在线伪原创检测(在线伪原创工具的开发过程百度百科上伪原创的定义)
优采云 发布时间: 2021-09-11 13:04在线伪原创检测(在线伪原创工具的开发过程百度百科上伪原创的定义)
在线伪原创工具的开发过程
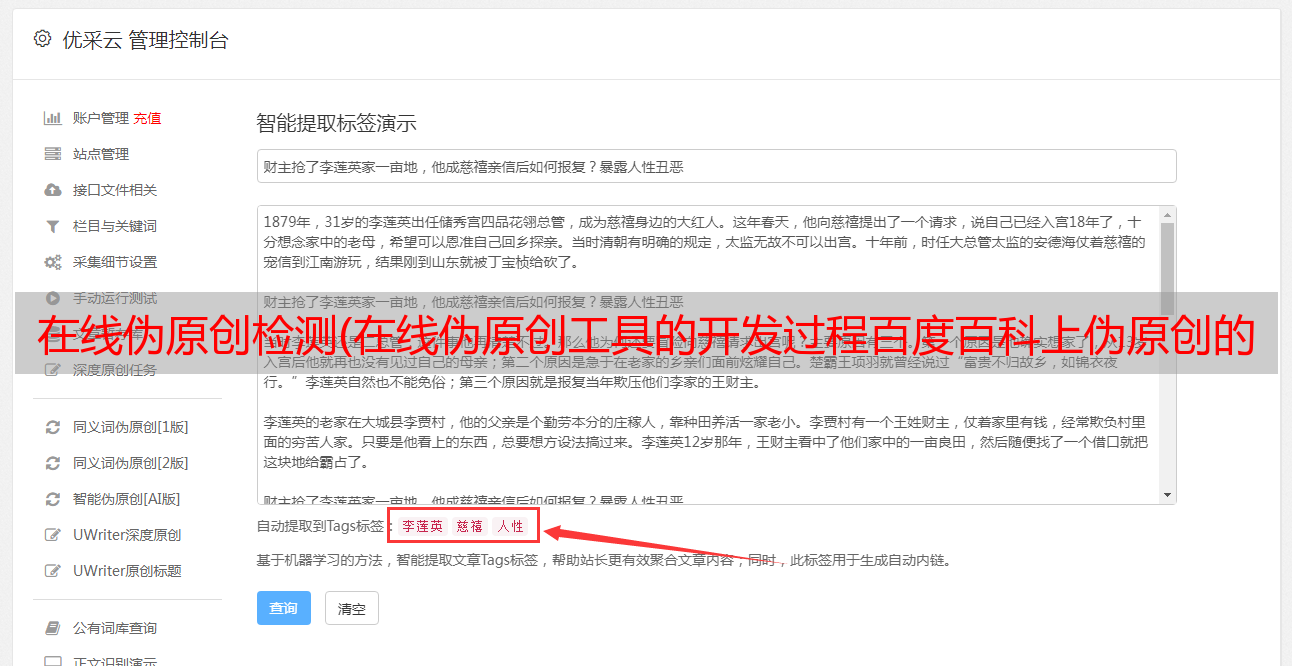
百度百科对伪原创的定义是“所谓伪原创就是对文章的一篇文章进行再加工,让搜索引擎认为它是原创文章的文章,从而增加网站“的重量。事实上,对于程序员来说,伪原创 的意思是“用文章 代替很多同义词”。 SEO朋友一定知道伪原创对于搜索引擎优化非常重要。成熟可靠的中文伪原创工具一直很少见。我在百度上搜索“中文伪原创”,在首页尝试了几个工具,但结果都不尽如人意。所以我开发了博乐伪原创,.
前言:
百度百科对伪原创的定义是“所谓伪原创就是对文章的文章进行再加工,让搜索引擎认为它是原创文章的文章,从而增加网站“的重量。事实上,对于程序员来说,伪原创的意思是“用文章代替很多同义词”。
SEO 朋友——尤其是黑帽 SEO 的朋友——必须知道伪原创 对搜索引擎优化至关重要。英文伪原创被称为“Spin”,成熟的英文伪原创工具包括TBS、Spinnerchief等,TBS的价格相当昂贵。但是,成熟可靠的中文伪原创工具一直很少见。我在百度上搜索“中文伪原创”,在首页尝试了几个工具,但结果都不尽如人意。
于是开发了Bole伪原创,有兴趣的朋友可以先体验一下。 (但要注意,这只是测试版,离正式版还差得很远。O(∩_∩)哦哈哈~)
中文伪原创tools需要考虑的问题
我开始思考,现有的中文伪原创工具有什么缺点?我想到了以下几点:
一、分词问题。
中文和英文是不同的。无论是搜索引擎蜘蛛还是其他自然语言处理语料分析,都需要进行分词。如果不先对分词进行预处理就开始“伪原创”,那肯定是不靠谱的。例如:“naive”和“pure”是同义词。在没有分词的情况下,“我有一个天真的表妹”仍然可以伪原创是“我有一个纯妹妹”,但是把“今天的热”当成“今天的纯热”是严重不可靠的。
