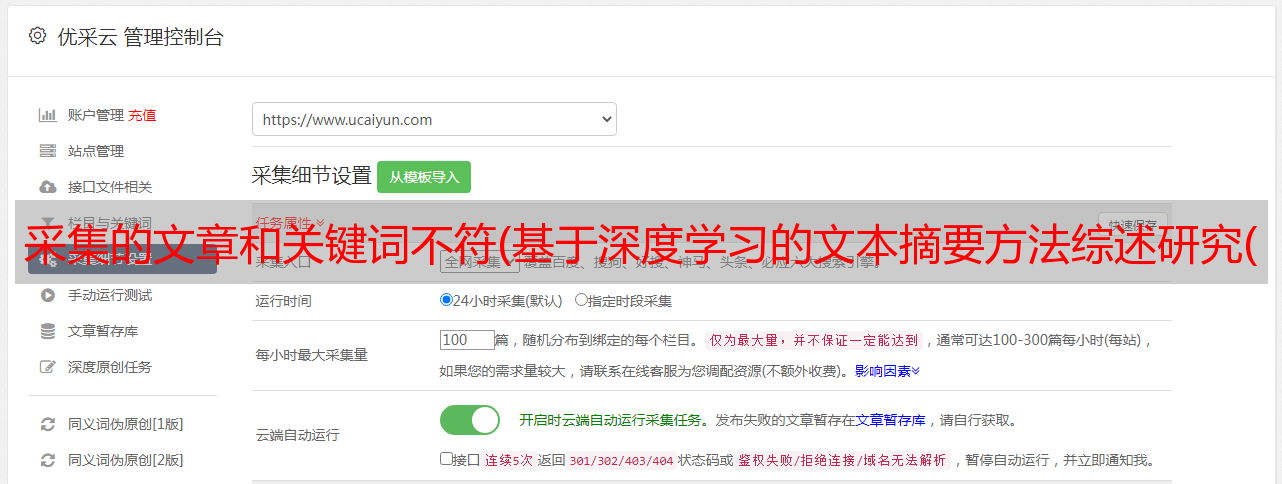
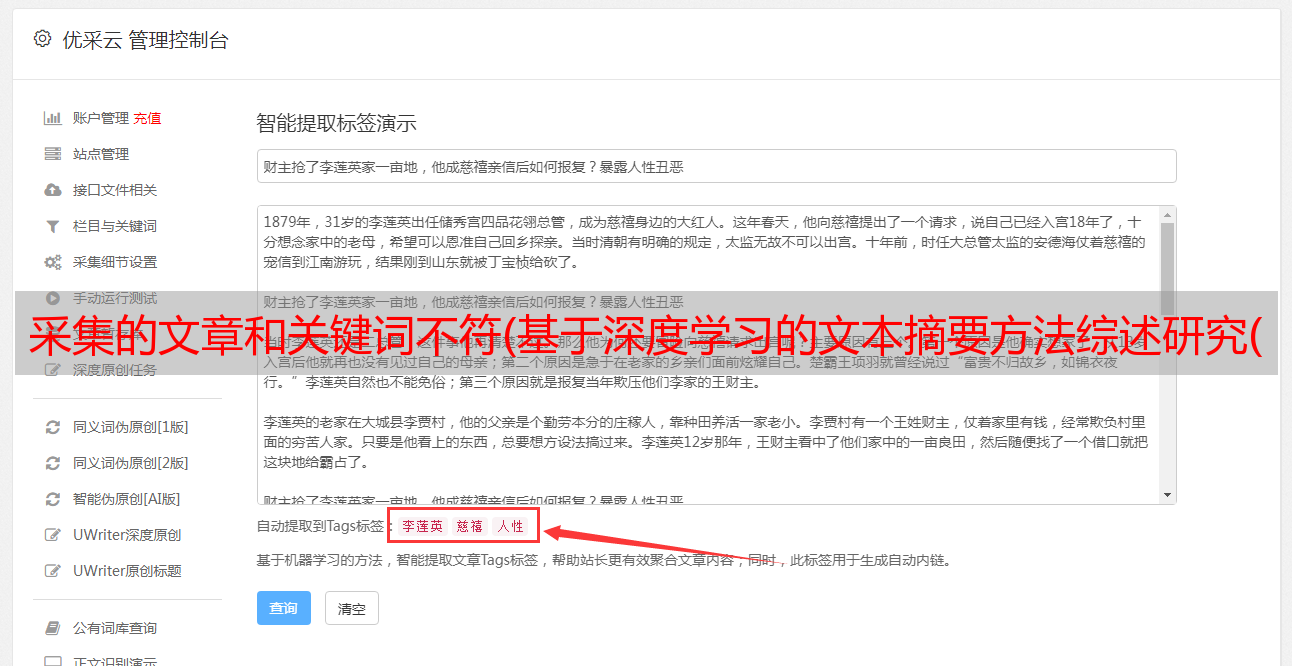
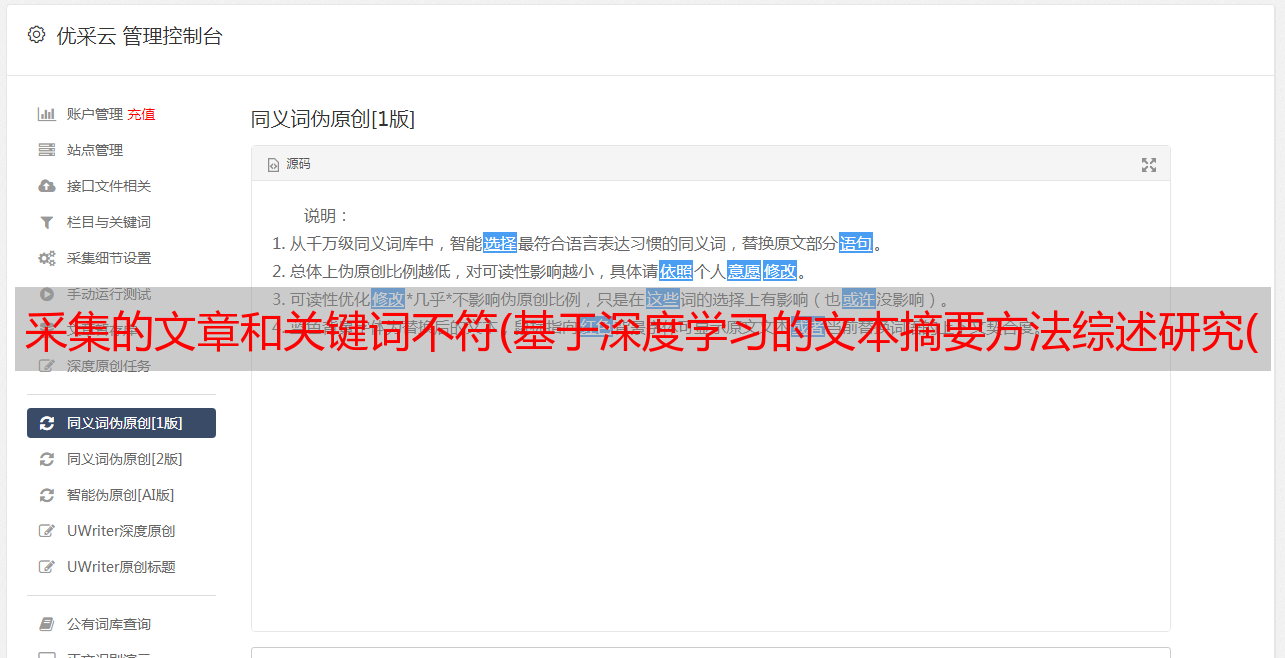
采集的文章和关键词不符(基于深度学习的文本摘要方法综述研究(Seq)+神经网络语言模型)
优采云 发布时间: 2021-10-04 16:01采集的文章和关键词不符(基于深度学习的文本摘要方法综述研究(Seq)+神经网络语言模型)
基于深度学习的文本摘要方法综述
序列到序列(Seq2Seq)框架模型
1.2015 年,受神经机器翻译 (NMT) 的启发,Rush 等人。首先提出了一种基于注意力机制(编码器)+神经网络语言模型(NNLM)(*敏*感*词*)的生成式摘要模型;
2016 年,Chopra 等人。改进了RNN(*敏*感*词*),效果显着,常用作基线模型;
同年,Nalapati 等人引入了一些新技术:在编码器中加入富文本特征捕获关键词;增加*敏*感*词*指针,解决字典外词汇(OOV)和低频词的问题;使用分层注意力机制来捕获不同级别的文档结构信息;
顾等人。提出了 CopyNet 复制网络。一方面,它可以复制和保留源文本中的重要信息。另一方面,输出可以生成一些与源文本不同措辞的摘要。限制:完整复制输入信息,不能灵活调整。;
见等。提出了一种灵活选择的指针*敏*感*词*网络,以及一种处理重复问题产生的覆盖机制;
2018年,Paulus等人首先提出使用强化学习,应用自我批评策略梯度算法训练模型,将强化学习损失与传统交叉熵损失相结合,因此可以使用不可微分的评价指标ROUGH和BLEU来提高可读性;
曹等人。使用开放信息提取和依赖分析技术从源文本中提取实际的事实描述,以避免模型生成的摘要中的信息不一致。他们还提出了双重注意。
序列到序列框架允许模型基于原创文本和提取的事实描述生成摘要。实验证明,它可以减少80%的虚假事实;
许等人。提出了提取和生成方法的组合。首先使用抽取模块对句子的重要性进行打分,并在此基础上使用生成模块更新每个词在原创文章值中的注意力权重,然后生成摘要逐字逐句;
周等人。在encoder中加入Selective gating network,将词的隐藏层状态和句子的隐藏层状态拼接在一起,输入前馈网络生成新的语义向量;
