
优采云自动文章采集 sign failed11
优采云自动文章采集是一个常见的错误信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2023-02-11 17:26
Sign failed11是一个常见的错误信息,表明优采云软件无法正常登录服务器。这可能是因为用户名/密码错误、网络不稳定、服务器出错等原因所导致的。因此,用户在遭遇sign failed11之前,应该先检查一下账号密码是否正确,再判断当前所处的网络情况。如果都无法解决问题,可以尝试联系优采云客服人员进行帮助。
优采云是一家专注于SEO内容优化技术的公司,其官方网站www.ucaiyun.com上提供了大量关于文章采集的相关信息和教程,用户也可以在上面找到很多帮助性的内容。此外,优采云也有一整套专业、专注、高效、全方位的SEO优化服务体系来帮助用户更好地开展文章采集工作。
总之,sign failed11是一个很常见但又不容易解决的问题。如果遭遇sign failed11问题,用户应该尝试根据上述方法进行尝试并排除出错原因。如果无法解决问题,不妨考虑使用优采云SEO优化来帮助文章采集工作。 查看全部
近年来,随着互联网的发展,文章采集已成为一种流行的媒体技术。在众多的文章采集软件中,优采云自动文章采集是一款性能卓越的软件,它可以帮助用户快速、高效地采集各种类型的文章。然而,有时用户可能会遇到sign failed11的问题,这时就需要更多的关注。

Sign failed11是一个常见的错误信息,表明优采云软件无法正常登录服务器。这可能是因为用户名/密码错误、网络不稳定、服务器出错等原因所导致的。因此,用户在遭遇sign failed11之前,应该先检查一下账号密码是否正确,再判断当前所处的网络情况。如果都无法解决问题,可以尝试联系优采云客服人员进行帮助。

优采云是一家专注于SEO内容优化技术的公司,其官方网站www.ucaiyun.com上提供了大量关于文章采集的相关信息和教程,用户也可以在上面找到很多帮助性的内容。此外,优采云也有一整套专业、专注、高效、全方位的SEO优化服务体系来帮助用户更好地开展文章采集工作。

总之,sign failed11是一个很常见但又不容易解决的问题。如果遭遇sign failed11问题,用户应该尝试根据上述方法进行尝试并排除出错原因。如果无法解决问题,不妨考虑使用优采云SEO优化来帮助文章采集工作。
事实:做了N个采集,都是处理内容失败(官方看下)
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2022-12-22 09:29
采集器的问题我们开发已经查过了,下面是他们的回答:
个别文章采集不到和跳课的原因主要有两个。
一种是php无法读取对方的网站。
二是php从对方服务器获取图片保存到本地的时间可能过长。 而且,有些东西读过了,但是图片读不出来(读图片的时候网络突然忙,导致图片打不开)。
这块不是程序造成的,原因是:
1.网络繁忙导致php执行超时
2、目标内容(包括:URL、图片)无响应、404错误或其他错误。
造成这种情况的原因有很多,比如网络拥堵,防盗机制,你自己的服务器突然以某种方式繁忙等等。
解决方案:
全部采集完之后,可以再进行一次采集,这样已经采集到的内容会被跳过,重新采集因为网络繁忙而失败的内容。
ss6 -> ss7采集机制调整不多,所以不会有6线7的不稳定因素
后续版本会在采集机制上做更多的优化。
定时任务采集、断点续采集、内容图片分离采集等。
汇总:渗透测试之信息收集篇(含思维导图)
爱站记录查询
域名助手备案信息查询
11、查询绿盟科技的whois信息
域名查询
查看注册人和邮箱获取更多域名
12. 采集子域 12.1。 子域的功能
采集子域名可以扩大测试范围,同一域名下的二级域名都属于目标范围。
12.2. 常用方法
子域中常见的资产类型一般包括办公系统、邮件系统、论坛、商城等管理系统,网站管理后台也可能出现在子域中。
首先找到目标站点,在官网可以找到相关资产(主要是办公系统、邮件系统等)。 关注页面底部,可能会有管理后台等收获。
查找目标域名信息的方法如下:
FOFA title="公司名称"
百度intitle=公司名称
Google intitle=公司名称
站长之家,可直接搜索名称或网站域名查看相关信息:
钟馗之眼站点=域名
找到官网后,采集子域名。 以下是一些采集子域名的推荐方法。 可以直接输入域名查询。
12.3. 域名类型
A记录、别名记录(CNAME)、MX记录、TXT记录、NS记录:
12.3.1。 A(地址)记录:
用于指定主机名(或域名)对应的IP地址记录。 用户可以将域名下的网站服务器指向自己的网站服务器。 同时,您还可以设置您的域名的二级域名。
12.3.2。 别名(CNAME)记录:
也称为规范名称。 这种类型的记录允许您将多个名称映射到同一台计算机。 通常用于同时提供 WWW 和 MAIL 服务的计算机。 例如,有一台名为“”的计算机(A记录)。 同时提供WWW和MAIL服务,方便用户访问服务。 可以为这台计算机设置两个别名(CNAME):WWW 和 MAIL。 这两个别名的全称是“”和“”。 其实都指向“”。
当你有多个域名需要指向同一个服务器IP时,可以使用同样的方法。 这时候可以给一个域名做一个A记录指向服务器IP,然后把其他域名别名到有之前A记录的域名上。 那么当你的服务器IP地址发生变化的时候,你就不用费心费力地一个一个的改域名了。 您只需要更改做A记录的域名,其他做别名的域名也会自动更改为新的IP地址。
12.3.3。 如何检测CNAME记录?
1、进入命令状态; (开始菜单-运行-CMD【回车】);
2、输入命令“nslookup -q=cname 此处填写对应的域名或二级域名”,查看返回结果是否与设置一致。
12.3.4。 MX(邮件交换器)记录:
它是一条邮件交换记录,指向一个邮件服务器,供电子邮件系统在发送邮件时根据收件人的地址后缀定位邮件服务器。 例如,当Internet上的用户要寄信给 时,用户的邮件系统通过DNS查找该域名的MX记录。 如果MX记录存在,则用户计算机将邮件发送到MX记录指定的邮件服务器。 .
12.3.5。 什么是 TXT 记录? :
TXT记录一般是指对主机名或域名的指令集,例如:
1) admin IN TXT "jack, mobile:";
2)mail IN TXT》邮件主机,存放于xxx,管理员:AAA,Jim IN TXT》联系人:
也就是你可以设置TXT,这样别人就可以联系到你了。
如何检测TXT记录?
1、进入命令状态; (开始菜单-运行-CMD【回车】);
2、输入命令“nslookup -q=txt 在此填写对应的域名或二级域名”,查看返回结果是否与设置一致。
12.3.6。 什么是 NS 记录?
ns记录的全称是Name Server,也就是域名服务器记录,用来明确你的域名当前是由哪台DNS服务器解析的。
12.3.7。 子域名在线查询1
12.3.8。 子域名在线查询2
12.3.9。 DNS检测
12.3.10。 IP138查询子域
12.3.11。 FOFA 搜索子域
语法:域=“”
Tips:以上两种方式不需要爆破,查询速度快。 当资产需要快速采集时,可以先使用,以后再通过其他方式补充。
12.3.12。 Hackertarget 查询子域
注意:通过该方法查询子域名可以得到目标的一个大概的ip段,然后就可以通过ip采集信息了。
12.4。 360映射空间
领域: ”*。”
12.4.1。 图层子域挖掘机
12.4.2。 子域蛮干
pip 安装 aiodns
运行命令 subDomainsBrute.py
subDomainsBrute.py --full -o freebuf2.txt
12.4.3。 子列表3r
pip install -r requirements.txt
提示:以上方法是对子域名进行爆破,因为字典功能更强大,所以效率更高。
帮助文档
<p style="margin-top: 0px;margin-bottom: 0px;">usage: sublist3r.py [-h] -d DOMAIN [-b [BRUTEFORCE]] [-p PORTS] [-v [VERBOSE]]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />[-t THREADS] [-e ENGINES] [-o OUTPUT] [-n]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />OPTIONS:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-h, --help show this help message and exit<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-d DOMAIN, --domain DOMAIN<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Domain name to enumerate it's subdomains<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-b [BRUTEFORCE], --bruteforce [BRUTEFORCE]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Enable the subbrute bruteforce module<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-p PORTS, --ports PORTS<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Scan the found subdomains against specified tcp ports<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-v [VERBOSE], --verbose [VERBOSE]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Enable Verbosity and display results in realtime<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-t THREADS, --threads THREADS<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Number of threads to use for subbrute bruteforce<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-e ENGINES, --engines ENGINES<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Specify a comma-separated list of search engines<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-o OUTPUT, --output OUTPUT<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Save the results to text file<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-n, --no-color Output without color</p>
示例:python sublist3r.py -d
中文翻译
-h:帮助
-d : 指定主域名枚举子域名
-b : 调用 subbrute 来暴力枚举子域名
-p : 指定扫描子域名的tpc端口
-v :显示实时详细结果
-t : 指定线程
-e : 指定搜索引擎
-o : 将结果保存到文本
-n : 没有颜色的输出
扫描子域的默认参数
python sublist3r.py -d
使用暴力枚举子域
python sublist3r -b -d
12.4.4。 python2.7.14环境
;C:\Python27;C:\Python27\脚本
12.4.5。 万物皆可
pip3 install --user -r requirements.txt -i
python3 oneforall.py --target run /*采集*/
爆炸子域
例子:
<p style="margin-top: 0px;margin-bottom: 0px;">brute.py --target domain.com --word True run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --targets ./domains.txt --word True run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target domain.com --word True --concurrent 2000 run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target domain.com --word True --wordlist subnames.txt run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target domain.com --word True --recursive True --depth 2 run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target d.com --fuzz True --place m.*.d.com --rule '[a-z]' run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target d.com --fuzz True --place m.*.d.com --fuzzlist subnames.txt run</p>
12.4.6。 域名
<p style="margin-top: 0px;margin-bottom: 0px;">dnsburte.py -d aliyun.com -f dnspod.csv -o aliyun.log<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />wydomain.py -d aliyun.com</p>
12.4.7。 模糊域
12.4.8。 隐藏域名主机冲突
隐藏资产检测-主机碰撞
很多时候访问目标资产的IP响应是:401、403、404、500,但是域名请求可以返回正常的业务系统(禁止直接IP访问),因为大部分需要绑定向主机正常请求访问(目前互联网公司的基本做法)(域名已经删除了A记录,但是反向生成的配置还没有更新),那么我们就可以将采集到的目标域名和目标资产的IP段,并用IP段+域名的形式进行捆绑碰撞,可以发现很多有趣的东西。
发送http请求时,将域名和IP列表配对,然后遍历发送请求(相当于修改本地hosts文件),对比对应的标题和响应包大小,快速找出一些隐藏资产。
Hosts collision需要目标的域名和目标的相关IP作为字典
更不用说域名了
相关IP来源有:
目标域名历史分析IP
ip 常规
13.端口扫描
确定目标的大概ip段后,可以先检测ip的开放端口。 某些特定服务可能会在默认端口上打开。 检测开放端口有利于快速采集目标资产,找到目标网站的其他功能站点。
13.1. msscan 端口扫描
msscan -p 1-65535 ip --rate=1000
13.2. 御剑端口扫描工具
13.3. nmap扫描端口并检测端口信息
常用参数,如:
nmap -sV 192.168.0.2
nmap -sT 92.168.0.2
nmap -Pn -A -sC 192.168.0.2
nmap -sU -sT -p0-65535 192.168.122.1
用于扫描目标主机服务版本号和开放端口
如果需要扫描多个ip或者ip段,可以保存到一个txt文件中
nmap -iL ip.txt
扫描列表中的所有 ip。
Nmap 是最常用的端口检测方法。 操作简单,输出结果非常直观。
13.4. 在线端口检测
13.5。 端口扫描器
御剑、msscan、nmap等
御剑高速端口扫描器:
填写你要扫描的ip段(如果只扫描一个ip,只需填写起始IP和结束IP),可以选择不更改默认端口列表,也可以选择自己指定端口。
13.6. 渗透端口
21,22,23,1433,152,3306,3389,5432,5900,50070,50030,50000,27017,27018,11211,9200,9300,7001,7002,6379,5984,873,443,8000-9090,80- 89,80,10000,8888,8649,8083,8080,8089,9090,7778,7001,7002,6082,5984,4440,3312,3311,3128,2601,2604,2222,2082,2083,389,88,512, 51 1025,111,1521,445,135,139,53
13.7。 穿透常用端口及对应服务
1、Web类(web漏洞/敏感目录)
第三方通用组件漏洞struts thinkphp jboss ganglia zabbix
80 网站
80-89网页
8000-9090 网页
2.数据库类(弱口令扫描)
第1433章
第1521章
3306 MySQL
5432 PostgreSQL 数据库
3.特殊服务类(未授权/命令执行类/漏洞)
第443章
873 Rsync 未经授权
5984 CouchDB:5984/_utils/
6379 Redis 未授权
7001,7002 WebLogic默认弱口令,反序列化
9200,9300 elasticsearch 参考WooYun:玩服务器ElasticSearch命令执行漏洞
11211 memcache 未授权访问
27017、27018 Mongodb 未授权访问
执行了 50000 个 SAP 命令
50070、50030 hadoop默认端口未授权访问
4.常用端口类(扫描弱口令/端口爆破)
21 英尺
22 SSH
23 远程登录
2601,2604 zebra路由,默认密码zebra
3389 远程桌面
5.端口总明细
21 英尺
22 SSH
23 远程登录
80 网站
80-89网页
第161话
第389章
443 SSL Heartbleed 和一些网络漏洞测试
445 家中小企业
512,513,514 雷克斯
873 Rsync 未经授权
1025,111 NFS
第1433章
1521 甲骨文:(iSqlPlus 端口:5560、7778)
2082/2083 cpanel主机管理系统登录(国外多用)
2222 DA虚拟主机管理系统登录(国外多用)
2601,2604 zebra路由,默认密码zebra
3128 squid代理默认端口,如果不设置密码,可以直接漫游内网
3306 MySQL
3312/3311康乐主机管理系统登录
3389 远程桌面
4440 rundeck 参考无云:借新浪服务成功漫游新浪内网
5432 PostgreSQL 数据库
5900 越南
5984 CouchDB:5984/_utils/
6082 Varnish 参考WooYun:Varnish HTTP加速器 CLI 未授权访问容易导致直接篡改网站或代理访问内网
6379 Redis 未授权
7001,7002 WebLogic默认弱口令,反序列化
7778 Kloxo 主机控制面板登录
8000-9090是一些常用的web端口,有些运维喜欢在这些非80端口上开启管理后台
8080 tomcat/WDCP主机管理系统,默认弱密码
8080、8089、9090 JBOSS
8083 Vestacp主机管理系统(国外多用)
8649 神经节
8888 amh/LuManager主机管理系统默认端口
9200,9300 elasticsearch 参考WooYun:玩服务器ElasticSearch命令执行漏洞
10000 Virtualmin/Webmin服务器虚拟主机管理系统
11211 memcache 未授权访问
27017、27018 Mongodb 未授权访问
28017 mongodb统计页面
执行了 50000 个 SAP 命令
50070、50030 hadoop默认端口未授权访问
13.8。 常用端口及攻击方式
14.查找真实ip
如果目标网站使用CDN,则隐藏cdn的真实ip。 要想找到真实服务器,就必须获取真实ip,根据这个ip继续查询侧站。
注意:很多情况下,虽然主站使用了CDN,但是子域名不一定使用CDN。 如果主网站和子域名在同一个ip段,那么也是找到子域名真实ip的一种方式。
14.1. Ping多处确认是否使用CDN
14.2. 查询历史DNS解析记录
在查询到的历史分析记录中,最早的历史分析IP很可能记录的是真实IP。 推荐使用此方法快速找到真实IP,但不是所有网站都能找到。
14.2.1。 域名数据库
14.2.2。 微步在线
14.2.3。
14.2.4。 查看DNS
14.3. php信息
如果目标网站存在phpinfo泄露等情况,可以在phpinfo中的SERVER_ADDR或_SERVER["SERVER_ADDR"]中查找真实ip
14.4. 绕过CDN
绕过CDN的方法有很多,请参考
15. 边站和C段
边站通常有业务功能站点。 建议先采集已有IP的边站,再检测C网段,确定C网段的目标后,在C网段的基础上重新采集边站。
辅助站点是与已知目标站点位于同一服务器上但具有不同端口的站点。 通过以下方法搜索到副站后,首先访问确定是否是您需要的站址信息。
15.1.1。 站长主页
用ip网站查询
15.2. 谷歌黑客
15.2.1。 网络空间搜索引擎
比如FOFA搜边站和C段
这种方式效率更高,可以直观的看到站点标题,但也有不收录不常用端口的情况。 虽然这种情况很少见,但您可以在后期补充资产时,通过以下方式再次扫描领取。
15.2.2。 线上段c
c部分使用脚本
<p style="margin-top: 0px;margin-bottom: 0px;">pip install requests<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />#coding:utf-8<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import requests<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import json<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />def get_c(ip):<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print("正在收集{}".format(ip))<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />url="http://api.webscan.cc/?action=query&ip={}".format(ip)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />req=requests.get(url=url)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />html=req.text<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />data=req.json()<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />if 'null' not in html:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />with open("resulit.txt", 'a', encoding='utf-8') as f:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />f.write(ip + '\n')<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />f.close()<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for i in data:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />with open("resulit.txt", 'a',encoding='utf-8') as f:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />f.write("\t{} {}\n".format(i['domain'],i['title']))<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print(" [+] {} {}[+]".format(i['domain'],i['title']))<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />f.close()<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />def get_ips(ip):<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />iplist=[]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />ips_str = ip[:ip.rfind('.')]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for ips in range(1, 256):<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />ipadd=ips_str + '.' + str(ips)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />iplist.append(ipadd)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />return iplist<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />ip=input("请你输入要查询的ip:")<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />ips=get_ips(ip)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for p in ips:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />get_c(p)</p>
15.2.3。 Nmap、Msscan扫描等
例如:nmap -p 80,443,8000,8080 -Pn 192.168.0.0/24
15.2.4。 公共端口表
21,22,23,80-90,161,389,443,445,873,1099,1433,1521,1900,2082,2083,2222,2601,2604,3128,3306,3311,3312,3389,4440,4848,5432,92,5569,5569,5569 ,6082,6379,7001-7010,7778,8080-8090,8649,8888,9000,9200,10000,11211,27017,28017,50000,50030,50060,135,139,445,53,88
注意:在检测网段C时,一定要确认ip是否属于目标,因为一个网段C中不一定所有的ip都属于目标。
16.网络空间搜索引擎
如果你想在短时间内快速采集资产,那么使用网络空间搜索引擎是一个不错的选择。 可以直观的看到边站、端口、站点标题、IP等信息,点击列出站点即可直接访问。 判断是否是您需要的站点信息。 FOFA 的通用语法
1、同IP端站:ip="192.168.0.1"
2、C段:ip="192.168.0.0/24"
3.子域名:domain=""
4.标题/关键字:title="百度"
5.如果需要将结果缩小到某个城市,可以拼接语句
title="百度" && region="北京"
17.扫描敏感目录/文件
扫描敏感目录需要强大的字典,需要平时积累。 拥有强大的词典可以更高效地查明网站的管理后台。 常见的敏感文件如.git文件泄露,.svn文件泄露,phpinfo泄露等,这一步就成功了一半,各种扫描器就够了。 在域名中输入目标站点,选择对应的词典类型,即可开始扫描,非常方便。
17.1. 御剑
17.2. 7kbstorm
17.3. 扫描仪
在已经安装pip的前提下,可以直接:
<p style="margin-top: 0px;margin-bottom: 0px;">pip install -r requirements.txt</p>
用法示例:
扫描单个 Web 服务
python BBScan.py --host
扫描下其他主机
python BBScan.py --host --network 28
扫描txt文件中的所有主机
蟒蛇 BBScan.py -f .txt
从文件夹中导入所有主机并扫描
python BBScan.py -d 目标/
--network参数用于设置子网掩码,小公司设置为28~30,中型公司设置为26~28,大公司设置为24~26
当然,尽量避免设置为24,扫描太耗时,除非你想在每个src中多扫描几个漏洞。
这个插件是从内部扫描器中提取的,感谢 Jekkay Hu
如果你有非常有用的规则,请找几个网站验证测试一下,然后pull request
脚本也会优化,接下来的事情:
添加有用的规则,更好地分类规则,细化
然后,您可以直接从 rules\request 文件夹中导入 HTTP_request
优化扫描逻辑
17.4. 目录映射
<p style="margin-top: 0px;margin-bottom: 0px;">pip install -r requirement.txt<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />https://github.com/H4ckForJob/dirmap</p>
单一目标
<p style="margin-top: 0px;margin-bottom: 0px;">python3 dirmap.py -i https://target.com -lcf</p>
多个目标
<p style="margin-top: 0px;margin-bottom: 0px;">python3 dirmap.py -iF urls.txt -lcf</p>
17.5。 直接搜索
解压目录搜索.zip
python3 dirsearch.py -u -e *
17.6. 火药
<p style="margin-top: 0px;margin-bottom: 0px;">sudo apt-get install gobuster<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />gobuster dir -u https://www.servyou.com.cn/ -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt -x php -t 50</p>
dir -u URL w dictionary -x 指定后缀 -t 线程数
<p style="margin-top: 0px;margin-bottom: 0px;">dir -u https://www.servyou.com.cn/ -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt -x "php,html,rar,zip" -d --wildcard -o servyou.log | grep ^"3402"</p>
17.7. 网站文件
机器人.txt
跨域.xml
站点地图.xml
后台目录
网站安装包
网站上传目录
mysql管理页面
php信息
网站文本编辑器
测试文件
网站备份文件(.rar、zip、.7z、.tar.gz、.bak)
DS_Store 文件
vim 编辑器备份文件 (.swp)
WEB—INF/web.xml 文件
15.git
16.svn
18.扫描网页备份
例如
配置.php
配置.php~
配置.php.bak
配置.php.swp
配置.php.rar
配置文件.php.tar.gz
19.网站头部信息采集
1.中间件:web服务【Web Servers】apache iis7 iis7.5 iis8 nginx WebLogic tomcat
2.网站组件:js组件jquery、vue页面布局bootstrap
通过浏览器访问
Firefox 插件 Wappalyzer
curl命令查询头部信息
卷曲-i
20. 敏感文件搜索 20.1. GitHub 搜索
in:name test #仓库标题搜索收录关键字test
in:descripton test #仓库描述搜索收录关键字
in:readme test #Readme文件搜索收录关键字
搜索某些系统的密码
++密码+3306&type=密码
github关键词监控
谷歌搜索
站点:sa 密码
站点:root密码
站点:用户;密码
网站:inurl:sql
SVN信息采集
站点:svn
站点:svn 用户名
站点:svn密码
站点:svn 用户名密码
综合信息采集
站点:密码
站点:ftp ftppassword
站点:密码
网站:内部
+&类型=代码
20.2. 谷歌黑客
站点:域名
inurl:url中存在的关键字网页
intext:网页正文中的关键词
filetype:指定文件类型
20.3。 乌云漏洞库
20.4。 网盘搜索
凌云搜索
潘多多:
泛搜索搜索:
泛搜索:
20.5。 社会工作图书馆
姓名/常用id/邮箱/密码/手机登录网盘网站邮箱查找敏感信息
机器人
20.6. 网站注册信息
查询网站注册信息
它通常与社会工程库一起使用。
20.7。 js敏感信息
20.7.1。 搜索器
python3 JSFinder.py -u
python3 JSFinder.py -u -d
python3 JSFinder.py -u -d -ou mi_url.txt -os mi_subdomain.txt
当你想获取更多信息时,可以使用-d进行深度爬取获取更多内容,使用命令-ou、-os指定子域保存的URL和文件名
批量指定url和js链接,获取里面的url。
指定网址:
python JSFinder.py -f 文本.txt
指定JS:
python JSFinder.py -f 文本.txt -j
20.7.2。 加壳模糊器
找到网站交互界面授权密钥
随着WEB前端打包工具的普及,你在日常的渗透测试和安全服务中是否遇到越来越多以Webpack packager为代表的网站? 这类打包器会将整个站点的API和API参数打包在一起进行集中web调用,也方便我们快速发现网站的功能和API列表,但是往往这些打包器生成的JS文件数量异常庞大且总是 JS 代码量极其庞大(高达数万行),给我们手动测试带来了极大的不便,于是 Packer Fuzzer 软件应运而生。
本工具支持自动模糊提取目标站点对应的API和API对应的参数内容,支持模糊高效模糊高效检测七大漏洞:未授权访问、敏感信息泄露、CORS、SQL注入、横向越权访问、弱口令、任意文件上传快速检测。 扫描结束后,该工具还支持自动生成扫描报告,可以选择便于分析的HTML版本,也可以选择比较正规的doc、pdf、txt版本。
sudo apt-get 安装 nodejs && sudo apt-get 安装 npm
混帐克隆
pip3 install -r requirements.txt
python3 PackerFuzzer.py -u
20.7.3。 秘密发现者
一个基于Python脚本的JavaScript敏感信息搜索工具
python3 SecretFinder.py -i -e
cms识别
采集网站信息后,应对网站进行指纹识别。 通过识别指纹,可以确定目标的cms和version,方便下一步测试计划的制定。 可以使用public poc或者自己积累相应的方法进行正式的渗透测试。
21.1. 云溪
21.2. 潮汐指纹
21.3。 CMS指纹识别
确认
21.4。 什么cms
21.5。 御cms识别
22. 非常规作业
1、如果找到了目标的某项资产,却无从下手搜集目标的其他资产,可以查看网站正文中是否有目标的特征,然后使用网络空间搜索引擎(如fofa , 等)特征进行搜索,如:body=”XX公司”或body=”baidu”等。
这种方式一般适用于特征明显、资产数量多的标的,效果往往比较突出。
2、通过以上方式找到特征后,再次搜索body,再搜索,此时fofa上显示的ip,大概率是真实ip。
3.如果需要针对政府网站,可以在批量获取网站首页的时候使用
然后可以结合上一步的方法进行进一步的信息采集。
23、SSL/TLS证书查询
SSL/TLS 证书通常收录域名、子域名和电子邮件地址等信息。 结合证书中的信息,您可以更快地定位到目标资产,获取目标资产的更多信息。
SSL证书搜索引擎:
%。
GetDomainsBySSL.py
24.找到厂商的ip段
25. 移动资产采集 25.1. 微信小程序 支付宝小程序 查看全部
事实:做了N个采集,都是处理内容失败(官方看下)
采集器的问题我们开发已经查过了,下面是他们的回答:
个别文章采集不到和跳课的原因主要有两个。
一种是php无法读取对方的网站。
二是php从对方服务器获取图片保存到本地的时间可能过长。 而且,有些东西读过了,但是图片读不出来(读图片的时候网络突然忙,导致图片打不开)。

这块不是程序造成的,原因是:
1.网络繁忙导致php执行超时
2、目标内容(包括:URL、图片)无响应、404错误或其他错误。
造成这种情况的原因有很多,比如网络拥堵,防盗机制,你自己的服务器突然以某种方式繁忙等等。
解决方案:

全部采集完之后,可以再进行一次采集,这样已经采集到的内容会被跳过,重新采集因为网络繁忙而失败的内容。
ss6 -> ss7采集机制调整不多,所以不会有6线7的不稳定因素
后续版本会在采集机制上做更多的优化。
定时任务采集、断点续采集、内容图片分离采集等。
汇总:渗透测试之信息收集篇(含思维导图)
爱站记录查询
域名助手备案信息查询
11、查询绿盟科技的whois信息
域名查询
查看注册人和邮箱获取更多域名
12. 采集子域 12.1。 子域的功能
采集子域名可以扩大测试范围,同一域名下的二级域名都属于目标范围。
12.2. 常用方法
子域中常见的资产类型一般包括办公系统、邮件系统、论坛、商城等管理系统,网站管理后台也可能出现在子域中。
首先找到目标站点,在官网可以找到相关资产(主要是办公系统、邮件系统等)。 关注页面底部,可能会有管理后台等收获。
查找目标域名信息的方法如下:
FOFA title="公司名称"
百度intitle=公司名称
Google intitle=公司名称
站长之家,可直接搜索名称或网站域名查看相关信息:
钟馗之眼站点=域名
找到官网后,采集子域名。 以下是一些采集子域名的推荐方法。 可以直接输入域名查询。
12.3. 域名类型
A记录、别名记录(CNAME)、MX记录、TXT记录、NS记录:
12.3.1。 A(地址)记录:
用于指定主机名(或域名)对应的IP地址记录。 用户可以将域名下的网站服务器指向自己的网站服务器。 同时,您还可以设置您的域名的二级域名。
12.3.2。 别名(CNAME)记录:
也称为规范名称。 这种类型的记录允许您将多个名称映射到同一台计算机。 通常用于同时提供 WWW 和 MAIL 服务的计算机。 例如,有一台名为“”的计算机(A记录)。 同时提供WWW和MAIL服务,方便用户访问服务。 可以为这台计算机设置两个别名(CNAME):WWW 和 MAIL。 这两个别名的全称是“”和“”。 其实都指向“”。
当你有多个域名需要指向同一个服务器IP时,可以使用同样的方法。 这时候可以给一个域名做一个A记录指向服务器IP,然后把其他域名别名到有之前A记录的域名上。 那么当你的服务器IP地址发生变化的时候,你就不用费心费力地一个一个的改域名了。 您只需要更改做A记录的域名,其他做别名的域名也会自动更改为新的IP地址。
12.3.3。 如何检测CNAME记录?
1、进入命令状态; (开始菜单-运行-CMD【回车】);
2、输入命令“nslookup -q=cname 此处填写对应的域名或二级域名”,查看返回结果是否与设置一致。
12.3.4。 MX(邮件交换器)记录:
它是一条邮件交换记录,指向一个邮件服务器,供电子邮件系统在发送邮件时根据收件人的地址后缀定位邮件服务器。 例如,当Internet上的用户要寄信给 时,用户的邮件系统通过DNS查找该域名的MX记录。 如果MX记录存在,则用户计算机将邮件发送到MX记录指定的邮件服务器。 .
12.3.5。 什么是 TXT 记录? :
TXT记录一般是指对主机名或域名的指令集,例如:
1) admin IN TXT "jack, mobile:";
2)mail IN TXT》邮件主机,存放于xxx,管理员:AAA,Jim IN TXT》联系人:
也就是你可以设置TXT,这样别人就可以联系到你了。
如何检测TXT记录?
1、进入命令状态; (开始菜单-运行-CMD【回车】);
2、输入命令“nslookup -q=txt 在此填写对应的域名或二级域名”,查看返回结果是否与设置一致。
12.3.6。 什么是 NS 记录?
ns记录的全称是Name Server,也就是域名服务器记录,用来明确你的域名当前是由哪台DNS服务器解析的。
12.3.7。 子域名在线查询1
12.3.8。 子域名在线查询2
12.3.9。 DNS检测
12.3.10。 IP138查询子域
12.3.11。 FOFA 搜索子域
语法:域=“”
Tips:以上两种方式不需要爆破,查询速度快。 当资产需要快速采集时,可以先使用,以后再通过其他方式补充。
12.3.12。 Hackertarget 查询子域
注意:通过该方法查询子域名可以得到目标的一个大概的ip段,然后就可以通过ip采集信息了。
12.4。 360映射空间
领域: ”*。”
12.4.1。 图层子域挖掘机
12.4.2。 子域蛮干
pip 安装 aiodns
运行命令 subDomainsBrute.py
subDomainsBrute.py --full -o freebuf2.txt
12.4.3。 子列表3r
pip install -r requirements.txt
提示:以上方法是对子域名进行爆破,因为字典功能更强大,所以效率更高。
帮助文档
<p style="margin-top: 0px;margin-bottom: 0px;">usage: sublist3r.py [-h] -d DOMAIN [-b [BRUTEFORCE]] [-p PORTS] [-v [VERBOSE]]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />[-t THREADS] [-e ENGINES] [-o OUTPUT] [-n]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />OPTIONS:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-h, --help show this help message and exit<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-d DOMAIN, --domain DOMAIN<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Domain name to enumerate it's subdomains<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-b [BRUTEFORCE], --bruteforce [BRUTEFORCE]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Enable the subbrute bruteforce module<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-p PORTS, --ports PORTS<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Scan the found subdomains against specified tcp ports<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-v [VERBOSE], --verbose [VERBOSE]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Enable Verbosity and display results in realtime<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-t THREADS, --threads THREADS<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Number of threads to use for subbrute bruteforce<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-e ENGINES, --engines ENGINES<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Specify a comma-separated list of search engines<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-o OUTPUT, --output OUTPUT<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Save the results to text file<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-n, --no-color Output without color</p>
示例:python sublist3r.py -d
中文翻译
-h:帮助
-d : 指定主域名枚举子域名
-b : 调用 subbrute 来暴力枚举子域名
-p : 指定扫描子域名的tpc端口
-v :显示实时详细结果
-t : 指定线程
-e : 指定搜索引擎
-o : 将结果保存到文本
-n : 没有颜色的输出
扫描子域的默认参数
python sublist3r.py -d
使用暴力枚举子域
python sublist3r -b -d
12.4.4。 python2.7.14环境
;C:\Python27;C:\Python27\脚本
12.4.5。 万物皆可
pip3 install --user -r requirements.txt -i
python3 oneforall.py --target run /*采集*/
爆炸子域
例子:
<p style="margin-top: 0px;margin-bottom: 0px;">brute.py --target domain.com --word True run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --targets ./domains.txt --word True run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target domain.com --word True --concurrent 2000 run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target domain.com --word True --wordlist subnames.txt run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target domain.com --word True --recursive True --depth 2 run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target d.com --fuzz True --place m.*.d.com --rule '[a-z]' run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target d.com --fuzz True --place m.*.d.com --fuzzlist subnames.txt run</p>
12.4.6。 域名
<p style="margin-top: 0px;margin-bottom: 0px;">dnsburte.py -d aliyun.com -f dnspod.csv -o aliyun.log<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />wydomain.py -d aliyun.com</p>
12.4.7。 模糊域
12.4.8。 隐藏域名主机冲突
隐藏资产检测-主机碰撞
很多时候访问目标资产的IP响应是:401、403、404、500,但是域名请求可以返回正常的业务系统(禁止直接IP访问),因为大部分需要绑定向主机正常请求访问(目前互联网公司的基本做法)(域名已经删除了A记录,但是反向生成的配置还没有更新),那么我们就可以将采集到的目标域名和目标资产的IP段,并用IP段+域名的形式进行捆绑碰撞,可以发现很多有趣的东西。
发送http请求时,将域名和IP列表配对,然后遍历发送请求(相当于修改本地hosts文件),对比对应的标题和响应包大小,快速找出一些隐藏资产。
Hosts collision需要目标的域名和目标的相关IP作为字典
更不用说域名了
相关IP来源有:
目标域名历史分析IP
ip 常规
13.端口扫描
确定目标的大概ip段后,可以先检测ip的开放端口。 某些特定服务可能会在默认端口上打开。 检测开放端口有利于快速采集目标资产,找到目标网站的其他功能站点。
13.1. msscan 端口扫描
msscan -p 1-65535 ip --rate=1000
13.2. 御剑端口扫描工具
13.3. nmap扫描端口并检测端口信息
常用参数,如:
nmap -sV 192.168.0.2
nmap -sT 92.168.0.2
nmap -Pn -A -sC 192.168.0.2
nmap -sU -sT -p0-65535 192.168.122.1
用于扫描目标主机服务版本号和开放端口
如果需要扫描多个ip或者ip段,可以保存到一个txt文件中
nmap -iL ip.txt
扫描列表中的所有 ip。
Nmap 是最常用的端口检测方法。 操作简单,输出结果非常直观。
13.4. 在线端口检测
13.5。 端口扫描器
御剑、msscan、nmap等
御剑高速端口扫描器:
填写你要扫描的ip段(如果只扫描一个ip,只需填写起始IP和结束IP),可以选择不更改默认端口列表,也可以选择自己指定端口。
13.6. 渗透端口
21,22,23,1433,152,3306,3389,5432,5900,50070,50030,50000,27017,27018,11211,9200,9300,7001,7002,6379,5984,873,443,8000-9090,80- 89,80,10000,8888,8649,8083,8080,8089,9090,7778,7001,7002,6082,5984,4440,3312,3311,3128,2601,2604,2222,2082,2083,389,88,512, 51 1025,111,1521,445,135,139,53
13.7。 穿透常用端口及对应服务
1、Web类(web漏洞/敏感目录)
第三方通用组件漏洞struts thinkphp jboss ganglia zabbix
80 网站
80-89网页

8000-9090 网页
2.数据库类(弱口令扫描)
第1433章
第1521章
3306 MySQL
5432 PostgreSQL 数据库
3.特殊服务类(未授权/命令执行类/漏洞)
第443章
873 Rsync 未经授权
5984 CouchDB:5984/_utils/
6379 Redis 未授权
7001,7002 WebLogic默认弱口令,反序列化
9200,9300 elasticsearch 参考WooYun:玩服务器ElasticSearch命令执行漏洞
11211 memcache 未授权访问
27017、27018 Mongodb 未授权访问
执行了 50000 个 SAP 命令
50070、50030 hadoop默认端口未授权访问
4.常用端口类(扫描弱口令/端口爆破)
21 英尺
22 SSH
23 远程登录
2601,2604 zebra路由,默认密码zebra
3389 远程桌面
5.端口总明细
21 英尺
22 SSH
23 远程登录
80 网站
80-89网页
第161话
第389章
443 SSL Heartbleed 和一些网络漏洞测试
445 家中小企业
512,513,514 雷克斯
873 Rsync 未经授权
1025,111 NFS
第1433章
1521 甲骨文:(iSqlPlus 端口:5560、7778)
2082/2083 cpanel主机管理系统登录(国外多用)
2222 DA虚拟主机管理系统登录(国外多用)
2601,2604 zebra路由,默认密码zebra
3128 squid代理默认端口,如果不设置密码,可以直接漫游内网
3306 MySQL
3312/3311康乐主机管理系统登录
3389 远程桌面
4440 rundeck 参考无云:借新浪服务成功漫游新浪内网
5432 PostgreSQL 数据库
5900 越南
5984 CouchDB:5984/_utils/
6082 Varnish 参考WooYun:Varnish HTTP加速器 CLI 未授权访问容易导致直接篡改网站或代理访问内网
6379 Redis 未授权
7001,7002 WebLogic默认弱口令,反序列化
7778 Kloxo 主机控制面板登录
8000-9090是一些常用的web端口,有些运维喜欢在这些非80端口上开启管理后台
8080 tomcat/WDCP主机管理系统,默认弱密码
8080、8089、9090 JBOSS
8083 Vestacp主机管理系统(国外多用)
8649 神经节
8888 amh/LuManager主机管理系统默认端口
9200,9300 elasticsearch 参考WooYun:玩服务器ElasticSearch命令执行漏洞
10000 Virtualmin/Webmin服务器虚拟主机管理系统
11211 memcache 未授权访问
27017、27018 Mongodb 未授权访问
28017 mongodb统计页面
执行了 50000 个 SAP 命令
50070、50030 hadoop默认端口未授权访问
13.8。 常用端口及攻击方式
14.查找真实ip
如果目标网站使用CDN,则隐藏cdn的真实ip。 要想找到真实服务器,就必须获取真实ip,根据这个ip继续查询侧站。
注意:很多情况下,虽然主站使用了CDN,但是子域名不一定使用CDN。 如果主网站和子域名在同一个ip段,那么也是找到子域名真实ip的一种方式。
14.1. Ping多处确认是否使用CDN
14.2. 查询历史DNS解析记录
在查询到的历史分析记录中,最早的历史分析IP很可能记录的是真实IP。 推荐使用此方法快速找到真实IP,但不是所有网站都能找到。
14.2.1。 域名数据库
14.2.2。 微步在线
14.2.3。
14.2.4。 查看DNS
14.3. php信息
如果目标网站存在phpinfo泄露等情况,可以在phpinfo中的SERVER_ADDR或_SERVER["SERVER_ADDR"]中查找真实ip
14.4. 绕过CDN
绕过CDN的方法有很多,请参考
15. 边站和C段
边站通常有业务功能站点。 建议先采集已有IP的边站,再检测C网段,确定C网段的目标后,在C网段的基础上重新采集边站。
辅助站点是与已知目标站点位于同一服务器上但具有不同端口的站点。 通过以下方法搜索到副站后,首先访问确定是否是您需要的站址信息。
15.1.1。 站长主页
用ip网站查询
15.2. 谷歌黑客
15.2.1。 网络空间搜索引擎
比如FOFA搜边站和C段
这种方式效率更高,可以直观的看到站点标题,但也有不收录不常用端口的情况。 虽然这种情况很少见,但您可以在后期补充资产时,通过以下方式再次扫描领取。
15.2.2。 线上段c
c部分使用脚本
<p style="margin-top: 0px;margin-bottom: 0px;">pip install requests<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />#coding:utf-8<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import requests<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import json<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />def get_c(ip):<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print("正在收集{}".format(ip))<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />url="http://api.webscan.cc/?action=query&ip={}".format(ip)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />req=requests.get(url=url)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />html=req.text<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />data=req.json()<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />if 'null' not in html:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />with open("resulit.txt", 'a', encoding='utf-8') as f:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />f.write(ip + '\n')<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />f.close()<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for i in data:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />with open("resulit.txt", 'a',encoding='utf-8') as f:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />f.write("\t{} {}\n".format(i['domain'],i['title']))<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print(" [+] {} {}[+]".format(i['domain'],i['title']))<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />f.close()<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />def get_ips(ip):<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />iplist=[]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />ips_str = ip[:ip.rfind('.')]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for ips in range(1, 256):<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />ipadd=ips_str + '.' + str(ips)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />iplist.append(ipadd)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />return iplist<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />ip=input("请你输入要查询的ip:")<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />ips=get_ips(ip)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for p in ips:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />get_c(p)</p>
15.2.3。 Nmap、Msscan扫描等
例如:nmap -p 80,443,8000,8080 -Pn 192.168.0.0/24
15.2.4。 公共端口表
21,22,23,80-90,161,389,443,445,873,1099,1433,1521,1900,2082,2083,2222,2601,2604,3128,3306,3311,3312,3389,4440,4848,5432,92,5569,5569,5569 ,6082,6379,7001-7010,7778,8080-8090,8649,8888,9000,9200,10000,11211,27017,28017,50000,50030,50060,135,139,445,53,88
注意:在检测网段C时,一定要确认ip是否属于目标,因为一个网段C中不一定所有的ip都属于目标。
16.网络空间搜索引擎
如果你想在短时间内快速采集资产,那么使用网络空间搜索引擎是一个不错的选择。 可以直观的看到边站、端口、站点标题、IP等信息,点击列出站点即可直接访问。 判断是否是您需要的站点信息。 FOFA 的通用语法
1、同IP端站:ip="192.168.0.1"
2、C段:ip="192.168.0.0/24"
3.子域名:domain=""
4.标题/关键字:title="百度"
5.如果需要将结果缩小到某个城市,可以拼接语句
title="百度" && region="北京"
17.扫描敏感目录/文件
扫描敏感目录需要强大的字典,需要平时积累。 拥有强大的词典可以更高效地查明网站的管理后台。 常见的敏感文件如.git文件泄露,.svn文件泄露,phpinfo泄露等,这一步就成功了一半,各种扫描器就够了。 在域名中输入目标站点,选择对应的词典类型,即可开始扫描,非常方便。
17.1. 御剑
17.2. 7kbstorm
17.3. 扫描仪
在已经安装pip的前提下,可以直接:
<p style="margin-top: 0px;margin-bottom: 0px;">pip install -r requirements.txt</p>
用法示例:
扫描单个 Web 服务
python BBScan.py --host
扫描下其他主机
python BBScan.py --host --network 28
扫描txt文件中的所有主机
蟒蛇 BBScan.py -f .txt
从文件夹中导入所有主机并扫描
python BBScan.py -d 目标/
--network参数用于设置子网掩码,小公司设置为28~30,中型公司设置为26~28,大公司设置为24~26
当然,尽量避免设置为24,扫描太耗时,除非你想在每个src中多扫描几个漏洞。
这个插件是从内部扫描器中提取的,感谢 Jekkay Hu
如果你有非常有用的规则,请找几个网站验证测试一下,然后pull request
脚本也会优化,接下来的事情:
添加有用的规则,更好地分类规则,细化
然后,您可以直接从 rules\request 文件夹中导入 HTTP_request
优化扫描逻辑
17.4. 目录映射
<p style="margin-top: 0px;margin-bottom: 0px;">pip install -r requirement.txt<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />https://github.com/H4ckForJob/dirmap</p>
单一目标
<p style="margin-top: 0px;margin-bottom: 0px;">python3 dirmap.py -i https://target.com -lcf</p>
多个目标
<p style="margin-top: 0px;margin-bottom: 0px;">python3 dirmap.py -iF urls.txt -lcf</p>
17.5。 直接搜索
解压目录搜索.zip
python3 dirsearch.py -u -e *
17.6. 火药
<p style="margin-top: 0px;margin-bottom: 0px;">sudo apt-get install gobuster<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />gobuster dir -u https://www.servyou.com.cn/ -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt -x php -t 50</p>
dir -u URL w dictionary -x 指定后缀 -t 线程数
<p style="margin-top: 0px;margin-bottom: 0px;">dir -u https://www.servyou.com.cn/ -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt -x "php,html,rar,zip" -d --wildcard -o servyou.log | grep ^"3402"</p>
17.7. 网站文件
机器人.txt
跨域.xml
站点地图.xml
后台目录
网站安装包
网站上传目录
mysql管理页面
php信息
网站文本编辑器
测试文件
网站备份文件(.rar、zip、.7z、.tar.gz、.bak)
DS_Store 文件
vim 编辑器备份文件 (.swp)
WEB—INF/web.xml 文件
15.git
16.svn
18.扫描网页备份
例如
配置.php
配置.php~
配置.php.bak
配置.php.swp
配置.php.rar
配置文件.php.tar.gz
19.网站头部信息采集
1.中间件:web服务【Web Servers】apache iis7 iis7.5 iis8 nginx WebLogic tomcat
2.网站组件:js组件jquery、vue页面布局bootstrap
通过浏览器访问
Firefox 插件 Wappalyzer
curl命令查询头部信息
卷曲-i
20. 敏感文件搜索 20.1. GitHub 搜索
in:name test #仓库标题搜索收录关键字test
in:descripton test #仓库描述搜索收录关键字
in:readme test #Readme文件搜索收录关键字
搜索某些系统的密码
++密码+3306&type=密码
github关键词监控
谷歌搜索
站点:sa 密码
站点:root密码
站点:用户;密码
网站:inurl:sql
SVN信息采集
站点:svn
站点:svn 用户名
站点:svn密码
站点:svn 用户名密码
综合信息采集
站点:密码
站点:ftp ftppassword
站点:密码
网站:内部
+&类型=代码
20.2. 谷歌黑客
站点:域名
inurl:url中存在的关键字网页
intext:网页正文中的关键词
filetype:指定文件类型
20.3。 乌云漏洞库
20.4。 网盘搜索
凌云搜索
潘多多:
泛搜索搜索:
泛搜索:
20.5。 社会工作图书馆
姓名/常用id/邮箱/密码/手机登录网盘网站邮箱查找敏感信息
机器人
20.6. 网站注册信息
查询网站注册信息
它通常与社会工程库一起使用。
20.7。 js敏感信息
20.7.1。 搜索器
python3 JSFinder.py -u
python3 JSFinder.py -u -d
python3 JSFinder.py -u -d -ou mi_url.txt -os mi_subdomain.txt
当你想获取更多信息时,可以使用-d进行深度爬取获取更多内容,使用命令-ou、-os指定子域保存的URL和文件名
批量指定url和js链接,获取里面的url。
指定网址:
python JSFinder.py -f 文本.txt
指定JS:
python JSFinder.py -f 文本.txt -j
20.7.2。 加壳模糊器
找到网站交互界面授权密钥
随着WEB前端打包工具的普及,你在日常的渗透测试和安全服务中是否遇到越来越多以Webpack packager为代表的网站? 这类打包器会将整个站点的API和API参数打包在一起进行集中web调用,也方便我们快速发现网站的功能和API列表,但是往往这些打包器生成的JS文件数量异常庞大且总是 JS 代码量极其庞大(高达数万行),给我们手动测试带来了极大的不便,于是 Packer Fuzzer 软件应运而生。
本工具支持自动模糊提取目标站点对应的API和API对应的参数内容,支持模糊高效模糊高效检测七大漏洞:未授权访问、敏感信息泄露、CORS、SQL注入、横向越权访问、弱口令、任意文件上传快速检测。 扫描结束后,该工具还支持自动生成扫描报告,可以选择便于分析的HTML版本,也可以选择比较正规的doc、pdf、txt版本。
sudo apt-get 安装 nodejs && sudo apt-get 安装 npm
混帐克隆
pip3 install -r requirements.txt
python3 PackerFuzzer.py -u
20.7.3。 秘密发现者
一个基于Python脚本的JavaScript敏感信息搜索工具
python3 SecretFinder.py -i -e
cms识别
采集网站信息后,应对网站进行指纹识别。 通过识别指纹,可以确定目标的cms和version,方便下一步测试计划的制定。 可以使用public poc或者自己积累相应的方法进行正式的渗透测试。
21.1. 云溪
21.2. 潮汐指纹
21.3。 CMS指纹识别
确认
21.4。 什么cms
21.5。 御cms识别
22. 非常规作业
1、如果找到了目标的某项资产,却无从下手搜集目标的其他资产,可以查看网站正文中是否有目标的特征,然后使用网络空间搜索引擎(如fofa , 等)特征进行搜索,如:body=”XX公司”或body=”baidu”等。
这种方式一般适用于特征明显、资产数量多的标的,效果往往比较突出。
2、通过以上方式找到特征后,再次搜索body,再搜索,此时fofa上显示的ip,大概率是真实ip。
3.如果需要针对政府网站,可以在批量获取网站首页的时候使用
然后可以结合上一步的方法进行进一步的信息采集。
23、SSL/TLS证书查询
SSL/TLS 证书通常收录域名、子域名和电子邮件地址等信息。 结合证书中的信息,您可以更快地定位到目标资产,获取目标资产的更多信息。
SSL证书搜索引擎:
%。
GetDomainsBySSL.py
24.找到厂商的ip段
25. 移动资产采集 25.1. 微信小程序 支付宝小程序
最新版本:iOS 开发苹果登录授权 Sign In with Apple
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-12-19 12:30
那里
网上关于苹果登录授权的文章很多,但大部分介绍都有些繁琐,实际操作简单。核心需要获取三个参数:team_id、client_id、key_id,然后通过uapp命令生成JWT令牌到后端。苹果
评测有规定,如果有微信、QQ、脸书等第三方账号登录,必须添加苹果登录名,否则将无法通过审核。苹果登录仅适用于iOS 13及更高版本。
1. 获得team_id和client_id
转到“标识符”页面:/帐户/资源/标识符/列表
单击标识符+,请注意此处输入的com.code0xff.uapp.login是client_id,请将其替换为您自己的。
查看下面的服务列表,勾选“通过 Apple 登录”,点按“编辑”,然后输入您自己的服务器端回调 URL:
到目前为止,我们已经成功获得了两个参数,team_id和client_id。
2. 获取钥匙.txt并key_id
转到密钥页面:/帐户/资源/身份验证密钥/列表
单击“密钥+”创建密钥,然后操作:输入“密钥名称”,选中“通过Apple登录”、“配置”。
配置页面,检查要在哪个应用程序中使用:
点击下载,下载后将文件名改为key.txt放入项目的jwt目录下:
jwt
├── config.json
└── key.txt
到目前为止,我们已经成功获得了钥匙.txt和key_id。
3. 通过 uapp 获取 JWT 代币
JWT 令牌适用于服务器,有效期为 6 个月,因此请记住在将近 6 个月时重新生成并替换它。
如果你还没有安装 uapp,你可以通过 npm 安装它:
npm i -g uapp
完成上述 jwt 目录有一个键.txt后,在下面创建 config.json 并放入上面获得的team_id、client_id key_id。
jwt/config.json如下:
{
"team_id": "3DSM494K6L",
"client_id": "com.code0xff.uapp.login",
"key_id": "3C7FMSZC8Z"
}
然后执行:
uapp info
您可以看到 JWT 令牌,将其发送到后端以供使用。
最近发布:atomic email hunter v11.0
原子邮箱猎手软件是一款非常简单实用的邮箱采集工具软件,原子邮箱猎手软件可以轻松扫描采集邮箱。除了搜索电子邮件地址、电话号码等出现在文本中的信息外,该软件还可以将电子邮件分类。用户可以使用软件进行搜索,用户只需输入关键词即可找到自己需要的内容,非常方便实用。
原子电子邮件猎人软件功能:
1. 如果您选择了 网站 并想从中提取电子邮件地址,请输入其 URL 地址
2. 该程序将采集 网站 上可用的所有电子邮件地址。
3. 您还可以从需要登录名和密码的页面中检索地址。
Atomic 电子邮件猎手软件亮点:
1.程序搜索与指定关键字匹配的网站,并从这些网站中提取电子邮件地址。
2. 如果您没有相关的 网站 列表来搜索电子邮件地址,这可以让您接触到目标受众。
3. 搜索网站邮箱的关键词,输入网址和关键字进行搜索。
原子电子邮件猎人软件功能:
1. 将从这些网页中提取电子邮件地址。搜索可以限于特定国家。
2. 程序将查找网站 中所有带有关键字的页面。从网页中提取电话号码。
3.这是唯一缺少原子猎人的设施,但您可以通过原子铅提取获得电话号码。
原子电子邮件猎手软件的优点:
1. 该程序可以猜测电子邮件地址所有者居住在哪个国家/地区
2. 此插件是为社交网络LinkedIn开发的,用于提取电子邮件地址。
3. 获得必要地址所需要做的就是选择关键词、区域和类别
原子邮件猎手软件介绍:
原子邮箱猎手邮箱采集软件是一款非常不错的邮箱采集软件,该软件可以扫描采集邮箱中的所有邮件,并对邮件进行分类,此外,您还可以搜索文本中出现的电子邮件地址、电话号码等。 查看全部
最新版本:iOS 开发苹果登录授权 Sign In with Apple
那里
网上关于苹果登录授权的文章很多,但大部分介绍都有些繁琐,实际操作简单。核心需要获取三个参数:team_id、client_id、key_id,然后通过uapp命令生成JWT令牌到后端。苹果
评测有规定,如果有微信、QQ、脸书等第三方账号登录,必须添加苹果登录名,否则将无法通过审核。苹果登录仅适用于iOS 13及更高版本。
1. 获得team_id和client_id
转到“标识符”页面:/帐户/资源/标识符/列表
单击标识符+,请注意此处输入的com.code0xff.uapp.login是client_id,请将其替换为您自己的。
查看下面的服务列表,勾选“通过 Apple 登录”,点按“编辑”,然后输入您自己的服务器端回调 URL:
到目前为止,我们已经成功获得了两个参数,team_id和client_id。
2. 获取钥匙.txt并key_id

