
从网页抓取视频
从网页抓取视频(如何100%提取网页中的视频、音乐歌曲、flash、图片等多媒体)
网站优化 • 优采云 发表了文章 • 0 个评论 • 303 次浏览 • 2021-11-26 05:22
以上步骤只能在观看视频后进行。体验内容仅供参考。如果您需要解决具体问题(尤其是法律、医学等),建议您详细咨询相关领域的专业人士。作者声明:本体验基于真实体验原创,未经许可。
如何抓取网页中的视频文件?_哔哩哔哩(゜-゜)つロ-bilibili。
教你如何从网页中提取视频、音乐、歌曲、flash、图片等多媒体文件(很实用)忘记图片网址或不想了。
如何在不安装各种软件的情况下100%提取网页视频_搜狗指南。
642,311 人观看了此视频。在日常生活中,我们经常浏览网页,看到一些不错的视频,就想下载。很多人教过各种方法,比如在设置里查看缓存,比如给网址加后缀,但是随着网站的升级,很多。
如何100%提取网页上的视频?可能很多朋友对此感到困惑。下面小编就为大家介绍一下具体的提取方法,希望对大家有所帮助。进入浏览器后,点击右上角的方法/步骤三横线图标。单击“工具”进行选择。
下面介绍一种无需借助任何软件即可从网页中提取视频的方法,希望对您有所帮助。方法/步骤我以360浏览器为例,这里可以随便打开一个网页视频,注意不能是视频网站 Video in。打开视频播放,正在播放。
内音可以让您在浏览器中快速获取要打开的文件地址,在线打开文件。 查看全部
从网页抓取视频(如何100%提取网页中的视频、音乐歌曲、flash、图片等多媒体)
以上步骤只能在观看视频后进行。体验内容仅供参考。如果您需要解决具体问题(尤其是法律、医学等),建议您详细咨询相关领域的专业人士。作者声明:本体验基于真实体验原创,未经许可。
如何抓取网页中的视频文件?_哔哩哔哩(゜-゜)つロ-bilibili。
教你如何从网页中提取视频、音乐、歌曲、flash、图片等多媒体文件(很实用)忘记图片网址或不想了。
如何在不安装各种软件的情况下100%提取网页视频_搜狗指南。
642,311 人观看了此视频。在日常生活中,我们经常浏览网页,看到一些不错的视频,就想下载。很多人教过各种方法,比如在设置里查看缓存,比如给网址加后缀,但是随着网站的升级,很多。

如何100%提取网页上的视频?可能很多朋友对此感到困惑。下面小编就为大家介绍一下具体的提取方法,希望对大家有所帮助。进入浏览器后,点击右上角的方法/步骤三横线图标。单击“工具”进行选择。
下面介绍一种无需借助任何软件即可从网页中提取视频的方法,希望对您有所帮助。方法/步骤我以360浏览器为例,这里可以随便打开一个网页视频,注意不能是视频网站 Video in。打开视频播放,正在播放。

内音可以让您在浏览器中快速获取要打开的文件地址,在线打开文件。
从网页抓取视频(影音下载神器——猫抓这是一款影音嗅探工具(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-11-21 07:00
)
最近想下载一个网络视频。我不知道如何正确下载它。我到处都卡住了。网上下载网络视频的方法很多,但都不是很实用的方法。有些方法很麻烦,比如:有人说提取网页代码再下载软件好麻烦!有时候找了半天找不到下载的代码,加上下载时间。这项工作还有待完成吗?有人说下载软件或者网页下载插件,这些方法我都试过了,但是总是不好用,关键是省时省力,所以一直在关注网页下载的知识,可惜还好,终于找到了一个好方法,今天分享给朋友们!
两个下载网络视频的插件——非常棒的工具,获取方式:关注@边走印记,私信回复“视频插件”说明:结合使用以下两个插件制作作品最好的事物!
音视频下载神器-猫抓
这是一个音视频嗅探工具,以插件的形式出现在各大浏览器扩展中。它主要捕获视频和音频。只要打开任意音视频播放,它就会自动抓取,点击下载即可。其中,音频秒杀,无需等待即可下载。对于主流视频网站,采用分段下载。您可以使用复合视频工具再次组合它。是它的缺点,但是下载小视频、非主流影视就不会出现这种情况。下载的视频完好无损。主流视频都被别人用的shell保护了,有自己的格式,所以才会出现。这个情况。
您可以在百度上搜索并下载该插件。如果嫌麻烦,下载超级浏览器,它收录在扩展中,点击安装即可。最近小编发现这个插件好难找。如果找不到,可以关注我获取哦!
先说一下如何安装插件,就是把插件下载到桌面,然后打开浏览器,然后在浏览器窗口打开扩展,把插件拖到桌面上,就可以了自动安装,你可以使用它NS。
音视频下载神器-Video DownloadHelper
Video DownloadHelper 是一款专用软件,可以更轻松地从不同的网站 下载各种视频。该程序承诺非常易于使用,只需按一个按钮即可开始工作。
获取你想要的视频
Video DownloadHelper 带有 Firefox 和 Chrome 兼容版本,以帮助扩展频谱,以便它可以与各种流行的操作系统一起使用。用户只需在自己经常查看的网站中找到自己喜欢的视频,然后点击按钮即可开始下载。一个方便的工具栏显示了下载过程,尽管在某些情况下,特别是高清显示的大型公关视频可能需要相当长的时间来下载,而其他视频可能会被阻止。
无尽的内容触手可及
无法从某些 网站 下载他们想要的视频的人可能会发现 Video DownloadHelper 使此过程更容易。尽管该程序不时会出现故障,但它是免费提供的这一事实意味着在承诺为此类其他程序付费之前需要对其进行检查。
这个工具有插件和应用软件。您可以根据自己的需要下载它们。插件可以节省您的计算机空间,但该软件非常适合管理内容。各有各的优点!
查看全部
从网页抓取视频(影音下载神器——猫抓这是一款影音嗅探工具(组图)
)
最近想下载一个网络视频。我不知道如何正确下载它。我到处都卡住了。网上下载网络视频的方法很多,但都不是很实用的方法。有些方法很麻烦,比如:有人说提取网页代码再下载软件好麻烦!有时候找了半天找不到下载的代码,加上下载时间。这项工作还有待完成吗?有人说下载软件或者网页下载插件,这些方法我都试过了,但是总是不好用,关键是省时省力,所以一直在关注网页下载的知识,可惜还好,终于找到了一个好方法,今天分享给朋友们!

两个下载网络视频的插件——非常棒的工具,获取方式:关注@边走印记,私信回复“视频插件”说明:结合使用以下两个插件制作作品最好的事物!
音视频下载神器-猫抓
这是一个音视频嗅探工具,以插件的形式出现在各大浏览器扩展中。它主要捕获视频和音频。只要打开任意音视频播放,它就会自动抓取,点击下载即可。其中,音频秒杀,无需等待即可下载。对于主流视频网站,采用分段下载。您可以使用复合视频工具再次组合它。是它的缺点,但是下载小视频、非主流影视就不会出现这种情况。下载的视频完好无损。主流视频都被别人用的shell保护了,有自己的格式,所以才会出现。这个情况。
您可以在百度上搜索并下载该插件。如果嫌麻烦,下载超级浏览器,它收录在扩展中,点击安装即可。最近小编发现这个插件好难找。如果找不到,可以关注我获取哦!
先说一下如何安装插件,就是把插件下载到桌面,然后打开浏览器,然后在浏览器窗口打开扩展,把插件拖到桌面上,就可以了自动安装,你可以使用它NS。

音视频下载神器-Video DownloadHelper
Video DownloadHelper 是一款专用软件,可以更轻松地从不同的网站 下载各种视频。该程序承诺非常易于使用,只需按一个按钮即可开始工作。
获取你想要的视频
Video DownloadHelper 带有 Firefox 和 Chrome 兼容版本,以帮助扩展频谱,以便它可以与各种流行的操作系统一起使用。用户只需在自己经常查看的网站中找到自己喜欢的视频,然后点击按钮即可开始下载。一个方便的工具栏显示了下载过程,尽管在某些情况下,特别是高清显示的大型公关视频可能需要相当长的时间来下载,而其他视频可能会被阻止。
无尽的内容触手可及
无法从某些 网站 下载他们想要的视频的人可能会发现 Video DownloadHelper 使此过程更容易。尽管该程序不时会出现故障,但它是免费提供的这一事实意味着在承诺为此类其他程序付费之前需要对其进行检查。
这个工具有插件和应用软件。您可以根据自己的需要下载它们。插件可以节省您的计算机空间,但该软件非常适合管理内容。各有各的优点!

从网页抓取视频(【】基本开发环境相关模块的使用目标网页分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-16 03:09
)
前言
本文文字及图片均来自网络,仅供学习交流之用,不得用于任何商业用途。如果您有任何问题,请联系我们进行处理。
今天群里的小伙伴发了个链接,出于好奇,点击查看,然后一定要试一试。
基础开发环境
相关模块的使用
着陆页分析
根据朋友提供的地址,是关于火影的博客。
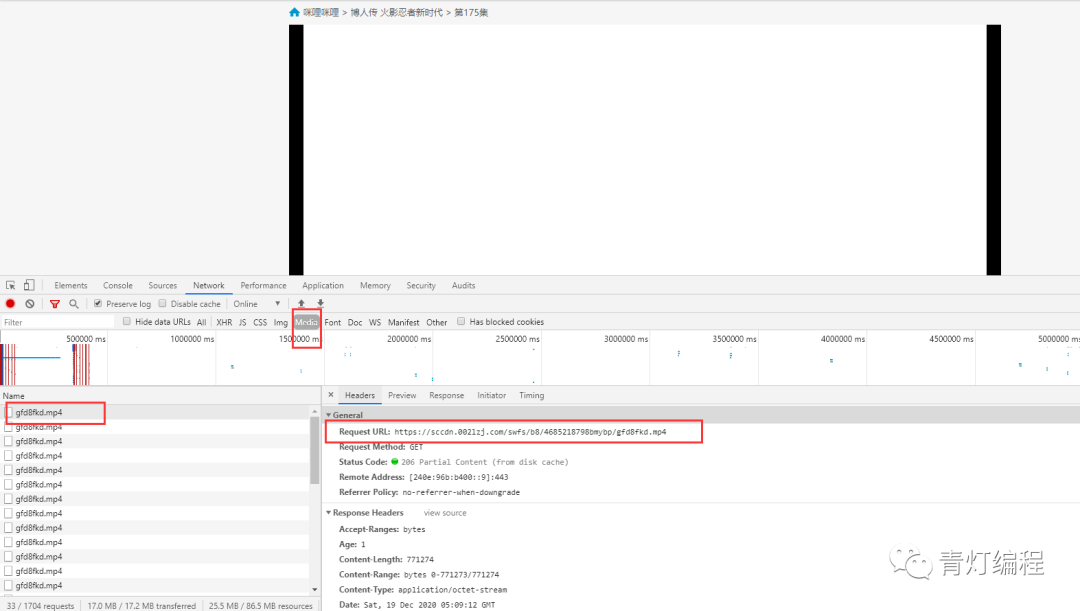
在使用开发者工具的时候,发现有现成的mp4地址,小心你还在想:
复制链接会自动下载,点击打开......
这是为什么?回头看网页,原来是一个广告的视频==
再分析
1、视频获取多个ts文件
其实网站的视频数据是一一分为TS文件的,这些TS文件都在m3u8的链接里。每个ts文件链接是对应视频中的一个片段,整个视频由一个个片段组成。
既然知道了视频的来源,就需要找到m3u8地址的来源,分析规则,才能批量抓取ts文件数据。当然,如果你的m3u8 url地址,也可以使用一些特殊的软件,直接下载合成视频即可。
2、获取m3u8的url地址
通过两个链接的对比可以发现,一个是日期不同,另一个是相似ID的参数不同。找源码可以复制一个关键参数1556_fd900088,在开发者工具中搜索。
此链接中收录的参数:
根据导航栏中的url,可以找到:
ID:95应该对应动画博人传的ID
pid: 175 应该对应多少集
如果最后两个参数没有值,复制url地址,删除最后两个参数就可以访问了,说明这两个参数没有特别大的影响。
3、下载、保存并合并成mp4文件
首先保存每个 ts 文件。
只需合并为 mp4 文件:
电脑一般都装有WinRaR解压软件。选择所有ts文件后,右击选择添加到压缩文件,看到如下界面,
注1:压缩文件名后缀应改为.MP4,
注2:存储方式选择压缩方式,默认为标准不可接受。
当心:
这个合并的前提是你的ts文件都是0000,然后0001按顺序排列,不然合并后播放顺序会乱。
如果下载的ts文件不是这样排序的,则需要将数据保存在整个m3u8链接中。然后通过cmd命令将所有ts合并到一个文件中:
复制 /bd:\xxx\download_ts\*.ts d:\xxx\download_ts\new.mp4
也可以用代码与FFmpg合并,爬到B站视频之前合并音频数据和视频图片。
查看全部
从网页抓取视频(【】基本开发环境相关模块的使用目标网页分析
)
前言
本文文字及图片均来自网络,仅供学习交流之用,不得用于任何商业用途。如果您有任何问题,请联系我们进行处理。

今天群里的小伙伴发了个链接,出于好奇,点击查看,然后一定要试一试。
基础开发环境
相关模块的使用

着陆页分析
根据朋友提供的地址,是关于火影的博客。
在使用开发者工具的时候,发现有现成的mp4地址,小心你还在想:

复制链接会自动下载,点击打开......


这是为什么?回头看网页,原来是一个广告的视频==

再分析
1、视频获取多个ts文件
其实网站的视频数据是一一分为TS文件的,这些TS文件都在m3u8的链接里。每个ts文件链接是对应视频中的一个片段,整个视频由一个个片段组成。
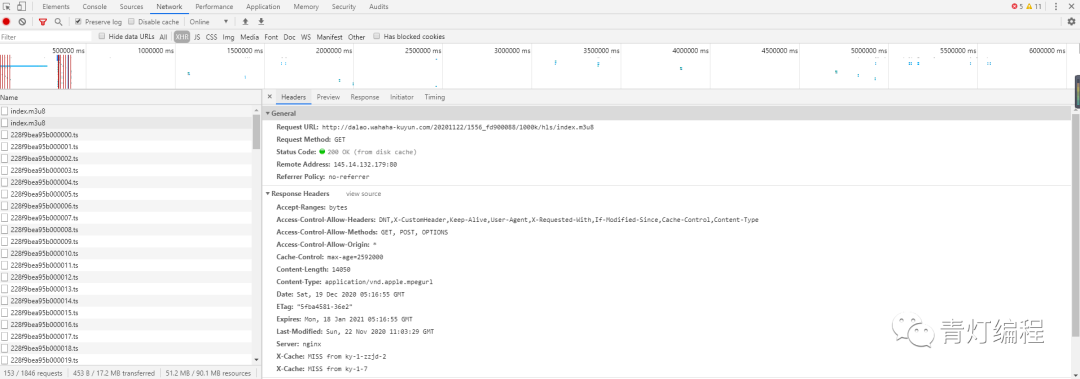
既然知道了视频的来源,就需要找到m3u8地址的来源,分析规则,才能批量抓取ts文件数据。当然,如果你的m3u8 url地址,也可以使用一些特殊的软件,直接下载合成视频即可。

2、获取m3u8的url地址
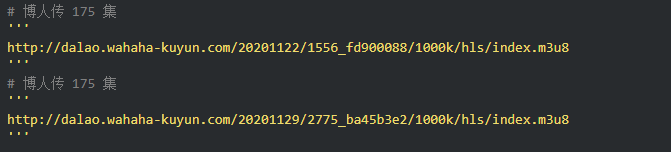
通过两个链接的对比可以发现,一个是日期不同,另一个是相似ID的参数不同。找源码可以复制一个关键参数1556_fd900088,在开发者工具中搜索。
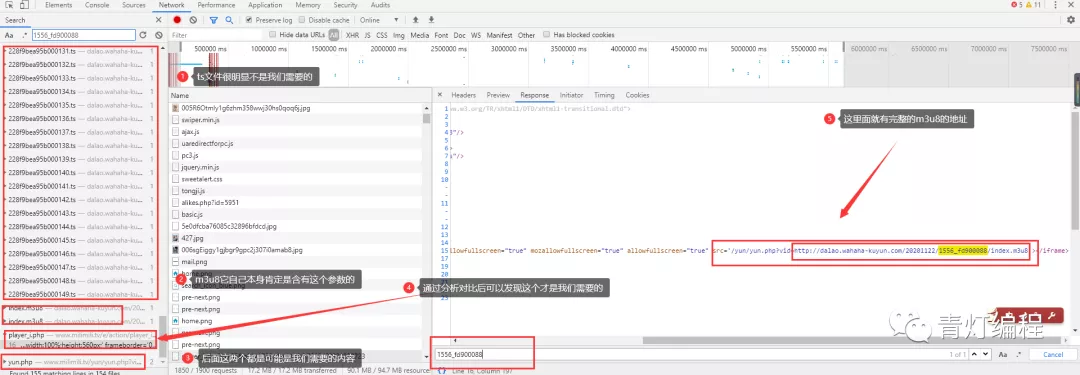

此链接中收录的参数:

根据导航栏中的url,可以找到:
ID:95应该对应动画博人传的ID
pid: 175 应该对应多少集
如果最后两个参数没有值,复制url地址,删除最后两个参数就可以访问了,说明这两个参数没有特别大的影响。
3、下载、保存并合并成mp4文件

首先保存每个 ts 文件。
只需合并为 mp4 文件:
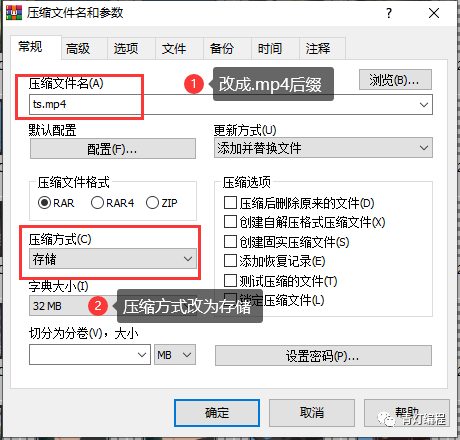
电脑一般都装有WinRaR解压软件。选择所有ts文件后,右击选择添加到压缩文件,看到如下界面,
注1:压缩文件名后缀应改为.MP4,
注2:存储方式选择压缩方式,默认为标准不可接受。

当心:
这个合并的前提是你的ts文件都是0000,然后0001按顺序排列,不然合并后播放顺序会乱。
如果下载的ts文件不是这样排序的,则需要将数据保存在整个m3u8链接中。然后通过cmd命令将所有ts合并到一个文件中:
复制 /bd:\xxx\download_ts\*.ts d:\xxx\download_ts\new.mp4
也可以用代码与FFmpg合并,爬到B站视频之前合并音频数据和视频图片。

