
云采集
优采云云采集监控预警功能上线!
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-05-03 13:09
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。 查看全部
优采云云采集监控预警功能上线!
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。
优采云云采集监控预警功能上线!
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2022-05-03 05:34
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。 查看全部
优采云云采集监控预警功能上线!
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。
智政云上新啦!云采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-04-30 22:27
智政云-专业SaaS云服务平台自开通运营以来,受到了用户的广泛好评,网站普查检测、云搜索、信息系统安全等级保护成为了2021年度云服务销量榜前三强。
2022年智政云上新服务了!云采集。下面我带领大家详细了解一下云采集服务的功能及特色:
一、采集方式多样
1.爬虫采集
云采集平台采用的核心技术是分布式网页爬虫系统。分布式爬虫系统采取弹性可扩展的互联网架构体系。使用python爬虫技术,支持css、xpath等不同选择器进行数据提取。
系统将网页的非结构化信息采集后,自动提取网页属性信息进行结构化的处理,字段提取(包括站点、来源、日期、标题、内容、图片、附件等)。
2.库表同步
在授权的情况下,可直接与数据库对接,将数据同步到平台中,相对于爬虫采集服务优势在更稳定、更快、更精准。
3.文件导入
支持将独立文件中承载的数据直接导入平台,支持多种格式,比如Excel文件、Access文件、CSV文件等。
二、易用可用好用
1.可视化配置:采集及分布式服务运行参数可视化配置。
2.定时任务:用户可以根据自身需求合理设置个性化定时计划任务,
3.状态实时监控:分布式服务与系统间建立长连接通道,平台可以实时感知分布式服务的状态以及采集任务的进度。
4.获得服务成本低:无须考虑系统部署、安全防护等方面的费用投入。以年服务费的形式就可以以非常优惠的费用获得采集服务。
同时,我们也欢迎其它厂商加入智政云服务平台,为用户提供更多实用的技术服务,更多云服务请访问:(专业SaaS云服务平台)。
智政科技-大数据与智能应用服务提供商
智政科技秉承“服务至上”的经营理念,坚持“大爱、开放、用心、团队”的核心价值观,以用户需求为导向,视用户口碑为生命,聚焦互联网+,与时俱进,持续创新,成为用户首选的“互联网+”大数据与智能应用服务提供商。
查看全部
智政云上新啦!云采集
智政云-专业SaaS云服务平台自开通运营以来,受到了用户的广泛好评,网站普查检测、云搜索、信息系统安全等级保护成为了2021年度云服务销量榜前三强。
2022年智政云上新服务了!云采集。下面我带领大家详细了解一下云采集服务的功能及特色:
一、采集方式多样
1.爬虫采集
云采集平台采用的核心技术是分布式网页爬虫系统。分布式爬虫系统采取弹性可扩展的互联网架构体系。使用python爬虫技术,支持css、xpath等不同选择器进行数据提取。
系统将网页的非结构化信息采集后,自动提取网页属性信息进行结构化的处理,字段提取(包括站点、来源、日期、标题、内容、图片、附件等)。
2.库表同步
在授权的情况下,可直接与数据库对接,将数据同步到平台中,相对于爬虫采集服务优势在更稳定、更快、更精准。
3.文件导入
支持将独立文件中承载的数据直接导入平台,支持多种格式,比如Excel文件、Access文件、CSV文件等。
二、易用可用好用
1.可视化配置:采集及分布式服务运行参数可视化配置。
2.定时任务:用户可以根据自身需求合理设置个性化定时计划任务,
3.状态实时监控:分布式服务与系统间建立长连接通道,平台可以实时感知分布式服务的状态以及采集任务的进度。
4.获得服务成本低:无须考虑系统部署、安全防护等方面的费用投入。以年服务费的形式就可以以非常优惠的费用获得采集服务。
同时,我们也欢迎其它厂商加入智政云服务平台,为用户提供更多实用的技术服务,更多云服务请访问:(专业SaaS云服务平台)。
智政科技-大数据与智能应用服务提供商
智政科技秉承“服务至上”的经营理念,坚持“大爱、开放、用心、团队”的核心价值观,以用户需求为导向,视用户口碑为生命,聚焦互联网+,与时俱进,持续创新,成为用户首选的“互联网+”大数据与智能应用服务提供商。
云采集(【技术公开】一种基于云平台智慧校园学生学生信息管理系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-04-20 10:33
本发明专利技术公开了一种基于云平台的智慧校园学生信息管理系统,涉及信息管理系统领域,包括中央管理模块,中央管理模块的输入端与信息电连接。 采集模块,中央管理模块的输出端与门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器模块电连接。本发明专利技术通过中央管理模块、信息采集模块、图书馆模块、体育馆模块、门禁模块、重要实验室模块、摄像头模块和指纹信息采集模块实现学生信息化。管理系统可与图书馆、体育馆、门禁及重要实验室联系。学生入场时无需携带学生证。有摄像头和指纹信息采集器供采集比对,判断是否为学校的学生,从而进入上述场所,减少人工验证程序,提高工作效率。
基于云平台的智能校园学生信息管理系统
本发明公开了一种基于云平台的智能校园学生信息管理系统,涉及信息管理系统领域,包括中心管理模块。中心管理模块的输入端与信息采集模块电连接,中心管理模块的输出端与门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器电连接模块 \u3002 本发明通过中央管理模块、信息采集模块、图书馆模块、体育馆模块、门禁模块、重要实验室模块、摄像头模块和指纹信息采集模块,实现了学生信息管理系统与图书馆的联系,健身房,
下载所有详细的技术数据
【技术实现步骤总结】
基于云平台的智慧校园学生信息管理系统
该专利技术涉及信息管理系统领域,具体涉及一种基于云平台的智慧校园学生信息管理系统。
技术介绍
学生信息管理系统是为学校人事处大量业务处理工作而开发的管理软件。主要用于学校学生信息管理。总体任务是实现学生信息关系的系统化、科学化、规范化和自动化。计算机用于日常管理学生的各种信息,如查询、修改、增删。此外,学生信息管理系统就是根据这些要求设计的,同时考虑到学生的选课情况。现有学生信息管理系统无法与学校图书馆、体育馆、门禁及重要实验室连接,学生需要出示学生证才能进入这些地方。操作麻烦,而且在现有的学生信息管理系统中,如果学生信息错误或以后发生变化,需要重新输入,操作繁琐。
技术实现思路
此项专利技术的目的是:为了解决现有学生信息管理系统无法与学校图书馆、体育馆、门禁及重要实验室进行通信,且学生信息出现错误或后期发生变化的问题,需要重新进入,操作繁琐 提供基于云平台的智慧校园学生信息管理系统。为实现上述目的,本专利技术提供以下技术方案:一种基于云平台的智慧校园学生信息管理系统,包括中央管理模块,中央管理模块的输入端与信息<< @采集 模块,中央管理模块的输出端与门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器模块电连接,门禁模块、重要实验室模块的输出端,图书馆和体育馆模块都是电气连接的。摄像头模块与指纹信息采集模块相连,中央管理模块的输出端与服务器模块电连接,服务器模块的输出端与学生模块和管理员电连接模块,学生模块是一个登录模块,与管理员模块的输出端电连接,查询模块和修改模块与登录模块的输出端电连接。优选地,摄像头模块和指纹信息采集模块与门禁模块、重要实验室模块、图书馆模块和体育馆模块均双向电连接,门禁模块、重要实验室模块、图书馆模块 体育馆模块和中央管理模块在两个方向上电连接。优选地,摄像头模块包括摄像头,指纹信息采集模块包括指纹信息采集器。图书馆模块和体育馆模块都是双向电连接的,门禁模块、重要实验室模块、图书馆模块体育馆模块和中央管理模块都是双向电连接的。优选地,摄像头模块包括摄像头,指纹信息采集模块包括指纹信息采集器。图书馆模块和体育馆模块都是双向电连接的,门禁模块、重要实验室模块、图书馆模块体育馆模块和中央管理模块都是双向电连接的。优选地,摄像头模块包括摄像头,指纹信息采集模块包括指纹信息采集器。
优选地,登录模块包括密码登录和身份证登录。优选地,修改模块的输出端与管理员模块电连接。优选地,中央管理模块包括信息存储模块、数据收发模块和中央处理器模块,中央管理模块与信息存储模块、数据收发模块和中央处理器模块以及中央管理器电连接。模块是双向电连接的。优选地,信息采集模块的输入端分别与身份证信息采集模块、录取信息采集模块、录取照片信息采集模块和指纹信息采集模块,信息采集模块分别与身份证信息采集模块、准入信息采集模块、准入照片信息采集模块和指纹信息采集模块已电连接。较佳地,修改模块箱的管理员发送加盖学校公章的图片和视频,管理员审核后直接登录修改。与现有技术相比,本专利技术的有益效果是:本专利技术设置的中央管理模块、信息采集模块、图书馆模块、体育馆模块、门禁模块、重要实验室模块、摄像头模块和指纹信息采集模块,实现了学生信息管理系统可以联系图书馆、体育馆、门禁和重要实验室。学生入场时无需携带学生证,而是直接有摄像头和指纹信息采集器对比采集,就可以判断是否是学校的学生,从而进入上述场所,减少人工验证程序,提高工作效率。修改模块实现在学生信息发生变化或输入错误后,学生登录服务器进入修改模块,并将加盖学校公章的文件的照片或视频发送给管理员。管理员收到审核后,直接进入修改模块进行修改。
附图说明图。图1是专利技术的系统流程图;如图。图2为本专利技术的中央管理模块流程图。具体实施方式下面将结合本专利技术实施例中的附图,对本专利技术实施例中的技术方案进行清楚、完整的描述。显然,所描述的实施例只是专利技术的一部分实施例,并非全部的例子。基于本专利技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本专利技术保护的范围。请参考图1-2,基于云平台的智慧校园学生信息管理系统,学生模块和管理员模块的输出电连接端子与日志模块电连接,日志模块的输出端子与查询模块和修改模块电连接。该专利技术通过中央管理模块、信息采集模块、图书馆模块、体育馆模块、门禁模块、重要实验室模块、摄像头模块和指纹信息采集模块实现对学生信息的管理。该系统可以与图书馆、体育馆、门禁和重要实验室进行通信。学生入场时无需携带学生证。采集 有摄像头和指纹信息 采集器
请参考图1。摄像头模块和指纹信息采集模块和门禁模块、重要实验室模块、图书馆模块和体育馆模块都在两个方向电连接,门禁模块,重要的实验室模块,图书馆模块与体育馆模块和中央管理模块都在两个方向上电连接。中央流水线模块中的中央管理者可以检查采集收到的信息,然后将检查结果传送到图书馆和其他场所的大门。. 请重点参考图1,摄像头模块包括摄像头,指纹信息采集模块包括指纹信息采集器,在图书馆等场所还设有与中央管理模块电连接的门。请参考图1。登录模块包括密码登录和身份证登录。如果忘记密码,可以用身份证号登录,方便快捷。请参考图1,修改模块的输出端与管理员模块电连接。修改页面将加盖学校公章的文件发送给管理员。修改模块会先审核,没有公章的文件不能上传。请参考图 如图2所示,中央管理模块包括信息存储模块、数据收发模块和中央处理器模块,中央管理模块与信息存储模块、数据收发模块和中央处理器模块电连接,中央管理模块双向电连接。信息存储模块负责采集的学生信息的采集,数据收发模块负责收发采集和比较数据。请参考图1 信息采集模块输入端连接身份证信息采集模块、录取信息采集模块、录取照片信息采集@ > 模块和指纹信息分别。采集 模块,以及信息采集
请参考图1。修改模块箱管理员发送图片和视频,并加盖学校公章。管理员审核后,直接登录修改即可。学生模块和管理员模块都有修改页面,但学生只能在修改页面修改页面。要选择发送选项,发件人是管理员。工作原理:使用时,通过信息采集模块,将学生的身份证信息、入学信息、入学照片信息、指纹信息全部录入中心管理模块,并有信息存储模块进行存储。整合学生信息后,学生和管理员可以通过登录服务器模块查看,并通过密码和身份证号登录。可以查看学生的姓名、班级、专业、外貌、成绩等。
【技术保护点】
1.一种基于云平台的智慧校园学生信息管理系统,包括中央管理模块,其特征在于:中央管理模块的输入端与信息采集模块电连接,中央管理模块是门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器模块的输出端,与门禁模块、重要实验室模块、图书馆和服务器模块的输出端电连接。体育馆模块。指纹信息采集模块,中央管理模块的输出端与服务器模块电连接,服务器模块的输出端与学生模块和管理员模块电连接,学生模块与管理员模块电连接登录模块的输出端与登录模块电连接,登录模块的输出端与查询模块和修改模块电连接。/n
【技术特点总结】
1.一种基于云平台的智慧校园学生信息管理系统,包括中央管理模块,其特征在于:中央管理模块的输入端与信息采集模块电连接,中央管理模块是门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器模块的输出端,与门禁模块、重要实验室模块、图书馆和服务器模块的输出端电连接。体育馆模块。指纹信息采集模块,中央管理模块的输出端与服务器模块电连接,服务器模块的输出端与学生模块和管理员模块电连接,
2.根据权利要求1所述的一种基于云平台的智慧校园学生信息管理系统,其特征在于:摄像头模块和指纹信息采集模块和门禁模块、重要实验室模块、图书馆模块和体育馆模块都在两个方向电连接,门禁模块、重要实验室模块、图书馆模块和体育馆模块和中央管理模块都在两个方向电连接。
3.根据权利要求1所述的基于云平台的智慧校园学生信息管理系统,其特征在于,所述摄像头模块包括摄像头,所述指纹信息采集模块包括指纹信息采集器。
4.根据右边...
【专利技术性质】
技术研发人员:姜志谋、叶迪、杨欣、
申请人(专利权)持有人:,
类型:发明
国家省份:安徽;34
下载所有详细的技术数据 我是该专利的所有者 查看全部
云采集(【技术公开】一种基于云平台智慧校园学生学生信息管理系统)
本发明专利技术公开了一种基于云平台的智慧校园学生信息管理系统,涉及信息管理系统领域,包括中央管理模块,中央管理模块的输入端与信息电连接。 采集模块,中央管理模块的输出端与门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器模块电连接。本发明专利技术通过中央管理模块、信息采集模块、图书馆模块、体育馆模块、门禁模块、重要实验室模块、摄像头模块和指纹信息采集模块实现学生信息化。管理系统可与图书馆、体育馆、门禁及重要实验室联系。学生入场时无需携带学生证。有摄像头和指纹信息采集器供采集比对,判断是否为学校的学生,从而进入上述场所,减少人工验证程序,提高工作效率。
基于云平台的智能校园学生信息管理系统
本发明公开了一种基于云平台的智能校园学生信息管理系统,涉及信息管理系统领域,包括中心管理模块。中心管理模块的输入端与信息采集模块电连接,中心管理模块的输出端与门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器电连接模块 \u3002 本发明通过中央管理模块、信息采集模块、图书馆模块、体育馆模块、门禁模块、重要实验室模块、摄像头模块和指纹信息采集模块,实现了学生信息管理系统与图书馆的联系,健身房,
下载所有详细的技术数据
【技术实现步骤总结】
基于云平台的智慧校园学生信息管理系统
该专利技术涉及信息管理系统领域,具体涉及一种基于云平台的智慧校园学生信息管理系统。
技术介绍
学生信息管理系统是为学校人事处大量业务处理工作而开发的管理软件。主要用于学校学生信息管理。总体任务是实现学生信息关系的系统化、科学化、规范化和自动化。计算机用于日常管理学生的各种信息,如查询、修改、增删。此外,学生信息管理系统就是根据这些要求设计的,同时考虑到学生的选课情况。现有学生信息管理系统无法与学校图书馆、体育馆、门禁及重要实验室连接,学生需要出示学生证才能进入这些地方。操作麻烦,而且在现有的学生信息管理系统中,如果学生信息错误或以后发生变化,需要重新输入,操作繁琐。
技术实现思路
此项专利技术的目的是:为了解决现有学生信息管理系统无法与学校图书馆、体育馆、门禁及重要实验室进行通信,且学生信息出现错误或后期发生变化的问题,需要重新进入,操作繁琐 提供基于云平台的智慧校园学生信息管理系统。为实现上述目的,本专利技术提供以下技术方案:一种基于云平台的智慧校园学生信息管理系统,包括中央管理模块,中央管理模块的输入端与信息<< @采集 模块,中央管理模块的输出端与门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器模块电连接,门禁模块、重要实验室模块的输出端,图书馆和体育馆模块都是电气连接的。摄像头模块与指纹信息采集模块相连,中央管理模块的输出端与服务器模块电连接,服务器模块的输出端与学生模块和管理员电连接模块,学生模块是一个登录模块,与管理员模块的输出端电连接,查询模块和修改模块与登录模块的输出端电连接。优选地,摄像头模块和指纹信息采集模块与门禁模块、重要实验室模块、图书馆模块和体育馆模块均双向电连接,门禁模块、重要实验室模块、图书馆模块 体育馆模块和中央管理模块在两个方向上电连接。优选地,摄像头模块包括摄像头,指纹信息采集模块包括指纹信息采集器。图书馆模块和体育馆模块都是双向电连接的,门禁模块、重要实验室模块、图书馆模块体育馆模块和中央管理模块都是双向电连接的。优选地,摄像头模块包括摄像头,指纹信息采集模块包括指纹信息采集器。图书馆模块和体育馆模块都是双向电连接的,门禁模块、重要实验室模块、图书馆模块体育馆模块和中央管理模块都是双向电连接的。优选地,摄像头模块包括摄像头,指纹信息采集模块包括指纹信息采集器。
优选地,登录模块包括密码登录和身份证登录。优选地,修改模块的输出端与管理员模块电连接。优选地,中央管理模块包括信息存储模块、数据收发模块和中央处理器模块,中央管理模块与信息存储模块、数据收发模块和中央处理器模块以及中央管理器电连接。模块是双向电连接的。优选地,信息采集模块的输入端分别与身份证信息采集模块、录取信息采集模块、录取照片信息采集模块和指纹信息采集模块,信息采集模块分别与身份证信息采集模块、准入信息采集模块、准入照片信息采集模块和指纹信息采集模块已电连接。较佳地,修改模块箱的管理员发送加盖学校公章的图片和视频,管理员审核后直接登录修改。与现有技术相比,本专利技术的有益效果是:本专利技术设置的中央管理模块、信息采集模块、图书馆模块、体育馆模块、门禁模块、重要实验室模块、摄像头模块和指纹信息采集模块,实现了学生信息管理系统可以联系图书馆、体育馆、门禁和重要实验室。学生入场时无需携带学生证,而是直接有摄像头和指纹信息采集器对比采集,就可以判断是否是学校的学生,从而进入上述场所,减少人工验证程序,提高工作效率。修改模块实现在学生信息发生变化或输入错误后,学生登录服务器进入修改模块,并将加盖学校公章的文件的照片或视频发送给管理员。管理员收到审核后,直接进入修改模块进行修改。
附图说明图。图1是专利技术的系统流程图;如图。图2为本专利技术的中央管理模块流程图。具体实施方式下面将结合本专利技术实施例中的附图,对本专利技术实施例中的技术方案进行清楚、完整的描述。显然,所描述的实施例只是专利技术的一部分实施例,并非全部的例子。基于本专利技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本专利技术保护的范围。请参考图1-2,基于云平台的智慧校园学生信息管理系统,学生模块和管理员模块的输出电连接端子与日志模块电连接,日志模块的输出端子与查询模块和修改模块电连接。该专利技术通过中央管理模块、信息采集模块、图书馆模块、体育馆模块、门禁模块、重要实验室模块、摄像头模块和指纹信息采集模块实现对学生信息的管理。该系统可以与图书馆、体育馆、门禁和重要实验室进行通信。学生入场时无需携带学生证。采集 有摄像头和指纹信息 采集器
请参考图1。摄像头模块和指纹信息采集模块和门禁模块、重要实验室模块、图书馆模块和体育馆模块都在两个方向电连接,门禁模块,重要的实验室模块,图书馆模块与体育馆模块和中央管理模块都在两个方向上电连接。中央流水线模块中的中央管理者可以检查采集收到的信息,然后将检查结果传送到图书馆和其他场所的大门。. 请重点参考图1,摄像头模块包括摄像头,指纹信息采集模块包括指纹信息采集器,在图书馆等场所还设有与中央管理模块电连接的门。请参考图1。登录模块包括密码登录和身份证登录。如果忘记密码,可以用身份证号登录,方便快捷。请参考图1,修改模块的输出端与管理员模块电连接。修改页面将加盖学校公章的文件发送给管理员。修改模块会先审核,没有公章的文件不能上传。请参考图 如图2所示,中央管理模块包括信息存储模块、数据收发模块和中央处理器模块,中央管理模块与信息存储模块、数据收发模块和中央处理器模块电连接,中央管理模块双向电连接。信息存储模块负责采集的学生信息的采集,数据收发模块负责收发采集和比较数据。请参考图1 信息采集模块输入端连接身份证信息采集模块、录取信息采集模块、录取照片信息采集@ > 模块和指纹信息分别。采集 模块,以及信息采集
请参考图1。修改模块箱管理员发送图片和视频,并加盖学校公章。管理员审核后,直接登录修改即可。学生模块和管理员模块都有修改页面,但学生只能在修改页面修改页面。要选择发送选项,发件人是管理员。工作原理:使用时,通过信息采集模块,将学生的身份证信息、入学信息、入学照片信息、指纹信息全部录入中心管理模块,并有信息存储模块进行存储。整合学生信息后,学生和管理员可以通过登录服务器模块查看,并通过密码和身份证号登录。可以查看学生的姓名、班级、专业、外貌、成绩等。
【技术保护点】
1.一种基于云平台的智慧校园学生信息管理系统,包括中央管理模块,其特征在于:中央管理模块的输入端与信息采集模块电连接,中央管理模块是门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器模块的输出端,与门禁模块、重要实验室模块、图书馆和服务器模块的输出端电连接。体育馆模块。指纹信息采集模块,中央管理模块的输出端与服务器模块电连接,服务器模块的输出端与学生模块和管理员模块电连接,学生模块与管理员模块电连接登录模块的输出端与登录模块电连接,登录模块的输出端与查询模块和修改模块电连接。/n
【技术特点总结】
1.一种基于云平台的智慧校园学生信息管理系统,包括中央管理模块,其特征在于:中央管理模块的输入端与信息采集模块电连接,中央管理模块是门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器模块的输出端,与门禁模块、重要实验室模块、图书馆和服务器模块的输出端电连接。体育馆模块。指纹信息采集模块,中央管理模块的输出端与服务器模块电连接,服务器模块的输出端与学生模块和管理员模块电连接,
2.根据权利要求1所述的一种基于云平台的智慧校园学生信息管理系统,其特征在于:摄像头模块和指纹信息采集模块和门禁模块、重要实验室模块、图书馆模块和体育馆模块都在两个方向电连接,门禁模块、重要实验室模块、图书馆模块和体育馆模块和中央管理模块都在两个方向电连接。
3.根据权利要求1所述的基于云平台的智慧校园学生信息管理系统,其特征在于,所述摄像头模块包括摄像头,所述指纹信息采集模块包括指纹信息采集器。
4.根据右边...
【专利技术性质】
技术研发人员:姜志谋、叶迪、杨欣、
申请人(专利权)持有人:,
类型:发明
国家省份:安徽;34
下载所有详细的技术数据 我是该专利的所有者
云采集(优采云7.0实验目的和要求1.1实验使用Pythonscrapy框架)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-04-18 12:14
1.实验目的和要求
1.1 实验目的
爬取公共管理学院所有新闻网站,了解和熟悉网络信息相关技术采集。
1.2 实验要求
使用任何可用的方法抓取四川大学公共管理学院()上的所有新闻,包括“新闻标题、新闻发布时间、新闻正文”三个字段。我们尝试过的方法有优采云data采集tools,Python爬虫代码。
2.实验环境
2.1优采云数据采集工具
优采云采集器是云采集服务平台,提供数据采集、数据分析等功能,可视化图形化操作采集器。它的simple采集、custom采集等基本功能都可以免费使用。本实验使用优采云7.0版本的自定义采集函数,使用本地采集方法。
2.2使用Python scrapy框架爬取
本实验使用的Python版本为2.7.14,安装了Scrapy。使用服务器采集的方法。
3.实验方案
3.1优采云采集器实验方案
3.1.1 登录版本优采云7.0,输入网址,新建采集任务
新任务.png
3.1.2为每个新闻链接制作翻页循环和点击循环
点击loop.png
翻页循环.png
3.1.3 指定具体的采集规则
对于每个新闻链接
采集rules.png
3.1.4 OK采集流程和数据
采集进程.png
采集格式预览.png
3.1.5采集工具结果界面
采集结果.png
3.1.6 错误报告和补充采集结果
经我们检查,报错页面有四种:
A.链接网页内部也有嵌套链接,如“120周年庆典”等特殊网页链接;
B.其他格式的网页,如视频、图片、外部网站链接等
C.网页出错,无法打开;
D.是一个单独的文章,但是可能会因为系统问题或者文章的不同格式(没有标题等)而爬不下来。
补充采集结果1.png
我们对每个出错的网页链接进行了单独的二次数据采集,图片、视频等B类格式的网页不是采集,最后是采集得到了导出数据结果的excel表格部分截图如下:
补充采集结果2.png
最后一节采集Results.png
以上是优采云
的一部分
3.2 使用Python scrapy框架爬取实验程序
3.2.1 云服务器配置:安装scrapy for Python
(1)检查当前服务器是否配置了scrapy
(2)退出Python交互,使用yum安装scrapy和一些依赖。
安装scrapy.png
经查询,解决办法是:
vi /usr/libexec/urlgrabber-ext-down
把head里的python改成和/usr/bin/yum里一样
修改完成后,再次使用yum安装scrapy:
修改后再次安装scrapy.png
3.2.2 检查scrapy安装
进入Python交互环境,导入scrapy enter,发现引用成功,退出交互环境。
查看安装结果.png
scrapy版本进入
查看scrapy version.png
版本信息检查成功。
至此,Python scrapy已经在云服务器上配置成功。
3.2.3编写代码并调试
根据之前优采云的经验,我们可以看到采集需要三个实体:标题、日期和文字(另外一个实体是图片,暂时不需要)。
scrapy startproject ggnews 进入
cd /ggnews/ggnews 进入
文件结构1.png
文件结构2.png
编写 ggnews.py
编写 ggnews.png
3.2.4 输入命令爬取获取数据
输入scrapy crawl ggnews -o ggnews.xml
出现以下错误
错误1.png
发生错误,但显然我们的代码中有一类项目。经查询,此错误用简单一句话描述:爬虫名称与项目名称相同,导致最终导入时出错。
将蜘蛛名称修改为spidernews.py。名字虽然有点长,但是好像很容易理解。
再次执行代码获取文件ggnews.json
初始爬取结果.png
发现初始爬取的结果是Unicode编码,不是理想的中文格式。查询后需要修改pipelines.py和settings.py这两个文件,使输出结果为中文格式。
3.2.5 修改 pipelines.py 和 settings.py 文件
修改管道文件.png
修改设置文件.png
3.2.6 解决压痕问题
修改完成后再次运行命令scrapy crawl spidernews。出现了一个新问题:
错误2.png
查询后,这是缩进的问题。 Python 语言是一种对缩进非常敏感的语言,这给很多初学者造成了困惑,即使是经验丰富的 Python 程序员也可能掉入陷阱。最常见的情况是制表符和空格的混合会导致错误,或者肉眼无法区分的缩进。编译的时候会出现这样的错误“IndentationError: expected an indented block”,意思是这里需要缩进。您只需要按空格或 Tab(但不能混合)键在发生错误的行上缩进。
修改完成,再次运行命令
第二次抓取结果.png
得到想要的结果。
至此,使用Python scrapy框架的爬取过程就结束了。
4.经验总结
4.1优采云采集器经验总结
经验总结
由于本实验仅使用数据采集的功能,所以评价和总结仅针对数据采集的功能。 优采云可视化数据采集。如果你完全不懂爬虫代码,优采云是一个方便的网络数据工具采集。根据经验,公共管理学院新闻网站的爬取速度约为29条/分钟,数据可以导出为excel、CSV等格式。
但是,它也有一些使用限制。首先,在成本方面,它的数据导出需要积分,每10条数据一个积分,不到10条数据计为10条。用户首次注册后,赠送2000积分;在采集数据数据量少的情况下可以免费使用,但是数据量大时需要支付一定的费用才能导出数据。二是使用方面。由于优采云是已经编写好的采集工具,使用采集数据会受到一定的限制,可能不如直接使用代码那么自由。指定采集数据的规则详情(如采集时间段、采集持续时间等)。
4.2Python scrapy实验总结
本次实验共爬取了407条数据,但大学新闻网站上却有458条新闻。为什么缺少 51 篇文章?我们还没有找到答案,希望在接下来的研究中解决这个问题!在data采集的过程中,爬取数据的规则和方法是最重要的部分。一定要充分利用浏览器的开发者工具,保证路径严格正确;此外,还有编码问题和分页问题。由于刚接触python,对python的需求不是很熟悉,导致修改时间比较长。在接下来的学习中,一定要尽快适应python的规则。此外,有足够的耐心和细心养好爬行动物。 查看全部
云采集(优采云7.0实验目的和要求1.1实验使用Pythonscrapy框架)
1.实验目的和要求
1.1 实验目的
爬取公共管理学院所有新闻网站,了解和熟悉网络信息相关技术采集。
1.2 实验要求
使用任何可用的方法抓取四川大学公共管理学院()上的所有新闻,包括“新闻标题、新闻发布时间、新闻正文”三个字段。我们尝试过的方法有优采云data采集tools,Python爬虫代码。
2.实验环境
2.1优采云数据采集工具
优采云采集器是云采集服务平台,提供数据采集、数据分析等功能,可视化图形化操作采集器。它的simple采集、custom采集等基本功能都可以免费使用。本实验使用优采云7.0版本的自定义采集函数,使用本地采集方法。
2.2使用Python scrapy框架爬取
本实验使用的Python版本为2.7.14,安装了Scrapy。使用服务器采集的方法。
3.实验方案
3.1优采云采集器实验方案
3.1.1 登录版本优采云7.0,输入网址,新建采集任务
新任务.png
3.1.2为每个新闻链接制作翻页循环和点击循环
点击loop.png
翻页循环.png
3.1.3 指定具体的采集规则
对于每个新闻链接
采集rules.png
3.1.4 OK采集流程和数据
采集进程.png
采集格式预览.png
3.1.5采集工具结果界面
采集结果.png
3.1.6 错误报告和补充采集结果
经我们检查,报错页面有四种:
A.链接网页内部也有嵌套链接,如“120周年庆典”等特殊网页链接;
B.其他格式的网页,如视频、图片、外部网站链接等
C.网页出错,无法打开;
D.是一个单独的文章,但是可能会因为系统问题或者文章的不同格式(没有标题等)而爬不下来。
补充采集结果1.png
我们对每个出错的网页链接进行了单独的二次数据采集,图片、视频等B类格式的网页不是采集,最后是采集得到了导出数据结果的excel表格部分截图如下:
补充采集结果2.png
最后一节采集Results.png
以上是优采云
的一部分
3.2 使用Python scrapy框架爬取实验程序
3.2.1 云服务器配置:安装scrapy for Python
(1)检查当前服务器是否配置了scrapy
(2)退出Python交互,使用yum安装scrapy和一些依赖。
安装scrapy.png
经查询,解决办法是:
vi /usr/libexec/urlgrabber-ext-down
把head里的python改成和/usr/bin/yum里一样
修改完成后,再次使用yum安装scrapy:
修改后再次安装scrapy.png
3.2.2 检查scrapy安装
进入Python交互环境,导入scrapy enter,发现引用成功,退出交互环境。
查看安装结果.png
scrapy版本进入
查看scrapy version.png
版本信息检查成功。
至此,Python scrapy已经在云服务器上配置成功。
3.2.3编写代码并调试
根据之前优采云的经验,我们可以看到采集需要三个实体:标题、日期和文字(另外一个实体是图片,暂时不需要)。
scrapy startproject ggnews 进入
cd /ggnews/ggnews 进入
文件结构1.png
文件结构2.png
编写 ggnews.py
编写 ggnews.png
3.2.4 输入命令爬取获取数据
输入scrapy crawl ggnews -o ggnews.xml
出现以下错误
错误1.png
发生错误,但显然我们的代码中有一类项目。经查询,此错误用简单一句话描述:爬虫名称与项目名称相同,导致最终导入时出错。
将蜘蛛名称修改为spidernews.py。名字虽然有点长,但是好像很容易理解。
再次执行代码获取文件ggnews.json
初始爬取结果.png
发现初始爬取的结果是Unicode编码,不是理想的中文格式。查询后需要修改pipelines.py和settings.py这两个文件,使输出结果为中文格式。
3.2.5 修改 pipelines.py 和 settings.py 文件
修改管道文件.png
修改设置文件.png
3.2.6 解决压痕问题
修改完成后再次运行命令scrapy crawl spidernews。出现了一个新问题:
错误2.png
查询后,这是缩进的问题。 Python 语言是一种对缩进非常敏感的语言,这给很多初学者造成了困惑,即使是经验丰富的 Python 程序员也可能掉入陷阱。最常见的情况是制表符和空格的混合会导致错误,或者肉眼无法区分的缩进。编译的时候会出现这样的错误“IndentationError: expected an indented block”,意思是这里需要缩进。您只需要按空格或 Tab(但不能混合)键在发生错误的行上缩进。
修改完成,再次运行命令
第二次抓取结果.png
得到想要的结果。
至此,使用Python scrapy框架的爬取过程就结束了。
4.经验总结
4.1优采云采集器经验总结
经验总结
由于本实验仅使用数据采集的功能,所以评价和总结仅针对数据采集的功能。 优采云可视化数据采集。如果你完全不懂爬虫代码,优采云是一个方便的网络数据工具采集。根据经验,公共管理学院新闻网站的爬取速度约为29条/分钟,数据可以导出为excel、CSV等格式。
但是,它也有一些使用限制。首先,在成本方面,它的数据导出需要积分,每10条数据一个积分,不到10条数据计为10条。用户首次注册后,赠送2000积分;在采集数据数据量少的情况下可以免费使用,但是数据量大时需要支付一定的费用才能导出数据。二是使用方面。由于优采云是已经编写好的采集工具,使用采集数据会受到一定的限制,可能不如直接使用代码那么自由。指定采集数据的规则详情(如采集时间段、采集持续时间等)。
4.2Python scrapy实验总结
本次实验共爬取了407条数据,但大学新闻网站上却有458条新闻。为什么缺少 51 篇文章?我们还没有找到答案,希望在接下来的研究中解决这个问题!在data采集的过程中,爬取数据的规则和方法是最重要的部分。一定要充分利用浏览器的开发者工具,保证路径严格正确;此外,还有编码问题和分页问题。由于刚接触python,对python的需求不是很熟悉,导致修改时间比较长。在接下来的学习中,一定要尽快适应python的规则。此外,有足够的耐心和细心养好爬行动物。
云采集( 优采云让数据触手可及视频教程PPT云采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-04-14 06:10
优采云让数据触手可及视频教程PPT云采集)
优采云让数据触手可及视频教程PPT云采集一、云采集,时序云采集二、云采集工作原理三、云采集规则,材料编码规则,三大专业,一个程序规则,文献编号规则,乒乓球比赛规则,动词不规则变化表,加速设置教程一、云< @采集,定时云采集Cloud采集是指使用优采云提供的服务器集群工作,处于7*24小时工作状态。客户端完成任务设置并提交至云服务执行云采集后,即可关闭软件、关机、下线采集,真正实现无人值守。另外,云采集 通过云服务器集群的分布式部署方式,多个节点可以同时进行操作,可以提高采集的效率,并且可以有效规避各种网站的IP阻塞策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 多个节点可以同时进行操作,可以提高采集的效率,并且可以有效的避免各种网站的IP阻塞策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 多个节点可以同时进行操作,可以提高采集的效率,并且可以有效的避免各种网站的IP阻塞策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 可以提高采集的效率,有效规避各种网站的IP屏蔽策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 可以提高采集的效率,有效规避各种网站的IP屏蔽策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 可以关机运行,可以设置定时云采集,加快采集的速度,增加采集的音量。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 可以关机运行,可以设置定时云采集,加快采集的速度,增加采集的音量。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1
, 一个云的规则任务采集至少占用一个云节点,最多可以占用所有云节点2、如果一个规则任务可以拆分成子任务,最多可以拆分成199个subtasks3、一个子任务占用一个节点,所有子任务完成即表示任务完成4、一个规则任务分为多个子任务分配到不同的云节点,达到加速的效果< @采集5、如果云节点已满,则新启动的任务或拆分的子任务将进入等待队列,直到用户的云节点执行完用户的任务并释放节点资源。三、云采集加速设置是基于云采集的原理。如果你想让一个任务的效果加速采集,那么任务必须满足拆分条件或者改变任务满足拆分条件的任务才能达到单任务加速的效果。满足拆分条件的任务有:1、URL列表循环2、文本列表循环3、固定元素列表循环三、云采集加速设置1、URL列表循环通过优采云自动拆分任务,将不同的URL拆分成不同的子任务分配给不同的云节点供数据采集,采集效果的示例URL单任务加速
:三、云端采集加速设置2、文本列表循环文本循环,原理同URL循环,通过文本循环的拆分,单任务加速采集 @> 采集速度示例 URL:三、云采集加速设置3、固定元素列表循环 固定元素列表循环也满足拆分条件,但需要结合循环点击一起使用,否则没有明显的加速效果。示例 URL:三、云采集加速设置 子任务 1:打开网页(20s)-提取位置 1 数据(0.1s)子任务 任务 2:打开网页(20s)-提取位置2 个数据 (0.1s) 子任务 3:打开网页 (20s) - 提取位置 3 数据 (0.1s)...子任务 10:
0=21S循环-提取数据三、云采集加速度设置子任务1:打开网页(20s)-点击元素1(20s)-提取位置1数据(0.1s)子任务任务2:打开网页(20s)-点击元素2(20s)提取位置2数据(0.1s)子任务3:打开网页(20s)-点击元素3(20s) - 提取位置 3 数据 (0.1s)...子任务 10:打开网页 (20s) - 单击元素 10 (20s) - 提取位置 10 数据 (0.1s) 子任务同时运行,总共需要:20 +20+0.1=40.1S 总任务:打开网页(20s)点击元素1(20s)-提取位置1数据(0.1s)点击元素2 (20s) - 提取位置 2 数据 (0.1s) 点击元素 3 (20s) - 提取位置 3 数据 (0.1s) .....点击位置元素 n (20s) - 提取位置 10 数据 (0.1s) 总共:20+(20+0.1)*10=221s 循环 - 点击元素 - 提取数据TheEnd 谢谢大家 查看全部
云采集(
优采云让数据触手可及视频教程PPT云采集)

优采云让数据触手可及视频教程PPT云采集一、云采集,时序云采集二、云采集工作原理三、云采集规则,材料编码规则,三大专业,一个程序规则,文献编号规则,乒乓球比赛规则,动词不规则变化表,加速设置教程一、云< @采集,定时云采集Cloud采集是指使用优采云提供的服务器集群工作,处于7*24小时工作状态。客户端完成任务设置并提交至云服务执行云采集后,即可关闭软件、关机、下线采集,真正实现无人值守。另外,云采集 通过云服务器集群的分布式部署方式,多个节点可以同时进行操作,可以提高采集的效率,并且可以有效规避各种网站的IP阻塞策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 多个节点可以同时进行操作,可以提高采集的效率,并且可以有效的避免各种网站的IP阻塞策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 多个节点可以同时进行操作,可以提高采集的效率,并且可以有效的避免各种网站的IP阻塞策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 可以提高采集的效率,有效规避各种网站的IP屏蔽策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 可以提高采集的效率,有效规避各种网站的IP屏蔽策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 可以关机运行,可以设置定时云采集,加快采集的速度,增加采集的音量。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 可以关机运行,可以设置定时云采集,加快采集的速度,增加采集的音量。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1

, 一个云的规则任务采集至少占用一个云节点,最多可以占用所有云节点2、如果一个规则任务可以拆分成子任务,最多可以拆分成199个subtasks3、一个子任务占用一个节点,所有子任务完成即表示任务完成4、一个规则任务分为多个子任务分配到不同的云节点,达到加速的效果< @采集5、如果云节点已满,则新启动的任务或拆分的子任务将进入等待队列,直到用户的云节点执行完用户的任务并释放节点资源。三、云采集加速设置是基于云采集的原理。如果你想让一个任务的效果加速采集,那么任务必须满足拆分条件或者改变任务满足拆分条件的任务才能达到单任务加速的效果。满足拆分条件的任务有:1、URL列表循环2、文本列表循环3、固定元素列表循环三、云采集加速设置1、URL列表循环通过优采云自动拆分任务,将不同的URL拆分成不同的子任务分配给不同的云节点供数据采集,采集效果的示例URL单任务加速

:三、云端采集加速设置2、文本列表循环文本循环,原理同URL循环,通过文本循环的拆分,单任务加速采集 @> 采集速度示例 URL:三、云采集加速设置3、固定元素列表循环 固定元素列表循环也满足拆分条件,但需要结合循环点击一起使用,否则没有明显的加速效果。示例 URL:三、云采集加速设置 子任务 1:打开网页(20s)-提取位置 1 数据(0.1s)子任务 任务 2:打开网页(20s)-提取位置2 个数据 (0.1s) 子任务 3:打开网页 (20s) - 提取位置 3 数据 (0.1s)...子任务 10:

0=21S循环-提取数据三、云采集加速度设置子任务1:打开网页(20s)-点击元素1(20s)-提取位置1数据(0.1s)子任务任务2:打开网页(20s)-点击元素2(20s)提取位置2数据(0.1s)子任务3:打开网页(20s)-点击元素3(20s) - 提取位置 3 数据 (0.1s)...子任务 10:打开网页 (20s) - 单击元素 10 (20s) - 提取位置 10 数据 (0.1s) 子任务同时运行,总共需要:20 +20+0.1=40.1S 总任务:打开网页(20s)点击元素1(20s)-提取位置1数据(0.1s)点击元素2 (20s) - 提取位置 2 数据 (0.1s) 点击元素 3 (20s) - 提取位置 3 数据 (0.1s) .....点击位置元素 n (20s) - 提取位置 10 数据 (0.1s) 总共:20+(20+0.1)*10=221s 循环 - 点击元素 - 提取数据TheEnd 谢谢大家
云采集(优采云采集器:最好用的网页数据采集器(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-04-07 17:25
优采云采集器:最好使用的网络数据采集器
优采云采集器是经过多年研发的业界领先的新一代智能通用网络数据采集器。使用简单,操作全可视化,无需专业知识,上网即可轻松掌握;功能强大,新闻、论坛、电话信箱、竞争对手、客户信息、汽车地产、电子商务等。任何网站都可以是采集;数据可以导出为多种格式;更多云采集、采集最快100倍、支持列表采集、分页采集定时采集等最好的免费网络数据采集器@ > 目前可用!
优采云可以做什么?
简而言之,使用 优采云 可以轻松采集从任何网页中精确获取所需的数据,并生成自定义的常规数据格式。优采云数据采集系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财务报告,自动包括每日最新净值采集;
2.各大新闻门户网站实时监控,自动更新和上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 监测各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要汽车网站具体新车和二手车信息;
8. 发现和采集潜在客户信息;
9. 采集行业网站 产品目录和产品信息;
10.在各大电商平台之间同步商品信息,做到在一个平台发布,在其他平台自动更新。
任何人都可以使用
你还在研究网页源码和抓包工具吗?现在不用了,能上网就可以采集,所见即所得的界面,可视化的流程,无需懂技术,鼠标点一下,2分钟快速上手.
任何 网站 都可以 采集
它不仅简单易用,而且功能强大:点击、登录、翻页,甚至识别验证码。当网页出现错误,或者多组模板完全不同时,可以根据不同的情况进行不同的处理。
云采集,你也可以关闭
采集 任务配置完成后,就可以关闭它了,任务就可以在云端执行了。大量企业云可以24*7不间断运行。您不必担心IP阻塞或网络中断,您可以立即采集大量数据。
最新消息:优采云完成500万天使轮融资 查看全部
云采集(优采云采集器:最好用的网页数据采集器(组图))
优采云采集器:最好使用的网络数据采集器
优采云采集器是经过多年研发的业界领先的新一代智能通用网络数据采集器。使用简单,操作全可视化,无需专业知识,上网即可轻松掌握;功能强大,新闻、论坛、电话信箱、竞争对手、客户信息、汽车地产、电子商务等。任何网站都可以是采集;数据可以导出为多种格式;更多云采集、采集最快100倍、支持列表采集、分页采集定时采集等最好的免费网络数据采集器@ > 目前可用!
优采云可以做什么?
简而言之,使用 优采云 可以轻松采集从任何网页中精确获取所需的数据,并生成自定义的常规数据格式。优采云数据采集系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财务报告,自动包括每日最新净值采集;
2.各大新闻门户网站实时监控,自动更新和上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 监测各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要汽车网站具体新车和二手车信息;
8. 发现和采集潜在客户信息;
9. 采集行业网站 产品目录和产品信息;
10.在各大电商平台之间同步商品信息,做到在一个平台发布,在其他平台自动更新。
任何人都可以使用
你还在研究网页源码和抓包工具吗?现在不用了,能上网就可以采集,所见即所得的界面,可视化的流程,无需懂技术,鼠标点一下,2分钟快速上手.
任何 网站 都可以 采集
它不仅简单易用,而且功能强大:点击、登录、翻页,甚至识别验证码。当网页出现错误,或者多组模板完全不同时,可以根据不同的情况进行不同的处理。
云采集,你也可以关闭
采集 任务配置完成后,就可以关闭它了,任务就可以在云端执行了。大量企业云可以24*7不间断运行。您不必担心IP阻塞或网络中断,您可以立即采集大量数据。
最新消息:优采云完成500万天使轮融资
云采集(BiliBli学习资源测评之阿婆主们的优质学习教程资源汇总)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2022-03-30 18:04
_
_
这么长的假期,相信很多同学都有学习一些科研软件的想法。BIliBIli上有很多非常好的教程。但是,初学者可能很难在短时间内找到最合适的教程。
因此,我们特地推出了“BiliBli学习资源评测”专栏,总结了奶奶的优质学习教程资源,帮助您快速选择适合自己的好教程。
本期重点整理3D Max和data采集相关资源。
1
3D 最大
3D Max是一款模型设计软件,应用于动画制作、建筑设计、游戏影视等领域。对于理工科研究生,我们主要使用3D Max来绘制模型示意图,尤其是封面。下面就给大家介绍几个适合科研制图的学习教程。
基本
奶奶:爱知兴趣教育
教程内容介绍:课程介绍了3D Max 2014版的一些基础知识,包括界面、操作、快捷键等,之后通过具体机型的制作过程,生动地向我们介绍了多种常用的制作方法,包括弯曲、锥度、扭曲等。每节课15分钟左右,讲解很详细。您可以以两倍的速度听课。
奶奶:龙雪傲
教程内容介绍:课程介绍3D Max 2016版的界面、主工具栏、基本操作等基础知识。与爱知趣教育的课程相比,本课程的讲解更加精炼。每节课5分钟以内,干货满满。本课程还增加了更高级的操作,比如添加动画编辑等。
具体型号文章
奶奶:独孤嘌呤
奶奶:R土豆被狙击
教程内容介绍:这两位up主用3D Max画了很多分子结构和细胞结构的模型图,比如碳纳米管的结构图,DNA双螺旋结构的图,高尔基体的图,对学生来说非常实用,我们可以参考他构建模型的过程,为我们的论文锦上添花。
数据采集
2
在日常生活中,我们经常需要各种数据来帮助决策,比如毕业论文、商业分析等等,都需要采集数据。在时间紧、任务重的情况下,尤其是非计算机专业的学生不能立即使用 Python 编写代码爬取数据。怎样才能方便快捷的获取我们想要的数据?
答案是:使用 采集 工具
目前常用的数据采集工具一般可以分为云爬虫和采集器两种。
云爬虫
云爬虫是直接在网页上创建爬虫并在网站服务器上运行,无需下载安装软件,享受网站提供的带宽和24小时服务。
目前国内最重要的是:优采云云爬虫。
其强大的功能涉及云爬虫、API、机器学习、数据清洗、数据销售、数据定制和私有化部署等;纯云端操作,跨系统操作无压力,隐私保护,用户IP可隐藏。不过由于是面向开发者的爬虫开发系统,提供了丰富的开发功能,网站看起来技术性很强,专业性很强,对于技术基础为零的用户来说也不是那么容易理解,所以有一定的使用门槛。这里不多介绍。
采集器
采集器一般需要下载安装软件,然后在机器上创建爬虫,使用自己的带宽,受限于电脑是否关机。当然,你也可以自己开发爬虫工具和爬虫框架。
优采云采集器
优采云采集器 是一款网络数据采集、处理、分析和挖掘软件。它可以灵活、快速的抓取网页上零散的信息,通过强大的处理功能,准确的挖掘出需要的数据。
优点:国内老牌采集器,经过多年积累,拥有丰富的采集功能;采集比较快,接口比较齐全,支持PHP和C#插件扩展;支持多种数据格式导出,可以进行数据替换等处理。
缺点:产品越老越容易陷入自己的固有体验,优采云很难摆脱这个问题。虽然功能丰富,但功能堆在那里,用户体验不好,让人不知从何下手;学过的人会觉得功能很强大,但是对于初学者来说,使用起来有一定的门槛,不学习一段时间是很难上手的。,基本不可能零基础上手。仅支持 Windows 版本,不支持其他操作系统。
免费与否:免费,但其实免费功能非常有限,只能导出单个txt或html文件。
B站教程:优采云采集器B站官方有专门的教程,课程安排有点混乱,不过有问题可以随时问奶奶。
奶奶:优采云采集器
优采云采集器
优采云采集器是一个可视化采集器,内置采集模板,支持各种网页数据采集。
优点:支持自定义模式,可视化采集操作,使用方便;支持简单采集模式,提供官方采集模板,支持云端采集操作;支持反屏蔽措施,例如代理IP切换和验证码服务;支持导出多种数据格式。
缺点:函数使用门槛高,很多函数限制在本地采集;采集慢,很多操作要卡住,云采集的10倍加速不明显;仅支持 Windows 版本,不支持其他操作系统。
是否免费:免费,但实际导出数据需要积分,做任务可以获得积分。
B站教程:优采云采集器官方在B站也有专门的教程,涵盖了文字、单页等多种数据采集方式。
奶奶:优采云采集器
优采云采集器
优采云采集器是前谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大,操作极其简单。
优点:支持智能采集模式,通过输入网址即可智能识别采集对象,无需配置采集规则,操作非常简单;支持流程图模式,可视化操作流程,可以使用简单的操作生成各种复杂的采集规则;支持反屏蔽措施,如代理IP切换等;支持多种数据格式的导出;支持定时采集和自动发布,发布接口丰富;支持Windows、Mac和Linux版本。
缺点:软件很久没有上线,部分功能还在完善中。Cloud 采集 功能暂时不支持。
是否免费:完全免费,对采集数据和手动导出采集结果没有限制,不需要积分。
教程:
(没找到B站教程,这是“互联网创新创业实践中心”公众号入门教程)
以上就是《B站学习资源总结》第一期的全部内容 查看全部
云采集(BiliBli学习资源测评之阿婆主们的优质学习教程资源汇总)
_
_
这么长的假期,相信很多同学都有学习一些科研软件的想法。BIliBIli上有很多非常好的教程。但是,初学者可能很难在短时间内找到最合适的教程。
因此,我们特地推出了“BiliBli学习资源评测”专栏,总结了奶奶的优质学习教程资源,帮助您快速选择适合自己的好教程。
本期重点整理3D Max和data采集相关资源。
1
3D 最大

3D Max是一款模型设计软件,应用于动画制作、建筑设计、游戏影视等领域。对于理工科研究生,我们主要使用3D Max来绘制模型示意图,尤其是封面。下面就给大家介绍几个适合科研制图的学习教程。
基本
奶奶:爱知兴趣教育
教程内容介绍:课程介绍了3D Max 2014版的一些基础知识,包括界面、操作、快捷键等,之后通过具体机型的制作过程,生动地向我们介绍了多种常用的制作方法,包括弯曲、锥度、扭曲等。每节课15分钟左右,讲解很详细。您可以以两倍的速度听课。

奶奶:龙雪傲
教程内容介绍:课程介绍3D Max 2016版的界面、主工具栏、基本操作等基础知识。与爱知趣教育的课程相比,本课程的讲解更加精炼。每节课5分钟以内,干货满满。本课程还增加了更高级的操作,比如添加动画编辑等。
具体型号文章
奶奶:独孤嘌呤
奶奶:R土豆被狙击
教程内容介绍:这两位up主用3D Max画了很多分子结构和细胞结构的模型图,比如碳纳米管的结构图,DNA双螺旋结构的图,高尔基体的图,对学生来说非常实用,我们可以参考他构建模型的过程,为我们的论文锦上添花。

数据采集
2
在日常生活中,我们经常需要各种数据来帮助决策,比如毕业论文、商业分析等等,都需要采集数据。在时间紧、任务重的情况下,尤其是非计算机专业的学生不能立即使用 Python 编写代码爬取数据。怎样才能方便快捷的获取我们想要的数据?
答案是:使用 采集 工具
目前常用的数据采集工具一般可以分为云爬虫和采集器两种。
云爬虫
云爬虫是直接在网页上创建爬虫并在网站服务器上运行,无需下载安装软件,享受网站提供的带宽和24小时服务。

目前国内最重要的是:优采云云爬虫。
其强大的功能涉及云爬虫、API、机器学习、数据清洗、数据销售、数据定制和私有化部署等;纯云端操作,跨系统操作无压力,隐私保护,用户IP可隐藏。不过由于是面向开发者的爬虫开发系统,提供了丰富的开发功能,网站看起来技术性很强,专业性很强,对于技术基础为零的用户来说也不是那么容易理解,所以有一定的使用门槛。这里不多介绍。
采集器
采集器一般需要下载安装软件,然后在机器上创建爬虫,使用自己的带宽,受限于电脑是否关机。当然,你也可以自己开发爬虫工具和爬虫框架。
优采云采集器
优采云采集器 是一款网络数据采集、处理、分析和挖掘软件。它可以灵活、快速的抓取网页上零散的信息,通过强大的处理功能,准确的挖掘出需要的数据。
优点:国内老牌采集器,经过多年积累,拥有丰富的采集功能;采集比较快,接口比较齐全,支持PHP和C#插件扩展;支持多种数据格式导出,可以进行数据替换等处理。
缺点:产品越老越容易陷入自己的固有体验,优采云很难摆脱这个问题。虽然功能丰富,但功能堆在那里,用户体验不好,让人不知从何下手;学过的人会觉得功能很强大,但是对于初学者来说,使用起来有一定的门槛,不学习一段时间是很难上手的。,基本不可能零基础上手。仅支持 Windows 版本,不支持其他操作系统。
免费与否:免费,但其实免费功能非常有限,只能导出单个txt或html文件。
B站教程:优采云采集器B站官方有专门的教程,课程安排有点混乱,不过有问题可以随时问奶奶。
奶奶:优采云采集器
优采云采集器
优采云采集器是一个可视化采集器,内置采集模板,支持各种网页数据采集。
优点:支持自定义模式,可视化采集操作,使用方便;支持简单采集模式,提供官方采集模板,支持云端采集操作;支持反屏蔽措施,例如代理IP切换和验证码服务;支持导出多种数据格式。
缺点:函数使用门槛高,很多函数限制在本地采集;采集慢,很多操作要卡住,云采集的10倍加速不明显;仅支持 Windows 版本,不支持其他操作系统。
是否免费:免费,但实际导出数据需要积分,做任务可以获得积分。
B站教程:优采云采集器官方在B站也有专门的教程,涵盖了文字、单页等多种数据采集方式。
奶奶:优采云采集器
优采云采集器
优采云采集器是前谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大,操作极其简单。
优点:支持智能采集模式,通过输入网址即可智能识别采集对象,无需配置采集规则,操作非常简单;支持流程图模式,可视化操作流程,可以使用简单的操作生成各种复杂的采集规则;支持反屏蔽措施,如代理IP切换等;支持多种数据格式的导出;支持定时采集和自动发布,发布接口丰富;支持Windows、Mac和Linux版本。
缺点:软件很久没有上线,部分功能还在完善中。Cloud 采集 功能暂时不支持。
是否免费:完全免费,对采集数据和手动导出采集结果没有限制,不需要积分。
教程:
(没找到B站教程,这是“互联网创新创业实践中心”公众号入门教程)
以上就是《B站学习资源总结》第一期的全部内容
云采集(众大云大叔要说采集这款dede模块详细解析采集模块介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-03-17 04:26
在这篇文章中,苏南大叔想讲一下dedecms的一个采集模块,叫做中大运采集。之所以要写一个文章来介绍中大运的dede模块采集并不是因为它的代码写的很好,而且他的产品模型比较新,采集模式比较特征。当然,本文不提供这个中大云采集的破解版。想要下载中大云破解版采集的新人请避开。
dedecms中大云采集的好用采集插件(图7-1)
本文测试环境为:dedeV5.7SP2,中大运采集9.4。
官方网站
中大云的官方域名采集比较有意思,叫csdn123。
dedecms,中大云采集的好用采集插件(图7-2)
这个“中大运采集”代码不仅适用于dedecms,还支持其他常用php语言的cms。免费版会在文字中有一个小广告,可以手动删除。当然,这个插件也很容易破解。苏南大叔在这里不断赚钱。如果你有钱,让我们帮助货币市场。毕竟函数写的挺好的(代码写的不是很好)。
截止发稿,中大云采集插件的版本号为9.4。大多数情况下,需要上传的插件文件是:下载的压缩包中的UTF8_install.xml文件。
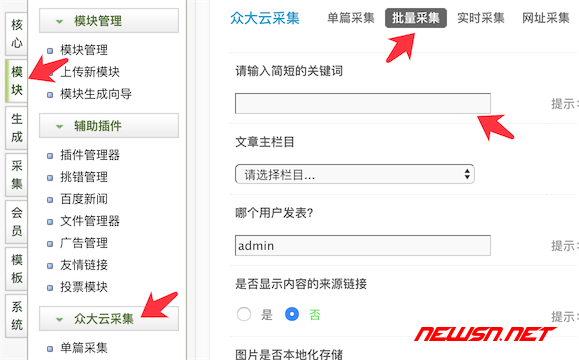
如何使用
在module=”Zhongdayun采集=”Batch采集,在这个菜单中,输入关键词,输入数量,可以得到一些随机相关的文章。使用方式非常无脑,非常适合新手。
dedecms、中大云采集的好用采集插件(图7-3)
导入数据库
中大云的数据库在某些情况下可能无法正常安装数据库。因此,可能需要手动执行sql。UTF8-install.xml 中加密的 sql 文本可以使用 php 的 base64_decode() 函数进行解密。
dedecms、中大云采集的好用采集插件(图7-4)
执行sql的方式取决于你的选择。苏南大叔推荐你使用navicat。
php72下兼容中大云采集
由于中大运采集在php72下无法正常运行,所以可以开启dede调试模式,方便调试。
修改文件:/include/common.inc.php。调试方法如下:修改常量DEDE_ENVIRONMENT为dev。
define('DEDE_ENVIRONMENT', 'dev');
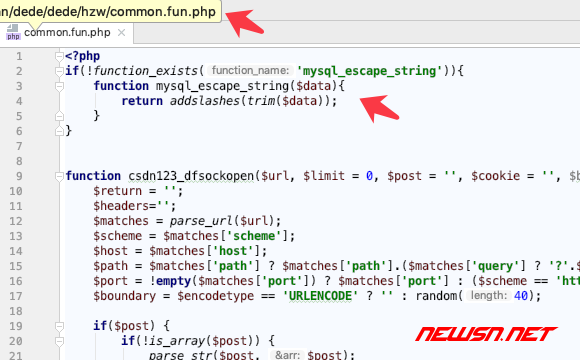
错误信息一:mysql_escape_string()
您可能会看到以下错误消息:
Uncaught Error: Call to undefined function mysql_escape_string()
php7 不再支持 php_mysql 扩展。既然没有 php_mysql 扩展,自然也就没有 mysql_escape_string 函数。
解决方案是兼容mysql_escape_string。修改文件:/dede/hzw/common.fun.php。添加以下兼容代码。
if(!function_exists('mysql_escape_string')){
function mysql_escape_string($data){
return addslashes(trim($data));
}
}
dedecms、中大云采集的好用采集插件(图7-5)
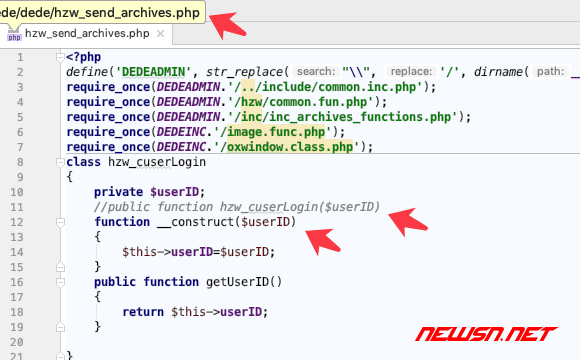
错误消息二:不推荐使用的构造函数警告
**Deprecated**: Methods with the same name as their class will not be constructors in a future version of PHP; hzw_cuserLogin has a deprecated constructor in **/dede/hzw_send_archives.php** on line **8**
修改文件/dede/hzw_send_archives.php,修改构造函数的编写方式。(将同名函数转成__construct)
//public function hzw_cuserLogin($userID)
function __construct($userID){
$this->userID=$userID;
}
dedecms,中大云采集的好用采集插件(图7-6)
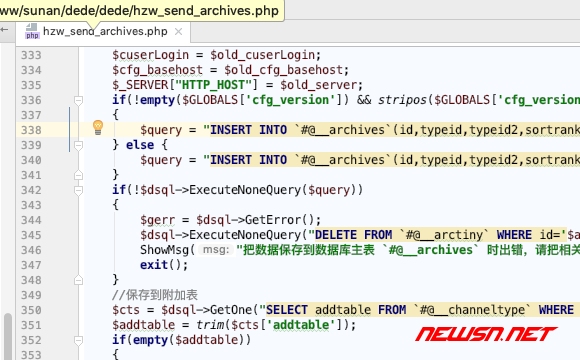
库存处于暂存状态
因为一般情况下,必须先发布中大云采集的充电提醒信息,才能修改提醒信息。这个设定很不人性化。因此,苏南叔将他设置为:采集完成后,将处于待释放状态,这种情况下,充电信息不会被释放。原则上,档案表中的 arcrank 字段设置为 -1。
if(!empty($GLOBALS['cfg_version']) && stripos($GLOBALS['cfg_version'],'V56')===false)
{
$query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle,color,writer,source,litpic,pubdate,senddate,mid,voteid,notpost,description,keywords,filename,dutyadmin,weight) VALUES ('$arcID','$cid','0','$sortrank','','0','$channelid','-1','$click','0','$title','','','$writer','','$litpic','$pubdate','$senddate','$adminid','0','0','$description','$keywords','','$adminid','0');";
} else {
$query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle,color,writer,source,litpic,pubdate,senddate,mid,notpost,description,keywords,filename,dutyadmin,weight) VALUES ('$arcID','$cid','0','$sortrank','','0','$channelid','-1','$click','0','$title','','','$writer','','$litpic','$pubdate','$senddate','$adminid','0','$description','$keywords','','$adminid','0');";
}
dedecms、中大云采集的好用采集插件(图7-7)
额外的信息
: 这里是 [作者] 的可见内容
总结
中大云采集的这种方法,非常适合小白初级编辑。不需要写规则,只需要定义关键词。
苏南大叔偶尔会写几篇关于德德经历的文章。不过,苏南大叔并不能真正欣赏dede的代码,而只能欣赏dede产品的成功。更多dede相关的话,请偶尔关注一下苏南大叔写的经验文章:
【源码】本文代码片段及相关软件,详情请点这里
【绝密】秘籍文章的入口,只传授给命中注定的人
php dede 查看全部
云采集(众大云大叔要说采集这款dede模块详细解析采集模块介绍)
在这篇文章中,苏南大叔想讲一下dedecms的一个采集模块,叫做中大运采集。之所以要写一个文章来介绍中大运的dede模块采集并不是因为它的代码写的很好,而且他的产品模型比较新,采集模式比较特征。当然,本文不提供这个中大云采集的破解版。想要下载中大云破解版采集的新人请避开。

dedecms中大云采集的好用采集插件(图7-1)
本文测试环境为:dedeV5.7SP2,中大运采集9.4。
官方网站
中大云的官方域名采集比较有意思,叫csdn123。
dedecms,中大云采集的好用采集插件(图7-2)
这个“中大运采集”代码不仅适用于dedecms,还支持其他常用php语言的cms。免费版会在文字中有一个小广告,可以手动删除。当然,这个插件也很容易破解。苏南大叔在这里不断赚钱。如果你有钱,让我们帮助货币市场。毕竟函数写的挺好的(代码写的不是很好)。
截止发稿,中大云采集插件的版本号为9.4。大多数情况下,需要上传的插件文件是:下载的压缩包中的UTF8_install.xml文件。
如何使用
在module=”Zhongdayun采集=”Batch采集,在这个菜单中,输入关键词,输入数量,可以得到一些随机相关的文章。使用方式非常无脑,非常适合新手。
dedecms、中大云采集的好用采集插件(图7-3)
导入数据库
中大云的数据库在某些情况下可能无法正常安装数据库。因此,可能需要手动执行sql。UTF8-install.xml 中加密的 sql 文本可以使用 php 的 base64_decode() 函数进行解密。
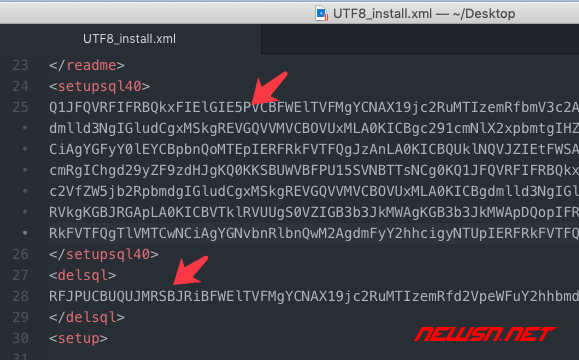
dedecms、中大云采集的好用采集插件(图7-4)
执行sql的方式取决于你的选择。苏南大叔推荐你使用navicat。
php72下兼容中大云采集
由于中大运采集在php72下无法正常运行,所以可以开启dede调试模式,方便调试。
修改文件:/include/common.inc.php。调试方法如下:修改常量DEDE_ENVIRONMENT为dev。
define('DEDE_ENVIRONMENT', 'dev');
错误信息一:mysql_escape_string()
您可能会看到以下错误消息:
Uncaught Error: Call to undefined function mysql_escape_string()
php7 不再支持 php_mysql 扩展。既然没有 php_mysql 扩展,自然也就没有 mysql_escape_string 函数。
解决方案是兼容mysql_escape_string。修改文件:/dede/hzw/common.fun.php。添加以下兼容代码。
if(!function_exists('mysql_escape_string')){
function mysql_escape_string($data){
return addslashes(trim($data));
}
}
dedecms、中大云采集的好用采集插件(图7-5)
错误消息二:不推荐使用的构造函数警告
**Deprecated**: Methods with the same name as their class will not be constructors in a future version of PHP; hzw_cuserLogin has a deprecated constructor in **/dede/hzw_send_archives.php** on line **8**
修改文件/dede/hzw_send_archives.php,修改构造函数的编写方式。(将同名函数转成__construct)
//public function hzw_cuserLogin($userID)
function __construct($userID){
$this->userID=$userID;
}
dedecms,中大云采集的好用采集插件(图7-6)
库存处于暂存状态
因为一般情况下,必须先发布中大云采集的充电提醒信息,才能修改提醒信息。这个设定很不人性化。因此,苏南叔将他设置为:采集完成后,将处于待释放状态,这种情况下,充电信息不会被释放。原则上,档案表中的 arcrank 字段设置为 -1。
if(!empty($GLOBALS['cfg_version']) && stripos($GLOBALS['cfg_version'],'V56')===false)
{
$query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle,color,writer,source,litpic,pubdate,senddate,mid,voteid,notpost,description,keywords,filename,dutyadmin,weight) VALUES ('$arcID','$cid','0','$sortrank','','0','$channelid','-1','$click','0','$title','','','$writer','','$litpic','$pubdate','$senddate','$adminid','0','0','$description','$keywords','','$adminid','0');";
} else {
$query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle,color,writer,source,litpic,pubdate,senddate,mid,notpost,description,keywords,filename,dutyadmin,weight) VALUES ('$arcID','$cid','0','$sortrank','','0','$channelid','-1','$click','0','$title','','','$writer','','$litpic','$pubdate','$senddate','$adminid','0','$description','$keywords','','$adminid','0');";
}
dedecms、中大云采集的好用采集插件(图7-7)
额外的信息
: 这里是 [作者] 的可见内容
总结
中大云采集的这种方法,非常适合小白初级编辑。不需要写规则,只需要定义关键词。
苏南大叔偶尔会写几篇关于德德经历的文章。不过,苏南大叔并不能真正欣赏dede的代码,而只能欣赏dede产品的成功。更多dede相关的话,请偶尔关注一下苏南大叔写的经验文章:
【源码】本文代码片段及相关软件,详情请点这里

【绝密】秘籍文章的入口,只传授给命中注定的人
php dede
云采集( 易蜂智能云采集LOGO图片已有48人成功下载点(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2022-03-05 19:21
易蜂智能云采集LOGO图片已有48人成功下载点(图))
亿丰智能云采集是一个全新的革命性网络爬虫系统。它将整个互联网视为数据源,智能地从中提取海量结构化数据,然后将互联网数据转化为内部数据库。一风云采集云端SaaS和DaaS,无需部署,几分钟内自定义爬虫规则,自动分布式爬取云端各类网站和APP,爬取海量网页,从从网页和APP中提取HTML结构化数据,结果直接存储在云端数据库中。它还可以与公司现有的数据仓库无缝集成,用于数据分析和业务决策。
注:中文翻译来自GOOGLE
亿丰智能云采集是一个全新的革命性网络爬虫系统。它将整个互联网视为数据源,智能地从中提取海量结构化数据,然后将互联网数据转化为内部数据库。一风云采集云端SaaS和DaaS,无需部署,几分钟内自定义爬虫规则,自动分布式爬取云端各类网站和APP,爬取海量网页,从从网页和APP中提取HTML结构化数据,结果直接存储在云端数据库中。它还可以与公司现有的数据仓库无缝集成,用于数据分析和业务决策。
易风云采集的智能识别和数据提取技术,可以智能识别不同性质的网页,快速实现数据可视化采集。易风云采集将网络数据的采集和整合自动化,大大降低了数据获取成本,提高了数据采集的效率。用户可以通过多种方式获取存储在云端的数据,包括导出下载(支持csv、json、Excel等格式)、推送(FTP、RSS、Email等)、API访问、云数据库访问、数据仓库集成等。亿丰智能云采集系统可广泛应用于电子商务、外贸、金融、市场分析、营销、房地产、汽车、舆情监测、招聘、社交等各个行业。
易蜂云采集插件LOGO图片
48人下载成功,点此进入下载页面 查看全部
云采集(
易蜂智能云采集LOGO图片已有48人成功下载点(图))




亿丰智能云采集是一个全新的革命性网络爬虫系统。它将整个互联网视为数据源,智能地从中提取海量结构化数据,然后将互联网数据转化为内部数据库。一风云采集云端SaaS和DaaS,无需部署,几分钟内自定义爬虫规则,自动分布式爬取云端各类网站和APP,爬取海量网页,从从网页和APP中提取HTML结构化数据,结果直接存储在云端数据库中。它还可以与公司现有的数据仓库无缝集成,用于数据分析和业务决策。
注:中文翻译来自GOOGLE
亿丰智能云采集是一个全新的革命性网络爬虫系统。它将整个互联网视为数据源,智能地从中提取海量结构化数据,然后将互联网数据转化为内部数据库。一风云采集云端SaaS和DaaS,无需部署,几分钟内自定义爬虫规则,自动分布式爬取云端各类网站和APP,爬取海量网页,从从网页和APP中提取HTML结构化数据,结果直接存储在云端数据库中。它还可以与公司现有的数据仓库无缝集成,用于数据分析和业务决策。
易风云采集的智能识别和数据提取技术,可以智能识别不同性质的网页,快速实现数据可视化采集。易风云采集将网络数据的采集和整合自动化,大大降低了数据获取成本,提高了数据采集的效率。用户可以通过多种方式获取存储在云端的数据,包括导出下载(支持csv、json、Excel等格式)、推送(FTP、RSS、Email等)、API访问、云数据库访问、数据仓库集成等。亿丰智能云采集系统可广泛应用于电子商务、外贸、金融、市场分析、营销、房地产、汽车、舆情监测、招聘、社交等各个行业。
易蜂云采集插件LOGO图片
48人下载成功,点此进入下载页面
云采集(众大智能云采集discuz插件,,成熟稳定等特性)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-02-23 23:16
其他相关
中大运采集破解版-中大运采集插件下载v9.7.0正式版--pc6 2020年6月19日中大运采集插件-in,中大云采集插件是一个数据采集插件,中大云采集插件易学、易懂、好用、成熟、 stable等采集器旧系统会出现在帖子、传送门、群页面顶部:[中大运采集下载]中大运采集pluginv9.7.0破解版-开心电玩2020年6月19日中大运采集是一款非常好用的资料采集插件,此版本完全免费供用户学习,易懂,易上手使用,成熟稳定的特点。中大云采集操作简单,2020win7会出现在发帖、门户、群的页面顶部:中大智能云采集discuz插件免费下载_中大智能云采集@ >discuz2012 2018年12月26日,安装中大智慧云采集discuz插件后,在论坛和门户发文章时,顶部会出现一个采集控制面板,进入关键词或者网站可以是智能云采集任何你想要的内容,今日头条和电脑城:中大运采集-知物应用中大运采集【温馨提示】 01.安装此插件后,您可以采集[当前热点内容][当前新闻头条][知乎][搜狐][网易][ZAKER新闻][腾讯网] 【搜狗提速:中大运采集外挂电脑端官方2020最新版免费下载2020年6月20日中大运采集外挂是数据采集外挂,中大运< @采集 插件易学易懂好用,成熟稳定等。采集器控制面板会出现在发布帖子、传送门、群的页面顶部,进入快猫:中大云采集插件破解版|中大云采集(网站内容采集工具)2018年5月10日下载中大云采集是一个强大的网站内容采集工具,集成了Discuz, 织梦dedecms、phpcms、Empirecms作为插件在建站系统中,任何内容都可以根据关键词自动采集 @>或URL,可代系统认证:中大云采集插件破解版|中大云采集插件免费版v9.7.0下载_June 19, 2020 中大云采集插件是一个非常好用的采集工具,可以帮助用户去采集论坛的帖子内容,也可以批量注册,评论等功能。 采集 函数实现自动采集。 discuz采集plugin v9.5|中大运采集discuz采集plugin 2018年10月29日中大运采集Discuz版是一个特殊的批量采集软件由 discuz 开发。
安装此插件后,采集器 控制面板将出现在发布帖子、门户和群组的页面顶部。输入关键词或URL智能采集内容一键重载:public大运采集插件破解版|中大运采集织梦无限V9. 7.0 Free June 20, 20, 14、@ >众大运采集可以一键获取当日实时热点内容,然后一键发布。 15、不限制采集的内容数量,不限制采集的使用次数,让你的网站快速填满优质内容。 16、插件win7: Discuz中大云采集插件v9.6.5_discuz插件-精准像素中大云采集使用说明01、安装后这个插件,你可以自己写采集规则或者输入你的网站关键词,一键批量采集任何内容到你的论坛版块或者门户版块,群集体发布。 02、可以下载为147: 查看全部
云采集(众大智能云采集discuz插件,,成熟稳定等特性)
其他相关
中大运采集破解版-中大运采集插件下载v9.7.0正式版--pc6 2020年6月19日中大运采集插件-in,中大云采集插件是一个数据采集插件,中大云采集插件易学、易懂、好用、成熟、 stable等采集器旧系统会出现在帖子、传送门、群页面顶部:[中大运采集下载]中大运采集pluginv9.7.0破解版-开心电玩2020年6月19日中大运采集是一款非常好用的资料采集插件,此版本完全免费供用户学习,易懂,易上手使用,成熟稳定的特点。中大云采集操作简单,2020win7会出现在发帖、门户、群的页面顶部:中大智能云采集discuz插件免费下载_中大智能云采集@ >discuz2012 2018年12月26日,安装中大智慧云采集discuz插件后,在论坛和门户发文章时,顶部会出现一个采集控制面板,进入关键词或者网站可以是智能云采集任何你想要的内容,今日头条和电脑城:中大运采集-知物应用中大运采集【温馨提示】 01.安装此插件后,您可以采集[当前热点内容][当前新闻头条][知乎][搜狐][网易][ZAKER新闻][腾讯网] 【搜狗提速:中大运采集外挂电脑端官方2020最新版免费下载2020年6月20日中大运采集外挂是数据采集外挂,中大运< @采集 插件易学易懂好用,成熟稳定等。采集器控制面板会出现在发布帖子、传送门、群的页面顶部,进入快猫:中大云采集插件破解版|中大云采集(网站内容采集工具)2018年5月10日下载中大云采集是一个强大的网站内容采集工具,集成了Discuz, 织梦dedecms、phpcms、Empirecms作为插件在建站系统中,任何内容都可以根据关键词自动采集 @>或URL,可代系统认证:中大云采集插件破解版|中大云采集插件免费版v9.7.0下载_June 19, 2020 中大云采集插件是一个非常好用的采集工具,可以帮助用户去采集论坛的帖子内容,也可以批量注册,评论等功能。 采集 函数实现自动采集。 discuz采集plugin v9.5|中大运采集discuz采集plugin 2018年10月29日中大运采集Discuz版是一个特殊的批量采集软件由 discuz 开发。
安装此插件后,采集器 控制面板将出现在发布帖子、门户和群组的页面顶部。输入关键词或URL智能采集内容一键重载:public大运采集插件破解版|中大运采集织梦无限V9. 7.0 Free June 20, 20, 14、@ >众大运采集可以一键获取当日实时热点内容,然后一键发布。 15、不限制采集的内容数量,不限制采集的使用次数,让你的网站快速填满优质内容。 16、插件win7: Discuz中大云采集插件v9.6.5_discuz插件-精准像素中大云采集使用说明01、安装后这个插件,你可以自己写采集规则或者输入你的网站关键词,一键批量采集任何内容到你的论坛版块或者门户版块,群集体发布。 02、可以下载为147:
云采集(要来一个事:云采集是如何颠覆整个爬虫界的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2022-02-17 09:17
摘要:其实云采集就是这么简单的一个东西,就是通过云采集服务器的控制,给每个服务器分配采集任务,控制它的采集 通过指令。但是,由于优采云是第一个云采集技术,也是用户量非常大的云采集平台,所以云采集、优采云已经走了好。很长的路。因此,我们一直坚持只有优采云的云采集才是真正的云采集。
先说一件事:“云采集”这个概念是我们优采云在2013年提出的,先于国内外。
2013年,优采云自2013年成立以来,创造了自己的云采集技术。我们可以在优采云的版本更新记录中找到这方面的痕迹。只是因为自己创业,没有足够的IP意识,也没有钱和精力去申请相关的知识产权。因此,许多竞争公司现在都在吹嘘自己拥有云采集 技术,但实际上许多公司并没有。了解真云采集技术。
2013-12-06 版本更新记录
2014-05-01 版本更新记录
今天我们要讲的就是云采集是如何颠覆整个爬虫世界的。当然,因为我们优采云是当事人,所以笔者可以带大家回顾一下云采集爬虫这几年的发展历程。
云采集是在什么背景下诞生的?
2006 年 8 月 9 日,谷歌 CEO Eric Schmidt 在搜索引擎大会(SES San Jose 2006))上首次提出了“云计算”的概念。谷歌“云计算”起源于谷歌工程师克里斯托弗·比西利亚的“谷歌101”项目。
直到 2008 年,中国 IT 行业才开始谈论云计算。笔者作为2007年计算机专业的毕业生,刚好赶上了这波热潮,但说实话,当时只是一个概念,还没有人看到真正的产品。,所以我不知道它是什么。顶多听说过Google的Google Charts、Google Words等等。当时,我并不了解这些产品的用途。不就是word和excel的网页版,不是微软的好用。
但是经过多年的工作,我意识到微软的word和excel只能在Windows机器上使用。如果你想在苹果电脑上使用它们,你必须努力工作。但是网页版不一样,它是跨平台的,你习惯了,到处都可以用,还可以把数据存到云端。更重要的是,帮助我们提高工作效率或组织管理的工作不再仅仅依靠软件,而是依靠云服务。
随着云计算的诞生,行业也诞生了以下三个层次的服务
基础设施级服务 (IaaS),
平台级服务 (PaaS),
软件级服务 (SaaS)。
我们可以简单地将SaaS理解为一种在云中提供标准化产品的服务模型。因为它的标准化,不管是一个企业使用还是100家企业使用,都是一个开发成本。这对产品在一定场景下的通用性有非常高的要求,但也大大提高了产品在市场上的竞争力。SaaS模式的效果与企业自建信息系统的效果基本相同,但节省了大量资金,大大降低了企业信息化的门槛和风险。
很多SaaS公司提供月费和年费的模式,不同于以往的软件以项目的形式,很受企业主的欢迎,所以在接下来的十年里,也演变成一种主流的企业服务。形式。
现在市场上有很多优秀的SaaS公司。国际知名的Salesforce,类似于CRM的鼻祖。我们国内的CRM专家,比如文档领域的石墨、表单领域的金数据等,在SaaS领域都做得特别好。的企业。
优采云创新利用云采集技术,提供SaaS运营模式,正是在云计算和SaaS趋势的背景下。用户只需在客户端上传采集规则,调用云分布式服务即可执行采集,每个云服务器都会按照采集规则到采集@ >。所以 优采云 团队将这个 采集 模型命名为“Cloud采集”
为什么“Cloud采集”会诞生
优采云出来创业的时候,市场上有非常成熟强大的竞争对手。但他们以传统软件运营商的模式运作,主要是以销售授权码的形式。如果用户想在计算机上运行它们,他们必须购买他的授权码。就像我们早期使用Word 2003、2007时,经常需要上网搜索破解密码。当时的竞争对手如火如荼,但它只是一个客户端软件,只能在本地计算机采集上进行。
优采云创始人刘宝强keven拥有多年在外企和海外工作的经验。他也是某数据方向的研发工程师采集。他想制作一个通用网页采集 产品来替代公司编写的大部分采集 代码。他深知各种采集技术的优缺点、问题和瓶颈。
凯文当时也知道他的竞争对手的实力。那个时候,他不敢想象自己能做出更好的采集产品,因为对手太强了,采集的世界里没有人。我不知道。但他知道,要超越竞争对手,往往不是遵循策略,而是颠覆并采用与他们的疲惫不同的思维方式。
根据Keven的分析,传统的从网络请求数据的方式仍然是http post和get请求。这确实是当时网页采集的主流模式,而且这种形式效率特别高,但是这种模式的复杂度很高。它也非常高。普通人是无法操作和配置的。能理解这套理论的人,大多是有发展背景的人。
他知道在大公司里,大部分做数据采集工作的人都不是电脑开发人员,所以他将自己的采集产品定位为普通人可以使用的采集产品,通过界面定位,拖放,可以配置规则。经过半年的研究,他突破了所有的难关,实现了所见即所得的采集工作流配置模式。
但是问题也随之而来,因为方法是通过浏览器加载网页然后获取数据,所以竞品可能一次请求就能获取数据,而且因为优采云需要加载整个网页,这可能涉及到数百个请求,所以在 采集 速度方面,似乎很慢。(可以使用httpwatch查看浏览器打开网页涉及多少请求)
解决可用性问题后遇到速度问题?
如何解决?
如果云端有多台机器同时挖矿,甚至在规则中拆分URL列表,让云端服务器同时分布采集,那么速度可以增加了 N 倍以上。这种方式是可行的,但是这种方式带来了另一个问题。
速度问题解决后会出现成本问题?
如何解决?
凯文判断,如果租用 10 台云服务器,通过共享经济的概念平均分摊成本,其实每个用户每月只需要几百块钱。与数据的价值相比,远远大于这个投入,应该有用户愿意为它买单。
而且成本问题应该不是大问题。根据摩尔定律,硬件成本只会越来越低。情况确实如此。包括后期,优采云通过与主流云服务商合作,有效控制了整个云服务器的成本,帮助用户降低了这个成本。
基于此,2013年Q4,在数据领域采集,优采云领先国内外龙头企业,创新打造采集模式-云采集 .
云背后的发展历程采集
其实云采集就是这么简单的一个东西,就是通过云采集服务器的控制,给每一个服务器分配采集任务,控制它的采集@ > 通过说明。但是优采云是创新的云采集技术和云采集平台,用户量非常大,所以云采集、优采云没了很长很长的路。因此,我们一直坚持只有优采云的云采集才是真正的云采集。
1 突破多项技术难点
优采云在5年的运营过程中,我们逐渐突破了云端的各种问题采集。这里的很多问题在大数据面前都不会出现。我举几个例子:
有一些项目标榜自己拥有云采集技术,但实际测试时,漏洞百出。比如我们可以控制100台服务器采集data,但是如果只有一个datastore支持导出数据,就会出现导出数据比采集慢100倍的窘境。只能看到库中的数据,不能移动。
有人认为,如果有一个服务器运行在云采集 中,则称为云采集。但他不知道,当同时有几十万台服务器时采集,他背后需要大数据存储解决方案的支持。只有这样采集接收到的数据才能不遗漏地存入数据库,有序存储,便于后期检索、查询和导出。
由于采集的网页数据状态不同,云端采集需要动态分配,需要做很多前期工作。有时一些网站 有防止采集 的策略。在采集之前,他们是否可以判断对方网站对你的一些措施和判断,或者如果他们在采集过程中动态调整服务器运行策略,也就是也是对云采集 解决方案的测试。
2 继续提供稳定的采集和导出服务
优采云现在全球有5000多台服务器,每天采集和导出的数据都由T计算服务给全球所有语言和领域的采集用户世界。对于企业级产品来说,除了技术,提供稳定运维的能力是一个关键问题。
优采云有多个运维后台,随时监控整个服务器集群中每台采集服务器的状态。>生产环境和数据保持相对稳定。
如此庞大的云服务器采集集群是任何竞争对手都无法比拟的,而在这个庞大的集群面前,优采云依然保持着稳定的采集和出口服务。
3 其他资格
优采云在中国大数据行业,连续三年在数据采集领域排名第一,足以证明优采云在数据领域的长期积累和贡献采集。
介绍的最后一段可以理解为又硬又宽,哈哈,我们知道云采集是怎么诞生的,是在什么条件下诞生的,还有主要的技术难点,我们一路突破了哪些问题大大地。回顾这段历史,我想告诉大家,我们优采云一直致力于提供稳定的云采集服务,还有很长的路要走,我们的压力也越来越大,我们也在不断的优化,这个过程有点坎坷,还需要我们优采云用户的大力支持,我们会尽最大努力给予反馈。
一起努力! 查看全部
云采集(要来一个事:云采集是如何颠覆整个爬虫界的)
摘要:其实云采集就是这么简单的一个东西,就是通过云采集服务器的控制,给每个服务器分配采集任务,控制它的采集 通过指令。但是,由于优采云是第一个云采集技术,也是用户量非常大的云采集平台,所以云采集、优采云已经走了好。很长的路。因此,我们一直坚持只有优采云的云采集才是真正的云采集。
先说一件事:“云采集”这个概念是我们优采云在2013年提出的,先于国内外。
2013年,优采云自2013年成立以来,创造了自己的云采集技术。我们可以在优采云的版本更新记录中找到这方面的痕迹。只是因为自己创业,没有足够的IP意识,也没有钱和精力去申请相关的知识产权。因此,许多竞争公司现在都在吹嘘自己拥有云采集 技术,但实际上许多公司并没有。了解真云采集技术。