二、顺序执行导致的简化。
无论是网上流行的中文伪原创词库,还是现成的中文伪原创工具,我都试过了。他们的词库格式如下:
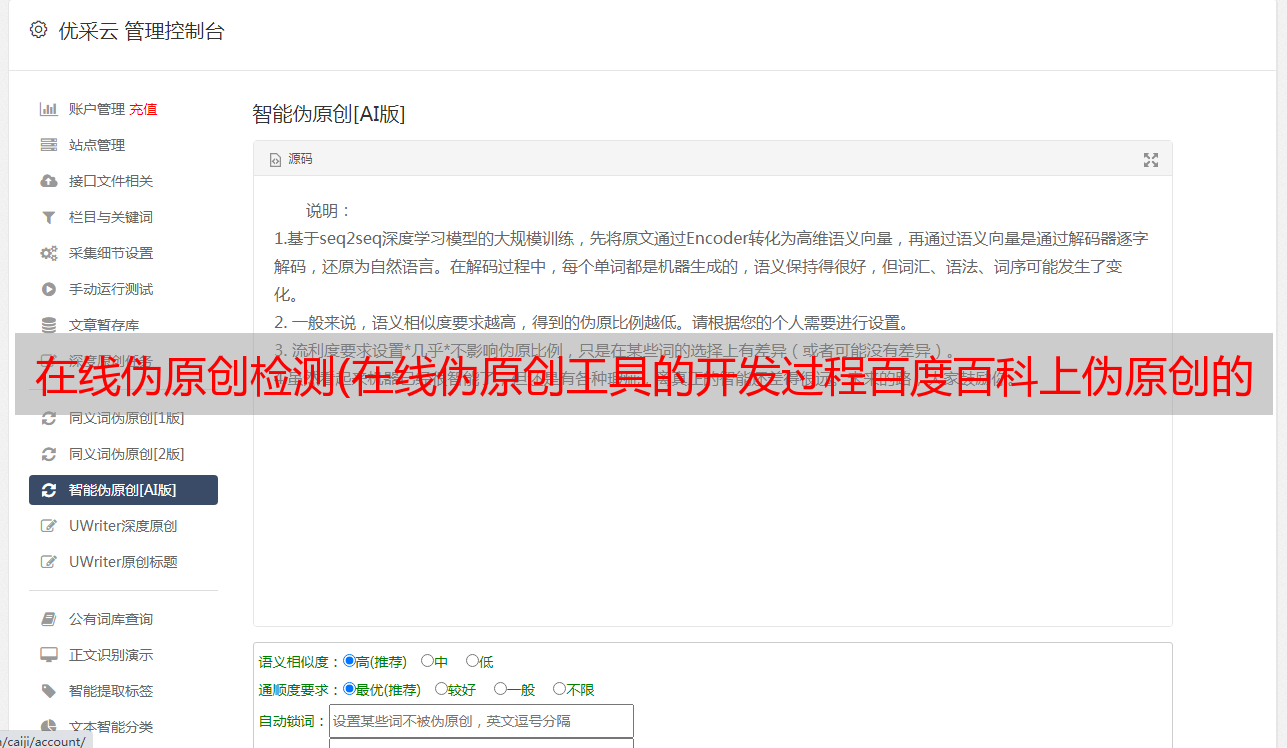
普通的算法是按顺序替换,那么,如图所示,“凡人”的同义词本来就有“陈欢”“陈健”“凡人”三个,但永远不会被替换成“凡人”最后两个字。
最理想的状态是能够根据上下文替换合适的词。例如,“天真”的近义词包括“无辜”、“无辜”、“纯洁”、“纯洁”等。并非每个词都可以在所有上下文中完全替换。当然,结合上下文是高级自然语言处理的范畴,简单到伪原创可以达到子理想状态就可以了:如果遇到多个同义词,随机替换其中一个。
三、Thesaurus 打架问题
我下载了网上流传的大部分同义词库,付费和免费,都试过了。发现没有人去解决词库打架的问题。
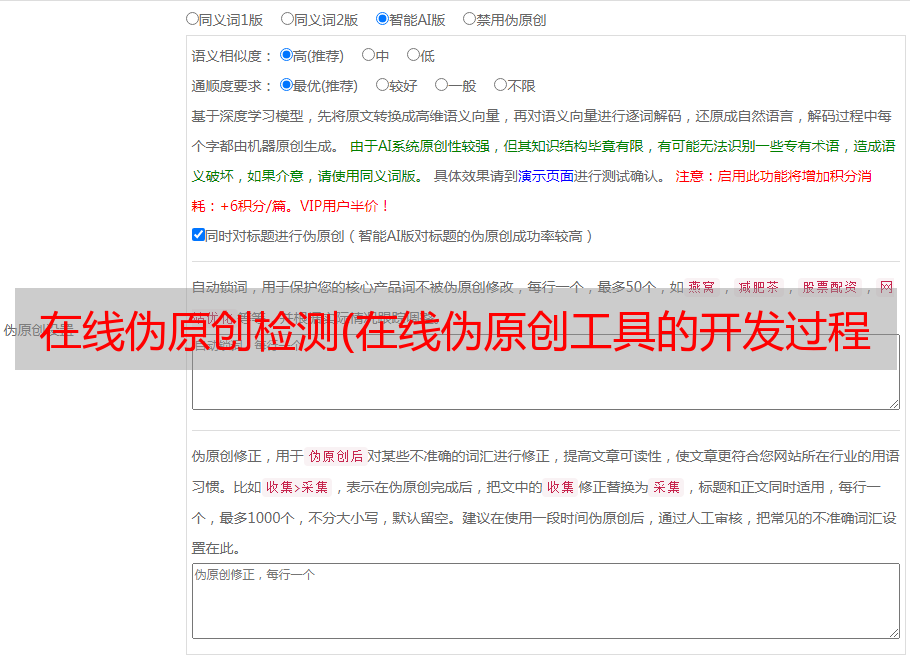
什么是“词库打架问题”?很简单,看这两组词。
按顺序执行替换后,你会发现文字绕回原点……这显然不是我们想要的,但是这个问题在现有词库和伪原创工具中很常见.
