
云端 自动 采集
直观:大数据时代,云端爬虫采集系统辅助网站实现内容自动化!
采集交流 • 优采云 发表了文章 • 0 个评论 • 389 次浏览 • 2020-09-18 08:22
大数据和云计算是当今Internet上使用最广泛的技术。面对数据的蓝色海洋,许多公司和个人并不完全具备数据挖掘的功能,只能使用第三方采集器软件来实现数据采集,而传统的采集软件大多附属于Windows系统,但现在是移动多平台时代,单个Windows 采集软件无法满足网站多方面的需求,并且费用昂贵,并且云同步能力很差,因而要花钱网站 ]最小。具有技术能力的公司或个人将开发自己的网站 采集程序,该程序涉及人员,周期和成本方面的大量投资,并且该程序的可伸缩性和多功能性在以后的维护中显而易见。缺点是消耗人力,物力和财力。
因此,什么样的采集软件对网站真正有价值,作者认为,既需要像传统采集软件一样具有数据挖掘能力,又要与时俱进,真正做到实现采集云化后,市场上的云采集仅在供应商的服务器采集上执行,客户没有完全的自治权,采集的效率受到供应商服务器的处理能力的限制,优采云采集器是真正的云数据采集发布系统。它使用类似于cms的系统来构建网站。它可以安装在客户自己的服务器上,并且可以通过浏览器访问服务器域名或ip进行操作。 采集,优采云采集器与客户自己的网站没有冲突。它是一个完全辅助的网站 采集系统,可以在服务器的任何子目录中建立,并且在不使用该软件时可以删除该软件所在的目录。
优采云采集器全名优采云数据采集发布系统,软件英文名称SkyCaiji,致力于网站数据自动化采集发布,使数据采集方便,智能且基于云。该软件是使用php + mysql开发的可视化网站系统,开源并且免费使用,几乎可以采集所有类型的网页,可以自定义采集规则,支持正则表达式,XPATH,JSON和其他语法,准确匹配任何信息流,可以智能识别大多数文章类型页面的正文内容。该软件可以与各种cms站点构建程序结合使用,以实现无需登录即可进行实时数据发布,支持自定义数据发布插件或直接导入数据库,存储为Excel文件,生成API接口等。定期自动定量发布采集,无需人工干预,节省了人力和物力!该操作界面具有完全相同的功能,非常适合计算机和移动终端,使您可以随时随地工作。借助内置的云平台,用户可以共享和下载采集规则,发布采集供求信息以及社区帮助和交流。它是大数据和云时代网站数据自动化采集发布的最佳云爬虫软件。
专业工作留给别人做,优采云采集()将为您提供一组数据采集发布解决方案! 查看全部
在大数据时代,云爬虫采集系统协助网站自动化内容!
大数据和云计算是当今Internet上使用最广泛的技术。面对数据的蓝色海洋,许多公司和个人并不完全具备数据挖掘的功能,只能使用第三方采集器软件来实现数据采集,而传统的采集软件大多附属于Windows系统,但现在是移动多平台时代,单个Windows 采集软件无法满足网站多方面的需求,并且费用昂贵,并且云同步能力很差,因而要花钱网站 ]最小。具有技术能力的公司或个人将开发自己的网站 采集程序,该程序涉及人员,周期和成本方面的大量投资,并且该程序的可伸缩性和多功能性在以后的维护中显而易见。缺点是消耗人力,物力和财力。
因此,什么样的采集软件对网站真正有价值,作者认为,既需要像传统采集软件一样具有数据挖掘能力,又要与时俱进,真正做到实现采集云化后,市场上的云采集仅在供应商的服务器采集上执行,客户没有完全的自治权,采集的效率受到供应商服务器的处理能力的限制,优采云采集器是真正的云数据采集发布系统。它使用类似于cms的系统来构建网站。它可以安装在客户自己的服务器上,并且可以通过浏览器访问服务器域名或ip进行操作。 采集,优采云采集器与客户自己的网站没有冲突。它是一个完全辅助的网站 采集系统,可以在服务器的任何子目录中建立,并且在不使用该软件时可以删除该软件所在的目录。
优采云采集器全名优采云数据采集发布系统,软件英文名称SkyCaiji,致力于网站数据自动化采集发布,使数据采集方便,智能且基于云。该软件是使用php + mysql开发的可视化网站系统,开源并且免费使用,几乎可以采集所有类型的网页,可以自定义采集规则,支持正则表达式,XPATH,JSON和其他语法,准确匹配任何信息流,可以智能识别大多数文章类型页面的正文内容。该软件可以与各种cms站点构建程序结合使用,以实现无需登录即可进行实时数据发布,支持自定义数据发布插件或直接导入数据库,存储为Excel文件,生成API接口等。定期自动定量发布采集,无需人工干预,节省了人力和物力!该操作界面具有完全相同的功能,非常适合计算机和移动终端,使您可以随时随地工作。借助内置的云平台,用户可以共享和下载采集规则,发布采集供求信息以及社区帮助和交流。它是大数据和云时代网站数据自动化采集发布的最佳云爬虫软件。
专业工作留给别人做,优采云采集()将为您提供一组数据采集发布解决方案!
解决方案:网站数据库格式网页数据采集如何导出为Excel、CSV、Html、数据库、API
采集交流 • 优采云 发表了文章 • 0 个评论 • 334 次浏览 • 2020-09-01 06:09
摘要: 该视频介绍了数据查看和导出. 单击“导出数据”后,将提示您是否删除重复项. 您可以选择导出所有数据,也可以选择在重复数据删除后导出. 数据仅存储在云中3个月(以采集时间计算),到期日期将被自动清除. Excel表文件(每个文件最多有20,000个数据,超过20,000个将自动拆分多个文件以进行导出. 如果单行数据太长,该行将被截断. 导出到数据库,支持SQL Server,MySQL, Oracle这三种类型的数据库都支持自动导出到数据库,未导出的数据将按计划定期导出.
网站数据库格式
此视频介绍了数据查看和导出.
如果本地采集数据具有重复数据. 单击“导出数据”后,将提示您是否删除重复项. 您可以选择导出所有数据,也可以选择在重复数据删除后导出.
导出后,本地数据不会自动清除. 您可以下次再次导出它或清除数据.
如果在云采集数据中采集了重复数据,它将在进入数据库之前自动进行重复数据删除,也就是说,您看到的数据不是重复数据.
导出后,云采集数据不会自动清除. 您下次可以再次导出或清除数据. 数据仅在云中存储3个月,以采集时间计算,到期日期将自动清除.
云采集数据按状态分类:
所有数据: 此任务的所有数据,每次将累积云采集数据时,如果不清除,则始终可以查看和导出.
未导出的数据: 从未导出采集中新到达的数据,但是任何导出格式或方法(只要已导出一次)都不是未导出的数据.
数据导出格式/方法:
Excel表文件(每个文件最多有20,000个数据,超过20,000个将自动拆分多个文件以进行导出. 如果一行数据太长,则该行将被截断. )
CSV文本文件(每个文件最多收录20,000个数据,超过20,000个将自动拆分多个文件以进行导出. 单行数据太长且不会被截断. )
HTML网页文件(一行数据,一个文件,例如采集具有100个数据,选择此格式将导出100个文件)
导出到数据库,支持三种类型的数据库: SQL Server,MySQL和Oracle. 支持自动导出到数据库,未导出的数据将按计划定期导出.
API接口导出,API文档参考 查看全部
网站如何将数据库格式采集的网页数据导出到Excel,CSV,HTML,数据库,API
摘要: 该视频介绍了数据查看和导出. 单击“导出数据”后,将提示您是否删除重复项. 您可以选择导出所有数据,也可以选择在重复数据删除后导出. 数据仅存储在云中3个月(以采集时间计算),到期日期将被自动清除. Excel表文件(每个文件最多有20,000个数据,超过20,000个将自动拆分多个文件以进行导出. 如果单行数据太长,该行将被截断. 导出到数据库,支持SQL Server,MySQL, Oracle这三种类型的数据库都支持自动导出到数据库,未导出的数据将按计划定期导出.
网站数据库格式

此视频介绍了数据查看和导出.
如果本地采集数据具有重复数据. 单击“导出数据”后,将提示您是否删除重复项. 您可以选择导出所有数据,也可以选择在重复数据删除后导出.
导出后,本地数据不会自动清除. 您可以下次再次导出它或清除数据.
如果在云采集数据中采集了重复数据,它将在进入数据库之前自动进行重复数据删除,也就是说,您看到的数据不是重复数据.
导出后,云采集数据不会自动清除. 您下次可以再次导出或清除数据. 数据仅在云中存储3个月,以采集时间计算,到期日期将自动清除.
云采集数据按状态分类:
所有数据: 此任务的所有数据,每次将累积云采集数据时,如果不清除,则始终可以查看和导出.
未导出的数据: 从未导出采集中新到达的数据,但是任何导出格式或方法(只要已导出一次)都不是未导出的数据.
数据导出格式/方法:
Excel表文件(每个文件最多有20,000个数据,超过20,000个将自动拆分多个文件以进行导出. 如果一行数据太长,则该行将被截断. )
CSV文本文件(每个文件最多收录20,000个数据,超过20,000个将自动拆分多个文件以进行导出. 单行数据太长且不会被截断. )
HTML网页文件(一行数据,一个文件,例如采集具有100个数据,选择此格式将导出100个文件)
导出到数据库,支持三种类型的数据库: SQL Server,MySQL和Oracle. 支持自动导出到数据库,未导出的数据将按计划定期导出.
API接口导出,API文档参考
云端主动采集 主动下发优采云采集器:云端文章自动采集发布系统-小哲博客
采集交流 • 优采云 发表了文章 • 0 个评论 • 309 次浏览 • 2020-08-30 05:01
摘要:优采云采集器是一款免费的文章采集系统,而且是云端手动采集系统,只要你有一台服务器甚至一台虚拟主机,就能实现网站内容手动更新。做网站的同事肯定都晓得采集文章的好处,小哲就不过多剖析采集的作用了,重点介绍一下优采云采集器的一些优点吧。优采云采集器不用你自己的笔记本能够实现采集,只要有服务器设置一台虚拟主机能够采集文章,其实优采云采集器类似一个博客系统,把源代码上传到服务器里面,通过域名进行访问安装,然后就可以使用了,这点和DZ、Wordpress、Z博客的安装过程一样
云端主动采集 主动下发
优采云采集器是一款免费的文章采集系统,而且是云端手动采集系统,只要你有一台服务器甚至一台虚拟主机,就能实现网站内容手动更新。做网站的同事肯定都晓得采集文章的好处,小哲就不过多剖析采集的作用了,重点介绍一下优采云采集器的一些优点吧
优采云采集器不用你自己的笔记本能够实现采集,只要有服务器设置一台虚拟主机能够采集文章,其实优采云采集器类似一个博客系统,把源代码上传到服务器里面,通过域名进行访问安装,然后就可以使用了,这点和DZ、Wordpress、Z博客的安装过程一样
优采云采集的安装简单,重点在于采集过程的配置。首先要找到目标网站的采集规则,这个须要你自己去创建规则的,优采云采集器官网有几个样例规则,不难理解,看懂就可以自己写规则了,支持正则、XPATH、JSON等,采集到的数据就可以发布内容到各大CMS平台上,包括Wordpress、Z博客等主流博客程序,下面是官方的一些发布插件,不用自己写插件了
其他细节东西你自己去研究就行了,比如图片本地化这些功能,你渐渐去尝试,小哲我就不讲很详尽了,如果你不会使用,可以来咨询小哲。不过小哲我平时消息比较多,不要催太紧,而且小哲我也不太支持采集,除非你有非常好的采集源,像采集源这些东西你自己去找,这个别来问我,我不可能晓得每位行业的网站的,有些行业小哲我根本不懂,比如建筑行业,所以也不可能晓得建筑行业那个网站值得采集
优采云采集器比优采云采集好的地方就在于支持在线采集,不需要你开笔记本,定时手动采集,这点十分便捷
优采云采集器官网:
网上挣钱的核心在于推广,想赚大钱就要学会推广,如果你对挣钱感兴趣,小哲博客首页有可以推广赚钱的手机APP和挣钱方法,都是小哲我认真推荐的,希望诸位路过的同事支持一下 查看全部
云端主动采集 主动下发优采云采集器:云端文章自动采集发布系统-小哲博客
摘要:优采云采集器是一款免费的文章采集系统,而且是云端手动采集系统,只要你有一台服务器甚至一台虚拟主机,就能实现网站内容手动更新。做网站的同事肯定都晓得采集文章的好处,小哲就不过多剖析采集的作用了,重点介绍一下优采云采集器的一些优点吧。优采云采集器不用你自己的笔记本能够实现采集,只要有服务器设置一台虚拟主机能够采集文章,其实优采云采集器类似一个博客系统,把源代码上传到服务器里面,通过域名进行访问安装,然后就可以使用了,这点和DZ、Wordpress、Z博客的安装过程一样
云端主动采集 主动下发

优采云采集器是一款免费的文章采集系统,而且是云端手动采集系统,只要你有一台服务器甚至一台虚拟主机,就能实现网站内容手动更新。做网站的同事肯定都晓得采集文章的好处,小哲就不过多剖析采集的作用了,重点介绍一下优采云采集器的一些优点吧
优采云采集器不用你自己的笔记本能够实现采集,只要有服务器设置一台虚拟主机能够采集文章,其实优采云采集器类似一个博客系统,把源代码上传到服务器里面,通过域名进行访问安装,然后就可以使用了,这点和DZ、Wordpress、Z博客的安装过程一样
优采云采集的安装简单,重点在于采集过程的配置。首先要找到目标网站的采集规则,这个须要你自己去创建规则的,优采云采集器官网有几个样例规则,不难理解,看懂就可以自己写规则了,支持正则、XPATH、JSON等,采集到的数据就可以发布内容到各大CMS平台上,包括Wordpress、Z博客等主流博客程序,下面是官方的一些发布插件,不用自己写插件了
其他细节东西你自己去研究就行了,比如图片本地化这些功能,你渐渐去尝试,小哲我就不讲很详尽了,如果你不会使用,可以来咨询小哲。不过小哲我平时消息比较多,不要催太紧,而且小哲我也不太支持采集,除非你有非常好的采集源,像采集源这些东西你自己去找,这个别来问我,我不可能晓得每位行业的网站的,有些行业小哲我根本不懂,比如建筑行业,所以也不可能晓得建筑行业那个网站值得采集
优采云采集器比优采云采集好的地方就在于支持在线采集,不需要你开笔记本,定时手动采集,这点十分便捷
优采云采集器官网:
网上挣钱的核心在于推广,想赚大钱就要学会推广,如果你对挣钱感兴趣,小哲博客首页有可以推广赚钱的手机APP和挣钱方法,都是小哲我认真推荐的,希望诸位路过的同事支持一下
2017 年,我用 Airtable 这款表格利器建了一个「量化自我」数据库
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-24 22:46
如今,数据早已被称之为信息时代的「黄金」,个人可以通过数据来量化自我,公司可以使用数据来帮助决策。互联网服务商可以通过搜集用户数据提供愈发个性化的服务,我们也可以搜集自己的数据来优化自己的生活方式。
近一年来,我开始意识到自己作为数据发生器的重要性,于是就开始下意识地集中搜集自己形成的各种数据,建立自己的数据搜集模式。而提到为何要集中搜集个人数据,主要缘由应当有两点:
目前使用了 Moves,RescueTime,Toggl 等各种应用来搜集自己的地理位置、时间消耗等数据。但是这种数据都存放于单独的应用之上,过于分散。自己看得见,摸得着的数据,比置于他人的服务器上更放心,也更容易集中加以借助。
集中搜集数据,意味着 Moves,RescueTime 等应用弄成了纯粹的搜集工具,而数据会汇总到自己手中。不同类型的数据一旦汇集到一起,不仅可以针对单一类别数据进行可视化展示,还能剖析出数据直接的关联性,对自己的行为更具有指导意义。
选择一款云端表格工具
数据搜集的末端,对应着用于储存数据的数据库。当然,对于个人数据搜集而言,我们常说的电子表格也许就足够了。最使大众熟知的电子表格工具一定是 Microsoft Excel 。但是,作为一款桌面软件,Excel 往往并不适用于现代的数据搜集流程。例如,你想将你的微博存档保留,难道是通过自动复制粘贴到 Excel 文档中吗?显然不太实际。
所以,如果我们有一个置于云端的电子表格,可想像的空间就大好多了。说到云端电子表格,不得不再度提及 Excel,只不过此次是它的孪生兄弟 Excel Online,作为 Office 365 的套件之一,Excel Online 除了未能处理宏命令,其他方面几乎就是桌面版 Excel 的完美克隆。
相比之下,本文的主角 Airtable 的名气就远不及 Excel 了。但是,作为一个典型的硅谷公司产品,Airtable 也拥有不错的口碑。此外,Google Sheets 也是优秀的云端表格工具,只是这朵云距我们稍为远了一些。
那么,对于这三款相对优秀的云端电子表格,到底哪一款愈发适宜用于个人数据搜集整理呢?我做了一个对比。
当我选择的时侯,最看重的功能虽然是 API 支持。只有具备了 API 接口,才能使数据搜集流程可以实现自动化,也才是名副其实的「云端表格」。而使我最终选择 Airtable 的缘由,应该有如下几点:
基础功能同另外的两个产品相比没有显著的缺位,甚至拥有象条形码输入、iframe 嵌入等更多差异化功能。Airtable 同时支持 IFTTT 和 Zapier 云端自动化工具,且 API 使用上去更简单便捷。很多时侯,就算使用现有工具难以满足需求,也可以按照开发者文档自行编撰代码实现数据读取和写入。Airtable 外观设计愈发漂亮,这一点在长时间的使用过程中特别重要。Airtable 使用简介
在即将介绍我是怎样使用 Airitable 集中整理数据之前,我想先对 Airtable 做一个简单介绍。
如下图所示,Airtable 主要收录有 6 个基本组件,分别是:
可以看出,Airtable 从诞生之初就具备了关系型数据库的样子,已经满足了对数据存储的日常需求。从功能上,除了 Excel Online,基本上没有竞品。
要想对个人数据进行集中搜集整理,首先须要在 Airtable 创建不同的数据库。建立数据库是个人数据搜集工程中的第一步,所以并不是随便乱建的。其中,我们须要先想一想搜集数据的大类,然后在细分大类中的小类,并对应到数据表中。我的数据库主要有下边 3 个,树形结构如图所示。
工作学习数据库
工作学习数据库会搜集平时我在工作或则学习中形成的相关数据。根据我的使用习惯,数据库收录了 4 张数据表,分别是:Calendar、Todoist、Trello 以及 Issues(同步 Github)。看到名子应当就很容易明白这 4 张表的意思了。
对于这四类服务的数据,我均是采用 IFTTT 或者 Zapier 将其同步到 Airtable 中。这里补充介绍一下 IFTTT 和 Zapier 的区别与联系。首先,二者都是整合不同应用提供的开发者 API 实现自动化流程的云端服务,这是她们的相同之处。但是,Zapier 相对于 IFTTT 会更强悍一些,它通常情况下会支持原服务更全面的 API 接口,且支持多个服务联动。相比之下,IFTTT 很多时侯只提供主要的插口,且只支持两个服务之间的数据传递。
举个反例,当我在使用 Zapier 实现 Google Calendar → Airtable 的过程中,Zapier 支持读取 Google Calendar 中的 43 项数据(虽然有一些不实用),但 IFTTT 只支持 8 个。当然,IFTTT 也有比 Zapier 好用的时侯。比如将 Todoist 完成任务同步到 Airtable 时,Zapier 不支持检测任意 Project 下完成的任务,需针对每位 Project 设置单独的流程。
四个服务同步到 Airtable 的设置都大同小异,这里我只拿 Todoist → Airtable 详细说明。当我选择 IFTTT 作为 Todoist → Airtable 的同步工具时,首先须要到 IFTTT 上看一看其支持读取 Todoist 的什么数据,你可以通过创建动作时查看。
我们可以看见从 Todoist → Airtable 一共支持 7 个类别的数据。那么,现在可以先新建这个动作。注意,你须要遵循 IFTTT 制定的句型格式,才能正确地将数据写入到 Airtable 中。
也就是说,如果要将这 7 类数据全部同步到 Airtable,你须要在 IFTTT 动作的最后输入如下所示的内容。我习惯之间使用 IFTTT 的 ingredient 名称作为 Airtable 中的列名称。
格式:::airtable::Airtable 中的列名::{{IFTTT 中的 ingredient}}
示例内容:
::airtable::TaskContent::{{TaskContent}}
::airtable::LinkToTask::{{LinkToTask}}
::airtable::Project::{{Project}}
::airtable::Labels::{{Labels}}
::airtable::Priority:: {{Priority}}
::airtable::CompletedAt::{{CompletedAt}}
::airtable::DueDate::{{DueDate}}
接下来,就可以到 Airtable 中设置相应的列名称了。在设置对应的列属性(文本、数字、图片等)时,我建议一开始统一设置为「Single line text」,也就是单行文本格式,以避免导出数据出错。
当测试导出成功以后,就可以调整列属性。例如这儿,Project 的数目是有限的,且每位任务只对应一个 Project。就可以将其列属性设定为 Single select(单选),这样也便捷日后对任务进行筛选。同样,日期可以使用 Date 属性,链接使用 URL 等。
如果调整列属性以后,表格显示为空白或报错,那就意味着通过 IFTTT 传过来的数据格式并不能挺好地被 Airtable 支持。比如这儿的 CompletedAt,也就是项目的完成日期 + 时间。IFTTT 输出的数据格式是象这样的 January 20, 2018 at 10:18AM,Airtable 无法之间将其转换为对应的「日期+时间」的格式。
为了便捷以后的数据剖析,我们当然更偏向于将其处理成时间序列,也就是按 Airtable 中的「日期+时间」格式保存。此时,我们可以通过新建中间列作为过渡,然后借助 Airtable 的 Formula 公式将原文本列转换为可辨识的「日期+时间」列。具体步骤如下:
明确区别: 原文本列格式为January 20, 2018 at 10:18AM,Airtable 可辨识的格式为January 20, 2018 10:18 AM。注意观察两者之间的区别,文本格式多了 at + 一个空格 字符,同时 AM 字符前缺乏一个空格。格式转换:明白区别以后就可以开始使用 Airtable 提供的 Formula 公式转换格式。首先是去除 at 字符,然后在结尾的 AM 或者 PM 前面降低空格。
这里使用了 SEARCH() 函数去定位要更改的位置,然后使用 REPLACE() 函数更改字符。最后再使用 DATATIME_FOMRMAT() 函数低格字符串为我们想要的「日期-时间」样式。一个小的方法是,如果你嫌降低的中间列较多,那么可以使用 Airtable 顶部菜单的 Hide fields 选项隐去不必要的列,只呈现我们须要的数据即可。
量化自我数据库
我的第二个主要数据库为量化自我数据库,它是由:Moves、Location、Apple Health、RescueTime 以及 Commute 等 5 个数据表组成。这 5 个数据表分别对应着 Moves 记录的地理位置数据、手动签到数据、Apple Health 记录的运动健康数据、RescueTime 记录的工作效率数据以及通勤时间统计数据。
Moves 数据
Moves 是我仍然在使用的地理位置追踪应用,它的运动状态辨识和地点辨识做的非常好,以至于如今都没有找到可取代的应用。Moves 其实拥有健全的 API,但因为其认证方法的特殊性,IFTTT 和 Zapier 都仍未支持与 Moves 连接。于是,我只能自己编撰一个 Moves → Airtable 的脚本,然后布署在云服务器上,每天手动将今天形成的数据同步的 Airtable 中去。
实现的过程比较麻烦,都能凑够一篇文章了,另找时间再细说。这里,Moves 的数据收录有经纬度信息,你可以直接使用 Airtable 提供的 Map Block 模块对地理位置可视化。
关于 Airtable Blocks 的更多介绍,可以阅读官方的文章《Getting started with Airtable blocks》
Location 数据
除了使用 Moves 自动记录地理位置信息,我还自己制做了一个辅助签到的 Workflow 用来标记我觉得重要的地点,并把地理位置数据实时上传到 Airtable 中的 Location 数据表中。
Workflow 非常简单,流程如下:定位 → 解析数据 [街道 - 城市 - 地区 - 国家] → 解析数据 [经度 - 纬度 - 高度] → 结合当前时间一并上传到 Airtable 中。
Apple Health 数据
目前,追踪健康信息主要是使用 Apple Watch 和 iPhone,通过本身的健康应用以及配合 Moves,Autosleep 等第三方应用完成。Apple Health 无法实现 iCloud 同步,更没有 API 支持,所以只能半自动同步到 Airtable。我采用的方式是定期从 Apple Health 中导入数据文件到 Dropbox 中,Dropbox 的数据压缩包会手动同步到云服务器中,再由云服务器中布署的 Python 脚本手动完成数据解析,并通过 API 同步到 Airtable 的表格中去。
RescueTime 数据
工作效率记录我会使用到 RescueTime 应用,RescueTime 会手动记录各种程序的前台运行时间,再和数据库进行比对得到相应应用属于效率应用还是非效率应用,从而手动统计每晚的工作效率。
RescueTime 的数据同步到 Airtable 就比较便捷了,可以使用 IFTTT,Zapier 或者开发者插口同步。我选择的是 Zapier,因为它可以同步多达 59 项数据信息。触发的动作选择「当每日数据汇总后」,然后再将对应的数据更新到对应的列即可。过程十分简单,就不再赘言了。
这里介绍一个使用 RescueTime 的一个小技巧,那就是最好定期去自动标记相应应用的效率属性。首先,我们每晚浏览的大多数网页或则使用的应用都是比较固定的,手动标记耗费的时间不多。其次,有一些应用对每个人的效率属性不一致。比如,我早已好多年没用 QQ 作为和他人的聊天工具了,所以但凡当使用 QQ 时,基本上都属于处理工作里面的事情,它对于我而言就是效率状态,而不是闲暇状态。
通勤时间数据
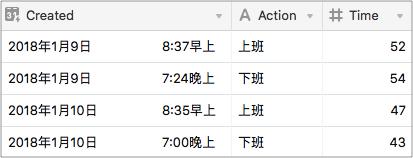
Commute 表拿来统计我的通勤时间。每天,我就会选择轻轨作为下班通勤的主要交通工具,虽然轻轨在站与站之间的运行时间比较确定,但因为存在换乘,所以每晚的通勤时间的变化就比较大了。打个比方,有时候晚上只晚出发 5 分钟,如果刚好赶上一波高峰,实际抵达公司的时间常常会晚 20 分钟。所以,我从年初就开始每晚记录自己的通勤时间,打算等到数据累计到一定量以后,通过数据剖析得到自己每晚的合理出发时间。
在记录通勤时间的时侯,由于打算将数据保存到 Airtable,所以一开始就直接就排除了现有的计时器或则第三方 App,然后把目标集中到 Workflow。但是,很快我就发觉 Workflow 的现有动作中,并没有支持在后台完成计时的动作。后来,我就想到了直接利用 Airtable 来完成这个功能,这个功能的逻辑十分简单。流程如下:
每天从屋内出发的时侯,点击 workflow 将此刻的时间上传到 Airtable,并记为出发时间。当抵达公司时,再次点击 Workflow 将时间上传到 Airtable 。由于 Airtable 本身可以使用数据函数,就能估算出两个时间差,并直接在我第二次点击 Workflow 上传时间后,将估算好的通勤时间推送到手机上。这样,既可以实时见到记录出来的通勤时间,也不再须要二次过程将数据上传到 Airtable 中。
信息存档数据库
信息存档数据库是拿来保存我觉得有必要存档的互联网数据。其中,主要有三个 Tables,分别是:微博、博客以及稍后读。
我喜欢定期清空自己的微博,防止在互联网上留下过多的「? 历史」。但又不想扔掉自己转发过的微博,于是就有了这个微博存档表。存档微博的方式十分简单,使用 IFTTT 新建一个动作,实时将微博记录到 Airtable 中保存。
同样,我使用 Pocket 作为稍后阅读工具,也就通过创建 IFTTT 动作,将保存在 Pocket 中的文章同步存档到 Airtable 中。
除此之外,博客存档表拿来备份自己在互联网上创作的内容。比如在少数派写的文章以及自己的博客文章。该表单使用了自己编撰的 Python 脚本,定期将我的博客文章以及在少数派发表的文章同步保存到 Airtable 中。
其他数据库
除了前面提及的这三个主要的数据库,我还有几个自己比较喜欢的数据库,也分享一下。
票据存档数据库
票据存档的数据库主要是记录平时我觉得比较重要的支票、发票、合同文件等。当然,超市购物小票这类不太重要的票据也就没必要存档了。
教育让利统计数据库
几个月前,我在少数派写过一篇 《在校师生福利:Apple、微软、Adobe 等产品怎样通过教育让利订购》 ,这篇文章中介绍一些院校中学生可以享受的教育让利项目。不久前,我通过 Airtable 整理了一份愈发详尽的教育让利表单,希望更多的中学生能享受到优价有品质的服务。
你可以通过检索的形式来获取自己感兴趣的教育让利项目。当然,我也号召你们来一起建立这个表单。如果有一些教育让利项目非常好,但表单中未涉及到,欢迎直接通过下边的链接补充递交到表单中去。
菜品、餐馆统计数据库
最近,我正在建立的一个数据库来源于我生活中的一个疼点,那就是常常不知道喝哪些。这个数据库中会记录下一些餐厅和食材。我会将平时喝过觉得不错的,或者想吃的餐厅信息添加到餐厅数据表中,同时会记录一些做过或则想做的菜肴。
当我自己想做饭喝的时侯,我都会通过 Workflow 随机返回食材作为灵感,而想出去喝的时侯,也可以随机返回餐厅信息。目前,这个数据库和 Workflow 还没有完全做好,等建立以后,会同你们一起分享。
另外,文中提及的一些自动化数据获取的 Python 脚本,我也会整理后择时与少数派读者分享。
结语
我虽然很早就晓得 Airtable 了,但真正有效地借助上去也是近一年才开始的。目前,虽然 Airtable 已经帮我存出来不少的数据,但是我对它的借助程度还并不满意,今年我会继续开掘 Airtable 的「正确使用方法」。
如今,我们都晓得经常须要备份自己的相片、手机、电脑,防止资料遗失。除此之外,我们同样应当注重起自己每晚形成的其他数据。目前初步构建上去的数据集中搜集模式只是开始。等待数据积累到一定量时,就须要着手「数据集中剖析」,使其真正地能帮助自己发觉某个坏习惯,提升一些效率,改变一些东西。
少数派一年一度的奖品超级优厚的 征文活动 又开始了!我们打算了 5 万+ 的奖品等你来拿。
本文是「我是少数派,这是我的 2017」征文活动的第入围作品。 查看全部
2017 年,我用 Airtable 这款表格利器建了一个「量化自我」数据库
如今,数据早已被称之为信息时代的「黄金」,个人可以通过数据来量化自我,公司可以使用数据来帮助决策。互联网服务商可以通过搜集用户数据提供愈发个性化的服务,我们也可以搜集自己的数据来优化自己的生活方式。
近一年来,我开始意识到自己作为数据发生器的重要性,于是就开始下意识地集中搜集自己形成的各种数据,建立自己的数据搜集模式。而提到为何要集中搜集个人数据,主要缘由应当有两点:
目前使用了 Moves,RescueTime,Toggl 等各种应用来搜集自己的地理位置、时间消耗等数据。但是这种数据都存放于单独的应用之上,过于分散。自己看得见,摸得着的数据,比置于他人的服务器上更放心,也更容易集中加以借助。
集中搜集数据,意味着 Moves,RescueTime 等应用弄成了纯粹的搜集工具,而数据会汇总到自己手中。不同类型的数据一旦汇集到一起,不仅可以针对单一类别数据进行可视化展示,还能剖析出数据直接的关联性,对自己的行为更具有指导意义。
选择一款云端表格工具
数据搜集的末端,对应着用于储存数据的数据库。当然,对于个人数据搜集而言,我们常说的电子表格也许就足够了。最使大众熟知的电子表格工具一定是 Microsoft Excel 。但是,作为一款桌面软件,Excel 往往并不适用于现代的数据搜集流程。例如,你想将你的微博存档保留,难道是通过自动复制粘贴到 Excel 文档中吗?显然不太实际。
所以,如果我们有一个置于云端的电子表格,可想像的空间就大好多了。说到云端电子表格,不得不再度提及 Excel,只不过此次是它的孪生兄弟 Excel Online,作为 Office 365 的套件之一,Excel Online 除了未能处理宏命令,其他方面几乎就是桌面版 Excel 的完美克隆。
相比之下,本文的主角 Airtable 的名气就远不及 Excel 了。但是,作为一个典型的硅谷公司产品,Airtable 也拥有不错的口碑。此外,Google Sheets 也是优秀的云端表格工具,只是这朵云距我们稍为远了一些。
那么,对于这三款相对优秀的云端电子表格,到底哪一款愈发适宜用于个人数据搜集整理呢?我做了一个对比。
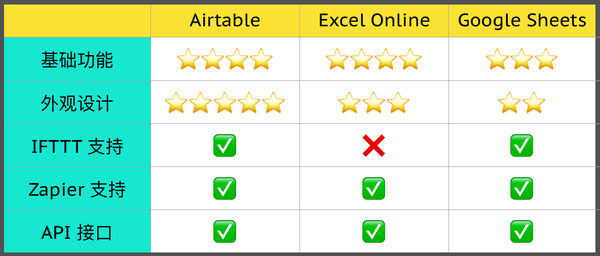
当我选择的时侯,最看重的功能虽然是 API 支持。只有具备了 API 接口,才能使数据搜集流程可以实现自动化,也才是名副其实的「云端表格」。而使我最终选择 Airtable 的缘由,应该有如下几点:
基础功能同另外的两个产品相比没有显著的缺位,甚至拥有象条形码输入、iframe 嵌入等更多差异化功能。Airtable 同时支持 IFTTT 和 Zapier 云端自动化工具,且 API 使用上去更简单便捷。很多时侯,就算使用现有工具难以满足需求,也可以按照开发者文档自行编撰代码实现数据读取和写入。Airtable 外观设计愈发漂亮,这一点在长时间的使用过程中特别重要。Airtable 使用简介
在即将介绍我是怎样使用 Airitable 集中整理数据之前,我想先对 Airtable 做一个简单介绍。
如下图所示,Airtable 主要收录有 6 个基本组件,分别是:
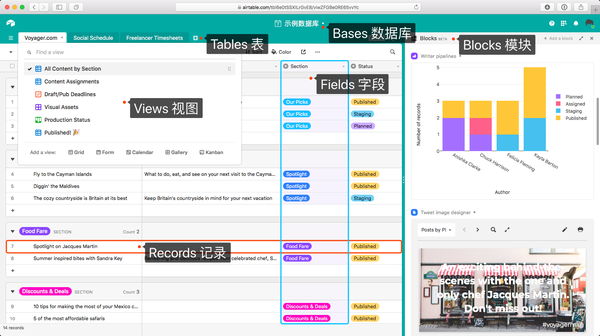
可以看出,Airtable 从诞生之初就具备了关系型数据库的样子,已经满足了对数据存储的日常需求。从功能上,除了 Excel Online,基本上没有竞品。
要想对个人数据进行集中搜集整理,首先须要在 Airtable 创建不同的数据库。建立数据库是个人数据搜集工程中的第一步,所以并不是随便乱建的。其中,我们须要先想一想搜集数据的大类,然后在细分大类中的小类,并对应到数据表中。我的数据库主要有下边 3 个,树形结构如图所示。
工作学习数据库
工作学习数据库会搜集平时我在工作或则学习中形成的相关数据。根据我的使用习惯,数据库收录了 4 张数据表,分别是:Calendar、Todoist、Trello 以及 Issues(同步 Github)。看到名子应当就很容易明白这 4 张表的意思了。
对于这四类服务的数据,我均是采用 IFTTT 或者 Zapier 将其同步到 Airtable 中。这里补充介绍一下 IFTTT 和 Zapier 的区别与联系。首先,二者都是整合不同应用提供的开发者 API 实现自动化流程的云端服务,这是她们的相同之处。但是,Zapier 相对于 IFTTT 会更强悍一些,它通常情况下会支持原服务更全面的 API 接口,且支持多个服务联动。相比之下,IFTTT 很多时侯只提供主要的插口,且只支持两个服务之间的数据传递。

