软文采集系统(一下VSflume:日志采集和日志解析中遇到的问题和处理方案)
优采云 发布时间: 2021-09-04 14:12软文采集系统(一下VSflume:日志采集和日志解析中遇到的问题和处理方案)
概述
这段时间有一部分时间花在处理消息总线和日志的连接上。下面是日志采集和日志分析中遇到的一些问题和解决方法。
Log采集-flumelogstash VS 水槽
先说说我们在日志采集器上的选择。因为我们选择使用 ElasticSearch 作为日志存储和搜索引擎。基于ELK(ElasticSearch、Logstash、Kibana)的技术栈在日志系统的方向如此火爆,所以将Logstash纳入考察对象也是合乎逻辑的。 Logstash 是各大日志采集器中的一颗冉冉升起的新星,被 Elastic 收购后更是如此。成熟,社区比较活跃。
Logstash 设计:输入、过滤器、输出。 Flume source、channel、sink的设计,当然flume也有*敏*感*词*。具体的设计就不废话了,大致就是拆分、解耦、流水线的思路。同时,它们都支持分布式扩展。比如Logstash既可以做shipper又可以做indexer,flume可以和多个agent组成分布式事件流。
我与flume的接触早于Logstash。我最近在研究 Logstash 时,对它强大的过滤器印象非常深刻,尤其是 grok。 flume 阵营最强调的是其对各种开源组件的 source、sink 和 channel 扩展支持非常强大。
Logstash 固然是一个不错的选择,但它使用 JRuby 语言(一种类似于 Ruby 语法的 JVM 平台语言)的实现使得它的定制不灵活。这是我放弃 Logstash 的主要原因。出于生态的原因,我确实需要Java技术栈提供的可扩展性(这里的主要目标是使用消息总线作为日志采集的缓存队列),而这正是flume的强项。但是,很少提到 Flume 中的日志解析支持。即使有支持正则的*敏*感*词*,也只有非常有限的搜索和替换。经过一番研究,发现Flume其实提供了这样的*敏*感*词*-morphline。可以完成对日志的分析。
Log analysis-morphline morphline介绍
Morphline 是 Flume 的母公司 cloudera 开源的 ETL 框架。它用于构建和更改基于 Hadoop 的 ETL(提取、传输、加载)流处理程序。 (值得一提的是flume是cloudera捐赠给Apache的,后来重构为flume-ng)。 Morphline 让您无需编码,也无需大量 MapReduce 技能即可构建 ETL 作业。
Morphline 是一个丰富的配置文件,可以轻松定义转换链,用于从任何数据源使用任何类型的数据,处理数据,然后将结果加载到 Hadoop 组件中。它以简单的配置步骤取代了 Java 编程。
Morphline 是一个可以嵌入任何 Java 程序的类库。 Morphline 是一个内存容器,可以存储转换命令。这些命令以插件的形式加载到 morphline 中以执行任务,例如加载、解析、转换或处理单个记录。记录是内存中名称-值对的数据结构。并且morphline具有可扩展性,可以集成现有功能和第三方系统。
这个文章不是morphline的软文,更多介绍请参考cloudera官方CDK文档。
下面是一张侧面图,形象地展示了morphline的粗加工模型:
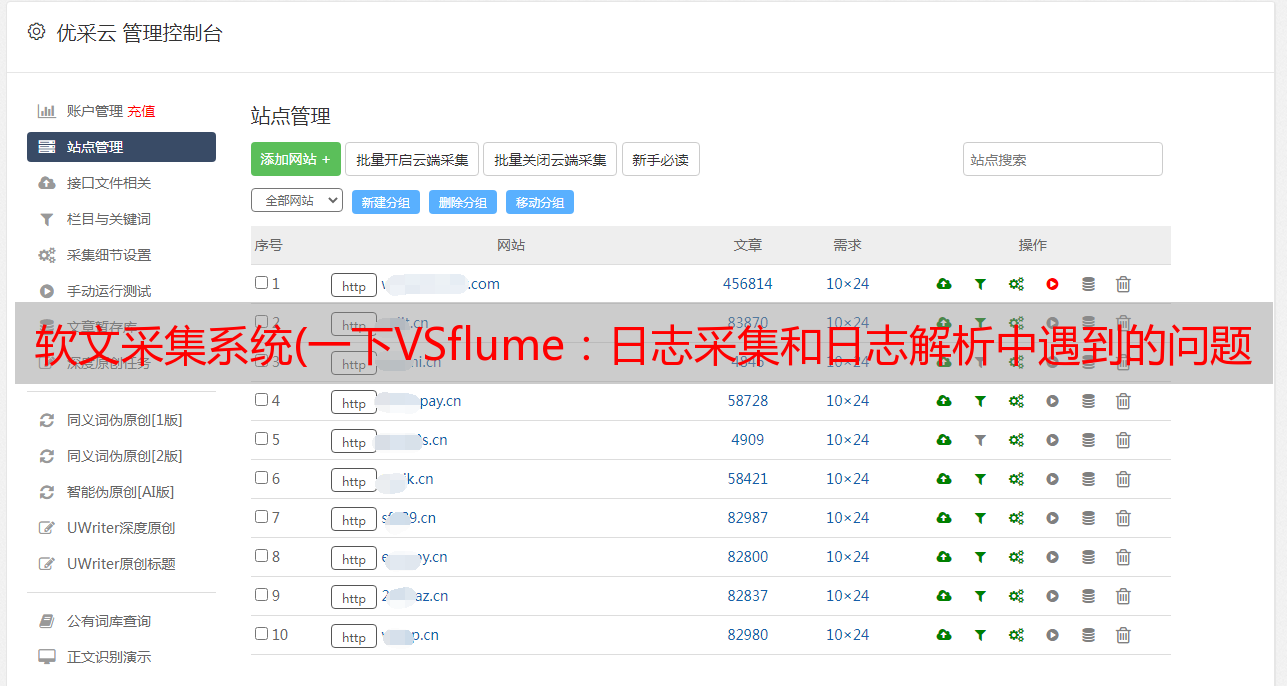
下图展示了大数据生态系统中morphline的架构模型:
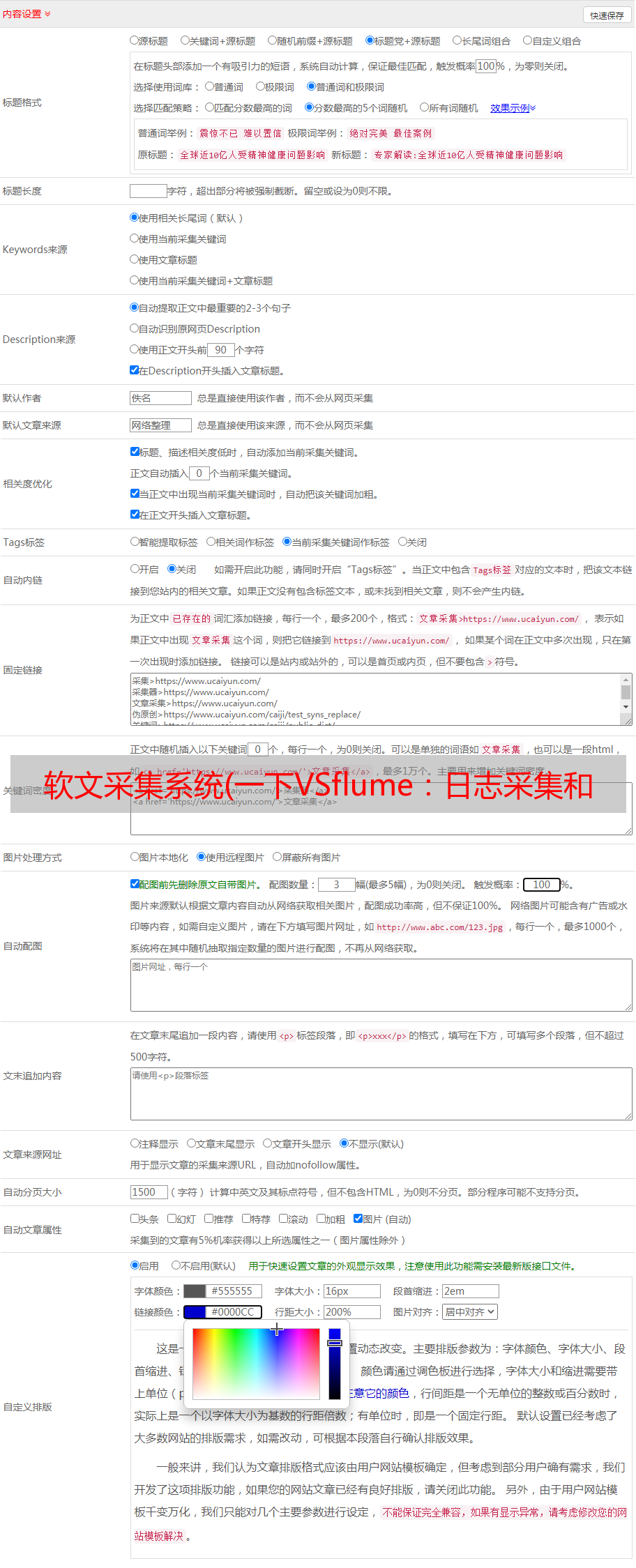
后来morphline的开发主要由Kite主导,Kite是一套建立在Hadoop上的抽象数据模型层API接口。这里是 kiteSDK 关于 morphline 的文档。
强大的常规提取器-grok
其实我找morphline是为了找到grok,或者找一个提供grok的入口点。 grok 使用常规分析功能从非结构化日志数据中提取结构化字段。因为Logstash已经提供了很多经过验证的grok规则,这就是Logstash的优势。如果这些规则可以直接在flume中使用,那么就可以直接集成Logstash的能力(其实只要有文字就是规则。常规规则可以提取出来,但是没必要花很多精力去验证是否已经有成熟的东西)。这里有grok的文档,就不过多介绍了。
服务器使用morphline
flume 在代理中使用吗啉。 ETL在客户端日志上的优势,可以利用客户端PC分散的算力,省去服务器端解析的麻烦,但是代理数量非常多,而且分散在各个生产服务器上,而且日志的格式也多种多样。换句话说,在代理中做太多事情会使我们在应对变化时变得不灵活。因此,我们只采集而不是在客户端解析。在服务器端,使用 morphline 来解析日志。相当于启动了一个解析服务,从日志采集队列中提取日志,使用morphline进行分析转换,然后将解析后的、结构化程度更高的日志发送到索引队列中,等待索引服务存储到ElasticSearch中整个过程大致如下:
<p>这个基于异步队列的管道其实和StZ是一样的? / KF /器皿/ VC / “目标= ”_空白“> vcm3V4tH5tcTB97SmwO3G97XEzayyvXBpcGVsaW5lsb7WysnPyuLNvs2suemjrLa8ysfU2sRC7PGWPCG示例程序 vcm3v4tH5tcTB97SmwO3G97XEzayyvXBpcGVsaW5lsb7WysnPyuLNvs2suemzlk0PGVPPCG9Pv2sRC7GQPPCG9 = Pv2c7Pg0Pg4示例程序

