网页抓取解密(Java自定义抓取方式(6)-上海怡诺唐咨询)
优采云 发布时间: 2021-09-24 17:09网页抓取解密(Java自定义抓取方式(6)-上海怡诺唐咨询)
自定义捕获方法包括三个部分:从页面提取数据、从浏览器提取数据和生成数据
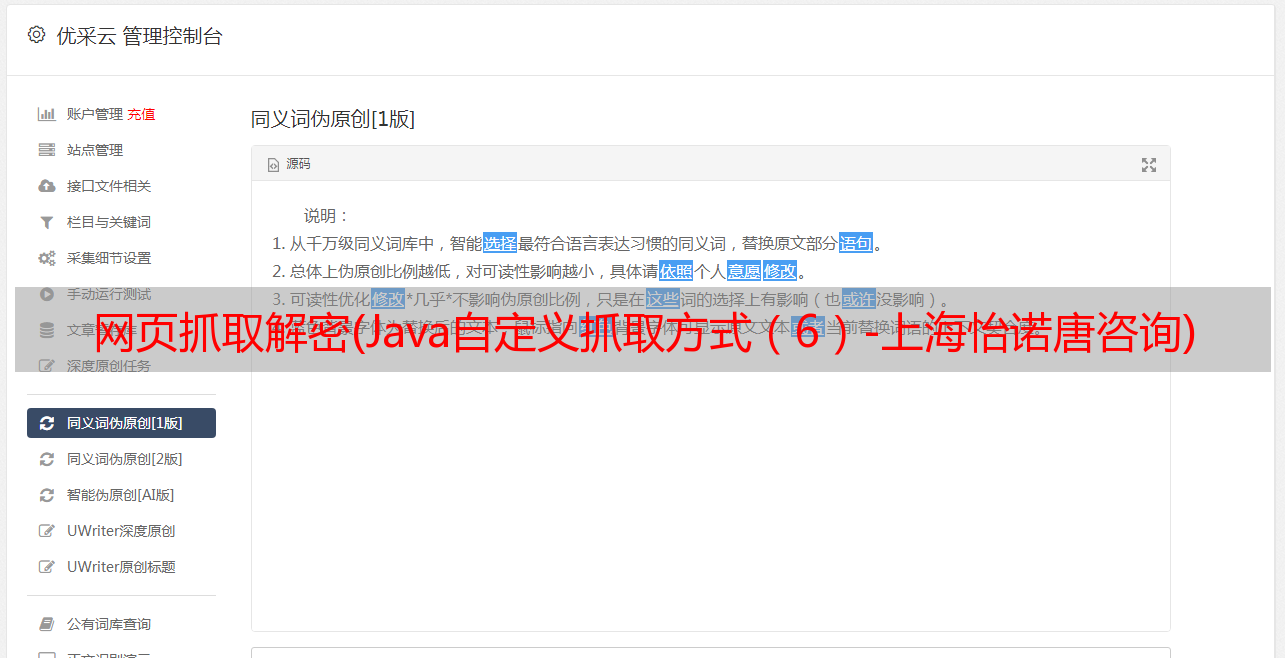
1、从页面中提取数据
(1)抓取元素的指定属性值:首先选择innerHTML和outerhtml以检查要提取的属性值是否存在,然后选择元素的指定属性值。例如,在流行的源代码中,ID、class和href是标记的属性。选择要提取的属性名称从下拉选项中提取属性的属性值,如下所示:
(2)抓取文本:提取网页中显示的内容和可见文本信息
(3)抓取地址:通常用于抓取图片地址或iframe地址。首先,在字段的XPath中找到IMG标记或iframe标记,并提取SRC属性值
(4)抓取所选项目的文本:尝试使用圆形下拉框提取当前所选项目的文本
(5)获取此元素的outerhtml和innerHTML:提取网页源代码
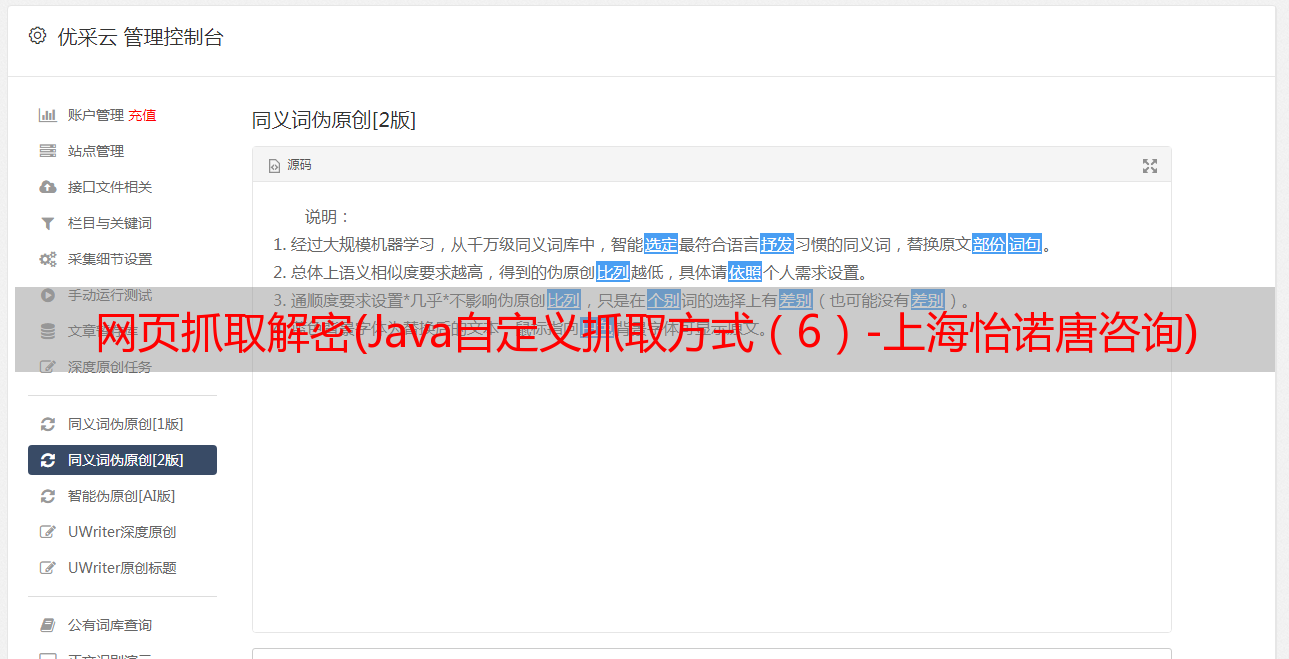
(6)抓取值:一般用于抓取输入框的文本,首先在字段的XPath中定位输入标签,提取值,演示如下:
(7)grab hyperlink:首先,找到字段到a标记的XPath,并从a标记中提取href的属性值。演示如下:
2、从浏览器中提取数据
(1)页面URL:与在其他特殊字段中添加捕获当前页面的URL效果相同
(2)页面标题:与在其他特殊字段中添加捕获当前页面的标题效果相同
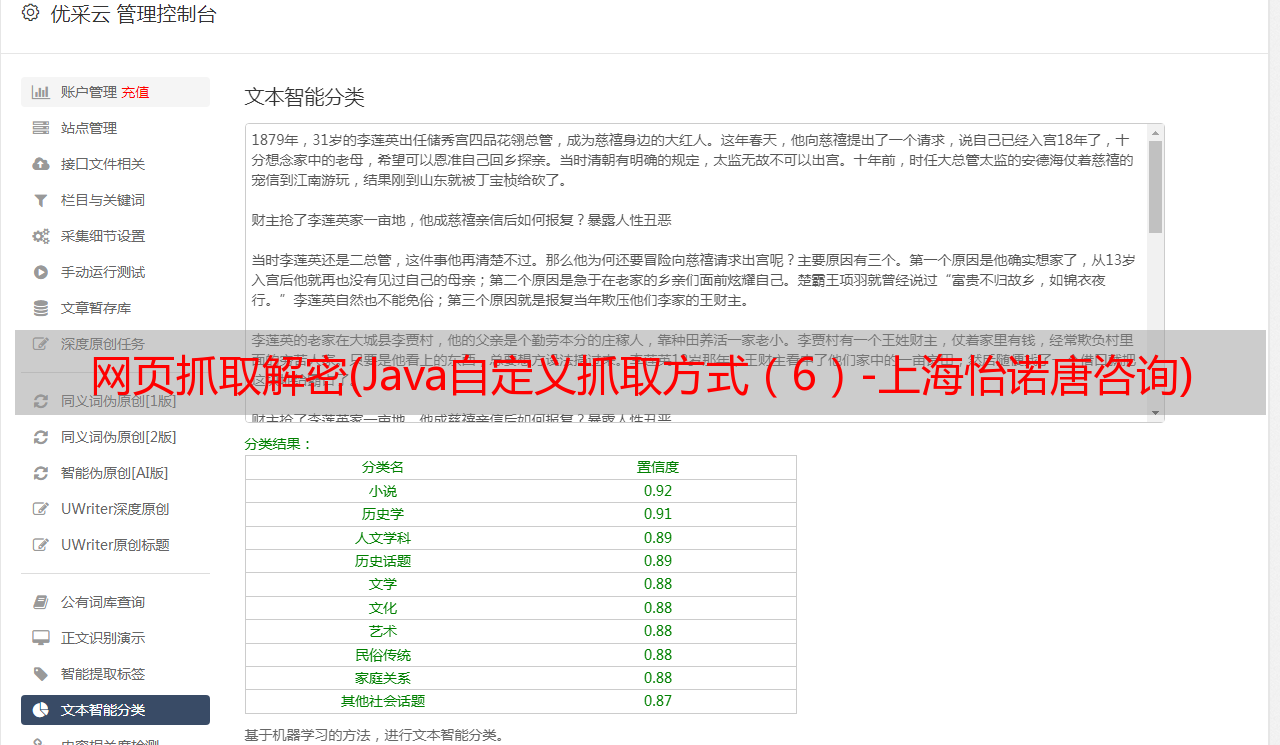
(3)grab from the page source code:您可以直接使用正则表达式从页面源代码中提取匹配数据
3、生成数据
(1)生成固定值:与在其他特殊字段中添加生成固定值的效果相同,通常用于设置发布到网站
(2)使用当前时间:与在其他特殊字段中添加使用当前时间记录时间的效果相同。此设置可能导致检测重复数据消除功能失败

