百度伪原创检测工具(为什么你通过采集发的文章没有排名被K站? )
优采云 发布时间: 2021-09-28 02:01百度伪原创检测工具(为什么你通过采集发的文章没有排名被K站?
)
自8月底飓风算法3.0上线以来,仅仅过去了20天,也就是2019年9月18日。百度发布了搜索违规处理通知,共处理了528万条不良信息案例采集网站。相信很多站长都欲哭无泪。
中国大环境浮躁,很多SEO人喜欢吃快餐。优采云、DEDEcms采集程序火爆,伪原创的工具也别具一格。但是3.0飓风过后,如果不改变采集的方式,采集会死得更快!
很多站长都没有意识到事情的严重性,一些智者(SHA)(HAI)(ZI)和一些纯粹的采集,一些牛破站长发誓要跟着代码粉丝说,老子的站还是收录没问题,老子的算法可以通过百度的原创检测,老子的伪原创工具很给力。你甚至不看你的网站收录。有500w,但是有多少索引词有排名?一周内 收录 还会增加多少?
您的 采集 站已关闭,而人们确实会出现 原创。Duang,一个代码迷的合作网站,突然词汇量翻倍,尴尬,幸福来的这么突然,哈哈哈。
好歹百度也养了一批985、211程序员。大搜的算法虽然垃圾,但百度三代原创检测系统升级后,大部分伪原创的方法至今没有效果。但这不代表你不能做采集,也不代表你不能做伪原创。码迷觉得飓风算法3.0没那么深,路一尺高,魔方一尺高。
同样是采集,同样是伪原创。有些人发了100篇文章,百度做了100次。而有的人发100篇文章,就可以进入百度的重要索引,索引词都在。
比如下面这个例子,采集处理的也是优质内容,就是首页排名。
今天就说说为什么你通过采集发送的文章没有排名,没有收录,甚至被K驻守。一些大神认为是运气,哈哈哈哈。很多人不知道,往往是因为他们甚至不知道百度飓风是什么。
已知无用 伪原创 意味着
《SEO实战密码》总结了6种内容作弊方式,已被百度识别。无论是同义词替换,还是干脆对原来的文章进行改动,都不可能出现收录。不再有用的 伪原创 方法包括以下内容:
1 更改(完全重写)标题
2 颠倒段落顺序
2 添加段落原创,比如在开头添加内容摘要
3 简单的文字增删改查,如感叹词、修饰语
4 同义词替换
5 强行插入关键词,如在小说中强行插入关键词
如果你作为一个黑帽SEO高手,还用上面的方法,放下屠刀成佛,做你该做的,别浪费时间了。
百度这块已经说了,百度有自己的词库,有的人做伪原创只是用同义词替换,特别是某站长工具站还推出了同义词替换工具,叫做Smart伪原创。聪明人,你比百度聪明吗??
例如,当您在百度上搜索xx 品牌时,这些品牌就会变得流行。
不敢写AI伪原创的评论,怕会得罪一些人,但在圈内找了几个用伪原创的站长,举报飓风3上线后, 收录@ >一日不如一日。比如你今天发了1000个伪原创文章,下午就会有收录500个,明天收录收录不到100个, 伪原创 90%以上的内容已被百度识别。
如下图,左边是原文,右边是AI伪原创的结果。可以看到句子和很多单词的顺序都发生了变化。基本上每个句子都不一样。最近很多人都在热推AI伪原创,认为百度收录可以用来排名。
呵呵,AI伪原创好鸡巴,关注采集的老站长感觉自己筋骨都打开了,终于可以大干一场了。
然后码迷直接问了做smart伪原创的卖家有没有百度的情况,然后就被他喷了又喷了。. . “我欠你的”?
码迷偶尔看到《SEO:搜索引擎如何识别内容原创?独家揭秘SEO指纹算法!》感觉很有道理。来源在哪里?如果是自己做的,这里省略100字。
SEO高手和小白有什么区别?只要知道它是什么以及为什么会这样。我见过太多的站长认为自己很棒,然后给自己打耳光。还没有轮到百度打他们。不知道原理就开始乱搞,有毛线效果。来吧,和粉丝一起潜入飓风算法。
根据专利《CN2-A网页重复判断系统及其判断方法》,这是2011年左右的老专利,可以说是百度第一代伪原创识别系统。主要的方法是对网页的结构化数据做simhash。
通过这种识别方式,采集连标题和正文都没有修改,基本没戏了。
主要步骤如下:
在本实施例中,在判断网页重复时,如果两个网页满足以下任意一项,则认为这两个网页是真实重复的:
1、两个网页真实标题的签名是一样的。
2、两个网页的网页内容的签名是一样的。
3、两页正文签名中的不同位数少于6位。
4、两个网页的页面位置签名相同,url文件名签名相同。
5、评论块签名、资源签名、标签标题签名、摘要签名、url文件名签名三个签名是一样的。
缺点:
该算法需要对网页的五个维度进行签名计算。代码迷觉得这个算法计算量太大了。估计百度试了一段时间就放弃了。
另外,修改一个字符签名就不一样了,很容易破解。
很多人说“百度就是垃圾”,码迷觉得有道理。码迷表示,第一代计算量太大,成本高。毕竟竞价排名赚钱。自然排名是通过这种高级重复数据删除算法实现的。彦宏不喜欢。那么如何找到最简单的减肥方法呢?
百度程序员说:
让我们从整个网页中提取一个最长的句子,并根据提取的最长句子的签名对其进行分组。在同组中,会根据标题的Pearson距离(计算网页内容的相似度)和链接发现时间进行原创性网页的识别,即判断谁是同组真正的原创。
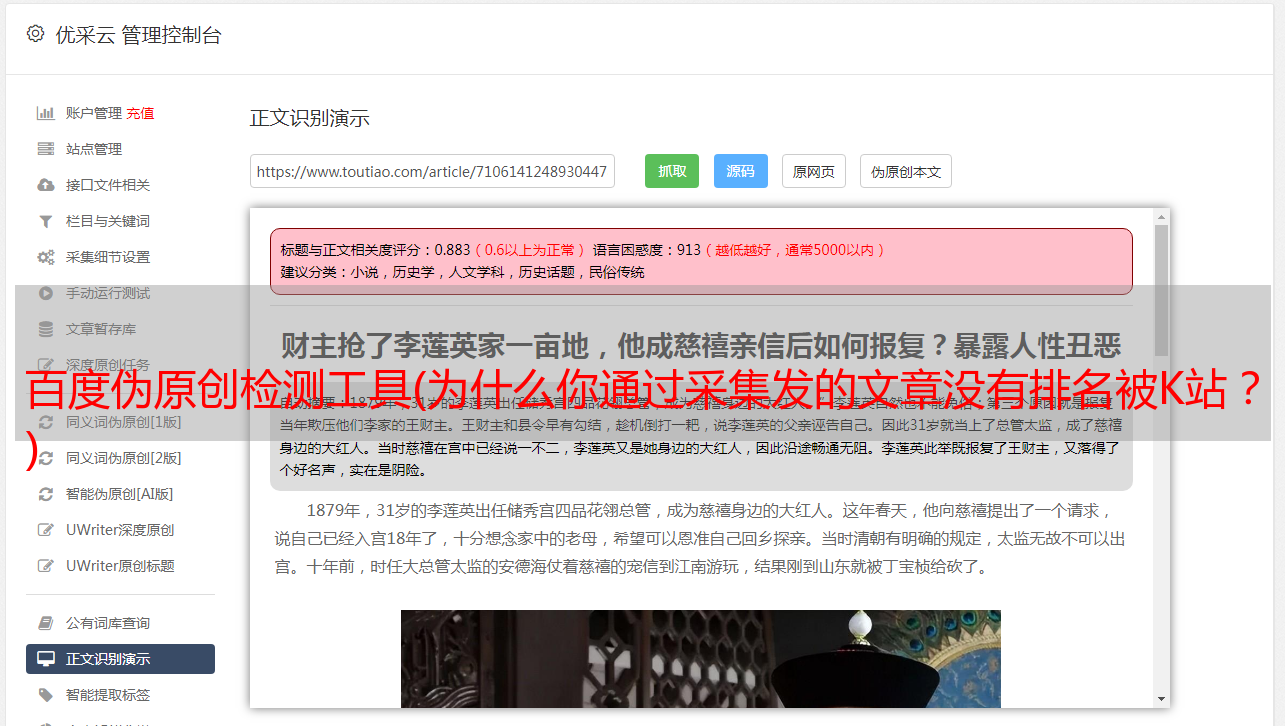
优势:
这个原创度识别方法码迷推测应该已经存在很久很久了。这种方法的优点是计算量小。
缺点(残缺):
仅以最长的句子为依据,误判率相当高。
由于二代方法效果不佳,百度终于推出了飓风算法(2017年7月7日上线),并且相应的专利申请是在2017年3月底,所以时间点也比较一致。基本思想是用simhash算法对句子进行签名,然后用汉明距离做原创度检测。
什么是同义词级 simhash