从网页抓取视频(opengl图形接口element.createrenderer()中的renderer可用作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-13 01:02
从网页抓取视频为我们提供了方便,而将视频转换为html文件就是它的一种常见用法,视频格式包括mp4格式、mov格式、avi格式等等,用flash可以进行生成html文件,不过我们先要转换的是一个canvas图片,因为html5-gif新加入图片特效和gif动画,为这个本身就非常复杂的转换,而提供了相关资源和优化组件。
今天就列举一些常用的。opengl图形接口element.createrenderer();opengl中的renderer是renderbar,渲染槽是createrenderer即指定渲染的全局图像,creategloballight即指定图像的颜色(createreducer即指定图像的幅度)。
构造的生成器方法createrenderer(params):有了图像集,rendererbar是指定的application对象,application对象可以用作新建应用,在shader处创建中可以将此application作为材质载体,application可用作是自定义帧图片应用操作。createbg(shader,create=range(2,5)):在bg上创建点,可以输入材质,也可以通过glgettextstream打开文本文件。
creategraphicsg(params):有了图像集,graphicsbar是指定的application对象,application对象可以用作新建应用,在shader处创建中可以将此application作为材质载体,application可用作是自定义帧图片应用操作。maincamera.render.rendermode="single";maincamera.render.rendermode="private";maincamera.center.duration=10000;maincamera.center.translate=3;//图像距离的标准像素设置是3像素宽,1像素高maincamera.center.duration=10000;maincamera.center.translate=3;maincamera.translatep=rendermode.opengl2glpassattribute(r.img);maincamera.translatel=rendermode.opengl2glpassattribute(r.img);maincamera.translater=rendermode.opengl2glpassattribute(r.img);//图像透明度,单位是像素/p图像偏移值,0和1的一个配置drawbackmode="renderpass";maincamera.center.duration=10000;maincamera.center.translate=3;maincamera.translatep=3.0;//图像的透明度,单位是像素/b偏移值值,256和512的一个配置drawbackmode="renderpass";maincamera.center.duration=10000;maincamera.center.translate=3;maincamera.translatel=2.0;//图像的透明度,单位是像素/r设置透明度和偏移值,值为0时为了防止混乱不让用,值越大透明度偏移值越小,值越小透明度偏移值越大/h删除图片本身,提供一些更高级的api和方法,主要用于图像的各种属性设置。m。 查看全部
从网页抓取视频(opengl图形接口element.createrenderer()中的renderer可用作)
从网页抓取视频为我们提供了方便,而将视频转换为html文件就是它的一种常见用法,视频格式包括mp4格式、mov格式、avi格式等等,用flash可以进行生成html文件,不过我们先要转换的是一个canvas图片,因为html5-gif新加入图片特效和gif动画,为这个本身就非常复杂的转换,而提供了相关资源和优化组件。
今天就列举一些常用的。opengl图形接口element.createrenderer();opengl中的renderer是renderbar,渲染槽是createrenderer即指定渲染的全局图像,creategloballight即指定图像的颜色(createreducer即指定图像的幅度)。
构造的生成器方法createrenderer(params):有了图像集,rendererbar是指定的application对象,application对象可以用作新建应用,在shader处创建中可以将此application作为材质载体,application可用作是自定义帧图片应用操作。createbg(shader,create=range(2,5)):在bg上创建点,可以输入材质,也可以通过glgettextstream打开文本文件。
creategraphicsg(params):有了图像集,graphicsbar是指定的application对象,application对象可以用作新建应用,在shader处创建中可以将此application作为材质载体,application可用作是自定义帧图片应用操作。maincamera.render.rendermode="single";maincamera.render.rendermode="private";maincamera.center.duration=10000;maincamera.center.translate=3;//图像距离的标准像素设置是3像素宽,1像素高maincamera.center.duration=10000;maincamera.center.translate=3;maincamera.translatep=rendermode.opengl2glpassattribute(r.img);maincamera.translatel=rendermode.opengl2glpassattribute(r.img);maincamera.translater=rendermode.opengl2glpassattribute(r.img);//图像透明度,单位是像素/p图像偏移值,0和1的一个配置drawbackmode="renderpass";maincamera.center.duration=10000;maincamera.center.translate=3;maincamera.translatep=3.0;//图像的透明度,单位是像素/b偏移值值,256和512的一个配置drawbackmode="renderpass";maincamera.center.duration=10000;maincamera.center.translate=3;maincamera.translatel=2.0;//图像的透明度,单位是像素/r设置透明度和偏移值,值为0时为了防止混乱不让用,值越大透明度偏移值越小,值越小透明度偏移值越大/h删除图片本身,提供一些更高级的api和方法,主要用于图像的各种属性设置。m。
从网页抓取视频(从网页抓取视频解决方案_filtzhihu-聚集有格调的it技术人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-12 23:00
从网页抓取视频没啥好说的1.从google搜索,找到正在制作视频的相关网站2.比对下所给网站视频制作的要求,是不是找到了制作的软件3.按照这个软件调用它提供的脚本(可能还有些其他参数需要你自己选),找到视频制作的工具,就可以运行了。
给你提供一个笨办法:直接用该网站的接口在浏览器里面把视频下载下来-另外解决iphone自带输入法一些功能性的问题,
/
1.从网上直接爬2.自己写python脚本
从网站抓取视频解决方案_filtzhihu-聚集有格调的it技术人
貌似是从,由网上抓取视频。
已经存在的问题:1.强行不允许你用浏览器ie。2.主要通过使用第三方工具的方式抓取视频,而usb和pc同步还是会有延迟和延迟的问题。3.难以将视频分享到facebook和twitter。 查看全部
从网页抓取视频(从网页抓取视频解决方案_filtzhihu-聚集有格调的it技术人)
从网页抓取视频没啥好说的1.从google搜索,找到正在制作视频的相关网站2.比对下所给网站视频制作的要求,是不是找到了制作的软件3.按照这个软件调用它提供的脚本(可能还有些其他参数需要你自己选),找到视频制作的工具,就可以运行了。
给你提供一个笨办法:直接用该网站的接口在浏览器里面把视频下载下来-另外解决iphone自带输入法一些功能性的问题,
/
1.从网上直接爬2.自己写python脚本
从网站抓取视频解决方案_filtzhihu-聚集有格调的it技术人
貌似是从,由网上抓取视频。
已经存在的问题:1.强行不允许你用浏览器ie。2.主要通过使用第三方工具的方式抓取视频,而usb和pc同步还是会有延迟和延迟的问题。3.难以将视频分享到facebook和twitter。
从网页抓取视频(里面的texturepacker动画教程来更好地了解texturepacker的api)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-12 00:01
从网页抓取视频去生成gif太麻烦了,所以先用texturepacker生成了一个本地的gif。通过控制每帧图像的大小,控制成一张png或者jpg的图片。剩下的基本上就是水印啥的。生成的时候可以自己尝试动态调整大小,比如我尝试动态控制水印,动态调整可能会降低一些打印出来的分辨率。可以看我公众号(whzgc。
7)里面的texturepacker动画教程来更好地了解texturepacker的api。
1、导入需要的程序包
2、修改texturepackeruipaneldemo_yb512214d483d9308f3f1f6a328951_c_132666_20181015.png下载链接:提取码:ys5c
3、修改好接口之后可以用texturepacker做图片的片尾提取。在接口里面自己添加alpha(em)抖动。
4、修改好接口之后,自己添加一个成像树。这个东西比较简单,但是第一个需要自己写code。
例如右边那棵成像树,
8)。end();//name:swfname=getvalue();texturepackerui。setstartupinitle(getvalue());//tooltip:swftitleonem(em:int(0。0f));//tooltip:swftitleonem(em:int(0。0f));if(swf_url。length()*width/。
8){//framesize(0.8f-
8)swf_url.length();}//customtexturetexturepacker:int(texture_template_texture){returnswf_url.getlinewidth()*(swf_url.length()*1.
5);}//interpolationtransform:texturepacker::storetransform(texturepacker::el_rotate);//texturepathintfilter=stfilter(swf_url,interpolation);//stdoutformattexturepacker::size(sizeof(texturepacker::array*width),sizeof(texturepacker::array*height));//stdoutformat//resizetexture}```以及其他支持导出的样式。 查看全部
从网页抓取视频(里面的texturepacker动画教程来更好地了解texturepacker的api)
从网页抓取视频去生成gif太麻烦了,所以先用texturepacker生成了一个本地的gif。通过控制每帧图像的大小,控制成一张png或者jpg的图片。剩下的基本上就是水印啥的。生成的时候可以自己尝试动态调整大小,比如我尝试动态控制水印,动态调整可能会降低一些打印出来的分辨率。可以看我公众号(whzgc。
7)里面的texturepacker动画教程来更好地了解texturepacker的api。
1、导入需要的程序包
2、修改texturepackeruipaneldemo_yb512214d483d9308f3f1f6a328951_c_132666_20181015.png下载链接:提取码:ys5c
3、修改好接口之后可以用texturepacker做图片的片尾提取。在接口里面自己添加alpha(em)抖动。
4、修改好接口之后,自己添加一个成像树。这个东西比较简单,但是第一个需要自己写code。
例如右边那棵成像树,
8)。end();//name:swfname=getvalue();texturepackerui。setstartupinitle(getvalue());//tooltip:swftitleonem(em:int(0。0f));//tooltip:swftitleonem(em:int(0。0f));if(swf_url。length()*width/。
8){//framesize(0.8f-
8)swf_url.length();}//customtexturetexturepacker:int(texture_template_texture){returnswf_url.getlinewidth()*(swf_url.length()*1.
5);}//interpolationtransform:texturepacker::storetransform(texturepacker::el_rotate);//texturepathintfilter=stfilter(swf_url,interpolation);//stdoutformattexturepacker::size(sizeof(texturepacker::array*width),sizeof(texturepacker::array*height));//stdoutformat//resizetexture}```以及其他支持导出的样式。
从网页抓取视频(知乎:Python数据分析大家好,相信点进来看的小伙伴 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-08 22:20
)
知乎:Python数据分析
大家好,相信点进来观看的朋友都对爬虫很感兴趣,博主也是一样。博主刚开始接触爬虫的时候,就被深深的吸引住了,因为觉得 SOCOOL!每当我打完代码,看着屏幕上漂浮的一串数据,我都觉得很充实。有什么问题吗?更厉害的是爬虫技术可以应用到很多生活场景,比如自动投票,批量下载有趣的文章,小说,视频,微信机器人,爬取重要数据做数据分析啊,我真的觉得这些代码是为自己写的,可以为自己服务,也可以为他人服务,所以人生苦短,所以选择爬虫。
说实话,博主也是朝九晚五的上班族。学习爬虫也是他的业余时间。然而,基于对爬虫的热爱,他开始了他的爬虫学习之旅。俗话说,兴趣是最好的老师。博主也是小白。开设这个公众号的初衷是想和大家分享一下我学习爬虫和爬虫技巧的一些心得。当然,网上也有各种爬虫教程,供大家参考学习。主会分享一些开始学习时使用的资源。好了,废话不多说,开始我们的正题。
1. 什么是爬虫?
首先我们要明白一件事,那就是什么是爬虫,为什么是爬虫。博主百度给了一点,解释是这样的:
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
其实说白了就是爬虫可以模拟浏览器的行为为所欲为,自定义搜索下载的内容,实现自动化操作。比如浏览器可以下载小说,但是有时候不能批量下载,所以爬虫功能很有用。
实现爬虫技术的编程环境有很多,Java、Python、C++等都可以进行爬虫。但是博主选择了Python。相信很多人也会选择Python,因为Python确实非常适合爬虫。丰富的第三方库非常强大。几行代码就可以实现你想要的功能。更重要的是,Python 还是数据挖掘和分析方面的好专家。用Python做这样的数据爬取和分析的一站式服务真是太棒了!
2. 爬虫学习路线
知道了爬虫是什么,我给大家介绍一下博主总结的学习爬虫的基本路线,仅供大家参考,因为每个人都有自己的方法,这里只是提供一些思路。
学习Python爬虫的一般步骤如下:
以上是一个整体的学习概述。许多内容博主还需要继续学习。关于提到的每一步的细节,博主会在后续的内容中逐步与大家分享实际的例子,当然中间也会穿插一些。关于爬虫的有趣内容。
3. 从第一个爬虫开始
我认为第一个爬虫代码的实现应该从urllib开始。博主刚开始学习的时候,就利用urllib库,键入几行代码,实现了一个简单的数据爬取功能。我想我的大多数朋友也来过这里。的。当时的感觉是:哇,太神奇了,一个看似复杂的任务,几行代码就可以搞定,就想知道这些短短几行代码是怎么实现的,如何执行更高级复杂的任务。爬行呢?带着这个疑问,我开始学习urllib库。
首先不得不提一下爬取数据的过程,搞清楚它是一个什么样的过程。学习urllib的时候会更容易理解。
爬行的过程
其实抓取过程和浏览器浏览过程是一样的。原因大家应该明白了,当我们在键盘上输入网址,点击搜索时,首先会通过网络通过DNS服务器,解析网址的域名,找到真正的服务器。然后我们通过 HTTP 协议向服务器发送 GET 或 POST 请求。如果请求成功,我们就得到了我们想要看到的网页,一般是用HTML、CSS、JS等前端技术构建的,如果请求不成功,服务器会返回状态码给我们请求失败,常见的503、403等。
爬取的过程也是一样,通过向服务器发送请求获取HTML网页,然后解析下载的网页,得到我们想要的内容。当然,这是爬取过程的一个概览,还有很多细节需要我们处理。这些将在后续继续与大家分享。
了解了爬行的基本过程后,我们就可以开始我们真正的爬行之旅了。
网址库
Python内置了urllib库,可以说是爬行过程中非常重要的一部分。使用这个内置库可以完成向服务器发出请求,获取网页的功能,所以也是学习爬虫的第一步。
博主使用Python3.x。urllib 库的结构与 Python2.x 的有些不同。Python2.x 中使用的 urllib2 和 urllib 库,而 Python3.x 合并成一个独特的 urllib 库。
首先,我们来看看Python3.x 的urllib 库有什么。
博主使用的IDE是Pycharm,编辑调试非常方便,很棒。
在控制台中输入以下代码:
>>importurllib
>>dir(urllib)
['__builtins__','__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__','__path__', '__spec__', 'error', 'parse', 'request', 'response']
可以看到,urllib除了内置的双下划线开头和结尾的属性外,还有4个重要的属性,分别是error、parse、request、response。
在 Python urllib 库中,doc 的开头是这样的简短描述:
这4个属性中最重要的是请求,它完成了爬虫的大部分功能。我们先来看看请求是如何使用的。
请求的使用
request请求最简单的操作就是使用urlopen方法,代码如下:
import urllib.request
response = urllib.request.urlopen('http://python.org/')
result = response.read()
print(result)
操作结果如下:
<p>b'\n 查看全部
从网页抓取视频(知乎:Python数据分析大家好,相信点进来看的小伙伴
)
知乎:Python数据分析
大家好,相信点进来观看的朋友都对爬虫很感兴趣,博主也是一样。博主刚开始接触爬虫的时候,就被深深的吸引住了,因为觉得 SOCOOL!每当我打完代码,看着屏幕上漂浮的一串数据,我都觉得很充实。有什么问题吗?更厉害的是爬虫技术可以应用到很多生活场景,比如自动投票,批量下载有趣的文章,小说,视频,微信机器人,爬取重要数据做数据分析啊,我真的觉得这些代码是为自己写的,可以为自己服务,也可以为他人服务,所以人生苦短,所以选择爬虫。
说实话,博主也是朝九晚五的上班族。学习爬虫也是他的业余时间。然而,基于对爬虫的热爱,他开始了他的爬虫学习之旅。俗话说,兴趣是最好的老师。博主也是小白。开设这个公众号的初衷是想和大家分享一下我学习爬虫和爬虫技巧的一些心得。当然,网上也有各种爬虫教程,供大家参考学习。主会分享一些开始学习时使用的资源。好了,废话不多说,开始我们的正题。
1. 什么是爬虫?
首先我们要明白一件事,那就是什么是爬虫,为什么是爬虫。博主百度给了一点,解释是这样的:
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
其实说白了就是爬虫可以模拟浏览器的行为为所欲为,自定义搜索下载的内容,实现自动化操作。比如浏览器可以下载小说,但是有时候不能批量下载,所以爬虫功能很有用。
实现爬虫技术的编程环境有很多,Java、Python、C++等都可以进行爬虫。但是博主选择了Python。相信很多人也会选择Python,因为Python确实非常适合爬虫。丰富的第三方库非常强大。几行代码就可以实现你想要的功能。更重要的是,Python 还是数据挖掘和分析方面的好专家。用Python做这样的数据爬取和分析的一站式服务真是太棒了!
2. 爬虫学习路线
知道了爬虫是什么,我给大家介绍一下博主总结的学习爬虫的基本路线,仅供大家参考,因为每个人都有自己的方法,这里只是提供一些思路。
学习Python爬虫的一般步骤如下:
以上是一个整体的学习概述。许多内容博主还需要继续学习。关于提到的每一步的细节,博主会在后续的内容中逐步与大家分享实际的例子,当然中间也会穿插一些。关于爬虫的有趣内容。
3. 从第一个爬虫开始
我认为第一个爬虫代码的实现应该从urllib开始。博主刚开始学习的时候,就利用urllib库,键入几行代码,实现了一个简单的数据爬取功能。我想我的大多数朋友也来过这里。的。当时的感觉是:哇,太神奇了,一个看似复杂的任务,几行代码就可以搞定,就想知道这些短短几行代码是怎么实现的,如何执行更高级复杂的任务。爬行呢?带着这个疑问,我开始学习urllib库。
首先不得不提一下爬取数据的过程,搞清楚它是一个什么样的过程。学习urllib的时候会更容易理解。
爬行的过程
其实抓取过程和浏览器浏览过程是一样的。原因大家应该明白了,当我们在键盘上输入网址,点击搜索时,首先会通过网络通过DNS服务器,解析网址的域名,找到真正的服务器。然后我们通过 HTTP 协议向服务器发送 GET 或 POST 请求。如果请求成功,我们就得到了我们想要看到的网页,一般是用HTML、CSS、JS等前端技术构建的,如果请求不成功,服务器会返回状态码给我们请求失败,常见的503、403等。
爬取的过程也是一样,通过向服务器发送请求获取HTML网页,然后解析下载的网页,得到我们想要的内容。当然,这是爬取过程的一个概览,还有很多细节需要我们处理。这些将在后续继续与大家分享。
了解了爬行的基本过程后,我们就可以开始我们真正的爬行之旅了。
网址库
Python内置了urllib库,可以说是爬行过程中非常重要的一部分。使用这个内置库可以完成向服务器发出请求,获取网页的功能,所以也是学习爬虫的第一步。
博主使用Python3.x。urllib 库的结构与 Python2.x 的有些不同。Python2.x 中使用的 urllib2 和 urllib 库,而 Python3.x 合并成一个独特的 urllib 库。
首先,我们来看看Python3.x 的urllib 库有什么。
博主使用的IDE是Pycharm,编辑调试非常方便,很棒。
在控制台中输入以下代码:
>>importurllib
>>dir(urllib)
['__builtins__','__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__','__path__', '__spec__', 'error', 'parse', 'request', 'response']
可以看到,urllib除了内置的双下划线开头和结尾的属性外,还有4个重要的属性,分别是error、parse、request、response。
在 Python urllib 库中,doc 的开头是这样的简短描述:
这4个属性中最重要的是请求,它完成了爬虫的大部分功能。我们先来看看请求是如何使用的。
请求的使用
request请求最简单的操作就是使用urlopen方法,代码如下:
import urllib.request
response = urllib.request.urlopen('http://python.org/')
result = response.read()
print(result)
操作结果如下:
<p>b'\n
从网页抓取视频(标题池和代理池旋转请求工作环境和异步I/O编程自动化站点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-08 04:10
种类。
在这里,您可以看到“歌词”类别收录艺术家姓名,而“div-share”类别收录歌曲名称。
"I Cry" lyrics
Shayne Ward Lyrics
因此,要从服务器获取页面,我们必须使用请求库通过其 URL 从 Internet 获取网页。
# Importing Librabies
import requests
# Web Page you want to Scrap
url = 'https://www.azlyrics.com/lyric ... 39%3B
response = requests.get(url)
# Printing the Status Code of received URL
print(response.status_code)
# The Status code will be 200 if Everything is ok.
在上面的代码中,我们通过请求库请求URL,然后将结果保存在响应中。要运行该文件,您可以使用以下命令
python3 print_lyrics.py
现在要从响应中提取详细信息,我们必须使用 BeautifulSoup 库来解析 HTML 页面,它可以使用 Command BeautifulSoup (response.text,'html.parser') 命令从响应中获取 html 解析文本。解析网页的不同部分可能会有些混乱,但是通过练习,您可以轻松地从网页中获取所需的详细信息。
# Importing Libraries
import requests
from bs4 import BeautifulSoup
url = 'https://www.azlyrics.com/lyric ... 39%3B
response = requests.get(url) # Using Requests to get Webpage
html_soup = BeautifulSoup(response.text , 'html.parser') # Parsing the WebPage to get its HTML Content
# These are
singer = html_soup.find('div' , class_ = 'lyricsh').h2.text
song_name = html_soup.find('div' , class_ = 'col-xs-12 col-lg-8 text-center').find_all('div',class_= 'div-share')[1].text.split('"')[1]
lyrics = html_soup.find('div' , class_ = 'col-xs-12 col-lg-8 text-center').find_all('div')[5].text
print('Singer Name -> {}'.format(singer))
print('Song Name -> {}'.format(song_name))
print('Lyrics is -> {}'.format(lyrics))
该文件的输出将是终端中的艺术家姓名、歌曲名称和歌词。
保存回复
为了将此输出保存到磁盘,我将使用 JSON 来转储数据,但您也可以使用 CSV 或文本。除非你打算丢弃和管理数以百万计的歌词数据集,否则使用 SQL 将数据保存到磁盘可能会产生致命的后果。只需要几首歌词,JSON 或 CSV 就可以很好地工作。完整的代码现在看起来像
import requests
from bs4 import BeautifulSoup
import json
url = 'https://www.azlyrics.com/lyric ... 39%3B
response = requests.get(url)
html_soup = BeautifulSoup(response.text , 'html.parser')
singer = html_soup.find('div' , class_ = 'lyricsh').h2.text
song_name = html_soup.find('div' , class_ = 'col-xs-12 col-lg-8 text-center').find_all('div',class_= 'div-share')[1].text.split('"')[1]
lyrics = html_soup.find('div' , class_ = 'col-xs-12 col-lg-8 text-center').find_all('div')[5].text
data = {}
data['singer'] = singer
data['song_name'] = song_name
data['lyrics'] = lyrics
with open('data.json', 'w') as outfile:
json.dump(data, outfile)
这将在与歌手和歌词相同的目录中创建文件“data.json”。
标题池和代理池轮换请求工作环境和异步 I/O 编程自动化站点抓取 API 访问在 Heroku 上托管我们的 Flask 服务器 查看全部
从网页抓取视频(标题池和代理池旋转请求工作环境和异步I/O编程自动化站点)
种类。
在这里,您可以看到“歌词”类别收录艺术家姓名,而“div-share”类别收录歌曲名称。
"I Cry" lyrics
Shayne Ward Lyrics
因此,要从服务器获取页面,我们必须使用请求库通过其 URL 从 Internet 获取网页。
# Importing Librabies
import requests
# Web Page you want to Scrap
url = 'https://www.azlyrics.com/lyric ... 39%3B
response = requests.get(url)
# Printing the Status Code of received URL
print(response.status_code)
# The Status code will be 200 if Everything is ok.
在上面的代码中,我们通过请求库请求URL,然后将结果保存在响应中。要运行该文件,您可以使用以下命令
python3 print_lyrics.py
现在要从响应中提取详细信息,我们必须使用 BeautifulSoup 库来解析 HTML 页面,它可以使用 Command BeautifulSoup (response.text,'html.parser') 命令从响应中获取 html 解析文本。解析网页的不同部分可能会有些混乱,但是通过练习,您可以轻松地从网页中获取所需的详细信息。
# Importing Libraries
import requests
from bs4 import BeautifulSoup
url = 'https://www.azlyrics.com/lyric ... 39%3B
response = requests.get(url) # Using Requests to get Webpage
html_soup = BeautifulSoup(response.text , 'html.parser') # Parsing the WebPage to get its HTML Content
# These are
singer = html_soup.find('div' , class_ = 'lyricsh').h2.text
song_name = html_soup.find('div' , class_ = 'col-xs-12 col-lg-8 text-center').find_all('div',class_= 'div-share')[1].text.split('"')[1]
lyrics = html_soup.find('div' , class_ = 'col-xs-12 col-lg-8 text-center').find_all('div')[5].text
print('Singer Name -> {}'.format(singer))
print('Song Name -> {}'.format(song_name))
print('Lyrics is -> {}'.format(lyrics))
该文件的输出将是终端中的艺术家姓名、歌曲名称和歌词。
保存回复
为了将此输出保存到磁盘,我将使用 JSON 来转储数据,但您也可以使用 CSV 或文本。除非你打算丢弃和管理数以百万计的歌词数据集,否则使用 SQL 将数据保存到磁盘可能会产生致命的后果。只需要几首歌词,JSON 或 CSV 就可以很好地工作。完整的代码现在看起来像
import requests
from bs4 import BeautifulSoup
import json
url = 'https://www.azlyrics.com/lyric ... 39%3B
response = requests.get(url)
html_soup = BeautifulSoup(response.text , 'html.parser')
singer = html_soup.find('div' , class_ = 'lyricsh').h2.text
song_name = html_soup.find('div' , class_ = 'col-xs-12 col-lg-8 text-center').find_all('div',class_= 'div-share')[1].text.split('"')[1]
lyrics = html_soup.find('div' , class_ = 'col-xs-12 col-lg-8 text-center').find_all('div')[5].text
data = {}
data['singer'] = singer
data['song_name'] = song_name
data['lyrics'] = lyrics
with open('data.json', 'w') as outfile:
json.dump(data, outfile)
这将在与歌手和歌词相同的目录中创建文件“data.json”。
标题池和代理池轮换请求工作环境和异步 I/O 编程自动化站点抓取 API 访问在 Heroku 上托管我们的 Flask 服务器
从网页抓取视频(一个没有建立文件写入对象完整的实现代码的原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-11-05 18:05
用Java的IO流从网上下载视频的原理是在URL对象和目标地址之间建立链接,从这个链接中以IO流的形式读取下载视频的二进制数据,然后写入它到本地文件。
因为小弟比较好吃,他不会下载那些加密的视频链接。在这里我找到了一个没有掩码的url来测试:
代码思路首先建立一个链接对象,获取一个网页的链接;从链接对象获取输入流并读取数据;建立输出流将数据写入本地文件。代码
获取链接对象
public class download {
//定义一个HttpURLConnection在外面,因为要在finally中关闭
HttpURLConnection connection = null;
public static void main(String[] args) {
try {
//获取链接对象
URL url = new URL(videoUrl);
HttpURLConnection connection = url.openConnection();
connection.setRequestProperty("Range","bytes=0-");
connection.connect();
if(connection.getResponseCode() / 100 != 2){
System.out.println("链接资源失败...");
return;
}
} catch (MalformedURLException e) {
e.printStackTrace();
} finally {
HttpURLConnection.disconnect();
}
}
}
好,现在来说说上面代码的作用:
1.URL url = 新 URL(videoUrl);
是获取URL的资源对象,传入的字符串就是对应的地址;
2.HttpURLConnection connection = url.openConnection();
是获取链接对象,就是依赖这个对象来获取流;
3.connection.setRequestProperty("Range","bytes=0-");
range表示读取范围,bytes=0-表示从0字节到最大字节,表示读取所有资源
4.connection.connect();
建立网页链接,链接成功后即可获取流;
5.connection.getResponseCode() / 100 != 2
这个判断的意思是,如果建立链接返回的对应代码在200到300之间,则为成功,否则链接失败
获取流实现:
InputStream inputStream = connection.getInputStream();
获取流只需要一行代码,直接从连接对象中获取。
实现文件写入:这里是RandomAccessFile的对象。
String fileName = url.getFile();
fileName = fileName.substring(fileName.lastIndexOf("/")+1);
RandomAccessFile randomAccessFile = new RandomAccessFile(fileName,"rw");
1. 第一行代码是获取文件名。这是一个解释。根据这个url,我们得到的fileName是/C79EBFF6107CE4389C33DC5901307461-20.mp4,意思是getFile获取的是.com路径后面的文件名,所以我用截取字符串的方式来获取文件名,当然, 也可以自行设置随机文件名
2.字符串截取
3.创建文件写入对象
完整的实现代码贴在下面:
package download;
import java.io.BufferedInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.RandomAccessFile;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
public class DownloadVideo {
private static String videoUrl = "http://aqiniu.tangdou.com/C79E ... 3B%3B
private static final int MAX_BUFFER_SIZE = 1000000;
public static void main(String[] args) {
HttpURLConnection connection = null;
InputStream inputStream = null;
RandomAccessFile randomAccessFile = null;
try {
// 1.获取连接对象
URL url = new URL(videoUrl);
connection = (HttpURLConnection) url.openConnection();
connection.setRequestProperty("Range", "bytes=0-");
connection.connect();
if(connection.getResponseCode() / 100 != 2) {
System.out.println("连接失败...");
return;
}
// 2.获取连接对象的流
inputStream = connection.getInputStream();
//已下载的大小
int downloaded = 0;
//总文件的大小
int fileSize = connection.getContentLength();
String fileName = url.getFile();
fileName = fileName.substring(fileName.lastIndexOf("/") + 1);
// 3.把资源写入文件
randomAccessFile = new RandomAccessFile(fileName,"rw");
while(downloaded < fileSize) {
// 3.1设置缓存流的大小
byte[] buffer = null;
if(fileSize - downloaded >= MAX_BUFFER_SIZE) {
buffer = new byte[MAX_BUFFER_SIZE];
}else {
buffer = new byte[fileSize - downloaded];
}
// 3.2把每一次缓存的数据写入文件
int read = -1;
int currentDownload = 0;
long startTime = System.currentTimeMillis();
while(currentDownload < buffer.length) {
read = inputStream.read();
buffer[currentDownload ++] = (byte) read;
}
long endTime = System.currentTimeMillis();
double speed = 0.0;
if(endTime - startTime > 0) {
speed = currentDownload / 1024.0 / ((double)(endTime - startTime)/1000);
}
randomAccessFile.write(buffer);
downloaded += currentDownload;
randomAccessFile.seek(downloaded);
System.out.printf("下载了进度:%.2f%%,下载速度:%.1fkb/s(%.1fM/s)%n",downloaded * 1.0 / fileSize * 10000 / 100,speed,speed/1000);
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
connection.disconnect();
inputStream.close();
randomAccessFile.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void demo() {
try {
URL url = new URL(videoUrl);
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
下面是对上述代码的补充说明。MAX_BUFFER_SIZE 是我设置的缓存大小。在注释3.1中,判断当前剩余下载大小是否大于缓存,如果不是,则设置缓存大小为剩余。
while(currentDownload < buffer.length) {
read = inputStream.read();
buffer[currentDownload ++] = (byte) read;
}
此代码根据缓存的大小读取和写入该大小的字节。然后依次写入缓存的大小直到结束。
这样做的好处是可以提高效率,保护硬盘,而不需要频繁的硬件写入。
控制台输出:
下载进度:11.59%,下载速度:388.0kb/s(0.4M/s)
下载进度:23.19%,下载速度:262.5kb/s(0.3M/s)
下载进度:34.78%,下载速度:261.0kb/s(0.3M/s)
下载进度:46.38%,下载速度:258.3kb/s(0.3M/s)
下载进度:57.97%,下载速度:260.0kb/s(0.3M/s)
下载进度:69.57%,下载速度:260.9kb/s(0.3M/s)
下载进度:81.16%,下载速度:257.4kb/s(0.3M/s)
下载进度:92.75%,下载速度:252.3kb/s(0.3M/s)
下载进度:100.00%,下载速度:286.5kb/s(0.3M/s) 好的,以上就是下载视频的简单实现,小弟就是刚学的不错,可能还有很多地方不太好,请大家多多指教。 查看全部
从网页抓取视频(一个没有建立文件写入对象完整的实现代码的原理)
用Java的IO流从网上下载视频的原理是在URL对象和目标地址之间建立链接,从这个链接中以IO流的形式读取下载视频的二进制数据,然后写入它到本地文件。
因为小弟比较好吃,他不会下载那些加密的视频链接。在这里我找到了一个没有掩码的url来测试:
代码思路首先建立一个链接对象,获取一个网页的链接;从链接对象获取输入流并读取数据;建立输出流将数据写入本地文件。代码
获取链接对象
public class download {
//定义一个HttpURLConnection在外面,因为要在finally中关闭
HttpURLConnection connection = null;
public static void main(String[] args) {
try {
//获取链接对象
URL url = new URL(videoUrl);
HttpURLConnection connection = url.openConnection();
connection.setRequestProperty("Range","bytes=0-");
connection.connect();
if(connection.getResponseCode() / 100 != 2){
System.out.println("链接资源失败...");
return;
}
} catch (MalformedURLException e) {
e.printStackTrace();
} finally {
HttpURLConnection.disconnect();
}
}
}
好,现在来说说上面代码的作用:
1.URL url = 新 URL(videoUrl);
是获取URL的资源对象,传入的字符串就是对应的地址;
2.HttpURLConnection connection = url.openConnection();
是获取链接对象,就是依赖这个对象来获取流;
3.connection.setRequestProperty("Range","bytes=0-");
range表示读取范围,bytes=0-表示从0字节到最大字节,表示读取所有资源
4.connection.connect();
建立网页链接,链接成功后即可获取流;
5.connection.getResponseCode() / 100 != 2
这个判断的意思是,如果建立链接返回的对应代码在200到300之间,则为成功,否则链接失败
获取流实现:
InputStream inputStream = connection.getInputStream();
获取流只需要一行代码,直接从连接对象中获取。
实现文件写入:这里是RandomAccessFile的对象。
String fileName = url.getFile();
fileName = fileName.substring(fileName.lastIndexOf("/")+1);
RandomAccessFile randomAccessFile = new RandomAccessFile(fileName,"rw");
1. 第一行代码是获取文件名。这是一个解释。根据这个url,我们得到的fileName是/C79EBFF6107CE4389C33DC5901307461-20.mp4,意思是getFile获取的是.com路径后面的文件名,所以我用截取字符串的方式来获取文件名,当然, 也可以自行设置随机文件名
2.字符串截取
3.创建文件写入对象
完整的实现代码贴在下面:
package download;
import java.io.BufferedInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.RandomAccessFile;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
public class DownloadVideo {
private static String videoUrl = "http://aqiniu.tangdou.com/C79E ... 3B%3B
private static final int MAX_BUFFER_SIZE = 1000000;
public static void main(String[] args) {
HttpURLConnection connection = null;
InputStream inputStream = null;
RandomAccessFile randomAccessFile = null;
try {
// 1.获取连接对象
URL url = new URL(videoUrl);
connection = (HttpURLConnection) url.openConnection();
connection.setRequestProperty("Range", "bytes=0-");
connection.connect();
if(connection.getResponseCode() / 100 != 2) {
System.out.println("连接失败...");
return;
}
// 2.获取连接对象的流
inputStream = connection.getInputStream();
//已下载的大小
int downloaded = 0;
//总文件的大小
int fileSize = connection.getContentLength();
String fileName = url.getFile();
fileName = fileName.substring(fileName.lastIndexOf("/") + 1);
// 3.把资源写入文件
randomAccessFile = new RandomAccessFile(fileName,"rw");
while(downloaded < fileSize) {
// 3.1设置缓存流的大小
byte[] buffer = null;
if(fileSize - downloaded >= MAX_BUFFER_SIZE) {
buffer = new byte[MAX_BUFFER_SIZE];
}else {
buffer = new byte[fileSize - downloaded];
}
// 3.2把每一次缓存的数据写入文件
int read = -1;
int currentDownload = 0;
long startTime = System.currentTimeMillis();
while(currentDownload < buffer.length) {
read = inputStream.read();
buffer[currentDownload ++] = (byte) read;
}
long endTime = System.currentTimeMillis();
double speed = 0.0;
if(endTime - startTime > 0) {
speed = currentDownload / 1024.0 / ((double)(endTime - startTime)/1000);
}
randomAccessFile.write(buffer);
downloaded += currentDownload;
randomAccessFile.seek(downloaded);
System.out.printf("下载了进度:%.2f%%,下载速度:%.1fkb/s(%.1fM/s)%n",downloaded * 1.0 / fileSize * 10000 / 100,speed,speed/1000);
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
connection.disconnect();
inputStream.close();
randomAccessFile.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void demo() {
try {
URL url = new URL(videoUrl);
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
下面是对上述代码的补充说明。MAX_BUFFER_SIZE 是我设置的缓存大小。在注释3.1中,判断当前剩余下载大小是否大于缓存,如果不是,则设置缓存大小为剩余。
while(currentDownload < buffer.length) {
read = inputStream.read();
buffer[currentDownload ++] = (byte) read;
}
此代码根据缓存的大小读取和写入该大小的字节。然后依次写入缓存的大小直到结束。
这样做的好处是可以提高效率,保护硬盘,而不需要频繁的硬件写入。
控制台输出:
下载进度:11.59%,下载速度:388.0kb/s(0.4M/s)
下载进度:23.19%,下载速度:262.5kb/s(0.3M/s)
下载进度:34.78%,下载速度:261.0kb/s(0.3M/s)
下载进度:46.38%,下载速度:258.3kb/s(0.3M/s)
下载进度:57.97%,下载速度:260.0kb/s(0.3M/s)
下载进度:69.57%,下载速度:260.9kb/s(0.3M/s)
下载进度:81.16%,下载速度:257.4kb/s(0.3M/s)
下载进度:92.75%,下载速度:252.3kb/s(0.3M/s)
下载进度:100.00%,下载速度:286.5kb/s(0.3M/s) 好的,以上就是下载视频的简单实现,小弟就是刚学的不错,可能还有很多地方不太好,请大家多多指教。
从网页抓取视频(从网页抓取视频做的渲染,帧率高能够更加真实还原打游戏快感)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-28 20:03
从网页抓取视频做的渲染,渲染的帧率据说是125fps(不知道现在有没有固定帧率的),帧率高能够更加真实还原打游戏的快感,大概是吧,
这个应该是转化后通过摄像头抓取的吧,能看到动画和声音的都不是一帧画面。
应该是在摄像头拍摄到一帧的动画帧后被绘制成图片。最后发布的视频格式应该是图片。
应该是处理了帧率。现实里帧率就是按照24帧来的。游戏里帧率统一是125hz,主要应该是因为这种设置效果更加真实。
下游也有个问题,游戏动作好多就是帧,操作的时候1秒一帧,何来24帧,
从别人那里学到的回答如果帧率和真实帧率一样,
帧率一定要比真实帧率高24帧吗。只有10帧跟24帧意义不一样,20帧跟60帧,
网络游戏一般有这么几种显示模式:720p240p2560p640p超高清真实输出是不可能超高清的。
建议用480p游戏
帧率是我们衡量画面的重要因素,“清晰”是一种指标,帧率过低会让画面表现出的画面细节、动态帧率变差,细节的差别与动态视频一样,看起来不真实,会让人产生时间的变化感,就好像进行过特殊处理的视频(如加速)。帧率在高帧率显示情况下,占比非常重要,通常400-600帧是游戏在线格式游戏非常理想的显示范围,玩游戏时你想看到什么就看到什么。 查看全部
从网页抓取视频(从网页抓取视频做的渲染,帧率高能够更加真实还原打游戏快感)
从网页抓取视频做的渲染,渲染的帧率据说是125fps(不知道现在有没有固定帧率的),帧率高能够更加真实还原打游戏的快感,大概是吧,
这个应该是转化后通过摄像头抓取的吧,能看到动画和声音的都不是一帧画面。
应该是在摄像头拍摄到一帧的动画帧后被绘制成图片。最后发布的视频格式应该是图片。
应该是处理了帧率。现实里帧率就是按照24帧来的。游戏里帧率统一是125hz,主要应该是因为这种设置效果更加真实。
下游也有个问题,游戏动作好多就是帧,操作的时候1秒一帧,何来24帧,
从别人那里学到的回答如果帧率和真实帧率一样,
帧率一定要比真实帧率高24帧吗。只有10帧跟24帧意义不一样,20帧跟60帧,
网络游戏一般有这么几种显示模式:720p240p2560p640p超高清真实输出是不可能超高清的。
建议用480p游戏
帧率是我们衡量画面的重要因素,“清晰”是一种指标,帧率过低会让画面表现出的画面细节、动态帧率变差,细节的差别与动态视频一样,看起来不真实,会让人产生时间的变化感,就好像进行过特殊处理的视频(如加速)。帧率在高帧率显示情况下,占比非常重要,通常400-600帧是游戏在线格式游戏非常理想的显示范围,玩游戏时你想看到什么就看到什么。
从网页抓取视频(从网页抓取视频的话是要走的,直接抓视频肯定是抓不到的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-28 07:06
从网页抓取视频的话是要走https的,直接抓视频肯定是抓不到的。我曾经去爬过某局域网内的某个视频,这个链接本身是带后缀的(比如),这个后缀在经过代理以后,会直接返回txt的格式视频文件,后缀为flv。我在网上抓取了解析https的视频链接时也遇到了同样的问题,无解,只能采用格式化视频流。在aria2或者迅雷下载之类的软件上定向下载到某个视频链接后,将https的视频链接与rmvb等格式视频导入aria2,这样就可以导入下载需要解析的视频了。
其他对视频的解析要么没有解析,要么还需要继续解析txt。不过会用视频管理软件的话,完全不用担心会被封。
有文件丢失和限制的情况出现,目前解决思路就是直接下载flv播放器,flash是目前安全性较高的视频编码方式,下载速度相对其他的视频来说是较快的,对于视频比较多的网站来说是个不错的选择。直接从本地下载是比较慢的,直接下载其实是缺点,没有服务器中转,解析起来也比较慢。我感觉主要是解析起来也慢,大部分的视频都有版权限制,解析速度慢。
不能从网站下载视频时,可以采用下边方法下载:首先把视频用下面方法去下载:通过链接提取视频:"id":"(\.+).*"然后就可以下载本地flv视频了。因为转码是视频处理软件来做的,如果你的电脑上没有安装任何的视频处理软件的话,是无法操作的。 查看全部
从网页抓取视频(从网页抓取视频的话是要走的,直接抓视频肯定是抓不到的)
从网页抓取视频的话是要走https的,直接抓视频肯定是抓不到的。我曾经去爬过某局域网内的某个视频,这个链接本身是带后缀的(比如),这个后缀在经过代理以后,会直接返回txt的格式视频文件,后缀为flv。我在网上抓取了解析https的视频链接时也遇到了同样的问题,无解,只能采用格式化视频流。在aria2或者迅雷下载之类的软件上定向下载到某个视频链接后,将https的视频链接与rmvb等格式视频导入aria2,这样就可以导入下载需要解析的视频了。
其他对视频的解析要么没有解析,要么还需要继续解析txt。不过会用视频管理软件的话,完全不用担心会被封。
有文件丢失和限制的情况出现,目前解决思路就是直接下载flv播放器,flash是目前安全性较高的视频编码方式,下载速度相对其他的视频来说是较快的,对于视频比较多的网站来说是个不错的选择。直接从本地下载是比较慢的,直接下载其实是缺点,没有服务器中转,解析起来也比较慢。我感觉主要是解析起来也慢,大部分的视频都有版权限制,解析速度慢。
不能从网站下载视频时,可以采用下边方法下载:首先把视频用下面方法去下载:通过链接提取视频:"id":"(\.+).*"然后就可以下载本地flv视频了。因为转码是视频处理软件来做的,如果你的电脑上没有安装任何的视频处理软件的话,是无法操作的。
从网页抓取视频(360浏览器怎么直接提取网页视频?(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-26 21:10
360浏览器如何直接提取网页视频?很多时候,我们需要下载或提取网页上的视频,但我们不知道如何去做。.
以上步骤只能在观看视频后进行。体验内容仅供参考。如果您需要解决具体问题(尤其是法律、医学等领域),建议您详细咨询相关领域的专业人士。作者声明:本经验基于事实。未经许可体验原创。
下面介绍一种无需借助任何软件即可从网页中提取视频的方法,希望对您有所帮助。方法/步骤我以360浏览器为例,这里可以随便打开一个网页视频,注意不能是视频网站 Video in。打开视频播放,正在播放。
但是,已经有很多视频提取网站,他们可以在网站上提取你要下载的视频,shuoshu网站就是其中之一。说一下使用说书提取网页视频的方法应该不会太晚。
教你如何从网页中提取视频、音乐、歌曲、Flash、图片等多媒体文件(非常实用)忘记图片网址或不想了。
如何下载网页上播放的视频 小雄科技教你如何下载天天科技faAndroid手机网页上的视频,因为视频很多网站,没有下载方法。只有通过这种方法才能实现。工具/原材料 xbrowser 方法/步骤。
642,311 人观看了此视频。在日常生活中,我们经常浏览网页,看到一些不错的视频,就想下载。很多人教过各种方法,比如在设置中查看缓存,比如给网址加后缀,但是随着网站的升级,很多。
如何提取网页上100%的视频?可能很多朋友对此感到困惑。下面小编就为大家介绍一下具体的提取方法,希望对大家有所帮助。进入浏览器后,点击右上角的方法/步骤三横线图标。单击“工具”进行选择。 查看全部
从网页抓取视频(360浏览器怎么直接提取网页视频?(一)(组图))
360浏览器如何直接提取网页视频?很多时候,我们需要下载或提取网页上的视频,但我们不知道如何去做。.
以上步骤只能在观看视频后进行。体验内容仅供参考。如果您需要解决具体问题(尤其是法律、医学等领域),建议您详细咨询相关领域的专业人士。作者声明:本经验基于事实。未经许可体验原创。
下面介绍一种无需借助任何软件即可从网页中提取视频的方法,希望对您有所帮助。方法/步骤我以360浏览器为例,这里可以随便打开一个网页视频,注意不能是视频网站 Video in。打开视频播放,正在播放。
但是,已经有很多视频提取网站,他们可以在网站上提取你要下载的视频,shuoshu网站就是其中之一。说一下使用说书提取网页视频的方法应该不会太晚。
教你如何从网页中提取视频、音乐、歌曲、Flash、图片等多媒体文件(非常实用)忘记图片网址或不想了。

