自然语言处理系列篇——关键词智能提取
优采云 发布时间: 2020-08-25 19:32自然语言处理系列篇——关键词智能提取
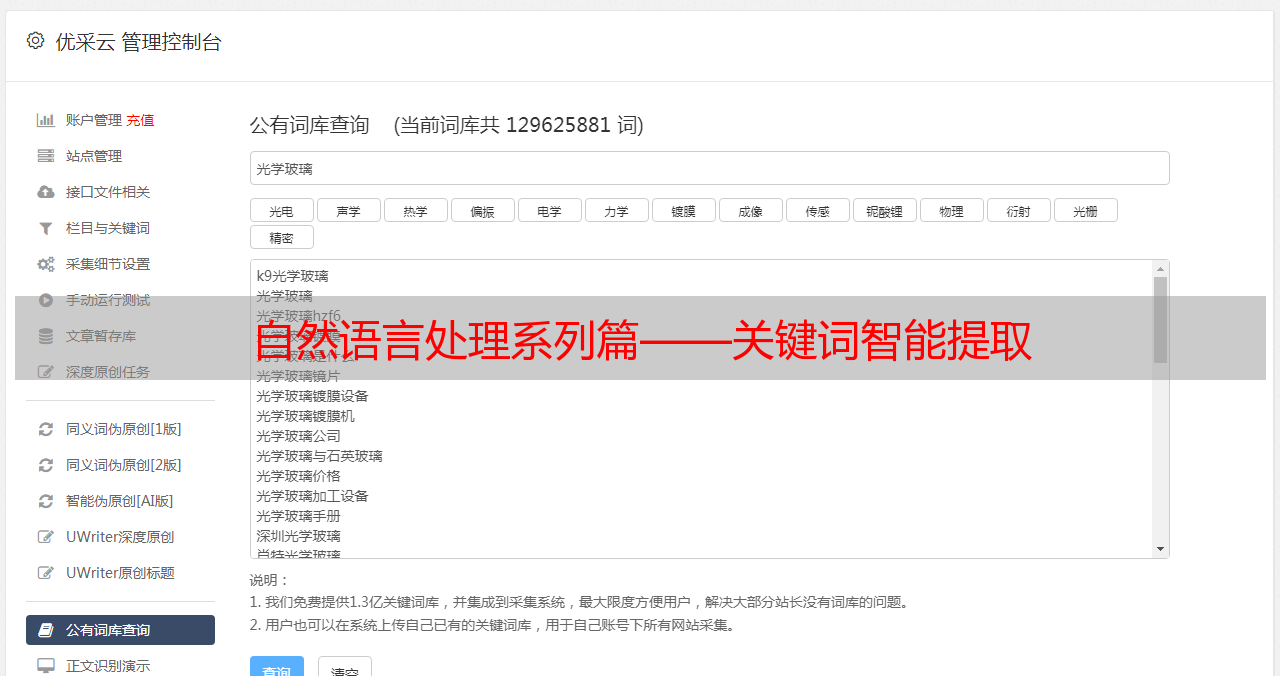
一.关键词手动标明简介
1.关键词手动标明
关键词是指能反映文本主题或则意思的词句,如论文中的Keyword主键。大多数人写文章的时侯,不会象写论文的那样明晰的强调文章的关键词是哪些,关键词手动标明任务正是在这些背景下形成的。
目前,关键词手动标明方式分为两类:1)关键词分配,预先定义一个关键词词库,对于一篇文章,从词库中选定若干词句作为文章的关键词;2)关键词抽取,从文章的内容中抽取一些词句作为关键词。
2.应用场景
在文献检索早期,由于当时还不支持全文搜索,关键词就成为了搜索文献的重要途径。随着网路规模的下降,关键词成为了用户获取所需信息的重要工具,从而诞生了如Google、百度等基于关键词的搜索引擎公司。
关键词手动标明技术在推荐领域也有着广泛的应用。如图1所示,当用户阅读图中右侧的新闻时,推荐系统可以给用户推荐收录关键词”Dropbox”、”云存储”的资讯,同时也可以依据文章关键词给用户推荐相关的广告。
图1基于关键词的资讯推荐系统关键词可以作为用户兴趣的特点,从而满足用户的长尾阅读兴趣。传统的信息订阅系统通常使用类别或则主题作为订阅的内容,如图2所示。如果用户想订阅更细细度的内容,这类系统就无能为力了。关键词作为一种对文章更细细度的描述,刚好可以满足上述需求。
图2传统的订阅系统不仅这种以外,关键词还在文本聚类、分类、摘要等领域中有着重要的作用。比如在降维时,将关键词相像的几篇文章看成一个类团可以大大提升K-means降维的收敛速率。从某日所有新闻中提取出这种新闻的关键词,就可以大致晓得这天发生了哪些事情。或者将某段时间中几个人的微博拼成一篇长文本,然后抽取关键词就可以晓得她们主要在讨论些哪些话题。
3.现有问题与挑战
文章的关键词一般具有以下三个特征[1]:
从上述三个特性,可以看见关键词标明算法的要求以及面临的挑战:a.新词发觉以及句子辨识问题,怎样快速辨识出网路上最新出现的词汇(人艰不拆、可行可珍视…)?b.关键词候选集合的问题,并不是文章中所有的成语都可以作为候选;c.怎么估算候选词和文章之间的相关性?d.如何覆盖文章的各个主题?