举个反例,当我在使用 Zapier 实现 Google Calendar → Airtable 的过程中,Zapier 支持读取 Google Calendar 中的 43 项数据(虽然有一些不实用),但 IFTTT 只支持 8 个。当然,IFTTT 也有比 Zapier 好用的时侯。比如将 Todoist 完成任务同步到 Airtable 时,Zapier 不支持检测任意 Project 下完成的任务,需针对每位 Project 设置单独的流程。
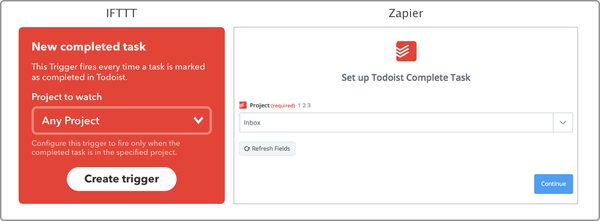
四个服务同步到 Airtable 的设置都大同小异,这里我只拿 Todoist → Airtable 详细说明。当我选择 IFTTT 作为 Todoist → Airtable 的同步工具时,首先须要到 IFTTT 上看一看其支持读取 Todoist 的什么数据,你可以通过创建动作时查看。

我们可以看见从 Todoist → Airtable 一共支持 7 个类别的数据。那么,现在可以先新建这个动作。注意,你须要遵循 IFTTT 制定的句型格式,才能正确地将数据写入到 Airtable 中。
也就是说,如果要将这 7 类数据全部同步到 Airtable,你须要在 IFTTT 动作的最后输入如下所示的内容。我习惯之间使用 IFTTT 的 ingredient 名称作为 Airtable 中的列名称。
格式:::airtable::Airtable 中的列名::{{IFTTT 中的 ingredient}}
示例内容:
::airtable::TaskContent::{{TaskContent}}
::airtable::LinkToTask::{{LinkToTask}}
::airtable::Project::{{Project}}
::airtable::Labels::{{Labels}}
::airtable::Priority:: {{Priority}}
::airtable::CompletedAt::{{CompletedAt}}
::airtable::DueDate::{{DueDate}}
接下来,就可以到 Airtable 中设置相应的列名称了。在设置对应的列属性(文本、数字、图片等)时,我建议一开始统一设置为「Single line text」,也就是单行文本格式,以避免导出数据出错。
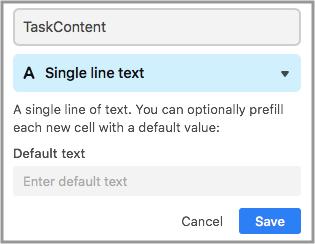
当测试导出成功以后,就可以调整列属性。例如这儿,Project 的数目是有限的,且每位任务只对应一个 Project。就可以将其列属性设定为 Single select(单选),这样也便捷日后对任务进行筛选。同样,日期可以使用 Date 属性,链接使用 URL 等。
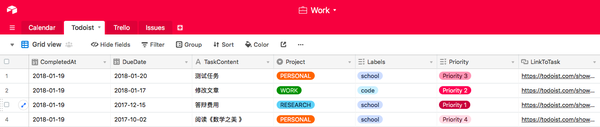
如果调整列属性以后,表格显示为空白或报错,那就意味着通过 IFTTT 传过来的数据格式并不能挺好地被 Airtable 支持。比如这儿的 CompletedAt,也就是项目的完成日期 + 时间。IFTTT 输出的数据格式是象这样的 January 20, 2018 at 10:18AM,Airtable 无法之间将其转换为对应的「日期+时间」的格式。
为了便捷以后的数据剖析,我们当然更偏向于将其处理成时间序列,也就是按 Airtable 中的「日期+时间」格式保存。此时,我们可以通过新建中间列作为过渡,然后借助 Airtable 的 Formula 公式将原文本列转换为可辨识的「日期+时间」列。具体步骤如下:
明确区别: 原文本列格式为January 20, 2018 at 10:18AM,Airtable 可辨识的格式为January 20, 2018 10:18 AM。注意观察两者之间的区别,文本格式多了 at + 一个空格 字符,同时 AM 字符前缺乏一个空格。格式转换:明白区别以后就可以开始使用 Airtable 提供的 Formula 公式转换格式。首先是去除 at 字符,然后在结尾的 AM 或者 PM 前面降低空格。
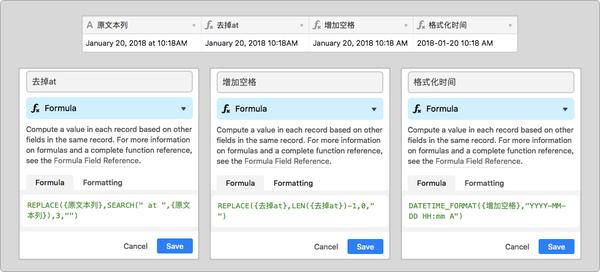
这里使用了 SEARCH() 函数去定位要更改的位置,然后使用 REPLACE() 函数更改字符。最后再使用 DATATIME_FOMRMAT() 函数低格字符串为我们想要的「日期-时间」样式。一个小的方法是,如果你嫌降低的中间列较多,那么可以使用 Airtable 顶部菜单的 Hide fields 选项隐去不必要的列,只呈现我们须要的数据即可。
量化自我数据库
我的第二个主要数据库为量化自我数据库,它是由:Moves、Location、Apple Health、RescueTime 以及 Commute 等 5 个数据表组成。这 5 个数据表分别对应着 Moves 记录的地理位置数据、手动签到数据、Apple Health 记录的运动健康数据、RescueTime 记录的工作效率数据以及通勤时间统计数据。
Moves 数据
Moves 是我仍然在使用的地理位置追踪应用,它的运动状态辨识和地点辨识做的非常好,以至于如今都没有找到可取代的应用。Moves 其实拥有健全的 API,但因为其认证方法的特殊性,IFTTT 和 Zapier 都仍未支持与 Moves 连接。于是,我只能自己编撰一个 Moves → Airtable 的脚本,然后布署在云服务器上,每天手动将今天形成的数据同步的 Airtable 中去。

实现的过程比较麻烦,都能凑够一篇文章了,另找时间再细说。这里,Moves 的数据收录有经纬度信息,你可以直接使用 Airtable 提供的 Map Block 模块对地理位置可视化。
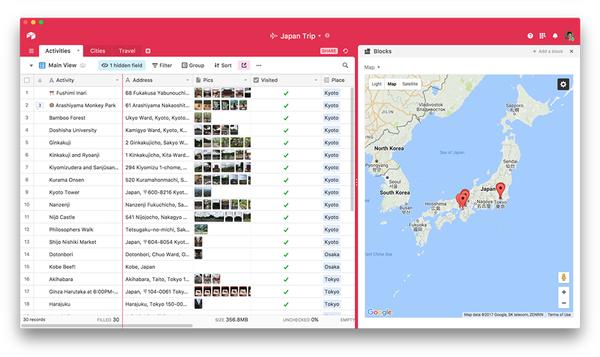
关于 Airtable Blocks 的更多介绍,可以阅读官方的文章《Getting started with Airtable blocks》
Location 数据
除了使用 Moves 自动记录地理位置信息,我还自己制做了一个辅助签到的 Workflow 用来标记我觉得重要的地点,并把地理位置数据实时上传到 Airtable 中的 Location 数据表中。

Workflow 非常简单,流程如下:定位 → 解析数据 [街道 - 城市 - 地区 - 国家] → 解析数据 [经度 - 纬度 - 高度] → 结合当前时间一并上传到 Airtable 中。

Apple Health 数据
目前,追踪健康信息主要是使用 Apple Watch 和 iPhone,通过本身的健康应用以及配合 Moves,Autosleep 等第三方应用完成。Apple Health 无法实现 iCloud 同步,更没有 API 支持,所以只能半自动同步到 Airtable。我采用的方式是定期从 Apple Health 中导入数据文件到 Dropbox 中,Dropbox 的数据压缩包会手动同步到云服务器中,再由云服务器中布署的 Python 脚本手动完成数据解析,并通过 API 同步到 Airtable 的表格中去。
RescueTime 数据
工作效率记录我会使用到 RescueTime 应用,RescueTime 会手动记录各种程序的前台运行时间,再和数据库进行比对得到相应应用属于效率应用还是非效率应用,从而手动统计每晚的工作效率。
RescueTime 的数据同步到 Airtable 就比较便捷了,可以使用 IFTTT,Zapier 或者开发者插口同步。我选择的是 Zapier,因为它可以同步多达 59 项数据信息。触发的动作选择「当每日数据汇总后」,然后再将对应的数据更新到对应的列即可。过程十分简单,就不再赘言了。
这里介绍一个使用 RescueTime 的一个小技巧,那就是最好定期去自动标记相应应用的效率属性。首先,我们每晚浏览的大多数网页或则使用的应用都是比较固定的,手动标记耗费的时间不多。其次,有一些应用对每个人的效率属性不一致。比如,我早已好多年没用 QQ 作为和他人的聊天工具了,所以但凡当使用 QQ 时,基本上都属于处理工作里面的事情,它对于我而言就是效率状态,而不是闲暇状态。
通勤时间数据
Commute 表拿来统计我的通勤时间。每天,我就会选择轻轨作为下班通勤的主要交通工具,虽然轻轨在站与站之间的运行时间比较确定,但因为存在换乘,所以每晚的通勤时间的变化就比较大了。打个比方,有时候晚上只晚出发 5 分钟,如果刚好赶上一波高峰,实际抵达公司的时间常常会晚 20 分钟。所以,我从年初就开始每晚记录自己的通勤时间,打算等到数据累计到一定量以后,通过数据剖析得到自己每晚的合理出发时间。
在记录通勤时间的时侯,由于打算将数据保存到 Airtable,所以一开始就直接就排除了现有的计时器或则第三方 App,然后把目标集中到 Workflow。但是,很快我就发觉 Workflow 的现有动作中,并没有支持在后台完成计时的动作。后来,我就想到了直接利用 Airtable 来完成这个功能,这个功能的逻辑十分简单。流程如下:
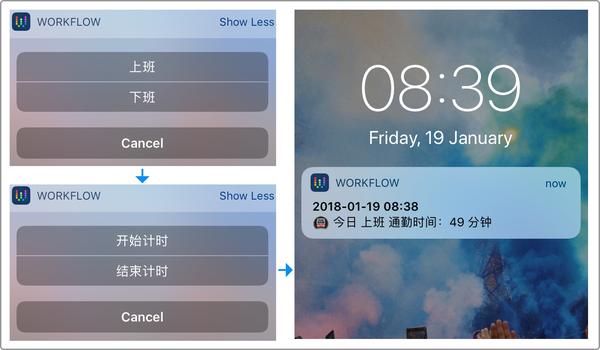
每天从屋内出发的时侯,点击 workflow 将此刻的时间上传到 Airtable,并记为出发时间。当抵达公司时,再次点击 Workflow 将时间上传到 Airtable 。由于 Airtable 本身可以使用数据函数,就能估算出两个时间差,并直接在我第二次点击 Workflow 上传时间后,将估算好的通勤时间推送到手机上。这样,既可以实时见到记录出来的通勤时间,也不再须要二次过程将数据上传到 Airtable 中。
信息存档数据库
信息存档数据库是拿来保存我觉得有必要存档的互联网数据。其中,主要有三个 Tables,分别是:微博、博客以及稍后读。
我喜欢定期清空自己的微博,防止在互联网上留下过多的「? 历史」。但又不想扔掉自己转发过的微博,于是就有了这个微博存档表。存档微博的方式十分简单,使用 IFTTT 新建一个动作,实时将微博记录到 Airtable 中保存。

同样,我使用 Pocket 作为稍后阅读工具,也就通过创建 IFTTT 动作,将保存在 Pocket 中的文章同步存档到 Airtable 中。
除此之外,博客存档表拿来备份自己在互联网上创作的内容。比如在少数派写的文章以及自己的博客文章。该表单使用了自己编撰的 Python 脚本,定期将我的博客文章以及在少数派发表的文章同步保存到 Airtable 中。
其他数据库
除了前面提及的这三个主要的数据库,我还有几个自己比较喜欢的数据库,也分享一下。
票据存档数据库
票据存档的数据库主要是记录平时我觉得比较重要的支票、发票、合同文件等。当然,超市购物小票这类不太重要的票据也就没必要存档了。

教育让利统计数据库
几个月前,我在少数派写过一篇 《在校师生福利:Apple、微软、Adobe 等产品怎样通过教育让利订购》 ,这篇文章中介绍一些院校中学生可以享受的教育让利项目。不久前,我通过 Airtable 整理了一份愈发详尽的教育让利表单,希望更多的中学生能享受到优价有品质的服务。
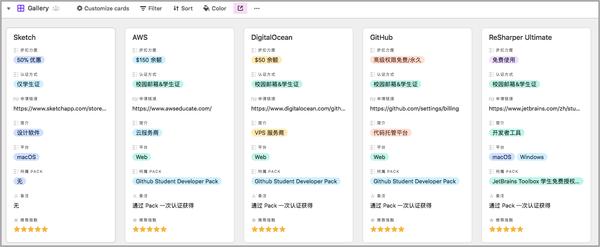
你可以通过检索的形式来获取自己感兴趣的教育让利项目。当然,我也号召你们来一起建立这个表单。如果有一些教育让利项目非常好,但表单中未涉及到,欢迎直接通过下边的链接补充递交到表单中去。
菜品、餐馆统计数据库
最近,我正在建立的一个数据库来源于我生活中的一个疼点,那就是常常不知道喝哪些。这个数据库中会记录下一些餐厅和食材。我会将平时喝过觉得不错的,或者想吃的餐厅信息添加到餐厅数据表中,同时会记录一些做过或则想做的菜肴。
当我自己想做饭喝的时侯,我都会通过 Workflow 随机返回食材作为灵感,而想出去喝的时侯,也可以随机返回餐厅信息。目前,这个数据库和 Workflow 还没有完全做好,等建立以后,会同你们一起分享。
另外,文中提及的一些自动化数据获取的 Python 脚本,我也会整理后择时与少数派读者分享。
结语
我虽然很早就晓得 Airtable 了,但真正有效地借助上去也是近一年才开始的。目前,虽然 Airtable 已经帮我存出来不少的数据,但是我对它的借助程度还并不满意,今年我会继续开掘 Airtable 的「正确使用方法」。
如今,我们都晓得经常须要备份自己的相片、手机、电脑,防止资料遗失。除此之外,我们同样应当注重起自己每晚形成的其他数据。目前初步构建上去的数据集中搜集模式只是开始。等待数据积累到一定量时,就须要着手「数据集中剖析」,使其真正地能帮助自己发觉某个坏习惯,提升一些效率,改变一些东西。
少数派一年一度的奖品超级优厚的 征文活动 又开始了!我们打算了 5 万+ 的奖品等你来拿。
本文是「我是少数派,这是我的 2017」征文活动的第入围作品。
怎样用Python透过树莓派采集到的温湿度信息传送到AWS IoT
采集交流 • 优采云 发表了文章 • 0 个评论 • 370 次浏览 • 2020-08-17 14:41
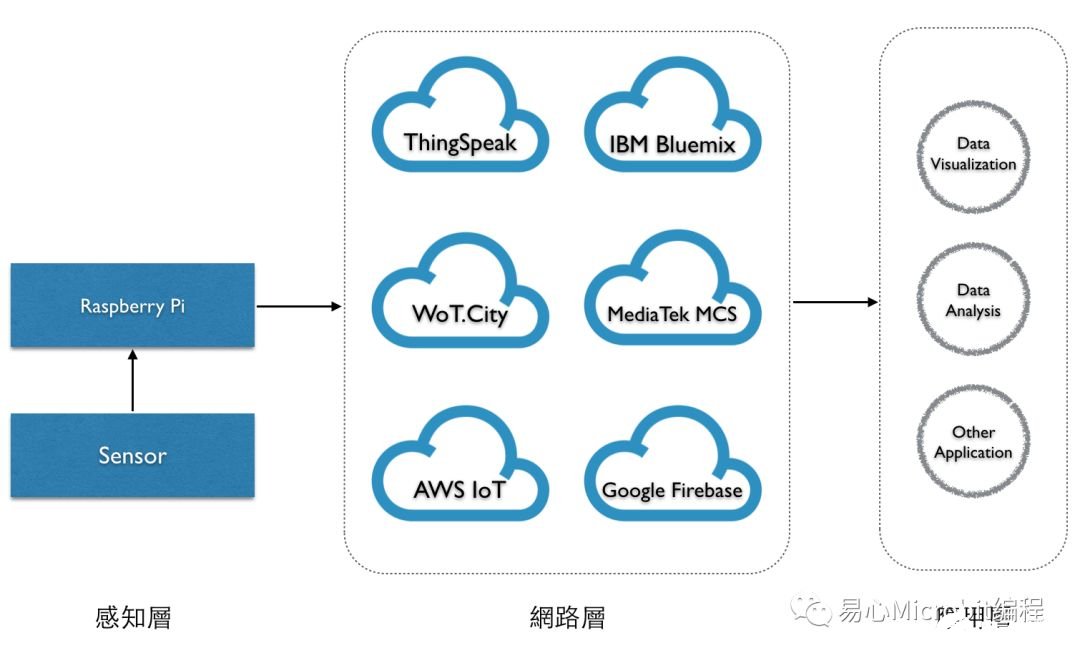
与 IoT 相关的云端服务为数诸多,例如:ThingSpeak、WoT.City、AWS、IBM Bluemix、MediaTek MCS、Google Firebase 等,并在透过这种云端服务可在对数据进行数据可视化、数据剖析与其它的应用,而本文用Python将透过 Raspberry Pi 采集到的温湿度信息传送到 AWS IoT。
情境
材料与打算
1.准备 Raspberry Pi 3Model B 开发板
2.准备 Micro SD (已安装 Raspbian)
3.将 Micro SD 装入到 RaspberryPi 中
4.设定好网路
5.安装 GrovePi+
6.安装 Grove – Temperatureand Humidity Sensor (D4)
7.安装 GROVE - LCD RGBBACKLIGHT (I2C-2)
8.安装 IDE ( Sublime Textor Visual Studio Code )
Sensor, LCD, GrovePi+ 与 RaspberryPi 连接如右图
AWS IoT 端
Step 1. 到 AWS 网站申请帐号
Step 2. 登入 AWS 网站
Step 3. 点击 Services AWS IoT
Step 4. 点击 Create a resource
Step 5. 点击 Create a thing 输入 thing Name Create
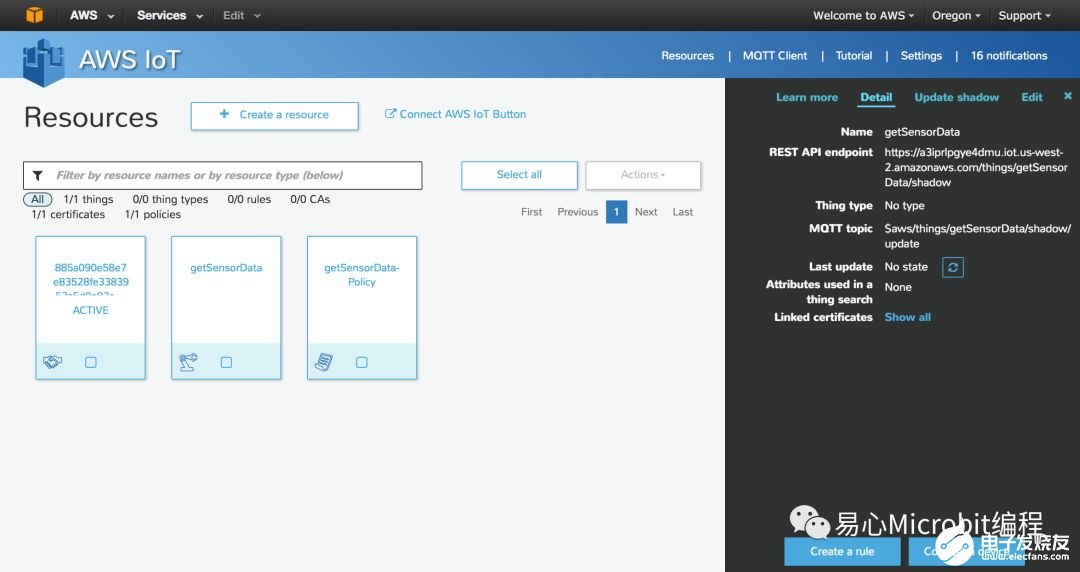
Step 6. 点击刚构建的 thing
Step 7. 点击 Connect a device
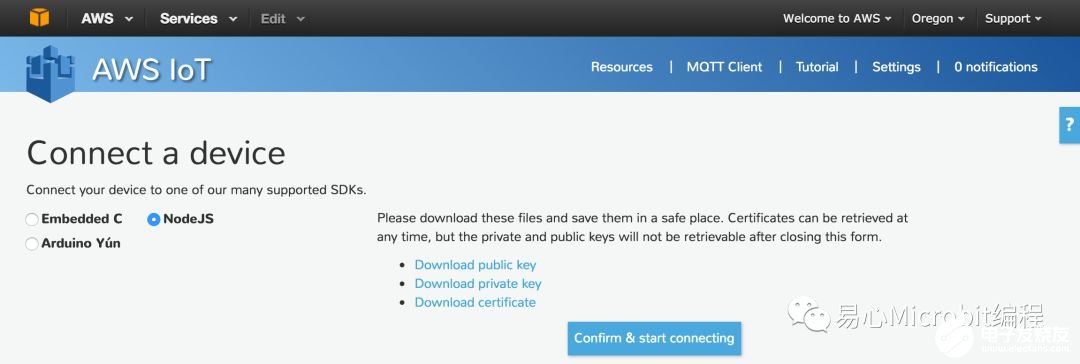
Step 8. 点击 Node.js Generate certificate and policy
Step 9. 下载 private 与 public keys
Step 10. 点击 Confirm &connecting
Step 11. 点击 Return to ThingDetail
Raspberry Pi 端
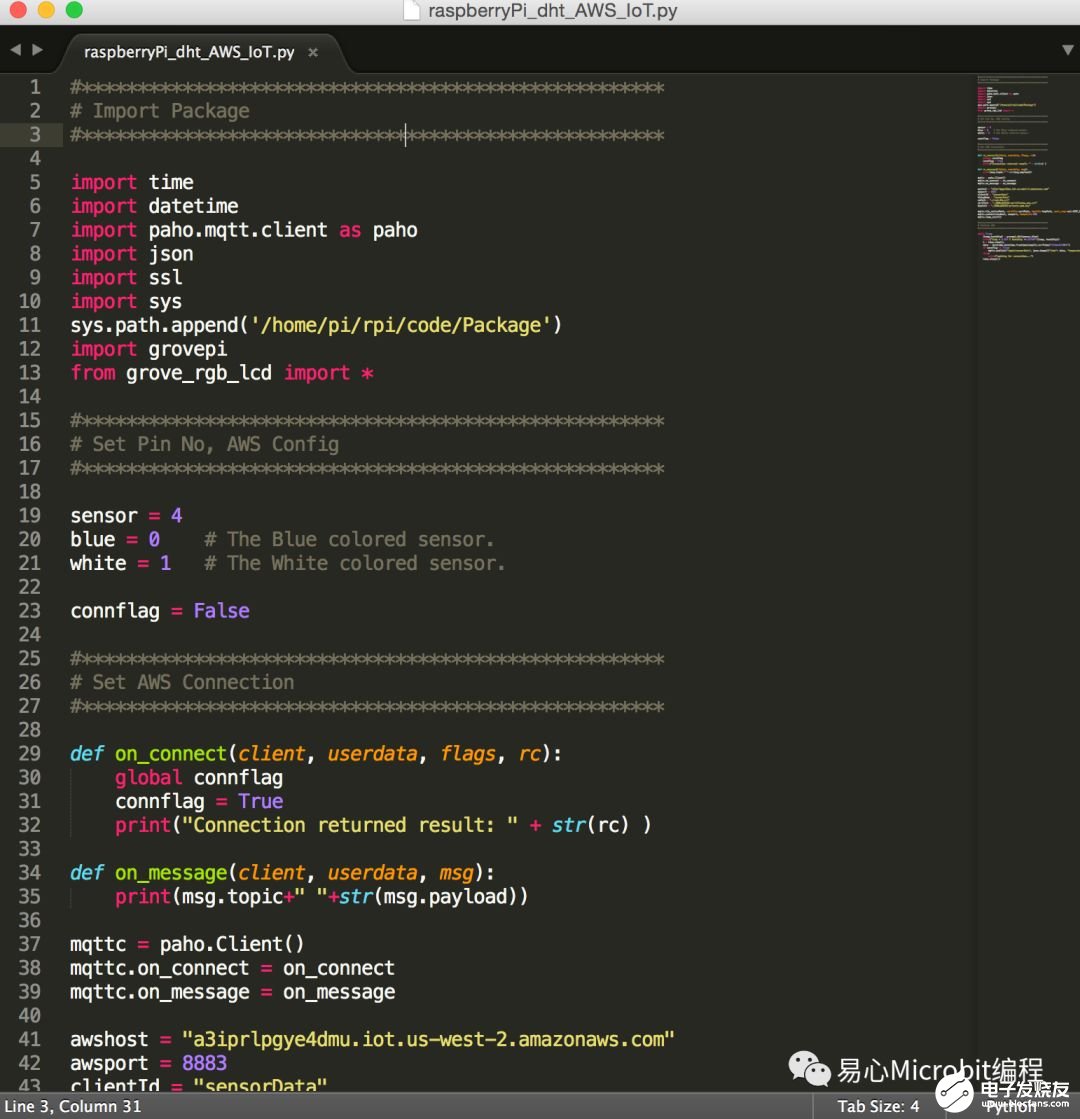
Step 1. 透过 Python 读取温湿度信息并传送到AWS IoT
#****************************************************
# Import Package
#****************************************************
import time
import datetime
import paho.mqtt.client as paho
import json
import ssl
import sys
sys.path.append(‘/home/pi/rpi/code/Package’)
import grovepi
from grove_rgb_lcd import *
#****************************************************
# Set Pin No, AWS Config
#****************************************************
sensor = 4
blue = 0 # The Blue colored sensor.
white = 1 # The White colored sensor.
connflag = False
#****************************************************
# Set AWS Connection
#****************************************************
def on_connect(client, userdata, flags,rc):
global connflag
connflag = True
print(“Connection returned result: ” + str(rc) )
def on_message(client, userdata, msg):
print(ic+“ ”+str(msg.payload))
mqttc = paho.Client()
mqttc.on_connect = on_connect
mqttc.on_message = on_message
awshost = “”
awsport = 8883
clientId = “sensorData”
thingName = “sensorData”
caPath = “。/root-CA.crt”
certPath =“。/000cd28455-certificate.pem.crt”
keyPath = “。/000cd28455-private.pem.key”
mqttc.tls_set(caPath, certfile=certPath, keyfile=keyPath,cert_reqs=ssl.CERT_REQUIRED, tls_version=ssl.PROTOCOL_TLSv1_2, ciphers=None)
mqttc.connect(awshost, awsport, keepalive=60)
mqttc.loop_start()
#****************************************************
# Publish AWS
#****************************************************
while True:
[temp,humidity] = grovepi.dht(sensor,blue)
print(“temp = %.02f C humidity =%.02f%%”%(temp, humidity))
t= time.time();
date = datetime.datetime.fromtimestamp(t).strftime(‘%Y%m%d%H%M%S’)
if connflag == True:
mqttc.publish(“topic/sensorData”,json.dumps({“time”: date, “temperature”: temp,“humidity”: humidity}), qos=1)
else:
print(“waiting for connection.。.”)
time.sleep(1)
Step 2. 将 Python Code 与 Keys 传送到 RaspberryPi
Step 3. 执行刚传到 Raspberry Pi 中的 Python 代码,python 檔名.py
Step 4. Console 执行画面 查看全部
怎样用Python透过树莓派采集到的温湿度信息传送到AWS IoT
与 IoT 相关的云端服务为数诸多,例如:ThingSpeak、WoT.City、AWS、IBM Bluemix、MediaTek MCS、Google Firebase 等,并在透过这种云端服务可在对数据进行数据可视化、数据剖析与其它的应用,而本文用Python将透过 Raspberry Pi 采集到的温湿度信息传送到 AWS IoT。
情境

材料与打算
1.准备 Raspberry Pi 3Model B 开发板
2.准备 Micro SD (已安装 Raspbian)
3.将 Micro SD 装入到 RaspberryPi 中
4.设定好网路
5.安装 GrovePi+
6.安装 Grove – Temperatureand Humidity Sensor (D4)
7.安装 GROVE - LCD RGBBACKLIGHT (I2C-2)
8.安装 IDE ( Sublime Textor Visual Studio Code )
Sensor, LCD, GrovePi+ 与 RaspberryPi 连接如右图


AWS IoT 端
Step 1. 到 AWS 网站申请帐号
Step 2. 登入 AWS 网站
Step 3. 点击 Services AWS IoT

Step 4. 点击 Create a resource
Step 5. 点击 Create a thing 输入 thing Name Create
Step 6. 点击刚构建的 thing
Step 7. 点击 Connect a device
Step 8. 点击 Node.js Generate certificate and policy
Step 9. 下载 private 与 public keys
Step 10. 点击 Confirm &connecting
Step 11. 点击 Return to ThingDetail

Raspberry Pi 端
Step 1. 透过 Python 读取温湿度信息并传送到AWS IoT
#****************************************************
# Import Package
#****************************************************
import time
import datetime
import paho.mqtt.client as paho
import json
import ssl
import sys
sys.path.append(‘/home/pi/rpi/code/Package’)
import grovepi
from grove_rgb_lcd import *
#****************************************************
# Set Pin No, AWS Config
#****************************************************
sensor = 4
blue = 0 # The Blue colored sensor.
white = 1 # The White colored sensor.
connflag = False
#****************************************************
# Set AWS Connection
#****************************************************
def on_connect(client, userdata, flags,rc):
global connflag
connflag = True
print(“Connection returned result: ” + str(rc) )
def on_message(client, userdata, msg):
print(ic+“ ”+str(msg.payload))
mqttc = paho.Client()
mqttc.on_connect = on_connect
mqttc.on_message = on_message
awshost = “”
awsport = 8883
clientId = “sensorData”
thingName = “sensorData”
caPath = “。/root-CA.crt”
certPath =“。/000cd28455-certificate.pem.crt”
keyPath = “。/000cd28455-private.pem.key”
mqttc.tls_set(caPath, certfile=certPath, keyfile=keyPath,cert_reqs=ssl.CERT_REQUIRED, tls_version=ssl.PROTOCOL_TLSv1_2, ciphers=None)
mqttc.connect(awshost, awsport, keepalive=60)
mqttc.loop_start()
#****************************************************
# Publish AWS
#****************************************************
while True:
[temp,humidity] = grovepi.dht(sensor,blue)
print(“temp = %.02f C humidity =%.02f%%”%(temp, humidity))
t= time.time();
date = datetime.datetime.fromtimestamp(t).strftime(‘%Y%m%d%H%M%S’)
if connflag == True:
mqttc.publish(“topic/sensorData”,json.dumps({“time”: date, “temperature”: temp,“humidity”: humidity}), qos=1)
else:
print(“waiting for connection.。.”)
time.sleep(1)
Step 2. 将 Python Code 与 Keys 传送到 RaspberryPi
Step 3. 执行刚传到 Raspberry Pi 中的 Python 代码,python 檔名.py
Step 4. Console 执行画面
APICloud:云端服务开发的硬核要素
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2020-08-13 11:30
各种PaaS平台为用户提供了效率化服务,开发者可依照自己的业务逻辑快速开发出相关的服务端程序。由于不用关注业务之外的环境配置,开发效率得到了极大增强,同时企业也得益于这些开发模式,提高了企业产品研制、上线的速率。本文,我们将解析开发云端服务的核心要素,了解这种有助于我们更好的选择和使用各类云端服务平台。
1
云数据库是否简单易用且功能强悍
开发者在开发服务器端应用的时侯常常须要对业务数据进行储存,这就须要一个云端数据库帮助实现这种工作。
各家云平台提供的云端数据库的使用方法和功能各不相同,开发者在选择的时侯须要依照自己的实际情况进行选择,首先要考虑的是自身业务是否有关键场景,如转帐、付款等操作。这些操作要求数据一致性比较高,需要有事务的能力,所以是否支持事务是须要考虑的第一诱因。其二是数据库的操作是否便捷,本地开发时通常使用navicat等工具联接到前端数据库进行相关的操作,但是云数据库常常是通过web页面进行配置,这时候页面配置的易用性、提供的数据库配置功能是否全面也是一个须要审视的诱因。第三是代码层面访问数据库是否便捷,提供的插口要以便对数据进行存取。
【APICloud数据云3.0 前沿谍报】
数据云3.0支持事务操作。
可视化的定义数据表结构,并对数据进行增删改查,支持在页面进行条件筛选完成查询。
界面支持对表建索引、设定表与表的关联关系、导入和导入等功能。
内置丰富的API函数,方便在程序中操作数据库
2
是否提供灵活的云函数及插口管理
在所有的云平台实现中,云函数是其中最重要的功能之一,我们在云函数中实现各自的业务逻辑。云函数的编撰是云开发中占用开发者时间最长的部份,云函数的功能是否强悍直接决定了开发者是否能便捷快捷的实现自己的业务逻辑。
同时,远程函数的插口管理也会涉及到比较多的工作。接口管理分为插口文档和插口联调两部份,API接口在设计时要编撰大量的文档,编写完成以后就会常常改动;实际的代码与文档有出入的时侯也须要进行处理。同样,随着版本的迭代,接口文档同步的问题又会彰显下来。进入到插口联调也须要开发者按照插口文档的内容在联调工具中进行配置完成。所以插口管理是后期保证开发进度的一个重要方面。
【APICloud数据云3.0 前沿谍报】
提供多达六种函数类型的支持,为开发者提供更多自定义业务逻辑的能力。
模型驱动的开发模式,更容易根据业务逻辑界定不同函数。
接口管理功能:内置符合swagger 规范的组件,直接从代码生成文档,无需在为插口文档的维护以及插口联调花费更多时间。
两套环境更放心,云函数分为测试环境和即将环境,测试通过后方更新到即将环境。
3
是否支持代码库或已有代码复用
对软件开发来说,通过直接使用第三方的代码、服务来整合功能可以大大降低项目的开发周期和风险,降低开发成本,同时提升代码的可靠性。所以一个云平台是否能提供便捷的代码复用能力就变得尤为重要。
【APICloud新产品前沿谍报】
即将发布的3.0版本通过模型驱动的形式进行服务器端功能逻辑的开发,可便捷的通过模型完成代码的复用。我们支持用两种方法实现代码的复用,并可以基于复用的代码进行二次开发完成自己的业务逻辑。
预置模型,我们为用户预置常用的数据模型,可直接添加使用。比如阿里云发邮件模型、微信小程序模型等
导入模型,可以从模型库或则自己的其他应用导出须要的模型,复用表结构和函数。
4
运维及监控
上线后的代码,平台是否提供相关的监控对开发人员尤为重要,开发人员须要通过某种形式了解自己代码实际运行的情况,如当前服务器是否因为触发异常而未能提供服务,自己复印的信息的查看,应用使用的流量以及占用的储存空间等。
【APICloud数据云3.0 前沿谍报】
APICloud对应用的数据储存、文件储存、流量、API恳求等进行了监控,并生成相应的药量—时间折线图,可以使用户更直观的了解使用情况。同时提供日志监控,便于及时发觉问题。
5
辅助功能,方便开发者使用
除了提供的基本开发能力以外,是否为用户提供一些便捷用户使用的组件也是审视一个云平台的重要方面。
【APICloud数据云3.0 前沿谍报】
内置session:通过配置开启,自动打开session功能。
内置的管理后台插件:应用开发的过程中通常须要一个管理后台提供操作基本信息查看及营运的工作。这种管理后台的功能差不多,基本就是菜单管理、权限管理、页面管理等。APICloud3.0考虑到这些通用型的需求,为开发者外置了一个基于amis作为解决方案管理后台,通过简单的拖放及配置即可使开发者拥有自己的管理后台。
目前,云计算仍处在快速发展阶段,在云端直接布署的需求越来越多,而国家颁布的利空新政,已让企业上云成为趋势,国内厂商也在积极拥抱云端能力;在实际运行疗效上,基于云端开发及运行应用服务优势显著,逐渐成为软件开发行业的主流选择。APICloud在产业转型的时尚下趁势而为,全新迭代的数据云3.0,将进一步为平台开发者的效率赋能,为用户在云端开发提供全新的使用体验。
APICloud是国外低代码开发平台的引领者与效率革命的探索者,基于对云原生、DevOps、混合开发等能力的集成,APICloud从移动开发演变为低代码开发平台,APICloud致力于为各行业提供app订制与企业数字化服务。 查看全部
随着云计算相关领域近几年的迅速发展,提供基于PaaS开发能力的平台越来越多,这促使好多开发者在编撰前端程序的时侯无需在服务器上从零建立自己的应用,无需考虑网路、存储、操作系统、运行环境等与开发关联不大的基础配置。这种基于Serverless方式的云计算服务,让应用开发得到了极大简化,甚至后期的运维、监控的工作平台也可以一并完成。
各种PaaS平台为用户提供了效率化服务,开发者可依照自己的业务逻辑快速开发出相关的服务端程序。由于不用关注业务之外的环境配置,开发效率得到了极大增强,同时企业也得益于这些开发模式,提高了企业产品研制、上线的速率。本文,我们将解析开发云端服务的核心要素,了解这种有助于我们更好的选择和使用各类云端服务平台。
1
云数据库是否简单易用且功能强悍
开发者在开发服务器端应用的时侯常常须要对业务数据进行储存,这就须要一个云端数据库帮助实现这种工作。
各家云平台提供的云端数据库的使用方法和功能各不相同,开发者在选择的时侯须要依照自己的实际情况进行选择,首先要考虑的是自身业务是否有关键场景,如转帐、付款等操作。这些操作要求数据一致性比较高,需要有事务的能力,所以是否支持事务是须要考虑的第一诱因。其二是数据库的操作是否便捷,本地开发时通常使用navicat等工具联接到前端数据库进行相关的操作,但是云数据库常常是通过web页面进行配置,这时候页面配置的易用性、提供的数据库配置功能是否全面也是一个须要审视的诱因。第三是代码层面访问数据库是否便捷,提供的插口要以便对数据进行存取。
【APICloud数据云3.0 前沿谍报】
数据云3.0支持事务操作。
可视化的定义数据表结构,并对数据进行增删改查,支持在页面进行条件筛选完成查询。
界面支持对表建索引、设定表与表的关联关系、导入和导入等功能。
内置丰富的API函数,方便在程序中操作数据库

2
是否提供灵活的云函数及插口管理
在所有的云平台实现中,云函数是其中最重要的功能之一,我们在云函数中实现各自的业务逻辑。云函数的编撰是云开发中占用开发者时间最长的部份,云函数的功能是否强悍直接决定了开发者是否能便捷快捷的实现自己的业务逻辑。
同时,远程函数的插口管理也会涉及到比较多的工作。接口管理分为插口文档和插口联调两部份,API接口在设计时要编撰大量的文档,编写完成以后就会常常改动;实际的代码与文档有出入的时侯也须要进行处理。同样,随着版本的迭代,接口文档同步的问题又会彰显下来。进入到插口联调也须要开发者按照插口文档的内容在联调工具中进行配置完成。所以插口管理是后期保证开发进度的一个重要方面。
【APICloud数据云3.0 前沿谍报】
提供多达六种函数类型的支持,为开发者提供更多自定义业务逻辑的能力。
模型驱动的开发模式,更容易根据业务逻辑界定不同函数。
接口管理功能:内置符合swagger 规范的组件,直接从代码生成文档,无需在为插口文档的维护以及插口联调花费更多时间。
两套环境更放心,云函数分为测试环境和即将环境,测试通过后方更新到即将环境。

3
是否支持代码库或已有代码复用
对软件开发来说,通过直接使用第三方的代码、服务来整合功能可以大大降低项目的开发周期和风险,降低开发成本,同时提升代码的可靠性。所以一个云平台是否能提供便捷的代码复用能力就变得尤为重要。
【APICloud新产品前沿谍报】
即将发布的3.0版本通过模型驱动的形式进行服务器端功能逻辑的开发,可便捷的通过模型完成代码的复用。我们支持用两种方法实现代码的复用,并可以基于复用的代码进行二次开发完成自己的业务逻辑。
预置模型,我们为用户预置常用的数据模型,可直接添加使用。比如阿里云发邮件模型、微信小程序模型等
导入模型,可以从模型库或则自己的其他应用导出须要的模型,复用表结构和函数。
4
运维及监控
上线后的代码,平台是否提供相关的监控对开发人员尤为重要,开发人员须要通过某种形式了解自己代码实际运行的情况,如当前服务器是否因为触发异常而未能提供服务,自己复印的信息的查看,应用使用的流量以及占用的储存空间等。
【APICloud数据云3.0 前沿谍报】
APICloud对应用的数据储存、文件储存、流量、API恳求等进行了监控,并生成相应的药量—时间折线图,可以使用户更直观的了解使用情况。同时提供日志监控,便于及时发觉问题。
5
辅助功能,方便开发者使用
除了提供的基本开发能力以外,是否为用户提供一些便捷用户使用的组件也是审视一个云平台的重要方面。
【APICloud数据云3.0 前沿谍报】
内置session:通过配置开启,自动打开session功能。
内置的管理后台插件:应用开发的过程中通常须要一个管理后台提供操作基本信息查看及营运的工作。这种管理后台的功能差不多,基本就是菜单管理、权限管理、页面管理等。APICloud3.0考虑到这些通用型的需求,为开发者外置了一个基于amis作为解决方案管理后台,通过简单的拖放及配置即可使开发者拥有自己的管理后台。

目前,云计算仍处在快速发展阶段,在云端直接布署的需求越来越多,而国家颁布的利空新政,已让企业上云成为趋势,国内厂商也在积极拥抱云端能力;在实际运行疗效上,基于云端开发及运行应用服务优势显著,逐渐成为软件开发行业的主流选择。APICloud在产业转型的时尚下趁势而为,全新迭代的数据云3.0,将进一步为平台开发者的效率赋能,为用户在云端开发提供全新的使用体验。

APICloud是国外低代码开发平台的引领者与效率革命的探索者,基于对云原生、DevOps、混合开发等能力的集成,APICloud从移动开发演变为低代码开发平台,APICloud致力于为各行业提供app订制与企业数字化服务。
【技术干货】云端自动化运维
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2020-08-09 19:13
运维自动化基本上可以这样去理解:可以实现在成千上万台服务器上做到批量执行命令,根据不同业务特点进行配置集中化管理、分发文件、采集服务器数据、操作系统基础及软件包管理等,这就是所谓的自动化运维。
闲话不多说,下面笔者就以自己近来的一个项目来说说在云端上的自动化运维,以及自动化运维的带来的价值彰显。
接手国外某小型旅游网站之前,它的几十台服务是她们自己内部管理,一个字“乱”,两个字“很乱”!具体假象:
系统层面:
1、系统版本不统一。
2、系统目录结构不统一。
3、服务器管理分散。
应用层面:
1、应用名称不规范。
2、环境布署不统一。
3、应用发布流程不规范。
4、人肉发布,工作量大、效率低。
监控层面:
1、没有一个迅速有效的监控平台。
2、业务中断故障排查难度大、耗时。
这个就大大降低后续的监控管理难度,还有对之后应用方面的管理,内容发布,数据的采集都会有很大的影响。最明显就彰显发布这一块,在一个应用诸多,部署不规范,服务器无章化的管理,发布无疑是一个苦闷的过程,每次的熬夜的发布,无数次的上传war包、发布、测试、回滚、再上传、再发布、再测试、再回滚,严重的影响工作效率,消耗大量的人工,而且效率极低,影响用户的体验度。最重要的是时常出现错误,无数个梦中被电话喊起!结合现存的众多疼点,着手从系统层面、应用层面、监控层面整体规划整修。
1、服务器统一化:
从系统版本的选择、数据盘目录挂载、系统名称、系统加固、系统优化、操作审计、等os层面的统一化,为后期的运维标准化和可集中化管理做打算。
2、应用布署统一化:
应用布署细化到目录位置、权限控制、日志分割、端口规划、代码路径、回滚形式、内存大小、连接数等各项配置做到统一化、根据业务需求做单独的差异化,为后期的应用布署、发布、回滚、检测做铺垫。
3、监控自动化:
zabbix通过端口的手动发觉新布署的应用,使用预定义好的监控规则手动监控,针对一个应用实现了40个items项监控。做到监控覆盖全面无盲点,故障定位确切、及时,给运维排除故障提供有力的参考。
系统根据规范布署完成以后,采用saltstack做集中化管理,通过saltstack可以对前端的服务器做各类的修改和集中化的操作,极大的提升了运维效率。稳定安全的系统加上合理的构架为后期的应用运维做打算。应用的运维采用saltstack加shell脚本一起完成。部署、监控、发布、回滚、重启、检查等脚本供saltstack远程调用,实现saltstack集中管理服务器和应用的各项秒级操作,全面彻底解决前期的关于系统和应用发布的头痛问题。
前期的构架其实运维方面和应用的发布方面得到了解决,但是还没有实现平台化的持续发布,为此我们再度整改结合jenkins、maven、git、gradle、sonar、rundeck、蒲公英等工具实现:
1)实现 Java 工程的自动化建立、自动化测试、发布;
2)实现 Node.js 工程的自动化建立、自动化测试、发布;
3)实现 IOS 工程的自动化建立、自动化测试、发布;
4)实现Android工程的自动化建立、自动化测试、发布渠道包(蒲公英) 查看全部
对于运维工作来说,我们运维工作的本身是可管理,可重复,可预测的,基于这样的理念,我们可以根据一定的规律,在基本运维的过程中实现自动化。
运维自动化基本上可以这样去理解:可以实现在成千上万台服务器上做到批量执行命令,根据不同业务特点进行配置集中化管理、分发文件、采集服务器数据、操作系统基础及软件包管理等,这就是所谓的自动化运维。
闲话不多说,下面笔者就以自己近来的一个项目来说说在云端上的自动化运维,以及自动化运维的带来的价值彰显。
接手国外某小型旅游网站之前,它的几十台服务是她们自己内部管理,一个字“乱”,两个字“很乱”!具体假象:
系统层面:
1、系统版本不统一。
2、系统目录结构不统一。
3、服务器管理分散。
应用层面:
1、应用名称不规范。
2、环境布署不统一。
3、应用发布流程不规范。
4、人肉发布,工作量大、效率低。
监控层面:
1、没有一个迅速有效的监控平台。
2、业务中断故障排查难度大、耗时。
这个就大大降低后续的监控管理难度,还有对之后应用方面的管理,内容发布,数据的采集都会有很大的影响。最明显就彰显发布这一块,在一个应用诸多,部署不规范,服务器无章化的管理,发布无疑是一个苦闷的过程,每次的熬夜的发布,无数次的上传war包、发布、测试、回滚、再上传、再发布、再测试、再回滚,严重的影响工作效率,消耗大量的人工,而且效率极低,影响用户的体验度。最重要的是时常出现错误,无数个梦中被电话喊起!结合现存的众多疼点,着手从系统层面、应用层面、监控层面整体规划整修。
1、服务器统一化:
从系统版本的选择、数据盘目录挂载、系统名称、系统加固、系统优化、操作审计、等os层面的统一化,为后期的运维标准化和可集中化管理做打算。
2、应用布署统一化:
应用布署细化到目录位置、权限控制、日志分割、端口规划、代码路径、回滚形式、内存大小、连接数等各项配置做到统一化、根据业务需求做单独的差异化,为后期的应用布署、发布、回滚、检测做铺垫。
3、监控自动化:
zabbix通过端口的手动发觉新布署的应用,使用预定义好的监控规则手动监控,针对一个应用实现了40个items项监控。做到监控覆盖全面无盲点,故障定位确切、及时,给运维排除故障提供有力的参考。
系统根据规范布署完成以后,采用saltstack做集中化管理,通过saltstack可以对前端的服务器做各类的修改和集中化的操作,极大的提升了运维效率。稳定安全的系统加上合理的构架为后期的应用运维做打算。应用的运维采用saltstack加shell脚本一起完成。部署、监控、发布、回滚、重启、检查等脚本供saltstack远程调用,实现saltstack集中管理服务器和应用的各项秒级操作,全面彻底解决前期的关于系统和应用发布的头痛问题。
前期的构架其实运维方面和应用的发布方面得到了解决,但是还没有实现平台化的持续发布,为此我们再度整改结合jenkins、maven、git、gradle、sonar、rundeck、蒲公英等工具实现:
1)实现 Java 工程的自动化建立、自动化测试、发布;
2)实现 Node.js 工程的自动化建立、自动化测试、发布;
3)实现 IOS 工程的自动化建立、自动化测试、发布;
4)实现Android工程的自动化建立、自动化测试、发布渠道包(蒲公英)
优采云采集器 v7.3.8 破解版
采集交流 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2020-08-09 17:33
优采云采集器就能对各类不同类型的网页进行大量的数据采集工作,类型涵括广泛,什么金融类的、交易类、社交网站、电商商品等等的网站数据都还能被规范性的采集下来,并且可以被导入。可以实现数据信息实时监控,自动抓取各项数据的变动信息。是一款功能强悍的数据采集软件,是数据剖析人事必备的一款软件。
优采云采集器软件特色:
1.操作简单:完全可视化图形操作,无需专业IT人员,任何会使用笔记本上网的人都可以轻松把握。
2.云采集技术:采集任务手动分配到云端多台服务器同时执行,提高采集效率,可以挺短的时间内 获取成千上万条信息。
3.拖拽式采集流程:模拟人的操作思维模式,可以登录,输入数据,点击链接,按钮等,还能对不同情况采取不同的采集流程。
4.图文辨识:内置可扩充的OCR插口,支持解析图片中的文字,可将图片上的文字提取下来。
5.定时手动采集:采集任务手动运行,可以根据指定的周期手动采集,并且还支持最快一分钟一次的实时采集。
6.两分钟快速入门:内置从入门到精通所须要的视频教程,两分钟才能上手使用,另外还有文档,论坛,qq群等。:
7.免费使用:它是免费的,并且免费版本没有任何功能限制,你如今就可以试一试,立即下载安装。
优采云采集器 查看全部
优采云采集器是一款可以从任何一个网页获取信息的必备利器。优采云采集器是一款可以使你的信息采集可以显得很简单的工具。该软件转变了传统对于网路上的数据思维方式,它使用户在网上抓取资料变的愈发简单和容易了。
优采云采集器就能对各类不同类型的网页进行大量的数据采集工作,类型涵括广泛,什么金融类的、交易类、社交网站、电商商品等等的网站数据都还能被规范性的采集下来,并且可以被导入。可以实现数据信息实时监控,自动抓取各项数据的变动信息。是一款功能强悍的数据采集软件,是数据剖析人事必备的一款软件。
优采云采集器软件特色:
1.操作简单:完全可视化图形操作,无需专业IT人员,任何会使用笔记本上网的人都可以轻松把握。
2.云采集技术:采集任务手动分配到云端多台服务器同时执行,提高采集效率,可以挺短的时间内 获取成千上万条信息。
3.拖拽式采集流程:模拟人的操作思维模式,可以登录,输入数据,点击链接,按钮等,还能对不同情况采取不同的采集流程。
4.图文辨识:内置可扩充的OCR插口,支持解析图片中的文字,可将图片上的文字提取下来。
5.定时手动采集:采集任务手动运行,可以根据指定的周期手动采集,并且还支持最快一分钟一次的实时采集。
6.两分钟快速入门:内置从入门到精通所须要的视频教程,两分钟才能上手使用,另外还有文档,论坛,qq群等。:
7.免费使用:它是免费的,并且免费版本没有任何功能限制,你如今就可以试一试,立即下载安装。
优采云采集器
优采云采集器破解版v7.3.8 软件截图
采集交流 • 优采云 发表了文章 • 0 个评论 • 690 次浏览 • 2020-08-09 17:28
优采云采集器破解版如何用?
首先打开优采云采集器→点击快速开始→新建任务,进入到任务配置页面:
选择任务组,自定义任务名称和备注;
上图配置完毕以后,选择下一步,进入到流程配置页面,往流程设计器中推入一个打开网页的步骤;
选中浏览器中的打开网页步骤,在左边的页面URL中输入网页URL并点击保存,系统会在软件下方的浏览器中手动打开对应网页:
下面进行数据字段的提取,点击浏览器中须要提取的数组,然后在弹出的选择对话框中选择抓取这个元素的文本;
上述操作以后,系统会在页面的右上方显示我们即将抓取的数组;
接下来配置页面中其他须要抓取的数组,配置完成以后更改数组名称;
修改完成以后点击上图中的保存按键,再点开图中的数据字段可以看见,系统将会显示最终的采集列表;
点击上图中的下一步→下一步→启动单机采集(调试模式),进入到任务检测页面,以确保任务的正确性;
点击开始单机采集,系统将会在本地执行采集流程并显示最终采集的结果。
优采云采集器破解版是哪些?
优采云采集器破解版是一款可以从任何一个网页获取信息的必备利器。优采云采集器破解版是一款可以使你的信息采集可以显得很简单的工具。该软件转变了传统对于网路上的数据思维方式,它使用户在网上抓取资料变的愈发简单和容易了。
优采云采集器破解版功能介绍:
优采云采集器破解版才能对各类不同类型的网页进行大量的数据采集工作,类型涵括广泛,什么金融类的、交易类、社交网站、电商商品等等的网站数据都还能被规范性的采集下来,并且可以被导入。可以实现数据信息实时监控,自动抓取各项数据的变动信息。是一款功能强悍的数据采集软件,是数据剖析人事必备的一款软件。
优采云采集器破解版软件特色:
1. 操作简单:完全可视化图形操作,无需专业IT人员,任何会使用笔记本上网的人都可以轻松把握。
2. 云采集技术:采集任务手动分配到云端多台服务器同时执行,提高采集效率,可以挺短的时间内 获取成千上万条信息。
3. 拖拽式采集流程:模拟人的操作思维模式,可以登录,输入数据,点击链接,按钮等,还能对不同情况采取不同的采集流程。
4. 图文辨识:内置可扩充的OCR插口,支持解析图片中的文字,可将图片上的文字提取下来。
5. 定时手动采集:采集任务手动运行,可以根据指定的周期手动采集,并且还支持最快一分钟一次的实时采集。
6. 两分钟快速入门:内置从入门到精通所须要的视频教程,两分钟才能上手使用,另外还有文档,论坛,qq群等。:
7. 免费使用:它是免费的,并且免费版本没有任何功能限制,你如今就可以试一试,立即下载安装。 查看全部
优采云采集器破解版以网页信息抓取为核心功能,帮助用户在庞大的网路资源库中迅速抓取到自己想要的信息。优采云采集器破解版可以对多个行业的信息进行采集,实现对数据的实时监控,方便用户的信息获取。而且这款软件的操作并不复杂,用户只须要几分钟能够快速入门,轻松驾驭没负担。除此之外,软件还支持定时采集功能,用户无需时刻盯住,可以解放你的右手,有须要的用户快来这里下载吧!
优采云采集器破解版如何用?
首先打开优采云采集器→点击快速开始→新建任务,进入到任务配置页面:
选择任务组,自定义任务名称和备注;
上图配置完毕以后,选择下一步,进入到流程配置页面,往流程设计器中推入一个打开网页的步骤;
选中浏览器中的打开网页步骤,在左边的页面URL中输入网页URL并点击保存,系统会在软件下方的浏览器中手动打开对应网页:
下面进行数据字段的提取,点击浏览器中须要提取的数组,然后在弹出的选择对话框中选择抓取这个元素的文本;
上述操作以后,系统会在页面的右上方显示我们即将抓取的数组;
接下来配置页面中其他须要抓取的数组,配置完成以后更改数组名称;
修改完成以后点击上图中的保存按键,再点开图中的数据字段可以看见,系统将会显示最终的采集列表;
点击上图中的下一步→下一步→启动单机采集(调试模式),进入到任务检测页面,以确保任务的正确性;
点击开始单机采集,系统将会在本地执行采集流程并显示最终采集的结果。
优采云采集器破解版是哪些?
优采云采集器破解版是一款可以从任何一个网页获取信息的必备利器。优采云采集器破解版是一款可以使你的信息采集可以显得很简单的工具。该软件转变了传统对于网路上的数据思维方式,它使用户在网上抓取资料变的愈发简单和容易了。
优采云采集器破解版功能介绍:
优采云采集器破解版才能对各类不同类型的网页进行大量的数据采集工作,类型涵括广泛,什么金融类的、交易类、社交网站、电商商品等等的网站数据都还能被规范性的采集下来,并且可以被导入。可以实现数据信息实时监控,自动抓取各项数据的变动信息。是一款功能强悍的数据采集软件,是数据剖析人事必备的一款软件。
优采云采集器破解版软件特色:
1. 操作简单:完全可视化图形操作,无需专业IT人员,任何会使用笔记本上网的人都可以轻松把握。
2. 云采集技术:采集任务手动分配到云端多台服务器同时执行,提高采集效率,可以挺短的时间内 获取成千上万条信息。
3. 拖拽式采集流程:模拟人的操作思维模式,可以登录,输入数据,点击链接,按钮等,还能对不同情况采取不同的采集流程。
4. 图文辨识:内置可扩充的OCR插口,支持解析图片中的文字,可将图片上的文字提取下来。
5. 定时手动采集:采集任务手动运行,可以根据指定的周期手动采集,并且还支持最快一分钟一次的实时采集。
6. 两分钟快速入门:内置从入门到精通所须要的视频教程,两分钟才能上手使用,另外还有文档,论坛,qq群等。:
7. 免费使用:它是免费的,并且免费版本没有任何功能限制,你如今就可以试一试,立即下载安装。
[经过测试的免费资源] [价值50元]①大数据采集标准版8
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2020-08-08 02:15
(同名资源应用程序中心的地址: [emailprotected] _bigdata.plugin)
本网站上的资源仅用于个人研究/学习/欣赏,请勿将其用于商业目的,否则后果自负!
Discuz!插件介绍
ONEXIN大数据(Open BigData,OBD),打开自动批采集.
支持超过98%的国内知名网站,请从云中体验采集器,我们在云中等待您.
此插件具有用于实现不同功能的扩展组件.
导入论坛高级模块2.6以支持图像本地化,模块名称: forumimg
导入高级门户模块2.6支持图像本地化,模块名称: portalimg
自动收货功能的经验描述(可选包装: 每1000件收50元,每天V1付款,每天300件,586元)
首先,安装插件
然后,您自己申请授权,进入ONEXIN平台()注册一个帐户以获得OID和令牌,并填写后台插件设置.
申请授权:
图形教程:
最后,如果您访问您的网站,则会成功发表一篇新文章. 就这么简单.
常见问题:
大数据采集插件与其他文章采集器之间的区别:
1. 大数据采集的采集列表和内容页面在云服务器端进行处理,从而进一步节省了服务器资源.
第二,该插件中的用户可以方便地管理需要发布的文章链接,并可以自由选择发布还是不发布.
3. 插件接口代码是开源的,输出结果可以自定义,功能可以扩展.
四个. 基于云和WEB插件,不需要zend,并且不受系统环境的影响
第五,不需要在计算机上安装软件,可以访问网站以自动更新文章.
六. 无需编写内容页面规则,它可以通过云采集自动识别,并且可以使用成千上万的资源.
兄弟亲测试源代码截图 查看全部
源代码兄弟已经对资源进行了安全检查,它安全无毒,可以放心使用!
(同名资源应用程序中心的地址: [emailprotected] _bigdata.plugin)
本网站上的资源仅用于个人研究/学习/欣赏,请勿将其用于商业目的,否则后果自负!
Discuz!插件介绍
ONEXIN大数据(Open BigData,OBD),打开自动批采集.
支持超过98%的国内知名网站,请从云中体验采集器,我们在云中等待您.
此插件具有用于实现不同功能的扩展组件.
导入论坛高级模块2.6以支持图像本地化,模块名称: forumimg
导入高级门户模块2.6支持图像本地化,模块名称: portalimg
自动收货功能的经验描述(可选包装: 每1000件收50元,每天V1付款,每天300件,586元)
首先,安装插件
然后,您自己申请授权,进入ONEXIN平台()注册一个帐户以获得OID和令牌,并填写后台插件设置.
申请授权:
图形教程:
最后,如果您访问您的网站,则会成功发表一篇新文章. 就这么简单.
常见问题:
大数据采集插件与其他文章采集器之间的区别:
1. 大数据采集的采集列表和内容页面在云服务器端进行处理,从而进一步节省了服务器资源.
第二,该插件中的用户可以方便地管理需要发布的文章链接,并可以自由选择发布还是不发布.
3. 插件接口代码是开源的,输出结果可以自定义,功能可以扩展.
四个. 基于云和WEB插件,不需要zend,并且不受系统环境的影响
第五,不需要在计算机上安装软件,可以访问网站以自动更新文章.
六. 无需编写内容页面规则,它可以通过云采集自动识别,并且可以使用成千上万的资源.
兄弟亲测试源代码截图
优采云网络数据采集器v7.5.8.10171正式版
采集交流 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2020-08-07 19:17
软件功能
简单的操作,完全可视化的图形操作,不需要专业的IT人员,任何可以使用计算机访问Internet的人都可以轻松掌握它.
云采集
采集任务会自动分发到云中的多个服务器以同时执行,从而提高了采集效率,并可以在短时间内获取数千条信息.
拖放采集过程
模仿人的操作思维方式,可以登录,输入数据,单击链接,按钮等,并且可以针对不同情况采用不同的采集程序.
图像识别
内置可扩展的OCR界面,支持解析图片中的文本,并提取图片中的文本.
定时自动采集
采集任务自动运行,可以根据指定的时间段自动采集,并且还支持每分钟一次的实时采集.
2分钟内快速入门
从入门到精通的内置视频教程,可以在2分钟内使用,并且还提供文档,论坛,QQ群组等.
免费使用
它是免费的,免费版本没有功能限制. 您可以立即尝试,立即下载并安装.
功能介绍
简而言之,您可以使用优采云轻松地从任何网页上采集所需的数据,并生成自定义的常规数据格式. 优采云数据采集系统可以执行的操作包括但不限于以下内容:
1. 财务数据,例如季度报告,年度报告,财务报告,包括自动采集最新的每日净资产;
2. 实时监控主要新闻门户,自动更新和上传最新新闻;
3. 监视竞争对手的最新信息,包括商品价格和库存; 查看全部
优采云采集器是一个多功能的Web数据采集工件,它改变了传统的Internet数据思维方式. 它以自主开发的分布式云计算平台为核心,采集任务自动分布到多个云平台. 服务器同时执行,提高了采集效率,可在短时间内获取数千条信息

