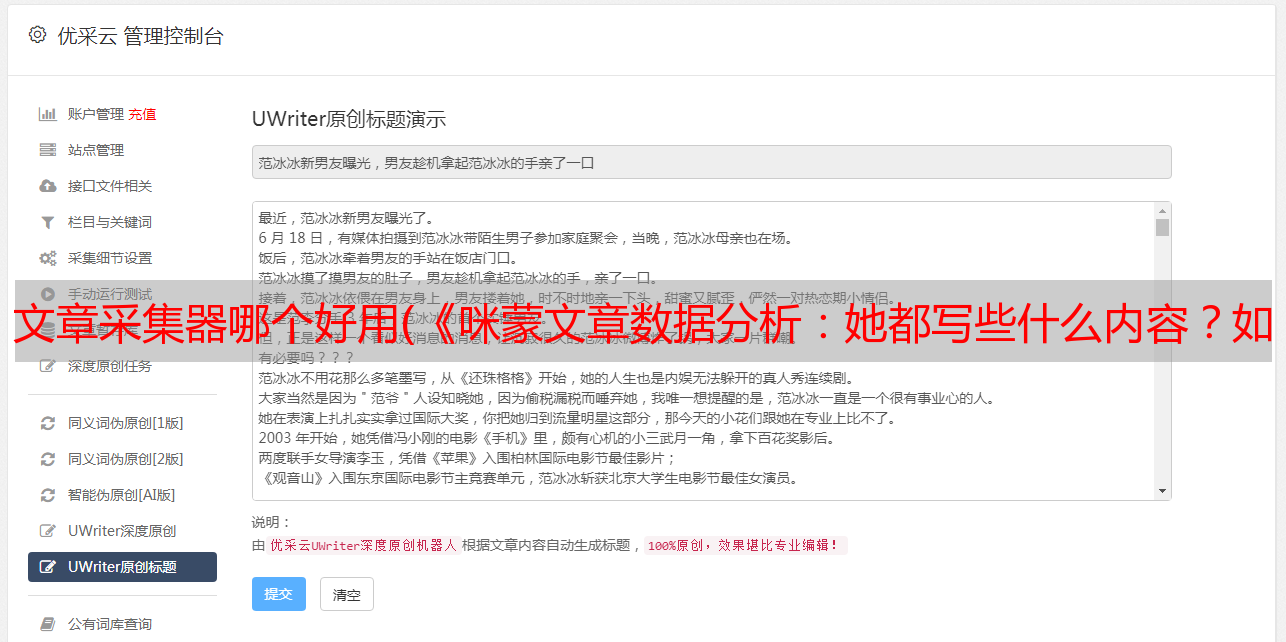
文章采集器哪个好用(《咪蒙文章数据分析:她都写些什么内容?如何刺激转发痛点?》 )
优采云 发布时间: 2021-09-03 22:25文章采集器哪个好用(《咪蒙文章数据分析:她都写些什么内容?如何刺激转发痛点?》
)
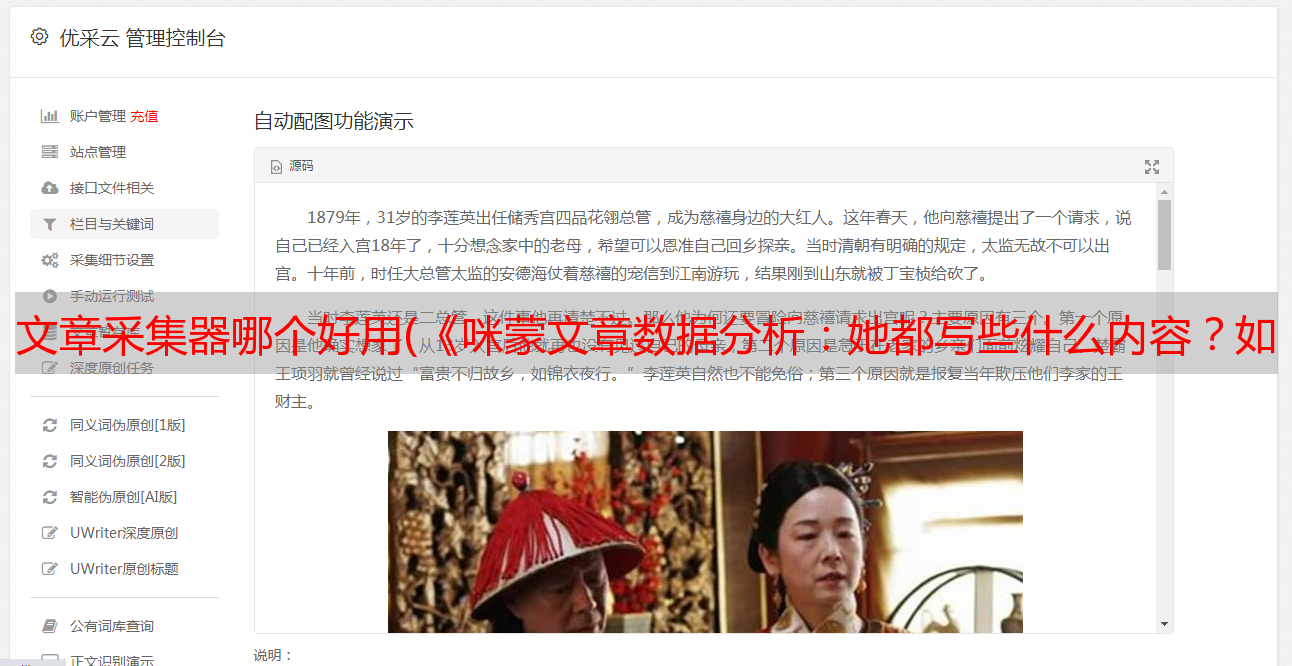
学会快速学习信息和数据采集非常有必要,因为可以大大提高工作效率。在学习python和优采云之前,网络爬虫是我最常用的采集工具。它设置简单且非常有效。 采集咪蒙文章标题只需要2分钟,采集58同城5000租房信息只需要5分钟。
我也用网页爬虫做相关的采集分析,比如文章《咪蒙文章数据分析:她写什么?如何激发转发痛点? 》,通过采集咪蒙全文章和微博分析得到,总共耗时不到5分钟。
Web scraper 是 Google 强大的插件库中非常强大的数据采集 插件。它具有强大的反爬虫能力。只需在插件上进行设置,即可快速抓取知乎、简书、豆瓣、大众、58等大、中、小等网站90%以上的内容,包括文字、图片、表格和其他内容,最后快速导出csv格式文件。谷歌官方给出的网络爬虫描述是:
使用我们的扩展程序,您可以创建计划(站点地图)、应如何遍历网站以及应提取的内容。使用这些站点地图,网络爬虫将相应地导航站点并提取所有数据。您可以稍后将剪辑的数据导出为 CSV。
这个系列是关于网络爬虫的介绍。完整介绍流程,以知乎、简书等网站为例介绍如何采集文本、表格、多元素爬取、不规则分页爬取、副页爬取、动态网站爬虫,以及一些反爬虫技术。
好的,现在我们来介绍一下网络爬虫的安装和完整的爬取过程。后面会介绍多页爬取、反爬虫、图片、链接、表格爬取。
一、web 爬虫安装
网络爬虫是谷歌浏览器的一个扩展插件,其安装与其他插件的安装相同。
如果你不能下载webscraper,可以通过微信或者公众号联系我。
二、以知乎为例介绍网络爬虫的完整爬取过程