2013-12-06 版本更新记录

2014-05-01 版本更新记录
今天我们要讲的就是云采集是如何颠覆整个爬虫世界的。当然,因为我们优采云是当事人,所以笔者可以带大家回顾一下云采集爬虫这几年的发展历程。
云采集是在什么背景下诞生的?
2006 年 8 月 9 日,谷歌 CEO Eric Schmidt 在搜索引擎大会(SES San Jose 2006))上首次提出了“云计算”的概念。谷歌“云计算”起源于谷歌工程师克里斯托弗·比西利亚的“谷歌101”项目。

直到 2008 年,中国 IT 行业才开始谈论云计算。笔者作为2007年计算机专业的毕业生,刚好赶上了这波热潮,但说实话,当时只是一个概念,还没有人看到真正的产品。,所以我不知道它是什么。顶多听说过Google的Google Charts、Google Words等等。当时,我并不了解这些产品的用途。不就是word和excel的网页版,不是微软的好用。
但是经过多年的工作,我意识到微软的word和excel只能在Windows机器上使用。如果你想在苹果电脑上使用它们,你必须努力工作。但是网页版不一样,它是跨平台的,你习惯了,到处都可以用,还可以把数据存到云端。更重要的是,帮助我们提高工作效率或组织管理的工作不再仅仅依靠软件,而是依靠云服务。
随着云计算的诞生,行业也诞生了以下三个层次的服务
基础设施级服务 (IaaS),
平台级服务 (PaaS),
软件级服务 (SaaS)。
我们可以简单地将SaaS理解为一种在云中提供标准化产品的服务模型。因为它的标准化,不管是一个企业使用还是100家企业使用,都是一个开发成本。这对产品在一定场景下的通用性有非常高的要求,但也大大提高了产品在市场上的竞争力。SaaS模式的效果与企业自建信息系统的效果基本相同,但节省了大量资金,大大降低了企业信息化的门槛和风险。

很多SaaS公司提供月费和年费的模式,不同于以往的软件以项目的形式,很受企业主的欢迎,所以在接下来的十年里,也演变成一种主流的企业服务。形式。
现在市场上有很多优秀的SaaS公司。国际知名的Salesforce,类似于CRM的鼻祖。我们国内的CRM专家,比如文档领域的石墨、表单领域的金数据等,在SaaS领域都做得特别好。的企业。
优采云创新利用云采集技术,提供SaaS运营模式,正是在云计算和SaaS趋势的背景下。用户只需在客户端上传采集规则,调用云分布式服务即可执行采集,每个云服务器都会按照采集规则到采集@ >。所以 优采云 团队将这个 采集 模型命名为“Cloud采集”
为什么“Cloud采集”会诞生
优采云出来创业的时候,市场上有非常成熟强大的竞争对手。但他们以传统软件运营商的模式运作,主要是以销售授权码的形式。如果用户想在计算机上运行它们,他们必须购买他的授权码。就像我们早期使用Word 2003、2007时,经常需要上网搜索破解密码。当时的竞争对手如火如荼,但它只是一个客户端软件,只能在本地计算机采集上进行。
优采云创始人刘宝强keven拥有多年在外企和海外工作的经验。他也是某数据方向的研发工程师采集。他想制作一个通用网页采集 产品来替代公司编写的大部分采集 代码。他深知各种采集技术的优缺点、问题和瓶颈。
凯文当时也知道他的竞争对手的实力。那个时候,他不敢想象自己能做出更好的采集产品,因为对手太强了,采集的世界里没有人。我不知道。但他知道,要超越竞争对手,往往不是遵循策略,而是颠覆并采用与他们的疲惫不同的思维方式。
根据Keven的分析,传统的从网络请求数据的方式仍然是http post和get请求。这确实是当时网页采集的主流模式,而且这种形式效率特别高,但是这种模式的复杂度很高。它也非常高。普通人是无法操作和配置的。能理解这套理论的人,大多是有发展背景的人。
他知道在大公司里,大部分做数据采集工作的人都不是电脑开发人员,所以他将自己的采集产品定位为普通人可以使用的采集产品,通过界面定位,拖放,可以配置规则。经过半年的研究,他突破了所有的难关,实现了所见即所得的采集工作流配置模式。

但是问题也随之而来,因为方法是通过浏览器加载网页然后获取数据,所以竞品可能一次请求就能获取数据,而且因为优采云需要加载整个网页,这可能涉及到数百个请求,所以在 采集 速度方面,似乎很慢。(可以使用httpwatch查看浏览器打开网页涉及多少请求)
解决可用性问题后遇到速度问题?
如何解决?
如果云端有多台机器同时挖矿,甚至在规则中拆分URL列表,让云端服务器同时分布采集,那么速度可以增加了 N 倍以上。这种方式是可行的,但是这种方式带来了另一个问题。
速度问题解决后会出现成本问题?
如何解决?
凯文判断,如果租用 10 台云服务器,通过共享经济的概念平均分摊成本,其实每个用户每月只需要几百块钱。与数据的价值相比,远远大于这个投入,应该有用户愿意为它买单。
而且成本问题应该不是大问题。根据摩尔定律,硬件成本只会越来越低。情况确实如此。包括后期,优采云通过与主流云服务商合作,有效控制了整个云服务器的成本,帮助用户降低了这个成本。
基于此,2013年Q4,在数据领域采集,优采云领先国内外龙头企业,创新打造采集模式-云采集 .

云背后的发展历程采集
其实云采集就是这么简单的一个东西,就是通过云采集服务器的控制,给每一个服务器分配采集任务,控制它的采集@ > 通过说明。但是优采云是创新的云采集技术和云采集平台,用户量非常大,所以云采集、优采云没了很长很长的路。因此,我们一直坚持只有优采云的云采集才是真正的云采集。
1 突破多项技术难点
优采云在5年的运营过程中,我们逐渐突破了云端的各种问题采集。这里的很多问题在大数据面前都不会出现。我举几个例子:
有一些项目标榜自己拥有云采集技术,但实际测试时,漏洞百出。比如我们可以控制100台服务器采集data,但是如果只有一个datastore支持导出数据,就会出现导出数据比采集慢100倍的窘境。只能看到库中的数据,不能移动。
有人认为,如果有一个服务器运行在云采集 中,则称为云采集。但他不知道,当同时有几十万台服务器时采集,他背后需要大数据存储解决方案的支持。只有这样采集接收到的数据才能不遗漏地存入数据库,有序存储,便于后期检索、查询和导出。
由于采集的网页数据状态不同,云端采集需要动态分配,需要做很多前期工作。有时一些网站 有防止采集 的策略。在采集之前,他们是否可以判断对方网站对你的一些措施和判断,或者如果他们在采集过程中动态调整服务器运行策略,也就是也是对云采集 解决方案的测试。
2 继续提供稳定的采集和导出服务
优采云现在全球有5000多台服务器,每天采集和导出的数据都由T计算服务给全球所有语言和领域的采集用户世界。对于企业级产品来说,除了技术,提供稳定运维的能力是一个关键问题。
优采云有多个运维后台,随时监控整个服务器集群中每台采集服务器的状态。>生产环境和数据保持相对稳定。
如此庞大的云服务器采集集群是任何竞争对手都无法比拟的,而在这个庞大的集群面前,优采云依然保持着稳定的采集和出口服务。
3 其他资格
优采云在中国大数据行业,连续三年在数据采集领域排名第一,足以证明优采云在数据领域的长期积累和贡献采集。
介绍的最后一段可以理解为又硬又宽,哈哈,我们知道云采集是怎么诞生的,是在什么条件下诞生的,还有主要的技术难点,我们一路突破了哪些问题大大地。回顾这段历史,我想告诉大家,我们优采云一直致力于提供稳定的云采集服务,还有很长的路要走,我们的压力也越来越大,我们也在不断的优化,这个过程有点坎坷,还需要我们优采云用户的大力支持,我们会尽最大努力给予反馈。
一起努力!
云采集(这是一个数据驱动商业发展的时代。(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-02-16 22:14
这是一个数据驱动业务发展的时代。
数据挖掘和分析不再仅仅是排他性的,它正逐渐成为广大中小企业的基本需求,也越来越迫切。并且随着网络爬虫的普及,云计算计算能力的提高,以及机器学习算法的发展,数据挖掘技能逐渐普及。广大中小企业也可以基于数据驱动提供更好的服务和产品,从而获得更大的发展。
数据挖掘实际上是一个很大的概念。本文主要讨论“挖掘”,或者说“网络爬虫”和“网络抓取”,比较容易理解。因为除了少数产品可以获取海量数据外,大部分企业都需要从公共数据中获取外部数据,主要是互联网,用于市场分析、舆情监测、竞品分析等。
在我看来,我更喜欢称它为“data采集”。分为“采集”和“采集”两个步骤。
对应的“采集”主要是数据的获取,可以通过多种方式获取。网页爬取为主,还有数据合作和采购。
对应的“集合”就是对数据进行清洗、连接、整合,将价值密度低的数据转化为价值密度高的数据。
数据采集 发展阶段
据笔者分析,数据采集从1990年代开始,在相当长的一段时间内,一直是技术开发者的一项特殊技能。但随着云计算、大数据甚至人工智能的发展,这个技能变得简单易用,就像“老王谢堂千言飞入寻常百姓家”。主要经历四个阶段。
熟悉爬虫的攻城狮会想说一堆喜欢的:Scrapy、WebMagic、Nutch、Heritrix等等,相信Github上的爬虫框架不下30个。它们的共同特点是:门槛高,仅供开发者使用,学习成本和维护成本高,企业组建爬虫团队往往成本高昂。
用户需要下载客户端并具备一定的HTML、正则表达式和CSS能力。国内最早的客户端叫做,属于一代爬虫工具,对html和正则表达式的要求还是比较高的(作者亲测)。
He等二代产品提供可视化爬取服务,通过点击爬取所需数据。其特点是:门槛进一步降低。对于非专业的开发者,经过一定的学习,可以自己爬取所需的公开数据。但是,它主要针对个人用户。由于用户客户端的限制,难以进行大规模连续爬取,数据存储和分析难以平衡。
首先,用户体验大大提升。他们中的大多数采用点击式方法。用户所见即所得。他们可以在不编写代码或了解 HTML、正则表达式和 CSS 样式的情况下自定义所需的爬虫。其次,无需担心自己电脑的限制。爬虫运行的云端可以固定时间,也可以爬取大量数据。您甚至可以在云中进行一定程度的数据清理和集成。
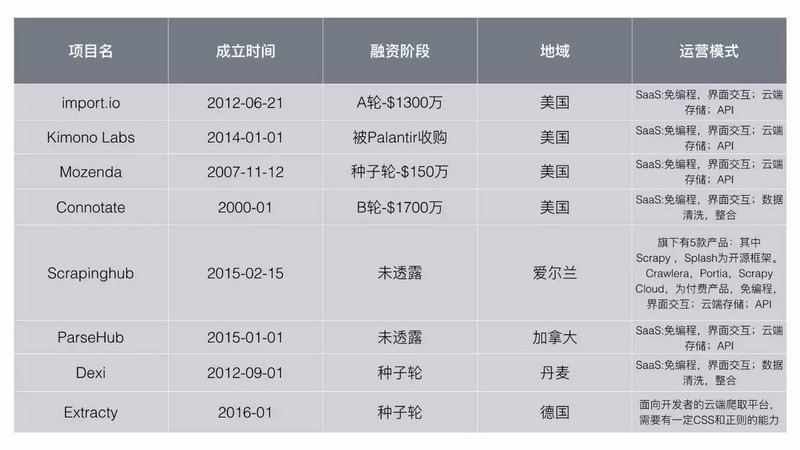
目前国外数据采集项目大多采用前端点击方式和后端云服务模式。以下为国外项目列表:
目前国内data采集项目分为三种:
1、基于客户端或插件的云采集服务。
客户端模式代表了项目的和谐。它不是单纯依赖客户端的计算资源,而是使用客户端的方式,更好更快的可视化和点击用户体验。同时将爬取的服务转移到云端,提供更大的数据爬取能力和数据整合能力。
浏览器插件方式例如是通过安装浏览器插件实现前端点击方式和后端云服务方式。
2.基于Web的云采集服务
用户无需安装,直接对网友进行点击操作,云端进行爬虫服务。这种方法的优点是用户可以随时随地使用,简单方便。国外很多项目都采用这种模式,比如国内采用这种模式的项目就是。但缺点是网页需要先在云端加载渲染,再呈现给用户,需要提供者大量的计算资源,而且速度往往很慢。
3. Cloud for Developers采集云服务开发
目前,一家名为China的公司正在提供此类服务。具备Java能力的开发者可以在平台上开发爬虫;没有开发能力的用户可以在爬虫市场购买或定制爬虫进行开发。
目前市场上,基本上80%的人都是采集20%的网络数据,比如企业信息、电商、O2O等,而这些网络数据往往具有很强的反爬能力。
笔者认为目前数据采集还处于3.阶段,还没有形成4.0阶段,即提供数据采集@ >、清洗、连接、分析等综合数据服务能力。
从3.0到4.0的阶段,在笔者看来,不仅仅是技术上的升级。不同行业、不同场景需要不同的数据,往往难以标准化,导致定制化,难以形成标准产品,难以大规模扩展。场景变化带来的技术挑战将凸显出来,因为真实场景所需的技术不是简单的升级,而是颠覆性的创新。
至于未来是否会完成跳跃,未来又会如何为大家服务,目前还很难说。目前国外import.io、dexi.io、Connotate、国内优采云、优采云、早书都在进行自己的探索。
合法性探讨
数据爬取的合法性在互联网领域一直存在争议,部分不法分子利用数据爬取工具进行黑商交易也是事实。数据抓取就像一把锋利的双刃剑,主要取决于用户是否以有益的方式应用它。
其实互联网数据爬取的主要原理就是Robots协议,也就是爬虫协议。网站通过Robots协议,告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。这原本主要针对搜索引擎公司,大家自觉遵守约定。
随着data采集范围的扩大,这个约定逐渐被打破,但也有既定的规则,广大data采集公司都应该遵守。
1、采集应该是互联网上的公开数据,数据的使用不能用于复制网站信息,或者干脆出售数据。更允许的情况是对多方采集的公开数据进行整合分析,形成数据分析服务。
2、采集的强度不应损害当前网站的性能,无形中增加目标网站的维护成本,甚至造成损失。
此外,我国刚刚于6月1日实施了《中华人民共和国互联网安全法》,这是我国网络领域的基本法,明确加强个人信息保护,打击网络诈骗。
《网络安全法》共7章79条,对个人信息泄露问题作出规定:网络产品和服务具有采集用户信息功能的,提供者应当明示并征得用户同意;网络运营者不得泄露、篡改、损毁其采集。任何个人和组织不得窃取或者以其他非法方式获取个人信息,不得非法出售或者非法向他人提供个人信息。这可能是对数据采集 公司更具方向性的指导。
数据采集发展到现在,怎么现在爆发了?
随着云计算、大数据、人工智能的发展,数据采集作为一种重要的数据手段,已成为企业的迫切需求。首当其冲的是中小企业的数据采集团队。不再需要维护一个完整的团队,大大降低了公司的成本。可以节省用户数据产品的开发,提升产品价值。对于普通个人来说,可以定制自己的data采集解决方案,门槛不高。更多行业、更多场景将被广泛应用。
人工智能的服务形态告诉我们,对于那些信息完备(Information-Complete)的领域,机器最终会超越并取代人类;
对于那些信息不完整(Information-Incomplete)的领域,也将通过人机协作推动新的发展;
对于那些抽象思维(Information-Free)的领域,仍然以人类为主,机器提供了一定的帮助。
Data采集 属于 Information-Complete 领域。机器可以在数据采集、清洗和整合上完全替代人类,然后通过与人类协作进行数据分析和预测。这将是即将发生的事情。
关于机器人云:
(微信公众号:vc-smart)是专业的创投机构投资管理服务商,帮助投资机构高效便捷管理投资项目,开发优质项目源,提供创投数据挖掘分析服务,助力投资管理人员可以快速获取项目、行业信息,协助行业分析。返回搜狐,查看更多 查看全部
云采集(这是一个数据驱动商业发展的时代。(组图))
这是一个数据驱动业务发展的时代。
数据挖掘和分析不再仅仅是排他性的,它正逐渐成为广大中小企业的基本需求,也越来越迫切。并且随着网络爬虫的普及,云计算计算能力的提高,以及机器学习算法的发展,数据挖掘技能逐渐普及。广大中小企业也可以基于数据驱动提供更好的服务和产品,从而获得更大的发展。
数据挖掘实际上是一个很大的概念。本文主要讨论“挖掘”,或者说“网络爬虫”和“网络抓取”,比较容易理解。因为除了少数产品可以获取海量数据外,大部分企业都需要从公共数据中获取外部数据,主要是互联网,用于市场分析、舆情监测、竞品分析等。

在我看来,我更喜欢称它为“data采集”。分为“采集”和“采集”两个步骤。
对应的“采集”主要是数据的获取,可以通过多种方式获取。网页爬取为主,还有数据合作和采购。
对应的“集合”就是对数据进行清洗、连接、整合,将价值密度低的数据转化为价值密度高的数据。
数据采集 发展阶段
据笔者分析,数据采集从1990年代开始,在相当长的一段时间内,一直是技术开发者的一项特殊技能。但随着云计算、大数据甚至人工智能的发展,这个技能变得简单易用,就像“老王谢堂千言飞入寻常百姓家”。主要经历四个阶段。
熟悉爬虫的攻城狮会想说一堆喜欢的:Scrapy、WebMagic、Nutch、Heritrix等等,相信Github上的爬虫框架不下30个。它们的共同特点是:门槛高,仅供开发者使用,学习成本和维护成本高,企业组建爬虫团队往往成本高昂。
用户需要下载客户端并具备一定的HTML、正则表达式和CSS能力。国内最早的客户端叫做,属于一代爬虫工具,对html和正则表达式的要求还是比较高的(作者亲测)。
He等二代产品提供可视化爬取服务,通过点击爬取所需数据。其特点是:门槛进一步降低。对于非专业的开发者,经过一定的学习,可以自己爬取所需的公开数据。但是,它主要针对个人用户。由于用户客户端的限制,难以进行大规模连续爬取,数据存储和分析难以平衡。
首先,用户体验大大提升。他们中的大多数采用点击式方法。用户所见即所得。他们可以在不编写代码或了解 HTML、正则表达式和 CSS 样式的情况下自定义所需的爬虫。其次,无需担心自己电脑的限制。爬虫运行的云端可以固定时间,也可以爬取大量数据。您甚至可以在云中进行一定程度的数据清理和集成。
目前国外数据采集项目大多采用前端点击方式和后端云服务模式。以下为国外项目列表:
目前国内data采集项目分为三种:
1、基于客户端或插件的云采集服务。
客户端模式代表了项目的和谐。它不是单纯依赖客户端的计算资源,而是使用客户端的方式,更好更快的可视化和点击用户体验。同时将爬取的服务转移到云端,提供更大的数据爬取能力和数据整合能力。
浏览器插件方式例如是通过安装浏览器插件实现前端点击方式和后端云服务方式。
2.基于Web的云采集服务
用户无需安装,直接对网友进行点击操作,云端进行爬虫服务。这种方法的优点是用户可以随时随地使用,简单方便。国外很多项目都采用这种模式,比如国内采用这种模式的项目就是。但缺点是网页需要先在云端加载渲染,再呈现给用户,需要提供者大量的计算资源,而且速度往往很慢。
3. Cloud for Developers采集云服务开发
目前,一家名为China的公司正在提供此类服务。具备Java能力的开发者可以在平台上开发爬虫;没有开发能力的用户可以在爬虫市场购买或定制爬虫进行开发。
目前市场上,基本上80%的人都是采集20%的网络数据,比如企业信息、电商、O2O等,而这些网络数据往往具有很强的反爬能力。
笔者认为目前数据采集还处于3.阶段,还没有形成4.0阶段,即提供数据采集@ >、清洗、连接、分析等综合数据服务能力。
从3.0到4.0的阶段,在笔者看来,不仅仅是技术上的升级。不同行业、不同场景需要不同的数据,往往难以标准化,导致定制化,难以形成标准产品,难以大规模扩展。场景变化带来的技术挑战将凸显出来,因为真实场景所需的技术不是简单的升级,而是颠覆性的创新。
至于未来是否会完成跳跃,未来又会如何为大家服务,目前还很难说。目前国外import.io、dexi.io、Connotate、国内优采云、优采云、早书都在进行自己的探索。
合法性探讨
数据爬取的合法性在互联网领域一直存在争议,部分不法分子利用数据爬取工具进行黑商交易也是事实。数据抓取就像一把锋利的双刃剑,主要取决于用户是否以有益的方式应用它。
其实互联网数据爬取的主要原理就是Robots协议,也就是爬虫协议。网站通过Robots协议,告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。这原本主要针对搜索引擎公司,大家自觉遵守约定。
随着data采集范围的扩大,这个约定逐渐被打破,但也有既定的规则,广大data采集公司都应该遵守。
1、采集应该是互联网上的公开数据,数据的使用不能用于复制网站信息,或者干脆出售数据。更允许的情况是对多方采集的公开数据进行整合分析,形成数据分析服务。
2、采集的强度不应损害当前网站的性能,无形中增加目标网站的维护成本,甚至造成损失。
此外,我国刚刚于6月1日实施了《中华人民共和国互联网安全法》,这是我国网络领域的基本法,明确加强个人信息保护,打击网络诈骗。
《网络安全法》共7章79条,对个人信息泄露问题作出规定:网络产品和服务具有采集用户信息功能的,提供者应当明示并征得用户同意;网络运营者不得泄露、篡改、损毁其采集。任何个人和组织不得窃取或者以其他非法方式获取个人信息,不得非法出售或者非法向他人提供个人信息。这可能是对数据采集 公司更具方向性的指导。
数据采集发展到现在,怎么现在爆发了?
随着云计算、大数据、人工智能的发展,数据采集作为一种重要的数据手段,已成为企业的迫切需求。首当其冲的是中小企业的数据采集团队。不再需要维护一个完整的团队,大大降低了公司的成本。可以节省用户数据产品的开发,提升产品价值。对于普通个人来说,可以定制自己的data采集解决方案,门槛不高。更多行业、更多场景将被广泛应用。
人工智能的服务形态告诉我们,对于那些信息完备(Information-Complete)的领域,机器最终会超越并取代人类;
对于那些信息不完整(Information-Incomplete)的领域,也将通过人机协作推动新的发展;
对于那些抽象思维(Information-Free)的领域,仍然以人类为主,机器提供了一定的帮助。
Data采集 属于 Information-Complete 领域。机器可以在数据采集、清洗和整合上完全替代人类,然后通过与人类协作进行数据分析和预测。这将是即将发生的事情。
关于机器人云:
(微信公众号:vc-smart)是专业的创投机构投资管理服务商,帮助投资机构高效便捷管理投资项目,开发优质项目源,提供创投数据挖掘分析服务,助力投资管理人员可以快速获取项目、行业信息,协助行业分析。返回搜狐,查看更多
云采集(运维上的日志目录路径及应用配置方案(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-02-14 09:12
有很多选项,其中一些在下面列出:
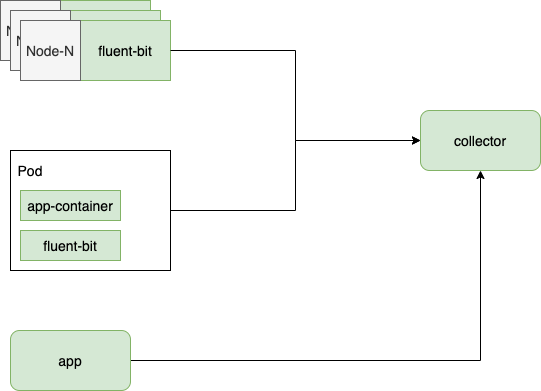
1、sidecar sidecar 模式,在每个 pod 中部署一个 filebeat sidecar 容器(共享空的 dir 卷进行日志记录采集)
2、应用容器pod中的直接部署日志采集agent for 采集;
3、打印到控制台,从主机的docker日志文件到采集(读取本地文件,不推荐)
4、打印到控制台,通过宿主机的docker日志驱动进入采集(二进制直接输出);
5、挂载k8s的flex volume,将log文件写入flex volume目录,然后从host到采集log文件。
...
注意:上面提到的host都是以DaemonSet的形式部署的,即一个Node节点(通常是物理机)部署一个DaemonSet pod节点。
主要从性能、操作维护方便、满足各种需求等方面考虑。5 这个方案(FlexVolume)比较好:
1)在性能方面,基于挂载的卷,日志直接放在磁盘上,容器内无代理,无开销,日志不经过docker log驱动,因此不会保存额外的副本。
2)采集都占用宿主机的资源。与每个pod部署一个agent相比,host上只部署一个agent来设置采集当前主机的所有pod,效率非常高。
3)在运维方面,每个应用都可以配置一个日志挂载目录,实际挂载目录会根据pod区分(自动)。也就是说,对于应用来说,只需要配置一个日志目录路径(这个是必须的),然后在宿主机上配置应用的日志采集进行运维。两者都是必要的步骤,而且再简单不过了。
满足需求,
1、日志文件放在磁盘上,可以永久存档(有些业务有这个要求),直接备份文件很方便。
2、查看日志,可以在统一的日志平台查看,也可以登录容器或主机,用tail查看。
3、日志采集配置,可根据应用名称等灵活处理,与普通日志文件采集方式相同。
那么我们来谈谈其他几种解决方案的缺点:
1)sidecar 模式上面已经讲过了。每个pod部署一个agent,估计占用30M资源。与一主机一代理相比,总资源占用率高出数倍。假设一台宿主机,如果部署 100 个 pod,宿主机的总内存消耗为 30×100M。
容器采集agent模式下的2)部署日志和sidecar模式有同样的缺点。占用资源较多,不方便统一管理。
3)基于主机DaemonSet日志驱动方式,日志一方面会被代理采集,另一方面通过日志驱动写入本地日志系统,双重消耗,不适合大型日志量大,而且最致命 是的,只能采集控制台打印的日志!(所有的日志都混在一起,无法分类),那么容器中的日志文件呢?
我们研究了市场上的各种日志解决方案。像阿里云这样的logtail功能强大,但是很多都是定制的,需要定制k8s组件。
阿里巴巴的k8s日志采集方案的“底层原理”还没有介绍,但是看起来和方案5的FlexVolume很像,也可以通过配置日志路径来采集。不像 sidecar,因为这会在 pod 中添加一个代理容器。
注意:我们使用的 FlexVolume 方案是 Rancher fluentd 提供的,提供了自动创建 FlexVolume 卷并挂载到 pod 的日志目录的功能,使用起来非常方便。
另外,我遇到了一个特殊的需求:
1、测试运维还是习惯在linux控制台看日志,同时打开10多个ssh接口一起看。
我的回答是:使用统一的日志平台,比如kibana,配置后查看日志的体验和控制台差不多。可以准实时刷新,功能比tail命令更强大。例如,如果您看到某个键日志,您可以暂停它。,可以来回翻页和查询,这是tail中没有的。并且在同一页面的下拉菜单中,可以在不同的应用程序之间进行切换,类似于切换SSH标签页的便利性。如果您想在一页上“同时”显示多个应用程序,您实际上可以做到。为您想要查看的多个应用程序构建聚合索引。特别是,您可以创建“*”来匹配所有应用程序,然后自己过滤它们。如果一定要挑剔,实时性不如控制台,还有一定的学习成本。关于实时性能,EFK(filebeat)延迟问题:kibana页面最多只能每5秒刷新一次。大概需要15秒左右,很不舒服,但是应该还有很大的优化空间,比如访问kafka,使用SSD硬盘等等。
还有一种方案,容器内外通用,我认为是最好的方案:(需要实现条件)
应用通过日志组件Appender直接将日志发送到最近的高速Loghub
也可以看看:
阿里云开源的各种Java日志组件的appender:
以上是针对Java的。同样,其他语言也有自己的日志组件,也可以实现类似的功能。
综上所述,最好的方案是在上述方案5中挂载FlexVolume+应用内日志组件直挖,相当于阿里云目前最先进的采集方案(阿里云只根据自己定制的方案5)平台),应用内日志采集使用自己的Logtail服务)。 查看全部
云采集(运维上的日志目录路径及应用配置方案(一))
有很多选项,其中一些在下面列出:
1、sidecar sidecar 模式,在每个 pod 中部署一个 filebeat sidecar 容器(共享空的 dir 卷进行日志记录采集)
2、应用容器pod中的直接部署日志采集agent for 采集;
3、打印到控制台,从主机的docker日志文件到采集(读取本地文件,不推荐)
4、打印到控制台,通过宿主机的docker日志驱动进入采集(二进制直接输出);
5、挂载k8s的flex volume,将log文件写入flex volume目录,然后从host到采集log文件。
...
注意:上面提到的host都是以DaemonSet的形式部署的,即一个Node节点(通常是物理机)部署一个DaemonSet pod节点。
主要从性能、操作维护方便、满足各种需求等方面考虑。5 这个方案(FlexVolume)比较好:
1)在性能方面,基于挂载的卷,日志直接放在磁盘上,容器内无代理,无开销,日志不经过docker log驱动,因此不会保存额外的副本。
2)采集都占用宿主机的资源。与每个pod部署一个agent相比,host上只部署一个agent来设置采集当前主机的所有pod,效率非常高。
3)在运维方面,每个应用都可以配置一个日志挂载目录,实际挂载目录会根据pod区分(自动)。也就是说,对于应用来说,只需要配置一个日志目录路径(这个是必须的),然后在宿主机上配置应用的日志采集进行运维。两者都是必要的步骤,而且再简单不过了。
满足需求,
1、日志文件放在磁盘上,可以永久存档(有些业务有这个要求),直接备份文件很方便。
2、查看日志,可以在统一的日志平台查看,也可以登录容器或主机,用tail查看。
3、日志采集配置,可根据应用名称等灵活处理,与普通日志文件采集方式相同。
那么我们来谈谈其他几种解决方案的缺点:
1)sidecar 模式上面已经讲过了。每个pod部署一个agent,估计占用30M资源。与一主机一代理相比,总资源占用率高出数倍。假设一台宿主机,如果部署 100 个 pod,宿主机的总内存消耗为 30×100M。
容器采集agent模式下的2)部署日志和sidecar模式有同样的缺点。占用资源较多,不方便统一管理。
3)基于主机DaemonSet日志驱动方式,日志一方面会被代理采集,另一方面通过日志驱动写入本地日志系统,双重消耗,不适合大型日志量大,而且最致命 是的,只能采集控制台打印的日志!(所有的日志都混在一起,无法分类),那么容器中的日志文件呢?
我们研究了市场上的各种日志解决方案。像阿里云这样的logtail功能强大,但是很多都是定制的,需要定制k8s组件。
阿里巴巴的k8s日志采集方案的“底层原理”还没有介绍,但是看起来和方案5的FlexVolume很像,也可以通过配置日志路径来采集。不像 sidecar,因为这会在 pod 中添加一个代理容器。
注意:我们使用的 FlexVolume 方案是 Rancher fluentd 提供的,提供了自动创建 FlexVolume 卷并挂载到 pod 的日志目录的功能,使用起来非常方便。
另外,我遇到了一个特殊的需求:
1、测试运维还是习惯在linux控制台看日志,同时打开10多个ssh接口一起看。
我的回答是:使用统一的日志平台,比如kibana,配置后查看日志的体验和控制台差不多。可以准实时刷新,功能比tail命令更强大。例如,如果您看到某个键日志,您可以暂停它。,可以来回翻页和查询,这是tail中没有的。并且在同一页面的下拉菜单中,可以在不同的应用程序之间进行切换,类似于切换SSH标签页的便利性。如果您想在一页上“同时”显示多个应用程序,您实际上可以做到。为您想要查看的多个应用程序构建聚合索引。特别是,您可以创建“*”来匹配所有应用程序,然后自己过滤它们。如果一定要挑剔,实时性不如控制台,还有一定的学习成本。关于实时性能,EFK(filebeat)延迟问题:kibana页面最多只能每5秒刷新一次。大概需要15秒左右,很不舒服,但是应该还有很大的优化空间,比如访问kafka,使用SSD硬盘等等。
还有一种方案,容器内外通用,我认为是最好的方案:(需要实现条件)
应用通过日志组件Appender直接将日志发送到最近的高速Loghub
也可以看看:
阿里云开源的各种Java日志组件的appender:
以上是针对Java的。同样,其他语言也有自己的日志组件,也可以实现类似的功能。
综上所述,最好的方案是在上述方案5中挂载FlexVolume+应用内日志组件直挖,相当于阿里云目前最先进的采集方案(阿里云只根据自己定制的方案5)平台),应用内日志采集使用自己的Logtail服务)。
云采集(指标采集方案介绍常见架构模式Daemons优采云采集器端agent(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-01-30 14:00
介绍:
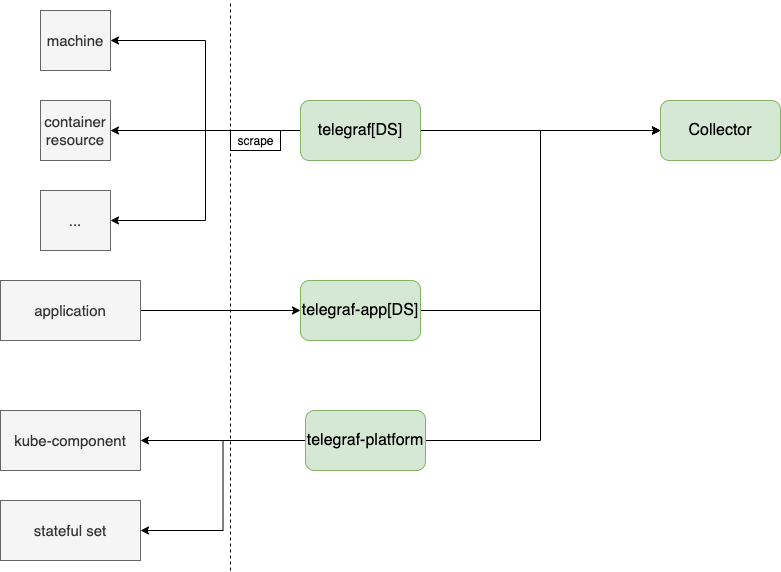
众所周知,对于一个云原生的PaaS平台来说,在页面上查看日志和指标是最基本的功能。无论是日志、指标还是链接跟踪,基本上都分为三个模块:采集、存储和展示。
在这里,笔者将介绍云原生下常用指标&日志的采集解决方案,以及Erda作为云原生PaaS平台是如何实现的。
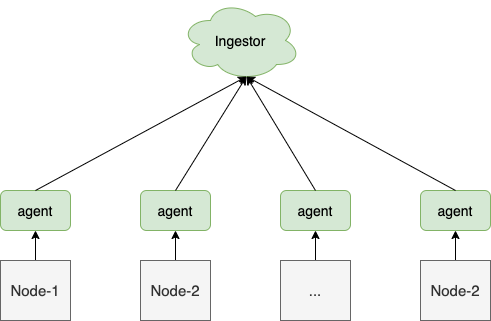
指标采集程序介绍常用架构模式1.守护进程
采集客户端代理通过Daemonset部署在各个节点上。这种模式下,指标通常由agent主动采集获取。常用代理有 telegraf、metricbeat、cadvisor 等。
应用场景:
2. 推拉
当我们需要采集程序的内部指标时,我们通常使用代理主动拉取指标或客户端主动推送指标。
应用场景:
那么,是推还是拉?
我认为这取决于实际的应用场景。比如对于短期任务,由于agent可能还没有启动采集,所以已经结束了,所以我们使用push方式;但是对于Web服务来说,这个问题就不存在了,pull的方式也可以减少用户端。负担。
开源解决方案简介
作为 CNCF 的 2 号毕业生,Prometheus 从诞生之初就基本成为了云原生尤其是 Kubernetes 的官方监控解决方案。
它其实是一个完整的解决方案,这里我们主要介绍它的采集功能。
和push&pull的方案基本一样,但是因为是丰富的exporter系统,所以基本可以采集在节点层面收录各种指标。
二达采用的架构方案
在Erda,目前的解决方案是通过二次打开telegraf,利用其丰富的采集插件,合并Daemonset和push-pull的解决方案。
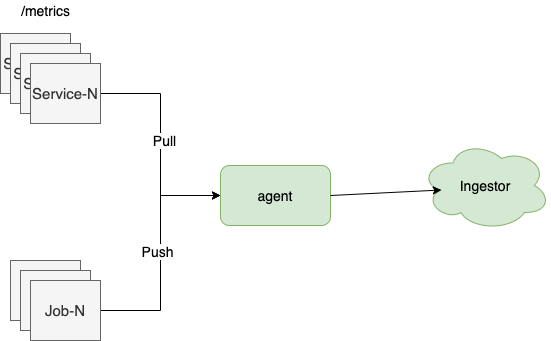
日志采集程序介绍常见架构模式1.守护进程
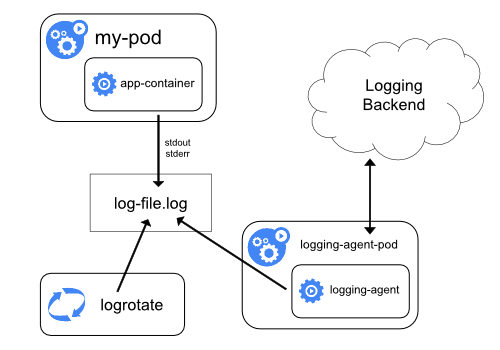
如果容器中的应用程序的日志输出到stdout,容器在运行时会通过logging-driver模块将日志输出到其他媒体,一般是在本地磁盘上。例如,Docker 通常通过 json-driver docker/containers//*.log 文件将日志输出到 /var/log/。
对于这种场景,我们一般使用Daemonset方案,即在每个节点上部署一个采集器,通过读取机器上的日志文件来采集日志。
2. 边车
Daemonset 方案也有一些限制,例如,当应用程序日志输出到日志文件时,或者当您要为日志配置一些处理规则(例如,多行规则、日志提取规则)时。
这时候可以使用Sidecar方案,logging-agent和应用容器可以共享日志目录,主动上报给采集。
3. 主动举报
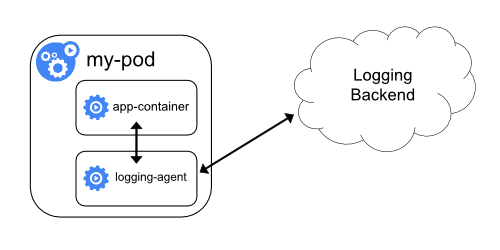
当然也可以主动上报日志(一般是通过厂商提供的SDK)。
常见的应用场景有:
开源解决方案简介
在业界,比较有名的是使用ELK作为日志解决方案,当然也是一个完整的解决方案。采集模块主要使用beats作为采集端,logstash作为日志采集的主要入口,elasticsearch作为存储,kibana作为展示层。
尔达的架构方案
在 Erda 中,我们使用 fluent-bit 进行日志记录采集器:
概括
不难看出,无论是指标还是日志,data采集方案都比较简单明了,我们可以根据实际场景进行混搭。
但是,随着集群规模的增长和用户定义需求的增加,往往会出现以下困难:
对于这些问题,我们也在不断的探索和实践中,会在后续的文章中分享。 查看全部
云采集(指标采集方案介绍常见架构模式Daemons优采云采集器端agent(组图))
介绍:
众所周知,对于一个云原生的PaaS平台来说,在页面上查看日志和指标是最基本的功能。无论是日志、指标还是链接跟踪,基本上都分为三个模块:采集、存储和展示。
在这里,笔者将介绍云原生下常用指标&日志的采集解决方案,以及Erda作为云原生PaaS平台是如何实现的。
指标采集程序介绍常用架构模式1.守护进程
采集客户端代理通过Daemonset部署在各个节点上。这种模式下,指标通常由agent主动采集获取。常用代理有 telegraf、metricbeat、cadvisor 等。
应用场景:
2. 推拉
当我们需要采集程序的内部指标时,我们通常使用代理主动拉取指标或客户端主动推送指标。
应用场景:
那么,是推还是拉?
我认为这取决于实际的应用场景。比如对于短期任务,由于agent可能还没有启动采集,所以已经结束了,所以我们使用push方式;但是对于Web服务来说,这个问题就不存在了,pull的方式也可以减少用户端。负担。
开源解决方案简介
作为 CNCF 的 2 号毕业生,Prometheus 从诞生之初就基本成为了云原生尤其是 Kubernetes 的官方监控解决方案。
它其实是一个完整的解决方案,这里我们主要介绍它的采集功能。
和push&pull的方案基本一样,但是因为是丰富的exporter系统,所以基本可以采集在节点层面收录各种指标。
二达采用的架构方案
在Erda,目前的解决方案是通过二次打开telegraf,利用其丰富的采集插件,合并Daemonset和push-pull的解决方案。
日志采集程序介绍常见架构模式1.守护进程
如果容器中的应用程序的日志输出到stdout,容器在运行时会通过logging-driver模块将日志输出到其他媒体,一般是在本地磁盘上。例如,Docker 通常通过 json-driver docker/containers//*.log 文件将日志输出到 /var/log/。
对于这种场景,我们一般使用Daemonset方案,即在每个节点上部署一个采集器,通过读取机器上的日志文件来采集日志。
2. 边车
Daemonset 方案也有一些限制,例如,当应用程序日志输出到日志文件时,或者当您要为日志配置一些处理规则(例如,多行规则、日志提取规则)时。
这时候可以使用Sidecar方案,logging-agent和应用容器可以共享日志目录,主动上报给采集。
3. 主动举报
当然也可以主动上报日志(一般是通过厂商提供的SDK)。
常见的应用场景有:
开源解决方案简介