转到密钥页面:/帐户/资源/身份验证密钥/列表
单击“密钥+”创建密钥,然后操作:输入“密钥名称”,选中“通过Apple登录”、“配置”。
配置页面,检查要在哪个应用程序中使用:
点击下载,下载后将文件名改为key.txt放入项目的jwt目录下:
jwt
├── config.json
└── key.txt
到目前为止,我们已经成功获得了钥匙.txt和key_id。
3. 通过 uapp 获取 JWT 代币
JWT 令牌适用于服务器,有效期为 6 个月,因此请记住在将近 6 个月时重新生成并替换它。

如果你还没有安装 uapp,你可以通过 npm 安装它:
npm i -g uapp
完成上述 jwt 目录有一个键.txt后,在下面创建 config.json 并放入上面获得的team_id、client_id key_id。
jwt/config.json如下:
{
"team_id": "3DSM494K6L",
"client_id": "com.code0xff.uapp.login",
"key_id": "3C7FMSZC8Z"
}
然后执行:
uapp info
您可以看到 JWT 令牌,将其发送到后端以供使用。
最近发布:atomic email hunter v11.0
原子邮箱猎手软件是一款非常简单实用的邮箱采集工具软件,原子邮箱猎手软件可以轻松扫描采集邮箱。除了搜索电子邮件地址、电话号码等出现在文本中的信息外,该软件还可以将电子邮件分类。用户可以使用软件进行搜索,用户只需输入关键词即可找到自己需要的内容,非常方便实用。
原子电子邮件猎人软件功能:
1. 如果您选择了 网站 并想从中提取电子邮件地址,请输入其 URL 地址
2. 该程序将采集 网站 上可用的所有电子邮件地址。
3. 您还可以从需要登录名和密码的页面中检索地址。
Atomic 电子邮件猎手软件亮点:
1.程序搜索与指定关键字匹配的网站,并从这些网站中提取电子邮件地址。
2. 如果您没有相关的 网站 列表来搜索电子邮件地址,这可以让您接触到目标受众。
3. 搜索网站邮箱的关键词,输入网址和关键字进行搜索。
原子电子邮件猎人软件功能:
1. 将从这些网页中提取电子邮件地址。搜索可以限于特定国家。
2. 程序将查找网站 中所有带有关键字的页面。从网页中提取电话号码。

3.这是唯一缺少原子猎人的设施,但您可以通过原子铅提取获得电话号码。
原子电子邮件猎手软件的优点:
1. 该程序可以猜测电子邮件地址所有者居住在哪个国家/地区
2. 此插件是为社交网络LinkedIn开发的,用于提取电子邮件地址。
3. 获得必要地址所需要做的就是选择关键词、区域和类别
原子邮件猎手软件介绍:
原子邮箱猎手邮箱采集软件是一款非常不错的邮箱采集软件,该软件可以扫描采集邮箱中的所有邮件,并对邮件进行分类,此外,您还可以搜索文本中出现的电子邮件地址、电话号码等。
汇总:免费的:WordPress自动采集多个网站数据并自动发布的免费插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-11-07 06:47
WordPress自动采集多个网站数据并自动发布免费插件
云简介采集
:
————————–
作为最新的采集器形式,云采集具有更新快的优点,没有传统软件采集器没有的本地操作。与插件采集器相比,它不会占用大量的服务器资源,将是新型采集器发展方向。
WordPress自动采集插件连接到免费优采云云采集系统,采集系统通过云采集自动发布模式进行真实*敏感*敏感*字*钱。
主要特点:
————————–
云配置采集脚本,自动发布到网站系统,支持网站,包括知乎、好搜索问答、天涯问答、豆瓣群、网站站长首页、汽车之家、*敏*感*字*知识、哔哔李碧丽视频、胡普论坛等。更多数据源正在不断添加!
特征:
————————–
* 云采集,无需安装软件
* 自动发布到网站和匹配字段
*支持采集用户名或当前用户随机提供
*支持将主题保存到自动采集
如何使用:
1. 注册账户
(登录官方网站注册账号)。
2. 获取规则
(转到规则市场获取免费规则模板)。
3. 采集数据
4. 安装插件
(登录到WordPress后端以安装优采云WordPress插件)。
5. 设置地址
(在发布设置中填写WordPress上的发布地址,可以手动或自动发布)。
6.选择要发布的版本
(采集完成后,选中“发布”或“自动发布”
.)
友情提醒:
————————–
优采云云采集的官方网站地址是:
优采云云采集有关如何
使用它的官方网站的图像和链接在下面的相关链接中。
我们仍在改进。如果您有任何需求或建议,可以直接与我们联系。
优采云采集器是一种网站采集器,它会自动采集云中的相关文章,并根据用户提供的关键词发布到用户的网站。它可以自动识别各种网页上的标题、正文等信息,不需要用户编写任何采集规则即可实现全网采集。采集内容后,自动计算内容与设定关键词的相关性,只向用户推送相关文章。支持标题前缀、自动加粗关键词、插入永久链接、自动提取标签标签、自动内部链接、自动映射、自动伪原创、内容过滤和替换、电话号码和URL清理、定时采集、百度主动提交等一系列SEO功能。用户只需设置关键词和相关要求,即可实现完全托管、零维护网站内容更新。无限数量的网站,无论是单网站还是大批量站群,都可以非常方便地管理。
官方发布:墨子学院为你揭秘:如何使用百度站长平台分析网站?
虽然这三种工具的数据功能领域相互渗透,但习惯上将三种工具的功能分开,让它们各司其职。站长工具(SEO综合查询)负责最外层数据,数据专家(百度统计)负责统计数据,百度站长平台负责内部数据。因此,站长需要了解SEO优化的数据分析。数据从何而来?数据是通过一些站长工具获取的。然后我们将与您讨论如何使用百度站长平台。
首先,让我们澄清一个概念。百度站长平台用于统计网站的内部数据。内部数据包括死链接、URL、索引量、关键词等,理清了这个概念后,分析百度站长平台的使用就更方便了。
1. 添加站点。不用说,注册一个站长账号,在“站点管理”下添加我们自己的网站域名,然后会弹出一个“验证站点”页面。站点验证包括文件验证、HTML标签验证和CNAME验证。个人 如果您习惯使用便捷的文件验证,您可以大致分两步完成验证:
1.下载验证文件。
2. 使用FTP工具将验证文件上传到网站的根目录。
简单方便。无需输入站长的个人信息。这主要是为了方便以后百度站长平台和个人站长之间的联系。
2. 站点地图。这里的sitemap其实和前面提到的sitemap是一样的。不同的是,站点地图是主动提交给百度的。前面提到的sitemap存放在网站根目录下,写入robots.txt文件。,属于被动等待蜘蛛索引网页的性质。说白了,就是一句话:主动攻击,被动等待。
3.死链接提交。向百度提交死链接报告后,搜索引擎会根据该报告识别并删除死链接页面的快照。在此之前,死链接需要针对404页面进行优化。具体操作如下:
1.使用检测死链接的URL。
2.将死链接URL放在一个txt文本中,每个URL单独一行(动态URL使用xml)。
3.将准备好的文本上传到网站根目录,然后将文件地址提交给百度站长平台。
四、网址提交。这个功能有点鸡肋。对于大中型的网站,不可能更新一篇文章文章,提交一个URL,但是对于博客或者小型网站,不提交肯定是收录。,至少黑苹果的博客投了几次(包括其他大的网站投稿),我觉得不可能收录或者收录,不是很有用。建议直接使用站点地图。
5、网站修订版,网站修订版包括域名修订版和目录修订版。顾名思义,域名改版其实就是域名的变更。首先,必须设置 301 永久重定向以定向到新域名。这个工具的作用是当网站修改后的URL发生变化(包括域名变化)并使用301重定向时,百度对301重定向的响应极慢,而网站修改工具提交是为了加快百度的响应速度。
目录修订也是如此。例如,如果更改了目录名称,或者更改了文本名称,设置重定向后,使用此工具向百度提交数据将有助于加快百度的响应时间。
第六,百度指数。收录查询,该工具已有站点数量,可以作为网站收录的参考,查询也比较方便。尽管百度曾表示网站数据不准确,但仍不能否认它的作用。对于索引卷查询,可以查询索引卷。
但是,该索引仅表示已被百度索引,并不表示将被收录发布。对于用户来说,网站收录查询的是目录,百度索引查询工具数据和收录相比,也是不准确的,所以它的意义不算太大,而且仅供参考。建议使用 site 指令来替换此功能。
7.外链分析。外链查询可以说是百度站长工具中最重要、最实用的工具之一。可以更好的查询自己网站的外链数据,了解分析自身网站在外链的优势和信息,了解网站的信息是一个工具不容忽视;其次,它可以了解和分析竞争对手的外部链接,也可以从其他网站中找到外部链接资源。
分析对手一直是网站seo不可缺少的部分,其中外链是重点之一,而百度外链工具可以对竞争对手进行比较好的分析,也可以分析竞争对手并寻找其他站点的外部链接资源,然后指定响应策略以超越它,以增强网站的竞争力。
除此之外,拒绝反向链接工具是一项功能。可以拒绝网站中存在的垃圾外链,避免垃圾外链对网站造成负面影响。这个工具可以很好的避开竞争对手的框架和无意生成的外部链接。垃圾链接。唯一的缺点是响应速度较慢,但缺点掩盖不了优点,它的作用不可否认。
8. 至于其他工具,比如爬取异常、爬取诊断等,这些工具不作为重点,你只需要了解它们是如何工作的。一些函数如搜索关键词 是数据的统计类别。我个人认为这些功能只是对百度站长平台的附加补充。
以上八项对百度站长平台有一定的经验和分享,百度站长平台的其他功能会在后续深入探讨,如关键词搭建分析、开放平台连接等一系列使用方法技能…… 查看全部
汇总:免费的:WordPress自动采集多个网站数据并自动发布的免费插件
WordPress自动采集多个网站数据并自动发布免费插件
云简介采集
:
————————–
作为最新的采集器形式,云采集具有更新快的优点,没有传统软件采集器没有的本地操作。与插件采集器相比,它不会占用大量的服务器资源,将是新型采集器发展方向。
WordPress自动采集插件连接到免费优采云云采集系统,采集系统通过云采集自动发布模式进行真实*敏感*敏感*字*钱。
主要特点:
————————–
云配置采集脚本,自动发布到网站系统,支持网站,包括知乎、好搜索问答、天涯问答、豆瓣群、网站站长首页、汽车之家、*敏*感*字*知识、哔哔李碧丽视频、胡普论坛等。更多数据源正在不断添加!
特征:
————————–
* 云采集,无需安装软件
* 自动发布到网站和匹配字段
*支持采集用户名或当前用户随机提供
*支持将主题保存到自动采集
如何使用:
1. 注册账户
(登录官方网站注册账号)。
2. 获取规则
(转到规则市场获取免费规则模板)。
3. 采集数据
4. 安装插件
(登录到WordPress后端以安装优采云WordPress插件)。
5. 设置地址
(在发布设置中填写WordPress上的发布地址,可以手动或自动发布)。
6.选择要发布的版本
(采集完成后,选中“发布”或“自动发布”
.)
友情提醒:
————————–
优采云云采集的官方网站地址是:
优采云云采集有关如何
使用它的官方网站的图像和链接在下面的相关链接中。
我们仍在改进。如果您有任何需求或建议,可以直接与我们联系。
优采云采集器是一种网站采集器,它会自动采集云中的相关文章,并根据用户提供的关键词发布到用户的网站。它可以自动识别各种网页上的标题、正文等信息,不需要用户编写任何采集规则即可实现全网采集。采集内容后,自动计算内容与设定关键词的相关性,只向用户推送相关文章。支持标题前缀、自动加粗关键词、插入永久链接、自动提取标签标签、自动内部链接、自动映射、自动伪原创、内容过滤和替换、电话号码和URL清理、定时采集、百度主动提交等一系列SEO功能。用户只需设置关键词和相关要求,即可实现完全托管、零维护网站内容更新。无限数量的网站,无论是单网站还是大批量站群,都可以非常方便地管理。
官方发布:墨子学院为你揭秘:如何使用百度站长平台分析网站?
虽然这三种工具的数据功能领域相互渗透,但习惯上将三种工具的功能分开,让它们各司其职。站长工具(SEO综合查询)负责最外层数据,数据专家(百度统计)负责统计数据,百度站长平台负责内部数据。因此,站长需要了解SEO优化的数据分析。数据从何而来?数据是通过一些站长工具获取的。然后我们将与您讨论如何使用百度站长平台。
首先,让我们澄清一个概念。百度站长平台用于统计网站的内部数据。内部数据包括死链接、URL、索引量、关键词等,理清了这个概念后,分析百度站长平台的使用就更方便了。
1. 添加站点。不用说,注册一个站长账号,在“站点管理”下添加我们自己的网站域名,然后会弹出一个“验证站点”页面。站点验证包括文件验证、HTML标签验证和CNAME验证。个人 如果您习惯使用便捷的文件验证,您可以大致分两步完成验证:
1.下载验证文件。
2. 使用FTP工具将验证文件上传到网站的根目录。
简单方便。无需输入站长的个人信息。这主要是为了方便以后百度站长平台和个人站长之间的联系。

2. 站点地图。这里的sitemap其实和前面提到的sitemap是一样的。不同的是,站点地图是主动提交给百度的。前面提到的sitemap存放在网站根目录下,写入robots.txt文件。,属于被动等待蜘蛛索引网页的性质。说白了,就是一句话:主动攻击,被动等待。
3.死链接提交。向百度提交死链接报告后,搜索引擎会根据该报告识别并删除死链接页面的快照。在此之前,死链接需要针对404页面进行优化。具体操作如下:
1.使用检测死链接的URL。
2.将死链接URL放在一个txt文本中,每个URL单独一行(动态URL使用xml)。
3.将准备好的文本上传到网站根目录,然后将文件地址提交给百度站长平台。
四、网址提交。这个功能有点鸡肋。对于大中型的网站,不可能更新一篇文章文章,提交一个URL,但是对于博客或者小型网站,不提交肯定是收录。,至少黑苹果的博客投了几次(包括其他大的网站投稿),我觉得不可能收录或者收录,不是很有用。建议直接使用站点地图。
5、网站修订版,网站修订版包括域名修订版和目录修订版。顾名思义,域名改版其实就是域名的变更。首先,必须设置 301 永久重定向以定向到新域名。这个工具的作用是当网站修改后的URL发生变化(包括域名变化)并使用301重定向时,百度对301重定向的响应极慢,而网站修改工具提交是为了加快百度的响应速度。
目录修订也是如此。例如,如果更改了目录名称,或者更改了文本名称,设置重定向后,使用此工具向百度提交数据将有助于加快百度的响应时间。

第六,百度指数。收录查询,该工具已有站点数量,可以作为网站收录的参考,查询也比较方便。尽管百度曾表示网站数据不准确,但仍不能否认它的作用。对于索引卷查询,可以查询索引卷。
但是,该索引仅表示已被百度索引,并不表示将被收录发布。对于用户来说,网站收录查询的是目录,百度索引查询工具数据和收录相比,也是不准确的,所以它的意义不算太大,而且仅供参考。建议使用 site 指令来替换此功能。
7.外链分析。外链查询可以说是百度站长工具中最重要、最实用的工具之一。可以更好的查询自己网站的外链数据,了解分析自身网站在外链的优势和信息,了解网站的信息是一个工具不容忽视;其次,它可以了解和分析竞争对手的外部链接,也可以从其他网站中找到外部链接资源。
分析对手一直是网站seo不可缺少的部分,其中外链是重点之一,而百度外链工具可以对竞争对手进行比较好的分析,也可以分析竞争对手并寻找其他站点的外部链接资源,然后指定响应策略以超越它,以增强网站的竞争力。
除此之外,拒绝反向链接工具是一项功能。可以拒绝网站中存在的垃圾外链,避免垃圾外链对网站造成负面影响。这个工具可以很好的避开竞争对手的框架和无意生成的外部链接。垃圾链接。唯一的缺点是响应速度较慢,但缺点掩盖不了优点,它的作用不可否认。
8. 至于其他工具,比如爬取异常、爬取诊断等,这些工具不作为重点,你只需要了解它们是如何工作的。一些函数如搜索关键词 是数据的统计类别。我个人认为这些功能只是对百度站长平台的附加补充。
以上八项对百度站长平台有一定的经验和分享,百度站长平台的其他功能会在后续深入探讨,如关键词搭建分析、开放平台连接等一系列使用方法技能……
解决方案:如何获取百度云下载直链
采集交流 • 优采云 发表了文章 • 0 个评论 • 345 次浏览 • 2022-11-03 11:17
2021-07-27
最近在百度云学习资源上遇到了一个大问题。百度云把我的速度锁死了。然后百度了一个PanDownload神器,感觉很好用。总的原则是获取直接链接,然后全速下载。我很好奇,想看看如何获取百度云直连。我找到了一个现在仍然可以使用的方法。虽然有缺陷,只能用于从下载直链获取单个文件,但没关系。毕竟压缩后的文件也是单个文件哈哈哈。
1.将要下载的资源保存到自己的网盘中。
2. 右键分享。创建公共链接,一定要创建公共链接。得到下面的结果。
3.复制链接并用Chrome打开。打开控制台
4、输入如下js代码,用ajax发送请求。
$.ajax({
type: "POST",
url: "/api/sharedownload?sign="+yunData.SIGN+"×tamp="+yunData.TIMESTAMP,
data: "encrypt=0&product=share&uk="+yunData.SHARE_UK+"&primaryid="+yunData.SHARE_ID+"&fid_list=%5B"+yunData.FS_ID+"%5D",
dataType: "json",
success: function(d){
<p>
window.location.href = d.list[0].dlink;
}
});</p>
5. 然后它会自动开始作为直接链接下载。
当然,最后还是推荐使用 Pandownload 之类的。当然,这种东西大家都知道,传播得越快,死的也就越快。在这种情况下,我们可以通过上面的方法获取直接链接,然后愉快的下载。其实感觉就是处理后才能得到直链,最后向Pandownload的作者们致敬!
分类:
技术要点:
相关文章:
解决方案:调用链系列(三):解读UAVStack中的贪吃蛇-调用链
为了从请求中提取body和header,使代码的改动尽可能小,进入容器的请求必须被统一拦截,否则代码必须嵌入到所有的HttpServlet实现类中。在这里,我们需要再次感谢 servlet 说明符为我们提供的过滤机制。
该规范指定过滤器是一段可重用的代码,用于转换 HTTP 请求、响应和标头信息的内容。过滤器通常不会为请求创建响应,而是修改或调整请求和响应。其中,filter主要提供四种拦截方式:
这里我们只使用 REQUEST 模式。配置过滤器后,我们可以从过滤器的doFilter方法中获取HttpServletRequest和HttpServletResponse(简称请求和响应)。
获取标题
在上面,我们通过过滤机制获得了请求和响应。打开对应的源码实现,我们可以找到如下API:
规范为我们提供了一个 API 来直接获取标头。通过结合 getHeaderNames() 和 getHeader(String name) 方法,我们可以轻松获取请求和响应中的标头。
得到身体
获取请求体和响应体的方法大致相同。这里以request为例,后面会调整差异。
从请求API中我们可以发现body在java中是以ServletInputStream的形式存储的,而ServletInputStream是一个继承的InputStream。如果我们直接读取,用户获取到的body会是空的(因为InputStream只能读取一次),除非可以把指针放回去)。这里需要用到servlet的包装机制。
Servlet 中的包装器
有的人可能不会用到requestWrapper和responseWrapper,这里简单介绍一下。wrapper 是通过继承 servlet 规范中的 HttpServletResponseWrapper 和 HttpServletRequestWrapper 实现的装饰模式。相当于请求和响应的一个shell,类似于java中的代理,这样操作请求和响应的所有动作都会经过我们自定义的wrapper,使得在请求中重复获取body成为可能和回应。
编写自己的包装器
我们以 request 为例来说明如何编写自定义包装器。打开servlet-api源码可以看到HttpServletRequestWrapper继承了ServletRequestWrapper,实现了HttpServletRequest接口。
并且大部分方法已经在 ServletRequestWrapper 中为我们实现了。
我们只需要重写我们关心的几个方法,例如:getInputStream和getReader等。
当用户尝试调用 getReader 或 getInputStream 时,我们将其替换为自己的流,并额外提供一个 getContent() 方法来提前读取 StringBuilder 或 byte[] 中的正文内容进行提取。
编写好自定义包装器后,我们可以将其放入我们上面定义的过滤器中,替换原来的请求。然后把用户的请求变成我们的requestWrapper。
优化提取逻辑
上面提到的方法等价于预先读取收录body的inputStream,并将其存储在一个中间byte[]或StringBuilder中。当用户调用 getInputStream 时,byte[] 或 StringBuilder 被转换为 inputStream 返回给用户。如果用户根本不关心这个http请求的body,也就是用户根本不使用这个请求的body,那么我们提前把它读出来,相当于做了无用功(浪费宝贵的 CPU 时间和内存资源)。如何保证inputStream在用户使用时是只读的,当用户或后续逻辑多次获取body时,是我们的优化目标。
对于答案,我们继续从源码中寻找。既然我们的数据在 inputStream 中,我们就跟着源码看看是怎么读取的。在servlet规范中,inputStream被封装成ServletInputStream,ServletInputStream提供了readLine方法。往里面看,可以看到它们都调用了inputStream中的read方法,如下图:
既然read方法是一个统一的入口,那我们只要自定义一个ServletInputStream,重写里面的read()方法,就可以修改所有的read方法吗?答案是肯定的。只要用户调用了read方法,我们就悄悄地把我们关心的内容复制一份,这样我们只在用户使用body的时候才去采集。
下一步是如何确保用户调用 read 多次,我们总是只读取一次。在这里,我们需要使用一个 AtomicBoolean 标志,当执行完整读取时将其设置为 true,否则设置为 false。最终效果如下:
举一反三
在这里,我们使用 servlet 规范中的过滤器和包装器机制来获取进入我们容器(tomcat)的所有 http 请求的主体和标头。这个能力在我们实际生产中可以进一步扩展,比如:我们需要在客户端加密一些敏感数据然后在服务端进行统一解密,格式化客户端发送的数据格式等等。可以限制你的是你的想象力。希望本次技术分享对您以后的工作和生活有所帮助。
总结
读完这篇文章,读者应该可以在不影响原代码的情况下,通过简单的代码获取所有进入容器的http请求的body和header。虽然可能需要适配一些特殊的技术栈,比如如果项目中使用了jersey,参数等信息以application/x-www-form-urlencoded的形式传递,而服务端不使用@ FormParam注解获取参数,那么我们获取body后,用户将无法获取参数;例如,如何区分媒体类型,如果是图像,则不会被提取。但我们已经验证,这条路是可行的,而且是成功的一半。 查看全部
解决方案:如何获取百度云下载直链
2021-07-27
最近在百度云学习资源上遇到了一个大问题。百度云把我的速度锁死了。然后百度了一个PanDownload神器,感觉很好用。总的原则是获取直接链接,然后全速下载。我很好奇,想看看如何获取百度云直连。我找到了一个现在仍然可以使用的方法。虽然有缺陷,只能用于从下载直链获取单个文件,但没关系。毕竟压缩后的文件也是单个文件哈哈哈。
1.将要下载的资源保存到自己的网盘中。
2. 右键分享。创建公共链接,一定要创建公共链接。得到下面的结果。
3.复制链接并用Chrome打开。打开控制台
4、输入如下js代码,用ajax发送请求。
$.ajax({
type: "POST",
url: "/api/sharedownload?sign="+yunData.SIGN+"×tamp="+yunData.TIMESTAMP,
data: "encrypt=0&product=share&uk="+yunData.SHARE_UK+"&primaryid="+yunData.SHARE_ID+"&fid_list=%5B"+yunData.FS_ID+"%5D",
dataType: "json",
success: function(d){
<p>

window.location.href = d.list[0].dlink;
}
});</p>
5. 然后它会自动开始作为直接链接下载。
当然,最后还是推荐使用 Pandownload 之类的。当然,这种东西大家都知道,传播得越快,死的也就越快。在这种情况下,我们可以通过上面的方法获取直接链接,然后愉快的下载。其实感觉就是处理后才能得到直链,最后向Pandownload的作者们致敬!
分类:
技术要点:
相关文章:
解决方案:调用链系列(三):解读UAVStack中的贪吃蛇-调用链
为了从请求中提取body和header,使代码的改动尽可能小,进入容器的请求必须被统一拦截,否则代码必须嵌入到所有的HttpServlet实现类中。在这里,我们需要再次感谢 servlet 说明符为我们提供的过滤机制。
该规范指定过滤器是一段可重用的代码,用于转换 HTTP 请求、响应和标头信息的内容。过滤器通常不会为请求创建响应,而是修改或调整请求和响应。其中,filter主要提供四种拦截方式:
这里我们只使用 REQUEST 模式。配置过滤器后,我们可以从过滤器的doFilter方法中获取HttpServletRequest和HttpServletResponse(简称请求和响应)。
获取标题
在上面,我们通过过滤机制获得了请求和响应。打开对应的源码实现,我们可以找到如下API:
规范为我们提供了一个 API 来直接获取标头。通过结合 getHeaderNames() 和 getHeader(String name) 方法,我们可以轻松获取请求和响应中的标头。
得到身体
获取请求体和响应体的方法大致相同。这里以request为例,后面会调整差异。
从请求API中我们可以发现body在java中是以ServletInputStream的形式存储的,而ServletInputStream是一个继承的InputStream。如果我们直接读取,用户获取到的body会是空的(因为InputStream只能读取一次),除非可以把指针放回去)。这里需要用到servlet的包装机制。
Servlet 中的包装器
有的人可能不会用到requestWrapper和responseWrapper,这里简单介绍一下。wrapper 是通过继承 servlet 规范中的 HttpServletResponseWrapper 和 HttpServletRequestWrapper 实现的装饰模式。相当于请求和响应的一个shell,类似于java中的代理,这样操作请求和响应的所有动作都会经过我们自定义的wrapper,使得在请求中重复获取body成为可能和回应。
编写自己的包装器
我们以 request 为例来说明如何编写自定义包装器。打开servlet-api源码可以看到HttpServletRequestWrapper继承了ServletRequestWrapper,实现了HttpServletRequest接口。
并且大部分方法已经在 ServletRequestWrapper 中为我们实现了。
我们只需要重写我们关心的几个方法,例如:getInputStream和getReader等。
当用户尝试调用 getReader 或 getInputStream 时,我们将其替换为自己的流,并额外提供一个 getContent() 方法来提前读取 StringBuilder 或 byte[] 中的正文内容进行提取。
编写好自定义包装器后,我们可以将其放入我们上面定义的过滤器中,替换原来的请求。然后把用户的请求变成我们的requestWrapper。

优化提取逻辑
上面提到的方法等价于预先读取收录body的inputStream,并将其存储在一个中间byte[]或StringBuilder中。当用户调用 getInputStream 时,byte[] 或 StringBuilder 被转换为 inputStream 返回给用户。如果用户根本不关心这个http请求的body,也就是用户根本不使用这个请求的body,那么我们提前把它读出来,相当于做了无用功(浪费宝贵的 CPU 时间和内存资源)。如何保证inputStream在用户使用时是只读的,当用户或后续逻辑多次获取body时,是我们的优化目标。
对于答案,我们继续从源码中寻找。既然我们的数据在 inputStream 中,我们就跟着源码看看是怎么读取的。在servlet规范中,inputStream被封装成ServletInputStream,ServletInputStream提供了readLine方法。往里面看,可以看到它们都调用了inputStream中的read方法,如下图:
既然read方法是一个统一的入口,那我们只要自定义一个ServletInputStream,重写里面的read()方法,就可以修改所有的read方法吗?答案是肯定的。只要用户调用了read方法,我们就悄悄地把我们关心的内容复制一份,这样我们只在用户使用body的时候才去采集。
下一步是如何确保用户调用 read 多次,我们总是只读取一次。在这里,我们需要使用一个 AtomicBoolean 标志,当执行完整读取时将其设置为 true,否则设置为 false。最终效果如下:
举一反三
在这里,我们使用 servlet 规范中的过滤器和包装器机制来获取进入我们容器(tomcat)的所有 http 请求的主体和标头。这个能力在我们实际生产中可以进一步扩展,比如:我们需要在客户端加密一些敏感数据然后在服务端进行统一解密,格式化客户端发送的数据格式等等。可以限制你的是你的想象力。希望本次技术分享对您以后的工作和生活有所帮助。
总结
读完这篇文章,读者应该可以在不影响原代码的情况下,通过简单的代码获取所有进入容器的http请求的body和header。虽然可能需要适配一些特殊的技术栈,比如如果项目中使用了jersey,参数等信息以application/x-www-form-urlencoded的形式传递,而服务端不使用@ FormParam注解获取参数,那么我们获取body后,用户将无法获取参数;例如,如何区分媒体类型,如果是图像,则不会被提取。但我们已经验证,这条路是可行的,而且是成功的一半。
定制化方案:fluent-bit debug调试,采集kubernetes podIP
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-10-30 09:19
有时候调试 fluent-bit 的配置以达到想要的输出效果并不是一件简单的事情,下面就是通过调试镜像来调试 fluent-bit 采集kubernetes pod 的 IP。
官方的流利位文档给出了一个用于调试的图像:docs.fluentbit.io/manual/installation/docker
dockerhub存储库链接到:/r/fluent/fluent-bit/
部署流畅位调试
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: fluent-bit-debug
name: fluent-bit-debug
namespace: kubesphere-logging-system
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app.kubernetes.io/name: fluent-bit-debug
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app.kubernetes.io/name: fluent-bit-debug
name: fluent-bit-debug
spec:
containers:
- env:
- name: NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
command:
- /usr/local/bin/sh
- -c
- sleep 9999
image: fluent/fluent-bit:1.6.9-debug
imagePullPolicy: IfNotPresent
name: fluent-bit
ports:
- containerPort: 2020
name: metrics
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/lib/docker/containers
name: varlibcontainers
readOnly: true
- mountPath: /fluent-bit/config
name: config
readOnly: true
- mountPath: /var/log/
name: varlogs
readOnly: true
- mountPath: /var/log/journal
name: systemd
readOnly: true
- mountPath: /fluent-bit/tail
name: positions
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: fluent-bit
serviceAccountName: fluent-bit
terminationGracePeriodSeconds: 30
volumes:
- hostPath:
path: /var/lib/docker/containers
type: ""
name: varlibcontainers
- name: config
secret:
defaultMode: 420
secretName: fluent-bit-debug-config
- hostPath:
path: /var/log
type: ""
name: varlogs
- hostPath:
path: /var/log/journal
type: ""
name: systemd
- emptyDir: {}
name: positions
使用的secret:fluent-bit-debug-config如下,收录两个键:
第一个 parsers.conf: 为空;配置详情请参考官方文档:配置文件
第二个 fluent-bit.conf 配置需要根据情况进行配置,下面主要针对不同场景给出。它还将涉及使用kubesphere和Filter CRD。
使用流利位exec 到容器中可以使用 /fluent-bit/
bin/fluent-bit 进行调试:
/fluent-bit/bin # ./fluent-bit -h
Usage: fluent-bit [OPTION]
Available Options
-b --storage_path=PATH specify a storage buffering path
-c --config=FILE specify an optional configuration file
-d, --daemon run Fluent Bit in background mode
-f, --flush=SECONDS flush timeout in seconds (default: 5)
-F --filter=FILTER set a filter
-i, --input=INPUT set an input
-m, --match=MATCH set plugin match, same as '-p match=abc'
-o, --output=OUTPUT set an output
-p, --prop="A=B" set plugin configuration property
-R, --parser=FILE specify a parser configuration file
-e, --plugin=FILE load an external plugin (shared lib)
-l, --log_file=FILE write log info to a file
-t, --tag=TAG set plugin tag, same as '-p tag=abc'
-T, --sp-task=SQL define a stream processor task
-v, --verbose increase logging verbosity (default: info)
-H, --http enable monitoring HTTP server
-P, --port set HTTP server TCP port (default: 2020)
-s, --coro_stack_size Set coroutines stack size in bytes (default: 24576)
-q, --quiet quiet mode
-S, --sosreport support report for Enterprise customers
-V, --version show version number
-h, --help print this help
Inputs
cpu CPU Usage
mem Memory Usage
thermal Thermal
kmsg Kernel Log Buffer
proc Check Process health
disk Diskstats
systemd Systemd (Journal) reader
netif Network Interface Usage
docker Docker containers metrics
docker_events Docker events
tail Tail files
dummy Generate dummy data
head Head Input
health Check TCP server health
collectd collectd input plugin
statsd StatsD input plugin
serial Serial input
stdin Standard Input
syslog Syslog
exec Exec Input
tcp TCP
mqtt MQTT, listen for Publish messages
forward Fluentd in-forward
<p>
random Random
Filters
alter_size Alter incoming chunk size
aws Add AWS Metadata
record_modifier modify record
throttle Throttle messages using sliding window algorithm
kubernetes Filter to append Kubernetes metadata
modify modify records by applying rules
nest nest events by specified field values
parser Parse events
expect Validate expected keys and values
grep grep events by specified field values
rewrite_tag Rewrite records tags
lua Lua Scripting Filter
stdout Filter events to STDOUT
Outputs
azure Send events to Azure HTTP Event Collector
azure_blob Azure Blob Storage
bigquery Send events to BigQuery via streaming insert
counter Records counter
datadog Send events to DataDog HTTP Event Collector
es Elasticsearch
exit Exit after a number of flushes (test purposes)
file Generate log file
forward Forward (Fluentd protocol)
http HTTP Output
influxdb InfluxDB Time Series
logdna LogDNA
loki Loki
kafka Kafka
kafka-rest Kafka REST Proxy
nats NATS Server
nrlogs New Relic
null Throws away events
plot Generate data file for GNU Plot
pgsql PostgreSQL
slack Send events to a Slack channel
splunk Send events to Splunk HTTP Event Collector
stackdriver Send events to Google Stackdriver Logging
stdout Prints events to STDOUT
syslog Syslog
tcp TCP Output
td Treasure Data
flowcounter FlowCounter
gelf GELF Output
cloudwatch_logs Send logs to Amazon CloudWatch
kinesis_firehose Send logs to Amazon Kinesis Firehose
s3 Send to S3
Internal
Event Loop = epoll
Build Flags = FLB_HAVE_HTTP_CLIENT_DEBUG FLB_HAVE_PARSER FLB_HAVE_RECORD_ACCESSOR FLB_HAVE_STREAM_PROCESSOR JSMN_PARENT_LINKS JSMN_STRICT FLB_HAVE_TLS FLB_HAVE_AWS FLB_HAVE_SIGNV4 FLB_HAVE_SQLDB FLB_HAVE_METRICS FLB_HAVE_HTTP_SERVER FLB_HAVE_SYSTEMD FLB_HAVE_FORK FLB_HAVE_TIMESPEC_GET FLB_HAVE_GMTOFF FLB_HAVE_UNIX_SOCKET FLB_HAVE_PROXY_GO FLB_HAVE_JEMALLOC JEMALLOC_MANGLE FLB_HAVE_LIBBACKTRACE FLB_HAVE_REGEX FLB_HAVE_UTF8_ENCODER FLB_HAVE_LUAJIT FLB_HAVE_C_TLS FLB_HAVE_ACCEPT4 FLB_HAVE_INOTIFY</p>
简单配置文件
以下是使用简单配置文件采集 calico-node-* pod 的日志:
[Service]
Parsers_File parsers.conf
[Input]
Name tail
Path /var/log/containers/*_kube-system_calico-node-*.log
Refresh_Interval 10
Skip_Long_Lines true
DB /fluent-bit/bin/pos.db
DB.Sync Normal
Mem_Buf_Limit 5MB
Parser docker
Tag kube.*
[Filter]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Labels false
Annotations true
[Output]
Name stdout
Match_Regex (?:kube|service)\.(.*)
使用以下命令在流畅位调试容器内启动测试:
/fluent-bit/bin # ./fluent-bit -c /fluent-bit/config/fluent-bit.conf
您可以看到标准输出日志输出:
[0] kube.var.log.containers.calico-node-lp4lm_kube-system_calico-node-cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81.log: [1634870260.700108403, {"log"=>"{"log":"2021-10-22 02:37:40.699 [INFO][85] monitor-addresses/startup.go 774: Using autodetected IPv4 address on interface bond4: 172.24.248.50/30\n","stream":"stdout","time":"2021-10-22T02:37:40.700056471Z"}", "kubernetes"=>{"pod_name"=>"calico-node-lp4lm", "namespace_name"=>"kube-system", "pod_id"=>"5a829979-9830-4b9c-a3cb-eeb6eee38bdd", "annotations"=>{"kubectl.kubernetes.io/restartedAt"=>"2021-10-20T23:00:27+08:00"}, "host"=>"node02", "container_name"=>"calico-node", "docker_id"=>"cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81", "container_hash"=>"calico/node@sha256:bc4a631d553b38fdc169ea4cb8027fa894a656e80d68d513359a4b9d46836b55", "container_image"=>"calico/node:v3.19.1"}}]
截取重要部分,查看尚未处理采集的K8s日志格式。
[
{
"kubernetes"=>{
"pod_name"=>"calico-node-lp4lm",
"namespace_name"=>"kube-system",
"pod_id"=>"5a829979-9830-4b9c-a3cb-eeb6eee38bdd",
"annotations"=>{
"kubectl.kubernetes.io/restartedAt"=>"2021-10-20T23:00:27+08:00"
},
"host"=>"node02",
"container_name"=>"calico-node",
"docker_id"=>"cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81",
"container_hash"=>"calico/node@sha256:bc4a631d553b38fdc169ea4cb8027fa894a656e80d68d513359a4b9d46836b55",
"container_image"=>"calico/node:v3.19.1"
}
}
]
添加了嵌套过滤器
展开 Kubernetes 块并添加 kubernetes_ 前缀:
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes
Add_prefix kubernetes_
这次测试输出,截取重要部分:
{
"kubernetes_pod_name"=>"calico-node-lp4lm",
"kubernetes_namespace_name"=>"kube-system",
"kubernetes_pod_id"=>"5a829979-9830-4b9c-a3cb-eeb6eee38bdd",
"kubernetes_annotations"=>{
"kubectl.kubernetes.io/restartedAt"=>"2021-10-20T23:00:27+08:00"
},
"kubernetes_host"=>"node02",
"kubernetes_container_name"=>"calico-node",
"kubernetes_docker_id"=>"cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81",
"kubernetes_container_hash"=>"calico/node@sha256:bc4a631d553b38fdc169ea4cb8027fa894a656e80d68d513359a4b9d46836b55",
"kubernetes_container_image"=>"calico/node:v3.19.1"
}
删除kubernetes_annotations块
[Filter]
Name modify
Match kube.*
Remove kubernetes_annotations
从kubernetes_annotations块中删除字段
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes_annotations
Add_prefix kubernetes_annotations_
[Filter]
Name modify
Match kube.*
Remove kubernetes_annotations_kubectl.kubernetes.io/restartedAt
或使用常规:
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes_annotations
Add_prefix kubernetes_annotations_
[Filter]
Name modify
Match kube.*
Remove_regex kubernetes_annotations_kubectl*
修改kubernetes_annotations块中的键名称
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes_annotations
Add_prefix kubernetes_annotations_
[Filter]
Name modify
Match kube.*
Rename kubernetes_annotations_kubectl.kubernetes.io/restartedAt podIPs
修改后:
[
{
"kubernetes_pod_name"=>"calico-node-lp4lm",
"kubernetes_namespace_name"=>"kube-system",
"kubernetes_pod_id"=>"5a829979-9830-4b9c-a3cb-eeb6eee38bdd",
"kubernetes_host"=>"node02",
"kubernetes_container_name"=>"calico-node",
"kubernetes_docker_id"=>"cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81",
"kubernetes_container_hash"=>"calico/node@sha256:bc4a631d553b38fdc169ea4cb8027fa894a656e80d68d513359a4b9d46836b55",
"kubernetes_container_image"=>"calico/node:v3.19.1",
"podIPs"=>"2021-10-20T23:00:27+08:00"
}
]
结合 ks 配置采集 podIP
结合 kubesphere Filter CR 来配置 采集podIP 并删除其他不相关的注释。
由于印花布用作 CNI,因此与 Pod IP 相关的注释将添加到 Pod 注释中。
您需要在注释 (/podIP) 中保留一个密钥并删除其他密钥,因此在更改下面要保留的密钥的名称后,删除整个注释。
Kubernetes Filter CR 配置如下:
apiVersion: logging.kubesphere.io/v1alpha2
kind: Filter
metadata:
labels:
logging.kubesphere.io/component: logging
logging.kubesphere.io/enabled: 'true'
name: kubernetes
namespace: kubesphere-logging-system
spec:
filters:
- kubernetes:
annotations: true
kubeCAFile: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
kubeTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
kubeURL: 'https://kubernetes.default.svc:443'
labels: false
- nest:
addPrefix: kubernetes_
nestedUnder: kubernetes
operation: lift
- nest:
addPrefix: kubernetes_annotations_
nestedUnder: kubernetes_annotations
operation: lift
- modify:
rules:
- remove: stream
- remove: kubernetes_pod_id
- remove: kubernetes_host
- remove: kubernetes_container_hash
- rename:
kubernetes_annotations_cni.projectcalico.org/podIPs: kubernetes_podIPs
- removeRegex: kubernetes_annotations*
- nest:
nestUnder: kubernetes_annotations
operation: nest
removePrefix: kubernetes_annotations_
wildcard:
- kubernetes_annotations_*
- nest:
nestUnder: kubernetes
operation: nest
removePrefix: kubernetes_
wildcard:
- kubernetes_*
match: kube.*
Kubernetes Filter CR
生成的流畅位配置配置如下(只看 Filter 部分,省略输入输出 CR)。
[Service]
Parsers_File parsers.conf
[Input]
Name tail
Path /var/log/containers/*.log
Exclude_Path /var/log/containers/*_kubesphere-logging-system_events-exporter*.log,/var/log/containers/kube-auditing-webhook*_kubesphere-logging-system_kube-auditing-webhook*.log
Refresh_Interval 10
Skip_Long_Lines true
DB /fluent-bit/tail/pos.db
DB.Sync Normal
Mem_Buf_Limit 5MB
Parser docker
Tag kube.*
[Filter]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Labels false
Annotations true
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes
Add_prefix kubernetes_
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes_annotations
Add_prefix kubernetes_annotations_
[Filter]
Name modify
Match kube.*
Remove stream
Remove kubernetes_pod_id
Remove kubernetes_host
Remove kubernetes_container_hash
Rename kubernetes_annotations_cni.projectcalico.org/podIPs kubernetes_podIPs
Remove_regex kubernetes_annotations*
[Filter]
Name nest
Match kube.*
Operation nest
Wildcard kubernetes_annotations_*
Nest_under kubernetes_annotations
Remove_prefix kubernetes_annotations_
[Filter]
Name nest
Match kube.*
Operation nest
Wildcard kubernetes_*
Nest_under kubernetes
Remove_prefix kubernetes_
[Output]
Name es
Match_Regex (?:kube|service)\.(.*)
Host es-cdc-a-es-http.cdc.svc.xke.test.cn
Port 9200
HTTP_User elastic
HTTP_Passwd elasticpwd
Logstash_Format true
Logstash_Prefix ks-logstash-log
Time_Key @timestamp
您可以在 kibana 中看到 podIP 采集:
作者简洁
作者:小万
唐,一个热爱写作、认真写作的家伙,目前维护着原创公众号:“我的小湾汤”,专注于撰写GO语言、Docker、Kubernetes、Java等开发、运维知识等提升硬实力文章,期待大家的关注。转载说明:请务必注明出处(注明:来自公众号:我的小碗汤,作者:小碗汤)。
整套解决方案:如何采集shopline产品并导入到店铺,一键刊登独立站shopify爆款产品
独立站的同学会遇到上架产品到店的问题。一个产品从title-main image-detail页面一个一个复制到自己的店铺,需要花费很多时间。
如果采集里面有几十个或者几百个产品,手动做显然是很难的。现在有一种方法可以帮助您快速轻松地解决它!!一键式采集产品神器
这是一套奶妈级教程,请耐心阅读,小案例使用!!
Step 1:首先我们要知道采集的store是什么saas平台
网页空白处右键——点击查看网页源代码
在源码页面按Ctrl+F弹出搜索框,进入建站平台,如shopline
第二步:进入Crossker官网-选择产品采集工具
扫一扫公众号登录,每天5次免费试用,联系客服获取更多试用
第三步:选择采集管理-产品分类采集,进入分类链接
时间不用填写,采集的个数不要超过2000
第 4 步:选择 采集管理 - 任务列表
有四种状态:采集表示采集成功,等待采集表示排队,点击右上角刷新按钮查看进度
第五步:选择产品管理——在产品管理中输入采集的编号,点击搜索
记得点击搜索全选,如果没有搜索到默认是30,点击导出为CSV格式
第六步:登录Shopline进入后台商品-商品管理,点击导入商品-shopify表格导入
上传并导入采集的CSV文件,完成导入
第八步:等待系统加载,所有产品导入完毕
除了支持shopline采集外,还支持Shopify、Shoplaza、Oemsaas(YY2.0)、Shopplus、Shopbase等主流SaaS平台的产品采集。WordPress、Woocommerce、Magento 项目、Aliexpress 项目也可以处理。Ueeshop、OpenCart等平台后续会更新!总之,有什么需要,都满足你!
您还在犹豫?都是小问题,联系客服免费试用Crossker产品采集工具
我们刚刚成立Crossker跨境交流群,欢迎各位跨境电商朋友加入!有任何问题请随时提出,我们将尽最大努力为您解答,帮助独立卖家共同成长!
客服C:Crossker-tool
扫描下方二维码加入群~ 查看全部
定制化方案:fluent-bit debug调试,采集kubernetes podIP
有时候调试 fluent-bit 的配置以达到想要的输出效果并不是一件简单的事情,下面就是通过调试镜像来调试 fluent-bit 采集kubernetes pod 的 IP。
官方的流利位文档给出了一个用于调试的图像:docs.fluentbit.io/manual/installation/docker
dockerhub存储库链接到:/r/fluent/fluent-bit/
部署流畅位调试
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: fluent-bit-debug
name: fluent-bit-debug
namespace: kubesphere-logging-system
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app.kubernetes.io/name: fluent-bit-debug
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app.kubernetes.io/name: fluent-bit-debug
name: fluent-bit-debug
spec:
containers:
- env:
- name: NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
command:
- /usr/local/bin/sh
- -c
- sleep 9999
image: fluent/fluent-bit:1.6.9-debug
imagePullPolicy: IfNotPresent
name: fluent-bit
ports:
- containerPort: 2020
name: metrics
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/lib/docker/containers
name: varlibcontainers
readOnly: true
- mountPath: /fluent-bit/config
name: config
readOnly: true
- mountPath: /var/log/
name: varlogs
readOnly: true
- mountPath: /var/log/journal
name: systemd
readOnly: true
- mountPath: /fluent-bit/tail
name: positions
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: fluent-bit
serviceAccountName: fluent-bit
terminationGracePeriodSeconds: 30
volumes:
- hostPath:
path: /var/lib/docker/containers
type: ""
name: varlibcontainers
- name: config
secret:
defaultMode: 420
secretName: fluent-bit-debug-config
- hostPath:
path: /var/log
type: ""
name: varlogs
- hostPath:
path: /var/log/journal
type: ""
name: systemd
- emptyDir: {}
name: positions
使用的secret:fluent-bit-debug-config如下,收录两个键:
第一个 parsers.conf: 为空;配置详情请参考官方文档:配置文件
第二个 fluent-bit.conf 配置需要根据情况进行配置,下面主要针对不同场景给出。它还将涉及使用kubesphere和Filter CRD。
使用流利位exec 到容器中可以使用 /fluent-bit/
bin/fluent-bit 进行调试:
/fluent-bit/bin # ./fluent-bit -h
Usage: fluent-bit [OPTION]
Available Options
-b --storage_path=PATH specify a storage buffering path
-c --config=FILE specify an optional configuration file
-d, --daemon run Fluent Bit in background mode
-f, --flush=SECONDS flush timeout in seconds (default: 5)
-F --filter=FILTER set a filter
-i, --input=INPUT set an input
-m, --match=MATCH set plugin match, same as '-p match=abc'
-o, --output=OUTPUT set an output
-p, --prop="A=B" set plugin configuration property
-R, --parser=FILE specify a parser configuration file
-e, --plugin=FILE load an external plugin (shared lib)
-l, --log_file=FILE write log info to a file
-t, --tag=TAG set plugin tag, same as '-p tag=abc'
-T, --sp-task=SQL define a stream processor task
-v, --verbose increase logging verbosity (default: info)
-H, --http enable monitoring HTTP server
-P, --port set HTTP server TCP port (default: 2020)
-s, --coro_stack_size Set coroutines stack size in bytes (default: 24576)
-q, --quiet quiet mode
-S, --sosreport support report for Enterprise customers
-V, --version show version number
-h, --help print this help
Inputs
cpu CPU Usage
mem Memory Usage
thermal Thermal
kmsg Kernel Log Buffer
proc Check Process health
disk Diskstats
systemd Systemd (Journal) reader
netif Network Interface Usage
docker Docker containers metrics
docker_events Docker events
tail Tail files
dummy Generate dummy data
head Head Input
health Check TCP server health
collectd collectd input plugin
statsd StatsD input plugin
serial Serial input
stdin Standard Input
syslog Syslog
exec Exec Input
tcp TCP
mqtt MQTT, listen for Publish messages
forward Fluentd in-forward
<p>

random Random
Filters
alter_size Alter incoming chunk size
aws Add AWS Metadata
record_modifier modify record
throttle Throttle messages using sliding window algorithm
kubernetes Filter to append Kubernetes metadata
modify modify records by applying rules
nest nest events by specified field values
parser Parse events
expect Validate expected keys and values
grep grep events by specified field values
rewrite_tag Rewrite records tags
lua Lua Scripting Filter
stdout Filter events to STDOUT
Outputs
azure Send events to Azure HTTP Event Collector
azure_blob Azure Blob Storage
bigquery Send events to BigQuery via streaming insert
counter Records counter
datadog Send events to DataDog HTTP Event Collector
es Elasticsearch
exit Exit after a number of flushes (test purposes)
file Generate log file
forward Forward (Fluentd protocol)
http HTTP Output
influxdb InfluxDB Time Series
logdna LogDNA
loki Loki
kafka Kafka
kafka-rest Kafka REST Proxy
nats NATS Server
nrlogs New Relic
null Throws away events
plot Generate data file for GNU Plot
pgsql PostgreSQL
slack Send events to a Slack channel
splunk Send events to Splunk HTTP Event Collector
stackdriver Send events to Google Stackdriver Logging
stdout Prints events to STDOUT
syslog Syslog
tcp TCP Output
td Treasure Data
flowcounter FlowCounter
gelf GELF Output
cloudwatch_logs Send logs to Amazon CloudWatch
kinesis_firehose Send logs to Amazon Kinesis Firehose
s3 Send to S3
Internal
Event Loop = epoll
Build Flags = FLB_HAVE_HTTP_CLIENT_DEBUG FLB_HAVE_PARSER FLB_HAVE_RECORD_ACCESSOR FLB_HAVE_STREAM_PROCESSOR JSMN_PARENT_LINKS JSMN_STRICT FLB_HAVE_TLS FLB_HAVE_AWS FLB_HAVE_SIGNV4 FLB_HAVE_SQLDB FLB_HAVE_METRICS FLB_HAVE_HTTP_SERVER FLB_HAVE_SYSTEMD FLB_HAVE_FORK FLB_HAVE_TIMESPEC_GET FLB_HAVE_GMTOFF FLB_HAVE_UNIX_SOCKET FLB_HAVE_PROXY_GO FLB_HAVE_JEMALLOC JEMALLOC_MANGLE FLB_HAVE_LIBBACKTRACE FLB_HAVE_REGEX FLB_HAVE_UTF8_ENCODER FLB_HAVE_LUAJIT FLB_HAVE_C_TLS FLB_HAVE_ACCEPT4 FLB_HAVE_INOTIFY</p>
简单配置文件
以下是使用简单配置文件采集 calico-node-* pod 的日志:
[Service]
Parsers_File parsers.conf
[Input]
Name tail
Path /var/log/containers/*_kube-system_calico-node-*.log
Refresh_Interval 10
Skip_Long_Lines true
DB /fluent-bit/bin/pos.db
DB.Sync Normal
Mem_Buf_Limit 5MB
Parser docker
Tag kube.*
[Filter]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Labels false
Annotations true
[Output]
Name stdout
Match_Regex (?:kube|service)\.(.*)
使用以下命令在流畅位调试容器内启动测试:
/fluent-bit/bin # ./fluent-bit -c /fluent-bit/config/fluent-bit.conf
您可以看到标准输出日志输出:
[0] kube.var.log.containers.calico-node-lp4lm_kube-system_calico-node-cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81.log: [1634870260.700108403, {"log"=>"{"log":"2021-10-22 02:37:40.699 [INFO][85] monitor-addresses/startup.go 774: Using autodetected IPv4 address on interface bond4: 172.24.248.50/30\n","stream":"stdout","time":"2021-10-22T02:37:40.700056471Z"}", "kubernetes"=>{"pod_name"=>"calico-node-lp4lm", "namespace_name"=>"kube-system", "pod_id"=>"5a829979-9830-4b9c-a3cb-eeb6eee38bdd", "annotations"=>{"kubectl.kubernetes.io/restartedAt"=>"2021-10-20T23:00:27+08:00"}, "host"=>"node02", "container_name"=>"calico-node", "docker_id"=>"cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81", "container_hash"=>"calico/node@sha256:bc4a631d553b38fdc169ea4cb8027fa894a656e80d68d513359a4b9d46836b55", "container_image"=>"calico/node:v3.19.1"}}]
截取重要部分,查看尚未处理采集的K8s日志格式。
[
{
"kubernetes"=>{
"pod_name"=>"calico-node-lp4lm",
"namespace_name"=>"kube-system",
"pod_id"=>"5a829979-9830-4b9c-a3cb-eeb6eee38bdd",
"annotations"=>{
"kubectl.kubernetes.io/restartedAt"=>"2021-10-20T23:00:27+08:00"
},
"host"=>"node02",
"container_name"=>"calico-node",
"docker_id"=>"cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81",
"container_hash"=>"calico/node@sha256:bc4a631d553b38fdc169ea4cb8027fa894a656e80d68d513359a4b9d46836b55",
"container_image"=>"calico/node:v3.19.1"
}
}
]
添加了嵌套过滤器
展开 Kubernetes 块并添加 kubernetes_ 前缀:
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes
Add_prefix kubernetes_
这次测试输出,截取重要部分:
{
"kubernetes_pod_name"=>"calico-node-lp4lm",
"kubernetes_namespace_name"=>"kube-system",
"kubernetes_pod_id"=>"5a829979-9830-4b9c-a3cb-eeb6eee38bdd",
"kubernetes_annotations"=>{
"kubectl.kubernetes.io/restartedAt"=>"2021-10-20T23:00:27+08:00"
},
"kubernetes_host"=>"node02",
"kubernetes_container_name"=>"calico-node",
"kubernetes_docker_id"=>"cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81",
"kubernetes_container_hash"=>"calico/node@sha256:bc4a631d553b38fdc169ea4cb8027fa894a656e80d68d513359a4b9d46836b55",
"kubernetes_container_image"=>"calico/node:v3.19.1"
}
删除kubernetes_annotations块
[Filter]
Name modify
Match kube.*
Remove kubernetes_annotations
从kubernetes_annotations块中删除字段
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes_annotations
Add_prefix kubernetes_annotations_
[Filter]
Name modify
Match kube.*
Remove kubernetes_annotations_kubectl.kubernetes.io/restartedAt
或使用常规:
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes_annotations
Add_prefix kubernetes_annotations_
[Filter]
Name modify
Match kube.*
Remove_regex kubernetes_annotations_kubectl*