如何下载网页上播放的视频 小雄科技教你如何下载天天科技faAndroid手机网页上的视频,因为视频很多网站,没有下载方法。只有通过这种方法才能实现。工具/原材料 xbrowser 方法/步骤。
642,311 人观看了此视频。在日常生活中,我们经常浏览网页,看到一些不错的视频,就想下载。很多人教过各种方法,比如在设置中查看缓存,比如给网址加后缀,但是随着网站的升级,很多。

如何提取网页上100%的视频?可能很多朋友对此感到困惑。下面小编就为大家介绍一下具体的提取方法,希望对大家有所帮助。进入浏览器后,点击右上角的方法/步骤三横线图标。单击“工具”进行选择。
从网页抓取视频(Moo0VideoDownloader1的新功能14:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-12 19:08
⒈ 一个简单易用的应用程序,可以帮助用户抓取来自不同网站的视频,同时提供出色的下载速度和剪贴板监控选项。
⒉ Moo0 Video Downloader 1新功能14:。
⒊ 主下载引擎的另一个更新。
⒋ 更多错误修复。
⒌ 阅读完整的更改日志。
⒍ Moo0 Video Downloader 是一款轻量级的Windows 应用程序,旨在帮助用户从不同的网站 下载视频并将剪辑保存到计算机以供离线观看。
它使用简洁明了的布局,让您只需点击几下即可设置整个过程。
Moo0 Video Downloader 通过启用剪贴板监控简化了下载过程,这意味着每次复制链接时,应用程序都会自动将其粘贴到主面板并开始下载过程。
此外,您可以将 URL 直接拖放到主窗口中。
更重要的是,您可以选择一个默认的保存目录,在专用对话框中手动插入一个有效的URL并启动下载任务,并可以查看有关捕获视频的详细信息,即标题、大小和状态。
该实用程序允许您使用默认视频播放器播放剪辑、打开存储项目的文件夹、将 URL 复制到剪贴板、从列表中删除项目、取消下载过程和从计算机中。
最后但并非最不重要的是,您可以将应用程序置于其他实用程序之上,如果 网站 需要密码验证,请指定用户名和密码,并检查日志部分以查看有关可能的错误信息的详细信息。
在我们的测试过程中,我们注意到该工具执行下载过程非常快,整个过程没有任何错误。它不会对CPU和内存造成很大压力,因此不会影响计算机的整体性能。
综上所述,Moo0 Video Downloader 让下载操作变得轻而易举。对于正在寻找易于使用的工具而无需太多配置设置的用户来说,它似乎是正确的选择。
提交它。
视频下载器视频 采集器 下载剪辑下载器下载 采集器 YouTube。
Moo0 Video Downloader 由 Ana Marculescu 4 0/5 审核。 查看全部
从网页抓取视频(Moo0VideoDownloader1的新功能14:)
⒈ 一个简单易用的应用程序,可以帮助用户抓取来自不同网站的视频,同时提供出色的下载速度和剪贴板监控选项。
⒉ Moo0 Video Downloader 1新功能14:。
⒊ 主下载引擎的另一个更新。
⒋ 更多错误修复。
⒌ 阅读完整的更改日志。
⒍ Moo0 Video Downloader 是一款轻量级的Windows 应用程序,旨在帮助用户从不同的网站 下载视频并将剪辑保存到计算机以供离线观看。
它使用简洁明了的布局,让您只需点击几下即可设置整个过程。
Moo0 Video Downloader 通过启用剪贴板监控简化了下载过程,这意味着每次复制链接时,应用程序都会自动将其粘贴到主面板并开始下载过程。
此外,您可以将 URL 直接拖放到主窗口中。
更重要的是,您可以选择一个默认的保存目录,在专用对话框中手动插入一个有效的URL并启动下载任务,并可以查看有关捕获视频的详细信息,即标题、大小和状态。
该实用程序允许您使用默认视频播放器播放剪辑、打开存储项目的文件夹、将 URL 复制到剪贴板、从列表中删除项目、取消下载过程和从计算机中。
最后但并非最不重要的是,您可以将应用程序置于其他实用程序之上,如果 网站 需要密码验证,请指定用户名和密码,并检查日志部分以查看有关可能的错误信息的详细信息。
在我们的测试过程中,我们注意到该工具执行下载过程非常快,整个过程没有任何错误。它不会对CPU和内存造成很大压力,因此不会影响计算机的整体性能。
综上所述,Moo0 Video Downloader 让下载操作变得轻而易举。对于正在寻找易于使用的工具而无需太多配置设置的用户来说,它似乎是正确的选择。
提交它。
视频下载器视频 采集器 下载剪辑下载器下载 采集器 YouTube。
Moo0 Video Downloader 由 Ana Marculescu 4 0/5 审核。
从网页抓取视频( 影音下载神器——猫抓这是一款影音嗅探工具(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-12 18:43
影音下载神器——猫抓这是一款影音嗅探工具(组图)
)
如何在网站上下载视频-如何在网站上抓取视频
最近想下载一个网络视频。我不知道如何正确下载它。我到处都卡住了。网上下载网络视频的方法有很多,但都不是很实用的方法。有些方法很麻烦,比如:有人说提取网页代码再下载软件好麻烦!有时候找了半天找不到下载的代码,加上下载时间。这项工作还有待完成吗?有人说下载软件或者网页下载插件,这些方法我都试过了,但是总是不好用,关键是省时省力,所以一直在关注网页下载的知识,可惜还好,终于找到了一个好方法,今天分享给朋友们!
两个下载网络视频的插件——非常棒的工具,获取方式:关注@边走印记,私信回复“视频插件”说明:结合使用以下两个插件制作作品最好的事物!
音视频下载神器-猫抓
这是一个音视频嗅探工具,以插件的形式出现在各大浏览器扩展中。它主要捕获视频和音频。只要打开任意音视频播放,它就会自动抓取,点击下载即可。其中,音频秒杀,无需等待即可下载。对于主流视频网站,采用分段下载。您可以使用复合视频工具再次组合它。是它的缺点,但是下载小视频、非主流影视就不会出现这种情况。下载的视频完好无损。主流视频都被别人用的shell保护了,有自己的格式,所以才会出现。这个情况。
您可以在百度上搜索并下载该插件。如果嫌麻烦,下载超级浏览器,它收录在扩展中,点击安装即可。最近小编发现这个插件好难找。如果找不到,可以关注我获取哦!
先说一下如何安装插件,就是把插件下载到桌面,然后打开浏览器,然后在浏览器窗口打开扩展,把插件拖到桌面上,就可以了自动安装,你可以使用它 NS。
音视频下载神器-Video DownloadHelper
Video DownloadHelper 是一款专用软件,可以更轻松地从不同的网站 下载各种视频。该程序承诺非常易于使用,只需按一个按钮即可开始工作。
获取你想要的视频
Video DownloadHelper 带有 Firefox 和 Chrome 兼容版本,以帮助扩展频谱,以便它可以与各种流行的操作系统一起使用。用户只需在自己经常查看的网站中找到自己喜欢的视频,然后点击按钮即可开始下载过程。一个方便的工具栏显示了下载过程,尽管在某些情况下,以高清显示的非常大的公关视频可能需要相当长的时间才能下载,而其他视频可能会被阻止。
无尽的内容触手可及
无法从某些 网站 下载他们想要的视频的人可能会发现 Video DownloadHelper 使此过程更容易。尽管该程序不时会出现故障,但免费提供的事实意味着在承诺为此类其他程序付费之前需要对其进行检查。
这个工具有插件和应用软件。您可以根据自己的需要下载它们。插件可以节省您的计算机空间,但该软件非常适合管理内容。各有各的优点!
查看全部
从网页抓取视频(
影音下载神器——猫抓这是一款影音嗅探工具(组图)
)
如何在网站上下载视频-如何在网站上抓取视频
最近想下载一个网络视频。我不知道如何正确下载它。我到处都卡住了。网上下载网络视频的方法有很多,但都不是很实用的方法。有些方法很麻烦,比如:有人说提取网页代码再下载软件好麻烦!有时候找了半天找不到下载的代码,加上下载时间。这项工作还有待完成吗?有人说下载软件或者网页下载插件,这些方法我都试过了,但是总是不好用,关键是省时省力,所以一直在关注网页下载的知识,可惜还好,终于找到了一个好方法,今天分享给朋友们!

两个下载网络视频的插件——非常棒的工具,获取方式:关注@边走印记,私信回复“视频插件”说明:结合使用以下两个插件制作作品最好的事物!
音视频下载神器-猫抓
这是一个音视频嗅探工具,以插件的形式出现在各大浏览器扩展中。它主要捕获视频和音频。只要打开任意音视频播放,它就会自动抓取,点击下载即可。其中,音频秒杀,无需等待即可下载。对于主流视频网站,采用分段下载。您可以使用复合视频工具再次组合它。是它的缺点,但是下载小视频、非主流影视就不会出现这种情况。下载的视频完好无损。主流视频都被别人用的shell保护了,有自己的格式,所以才会出现。这个情况。
您可以在百度上搜索并下载该插件。如果嫌麻烦,下载超级浏览器,它收录在扩展中,点击安装即可。最近小编发现这个插件好难找。如果找不到,可以关注我获取哦!
先说一下如何安装插件,就是把插件下载到桌面,然后打开浏览器,然后在浏览器窗口打开扩展,把插件拖到桌面上,就可以了自动安装,你可以使用它 NS。

音视频下载神器-Video DownloadHelper
Video DownloadHelper 是一款专用软件,可以更轻松地从不同的网站 下载各种视频。该程序承诺非常易于使用,只需按一个按钮即可开始工作。
获取你想要的视频
Video DownloadHelper 带有 Firefox 和 Chrome 兼容版本,以帮助扩展频谱,以便它可以与各种流行的操作系统一起使用。用户只需在自己经常查看的网站中找到自己喜欢的视频,然后点击按钮即可开始下载过程。一个方便的工具栏显示了下载过程,尽管在某些情况下,以高清显示的非常大的公关视频可能需要相当长的时间才能下载,而其他视频可能会被阻止。
无尽的内容触手可及
无法从某些 网站 下载他们想要的视频的人可能会发现 Video DownloadHelper 使此过程更容易。尽管该程序不时会出现故障,但免费提供的事实意味着在承诺为此类其他程序付费之前需要对其进行检查。
这个工具有插件和应用软件。您可以根据自己的需要下载它们。插件可以节省您的计算机空间,但该软件非常适合管理内容。各有各的优点!

从网页抓取视频(一键下载高清视频专注于下载YouTube视频视频的获取方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2021-10-08 10:27
)
1、高清视频一键下载
专注下载YouTube超高清视频,支持720P、1080P、2K、4K、8K分辨率视频采集。不仅可以下载YouTube视频,TubeGet还支持从各种流媒体网站获取视频内容:包括Vimeo、Lynda、Twitch等视频网站、Facebook、Twitter、Instagram、Tumblr等社交媒体,以及Vevo 和 SoundCloud 等音乐服务网站。
除了下载单个 YouTube 视频外,它还支持批量下载播放列表和频道中的所有视频。YouTube上的字幕文件(收录、自动生成、翻译)、360°VR全景视频、48/60FPS高帧率视频、高清封面、3D视频等都支持保存。此外,这款 YouTube 下载器还可以将音乐视频转换为 MP3 音频格式。
2、集成多种实用工具
独有的一键下载模式,只需提前设置下载分辨率、下载位置、字幕语言,即可将YouTube视频快速保存到Windows或Mac电脑。除了YouTube视频保存功能,Gihosoft TubeGet还有视频格式转换功能,可以将下载的YouTube WebM视频转换成MP4、MKV、AVI、MOV格式。
在转换视频的同时,您还可以合成视频和字幕文件。选择转换格式后,点击“添加字幕”选项,导入下载的字幕文件。然后选择将字幕合成为硬字幕或软字幕,最后点击“转换”按钮将字幕文件和视频合并为一个整体。
3、在 YouTube 上下载任何内容和格式
Gihosoft TubeGet 可以下载各种格式的 YouTube 视频、播放列表、频道和类别,例如 MP4、WebM、3GP、FLV、AVI、MKV 等,以及不同的分辨率,包括 4K、1440P、1080P、720P、480P、360P 和240P等,最多可以下载5个YouTube视频并恢复下载失败。如果您的互联网连接速度较慢,您可以将下载速度限制为 4MBps、2MBps、1MBps、700KBps、200KBps 等。
4、下载 YouTube 视频并将其转换为 MP3
Gihosoft TubeGet 不仅可以用作免费的 YouTube 视频下载软件,还可以用作在线音乐爱好者的完美免费 YouTube 转 MP3 工具。使用它,您可以直接从 YouTube 和其他视频中提取和下载 MP3 文件网站,而无需下载整个视频文件。
查看全部
从网页抓取视频(一键下载高清视频专注于下载YouTube视频视频的获取方法
)
1、高清视频一键下载
专注下载YouTube超高清视频,支持720P、1080P、2K、4K、8K分辨率视频采集。不仅可以下载YouTube视频,TubeGet还支持从各种流媒体网站获取视频内容:包括Vimeo、Lynda、Twitch等视频网站、Facebook、Twitter、Instagram、Tumblr等社交媒体,以及Vevo 和 SoundCloud 等音乐服务网站。
除了下载单个 YouTube 视频外,它还支持批量下载播放列表和频道中的所有视频。YouTube上的字幕文件(收录、自动生成、翻译)、360°VR全景视频、48/60FPS高帧率视频、高清封面、3D视频等都支持保存。此外,这款 YouTube 下载器还可以将音乐视频转换为 MP3 音频格式。

2、集成多种实用工具
独有的一键下载模式,只需提前设置下载分辨率、下载位置、字幕语言,即可将YouTube视频快速保存到Windows或Mac电脑。除了YouTube视频保存功能,Gihosoft TubeGet还有视频格式转换功能,可以将下载的YouTube WebM视频转换成MP4、MKV、AVI、MOV格式。
在转换视频的同时,您还可以合成视频和字幕文件。选择转换格式后,点击“添加字幕”选项,导入下载的字幕文件。然后选择将字幕合成为硬字幕或软字幕,最后点击“转换”按钮将字幕文件和视频合并为一个整体。
3、在 YouTube 上下载任何内容和格式
Gihosoft TubeGet 可以下载各种格式的 YouTube 视频、播放列表、频道和类别,例如 MP4、WebM、3GP、FLV、AVI、MKV 等,以及不同的分辨率,包括 4K、1440P、1080P、720P、480P、360P 和240P等,最多可以下载5个YouTube视频并恢复下载失败。如果您的互联网连接速度较慢,您可以将下载速度限制为 4MBps、2MBps、1MBps、700KBps、200KBps 等。
4、下载 YouTube 视频并将其转换为 MP3
Gihosoft TubeGet 不仅可以用作免费的 YouTube 视频下载软件,还可以用作在线音乐爱好者的完美免费 YouTube 转 MP3 工具。使用它,您可以直接从 YouTube 和其他视频中提取和下载 MP3 文件网站,而无需下载整个视频文件。