在业界,比较有名的是使用ELK作为日志解决方案,当然也是一个完整的解决方案。采集模块主要使用beats作为采集端,logstash作为日志采集的主要入口,elasticsearch作为存储,kibana作为展示层。
尔达的架构方案
在 Erda 中,我们使用 fluent-bit 进行日志记录采集器:
概括
不难看出,无论是指标还是日志,data采集方案都比较简单明了,我们可以根据实际场景进行混搭。
但是,随着集群规模的增长和用户定义需求的增加,往往会出现以下困难:
对于这些问题,我们也在不断的探索和实践中,会在后续的文章中分享。
云采集(几招如何防止IP本封锁的方法?教你几招方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-01-27 20:20
随着现在反爬机制越来越成熟,很多新的入口数据采集小白会直接把自己的本地IP挂在脚本上,很容易被服务器检测到并封杀。下面小编就教大家几个防止IP阻塞的小技巧:
方法一:使用代理IP
在连接外网IP即公网IP的程序上,我们可以部署一个适合爬虫软件运行的代理服务器(代理IP)。并使用循环替换的方式让代理IP访问想要采集数据的服务器网站服务器。这种方式的好处是对程序逻辑的改动很小,只需要在脚本中插入代理功能和连接代理IP的接口即可。并且根据对方的网站屏蔽规则,只需要添加更多的代理IP即可。另外,即使特定IP被封杀,也可以直接在代理服务器上注销该IP,程序逻辑不需要大的改动和改动。
方法二:冒充普通用户
因为目前的网站服务器主要是通过机器程序来识别,每个服务器程序都有自己的一套识别标准。只要尽可能地模拟常规用户行为,满足程序识别标准,就可以将系统不识别的程度降到最低。比如对于UserAgent,我们可以经常改变它;我们可以设置访问目标网站的服务器的时间间隔更长,访问时间可以设置为30分钟以上;我们也可以随机设置访问页面的顺序。
方法 3:了解 网站 阻止条件
目前,网站服务器的主流评价标准是指定IP在一定时间段内(约5分钟)的访问次数。因此,我们可以根据目标服务器站点的IP对采集的任务进行分组。一个IP在一定时间内发送的任务数,以避免被阻塞。当然,这种方法的前提是我们需要采集多个网站。如果只有采集一个网站,那么我们只能通过添加多个外部IP来实现。
总结:
1. 我们的UserAgent需要经常更换
2. 尝试模拟普通用户对 网站 的访问。
3. 尽量使用代理IP。 查看全部
云采集(几招如何防止IP本封锁的方法?教你几招方法)
随着现在反爬机制越来越成熟,很多新的入口数据采集小白会直接把自己的本地IP挂在脚本上,很容易被服务器检测到并封杀。下面小编就教大家几个防止IP阻塞的小技巧:
方法一:使用代理IP
在连接外网IP即公网IP的程序上,我们可以部署一个适合爬虫软件运行的代理服务器(代理IP)。并使用循环替换的方式让代理IP访问想要采集数据的服务器网站服务器。这种方式的好处是对程序逻辑的改动很小,只需要在脚本中插入代理功能和连接代理IP的接口即可。并且根据对方的网站屏蔽规则,只需要添加更多的代理IP即可。另外,即使特定IP被封杀,也可以直接在代理服务器上注销该IP,程序逻辑不需要大的改动和改动。
方法二:冒充普通用户
因为目前的网站服务器主要是通过机器程序来识别,每个服务器程序都有自己的一套识别标准。只要尽可能地模拟常规用户行为,满足程序识别标准,就可以将系统不识别的程度降到最低。比如对于UserAgent,我们可以经常改变它;我们可以设置访问目标网站的服务器的时间间隔更长,访问时间可以设置为30分钟以上;我们也可以随机设置访问页面的顺序。
方法 3:了解 网站 阻止条件
目前,网站服务器的主流评价标准是指定IP在一定时间段内(约5分钟)的访问次数。因此,我们可以根据目标服务器站点的IP对采集的任务进行分组。一个IP在一定时间内发送的任务数,以避免被阻塞。当然,这种方法的前提是我们需要采集多个网站。如果只有采集一个网站,那么我们只能通过添加多个外部IP来实现。
总结:
1. 我们的UserAgent需要经常更换
2. 尝试模拟普通用户对 网站 的访问。
3. 尽量使用代理IP。
云采集(前文:LoggingOperator的文章(图):且架构足够清晰)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-01-22 05:10
上一篇:Logging Operator 的文章 去年延迟了很久。原以为不会有进展,但最近在我的 KubeGems 项目中遇到需要处理日志可观察性部分的时候重新研究了一下。,因此是本系列的第三篇文章。
Logging Operator 是 BanzaiCloud 下云原生场景的开源 log采集 解决方案。2020年3月重构为v3版本,高效的fluentbit和丰富的底层插件flunetd,Logging Operator几乎完美适配kubernetes模式下的log采集场景。预计。去年偶然发现Rancher在2.5版本之后也采用了Logging Operator作为统一的日志解决方案,足以说明它正在被一些以Kubernetes为中心的管理平台所接受,并融入到内部(包括小白)。库贝宝石)。
作为前两篇文章的延续,本文主要讲小白最近使用Logging Operator解决用户需求的案例和感受,所以不打算花篇幅来描述它的架构和使用。有兴趣的同学可以通过小白的文章去Flip。
关于指标
在应用容器化的过程中,由于容器文件系统的临时性,开发者总是面临着将自己的日志文件放在磁盘上并输出stdout的困境。当研发将应用日志管理权交给平台时,意味着平台需要做的事情远比应用一对一复杂得多采集。在众多需求中,有一天一位 SRE 同学问:“我们可以看到阿里云日志采集的实时率,我们需要为此定制质量监控指标。” 这个问题也让我警醒。当我们在私有云上工作时,从平台外部观察 log采集 管道内部一直处于信息缺失的盲点。幸运的是,
图像
首先,我们定义日志的时候,可以让fluent bit(d)打开prometheus的采集
spec:
fluentdSpec:
metrics:
serviceMonitor: true
serviceMonitorConfig:
honorLabels: true // 打开honorLabels主要是为了保持组件原有的label,避免标签被覆盖。
fluentbitSpec:
metrics:
serviceMonitor: true
这里可以看到Logging Operator在采集端主要依赖ServiceMonitor进行服务发现。这里需要在集群内部运行 Prometheus Operator 来支持 CRD。如果集群内部没有改变资源类型,也可以使用Prometheus自带的服务发现机制完成指标发现和采集。
但是,这里只声明了 采集 端的指标条目。默认只收录 Fluent bit(d) 的基本内部运行状态。如果要进一步监控日志率,则需要使用 Flunetd。早些年在谷歌的GKE采集器上还是用Fluentd做日志的时候,无意中看到的一个Prometheus插件配置(故意抄袭)引起了我的兴趣
@type prometheus
type counter
name logging_entry_count
desc Total number of log entries generated by either application containers or system components
container: $.kubernetes.container_name
pod: $.kubernetes.pod_name
该规则将匹配所有进入 Fluentd 的日志,并进入 Prometheus 的过滤器进行计数处理。统计信息被命名为logging_entry_count,日志中的一些元数据信息作为指标的标签来区分不同的容器。
由于需要解析日志的kubernetes元数据,所以需要Fluentd的kubernetes-metadata-filter插件来提取容器元数据。在 Logging Operator 中,Kubernetes 的元数据在 Fluent Bit 中解析,无需在 Fluentd 中添加此插件。
尽管 Google GKE 现在也将日志 采集器 替换为 Fluent Bit,但上述配置在 Logging Operator 中并没有“过时”。结合之前的经验,我们可以在租户的日志采集器(Flow / ClusterFlow)中引入Prometheus插件来分析日志率。其中最简单的做法如下:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: default
namespace: demo
spec:
- prometheus:
labels:
container: $.kubernetes.container_name
namespace: $.kubernetes.namespace_name
node: $.kubernetes.host
pod: $.kubernetes.pod_name
metrics:
- desc: Total number of log entries generated by either application containers
or system components
name: logging_entry_count
type: counter
globalOutputRefs:
- containers-console
match:
- select:
labels:
what.you.want: collect
上述指标存入 Prometheus 后,我们可以通过这条语句找出当前集群下日志采集器的应用率
sum by (pod) (rate(logging_entry_count[1m]))
此时,如果云平台是基于多租户多环境的架构,你甚至可以按租户环境和租户级别聚合日志率。
文件
以上只是对日志整体速率的监控。如果我们需要统计日志中的具体内容或者日志的字节数,需要结合其他插件。目前Logging Operator支持的插件远不如Fluentd丰富,但是我们可以参考官方文档编写需要的插件并集成到Operator中。记录操作员开发人员手册
对于日志组件内部的监控和告警,Logging Operator 有自己的一套规则,可以在日志 CR 中启用。
spec:
fluentbitSpec:
metrics:
prometheusRules: true
fluentdSpec:
metrics:
prometheusRules: true
这里的prometheusRules也是Prometheus Operator管理的资源。如果集群中没有这样的资源类型,可以手动配置Prometheus的Rules
回到原来的问题,如果需要用日志的采集率作为应用的量化指标,可以使用logging_entry_count。
关于抽样
大多数情况下,日志架构不应该对业务日志采取一些不可控的策略,导致应用日志不完整,比如采样。显然,我也不建议您在现有架构中启用此功能。然而,有时,或者当一些魔术师无法有效控制“狂野之力”而疯狂输出时,平台可以为这种漂亮的应用程序采样解决方案。毕竟,保证整个日志通道的可用性是平台的第一要务。要考虑的因素。
Logging Operator 在日志采样中使用 Throttle 插件速率限制器。一句话总结这个插件,它为每个进入过滤器日志的管道引入了漏桶算法,允许它丢弃超过速率限制的日志。
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: default
namespace: demo
spec:
- throttle:
group_bucket_limit: 3000
group_bucket_period_s: 10
group_key: kubernetes.pod_name
globalOutputRefs:
- containers-console
match:
- select:
labels:
what.you.want: collect
日志的采样率由公式 group_bucket_limit / group_bucket_period_s 计算得出。当 group_key 中的 log rate 超过该值时,后续的日志将被丢弃。
由于 Throttle 没有使用令牌桶算法,所以不会有突发处理日志量 采集 的突发情况。
关于日志放置
如前所述,对于所有基于容器的应用程序,日志记录的最佳实践是将日志定向到 stdout 和 stderr,但并非所有“魔术师”都遵循此约定,将文件记录到磁盘仍然是当今大多数研发的选择。. 虽然理论上容器的标准(错误)输出也是将日志流重定位到/var/log/containers下的日志文件,但还是受限于运行时配置或其他硬盘原因造成的不可控因素。
对于日志放置的场景,目前业界还没有统一的解决方案,但总结起来,其实有两种实现方式:
此方案是将日志采集器跟随应用容器一同运行在pod 当中,通过 volume 共享日志路径的方式采集。常见的是方式是为 kubernetes 开发一套单独的控制器,并采用`MutatingWebhook`在pod 启动阶段将 sidecar 的信息注入。
sidecar 的方案优势在于为每个应用的 sidecar 配置相对独立,但劣势除占用过多资源外,**采集器的更新迭代需跟随应用的生命周期**,对于持续维护不太优雅。
此方案将日志采集器以 `DaemonSet` 的方式运行在每个 Node 当中,然后在操作系统层面进行集中采集。通常此方案需要平台的研发需要做一定路径策略,将固定 `hostpath`的 vulume 挂载给容器用于应用日志落盘时使用。除此之外,我们知道所有 Kubernetes 默认的存储类型或者第三方的遵循 CSI 标准的存储,都会将Volume挂载到`/var/lib/kubelet/pods//volumes/kubernetes.io~//mount`目录下,所以对于 node agent 更加优雅一点的方案是在 node agent 中赋予调用 Kubernetes API 的权限,让其知晓被采集容器日志映射在主机下的路径。
node agent的方案的优势在于配置集中管理,采集器跟应用容器解耦,互不影响。缺点在于采集器存在吞吐不足的风险。
可以看出,上述两种方案中,都与Logging Operator无关。确实,目前的社区并没有针对这种场景的有效解决方案,但是按照它的思路,我们可以将日志文件转换成标准(错误)输出流,变相处理这个问题。
用tail给出一个直观的例子来说明上面的方案。
...
containers:
- args:
- -F
- /path/to/your/log/file.log
command:
- tail
image: busybox
name: stream-log-file-[name]
volumeMounts:
- mountPath: /path/to/your/log
name: mounted-log
...
虽然tail是一种极其简单粗暴的方法,无法解决日志轮转等问题,但它确实为Logging Operator在日志放置场景下提供了一种新的解决方案。虽然看起来和 sidecar 一样,但最大的不同是这个方案无缝兼容了 Logging Operator 现有的日志管道,日志经过 采集 后仍然可以在 flow 阶段进行处理。
总结
从自动化运维的角度来看,Logging Operator 确实有效解决了 Kubernetes 场景下复杂的日志架构和应用日志采集 问题,虽然目前对放置日志的支持还不够全面。但随着连接用户数量的增长,未来可能会有更好的解决当前问题的方法。然而,它确实是目前最好的云原生日志架构之一。 查看全部
云采集(前文:LoggingOperator的文章(图):且架构足够清晰)
上一篇:Logging Operator 的文章 去年延迟了很久。原以为不会有进展,但最近在我的 KubeGems 项目中遇到需要处理日志可观察性部分的时候重新研究了一下。,因此是本系列的第三篇文章。
Logging Operator 是 BanzaiCloud 下云原生场景的开源 log采集 解决方案。2020年3月重构为v3版本,高效的fluentbit和丰富的底层插件flunetd,Logging Operator几乎完美适配kubernetes模式下的log采集场景。预计。去年偶然发现Rancher在2.5版本之后也采用了Logging Operator作为统一的日志解决方案,足以说明它正在被一些以Kubernetes为中心的管理平台所接受,并融入到内部(包括小白)。库贝宝石)。
作为前两篇文章的延续,本文主要讲小白最近使用Logging Operator解决用户需求的案例和感受,所以不打算花篇幅来描述它的架构和使用。有兴趣的同学可以通过小白的文章去Flip。
关于指标
在应用容器化的过程中,由于容器文件系统的临时性,开发者总是面临着将自己的日志文件放在磁盘上并输出stdout的困境。当研发将应用日志管理权交给平台时,意味着平台需要做的事情远比应用一对一复杂得多采集。在众多需求中,有一天一位 SRE 同学问:“我们可以看到阿里云日志采集的实时率,我们需要为此定制质量监控指标。” 这个问题也让我警醒。当我们在私有云上工作时,从平台外部观察 log采集 管道内部一直处于信息缺失的盲点。幸运的是,
图像
首先,我们定义日志的时候,可以让fluent bit(d)打开prometheus的采集
spec:
fluentdSpec:
metrics:
serviceMonitor: true
serviceMonitorConfig:
honorLabels: true // 打开honorLabels主要是为了保持组件原有的label,避免标签被覆盖。
fluentbitSpec:
metrics:
serviceMonitor: true
这里可以看到Logging Operator在采集端主要依赖ServiceMonitor进行服务发现。这里需要在集群内部运行 Prometheus Operator 来支持 CRD。如果集群内部没有改变资源类型,也可以使用Prometheus自带的服务发现机制完成指标发现和采集。
但是,这里只声明了 采集 端的指标条目。默认只收录 Fluent bit(d) 的基本内部运行状态。如果要进一步监控日志率,则需要使用 Flunetd。早些年在谷歌的GKE采集器上还是用Fluentd做日志的时候,无意中看到的一个Prometheus插件配置(故意抄袭)引起了我的兴趣
@type prometheus
type counter
name logging_entry_count
desc Total number of log entries generated by either application containers or system components
container: $.kubernetes.container_name
pod: $.kubernetes.pod_name
该规则将匹配所有进入 Fluentd 的日志,并进入 Prometheus 的过滤器进行计数处理。统计信息被命名为logging_entry_count,日志中的一些元数据信息作为指标的标签来区分不同的容器。
由于需要解析日志的kubernetes元数据,所以需要Fluentd的kubernetes-metadata-filter插件来提取容器元数据。在 Logging Operator 中,Kubernetes 的元数据在 Fluent Bit 中解析,无需在 Fluentd 中添加此插件。
尽管 Google GKE 现在也将日志 采集器 替换为 Fluent Bit,但上述配置在 Logging Operator 中并没有“过时”。结合之前的经验,我们可以在租户的日志采集器(Flow / ClusterFlow)中引入Prometheus插件来分析日志率。其中最简单的做法如下:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: default
namespace: demo
spec:
- prometheus:
labels:
container: $.kubernetes.container_name
namespace: $.kubernetes.namespace_name
node: $.kubernetes.host
pod: $.kubernetes.pod_name
metrics:
- desc: Total number of log entries generated by either application containers
or system components
name: logging_entry_count
type: counter
globalOutputRefs:
- containers-console
match:
- select:
labels:
what.you.want: collect
上述指标存入 Prometheus 后,我们可以通过这条语句找出当前集群下日志采集器的应用率
sum by (pod) (rate(logging_entry_count[1m]))
此时,如果云平台是基于多租户多环境的架构,你甚至可以按租户环境和租户级别聚合日志率。
文件
以上只是对日志整体速率的监控。如果我们需要统计日志中的具体内容或者日志的字节数,需要结合其他插件。目前Logging Operator支持的插件远不如Fluentd丰富,但是我们可以参考官方文档编写需要的插件并集成到Operator中。记录操作员开发人员手册
对于日志组件内部的监控和告警,Logging Operator 有自己的一套规则,可以在日志 CR 中启用。
spec:
fluentbitSpec:
metrics:
prometheusRules: true
fluentdSpec:
metrics:
prometheusRules: true
这里的prometheusRules也是Prometheus Operator管理的资源。如果集群中没有这样的资源类型,可以手动配置Prometheus的Rules
回到原来的问题,如果需要用日志的采集率作为应用的量化指标,可以使用logging_entry_count。
关于抽样
大多数情况下,日志架构不应该对业务日志采取一些不可控的策略,导致应用日志不完整,比如采样。显然,我也不建议您在现有架构中启用此功能。然而,有时,或者当一些魔术师无法有效控制“狂野之力”而疯狂输出时,平台可以为这种漂亮的应用程序采样解决方案。毕竟,保证整个日志通道的可用性是平台的第一要务。要考虑的因素。
Logging Operator 在日志采样中使用 Throttle 插件速率限制器。一句话总结这个插件,它为每个进入过滤器日志的管道引入了漏桶算法,允许它丢弃超过速率限制的日志。
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: default
namespace: demo
spec:
- throttle:
group_bucket_limit: 3000
group_bucket_period_s: 10
group_key: kubernetes.pod_name
globalOutputRefs:
- containers-console
match:
- select:
labels:
what.you.want: collect
日志的采样率由公式 group_bucket_limit / group_bucket_period_s 计算得出。当 group_key 中的 log rate 超过该值时,后续的日志将被丢弃。
由于 Throttle 没有使用令牌桶算法,所以不会有突发处理日志量 采集 的突发情况。
关于日志放置
如前所述,对于所有基于容器的应用程序,日志记录的最佳实践是将日志定向到 stdout 和 stderr,但并非所有“魔术师”都遵循此约定,将文件记录到磁盘仍然是当今大多数研发的选择。. 虽然理论上容器的标准(错误)输出也是将日志流重定位到/var/log/containers下的日志文件,但还是受限于运行时配置或其他硬盘原因造成的不可控因素。
对于日志放置的场景,目前业界还没有统一的解决方案,但总结起来,其实有两种实现方式:
此方案是将日志采集器跟随应用容器一同运行在pod 当中,通过 volume 共享日志路径的方式采集。常见的是方式是为 kubernetes 开发一套单独的控制器,并采用`MutatingWebhook`在pod 启动阶段将 sidecar 的信息注入。
sidecar 的方案优势在于为每个应用的 sidecar 配置相对独立,但劣势除占用过多资源外,**采集器的更新迭代需跟随应用的生命周期**,对于持续维护不太优雅。
此方案将日志采集器以 `DaemonSet` 的方式运行在每个 Node 当中,然后在操作系统层面进行集中采集。通常此方案需要平台的研发需要做一定路径策略,将固定 `hostpath`的 vulume 挂载给容器用于应用日志落盘时使用。除此之外,我们知道所有 Kubernetes 默认的存储类型或者第三方的遵循 CSI 标准的存储,都会将Volume挂载到`/var/lib/kubelet/pods//volumes/kubernetes.io~//mount`目录下,所以对于 node agent 更加优雅一点的方案是在 node agent 中赋予调用 Kubernetes API 的权限,让其知晓被采集容器日志映射在主机下的路径。
node agent的方案的优势在于配置集中管理,采集器跟应用容器解耦,互不影响。缺点在于采集器存在吞吐不足的风险。
可以看出,上述两种方案中,都与Logging Operator无关。确实,目前的社区并没有针对这种场景的有效解决方案,但是按照它的思路,我们可以将日志文件转换成标准(错误)输出流,变相处理这个问题。
用tail给出一个直观的例子来说明上面的方案。
...
containers:
- args:
- -F
- /path/to/your/log/file.log
command:
- tail
image: busybox
name: stream-log-file-[name]
volumeMounts:
- mountPath: /path/to/your/log
name: mounted-log
...
虽然tail是一种极其简单粗暴的方法,无法解决日志轮转等问题,但它确实为Logging Operator在日志放置场景下提供了一种新的解决方案。虽然看起来和 sidecar 一样,但最大的不同是这个方案无缝兼容了 Logging Operator 现有的日志管道,日志经过 采集 后仍然可以在 flow 阶段进行处理。
总结
从自动化运维的角度来看,Logging Operator 确实有效解决了 Kubernetes 场景下复杂的日志架构和应用日志采集 问题,虽然目前对放置日志的支持还不够全面。但随着连接用户数量的增长,未来可能会有更好的解决当前问题的方法。然而,它确实是目前最好的云原生日志架构之一。
云采集(为什么分布式数据采集软件能够收到互联网发展的青睐呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-01-19 13:23
为什么分布式数据采集软件受到互联网发展的青睐?在大数据时代的发展中,大数据在当前企业发展、政府决策和社会动态分析等方面发挥着重要作用。如何实现大规模快速采集数据成为焦点。
与传统数据采集软件相比,分布式数据采集软件解决了互联网数据采集海量存储和分析不便的问题。存在不统一、系统扩展性能低、维护困难等诸多难题。
分布式数据采集软件有什么优势?
1.海量数据采集
实现多数据源、大数据采集、高实时性采集的需求,同时具有高扩展性和定制化服务的特点。
2.云采集
大量云服务器支持,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活贴合业务场景,助您提升采集效率,并确保数据的及时性。
3.快速响应:
分布式大数据采集系统,具备数据分析、日志分析、商业智能分析、客户营销、大规模索引等服务,采集速度快,操作方便。
4.支持自助登录采集
只需要配置目标网站的账号密码,就可以使用该模块采集登录数据。同时具有采集cookie自定义功能。首次登录后可自动记住cookie,免去多次输入密码的繁琐,支持网站的更多采集。
分布式数据采集,数道云大数据,帮助互联网上的政企、金融、银行、教育、高校等建立易操作的解决方案,解决行业当前面临的数据问题< @采集问题。 查看全部
云采集(为什么分布式数据采集软件能够收到互联网发展的青睐呢?)
为什么分布式数据采集软件受到互联网发展的青睐?在大数据时代的发展中,大数据在当前企业发展、政府决策和社会动态分析等方面发挥着重要作用。如何实现大规模快速采集数据成为焦点。
与传统数据采集软件相比,分布式数据采集软件解决了互联网数据采集海量存储和分析不便的问题。存在不统一、系统扩展性能低、维护困难等诸多难题。
分布式数据采集软件有什么优势?
1.海量数据采集
实现多数据源、大数据采集、高实时性采集的需求,同时具有高扩展性和定制化服务的特点。
2.云采集
大量云服务器支持,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活贴合业务场景,助您提升采集效率,并确保数据的及时性。
3.快速响应:
分布式大数据采集系统,具备数据分析、日志分析、商业智能分析、客户营销、大规模索引等服务,采集速度快,操作方便。
4.支持自助登录采集
只需要配置目标网站的账号密码,就可以使用该模块采集登录数据。同时具有采集cookie自定义功能。首次登录后可自动记住cookie,免去多次输入密码的繁琐,支持网站的更多采集。
分布式数据采集,数道云大数据,帮助互联网上的政企、金融、银行、教育、高校等建立易操作的解决方案,解决行业当前面临的数据问题< @采集问题。
云采集(指标采集方案介绍常见架构模式Daemons优采云采集器端agent(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-01-16 07:03
介绍:
众所周知,对于一个云原生的PaaS平台来说,在页面上查看日志和指标是最基本的功能。无论是日志、指标还是链接跟踪,基本上都分为三个模块:采集、存储和展示。
在这里,笔者将介绍云原生下常用指标&日志的采集解决方案,以及Erda作为云原生PaaS平台是如何实现的。
指标采集程序介绍常用架构模式1.守护进程
采集客户端代理通过Daemonset部署在各个节点上。这种模式下,agent通常会主动采集来获取指标。常用代理有 telegraf、metricbeat、cadvisor 等。
应用场景:
2. 推拉
当我们需要采集程序的内部指标时,我们通常使用代理主动拉取指标或客户端主动推送指标。
应用场景:
那么,是推还是拉?
我认为这取决于实际的应用场景。比如对于短期任务,由于agent可能还没有启动采集,所以已经结束了,所以我们使用push方式;但是对于Web服务来说,这个问题就不存在了,pull的方式也可以减少用户端。负担。
开源解决方案简介
作为 CNCF 的 2 号毕业生,Prometheus 从诞生之初就基本成为了云原生尤其是 Kubernetes 的官方监控解决方案。
它其实是一个完整的解决方案,这里我们主要介绍它的采集功能。
和push&pull的方案基本一样,但是因为是丰富的exporter系统,所以基本可以采集在节点层面收录各种指标。
二达采用的架构方案
在Erda,目前的解决方案是通过二次打开telegraf,利用其丰富的采集插件,合并Daemonset和push-pull的解决方案。
日志采集程序介绍常见架构模式1.守护进程
如果容器中的应用程序的日志输出到stdout,容器在运行时会通过logging-driver模块将日志输出到其他媒体,一般是在本地磁盘上。例如,Docker 通常通过 json-driver docker/containers//*.log 文件将日志输出到 /var/log/。
对于这种场景,我们一般使用Daemonset方案,即在每个节点上部署一个采集器,通过读取机器上的日志文件来采集日志。
2. 边车
Daemonset 方案也有一些限制,例如,当应用程序日志输出到日志文件时,或者当您要为日志配置一些处理规则(例如,多行规则、日志提取规则)时。
这时候可以使用Sidecar方案,logging-agent和应用容器可以共享日志目录,主动上报给采集。
3. 主动举报
当然也可以主动上报日志(一般是通过厂商提供的SDK)。
常见的应用场景有:
开源解决方案简介
在业界,比较有名的是使用ELK作为日志解决方案,当然也是一个完整的解决方案。采集模块主要使用beats作为采集端,logstash作为日志采集的主要入口,elasticsearch作为存储,kibana作为展示层。
尔达的架构方案
在 Erda 中,我们使用 fluent-bit 进行日志记录采集器:
概括
不难看出,无论是指标还是日志,data采集方案都比较简单明了,我们可以根据实际场景进行混搭。但是,随着集群规模的增长和用户定义需求的增加,往往会出现以下困难:
对于这些问题,我们也在不断的探索和实践中,会在后续的文章中分享。 查看全部
云采集(指标采集方案介绍常见架构模式Daemons优采云采集器端agent(组图))
介绍:
众所周知,对于一个云原生的PaaS平台来说,在页面上查看日志和指标是最基本的功能。无论是日志、指标还是链接跟踪,基本上都分为三个模块:采集、存储和展示。
在这里,笔者将介绍云原生下常用指标&日志的采集解决方案,以及Erda作为云原生PaaS平台是如何实现的。
指标采集程序介绍常用架构模式1.守护进程
采集客户端代理通过Daemonset部署在各个节点上。这种模式下,agent通常会主动采集来获取指标。常用代理有 telegraf、metricbeat、cadvisor 等。
应用场景:
2. 推拉
当我们需要采集程序的内部指标时,我们通常使用代理主动拉取指标或客户端主动推送指标。
应用场景:
那么,是推还是拉?
我认为这取决于实际的应用场景。比如对于短期任务,由于agent可能还没有启动采集,所以已经结束了,所以我们使用push方式;但是对于Web服务来说,这个问题就不存在了,pull的方式也可以减少用户端。负担。
开源解决方案简介
作为 CNCF 的 2 号毕业生,Prometheus 从诞生之初就基本成为了云原生尤其是 Kubernetes 的官方监控解决方案。
它其实是一个完整的解决方案,这里我们主要介绍它的采集功能。
和push&pull的方案基本一样,但是因为是丰富的exporter系统,所以基本可以采集在节点层面收录各种指标。
二达采用的架构方案
在Erda,目前的解决方案是通过二次打开telegraf,利用其丰富的采集插件,合并Daemonset和push-pull的解决方案。
日志采集程序介绍常见架构模式1.守护进程
如果容器中的应用程序的日志输出到stdout,容器在运行时会通过logging-driver模块将日志输出到其他媒体,一般是在本地磁盘上。例如,Docker 通常通过 json-driver docker/containers//*.log 文件将日志输出到 /var/log/。
对于这种场景,我们一般使用Daemonset方案,即在每个节点上部署一个采集器,通过读取机器上的日志文件来采集日志。
2. 边车
Daemonset 方案也有一些限制,例如,当应用程序日志输出到日志文件时,或者当您要为日志配置一些处理规则(例如,多行规则、日志提取规则)时。
这时候可以使用Sidecar方案,logging-agent和应用容器可以共享日志目录,主动上报给采集。
3. 主动举报
当然也可以主动上报日志(一般是通过厂商提供的SDK)。
常见的应用场景有:
开源解决方案简介
在业界,比较有名的是使用ELK作为日志解决方案,当然也是一个完整的解决方案。采集模块主要使用beats作为采集端,logstash作为日志采集的主要入口,elasticsearch作为存储,kibana作为展示层。
尔达的架构方案
在 Erda 中,我们使用 fluent-bit 进行日志记录采集器:
概括
不难看出,无论是指标还是日志,data采集方案都比较简单明了,我们可以根据实际场景进行混搭。但是,随着集群规模的增长和用户定义需求的增加,往往会出现以下困难:
对于这些问题,我们也在不断的探索和实践中,会在后续的文章中分享。
云采集(指标采集方案介绍常见架构模式Daemons优采云采集器端agent(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-15 08:18
介绍:
众所周知,对于一个云原生的PaaS平台来说,在页面上查看日志和指标是最基本的功能。无论是日志、指标还是链接跟踪,基本上都分为三个模块:采集、存储和展示。
在这里,笔者将介绍云原生下常用指标&日志的采集解决方案,以及Erda作为云原生PaaS平台是如何实现的。
指标采集程序介绍常用架构模式1.守护进程
采集客户端代理通过Daemonset部署在各个节点上。这种模式下,指标通常由agent主动采集获取。常用代理有 telegraf、metricbeat、cadvisor 等。
应用场景:
2. 推拉
当我们需要采集程序的内部指标时,我们通常使用代理主动拉取指标或客户端主动推送指标。
应用场景:
那么,是推还是拉?
我认为这取决于实际的应用场景。比如对于短期任务,由于agent可能还没有启动采集,所以已经结束了,所以我们使用push方式;但是对于Web服务来说,这个问题就不存在了,pull的方式也可以减少用户端。负担。
开源解决方案简介
作为 CNCF 的 2 号毕业生,Prometheus 从诞生之初就基本成为了云原生尤其是 Kubernetes 的官方监控解决方案。
它其实是一个完整的解决方案,这里我们主要介绍它的采集功能。
和push&pull的方案基本一样,但是因为是丰富的exporter系统,所以基本可以采集在节点层面收录各种指标。
二达采用的架构方案
在Erda,目前的解决方案是通过二次打开telegraf,利用其丰富的采集插件,合并Daemonset和push-pull的解决方案。
日志采集程序介绍常见架构模式1.守护进程
如果容器中应用的日志输出到stdout,容器运行时会通过logging-driver模块输出到其他媒体,一般是本地磁盘。比如Docker通常通过json-driver docker/containers//*.log文件将日志输出到/var/log/。
对于这种场景,我们一般使用Daemonset方案,即在每个节点上部署一个采集器,通过读取机器上的日志文件来记录采集日志。
2. 边车
Daemonset 方案也有一些限制,例如,当应用程序日志输出到日志文件时,或者当您要为日志配置一些处理规则(例如,多行规则、日志提取规则)时。
这时候可以使用Sidecar方案,logging-agent和应用容器可以共享日志目录,主动上报给采集。
3. 主动举报
当然也可以主动上报日志(一般是通过厂商提供的SDK)。
常见的应用场景有:
开源解决方案简介
在业界,比较有名的是使用ELK作为日志解决方案,当然也是一个完整的解决方案。采集模块主要使用beats作为采集端,logstash作为日志采集的主要入口,elasticsearch作为存储,kibana作为展示层。
尔达的建筑
在 Erda 中,我们使用 fluent-bit 进行日志记录采集器:
概括
不难看出,无论是指标还是日志,data采集方案都比较简单明了,我们可以根据实际场景进行混搭。但是,随着集群规模的增长和用户定义需求的增加,往往会出现以下困难:
对于这些问题,我们也在不断的探索和实践中,会在后续的文章中分享。 查看全部
云采集(指标采集方案介绍常见架构模式Daemons优采云采集器端agent(组图))
介绍:
众所周知,对于一个云原生的PaaS平台来说,在页面上查看日志和指标是最基本的功能。无论是日志、指标还是链接跟踪,基本上都分为三个模块:采集、存储和展示。
在这里,笔者将介绍云原生下常用指标&日志的采集解决方案,以及Erda作为云原生PaaS平台是如何实现的。
指标采集程序介绍常用架构模式1.守护进程
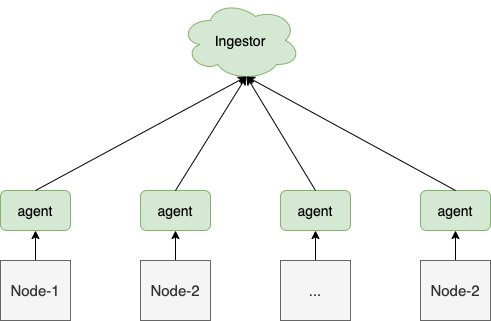
采集客户端代理通过Daemonset部署在各个节点上。这种模式下,指标通常由agent主动采集获取。常用代理有 telegraf、metricbeat、cadvisor 等。
应用场景:
2. 推拉
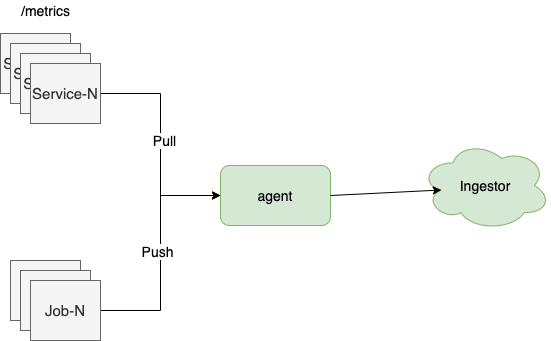
当我们需要采集程序的内部指标时,我们通常使用代理主动拉取指标或客户端主动推送指标。
应用场景:
那么,是推还是拉?
我认为这取决于实际的应用场景。比如对于短期任务,由于agent可能还没有启动采集,所以已经结束了,所以我们使用push方式;但是对于Web服务来说,这个问题就不存在了,pull的方式也可以减少用户端。负担。
开源解决方案简介

作为 CNCF 的 2 号毕业生,Prometheus 从诞生之初就基本成为了云原生尤其是 Kubernetes 的官方监控解决方案。
它其实是一个完整的解决方案,这里我们主要介绍它的采集功能。
和push&pull的方案基本一样,但是因为是丰富的exporter系统,所以基本可以采集在节点层面收录各种指标。
二达采用的架构方案
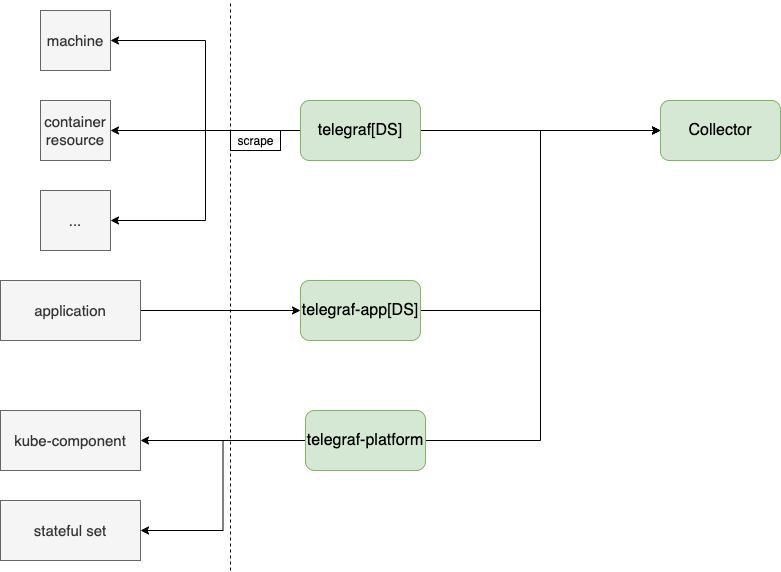
在Erda,目前的解决方案是通过二次打开telegraf,利用其丰富的采集插件,合并Daemonset和push-pull的解决方案。
日志采集程序介绍常见架构模式1.守护进程

如果容器中应用的日志输出到stdout,容器运行时会通过logging-driver模块输出到其他媒体,一般是本地磁盘。比如Docker通常通过json-driver docker/containers//*.log文件将日志输出到/var/log/。
对于这种场景,我们一般使用Daemonset方案,即在每个节点上部署一个采集器,通过读取机器上的日志文件来记录采集日志。
2. 边车
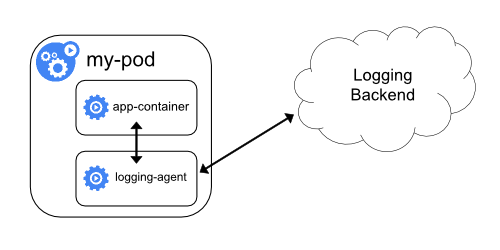
Daemonset 方案也有一些限制,例如,当应用程序日志输出到日志文件时,或者当您要为日志配置一些处理规则(例如,多行规则、日志提取规则)时。
这时候可以使用Sidecar方案,logging-agent和应用容器可以共享日志目录,主动上报给采集。
3. 主动举报
当然也可以主动上报日志(一般是通过厂商提供的SDK)。
常见的应用场景有:
开源解决方案简介

