不用采集规则就可以采集(网络神采:入门采集新闻采集任务的优势及优势(图))
优采云 发布时间: 2021-09-08 16:02不用采集规则就可以采集(网络神采:入门采集新闻采集任务的优势及优势(图))
网络神彩是一款轻量级的数据采集软件,该软件无需安装,解压后即可使用,免费版,无时间限制,可用于快速采集,下载网页数据,并支持网站login采集、网站cross-layer采集、POST采集、脚本采集、动态页面采集等高级功能。是网上最快最高效的采集。 @软件。全新的网络精神全面优化升级。它快速、易于使用且免费。支持智能采集(无需规则)、可视化采集(无需看源文件)、二次开发、分布式部署。可为用户的大数据分析和信息平台提供稳定、连续、准确的数据资源。欢迎免费下载体验。
网络魅力四射的功能和优势
1、采集力量
支持JS解析、POST分页、登录采集、跨层采集。对于困难的采集页面,有成熟的解决方案。
2、速快
支持多任务同时运行,每个任务可以设置多线程,保证运行效率。
3、Scaleization
支持任务的多级分类和批量管理。支持云服务器分布式部署,支持管理员团队协作。
4、proceduralization
支持定时采集,任务会定时自动开始。通过二次开发,实现流程信息采集和信息处理。
5、稳定运行
系统运行稳定,需要“0 bug”。登陆页面修改后,会自动通知管理员。
6、Accuracy
任务定制后,采集的准确率可以达到100%,也就是一个不漏。
网络魅力:入门采集example
News采集 是最常用也最容易理解的。让我们以一个简单的 news采集task 作为入门示例。这个任务有两个层次:“新闻列表”和“新闻内容”。我们以新闻列表作为“起始地址”,然后通过“导航规则”从“新闻列表”中提取“新闻内容”的URL,最后按照“采集法”采集。
1、创建任务
在网络神彩软件主窗口中,点击菜单“任务”->“新建”,打开“任务编辑”对话框,创建任务。下面我们通过图片和文字的混合来讨论如何一步一步填写设置:
第一步:任务概览
在“任务概览”中,我们只需要填写一个任务名称:郑州大学新闻资讯。其他设置暂不讨论,请熟练后参考我们的帮助文件。
第 2 步:起始地址