1、Open target网站,这里以采集知乎第一大v张佳玮的follower为例,需要爬取的是知乎名字,回答数,文章关注@Quantity,关注数量。
2、在网页上右击,选择勾选选项,或者使用快捷键Ctrl+Shift+I/F12打开Web Scraper。
3、打开后,点击创建站点地图,选择创建站点地图,创建站点地图。
点击create sitemap后,会出现如图所示的页面。您需要填写站点地图名称,即站点的名称。你可以随便写,只要你能看懂;您还需要填写起始网址,即抓取页面的链接。填写完毕后,点击创建站点地图,完成站点地图的创建。
详情如下:
4、设置一级选择器:选择采集范围
接下来是重中之重。这里介绍一下网络爬虫的爬取逻辑:需要设置一级选择器(selector),设置要爬取的范围;在一级选择器下创建二级选择器(selector),并设置需要爬取Elements和content。
以抓张嘉伟的粉丝为例。我们的范围是张家伟关注的对象。然后我们需要为这个范围创建一个选择器;而张嘉伟关注的粉丝数、文章number等则是次要选择器的内容。具体步骤如下:
(1)添加新选择器创建一级选择器选择器:
点击后可以得到如下页面,需要抓取的内容都设置在这个页面上。
l id:就叫selector,同理,只要自己能理解,这里就叫jiawei-scrap。
l Type:是要抓取的内容类型,比如element element/text/link link/picture image/Element Scroll Down 动态加载等,这里如果有多个元素,选择element。
l Selector:指选择要抓取的内容。单击选择以选择页面上的内容。下面详细介绍这部分。
l Check Multiple:勾选 Multiple 前面的小方框,因为要选中多个元素而不是单个元素。勾选后,爬虫插件会识别页面下具有相同属性的内容;
(2)这一步需要设置选中的内容,点击select选项下的select得到如下图:
之后,将鼠标移动到需要选择的内容上,需要的内容会变成绿色表示被选中。这里需要提醒一下,如果你需要的内容是多元素的,你需要把元素都改为Select both。例如如下图,绿色表示选中的内容在绿色范围内。