修改kubernetes_annotations块中的键名称
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes_annotations
Add_prefix kubernetes_annotations_
[Filter]
Name modify
Match kube.*
Rename kubernetes_annotations_kubectl.kubernetes.io/restartedAt podIPs
修改后:
[
{
"kubernetes_pod_name"=>"calico-node-lp4lm",
"kubernetes_namespace_name"=>"kube-system",
"kubernetes_pod_id"=>"5a829979-9830-4b9c-a3cb-eeb6eee38bdd",
"kubernetes_host"=>"node02",
"kubernetes_container_name"=>"calico-node",
"kubernetes_docker_id"=>"cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81",
"kubernetes_container_hash"=>"calico/node@sha256:bc4a631d553b38fdc169ea4cb8027fa894a656e80d68d513359a4b9d46836b55",
"kubernetes_container_image"=>"calico/node:v3.19.1",
"podIPs"=>"2021-10-20T23:00:27+08:00"
}
]
结合 ks 配置采集 podIP
结合 kubesphere Filter CR 来配置 采集podIP 并删除其他不相关的注释。
由于印花布用作 CNI,因此与 Pod IP 相关的注释将添加到 Pod 注释中。
您需要在注释 (/podIP) 中保留一个密钥并删除其他密钥,因此在更改下面要保留的密钥的名称后,删除整个注释。
Kubernetes Filter CR 配置如下:
apiVersion: logging.kubesphere.io/v1alpha2
kind: Filter
metadata:
labels:
logging.kubesphere.io/component: logging
logging.kubesphere.io/enabled: 'true'
name: kubernetes
namespace: kubesphere-logging-system
spec:
filters:
- kubernetes:
annotations: true
kubeCAFile: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
kubeTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
kubeURL: 'https://kubernetes.default.svc:443'
labels: false
- nest:
addPrefix: kubernetes_
nestedUnder: kubernetes
operation: lift
- nest:
addPrefix: kubernetes_annotations_
nestedUnder: kubernetes_annotations
operation: lift
- modify:
rules:
- remove: stream
- remove: kubernetes_pod_id
- remove: kubernetes_host
- remove: kubernetes_container_hash
- rename:
kubernetes_annotations_cni.projectcalico.org/podIPs: kubernetes_podIPs
- removeRegex: kubernetes_annotations*
- nest:
nestUnder: kubernetes_annotations
operation: nest
removePrefix: kubernetes_annotations_
wildcard:
- kubernetes_annotations_*
- nest:
nestUnder: kubernetes
operation: nest
removePrefix: kubernetes_
wildcard:
- kubernetes_*
match: kube.*
Kubernetes Filter CR
生成的流畅位配置配置如下(只看 Filter 部分,省略输入输出 CR)。
[Service]
Parsers_File parsers.conf
[Input]
Name tail
Path /var/log/containers/*.log
Exclude_Path /var/log/containers/*_kubesphere-logging-system_events-exporter*.log,/var/log/containers/kube-auditing-webhook*_kubesphere-logging-system_kube-auditing-webhook*.log
Refresh_Interval 10
Skip_Long_Lines true
DB /fluent-bit/tail/pos.db
DB.Sync Normal
Mem_Buf_Limit 5MB
Parser docker
Tag kube.*
[Filter]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Labels false
Annotations true
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes
Add_prefix kubernetes_
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes_annotations
Add_prefix kubernetes_annotations_
[Filter]
Name modify
Match kube.*
Remove stream
Remove kubernetes_pod_id
Remove kubernetes_host
Remove kubernetes_container_hash
Rename kubernetes_annotations_cni.projectcalico.org/podIPs kubernetes_podIPs
Remove_regex kubernetes_annotations*
[Filter]
Name nest
Match kube.*
Operation nest
Wildcard kubernetes_annotations_*
Nest_under kubernetes_annotations
Remove_prefix kubernetes_annotations_
[Filter]
Name nest
Match kube.*
Operation nest
Wildcard kubernetes_*
Nest_under kubernetes
Remove_prefix kubernetes_
[Output]
Name es
Match_Regex (?:kube|service)\.(.*)
Host es-cdc-a-es-http.cdc.svc.xke.test.cn
Port 9200
HTTP_User elastic
HTTP_Passwd elasticpwd
Logstash_Format true
Logstash_Prefix ks-logstash-log
Time_Key @timestamp
您可以在 kibana 中看到 podIP 采集:
作者简洁
作者:小万
唐,一个热爱写作、认真写作的家伙,目前维护着原创公众号:“我的小湾汤”,专注于撰写GO语言、Docker、Kubernetes、Java等开发、运维知识等提升硬实力文章,期待大家的关注。转载说明:请务必注明出处(注明:来自公众号:我的小碗汤,作者:小碗汤)。
整套解决方案:如何采集shopline产品并导入到店铺,一键刊登独立站shopify爆款产品
独立站的同学会遇到上架产品到店的问题。一个产品从title-main image-detail页面一个一个复制到自己的店铺,需要花费很多时间。
如果采集里面有几十个或者几百个产品,手动做显然是很难的。现在有一种方法可以帮助您快速轻松地解决它!!一键式采集产品神器
这是一套奶妈级教程,请耐心阅读,小案例使用!!
Step 1:首先我们要知道采集的store是什么saas平台
网页空白处右键——点击查看网页源代码
在源码页面按Ctrl+F弹出搜索框,进入建站平台,如shopline
第二步:进入Crossker官网-选择产品采集工具
扫一扫公众号登录,每天5次免费试用,联系客服获取更多试用
第三步:选择采集管理-产品分类采集,进入分类链接
时间不用填写,采集的个数不要超过2000
第 4 步:选择 采集管理 - 任务列表
有四种状态:采集表示采集成功,等待采集表示排队,点击右上角刷新按钮查看进度
第五步:选择产品管理——在产品管理中输入采集的编号,点击搜索
记得点击搜索全选,如果没有搜索到默认是30,点击导出为CSV格式
第六步:登录Shopline进入后台商品-商品管理,点击导入商品-shopify表格导入
上传并导入采集的CSV文件,完成导入
第八步:等待系统加载,所有产品导入完毕
除了支持shopline采集外,还支持Shopify、Shoplaza、Oemsaas(YY2.0)、Shopplus、Shopbase等主流SaaS平台的产品采集。WordPress、Woocommerce、Magento 项目、Aliexpress 项目也可以处理。Ueeshop、OpenCart等平台后续会更新!总之,有什么需要,都满足你!
您还在犹豫?都是小问题,联系客服免费试用Crossker产品采集工具
我们刚刚成立Crossker跨境交流群,欢迎各位跨境电商朋友加入!有任何问题请随时提出,我们将尽最大努力为您解答,帮助独立卖家共同成长!
客服C:Crossker-tool
扫描下方二维码加入群~
内容分享:【网站采集工具】优采云文章自动采集器,独树一帜打造专业新闻内容采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-10-11 08:15
在互联网飞速发展的今天,很多人都将目光转向了网络营销和推广。事实证明,网络营销的方向会比实体的和传统的销售方向有更高的回报率。想要取得更好的网络营销效果,企业网站的后期维护和优化尤为重要。在网站后期维护和优化的过程中,网站的日常内容更新工作是一个非常重要但又极其重复和乏味的过程。那么如何以更简单、更快捷、省时省力的方式,为网站更新更多符合搜索引擎SEO规则的优质文章内容呢?作为业界顶级的网站采集软件,<
优采云文章自动采集器作为一个智能平台,根据用户提供的关键词等参数,真正实现文章自动采集,处理,出版。为了达到更好的采集效果,优采云在创作过程中不断优化自身的专业能力,从而实现无需用户自动识别各种在线标题、文字等信息的能力写任何采集规则可以实现全网采集。完成基础内容采集后,会自动计算内容与集合关键词的相关度,并将相关的文章推送给用户。
之所以能引领行业,成为很多人喜欢的网站采集工具,优采云在功能和细节上做到了极致。主要功能方面,优采云拥有近50个主流采集工具必备功能,SEO功能非常齐全。例如,为了方便用户按照网站的主题布局内容,优采云提供了亿+量级的庞大关键词库,可以根据用户输入的任何文本。,经过简单的检查,就可以直接采集,大大减少了用户采集整理关键词所消耗的时间和精力;同时,用户还可以上传已有的关键词,创建属于自己的私有词库,
为满足客户的各种需求,采集文章源汇集了百度、搜狗、好搜、神马、必应、今日头条、微信等拥有庞大用户群的主流搜索引擎. ,确保您能找到更符合您客户的关键词优质文章内容。同时优采云还具有自动识别网页代码、标题、正文等信息的功能,因此无需为每个不同的来源设置不同的采集规则网站,维护成本会比其他相关类型的网站采集软件低很多,为客户节省更多的能源。强大的自然语言处理算法保证了文章的流畅性和关键词的相关性,紧密满足客户需求。确保标题描述与关键词相关,在标题中自动插入关键词提高相关性,并根据文章的内容自动生成高质量的原创标题>。采集成功后还有自动发布、自动执行搜索引擎推送等功能。借助采集系统的定时定量功能,客户即使在关机睡觉的时候也可以做SEO。它还具有自动发布和自动执行搜索引擎推送等功能。借助采集系统的定时定量功能,客户即使在关机睡觉的时候也可以做SEO。它还具有自动发布和自动执行搜索引擎推送等功能。借助采集系统的定时定量功能,客户即使在关机睡觉的时候也可以做SEO。
优采云不仅相关功能强大全面,细节上也做到极致。无论是标题前缀、关键词自动加粗,还是插入固定链接等,都可以帮助客户一键解决问题,用户只需设置关键词及相关要求,完全可以去除文章编辑的痛苦,网站文章更新和维护不再是没有反馈的费时费力的工作。
需要提醒的是,企业网站的维护和后期优化其实是一个比较复杂的过程,而文章的采集编辑和发布其实只是其中的一种优化网站 的。对于更大的比例,用户在做自己的网站文章内容的同时,需要全面掌控SEO的各个方面,比如外链搭建、服务器稳定性、页面打开速度等,都需要持续维护。不仅如此,网站的维护和优化是一场持久战。如果想在短时间内达到很好的搜索效果,往往太仓促了。做好长期持久战的准备,再加上优采云在如此优秀的网站采集器的帮助下,
推荐文章:基于网络爬虫C#网络新闻采集系统设计+文献综述.doc 15页
基于网络爬虫C#网络新闻采集系统设计+文献综述摘要随着信息时代的飞速发展,网络技术对我们的生活和工作越来越重要,尤其是在信息高度发达的今天,传统报纸杂志已经远远不能满足人们的需求。互联网已成为人们快速获取、发布和传递信息的重要渠道。它在人们的政治、经济和生活中发挥着重要作用。简而言之,新闻采集系统作为一种网络新闻媒体,主要实现新闻的分类、上传、审核和发布,模拟一般新闻媒体的新闻发布过程。本软件是基于网络爬虫软件开发的。网络新闻资讯采集系统的主要功能是:根据用户自定义的任务配置,批量准确提取互联网目标网页中的半结构化和非结构化数据,转换成结构化记录,保存它们在本地数据库中,用于内部使用或外网发布,快速实现外部信息的获取。系统的基本功能模块包括:用户登录、站点管理和新闻采集、采集结果的筛选和关键字搜索、数据库管理。具体如下: 1、实现管理员和用户的登录和用户信息的管理;2. 2.实现指定网页新闻的采集和采集站点的添加和管理;3. 实现对采集收到的消息进行过滤和关键词搜索的功能;实现采集接收到的新闻信息的数据库管理。8210关键词:网络爬虫新闻采集新闻管理数据保存研究生设计指导(论文)外文摘要标题网页信息获取摘要:随着信息时代的飞速发展,网络技术对我们的生活和工作越来越重要,尤其是现在高度发达,
当今社会,人们已经离不开互联网,互联网已经成为人与人之间的一种交流方式,可以将事物的复杂化为简单化。新闻采集系统的引入,使电视不再是唯一的新闻媒体,互联网也从此成为重要的新闻媒体。简而言之,新闻发布系统作为一个网络新闻媒体,主要实现新闻的分类、上传、审核、发布,模拟一般新闻媒体的新闻发布流程,通过不同权限的账号实现上述功能. 当然,这些功能也可以由某个账户全部拥有。随着互联网的进一步发展,网络媒体在人们心中的地位进一步提高。作为网络媒体的核心系统,新闻发布系统的重要性越来越重要:一方面,它提供了新闻管理和发布的功能;一方面,时事新闻采集需要与普通用户互动,用户可以很容易地参与到相关新闻的一些调查和评论中,这对于其他一些媒体(电视、广播等)来说也是不可能的,同时,随着互联网在今天的发展,可以说只要上网,就会接触到新闻发布系统。新闻采集系统的用户相当惊人,其重要性毋庸置疑。当然,这也对新闻采集系统的开发提出了更高的要求。网站新闻采集
有两种传统的网站 新闻管理方法。一种是静态 HTML 页面。更新信息时,需要重新创建页面,然后上传页面并修改相应的链接。这种方法没有用,因为它的效率低。二是将动态网页与数据库相结合,通过应用程序处理新闻,这是目前比较流行的做法。人们对最新信息的需求和对发布及时性的迫切需求,而动态交互网页正好提供了这些功能。本系统是一个可以实现新闻在线的在线采集,是一个多栏目管理的在线交互系统。(3) 数据库:访问数据库。Access 是一个基于 Windows 的桌面关系数据库管理系统(RDBMS,微软公司推出的关系型数据库管理系统,是Office系列应用软件之一。提供表格、查询、表格、报表、页面、宏、模块7种对象用于构建数据库系统;提供各种向导、生成器、模板、数据存储、数据查询、界面设计、报表生成等操作标准化;它为建立功能齐全的数据库管理系统提供了便利,也使普通用户无需编写代码即可完成大部分数据管理任务。2网页新闻采集系统 2.1 系统概述 新闻采集系统是一个从多个新闻源网页中提取非结构化新闻文章并将其存储在结构化数据库中的软件。根据用户自定义任务配置,消息或<
新闻采集系统的核心技术是模式定义和模式匹配。模式属于人工智能的术语,是对前人积累的经验的抽象和升华。简单地说,它是从反复发生的事件中发现和抽象出来的规则,是解决问题的经验总结。只要是一遍又一遍地重复的东西,就可能有规律。因此,新闻采集 系统要工作,目标网站 必须具有重复出现的特征。目前大部分网站都是动态生成的,这样同模板的页面会收录相同的内容,而新闻采集系统使用相同的内容来定位采集数据。新闻中的大部分模式采集 系统不会被程序自动发现。目前几乎所有的新闻采集系统产品都需要手动定义。但是模式本身是一个非常复杂和抽象的内容,所以开发者的全部精力都花在了如何让模式定义更简单、更准确上,这也是衡量新闻采集系统竞争力的标准。如下图2.1所示: 图2.1 采集系统工作原理爬虫工作原理及关键技术概述网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。
然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。由于用户范围广,通用爬虫大多使用较高的W曲线覆盖率,因此通常使用广度优先或深度优先的策略搜索。万能爬虫实际上代替了人在目录搜索引擎中的工作。它从种子链接开始,不断爬取 URL 网页。当万能爬虫进入某个超文本时,它利用HTML语言的标记结构来搜索信息并获取信息。指向其他超文本的URL地址可以实现自动“爬网”和网络搜索,无需用户干预。如果这些链接还没有被爬虫访问过,爬虫就会被放到下载队列中进行爬取。万能爬虫就是采用这样的方式,不断的遍历整个互联网,直到下载队列为空或者达到系统给定的停止条件。一般爬虫都是以传统的图算法为工作原理的。它通常只使用一个或几个 URL 作为种子,而不考虑网页的内容,并使用宽度或深度优先算法访问整个 Internet。这种爬虫的目标是覆盖整个网络。2.3 新闻采集系统发展趋势 现有常见应用:?环球新闻采集器?新浪新闻采集器?优采云采集器? 远景新闻采集器发展趋势:新闻在网络上的发布频率非常高。如果将静态网页作为新闻页面,维护工作会非常繁琐,管理员每天需要制作大量的网页,浪费了大量的时间和精力。
使用后台管理系统,可以轻松管理系统、新闻、软件、消息、会员及相关指令等功能模块。如果管理员要发布新闻,只需要设置新闻的标题、内容、图片等,系统会自动生成相应的网页。3 开发技术与工具 3.1 系统开发工具 3.1.1 Visual Studio 2005vs2005是基于.NET2.0框架的。• 用户界面集成:工具之间的无缝集成是提高生产力的关键。Visual Studio Team System 在整个 SDLC 工具套件中提供一致的用户体验。对于开发人员,某些活动(例如,单元测试、工作项跟踪、代码分析和代码分析)在他们当前的开发环境中可用。• 数据集成:Visual Studio Team System 通过使用通用的跨工具集数据仓库解决了在大多数 SDLC 工具中构建数据仓库的问题,并启用了项目状态的聚合视图。团队根据可以采集的规则管理项目。今天,数据主要限于缺陷跟踪。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。Visual Studio Team System 通过使用通用的跨工具集数据仓库解决了大多数 SDLC 工具中构建数据仓库的问题,并启用了项目状态的聚合视图。团队根据可以采集的规则管理项目。今天,数据主要限于缺陷跟踪。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。Visual Studio Team System 通过使用通用的跨工具集数据仓库解决了大多数 SDLC 工具中构建数据仓库的问题,并启用了项目状态的聚合视图。团队根据可以采集的规则管理项目。今天,数据主要限于缺陷跟踪。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。
此数据以某种标准报告格式呈现,客户和 Microsoft 内部团队已根据该格式建立成功项目管理的关键规程。此外,团队能够创建自定义报告。只有在项目的广泛背景下查看数据时,团队才能准确报告项目状态。C# (C SHARP) 是微软针对这个问题的解决方案。C# 是一种最新的、面向对象的编程语言。它使程序员能够基于MICROSOFT .NET 平台快速编写各种应用程序,MICROSOFT .NET 提供一系列工具和服务,最大限度地开发和利用计算和通信领域。正是由于 C# 优秀的面向对象设计,它非常适合构建各种组件——无论是高级业务对象还是系统级应用程序。使用简单的 C# 语言结构,这些组件可以很容易地转换为 XML Web 服务,因此它们可以在 Internet 上由任何操作系统上的任何语言调用。最重要的是,C#使C++程序员能够高效地开发程序,同时又不失C/C++原有的强大功能。由于这种继承关系,C#与C/C++非常相似,熟悉类似语言的开发者可以快速转向C#。3.2 数据库 通俗地说,数据库是数据或信息的集合。从专业上讲,数据库是由许多数据表组成的一组计算机组织的数据。
Access是微软推出的基于Windows的桌面关系数据库管理系统(RDBMS,Relational Database Management System),是Office系列应用软件之一。提供表格、查询、表格、报表、页面、宏、模块7种对象用于构建数据库系统;提供各种向导、生成器、模板、数据存储、数据查询、界面设计、报表生成等操作标准化;它为建立功能齐全的数据库管理系统提供了便利,也使普通用户无需编写代码即可完成大部分数据管理任务。Access的优点 (1)存储方式简单,易于维护和管理。Access 管理的对象包括表、查询、表单、报表、页面、宏和模块。上述对象存储在后缀为(.mdb 或 .accdb)的数据库文件中。,方便用户操作和管理。(2)面向对象的Access是一种面向对象的开发工具,它采用面向对象的方法将数据库系统中的各种功能对象化,将数据库管理的各种功能封装在各种对象中。它将应用系统视为一系列对象。对于每个对象,它定义了一组方法和属性来定义对象的行为和外国。用户还可以根据需要将方法和属性扩展到对象。数据库的操作和管理都是通过对象的方法和属性来完成的,大大简化了用户的开发工作。同时,这种面向对象的开发方法使开发应用程序变得更加容易。简而言之,Access是一个只能用来存储数据的数据库,也可以作为开发数据库应用系统的客户端开发工具;即可以开发方便易用的小型软件,也可以用于开发大型应用系统。基于网络爬虫C#网络新闻采集系统设计+文献综述(七):范文最新推荐1 / 1 查看全部
内容分享:【网站采集工具】优采云文章自动采集器,独树一帜打造专业新闻内容采集工具
在互联网飞速发展的今天,很多人都将目光转向了网络营销和推广。事实证明,网络营销的方向会比实体的和传统的销售方向有更高的回报率。想要取得更好的网络营销效果,企业网站的后期维护和优化尤为重要。在网站后期维护和优化的过程中,网站的日常内容更新工作是一个非常重要但又极其重复和乏味的过程。那么如何以更简单、更快捷、省时省力的方式,为网站更新更多符合搜索引擎SEO规则的优质文章内容呢?作为业界顶级的网站采集软件,<
优采云文章自动采集器作为一个智能平台,根据用户提供的关键词等参数,真正实现文章自动采集,处理,出版。为了达到更好的采集效果,优采云在创作过程中不断优化自身的专业能力,从而实现无需用户自动识别各种在线标题、文字等信息的能力写任何采集规则可以实现全网采集。完成基础内容采集后,会自动计算内容与集合关键词的相关度,并将相关的文章推送给用户。
之所以能引领行业,成为很多人喜欢的网站采集工具,优采云在功能和细节上做到了极致。主要功能方面,优采云拥有近50个主流采集工具必备功能,SEO功能非常齐全。例如,为了方便用户按照网站的主题布局内容,优采云提供了亿+量级的庞大关键词库,可以根据用户输入的任何文本。,经过简单的检查,就可以直接采集,大大减少了用户采集整理关键词所消耗的时间和精力;同时,用户还可以上传已有的关键词,创建属于自己的私有词库,
为满足客户的各种需求,采集文章源汇集了百度、搜狗、好搜、神马、必应、今日头条、微信等拥有庞大用户群的主流搜索引擎. ,确保您能找到更符合您客户的关键词优质文章内容。同时优采云还具有自动识别网页代码、标题、正文等信息的功能,因此无需为每个不同的来源设置不同的采集规则网站,维护成本会比其他相关类型的网站采集软件低很多,为客户节省更多的能源。强大的自然语言处理算法保证了文章的流畅性和关键词的相关性,紧密满足客户需求。确保标题描述与关键词相关,在标题中自动插入关键词提高相关性,并根据文章的内容自动生成高质量的原创标题>。采集成功后还有自动发布、自动执行搜索引擎推送等功能。借助采集系统的定时定量功能,客户即使在关机睡觉的时候也可以做SEO。它还具有自动发布和自动执行搜索引擎推送等功能。借助采集系统的定时定量功能,客户即使在关机睡觉的时候也可以做SEO。它还具有自动发布和自动执行搜索引擎推送等功能。借助采集系统的定时定量功能,客户即使在关机睡觉的时候也可以做SEO。
优采云不仅相关功能强大全面,细节上也做到极致。无论是标题前缀、关键词自动加粗,还是插入固定链接等,都可以帮助客户一键解决问题,用户只需设置关键词及相关要求,完全可以去除文章编辑的痛苦,网站文章更新和维护不再是没有反馈的费时费力的工作。
需要提醒的是,企业网站的维护和后期优化其实是一个比较复杂的过程,而文章的采集编辑和发布其实只是其中的一种优化网站 的。对于更大的比例,用户在做自己的网站文章内容的同时,需要全面掌控SEO的各个方面,比如外链搭建、服务器稳定性、页面打开速度等,都需要持续维护。不仅如此,网站的维护和优化是一场持久战。如果想在短时间内达到很好的搜索效果,往往太仓促了。做好长期持久战的准备,再加上优采云在如此优秀的网站采集器的帮助下,
推荐文章:基于网络爬虫C#网络新闻采集系统设计+文献综述.doc 15页
基于网络爬虫C#网络新闻采集系统设计+文献综述摘要随着信息时代的飞速发展,网络技术对我们的生活和工作越来越重要,尤其是在信息高度发达的今天,传统报纸杂志已经远远不能满足人们的需求。互联网已成为人们快速获取、发布和传递信息的重要渠道。它在人们的政治、经济和生活中发挥着重要作用。简而言之,新闻采集系统作为一种网络新闻媒体,主要实现新闻的分类、上传、审核和发布,模拟一般新闻媒体的新闻发布过程。本软件是基于网络爬虫软件开发的。网络新闻资讯采集系统的主要功能是:根据用户自定义的任务配置,批量准确提取互联网目标网页中的半结构化和非结构化数据,转换成结构化记录,保存它们在本地数据库中,用于内部使用或外网发布,快速实现外部信息的获取。系统的基本功能模块包括:用户登录、站点管理和新闻采集、采集结果的筛选和关键字搜索、数据库管理。具体如下: 1、实现管理员和用户的登录和用户信息的管理;2. 2.实现指定网页新闻的采集和采集站点的添加和管理;3. 实现对采集收到的消息进行过滤和关键词搜索的功能;实现采集接收到的新闻信息的数据库管理。8210关键词:网络爬虫新闻采集新闻管理数据保存研究生设计指导(论文)外文摘要标题网页信息获取摘要:随着信息时代的飞速发展,网络技术对我们的生活和工作越来越重要,尤其是现在高度发达,
当今社会,人们已经离不开互联网,互联网已经成为人与人之间的一种交流方式,可以将事物的复杂化为简单化。新闻采集系统的引入,使电视不再是唯一的新闻媒体,互联网也从此成为重要的新闻媒体。简而言之,新闻发布系统作为一个网络新闻媒体,主要实现新闻的分类、上传、审核、发布,模拟一般新闻媒体的新闻发布流程,通过不同权限的账号实现上述功能. 当然,这些功能也可以由某个账户全部拥有。随着互联网的进一步发展,网络媒体在人们心中的地位进一步提高。作为网络媒体的核心系统,新闻发布系统的重要性越来越重要:一方面,它提供了新闻管理和发布的功能;一方面,时事新闻采集需要与普通用户互动,用户可以很容易地参与到相关新闻的一些调查和评论中,这对于其他一些媒体(电视、广播等)来说也是不可能的,同时,随着互联网在今天的发展,可以说只要上网,就会接触到新闻发布系统。新闻采集系统的用户相当惊人,其重要性毋庸置疑。当然,这也对新闻采集系统的开发提出了更高的要求。网站新闻采集
有两种传统的网站 新闻管理方法。一种是静态 HTML 页面。更新信息时,需要重新创建页面,然后上传页面并修改相应的链接。这种方法没有用,因为它的效率低。二是将动态网页与数据库相结合,通过应用程序处理新闻,这是目前比较流行的做法。人们对最新信息的需求和对发布及时性的迫切需求,而动态交互网页正好提供了这些功能。本系统是一个可以实现新闻在线的在线采集,是一个多栏目管理的在线交互系统。(3) 数据库:访问数据库。Access 是一个基于 Windows 的桌面关系数据库管理系统(RDBMS,微软公司推出的关系型数据库管理系统,是Office系列应用软件之一。提供表格、查询、表格、报表、页面、宏、模块7种对象用于构建数据库系统;提供各种向导、生成器、模板、数据存储、数据查询、界面设计、报表生成等操作标准化;它为建立功能齐全的数据库管理系统提供了便利,也使普通用户无需编写代码即可完成大部分数据管理任务。2网页新闻采集系统 2.1 系统概述 新闻采集系统是一个从多个新闻源网页中提取非结构化新闻文章并将其存储在结构化数据库中的软件。根据用户自定义任务配置,消息或<
新闻采集系统的核心技术是模式定义和模式匹配。模式属于人工智能的术语,是对前人积累的经验的抽象和升华。简单地说,它是从反复发生的事件中发现和抽象出来的规则,是解决问题的经验总结。只要是一遍又一遍地重复的东西,就可能有规律。因此,新闻采集 系统要工作,目标网站 必须具有重复出现的特征。目前大部分网站都是动态生成的,这样同模板的页面会收录相同的内容,而新闻采集系统使用相同的内容来定位采集数据。新闻中的大部分模式采集 系统不会被程序自动发现。目前几乎所有的新闻采集系统产品都需要手动定义。但是模式本身是一个非常复杂和抽象的内容,所以开发者的全部精力都花在了如何让模式定义更简单、更准确上,这也是衡量新闻采集系统竞争力的标准。如下图2.1所示: 图2.1 采集系统工作原理爬虫工作原理及关键技术概述网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。
然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。由于用户范围广,通用爬虫大多使用较高的W曲线覆盖率,因此通常使用广度优先或深度优先的策略搜索。万能爬虫实际上代替了人在目录搜索引擎中的工作。它从种子链接开始,不断爬取 URL 网页。当万能爬虫进入某个超文本时,它利用HTML语言的标记结构来搜索信息并获取信息。指向其他超文本的URL地址可以实现自动“爬网”和网络搜索,无需用户干预。如果这些链接还没有被爬虫访问过,爬虫就会被放到下载队列中进行爬取。万能爬虫就是采用这样的方式,不断的遍历整个互联网,直到下载队列为空或者达到系统给定的停止条件。一般爬虫都是以传统的图算法为工作原理的。它通常只使用一个或几个 URL 作为种子,而不考虑网页的内容,并使用宽度或深度优先算法访问整个 Internet。这种爬虫的目标是覆盖整个网络。2.3 新闻采集系统发展趋势 现有常见应用:?环球新闻采集器?新浪新闻采集器?优采云采集器? 远景新闻采集器发展趋势:新闻在网络上的发布频率非常高。如果将静态网页作为新闻页面,维护工作会非常繁琐,管理员每天需要制作大量的网页,浪费了大量的时间和精力。
使用后台管理系统,可以轻松管理系统、新闻、软件、消息、会员及相关指令等功能模块。如果管理员要发布新闻,只需要设置新闻的标题、内容、图片等,系统会自动生成相应的网页。3 开发技术与工具 3.1 系统开发工具 3.1.1 Visual Studio 2005vs2005是基于.NET2.0框架的。• 用户界面集成:工具之间的无缝集成是提高生产力的关键。Visual Studio Team System 在整个 SDLC 工具套件中提供一致的用户体验。对于开发人员,某些活动(例如,单元测试、工作项跟踪、代码分析和代码分析)在他们当前的开发环境中可用。• 数据集成:Visual Studio Team System 通过使用通用的跨工具集数据仓库解决了在大多数 SDLC 工具中构建数据仓库的问题,并启用了项目状态的聚合视图。团队根据可以采集的规则管理项目。今天,数据主要限于缺陷跟踪。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。Visual Studio Team System 通过使用通用的跨工具集数据仓库解决了大多数 SDLC 工具中构建数据仓库的问题,并启用了项目状态的聚合视图。团队根据可以采集的规则管理项目。今天,数据主要限于缺陷跟踪。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。Visual Studio Team System 通过使用通用的跨工具集数据仓库解决了大多数 SDLC 工具中构建数据仓库的问题,并启用了项目状态的聚合视图。团队根据可以采集的规则管理项目。今天,数据主要限于缺陷跟踪。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。
此数据以某种标准报告格式呈现,客户和 Microsoft 内部团队已根据该格式建立成功项目管理的关键规程。此外,团队能够创建自定义报告。只有在项目的广泛背景下查看数据时,团队才能准确报告项目状态。C# (C SHARP) 是微软针对这个问题的解决方案。C# 是一种最新的、面向对象的编程语言。它使程序员能够基于MICROSOFT .NET 平台快速编写各种应用程序,MICROSOFT .NET 提供一系列工具和服务,最大限度地开发和利用计算和通信领域。正是由于 C# 优秀的面向对象设计,它非常适合构建各种组件——无论是高级业务对象还是系统级应用程序。使用简单的 C# 语言结构,这些组件可以很容易地转换为 XML Web 服务,因此它们可以在 Internet 上由任何操作系统上的任何语言调用。最重要的是,C#使C++程序员能够高效地开发程序,同时又不失C/C++原有的强大功能。由于这种继承关系,C#与C/C++非常相似,熟悉类似语言的开发者可以快速转向C#。3.2 数据库 通俗地说,数据库是数据或信息的集合。从专业上讲,数据库是由许多数据表组成的一组计算机组织的数据。
Access是微软推出的基于Windows的桌面关系数据库管理系统(RDBMS,Relational Database Management System),是Office系列应用软件之一。提供表格、查询、表格、报表、页面、宏、模块7种对象用于构建数据库系统;提供各种向导、生成器、模板、数据存储、数据查询、界面设计、报表生成等操作标准化;它为建立功能齐全的数据库管理系统提供了便利,也使普通用户无需编写代码即可完成大部分数据管理任务。Access的优点 (1)存储方式简单,易于维护和管理。Access 管理的对象包括表、查询、表单、报表、页面、宏和模块。上述对象存储在后缀为(.mdb 或 .accdb)的数据库文件中。,方便用户操作和管理。(2)面向对象的Access是一种面向对象的开发工具,它采用面向对象的方法将数据库系统中的各种功能对象化,将数据库管理的各种功能封装在各种对象中。它将应用系统视为一系列对象。对于每个对象,它定义了一组方法和属性来定义对象的行为和外国。用户还可以根据需要将方法和属性扩展到对象。数据库的操作和管理都是通过对象的方法和属性来完成的,大大简化了用户的开发工作。同时,这种面向对象的开发方法使开发应用程序变得更加容易。简而言之,Access是一个只能用来存储数据的数据库,也可以作为开发数据库应用系统的客户端开发工具;即可以开发方便易用的小型软件,也可以用于开发大型应用系统。基于网络爬虫C#网络新闻采集系统设计+文献综述(七):范文最新推荐1 / 1
优采云自动文章采集 sign failed11(前缀关键词自动加粗*固定链接自动提取标签(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-03-29 00:20
<p>. . . . . . 如果用户写了任何采集规则,全网可以采集采集会自动计算内容与集合关键词的相关性,只有相关的采集 @文章推送给用户支持标题前缀关键词自动加粗*永久链接自动提取标签自动内部链接自动伪原创内容过滤替换*号码和URL清洗百度主动提交等对用户的功能只需要设置关键词及相关需求即可实现全托管、零维护网站无限内容更新网站无论是单个网站还是大批量站群 都可以轻松管理 研发背景 查看全部
优采云自动文章采集 sign failed11(Zblog采集支持任意版本Nginx采集插件处理 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-03-28 07:20
)
Zblog是Zblog开发团队开发的一个基于Asp和PHP平台的小而强大的开源程序,但是插件市场上的Zblog采集插件没有一个能被打败,或者有是没有 SEO 文章内容处理,或单一功能。适合 SEO 站长的 Zblog采集 很少。
大家都知道Zblog采集接口是不熟悉Zblog的人做的采集,很多人用模拟登录的方式发布文章,很多人直接操作数据库发布文章,然而,所有这些都或多或少地引起了各种问题。发布速度慢,文章的内容没有经过严格过滤,导致安全问题,无法发送标签,无法自动创建分类等。但是,使用Zblog采集快速发布, 文章内容经过严格过滤,不存在安全问题,可以发送TAG,支持自动创建分类。
Zblog采集可以帮站内省去很多搬运工,插件不仅支持文章采集,还支持文章采集@中的评论> ,其他插件的数据 采集(不是 文章)。
Zblog采集还支持Empirecms、易友、Zblog采集、dedecms、WordPress、PBoot、Applecms、迅瑞cms@ >、PHPcms、Applecms、人人网cms、美图cms、云游cms、Cyclone站群、THINKCMF、建展ABC、凡客cms、一气cms、Oceancms、飞飞cms、Local Release、搜外等各大cms,一个可以批量管理,同时发布。
Zblog采集支持任意PHP版本Zblog采集支持任意版本MysqlZblog采集,Zblog采集支持任意版本Nginx。
Zblog采集支持内容替换,Zblog采集支持HTML过滤,Zblog采集支持正则提取,Zblog采集支持字符截取,Zblog采集支持前后追加内容,Zblog采集支持空内容默认值,Zblog采集支持关键词分词。 Zblog采集支持同义词替换,Zblog采集支持关键词内链。
Zblog采集 支持任何 Zblog采集 版本。 Zblog采集作者声明永久免费。
Zblog采集不会因为版本不匹配或服务器环境不支持等其他原因而无法使用Zblog采集。
Zblog采集配置简单,Zblog采集不需要花很多时间学习软件操作,不用配置采集规则,一分钟就能上手,只需输入 关键词采集。
Zblog采集可以对字段内容进行二次处理,Zblog采集还可以结合内容页面衍生的多级页面。
Zblog采集有很好的字段使用方法,可以自动分段Zblog采集同义词转换,供关键词Zblog采集关键词内链过滤查看(编辑)zblog采集可以查看已经采集的数据,zblog采集支持php扩展。 Zblog采集可以查看javascript扩展。
Zblog采集提供一站式网站文章解决方案,无需人工干预,设置任务自动执行采集releases。
Zblog采集可以实现几十万个不同的cms网站的统一管理。一个人维护数百个 网站文章 更新也不是问题。
Zblog采集第三方采集软件很强大,只要输入关键词采集,通过软件就可以完全自动化采集@ >采集并发布文章,为了让搜索引擎收录你的网站,我们还可以设置自动下载图片和替换链接,图片存储方式支持:阿里云OSS、七牛对象存储、腾讯云、拍云等
{foreach $dayHotArticle as $articles}
{$articles.Title}
{/foreach}
Zblog采集还配备了自动内部链接,内容或标题前后插入的某些内容形成“伪原创”。 Zblog采集还有监控功能,可以通过软件直接查看文章采集的发布状态。
今天关于Zblog的分享采集就到这里,下期会分享更多seo相关知识。希望能在SEO网站优化的道路上对您有所帮助。如果喜欢,不妨点击三个链接。
查看全部
优采云自动文章采集 sign failed11(Zblog采集支持任意版本Nginx采集插件处理
)
Zblog是Zblog开发团队开发的一个基于Asp和PHP平台的小而强大的开源程序,但是插件市场上的Zblog采集插件没有一个能被打败,或者有是没有 SEO 文章内容处理,或单一功能。适合 SEO 站长的 Zblog采集 很少。
大家都知道Zblog采集接口是不熟悉Zblog的人做的采集,很多人用模拟登录的方式发布文章,很多人直接操作数据库发布文章,然而,所有这些都或多或少地引起了各种问题。发布速度慢,文章的内容没有经过严格过滤,导致安全问题,无法发送标签,无法自动创建分类等。但是,使用Zblog采集快速发布, 文章内容经过严格过滤,不存在安全问题,可以发送TAG,支持自动创建分类。
Zblog采集可以帮站内省去很多搬运工,插件不仅支持文章采集,还支持文章采集@中的评论> ,其他插件的数据 采集(不是 文章)。
Zblog采集还支持Empirecms、易友、Zblog采集、dedecms、WordPress、PBoot、Applecms、迅瑞cms@ >、PHPcms、Applecms、人人网cms、美图cms、云游cms、Cyclone站群、THINKCMF、建展ABC、凡客cms、一气cms、Oceancms、飞飞cms、Local Release、搜外等各大cms,一个可以批量管理,同时发布。
Zblog采集支持任意PHP版本Zblog采集支持任意版本MysqlZblog采集,Zblog采集支持任意版本Nginx。
Zblog采集支持内容替换,Zblog采集支持HTML过滤,Zblog采集支持正则提取,Zblog采集支持字符截取,Zblog采集支持前后追加内容,Zblog采集支持空内容默认值,Zblog采集支持关键词分词。 Zblog采集支持同义词替换,Zblog采集支持关键词内链。
Zblog采集 支持任何 Zblog采集 版本。 Zblog采集作者声明永久免费。
Zblog采集不会因为版本不匹配或服务器环境不支持等其他原因而无法使用Zblog采集。
Zblog采集配置简单,Zblog采集不需要花很多时间学习软件操作,不用配置采集规则,一分钟就能上手,只需输入 关键词采集。
Zblog采集可以对字段内容进行二次处理,Zblog采集还可以结合内容页面衍生的多级页面。
Zblog采集有很好的字段使用方法,可以自动分段Zblog采集同义词转换,供关键词Zblog采集关键词内链过滤查看(编辑)zblog采集可以查看已经采集的数据,zblog采集支持php扩展。 Zblog采集可以查看javascript扩展。
Zblog采集提供一站式网站文章解决方案,无需人工干预,设置任务自动执行采集releases。
Zblog采集可以实现几十万个不同的cms网站的统一管理。一个人维护数百个 网站文章 更新也不是问题。
Zblog采集第三方采集软件很强大,只要输入关键词采集,通过软件就可以完全自动化采集@ >采集并发布文章,为了让搜索引擎收录你的网站,我们还可以设置自动下载图片和替换链接,图片存储方式支持:阿里云OSS、七牛对象存储、腾讯云、拍云等
{foreach $dayHotArticle as $articles}
{$articles.Title}
{/foreach}
Zblog采集还配备了自动内部链接,内容或标题前后插入的某些内容形成“伪原创”。 Zblog采集还有监控功能,可以通过软件直接查看文章采集的发布状态。
今天关于Zblog的分享采集就到这里,下期会分享更多seo相关知识。希望能在SEO网站优化的道路上对您有所帮助。如果喜欢,不妨点击三个链接。
优采云自动文章采集 sign failed11(为什么要用帝国CMS插件?如何利用网站收录以及关键词排名 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-03-19 11:24
)
为什么要使用 Empire cms 插件?如何使用 Empire cms 插件对 网站收录 和 关键词 进行排名。网站seo优化是对网站的节目、域名注册查询、内容、版块、版面、目标关键词等方面的优化调整,即网站被设计为适用于搜索引擎检索,满足搜索引擎排名的指标,从而在搜索引擎检索中获得流量排名靠前,增强搜索引擎营销效果,使网站相关关键词能够有一个很好的排名。网站seo优化的目的是让网站更容易被搜索引擎收录访问,提升用户体验(UE)和转化率,创造价值。那么<的核心内容是什么?
第一个核心:页面评分核心
搜索引擎在抓取网站网站时,首先判断网站的内容质量,是动态路径还是静态路径,是否使用二级域名, 网站的质量取决于网站的用户,其次是收录搜索的页数。每一页的关键词的等级,能不能再回来?从标题看,搜索引擎抓取的时候,首先看你的标题,页面的关键词是否与内容匹配。关键词 的整体类型是否与用户搜索的 关键词 匹配?这时候就需要分析一下为什么产品页面收录那么低,根据产品类别展开相关的长尾。如果内容质量好,找关键词多带点,整体关键词
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以通过Empire cms插件实现采集伪原创自动发布和主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站< @k10@ > 和 关键词 排名。
一、自由帝国采集插件
Free Empire采集 插件的特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体中文翻译+百度翻译+147翻译+有道翻译+谷歌翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)
3、伪原创(标题+内容)
4、替换图片防止侵权
5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章前后插入内容/标题关键词与内容一致关键词/随机插入图片/随机属性添加页面原创度)
6、对应栏:对应文章可以发布对应栏/支持多栏发布
7、定期发布:可控发布间隔/每天发布总数
8、监控数据:直接监控已经发布、待发布的软件,是否为伪原创、发布状态、URL、程序、发布时间等。
第二个核心:关键词 核心
做大网站需要一个团队的运作。如果频道页很大,就离不开关键词。需要一个优化器加一两个编辑器,优化器需要优化选择关键词,选择关键词,如果小网站需要更新网站@对应的内容> 每天,内容标题是否整合到关键词,需要匹配用户搜索到的关键词,可以出现在文章中,这些词应该出现在哪个栏目下。匹配度越高越好,因为需要匹配的内容量大,主题页的排名方案也是可以接受的。因此,排名研究与关键词有关。在优化 网站 时,
第三核心:差异化核心
网站 的优化方法不同,导致有人想模仿。效果不好,尽量发挥自己的优势。对标题或关键词、内容页面、网站布局等的动作。关键词为了达到标题和内容的匹配度,网站的页面是做好内容,原创提高质量,让同学们互相分享,达到网站的差异化排名指日可待。
在网站的优化中,有两种标签在站长看来可以起到很小的作用。这两种标签分别是关键词标签和description标签,尤其是description标签被很多人使用网站已经没用了。然而,作者并不这么认为。目前的描述标签虽然和排名没有直接关系,但是对网站等方面的优化影响很大,比如网站的专业性,用户是否网站的内容@>可以从搜索结果等中快速判断,这些都可以通过description标签来实现。而且,在搜索引擎看来,描述标签在用户体验中也可以起到非常重要的作用。
一、有助于提高网站的专业水平
当用户判断一个网站是否专业时,首先要从搜索结果的描述标签判断网站是否专业。例如,当用户搜索女装信息时,标题是写女装,而描述是女鞋。这样的网站如何让用户感受到他的专业?还有就是没有写description标签,导致搜索引擎随机爬取网站@网站上的一段内容,用来描述和展示结果。众所周知,搜索引擎很难随便爬取来完美展示其网站的大致内容,提升网站的性能非常重要。专业性很差。
二、缩小搜索引擎判断页面的范围关键词
<p>搜索引擎在提取页面的关键词时,并不是单纯的依靠页面的标题来选择,还有一个重要的参考地方,那就是页面的描述标签。一般来说,写好每个页面的description标签,可以让搜索引擎更快的提取出这个页面的关键词,同时也可以缩小搜索引擎判断页面 查看全部
优采云自动文章采集 sign failed11(为什么要用帝国CMS插件?如何利用网站收录以及关键词排名
)
为什么要使用 Empire cms 插件?如何使用 Empire cms 插件对 网站收录 和 关键词 进行排名。网站seo优化是对网站的节目、域名注册查询、内容、版块、版面、目标关键词等方面的优化调整,即网站被设计为适用于搜索引擎检索,满足搜索引擎排名的指标,从而在搜索引擎检索中获得流量排名靠前,增强搜索引擎营销效果,使网站相关关键词能够有一个很好的排名。网站seo优化的目的是让网站更容易被搜索引擎收录访问,提升用户体验(UE)和转化率,创造价值。那么<的核心内容是什么?