关键词分配算法须要预先定义一个关键词词库,这就限定了关键词候选范围,算法的可扩展性较差,且历时耗力;关键词抽取算法是从文章的内容中抽取一些成语作为标签词,当文章中没有质量较高的词句时,这类方式就无能为力了。为了解决上述这种问题和挑战,我们设计了层次化关键词手动标明算法.
二.层次化关键词手动标明算法
1.层次化关键词体系
针对新闻的关键词辨识任务,我们设计了一套层次化的关键词体系,如图3所示。第一层是新闻频道(体育、娱乐、科技、etc),第二层是新闻的主题(一篇新闻可以收录多个主题),第三次是文章中出现的标签词。
图3层次化关键词体系三层关键词体系有以下几个优点:
2.算法流程
从图3中可以看出,主题和标签词依赖于新闻频道,所以在标明一篇新闻的关键词时,首先须要获取新闻的类别,然后按照新闻的类别选择不同的主题模型预测新闻的主题,最后再抽取新闻中的标签词。
在关键词标明方式上,我们融合了关键词分配和关键词抽取两类技巧。图5描述了算法处理一篇文章的流程。其中频道和主题的抽取方式属于关键词分配这一类算法,标签词抽取则属于关键词抽取这一类算法。除了上一节中所说的层次化关键词的两个优点之外,我们的算法有如下几点益处:
2.1 文本分类器
文本分类器我们采用最大熵模型[2],使用业务最近一年带频道标签的新闻作为训练集。每个频道选定频道相关度最高的1W个词句作为分类特点。
对于最大熵模型,网上可以找到好多相关资料,这里就不作介绍了。
2.2 主题预测
