软文采集( 一下自定义数据合并方式详解教程-1zdyhb_7)
优采云 发布时间: 2021-09-19 01:24软文采集(
一下自定义数据合并方式详解教程-1zdyhb_7)
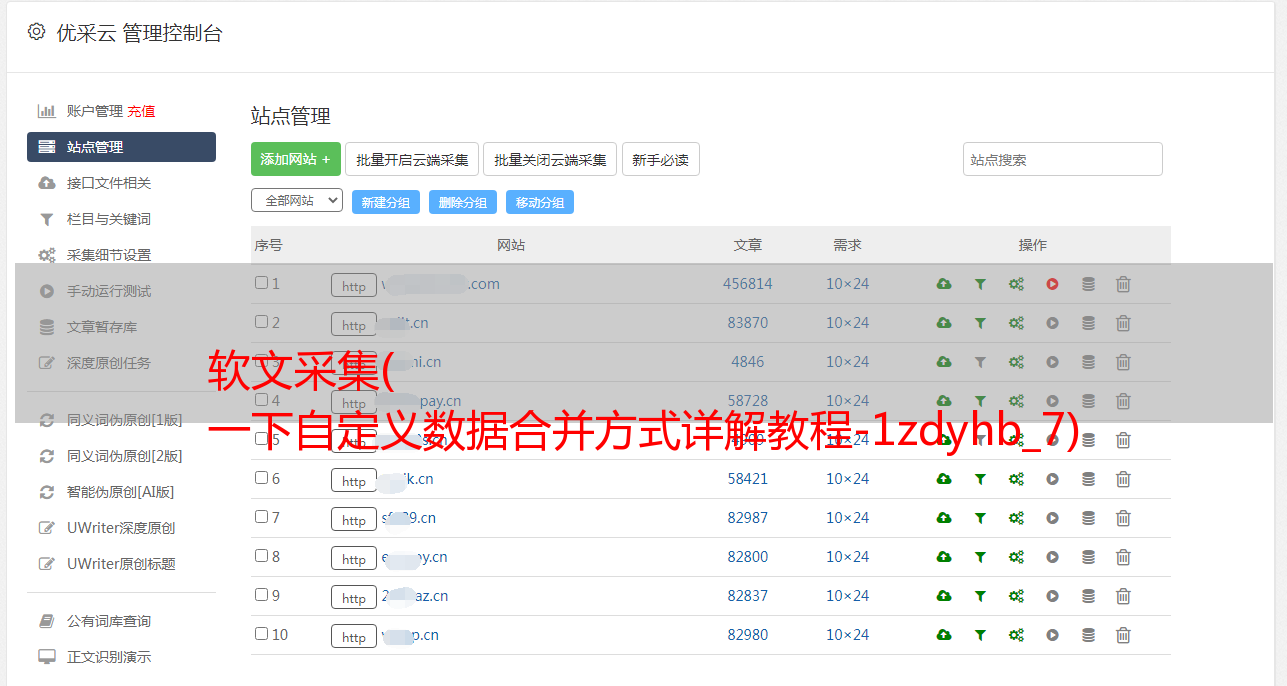
微信的流行文章采集方法及详细步骤本文将以搜狗微信文章为例,介绍使用优采云采集webpage文章body的方法。文章正文通常包括文本和图片。在本文中,@K11文章正文中文本和图片的URL将是采集以下字段文章标题乘法、100个问题的口头计算、7年级有理数的混合运算、100个问题、,计算机一级题库的二进制一阶方程请注意,同时,将使用采集文章文本中文本图片的URL来判断条件。在以下两个教程中,有许多地方需要注意。您可以先熟悉自定义数据合并方法详细说明教程httpwwwba zhuayu com universal detail-1zdyhb_u详细说明7html判断条件-1judgehtml采集网站httpweixinsogoucom使用功能节点对入党积极分子列表进行分页,以比较项目数量和mm教师职称等级表员工考核分数表普通年金现值系数表信息采集httpwwwbazhuayucomtutorialfylb-70aspxt1xpathTpWWwBazhuayucomSearchQueryXpathAjax点击并翻页7aspxt1判断条件httpWWBAZhuayucomortarialdeail-1judgehtmlajax滚动httpwwba Zhuayucomortarialdeail-1ajgd_7;html步骤1创建采集task 1进入主界面,选择自定义模式wechat popular文章采集method步骤12复制并将网站的URL粘贴到采集输入框中,然后点击保存网站wechat popular文章采集method step 2 step 2创建翻页循环,在员工流程页面右上角打开流程仓库管理流程财务报销流程离职流程报销流程新员工,显示流程设计器,自定义当前操作
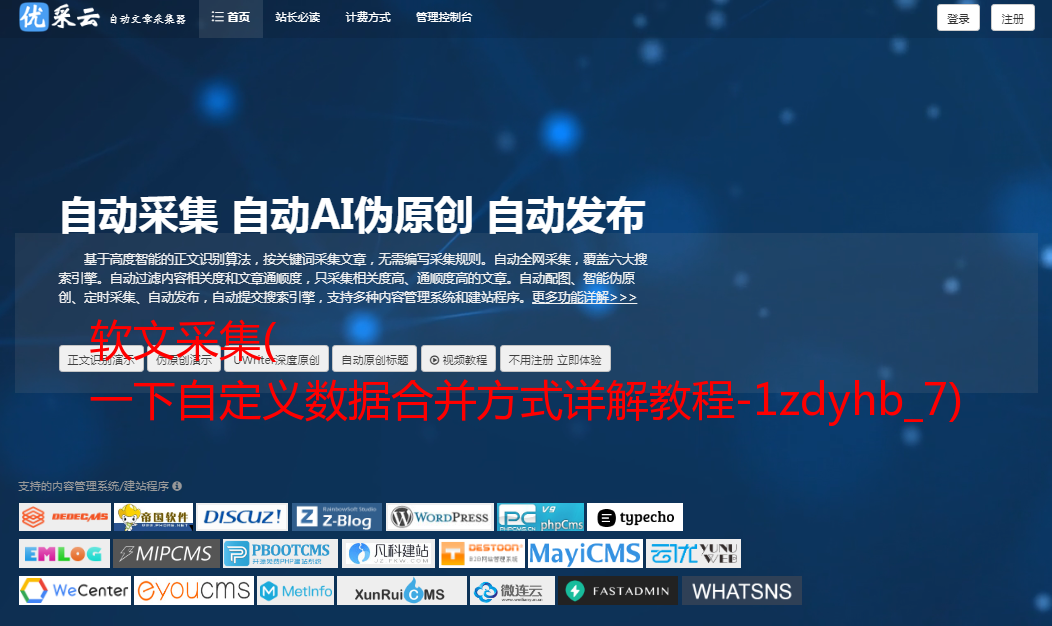
打开节网页后,默认情况下会显示常用的文章下拉页面。找到并单击“加载更多内容”按钮,在操作提示框中选择更多受欢迎的文章采集方法。步骤3选择循环单击单个元素创建一个翻页循环文章采集methods步骤4因为此网页涉及Ajax技术,我们需要设置一些高级选项单击元素步骤打开高级选项检查Ajax加载数据设置时间为2秒文章采集method步骤5注意Ajax是一种延迟加载异步更新的脚本技术。通过在后台与服务器进行少量数据交换,您可以更新网页的一部分,而无需重新加载整个网页。性能特征a当您单击网页中的某个选项时,大多数@K@17@的网址不会更改。B网页未完全加载,但数据在本地加载。验证方法已更改。单击后,浏览器中的“web地址”输入字段中将没有加载状态或旋转状态。观察网页,我们发现通过5次点击可以加载更多的内容页面,底部文章共显示100页,因此我们将整个循环翻页步骤行设置5次选择循环翻页步骤打开高级选项打开退出循环设置当满足以下条件时循环数等于5次单击确认微信流行文章采集方法步骤6步骤3创建列表循环并提取数据移动鼠标选择页面中的第一个文章链接系统将自动识别类似链接在操作提示框中选择所有微信流行文章采集方法步骤7选择微信流行文章采集方法重复单击每个链接步骤8系统将自动进入文章详细信息页面,然后单击所需的采集字段。在这里,单击文章标题并在操作提示框中选择元素文章release time文章source字段的采集文本的采集方法。同样,微信流行的文章采集方法的步骤9。接下来,启动采集文章文本,在第一段中首先单击文章文本,系统将自动识别页面中类似的元素,并选择所有微信流行的文章采集方法。在步骤105中,您可以看到所有文本段落都被选择为变绿,并选择以下元素采集
纯文本文章采集方法步骤11请注意,可以在字段表中自定义和修改字段。微信流行文章采集方法第126步完成上述操作后,文本将全部采集向下。默认情况下,每个文本都是一个单元格。一般来说,我们希望采集的文本合并到同一个单元格中。单击“自定义数据字段”按钮,选择自定义数据合并方法检查同一字段,多次提取并合并为一行,然后将其添加到同一字段,如文本页合并,然后单击确定微信流行文章采集方法步骤13自定义数据字段按钮,选择自定义数据合并方法微信流行文章采集方法步骤14,如图所示。选中微信流行文章采集方法步骤15步骤4修改xpath1,并在打开高级选项时选中整个循环步骤,您可以看到优采云默认生成一个固定元素列表,查找前20个文章wechat热门文章采集方法的链接步骤162在Firefox浏览器中打开网页到采集并查看源代码。我们发现通过这个xpathdiv[classmain left]div[3]ulidiv[2]H3[1]a页所需的100篇文章文章已位于微信热门文章采集方法步骤173中复制并粘贴修改后的XPath到优采云中显示的位置,然后单击确定微信热门文章采集方法步骤18步骤5修改流程图采购流程图破产重组程序流程图文件管理流程图财务报销流程图工作流程图模板结构。我们继续观察并传递它5次单击以加载更多内容,所有100文章文章都将加载到此网页上。因此,配置规则材料编码规则三重一大程序规则文档编号规则乒乓球游戏规则动词不规则更改表的想法是,首先创建一个翻页循环以加载所有100文章文章,然后创建一个循环列表以提取数据。