第一个核心:页面评分核心
搜索引擎在抓取网站网站时,首先判断网站的内容质量,是动态路径还是静态路径,是否使用二级域名, 网站的质量取决于网站的用户,其次是收录搜索的页数。每一页的关键词的等级,能不能再回来?从标题看,搜索引擎抓取的时候,首先看你的标题,页面的关键词是否与内容匹配。关键词 的整体类型是否与用户搜索的 关键词 匹配?这时候就需要分析一下为什么产品页面收录那么低,根据产品类别展开相关的长尾。如果内容质量好,找关键词多带点,整体关键词
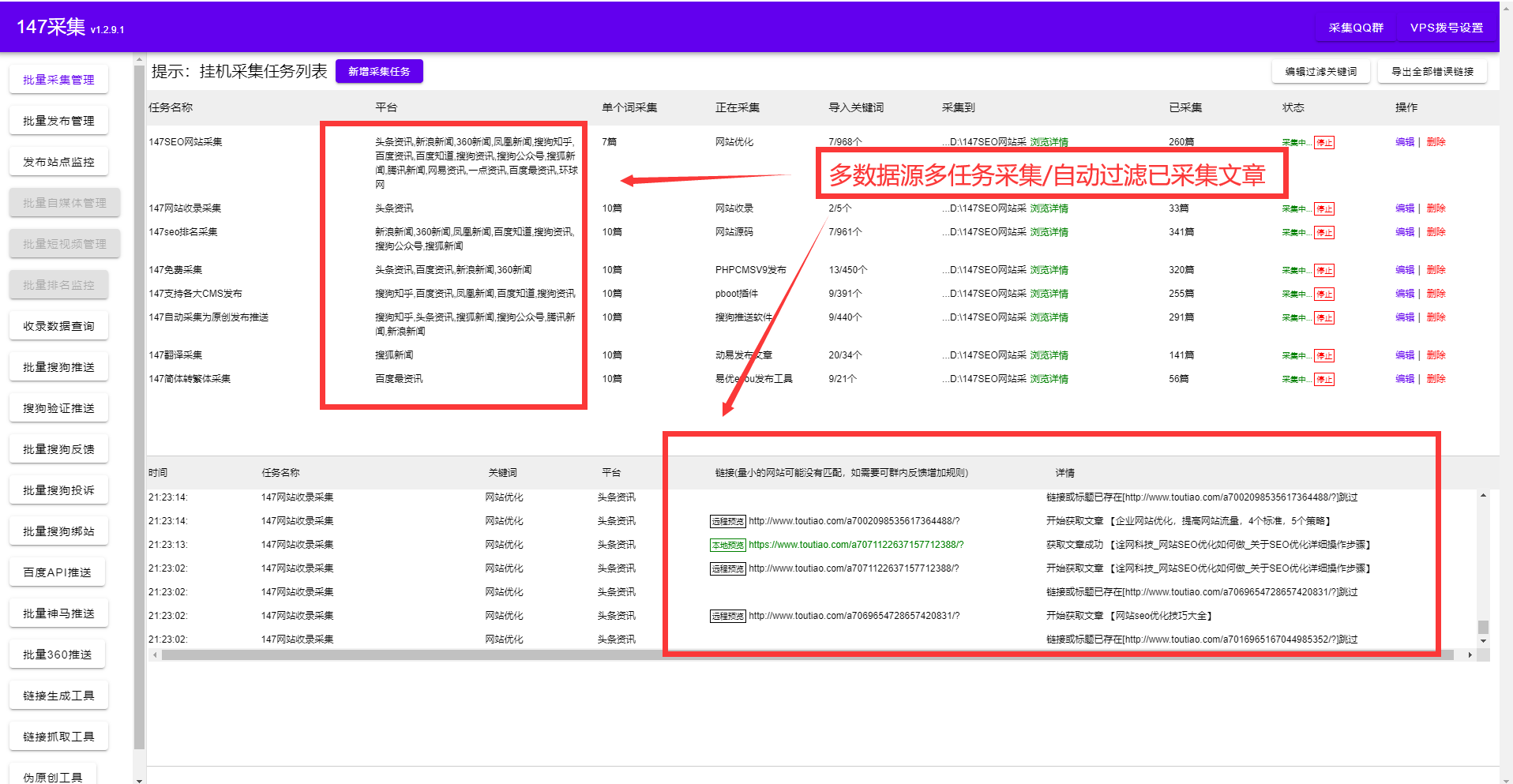
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以通过Empire cms插件实现采集伪原创自动发布和主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站< @k10@ > 和 关键词 排名。
一、自由帝国采集插件
Free Empire采集 插件的特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)
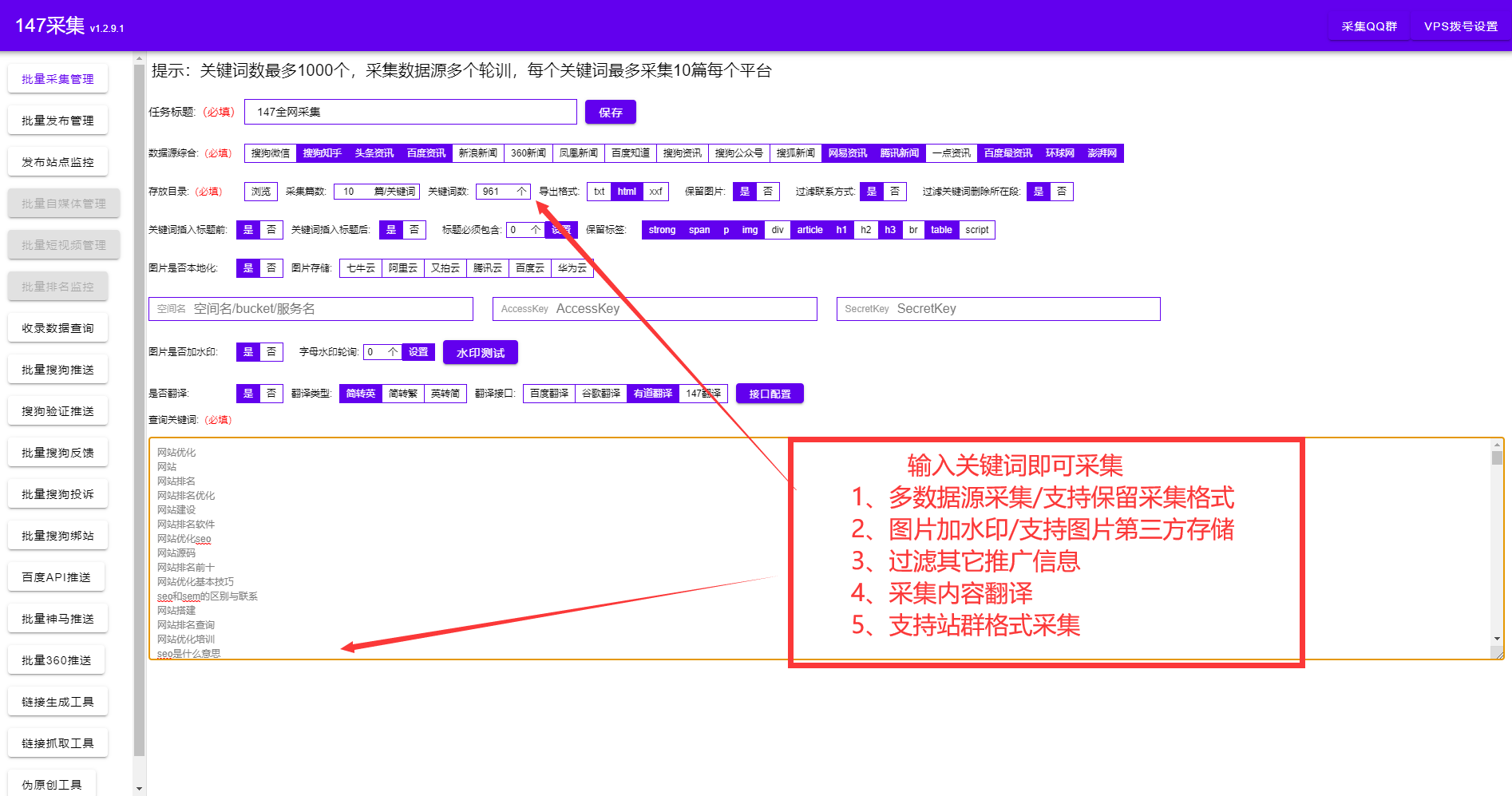
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体中文翻译+百度翻译+147翻译+有道翻译+谷歌翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)

3、伪原创(标题+内容)
4、替换图片防止侵权
5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章前后插入内容/标题关键词与内容一致关键词/随机插入图片/随机属性添加页面原创度)
6、对应栏:对应文章可以发布对应栏/支持多栏发布
7、定期发布:可控发布间隔/每天发布总数
8、监控数据:直接监控已经发布、待发布的软件,是否为伪原创、发布状态、URL、程序、发布时间等。
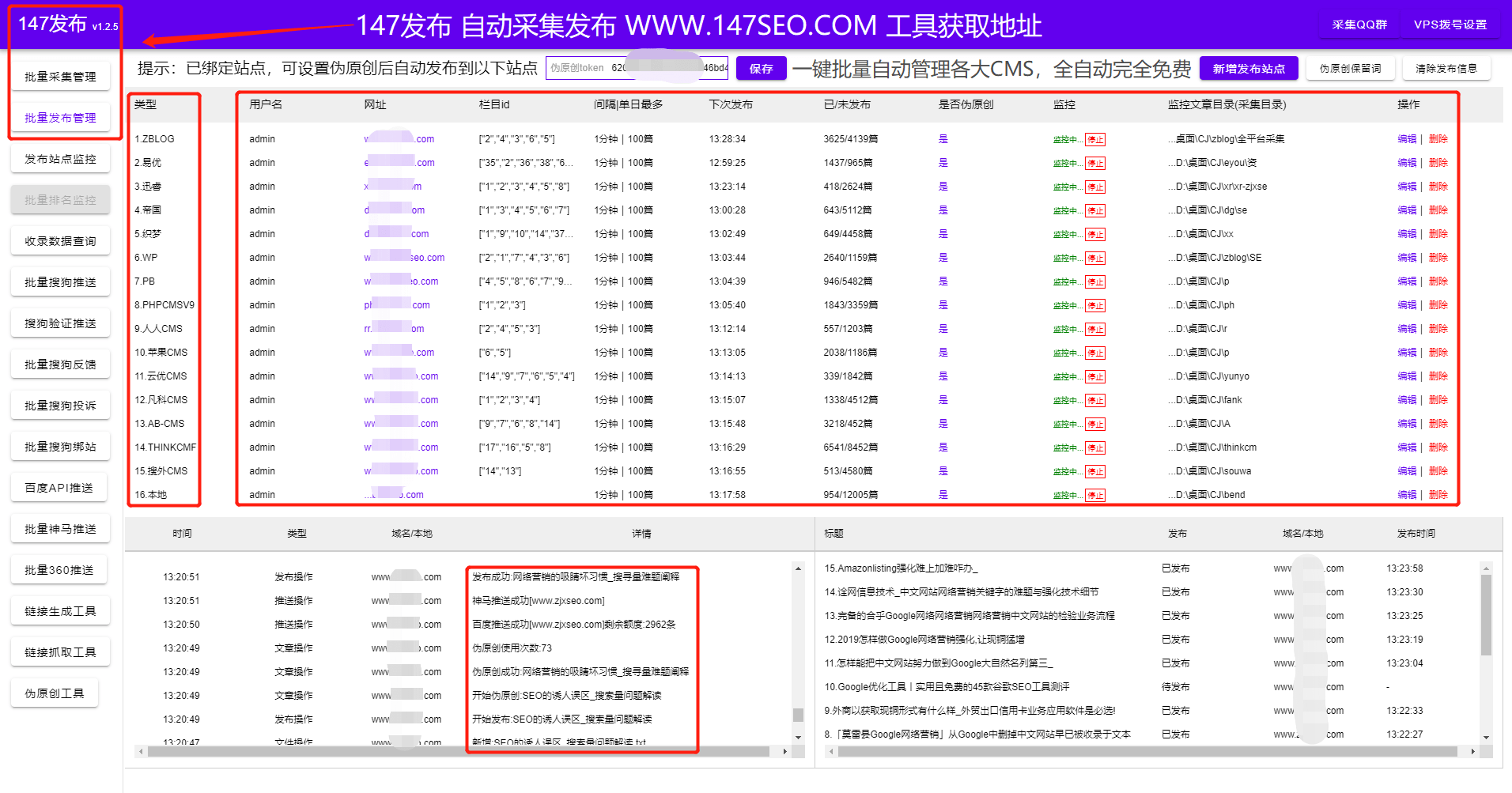
第二个核心:关键词 核心
做大网站需要一个团队的运作。如果频道页很大,就离不开关键词。需要一个优化器加一两个编辑器,优化器需要优化选择关键词,选择关键词,如果小网站需要更新网站@对应的内容> 每天,内容标题是否整合到关键词,需要匹配用户搜索到的关键词,可以出现在文章中,这些词应该出现在哪个栏目下。匹配度越高越好,因为需要匹配的内容量大,主题页的排名方案也是可以接受的。因此,排名研究与关键词有关。在优化 网站 时,
第三核心:差异化核心
网站 的优化方法不同,导致有人想模仿。效果不好,尽量发挥自己的优势。对标题或关键词、内容页面、网站布局等的动作。关键词为了达到标题和内容的匹配度,网站的页面是做好内容,原创提高质量,让同学们互相分享,达到网站的差异化排名指日可待。
在网站的优化中,有两种标签在站长看来可以起到很小的作用。这两种标签分别是关键词标签和description标签,尤其是description标签被很多人使用网站已经没用了。然而,作者并不这么认为。目前的描述标签虽然和排名没有直接关系,但是对网站等方面的优化影响很大,比如网站的专业性,用户是否网站的内容@>可以从搜索结果等中快速判断,这些都可以通过description标签来实现。而且,在搜索引擎看来,描述标签在用户体验中也可以起到非常重要的作用。
一、有助于提高网站的专业水平
当用户判断一个网站是否专业时,首先要从搜索结果的描述标签判断网站是否专业。例如,当用户搜索女装信息时,标题是写女装,而描述是女鞋。这样的网站如何让用户感受到他的专业?还有就是没有写description标签,导致搜索引擎随机爬取网站@网站上的一段内容,用来描述和展示结果。众所周知,搜索引擎很难随便爬取来完美展示其网站的大致内容,提升网站的性能非常重要。专业性很差。
二、缩小搜索引擎判断页面的范围关键词
<p>搜索引擎在提取页面的关键词时,并不是单纯的依靠页面的标题来选择,还有一个重要的参考地方,那就是页面的描述标签。一般来说,写好每个页面的description标签,可以让搜索引擎更快的提取出这个页面的关键词,同时也可以缩小搜索引擎判断页面
优采云自动文章采集 sign failed11(云优CMS采集的四张配图之中,不需要看文章!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-03-19 07:30
云游cms采集,很多把云游cms当成网站的站长,有个麻烦点就是采集的云游cms@>工具难找不到,而且可用的插件很少,与其他cms相比,确实很不方便。云游cms采集,自动批量采集全网文章,自动伪原创发到云游cms。本文章重点讲四张图,不用看文章,看图就懂云游cms采集。【看图一,云游cms采集,永远完全免费】
高质量内容的一个关键要素是确保它始终是最新的并且相关的词是相关的。云游cms采集发布一个高质量的页面或文章并不是这个过程的最后一步。网站内容也必须不时更新,以确保用户可以在那里找到正确的信息。这对 网站 的用户很重要,因为它向他们表明 网站 是最新的和最新的,并且始终拥有他们想要的信息。【见图二,云游cms采集,有钱有势】
这可以建立信任并将用户带到 网站。这对 SEO 也很重要,因为云游 cms采集 的内容将向搜索引擎展示 网站 的活跃度和相关性。因此,云游cms采集让网站保持内容新鲜,打造优质内容是重要的一步。云游cms采集可以保证网站的内容每天定时更新。【看图3,云游cms采集,工作高效简单】
Yunyoucms采集 在为特定页面创建内容时考虑搜索意图很重要。因此,您可以关键词将您自己的目标与用户可能拥有的不同搜索意图相匹配。网站 的目标之一是吸引更多实时热点话题文章,其中收录许多与网站 所在行业相关的新闻和其他相关信息。然后,云游cms采集将内容采集添加回网站对用户有信息意图的页面。【见图4,云游cms采集,站长优化必备】
当用户输入 网站 时,建立信任也很重要。尤其是当他们还不熟悉这个网站时,网站必须向他们证明他们是值得信赖的。云游cms采集以清晰和面向用户的方式编写代码可以帮助网站奠定基础,云游cms采集可以做更多的事情。添加更多真实的图像可以增加信任并使 网站 人感到更友好和更真实。
网站SEO 优化还可以考虑在搜索引擎上添加评分、在正确的页面上使用推荐内容、设置 HTTPS 以及添加其他信任信号。这一切都有助于网站的用户和搜索引擎知道网站属于一个真实的企业或真实的人,让他们可以轻松方便地浏览网站。
最后,云游cms采集从了解搜索意图开始,这是用户进行特定搜索的原因,用于描述在线搜索的目的。用户的搜索意图会影响搜索引擎如何看待网站的内容质量,当然云游cms采集是符合他们需求的。然后他们将在页面上停留 网站 更长时间。 查看全部
优采云自动文章采集 sign failed11(云优CMS采集的四张配图之中,不需要看文章!)
云游cms采集,很多把云游cms当成网站的站长,有个麻烦点就是采集的云游cms@>工具难找不到,而且可用的插件很少,与其他cms相比,确实很不方便。云游cms采集,自动批量采集全网文章,自动伪原创发到云游cms。本文章重点讲四张图,不用看文章,看图就懂云游cms采集。【看图一,云游cms采集,永远完全免费】
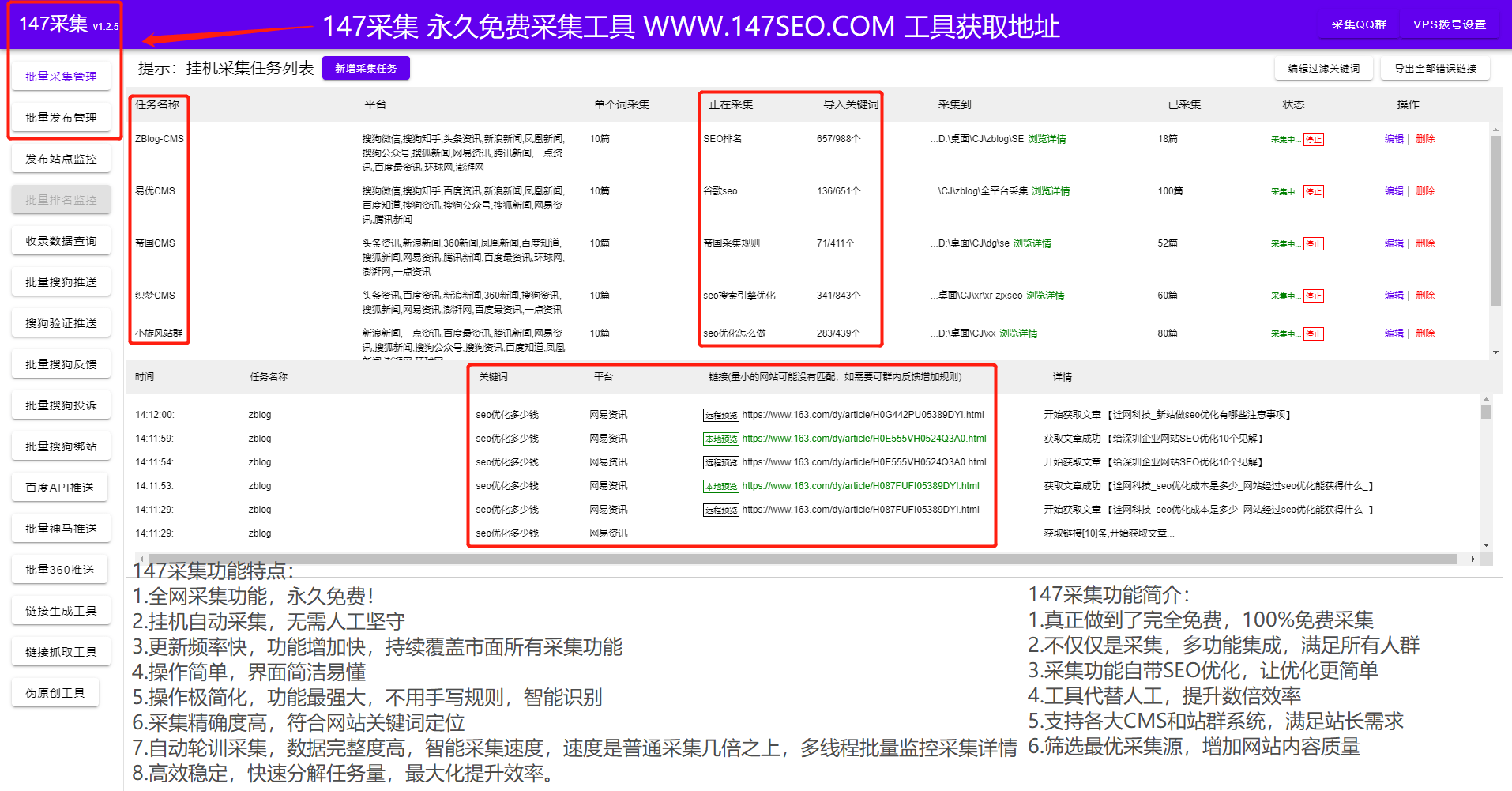
高质量内容的一个关键要素是确保它始终是最新的并且相关的词是相关的。云游cms采集发布一个高质量的页面或文章并不是这个过程的最后一步。网站内容也必须不时更新,以确保用户可以在那里找到正确的信息。这对 网站 的用户很重要,因为它向他们表明 网站 是最新的和最新的,并且始终拥有他们想要的信息。【见图二,云游cms采集,有钱有势】

这可以建立信任并将用户带到 网站。这对 SEO 也很重要,因为云游 cms采集 的内容将向搜索引擎展示 网站 的活跃度和相关性。因此,云游cms采集让网站保持内容新鲜,打造优质内容是重要的一步。云游cms采集可以保证网站的内容每天定时更新。【看图3,云游cms采集,工作高效简单】

Yunyoucms采集 在为特定页面创建内容时考虑搜索意图很重要。因此,您可以关键词将您自己的目标与用户可能拥有的不同搜索意图相匹配。网站 的目标之一是吸引更多实时热点话题文章,其中收录许多与网站 所在行业相关的新闻和其他相关信息。然后,云游cms采集将内容采集添加回网站对用户有信息意图的页面。【见图4,云游cms采集,站长优化必备】

当用户输入 网站 时,建立信任也很重要。尤其是当他们还不熟悉这个网站时,网站必须向他们证明他们是值得信赖的。云游cms采集以清晰和面向用户的方式编写代码可以帮助网站奠定基础,云游cms采集可以做更多的事情。添加更多真实的图像可以增加信任并使 网站 人感到更友好和更真实。
网站SEO 优化还可以考虑在搜索引擎上添加评分、在正确的页面上使用推荐内容、设置 HTTPS 以及添加其他信任信号。这一切都有助于网站的用户和搜索引擎知道网站属于一个真实的企业或真实的人,让他们可以轻松方便地浏览网站。

最后,云游cms采集从了解搜索意图开始,这是用户进行特定搜索的原因,用于描述在线搜索的目的。用户的搜索意图会影响搜索引擎如何看待网站的内容质量,当然云游cms采集是符合他们需求的。然后他们将在页面上停留 网站 更长时间。
优采云自动文章采集 sign failed11(网络信息采集的难点是什么?数据比较复杂,形式多样;形式多样)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-16 07:15
信息采集的难度是多少?数据更加复杂多样;下载后有什么困难?数据管理。网络信息大师(netget)的主要功能就是解决这两个问题。网络信息采集基于快讯采集,实时在线信息监控,为企业决策、网站建设、局域网新闻系统建设等提供快速,完整而强大的解决方案。现有功能介绍:1.采集 丰富的信息类型。采集几乎任何类型的网站信息,包括静态htm、html类型和动态asp、aspx、jsp等。2.网站登录。获取需要的信息要登录才能看到,先登录在“ 图片可通过设置自动下载,文中图片的网络路径可自动更改为本地文件路径(也可保持原样);可以将采集新闻自动处理成自己设计的模板格式;采集 分页格式的新闻可用。
有了这些功能,无需人工干预,只需简单的设置就可以在本地建立一个强大的新闻系统。7.可以设置为采集,数据量一定后会自动存入库,内存会自动清空。该功能可以连续采集10万级、百万级数据,不占用系统资源。8. 信息会自动重新处理。采集的信息可以分两批重新处理,使其更符合您的实际需求。还可以设置自动处理公式。采集过程中,根据公式自动处理,包括数据合并、数据替换等。9.可以自动下载二进制文件,如图片、软件、mp3等 10. 实时监控和发布(任务调度)。指定某些任务自动运行,自动去除重复后将采集的数据导入数据库(可指定唯一组合)。它可以循环运行。您可以指定在某个时间点运行的任务。11.采集 本地磁盘信息。使用'列表类型'的任务可以是采集网络上的信息,本地磁盘采集上的信息。12.通过发布页面将采集的数据发布到网站的数据库中。即海量发送数据的方式,模拟手动提交数据。13.无人值守采集。开始任务后,您可以采集,自动存入数据库,采集完成后自动关闭。不仅能提高工作效率,还能最大程度地节约能源。14.access、sqlserver、oracle、mysql的数据库测试已经完全通过。 查看全部
优采云自动文章采集 sign failed11(网络信息采集的难点是什么?数据比较复杂,形式多样;形式多样)
信息采集的难度是多少?数据更加复杂多样;下载后有什么困难?数据管理。网络信息大师(netget)的主要功能就是解决这两个问题。网络信息采集基于快讯采集,实时在线信息监控,为企业决策、网站建设、局域网新闻系统建设等提供快速,完整而强大的解决方案。现有功能介绍:1.采集 丰富的信息类型。采集几乎任何类型的网站信息,包括静态htm、html类型和动态asp、aspx、jsp等。2.网站登录。获取需要的信息要登录才能看到,先登录在“ 图片可通过设置自动下载,文中图片的网络路径可自动更改为本地文件路径(也可保持原样);可以将采集新闻自动处理成自己设计的模板格式;采集 分页格式的新闻可用。
有了这些功能,无需人工干预,只需简单的设置就可以在本地建立一个强大的新闻系统。7.可以设置为采集,数据量一定后会自动存入库,内存会自动清空。该功能可以连续采集10万级、百万级数据,不占用系统资源。8. 信息会自动重新处理。采集的信息可以分两批重新处理,使其更符合您的实际需求。还可以设置自动处理公式。采集过程中,根据公式自动处理,包括数据合并、数据替换等。9.可以自动下载二进制文件,如图片、软件、mp3等 10. 实时监控和发布(任务调度)。指定某些任务自动运行,自动去除重复后将采集的数据导入数据库(可指定唯一组合)。它可以循环运行。您可以指定在某个时间点运行的任务。11.采集 本地磁盘信息。使用'列表类型'的任务可以是采集网络上的信息,本地磁盘采集上的信息。12.通过发布页面将采集的数据发布到网站的数据库中。即海量发送数据的方式,模拟手动提交数据。13.无人值守采集。开始任务后,您可以采集,自动存入数据库,采集完成后自动关闭。不仅能提高工作效率,还能最大程度地节约能源。14.access、sqlserver、oracle、mysql的数据库测试已经完全通过。
优采云自动文章采集 sign failed11(优采云采集器为每个网站设置不同的采集规则(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-12-15 04:24
优采云采集器是一个由用户提供的关键词,云端自动将采集相关文章发布给用户网站网站@ > 采集器。可自动识别各种网页的标题、正文等信息,实现全网采集,无需用户编写任何采集规则。采集到达内容后,会自动计算该内容与集合关键词的相关性,只推送相关的文章给用户。支持标题前缀、关键词自动加粗、插入固定链接、自动提取Tag标签、自动内部链接、自动图片分配、自动伪原创、内容过滤和替换、电话号码和URL清洗、定时< @采集,百度主动提交一系列SEO功能。用户只需设置关键词及相关要求,即可实现全托管零维护网站内容更新。网站的数量没有限制,无论是单个网站还是大批量的站群,都可以轻松管理。
研发背景
文章采集器是大多数网站管理员必备的网站更新工具。传统的采集器提取网页信息主要是根据正则表达式匹配网页内容,实现起来快捷方便,但是不同的网站页面结构不同,需要编写不同的采集规则,需要大量的工作并且难以维护。而且,用户需要自己寻找采集的来源,还需要自己挂机运行采集器,甚至涉及IP被封的可能性等一系列问题。需要使用代理IP。
主要功能
提供1亿+级的庞大关键词库,可根据用户输入的任意文本搜索关键词,简单查询后即可用于采集,大大减少用户集合关键词的时间和精力。用户还可以创建自己的私人词汇,可以分组,数以百万计的关键词可以轻松管理,也可以满足更加个性化的关键词需求。按关键词采集文章,基于百度、搜狗、好搜等搜索引擎,全网采集精美好文章,用户不用花钱去找到采集能量的来源。自动识别网页编码、标题、正文等信息,无需为每个网站设置不同的采集规则,无需到处找人写采集规则,无需懂html源码,完全零维护。您可以设置所需的文本长度,例如 500 字、750 字和 1000 字。不符合标准的内容会被自动丢弃。系统内置多种自然语言处理算法,自动计算文章文本与关键词的相关性(特征向量间的余弦距离),并自动滤除文章 相关性低。将高度相关的 文章 留给用户。自动计算文章文本的平滑度(语言混淆),丢弃平滑度低的文章,把平滑度高的文章留给用户。自动计算标题(Title)和描述(Description)与关键词的相关性。如果相关性较低,可以在标题和描述中自动插入关键词,以提高相关性。您也可以为标题设置前缀关键词,每次从多个设置的前缀中随机选择一个添加到文章标题的头部。基于机器学习算法的文字色情可以对采集的内容进行审核,保障用户内容安全。实现伪原创基于同义词替换功能,从2000万对同义词中,选出最适合语言表达习惯的词,替换原文中的词,保证文章的可读性最大程度。基于机器学习实现智能AI< @伪原创,先将原文编码成高维语义向量,再通过解码器逐字解码,实现对整个文章的完全重写,伪原创高度,好可读性。Tags 标签自动提取,在此基础上实现自动内链。当正文中出现标签对应的文字时,在正文中添加网站文章的链接,指向同主题文章的文章,实现内部自动化、科学、有效链建设。您还可以设置固定链接。当正文中出现一些固定文本时,为其添加一个固定链接,指向站内或站外的文章。根据文章的内容自动匹配图片,这样即使你是采集的文章,您还可以同时显示图片和文字。您可以设置图片本地化或使用远程图片,并屏蔽所有图片。您可以设置阻止某些网站而不是采集,或者收录某些不是采集的词的内容。自动过滤文章前后的联系方式、网址、广告内容等冗余信息,并清理所有标签,只保留正文部分 图片和文字也可以合并。您可以设置图片本地化或使用远程图片,并屏蔽所有图片。您可以设置阻止某些网站而不是采集,或者收录某些不是采集的词的内容。自动过滤文章前后的联系方式、网址、广告内容等冗余信息,并清理所有标签,并且只保留正文部分图片和文字也可以组合。您可以设置图片本地化或使用远程图片,并屏蔽所有图片。您可以设置阻止某些网站而不是采集,或者收录某些不是采集的词的内容。自动过滤文章前后的联系方式、网址、广告内容等冗余信息,并清理所有标签,只保留正文部分
段落标签和图片
标签不收录任何乱码,也不收录任何排版格式,方便用户通过css样式自定义外观。严格的防重复机制,整个平台的每个URL只有采集一次,而不是采集。在同一个网站下,同名的文章只会出现采集一次,不会重复采集。您可以指定每个关键词允许采集实现大量长尾关键词非重复布局的文章数量。云端自动运行采集任务,可调度量化采集。用户不需要在自己的电脑上安装任何软件,不需要挂断采集,甚至不需要打开浏览器。采集 会自动发布到用户的网站后台。用户只需将接口文件下载并上传到网站的根目录即可完成对接。采集会自动实现百度主动推送,让蜘蛛快速找到你的文章。
支持的网站建设程序/内容管理系统
织梦内容管理系统(DEDEcms)帝国网站管理系统社区力量DISCUZ(论坛版) Z-BLOGWordPressOld y文章管理系统EMLOGMIPcms范克旺(凡客建站)易友企业建站系统(EYOUcms)米拓建站(MetInfo)江湖cms微连云PHPcmsDESTOON(B2B网站系统) 查看全部
优采云自动文章采集 sign failed11(优采云采集器为每个网站设置不同的采集规则(图))
优采云采集器是一个由用户提供的关键词,云端自动将采集相关文章发布给用户网站网站@ > 采集器。可自动识别各种网页的标题、正文等信息,实现全网采集,无需用户编写任何采集规则。采集到达内容后,会自动计算该内容与集合关键词的相关性,只推送相关的文章给用户。支持标题前缀、关键词自动加粗、插入固定链接、自动提取Tag标签、自动内部链接、自动图片分配、自动伪原创、内容过滤和替换、电话号码和URL清洗、定时< @采集,百度主动提交一系列SEO功能。用户只需设置关键词及相关要求,即可实现全托管零维护网站内容更新。网站的数量没有限制,无论是单个网站还是大批量的站群,都可以轻松管理。
研发背景
文章采集器是大多数网站管理员必备的网站更新工具。传统的采集器提取网页信息主要是根据正则表达式匹配网页内容,实现起来快捷方便,但是不同的网站页面结构不同,需要编写不同的采集规则,需要大量的工作并且难以维护。而且,用户需要自己寻找采集的来源,还需要自己挂机运行采集器,甚至涉及IP被封的可能性等一系列问题。需要使用代理IP。
主要功能
提供1亿+级的庞大关键词库,可根据用户输入的任意文本搜索关键词,简单查询后即可用于采集,大大减少用户集合关键词的时间和精力。用户还可以创建自己的私人词汇,可以分组,数以百万计的关键词可以轻松管理,也可以满足更加个性化的关键词需求。按关键词采集文章,基于百度、搜狗、好搜等搜索引擎,全网采集精美好文章,用户不用花钱去找到采集能量的来源。自动识别网页编码、标题、正文等信息,无需为每个网站设置不同的采集规则,无需到处找人写采集规则,无需懂html源码,完全零维护。您可以设置所需的文本长度,例如 500 字、750 字和 1000 字。不符合标准的内容会被自动丢弃。系统内置多种自然语言处理算法,自动计算文章文本与关键词的相关性(特征向量间的余弦距离),并自动滤除文章 相关性低。将高度相关的 文章 留给用户。自动计算文章文本的平滑度(语言混淆),丢弃平滑度低的文章,把平滑度高的文章留给用户。自动计算标题(Title)和描述(Description)与关键词的相关性。如果相关性较低,可以在标题和描述中自动插入关键词,以提高相关性。您也可以为标题设置前缀关键词,每次从多个设置的前缀中随机选择一个添加到文章标题的头部。基于机器学习算法的文字色情可以对采集的内容进行审核,保障用户内容安全。实现伪原创基于同义词替换功能,从2000万对同义词中,选出最适合语言表达习惯的词,替换原文中的词,保证文章的可读性最大程度。基于机器学习实现智能AI< @伪原创,先将原文编码成高维语义向量,再通过解码器逐字解码,实现对整个文章的完全重写,伪原创高度,好可读性。Tags 标签自动提取,在此基础上实现自动内链。当正文中出现标签对应的文字时,在正文中添加网站文章的链接,指向同主题文章的文章,实现内部自动化、科学、有效链建设。您还可以设置固定链接。当正文中出现一些固定文本时,为其添加一个固定链接,指向站内或站外的文章。根据文章的内容自动匹配图片,这样即使你是采集的文章,您还可以同时显示图片和文字。您可以设置图片本地化或使用远程图片,并屏蔽所有图片。您可以设置阻止某些网站而不是采集,或者收录某些不是采集的词的内容。自动过滤文章前后的联系方式、网址、广告内容等冗余信息,并清理所有标签,只保留正文部分 图片和文字也可以合并。您可以设置图片本地化或使用远程图片,并屏蔽所有图片。您可以设置阻止某些网站而不是采集,或者收录某些不是采集的词的内容。自动过滤文章前后的联系方式、网址、广告内容等冗余信息,并清理所有标签,并且只保留正文部分图片和文字也可以组合。您可以设置图片本地化或使用远程图片,并屏蔽所有图片。您可以设置阻止某些网站而不是采集,或者收录某些不是采集的词的内容。自动过滤文章前后的联系方式、网址、广告内容等冗余信息,并清理所有标签,只保留正文部分
段落标签和图片
标签不收录任何乱码,也不收录任何排版格式,方便用户通过css样式自定义外观。严格的防重复机制,整个平台的每个URL只有采集一次,而不是采集。在同一个网站下,同名的文章只会出现采集一次,不会重复采集。您可以指定每个关键词允许采集实现大量长尾关键词非重复布局的文章数量。云端自动运行采集任务,可调度量化采集。用户不需要在自己的电脑上安装任何软件,不需要挂断采集,甚至不需要打开浏览器。采集 会自动发布到用户的网站后台。用户只需将接口文件下载并上传到网站的根目录即可完成对接。采集会自动实现百度主动推送,让蜘蛛快速找到你的文章。
支持的网站建设程序/内容管理系统
织梦内容管理系统(DEDEcms)帝国网站管理系统社区力量DISCUZ(论坛版) Z-BLOGWordPressOld y文章管理系统EMLOGMIPcms范克旺(凡客建站)易友企业建站系统(EYOUcms)米拓建站(MetInfo)江湖cms微连云PHPcmsDESTOON(B2B网站系统)
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-12-15 04:23
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器可以非常得心应手。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想网站 什么样的网站,不管你导出成什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也能让你轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的一个插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要面对一个简单的编程界面,可以大大降低工作强度。这是一个漂亮的数据采集 解决方案,它将特定的采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin是一个Eclipse插件,可用于任务开发和调试。这个插件的功能会越来越丰富。
菜库服务器完全免费! 查看全部
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器可以非常得心应手。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想网站 什么样的网站,不管你导出成什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也能让你轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的一个插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要面对一个简单的编程界面,可以大大降低工作强度。这是一个漂亮的数据采集 解决方案,它将特定的采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin是一个Eclipse插件,可用于任务开发和调试。这个插件的功能会越来越丰富。
菜库服务器完全免费!
优采云自动文章采集 sign failed11(优采云是一款网页爬虫工具,可以不用编写代码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-14 08:35
优采云是一款无需编写代码即可快速抓取网络数据的网络爬虫工具。
其基本操作可以在其官网教程中查看。主要是它的翻页和登录验证码和xpath操作。
特殊翻页 数字翻页
制作采集规则时,页面上没有“下一页”等翻页按钮,而是一行页码,例如“1”、“2”、“3”、“4” ,“5”...
数字翻页如何处理?
解决方案:
找到一个 xpath,以便下一页始终位于当前页面上(未分页的页面除外)。
示例网址:
常用函数:follow-sibling::*
例如://span[@class="page_curl"]/follow-sibling=a[1]
其中,首先找到数字1所在的位置为span,它的class为page_url,这样就找到了数字1所在的span。然后使用following-sibling查找其兄弟元素定位下一页,找到下一页,也就是a标签的第二页所在的位置,因为同级的所有后续元素的页码都是a 标签,所以使用 a[1] 表示第一页之后的第一个 a 标签。
“加载更多”翻页表单
应用情况:
如果采集的网页中有“加载更多”或“再显示20个”等按钮,点击这些按钮后,采集的数据就会全部显示出来。
例如,在以下情况下,您需要单击“加载更多内容”,每次单击将显示 20 多条数据:
解决方案:
按照正常操作创建一个翻页循环,然后将循环翻页步骤拖到循环提取数据步骤之前。所有翻页完成后,进行循环数据提取步骤,否则会出现大量重复数据。
循环翻页的点击按钮一般是ajax加载,即点击翻页高级选项需要勾选ajax,并设置超时时间(时间长短根据数据加载速度设置),不要检查新标签。
比如网页,习惯上先循环点击“加载更多内容”,如下左图。如果这样执行采集数据,会得到前20个数据采集的循环。
在这种情况下,我们需要在循环翻转下方拖动循环提取数据,如右图,这样会先添加所有数据,然后一起进行数据提取。请注意,有时如果数据过多,它会无限制地加载数据。这时候可以对翻页的循环次数进行限制。另外需要修改下图循环提取数据的xpath,否则只能提取前20条数据。
某些页面出现重复循环现象
适用场景:重复网页中几页的数据采集
现象:
采集 结果重复。翻阅资料,发现网页采集的部分资料页面有重复。例如,重复采集 一页或两页数据。
原因分析:
网页中有上一页按钮和下一页按钮,xpath定位不准确,上一页按钮会定位在某个页面,导致部分页面数据重复采集
解决方案:
修改xpath,使得在当前页面(最后一页除外),只能定位到下一页按钮
例如:当某些网页在某一页后进行翻页时,其xpath会同时定位上一页和下一页按钮。这时候就需要修改它的xpath,让它只能定位到下一页。, 如原来的xpath://a[@class="next"],观察其源码,需要修改为://a[@class="next" and text()="next page" ]
最后一页死循环现象
应用情况:
对于采集的网页,明明最后一页的数据已经采集到了,但是采集的最后一页的数据却不断重复,没有停止采集。
或者在不翻页的情况下循环点击下一页,某一页的数据总是采集。
原因分析:
xpath定位不准确,“下一页”按钮可以定位到最后一页,无法结束翻页的循环。
解决方案:
修改xpath,使当前页为最后一页时无法定位“下一页”按钮,但当前页为最后一页时可以定位到“下一页”(观察当前页为最后一页时)上一页而不是下一页的最后一个位置xpath,然后修改它的xpath)
其他翻页现象
1.输入页码,点击“跳转”或“确定”按钮翻页
示例 网站:
点击输入编号页码输入框,选择输入文字,点击确定,然后在此过程中拖入一个循环框,将输入的文字拖入循环框,设置为从循环中选择内容,然后将循环内容设置为 1、2,页码 3 就可以了。
2.将翻页周期转换为URL周期
这样就可以在输入网址的时候直接输入多个网址,用换行符包裹起来,然后执行采集数据。
3.翻几页后,直接跳转到下几页(missing data-几页的缺失数据不是采集)
适用场景:
由于点击翻页,有些页面不是采集。比如翻了几页后,直接跳到下几页。
示例网址:
解决方案:
找到一个 xpath,以便下一页始终位于当前页面上(未分页的页面除外)。
示例 网站:
上述方法不仅可以解决一些网站无法翻页或翻页后容易出现采集中断的问题,还可以避免网站的反采集措施在某种程度上。
登录和验证码 Cookie 登录
输入账号密码登录后,打开网页步骤设置获取cookie。这时候就可以删除之前输入账号密码的步骤了。如果想用当前账号新建任务,也可以复制打开网页的网址新建任务。注意:Cookie 有生命周期;如果您想更改您的帐户,请在打开网页时将缓存设置为清除。
验证码登录:设置执行前等待的方法
适用场景:
在登录页面输入用户名和密码后,需要验证码识别才能正常登录。
重点验证通过拖动滑块,点击选择一些图片或文字,拼图验证,
以及其他验证码识别控件无法自动识别的验证码类型。
对于这种需要验证码登录的场景,可以通过设置执行前等待来完成验证码识别。
方法:输入账号密码后,点击登录步骤,设置执行前的等待时间,如15s。当输入采集数据时,到了输入验证码的时候,系统会留15s给用户输入验证码,15s后会自动执行登录步骤。注意:仅适用于本地采集,不适用于云采集。
验证码登录:控制识别方法
对于需要输入验证码的情况,也可以设置控件识别。做法是:
如下图,输入账号密码后,先点击验证码图片,再点击验证码输入框,然后根据提示输入验证码识别错误和正确的配置信息。
内嵌框架
什么是 Iframe 框架:
一些 网站 登录框实际上是 iframe 登录框。iframe 是 html 标签,它创建了一个收录另一个文档的内联框架(即内联框架),这意味着一个网页中的一个网页。有时无法定位输入框,因为网页使用了 iframe 框架。
如何检查网页是否使用 iframe 框架:
使用火狐查看。看一下具体的网址。例如,天猫的登录页面使用iframe登录框架。
1、在火狐浏览器中打开网页
2、将鼠标移至天猫登录框,右击选择“本框”>>“在新标签中打开框”
优采云iframe框架的处理:
优采云 一般可以自动识别网页中的iframe frame,生成对应iframe frame的XPath。如果遇到无法生成的东西,需要先在浏览器中定位frame,然后在优采云中填写iframe frame的XPath。软件支持一层iframe框架。如果网站中有多层框架,则应先去除多余的框架。或者将浏览器中获取到的frame地址复制到优采云中。
XPath
XPath 简介
XPath 是专门为 xml 设计的。它是一种在复杂结构化数据中查找信息的语言。简单来说就是使用路径表达式来查找我们需要的数据位置。
查看/自动生成xpath方法
1、通过Firefox中的firebug和firepath插件生成/查看XPath
注意:Firefox 浏览器的版本必须为 55 或更低。如果版本太高,firebug 和 firepath 插件可能不可用。安装过程中和安装后必须禁止浏览器的自动更新。
火狐浏览器54版下载地址:
64 位 Firefox 54:
32 位 Firefox 54:
其他版本下载地址:
在火狐浏览器菜单中的附件管理器中搜索firebug和firepath插件进行安装,安装后需要重启才能使用。
2、通过优采云采集器生成/查看XPath
html有一套XPath引擎,可以直接使用XPath准确地查找和定位网页中的数据,从而提取数据。在优采云中配置规则时,会自动生成定位数据的XPath
在优采云规则配置中,除了没有XPath打开网页的步骤外,其他步骤都涉及XPath定位
找到xpath的方式,如下图:
XPath节点
在 XPath 中,一切都是一个节点。节点有七种类型:元素、属性、文本、命名空间、处理指令、注释、文档(根)节点。
XPath 语法
XPath 轴:定义当前节点与其他节点的关系。
XPath 语法:使用路径表达式来选择 html 文档中的节点或节点集。
谓词:路径表达式的附加条件,进一步过滤节点,嵌入在 [] 中。在使用谓词时,我们经常使用一些 XPath 函数。
应用-修改提取的数据字段xpath
适用于调整XPath,解决采集数据中的数据泄露和数据错位问题。
应用场景:
1.网页上有信息,采集的结果中有些字段没有被采集到达。
2.采集 导致部分字段数据错位,采集的实际内容与字段名不符。
原因分析:
网页结构不一致,导致原来的xpath在某些页面上无法正确定位到需要的数据。
解决方案:
修改问题字段的xpath,使其能够在所有页面上准确定位所需数据。
应用-修改循环列表xpath
适用于修改循环列表的XPath,解决部分数据泄露和冗余项的问题。
应用场景:
点击生成的循环列表没有收录所有需要的数据,缺少一些循环项。
原因分析:
网页的特殊结构导致原创xpath无法匹配页面上所有需要的数据。
解决方案:
修改循环列表的xpath,使其能够匹配页面上所有需要的数据,消除多余的循环项。 查看全部
优采云自动文章采集 sign failed11(优采云是一款网页爬虫工具,可以不用编写代码)
优采云是一款无需编写代码即可快速抓取网络数据的网络爬虫工具。
其基本操作可以在其官网教程中查看。主要是它的翻页和登录验证码和xpath操作。
特殊翻页 数字翻页
制作采集规则时,页面上没有“下一页”等翻页按钮,而是一行页码,例如“1”、“2”、“3”、“4” ,“5”...
数字翻页如何处理?
解决方案:
找到一个 xpath,以便下一页始终位于当前页面上(未分页的页面除外)。
示例网址:
常用函数:follow-sibling::*
例如://span[@class="page_curl"]/follow-sibling=a[1]
其中,首先找到数字1所在的位置为span,它的class为page_url,这样就找到了数字1所在的span。然后使用following-sibling查找其兄弟元素定位下一页,找到下一页,也就是a标签的第二页所在的位置,因为同级的所有后续元素的页码都是a 标签,所以使用 a[1] 表示第一页之后的第一个 a 标签。
“加载更多”翻页表单
应用情况:
如果采集的网页中有“加载更多”或“再显示20个”等按钮,点击这些按钮后,采集的数据就会全部显示出来。
例如,在以下情况下,您需要单击“加载更多内容”,每次单击将显示 20 多条数据:
解决方案:
按照正常操作创建一个翻页循环,然后将循环翻页步骤拖到循环提取数据步骤之前。所有翻页完成后,进行循环数据提取步骤,否则会出现大量重复数据。
循环翻页的点击按钮一般是ajax加载,即点击翻页高级选项需要勾选ajax,并设置超时时间(时间长短根据数据加载速度设置),不要检查新标签。
比如网页,习惯上先循环点击“加载更多内容”,如下左图。如果这样执行采集数据,会得到前20个数据采集的循环。
在这种情况下,我们需要在循环翻转下方拖动循环提取数据,如右图,这样会先添加所有数据,然后一起进行数据提取。请注意,有时如果数据过多,它会无限制地加载数据。这时候可以对翻页的循环次数进行限制。另外需要修改下图循环提取数据的xpath,否则只能提取前20条数据。


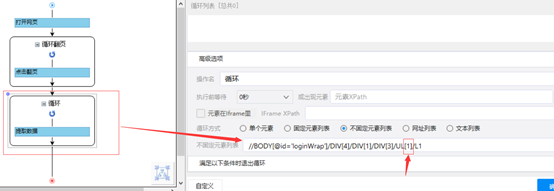
某些页面出现重复循环现象
适用场景:重复网页中几页的数据采集
现象:
采集 结果重复。翻阅资料,发现网页采集的部分资料页面有重复。例如,重复采集 一页或两页数据。
原因分析:
网页中有上一页按钮和下一页按钮,xpath定位不准确,上一页按钮会定位在某个页面,导致部分页面数据重复采集
解决方案:
修改xpath,使得在当前页面(最后一页除外),只能定位到下一页按钮
例如:当某些网页在某一页后进行翻页时,其xpath会同时定位上一页和下一页按钮。这时候就需要修改它的xpath,让它只能定位到下一页。, 如原来的xpath://a[@class="next"],观察其源码,需要修改为://a[@class="next" and text()="next page" ]
最后一页死循环现象
应用情况:
对于采集的网页,明明最后一页的数据已经采集到了,但是采集的最后一页的数据却不断重复,没有停止采集。
或者在不翻页的情况下循环点击下一页,某一页的数据总是采集。
原因分析:
xpath定位不准确,“下一页”按钮可以定位到最后一页,无法结束翻页的循环。
解决方案:
修改xpath,使当前页为最后一页时无法定位“下一页”按钮,但当前页为最后一页时可以定位到“下一页”(观察当前页为最后一页时)上一页而不是下一页的最后一个位置xpath,然后修改它的xpath)
其他翻页现象
1.输入页码,点击“跳转”或“确定”按钮翻页
示例 网站:
点击输入编号页码输入框,选择输入文字,点击确定,然后在此过程中拖入一个循环框,将输入的文字拖入循环框,设置为从循环中选择内容,然后将循环内容设置为 1、2,页码 3 就可以了。
2.将翻页周期转换为URL周期
这样就可以在输入网址的时候直接输入多个网址,用换行符包裹起来,然后执行采集数据。
3.翻几页后,直接跳转到下几页(missing data-几页的缺失数据不是采集)
适用场景:
由于点击翻页,有些页面不是采集。比如翻了几页后,直接跳到下几页。
示例网址:
解决方案:
找到一个 xpath,以便下一页始终位于当前页面上(未分页的页面除外)。
示例 网站:
上述方法不仅可以解决一些网站无法翻页或翻页后容易出现采集中断的问题,还可以避免网站的反采集措施在某种程度上。
登录和验证码 Cookie 登录
输入账号密码登录后,打开网页步骤设置获取cookie。这时候就可以删除之前输入账号密码的步骤了。如果想用当前账号新建任务,也可以复制打开网页的网址新建任务。注意:Cookie 有生命周期;如果您想更改您的帐户,请在打开网页时将缓存设置为清除。
验证码登录:设置执行前等待的方法
适用场景:
在登录页面输入用户名和密码后,需要验证码识别才能正常登录。
重点验证通过拖动滑块,点击选择一些图片或文字,拼图验证,
以及其他验证码识别控件无法自动识别的验证码类型。
对于这种需要验证码登录的场景,可以通过设置执行前等待来完成验证码识别。
方法:输入账号密码后,点击登录步骤,设置执行前的等待时间,如15s。当输入采集数据时,到了输入验证码的时候,系统会留15s给用户输入验证码,15s后会自动执行登录步骤。注意:仅适用于本地采集,不适用于云采集。
验证码登录:控制识别方法
对于需要输入验证码的情况,也可以设置控件识别。做法是:
如下图,输入账号密码后,先点击验证码图片,再点击验证码输入框,然后根据提示输入验证码识别错误和正确的配置信息。
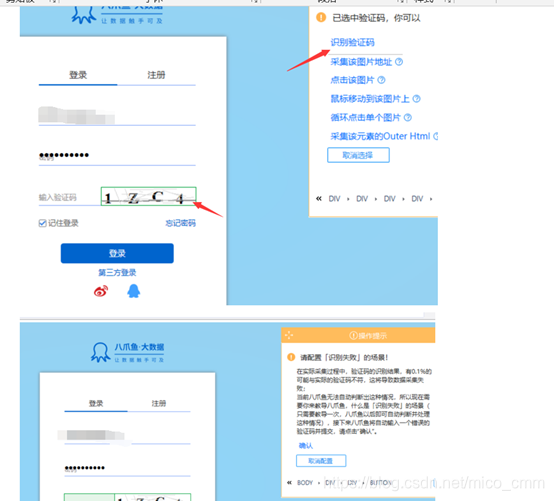
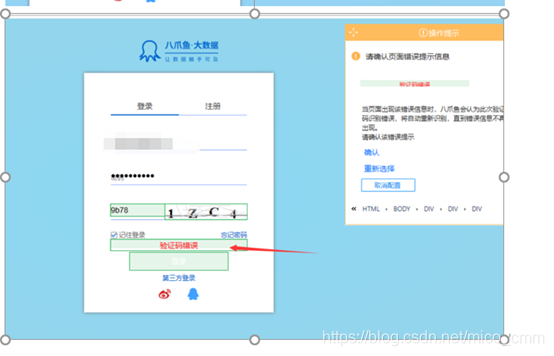
内嵌框架
什么是 Iframe 框架:
一些 网站 登录框实际上是 iframe 登录框。iframe 是 html 标签,它创建了一个收录另一个文档的内联框架(即内联框架),这意味着一个网页中的一个网页。有时无法定位输入框,因为网页使用了 iframe 框架。
如何检查网页是否使用 iframe 框架:
使用火狐查看。看一下具体的网址。例如,天猫的登录页面使用iframe登录框架。
1、在火狐浏览器中打开网页
2、将鼠标移至天猫登录框,右击选择“本框”>>“在新标签中打开框”
优采云iframe框架的处理:
优采云 一般可以自动识别网页中的iframe frame,生成对应iframe frame的XPath。如果遇到无法生成的东西,需要先在浏览器中定位frame,然后在优采云中填写iframe frame的XPath。软件支持一层iframe框架。如果网站中有多层框架,则应先去除多余的框架。或者将浏览器中获取到的frame地址复制到优采云中。
XPath
XPath 简介
XPath 是专门为 xml 设计的。它是一种在复杂结构化数据中查找信息的语言。简单来说就是使用路径表达式来查找我们需要的数据位置。
查看/自动生成xpath方法
1、通过Firefox中的firebug和firepath插件生成/查看XPath
注意:Firefox 浏览器的版本必须为 55 或更低。如果版本太高,firebug 和 firepath 插件可能不可用。安装过程中和安装后必须禁止浏览器的自动更新。
火狐浏览器54版下载地址:
64 位 Firefox 54:
32 位 Firefox 54:
其他版本下载地址:
在火狐浏览器菜单中的附件管理器中搜索firebug和firepath插件进行安装,安装后需要重启才能使用。
2、通过优采云采集器生成/查看XPath
html有一套XPath引擎,可以直接使用XPath准确地查找和定位网页中的数据,从而提取数据。在优采云中配置规则时,会自动生成定位数据的XPath
在优采云规则配置中,除了没有XPath打开网页的步骤外,其他步骤都涉及XPath定位
找到xpath的方式,如下图:


XPath节点
在 XPath 中,一切都是一个节点。节点有七种类型:元素、属性、文本、命名空间、处理指令、注释、文档(根)节点。
XPath 语法
XPath 轴:定义当前节点与其他节点的关系。
XPath 语法:使用路径表达式来选择 html 文档中的节点或节点集。
谓词:路径表达式的附加条件,进一步过滤节点,嵌入在 [] 中。在使用谓词时,我们经常使用一些 XPath 函数。



应用-修改提取的数据字段xpath
适用于调整XPath,解决采集数据中的数据泄露和数据错位问题。
应用场景:
1.网页上有信息,采集的结果中有些字段没有被采集到达。
2.采集 导致部分字段数据错位,采集的实际内容与字段名不符。
原因分析:
网页结构不一致,导致原来的xpath在某些页面上无法正确定位到需要的数据。
解决方案:
修改问题字段的xpath,使其能够在所有页面上准确定位所需数据。
应用-修改循环列表xpath
适用于修改循环列表的XPath,解决部分数据泄露和冗余项的问题。
应用场景:
点击生成的循环列表没有收录所有需要的数据,缺少一些循环项。
原因分析:
网页的特殊结构导致原创xpath无法匹配页面上所有需要的数据。
解决方案:
修改循环列表的xpath,使其能够匹配页面上所有需要的数据,消除多余的循环项。
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-12-09 01:01
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化方案、定时任务、后端索引等,菜库服务器都能轻松搞定。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想网站 什么样的网站,不管你导出成什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也能让你轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要面对一个简单的编程界面,可以大大降低工作强度。这是一个漂亮的数据采集 解决方案,它将特定的采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin是一个Eclipse插件,可用于任务开发和调试。这个插件的功能会越来越丰富。
菜库服务器完全免费! 查看全部
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化方案、定时任务、后端索引等,菜库服务器都能轻松搞定。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想网站 什么样的网站,不管你导出成什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也能让你轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要面对一个简单的编程界面,可以大大降低工作强度。这是一个漂亮的数据采集 解决方案,它将特定的采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin是一个Eclipse插件,可用于任务开发和调试。这个插件的功能会越来越丰富。
菜库服务器完全免费!
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-12-05 17:25
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器可以非常得心应手。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想网站 什么样的网站,不管你导出成什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也能让你轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要面对一个简单的编程界面,可以大大降低工作强度。这是一个漂亮的数据采集 解决方案,它将特定的采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin是一个Eclipse插件,可用于任务开发和调试。这个插件的功能会越来越丰富。
菜库服务器完全免费! 查看全部
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器可以非常得心应手。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想网站 什么样的网站,不管你导出成什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也能让你轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要面对一个简单的编程界面,可以大大降低工作强度。这是一个漂亮的数据采集 解决方案,它将特定的采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin是一个Eclipse插件,可用于任务开发和调试。这个插件的功能会越来越丰富。
菜库服务器完全免费!
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-12-03 15:27
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器可以非常得心应手。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想网站 什么样的网站,不管你导出成什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也能让你轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要面对一个简单的编程界面,可以大大降低工作强度。这是一个漂亮的数据采集 解决方案,它将特定的采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin是一个Eclipse插件,可用于任务开发和调试。这个插件的功能会越来越丰富。
菜库服务器完全免费! 查看全部
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器可以非常得心应手。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想网站 什么样的网站,不管你导出成什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也能让你轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要面对一个简单的编程界面,可以大大降低工作强度。这是一个漂亮的数据采集 解决方案,它将特定的采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin是一个Eclipse插件,可用于任务开发和调试。这个插件的功能会越来越丰富。
菜库服务器完全免费!
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-09 04:21
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器可以非常得心应手。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想要什么样的网站采集,不管你导出什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也让你可以轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要简单的接口编程,可以大大减轻工作强度。这是一个漂亮的数据 采集 解决方案,它将特定的 采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin 是一个可用于任务开发和调试的 Eclipse 插件。这个插件的功能会越来越丰富。
菜库服务器完全免费! 查看全部
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器可以非常得心应手。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想要什么样的网站采集,不管你导出什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也让你可以轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要简单的接口编程,可以大大减轻工作强度。这是一个漂亮的数据 采集 解决方案,它将特定的 采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin 是一个可用于任务开发和调试的 Eclipse 插件。这个插件的功能会越来越丰富。
菜库服务器完全免费!
优采云自动文章采集 sign failed11(优采云自动文章采集器-优采云采集软件采集工具采集系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-11-07 07:07
名称:优采云Auto文章采集器-按关键词Auto采集发布网站文章采集工具
优采云采集文章采集采集器采集软件采集工具采集系统关键词采集文章文章自动采集发布站长工具
网站关键词(52 个字符):
优采云采集文章采集采集器采集软件采集工具采集系统关键词采集文章文章自动采集发布站长工具
网站 描述性词(119 个字符):
优采云Auto文章采集器是关键词auto采集网站文章采集发布的一款工具,免费提供亿个关键词库,自动识别网页正文,无需编写采集规则,智能计算文章与关键词的相关性,NLP技术< @伪原创,指定采集最新内容,指定采集目标网站,是站长必备的数据采集工具。
相关网站介绍:站长工具》优采云Auto文章采集器-按关键词Auto采集发布网站文章采集工具》网友主动提交查询整理收录,有的网站可能跑题,打不开,关闭等,不能访问,不能访问原因等等,什么,怎么办,好吗?诸如“如何”、“好”等问题与本网站无关。本站只提供基本参考信息显示:IP地址:-地址:-,百度权重为<@1、百度手机权重为,百度收录为17800,360收录为1640,搜狗收录为32640,谷歌收录为-,百度流量约59-68,百度手机流量约6-7,备案号蜀ICP备14020125-4、@ > 查看全部
优采云自动文章采集 sign failed11(优采云自动文章采集器-优采云采集软件采集工具采集系统)
名称:优采云Auto文章采集器-按关键词Auto采集发布网站文章采集工具
优采云采集文章采集采集器采集软件采集工具采集系统关键词采集文章文章自动采集发布站长工具
网站关键词(52 个字符):
优采云采集文章采集采集器采集软件采集工具采集系统关键词采集文章文章自动采集发布站长工具
网站 描述性词(119 个字符):
优采云Auto文章采集器是关键词auto采集网站文章采集发布的一款工具,免费提供亿个关键词库,自动识别网页正文,无需编写采集规则,智能计算文章与关键词的相关性,NLP技术< @伪原创,指定采集最新内容,指定采集目标网站,是站长必备的数据采集工具。
相关网站介绍:站长工具》优采云Auto文章采集器-按关键词Auto采集发布网站文章采集工具》网友主动提交查询整理收录,有的网站可能跑题,打不开,关闭等,不能访问,不能访问原因等等,什么,怎么办,好吗?诸如“如何”、“好”等问题与本网站无关。本站只提供基本参考信息显示:IP地址:-地址:-,百度权重为<@1、百度手机权重为,百度收录为17800,360收录为1640,搜狗收录为32640,谷歌收录为-,百度流量约59-68,百度手机流量约6-7,备案号蜀ICP备14020125-4、@ >
优采云自动文章采集是一个常见的错误信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2023-02-11 17:26
Sign failed11是一个常见的错误信息,表明优采云软件无法正常登录服务器。这可能是因为用户名/密码错误、网络不稳定、服务器出错等原因所导致的。因此,用户在遭遇sign failed11之前,应该先检查一下账号密码是否正确,再判断当前所处的网络情况。如果都无法解决问题,可以尝试联系优采云客服人员进行帮助。
优采云是一家专注于SEO内容优化技术的公司,其官方网站www.ucaiyun.com上提供了大量关于文章采集的相关信息和教程,用户也可以在上面找到很多帮助性的内容。此外,优采云也有一整套专业、专注、高效、全方位的SEO优化服务体系来帮助用户更好地开展文章采集工作。
总之,sign failed11是一个很常见但又不容易解决的问题。如果遭遇sign failed11问题,用户应该尝试根据上述方法进行尝试并排除出错原因。如果无法解决问题,不妨考虑使用优采云SEO优化来帮助文章采集工作。 查看全部
近年来,随着互联网的发展,文章采集已成为一种流行的媒体技术。在众多的文章采集软件中,优采云自动文章采集是一款性能卓越的软件,它可以帮助用户快速、高效地采集各种类型的文章。然而,有时用户可能会遇到sign failed11的问题,这时就需要更多的关注。
Sign failed11是一个常见的错误信息,表明优采云软件无法正常登录服务器。这可能是因为用户名/密码错误、网络不稳定、服务器出错等原因所导致的。因此,用户在遭遇sign failed11之前,应该先检查一下账号密码是否正确,再判断当前所处的网络情况。如果都无法解决问题,可以尝试联系优采云客服人员进行帮助。
优采云是一家专注于SEO内容优化技术的公司,其官方网站www.ucaiyun.com上提供了大量关于文章采集的相关信息和教程,用户也可以在上面找到很多帮助性的内容。此外,优采云也有一整套专业、专注、高效、全方位的SEO优化服务体系来帮助用户更好地开展文章采集工作。
总之,sign failed11是一个很常见但又不容易解决的问题。如果遭遇sign failed11问题,用户应该尝试根据上述方法进行尝试并排除出错原因。如果无法解决问题,不妨考虑使用优采云SEO优化来帮助文章采集工作。
事实:做了N个采集,都是处理内容失败(官方看下)
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2022-12-22 09:29
采集器的问题我们开发已经查过了,下面是他们的回答:
个别文章采集不到和跳课的原因主要有两个。
一种是php无法读取对方的网站。
二是php从对方服务器获取图片保存到本地的时间可能过长。 而且,有些东西读过了,但是图片读不出来(读图片的时候网络突然忙,导致图片打不开)。
这块不是程序造成的,原因是:
1.网络繁忙导致php执行超时
2、目标内容(包括:URL、图片)无响应、404错误或其他错误。
造成这种情况的原因有很多,比如网络拥堵,防盗机制,你自己的服务器突然以某种方式繁忙等等。
解决方案:
全部采集完之后,可以再进行一次采集,这样已经采集到的内容会被跳过,重新采集因为网络繁忙而失败的内容。
ss6 -> ss7采集机制调整不多,所以不会有6线7的不稳定因素
后续版本会在采集机制上做更多的优化。
定时任务采集、断点续采集、内容图片分离采集等。
汇总:渗透测试之信息收集篇(含思维导图)
爱站记录查询
域名助手备案信息查询
11、查询绿盟科技的whois信息
域名查询
查看注册人和邮箱获取更多域名
12. 采集子域 12.1。 子域的功能
采集子域名可以扩大测试范围,同一域名下的二级域名都属于目标范围。
12.2. 常用方法
子域中常见的资产类型一般包括办公系统、邮件系统、论坛、商城等管理系统,网站管理后台也可能出现在子域中。
首先找到目标站点,在官网可以找到相关资产(主要是办公系统、邮件系统等)。 关注页面底部,可能会有管理后台等收获。
查找目标域名信息的方法如下:
FOFA title="公司名称"
百度intitle=公司名称
Google intitle=公司名称
站长之家,可直接搜索名称或网站域名查看相关信息:
钟馗之眼站点=域名
找到官网后,采集子域名。 以下是一些采集子域名的推荐方法。 可以直接输入域名查询。
12.3. 域名类型
A记录、别名记录(CNAME)、MX记录、TXT记录、NS记录:
12.3.1。 A(地址)记录:
用于指定主机名(或域名)对应的IP地址记录。 用户可以将域名下的网站服务器指向自己的网站服务器。 同时,您还可以设置您的域名的二级域名。
12.3.2。 别名(CNAME)记录:
也称为规范名称。 这种类型的记录允许您将多个名称映射到同一台计算机。 通常用于同时提供 WWW 和 MAIL 服务的计算机。 例如,有一台名为“”的计算机(A记录)。 同时提供WWW和MAIL服务,方便用户访问服务。 可以为这台计算机设置两个别名(CNAME):WWW 和 MAIL。 这两个别名的全称是“”和“”。 其实都指向“”。
当你有多个域名需要指向同一个服务器IP时,可以使用同样的方法。 这时候可以给一个域名做一个A记录指向服务器IP,然后把其他域名别名到有之前A记录的域名上。 那么当你的服务器IP地址发生变化的时候,你就不用费心费力地一个一个的改域名了。 您只需要更改做A记录的域名,其他做别名的域名也会自动更改为新的IP地址。
12.3.3。 如何检测CNAME记录?
1、进入命令状态; (开始菜单-运行-CMD【回车】);
2、输入命令“nslookup -q=cname 此处填写对应的域名或二级域名”,查看返回结果是否与设置一致。
12.3.4。 MX(邮件交换器)记录:
它是一条邮件交换记录,指向一个邮件服务器,供电子邮件系统在发送邮件时根据收件人的地址后缀定位邮件服务器。 例如,当Internet上的用户要寄信给 时,用户的邮件系统通过DNS查找该域名的MX记录。 如果MX记录存在,则用户计算机将邮件发送到MX记录指定的邮件服务器。 .
12.3.5。 什么是 TXT 记录? :
TXT记录一般是指对主机名或域名的指令集,例如:
1) admin IN TXT "jack, mobile:";
2)mail IN TXT》邮件主机,存放于xxx,管理员:AAA,Jim IN TXT》联系人:
也就是你可以设置TXT,这样别人就可以联系到你了。
如何检测TXT记录?
1、进入命令状态; (开始菜单-运行-CMD【回车】);
2、输入命令“nslookup -q=txt 在此填写对应的域名或二级域名”,查看返回结果是否与设置一致。
12.3.6。 什么是 NS 记录?
ns记录的全称是Name Server,也就是域名服务器记录,用来明确你的域名当前是由哪台DNS服务器解析的。
12.3.7。 子域名在线查询1
12.3.8。 子域名在线查询2
12.3.9。 DNS检测
12.3.10。 IP138查询子域
12.3.11。 FOFA 搜索子域
语法:域=“”
Tips:以上两种方式不需要爆破,查询速度快。 当资产需要快速采集时,可以先使用,以后再通过其他方式补充。
12.3.12。 Hackertarget 查询子域
注意:通过该方法查询子域名可以得到目标的一个大概的ip段,然后就可以通过ip采集信息了。
12.4。 360映射空间
领域: ”*。”
12.4.1。 图层子域挖掘机
12.4.2。 子域蛮干
pip 安装 aiodns
运行命令 subDomainsBrute.py
subDomainsBrute.py --full -o freebuf2.txt
12.4.3。 子列表3r
pip install -r requirements.txt
提示:以上方法是对子域名进行爆破,因为字典功能更强大,所以效率更高。
帮助文档
<p style="margin-top: 0px;margin-bottom: 0px;">usage: sublist3r.py [-h] -d DOMAIN [-b [BRUTEFORCE]] [-p PORTS] [-v [VERBOSE]]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />[-t THREADS] [-e ENGINES] [-o OUTPUT] [-n]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />OPTIONS:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-h, --help show this help message and exit<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-d DOMAIN, --domain DOMAIN<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Domain name to enumerate it's subdomains<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-b [BRUTEFORCE], --bruteforce [BRUTEFORCE]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Enable the subbrute bruteforce module<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-p PORTS, --ports PORTS<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Scan the found subdomains against specified tcp ports<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-v [VERBOSE], --verbose [VERBOSE]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Enable Verbosity and display results in realtime<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-t THREADS, --threads THREADS<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Number of threads to use for subbrute bruteforce<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-e ENGINES, --engines ENGINES<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Specify a comma-separated list of search engines<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-o OUTPUT, --output OUTPUT<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Save the results to text file<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-n, --no-color Output without color</p>
示例:python sublist3r.py -d
中文翻译
-h:帮助
-d : 指定主域名枚举子域名
-b : 调用 subbrute 来暴力枚举子域名
-p : 指定扫描子域名的tpc端口
-v :显示实时详细结果
-t : 指定线程
-e : 指定搜索引擎
-o : 将结果保存到文本
-n : 没有颜色的输出
扫描子域的默认参数
python sublist3r.py -d
使用暴力枚举子域
python sublist3r -b -d
12.4.4。 python2.7.14环境
;C:\Python27;C:\Python27\脚本
12.4.5。 万物皆可
pip3 install --user -r requirements.txt -i
python3 oneforall.py --target run /*采集*/
爆炸子域
例子:
<p style="margin-top: 0px;margin-bottom: 0px;">brute.py --target domain.com --word True run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --targets ./domains.txt --word True run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target domain.com --word True --concurrent 2000 run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target domain.com --word True --wordlist subnames.txt run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target domain.com --word True --recursive True --depth 2 run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target d.com --fuzz True --place m.*.d.com --rule '[a-z]' run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target d.com --fuzz True --place m.*.d.com --fuzzlist subnames.txt run</p>
12.4.6。 域名
<p style="margin-top: 0px;margin-bottom: 0px;">dnsburte.py -d aliyun.com -f dnspod.csv -o aliyun.log<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />wydomain.py -d aliyun.com</p>
12.4.7。 模糊域
12.4.8。 隐藏域名主机冲突
隐藏资产检测-主机碰撞
很多时候访问目标资产的IP响应是:401、403、404、500,但是域名请求可以返回正常的业务系统(禁止直接IP访问),因为大部分需要绑定向主机正常请求访问(目前互联网公司的基本做法)(域名已经删除了A记录,但是反向生成的配置还没有更新),那么我们就可以将采集到的目标域名和目标资产的IP段,并用IP段+域名的形式进行捆绑碰撞,可以发现很多有趣的东西。
发送http请求时,将域名和IP列表配对,然后遍历发送请求(相当于修改本地hosts文件),对比对应的标题和响应包大小,快速找出一些隐藏资产。
Hosts collision需要目标的域名和目标的相关IP作为字典
更不用说域名了
相关IP来源有:
目标域名历史分析IP
ip 常规
13.端口扫描
确定目标的大概ip段后,可以先检测ip的开放端口。 某些特定服务可能会在默认端口上打开。 检测开放端口有利于快速采集目标资产,找到目标网站的其他功能站点。
13.1. msscan 端口扫描
msscan -p 1-65535 ip --rate=1000
13.2. 御剑端口扫描工具
13.3. nmap扫描端口并检测端口信息
常用参数,如:
nmap -sV 192.168.0.2
nmap -sT 92.168.0.2
nmap -Pn -A -sC 192.168.0.2
nmap -sU -sT -p0-65535 192.168.122.1
用于扫描目标主机服务版本号和开放端口
如果需要扫描多个ip或者ip段,可以保存到一个txt文件中
nmap -iL ip.txt
扫描列表中的所有 ip。
Nmap 是最常用的端口检测方法。 操作简单,输出结果非常直观。
13.4. 在线端口检测
13.5。 端口扫描器
御剑、msscan、nmap等
御剑高速端口扫描器:
填写你要扫描的ip段(如果只扫描一个ip,只需填写起始IP和结束IP),可以选择不更改默认端口列表,也可以选择自己指定端口。
13.6. 渗透端口
21,22,23,1433,152,3306,3389,5432,5900,50070,50030,50000,27017,27018,11211,9200,9300,7001,7002,6379,5984,873,443,8000-9090,80- 89,80,10000,8888,8649,8083,8080,8089,9090,7778,7001,7002,6082,5984,4440,3312,3311,3128,2601,2604,2222,2082,2083,389,88,512, 51 1025,111,1521,445,135,139,53
13.7。 穿透常用端口及对应服务
1、Web类(web漏洞/敏感目录)
第三方通用组件漏洞struts thinkphp jboss ganglia zabbix
80 网站
80-89网页
8000-9090 网页
2.数据库类(弱口令扫描)
第1433章
第1521章
3306 MySQL
5432 PostgreSQL 数据库
3.特殊服务类(未授权/命令执行类/漏洞)
第443章
873 Rsync 未经授权
5984 CouchDB:5984/_utils/
6379 Redis 未授权
7001,7002 WebLogic默认弱口令,反序列化
9200,9300 elasticsearch 参考WooYun:玩服务器ElasticSearch命令执行漏洞
11211 memcache 未授权访问
27017、27018 Mongodb 未授权访问
执行了 50000 个 SAP 命令
50070、50030 hadoop默认端口未授权访问
4.常用端口类(扫描弱口令/端口爆破)
21 英尺
22 SSH
23 远程登录
2601,2604 zebra路由,默认密码zebra
3389 远程桌面
5.端口总明细
21 英尺
22 SSH
23 远程登录
80 网站
80-89网页
第161话
第389章
443 SSL Heartbleed 和一些网络漏洞测试
445 家中小企业
512,513,514 雷克斯
873 Rsync 未经授权
1025,111 NFS
第1433章
1521 甲骨文:(iSqlPlus 端口:5560、7778)
2082/2083 cpanel主机管理系统登录(国外多用)
2222 DA虚拟主机管理系统登录(国外多用)
2601,2604 zebra路由,默认密码zebra
3128 squid代理默认端口,如果不设置密码,可以直接漫游内网
3306 MySQL
3312/3311康乐主机管理系统登录
3389 远程桌面
4440 rundeck 参考无云:借新浪服务成功漫游新浪内网
5432 PostgreSQL 数据库
5900 越南
5984 CouchDB:5984/_utils/
6082 Varnish 参考WooYun:Varnish HTTP加速器 CLI 未授权访问容易导致直接篡改网站或代理访问内网
6379 Redis 未授权
7001,7002 WebLogic默认弱口令,反序列化
7778 Kloxo 主机控制面板登录
8000-9090是一些常用的web端口,有些运维喜欢在这些非80端口上开启管理后台
8080 tomcat/WDCP主机管理系统,默认弱密码
8080、8089、9090 JBOSS
8083 Vestacp主机管理系统(国外多用)
8649 神经节
8888 amh/LuManager主机管理系统默认端口
9200,9300 elasticsearch 参考WooYun:玩服务器ElasticSearch命令执行漏洞
10000 Virtualmin/Webmin服务器虚拟主机管理系统
11211 memcache 未授权访问
27017、27018 Mongodb 未授权访问
28017 mongodb统计页面
执行了 50000 个 SAP 命令
50070、50030 hadoop默认端口未授权访问
13.8。 常用端口及攻击方式
14.查找真实ip
如果目标网站使用CDN,则隐藏cdn的真实ip。 要想找到真实服务器,就必须获取真实ip,根据这个ip继续查询侧站。
注意:很多情况下,虽然主站使用了CDN,但是子域名不一定使用CDN。 如果主网站和子域名在同一个ip段,那么也是找到子域名真实ip的一种方式。
14.1. Ping多处确认是否使用CDN
14.2. 查询历史DNS解析记录
在查询到的历史分析记录中,最早的历史分析IP很可能记录的是真实IP。 推荐使用此方法快速找到真实IP,但不是所有网站都能找到。
14.2.1。 域名数据库
14.2.2。 微步在线
14.2.3。
14.2.4。 查看DNS
14.3. php信息
如果目标网站存在phpinfo泄露等情况,可以在phpinfo中的SERVER_ADDR或_SERVER["SERVER_ADDR"]中查找真实ip
14.4. 绕过CDN
绕过CDN的方法有很多,请参考
15. 边站和C段
边站通常有业务功能站点。 建议先采集已有IP的边站,再检测C网段,确定C网段的目标后,在C网段的基础上重新采集边站。
辅助站点是与已知目标站点位于同一服务器上但具有不同端口的站点。 通过以下方法搜索到副站后,首先访问确定是否是您需要的站址信息。
15.1.1。 站长主页
用ip网站查询
15.2. 谷歌黑客
15.2.1。 网络空间搜索引擎
比如FOFA搜边站和C段
这种方式效率更高,可以直观的看到站点标题,但也有不收录不常用端口的情况。 虽然这种情况很少见,但您可以在后期补充资产时,通过以下方式再次扫描领取。
15.2.2。 线上段c
c部分使用脚本
<p style="margin-top: 0px;margin-bottom: 0px;">pip install requests<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />#coding:utf-8<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import requests<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import json<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />def get_c(ip):<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print("正在收集{}".format(ip))<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />url="http://api.webscan.cc/?action=query&ip={}".format(ip)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />req=requests.get(url=url)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />html=req.text<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />data=req.json()<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />if 'null' not in html:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />with open("resulit.txt", 'a', encoding='utf-8') as f:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />f.write(ip + '\n')<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />f.close()<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for i in data:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />with open("resulit.txt", 'a',encoding='utf-8') as f:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />f.write("\t{} {}\n".format(i['domain'],i['title']))<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print(" [+] {} {}[+]".format(i['domain'],i['title']))<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />f.close()<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />def get_ips(ip):<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />iplist=[]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />ips_str = ip[:ip.rfind('.')]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for ips in range(1, 256):<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />ipadd=ips_str + '.' + str(ips)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />iplist.append(ipadd)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />return iplist<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />ip=input("请你输入要查询的ip:")<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />ips=get_ips(ip)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for p in ips:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />get_c(p)</p>
15.2.3。 Nmap、Msscan扫描等
例如:nmap -p 80,443,8000,8080 -Pn 192.168.0.0/24
15.2.4。 公共端口表
21,22,23,80-90,161,389,443,445,873,1099,1433,1521,1900,2082,2083,2222,2601,2604,3128,3306,3311,3312,3389,4440,4848,5432,92,5569,5569,5569 ,6082,6379,7001-7010,7778,8080-8090,8649,8888,9000,9200,10000,11211,27017,28017,50000,50030,50060,135,139,445,53,88
注意:在检测网段C时,一定要确认ip是否属于目标,因为一个网段C中不一定所有的ip都属于目标。
16.网络空间搜索引擎
如果你想在短时间内快速采集资产,那么使用网络空间搜索引擎是一个不错的选择。 可以直观的看到边站、端口、站点标题、IP等信息,点击列出站点即可直接访问。 判断是否是您需要的站点信息。 FOFA 的通用语法
1、同IP端站:ip="192.168.0.1"
2、C段:ip="192.168.0.0/24"
3.子域名:domain=""
4.标题/关键字:title="百度"
5.如果需要将结果缩小到某个城市,可以拼接语句
title="百度" && region="北京"
17.扫描敏感目录/文件
扫描敏感目录需要强大的字典,需要平时积累。 拥有强大的词典可以更高效地查明网站的管理后台。 常见的敏感文件如.git文件泄露,.svn文件泄露,phpinfo泄露等,这一步就成功了一半,各种扫描器就够了。 在域名中输入目标站点,选择对应的词典类型,即可开始扫描,非常方便。
17.1. 御剑
17.2. 7kbstorm
17.3. 扫描仪
在已经安装pip的前提下,可以直接:
<p style="margin-top: 0px;margin-bottom: 0px;">pip install -r requirements.txt</p>
用法示例:
扫描单个 Web 服务
python BBScan.py --host
扫描下其他主机
python BBScan.py --host --network 28
扫描txt文件中的所有主机
蟒蛇 BBScan.py -f .txt
从文件夹中导入所有主机并扫描
python BBScan.py -d 目标/
--network参数用于设置子网掩码,小公司设置为28~30,中型公司设置为26~28,大公司设置为24~26
当然,尽量避免设置为24,扫描太耗时,除非你想在每个src中多扫描几个漏洞。
这个插件是从内部扫描器中提取的,感谢 Jekkay Hu
如果你有非常有用的规则,请找几个网站验证测试一下,然后pull request
脚本也会优化,接下来的事情:
添加有用的规则,更好地分类规则,细化
然后,您可以直接从 rules\request 文件夹中导入 HTTP_request
优化扫描逻辑
17.4. 目录映射
<p style="margin-top: 0px;margin-bottom: 0px;">pip install -r requirement.txt<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />https://github.com/H4ckForJob/dirmap</p>
单一目标
<p style="margin-top: 0px;margin-bottom: 0px;">python3 dirmap.py -i https://target.com -lcf</p>
多个目标
<p style="margin-top: 0px;margin-bottom: 0px;">python3 dirmap.py -iF urls.txt -lcf</p>
17.5。 直接搜索
解压目录搜索.zip
python3 dirsearch.py -u -e *
17.6. 火药
<p style="margin-top: 0px;margin-bottom: 0px;">sudo apt-get install gobuster<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />gobuster dir -u https://www.servyou.com.cn/ -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt -x php -t 50</p>
dir -u URL w dictionary -x 指定后缀 -t 线程数
<p style="margin-top: 0px;margin-bottom: 0px;">dir -u https://www.servyou.com.cn/ -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt -x "php,html,rar,zip" -d --wildcard -o servyou.log | grep ^"3402"</p>
17.7. 网站文件
机器人.txt
跨域.xml
站点地图.xml
后台目录
网站安装包
网站上传目录
mysql管理页面
php信息
网站文本编辑器
测试文件
网站备份文件(.rar、zip、.7z、.tar.gz、.bak)
DS_Store 文件
vim 编辑器备份文件 (.swp)
WEB—INF/web.xml 文件
15.git
16.svn
18.扫描网页备份
例如
配置.php
配置.php~
配置.php.bak
配置.php.swp
配置.php.rar
配置文件.php.tar.gz
19.网站头部信息采集
1.中间件:web服务【Web Servers】apache iis7 iis7.5 iis8 nginx WebLogic tomcat
2.网站组件:js组件jquery、vue页面布局bootstrap
通过浏览器访问
Firefox 插件 Wappalyzer
curl命令查询头部信息
卷曲-i
20. 敏感文件搜索 20.1. GitHub 搜索
in:name test #仓库标题搜索收录关键字test
in:descripton test #仓库描述搜索收录关键字
in:readme test #Readme文件搜索收录关键字
搜索某些系统的密码
++密码+3306&type=密码
github关键词监控
谷歌搜索
站点:sa 密码
站点:root密码
站点:用户;密码
网站:inurl:sql
SVN信息采集
站点:svn
站点:svn 用户名
站点:svn密码
站点:svn 用户名密码
综合信息采集
站点:密码
站点:ftp ftppassword
站点:密码
网站:内部
+&类型=代码
20.2. 谷歌黑客
站点:域名
inurl:url中存在的关键字网页
intext:网页正文中的关键词
filetype:指定文件类型
20.3。 乌云漏洞库
20.4。 网盘搜索
凌云搜索
潘多多:
泛搜索搜索:
泛搜索:
20.5。 社会工作图书馆
姓名/常用id/邮箱/密码/手机登录网盘网站邮箱查找敏感信息
机器人
20.6. 网站注册信息
查询网站注册信息
它通常与社会工程库一起使用。
20.7。 js敏感信息
20.7.1。 搜索器
python3 JSFinder.py -u
python3 JSFinder.py -u -d
python3 JSFinder.py -u -d -ou mi_url.txt -os mi_subdomain.txt
当你想获取更多信息时,可以使用-d进行深度爬取获取更多内容,使用命令-ou、-os指定子域保存的URL和文件名
批量指定url和js链接,获取里面的url。
指定网址:
python JSFinder.py -f 文本.txt
指定JS:
python JSFinder.py -f 文本.txt -j
20.7.2。 加壳模糊器
找到网站交互界面授权密钥
随着WEB前端打包工具的普及,你在日常的渗透测试和安全服务中是否遇到越来越多以Webpack packager为代表的网站? 这类打包器会将整个站点的API和API参数打包在一起进行集中web调用,也方便我们快速发现网站的功能和API列表,但是往往这些打包器生成的JS文件数量异常庞大且总是 JS 代码量极其庞大(高达数万行),给我们手动测试带来了极大的不便,于是 Packer Fuzzer 软件应运而生。
本工具支持自动模糊提取目标站点对应的API和API对应的参数内容,支持模糊高效模糊高效检测七大漏洞:未授权访问、敏感信息泄露、CORS、SQL注入、横向越权访问、弱口令、任意文件上传快速检测。 扫描结束后,该工具还支持自动生成扫描报告,可以选择便于分析的HTML版本,也可以选择比较正规的doc、pdf、txt版本。
sudo apt-get 安装 nodejs && sudo apt-get 安装 npm
混帐克隆
pip3 install -r requirements.txt
python3 PackerFuzzer.py -u
20.7.3。 秘密发现者
一个基于Python脚本的JavaScript敏感信息搜索工具
python3 SecretFinder.py -i -e
cms识别
采集网站信息后,应对网站进行指纹识别。 通过识别指纹,可以确定目标的cms和version,方便下一步测试计划的制定。 可以使用public poc或者自己积累相应的方法进行正式的渗透测试。
21.1. 云溪
21.2. 潮汐指纹
21.3。 CMS指纹识别
确认
21.4。 什么cms
21.5。 御cms识别
22. 非常规作业
1、如果找到了目标的某项资产,却无从下手搜集目标的其他资产,可以查看网站正文中是否有目标的特征,然后使用网络空间搜索引擎(如fofa , 等)特征进行搜索,如:body=”XX公司”或body=”baidu”等。
这种方式一般适用于特征明显、资产数量多的标的,效果往往比较突出。
2、通过以上方式找到特征后,再次搜索body,再搜索,此时fofa上显示的ip,大概率是真实ip。
3.如果需要针对政府网站,可以在批量获取网站首页的时候使用
然后可以结合上一步的方法进行进一步的信息采集。
23、SSL/TLS证书查询
SSL/TLS 证书通常收录域名、子域名和电子邮件地址等信息。 结合证书中的信息,您可以更快地定位到目标资产,获取目标资产的更多信息。
SSL证书搜索引擎:
%。
GetDomainsBySSL.py
24.找到厂商的ip段
25. 移动资产采集 25.1. 微信小程序 支付宝小程序 查看全部
事实:做了N个采集,都是处理内容失败(官方看下)
采集器的问题我们开发已经查过了,下面是他们的回答:
个别文章采集不到和跳课的原因主要有两个。
一种是php无法读取对方的网站。
二是php从对方服务器获取图片保存到本地的时间可能过长。 而且,有些东西读过了,但是图片读不出来(读图片的时候网络突然忙,导致图片打不开)。
这块不是程序造成的,原因是:
1.网络繁忙导致php执行超时
2、目标内容(包括:URL、图片)无响应、404错误或其他错误。
造成这种情况的原因有很多,比如网络拥堵,防盗机制,你自己的服务器突然以某种方式繁忙等等。
解决方案:
全部采集完之后,可以再进行一次采集,这样已经采集到的内容会被跳过,重新采集因为网络繁忙而失败的内容。
ss6 -> ss7采集机制调整不多,所以不会有6线7的不稳定因素
后续版本会在采集机制上做更多的优化。
定时任务采集、断点续采集、内容图片分离采集等。
汇总:渗透测试之信息收集篇(含思维导图)
爱站记录查询
域名助手备案信息查询
11、查询绿盟科技的whois信息
域名查询
查看注册人和邮箱获取更多域名
12. 采集子域 12.1。 子域的功能
采集子域名可以扩大测试范围,同一域名下的二级域名都属于目标范围。
12.2. 常用方法
子域中常见的资产类型一般包括办公系统、邮件系统、论坛、商城等管理系统,网站管理后台也可能出现在子域中。
首先找到目标站点,在官网可以找到相关资产(主要是办公系统、邮件系统等)。 关注页面底部,可能会有管理后台等收获。
查找目标域名信息的方法如下:
FOFA title="公司名称"
百度intitle=公司名称
Google intitle=公司名称
站长之家,可直接搜索名称或网站域名查看相关信息:
钟馗之眼站点=域名
找到官网后,采集子域名。 以下是一些采集子域名的推荐方法。 可以直接输入域名查询。
12.3. 域名类型
A记录、别名记录(CNAME)、MX记录、TXT记录、NS记录:
12.3.1。 A(地址)记录:
用于指定主机名(或域名)对应的IP地址记录。 用户可以将域名下的网站服务器指向自己的网站服务器。 同时,您还可以设置您的域名的二级域名。
12.3.2。 别名(CNAME)记录:
也称为规范名称。 这种类型的记录允许您将多个名称映射到同一台计算机。 通常用于同时提供 WWW 和 MAIL 服务的计算机。 例如,有一台名为“”的计算机(A记录)。 同时提供WWW和MAIL服务,方便用户访问服务。 可以为这台计算机设置两个别名(CNAME):WWW 和 MAIL。 这两个别名的全称是“”和“”。 其实都指向“”。
当你有多个域名需要指向同一个服务器IP时,可以使用同样的方法。 这时候可以给一个域名做一个A记录指向服务器IP,然后把其他域名别名到有之前A记录的域名上。 那么当你的服务器IP地址发生变化的时候,你就不用费心费力地一个一个的改域名了。 您只需要更改做A记录的域名,其他做别名的域名也会自动更改为新的IP地址。
12.3.3。 如何检测CNAME记录?
1、进入命令状态; (开始菜单-运行-CMD【回车】);
2、输入命令“nslookup -q=cname 此处填写对应的域名或二级域名”,查看返回结果是否与设置一致。
12.3.4。 MX(邮件交换器)记录:
它是一条邮件交换记录,指向一个邮件服务器,供电子邮件系统在发送邮件时根据收件人的地址后缀定位邮件服务器。 例如,当Internet上的用户要寄信给 时,用户的邮件系统通过DNS查找该域名的MX记录。 如果MX记录存在,则用户计算机将邮件发送到MX记录指定的邮件服务器。 .
12.3.5。 什么是 TXT 记录? :
TXT记录一般是指对主机名或域名的指令集,例如:
1) admin IN TXT "jack, mobile:";
2)mail IN TXT》邮件主机,存放于xxx,管理员:AAA,Jim IN TXT》联系人:
也就是你可以设置TXT,这样别人就可以联系到你了。
如何检测TXT记录?
1、进入命令状态; (开始菜单-运行-CMD【回车】);
2、输入命令“nslookup -q=txt 在此填写对应的域名或二级域名”,查看返回结果是否与设置一致。
12.3.6。 什么是 NS 记录?
ns记录的全称是Name Server,也就是域名服务器记录,用来明确你的域名当前是由哪台DNS服务器解析的。
12.3.7。 子域名在线查询1
12.3.8。 子域名在线查询2
12.3.9。 DNS检测
12.3.10。 IP138查询子域
12.3.11。 FOFA 搜索子域
语法:域=“”
Tips:以上两种方式不需要爆破,查询速度快。 当资产需要快速采集时,可以先使用,以后再通过其他方式补充。
12.3.12。 Hackertarget 查询子域
注意:通过该方法查询子域名可以得到目标的一个大概的ip段,然后就可以通过ip采集信息了。
12.4。 360映射空间
领域: ”*。”
12.4.1。 图层子域挖掘机
12.4.2。 子域蛮干
pip 安装 aiodns
运行命令 subDomainsBrute.py
subDomainsBrute.py --full -o freebuf2.txt
12.4.3。 子列表3r
pip install -r requirements.txt
提示:以上方法是对子域名进行爆破,因为字典功能更强大,所以效率更高。
帮助文档
<p style="margin-top: 0px;margin-bottom: 0px;">usage: sublist3r.py [-h] -d DOMAIN [-b [BRUTEFORCE]] [-p PORTS] [-v [VERBOSE]]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />[-t THREADS] [-e ENGINES] [-o OUTPUT] [-n]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />OPTIONS:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-h, --help show this help message and exit<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-d DOMAIN, --domain DOMAIN<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Domain name to enumerate it's subdomains<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-b [BRUTEFORCE], --bruteforce [BRUTEFORCE]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Enable the subbrute bruteforce module<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-p PORTS, --ports PORTS<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Scan the found subdomains against specified tcp ports<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-v [VERBOSE], --verbose [VERBOSE]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Enable Verbosity and display results in realtime<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-t THREADS, --threads THREADS<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Number of threads to use for subbrute bruteforce<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-e ENGINES, --engines ENGINES<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Specify a comma-separated list of search engines<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-o OUTPUT, --output OUTPUT<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />Save the results to text file<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />-n, --no-color Output without color</p>
示例:python sublist3r.py -d
中文翻译
-h:帮助
-d : 指定主域名枚举子域名
-b : 调用 subbrute 来暴力枚举子域名
-p : 指定扫描子域名的tpc端口
-v :显示实时详细结果
-t : 指定线程
-e : 指定搜索引擎
-o : 将结果保存到文本
-n : 没有颜色的输出
扫描子域的默认参数
python sublist3r.py -d
使用暴力枚举子域
python sublist3r -b -d
12.4.4。 python2.7.14环境
;C:\Python27;C:\Python27\脚本
12.4.5。 万物皆可
pip3 install --user -r requirements.txt -i
python3 oneforall.py --target run /*采集*/
爆炸子域
例子:
<p style="margin-top: 0px;margin-bottom: 0px;">brute.py --target domain.com --word True run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --targets ./domains.txt --word True run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target domain.com --word True --concurrent 2000 run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target domain.com --word True --wordlist subnames.txt run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target domain.com --word True --recursive True --depth 2 run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target d.com --fuzz True --place m.*.d.com --rule '[a-z]' run<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />brute.py --target d.com --fuzz True --place m.*.d.com --fuzzlist subnames.txt run</p>
12.4.6。 域名
<p style="margin-top: 0px;margin-bottom: 0px;">dnsburte.py -d aliyun.com -f dnspod.csv -o aliyun.log<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />wydomain.py -d aliyun.com</p>
12.4.7。 模糊域
12.4.8。 隐藏域名主机冲突
隐藏资产检测-主机碰撞
很多时候访问目标资产的IP响应是:401、403、404、500,但是域名请求可以返回正常的业务系统(禁止直接IP访问),因为大部分需要绑定向主机正常请求访问(目前互联网公司的基本做法)(域名已经删除了A记录,但是反向生成的配置还没有更新),那么我们就可以将采集到的目标域名和目标资产的IP段,并用IP段+域名的形式进行捆绑碰撞,可以发现很多有趣的东西。
发送http请求时,将域名和IP列表配对,然后遍历发送请求(相当于修改本地hosts文件),对比对应的标题和响应包大小,快速找出一些隐藏资产。
Hosts collision需要目标的域名和目标的相关IP作为字典
更不用说域名了
相关IP来源有:
目标域名历史分析IP
ip 常规
13.端口扫描
确定目标的大概ip段后,可以先检测ip的开放端口。 某些特定服务可能会在默认端口上打开。 检测开放端口有利于快速采集目标资产,找到目标网站的其他功能站点。
13.1. msscan 端口扫描
msscan -p 1-65535 ip --rate=1000
13.2. 御剑端口扫描工具
13.3. nmap扫描端口并检测端口信息
常用参数,如:
nmap -sV 192.168.0.2
nmap -sT 92.168.0.2
nmap -Pn -A -sC 192.168.0.2
nmap -sU -sT -p0-65535 192.168.122.1
用于扫描目标主机服务版本号和开放端口
如果需要扫描多个ip或者ip段,可以保存到一个txt文件中
nmap -iL ip.txt
扫描列表中的所有 ip。
Nmap 是最常用的端口检测方法。 操作简单,输出结果非常直观。
13.4. 在线端口检测
13.5。 端口扫描器
御剑、msscan、nmap等
御剑高速端口扫描器:
填写你要扫描的ip段(如果只扫描一个ip,只需填写起始IP和结束IP),可以选择不更改默认端口列表,也可以选择自己指定端口。
13.6. 渗透端口
21,22,23,1433,152,3306,3389,5432,5900,50070,50030,50000,27017,27018,11211,9200,9300,7001,7002,6379,5984,873,443,8000-9090,80- 89,80,10000,8888,8649,8083,8080,8089,9090,7778,7001,7002,6082,5984,4440,3312,3311,3128,2601,2604,2222,2082,2083,389,88,512, 51 1025,111,1521,445,135,139,53
13.7。 穿透常用端口及对应服务
1、Web类(web漏洞/敏感目录)
第三方通用组件漏洞struts thinkphp jboss ganglia zabbix
80 网站
80-89网页
8000-9090 网页
2.数据库类(弱口令扫描)
第1433章
第1521章
3306 MySQL
5432 PostgreSQL 数据库
3.特殊服务类(未授权/命令执行类/漏洞)
第443章
873 Rsync 未经授权
5984 CouchDB:5984/_utils/
6379 Redis 未授权
7001,7002 WebLogic默认弱口令,反序列化
9200,9300 elasticsearch 参考WooYun:玩服务器ElasticSearch命令执行漏洞
11211 memcache 未授权访问
27017、27018 Mongodb 未授权访问
执行了 50000 个 SAP 命令
50070、50030 hadoop默认端口未授权访问
4.常用端口类(扫描弱口令/端口爆破)
21 英尺
22 SSH
23 远程登录
2601,2604 zebra路由,默认密码zebra
3389 远程桌面
5.端口总明细
21 英尺
22 SSH
23 远程登录
80 网站
80-89网页
第161话
第389章
443 SSL Heartbleed 和一些网络漏洞测试
445 家中小企业
512,513,514 雷克斯
873 Rsync 未经授权
1025,111 NFS
第1433章
1521 甲骨文:(iSqlPlus 端口:5560、7778)
2082/2083 cpanel主机管理系统登录(国外多用)
2222 DA虚拟主机管理系统登录(国外多用)
2601,2604 zebra路由,默认密码zebra
3128 squid代理默认端口,如果不设置密码,可以直接漫游内网
3306 MySQL
3312/3311康乐主机管理系统登录
3389 远程桌面
4440 rundeck 参考无云:借新浪服务成功漫游新浪内网
5432 PostgreSQL 数据库
5900 越南
5984 CouchDB:5984/_utils/
6082 Varnish 参考WooYun:Varnish HTTP加速器 CLI 未授权访问容易导致直接篡改网站或代理访问内网
6379 Redis 未授权
7001,7002 WebLogic默认弱口令,反序列化
7778 Kloxo 主机控制面板登录
8000-9090是一些常用的web端口,有些运维喜欢在这些非80端口上开启管理后台
8080 tomcat/WDCP主机管理系统,默认弱密码
8080、8089、9090 JBOSS
8083 Vestacp主机管理系统(国外多用)
8649 神经节
8888 amh/LuManager主机管理系统默认端口
9200,9300 elasticsearch 参考WooYun:玩服务器ElasticSearch命令执行漏洞
10000 Virtualmin/Webmin服务器虚拟主机管理系统
11211 memcache 未授权访问
27017、27018 Mongodb 未授权访问
28017 mongodb统计页面
执行了 50000 个 SAP 命令
50070、50030 hadoop默认端口未授权访问
13.8。 常用端口及攻击方式
14.查找真实ip
如果目标网站使用CDN,则隐藏cdn的真实ip。 要想找到真实服务器,就必须获取真实ip,根据这个ip继续查询侧站。
注意:很多情况下,虽然主站使用了CDN,但是子域名不一定使用CDN。 如果主网站和子域名在同一个ip段,那么也是找到子域名真实ip的一种方式。
14.1. Ping多处确认是否使用CDN
14.2. 查询历史DNS解析记录
在查询到的历史分析记录中,最早的历史分析IP很可能记录的是真实IP。 推荐使用此方法快速找到真实IP,但不是所有网站都能找到。
14.2.1。 域名数据库
14.2.2。 微步在线
14.2.3。
14.2.4。 查看DNS
14.3. php信息
如果目标网站存在phpinfo泄露等情况,可以在phpinfo中的SERVER_ADDR或_SERVER["SERVER_ADDR"]中查找真实ip
14.4. 绕过CDN
绕过CDN的方法有很多,请参考
15. 边站和C段
边站通常有业务功能站点。 建议先采集已有IP的边站,再检测C网段,确定C网段的目标后,在C网段的基础上重新采集边站。
辅助站点是与已知目标站点位于同一服务器上但具有不同端口的站点。 通过以下方法搜索到副站后,首先访问确定是否是您需要的站址信息。
15.1.1。 站长主页
用ip网站查询
15.2. 谷歌黑客
15.2.1。 网络空间搜索引擎
比如FOFA搜边站和C段
这种方式效率更高,可以直观的看到站点标题,但也有不收录不常用端口的情况。 虽然这种情况很少见,但您可以在后期补充资产时,通过以下方式再次扫描领取。
15.2.2。 线上段c
c部分使用脚本
<p style="margin-top: 0px;margin-bottom: 0px;">pip install requests<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />#coding:utf-8<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import requests<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />import json<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />def get_c(ip):<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print("正在收集{}".format(ip))<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />url="http://api.webscan.cc/?action=query&ip={}".format(ip)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />req=requests.get(url=url)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />html=req.text<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />data=req.json()<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />if 'null' not in html:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />with open("resulit.txt", 'a', encoding='utf-8') as f:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />f.write(ip + '\n')<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />f.close()<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for i in data:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />with open("resulit.txt", 'a',encoding='utf-8') as f:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />f.write("\t{} {}\n".format(i['domain'],i['title']))<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print(" [+] {} {}[+]".format(i['domain'],i['title']))<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />f.close()<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />def get_ips(ip):<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />iplist=[]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />ips_str = ip[:ip.rfind('.')]<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for ips in range(1, 256):<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />ipadd=ips_str + '.' + str(ips)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />iplist.append(ipadd)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />return iplist<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />ip=input("请你输入要查询的ip:")<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />ips=get_ips(ip)<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />for p in ips:<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />get_c(p)</p>
15.2.3。 Nmap、Msscan扫描等
例如:nmap -p 80,443,8000,8080 -Pn 192.168.0.0/24
15.2.4。 公共端口表
21,22,23,80-90,161,389,443,445,873,1099,1433,1521,1900,2082,2083,2222,2601,2604,3128,3306,3311,3312,3389,4440,4848,5432,92,5569,5569,5569 ,6082,6379,7001-7010,7778,8080-8090,8649,8888,9000,9200,10000,11211,27017,28017,50000,50030,50060,135,139,445,53,88
注意:在检测网段C时,一定要确认ip是否属于目标,因为一个网段C中不一定所有的ip都属于目标。
16.网络空间搜索引擎
如果你想在短时间内快速采集资产,那么使用网络空间搜索引擎是一个不错的选择。 可以直观的看到边站、端口、站点标题、IP等信息,点击列出站点即可直接访问。 判断是否是您需要的站点信息。 FOFA 的通用语法
1、同IP端站:ip="192.168.0.1"
2、C段:ip="192.168.0.0/24"
3.子域名:domain=""
4.标题/关键字:title="百度"
5.如果需要将结果缩小到某个城市,可以拼接语句
title="百度" && region="北京"
17.扫描敏感目录/文件
扫描敏感目录需要强大的字典,需要平时积累。 拥有强大的词典可以更高效地查明网站的管理后台。 常见的敏感文件如.git文件泄露,.svn文件泄露,phpinfo泄露等,这一步就成功了一半,各种扫描器就够了。 在域名中输入目标站点,选择对应的词典类型,即可开始扫描,非常方便。
17.1. 御剑
17.2. 7kbstorm
17.3. 扫描仪
在已经安装pip的前提下,可以直接:
<p style="margin-top: 0px;margin-bottom: 0px;">pip install -r requirements.txt</p>
用法示例:
扫描单个 Web 服务
python BBScan.py --host
扫描下其他主机
python BBScan.py --host --network 28
扫描txt文件中的所有主机
蟒蛇 BBScan.py -f .txt
从文件夹中导入所有主机并扫描
python BBScan.py -d 目标/
--network参数用于设置子网掩码,小公司设置为28~30,中型公司设置为26~28,大公司设置为24~26
当然,尽量避免设置为24,扫描太耗时,除非你想在每个src中多扫描几个漏洞。
这个插件是从内部扫描器中提取的,感谢 Jekkay Hu
如果你有非常有用的规则,请找几个网站验证测试一下,然后pull request
脚本也会优化,接下来的事情:
添加有用的规则,更好地分类规则,细化
然后,您可以直接从 rules\request 文件夹中导入 HTTP_request
优化扫描逻辑
17.4. 目录映射
<p style="margin-top: 0px;margin-bottom: 0px;">pip install -r requirement.txt<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />https://github.com/H4ckForJob/dirmap</p>
单一目标
<p style="margin-top: 0px;margin-bottom: 0px;">python3 dirmap.py -i https://target.com -lcf</p>
多个目标
<p style="margin-top: 0px;margin-bottom: 0px;">python3 dirmap.py -iF urls.txt -lcf</p>
17.5。 直接搜索
解压目录搜索.zip
python3 dirsearch.py -u -e *
17.6. 火药
<p style="margin-top: 0px;margin-bottom: 0px;">sudo apt-get install gobuster<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />gobuster dir -u https://www.servyou.com.cn/ -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt -x php -t 50</p>
dir -u URL w dictionary -x 指定后缀 -t 线程数
<p style="margin-top: 0px;margin-bottom: 0px;">dir -u https://www.servyou.com.cn/ -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt -x "php,html,rar,zip" -d --wildcard -o servyou.log | grep ^"3402"</p>
17.7. 网站文件
机器人.txt
跨域.xml
站点地图.xml
后台目录
网站安装包
网站上传目录
mysql管理页面
php信息
网站文本编辑器
测试文件
网站备份文件(.rar、zip、.7z、.tar.gz、.bak)
DS_Store 文件
vim 编辑器备份文件 (.swp)
WEB—INF/web.xml 文件
15.git
16.svn
18.扫描网页备份
例如
配置.php
配置.php~
配置.php.bak
配置.php.swp
配置.php.rar
配置文件.php.tar.gz
19.网站头部信息采集
1.中间件:web服务【Web Servers】apache iis7 iis7.5 iis8 nginx WebLogic tomcat
2.网站组件:js组件jquery、vue页面布局bootstrap
通过浏览器访问
Firefox 插件 Wappalyzer
curl命令查询头部信息
卷曲-i
20. 敏感文件搜索 20.1. GitHub 搜索
in:name test #仓库标题搜索收录关键字test
in:descripton test #仓库描述搜索收录关键字
in:readme test #Readme文件搜索收录关键字
搜索某些系统的密码
++密码+3306&type=密码
github关键词监控
谷歌搜索
站点:sa 密码
站点:root密码
站点:用户;密码
网站:inurl:sql
SVN信息采集
站点:svn
站点:svn 用户名
站点:svn密码
站点:svn 用户名密码
综合信息采集
站点:密码
站点:ftp ftppassword
站点:密码
网站:内部
+&类型=代码
20.2. 谷歌黑客
站点:域名
inurl:url中存在的关键字网页
intext:网页正文中的关键词
filetype:指定文件类型
20.3。 乌云漏洞库
20.4。 网盘搜索
凌云搜索
潘多多:
泛搜索搜索:
泛搜索:
20.5。 社会工作图书馆
姓名/常用id/邮箱/密码/手机登录网盘网站邮箱查找敏感信息
机器人
20.6. 网站注册信息
查询网站注册信息
它通常与社会工程库一起使用。
20.7。 js敏感信息
20.7.1。 搜索器
python3 JSFinder.py -u
python3 JSFinder.py -u -d
python3 JSFinder.py -u -d -ou mi_url.txt -os mi_subdomain.txt
当你想获取更多信息时,可以使用-d进行深度爬取获取更多内容,使用命令-ou、-os指定子域保存的URL和文件名
批量指定url和js链接,获取里面的url。
指定网址:
python JSFinder.py -f 文本.txt
指定JS:
python JSFinder.py -f 文本.txt -j
20.7.2。 加壳模糊器
找到网站交互界面授权密钥
随着WEB前端打包工具的普及,你在日常的渗透测试和安全服务中是否遇到越来越多以Webpack packager为代表的网站? 这类打包器会将整个站点的API和API参数打包在一起进行集中web调用,也方便我们快速发现网站的功能和API列表,但是往往这些打包器生成的JS文件数量异常庞大且总是 JS 代码量极其庞大(高达数万行),给我们手动测试带来了极大的不便,于是 Packer Fuzzer 软件应运而生。
本工具支持自动模糊提取目标站点对应的API和API对应的参数内容,支持模糊高效模糊高效检测七大漏洞:未授权访问、敏感信息泄露、CORS、SQL注入、横向越权访问、弱口令、任意文件上传快速检测。 扫描结束后,该工具还支持自动生成扫描报告,可以选择便于分析的HTML版本,也可以选择比较正规的doc、pdf、txt版本。
sudo apt-get 安装 nodejs && sudo apt-get 安装 npm
混帐克隆
pip3 install -r requirements.txt
python3 PackerFuzzer.py -u
20.7.3。 秘密发现者
一个基于Python脚本的JavaScript敏感信息搜索工具
python3 SecretFinder.py -i -e
cms识别
采集网站信息后,应对网站进行指纹识别。 通过识别指纹,可以确定目标的cms和version,方便下一步测试计划的制定。 可以使用public poc或者自己积累相应的方法进行正式的渗透测试。
21.1. 云溪
21.2. 潮汐指纹
21.3。 CMS指纹识别
确认
21.4。 什么cms
21.5。 御cms识别
22. 非常规作业
1、如果找到了目标的某项资产,却无从下手搜集目标的其他资产,可以查看网站正文中是否有目标的特征,然后使用网络空间搜索引擎(如fofa , 等)特征进行搜索,如:body=”XX公司”或body=”baidu”等。
这种方式一般适用于特征明显、资产数量多的标的,效果往往比较突出。
2、通过以上方式找到特征后,再次搜索body,再搜索,此时fofa上显示的ip,大概率是真实ip。
3.如果需要针对政府网站,可以在批量获取网站首页的时候使用
然后可以结合上一步的方法进行进一步的信息采集。
23、SSL/TLS证书查询
SSL/TLS 证书通常收录域名、子域名和电子邮件地址等信息。 结合证书中的信息,您可以更快地定位到目标资产,获取目标资产的更多信息。
SSL证书搜索引擎:
%。
GetDomainsBySSL.py
24.找到厂商的ip段
25. 移动资产采集 25.1. 微信小程序 支付宝小程序
最新版本:iOS 开发苹果登录授权 Sign In with Apple
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-12-19 12:30
那里
网上关于苹果登录授权的文章很多,但大部分介绍都有些繁琐,实际操作简单。核心需要获取三个参数:team_id、client_id、key_id,然后通过uapp命令生成JWT令牌到后端。苹果
评测有规定,如果有微信、QQ、脸书等第三方账号登录,必须添加苹果登录名,否则将无法通过审核。苹果登录仅适用于iOS 13及更高版本。
1. 获得team_id和client_id
转到“标识符”页面:/帐户/资源/标识符/列表
单击标识符+,请注意此处输入的com.code0xff.uapp.login是client_id,请将其替换为您自己的。
查看下面的服务列表,勾选“通过 Apple 登录”,点按“编辑”,然后输入您自己的服务器端回调 URL:
到目前为止,我们已经成功获得了两个参数,team_id和client_id。
2. 获取钥匙.txt并key_id
转到密钥页面:/帐户/资源/身份验证密钥/列表
单击“密钥+”创建密钥,然后操作:输入“密钥名称”,选中“通过Apple登录”、“配置”。
配置页面,检查要在哪个应用程序中使用:
点击下载,下载后将文件名改为key.txt放入项目的jwt目录下:
jwt
├── config.json
└── key.txt
到目前为止,我们已经成功获得了钥匙.txt和key_id。
3. 通过 uapp 获取 JWT 代币
JWT 令牌适用于服务器,有效期为 6 个月,因此请记住在将近 6 个月时重新生成并替换它。
如果你还没有安装 uapp,你可以通过 npm 安装它:
npm i -g uapp
完成上述 jwt 目录有一个键.txt后,在下面创建 config.json 并放入上面获得的team_id、client_id key_id。
jwt/config.json如下:
{
"team_id": "3DSM494K6L",
"client_id": "com.code0xff.uapp.login",
"key_id": "3C7FMSZC8Z"
}
然后执行:
uapp info
您可以看到 JWT 令牌,将其发送到后端以供使用。
最近发布:atomic email hunter v11.0
原子邮箱猎手软件是一款非常简单实用的邮箱采集工具软件,原子邮箱猎手软件可以轻松扫描采集邮箱。除了搜索电子邮件地址、电话号码等出现在文本中的信息外,该软件还可以将电子邮件分类。用户可以使用软件进行搜索,用户只需输入关键词即可找到自己需要的内容,非常方便实用。
原子电子邮件猎人软件功能:
1. 如果您选择了 网站 并想从中提取电子邮件地址,请输入其 URL 地址
2. 该程序将采集 网站 上可用的所有电子邮件地址。
3. 您还可以从需要登录名和密码的页面中检索地址。
Atomic 电子邮件猎手软件亮点:
1.程序搜索与指定关键字匹配的网站,并从这些网站中提取电子邮件地址。
2. 如果您没有相关的 网站 列表来搜索电子邮件地址,这可以让您接触到目标受众。
3. 搜索网站邮箱的关键词,输入网址和关键字进行搜索。
原子电子邮件猎人软件功能:
1. 将从这些网页中提取电子邮件地址。搜索可以限于特定国家。
2. 程序将查找网站 中所有带有关键字的页面。从网页中提取电话号码。
3.这是唯一缺少原子猎人的设施,但您可以通过原子铅提取获得电话号码。
原子电子邮件猎手软件的优点:
1. 该程序可以猜测电子邮件地址所有者居住在哪个国家/地区
2. 此插件是为社交网络LinkedIn开发的,用于提取电子邮件地址。
3. 获得必要地址所需要做的就是选择关键词、区域和类别
原子邮件猎手软件介绍:
原子邮箱猎手邮箱采集软件是一款非常不错的邮箱采集软件,该软件可以扫描采集邮箱中的所有邮件,并对邮件进行分类,此外,您还可以搜索文本中出现的电子邮件地址、电话号码等。 查看全部
最新版本:iOS 开发苹果登录授权 Sign In with Apple
那里
网上关于苹果登录授权的文章很多,但大部分介绍都有些繁琐,实际操作简单。核心需要获取三个参数:team_id、client_id、key_id,然后通过uapp命令生成JWT令牌到后端。苹果
评测有规定,如果有微信、QQ、脸书等第三方账号登录,必须添加苹果登录名,否则将无法通过审核。苹果登录仅适用于iOS 13及更高版本。
1. 获得team_id和client_id
转到“标识符”页面:/帐户/资源/标识符/列表
单击标识符+,请注意此处输入的com.code0xff.uapp.login是client_id,请将其替换为您自己的。
查看下面的服务列表,勾选“通过 Apple 登录”,点按“编辑”,然后输入您自己的服务器端回调 URL:
到目前为止,我们已经成功获得了两个参数,team_id和client_id。
2. 获取钥匙.txt并key_id
转到密钥页面:/帐户/资源/身份验证密钥/列表
单击“密钥+”创建密钥,然后操作:输入“密钥名称”,选中“通过Apple登录”、“配置”。
配置页面,检查要在哪个应用程序中使用:
点击下载,下载后将文件名改为key.txt放入项目的jwt目录下:
jwt
├── config.json
└── key.txt
到目前为止,我们已经成功获得了钥匙.txt和key_id。
3. 通过 uapp 获取 JWT 代币
JWT 令牌适用于服务器,有效期为 6 个月,因此请记住在将近 6 个月时重新生成并替换它。
如果你还没有安装 uapp,你可以通过 npm 安装它:
npm i -g uapp
完成上述 jwt 目录有一个键.txt后,在下面创建 config.json 并放入上面获得的team_id、client_id key_id。
jwt/config.json如下:
{
"team_id": "3DSM494K6L",
"client_id": "com.code0xff.uapp.login",
"key_id": "3C7FMSZC8Z"
}
然后执行:
uapp info
您可以看到 JWT 令牌,将其发送到后端以供使用。
最近发布:atomic email hunter v11.0
原子邮箱猎手软件是一款非常简单实用的邮箱采集工具软件,原子邮箱猎手软件可以轻松扫描采集邮箱。除了搜索电子邮件地址、电话号码等出现在文本中的信息外,该软件还可以将电子邮件分类。用户可以使用软件进行搜索,用户只需输入关键词即可找到自己需要的内容,非常方便实用。
原子电子邮件猎人软件功能:
1. 如果您选择了 网站 并想从中提取电子邮件地址,请输入其 URL 地址
2. 该程序将采集 网站 上可用的所有电子邮件地址。
3. 您还可以从需要登录名和密码的页面中检索地址。
Atomic 电子邮件猎手软件亮点:
1.程序搜索与指定关键字匹配的网站,并从这些网站中提取电子邮件地址。
2. 如果您没有相关的 网站 列表来搜索电子邮件地址,这可以让您接触到目标受众。
3. 搜索网站邮箱的关键词,输入网址和关键字进行搜索。
原子电子邮件猎人软件功能:
1. 将从这些网页中提取电子邮件地址。搜索可以限于特定国家。
2. 程序将查找网站 中所有带有关键字的页面。从网页中提取电话号码。
3.这是唯一缺少原子猎人的设施,但您可以通过原子铅提取获得电话号码。
原子电子邮件猎手软件的优点:
1. 该程序可以猜测电子邮件地址所有者居住在哪个国家/地区
2. 此插件是为社交网络LinkedIn开发的,用于提取电子邮件地址。
3. 获得必要地址所需要做的就是选择关键词、区域和类别
原子邮件猎手软件介绍:
原子邮箱猎手邮箱采集软件是一款非常不错的邮箱采集软件,该软件可以扫描采集邮箱中的所有邮件,并对邮件进行分类,此外,您还可以搜索文本中出现的电子邮件地址、电话号码等。
汇总:免费的:WordPress自动采集多个网站数据并自动发布的免费插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-11-07 06:47
WordPress自动采集多个网站数据并自动发布免费插件
云简介采集
:
————————–
作为最新的采集器形式,云采集具有更新快的优点,没有传统软件采集器没有的本地操作。与插件采集器相比,它不会占用大量的服务器资源,将是新型采集器发展方向。
WordPress自动采集插件连接到免费优采云云采集系统,采集系统通过云采集自动发布模式进行真实*敏感*敏感*字*钱。
主要特点:
————————–
云配置采集脚本,自动发布到网站系统,支持网站,包括知乎、好搜索问答、天涯问答、豆瓣群、网站站长首页、汽车之家、*敏*感*字*知识、哔哔李碧丽视频、胡普论坛等。更多数据源正在不断添加!
特征:
————————–
* 云采集,无需安装软件
* 自动发布到网站和匹配字段
*支持采集用户名或当前用户随机提供
*支持将主题保存到自动采集
如何使用:
1. 注册账户
(登录官方网站注册账号)。
2. 获取规则
(转到规则市场获取免费规则模板)。
3. 采集数据
4. 安装插件
(登录到WordPress后端以安装优采云WordPress插件)。
5. 设置地址
(在发布设置中填写WordPress上的发布地址,可以手动或自动发布)。
6.选择要发布的版本
(采集完成后,选中“发布”或“自动发布”
.)
友情提醒:
————————–
优采云云采集的官方网站地址是:
优采云云采集有关如何
使用它的官方网站的图像和链接在下面的相关链接中。
我们仍在改进。如果您有任何需求或建议,可以直接与我们联系。
优采云采集器是一种网站采集器,它会自动采集云中的相关文章,并根据用户提供的关键词发布到用户的网站。它可以自动识别各种网页上的标题、正文等信息,不需要用户编写任何采集规则即可实现全网采集。采集内容后,自动计算内容与设定关键词的相关性,只向用户推送相关文章。支持标题前缀、自动加粗关键词、插入永久链接、自动提取标签标签、自动内部链接、自动映射、自动伪原创、内容过滤和替换、电话号码和URL清理、定时采集、百度主动提交等一系列SEO功能。用户只需设置关键词和相关要求,即可实现完全托管、零维护网站内容更新。无限数量的网站,无论是单网站还是大批量站群,都可以非常方便地管理。
官方发布:墨子学院为你揭秘:如何使用百度站长平台分析网站?
虽然这三种工具的数据功能领域相互渗透,但习惯上将三种工具的功能分开,让它们各司其职。站长工具(SEO综合查询)负责最外层数据,数据专家(百度统计)负责统计数据,百度站长平台负责内部数据。因此,站长需要了解SEO优化的数据分析。数据从何而来?数据是通过一些站长工具获取的。然后我们将与您讨论如何使用百度站长平台。
首先,让我们澄清一个概念。百度站长平台用于统计网站的内部数据。内部数据包括死链接、URL、索引量、关键词等,理清了这个概念后,分析百度站长平台的使用就更方便了。
1. 添加站点。不用说,注册一个站长账号,在“站点管理”下添加我们自己的网站域名,然后会弹出一个“验证站点”页面。站点验证包括文件验证、HTML标签验证和CNAME验证。个人 如果您习惯使用便捷的文件验证,您可以大致分两步完成验证:
1.下载验证文件。
2. 使用FTP工具将验证文件上传到网站的根目录。
简单方便。无需输入站长的个人信息。这主要是为了方便以后百度站长平台和个人站长之间的联系。
2. 站点地图。这里的sitemap其实和前面提到的sitemap是一样的。不同的是,站点地图是主动提交给百度的。前面提到的sitemap存放在网站根目录下,写入robots.txt文件。,属于被动等待蜘蛛索引网页的性质。说白了,就是一句话:主动攻击,被动等待。
3.死链接提交。向百度提交死链接报告后,搜索引擎会根据该报告识别并删除死链接页面的快照。在此之前,死链接需要针对404页面进行优化。具体操作如下:
1.使用检测死链接的URL。
2.将死链接URL放在一个txt文本中,每个URL单独一行(动态URL使用xml)。
3.将准备好的文本上传到网站根目录,然后将文件地址提交给百度站长平台。
四、网址提交。这个功能有点鸡肋。对于大中型的网站,不可能更新一篇文章文章,提交一个URL,但是对于博客或者小型网站,不提交肯定是收录。,至少黑苹果的博客投了几次(包括其他大的网站投稿),我觉得不可能收录或者收录,不是很有用。建议直接使用站点地图。
5、网站修订版,网站修订版包括域名修订版和目录修订版。顾名思义,域名改版其实就是域名的变更。首先,必须设置 301 永久重定向以定向到新域名。这个工具的作用是当网站修改后的URL发生变化(包括域名变化)并使用301重定向时,百度对301重定向的响应极慢,而网站修改工具提交是为了加快百度的响应速度。
目录修订也是如此。例如,如果更改了目录名称,或者更改了文本名称,设置重定向后,使用此工具向百度提交数据将有助于加快百度的响应时间。
第六,百度指数。收录查询,该工具已有站点数量,可以作为网站收录的参考,查询也比较方便。尽管百度曾表示网站数据不准确,但仍不能否认它的作用。对于索引卷查询,可以查询索引卷。
但是,该索引仅表示已被百度索引,并不表示将被收录发布。对于用户来说,网站收录查询的是目录,百度索引查询工具数据和收录相比,也是不准确的,所以它的意义不算太大,而且仅供参考。建议使用 site 指令来替换此功能。
7.外链分析。外链查询可以说是百度站长工具中最重要、最实用的工具之一。可以更好的查询自己网站的外链数据,了解分析自身网站在外链的优势和信息,了解网站的信息是一个工具不容忽视;其次,它可以了解和分析竞争对手的外部链接,也可以从其他网站中找到外部链接资源。
分析对手一直是网站seo不可缺少的部分,其中外链是重点之一,而百度外链工具可以对竞争对手进行比较好的分析,也可以分析竞争对手并寻找其他站点的外部链接资源,然后指定响应策略以超越它,以增强网站的竞争力。
除此之外,拒绝反向链接工具是一项功能。可以拒绝网站中存在的垃圾外链,避免垃圾外链对网站造成负面影响。这个工具可以很好的避开竞争对手的框架和无意生成的外部链接。垃圾链接。唯一的缺点是响应速度较慢,但缺点掩盖不了优点,它的作用不可否认。
8. 至于其他工具,比如爬取异常、爬取诊断等,这些工具不作为重点,你只需要了解它们是如何工作的。一些函数如搜索关键词 是数据的统计类别。我个人认为这些功能只是对百度站长平台的附加补充。
以上八项对百度站长平台有一定的经验和分享,百度站长平台的其他功能会在后续深入探讨,如关键词搭建分析、开放平台连接等一系列使用方法技能…… 查看全部
汇总:免费的:WordPress自动采集多个网站数据并自动发布的免费插件
WordPress自动采集多个网站数据并自动发布免费插件
云简介采集
:
————————–
作为最新的采集器形式,云采集具有更新快的优点,没有传统软件采集器没有的本地操作。与插件采集器相比,它不会占用大量的服务器资源,将是新型采集器发展方向。
WordPress自动采集插件连接到免费优采云云采集系统,采集系统通过云采集自动发布模式进行真实*敏感*敏感*字*钱。
主要特点:
————————–
云配置采集脚本,自动发布到网站系统,支持网站,包括知乎、好搜索问答、天涯问答、豆瓣群、网站站长首页、汽车之家、*敏*感*字*知识、哔哔李碧丽视频、胡普论坛等。更多数据源正在不断添加!
特征:
————————–
* 云采集,无需安装软件
* 自动发布到网站和匹配字段
*支持采集用户名或当前用户随机提供
*支持将主题保存到自动采集
如何使用:
1. 注册账户
(登录官方网站注册账号)。
2. 获取规则
(转到规则市场获取免费规则模板)。
3. 采集数据
4. 安装插件
(登录到WordPress后端以安装优采云WordPress插件)。
5. 设置地址
(在发布设置中填写WordPress上的发布地址,可以手动或自动发布)。
6.选择要发布的版本
(采集完成后,选中“发布”或“自动发布”
.)
友情提醒:
————————–
优采云云采集的官方网站地址是:
优采云云采集有关如何
使用它的官方网站的图像和链接在下面的相关链接中。
我们仍在改进。如果您有任何需求或建议,可以直接与我们联系。
优采云采集器是一种网站采集器,它会自动采集云中的相关文章,并根据用户提供的关键词发布到用户的网站。它可以自动识别各种网页上的标题、正文等信息,不需要用户编写任何采集规则即可实现全网采集。采集内容后,自动计算内容与设定关键词的相关性,只向用户推送相关文章。支持标题前缀、自动加粗关键词、插入永久链接、自动提取标签标签、自动内部链接、自动映射、自动伪原创、内容过滤和替换、电话号码和URL清理、定时采集、百度主动提交等一系列SEO功能。用户只需设置关键词和相关要求,即可实现完全托管、零维护网站内容更新。无限数量的网站,无论是单网站还是大批量站群,都可以非常方便地管理。
官方发布:墨子学院为你揭秘:如何使用百度站长平台分析网站?
虽然这三种工具的数据功能领域相互渗透,但习惯上将三种工具的功能分开,让它们各司其职。站长工具(SEO综合查询)负责最外层数据,数据专家(百度统计)负责统计数据,百度站长平台负责内部数据。因此,站长需要了解SEO优化的数据分析。数据从何而来?数据是通过一些站长工具获取的。然后我们将与您讨论如何使用百度站长平台。
首先,让我们澄清一个概念。百度站长平台用于统计网站的内部数据。内部数据包括死链接、URL、索引量、关键词等,理清了这个概念后,分析百度站长平台的使用就更方便了。
1. 添加站点。不用说,注册一个站长账号,在“站点管理”下添加我们自己的网站域名,然后会弹出一个“验证站点”页面。站点验证包括文件验证、HTML标签验证和CNAME验证。个人 如果您习惯使用便捷的文件验证,您可以大致分两步完成验证:
1.下载验证文件。
2. 使用FTP工具将验证文件上传到网站的根目录。
简单方便。无需输入站长的个人信息。这主要是为了方便以后百度站长平台和个人站长之间的联系。
2. 站点地图。这里的sitemap其实和前面提到的sitemap是一样的。不同的是,站点地图是主动提交给百度的。前面提到的sitemap存放在网站根目录下,写入robots.txt文件。,属于被动等待蜘蛛索引网页的性质。说白了,就是一句话:主动攻击,被动等待。
3.死链接提交。向百度提交死链接报告后,搜索引擎会根据该报告识别并删除死链接页面的快照。在此之前,死链接需要针对404页面进行优化。具体操作如下:
1.使用检测死链接的URL。
2.将死链接URL放在一个txt文本中,每个URL单独一行(动态URL使用xml)。
3.将准备好的文本上传到网站根目录,然后将文件地址提交给百度站长平台。
四、网址提交。这个功能有点鸡肋。对于大中型的网站,不可能更新一篇文章文章,提交一个URL,但是对于博客或者小型网站,不提交肯定是收录。,至少黑苹果的博客投了几次(包括其他大的网站投稿),我觉得不可能收录或者收录,不是很有用。建议直接使用站点地图。
5、网站修订版,网站修订版包括域名修订版和目录修订版。顾名思义,域名改版其实就是域名的变更。首先,必须设置 301 永久重定向以定向到新域名。这个工具的作用是当网站修改后的URL发生变化(包括域名变化)并使用301重定向时,百度对301重定向的响应极慢,而网站修改工具提交是为了加快百度的响应速度。
目录修订也是如此。例如,如果更改了目录名称,或者更改了文本名称,设置重定向后,使用此工具向百度提交数据将有助于加快百度的响应时间。
第六,百度指数。收录查询,该工具已有站点数量,可以作为网站收录的参考,查询也比较方便。尽管百度曾表示网站数据不准确,但仍不能否认它的作用。对于索引卷查询,可以查询索引卷。
但是,该索引仅表示已被百度索引,并不表示将被收录发布。对于用户来说,网站收录查询的是目录,百度索引查询工具数据和收录相比,也是不准确的,所以它的意义不算太大,而且仅供参考。建议使用 site 指令来替换此功能。
7.外链分析。外链查询可以说是百度站长工具中最重要、最实用的工具之一。可以更好的查询自己网站的外链数据,了解分析自身网站在外链的优势和信息,了解网站的信息是一个工具不容忽视;其次,它可以了解和分析竞争对手的外部链接,也可以从其他网站中找到外部链接资源。
分析对手一直是网站seo不可缺少的部分,其中外链是重点之一,而百度外链工具可以对竞争对手进行比较好的分析,也可以分析竞争对手并寻找其他站点的外部链接资源,然后指定响应策略以超越它,以增强网站的竞争力。
除此之外,拒绝反向链接工具是一项功能。可以拒绝网站中存在的垃圾外链,避免垃圾外链对网站造成负面影响。这个工具可以很好的避开竞争对手的框架和无意生成的外部链接。垃圾链接。唯一的缺点是响应速度较慢,但缺点掩盖不了优点,它的作用不可否认。
8. 至于其他工具,比如爬取异常、爬取诊断等,这些工具不作为重点,你只需要了解它们是如何工作的。一些函数如搜索关键词 是数据的统计类别。我个人认为这些功能只是对百度站长平台的附加补充。
以上八项对百度站长平台有一定的经验和分享,百度站长平台的其他功能会在后续深入探讨,如关键词搭建分析、开放平台连接等一系列使用方法技能……
解决方案:如何获取百度云下载直链
采集交流 • 优采云 发表了文章 • 0 个评论 • 345 次浏览 • 2022-11-03 11:17
2021-07-27
最近在百度云学习资源上遇到了一个大问题。百度云把我的速度锁死了。然后百度了一个PanDownload神器,感觉很好用。总的原则是获取直接链接,然后全速下载。我很好奇,想看看如何获取百度云直连。我找到了一个现在仍然可以使用的方法。虽然有缺陷,只能用于从下载直链获取单个文件,但没关系。毕竟压缩后的文件也是单个文件哈哈哈。
1.将要下载的资源保存到自己的网盘中。
2. 右键分享。创建公共链接,一定要创建公共链接。得到下面的结果。
3.复制链接并用Chrome打开。打开控制台
4、输入如下js代码,用ajax发送请求。
$.ajax({
type: "POST",
url: "/api/sharedownload?sign="+yunData.SIGN+"×tamp="+yunData.TIMESTAMP,
data: "encrypt=0&product=share&uk="+yunData.SHARE_UK+"&primaryid="+yunData.SHARE_ID+"&fid_list=%5B"+yunData.FS_ID+"%5D",
dataType: "json",
success: function(d){
<p>
window.location.href = d.list[0].dlink;
}
});</p>
5. 然后它会自动开始作为直接链接下载。
当然,最后还是推荐使用 Pandownload 之类的。当然,这种东西大家都知道,传播得越快,死的也就越快。在这种情况下,我们可以通过上面的方法获取直接链接,然后愉快的下载。其实感觉就是处理后才能得到直链,最后向Pandownload的作者们致敬!
分类:
技术要点:
相关文章:
解决方案:调用链系列(三):解读UAVStack中的贪吃蛇-调用链
为了从请求中提取body和header,使代码的改动尽可能小,进入容器的请求必须被统一拦截,否则代码必须嵌入到所有的HttpServlet实现类中。在这里,我们需要再次感谢 servlet 说明符为我们提供的过滤机制。
该规范指定过滤器是一段可重用的代码,用于转换 HTTP 请求、响应和标头信息的内容。过滤器通常不会为请求创建响应,而是修改或调整请求和响应。其中,filter主要提供四种拦截方式:
这里我们只使用 REQUEST 模式。配置过滤器后,我们可以从过滤器的doFilter方法中获取HttpServletRequest和HttpServletResponse(简称请求和响应)。
获取标题
在上面,我们通过过滤机制获得了请求和响应。打开对应的源码实现,我们可以找到如下API:
规范为我们提供了一个 API 来直接获取标头。通过结合 getHeaderNames() 和 getHeader(String name) 方法,我们可以轻松获取请求和响应中的标头。
得到身体
获取请求体和响应体的方法大致相同。这里以request为例,后面会调整差异。
从请求API中我们可以发现body在java中是以ServletInputStream的形式存储的,而ServletInputStream是一个继承的InputStream。如果我们直接读取,用户获取到的body会是空的(因为InputStream只能读取一次),除非可以把指针放回去)。这里需要用到servlet的包装机制。
Servlet 中的包装器
有的人可能不会用到requestWrapper和responseWrapper,这里简单介绍一下。wrapper 是通过继承 servlet 规范中的 HttpServletResponseWrapper 和 HttpServletRequestWrapper 实现的装饰模式。相当于请求和响应的一个shell,类似于java中的代理,这样操作请求和响应的所有动作都会经过我们自定义的wrapper,使得在请求中重复获取body成为可能和回应。
编写自己的包装器
我们以 request 为例来说明如何编写自定义包装器。打开servlet-api源码可以看到HttpServletRequestWrapper继承了ServletRequestWrapper,实现了HttpServletRequest接口。
并且大部分方法已经在 ServletRequestWrapper 中为我们实现了。
我们只需要重写我们关心的几个方法,例如:getInputStream和getReader等。
当用户尝试调用 getReader 或 getInputStream 时,我们将其替换为自己的流,并额外提供一个 getContent() 方法来提前读取 StringBuilder 或 byte[] 中的正文内容进行提取。
编写好自定义包装器后,我们可以将其放入我们上面定义的过滤器中,替换原来的请求。然后把用户的请求变成我们的requestWrapper。
优化提取逻辑
上面提到的方法等价于预先读取收录body的inputStream,并将其存储在一个中间byte[]或StringBuilder中。当用户调用 getInputStream 时,byte[] 或 StringBuilder 被转换为 inputStream 返回给用户。如果用户根本不关心这个http请求的body,也就是用户根本不使用这个请求的body,那么我们提前把它读出来,相当于做了无用功(浪费宝贵的 CPU 时间和内存资源)。如何保证inputStream在用户使用时是只读的,当用户或后续逻辑多次获取body时,是我们的优化目标。
对于答案,我们继续从源码中寻找。既然我们的数据在 inputStream 中,我们就跟着源码看看是怎么读取的。在servlet规范中,inputStream被封装成ServletInputStream,ServletInputStream提供了readLine方法。往里面看,可以看到它们都调用了inputStream中的read方法,如下图:
既然read方法是一个统一的入口,那我们只要自定义一个ServletInputStream,重写里面的read()方法,就可以修改所有的read方法吗?答案是肯定的。只要用户调用了read方法,我们就悄悄地把我们关心的内容复制一份,这样我们只在用户使用body的时候才去采集。
下一步是如何确保用户调用 read 多次,我们总是只读取一次。在这里,我们需要使用一个 AtomicBoolean 标志,当执行完整读取时将其设置为 true,否则设置为 false。最终效果如下:
举一反三
在这里,我们使用 servlet 规范中的过滤器和包装器机制来获取进入我们容器(tomcat)的所有 http 请求的主体和标头。这个能力在我们实际生产中可以进一步扩展,比如:我们需要在客户端加密一些敏感数据然后在服务端进行统一解密,格式化客户端发送的数据格式等等。可以限制你的是你的想象力。希望本次技术分享对您以后的工作和生活有所帮助。
总结
读完这篇文章,读者应该可以在不影响原代码的情况下,通过简单的代码获取所有进入容器的http请求的body和header。虽然可能需要适配一些特殊的技术栈,比如如果项目中使用了jersey,参数等信息以application/x-www-form-urlencoded的形式传递,而服务端不使用@ FormParam注解获取参数,那么我们获取body后,用户将无法获取参数;例如,如何区分媒体类型,如果是图像,则不会被提取。但我们已经验证,这条路是可行的,而且是成功的一半。 查看全部
解决方案:如何获取百度云下载直链
2021-07-27
最近在百度云学习资源上遇到了一个大问题。百度云把我的速度锁死了。然后百度了一个PanDownload神器,感觉很好用。总的原则是获取直接链接,然后全速下载。我很好奇,想看看如何获取百度云直连。我找到了一个现在仍然可以使用的方法。虽然有缺陷,只能用于从下载直链获取单个文件,但没关系。毕竟压缩后的文件也是单个文件哈哈哈。
1.将要下载的资源保存到自己的网盘中。
2. 右键分享。创建公共链接,一定要创建公共链接。得到下面的结果。
3.复制链接并用Chrome打开。打开控制台
4、输入如下js代码,用ajax发送请求。
$.ajax({
type: "POST",
url: "/api/sharedownload?sign="+yunData.SIGN+"×tamp="+yunData.TIMESTAMP,
data: "encrypt=0&product=share&uk="+yunData.SHARE_UK+"&primaryid="+yunData.SHARE_ID+"&fid_list=%5B"+yunData.FS_ID+"%5D",
dataType: "json",
success: function(d){
<p>
window.location.href = d.list[0].dlink;
}
});</p>
5. 然后它会自动开始作为直接链接下载。
当然,最后还是推荐使用 Pandownload 之类的。当然,这种东西大家都知道,传播得越快,死的也就越快。在这种情况下,我们可以通过上面的方法获取直接链接,然后愉快的下载。其实感觉就是处理后才能得到直链,最后向Pandownload的作者们致敬!
分类:
技术要点:
相关文章:
解决方案:调用链系列(三):解读UAVStack中的贪吃蛇-调用链
为了从请求中提取body和header,使代码的改动尽可能小,进入容器的请求必须被统一拦截,否则代码必须嵌入到所有的HttpServlet实现类中。在这里,我们需要再次感谢 servlet 说明符为我们提供的过滤机制。
该规范指定过滤器是一段可重用的代码,用于转换 HTTP 请求、响应和标头信息的内容。过滤器通常不会为请求创建响应,而是修改或调整请求和响应。其中,filter主要提供四种拦截方式:
这里我们只使用 REQUEST 模式。配置过滤器后,我们可以从过滤器的doFilter方法中获取HttpServletRequest和HttpServletResponse(简称请求和响应)。
获取标题
在上面,我们通过过滤机制获得了请求和响应。打开对应的源码实现,我们可以找到如下API:
规范为我们提供了一个 API 来直接获取标头。通过结合 getHeaderNames() 和 getHeader(String name) 方法,我们可以轻松获取请求和响应中的标头。
得到身体
获取请求体和响应体的方法大致相同。这里以request为例,后面会调整差异。
从请求API中我们可以发现body在java中是以ServletInputStream的形式存储的,而ServletInputStream是一个继承的InputStream。如果我们直接读取,用户获取到的body会是空的(因为InputStream只能读取一次),除非可以把指针放回去)。这里需要用到servlet的包装机制。
Servlet 中的包装器
有的人可能不会用到requestWrapper和responseWrapper,这里简单介绍一下。wrapper 是通过继承 servlet 规范中的 HttpServletResponseWrapper 和 HttpServletRequestWrapper 实现的装饰模式。相当于请求和响应的一个shell,类似于java中的代理,这样操作请求和响应的所有动作都会经过我们自定义的wrapper,使得在请求中重复获取body成为可能和回应。
编写自己的包装器
我们以 request 为例来说明如何编写自定义包装器。打开servlet-api源码可以看到HttpServletRequestWrapper继承了ServletRequestWrapper,实现了HttpServletRequest接口。
并且大部分方法已经在 ServletRequestWrapper 中为我们实现了。
我们只需要重写我们关心的几个方法,例如:getInputStream和getReader等。
当用户尝试调用 getReader 或 getInputStream 时,我们将其替换为自己的流,并额外提供一个 getContent() 方法来提前读取 StringBuilder 或 byte[] 中的正文内容进行提取。
编写好自定义包装器后,我们可以将其放入我们上面定义的过滤器中,替换原来的请求。然后把用户的请求变成我们的requestWrapper。
优化提取逻辑
上面提到的方法等价于预先读取收录body的inputStream,并将其存储在一个中间byte[]或StringBuilder中。当用户调用 getInputStream 时,byte[] 或 StringBuilder 被转换为 inputStream 返回给用户。如果用户根本不关心这个http请求的body,也就是用户根本不使用这个请求的body,那么我们提前把它读出来,相当于做了无用功(浪费宝贵的 CPU 时间和内存资源)。如何保证inputStream在用户使用时是只读的,当用户或后续逻辑多次获取body时,是我们的优化目标。
对于答案,我们继续从源码中寻找。既然我们的数据在 inputStream 中,我们就跟着源码看看是怎么读取的。在servlet规范中,inputStream被封装成ServletInputStream,ServletInputStream提供了readLine方法。往里面看,可以看到它们都调用了inputStream中的read方法,如下图:
既然read方法是一个统一的入口,那我们只要自定义一个ServletInputStream,重写里面的read()方法,就可以修改所有的read方法吗?答案是肯定的。只要用户调用了read方法,我们就悄悄地把我们关心的内容复制一份,这样我们只在用户使用body的时候才去采集。
下一步是如何确保用户调用 read 多次,我们总是只读取一次。在这里,我们需要使用一个 AtomicBoolean 标志,当执行完整读取时将其设置为 true,否则设置为 false。最终效果如下:
举一反三
在这里,我们使用 servlet 规范中的过滤器和包装器机制来获取进入我们容器(tomcat)的所有 http 请求的主体和标头。这个能力在我们实际生产中可以进一步扩展,比如:我们需要在客户端加密一些敏感数据然后在服务端进行统一解密,格式化客户端发送的数据格式等等。可以限制你的是你的想象力。希望本次技术分享对您以后的工作和生活有所帮助。
总结
读完这篇文章,读者应该可以在不影响原代码的情况下,通过简单的代码获取所有进入容器的http请求的body和header。虽然可能需要适配一些特殊的技术栈,比如如果项目中使用了jersey,参数等信息以application/x-www-form-urlencoded的形式传递,而服务端不使用@ FormParam注解获取参数,那么我们获取body后,用户将无法获取参数;例如,如何区分媒体类型,如果是图像,则不会被提取。但我们已经验证,这条路是可行的,而且是成功的一半。
定制化方案:fluent-bit debug调试,采集kubernetes podIP
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-10-30 09:19
有时候调试 fluent-bit 的配置以达到想要的输出效果并不是一件简单的事情,下面就是通过调试镜像来调试 fluent-bit 采集kubernetes pod 的 IP。
官方的流利位文档给出了一个用于调试的图像:docs.fluentbit.io/manual/installation/docker
dockerhub存储库链接到:/r/fluent/fluent-bit/
部署流畅位调试
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: fluent-bit-debug
name: fluent-bit-debug
namespace: kubesphere-logging-system
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app.kubernetes.io/name: fluent-bit-debug
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app.kubernetes.io/name: fluent-bit-debug
name: fluent-bit-debug
spec:
containers:
- env:
- name: NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
command:
- /usr/local/bin/sh
- -c
- sleep 9999
image: fluent/fluent-bit:1.6.9-debug
imagePullPolicy: IfNotPresent
name: fluent-bit
ports:
- containerPort: 2020
name: metrics
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/lib/docker/containers
name: varlibcontainers
readOnly: true
- mountPath: /fluent-bit/config
name: config
readOnly: true
- mountPath: /var/log/
name: varlogs
readOnly: true
- mountPath: /var/log/journal
name: systemd
readOnly: true
- mountPath: /fluent-bit/tail
name: positions
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: fluent-bit
serviceAccountName: fluent-bit
terminationGracePeriodSeconds: 30
volumes:
- hostPath:
path: /var/lib/docker/containers
type: ""
name: varlibcontainers
- name: config
secret:
defaultMode: 420
secretName: fluent-bit-debug-config
- hostPath:
path: /var/log
type: ""
name: varlogs
- hostPath:
path: /var/log/journal
type: ""
name: systemd
- emptyDir: {}
name: positions
使用的secret:fluent-bit-debug-config如下,收录两个键:
第一个 parsers.conf: 为空;配置详情请参考官方文档:配置文件
第二个 fluent-bit.conf 配置需要根据情况进行配置,下面主要针对不同场景给出。它还将涉及使用kubesphere和Filter CRD。
使用流利位exec 到容器中可以使用 /fluent-bit/
bin/fluent-bit 进行调试:
/fluent-bit/bin # ./fluent-bit -h
Usage: fluent-bit [OPTION]
Available Options
-b --storage_path=PATH specify a storage buffering path
-c --config=FILE specify an optional configuration file
-d, --daemon run Fluent Bit in background mode
-f, --flush=SECONDS flush timeout in seconds (default: 5)
-F --filter=FILTER set a filter
-i, --input=INPUT set an input
-m, --match=MATCH set plugin match, same as '-p match=abc'
-o, --output=OUTPUT set an output
-p, --prop="A=B" set plugin configuration property
-R, --parser=FILE specify a parser configuration file
-e, --plugin=FILE load an external plugin (shared lib)
-l, --log_file=FILE write log info to a file
-t, --tag=TAG set plugin tag, same as '-p tag=abc'
-T, --sp-task=SQL define a stream processor task
-v, --verbose increase logging verbosity (default: info)
-H, --http enable monitoring HTTP server
-P, --port set HTTP server TCP port (default: 2020)
-s, --coro_stack_size Set coroutines stack size in bytes (default: 24576)
-q, --quiet quiet mode
-S, --sosreport support report for Enterprise customers
-V, --version show version number
-h, --help print this help
Inputs
cpu CPU Usage
mem Memory Usage
thermal Thermal
kmsg Kernel Log Buffer
proc Check Process health
disk Diskstats
systemd Systemd (Journal) reader
netif Network Interface Usage
docker Docker containers metrics
docker_events Docker events
tail Tail files
dummy Generate dummy data
head Head Input
health Check TCP server health
collectd collectd input plugin
statsd StatsD input plugin
serial Serial input
stdin Standard Input
syslog Syslog
exec Exec Input
tcp TCP
mqtt MQTT, listen for Publish messages
forward Fluentd in-forward
<p>
random Random
Filters
alter_size Alter incoming chunk size
aws Add AWS Metadata
record_modifier modify record
throttle Throttle messages using sliding window algorithm
kubernetes Filter to append Kubernetes metadata
modify modify records by applying rules
nest nest events by specified field values
parser Parse events
expect Validate expected keys and values
grep grep events by specified field values
rewrite_tag Rewrite records tags
lua Lua Scripting Filter
stdout Filter events to STDOUT
Outputs
azure Send events to Azure HTTP Event Collector
azure_blob Azure Blob Storage
bigquery Send events to BigQuery via streaming insert
counter Records counter
datadog Send events to DataDog HTTP Event Collector
es Elasticsearch
exit Exit after a number of flushes (test purposes)
file Generate log file
forward Forward (Fluentd protocol)
http HTTP Output
influxdb InfluxDB Time Series
logdna LogDNA
loki Loki
kafka Kafka
kafka-rest Kafka REST Proxy
nats NATS Server
nrlogs New Relic
null Throws away events
plot Generate data file for GNU Plot
pgsql PostgreSQL
slack Send events to a Slack channel
splunk Send events to Splunk HTTP Event Collector
stackdriver Send events to Google Stackdriver Logging
stdout Prints events to STDOUT
syslog Syslog
tcp TCP Output
td Treasure Data
flowcounter FlowCounter
gelf GELF Output
cloudwatch_logs Send logs to Amazon CloudWatch
kinesis_firehose Send logs to Amazon Kinesis Firehose
s3 Send to S3
Internal
Event Loop = epoll
Build Flags = FLB_HAVE_HTTP_CLIENT_DEBUG FLB_HAVE_PARSER FLB_HAVE_RECORD_ACCESSOR FLB_HAVE_STREAM_PROCESSOR JSMN_PARENT_LINKS JSMN_STRICT FLB_HAVE_TLS FLB_HAVE_AWS FLB_HAVE_SIGNV4 FLB_HAVE_SQLDB FLB_HAVE_METRICS FLB_HAVE_HTTP_SERVER FLB_HAVE_SYSTEMD FLB_HAVE_FORK FLB_HAVE_TIMESPEC_GET FLB_HAVE_GMTOFF FLB_HAVE_UNIX_SOCKET FLB_HAVE_PROXY_GO FLB_HAVE_JEMALLOC JEMALLOC_MANGLE FLB_HAVE_LIBBACKTRACE FLB_HAVE_REGEX FLB_HAVE_UTF8_ENCODER FLB_HAVE_LUAJIT FLB_HAVE_C_TLS FLB_HAVE_ACCEPT4 FLB_HAVE_INOTIFY</p>
简单配置文件
以下是使用简单配置文件采集 calico-node-* pod 的日志:
[Service]
Parsers_File parsers.conf
[Input]
Name tail
Path /var/log/containers/*_kube-system_calico-node-*.log
Refresh_Interval 10
Skip_Long_Lines true
DB /fluent-bit/bin/pos.db
DB.Sync Normal
Mem_Buf_Limit 5MB
Parser docker
Tag kube.*
[Filter]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Labels false
Annotations true
[Output]
Name stdout
Match_Regex (?:kube|service)\.(.*)
使用以下命令在流畅位调试容器内启动测试:
/fluent-bit/bin # ./fluent-bit -c /fluent-bit/config/fluent-bit.conf
您可以看到标准输出日志输出:
[0] kube.var.log.containers.calico-node-lp4lm_kube-system_calico-node-cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81.log: [1634870260.700108403, {"log"=>"{"log":"2021-10-22 02:37:40.699 [INFO][85] monitor-addresses/startup.go 774: Using autodetected IPv4 address on interface bond4: 172.24.248.50/30\n","stream":"stdout","time":"2021-10-22T02:37:40.700056471Z"}", "kubernetes"=>{"pod_name"=>"calico-node-lp4lm", "namespace_name"=>"kube-system", "pod_id"=>"5a829979-9830-4b9c-a3cb-eeb6eee38bdd", "annotations"=>{"kubectl.kubernetes.io/restartedAt"=>"2021-10-20T23:00:27+08:00"}, "host"=>"node02", "container_name"=>"calico-node", "docker_id"=>"cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81", "container_hash"=>"calico/node@sha256:bc4a631d553b38fdc169ea4cb8027fa894a656e80d68d513359a4b9d46836b55", "container_image"=>"calico/node:v3.19.1"}}]
截取重要部分,查看尚未处理采集的K8s日志格式。
[
{
"kubernetes"=>{
"pod_name"=>"calico-node-lp4lm",
"namespace_name"=>"kube-system",
"pod_id"=>"5a829979-9830-4b9c-a3cb-eeb6eee38bdd",
"annotations"=>{
"kubectl.kubernetes.io/restartedAt"=>"2021-10-20T23:00:27+08:00"
},
"host"=>"node02",
"container_name"=>"calico-node",
"docker_id"=>"cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81",