四、可读性太差
为什么可读性这么强?因为现有的中文伪原创工具在整篇文章中都被替换掉了。如果同义词库中有100,000组同义词,程序将遍历一次并将原创文本中的所有可替换字符串“挤干”。这样一来,虽然伪原创成功了,可读性却无限接近于零。我们来看这样一组例子:
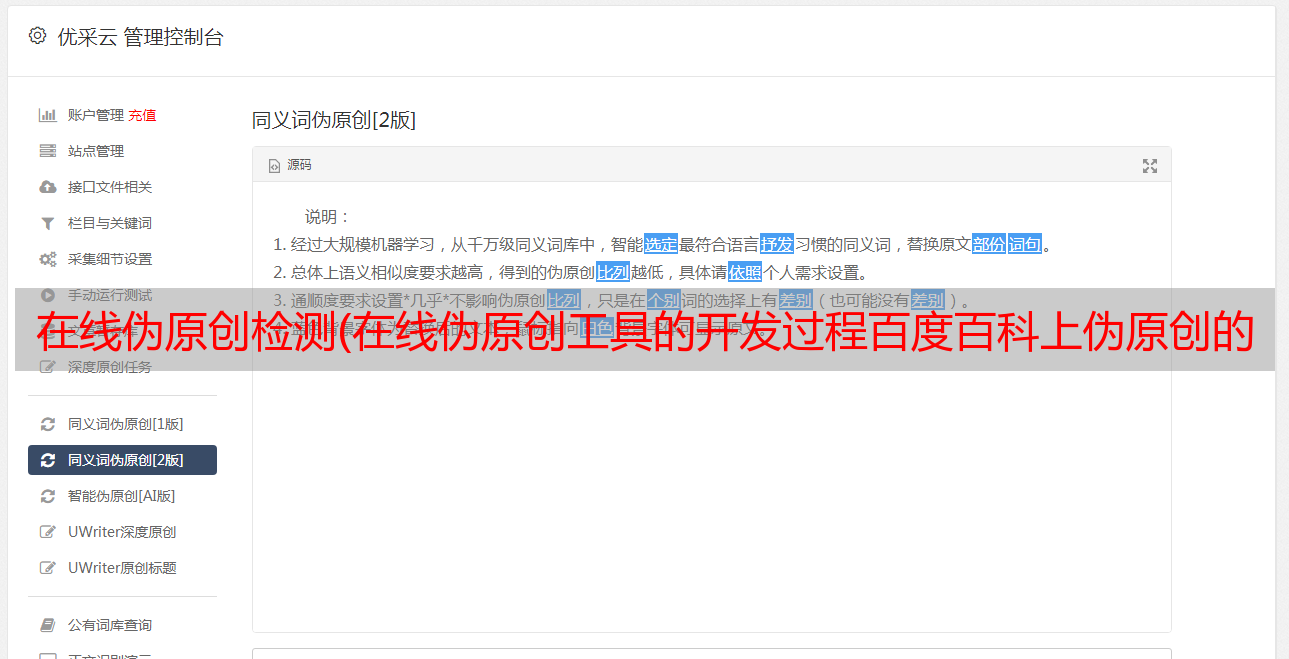
伪原创后:
如果读者直接阅读伪原创之后的文字,能看懂吗?