在业界,比较有名的是使用ELK作为日志解决方案,当然也是一个完整的解决方案。采集模块主要使用beats作为采集端,logstash作为日志采集的主要入口,elasticsearch作为存储,kibana作为展示层。
尔达的建筑
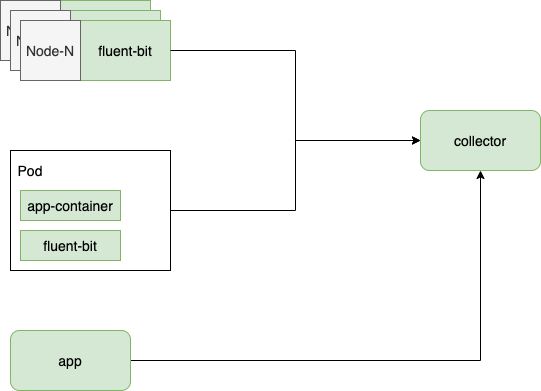
在 Erda 中,我们使用 fluent-bit 进行日志记录采集器:
概括
不难看出,无论是指标还是日志,data采集方案都比较简单明了,我们可以根据实际场景进行混搭。但是,随着集群规模的增长和用户定义需求的增加,往往会出现以下困难:
对于这些问题,我们也在不断的探索和实践中,会在后续的文章中分享。
优采云云采集监控预警功能上线!
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-05-03 13:09
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。 查看全部
优采云云采集监控预警功能上线!
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。
优采云云采集监控预警功能上线!
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2022-05-03 05:34
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。 查看全部
优采云云采集监控预警功能上线!
经过多个版本内测,优采云云采集监控预警功能已经正式上线!
优采云【云采集监控预警】聚焦监控近24小时云采集的任务概况、云节点配置情况以及问题预警功能,为用户提供云采集任务实时动态,并提供微信通知预警功能,帮助用户迅速发现云采集过程中出现的各类问题并及时解决。
【云采集监控预警】页面入口
【云采集监控预警】页面展示
1.任务概况
实时监控各类任务和子任务运行情况数据,帮助用户了解任务运行中资源的分配情况,协助进行资源优化。
点击数量可以进入任务列表页并查看任务详情。
2.监控预警
监控近24小时内的任务,及时发现云采集过程中出现的各类问题。
2.1功能共包含9个预警指标,包括【已完成采集数量为0】、【超过10分钟采集数量为0】、【数据重复率 ≥ 20%】等,指标分为高、中、低三个预警等级,用户可以根据自己的实际需求调整预警指标参数及风险等级。
2.2在单个监控预警指标中,可以点击指标右上角点击【...】按钮选择打开【预警开关】。
2.3进入【预警设置】界面自定义设置预警指标,更高预警等级,还可以绑定【微信通知】实时获取云采集监控预警通知,并指定某个任务或任务组进行监控预警。
2.4微信通知界面
3.数据看板
查看实时/每日/近7天/近30天采集速度,跟进对比采集情况,从数据波动情况分析问题所在。
3.1 可查看当前采集速度(分钟级),获取最新采集情况,可以切换选择实时或者24小时;
3.2 可查看今日及昨日任务采集数量对比,同时可筛选任务组,查看任务组内的采集量情况;
3.3 可查看近7天/15天/30天的每日采集数据量,分析对比近期采集量趋势。
目前优采云【云采集监控预警】功能处于试运营阶段,所有旗舰版及以上版本的用户均可以免费体验,如果您在使用过程中有任何意见或建议,欢迎联系我们的客服反馈。
智政云上新啦!云采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-04-30 22:27
智政云-专业SaaS云服务平台自开通运营以来,受到了用户的广泛好评,网站普查检测、云搜索、信息系统安全等级保护成为了2021年度云服务销量榜前三强。
2022年智政云上新服务了!云采集。下面我带领大家详细了解一下云采集服务的功能及特色:
一、采集方式多样
1.爬虫采集
云采集平台采用的核心技术是分布式网页爬虫系统。分布式爬虫系统采取弹性可扩展的互联网架构体系。使用python爬虫技术,支持css、xpath等不同选择器进行数据提取。
系统将网页的非结构化信息采集后,自动提取网页属性信息进行结构化的处理,字段提取(包括站点、来源、日期、标题、内容、图片、附件等)。
2.库表同步
在授权的情况下,可直接与数据库对接,将数据同步到平台中,相对于爬虫采集服务优势在更稳定、更快、更精准。
3.文件导入
支持将独立文件中承载的数据直接导入平台,支持多种格式,比如Excel文件、Access文件、CSV文件等。
二、易用可用好用
1.可视化配置:采集及分布式服务运行参数可视化配置。
2.定时任务:用户可以根据自身需求合理设置个性化定时计划任务,
3.状态实时监控:分布式服务与系统间建立长连接通道,平台可以实时感知分布式服务的状态以及采集任务的进度。
4.获得服务成本低:无须考虑系统部署、安全防护等方面的费用投入。以年服务费的形式就可以以非常优惠的费用获得采集服务。
同时,我们也欢迎其它厂商加入智政云服务平台,为用户提供更多实用的技术服务,更多云服务请访问:(专业SaaS云服务平台)。
智政科技-大数据与智能应用服务提供商
智政科技秉承“服务至上”的经营理念,坚持“大爱、开放、用心、团队”的核心价值观,以用户需求为导向,视用户口碑为生命,聚焦互联网+,与时俱进,持续创新,成为用户首选的“互联网+”大数据与智能应用服务提供商。
查看全部
智政云上新啦!云采集
智政云-专业SaaS云服务平台自开通运营以来,受到了用户的广泛好评,网站普查检测、云搜索、信息系统安全等级保护成为了2021年度云服务销量榜前三强。
2022年智政云上新服务了!云采集。下面我带领大家详细了解一下云采集服务的功能及特色:
一、采集方式多样
1.爬虫采集
云采集平台采用的核心技术是分布式网页爬虫系统。分布式爬虫系统采取弹性可扩展的互联网架构体系。使用python爬虫技术,支持css、xpath等不同选择器进行数据提取。
系统将网页的非结构化信息采集后,自动提取网页属性信息进行结构化的处理,字段提取(包括站点、来源、日期、标题、内容、图片、附件等)。
2.库表同步
在授权的情况下,可直接与数据库对接,将数据同步到平台中,相对于爬虫采集服务优势在更稳定、更快、更精准。
3.文件导入
支持将独立文件中承载的数据直接导入平台,支持多种格式,比如Excel文件、Access文件、CSV文件等。
二、易用可用好用
1.可视化配置:采集及分布式服务运行参数可视化配置。
2.定时任务:用户可以根据自身需求合理设置个性化定时计划任务,
3.状态实时监控:分布式服务与系统间建立长连接通道,平台可以实时感知分布式服务的状态以及采集任务的进度。
4.获得服务成本低:无须考虑系统部署、安全防护等方面的费用投入。以年服务费的形式就可以以非常优惠的费用获得采集服务。
同时,我们也欢迎其它厂商加入智政云服务平台,为用户提供更多实用的技术服务,更多云服务请访问:(专业SaaS云服务平台)。
智政科技-大数据与智能应用服务提供商
智政科技秉承“服务至上”的经营理念,坚持“大爱、开放、用心、团队”的核心价值观,以用户需求为导向,视用户口碑为生命,聚焦互联网+,与时俱进,持续创新,成为用户首选的“互联网+”大数据与智能应用服务提供商。
云采集(【技术公开】一种基于云平台智慧校园学生学生信息管理系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-04-20 10:33
本发明专利技术公开了一种基于云平台的智慧校园学生信息管理系统,涉及信息管理系统领域,包括中央管理模块,中央管理模块的输入端与信息电连接。 采集模块,中央管理模块的输出端与门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器模块电连接。本发明专利技术通过中央管理模块、信息采集模块、图书馆模块、体育馆模块、门禁模块、重要实验室模块、摄像头模块和指纹信息采集模块实现学生信息化。管理系统可与图书馆、体育馆、门禁及重要实验室联系。学生入场时无需携带学生证。有摄像头和指纹信息采集器供采集比对,判断是否为学校的学生,从而进入上述场所,减少人工验证程序,提高工作效率。
基于云平台的智能校园学生信息管理系统
本发明公开了一种基于云平台的智能校园学生信息管理系统,涉及信息管理系统领域,包括中心管理模块。中心管理模块的输入端与信息采集模块电连接,中心管理模块的输出端与门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器电连接模块 \u3002 本发明通过中央管理模块、信息采集模块、图书馆模块、体育馆模块、门禁模块、重要实验室模块、摄像头模块和指纹信息采集模块,实现了学生信息管理系统与图书馆的联系,健身房,
下载所有详细的技术数据
【技术实现步骤总结】
基于云平台的智慧校园学生信息管理系统
该专利技术涉及信息管理系统领域,具体涉及一种基于云平台的智慧校园学生信息管理系统。
技术介绍
学生信息管理系统是为学校人事处大量业务处理工作而开发的管理软件。主要用于学校学生信息管理。总体任务是实现学生信息关系的系统化、科学化、规范化和自动化。计算机用于日常管理学生的各种信息,如查询、修改、增删。此外,学生信息管理系统就是根据这些要求设计的,同时考虑到学生的选课情况。现有学生信息管理系统无法与学校图书馆、体育馆、门禁及重要实验室连接,学生需要出示学生证才能进入这些地方。操作麻烦,而且在现有的学生信息管理系统中,如果学生信息错误或以后发生变化,需要重新输入,操作繁琐。
技术实现思路
此项专利技术的目的是:为了解决现有学生信息管理系统无法与学校图书馆、体育馆、门禁及重要实验室进行通信,且学生信息出现错误或后期发生变化的问题,需要重新进入,操作繁琐 提供基于云平台的智慧校园学生信息管理系统。为实现上述目的,本专利技术提供以下技术方案:一种基于云平台的智慧校园学生信息管理系统,包括中央管理模块,中央管理模块的输入端与信息<< @采集 模块,中央管理模块的输出端与门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器模块电连接,门禁模块、重要实验室模块的输出端,图书馆和体育馆模块都是电气连接的。摄像头模块与指纹信息采集模块相连,中央管理模块的输出端与服务器模块电连接,服务器模块的输出端与学生模块和管理员电连接模块,学生模块是一个登录模块,与管理员模块的输出端电连接,查询模块和修改模块与登录模块的输出端电连接。优选地,摄像头模块和指纹信息采集模块与门禁模块、重要实验室模块、图书馆模块和体育馆模块均双向电连接,门禁模块、重要实验室模块、图书馆模块 体育馆模块和中央管理模块在两个方向上电连接。优选地,摄像头模块包括摄像头,指纹信息采集模块包括指纹信息采集器。图书馆模块和体育馆模块都是双向电连接的,门禁模块、重要实验室模块、图书馆模块体育馆模块和中央管理模块都是双向电连接的。优选地,摄像头模块包括摄像头,指纹信息采集模块包括指纹信息采集器。图书馆模块和体育馆模块都是双向电连接的,门禁模块、重要实验室模块、图书馆模块体育馆模块和中央管理模块都是双向电连接的。优选地,摄像头模块包括摄像头,指纹信息采集模块包括指纹信息采集器。
优选地,登录模块包括密码登录和身份证登录。优选地,修改模块的输出端与管理员模块电连接。优选地,中央管理模块包括信息存储模块、数据收发模块和中央处理器模块,中央管理模块与信息存储模块、数据收发模块和中央处理器模块以及中央管理器电连接。模块是双向电连接的。优选地,信息采集模块的输入端分别与身份证信息采集模块、录取信息采集模块、录取照片信息采集模块和指纹信息采集模块,信息采集模块分别与身份证信息采集模块、准入信息采集模块、准入照片信息采集模块和指纹信息采集模块已电连接。较佳地,修改模块箱的管理员发送加盖学校公章的图片和视频,管理员审核后直接登录修改。与现有技术相比,本专利技术的有益效果是:本专利技术设置的中央管理模块、信息采集模块、图书馆模块、体育馆模块、门禁模块、重要实验室模块、摄像头模块和指纹信息采集模块,实现了学生信息管理系统可以联系图书馆、体育馆、门禁和重要实验室。学生入场时无需携带学生证,而是直接有摄像头和指纹信息采集器对比采集,就可以判断是否是学校的学生,从而进入上述场所,减少人工验证程序,提高工作效率。修改模块实现在学生信息发生变化或输入错误后,学生登录服务器进入修改模块,并将加盖学校公章的文件的照片或视频发送给管理员。管理员收到审核后,直接进入修改模块进行修改。
附图说明图。图1是专利技术的系统流程图;如图。图2为本专利技术的中央管理模块流程图。具体实施方式下面将结合本专利技术实施例中的附图,对本专利技术实施例中的技术方案进行清楚、完整的描述。显然,所描述的实施例只是专利技术的一部分实施例,并非全部的例子。基于本专利技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本专利技术保护的范围。请参考图1-2,基于云平台的智慧校园学生信息管理系统,学生模块和管理员模块的输出电连接端子与日志模块电连接,日志模块的输出端子与查询模块和修改模块电连接。该专利技术通过中央管理模块、信息采集模块、图书馆模块、体育馆模块、门禁模块、重要实验室模块、摄像头模块和指纹信息采集模块实现对学生信息的管理。该系统可以与图书馆、体育馆、门禁和重要实验室进行通信。学生入场时无需携带学生证。采集 有摄像头和指纹信息 采集器
请参考图1。摄像头模块和指纹信息采集模块和门禁模块、重要实验室模块、图书馆模块和体育馆模块都在两个方向电连接,门禁模块,重要的实验室模块,图书馆模块与体育馆模块和中央管理模块都在两个方向上电连接。中央流水线模块中的中央管理者可以检查采集收到的信息,然后将检查结果传送到图书馆和其他场所的大门。. 请重点参考图1,摄像头模块包括摄像头,指纹信息采集模块包括指纹信息采集器,在图书馆等场所还设有与中央管理模块电连接的门。请参考图1。登录模块包括密码登录和身份证登录。如果忘记密码,可以用身份证号登录,方便快捷。请参考图1,修改模块的输出端与管理员模块电连接。修改页面将加盖学校公章的文件发送给管理员。修改模块会先审核,没有公章的文件不能上传。请参考图 如图2所示,中央管理模块包括信息存储模块、数据收发模块和中央处理器模块,中央管理模块与信息存储模块、数据收发模块和中央处理器模块电连接,中央管理模块双向电连接。信息存储模块负责采集的学生信息的采集,数据收发模块负责收发采集和比较数据。请参考图1 信息采集模块输入端连接身份证信息采集模块、录取信息采集模块、录取照片信息采集@ > 模块和指纹信息分别。采集 模块,以及信息采集
请参考图1。修改模块箱管理员发送图片和视频,并加盖学校公章。管理员审核后,直接登录修改即可。学生模块和管理员模块都有修改页面,但学生只能在修改页面修改页面。要选择发送选项,发件人是管理员。工作原理:使用时,通过信息采集模块,将学生的身份证信息、入学信息、入学照片信息、指纹信息全部录入中心管理模块,并有信息存储模块进行存储。整合学生信息后,学生和管理员可以通过登录服务器模块查看,并通过密码和身份证号登录。可以查看学生的姓名、班级、专业、外貌、成绩等。
【技术保护点】
1.一种基于云平台的智慧校园学生信息管理系统,包括中央管理模块,其特征在于:中央管理模块的输入端与信息采集模块电连接,中央管理模块是门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器模块的输出端,与门禁模块、重要实验室模块、图书馆和服务器模块的输出端电连接。体育馆模块。指纹信息采集模块,中央管理模块的输出端与服务器模块电连接,服务器模块的输出端与学生模块和管理员模块电连接,学生模块与管理员模块电连接登录模块的输出端与登录模块电连接,登录模块的输出端与查询模块和修改模块电连接。/n
【技术特点总结】
1.一种基于云平台的智慧校园学生信息管理系统,包括中央管理模块,其特征在于:中央管理模块的输入端与信息采集模块电连接,中央管理模块是门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器模块的输出端,与门禁模块、重要实验室模块、图书馆和服务器模块的输出端电连接。体育馆模块。指纹信息采集模块,中央管理模块的输出端与服务器模块电连接,服务器模块的输出端与学生模块和管理员模块电连接,
2.根据权利要求1所述的一种基于云平台的智慧校园学生信息管理系统,其特征在于:摄像头模块和指纹信息采集模块和门禁模块、重要实验室模块、图书馆模块和体育馆模块都在两个方向电连接,门禁模块、重要实验室模块、图书馆模块和体育馆模块和中央管理模块都在两个方向电连接。
3.根据权利要求1所述的基于云平台的智慧校园学生信息管理系统,其特征在于,所述摄像头模块包括摄像头,所述指纹信息采集模块包括指纹信息采集器。
4.根据右边...
【专利技术性质】
技术研发人员:姜志谋、叶迪、杨欣、
申请人(专利权)持有人:,
类型:发明
国家省份:安徽;34
下载所有详细的技术数据 我是该专利的所有者 查看全部
云采集(【技术公开】一种基于云平台智慧校园学生学生信息管理系统)
本发明专利技术公开了一种基于云平台的智慧校园学生信息管理系统,涉及信息管理系统领域,包括中央管理模块,中央管理模块的输入端与信息电连接。 采集模块,中央管理模块的输出端与门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器模块电连接。本发明专利技术通过中央管理模块、信息采集模块、图书馆模块、体育馆模块、门禁模块、重要实验室模块、摄像头模块和指纹信息采集模块实现学生信息化。管理系统可与图书馆、体育馆、门禁及重要实验室联系。学生入场时无需携带学生证。有摄像头和指纹信息采集器供采集比对,判断是否为学校的学生,从而进入上述场所,减少人工验证程序,提高工作效率。
基于云平台的智能校园学生信息管理系统
本发明公开了一种基于云平台的智能校园学生信息管理系统,涉及信息管理系统领域,包括中心管理模块。中心管理模块的输入端与信息采集模块电连接,中心管理模块的输出端与门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器电连接模块 \u3002 本发明通过中央管理模块、信息采集模块、图书馆模块、体育馆模块、门禁模块、重要实验室模块、摄像头模块和指纹信息采集模块,实现了学生信息管理系统与图书馆的联系,健身房,
下载所有详细的技术数据
【技术实现步骤总结】
基于云平台的智慧校园学生信息管理系统
该专利技术涉及信息管理系统领域,具体涉及一种基于云平台的智慧校园学生信息管理系统。
技术介绍
学生信息管理系统是为学校人事处大量业务处理工作而开发的管理软件。主要用于学校学生信息管理。总体任务是实现学生信息关系的系统化、科学化、规范化和自动化。计算机用于日常管理学生的各种信息,如查询、修改、增删。此外,学生信息管理系统就是根据这些要求设计的,同时考虑到学生的选课情况。现有学生信息管理系统无法与学校图书馆、体育馆、门禁及重要实验室连接,学生需要出示学生证才能进入这些地方。操作麻烦,而且在现有的学生信息管理系统中,如果学生信息错误或以后发生变化,需要重新输入,操作繁琐。
技术实现思路
此项专利技术的目的是:为了解决现有学生信息管理系统无法与学校图书馆、体育馆、门禁及重要实验室进行通信,且学生信息出现错误或后期发生变化的问题,需要重新进入,操作繁琐 提供基于云平台的智慧校园学生信息管理系统。为实现上述目的,本专利技术提供以下技术方案:一种基于云平台的智慧校园学生信息管理系统,包括中央管理模块,中央管理模块的输入端与信息<< @采集 模块,中央管理模块的输出端与门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器模块电连接,门禁模块、重要实验室模块的输出端,图书馆和体育馆模块都是电气连接的。摄像头模块与指纹信息采集模块相连,中央管理模块的输出端与服务器模块电连接,服务器模块的输出端与学生模块和管理员电连接模块,学生模块是一个登录模块,与管理员模块的输出端电连接,查询模块和修改模块与登录模块的输出端电连接。优选地,摄像头模块和指纹信息采集模块与门禁模块、重要实验室模块、图书馆模块和体育馆模块均双向电连接,门禁模块、重要实验室模块、图书馆模块 体育馆模块和中央管理模块在两个方向上电连接。优选地,摄像头模块包括摄像头,指纹信息采集模块包括指纹信息采集器。图书馆模块和体育馆模块都是双向电连接的,门禁模块、重要实验室模块、图书馆模块体育馆模块和中央管理模块都是双向电连接的。优选地,摄像头模块包括摄像头,指纹信息采集模块包括指纹信息采集器。图书馆模块和体育馆模块都是双向电连接的,门禁模块、重要实验室模块、图书馆模块体育馆模块和中央管理模块都是双向电连接的。优选地,摄像头模块包括摄像头,指纹信息采集模块包括指纹信息采集器。
优选地,登录模块包括密码登录和身份证登录。优选地,修改模块的输出端与管理员模块电连接。优选地,中央管理模块包括信息存储模块、数据收发模块和中央处理器模块,中央管理模块与信息存储模块、数据收发模块和中央处理器模块以及中央管理器电连接。模块是双向电连接的。优选地,信息采集模块的输入端分别与身份证信息采集模块、录取信息采集模块、录取照片信息采集模块和指纹信息采集模块,信息采集模块分别与身份证信息采集模块、准入信息采集模块、准入照片信息采集模块和指纹信息采集模块已电连接。较佳地,修改模块箱的管理员发送加盖学校公章的图片和视频,管理员审核后直接登录修改。与现有技术相比,本专利技术的有益效果是:本专利技术设置的中央管理模块、信息采集模块、图书馆模块、体育馆模块、门禁模块、重要实验室模块、摄像头模块和指纹信息采集模块,实现了学生信息管理系统可以联系图书馆、体育馆、门禁和重要实验室。学生入场时无需携带学生证,而是直接有摄像头和指纹信息采集器对比采集,就可以判断是否是学校的学生,从而进入上述场所,减少人工验证程序,提高工作效率。修改模块实现在学生信息发生变化或输入错误后,学生登录服务器进入修改模块,并将加盖学校公章的文件的照片或视频发送给管理员。管理员收到审核后,直接进入修改模块进行修改。
附图说明图。图1是专利技术的系统流程图;如图。图2为本专利技术的中央管理模块流程图。具体实施方式下面将结合本专利技术实施例中的附图,对本专利技术实施例中的技术方案进行清楚、完整的描述。显然,所描述的实施例只是专利技术的一部分实施例,并非全部的例子。基于本专利技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本专利技术保护的范围。请参考图1-2,基于云平台的智慧校园学生信息管理系统,学生模块和管理员模块的输出电连接端子与日志模块电连接,日志模块的输出端子与查询模块和修改模块电连接。该专利技术通过中央管理模块、信息采集模块、图书馆模块、体育馆模块、门禁模块、重要实验室模块、摄像头模块和指纹信息采集模块实现对学生信息的管理。该系统可以与图书馆、体育馆、门禁和重要实验室进行通信。学生入场时无需携带学生证。采集 有摄像头和指纹信息 采集器
请参考图1。摄像头模块和指纹信息采集模块和门禁模块、重要实验室模块、图书馆模块和体育馆模块都在两个方向电连接,门禁模块,重要的实验室模块,图书馆模块与体育馆模块和中央管理模块都在两个方向上电连接。中央流水线模块中的中央管理者可以检查采集收到的信息,然后将检查结果传送到图书馆和其他场所的大门。. 请重点参考图1,摄像头模块包括摄像头,指纹信息采集模块包括指纹信息采集器,在图书馆等场所还设有与中央管理模块电连接的门。请参考图1。登录模块包括密码登录和身份证登录。如果忘记密码,可以用身份证号登录,方便快捷。请参考图1,修改模块的输出端与管理员模块电连接。修改页面将加盖学校公章的文件发送给管理员。修改模块会先审核,没有公章的文件不能上传。请参考图 如图2所示,中央管理模块包括信息存储模块、数据收发模块和中央处理器模块,中央管理模块与信息存储模块、数据收发模块和中央处理器模块电连接,中央管理模块双向电连接。信息存储模块负责采集的学生信息的采集,数据收发模块负责收发采集和比较数据。请参考图1 信息采集模块输入端连接身份证信息采集模块、录取信息采集模块、录取照片信息采集@ > 模块和指纹信息分别。采集 模块,以及信息采集
请参考图1。修改模块箱管理员发送图片和视频,并加盖学校公章。管理员审核后,直接登录修改即可。学生模块和管理员模块都有修改页面,但学生只能在修改页面修改页面。要选择发送选项,发件人是管理员。工作原理:使用时,通过信息采集模块,将学生的身份证信息、入学信息、入学照片信息、指纹信息全部录入中心管理模块,并有信息存储模块进行存储。整合学生信息后,学生和管理员可以通过登录服务器模块查看,并通过密码和身份证号登录。可以查看学生的姓名、班级、专业、外貌、成绩等。
【技术保护点】
1.一种基于云平台的智慧校园学生信息管理系统,包括中央管理模块,其特征在于:中央管理模块的输入端与信息采集模块电连接,中央管理模块是门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器模块的输出端,与门禁模块、重要实验室模块、图书馆和服务器模块的输出端电连接。体育馆模块。指纹信息采集模块,中央管理模块的输出端与服务器模块电连接,服务器模块的输出端与学生模块和管理员模块电连接,学生模块与管理员模块电连接登录模块的输出端与登录模块电连接,登录模块的输出端与查询模块和修改模块电连接。/n
【技术特点总结】
1.一种基于云平台的智慧校园学生信息管理系统,包括中央管理模块,其特征在于:中央管理模块的输入端与信息采集模块电连接,中央管理模块是门禁模块、重要实验室模块、图书馆模块、体育馆模块和服务器模块的输出端,与门禁模块、重要实验室模块、图书馆和服务器模块的输出端电连接。体育馆模块。指纹信息采集模块,中央管理模块的输出端与服务器模块电连接,服务器模块的输出端与学生模块和管理员模块电连接,
2.根据权利要求1所述的一种基于云平台的智慧校园学生信息管理系统,其特征在于:摄像头模块和指纹信息采集模块和门禁模块、重要实验室模块、图书馆模块和体育馆模块都在两个方向电连接,门禁模块、重要实验室模块、图书馆模块和体育馆模块和中央管理模块都在两个方向电连接。
3.根据权利要求1所述的基于云平台的智慧校园学生信息管理系统,其特征在于,所述摄像头模块包括摄像头,所述指纹信息采集模块包括指纹信息采集器。
4.根据右边...
【专利技术性质】
技术研发人员:姜志谋、叶迪、杨欣、
申请人(专利权)持有人:,
类型:发明
国家省份:安徽;34
下载所有详细的技术数据 我是该专利的所有者
云采集(优采云7.0实验目的和要求1.1实验使用Pythonscrapy框架)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-04-18 12:14
1.实验目的和要求
1.1 实验目的
爬取公共管理学院所有新闻网站,了解和熟悉网络信息相关技术采集。
1.2 实验要求
使用任何可用的方法抓取四川大学公共管理学院()上的所有新闻,包括“新闻标题、新闻发布时间、新闻正文”三个字段。我们尝试过的方法有优采云data采集tools,Python爬虫代码。
2.实验环境
2.1优采云数据采集工具
优采云采集器是云采集服务平台,提供数据采集、数据分析等功能,可视化图形化操作采集器。它的simple采集、custom采集等基本功能都可以免费使用。本实验使用优采云7.0版本的自定义采集函数,使用本地采集方法。
2.2使用Python scrapy框架爬取
本实验使用的Python版本为2.7.14,安装了Scrapy。使用服务器采集的方法。
3.实验方案
3.1优采云采集器实验方案
3.1.1 登录版本优采云7.0,输入网址,新建采集任务
新任务.png
3.1.2为每个新闻链接制作翻页循环和点击循环
点击loop.png
翻页循环.png
3.1.3 指定具体的采集规则
对于每个新闻链接
采集rules.png
3.1.4 OK采集流程和数据
采集进程.png
采集格式预览.png
3.1.5采集工具结果界面
采集结果.png
3.1.6 错误报告和补充采集结果
经我们检查,报错页面有四种:
A.链接网页内部也有嵌套链接,如“120周年庆典”等特殊网页链接;
B.其他格式的网页,如视频、图片、外部网站链接等
C.网页出错,无法打开;
D.是一个单独的文章,但是可能会因为系统问题或者文章的不同格式(没有标题等)而爬不下来。
补充采集结果1.png
我们对每个出错的网页链接进行了单独的二次数据采集,图片、视频等B类格式的网页不是采集,最后是采集得到了导出数据结果的excel表格部分截图如下:
补充采集结果2.png
最后一节采集Results.png
以上是优采云
的一部分
3.2 使用Python scrapy框架爬取实验程序
3.2.1 云服务器配置:安装scrapy for Python
(1)检查当前服务器是否配置了scrapy
(2)退出Python交互,使用yum安装scrapy和一些依赖。
安装scrapy.png
经查询,解决办法是:
vi /usr/libexec/urlgrabber-ext-down
把head里的python改成和/usr/bin/yum里一样
修改完成后,再次使用yum安装scrapy:
修改后再次安装scrapy.png
3.2.2 检查scrapy安装
进入Python交互环境,导入scrapy enter,发现引用成功,退出交互环境。
查看安装结果.png
scrapy版本进入
查看scrapy version.png
版本信息检查成功。
至此,Python scrapy已经在云服务器上配置成功。
3.2.3编写代码并调试
根据之前优采云的经验,我们可以看到采集需要三个实体:标题、日期和文字(另外一个实体是图片,暂时不需要)。
scrapy startproject ggnews 进入
cd /ggnews/ggnews 进入
文件结构1.png
文件结构2.png
编写 ggnews.py
编写 ggnews.png
3.2.4 输入命令爬取获取数据
输入scrapy crawl ggnews -o ggnews.xml
出现以下错误
错误1.png
发生错误,但显然我们的代码中有一类项目。经查询,此错误用简单一句话描述:爬虫名称与项目名称相同,导致最终导入时出错。
将蜘蛛名称修改为spidernews.py。名字虽然有点长,但是好像很容易理解。
再次执行代码获取文件ggnews.json
初始爬取结果.png
发现初始爬取的结果是Unicode编码,不是理想的中文格式。查询后需要修改pipelines.py和settings.py这两个文件,使输出结果为中文格式。
3.2.5 修改 pipelines.py 和 settings.py 文件
修改管道文件.png
修改设置文件.png
3.2.6 解决压痕问题
修改完成后再次运行命令scrapy crawl spidernews。出现了一个新问题:
错误2.png
查询后,这是缩进的问题。 Python 语言是一种对缩进非常敏感的语言,这给很多初学者造成了困惑,即使是经验丰富的 Python 程序员也可能掉入陷阱。最常见的情况是制表符和空格的混合会导致错误,或者肉眼无法区分的缩进。编译的时候会出现这样的错误“IndentationError: expected an indented block”,意思是这里需要缩进。您只需要按空格或 Tab(但不能混合)键在发生错误的行上缩进。
修改完成,再次运行命令
第二次抓取结果.png
得到想要的结果。
至此,使用Python scrapy框架的爬取过程就结束了。
4.经验总结
4.1优采云采集器经验总结
经验总结
由于本实验仅使用数据采集的功能,所以评价和总结仅针对数据采集的功能。 优采云可视化数据采集。如果你完全不懂爬虫代码,优采云是一个方便的网络数据工具采集。根据经验,公共管理学院新闻网站的爬取速度约为29条/分钟,数据可以导出为excel、CSV等格式。
但是,它也有一些使用限制。首先,在成本方面,它的数据导出需要积分,每10条数据一个积分,不到10条数据计为10条。用户首次注册后,赠送2000积分;在采集数据数据量少的情况下可以免费使用,但是数据量大时需要支付一定的费用才能导出数据。二是使用方面。由于优采云是已经编写好的采集工具,使用采集数据会受到一定的限制,可能不如直接使用代码那么自由。指定采集数据的规则详情(如采集时间段、采集持续时间等)。
4.2Python scrapy实验总结
本次实验共爬取了407条数据,但大学新闻网站上却有458条新闻。为什么缺少 51 篇文章?我们还没有找到答案,希望在接下来的研究中解决这个问题!在data采集的过程中,爬取数据的规则和方法是最重要的部分。一定要充分利用浏览器的开发者工具,保证路径严格正确;此外,还有编码问题和分页问题。由于刚接触python,对python的需求不是很熟悉,导致修改时间比较长。在接下来的学习中,一定要尽快适应python的规则。此外,有足够的耐心和细心养好爬行动物。 查看全部
云采集(优采云7.0实验目的和要求1.1实验使用Pythonscrapy框架)
1.实验目的和要求
1.1 实验目的
爬取公共管理学院所有新闻网站,了解和熟悉网络信息相关技术采集。
1.2 实验要求
使用任何可用的方法抓取四川大学公共管理学院()上的所有新闻,包括“新闻标题、新闻发布时间、新闻正文”三个字段。我们尝试过的方法有优采云data采集tools,Python爬虫代码。
2.实验环境
2.1优采云数据采集工具
优采云采集器是云采集服务平台,提供数据采集、数据分析等功能,可视化图形化操作采集器。它的simple采集、custom采集等基本功能都可以免费使用。本实验使用优采云7.0版本的自定义采集函数,使用本地采集方法。
2.2使用Python scrapy框架爬取
本实验使用的Python版本为2.7.14,安装了Scrapy。使用服务器采集的方法。
3.实验方案
3.1优采云采集器实验方案
3.1.1 登录版本优采云7.0,输入网址,新建采集任务
新任务.png
3.1.2为每个新闻链接制作翻页循环和点击循环
点击loop.png
翻页循环.png
3.1.3 指定具体的采集规则
对于每个新闻链接
采集rules.png
3.1.4 OK采集流程和数据
采集进程.png
采集格式预览.png
3.1.5采集工具结果界面
采集结果.png
3.1.6 错误报告和补充采集结果
经我们检查,报错页面有四种:
A.链接网页内部也有嵌套链接,如“120周年庆典”等特殊网页链接;
B.其他格式的网页,如视频、图片、外部网站链接等
C.网页出错,无法打开;
D.是一个单独的文章,但是可能会因为系统问题或者文章的不同格式(没有标题等)而爬不下来。
补充采集结果1.png
我们对每个出错的网页链接进行了单独的二次数据采集,图片、视频等B类格式的网页不是采集,最后是采集得到了导出数据结果的excel表格部分截图如下:
补充采集结果2.png
最后一节采集Results.png
以上是优采云
的一部分
3.2 使用Python scrapy框架爬取实验程序
3.2.1 云服务器配置:安装scrapy for Python
(1)检查当前服务器是否配置了scrapy
(2)退出Python交互,使用yum安装scrapy和一些依赖。
安装scrapy.png
经查询,解决办法是:
vi /usr/libexec/urlgrabber-ext-down
把head里的python改成和/usr/bin/yum里一样
修改完成后,再次使用yum安装scrapy:
修改后再次安装scrapy.png
3.2.2 检查scrapy安装
进入Python交互环境,导入scrapy enter,发现引用成功,退出交互环境。
查看安装结果.png
scrapy版本进入
查看scrapy version.png
版本信息检查成功。
至此,Python scrapy已经在云服务器上配置成功。
3.2.3编写代码并调试
根据之前优采云的经验,我们可以看到采集需要三个实体:标题、日期和文字(另外一个实体是图片,暂时不需要)。
scrapy startproject ggnews 进入
cd /ggnews/ggnews 进入
文件结构1.png
文件结构2.png
编写 ggnews.py
编写 ggnews.png
3.2.4 输入命令爬取获取数据
输入scrapy crawl ggnews -o ggnews.xml
出现以下错误
错误1.png
发生错误,但显然我们的代码中有一类项目。经查询,此错误用简单一句话描述:爬虫名称与项目名称相同,导致最终导入时出错。
将蜘蛛名称修改为spidernews.py。名字虽然有点长,但是好像很容易理解。
再次执行代码获取文件ggnews.json
初始爬取结果.png
发现初始爬取的结果是Unicode编码,不是理想的中文格式。查询后需要修改pipelines.py和settings.py这两个文件,使输出结果为中文格式。
3.2.5 修改 pipelines.py 和 settings.py 文件
修改管道文件.png
修改设置文件.png
3.2.6 解决压痕问题
修改完成后再次运行命令scrapy crawl spidernews。出现了一个新问题:
错误2.png
查询后,这是缩进的问题。 Python 语言是一种对缩进非常敏感的语言,这给很多初学者造成了困惑,即使是经验丰富的 Python 程序员也可能掉入陷阱。最常见的情况是制表符和空格的混合会导致错误,或者肉眼无法区分的缩进。编译的时候会出现这样的错误“IndentationError: expected an indented block”,意思是这里需要缩进。您只需要按空格或 Tab(但不能混合)键在发生错误的行上缩进。
修改完成,再次运行命令
第二次抓取结果.png
得到想要的结果。
至此,使用Python scrapy框架的爬取过程就结束了。
4.经验总结
4.1优采云采集器经验总结
经验总结
由于本实验仅使用数据采集的功能,所以评价和总结仅针对数据采集的功能。 优采云可视化数据采集。如果你完全不懂爬虫代码,优采云是一个方便的网络数据工具采集。根据经验,公共管理学院新闻网站的爬取速度约为29条/分钟,数据可以导出为excel、CSV等格式。
但是,它也有一些使用限制。首先,在成本方面,它的数据导出需要积分,每10条数据一个积分,不到10条数据计为10条。用户首次注册后,赠送2000积分;在采集数据数据量少的情况下可以免费使用,但是数据量大时需要支付一定的费用才能导出数据。二是使用方面。由于优采云是已经编写好的采集工具,使用采集数据会受到一定的限制,可能不如直接使用代码那么自由。指定采集数据的规则详情(如采集时间段、采集持续时间等)。
4.2Python scrapy实验总结
本次实验共爬取了407条数据,但大学新闻网站上却有458条新闻。为什么缺少 51 篇文章?我们还没有找到答案,希望在接下来的研究中解决这个问题!在data采集的过程中,爬取数据的规则和方法是最重要的部分。一定要充分利用浏览器的开发者工具,保证路径严格正确;此外,还有编码问题和分页问题。由于刚接触python,对python的需求不是很熟悉,导致修改时间比较长。在接下来的学习中,一定要尽快适应python的规则。此外,有足够的耐心和细心养好爬行动物。
云采集( 优采云让数据触手可及视频教程PPT云采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-04-14 06:10
优采云让数据触手可及视频教程PPT云采集)
优采云让数据触手可及视频教程PPT云采集一、云采集,时序云采集二、云采集工作原理三、云采集规则,材料编码规则,三大专业,一个程序规则,文献编号规则,乒乓球比赛规则,动词不规则变化表,加速设置教程一、云< @采集,定时云采集Cloud采集是指使用优采云提供的服务器集群工作,处于7*24小时工作状态。客户端完成任务设置并提交至云服务执行云采集后,即可关闭软件、关机、下线采集,真正实现无人值守。另外,云采集 通过云服务器集群的分布式部署方式,多个节点可以同时进行操作,可以提高采集的效率,并且可以有效规避各种网站的IP阻塞策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 多个节点可以同时进行操作,可以提高采集的效率,并且可以有效的避免各种网站的IP阻塞策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 多个节点可以同时进行操作,可以提高采集的效率,并且可以有效的避免各种网站的IP阻塞策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 可以提高采集的效率,有效规避各种网站的IP屏蔽策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 可以提高采集的效率,有效规避各种网站的IP屏蔽策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 可以关机运行,可以设置定时云采集,加快采集的速度,增加采集的音量。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 可以关机运行,可以设置定时云采集,加快采集的速度,增加采集的音量。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1
, 一个云的规则任务采集至少占用一个云节点,最多可以占用所有云节点2、如果一个规则任务可以拆分成子任务,最多可以拆分成199个subtasks3、一个子任务占用一个节点,所有子任务完成即表示任务完成4、一个规则任务分为多个子任务分配到不同的云节点,达到加速的效果< @采集5、如果云节点已满,则新启动的任务或拆分的子任务将进入等待队列,直到用户的云节点执行完用户的任务并释放节点资源。三、云采集加速设置是基于云采集的原理。如果你想让一个任务的效果加速采集,那么任务必须满足拆分条件或者改变任务满足拆分条件的任务才能达到单任务加速的效果。满足拆分条件的任务有:1、URL列表循环2、文本列表循环3、固定元素列表循环三、云采集加速设置1、URL列表循环通过优采云自动拆分任务,将不同的URL拆分成不同的子任务分配给不同的云节点供数据采集,采集效果的示例URL单任务加速
:三、云端采集加速设置2、文本列表循环文本循环,原理同URL循环,通过文本循环的拆分,单任务加速采集 @> 采集速度示例 URL:三、云采集加速设置3、固定元素列表循环 固定元素列表循环也满足拆分条件,但需要结合循环点击一起使用,否则没有明显的加速效果。示例 URL:三、云采集加速设置 子任务 1:打开网页(20s)-提取位置 1 数据(0.1s)子任务 任务 2:打开网页(20s)-提取位置2 个数据 (0.1s) 子任务 3:打开网页 (20s) - 提取位置 3 数据 (0.1s)...子任务 10:
0=21S循环-提取数据三、云采集加速度设置子任务1:打开网页(20s)-点击元素1(20s)-提取位置1数据(0.1s)子任务任务2:打开网页(20s)-点击元素2(20s)提取位置2数据(0.1s)子任务3:打开网页(20s)-点击元素3(20s) - 提取位置 3 数据 (0.1s)...子任务 10:打开网页 (20s) - 单击元素 10 (20s) - 提取位置 10 数据 (0.1s) 子任务同时运行,总共需要:20 +20+0.1=40.1S 总任务:打开网页(20s)点击元素1(20s)-提取位置1数据(0.1s)点击元素2 (20s) - 提取位置 2 数据 (0.1s) 点击元素 3 (20s) - 提取位置 3 数据 (0.1s) .....点击位置元素 n (20s) - 提取位置 10 数据 (0.1s) 总共:20+(20+0.1)*10=221s 循环 - 点击元素 - 提取数据TheEnd 谢谢大家 查看全部
云采集(
优采云让数据触手可及视频教程PPT云采集)
优采云让数据触手可及视频教程PPT云采集一、云采集,时序云采集二、云采集工作原理三、云采集规则,材料编码规则,三大专业,一个程序规则,文献编号规则,乒乓球比赛规则,动词不规则变化表,加速设置教程一、云< @采集,定时云采集Cloud采集是指使用优采云提供的服务器集群工作,处于7*24小时工作状态。客户端完成任务设置并提交至云服务执行云采集后,即可关闭软件、关机、下线采集,真正实现无人值守。另外,云采集 通过云服务器集群的分布式部署方式,多个节点可以同时进行操作,可以提高采集的效率,并且可以有效规避各种网站的IP阻塞策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 多个节点可以同时进行操作,可以提高采集的效率,并且可以有效的避免各种网站的IP阻塞策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 多个节点可以同时进行操作,可以提高采集的效率,并且可以有效的避免各种网站的IP阻塞策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 可以提高采集的效率,有效规避各种网站的IP屏蔽策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 可以提高采集的效率,有效规避各种网站的IP屏蔽策略。云采集的优点:可以关机运行,可以设置定时云采集,加快采集的速度,增加采集@的音量>。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 可以关机运行,可以设置定时云采集,加快采集的速度,增加采集的音量。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1 可以关机运行,可以设置定时云采集,加快采集的速度,增加采集的音量。一、Cloud采集、Timing Cloud采集1、Cloud采集Setup Startup Cloud采集共有三种方式(立即启动,只运行一次) 2、定时云采集设置定时云采集有两种设置方式3、任务组定时设置可以为任务组设置定时采集二、云采集作品云采集作品1
, 一个云的规则任务采集至少占用一个云节点,最多可以占用所有云节点2、如果一个规则任务可以拆分成子任务,最多可以拆分成199个subtasks3、一个子任务占用一个节点,所有子任务完成即表示任务完成4、一个规则任务分为多个子任务分配到不同的云节点,达到加速的效果< @采集5、如果云节点已满,则新启动的任务或拆分的子任务将进入等待队列,直到用户的云节点执行完用户的任务并释放节点资源。三、云采集加速设置是基于云采集的原理。如果你想让一个任务的效果加速采集,那么任务必须满足拆分条件或者改变任务满足拆分条件的任务才能达到单任务加速的效果。满足拆分条件的任务有:1、URL列表循环2、文本列表循环3、固定元素列表循环三、云采集加速设置1、URL列表循环通过优采云自动拆分任务,将不同的URL拆分成不同的子任务分配给不同的云节点供数据采集,采集效果的示例URL单任务加速
:三、云端采集加速设置2、文本列表循环文本循环,原理同URL循环,通过文本循环的拆分,单任务加速采集 @> 采集速度示例 URL:三、云采集加速设置3、固定元素列表循环 固定元素列表循环也满足拆分条件,但需要结合循环点击一起使用,否则没有明显的加速效果。示例 URL:三、云采集加速设置 子任务 1:打开网页(20s)-提取位置 1 数据(0.1s)子任务 任务 2:打开网页(20s)-提取位置2 个数据 (0.1s) 子任务 3:打开网页 (20s) - 提取位置 3 数据 (0.1s)...子任务 10:
0=21S循环-提取数据三、云采集加速度设置子任务1:打开网页(20s)-点击元素1(20s)-提取位置1数据(0.1s)子任务任务2:打开网页(20s)-点击元素2(20s)提取位置2数据(0.1s)子任务3:打开网页(20s)-点击元素3(20s) - 提取位置 3 数据 (0.1s)...子任务 10:打开网页 (20s) - 单击元素 10 (20s) - 提取位置 10 数据 (0.1s) 子任务同时运行,总共需要:20 +20+0.1=40.1S 总任务:打开网页(20s)点击元素1(20s)-提取位置1数据(0.1s)点击元素2 (20s) - 提取位置 2 数据 (0.1s) 点击元素 3 (20s) - 提取位置 3 数据 (0.1s) .....点击位置元素 n (20s) - 提取位置 10 数据 (0.1s) 总共:20+(20+0.1)*10=221s 循环 - 点击元素 - 提取数据TheEnd 谢谢大家
云采集(优采云采集器:最好用的网页数据采集器(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-04-07 17:25
优采云采集器:最好使用的网络数据采集器
优采云采集器是经过多年研发的业界领先的新一代智能通用网络数据采集器。使用简单,操作全可视化,无需专业知识,上网即可轻松掌握;功能强大,新闻、论坛、电话信箱、竞争对手、客户信息、汽车地产、电子商务等。任何网站都可以是采集;数据可以导出为多种格式;更多云采集、采集最快100倍、支持列表采集、分页采集定时采集等最好的免费网络数据采集器@ > 目前可用!
优采云可以做什么?
简而言之,使用 优采云 可以轻松采集从任何网页中精确获取所需的数据,并生成自定义的常规数据格式。优采云数据采集系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财务报告,自动包括每日最新净值采集;
2.各大新闻门户网站实时监控,自动更新和上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 监测各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要汽车网站具体新车和二手车信息;
8. 发现和采集潜在客户信息;
9. 采集行业网站 产品目录和产品信息;
10.在各大电商平台之间同步商品信息,做到在一个平台发布,在其他平台自动更新。
任何人都可以使用
你还在研究网页源码和抓包工具吗?现在不用了,能上网就可以采集,所见即所得的界面,可视化的流程,无需懂技术,鼠标点一下,2分钟快速上手.
任何 网站 都可以 采集
它不仅简单易用,而且功能强大:点击、登录、翻页,甚至识别验证码。当网页出现错误,或者多组模板完全不同时,可以根据不同的情况进行不同的处理。
云采集,你也可以关闭
采集 任务配置完成后,就可以关闭它了,任务就可以在云端执行了。大量企业云可以24*7不间断运行。您不必担心IP阻塞或网络中断,您可以立即采集大量数据。
最新消息:优采云完成500万天使轮融资 查看全部
云采集(优采云采集器:最好用的网页数据采集器(组图))
优采云采集器:最好使用的网络数据采集器
优采云采集器是经过多年研发的业界领先的新一代智能通用网络数据采集器。使用简单,操作全可视化,无需专业知识,上网即可轻松掌握;功能强大,新闻、论坛、电话信箱、竞争对手、客户信息、汽车地产、电子商务等。任何网站都可以是采集;数据可以导出为多种格式;更多云采集、采集最快100倍、支持列表采集、分页采集定时采集等最好的免费网络数据采集器@ > 目前可用!
优采云可以做什么?
简而言之,使用 优采云 可以轻松采集从任何网页中精确获取所需的数据,并生成自定义的常规数据格式。优采云数据采集系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财务报告,自动包括每日最新净值采集;
2.各大新闻门户网站实时监控,自动更新和上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 监测各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要汽车网站具体新车和二手车信息;
8. 发现和采集潜在客户信息;
9. 采集行业网站 产品目录和产品信息;
10.在各大电商平台之间同步商品信息,做到在一个平台发布,在其他平台自动更新。
任何人都可以使用
你还在研究网页源码和抓包工具吗?现在不用了,能上网就可以采集,所见即所得的界面,可视化的流程,无需懂技术,鼠标点一下,2分钟快速上手.
任何 网站 都可以 采集
它不仅简单易用,而且功能强大:点击、登录、翻页,甚至识别验证码。当网页出现错误,或者多组模板完全不同时,可以根据不同的情况进行不同的处理。
云采集,你也可以关闭
采集 任务配置完成后,就可以关闭它了,任务就可以在云端执行了。大量企业云可以24*7不间断运行。您不必担心IP阻塞或网络中断,您可以立即采集大量数据。
最新消息:优采云完成500万天使轮融资
云采集(BiliBli学习资源测评之阿婆主们的优质学习教程资源汇总)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2022-03-30 18:04
_
_
这么长的假期,相信很多同学都有学习一些科研软件的想法。BIliBIli上有很多非常好的教程。但是,初学者可能很难在短时间内找到最合适的教程。
因此,我们特地推出了“BiliBli学习资源评测”专栏,总结了奶奶的优质学习教程资源,帮助您快速选择适合自己的好教程。
本期重点整理3D Max和data采集相关资源。
1
3D 最大
3D Max是一款模型设计软件,应用于动画制作、建筑设计、游戏影视等领域。对于理工科研究生,我们主要使用3D Max来绘制模型示意图,尤其是封面。下面就给大家介绍几个适合科研制图的学习教程。
基本
奶奶:爱知兴趣教育
教程内容介绍:课程介绍了3D Max 2014版的一些基础知识,包括界面、操作、快捷键等,之后通过具体机型的制作过程,生动地向我们介绍了多种常用的制作方法,包括弯曲、锥度、扭曲等。每节课15分钟左右,讲解很详细。您可以以两倍的速度听课。
奶奶:龙雪傲
教程内容介绍:课程介绍3D Max 2016版的界面、主工具栏、基本操作等基础知识。与爱知趣教育的课程相比,本课程的讲解更加精炼。每节课5分钟以内,干货满满。本课程还增加了更高级的操作,比如添加动画编辑等。
具体型号文章
奶奶:独孤嘌呤
奶奶:R土豆被狙击
教程内容介绍:这两位up主用3D Max画了很多分子结构和细胞结构的模型图,比如碳纳米管的结构图,DNA双螺旋结构的图,高尔基体的图,对学生来说非常实用,我们可以参考他构建模型的过程,为我们的论文锦上添花。
数据采集
2
在日常生活中,我们经常需要各种数据来帮助决策,比如毕业论文、商业分析等等,都需要采集数据。在时间紧、任务重的情况下,尤其是非计算机专业的学生不能立即使用 Python 编写代码爬取数据。怎样才能方便快捷的获取我们想要的数据?
答案是:使用 采集 工具
目前常用的数据采集工具一般可以分为云爬虫和采集器两种。
云爬虫
云爬虫是直接在网页上创建爬虫并在网站服务器上运行,无需下载安装软件,享受网站提供的带宽和24小时服务。
目前国内最重要的是:优采云云爬虫。
其强大的功能涉及云爬虫、API、机器学习、数据清洗、数据销售、数据定制和私有化部署等;纯云端操作,跨系统操作无压力,隐私保护,用户IP可隐藏。不过由于是面向开发者的爬虫开发系统,提供了丰富的开发功能,网站看起来技术性很强,专业性很强,对于技术基础为零的用户来说也不是那么容易理解,所以有一定的使用门槛。这里不多介绍。
采集器
采集器一般需要下载安装软件,然后在机器上创建爬虫,使用自己的带宽,受限于电脑是否关机。当然,你也可以自己开发爬虫工具和爬虫框架。
优采云采集器
优采云采集器 是一款网络数据采集、处理、分析和挖掘软件。它可以灵活、快速的抓取网页上零散的信息,通过强大的处理功能,准确的挖掘出需要的数据。
优点:国内老牌采集器,经过多年积累,拥有丰富的采集功能;采集比较快,接口比较齐全,支持PHP和C#插件扩展;支持多种数据格式导出,可以进行数据替换等处理。
缺点:产品越老越容易陷入自己的固有体验,优采云很难摆脱这个问题。虽然功能丰富,但功能堆在那里,用户体验不好,让人不知从何下手;学过的人会觉得功能很强大,但是对于初学者来说,使用起来有一定的门槛,不学习一段时间是很难上手的。,基本不可能零基础上手。仅支持 Windows 版本,不支持其他操作系统。
免费与否:免费,但其实免费功能非常有限,只能导出单个txt或html文件。
B站教程:优采云采集器B站官方有专门的教程,课程安排有点混乱,不过有问题可以随时问奶奶。
奶奶:优采云采集器
优采云采集器
优采云采集器是一个可视化采集器,内置采集模板,支持各种网页数据采集。
优点:支持自定义模式,可视化采集操作,使用方便;支持简单采集模式,提供官方采集模板,支持云端采集操作;支持反屏蔽措施,例如代理IP切换和验证码服务;支持导出多种数据格式。
缺点:函数使用门槛高,很多函数限制在本地采集;采集慢,很多操作要卡住,云采集的10倍加速不明显;仅支持 Windows 版本,不支持其他操作系统。
是否免费:免费,但实际导出数据需要积分,做任务可以获得积分。
B站教程:优采云采集器官方在B站也有专门的教程,涵盖了文字、单页等多种数据采集方式。
奶奶:优采云采集器
优采云采集器
优采云采集器是前谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大,操作极其简单。
优点:支持智能采集模式,通过输入网址即可智能识别采集对象,无需配置采集规则,操作非常简单;支持流程图模式,可视化操作流程,可以使用简单的操作生成各种复杂的采集规则;支持反屏蔽措施,如代理IP切换等;支持多种数据格式的导出;支持定时采集和自动发布,发布接口丰富;支持Windows、Mac和Linux版本。
缺点:软件很久没有上线,部分功能还在完善中。Cloud 采集 功能暂时不支持。
是否免费:完全免费,对采集数据和手动导出采集结果没有限制,不需要积分。
教程:
(没找到B站教程,这是“互联网创新创业实践中心”公众号入门教程)
以上就是《B站学习资源总结》第一期的全部内容 查看全部
云采集(BiliBli学习资源测评之阿婆主们的优质学习教程资源汇总)
_
_
这么长的假期,相信很多同学都有学习一些科研软件的想法。BIliBIli上有很多非常好的教程。但是,初学者可能很难在短时间内找到最合适的教程。
因此,我们特地推出了“BiliBli学习资源评测”专栏,总结了奶奶的优质学习教程资源,帮助您快速选择适合自己的好教程。
本期重点整理3D Max和data采集相关资源。
1
3D 最大