在抽取方法中,深度学习的作用主要体现在提升分类模型的性能,尽可能使输出结果符合标准数据的分布。生成方法取得突破,改变了生成自动摘要的研究思路,
基于深度学习的生成方法模拟人类书写习惯,输出结果收录原文中不存在的表达。深度学习端到端的训练方法,正式让自动摘要的任务成为迈向人工智能的重要一步。但这是不可避免的
,深度学习方法也存在一些不足,比如需要大量高质量的标注数据,缺乏参数调整的理论指导。未来,研究人员需要设计更高效的算法来满足大数据下自动摘要的需求。
2.数据集介绍
中文数据集:
1)LCSTS:中文短文本摘要数据集,采集认证用户在新浪微博上发布的超过200万条中文短文本。2.4×10(6)文本对训练集,1×10(4)文本对验证集和1.1×10(3)
一组测试文本对。其中,验证集和测试集增加了摘要与原文的相关性得分。得分越高,相关性越高,便于研究者根据不同任务的特点调整数据集的使用。
2)NLPCC:中文微博新闻摘要。NLPCC-2015收录从新闻门户网站采集的140篇标题新闻文章文章,每篇对应2个人工生成的标准摘要(不超过140个汉字);NLPCC-2017 提供了收录标准摘要和两个不收录标准摘要的训练数据集。每个训练集收录 5000 个新闻文档。
3)搜狐新闻数据集:根据不同的预处理方式,可用于文本分类、事件检测与跟踪、新词发现、命名实体识别、自动抽象等任务,收录140万条新闻文本和新闻标题。
英文数据集:
1)CNN/Darly Mail:新闻数据集,包括286817个训练对、13368个验证对和11487个测试对;
2)Gigaword:海量数据,约950万篇新闻文章文章,3.8*10^6训练集,1.89*10^5验证集和1951测试集。
3)DUC/TAC:仅用于评估目的的小规模数据集,
目前常用的汇总数据集有DUC-2002、DUC-2003、DUC-2004。DUC-2002 收录 567 个文档,每个文档有 2 个人工生成的 100 字的摘要;DUC-2003 收录
624对文章摘要;DUC-2004 收录 500 篇文档,每篇新闻文章都有对应的 4 个不同的人工生成的 75B 截取的参考摘要
4)纽约时报:纽约时报经过预处理,由员工撰写的 650,000 多篇摘要和 150 万篇人工注释的 文章 以及个人、组织、地点和主题内容组成。归一化索引表可用于自动摘要、文本分类和内容提取等任务。更适合作为抽取式自动文摘。