从网页抓取视频(如何支持多种视频格式转换的软件有很多种?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-10-03 22:02
从网页抓取视频后,下载地址中网站的每个视频,然后通过ae渲染,导出为mp4即可用,或者用adsafe插件也可以。这么做的理由是,如果网站把高清视频全下了,网站的用户体验会下降。
用动态小视频在线下载工具,效果和ae差不多,特别简单只需要输入url或在浏览器直接打开网址即可。
很多人为了下载很小清晰的视频,会去寻找很麻烦,并且要付费使用的那种方法,非常烦人。目前支持多种视频格式转换的软件有很多,一般是用这种办法,比如下载酷6的视频,那么他的视频的格式文件就是swf格式,所以你就可以用格式工厂等软件把其他一些视频格式转换一下。如果视频格式是mp4或者wmv,这就好办了,还是可以用ae、pr、finalcut这些工具将其他的转换一下格式,把画质改为1080p。
下面是我今天下载的,我就直接把其他软件下载的视频格式转换了一下,感觉还行,毕竟一般视频不会是5g这么大的,有可能有些朋友下载的时候,视频不止5g,但是大部分人并不知道。使用简单,可不要用教程了,好好琢磨一下,下个软件,也很方便。
支持,准备好下载包和拖拉机,出门右转,百度搜youhouboy,
windows下你需要打开命令提示符
不清楚ps,ae是啥。但是高清这个概念大多是指1080p,对于小一点的体积,比如2g、4g视频来说。真的没有卵用ps比较常用,ae经常用,我们做电商产品,还有一些电视广告什么的。flash、cc2013可以用,像我们做小说电视剧的真心不行。你的这个视频是1080p有可能是电视级别。所以,不是特别清晰。 查看全部
从网页抓取视频(如何支持多种视频格式转换的软件有很多种?)
从网页抓取视频后,下载地址中网站的每个视频,然后通过ae渲染,导出为mp4即可用,或者用adsafe插件也可以。这么做的理由是,如果网站把高清视频全下了,网站的用户体验会下降。
用动态小视频在线下载工具,效果和ae差不多,特别简单只需要输入url或在浏览器直接打开网址即可。
很多人为了下载很小清晰的视频,会去寻找很麻烦,并且要付费使用的那种方法,非常烦人。目前支持多种视频格式转换的软件有很多,一般是用这种办法,比如下载酷6的视频,那么他的视频的格式文件就是swf格式,所以你就可以用格式工厂等软件把其他一些视频格式转换一下。如果视频格式是mp4或者wmv,这就好办了,还是可以用ae、pr、finalcut这些工具将其他的转换一下格式,把画质改为1080p。
下面是我今天下载的,我就直接把其他软件下载的视频格式转换了一下,感觉还行,毕竟一般视频不会是5g这么大的,有可能有些朋友下载的时候,视频不止5g,但是大部分人并不知道。使用简单,可不要用教程了,好好琢磨一下,下个软件,也很方便。
支持,准备好下载包和拖拉机,出门右转,百度搜youhouboy,
windows下你需要打开命令提示符
不清楚ps,ae是啥。但是高清这个概念大多是指1080p,对于小一点的体积,比如2g、4g视频来说。真的没有卵用ps比较常用,ae经常用,我们做电商产品,还有一些电视广告什么的。flash、cc2013可以用,像我们做小说电视剧的真心不行。你的这个视频是1080p有可能是电视级别。所以,不是特别清晰。
从网页抓取视频(本期目录01网页抓取02中文分词03文档矩阵04共现05文本聚类)
网站优化 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-10-03 00:00
本期目录
01
网页抓取
02
中文分词
03
文档矩阵
04
词频共现
05
文本聚类
06
主题建模
07
情绪分析
08
词频统计
09
绘制词云
失去
随着科技的进步,定量分析方法不再仅仅通过问卷、二手数据库等方式采集数据,而不再仅仅通过数理统计、回归分析等手段来分析数据。针对不同的研究需求,产生了越来越多的新方法和新工具:
例如,以元胞自动机为代表的生命体建模技术,以马尔可夫链蒙特卡罗(MCMC)算法为代表的计算机仿真技术等。
本期介绍使用爬虫技术抓取网页的实际案例,并对获取的网页文本数据进行后续分析。我将用网友对《流浪地球》豆瓣影评正文的获取和分析全过程作为示范案例。
文本挖掘的本质是通过自然语言处理(NLP)和分析方法将文本转化为数据进行分析。因此,阅读本文需要一定的知识基础,包括网页设计和自然语言处理方法,我会在文章中适当添加。
➡ 1.准备
在分析工作之前,需要配置软件的工作环境,包括设置工作目录、调用所需的程序包等。采集接收到的文本数据、各种词典、输出结果等都会存放在工作目录中;首次使用前需要安装外部程序包。
###备工作#设置工作目录setwd('D:/流浪地球')#加载需要的包 library('rvest')library('stringr')library('jiebaRD')library('jiebaR') library('plyr')library('rJava')library('tm')library('tmcn')library('proxy')library('topicmodels')library('sqldf')library('wordcloud2')
➡ 2.网页抓取
我仍然遵循定量分析的传统套路,将整个分析过程分为数据采集和数据分析两部分。第一步是通过爬虫技术抓取网页。
网络爬虫,也称为蜘蛛,是一种自动浏览万维网的网络机器人。它的目的一般是编译一个网络索引。爬虫访问网站的过程会消耗目标系统资源,很多网络系统默认是不允许爬虫工作的。因此,在访问大量页面时,爬虫需要考虑规划、加载和“礼貌”。使用robots.txt文件和其他方法可以避免爬虫不愿意访问和爬虫所有者已知的公共站点。
例如豆瓣电影()的robots.txt规定如下:
用户代理:*Disallow:/subject_searchDisallow:/amazon_searchDisallow:/searchDisallow:/group/searchDisallow:/event/searchDisallow:/celebrities/searchDisallow:/location/drama/searchDisallow:/forum/Disallow:/new_subjectDisallow:/service/iframeDisallow : /j/Disallow: /link2/Disallow: /recommend/Disallow: /doubanapp/cardDisallow: /update/topic/Sitemap: Sitemap: #Crawl-delay: 5
User-agent: 玩豆家 SpiderDisallow: /
在实际应用中,网络爬虫技术并不是特别复杂。在很多情况下,我们倾向于指定网站并抓取内容,更喜欢网页采集而不是网络爬虫。在此之前,希望读者了解网页源代码的相关知识,尤其是标记语言(HTML,只有语法,没有变量和逻辑)、层叠样式表(CSS,用于控制元素的显示形式) )、脚本语言(Java、HTML中元素增删改查的操作)在网页设计中。
另外,当网页以更复杂的表现形式出现时,如URL分页、超链接、异步加载等,需要读者有更多的理论知识。
###网页采集#observation URL pattern index #批量爬取好评数据评论为(i in index){#Read URL url = paste("",i,"&limit=20&sort=new_score&status=P&percent_type= h" ,sep="")web #爬取豆瓣赞词%html_nodes('#comments p')%>%html_text()#创建一个数据框存放上述信息comments_datacomments }#保存豆瓣赞为CSV文件写入。csv(评论,文件=“赞美.csv”,row.names=FALSE)
以上是本期抓取网页文本数据的代码。我从豆瓣电影网站中抓取了220条网友为《流浪地球》点赞的文字,保存为“praise.csv”文件。HTTP错误403错误不影响结果,这意味着从R进入的网页被识别为爬虫,访问被拒绝更多,并且由于限制而无法爬取所有评论:
一般纳税人公司注册费?价格透明,全程免费,中途不收取任何额外费用。
图1:豆瓣电影网站截图
注册一家公司需要多少钱?
图2:截取的220条评论文本数据截图
➡ 3.中文分词
中文自动分词是指使用计算机对中文文本进行自动分词,即中文句子中的单词之间有空格,以便像英文一样进行识别。中文自动分词被认为是中文自然语言处理中最基本的环节之一。
许多教科书以英文文本作为教学案例,分词所用的程序包与处理中文文本时所用的程序包不同。读者需注意自学。
###中文分词#获取当前工作目录getwd()#设置自定义词典并停止词汇引擎#导入赞美文字good names(good)nchar(good)#文字预处理good_res = good[good!=" "]ls ()fix(good_res)#赞美文字切分good_segwords fix(good_segwords)#删除未过滤出停止词表过滤器的词 filter_segment(good_segwords, filter)fix(good_segwords)
需要特别注意的是,用户自定义词典和停用词列表需要放在工作路径中,并保存为UTF-8编码格式的txt文本文件。传统上,第一行可以留空:
广告精品课程值得信赖!名师一对一指导,免费视频全真考,国家注册会计师名师指导,轻松通过考试!
图 3:我的用户定义词典和停用词列表的屏幕截图
自定义词典是为了防止固定词汇被拆解。例如,如果不设置自定义词典,“漫游空间2001”将被拆分为三个词:“漫游”、“空间”和“2001”;“韩多”“多”将拆分为“韩”和“多”两个字;这会给我们后续的分析带来麻烦。
过滤停用词列表就是删除我们在中文文本中不需要的虚词,例如“啊”、“啊”、“?” 以及其他词,“应该”、“是”等不相关的词、英文字母、标点符号和阿拉伯数字等。
对于不同的研究问题,自定义词典和停用词表每次分析都是不一样的,需要根据不同问题的需要不断调整修改。以下是部分文本使用自定义词典和停用词表后的分词效果:
图4:部分文字切分效果截图
➡ 4.文档矩阵
使用文档术语矩阵 (DTM),可以构建文本数据。DTM矩阵是转置后的TDM。DTM矩阵的形式是矩阵的行代表文档,矩阵的列代表词,矩阵元素是某个词在文档中出现的次数。
特别提示:需要先用Excel打开“Praise.csv”文件,使用“Review-Traditional to Simplified”将繁体字全部转为简体字,否则构建文档矩阵时会报错;文档-词频矩阵的构建是为了后续分析的基础:
###文档矩阵#创建好文本的DTM文件 good_corpus inspect(good_corpus[1:10])good_corpusctrlgood_dtminspect(good_dtm[1:10, 110:112])good_dtm
➡ 5. 词频共现
共现分析利用词语的共现来定量研究文本关系。因此,通过统计一组词在同一文本中出现的频率,可以形成由这些词对关联组成的共同词网络,网络中节点之间的距离可以反映内容的接近程度。
###词词共现#以术语“硬核科幻”0.5关系及以上为例 findAssocs(good_dtm, "hard core sci-fi", 0.5)
我以“硬核科幻”这个词0.5和上面的词汇结果为例,发现“硬核科幻”这个词和情节,气势磅礴,激情澎湃,社会秩序,低成本,完整,圆满词,例如,所有人类都有很强的共现关系:
$硬核科幻剧情,低成本,气势磅礴,第一次,气势磅礴参考奇伟的血统人类学想象社会秩序0.94 0.87 0.87 0. 87 0.87 < @0.87 0.87 0.87 0.87 0.87 想不到新的起点,烟花爆竹印象预告片,彻底的灾难,完整的世界和全人类0.87 0.87 0.87 0.87 0.87 0.87 < @0.85 0.71 0.57 0.55
➡ 6. 文本聚类
聚类分析是研究分类问题的统计分析方法,也是数据挖掘的重要算法。聚类分析由几种模式组成。通常,模式是一个测量向量,或者是多维空间中的一个点。聚类分析基于相似性,一个聚类中的模式之间的相似性比不在同一聚类中的模式更多。
###文本聚类#删除稀疏矩阵 good_dtm_sub dim(good_dtm_sub)#好的文本聚类 good_dist heatmap(as.matrix(good_dist),labRow=FALSE, labCol=FALSE)good_clust plot(good_clust)result1result2summary(result1)@ >sum (result2)result1result2plot(good_clust)
稀疏矩阵对分类预测系统的效率和预测精度有负面影响。因此,需要降低词频矩阵的维数,删除稀疏条目。
上面使用的是余弦相似度算法。通过测量两个向量之间夹角的余弦,来测量它们之间的相似度。0度角的余弦值为1,其他任何角度的余弦值都不大于1;其最小值为-1;因此两个向量之间夹角的余弦值决定了这两个向量是否大致指向同一方向。
结果与向量的长度无关,只与向量的方向有关。余弦相似度通常用在正空间,所以给定的值在0到1之间。 比如在信息检索中,每个term被赋予不同的维度,一个文档用一个向量表示,每个维度的值对应到文档中术语的频率。因此,余弦相似度可以给出两个文档在主题方面的相似度。
我分别使用 k=5 和 k=10 时的结果进行比较。220条评论的数量让树状图有点乱,但是聚类报告非常清晰。下图显示了 k=5 时的 220 条评论。文本聚类结果:
广告是秃头?别再用生姜洗头了,试试用生姜吧,稀疏的头发瞬间变得浓密
图5:k=5时220条评论文本的聚类结果
➡ 7. 主题建模
<p>主题模型是一种统计模型,用于在机器学习和自然语言处理领域的一系列文档中发现抽象主题。直观来说,如果一篇文章文章有一个中心思想,那么一些特定的词就会出现得更频繁。例如,如果一篇文章是关于狗的,那么“狗”和“骨头”这两个词会出现得更频繁;如果一篇文章文章是关于猫的,那么“cat”和“fish”等词出现的频率会更高。一些词例如“this”和“he”在这两个 查看全部
从网页抓取视频(本期目录01网页抓取02中文分词03文档矩阵04共现05文本聚类)
本期目录
01
网页抓取
02
中文分词
03
文档矩阵
04
词频共现
05
文本聚类
06
主题建模
07
情绪分析
08
词频统计
09
绘制词云
失去
随着科技的进步,定量分析方法不再仅仅通过问卷、二手数据库等方式采集数据,而不再仅仅通过数理统计、回归分析等手段来分析数据。针对不同的研究需求,产生了越来越多的新方法和新工具:
例如,以元胞自动机为代表的生命体建模技术,以马尔可夫链蒙特卡罗(MCMC)算法为代表的计算机仿真技术等。
本期介绍使用爬虫技术抓取网页的实际案例,并对获取的网页文本数据进行后续分析。我将用网友对《流浪地球》豆瓣影评正文的获取和分析全过程作为示范案例。
文本挖掘的本质是通过自然语言处理(NLP)和分析方法将文本转化为数据进行分析。因此,阅读本文需要一定的知识基础,包括网页设计和自然语言处理方法,我会在文章中适当添加。
➡ 1.准备
在分析工作之前,需要配置软件的工作环境,包括设置工作目录、调用所需的程序包等。采集接收到的文本数据、各种词典、输出结果等都会存放在工作目录中;首次使用前需要安装外部程序包。
###备工作#设置工作目录setwd('D:/流浪地球')#加载需要的包 library('rvest')library('stringr')library('jiebaRD')library('jiebaR') library('plyr')library('rJava')library('tm')library('tmcn')library('proxy')library('topicmodels')library('sqldf')library('wordcloud2')
➡ 2.网页抓取
我仍然遵循定量分析的传统套路,将整个分析过程分为数据采集和数据分析两部分。第一步是通过爬虫技术抓取网页。
网络爬虫,也称为蜘蛛,是一种自动浏览万维网的网络机器人。它的目的一般是编译一个网络索引。爬虫访问网站的过程会消耗目标系统资源,很多网络系统默认是不允许爬虫工作的。因此,在访问大量页面时,爬虫需要考虑规划、加载和“礼貌”。使用robots.txt文件和其他方法可以避免爬虫不愿意访问和爬虫所有者已知的公共站点。
例如豆瓣电影()的robots.txt规定如下:
用户代理:*Disallow:/subject_searchDisallow:/amazon_searchDisallow:/searchDisallow:/group/searchDisallow:/event/searchDisallow:/celebrities/searchDisallow:/location/drama/searchDisallow:/forum/Disallow:/new_subjectDisallow:/service/iframeDisallow : /j/Disallow: /link2/Disallow: /recommend/Disallow: /doubanapp/cardDisallow: /update/topic/Sitemap: Sitemap: #Crawl-delay: 5
User-agent: 玩豆家 SpiderDisallow: /
在实际应用中,网络爬虫技术并不是特别复杂。在很多情况下,我们倾向于指定网站并抓取内容,更喜欢网页采集而不是网络爬虫。在此之前,希望读者了解网页源代码的相关知识,尤其是标记语言(HTML,只有语法,没有变量和逻辑)、层叠样式表(CSS,用于控制元素的显示形式) )、脚本语言(Java、HTML中元素增删改查的操作)在网页设计中。
另外,当网页以更复杂的表现形式出现时,如URL分页、超链接、异步加载等,需要读者有更多的理论知识。
###网页采集#observation URL pattern index #批量爬取好评数据评论为(i in index){#Read URL url = paste("",i,"&limit=20&sort=new_score&status=P&percent_type= h" ,sep="")web #爬取豆瓣赞词%html_nodes('#comments p')%>%html_text()#创建一个数据框存放上述信息comments_datacomments }#保存豆瓣赞为CSV文件写入。csv(评论,文件=“赞美.csv”,row.names=FALSE)
以上是本期抓取网页文本数据的代码。我从豆瓣电影网站中抓取了220条网友为《流浪地球》点赞的文字,保存为“praise.csv”文件。HTTP错误403错误不影响结果,这意味着从R进入的网页被识别为爬虫,访问被拒绝更多,并且由于限制而无法爬取所有评论:
一般纳税人公司注册费?价格透明,全程免费,中途不收取任何额外费用。
图1:豆瓣电影网站截图

注册一家公司需要多少钱?
图2:截取的220条评论文本数据截图
➡ 3.中文分词
中文自动分词是指使用计算机对中文文本进行自动分词,即中文句子中的单词之间有空格,以便像英文一样进行识别。中文自动分词被认为是中文自然语言处理中最基本的环节之一。
许多教科书以英文文本作为教学案例,分词所用的程序包与处理中文文本时所用的程序包不同。读者需注意自学。
###中文分词#获取当前工作目录getwd()#设置自定义词典并停止词汇引擎#导入赞美文字good names(good)nchar(good)#文字预处理good_res = good[good!=" "]ls ()fix(good_res)#赞美文字切分good_segwords fix(good_segwords)#删除未过滤出停止词表过滤器的词 filter_segment(good_segwords, filter)fix(good_segwords)
需要特别注意的是,用户自定义词典和停用词列表需要放在工作路径中,并保存为UTF-8编码格式的txt文本文件。传统上,第一行可以留空:

广告精品课程值得信赖!名师一对一指导,免费视频全真考,国家注册会计师名师指导,轻松通过考试!
图 3:我的用户定义词典和停用词列表的屏幕截图
自定义词典是为了防止固定词汇被拆解。例如,如果不设置自定义词典,“漫游空间2001”将被拆分为三个词:“漫游”、“空间”和“2001”;“韩多”“多”将拆分为“韩”和“多”两个字;这会给我们后续的分析带来麻烦。
过滤停用词列表就是删除我们在中文文本中不需要的虚词,例如“啊”、“啊”、“?” 以及其他词,“应该”、“是”等不相关的词、英文字母、标点符号和阿拉伯数字等。
对于不同的研究问题,自定义词典和停用词表每次分析都是不一样的,需要根据不同问题的需要不断调整修改。以下是部分文本使用自定义词典和停用词表后的分词效果:

图4:部分文字切分效果截图
➡ 4.文档矩阵
使用文档术语矩阵 (DTM),可以构建文本数据。DTM矩阵是转置后的TDM。DTM矩阵的形式是矩阵的行代表文档,矩阵的列代表词,矩阵元素是某个词在文档中出现的次数。
特别提示:需要先用Excel打开“Praise.csv”文件,使用“Review-Traditional to Simplified”将繁体字全部转为简体字,否则构建文档矩阵时会报错;文档-词频矩阵的构建是为了后续分析的基础:
###文档矩阵#创建好文本的DTM文件 good_corpus inspect(good_corpus[1:10])good_corpusctrlgood_dtminspect(good_dtm[1:10, 110:112])good_dtm
➡ 5. 词频共现
共现分析利用词语的共现来定量研究文本关系。因此,通过统计一组词在同一文本中出现的频率,可以形成由这些词对关联组成的共同词网络,网络中节点之间的距离可以反映内容的接近程度。
###词词共现#以术语“硬核科幻”0.5关系及以上为例 findAssocs(good_dtm, "hard core sci-fi", 0.5)
我以“硬核科幻”这个词0.5和上面的词汇结果为例,发现“硬核科幻”这个词和情节,气势磅礴,激情澎湃,社会秩序,低成本,完整,圆满词,例如,所有人类都有很强的共现关系:
$硬核科幻剧情,低成本,气势磅礴,第一次,气势磅礴参考奇伟的血统人类学想象社会秩序0.94 0.87 0.87 0. 87 0.87 < @0.87 0.87 0.87 0.87 0.87 想不到新的起点,烟花爆竹印象预告片,彻底的灾难,完整的世界和全人类0.87 0.87 0.87 0.87 0.87 0.87 < @0.85 0.71 0.57 0.55
➡ 6. 文本聚类
聚类分析是研究分类问题的统计分析方法,也是数据挖掘的重要算法。聚类分析由几种模式组成。通常,模式是一个测量向量,或者是多维空间中的一个点。聚类分析基于相似性,一个聚类中的模式之间的相似性比不在同一聚类中的模式更多。
###文本聚类#删除稀疏矩阵 good_dtm_sub dim(good_dtm_sub)#好的文本聚类 good_dist heatmap(as.matrix(good_dist),labRow=FALSE, labCol=FALSE)good_clust plot(good_clust)result1result2summary(result1)@ >sum (result2)result1result2plot(good_clust)
稀疏矩阵对分类预测系统的效率和预测精度有负面影响。因此,需要降低词频矩阵的维数,删除稀疏条目。
上面使用的是余弦相似度算法。通过测量两个向量之间夹角的余弦,来测量它们之间的相似度。0度角的余弦值为1,其他任何角度的余弦值都不大于1;其最小值为-1;因此两个向量之间夹角的余弦值决定了这两个向量是否大致指向同一方向。
结果与向量的长度无关,只与向量的方向有关。余弦相似度通常用在正空间,所以给定的值在0到1之间。 比如在信息检索中,每个term被赋予不同的维度,一个文档用一个向量表示,每个维度的值对应到文档中术语的频率。因此,余弦相似度可以给出两个文档在主题方面的相似度。
我分别使用 k=5 和 k=10 时的结果进行比较。220条评论的数量让树状图有点乱,但是聚类报告非常清晰。下图显示了 k=5 时的 220 条评论。文本聚类结果:

广告是秃头?别再用生姜洗头了,试试用生姜吧,稀疏的头发瞬间变得浓密
图5:k=5时220条评论文本的聚类结果
➡ 7. 主题建模
<p>主题模型是一种统计模型,用于在机器学习和自然语言处理领域的一系列文档中发现抽象主题。直观来说,如果一篇文章文章有一个中心思想,那么一些特定的词就会出现得更频繁。例如,如果一篇文章是关于狗的,那么“狗”和“骨头”这两个词会出现得更频繁;如果一篇文章文章是关于猫的,那么“cat”和“fish”等词出现的频率会更高。一些词例如“this”和“he”在这两个
从网页抓取视频( 教你如何提取网页中的视频音乐歌曲flash图片等多媒体文件很实用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 372 次浏览 • 2021-10-01 22:01
教你如何提取网页中的视频音乐歌曲flash图片等多媒体文件很实用)
教你如何从网页中提取视频、音乐、歌曲、flash图片等多媒体文件。这是非常有用的。打开网页后,发现里面有好听的视频、好听的音乐、好听的图片、炫目的flash。你想把它们放在你的电脑或手机上的mp4吗?但是很多时候视频下载不了,音乐只能试听,或者好听的背景音乐不知道叫什么名字,更别提怎么下载了。至于图片,你可以直接右键另存为。但是如果网页突然关闭了,但又想把看到的图片保存下来,忘记了图片的网址或者不想通过历史记录打开怎么办?其实这些问题
问题可以很好的解决,而且很简单。只需使用软件从计算机的缓存中搜索您即可。就可以了,因为网页上显示的内容基本上都在缓存中了。如果自己手动搜索,会很累。迪不容易找到太多东西,也没有分类。无意中发现了一个对它很感兴趣的小软件。玩过无数小软件。我一直在用,也用它帮助了很多网友解决了他们的问题。所以我拿了它和我的朋友们分享,没有废话。现在进入主题。这个免费的小软件是YuanBox元宝盒v16。可以在百度上搜索下载。以下是我自己整理的使用。
步骤供大家参考。实际上,您不需要阅读该软件。这很简单。我不需要学习它。我只是用了很长时间。我很熟练。下载软件后,解压并打开里面的YuanBoxexe。您可以稍后将其关闭。这是为了确保计算机缓存中有您想要的内容。运行软件的初始界面如下图所示。flv格式视频搜索结果的界面直接在界面之后。原因是这个软件的全称是Ingot Box。FLV 视频下载专家不想要视频。如果点击最上面的设置或者最下面的高级设置来设置搜索范围,下面是搜索条件设置
界面以swf格式flash为例,搜索选择类型中的第二项。单击“确定”开始搜索结果。单击保存此项进行保存。下面重点介绍网页中音乐的提取过程。音乐软件上有提示只要网页没有关闭,点击右上角的刷新视频可以加快缓冲。缓冲后,会出现下图中的第二项。缓冲后,您可以预览试听或保存部分,但可以识别。找出它是否是您要查找的内容,然后决定让它完成缓冲。
单击预览以收听音乐。预览所有操作,如下图所示。保存界面如下。点击复制媒体地址复制原链接,即外链地址或下载地址。单击原创链接将打开播放器并使用原创链接地址播放在线音乐。还有一种直观的查看原创链接地址的方法 方法上面的方法要粘在一个地方才能看到下面的方法。右键单击原创链接并选择“属性”将其打开。
性界面如下。搜索其他媒体类型底部的原创链接地址大致相同。让我们谈谈设置中的情况。大小限制设置将缩小搜索范围。快速找到你想要的,最后证明图片和视频的搜索过程太简单了。实际上,你不需要看跌落。下面是flv视频的预览。 查看全部
从网页抓取视频(
教你如何提取网页中的视频音乐歌曲flash图片等多媒体文件很实用)

教你如何从网页中提取视频、音乐、歌曲、flash图片等多媒体文件。这是非常有用的。打开网页后,发现里面有好听的视频、好听的音乐、好听的图片、炫目的flash。你想把它们放在你的电脑或手机上的mp4吗?但是很多时候视频下载不了,音乐只能试听,或者好听的背景音乐不知道叫什么名字,更别提怎么下载了。至于图片,你可以直接右键另存为。但是如果网页突然关闭了,但又想把看到的图片保存下来,忘记了图片的网址或者不想通过历史记录打开怎么办?其实这些问题

问题可以很好的解决,而且很简单。只需使用软件从计算机的缓存中搜索您即可。就可以了,因为网页上显示的内容基本上都在缓存中了。如果自己手动搜索,会很累。迪不容易找到太多东西,也没有分类。无意中发现了一个对它很感兴趣的小软件。玩过无数小软件。我一直在用,也用它帮助了很多网友解决了他们的问题。所以我拿了它和我的朋友们分享,没有废话。现在进入主题。这个免费的小软件是YuanBox元宝盒v16。可以在百度上搜索下载。以下是我自己整理的使用。

步骤供大家参考。实际上,您不需要阅读该软件。这很简单。我不需要学习它。我只是用了很长时间。我很熟练。下载软件后,解压并打开里面的YuanBoxexe。您可以稍后将其关闭。这是为了确保计算机缓存中有您想要的内容。运行软件的初始界面如下图所示。flv格式视频搜索结果的界面直接在界面之后。原因是这个软件的全称是Ingot Box。FLV 视频下载专家不想要视频。如果点击最上面的设置或者最下面的高级设置来设置搜索范围,下面是搜索条件设置

界面以swf格式flash为例,搜索选择类型中的第二项。单击“确定”开始搜索结果。单击保存此项进行保存。下面重点介绍网页中音乐的提取过程。音乐软件上有提示只要网页没有关闭,点击右上角的刷新视频可以加快缓冲。缓冲后,会出现下图中的第二项。缓冲后,您可以预览试听或保存部分,但可以识别。找出它是否是您要查找的内容,然后决定让它完成缓冲。

单击预览以收听音乐。预览所有操作,如下图所示。保存界面如下。点击复制媒体地址复制原链接,即外链地址或下载地址。单击原创链接将打开播放器并使用原创链接地址播放在线音乐。还有一种直观的查看原创链接地址的方法 方法上面的方法要粘在一个地方才能看到下面的方法。右键单击原创链接并选择“属性”将其打开。

性界面如下。搜索其他媒体类型底部的原创链接地址大致相同。让我们谈谈设置中的情况。大小限制设置将缩小搜索范围。快速找到你想要的,最后证明图片和视频的搜索过程太简单了。实际上,你不需要看跌落。下面是flv视频的预览。
从网页抓取视频(网页抓取工具优采云采集器V9实现抓取商品信息的方法(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2021-10-01 16:16
)
大数据时代的经销商,无论是经营线上门店还是线下实体店,都必须具备敏锐的信息洞察能力,才能在市场中寻找空缺,在竞争中寻求突破。除了正确的视角,信息的洞察力还需要一个方便的爬虫工具。优采云采集器作为领先的网页抓取工具品牌,可以为企业快速稳定的抓取网页。获取产品信息的功能为洞察和分析市场提供了必要的前提。
下面介绍一下网络爬虫工具优采云采集器优采云采集器V9实现产品信息抓取的方法:优采云采集器是其中一种一个高效稳定的网络爬虫工具。其工作原理是基于WEB结构的源代码提取。按照从主URL进入内容页面再提取内容的过程,可以从网页中提取文本、图片、压缩文件等,这意味着对于商家来说,商品等一系列属性内容所有电商网站中出现的价格、图片、教程文件都可以轻松提取。
使用网页爬虫工具优采云采集器V9抓取商品信息时,需要注意以下几点:
1、判断这个页面的信息是否全面展示。如果有需要登录才能看到的信息,需要在优采云采集器中进行登录采集相关设置。
2、写入内容采集 按规则下载图片时,edit标签的数据处理中有文件下载选项。有四个选项,其中之一是下载图片。您可以通过检查下载图片。优采云采集器V9 这里是默认下载带有html标签的图片。所以对于没有html标签的图片,比如缩略图,一定要勾选“检测文件并下载”。在这种情况下,优采云采集器会自动检测到这种图片文件并下载。
3、如果在当你请求新内容时,页面只进行局部刷新,而地址栏中的URL不变,这种post网址想要获取到就要使用抓包工具,截取请求时提交的内容找出共同特点,用
火车采集器中的“分页”变量进行替换并给定值范围,这样火车采集器在采集时会自动提交请求内容得到新的内容列表进行采集。网页抓取工具火车采集器V9还有更
多让人惊艳的功能,更多操作可以访问官网(www.locoy.com)的帮助手册或视频教程进行学习。
电子商务运营商使用网络爬虫工具优采云采集器V9抓取同类产品的属性、评价、价格、市场销售等数据,并利用这些数据推导出产品的相关特征信息. 对某个商品名称进行搜索优化,或者根据相似体验制作热门商品,在充分了解用户行为的基础上开展经营活动,可以大大提高网店的运营水平和效率。所以优采云采集器不过据说是经销商玩大数据的首选!
查看全部
从网页抓取视频(网页抓取工具优采云采集器V9实现抓取商品信息的方法(图)
)
大数据时代的经销商,无论是经营线上门店还是线下实体店,都必须具备敏锐的信息洞察能力,才能在市场中寻找空缺,在竞争中寻求突破。除了正确的视角,信息的洞察力还需要一个方便的爬虫工具。优采云采集器作为领先的网页抓取工具品牌,可以为企业快速稳定的抓取网页。获取产品信息的功能为洞察和分析市场提供了必要的前提。
下面介绍一下网络爬虫工具优采云采集器优采云采集器V9实现产品信息抓取的方法:优采云采集器是其中一种一个高效稳定的网络爬虫工具。其工作原理是基于WEB结构的源代码提取。按照从主URL进入内容页面再提取内容的过程,可以从网页中提取文本、图片、压缩文件等,这意味着对于商家来说,商品等一系列属性内容所有电商网站中出现的价格、图片、教程文件都可以轻松提取。
使用网页爬虫工具优采云采集器V9抓取商品信息时,需要注意以下几点:
1、判断这个页面的信息是否全面展示。如果有需要登录才能看到的信息,需要在优采云采集器中进行登录采集相关设置。
2、写入内容采集 按规则下载图片时,edit标签的数据处理中有文件下载选项。有四个选项,其中之一是下载图片。您可以通过检查下载图片。优采云采集器V9 这里是默认下载带有html标签的图片。所以对于没有html标签的图片,比如缩略图,一定要勾选“检测文件并下载”。在这种情况下,优采云采集器会自动检测到这种图片文件并下载。
3、如果在当你请求新内容时,页面只进行局部刷新,而地址栏中的URL不变,这种post网址想要获取到就要使用抓包工具,截取请求时提交的内容找出共同特点,用
火车采集器中的“分页”变量进行替换并给定值范围,这样火车采集器在采集时会自动提交请求内容得到新的内容列表进行采集。网页抓取工具火车采集器V9还有更
多让人惊艳的功能,更多操作可以访问官网(www.locoy.com)的帮助手册或视频教程进行学习。
电子商务运营商使用网络爬虫工具优采云采集器V9抓取同类产品的属性、评价、价格、市场销售等数据,并利用这些数据推导出产品的相关特征信息. 对某个商品名称进行搜索优化,或者根据相似体验制作热门商品,在充分了解用户行为的基础上开展经营活动,可以大大提高网店的运营水平和效率。所以优采云采集器不过据说是经销商玩大数据的首选!

