整套解决方案:声动说|产品分析必备,用数据驱动产品改进和运营优化
优采云 发布时间: 2020-09-06 08:40Shengdongshuo |必须进行产品分析,使用数据来推动产品改进和运营优化
“ Sound Motion Group”专注于互联网价值的传播,并在与您建立良好联系的时代分享一切!
本文约为3000个单词,需要8分钟阅读时间
前一段时间,他们与产品人员和操作员讨论了与产品相关的问题。他们建议他们想采集一些网站数据来分析其他产品功能的数据并制定促销计划,因此他们了解了爬虫。
爬虫遍历页面URL算法时,经常使用深度优先和宽度优先的算法。在本文中,作者主要与您分享这两种算法的原理。
1
#网站的网址结构#
每个网站具有一定级别的结构。一个主域名下可能有多个内容模块。 网站的所有内容逐层类似于树形结构,如下所示:
2
#原理分析#
我们将网站的结构理解为树形结构,并且每个页面都是一个节点,如图所示:
▎深度优先算法
深度优先遍历的结果是:A-> B-> D-> H-> E-> C-> F-> G
简而言之,深度优先算法过程是将每个可能的分支路径加深到无法继续的点,并且每个节点只能访问一次:
●首先访问根节点,然后依次从根节点未访问的相邻点继续进行,并执行深度优先遍历,直到访问所有具有到根节点路径的节点为止。
●如果此时未访问任何节点(从未访问的节点开始),则将重复深度优先遍历,直到所有顶点都被访问为止。
伪代码如下:
从深度优先算法的规则可以看出,该算法是使用递归实现的。
▎宽度优先算法
广度优先遍历的结果是:A-> B-> C-> D-> E-> F-> G-> H
广度优先算法从一个节点开始,按照级别从上到下遍历节点,然后在同一层中从左到右遍历节点:
●首先访问根节点,然后访问距根节点1的距离的顶点。假设根节点附近有3个节点,深度优化搜索将在访问根节点后访问这3个节点。
●完成访问与根节点距离为1的节点后,将其取出并重复相同的过程。根据队列的数据结构处理哪个节点是第一个节点。
伪代码如下:
因此,广度优化算法也称为水平顺序遍历,因为它逐层访问节点。广度优化搜索是通过队列实现的。
3
#简单练习#
这两个算法通常在爬网程序遍历页面时使用。我使用了广度优先算法来制作一个简单的演示,以抓取网站所有网址。该演示主要使用python3,urllib,BeautifulSoup和ssl这三个库。
Urllib库用于获取网页请求和响应; BeautifulSoup库用于将html解析为对象进行处理; ssl用于解决访问Https时不受信任的SSL证书的问题;这些库还有其他有趣的功能。您可以了解其API:
●导入urllib,BeautifulSoup库
从bs4导入sslimport urllib.request导入BeautifulSoup
●获取网页内容
#解决访问Https context = ssl._create_unverified_context()时不可信的SSL证书的问题#使用urllib库获取URL内容resp = urllib.request.urlopen(link_url,context = context)html = resp.read( )
●分析网页的内容(此处仅解析和提取网页中的链接)
#使用BeautifulSoup库解析网站内容汤= BeautifulSoup(html,'html.parser')标签= soup.find_all('a')用于标签中的标签:child_urls.add(tag.attrs('href') )
●使用广度优先算法进行爬网
whilenotqueue.empty():如果cur_url不在网址中,则cur_url = queue.get():urls.add(cur_url)quene.put(getLink(cur_url))4
#比较分析#