5)Newsroom:可用于训练和评估自动摘要系统的大型数据集,包括 130 万个 文章 和摘要,可用作生成和提取方法。
6)Bytecup:130万条新闻文章的文本摘要方法回顾
序列到序列(Seq2Seq)框架模型
1.2015 年,受神经机器翻译 (NMT) 的启发,Rush 等人。首先提出了一种基于注意力机制(编码器)+神经网络语言模型(NNLM)(*敏*感*词*)的生成式摘要模型;
2016 年,Chopra 等人。改进了RNN(*敏*感*词*),效果显着,常用作基线模型;
同年,Nalapati 等人引入了一些新技术:在编码器中加入富文本特征捕获关键词;增加*敏*感*词*指针,解决字典外词汇(OOV)和低频词的问题;使用分层注意力机制来捕获不同级别的文档结构信息;
顾等人。提出了 CopyNet 复制网络。一方面,它可以复制和保留源文本中的重要信息。另一方面,输出可以生成一些与源文本不同措辞的摘要。限制:完整复制输入信息,不能灵活调整。;
见等。提出了一种灵活选择的指针*敏*感*词*网络,以及一种处理重复问题产生的覆盖机制;
2018年,Paulus等人首先提出使用强化学习,应用自我批评策略梯度算法训练模型,将强化学习损失与传统交叉熵损失相结合,因此可以使用不可微分的评价指标ROUGH和BLEU来提高可读性;
曹等人。使用开放信息提取和依赖分析技术从源文本中提取实际的事实描述,以避免模型生成的摘要中的信息不一致。他们还提出了双重注意。
序列到序列框架允许模型基于原创文本和提取的事实描述生成摘要。实验证明,它可以减少80%的虚假事实;
许等人。提出了提取和生成方法的组合。首先使用抽取模块对句子的重要性进行打分,并在此基础上使用生成模块更新每个词在原创文章值中的注意力权重,然后生成摘要逐字逐句;
周等人。在encoder中加入Selective gating network,将词的隐藏层状态和句子的隐藏层状态拼接在一起,输入前馈网络生成新的语义向量;
在抽取方法中,深度学习的作用主要体现在提升分类模型的性能,尽可能使输出结果符合标准数据的分布。生成方法取得突破,改变了生成自动摘要的研究思路,
基于深度学习的生成方法模拟人类书写习惯,输出结果收录原文中不存在的表达。深度学习端到端的训练方法,正式让自动摘要的任务成为迈向人工智能的重要一步。但这是不可避免的