软件功能
简单的操作,完全可视化的图形操作,不需要专业的IT人员,任何可以使用计算机访问Internet的人都可以轻松掌握它.
云采集
采集任务会自动分发到云中的多个服务器以同时执行,从而提高了采集效率,并可以在短时间内获取数千条信息.
拖放采集过程
模仿人的操作思维方式,可以登录,输入数据,单击链接,按钮等,并且可以针对不同情况采用不同的采集程序.
图像识别
内置可扩展的OCR界面,支持解析图片中的文本,并提取图片中的文本.
定时自动采集
采集任务自动运行,可以根据指定的时间段自动采集,并且还支持每分钟一次的实时采集.
2分钟内快速入门
从入门到精通的内置视频教程,可以在2分钟内使用,并且还提供文档,论坛,QQ群组等.
免费使用
它是免费的,免费版本没有功能限制. 您可以立即尝试,立即下载并安装.

功能介绍
简而言之,您可以使用优采云轻松地从任何网页上采集所需的数据,并生成自定义的常规数据格式. 优采云数据采集系统可以执行的操作包括但不限于以下内容:
1. 财务数据,例如季度报告,年度报告,财务报告,包括自动采集最新的每日净资产;
2. 实时监控主要新闻门户,自动更新和上传最新新闻;
3. 监视竞争对手的最新信息,包括商品价格和库存;
没有爬虫团队,公司如何实现1000万级别的数据采集?
采集交流 • 优采云 发表了文章 • 0 个评论 • 354 次浏览 • 2020-08-07 16:07
当前,源自爬虫技术的经典商业项目,我相信您也必须使用它们:
Enterprise Check是一种企业信息查询工具,它将80个产业链,8,000个行业,6,000个市场和超过8,000万家国内市场的公司的数据汇总在一起.
企业如何检查海量数据?
企业搜索的数据源主要来自以下三个方面.
①Web爬网程序采集数据
②第三方合作数据
③有些数据更新任务是由用户触发的
它通过Web爬网程序采集数据,执行初步清理并将其合并到其数据库中,并使用算法进行处理,最后向用户打开以提供查询和搜索.
柴柴目前的估值已经达到5亿元.
事实证明,履带技术具有这种商业价值吗?
我们公司可以自己做并抓取数据以增强竞争力吗?
太年轻太天真
一位伟大的神之智说: “履带进入的门槛很低,但是在实际操作的后期阶段,它们确实会使您崩溃. 例如,您肯定会遇到以下问题. ”
您必须至少了解一个或多个主题,而不仅仅是爬虫,而且您刚刚开始学习爬网.
来源
如果企业组建了爬虫专家团队,则需要从零开始.
对于企业来说,这是一笔很大的开销,包括管理成本和时间成本.
我们如何打破这个僵局?
实际上,这位智虎神给出了答案:
“不要重新发明轮子”
市场上已经有许多简单,易于使用的专业爬虫服务和工具,它们使企业能够以更灵活,更轻便,成本更低的方式获取大量数据.
例如,优采云用于采集数据的企业私有云.
优采云的私有云版本是针对具有大量数据采集需求的公司量身定制的爬虫工具.
企业无需添加任何履带技术人员. 优采云的私有云可以完全满足企业进行海量信息采集的需求.
为什么选择优秀彩云?
优采云自2013年投入市场以来,一直致力于为用户提供易于使用,快速且稳定的数据抓取工具.
经过几年的发展,用户规模不断扩大,全球拥有120万用户. 通过专业的数据抓取能力和经验积累,我们开发了许多业内知名公司,例如平安,腾讯,万达,政府机构,科学研究所以及公安部,税务局,清华大学等成功的数据项目案例. 用户对优采云在数据采集方面的专业能力的认可.
优采云数据采集成功地被中华人民共和国工业和信息化部评选为“ 2019年度杰出大数据产品和应用解决方案”. 优采云连续5年在“中国大数据企业排名”中排名第一.
优采云私有云如何满足企业需求?
01. 专业的数据采集器服务功能
优采云可以采集在Internet上公开显示的数据,只要这些数据肉眼可见并且可以复制即可.
优采云支持文本,数字,图片,视频和源代码等数据类型,而不仅限于数据格式.
02. 在云中高效地分布式采集海量数据
优采云使用高效的云分布式采集,并由5000多个云服务器提供支持. 优采云私有云可根据企业需求配备30-100个以上的云节点,相当于同时运行近百台服务器,实现多任务并发采集.
使用分布式采集的时间明显短于企业使用自己的服务器所需的时间. 普通企业很难拥有像专业爬网程序这样的大量服务器资源来支持海量数据采集.
云分布式采集可以帮助公司实现在短时间内采集大量数据的目的,使公司每天可以轻松采集数百万甚至数千万的数据.
由于长期以来对大量数据采集器的需求,优采云已成为“阿里云VIP企业客户”. 优采云私有云用户可以通过优采云直接享受阿里云提供的“企业级优质云节点”,进一步实现快速稳定的云爬虫服务.
03. 独家智能防封技术组合
正如上面提到的知乎 Dashen所说,网站上存在多种反爬虫策略,并且大多数公司爬虫工程师在这种情况下只能无能为力.
经过6年以上的实战经验,优采云已经形成了独家的智能防封技术组合,可以有效地克服大多数网站的防采集措施.
1个高质量的代理IP池
优采云可以为私有云用户提供高质量的代理IP池,允许用户在采集过程中灵活切换IP,有效避免网站反采集.
2自动识别验证码
优采云支持9种类型的验证码的自动识别,可以有效破解网站验证码以防止被采集.
9种验证码
3个Cookie,UA
优采云还可以灵活设置cookie(用户身份),定期切换UA(用户代理)以及突破对方的反阻塞方法,从而使企业可以稳定地获取高质量的数据源.
04. 企业协作数据资源共享
考虑到企业数据采集通常是一个内部的多人协作项目,优采云私有云为用户提供了团队协作功能,可以实现跨账户数据,云节点(可以理解为服务器)和IP共享资源(例如座席池)是团队协作的最佳武器.
05. 与企业数据库的无缝连接
数据采集后,优采云可以自动导入企业数据库,并且我们支持Oracle和MySQL等常见的企业数据库.
无缝链接企业业务系统,实现高效的数据归档,并消除繁琐而复杂的手动操作.
06. 多个高级API数据接口
私有云用户可以调用优采云的数据导出API接口和增值API接口.
使用上述两个界面,私有云用户的开发人员可以轻松地通过API获取有才运的任务信息并采集数据. 您可以在不登录优采云的情况下调用和控制优采云. 任务的状态减少了工作场景的来回切换.
07. 满足企业的灵活个性化需求
在指定时间进行1次灵活采集
定时采集功能是自定义设置的功能,适用于需要定期更新网站最新信息的公司用户,精确到分钟.
有了定时采集功能,用户可以在24小时内灵活选择采集时间,而优采云将在“关键时刻”自动开始工作,从而节省了用户的烦恼和精力.
2新增了准确的数据采集
智能识别新添加的数据以进行准确的采集,而无需进行历史性的重复工作,从而节省了时间和节点资源.
3个工作7 * 24h,即使关机也可以
在私有云任务开始运行采集任务之后,即使您关闭也不必担心. 优采云将继续在云中为您服务7 * 24小时,直到采集所有数据为止.
您可以安全地关机并下班,享受放松的时间.
08. 享受卓越的彩云MAX性能配置
1个无限的任务存储空间
您可以自由,随意地创建采集任务,而不必担心由于任务数量有限而定期删除或导出任务,从而减轻了烦人的工作量.
2个无限帐户同时在线
您的团队可以共享一个优采云私有云帐户,即使在不同的位置和不同的计算机上,您也可以同时登录并进行操作.
3个无限客户端同时打开
一台计算机可以同时打开多个客户端,这挑战了计算机的MAX性能.
4个无限量的数据可以随时导出
从优采云采集的10,000,000+数据可以无限次直接导入您的业务系统.
09. 私有云VIP爬虫专家咨询服务
每个私有云用户将配备VIP履带专家咨询团队,以提供及时的响应和熟练的专业售后服务.
10. “优采云”值得信赖的品牌
部分客户展示
油菜云获得了柔软度方面的主要奖项
优缺点比较
如果您的公司没有爬虫,但是您希望快速为其配备具备以低成本获取海量数据的能力,那么Wall Crack建议您使用优采云私有云!
优采云·触手可及的数据
官方帐户[优采云大数据] 查看全部
随着数据智能时代的到来,越来越多的公司重视数据,并使用采集器技术在Internet上获取大量公共数据以增强其业务能力.
当前,源自爬虫技术的经典商业项目,我相信您也必须使用它们:

Enterprise Check是一种企业信息查询工具,它将80个产业链,8,000个行业,6,000个市场和超过8,000万家国内市场的公司的数据汇总在一起.
企业如何检查海量数据?
企业搜索的数据源主要来自以下三个方面.
①Web爬网程序采集数据
②第三方合作数据
③有些数据更新任务是由用户触发的
它通过Web爬网程序采集数据,执行初步清理并将其合并到其数据库中,并使用算法进行处理,最后向用户打开以提供查询和搜索.
柴柴目前的估值已经达到5亿元.

事实证明,履带技术具有这种商业价值吗?
我们公司可以自己做并抓取数据以增强竞争力吗?
太年轻太天真
一位伟大的神之智说: “履带进入的门槛很低,但是在实际操作的后期阶段,它们确实会使您崩溃. 例如,您肯定会遇到以下问题. ”

您必须至少了解一个或多个主题,而不仅仅是爬虫,而且您刚刚开始学习爬网.

来源
如果企业组建了爬虫专家团队,则需要从零开始.
对于企业来说,这是一笔很大的开销,包括管理成本和时间成本.
我们如何打破这个僵局?
实际上,这位智虎神给出了答案:
“不要重新发明轮子”
市场上已经有许多简单,易于使用的专业爬虫服务和工具,它们使企业能够以更灵活,更轻便,成本更低的方式获取大量数据.
例如,优采云用于采集数据的企业私有云.
优采云的私有云版本是针对具有大量数据采集需求的公司量身定制的爬虫工具.
企业无需添加任何履带技术人员. 优采云的私有云可以完全满足企业进行海量信息采集的需求.
为什么选择优秀彩云?
优采云自2013年投入市场以来,一直致力于为用户提供易于使用,快速且稳定的数据抓取工具.
经过几年的发展,用户规模不断扩大,全球拥有120万用户. 通过专业的数据抓取能力和经验积累,我们开发了许多业内知名公司,例如平安,腾讯,万达,政府机构,科学研究所以及公安部,税务局,清华大学等成功的数据项目案例. 用户对优采云在数据采集方面的专业能力的认可.

优采云数据采集成功地被中华人民共和国工业和信息化部评选为“ 2019年度杰出大数据产品和应用解决方案”. 优采云连续5年在“中国大数据企业排名”中排名第一.

优采云私有云如何满足企业需求?
01. 专业的数据采集器服务功能
优采云可以采集在Internet上公开显示的数据,只要这些数据肉眼可见并且可以复制即可.
优采云支持文本,数字,图片,视频和源代码等数据类型,而不仅限于数据格式.
02. 在云中高效地分布式采集海量数据

优采云使用高效的云分布式采集,并由5000多个云服务器提供支持. 优采云私有云可根据企业需求配备30-100个以上的云节点,相当于同时运行近百台服务器,实现多任务并发采集.
使用分布式采集的时间明显短于企业使用自己的服务器所需的时间. 普通企业很难拥有像专业爬网程序这样的大量服务器资源来支持海量数据采集.
云分布式采集可以帮助公司实现在短时间内采集大量数据的目的,使公司每天可以轻松采集数百万甚至数千万的数据.

由于长期以来对大量数据采集器的需求,优采云已成为“阿里云VIP企业客户”. 优采云私有云用户可以通过优采云直接享受阿里云提供的“企业级优质云节点”,进一步实现快速稳定的云爬虫服务.
03. 独家智能防封技术组合
正如上面提到的知乎 Dashen所说,网站上存在多种反爬虫策略,并且大多数公司爬虫工程师在这种情况下只能无能为力.
经过6年以上的实战经验,优采云已经形成了独家的智能防封技术组合,可以有效地克服大多数网站的防采集措施.
1个高质量的代理IP池
优采云可以为私有云用户提供高质量的代理IP池,允许用户在采集过程中灵活切换IP,有效避免网站反采集.
2自动识别验证码
优采云支持9种类型的验证码的自动识别,可以有效破解网站验证码以防止被采集.

9种验证码
3个Cookie,UA
优采云还可以灵活设置cookie(用户身份),定期切换UA(用户代理)以及突破对方的反阻塞方法,从而使企业可以稳定地获取高质量的数据源.
04. 企业协作数据资源共享

考虑到企业数据采集通常是一个内部的多人协作项目,优采云私有云为用户提供了团队协作功能,可以实现跨账户数据,云节点(可以理解为服务器)和IP共享资源(例如座席池)是团队协作的最佳武器.
05. 与企业数据库的无缝连接
数据采集后,优采云可以自动导入企业数据库,并且我们支持Oracle和MySQL等常见的企业数据库.
无缝链接企业业务系统,实现高效的数据归档,并消除繁琐而复杂的手动操作.
06. 多个高级API数据接口
私有云用户可以调用优采云的数据导出API接口和增值API接口.
使用上述两个界面,私有云用户的开发人员可以轻松地通过API获取有才运的任务信息并采集数据. 您可以在不登录优采云的情况下调用和控制优采云. 任务的状态减少了工作场景的来回切换.
07. 满足企业的灵活个性化需求
在指定时间进行1次灵活采集
定时采集功能是自定义设置的功能,适用于需要定期更新网站最新信息的公司用户,精确到分钟.
有了定时采集功能,用户可以在24小时内灵活选择采集时间,而优采云将在“关键时刻”自动开始工作,从而节省了用户的烦恼和精力.
2新增了准确的数据采集
智能识别新添加的数据以进行准确的采集,而无需进行历史性的重复工作,从而节省了时间和节点资源.
3个工作7 * 24h,即使关机也可以
在私有云任务开始运行采集任务之后,即使您关闭也不必担心. 优采云将继续在云中为您服务7 * 24小时,直到采集所有数据为止.
您可以安全地关机并下班,享受放松的时间.
08. 享受卓越的彩云MAX性能配置
1个无限的任务存储空间
您可以自由,随意地创建采集任务,而不必担心由于任务数量有限而定期删除或导出任务,从而减轻了烦人的工作量.
2个无限帐户同时在线
您的团队可以共享一个优采云私有云帐户,即使在不同的位置和不同的计算机上,您也可以同时登录并进行操作.
3个无限客户端同时打开
一台计算机可以同时打开多个客户端,这挑战了计算机的MAX性能.
4个无限量的数据可以随时导出
从优采云采集的10,000,000+数据可以无限次直接导入您的业务系统.
09. 私有云VIP爬虫专家咨询服务
每个私有云用户将配备VIP履带专家咨询团队,以提供及时的响应和熟练的专业售后服务.
10. “优采云”值得信赖的品牌

部分客户展示

油菜云获得了柔软度方面的主要奖项
优缺点比较

如果您的公司没有爬虫,但是您希望快速为其配备具备以低成本获取海量数据的能力,那么Wall Crack建议您使用优采云私有云!
优采云·触手可及的数据
官方帐户[优采云大数据]
淘宝联盟如何自动发布订单?有什么方法?
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-08-07 01:18
淘宝联盟是Alimama平台为Taoke推广者建立的推广平台. 您可以在淘宝联盟的后台进行诸如连锁促销和现金提取等一系列操作.
想要在淘宝联盟中推广的用户,即淘宝客户,可以在他们的网站,微博,个人主页等上放置他们想要推广的产品的链接. 如果买家通过该链接购买淘宝商品,参加淘宝联盟的淘宝客户可以获得一定比例的佣金.
淘宝联盟如何自动发布订单?
1. 首先,我们首先从互联网下载相关的淘宝联盟自动计费软件
2. 打开软件,这里的第一个界面是云采集界面,您可以在云中读取高质量的产品库,在发送之前,我们需要在软件右侧添加Alimama帐户,并发送qq组或发送微信群组已添加到软件中,以便您可以直接在通讯工具中自动发送订单,并登录到淘宝联盟帐户.
3. 第二个接口是采集和转发接口. 采集和转发界面是从其他组采集高质量的产品并将链接转换为我们自己的Taoke链接!
这可以在淘宝联盟的背景下自动更新其他人的高质量产品,并将其转换为自己的Taoke链接.
4. 第三个接口是本地库转发接口,我们可以添加自己的产品并将其转发给组!
在这里,您可以设置要在组中推广的产品链接,并自动生成并将其发送给组.
对于特定的操作步骤,您可以自己检查相关的软件规则. 这里简要讨论了几点. 查看全部
淘宝联盟自动计费软件是一款可帮助淘宝批量发送商品的软件. 它可以自动将链接转换为淘宝链接并执行智能群组发送. 它支持三种模式: 云,集合和本地!那么淘宝联盟如何自动发布订单?

