定,实时显示采集速度和进程;
软件可切换后台运行,不打扰前台工作。
2、导出发布采集的数据
采集 数据自动制表,字段可自由配置;
支持数据导出到Excel等本地文件;
并一键发布到cms网站/database/微信公众号等媒体。
优采云采集器 使用说明
如何自定义采集百度搜索结果数据
第一步:创建采集任务
1)启动优采云采集器,进入主界面,选择自定义采集,点击创建任务按钮,创建“自定义采集任务”
2)输入百度搜索的网址,三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分隔。
2、 点击读取文件:用户选择一个文件来存储 URL。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址。
第二步:自定义采集流程
1) 点击创建后,会自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区域用于拖放到画布上生成新的流程块;点击打开网页中的属性按钮,修改打开的网址。
2)添加文本输入流程块:将底部模板区域中的输入文本块拖到打开的网页块的后面。出现阴影区域时,松开鼠标,此时会自动连接,添加完成。
3) 生成一个完整的流程图: 按照上面添加输入文本流程块的拖放流程添加一个新块:如下图所示:
关键步骤块设置介绍
第二步:定时等待用于等待之前打开的网页完成。
第三步:点击输入框的Xpath属性按钮,点击属性菜单中的图标选择网页上的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
第四步:设置,点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页上的百度按钮确定。
第五步:用于设置加载下一个列表页面的周期。在循环块内的循环条件块中设置详细条件。单击此处的操作按钮选择单个元素,然后在属性菜单中单击该元素的xpath 属性按钮,然后在网页中单击下一页按钮,如上。循环次数属性按钮可以默认为0,即下一页没有点击次数限制。
第六步:用于设置列表页数据的循环抽取。在循环块内部的循环条件块中设置详细条件,点击这里的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后在网页中点击两次即可提取第一个块和第二个元素。循环次数属性按钮可以默认为0,即不限制列表中采集的字段数。
Step 7:用于执行点击下一页按钮、点击元素xpath属性按钮、选择当前循环中元素的xpath选项的操作。
第八步:同样用于设置网页加载的等待时间。
第九步:用于在列表页面设置要提取的字段规则,点击属性按钮中的循环中使用元素按钮,选择循环中使用元素的选项。单击元素模板属性按钮在字段表中添加和减去字段以添加和删除字段。添加字段使用点击操作,即点击加号,然后将鼠标移动到网页元素上,点击选择。
4)点击开始采集,开始采集
第三步:数据采集并导出
1)采集 任务正在运行
2)采集 完成后,选择Export Data,将所有数据导出到本地文件。
3)选择导出方式,导出采集的好数据。在这里您可以选择excel作为导出格式。
界面预览:
查看全部
免费网页采集器(优采云采集器软件特色介绍及解决方法步骤介绍-苏州安嘉
)
优采云采集器是一款专业的网页数据采集软件,可以一键使用采集网页数据功能,任何人都可以使用,可视化,无需开发,无需导出数据限制,支持后台操作,速度实时显示,非常方便。优采云采集器软件特点
1、运行批处理采集数据
软件根据采集的处理和提取规则自动对采集进行批量处理;
快速稳定,实时显示采集速度和进程;
软件可切换后台运行,不打扰前台工作。
2、导出发布采集的数据
采集 数据自动制表,字段可自由配置;
支持数据导出到Excel等本地文件;
并一键发布到cms网站/database/微信公众号等媒体。
优采云采集器 使用说明
如何自定义采集百度搜索结果数据
第一步:创建采集任务
1)启动优采云采集器,进入主界面,选择自定义采集,点击创建任务按钮,创建“自定义采集任务”
2)输入百度搜索的网址,三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分隔。
2、 点击读取文件:用户选择一个文件来存储 URL。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址。
第二步:自定义采集流程
1) 点击创建后,会自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区域用于拖放到画布上生成新的流程块;点击打开网页中的属性按钮,修改打开的网址。
2)添加文本输入流程块:将底部模板区域中的输入文本块拖到打开的网页块的后面。出现阴影区域时,松开鼠标,此时会自动连接,添加完成。
3) 生成一个完整的流程图: 按照上面添加输入文本流程块的拖放流程添加一个新块:如下图所示:
关键步骤块设置介绍
第二步:定时等待用于等待之前打开的网页完成。
第三步:点击输入框的Xpath属性按钮,点击属性菜单中的图标选择网页上的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
第四步:设置,点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页上的百度按钮确定。
第五步:用于设置加载下一个列表页面的周期。在循环块内的循环条件块中设置详细条件。单击此处的操作按钮选择单个元素,然后在属性菜单中单击该元素的xpath 属性按钮,然后在网页中单击下一页按钮,如上。循环次数属性按钮可以默认为0,即下一页没有点击次数限制。
第六步:用于设置列表页数据的循环抽取。在循环块内部的循环条件块中设置详细条件,点击这里的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后在网页中点击两次即可提取第一个块和第二个元素。循环次数属性按钮可以默认为0,即不限制列表中采集的字段数。
Step 7:用于执行点击下一页按钮、点击元素xpath属性按钮、选择当前循环中元素的xpath选项的操作。
第八步:同样用于设置网页加载的等待时间。
第九步:用于在列表页面设置要提取的字段规则,点击属性按钮中的循环中使用元素按钮,选择循环中使用元素的选项。单击元素模板属性按钮在字段表中添加和减去字段以添加和删除字段。添加字段使用点击操作,即点击加号,然后将鼠标移动到网页元素上,点击选择。
4)点击开始采集,开始采集
第三步:数据采集并导出
1)采集 任务正在运行
2)采集 完成后,选择Export Data,将所有数据导出到本地文件。
3)选择导出方式,导出采集的好数据。在这里您可以选择excel作为导出格式。
界面预览:

