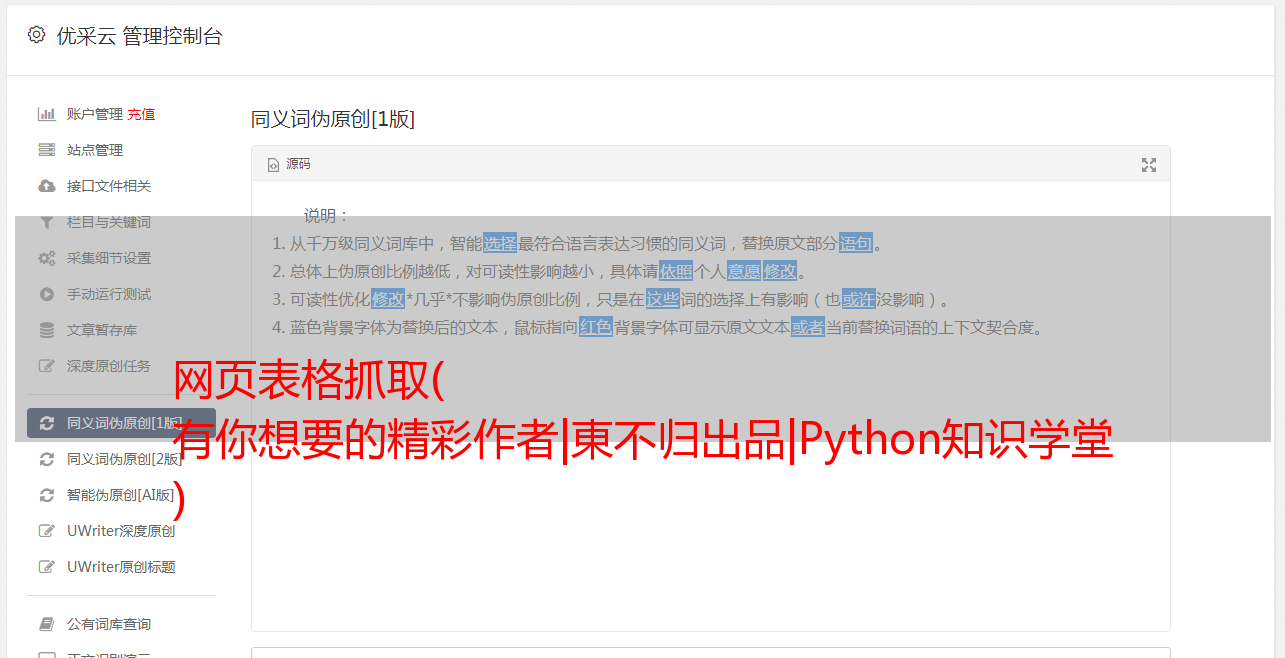
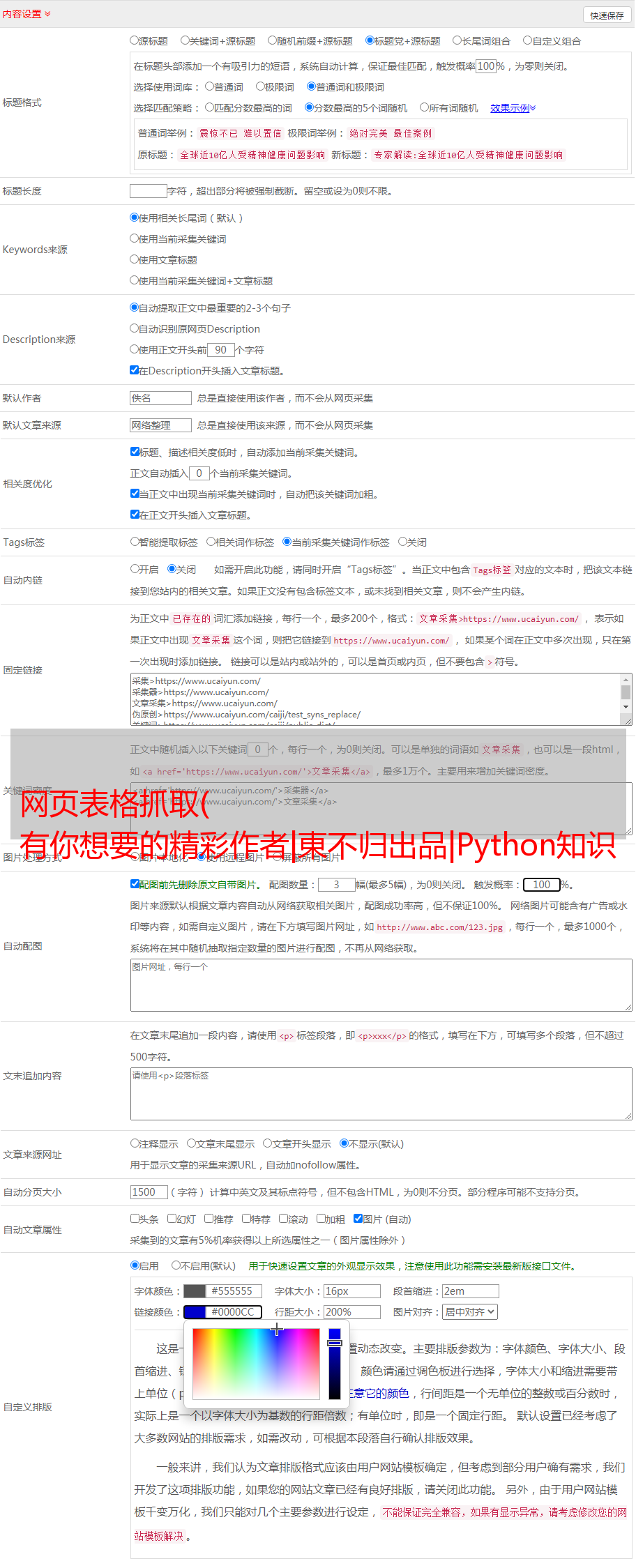
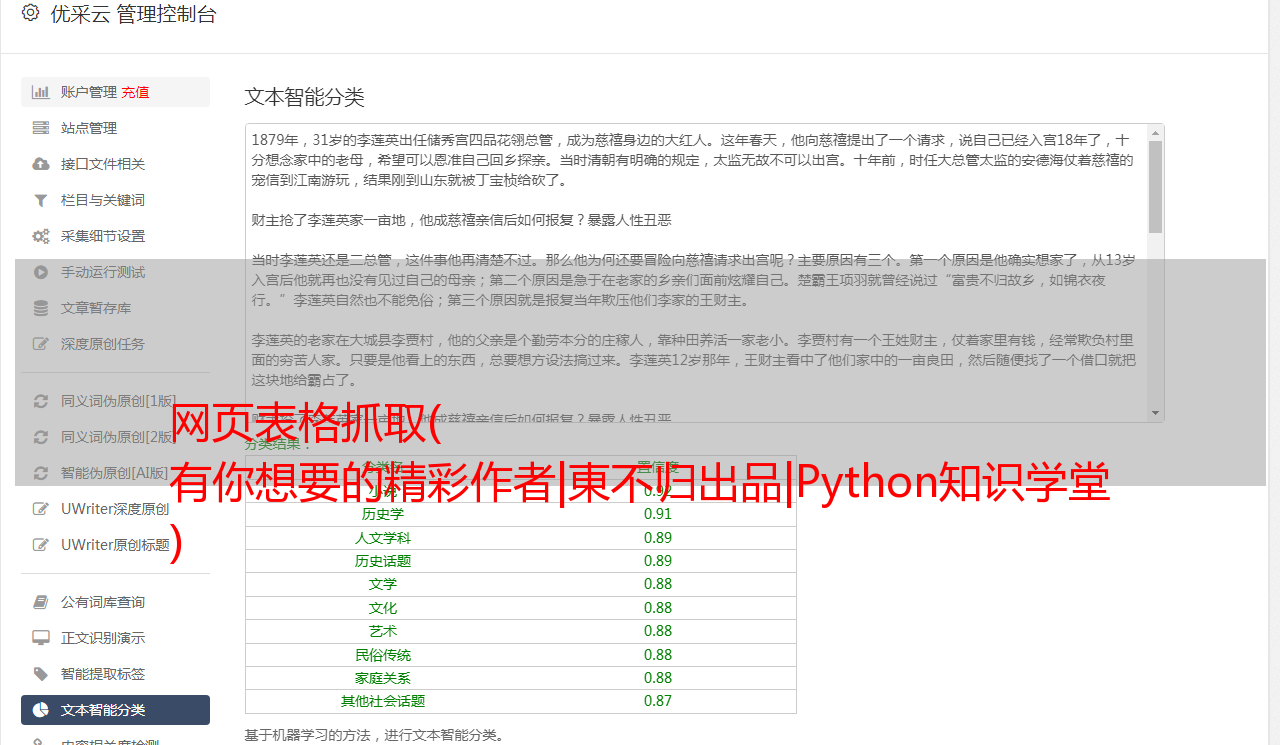