1选择整个循环步骤并将其拖出循环翻页步骤。如果不输入,则在文章采集方法步骤19中会有许多重复数据。拖动后,如下图所示,单击文章采集方法步骤20、步骤6数据采集和导出1。单击左上角的保存,然后单击开始采集以开始本地采集wechat popular文章采集方法步骤21采集完成后,系统会提示您选择导出数据
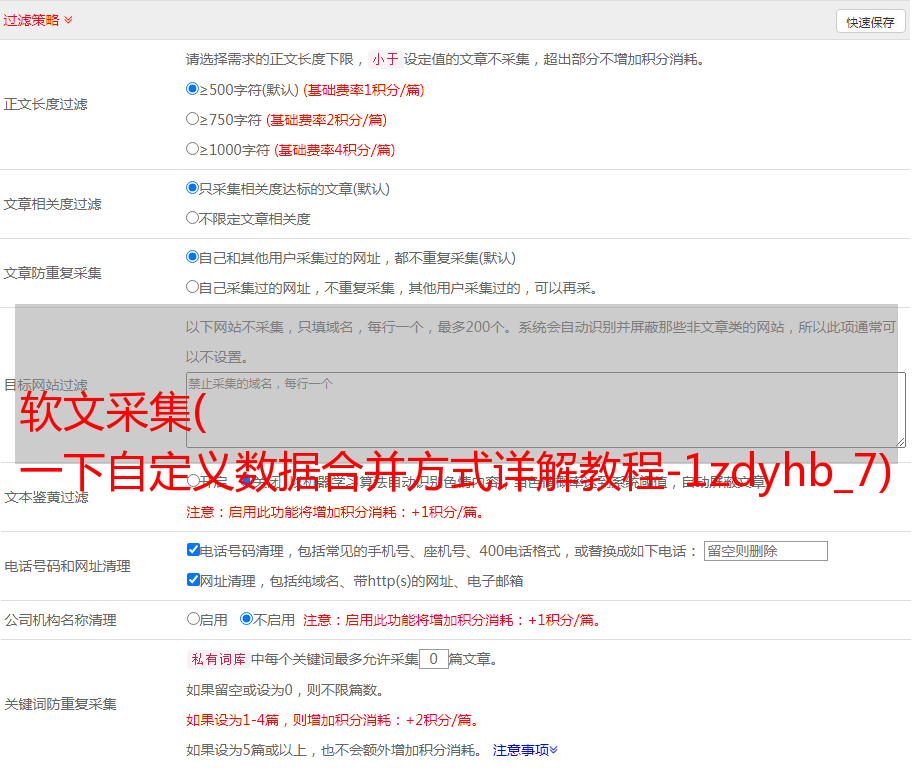
选择合适的导出方法将采集好数据导出到微信流行文章采集方法步骤223这里我们选择excel作为导出格式数据,如下图所示。微信流行文章采集方法步骤23如上图所示。文章的文本没有采集因为系统自动生成文章text P循环列表的XPath[ID“js_content”]无法找到本文的正文文章并将XPath修改为[ID“js_content”]P所有文章文本在修改XPath步骤24之前可定位到微信流行文章采集方法微信流行文章采集方法在修改XPath步骤25步骤7之后通过前六个步骤添加判断条件,我们只采集微信文章中的文本内容不包括文章. 如果需要采集picture URL,我们需要在规则中添加一个判断条件来修改文章content list判断是否收录IMG元素picture,执行picture采集branch。如果不包括IMG元素图片,则执行文本采集branch。同时,在优采云中默认设置左分支的判断条件。如果满足判断条件,则执行左分支。默认情况下,不会判断最右边的分支,而是始终执行该分支。也就是说,当不满足左分支的判断条件时,执行最右边的分支并返回到此规则,然后设置左分支的条件。如果包括IMG元素图片,则将执行左分支。如果不满足左条件分支的条件,即不包括IMG元素,则将执行右分支。具体操作如下:将判断条件步骤从左侧工具栏拖动到流程中。选择图标并将其拖动到箭头所示的绿色加号位置。Wechat popular文章采集方法步骤26处理判断条件如图所示。我们将数据提取步骤移动到右分支中的绿色加号,然后单击右分支。在结果页面上,分支条件检测结果-检测结果始终为真。单击“确定”将元素提取步骤拖动到右分支微信流行文章采集方法步骤27右分支-检测结果始终为真微信流行文章采集方法步骤28单击左侧分支
结果页面的分支条件检测结果-检测结果始终为真。单击〖确定〗按钮,设置判断条件。检查当前周期项目,包括元素输入元素xpathimg代表性图片,然后单击确定。单击左分支微信流行文章采集方法步骤29,设置左分支微信流行文章采集方法步骤304的判断条件。设置左分支条件后,将数据提取步骤从左工具栏拖到绿色加号处

