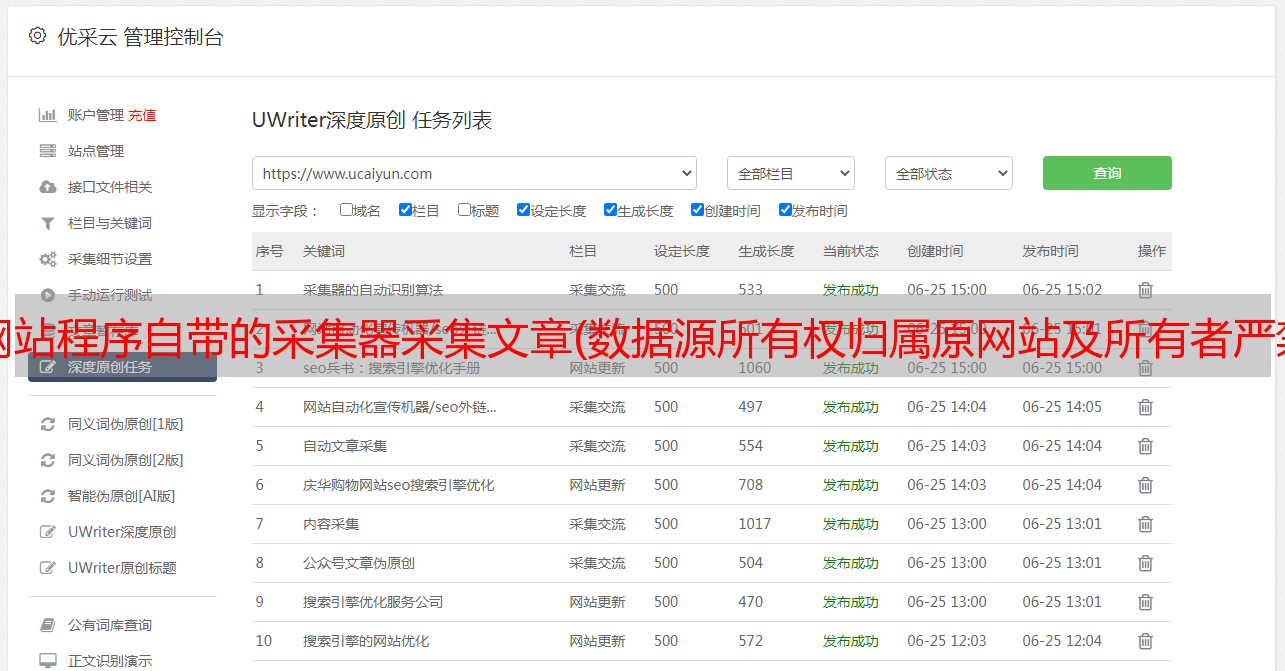
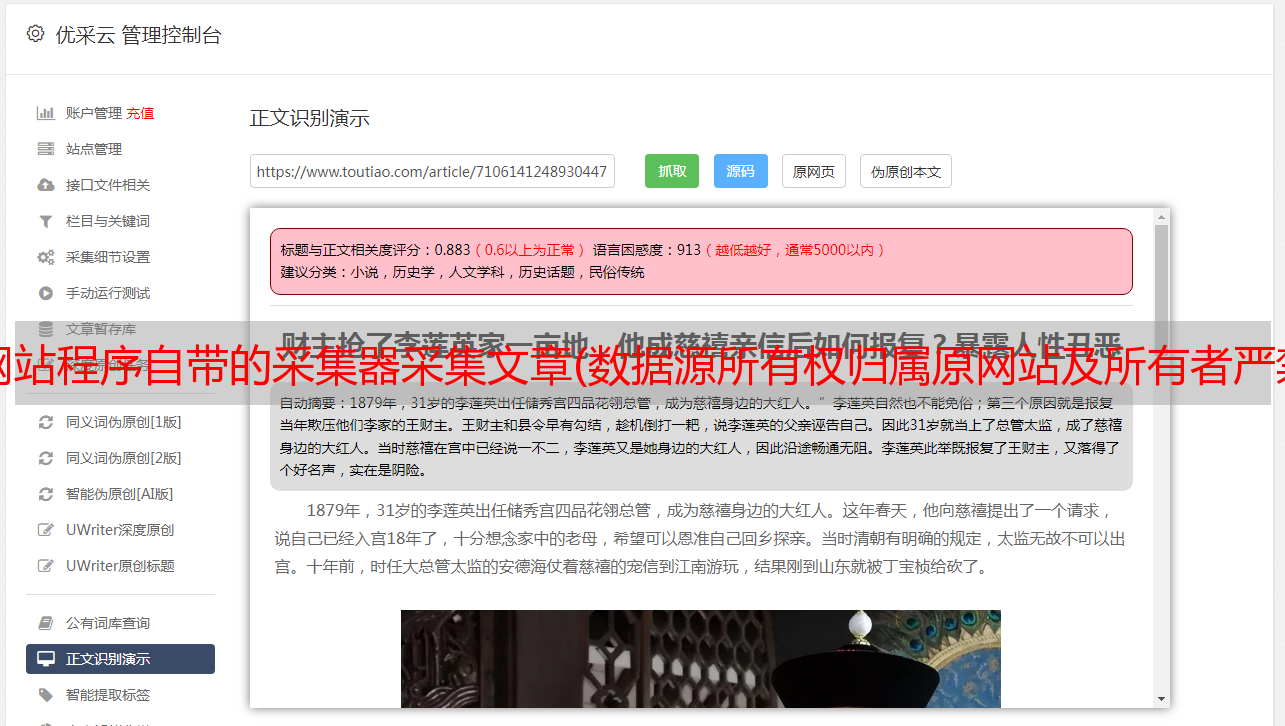
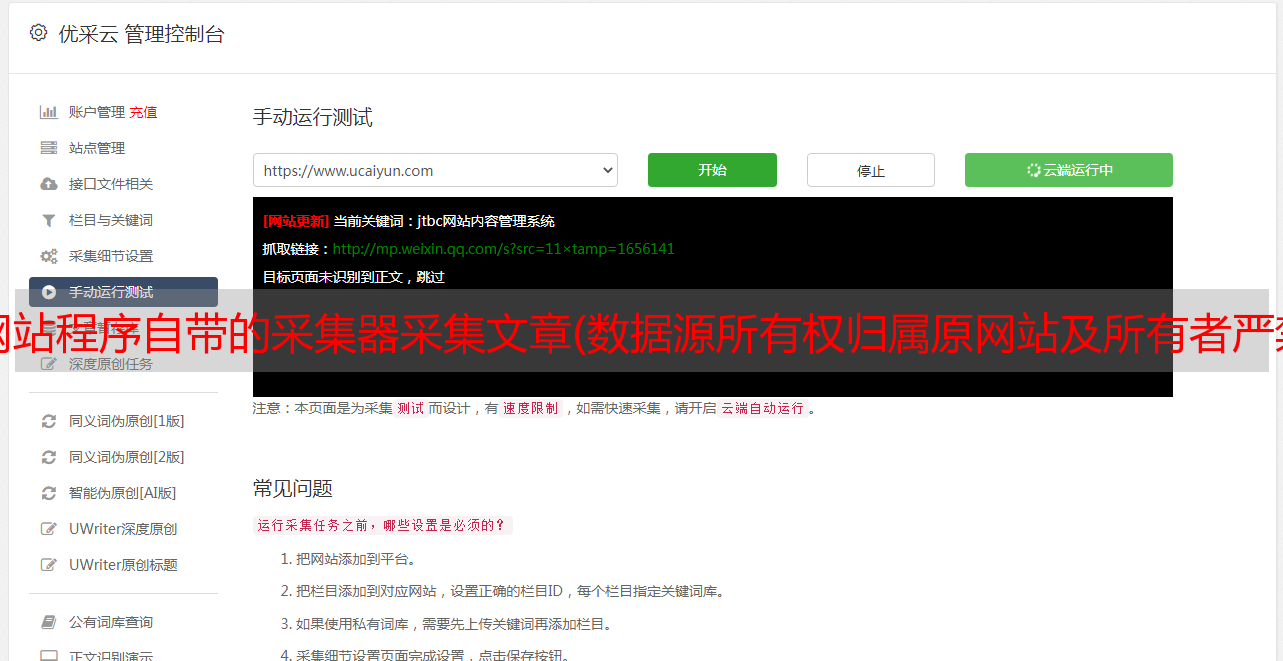
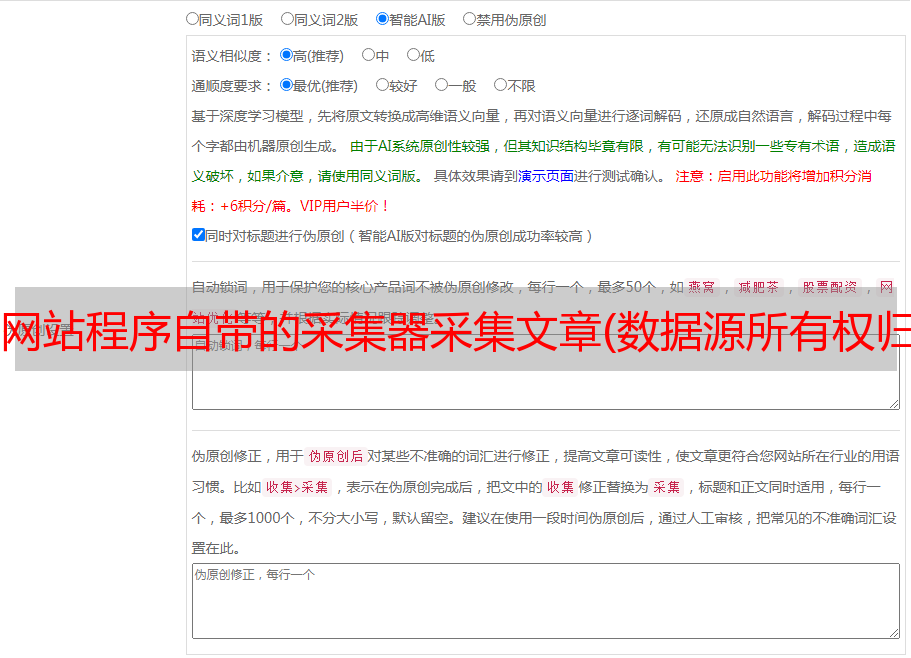
网站程序自带的采集器采集文章(数据源所有权归属原网站及所有者严禁利用webscraper进行数据采集)
优采云 发布时间: 2021-09-13 09:09网站程序自带的采集器采集文章(数据源所有权归属原网站及所有者严禁利用webscraper进行数据采集)
此文章仅供学习交流之用。数据源的所有权属于原网站和所有者。严禁将本文提及的流程和数据用于牟利。
“打钉子的方法很多,有时候我最熟悉的锤子会打我”
背景
最近收到一个求助请求,是采集一个网站,传统的“列表+内容”页面模式,用PHP或者采集器总会出现各种莫名其妙的问题,基本上这一步以后,我将使用“node+pupteer”来做,并使用自动化测试工具来模拟操作。