怎么解决这个问题,我觉得,可以设置一个百分比,或者伪原创level。比如“微柔、温和、暴力、变态、面目全非、面目全非”七个等级。当用户选择“温和”时,100个可替换同义词中仅随机替换10个,选择“中等”时,100个可替换同义词中随机替换50个,以此类推。这允许用户在“可读性”“原创度”之前自由权衡自己。
我心中的完美中文伪原创工具
功能模块
功能说明
技术实现
智能分词
避免“今天真热”变成“今天又热又热”的问题。
可以使用现有的中文分词开源组件。
随机性
即使是同一篇文章文章,每个伪原创的结果都不一样。
引入随机入口。
伪原创强度调整
定义伪原创的百分比,让用户在“可读性”和“原创degree”之间自由权衡。
介绍关卡设置并随机挑选条目。
不要与词库争吵
避免或减少将“swear”换成“swear”然后又变回“swear”的情况。
放弃顺序执行。
统计数据
统计伪原创后替换了多少词
替换时插入标签
标签
标记替换的单词以便于查看和校对
替换时插入标签
核心程序实现
综合以上多方面考虑,程序还是比较长的,接近10000行。下面我只列出几个核心代码供大家参考讨论。
一、分词。
分词其实很容易,因为对开源组件有很好的了解可以使用。我最喜欢的是 SCWS。官网地址是
SCWS原本是一个PHP中文分词解决方案,但是它提供了一个API,我们的C#程序员也可以毫无压力地调用它。
查看代码
publicstaticstringSegment(stringstr)
{
System.Text.StringBuildersb=newSystem.Text.StringBuilder();
试试
{
strings=string.Empty;
System.Net.CookieContainercookieContainer=newSystem.Net.CookieContainer();
//将提交的字符串数据转换成字节数组
byte[]postData=System.Text.Encoding.ASCII.GetBytes("data="+System.Web.HttpUtility.UrlEncode(str)+"&respond=json&charset=utf8&ignore=yes&duality=no&traditional=no&multi=0") ;
//设置提交的相关参数
System.Net.HttpWebRequestrequest=System.Net.WebRequest.Create("")asSystem.Net.HttpWebRequest;
request.Method="POST";
request.KeepAlive=false;
request.ContentType="application/x-www-form-urlencoded";
request.CookieContainer=cookieContainer;
request.ContentLength=postData.Length;
//提交请求数据
System.IO.StreamoutputStream=request.GetRequestStream();
outputStream.Write(postData,0,postData.Length);
outputStream.Close();
//接收返回的页面
System.Net.HttpWebResponseresponse=request.GetResponse()asSystem.Net.HttpWebResponse;
System.IO.StreamresponseStream=response.GetResponseStream();
System.IO.StreamReaderreader=newSystem.IO.StreamReader(responseStream,System.Text.Encoding.GetEncoding("utf-8"));
stringval=reader.ReadToEnd();
Newtonsoft.Json.Linq.JObjectresults=Newtonsoft.Json.Linq.JObject.Parse(val);
foreach(varieminresults["words"].Children())
{
Newtonsoft.Json.Linq.JObjectword=Newtonsoft.Json.Linq.JObject.Parse(item.ToString());
sb.Append(word["word"].ToString()+"");
}
}
抓住
{
}
returnsb.ToString();
}
二、 解决词库打架问题。
没有什么可说的。程序只有一句话。
三、 根据百分比随机选择 x 条记录。
获取随机记录,最方便的是Mysql数据库,select中可以使用内置的rand()函数。如果用SQL Server稍微麻烦一点,效率会低一些。
参考
四、 替换同义词主函数。
请查看代码中的注释。
publicstringReplaceArticle(stringold,intstrength,boolmarkRed,refintreplacedcount)
{
stringnewArticle=old;
intwordsAmount=180482;//词库总数
intkwcount=Convert.ToInt32(strength*1.0/100*wordsAmount);//根据传入的百分比计算需要取多少词
vardataset=SQLHelper.ExecuteDataset(SQLHelper.connectionString,System.Data.CommandType.Text,"select*fromwordsorderbyrand()limit"+kwcount);//随机取kwcount组词
foreach(DataRowrindataset.Tables[0].Rows)
{
//随机。对于字典中的短语 A->B。随机决定这个替换是Replace(A,B)还是Replace(B,A)
inti=newRandom().Next(0,1);
newArticle=newArticle.Replace(r[i].ToString()
,string.Format("{0}",r[1-i].ToString()));
}
//要替换的字数。
replacedcount=newArticle.Split(newstring[]{""},StringSplitOptions.None).Length-1;
if(!markRed)
{
//如果用户不需要标记,则去掉标记。
newArticle=newArticle.Replace("",string.Empty).Replace("",string.Empty);
}
returnnewArticle;
}
最终程序界面
终于
如上所述,中文伪原创几乎是空白的。希望这篇文章能起到启发作用,也希望有兴趣的同学可以和我一起继续完善和完善。
博乐伪原创
发表于 2012-08-29 03:18 刘牛木马阅读(5310)评论(4)Edit)