3D Max是一款模型设计软件,应用于动画制作、建筑设计、游戏影视等领域。对于理工科研究生,我们主要使用3D Max来绘制模型示意图,尤其是封面。下面就给大家介绍几个适合科研制图的学习教程。
基本
奶奶:爱知兴趣教育
教程内容介绍:课程介绍了3D Max 2014版的一些基础知识,包括界面、操作、快捷键等,之后通过具体机型的制作过程,生动地向我们介绍了多种常用的制作方法,包括弯曲、锥度、扭曲等。每节课15分钟左右,讲解很详细。您可以以两倍的速度听课。
奶奶:龙雪傲
教程内容介绍:课程介绍3D Max 2016版的界面、主工具栏、基本操作等基础知识。与爱知趣教育的课程相比,本课程的讲解更加精炼。每节课5分钟以内,干货满满。本课程还增加了更高级的操作,比如添加动画编辑等。
具体型号文章
奶奶:独孤嘌呤
奶奶:R土豆被狙击
教程内容介绍:这两位up主用3D Max画了很多分子结构和细胞结构的模型图,比如碳纳米管的结构图,DNA双螺旋结构的图,高尔基体的图,对学生来说非常实用,我们可以参考他构建模型的过程,为我们的论文锦上添花。
数据采集
2
在日常生活中,我们经常需要各种数据来帮助决策,比如毕业论文、商业分析等等,都需要采集数据。在时间紧、任务重的情况下,尤其是非计算机专业的学生不能立即使用 Python 编写代码爬取数据。怎样才能方便快捷的获取我们想要的数据?
答案是:使用 采集 工具
目前常用的数据采集工具一般可以分为云爬虫和采集器两种。
云爬虫
云爬虫是直接在网页上创建爬虫并在网站服务器上运行,无需下载安装软件,享受网站提供的带宽和24小时服务。
目前国内最重要的是:优采云云爬虫。
其强大的功能涉及云爬虫、API、机器学习、数据清洗、数据销售、数据定制和私有化部署等;纯云端操作,跨系统操作无压力,隐私保护,用户IP可隐藏。不过由于是面向开发者的爬虫开发系统,提供了丰富的开发功能,网站看起来技术性很强,专业性很强,对于技术基础为零的用户来说也不是那么容易理解,所以有一定的使用门槛。这里不多介绍。
采集器
采集器一般需要下载安装软件,然后在机器上创建爬虫,使用自己的带宽,受限于电脑是否关机。当然,你也可以自己开发爬虫工具和爬虫框架。
优采云采集器
优采云采集器 是一款网络数据采集、处理、分析和挖掘软件。它可以灵活、快速的抓取网页上零散的信息,通过强大的处理功能,准确的挖掘出需要的数据。
优点:国内老牌采集器,经过多年积累,拥有丰富的采集功能;采集比较快,接口比较齐全,支持PHP和C#插件扩展;支持多种数据格式导出,可以进行数据替换等处理。
缺点:产品越老越容易陷入自己的固有体验,优采云很难摆脱这个问题。虽然功能丰富,但功能堆在那里,用户体验不好,让人不知从何下手;学过的人会觉得功能很强大,但是对于初学者来说,使用起来有一定的门槛,不学习一段时间是很难上手的。,基本不可能零基础上手。仅支持 Windows 版本,不支持其他操作系统。
免费与否:免费,但其实免费功能非常有限,只能导出单个txt或html文件。
B站教程:优采云采集器B站官方有专门的教程,课程安排有点混乱,不过有问题可以随时问奶奶。
奶奶:优采云采集器
优采云采集器
优采云采集器是一个可视化采集器,内置采集模板,支持各种网页数据采集。
优点:支持自定义模式,可视化采集操作,使用方便;支持简单采集模式,提供官方采集模板,支持云端采集操作;支持反屏蔽措施,例如代理IP切换和验证码服务;支持导出多种数据格式。
缺点:函数使用门槛高,很多函数限制在本地采集;采集慢,很多操作要卡住,云采集的10倍加速不明显;仅支持 Windows 版本,不支持其他操作系统。
是否免费:免费,但实际导出数据需要积分,做任务可以获得积分。
B站教程:优采云采集器官方在B站也有专门的教程,涵盖了文字、单页等多种数据采集方式。
奶奶:优采云采集器
优采云采集器
优采云采集器是前谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大,操作极其简单。
优点:支持智能采集模式,通过输入网址即可智能识别采集对象,无需配置采集规则,操作非常简单;支持流程图模式,可视化操作流程,可以使用简单的操作生成各种复杂的采集规则;支持反屏蔽措施,如代理IP切换等;支持多种数据格式的导出;支持定时采集和自动发布,发布接口丰富;支持Windows、Mac和Linux版本。
缺点:软件很久没有上线,部分功能还在完善中。Cloud 采集 功能暂时不支持。
是否免费:完全免费,对采集数据和手动导出采集结果没有限制,不需要积分。
教程:
(没找到B站教程,这是“互联网创新创业实践中心”公众号入门教程)
以上就是《B站学习资源总结》第一期的全部内容
云采集(众大云大叔要说采集这款dede模块详细解析采集模块介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-03-17 04:26
在这篇文章中,苏南大叔想讲一下dedecms的一个采集模块,叫做中大运采集。之所以要写一个文章来介绍中大运的dede模块采集并不是因为它的代码写的很好,而且他的产品模型比较新,采集模式比较特征。当然,本文不提供这个中大云采集的破解版。想要下载中大云破解版采集的新人请避开。
dedecms中大云采集的好用采集插件(图7-1)
本文测试环境为:dedeV5.7SP2,中大运采集9.4。
官方网站
中大云的官方域名采集比较有意思,叫csdn123。
dedecms,中大云采集的好用采集插件(图7-2)
这个“中大运采集”代码不仅适用于dedecms,还支持其他常用php语言的cms。免费版会在文字中有一个小广告,可以手动删除。当然,这个插件也很容易破解。苏南大叔在这里不断赚钱。如果你有钱,让我们帮助货币市场。毕竟函数写的挺好的(代码写的不是很好)。
截止发稿,中大云采集插件的版本号为9.4。大多数情况下,需要上传的插件文件是:下载的压缩包中的UTF8_install.xml文件。
如何使用
在module=”Zhongdayun采集=”Batch采集,在这个菜单中,输入关键词,输入数量,可以得到一些随机相关的文章。使用方式非常无脑,非常适合新手。
dedecms、中大云采集的好用采集插件(图7-3)
导入数据库
中大云的数据库在某些情况下可能无法正常安装数据库。因此,可能需要手动执行sql。UTF8-install.xml 中加密的 sql 文本可以使用 php 的 base64_decode() 函数进行解密。
dedecms、中大云采集的好用采集插件(图7-4)
执行sql的方式取决于你的选择。苏南大叔推荐你使用navicat。
php72下兼容中大云采集
由于中大运采集在php72下无法正常运行,所以可以开启dede调试模式,方便调试。
修改文件:/include/common.inc.php。调试方法如下:修改常量DEDE_ENVIRONMENT为dev。
define('DEDE_ENVIRONMENT', 'dev');
错误信息一:mysql_escape_string()
您可能会看到以下错误消息:
Uncaught Error: Call to undefined function mysql_escape_string()
php7 不再支持 php_mysql 扩展。既然没有 php_mysql 扩展,自然也就没有 mysql_escape_string 函数。
解决方案是兼容mysql_escape_string。修改文件:/dede/hzw/common.fun.php。添加以下兼容代码。
if(!function_exists('mysql_escape_string')){
function mysql_escape_string($data){
return addslashes(trim($data));
}
}
dedecms、中大云采集的好用采集插件(图7-5)
错误消息二:不推荐使用的构造函数警告
**Deprecated**: Methods with the same name as their class will not be constructors in a future version of PHP; hzw_cuserLogin has a deprecated constructor in **/dede/hzw_send_archives.php** on line **8**
修改文件/dede/hzw_send_archives.php,修改构造函数的编写方式。(将同名函数转成__construct)
//public function hzw_cuserLogin($userID)
function __construct($userID){
$this->userID=$userID;
}
dedecms,中大云采集的好用采集插件(图7-6)
库存处于暂存状态
因为一般情况下,必须先发布中大云采集的充电提醒信息,才能修改提醒信息。这个设定很不人性化。因此,苏南叔将他设置为:采集完成后,将处于待释放状态,这种情况下,充电信息不会被释放。原则上,档案表中的 arcrank 字段设置为 -1。
if(!empty($GLOBALS['cfg_version']) && stripos($GLOBALS['cfg_version'],'V56')===false)
{
$query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle,color,writer,source,litpic,pubdate,senddate,mid,voteid,notpost,description,keywords,filename,dutyadmin,weight) VALUES ('$arcID','$cid','0','$sortrank','','0','$channelid','-1','$click','0','$title','','','$writer','','$litpic','$pubdate','$senddate','$adminid','0','0','$description','$keywords','','$adminid','0');";
} else {
$query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle,color,writer,source,litpic,pubdate,senddate,mid,notpost,description,keywords,filename,dutyadmin,weight) VALUES ('$arcID','$cid','0','$sortrank','','0','$channelid','-1','$click','0','$title','','','$writer','','$litpic','$pubdate','$senddate','$adminid','0','$description','$keywords','','$adminid','0');";
}
dedecms、中大云采集的好用采集插件(图7-7)
额外的信息
: 这里是 [作者] 的可见内容
总结
中大云采集的这种方法,非常适合小白初级编辑。不需要写规则,只需要定义关键词。
苏南大叔偶尔会写几篇关于德德经历的文章。不过,苏南大叔并不能真正欣赏dede的代码,而只能欣赏dede产品的成功。更多dede相关的话,请偶尔关注一下苏南大叔写的经验文章:
【源码】本文代码片段及相关软件,详情请点这里
【绝密】秘籍文章的入口,只传授给命中注定的人
php dede 查看全部
云采集(众大云大叔要说采集这款dede模块详细解析采集模块介绍)
在这篇文章中,苏南大叔想讲一下dedecms的一个采集模块,叫做中大运采集。之所以要写一个文章来介绍中大运的dede模块采集并不是因为它的代码写的很好,而且他的产品模型比较新,采集模式比较特征。当然,本文不提供这个中大云采集的破解版。想要下载中大云破解版采集的新人请避开。
dedecms中大云采集的好用采集插件(图7-1)
本文测试环境为:dedeV5.7SP2,中大运采集9.4。
官方网站
中大云的官方域名采集比较有意思,叫csdn123。
dedecms,中大云采集的好用采集插件(图7-2)
这个“中大运采集”代码不仅适用于dedecms,还支持其他常用php语言的cms。免费版会在文字中有一个小广告,可以手动删除。当然,这个插件也很容易破解。苏南大叔在这里不断赚钱。如果你有钱,让我们帮助货币市场。毕竟函数写的挺好的(代码写的不是很好)。
截止发稿,中大云采集插件的版本号为9.4。大多数情况下,需要上传的插件文件是:下载的压缩包中的UTF8_install.xml文件。
如何使用
在module=”Zhongdayun采集=”Batch采集,在这个菜单中,输入关键词,输入数量,可以得到一些随机相关的文章。使用方式非常无脑,非常适合新手。
dedecms、中大云采集的好用采集插件(图7-3)
导入数据库
中大云的数据库在某些情况下可能无法正常安装数据库。因此,可能需要手动执行sql。UTF8-install.xml 中加密的 sql 文本可以使用 php 的 base64_decode() 函数进行解密。
dedecms、中大云采集的好用采集插件(图7-4)
执行sql的方式取决于你的选择。苏南大叔推荐你使用navicat。
php72下兼容中大云采集
由于中大运采集在php72下无法正常运行,所以可以开启dede调试模式,方便调试。
修改文件:/include/common.inc.php。调试方法如下:修改常量DEDE_ENVIRONMENT为dev。
define('DEDE_ENVIRONMENT', 'dev');
错误信息一:mysql_escape_string()
您可能会看到以下错误消息:
Uncaught Error: Call to undefined function mysql_escape_string()
php7 不再支持 php_mysql 扩展。既然没有 php_mysql 扩展,自然也就没有 mysql_escape_string 函数。
解决方案是兼容mysql_escape_string。修改文件:/dede/hzw/common.fun.php。添加以下兼容代码。
if(!function_exists('mysql_escape_string')){
function mysql_escape_string($data){
return addslashes(trim($data));
}
}
dedecms、中大云采集的好用采集插件(图7-5)
错误消息二:不推荐使用的构造函数警告
**Deprecated**: Methods with the same name as their class will not be constructors in a future version of PHP; hzw_cuserLogin has a deprecated constructor in **/dede/hzw_send_archives.php** on line **8**
修改文件/dede/hzw_send_archives.php,修改构造函数的编写方式。(将同名函数转成__construct)
//public function hzw_cuserLogin($userID)
function __construct($userID){
$this->userID=$userID;
}
dedecms,中大云采集的好用采集插件(图7-6)
库存处于暂存状态
因为一般情况下,必须先发布中大云采集的充电提醒信息,才能修改提醒信息。这个设定很不人性化。因此,苏南叔将他设置为:采集完成后,将处于待释放状态,这种情况下,充电信息不会被释放。原则上,档案表中的 arcrank 字段设置为 -1。
if(!empty($GLOBALS['cfg_version']) && stripos($GLOBALS['cfg_version'],'V56')===false)
{
$query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle,color,writer,source,litpic,pubdate,senddate,mid,voteid,notpost,description,keywords,filename,dutyadmin,weight) VALUES ('$arcID','$cid','0','$sortrank','','0','$channelid','-1','$click','0','$title','','','$writer','','$litpic','$pubdate','$senddate','$adminid','0','0','$description','$keywords','','$adminid','0');";
} else {
$query = "INSERT INTO `#@__archives`(id,typeid,typeid2,sortrank,flag,ismake,channel,arcrank,click,money,title,shorttitle,color,writer,source,litpic,pubdate,senddate,mid,notpost,description,keywords,filename,dutyadmin,weight) VALUES ('$arcID','$cid','0','$sortrank','','0','$channelid','-1','$click','0','$title','','','$writer','','$litpic','$pubdate','$senddate','$adminid','0','$description','$keywords','','$adminid','0');";
}
dedecms、中大云采集的好用采集插件(图7-7)
额外的信息
: 这里是 [作者] 的可见内容
总结
中大云采集的这种方法,非常适合小白初级编辑。不需要写规则,只需要定义关键词。
苏南大叔偶尔会写几篇关于德德经历的文章。不过,苏南大叔并不能真正欣赏dede的代码,而只能欣赏dede产品的成功。更多dede相关的话,请偶尔关注一下苏南大叔写的经验文章:
【源码】本文代码片段及相关软件,详情请点这里
【绝密】秘籍文章的入口,只传授给命中注定的人
php dede
云采集( 易蜂智能云采集LOGO图片已有48人成功下载点(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2022-03-05 19:21
易蜂智能云采集LOGO图片已有48人成功下载点(图))
亿丰智能云采集是一个全新的革命性网络爬虫系统。它将整个互联网视为数据源,智能地从中提取海量结构化数据,然后将互联网数据转化为内部数据库。一风云采集云端SaaS和DaaS,无需部署,几分钟内自定义爬虫规则,自动分布式爬取云端各类网站和APP,爬取海量网页,从从网页和APP中提取HTML结构化数据,结果直接存储在云端数据库中。它还可以与公司现有的数据仓库无缝集成,用于数据分析和业务决策。
注:中文翻译来自GOOGLE
亿丰智能云采集是一个全新的革命性网络爬虫系统。它将整个互联网视为数据源,智能地从中提取海量结构化数据,然后将互联网数据转化为内部数据库。一风云采集云端SaaS和DaaS,无需部署,几分钟内自定义爬虫规则,自动分布式爬取云端各类网站和APP,爬取海量网页,从从网页和APP中提取HTML结构化数据,结果直接存储在云端数据库中。它还可以与公司现有的数据仓库无缝集成,用于数据分析和业务决策。
易风云采集的智能识别和数据提取技术,可以智能识别不同性质的网页,快速实现数据可视化采集。易风云采集将网络数据的采集和整合自动化,大大降低了数据获取成本,提高了数据采集的效率。用户可以通过多种方式获取存储在云端的数据,包括导出下载(支持csv、json、Excel等格式)、推送(FTP、RSS、Email等)、API访问、云数据库访问、数据仓库集成等。亿丰智能云采集系统可广泛应用于电子商务、外贸、金融、市场分析、营销、房地产、汽车、舆情监测、招聘、社交等各个行业。
易蜂云采集插件LOGO图片
48人下载成功,点此进入下载页面 查看全部
云采集(
易蜂智能云采集LOGO图片已有48人成功下载点(图))
亿丰智能云采集是一个全新的革命性网络爬虫系统。它将整个互联网视为数据源,智能地从中提取海量结构化数据,然后将互联网数据转化为内部数据库。一风云采集云端SaaS和DaaS,无需部署,几分钟内自定义爬虫规则,自动分布式爬取云端各类网站和APP,爬取海量网页,从从网页和APP中提取HTML结构化数据,结果直接存储在云端数据库中。它还可以与公司现有的数据仓库无缝集成,用于数据分析和业务决策。
注:中文翻译来自GOOGLE
亿丰智能云采集是一个全新的革命性网络爬虫系统。它将整个互联网视为数据源,智能地从中提取海量结构化数据,然后将互联网数据转化为内部数据库。一风云采集云端SaaS和DaaS,无需部署,几分钟内自定义爬虫规则,自动分布式爬取云端各类网站和APP,爬取海量网页,从从网页和APP中提取HTML结构化数据,结果直接存储在云端数据库中。它还可以与公司现有的数据仓库无缝集成,用于数据分析和业务决策。
易风云采集的智能识别和数据提取技术,可以智能识别不同性质的网页,快速实现数据可视化采集。易风云采集将网络数据的采集和整合自动化,大大降低了数据获取成本,提高了数据采集的效率。用户可以通过多种方式获取存储在云端的数据,包括导出下载(支持csv、json、Excel等格式)、推送(FTP、RSS、Email等)、API访问、云数据库访问、数据仓库集成等。亿丰智能云采集系统可广泛应用于电子商务、外贸、金融、市场分析、营销、房地产、汽车、舆情监测、招聘、社交等各个行业。
易蜂云采集插件LOGO图片
48人下载成功,点此进入下载页面
云采集(众大智能云采集discuz插件,,成熟稳定等特性)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-02-23 23:16
其他相关
中大运采集破解版-中大运采集插件下载v9.7.0正式版--pc6 2020年6月19日中大运采集插件-in,中大云采集插件是一个数据采集插件,中大云采集插件易学、易懂、好用、成熟、 stable等采集器旧系统会出现在帖子、传送门、群页面顶部:[中大运采集下载]中大运采集pluginv9.7.0破解版-开心电玩2020年6月19日中大运采集是一款非常好用的资料采集插件,此版本完全免费供用户学习,易懂,易上手使用,成熟稳定的特点。中大云采集操作简单,2020win7会出现在发帖、门户、群的页面顶部:中大智能云采集discuz插件免费下载_中大智能云采集@ >discuz2012 2018年12月26日,安装中大智慧云采集discuz插件后,在论坛和门户发文章时,顶部会出现一个采集控制面板,进入关键词或者网站可以是智能云采集任何你想要的内容,今日头条和电脑城:中大运采集-知物应用中大运采集【温馨提示】 01.安装此插件后,您可以采集[当前热点内容][当前新闻头条][知乎][搜狐][网易][ZAKER新闻][腾讯网] 【搜狗提速:中大运采集外挂电脑端官方2020最新版免费下载2020年6月20日中大运采集外挂是数据采集外挂,中大运< @采集 插件易学易懂好用,成熟稳定等。采集器控制面板会出现在发布帖子、传送门、群的页面顶部,进入快猫:中大云采集插件破解版|中大云采集(网站内容采集工具)2018年5月10日下载中大云采集是一个强大的网站内容采集工具,集成了Discuz, 织梦dedecms、phpcms、Empirecms作为插件在建站系统中,任何内容都可以根据关键词自动采集 @>或URL,可代系统认证:中大云采集插件破解版|中大云采集插件免费版v9.7.0下载_June 19, 2020 中大云采集插件是一个非常好用的采集工具,可以帮助用户去采集论坛的帖子内容,也可以批量注册,评论等功能。 采集 函数实现自动采集。 discuz采集plugin v9.5|中大运采集discuz采集plugin 2018年10月29日中大运采集Discuz版是一个特殊的批量采集软件由 discuz 开发。
安装此插件后,采集器 控制面板将出现在发布帖子、门户和群组的页面顶部。输入关键词或URL智能采集内容一键重载:public大运采集插件破解版|中大运采集织梦无限V9. 7.0 Free June 20, 20, 14、@ >众大运采集可以一键获取当日实时热点内容,然后一键发布。 15、不限制采集的内容数量,不限制采集的使用次数,让你的网站快速填满优质内容。 16、插件win7: Discuz中大云采集插件v9.6.5_discuz插件-精准像素中大云采集使用说明01、安装后这个插件,你可以自己写采集规则或者输入你的网站关键词,一键批量采集任何内容到你的论坛版块或者门户版块,群集体发布。 02、可以下载为147: 查看全部
云采集(众大智能云采集discuz插件,,成熟稳定等特性)
其他相关
中大运采集破解版-中大运采集插件下载v9.7.0正式版--pc6 2020年6月19日中大运采集插件-in,中大云采集插件是一个数据采集插件,中大云采集插件易学、易懂、好用、成熟、 stable等采集器旧系统会出现在帖子、传送门、群页面顶部:[中大运采集下载]中大运采集pluginv9.7.0破解版-开心电玩2020年6月19日中大运采集是一款非常好用的资料采集插件,此版本完全免费供用户学习,易懂,易上手使用,成熟稳定的特点。中大云采集操作简单,2020win7会出现在发帖、门户、群的页面顶部:中大智能云采集discuz插件免费下载_中大智能云采集@ >discuz2012 2018年12月26日,安装中大智慧云采集discuz插件后,在论坛和门户发文章时,顶部会出现一个采集控制面板,进入关键词或者网站可以是智能云采集任何你想要的内容,今日头条和电脑城:中大运采集-知物应用中大运采集【温馨提示】 01.安装此插件后,您可以采集[当前热点内容][当前新闻头条][知乎][搜狐][网易][ZAKER新闻][腾讯网] 【搜狗提速:中大运采集外挂电脑端官方2020最新版免费下载2020年6月20日中大运采集外挂是数据采集外挂,中大运< @采集 插件易学易懂好用,成熟稳定等。采集器控制面板会出现在发布帖子、传送门、群的页面顶部,进入快猫:中大云采集插件破解版|中大云采集(网站内容采集工具)2018年5月10日下载中大云采集是一个强大的网站内容采集工具,集成了Discuz, 织梦dedecms、phpcms、Empirecms作为插件在建站系统中,任何内容都可以根据关键词自动采集 @>或URL,可代系统认证:中大云采集插件破解版|中大云采集插件免费版v9.7.0下载_June 19, 2020 中大云采集插件是一个非常好用的采集工具,可以帮助用户去采集论坛的帖子内容,也可以批量注册,评论等功能。 采集 函数实现自动采集。 discuz采集plugin v9.5|中大运采集discuz采集plugin 2018年10月29日中大运采集Discuz版是一个特殊的批量采集软件由 discuz 开发。
安装此插件后,采集器 控制面板将出现在发布帖子、门户和群组的页面顶部。输入关键词或URL智能采集内容一键重载:public大运采集插件破解版|中大运采集织梦无限V9. 7.0 Free June 20, 20, 14、@ >众大运采集可以一键获取当日实时热点内容,然后一键发布。 15、不限制采集的内容数量,不限制采集的使用次数,让你的网站快速填满优质内容。 16、插件win7: Discuz中大云采集插件v9.6.5_discuz插件-精准像素中大云采集使用说明01、安装后这个插件,你可以自己写采集规则或者输入你的网站关键词,一键批量采集任何内容到你的论坛版块或者门户版块,群集体发布。 02、可以下载为147:
云采集(要来一个事:云采集是如何颠覆整个爬虫界的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2022-02-17 09:17
摘要:其实云采集就是这么简单的一个东西,就是通过云采集服务器的控制,给每个服务器分配采集任务,控制它的采集 通过指令。但是,由于优采云是第一个云采集技术,也是用户量非常大的云采集平台,所以云采集、优采云已经走了好。很长的路。因此,我们一直坚持只有优采云的云采集才是真正的云采集。
先说一件事:“云采集”这个概念是我们优采云在2013年提出的,先于国内外。
2013年,优采云自2013年成立以来,创造了自己的云采集技术。我们可以在优采云的版本更新记录中找到这方面的痕迹。只是因为自己创业,没有足够的IP意识,也没有钱和精力去申请相关的知识产权。因此,许多竞争公司现在都在吹嘘自己拥有云采集 技术,但实际上许多公司并没有。了解真云采集技术。
2013-12-06 版本更新记录
2014-05-01 版本更新记录
今天我们要讲的就是云采集是如何颠覆整个爬虫世界的。当然,因为我们优采云是当事人,所以笔者可以带大家回顾一下云采集爬虫这几年的发展历程。
云采集是在什么背景下诞生的?
2006 年 8 月 9 日,谷歌 CEO Eric Schmidt 在搜索引擎大会(SES San Jose 2006))上首次提出了“云计算”的概念。谷歌“云计算”起源于谷歌工程师克里斯托弗·比西利亚的“谷歌101”项目。
直到 2008 年,中国 IT 行业才开始谈论云计算。笔者作为2007年计算机专业的毕业生,刚好赶上了这波热潮,但说实话,当时只是一个概念,还没有人看到真正的产品。,所以我不知道它是什么。顶多听说过Google的Google Charts、Google Words等等。当时,我并不了解这些产品的用途。不就是word和excel的网页版,不是微软的好用。
但是经过多年的工作,我意识到微软的word和excel只能在Windows机器上使用。如果你想在苹果电脑上使用它们,你必须努力工作。但是网页版不一样,它是跨平台的,你习惯了,到处都可以用,还可以把数据存到云端。更重要的是,帮助我们提高工作效率或组织管理的工作不再仅仅依靠软件,而是依靠云服务。
随着云计算的诞生,行业也诞生了以下三个层次的服务
基础设施级服务 (IaaS),
平台级服务 (PaaS),
软件级服务 (SaaS)。
我们可以简单地将SaaS理解为一种在云中提供标准化产品的服务模型。因为它的标准化,不管是一个企业使用还是100家企业使用,都是一个开发成本。这对产品在一定场景下的通用性有非常高的要求,但也大大提高了产品在市场上的竞争力。SaaS模式的效果与企业自建信息系统的效果基本相同,但节省了大量资金,大大降低了企业信息化的门槛和风险。
很多SaaS公司提供月费和年费的模式,不同于以往的软件以项目的形式,很受企业主的欢迎,所以在接下来的十年里,也演变成一种主流的企业服务。形式。
现在市场上有很多优秀的SaaS公司。国际知名的Salesforce,类似于CRM的鼻祖。我们国内的CRM专家,比如文档领域的石墨、表单领域的金数据等,在SaaS领域都做得特别好。的企业。
优采云创新利用云采集技术,提供SaaS运营模式,正是在云计算和SaaS趋势的背景下。用户只需在客户端上传采集规则,调用云分布式服务即可执行采集,每个云服务器都会按照采集规则到采集@ >。所以 优采云 团队将这个 采集 模型命名为“Cloud采集”
为什么“Cloud采集”会诞生
优采云出来创业的时候,市场上有非常成熟强大的竞争对手。但他们以传统软件运营商的模式运作,主要是以销售授权码的形式。如果用户想在计算机上运行它们,他们必须购买他的授权码。就像我们早期使用Word 2003、2007时,经常需要上网搜索破解密码。当时的竞争对手如火如荼,但它只是一个客户端软件,只能在本地计算机采集上进行。
优采云创始人刘宝强keven拥有多年在外企和海外工作的经验。他也是某数据方向的研发工程师采集。他想制作一个通用网页采集 产品来替代公司编写的大部分采集 代码。他深知各种采集技术的优缺点、问题和瓶颈。
凯文当时也知道他的竞争对手的实力。那个时候,他不敢想象自己能做出更好的采集产品,因为对手太强了,采集的世界里没有人。我不知道。但他知道,要超越竞争对手,往往不是遵循策略,而是颠覆并采用与他们的疲惫不同的思维方式。
根据Keven的分析,传统的从网络请求数据的方式仍然是http post和get请求。这确实是当时网页采集的主流模式,而且这种形式效率特别高,但是这种模式的复杂度很高。它也非常高。普通人是无法操作和配置的。能理解这套理论的人,大多是有发展背景的人。
他知道在大公司里,大部分做数据采集工作的人都不是电脑开发人员,所以他将自己的采集产品定位为普通人可以使用的采集产品,通过界面定位,拖放,可以配置规则。经过半年的研究,他突破了所有的难关,实现了所见即所得的采集工作流配置模式。
但是问题也随之而来,因为方法是通过浏览器加载网页然后获取数据,所以竞品可能一次请求就能获取数据,而且因为优采云需要加载整个网页,这可能涉及到数百个请求,所以在 采集 速度方面,似乎很慢。(可以使用httpwatch查看浏览器打开网页涉及多少请求)
解决可用性问题后遇到速度问题?
如何解决?
如果云端有多台机器同时挖矿,甚至在规则中拆分URL列表,让云端服务器同时分布采集,那么速度可以增加了 N 倍以上。这种方式是可行的,但是这种方式带来了另一个问题。
速度问题解决后会出现成本问题?
如何解决?
凯文判断,如果租用 10 台云服务器,通过共享经济的概念平均分摊成本,其实每个用户每月只需要几百块钱。与数据的价值相比,远远大于这个投入,应该有用户愿意为它买单。
而且成本问题应该不是大问题。根据摩尔定律,硬件成本只会越来越低。情况确实如此。包括后期,优采云通过与主流云服务商合作,有效控制了整个云服务器的成本,帮助用户降低了这个成本。
基于此,2013年Q4,在数据领域采集,优采云领先国内外龙头企业,创新打造采集模式-云采集 .
云背后的发展历程采集
其实云采集就是这么简单的一个东西,就是通过云采集服务器的控制,给每一个服务器分配采集任务,控制它的采集@ > 通过说明。但是优采云是创新的云采集技术和云采集平台,用户量非常大,所以云采集、优采云没了很长很长的路。因此,我们一直坚持只有优采云的云采集才是真正的云采集。
1 突破多项技术难点
优采云在5年的运营过程中,我们逐渐突破了云端的各种问题采集。这里的很多问题在大数据面前都不会出现。我举几个例子:
有一些项目标榜自己拥有云采集技术,但实际测试时,漏洞百出。比如我们可以控制100台服务器采集data,但是如果只有一个datastore支持导出数据,就会出现导出数据比采集慢100倍的窘境。只能看到库中的数据,不能移动。
有人认为,如果有一个服务器运行在云采集 中,则称为云采集。但他不知道,当同时有几十万台服务器时采集,他背后需要大数据存储解决方案的支持。只有这样采集接收到的数据才能不遗漏地存入数据库,有序存储,便于后期检索、查询和导出。
由于采集的网页数据状态不同,云端采集需要动态分配,需要做很多前期工作。有时一些网站 有防止采集 的策略。在采集之前,他们是否可以判断对方网站对你的一些措施和判断,或者如果他们在采集过程中动态调整服务器运行策略,也就是也是对云采集 解决方案的测试。
2 继续提供稳定的采集和导出服务
优采云现在全球有5000多台服务器,每天采集和导出的数据都由T计算服务给全球所有语言和领域的采集用户世界。对于企业级产品来说,除了技术,提供稳定运维的能力是一个关键问题。
优采云有多个运维后台,随时监控整个服务器集群中每台采集服务器的状态。>生产环境和数据保持相对稳定。
如此庞大的云服务器采集集群是任何竞争对手都无法比拟的,而在这个庞大的集群面前,优采云依然保持着稳定的采集和出口服务。
3 其他资格
优采云在中国大数据行业,连续三年在数据采集领域排名第一,足以证明优采云在数据领域的长期积累和贡献采集。
介绍的最后一段可以理解为又硬又宽,哈哈,我们知道云采集是怎么诞生的,是在什么条件下诞生的,还有主要的技术难点,我们一路突破了哪些问题大大地。回顾这段历史,我想告诉大家,我们优采云一直致力于提供稳定的云采集服务,还有很长的路要走,我们的压力也越来越大,我们也在不断的优化,这个过程有点坎坷,还需要我们优采云用户的大力支持,我们会尽最大努力给予反馈。
一起努力! 查看全部
云采集(要来一个事:云采集是如何颠覆整个爬虫界的)
摘要:其实云采集就是这么简单的一个东西,就是通过云采集服务器的控制,给每个服务器分配采集任务,控制它的采集 通过指令。但是,由于优采云是第一个云采集技术,也是用户量非常大的云采集平台,所以云采集、优采云已经走了好。很长的路。因此,我们一直坚持只有优采云的云采集才是真正的云采集。
先说一件事:“云采集”这个概念是我们优采云在2013年提出的,先于国内外。
2013年,优采云自2013年成立以来,创造了自己的云采集技术。我们可以在优采云的版本更新记录中找到这方面的痕迹。只是因为自己创业,没有足够的IP意识,也没有钱和精力去申请相关的知识产权。因此,许多竞争公司现在都在吹嘘自己拥有云采集 技术,但实际上许多公司并没有。了解真云采集技术。
2013-12-06 版本更新记录
2014-05-01 版本更新记录
今天我们要讲的就是云采集是如何颠覆整个爬虫世界的。当然,因为我们优采云是当事人,所以笔者可以带大家回顾一下云采集爬虫这几年的发展历程。
云采集是在什么背景下诞生的?
2006 年 8 月 9 日,谷歌 CEO Eric Schmidt 在搜索引擎大会(SES San Jose 2006))上首次提出了“云计算”的概念。谷歌“云计算”起源于谷歌工程师克里斯托弗·比西利亚的“谷歌101”项目。
直到 2008 年,中国 IT 行业才开始谈论云计算。笔者作为2007年计算机专业的毕业生,刚好赶上了这波热潮,但说实话,当时只是一个概念,还没有人看到真正的产品。,所以我不知道它是什么。顶多听说过Google的Google Charts、Google Words等等。当时,我并不了解这些产品的用途。不就是word和excel的网页版,不是微软的好用。
但是经过多年的工作,我意识到微软的word和excel只能在Windows机器上使用。如果你想在苹果电脑上使用它们,你必须努力工作。但是网页版不一样,它是跨平台的,你习惯了,到处都可以用,还可以把数据存到云端。更重要的是,帮助我们提高工作效率或组织管理的工作不再仅仅依靠软件,而是依靠云服务。
随着云计算的诞生,行业也诞生了以下三个层次的服务
基础设施级服务 (IaaS),
平台级服务 (PaaS),
软件级服务 (SaaS)。
我们可以简单地将SaaS理解为一种在云中提供标准化产品的服务模型。因为它的标准化,不管是一个企业使用还是100家企业使用,都是一个开发成本。这对产品在一定场景下的通用性有非常高的要求,但也大大提高了产品在市场上的竞争力。SaaS模式的效果与企业自建信息系统的效果基本相同,但节省了大量资金,大大降低了企业信息化的门槛和风险。
很多SaaS公司提供月费和年费的模式,不同于以往的软件以项目的形式,很受企业主的欢迎,所以在接下来的十年里,也演变成一种主流的企业服务。形式。
现在市场上有很多优秀的SaaS公司。国际知名的Salesforce,类似于CRM的鼻祖。我们国内的CRM专家,比如文档领域的石墨、表单领域的金数据等,在SaaS领域都做得特别好。的企业。
优采云创新利用云采集技术,提供SaaS运营模式,正是在云计算和SaaS趋势的背景下。用户只需在客户端上传采集规则,调用云分布式服务即可执行采集,每个云服务器都会按照采集规则到采集@ >。所以 优采云 团队将这个 采集 模型命名为“Cloud采集”
为什么“Cloud采集”会诞生
优采云出来创业的时候,市场上有非常成熟强大的竞争对手。但他们以传统软件运营商的模式运作,主要是以销售授权码的形式。如果用户想在计算机上运行它们,他们必须购买他的授权码。就像我们早期使用Word 2003、2007时,经常需要上网搜索破解密码。当时的竞争对手如火如荼,但它只是一个客户端软件,只能在本地计算机采集上进行。
优采云创始人刘宝强keven拥有多年在外企和海外工作的经验。他也是某数据方向的研发工程师采集。他想制作一个通用网页采集 产品来替代公司编写的大部分采集 代码。他深知各种采集技术的优缺点、问题和瓶颈。
凯文当时也知道他的竞争对手的实力。那个时候,他不敢想象自己能做出更好的采集产品,因为对手太强了,采集的世界里没有人。我不知道。但他知道,要超越竞争对手,往往不是遵循策略,而是颠覆并采用与他们的疲惫不同的思维方式。
根据Keven的分析,传统的从网络请求数据的方式仍然是http post和get请求。这确实是当时网页采集的主流模式,而且这种形式效率特别高,但是这种模式的复杂度很高。它也非常高。普通人是无法操作和配置的。能理解这套理论的人,大多是有发展背景的人。
他知道在大公司里,大部分做数据采集工作的人都不是电脑开发人员,所以他将自己的采集产品定位为普通人可以使用的采集产品,通过界面定位,拖放,可以配置规则。经过半年的研究,他突破了所有的难关,实现了所见即所得的采集工作流配置模式。
但是问题也随之而来,因为方法是通过浏览器加载网页然后获取数据,所以竞品可能一次请求就能获取数据,而且因为优采云需要加载整个网页,这可能涉及到数百个请求,所以在 采集 速度方面,似乎很慢。(可以使用httpwatch查看浏览器打开网页涉及多少请求)
解决可用性问题后遇到速度问题?
如何解决?
如果云端有多台机器同时挖矿,甚至在规则中拆分URL列表,让云端服务器同时分布采集,那么速度可以增加了 N 倍以上。这种方式是可行的,但是这种方式带来了另一个问题。
速度问题解决后会出现成本问题?
如何解决?
凯文判断,如果租用 10 台云服务器,通过共享经济的概念平均分摊成本,其实每个用户每月只需要几百块钱。与数据的价值相比,远远大于这个投入,应该有用户愿意为它买单。
而且成本问题应该不是大问题。根据摩尔定律,硬件成本只会越来越低。情况确实如此。包括后期,优采云通过与主流云服务商合作,有效控制了整个云服务器的成本,帮助用户降低了这个成本。
基于此,2013年Q4,在数据领域采集,优采云领先国内外龙头企业,创新打造采集模式-云采集 .
云背后的发展历程采集
其实云采集就是这么简单的一个东西,就是通过云采集服务器的控制,给每一个服务器分配采集任务,控制它的采集@ > 通过说明。但是优采云是创新的云采集技术和云采集平台,用户量非常大,所以云采集、优采云没了很长很长的路。因此,我们一直坚持只有优采云的云采集才是真正的云采集。
1 突破多项技术难点
优采云在5年的运营过程中,我们逐渐突破了云端的各种问题采集。这里的很多问题在大数据面前都不会出现。我举几个例子:
有一些项目标榜自己拥有云采集技术,但实际测试时,漏洞百出。比如我们可以控制100台服务器采集data,但是如果只有一个datastore支持导出数据,就会出现导出数据比采集慢100倍的窘境。只能看到库中的数据,不能移动。
有人认为,如果有一个服务器运行在云采集 中,则称为云采集。但他不知道,当同时有几十万台服务器时采集,他背后需要大数据存储解决方案的支持。只有这样采集接收到的数据才能不遗漏地存入数据库,有序存储,便于后期检索、查询和导出。
由于采集的网页数据状态不同,云端采集需要动态分配,需要做很多前期工作。有时一些网站 有防止采集 的策略。在采集之前,他们是否可以判断对方网站对你的一些措施和判断,或者如果他们在采集过程中动态调整服务器运行策略,也就是也是对云采集 解决方案的测试。
2 继续提供稳定的采集和导出服务
优采云现在全球有5000多台服务器,每天采集和导出的数据都由T计算服务给全球所有语言和领域的采集用户世界。对于企业级产品来说,除了技术,提供稳定运维的能力是一个关键问题。
优采云有多个运维后台,随时监控整个服务器集群中每台采集服务器的状态。>生产环境和数据保持相对稳定。
如此庞大的云服务器采集集群是任何竞争对手都无法比拟的,而在这个庞大的集群面前,优采云依然保持着稳定的采集和出口服务。
3 其他资格
优采云在中国大数据行业,连续三年在数据采集领域排名第一,足以证明优采云在数据领域的长期积累和贡献采集。
介绍的最后一段可以理解为又硬又宽,哈哈,我们知道云采集是怎么诞生的,是在什么条件下诞生的,还有主要的技术难点,我们一路突破了哪些问题大大地。回顾这段历史,我想告诉大家,我们优采云一直致力于提供稳定的云采集服务,还有很长的路要走,我们的压力也越来越大,我们也在不断的优化,这个过程有点坎坷,还需要我们优采云用户的大力支持,我们会尽最大努力给予反馈。
一起努力!
云采集(这是一个数据驱动商业发展的时代。(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-02-16 22:14
这是一个数据驱动业务发展的时代。
数据挖掘和分析不再仅仅是排他性的,它正逐渐成为广大中小企业的基本需求,也越来越迫切。并且随着网络爬虫的普及,云计算计算能力的提高,以及机器学习算法的发展,数据挖掘技能逐渐普及。广大中小企业也可以基于数据驱动提供更好的服务和产品,从而获得更大的发展。
数据挖掘实际上是一个很大的概念。本文主要讨论“挖掘”,或者说“网络爬虫”和“网络抓取”,比较容易理解。因为除了少数产品可以获取海量数据外,大部分企业都需要从公共数据中获取外部数据,主要是互联网,用于市场分析、舆情监测、竞品分析等。
在我看来,我更喜欢称它为“data采集”。分为“采集”和“采集”两个步骤。
对应的“采集”主要是数据的获取,可以通过多种方式获取。网页爬取为主,还有数据合作和采购。
对应的“集合”就是对数据进行清洗、连接、整合,将价值密度低的数据转化为价值密度高的数据。
数据采集 发展阶段
据笔者分析,数据采集从1990年代开始,在相当长的一段时间内,一直是技术开发者的一项特殊技能。但随着云计算、大数据甚至人工智能的发展,这个技能变得简单易用,就像“老王谢堂千言飞入寻常百姓家”。主要经历四个阶段。
熟悉爬虫的攻城狮会想说一堆喜欢的:Scrapy、WebMagic、Nutch、Heritrix等等,相信Github上的爬虫框架不下30个。它们的共同特点是:门槛高,仅供开发者使用,学习成本和维护成本高,企业组建爬虫团队往往成本高昂。
用户需要下载客户端并具备一定的HTML、正则表达式和CSS能力。国内最早的客户端叫做,属于一代爬虫工具,对html和正则表达式的要求还是比较高的(作者亲测)。
He等二代产品提供可视化爬取服务,通过点击爬取所需数据。其特点是:门槛进一步降低。对于非专业的开发者,经过一定的学习,可以自己爬取所需的公开数据。但是,它主要针对个人用户。由于用户客户端的限制,难以进行大规模连续爬取,数据存储和分析难以平衡。
首先,用户体验大大提升。他们中的大多数采用点击式方法。用户所见即所得。他们可以在不编写代码或了解 HTML、正则表达式和 CSS 样式的情况下自定义所需的爬虫。其次,无需担心自己电脑的限制。爬虫运行的云端可以固定时间,也可以爬取大量数据。您甚至可以在云中进行一定程度的数据清理和集成。
目前国外数据采集项目大多采用前端点击方式和后端云服务模式。以下为国外项目列表:
目前国内data采集项目分为三种:
1、基于客户端或插件的云采集服务。
客户端模式代表了项目的和谐。它不是单纯依赖客户端的计算资源,而是使用客户端的方式,更好更快的可视化和点击用户体验。同时将爬取的服务转移到云端,提供更大的数据爬取能力和数据整合能力。
浏览器插件方式例如是通过安装浏览器插件实现前端点击方式和后端云服务方式。
2.基于Web的云采集服务
用户无需安装,直接对网友进行点击操作,云端进行爬虫服务。这种方法的优点是用户可以随时随地使用,简单方便。国外很多项目都采用这种模式,比如国内采用这种模式的项目就是。但缺点是网页需要先在云端加载渲染,再呈现给用户,需要提供者大量的计算资源,而且速度往往很慢。
3. Cloud for Developers采集云服务开发
目前,一家名为China的公司正在提供此类服务。具备Java能力的开发者可以在平台上开发爬虫;没有开发能力的用户可以在爬虫市场购买或定制爬虫进行开发。
目前市场上,基本上80%的人都是采集20%的网络数据,比如企业信息、电商、O2O等,而这些网络数据往往具有很强的反爬能力。
笔者认为目前数据采集还处于3.阶段,还没有形成4.0阶段,即提供数据采集@ >、清洗、连接、分析等综合数据服务能力。
从3.0到4.0的阶段,在笔者看来,不仅仅是技术上的升级。不同行业、不同场景需要不同的数据,往往难以标准化,导致定制化,难以形成标准产品,难以大规模扩展。场景变化带来的技术挑战将凸显出来,因为真实场景所需的技术不是简单的升级,而是颠覆性的创新。
至于未来是否会完成跳跃,未来又会如何为大家服务,目前还很难说。目前国外import.io、dexi.io、Connotate、国内优采云、优采云、早书都在进行自己的探索。
合法性探讨
数据爬取的合法性在互联网领域一直存在争议,部分不法分子利用数据爬取工具进行黑商交易也是事实。数据抓取就像一把锋利的双刃剑,主要取决于用户是否以有益的方式应用它。
其实互联网数据爬取的主要原理就是Robots协议,也就是爬虫协议。网站通过Robots协议,告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。这原本主要针对搜索引擎公司,大家自觉遵守约定。
随着data采集范围的扩大,这个约定逐渐被打破,但也有既定的规则,广大data采集公司都应该遵守。
1、采集应该是互联网上的公开数据,数据的使用不能用于复制网站信息,或者干脆出售数据。更允许的情况是对多方采集的公开数据进行整合分析,形成数据分析服务。
2、采集的强度不应损害当前网站的性能,无形中增加目标网站的维护成本,甚至造成损失。
此外,我国刚刚于6月1日实施了《中华人民共和国互联网安全法》,这是我国网络领域的基本法,明确加强个人信息保护,打击网络诈骗。
《网络安全法》共7章79条,对个人信息泄露问题作出规定:网络产品和服务具有采集用户信息功能的,提供者应当明示并征得用户同意;网络运营者不得泄露、篡改、损毁其采集。任何个人和组织不得窃取或者以其他非法方式获取个人信息,不得非法出售或者非法向他人提供个人信息。这可能是对数据采集 公司更具方向性的指导。
数据采集发展到现在,怎么现在爆发了?
随着云计算、大数据、人工智能的发展,数据采集作为一种重要的数据手段,已成为企业的迫切需求。首当其冲的是中小企业的数据采集团队。不再需要维护一个完整的团队,大大降低了公司的成本。可以节省用户数据产品的开发,提升产品价值。对于普通个人来说,可以定制自己的data采集解决方案,门槛不高。更多行业、更多场景将被广泛应用。
人工智能的服务形态告诉我们,对于那些信息完备(Information-Complete)的领域,机器最终会超越并取代人类;
对于那些信息不完整(Information-Incomplete)的领域,也将通过人机协作推动新的发展;
对于那些抽象思维(Information-Free)的领域,仍然以人类为主,机器提供了一定的帮助。
Data采集 属于 Information-Complete 领域。机器可以在数据采集、清洗和整合上完全替代人类,然后通过与人类协作进行数据分析和预测。这将是即将发生的事情。
关于机器人云:
(微信公众号:vc-smart)是专业的创投机构投资管理服务商,帮助投资机构高效便捷管理投资项目,开发优质项目源,提供创投数据挖掘分析服务,助力投资管理人员可以快速获取项目、行业信息,协助行业分析。返回搜狐,查看更多 查看全部
云采集(这是一个数据驱动商业发展的时代。(组图))
这是一个数据驱动业务发展的时代。
数据挖掘和分析不再仅仅是排他性的,它正逐渐成为广大中小企业的基本需求,也越来越迫切。并且随着网络爬虫的普及,云计算计算能力的提高,以及机器学习算法的发展,数据挖掘技能逐渐普及。广大中小企业也可以基于数据驱动提供更好的服务和产品,从而获得更大的发展。
数据挖掘实际上是一个很大的概念。本文主要讨论“挖掘”,或者说“网络爬虫”和“网络抓取”,比较容易理解。因为除了少数产品可以获取海量数据外,大部分企业都需要从公共数据中获取外部数据,主要是互联网,用于市场分析、舆情监测、竞品分析等。
在我看来,我更喜欢称它为“data采集”。分为“采集”和“采集”两个步骤。
对应的“采集”主要是数据的获取,可以通过多种方式获取。网页爬取为主,还有数据合作和采购。
对应的“集合”就是对数据进行清洗、连接、整合,将价值密度低的数据转化为价值密度高的数据。
数据采集 发展阶段
据笔者分析,数据采集从1990年代开始,在相当长的一段时间内,一直是技术开发者的一项特殊技能。但随着云计算、大数据甚至人工智能的发展,这个技能变得简单易用,就像“老王谢堂千言飞入寻常百姓家”。主要经历四个阶段。
熟悉爬虫的攻城狮会想说一堆喜欢的:Scrapy、WebMagic、Nutch、Heritrix等等,相信Github上的爬虫框架不下30个。它们的共同特点是:门槛高,仅供开发者使用,学习成本和维护成本高,企业组建爬虫团队往往成本高昂。
用户需要下载客户端并具备一定的HTML、正则表达式和CSS能力。国内最早的客户端叫做,属于一代爬虫工具,对html和正则表达式的要求还是比较高的(作者亲测)。
He等二代产品提供可视化爬取服务,通过点击爬取所需数据。其特点是:门槛进一步降低。对于非专业的开发者,经过一定的学习,可以自己爬取所需的公开数据。但是,它主要针对个人用户。由于用户客户端的限制,难以进行大规模连续爬取,数据存储和分析难以平衡。
首先,用户体验大大提升。他们中的大多数采用点击式方法。用户所见即所得。他们可以在不编写代码或了解 HTML、正则表达式和 CSS 样式的情况下自定义所需的爬虫。其次,无需担心自己电脑的限制。爬虫运行的云端可以固定时间,也可以爬取大量数据。您甚至可以在云中进行一定程度的数据清理和集成。
目前国外数据采集项目大多采用前端点击方式和后端云服务模式。以下为国外项目列表:
目前国内data采集项目分为三种:
1、基于客户端或插件的云采集服务。
客户端模式代表了项目的和谐。它不是单纯依赖客户端的计算资源,而是使用客户端的方式,更好更快的可视化和点击用户体验。同时将爬取的服务转移到云端,提供更大的数据爬取能力和数据整合能力。
浏览器插件方式例如是通过安装浏览器插件实现前端点击方式和后端云服务方式。
2.基于Web的云采集服务
用户无需安装,直接对网友进行点击操作,云端进行爬虫服务。这种方法的优点是用户可以随时随地使用,简单方便。国外很多项目都采用这种模式,比如国内采用这种模式的项目就是。但缺点是网页需要先在云端加载渲染,再呈现给用户,需要提供者大量的计算资源,而且速度往往很慢。
3. Cloud for Developers采集云服务开发
目前,一家名为China的公司正在提供此类服务。具备Java能力的开发者可以在平台上开发爬虫;没有开发能力的用户可以在爬虫市场购买或定制爬虫进行开发。
目前市场上,基本上80%的人都是采集20%的网络数据,比如企业信息、电商、O2O等,而这些网络数据往往具有很强的反爬能力。
笔者认为目前数据采集还处于3.阶段,还没有形成4.0阶段,即提供数据采集@ >、清洗、连接、分析等综合数据服务能力。
从3.0到4.0的阶段,在笔者看来,不仅仅是技术上的升级。不同行业、不同场景需要不同的数据,往往难以标准化,导致定制化,难以形成标准产品,难以大规模扩展。场景变化带来的技术挑战将凸显出来,因为真实场景所需的技术不是简单的升级,而是颠覆性的创新。
至于未来是否会完成跳跃,未来又会如何为大家服务,目前还很难说。目前国外import.io、dexi.io、Connotate、国内优采云、优采云、早书都在进行自己的探索。
合法性探讨
数据爬取的合法性在互联网领域一直存在争议,部分不法分子利用数据爬取工具进行黑商交易也是事实。数据抓取就像一把锋利的双刃剑,主要取决于用户是否以有益的方式应用它。
其实互联网数据爬取的主要原理就是Robots协议,也就是爬虫协议。网站通过Robots协议,告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。这原本主要针对搜索引擎公司,大家自觉遵守约定。
随着data采集范围的扩大,这个约定逐渐被打破,但也有既定的规则,广大data采集公司都应该遵守。
1、采集应该是互联网上的公开数据,数据的使用不能用于复制网站信息,或者干脆出售数据。更允许的情况是对多方采集的公开数据进行整合分析,形成数据分析服务。
2、采集的强度不应损害当前网站的性能,无形中增加目标网站的维护成本,甚至造成损失。
此外,我国刚刚于6月1日实施了《中华人民共和国互联网安全法》,这是我国网络领域的基本法,明确加强个人信息保护,打击网络诈骗。
《网络安全法》共7章79条,对个人信息泄露问题作出规定:网络产品和服务具有采集用户信息功能的,提供者应当明示并征得用户同意;网络运营者不得泄露、篡改、损毁其采集。任何个人和组织不得窃取或者以其他非法方式获取个人信息,不得非法出售或者非法向他人提供个人信息。这可能是对数据采集 公司更具方向性的指导。
数据采集发展到现在,怎么现在爆发了?
随着云计算、大数据、人工智能的发展,数据采集作为一种重要的数据手段,已成为企业的迫切需求。首当其冲的是中小企业的数据采集团队。不再需要维护一个完整的团队,大大降低了公司的成本。可以节省用户数据产品的开发,提升产品价值。对于普通个人来说,可以定制自己的data采集解决方案,门槛不高。更多行业、更多场景将被广泛应用。
人工智能的服务形态告诉我们,对于那些信息完备(Information-Complete)的领域,机器最终会超越并取代人类;
对于那些信息不完整(Information-Incomplete)的领域,也将通过人机协作推动新的发展;
对于那些抽象思维(Information-Free)的领域,仍然以人类为主,机器提供了一定的帮助。
Data采集 属于 Information-Complete 领域。机器可以在数据采集、清洗和整合上完全替代人类,然后通过与人类协作进行数据分析和预测。这将是即将发生的事情。
关于机器人云:
(微信公众号:vc-smart)是专业的创投机构投资管理服务商,帮助投资机构高效便捷管理投资项目,开发优质项目源,提供创投数据挖掘分析服务,助力投资管理人员可以快速获取项目、行业信息,协助行业分析。返回搜狐,查看更多
云采集(运维上的日志目录路径及应用配置方案(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-02-14 09:12