虽然是万能锤,但是这个锤子的*敏*感*词*和技术复杂度还是存在的,所以我转向了我之前考虑过但没有尝试的东西。方向-浏览器插件,基本原理和思路和自动化工具基本一致,但是目标逻辑更好的与浏览器匹配,感觉更优雅。
我查资料的时候,发现了Web Scraper。我通过参考文档和教程将其应用于目标网站采集。终于,我得到了数据。如果熟悉整个操作流程,可以快速设置。相应的规则实现采集,现将过程记录。
过程
1. 安装网络爬虫
如果你掌握了科学上网技巧,可以登录chorme网店直接搜索安装
或者百度搜索“网络爬虫离线安装包”获取相关支持,离线安装过程不再赘述。
2.分析目标站
可以看到这是典型的列表+内容展示方式。现在您需要采集 向下列表和内容页面。传统的采集思路是用程序把整个列表页面拉回来,然后再解析。超链接在里面跳转,然后就得到了内容页。
现在我们来看看采集如何使用网络爬虫获取数据。
3.设置规则
由于采集工具是通用的,至于如何采集和采集这些数据,这些规则需要用户根据实际情况进行配置。首先我们来了解一下网络爬虫是如何打开的以及基本页面
①打开工具
在目标页面页面打开开发者工具(F11或右键-check),可以看到工具栏末尾有一个同名的tab,点击tab进入工具页面
②新采集task
采集在需要创建Sitemap之前,可以理解为一个任务,选择Create new sitemap-Create Sitemap
站点地图名称为任务名称,可根据需要创建。
起始 URL 是您的 采集 页面。如果是列表+内容模式,建议填写列表页。
然后创建Sitemap,一个基本的任务就建立起来了。
③建立列表页面规则
点击添加新选择器创建一个选择器,告诉插件应该选择哪个节点。对于这种列表页面上也有信息的页面,我们将每条信息作为一个块,块中收录各种属性信息。创建方法如下:
需要勾选Multiple选项,可以理解为需要循环获取。
添加后,我们应该在信息块中标记内容。具体操作方法同上,但要选择信息的父选择器作为刚刚创建的信息块节点。
其他节点的数据操作一样,记得选择父节点。
④ 检查既定规则

