自动采集数据(【干货】一下数据采集的重要性、数据划分、采集方式)
优采云 发布时间: 2021-09-08 07:02自动采集数据(【干货】一下数据采集的重要性、数据划分、采集方式)
前言
相信业务团队对这样的场景不会太陌生:
这个数据很重要。下面从数据采集的重要性、数据的划分、采集的方法、微信小程序的埋点方案等方面详细说说数据。 采集。
一、数据采集的重要性
在本文中,我们将重点关注数据采集。我们不会详细讨论数据的作用。首先,我们将总结和总结数据在性能优化、业务增长和在线故障排除中的重要作用。这就是为什么我们需要埋藏一些要点。 .
数据在在线故障排除中的作用:
数据在性能优化中的作用:
数据对业务增长的作用:
二、采集数据划分与排序
从第一点开始,我们总结了数据的重要性。不同的业务项目对数据的重要性有不同的重视。 data采集需要采集什么样的数据?
一、闭环数据包括:
用户行为用户信息、CRM(客户关系)交易数据、服务器日志数据
以上三项数据可以看作是一个完整的数据流闭环。当然,不同业务场景下的数据可以进一步细分为更多的细节,一般的关键点基本不超过这三项。对于前端数据采集,闭环数据的前两项主要由客户端上报,第三点主要由服务器记录并由客户端辅助,因为事务请求实际上到达服务器完成处理。一个闭环。用户行为数据还包括时间(when)、地点(where)、人物(who)、互动(how)、互动内容(what)五个要素,类似于新闻的五个要素;一些与用户信息相关的业务 用户敏感信息和隐私需要经过授权,所以用户信息由业务场景决定。最基本的数据需求是唯一标识用户; CRM、交易数据和用户信息类似,具体需要的数据细节由业务场景决定。 CRM 的基本数据要求是登录信息和会员相关信息。交易数据包括交易时间、交易对象、交易内容、交易金额、交易状态。
三、数据上报方式
说完数据,下一步就是要知道如何获取我们真正需要的数据。数据上报方式大致可以分为三类:
重点是非埋点。可视化的埋点实际上可以看作是非埋点的衍生。这里不讨论视觉掩埋点。主要比较代码埋点和非埋点。
3.1 代码埋点或Capture模式埋点的弊端
对于数据产品:
依靠人类经验和直觉判断。
业务相关的埋地需要数据产品或业务产品的主观判断,技术相关的埋地需要技术人员的主观判断。通信成本高
确定数据产品所需要的数据,需要提出需求并与开发沟通,数据人员对技术不是特别熟悉,需要与开发人员明确是否相关信息可报告可行性。有数据清理成本
随着业务的变化和变化,之前主观判断所需的数据也会发生变化。这时候之前管理的数据需要人工清洗,清洗工作量不小。
用于开发:
开发者能耗
对于业务团队来说,经常受到相关开发者的诟病。开发和技术人员不仅要专注于技术,还需要分散精力去做埋点等高重复性和机械性的任务。嵌入式代码具有很强的侵入性,对系统设计和代码可维护性产生负面影响
大部分业务相关的数据点都需要人工进行埋点,埋点的代码必须与业务代码强耦合。即便业界没有sdk,数据产品专注的特殊业务点也逃不过人工埋葬。
由于业务不断变化下数据需求的变化,embedding的相关代码也需要做相应的改变。进一步增加开发和代码维护成本。容易出错和遗漏
由于人工管理的主观差异,放置位置的准确度难以控制,易泄露数据在管理过程中存在成本
当数据丢失或错误采集时,必须重新经历开发过程和在线过程,效率低下。 3.2无埋藏优势
与人工埋点相比,无埋点的优势无需说明。
提高效率,数据更全面,按需抽取减少代码入侵四、微信小程序无埋点sdk解决方案4.1无埋点数据需求
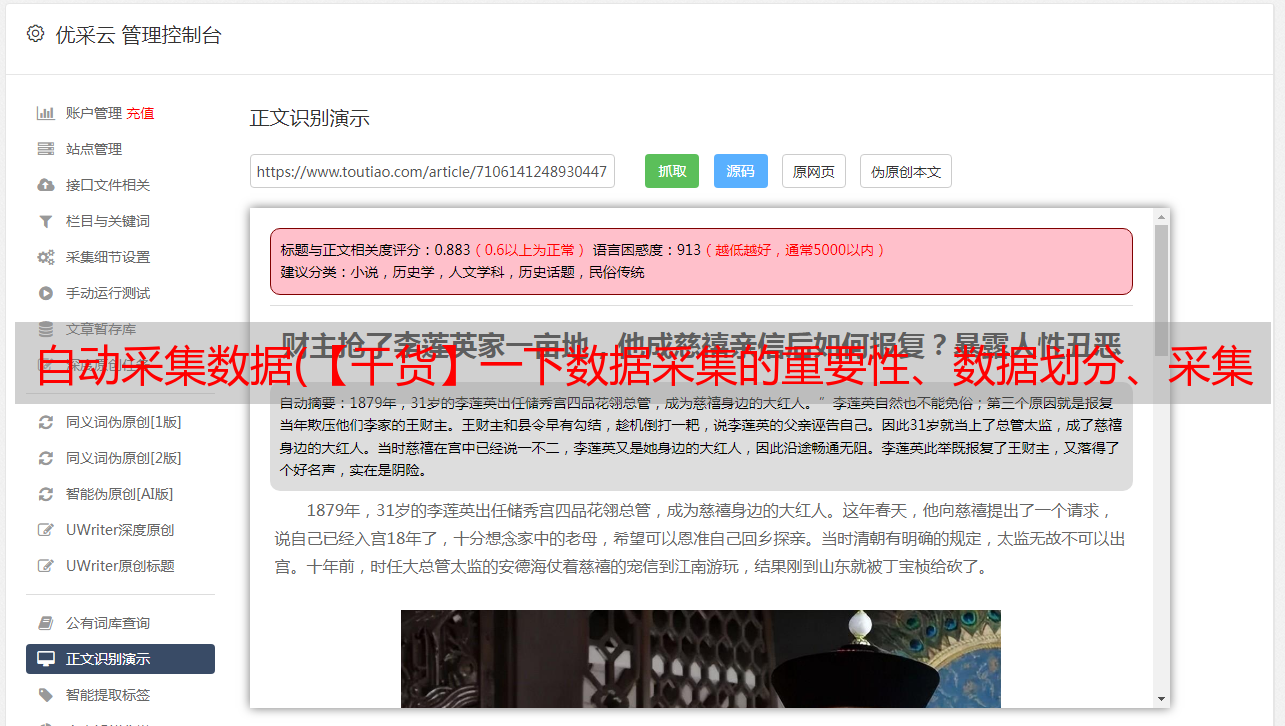
双向监控逻辑图
清晰图片地址戳
由于applet和web服务不同,没有js/css资源加载这样的东西,所以我比较关注applet初始化状态和执行的记录、捕获和上报。图中资源完整性检查对应初始化完成。检查的。在线小程序中请求的域名必须是https协议,所以DNS劫持的概率大大降低甚至不太可能发生,从客户端监控DNS劫持的可行性低(存在悖论),所以DNS劫持暂时不考虑捕获条件。
4.2 开发微信小程序非嵌入式sdk的难点和要点
微信请求通过微信API统一完成,请求模块已经被微信方封装,小程序的运行环境不是浏览器对象,所以不容易像web应用那样重写封装.
无法直接监控用户行为。强大的可扩展性需要适合多种架构设计场景(小程序)。 SDK 需要轻量级。每个小程序有2M的限制,小程序不支持引入代码。 npm 包,所以 sdk 本身会占用 2M 大小限制。小程序虽然分包了内测,但是这个功能还没有完全发布,作为一个SDK过大也是不合理的。海量数据采集,在不影响业务的前提下最大限度降低性能损失(基本要求)
4.3 微信小程序无埋点sdk设计
数据层设计:
数据层设计
清晰的数据层设计图地址戳
数据流向设计:
数据流向图片的清晰地址戳
采集方法设计:
采集设计图片清晰地址戳
访问方式:
在小程序初始化代码之前介绍sdk npm包代码。小程序打包代码时,将sdk代码导入到项目中,初始化后自动采集数据。初始化示例如下:
import Prajna from './lib/prajna-wxapp-sdk.js';
Prajna.init({
channel: 'channel',
env: config.IS_PRODUCION ? 'product': 'beta',
project: 'yourProjectName',
methodConfg: {} // 业务特殊关注的方法执行和自定义打点名称
})
无埋点结合埋点:
小程序的非嵌入方式可以获得大量数据,基本可以实现对用户使用场景的高度还原。 SDK管理的粒度是某种方法的执行。当特殊业务关注的粒度小于SDK的粒度时,没有埋点,SDK无法完全解决。可以使用无埋点和埋点的组合,所以我们的小程序并没有埋点SDK也提供了手动埋点的API接口,以提高数据的完整性,解决更多的问题(复习中提到的作用数据的重要性)。
五、无埋点SDK小程序遇到的问题
除了解决了前面提到的微信小程序非嵌入式sdk开发的难点和关键问题,也遇到了一些新的问题。
SDK 本身会对业务表现产生一定的影响。数据暂存在小程序的localstorage中,当业务本身对性能的消耗较大时,会暴露出频繁存储和检索的小程序的localstorage。操作卡住了。减少本地存储的存储/检索操作。只有关闭页面时没有上传的数据才会存储在localstorage中。没有埋点的全量数据是巨大的。灰度上线时,遇到了服务器过载、服务器可用性降低的问题。后续控制上报数据量,仅自动上报关键节点数据,其他业务重点节点可在访问初始化时通过针对性配置上报,避免上报过多冗余数据。此外,应特别注意报告数据结构的设计。结构目标是清晰、简洁、便于数据检索(区分)。初期想对是否使用SDK进行灰度在线做一个“切换”,避免小程序回滚过程。由于“开关”依赖于服务器接口控制,并且请求是异步的,意味着初始化过程和小程序的启动必须等到控制开关的接口返回,否则“开关”就相当于失败考虑到SDK不会影响业务性能,舍弃“开关”,做好SDK内部的try-catch,避免影响业务可用性。
有了不埋点上报得到的数据,以后可以用这些数据解决很多问题。关于数据的使用,敬请期待下一节——数据应用。
参考文献:
[1] [美国] 裴骥,译者姚军等,《深入理解网站optimization》,出版社:机械工业出版社,出版时间:2013-08
[2] 张希萌,“首席成长官”,出版社:机械工业出版社,出版日期:第1版(2017年11月6日)

