持续更新,微信公众号文章批量采集系统的完善
优采云 发布时间: 2020-08-19 08:39持续更新,微信公众号文章批量采集系统的建立
2019年10月28日更新:
录制了一个YouTube视频来具体讲解操作步骤:
youtu.be
================原文===========================
我从2014年就开始做微信公众号内容的批量采集,最开始的目的是为了做一个html5的垃圾内容网站。当时垃圾站采集到的微信公众号的内容很容易在公众号上面传播。当时批量采集特别好做,采集入口是公众号的历史消息页。这个入口到如今也是一样,只不过越来越难采集了。采集的形式也更新换代了好多个版本。后来在2015年html5垃圾站不做了,转向将采集目标定位在本地新闻资讯类公众号,前端显示弄成了app。所以就产生了一个可以手动采集公众号内容的新闻app。曾经我仍然担忧有三天陌陌技术升级以后难以采集内容了,我的新闻app就失效了。但随着陌陌不断的技术升级,采集方法也骤然升级,反而让我越来越有信心。只要公众号历史消息页存在,就能批量采集到内容。所以明天决定将采集方法整理过后写出来。我的方式来源于许多同行的分享精神,所以我也会延续这个精神,将我的成果分享下来。
本篇文章将持续更新,你所看见的内容将保证在听到的时间是可用的。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/getmasssendmsg?__biz=MjM5MzczNjY2NA==#wechat_webview_type=1&wechat_redirect
=========2017年1月11日更新=========
现在按照不同的陌陌个人号,会出现两种不同的历史消息页面地址,下面是另一种历史消息页的地址,第一种地址的链接会在anyproxy中显示302跳转:
https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MzA3NDk5MjYzNg==&scene=124#wechat_redirect
第一种链接地址的页面款式:
第二种链接地址的页面款式:
根据目前把握的信息,两种页面方式无规律的出现在不同的微信号中,有的微信号仍然是第一种页面方式,有的就一直是第二种页面方式。
上面这个链接是一个微信公众号历史消息页面的真实链接,但是我们把这个链接输入到浏览器中会显示:请从陌陌客户端访问。这是因为实际上这个链接地址还须要几个参数能够正常显示内容。下面我们就来瞧瞧可以正常显示内容的完整链接是什么样的:
//第一种链接
http://mp.weixin.qq.com/mp/getmasssendmsg?__biz=MjM5NTM1NjczMw==&uin=NzM4MTk1ODgx&key=a226a081696afed0d9dfa0972fa431e116e5c4572ce52343178ad4e9a2b94aeaad6ac4dd87de3e56f72209a73a32e9cc2052f68aca4884e36cf726e99f2671630c741d8e4c29abe4a049d1a71eeb2be5&devicetype=android-17&version=2605033c&lang=zh_CN&nettype=WIFI&ascene=1&pass_ticket=zbA7PswOPKySRpyEYI5kDCjRiljxcpzdbTuVMauFGemgdp8R1DY1uQY49srehWab&wx_header=1
//第二种
http://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MzA3NDk5MjYzNg==&scene=124&uin=NzM4MTk1ODgx&key=5134ab1cc362a0324183dbd55a2680d11ccbaa34cdb349ee9be58f5b666092ddb17adf8a88dc788831923f3c6087547d651f04209f72334d511c9e118a3800d7b05a324a38903f79cff940cf749ecd5a&devicetype=android-17&version=2605033c&lang=zh_CN&nettype=WIFI&a8scene=3&pass_ticket=Fo3zjtJcbPfijNHKUIQbV%2BeHsAqhbjJCwzTfV48u%2FCZRRGTmI8oqmHDxxfEL8ke%2B&wx_header=1
这个地址是通过陌陌客户端打开历史消息页面然后,再使用前面介绍的代理服务器软件获取到的。这上面有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
其中重要的参数是:__biz;uin=;key=;pass_ticket=;这4个参数。
