用python抓取某刊物最近5年发表的所有文章的关键词和摘要
优采云 发布时间: 2020-08-20 12:52用python抓取某刊物最近5年发表的所有文章的关键词和摘要
在学术研究中,经常须要了解某个领域的最新发展趋势,比如说,发掘最热门、上升速率最快的几个关键词。有些学术服务网站,比如Web of Science,提供类似的服务,但一些高校并没有购买这种服务,而且使用中难免会碰到各类问题,比如多样化不足等。在这篇文章中,我们来阐述怎样借助python及免费资源,进行基于论文关键词的研究趋势剖析。
选定刊物
我想要了解国际商务(international business)领域近些年来发表的文章,在google中搜索“google scholar journal ranking international business”,点开第一个链接,得到如下页面:
这里以排行第一的Journal of International Business Studies为例,示意怎么抓取近些年来发表的所有文章的信息。
找到文章列表
经过一番搜救,我找到了自2013年以来发表的全部442篇文章的列表:
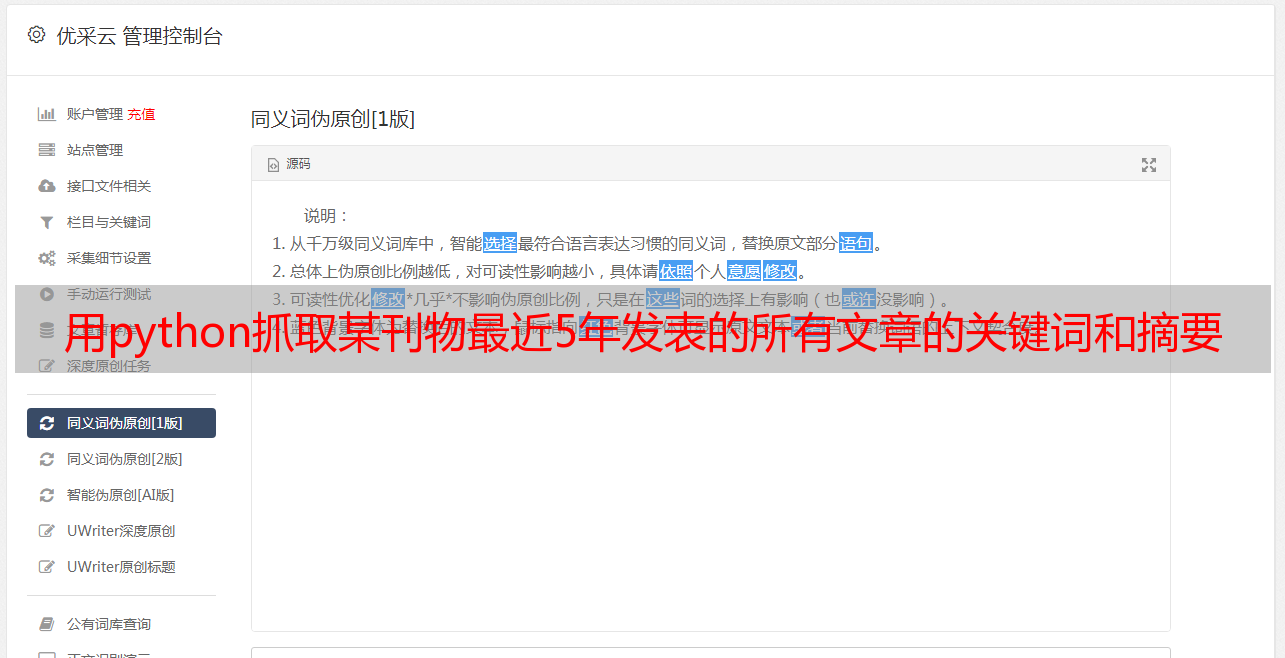
点击图中红框中的按键,可以将全部442篇文章的信息导入到CSV文件。
然而,文件中只有整篇文章的篇名(item title)、作者(authors)和链接(URL),没有关键词(key words)和摘要(abstract)这些重要信息。
接下来,我们用python编撰一个循环,打开每一篇文章的链接,抓取关键词和摘要。
抓取网页元素
首先,我们定义一个get_keywords_abstract()函数,用来抓取给定网页中的相关元素,代码如下:
import requests
from scrapy import Selector
def get_keywords_abstract(url):
r = requests.get(url) #打开网页
if r.status_code != 200: #如果网页连接错误,就返回空字符串
print("Connection error: {}".format(url))
return "", ""
selector = Selector(text=r.text)
keywords = selector.css('.Keyword::text').extract()
abstract = selector.css('#Abs1 p::text').extract_first()
return keywords, abstract
值得说明的是,我使用了scrapy库上面的Selector类来解析网页。之所以如此做,是因为与Beautiful Soup、Pyquery等库相比,我比较熟悉scrapy下的css选择器的使用方式。
为了验证以上代码是否正确,我在命令行中执行以下测试代码:
test_url = 'https://link.springer.com/article/10.1057%2Fs41267-019-00235-7'
keywords, abstract = get_keywords_abstract(test_url)
print(keywords)
print(abstract)
结果有点出人意表:
>>> print(keywords)
['entry mode\xa0', 'deviation from prediction\xa0', 'internalization theory\xa0', 'bounded rationality\xa0', 'cognitive bias\xa0']
>>> print(abstract)
'We explore when and why decision makers choose international entry modes (e.g., hierarchies or markets) that deviate from internalization theory’s predictions. By applying a cognitive perspective on entry mode decision making, we propose that the performance of prior international activities influences decision makers’ behavior in different ways than assumed in internalization theory. More specifically, due to a'
关键词末尾有多余的字符,这个问题不大,可以在后续处理中批量删掉。真正的问题在于,摘要不完整。