淘宝联盟是Alimama平台为Taoke推广者建立的推广平台. 您可以在淘宝联盟的后台进行诸如连锁促销和现金提取等一系列操作.
想要在淘宝联盟中推广的用户,即淘宝客户,可以在他们的网站,微博,个人主页等上放置他们想要推广的产品的链接. 如果买家通过该链接购买淘宝商品,参加淘宝联盟的淘宝客户可以获得一定比例的佣金.
淘宝联盟如何自动发布订单?
1. 首先,我们首先从互联网下载相关的淘宝联盟自动计费软件
2. 打开软件,这里的第一个界面是云采集界面,您可以在云中读取高质量的产品库,在发送之前,我们需要在软件右侧添加Alimama帐户,并发送qq组或发送微信群组已添加到软件中,以便您可以直接在通讯工具中自动发送订单,并登录到淘宝联盟帐户.
3. 第二个接口是采集和转发接口. 采集和转发界面是从其他组采集高质量的产品并将链接转换为我们自己的Taoke链接!
这可以在淘宝联盟的背景下自动更新其他人的高质量产品,并将其转换为自己的Taoke链接.
4. 第三个接口是本地库转发接口,我们可以添加自己的产品并将其转发给组!
在这里,您可以设置要在组中推广的产品链接,并自动生成并将其发送给组.
对于特定的操作步骤,您可以自己检查相关的软件规则. 这里简要讨论了几点.
优采云 云端自动化数据采集发布系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2020-08-04 10:00
感谢您使用SkyCaiji(蓝天数据采集发布系统), 希望我们的努力能为您提供一套数据自动化解决方案!
PHP版本要求
PHP5.3以上版本(注意:PHP5.3dev版本和PHP6均不支持)
安装环境要求
操作系统:Linux/Unix/Windows
软件环境:IIS/Apache/Nginx + MySQL 5.0 及以上
下载软件
当前版本:SkyCaiji V1.2 站长下载 Github 码云
上传至服务器
将下载的软件上传至您的服务器,如果根目录有站点建议置于子目录里,解压后打开浏览器输入您的服务器域名或ip地址(存放在子目录则加上子目录的名称),进入安装界面
点击“接受”,进入环境检测页面
必须确保所有参数都正确,否则使用中会出现错误,点击“下一步”进入数据安装界面
填写好数据库及创始人配置,点击“下一步”
最后安装完成,现在可以使用优采云了!
关于软件
SkyCaiji(蓝天数据采集发布系统),致力于网站数据自动化采集发布,系统采用PHP+Mysql开发云端 自动 采集,可布署在云端服务器,使数据采集便捷化、智能化、云端化云端 自动 采集,让您随时随地联通办公!
数据采集
自定义采集规则(支持正则、XPATH、JSON等)精准匹配任意信息流,几乎能采集所有类型的网页,绝大多数文章类型页面内容可实现智能辨识
内容发布
无缝耦合各种CMS建站程序,实现免登录导出数据,支持自定义数据发布插件,也可以直接导出数据库、存储为Excel文件、生成API接口等
自动化及云平台
软件实现定时定量全手动采集发布,无需人工干预!内置云平台,用户可分享及下载采集规则,发布供求信息以及社区求救、交流等 查看全部
优采云
感谢您使用SkyCaiji(蓝天数据采集发布系统), 希望我们的努力能为您提供一套数据自动化解决方案!
PHP版本要求
PHP5.3以上版本(注意:PHP5.3dev版本和PHP6均不支持)
安装环境要求
操作系统:Linux/Unix/Windows
软件环境:IIS/Apache/Nginx + MySQL 5.0 及以上
下载软件
当前版本:SkyCaiji V1.2 站长下载 Github 码云
上传至服务器
将下载的软件上传至您的服务器,如果根目录有站点建议置于子目录里,解压后打开浏览器输入您的服务器域名或ip地址(存放在子目录则加上子目录的名称),进入安装界面
点击“接受”,进入环境检测页面
必须确保所有参数都正确,否则使用中会出现错误,点击“下一步”进入数据安装界面
填写好数据库及创始人配置,点击“下一步”
最后安装完成,现在可以使用优采云了!
关于软件
SkyCaiji(蓝天数据采集发布系统),致力于网站数据自动化采集发布,系统采用PHP+Mysql开发云端 自动 采集,可布署在云端服务器,使数据采集便捷化、智能化、云端化云端 自动 采集,让您随时随地联通办公!
数据采集
自定义采集规则(支持正则、XPATH、JSON等)精准匹配任意信息流,几乎能采集所有类型的网页,绝大多数文章类型页面内容可实现智能辨识
内容发布
无缝耦合各种CMS建站程序,实现免登录导出数据,支持自定义数据发布插件,也可以直接导出数据库、存储为Excel文件、生成API接口等
自动化及云平台
软件实现定时定量全手动采集发布,无需人工干预!内置云平台,用户可分享及下载采集规则,发布供求信息以及社区求救、交流等
直观:大数据时代,云端爬虫采集系统辅助网站实现内容自动化!
采集交流 • 优采云 发表了文章 • 0 个评论 • 389 次浏览 • 2020-09-18 08:22
大数据和云计算是当今Internet上使用最广泛的技术。面对数据的蓝色海洋,许多公司和个人并不完全具备数据挖掘的功能,只能使用第三方采集器软件来实现数据采集,而传统的采集软件大多附属于Windows系统,但现在是移动多平台时代,单个Windows 采集软件无法满足网站多方面的需求,并且费用昂贵,并且云同步能力很差,因而要花钱网站 ]最小。具有技术能力的公司或个人将开发自己的网站 采集程序,该程序涉及人员,周期和成本方面的大量投资,并且该程序的可伸缩性和多功能性在以后的维护中显而易见。缺点是消耗人力,物力和财力。
因此,什么样的采集软件对网站真正有价值,作者认为,既需要像传统采集软件一样具有数据挖掘能力,又要与时俱进,真正做到实现采集云化后,市场上的云采集仅在供应商的服务器采集上执行,客户没有完全的自治权,采集的效率受到供应商服务器的处理能力的限制,优采云采集器是真正的云数据采集发布系统。它使用类似于cms的系统来构建网站。它可以安装在客户自己的服务器上,并且可以通过浏览器访问服务器域名或ip进行操作。 采集,优采云采集器与客户自己的网站没有冲突。它是一个完全辅助的网站 采集系统,可以在服务器的任何子目录中建立,并且在不使用该软件时可以删除该软件所在的目录。
优采云采集器全名优采云数据采集发布系统,软件英文名称SkyCaiji,致力于网站数据自动化采集发布,使数据采集方便,智能且基于云。该软件是使用php + mysql开发的可视化网站系统,开源并且免费使用,几乎可以采集所有类型的网页,可以自定义采集规则,支持正则表达式,XPATH,JSON和其他语法,准确匹配任何信息流,可以智能识别大多数文章类型页面的正文内容。该软件可以与各种cms站点构建程序结合使用,以实现无需登录即可进行实时数据发布,支持自定义数据发布插件或直接导入数据库,存储为Excel文件,生成API接口等。定期自动定量发布采集,无需人工干预,节省了人力和物力!该操作界面具有完全相同的功能,非常适合计算机和移动终端,使您可以随时随地工作。借助内置的云平台,用户可以共享和下载采集规则,发布采集供求信息以及社区帮助和交流。它是大数据和云时代网站数据自动化采集发布的最佳云爬虫软件。
专业工作留给别人做,优采云采集()将为您提供一组数据采集发布解决方案! 查看全部
在大数据时代,云爬虫采集系统协助网站自动化内容!
大数据和云计算是当今Internet上使用最广泛的技术。面对数据的蓝色海洋,许多公司和个人并不完全具备数据挖掘的功能,只能使用第三方采集器软件来实现数据采集,而传统的采集软件大多附属于Windows系统,但现在是移动多平台时代,单个Windows 采集软件无法满足网站多方面的需求,并且费用昂贵,并且云同步能力很差,因而要花钱网站 ]最小。具有技术能力的公司或个人将开发自己的网站 采集程序,该程序涉及人员,周期和成本方面的大量投资,并且该程序的可伸缩性和多功能性在以后的维护中显而易见。缺点是消耗人力,物力和财力。
因此,什么样的采集软件对网站真正有价值,作者认为,既需要像传统采集软件一样具有数据挖掘能力,又要与时俱进,真正做到实现采集云化后,市场上的云采集仅在供应商的服务器采集上执行,客户没有完全的自治权,采集的效率受到供应商服务器的处理能力的限制,优采云采集器是真正的云数据采集发布系统。它使用类似于cms的系统来构建网站。它可以安装在客户自己的服务器上,并且可以通过浏览器访问服务器域名或ip进行操作。 采集,优采云采集器与客户自己的网站没有冲突。它是一个完全辅助的网站 采集系统,可以在服务器的任何子目录中建立,并且在不使用该软件时可以删除该软件所在的目录。
优采云采集器全名优采云数据采集发布系统,软件英文名称SkyCaiji,致力于网站数据自动化采集发布,使数据采集方便,智能且基于云。该软件是使用php + mysql开发的可视化网站系统,开源并且免费使用,几乎可以采集所有类型的网页,可以自定义采集规则,支持正则表达式,XPATH,JSON和其他语法,准确匹配任何信息流,可以智能识别大多数文章类型页面的正文内容。该软件可以与各种cms站点构建程序结合使用,以实现无需登录即可进行实时数据发布,支持自定义数据发布插件或直接导入数据库,存储为Excel文件,生成API接口等。定期自动定量发布采集,无需人工干预,节省了人力和物力!该操作界面具有完全相同的功能,非常适合计算机和移动终端,使您可以随时随地工作。借助内置的云平台,用户可以共享和下载采集规则,发布采集供求信息以及社区帮助和交流。它是大数据和云时代网站数据自动化采集发布的最佳云爬虫软件。
专业工作留给别人做,优采云采集()将为您提供一组数据采集发布解决方案!
解决方案:网站数据库格式网页数据采集如何导出为Excel、CSV、Html、数据库、API
采集交流 • 优采云 发表了文章 • 0 个评论 • 334 次浏览 • 2020-09-01 06:09
摘要: 该视频介绍了数据查看和导出. 单击“导出数据”后,将提示您是否删除重复项. 您可以选择导出所有数据,也可以选择在重复数据删除后导出. 数据仅存储在云中3个月(以采集时间计算),到期日期将被自动清除. Excel表文件(每个文件最多有20,000个数据,超过20,000个将自动拆分多个文件以进行导出. 如果单行数据太长,该行将被截断. 导出到数据库,支持SQL Server,MySQL, Oracle这三种类型的数据库都支持自动导出到数据库,未导出的数据将按计划定期导出.
网站数据库格式
此视频介绍了数据查看和导出.
如果本地采集数据具有重复数据. 单击“导出数据”后,将提示您是否删除重复项. 您可以选择导出所有数据,也可以选择在重复数据删除后导出.
导出后,本地数据不会自动清除. 您可以下次再次导出它或清除数据.
如果在云采集数据中采集了重复数据,它将在进入数据库之前自动进行重复数据删除,也就是说,您看到的数据不是重复数据.
导出后,云采集数据不会自动清除. 您下次可以再次导出或清除数据. 数据仅在云中存储3个月,以采集时间计算,到期日期将自动清除.
云采集数据按状态分类:
所有数据: 此任务的所有数据,每次将累积云采集数据时,如果不清除,则始终可以查看和导出.
未导出的数据: 从未导出采集中新到达的数据,但是任何导出格式或方法(只要已导出一次)都不是未导出的数据.
数据导出格式/方法:
Excel表文件(每个文件最多有20,000个数据,超过20,000个将自动拆分多个文件以进行导出. 如果一行数据太长,则该行将被截断. )
CSV文本文件(每个文件最多收录20,000个数据,超过20,000个将自动拆分多个文件以进行导出. 单行数据太长且不会被截断. )
HTML网页文件(一行数据,一个文件,例如采集具有100个数据,选择此格式将导出100个文件)
导出到数据库,支持三种类型的数据库: SQL Server,MySQL和Oracle. 支持自动导出到数据库,未导出的数据将按计划定期导出.
API接口导出,API文档参考 查看全部
网站如何将数据库格式采集的网页数据导出到Excel,CSV,HTML,数据库,API
摘要: 该视频介绍了数据查看和导出. 单击“导出数据”后,将提示您是否删除重复项. 您可以选择导出所有数据,也可以选择在重复数据删除后导出. 数据仅存储在云中3个月(以采集时间计算),到期日期将被自动清除. Excel表文件(每个文件最多有20,000个数据,超过20,000个将自动拆分多个文件以进行导出. 如果单行数据太长,该行将被截断. 导出到数据库,支持SQL Server,MySQL, Oracle这三种类型的数据库都支持自动导出到数据库,未导出的数据将按计划定期导出.
网站数据库格式
此视频介绍了数据查看和导出.
如果本地采集数据具有重复数据. 单击“导出数据”后,将提示您是否删除重复项. 您可以选择导出所有数据,也可以选择在重复数据删除后导出.
导出后,本地数据不会自动清除. 您可以下次再次导出它或清除数据.
如果在云采集数据中采集了重复数据,它将在进入数据库之前自动进行重复数据删除,也就是说,您看到的数据不是重复数据.
导出后,云采集数据不会自动清除. 您下次可以再次导出或清除数据. 数据仅在云中存储3个月,以采集时间计算,到期日期将自动清除.
云采集数据按状态分类:
所有数据: 此任务的所有数据,每次将累积云采集数据时,如果不清除,则始终可以查看和导出.
未导出的数据: 从未导出采集中新到达的数据,但是任何导出格式或方法(只要已导出一次)都不是未导出的数据.
数据导出格式/方法:
Excel表文件(每个文件最多有20,000个数据,超过20,000个将自动拆分多个文件以进行导出. 如果一行数据太长,则该行将被截断. )
CSV文本文件(每个文件最多收录20,000个数据,超过20,000个将自动拆分多个文件以进行导出. 单行数据太长且不会被截断. )
HTML网页文件(一行数据,一个文件,例如采集具有100个数据,选择此格式将导出100个文件)
导出到数据库,支持三种类型的数据库: SQL Server,MySQL和Oracle. 支持自动导出到数据库,未导出的数据将按计划定期导出.
API接口导出,API文档参考
云端主动采集 主动下发优采云采集器:云端文章自动采集发布系统-小哲博客
采集交流 • 优采云 发表了文章 • 0 个评论 • 309 次浏览 • 2020-08-30 05:01
摘要:优采云采集器是一款免费的文章采集系统,而且是云端手动采集系统,只要你有一台服务器甚至一台虚拟主机,就能实现网站内容手动更新。做网站的同事肯定都晓得采集文章的好处,小哲就不过多剖析采集的作用了,重点介绍一下优采云采集器的一些优点吧。优采云采集器不用你自己的笔记本能够实现采集,只要有服务器设置一台虚拟主机能够采集文章,其实优采云采集器类似一个博客系统,把源代码上传到服务器里面,通过域名进行访问安装,然后就可以使用了,这点和DZ、Wordpress、Z博客的安装过程一样
云端主动采集 主动下发
优采云采集器是一款免费的文章采集系统,而且是云端手动采集系统,只要你有一台服务器甚至一台虚拟主机,就能实现网站内容手动更新。做网站的同事肯定都晓得采集文章的好处,小哲就不过多剖析采集的作用了,重点介绍一下优采云采集器的一些优点吧
优采云采集器不用你自己的笔记本能够实现采集,只要有服务器设置一台虚拟主机能够采集文章,其实优采云采集器类似一个博客系统,把源代码上传到服务器里面,通过域名进行访问安装,然后就可以使用了,这点和DZ、Wordpress、Z博客的安装过程一样
优采云采集的安装简单,重点在于采集过程的配置。首先要找到目标网站的采集规则,这个须要你自己去创建规则的,优采云采集器官网有几个样例规则,不难理解,看懂就可以自己写规则了,支持正则、XPATH、JSON等,采集到的数据就可以发布内容到各大CMS平台上,包括Wordpress、Z博客等主流博客程序,下面是官方的一些发布插件,不用自己写插件了
其他细节东西你自己去研究就行了,比如图片本地化这些功能,你渐渐去尝试,小哲我就不讲很详尽了,如果你不会使用,可以来咨询小哲。不过小哲我平时消息比较多,不要催太紧,而且小哲我也不太支持采集,除非你有非常好的采集源,像采集源这些东西你自己去找,这个别来问我,我不可能晓得每位行业的网站的,有些行业小哲我根本不懂,比如建筑行业,所以也不可能晓得建筑行业那个网站值得采集
优采云采集器比优采云采集好的地方就在于支持在线采集,不需要你开笔记本,定时手动采集,这点十分便捷
优采云采集器官网:
网上挣钱的核心在于推广,想赚大钱就要学会推广,如果你对挣钱感兴趣,小哲博客首页有可以推广赚钱的手机APP和挣钱方法,都是小哲我认真推荐的,希望诸位路过的同事支持一下 查看全部
云端主动采集 主动下发优采云采集器:云端文章自动采集发布系统-小哲博客
摘要:优采云采集器是一款免费的文章采集系统,而且是云端手动采集系统,只要你有一台服务器甚至一台虚拟主机,就能实现网站内容手动更新。做网站的同事肯定都晓得采集文章的好处,小哲就不过多剖析采集的作用了,重点介绍一下优采云采集器的一些优点吧。优采云采集器不用你自己的笔记本能够实现采集,只要有服务器设置一台虚拟主机能够采集文章,其实优采云采集器类似一个博客系统,把源代码上传到服务器里面,通过域名进行访问安装,然后就可以使用了,这点和DZ、Wordpress、Z博客的安装过程一样
云端主动采集 主动下发
优采云采集器是一款免费的文章采集系统,而且是云端手动采集系统,只要你有一台服务器甚至一台虚拟主机,就能实现网站内容手动更新。做网站的同事肯定都晓得采集文章的好处,小哲就不过多剖析采集的作用了,重点介绍一下优采云采集器的一些优点吧
优采云采集器不用你自己的笔记本能够实现采集,只要有服务器设置一台虚拟主机能够采集文章,其实优采云采集器类似一个博客系统,把源代码上传到服务器里面,通过域名进行访问安装,然后就可以使用了,这点和DZ、Wordpress、Z博客的安装过程一样
优采云采集的安装简单,重点在于采集过程的配置。首先要找到目标网站的采集规则,这个须要你自己去创建规则的,优采云采集器官网有几个样例规则,不难理解,看懂就可以自己写规则了,支持正则、XPATH、JSON等,采集到的数据就可以发布内容到各大CMS平台上,包括Wordpress、Z博客等主流博客程序,下面是官方的一些发布插件,不用自己写插件了
其他细节东西你自己去研究就行了,比如图片本地化这些功能,你渐渐去尝试,小哲我就不讲很详尽了,如果你不会使用,可以来咨询小哲。不过小哲我平时消息比较多,不要催太紧,而且小哲我也不太支持采集,除非你有非常好的采集源,像采集源这些东西你自己去找,这个别来问我,我不可能晓得每位行业的网站的,有些行业小哲我根本不懂,比如建筑行业,所以也不可能晓得建筑行业那个网站值得采集
优采云采集器比优采云采集好的地方就在于支持在线采集,不需要你开笔记本,定时手动采集,这点十分便捷
优采云采集器官网:
网上挣钱的核心在于推广,想赚大钱就要学会推广,如果你对挣钱感兴趣,小哲博客首页有可以推广赚钱的手机APP和挣钱方法,都是小哲我认真推荐的,希望诸位路过的同事支持一下
2017 年,我用 Airtable 这款表格利器建了一个「量化自我」数据库
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-24 22:46
如今,数据早已被称之为信息时代的「黄金」,个人可以通过数据来量化自我,公司可以使用数据来帮助决策。互联网服务商可以通过搜集用户数据提供愈发个性化的服务,我们也可以搜集自己的数据来优化自己的生活方式。
近一年来,我开始意识到自己作为数据发生器的重要性,于是就开始下意识地集中搜集自己形成的各种数据,建立自己的数据搜集模式。而提到为何要集中搜集个人数据,主要缘由应当有两点:
目前使用了 Moves,RescueTime,Toggl 等各种应用来搜集自己的地理位置、时间消耗等数据。但是这种数据都存放于单独的应用之上,过于分散。自己看得见,摸得着的数据,比置于他人的服务器上更放心,也更容易集中加以借助。
集中搜集数据,意味着 Moves,RescueTime 等应用弄成了纯粹的搜集工具,而数据会汇总到自己手中。不同类型的数据一旦汇集到一起,不仅可以针对单一类别数据进行可视化展示,还能剖析出数据直接的关联性,对自己的行为更具有指导意义。
选择一款云端表格工具
数据搜集的末端,对应着用于储存数据的数据库。当然,对于个人数据搜集而言,我们常说的电子表格也许就足够了。最使大众熟知的电子表格工具一定是 Microsoft Excel 。但是,作为一款桌面软件,Excel 往往并不适用于现代的数据搜集流程。例如,你想将你的微博存档保留,难道是通过自动复制粘贴到 Excel 文档中吗?显然不太实际。
所以,如果我们有一个置于云端的电子表格,可想像的空间就大好多了。说到云端电子表格,不得不再度提及 Excel,只不过此次是它的孪生兄弟 Excel Online,作为 Office 365 的套件之一,Excel Online 除了未能处理宏命令,其他方面几乎就是桌面版 Excel 的完美克隆。
相比之下,本文的主角 Airtable 的名气就远不及 Excel 了。但是,作为一个典型的硅谷公司产品,Airtable 也拥有不错的口碑。此外,Google Sheets 也是优秀的云端表格工具,只是这朵云距我们稍为远了一些。
那么,对于这三款相对优秀的云端电子表格,到底哪一款愈发适宜用于个人数据搜集整理呢?我做了一个对比。
当我选择的时侯,最看重的功能虽然是 API 支持。只有具备了 API 接口,才能使数据搜集流程可以实现自动化,也才是名副其实的「云端表格」。而使我最终选择 Airtable 的缘由,应该有如下几点:
基础功能同另外的两个产品相比没有显著的缺位,甚至拥有象条形码输入、iframe 嵌入等更多差异化功能。Airtable 同时支持 IFTTT 和 Zapier 云端自动化工具,且 API 使用上去更简单便捷。很多时侯,就算使用现有工具难以满足需求,也可以按照开发者文档自行编撰代码实现数据读取和写入。Airtable 外观设计愈发漂亮,这一点在长时间的使用过程中特别重要。Airtable 使用简介
在即将介绍我是怎样使用 Airitable 集中整理数据之前,我想先对 Airtable 做一个简单介绍。
如下图所示,Airtable 主要收录有 6 个基本组件,分别是:
可以看出,Airtable 从诞生之初就具备了关系型数据库的样子,已经满足了对数据存储的日常需求。从功能上,除了 Excel Online,基本上没有竞品。
要想对个人数据进行集中搜集整理,首先须要在 Airtable 创建不同的数据库。建立数据库是个人数据搜集工程中的第一步,所以并不是随便乱建的。其中,我们须要先想一想搜集数据的大类,然后在细分大类中的小类,并对应到数据表中。我的数据库主要有下边 3 个,树形结构如图所示。
工作学习数据库
工作学习数据库会搜集平时我在工作或则学习中形成的相关数据。根据我的使用习惯,数据库收录了 4 张数据表,分别是:Calendar、Todoist、Trello 以及 Issues(同步 Github)。看到名子应当就很容易明白这 4 张表的意思了。
对于这四类服务的数据,我均是采用 IFTTT 或者 Zapier 将其同步到 Airtable 中。这里补充介绍一下 IFTTT 和 Zapier 的区别与联系。首先,二者都是整合不同应用提供的开发者 API 实现自动化流程的云端服务,这是她们的相同之处。但是,Zapier 相对于 IFTTT 会更强悍一些,它通常情况下会支持原服务更全面的 API 接口,且支持多个服务联动。相比之下,IFTTT 很多时侯只提供主要的插口,且只支持两个服务之间的数据传递。
举个反例,当我在使用 Zapier 实现 Google Calendar → Airtable 的过程中,Zapier 支持读取 Google Calendar 中的 43 项数据(虽然有一些不实用),但 IFTTT 只支持 8 个。当然,IFTTT 也有比 Zapier 好用的时侯。比如将 Todoist 完成任务同步到 Airtable 时,Zapier 不支持检测任意 Project 下完成的任务,需针对每位 Project 设置单独的流程。
四个服务同步到 Airtable 的设置都大同小异,这里我只拿 Todoist → Airtable 详细说明。当我选择 IFTTT 作为 Todoist → Airtable 的同步工具时,首先须要到 IFTTT 上看一看其支持读取 Todoist 的什么数据,你可以通过创建动作时查看。
我们可以看见从 Todoist → Airtable 一共支持 7 个类别的数据。那么,现在可以先新建这个动作。注意,你须要遵循 IFTTT 制定的句型格式,才能正确地将数据写入到 Airtable 中。
也就是说,如果要将这 7 类数据全部同步到 Airtable,你须要在 IFTTT 动作的最后输入如下所示的内容。我习惯之间使用 IFTTT 的 ingredient 名称作为 Airtable 中的列名称。
格式:::airtable::Airtable 中的列名::{{IFTTT 中的 ingredient}}
示例内容:
::airtable::TaskContent::{{TaskContent}}
::airtable::LinkToTask::{{LinkToTask}}
::airtable::Project::{{Project}}
::airtable::Labels::{{Labels}}
::airtable::Priority:: {{Priority}}
::airtable::CompletedAt::{{CompletedAt}}
::airtable::DueDate::{{DueDate}}
接下来,就可以到 Airtable 中设置相应的列名称了。在设置对应的列属性(文本、数字、图片等)时,我建议一开始统一设置为「Single line text」,也就是单行文本格式,以避免导出数据出错。
当测试导出成功以后,就可以调整列属性。例如这儿,Project 的数目是有限的,且每位任务只对应一个 Project。就可以将其列属性设定为 Single select(单选),这样也便捷日后对任务进行筛选。同样,日期可以使用 Date 属性,链接使用 URL 等。
如果调整列属性以后,表格显示为空白或报错,那就意味着通过 IFTTT 传过来的数据格式并不能挺好地被 Airtable 支持。比如这儿的 CompletedAt,也就是项目的完成日期 + 时间。IFTTT 输出的数据格式是象这样的 January 20, 2018 at 10:18AM,Airtable 无法之间将其转换为对应的「日期+时间」的格式。
为了便捷以后的数据剖析,我们当然更偏向于将其处理成时间序列,也就是按 Airtable 中的「日期+时间」格式保存。此时,我们可以通过新建中间列作为过渡,然后借助 Airtable 的 Formula 公式将原文本列转换为可辨识的「日期+时间」列。具体步骤如下:
明确区别: 原文本列格式为January 20, 2018 at 10:18AM,Airtable 可辨识的格式为January 20, 2018 10:18 AM。注意观察两者之间的区别,文本格式多了 at + 一个空格 字符,同时 AM 字符前缺乏一个空格。格式转换:明白区别以后就可以开始使用 Airtable 提供的 Formula 公式转换格式。首先是去除 at 字符,然后在结尾的 AM 或者 PM 前面降低空格。
这里使用了 SEARCH() 函数去定位要更改的位置,然后使用 REPLACE() 函数更改字符。最后再使用 DATATIME_FOMRMAT() 函数低格字符串为我们想要的「日期-时间」样式。一个小的方法是,如果你嫌降低的中间列较多,那么可以使用 Airtable 顶部菜单的 Hide fields 选项隐去不必要的列,只呈现我们须要的数据即可。
量化自我数据库
我的第二个主要数据库为量化自我数据库,它是由:Moves、Location、Apple Health、RescueTime 以及 Commute 等 5 个数据表组成。这 5 个数据表分别对应着 Moves 记录的地理位置数据、手动签到数据、Apple Health 记录的运动健康数据、RescueTime 记录的工作效率数据以及通勤时间统计数据。
Moves 数据
Moves 是我仍然在使用的地理位置追踪应用,它的运动状态辨识和地点辨识做的非常好,以至于如今都没有找到可取代的应用。Moves 其实拥有健全的 API,但因为其认证方法的特殊性,IFTTT 和 Zapier 都仍未支持与 Moves 连接。于是,我只能自己编撰一个 Moves → Airtable 的脚本,然后布署在云服务器上,每天手动将今天形成的数据同步的 Airtable 中去。
实现的过程比较麻烦,都能凑够一篇文章了,另找时间再细说。这里,Moves 的数据收录有经纬度信息,你可以直接使用 Airtable 提供的 Map Block 模块对地理位置可视化。
关于 Airtable Blocks 的更多介绍,可以阅读官方的文章《Getting started with Airtable blocks》
Location 数据
除了使用 Moves 自动记录地理位置信息,我还自己制做了一个辅助签到的 Workflow 用来标记我觉得重要的地点,并把地理位置数据实时上传到 Airtable 中的 Location 数据表中。
Workflow 非常简单,流程如下:定位 → 解析数据 [街道 - 城市 - 地区 - 国家] → 解析数据 [经度 - 纬度 - 高度] → 结合当前时间一并上传到 Airtable 中。
Apple Health 数据