起始地址是我们想要采集内容的入口地址,这里是“新闻列表”:{1,100}。其中,“pn”为分页变量的名称,在浏览“新闻列表”时翻页观察即可获得。如果“pn=1”表示第一页,“pn=2”表示第二页,以此类推。我们为“pn”指定一个变量值:{1,100},这意味着会有采集1到100页。这种分页变量格式由我们的软件定义。您可以通过单击“插入”按钮来插入预设的分页变量。
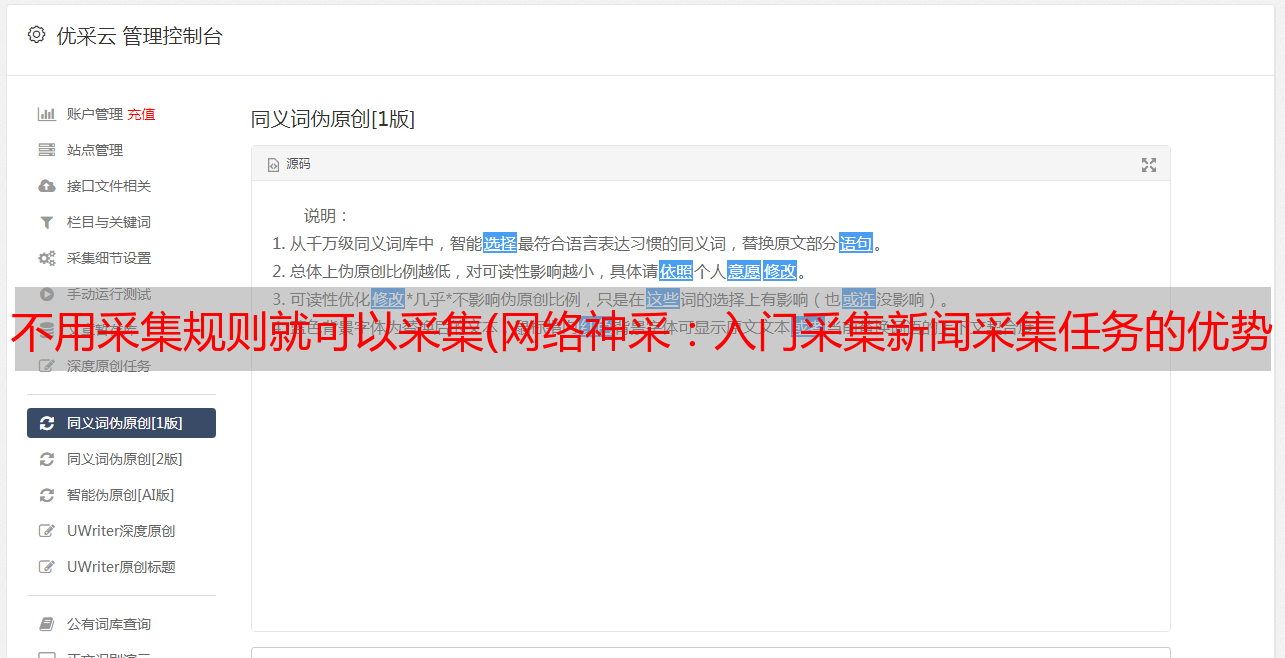
第 3 步:导航规则
因为任务有两个层次,所以需要构建两个“导航规则”,分别命名为“新闻列表”和“新闻内容”。我们需要从“新闻列表”中提取“新闻内容”的URL来实现导航。因此,将“新闻列表”设置为“中间层”并填写“下一层URL模板”以提取URL。对于“新闻内容”,只需选择“最后一页”并保存即可。
如何确定“新闻列表”的“下一级网址模板”?请看下图。
通过查看“新闻列表”的源文件,我们可以找到“新闻内容”的网址,以*敏*感*词*显示。我们将URL的可变部分替换为“*”(通配符),即“下一级URL模板”,即:*。这样,我们提取的时候就有了一个依据:只提取与模板匹配的网址,其他网址跳过。
“导航规则”的最终设置如下:
第 4 步:采集rules
通过“导航规则”我们一直到了“最后一页”,也就是“新闻内容”,然后我们需要按照“采集法”采集要求的内容。如上图所示,一条“采集规则”对应一个数据库字段,是一种信息类型,如标题、出版商、投稿人、内容等。“数据库字段”可以留空,默认是规则名称。 “归属层”是一个跨层的采集函数,本例中不使用,保持默认即可。
以下是最重要的:“前信息标记”和“后信息标记”。软件通过在源文件中搜索“Before and After Mark”来定位采集的信息。那么如何获取信息的前后标识呢?请看下图。
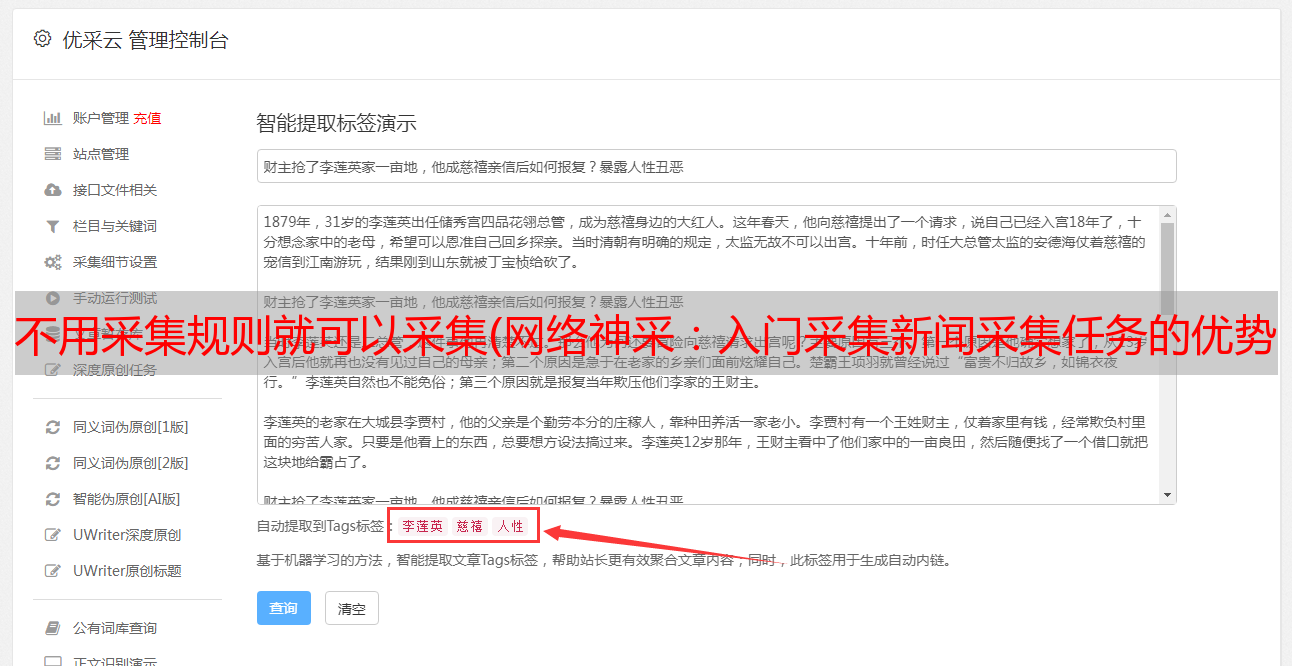
如图,“红色部分”代表信息的正面标志,“*敏*感*词*部分”是背面标志。夹在中间的“蓝色部分”就是我们需要的采集。顺序为:“标题”、“出版商”、“贡献者”、“出版日期”、“阅读次数”、“内容”。
“采集Rules”的最终设置如下:
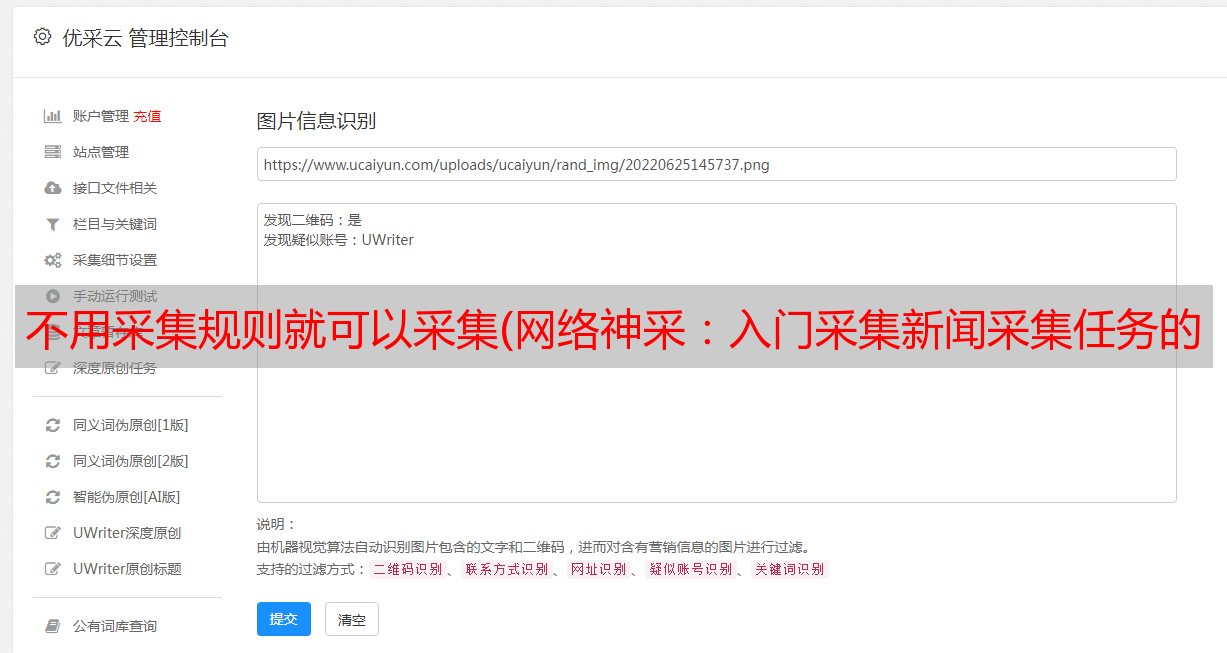
注意:
1、如果使用“前后标志”采集信息,必须与“网页源文件”中出现的顺序一致。
2、应用“采集规则”后,以“采集内容”结尾作为“当前位置”,然后“当前位置”搜索下一个“ 采集规则“信息前台标志”。
3、如果选择了“全局规则”和“静态规则”,它们将不再受“当前位置”的影响。
第 5 步:采集Result
如图所示,这里我们不做任何设置,直接在采集后导出结果即可。
更新日志
网络神采v6.3.15更新日志
1、 增加了定时重启软件的功能。
2、修复bug:采集启动任务时,会进入队列两次。
3、添加设置:特殊结果设置->记录任务名称。
4、Fix bug: Win7下启动服务IO异常。
5、Statistics 插件,按任务分类。
6、Fix the bug: 当文本查看器切换到空白单元格时发生错误。
7、如果你不下载文件,不要生成子目录(即使你选择了设置)。
8、F9 文件夹内所有任务运行后,子文件夹的任务状态没有变化。
9、修复bug:访问休息间隔设置为“0-1秒”时无效。
10、在JS中处理相对地址时,可以识别“'”前面的转义字符“\”。
11、当出现Worker Thread Error异常时,可以记录异常详情。
12、 在读取 URL 时发生错误后,您可以暂停任务。
13、 Worker Thread Error 异常时,可以挂起任务;如果挂起失败,任务将停止。
14、修复bug:继续任务时,如果任务进入任务队列,任务将重新启动。
15、停止任务并写日志。
16、 改进了任务队列的查询算法。
17、 提高机器码的可读性。
18、Worker 线程错误:抛出了“System.OutOfMemoryException”类型的异常。异常发生后,可以暂停任务。
19、如果保存“提取网址”时出错,可以恢复。
20、Add设置:如果“使用插件处理采集result数据行”失败(即返回“false”),采集结果仍会显示。
21、Abandoned 设置:关闭软件时,如果有任何软件正在运行,将强制停止所有任务。
22、在3个方面提升“源文件查看器”的用户体验:Cookie更改、粘贴POST参数时自动分离、菜单快捷方式。
23、捕获地址时,如果参数发生变化,文本框的背景颜色变为红色。
24、将检查“关键规则”调整为“采集result筛选”之前。
25、Update 插件接口(IBget 3.4),更新内容:CheckSchedule,新建参数:lastTaskState、lastPausingReason。
26、 请求中断间隔,支持随机数。
27、Request 可以设置无限次重试,同时增加“重试休息间隔”和“重试错误范围”设置。
28、Task 增加设置:动作失败后不会暂停任务。
29、 下载文件时,只请求一次。
30、运行整个文件夹的任务时,添加快捷键:F9。
31、修复bug:批量挂起正在启动的任务时,“running”状态会闪烁。
32、已解决:操作信息窗口的资源释放问题。
33、使用插件处理结果数据行后,如果返回false,数据行将不再显示。
34、Loop 采集分割字符串数组时,保留空值。
35、修复内存错误。
36、Fix bug:查看等待区出错:采集已修改;可能无法执行枚举操作。
37、修复bug:由于插件日志回调事件,会抛出异常:远程对象已断开连接。
38、修复bug:设置窗口未操作,2分钟后抛出异常:远程对象已断开连接。
39、更新插件接口(IBget3.3),更新内容:ExtractResult新参数:rowIndex;创建新参数:supportAsyncCall。
40、如果创建插件时出错,任务将不再提示连接数据库。
41、Special Results -》记录当前的URL,如果有POST参数,则收录。
42、修复bug:任务完成后取消定时采集,选中“使用插件查看定时采集”后依然有效。
43、Fixed bug:源文件查看器的预览功能无法预览框架页面。
44、 增加了复制采集规则的功能。
45、 提取下一个网址时,如果在网址队列中重复,会提示:提取n个,重复的已经去掉。
46、下一级网址提取失败次数达到n次后,下一页网址不再提取,否则下次请求会重复提取。
47、修复几个内存溢出问题。
48、修复bug:以html模式查看文本查看器。关闭窗口后,打开错误“对象引用未设置到实例”。
49、Improved Timing采集检查思路:取当前时间缓存,不存在时序偏差。