使用LDA[3]作为主题降维模型。LDA开源的大部分开源实现都是单进程的,在处理较*敏*感*词*的语料时,其时间和显存开支都十分大,无法满足我们的要求。因此我们实现了一套分布式的LDA平台,使得就能快速处理*敏*感*词*的数据。
语料通过LDA平台处理后,会得到每位主题下机率较高的熟语。人工选定质量较高的主题,并使用一个成语或则词性概括这个主题。对于一篇文章,LDA的inference结果是一个机率向量,我们选定概率值小于阀值的主题作为文章所属的主题。
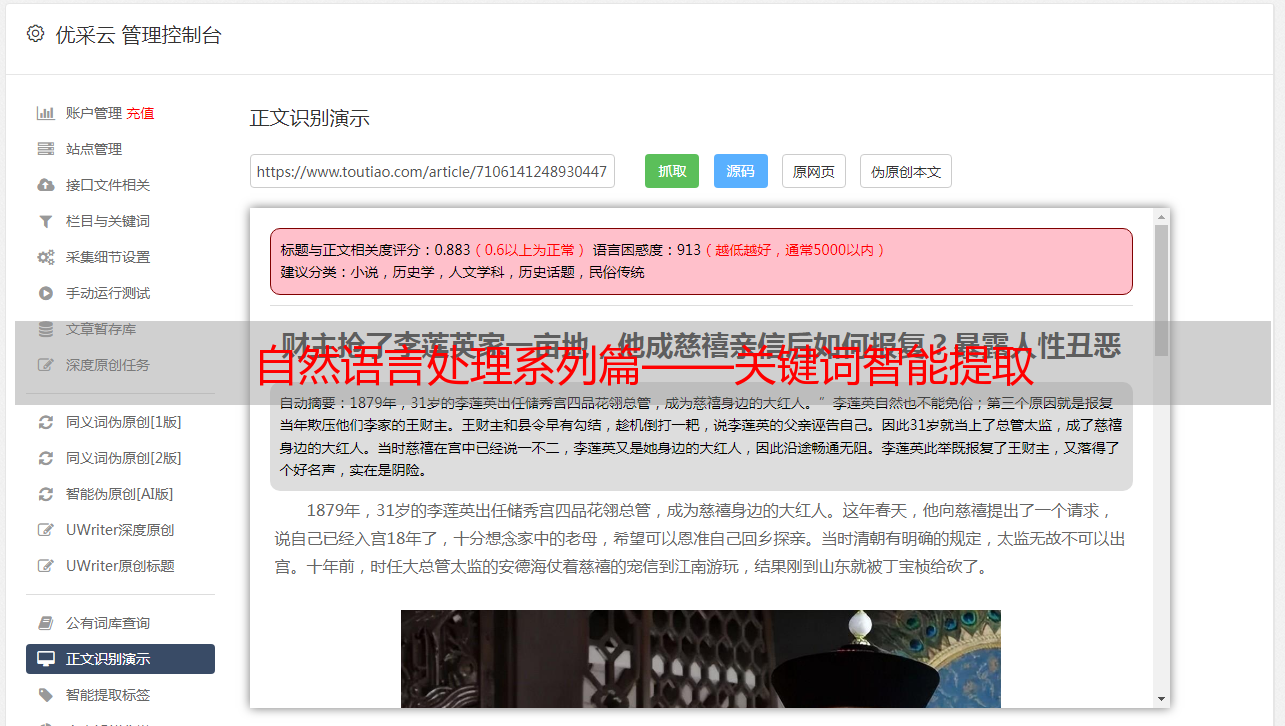
图6高质量的主题
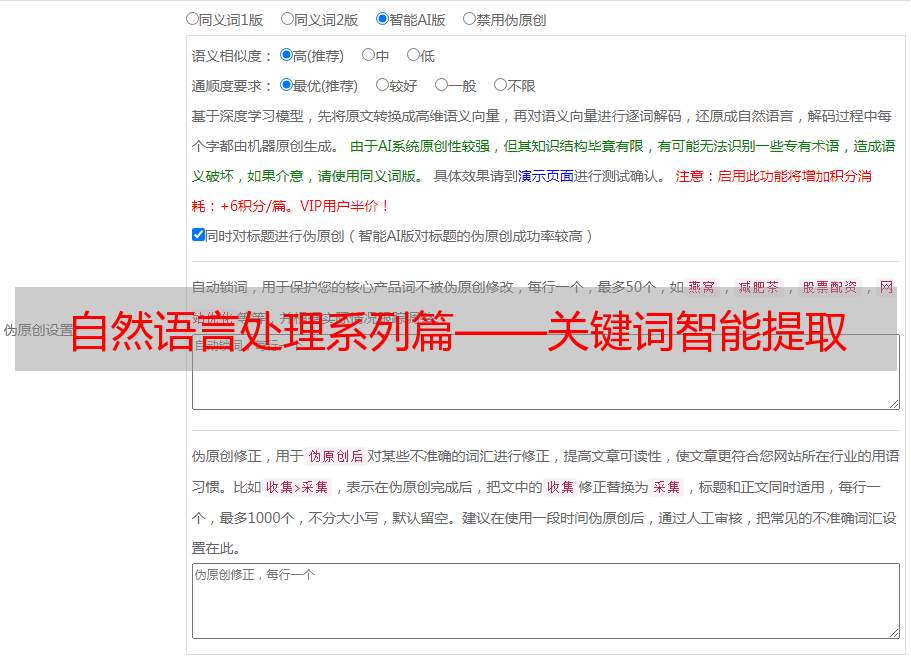
图7文章的主题关键词
2.3 标签词抽取
标签词抽取包括:生成候选词和相关性估算。下面分别介绍这两部份。
1)生成候选词
通过动词得到的基本词、短语等,过滤掉基本词中的停用词
命名实体(有效解决新词、热词的手动发觉)
2)相关性估算
使用线性加权对候选词打分,其特点包括:
选取相关性得分小于阀值的候选词作为文章的标签词。
3.效果评价
在腾讯网上随机抽取的351篇新闻上做测试,各项指标如表格1所示。由于主题集合的开放性,其召回率很难评价,故只评价其准确率。
表格1 层次化关键词手动标明算法准召率
三.接入业务与展望
对抽取错误的关键词进行剖析,算法还存在一些问题,后续会针对那些问题继续改进。
泛义词过滤不彻底,后续须要继续优化候选词过滤模块。抽取下来的两个关键词可能是叙述同一个语义,后续引入同义词等资源解决。
目前早已接入的公司业务有:腾讯新闻客户端、手机Qzone个性化资讯。欢迎有需求的团队联系我们,使用腾讯文智自然语言处理。