有很多选项,其中一些在下面列出:
1、sidecar sidecar 模式,在每个 pod 中部署一个 filebeat sidecar 容器(共享空的 dir 卷进行日志记录采集)
2、应用容器pod中的直接部署日志采集agent for 采集;
3、打印到控制台,从主机的docker日志文件到采集(读取本地文件,不推荐)
4、打印到控制台,通过宿主机的docker日志驱动进入采集(二进制直接输出);
5、挂载k8s的flex volume,将log文件写入flex volume目录,然后从host到采集log文件。
...
注意:上面提到的host都是以DaemonSet的形式部署的,即一个Node节点(通常是物理机)部署一个DaemonSet pod节点。
主要从性能、操作维护方便、满足各种需求等方面考虑。5 这个方案(FlexVolume)比较好:
1)在性能方面,基于挂载的卷,日志直接放在磁盘上,容器内无代理,无开销,日志不经过docker log驱动,因此不会保存额外的副本。
2)采集都占用宿主机的资源。与每个pod部署一个agent相比,host上只部署一个agent来设置采集当前主机的所有pod,效率非常高。
3)在运维方面,每个应用都可以配置一个日志挂载目录,实际挂载目录会根据pod区分(自动)。也就是说,对于应用来说,只需要配置一个日志目录路径(这个是必须的),然后在宿主机上配置应用的日志采集进行运维。两者都是必要的步骤,而且再简单不过了。
满足需求,
1、日志文件放在磁盘上,可以永久存档(有些业务有这个要求),直接备份文件很方便。
2、查看日志,可以在统一的日志平台查看,也可以登录容器或主机,用tail查看。
3、日志采集配置,可根据应用名称等灵活处理,与普通日志文件采集方式相同。
那么我们来谈谈其他几种解决方案的缺点:
1)sidecar 模式上面已经讲过了。每个pod部署一个agent,估计占用30M资源。与一主机一代理相比,总资源占用率高出数倍。假设一台宿主机,如果部署 100 个 pod,宿主机的总内存消耗为 30×100M。
容器采集agent模式下的2)部署日志和sidecar模式有同样的缺点。占用资源较多,不方便统一管理。
3)基于主机DaemonSet日志驱动方式,日志一方面会被代理采集,另一方面通过日志驱动写入本地日志系统,双重消耗,不适合大型日志量大,而且最致命 是的,只能采集控制台打印的日志!(所有的日志都混在一起,无法分类),那么容器中的日志文件呢?
我们研究了市场上的各种日志解决方案。像阿里云这样的logtail功能强大,但是很多都是定制的,需要定制k8s组件。
阿里巴巴的k8s日志采集方案的“底层原理”还没有介绍,但是看起来和方案5的FlexVolume很像,也可以通过配置日志路径来采集。不像 sidecar,因为这会在 pod 中添加一个代理容器。
注意:我们使用的 FlexVolume 方案是 Rancher fluentd 提供的,提供了自动创建 FlexVolume 卷并挂载到 pod 的日志目录的功能,使用起来非常方便。
另外,我遇到了一个特殊的需求:
1、测试运维还是习惯在linux控制台看日志,同时打开10多个ssh接口一起看。
我的回答是:使用统一的日志平台,比如kibana,配置后查看日志的体验和控制台差不多。可以准实时刷新,功能比tail命令更强大。例如,如果您看到某个键日志,您可以暂停它。,可以来回翻页和查询,这是tail中没有的。并且在同一页面的下拉菜单中,可以在不同的应用程序之间进行切换,类似于切换SSH标签页的便利性。如果您想在一页上“同时”显示多个应用程序,您实际上可以做到。为您想要查看的多个应用程序构建聚合索引。特别是,您可以创建“*”来匹配所有应用程序,然后自己过滤它们。如果一定要挑剔,实时性不如控制台,还有一定的学习成本。关于实时性能,EFK(filebeat)延迟问题:kibana页面最多只能每5秒刷新一次。大概需要15秒左右,很不舒服,但是应该还有很大的优化空间,比如访问kafka,使用SSD硬盘等等。
还有一种方案,容器内外通用,我认为是最好的方案:(需要实现条件)
应用通过日志组件Appender直接将日志发送到最近的高速Loghub
也可以看看:
阿里云开源的各种Java日志组件的appender:
以上是针对Java的。同样,其他语言也有自己的日志组件,也可以实现类似的功能。
综上所述,最好的方案是在上述方案5中挂载FlexVolume+应用内日志组件直挖,相当于阿里云目前最先进的采集方案(阿里云只根据自己定制的方案5)平台),应用内日志采集使用自己的Logtail服务)。 查看全部
云采集(运维上的日志目录路径及应用配置方案(一))
有很多选项,其中一些在下面列出:
1、sidecar sidecar 模式,在每个 pod 中部署一个 filebeat sidecar 容器(共享空的 dir 卷进行日志记录采集)
2、应用容器pod中的直接部署日志采集agent for 采集;
3、打印到控制台,从主机的docker日志文件到采集(读取本地文件,不推荐)
4、打印到控制台,通过宿主机的docker日志驱动进入采集(二进制直接输出);
5、挂载k8s的flex volume,将log文件写入flex volume目录,然后从host到采集log文件。
...
注意:上面提到的host都是以DaemonSet的形式部署的,即一个Node节点(通常是物理机)部署一个DaemonSet pod节点。
主要从性能、操作维护方便、满足各种需求等方面考虑。5 这个方案(FlexVolume)比较好:
1)在性能方面,基于挂载的卷,日志直接放在磁盘上,容器内无代理,无开销,日志不经过docker log驱动,因此不会保存额外的副本。
2)采集都占用宿主机的资源。与每个pod部署一个agent相比,host上只部署一个agent来设置采集当前主机的所有pod,效率非常高。
3)在运维方面,每个应用都可以配置一个日志挂载目录,实际挂载目录会根据pod区分(自动)。也就是说,对于应用来说,只需要配置一个日志目录路径(这个是必须的),然后在宿主机上配置应用的日志采集进行运维。两者都是必要的步骤,而且再简单不过了。
满足需求,
1、日志文件放在磁盘上,可以永久存档(有些业务有这个要求),直接备份文件很方便。
2、查看日志,可以在统一的日志平台查看,也可以登录容器或主机,用tail查看。
3、日志采集配置,可根据应用名称等灵活处理,与普通日志文件采集方式相同。
那么我们来谈谈其他几种解决方案的缺点:
1)sidecar 模式上面已经讲过了。每个pod部署一个agent,估计占用30M资源。与一主机一代理相比,总资源占用率高出数倍。假设一台宿主机,如果部署 100 个 pod,宿主机的总内存消耗为 30×100M。
容器采集agent模式下的2)部署日志和sidecar模式有同样的缺点。占用资源较多,不方便统一管理。
3)基于主机DaemonSet日志驱动方式,日志一方面会被代理采集,另一方面通过日志驱动写入本地日志系统,双重消耗,不适合大型日志量大,而且最致命 是的,只能采集控制台打印的日志!(所有的日志都混在一起,无法分类),那么容器中的日志文件呢?
我们研究了市场上的各种日志解决方案。像阿里云这样的logtail功能强大,但是很多都是定制的,需要定制k8s组件。
阿里巴巴的k8s日志采集方案的“底层原理”还没有介绍,但是看起来和方案5的FlexVolume很像,也可以通过配置日志路径来采集。不像 sidecar,因为这会在 pod 中添加一个代理容器。
注意:我们使用的 FlexVolume 方案是 Rancher fluentd 提供的,提供了自动创建 FlexVolume 卷并挂载到 pod 的日志目录的功能,使用起来非常方便。
另外,我遇到了一个特殊的需求:
1、测试运维还是习惯在linux控制台看日志,同时打开10多个ssh接口一起看。
我的回答是:使用统一的日志平台,比如kibana,配置后查看日志的体验和控制台差不多。可以准实时刷新,功能比tail命令更强大。例如,如果您看到某个键日志,您可以暂停它。,可以来回翻页和查询,这是tail中没有的。并且在同一页面的下拉菜单中,可以在不同的应用程序之间进行切换,类似于切换SSH标签页的便利性。如果您想在一页上“同时”显示多个应用程序,您实际上可以做到。为您想要查看的多个应用程序构建聚合索引。特别是,您可以创建“*”来匹配所有应用程序,然后自己过滤它们。如果一定要挑剔,实时性不如控制台,还有一定的学习成本。关于实时性能,EFK(filebeat)延迟问题:kibana页面最多只能每5秒刷新一次。大概需要15秒左右,很不舒服,但是应该还有很大的优化空间,比如访问kafka,使用SSD硬盘等等。
还有一种方案,容器内外通用,我认为是最好的方案:(需要实现条件)
应用通过日志组件Appender直接将日志发送到最近的高速Loghub
也可以看看:
阿里云开源的各种Java日志组件的appender:
以上是针对Java的。同样,其他语言也有自己的日志组件,也可以实现类似的功能。
综上所述,最好的方案是在上述方案5中挂载FlexVolume+应用内日志组件直挖,相当于阿里云目前最先进的采集方案(阿里云只根据自己定制的方案5)平台),应用内日志采集使用自己的Logtail服务)。
云采集(指标采集方案介绍常见架构模式Daemons优采云采集器端agent(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-01-30 14:00
介绍:
众所周知,对于一个云原生的PaaS平台来说,在页面上查看日志和指标是最基本的功能。无论是日志、指标还是链接跟踪,基本上都分为三个模块:采集、存储和展示。
在这里,笔者将介绍云原生下常用指标&日志的采集解决方案,以及Erda作为云原生PaaS平台是如何实现的。
指标采集程序介绍常用架构模式1.守护进程
采集客户端代理通过Daemonset部署在各个节点上。这种模式下,指标通常由agent主动采集获取。常用代理有 telegraf、metricbeat、cadvisor 等。
应用场景:
2. 推拉
当我们需要采集程序的内部指标时,我们通常使用代理主动拉取指标或客户端主动推送指标。
应用场景:
那么,是推还是拉?
我认为这取决于实际的应用场景。比如对于短期任务,由于agent可能还没有启动采集,所以已经结束了,所以我们使用push方式;但是对于Web服务来说,这个问题就不存在了,pull的方式也可以减少用户端。负担。
开源解决方案简介
作为 CNCF 的 2 号毕业生,Prometheus 从诞生之初就基本成为了云原生尤其是 Kubernetes 的官方监控解决方案。
它其实是一个完整的解决方案,这里我们主要介绍它的采集功能。
和push&pull的方案基本一样,但是因为是丰富的exporter系统,所以基本可以采集在节点层面收录各种指标。
二达采用的架构方案
在Erda,目前的解决方案是通过二次打开telegraf,利用其丰富的采集插件,合并Daemonset和push-pull的解决方案。
日志采集程序介绍常见架构模式1.守护进程
如果容器中的应用程序的日志输出到stdout,容器在运行时会通过logging-driver模块将日志输出到其他媒体,一般是在本地磁盘上。例如,Docker 通常通过 json-driver docker/containers//*.log 文件将日志输出到 /var/log/。
对于这种场景,我们一般使用Daemonset方案,即在每个节点上部署一个采集器,通过读取机器上的日志文件来采集日志。
2. 边车
Daemonset 方案也有一些限制,例如,当应用程序日志输出到日志文件时,或者当您要为日志配置一些处理规则(例如,多行规则、日志提取规则)时。
这时候可以使用Sidecar方案,logging-agent和应用容器可以共享日志目录,主动上报给采集。
3. 主动举报
当然也可以主动上报日志(一般是通过厂商提供的SDK)。
常见的应用场景有:
开源解决方案简介
在业界,比较有名的是使用ELK作为日志解决方案,当然也是一个完整的解决方案。采集模块主要使用beats作为采集端,logstash作为日志采集的主要入口,elasticsearch作为存储,kibana作为展示层。
尔达的架构方案
在 Erda 中,我们使用 fluent-bit 进行日志记录采集器:
概括
不难看出,无论是指标还是日志,data采集方案都比较简单明了,我们可以根据实际场景进行混搭。
但是,随着集群规模的增长和用户定义需求的增加,往往会出现以下困难:
对于这些问题,我们也在不断的探索和实践中,会在后续的文章中分享。 查看全部
云采集(指标采集方案介绍常见架构模式Daemons优采云采集器端agent(组图))
介绍:
众所周知,对于一个云原生的PaaS平台来说,在页面上查看日志和指标是最基本的功能。无论是日志、指标还是链接跟踪,基本上都分为三个模块:采集、存储和展示。
在这里,笔者将介绍云原生下常用指标&日志的采集解决方案,以及Erda作为云原生PaaS平台是如何实现的。
指标采集程序介绍常用架构模式1.守护进程
采集客户端代理通过Daemonset部署在各个节点上。这种模式下,指标通常由agent主动采集获取。常用代理有 telegraf、metricbeat、cadvisor 等。
应用场景:
2. 推拉
当我们需要采集程序的内部指标时,我们通常使用代理主动拉取指标或客户端主动推送指标。
应用场景:
那么,是推还是拉?
我认为这取决于实际的应用场景。比如对于短期任务,由于agent可能还没有启动采集,所以已经结束了,所以我们使用push方式;但是对于Web服务来说,这个问题就不存在了,pull的方式也可以减少用户端。负担。
开源解决方案简介
作为 CNCF 的 2 号毕业生,Prometheus 从诞生之初就基本成为了云原生尤其是 Kubernetes 的官方监控解决方案。
它其实是一个完整的解决方案,这里我们主要介绍它的采集功能。
和push&pull的方案基本一样,但是因为是丰富的exporter系统,所以基本可以采集在节点层面收录各种指标。
二达采用的架构方案
在Erda,目前的解决方案是通过二次打开telegraf,利用其丰富的采集插件,合并Daemonset和push-pull的解决方案。
日志采集程序介绍常见架构模式1.守护进程
如果容器中的应用程序的日志输出到stdout,容器在运行时会通过logging-driver模块将日志输出到其他媒体,一般是在本地磁盘上。例如,Docker 通常通过 json-driver docker/containers//*.log 文件将日志输出到 /var/log/。
对于这种场景,我们一般使用Daemonset方案,即在每个节点上部署一个采集器,通过读取机器上的日志文件来采集日志。
2. 边车
Daemonset 方案也有一些限制,例如,当应用程序日志输出到日志文件时,或者当您要为日志配置一些处理规则(例如,多行规则、日志提取规则)时。
这时候可以使用Sidecar方案,logging-agent和应用容器可以共享日志目录,主动上报给采集。
3. 主动举报
当然也可以主动上报日志(一般是通过厂商提供的SDK)。
常见的应用场景有:
开源解决方案简介
在业界,比较有名的是使用ELK作为日志解决方案,当然也是一个完整的解决方案。采集模块主要使用beats作为采集端,logstash作为日志采集的主要入口,elasticsearch作为存储,kibana作为展示层。
尔达的架构方案
在 Erda 中,我们使用 fluent-bit 进行日志记录采集器:
概括
不难看出,无论是指标还是日志,data采集方案都比较简单明了,我们可以根据实际场景进行混搭。
但是,随着集群规模的增长和用户定义需求的增加,往往会出现以下困难:
对于这些问题,我们也在不断的探索和实践中,会在后续的文章中分享。
云采集(几招如何防止IP本封锁的方法?教你几招方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-01-27 20:20
随着现在反爬机制越来越成熟,很多新的入口数据采集小白会直接把自己的本地IP挂在脚本上,很容易被服务器检测到并封杀。下面小编就教大家几个防止IP阻塞的小技巧:
方法一:使用代理IP
在连接外网IP即公网IP的程序上,我们可以部署一个适合爬虫软件运行的代理服务器(代理IP)。并使用循环替换的方式让代理IP访问想要采集数据的服务器网站服务器。这种方式的好处是对程序逻辑的改动很小,只需要在脚本中插入代理功能和连接代理IP的接口即可。并且根据对方的网站屏蔽规则,只需要添加更多的代理IP即可。另外,即使特定IP被封杀,也可以直接在代理服务器上注销该IP,程序逻辑不需要大的改动和改动。
方法二:冒充普通用户
因为目前的网站服务器主要是通过机器程序来识别,每个服务器程序都有自己的一套识别标准。只要尽可能地模拟常规用户行为,满足程序识别标准,就可以将系统不识别的程度降到最低。比如对于UserAgent,我们可以经常改变它;我们可以设置访问目标网站的服务器的时间间隔更长,访问时间可以设置为30分钟以上;我们也可以随机设置访问页面的顺序。
方法 3:了解 网站 阻止条件
目前,网站服务器的主流评价标准是指定IP在一定时间段内(约5分钟)的访问次数。因此,我们可以根据目标服务器站点的IP对采集的任务进行分组。一个IP在一定时间内发送的任务数,以避免被阻塞。当然,这种方法的前提是我们需要采集多个网站。如果只有采集一个网站,那么我们只能通过添加多个外部IP来实现。
总结:
1. 我们的UserAgent需要经常更换
2. 尝试模拟普通用户对 网站 的访问。
3. 尽量使用代理IP。 查看全部
云采集(几招如何防止IP本封锁的方法?教你几招方法)
随着现在反爬机制越来越成熟,很多新的入口数据采集小白会直接把自己的本地IP挂在脚本上,很容易被服务器检测到并封杀。下面小编就教大家几个防止IP阻塞的小技巧:
方法一:使用代理IP
在连接外网IP即公网IP的程序上,我们可以部署一个适合爬虫软件运行的代理服务器(代理IP)。并使用循环替换的方式让代理IP访问想要采集数据的服务器网站服务器。这种方式的好处是对程序逻辑的改动很小,只需要在脚本中插入代理功能和连接代理IP的接口即可。并且根据对方的网站屏蔽规则,只需要添加更多的代理IP即可。另外,即使特定IP被封杀,也可以直接在代理服务器上注销该IP,程序逻辑不需要大的改动和改动。
方法二:冒充普通用户
因为目前的网站服务器主要是通过机器程序来识别,每个服务器程序都有自己的一套识别标准。只要尽可能地模拟常规用户行为,满足程序识别标准,就可以将系统不识别的程度降到最低。比如对于UserAgent,我们可以经常改变它;我们可以设置访问目标网站的服务器的时间间隔更长,访问时间可以设置为30分钟以上;我们也可以随机设置访问页面的顺序。
方法 3:了解 网站 阻止条件
目前,网站服务器的主流评价标准是指定IP在一定时间段内(约5分钟)的访问次数。因此,我们可以根据目标服务器站点的IP对采集的任务进行分组。一个IP在一定时间内发送的任务数,以避免被阻塞。当然,这种方法的前提是我们需要采集多个网站。如果只有采集一个网站,那么我们只能通过添加多个外部IP来实现。
总结:
1. 我们的UserAgent需要经常更换
2. 尝试模拟普通用户对 网站 的访问。
3. 尽量使用代理IP。
云采集(前文:LoggingOperator的文章(图):且架构足够清晰)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-01-22 05:10
上一篇:Logging Operator 的文章 去年延迟了很久。原以为不会有进展,但最近在我的 KubeGems 项目中遇到需要处理日志可观察性部分的时候重新研究了一下。,因此是本系列的第三篇文章。
Logging Operator 是 BanzaiCloud 下云原生场景的开源 log采集 解决方案。2020年3月重构为v3版本,高效的fluentbit和丰富的底层插件flunetd,Logging Operator几乎完美适配kubernetes模式下的log采集场景。预计。去年偶然发现Rancher在2.5版本之后也采用了Logging Operator作为统一的日志解决方案,足以说明它正在被一些以Kubernetes为中心的管理平台所接受,并融入到内部(包括小白)。库贝宝石)。
作为前两篇文章的延续,本文主要讲小白最近使用Logging Operator解决用户需求的案例和感受,所以不打算花篇幅来描述它的架构和使用。有兴趣的同学可以通过小白的文章去Flip。
关于指标
在应用容器化的过程中,由于容器文件系统的临时性,开发者总是面临着将自己的日志文件放在磁盘上并输出stdout的困境。当研发将应用日志管理权交给平台时,意味着平台需要做的事情远比应用一对一复杂得多采集。在众多需求中,有一天一位 SRE 同学问:“我们可以看到阿里云日志采集的实时率,我们需要为此定制质量监控指标。” 这个问题也让我警醒。当我们在私有云上工作时,从平台外部观察 log采集 管道内部一直处于信息缺失的盲点。幸运的是,
图像
首先,我们定义日志的时候,可以让fluent bit(d)打开prometheus的采集
spec:
fluentdSpec:
metrics:
serviceMonitor: true
serviceMonitorConfig:
honorLabels: true // 打开honorLabels主要是为了保持组件原有的label,避免标签被覆盖。
fluentbitSpec:
metrics:
serviceMonitor: true
这里可以看到Logging Operator在采集端主要依赖ServiceMonitor进行服务发现。这里需要在集群内部运行 Prometheus Operator 来支持 CRD。如果集群内部没有改变资源类型,也可以使用Prometheus自带的服务发现机制完成指标发现和采集。
但是,这里只声明了 采集 端的指标条目。默认只收录 Fluent bit(d) 的基本内部运行状态。如果要进一步监控日志率,则需要使用 Flunetd。早些年在谷歌的GKE采集器上还是用Fluentd做日志的时候,无意中看到的一个Prometheus插件配置(故意抄袭)引起了我的兴趣
@type prometheus
type counter
name logging_entry_count
desc Total number of log entries generated by either application containers or system components
container: $.kubernetes.container_name
pod: $.kubernetes.pod_name
该规则将匹配所有进入 Fluentd 的日志,并进入 Prometheus 的过滤器进行计数处理。统计信息被命名为logging_entry_count,日志中的一些元数据信息作为指标的标签来区分不同的容器。
由于需要解析日志的kubernetes元数据,所以需要Fluentd的kubernetes-metadata-filter插件来提取容器元数据。在 Logging Operator 中,Kubernetes 的元数据在 Fluent Bit 中解析,无需在 Fluentd 中添加此插件。
尽管 Google GKE 现在也将日志 采集器 替换为 Fluent Bit,但上述配置在 Logging Operator 中并没有“过时”。结合之前的经验,我们可以在租户的日志采集器(Flow / ClusterFlow)中引入Prometheus插件来分析日志率。其中最简单的做法如下:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: default
namespace: demo
spec:
- prometheus:
labels:
container: $.kubernetes.container_name
namespace: $.kubernetes.namespace_name
node: $.kubernetes.host
pod: $.kubernetes.pod_name
metrics:
- desc: Total number of log entries generated by either application containers
or system components
name: logging_entry_count
type: counter
globalOutputRefs:
- containers-console
match:
- select:
labels:
what.you.want: collect
上述指标存入 Prometheus 后,我们可以通过这条语句找出当前集群下日志采集器的应用率
sum by (pod) (rate(logging_entry_count[1m]))
此时,如果云平台是基于多租户多环境的架构,你甚至可以按租户环境和租户级别聚合日志率。
文件
以上只是对日志整体速率的监控。如果我们需要统计日志中的具体内容或者日志的字节数,需要结合其他插件。目前Logging Operator支持的插件远不如Fluentd丰富,但是我们可以参考官方文档编写需要的插件并集成到Operator中。记录操作员开发人员手册
对于日志组件内部的监控和告警,Logging Operator 有自己的一套规则,可以在日志 CR 中启用。
spec:
fluentbitSpec:
metrics:
prometheusRules: true
fluentdSpec:
metrics:
prometheusRules: true
这里的prometheusRules也是Prometheus Operator管理的资源。如果集群中没有这样的资源类型,可以手动配置Prometheus的Rules
回到原来的问题,如果需要用日志的采集率作为应用的量化指标,可以使用logging_entry_count。
关于抽样
大多数情况下,日志架构不应该对业务日志采取一些不可控的策略,导致应用日志不完整,比如采样。显然,我也不建议您在现有架构中启用此功能。然而,有时,或者当一些魔术师无法有效控制“狂野之力”而疯狂输出时,平台可以为这种漂亮的应用程序采样解决方案。毕竟,保证整个日志通道的可用性是平台的第一要务。要考虑的因素。
Logging Operator 在日志采样中使用 Throttle 插件速率限制器。一句话总结这个插件,它为每个进入过滤器日志的管道引入了漏桶算法,允许它丢弃超过速率限制的日志。
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: default
namespace: demo
spec:
- throttle:
group_bucket_limit: 3000
group_bucket_period_s: 10
group_key: kubernetes.pod_name
globalOutputRefs:
- containers-console
match:
- select:
labels:
what.you.want: collect
日志的采样率由公式 group_bucket_limit / group_bucket_period_s 计算得出。当 group_key 中的 log rate 超过该值时,后续的日志将被丢弃。
由于 Throttle 没有使用令牌桶算法,所以不会有突发处理日志量 采集 的突发情况。
关于日志放置
如前所述,对于所有基于容器的应用程序,日志记录的最佳实践是将日志定向到 stdout 和 stderr,但并非所有“魔术师”都遵循此约定,将文件记录到磁盘仍然是当今大多数研发的选择。. 虽然理论上容器的标准(错误)输出也是将日志流重定位到/var/log/containers下的日志文件,但还是受限于运行时配置或其他硬盘原因造成的不可控因素。
对于日志放置的场景,目前业界还没有统一的解决方案,但总结起来,其实有两种实现方式:
此方案是将日志采集器跟随应用容器一同运行在pod 当中,通过 volume 共享日志路径的方式采集。常见的是方式是为 kubernetes 开发一套单独的控制器,并采用`MutatingWebhook`在pod 启动阶段将 sidecar 的信息注入。
sidecar 的方案优势在于为每个应用的 sidecar 配置相对独立,但劣势除占用过多资源外,**采集器的更新迭代需跟随应用的生命周期**,对于持续维护不太优雅。
此方案将日志采集器以 `DaemonSet` 的方式运行在每个 Node 当中,然后在操作系统层面进行集中采集。通常此方案需要平台的研发需要做一定路径策略,将固定 `hostpath`的 vulume 挂载给容器用于应用日志落盘时使用。除此之外,我们知道所有 Kubernetes 默认的存储类型或者第三方的遵循 CSI 标准的存储,都会将Volume挂载到`/var/lib/kubelet/pods//volumes/kubernetes.io~//mount`目录下,所以对于 node agent 更加优雅一点的方案是在 node agent 中赋予调用 Kubernetes API 的权限,让其知晓被采集容器日志映射在主机下的路径。
node agent的方案的优势在于配置集中管理,采集器跟应用容器解耦,互不影响。缺点在于采集器存在吞吐不足的风险。
可以看出,上述两种方案中,都与Logging Operator无关。确实,目前的社区并没有针对这种场景的有效解决方案,但是按照它的思路,我们可以将日志文件转换成标准(错误)输出流,变相处理这个问题。
用tail给出一个直观的例子来说明上面的方案。
...
containers:
- args:
- -F
- /path/to/your/log/file.log
command:
- tail
image: busybox
name: stream-log-file-[name]
volumeMounts:
- mountPath: /path/to/your/log
name: mounted-log
...
虽然tail是一种极其简单粗暴的方法,无法解决日志轮转等问题,但它确实为Logging Operator在日志放置场景下提供了一种新的解决方案。虽然看起来和 sidecar 一样,但最大的不同是这个方案无缝兼容了 Logging Operator 现有的日志管道,日志经过 采集 后仍然可以在 flow 阶段进行处理。
总结
从自动化运维的角度来看,Logging Operator 确实有效解决了 Kubernetes 场景下复杂的日志架构和应用日志采集 问题,虽然目前对放置日志的支持还不够全面。但随着连接用户数量的增长,未来可能会有更好的解决当前问题的方法。然而,它确实是目前最好的云原生日志架构之一。 查看全部
云采集(前文:LoggingOperator的文章(图):且架构足够清晰)
上一篇:Logging Operator 的文章 去年延迟了很久。原以为不会有进展,但最近在我的 KubeGems 项目中遇到需要处理日志可观察性部分的时候重新研究了一下。,因此是本系列的第三篇文章。
Logging Operator 是 BanzaiCloud 下云原生场景的开源 log采集 解决方案。2020年3月重构为v3版本,高效的fluentbit和丰富的底层插件flunetd,Logging Operator几乎完美适配kubernetes模式下的log采集场景。预计。去年偶然发现Rancher在2.5版本之后也采用了Logging Operator作为统一的日志解决方案,足以说明它正在被一些以Kubernetes为中心的管理平台所接受,并融入到内部(包括小白)。库贝宝石)。
作为前两篇文章的延续,本文主要讲小白最近使用Logging Operator解决用户需求的案例和感受,所以不打算花篇幅来描述它的架构和使用。有兴趣的同学可以通过小白的文章去Flip。
关于指标
在应用容器化的过程中,由于容器文件系统的临时性,开发者总是面临着将自己的日志文件放在磁盘上并输出stdout的困境。当研发将应用日志管理权交给平台时,意味着平台需要做的事情远比应用一对一复杂得多采集。在众多需求中,有一天一位 SRE 同学问:“我们可以看到阿里云日志采集的实时率,我们需要为此定制质量监控指标。” 这个问题也让我警醒。当我们在私有云上工作时,从平台外部观察 log采集 管道内部一直处于信息缺失的盲点。幸运的是,
图像
首先,我们定义日志的时候,可以让fluent bit(d)打开prometheus的采集
spec:
fluentdSpec:
metrics:
serviceMonitor: true
serviceMonitorConfig:
honorLabels: true // 打开honorLabels主要是为了保持组件原有的label,避免标签被覆盖。
fluentbitSpec:
metrics:
serviceMonitor: true
这里可以看到Logging Operator在采集端主要依赖ServiceMonitor进行服务发现。这里需要在集群内部运行 Prometheus Operator 来支持 CRD。如果集群内部没有改变资源类型,也可以使用Prometheus自带的服务发现机制完成指标发现和采集。
但是,这里只声明了 采集 端的指标条目。默认只收录 Fluent bit(d) 的基本内部运行状态。如果要进一步监控日志率,则需要使用 Flunetd。早些年在谷歌的GKE采集器上还是用Fluentd做日志的时候,无意中看到的一个Prometheus插件配置(故意抄袭)引起了我的兴趣
@type prometheus
type counter
name logging_entry_count
desc Total number of log entries generated by either application containers or system components
container: $.kubernetes.container_name
pod: $.kubernetes.pod_name
该规则将匹配所有进入 Fluentd 的日志,并进入 Prometheus 的过滤器进行计数处理。统计信息被命名为logging_entry_count,日志中的一些元数据信息作为指标的标签来区分不同的容器。
由于需要解析日志的kubernetes元数据,所以需要Fluentd的kubernetes-metadata-filter插件来提取容器元数据。在 Logging Operator 中,Kubernetes 的元数据在 Fluent Bit 中解析,无需在 Fluentd 中添加此插件。
尽管 Google GKE 现在也将日志 采集器 替换为 Fluent Bit,但上述配置在 Logging Operator 中并没有“过时”。结合之前的经验,我们可以在租户的日志采集器(Flow / ClusterFlow)中引入Prometheus插件来分析日志率。其中最简单的做法如下:
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: default
namespace: demo
spec:
- prometheus:
labels:
container: $.kubernetes.container_name
namespace: $.kubernetes.namespace_name
node: $.kubernetes.host
pod: $.kubernetes.pod_name
metrics:
- desc: Total number of log entries generated by either application containers
or system components
name: logging_entry_count
type: counter
globalOutputRefs:
- containers-console
match:
- select:
labels:
what.you.want: collect
上述指标存入 Prometheus 后,我们可以通过这条语句找出当前集群下日志采集器的应用率
sum by (pod) (rate(logging_entry_count[1m]))
此时,如果云平台是基于多租户多环境的架构,你甚至可以按租户环境和租户级别聚合日志率。
文件
以上只是对日志整体速率的监控。如果我们需要统计日志中的具体内容或者日志的字节数,需要结合其他插件。目前Logging Operator支持的插件远不如Fluentd丰富,但是我们可以参考官方文档编写需要的插件并集成到Operator中。记录操作员开发人员手册
对于日志组件内部的监控和告警,Logging Operator 有自己的一套规则,可以在日志 CR 中启用。
spec:
fluentbitSpec:
metrics:
prometheusRules: true
fluentdSpec:
metrics:
prometheusRules: true
这里的prometheusRules也是Prometheus Operator管理的资源。如果集群中没有这样的资源类型,可以手动配置Prometheus的Rules
回到原来的问题,如果需要用日志的采集率作为应用的量化指标,可以使用logging_entry_count。
关于抽样
大多数情况下,日志架构不应该对业务日志采取一些不可控的策略,导致应用日志不完整,比如采样。显然,我也不建议您在现有架构中启用此功能。然而,有时,或者当一些魔术师无法有效控制“狂野之力”而疯狂输出时,平台可以为这种漂亮的应用程序采样解决方案。毕竟,保证整个日志通道的可用性是平台的第一要务。要考虑的因素。
Logging Operator 在日志采样中使用 Throttle 插件速率限制器。一句话总结这个插件,它为每个进入过滤器日志的管道引入了漏桶算法,允许它丢弃超过速率限制的日志。
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: default
namespace: demo
spec:
- throttle:
group_bucket_limit: 3000
group_bucket_period_s: 10
group_key: kubernetes.pod_name
globalOutputRefs:
- containers-console
match:
- select:
labels:
what.you.want: collect
日志的采样率由公式 group_bucket_limit / group_bucket_period_s 计算得出。当 group_key 中的 log rate 超过该值时,后续的日志将被丢弃。
由于 Throttle 没有使用令牌桶算法,所以不会有突发处理日志量 采集 的突发情况。
关于日志放置
如前所述,对于所有基于容器的应用程序,日志记录的最佳实践是将日志定向到 stdout 和 stderr,但并非所有“魔术师”都遵循此约定,将文件记录到磁盘仍然是当今大多数研发的选择。. 虽然理论上容器的标准(错误)输出也是将日志流重定位到/var/log/containers下的日志文件,但还是受限于运行时配置或其他硬盘原因造成的不可控因素。
对于日志放置的场景,目前业界还没有统一的解决方案,但总结起来,其实有两种实现方式:
此方案是将日志采集器跟随应用容器一同运行在pod 当中,通过 volume 共享日志路径的方式采集。常见的是方式是为 kubernetes 开发一套单独的控制器,并采用`MutatingWebhook`在pod 启动阶段将 sidecar 的信息注入。
sidecar 的方案优势在于为每个应用的 sidecar 配置相对独立,但劣势除占用过多资源外,**采集器的更新迭代需跟随应用的生命周期**,对于持续维护不太优雅。
此方案将日志采集器以 `DaemonSet` 的方式运行在每个 Node 当中,然后在操作系统层面进行集中采集。通常此方案需要平台的研发需要做一定路径策略,将固定 `hostpath`的 vulume 挂载给容器用于应用日志落盘时使用。除此之外,我们知道所有 Kubernetes 默认的存储类型或者第三方的遵循 CSI 标准的存储,都会将Volume挂载到`/var/lib/kubelet/pods//volumes/kubernetes.io~//mount`目录下,所以对于 node agent 更加优雅一点的方案是在 node agent 中赋予调用 Kubernetes API 的权限,让其知晓被采集容器日志映射在主机下的路径。
node agent的方案的优势在于配置集中管理,采集器跟应用容器解耦,互不影响。缺点在于采集器存在吞吐不足的风险。
可以看出,上述两种方案中,都与Logging Operator无关。确实,目前的社区并没有针对这种场景的有效解决方案,但是按照它的思路,我们可以将日志文件转换成标准(错误)输出流,变相处理这个问题。
用tail给出一个直观的例子来说明上面的方案。
...
containers:
- args:
- -F
- /path/to/your/log/file.log
command:
- tail
image: busybox
name: stream-log-file-[name]
volumeMounts:
- mountPath: /path/to/your/log
name: mounted-log
...
虽然tail是一种极其简单粗暴的方法,无法解决日志轮转等问题,但它确实为Logging Operator在日志放置场景下提供了一种新的解决方案。虽然看起来和 sidecar 一样,但最大的不同是这个方案无缝兼容了 Logging Operator 现有的日志管道,日志经过 采集 后仍然可以在 flow 阶段进行处理。
总结
从自动化运维的角度来看,Logging Operator 确实有效解决了 Kubernetes 场景下复杂的日志架构和应用日志采集 问题,虽然目前对放置日志的支持还不够全面。但随着连接用户数量的增长,未来可能会有更好的解决当前问题的方法。然而,它确实是目前最好的云原生日志架构之一。
云采集(为什么分布式数据采集软件能够收到互联网发展的青睐呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-01-19 13:23
为什么分布式数据采集软件受到互联网发展的青睐?在大数据时代的发展中,大数据在当前企业发展、政府决策和社会动态分析等方面发挥着重要作用。如何实现大规模快速采集数据成为焦点。
与传统数据采集软件相比,分布式数据采集软件解决了互联网数据采集海量存储和分析不便的问题。存在不统一、系统扩展性能低、维护困难等诸多难题。
分布式数据采集软件有什么优势?
1.海量数据采集
实现多数据源、大数据采集、高实时性采集的需求,同时具有高扩展性和定制化服务的特点。
2.云采集
大量云服务器支持,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活贴合业务场景,助您提升采集效率,并确保数据的及时性。
3.快速响应:
分布式大数据采集系统,具备数据分析、日志分析、商业智能分析、客户营销、大规模索引等服务,采集速度快,操作方便。
4.支持自助登录采集
只需要配置目标网站的账号密码,就可以使用该模块采集登录数据。同时具有采集cookie自定义功能。首次登录后可自动记住cookie,免去多次输入密码的繁琐,支持网站的更多采集。
分布式数据采集,数道云大数据,帮助互联网上的政企、金融、银行、教育、高校等建立易操作的解决方案,解决行业当前面临的数据问题< @采集问题。 查看全部
云采集(为什么分布式数据采集软件能够收到互联网发展的青睐呢?)
为什么分布式数据采集软件受到互联网发展的青睐?在大数据时代的发展中,大数据在当前企业发展、政府决策和社会动态分析等方面发挥着重要作用。如何实现大规模快速采集数据成为焦点。
与传统数据采集软件相比,分布式数据采集软件解决了互联网数据采集海量存储和分析不便的问题。存在不统一、系统扩展性能低、维护困难等诸多难题。
分布式数据采集软件有什么优势?
1.海量数据采集
实现多数据源、大数据采集、高实时性采集的需求,同时具有高扩展性和定制化服务的特点。
2.云采集
大量云服务器支持,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活贴合业务场景,助您提升采集效率,并确保数据的及时性。
3.快速响应:
分布式大数据采集系统,具备数据分析、日志分析、商业智能分析、客户营销、大规模索引等服务,采集速度快,操作方便。
4.支持自助登录采集
只需要配置目标网站的账号密码,就可以使用该模块采集登录数据。同时具有采集cookie自定义功能。首次登录后可自动记住cookie,免去多次输入密码的繁琐,支持网站的更多采集。
分布式数据采集,数道云大数据,帮助互联网上的政企、金融、银行、教育、高校等建立易操作的解决方案,解决行业当前面临的数据问题< @采集问题。
云采集(指标采集方案介绍常见架构模式Daemons优采云采集器端agent(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-01-16 07:03
介绍:
众所周知,对于一个云原生的PaaS平台来说,在页面上查看日志和指标是最基本的功能。无论是日志、指标还是链接跟踪,基本上都分为三个模块:采集、存储和展示。
在这里,笔者将介绍云原生下常用指标&日志的采集解决方案,以及Erda作为云原生PaaS平台是如何实现的。
指标采集程序介绍常用架构模式1.守护进程
采集客户端代理通过Daemonset部署在各个节点上。这种模式下,agent通常会主动采集来获取指标。常用代理有 telegraf、metricbeat、cadvisor 等。
应用场景:
2. 推拉
当我们需要采集程序的内部指标时,我们通常使用代理主动拉取指标或客户端主动推送指标。
应用场景:
那么,是推还是拉?
我认为这取决于实际的应用场景。比如对于短期任务,由于agent可能还没有启动采集,所以已经结束了,所以我们使用push方式;但是对于Web服务来说,这个问题就不存在了,pull的方式也可以减少用户端。负担。
开源解决方案简介
作为 CNCF 的 2 号毕业生,Prometheus 从诞生之初就基本成为了云原生尤其是 Kubernetes 的官方监控解决方案。
它其实是一个完整的解决方案,这里我们主要介绍它的采集功能。
和push&pull的方案基本一样,但是因为是丰富的exporter系统,所以基本可以采集在节点层面收录各种指标。
二达采用的架构方案
在Erda,目前的解决方案是通过二次打开telegraf,利用其丰富的采集插件,合并Daemonset和push-pull的解决方案。
日志采集程序介绍常见架构模式1.守护进程
如果容器中的应用程序的日志输出到stdout,容器在运行时会通过logging-driver模块将日志输出到其他媒体,一般是在本地磁盘上。例如,Docker 通常通过 json-driver docker/containers//*.log 文件将日志输出到 /var/log/。
对于这种场景,我们一般使用Daemonset方案,即在每个节点上部署一个采集器,通过读取机器上的日志文件来采集日志。
2. 边车
Daemonset 方案也有一些限制,例如,当应用程序日志输出到日志文件时,或者当您要为日志配置一些处理规则(例如,多行规则、日志提取规则)时。
这时候可以使用Sidecar方案,logging-agent和应用容器可以共享日志目录,主动上报给采集。
3. 主动举报
当然也可以主动上报日志(一般是通过厂商提供的SDK)。
常见的应用场景有:
开源解决方案简介
在业界,比较有名的是使用ELK作为日志解决方案,当然也是一个完整的解决方案。采集模块主要使用beats作为采集端,logstash作为日志采集的主要入口,elasticsearch作为存储,kibana作为展示层。
尔达的架构方案
在 Erda 中,我们使用 fluent-bit 进行日志记录采集器:
概括
不难看出,无论是指标还是日志,data采集方案都比较简单明了,我们可以根据实际场景进行混搭。但是,随着集群规模的增长和用户定义需求的增加,往往会出现以下困难:
对于这些问题,我们也在不断的探索和实践中,会在后续的文章中分享。 查看全部
云采集(指标采集方案介绍常见架构模式Daemons优采云采集器端agent(组图))
介绍:
众所周知,对于一个云原生的PaaS平台来说,在页面上查看日志和指标是最基本的功能。无论是日志、指标还是链接跟踪,基本上都分为三个模块:采集、存储和展示。
在这里,笔者将介绍云原生下常用指标&日志的采集解决方案,以及Erda作为云原生PaaS平台是如何实现的。
指标采集程序介绍常用架构模式1.守护进程
采集客户端代理通过Daemonset部署在各个节点上。这种模式下,agent通常会主动采集来获取指标。常用代理有 telegraf、metricbeat、cadvisor 等。
应用场景:
2. 推拉
当我们需要采集程序的内部指标时,我们通常使用代理主动拉取指标或客户端主动推送指标。
应用场景:
那么,是推还是拉?
我认为这取决于实际的应用场景。比如对于短期任务,由于agent可能还没有启动采集,所以已经结束了,所以我们使用push方式;但是对于Web服务来说,这个问题就不存在了,pull的方式也可以减少用户端。负担。
开源解决方案简介
作为 CNCF 的 2 号毕业生,Prometheus 从诞生之初就基本成为了云原生尤其是 Kubernetes 的官方监控解决方案。
它其实是一个完整的解决方案,这里我们主要介绍它的采集功能。
和push&pull的方案基本一样,但是因为是丰富的exporter系统,所以基本可以采集在节点层面收录各种指标。
二达采用的架构方案
在Erda,目前的解决方案是通过二次打开telegraf,利用其丰富的采集插件,合并Daemonset和push-pull的解决方案。
日志采集程序介绍常见架构模式1.守护进程
如果容器中的应用程序的日志输出到stdout,容器在运行时会通过logging-driver模块将日志输出到其他媒体,一般是在本地磁盘上。例如,Docker 通常通过 json-driver docker/containers//*.log 文件将日志输出到 /var/log/。
对于这种场景,我们一般使用Daemonset方案,即在每个节点上部署一个采集器,通过读取机器上的日志文件来采集日志。
2. 边车
Daemonset 方案也有一些限制,例如,当应用程序日志输出到日志文件时,或者当您要为日志配置一些处理规则(例如,多行规则、日志提取规则)时。
这时候可以使用Sidecar方案,logging-agent和应用容器可以共享日志目录,主动上报给采集。
3. 主动举报
当然也可以主动上报日志(一般是通过厂商提供的SDK)。
常见的应用场景有:
开源解决方案简介
在业界,比较有名的是使用ELK作为日志解决方案,当然也是一个完整的解决方案。采集模块主要使用beats作为采集端,logstash作为日志采集的主要入口,elasticsearch作为存储,kibana作为展示层。
尔达的架构方案
在 Erda 中,我们使用 fluent-bit 进行日志记录采集器:
概括
不难看出,无论是指标还是日志,data采集方案都比较简单明了,我们可以根据实际场景进行混搭。但是,随着集群规模的增长和用户定义需求的增加,往往会出现以下困难:
对于这些问题,我们也在不断的探索和实践中,会在后续的文章中分享。
云采集(指标采集方案介绍常见架构模式Daemons优采云采集器端agent(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-15 08:18
介绍:
众所周知,对于一个云原生的PaaS平台来说,在页面上查看日志和指标是最基本的功能。无论是日志、指标还是链接跟踪,基本上都分为三个模块:采集、存储和展示。
在这里,笔者将介绍云原生下常用指标&日志的采集解决方案,以及Erda作为云原生PaaS平台是如何实现的。
指标采集程序介绍常用架构模式1.守护进程
采集客户端代理通过Daemonset部署在各个节点上。这种模式下,指标通常由agent主动采集获取。常用代理有 telegraf、metricbeat、cadvisor 等。
应用场景:
2. 推拉
当我们需要采集程序的内部指标时,我们通常使用代理主动拉取指标或客户端主动推送指标。
应用场景:
那么,是推还是拉?
我认为这取决于实际的应用场景。比如对于短期任务,由于agent可能还没有启动采集,所以已经结束了,所以我们使用push方式;但是对于Web服务来说,这个问题就不存在了,pull的方式也可以减少用户端。负担。
开源解决方案简介
作为 CNCF 的 2 号毕业生,Prometheus 从诞生之初就基本成为了云原生尤其是 Kubernetes 的官方监控解决方案。
它其实是一个完整的解决方案,这里我们主要介绍它的采集功能。
和push&pull的方案基本一样,但是因为是丰富的exporter系统,所以基本可以采集在节点层面收录各种指标。
二达采用的架构方案
在Erda,目前的解决方案是通过二次打开telegraf,利用其丰富的采集插件,合并Daemonset和push-pull的解决方案。
日志采集程序介绍常见架构模式1.守护进程
如果容器中应用的日志输出到stdout,容器运行时会通过logging-driver模块输出到其他媒体,一般是本地磁盘。比如Docker通常通过json-driver docker/containers//*.log文件将日志输出到/var/log/。
对于这种场景,我们一般使用Daemonset方案,即在每个节点上部署一个采集器,通过读取机器上的日志文件来记录采集日志。
2. 边车
Daemonset 方案也有一些限制,例如,当应用程序日志输出到日志文件时,或者当您要为日志配置一些处理规则(例如,多行规则、日志提取规则)时。
这时候可以使用Sidecar方案,logging-agent和应用容器可以共享日志目录,主动上报给采集。
3. 主动举报
当然也可以主动上报日志(一般是通过厂商提供的SDK)。
常见的应用场景有:
开源解决方案简介
在业界,比较有名的是使用ELK作为日志解决方案,当然也是一个完整的解决方案。采集模块主要使用beats作为采集端,logstash作为日志采集的主要入口,elasticsearch作为存储,kibana作为展示层。
尔达的建筑
在 Erda 中,我们使用 fluent-bit 进行日志记录采集器:
概括
不难看出,无论是指标还是日志,data采集方案都比较简单明了,我们可以根据实际场景进行混搭。但是,随着集群规模的增长和用户定义需求的增加,往往会出现以下困难:
对于这些问题,我们也在不断的探索和实践中,会在后续的文章中分享。 查看全部
云采集(指标采集方案介绍常见架构模式Daemons优采云采集器端agent(组图))
介绍:
众所周知,对于一个云原生的PaaS平台来说,在页面上查看日志和指标是最基本的功能。无论是日志、指标还是链接跟踪,基本上都分为三个模块:采集、存储和展示。
在这里,笔者将介绍云原生下常用指标&日志的采集解决方案,以及Erda作为云原生PaaS平台是如何实现的。
指标采集程序介绍常用架构模式1.守护进程
采集客户端代理通过Daemonset部署在各个节点上。这种模式下,指标通常由agent主动采集获取。常用代理有 telegraf、metricbeat、cadvisor 等。
应用场景:
2. 推拉
当我们需要采集程序的内部指标时,我们通常使用代理主动拉取指标或客户端主动推送指标。
应用场景:
那么,是推还是拉?
我认为这取决于实际的应用场景。比如对于短期任务,由于agent可能还没有启动采集,所以已经结束了,所以我们使用push方式;但是对于Web服务来说,这个问题就不存在了,pull的方式也可以减少用户端。负担。
开源解决方案简介
作为 CNCF 的 2 号毕业生,Prometheus 从诞生之初就基本成为了云原生尤其是 Kubernetes 的官方监控解决方案。
它其实是一个完整的解决方案,这里我们主要介绍它的采集功能。
和push&pull的方案基本一样,但是因为是丰富的exporter系统,所以基本可以采集在节点层面收录各种指标。
二达采用的架构方案
在Erda,目前的解决方案是通过二次打开telegraf,利用其丰富的采集插件,合并Daemonset和push-pull的解决方案。
日志采集程序介绍常见架构模式1.守护进程
如果容器中应用的日志输出到stdout,容器运行时会通过logging-driver模块输出到其他媒体,一般是本地磁盘。比如Docker通常通过json-driver docker/containers//*.log文件将日志输出到/var/log/。
对于这种场景,我们一般使用Daemonset方案,即在每个节点上部署一个采集器,通过读取机器上的日志文件来记录采集日志。
2. 边车
Daemonset 方案也有一些限制,例如,当应用程序日志输出到日志文件时,或者当您要为日志配置一些处理规则(例如,多行规则、日志提取规则)时。
这时候可以使用Sidecar方案,logging-agent和应用容器可以共享日志目录,主动上报给采集。
3. 主动举报
当然也可以主动上报日志(一般是通过厂商提供的SDK)。
常见的应用场景有:
开源解决方案简介
在业界,比较有名的是使用ELK作为日志解决方案,当然也是一个完整的解决方案。采集模块主要使用beats作为采集端,logstash作为日志采集的主要入口,elasticsearch作为存储,kibana作为展示层。
尔达的建筑
在 Erda 中,我们使用 fluent-bit 进行日志记录采集器:
概括
不难看出,无论是指标还是日志,data采集方案都比较简单明了,我们可以根据实际场景进行混搭。但是,随着集群规模的增长和用户定义需求的增加,往往会出现以下困难:
对于这些问题,我们也在不断的探索和实践中,会在后续的文章中分享。

