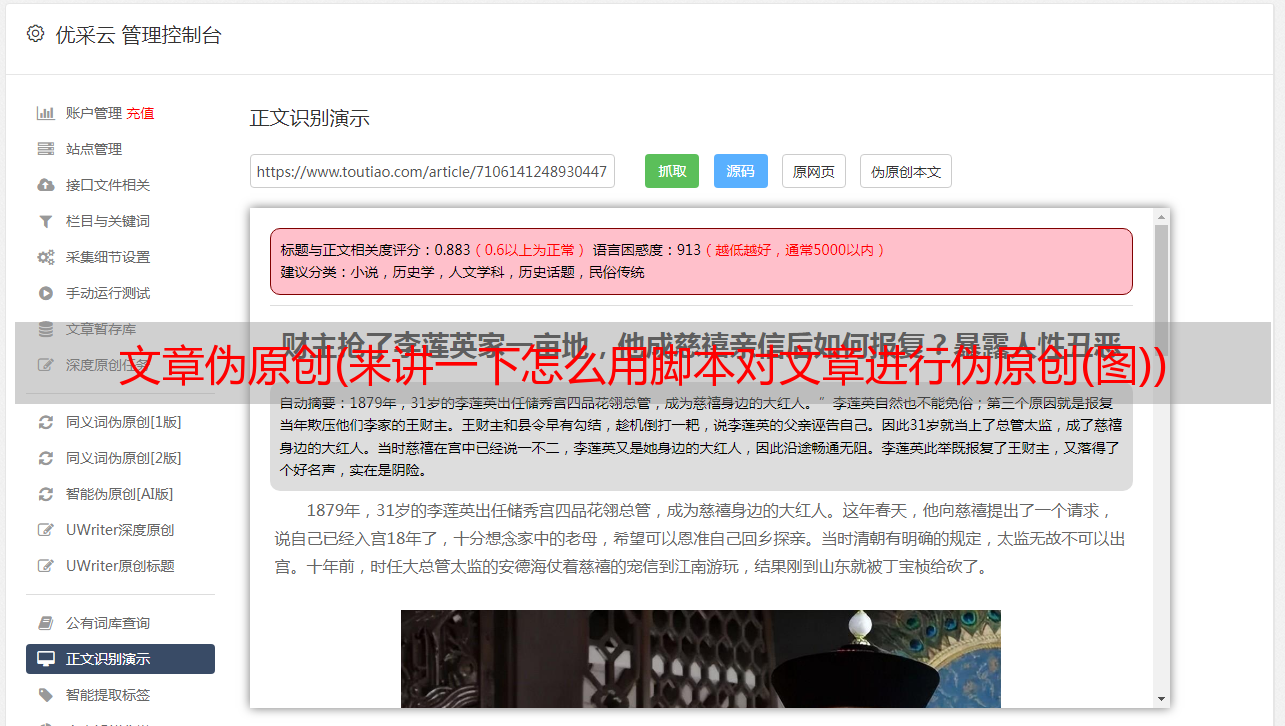
文章伪原创(来讲一下怎么用脚本对文章进行伪原创(图))
优采云 发布时间: 2021-09-26 00:20文章伪原创(来讲一下怎么用脚本对文章进行伪原创(图))
大家好,我是3分钟学校公众号郭丽。今天继续讲解安卓版的按钮精灵。本期我们将讨论如何使用脚本将文章转为伪原创。
什么是文章伪原创
伪原创的意思是重新处理原创的文章的一篇文章,让搜索引擎认为它是一篇原创文章,从而提高网站重量。编辑方式有两种:一键修改标题,二是首尾小结。
参考数字代换法、词代换法、文字排序法、首段汇总法、尾汇总法、新增图片、段落替换法、关键词替换法。
文章伪原创有什么用
这东西现在其实用处不大。它通常用于搜索引擎优化。对搜索引擎(百度、谷歌、360搜索)“撒谎”,让搜索引擎认为你发的文章是原创,认为你的文章有价值,然后为您的页面提供更高的搜索排名。
那为什么没用呢?
一是搜索引擎(百度、谷歌、360搜索)越来越智能了,稍微改动一下就知道了。
二是搜索引擎本身没有流量,靠他们吃饭有什么前途。
文章伪原创 词替换法
伪原创的单词替换方法是用同义词替换,比如:
原文:大多数女人喜欢买化妆品。
伪原创:很多女性喜欢买护肤品。
这两个句子在文本层面上有所不同,但从句的含义却非常相似。这是伪原创。
在上面的例子中,我们具体替换哪些词,我们一一抽取:
女人 => 女士
大部分 => 很多
爱 => 喜欢
化妆品=>护肤品
伪原创 工具的同义词“库”中的单词越多,伪原创 就越好。因此,当我们自己制作伪原创脚本时,同义词词典必须不断更新和完善。
当然,伪原创 也有它的缺点。我们知道,汉字博大精深。有时经过一点点改动和词变,它们看起来不像人类语言。所以在伪原创之后你需要稍微阅读一下,看看是否有任何明显的语言障碍。地方,如果有任何手动修改。
伪原创脚本说明
一、伪原创 脚本中使用的命令:
(1)for 循环,用于遍历所有同义词
(2)replace 替换命令,用于替换同义词
这两个是主要的命令,还有读文本命令和写文本命令。
二、脚本创意
(1) 先把同义词写入库(正文)。
考虑到文本utf8编码,因为bom头在文本开头会有一个问号,文本第一行空白,第二行写。
注:Curry同义词越多越好,如果需要伪原创平时积累更多同义词,或者百度查同义词。
(2)读取测试
Dim ku=file.readlines("/sdcard/pictures/伪原创.txt")
对于 i = 0 到 UBOUND(ku)
TracePrint ku(i)
下一个
(3) 拆分相似的词
Dim ku=file.readlines("/sdcard/pictures/伪原创.txt")
点心
对于 i = 1 到 UBOUND(ku)
ci = Split(ku(i), "----")
TracePrint ci(0)
TracePrint ci(1)
下一个
(4)单向替换
所谓单向替换,就是用后面的词替换前一个词,比如woman-lady,单向替换,即只有woman才能被woman替换。
Dim ku=file.readlines("/sdcard/pictures/伪原创.txt")
” Dim str="大多数女性喜欢购买化妆品。
点心
对于 i = 1 到 UBOUND(ku)
ci = Split(ku(i), "----")
TracePrint ci(0), ci(1)
str = 替换(str, ci(0), ci(1))
下一个
跟踪打印字符串
单向替换是有问题的,它会减少一半的同义词,所以我们不得不使用双向替换。
(5) 双向替换
双向替换,第一反应是反方向进行同义词替换,即将后面的词替换为前面的词。
思路是对的,但是实际写起来会有问题。
让我们以女人和女士的同义词对为例。例如,文章 中有两个词。
如原文:woman和lady是一组同义词。
替换①:女性替换女性
伪原创:Ms. 和 Ms. 是一组同义词。
基于替换的反向替换①:
替换②:女性替换女性
伪原创:女人和女人是一组同义词。
双向替换后,我们会发现根本不是我们想要的,我们想要的是:
原文:woman和lady是一组同义词。
伪原创:lady 和woman 是一组同义词。
问题出在哪儿?
第一次替换的内容被第二次替换。当我们实际上希望替换后的 关键词 不会改变。
我想到的解决方案是“保护”替换的单词,那么如何保护呢?
使用特殊符号拆分和包装替换的单词。
比如女性代替女性,我们用※来保护:
如原文:woman和lady是一组同义词。
保护替代①:女性替代女性
伪原创:※女※士※和女士是一组近义词。
基于替换的反向替换①:
替换②:女性替换女性
伪原创:※女※士※和※女※人※是一组同义词。
TracePrint baohu("abc")
函数包呼(n)
昏暗的 arr()
For i = 1 To UTF8.Len(replace(n," ",""))
arr[i]=UTF8.StrGetAt(n,i)
下一个
baohu="※"&join(arr,"※")&"※"
结束函数
当所有更换完成后,我们会再次解除※保护,恢复正常文章。
这里特别强调的是,用于保护的符号非常罕见。如果 文章 有这个符号,它也会被删除。
脚本代码及注意事项
关于file命令,如果您是低版本的按键助手,可以直接使用,如果您是高版本的按键助手,请使用自带的fileEx命令,防止代码因以下原因无法使用命令错误。
我这里关键助手的版本是3.6.5,所以我使用fileEx命令。
导入“fileEx.lua”
Dim ku=fileEx.readlines("/sdcard/pictures/伪原创.txt")
Dim str="woman 和 Lady 是一组同义词"
Dim ci,qian,hou,ret
对于 i = 1 到 1
ci = Split(ku(i), "----")
qian = baohu(ci(0))
hou = baohu(ci(1))
str = Replace(str, ci(0), hou)
str = 替换(str, ci(1), qian)
下一个
ret = Replace(str, "※", "")
TracePrint ret
函数包呼(n)
昏暗的 arr()
For i = 1 To UTF8.Len(replace(n," ",""))
arr[i]=UTF8.StrGetAt(n,i)
下一个
baohu="※"&join(arr,"※")&"※"
结束函数