"container_hash"=>"calico/node@sha256:bc4a631d553b38fdc169ea4cb8027fa894a656e80d68d513359a4b9d46836b55",
"container_image"=>"calico/node:v3.19.1"
}
}
]
添加了嵌套过滤器
展开 Kubernetes 块并添加 kubernetes_ 前缀:
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes
Add_prefix kubernetes_
这次测试输出,截取重要部分:
{
"kubernetes_pod_name"=>"calico-node-lp4lm",
"kubernetes_namespace_name"=>"kube-system",
"kubernetes_pod_id"=>"5a829979-9830-4b9c-a3cb-eeb6eee38bdd",
"kubernetes_annotations"=>{
"kubectl.kubernetes.io/restartedAt"=>"2021-10-20T23:00:27+08:00"
},
"kubernetes_host"=>"node02",
"kubernetes_container_name"=>"calico-node",
"kubernetes_docker_id"=>"cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81",
"kubernetes_container_hash"=>"calico/node@sha256:bc4a631d553b38fdc169ea4cb8027fa894a656e80d68d513359a4b9d46836b55",
"kubernetes_container_image"=>"calico/node:v3.19.1"
}
删除kubernetes_annotations块
[Filter]
Name modify
Match kube.*
Remove kubernetes_annotations
从kubernetes_annotations块中删除字段
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes_annotations
Add_prefix kubernetes_annotations_
[Filter]
Name modify
Match kube.*
Remove kubernetes_annotations_kubectl.kubernetes.io/restartedAt
或使用常规:
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes_annotations
Add_prefix kubernetes_annotations_
[Filter]
Name modify
Match kube.*
Remove_regex kubernetes_annotations_kubectl*
修改kubernetes_annotations块中的键名称
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes_annotations
Add_prefix kubernetes_annotations_
[Filter]
Name modify
Match kube.*
Rename kubernetes_annotations_kubectl.kubernetes.io/restartedAt podIPs
修改后:
[
{
"kubernetes_pod_name"=>"calico-node-lp4lm",
"kubernetes_namespace_name"=>"kube-system",
"kubernetes_pod_id"=>"5a829979-9830-4b9c-a3cb-eeb6eee38bdd",
"kubernetes_host"=>"node02",
"kubernetes_container_name"=>"calico-node",
"kubernetes_docker_id"=>"cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81",
"kubernetes_container_hash"=>"calico/node@sha256:bc4a631d553b38fdc169ea4cb8027fa894a656e80d68d513359a4b9d46836b55",
"kubernetes_container_image"=>"calico/node:v3.19.1",
"podIPs"=>"2021-10-20T23:00:27+08:00"
}
]
结合 ks 配置采集 podIP
结合 kubesphere Filter CR 来配置 采集podIP 并删除其他不相关的注释。
由于印花布用作 CNI,因此与 Pod IP 相关的注释将添加到 Pod 注释中。
您需要在注释 (/podIP) 中保留一个密钥并删除其他密钥,因此在更改下面要保留的密钥的名称后,删除整个注释。
Kubernetes Filter CR 配置如下:
apiVersion: logging.kubesphere.io/v1alpha2
kind: Filter
metadata:
labels:
logging.kubesphere.io/component: logging
logging.kubesphere.io/enabled: 'true'
name: kubernetes
namespace: kubesphere-logging-system
spec:
filters:
- kubernetes:
annotations: true
kubeCAFile: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
kubeTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
kubeURL: 'https://kubernetes.default.svc:443'
labels: false
- nest:
addPrefix: kubernetes_
nestedUnder: kubernetes
operation: lift
- nest:
addPrefix: kubernetes_annotations_
nestedUnder: kubernetes_annotations
operation: lift
- modify:
rules:
- remove: stream
- remove: kubernetes_pod_id
- remove: kubernetes_host
- remove: kubernetes_container_hash
- rename:
kubernetes_annotations_cni.projectcalico.org/podIPs: kubernetes_podIPs
- removeRegex: kubernetes_annotations*
- nest:
nestUnder: kubernetes_annotations
operation: nest
removePrefix: kubernetes_annotations_
wildcard:
- kubernetes_annotations_*
- nest:
nestUnder: kubernetes
operation: nest
removePrefix: kubernetes_
wildcard:
- kubernetes_*
match: kube.*
Kubernetes Filter CR
生成的流畅位配置配置如下(只看 Filter 部分,省略输入输出 CR)。
[Service]
Parsers_File parsers.conf
[Input]
Name tail
Path /var/log/containers/*.log
Exclude_Path /var/log/containers/*_kubesphere-logging-system_events-exporter*.log,/var/log/containers/kube-auditing-webhook*_kubesphere-logging-system_kube-auditing-webhook*.log
Refresh_Interval 10
Skip_Long_Lines true
DB /fluent-bit/tail/pos.db
DB.Sync Normal
Mem_Buf_Limit 5MB
Parser docker
Tag kube.*
[Filter]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Labels false
Annotations true
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes
Add_prefix kubernetes_
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes_annotations
Add_prefix kubernetes_annotations_
[Filter]
Name modify
Match kube.*
Remove stream
Remove kubernetes_pod_id
Remove kubernetes_host
Remove kubernetes_container_hash
Rename kubernetes_annotations_cni.projectcalico.org/podIPs kubernetes_podIPs
Remove_regex kubernetes_annotations*
[Filter]
Name nest
Match kube.*
Operation nest
Wildcard kubernetes_annotations_*
Nest_under kubernetes_annotations
Remove_prefix kubernetes_annotations_
[Filter]
Name nest
Match kube.*
Operation nest
Wildcard kubernetes_*
Nest_under kubernetes
Remove_prefix kubernetes_
[Output]
Name es
Match_Regex (?:kube|service)\.(.*)
Host es-cdc-a-es-http.cdc.svc.xke.test.cn
Port 9200
HTTP_User elastic
HTTP_Passwd elasticpwd
Logstash_Format true
Logstash_Prefix ks-logstash-log
Time_Key @timestamp
您可以在 kibana 中看到 podIP 采集:
作者简洁
作者:小万
唐,一个热爱写作、认真写作的家伙,目前维护着原创公众号:“我的小湾汤”,专注于撰写GO语言、Docker、Kubernetes、Java等开发、运维知识等提升硬实力文章,期待大家的关注。转载说明:请务必注明出处(注明:来自公众号:我的小碗汤,作者:小碗汤)。
整套解决方案:如何采集shopline产品并导入到店铺,一键刊登独立站shopify爆款产品
独立站的同学会遇到上架产品到店的问题。一个产品从title-main image-detail页面一个一个复制到自己的店铺,需要花费很多时间。
如果采集里面有几十个或者几百个产品,手动做显然是很难的。现在有一种方法可以帮助您快速轻松地解决它!!一键式采集产品神器
这是一套奶妈级教程,请耐心阅读,小案例使用!!
Step 1:首先我们要知道采集的store是什么saas平台
网页空白处右键——点击查看网页源代码
在源码页面按Ctrl+F弹出搜索框,进入建站平台,如shopline
第二步:进入Crossker官网-选择产品采集工具
扫一扫公众号登录,每天5次免费试用,联系客服获取更多试用
第三步:选择采集管理-产品分类采集,进入分类链接
时间不用填写,采集的个数不要超过2000
第 4 步:选择 采集管理 - 任务列表
有四种状态:采集表示采集成功,等待采集表示排队,点击右上角刷新按钮查看进度
第五步:选择产品管理——在产品管理中输入采集的编号,点击搜索
记得点击搜索全选,如果没有搜索到默认是30,点击导出为CSV格式
第六步:登录Shopline进入后台商品-商品管理,点击导入商品-shopify表格导入
上传并导入采集的CSV文件,完成导入
第八步:等待系统加载,所有产品导入完毕
除了支持shopline采集外,还支持Shopify、Shoplaza、Oemsaas(YY2.0)、Shopplus、Shopbase等主流SaaS平台的产品采集。WordPress、Woocommerce、Magento 项目、Aliexpress 项目也可以处理。Ueeshop、OpenCart等平台后续会更新!总之,有什么需要,都满足你!
您还在犹豫?都是小问题,联系客服免费试用Crossker产品采集工具
我们刚刚成立Crossker跨境交流群,欢迎各位跨境电商朋友加入!有任何问题请随时提出,我们将尽最大努力为您解答,帮助独立卖家共同成长!
客服C:Crossker-tool
扫描下方二维码加入群~ 查看全部
定制化方案:fluent-bit debug调试,采集kubernetes podIP
有时候调试 fluent-bit 的配置以达到想要的输出效果并不是一件简单的事情,下面就是通过调试镜像来调试 fluent-bit 采集kubernetes pod 的 IP。
官方的流利位文档给出了一个用于调试的图像:docs.fluentbit.io/manual/installation/docker
dockerhub存储库链接到:/r/fluent/fluent-bit/
部署流畅位调试
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: fluent-bit-debug
name: fluent-bit-debug
namespace: kubesphere-logging-system
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app.kubernetes.io/name: fluent-bit-debug
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app.kubernetes.io/name: fluent-bit-debug
name: fluent-bit-debug
spec:
containers:
- env:
- name: NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
command:
- /usr/local/bin/sh
- -c
- sleep 9999
image: fluent/fluent-bit:1.6.9-debug
imagePullPolicy: IfNotPresent
name: fluent-bit
ports:
- containerPort: 2020
name: metrics
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/lib/docker/containers
name: varlibcontainers
readOnly: true
- mountPath: /fluent-bit/config
name: config
readOnly: true
- mountPath: /var/log/
name: varlogs
readOnly: true
- mountPath: /var/log/journal
name: systemd
readOnly: true
- mountPath: /fluent-bit/tail
name: positions
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: fluent-bit
serviceAccountName: fluent-bit
terminationGracePeriodSeconds: 30
volumes:
- hostPath:
path: /var/lib/docker/containers
type: ""
name: varlibcontainers
- name: config
secret:
defaultMode: 420
secretName: fluent-bit-debug-config
- hostPath:
path: /var/log
type: ""
name: varlogs
- hostPath:
path: /var/log/journal
type: ""
name: systemd
- emptyDir: {}
name: positions
使用的secret:fluent-bit-debug-config如下,收录两个键:
第一个 parsers.conf: 为空;配置详情请参考官方文档:配置文件
第二个 fluent-bit.conf 配置需要根据情况进行配置,下面主要针对不同场景给出。它还将涉及使用kubesphere和Filter CRD。
使用流利位exec 到容器中可以使用 /fluent-bit/
bin/fluent-bit 进行调试:
/fluent-bit/bin # ./fluent-bit -h
Usage: fluent-bit [OPTION]
Available Options
-b --storage_path=PATH specify a storage buffering path
-c --config=FILE specify an optional configuration file
-d, --daemon run Fluent Bit in background mode
-f, --flush=SECONDS flush timeout in seconds (default: 5)
-F --filter=FILTER set a filter
-i, --input=INPUT set an input
-m, --match=MATCH set plugin match, same as '-p match=abc'
-o, --output=OUTPUT set an output
-p, --prop="A=B" set plugin configuration property
-R, --parser=FILE specify a parser configuration file
-e, --plugin=FILE load an external plugin (shared lib)
-l, --log_file=FILE write log info to a file
-t, --tag=TAG set plugin tag, same as '-p tag=abc'
-T, --sp-task=SQL define a stream processor task
-v, --verbose increase logging verbosity (default: info)
-H, --http enable monitoring HTTP server
-P, --port set HTTP server TCP port (default: 2020)
-s, --coro_stack_size Set coroutines stack size in bytes (default: 24576)
-q, --quiet quiet mode
-S, --sosreport support report for Enterprise customers
-V, --version show version number
-h, --help print this help
Inputs
cpu CPU Usage
mem Memory Usage
thermal Thermal
kmsg Kernel Log Buffer
proc Check Process health
disk Diskstats
systemd Systemd (Journal) reader
netif Network Interface Usage
docker Docker containers metrics
docker_events Docker events
tail Tail files
dummy Generate dummy data
head Head Input
health Check TCP server health
collectd collectd input plugin
statsd StatsD input plugin
serial Serial input
stdin Standard Input
syslog Syslog
exec Exec Input
tcp TCP
mqtt MQTT, listen for Publish messages
forward Fluentd in-forward
<p>
random Random
Filters
alter_size Alter incoming chunk size
aws Add AWS Metadata
record_modifier modify record
throttle Throttle messages using sliding window algorithm
kubernetes Filter to append Kubernetes metadata
modify modify records by applying rules
nest nest events by specified field values
parser Parse events
expect Validate expected keys and values
grep grep events by specified field values
rewrite_tag Rewrite records tags
lua Lua Scripting Filter
stdout Filter events to STDOUT
Outputs
azure Send events to Azure HTTP Event Collector
azure_blob Azure Blob Storage
bigquery Send events to BigQuery via streaming insert
counter Records counter
datadog Send events to DataDog HTTP Event Collector
es Elasticsearch
exit Exit after a number of flushes (test purposes)
file Generate log file
forward Forward (Fluentd protocol)
http HTTP Output
influxdb InfluxDB Time Series
logdna LogDNA
loki Loki
kafka Kafka
kafka-rest Kafka REST Proxy
nats NATS Server
nrlogs New Relic
null Throws away events
plot Generate data file for GNU Plot
pgsql PostgreSQL
slack Send events to a Slack channel
splunk Send events to Splunk HTTP Event Collector
stackdriver Send events to Google Stackdriver Logging
stdout Prints events to STDOUT
syslog Syslog
tcp TCP Output
td Treasure Data
flowcounter FlowCounter
gelf GELF Output
cloudwatch_logs Send logs to Amazon CloudWatch
kinesis_firehose Send logs to Amazon Kinesis Firehose
s3 Send to S3
Internal
Event Loop = epoll
Build Flags = FLB_HAVE_HTTP_CLIENT_DEBUG FLB_HAVE_PARSER FLB_HAVE_RECORD_ACCESSOR FLB_HAVE_STREAM_PROCESSOR JSMN_PARENT_LINKS JSMN_STRICT FLB_HAVE_TLS FLB_HAVE_AWS FLB_HAVE_SIGNV4 FLB_HAVE_SQLDB FLB_HAVE_METRICS FLB_HAVE_HTTP_SERVER FLB_HAVE_SYSTEMD FLB_HAVE_FORK FLB_HAVE_TIMESPEC_GET FLB_HAVE_GMTOFF FLB_HAVE_UNIX_SOCKET FLB_HAVE_PROXY_GO FLB_HAVE_JEMALLOC JEMALLOC_MANGLE FLB_HAVE_LIBBACKTRACE FLB_HAVE_REGEX FLB_HAVE_UTF8_ENCODER FLB_HAVE_LUAJIT FLB_HAVE_C_TLS FLB_HAVE_ACCEPT4 FLB_HAVE_INOTIFY</p>
简单配置文件
以下是使用简单配置文件采集 calico-node-* pod 的日志:
[Service]
Parsers_File parsers.conf
[Input]
Name tail
Path /var/log/containers/*_kube-system_calico-node-*.log
Refresh_Interval 10
Skip_Long_Lines true
DB /fluent-bit/bin/pos.db
DB.Sync Normal
Mem_Buf_Limit 5MB
Parser docker
Tag kube.*
[Filter]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Labels false
Annotations true
[Output]
Name stdout
Match_Regex (?:kube|service)\.(.*)
使用以下命令在流畅位调试容器内启动测试:
/fluent-bit/bin # ./fluent-bit -c /fluent-bit/config/fluent-bit.conf
您可以看到标准输出日志输出:
[0] kube.var.log.containers.calico-node-lp4lm_kube-system_calico-node-cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81.log: [1634870260.700108403, {"log"=>"{"log":"2021-10-22 02:37:40.699 [INFO][85] monitor-addresses/startup.go 774: Using autodetected IPv4 address on interface bond4: 172.24.248.50/30\n","stream":"stdout","time":"2021-10-22T02:37:40.700056471Z"}", "kubernetes"=>{"pod_name"=>"calico-node-lp4lm", "namespace_name"=>"kube-system", "pod_id"=>"5a829979-9830-4b9c-a3cb-eeb6eee38bdd", "annotations"=>{"kubectl.kubernetes.io/restartedAt"=>"2021-10-20T23:00:27+08:00"}, "host"=>"node02", "container_name"=>"calico-node", "docker_id"=>"cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81", "container_hash"=>"calico/node@sha256:bc4a631d553b38fdc169ea4cb8027fa894a656e80d68d513359a4b9d46836b55", "container_image"=>"calico/node:v3.19.1"}}]
截取重要部分,查看尚未处理采集的K8s日志格式。
[
{
"kubernetes"=>{
"pod_name"=>"calico-node-lp4lm",
"namespace_name"=>"kube-system",
"pod_id"=>"5a829979-9830-4b9c-a3cb-eeb6eee38bdd",
"annotations"=>{
"kubectl.kubernetes.io/restartedAt"=>"2021-10-20T23:00:27+08:00"
},
"host"=>"node02",
"container_name"=>"calico-node",
"docker_id"=>"cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81",
"container_hash"=>"calico/node@sha256:bc4a631d553b38fdc169ea4cb8027fa894a656e80d68d513359a4b9d46836b55",
"container_image"=>"calico/node:v3.19.1"
}
}
]
添加了嵌套过滤器
展开 Kubernetes 块并添加 kubernetes_ 前缀:
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes
Add_prefix kubernetes_
这次测试输出,截取重要部分:
{
"kubernetes_pod_name"=>"calico-node-lp4lm",
"kubernetes_namespace_name"=>"kube-system",
"kubernetes_pod_id"=>"5a829979-9830-4b9c-a3cb-eeb6eee38bdd",
"kubernetes_annotations"=>{
"kubectl.kubernetes.io/restartedAt"=>"2021-10-20T23:00:27+08:00"
},
"kubernetes_host"=>"node02",
"kubernetes_container_name"=>"calico-node",
"kubernetes_docker_id"=>"cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81",
"kubernetes_container_hash"=>"calico/node@sha256:bc4a631d553b38fdc169ea4cb8027fa894a656e80d68d513359a4b9d46836b55",
"kubernetes_container_image"=>"calico/node:v3.19.1"
}
删除kubernetes_annotations块
[Filter]
Name modify
Match kube.*
Remove kubernetes_annotations
从kubernetes_annotations块中删除字段
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes_annotations
Add_prefix kubernetes_annotations_
[Filter]
Name modify
Match kube.*
Remove kubernetes_annotations_kubectl.kubernetes.io/restartedAt
或使用常规:
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes_annotations
Add_prefix kubernetes_annotations_
[Filter]
Name modify
Match kube.*
Remove_regex kubernetes_annotations_kubectl*
修改kubernetes_annotations块中的键名称
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes_annotations
Add_prefix kubernetes_annotations_
[Filter]
Name modify
Match kube.*
Rename kubernetes_annotations_kubectl.kubernetes.io/restartedAt podIPs
修改后:
[
{
"kubernetes_pod_name"=>"calico-node-lp4lm",
"kubernetes_namespace_name"=>"kube-system",
"kubernetes_pod_id"=>"5a829979-9830-4b9c-a3cb-eeb6eee38bdd",
"kubernetes_host"=>"node02",
"kubernetes_container_name"=>"calico-node",
"kubernetes_docker_id"=>"cca502a39695f7452fd999af97bfbca5d74d2a372d94e0cacf2045f5f9721a81",
"kubernetes_container_hash"=>"calico/node@sha256:bc4a631d553b38fdc169ea4cb8027fa894a656e80d68d513359a4b9d46836b55",
"kubernetes_container_image"=>"calico/node:v3.19.1",
"podIPs"=>"2021-10-20T23:00:27+08:00"
}
]
结合 ks 配置采集 podIP
结合 kubesphere Filter CR 来配置 采集podIP 并删除其他不相关的注释。
由于印花布用作 CNI,因此与 Pod IP 相关的注释将添加到 Pod 注释中。
您需要在注释 (/podIP) 中保留一个密钥并删除其他密钥,因此在更改下面要保留的密钥的名称后,删除整个注释。
Kubernetes Filter CR 配置如下:
apiVersion: logging.kubesphere.io/v1alpha2
kind: Filter
metadata:
labels:
logging.kubesphere.io/component: logging
logging.kubesphere.io/enabled: 'true'
name: kubernetes
namespace: kubesphere-logging-system
spec:
filters:
- kubernetes:
annotations: true
kubeCAFile: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
kubeTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
kubeURL: 'https://kubernetes.default.svc:443'
labels: false
- nest:
addPrefix: kubernetes_
nestedUnder: kubernetes
operation: lift
- nest:
addPrefix: kubernetes_annotations_
nestedUnder: kubernetes_annotations
operation: lift
- modify:
rules:
- remove: stream
- remove: kubernetes_pod_id
- remove: kubernetes_host
- remove: kubernetes_container_hash
- rename:
kubernetes_annotations_cni.projectcalico.org/podIPs: kubernetes_podIPs
- removeRegex: kubernetes_annotations*
- nest:
nestUnder: kubernetes_annotations
operation: nest
removePrefix: kubernetes_annotations_
wildcard:
- kubernetes_annotations_*
- nest:
nestUnder: kubernetes
operation: nest
removePrefix: kubernetes_
wildcard:
- kubernetes_*
match: kube.*
Kubernetes Filter CR
生成的流畅位配置配置如下(只看 Filter 部分,省略输入输出 CR)。
[Service]
Parsers_File parsers.conf
[Input]
Name tail
Path /var/log/containers/*.log
Exclude_Path /var/log/containers/*_kubesphere-logging-system_events-exporter*.log,/var/log/containers/kube-auditing-webhook*_kubesphere-logging-system_kube-auditing-webhook*.log
Refresh_Interval 10
Skip_Long_Lines true
DB /fluent-bit/tail/pos.db
DB.Sync Normal
Mem_Buf_Limit 5MB
Parser docker
Tag kube.*
[Filter]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Labels false
Annotations true
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes
Add_prefix kubernetes_
[Filter]
Name nest
Match kube.*
Operation lift
Nested_under kubernetes_annotations
Add_prefix kubernetes_annotations_
[Filter]
Name modify
Match kube.*
Remove stream
Remove kubernetes_pod_id
Remove kubernetes_host
Remove kubernetes_container_hash
Rename kubernetes_annotations_cni.projectcalico.org/podIPs kubernetes_podIPs
Remove_regex kubernetes_annotations*
[Filter]
Name nest
Match kube.*
Operation nest
Wildcard kubernetes_annotations_*
Nest_under kubernetes_annotations
Remove_prefix kubernetes_annotations_
[Filter]
Name nest
Match kube.*
Operation nest
Wildcard kubernetes_*
Nest_under kubernetes
Remove_prefix kubernetes_
[Output]
Name es
Match_Regex (?:kube|service)\.(.*)
Host es-cdc-a-es-http.cdc.svc.xke.test.cn
Port 9200
HTTP_User elastic
HTTP_Passwd elasticpwd
Logstash_Format true
Logstash_Prefix ks-logstash-log
Time_Key @timestamp
您可以在 kibana 中看到 podIP 采集:
作者简洁
作者:小万
唐,一个热爱写作、认真写作的家伙,目前维护着原创公众号:“我的小湾汤”,专注于撰写GO语言、Docker、Kubernetes、Java等开发、运维知识等提升硬实力文章,期待大家的关注。转载说明:请务必注明出处(注明:来自公众号:我的小碗汤,作者:小碗汤)。
整套解决方案:如何采集shopline产品并导入到店铺,一键刊登独立站shopify爆款产品
独立站的同学会遇到上架产品到店的问题。一个产品从title-main image-detail页面一个一个复制到自己的店铺,需要花费很多时间。
如果采集里面有几十个或者几百个产品,手动做显然是很难的。现在有一种方法可以帮助您快速轻松地解决它!!一键式采集产品神器
这是一套奶妈级教程,请耐心阅读,小案例使用!!
Step 1:首先我们要知道采集的store是什么saas平台
网页空白处右键——点击查看网页源代码
在源码页面按Ctrl+F弹出搜索框,进入建站平台,如shopline
第二步:进入Crossker官网-选择产品采集工具
扫一扫公众号登录,每天5次免费试用,联系客服获取更多试用
第三步:选择采集管理-产品分类采集,进入分类链接
时间不用填写,采集的个数不要超过2000
第 4 步:选择 采集管理 - 任务列表
有四种状态:采集表示采集成功,等待采集表示排队,点击右上角刷新按钮查看进度
第五步:选择产品管理——在产品管理中输入采集的编号,点击搜索
记得点击搜索全选,如果没有搜索到默认是30,点击导出为CSV格式
第六步:登录Shopline进入后台商品-商品管理,点击导入商品-shopify表格导入
上传并导入采集的CSV文件,完成导入
第八步:等待系统加载,所有产品导入完毕
除了支持shopline采集外,还支持Shopify、Shoplaza、Oemsaas(YY2.0)、Shopplus、Shopbase等主流SaaS平台的产品采集。WordPress、Woocommerce、Magento 项目、Aliexpress 项目也可以处理。Ueeshop、OpenCart等平台后续会更新!总之,有什么需要,都满足你!
您还在犹豫?都是小问题,联系客服免费试用Crossker产品采集工具
我们刚刚成立Crossker跨境交流群,欢迎各位跨境电商朋友加入!有任何问题请随时提出,我们将尽最大努力为您解答,帮助独立卖家共同成长!
客服C:Crossker-tool
扫描下方二维码加入群~
内容分享:【网站采集工具】优采云文章自动采集器,独树一帜打造专业新闻内容采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-10-11 08:15
在互联网飞速发展的今天,很多人都将目光转向了网络营销和推广。事实证明,网络营销的方向会比实体的和传统的销售方向有更高的回报率。想要取得更好的网络营销效果,企业网站的后期维护和优化尤为重要。在网站后期维护和优化的过程中,网站的日常内容更新工作是一个非常重要但又极其重复和乏味的过程。那么如何以更简单、更快捷、省时省力的方式,为网站更新更多符合搜索引擎SEO规则的优质文章内容呢?作为业界顶级的网站采集软件,<
优采云文章自动采集器作为一个智能平台,根据用户提供的关键词等参数,真正实现文章自动采集,处理,出版。为了达到更好的采集效果,优采云在创作过程中不断优化自身的专业能力,从而实现无需用户自动识别各种在线标题、文字等信息的能力写任何采集规则可以实现全网采集。完成基础内容采集后,会自动计算内容与集合关键词的相关度,并将相关的文章推送给用户。
之所以能引领行业,成为很多人喜欢的网站采集工具,优采云在功能和细节上做到了极致。主要功能方面,优采云拥有近50个主流采集工具必备功能,SEO功能非常齐全。例如,为了方便用户按照网站的主题布局内容,优采云提供了亿+量级的庞大关键词库,可以根据用户输入的任何文本。,经过简单的检查,就可以直接采集,大大减少了用户采集整理关键词所消耗的时间和精力;同时,用户还可以上传已有的关键词,创建属于自己的私有词库,
为满足客户的各种需求,采集文章源汇集了百度、搜狗、好搜、神马、必应、今日头条、微信等拥有庞大用户群的主流搜索引擎. ,确保您能找到更符合您客户的关键词优质文章内容。同时优采云还具有自动识别网页代码、标题、正文等信息的功能,因此无需为每个不同的来源设置不同的采集规则网站,维护成本会比其他相关类型的网站采集软件低很多,为客户节省更多的能源。强大的自然语言处理算法保证了文章的流畅性和关键词的相关性,紧密满足客户需求。确保标题描述与关键词相关,在标题中自动插入关键词提高相关性,并根据文章的内容自动生成高质量的原创标题>。采集成功后还有自动发布、自动执行搜索引擎推送等功能。借助采集系统的定时定量功能,客户即使在关机睡觉的时候也可以做SEO。它还具有自动发布和自动执行搜索引擎推送等功能。借助采集系统的定时定量功能,客户即使在关机睡觉的时候也可以做SEO。它还具有自动发布和自动执行搜索引擎推送等功能。借助采集系统的定时定量功能,客户即使在关机睡觉的时候也可以做SEO。
优采云不仅相关功能强大全面,细节上也做到极致。无论是标题前缀、关键词自动加粗,还是插入固定链接等,都可以帮助客户一键解决问题,用户只需设置关键词及相关要求,完全可以去除文章编辑的痛苦,网站文章更新和维护不再是没有反馈的费时费力的工作。
需要提醒的是,企业网站的维护和后期优化其实是一个比较复杂的过程,而文章的采集编辑和发布其实只是其中的一种优化网站 的。对于更大的比例,用户在做自己的网站文章内容的同时,需要全面掌控SEO的各个方面,比如外链搭建、服务器稳定性、页面打开速度等,都需要持续维护。不仅如此,网站的维护和优化是一场持久战。如果想在短时间内达到很好的搜索效果,往往太仓促了。做好长期持久战的准备,再加上优采云在如此优秀的网站采集器的帮助下,
推荐文章:基于网络爬虫C#网络新闻采集系统设计+文献综述.doc 15页
基于网络爬虫C#网络新闻采集系统设计+文献综述摘要随着信息时代的飞速发展,网络技术对我们的生活和工作越来越重要,尤其是在信息高度发达的今天,传统报纸杂志已经远远不能满足人们的需求。互联网已成为人们快速获取、发布和传递信息的重要渠道。它在人们的政治、经济和生活中发挥着重要作用。简而言之,新闻采集系统作为一种网络新闻媒体,主要实现新闻的分类、上传、审核和发布,模拟一般新闻媒体的新闻发布过程。本软件是基于网络爬虫软件开发的。网络新闻资讯采集系统的主要功能是:根据用户自定义的任务配置,批量准确提取互联网目标网页中的半结构化和非结构化数据,转换成结构化记录,保存它们在本地数据库中,用于内部使用或外网发布,快速实现外部信息的获取。系统的基本功能模块包括:用户登录、站点管理和新闻采集、采集结果的筛选和关键字搜索、数据库管理。具体如下: 1、实现管理员和用户的登录和用户信息的管理;2. 2.实现指定网页新闻的采集和采集站点的添加和管理;3. 实现对采集收到的消息进行过滤和关键词搜索的功能;实现采集接收到的新闻信息的数据库管理。8210关键词:网络爬虫新闻采集新闻管理数据保存研究生设计指导(论文)外文摘要标题网页信息获取摘要:随着信息时代的飞速发展,网络技术对我们的生活和工作越来越重要,尤其是现在高度发达,
当今社会,人们已经离不开互联网,互联网已经成为人与人之间的一种交流方式,可以将事物的复杂化为简单化。新闻采集系统的引入,使电视不再是唯一的新闻媒体,互联网也从此成为重要的新闻媒体。简而言之,新闻发布系统作为一个网络新闻媒体,主要实现新闻的分类、上传、审核、发布,模拟一般新闻媒体的新闻发布流程,通过不同权限的账号实现上述功能. 当然,这些功能也可以由某个账户全部拥有。随着互联网的进一步发展,网络媒体在人们心中的地位进一步提高。作为网络媒体的核心系统,新闻发布系统的重要性越来越重要:一方面,它提供了新闻管理和发布的功能;一方面,时事新闻采集需要与普通用户互动,用户可以很容易地参与到相关新闻的一些调查和评论中,这对于其他一些媒体(电视、广播等)来说也是不可能的,同时,随着互联网在今天的发展,可以说只要上网,就会接触到新闻发布系统。新闻采集系统的用户相当惊人,其重要性毋庸置疑。当然,这也对新闻采集系统的开发提出了更高的要求。网站新闻采集
有两种传统的网站 新闻管理方法。一种是静态 HTML 页面。更新信息时,需要重新创建页面,然后上传页面并修改相应的链接。这种方法没有用,因为它的效率低。二是将动态网页与数据库相结合,通过应用程序处理新闻,这是目前比较流行的做法。人们对最新信息的需求和对发布及时性的迫切需求,而动态交互网页正好提供了这些功能。本系统是一个可以实现新闻在线的在线采集,是一个多栏目管理的在线交互系统。(3) 数据库:访问数据库。Access 是一个基于 Windows 的桌面关系数据库管理系统(RDBMS,微软公司推出的关系型数据库管理系统,是Office系列应用软件之一。提供表格、查询、表格、报表、页面、宏、模块7种对象用于构建数据库系统;提供各种向导、生成器、模板、数据存储、数据查询、界面设计、报表生成等操作标准化;它为建立功能齐全的数据库管理系统提供了便利,也使普通用户无需编写代码即可完成大部分数据管理任务。2网页新闻采集系统 2.1 系统概述 新闻采集系统是一个从多个新闻源网页中提取非结构化新闻文章并将其存储在结构化数据库中的软件。根据用户自定义任务配置,消息或<
新闻采集系统的核心技术是模式定义和模式匹配。模式属于人工智能的术语,是对前人积累的经验的抽象和升华。简单地说,它是从反复发生的事件中发现和抽象出来的规则,是解决问题的经验总结。只要是一遍又一遍地重复的东西,就可能有规律。因此,新闻采集 系统要工作,目标网站 必须具有重复出现的特征。目前大部分网站都是动态生成的,这样同模板的页面会收录相同的内容,而新闻采集系统使用相同的内容来定位采集数据。新闻中的大部分模式采集 系统不会被程序自动发现。目前几乎所有的新闻采集系统产品都需要手动定义。但是模式本身是一个非常复杂和抽象的内容,所以开发者的全部精力都花在了如何让模式定义更简单、更准确上,这也是衡量新闻采集系统竞争力的标准。如下图2.1所示: 图2.1 采集系统工作原理爬虫工作原理及关键技术概述网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。
然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。由于用户范围广,通用爬虫大多使用较高的W曲线覆盖率,因此通常使用广度优先或深度优先的策略搜索。万能爬虫实际上代替了人在目录搜索引擎中的工作。它从种子链接开始,不断爬取 URL 网页。当万能爬虫进入某个超文本时,它利用HTML语言的标记结构来搜索信息并获取信息。指向其他超文本的URL地址可以实现自动“爬网”和网络搜索,无需用户干预。如果这些链接还没有被爬虫访问过,爬虫就会被放到下载队列中进行爬取。万能爬虫就是采用这样的方式,不断的遍历整个互联网,直到下载队列为空或者达到系统给定的停止条件。一般爬虫都是以传统的图算法为工作原理的。它通常只使用一个或几个 URL 作为种子,而不考虑网页的内容,并使用宽度或深度优先算法访问整个 Internet。这种爬虫的目标是覆盖整个网络。2.3 新闻采集系统发展趋势 现有常见应用:?环球新闻采集器?新浪新闻采集器?优采云采集器? 远景新闻采集器发展趋势:新闻在网络上的发布频率非常高。如果将静态网页作为新闻页面,维护工作会非常繁琐,管理员每天需要制作大量的网页,浪费了大量的时间和精力。
使用后台管理系统,可以轻松管理系统、新闻、软件、消息、会员及相关指令等功能模块。如果管理员要发布新闻,只需要设置新闻的标题、内容、图片等,系统会自动生成相应的网页。3 开发技术与工具 3.1 系统开发工具 3.1.1 Visual Studio 2005vs2005是基于.NET2.0框架的。• 用户界面集成:工具之间的无缝集成是提高生产力的关键。Visual Studio Team System 在整个 SDLC 工具套件中提供一致的用户体验。对于开发人员,某些活动(例如,单元测试、工作项跟踪、代码分析和代码分析)在他们当前的开发环境中可用。• 数据集成:Visual Studio Team System 通过使用通用的跨工具集数据仓库解决了在大多数 SDLC 工具中构建数据仓库的问题,并启用了项目状态的聚合视图。团队根据可以采集的规则管理项目。今天,数据主要限于缺陷跟踪。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。Visual Studio Team System 通过使用通用的跨工具集数据仓库解决了大多数 SDLC 工具中构建数据仓库的问题,并启用了项目状态的聚合视图。团队根据可以采集的规则管理项目。今天,数据主要限于缺陷跟踪。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。Visual Studio Team System 通过使用通用的跨工具集数据仓库解决了大多数 SDLC 工具中构建数据仓库的问题,并启用了项目状态的聚合视图。团队根据可以采集的规则管理项目。今天,数据主要限于缺陷跟踪。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。
此数据以某种标准报告格式呈现,客户和 Microsoft 内部团队已根据该格式建立成功项目管理的关键规程。此外,团队能够创建自定义报告。只有在项目的广泛背景下查看数据时,团队才能准确报告项目状态。C# (C SHARP) 是微软针对这个问题的解决方案。C# 是一种最新的、面向对象的编程语言。它使程序员能够基于MICROSOFT .NET 平台快速编写各种应用程序,MICROSOFT .NET 提供一系列工具和服务,最大限度地开发和利用计算和通信领域。正是由于 C# 优秀的面向对象设计,它非常适合构建各种组件——无论是高级业务对象还是系统级应用程序。使用简单的 C# 语言结构,这些组件可以很容易地转换为 XML Web 服务,因此它们可以在 Internet 上由任何操作系统上的任何语言调用。最重要的是,C#使C++程序员能够高效地开发程序,同时又不失C/C++原有的强大功能。由于这种继承关系,C#与C/C++非常相似,熟悉类似语言的开发者可以快速转向C#。3.2 数据库 通俗地说,数据库是数据或信息的集合。从专业上讲,数据库是由许多数据表组成的一组计算机组织的数据。
Access是微软推出的基于Windows的桌面关系数据库管理系统(RDBMS,Relational Database Management System),是Office系列应用软件之一。提供表格、查询、表格、报表、页面、宏、模块7种对象用于构建数据库系统;提供各种向导、生成器、模板、数据存储、数据查询、界面设计、报表生成等操作标准化;它为建立功能齐全的数据库管理系统提供了便利,也使普通用户无需编写代码即可完成大部分数据管理任务。Access的优点 (1)存储方式简单,易于维护和管理。Access 管理的对象包括表、查询、表单、报表、页面、宏和模块。上述对象存储在后缀为(.mdb 或 .accdb)的数据库文件中。,方便用户操作和管理。(2)面向对象的Access是一种面向对象的开发工具,它采用面向对象的方法将数据库系统中的各种功能对象化,将数据库管理的各种功能封装在各种对象中。它将应用系统视为一系列对象。对于每个对象,它定义了一组方法和属性来定义对象的行为和外国。用户还可以根据需要将方法和属性扩展到对象。数据库的操作和管理都是通过对象的方法和属性来完成的,大大简化了用户的开发工作。同时,这种面向对象的开发方法使开发应用程序变得更加容易。简而言之,Access是一个只能用来存储数据的数据库,也可以作为开发数据库应用系统的客户端开发工具;即可以开发方便易用的小型软件,也可以用于开发大型应用系统。基于网络爬虫C#网络新闻采集系统设计+文献综述(七):范文最新推荐1 / 1 查看全部
内容分享:【网站采集工具】优采云文章自动采集器,独树一帜打造专业新闻内容采集工具
在互联网飞速发展的今天,很多人都将目光转向了网络营销和推广。事实证明,网络营销的方向会比实体的和传统的销售方向有更高的回报率。想要取得更好的网络营销效果,企业网站的后期维护和优化尤为重要。在网站后期维护和优化的过程中,网站的日常内容更新工作是一个非常重要但又极其重复和乏味的过程。那么如何以更简单、更快捷、省时省力的方式,为网站更新更多符合搜索引擎SEO规则的优质文章内容呢?作为业界顶级的网站采集软件,<
优采云文章自动采集器作为一个智能平台,根据用户提供的关键词等参数,真正实现文章自动采集,处理,出版。为了达到更好的采集效果,优采云在创作过程中不断优化自身的专业能力,从而实现无需用户自动识别各种在线标题、文字等信息的能力写任何采集规则可以实现全网采集。完成基础内容采集后,会自动计算内容与集合关键词的相关度,并将相关的文章推送给用户。
之所以能引领行业,成为很多人喜欢的网站采集工具,优采云在功能和细节上做到了极致。主要功能方面,优采云拥有近50个主流采集工具必备功能,SEO功能非常齐全。例如,为了方便用户按照网站的主题布局内容,优采云提供了亿+量级的庞大关键词库,可以根据用户输入的任何文本。,经过简单的检查,就可以直接采集,大大减少了用户采集整理关键词所消耗的时间和精力;同时,用户还可以上传已有的关键词,创建属于自己的私有词库,
为满足客户的各种需求,采集文章源汇集了百度、搜狗、好搜、神马、必应、今日头条、微信等拥有庞大用户群的主流搜索引擎. ,确保您能找到更符合您客户的关键词优质文章内容。同时优采云还具有自动识别网页代码、标题、正文等信息的功能,因此无需为每个不同的来源设置不同的采集规则网站,维护成本会比其他相关类型的网站采集软件低很多,为客户节省更多的能源。强大的自然语言处理算法保证了文章的流畅性和关键词的相关性,紧密满足客户需求。确保标题描述与关键词相关,在标题中自动插入关键词提高相关性,并根据文章的内容自动生成高质量的原创标题>。采集成功后还有自动发布、自动执行搜索引擎推送等功能。借助采集系统的定时定量功能,客户即使在关机睡觉的时候也可以做SEO。它还具有自动发布和自动执行搜索引擎推送等功能。借助采集系统的定时定量功能,客户即使在关机睡觉的时候也可以做SEO。它还具有自动发布和自动执行搜索引擎推送等功能。借助采集系统的定时定量功能,客户即使在关机睡觉的时候也可以做SEO。
优采云不仅相关功能强大全面,细节上也做到极致。无论是标题前缀、关键词自动加粗,还是插入固定链接等,都可以帮助客户一键解决问题,用户只需设置关键词及相关要求,完全可以去除文章编辑的痛苦,网站文章更新和维护不再是没有反馈的费时费力的工作。
需要提醒的是,企业网站的维护和后期优化其实是一个比较复杂的过程,而文章的采集编辑和发布其实只是其中的一种优化网站 的。对于更大的比例,用户在做自己的网站文章内容的同时,需要全面掌控SEO的各个方面,比如外链搭建、服务器稳定性、页面打开速度等,都需要持续维护。不仅如此,网站的维护和优化是一场持久战。如果想在短时间内达到很好的搜索效果,往往太仓促了。做好长期持久战的准备,再加上优采云在如此优秀的网站采集器的帮助下,
推荐文章:基于网络爬虫C#网络新闻采集系统设计+文献综述.doc 15页
基于网络爬虫C#网络新闻采集系统设计+文献综述摘要随着信息时代的飞速发展,网络技术对我们的生活和工作越来越重要,尤其是在信息高度发达的今天,传统报纸杂志已经远远不能满足人们的需求。互联网已成为人们快速获取、发布和传递信息的重要渠道。它在人们的政治、经济和生活中发挥着重要作用。简而言之,新闻采集系统作为一种网络新闻媒体,主要实现新闻的分类、上传、审核和发布,模拟一般新闻媒体的新闻发布过程。本软件是基于网络爬虫软件开发的。网络新闻资讯采集系统的主要功能是:根据用户自定义的任务配置,批量准确提取互联网目标网页中的半结构化和非结构化数据,转换成结构化记录,保存它们在本地数据库中,用于内部使用或外网发布,快速实现外部信息的获取。系统的基本功能模块包括:用户登录、站点管理和新闻采集、采集结果的筛选和关键字搜索、数据库管理。具体如下: 1、实现管理员和用户的登录和用户信息的管理;2. 2.实现指定网页新闻的采集和采集站点的添加和管理;3. 实现对采集收到的消息进行过滤和关键词搜索的功能;实现采集接收到的新闻信息的数据库管理。8210关键词:网络爬虫新闻采集新闻管理数据保存研究生设计指导(论文)外文摘要标题网页信息获取摘要:随着信息时代的飞速发展,网络技术对我们的生活和工作越来越重要,尤其是现在高度发达,
当今社会,人们已经离不开互联网,互联网已经成为人与人之间的一种交流方式,可以将事物的复杂化为简单化。新闻采集系统的引入,使电视不再是唯一的新闻媒体,互联网也从此成为重要的新闻媒体。简而言之,新闻发布系统作为一个网络新闻媒体,主要实现新闻的分类、上传、审核、发布,模拟一般新闻媒体的新闻发布流程,通过不同权限的账号实现上述功能. 当然,这些功能也可以由某个账户全部拥有。随着互联网的进一步发展,网络媒体在人们心中的地位进一步提高。作为网络媒体的核心系统,新闻发布系统的重要性越来越重要:一方面,它提供了新闻管理和发布的功能;一方面,时事新闻采集需要与普通用户互动,用户可以很容易地参与到相关新闻的一些调查和评论中,这对于其他一些媒体(电视、广播等)来说也是不可能的,同时,随着互联网在今天的发展,可以说只要上网,就会接触到新闻发布系统。新闻采集系统的用户相当惊人,其重要性毋庸置疑。当然,这也对新闻采集系统的开发提出了更高的要求。网站新闻采集
有两种传统的网站 新闻管理方法。一种是静态 HTML 页面。更新信息时,需要重新创建页面,然后上传页面并修改相应的链接。这种方法没有用,因为它的效率低。二是将动态网页与数据库相结合,通过应用程序处理新闻,这是目前比较流行的做法。人们对最新信息的需求和对发布及时性的迫切需求,而动态交互网页正好提供了这些功能。本系统是一个可以实现新闻在线的在线采集,是一个多栏目管理的在线交互系统。(3) 数据库:访问数据库。Access 是一个基于 Windows 的桌面关系数据库管理系统(RDBMS,微软公司推出的关系型数据库管理系统,是Office系列应用软件之一。提供表格、查询、表格、报表、页面、宏、模块7种对象用于构建数据库系统;提供各种向导、生成器、模板、数据存储、数据查询、界面设计、报表生成等操作标准化;它为建立功能齐全的数据库管理系统提供了便利,也使普通用户无需编写代码即可完成大部分数据管理任务。2网页新闻采集系统 2.1 系统概述 新闻采集系统是一个从多个新闻源网页中提取非结构化新闻文章并将其存储在结构化数据库中的软件。根据用户自定义任务配置,消息或<
新闻采集系统的核心技术是模式定义和模式匹配。模式属于人工智能的术语,是对前人积累的经验的抽象和升华。简单地说,它是从反复发生的事件中发现和抽象出来的规则,是解决问题的经验总结。只要是一遍又一遍地重复的东西,就可能有规律。因此,新闻采集 系统要工作,目标网站 必须具有重复出现的特征。目前大部分网站都是动态生成的,这样同模板的页面会收录相同的内容,而新闻采集系统使用相同的内容来定位采集数据。新闻中的大部分模式采集 系统不会被程序自动发现。目前几乎所有的新闻采集系统产品都需要手动定义。但是模式本身是一个非常复杂和抽象的内容,所以开发者的全部精力都花在了如何让模式定义更简单、更准确上,这也是衡量新闻采集系统竞争力的标准。如下图2.1所示: 图2.1 采集系统工作原理爬虫工作原理及关键技术概述网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。
然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。由于用户范围广,通用爬虫大多使用较高的W曲线覆盖率,因此通常使用广度优先或深度优先的策略搜索。万能爬虫实际上代替了人在目录搜索引擎中的工作。它从种子链接开始,不断爬取 URL 网页。当万能爬虫进入某个超文本时,它利用HTML语言的标记结构来搜索信息并获取信息。指向其他超文本的URL地址可以实现自动“爬网”和网络搜索,无需用户干预。如果这些链接还没有被爬虫访问过,爬虫就会被放到下载队列中进行爬取。万能爬虫就是采用这样的方式,不断的遍历整个互联网,直到下载队列为空或者达到系统给定的停止条件。一般爬虫都是以传统的图算法为工作原理的。它通常只使用一个或几个 URL 作为种子,而不考虑网页的内容,并使用宽度或深度优先算法访问整个 Internet。这种爬虫的目标是覆盖整个网络。2.3 新闻采集系统发展趋势 现有常见应用:?环球新闻采集器?新浪新闻采集器?优采云采集器? 远景新闻采集器发展趋势:新闻在网络上的发布频率非常高。如果将静态网页作为新闻页面,维护工作会非常繁琐,管理员每天需要制作大量的网页,浪费了大量的时间和精力。
使用后台管理系统,可以轻松管理系统、新闻、软件、消息、会员及相关指令等功能模块。如果管理员要发布新闻,只需要设置新闻的标题、内容、图片等,系统会自动生成相应的网页。3 开发技术与工具 3.1 系统开发工具 3.1.1 Visual Studio 2005vs2005是基于.NET2.0框架的。• 用户界面集成:工具之间的无缝集成是提高生产力的关键。Visual Studio Team System 在整个 SDLC 工具套件中提供一致的用户体验。对于开发人员,某些活动(例如,单元测试、工作项跟踪、代码分析和代码分析)在他们当前的开发环境中可用。• 数据集成:Visual Studio Team System 通过使用通用的跨工具集数据仓库解决了在大多数 SDLC 工具中构建数据仓库的问题,并启用了项目状态的聚合视图。团队根据可以采集的规则管理项目。今天,数据主要限于缺陷跟踪。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。Visual Studio Team System 通过使用通用的跨工具集数据仓库解决了大多数 SDLC 工具中构建数据仓库的问题,并启用了项目状态的聚合视图。团队根据可以采集的规则管理项目。今天,数据主要限于缺陷跟踪。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。Visual Studio Team System 通过使用通用的跨工具集数据仓库解决了大多数 SDLC 工具中构建数据仓库的问题,并启用了项目状态的聚合视图。团队根据可以采集的规则管理项目。今天,数据主要限于缺陷跟踪。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。Visual Studio Team System 中的集成数据将通过利用整个 SDLC 中的大量多样数据,开辟一种管理项目规则的新方法。Visual Studio Team System 采集精确的数据——不仅是缺陷跟踪,还包括测试结果、代码覆盖率、代码生成、任务进度以及整个团队常规工作流程中的更多数据。
此数据以某种标准报告格式呈现,客户和 Microsoft 内部团队已根据该格式建立成功项目管理的关键规程。此外,团队能够创建自定义报告。只有在项目的广泛背景下查看数据时,团队才能准确报告项目状态。C# (C SHARP) 是微软针对这个问题的解决方案。C# 是一种最新的、面向对象的编程语言。它使程序员能够基于MICROSOFT .NET 平台快速编写各种应用程序,MICROSOFT .NET 提供一系列工具和服务,最大限度地开发和利用计算和通信领域。正是由于 C# 优秀的面向对象设计,它非常适合构建各种组件——无论是高级业务对象还是系统级应用程序。使用简单的 C# 语言结构,这些组件可以很容易地转换为 XML Web 服务,因此它们可以在 Internet 上由任何操作系统上的任何语言调用。最重要的是,C#使C++程序员能够高效地开发程序,同时又不失C/C++原有的强大功能。由于这种继承关系,C#与C/C++非常相似,熟悉类似语言的开发者可以快速转向C#。3.2 数据库 通俗地说,数据库是数据或信息的集合。从专业上讲,数据库是由许多数据表组成的一组计算机组织的数据。
