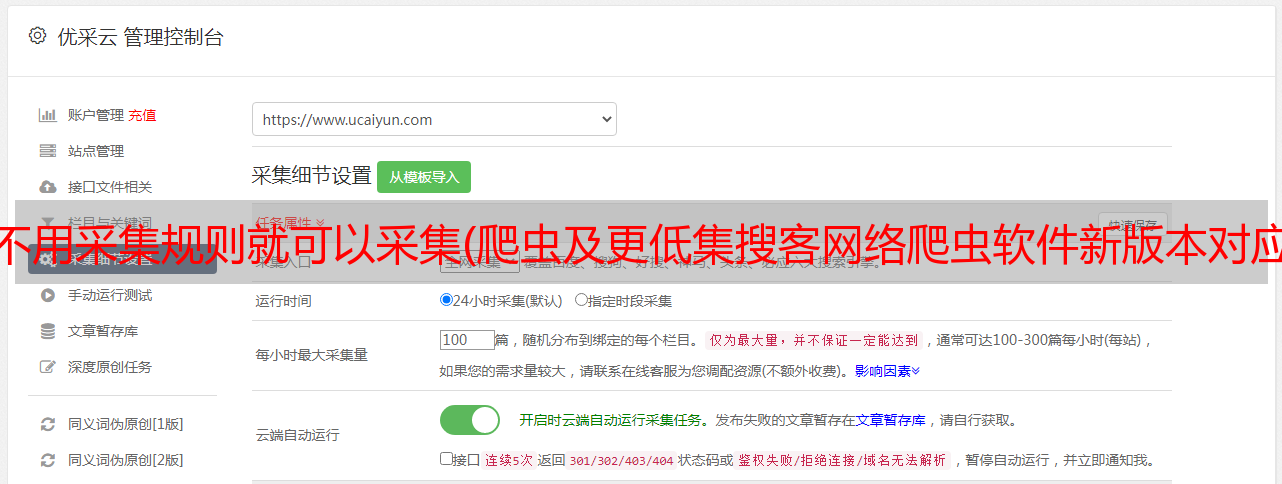
不用采集规则就可以采集(爬虫及更低集搜客网络爬虫软件新版本对应教程:V10及 )
优采云 发布时间: 2021-09-14 10:00不用采集规则就可以采集(爬虫及更低集搜客网络爬虫软件新版本对应教程:V10及
)
支持软件版本:V9及更低版本的Jisuke网络爬虫软件
新版本对应教程:V10及更高版本Data Manager-增强型网络爬虫对应教程为“Start Data采集”
注意:根据以上提示,请尽量使用最新版本的Data Manager-Enhanced Web Crawler
GooSeeker爬虫从V5.6.0版本开始增加了爬虫组功能,支持多爬虫在一台电脑上并发运行。爬虫组和规则制定可以同时运行,但爬虫组只会使用采集调度池中的规则。如果你想自动采集任何规则,只要把它扔进调度池。调度池相当于一个指挥中心。 , 会自动为每个爬虫分配采集任务,所以爬虫组运行、制定规则、调度这三个步骤是必须的,三者没有特定的先后顺序。
一、采集Rules
首先你得有自己的采集规则,可以自己做,也可以从别人那里下载。具体有以下三种方式:
1)自己做规则,选择一个网页作为样本定义采集rules,具体操作请学习gooseeker教程
2)直接下载资源库的规则。资源库拥有大量成熟的规则模板,提供微信、微博、电商、新闻、论坛、行业等。网站采集规则模板,可以满足大多数人的数据需求
3)找人自定义采集Rules,如果资源库没有你想要的网站规则,可以找集收客定制,或者发布规则奖励任务,找合适的人帮忙你制定规则
二、运行爬虫群
通过爬虫群实现采集自动化,需要配置爬虫群和调度规则,最后运行爬虫群采集数据。
2.1 爬虫组配置
配置过程主要解决以下两个问题:
1)一台电脑上同时运行了多少个并发爬虫窗口?这由配置的线程数决定。
2)DS 在软件启动时打开这些窗口?还是手动打开?这是自启动模式。
配置过程的基本操作:
选择DS点数机菜单爬虫组->配置,弹出配置窗口,点击添加新建爬虫(DS点数机窗口)。如果要自动弹出爬虫,勾选自动启动,然后点击保存,最后关闭窗口。