从网页抓取视频(从网页抓取视频,下载后看电视?所有web视频格式皆可播放)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-09-26 22:10
从网页抓取视频,下载后看电视?所有web视频格式皆可播放,且格式没有上限,是屏幕所见即所得视频格式。本视频是免费公开的web视频格式mp4,主要功能为下载各类卫视直播、电视台直播、央视视频、点播等,支持所有web视频标准:http、m3u8、ts等。最后问一句:视频下载该用哪个app?appstore目前可以下载到的几个视频app有:新浪微博视频观看器:新浪微博官方的播放器,支持的网站如新浪博客、新浪微博、twitter等直播平台;荔枝fm:appstore搜索荔枝fm,即可下载;腾讯视频:qq视频客户端:安卓版可以同步观看视频,页面简洁且下载方便;网易视频:网易播放器-网易旗下pgc专业的网络电视频道。以上几个皆可以播放mp4格式视频。
上买一个转换器,基本无损的mp4转换器都可以转换的,我都是上买的。
怎么回答你我不知道,因为我不用mp4播放器。就我用过的而言。硬解比软解还是好点的。不会损失文件。如果你真是没得选。下载下来就用mp4播放器看。
准备ps当手办的图片我给你找网上打包出售的版本
ios系统的一加5直接支持webm电视服务
完全没有必要,sony自家就有一款系统播放器,可以兼容所有,所以根本就不用考虑兼容性的问题。 查看全部
从网页抓取视频(从网页抓取视频,下载后看电视?所有web视频格式皆可播放)
从网页抓取视频,下载后看电视?所有web视频格式皆可播放,且格式没有上限,是屏幕所见即所得视频格式。本视频是免费公开的web视频格式mp4,主要功能为下载各类卫视直播、电视台直播、央视视频、点播等,支持所有web视频标准:http、m3u8、ts等。最后问一句:视频下载该用哪个app?appstore目前可以下载到的几个视频app有:新浪微博视频观看器:新浪微博官方的播放器,支持的网站如新浪博客、新浪微博、twitter等直播平台;荔枝fm:appstore搜索荔枝fm,即可下载;腾讯视频:qq视频客户端:安卓版可以同步观看视频,页面简洁且下载方便;网易视频:网易播放器-网易旗下pgc专业的网络电视频道。以上几个皆可以播放mp4格式视频。
上买一个转换器,基本无损的mp4转换器都可以转换的,我都是上买的。
怎么回答你我不知道,因为我不用mp4播放器。就我用过的而言。硬解比软解还是好点的。不会损失文件。如果你真是没得选。下载下来就用mp4播放器看。
准备ps当手办的图片我给你找网上打包出售的版本
ios系统的一加5直接支持webm电视服务
完全没有必要,sony自家就有一款系统播放器,可以兼容所有,所以根本就不用考虑兼容性的问题。
从网页抓取视频(如何100%提取网页中的视频、音乐歌曲、flash、图片等多媒体)
网站优化 • 优采云 发表了文章 • 0 个评论 • 303 次浏览 • 2021-11-26 05:22
以上步骤只能在观看视频后进行。体验内容仅供参考。如果您需要解决具体问题(尤其是法律、医学等),建议您详细咨询相关领域的专业人士。作者声明:本体验基于真实体验原创,未经许可。
如何抓取网页中的视频文件?_哔哩哔哩(゜-゜)つロ-bilibili。
教你如何从网页中提取视频、音乐、歌曲、flash、图片等多媒体文件(很实用)忘记图片网址或不想了。
如何在不安装各种软件的情况下100%提取网页视频_搜狗指南。
642,311 人观看了此视频。在日常生活中,我们经常浏览网页,看到一些不错的视频,就想下载。很多人教过各种方法,比如在设置里查看缓存,比如给网址加后缀,但是随着网站的升级,很多。
如何100%提取网页上的视频?可能很多朋友对此感到困惑。下面小编就为大家介绍一下具体的提取方法,希望对大家有所帮助。进入浏览器后,点击右上角的方法/步骤三横线图标。单击“工具”进行选择。
下面介绍一种无需借助任何软件即可从网页中提取视频的方法,希望对您有所帮助。方法/步骤我以360浏览器为例,这里可以随便打开一个网页视频,注意不能是视频网站 Video in。打开视频播放,正在播放。
内音可以让您在浏览器中快速获取要打开的文件地址,在线打开文件。 查看全部
从网页抓取视频(如何100%提取网页中的视频、音乐歌曲、flash、图片等多媒体)
以上步骤只能在观看视频后进行。体验内容仅供参考。如果您需要解决具体问题(尤其是法律、医学等),建议您详细咨询相关领域的专业人士。作者声明:本体验基于真实体验原创,未经许可。
如何抓取网页中的视频文件?_哔哩哔哩(゜-゜)つロ-bilibili。
教你如何从网页中提取视频、音乐、歌曲、flash、图片等多媒体文件(很实用)忘记图片网址或不想了。
如何在不安装各种软件的情况下100%提取网页视频_搜狗指南。
642,311 人观看了此视频。在日常生活中,我们经常浏览网页,看到一些不错的视频,就想下载。很多人教过各种方法,比如在设置里查看缓存,比如给网址加后缀,但是随着网站的升级,很多。
如何100%提取网页上的视频?可能很多朋友对此感到困惑。下面小编就为大家介绍一下具体的提取方法,希望对大家有所帮助。进入浏览器后,点击右上角的方法/步骤三横线图标。单击“工具”进行选择。
下面介绍一种无需借助任何软件即可从网页中提取视频的方法,希望对您有所帮助。方法/步骤我以360浏览器为例,这里可以随便打开一个网页视频,注意不能是视频网站 Video in。打开视频播放,正在播放。
内音可以让您在浏览器中快速获取要打开的文件地址,在线打开文件。
从网页抓取视频(影音下载神器——猫抓这是一款影音嗅探工具(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-11-21 07:00
)
最近想下载一个网络视频。我不知道如何正确下载它。我到处都卡住了。网上下载网络视频的方法很多,但都不是很实用的方法。有些方法很麻烦,比如:有人说提取网页代码再下载软件好麻烦!有时候找了半天找不到下载的代码,加上下载时间。这项工作还有待完成吗?有人说下载软件或者网页下载插件,这些方法我都试过了,但是总是不好用,关键是省时省力,所以一直在关注网页下载的知识,可惜还好,终于找到了一个好方法,今天分享给朋友们!
两个下载网络视频的插件——非常棒的工具,获取方式:关注@边走印记,私信回复“视频插件”说明:结合使用以下两个插件制作作品最好的事物!
音视频下载神器-猫抓
这是一个音视频嗅探工具,以插件的形式出现在各大浏览器扩展中。它主要捕获视频和音频。只要打开任意音视频播放,它就会自动抓取,点击下载即可。其中,音频秒杀,无需等待即可下载。对于主流视频网站,采用分段下载。您可以使用复合视频工具再次组合它。是它的缺点,但是下载小视频、非主流影视就不会出现这种情况。下载的视频完好无损。主流视频都被别人用的shell保护了,有自己的格式,所以才会出现。这个情况。
您可以在百度上搜索并下载该插件。如果嫌麻烦,下载超级浏览器,它收录在扩展中,点击安装即可。最近小编发现这个插件好难找。如果找不到,可以关注我获取哦!
先说一下如何安装插件,就是把插件下载到桌面,然后打开浏览器,然后在浏览器窗口打开扩展,把插件拖到桌面上,就可以了自动安装,你可以使用它NS。
音视频下载神器-Video DownloadHelper
Video DownloadHelper 是一款专用软件,可以更轻松地从不同的网站 下载各种视频。该程序承诺非常易于使用,只需按一个按钮即可开始工作。
获取你想要的视频
Video DownloadHelper 带有 Firefox 和 Chrome 兼容版本,以帮助扩展频谱,以便它可以与各种流行的操作系统一起使用。用户只需在自己经常查看的网站中找到自己喜欢的视频,然后点击按钮即可开始下载。一个方便的工具栏显示了下载过程,尽管在某些情况下,特别是高清显示的大型公关视频可能需要相当长的时间来下载,而其他视频可能会被阻止。
无尽的内容触手可及
无法从某些 网站 下载他们想要的视频的人可能会发现 Video DownloadHelper 使此过程更容易。尽管该程序不时会出现故障,但它是免费提供的这一事实意味着在承诺为此类其他程序付费之前需要对其进行检查。
这个工具有插件和应用软件。您可以根据自己的需要下载它们。插件可以节省您的计算机空间,但该软件非常适合管理内容。各有各的优点!
查看全部
从网页抓取视频(影音下载神器——猫抓这是一款影音嗅探工具(组图)
)
最近想下载一个网络视频。我不知道如何正确下载它。我到处都卡住了。网上下载网络视频的方法很多,但都不是很实用的方法。有些方法很麻烦,比如:有人说提取网页代码再下载软件好麻烦!有时候找了半天找不到下载的代码,加上下载时间。这项工作还有待完成吗?有人说下载软件或者网页下载插件,这些方法我都试过了,但是总是不好用,关键是省时省力,所以一直在关注网页下载的知识,可惜还好,终于找到了一个好方法,今天分享给朋友们!
两个下载网络视频的插件——非常棒的工具,获取方式:关注@边走印记,私信回复“视频插件”说明:结合使用以下两个插件制作作品最好的事物!
音视频下载神器-猫抓
这是一个音视频嗅探工具,以插件的形式出现在各大浏览器扩展中。它主要捕获视频和音频。只要打开任意音视频播放,它就会自动抓取,点击下载即可。其中,音频秒杀,无需等待即可下载。对于主流视频网站,采用分段下载。您可以使用复合视频工具再次组合它。是它的缺点,但是下载小视频、非主流影视就不会出现这种情况。下载的视频完好无损。主流视频都被别人用的shell保护了,有自己的格式,所以才会出现。这个情况。
您可以在百度上搜索并下载该插件。如果嫌麻烦,下载超级浏览器,它收录在扩展中,点击安装即可。最近小编发现这个插件好难找。如果找不到,可以关注我获取哦!
先说一下如何安装插件,就是把插件下载到桌面,然后打开浏览器,然后在浏览器窗口打开扩展,把插件拖到桌面上,就可以了自动安装,你可以使用它NS。
音视频下载神器-Video DownloadHelper
Video DownloadHelper 是一款专用软件,可以更轻松地从不同的网站 下载各种视频。该程序承诺非常易于使用,只需按一个按钮即可开始工作。
获取你想要的视频
Video DownloadHelper 带有 Firefox 和 Chrome 兼容版本,以帮助扩展频谱,以便它可以与各种流行的操作系统一起使用。用户只需在自己经常查看的网站中找到自己喜欢的视频,然后点击按钮即可开始下载。一个方便的工具栏显示了下载过程,尽管在某些情况下,特别是高清显示的大型公关视频可能需要相当长的时间来下载,而其他视频可能会被阻止。
无尽的内容触手可及
无法从某些 网站 下载他们想要的视频的人可能会发现 Video DownloadHelper 使此过程更容易。尽管该程序不时会出现故障,但它是免费提供的这一事实意味着在承诺为此类其他程序付费之前需要对其进行检查。
这个工具有插件和应用软件。您可以根据自己的需要下载它们。插件可以节省您的计算机空间,但该软件非常适合管理内容。各有各的优点!
从网页抓取视频(【】基本开发环境相关模块的使用目标网页分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-16 03:09
)
前言
本文文字及图片均来自网络,仅供学习交流之用,不得用于任何商业用途。如果您有任何问题,请联系我们进行处理。
今天群里的小伙伴发了个链接,出于好奇,点击查看,然后一定要试一试。
基础开发环境
相关模块的使用
着陆页分析
根据朋友提供的地址,是关于火影的博客。
在使用开发者工具的时候,发现有现成的mp4地址,小心你还在想:
复制链接会自动下载,点击打开......
这是为什么?回头看网页,原来是一个广告的视频==
再分析
1、视频获取多个ts文件
其实网站的视频数据是一一分为TS文件的,这些TS文件都在m3u8的链接里。每个ts文件链接是对应视频中的一个片段,整个视频由一个个片段组成。
既然知道了视频的来源,就需要找到m3u8地址的来源,分析规则,才能批量抓取ts文件数据。当然,如果你的m3u8 url地址,也可以使用一些特殊的软件,直接下载合成视频即可。
2、获取m3u8的url地址
通过两个链接的对比可以发现,一个是日期不同,另一个是相似ID的参数不同。找源码可以复制一个关键参数1556_fd900088,在开发者工具中搜索。
此链接中收录的参数:
根据导航栏中的url,可以找到:
ID:95应该对应动画博人传的ID
pid: 175 应该对应多少集
如果最后两个参数没有值,复制url地址,删除最后两个参数就可以访问了,说明这两个参数没有特别大的影响。
3、下载、保存并合并成mp4文件
首先保存每个 ts 文件。
只需合并为 mp4 文件:
电脑一般都装有WinRaR解压软件。选择所有ts文件后,右击选择添加到压缩文件,看到如下界面,
注1:压缩文件名后缀应改为.MP4,
注2:存储方式选择压缩方式,默认为标准不可接受。
当心:
这个合并的前提是你的ts文件都是0000,然后0001按顺序排列,不然合并后播放顺序会乱。
如果下载的ts文件不是这样排序的,则需要将数据保存在整个m3u8链接中。然后通过cmd命令将所有ts合并到一个文件中:
复制 /bd:\xxx\download_ts\*.ts d:\xxx\download_ts\new.mp4
也可以用代码与FFmpg合并,爬到B站视频之前合并音频数据和视频图片。
查看全部
从网页抓取视频(【】基本开发环境相关模块的使用目标网页分析
)
前言
本文文字及图片均来自网络,仅供学习交流之用,不得用于任何商业用途。如果您有任何问题,请联系我们进行处理。
今天群里的小伙伴发了个链接,出于好奇,点击查看,然后一定要试一试。
基础开发环境
相关模块的使用
着陆页分析
根据朋友提供的地址,是关于火影的博客。
在使用开发者工具的时候,发现有现成的mp4地址,小心你还在想:
复制链接会自动下载,点击打开......
这是为什么?回头看网页,原来是一个广告的视频==
再分析
1、视频获取多个ts文件
其实网站的视频数据是一一分为TS文件的,这些TS文件都在m3u8的链接里。每个ts文件链接是对应视频中的一个片段,整个视频由一个个片段组成。
既然知道了视频的来源,就需要找到m3u8地址的来源,分析规则,才能批量抓取ts文件数据。当然,如果你的m3u8 url地址,也可以使用一些特殊的软件,直接下载合成视频即可。
2、获取m3u8的url地址
通过两个链接的对比可以发现,一个是日期不同,另一个是相似ID的参数不同。找源码可以复制一个关键参数1556_fd900088,在开发者工具中搜索。
此链接中收录的参数:
根据导航栏中的url,可以找到:
ID:95应该对应动画博人传的ID
pid: 175 应该对应多少集
如果最后两个参数没有值,复制url地址,删除最后两个参数就可以访问了,说明这两个参数没有特别大的影响。
3、下载、保存并合并成mp4文件
首先保存每个 ts 文件。
只需合并为 mp4 文件:
电脑一般都装有WinRaR解压软件。选择所有ts文件后,右击选择添加到压缩文件,看到如下界面,
注1:压缩文件名后缀应改为.MP4,
注2:存储方式选择压缩方式,默认为标准不可接受。
当心:
这个合并的前提是你的ts文件都是0000,然后0001按顺序排列,不然合并后播放顺序会乱。
如果下载的ts文件不是这样排序的,则需要将数据保存在整个m3u8链接中。然后通过cmd命令将所有ts合并到一个文件中:
复制 /bd:\xxx\download_ts\*.ts d:\xxx\download_ts\new.mp4
也可以用代码与FFmpg合并,爬到B站视频之前合并音频数据和视频图片。
从网页抓取视频(opengl图形接口element.createrenderer()中的renderer可用作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-13 01:02
从网页抓取视频为我们提供了方便,而将视频转换为html文件就是它的一种常见用法,视频格式包括mp4格式、mov格式、avi格式等等,用flash可以进行生成html文件,不过我们先要转换的是一个canvas图片,因为html5-gif新加入图片特效和gif动画,为这个本身就非常复杂的转换,而提供了相关资源和优化组件。
今天就列举一些常用的。opengl图形接口element.createrenderer();opengl中的renderer是renderbar,渲染槽是createrenderer即指定渲染的全局图像,creategloballight即指定图像的颜色(createreducer即指定图像的幅度)。
构造的生成器方法createrenderer(params):有了图像集,rendererbar是指定的application对象,application对象可以用作新建应用,在shader处创建中可以将此application作为材质载体,application可用作是自定义帧图片应用操作。createbg(shader,create=range(2,5)):在bg上创建点,可以输入材质,也可以通过glgettextstream打开文本文件。
creategraphicsg(params):有了图像集,graphicsbar是指定的application对象,application对象可以用作新建应用,在shader处创建中可以将此application作为材质载体,application可用作是自定义帧图片应用操作。maincamera.render.rendermode="single";maincamera.render.rendermode="private";maincamera.center.duration=10000;maincamera.center.translate=3;//图像距离的标准像素设置是3像素宽,1像素高maincamera.center.duration=10000;maincamera.center.translate=3;maincamera.translatep=rendermode.opengl2glpassattribute(r.img);maincamera.translatel=rendermode.opengl2glpassattribute(r.img);maincamera.translater=rendermode.opengl2glpassattribute(r.img);//图像透明度,单位是像素/p图像偏移值,0和1的一个配置drawbackmode="renderpass";maincamera.center.duration=10000;maincamera.center.translate=3;maincamera.translatep=3.0;//图像的透明度,单位是像素/b偏移值值,256和512的一个配置drawbackmode="renderpass";maincamera.center.duration=10000;maincamera.center.translate=3;maincamera.translatel=2.0;//图像的透明度,单位是像素/r设置透明度和偏移值,值为0时为了防止混乱不让用,值越大透明度偏移值越小,值越小透明度偏移值越大/h删除图片本身,提供一些更高级的api和方法,主要用于图像的各种属性设置。m。 查看全部
从网页抓取视频(opengl图形接口element.createrenderer()中的renderer可用作)
从网页抓取视频为我们提供了方便,而将视频转换为html文件就是它的一种常见用法,视频格式包括mp4格式、mov格式、avi格式等等,用flash可以进行生成html文件,不过我们先要转换的是一个canvas图片,因为html5-gif新加入图片特效和gif动画,为这个本身就非常复杂的转换,而提供了相关资源和优化组件。
今天就列举一些常用的。opengl图形接口element.createrenderer();opengl中的renderer是renderbar,渲染槽是createrenderer即指定渲染的全局图像,creategloballight即指定图像的颜色(createreducer即指定图像的幅度)。
构造的生成器方法createrenderer(params):有了图像集,rendererbar是指定的application对象,application对象可以用作新建应用,在shader处创建中可以将此application作为材质载体,application可用作是自定义帧图片应用操作。createbg(shader,create=range(2,5)):在bg上创建点,可以输入材质,也可以通过glgettextstream打开文本文件。
creategraphicsg(params):有了图像集,graphicsbar是指定的application对象,application对象可以用作新建应用,在shader处创建中可以将此application作为材质载体,application可用作是自定义帧图片应用操作。maincamera.render.rendermode="single";maincamera.render.rendermode="private";maincamera.center.duration=10000;maincamera.center.translate=3;//图像距离的标准像素设置是3像素宽,1像素高maincamera.center.duration=10000;maincamera.center.translate=3;maincamera.translatep=rendermode.opengl2glpassattribute(r.img);maincamera.translatel=rendermode.opengl2glpassattribute(r.img);maincamera.translater=rendermode.opengl2glpassattribute(r.img);//图像透明度,单位是像素/p图像偏移值,0和1的一个配置drawbackmode="renderpass";maincamera.center.duration=10000;maincamera.center.translate=3;maincamera.translatep=3.0;//图像的透明度,单位是像素/b偏移值值,256和512的一个配置drawbackmode="renderpass";maincamera.center.duration=10000;maincamera.center.translate=3;maincamera.translatel=2.0;//图像的透明度,单位是像素/r设置透明度和偏移值,值为0时为了防止混乱不让用,值越大透明度偏移值越小,值越小透明度偏移值越大/h删除图片本身,提供一些更高级的api和方法,主要用于图像的各种属性设置。m。
从网页抓取视频(从网页抓取视频解决方案_filtzhihu-聚集有格调的it技术人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-12 23:00
从网页抓取视频没啥好说的1.从google搜索,找到正在制作视频的相关网站2.比对下所给网站视频制作的要求,是不是找到了制作的软件3.按照这个软件调用它提供的脚本(可能还有些其他参数需要你自己选),找到视频制作的工具,就可以运行了。
给你提供一个笨办法:直接用该网站的接口在浏览器里面把视频下载下来-另外解决iphone自带输入法一些功能性的问题,
/
1.从网上直接爬2.自己写python脚本
从网站抓取视频解决方案_filtzhihu-聚集有格调的it技术人
貌似是从,由网上抓取视频。
已经存在的问题:1.强行不允许你用浏览器ie。2.主要通过使用第三方工具的方式抓取视频,而usb和pc同步还是会有延迟和延迟的问题。3.难以将视频分享到facebook和twitter。 查看全部
从网页抓取视频(从网页抓取视频解决方案_filtzhihu-聚集有格调的it技术人)
从网页抓取视频没啥好说的1.从google搜索,找到正在制作视频的相关网站2.比对下所给网站视频制作的要求,是不是找到了制作的软件3.按照这个软件调用它提供的脚本(可能还有些其他参数需要你自己选),找到视频制作的工具,就可以运行了。
给你提供一个笨办法:直接用该网站的接口在浏览器里面把视频下载下来-另外解决iphone自带输入法一些功能性的问题,
/
1.从网上直接爬2.自己写python脚本
从网站抓取视频解决方案_filtzhihu-聚集有格调的it技术人
貌似是从,由网上抓取视频。
已经存在的问题:1.强行不允许你用浏览器ie。2.主要通过使用第三方工具的方式抓取视频,而usb和pc同步还是会有延迟和延迟的问题。3.难以将视频分享到facebook和twitter。
从网页抓取视频(里面的texturepacker动画教程来更好地了解texturepacker的api)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-12 00:01
从网页抓取视频去生成gif太麻烦了,所以先用texturepacker生成了一个本地的gif。通过控制每帧图像的大小,控制成一张png或者jpg的图片。剩下的基本上就是水印啥的。生成的时候可以自己尝试动态调整大小,比如我尝试动态控制水印,动态调整可能会降低一些打印出来的分辨率。可以看我公众号(whzgc。
7)里面的texturepacker动画教程来更好地了解texturepacker的api。
1、导入需要的程序包
2、修改texturepackeruipaneldemo_yb512214d483d9308f3f1f6a328951_c_132666_20181015.png下载链接:提取码:ys5c
3、修改好接口之后可以用texturepacker做图片的片尾提取。在接口里面自己添加alpha(em)抖动。
4、修改好接口之后,自己添加一个成像树。这个东西比较简单,但是第一个需要自己写code。
例如右边那棵成像树,
8)。end();//name:swfname=getvalue();texturepackerui。setstartupinitle(getvalue());//tooltip:swftitleonem(em:int(0。0f));//tooltip:swftitleonem(em:int(0。0f));if(swf_url。length()*width/。
8){//framesize(0.8f-
8)swf_url.length();}//customtexturetexturepacker:int(texture_template_texture){returnswf_url.getlinewidth()*(swf_url.length()*1.
5);}//interpolationtransform:texturepacker::storetransform(texturepacker::el_rotate);//texturepathintfilter=stfilter(swf_url,interpolation);//stdoutformattexturepacker::size(sizeof(texturepacker::array*width),sizeof(texturepacker::array*height));//stdoutformat//resizetexture}```以及其他支持导出的样式。 查看全部
从网页抓取视频(里面的texturepacker动画教程来更好地了解texturepacker的api)
从网页抓取视频去生成gif太麻烦了,所以先用texturepacker生成了一个本地的gif。通过控制每帧图像的大小,控制成一张png或者jpg的图片。剩下的基本上就是水印啥的。生成的时候可以自己尝试动态调整大小,比如我尝试动态控制水印,动态调整可能会降低一些打印出来的分辨率。可以看我公众号(whzgc。
7)里面的texturepacker动画教程来更好地了解texturepacker的api。
1、导入需要的程序包
2、修改texturepackeruipaneldemo_yb512214d483d9308f3f1f6a328951_c_132666_20181015.png下载链接:提取码:ys5c
3、修改好接口之后可以用texturepacker做图片的片尾提取。在接口里面自己添加alpha(em)抖动。
4、修改好接口之后,自己添加一个成像树。这个东西比较简单,但是第一个需要自己写code。
例如右边那棵成像树,
8)。end();//name:swfname=getvalue();texturepackerui。setstartupinitle(getvalue());//tooltip:swftitleonem(em:int(0。0f));//tooltip:swftitleonem(em:int(0。0f));if(swf_url。length()*width/。
8){//framesize(0.8f-
8)swf_url.length();}//customtexturetexturepacker:int(texture_template_texture){returnswf_url.getlinewidth()*(swf_url.length()*1.
5);}//interpolationtransform:texturepacker::storetransform(texturepacker::el_rotate);//texturepathintfilter=stfilter(swf_url,interpolation);//stdoutformattexturepacker::size(sizeof(texturepacker::array*width),sizeof(texturepacker::array*height));//stdoutformat//resizetexture}```以及其他支持导出的样式。
从网页抓取视频(知乎:Python数据分析大家好,相信点进来看的小伙伴 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-08 22:20
)
知乎:Python数据分析
大家好,相信点进来观看的朋友都对爬虫很感兴趣,博主也是一样。博主刚开始接触爬虫的时候,就被深深的吸引住了,因为觉得 SOCOOL!每当我打完代码,看着屏幕上漂浮的一串数据,我都觉得很充实。有什么问题吗?更厉害的是爬虫技术可以应用到很多生活场景,比如自动投票,批量下载有趣的文章,小说,视频,微信机器人,爬取重要数据做数据分析啊,我真的觉得这些代码是为自己写的,可以为自己服务,也可以为他人服务,所以人生苦短,所以选择爬虫。
说实话,博主也是朝九晚五的上班族。学习爬虫也是他的业余时间。然而,基于对爬虫的热爱,他开始了他的爬虫学习之旅。俗话说,兴趣是最好的老师。博主也是小白。开设这个公众号的初衷是想和大家分享一下我学习爬虫和爬虫技巧的一些心得。当然,网上也有各种爬虫教程,供大家参考学习。主会分享一些开始学习时使用的资源。好了,废话不多说,开始我们的正题。
1. 什么是爬虫?
首先我们要明白一件事,那就是什么是爬虫,为什么是爬虫。博主百度给了一点,解释是这样的:
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
其实说白了就是爬虫可以模拟浏览器的行为为所欲为,自定义搜索下载的内容,实现自动化操作。比如浏览器可以下载小说,但是有时候不能批量下载,所以爬虫功能很有用。
实现爬虫技术的编程环境有很多,Java、Python、C++等都可以进行爬虫。但是博主选择了Python。相信很多人也会选择Python,因为Python确实非常适合爬虫。丰富的第三方库非常强大。几行代码就可以实现你想要的功能。更重要的是,Python 还是数据挖掘和分析方面的好专家。用Python做这样的数据爬取和分析的一站式服务真是太棒了!
2. 爬虫学习路线
知道了爬虫是什么,我给大家介绍一下博主总结的学习爬虫的基本路线,仅供大家参考,因为每个人都有自己的方法,这里只是提供一些思路。
学习Python爬虫的一般步骤如下:
以上是一个整体的学习概述。许多内容博主还需要继续学习。关于提到的每一步的细节,博主会在后续的内容中逐步与大家分享实际的例子,当然中间也会穿插一些。关于爬虫的有趣内容。
3. 从第一个爬虫开始
我认为第一个爬虫代码的实现应该从urllib开始。博主刚开始学习的时候,就利用urllib库,键入几行代码,实现了一个简单的数据爬取功能。我想我的大多数朋友也来过这里。的。当时的感觉是:哇,太神奇了,一个看似复杂的任务,几行代码就可以搞定,就想知道这些短短几行代码是怎么实现的,如何执行更高级复杂的任务。爬行呢?带着这个疑问,我开始学习urllib库。
首先不得不提一下爬取数据的过程,搞清楚它是一个什么样的过程。学习urllib的时候会更容易理解。
爬行的过程
其实抓取过程和浏览器浏览过程是一样的。原因大家应该明白了,当我们在键盘上输入网址,点击搜索时,首先会通过网络通过DNS服务器,解析网址的域名,找到真正的服务器。然后我们通过 HTTP 协议向服务器发送 GET 或 POST 请求。如果请求成功,我们就得到了我们想要看到的网页,一般是用HTML、CSS、JS等前端技术构建的,如果请求不成功,服务器会返回状态码给我们请求失败,常见的503、403等。