目前,追踪健康信息主要是使用 Apple Watch 和 iPhone,通过本身的健康应用以及配合 Moves,Autosleep 等第三方应用完成。Apple Health 无法实现 iCloud 同步,更没有 API 支持,所以只能半自动同步到 Airtable。我采用的方式是定期从 Apple Health 中导入数据文件到 Dropbox 中,Dropbox 的数据压缩包会手动同步到云服务器中,再由云服务器中布署的 Python 脚本手动完成数据解析,并通过 API 同步到 Airtable 的表格中去。
RescueTime 数据
工作效率记录我会使用到 RescueTime 应用,RescueTime 会手动记录各种程序的前台运行时间,再和数据库进行比对得到相应应用属于效率应用还是非效率应用,从而手动统计每晚的工作效率。
RescueTime 的数据同步到 Airtable 就比较便捷了,可以使用 IFTTT,Zapier 或者开发者插口同步。我选择的是 Zapier,因为它可以同步多达 59 项数据信息。触发的动作选择「当每日数据汇总后」,然后再将对应的数据更新到对应的列即可。过程十分简单,就不再赘言了。
这里介绍一个使用 RescueTime 的一个小技巧,那就是最好定期去自动标记相应应用的效率属性。首先,我们每晚浏览的大多数网页或则使用的应用都是比较固定的,手动标记耗费的时间不多。其次,有一些应用对每个人的效率属性不一致。比如,我早已好多年没用 QQ 作为和他人的聊天工具了,所以但凡当使用 QQ 时,基本上都属于处理工作里面的事情,它对于我而言就是效率状态,而不是闲暇状态。
通勤时间数据
Commute 表拿来统计我的通勤时间。每天,我就会选择轻轨作为下班通勤的主要交通工具,虽然轻轨在站与站之间的运行时间比较确定,但因为存在换乘,所以每晚的通勤时间的变化就比较大了。打个比方,有时候晚上只晚出发 5 分钟,如果刚好赶上一波高峰,实际抵达公司的时间常常会晚 20 分钟。所以,我从年初就开始每晚记录自己的通勤时间,打算等到数据累计到一定量以后,通过数据剖析得到自己每晚的合理出发时间。
在记录通勤时间的时侯,由于打算将数据保存到 Airtable,所以一开始就直接就排除了现有的计时器或则第三方 App,然后把目标集中到 Workflow。但是,很快我就发觉 Workflow 的现有动作中,并没有支持在后台完成计时的动作。后来,我就想到了直接利用 Airtable 来完成这个功能,这个功能的逻辑十分简单。流程如下:
每天从屋内出发的时侯,点击 workflow 将此刻的时间上传到 Airtable,并记为出发时间。当抵达公司时,再次点击 Workflow 将时间上传到 Airtable 。由于 Airtable 本身可以使用数据函数,就能估算出两个时间差,并直接在我第二次点击 Workflow 上传时间后,将估算好的通勤时间推送到手机上。这样,既可以实时见到记录出来的通勤时间,也不再须要二次过程将数据上传到 Airtable 中。
信息存档数据库
信息存档数据库是拿来保存我觉得有必要存档的互联网数据。其中,主要有三个 Tables,分别是:微博、博客以及稍后读。
我喜欢定期清空自己的微博,防止在互联网上留下过多的「? 历史」。但又不想扔掉自己转发过的微博,于是就有了这个微博存档表。存档微博的方式十分简单,使用 IFTTT 新建一个动作,实时将微博记录到 Airtable 中保存。
同样,我使用 Pocket 作为稍后阅读工具,也就通过创建 IFTTT 动作,将保存在 Pocket 中的文章同步存档到 Airtable 中。
除此之外,博客存档表拿来备份自己在互联网上创作的内容。比如在少数派写的文章以及自己的博客文章。该表单使用了自己编撰的 Python 脚本,定期将我的博客文章以及在少数派发表的文章同步保存到 Airtable 中。
其他数据库
除了前面提及的这三个主要的数据库,我还有几个自己比较喜欢的数据库,也分享一下。
票据存档数据库
票据存档的数据库主要是记录平时我觉得比较重要的支票、发票、合同文件等。当然,超市购物小票这类不太重要的票据也就没必要存档了。
教育让利统计数据库
几个月前,我在少数派写过一篇 《在校师生福利:Apple、微软、Adobe 等产品怎样通过教育让利订购》 ,这篇文章中介绍一些院校中学生可以享受的教育让利项目。不久前,我通过 Airtable 整理了一份愈发详尽的教育让利表单,希望更多的中学生能享受到优价有品质的服务。
你可以通过检索的形式来获取自己感兴趣的教育让利项目。当然,我也号召你们来一起建立这个表单。如果有一些教育让利项目非常好,但表单中未涉及到,欢迎直接通过下边的链接补充递交到表单中去。
菜品、餐馆统计数据库
最近,我正在建立的一个数据库来源于我生活中的一个疼点,那就是常常不知道喝哪些。这个数据库中会记录下一些餐厅和食材。我会将平时喝过觉得不错的,或者想吃的餐厅信息添加到餐厅数据表中,同时会记录一些做过或则想做的菜肴。
当我自己想做饭喝的时侯,我都会通过 Workflow 随机返回食材作为灵感,而想出去喝的时侯,也可以随机返回餐厅信息。目前,这个数据库和 Workflow 还没有完全做好,等建立以后,会同你们一起分享。
另外,文中提及的一些自动化数据获取的 Python 脚本,我也会整理后择时与少数派读者分享。
结语
我虽然很早就晓得 Airtable 了,但真正有效地借助上去也是近一年才开始的。目前,虽然 Airtable 已经帮我存出来不少的数据,但是我对它的借助程度还并不满意,今年我会继续开掘 Airtable 的「正确使用方法」。
如今,我们都晓得经常须要备份自己的相片、手机、电脑,防止资料遗失。除此之外,我们同样应当注重起自己每晚形成的其他数据。目前初步构建上去的数据集中搜集模式只是开始。等待数据积累到一定量时,就须要着手「数据集中剖析」,使其真正地能帮助自己发觉某个坏习惯,提升一些效率,改变一些东西。
少数派一年一度的奖品超级优厚的 征文活动 又开始了!我们打算了 5 万+ 的奖品等你来拿。
本文是「我是少数派,这是我的 2017」征文活动的第入围作品。 查看全部
2017 年,我用 Airtable 这款表格利器建了一个「量化自我」数据库
如今,数据早已被称之为信息时代的「黄金」,个人可以通过数据来量化自我,公司可以使用数据来帮助决策。互联网服务商可以通过搜集用户数据提供愈发个性化的服务,我们也可以搜集自己的数据来优化自己的生活方式。
近一年来,我开始意识到自己作为数据发生器的重要性,于是就开始下意识地集中搜集自己形成的各种数据,建立自己的数据搜集模式。而提到为何要集中搜集个人数据,主要缘由应当有两点:
目前使用了 Moves,RescueTime,Toggl 等各种应用来搜集自己的地理位置、时间消耗等数据。但是这种数据都存放于单独的应用之上,过于分散。自己看得见,摸得着的数据,比置于他人的服务器上更放心,也更容易集中加以借助。
集中搜集数据,意味着 Moves,RescueTime 等应用弄成了纯粹的搜集工具,而数据会汇总到自己手中。不同类型的数据一旦汇集到一起,不仅可以针对单一类别数据进行可视化展示,还能剖析出数据直接的关联性,对自己的行为更具有指导意义。
选择一款云端表格工具
数据搜集的末端,对应着用于储存数据的数据库。当然,对于个人数据搜集而言,我们常说的电子表格也许就足够了。最使大众熟知的电子表格工具一定是 Microsoft Excel 。但是,作为一款桌面软件,Excel 往往并不适用于现代的数据搜集流程。例如,你想将你的微博存档保留,难道是通过自动复制粘贴到 Excel 文档中吗?显然不太实际。
所以,如果我们有一个置于云端的电子表格,可想像的空间就大好多了。说到云端电子表格,不得不再度提及 Excel,只不过此次是它的孪生兄弟 Excel Online,作为 Office 365 的套件之一,Excel Online 除了未能处理宏命令,其他方面几乎就是桌面版 Excel 的完美克隆。
相比之下,本文的主角 Airtable 的名气就远不及 Excel 了。但是,作为一个典型的硅谷公司产品,Airtable 也拥有不错的口碑。此外,Google Sheets 也是优秀的云端表格工具,只是这朵云距我们稍为远了一些。
那么,对于这三款相对优秀的云端电子表格,到底哪一款愈发适宜用于个人数据搜集整理呢?我做了一个对比。
当我选择的时侯,最看重的功能虽然是 API 支持。只有具备了 API 接口,才能使数据搜集流程可以实现自动化,也才是名副其实的「云端表格」。而使我最终选择 Airtable 的缘由,应该有如下几点:
基础功能同另外的两个产品相比没有显著的缺位,甚至拥有象条形码输入、iframe 嵌入等更多差异化功能。Airtable 同时支持 IFTTT 和 Zapier 云端自动化工具,且 API 使用上去更简单便捷。很多时侯,就算使用现有工具难以满足需求,也可以按照开发者文档自行编撰代码实现数据读取和写入。Airtable 外观设计愈发漂亮,这一点在长时间的使用过程中特别重要。Airtable 使用简介
在即将介绍我是怎样使用 Airitable 集中整理数据之前,我想先对 Airtable 做一个简单介绍。
如下图所示,Airtable 主要收录有 6 个基本组件,分别是:
可以看出,Airtable 从诞生之初就具备了关系型数据库的样子,已经满足了对数据存储的日常需求。从功能上,除了 Excel Online,基本上没有竞品。
要想对个人数据进行集中搜集整理,首先须要在 Airtable 创建不同的数据库。建立数据库是个人数据搜集工程中的第一步,所以并不是随便乱建的。其中,我们须要先想一想搜集数据的大类,然后在细分大类中的小类,并对应到数据表中。我的数据库主要有下边 3 个,树形结构如图所示。
工作学习数据库
工作学习数据库会搜集平时我在工作或则学习中形成的相关数据。根据我的使用习惯,数据库收录了 4 张数据表,分别是:Calendar、Todoist、Trello 以及 Issues(同步 Github)。看到名子应当就很容易明白这 4 张表的意思了。
对于这四类服务的数据,我均是采用 IFTTT 或者 Zapier 将其同步到 Airtable 中。这里补充介绍一下 IFTTT 和 Zapier 的区别与联系。首先,二者都是整合不同应用提供的开发者 API 实现自动化流程的云端服务,这是她们的相同之处。但是,Zapier 相对于 IFTTT 会更强悍一些,它通常情况下会支持原服务更全面的 API 接口,且支持多个服务联动。相比之下,IFTTT 很多时侯只提供主要的插口,且只支持两个服务之间的数据传递。
举个反例,当我在使用 Zapier 实现 Google Calendar → Airtable 的过程中,Zapier 支持读取 Google Calendar 中的 43 项数据(虽然有一些不实用),但 IFTTT 只支持 8 个。当然,IFTTT 也有比 Zapier 好用的时侯。比如将 Todoist 完成任务同步到 Airtable 时,Zapier 不支持检测任意 Project 下完成的任务,需针对每位 Project 设置单独的流程。
四个服务同步到 Airtable 的设置都大同小异,这里我只拿 Todoist → Airtable 详细说明。当我选择 IFTTT 作为 Todoist → Airtable 的同步工具时,首先须要到 IFTTT 上看一看其支持读取 Todoist 的什么数据,你可以通过创建动作时查看。
我们可以看见从 Todoist → Airtable 一共支持 7 个类别的数据。那么,现在可以先新建这个动作。注意,你须要遵循 IFTTT 制定的句型格式,才能正确地将数据写入到 Airtable 中。
也就是说,如果要将这 7 类数据全部同步到 Airtable,你须要在 IFTTT 动作的最后输入如下所示的内容。我习惯之间使用 IFTTT 的 ingredient 名称作为 Airtable 中的列名称。
格式:::airtable::Airtable 中的列名::{{IFTTT 中的 ingredient}}
示例内容:
::airtable::TaskContent::{{TaskContent}}
::airtable::LinkToTask::{{LinkToTask}}
::airtable::Project::{{Project}}
::airtable::Labels::{{Labels}}
::airtable::Priority:: {{Priority}}
::airtable::CompletedAt::{{CompletedAt}}
::airtable::DueDate::{{DueDate}}
接下来,就可以到 Airtable 中设置相应的列名称了。在设置对应的列属性(文本、数字、图片等)时,我建议一开始统一设置为「Single line text」,也就是单行文本格式,以避免导出数据出错。
当测试导出成功以后,就可以调整列属性。例如这儿,Project 的数目是有限的,且每位任务只对应一个 Project。就可以将其列属性设定为 Single select(单选),这样也便捷日后对任务进行筛选。同样,日期可以使用 Date 属性,链接使用 URL 等。
如果调整列属性以后,表格显示为空白或报错,那就意味着通过 IFTTT 传过来的数据格式并不能挺好地被 Airtable 支持。比如这儿的 CompletedAt,也就是项目的完成日期 + 时间。IFTTT 输出的数据格式是象这样的 January 20, 2018 at 10:18AM,Airtable 无法之间将其转换为对应的「日期+时间」的格式。
为了便捷以后的数据剖析,我们当然更偏向于将其处理成时间序列,也就是按 Airtable 中的「日期+时间」格式保存。此时,我们可以通过新建中间列作为过渡,然后借助 Airtable 的 Formula 公式将原文本列转换为可辨识的「日期+时间」列。具体步骤如下:
明确区别: 原文本列格式为January 20, 2018 at 10:18AM,Airtable 可辨识的格式为January 20, 2018 10:18 AM。注意观察两者之间的区别,文本格式多了 at + 一个空格 字符,同时 AM 字符前缺乏一个空格。格式转换:明白区别以后就可以开始使用 Airtable 提供的 Formula 公式转换格式。首先是去除 at 字符,然后在结尾的 AM 或者 PM 前面降低空格。
这里使用了 SEARCH() 函数去定位要更改的位置,然后使用 REPLACE() 函数更改字符。最后再使用 DATATIME_FOMRMAT() 函数低格字符串为我们想要的「日期-时间」样式。一个小的方法是,如果你嫌降低的中间列较多,那么可以使用 Airtable 顶部菜单的 Hide fields 选项隐去不必要的列,只呈现我们须要的数据即可。
量化自我数据库
我的第二个主要数据库为量化自我数据库,它是由:Moves、Location、Apple Health、RescueTime 以及 Commute 等 5 个数据表组成。这 5 个数据表分别对应着 Moves 记录的地理位置数据、手动签到数据、Apple Health 记录的运动健康数据、RescueTime 记录的工作效率数据以及通勤时间统计数据。
Moves 数据
Moves 是我仍然在使用的地理位置追踪应用,它的运动状态辨识和地点辨识做的非常好,以至于如今都没有找到可取代的应用。Moves 其实拥有健全的 API,但因为其认证方法的特殊性,IFTTT 和 Zapier 都仍未支持与 Moves 连接。于是,我只能自己编撰一个 Moves → Airtable 的脚本,然后布署在云服务器上,每天手动将今天形成的数据同步的 Airtable 中去。
实现的过程比较麻烦,都能凑够一篇文章了,另找时间再细说。这里,Moves 的数据收录有经纬度信息,你可以直接使用 Airtable 提供的 Map Block 模块对地理位置可视化。
关于 Airtable Blocks 的更多介绍,可以阅读官方的文章《Getting started with Airtable blocks》
Location 数据
除了使用 Moves 自动记录地理位置信息,我还自己制做了一个辅助签到的 Workflow 用来标记我觉得重要的地点,并把地理位置数据实时上传到 Airtable 中的 Location 数据表中。
Workflow 非常简单,流程如下:定位 → 解析数据 [街道 - 城市 - 地区 - 国家] → 解析数据 [经度 - 纬度 - 高度] → 结合当前时间一并上传到 Airtable 中。
Apple Health 数据
目前,追踪健康信息主要是使用 Apple Watch 和 iPhone,通过本身的健康应用以及配合 Moves,Autosleep 等第三方应用完成。Apple Health 无法实现 iCloud 同步,更没有 API 支持,所以只能半自动同步到 Airtable。我采用的方式是定期从 Apple Health 中导入数据文件到 Dropbox 中,Dropbox 的数据压缩包会手动同步到云服务器中,再由云服务器中布署的 Python 脚本手动完成数据解析,并通过 API 同步到 Airtable 的表格中去。
RescueTime 数据
工作效率记录我会使用到 RescueTime 应用,RescueTime 会手动记录各种程序的前台运行时间,再和数据库进行比对得到相应应用属于效率应用还是非效率应用,从而手动统计每晚的工作效率。
RescueTime 的数据同步到 Airtable 就比较便捷了,可以使用 IFTTT,Zapier 或者开发者插口同步。我选择的是 Zapier,因为它可以同步多达 59 项数据信息。触发的动作选择「当每日数据汇总后」,然后再将对应的数据更新到对应的列即可。过程十分简单,就不再赘言了。
这里介绍一个使用 RescueTime 的一个小技巧,那就是最好定期去自动标记相应应用的效率属性。首先,我们每晚浏览的大多数网页或则使用的应用都是比较固定的,手动标记耗费的时间不多。其次,有一些应用对每个人的效率属性不一致。比如,我早已好多年没用 QQ 作为和他人的聊天工具了,所以但凡当使用 QQ 时,基本上都属于处理工作里面的事情,它对于我而言就是效率状态,而不是闲暇状态。
通勤时间数据
Commute 表拿来统计我的通勤时间。每天,我就会选择轻轨作为下班通勤的主要交通工具,虽然轻轨在站与站之间的运行时间比较确定,但因为存在换乘,所以每晚的通勤时间的变化就比较大了。打个比方,有时候晚上只晚出发 5 分钟,如果刚好赶上一波高峰,实际抵达公司的时间常常会晚 20 分钟。所以,我从年初就开始每晚记录自己的通勤时间,打算等到数据累计到一定量以后,通过数据剖析得到自己每晚的合理出发时间。
在记录通勤时间的时侯,由于打算将数据保存到 Airtable,所以一开始就直接就排除了现有的计时器或则第三方 App,然后把目标集中到 Workflow。但是,很快我就发觉 Workflow 的现有动作中,并没有支持在后台完成计时的动作。后来,我就想到了直接利用 Airtable 来完成这个功能,这个功能的逻辑十分简单。流程如下:
每天从屋内出发的时侯,点击 workflow 将此刻的时间上传到 Airtable,并记为出发时间。当抵达公司时,再次点击 Workflow 将时间上传到 Airtable 。由于 Airtable 本身可以使用数据函数,就能估算出两个时间差,并直接在我第二次点击 Workflow 上传时间后,将估算好的通勤时间推送到手机上。这样,既可以实时见到记录出来的通勤时间,也不再须要二次过程将数据上传到 Airtable 中。
信息存档数据库
信息存档数据库是拿来保存我觉得有必要存档的互联网数据。其中,主要有三个 Tables,分别是:微博、博客以及稍后读。
我喜欢定期清空自己的微博,防止在互联网上留下过多的「? 历史」。但又不想扔掉自己转发过的微博,于是就有了这个微博存档表。存档微博的方式十分简单,使用 IFTTT 新建一个动作,实时将微博记录到 Airtable 中保存。
同样,我使用 Pocket 作为稍后阅读工具,也就通过创建 IFTTT 动作,将保存在 Pocket 中的文章同步存档到 Airtable 中。
除此之外,博客存档表拿来备份自己在互联网上创作的内容。比如在少数派写的文章以及自己的博客文章。该表单使用了自己编撰的 Python 脚本,定期将我的博客文章以及在少数派发表的文章同步保存到 Airtable 中。
其他数据库
除了前面提及的这三个主要的数据库,我还有几个自己比较喜欢的数据库,也分享一下。
票据存档数据库
票据存档的数据库主要是记录平时我觉得比较重要的支票、发票、合同文件等。当然,超市购物小票这类不太重要的票据也就没必要存档了。
教育让利统计数据库
几个月前,我在少数派写过一篇 《在校师生福利:Apple、微软、Adobe 等产品怎样通过教育让利订购》 ,这篇文章中介绍一些院校中学生可以享受的教育让利项目。不久前,我通过 Airtable 整理了一份愈发详尽的教育让利表单,希望更多的中学生能享受到优价有品质的服务。
你可以通过检索的形式来获取自己感兴趣的教育让利项目。当然,我也号召你们来一起建立这个表单。如果有一些教育让利项目非常好,但表单中未涉及到,欢迎直接通过下边的链接补充递交到表单中去。
菜品、餐馆统计数据库
最近,我正在建立的一个数据库来源于我生活中的一个疼点,那就是常常不知道喝哪些。这个数据库中会记录下一些餐厅和食材。我会将平时喝过觉得不错的,或者想吃的餐厅信息添加到餐厅数据表中,同时会记录一些做过或则想做的菜肴。
当我自己想做饭喝的时侯,我都会通过 Workflow 随机返回食材作为灵感,而想出去喝的时侯,也可以随机返回餐厅信息。目前,这个数据库和 Workflow 还没有完全做好,等建立以后,会同你们一起分享。
另外,文中提及的一些自动化数据获取的 Python 脚本,我也会整理后择时与少数派读者分享。
结语
我虽然很早就晓得 Airtable 了,但真正有效地借助上去也是近一年才开始的。目前,虽然 Airtable 已经帮我存出来不少的数据,但是我对它的借助程度还并不满意,今年我会继续开掘 Airtable 的「正确使用方法」。
如今,我们都晓得经常须要备份自己的相片、手机、电脑,防止资料遗失。除此之外,我们同样应当注重起自己每晚形成的其他数据。目前初步构建上去的数据集中搜集模式只是开始。等待数据积累到一定量时,就须要着手「数据集中剖析」,使其真正地能帮助自己发觉某个坏习惯,提升一些效率,改变一些东西。
少数派一年一度的奖品超级优厚的 征文活动 又开始了!我们打算了 5 万+ 的奖品等你来拿。
本文是「我是少数派,这是我的 2017」征文活动的第入围作品。
怎样用Python透过树莓派采集到的温湿度信息传送到AWS IoT
采集交流 • 优采云 发表了文章 • 0 个评论 • 370 次浏览 • 2020-08-17 14:41
与 IoT 相关的云端服务为数诸多,例如:ThingSpeak、WoT.City、AWS、IBM Bluemix、MediaTek MCS、Google Firebase 等,并在透过这种云端服务可在对数据进行数据可视化、数据剖析与其它的应用,而本文用Python将透过 Raspberry Pi 采集到的温湿度信息传送到 AWS IoT。
情境
材料与打算
1.准备 Raspberry Pi 3Model B 开发板
2.准备 Micro SD (已安装 Raspbian)
3.将 Micro SD 装入到 RaspberryPi 中
4.设定好网路
5.安装 GrovePi+
6.安装 Grove – Temperatureand Humidity Sensor (D4)
7.安装 GROVE - LCD RGBBACKLIGHT (I2C-2)
8.安装 IDE ( Sublime Textor Visual Studio Code )
Sensor, LCD, GrovePi+ 与 RaspberryPi 连接如右图
AWS IoT 端
Step 1. 到 AWS 网站申请帐号
Step 2. 登入 AWS 网站
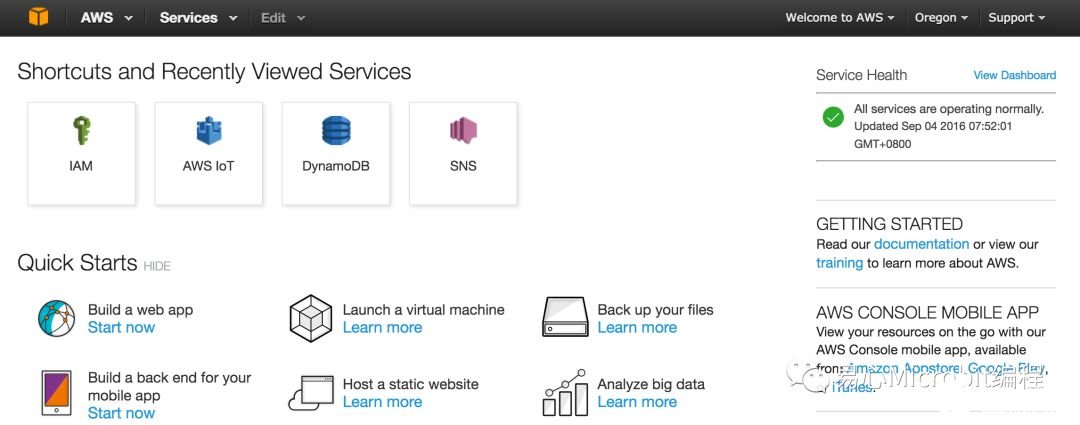
Step 3. 点击 Services AWS IoT
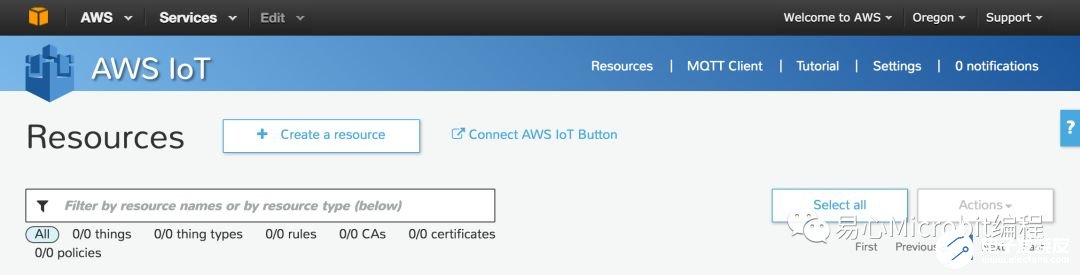
Step 4. 点击 Create a resource
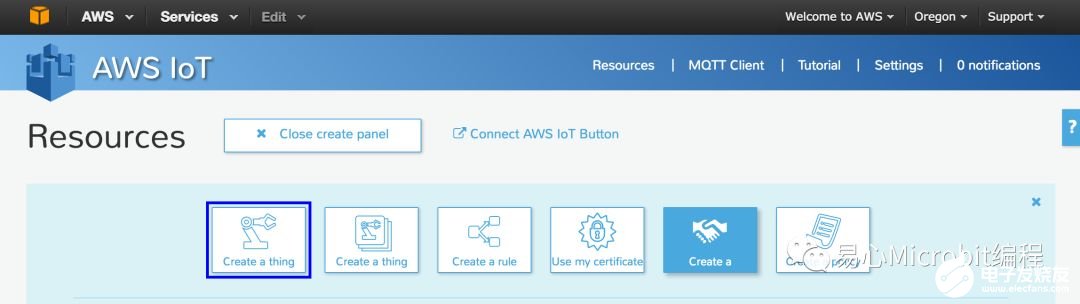
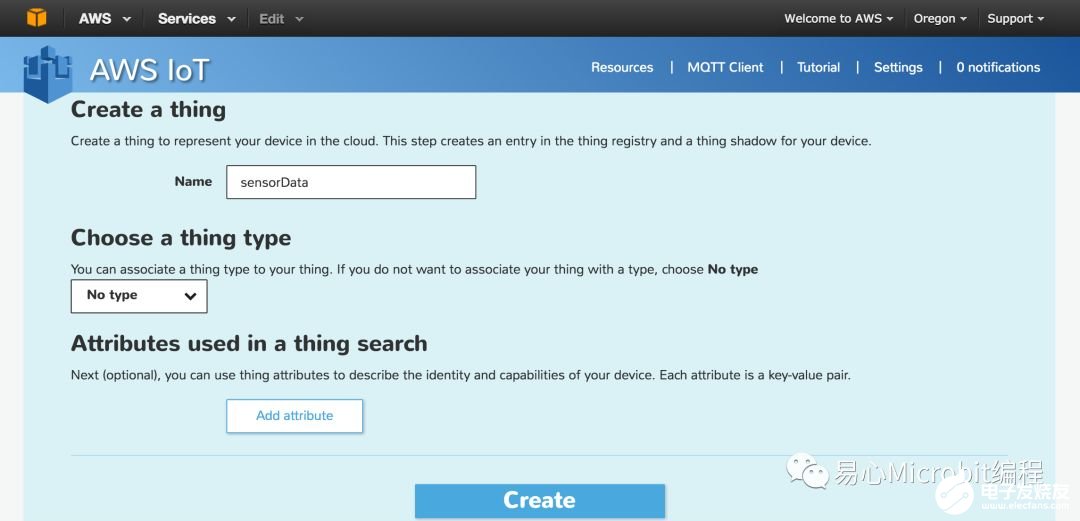
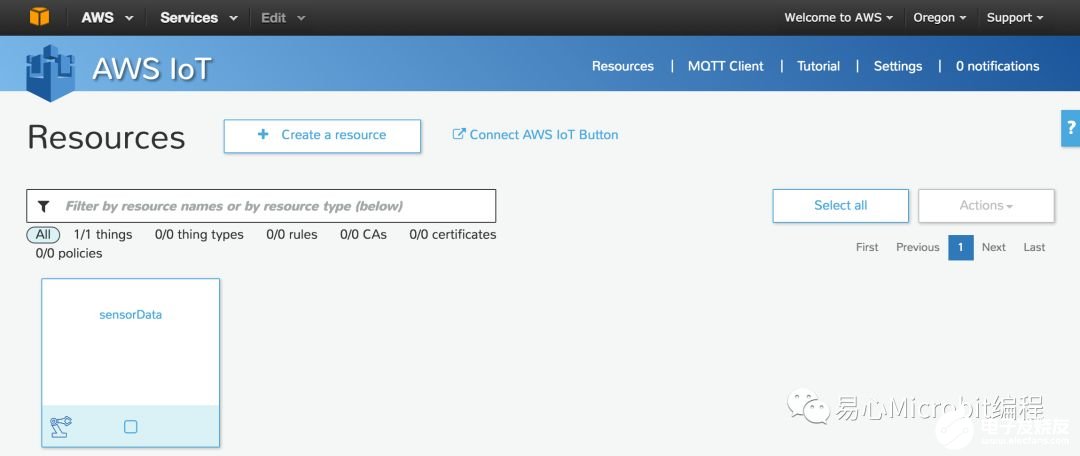
Step 5. 点击 Create a thing 输入 thing Name Create
Step 6. 点击刚构建的 thing
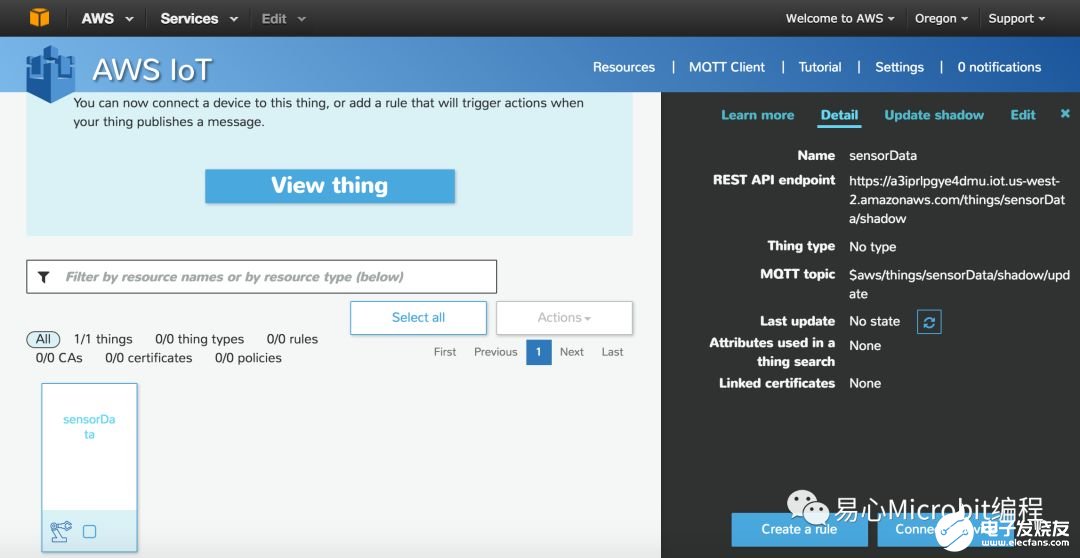
Step 7. 点击 Connect a device
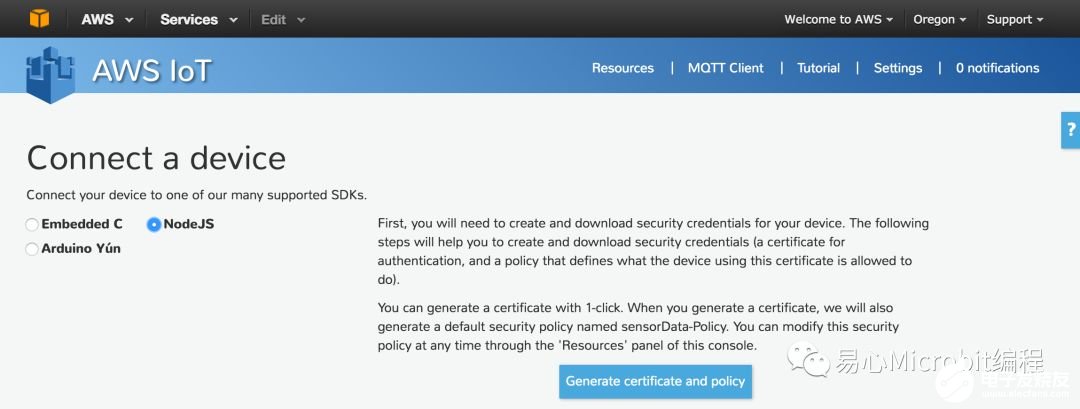
Step 8. 点击 Node.js Generate certificate and policy
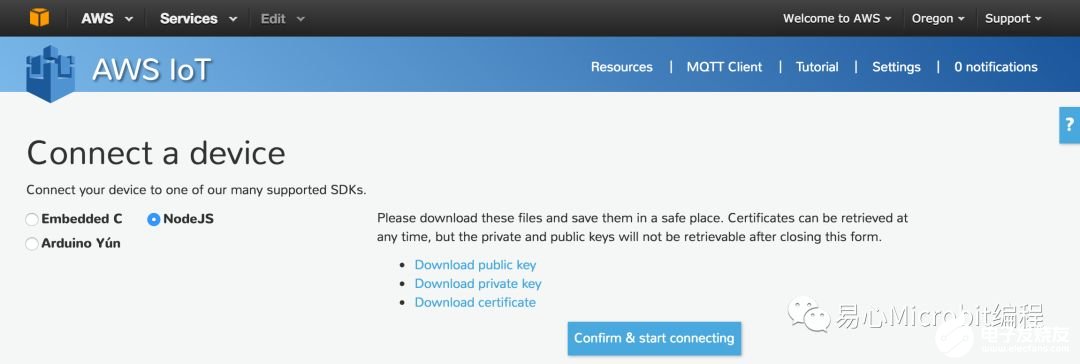
Step 9. 下载 private 与 public keys
Step 10. 点击 Confirm &connecting
Step 11. 点击 Return to ThingDetail
Raspberry Pi 端
Step 1. 透过 Python 读取温湿度信息并传送到AWS IoT
#****************************************************
# Import Package
#****************************************************
import time
import datetime
import paho.mqtt.client as paho
import json
import ssl
import sys
sys.path.append(‘/home/pi/rpi/code/Package’)
import grovepi
from grove_rgb_lcd import *
#****************************************************
# Set Pin No, AWS Config
#****************************************************
sensor = 4
blue = 0 # The Blue colored sensor.
white = 1 # The White colored sensor.
connflag = False
#****************************************************
# Set AWS Connection
#****************************************************
def on_connect(client, userdata, flags,rc):
global connflag
connflag = True
print(“Connection returned result: ” + str(rc) )
def on_message(client, userdata, msg):
print(ic+“ ”+str(msg.payload))
mqttc = paho.Client()
mqttc.on_connect = on_connect
mqttc.on_message = on_message
awshost = “”
awsport = 8883
clientId = “sensorData”
thingName = “sensorData”
caPath = “。/root-CA.crt”
certPath =“。/000cd28455-certificate.pem.crt”
keyPath = “。/000cd28455-private.pem.key”
mqttc.tls_set(caPath, certfile=certPath, keyfile=keyPath,cert_reqs=ssl.CERT_REQUIRED, tls_version=ssl.PROTOCOL_TLSv1_2, ciphers=None)
mqttc.connect(awshost, awsport, keepalive=60)
mqttc.loop_start()
#****************************************************
# Publish AWS
#****************************************************
while True:
[temp,humidity] = grovepi.dht(sensor,blue)
print(“temp = %.02f C humidity =%.02f%%”%(temp, humidity))
t= time.time();
date = datetime.datetime.fromtimestamp(t).strftime(‘%Y%m%d%H%M%S’)
if connflag == True:
mqttc.publish(“topic/sensorData”,json.dumps({“time”: date, “temperature”: temp,“humidity”: humidity}), qos=1)
else:
print(“waiting for connection.。.”)
time.sleep(1)
Step 2. 将 Python Code 与 Keys 传送到 RaspberryPi
Step 3. 执行刚传到 Raspberry Pi 中的 Python 代码,python 檔名.py
Step 4. Console 执行画面 查看全部
怎样用Python透过树莓派采集到的温湿度信息传送到AWS IoT
与 IoT 相关的云端服务为数诸多,例如:ThingSpeak、WoT.City、AWS、IBM Bluemix、MediaTek MCS、Google Firebase 等,并在透过这种云端服务可在对数据进行数据可视化、数据剖析与其它的应用,而本文用Python将透过 Raspberry Pi 采集到的温湿度信息传送到 AWS IoT。
情境
材料与打算
1.准备 Raspberry Pi 3Model B 开发板
2.准备 Micro SD (已安装 Raspbian)
3.将 Micro SD 装入到 RaspberryPi 中
4.设定好网路
5.安装 GrovePi+
6.安装 Grove – Temperatureand Humidity Sensor (D4)
7.安装 GROVE - LCD RGBBACKLIGHT (I2C-2)
8.安装 IDE ( Sublime Textor Visual Studio Code )
Sensor, LCD, GrovePi+ 与 RaspberryPi 连接如右图
AWS IoT 端
Step 1. 到 AWS 网站申请帐号
Step 2. 登入 AWS 网站
Step 3. 点击 Services AWS IoT
Step 4. 点击 Create a resource
Step 5. 点击 Create a thing 输入 thing Name Create
Step 6. 点击刚构建的 thing
Step 7. 点击 Connect a device
Step 8. 点击 Node.js Generate certificate and policy
Step 9. 下载 private 与 public keys
Step 10. 点击 Confirm &connecting
Step 11. 点击 Return to ThingDetail
Raspberry Pi 端
Step 1. 透过 Python 读取温湿度信息并传送到AWS IoT
#****************************************************
# Import Package
#****************************************************
import time
import datetime
import paho.mqtt.client as paho
import json
import ssl
import sys
sys.path.append(‘/home/pi/rpi/code/Package’)
import grovepi
from grove_rgb_lcd import *
#****************************************************
# Set Pin No, AWS Config
#****************************************************
sensor = 4
blue = 0 # The Blue colored sensor.
white = 1 # The White colored sensor.
connflag = False
#****************************************************
# Set AWS Connection
#****************************************************
def on_connect(client, userdata, flags,rc):
global connflag
connflag = True
print(“Connection returned result: ” + str(rc) )
def on_message(client, userdata, msg):
print(ic+“ ”+str(msg.payload))
mqttc = paho.Client()
mqttc.on_connect = on_connect
mqttc.on_message = on_message
awshost = “”
awsport = 8883
clientId = “sensorData”
thingName = “sensorData”
caPath = “。/root-CA.crt”
certPath =“。/000cd28455-certificate.pem.crt”
keyPath = “。/000cd28455-private.pem.key”
mqttc.tls_set(caPath, certfile=certPath, keyfile=keyPath,cert_reqs=ssl.CERT_REQUIRED, tls_version=ssl.PROTOCOL_TLSv1_2, ciphers=None)
mqttc.connect(awshost, awsport, keepalive=60)
mqttc.loop_start()
#****************************************************
# Publish AWS
#****************************************************
while True:
[temp,humidity] = grovepi.dht(sensor,blue)
print(“temp = %.02f C humidity =%.02f%%”%(temp, humidity))
t= time.time();
date = datetime.datetime.fromtimestamp(t).strftime(‘%Y%m%d%H%M%S’)
if connflag == True:
mqttc.publish(“topic/sensorData”,json.dumps({“time”: date, “temperature”: temp,“humidity”: humidity}), qos=1)
else:
print(“waiting for connection.。.”)
time.sleep(1)
Step 2. 将 Python Code 与 Keys 传送到 RaspberryPi
Step 3. 执行刚传到 Raspberry Pi 中的 Python 代码,python 檔名.py
Step 4. Console 执行画面
APICloud:云端服务开发的硬核要素
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2020-08-13 11:30
各种PaaS平台为用户提供了效率化服务,开发者可依照自己的业务逻辑快速开发出相关的服务端程序。由于不用关注业务之外的环境配置,开发效率得到了极大增强,同时企业也得益于这些开发模式,提高了企业产品研制、上线的速率。本文,我们将解析开发云端服务的核心要素,了解这种有助于我们更好的选择和使用各类云端服务平台。
1
云数据库是否简单易用且功能强悍
开发者在开发服务器端应用的时侯常常须要对业务数据进行储存,这就须要一个云端数据库帮助实现这种工作。
各家云平台提供的云端数据库的使用方法和功能各不相同,开发者在选择的时侯须要依照自己的实际情况进行选择,首先要考虑的是自身业务是否有关键场景,如转帐、付款等操作。这些操作要求数据一致性比较高,需要有事务的能力,所以是否支持事务是须要考虑的第一诱因。其二是数据库的操作是否便捷,本地开发时通常使用navicat等工具联接到前端数据库进行相关的操作,但是云数据库常常是通过web页面进行配置,这时候页面配置的易用性、提供的数据库配置功能是否全面也是一个须要审视的诱因。第三是代码层面访问数据库是否便捷,提供的插口要以便对数据进行存取。
【APICloud数据云3.0 前沿谍报】
数据云3.0支持事务操作。
可视化的定义数据表结构,并对数据进行增删改查,支持在页面进行条件筛选完成查询。
界面支持对表建索引、设定表与表的关联关系、导入和导入等功能。
内置丰富的API函数,方便在程序中操作数据库
2
是否提供灵活的云函数及插口管理
在所有的云平台实现中,云函数是其中最重要的功能之一,我们在云函数中实现各自的业务逻辑。云函数的编撰是云开发中占用开发者时间最长的部份,云函数的功能是否强悍直接决定了开发者是否能便捷快捷的实现自己的业务逻辑。
同时,远程函数的插口管理也会涉及到比较多的工作。接口管理分为插口文档和插口联调两部份,API接口在设计时要编撰大量的文档,编写完成以后就会常常改动;实际的代码与文档有出入的时侯也须要进行处理。同样,随着版本的迭代,接口文档同步的问题又会彰显下来。进入到插口联调也须要开发者按照插口文档的内容在联调工具中进行配置完成。所以插口管理是后期保证开发进度的一个重要方面。
【APICloud数据云3.0 前沿谍报】
提供多达六种函数类型的支持,为开发者提供更多自定义业务逻辑的能力。
模型驱动的开发模式,更容易根据业务逻辑界定不同函数。
接口管理功能:内置符合swagger 规范的组件,直接从代码生成文档,无需在为插口文档的维护以及插口联调花费更多时间。
两套环境更放心,云函数分为测试环境和即将环境,测试通过后方更新到即将环境。
3
是否支持代码库或已有代码复用
对软件开发来说,通过直接使用第三方的代码、服务来整合功能可以大大降低项目的开发周期和风险,降低开发成本,同时提升代码的可靠性。所以一个云平台是否能提供便捷的代码复用能力就变得尤为重要。
【APICloud新产品前沿谍报】
即将发布的3.0版本通过模型驱动的形式进行服务器端功能逻辑的开发,可便捷的通过模型完成代码的复用。我们支持用两种方法实现代码的复用,并可以基于复用的代码进行二次开发完成自己的业务逻辑。
预置模型,我们为用户预置常用的数据模型,可直接添加使用。比如阿里云发邮件模型、微信小程序模型等
导入模型,可以从模型库或则自己的其他应用导出须要的模型,复用表结构和函数。
4
运维及监控
上线后的代码,平台是否提供相关的监控对开发人员尤为重要,开发人员须要通过某种形式了解自己代码实际运行的情况,如当前服务器是否因为触发异常而未能提供服务,自己复印的信息的查看,应用使用的流量以及占用的储存空间等。
【APICloud数据云3.0 前沿谍报】
APICloud对应用的数据储存、文件储存、流量、API恳求等进行了监控,并生成相应的药量—时间折线图,可以使用户更直观的了解使用情况。同时提供日志监控,便于及时发觉问题。
5
辅助功能,方便开发者使用
除了提供的基本开发能力以外,是否为用户提供一些便捷用户使用的组件也是审视一个云平台的重要方面。
【APICloud数据云3.0 前沿谍报】
内置session:通过配置开启,自动打开session功能。
内置的管理后台插件:应用开发的过程中通常须要一个管理后台提供操作基本信息查看及营运的工作。这种管理后台的功能差不多,基本就是菜单管理、权限管理、页面管理等。APICloud3.0考虑到这些通用型的需求,为开发者外置了一个基于amis作为解决方案管理后台,通过简单的拖放及配置即可使开发者拥有自己的管理后台。
目前,云计算仍处在快速发展阶段,在云端直接布署的需求越来越多,而国家颁布的利空新政,已让企业上云成为趋势,国内厂商也在积极拥抱云端能力;在实际运行疗效上,基于云端开发及运行应用服务优势显著,逐渐成为软件开发行业的主流选择。APICloud在产业转型的时尚下趁势而为,全新迭代的数据云3.0,将进一步为平台开发者的效率赋能,为用户在云端开发提供全新的使用体验。
APICloud是国外低代码开发平台的引领者与效率革命的探索者,基于对云原生、DevOps、混合开发等能力的集成,APICloud从移动开发演变为低代码开发平台,APICloud致力于为各行业提供app订制与企业数字化服务。 查看全部
随着云计算相关领域近几年的迅速发展,提供基于PaaS开发能力的平台越来越多,这促使好多开发者在编撰前端程序的时侯无需在服务器上从零建立自己的应用,无需考虑网路、存储、操作系统、运行环境等与开发关联不大的基础配置。这种基于Serverless方式的云计算服务,让应用开发得到了极大简化,甚至后期的运维、监控的工作平台也可以一并完成。
各种PaaS平台为用户提供了效率化服务,开发者可依照自己的业务逻辑快速开发出相关的服务端程序。由于不用关注业务之外的环境配置,开发效率得到了极大增强,同时企业也得益于这些开发模式,提高了企业产品研制、上线的速率。本文,我们将解析开发云端服务的核心要素,了解这种有助于我们更好的选择和使用各类云端服务平台。
1
云数据库是否简单易用且功能强悍
开发者在开发服务器端应用的时侯常常须要对业务数据进行储存,这就须要一个云端数据库帮助实现这种工作。
各家云平台提供的云端数据库的使用方法和功能各不相同,开发者在选择的时侯须要依照自己的实际情况进行选择,首先要考虑的是自身业务是否有关键场景,如转帐、付款等操作。这些操作要求数据一致性比较高,需要有事务的能力,所以是否支持事务是须要考虑的第一诱因。其二是数据库的操作是否便捷,本地开发时通常使用navicat等工具联接到前端数据库进行相关的操作,但是云数据库常常是通过web页面进行配置,这时候页面配置的易用性、提供的数据库配置功能是否全面也是一个须要审视的诱因。第三是代码层面访问数据库是否便捷,提供的插口要以便对数据进行存取。
【APICloud数据云3.0 前沿谍报】
数据云3.0支持事务操作。
可视化的定义数据表结构,并对数据进行增删改查,支持在页面进行条件筛选完成查询。
界面支持对表建索引、设定表与表的关联关系、导入和导入等功能。
内置丰富的API函数,方便在程序中操作数据库
2
是否提供灵活的云函数及插口管理
在所有的云平台实现中,云函数是其中最重要的功能之一,我们在云函数中实现各自的业务逻辑。云函数的编撰是云开发中占用开发者时间最长的部份,云函数的功能是否强悍直接决定了开发者是否能便捷快捷的实现自己的业务逻辑。
同时,远程函数的插口管理也会涉及到比较多的工作。接口管理分为插口文档和插口联调两部份,API接口在设计时要编撰大量的文档,编写完成以后就会常常改动;实际的代码与文档有出入的时侯也须要进行处理。同样,随着版本的迭代,接口文档同步的问题又会彰显下来。进入到插口联调也须要开发者按照插口文档的内容在联调工具中进行配置完成。所以插口管理是后期保证开发进度的一个重要方面。
【APICloud数据云3.0 前沿谍报】
提供多达六种函数类型的支持,为开发者提供更多自定义业务逻辑的能力。
模型驱动的开发模式,更容易根据业务逻辑界定不同函数。
接口管理功能:内置符合swagger 规范的组件,直接从代码生成文档,无需在为插口文档的维护以及插口联调花费更多时间。
两套环境更放心,云函数分为测试环境和即将环境,测试通过后方更新到即将环境。
3
是否支持代码库或已有代码复用
对软件开发来说,通过直接使用第三方的代码、服务来整合功能可以大大降低项目的开发周期和风险,降低开发成本,同时提升代码的可靠性。所以一个云平台是否能提供便捷的代码复用能力就变得尤为重要。
【APICloud新产品前沿谍报】
即将发布的3.0版本通过模型驱动的形式进行服务器端功能逻辑的开发,可便捷的通过模型完成代码的复用。我们支持用两种方法实现代码的复用,并可以基于复用的代码进行二次开发完成自己的业务逻辑。
预置模型,我们为用户预置常用的数据模型,可直接添加使用。比如阿里云发邮件模型、微信小程序模型等
导入模型,可以从模型库或则自己的其他应用导出须要的模型,复用表结构和函数。
4
运维及监控
上线后的代码,平台是否提供相关的监控对开发人员尤为重要,开发人员须要通过某种形式了解自己代码实际运行的情况,如当前服务器是否因为触发异常而未能提供服务,自己复印的信息的查看,应用使用的流量以及占用的储存空间等。
【APICloud数据云3.0 前沿谍报】
APICloud对应用的数据储存、文件储存、流量、API恳求等进行了监控,并生成相应的药量—时间折线图,可以使用户更直观的了解使用情况。同时提供日志监控,便于及时发觉问题。
5
辅助功能,方便开发者使用
除了提供的基本开发能力以外,是否为用户提供一些便捷用户使用的组件也是审视一个云平台的重要方面。
【APICloud数据云3.0 前沿谍报】
内置session:通过配置开启,自动打开session功能。
内置的管理后台插件:应用开发的过程中通常须要一个管理后台提供操作基本信息查看及营运的工作。这种管理后台的功能差不多,基本就是菜单管理、权限管理、页面管理等。APICloud3.0考虑到这些通用型的需求,为开发者外置了一个基于amis作为解决方案管理后台,通过简单的拖放及配置即可使开发者拥有自己的管理后台。
目前,云计算仍处在快速发展阶段,在云端直接布署的需求越来越多,而国家颁布的利空新政,已让企业上云成为趋势,国内厂商也在积极拥抱云端能力;在实际运行疗效上,基于云端开发及运行应用服务优势显著,逐渐成为软件开发行业的主流选择。APICloud在产业转型的时尚下趁势而为,全新迭代的数据云3.0,将进一步为平台开发者的效率赋能,为用户在云端开发提供全新的使用体验。
APICloud是国外低代码开发平台的引领者与效率革命的探索者,基于对云原生、DevOps、混合开发等能力的集成,APICloud从移动开发演变为低代码开发平台,APICloud致力于为各行业提供app订制与企业数字化服务。
【技术干货】云端自动化运维
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2020-08-09 19:13
运维自动化基本上可以这样去理解:可以实现在成千上万台服务器上做到批量执行命令,根据不同业务特点进行配置集中化管理、分发文件、采集服务器数据、操作系统基础及软件包管理等,这就是所谓的自动化运维。
闲话不多说,下面笔者就以自己近来的一个项目来说说在云端上的自动化运维,以及自动化运维的带来的价值彰显。
接手国外某小型旅游网站之前,它的几十台服务是她们自己内部管理,一个字“乱”,两个字“很乱”!具体假象:
系统层面:
1、系统版本不统一。
2、系统目录结构不统一。
3、服务器管理分散。
应用层面:
1、应用名称不规范。
2、环境布署不统一。
3、应用发布流程不规范。
4、人肉发布,工作量大、效率低。
监控层面:
1、没有一个迅速有效的监控平台。
2、业务中断故障排查难度大、耗时。
这个就大大降低后续的监控管理难度,还有对之后应用方面的管理,内容发布,数据的采集都会有很大的影响。最明显就彰显发布这一块,在一个应用诸多,部署不规范,服务器无章化的管理,发布无疑是一个苦闷的过程,每次的熬夜的发布,无数次的上传war包、发布、测试、回滚、再上传、再发布、再测试、再回滚,严重的影响工作效率,消耗大量的人工,而且效率极低,影响用户的体验度。最重要的是时常出现错误,无数个梦中被电话喊起!结合现存的众多疼点,着手从系统层面、应用层面、监控层面整体规划整修。
1、服务器统一化:
从系统版本的选择、数据盘目录挂载、系统名称、系统加固、系统优化、操作审计、等os层面的统一化,为后期的运维标准化和可集中化管理做打算。
2、应用布署统一化:
应用布署细化到目录位置、权限控制、日志分割、端口规划、代码路径、回滚形式、内存大小、连接数等各项配置做到统一化、根据业务需求做单独的差异化,为后期的应用布署、发布、回滚、检测做铺垫。
3、监控自动化:
zabbix通过端口的手动发觉新布署的应用,使用预定义好的监控规则手动监控,针对一个应用实现了40个items项监控。做到监控覆盖全面无盲点,故障定位确切、及时,给运维排除故障提供有力的参考。
系统根据规范布署完成以后,采用saltstack做集中化管理,通过saltstack可以对前端的服务器做各类的修改和集中化的操作,极大的提升了运维效率。稳定安全的系统加上合理的构架为后期的应用运维做打算。应用的运维采用saltstack加shell脚本一起完成。部署、监控、发布、回滚、重启、检查等脚本供saltstack远程调用,实现saltstack集中管理服务器和应用的各项秒级操作,全面彻底解决前期的关于系统和应用发布的头痛问题。
前期的构架其实运维方面和应用的发布方面得到了解决,但是还没有实现平台化的持续发布,为此我们再度整改结合jenkins、maven、git、gradle、sonar、rundeck、蒲公英等工具实现:
1)实现 Java 工程的自动化建立、自动化测试、发布;
2)实现 Node.js 工程的自动化建立、自动化测试、发布;
3)实现 IOS 工程的自动化建立、自动化测试、发布;
4)实现Android工程的自动化建立、自动化测试、发布渠道包(蒲公英) 查看全部
对于运维工作来说,我们运维工作的本身是可管理,可重复,可预测的,基于这样的理念,我们可以根据一定的规律,在基本运维的过程中实现自动化。
运维自动化基本上可以这样去理解:可以实现在成千上万台服务器上做到批量执行命令,根据不同业务特点进行配置集中化管理、分发文件、采集服务器数据、操作系统基础及软件包管理等,这就是所谓的自动化运维。
闲话不多说,下面笔者就以自己近来的一个项目来说说在云端上的自动化运维,以及自动化运维的带来的价值彰显。
接手国外某小型旅游网站之前,它的几十台服务是她们自己内部管理,一个字“乱”,两个字“很乱”!具体假象:
系统层面:
1、系统版本不统一。
2、系统目录结构不统一。
3、服务器管理分散。
应用层面:
1、应用名称不规范。
2、环境布署不统一。
3、应用发布流程不规范。
4、人肉发布,工作量大、效率低。
监控层面:
1、没有一个迅速有效的监控平台。
2、业务中断故障排查难度大、耗时。
这个就大大降低后续的监控管理难度,还有对之后应用方面的管理,内容发布,数据的采集都会有很大的影响。最明显就彰显发布这一块,在一个应用诸多,部署不规范,服务器无章化的管理,发布无疑是一个苦闷的过程,每次的熬夜的发布,无数次的上传war包、发布、测试、回滚、再上传、再发布、再测试、再回滚,严重的影响工作效率,消耗大量的人工,而且效率极低,影响用户的体验度。最重要的是时常出现错误,无数个梦中被电话喊起!结合现存的众多疼点,着手从系统层面、应用层面、监控层面整体规划整修。
1、服务器统一化:
从系统版本的选择、数据盘目录挂载、系统名称、系统加固、系统优化、操作审计、等os层面的统一化,为后期的运维标准化和可集中化管理做打算。
2、应用布署统一化:
应用布署细化到目录位置、权限控制、日志分割、端口规划、代码路径、回滚形式、内存大小、连接数等各项配置做到统一化、根据业务需求做单独的差异化,为后期的应用布署、发布、回滚、检测做铺垫。
3、监控自动化:
zabbix通过端口的手动发觉新布署的应用,使用预定义好的监控规则手动监控,针对一个应用实现了40个items项监控。做到监控覆盖全面无盲点,故障定位确切、及时,给运维排除故障提供有力的参考。
系统根据规范布署完成以后,采用saltstack做集中化管理,通过saltstack可以对前端的服务器做各类的修改和集中化的操作,极大的提升了运维效率。稳定安全的系统加上合理的构架为后期的应用运维做打算。应用的运维采用saltstack加shell脚本一起完成。部署、监控、发布、回滚、重启、检查等脚本供saltstack远程调用,实现saltstack集中管理服务器和应用的各项秒级操作,全面彻底解决前期的关于系统和应用发布的头痛问题。
前期的构架其实运维方面和应用的发布方面得到了解决,但是还没有实现平台化的持续发布,为此我们再度整改结合jenkins、maven、git、gradle、sonar、rundeck、蒲公英等工具实现:
1)实现 Java 工程的自动化建立、自动化测试、发布;
2)实现 Node.js 工程的自动化建立、自动化测试、发布;
3)实现 IOS 工程的自动化建立、自动化测试、发布;
4)实现Android工程的自动化建立、自动化测试、发布渠道包(蒲公英)
优采云采集器 v7.3.8 破解版
采集交流 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2020-08-09 17:33
优采云采集器就能对各类不同类型的网页进行大量的数据采集工作,类型涵括广泛,什么金融类的、交易类、社交网站、电商商品等等的网站数据都还能被规范性的采集下来,并且可以被导入。可以实现数据信息实时监控,自动抓取各项数据的变动信息。是一款功能强悍的数据采集软件,是数据剖析人事必备的一款软件。
优采云采集器软件特色:
1.操作简单:完全可视化图形操作,无需专业IT人员,任何会使用笔记本上网的人都可以轻松把握。
2.云采集技术:采集任务手动分配到云端多台服务器同时执行,提高采集效率,可以挺短的时间内 获取成千上万条信息。
3.拖拽式采集流程:模拟人的操作思维模式,可以登录,输入数据,点击链接,按钮等,还能对不同情况采取不同的采集流程。
4.图文辨识:内置可扩充的OCR插口,支持解析图片中的文字,可将图片上的文字提取下来。
5.定时手动采集:采集任务手动运行,可以根据指定的周期手动采集,并且还支持最快一分钟一次的实时采集。
6.两分钟快速入门:内置从入门到精通所须要的视频教程,两分钟才能上手使用,另外还有文档,论坛,qq群等。:
7.免费使用:它是免费的,并且免费版本没有任何功能限制,你如今就可以试一试,立即下载安装。
优采云采集器 查看全部
优采云采集器是一款可以从任何一个网页获取信息的必备利器。优采云采集器是一款可以使你的信息采集可以显得很简单的工具。该软件转变了传统对于网路上的数据思维方式,它使用户在网上抓取资料变的愈发简单和容易了。
优采云采集器就能对各类不同类型的网页进行大量的数据采集工作,类型涵括广泛,什么金融类的、交易类、社交网站、电商商品等等的网站数据都还能被规范性的采集下来,并且可以被导入。可以实现数据信息实时监控,自动抓取各项数据的变动信息。是一款功能强悍的数据采集软件,是数据剖析人事必备的一款软件。
优采云采集器软件特色:
1.操作简单:完全可视化图形操作,无需专业IT人员,任何会使用笔记本上网的人都可以轻松把握。
2.云采集技术:采集任务手动分配到云端多台服务器同时执行,提高采集效率,可以挺短的时间内 获取成千上万条信息。
3.拖拽式采集流程:模拟人的操作思维模式,可以登录,输入数据,点击链接,按钮等,还能对不同情况采取不同的采集流程。
4.图文辨识:内置可扩充的OCR插口,支持解析图片中的文字,可将图片上的文字提取下来。
5.定时手动采集:采集任务手动运行,可以根据指定的周期手动采集,并且还支持最快一分钟一次的实时采集。
6.两分钟快速入门:内置从入门到精通所须要的视频教程,两分钟才能上手使用,另外还有文档,论坛,qq群等。:
7.免费使用:它是免费的,并且免费版本没有任何功能限制,你如今就可以试一试,立即下载安装。
优采云采集器
优采云采集器破解版v7.3.8 软件截图
采集交流 • 优采云 发表了文章 • 0 个评论 • 690 次浏览 • 2020-08-09 17:28
优采云采集器破解版如何用?
首先打开优采云采集器→点击快速开始→新建任务,进入到任务配置页面:
选择任务组,自定义任务名称和备注;
上图配置完毕以后,选择下一步,进入到流程配置页面,往流程设计器中推入一个打开网页的步骤;
选中浏览器中的打开网页步骤,在左边的页面URL中输入网页URL并点击保存,系统会在软件下方的浏览器中手动打开对应网页:
下面进行数据字段的提取,点击浏览器中须要提取的数组,然后在弹出的选择对话框中选择抓取这个元素的文本;
上述操作以后,系统会在页面的右上方显示我们即将抓取的数组;
接下来配置页面中其他须要抓取的数组,配置完成以后更改数组名称;
修改完成以后点击上图中的保存按键,再点开图中的数据字段可以看见,系统将会显示最终的采集列表;
点击上图中的下一步→下一步→启动单机采集(调试模式),进入到任务检测页面,以确保任务的正确性;
点击开始单机采集,系统将会在本地执行采集流程并显示最终采集的结果。
优采云采集器破解版是哪些?
优采云采集器破解版是一款可以从任何一个网页获取信息的必备利器。优采云采集器破解版是一款可以使你的信息采集可以显得很简单的工具。该软件转变了传统对于网路上的数据思维方式,它使用户在网上抓取资料变的愈发简单和容易了。
优采云采集器破解版功能介绍:
优采云采集器破解版才能对各类不同类型的网页进行大量的数据采集工作,类型涵括广泛,什么金融类的、交易类、社交网站、电商商品等等的网站数据都还能被规范性的采集下来,并且可以被导入。可以实现数据信息实时监控,自动抓取各项数据的变动信息。是一款功能强悍的数据采集软件,是数据剖析人事必备的一款软件。
优采云采集器破解版软件特色:
1. 操作简单:完全可视化图形操作,无需专业IT人员,任何会使用笔记本上网的人都可以轻松把握。
2. 云采集技术:采集任务手动分配到云端多台服务器同时执行,提高采集效率,可以挺短的时间内 获取成千上万条信息。
