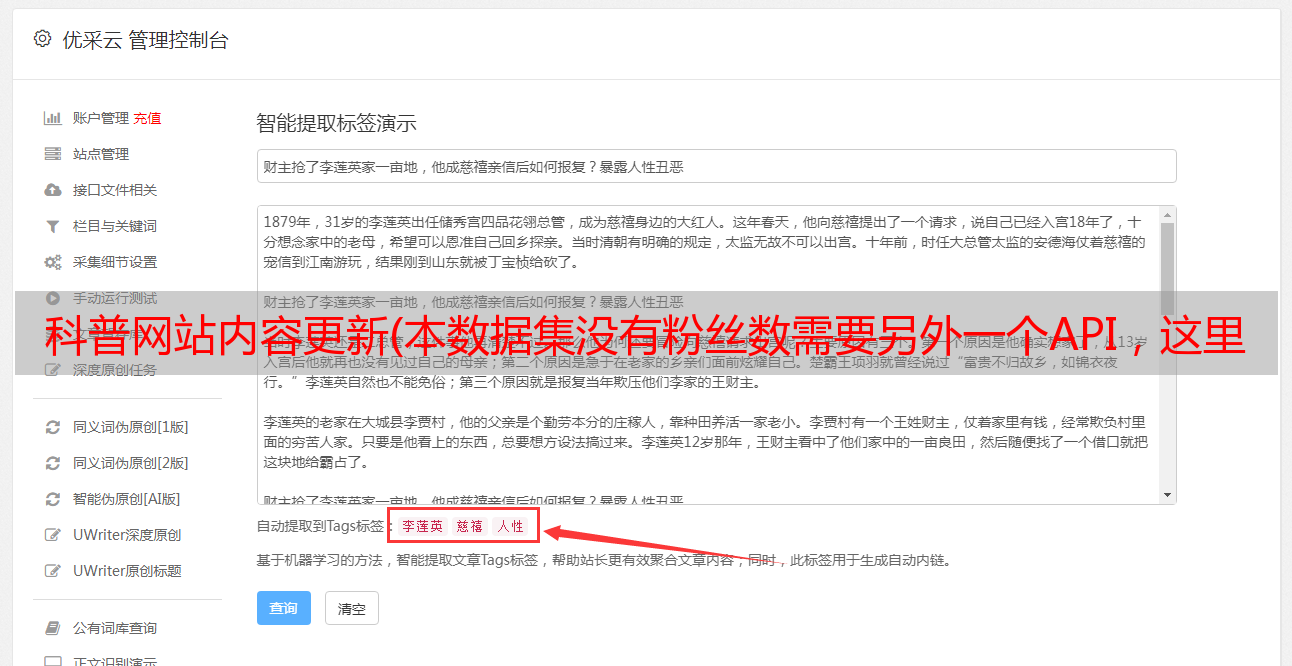
科普网站内容更新(本数据集没有粉丝数需要另外一个API,这里我很多小伙伴都已经写过怎么爬去数)
优采云 发布时间: 2021-10-04 03:37科普网站内容更新(本数据集没有粉丝数需要另外一个API,这里我很多小伙伴都已经写过怎么爬去数)
注:本数据集没有粉丝数。粉丝数量需要另一个API。很多朋友已经写过粉丝数的爬升方法了,就不赘述了。
文章内容
目的明确
首先,在进行数据分析之前,我们需要知道我们用这些做什么?? ?
这很简单!想去B站,关注一些优质科普(技术)UP帮我学习~
读取数据
我们只需要科普区,提取关键栏目“科普”,提取我们要使用的关键字段进行分析
注:数据集303M已经爬取了很多,不光是科普区,其他的也有。我这里只提取了部分数据进行分析。
import pandas as pd
data=pd.read_csv('./tech.csv')
sci=data.loc[data['分区']=='科学科普']
sci=sci[['分区','author','coins','danmu','favorite','likes','reply','share','view','title','date']]
sci.head()
RFM-IFL模型
我们如何得到我们想要的成员!相信很多朋友都知道RFM模型是用来做用户画像的,所以我们同样使用RFM的原理来搭建IFL模型
I:interaction_rate 反映了每个视频的平均交互率
F:Frequency代表每个视频的平均发布周期
L:like_rate 表示统计期内发布视频的平均点赞率
IFL 模型评估和分析视频质量
F
F 反映视频周期。与 RFM 模型一样,它也对频率做出响应。这是响应更新的频率。经常摘下来就不行了!
首先肯定是视频数量超过5个以上,不然我关注她的照片,是不是比我年轻漂亮
count=sci.groupby("author")['分区'].count().reset_index()
count.columns=['author','times']
com_m=pd.merge(count,sci,on='author',how='inner')
com=com_m[com_m['times']>=5]
com
那我们就开始计算平均更新间隔吧~更新时间太长了,不行不行,我等不及了,越小越好?不不不!如果只有0,那肯定是转发,不行不行,这样不行。
import datetime as dt
com['date']=pd.to_datetime(com.date)
last=com.groupby("author")['date'].max()
late=com.groupby("author")['date'].min()
F=round((last-late).dt.days/com.groupby("author")['date'].count()).reset_index()
F.columns=['author','F']
F=pd.merge(com,F,on='author',how='inner')
F.describe()
F
这个不够直观,用describe()看看F是什么样子的
果然有喜欢转发的,看到F下面的0了吗!找到它,删除它!如何找到它(索引)?当然是idxmin函数啦~
F.loc[F['F'].idxmin()]
我让他有机会看看这个 UP 有什么其他特点
emmmmmm 不太好,好吧,都是转载的,可惜这个UP被我删了
F=F.loc[F['F']>0]
F.describe()
找到 F 值。接下来我们来看看I值的效果,看看大家有没有和这个UP互动过。如果再多点互动,应该还是证明UP是一个很温柔很漂亮的人。
一世
什么指标可以反映I值?
大家可以看看他的回复(reply)评论之类的,看看他们的总和!越多越好!
danmu=F.groupby('author')['danmu'].sum()
reply=F.groupby('author')['reply'].sum()
view=F.groupby("author")['view'].sum()
count=F.groupby("author")['date'].count()
I=round((danmu+reply)/view/count*100,2).reset_index()
I.columns=['author','I']
I=pd.merge(F,I,on='author',how='inner')
I
L值
点赞率有多重要?咳咳暗示大家给我点赞和评论。哈哈哈,点赞率可以反映大家对这个UP视频的认可度。当然,L值越大越好!
I['xixi']=(I['likes']+I['coins']*2+I['favorite']*3)/I['view']*100
L=(I.groupby("author")['xixi'].sum()/I.groupby("author")['date'].count()).reset_index()
L.columns=['author','L']
IFL=pd.merge(I,L,on='author',how='inner')
IFL=IFL[['author','I','F','L']]
IFL
造型
你认为IFL可以计算吗?如何衡量它们的质量?当然是建立指标。
三项指标均取平均值。先打分。如果F值大于平均值,即emmmm发生变化。给他打0分一点也不为过,我们要严格一些。现在有一个可以选择的UP。哈哈哈,大于平均值设置为1;其他两个指标如果大于平均值则设置为1,如果小于平均值则设置为0。
分数
首先为他们画一个舞台
IFL['I_score']=pd.cut(IFL['I'],bins=[0,0.03,0.06,0.11,1000],labels=[1,2,3,4],right=False).astype(float)
IFL['F_score']=pd.cut(IFL['F'],bins=[0,7,15,30,90,1000],labels=[5,4,3,2,1],right=False).astype(float)
IFL['L_score']=pd.cut(IFL['L'],bins=[0,5.39,9.07,15.58,1000],labels=[1,2,3,4],right=False).astype(float)
IFL.head()
平均除法
IFL['I_OK']=(IFL['I_score']>IFL['I_score'].mean())*1
IFL['F_OK']=(IFL['F_score']>IFL['F_score'].mean())*1
IFL['L_OK']=(IFL['L_score']>IFL['L_score'].mean())*1
IFL
类型划分
IFL['人群数值']=(IFL['I_OK']*100)+(IFL['F_OK']*10)+(IFL['L_OK']*1)
IFL
def transform_label(x):
if x==111:
label='高质量UP主'
elif x==101:
label='高质量拖更UP主'
elif x==11:
label='高质量内容高深UP主'
elif x==1:
label='高质量内容高深托更UP主'
elif x==110:
label='接地气活跃UP主'
elif x==10:
label='活跃UP主'
elif x==100:
label='接地气UP主'
elif x==0:
label='还在成长的UP主'
return label
IFL['人群类型']=IFL['人群数值'].apply(transform_label)
data=IFL[['人群类型','author']]
data=pd.merge(sci,data,on='author',how='inner')
data=data[['author','title','人群类型']]
data=data.drop_duplicates("author").reset_index()
data.to_csv("/media/yefanyefan/新加卷/AA/work/fin/UP.csv",index=False)
好吧~根据自己的需要去分析一下你要关注的UP~