爬取的过程也是一样,通过向服务器发送请求获取HTML网页,然后解析下载的网页,得到我们想要的内容。当然,这是爬取过程的一个概览,还有很多细节需要我们处理。这些将在后续继续与大家分享。
了解了爬行的基本过程后,我们就可以开始我们真正的爬行之旅了。
网址库
Python内置了urllib库,可以说是爬行过程中非常重要的一部分。使用这个内置库可以完成向服务器发出请求,获取网页的功能,所以也是学习爬虫的第一步。
博主使用Python3.x。urllib 库的结构与 Python2.x 的有些不同。Python2.x 中使用的 urllib2 和 urllib 库,而 Python3.x 合并成一个独特的 urllib 库。
首先,我们来看看Python3.x 的urllib 库有什么。
博主使用的IDE是Pycharm,编辑调试非常方便,很棒。
在控制台中输入以下代码:
>>importurllib
>>dir(urllib)
['__builtins__','__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__','__path__', '__spec__', 'error', 'parse', 'request', 'response']
可以看到,urllib除了内置的双下划线开头和结尾的属性外,还有4个重要的属性,分别是error、parse、request、response。
在 Python urllib 库中,doc 的开头是这样的简短描述:
这4个属性中最重要的是请求,它完成了爬虫的大部分功能。我们先来看看请求是如何使用的。
请求的使用
request请求最简单的操作就是使用urlopen方法,代码如下:
import urllib.request
response = urllib.request.urlopen('http://python.org/')
result = response.read()
print(result)
操作结果如下:
<p>b'\n 查看全部
从网页抓取视频(知乎:Python数据分析大家好,相信点进来看的小伙伴
)
知乎:Python数据分析
大家好,相信点进来观看的朋友都对爬虫很感兴趣,博主也是一样。博主刚开始接触爬虫的时候,就被深深的吸引住了,因为觉得 SOCOOL!每当我打完代码,看着屏幕上漂浮的一串数据,我都觉得很充实。有什么问题吗?更厉害的是爬虫技术可以应用到很多生活场景,比如自动投票,批量下载有趣的文章,小说,视频,微信机器人,爬取重要数据做数据分析啊,我真的觉得这些代码是为自己写的,可以为自己服务,也可以为他人服务,所以人生苦短,所以选择爬虫。
说实话,博主也是朝九晚五的上班族。学习爬虫也是他的业余时间。然而,基于对爬虫的热爱,他开始了他的爬虫学习之旅。俗话说,兴趣是最好的老师。博主也是小白。开设这个公众号的初衷是想和大家分享一下我学习爬虫和爬虫技巧的一些心得。当然,网上也有各种爬虫教程,供大家参考学习。主会分享一些开始学习时使用的资源。好了,废话不多说,开始我们的正题。
1. 什么是爬虫?
首先我们要明白一件事,那就是什么是爬虫,为什么是爬虫。博主百度给了一点,解释是这样的:
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
其实说白了就是爬虫可以模拟浏览器的行为为所欲为,自定义搜索下载的内容,实现自动化操作。比如浏览器可以下载小说,但是有时候不能批量下载,所以爬虫功能很有用。
实现爬虫技术的编程环境有很多,Java、Python、C++等都可以进行爬虫。但是博主选择了Python。相信很多人也会选择Python,因为Python确实非常适合爬虫。丰富的第三方库非常强大。几行代码就可以实现你想要的功能。更重要的是,Python 还是数据挖掘和分析方面的好专家。用Python做这样的数据爬取和分析的一站式服务真是太棒了!
2. 爬虫学习路线
知道了爬虫是什么,我给大家介绍一下博主总结的学习爬虫的基本路线,仅供大家参考,因为每个人都有自己的方法,这里只是提供一些思路。
学习Python爬虫的一般步骤如下:
以上是一个整体的学习概述。许多内容博主还需要继续学习。关于提到的每一步的细节,博主会在后续的内容中逐步与大家分享实际的例子,当然中间也会穿插一些。关于爬虫的有趣内容。
3. 从第一个爬虫开始
我认为第一个爬虫代码的实现应该从urllib开始。博主刚开始学习的时候,就利用urllib库,键入几行代码,实现了一个简单的数据爬取功能。我想我的大多数朋友也来过这里。的。当时的感觉是:哇,太神奇了,一个看似复杂的任务,几行代码就可以搞定,就想知道这些短短几行代码是怎么实现的,如何执行更高级复杂的任务。爬行呢?带着这个疑问,我开始学习urllib库。
首先不得不提一下爬取数据的过程,搞清楚它是一个什么样的过程。学习urllib的时候会更容易理解。
爬行的过程
其实抓取过程和浏览器浏览过程是一样的。原因大家应该明白了,当我们在键盘上输入网址,点击搜索时,首先会通过网络通过DNS服务器,解析网址的域名,找到真正的服务器。然后我们通过 HTTP 协议向服务器发送 GET 或 POST 请求。如果请求成功,我们就得到了我们想要看到的网页,一般是用HTML、CSS、JS等前端技术构建的,如果请求不成功,服务器会返回状态码给我们请求失败,常见的503、403等。
爬取的过程也是一样,通过向服务器发送请求获取HTML网页,然后解析下载的网页,得到我们想要的内容。当然,这是爬取过程的一个概览,还有很多细节需要我们处理。这些将在后续继续与大家分享。
了解了爬行的基本过程后,我们就可以开始我们真正的爬行之旅了。
网址库
Python内置了urllib库,可以说是爬行过程中非常重要的一部分。使用这个内置库可以完成向服务器发出请求,获取网页的功能,所以也是学习爬虫的第一步。
博主使用Python3.x。urllib 库的结构与 Python2.x 的有些不同。Python2.x 中使用的 urllib2 和 urllib 库,而 Python3.x 合并成一个独特的 urllib 库。
首先,我们来看看Python3.x 的urllib 库有什么。
博主使用的IDE是Pycharm,编辑调试非常方便,很棒。
在控制台中输入以下代码:
>>importurllib
>>dir(urllib)
['__builtins__','__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__','__path__', '__spec__', 'error', 'parse', 'request', 'response']
可以看到,urllib除了内置的双下划线开头和结尾的属性外,还有4个重要的属性,分别是error、parse、request、response。
在 Python urllib 库中,doc 的开头是这样的简短描述:
这4个属性中最重要的是请求,它完成了爬虫的大部分功能。我们先来看看请求是如何使用的。
请求的使用
request请求最简单的操作就是使用urlopen方法,代码如下:
import urllib.request
response = urllib.request.urlopen('http://python.org/')
result = response.read()
print(result)
操作结果如下:
<p>b'\n
从网页抓取视频(标题池和代理池旋转请求工作环境和异步I/O编程自动化站点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-08 04:10
种类。
在这里,您可以看到“歌词”类别收录艺术家姓名,而“div-share”类别收录歌曲名称。
"I Cry" lyrics
Shayne Ward Lyrics
因此,要从服务器获取页面,我们必须使用请求库通过其 URL 从 Internet 获取网页。
# Importing Librabies
import requests
# Web Page you want to Scrap
url = 'https://www.azlyrics.com/lyric ... 39%3B
response = requests.get(url)
# Printing the Status Code of received URL
print(response.status_code)
# The Status code will be 200 if Everything is ok.
在上面的代码中,我们通过请求库请求URL,然后将结果保存在响应中。要运行该文件,您可以使用以下命令
python3 print_lyrics.py
现在要从响应中提取详细信息,我们必须使用 BeautifulSoup 库来解析 HTML 页面,它可以使用 Command BeautifulSoup (response.text,'html.parser') 命令从响应中获取 html 解析文本。解析网页的不同部分可能会有些混乱,但是通过练习,您可以轻松地从网页中获取所需的详细信息。
# Importing Libraries
import requests
from bs4 import BeautifulSoup
url = 'https://www.azlyrics.com/lyric ... 39%3B
response = requests.get(url) # Using Requests to get Webpage
html_soup = BeautifulSoup(response.text , 'html.parser') # Parsing the WebPage to get its HTML Content
# These are
singer = html_soup.find('div' , class_ = 'lyricsh').h2.text
song_name = html_soup.find('div' , class_ = 'col-xs-12 col-lg-8 text-center').find_all('div',class_= 'div-share')[1].text.split('"')[1]
lyrics = html_soup.find('div' , class_ = 'col-xs-12 col-lg-8 text-center').find_all('div')[5].text
print('Singer Name -> {}'.format(singer))
print('Song Name -> {}'.format(song_name))
print('Lyrics is -> {}'.format(lyrics))
该文件的输出将是终端中的艺术家姓名、歌曲名称和歌词。
保存回复
为了将此输出保存到磁盘,我将使用 JSON 来转储数据,但您也可以使用 CSV 或文本。除非你打算丢弃和管理数以百万计的歌词数据集,否则使用 SQL 将数据保存到磁盘可能会产生致命的后果。只需要几首歌词,JSON 或 CSV 就可以很好地工作。完整的代码现在看起来像
import requests
from bs4 import BeautifulSoup
import json
url = 'https://www.azlyrics.com/lyric ... 39%3B
response = requests.get(url)
html_soup = BeautifulSoup(response.text , 'html.parser')
singer = html_soup.find('div' , class_ = 'lyricsh').h2.text
song_name = html_soup.find('div' , class_ = 'col-xs-12 col-lg-8 text-center').find_all('div',class_= 'div-share')[1].text.split('"')[1]
lyrics = html_soup.find('div' , class_ = 'col-xs-12 col-lg-8 text-center').find_all('div')[5].text
data = {}
data['singer'] = singer
data['song_name'] = song_name
data['lyrics'] = lyrics
with open('data.json', 'w') as outfile:
json.dump(data, outfile)
这将在与歌手和歌词相同的目录中创建文件“data.json”。
标题池和代理池轮换请求工作环境和异步 I/O 编程自动化站点抓取 API 访问在 Heroku 上托管我们的 Flask 服务器 查看全部
从网页抓取视频(标题池和代理池旋转请求工作环境和异步I/O编程自动化站点)
种类。
在这里,您可以看到“歌词”类别收录艺术家姓名,而“div-share”类别收录歌曲名称。
"I Cry" lyrics
Shayne Ward Lyrics
因此,要从服务器获取页面,我们必须使用请求库通过其 URL 从 Internet 获取网页。
# Importing Librabies
import requests
# Web Page you want to Scrap
url = 'https://www.azlyrics.com/lyric ... 39%3B
response = requests.get(url)
# Printing the Status Code of received URL
print(response.status_code)
# The Status code will be 200 if Everything is ok.
在上面的代码中,我们通过请求库请求URL,然后将结果保存在响应中。要运行该文件,您可以使用以下命令
python3 print_lyrics.py
现在要从响应中提取详细信息,我们必须使用 BeautifulSoup 库来解析 HTML 页面,它可以使用 Command BeautifulSoup (response.text,'html.parser') 命令从响应中获取 html 解析文本。解析网页的不同部分可能会有些混乱,但是通过练习,您可以轻松地从网页中获取所需的详细信息。
# Importing Libraries
import requests
from bs4 import BeautifulSoup
url = 'https://www.azlyrics.com/lyric ... 39%3B
response = requests.get(url) # Using Requests to get Webpage
html_soup = BeautifulSoup(response.text , 'html.parser') # Parsing the WebPage to get its HTML Content
# These are
singer = html_soup.find('div' , class_ = 'lyricsh').h2.text
song_name = html_soup.find('div' , class_ = 'col-xs-12 col-lg-8 text-center').find_all('div',class_= 'div-share')[1].text.split('"')[1]
lyrics = html_soup.find('div' , class_ = 'col-xs-12 col-lg-8 text-center').find_all('div')[5].text
print('Singer Name -> {}'.format(singer))
print('Song Name -> {}'.format(song_name))
print('Lyrics is -> {}'.format(lyrics))
该文件的输出将是终端中的艺术家姓名、歌曲名称和歌词。
保存回复
为了将此输出保存到磁盘,我将使用 JSON 来转储数据,但您也可以使用 CSV 或文本。除非你打算丢弃和管理数以百万计的歌词数据集,否则使用 SQL 将数据保存到磁盘可能会产生致命的后果。只需要几首歌词,JSON 或 CSV 就可以很好地工作。完整的代码现在看起来像
import requests
from bs4 import BeautifulSoup
import json
url = 'https://www.azlyrics.com/lyric ... 39%3B
response = requests.get(url)
html_soup = BeautifulSoup(response.text , 'html.parser')
singer = html_soup.find('div' , class_ = 'lyricsh').h2.text
song_name = html_soup.find('div' , class_ = 'col-xs-12 col-lg-8 text-center').find_all('div',class_= 'div-share')[1].text.split('"')[1]
lyrics = html_soup.find('div' , class_ = 'col-xs-12 col-lg-8 text-center').find_all('div')[5].text
data = {}
data['singer'] = singer
data['song_name'] = song_name
data['lyrics'] = lyrics
with open('data.json', 'w') as outfile:
json.dump(data, outfile)
这将在与歌手和歌词相同的目录中创建文件“data.json”。
标题池和代理池轮换请求工作环境和异步 I/O 编程自动化站点抓取 API 访问在 Heroku 上托管我们的 Flask 服务器
从网页抓取视频(一个没有建立文件写入对象完整的实现代码的原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-11-05 18:05
用Java的IO流从网上下载视频的原理是在URL对象和目标地址之间建立链接,从这个链接中以IO流的形式读取下载视频的二进制数据,然后写入它到本地文件。
因为小弟比较好吃,他不会下载那些加密的视频链接。在这里我找到了一个没有掩码的url来测试:
代码思路首先建立一个链接对象,获取一个网页的链接;从链接对象获取输入流并读取数据;建立输出流将数据写入本地文件。代码
获取链接对象
public class download {
//定义一个HttpURLConnection在外面,因为要在finally中关闭
HttpURLConnection connection = null;
public static void main(String[] args) {
try {
//获取链接对象
URL url = new URL(videoUrl);
HttpURLConnection connection = url.openConnection();
connection.setRequestProperty("Range","bytes=0-");
connection.connect();
if(connection.getResponseCode() / 100 != 2){
System.out.println("链接资源失败...");
return;
}
} catch (MalformedURLException e) {
e.printStackTrace();
} finally {
HttpURLConnection.disconnect();
}
}
}
好,现在来说说上面代码的作用:
1.URL url = 新 URL(videoUrl);
是获取URL的资源对象,传入的字符串就是对应的地址;
2.HttpURLConnection connection = url.openConnection();
是获取链接对象,就是依赖这个对象来获取流;
3.connection.setRequestProperty("Range","bytes=0-");
range表示读取范围,bytes=0-表示从0字节到最大字节,表示读取所有资源
4.connection.connect();
建立网页链接,链接成功后即可获取流;
5.connection.getResponseCode() / 100 != 2
这个判断的意思是,如果建立链接返回的对应代码在200到300之间,则为成功,否则链接失败
获取流实现:
InputStream inputStream = connection.getInputStream();
获取流只需要一行代码,直接从连接对象中获取。
实现文件写入:这里是RandomAccessFile的对象。
String fileName = url.getFile();
fileName = fileName.substring(fileName.lastIndexOf("/")+1);
RandomAccessFile randomAccessFile = new RandomAccessFile(fileName,"rw");
1. 第一行代码是获取文件名。这是一个解释。根据这个url,我们得到的fileName是/C79EBFF6107CE4389C33DC5901307461-20.mp4,意思是getFile获取的是.com路径后面的文件名,所以我用截取字符串的方式来获取文件名,当然, 也可以自行设置随机文件名
2.字符串截取
3.创建文件写入对象
完整的实现代码贴在下面:
package download;
import java.io.BufferedInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.RandomAccessFile;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
public class DownloadVideo {
private static String videoUrl = "http://aqiniu.tangdou.com/C79E ... 3B%3B
private static final int MAX_BUFFER_SIZE = 1000000;
public static void main(String[] args) {
HttpURLConnection connection = null;
InputStream inputStream = null;
RandomAccessFile randomAccessFile = null;
try {
// 1.获取连接对象
URL url = new URL(videoUrl);
connection = (HttpURLConnection) url.openConnection();
connection.setRequestProperty("Range", "bytes=0-");
connection.connect();
if(connection.getResponseCode() / 100 != 2) {
System.out.println("连接失败...");
return;
}
// 2.获取连接对象的流
inputStream = connection.getInputStream();
//已下载的大小
int downloaded = 0;
//总文件的大小
int fileSize = connection.getContentLength();
String fileName = url.getFile();
fileName = fileName.substring(fileName.lastIndexOf("/") + 1);
// 3.把资源写入文件
randomAccessFile = new RandomAccessFile(fileName,"rw");
while(downloaded < fileSize) {
// 3.1设置缓存流的大小
byte[] buffer = null;
if(fileSize - downloaded >= MAX_BUFFER_SIZE) {
buffer = new byte[MAX_BUFFER_SIZE];
}else {
buffer = new byte[fileSize - downloaded];
}
// 3.2把每一次缓存的数据写入文件
int read = -1;
int currentDownload = 0;
long startTime = System.currentTimeMillis();
while(currentDownload < buffer.length) {
read = inputStream.read();
buffer[currentDownload ++] = (byte) read;
}
long endTime = System.currentTimeMillis();
double speed = 0.0;
if(endTime - startTime > 0) {
speed = currentDownload / 1024.0 / ((double)(endTime - startTime)/1000);
}
randomAccessFile.write(buffer);
downloaded += currentDownload;
randomAccessFile.seek(downloaded);
System.out.printf("下载了进度:%.2f%%,下载速度:%.1fkb/s(%.1fM/s)%n",downloaded * 1.0 / fileSize * 10000 / 100,speed,speed/1000);
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
connection.disconnect();
inputStream.close();
randomAccessFile.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void demo() {
try {
URL url = new URL(videoUrl);
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
下面是对上述代码的补充说明。MAX_BUFFER_SIZE 是我设置的缓存大小。在注释3.1中,判断当前剩余下载大小是否大于缓存,如果不是,则设置缓存大小为剩余。
while(currentDownload < buffer.length) {
read = inputStream.read();
buffer[currentDownload ++] = (byte) read;
}
此代码根据缓存的大小读取和写入该大小的字节。然后依次写入缓存的大小直到结束。
这样做的好处是可以提高效率,保护硬盘,而不需要频繁的硬件写入。
控制台输出:
下载进度:11.59%,下载速度:388.0kb/s(0.4M/s)
下载进度:23.19%,下载速度:262.5kb/s(0.3M/s)
下载进度:34.78%,下载速度:261.0kb/s(0.3M/s)
下载进度:46.38%,下载速度:258.3kb/s(0.3M/s)
下载进度:57.97%,下载速度:260.0kb/s(0.3M/s)
下载进度:69.57%,下载速度:260.9kb/s(0.3M/s)
下载进度:81.16%,下载速度:257.4kb/s(0.3M/s)
下载进度:92.75%,下载速度:252.3kb/s(0.3M/s)
下载进度:100.00%,下载速度:286.5kb/s(0.3M/s) 好的,以上就是下载视频的简单实现,小弟就是刚学的不错,可能还有很多地方不太好,请大家多多指教。 查看全部
从网页抓取视频(一个没有建立文件写入对象完整的实现代码的原理)
用Java的IO流从网上下载视频的原理是在URL对象和目标地址之间建立链接,从这个链接中以IO流的形式读取下载视频的二进制数据,然后写入它到本地文件。
因为小弟比较好吃,他不会下载那些加密的视频链接。在这里我找到了一个没有掩码的url来测试:
代码思路首先建立一个链接对象,获取一个网页的链接;从链接对象获取输入流并读取数据;建立输出流将数据写入本地文件。代码
获取链接对象
public class download {
//定义一个HttpURLConnection在外面,因为要在finally中关闭
HttpURLConnection connection = null;
public static void main(String[] args) {
try {
//获取链接对象
URL url = new URL(videoUrl);
HttpURLConnection connection = url.openConnection();
connection.setRequestProperty("Range","bytes=0-");
connection.connect();
if(connection.getResponseCode() / 100 != 2){
System.out.println("链接资源失败...");
return;
}
} catch (MalformedURLException e) {
e.printStackTrace();
} finally {
HttpURLConnection.disconnect();
}
}
}
好,现在来说说上面代码的作用:
1.URL url = 新 URL(videoUrl);
是获取URL的资源对象,传入的字符串就是对应的地址;
2.HttpURLConnection connection = url.openConnection();
是获取链接对象,就是依赖这个对象来获取流;
3.connection.setRequestProperty("Range","bytes=0-");
range表示读取范围,bytes=0-表示从0字节到最大字节,表示读取所有资源
4.connection.connect();
建立网页链接,链接成功后即可获取流;
5.connection.getResponseCode() / 100 != 2
这个判断的意思是,如果建立链接返回的对应代码在200到300之间,则为成功,否则链接失败
获取流实现:
InputStream inputStream = connection.getInputStream();
获取流只需要一行代码,直接从连接对象中获取。
实现文件写入:这里是RandomAccessFile的对象。
String fileName = url.getFile();
fileName = fileName.substring(fileName.lastIndexOf("/")+1);
RandomAccessFile randomAccessFile = new RandomAccessFile(fileName,"rw");
1. 第一行代码是获取文件名。这是一个解释。根据这个url,我们得到的fileName是/C79EBFF6107CE4389C33DC5901307461-20.mp4,意思是getFile获取的是.com路径后面的文件名,所以我用截取字符串的方式来获取文件名,当然, 也可以自行设置随机文件名
2.字符串截取
3.创建文件写入对象
完整的实现代码贴在下面:
package download;
import java.io.BufferedInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.RandomAccessFile;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
public class DownloadVideo {
private static String videoUrl = "http://aqiniu.tangdou.com/C79E ... 3B%3B
private static final int MAX_BUFFER_SIZE = 1000000;
public static void main(String[] args) {
HttpURLConnection connection = null;
InputStream inputStream = null;
RandomAccessFile randomAccessFile = null;
try {
// 1.获取连接对象