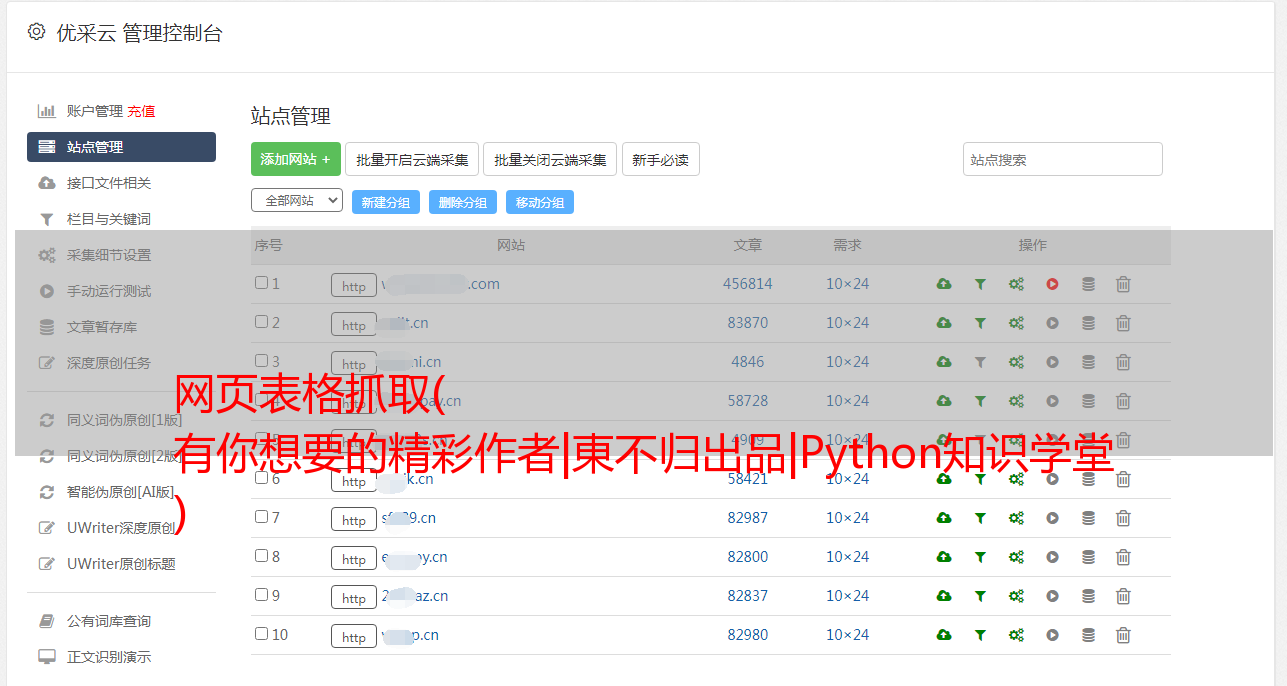
网页表格抓取( 有你想要的精彩作者|東不归出品|Python知识学堂 )
优采云 发布时间: 2021-10-15 15:08网页表格抓取(
有你想要的精彩作者|東不归出品|Python知识学堂
)
有你想要的
作者 | 东不归出品| Python知识学校
大家好,上一条推文介绍了爬虫需要注意的点,使用vscode开发环境时遇到的问题,正则表达式爬取页面信息的使用。本文主要介绍BeautifulSoup模块的使用。.
BeautifulSoup的描述
引用官方解释:
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它可以使用您喜欢的转换器来实现惯用的文档导航、查找和修改文档。
简单的说,Beautiful Soup 是一个python 库,一个可以抓取网页数据的工具。
官方文件:
BeautifulSoup 安装
pip 安装 beautifulsoup4
或者
pip 安装 beautifulsoup4
-一世
--可信主机
顺便说一句:我用的开发工具还是vscode,不知道看之前的推文。
BeautifulSoup 解析器
html.parse
html.parse 是内置的,不需要安装
import requestsfrom bs4 import BeautifulSoupurl='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'html.parser')<br />print(soup.prettify())
结果
xml文件
安装 pip install lxml 需要 lxml
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'lxml')<br />print(soup)
结果
lxml-xml/xml
lxml-xml/Xm 是需要安装的pip install lxml
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'xml')<br />print(soup)
结果
html5lib
html5lib是需要安装的pip install html5lib
import requestsfrom bs4 import BeautifulSoup<br />url='https://www.baidu.com'<br />response=requests.get(url)<br />response.encoding = 'utf-8'<br />soup = BeautifulSoup(response.text, 'html5lib')<br />print(soup)
结果
可以看到,这些解析器解析出来的记录基本相同,但是如果一段 HTML 或者 XML 文档的格式不正确,不同解析器返回的结果可能会有所不同。什么是 HTML 或 XML 文档格式不正确?简单地说,就是缺少不必要的标签或者标签没有关闭。比如页面缺少body标签,只有a标签的开头部分缺少a标签的结尾部分(这里有一些前端知识,不明白的可以搜索一下,很简单)。
咱们试试吧
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'html.parser')
打印(“html.parser 结果:”)
打印(汤)
汤1=BeautifulSoup(html,'lxml')
打印(“lxml 结果:”)
打印(汤1)
汤2=BeautifulSoup(html,'xml')
打印(“xml结果:”)
打印(汤2)
汤3=BeautifulSoup(html,'html5lib')
打印(“html5lib 结果:”)
打印(汤3)
结果
可以看到html.parser和lxml会填充标签,但是lxml会填充html标签,xml也会填充标签,还会添加xml文档的版本编码方式等信息,但不是会补全html标签,而且html5lib不仅会补全html标签,还会补全整个页面的head标签。
这验证了上表中的html5lib具有最好的容错性,但是html5lib解析器的速度并不快。如果内容较少,则速度不会有差异。因此,推荐使用lxml作为解析器,因为这样效率更高。对于 Python2.7.3 之前的版本和 Python3 中 3.2.2 之前的版本,必须安装 lxml 或 html5lib,因为这些 Python 版本具有内置的 HTML标准库中的分析方法不够稳定。
如果我们不指定解析器怎么办?
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=美丽的汤(html)
打印(“html.parser 结果:”)
打印(汤)
结果
从结果可以得出结论,如果不指定解析器,他会给出系统中最好的解析器。我的系统是lxml。如果你没有在其他环境中安装 lxml,它可能是另一个解析器。总之系统会默认为你选择最好的解析器,所以你不需要指定它。这不是更用户友好。
BeautifulSoup 对象类型
Beautiful Soup 将复杂的 HTML 文档转换为复杂的树结构。每个节点都是一个 Python 对象。所有对象可以概括为 4 种类型:Tag、NavigableString、BeautifulSoup、Comment。
标签
标签中最重要的属性:名称和属性
from bs4 import BeautifulSoup<br />html="
Python知识学校
Python知识学校”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
结果
上面代码中的a标签表示一个标签,test被认为是一个标签。测试是我随便写的,所以Beautiful Soup中的html标签和自定义标签都可以看作是标签。是不是很强大?
那么什么是属性呢?看上面代码中的data-id和class一个标签,即使它们是标签中的属性;
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
打印(标签。属性)
结果:
如果要获取某个属性,可以使用 tag['data-id'] 或 tag.attrs['data-id']。
这个最有用的应该是获取a标签的链接地址和img标签的媒体文件地址。
如果里面有多个值,会返回一个列表
from bs4 import BeautifulSoup<br />html="
Python知识学校
”
汤=BeautifulSoup(html,'lxml')
打印(标签 ['数据 ID'])
结果:
导航字符串
标签中收录的字符串可以通过NavigableString类直接获取,也称为可遍历字符串。
from bs4 import BeautifulSoup<br />html="
Python 知识学院,欢迎您!
”
汤=BeautifulSoup(html,'lxml')
标签=汤.a
打印(标签。字符串)
结果:
这个比较简单,就不多说了;
美汤
BeautifulSoup 对象表示文档的全部内容。大多数时候,它可以看作是一个 Tag 对象,它支持遍历文档树和搜索文档树中描述的大部分方法。
先大致了解一下,后面会有遍历文档和搜索文档的说明;
评论
主要是文档中的注释部分。
Comment 对象是一种特殊类型的 NavigableString 对象:
from bs4 import BeautifulSoup<br />html= "<b>"soup = BeautifulSoup(html,'lxml')<br />comment = soup.b.string<br />print(comment)
结果
但是下面的情况是不可用的
from bs4 import BeautifulSoup<br />html= "<b>我是谁?"<br />soup = BeautifulSoup(html,'lxml')<br />comment = soup.b.string<br />print(comment)
结果
可以看到返回的结果是None,所以评论的内容只能在特殊情况下才能获取;
遍历文档树
只看代码
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
上面的知识简单列举了几种获取树节点的方法,还有很多其他的方法,比如获取父节点、兄弟节点等等。有点类似于 jQuery 遍历 DOM 的概念。
搜索文档树
Beautiful Soup 定义了很多搜索方法,这里介绍两个比较常用的方法:find() 和 find_all()。其他的可以类似地使用,以此类推。
筛选
细绳
正则表达式
列表
真的
方法
from bs4 import BeautifulSoupimport re<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
找到所有()
Name:可以找到所有名称为name的标签,string对象会被自动忽略;
关键字参数:如果指定名称的参数不是内置参数名称,则搜索时将作为指定名称标签的属性进行搜索。如果它收录一个名为 id 的参数,Beautiful Soup 将搜索每个标签的“id”属性;
按CSS搜索:按CSS类名搜索标签的功能很实用,但是标识CSS类名的关键字class在Python中是保留字。使用类作为参数会导致语法错误。来自Beautiful Soup的4.< 从@1.1版本开始,可以通过class_参数搜索指定CSS类名的标签;
字符串参数:可以通过字符串参数搜索文档中的字符串内容。与 name 参数的可选值一样,string 参数接受字符串、正则表达式、列表和 True。
limit 参数:find_all() 方法返回所有搜索结构。如果文档树很大,搜索会很慢。如果我们不需要所有的结果,我们可以使用 limit 参数来限制返回的结果数量。作用类似于SQL中的limit关键字,当搜索结果数达到limit限制时,停止搜索返回结果;
递归参数:调用标签的 find_all() 方法时,Beautiful Soup 会检索当前标签的所有后代节点。如果只想搜索标签的直接子节点,可以使用参数recursive=False。
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果:
请注意,只有 find_all() 和 find() 支持递归参数。
find() 方法与 find_all() 方法基本相同。唯一的区别是 find_all() 方法的返回结果是一个收录一个元素的列表,而 find() 方法直接返回结果。
输出
格式化输出
压缩输出
输出格式
获取文本()
from bs4 import BeautifulSoup<br />html=' python 知识学堂
欢迎来到 Python 知识学院
'
结果我就不贴了,自己执行吧。
当然还有很多其他的方法,这里不再赘述,可以直接参考官方
Buaautiful汤的功能还是很强大的,这里只是简单介绍一些爬虫常用的东西。
现在就做,我们以上一篇文章获取省市为例
实例
我们仍然以上一篇文章中的省市收购为例。
import requestsfrom bs4 import BeautifulSoupimport timeclass Demo():def __init__(self):try:base_url = 'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/'<br /> trlist = self.get_data(base_url, "provincetable",'provincetr')
结果
我直接给你看看你上一个省市的结果。请注意获取每个页面信息的时间间隔;
总结
本文文章介绍了BeautifulSoup的一些基础内容,主要是爬虫相关的,BeautifulSoup还有很多其他的功能,大家可以到官网自行学习。
再贴一下官网地址:
下一个预览
下一条推文是关于lxml模块的基本内容,但下周的推文是关于深度学习的。爬虫可能要等到下周。感谢您的支持!
过去的选择(点击查看)
Python爬虫基础教程-正则表达式爬取入门
2020-08-30
Python实战教程系列-VSCode Python开发环境搭建
2020-08-01
Python实战教程系列——异常处理
2020-07-05
喜欢就看看