Access是微软推出的基于Windows的桌面关系数据库管理系统(RDBMS,Relational Database Management System),是Office系列应用软件之一。提供表格、查询、表格、报表、页面、宏、模块7种对象用于构建数据库系统;提供各种向导、生成器、模板、数据存储、数据查询、界面设计、报表生成等操作标准化;它为建立功能齐全的数据库管理系统提供了便利,也使普通用户无需编写代码即可完成大部分数据管理任务。Access的优点 (1)存储方式简单,易于维护和管理。Access 管理的对象包括表、查询、表单、报表、页面、宏和模块。上述对象存储在后缀为(.mdb 或 .accdb)的数据库文件中。,方便用户操作和管理。(2)面向对象的Access是一种面向对象的开发工具,它采用面向对象的方法将数据库系统中的各种功能对象化,将数据库管理的各种功能封装在各种对象中。它将应用系统视为一系列对象。对于每个对象,它定义了一组方法和属性来定义对象的行为和外国。用户还可以根据需要将方法和属性扩展到对象。数据库的操作和管理都是通过对象的方法和属性来完成的,大大简化了用户的开发工作。同时,这种面向对象的开发方法使开发应用程序变得更加容易。简而言之,Access是一个只能用来存储数据的数据库,也可以作为开发数据库应用系统的客户端开发工具;即可以开发方便易用的小型软件,也可以用于开发大型应用系统。基于网络爬虫C#网络新闻采集系统设计+文献综述(七):范文最新推荐1 / 1
优采云自动文章采集 sign failed11(前缀关键词自动加粗*固定链接自动提取标签(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-03-29 00:20
<p>. . . . . . 如果用户写了任何采集规则,全网可以采集采集会自动计算内容与集合关键词的相关性,只有相关的采集 @文章推送给用户支持标题前缀关键词自动加粗*永久链接自动提取标签自动内部链接自动伪原创内容过滤替换*号码和URL清洗百度主动提交等对用户的功能只需要设置关键词及相关需求即可实现全托管、零维护网站无限内容更新网站无论是单个网站还是大批量站群 都可以轻松管理 研发背景 查看全部
优采云自动文章采集 sign failed11(Zblog采集支持任意版本Nginx采集插件处理 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-03-28 07:20
)
Zblog是Zblog开发团队开发的一个基于Asp和PHP平台的小而强大的开源程序,但是插件市场上的Zblog采集插件没有一个能被打败,或者有是没有 SEO 文章内容处理,或单一功能。适合 SEO 站长的 Zblog采集 很少。
大家都知道Zblog采集接口是不熟悉Zblog的人做的采集,很多人用模拟登录的方式发布文章,很多人直接操作数据库发布文章,然而,所有这些都或多或少地引起了各种问题。发布速度慢,文章的内容没有经过严格过滤,导致安全问题,无法发送标签,无法自动创建分类等。但是,使用Zblog采集快速发布, 文章内容经过严格过滤,不存在安全问题,可以发送TAG,支持自动创建分类。
Zblog采集可以帮站内省去很多搬运工,插件不仅支持文章采集,还支持文章采集@中的评论> ,其他插件的数据 采集(不是 文章)。
Zblog采集还支持Empirecms、易友、Zblog采集、dedecms、WordPress、PBoot、Applecms、迅瑞cms@ >、PHPcms、Applecms、人人网cms、美图cms、云游cms、Cyclone站群、THINKCMF、建展ABC、凡客cms、一气cms、Oceancms、飞飞cms、Local Release、搜外等各大cms,一个可以批量管理,同时发布。
Zblog采集支持任意PHP版本Zblog采集支持任意版本MysqlZblog采集,Zblog采集支持任意版本Nginx。
Zblog采集支持内容替换,Zblog采集支持HTML过滤,Zblog采集支持正则提取,Zblog采集支持字符截取,Zblog采集支持前后追加内容,Zblog采集支持空内容默认值,Zblog采集支持关键词分词。 Zblog采集支持同义词替换,Zblog采集支持关键词内链。
Zblog采集 支持任何 Zblog采集 版本。 Zblog采集作者声明永久免费。
Zblog采集不会因为版本不匹配或服务器环境不支持等其他原因而无法使用Zblog采集。
Zblog采集配置简单,Zblog采集不需要花很多时间学习软件操作,不用配置采集规则,一分钟就能上手,只需输入 关键词采集。
Zblog采集可以对字段内容进行二次处理,Zblog采集还可以结合内容页面衍生的多级页面。
Zblog采集有很好的字段使用方法,可以自动分段Zblog采集同义词转换,供关键词Zblog采集关键词内链过滤查看(编辑)zblog采集可以查看已经采集的数据,zblog采集支持php扩展。 Zblog采集可以查看javascript扩展。
Zblog采集提供一站式网站文章解决方案,无需人工干预,设置任务自动执行采集releases。
Zblog采集可以实现几十万个不同的cms网站的统一管理。一个人维护数百个 网站文章 更新也不是问题。
Zblog采集第三方采集软件很强大,只要输入关键词采集,通过软件就可以完全自动化采集@ >采集并发布文章,为了让搜索引擎收录你的网站,我们还可以设置自动下载图片和替换链接,图片存储方式支持:阿里云OSS、七牛对象存储、腾讯云、拍云等
{foreach $dayHotArticle as $articles}
{$articles.Title}
{/foreach}
Zblog采集还配备了自动内部链接,内容或标题前后插入的某些内容形成“伪原创”。 Zblog采集还有监控功能,可以通过软件直接查看文章采集的发布状态。
今天关于Zblog的分享采集就到这里,下期会分享更多seo相关知识。希望能在SEO网站优化的道路上对您有所帮助。如果喜欢,不妨点击三个链接。
查看全部
优采云自动文章采集 sign failed11(Zblog采集支持任意版本Nginx采集插件处理
)
Zblog是Zblog开发团队开发的一个基于Asp和PHP平台的小而强大的开源程序,但是插件市场上的Zblog采集插件没有一个能被打败,或者有是没有 SEO 文章内容处理,或单一功能。适合 SEO 站长的 Zblog采集 很少。
大家都知道Zblog采集接口是不熟悉Zblog的人做的采集,很多人用模拟登录的方式发布文章,很多人直接操作数据库发布文章,然而,所有这些都或多或少地引起了各种问题。发布速度慢,文章的内容没有经过严格过滤,导致安全问题,无法发送标签,无法自动创建分类等。但是,使用Zblog采集快速发布, 文章内容经过严格过滤,不存在安全问题,可以发送TAG,支持自动创建分类。
Zblog采集可以帮站内省去很多搬运工,插件不仅支持文章采集,还支持文章采集@中的评论> ,其他插件的数据 采集(不是 文章)。
Zblog采集还支持Empirecms、易友、Zblog采集、dedecms、WordPress、PBoot、Applecms、迅瑞cms@ >、PHPcms、Applecms、人人网cms、美图cms、云游cms、Cyclone站群、THINKCMF、建展ABC、凡客cms、一气cms、Oceancms、飞飞cms、Local Release、搜外等各大cms,一个可以批量管理,同时发布。
Zblog采集支持任意PHP版本Zblog采集支持任意版本MysqlZblog采集,Zblog采集支持任意版本Nginx。
Zblog采集支持内容替换,Zblog采集支持HTML过滤,Zblog采集支持正则提取,Zblog采集支持字符截取,Zblog采集支持前后追加内容,Zblog采集支持空内容默认值,Zblog采集支持关键词分词。 Zblog采集支持同义词替换,Zblog采集支持关键词内链。
Zblog采集 支持任何 Zblog采集 版本。 Zblog采集作者声明永久免费。
Zblog采集不会因为版本不匹配或服务器环境不支持等其他原因而无法使用Zblog采集。
Zblog采集配置简单,Zblog采集不需要花很多时间学习软件操作,不用配置采集规则,一分钟就能上手,只需输入 关键词采集。
Zblog采集可以对字段内容进行二次处理,Zblog采集还可以结合内容页面衍生的多级页面。
Zblog采集有很好的字段使用方法,可以自动分段Zblog采集同义词转换,供关键词Zblog采集关键词内链过滤查看(编辑)zblog采集可以查看已经采集的数据,zblog采集支持php扩展。 Zblog采集可以查看javascript扩展。
Zblog采集提供一站式网站文章解决方案,无需人工干预,设置任务自动执行采集releases。
Zblog采集可以实现几十万个不同的cms网站的统一管理。一个人维护数百个 网站文章 更新也不是问题。
Zblog采集第三方采集软件很强大,只要输入关键词采集,通过软件就可以完全自动化采集@ >采集并发布文章,为了让搜索引擎收录你的网站,我们还可以设置自动下载图片和替换链接,图片存储方式支持:阿里云OSS、七牛对象存储、腾讯云、拍云等
{foreach $dayHotArticle as $articles}
{$articles.Title}
{/foreach}
Zblog采集还配备了自动内部链接,内容或标题前后插入的某些内容形成“伪原创”。 Zblog采集还有监控功能,可以通过软件直接查看文章采集的发布状态。
今天关于Zblog的分享采集就到这里,下期会分享更多seo相关知识。希望能在SEO网站优化的道路上对您有所帮助。如果喜欢,不妨点击三个链接。
优采云自动文章采集 sign failed11(为什么要用帝国CMS插件?如何利用网站收录以及关键词排名 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-03-19 11:24
)
为什么要使用 Empire cms 插件?如何使用 Empire cms 插件对 网站收录 和 关键词 进行排名。网站seo优化是对网站的节目、域名注册查询、内容、版块、版面、目标关键词等方面的优化调整,即网站被设计为适用于搜索引擎检索,满足搜索引擎排名的指标,从而在搜索引擎检索中获得流量排名靠前,增强搜索引擎营销效果,使网站相关关键词能够有一个很好的排名。网站seo优化的目的是让网站更容易被搜索引擎收录访问,提升用户体验(UE)和转化率,创造价值。那么<的核心内容是什么?
第一个核心:页面评分核心
搜索引擎在抓取网站网站时,首先判断网站的内容质量,是动态路径还是静态路径,是否使用二级域名, 网站的质量取决于网站的用户,其次是收录搜索的页数。每一页的关键词的等级,能不能再回来?从标题看,搜索引擎抓取的时候,首先看你的标题,页面的关键词是否与内容匹配。关键词 的整体类型是否与用户搜索的 关键词 匹配?这时候就需要分析一下为什么产品页面收录那么低,根据产品类别展开相关的长尾。如果内容质量好,找关键词多带点,整体关键词
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以通过Empire cms插件实现采集伪原创自动发布和主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站< @k10@ > 和 关键词 排名。
一、自由帝国采集插件
Free Empire采集 插件的特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体中文翻译+百度翻译+147翻译+有道翻译+谷歌翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)
3、伪原创(标题+内容)
4、替换图片防止侵权
5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章前后插入内容/标题关键词与内容一致关键词/随机插入图片/随机属性添加页面原创度)
6、对应栏:对应文章可以发布对应栏/支持多栏发布
7、定期发布:可控发布间隔/每天发布总数
8、监控数据:直接监控已经发布、待发布的软件,是否为伪原创、发布状态、URL、程序、发布时间等。
第二个核心:关键词 核心
做大网站需要一个团队的运作。如果频道页很大,就离不开关键词。需要一个优化器加一两个编辑器,优化器需要优化选择关键词,选择关键词,如果小网站需要更新网站@对应的内容> 每天,内容标题是否整合到关键词,需要匹配用户搜索到的关键词,可以出现在文章中,这些词应该出现在哪个栏目下。匹配度越高越好,因为需要匹配的内容量大,主题页的排名方案也是可以接受的。因此,排名研究与关键词有关。在优化 网站 时,
第三核心:差异化核心
网站 的优化方法不同,导致有人想模仿。效果不好,尽量发挥自己的优势。对标题或关键词、内容页面、网站布局等的动作。关键词为了达到标题和内容的匹配度,网站的页面是做好内容,原创提高质量,让同学们互相分享,达到网站的差异化排名指日可待。
在网站的优化中,有两种标签在站长看来可以起到很小的作用。这两种标签分别是关键词标签和description标签,尤其是description标签被很多人使用网站已经没用了。然而,作者并不这么认为。目前的描述标签虽然和排名没有直接关系,但是对网站等方面的优化影响很大,比如网站的专业性,用户是否网站的内容@>可以从搜索结果等中快速判断,这些都可以通过description标签来实现。而且,在搜索引擎看来,描述标签在用户体验中也可以起到非常重要的作用。
一、有助于提高网站的专业水平
当用户判断一个网站是否专业时,首先要从搜索结果的描述标签判断网站是否专业。例如,当用户搜索女装信息时,标题是写女装,而描述是女鞋。这样的网站如何让用户感受到他的专业?还有就是没有写description标签,导致搜索引擎随机爬取网站@网站上的一段内容,用来描述和展示结果。众所周知,搜索引擎很难随便爬取来完美展示其网站的大致内容,提升网站的性能非常重要。专业性很差。
二、缩小搜索引擎判断页面的范围关键词
<p>搜索引擎在提取页面的关键词时,并不是单纯的依靠页面的标题来选择,还有一个重要的参考地方,那就是页面的描述标签。一般来说,写好每个页面的description标签,可以让搜索引擎更快的提取出这个页面的关键词,同时也可以缩小搜索引擎判断页面 查看全部
优采云自动文章采集 sign failed11(为什么要用帝国CMS插件?如何利用网站收录以及关键词排名
)
为什么要使用 Empire cms 插件?如何使用 Empire cms 插件对 网站收录 和 关键词 进行排名。网站seo优化是对网站的节目、域名注册查询、内容、版块、版面、目标关键词等方面的优化调整,即网站被设计为适用于搜索引擎检索,满足搜索引擎排名的指标,从而在搜索引擎检索中获得流量排名靠前,增强搜索引擎营销效果,使网站相关关键词能够有一个很好的排名。网站seo优化的目的是让网站更容易被搜索引擎收录访问,提升用户体验(UE)和转化率,创造价值。那么<的核心内容是什么?
第一个核心:页面评分核心
搜索引擎在抓取网站网站时,首先判断网站的内容质量,是动态路径还是静态路径,是否使用二级域名, 网站的质量取决于网站的用户,其次是收录搜索的页数。每一页的关键词的等级,能不能再回来?从标题看,搜索引擎抓取的时候,首先看你的标题,页面的关键词是否与内容匹配。关键词 的整体类型是否与用户搜索的 关键词 匹配?这时候就需要分析一下为什么产品页面收录那么低,根据产品类别展开相关的长尾。如果内容质量好,找关键词多带点,整体关键词
网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以通过Empire cms插件实现采集伪原创自动发布和主动推送给搜索引擎,增加搜索引擎的抓取频率,从而增加网站< @k10@ > 和 关键词 排名。
一、自由帝国采集插件
Free Empire采集 插件的特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词。
2、支持多消息源:问答和各种消息源(可同时设置多个采集消息源采集/采集消息源稍后添加)
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译(简体中文和繁体中文翻译+百度翻译+147翻译+有道翻译+谷歌翻译)
6、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、在所有平台上发布插件
全平台cms发布者的特点:
1、cms发布:目前市面上唯一支持Empirecms、易友、ZBLOG、dedecms、WordPress、PBoot、Applecms、迅锐cms、PHPcms、苹果cms、人人网cms、米拓cms、云游cms、小旋风站群 , THINKCMF, 建站ABC, 凡客cms, 一骑cms, 海洋cms, 飞飞cms, 本地发布, 搜外 等cms ,并同时进行批量管理和发布的工具
2、全网推送(百度/360/搜狗/神马)
3、伪原创(标题+内容)
4、替换图片防止侵权
5、强大的SEO功能(自动图片放置/插入内外链接/标题和文章前后插入内容/标题关键词与内容一致关键词/随机插入图片/随机属性添加页面原创度)
6、对应栏:对应文章可以发布对应栏/支持多栏发布
7、定期发布:可控发布间隔/每天发布总数
8、监控数据:直接监控已经发布、待发布的软件,是否为伪原创、发布状态、URL、程序、发布时间等。
第二个核心:关键词 核心
做大网站需要一个团队的运作。如果频道页很大,就离不开关键词。需要一个优化器加一两个编辑器,优化器需要优化选择关键词,选择关键词,如果小网站需要更新网站@对应的内容> 每天,内容标题是否整合到关键词,需要匹配用户搜索到的关键词,可以出现在文章中,这些词应该出现在哪个栏目下。匹配度越高越好,因为需要匹配的内容量大,主题页的排名方案也是可以接受的。因此,排名研究与关键词有关。在优化 网站 时,
第三核心:差异化核心
网站 的优化方法不同,导致有人想模仿。效果不好,尽量发挥自己的优势。对标题或关键词、内容页面、网站布局等的动作。关键词为了达到标题和内容的匹配度,网站的页面是做好内容,原创提高质量,让同学们互相分享,达到网站的差异化排名指日可待。
在网站的优化中,有两种标签在站长看来可以起到很小的作用。这两种标签分别是关键词标签和description标签,尤其是description标签被很多人使用网站已经没用了。然而,作者并不这么认为。目前的描述标签虽然和排名没有直接关系,但是对网站等方面的优化影响很大,比如网站的专业性,用户是否网站的内容@>可以从搜索结果等中快速判断,这些都可以通过description标签来实现。而且,在搜索引擎看来,描述标签在用户体验中也可以起到非常重要的作用。
一、有助于提高网站的专业水平
当用户判断一个网站是否专业时,首先要从搜索结果的描述标签判断网站是否专业。例如,当用户搜索女装信息时,标题是写女装,而描述是女鞋。这样的网站如何让用户感受到他的专业?还有就是没有写description标签,导致搜索引擎随机爬取网站@网站上的一段内容,用来描述和展示结果。众所周知,搜索引擎很难随便爬取来完美展示其网站的大致内容,提升网站的性能非常重要。专业性很差。
二、缩小搜索引擎判断页面的范围关键词
<p>搜索引擎在提取页面的关键词时,并不是单纯的依靠页面的标题来选择,还有一个重要的参考地方,那就是页面的描述标签。一般来说,写好每个页面的description标签,可以让搜索引擎更快的提取出这个页面的关键词,同时也可以缩小搜索引擎判断页面
优采云自动文章采集 sign failed11(云优CMS采集的四张配图之中,不需要看文章!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-03-19 07:30
云游cms采集,很多把云游cms当成网站的站长,有个麻烦点就是采集的云游cms@>工具难找不到,而且可用的插件很少,与其他cms相比,确实很不方便。云游cms采集,自动批量采集全网文章,自动伪原创发到云游cms。本文章重点讲四张图,不用看文章,看图就懂云游cms采集。【看图一,云游cms采集,永远完全免费】
高质量内容的一个关键要素是确保它始终是最新的并且相关的词是相关的。云游cms采集发布一个高质量的页面或文章并不是这个过程的最后一步。网站内容也必须不时更新,以确保用户可以在那里找到正确的信息。这对 网站 的用户很重要,因为它向他们表明 网站 是最新的和最新的,并且始终拥有他们想要的信息。【见图二,云游cms采集,有钱有势】
这可以建立信任并将用户带到 网站。这对 SEO 也很重要,因为云游 cms采集 的内容将向搜索引擎展示 网站 的活跃度和相关性。因此,云游cms采集让网站保持内容新鲜,打造优质内容是重要的一步。云游cms采集可以保证网站的内容每天定时更新。【看图3,云游cms采集,工作高效简单】
Yunyoucms采集 在为特定页面创建内容时考虑搜索意图很重要。因此,您可以关键词将您自己的目标与用户可能拥有的不同搜索意图相匹配。网站 的目标之一是吸引更多实时热点话题文章,其中收录许多与网站 所在行业相关的新闻和其他相关信息。然后,云游cms采集将内容采集添加回网站对用户有信息意图的页面。【见图4,云游cms采集,站长优化必备】
当用户输入 网站 时,建立信任也很重要。尤其是当他们还不熟悉这个网站时,网站必须向他们证明他们是值得信赖的。云游cms采集以清晰和面向用户的方式编写代码可以帮助网站奠定基础,云游cms采集可以做更多的事情。添加更多真实的图像可以增加信任并使 网站 人感到更友好和更真实。
网站SEO 优化还可以考虑在搜索引擎上添加评分、在正确的页面上使用推荐内容、设置 HTTPS 以及添加其他信任信号。这一切都有助于网站的用户和搜索引擎知道网站属于一个真实的企业或真实的人,让他们可以轻松方便地浏览网站。
最后,云游cms采集从了解搜索意图开始,这是用户进行特定搜索的原因,用于描述在线搜索的目的。用户的搜索意图会影响搜索引擎如何看待网站的内容质量,当然云游cms采集是符合他们需求的。然后他们将在页面上停留 网站 更长时间。 查看全部
优采云自动文章采集 sign failed11(云优CMS采集的四张配图之中,不需要看文章!)
云游cms采集,很多把云游cms当成网站的站长,有个麻烦点就是采集的云游cms@>工具难找不到,而且可用的插件很少,与其他cms相比,确实很不方便。云游cms采集,自动批量采集全网文章,自动伪原创发到云游cms。本文章重点讲四张图,不用看文章,看图就懂云游cms采集。【看图一,云游cms采集,永远完全免费】
高质量内容的一个关键要素是确保它始终是最新的并且相关的词是相关的。云游cms采集发布一个高质量的页面或文章并不是这个过程的最后一步。网站内容也必须不时更新,以确保用户可以在那里找到正确的信息。这对 网站 的用户很重要,因为它向他们表明 网站 是最新的和最新的,并且始终拥有他们想要的信息。【见图二,云游cms采集,有钱有势】
这可以建立信任并将用户带到 网站。这对 SEO 也很重要,因为云游 cms采集 的内容将向搜索引擎展示 网站 的活跃度和相关性。因此,云游cms采集让网站保持内容新鲜,打造优质内容是重要的一步。云游cms采集可以保证网站的内容每天定时更新。【看图3,云游cms采集,工作高效简单】
Yunyoucms采集 在为特定页面创建内容时考虑搜索意图很重要。因此,您可以关键词将您自己的目标与用户可能拥有的不同搜索意图相匹配。网站 的目标之一是吸引更多实时热点话题文章,其中收录许多与网站 所在行业相关的新闻和其他相关信息。然后,云游cms采集将内容采集添加回网站对用户有信息意图的页面。【见图4,云游cms采集,站长优化必备】
当用户输入 网站 时,建立信任也很重要。尤其是当他们还不熟悉这个网站时,网站必须向他们证明他们是值得信赖的。云游cms采集以清晰和面向用户的方式编写代码可以帮助网站奠定基础,云游cms采集可以做更多的事情。添加更多真实的图像可以增加信任并使 网站 人感到更友好和更真实。
网站SEO 优化还可以考虑在搜索引擎上添加评分、在正确的页面上使用推荐内容、设置 HTTPS 以及添加其他信任信号。这一切都有助于网站的用户和搜索引擎知道网站属于一个真实的企业或真实的人,让他们可以轻松方便地浏览网站。
最后,云游cms采集从了解搜索意图开始,这是用户进行特定搜索的原因,用于描述在线搜索的目的。用户的搜索意图会影响搜索引擎如何看待网站的内容质量,当然云游cms采集是符合他们需求的。然后他们将在页面上停留 网站 更长时间。
优采云自动文章采集 sign failed11(网络信息采集的难点是什么?数据比较复杂,形式多样;形式多样)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-16 07:15
信息采集的难度是多少?数据更加复杂多样;下载后有什么困难?数据管理。网络信息大师(netget)的主要功能就是解决这两个问题。网络信息采集基于快讯采集,实时在线信息监控,为企业决策、网站建设、局域网新闻系统建设等提供快速,完整而强大的解决方案。现有功能介绍:1.采集 丰富的信息类型。采集几乎任何类型的网站信息,包括静态htm、html类型和动态asp、aspx、jsp等。2.网站登录。获取需要的信息要登录才能看到,先登录在“ 图片可通过设置自动下载,文中图片的网络路径可自动更改为本地文件路径(也可保持原样);可以将采集新闻自动处理成自己设计的模板格式;采集 分页格式的新闻可用。
有了这些功能,无需人工干预,只需简单的设置就可以在本地建立一个强大的新闻系统。7.可以设置为采集,数据量一定后会自动存入库,内存会自动清空。该功能可以连续采集10万级、百万级数据,不占用系统资源。8. 信息会自动重新处理。采集的信息可以分两批重新处理,使其更符合您的实际需求。还可以设置自动处理公式。采集过程中,根据公式自动处理,包括数据合并、数据替换等。9.可以自动下载二进制文件,如图片、软件、mp3等 10. 实时监控和发布(任务调度)。指定某些任务自动运行,自动去除重复后将采集的数据导入数据库(可指定唯一组合)。它可以循环运行。您可以指定在某个时间点运行的任务。11.采集 本地磁盘信息。使用'列表类型'的任务可以是采集网络上的信息,本地磁盘采集上的信息。12.通过发布页面将采集的数据发布到网站的数据库中。即海量发送数据的方式,模拟手动提交数据。13.无人值守采集。开始任务后,您可以采集,自动存入数据库,采集完成后自动关闭。不仅能提高工作效率,还能最大程度地节约能源。14.access、sqlserver、oracle、mysql的数据库测试已经完全通过。 查看全部
优采云自动文章采集 sign failed11(网络信息采集的难点是什么?数据比较复杂,形式多样;形式多样)
信息采集的难度是多少?数据更加复杂多样;下载后有什么困难?数据管理。网络信息大师(netget)的主要功能就是解决这两个问题。网络信息采集基于快讯采集,实时在线信息监控,为企业决策、网站建设、局域网新闻系统建设等提供快速,完整而强大的解决方案。现有功能介绍:1.采集 丰富的信息类型。采集几乎任何类型的网站信息,包括静态htm、html类型和动态asp、aspx、jsp等。2.网站登录。获取需要的信息要登录才能看到,先登录在“ 图片可通过设置自动下载,文中图片的网络路径可自动更改为本地文件路径(也可保持原样);可以将采集新闻自动处理成自己设计的模板格式;采集 分页格式的新闻可用。
有了这些功能,无需人工干预,只需简单的设置就可以在本地建立一个强大的新闻系统。7.可以设置为采集,数据量一定后会自动存入库,内存会自动清空。该功能可以连续采集10万级、百万级数据,不占用系统资源。8. 信息会自动重新处理。采集的信息可以分两批重新处理,使其更符合您的实际需求。还可以设置自动处理公式。采集过程中,根据公式自动处理,包括数据合并、数据替换等。9.可以自动下载二进制文件,如图片、软件、mp3等 10. 实时监控和发布(任务调度)。指定某些任务自动运行,自动去除重复后将采集的数据导入数据库(可指定唯一组合)。它可以循环运行。您可以指定在某个时间点运行的任务。11.采集 本地磁盘信息。使用'列表类型'的任务可以是采集网络上的信息,本地磁盘采集上的信息。12.通过发布页面将采集的数据发布到网站的数据库中。即海量发送数据的方式,模拟手动提交数据。13.无人值守采集。开始任务后,您可以采集,自动存入数据库,采集完成后自动关闭。不仅能提高工作效率,还能最大程度地节约能源。14.access、sqlserver、oracle、mysql的数据库测试已经完全通过。
优采云自动文章采集 sign failed11(优采云采集器为每个网站设置不同的采集规则(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-12-15 04:24
优采云采集器是一个由用户提供的关键词,云端自动将采集相关文章发布给用户网站网站@ > 采集器。可自动识别各种网页的标题、正文等信息,实现全网采集,无需用户编写任何采集规则。采集到达内容后,会自动计算该内容与集合关键词的相关性,只推送相关的文章给用户。支持标题前缀、关键词自动加粗、插入固定链接、自动提取Tag标签、自动内部链接、自动图片分配、自动伪原创、内容过滤和替换、电话号码和URL清洗、定时< @采集,百度主动提交一系列SEO功能。用户只需设置关键词及相关要求,即可实现全托管零维护网站内容更新。网站的数量没有限制,无论是单个网站还是大批量的站群,都可以轻松管理。
研发背景
文章采集器是大多数网站管理员必备的网站更新工具。传统的采集器提取网页信息主要是根据正则表达式匹配网页内容,实现起来快捷方便,但是不同的网站页面结构不同,需要编写不同的采集规则,需要大量的工作并且难以维护。而且,用户需要自己寻找采集的来源,还需要自己挂机运行采集器,甚至涉及IP被封的可能性等一系列问题。需要使用代理IP。
主要功能
提供1亿+级的庞大关键词库,可根据用户输入的任意文本搜索关键词,简单查询后即可用于采集,大大减少用户集合关键词的时间和精力。用户还可以创建自己的私人词汇,可以分组,数以百万计的关键词可以轻松管理,也可以满足更加个性化的关键词需求。按关键词采集文章,基于百度、搜狗、好搜等搜索引擎,全网采集精美好文章,用户不用花钱去找到采集能量的来源。自动识别网页编码、标题、正文等信息,无需为每个网站设置不同的采集规则,无需到处找人写采集规则,无需懂html源码,完全零维护。您可以设置所需的文本长度,例如 500 字、750 字和 1000 字。不符合标准的内容会被自动丢弃。系统内置多种自然语言处理算法,自动计算文章文本与关键词的相关性(特征向量间的余弦距离),并自动滤除文章 相关性低。将高度相关的 文章 留给用户。自动计算文章文本的平滑度(语言混淆),丢弃平滑度低的文章,把平滑度高的文章留给用户。自动计算标题(Title)和描述(Description)与关键词的相关性。如果相关性较低,可以在标题和描述中自动插入关键词,以提高相关性。您也可以为标题设置前缀关键词,每次从多个设置的前缀中随机选择一个添加到文章标题的头部。基于机器学习算法的文字色情可以对采集的内容进行审核,保障用户内容安全。实现伪原创基于同义词替换功能,从2000万对同义词中,选出最适合语言表达习惯的词,替换原文中的词,保证文章的可读性最大程度。基于机器学习实现智能AI< @伪原创,先将原文编码成高维语义向量,再通过解码器逐字解码,实现对整个文章的完全重写,伪原创高度,好可读性。Tags 标签自动提取,在此基础上实现自动内链。当正文中出现标签对应的文字时,在正文中添加网站文章的链接,指向同主题文章的文章,实现内部自动化、科学、有效链建设。您还可以设置固定链接。当正文中出现一些固定文本时,为其添加一个固定链接,指向站内或站外的文章。根据文章的内容自动匹配图片,这样即使你是采集的文章,您还可以同时显示图片和文字。您可以设置图片本地化或使用远程图片,并屏蔽所有图片。您可以设置阻止某些网站而不是采集,或者收录某些不是采集的词的内容。自动过滤文章前后的联系方式、网址、广告内容等冗余信息,并清理所有标签,只保留正文部分 图片和文字也可以合并。您可以设置图片本地化或使用远程图片,并屏蔽所有图片。您可以设置阻止某些网站而不是采集,或者收录某些不是采集的词的内容。自动过滤文章前后的联系方式、网址、广告内容等冗余信息,并清理所有标签,并且只保留正文部分图片和文字也可以组合。您可以设置图片本地化或使用远程图片,并屏蔽所有图片。您可以设置阻止某些网站而不是采集,或者收录某些不是采集的词的内容。自动过滤文章前后的联系方式、网址、广告内容等冗余信息,并清理所有标签,只保留正文部分
段落标签和图片
标签不收录任何乱码,也不收录任何排版格式,方便用户通过css样式自定义外观。严格的防重复机制,整个平台的每个URL只有采集一次,而不是采集。在同一个网站下,同名的文章只会出现采集一次,不会重复采集。您可以指定每个关键词允许采集实现大量长尾关键词非重复布局的文章数量。云端自动运行采集任务,可调度量化采集。用户不需要在自己的电脑上安装任何软件,不需要挂断采集,甚至不需要打开浏览器。采集 会自动发布到用户的网站后台。用户只需将接口文件下载并上传到网站的根目录即可完成对接。采集会自动实现百度主动推送,让蜘蛛快速找到你的文章。
支持的网站建设程序/内容管理系统
织梦内容管理系统(DEDEcms)帝国网站管理系统社区力量DISCUZ(论坛版) Z-BLOGWordPressOld y文章管理系统EMLOGMIPcms范克旺(凡客建站)易友企业建站系统(EYOUcms)米拓建站(MetInfo)江湖cms微连云PHPcmsDESTOON(B2B网站系统) 查看全部
优采云自动文章采集 sign failed11(优采云采集器为每个网站设置不同的采集规则(图))
优采云采集器是一个由用户提供的关键词,云端自动将采集相关文章发布给用户网站网站@ > 采集器。可自动识别各种网页的标题、正文等信息,实现全网采集,无需用户编写任何采集规则。采集到达内容后,会自动计算该内容与集合关键词的相关性,只推送相关的文章给用户。支持标题前缀、关键词自动加粗、插入固定链接、自动提取Tag标签、自动内部链接、自动图片分配、自动伪原创、内容过滤和替换、电话号码和URL清洗、定时< @采集,百度主动提交一系列SEO功能。用户只需设置关键词及相关要求,即可实现全托管零维护网站内容更新。网站的数量没有限制,无论是单个网站还是大批量的站群,都可以轻松管理。
研发背景
文章采集器是大多数网站管理员必备的网站更新工具。传统的采集器提取网页信息主要是根据正则表达式匹配网页内容,实现起来快捷方便,但是不同的网站页面结构不同,需要编写不同的采集规则,需要大量的工作并且难以维护。而且,用户需要自己寻找采集的来源,还需要自己挂机运行采集器,甚至涉及IP被封的可能性等一系列问题。需要使用代理IP。
主要功能
提供1亿+级的庞大关键词库,可根据用户输入的任意文本搜索关键词,简单查询后即可用于采集,大大减少用户集合关键词的时间和精力。用户还可以创建自己的私人词汇,可以分组,数以百万计的关键词可以轻松管理,也可以满足更加个性化的关键词需求。按关键词采集文章,基于百度、搜狗、好搜等搜索引擎,全网采集精美好文章,用户不用花钱去找到采集能量的来源。自动识别网页编码、标题、正文等信息,无需为每个网站设置不同的采集规则,无需到处找人写采集规则,无需懂html源码,完全零维护。您可以设置所需的文本长度,例如 500 字、750 字和 1000 字。不符合标准的内容会被自动丢弃。系统内置多种自然语言处理算法,自动计算文章文本与关键词的相关性(特征向量间的余弦距离),并自动滤除文章 相关性低。将高度相关的 文章 留给用户。自动计算文章文本的平滑度(语言混淆),丢弃平滑度低的文章,把平滑度高的文章留给用户。自动计算标题(Title)和描述(Description)与关键词的相关性。如果相关性较低,可以在标题和描述中自动插入关键词,以提高相关性。您也可以为标题设置前缀关键词,每次从多个设置的前缀中随机选择一个添加到文章标题的头部。基于机器学习算法的文字色情可以对采集的内容进行审核,保障用户内容安全。实现伪原创基于同义词替换功能,从2000万对同义词中,选出最适合语言表达习惯的词,替换原文中的词,保证文章的可读性最大程度。基于机器学习实现智能AI< @伪原创,先将原文编码成高维语义向量,再通过解码器逐字解码,实现对整个文章的完全重写,伪原创高度,好可读性。Tags 标签自动提取,在此基础上实现自动内链。当正文中出现标签对应的文字时,在正文中添加网站文章的链接,指向同主题文章的文章,实现内部自动化、科学、有效链建设。您还可以设置固定链接。当正文中出现一些固定文本时,为其添加一个固定链接,指向站内或站外的文章。根据文章的内容自动匹配图片,这样即使你是采集的文章,您还可以同时显示图片和文字。您可以设置图片本地化或使用远程图片,并屏蔽所有图片。您可以设置阻止某些网站而不是采集,或者收录某些不是采集的词的内容。自动过滤文章前后的联系方式、网址、广告内容等冗余信息,并清理所有标签,只保留正文部分 图片和文字也可以合并。您可以设置图片本地化或使用远程图片,并屏蔽所有图片。您可以设置阻止某些网站而不是采集,或者收录某些不是采集的词的内容。自动过滤文章前后的联系方式、网址、广告内容等冗余信息,并清理所有标签,并且只保留正文部分图片和文字也可以组合。您可以设置图片本地化或使用远程图片,并屏蔽所有图片。您可以设置阻止某些网站而不是采集,或者收录某些不是采集的词的内容。自动过滤文章前后的联系方式、网址、广告内容等冗余信息,并清理所有标签,只保留正文部分
段落标签和图片
标签不收录任何乱码,也不收录任何排版格式,方便用户通过css样式自定义外观。严格的防重复机制,整个平台的每个URL只有采集一次,而不是采集。在同一个网站下,同名的文章只会出现采集一次,不会重复采集。您可以指定每个关键词允许采集实现大量长尾关键词非重复布局的文章数量。云端自动运行采集任务,可调度量化采集。用户不需要在自己的电脑上安装任何软件,不需要挂断采集,甚至不需要打开浏览器。采集 会自动发布到用户的网站后台。用户只需将接口文件下载并上传到网站的根目录即可完成对接。采集会自动实现百度主动推送,让蜘蛛快速找到你的文章。
支持的网站建设程序/内容管理系统
织梦内容管理系统(DEDEcms)帝国网站管理系统社区力量DISCUZ(论坛版) Z-BLOGWordPressOld y文章管理系统EMLOGMIPcms范克旺(凡客建站)易友企业建站系统(EYOUcms)米拓建站(MetInfo)江湖cms微连云PHPcmsDESTOON(B2B网站系统)
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-12-15 04:23
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器可以非常得心应手。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想网站 什么样的网站,不管你导出成什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也能让你轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的一个插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要面对一个简单的编程界面,可以大大降低工作强度。这是一个漂亮的数据采集 解决方案,它将特定的采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin是一个Eclipse插件,可用于任务开发和调试。这个插件的功能会越来越丰富。
菜库服务器完全免费! 查看全部
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器可以非常得心应手。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想网站 什么样的网站,不管你导出成什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也能让你轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的一个插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要面对一个简单的编程界面,可以大大降低工作强度。这是一个漂亮的数据采集 解决方案,它将特定的采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin是一个Eclipse插件,可用于任务开发和调试。这个插件的功能会越来越丰富。
菜库服务器完全免费!
优采云自动文章采集 sign failed11(优采云是一款网页爬虫工具,可以不用编写代码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-14 08:35
优采云是一款无需编写代码即可快速抓取网络数据的网络爬虫工具。
其基本操作可以在其官网教程中查看。主要是它的翻页和登录验证码和xpath操作。
特殊翻页 数字翻页
制作采集规则时,页面上没有“下一页”等翻页按钮,而是一行页码,例如“1”、“2”、“3”、“4” ,“5”...
数字翻页如何处理?
解决方案:
找到一个 xpath,以便下一页始终位于当前页面上(未分页的页面除外)。
示例网址:
常用函数:follow-sibling::*
例如://span[@class="page_curl"]/follow-sibling=a[1]
其中,首先找到数字1所在的位置为span,它的class为page_url,这样就找到了数字1所在的span。然后使用following-sibling查找其兄弟元素定位下一页,找到下一页,也就是a标签的第二页所在的位置,因为同级的所有后续元素的页码都是a 标签,所以使用 a[1] 表示第一页之后的第一个 a 标签。
“加载更多”翻页表单
应用情况:
如果采集的网页中有“加载更多”或“再显示20个”等按钮,点击这些按钮后,采集的数据就会全部显示出来。
例如,在以下情况下,您需要单击“加载更多内容”,每次单击将显示 20 多条数据:
解决方案:
按照正常操作创建一个翻页循环,然后将循环翻页步骤拖到循环提取数据步骤之前。所有翻页完成后,进行循环数据提取步骤,否则会出现大量重复数据。
循环翻页的点击按钮一般是ajax加载,即点击翻页高级选项需要勾选ajax,并设置超时时间(时间长短根据数据加载速度设置),不要检查新标签。
比如网页,习惯上先循环点击“加载更多内容”,如下左图。如果这样执行采集数据,会得到前20个数据采集的循环。
在这种情况下,我们需要在循环翻转下方拖动循环提取数据,如右图,这样会先添加所有数据,然后一起进行数据提取。请注意,有时如果数据过多,它会无限制地加载数据。这时候可以对翻页的循环次数进行限制。另外需要修改下图循环提取数据的xpath,否则只能提取前20条数据。
某些页面出现重复循环现象
适用场景:重复网页中几页的数据采集
现象:
采集 结果重复。翻阅资料,发现网页采集的部分资料页面有重复。例如,重复采集 一页或两页数据。
原因分析:
网页中有上一页按钮和下一页按钮,xpath定位不准确,上一页按钮会定位在某个页面,导致部分页面数据重复采集
解决方案:
修改xpath,使得在当前页面(最后一页除外),只能定位到下一页按钮
例如:当某些网页在某一页后进行翻页时,其xpath会同时定位上一页和下一页按钮。这时候就需要修改它的xpath,让它只能定位到下一页。, 如原来的xpath://a[@class="next"],观察其源码,需要修改为://a[@class="next" and text()="next page" ]
最后一页死循环现象
应用情况:
对于采集的网页,明明最后一页的数据已经采集到了,但是采集的最后一页的数据却不断重复,没有停止采集。
或者在不翻页的情况下循环点击下一页,某一页的数据总是采集。
原因分析:
xpath定位不准确,“下一页”按钮可以定位到最后一页,无法结束翻页的循环。
解决方案:
修改xpath,使当前页为最后一页时无法定位“下一页”按钮,但当前页为最后一页时可以定位到“下一页”(观察当前页为最后一页时)上一页而不是下一页的最后一个位置xpath,然后修改它的xpath)
其他翻页现象
1.输入页码,点击“跳转”或“确定”按钮翻页
示例 网站:
点击输入编号页码输入框,选择输入文字,点击确定,然后在此过程中拖入一个循环框,将输入的文字拖入循环框,设置为从循环中选择内容,然后将循环内容设置为 1、2,页码 3 就可以了。
2.将翻页周期转换为URL周期
这样就可以在输入网址的时候直接输入多个网址,用换行符包裹起来,然后执行采集数据。
3.翻几页后,直接跳转到下几页(missing data-几页的缺失数据不是采集)
适用场景:
由于点击翻页,有些页面不是采集。比如翻了几页后,直接跳到下几页。
示例网址:
解决方案:
找到一个 xpath,以便下一页始终位于当前页面上(未分页的页面除外)。
示例 网站:
上述方法不仅可以解决一些网站无法翻页或翻页后容易出现采集中断的问题,还可以避免网站的反采集措施在某种程度上。
登录和验证码 Cookie 登录
输入账号密码登录后,打开网页步骤设置获取cookie。这时候就可以删除之前输入账号密码的步骤了。如果想用当前账号新建任务,也可以复制打开网页的网址新建任务。注意:Cookie 有生命周期;如果您想更改您的帐户,请在打开网页时将缓存设置为清除。
验证码登录:设置执行前等待的方法
适用场景:
在登录页面输入用户名和密码后,需要验证码识别才能正常登录。
重点验证通过拖动滑块,点击选择一些图片或文字,拼图验证,
以及其他验证码识别控件无法自动识别的验证码类型。
对于这种需要验证码登录的场景,可以通过设置执行前等待来完成验证码识别。
方法:输入账号密码后,点击登录步骤,设置执行前的等待时间,如15s。当输入采集数据时,到了输入验证码的时候,系统会留15s给用户输入验证码,15s后会自动执行登录步骤。注意:仅适用于本地采集,不适用于云采集。
验证码登录:控制识别方法
对于需要输入验证码的情况,也可以设置控件识别。做法是:
如下图,输入账号密码后,先点击验证码图片,再点击验证码输入框,然后根据提示输入验证码识别错误和正确的配置信息。
内嵌框架
什么是 Iframe 框架:
一些 网站 登录框实际上是 iframe 登录框。iframe 是 html 标签,它创建了一个收录另一个文档的内联框架(即内联框架),这意味着一个网页中的一个网页。有时无法定位输入框,因为网页使用了 iframe 框架。
如何检查网页是否使用 iframe 框架:
使用火狐查看。看一下具体的网址。例如,天猫的登录页面使用iframe登录框架。
1、在火狐浏览器中打开网页
2、将鼠标移至天猫登录框,右击选择“本框”>>“在新标签中打开框”
优采云iframe框架的处理:
优采云 一般可以自动识别网页中的iframe frame,生成对应iframe frame的XPath。如果遇到无法生成的东西,需要先在浏览器中定位frame,然后在优采云中填写iframe frame的XPath。软件支持一层iframe框架。如果网站中有多层框架,则应先去除多余的框架。或者将浏览器中获取到的frame地址复制到优采云中。
XPath
XPath 简介
XPath 是专门为 xml 设计的。它是一种在复杂结构化数据中查找信息的语言。简单来说就是使用路径表达式来查找我们需要的数据位置。
查看/自动生成xpath方法
1、通过Firefox中的firebug和firepath插件生成/查看XPath
注意:Firefox 浏览器的版本必须为 55 或更低。如果版本太高,firebug 和 firepath 插件可能不可用。安装过程中和安装后必须禁止浏览器的自动更新。
火狐浏览器54版下载地址:
64 位 Firefox 54:
32 位 Firefox 54:
其他版本下载地址:
在火狐浏览器菜单中的附件管理器中搜索firebug和firepath插件进行安装,安装后需要重启才能使用。
2、通过优采云采集器生成/查看XPath
html有一套XPath引擎,可以直接使用XPath准确地查找和定位网页中的数据,从而提取数据。在优采云中配置规则时,会自动生成定位数据的XPath
在优采云规则配置中,除了没有XPath打开网页的步骤外,其他步骤都涉及XPath定位
找到xpath的方式,如下图:
XPath节点
在 XPath 中,一切都是一个节点。节点有七种类型:元素、属性、文本、命名空间、处理指令、注释、文档(根)节点。
XPath 语法
XPath 轴:定义当前节点与其他节点的关系。
XPath 语法:使用路径表达式来选择 html 文档中的节点或节点集。
谓词:路径表达式的附加条件,进一步过滤节点,嵌入在 [] 中。在使用谓词时,我们经常使用一些 XPath 函数。
应用-修改提取的数据字段xpath
适用于调整XPath,解决采集数据中的数据泄露和数据错位问题。
应用场景:
1.网页上有信息,采集的结果中有些字段没有被采集到达。
2.采集 导致部分字段数据错位,采集的实际内容与字段名不符。
原因分析:
网页结构不一致,导致原来的xpath在某些页面上无法正确定位到需要的数据。
解决方案:
修改问题字段的xpath,使其能够在所有页面上准确定位所需数据。
应用-修改循环列表xpath
适用于修改循环列表的XPath,解决部分数据泄露和冗余项的问题。
应用场景:
点击生成的循环列表没有收录所有需要的数据,缺少一些循环项。
原因分析:
网页的特殊结构导致原创xpath无法匹配页面上所有需要的数据。
解决方案:
修改循环列表的xpath,使其能够匹配页面上所有需要的数据,消除多余的循环项。 查看全部
优采云自动文章采集 sign failed11(优采云是一款网页爬虫工具,可以不用编写代码)
优采云是一款无需编写代码即可快速抓取网络数据的网络爬虫工具。
其基本操作可以在其官网教程中查看。主要是它的翻页和登录验证码和xpath操作。
特殊翻页 数字翻页
制作采集规则时,页面上没有“下一页”等翻页按钮,而是一行页码,例如“1”、“2”、“3”、“4” ,“5”...
数字翻页如何处理?
解决方案:
找到一个 xpath,以便下一页始终位于当前页面上(未分页的页面除外)。
示例网址:
常用函数:follow-sibling::*
例如://span[@class="page_curl"]/follow-sibling=a[1]
其中,首先找到数字1所在的位置为span,它的class为page_url,这样就找到了数字1所在的span。然后使用following-sibling查找其兄弟元素定位下一页,找到下一页,也就是a标签的第二页所在的位置,因为同级的所有后续元素的页码都是a 标签,所以使用 a[1] 表示第一页之后的第一个 a 标签。
“加载更多”翻页表单
应用情况:
如果采集的网页中有“加载更多”或“再显示20个”等按钮,点击这些按钮后,采集的数据就会全部显示出来。
例如,在以下情况下,您需要单击“加载更多内容”,每次单击将显示 20 多条数据:
解决方案:
按照正常操作创建一个翻页循环,然后将循环翻页步骤拖到循环提取数据步骤之前。所有翻页完成后,进行循环数据提取步骤,否则会出现大量重复数据。
循环翻页的点击按钮一般是ajax加载,即点击翻页高级选项需要勾选ajax,并设置超时时间(时间长短根据数据加载速度设置),不要检查新标签。
比如网页,习惯上先循环点击“加载更多内容”,如下左图。如果这样执行采集数据,会得到前20个数据采集的循环。
在这种情况下,我们需要在循环翻转下方拖动循环提取数据,如右图,这样会先添加所有数据,然后一起进行数据提取。请注意,有时如果数据过多,它会无限制地加载数据。这时候可以对翻页的循环次数进行限制。另外需要修改下图循环提取数据的xpath,否则只能提取前20条数据。
某些页面出现重复循环现象
适用场景:重复网页中几页的数据采集
现象:
采集 结果重复。翻阅资料,发现网页采集的部分资料页面有重复。例如,重复采集 一页或两页数据。
原因分析:
网页中有上一页按钮和下一页按钮,xpath定位不准确,上一页按钮会定位在某个页面,导致部分页面数据重复采集
解决方案:
修改xpath,使得在当前页面(最后一页除外),只能定位到下一页按钮
例如:当某些网页在某一页后进行翻页时,其xpath会同时定位上一页和下一页按钮。这时候就需要修改它的xpath,让它只能定位到下一页。, 如原来的xpath://a[@class="next"],观察其源码,需要修改为://a[@class="next" and text()="next page" ]
最后一页死循环现象
应用情况:
对于采集的网页,明明最后一页的数据已经采集到了,但是采集的最后一页的数据却不断重复,没有停止采集。
或者在不翻页的情况下循环点击下一页,某一页的数据总是采集。
原因分析:
xpath定位不准确,“下一页”按钮可以定位到最后一页,无法结束翻页的循环。
解决方案:
修改xpath,使当前页为最后一页时无法定位“下一页”按钮,但当前页为最后一页时可以定位到“下一页”(观察当前页为最后一页时)上一页而不是下一页的最后一个位置xpath,然后修改它的xpath)
其他翻页现象
1.输入页码,点击“跳转”或“确定”按钮翻页
示例 网站:
点击输入编号页码输入框,选择输入文字,点击确定,然后在此过程中拖入一个循环框,将输入的文字拖入循环框,设置为从循环中选择内容,然后将循环内容设置为 1、2,页码 3 就可以了。
2.将翻页周期转换为URL周期
这样就可以在输入网址的时候直接输入多个网址,用换行符包裹起来,然后执行采集数据。
3.翻几页后,直接跳转到下几页(missing data-几页的缺失数据不是采集)
适用场景:
由于点击翻页,有些页面不是采集。比如翻了几页后,直接跳到下几页。
示例网址:
解决方案:
找到一个 xpath,以便下一页始终位于当前页面上(未分页的页面除外)。
示例 网站:
上述方法不仅可以解决一些网站无法翻页或翻页后容易出现采集中断的问题,还可以避免网站的反采集措施在某种程度上。
登录和验证码 Cookie 登录
输入账号密码登录后,打开网页步骤设置获取cookie。这时候就可以删除之前输入账号密码的步骤了。如果想用当前账号新建任务,也可以复制打开网页的网址新建任务。注意:Cookie 有生命周期;如果您想更改您的帐户,请在打开网页时将缓存设置为清除。
验证码登录:设置执行前等待的方法
适用场景:
在登录页面输入用户名和密码后,需要验证码识别才能正常登录。
重点验证通过拖动滑块,点击选择一些图片或文字,拼图验证,
以及其他验证码识别控件无法自动识别的验证码类型。
对于这种需要验证码登录的场景,可以通过设置执行前等待来完成验证码识别。
方法:输入账号密码后,点击登录步骤,设置执行前的等待时间,如15s。当输入采集数据时,到了输入验证码的时候,系统会留15s给用户输入验证码,15s后会自动执行登录步骤。注意:仅适用于本地采集,不适用于云采集。
验证码登录:控制识别方法
对于需要输入验证码的情况,也可以设置控件识别。做法是:
如下图,输入账号密码后,先点击验证码图片,再点击验证码输入框,然后根据提示输入验证码识别错误和正确的配置信息。
内嵌框架
什么是 Iframe 框架:
一些 网站 登录框实际上是 iframe 登录框。iframe 是 html 标签,它创建了一个收录另一个文档的内联框架(即内联框架),这意味着一个网页中的一个网页。有时无法定位输入框,因为网页使用了 iframe 框架。
如何检查网页是否使用 iframe 框架:
使用火狐查看。看一下具体的网址。例如,天猫的登录页面使用iframe登录框架。
1、在火狐浏览器中打开网页
2、将鼠标移至天猫登录框,右击选择“本框”>>“在新标签中打开框”
优采云iframe框架的处理:
优采云 一般可以自动识别网页中的iframe frame,生成对应iframe frame的XPath。如果遇到无法生成的东西,需要先在浏览器中定位frame,然后在优采云中填写iframe frame的XPath。软件支持一层iframe框架。如果网站中有多层框架,则应先去除多余的框架。或者将浏览器中获取到的frame地址复制到优采云中。
XPath
XPath 简介
XPath 是专门为 xml 设计的。它是一种在复杂结构化数据中查找信息的语言。简单来说就是使用路径表达式来查找我们需要的数据位置。
查看/自动生成xpath方法
1、通过Firefox中的firebug和firepath插件生成/查看XPath
注意:Firefox 浏览器的版本必须为 55 或更低。如果版本太高,firebug 和 firepath 插件可能不可用。安装过程中和安装后必须禁止浏览器的自动更新。
火狐浏览器54版下载地址:
64 位 Firefox 54:
32 位 Firefox 54:
其他版本下载地址:
在火狐浏览器菜单中的附件管理器中搜索firebug和firepath插件进行安装,安装后需要重启才能使用。
2、通过优采云采集器生成/查看XPath
html有一套XPath引擎,可以直接使用XPath准确地查找和定位网页中的数据,从而提取数据。在优采云中配置规则时,会自动生成定位数据的XPath
在优采云规则配置中,除了没有XPath打开网页的步骤外,其他步骤都涉及XPath定位
找到xpath的方式,如下图:
XPath节点
在 XPath 中,一切都是一个节点。节点有七种类型:元素、属性、文本、命名空间、处理指令、注释、文档(根)节点。
XPath 语法
XPath 轴:定义当前节点与其他节点的关系。
XPath 语法:使用路径表达式来选择 html 文档中的节点或节点集。
谓词:路径表达式的附加条件,进一步过滤节点,嵌入在 [] 中。在使用谓词时,我们经常使用一些 XPath 函数。
应用-修改提取的数据字段xpath
适用于调整XPath,解决采集数据中的数据泄露和数据错位问题。
应用场景:
1.网页上有信息,采集的结果中有些字段没有被采集到达。
2.采集 导致部分字段数据错位,采集的实际内容与字段名不符。
原因分析:
网页结构不一致,导致原来的xpath在某些页面上无法正确定位到需要的数据。
解决方案:
修改问题字段的xpath,使其能够在所有页面上准确定位所需数据。
应用-修改循环列表xpath
适用于修改循环列表的XPath,解决部分数据泄露和冗余项的问题。
应用场景:
点击生成的循环列表没有收录所有需要的数据,缺少一些循环项。
原因分析:
网页的特殊结构导致原创xpath无法匹配页面上所有需要的数据。
解决方案:
修改循环列表的xpath,使其能够匹配页面上所有需要的数据,消除多余的循环项。
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-12-09 01:01
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化方案、定时任务、后端索引等,菜库服务器都能轻松搞定。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想网站 什么样的网站,不管你导出成什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也能让你轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要面对一个简单的编程界面,可以大大降低工作强度。这是一个漂亮的数据采集 解决方案,它将特定的采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin是一个Eclipse插件,可用于任务开发和调试。这个插件的功能会越来越丰富。
菜库服务器完全免费! 查看全部
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化方案、定时任务、后端索引等,菜库服务器都能轻松搞定。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想网站 什么样的网站,不管你导出成什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也能让你轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要面对一个简单的编程界面,可以大大降低工作强度。这是一个漂亮的数据采集 解决方案,它将特定的采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin是一个Eclipse插件,可用于任务开发和调试。这个插件的功能会越来越丰富。
菜库服务器完全免费!
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-12-05 17:25
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器可以非常得心应手。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想网站 什么样的网站,不管你导出成什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也能让你轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要面对一个简单的编程界面,可以大大降低工作强度。这是一个漂亮的数据采集 解决方案,它将特定的采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin是一个Eclipse插件,可用于任务开发和调试。这个插件的功能会越来越丰富。
菜库服务器完全免费! 查看全部
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器可以非常得心应手。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想网站 什么样的网站,不管你导出成什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也能让你轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要面对一个简单的编程界面,可以大大降低工作强度。这是一个漂亮的数据采集 解决方案,它将特定的采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin是一个Eclipse插件,可用于任务开发和调试。这个插件的功能会越来越丰富。
菜库服务器完全免费!
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-12-03 15:27
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器可以非常得心应手。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想网站 什么样的网站,不管你导出成什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也能让你轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要面对一个简单的编程界面,可以大大降低工作强度。这是一个漂亮的数据采集 解决方案,它将特定的采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin是一个Eclipse插件,可用于任务开发和调试。这个插件的功能会越来越丰富。
菜库服务器完全免费! 查看全部
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器可以非常得心应手。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想网站 什么样的网站,不管你导出成什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也能让你轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要面对一个简单的编程界面,可以大大降低工作强度。这是一个漂亮的数据采集 解决方案,它将特定的采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin是一个Eclipse插件,可用于任务开发和调试。这个插件的功能会越来越丰富。
菜库服务器完全免费!
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-09 04:21
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器可以非常得心应手。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想要什么样的网站采集,不管你导出什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也让你可以轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要简单的接口编程,可以大大减轻工作强度。这是一个漂亮的数据 采集 解决方案,它将特定的 采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin 是一个可用于任务开发和调试的 Eclipse 插件。这个插件的功能会越来越丰富。
菜库服务器完全免费! 查看全部
优采云自动文章采集 sign failed11(构建一个垂直搜索系统的采酷服务器开发插件(图))
Cycrawl Server 是世界上第一个免费可编程 采集 服务器。服务器由强大的多线程采集内核和一系列配套功能组成。为了保持服务器的稳定性和健壮性。这些配套功能大多采用工业级开源解决方案。对于网站数据采集、结构化信息处理、数据库持久化解决方案、定时任务、后端索引,菜库服务器可以非常得心应手。
海量的任务吞吐能力使得菜库服务器几乎可以处理任何类型的信息采集。不管你想要什么样的网站采集,不管你导出什么格式,不管你导入什么数据库。或者你打算开发一个无人值守的计时采集程序(所谓的小偷采集)。当然,他对各种开源辅助功能的无缝集成,也让你可以轻松搭建垂直搜索系统。
当我们要实现一个网站数据采集时,我们只需要实现一个任务。任务,类似于服务器中的插件。服务器启动时。将驱动部署在服务器上的海量任务进行数据采集。使用彩酷服务器,二次开发者只需要简单的接口编程,可以大大减轻工作强度。这是一个漂亮的数据 采集 解决方案,它将特定的 采集 逻辑与信息引擎松散耦合。岗位职责明确,整个系统架构清晰。
与市面上大多数采集软件相比,菜库服务器没有可视化编辑界面。熟悉Java语言的二次开发者只需要实现三个接口就可以完成一个任务的开发。正是这种实现方式,给信息的采集带来了无限的灵活性。正因如此,才库服务器被称为垂直搜索引擎。
Cycrawl Server Eclipse Plugin 是一个可用于任务开发和调试的 Eclipse 插件。这个插件的功能会越来越丰富。
菜库服务器完全免费!
优采云自动文章采集 sign failed11(优采云自动文章采集器-优采云采集软件采集工具采集系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-11-07 07:07
名称:优采云Auto文章采集器-按关键词Auto采集发布网站文章采集工具
优采云采集文章采集采集器采集软件采集工具采集系统关键词采集文章文章自动采集发布站长工具
网站关键词(52 个字符):
优采云采集文章采集采集器采集软件采集工具采集系统关键词采集文章文章自动采集发布站长工具
网站 描述性词(119 个字符):
优采云Auto文章采集器是关键词auto采集网站文章采集发布的一款工具,免费提供亿个关键词库,自动识别网页正文,无需编写采集规则,智能计算文章与关键词的相关性,NLP技术< @伪原创,指定采集最新内容,指定采集目标网站,是站长必备的数据采集工具。
相关网站介绍:站长工具》优采云Auto文章采集器-按关键词Auto采集发布网站文章采集工具》网友主动提交查询整理收录,有的网站可能跑题,打不开,关闭等,不能访问,不能访问原因等等,什么,怎么办,好吗?诸如“如何”、“好”等问题与本网站无关。本站只提供基本参考信息显示:IP地址:-地址:-,百度权重为<@1、百度手机权重为,百度收录为17800,360收录为1640,搜狗收录为32640,谷歌收录为-,百度流量约59-68,百度手机流量约6-7,备案号蜀ICP备14020125-4、@ > 查看全部
优采云自动文章采集 sign failed11(优采云自动文章采集器-优采云采集软件采集工具采集系统)
名称:优采云Auto文章采集器-按关键词Auto采集发布网站文章采集工具
优采云采集文章采集采集器采集软件采集工具采集系统关键词采集文章文章自动采集发布站长工具
网站关键词(52 个字符):
优采云采集文章采集采集器采集软件采集工具采集系统关键词采集文章文章自动采集发布站长工具
网站 描述性词(119 个字符):
优采云Auto文章采集器是关键词auto采集网站文章采集发布的一款工具,免费提供亿个关键词库,自动识别网页正文,无需编写采集规则,智能计算文章与关键词的相关性,NLP技术< @伪原创,指定采集最新内容,指定采集目标网站,是站长必备的数据采集工具。
相关网站介绍:站长工具》优采云Auto文章采集器-按关键词Auto采集发布网站文章采集工具》网友主动提交查询整理收录,有的网站可能跑题,打不开,关闭等,不能访问,不能访问原因等等,什么,怎么办,好吗?诸如“如何”、“好”等问题与本网站无关。本站只提供基本参考信息显示:IP地址:-地址:-,百度权重为<@1、百度手机权重为,百度收录为17800,360收录为1640,搜狗收录为32640,谷歌收录为-,百度流量约59-68,百度手机流量约6-7,备案号蜀ICP备14020125-4、@ >