URL url = new URL(videoUrl);
connection = (HttpURLConnection) url.openConnection();
connection.setRequestProperty("Range", "bytes=0-");
connection.connect();
if(connection.getResponseCode() / 100 != 2) {
System.out.println("连接失败...");
return;
}
// 2.获取连接对象的流
inputStream = connection.getInputStream();
//已下载的大小
int downloaded = 0;
//总文件的大小
int fileSize = connection.getContentLength();
String fileName = url.getFile();
fileName = fileName.substring(fileName.lastIndexOf("/") + 1);
// 3.把资源写入文件
randomAccessFile = new RandomAccessFile(fileName,"rw");
while(downloaded < fileSize) {
// 3.1设置缓存流的大小
byte[] buffer = null;
if(fileSize - downloaded >= MAX_BUFFER_SIZE) {
buffer = new byte[MAX_BUFFER_SIZE];
}else {
buffer = new byte[fileSize - downloaded];
}
// 3.2把每一次缓存的数据写入文件
int read = -1;
int currentDownload = 0;
long startTime = System.currentTimeMillis();
while(currentDownload < buffer.length) {
read = inputStream.read();
buffer[currentDownload ++] = (byte) read;
}
long endTime = System.currentTimeMillis();
double speed = 0.0;
if(endTime - startTime > 0) {
speed = currentDownload / 1024.0 / ((double)(endTime - startTime)/1000);
}
randomAccessFile.write(buffer);
downloaded += currentDownload;
randomAccessFile.seek(downloaded);
System.out.printf("下载了进度:%.2f%%,下载速度:%.1fkb/s(%.1fM/s)%n",downloaded * 1.0 / fileSize * 10000 / 100,speed,speed/1000);
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
connection.disconnect();
inputStream.close();
randomAccessFile.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void demo() {
try {
URL url = new URL(videoUrl);
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
下面是对上述代码的补充说明。MAX_BUFFER_SIZE 是我设置的缓存大小。在注释3.1中,判断当前剩余下载大小是否大于缓存,如果不是,则设置缓存大小为剩余。
while(currentDownload < buffer.length) {
read = inputStream.read();
buffer[currentDownload ++] = (byte) read;
}
此代码根据缓存的大小读取和写入该大小的字节。然后依次写入缓存的大小直到结束。
这样做的好处是可以提高效率,保护硬盘,而不需要频繁的硬件写入。
控制台输出:
下载进度:11.59%,下载速度:388.0kb/s(0.4M/s)
下载进度:23.19%,下载速度:262.5kb/s(0.3M/s)
下载进度:34.78%,下载速度:261.0kb/s(0.3M/s)
下载进度:46.38%,下载速度:258.3kb/s(0.3M/s)
下载进度:57.97%,下载速度:260.0kb/s(0.3M/s)
下载进度:69.57%,下载速度:260.9kb/s(0.3M/s)
下载进度:81.16%,下载速度:257.4kb/s(0.3M/s)
下载进度:92.75%,下载速度:252.3kb/s(0.3M/s)
下载进度:100.00%,下载速度:286.5kb/s(0.3M/s) 好的,以上就是下载视频的简单实现,小弟就是刚学的不错,可能还有很多地方不太好,请大家多多指教。
从网页抓取视频(从网页抓取视频做的渲染,帧率高能够更加真实还原打游戏快感)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-28 20:03
从网页抓取视频做的渲染,渲染的帧率据说是125fps(不知道现在有没有固定帧率的),帧率高能够更加真实还原打游戏的快感,大概是吧,
这个应该是转化后通过摄像头抓取的吧,能看到动画和声音的都不是一帧画面。
应该是在摄像头拍摄到一帧的动画帧后被绘制成图片。最后发布的视频格式应该是图片。
应该是处理了帧率。现实里帧率就是按照24帧来的。游戏里帧率统一是125hz,主要应该是因为这种设置效果更加真实。
下游也有个问题,游戏动作好多就是帧,操作的时候1秒一帧,何来24帧,
从别人那里学到的回答如果帧率和真实帧率一样,
帧率一定要比真实帧率高24帧吗。只有10帧跟24帧意义不一样,20帧跟60帧,
网络游戏一般有这么几种显示模式:720p240p2560p640p超高清真实输出是不可能超高清的。
建议用480p游戏
帧率是我们衡量画面的重要因素,“清晰”是一种指标,帧率过低会让画面表现出的画面细节、动态帧率变差,细节的差别与动态视频一样,看起来不真实,会让人产生时间的变化感,就好像进行过特殊处理的视频(如加速)。帧率在高帧率显示情况下,占比非常重要,通常400-600帧是游戏在线格式游戏非常理想的显示范围,玩游戏时你想看到什么就看到什么。 查看全部
从网页抓取视频(从网页抓取视频做的渲染,帧率高能够更加真实还原打游戏快感)
从网页抓取视频做的渲染,渲染的帧率据说是125fps(不知道现在有没有固定帧率的),帧率高能够更加真实还原打游戏的快感,大概是吧,
这个应该是转化后通过摄像头抓取的吧,能看到动画和声音的都不是一帧画面。
应该是在摄像头拍摄到一帧的动画帧后被绘制成图片。最后发布的视频格式应该是图片。
应该是处理了帧率。现实里帧率就是按照24帧来的。游戏里帧率统一是125hz,主要应该是因为这种设置效果更加真实。
下游也有个问题,游戏动作好多就是帧,操作的时候1秒一帧,何来24帧,
从别人那里学到的回答如果帧率和真实帧率一样,
帧率一定要比真实帧率高24帧吗。只有10帧跟24帧意义不一样,20帧跟60帧,
网络游戏一般有这么几种显示模式:720p240p2560p640p超高清真实输出是不可能超高清的。
建议用480p游戏
帧率是我们衡量画面的重要因素,“清晰”是一种指标,帧率过低会让画面表现出的画面细节、动态帧率变差,细节的差别与动态视频一样,看起来不真实,会让人产生时间的变化感,就好像进行过特殊处理的视频(如加速)。帧率在高帧率显示情况下,占比非常重要,通常400-600帧是游戏在线格式游戏非常理想的显示范围,玩游戏时你想看到什么就看到什么。
从网页抓取视频(从网页抓取视频的话是要走的,直接抓视频肯定是抓不到的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-28 07:06
从网页抓取视频的话是要走https的,直接抓视频肯定是抓不到的。我曾经去爬过某局域网内的某个视频,这个链接本身是带后缀的(比如),这个后缀在经过代理以后,会直接返回txt的格式视频文件,后缀为flv。我在网上抓取了解析https的视频链接时也遇到了同样的问题,无解,只能采用格式化视频流。在aria2或者迅雷下载之类的软件上定向下载到某个视频链接后,将https的视频链接与rmvb等格式视频导入aria2,这样就可以导入下载需要解析的视频了。
其他对视频的解析要么没有解析,要么还需要继续解析txt。不过会用视频管理软件的话,完全不用担心会被封。
有文件丢失和限制的情况出现,目前解决思路就是直接下载flv播放器,flash是目前安全性较高的视频编码方式,下载速度相对其他的视频来说是较快的,对于视频比较多的网站来说是个不错的选择。直接从本地下载是比较慢的,直接下载其实是缺点,没有服务器中转,解析起来也比较慢。我感觉主要是解析起来也慢,大部分的视频都有版权限制,解析速度慢。
不能从网站下载视频时,可以采用下边方法下载:首先把视频用下面方法去下载:通过链接提取视频:"id":"(\.+).*"然后就可以下载本地flv视频了。因为转码是视频处理软件来做的,如果你的电脑上没有安装任何的视频处理软件的话,是无法操作的。 查看全部
从网页抓取视频(从网页抓取视频的话是要走的,直接抓视频肯定是抓不到的)
从网页抓取视频的话是要走https的,直接抓视频肯定是抓不到的。我曾经去爬过某局域网内的某个视频,这个链接本身是带后缀的(比如),这个后缀在经过代理以后,会直接返回txt的格式视频文件,后缀为flv。我在网上抓取了解析https的视频链接时也遇到了同样的问题,无解,只能采用格式化视频流。在aria2或者迅雷下载之类的软件上定向下载到某个视频链接后,将https的视频链接与rmvb等格式视频导入aria2,这样就可以导入下载需要解析的视频了。
其他对视频的解析要么没有解析,要么还需要继续解析txt。不过会用视频管理软件的话,完全不用担心会被封。
有文件丢失和限制的情况出现,目前解决思路就是直接下载flv播放器,flash是目前安全性较高的视频编码方式,下载速度相对其他的视频来说是较快的,对于视频比较多的网站来说是个不错的选择。直接从本地下载是比较慢的,直接下载其实是缺点,没有服务器中转,解析起来也比较慢。我感觉主要是解析起来也慢,大部分的视频都有版权限制,解析速度慢。
不能从网站下载视频时,可以采用下边方法下载:首先把视频用下面方法去下载:通过链接提取视频:"id":"(\.+).*"然后就可以下载本地flv视频了。因为转码是视频处理软件来做的,如果你的电脑上没有安装任何的视频处理软件的话,是无法操作的。
从网页抓取视频(360浏览器怎么直接提取网页视频?(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-26 21:10
360浏览器如何直接提取网页视频?很多时候,我们需要下载或提取网页上的视频,但我们不知道如何去做。.
以上步骤只能在观看视频后进行。体验内容仅供参考。如果您需要解决具体问题(尤其是法律、医学等领域),建议您详细咨询相关领域的专业人士。作者声明:本经验基于事实。未经许可体验原创。
下面介绍一种无需借助任何软件即可从网页中提取视频的方法,希望对您有所帮助。方法/步骤我以360浏览器为例,这里可以随便打开一个网页视频,注意不能是视频网站 Video in。打开视频播放,正在播放。
但是,已经有很多视频提取网站,他们可以在网站上提取你要下载的视频,shuoshu网站就是其中之一。说一下使用说书提取网页视频的方法应该不会太晚。
教你如何从网页中提取视频、音乐、歌曲、Flash、图片等多媒体文件(非常实用)忘记图片网址或不想了。
如何下载网页上播放的视频 小雄科技教你如何下载天天科技faAndroid手机网页上的视频,因为视频很多网站,没有下载方法。只有通过这种方法才能实现。工具/原材料 xbrowser 方法/步骤。
642,311 人观看了此视频。在日常生活中,我们经常浏览网页,看到一些不错的视频,就想下载。很多人教过各种方法,比如在设置中查看缓存,比如给网址加后缀,但是随着网站的升级,很多。
如何提取网页上100%的视频?可能很多朋友对此感到困惑。下面小编就为大家介绍一下具体的提取方法,希望对大家有所帮助。进入浏览器后,点击右上角的方法/步骤三横线图标。单击“工具”进行选择。 查看全部
从网页抓取视频(360浏览器怎么直接提取网页视频?(一)(组图))
360浏览器如何直接提取网页视频?很多时候,我们需要下载或提取网页上的视频,但我们不知道如何去做。.
以上步骤只能在观看视频后进行。体验内容仅供参考。如果您需要解决具体问题(尤其是法律、医学等领域),建议您详细咨询相关领域的专业人士。作者声明:本经验基于事实。未经许可体验原创。
下面介绍一种无需借助任何软件即可从网页中提取视频的方法,希望对您有所帮助。方法/步骤我以360浏览器为例,这里可以随便打开一个网页视频,注意不能是视频网站 Video in。打开视频播放,正在播放。
但是,已经有很多视频提取网站,他们可以在网站上提取你要下载的视频,shuoshu网站就是其中之一。说一下使用说书提取网页视频的方法应该不会太晚。
教你如何从网页中提取视频、音乐、歌曲、Flash、图片等多媒体文件(非常实用)忘记图片网址或不想了。
如何下载网页上播放的视频 小雄科技教你如何下载天天科技faAndroid手机网页上的视频,因为视频很多网站,没有下载方法。只有通过这种方法才能实现。工具/原材料 xbrowser 方法/步骤。
642,311 人观看了此视频。在日常生活中,我们经常浏览网页,看到一些不错的视频,就想下载。很多人教过各种方法,比如在设置中查看缓存,比如给网址加后缀,但是随着网站的升级,很多。
如何提取网页上100%的视频?可能很多朋友对此感到困惑。下面小编就为大家介绍一下具体的提取方法,希望对大家有所帮助。进入浏览器后,点击右上角的方法/步骤三横线图标。单击“工具”进行选择。
从网页抓取视频(Moo0VideoDownloader1的新功能14:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-12 19:08
⒈ 一个简单易用的应用程序,可以帮助用户抓取来自不同网站的视频,同时提供出色的下载速度和剪贴板监控选项。
⒉ Moo0 Video Downloader 1新功能14:。
⒊ 主下载引擎的另一个更新。
⒋ 更多错误修复。
⒌ 阅读完整的更改日志。
⒍ Moo0 Video Downloader 是一款轻量级的Windows 应用程序,旨在帮助用户从不同的网站 下载视频并将剪辑保存到计算机以供离线观看。
它使用简洁明了的布局,让您只需点击几下即可设置整个过程。
Moo0 Video Downloader 通过启用剪贴板监控简化了下载过程,这意味着每次复制链接时,应用程序都会自动将其粘贴到主面板并开始下载过程。
此外,您可以将 URL 直接拖放到主窗口中。
更重要的是,您可以选择一个默认的保存目录,在专用对话框中手动插入一个有效的URL并启动下载任务,并可以查看有关捕获视频的详细信息,即标题、大小和状态。
该实用程序允许您使用默认视频播放器播放剪辑、打开存储项目的文件夹、将 URL 复制到剪贴板、从列表中删除项目、取消下载过程和从计算机中。
最后但并非最不重要的是,您可以将应用程序置于其他实用程序之上,如果 网站 需要密码验证,请指定用户名和密码,并检查日志部分以查看有关可能的错误信息的详细信息。
在我们的测试过程中,我们注意到该工具执行下载过程非常快,整个过程没有任何错误。它不会对CPU和内存造成很大压力,因此不会影响计算机的整体性能。
综上所述,Moo0 Video Downloader 让下载操作变得轻而易举。对于正在寻找易于使用的工具而无需太多配置设置的用户来说,它似乎是正确的选择。
提交它。
视频下载器视频 采集器 下载剪辑下载器下载 采集器 YouTube。
Moo0 Video Downloader 由 Ana Marculescu 4 0/5 审核。 查看全部
从网页抓取视频(Moo0VideoDownloader1的新功能14:)
⒈ 一个简单易用的应用程序,可以帮助用户抓取来自不同网站的视频,同时提供出色的下载速度和剪贴板监控选项。
⒉ Moo0 Video Downloader 1新功能14:。
⒊ 主下载引擎的另一个更新。
⒋ 更多错误修复。
⒌ 阅读完整的更改日志。
⒍ Moo0 Video Downloader 是一款轻量级的Windows 应用程序,旨在帮助用户从不同的网站 下载视频并将剪辑保存到计算机以供离线观看。
它使用简洁明了的布局,让您只需点击几下即可设置整个过程。
Moo0 Video Downloader 通过启用剪贴板监控简化了下载过程,这意味着每次复制链接时,应用程序都会自动将其粘贴到主面板并开始下载过程。
此外,您可以将 URL 直接拖放到主窗口中。
更重要的是,您可以选择一个默认的保存目录,在专用对话框中手动插入一个有效的URL并启动下载任务,并可以查看有关捕获视频的详细信息,即标题、大小和状态。
该实用程序允许您使用默认视频播放器播放剪辑、打开存储项目的文件夹、将 URL 复制到剪贴板、从列表中删除项目、取消下载过程和从计算机中。
最后但并非最不重要的是,您可以将应用程序置于其他实用程序之上,如果 网站 需要密码验证,请指定用户名和密码,并检查日志部分以查看有关可能的错误信息的详细信息。
在我们的测试过程中,我们注意到该工具执行下载过程非常快,整个过程没有任何错误。它不会对CPU和内存造成很大压力,因此不会影响计算机的整体性能。
综上所述,Moo0 Video Downloader 让下载操作变得轻而易举。对于正在寻找易于使用的工具而无需太多配置设置的用户来说,它似乎是正确的选择。
提交它。
视频下载器视频 采集器 下载剪辑下载器下载 采集器 YouTube。
Moo0 Video Downloader 由 Ana Marculescu 4 0/5 审核。
从网页抓取视频( 影音下载神器——猫抓这是一款影音嗅探工具(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-12 18:43
影音下载神器——猫抓这是一款影音嗅探工具(组图)
)
如何在网站上下载视频-如何在网站上抓取视频
最近想下载一个网络视频。我不知道如何正确下载它。我到处都卡住了。网上下载网络视频的方法有很多,但都不是很实用的方法。有些方法很麻烦,比如:有人说提取网页代码再下载软件好麻烦!有时候找了半天找不到下载的代码,加上下载时间。这项工作还有待完成吗?有人说下载软件或者网页下载插件,这些方法我都试过了,但是总是不好用,关键是省时省力,所以一直在关注网页下载的知识,可惜还好,终于找到了一个好方法,今天分享给朋友们!
两个下载网络视频的插件——非常棒的工具,获取方式:关注@边走印记,私信回复“视频插件”说明:结合使用以下两个插件制作作品最好的事物!
音视频下载神器-猫抓
这是一个音视频嗅探工具,以插件的形式出现在各大浏览器扩展中。它主要捕获视频和音频。只要打开任意音视频播放,它就会自动抓取,点击下载即可。其中,音频秒杀,无需等待即可下载。对于主流视频网站,采用分段下载。您可以使用复合视频工具再次组合它。是它的缺点,但是下载小视频、非主流影视就不会出现这种情况。下载的视频完好无损。主流视频都被别人用的shell保护了,有自己的格式,所以才会出现。这个情况。
您可以在百度上搜索并下载该插件。如果嫌麻烦,下载超级浏览器,它收录在扩展中,点击安装即可。最近小编发现这个插件好难找。如果找不到,可以关注我获取哦!
先说一下如何安装插件,就是把插件下载到桌面,然后打开浏览器,然后在浏览器窗口打开扩展,把插件拖到桌面上,就可以了自动安装,你可以使用它 NS。
音视频下载神器-Video DownloadHelper
Video DownloadHelper 是一款专用软件,可以更轻松地从不同的网站 下载各种视频。该程序承诺非常易于使用,只需按一个按钮即可开始工作。
获取你想要的视频
Video DownloadHelper 带有 Firefox 和 Chrome 兼容版本,以帮助扩展频谱,以便它可以与各种流行的操作系统一起使用。用户只需在自己经常查看的网站中找到自己喜欢的视频,然后点击按钮即可开始下载过程。一个方便的工具栏显示了下载过程,尽管在某些情况下,以高清显示的非常大的公关视频可能需要相当长的时间才能下载,而其他视频可能会被阻止。
无尽的内容触手可及
无法从某些 网站 下载他们想要的视频的人可能会发现 Video DownloadHelper 使此过程更容易。尽管该程序不时会出现故障,但免费提供的事实意味着在承诺为此类其他程序付费之前需要对其进行检查。
这个工具有插件和应用软件。您可以根据自己的需要下载它们。插件可以节省您的计算机空间,但该软件非常适合管理内容。各有各的优点!
查看全部
从网页抓取视频(
影音下载神器——猫抓这是一款影音嗅探工具(组图)
)
如何在网站上下载视频-如何在网站上抓取视频
最近想下载一个网络视频。我不知道如何正确下载它。我到处都卡住了。网上下载网络视频的方法有很多,但都不是很实用的方法。有些方法很麻烦,比如:有人说提取网页代码再下载软件好麻烦!有时候找了半天找不到下载的代码,加上下载时间。这项工作还有待完成吗?有人说下载软件或者网页下载插件,这些方法我都试过了,但是总是不好用,关键是省时省力,所以一直在关注网页下载的知识,可惜还好,终于找到了一个好方法,今天分享给朋友们!
两个下载网络视频的插件——非常棒的工具,获取方式:关注@边走印记,私信回复“视频插件”说明:结合使用以下两个插件制作作品最好的事物!
音视频下载神器-猫抓
这是一个音视频嗅探工具,以插件的形式出现在各大浏览器扩展中。它主要捕获视频和音频。只要打开任意音视频播放,它就会自动抓取,点击下载即可。其中,音频秒杀,无需等待即可下载。对于主流视频网站,采用分段下载。您可以使用复合视频工具再次组合它。是它的缺点,但是下载小视频、非主流影视就不会出现这种情况。下载的视频完好无损。主流视频都被别人用的shell保护了,有自己的格式,所以才会出现。这个情况。
您可以在百度上搜索并下载该插件。如果嫌麻烦,下载超级浏览器,它收录在扩展中,点击安装即可。最近小编发现这个插件好难找。如果找不到,可以关注我获取哦!
先说一下如何安装插件,就是把插件下载到桌面,然后打开浏览器,然后在浏览器窗口打开扩展,把插件拖到桌面上,就可以了自动安装,你可以使用它 NS。
音视频下载神器-Video DownloadHelper
Video DownloadHelper 是一款专用软件,可以更轻松地从不同的网站 下载各种视频。该程序承诺非常易于使用,只需按一个按钮即可开始工作。
获取你想要的视频
Video DownloadHelper 带有 Firefox 和 Chrome 兼容版本,以帮助扩展频谱,以便它可以与各种流行的操作系统一起使用。用户只需在自己经常查看的网站中找到自己喜欢的视频,然后点击按钮即可开始下载过程。一个方便的工具栏显示了下载过程,尽管在某些情况下,以高清显示的非常大的公关视频可能需要相当长的时间才能下载,而其他视频可能会被阻止。
无尽的内容触手可及
无法从某些 网站 下载他们想要的视频的人可能会发现 Video DownloadHelper 使此过程更容易。尽管该程序不时会出现故障,但免费提供的事实意味着在承诺为此类其他程序付费之前需要对其进行检查。
这个工具有插件和应用软件。您可以根据自己的需要下载它们。插件可以节省您的计算机空间,但该软件非常适合管理内容。各有各的优点!
从网页抓取视频(一键下载高清视频专注于下载YouTube视频视频的获取方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2021-10-08 10:27
)
1、高清视频一键下载
专注下载YouTube超高清视频,支持720P、1080P、2K、4K、8K分辨率视频采集。不仅可以下载YouTube视频,TubeGet还支持从各种流媒体网站获取视频内容:包括Vimeo、Lynda、Twitch等视频网站、Facebook、Twitter、Instagram、Tumblr等社交媒体,以及Vevo 和 SoundCloud 等音乐服务网站。
除了下载单个 YouTube 视频外,它还支持批量下载播放列表和频道中的所有视频。YouTube上的字幕文件(收录、自动生成、翻译)、360°VR全景视频、48/60FPS高帧率视频、高清封面、3D视频等都支持保存。此外,这款 YouTube 下载器还可以将音乐视频转换为 MP3 音频格式。
2、集成多种实用工具
独有的一键下载模式,只需提前设置下载分辨率、下载位置、字幕语言,即可将YouTube视频快速保存到Windows或Mac电脑。除了YouTube视频保存功能,Gihosoft TubeGet还有视频格式转换功能,可以将下载的YouTube WebM视频转换成MP4、MKV、AVI、MOV格式。
在转换视频的同时,您还可以合成视频和字幕文件。选择转换格式后,点击“添加字幕”选项,导入下载的字幕文件。然后选择将字幕合成为硬字幕或软字幕,最后点击“转换”按钮将字幕文件和视频合并为一个整体。
3、在 YouTube 上下载任何内容和格式
Gihosoft TubeGet 可以下载各种格式的 YouTube 视频、播放列表、频道和类别,例如 MP4、WebM、3GP、FLV、AVI、MKV 等,以及不同的分辨率,包括 4K、1440P、1080P、720P、480P、360P 和240P等,最多可以下载5个YouTube视频并恢复下载失败。如果您的互联网连接速度较慢,您可以将下载速度限制为 4MBps、2MBps、1MBps、700KBps、200KBps 等。
4、下载 YouTube 视频并将其转换为 MP3
Gihosoft TubeGet 不仅可以用作免费的 YouTube 视频下载软件,还可以用作在线音乐爱好者的完美免费 YouTube 转 MP3 工具。使用它,您可以直接从 YouTube 和其他视频中提取和下载 MP3 文件网站,而无需下载整个视频文件。
查看全部
从网页抓取视频(一键下载高清视频专注于下载YouTube视频视频的获取方法
)
1、高清视频一键下载
专注下载YouTube超高清视频,支持720P、1080P、2K、4K、8K分辨率视频采集。不仅可以下载YouTube视频,TubeGet还支持从各种流媒体网站获取视频内容:包括Vimeo、Lynda、Twitch等视频网站、Facebook、Twitter、Instagram、Tumblr等社交媒体,以及Vevo 和 SoundCloud 等音乐服务网站。
除了下载单个 YouTube 视频外,它还支持批量下载播放列表和频道中的所有视频。YouTube上的字幕文件(收录、自动生成、翻译)、360°VR全景视频、48/60FPS高帧率视频、高清封面、3D视频等都支持保存。此外,这款 YouTube 下载器还可以将音乐视频转换为 MP3 音频格式。
2、集成多种实用工具
独有的一键下载模式,只需提前设置下载分辨率、下载位置、字幕语言,即可将YouTube视频快速保存到Windows或Mac电脑。除了YouTube视频保存功能,Gihosoft TubeGet还有视频格式转换功能,可以将下载的YouTube WebM视频转换成MP4、MKV、AVI、MOV格式。
在转换视频的同时,您还可以合成视频和字幕文件。选择转换格式后,点击“添加字幕”选项,导入下载的字幕文件。然后选择将字幕合成为硬字幕或软字幕,最后点击“转换”按钮将字幕文件和视频合并为一个整体。
3、在 YouTube 上下载任何内容和格式
Gihosoft TubeGet 可以下载各种格式的 YouTube 视频、播放列表、频道和类别,例如 MP4、WebM、3GP、FLV、AVI、MKV 等,以及不同的分辨率,包括 4K、1440P、1080P、720P、480P、360P 和240P等,最多可以下载5个YouTube视频并恢复下载失败。如果您的互联网连接速度较慢,您可以将下载速度限制为 4MBps、2MBps、1MBps、700KBps、200KBps 等。
4、下载 YouTube 视频并将其转换为 MP3
Gihosoft TubeGet 不仅可以用作免费的 YouTube 视频下载软件,还可以用作在线音乐爱好者的完美免费 YouTube 转 MP3 工具。使用它,您可以直接从 YouTube 和其他视频中提取和下载 MP3 文件网站,而无需下载整个视频文件。
从网页抓取视频(如何支持多种视频格式转换的软件有很多种?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-10-03 22:02
从网页抓取视频后,下载地址中网站的每个视频,然后通过ae渲染,导出为mp4即可用,或者用adsafe插件也可以。这么做的理由是,如果网站把高清视频全下了,网站的用户体验会下降。
用动态小视频在线下载工具,效果和ae差不多,特别简单只需要输入url或在浏览器直接打开网址即可。
很多人为了下载很小清晰的视频,会去寻找很麻烦,并且要付费使用的那种方法,非常烦人。目前支持多种视频格式转换的软件有很多,一般是用这种办法,比如下载酷6的视频,那么他的视频的格式文件就是swf格式,所以你就可以用格式工厂等软件把其他一些视频格式转换一下。如果视频格式是mp4或者wmv,这就好办了,还是可以用ae、pr、finalcut这些工具将其他的转换一下格式,把画质改为1080p。
下面是我今天下载的,我就直接把其他软件下载的视频格式转换了一下,感觉还行,毕竟一般视频不会是5g这么大的,有可能有些朋友下载的时候,视频不止5g,但是大部分人并不知道。使用简单,可不要用教程了,好好琢磨一下,下个软件,也很方便。
支持,准备好下载包和拖拉机,出门右转,百度搜youhouboy,
windows下你需要打开命令提示符
不清楚ps,ae是啥。但是高清这个概念大多是指1080p,对于小一点的体积,比如2g、4g视频来说。真的没有卵用ps比较常用,ae经常用,我们做电商产品,还有一些电视广告什么的。flash、cc2013可以用,像我们做小说电视剧的真心不行。你的这个视频是1080p有可能是电视级别。所以,不是特别清晰。 查看全部
从网页抓取视频(如何支持多种视频格式转换的软件有很多种?)
从网页抓取视频后,下载地址中网站的每个视频,然后通过ae渲染,导出为mp4即可用,或者用adsafe插件也可以。这么做的理由是,如果网站把高清视频全下了,网站的用户体验会下降。
用动态小视频在线下载工具,效果和ae差不多,特别简单只需要输入url或在浏览器直接打开网址即可。
很多人为了下载很小清晰的视频,会去寻找很麻烦,并且要付费使用的那种方法,非常烦人。目前支持多种视频格式转换的软件有很多,一般是用这种办法,比如下载酷6的视频,那么他的视频的格式文件就是swf格式,所以你就可以用格式工厂等软件把其他一些视频格式转换一下。如果视频格式是mp4或者wmv,这就好办了,还是可以用ae、pr、finalcut这些工具将其他的转换一下格式,把画质改为1080p。
下面是我今天下载的,我就直接把其他软件下载的视频格式转换了一下,感觉还行,毕竟一般视频不会是5g这么大的,有可能有些朋友下载的时候,视频不止5g,但是大部分人并不知道。使用简单,可不要用教程了,好好琢磨一下,下个软件,也很方便。
支持,准备好下载包和拖拉机,出门右转,百度搜youhouboy,
windows下你需要打开命令提示符
不清楚ps,ae是啥。但是高清这个概念大多是指1080p,对于小一点的体积,比如2g、4g视频来说。真的没有卵用ps比较常用,ae经常用,我们做电商产品,还有一些电视广告什么的。flash、cc2013可以用,像我们做小说电视剧的真心不行。你的这个视频是1080p有可能是电视级别。所以,不是特别清晰。
从网页抓取视频(本期目录01网页抓取02中文分词03文档矩阵04共现05文本聚类)
网站优化 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-10-03 00:00
本期目录
01
网页抓取
02
中文分词
03
文档矩阵
04
词频共现
05
文本聚类
06
主题建模
07
情绪分析
08
词频统计
09
绘制词云
失去
随着科技的进步,定量分析方法不再仅仅通过问卷、二手数据库等方式采集数据,而不再仅仅通过数理统计、回归分析等手段来分析数据。针对不同的研究需求,产生了越来越多的新方法和新工具:
例如,以元胞自动机为代表的生命体建模技术,以马尔可夫链蒙特卡罗(MCMC)算法为代表的计算机仿真技术等。
本期介绍使用爬虫技术抓取网页的实际案例,并对获取的网页文本数据进行后续分析。我将用网友对《流浪地球》豆瓣影评正文的获取和分析全过程作为示范案例。
文本挖掘的本质是通过自然语言处理(NLP)和分析方法将文本转化为数据进行分析。因此,阅读本文需要一定的知识基础,包括网页设计和自然语言处理方法,我会在文章中适当添加。
➡ 1.准备