3. 拖拽式采集流程:模拟人的操作思维模式,可以登录,输入数据,点击链接,按钮等,还能对不同情况采取不同的采集流程。
4. 图文辨识:内置可扩充的OCR插口,支持解析图片中的文字,可将图片上的文字提取下来。
5. 定时手动采集:采集任务手动运行,可以根据指定的周期手动采集,并且还支持最快一分钟一次的实时采集。
6. 两分钟快速入门:内置从入门到精通所须要的视频教程,两分钟才能上手使用,另外还有文档,论坛,qq群等。:
7. 免费使用:它是免费的,并且免费版本没有任何功能限制,你如今就可以试一试,立即下载安装。 查看全部
优采云采集器破解版以网页信息抓取为核心功能,帮助用户在庞大的网路资源库中迅速抓取到自己想要的信息。优采云采集器破解版可以对多个行业的信息进行采集,实现对数据的实时监控,方便用户的信息获取。而且这款软件的操作并不复杂,用户只须要几分钟能够快速入门,轻松驾驭没负担。除此之外,软件还支持定时采集功能,用户无需时刻盯住,可以解放你的右手,有须要的用户快来这里下载吧!
优采云采集器破解版如何用?
首先打开优采云采集器→点击快速开始→新建任务,进入到任务配置页面:
选择任务组,自定义任务名称和备注;
上图配置完毕以后,选择下一步,进入到流程配置页面,往流程设计器中推入一个打开网页的步骤;
选中浏览器中的打开网页步骤,在左边的页面URL中输入网页URL并点击保存,系统会在软件下方的浏览器中手动打开对应网页:
下面进行数据字段的提取,点击浏览器中须要提取的数组,然后在弹出的选择对话框中选择抓取这个元素的文本;
上述操作以后,系统会在页面的右上方显示我们即将抓取的数组;
接下来配置页面中其他须要抓取的数组,配置完成以后更改数组名称;
修改完成以后点击上图中的保存按键,再点开图中的数据字段可以看见,系统将会显示最终的采集列表;
点击上图中的下一步→下一步→启动单机采集(调试模式),进入到任务检测页面,以确保任务的正确性;
点击开始单机采集,系统将会在本地执行采集流程并显示最终采集的结果。
优采云采集器破解版是哪些?
优采云采集器破解版是一款可以从任何一个网页获取信息的必备利器。优采云采集器破解版是一款可以使你的信息采集可以显得很简单的工具。该软件转变了传统对于网路上的数据思维方式,它使用户在网上抓取资料变的愈发简单和容易了。
优采云采集器破解版功能介绍:
优采云采集器破解版才能对各类不同类型的网页进行大量的数据采集工作,类型涵括广泛,什么金融类的、交易类、社交网站、电商商品等等的网站数据都还能被规范性的采集下来,并且可以被导入。可以实现数据信息实时监控,自动抓取各项数据的变动信息。是一款功能强悍的数据采集软件,是数据剖析人事必备的一款软件。
优采云采集器破解版软件特色:
1. 操作简单:完全可视化图形操作,无需专业IT人员,任何会使用笔记本上网的人都可以轻松把握。
2. 云采集技术:采集任务手动分配到云端多台服务器同时执行,提高采集效率,可以挺短的时间内 获取成千上万条信息。
3. 拖拽式采集流程:模拟人的操作思维模式,可以登录,输入数据,点击链接,按钮等,还能对不同情况采取不同的采集流程。
4. 图文辨识:内置可扩充的OCR插口,支持解析图片中的文字,可将图片上的文字提取下来。
5. 定时手动采集:采集任务手动运行,可以根据指定的周期手动采集,并且还支持最快一分钟一次的实时采集。
6. 两分钟快速入门:内置从入门到精通所须要的视频教程,两分钟才能上手使用,另外还有文档,论坛,qq群等。:
7. 免费使用:它是免费的,并且免费版本没有任何功能限制,你如今就可以试一试,立即下载安装。
[经过测试的免费资源] [价值50元]①大数据采集标准版8
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2020-08-08 02:15
(同名资源应用程序中心的地址: [emailprotected] _bigdata.plugin)
本网站上的资源仅用于个人研究/学习/欣赏,请勿将其用于商业目的,否则后果自负!
Discuz!插件介绍
ONEXIN大数据(Open BigData,OBD),打开自动批采集.
支持超过98%的国内知名网站,请从云中体验采集器,我们在云中等待您.
此插件具有用于实现不同功能的扩展组件.
导入论坛高级模块2.6以支持图像本地化,模块名称: forumimg
导入高级门户模块2.6支持图像本地化,模块名称: portalimg
自动收货功能的经验描述(可选包装: 每1000件收50元,每天V1付款,每天300件,586元)
首先,安装插件
然后,您自己申请授权,进入ONEXIN平台()注册一个帐户以获得OID和令牌,并填写后台插件设置.
申请授权:
图形教程:
最后,如果您访问您的网站,则会成功发表一篇新文章. 就这么简单.
常见问题:
大数据采集插件与其他文章采集器之间的区别:
1. 大数据采集的采集列表和内容页面在云服务器端进行处理,从而进一步节省了服务器资源.
第二,该插件中的用户可以方便地管理需要发布的文章链接,并可以自由选择发布还是不发布.
3. 插件接口代码是开源的,输出结果可以自定义,功能可以扩展.
四个. 基于云和WEB插件,不需要zend,并且不受系统环境的影响
第五,不需要在计算机上安装软件,可以访问网站以自动更新文章.
六. 无需编写内容页面规则,它可以通过云采集自动识别,并且可以使用成千上万的资源.
兄弟亲测试源代码截图 查看全部
源代码兄弟已经对资源进行了安全检查,它安全无毒,可以放心使用!
(同名资源应用程序中心的地址: [emailprotected] _bigdata.plugin)
本网站上的资源仅用于个人研究/学习/欣赏,请勿将其用于商业目的,否则后果自负!
Discuz!插件介绍
ONEXIN大数据(Open BigData,OBD),打开自动批采集.
支持超过98%的国内知名网站,请从云中体验采集器,我们在云中等待您.
此插件具有用于实现不同功能的扩展组件.
导入论坛高级模块2.6以支持图像本地化,模块名称: forumimg
导入高级门户模块2.6支持图像本地化,模块名称: portalimg
自动收货功能的经验描述(可选包装: 每1000件收50元,每天V1付款,每天300件,586元)
首先,安装插件
然后,您自己申请授权,进入ONEXIN平台()注册一个帐户以获得OID和令牌,并填写后台插件设置.
申请授权:
图形教程:
最后,如果您访问您的网站,则会成功发表一篇新文章. 就这么简单.
常见问题:
大数据采集插件与其他文章采集器之间的区别:
1. 大数据采集的采集列表和内容页面在云服务器端进行处理,从而进一步节省了服务器资源.
第二,该插件中的用户可以方便地管理需要发布的文章链接,并可以自由选择发布还是不发布.
3. 插件接口代码是开源的,输出结果可以自定义,功能可以扩展.
四个. 基于云和WEB插件,不需要zend,并且不受系统环境的影响
第五,不需要在计算机上安装软件,可以访问网站以自动更新文章.
六. 无需编写内容页面规则,它可以通过云采集自动识别,并且可以使用成千上万的资源.
兄弟亲测试源代码截图
优采云网络数据采集器v7.5.8.10171正式版
采集交流 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2020-08-07 19:17
软件功能
简单的操作,完全可视化的图形操作,不需要专业的IT人员,任何可以使用计算机访问Internet的人都可以轻松掌握它.
云采集
采集任务会自动分发到云中的多个服务器以同时执行,从而提高了采集效率,并可以在短时间内获取数千条信息.
拖放采集过程
模仿人的操作思维方式,可以登录,输入数据,单击链接,按钮等,并且可以针对不同情况采用不同的采集程序.
图像识别
内置可扩展的OCR界面,支持解析图片中的文本,并提取图片中的文本.
定时自动采集
采集任务自动运行,可以根据指定的时间段自动采集,并且还支持每分钟一次的实时采集.
2分钟内快速入门
从入门到精通的内置视频教程,可以在2分钟内使用,并且还提供文档,论坛,QQ群组等.
免费使用
它是免费的,免费版本没有功能限制. 您可以立即尝试,立即下载并安装.
功能介绍
简而言之,您可以使用优采云轻松地从任何网页上采集所需的数据,并生成自定义的常规数据格式. 优采云数据采集系统可以执行的操作包括但不限于以下内容:
1. 财务数据,例如季度报告,年度报告,财务报告,包括自动采集最新的每日净资产;
2. 实时监控主要新闻门户,自动更新和上传最新新闻;
3. 监视竞争对手的最新信息,包括商品价格和库存; 查看全部
优采云采集器是一个多功能的Web数据采集工件,它改变了传统的Internet数据思维方式. 它以自主开发的分布式云计算平台为核心,采集任务自动分布到多个云平台. 服务器同时执行,提高了采集效率,可在短时间内获取数千条信息
软件功能
简单的操作,完全可视化的图形操作,不需要专业的IT人员,任何可以使用计算机访问Internet的人都可以轻松掌握它.
云采集
采集任务会自动分发到云中的多个服务器以同时执行,从而提高了采集效率,并可以在短时间内获取数千条信息.
拖放采集过程
模仿人的操作思维方式,可以登录,输入数据,单击链接,按钮等,并且可以针对不同情况采用不同的采集程序.
图像识别
内置可扩展的OCR界面,支持解析图片中的文本,并提取图片中的文本.
定时自动采集
采集任务自动运行,可以根据指定的时间段自动采集,并且还支持每分钟一次的实时采集.
2分钟内快速入门
从入门到精通的内置视频教程,可以在2分钟内使用,并且还提供文档,论坛,QQ群组等.
免费使用
它是免费的,免费版本没有功能限制. 您可以立即尝试,立即下载并安装.
功能介绍
简而言之,您可以使用优采云轻松地从任何网页上采集所需的数据,并生成自定义的常规数据格式. 优采云数据采集系统可以执行的操作包括但不限于以下内容:
1. 财务数据,例如季度报告,年度报告,财务报告,包括自动采集最新的每日净资产;
2. 实时监控主要新闻门户,自动更新和上传最新新闻;
3. 监视竞争对手的最新信息,包括商品价格和库存;
没有爬虫团队,公司如何实现1000万级别的数据采集?
采集交流 • 优采云 发表了文章 • 0 个评论 • 354 次浏览 • 2020-08-07 16:07
当前,源自爬虫技术的经典商业项目,我相信您也必须使用它们:
Enterprise Check是一种企业信息查询工具,它将80个产业链,8,000个行业,6,000个市场和超过8,000万家国内市场的公司的数据汇总在一起.
企业如何检查海量数据?
企业搜索的数据源主要来自以下三个方面.
①Web爬网程序采集数据
②第三方合作数据
③有些数据更新任务是由用户触发的
它通过Web爬网程序采集数据,执行初步清理并将其合并到其数据库中,并使用算法进行处理,最后向用户打开以提供查询和搜索.
柴柴目前的估值已经达到5亿元.
事实证明,履带技术具有这种商业价值吗?
我们公司可以自己做并抓取数据以增强竞争力吗?
太年轻太天真
一位伟大的神之智说: “履带进入的门槛很低,但是在实际操作的后期阶段,它们确实会使您崩溃. 例如,您肯定会遇到以下问题. ”
您必须至少了解一个或多个主题,而不仅仅是爬虫,而且您刚刚开始学习爬网.
来源
如果企业组建了爬虫专家团队,则需要从零开始.
对于企业来说,这是一笔很大的开销,包括管理成本和时间成本.
我们如何打破这个僵局?
实际上,这位智虎神给出了答案:
“不要重新发明轮子”
市场上已经有许多简单,易于使用的专业爬虫服务和工具,它们使企业能够以更灵活,更轻便,成本更低的方式获取大量数据.
例如,优采云用于采集数据的企业私有云.
优采云的私有云版本是针对具有大量数据采集需求的公司量身定制的爬虫工具.
企业无需添加任何履带技术人员. 优采云的私有云可以完全满足企业进行海量信息采集的需求.
为什么选择优秀彩云?
优采云自2013年投入市场以来,一直致力于为用户提供易于使用,快速且稳定的数据抓取工具.
经过几年的发展,用户规模不断扩大,全球拥有120万用户. 通过专业的数据抓取能力和经验积累,我们开发了许多业内知名公司,例如平安,腾讯,万达,政府机构,科学研究所以及公安部,税务局,清华大学等成功的数据项目案例. 用户对优采云在数据采集方面的专业能力的认可.
优采云数据采集成功地被中华人民共和国工业和信息化部评选为“ 2019年度杰出大数据产品和应用解决方案”. 优采云连续5年在“中国大数据企业排名”中排名第一.
优采云私有云如何满足企业需求?
01. 专业的数据采集器服务功能
优采云可以采集在Internet上公开显示的数据,只要这些数据肉眼可见并且可以复制即可.
优采云支持文本,数字,图片,视频和源代码等数据类型,而不仅限于数据格式.
02. 在云中高效地分布式采集海量数据
优采云使用高效的云分布式采集,并由5000多个云服务器提供支持. 优采云私有云可根据企业需求配备30-100个以上的云节点,相当于同时运行近百台服务器,实现多任务并发采集.
使用分布式采集的时间明显短于企业使用自己的服务器所需的时间. 普通企业很难拥有像专业爬网程序这样的大量服务器资源来支持海量数据采集.
云分布式采集可以帮助公司实现在短时间内采集大量数据的目的,使公司每天可以轻松采集数百万甚至数千万的数据.
由于长期以来对大量数据采集器的需求,优采云已成为“阿里云VIP企业客户”. 优采云私有云用户可以通过优采云直接享受阿里云提供的“企业级优质云节点”,进一步实现快速稳定的云爬虫服务.
03. 独家智能防封技术组合
正如上面提到的知乎 Dashen所说,网站上存在多种反爬虫策略,并且大多数公司爬虫工程师在这种情况下只能无能为力.
经过6年以上的实战经验,优采云已经形成了独家的智能防封技术组合,可以有效地克服大多数网站的防采集措施.
1个高质量的代理IP池
优采云可以为私有云用户提供高质量的代理IP池,允许用户在采集过程中灵活切换IP,有效避免网站反采集.
2自动识别验证码
优采云支持9种类型的验证码的自动识别,可以有效破解网站验证码以防止被采集.
9种验证码
3个Cookie,UA
优采云还可以灵活设置cookie(用户身份),定期切换UA(用户代理)以及突破对方的反阻塞方法,从而使企业可以稳定地获取高质量的数据源.
04. 企业协作数据资源共享
考虑到企业数据采集通常是一个内部的多人协作项目,优采云私有云为用户提供了团队协作功能,可以实现跨账户数据,云节点(可以理解为服务器)和IP共享资源(例如座席池)是团队协作的最佳武器.
05. 与企业数据库的无缝连接
数据采集后,优采云可以自动导入企业数据库,并且我们支持Oracle和MySQL等常见的企业数据库.
无缝链接企业业务系统,实现高效的数据归档,并消除繁琐而复杂的手动操作.
06. 多个高级API数据接口
私有云用户可以调用优采云的数据导出API接口和增值API接口.
使用上述两个界面,私有云用户的开发人员可以轻松地通过API获取有才运的任务信息并采集数据. 您可以在不登录优采云的情况下调用和控制优采云. 任务的状态减少了工作场景的来回切换.
07. 满足企业的灵活个性化需求
在指定时间进行1次灵活采集
定时采集功能是自定义设置的功能,适用于需要定期更新网站最新信息的公司用户,精确到分钟.
有了定时采集功能,用户可以在24小时内灵活选择采集时间,而优采云将在“关键时刻”自动开始工作,从而节省了用户的烦恼和精力.
2新增了准确的数据采集
智能识别新添加的数据以进行准确的采集,而无需进行历史性的重复工作,从而节省了时间和节点资源.
3个工作7 * 24h,即使关机也可以
在私有云任务开始运行采集任务之后,即使您关闭也不必担心. 优采云将继续在云中为您服务7 * 24小时,直到采集所有数据为止.
您可以安全地关机并下班,享受放松的时间.
08. 享受卓越的彩云MAX性能配置
1个无限的任务存储空间
您可以自由,随意地创建采集任务,而不必担心由于任务数量有限而定期删除或导出任务,从而减轻了烦人的工作量.
2个无限帐户同时在线
您的团队可以共享一个优采云私有云帐户,即使在不同的位置和不同的计算机上,您也可以同时登录并进行操作.
3个无限客户端同时打开
一台计算机可以同时打开多个客户端,这挑战了计算机的MAX性能.
4个无限量的数据可以随时导出
从优采云采集的10,000,000+数据可以无限次直接导入您的业务系统.
09. 私有云VIP爬虫专家咨询服务
每个私有云用户将配备VIP履带专家咨询团队,以提供及时的响应和熟练的专业售后服务.
10. “优采云”值得信赖的品牌
部分客户展示
油菜云获得了柔软度方面的主要奖项
优缺点比较
如果您的公司没有爬虫,但是您希望快速为其配备具备以低成本获取海量数据的能力,那么Wall Crack建议您使用优采云私有云!
优采云·触手可及的数据
官方帐户[优采云大数据] 查看全部
随着数据智能时代的到来,越来越多的公司重视数据,并使用采集器技术在Internet上获取大量公共数据以增强其业务能力.
当前,源自爬虫技术的经典商业项目,我相信您也必须使用它们:
Enterprise Check是一种企业信息查询工具,它将80个产业链,8,000个行业,6,000个市场和超过8,000万家国内市场的公司的数据汇总在一起.
企业如何检查海量数据?
企业搜索的数据源主要来自以下三个方面.
①Web爬网程序采集数据
②第三方合作数据
③有些数据更新任务是由用户触发的
它通过Web爬网程序采集数据,执行初步清理并将其合并到其数据库中,并使用算法进行处理,最后向用户打开以提供查询和搜索.
柴柴目前的估值已经达到5亿元.
事实证明,履带技术具有这种商业价值吗?
我们公司可以自己做并抓取数据以增强竞争力吗?
太年轻太天真
一位伟大的神之智说: “履带进入的门槛很低,但是在实际操作的后期阶段,它们确实会使您崩溃. 例如,您肯定会遇到以下问题. ”
您必须至少了解一个或多个主题,而不仅仅是爬虫,而且您刚刚开始学习爬网.
来源
如果企业组建了爬虫专家团队,则需要从零开始.
对于企业来说,这是一笔很大的开销,包括管理成本和时间成本.
我们如何打破这个僵局?
实际上,这位智虎神给出了答案:
“不要重新发明轮子”
市场上已经有许多简单,易于使用的专业爬虫服务和工具,它们使企业能够以更灵活,更轻便,成本更低的方式获取大量数据.
例如,优采云用于采集数据的企业私有云.
优采云的私有云版本是针对具有大量数据采集需求的公司量身定制的爬虫工具.
企业无需添加任何履带技术人员. 优采云的私有云可以完全满足企业进行海量信息采集的需求.
为什么选择优秀彩云?
优采云自2013年投入市场以来,一直致力于为用户提供易于使用,快速且稳定的数据抓取工具.
经过几年的发展,用户规模不断扩大,全球拥有120万用户. 通过专业的数据抓取能力和经验积累,我们开发了许多业内知名公司,例如平安,腾讯,万达,政府机构,科学研究所以及公安部,税务局,清华大学等成功的数据项目案例. 用户对优采云在数据采集方面的专业能力的认可.
优采云数据采集成功地被中华人民共和国工业和信息化部评选为“ 2019年度杰出大数据产品和应用解决方案”. 优采云连续5年在“中国大数据企业排名”中排名第一.
优采云私有云如何满足企业需求?
01. 专业的数据采集器服务功能
优采云可以采集在Internet上公开显示的数据,只要这些数据肉眼可见并且可以复制即可.
优采云支持文本,数字,图片,视频和源代码等数据类型,而不仅限于数据格式.
02. 在云中高效地分布式采集海量数据
优采云使用高效的云分布式采集,并由5000多个云服务器提供支持. 优采云私有云可根据企业需求配备30-100个以上的云节点,相当于同时运行近百台服务器,实现多任务并发采集.
使用分布式采集的时间明显短于企业使用自己的服务器所需的时间. 普通企业很难拥有像专业爬网程序这样的大量服务器资源来支持海量数据采集.
云分布式采集可以帮助公司实现在短时间内采集大量数据的目的,使公司每天可以轻松采集数百万甚至数千万的数据.
由于长期以来对大量数据采集器的需求,优采云已成为“阿里云VIP企业客户”. 优采云私有云用户可以通过优采云直接享受阿里云提供的“企业级优质云节点”,进一步实现快速稳定的云爬虫服务.
03. 独家智能防封技术组合
正如上面提到的知乎 Dashen所说,网站上存在多种反爬虫策略,并且大多数公司爬虫工程师在这种情况下只能无能为力.
经过6年以上的实战经验,优采云已经形成了独家的智能防封技术组合,可以有效地克服大多数网站的防采集措施.
1个高质量的代理IP池
优采云可以为私有云用户提供高质量的代理IP池,允许用户在采集过程中灵活切换IP,有效避免网站反采集.
2自动识别验证码
优采云支持9种类型的验证码的自动识别,可以有效破解网站验证码以防止被采集.
9种验证码
3个Cookie,UA
优采云还可以灵活设置cookie(用户身份),定期切换UA(用户代理)以及突破对方的反阻塞方法,从而使企业可以稳定地获取高质量的数据源.
04. 企业协作数据资源共享
考虑到企业数据采集通常是一个内部的多人协作项目,优采云私有云为用户提供了团队协作功能,可以实现跨账户数据,云节点(可以理解为服务器)和IP共享资源(例如座席池)是团队协作的最佳武器.
05. 与企业数据库的无缝连接
数据采集后,优采云可以自动导入企业数据库,并且我们支持Oracle和MySQL等常见的企业数据库.
无缝链接企业业务系统,实现高效的数据归档,并消除繁琐而复杂的手动操作.
06. 多个高级API数据接口
私有云用户可以调用优采云的数据导出API接口和增值API接口.
使用上述两个界面,私有云用户的开发人员可以轻松地通过API获取有才运的任务信息并采集数据. 您可以在不登录优采云的情况下调用和控制优采云. 任务的状态减少了工作场景的来回切换.
07. 满足企业的灵活个性化需求
在指定时间进行1次灵活采集
定时采集功能是自定义设置的功能,适用于需要定期更新网站最新信息的公司用户,精确到分钟.
有了定时采集功能,用户可以在24小时内灵活选择采集时间,而优采云将在“关键时刻”自动开始工作,从而节省了用户的烦恼和精力.
2新增了准确的数据采集
智能识别新添加的数据以进行准确的采集,而无需进行历史性的重复工作,从而节省了时间和节点资源.
3个工作7 * 24h,即使关机也可以
在私有云任务开始运行采集任务之后,即使您关闭也不必担心. 优采云将继续在云中为您服务7 * 24小时,直到采集所有数据为止.
您可以安全地关机并下班,享受放松的时间.
08. 享受卓越的彩云MAX性能配置
1个无限的任务存储空间
您可以自由,随意地创建采集任务,而不必担心由于任务数量有限而定期删除或导出任务,从而减轻了烦人的工作量.
2个无限帐户同时在线
您的团队可以共享一个优采云私有云帐户,即使在不同的位置和不同的计算机上,您也可以同时登录并进行操作.
3个无限客户端同时打开
一台计算机可以同时打开多个客户端,这挑战了计算机的MAX性能.
4个无限量的数据可以随时导出
从优采云采集的10,000,000+数据可以无限次直接导入您的业务系统.
09. 私有云VIP爬虫专家咨询服务
每个私有云用户将配备VIP履带专家咨询团队,以提供及时的响应和熟练的专业售后服务.
10. “优采云”值得信赖的品牌
部分客户展示
油菜云获得了柔软度方面的主要奖项
优缺点比较
如果您的公司没有爬虫,但是您希望快速为其配备具备以低成本获取海量数据的能力,那么Wall Crack建议您使用优采云私有云!
优采云·触手可及的数据
官方帐户[优采云大数据]
淘宝联盟如何自动发布订单?有什么方法?
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-08-07 01:18
淘宝联盟是Alimama平台为Taoke推广者建立的推广平台. 您可以在淘宝联盟的后台进行诸如连锁促销和现金提取等一系列操作.
想要在淘宝联盟中推广的用户,即淘宝客户,可以在他们的网站,微博,个人主页等上放置他们想要推广的产品的链接. 如果买家通过该链接购买淘宝商品,参加淘宝联盟的淘宝客户可以获得一定比例的佣金.
淘宝联盟如何自动发布订单?
1. 首先,我们首先从互联网下载相关的淘宝联盟自动计费软件
2. 打开软件,这里的第一个界面是云采集界面,您可以在云中读取高质量的产品库,在发送之前,我们需要在软件右侧添加Alimama帐户,并发送qq组或发送微信群组已添加到软件中,以便您可以直接在通讯工具中自动发送订单,并登录到淘宝联盟帐户.
3. 第二个接口是采集和转发接口. 采集和转发界面是从其他组采集高质量的产品并将链接转换为我们自己的Taoke链接!
这可以在淘宝联盟的背景下自动更新其他人的高质量产品,并将其转换为自己的Taoke链接.
4. 第三个接口是本地库转发接口,我们可以添加自己的产品并将其转发给组!
在这里,您可以设置要在组中推广的产品链接,并自动生成并将其发送给组.
对于特定的操作步骤,您可以自己检查相关的软件规则. 这里简要讨论了几点. 查看全部
淘宝联盟自动计费软件是一款可帮助淘宝批量发送商品的软件. 它可以自动将链接转换为淘宝链接并执行智能群组发送. 它支持三种模式: 云,集合和本地!那么淘宝联盟如何自动发布订单?
淘宝联盟是Alimama平台为Taoke推广者建立的推广平台. 您可以在淘宝联盟的后台进行诸如连锁促销和现金提取等一系列操作.
想要在淘宝联盟中推广的用户,即淘宝客户,可以在他们的网站,微博,个人主页等上放置他们想要推广的产品的链接. 如果买家通过该链接购买淘宝商品,参加淘宝联盟的淘宝客户可以获得一定比例的佣金.
淘宝联盟如何自动发布订单?
1. 首先,我们首先从互联网下载相关的淘宝联盟自动计费软件
2. 打开软件,这里的第一个界面是云采集界面,您可以在云中读取高质量的产品库,在发送之前,我们需要在软件右侧添加Alimama帐户,并发送qq组或发送微信群组已添加到软件中,以便您可以直接在通讯工具中自动发送订单,并登录到淘宝联盟帐户.
3. 第二个接口是采集和转发接口. 采集和转发界面是从其他组采集高质量的产品并将链接转换为我们自己的Taoke链接!
这可以在淘宝联盟的背景下自动更新其他人的高质量产品,并将其转换为自己的Taoke链接.
4. 第三个接口是本地库转发接口,我们可以添加自己的产品并将其转发给组!
在这里,您可以设置要在组中推广的产品链接,并自动生成并将其发送给组.
对于特定的操作步骤,您可以自己检查相关的软件规则. 这里简要讨论了几点.
优采云 云端自动化数据采集发布系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2020-08-04 10:00
感谢您使用SkyCaiji(蓝天数据采集发布系统), 希望我们的努力能为您提供一套数据自动化解决方案!
PHP版本要求
PHP5.3以上版本(注意:PHP5.3dev版本和PHP6均不支持)
安装环境要求
操作系统:Linux/Unix/Windows
软件环境:IIS/Apache/Nginx + MySQL 5.0 及以上
下载软件
当前版本:SkyCaiji V1.2 站长下载 Github 码云
上传至服务器
将下载的软件上传至您的服务器,如果根目录有站点建议置于子目录里,解压后打开浏览器输入您的服务器域名或ip地址(存放在子目录则加上子目录的名称),进入安装界面
点击“接受”,进入环境检测页面
必须确保所有参数都正确,否则使用中会出现错误,点击“下一步”进入数据安装界面
填写好数据库及创始人配置,点击“下一步”
最后安装完成,现在可以使用优采云了!
关于软件
SkyCaiji(蓝天数据采集发布系统),致力于网站数据自动化采集发布,系统采用PHP+Mysql开发云端 自动 采集,可布署在云端服务器,使数据采集便捷化、智能化、云端化云端 自动 采集,让您随时随地联通办公!
数据采集
自定义采集规则(支持正则、XPATH、JSON等)精准匹配任意信息流,几乎能采集所有类型的网页,绝大多数文章类型页面内容可实现智能辨识
内容发布
无缝耦合各种CMS建站程序,实现免登录导出数据,支持自定义数据发布插件,也可以直接导出数据库、存储为Excel文件、生成API接口等
自动化及云平台
软件实现定时定量全手动采集发布,无需人工干预!内置云平台,用户可分享及下载采集规则,发布供求信息以及社区求救、交流等 查看全部
优采云
感谢您使用SkyCaiji(蓝天数据采集发布系统), 希望我们的努力能为您提供一套数据自动化解决方案!
PHP版本要求
PHP5.3以上版本(注意:PHP5.3dev版本和PHP6均不支持)
安装环境要求
操作系统:Linux/Unix/Windows
软件环境:IIS/Apache/Nginx + MySQL 5.0 及以上
下载软件
当前版本:SkyCaiji V1.2 站长下载 Github 码云
上传至服务器
将下载的软件上传至您的服务器,如果根目录有站点建议置于子目录里,解压后打开浏览器输入您的服务器域名或ip地址(存放在子目录则加上子目录的名称),进入安装界面
点击“接受”,进入环境检测页面
必须确保所有参数都正确,否则使用中会出现错误,点击“下一步”进入数据安装界面
填写好数据库及创始人配置,点击“下一步”
最后安装完成,现在可以使用优采云了!
关于软件
SkyCaiji(蓝天数据采集发布系统),致力于网站数据自动化采集发布,系统采用PHP+Mysql开发云端 自动 采集,可布署在云端服务器,使数据采集便捷化、智能化、云端化云端 自动 采集,让您随时随地联通办公!
数据采集
自定义采集规则(支持正则、XPATH、JSON等)精准匹配任意信息流,几乎能采集所有类型的网页,绝大多数文章类型页面内容可实现智能辨识
内容发布
无缝耦合各种CMS建站程序,实现免登录导出数据,支持自定义数据发布插件,也可以直接导出数据库、存储为Excel文件、生成API接口等
自动化及云平台
软件实现定时定量全手动采集发布,无需人工干预!内置云平台,用户可分享及下载采集规则,发布供求信息以及社区求救、交流等