当一个内容变成红色时,我们可以选择下一秒的内容。点击后,网络爬虫会自动识别你想要的内容,元素相同的内容都会变成红色。如下图所示:
确认页面上我们需要的所有内容都变成红色后,点击完成选择选项,可以得到如下图:
点击保存选择器保存设置。在此之后,创建了第一级选择器。
5、设置二级选择器:选择需要采集的元素内容。
(1)点击下图中红框内容进入一级选择器jiawei-scrap:
5、设置二级选择器:选择需要采集的元素内容。
(1)点击下图
红框内容会进入一级选择器jiawei-scrap:
(2)点击添加新选择器创建二级选择器来选择特定内容。
得到如下图,与一级选择器的内容相同,只是设置不同。
得到如下图,与一级选择器的内容相同,只是设置不同。
Ø id:表示要获取的字段。您可以参加该领域的英语。比如要选择“作者”,就写“作者”;
Ø Type:这里选择Text选项,因为你要抓取的是文本内容;
Ø Multiple:Multiple前面的小方框不要打勾,因为这里是要捕获的单个元素;
Ø 保持设置:其余未提及部分保持默认设置。
(3)点击选择选项后,将鼠标移动到特定元素上,该元素会变成*敏*感*词*,如下图:
点击特定元素后,该元素会变成红色,表示内容被选中。
(4)点击Done selection完成选择,然后点击保存选择器完成目标知乎名称的选择。
重复以上操作,直到选择好要攀爬的场地。
(5)点击红框可以看到采集的内容。
数据预览可以看到采集的内容,编辑可以修改设置内容。
6、爬取数据
(1)只需要设置好所有的Selectors,就可以开始爬取数据了,点击Scrape map,
选择刮取;:
(2)点击后会跳转到时间设置页面,如下图。由于采集数量不多,可以保存默认。点击开始抓取,出现一个会弹出窗口,官方采集Up。
(3)稍等片刻,得到采集效果,如下图:
(4)选择sitemap下的export data as csv选项,以表格的形式导出采集的结果。