不懂也没关系,先了解一下simhash算法吧。码迷简单举个例子。一张图片胜过千言万语。
如果您是算法专家,可以访问门户:了解 simhash 算法。
那么回到AI原创的问题,因为百度飓风3.0根据句子级别的simhash去重,我们假设:
前提1:伪原创为100字的句子长度
先决条件2:比较句子的签名,伪原创,编辑距离后位数小于10,汉明距离小于10,汉明相似度大于80%
判断结果:抄袭
百度一定有自己的汉明距离阈值。一个 100 个字符的句子已经是一个很长的句子。其实百度的汉明距离阈值应该更小。我们上面的假设已经相当广泛。
如果不知道编辑距离,可以看汉明距离(也叫汉明距离)
百度百科“编辑距离”:%E7%BC%96%E8%BE%91%E8%B7%9D%E7%A6%BB/8010193?fr=aladdin
百度百科《汉明距离》:%E6%B5%B7%E6%98%8E%E8%B7%9D%E7%A6%BB/4235876?fr=aladdin
你不会编程,没关系,代码爱好者会的。码迷有现成的分词方法,还有停用词过滤程序,直接使用github上的程序。
参考:
码迷在网易的文章上随便找了一篇文章,询问simhash的编辑距离和汉明距离。
最后结果:
百度的原创级别无假设,编辑距离6,汉明距离8,相似度高达87.5%
马咪不死心,又要了一个AI伪原创:
最后结果:
百度的原创级无假设,编辑距离7,汉明距离10,相似度高达84.3%
码迷还不死心,又要了一个AI伪原创:
最后结果:
他xx什么破AI伪原创,编辑距离才4,汉明距离6,相似度高达90%!百度一个渣子都没有了,别让孩子走,好吗?
首先,直接伪原创传百度原创并不容易
如果百度有几千人做开发,一个伪原创能通过百度测试吗?所以大家,不要直接采集别人的内容,给自己网站发一点伪原创,这就是死。
其次,反义词替换句子没用
一些 网站 声称拥有数十万同义词数据库。码迷告诉大家百度的词库比你们任何词库都要丰富得多,为了压缩索引,他们的词库还是词性。另外,句子反转不会影响simhash算法的结果。
但是有些人是靠采集来做排名的。为什么?有些人可以通过采集的组合进行排名,即使不需要去伪原创,也可以在百度上排名。码凡网站的一个合伙人,还没起床之前被飓风算法打过的人渣,但是码凡研究过要求他更新采集组合算法后,又回到了过去的美好~