在分析工作之前,需要配置软件的工作环境,包括设置工作目录、调用所需的程序包等。采集接收到的文本数据、各种词典、输出结果等都会存放在工作目录中;首次使用前需要安装外部程序包。
###备工作#设置工作目录setwd('D:/流浪地球')#加载需要的包 library('rvest')library('stringr')library('jiebaRD')library('jiebaR') library('plyr')library('rJava')library('tm')library('tmcn')library('proxy')library('topicmodels')library('sqldf')library('wordcloud2')
➡ 2.网页抓取
我仍然遵循定量分析的传统套路,将整个分析过程分为数据采集和数据分析两部分。第一步是通过爬虫技术抓取网页。
网络爬虫,也称为蜘蛛,是一种自动浏览万维网的网络机器人。它的目的一般是编译一个网络索引。爬虫访问网站的过程会消耗目标系统资源,很多网络系统默认是不允许爬虫工作的。因此,在访问大量页面时,爬虫需要考虑规划、加载和“礼貌”。使用robots.txt文件和其他方法可以避免爬虫不愿意访问和爬虫所有者已知的公共站点。
例如豆瓣电影()的robots.txt规定如下:
用户代理:*Disallow:/subject_searchDisallow:/amazon_searchDisallow:/searchDisallow:/group/searchDisallow:/event/searchDisallow:/celebrities/searchDisallow:/location/drama/searchDisallow:/forum/Disallow:/new_subjectDisallow:/service/iframeDisallow : /j/Disallow: /link2/Disallow: /recommend/Disallow: /doubanapp/cardDisallow: /update/topic/Sitemap: Sitemap: #Crawl-delay: 5
User-agent: 玩豆家 SpiderDisallow: /
在实际应用中,网络爬虫技术并不是特别复杂。在很多情况下,我们倾向于指定网站并抓取内容,更喜欢网页采集而不是网络爬虫。在此之前,希望读者了解网页源代码的相关知识,尤其是标记语言(HTML,只有语法,没有变量和逻辑)、层叠样式表(CSS,用于控制元素的显示形式) )、脚本语言(Java、HTML中元素增删改查的操作)在网页设计中。
另外,当网页以更复杂的表现形式出现时,如URL分页、超链接、异步加载等,需要读者有更多的理论知识。
###网页采集#observation URL pattern index #批量爬取好评数据评论为(i in index){#Read URL url = paste("",i,"&limit=20&sort=new_score&status=P&percent_type= h" ,sep="")web #爬取豆瓣赞词%html_nodes('#comments p')%>%html_text()#创建一个数据框存放上述信息comments_datacomments }#保存豆瓣赞为CSV文件写入。csv(评论,文件=“赞美.csv”,row.names=FALSE)
以上是本期抓取网页文本数据的代码。我从豆瓣电影网站中抓取了220条网友为《流浪地球》点赞的文字,保存为“praise.csv”文件。HTTP错误403错误不影响结果,这意味着从R进入的网页被识别为爬虫,访问被拒绝更多,并且由于限制而无法爬取所有评论:
一般纳税人公司注册费?价格透明,全程免费,中途不收取任何额外费用。
图1:豆瓣电影网站截图
注册一家公司需要多少钱?
图2:截取的220条评论文本数据截图
➡ 3.中文分词
中文自动分词是指使用计算机对中文文本进行自动分词,即中文句子中的单词之间有空格,以便像英文一样进行识别。中文自动分词被认为是中文自然语言处理中最基本的环节之一。
许多教科书以英文文本作为教学案例,分词所用的程序包与处理中文文本时所用的程序包不同。读者需注意自学。
###中文分词#获取当前工作目录getwd()#设置自定义词典并停止词汇引擎#导入赞美文字good names(good)nchar(good)#文字预处理good_res = good[good!=" "]ls ()fix(good_res)#赞美文字切分good_segwords fix(good_segwords)#删除未过滤出停止词表过滤器的词 filter_segment(good_segwords, filter)fix(good_segwords)
需要特别注意的是,用户自定义词典和停用词列表需要放在工作路径中,并保存为UTF-8编码格式的txt文本文件。传统上,第一行可以留空:
广告精品课程值得信赖!名师一对一指导,免费视频全真考,国家注册会计师名师指导,轻松通过考试!
图 3:我的用户定义词典和停用词列表的屏幕截图
自定义词典是为了防止固定词汇被拆解。例如,如果不设置自定义词典,“漫游空间2001”将被拆分为三个词:“漫游”、“空间”和“2001”;“韩多”“多”将拆分为“韩”和“多”两个字;这会给我们后续的分析带来麻烦。
过滤停用词列表就是删除我们在中文文本中不需要的虚词,例如“啊”、“啊”、“?” 以及其他词,“应该”、“是”等不相关的词、英文字母、标点符号和阿拉伯数字等。
对于不同的研究问题,自定义词典和停用词表每次分析都是不一样的,需要根据不同问题的需要不断调整修改。以下是部分文本使用自定义词典和停用词表后的分词效果:
图4:部分文字切分效果截图
➡ 4.文档矩阵
使用文档术语矩阵 (DTM),可以构建文本数据。DTM矩阵是转置后的TDM。DTM矩阵的形式是矩阵的行代表文档,矩阵的列代表词,矩阵元素是某个词在文档中出现的次数。
特别提示:需要先用Excel打开“Praise.csv”文件,使用“Review-Traditional to Simplified”将繁体字全部转为简体字,否则构建文档矩阵时会报错;文档-词频矩阵的构建是为了后续分析的基础:
###文档矩阵#创建好文本的DTM文件 good_corpus inspect(good_corpus[1:10])good_corpusctrlgood_dtminspect(good_dtm[1:10, 110:112])good_dtm
➡ 5. 词频共现
共现分析利用词语的共现来定量研究文本关系。因此,通过统计一组词在同一文本中出现的频率,可以形成由这些词对关联组成的共同词网络,网络中节点之间的距离可以反映内容的接近程度。
###词词共现#以术语“硬核科幻”0.5关系及以上为例 findAssocs(good_dtm, "hard core sci-fi", 0.5)
我以“硬核科幻”这个词0.5和上面的词汇结果为例,发现“硬核科幻”这个词和情节,气势磅礴,激情澎湃,社会秩序,低成本,完整,圆满词,例如,所有人类都有很强的共现关系:
$硬核科幻剧情,低成本,气势磅礴,第一次,气势磅礴参考奇伟的血统人类学想象社会秩序0.94 0.87 0.87 0. 87 0.87 < @0.87 0.87 0.87 0.87 0.87 想不到新的起点,烟花爆竹印象预告片,彻底的灾难,完整的世界和全人类0.87 0.87 0.87 0.87 0.87 0.87 < @0.85 0.71 0.57 0.55
➡ 6. 文本聚类
聚类分析是研究分类问题的统计分析方法,也是数据挖掘的重要算法。聚类分析由几种模式组成。通常,模式是一个测量向量,或者是多维空间中的一个点。聚类分析基于相似性,一个聚类中的模式之间的相似性比不在同一聚类中的模式更多。
###文本聚类#删除稀疏矩阵 good_dtm_sub dim(good_dtm_sub)#好的文本聚类 good_dist heatmap(as.matrix(good_dist),labRow=FALSE, labCol=FALSE)good_clust plot(good_clust)result1result2summary(result1)@ >sum (result2)result1result2plot(good_clust)
稀疏矩阵对分类预测系统的效率和预测精度有负面影响。因此,需要降低词频矩阵的维数,删除稀疏条目。
上面使用的是余弦相似度算法。通过测量两个向量之间夹角的余弦,来测量它们之间的相似度。0度角的余弦值为1,其他任何角度的余弦值都不大于1;其最小值为-1;因此两个向量之间夹角的余弦值决定了这两个向量是否大致指向同一方向。
结果与向量的长度无关,只与向量的方向有关。余弦相似度通常用在正空间,所以给定的值在0到1之间。 比如在信息检索中,每个term被赋予不同的维度,一个文档用一个向量表示,每个维度的值对应到文档中术语的频率。因此,余弦相似度可以给出两个文档在主题方面的相似度。
我分别使用 k=5 和 k=10 时的结果进行比较。220条评论的数量让树状图有点乱,但是聚类报告非常清晰。下图显示了 k=5 时的 220 条评论。文本聚类结果:
广告是秃头?别再用生姜洗头了,试试用生姜吧,稀疏的头发瞬间变得浓密
图5:k=5时220条评论文本的聚类结果
➡ 7. 主题建模
<p>主题模型是一种统计模型,用于在机器学习和自然语言处理领域的一系列文档中发现抽象主题。直观来说,如果一篇文章文章有一个中心思想,那么一些特定的词就会出现得更频繁。例如,如果一篇文章是关于狗的,那么“狗”和“骨头”这两个词会出现得更频繁;如果一篇文章文章是关于猫的,那么“cat”和“fish”等词出现的频率会更高。一些词例如“this”和“he”在这两个 查看全部
从网页抓取视频(本期目录01网页抓取02中文分词03文档矩阵04共现05文本聚类)
本期目录
01
网页抓取
02
中文分词
03
文档矩阵
04
词频共现
05
文本聚类
06
主题建模
07
情绪分析
08
词频统计
09
绘制词云
失去
随着科技的进步,定量分析方法不再仅仅通过问卷、二手数据库等方式采集数据,而不再仅仅通过数理统计、回归分析等手段来分析数据。针对不同的研究需求,产生了越来越多的新方法和新工具:
例如,以元胞自动机为代表的生命体建模技术,以马尔可夫链蒙特卡罗(MCMC)算法为代表的计算机仿真技术等。
本期介绍使用爬虫技术抓取网页的实际案例,并对获取的网页文本数据进行后续分析。我将用网友对《流浪地球》豆瓣影评正文的获取和分析全过程作为示范案例。
文本挖掘的本质是通过自然语言处理(NLP)和分析方法将文本转化为数据进行分析。因此,阅读本文需要一定的知识基础,包括网页设计和自然语言处理方法,我会在文章中适当添加。
➡ 1.准备
在分析工作之前,需要配置软件的工作环境,包括设置工作目录、调用所需的程序包等。采集接收到的文本数据、各种词典、输出结果等都会存放在工作目录中;首次使用前需要安装外部程序包。
###备工作#设置工作目录setwd('D:/流浪地球')#加载需要的包 library('rvest')library('stringr')library('jiebaRD')library('jiebaR') library('plyr')library('rJava')library('tm')library('tmcn')library('proxy')library('topicmodels')library('sqldf')library('wordcloud2')
➡ 2.网页抓取
我仍然遵循定量分析的传统套路,将整个分析过程分为数据采集和数据分析两部分。第一步是通过爬虫技术抓取网页。
网络爬虫,也称为蜘蛛,是一种自动浏览万维网的网络机器人。它的目的一般是编译一个网络索引。爬虫访问网站的过程会消耗目标系统资源,很多网络系统默认是不允许爬虫工作的。因此,在访问大量页面时,爬虫需要考虑规划、加载和“礼貌”。使用robots.txt文件和其他方法可以避免爬虫不愿意访问和爬虫所有者已知的公共站点。
例如豆瓣电影()的robots.txt规定如下:
用户代理:*Disallow:/subject_searchDisallow:/amazon_searchDisallow:/searchDisallow:/group/searchDisallow:/event/searchDisallow:/celebrities/searchDisallow:/location/drama/searchDisallow:/forum/Disallow:/new_subjectDisallow:/service/iframeDisallow : /j/Disallow: /link2/Disallow: /recommend/Disallow: /doubanapp/cardDisallow: /update/topic/Sitemap: Sitemap: #Crawl-delay: 5
User-agent: 玩豆家 SpiderDisallow: /
在实际应用中,网络爬虫技术并不是特别复杂。在很多情况下,我们倾向于指定网站并抓取内容,更喜欢网页采集而不是网络爬虫。在此之前,希望读者了解网页源代码的相关知识,尤其是标记语言(HTML,只有语法,没有变量和逻辑)、层叠样式表(CSS,用于控制元素的显示形式) )、脚本语言(Java、HTML中元素增删改查的操作)在网页设计中。
另外,当网页以更复杂的表现形式出现时,如URL分页、超链接、异步加载等,需要读者有更多的理论知识。
###网页采集#observation URL pattern index #批量爬取好评数据评论为(i in index){#Read URL url = paste("",i,"&limit=20&sort=new_score&status=P&percent_type= h" ,sep="")web #爬取豆瓣赞词%html_nodes('#comments p')%>%html_text()#创建一个数据框存放上述信息comments_datacomments }#保存豆瓣赞为CSV文件写入。csv(评论,文件=“赞美.csv”,row.names=FALSE)
以上是本期抓取网页文本数据的代码。我从豆瓣电影网站中抓取了220条网友为《流浪地球》点赞的文字,保存为“praise.csv”文件。HTTP错误403错误不影响结果,这意味着从R进入的网页被识别为爬虫,访问被拒绝更多,并且由于限制而无法爬取所有评论:
一般纳税人公司注册费?价格透明,全程免费,中途不收取任何额外费用。
图1:豆瓣电影网站截图
注册一家公司需要多少钱?
图2:截取的220条评论文本数据截图
➡ 3.中文分词
中文自动分词是指使用计算机对中文文本进行自动分词,即中文句子中的单词之间有空格,以便像英文一样进行识别。中文自动分词被认为是中文自然语言处理中最基本的环节之一。
许多教科书以英文文本作为教学案例,分词所用的程序包与处理中文文本时所用的程序包不同。读者需注意自学。
###中文分词#获取当前工作目录getwd()#设置自定义词典并停止词汇引擎#导入赞美文字good names(good)nchar(good)#文字预处理good_res = good[good!=" "]ls ()fix(good_res)#赞美文字切分good_segwords fix(good_segwords)#删除未过滤出停止词表过滤器的词 filter_segment(good_segwords, filter)fix(good_segwords)
需要特别注意的是,用户自定义词典和停用词列表需要放在工作路径中,并保存为UTF-8编码格式的txt文本文件。传统上,第一行可以留空:
广告精品课程值得信赖!名师一对一指导,免费视频全真考,国家注册会计师名师指导,轻松通过考试!
图 3:我的用户定义词典和停用词列表的屏幕截图
自定义词典是为了防止固定词汇被拆解。例如,如果不设置自定义词典,“漫游空间2001”将被拆分为三个词:“漫游”、“空间”和“2001”;“韩多”“多”将拆分为“韩”和“多”两个字;这会给我们后续的分析带来麻烦。
过滤停用词列表就是删除我们在中文文本中不需要的虚词,例如“啊”、“啊”、“?” 以及其他词,“应该”、“是”等不相关的词、英文字母、标点符号和阿拉伯数字等。
对于不同的研究问题,自定义词典和停用词表每次分析都是不一样的,需要根据不同问题的需要不断调整修改。以下是部分文本使用自定义词典和停用词表后的分词效果:
图4:部分文字切分效果截图
➡ 4.文档矩阵
使用文档术语矩阵 (DTM),可以构建文本数据。DTM矩阵是转置后的TDM。DTM矩阵的形式是矩阵的行代表文档,矩阵的列代表词,矩阵元素是某个词在文档中出现的次数。
特别提示:需要先用Excel打开“Praise.csv”文件,使用“Review-Traditional to Simplified”将繁体字全部转为简体字,否则构建文档矩阵时会报错;文档-词频矩阵的构建是为了后续分析的基础:
###文档矩阵#创建好文本的DTM文件 good_corpus inspect(good_corpus[1:10])good_corpusctrlgood_dtminspect(good_dtm[1:10, 110:112])good_dtm
➡ 5. 词频共现
共现分析利用词语的共现来定量研究文本关系。因此,通过统计一组词在同一文本中出现的频率,可以形成由这些词对关联组成的共同词网络,网络中节点之间的距离可以反映内容的接近程度。
###词词共现#以术语“硬核科幻”0.5关系及以上为例 findAssocs(good_dtm, "hard core sci-fi", 0.5)
我以“硬核科幻”这个词0.5和上面的词汇结果为例,发现“硬核科幻”这个词和情节,气势磅礴,激情澎湃,社会秩序,低成本,完整,圆满词,例如,所有人类都有很强的共现关系:
$硬核科幻剧情,低成本,气势磅礴,第一次,气势磅礴参考奇伟的血统人类学想象社会秩序0.94 0.87 0.87 0. 87 0.87 < @0.87 0.87 0.87 0.87 0.87 想不到新的起点,烟花爆竹印象预告片,彻底的灾难,完整的世界和全人类0.87 0.87 0.87 0.87 0.87 0.87 < @0.85 0.71 0.57 0.55
➡ 6. 文本聚类
聚类分析是研究分类问题的统计分析方法,也是数据挖掘的重要算法。聚类分析由几种模式组成。通常,模式是一个测量向量,或者是多维空间中的一个点。聚类分析基于相似性,一个聚类中的模式之间的相似性比不在同一聚类中的模式更多。
###文本聚类#删除稀疏矩阵 good_dtm_sub dim(good_dtm_sub)#好的文本聚类 good_dist heatmap(as.matrix(good_dist),labRow=FALSE, labCol=FALSE)good_clust plot(good_clust)result1result2summary(result1)@ >sum (result2)result1result2plot(good_clust)
稀疏矩阵对分类预测系统的效率和预测精度有负面影响。因此,需要降低词频矩阵的维数,删除稀疏条目。
上面使用的是余弦相似度算法。通过测量两个向量之间夹角的余弦,来测量它们之间的相似度。0度角的余弦值为1,其他任何角度的余弦值都不大于1;其最小值为-1;因此两个向量之间夹角的余弦值决定了这两个向量是否大致指向同一方向。
结果与向量的长度无关,只与向量的方向有关。余弦相似度通常用在正空间,所以给定的值在0到1之间。 比如在信息检索中,每个term被赋予不同的维度,一个文档用一个向量表示,每个维度的值对应到文档中术语的频率。因此,余弦相似度可以给出两个文档在主题方面的相似度。
我分别使用 k=5 和 k=10 时的结果进行比较。220条评论的数量让树状图有点乱,但是聚类报告非常清晰。下图显示了 k=5 时的 220 条评论。文本聚类结果:
广告是秃头?别再用生姜洗头了,试试用生姜吧,稀疏的头发瞬间变得浓密
图5:k=5时220条评论文本的聚类结果
➡ 7. 主题建模
<p>主题模型是一种统计模型,用于在机器学习和自然语言处理领域的一系列文档中发现抽象主题。直观来说,如果一篇文章文章有一个中心思想,那么一些特定的词就会出现得更频繁。例如,如果一篇文章是关于狗的,那么“狗”和“骨头”这两个词会出现得更频繁;如果一篇文章文章是关于猫的,那么“cat”和“fish”等词出现的频率会更高。一些词例如“this”和“he”在这两个
从网页抓取视频( 教你如何提取网页中的视频音乐歌曲flash图片等多媒体文件很实用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 372 次浏览 • 2021-10-01 22:01
教你如何提取网页中的视频音乐歌曲flash图片等多媒体文件很实用)
教你如何从网页中提取视频、音乐、歌曲、flash图片等多媒体文件。这是非常有用的。打开网页后,发现里面有好听的视频、好听的音乐、好听的图片、炫目的flash。你想把它们放在你的电脑或手机上的mp4吗?但是很多时候视频下载不了,音乐只能试听,或者好听的背景音乐不知道叫什么名字,更别提怎么下载了。至于图片,你可以直接右键另存为。但是如果网页突然关闭了,但又想把看到的图片保存下来,忘记了图片的网址或者不想通过历史记录打开怎么办?其实这些问题
问题可以很好的解决,而且很简单。只需使用软件从计算机的缓存中搜索您即可。就可以了,因为网页上显示的内容基本上都在缓存中了。如果自己手动搜索,会很累。迪不容易找到太多东西,也没有分类。无意中发现了一个对它很感兴趣的小软件。玩过无数小软件。我一直在用,也用它帮助了很多网友解决了他们的问题。所以我拿了它和我的朋友们分享,没有废话。现在进入主题。这个免费的小软件是YuanBox元宝盒v16。可以在百度上搜索下载。以下是我自己整理的使用。
步骤供大家参考。实际上,您不需要阅读该软件。这很简单。我不需要学习它。我只是用了很长时间。我很熟练。下载软件后,解压并打开里面的YuanBoxexe。您可以稍后将其关闭。这是为了确保计算机缓存中有您想要的内容。运行软件的初始界面如下图所示。flv格式视频搜索结果的界面直接在界面之后。原因是这个软件的全称是Ingot Box。FLV 视频下载专家不想要视频。如果点击最上面的设置或者最下面的高级设置来设置搜索范围,下面是搜索条件设置
界面以swf格式flash为例,搜索选择类型中的第二项。单击“确定”开始搜索结果。单击保存此项进行保存。下面重点介绍网页中音乐的提取过程。音乐软件上有提示只要网页没有关闭,点击右上角的刷新视频可以加快缓冲。缓冲后,会出现下图中的第二项。缓冲后,您可以预览试听或保存部分,但可以识别。找出它是否是您要查找的内容,然后决定让它完成缓冲。
单击预览以收听音乐。预览所有操作,如下图所示。保存界面如下。点击复制媒体地址复制原链接,即外链地址或下载地址。单击原创链接将打开播放器并使用原创链接地址播放在线音乐。还有一种直观的查看原创链接地址的方法 方法上面的方法要粘在一个地方才能看到下面的方法。右键单击原创链接并选择“属性”将其打开。
性界面如下。搜索其他媒体类型底部的原创链接地址大致相同。让我们谈谈设置中的情况。大小限制设置将缩小搜索范围。快速找到你想要的,最后证明图片和视频的搜索过程太简单了。实际上,你不需要看跌落。下面是flv视频的预览。 查看全部
从网页抓取视频(
教你如何提取网页中的视频音乐歌曲flash图片等多媒体文件很实用)
教你如何从网页中提取视频、音乐、歌曲、flash图片等多媒体文件。这是非常有用的。打开网页后,发现里面有好听的视频、好听的音乐、好听的图片、炫目的flash。你想把它们放在你的电脑或手机上的mp4吗?但是很多时候视频下载不了,音乐只能试听,或者好听的背景音乐不知道叫什么名字,更别提怎么下载了。至于图片,你可以直接右键另存为。但是如果网页突然关闭了,但又想把看到的图片保存下来,忘记了图片的网址或者不想通过历史记录打开怎么办?其实这些问题
问题可以很好的解决,而且很简单。只需使用软件从计算机的缓存中搜索您即可。就可以了,因为网页上显示的内容基本上都在缓存中了。如果自己手动搜索,会很累。迪不容易找到太多东西,也没有分类。无意中发现了一个对它很感兴趣的小软件。玩过无数小软件。我一直在用,也用它帮助了很多网友解决了他们的问题。所以我拿了它和我的朋友们分享,没有废话。现在进入主题。这个免费的小软件是YuanBox元宝盒v16。可以在百度上搜索下载。以下是我自己整理的使用。
步骤供大家参考。实际上,您不需要阅读该软件。这很简单。我不需要学习它。我只是用了很长时间。我很熟练。下载软件后,解压并打开里面的YuanBoxexe。您可以稍后将其关闭。这是为了确保计算机缓存中有您想要的内容。运行软件的初始界面如下图所示。flv格式视频搜索结果的界面直接在界面之后。原因是这个软件的全称是Ingot Box。FLV 视频下载专家不想要视频。如果点击最上面的设置或者最下面的高级设置来设置搜索范围,下面是搜索条件设置
界面以swf格式flash为例,搜索选择类型中的第二项。单击“确定”开始搜索结果。单击保存此项进行保存。下面重点介绍网页中音乐的提取过程。音乐软件上有提示只要网页没有关闭,点击右上角的刷新视频可以加快缓冲。缓冲后,会出现下图中的第二项。缓冲后,您可以预览试听或保存部分,但可以识别。找出它是否是您要查找的内容,然后决定让它完成缓冲。
单击预览以收听音乐。预览所有操作,如下图所示。保存界面如下。点击复制媒体地址复制原链接,即外链地址或下载地址。单击原创链接将打开播放器并使用原创链接地址播放在线音乐。还有一种直观的查看原创链接地址的方法 方法上面的方法要粘在一个地方才能看到下面的方法。右键单击原创链接并选择“属性”将其打开。
性界面如下。搜索其他媒体类型底部的原创链接地址大致相同。让我们谈谈设置中的情况。大小限制设置将缩小搜索范围。快速找到你想要的,最后证明图片和视频的搜索过程太简单了。实际上,你不需要看跌落。下面是flv视频的预览。
从网页抓取视频(网页抓取工具优采云采集器V9实现抓取商品信息的方法(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 416 次浏览 • 2021-10-01 16:16
)
大数据时代的经销商,无论是经营线上门店还是线下实体店,都必须具备敏锐的信息洞察能力,才能在市场中寻找空缺,在竞争中寻求突破。除了正确的视角,信息的洞察力还需要一个方便的爬虫工具。优采云采集器作为领先的网页抓取工具品牌,可以为企业快速稳定的抓取网页。获取产品信息的功能为洞察和分析市场提供了必要的前提。
下面介绍一下网络爬虫工具优采云采集器优采云采集器V9实现产品信息抓取的方法:优采云采集器是其中一种一个高效稳定的网络爬虫工具。其工作原理是基于WEB结构的源代码提取。按照从主URL进入内容页面再提取内容的过程,可以从网页中提取文本、图片、压缩文件等,这意味着对于商家来说,商品等一系列属性内容所有电商网站中出现的价格、图片、教程文件都可以轻松提取。
使用网页爬虫工具优采云采集器V9抓取商品信息时,需要注意以下几点:
1、判断这个页面的信息是否全面展示。如果有需要登录才能看到的信息,需要在优采云采集器中进行登录采集相关设置。
2、写入内容采集 按规则下载图片时,edit标签的数据处理中有文件下载选项。有四个选项,其中之一是下载图片。您可以通过检查下载图片。优采云采集器V9 这里是默认下载带有html标签的图片。所以对于没有html标签的图片,比如缩略图,一定要勾选“检测文件并下载”。在这种情况下,优采云采集器会自动检测到这种图片文件并下载。
3、如果在当你请求新内容时,页面只进行局部刷新,而地址栏中的URL不变,这种post网址想要获取到就要使用抓包工具,截取请求时提交的内容找出共同特点,用
火车采集器中的“分页”变量进行替换并给定值范围,这样火车采集器在采集时会自动提交请求内容得到新的内容列表进行采集。网页抓取工具火车采集器V9还有更
多让人惊艳的功能,更多操作可以访问官网(www.locoy.com)的帮助手册或视频教程进行学习。
电子商务运营商使用网络爬虫工具优采云采集器V9抓取同类产品的属性、评价、价格、市场销售等数据,并利用这些数据推导出产品的相关特征信息. 对某个商品名称进行搜索优化,或者根据相似体验制作热门商品,在充分了解用户行为的基础上开展经营活动,可以大大提高网店的运营水平和效率。所以优采云采集器不过据说是经销商玩大数据的首选!
查看全部
从网页抓取视频(网页抓取工具优采云采集器V9实现抓取商品信息的方法(图)
)
大数据时代的经销商,无论是经营线上门店还是线下实体店,都必须具备敏锐的信息洞察能力,才能在市场中寻找空缺,在竞争中寻求突破。除了正确的视角,信息的洞察力还需要一个方便的爬虫工具。优采云采集器作为领先的网页抓取工具品牌,可以为企业快速稳定的抓取网页。获取产品信息的功能为洞察和分析市场提供了必要的前提。
下面介绍一下网络爬虫工具优采云采集器优采云采集器V9实现产品信息抓取的方法:优采云采集器是其中一种一个高效稳定的网络爬虫工具。其工作原理是基于WEB结构的源代码提取。按照从主URL进入内容页面再提取内容的过程,可以从网页中提取文本、图片、压缩文件等,这意味着对于商家来说,商品等一系列属性内容所有电商网站中出现的价格、图片、教程文件都可以轻松提取。
使用网页爬虫工具优采云采集器V9抓取商品信息时,需要注意以下几点:
1、判断这个页面的信息是否全面展示。如果有需要登录才能看到的信息,需要在优采云采集器中进行登录采集相关设置。
2、写入内容采集 按规则下载图片时,edit标签的数据处理中有文件下载选项。有四个选项,其中之一是下载图片。您可以通过检查下载图片。优采云采集器V9 这里是默认下载带有html标签的图片。所以对于没有html标签的图片,比如缩略图,一定要勾选“检测文件并下载”。在这种情况下,优采云采集器会自动检测到这种图片文件并下载。
3、如果在当你请求新内容时,页面只进行局部刷新,而地址栏中的URL不变,这种post网址想要获取到就要使用抓包工具,截取请求时提交的内容找出共同特点,用
火车采集器中的“分页”变量进行替换并给定值范围,这样火车采集器在采集时会自动提交请求内容得到新的内容列表进行采集。网页抓取工具火车采集器V9还有更
多让人惊艳的功能,更多操作可以访问官网(www.locoy.com)的帮助手册或视频教程进行学习。
电子商务运营商使用网络爬虫工具优采云采集器V9抓取同类产品的属性、评价、价格、市场销售等数据,并利用这些数据推导出产品的相关特征信息. 对某个商品名称进行搜索优化,或者根据相似体验制作热门商品,在充分了解用户行为的基础上开展经营活动,可以大大提高网店的运营水平和效率。所以优采云采集器不过据说是经销商玩大数据的首选!
从网页抓取视频(从网页抓取视频,下载后看电视?所有web视频格式皆可播放)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-09-26 22:10
从网页抓取视频,下载后看电视?所有web视频格式皆可播放,且格式没有上限,是屏幕所见即所得视频格式。本视频是免费公开的web视频格式mp4,主要功能为下载各类卫视直播、电视台直播、央视视频、点播等,支持所有web视频标准:http、m3u8、ts等。最后问一句:视频下载该用哪个app?appstore目前可以下载到的几个视频app有:新浪微博视频观看器:新浪微博官方的播放器,支持的网站如新浪博客、新浪微博、twitter等直播平台;荔枝fm:appstore搜索荔枝fm,即可下载;腾讯视频:qq视频客户端:安卓版可以同步观看视频,页面简洁且下载方便;网易视频:网易播放器-网易旗下pgc专业的网络电视频道。以上几个皆可以播放mp4格式视频。
上买一个转换器,基本无损的mp4转换器都可以转换的,我都是上买的。
怎么回答你我不知道,因为我不用mp4播放器。就我用过的而言。硬解比软解还是好点的。不会损失文件。如果你真是没得选。下载下来就用mp4播放器看。
准备ps当手办的图片我给你找网上打包出售的版本
ios系统的一加5直接支持webm电视服务
完全没有必要,sony自家就有一款系统播放器,可以兼容所有,所以根本就不用考虑兼容性的问题。 查看全部
从网页抓取视频(从网页抓取视频,下载后看电视?所有web视频格式皆可播放)
从网页抓取视频,下载后看电视?所有web视频格式皆可播放,且格式没有上限,是屏幕所见即所得视频格式。本视频是免费公开的web视频格式mp4,主要功能为下载各类卫视直播、电视台直播、央视视频、点播等,支持所有web视频标准:http、m3u8、ts等。最后问一句:视频下载该用哪个app?appstore目前可以下载到的几个视频app有:新浪微博视频观看器:新浪微博官方的播放器,支持的网站如新浪博客、新浪微博、twitter等直播平台;荔枝fm:appstore搜索荔枝fm,即可下载;腾讯视频:qq视频客户端:安卓版可以同步观看视频,页面简洁且下载方便;网易视频:网易播放器-网易旗下pgc专业的网络电视频道。以上几个皆可以播放mp4格式视频。
上买一个转换器,基本无损的mp4转换器都可以转换的,我都是上买的。
怎么回答你我不知道,因为我不用mp4播放器。就我用过的而言。硬解比软解还是好点的。不会损失文件。如果你真是没得选。下载下来就用mp4播放器看。
准备ps当手办的图片我给你找网上打包出售的版本
ios系统的一加5直接支持webm电视服务
完全没有必要,sony自家就有一款系统播放器,可以兼容所有,所以根本就不用考虑兼容性的问题。