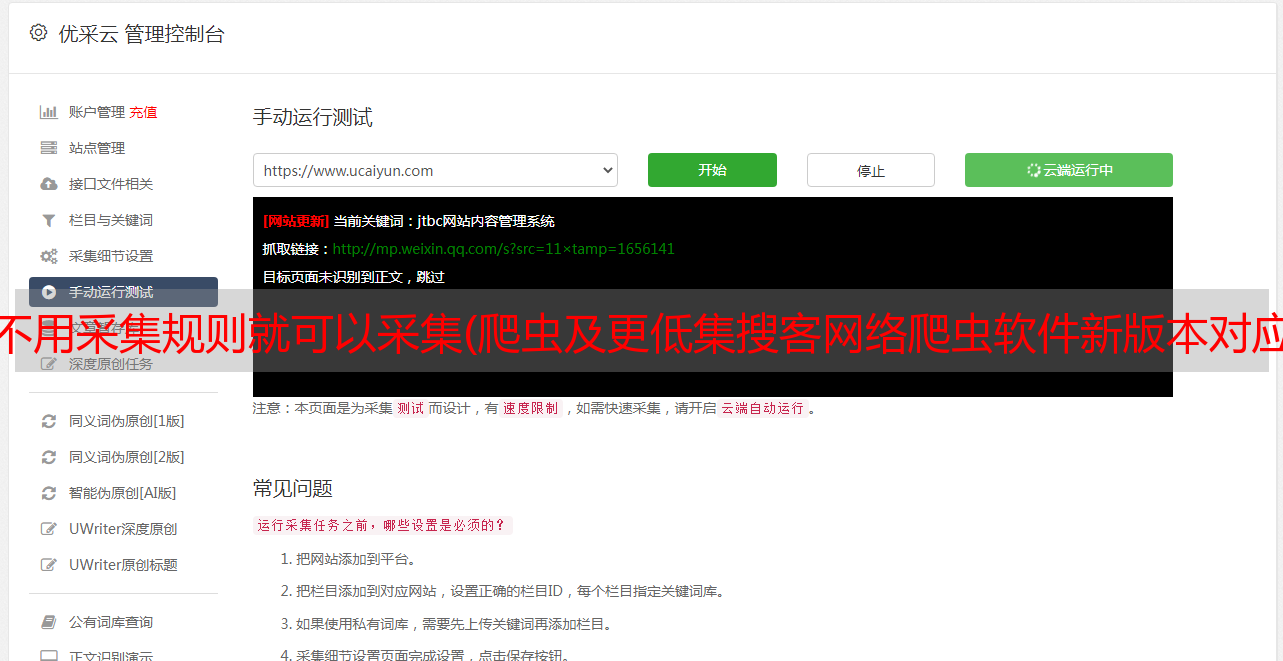
2.2 启动爬虫群
自动启动:如果设置了自启动爬虫,重启DS计数器会自动弹出多个爬虫(DS窗口)。
手动启动:如果没有设置自启动爬虫,打开DS计数器爬虫组菜单->启动,会弹出爬虫列表。一一选择确认后,会弹出一个新的DS窗口。
三、调度规则
每个规则对应一个运行/暂停按钮和一个计划按钮。如果你想自动采集哪个规则,你可以为它设置时间表。可以同时调度多个规则。每增加一个调度规则,必须点击调度按钮进行设置,最终调度池会统一为每个爬虫分配采集任务。
3.1 调度
1)DS 点击爬虫群菜单->号码机中的调度,进入会员中心的规则管理页面,可以看到你所有的规则。如果你想自动采集哪个规则,点击它的调度按钮。
2) 然后进入调度页面。如果要转换excel格式,可以查看结果并存入库中。其他设置都是调试好的,不需要修改。我们只需要默认它。最后,点击确定就大功告成了。爬虫会在每轮采集到线索后自动将数据录入数据库。
3)调度后,如果要暂停采集***主题,点击运行/暂停按钮,则爬虫群采集当前***主题的采集后会暂停任务。这是因为一个回合的默认线索数是20条,直到采集到线索,爬虫才会停止。如果你想立即停止采集,只需关闭爬虫群即可。
4)可以通过设置调度参数来控制采集时间、采集速度、数据存储、翻页、循环增量采集最新数据等。如果您希望抓取更灵活,请根据实际网页情况设置调度参数。有时需要多次测试才能找到合适的参数组合。各个调度参数的含义可以查看教程crontab爬虫调度。
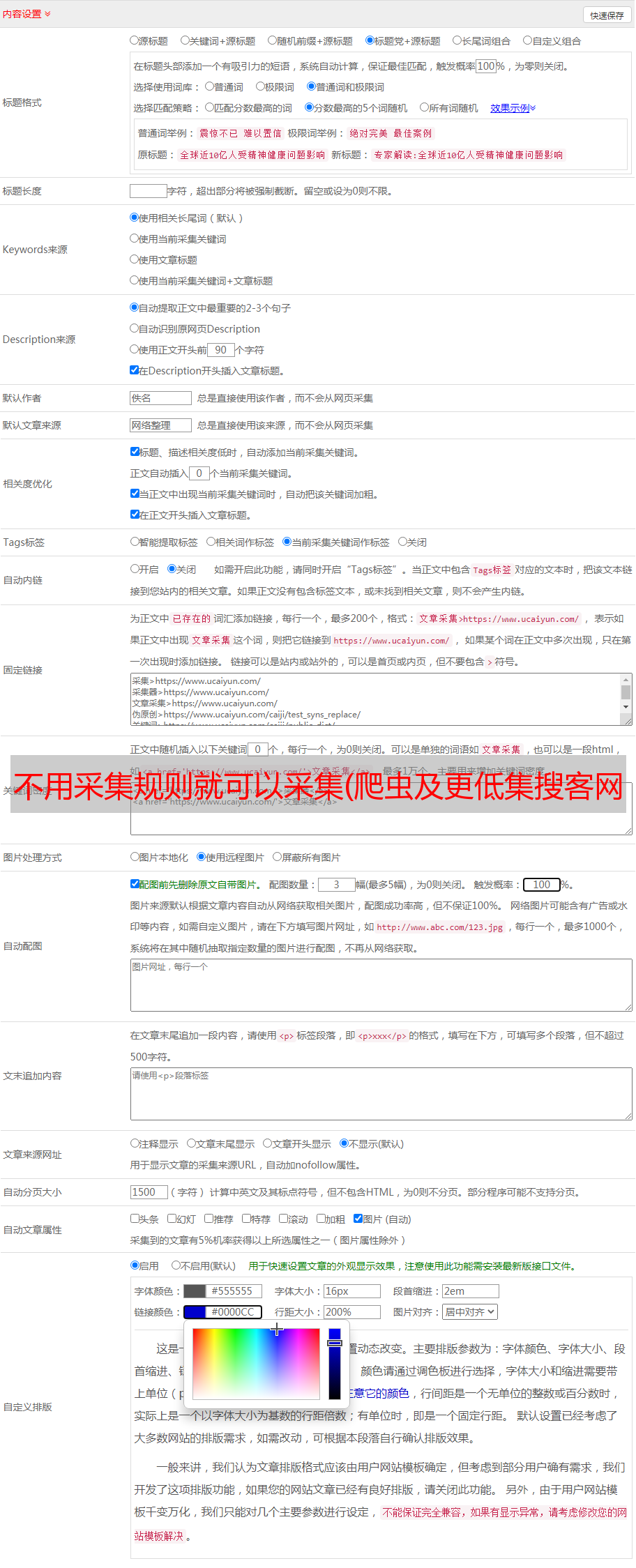
注意:通过设置最大允许爬虫数,一个windows账号可以同时运行1-20个DS计数器窗口。请综合考虑采集stability和效率设置合理的爬虫数量和控制规则采集Speed(由调度参数控制:线索间最短等待时间、线索间最长等待时间、延迟抓取时间、滚动速度、滚动次数等)。
3.2 激活/添加线索