◄深度优先算法VS宽度优先算法►
◆深度优先算法采用堆栈方法,具有回溯操作,不会保留所有节点,占用空间较小,但运行缓慢。
◆广度优先算法采用队列方法,无回溯操作,并且保留了所有节点。它运行速度更快,但占用更多空间。
◆深度优先算法和广度优先算法的时间复杂度均为O(n 2),n为节点数。
5
#工具推荐#
使用代码来获取所需的数据并执行可视化分析是最方便,最灵活的方法,但是在学习代码时,许多产品和操作可能会立即放弃。
那么有一种方法可以在不了解代码的情况下捕获数据并执行可视化分析?这是我为大家推荐的三种工具:
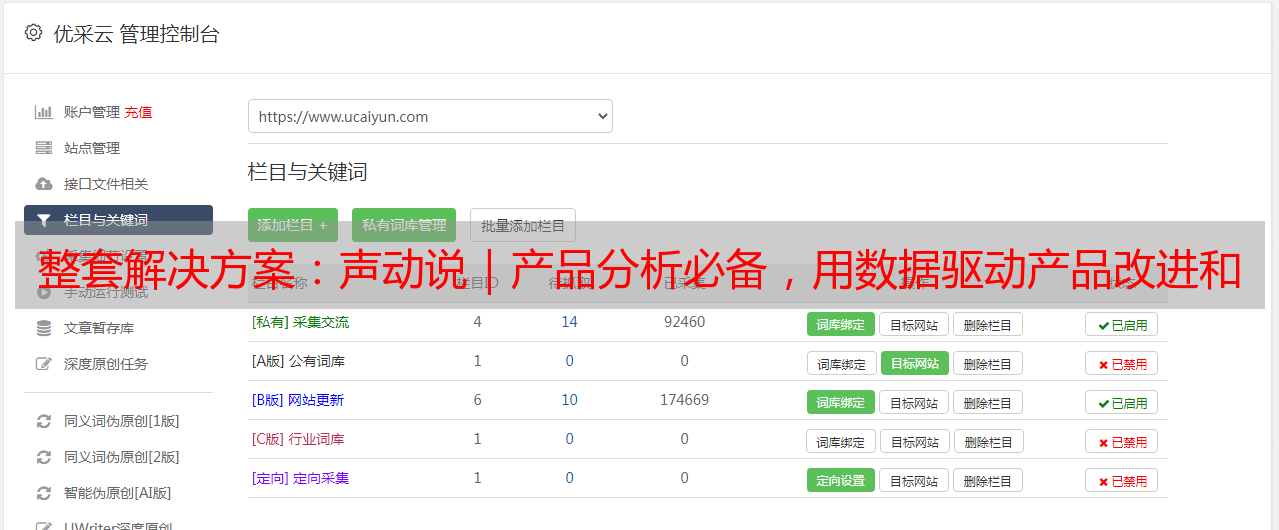
-1号优采云 采集器-
优采云可以轻松地采集您需要的网页数据,涵盖电子商务,生活服务,社交媒体和论坛。
▎优采云 采集器优点:
●易于操作,完全可视化的图形操作,不需要专业的IT人员,任何可以使用计算机访问Internet的人都可以轻松掌握它。
●采集任务自动分配到云中的多个服务器以同时执行,从而提高了采集的效率并可以在短时间内获得数千条信息。
●模仿人的操作思维方式,可以登录,输入数据,单击链接,按钮等,还可以针对不同情况采用不同的采集流程。
●内置可扩展的OCR界面,支持解析图片中的文本,并提取图片中的文本。
●采集任务自动运行,可以根据指定的周期自动运行采集,并且还支持每分钟一次的实时采集。
●从入门到精通的内置视频教程,可以在2分钟内使用。此外,还有文档,论坛,QQ群组等。
▎优采云 采集器缺点:
●它有一个免费版本,当然,许*敏*感*词*都需要付款或积分。
●采集数据很多时,很容易出现不完整的采集。
●判断语录薄弱,无法做出复杂的判断和执行复杂的逻辑。
-2号优采云 采集器-
优采云 采集器已经建立很长时间了。经过十多年的迭代,它可以实现爬网,清理,分析,挖掘以及最终可用的数据表示,以及一整套服务。
▎优采云 采集器优点:
●采集该原理基于Web结构的源代码提取,适用于几乎所有网页以及该网页中可以看到的所有内容;
●它支持接口和插件的多种扩展,以满足更多样化的使用需求,使优采云 采集器真正在整个网络中通用。
●已针对每种功能进行了优化设置。除了最基本的数据采集之外,它还具有强大的数据处理和数据发布功能,可以全面改善整个数据利用过程。
●优采云 采集器在许多详细操作中配置多个选项。
●分布式高速采集系统,占用的资源更少。
●实时监控采集,数据不容错过。
▎优采云 采集器缺点:
●规则配置繁琐。
●相比于占用内存和CPU资源,大批处理采集的速度并不好,并且资源恢复没有得到很好的控制。
●高级功能必须在付费版本中使用。
-NO.3 Tableau-
Tableau是用于数据可视化的最佳平台之一,具有非常强大的功能。
▎Tableau的优势:
●出色的数据可视化显示效果,强大的数据图表生成能力
●操作简单,无需编写代码即可入门,数据导入和加载均受指导
●内置美观的图表,无需考虑颜色匹配,只需很好地处理表格的格式即可。
▎Tableau的缺点:
●基于数据查询的工具难以处理不规则数据,也难以转换复杂模型。
●对输入数据的类型有要求,它运行缓慢,并且只能支持PC计算机,这就是为什么许多Newsroom后来都放弃了它的原因。
●它没有后端数据仓库,并且声称是内存中的BI。实际上,它需要极高的硬件要求。要对超过1000万条数据进行数据分析,必须在执行前端分析之前使用其他ETL工具来处理数据
●不支持中国式复杂表格
●本地化服务较差
●价格昂贵
可以看出,工具具有许多优点,但也有其局限性。对于大量数据和更复杂的要求,仍然需要通过代码来实现它们。建议感兴趣的产品和操作可以了解python。
以上是我对深度优先遍历算法和广度优先遍历算法以及三个推荐工具中的一些个人的理解。随着大数据时代的到来,对数据爬网的需求正在增加。让我们一起学习。