,深度学习方法也存在一些不足,比如需要大量高质量的标注数据,缺乏参数调整的理论指导。未来,研究人员需要设计更高效的算法来满足大数据下自动摘要的需求。
2.数据集介绍
中文数据集:
1)LCSTS:中文短文本摘要数据集,采集认证用户在新浪微博上发布的超过200万条中文短文本。2.4×10(6)文本对训练集,1×10(4)文本对验证集和1.1×10(3)
一组测试文本对。其中,验证集和测试集增加了摘要与原文的相关性得分。得分越高,相关性越高,便于研究者根据不同任务的特点调整数据集的使用。
2)NLPCC:中文微博新闻摘要。NLPCC-2015收录从新闻门户网站采集的140篇标题新闻文章文章,每篇对应2个人工生成的标准摘要(不超过140个汉字);NLPCC-2017 提供了收录标准摘要和两个不收录标准摘要的训练数据集。每个训练集收录 5000 个新闻文档。
3)搜狐新闻数据集:根据不同的预处理方式,可用于文本分类、事件检测与跟踪、新词发现、命名实体识别、自动抽象等任务,收录140万条新闻文本和新闻标题。
英文数据集:
1)CNN/Darly Mail:新闻数据集,包括286817个训练对、13368个验证对和11487个测试对;
2)Gigaword:海量数据,约950万篇新闻文章文章,3.8*10^6训练集,1.89*10^5验证集和1951测试集。
3)DUC/TAC:仅用于评估目的的小规模数据集,
目前常用的汇总数据集有DUC-2002、DUC-2003、DUC-2004。DUC-2002 收录 567 个文档,每个文档有 2 个人工生成的 100 字的摘要;DUC-2003 收录
624对文章摘要;DUC-2004 收录 500 篇文档,每篇新闻文章都有对应的 4 个不同的人工生成的 75B 截取的参考摘要
4)纽约时报:纽约时报经过预处理,由员工撰写的 650,000 多篇摘要和 150 万篇人工注释的 文章 以及个人、组织、地点和主题内容组成。归一化索引表可用于自动摘要、文本分类和内容提取等任务。更适合作为抽取式自动文摘。
5)Newsroom:可用于训练和评估自动摘要系统的大型数据集,包括 130 万个 文章 和摘要,可用作生成和提取方法。
6)Bytecup:130 万篇新闻文章文章 收录 110 万篇文章作为训练集。每篇文章文章收录文章 ID、内容和标题。由于标题较短,更适合生成。