如果规则中有线索等待爬取,爬虫会自动调用规则进行数据采集;如果没有线索等待爬取,如果要爬取采集data,必须先到会员中心爬虫管理->规则管理添加/激活线索。
如果你想重复采集***话题下的所有线索,又不想每次都手动激活线索,可以在日程中设置激活线索。请根据您的需要选择激活时间类型、时间和激活方式。 (无条件激活是指即使没有采集到所有线索,只要时间到了就会重新激活所有线索;没有剩余线索时激活是指即使时间到了,也必须将所有线索都采集起来在采集所有线索之前激活)
四、导出数据,转换格式
如果在“排期”中设置了自动存储,数据将由DS号机采集并上传至会员中心数据库。数据采集完成后,进入爬虫管理->规则管理或数据管理,点击导出数据即可得到excel表格的zip压缩包,在历史记录中可以查看导出记录和重复下载。
如果没有设置自动存储,进入对应规则的管理页面,点击激活存储,然后将本地电脑中的数据文件打包成zip,然后点击导入数据,选择单个附件中的xml文件或xml文件的压缩包zip,导入成功后即可导出数据。
【注意】您可以免费导出10,000条数据。如果超过数量,请在继续导出数据前购买“专业或终极爬虫”或“数据仓库”扩展存储容量,或购买“仓库清理”保存原创数据清理后使用。
爬虫swarm模式是本地采集模式。捕获的数据文件仍保存在本地计算机的 DataScraperworks 文件夹中。如果勾选了自动存储,每次采集到线索数量都会自动保存xml文件。打包成zip,一次导入最大20M的zip数据包。如果超过,导入将失败。存储成功后,xml文件会转移到导入的文件夹中。
如果没有勾选自动存储,请手动将xml文件打包成zip然后导入数据,每次导入zip数据包最大10M。
五、关于爬虫组模式
爬虫组模式是在一台电脑上同时开启多个爬虫(即DS计数器窗口)。通过设置更多的爬虫数量和合理的爬取速度,不仅降低了IP被封的风险,还能抓取更多的数据,是一种非常稳定高效的本地采集模式。集成了crontab爬虫调度器、DS计数机主要功能、数据库存储三大功能块,让您自由控制爬虫数量和运行,还有专用数据库高效处理千万级数据。
如果您有任何问题,可以或