__biz是公众号的一个类似id的参数,每个公众号拥有一个陌陌的biz,目前极小机率会发生公众号的biz会变化的风波;
剩下的3个参数是有关用户的id和令牌票据之类的意思,这3个参数的值是通过陌陌的客户端生成后手动补充到地址栏中的。所以我们想采集公众号就必须通过一个陌陌客户端app。在先前的陌陌版本中这3个参数还可以获取一次以后在有效期之内多个公众号通用。现在的版本早已是每次访问一个公众号就会更换参数值。
我如今所使用的方式只须要关注__biz这个参数就可以了。
我的采集系统由以下几部份组成:
1、一个陌陌客户端:可以是一台手机安装了陌陌的app,或者是用笔记本中的安卓模拟器。经过实测ios的陌陌客户端在批量采集过程中崩溃率低于安卓系统。为了增加成本,我使用的是安卓模拟器。
2、一个陌陌个人号:为了采集内容除了须要陌陌客户端,还要有一个陌陌个人号专门用于采集,因为这个微信号就干不了其它事情了。
3、本地代理服务器系统:目前使用的方式是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器上。具体安装设置方式在前面详尽介绍。
4、文章列表剖析与入库系统:我用的是php语言编撰的,后文将详尽介绍怎么剖析文章列表和完善采集队列实现批量采集内容。
步骤
一、安装模拟器或使用手机安装陌陌客户端app,申请陌陌个人号并登陆到app里面。这一点就不过多介绍了,大家还会。
二、代理服务器系统安装
目前我使用的是Anyproxy,AnyProxy 。这个软件的特性是可以获取到https链接的内容。在2016年年初的时侯微信公众号和陌陌文章开始使用https链接。并且Anyproxy可以通过更改rule配置实现向公众号的页面中插入脚本代码。下面开始介绍安装与配置过程。
1、安装 NodeJS
2、在命令行或则终端运行 npm install -g anyproxy,mac系统须要加上sudo;
3、生成RootCA,https须要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);---------------2019年10月28日更新:这行命令已然失效!!!跳过这一步
4、启动anyproxy运行命令:sudo anyproxy -i;参数-i是解析HTTPS的意思;
5、安装证书,在手机或安卓模拟器中安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网段,可以通过吧dhcp设置为静态后见到网段地址,看完后别忘了再设置为手动。手机中的代理服务器地址就是运行anyproxy的笔记本的ip地址。代理服务器默认端口是8001;
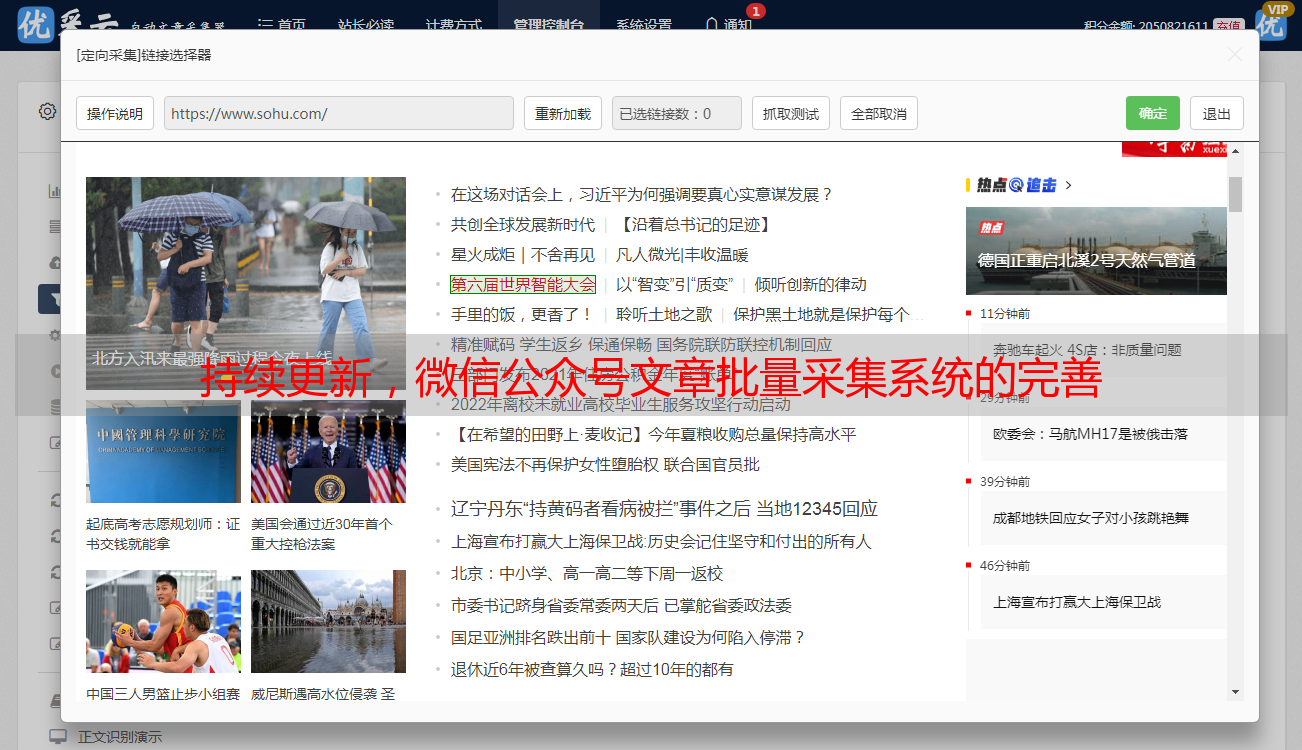
现在打开陌陌,点击到任意一个公众号历史消息或文章中,在终端都可以见到响应的代码滚动。如果没有出现,请复查手机的代理设置是否正确。
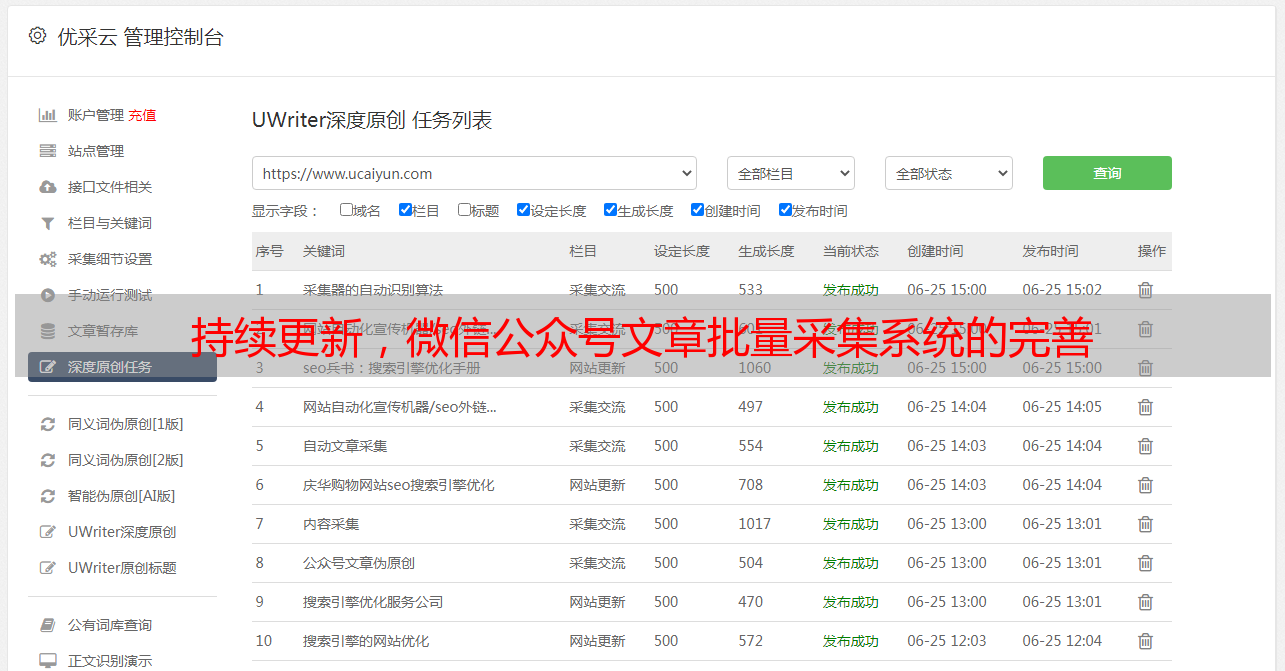
现在打开浏览器地址:8002 可以看见anyproxy的web界面。从陌陌中点开一个历史消息页面,然后再看浏览器的web界面,会滚动出现历史消息页面的地址。
以/mp/getmasssendmsg开头的网址就是陌陌历史消息页面。左边一个小锁头表示这个页面是https加密的。现在我们点击一下这一行;
=========2017年1月11日更新=========
部分微信号以/mp/getmasssendmsg开头的网址会出现302跳转,跳转到了/mp/profile_ext?action=home开头的地址。所以点开这个地址才可以看见内容。
右边假如出现了html的文件内容则表示揭秘成功。如果没有内容,请复查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机是否正确安装证书。
现在我们的手机中的所有内容都早已可以明文通过代理服务器了。下面我们要更改配置代理服务器,使公众号内容被获取到。
一、找到配置文件:
mac系统中配置文件的位置在/usr/local/lib/node_modules/anyproxy/lib/;windows系统请原谅我暂时不知道。应该可以按照类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
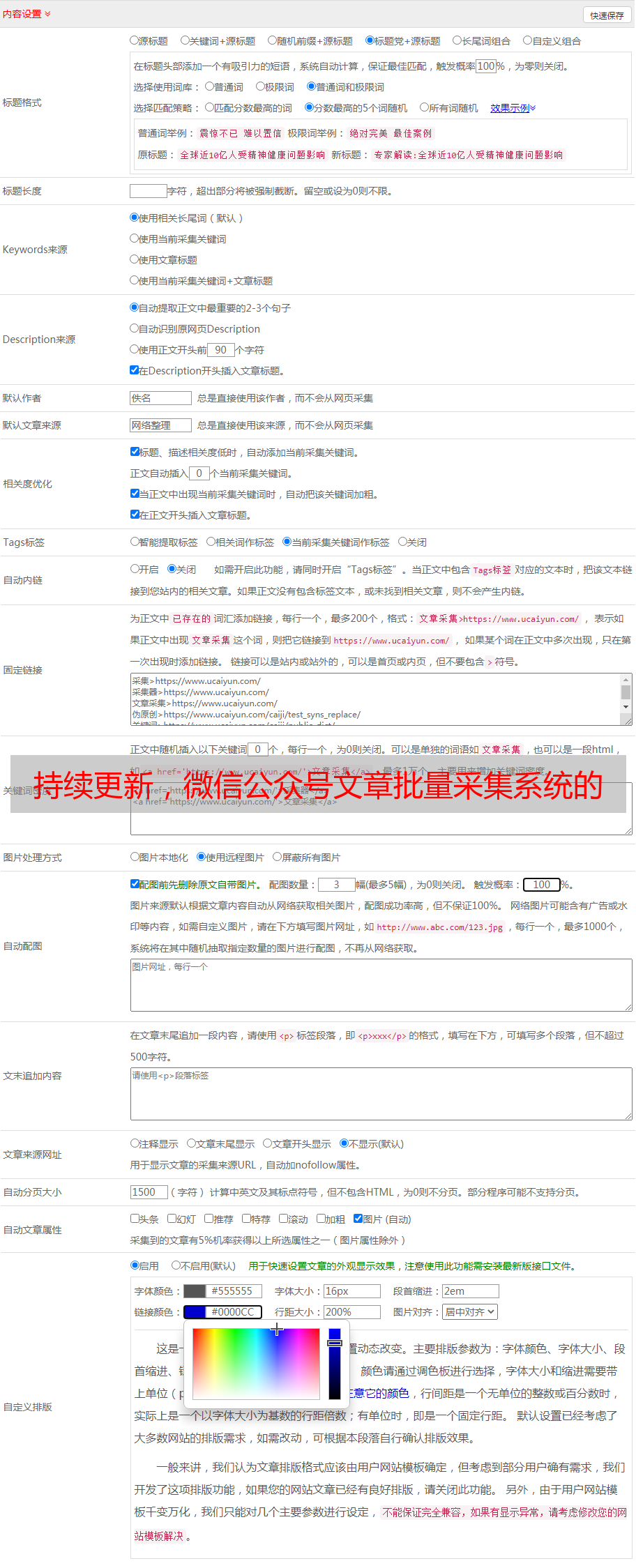
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请注意详尽阅读注释,这里只是介绍原理,理解后依照自己的条件更改内容):
=========2017年1月11日更新=========
因为出现了两种页面方式,且在不同的微信号中仍然显示同一种页面方式,但为了能兼容两种页面方式,以下的代码会保留两种页面方式的判定,你也可以按照自己的页面方式除去li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
上面这段代码是借助anyproxy可以更改返回页面内容的功能,向页面注入脚本,和将页面内容发送到服务器上。使用这个原理来批量采集公众号内容和阅读量。这段脚本中自定义了一个函数,下面详尽介绍:
在rule_default.js文件末尾添加以下代码:

